
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
sequencelengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 19:36:41
2024-08-02 10:23:00
| paper_updated_date
stringdate 2014-06-27 01:00:59
2025-04-23 08:12:32
| categories
sequencelengths 1
7
| title
stringlengths 16
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
1408.0113v1 | ## Difference Krichever-Novikov operators
Gulnara S. Mauleshova and Andrey E. Mironov
## Abstract
In this paper we study commuting difference operators of rank two. We introduce an equation on potentials V ( n , W ) ( n ) of the difference operator L 4 = ( T + V ( n T ) -1 ) 2 + W n ( ) and some additional data. With the help of this equation we find the first examples of commuting difference operators of rank two corresponding to spectral curves of higher genus.
## 1 Introduction and main results
I.M. Krichever and S.P. Novikov [1], [2] discovered a remarkable class of solutions of soliton equations - algebro-geometric solutions of rank l > 1. This class is determined by the following condition: common eigenfunctions of auxiliary commuting ordinary differential or difference operators form a vector bundle of rank l over the spectral curve. Rank two solutions of the Kadomtsev-Petviashvili (KP) equation and 2D-Toda chain corresponding to the spectral curves of genus g = 1 were found in [1], [2]. To find higher rank solutions one has to find higher rank commuting operators and their appropriate deformations. The problem of classification of commuting differential and difference operators was solved in [2]-[4]; however, finding the operators themselves has remained an open problem. Moreover, no examples of commuting differential operators of rank l > 1 at g > 1 were known before the recent paper [5] (see also [6]).
In this paper we study commuting difference operators. We denote by L , L k s the operators of orders k = N -+ N + and s = M -+ M +
$$L _ { k } = \sum _ { j = N _ { - } } ^ { N _ { + } } u _ { j } ( n ) T ^ { j }, \ \ L _ { s } = \sum _ { j = M _ { - } } ^ { M _ { + } } v _ { j } ( n ) T ^ { j }, \ \ n \in \mathbb { Z },$$
where T is the shift operator. The condition of their commutativity is equivalent to a complicated system of nonlinear difference equations on the coefficients. These equations have been studied since the beginning of the 20th century (see [7]). An analogue of the Burchnall-Chaundy lemma [8] holds. Namely, if L L k s = L L s k , then there exists a nonzero polynomial F z, w ( ) such that F L , L ( k s ) = 0 [9]. The polynomial F defines the spectral curve
$$\Gamma = \{ ( z, w ) \in \mathbb { C } ^ { 2 } | F ( z, w ) = 0 \}.$$
The spectral curve parametrizes common eigenvalues, i.e. if
$$L _ { k } \psi = z \psi, \quad L _ { s } \psi = w \psi,$$
then ( z, w ) ∈ Γ . The dimension of the space of common eigenfunctions with the fixed eigenvalues is called the rank of the pair L , L k s
$$l = \dim \{ \psi \, \colon L _ { k } \psi = z \psi, \ \ L _ { s } \psi = w \psi \},$$
where the point ( z, w ) ∈ Γ is in general position. Thus the spectral curve and the rank are defined exactly the same way as in the case of the differential operators.
Before discussing difference operators we briefly discuss differential operators. The first important results relating to commuting differential operators of rank l > 1 were obtained by J. Dixmier [10] and V.G. Drinfel'd [11]. The operators of rank l with periodic coefficients were studied in [12]. Rank two operators at g = 1 were found by I.M. Krichever and S.P. Novikov [1]. These operators were studied in [13]-[20] (see also [21]-[24] for g = 2-4 , l = 2 3). , At g = 1 , l = 3 operators were found in [25]. Methods of [5] allow to construct and study higher rank operators at g > 1 [26]-[31].
The maximal commutative ring of difference operators containing L k and L s is isomorphic to the ring of meromorphic functions on an algebraic spectral curve Γ with poles q , . . . , q 1 m ∈ Γ (see [2]). Such operators are called m -points operators . We note that any ring of commuting differential operators is isomorphic to a ring of meromorphic functions on a spectral curve with a unique pole. The commuting difference operators of rank one were found by I.M. Krichever [9] and D. Mumford [32]. Eigenfunctions (Baker-Akhiezer functions) and coefficients of such operators can be found explicitly with the help of theta-functions of the Jacobi varieties of spectral curves. In the case of l > 1 eigenfunctions cannot be found explicitly. Finding such operators is still an open problem. Rank two one-point operators at g = 1 were found in [2], operators with polynomial coefficients among them were obtained in [33].
In this paper we consider one-point operators of rank two L , L 4 4 g +2 corresponding to the hyperelliptic spectral curve Γ
$$w ^ { 2 } = F _ { g } ( z ) = z ^ { 2 g + 1 } + c _ { 2 g } z ^ { 2 g } + c _ { 2 g - 1 } z ^ { 2 g - 1 } + \dots + c _ { 0 },$$
herewith
$$L _ { 4 } = \sum _ { i = - 2 } ^ { 2 } u _ { i } ( n ) T ^ { i }, \quad L _ { 4 g + 2 } = \sum _ { i = - ( 2 g + 1 ) } ^ { 2 g + 1 } v _ { i } ( n ) T ^ { i }, \quad u _ { 2 } = v _ { 2 g + 1 } = 1, \quad \ ( 2 ) \\ _ { - } \cdot \cdot \cdot \cdot _ { - } \cdot \cdot \cdot \cdot _ { - } \cdot \cdot \cdot \cdot _ { - } \cdot \cdot \cdot \cdot _ { - } \cdot \cdot \cdot \cdot \cdot _ { - } \cdot \cdot \cdot \cdot \cdot$$
$$L _ { 4 } \psi = z \psi, \quad L _ { 4 g + 2 } \psi = w \psi, \quad \psi = \psi ( n, P ), \quad P = ( z, w ) \in \Gamma. \quad \ \ ( 3 )$$
Common eigenfunctions of L 4 and L 4 g +2 satisfy the equation
$$\psi ( n + 1, P ) = \chi _ { 1 } ( n, P ) \psi ( n - 1, P ) + \chi _ { 2 } ( n, P ) \psi ( n, P ),$$
where χ 1 ( n, P ) and χ 2 ( n, P ) are rational functions on Γ having 2 g simple poles, depending on n (see [2]). The function χ 2 ( n, P ) additionally has a simple pole at q = ∞ . To
find L 4 and L 4 g +2 it is sufficient to find χ 1 and χ . 2 Let σ be the holomorphic involution on Γ , σ z, w ( ) = σ z, ( -w . ) The main results of this paper are Theorems 1-4.
## Theorem 1 If
$$\chi _ { 1 } ( n, P ) = \chi _ { 1 } ( n, \sigma ( P ) ), \quad \chi _ { 2 } ( n, P ) = - \chi _ { 2 } ( n, \sigma ( P ) ),$$
then L 4 has the form
$$L _ { 4 } = ( T + V _ { n } T ^ { - 1 } ) ^ { 2 } + W _ { n },$$
where
$$\chi _ { 1 } = - V _ { n } \frac { Q _ { n + 1 } } { Q _ { n } }, \quad \chi _ { 2 } = \frac { w } { Q _ { n } }, \quad Q _ { n } ( z ) = z ^ { g } + \alpha _ { g - 1 } ( n ) z ^ { g - 1 } + \dots + \alpha _ { 0 } ( n ). \quad ( 7 )$$
Functions V , W , Q n n n satisfy
$$F _ { g } ( z ) = Q _ { n - 1 } Q _ { n + 1 } V _ { n } + Q _ { n } Q _ { n + 2 } V _ { n + 1 } + Q _ { n } Q _ { n + 1 } ( z - V _ { n } - V _ { n + 1 } - W _ { n } ).$$
In Theorem 1 and further we use the notations V n = V ( n , W ) n = W n ( ). It is a remarkable fact that (8) can be linearized. Namely, if we replace n → n +1 and take the difference with (8), then the result can be divided by Q n +1 ( z . ) Finally we obtain the linear equation on Q n ( z ).
Corollary 1 Functions Q n ( z , V ) n , W n satisfy
$$Q _ { n - 1 } V _ { n } + Q _ { n } ( z - V _ { n } - V _ { n + 1 } - W _ { n } ) - Q _ { n + 2 } ( z - V _ { n + 1 } - V _ { n + 2 } - W _ { n + 1 } ) - Q _ { n + 3 } V _ { n + 2 } = 0. \ ( 9 )$$
At g = 1, the equation (8) allows us to express V , W n n via a functional parameter γ . n
Corollary 2 The operator L 4 = ( T + V T n -1 ) 2 + W , n where
$$V _ { n } = \frac { F _ { 1 } ( \gamma _ { n } ) } { ( \gamma _ { n } - \gamma _ { n - 1 } ) ( \gamma _ { n } - \gamma _ { n + 1 } ) }, \quad W _ { n } = - c _ { 2 } - \gamma _ { n } - \gamma _ { n + 1 },$$
commutes with
$$L _ { 6 } = T ^ { 3 } + ( V _ { n } + V _ { n + 1 } + V _ { n + 2 } + W _ { n } - \gamma _ { n + 2 } ) T +$$
$$\begin{matrix} + V _ { n } ( V _ { n - 1 } + V _ { n } + V _ { n + 1 } + W _ { n } - \gamma _ { n - 1 } ) T ^ { - 1 } + V _ { n - 2 } V _ { n - 1 } V _ { n } T ^ { - 3 }. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{matrix}$$
The spectral curve of L , L 4 6 is w 2 = F 1 ( z . )
In the theory of commuting ordinary differential operators there are equations which are similar to (8), (9). Let us compare (8), (9) with their smooth analogues. First, we consider the one-dimensional finite-gap Schr¨dinger operator o L 2 = -∂ 2 x + V ( x ) commuting with a differential operator L 2 g +1 of order 2 g +1. The theory of such operators is
closely related to the theory of periodic and quasiperiodic solutions of the Korteweg-de Vries equation (see [34]-[36]). Denote by ψ a common eigenfunction
$$( - \partial _ { x } ^ { 2 } + \mathcal { V } ( x ) ) \psi = z \psi, \quad \mathcal { L } _ { 2 g + 1 } \psi = w \psi.$$
The point P = ( z, w ) belongs to the spectral curve (1). Function ψ x, P ( ) satisfies
$$\psi ^ { \prime } ( x, P ) = i \chi _ { 0 } ( x, P ) \psi ( x, P ),$$
where
$$\chi _ { 0 } = \frac { \mathcal { Q } _ { x } } { 2 i \mathcal { Q } } + \frac { w } { \mathcal { Q } }, \quad \mathcal { Q } = z ^ { g } + \alpha _ { g - 1 } ( x ) z ^ { g - 1 } + \dots + \alpha _ { 0 } ( x ).$$
Polynomial Q satisfies the equation
$$4 F _ { g } ( z ) = 4 ( z - \mathcal { V } ) \mathcal { Q } ^ { 2 } - ( \mathcal { Q } _ { x } ) ^ { 2 } + 2 \mathcal { Q } \mathcal { Q } _ { x x },$$
which is linearized as well as (8) (see [37], [38])
$$\mathcal { Q } _ { x x x } - 4 \mathcal { Q } _ { x } ( \mathcal { V } - z ) - 2 \mathcal { V } _ { x } \mathcal { Q } = 0.$$
Equations (8), (9) are analogues of the last two.
Let us consider one more example. We denote by L 4 , L 4 g +2 rank two commuting differential operators with the spectral curve (1). The common eigenfunctions of L 4 and L 4 g +2 satisfy
$$\psi ^ { ^ { \prime \prime } } = \chi _ { 1 } ( x, P ) \psi ^ { \prime } + \chi _ { 0 } ( x, P ) \psi.$$
In [5] it was proved that L 4 is self-adjoint if and only if χ 1 ( x, P ) = χ 1 ( x, σ ( P )) , herewith
$$\mathcal { L } _ { 4 } = ( \partial _ { x } ^ { 2 } + \mathcal { V } ( x ) ) ^ { 2 } + \mathcal { W } ( x ),$$
$$\chi _ { 0 } = - \frac { 1 } { 2 } \frac { \mathcal { Q } _ { x x } } { \mathcal { Q } } + \frac { w } { \mathcal { Q } } - \mathcal { V }, \quad \chi _ { 1 } = \frac { \mathcal { Q } _ { x } } { \mathcal { Q } }, \quad \mathcal { Q } = z ^ { g } + \alpha _ { g - 1 } ( x ) z ^ { g - 1 } + \dots + \alpha _ { 0 } ( x ),$$
polynomial Q satisfies
$$4 F _ { g } ( z ) = 4 ( z - \mathcal { W } ) \mathcal { Q } ^ { 2 } - 4 \mathcal { V } ( \mathcal { Q } _ { x } ) ^ { 2 } + \mathcal { Q } _ { x x } ^ { 2 } - 2 \mathcal { Q } _ { x } \mathcal { Q } _ { x x x } + 2 \mathcal { Q } ( 2 \mathcal { V } _ { x } \mathcal { Q } _ { x } + 4 \mathcal { V } \mathcal { Q } _ { x x } + \mathcal { Q } _ { x x x x } ), \ ( 1 1 )$$
and also satisfies
$$\partial _ { x } ^ { 5 } \mathcal { Q } + 4 \mathcal { V } \mathcal { Q } _ { x x x } + 2 \mathcal { Q } _ { x } ( 2 z - 2 \mathcal { W } - \mathcal { V } _ { x x } ) + 6 \mathcal { V } _ { x } \mathcal { Q } _ { x x } - 2 \mathcal { Q } \mathcal { W } _ { x } = 0.$$
Equations (8), (9) are discrete analogues of (11), (12).
Theorem 1 allows us to construct the examples.
## Theorem 2 The operator
/negationslash
$$L _ { 4 } ^ { \mathfrak { f } } = ( T + ( r _ { 3 } n ^ { 3 } + r _ { 2 } n ^ { 2 } + r _ { 1 } n + r _ { 0 } ) T ^ { - 1 } ) ^ { 2 } + g ( g + 1 ) r _ { 3 } n, \quad r _ { 3 } \neq 0$$
commutes with a difference operator L /sharp 4 g +2 .
Theorem 3 The operator
/negationslash
$$L _ { 4 } ^ { \ < } = ( T + ( r _ { 1 } a ^ { n } + r _ { 0 } ) T ^ { - 1 } ) ^ { 2 } + r _ { 1 } ( a ^ { 2 g + 1 } - a ^ { g + 1 } - a ^ { g } + 1 ) a ^ { n - g }, \quad r _ { 1 }, a \neq 0,$$
/negationslash where a 2 g +1 -a g +1 -a g +1 = 0 , commutes with a difference operator L /check 4 g +2 .
## Theorem 4 The operator
/negationslash
$$L _ { 4 } ^ { \ddagger } = ( T + ( r _ { 1 } \cos ( n ) + r _ { 0 } ) T ^ { - 1 } ) ^ { 2 } - 4 r _ { 1 } \sin ( \frac { g } { 2 } ) \sin ( \frac { g + 1 } { 2 } ) \cos ( n + \frac { 1 } { 2 } ), \quad r _ { 1 } \neq 0$$
commutes with a difference operator L /natural 4 g +2 .
In Section 2 we recall the Krichever-Novikov equations on Tyurin parameters.
In Section 3 we prove Theorems 1-4 and consider examples.
In Appendix we consider the differential-difference system on V n ( ) t , W t n ( )
$$\dot { V } _ { n } = V _ { n } ( W _ { n - 1 } - W _ { n } + V _ { n - 1 } - V _ { n + 1 } ),$$
$$\dot { W } _ { n } = ( W _ { n } - W _ { n - 1 } ) V _ { n } + ( W _ { n + 1 } - W _ { n } ) V _ { n + 1 }.$$
$$\mathcal { W } _ { n } - W _ { n - 1 } ) V _ { n } + \underset { \dots } { ( W _ { n + 1 } - W _ { n } ) V _ { n + 1 } }. \underset { \dots } { ( W _ { n + 1 } - W _ { n } ) V _ { n + 1 } }. \underset { \dots } { ( 1 4 ) }$$
From (13), (14) it follows that ϕ n ( ), where t e ϕ n ( ) t = V n ( ), satisfies the generalized Toda t chain
$$\ddot { \varphi } _ { n } = e ^ { \varphi _ { n - 2 } + \varphi _ { n - 1 } } - e ^ { \varphi _ { n - 1 } + \varphi _ { n } } + e ^ { \varphi _ { n + 1 } + \varphi _ { n + 2 } } - e ^ { \varphi _ { n + 1 } + \varphi _ { n } }.$$
From (13), (14) it follows also that
$$[ L _ { 4 }, \partial _ { t } - V _ { n - 1 } ( t ) V _ { n } ( t ) T ^ { - 2 } ] = 0,$$
where L 4 = ( T + V n ( ) t T -1 ) 2 + W t . n ( ) Following [1], [2] we call the solution V n ( ) t , W n ( ) t of (13), (14) the solution of rank two , if additionally [ L , L 4 4 g +2 ] = 0 for some difference operator L 4 g +2 . In the case of rank two solutions an evolution equation on Q n ( ) t is obtained in Theorem 5. At g = 1 this equation is reduced to a discrete analogue of the Krichever-Novikov equation, which appeared in the theory of rank two solutions of KP.
## 2 Discrete dynamics of the Tyurin parameters
As mentioned above, in the case of rank one operators the eigenfunctions can be found explicitly in terms of theta-functions of the Jacobi varieties of spectral curves. Let us consider the simplest example. Let Γ be an elliptic curve Γ = C / { Z + τ Z } , τ ∈ C , Im τ > 0 , and θ z ( ) the theta-function θ z ( ) = ∑ n ∈ Z exp( πin τ 2 + 2 πinz . ) The Baker-Akhiezer function has the form
$$\psi ( n, z ) = \frac { \theta ( z + c + n h ) } { \theta ( z ) } \left ( \frac { \theta ( z - h ) } { \theta ( z ) } \right ) ^ { n }, \quad c, h \notin \{ \mathbb { Z } + \tau \mathbb { Z } \}.$$
For the meromorphic function λ = θ z ( -a 1 ) ... ( z -a k ) θ k ( z ) , a 1 + . . . + a k = 0 there is a unique operator L λ ( ) = v k ( n T ) k + . . . + v 0 ( n ) such that L λ ψ ( ) = λψ. Coefficients of L λ ( ) can be found from the last identity (see [39]). Operators L λ ( ) for different λ form a commutative ring of difference operators. This example can be generalized from the elliptic spectral curves to the principle polarized abelian spectral varieties. It allows to construct commuting difference operators in several discrete variables with matrix coefficients (see [39]).
At l > 1 common eigenfunctions cannot be found explicitly. This is the main difficulty for constructing higher rank operators and higher rank solutions of the 2DToda chain. Recall the needed results of [2]. One-point commuting operators of rank l have the form
$$L = \sum _ { i = - N r _ { - } } ^ { N r _ { + } } u _ { i } ( n ) T ^ { i }, \quad A = \sum _ { i = - M r _ { - } } ^ { M r _ { + } } v _ { i } ( n ) T ^ { i }, \\ + \, r \,. \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \, \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
where l = r -+ r + , ( N,M ) = 1. Consider the space H ( z ) of solutions of the equation Ly = zy. We have dim H ( z ) = N r ( -+ r + ) . The operator A defines the linear operator A z ( ) on H ( z . ) Let us choose the basis ϕ i ( n ) in H ( z ), satisfying the normalization conditions ϕ i ( n ) = δ in , -Nr -≤ i, n < Nr . + The components of A z ( ) in the basis ϕ i ( n ) are polynomials in z . The characteristic polynomial of A z ( ) has the form det( w -A z ( )) = R w,z . l ( ) Polynomial R defines the spectral curve Γ, i.e.
$$L \psi = z \psi, \quad A \psi = w \psi, \quad R ( z, w ) = 0.$$
Common eigenfunctions of L and A form a vector bundle of rank l over the affine part of Γ. Let us choose the basis in the space of common eigenfunctions such that
$$\psi _ { n } ^ { i } ( P ) = \delta _ { i, n }, \quad - r _ { - } \leq i, n < r _ { + }, \quad P = ( z, w ) \in \Gamma.$$
Functions ψ i n ( P ) have the pole divisor γ = γ 1 + . . . + γ lg of degree lg . We have the following identities
$$\alpha _ { s } ^ { j } \text{Res} _ { \gamma _ { s } } \psi _ { n } ^ { i } ( P ) = \alpha _ { s } ^ { i } \text{Res} _ { \gamma _ { s } } \psi _ { n } ^ { j } ( P ).$$
The pair ( γ, α ) is called the Tyurin parameters , where α is the set of vectors
$$\alpha _ { 1 }, \dots, \alpha _ { l g }, \quad \alpha _ { s } = ( \alpha _ { s } ^ { - r _ { - } }, \dots, \alpha _ { s } ^ { r _ { + } - 1 } ).$$
The Tyurin parameters define a stable holomorphic vector bundle on Γ of degree lg with holomorphic sections ζ -r -, . . . , ζ r + -1 , where γ is the divisor of their linear dependence ∑ r + -1 j = -r -α ζ j s j ( γ s ) = 0 . Let Ψ( n, P ) be the Wronski matrix with the components Ψ ( ij n, P ) = ψ i n + j ( P , ) -r -≤ i, j < r + . Function detΨ( n, P ) is holomorphic in the neighbourhood of q = ∞ . The pole divisor of detΨ( n, P ) is γ , the zero divisor of detΨ( n, P ) is γ n ( ) = γ 1 ( n ) + · · · + γ lg ( n , ) herewith γ (0) = γ . Consider the matrix function χ n, P ( ) = Ψ( n +1 , P )Ψ -1 ( n, P ) ,
$$\text{uncon } \chi ( n, r ) = \Psi ( n + 1, r ) \Psi ( n, r ), \\ \chi ( n, P ) = \left ( \begin{array} { c c c c c } 0 & 1 & 0 & \dots & 0 \\ 0 & 0 & 1 & \dots & 0 \\ \dots & \dots & \dots & \dots \\ 0 & 0 & 0 & \dots & 1 \\ \chi _ { - r _ { - } } ( n, P ) & \chi _ { - r _ { - } + 1 } ( n, P ) & \chi _ { - r _ { - } + 2 } ( n, P ) & \dots & \chi _ { r _ { + } - 1 } ( n, P ) \end{array} \right ). \\ \text{$\kappa }$$
In the neighbourhood of q we have χ i ( n, k ) = k -1 δ i, 0 -f i ( n, k ) , where k is a local parameter near q , f i ( n, k ) is an analytical function in the neighbourhood of q .
Theorem (I.M. Krichever, S.P. Novikov)
The matrix function χ n, P ( ) has simple poles in γ s ( n ) , and
$$\alpha _ { s } ^ { j } ( n ) \text{Res} _ { \gamma _ { s } ( n ) } \chi _ { i } ( n, P ) = \alpha _ { s } ^ { i } ( n ) \text{Res} _ { \gamma _ { s } ( n ) } \chi _ { j } ( n, P ).$$
Points γ s ( n +1) are zeros of det χ n, P ( )
$$\det \chi ( n, \gamma _ { s } ( n + 1 ) ) = 0.$$
Vectors α j ( n +1) = ( α -r -s ( n +1) , . . . , α r + -1 s ( n +1)) satisfy
$$\alpha _ { s } ( n + 1 ) \chi ( n, \gamma _ { s } ( n + 1 ) ) = 0.$$
Equations (16)-(18) define the discrete dynamics of the Tyurin parameters. In [2] solutions of (16)-(18) are found at g = 1 , l = 2. The corresponding operators in the simplest case have the form
$$L = L _ { 2 } ^ { 2 } - \wp ( \gamma _ { n } ) - \wp ( \gamma _ { n - 1 } ),$$
L 2 is the difference Schr¨dinger operator o L 2 = T + v n + c n T -1 with the coefficients
$$c _ { n } = \frac { 1 } { 4 } ( s _ { n - 1 } ^ { 2 } - 1 ) F ( \gamma _ { n }, \gamma _ { n - 1 } ) F ( \gamma _ { n - 2 }, \gamma _ { n - 1 } ), \quad v _ { n } = \frac { 1 } { 2 } ( s _ { n - 1 } F ( \gamma _ { n }, \gamma _ { n - 1 } ) - s _ { n } F ( \gamma _ { n - 1 }, \gamma _ { n } ) ),$$
where
$$F ( u, v ) = \zeta ( u + v ) - \zeta ( u - v ) - 2 \zeta ( v ).$$
Here, ℘ u , ζ ( ) ( u ) are the Weierstrass functions, s n , γ n are the functional parameters.
## 3 Proof of Theorems 1-4
Let Γ be the hyperelliptic spectral curve (1), L , L 4 4 g +2 are operators of the form (2) with the properties (3). Matrix χ n, P ( ) = Ψ( n +1 , P )Ψ -1 ( n, P ) has the form
$$\chi ( n, P ) = \left ( \begin{array} { c c } 0 & 1 \\ \chi _ { 1 } ( n, P ) & \chi _ { 2 } ( n, P ) \end{array} \right ).$$
The functions χ , χ 1 2 have the following expansions in the neighbourhood of q = ∞ :
$$\chi _ { 1 } ( n ) = b _ { 0 } ( n ) + b _ { 1 } ( n ) k + \dots, \quad \chi _ { 2 } ( n ) = 1 / k + e _ { 0 } ( n ) + e _ { 1 } ( n ) k + \dots, \quad ( 1 9 )$$
where k = 1 √ z .
## Lemma 1 The operator
$$L _ { 4 } = T ^ { 2 } + u _ { 1 } ( n ) T + u _ { 0 } ( n ) + u _ { - 1 } ( n ) T ^ { - 1 } + u _ { - 2 } ( n ) T ^ { - 2 }$$
has the coefficients:
$$u _ { 1 } ( n ) = - e _ { 0 } ( n ) - e _ { 0 } ( n + 1 ), \quad u _ { 0 } ( n ) = e _ { 0 } ^ { 2 } ( n ) + e _ { 1 } ( n ) - e _ { 1 } ( n + 1 ) - b _ { 0 } ( n ) - b _ { 0 } ( n + 1 ),$$
$$u _ { - 1 } ( n ) = b _ { 0 } ( n ) \left ( e _ { 0 } ( n ) + e _ { 0 } ( n - 1 ) - \frac { b _ { 1 } ( n - 1 ) } { b _ { 0 } ( n - 1 ) } \right ) - b _ { 1 } ( n ), \quad u _ { - 2 } ( n ) = b _ { 0 } ( n ) b _ { 0 } ( n - 1 ).$$
If b 1 ( n ) = 0 , e 0 ( n ) = 0 , then L 4 can be written in the form (6), where
$$V _ { n } = - b _ { 0 } ( n ), \quad W _ { n } = - e _ { 1 } ( n ) - e _ { 1 } ( n + 1 ).$$
Proof Using (4) let us express ψ n +2 ( P ) and ψ n -2 ( P ) via ψ n -1 ( P , ψ ) n ( P , χ ) 1 ( n, P ) , χ 2 ( n, P )
$$\psi _ { n + 2 } = \psi _ { n - 1 } \chi _ { 1 } ( n ) \chi _ { 2 } ( n + 1 ) + \psi _ { n } ( \chi _ { 1 } ( n + 1 ) + \chi _ { 2 } ( n ) \chi _ { 2 } ( n + 1 ) ), \quad \psi _ { n - 2 } = \frac { \psi _ { n } - \psi _ { n - 1 } \chi _ { 2 } ( n - 1 ) } { \chi _ { 1 } ( n - 1 ) },$$
and substitute it in L ψ 4 n = zψ n . We get P 1 ( n, P ) ψ n ( P ) + P 2 ( n, P ) ψ n -1 ( P ) = zψ n ( P , ) where
$$P _ { 1 } ( n ) = \chi _ { 1 } ( n + 1 ) + \chi _ { 2 } ( n + 1 ) \chi _ { 2 } ( n ) + u _ { 1 } ( n ) \chi _ { 2 } ( n ) + u _ { 0 } ( n ) + \frac { u _ { - 2 } ( n ) } { \chi _ { 1 } ( n - 1 ) },$$
$$P _ { 2 } ( n ) = \chi _ { 2 } ( n + 1 ) \chi _ { 1 } ( n ) + u _ { 1 } ( n ) \chi _ { 1 } ( n ) + u _ { - 1 } ( n ) - u _ { - 2 } ( n ) \frac { \chi _ { 2 } ( n - 1 ) } { \chi _ { 1 } ( n - 1 ) }.$$
Consequently we have
$$P _ { 1 } = z = \frac { 1 } { k ^ { 2 } }, \quad P _ { 2 } = 0.$$
From (19), (20) it follows that
$$P _ { 1 } - \frac { 1 } { k ^ { 2 } } = \frac { e _ { 0 } ( n ) + e _ { 0 } ( n + 1 ) + u _ { 1 } ( n ) } { k } + ( b _ { 0 } ( n + 1 ) + e _ { 0 } ( n ) e _ { 0 } ( n + 1 ) + e _ { 1 } ( n ) +$$
$$e _ { 1 } ( n + 1 ) + u _ { 0 } ( n ) + e _ { 0 } ( n ) u _ { 1 } ( n ) + \frac { u _ { - 2 } ( n ) } { b _ { 0 } ( n - 1 ) } \Big ) + O ( k ) = 0,$$
$$P _ { 2 } = \frac { b _ { 0 } ( n ) - \frac { u _ { - 2 } ( n ) } { b _ { 0 } ( n - 1 ) } } { k } + ( b _ { 1 } ( n ) + b _ { 0 } ( n ) e _ { 0 } ( n + 1 ) + b _ { 0 } ( n ) u _ { 1 } ( n ) + \\........................................................................................................................................................................................................$$
$$u _ { - 1 } ( n ) + \frac { b _ { 1 } ( n - 1$$
This yields the formulas for the coefficients of L . 4 By direct calculations one can check that if b 1 ( n ) = e 0 ( n ) = 0, then L 4 has the form (6). Lemma 1 is proved.
Thus if χ , χ 1 2 satisfy (5), then b 1 ( n ) = e 0 ( n ) = 0 , and hence L 4 has the form (6). Operators L 4 -z and L 4 g +2 -w have the common right divisor T -χ 2 ( n ) -χ 1 ( n T ) -1 , i.e.
$$L _ { 4 } - z = l _ { 1 } ( T - \chi _ { 2 }$$
where l 1 and l 2 are operators of orders 2 and 4 g . Let us assume that (5) holds. Then
$$( T + V _ { n } T ^ { - 1 } ) ^ { 2 } + W _$$
where χ 1 , χ 2 satisfy the equations
$$V _ { n - 1 } V _ { n } + \chi _ { 1 } ( n -$$
$$\begin{array} {$$
We have det χ n, P ( ) = -χ 1 ( n, P ) = detΨ( n + 1 , P )(detΨ( n, P )) -1 . The degree of the zero divisor γ n ( ) of detΨ( n, P ) is 2 g. Since χ 1 is invariant under the involution σ , the divisor γ n ( ) has the form
$$\gamma ( n ) = \gamma _ { 1 } ( n ) + \sigma \gamma _ { 1 } ( n ) + \dots + \gamma _ { g } ( n ) + \sigma \gamma _ { g } ( n ).$$
Let γ i ( n ) have the coordinates ( µ i ( n , w ) i ( n )) . We introduce the polynomial in z
$$Q _ { n } = ( z - \mu _ { 1 } ( n ) ) \dots ( z - \mu _ { g } ( n ) ).$$
From (17) we have χ 1 ( n, P ) = b 0 ( n ) Q n +1 Q n , where b 0 ( n ) is some function. In the neighbourhood of q we have
$$\chi _ { 1 } = b _ { 0 } ( n ) + b _ { 2 } ( n ) k ^ { 2 } + O ( k ^ { 4 } ).$$
By Lemma 1 V n = -b 0 ( n , ) so we get χ 1 ( n, P ) = -V n Q n +1 Q n .
Since the pole divisor of χ 2 ( n, P ) is γ n ( ) and in the neighborhood of q we have (19), then χ 2 ( n, P ) = w Q n .
If χ 1 ( n, P ) = -V n Q n +1 Q n and χ 2 ( n, P ) = w Q n , then (22) holds identically, and (21) is reduced to (8). Theorem 1 is proved.
To prove Theorems 2-4 it is sufficient to prove that for potentials V , W n n from Theorems 2-4 there are polynomials Q n ( z ) of degree g in z which satisfy (9) (and hence satisfy (8)).
## 3.1 Theorem 2
Let V n = r n 3 3 + r n 2 2 + r n 1 + r , W 0 n = g g ( +1) r n, 3 then (9) takes the form
Q n -1 ( n r 3 3 + n r 2 2 + nr 1 + r 0 )+ Q n ( z -2 n r 3 3 -n 2 (2 r 2 +3 r 3 ) -n (2 r 1 +2 r 2 +3 r 3 + ( g g +1) r 3 )
$$- \left ( 2 r _ { 0 } + r _ { 1 } + r _ { 2 } + r _ { 3 } \right ) \right ) - Q _ { n + 2 } \left ( z - 2 n ^ { 3 } r _ { 3 } - n ^ { 2 } ( 2 r _ { 2 } + 9 r _ { 3 } ) - \\ \wedge$$
n
(2
r
1
+6
r
2
+15
r
3
+ (1 +
g
g r
)
3
)
-
(2
r
0
+3
r
1
+5
r
2
+9
r
3
+ (
g g
+1)
r
3
))
-
$$Q _ { n + 3 } \left ( n ^ { 3 } r _ { 3 } + n ^ { 2 } ( r _ { 2 } + 6 r _ { 3 } ) + n ( r _ { 1 } + 4 r _ { 2 } + 1 2 r _ { 3 } ) + r _ { 0 } + 2 r _ { 1 } + 4 r _ { 2 } + 8 r _ { 3 } \right ) & = 0. \quad ( 2 3 ) \\ \text{Let us take the following ansatz for } Q _ { n } ( z )$$
Let us take the following ansatz for Q n ( z )
$$Q _ { n } = \delta _ { g } n ^ { g } + \dots + \delta _ { 1 } n + \delta _ { 0 }, \quad \delta _ { i } = \delta _ { i } ( z ),$$
then (23) can be rewritten in the form
$$\beta _ { g + 3 } ( z ) n ^ { g + 3 } + \beta _ { g + 2 } ( z ) n ^ { g + 2 } + \dots + \beta _ { 0 } ( z ) = 0$$
for some β s ( z ). Potentials V , W n n have the following remarkable properties: it turns out that
$$\beta _ { g } = \beta _ { g + 1 } = \beta _ { g + 2 } = \beta _ { g + 3 } = 0$$
automatically (this can be checked by direct calculations). From (23) we find β s
$$\beta _ { s } & = r _ { 3 } ( 2 s + 1 ) ( g ( g + 1 ) - s ( s + 1 ) ) \delta _ { s } + \sum _ { m = 1 } ^ { g } \left ( ( - 1 ) ^ { m } \left ( C _ { s + m } ^ { m } r _ { 0 } - C _ { s + m } ^ { m + 1 } r _ { 1 } \, + \\ _ { \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots }.$$
$$\overline { m = 1 } \quad \begin{array} { c } \\ C ^ { m + 2 } _ { s + m } r _ { 2 } - C ^ { m + 3 } _ { s + m } r _ { 3 } \right ) + 2 ^ { m } \left ( C ^ { m } _ { s + m } ( 2 r _ { 0 } + 3 r _ { 1 } + 5 r _ { 2 } + 9 r _ { 3 } + g ( g + 1 ) r _ { 3 } - z ) + \\ 2 C ^ { m + 1 } _ { s + m } ( 2 r _ { 1 } + 6 r _ { 2 } + 1 5 r _ { 3 } + g ( g + 1 ) r _ { 3 } ) + 4 C ^ { m + 2 } _ { s + m } ( 2 r _ { 2 } + 9 r _ { 3 } ) + 1 6 C ^ { m + 3 } _ { s + m } r _ { 3 } \right ) - \\ 3 ^ { m } \left ( C ^ { m } _ { s + m } ( r _ { 0 } + 2 r _ { 1 } + 4 r _ { 2 } + 8 r _ { 3 } ) + 3 C ^ { m + 1 } _ { s + m } ( r _ { 1 } + 4 r _ { 2 } + 1 2 r _ { 3 } ) + \\ 3 ^ { m } \left ( C ^ { m } _ { s + m } ( r _ { 0 } + 2 r _ { 1 } + 4 r _ { 2 } + 8 r _ { 3 } ) + 3 C ^ { m + 1 } _ { s + m } ( r _ { 1 } + 4 r _ { 2 } + 1 2 r _ { 3 } ) + \\ 9 C ^ { m + 2 } _ { s + m } ( r _ { 2 } + 6 r _ { 3 } ) + 2 7 C ^ { m + 3 } _ { s + m } r _ { 3 } \right ) \right ) \delta _ { s + m }, \\ \text{where } 0 \leq s < g - 1, \text{ } C ^ { k } _ { m } = \frac { m! } { k! ( m - k )! } \text{ at } m \geq k, C ^ { k } _ { m } = 0 \text{ at } m < k, \delta _ { g } \text{ is a constant and} \\ \delta _ { s } = 0, \text{ if } s > g. \text{ From } \beta _ { s } = 0 \text{ we express } \delta _ { s } \text{ via } \delta _ { s + 1 }, \dots, \delta _ { g }. \text{ In particular}, \end{array}$$
where 0 ≤ s < g -1 , C k m = m ! k !( m k -)! at m ≥ k, C k m = 0 at m < k, δ g is a constant and δ s = 0 , if s > g. From β s = 0 we express δ s via δ s +1 , . . . , δ g . In particular,
$$\delta _ { g - 1 } = \frac { \delta _ { g } ( 2 g ^ { 2 } r _ { 2 } + g ( g + 1 ) r _ { 3 } + 2 z ) } { 2 ( 2 g - 1 ) r _ { 3 } }.$$
For a suitable δ g we have Q n = z g + α g -1 ( n z ) g -1 + . . . + α 0 ( n . ) So we proved that there exists Q n satisfying (9). Theorem 2 is proved.
In [5] it was proved that
$$\mathcal { L } _ { 4 } ^ { \ddagger } = ( \partial _ { x } ^ { 2 } + r _ { 3 } x ^ { 3 } + r _ { 2 } x ^ { 2 } + r _ { 1 } x + r _ { 0 } ) ^ { 2 } + g ( g + 1 ) r _ { 3 } x$$
commutes with a differential operator L /sharp 4 g +2 of order 4 g + 2. The operator L /sharp 4 is a discrete analogue of L /sharp 4 . At g = 1 the operators L /sharp 4 , L /sharp 6 were found by Dixmier [10]. The operators L /sharp 4 , L /sharp 4 g +2 define a commutative subalgebra in the first Weyl algebra.
Let us consider the algebra W generated by two elements p and q with the relation [ p, q ] = p. Since [ T, n ] = T , the algebra is isomorphic to the algebra of difference operators with polynomial coefficients. The algebra W has the following automorphisms
$$H \, \colon W \to W, \quad H ( p ) = p, \quad H ( q ) = q + G ( p ),$$
where G is an arbitrary polynomial. Operators L /sharp 4 , L /sharp 4 g +2 define the commutative subalgebra in W . Consequently, if we replace n → n + G T ( ) in L /sharp 4 , L /sharp 4 g +2 , then we obtain the new commuting difference operators with polynomial coefficients.
## 3.2 Theorem 3
Let V n = r a 1 n + r 0 , W n = ( a 2 g +1 -a g +1 -a g +1) r a 1 n -g , then (9) takes the form
$$Q _ { n + 2 } \left ( 2 r _ { 0 } + a ^ { n + 1 - g } r _ { 1 } + a ^ { n + g + 2 } r _ { 1 } - z \right ) - Q _ { n + 3 } \left ( r _ { 0 } + a ^ { n + 2 } r _ { 1 } \right ) = 0.$$
Let Q n = B a g gn + B g -1 a ( g -1) n + . . . + B a 1 n + B , B 0 i = B z . i ( ) We introduce the notation y = a n , then Q n = B y g g + · · · + B 0 , and (25) takes the form
$$Q _ { n - 1 } \left ( r _ { 0 } + a ^ { n } r _ { 1 } \right ) + Q _ { n } \left ( z - 2 r _ { 0 } - a ^ { n - g } r _ { 1 } - a ^ { n + g + 1 } r _ { 1 } \right ) + \\ Q _ { n + 2 } \left ( 2 r _ { 0 } + a ^ { n + 1 - g } r _ { 1 } + a ^ { n + g + 2 } r _ { 1 } - z \right ) - Q _ { n + 3 } \left ( r _ { 0 } + a ^ { n + 2 } r _ { 1 } \right ) = 0. \\ \varepsilon = B _ { g } a _ { \begin{smallmatrix} g ^ { n } \\ \varepsilon \end{smallmatrix} } ^ { g n } + B _ { g - 1 } a _ { \begin{smallmatrix} a ^ { ( g - 1 ) n } + \dots + B _ { 1 } a ^ { n } + B _ { 0 }, B _ { i } = B _ { i } ( z ). \text{ We introduce the nc} \end{smallmatrix} }$$
$$\sum _ { s = 0 } ^ { g } B _ { s } ( a ^ { - g - s } ( a ^ { g } - a ^ { s } ) ( a ^ { g + s + 1 } - 1 ) ( a ^ { 2 s + 1 } - 1 ) r _ { 1 } y ^ { s + 1 } - a ^ { - s } ( a ^ { 2 s } - 1 ) ( ( a ^ { s } - 1 ) ^ { 2 } r _ { 0 } + a ^ { s } z ) y ^ { s } ) =$$
$$\sum _ { s = 1 } ^ { g } y ^ { s } ( B _ { s } a ^ { - s } ( 1 - a ^ { 2 s } ) ( ( a ^ { s } - 1 ) ^ { 2 } r _ { 0 } + a ^ { s } z ) + B _ { s - 1 } a ^ { 1 - g - s } ( a ^ { g } - a ^ { s - 1 } ) ( a ^ { g + s } - 1 ) ( a ^ { 2 s - 1 } - 1 ) r _ { 1 } ) = 0. \\ \dots \dots$$
Hence we obtain
$$B _ { s - 1 } = B _ { s } \frac { a ^ { - s } ( a ^ { 2 s } - 1 ) ( ( a ^ { s } - 1 ) ^ { 2 } r _ { 0 } + a ^ { s } z ) } { a ^ { 1 - g - s } ( a ^ { g } - a ^ { s - 1 } ) ( a ^ { g + s } - 1 ) ( a ^ { 2 s - 1 } - 1 ) r _ { 1 } }, \quad s = 1, \dots, g.$$
Thus we found the polynomial Q , n satisfying (9). Theorem 3 is proved.
The operator L /check 4 is a discrete analogue of
$$\mathcal { L } _ { 4 } ^ { \vee } = ( \partial _ { x } ^ { 2 } + r _ { 1 } a ^ { x } + r _ { 0 } ) ^ { 2 } + g ( g + 1 ) r _ { 1 } a ^ { x }$$
from [26], which commutes with a differential operator of order 4 g +2.
## 3.3 Theorem 4
Let V n = r 1 cos( n ) + r , 0 W n = -4 r 1 sin( g 2 ) sin( g +1 2 ) cos( n + 1 2 ) . Equation (9) takes the form
$$& Q _ { n - 1 } \left ( r _ { 0 } + r _ { 1 } \cos ( n ) \right ) + Q _ { n } \left ( z - 2 r _ { 0 } - 2 r _ { 1 } \cos ( g + \frac { 1 } { 2 } ) \cos ( n + \frac { 1 } { 2 } ) \right ) - \\ Q _ { n + 2 } \left ( z - 2 r _ { 0 } - 2 r _ { 1 } \cos ( g + \frac { 1 } { 2 } ) \cos ( n + \frac { 3 } { 2 } ) \right ) - Q _ { n + 3 } \left ( r _ { 0 } + r _ { 1 } \cos ( n + 2 ) \right ) = 0. \\ & \text{Let us take the following ansatz}$$
Let us take the following ansatz
$$Q _ { n } = A _ { g } \cos ( g n ) + A _ { g - 1 } \cos ( ( g - 1 ) n ) + \dots + A _ { 1 } \cos ( n ) + A _ { 0 }, \quad A _ { i } = A _ { i } ( z ).$$
We substitute Q n in (26) and after some simplifications we obtain
$$A _ { 0 } = A _ { 1 } \frac { ( z - 2 r _ { 0 } + 2 r _ { 0 } \cos ( 1 ) ) \sin ( 1 ) } { 2 r _ { 1 } ( \cos ( g + \frac { 1 } { 2 } ) - \cos ( \frac { 1 } { 2 } ) ) \sin ( \frac { 1 } { 2 } ) },$$
$$A _ { s - 1 } = \frac { A _ { s } ( z - 2 r _ { 0 } + 2 r _ { 0 } \cos ( s ) ) \sin ( s ) + A _ { s + 1 } r _ { 1 } ( \cos ( s - \frac { 3 } { 2 } ) - \cos ( g + \frac { 1 } { 2 } ) ) \sin ( s - \frac { 3 } { 2 } ) } { r _ { 1 } ( \cos ( g + \frac { 1 } { 2 } ) - \cos ( s - \frac { 1 } { 2 } ) ) \sin ( s - \frac { 1 } { 2 } ) },$$
where 2 ≤ s ≤ g , A g +1 = 0, A g is a suitable constant. We found Q n satisfying (9). Theorem 4 is proved.
The operator L /natural 4 is a discrete analogue of
$$\mathcal { L } _ { 4 } ^ { \natural } = ( \partial _ { x } ^ { 2 } + r _ { 1 } \cos ( x ) + r _ { 0 } ) ^ { 2 } + g ( g + 1 ) r _ { 1 } \cos ( x )$$
from [29], which commutes with a differential operator of order 4 g +2. Let us consider several examples.
Example 1 We introduce the notation f ( n ) = r n 3 3 + r n 2 2 + r n 1 + r 0 . The operator
$$L _ { 4 } ^ { \mathfrak { z } } = ( T + f ( n ) T ^ { - 1 } ) ^ { 2 } + 2 r _ { 3 } n$$
commutes with
$$L _ { 6 } ^ { t } & = T ^ { 3 } + 3 ( f ( n ) + f ^ { \prime } ( n ) + f ^ { \prime \prime } ( n ) + 4 r _ { 3 } ) T + 3 ( f ( n ) + 3 r _ { 3 } n + r _ { 2 } ) T ^ { - 1 } + \\ & ( f ( n - 2 ) f ^ { \prime } ( n ) + 2 f ^ { \prime \prime } ( n ) - 8 r _ { 3 } ) ( f ( n ) - f ^ { \prime } ( n ) + 3 r _ { 3 } n - r _ { 3 } + r _ { 2 } ) f ( n ) T ^ { - 3 }.$$
The spectral curve is
$$w ^ { 2 } = z ^ { 3 } + ( 2 r _ { 2 } + 3 r _ { 3 } ) z ^ { 2 } + ( r _ { 1 } r _ { 3 } + ( r _ { 2 } + r _ { 3 } ) ( r _ { 2 } + 3 r _ { 3 } ) ) z + r _ { 3 } ( ( r _ { 2 } + r _ { 3 } ) ( r _ { 1 } + r _ { 2 } + r _ { 3 } ) - r _ { 0 } r _ { 3 } ).$$
Example 2 The operator
$$L _ { 4 } ^ { \breve { \cdot } } = ( T + ( r _ { 1 } a ^ { n } + r _ { 0 } ) T ^ { - 1 } ) ^ { 2 } + r _ { 1 } ( a ^ { 3 } - a ^ { 2 } - a + 1 ) a ^ { n - 1 }$$
commutes with
$$L _ { 6 } ^ { \cdot } = T ^ { 3 } + \left ( r _ { 0 } ( a + 1 + a ^ { - 1 } ) + r _ { 1 } a ^ { n - 1 } ( a ^ { 4 } + a ^ { 2 } + 1 ) \right ) T + ( a + 1 + a ^ { - 1 } ) ( r _ { 1 } a ^ { n } + r _ { 0 } ) \times \\ ( r _ { 1 } a ^ { n + 1 } - r _ { 1 } a ^ { n } + r _ { 1 } a ^ { n - 1 } + r _ { 0 } ) T ^ { - 1 } + ( r _ { 1 } a ^ { n } + r _ { 0 } ) ( r _ { 1 } a ^ { n - 1 } + r _ { 0 } ) ( r _ { 1 } a ^ { n - 2 } + r _ { 0 } ) T ^ { - 3 }. \\ \text{The spectral curve is $w^{2}=z^{3}+\frac{2r_{0}(a-1)^{2}} a z^{2}+\frac{r_{0}(a-1)^{4}} a z.$$
The spectral curve is a a
## Example 3 The operator
$$L _ { 4 } ^ { \natural } & = ( T + ( r _ { 1 } \cos ( n ) + r _ { 0 } ) T ^ { - 1 } ) ^ { 2 } - 4 r _ { 1 } \sin ( \frac { 1 } { 2 } ) \sin ( 1 ) \cos ( n + \frac { 1 } { 2 } ) \\ \dots$$
commutes with
$$L _ { 6 } ^ { \natural } = T ^ { 3 } + ( 2 \cos ( 1 ) + 1 ) ( r _ { 1 } ( 2 \cos ( 1 ) - 1 ) \cos ( n + 1 ) + r _ { 0 } ) \, T +$$
$$( 2 \cos ( 1 ) + 1 ) ( r _ { 1 } \cos ( n ) + r _ { 0 } ) ( r _ { 1 } ( 2 \cos ( 1 ) - 1 ) \cos ( n ) + r _ { 0 } ) T ^ { - 1 } +$$
$$( r _ { 1 } \cos ( n - 1 ) + r _ { 0 } ) ( r _ { 1 } \cos ( n - 2 ) + r _ { 0 } ) ( r _ { 1 } \cos ( n ) + r _ { 0 } ) T ^ { - 3 }.$$
The spectral curve is w 2 = z 3 -8 r 0 sin 2 ( 1 2 ) z 2 -8( r 2 1 (cos(1) + 1) -2 r 2 0 ) sin 4 ( 1 2 ) z.
Remark We see that the pairs of commuting operators L , L 4 4 g +2 and L 4 , L 4 g +2 have similar properties, and there are similar examples of such operators. It would be interesting to explain this duality. So far, our attempts to do so by some discretization were not successful.
Acknowledgements The authors are supported by a Grant of the Russian Federation for the State Support of Researches (Agreement No 14.B25.31.0029).
## Appendix
Consider the differential-difference system (13), (14).
Theorem 5 Let us assume that the potentials V n ( ) t , W t n ( ) of L 4 = ( T + V n ( ) t T -1 ) 2 + W t n ( ) satisfy (13), (14). We additionally assume that [ L , L 4 4 g +2 ] = 0 for some difference operator L 4 g +2 . Then Q n ( ) t associated with L 4 satisfies the evolution equation
$$\dot { Q } _ { n } = V _ { n } ( Q _ { n + 1 } - Q _ { n - 1 } ).$$
Equation (27) defines the symmetry of (8). At g = 1 functions V n ( ) t , W t n ( ) can be expressed via γ n ( ) using (9). t In this case the system (13), (14) and the equation (27) are reduced to one equation
$$\dot { \gamma } _ { n } = \frac { F _ { 1 } ( \gamma _ { n } ) ( \gamma _ { n - 1 } - \gamma _ { n + 1 } ) } { ( \gamma _ { n - 1 } - \gamma _ { n } ) ( \gamma _ { n } - \gamma _ { n + 1 } ) }.$$
This equation is a discrete analogue of the Krichever-Novikov equation, which appeared in the theory of rank two solutions of KP [1]. Equations similar to (13), (14) and (28) were considered in [40], [41].
Proof Using ( ∂ t -V n -1 ( ) t V n ( ) t T -2 ) ψ n = 0 , and (4) let us express ˙ ψ n -1 , ˙ ψ , ψ n ˙ n +1 , ψ n -2 , ψ n -3 in terms of ψ n -1 , ψ n , χ 1 ( n , χ ) 2 ( n )
$$\psi _ { n - 3 } \, \min \, \vee \, \psi _ { n - 1 }, \, \psi _ { n }, \, \lambda _ { 1 } \nwarrow, \, \lambda _ { 2 } \nwarrow \, \\ \dot { \psi } _ { n - 1 } = V _ { n - 2 } V _ { n - 1 } \psi _ { n - 3 }, \quad \dot { \psi } _ { n } = V _ { n - 1 } V _ { n } \psi _ { n - 2 }, \quad \dot { \psi } _ { n + 1 } = V _ { n } V _ { n + 1 } \psi _ { n - 1 }, \\ \psi _ { n - 2 } = \frac { \psi _ { n } - \psi _ { n - 1 } \chi _ { 2 } ( n - 1 ) } { \chi _ { 1 } ( n - 1 ) }, \\ \psi _ { n - 3 } = \frac { \psi _ { n - 1 } ( \chi _ { 1 } ( n - 1 ) + \chi _ { 2 } ( n - 2 ) \chi _ { 1 } ( n - 1 ) ) - \psi _ { n } \chi _ { 2 } ( n - 2 ) } { \chi _ { 1 } ( n - 2 ) \chi _ { 1 } ( n - 1 ) }. \\ \text{From } ( 4 ) \, \text{it follows that}$$
$$\dots$$
From (4) it follows that
$$\dot { \psi } _ { n + 1 } - \chi _ { 1 } ( n ) \dot { \psi } _ { n - 1 } - \dot { \chi } _ { 1 } ( n ) \psi _ { n - 1 } - \chi _ { 2 } ( n ) \dot { \psi } _ { n } - \dot { \chi } _ { 2 } ( n ) \psi _ { n } = \mathcal { A } _ { n } \psi _ { n } + \mathcal { B } _ { n } \psi _ { n - 1 } = 0,$$
where
$$\mathcal { A } _ { n } = V _ { n - 2 } V _ { n - 1 } \chi _ { 1 } ( n ) \chi _ { 2 } ( n - 2 ) - \chi _ { 1 } ( n - 2 ) ( V _ { n - 1 } V _ { n } \chi _ { 2 } ( n ) + \chi _ { 1 } ( n - 1 ) \dot { \chi } _ { 2 } ( n ) ),$$
$$\mathcal { B } _ { n } = V _ { n - 2 } V _ { n - 1 } \chi _ { 1 } ( n ) \left ( \chi _ { 1 } ( n - 1 ) + \chi _ { 2 } ( n - 2 ) \chi _ { 2 } ( n - 1 ) \right ) +$$
+ V χ n 1 ( n -2) ( V n +1 χ 1 ( n -1) + V n -1 χ 2 ( n -1) χ 2 ( n )) -χ 1 ( n -2) χ 1 ( n -1) ˙ χ 1 ( n . )
Consequently, we have A n = B n = 0. For χ 1 = -V n ( ) t Q n +1 ( ) t Q n ( ) t , χ 2 = w Q n ( ) t it follows from (8) and from A n = B n = 0 that Q n ( ) satisfies (27). t Theorem 5 is proved.
## References
- [1] I.M. Krichever, S.P. Novikov, Holomorphic bundles over algebraic curves and nonlinear equations , Russian Math. Surveys, 35 :6 (1980), 53-79.
- [2] I.M. Krichever, S.P. Novikov, Two-dimensional Toda lattice, commuting difference operators, and holomorphic bundles , Russian Math. Surveys, 58 :3 (2003), 473-510.
- [3] I.M. Krichever, Integration of nonlinear equations by the methods of algebraic geometry , Functional Anal. Appl., 11 :1 (1977), 12-26.
- [4] I.M. Krichever, Commutative rings of ordinary linear differential operators , Functional Anal. Appl., 12 :3 (1978), 175-185.
- [5] A.E. Mironov, Self-adjoint commuting differential operators , Inventiones Math. 197 :2 (2014), 417-431.
- [6] A.E. Mironov, Commuting higher rank ordinary differential operators , Proceedings of the 6th European Congress of Math., (2013), 459-473.
- [7] G. Wallenberg, ¨ ber die Vertauschbarkeit homogener linearer Differenzenausdr¨cke U u , Arch. Math. Phys. bd., 15 (1909), 151-157.
- [8] J.L. Burchnall, I.W. Chaundy, Commutative ordinary differential operators , Proc. Lond. Math. Soc. Ser., 21 :2 (1923), 420-440.
- [9] I.M. Krichever, Algebraic curves and non-linear difference equations , Russian Math. Surveys, 33 :4 (1978), 255-256.
- [10] J. Dixmier, Sur les alg`bres de Weyl e , Bull. Soc. Math. France, 96 (1968), 209-242.
- [11] V.G. Drinfel'd, Commutative subrings of certain noncommutative rings , Functional Anal. Appl., 11 :1 (1977), 9-12.
- [12] S.P. Novikov, Commuting operators of rank l > 1 with periodic coefficients , (Russian) Dokl. Akad. Nauk SSSR, 263 :6 (1982), 1311-1314.
- [13] F.Kh. Baichorova, Z.S. Elkanova, Commuting differential operators of order 4 and 6 , Ufa Math. J. 5 :3 (2013), 11-19.
- [14] P. Dehornoy, Op´ erateurs diff´rentiels et courbes elliptiques e , Compositio Math., 43 :1 (1981), 71-99.
- [15] P.G. Grinevich, Rational solutions for the equation of commutation of differential operators , Functional Anal. Appl., 16 :1 (1982), 15-19.
- [16] P.G. Grinevich, S.P. Novikov, Spectral theory of commuting operators of rank two with periodic coefficients , Functional Anal. Appl., 16 :1 (1982), 19-20.
| [17] | F. Grunbaum, Commuting pairs of linear ordinary differential operators of orders four and six , Phys. D, 31 :3 (1988), 424-433. |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | G. Latham, Rank 2 commuting ordinary differential operators and Darboux conju- gates of KdV , Appl. Math. Lett., 8 :6 (1995), 73-78. |
| [19] | G. Latham, E. Previato, Darboux transformations for higher-rank Kadomtsev- Petviashvili and Krichever-Novikov equations , Acta Appl. Math., 39 (1995), 405- 433. |
| [20] | E. Previato, G. Wilson, Differential operators and rank 2 bundles over elliptic curves , Compositio Math., 81 :1 (1992), 107-119. |
| [21] | A.E. Mironov, A ring of commuting differential operators of rank 2 corresponding to a curve of genus 2 , Sbornik: Math., 195 :5 (2004), 711-722. |
| [22] | A.E. Mironov, Commuting rank 2 differential operators corresponding to a curve of genus 2 , Functional Anal. Appl., 39 :3 (2005), 240-243. |
| [23] | A.E. Mironov, On commuting differential operators of rank 2 , Siberian Electronic Math. Reports., 6 (2009), 533-536. |
| [24] | D. Zuo, Commuting differential operators of rank 3 associated to a curve of genus 2 , SIGMA, 8 (2012), 044. |
| [25] | O.I. Mokhov, Commuting differential operators of rank 3 and nonlinear differential equations , Mathematics of the USSR-Izvestiya, 35 :3 (1990), 629-655. |
| [26] | V.N. Davletshina, On self-adjoint commuting differential operators of rank two , Siberian Electronic Math. Reports, 10 (2013), 109-112. |
| [27] | V.N. Davletshina, Self-adjoint commuting differential operators of rank 2 and their deformations given by the soliton equations , Math. Notes (to appear). |
| [28] | V.N. Davletshina, E.I. Shamaev, On commuting differential opetators of rank two , Siberian Math. J. 55 :4 (2014). |
| [29] | A.E. Mironov, Periodic and rapid decay rank two self-adjoint commuting differential operators , American Math. Soc. Translations: Ser. 2 (to appear). |
| [30] | O.I. Mokhov, On commutative subalgebras of the Weyl algebra related to commuting operators of arbitrary rank and genus , Math. Notes, 94 :2 (2013), 298-300. |
| [31] | O.I. Mokhov, Commuting ordinary differential operators of arbitrary genus and arbitrary rank with polynomial coefficients , American Math. Soc. Translations: Ser. 2 (to appear). |
- [32] D. Mumford, An algebro-geometric construction of commuting operators and of solutions to the Toda lattice equation, Korteweg-de Vries equation and related nonlinear equations , Proceedings of the International Symposium on Algebraic Geometry (Kyoto Univ., Kyoto, 1977), Kinokuniya, Tokyo, 1978, 115-153.
- [33] A.E. Mironov, Discrete analogues of Dixmier operators , Sbornik: Math., 198 :10 (2007), 1433-1442.
- [34] S.P. Novikov, The periodic problem for the Korteweg-de Vries equation , Functional Anal. Appl., 8 (1974), 236-246.
- [35] B.A. Dubrovin, Periodic problems for the Korteweg-de Vries equation in the class of finite-gap potentials , Functional Anal. Appl., 9 :3 (1975), 215-223.
- [36] A.R. Its, V.B. Matveev, Schr¨dinger operators o with finite-gap spectrum and Nsoliton solutions of the Korteweg-de Vries equation , Theoretical and Math. Phys., 23 :1 (1975), 343-355.
- [37] B.A. Dubrovin, V.B. Matveev, S.P. Novikov, Non-linear equations of Kortewegde Vries type, finite-zone linear operators, and Abelian varieties , Russian Math. Surveys, 31 :1 (1976), 59-146.
- [38] I.M. Gel'fand, L.A. Dikii, Asimptotic behaviour of the resolvent of Sturm-Liouville equations and of the Korteweg-de Vries equations , Russian Math. Surveys, 30 :5 (1975), 77-113.
- [39] A.E. Mironov, A. Nakayashiki, Discretization of Baker-Akhiezer Modulas and Commuting Difference Operators in Several Discrete Variables , Trans. Moscow Math. Soc., 74 :2 (2013), 261-279.
- [40] V.E. Adler, A.B. Shabat, First integrals of generalized Toda chains , Theoretical and Math. Phys., 115 :3 (1998), 339-346.
- [41] D. Levi, P. Winternitz, R. Yamilov, Symmetries of the Continuous and Discrete Krichever-Novikov Equation , SIGMA, 7 (2011), 097.
- G.S. Mauleshova , Novosibirsk State University, Russia e-mail: guna [email protected]
- A.E. Mironov , Sobolev Institute of Mathematics, Novosibirsk, Russia and Laboratory of Geometric Methods in Mathematical Physics, Moscow State University e-mail: [email protected] | null | [
"Gulnara S. Mauleshova",
"Andrey E. Mironov"
] | 2014-08-01T09:42:22+00:00 | 2014-08-01T09:42:22+00:00 | [
"nlin.SI"
] | Difference Krichever-Novikov operators | In this paper we study commuting difference operators of rank two. We
introduce an equation on potentials $V(n),W(n)$ of the difference operator
$L_4=(T+V(n)T^{-1})^2+W(n)$ and some additional data. With the help of this
equation we find the first examples of commuting difference operators of rank
two corresponding to spectral curves of higher genus. |
1408.0114v1 | ## A Real-Time Spatial Index for In-Vehicle Units
Magnus Lie Hetland 1 and Ola Martin Lykkja 2
1 Norwegian University of Science and Technology, [email protected] 2 Q-Free ASA, Trondheim, Norway, [email protected]
## Abstract
We construct a spatial indexing solution for the highly constrained environment of an in-vehicle unit in a distributed vehicle tolling scheme based on satellite navigation ( gnss ). We show that a purely functional implementation of a high-fanout quadtree is a simple, practical solution that satisfies all the requirements of such a system.
## 1 Introduction
Open road tolling is an increasingly common phenomenon, with transponder-based tolling proposed as early as in 1959 [1], and a wide variety of more complex technologies emerging over the recent decades [2]. One of the more recent developments is the use of satellite navigation ( gnss ), with geographical points and zones determining the pricing [see, e.g., 3]. In this paper, we examine the feasibility of maintaining a geographical database in an in-vehicle unit, which can perform many of the tasks of such a location-based system independently.
This is a proof-of-concept application paper. Our main contributions can be summed up as follows: ( i ) We specify a set of requirements for a spatial database to be used in the highly constrained environment of a real-time, low-cost in-vehicle unit in Section 2; ( ii ) we construct a simple data structure that satisfies these requirements in Section 3; and ( iii ) we tentatively establish the feasibility of the solution through an experimental evaluation in Section 4. In the interest of brevity, some technical details have been omitted. See the report by Lykkja [4] for more information.
## 2 The Problem: Highly Constrained Spatial Indexing
The basic functionality of our system is to retrieve relevant geographic (i.e., geometric) objects, that is, the tolling zones and virtual toll gantries that are within a certain distance of the vehicle. Given the real-time requirements and the limited speed of the available hardware, a plain linear scan of the data would be infeasible even with about 50 objects. A real map of zones and gantries would hold orders of magnitude more objects than that (c.f., Table 3). This calls for some kind of geometric or spatial indexing [5], although the context places some heavy constraints
This paper was presented at the NIK-2014 conference; see http://www.nik.no/ .
on the data structure used. One fundamental consideration is the complexity of the solution. In order to reduce the probability of errors, a simple data structure would be preferable. Beyond simplicity, and the need for high responsiveness, we have a rather non-standard hardware architecture to contend with.
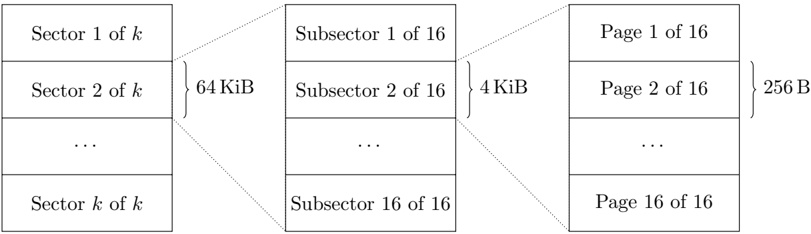
The memory of the on-board unit is assumed to be primarily flash memory with serial access. The scenario is similar to that of a desktop computer, where the index would be stored on a hard drive, with a subset in RAM and the L2 cache. For an overview of the hierarchical nature of the memory architecture, see Fig. 1 and Table 1. The serial nature of the memory forces us to read and write single bits at a time in a page. A read operation takes 50 µ s. A write operation takes 1 ms, and may only alter a bit value of 1 to a bit value of 0. A sector, subsector or page may be erased in a single operation, filling it with 1-bits in approximately 500 ms. One important constraint is also that each page may typically only be erased a limited number of times (about 100 000), so it is crucial that our solution use the pages cyclically, rather than simply modifying the current ones in-place, to ensure wear leveling.
Based on general needs of a self-contained tolling system, and on the hardware capabilities just described, we derive the following set of requirements:
- A. The system must accommodate multiple versions of the same index structure at one time. The information may officially change at a given date, but the relevant data must be distributed to the units ahead of time.
- B. It must be possible to distribute new versions as incremental updates, rather than a full replacement. This is crucial in order to reduce communication costs and data transfer times. It will also make it less problematic to apply minor corrections to the database.
- C. The memory footprint must be low, as the memory available is highly limited.
- D. The database must maintain 100 % integrity, even during updates, to ensure uninterrupted access. It must be possible to roll back failed updates without affecting the current database.
- E. The indexing structure must be efficient in terms of CPU cycles during typical operations. Both available processing time and energy is highly limited and must not be wasted on, say, a linear scan over the data.
k
= 16
. . .
64
Figure 1: Flash memory architecture
Table 1: Hierarchical memory architecture
| Description | Size | Access time | Persistent? |
|---------------------------|-----------------|----------------------|---------------|
| Processor internal memory | Ki-bytes | Zero wait state | No |
| External RAM | 100 KiB | Non-zero wait states | No |
| Serial Flash | 8, 16 or 32 MiB | See main text | Yes |
- F. The relevant data structure must minimize the number of flash page reads needed to perform typical operations, especially for search. Flash-page reads will be a limiting factor for some operations, so this is necessary to meet the real-time operation requirements.
- G. In order to avoid overloading individual pages (see discussion of memory architecture, above), wear leveling must be ensured through cyclic use.
- H. The typical operations that must be available under these constraints are basic two-dimensional geometric queries (finding nearby points or zones) as well as modification by adding and removing objects.
In addition, the system must accommodate multiple independent databases, such as tolling information for adjacent countries. Such databases can be downloaded on demand (e.g., when within a given distance of a border), cached, and deleted on a least-recently-used basis, for example. We do not address this directly as a requirement, as it is covered by the need for a low memory footprint per database (Req. C).
As in most substantial lists of requirements, there are obvious synergies between some (e.g., Reqs. E and F) while some are orthogonal and some seem to be in direct opposition to each other (e.g., Reqs. A and C). In Section 3, we describe a simple index structure that allows us to satisfy all our requirements to a satisfactory degree.
## 3 Our Solution: Immutable 9-by-9 Quadtrees
The solution to the indexing problem lies in combining two well-known technologies: quadtrees and immutable data structures.
In the field of geographic and geometric databases, one of the simplest and most well-known data structures is the quadtree, which is a two-dimensional extension of the basic binary search tree. Just as a binary search tree partitions R into two halves, recursively, the quadtree partitions R 2 into quadrants. A difference between the two is that where the binary search tree splits based on keys in the data set, the quadtree computes its quadrants from the geometry of the space itself. ∗ In order to reduce the number of node (i.e., page) accesses, at the expense of more coordinate computations, we increase the grid of our tree from 2-by-2 to 9-by-9. The specific choice of this grid size is motivated by the constraints of the system. We need 3 bytes to address a flash page and with a 9-by-9 grid, we can fit one node into 9 · 9 · 3 = 243 bytes, which permits us to fit one node (along with some book-keeping data) into a 256 B flash page. This gives us a very shallow tree, with a fanout of 81, which reduces the number of flash page accesses considerably. For an example
∗ Technically, this is the form of quadtrees known as PR Quadtrees [5, § 1.4.2.2].
of the resulting node sizes (area of ground covered), see Table 2. The last three columns show the number of leaf nodes at the various levels in the experimental build described in Section 4.
Immutable data structures have been used in purely functional programming for decades [see, e.g., 6], and they have recently become more well known to the mainstream programming community through the data model used in, for example, the Git version control system [see, e.g., 7, p. 3]. The main idea is that instead of modifying a data structure in place, any nodes that would be affected by the modification are duplicated. For a tree structure, this generally means the ancestor nodes of the one that is, say, added. Consider the example in Fig. 2. In Fig. 2(a), we see a tree consisting of nodes a through f , and we are about to insert g . Rather than adding a child to c , which is not permitted, we duplicate the path up to the root, with the duplicated nodes getting the appropriate child-pointers, as shown in Fig.2(b), where the duplicated nodes are highlighted. As can be seen, the old nodes (dotted) are still there, and if we treat the old a as the root, we still have access to the entire previous version of the tree.
## 4 Experimental Evaluation
Our experiments were performed with a data set of approximately 30 000 virtual gantries (see Fig. 3(a)), generated from publicly available maps [8]. The maps describe the main roads of Norway with limited accuracy. Additionally, more detailed and accurate virtual gantries were created manually for some locations in Oslo and Trondheim. Fig. 4(a) shows the relevant virtual gantries in downtown Oslo, used in our test drive. There are about 35 virtual gantries on this route, and many of these are very close together. In general, there is one virtual gantry before every intersection.
Each local administrative unit ( kommune ) is present in the maps used [8], with fairly accurate and detailed boundaries. There are 446 such zones in total (see Fig. 3(b)). In addition, more detailed and accurate zones were created manually for some locations in the cities of Oslo and Trondheim. Some of these are quite small, very close together, and partially overlapping (see Fig. 4(b)).
## Data Structure Build
These test data were inserted into the quadtree as described in Section 3. Table 3 summarizes the important statistics of the resulting structure. The numbers for memory usage are also shown in Fig. 5, for easier comparison.
Table 2: Tree levels. Sizes are approximate
| Level | Size | Zone | VG | Both |
|---------|----------------|--------|--------|--------|
| Top | 2 . 0 × 10 6 m | 0 | 0 | 0 |
| 1 | 2 . 1 × 10 5 m | 15 | 0 | 4 |
| 2 | 2 . 4 × 10 4 m | 625 | 168 | 471 |
| 3 | 2 . 5 × 10 3 m | 81 | 12 353 | 39 721 |
| 4 | 3 . 0 × 10 2 m | 0 | 157 | 486 |
| 5 | 3 . 0 × 10 1 m | 0 | 0 | 0 |
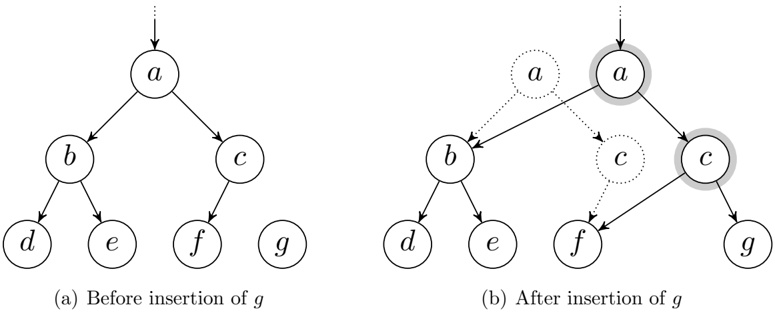
Figure 2: Node g is inserted by creating new versions of node a and c (highlighted), leaving the old ones (dotted) in place
Figure 3: Virtual gantries and zones of Norway, with an illustrative quadtree grid
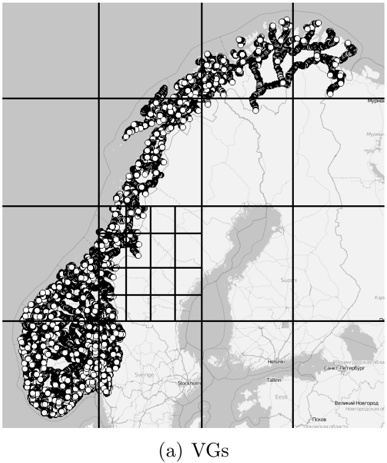
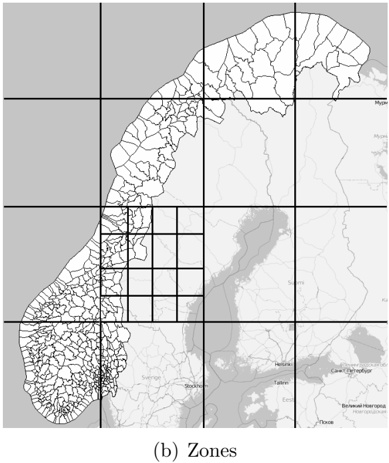
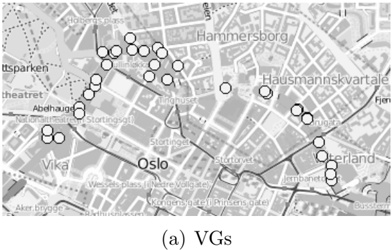
Figure 4: Virtual gantries and overlapping zones in downtown Oslo
Table 3: Tree performance numbers
| | Description | Zones | VGs | Both |
|----|-----------------------------------|---------|---------|---------|
| a | Number of objects in database | 448 | 29 037 | 29 485 |
| b | Flash pages for index and data | 2164 | 42 217 | 71 675 |
| c | Size (MiB) | 0 . 53 | 10 . 31 | 17 . 50 |
| d | Flash pages for index | 1716 | 13 180 | 42 190 |
| e | Objects referenced by leafs | 2481 | 43 263 | 95 272 |
| f | Leaf nodes per object | 5 . 5 | 1 . 5 | 115 |
| g | Leaf entries not used, empty | 240 | 27 403 | 1319 |
| h | Leaf entries set | 733 | 13 179 | 41 207 |
| i | Max index tree depth | 3 | 4 | 4 |
| j | Zone inside entries | 57 | | 30 379 |
| k | Zone edge entries | 2406 | | 21 333 |
| l | Distinct leaf pages | 578 | 11 608 | 14 138 |
| m | Total leaf pages | 721 | 12 678 | 40 682 |
| n | Duplicate leaf pages | 143 | 1070 | 26 544 |
| o | Flash pages, dups removed | 2021 | 41 147 | 45 131 |
| p | Size, dups removed (MiB) | 0 . 49 | 10 . 05 | 11 . 02 |
| q | Index pages, dups removed | 1573 | 12 110 | 15 646 |
| r | Size of index, dups removed (MiB) | 0 . 38 | 2 . 96 | 3 . 82 |
Figure 5: The plot shows total flash pages used ( ) and flash pages used for the index ( ), as well as the same with duplicates removed ( and , respectively) for a data base consisting of zones, virtual gantries, or both (c.f., Table 3)
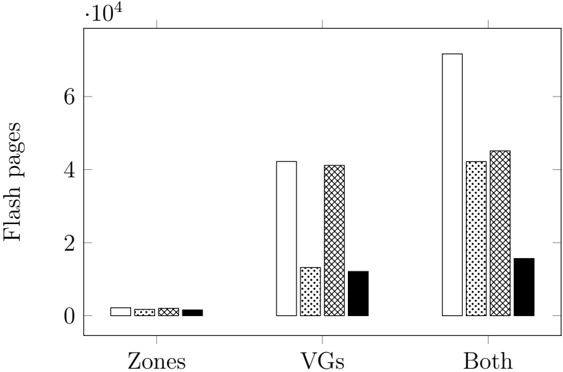
Judging from these numbers (row r ), a database containing only zones would be quite small (about 0 38 MiB). . Each zone is referenced by 5 5 leaf nodes on average . (row f ). Also note that only 57 leaf nodes (squares) are entirely contained in a zone (row j ). This implies that the geometric inside/outside calculations will need to be computed in most cases.
This can be contrasted with the combined database of gantries and zones. The index is larger (3 82 MiB, row . r ), but the performance of polygon assessments is much better. Each polygon is referenced from 115 leaf nodes (row f ) and there are more inside entries than edge entries (30 379 vs 21 333). This indicates that the geometric computations will be needed much less frequently.
Each of the three scenarios creates a number of duplicate leaf pages. Many leaf pages will contain the same zone edge/inside information. In our implementation of the algorithm, this issue is not addressed or optimized. It is, however, quite easy to introduce a reference-counting scheme or the like to eliminate duplicates, in this scenario saving 6 MiB (as shown in rows o through r ).
The zone database contains very few empty leaf entries (row g ), because the union of the regions covers the entire country, with empty regions found in the sea or in neighboring countries.
## Flash Access in a Real-World Scenario
The index was also tested in a 2 km drive, eastbound on Ibsenringen, in downtown Oslo. The relevant virtual gantries are shown in the map in Fig. 4(a). The inmemory flash cache used was 15 pages (15 · 256 B), and the cache was invalidated before test start. Fig. 6 shows the result, in terms of flash accesses and the number of gantries found.
## 5 Discussion
To view our results in the context of the initial problem, we revisit our requirement list from Section 2. We can break our solution into three main features: ( i ) The use of quadtrees for indexing; ( ii ) purely functional updates and immutability; and ( iii ) high fanout, with a 9-by-9 grid. Table 4 summarizes how these features, taken together, satisfy all our requirements. Each feature is either partly or fully relevant for any requirement it helps satisfy (indicated by ◦ or · , respectively).
Our starting-point is the need for spatial (two-dimensional) indexing (Req. H), and a desire for simplicity in our solution. The slowness of our hardware made a straightforward linear scan impossible, even with a data set of limited size. This led us to the use of quadtrees, whose primary function, seen in isolation, is satisfying Req. E, CPU efficiency. It also supports Req. C (low memory footprint) by giving us a platform for reducing duplication. Lastly, it supports efficiency in terms of flash page accesses (Req. F), which is primarily handled by high fanout, using the nine-by-nine grid.
The purely functional updates, and the immutable nature of our structure, satisfies a slew of requirements by itself. Just as in modern version control systems such as Git [7], immutable tree structures where subtrees are shared between versions gives us a highly space-efficient way of distributing and storing multiple, incremental versions of the database (Reqs. A to C). This also gives us the ability to keep using the database during an update, and to roll back the update if an error occurs,
Figure 6: Flash access in an actual drive (Oslo Ring-1 Eastbound): flash pages read (vertical bars) and virtual gantries found (horizontal lines)
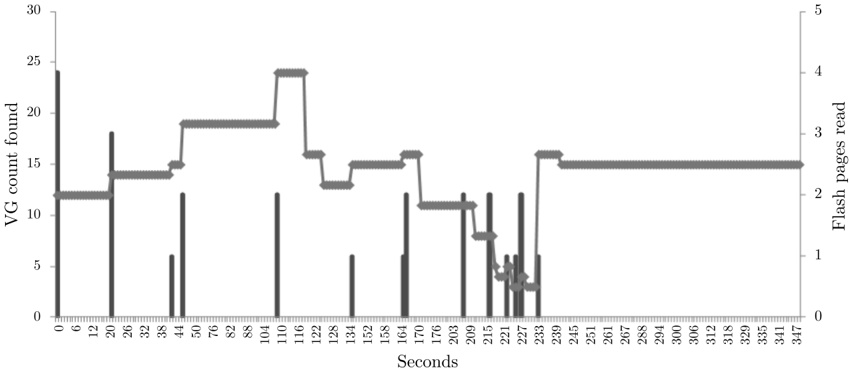
without any impact on the database use, as the original database is not modified (Req. D). Finally, because modifications will always use new flash pages, we avoid excessive modifiations of, say, the root node, and can schedule the list of free nodes to attain a high degree of wear leveling (Req. G).
In our tests, as discussed in the previous section, we found that the solution satisfied our requirements not only conceptually, but also in actual operation. It can contain real-world data within real-world memory constraints (Table 3), and can serve up results in real time during actual operation, with relatively low flash access rates (Fig. 6).
## 6 Conclusion & Future Work
We have described the problem of real-time spatial indexing in an in-vehicle satellite navigation ( gnss ) unit for the purposes of open-road tolling. From this problem we have elaborated a set of performance and functionality requirements. These requirements include issues that are not commonly found in indexing for ordinary computers, such as the need for wear-leveling over memory locations. By modifying the widely used quadtree data structure to use a higher fanout, and by making it immutable, using purely functional updates, we were able to satisfy our entire list of requirements. We also tested the solution empirically, on real-world data and in a real-world context of a vehicle run, and found that it performed satisfactorily.
Although our object of focus has been a rather limited family of hardware
Table 4: How components of the solution satisfy various requirements
| Feature | A | B | C | D | E | F | H |
|--------------------------------------------|-----|-----|-----|-----|-----|-----|-----|
| The use of quadtrees for indexing | | | ◦ | | • | ◦ | • |
| Purely functional updates and immutability | • | • | • | • | | | • |
| High fanout, with 9-by-9 grid | | | | | | • | |
architectures, the simple, basic ideas of our index chould be useful also for other devices and applications where real-time spatial indexing is required under somewhat similar flash memory conditions. Possible extensions of our work could be to test the method under different conditions, perhaps by developing a simulator for in-vehicle units with different architectures and parameters. This could be useful for choosing among different hardware solutions, as well as for tuning the index structure and database.
Disclaimer & Acknowledgements Magnus Lie Hetland introduced the main design idea of using immutable, high-fanout quadtrees for the database structure. He wrote the majority of the text of the current paper, based in large part on the technical report of Lykkja [4]. Ola Martin Lykkja implemented and benchmarked the database structure and documented the experiments [4]. Neither author declares any conflicts of interest. Both authors have revised the paper and approved the final version. The authors would like to thank Hans Christian Bolstad for fruitful discussions on the topic of the paper. This work has in part been financed by the Norwegian Research Council (BIA project no. 210545, 'SAVE').
## References
- [1] Frank Kelly. Road pricing: addressing congestion, pollution and the financing of britain's roads. Ingenia , 29:34-40, December 2006.
- [2] Peter Hills and Phil Blythe. For whom the road tolls? Ingenia , 14:21-28, November 2002.
- [3] Bern Grush. Road tolling isn't navigation. European Journal of Navigation , 6 (1), February 2008.
- [4] Ola Martin Lykkja. SAVE tolling objects database design. Technical Report QFR01-207-1492 0.7, Q-Free ASA, Trondheim, Norway, 2012.
- [5] Hanan Samet. Foundations of Multidimensional and Metric Data Structures . Morgan Kaufmann, 2006.
- [6] Chris Okasaki. Purely Functional Data Structures . Cambridge University Press, 1999.
- [7] Jon Loeliger and Matthew McCullough. Version Control with Git . O'Reilly, second edition, 2012.
- [8] Kartverket. N2000 kartdata. Available from http://www.kartverket.no/Kart/ Kartdata/Vektorkart/N2000 , 2012. | null | [
"Magnus Lie Hetland",
"Ola Martin Lykkja"
] | 2014-08-01T09:42:45+00:00 | 2014-08-01T09:42:45+00:00 | [
"cs.DS"
] | A Real-Time Spatial Index for In-Vehicle Units | We construct a spatial indexing solution for the highly constrained
environment of an in-vehicle unit in a distributed vehicle tolling scheme based
on satellite navigation (GNSS). We show that an immutable, purely functional
implementation of a high-fanout quadtree is a simple, practical solution that
satisfies all the requirements of such a system. |
1408.0115v1 | ## Gauge-covariant extensions of Killing tensors and conservation laws
J.W. van Holten a
## Nikhef
Science Park 105, Amsterdam NL
and
Lorentz Institute, Leiden University
Niels Bohrweg 2, Leiden NL
## Abstract
In classical and quantum mechanical systems on manifolds with gauge-field fluxes, constants of motion are constructed from gauge-covariant extensions of Killing vectors and tensors. This construction can be carried out using a manifestly covariant procedure, in terms of covariant phase space with a covariant generalization of the Poisson brackets, c.q. quantum commutators. Some examples of this construction are presented.
a e-mail: [email protected]
## 1 Noether's theorem
This paper discusses symmetries and conservation laws in the context of hamiltonian dynamics. The discussion is framed predominantly in the language of classical dynamics, but the use of Poisson brackets and their correspondence with quantum commutators, guarantees that many results also apply to the operator formulation of quantum dynamics. The main difference is the operator ordering to be implemented in quantum theory, the technicalities of which are not relevant to the issues I focus on.
The connection between continuous symmetries and conservation laws is established by Noether's theorem [1]. I briefly review the theorem by considering infinitesimal transformations on phase-space variables ( x, p ) obtained from a generating function G x, p ( ) through the Poisson brackets
$$\delta x = \{ x, G \} = \frac { \partial G } { \partial p }, \quad \delta G = \{ p, G \} = - \frac { \partial G } { \partial x }.$$
Observe, that these variations are defined such that G itself is an invariant:
$$\delta G = \delta x \frac { \partial G } { \partial x } + \delta p \frac { \partial G } { \partial p } = \{ G, G \} = 0.$$
Under such transformations the hamiltonian of the system changes by
$$\delta H = \{ H, G \} = - \frac { d G } { d t },$$
the change of G along the phase-space trajectory ( x t , p ( ) ( )) t generated by the hamiltonian H . It follows immediately, that G is a constant of motion if the hamiltonian is invariant under the transformations (1).
It is also of some interest to consider the variation of the action
$$S = \int _ { 1 } ^ { 2 } d t \left ( p \, \frac { d x } { d t } - H ( x, p ) \right ).$$
Applying the variations (1)
$$\delta S = \int _ { 1 } ^ { 2 } d t \left [ \frac { d } { d t } \left ( p \, \frac { \partial G } { \partial p } - G \right ) - \{ H, G \} \right ] = \left [ p \frac { \partial G } { \partial p } - G \right ] _ { 1 } ^ { 2 }.$$
Thus variations under which the hamiltonian is invariant, leave the action invariant modulo boundary terms. This is sufficient for G to be a constant of motion.
## 2 Isometries of manifolds
On a manifold with (local) co-ordinates x µ and metric g µν ( x ) the geodesics can be obtained as the trajectories of test-particles with proper-time hamiltonian
$$H = \frac { 1 } { 2 } \, g ^ { \mu \nu } p _ { \mu } p _ { \nu }.$$
Indeed, using the overdot notation for proper-time derivatives, the hamilton equations take the form
$$\dot { x } ^ { \mu } = g ^ { \mu \nu } p _ { \nu }, \quad \dot { p } _ { \mu } = - \frac { 1 } { 2 } \, \frac { \partial g ^ { \nu \lambda } } { \partial x ^ { \mu } } \, p _ { \nu } p _ { \lambda } = \frac { 1 } { 2 } \, \frac { \partial g _ { \nu \lambda } } { \partial x ^ { \mu } } \, \dot { x } ^ { \nu } \dot { x } ^ { \lambda }.$$
The last expression is equivalent to the geodesic equation
$$\ddot { x } ^ { \mu } + \Gamma _ { \lambda \nu } ^ { \ \mu } \, \dot { x } ^ { \lambda } \dot { x } ^ { \nu } = 0.$$
In this language, isometries of the manifold are found as constants of motion which are linear in the momentum:
$$J ( x, p ) = J ^ { \mu } ( x ) p _ { \mu }, \quad \left \{ J, H \right \} = ( \nabla _ { \mu } J _ { \nu } ) \, p ^ { \mu } p ^ { \nu } = 0,$$
where (in a somewhat hybrid notation) the contravariant components of the momentum are p µ = ˙ x µ . Hence the covariant coefficient functions J µ form a Killing vector, a solution of the Killing equation
$$\nabla _ { \mu } J _ { \nu } + \nabla _ { \nu } J _ { \mu } = 0 \quad \Leftrightarrow \quad J ^ { \lambda } \frac { \partial g _ { \mu \nu } } { \partial x ^ { \lambda } } + \frac { \partial J ^ { \lambda } } { \partial x ^ { \mu } } \, g _ { \lambda \nu } + \frac { \partial J ^ { \lambda } } { \partial x ^ { \nu } } \, g _ { \mu \lambda } = 0. \quad \ \ ( 1 0 )$$
The second (contravariant) form of the equation states that the Lie-derivative of the metric w.r.t. the vector J µ vanishes, which is the usual definition of an isometry. Also note, that the constants of motion defined by Killing vectors are precisely those, for which
$$p \, \frac { \partial G } { \partial p } = G,$$
and therefore generates transformations under which the action is strictly invariant. This is to be expected for an isometry which by construction leaves the line element ds 2 = g µν dx dx µ ν invariant.
Although the coordinate transformations δx µ generated by Killing vectors thus have an elegant interpretation, this does not hold for the corresponding transformations of the canonical momenta p µ :
$$\delta p _ { \mu } = A _ { \mu } ^ { \nu } ( x ) p _ { \nu }, \quad A _ { \mu } ^ { \nu } = - \frac { \partial J ^ { \nu } } { \partial x ^ { \mu } }.$$
This transformation rule is not general covariant; as A ν µ ( x ) is point-dependent, covariance requires δp to be corrected for the parallel displacement generated by
the translation δx µ . Thus a set of covariant transformations in phase space is defined by
$$\Delta x ^ { \mu } = \delta x ^ { \mu }, \quad \Delta p _ { \mu } = \delta p _ { \mu } - \delta x ^ { \lambda } \Gamma _ { \lambda \mu } ^ { \ \nu } p _ { \nu }.$$
In order for these transformations to respect the Poisson brackets (2) and (3), it is then necessary to introduce a covariant derivative
$$\mathcal { D } _ { \mu } G = \frac { \partial G } { \partial x ^ { \mu } } + \Gamma _ { \mu \nu } ^ { \ \lambda } p _ { \lambda } \, \frac { \partial G } { \partial p _ { \nu } } = - \Delta p _ { \mu },$$
such that
$$\Delta G = \Delta x ^ { \mu } \mathcal { D } _ { \mu } G + \Delta p _ { \mu } \frac { \partial G } { \partial p _ { \mu } } = \{ G, G \} = 0,$$
and
$$\Delta H = \Delta x ^ { \mu } \mathcal { D } _ { \mu } H + \Delta p _ { \mu } \frac { \partial H } { \partial p _ { \mu } } = \{ H, G \} = - \frac { d G } { d \tau }.$$
Thus we have constructed a covariant expression for the Poisson bracket of two arbitrary scalar phase-space functions:
$$\{ G, K \} = \mathcal { D } _ { \mu } G \, \frac { \partial K } { \partial p _ { \mu } } - \frac { \partial G } { \partial p _ { \mu } } \, \mathcal { D } _ { \mu } K.$$
## 3 Killing tensors
The metric postulate guarantees that the geodesic hamiltonian (6) is covariantly constant:
$$\nabla _ { \lambda } g _ { \mu \nu } = 0 \quad \Leftrightarrow \quad \mathcal { D } H = 0.$$
The condition for a constant of geodesic motion then takes the simple form
$$\{ G, H \} = p ^ { \mu } \mathcal { D } _ { \mu } G = 0.$$
Applying this to a general expression of homogeneous rank n in the momenta
$$G ( x, p ) = G ^ { \mu _ { 1 } \dots \mu _ { n } } ( x ) p _ { \mu _ { 1 } } \dots p _ { \mu _ { n } } \quad \Rightarrow \quad p ^ { \mu } \mathcal { D } _ { \mu } G = \left ( \nabla _ { \mu _ { n + 1 } } G _ { \mu _ { 1 } \dots \mu _ { n } } \right ) p ^ { \mu _ { 1 } } \dots p ^ { \mu _ { n + 1 } }, \ \ ( 2 0 )$$
the condition for a constant of motion becomes a generalization of the Killing equation (10):
$$\nabla _ { ( \mu _ { n + 1 } } G _ { \mu _ { 1 } \dots \mu _ { n } ) } = 0.$$
The solutions of these equations are therefore known as Killing tensors [3, 4].
The geometrical interpretation of the transformations generated by constants of motion constructed from Killing tensors of rank 2 or higher, is more complicated than for Killing vectors. They do not generate transformations in the manifold, but in the tangent bundle, the physical phase-space:
$$\Delta x ^ { \mu } = \frac { \partial G } { \partial p _ { \mu } } = n G ^ { \mu \mu _ { 1 } \dots \mu _ { n - 1 } } p _ { \mu _ { 1 } } \dots p _ { \mu _ { n - 1 } },$$
$$\Delta p _ { \mu } = - \mathcal { D } _ { \mu } G = - \left ( \nabla _ { \mu } G ^ { \mu _ { 1 } \dots \mu _ { n } } \right ) p _ { \mu _ { 1 } } \dots p _ { \mu _ { n } }.$$
Note, that for transformations with n ≥ 2 the action actually transforms by boundary terms:
$$p _ { \mu } \, \frac { \partial G } { \partial p _ { \mu } } = n G \quad \Rightarrow \quad \Delta S = ( n - 1 ) \left [ G ( x _ { 2 }, p _ { 2 } ) - G ( x _ { 1 }, p _ { 1 } ) \right ]. \quad \quad ( 2 3 )$$
Obviously, as G is a constant of motion the action is still invariant along geodesics.
## Example: Kerr geometry [2, 3]
The Kerr geometry is a Ricci-flat geometry in 4-dimensional space-time: R µν = 0, implying it is a solution of the Einstein equations of General Relativity in empty space-time. This solutions describes a rotating black hole with constant mass M and angular momentum J . The geodesic hamiltonian reads
$$H = \frac { 1 } { 2 \rho ^ { 2 } } \left [ \Delta ^ { 2 } p _ { r } ^ { 2 } + p _ { \theta } ^ { 2 } + \left ( a \sin \theta \, p _ { t } + \frac { p _ { \varphi } } { \sin \theta } \right ) ^ { 2 } - \frac { 1 } { \Delta ^ { 2 } } \left ( ( r ^ { 2 } + a ^ { 2 } ) p _ { t } + a p _ { \varphi } \right ) ^ { 2 } \right ], \ \ ( 2 4 )$$
where a = J/M is the angular momentum per unit of mass, and the notation follows standard conventions:
$$\Delta ^ { 2 } = r ^ { 2 } - 2 M r + a ^ { 2 }, \quad \rho ^ { 2 } = r ^ { 2 } + a ^ { 2 } \cos ^ { 2 } \theta.$$
This space-time geometry admits a rank-2 Killing tensor, coding the well-known Carter constant of motion:
$$\text{canvas convvex} & \text{in move}. \\ K \ = \ \frac { 1 } { 2 \rho ^ { 2 } } \left [ - \Delta ^ { 2 } a ^ { 2 } \cos ^ { 2 } \theta \, p _ { r } ^ { 2 } + r ^ { 2 } p _ { \theta } ^ { 2 } + r ^ { 2 } \left ( a p _ { t } + \frac { p _ { \varphi } } { \sin ^ { 2 } \theta } \right ) ^ { 2 } \\ & \quad + \frac { a ^ { 2 } \cos ^ { 2 } \theta } { \Delta ^ { 2 } } \left ( ( r ^ { 2 } + a ^ { 2 } ) p _ { t } + a p _ { \varphi } \right ) ^ { 2 } \right ]. \\ - - \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
This constant of motion can be generalized to neutral and charged, spinless and spinning particles in Kerr-Newman space-time of charged black holes [3, 5, 6, 7].
## 4 Bracket algebra
The generators of hamiltonian symmetry transformations, defining constants of motion, define a Lie-algebra by their bracket relations (17); this follows from the Jacobi identity
$$\left \{ \left \{ G, K \right \}, J \right \} + \left \{ \left \{ K, J \right \}, G \right \} + \left \{ \left \{ J, G \right \}, K \right \} = 0.$$
Applying the identity to the special case where one of the functions is the hamiltonian: J = H , implies that constants of motion ( G,K ) satisfy
$$\left \{ \left \{ G, K \right \}, H \right \} = 0.$$
Hence the bracket of two constants of motion produces another constant of motion, and the set of such constants is closed under the bracket operation. Here we summarize some properties of this algebra [4].
The generators J = J µ p µ linear in momentum define a Lie subalgebra of the full algebra:
$$\{ J _ { 1 }, J _ { 2 } \} = J _ { 3 }, \quad J _ { 3 } ^ { \mu } = J _ { 2 } ^ { \nu } \, \nabla _ { \nu } J _ { 1 } ^ { \mu } - J _ { 1 } ^ { \nu } \, \nabla _ { \nu } J _ { 2 } ^ { \mu }.$$
The constants of motion of rank n ≥ 2 then define representations of this subalgebra , characterized by the transformation rule 1
$$\{ G _ { 1 }, J \} = G _ { 2 }, \quad G _ { 2 } ^ { \mu _ { 1 } \dots \mu _ { n } } = J ^ { \lambda } \nabla _ { \lambda } G ^ { \mu _ { 1 } \dots \mu _ { n } } - n G ^ { \lambda ( \mu _ { 1 } \dots \mu _ { n - 1 } } \nabla _ { \lambda } J ^ { \mu _ { n } ) }. \quad ( 2 9 )$$
The Jacobi identity
$$\left \{ \left \{ G, J _ { 1 } \right \}, J _ { 2 } \right \} - \left \{ \left \{ G, J _ { 2 } \right \}, J _ { 1 } \right \} = \left \{ G, \left \{ J _ { 1 }, J _ { 2 } \right \} \right \},$$
then guarantees that the transformations generated by the linear J x, p ( ) on the rankn tensors G x, p ( ) obey the composition rules of the subalgebra spanned by the linear J x, p ( ) themselves.
As for the brackets of a generator G ( n ) of rank n , and a generator G ( m ) of rank m , with both ( n, m ) ≥ 2, it is easily recognized that any non-vanishng brackets of such quantities must be a generator G ( n + m -1) , of rank n + m -1 exceeding both n and m :
$$\left \{ G ^ { ( n ) }, G ^ { ( m ) } \right \} \sim G ^ { ( n + m - 1 ) }.$$
Therefore non-vanishing brackets of higher-rank generators will potentially lead to an infinite set of generators of arbitrary high rank. Well-known examples of such algebras are the Virasoro and Kac-Moody algebras of 2-D conformal field theories.
## 5 Abelian gauge interactions
Geodesic motion on a manifold applies to the motion of a pure mass point subject only to geometrical forces. However, Noether's theorem is very general and can be applied also in presence of external force fields [8, 9]. In this section I consider abelian gauge interactions transmitted by a vector field A µ ( x ), acting on a point mass m with charge q . For such a particle the canonical hamiltonian reads
$$H = \frac { 1 } { 2 m } \, g ^ { \mu \nu } \left ( p _ { \mu } - q A _ { \mu } \right ) \left ( p _ { \nu } - q A _ { \nu } \right ).$$
The hamiltonian equations of motion (7), (8) are generalized to
$$p _ { \mu } = m g _ { \mu \nu } \dot { x } ^ { \nu } + q A _ { \mu }, \quad g _ { \mu \nu } \left ( \ddot { x } ^ { \nu } + \Gamma _ { \kappa \lambda } ^ { \ \nu } \dot { x } ^ { \kappa } \dot { x } ^ { \lambda } \right ) = \frac { q } { m } \, F _ { \mu \nu } \, \dot { x } ^ { \nu },$$
1 The parenthesis around the indices ( µ ...µ 1 n ) denote complete symmetrization with unit weight.
which is the Lorentz force law on curved manifolds.
A drawback of this hamiltonian formulation is, that the canonical momentum is not gauge invariant; under gauge transformations
$$A ^ { \prime } _ { \mu } = A _ { \mu } + \nabla _ { \mu } \Lambda, \quad p ^ { \prime } _ { \mu } = p _ { \mu } + q \nabla _ { \mu } \Lambda.$$
Therefore it is preferable to work with the covariant momentum [7, 10]
$$\pi _ { \mu } = p _ { \mu } - q A _ { \mu } = m g _ { \mu \nu } \dot { x } ^ { \nu },$$
in terms of which the hamiltonian takes the simple form
$$H = \frac { 1 } { 2 m } \, g ^ { \mu \nu } \pi _ { \mu } \pi _ { \nu }.$$
If the covariant derivative D now is generalized to
$$\mathcal { D } _ { \mu } G = \frac { \partial G } { \partial x ^ { \mu } } + \Gamma _ { \mu \nu } ^ { \ \lambda } \pi _ { \lambda } \, \frac { \partial G } { \partial \pi _ { \nu } },$$
then as before the metric postulate can be used to show that
$$\mathcal { D } _ { \mu } H = 0.$$
Moreover, the correct dynamics is reproduced as usual by
$$\frac { d G } { d \tau } = \left \{ G, H \right \},$$
when supplemented by the covariant brackets
$$\{ G, K \} = \mathcal { D } _ { \mu } G \, \frac { \partial K } { \partial \pi _ { \mu } } - \frac { \partial G } { \partial \pi _ { \mu } } \, \mathcal { D } _ { \mu } K + q F _ { \mu \nu } \, \frac { \partial G } { \partial \pi _ { \mu } } \frac { \partial K } { \partial \pi _ { \nu } }.$$
In particular, this bracket reproduces the Ricci identity in the form
$$\{ \pi _ { \mu }, \pi _ { \nu } \} = q F _ { \mu \nu }.$$
In view of the identity (38) and the anti-symmetry of the field strength tensor F µν , the condition for a scalar quantity G x, π ( ) to be constant of motion becomes [10]
$$\{ G, H \} = 0 \quad \Rightarrow \quad \pi ^ { \mu } \mathcal { D } _ { \mu } G = q \pi ^ { \mu } F _ { \mu \nu } \, \frac { \partial G } { \partial \pi _ { \nu } }.$$
In particular, if G can be expressed as a power series
$$G ( x, \pi ) = \sum _ { n } \frac { 1 } { n! } \, G ^ { ( n ) \, \mu _ { 1 } \dots \mu _ { n } } ( x ) \, \pi _ { \mu _ { 1 } } \dots \pi _ { \mu _ { n } },$$
then eq. (42) takes the form of a first-order p.d.e.
$$\nabla _ { ( \mu _ { 1 } } G ^ { ( n ) } _ { \mu _ { 2 } \dots \mu _ { n + 1 } ) } = q F ^ { \ \nu } _ { ( \mu _ { 1 } } G ^ { ( n + 1 ) } _ { \mu _ { 2 } \dots \mu _ { n + 1 } ) \nu }.$$
This is a generalization of equation (21) for Killing tensors, forming a hierarchy of equation connecting tensors of different rank. Nevertheless, the existence of a Killing tensor of rank n still provides a constant of motion: it allows the series expansion (43) to be truncated, with all higher-rank components vanishing:
$$\nabla _ { ( \mu _ { 1 } } G ^ { ( n ) } _ { \mu _ { 2 } \dots \mu _ { n + 1 } ) } = 0 \ \Rightarrow \ \ G ^ { ( n + k ) } _ { \mu _ { 1 } \dots \mu _ { n + k } } = 0, \ \forall k \geq 0,$$
while all lower-rank components are obtained by solving eq. (44) with the allready known higher-rank ones as inhomegenous source term on the right-hand side [10].
Finally note, that it is straightforward to include a scalar potential Φ( x ) as well:
$$H = \frac { 1 } { 2 m } \, g ^ { \mu \nu } \pi _ { \mu } \pi _ { \nu } + \Phi, \ \Rightarrow \ \mathcal { D } _ { \mu } H = \frac { \partial \Phi } { \partial x ^ { \mu } }.$$
This modifies the generalization of the Killing equation to include a gradient term [11]
$$\pi ^ { \mu } \mathcal { D } _ { \mu } G = q \pi ^ { \mu } F _ { \mu \nu } \frac { \partial G } { \partial \pi _ { \nu } } + \frac { \partial \Phi } { \partial x ^ { \mu } } \frac { \partial G } { \partial \pi _ { \mu } }.$$
## Example: a quantum-dot model
A model of a quantum-dot, consisting of 2 electrons moving as a non-relativistic bound pair with Coulomb interaction in a confining harmonic potential and a magnetic field, was studied in ref. [12]. Ignoring the center-of-mass motion, the pair can be described in axial co-ordinates ( ρ, z, ϕ ) as a single particle with hamiltonian
$$H _ { C M } = \frac { 1 } { 2 } \, g ^ { i j } \pi _ { i } \pi _ { j } + \Phi,$$
where
$$\text{where} \quad g _ { i j } = \text{diag} ( 1, 1, \rho ^ { 2 } ), \quad \Phi = \frac { 1 } { 2 } \left ( \omega _ { 0 } ^ { 2 } \rho ^ { 2 } + \omega _ { z } ^ { 2 } z ^ { 2 } \right ) - \frac { \kappa } { \sqrt { \rho ^ { 2 } + z ^ { 2 } } }. \quad \quad ( 4 9 )$$
The definition of the dynamics is completed by the brackets
$$\{ G, K \} = \mathcal { D } _ { i } G \frac { \partial K } { \partial \pi _ { i } } - \frac { \partial G } { \partial \pi _ { i } } \mathcal { D } _ { i } K - 2 \omega _ { L } \rho \left ( \frac { \partial G } { \partial \pi _ { \rho } } \frac { \partial K } { \partial \pi _ { \varphi } } - \frac { \partial G } { \partial \pi _ { \varphi } } \frac { \partial K } { \partial \pi _ { \rho } } \right ),$$
where ω L = eB/ 2 is the Larmor frequency.
To guarantee that a Killing tensor can be completed to a full constant of motion, solving eq. (47), it may be necessary to tune the parameters in the scalar potential. In the case of the quantum dot, there is a rank-4 Killing tensor which can be completed to a full constant of motion provided the magnetic field is tuned
to a value such that the Larmor frequency is a fixed combination of the harmonic frequencies:
$$\omega _ { L } ^ { 2 } + \omega _ { 0 } ^ { 2 } = 4 \omega _ { z } ^ { 2 }.$$
Then the following expression is a solution of eq. (47) for this system:
$$G = \rho ^ { 2 } \pi _ { z } ^ { 4 } - 2 \rho z \pi _ { \rho } \pi _ { z } ^ { 3 } + z ^ { 2 } \pi _ { \rho } ^ { 2 } \pi _ { z } ^ { 2 } + \frac { 1 } { \rho ^ { 2 } } \pi _ { \varphi } ^ { 4 } + \pi _ { \rho } ^ { 2 } \pi _ { \varphi } ^ { 2 } + \left ( 2 + \frac { z ^ { 2 } } { \rho ^ { 2 } } \right ) \pi _ { z } ^ { 2 } \pi _ { \varphi } ^ { 2 }$$
$$G & = \rho ^ { 2 } \pi _ { z } ^ { 4 } - 2 \rho z \pi _ { \rho } ^ { 3 } z ^ { 2 } \pi _ { \rho } ^ { 2 } z ^ { 2 } + \frac { 1 } { \rho ^ { 2 } } \pi _ { \rho } ^ { 4 } + \pi _ { \rho } ^ { 2 } \pi _ { \rho } ^ { 2 } + \left ( 2 + \frac { z ^ { z } } { \rho ^ { 2 } } \right ) \pi _ { z } ^ { 2 } \pi _ { \rho } ^ { 2 } \\ & + 2 \omega _ { L } \pi _ { \varphi } \left ( \rho ^ { 2 } \pi _ { \rho } ^ { 2 } + ( 2 \rho ^ { 2 } + z ^ { 2 } ) \pi _ { z } ^ { 2 } \right ) + \left [ 2 \omega _ { z } ^ { 2 } z ^ { 3 } \rho + \frac { 2 \kappa z \rho } { \sqrt { \rho ^ { 2 } } + z ^ { 2 } } \right ] \pi _ { \rho } \pi _ { z } \\ & + \left [ ( 2 \omega _ { z } ^ { 2 } - \omega _ { 0 } ^ { 2 } ) z ^ { 2 } \rho ^ { 2 } + 2 \omega _ { L } ^ { 2 } \rho ^ { 4 } - \frac { 2 \kappa \rho ^ { 2 } } { \sqrt { \rho ^ { 2 } } + z ^ { 2 } } \right ] \pi _ { z } ^ { 2 } + \omega _ { L } ^ { 2 } \rho ^ { 4 } \pi _ { \rho } ^ { 2 } \\ & + \left [ 2 \omega _ { z } ^ { 2 } z ^ { 2 } + ( \omega _ { 0 } ^ { 2 } - 5 \omega _ { L } ^ { 2 } ) \rho ^ { 2 } - \frac { 2 \kappa } { \sqrt { \rho ^ { 2 } } + z ^ { 2 } } \right ] \pi _ { \varphi } ^ { 2 } \\ & - 2 \omega _ { L } \pi _ { \varphi } \left [ ( 3 \omega _ { L } ^ { 2 } - \omega _ { 0 } ^ { 2 } ) \rho ^ { 4 } - 2 \omega _ { z } ^ { 2 } \rho ^ { 2 } z ^ { 2 } + \frac { 2 \kappa \rho ^ { 2 } } { \sqrt { \rho ^ { 2 } } + z ^ { 2 } } \right ] + \omega _ { z } ^ { 4 } \rho ^ { 2 } z ^ { 4 } + 2 \omega _ { z } ^ { 2 } \omega _ { L } ^ { 2 } \rho ^ { 4 } z ^ { 2 } \\ & - \omega _ { L } ^ { 2 } ( 3 \omega _ { L } ^ { 2 } - 4 \omega _ { z } ^ { 2 } ) \rho ^ { 6 } + \frac { 2 \kappa } { \sqrt { \rho ^ { 2 } } + z ^ { 2 } } \left ( \omega _ { z } ^ { 2 } \rho ^ { 2 } z ^ { 2 } - \omega _ { L } ^ { 2 } \rho ^ { 4 } \right ) + \frac { \kappa ^ { 2 } } { 2 } \, \rho ^ { 2 } + z ^ { 2 }.$$
$$- \omega _ { L } ^ { 2 } ( 3 \omega _ { L } ^ { 2 } - 4 \omega _ { z } ^ { 2 } ) \rho ^ { 6 } + \frac { 2 \kappa } { \sqrt { \rho ^ { 2 } + z ^ { 2 } } } \left ( \omega _ { z } ^ { 2 } \rho ^ { 2 } z ^ { 2 } - \omega _ { L } ^ { 2 } \rho ^ { 4 } \right ) + \frac { \kappa ^ { 2 } } { 2 } \, \frac { \rho ^ { 2 } - z ^ { 2 } } { \rho ^ { 2 } + z ^ { 2 } }.$$
## 6 Non-abelian gauge interactions
The dynamics of a particle with non-abelian gauge interactions is described by Wong's generalization of the Lorentz force law [13]
$$g _ { \mu \nu } \left ( \ddot { x } ^ { \nu } + \Gamma _ { \kappa \lambda } ^ { \ \nu } \dot { x } ^ { \kappa } \dot { x } ^ { \lambda } \right ) = \frac { g } { m } \, t _ { a } F _ { \mu \nu } ^ { a } \dot { x } ^ { \nu }, \quad \dot { t } _ { a } + g f _ { a b } ^ { \ \ c } t _ { c } A _ { \mu } ^ { \ \ b } \dot { x } ^ { \mu }.$$
Here g is the coupling constant, f c ab are the structure constants of the Lie algebra of gauge charges t a , and the non-abelian field-strength tensor is
$$F _ { \mu \nu } ^ { a } = \nabla _ { \mu } A _ { \nu } ^ { a } - \nabla _ { \nu } A _ { \mu } ^ { a } + g f _ { b c } ^ { \ a } A _ { \mu } ^ { b } A _ { \nu } ^ { c }.$$
The theory can be cast in hamiltonian form [10] by introducing covariant momenta π µ and a canonical hamiltonian
$$H = \frac { 1 } { 2 m } \, g ^ { \mu \nu } \pi _ { \mu } \pi _ { \nu },$$
supplemented with brackets
$$& \{ G, K \} = \mathcal { D } _ { \mu } G \frac { \partial K } { \partial \pi _ { \mu } } - \frac { \partial G } { \partial \pi _ { \mu } } \mathcal { D } _ { \mu } K + g t _ { a } F _ { \mu \nu } ^ { a } \frac { \partial G } { \partial \pi _ { \mu } } \frac { \partial K } { \partial \pi _ { \nu } } + f _ { a b } ^ { c } t _ { c } \frac { \partial G } { \partial t _ { a } } \frac { \partial K } { \partial t _ { b } }, \\ & \mathcal { D } _ { \mu } G \equiv \frac { \partial G } { \partial x ^ { \mu } } + \Gamma _ { \mu \nu } ^ { \lambda } \pi _ { \lambda } \frac { \partial G } { \partial \pi _ { \nu } } + g f _ { a b } ^ { c } t _ { c } A _ { \mu } ^ { a } \frac { \partial G } { \partial t _ { b } }. \\ \psi & \quad. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
In particular these brackets guarantee the Ricci identity and the Lie-algebra of gauge charges:
$$\bar { \Phi } _ { 0 } \{ \pi _ { \mu }, \pi _ { \nu } \} = g t _ { a } \, F _ { \mu \nu } ^ { a }, \quad \{ t _ { a }, t _ { b } \} = f _ { a b } ^ { \ c } t _ { c }.$$
It is now straightforward to derive the condition for the existence of constants of motion:
$$\cdot \\ \{ G, H \} = 0 \quad \Rightarrow \quad \pi ^ { \mu } \mathcal { D } _ { \mu } G = g t _ { a } F ^ { a } _ { \mu \nu } \, \pi ^ { \mu } \frac { \partial G } { \partial \pi _ { \nu } }.$$
In components this gives us a hierarchy of equations similar to (44) for the abelian case:
$$\mathcal { D } _ { \mu } G ^ { ( 0 ) } & = g t _ { a } F _ { \mu } ^ { a \nu } G _ { \nu } ^ { ( 1 ) }, \\ \mathcal { D } _ { \mu } G _ { \nu } ^ { ( 1 ) } & + \mathcal { D } _ { \nu } G _ { \mu } ^ { ( 1 ) } = g t _ { a } \left ( F _ { \mu } ^ { a \lambda } G _ { \lambda \nu } ^ { ( 2 ) } + F _ { \nu } ^ { a \lambda } G _ { \lambda \mu } ^ { ( 2 ) } \right ), \\ \mathcal { D } _ { \mu } G _ { \nu \lambda } ^ { ( 2 ) } & + \mathcal { D } _ { \nu } G _ { \lambda \mu } ^ { ( 2 ) } + \mathcal { D } _ { \lambda } G _ { \mu \nu } ^ { ( 2 ) } = g t _ { a } \left ( F _ { \mu } ^ { a \kappa } G _ { \kappa \lambda \nu } ^ { ( 3 ) } + F _ { \nu } ^ { a \kappa } G _ { \kappa \lambda \mu } ^ { ( 2 ) } + F _ { \lambda } ^ { a \kappa } G _ { \kappa \mu \nu } ^ { ( 3 ) } \right ),$$
...
Example: 2-D SU (2) Yang-Mills point charge
As a simple example consider the dynamics of a non-abelian point charge in a static magnetic SU (2)-field in the euclidean plane. In the 2-dimensional plane such a magnetic field can be written as
$$F _ { i j } ^ { a } = \varepsilon _ { i j } B ^ { a },$$
where a represents an adjoint vector component in 3-dimensional internal SU (2)space. The free Yang-Mills equation then implies
$$\nabla _ { i } B ^ { a } + g \varepsilon ^ { a b c } A _ { i } ^ { b } B ^ { c } = 0 \quad \Rightarrow \quad \nabla _ { i } B ^ { a \, 2 } = 0,$$
and the modulus of B a is constant. Now the direction of B a can be rotated point-wise in the plane by a local gauge transformation, and this freedom can be used to make B a constant. Such a constant B a -field is derived from a vector potential
$$A _ { i } ^ { a } = - \frac { 1 } { 2 } \, \varepsilon _ { i j } x ^ { j } B ^ { a }.$$
Now the 2-dimensional euclidean plane is invariant under translations and rotations, guaranteeing conservation of momentum and angular momentum. Our construction implies, that the angular momentum will obtain a field dependent addition:
$$J = \varepsilon _ { i j } x _ { i } \pi _ { j } + \frac { g } { 2 } \, t _ { a } B ^ { a } x _ { i } ^ { 2 }.$$
In addition, there is also a pair of of rank-2 Killing tensors, generating a conserved Runge-Lenz vector:
$$K _ { i } = x _ { i } \pi _ { j } ^ { 2 } - \pi _ { i } \pi _ { j } x _ { j } + g B ^ { a } t _ { a } \left ( \frac { 1 } { 2 } \, \varepsilon _ { i j } \pi _ { j } x _ { k } ^ { 2 } + x _ { i } x _ { j } \varepsilon _ { j k } \pi _ { k } \right ) + \frac { 1 } { 2 } \, \left ( g B ^ { a } t _ { a } \right ) ^ { 2 } x _ { i } \, x _ { j } ^ { 2 }. \ \ ( 6 4 )$$
## Acknowledgement
The work described in this paper is supported by the Foundation for Fundamental Research of Matter (FOM), as part of the research programme Theoretical Particle Physics in the Era of the LHC .
## References
- [1] E. Noether, Invariante Variationsprobleme , Nachr. D. Knig. Gesellsch. D. Wiss. Zu G¨ttingen, Math-phys. Klasse 1918: o 235
- [2] B. Carter, Global Structure of the Kerr Family of Gravitational Fields , Phys. Rev. 174 (1968), 1559
- [3] B. Carter, Killing tensor quantum numbers and conserved currents in curved space Phys. Rev. D16 (1977), 3395
- [4] J.W. van Holten and R.H. Rietdijk, Symmetries and motions in manifolds , J. Geom. and Physics 11 (1993), 559; arXiv:hep-th/9205074
- [5] R. Penrose, Ann. N. Y. Acad. Sci. 224 (1973), 125;
- [6] R. Floyd, The Dynamics of Kerr Fields PhD. Thesis (London 1973)
- [7] G.W. Gibbons, R.H. Rietdijk and J.W. van Holten, SUSY in the sky , Nucl. Phys. B404 (1993), 42; arXiv:hep-th/9303112
- [8]
- R. Jackiw and N.S. Manton, Symmetries and conservation laws in gauge theories . Ann. Phys. (NY) 127 (1980), 257
- [9] C. Duval and P. Horvathy, Particles with internal structure: the geometry of classical motions and conservation laws , Ann. Phys. (NY) 142 (1982), 10
- [10] J.W. van Holten, Covariant hamiltonian dynamics Phys. Rev. D75 (2007) 025027; arXiv:hep-th/0612216
- [11]
- M. Visinescu, Higher order first integrals of motion in a gauge covariant Hamiltonian framework Mod. Phys. Lett. A25 (2010), 341; arXiv:0910.3474v2 [hep-th]
- M. Cariglia, G.W. Gibbons, J.-W. van Holten, P.A. Horvathy, P. Kos´ ınski and P.-M. Zhang, Killing tensors and canonical geometry in classical dynamics
- [12] Class. Quantum Grav. (in press); arXiv:1401.8195 [hep-th]
- [13] S.K. Wong, Field and particle equations for the classical Yang-Mills field and particles with isotopic spin , Nuov. Cim. 65A (1970), 689 | 10.1088/1742-6596/597/1/012072 | [
"J. W. van Holten"
] | 2014-08-01T09:43:32+00:00 | 2014-08-01T09:43:32+00:00 | [
"math-ph",
"hep-th",
"math.MP"
] | Gauge-covariant extensions of Killing tensors and conservation laws | In classical and quantum mechanical systems on manifolds with gauge-field
fluxes, constants of motion are constructed from gauge-covariant extensions of
Killing vectors and tensors. This construction can be carried out using a
manifestly covariant procedure, in terms of covariant phase space with a
covariant generalization of the Poisson brackets, c.q. quantum commutators.
Some examples of this construction are presented. |
1408.0116v2 | ## STRICTLY COMMUTATIVE MODELS FOR E ∞ QUASI-CATEGORIES
## DIMITAR KODJABACHEV AND STEFFEN SAGAVE
Abstract. In this short note we show that E ∞ quasi-categories can be replaced by strictly commutative objects in the larger category of diagrams of simplicial sets indexed by finite sets and injections. This complements earlier work on diagram spaces by Christian Schlichtkrull and the second author.
## 1. Introduction
An E ∞ space is a space with a multiplicative structure encoded by the action of an E ∞ operad, i.e., an operad consisting of contractible spaces with a free Σ n -action. It is shown in joint work by Christian Schlichtkrull and the second author [SS12] that E ∞ spaces can be rigidified to strictly commutative objects if one passes to a larger category of I -spaces: if I denotes the category of finite sets n = { 1 , . . . , n } and injective maps, then the functor category sSet I has a symmetric monoidal convolution product, and the category sSet I [ C ] of commutative monoid objects in sSet I admits a model structure making it Quillen equivalent to the category of E ∞ spaces.
The following construction, due to Mirjam Solberg [SS, Section 4.14], shows that symmetric monoidal categories give rise to commutative monoid objects in sSet I in a natural way.
Example 1.1. Let ( A ⊗ , ) be a symmetric monoidal category. We consider the functor Φ( A ): I → Cat with objects of Φ( A )( n ) the n -tuples ( a , . . . , a 1 n ) of objects in A and morphisms
$$\Phi ( \mathcal { A } ) ( \mathbf n ) ( ( a _ { 1 }, \dots, a _ { n } ), ( b _ { 1 }, \dots, b _ { n } ) ) = \mathcal { A } ( a _ { 1 } \otimes \dots \otimes a _ { n }, b _ { 1 } \otimes \dots \otimes b _ { n } ).$$
Functoriality in I is induced by permutation of entries and insertion of the unit object of A . Composing with the nerve functor N gives an I -simplicial set N Φ( A ), and the symmetric monoidal structure of A makes N Φ( A ) a commutative monoid object in sSet I , see [SS, Proposition 4.16].
Equipped with the (standard or Kan) model structure, the category of simplicial sets sSet is Quillen equivalent to the category of topological spaces. Therefore, weak homotopy types of spaces are represented by simplicial sets. But simplicial sets also model quasi-categories up to Joyal equivalence: there is a finer Joyal model structure on sSet whose fibrant objects are the quasi-categories and whose weak equivalences are called Joyal equivalences (see e.g. [Lur09a] or [DS11] for published references). Simplicial sets with E ∞ structures are also interesting from this perspective since they model symmetric monoidal ( ∞ , 1)-categories [Lur]. These play a prominent role in Lurie's work on the cobordism hypothesis [Lur09b].
In view of these two interpretations of simplicial sets, it is an obvious question if the above comparison of E ∞ objects in sSet and strictly commutative objects in sSet I still holds if we regard simplicial sets as models for quasi-categories. The aim of this note is to prove that this is indeed the case:
Date : October 27, 2014.
- Theorem 1.2. (i) The category sSet I [ C ] of commutative monoid objects in sSet I admits a left proper positive I -model structure where a map f is a weak equivalence if and only if hocolim I f is a Joyal equivalence.
- (ii) If D is an E ∞ operad, then there is a chain of Quillen equivalences relating sSet I [ C ] and the category sSet[ D ] of E ∞ simplicial sets with the model structure lifted from the Joyal model structure.
Here an E ∞ operad is an operad D in simplicial sets such that D ( n ) has a free Σ n -action and D ( n ) is contractible with respect to the Joyal model structure. Every E ∞ operad in this sense is an E ∞ operad in the classical sense since being contractible with respect to the Joyal model structure implies being contractible with respect to the Kan model structure. Moreover, every operad D with D ( n ) a Σ -free Kan complex such that n D ( n ) → ∗ is a weak homotopy equivalence is an E ∞ -operad in the sense of the theorem, for example the Barratt-Eccles operad whose n -th space is E Σ . n
By [SS, Lemma 4.15], the object N Φ( A ) in sSet I [ C ] considered in Example 1.1 is fibrant in the model structure of Theorem 1.2(i). It models the E ∞ quasi-category N A associated with the symmetric monoidal category A . Therefore Example 1.1 shows that the nerve of a symmetric monoidal category can be rigidified to a commutative monoid object in sSet I in a natural way.
More generally, it follows from Theorem 1.2 that for any E ∞ simplicial set X in the sense of the theorem, there is an A ∈ sSet I [ C ] and a chain of maps A ← B → const I X of E ∞ objects in sSet I that induces a chain of Joyal equivalences when applying hocolim I (compare [SS12, Corollary 3.7]). Hence the E ∞ object X can be replaced by the strictly commutative object A . Although this rigidification of a structure up to homotopy by a strict one is in contrast to the philosophy of quasi-categories, we think that it is valuable to observe that E ∞ quasi-categories can be expressed this way: when viewing simplicial sets as models for spaces, it is often easy to write down explicit objects in sSet I [ C ] that model E ∞ spaces. This applies for example to Q X ( ) if X is connected [SS12, Example 1.3] or to B GL ∞ ( R ) + [Sch04, Remark 2.2]. It is likely that besides Example 1.1 above, there are more instances where interesting E ∞ quasi-categories arise from commutative I -functors.
Theorem 1.2 and the corresponding statement about weak homotopy types of E ∞ spaces [SS12, Theorem 1.2] refer to different model structures on the same categories that have the same cofibrations. Nonetheless, several arguments from [SS12] do not apply here since [SS12, Theorem 1.2] was derived from a result about diagram spaces indexed by more general categories than I , and some of the more general arguments were based on special features of the Kan model structure. However, the Joyal model structure differs from the Kan model structure since it fails to be right proper and simplicial, and because it doesn't have an explicit set of generating acyclic cofibrations. In the proof of Theorem 1.2 presented here, we put emphasis on the points where new arguments are required and simply cite those parts of the proof of [SS12, Theorem 1.2] that also apply here.
This note is a condensed and revised version of the first author's master's thesis at the University of Bonn, supervised by the second author. We thank an anonymous referee for a quick and helpful report on an earlier version of this note.
## 2. Model structures on I -simplicial sets
The category of simplicial sets sSet admits a Joyal model structure with cofibrations the monomorphisms and fibrant objects the quasi-categories, i.e., the weak or inner Kan complexes. See [Lur09a, Theorem 2.2.5.1] or [DS11, Theorem 2.13]. The Joyal model structure is cofibrantly generated with generating cofibrations
I = { ∂ ∆ n → ∆ n | n ≥ 0 } . We let J be a set of generating acyclic cofibrations. (There is no known explicit description of such a set J .)
Let I be the category with objects the finite sets n = { 1 , . . . , n } for n ≥ 0 and morphisms the injections. Concatenation of ordered sets glyph[unionsq] makes I a symmetric monoidal category with unit 0 and symmetry isomorphism the obvious shuffle map. Let sSet I be the functor category of I -diagrams of simplicial sets. For every object n of I , there is a free/forgetful adjunction F I n : sSet glyph[arrowparrrightleft] sSet I : Ev n with F I n ( K ) = I ( n , - × ) K and Ev n ( X ) = X ( n ). For X and Y in sSet I , the left Kan extension of the I × I -diagram X ( - × ) Y ( -) along glyph[unionsq] : I × I → I defines an object X glyph[squaremultiply] Y in sSet I . This construction defines a symmetric monoidal product glyph[squaremultiply] : sSet I × sSet I → sSet I with unit F I 0 ( ∗ ).
We now start to consider model structures on sSet I . Let I + be the full subcategory of I on the objects n with | n | ≥ 1. We say that a map f : X → Y in sSet I is an absolute (resp. positive) level equivalence if f : X ( n ) → Y ( n ) is a Joyal equivalence for all n in I (resp. all n in I + ), and an absolute (resp. positive) level fibration if f : X ( n ) → Y ( n ) is a fibration in the Joyal model structure for all n in I (resp. all n in I + ). A map is an absolute (resp. positive) level cofibration if it has the left lifting property with respect to any map that is both an absolute (resp. positive) level fibration and level equivalence.
Lemma 2.1. These classes of maps define two cofibrantly generated left proper model structures on sSet I , called the absolute and the positive level model structures.
Proof of Lemma 2.1. The absolute case follows from [Hir03, Theorem 11.6.1], and the positive case works as in [SS12, Proposition 6.7]. The sets
$$( 2. 1 ) \quad \ I _ { \text{abs} } ^ { \text{level} } = \{ F _ { \text{n} } ^ { \mathcal { I } } ( i ) \, | \, i \in I, \mathbf n \in \mathcal { I } \} \text{ and } I _ { \text{pos} } ^ { \text{level} } = \{ F _ { \text{n} } ^ { \mathcal { I } } ( i ) \, | \, i \in I, \mathbf n \in \mathcal { I } _ { + } \}$$
provide the generating cofibrations. The generating acyclic cofibrations J level abs and J level pos are defined similarly with J in place of I . glyph[square]
Since the Joyal model structure fails to be simplicial, the usual Bousfield-Kan formula does not provide a homotopy invariant homotopy colimit functor. In the following, hocolim I : sSet I → sSet denotes the functor constructed in [Hir03, § 19] using cosimplicial frames. We recall from [Hir03, Example 19.2.10] that there is a natural map hocolim I X → colim I X .
Lemma 2.2. If X is absolute or positive level cofibrant in sSet I , then the map hocolim I X → colim I X is a Joyal equivalence.
Proof. This is analogous to [Hir03, Theorem 19.9.1], with the absolute level model structure replacing the Reedy model structure in that reference. glyph[square]
We say that a map f : X → Y in sSet I is an I -equivalence if hocolim I f is a Joyal equivalence of simplicial sets, and an absolute (resp. positive) I -cofibration if it is an absolute (resp. positive) level cofibration. A map is an absolute (resp. positive) I -fibration if it has the right lifting property with respect to any map that is both an absolute (resp. positive) I -cofibration and an I -equivalence.
Proposition 2.3. These classes of maps define two cofibrantly generated left proper model structures on sSet I , called the absolute and the positive I -model structures.
We write sSet I abs and sSet I pos for these model categories. These (Joyal) I -model structures have the same cofibrations as the corresponding (Kan) I -model structures constructed in [SS12, Proposition 6.16] by a different technique.
Proof. Since I has an initial object, its classifying space is contractible. Hence the existence of the absolute I -model structure follows from [Dug01, Theorem 5.2], and we recall from [Dug01] that it is constructed as the left Bousfield localization of the absolute level model structure at S = { α ∗ : F I n ( ∗ ) → F I m ( ∗ ) | α : m → n ∈ I} .
The positive I -model structure is defined to be the left Bousfield localization of the positive level model structure with respect to
$$T = \{ \alpha ^ { * } \colon F _ { \mathbf n } ^ { \mathcal { I } } ( * ) \to F _ { \mathbf m } ^ { \mathcal { I } } ( * ) \, | \, \alpha \colon \mathbf m \to \mathbf n \in \mathcal { I } _ { + } \}.$$
It exists and is left proper by [Hir03, Theorem 4.1.1]. Hence it remains to show that its weak equivalences, the T -local equivalences , are the I -equivalences. Since T ⊂ S , every T -local equivalence is an I -equivalence. Let f be an I -equivalence. Passing to fibrant replacements, we may assume that f is a map of T -local objects. Restricting f along the inclusion I + → I and applying [Dug01, Theorem 5.2] to sSet I + , it follows that hocolim I + f is a Joyal equivalence. Since I + → I is homotopy cofinal [SS12, Proof of Corollary 5.9], this implies the claim. glyph[square]
Corollary 2.4. There is a chain of Quillen equivalences
o
$$s \text{Set} _ { \text{pos} } ^ { \mathcal { I } } \overline { \underset { \text{id} } { \longleftarrow } } s \text{Set} _ { \text{abs} } ^ { \mathcal { I } } \overline { \underset { \text{const} } { \longleftarrow } } \overline { \underset { \text{const} } { \longleftarrow } } s \text{Set}$$
/
/
o
/
/
o
o
relating sSet I equipped with the positive and absolute I -model structures and sSet equipped with the Joyal model structure.
Proof. It is clear that (id , id) is a Quillen equivalence. The adjunction (colim I , const I ) is a Quillen equivalence by [Dug01, Theorem 5.2(b)]. glyph[square]
The next lemma and the subsequent proposition are analogous to [SS12, Proposition 7.1(iii)-(v) and Proposition 8.2]. The proofs given here avoid using features of the Bousfield-Kan formula for homotopy colimits.
Lemma 2.5. (i) The gluing lemma for levelwise monomorphisms and level equivalences holds.
- (ii) The gluing lemma for levelwise monomorphisms and I -equivalences holds.
- (iii) For any ordinal λ and any λ -sequence ( X α α<λ ) of levelwise monomorphisms, the canonical map hocolim α<λ X α → colim α<λ X α is a level equivalence.
Proof. Part (i) follows from the gluing lemma in left proper model categories [Hir03, Proposition 13.5.4]. Using (i) and the absolute level cofibrant replacement, it is enough to show (ii) for a diagram of absolute cofibrant objects. This special case follows from the gluing lemma in the Joyal model structure by applying colim I . Part (iii) follows from [Hir03, Theorem 19.9.1]. glyph[square]
Proposition 2.6. If X is absolute cofibrant in sSet I , then X glyph[squaremultiply] -preserves I -equivalences between not necessarily cofibrant objects.
Proof. We first assume that X = F I k ( L ) with L ∈ sSet and k ∈ I . Let Y → Z be an I -equivalence. If Y and Z are absolute cofibrant, then the claim follows by applying the strong symmetric monoidal functor colim I and using Corollary 2.4 and the pushout-product axiom for the Joyal model structure [DS11, 2.15 Proposition]. If Y c → Y is an absolute level cofibrant replacement, then [SS12, Lemma 5.6] implies that ( X glyph[squaremultiply] ( Y c → Y ))( m ) is isomorphic to
$$( 2. 2 ) \quad \ \ L \times \text{colim} _ { k \sqcup 1 \to m } Y ^ { c } ( 1 ) \to L \times \text{colim} _ { k \sqcup 1 \to m } Y ( 1 ).$$
Since each connected component of the comma category k glyph[unionsq] - ↓ m has a terminal object [SS12, Corollary 5.9], the colimits in (2.2) are Joyal equivalent to the corresponding homotopy colimits and (2.2) is a level equivalence. It follows that
X glyph[squaremultiply] ( Y → Z ) is an I -equivalence since X glyph[squaremultiply] ( Y c → Z c ) is. With Lemma 2.5 replacing those parts of [SS12, Proposition 7.1] that involve weak equivalences, the case of general X follows as in the proof of [SS12, Proposition 8.2]. glyph[square]
Corollary 2.7. The absolute and positive I -model structures on sSet I satisfy the pushout-product axiom and the monoid axiom.
Proof. The part of the pushout-product axiom involving only cofibrations results from [SS12, Proposition 8.4]. As in [SS12, § 8], Proposition 2.6 implies the rest. glyph[square]
The following lemma is analogous to [SS12, Lemma 8.1].
Lemma 2.8. Let G be a finite group and let f : X → Y and Y → E be morphisms in (sSet I ) G such that hocolim I f is a Joyal equivalence. If G acts freely on E ( m ) for every object m in I , then f/G : X/G → Y/G is an I -equivalence.
Proof. Since there is a G -map Y → E , the G -action on Y ( m ) is also free. Hence hocolim G Y ( m ) → colim G Y ( m ) ∼ = ( Y/G )( m ) is a Joyal equivalence. Using the same argument for X , it follows that hocolim G hocolim I f glyph[similarequal] hocolim I hocolim G f glyph[similarequal] hocolim I ( f/G )
is a Joyal equivalence.
glyph[square]
The use of the positive model structure is motivated by the positive model structure for symmetric spectra discovered by Jeff Smith. The next lemma highlights one of its key features.
Lemma 2.9. If X is positive I -cofibrant, then the Σ n -action on the simplicial set ( X glyph[squaremultiply] n )( m ) is free for every object m of I .
Proof. Let f : U → V and U → Y be maps in sSet I . By a cell induction argument, it is enough to show that if f is a generating cofibration and Σ n acts freely on ( Y glyph[squaremultiply] n )( m ) for every m in I , then Z = Y ∐ U V has this property. By [SS12, Lemma A.8], Y glyph[squaremultiply] n → Z glyph[squaremultiply] n has a filtration by maps that are cobase changes of maps of the form Σ n × Σ n -i × Σ i Y glyph[squaremultiply] n -i glyph[squaremultiply] f glyph[square] i where f glyph[square] i is the i -fold iterated pushout product map in (sSet I , glyph[squaremultiply] ). Hence it suffices to show that ( Y glyph[squaremultiply] n -i glyph[squaremultiply] f glyph[square] i )( m ) is a (Σ n -i × Σ )-projective cofibration of simplicial sets with (Σ i n -i × Σ )-action. i Since f = F I k ( ∗ ) × g with g a generating cofibration for sSet and k ∈ I + , it follows from [SS12, Lemma 5.6] that there is an isomorphism
$$( 2. 3 ) \quad \ \ ( Y ^ { \Im n - i } \otimes f ^ { \Box i } ) ( \mathbf m ) \cong ( \text{colim} _ { \mathbf k ^ { \cup i } \cup 1 \to \mathbf m } Y ^ { \Box n - i } ( 1 ) ) \times g ^ { \Box i }$$
where g glyph[square] i is the i -fold iterated pushout-product map of g in (sSet , × ). By [SS12, Corollary 5.9], each connected component of the indexing category k glyph[unionsq] i glyph[unionsq] - ↓ m has a terminal object, and Σ i acts freely on the set of connected components. Hence colim k glyph[unionsq] i glyph[unionsq] l → m Y glyph[squaremultiply] n -i ( ) l is a (Σ n -i × Σ )-free i simplicial set, and (2.3) is a (Σ n -i × Σ )-projective cofibration. i glyph[square]
## 3. Model structures on structured diagrams of simplicial sets
In the following, an operad D denotes a sequence of simplicial sets D ( n ) with Σ n -action such that D (0) = ∗ , there is a unit map ∗ → D (1), and there are structure maps D ( n ) ×D ( i 1 ) ×···×D ( i n ) →D ( i 1 + · · · + i n ) satisfying the usual associativity, unit and equivariance relations. It is called Σ -free if Σ n acts freely on D ( n ) for all n .
Let sSet I [ D ] be the category of D -algebras in (sSet I , glyph[squaremultiply] ). We say that a model structure on sSet I lifts to sSet I [ D ] if sSet I [ D ] admits a model structure where a map is a weak equivalence or fibration if the underlying map in sSet I is.
Theorem 3.1. Let D be an operad. The positive I -model structure lifts to sSet I [ D ] , and the absolute I -model structure lifts to sSet I [ D ] if D is Σ -free.
Since the generating cofibrations coincide, these model structures have the same cofibrations as the corresponding Kan I -model structures [SS12, Proposition 9.3].
Proof. As in the analogous statement about the Kan I -model structure [SS12, Proposition 9.3], the claim reduces to showing that for a generating acyclic cofibration f : U → V in sSet I , the bottom map in a pushout square
/
/
GLYPH<15>
GLYPH<15>
GLYPH<15>
GLYPH<15>
/
$$\coprod _ { n \geq 0 } \mathcal { D } ( n ) \times _ { \Sigma _ { n } } U ^ { \varnothing n } \longrightarrow \coprod _ { n \geq 0 } \mathcal { D } ( n ) \times _ { \Sigma _ { n } } V ^ { \varnothing n } \\ \downarrow \quad \downarrow \quad \downarrow \quad Y$$
/
in sSet I [ D ] is an I -equivalence. Replacing [SS12, Propositions 8.4 and 8.6] by Corollary 2.7 and [SS12, Lemma 8.1] by Lemma 2.8, the argument given in the proof of [SS12, Lemma 9.5] applies verbatim with one exception: we need to show that for any n ≥ 0 and any m in I , the group Σ n acts freely on V glyph[squaremultiply] n ( m ). Using that the generating cofibrations have cofibrant domains and codomains, we may assume that this also holds for the generating acyclic cofibrations [Bar10, Corollaries 2.7 and 2.8]. Hence the last claim follows from Lemma 2.9. glyph[square]
We recall that a morphism of operads Φ: D → E induces an adjunction
$$\Phi _ { * } \colon s { \text{Set} } ^ { \mathcal { I } } [ \mathcal { D } ] \Rightarrow s { \text{Set} } ^ { \mathcal { I } } [ \mathcal { E } ] \colon \Phi ^ { * }.$$
Proposition 3.2. Let Φ: D → E be a morphism of operads with Φ : n D ( n ) →E ( n ) a Joyal equivalence for each n ≥ 0 . Then (Φ ∗ , Φ ) ∗ is a Quillen equivalence with respect to the positive I -model structures. If D and E are Σ -free, then it is also a Quillen equivalence with respect to the absolute I -model structures.
Proof. Again the proof of the analogous statement about the Kan I -model structure [SS12, Proposition 9.12] applies almost verbatim: in the key ingredient [SS12, Lemma 9.13], Lemma 2.5 replaces those parts of [SS12, Proposition 7.1] that involve weak equivalences, Corollary 2.7 replaces [SS12, Proposition 8.4], Proposition 2.6 replaces [SS12, Proposition 8.2], and Lemma 2.8 replaces [SS12, Lemma 8.1]. glyph[square]
Proof of Theorem 1.2. Part (i) follows from Theorem 3.1 applied to the commutativity operad C with C ( n ) = ∗ for every n . Left properness follows by the arguments from [SS12, Lemma 11.8 and Proposition 11.9], where again the results from Section 2 replace the corresponding statements in [SS12].
If D is an E ∞ operad, then there is a canonical morphism Φ: D → C , and we obtain a chain of Quillen adjunctions
o
$$\ s S e t _ { \text{pos} } ^ { \mathcal { I } } [ \mathcal { C } ] \xleftarrow { \Phi _ { * } } \ s S e t _ { \text{pos} } ^ { \mathcal { I } } [ \mathcal { D } ] \xleftarrow { \text{id} } \ s S e t _ { \text{abs} } ^ { \mathcal { I } } [ \mathcal { D } ] \xleftarrow { \text{optim} } \ s S e t [ \mathcal { D } ]$$
/
/
/
/
o
o
o
/
/
o
o
The first adjunction is a Quillen equivalence by Proposition 3.2. The last two adjunctions are Quillen equivalences by Corollary 2.4 and the fact that cofibrant objects in sSet I abs [ D ] are cofibrant in sSet I abs if D is Σ-free [SS12, Corollary 12.3]. glyph[square]
## References
[Bar10] C. Barwick, On left and right model categories and left and right Bousfield localizations , Homology, Homotopy Appl. 12 (2010), no. 2, 245-320.
[DS11] D. Dugger and D. I. Spivak, Mapping spaces in quasi-categories , Algebr. Geom. Topol. 11 (2011), no. 1, 263-325.
[Dug01] D. Dugger, Replacing model categories with simplicial ones , Trans. Amer. Math. Soc. 353 (2001), no. 12, 5003-5027 (electronic).
[Hir03] P. S. Hirschhorn, Model categories and their localizations , Mathematical Surveys and Monographs, vol. 99, American Mathematical Society, Providence, RI, 2003.
[Lur09a]
J. Lurie, Higher topos theory , Annals of Mathematics Studies, vol. 170, Princeton University Press, Princeton, NJ, 2009.
[Lur09b]
[Lur] [Sch04]
, On the classification of topological field theories , Current developments in mathematics, 2008, 2009, pp. 129-280.
, Higher algebra . Preprint, available at http://www.math.harvard.edu/ ~ lurie/ . C. Schlichtkrull, Units of ring spectra and their traces in algebraic K -theory , Geom. Topol. 8 (2004), 645-673 (electronic).
[SS12]
S. Sagave and C. Schlichtkrull, Diagram spaces and symmetric spectra , Adv. Math. 231 (2012), no. 3-4, 2116-2193.
[SS] C. Schlichtkrull and M. Solberg, Braided injections and double loop spaces . arXiv:1403.1101 .
School of Mathematics and Statistics, University of Sheffield, Hicks Building, Sheffield, S3 7RH, UK
E-mail address : [email protected]
Department of Mathematics and Informatics, Bergische Universit¨t Wuppertal, Gaußa str. 20, 42119 Wuppertal, Germany
E-mail address : [email protected] | 10.4310/HHA.2015.v17.n1.a5 | [
"Dimitar Kodjabachev",
"Steffen Sagave"
] | 2014-08-01T09:49:14+00:00 | 2014-10-24T07:11:01+00:00 | [
"math.AT",
"math.CT"
] | Strictly commutative models for E-infinity quasi-categories | In this short note we show that E-infinity quasi-categories can be replaced
by strictly commutative objects in the larger category of diagrams of
simplicial sets indexed by finite sets and injections. This complements earlier
work on diagram spaces by Christian Schlichtkrull and the second author. |
1408.0117v1 | ## High-Resolution Imaging in the Visible on Large Ground-Based Telescopes.
Craig Mackay* , Rafael Rebolo a ,e , Jonathan Crass , David L. King , Lucas Labadie , Víctor a a d González-Escélera , Marta Puga , Antonio Pérez-Garrido , Roberto López , Alejandro Oscoz , Jorge b b c b b A. Pérez-Prieto , Luis F. Rodríguez-Ramos , Sergio Velasco , Isidro Villó , b b b c a Institute of Astronomy, University of Cambridge, Madingley Road, Cambridge CB3 0HA, UK b Instituto de Astrofisica de Canarias, C/ Vía Láctea s/n, La Laguna, Tenerife E-38205, Spain and Departamento de Astrofísica, Universidad de La Laguna, La Laguna, Spain c Universidad Politecnica de Cartagena, Campus Muralla del Mar, Cartagena, Murcia E-30202, Spain d I. Physikalsiches Institut, Universität zu Köln, Zülpicher Strasse 77,50937 Köln, Germany 38700
e Consejo Superior de Investigaciones Científicas, Spain
## ABSTRACT
Lucky Imaging combined with a low order adaptive optics system has given the highest resolution images ever taken in the visible or near infrared of faint astronomical objects. This paper describes a new instrument that has already been deployed on the WHT 4.2m telescope on La Palma, with particular emphasis on the optical design and the predicted system performance. A new design of low order wavefront sensor using photon counting CCD detectors and multi-plane curvature wavefront sensor will allow virtually full sky coverage with faint natural guide stars. With a 2 x 2 array of 1024 x 1024 photon counting EMCCDs, AOLI is the first of the new class of high sensitivity, near diffraction limited imaging systems giving higher resolution in the visible from the ground than hitherto been possible from space.
Keywords: Lucky Imaging, adaptive optics, Charge coupled devices, EMCCDs, low light level imaging, nlCWFS.
## 1. INTRODUCTION
The Hubble Space Telescope (HST) has revolutionised many branches of astronomy by delivering much higher angular resolution than is possible with conventional ground-based telescopes. Although large telescopes are capable of much better angular resolution it has been very difficult to achieve major improvements. Most progress has been made in the near infrared on large (4-10 m class) telescopes. In the visible only one technique has demonstrated Hubble resolution on a Hubble sized (2.5 m diameter) telescope on the ground. This technique is known as Lucky Imaging. It was suggested originally by Hufnagel in 1966 and given its name by Fried in 1978. Images are recorded at high frame rates 1 2 to freeze the motion caused by atmospheric turbulence. A relatively bright reference star in the field allows image quality to be determined. The best fraction of images are shifted and added to give a combined image close to diffraction limited in their image quality when a fraction of ~5-30% is selected, the percentage depending on the atmospheric conditions at the time.
The Lucky Imaging technique has become viable in recent years principally because of the development of electron multiplying CCDs (EMCCDs) particularly by E2V Technologies Ltd (Chelmsford, UK). These devices have most of the characteristics of conventional CCDs used routinely by astronomers and which are read out at low speed. However, a modification of the device output register provides internal amplification by large factors, up to a few thousand times. 3 At high pixel rates of up to 30 MHz and readout noise of around 100 electrons RMS this gain allows individual photons to be detected with good signal-to-noise. This permits imaging at high frame rates without any read noise penalty. In photon counting mode it is possible to operate with almost all of the quantum efficiency of a conventional CCD making these devices particularly attractive for a range of high-speed imaging and spectroscopy applications in astronomy and other research areas.
*cdm <at> ast.cam.ac.uk
In principle, large telescopes can deliver sharper images than HST. However, the probability of the Lucky Imaging technique delivering near diffraction limited images becomes vanishingly small for telescopes significantly larger than the HST . This is because the number of turbulent cells across the diameter of the telescope is too large for there to be a 2 significant chance of a relatively flat wavefront (and hence a near diffraction-limited image) across the aperture of the telescope. By increasing the diameter of the telescope we bring in the effects of yet larger scales of atmospheric turbulence. In principle, if we could eliminate the largest turbulent scales where most of the power in the atmospheric turbulence resides then the probability of recording a sharp image will increase. Essentially, eliminating one turbulent 4 scale reduces the phase variance across that scale so that the characteristic cell size, r (defined as the scale size over 0 which the variance is ~1 radian ) is increased. Provided enough of the large turbulent scales are removed, the corrected 2 r will be large enough so the number of cells across the diameter of the telescope is similar to those typically 0 encountered with an uncorrected 2.4 m aperture, the largest diameter for which the Lucky Imaging technique normally gives good results.
In order to demonstrate this, one of the Cambridge Lucky Imaging cameras was mounted on the Palomar 5-m telescope behind the low order adaptive optics system PALMAO . We obtained images with a resolution more than 3 times that of 5 the HST. The performance of this combination of Lucky Imaging plus low order adaptive optics is compared with that of the Advanced Camera for Surveys on HST in Figure 1. Lucky Imaging has now been used by a number of groups both in Europe and in the US and this has contributed to the scientific development of optical Lucky Imaging 6,7,8,9 . For example, FastCam and AstraLux have worked on 2-m and 4-m class telescopes achieving full diffraction-limited resolution in the z'- and I- bands. In the US, projects aiming at developing visible AO systems are also continuing 10 . New post-processing approaches have also been successfully implemented to further improve on the image sharpness and quality of the delivered images, reaching Strehl ratio significantly higher than possible with classical LI 11,12 .
Figure 1: Comparison images of the core of the globular cluster M 13. On the left the image with natural (~0.65 arcsec) seeing on the Palomar 5-m telescope, the Hubble Advanced Camera for Surveys with ~120 milliarcsecond resolution (middle) and the Lucky Camera plus Low-Order AO image with 35 milliarcsecond resolution (right).



In common with most Shack-Hartmann based AO systems, PALMAO requires a very bright reference star for the Shack-Hartmann wavefront sensor. Shack-Hartmann AO systems generally need reference stars of I~12-14 magnitude, and these are very scarce 13 . AO systems that try to recover every moment on the telescope also have a very small isoplanatic patch in the visible of only a few arcseconds in diameter 14 . The net effect is that conventional ShackHartmann AO based systems can only be used over a very small fraction of the sky, < 0.1%. Laser guide stars have problems in delivering images with ~0.1 arcseconds accuracy. The consequence of these considerations is that it is very hard to achieve a resolution better than 0.1 arcseconds even in the near infrared on large telescopes although this has been achieved in a limited number of instances, particularly on very bright targets.
A study by Racine 15 showed that curvature sensors actually deployed on telescopes are significantly more sensitive than Shack-Hartmann sensors particularly when used for relatively low order turbulent correction. Olivier Guyon 16 simulated the performance of pupil plane curvature sensors and showed that they are very attractive in general and, when combined with EMCCDs, ought to give a substantial improvement in sensitivity over Shack-Hartmann sensors. This would allow operation over a much larger fraction of the sky. We have designed a new instrument, AOLI (Adaptive Optics assisted Lucky Imager), to let us carry out science combining Lucky Imaging and low order adaptive optics on targets over much of the sky. AOLI is a collaboration between the Instituto de Astrofisica de Canarias/Universidad de La Laguna
(Tenerife, Spain), the Universidad Politecnica de Cartagena (Spain), Universität zu Köln (Germany), the Isaac Newton Group of Telescopes (La Palma, Spain) and the Institute of Astronomy in the University of Cambridge (UK). This paper describes the current status of the instrument, its optical configuration and performance.
## 2. AOLI: GENERAL CONFIGURATION
The AOLI instrument consists of a non-linear curvature wavefront sensor and a low order adaptive optics wavefront corrector using a deformable mirror in conjunction with a wide-field, array detector Lucky Imaging camera. It is designed specifically for use on the WHT 4.2-m and the GTC 10.4-m telescopes on La Palma but it could be used on almost any large telescope without major modification.
Figure 2: The optical layout of AOLI. Light enters AOLI from the bottom left-hand corner after passing through an image de-rotator mounted on the Naysmith instrument ring before reaching the telescope focus. The light is collimated and passed through an atmospheric dispersion corrector before it strikes a deformable mirror (DM). We selected the ALPAODM241 unit as it has excellent stability and provides an unusually long stroke. The light is then reflected and, after a fold mirror, is reimaged on to a pickoff mirror. The pickoff mirror deflects light towards the science camera (Figure 4). The light from the reference star goes directly on to the wavefront sensor (WFS). The telescope pupil is reimaged down to approximately 2 mm diameter from its original 4.2 m. Figure 3 shows the details of the wavefront sensor arrangement. In addition we have a calibration system which is designed to provide calibration sources that are of the same diameter in the telescope focal plane as the diffraction limit of the principal telescope. This is needed particularly to feed the wavefront sensor for setup and alignment. The wavefront sensor uses broadband light between 500 and 950 nm and therefore the calibration system has to be achromatic. Rather than using any refractive optics it uses off-axis paraboloid mirrors.
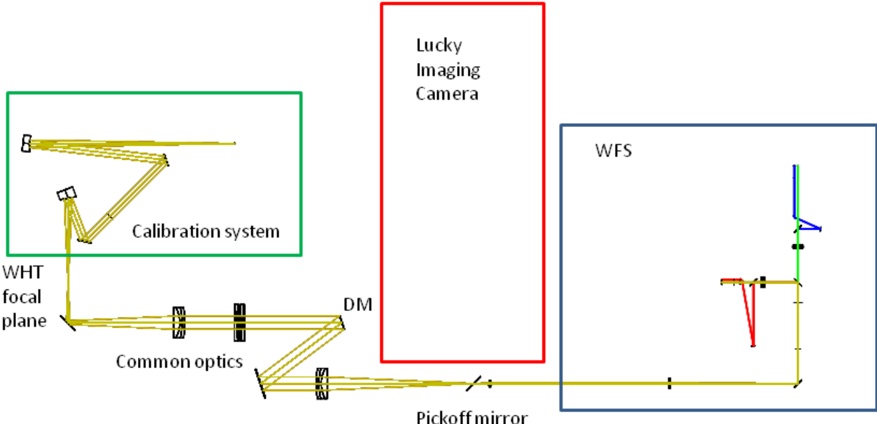
Figure 3: A model of the optical arrangement of the curvature sensor. The common optics take light from the WHT focus to the pickoff mirror where the light for the science camera is diverted to the science camera assembly. The light to the wavefront sensor passes through the pickoff mirror where is split into 2 beams with a dichroic beam splitter working at approximately 700 nm. Each beam is then split again with the second dichroic, one at 600 nm giving pupil images at wavelengths of ~550 nm and ~650 nm for one pair of beams and, with another dichroic beam splitter centred on about 800 nm gives a pair of pupil images at wavelengths of ~750 nm and ~870 nm. The pupil images are recorded with a pair of photon counting electron multiplying CCD cameras developed in Cambridge running at about 100 Hz frame rate. The data from these detectors are processed to derive the wavefront errors and these values are then used to drive the deformable mirror to remove the largest scales of turbulence from the wavefront. The science beam is turned 90° by the pickoff mirror plane to the science imaging detector (see Figure 4) which is then used in conventional Lucky Imaging mode.
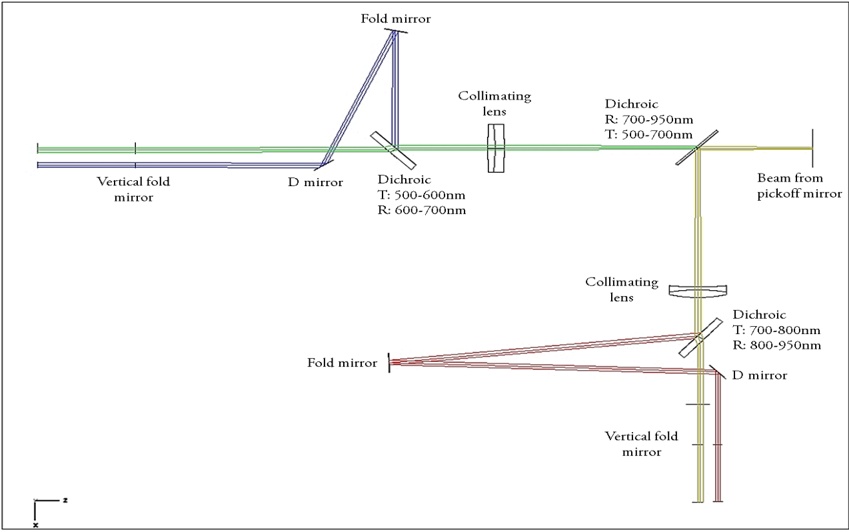
AOLI includes an atmospheric dispersion corrector, essential for work away from the zenith, after the collimating lens and before the deformable mirror (the ADC is not marked in the figure). In Figure 2 the science beam goes from the telescope to a pickoff mirror which deflects light from the science beam towards the science camera shown in figure 4. The reference star is located on the optical axis of the telescope and passes through the pickoff mirror to the wavefront sensor. The light from the telescope is reflected via a deformable mirror set in a pupil plane of the telescope which allows the curvature errors determined by the curvature sensor sub-system to be corrected directly. The deformable mirror is manufactured by ALPAO (France) with 241 elements over the pupil. It will allow correction of wavefront errors on scales of > ~0.5m on the 4.2 m diameter WHT telescope. Our simulations 17 suggest that this will then give us a Lucky Imaging selection percentage under typical/good conditions of about 25-30% in I band. In addition, our simulations suggest that this deformable mirror will have a high enough resolution to achieve satisfactory correction on the GTC 10.4 m telescope. Our approach is to develop a system optimised for the WHT that may be modified and redeployed quickly in order to demonstrate the technologies as convincingly as possible. Its subsequent deployment to the GTC will then follow.
The science camera (Figure 4) is a simple magnifier using custom optics to give diffraction limited performance. The camera is optimised for the 500nm to 1 micron wavelength range. The diffraction limit of the WHT (GTC) at 0.8µm (I band) is about 40 (15) mas and the camera offers a range of pixel scales of between 15 and 55 mas on the WHT. The camera uses an array of 4 photon counting, electron multiplying, back illuminated CCD201s manufactured by E2V Technologies Ltd, each 1024 x 1024 pixels. As the CCDs are non-buttable we use an arrangement similar to that of the original HST WF/PC (see Figure 4). Four small contiguous mirrors in the focal plane are slightly tilted and then individually reimaged on to a separate CCD. Each CCD has its own filter wheel. This allows the use of a narrowband filter, for example, for the science object with a broad filter for the reference star. The configuration allows a contiguous region of 2000 x 2000 pixels giving a field of view of from 112 x 112 arcsec down to 30 x 30 arcseconds on the WHT, depending on the magnification selected.
Figure 4: The science camera optical arrangement whereby the light from a single area of sky is split on to four separated and non-buttable CCDs. The magnified image (optics not shown) of the sky is projected onto a pyramid of four mirrors that reflects the light on to relay mirrors and via reimaging optics onto four electron multiplying detectors. This structure was suggested by the design of the original widefield/planetary camera installed on the HST.
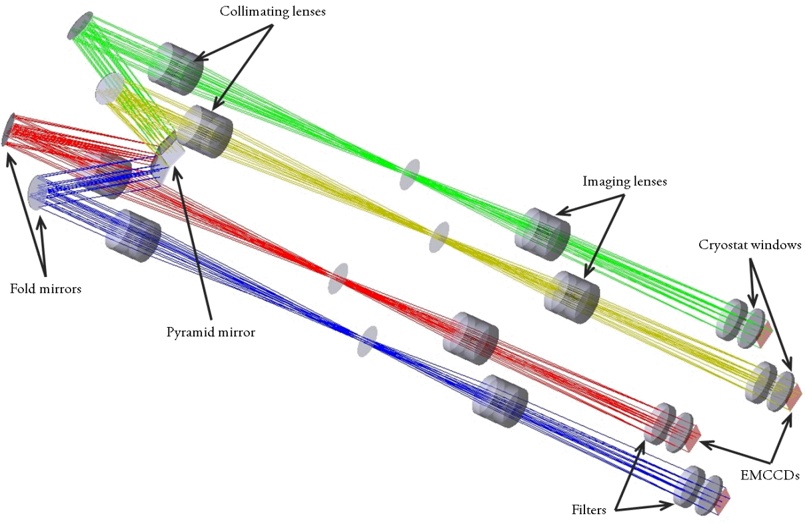
The CCDs are back illuminated (thinned) with very high quantum efficiency (peak >95%) from E2V Technologies. Custom electronics developed in Cambridge give up to 30 MHz pixel rate, and 25 frames per sec. Higher frame rates are possible. A readout format of 2000 x 100 pixels gives ~200 fps, allowing high time resolution astronomy as well with the instrument. The data (~220 MBytes/sec continually) are streamed via the host computer to high-capacity RAID disk drive systems after lossless compression. The host computer performs basic lucky imaging selection, allowing image quality to be assessed while the exposure is progressing. The construction of the unit has been kept relatively low-cost. The instrument will be mounted at Nasmyth focus on an optical bench behind the WHT image rotator. On the GTC it is probable that the instrument would be mounted on one of the folded Cassegrain ports.
## 3. NON-LINEAR PHOTON COUNTING CURVATURE WAVEFRONT SENSORS
Adaptive optic systems most frequently depend on Shack-Hartmann wavefront sensors which require very bright and scarce reference stars (typically I~12-14 magnitude). Low order correction may be achieved in principle with much fainter reference stars. Curvature wavefront sensors work by taking images on either side of a conjugate pupil plane and by measuring changes in the intensity of illumination as the wavefront passes through the pupil. A part of the wavefront that becomes fainter as it goes through the pupil must correspond to a part of the wavefront that is diverging while if it becomes brighter it is converging. Racine 15 has shown that curvature sensors actually deployed on telescopes are typically 10 times (2.5 magnitudes) more sensitive than Shack-Hartmann sensors for the same degree of correction. In addition they are very much more sensitive again when used for low order correction as the system cell size is dynamically increased and the wavefront sensor readout rate/integration time may be significantly reduced. Correction 8 with coarse cell sizes allows averaging sensor signals over significant areas of the curvature sensor.
AOLI uses a more advanced version of this approach, the non-linear curvature wavefront sensor that uses four pupil planes to provide a more rapid and faster convergence in achieving a wavefront fit. The angular resolution we should achieve on the WHT/GTC will be typically 40/15 milliarcseconds in the visible to I-band range. Our simulations suggest that we should be able to operate at the faintest level of the reference star of about 17.5-18.0 on the WHT and about 18.519.0 mag on the GTC. This will allow us to find reference stars over nearly all the sky even at high galactic latitudes (>85%) 13 . At the fainter end of these ranges it is probable that we will only be able to achieve partial correction but enough to improve the variance of the wavefront entering the science camera. The AOLI wavefront sensor is described in more detail in another paper in this conference from Crass at al 18 .
## 4. AOLI CALIBRATION SYSTEM
Any instrument design must take particular care to provide proper calibration facilities that allow the instrument to be set up fully in the laboratory or on the telescope during the daytime. The most demanding feature of AOLI is the need to generate an artificial star at the telescope focal plane no bigger than the diffraction limit of the telescope. This is further complicated because the curvature wavefront sensor design described above and by Crass et al. 18 , uses light between 500 and 950 nm making the use of refractive optics unrealistically difficult. Because of this, we have developed an optical arrangement which uses a pair of off-axis paraboloids to give the necessary image quality. The outline design is shown in figure 5. The calibration system is described in more detail in another paper presented as part of this conference (Antolin et al 19 ).
Figure 5: the AOLI calibration system uses a fibre source to generate a broadband input to a 2.5: 1 demagnification optical arrangement that uses a pair of off-axis paraboloids to produce a compact image at the same position as the focus of the telescope but can be used to feed the wavefront sensor and science camera optics of AOLI. It turbulence simulator is located close to the pupil plane of the reimaging system (OAP design from David King).
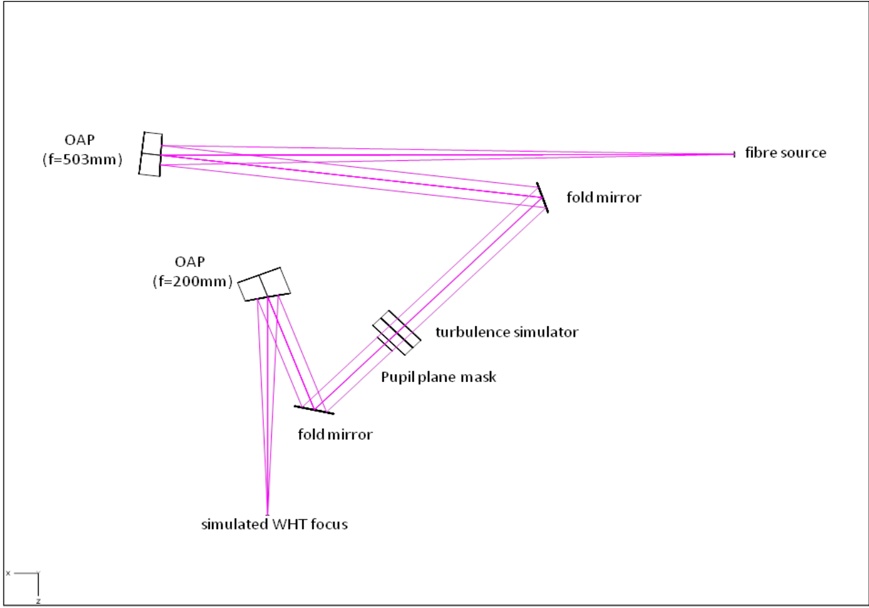
## 5. FIRST LIGHT EXPERIENCES WITH AOLI
The first observing run with AOLI was on the 4.2 m William Herschel telescope (WHT) in September 2013. In most respects the instrument worked well and Figure 6 shows it mounted at the Naysmith focus of the WHT. Unfortunately the weather conditions while at the telescope were remarkably poor with very poor seeing, high humidity and frequent dome closures. As a consequence very little in the way of scientific results were actually obtained. Nevertheless, a paper is in preparation describing results that were obtained ( Velasco et al. 20 ).
Figure 6: AOLI mounted at the Naysmith focus of the William Herschel 4.2 m Telescope in September 2013. Light comes from the telescope through the collimating optics immediately at the front of the picture. The deformable mirror is to the right and one of the curvature wavefront sensor EMCCD cameras is at the edge of the picture on the left. The science camera is vertically mounted at the far end of the instrument. Most of the light baffles used in the instrument were removed before this photograph was taken.

## 6. CONCLUSIONS
For many years instrument developers have been trying to produce an instrument capable of observing close to the diffraction limit of large telescopes in the visible from the ground, over the full sky with good observing efficiency. High-speed, high efficiency, photon counting detector availability has transformed our capacity to build instruments capable of working with the rapidly changing atmosphere and using very faint reference stars to let us optimise our recording of light from the sky. The combination of these EMCCDs with low order curvature wavefront sensors (also using EMCCDs) will allow a new generation of astronomers to explore the Universe with as big a step change in resolution as Hubble provided over 20 years ago. Hubble provided an eight-fold improvement over the typical groundbased image resolution of ~1 arcsec to give images of ~0.12 arcsec resolution. We have already demonstrated a further improvement over Hubble with the Palomar 5 m telescope by imaging with ~0.035 arcsec resolution. AOLI in the visible on the GTC 10.4m telescope has the diffraction limit of eight times better than HST of ~0.015 arcsec resolution, roughly 60 times the resolution when limited by atmospheric turbulence. There is every expectation that by making such high resolution images and spectra available more routinely many fields of astronomy will be revolutionised yet again.
## REFERENCES
- [1] R.E.Hufnagel, in "Restoration of Atmospheric and Degraded Images" (National Academy Of Sciences, Washington, DC, 1966), vol 3, Appendix 2, p11, (1966).
- [2] D. L. Fried, "Probability of Getting a Lucky Short-Exposure Image through Turbulence", JOSA, vol 68, p1651-1658,(1978).
- [3] C. D. Mackay, T. D. Staley, D. King, F. Suess and K. Weller, "High-speed photon-counting CCD cameras for astronomy", Proc SPIE 7742, p. 1-11,(2010).
- [4] Noll, R. J., "Zernike Polynomials and Atmospheric Turbulence", JOSA, vol 66, p207-211, (1976).
- [5] N.M. Law, C.D. Mackay, R.G. Dekany, M. Ireland, J. P. Lloyd, A. M. Moore, J.G. Robertson, P. Tuthill, H. Woodruff, "Getting Lucky with Adaptive Optics", ApJ ,vol. 692 p.924-930, (2009).
- [6] C. Bergfors, W. Brandner, M. Janson et al. "Lucky Imaging Survey for southern M dwarf binaries', Astron & Astrophys, vol. 520, A54 (2010).
- [7] D. Peter, M. Feldt, Th. Henning, and F. Hormuth, 'Massive binaries in the Cepheus OB2/3 region Constraining the formation mechanism of massive stars', Astron. & Astrophys., vol. 538, A74 (2012).
- [8] L. Labadie, R. Rebolo, I. Villo et al., 'High-contrast optical imaging of companions: the case of the brown dwarf binary HD 130948 BC', Astron. & Astrophys., vol. 526, A144 (2011).
- [9] B. Femenia, R. Rebolo, J. A. Perez-Prieto et al., 'Lucky Imaging Adaptive Optics of the brown dwarf binary GJ569Bab', MNRAS, vol. 413, p.1524-1536 (2011).
- [10] L.M. Close, V. Gasho, D. Kopon et al.,'The Magellan Telescope Adaptive Secondary AO System: AO Science in the Visible and Mid-IR', Proc. of the SPIE, vol. 7736, pp. 773605-773605-12 (2010).
- [11] R. Schödel, et al. , "Holographic Imaging of Crowded Fields: High Angular Resolution Imaging with Excellent Quality at Very Low Cost", MNRAS 429.1367(2013).
- [12] C. Mackay, et al. "High-efficiency lucky imaging", MNRAS 432, 702 (2013).
- [13] D. Simons, " Longitudinally Averaged R-Band Field Star Counts across the Entire Sky ", Gemini Observatory technical note, (1995).
- [14] M. Sarazin and A. Tokovinin, "The Statistics of Isoplanatic Angle and Adaptive Optics Time Constant Derived from DIMM Data", conference "Beyond Conventional Adaptive Optics", Venice (2001).
- [15] R. Racine,"The Strehl Efficiency of Adaptive Optics Systems", Pub. Astr. Soc Pacific, vol 118, p10661075, (2006).
- [16] O. Guyon "Limits of Adaptive Optics for High-Contrast Imaging", Ap J, vol 629,p 592-614,(2005)
- [17] J. Crass, C.D. Mackay, et al, "The AOLI low-order non-linear curvature wavefront sensor: a method for high sensitivity wavefront reconstruction", Proc SPIE 8447, (2012).
- [18] J. Crass, D. King, C. Mackay, " AOLI low-order non-linear curvature wavefront sensor: laboratory and on-sky results", SPIE 9148-81, Montréal, June 2014.
- [19] M. Puga, et al., "An atmospheric turbulence and telescope simulator for the development of AOLI", SPIE 9147-294, Montreal, June 2014.
- [20] S. Velasco, et al. (in preparation, MNRAS) | 10.1117/12.2055907 | [
"Craig Mackay",
"Rafael Rebolo",
"Jonathan Crass",
"David L. King",
"Lucas Labadie",
"Víctor González-Escélera",
"Marta Puga",
"Antonio Pérez-Garrido",
"Roberto López",
"Alejandro Oscoz",
"Jorge A. Pérez-Prieto",
"Luis F. Rodríguez-Ramos",
"Sergio Velasco",
"Isidro Villó"
] | 2014-08-01T09:49:27+00:00 | 2014-08-01T09:49:27+00:00 | [
"astro-ph.IM"
] | High-Resolution Imaging in the Visible on Large Ground-Based Telescopes | Lucky Imaging combined with a low order adaptive optics system has given the
highest resolution images ever taken in the visible or near infrared of faint
astronomical objects. This paper describes a new instrument that has already
been deployed on the WHT 4.2m telescope on La Palma, with particular emphasis
on the optical design and the predicted system performance. A new design of low
order wavefront sensor using photon counting CCD detectors and multi-plane
curvature wavefront sensor will allow virtually full sky coverage with faint
natural guide stars. With a 2 x 2 array of 1024 x 1024 photon counting EMCCDs,
AOLI is the first of the new class of high sensitivity, near diffraction
limited imaging systems giving higher resolution in the visible from the ground
than hitherto been possible from space. |
1408.0118v1 | ## K d -→ π Σ n reactions and structure of the Λ(1405)
## S Ohnishi 1 2 , , Y Ikeda , T Hyodo , E Hiyama , W Weise 2 3 2 4 5 ,
- 1 Department of Physics, Tokyo Institute of Technology, Tokyo 152-8551, Japan
- 2 RIKEN Nishina Center, Wako, Saitama 351-0198, Japan
- 3 Yukawa Institute for Theoretical Physics, Kyoto University, Kyoto 606-8502, Japan
- 4 ECT*, Villa Tambosi, I-38123 Villazzano (Trento), Italy
- 5 Physik Department, Technische Universit¨t M¨nchen, D-85747 Garching, Germany a u
E-mail: s [email protected]
Abstract. We report on the first results of a full three-body calculation of the ¯ KNN πYN -amplitude for the K d -→ π Σ n reaction, and examine how the Λ(1405) resonance manifests itself in the neutron energy distributions of K d -→ π Σ n reactions. The amplitudes are computed using the ¯ KNN πYN -coupled-channels Alt-Grassberger-Sandhas (AGS) equations. Two types of models are considered for the two-body meson-baryon interactions: an energy-independent interaction and an energy-dependent one, both derived from the leading order chiral SU(3) Lagrangian. These two models have different off-shell properties that cause correspondingly different behaviors in the three-body system. As a remarkable result of this investigation, it is found that the neutron energy spectrum, reflecting the Λ(1405) mass distribution and width, depends quite sensitively on the (energy-dependent or energy-independent) model used. Hence accurate measurements of the π Σ mass distribution have the potential to discriminate between possible mechanisms at work in the formation of the Λ(1405).
## 1. Introduction
Understanding the structure of the Λ(1405) with spin-parity J π = 1 2 / -and strangeness S = -1 is a long-standing issue in hadron physics. The mass of the Λ(1405) is slightly less than the ¯ KN threshold energy. The Λ(1405) can be considered as a ¯ KN quasi-bound state embedded in the π Σ continuum [1, 2]. Guided by this picture, ¯ KN interactions which reproduce the mass of Λ(1405) and two-body scattering data have been constructed phenomenologically [3, 4]. On the other hand, ¯ KN interactions have been studied for a long time based on chiral SU(3) dynamics [5, 6, 7]. Between the phenomenological and chiral SU(3) ¯ KN interactions, subthreshold ¯ KN amplitudes are quite different [8]. The phenomenological model describes Λ(1405) as a single pole of the scattering amplitude around 1405 MeV. The ¯ KN amplitude from the interaction based on chiral SU(3) dynamics has two poles, one of which located not at 1405 MeV but around 1420 MeV [9, 10]. The differences in the pole structure come from the different off-shell behavior, especially as a consequence of the energy-dependence of the ¯ KN interaction. The ¯ KN interaction based on chiral SU(3) dynamics is energy-dependent, and its attraction becomes weaker as one moves below the ¯ KN threshold energy. Hence the (upper) pole of the ¯ KN amplitude shows up around 1420 MeV. On the other hand, the phenomenological ¯ KN interaction is energy-independent and strongly attractive so that the pole shows up around 1405 MeV. These differences are enhanced in the so-called few-body kaonic nuclei, such as the strange dibaryon resonance under discussion in the ¯ KNN πYN - coupled system [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]. How a possible signature of this strange dibaryon resonance shows up in the resonance production reaction is also of interest as it reflects the two-body dynamics of the Λ(1405) [22].
One of the possible kaon-induced processes forming the Λ(1405) is K d -→ Λ(1405) n . The signature of the Λ(1405) was observed in an old bubble-chamber experiment that measured the π Σ invariant mass distribution in the K d -→ π + Σ -n reaction [23]. A new experiment is planned at J-PARC [24]. Theoretical investigations of the K d -→ π Σ n reaction have previously been performed in simplified models assuming a two-step process [25, 26, 27, 28].
In this contribution we examine how the Λ(1405) resonance shows up in the K d -→ π Σ n reaction by making use of the approach based on the coupled-channels Alt-GrassbergerSandhas (AGS) equations developed in Refs. [19, 20, 21, 22]. This is the first calculation of this process which incorporates the full three-body dynamics.
## 2. Three-body Scattering Equations
Throughout this paper, we assume that the three-body processes take place via separable twobody interactions, which have the following form in the two-body center-of-mass (CM) frame,
$$V _ { \alpha \beta } ( \vec { q } _ { \alpha }, \vec { q } _ { \beta } ; E ) = g _ { \alpha } ( \vec { q } _ { \alpha } ) \lambda _ { \alpha \beta } ( E ) g _ { \beta } ( \vec { q } _ { \beta } )$$
where /vector q α [ g α ( /vector q α )] is the relative momentum [form factor] of the two-body channel α ; E is the total energy of the two-body system. With this assumption the amplitudes for the quasi-twobody scattering of an 'isobar' and a spectator particle, X ij ( /vector p , /vector i p j ; W ), are then obtained by solving the AGS equations [29, 30],
/negationslash
$$X _ { i j } ( \vec { p } _ { i }, \vec { p } _ { j }, W ) & = ( 1 - \delta _ { i j } ) Z _ { i j } ( \vec { p } _ { i }, \vec { p } _ { j }, W ) \\ & + \sum _ { n \neq i } \int d \vec { p } _ { n } Z _ { i n } ( \vec { p } _ { i }, \vec { p } _ { n }, W ) \tau _ { n } \left ( W - E _ { n } ( \vec { p } _ { n } ) \right ) X _ { n j } ( \vec { p } _ { n }, \vec { p } _ { j }, W ) \. \\ \text{Here the substraints $i$ $ $i$ $ $n$ serifv the reaction channels $. $ W$ and $\vec{n}$ are the total scatterino$ energy energy}$$
Here the subscripts i, j, n specify the reaction channels; W and /vector p i are the total scattering energy and the relative momentum of channel i in the three-body CM frame, respectively; Z ij ( /vector p , /vector i p j ; W ) and τ i ( W -E /vector i ( p i )) are the one-particle exchange potential and the two-body propagator.
With the quasi-two-body amplitudes, the scattering amplitudes for the break-up process d + ¯ K → π +Σ+ N are obtained as
$$T _ { \pi \Sigma N - \tilde { K } d } ( \vec { q } _ { N }, \vec { p } _ { N }, \vec { p } _ { \tilde { K } }, W ) & = g _ { \gamma } ( \vec { q } _ { N } ) \tau _ { \gamma _ { \gamma } Y _ { \gamma } } \left ( W - E _ { N } ( \vec { p } _ { N } ) \right ) X _ { Y _ { K } d } ( \vec { p } _ { N }, \vec { p } _ { \tilde { K } }, W ) \\ & + g _ { Y _ { \pi } } ( \vec { q } _ { N } ) \tau _ { Y _ { \pi } Y _ { \pi } } \left ( W - E _ { N } ( \vec { p } _ { N } ) \right ) X _ { Y _ { \pi } d } ( \vec { p } _ { N }, \vec { p } _ { \tilde { K } }, W ) \\ & + g _ { N ^ { * } } ( \vec { q } _ { \Sigma } ) \tau _ { N ^ { * } N ^ { * } } \left ( W - E _ { \Sigma } ( \vec { p } _ { \Sigma } ) \right ) X _ { N ^ { * } d } ( \vec { p } _ { \Sigma }, \vec { p } _ { \tilde { K } }, W ) \\ & + g _ { d _ { y } } ( \vec { q } _ { \pi } ) \tau _ { d _ { y } d _ { y } } \left ( W - E _ { \pi } ( \vec { p } _ { \pi } ) \right ) X _ { d _ { y } d } ( \vec { p } _ { \pi }, \vec { p } _ { \tilde { K } }, W ) \, \\ \text{where} \ X _ { Y _ { \tilde { K } } d } ( \vec { p } _ { N }, \vec { p } _ { \tilde { K } }, W ) \text{ is the quasi-two-body amplitude anti-symmetrized for two nucleons; the}$$
where X Y K d ( /vector p N , /vector p ¯ K , W ) is the quasi-two-body amplitude anti-symmetrized for two nucleons; the subscripts denote the isobars. The notations for the isobars are Y K = ¯ KN Y , π = πY , d = NN , N ∗ = πN and d y = Y N , respectively.
In this contribution we employ the first two terms of Eq. (3) as a first step. These terms emerge directly from the Λ(1405) in the final state interaction; they are the dominant parts of the full T-matrix. Using this T-matrix, the differential cross section of the break-up process d + ¯ K → π +Σ+ N is calculated as:
$$\neg n \top \omega \times \infty & \text{sources} \quad \text{s}. \\ \frac { d \sigma } { d E _ { n } } & = ( 2 \pi ) ^ { 4 } \frac { E _ { d } E _ { \bar { K } } } { W p _ { \bar { K } } } \frac { m _ { N } m _ { \Sigma } m _ { \pi } } { m _ { N } + m _ { \Sigma } + m _ { \pi } } \\ & \times \int d \Omega _ { p _ { N } } d \Omega _ { q _ { N } } p _ { N } q _ { N } \sum _ { \bar { i } f } | < N \Sigma \pi | T ( W ) | d \bar { K } > | ^ { 2 }$$
Table 1. Cutoff parameters of ¯ KN πY -interaction.
| | Λ I =0 ¯ KN (MeV) | Λ I =0 π Σ (MeV) | Λ I =1 ¯ KN (MeV) | Λ I =1 π Σ (MeV) | Λ I =1 π Λ (MeV) |
|---------|---------------------|--------------------|---------------------|--------------------|--------------------|
| E-dep | 1000 | 700 | 725 | 725 | 725 |
| E-indep | 1000 | 700 | 920 | 960 | 640 |
where E n is the neutron energy in the center-of-mass frame of π Σ defined by
$$E _ { n } = m _ { N } + \frac { p _ { N } ^ { 2 } } { 2 \eta _ { N } } \ \.$$
## 3. Models of Two-body Interaction
We use two-body s -wave meson-baryon interactions obtained from the leading order chiral Lagrangian,
$$L _ { W T } = \frac { i } { 8 F _ { \pi } ^ { 2 } } T r ( \bar { \psi } _ { B } \gamma ^ { \mu } [ [ \phi, \partial _ { \mu } \phi ], \psi _ { B } ] ).$$
Here, we examine two interaction models, both of which are derived from the above Lagrangian but have different off-shell behavior: one is the energy dependent model (E-dep),
$$V _ { \alpha \beta } ( q ^ { \prime }, q ; E ) = \ - \ \lambda _ { \alpha \beta } \frac { 1 } { 3 2 \pi ^ { 2 } F _ { \pi } ^ { 2 } } \frac { 2 E - M _ { \alpha } - M _ { \beta } } { \sqrt { m _ { \alpha } m _ { \beta } } } \left ( \frac { \Lambda _ { \alpha } ^ { 2 } } { q ^ { \prime } \, ^ { 2 } + \Lambda _ { \alpha } ^ { 2 } } \right ) ^ { 2 } \left ( \frac { \Lambda _ { \beta } ^ { 2 } } { q ^ { 2 } + \Lambda _ { \beta } ^ { 2 } } \right ) ^ { 2 }.$$
while the other is the energy independent model (E-indep),
$$V _ { \alpha \beta } ( q ^ { \prime }, q ) = \ - \ \lambda _ { \alpha \beta } \frac { 1 } { 3 2 \pi ^ { 2 } F _ { \pi } ^ { 2 } } \frac { m _ { \alpha } + m _ { \beta } } { \sqrt { m _ { \alpha } m _ { \beta } } } \left ( \frac { \Lambda _ { \alpha } ^ { 2 } } { q ^ { \prime \, 2 } + \Lambda _ { \alpha } ^ { 2 } } \right ) ^ { 2 } \left ( \frac { \Lambda _ { \beta } ^ { 2 } } { q ^ { 2 } + \Lambda _ { \beta } ^ { 2 } } \right ) ^ { 2 },$$
Here, m α ( M α ) is the meson (baryon) mass; F π is the pion decay constant; λ αβ are determined by the flavor SU(3) structure of the chiral Lagrangian.
In the derivation of these potentials we have assumed the so-called 'on-shell factorization' [6] for Eq. (7) and q, q ′ /lessmuch M α for Eq. (8). The cutoff parameters Λ are determined by fitting experimental data as shown in Table 1.
In the E-dep model, the ¯ KN amplitudes have two poles for l = I = 0 in the ¯ KN -physical and π Σ-unphysical sheets, corresponding to those derived from the chiral unitary model [10]. On the other hand, the E-indep model has a single pole that corresponds to Λ(1405). It is interesting to examine how this difference of the two-body interaction models appears in the neutron energy spectrum of the K d -→ π Σ n reaction.
## 4. Results and Discussion
In Fig.1, we present the differential cross section of K d -→ π Σ n [Eq. (4)] computed using the E-dep (a) and E-indep (b) models, respectively. We investigate the cross section for initial kaon momentum p lab K -= 1000 MeV in accordance with the planned J-PARC experiment [24]. Here, we decompose the isospin basis states into charge basis states using ClebschGordan coefficients: the solid curve represents the K -+ d → π + + Σ -+ n ; the dashed curve refers to the K -+ d → π -+Σ + ; the dotted curve represents the + n K -+ d → π 0 +Σ + 0 n reaction, respectively.
Figure 1. Differential cross section dσ/dE n for K -+ d → π +Σ+ . The initial kaon momentum n is set to p lab K -= 1000 MeV. Panel (a): the E-dep model; Panel (b) the E-indep model. Solid curves: π + Σ -n ; dashed curves: π -Σ + n ; dotted curves: π 0 Σ 0 n in the final state, respectively.
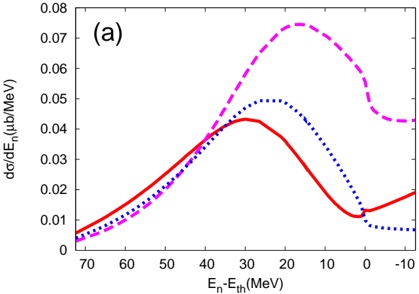
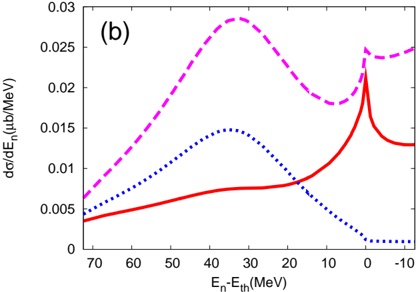
Figure 2. Contribution of each partial wave component to the differential cross section dσ/dE n for d + K -→ π + +Σ + . Panel (a): the E-dep model; Panel (b) the E-indep model. The thick -n solid curve represents the summation of total orbital angular momentum L = 0 to 14; The thin solid curve represents L = 0 only; The dashed curve represents L = 1 only; The dotted curve represents L = 2 only; The dashed-dotted curve represents L = 3 only; The dashed-two-dotted curve represents L = 4 only, respectively. The initial kaon momentum is set to p lab K -= 1000 MeV.
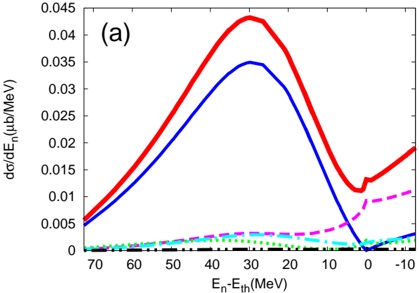
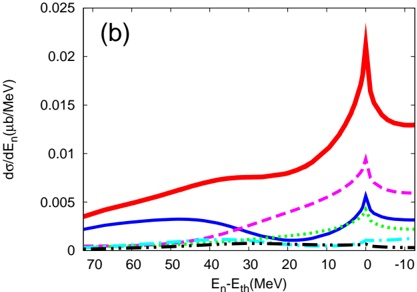
We subtract the neutron energy E th at which the amplitudes have the ¯ KN threshold cusp from the neutron energy E n , i.e. ¯ KN threshold cusp shows up on the differential cross section at E n -E th = 0. Well defined maxima are found at E n ∼ 17-30 MeV for the E-dep model and a peak or bumps at E n ∼ 32-38 MeV for the E-indep model, depending in the charge combination of π Σ in the final state. These peak and bump structures appear about 5 MeV higher in energy than the calculated binding energy of the Λ(1405) ( E B ∼ 13 MeV for the E-dep model and E B ∼ 28 MeV for the E-indep model). The magnitude of the differential cross section for the E-dep model is twice larger than that for the E-indep model, and the interference patterns with backgrounds are quite different between these two models. This clear difference in the differential cross section, arising from the model dependence of the two-body interactions, suggests that the K d -→ π Σ n reaction can indeed provide useful information on the ¯ KN πY -system.
Finally, we examine the contribution of each partial wave component for total orbital angular momentum L to the differential cross section (Fig. 2). We conclude that the s -wave component is dominant in the low-energy region, but around the ¯ KN threshold higher partial waves such as the p -wave component become important.
In summary, we have calculated the differential cross sections (4) for K -+ d → π +Σ+ n reactions. We have found peak and bump structures in the neutron energy spectrum, and therefore it is possible to observe the signal of the Λ(1405) resonance in the physical cross sections. We have also shown that the K d -→ π Σ n reactions are useful for judging existing dynamical models of ¯ KN π -Σ coupled systems with Λ(1405). Further improvements of the present model to account for the neglected contributions in Eq. (3) and relativistic corrections are under investigation.
## Acknowledgments
The simulation has been performed on a supercomputer (NEC SX8R) at the Research Center for Nuclear Physics, Osaka University. This work was partly supported by RIKEN Junior Research Associate Program, by RIKEN iTHES Project and by JSPS KAKENHI Grants Nos. 25800170, 24740152 and 23224006.
## References
- [1] Dalitz R and Tuan S 1959 Phys. Rev. Lett. 2 425-428
- [2] Dalitz R and Tuan S 1960 Annals Phys. 10 307-351
- [3] Akaishi Y and Yamazaki T 2002 Phys. Rev. C65 044005
- [4] Shevchenko N 2012 Phys. Rev. C85 034001 ( Preprint 1103.4974 )
- [5] Kaiser N, Siegel P and Weise W 1995 Nucl. Phys. A594 325-345 ( Preprint nucl-th/9505043 )
- [6] Oset E and Ramos A 1998 Nucl. Phys. A635 99-120 ( Preprint nucl-th/9711022 )
- [7] Hyodo T and Jido D 2012 Prog. Part. Nucl. Phys. 67 55-98 ( Preprint 1104.4474 )
- [8] Hyodo T and Weise W 2008 Phys. Rev. C77 035204 ( Preprint 0712.1613 )
- [9] Oller J and Meissner U G 2001 Phys. Lett. B500 263-272 ( Preprint hep-ph/0011146 )
- [10] Jido D, Oller J, Oset E, Ramos A and Meissner U 2003 Nucl. Phys. A725 181-200 ( Preprint nucl-th/0303062 )
- [11] Yamazaki T and Akaishi Y 2002 Phys. Lett. B535 70-76
- [12] Yamazaki T and Akaishi Y 2007 Phys. Rev. C76 045201 ( Preprint 0709.0630 )
- [13] Dote A, Hyodo T and Weise W 2008 Nucl. Phys. A804 197-206 ( Preprint 0802.0238 )
- [14] Dote A, Hyodo T and Weise W 2009 Phys. Rev. C79 014003 ( Preprint 0806.4917 )
- [15] Wycech S and Green A 2009 Phys. Rev. C79 014001 ( Preprint 0808.3329 )
- [16] Barnea N, Gal A and Liverts E 2012 Phys. Lett. B712 132-137 ( Preprint 1203.5234 )
- [17] Shevchenko N, Gal A and Mares J 2007 Phys. Rev. Lett. 98 082301 ( Preprint nucl-th/0610022 )
- [18] Shevchenko N, Gal A, Mares J and Revai J 2007 Phys. Rev. C76 044004 ( Preprint 0706.4393 )
- [19] Ikeda Y and Sato T 2007 Phys. Rev. C76 035203 ( Preprint 0704.1978 )
- [20] Ikeda Y and Sato T 2009 Phys. Rev. C79 035201 ( Preprint 0809.1285 )
- [21] Ikeda Y, Kamano H and Sato T 2010 Prog. Theor. Phys. 124 533-539 ( Preprint 1004.4877 )
- [22] Ohnishi S, Ikeda Y, Kamano H and Sato T 2013 Phys. Rev. C88 025204 ( Preprint 1302.2301 )
- [23] Braun O, Grimm H, Hepp V, Strobele H, Thol C et al. 1977 Nucl. Phys. B129 1
- [24] Noumi H et al. 2009 J-PARC proposal E31 URL http://j-parc.jp/researcher/Hadron/en/pac\_0907/pdf/Noumi.pdf
- [25] Jido D, Oset E and Sekihara T 2009 Eur. Phys. J. A42 257-268 ( Preprint 0904.3410 )
- [26] Miyagawa K and Haidenbauer J 2012 Phys. Rev. C85 065201 ( Preprint 1202.4272 )
- [27] Jido D, Oset E and Sekihara T 2013 Eur. Phys. J. A49 95 ( Preprint 1207.5350 )
- [28] Yamagata-Sekihara J, Sekihara T and Jido D 2013 PTEP 2013 043D02 ( Preprint 1210.6108 )
- [29] Alt E, Grassberger P and Sandhas W 1967 Nucl. Phys. B2 167-180
- [30] Amado R D 1963 Phys. Rev. 132 485-494 | 10.1088/1742-6596/569/1/012077 | [
"Shota Ohnishi",
"Yoichi Ikeda",
"Tetsuo Hyodo",
"Emiko Hiyama",
"Wolfram Weise"
] | 2014-08-01T09:52:13+00:00 | 2014-08-01T09:52:13+00:00 | [
"nucl-th",
"hep-ph"
] | $K^-d\rightarrow πΣn$ reactions and structure of the $Λ(1405)$ | We report on the first results of a full three-body calculation of the
$\bar{K}NN$-$\pi YN$ amplitude for the $K^-d\rightarrow\pi\Sigma n$ reaction,
and examine how the $\Lambda(1405)$ resonance manifests itself in the neutron
energy distributions of $K^-d\rightarrow\pi\Sigma n$ reactions. The amplitudes
are computed using the $\bar{K}NN$-$\pi YN$ coupled-channels
Alt-Grassberger-Sandhas (AGS) equations. Two types of models are considered for
the two-body meson-baryon interactions: an energy-independent interaction and
an energy-dependent one, both derived from the leading order chiral SU(3)
Lagrangian. These two models have different off-shell properties that cause
correspondingly different behaviors in the three-body system. As a remarkable
result of this investigation, it is found that the neutron energy spectrum,
reflecting the $\Lambda(1405)$ mass distribution and width, depends quite
sensitively on the (energy-dependent or energy-independent) model used. Hence
accurate measurements of the $\pi\Sigma$ mass distribution have the potential
to discriminate between possible mechanisms at work in the formation of the
$\Lambda(1405)$. |
1408.0119v2 | 
## JouRNAL OF INTERDISCIPLINARY METHODOLOGIES AND IssUEs IN SCIENCE

## The Problem of Action at a Distance in Networks and the Emergence of Preferential Attachment from Triadic Closure
## J´ erˆme KUNEGIS o *1,2 , Fariba KARIMI 2,3 , SUN Jun 2
1
University of Namur, Belgium 2 University of Koblenz-Landau, Germany 3 GESIS - Leibniz Institute for the Social Sciences, Germany
*Corresponding author: [email protected]
## DOI: 10.18713/JIMIS-140417-2-4
Submitted: September 6 2016
-Published: April 14 2017
Volume: 2 - Year:
2017
Issue:
Graphs & Social Systems
Editors:
Rosa Figueiredo & Vincent Labatut
## Abstract
In this paper, we characterise the notion of preferential attachment in networks as action at a distance, and argue that it can only be an emergent phenomenon - the actual mechanism by which networks grow always being the closing of triangles. After a review of the concepts of triangle closing and preferential attachment, we present our argument, as well as a simplified model in which preferential attachment can be derived mathematically from triangle closing. Additionally, we perform experiments on synthetic graphs to demonstrate the emergence of preferential attachment in graph growth models based only on triangle closing.
## Keywords
networks; preferential attachment; triangle closing; action at a distance
## I INTRODUCTION
Many natural and man-made phenomena are networks - i.e., ensembles of interconnected entities. To understand such structures is to understand their creation, their evolution and their decay. In fact, many models have been proposed for the evolution of networks, for the simple reason that a very large number of real-world systems can be modelled as networks. Rules for the evolution of networks can be broadly classified into two classes: those postulating local growth, and those postulating global growth. An example for a mechanism of local growth is triangle closing: When two people become friends because they have a common friend, then a new triangle is formed, consisting of three persons. 1 This tendency of networks to form trian-
1 In this paper, we use the terms triangle closing and triadic closure exchangably. The notion of triadic closure
c JIMIS, Creative Commons ©
Volume: 2 - Year: 2017 , DOI: 10.18713/JIMIS-140417-2-4
Figure 1: The two network growth mechanisms considered in this article: triangle closing and preferential attachment. In both models, new edges appear (shown as dashed lines), based on the network environment of the current graph. (a) Triangle closing: an edge is more likely to appear between nodes that have common neighbours, (b) Preferential attachment: A node with higher degree is more likely to receive an edge.
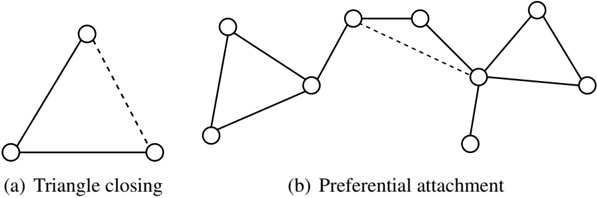
gles is a natural model not only for social networks, but for almost all types of networked data. For instance, if Alice likes a movie and Bob is a friend of Alice, Bob might also come to like that movie. In this case, the triangle consists of two persons and one movie. In general, networks can contain any type of object being connected by many different types of connections, and thus many different types of such triangle closings are possible. We call this type of growth local because it only depends on the immediate neighbourhood of the two connected nodes; the rest of the network does not play a role.
In contrast to local graph growth rules, there is the phenomenon of preferential attachment. When, for instance, two people become friends with each other, not because they have a common friend, or go to the same class, but because one of them or both of them are popular. 2 Given a popular person, i.e. with many friends, it is more likely that he will be chosen as a friend, than an unpopular person, all else being equal. This phenomenon is referred to as preferential attachment. Preferential attachment is an often-used strategy to predict new connections, not only in social networks: a frequent movie-goer is much more likely to watch a popular film, than someone who almost never goes out to the movies watching an obscure film almost nobody knows or has seen. These types of statements seem obviously true and indeed they are used widely in application systems: recommender systems give a big preference to popular movies, search engines give higher weight to well-connected web pages, and Facebook or Twitter will make a point to show you pictures that already have many likes. In that sense, preferential attachment is true empirically, and has been verified many times in experiments. However, preferential attachment has one problematic property: It relies on connecting any two completely unrelated nodes, merely because of their degree, without considering their interconnections. Preferential attachment can thus be labelled as 'action at a distance'. For this reason, we argue that preferential attachment is never a primitive phenomenon, but always a derived phenomenon, emerging as a result of more basic network evolution rules, which themselves do not involve action at a distance.
So, if preferential attachment is not a primitive network evolution mechanism, which network evolution rules should then be considered as primitive in our network growth model? We will present in this paper arguments for the thesis that only the principle of triangle closing is funda-
has been alluded to multiple times in the history of the social sciences; and became mainstream with the work of Mark Granovetter (1985).
2 Preferential attachment, too, is a concept with a long history, having been alluded to under multiple names. See the references in (Kunegis et al. , 2013) for an account of the early work on it.
mental, all forms of preferential attachment being derived from it. To give an argument in favour of our thesis, we will first review basic notions of networks and network evolution models, and then review preferential attachment, proposing various mechanisms by which it can arise from triangle closing, a fundamental notion in the evolution of networks. Finally, we perform experiments on synthetic graphs to test to what extent preferential attachment may emerge from graph growth models that include only triangle closing and/or random addition of edges.
## II RELATED WORK
The debate over the nature of preferential attachment mechanisms dates back to the 1960s, when the economist Herbert Simon defended the role of randomness and the mathematician Benoˆ ıt Mandelbrot defended the role of optimisation (Barab´ asi, 2012). The concept of preferential attachment is also used to explain the nature of scale-free degree distributions in biological networks such as metabolic networks (Jeong et al. , 2000) and protein networks (Jeong et al. , 2001). There are various suggestions to explain the nature of preferential attachment for instance by introducing hidden variable models in which nodes possess an intrinsic fitness to other nodes in unipartite (Bogu˜ ´ a and Pastor-Satorras, 2003) or bipartite networks (Kitsak and Krioukov, n 2011). In a recent Nature paper, Papadopoulos and colleagues proposed a model based on geometric optimisation of homophily space (2012). However, in these models, triadic closure is not defined as the main principle for the formation of edges.
Triadic closure, a tendency to connect to the friend of a friend (Rapoport, 1953), has been observed undeniably in many social networks such as friendship at a university (Kossinets and Watts, 2006), scientific collaborations (Newman, 2001) and in the World Wide Web (Adamic, 1999). The concept of triadic closure was first suggested by German sociologist Georg Simmel and colleagues (1950) and later on popularised by Fritz Heider and Mark Granovetter as the theory of cognitive balance in which if two individuals feel the same way about an object or a person, they seek closure by closing the triad between themselves (Heider, 2013). Since the classic preferential attachment model fails to explain the number of clusters in many social networks, many attempts have been made to include triadic closure to the model (Holme and Kim, 2002; V´ azquez, 2003), in which nodes connect with certain probabilities based on the principle of triadic closure. These works have shown that the scaling law for the degree distribution and clustering coefficient can be reproduced based on these models (Klimek and Thurner, 2013). Similarly, models based on random walks as local processes have been proposed, too, of which triangle closing is a special case (Evans and Saram¨ aki, 2005).
Hence, the scale-free nature of networks and the abundance of triangles in socio-technical networks beg for a more fundamental explanation. Moreover, the observable part of these systems is not necessarily completely representative for the entire system. Networks are generally multi-layered or multiplex, in which some layers can be hidden or simply not possible to observe (Kivel¨ a et al. , 2014). For instance, the creation of a new Facebook tie can be caused by attending the same class, sharing the same hobby or living in a same neighbourhood, which is hidden from the observable data. Consequently, these focal points contribute to the tie creation known as focal closure and need to be considered in modelling realistic networks, as argued by Kossinets and Watts (2006).
## III NETWORKS
The assertion that networks are to be found everywhere has become a clich´ e because it is true. Social networks, knowledge networks, information networks, communication networks - many papers in the field of network science motivate their use by enumerating fields in which they
Volume: 2 - Year: 2017 , DOI: 10.18713/JIMIS-140417-2-4
play a central role. Biological networks, molecules, lexical networks, Feynman diagrams hardly a scientific field exists in which networks do not play a fundamental role. Instead of giving a hopelessly incomplete enumeration of examples, we will simply refer the reader to the introductory section of our Handbook of Network Analysis (Kunegis, 2017), in case she wishes to convince herself of this fact. In case this is not enough, we may point to the existence of entire fields of research incorporating the word network and synonyms that have emerged in the last decade: network science (B¨rner o et al. , 2007; Newman, 2010), web science (Hendler et al. , 2008), and others (Tiropanis et al. , 2015). There are many ways to justify the ubiquitous use of networks as a model. As an example, we may consider their use in the field of machine learning. Most classical machine learning algorithms deal with datasets consisting of data points, each consisting of the same features. Mathematically, we may model such a dataset as a set of points in a space whose dimensions are the individual features (Salton et al. , 1975). This formalism is very powerful, and still constitutes the backbone of many machine learning and data mining methods to this day. The standard formulation of classification, clustering and other learning problems all rely on the set-of-points-in-a-space model. However, not all machine learning problems are well described by the set of points model. While the set of words contained in text documents are well represented by the bag of words model (Baeza-Yates and Ribeiro-Neto, 1999), a social network is not. We may try to represent a social network as a bag of friends, but this representation is very unsatisfactory: each person has a set of friends, but the model does not reflect the fact that a person contained in one of these bags is the same person as one having a bag of friends. Thus, the vector space model cannot find connections such as 'the friend of my friend' - it can only find 'a person that has the same friend as me'. In other words, the vector space model disconnects the role of having friends and that of being a friend . Instead, the natural way to represent friendships is as a network. Using a network model, the symmetry of the friend relationship is included automatically in the model, and relationships such as the friend of my friend arise as the natural way to create new edges in the network, i.e., triangle closing. In fact, we will argue that this is the only way new edges can be created in a network, and that other models are merely consequences of it, such as preferential attachment.
As an additional remark, the terms network and graph are often used interchangeably. Strictly speaking, a network is the real-world object to be analysed, such as a social network, while a graph is a mathematical structure used to model it.
## IV PREFERENTIAL ATTACHMENT
Preferential attachment, also referred to by the phrase 'the rich get richer', or as the Matthew effect, is observed empirically in many social networks (Kunegis et al. , 2013). In fact, the phenomenon of preferential attachment is known by many other names in different contexts; see the references within (Kunegis et al. , 2013) for an account. In other words, who has many friends, will get more new friends than who has few. Movies that have been seen by many people will be seen by more people than movies that have not. Websites that have been linked to many times will receive more new links because of this. These statements seem true, and indeed, they are true empirically for many different network types.
In fact, preferential attachment is the basis for a whole class of network models. The most basic of these, the model of Barab´ asi and Albert (1999), describes the growth of a network, which proceeds as follow: Start with a small graph, and at each step, add a node, and connect that node to k existing nodes with a probability proportional to the number of neighbours for each existing node. In the limit where many nodes have been added in that way, the network tends to become scale-free , i.e. tends to have a distribution of neighbour counts that follow a power
Volume: 2 - Year: 2017 , DOI: 10.18713/JIMIS-140417-2-4
law. Since power law degree distributions are observed in many natural networks, the usual conclusion is that preferential attachment is correct.
Preferential attachment is thus undeniably real. Why then, are we arguing against it? The reason is that preferential attachment cannot be a fundamental driving force for tie creation. How are two nodes, completely unconnected from each other, be supposed to choose to connect with each other? How can two completely disconnected nodes even know of each other's existence? This is a fundamental problem with all nonlocal interactions. For instance, the classical theory of gravitation as defined and used by Isaac Newton (1687) includes nonlocal interactions. In that theory, two masses exert a force on each other, regardless of their position. While the force decreases with distance, it is always nonzero, and instantaneous. The conceptual problem with this type of interaction had been identified already by Newton himself (Hesse, 1955). In modern physics, Newton's formalism is replaced by more precise theories that do not include any action at a distance. The theory of general relativity as defined by Albert Einstein (1916) for instance, only includes local interactions in the form of the Einstein field equations. Einstein's general relativity is thus free from any problematic action at a distance , and has been verified at many experimental scales. This is also true for other types of physical interactions - instead of a force that acts at a distance between matter particles, quantum field theory models bosons that connect particles. In fact, such interactions can be represented by Feynman diagrams: graphlike representations of particles in which edges are particles and nodes are interactions - any interacting particles must be connected in one diagram, directly or indirectly. In this light, we may interpret preferential attachment as a theory that is true superficially, but must be explained by an underlying phenomenon. Specifically, an underlying phenomenon that does not rely on action at a distance. As this phenomenon, we propose the known mechanism of triangle closing.
## V TRIANGLE CLOSING
How do we make new friends? By meeting the friends of our friends. This represents a triangle formed by ourselves, our previous friend, and our new friend. What if we meet our new friend in another way - maybe at a party, or a concert, or at work . . . in any case, there is always some element in common. If we meet our new friend at a party, then we are both connected to the party, and by modelling the party as a node in our network, that new friendship is indeed created by the closing of a person-person-party triangle. Of course, we may continue to ask how our connection to the party arose. After all, we did not come to a party randomly. No, we came to the party because a friend invited us, or for any other reason, as long as there is some connection. This game of connections can be played to any desired degree of precision. Maybe we really went from door to door until we found a party with many people. But then, how did we get from door to door? We surely must have started somewhere, likely near to our home, and have then gone on to the next door, and to the next door, and so on. In doing this, we have only followed links: We are connected to our home by living there; our home is connected to the neighbouring house, which itself is connected to the next house, and so on. This example is of course exaggerated, but serves to illustrate the principle: in order for a new edge to appear, a path has to exist from one node to another; this can go over nodes representing any type of entity, and these nodes may be visible or hidden. All in all, there is no escaping the principle of triangle closing. However we arrived at the party, it must have been by a series of triangle closings.
Thus, triangle closing fulfils the expected role as a fundamental mechanism of network growth, as it is purely local. However, we cannot deny the existence of preferential attachment, for which we must now find suitable explanations.
Volume: 2 - Year: 2017 , DOI: 10.18713/JIMIS-140417-2-4
## VI EXPLANATIONS
In recommender systems, such as those used on web sites that recommend movies to watch, preferential attachment is often taken as a solution to the cold start problem. The cold start problem in recommender systems refers to the situation in which a user has not yet entered any information about herself, and thus triangle closing cannot be used to recommend her anything. If the user has watched only a single movie, then we can find similar movies and recommend them. If a user has added only a single friend, then we can take movies liked by that friend and recommend them. But if the user is completely new, as has no friends and no ratings yet, then this strategy will not work. How then, do recommender systems give recommendations to new users? The solution is simple: they recommend the most popular items. If you subscribe to Twitter, you will be recommended popular accounts to follow. If you subscribe to Last.fm, you will be recommended popular music. For these sites, this strategy is better than not recommending anything, and in fact is a form of preferential attachment: Create, or rather recommend, links to nodes with many neighbours. How can we interpret this in terms of triangle closing? If a node has no connections yet, then surely it cannot acquire new nodes by triangle closing. How then will a node ever acquire new edges, if it starts without neighbours? The answer is that a node does not start without any neighbours. Everything is connected. A child when it is born does not start without connections; it is already connected to its parents and to its birthplace. Likewise, a user on the Web never starts from scratch: every page has a referrer, and thus the user can be connected to another website. Even if the referring web page is not known, there has to be a referrer. If a user types in a URL by hand, she has to have taken it somewhere: maybe a friend gave it to her, maybe she read it in a magazine, on a billboard, or on a truck . . . in all cases, the newly created connection is not created ex nihilo - it is created by triangle closing.
The explanation for preferential attachment thus lies in hidden nodes: Nodes that make indirect connections between things, but do not appear in the model. On Facebook for instance, many new friendships are created between people who do not have common friends. These new friendships seemingly appear without the help of triangle closing. However, that is always due to the fact that Facebook does not know everything. Some people are simply not on Facebook, which means that if one meets a new friend through a friend that is not on Facebook and then connects the new friend via Facebook, then from the point of view of Facebook a new edge was created without triangle closing. But that is only true because Facebook does not know my initial friend. If it did, it could correctly infer the new friendship via triangle closing. Thus, any two nodes in a network can potentially be linked, even if they do not share common neighbours in the network at hand , because they may share a hidden common neighbour. The same argumentation applies to hidden nodes that represent non-actors, such as classes, hometowns, parties, etc.
In order to justify preferential attachment as an emergent phenomenon, we must thus derive the mechanism that leads to edges being created specifically between nodes of high degrees. Consider a network, for instance a social network. Call this the known network. Then, consider a certain number of nodes outside of that network, that are connected at random to the nodes in the known network. Call these the unknown nodes. How many common neighbours do two members of the known network have outside of the known network? Without knowing the distribution of hidden edges, this question cannot be answered. But consider that triangle closing acts not only on known-unknown-known paths, but also on known-known-unknown paths. Starting with an equal probability for all known-unknown edges, performing triangle closing will lead to the creation of known-known-unknown triangles. The newly created known-unknown
edges can then be combined with other unknown-known edges to perform, again, triangle closing, leading to new known-known edges. The result are new edges in the observed social network, with a probability proportional to the number of the initial known node's neighbours. Thus, preferential attachment emerges as a necessary consequence of iterated triangle closing, if hidden nodes are admitted. The next section will make this heuristic argument precise.
## VII DERIVATION
This section gives an exemplary derivation of a simplified model that we introduce to illustrate that preferential attachment arises as a consequence of triangle closing in the presence of hidden nodes. The given scenario is very general and may be generalised easily for instance by considering multiple node types or multiple edge types. In this model, we distinguish two types of nodes: visible nodes in the set V , and hidden nodes in the set W . We will assume that there is a given, fixed number of visible nodes | V | , and a possibly very large number of hidden nodes | W | . In particular, we will consider the limit | W | →∞ .
Let G = ( V ∪ W,E ) be the graph representing the complete system, in which V is the set of visible nodes, and W the set of hidden nodes. Additionally, E is the set of edges connecting nodes in V with nodes in W . While we assume that the individual edges in E are hidden, the degree of the nodes in V is not hidden. In other words, the number of edges of E incident to each node in V is known. Edges between nodes in V will not be considered. Likewise, edges between nodes in W need not be considered, since they do not contribute to the degree of nodes in V . Thus, the considered network G is bipartite. We will use the convention that n = | W | , and the degree of a node u is denoted by d u ( ) . We now assume that the graph G will receive new edges according to the principle of triangle closing. Thus, two nodes in V will connect with a probability proportional to the number of common neighbours they have. Seeing only nodes in V and their degree, preferential attachment can then be observed as described in the following.
In order to make our derivation, we need to make two assumptions:
- · The triangle closing process is random in the sense that new edges are added between any possible node pairs with equal probability.
- · The typical degree of nodes is significantly smaller than the number of nodes, i.e., d x ( ) glyph[lessmuch] n . This is precise when n goes to infinity.
Let u, v ∈ V be two nodes of the network. Under the assumption that the edges are distributed randomly in the graph, the probability p that u and v are connected can be derived combinatorically by considering the number of configurations in which the two nodes do not share a common neighbour. Given that u and v have degree d u ( ) and d v ( ) respectively, the total number of configurations for the edges connected to the nodes is
$$\binom { n } { d ( u ) } \binom { n } { d ( v ) }.$$
Out of those, the number of configurations in which the neighbours of the two nodes are disjoint is given by
$$\binom { n } { d ( u ) } \binom { n - d ( u ) } { d ( v ) }.$$
Thus, the probability that the two nodes share a common neighbour is given by
$$p = 1 - \frac { \binom { n } { d ( u ) } \binom { n - d ( u ) } { d ( v ) } } { \binom { n } { d ( u ) } \binom { n } { d ( v ) } } = 1 - \frac { \binom { n - d ( u ) } { d ( v ) } } { \binom { n } { d ( v ) } }.$$
We now use the falling factorial to express binomial coefficients, i.e.,
$$n ^ { \underline { a } } = n ( n - 1 ) ( n - 2 ) \cdots ( n - a + 1 ).$$
The falling factorial has the property that in the limit where a is constant and n goes to infinity, we have
$$\lim _ { n \to \infty } \frac { n ^ { a } } { n ^ { a } } = 1$$
and also,
$$\binom { n } { a } = \frac { n ^ { \underline { a } } } { a! },$$
and thus
$$p = 1 - \frac { ( n - d ( u ) ) ^ { \underline { d ( v ) } } d ( v )! } { d ( v )! n ^ { \underline { d ( v ) } } } = 1 - \frac { ( n - d ( u ) ) ^ { \underline { d ( v ) } } } { n ^ { \underline { d ( v ) } } }.$$
In the limit when n goes to infinity we may thus assume that
$$p = 1 - \frac { ( n - d ( u ) ) ^ { d ( v ) } } { n ^ { d ( v ) } } = 1 - \left ( 1 - \frac { d ( u ) } { n } \right ) ^ { d ( v ) }$$
and using again the limit n →∞ , and the property that in the limit where ε goes to zero, (1 -ε ) k goes to (1 -kε ) ,
$$p = \frac { d ( u ) d ( v ) } { n }.$$
It thus follows that p ∼ d u d v ( ) ( ) , i.e., the probability of the nodes u and v being connected is proportional to both d u ( ) and d v ( ) . Thus, we find that preferential attachment is a consequence of the triangle closing model. Preferential attachment itself then leads to a scale-free degree distribution, as per Barab´si and Albert (1999). a
## VIII EXPERIMENTS
In this section, we give empirical evidence for the emergence of preferential attachment in graph growth models that do not include it. In the experiments, we generate synthetic networks via a random growth process that does not include preferential attachment, as well as using random growth processes that do include preferential attachment. In all generated networks, effects of preferential attachment are then measured empirically. All generated networks have 1,000 nodes and 10,000 edges, and are undirected, loopless, and do not allow multiple edges. In all cases, the graphs are generated by starting with a graph of 1,000 nodes and without edges, and adding edges one by one. For each edge that is added, one of the following three methods is chosen at random:
- · Random : With probability p r , an edge is added randomly between two unconnected nodes. All pairs of distinct unconnected nodes are chosen with equal probability.
- · Triangle closing : With probability p tc , among all unclosed triads, one is chosen randomly with equal probability, and the third edge is added. An unclosed triad is a triple of nodes ( u, v, w ) such that ( u, v ) and ( u, w ) are connected, but v and w are not connected. If chosen, the triangle is completed by adding the edge ( v, w ) . If no unclosed triads are present, an edge is added at random as described in the previous case.
- · Preferential attachment : With probability p pa , a node is chosen with a probability proportional to the node's current degree. Then, out of all nodes not connected to that node, one is chosen randomly and with equal probability, and an edge is added between the two selected nodes. If there is not at least one unconnected pair of nodes with nonzero degree, an edge is added at random as described in the first case.
In each experimental trial, the three probabilities are chosen such that p r + p tc + p pa = 1 . Each of these probabilities is varied from 0 to 1 in increments of 1/11, excluding the case p r = 0 in order to avoid the runaway case of an individual node accumulating all edges. 3
First, in order to verify whether a graph created by the process of triangle closing display scalefree behaviour, we compare the generated distribution of the triangle closing case with the degree distributions for the random and preferential attachment cases. 4 All three degree distributions are shown in Figure 2. In the plot, several observations can be made. The degree distribution for the triangle closing case displays power law-like behaviour over multiple orders of magnitude, from the smallest degrees of one, to approximately one hundred. While the networks generated by triangle closing and preferential attachment have similar power-like degree distribution, both with comparable exponent, we must note that the maximum degree in the preferential attachment case is larger than in the triangle closing case. However, the triangle closing model displays a power law degree distribution with exponential cut-off that has been observed in many real networks due to finite size effect (Bogu˜ ´ a n et al. , 2004; Clauset et al. , 2009). For comparison, the preferential attachment case also displays power law-like behaviour, although not for very small degrees (under about 10), and additionally has a well-defined long tail. The purely random case leads to a degree distribution that shows no scale-free behaviour.
Wemeasure the equality of the distribution of edges, or its opposite, its skewness, as the primary consequence of the preferential attachment process. As a measure, we use the Gini coefficient of the degree distribution, as defined in (Kunegis and Preusse, 2012). The Gini coefficient is zero when all nodes have equal degree, and attains its theoretical maximum of one when all nodes except a single one have degree zero. 5
The experimental results are shown in Figure 3. In the triangle shown in the figure, the topto-bottom-right edge shows the cases in which preferential attachment is excluded, while the bottom-left corner ( Pref. att. = 100% ) represents the case of exclusive preferential attachment. As expected, the 100% random case results in an Erd˝ os-R´ enyi graph in which the degrees have a Poisson distribution, and thus a very uniform number of edges over all nodes, giving a small Gini coefficient of 17.7%. The pure preferential attachment case gives a higher value
3 In the degenerate case of p r = 0 , almost all edges will be attached to a single node in the n →∞ limit.
4 As described in the previous paragraph, the cases of pure triangle closing and preferential attachment also include 1/11 of edges based on random assignment.
5 Since an edge always connects two nodes, the actual maximum is attained in star graphs, in which all edges attach to a single node, and other nodes have a degree of zero and one. In the large-graph limit, the Gini coefficient in such graphs tends to one.
Figure 2: The cumulative degree distribution for the three extremal generated networks.
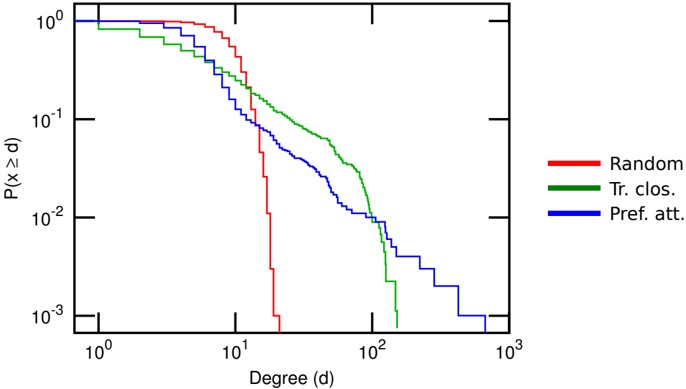
Figure 3: Experimental results: Each cell shows one experimental run with a different probability of adding each edge at random (top), via triangle closing (bottom right), and preferential attachment (bottom left). The bottom row was not executed due to the tendency of models with random edges to attach all edges to a single node, giving values of the Gini coefficient very close to the theoretical maximum of one.
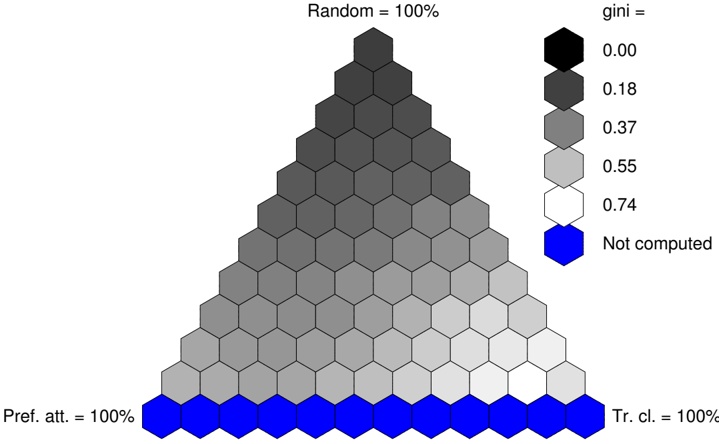
of about 51.5%. 6 The pure triangle closing method results in a value of the Gini coefficient of 65.1%, a value similar to (and even superior to) the value in the pure preferential attachment case. Thus, it is indeed the case that a skewed degree distribution is generated by a purely local process of triangle closing, without the need for explicit preferential attachment. We note also that preferential attachment is observed even though the number of nodes in the network ( n = 1 000 , ) is relatively small when compared to the theoretical model described in the previous section in which the limit n →∞ is taken.
## IX DISCUSSION
Our experiments have allowed us to observed that triangle closing leads to skewed and scalefree degree distributions. However, the status of a mechanism as fundamental is not clear cut. When a phenomenon is explained by another, more fundamental phenomenon, we can consider it as derived. But how can we be sure that a phenomenon is not explained by a more basic phenomenon? What does it mean for a phenomenon to be fundamental? Just as physics cannot declare one theory to be final, we cannot declare one network growth mechanism to be final. Thus, individual instances of triangle closing can for instance be explained by several layers of triangle closing, just as in physics a direct interaction can be explained by a new mediating particle. In the end however, this applies only to specific instances of triangle closing, as it replaces them with other, more detailed instances of triangle closing. Thus, triangle closing does play a fundamental role in growing network models, only that it cannot always be derived which three nodes are taking part in it, as one of the three nodes is often hidden. In the end, the only judge of the validity of a model remains the experiment, and in practice, used models do not have to be fundamental - recommenders and information retrieval systems have had enough success by applying preferential attachment directly.
As mentioned in the introduction, triangle closing is itself a general phenomenon that not only applies to pure social networks, but also to other types of networks. In the case of property networks, i.e., networks containing edges between persons and the properties they have, triangle closing can be identified with the concept of homophily, i.e., the concept that friends tend to be similar. As an example, the fact that two smokers become friends can be modelled as the closure of the (person A)-(colleague + smoker)-(person B) triangle, in which 'colleague + smoker' is a non-person node of the network representing the property of being a colleague and a smoker . Thus, the fact that friends of smokers are more likely to be smokers too (a classical example of homophily) can be analysed as a form of triangle closing in a graph that is not purely a social network, as it contains non-person nodes. Homophily is thus consistent with the view that triangle closing is fundamental (Shalizi and Thomas, 2011).
The problem posed in this paper can be generalised to other graph growth mechanisms. For instance, we may ask whether assortativity (the tendency of connected nodes to have correlated degrees) or community structures emerge from triangle closing alone. In the case of community structures, triangle closing trivially plays a role, as triangle closing by construction leads to tightly connected graphs. As for assortativity, the fact that both assortativity (a positive correlation between degrees) and dissortativity (a negative correlation between degrees) have been observed in social networks points to the fact that a single model such as triangle closing cannot (and is not expected to) explain all properties of a social network, and other phenomena must be at work, which may or may not be local.
6 In this and all subsequent cases labelled as pure , the method in question has a probability of p tc pa , = 10 11 / while a random edge is added with a probability of p r = 1 11 / .
Volume: 2 - Year: 2017 , DOI: 10.18713/JIMIS-140417-2-4
## References
Adamic L. A. (1999). The small world web. In Int. Conf. on Theory and Practice of Digital Libraries , pp. 443-452.
- Baeza-Yates R., Ribeiro-Neto B. (1999). Modern Information Retrieval . Addison-Wesley.
- Barab´ asi A.-L. (2012). Network science: Luck or reason. Nature 489 (7417), 507-508.
- Barab´ asi A.-L., Albert R. (1999). Emergence of scaling in random networks. Science 286 (5439), 509-512.
- Bogu˜ n´ a M., Pastor-Satorras R. (2003). Class of correlated random networks with hidden variables. Phys. Rev. E 68 (3), 036112.
- Bogu˜ n´ M., Pastor-Satorras R., Vespignani A. (2004). a Cut-offs and finite size effects in scale-free networks. Eur. Phys. J. B 38 (2), 205-209.
- B¨ orner K., Sanyal S., Vespignani A. (2007). Network science. Annual Rev. of Information Science and Technology 41 (1), 537-607.
- Clauset A., Shalizi C. R., Newman M. E. J. (2009). Power-law distributions in empirical data. SIAM Review 51 (4), 661-703.
- Einstein A. (1916). Die Grundlagen der allgemeinen Relativit¨ atstheorie. Ann. Phys. 49 , 769-822.
- Evans T. S., Saram¨ aki J. P. (2005). Scale-free networks from self-organization. Phys. Rev. E 72 (2), 026138.
- Granovetter M. (1985). The strength of weak ties. American J. of Sociology 91 , 481-510.
- Heider F. (2013). The Psychology of Interpersonal Relations . Psychol. Press.
- Hendler J., Shadbolt N., Hall W., Berners-Lee T., Weitzner D. (2008). Web science: An interdisciplinary approach to understanding the web. Commun. ACM 51 (7), 60-69.
- Hesse M. B. (1955). Action at a distance in classical physics. Isis 46 (4), 337-353.
- Holme P., Kim B. J. (2002). Growing scale-free networks with tunable clustering. Phys. Rev. E 65 (2), 026107.
- Jeong H., Mason S. P., Barab´ asi A.-L., Oltvai Z. N. (2001). Lethality and centrality in protein networks. Nature 411 (6833), 41-42.
- Jeong H., Tombor B., Albert R., Oltvai Z. N., Barab´ asi A.-L. (2000). The large-scale organization of metabolic networks. Nature 407 (6804), 651-654.
- Kitsak M., Krioukov D. (2011). Hidden variables in bipartite networks. Phys. Rev. E 84 , 026114.
- Kivel¨ a M., Arenas A., Barthelemy M., Gleeson J. P., Moreno Y., Porter M. A. (2014). Multilayer networks. J. of Complex Networks 2 (3), 203-271.
- Klimek P., Thurner S. (2013). Triadic closure dynamics drives scaling laws in social multiplex networks. New J. of Phys. 15 (6), 063008.
- Kossinets G., Watts D. J. (2006). Empirical analysis of an evolving social network. Science 311 (5757), 88-90.
- Kunegis J. (2017). Handbook of Network Analysis [KONECT - the Koblenz Network Collection] .
- Kunegis J., Blattner M., Moser C. (2013). Preferential attachment in online networks: Measurement and explanations. In Proc. Web Science Conf. , pp. 205-214.
- Kunegis J., Preusse J. (2012). Fairness on the web: Alternatives to the power law. In Proc. Web Science Conf. , pp. 175-184.
- Newman M. E. J. (2001). Clustering and preferential attachment in growing networks. Phys. Rev. E 64 (2), 025102.
- Newman M. E. J. (2010). Networks: An introduction . Oxford University Press.
- Newton I. (1687). Philosophiæ Naturalis Principia Mathematica . First edition.
- Papadopoulos F., Kitsak M., Serrano M. A., Bogu˜ n´ a M., Krioukov D. (2012). Popularity versus similarity in growing networks. Nature 489 (7417), 537-540.
- Rapoport A. (1953). Spread of information through a population with socio-structural bias: II. Various models with partial transitivity. The Bull. of Math. Biophys. 15 (4), 535-546.
- Salton G., Wong A., Yang C. S. (1975, November). A vector space model for automatic indexing. Commun. ACM 18 (11), 613-620.
- Shalizi C. R., Thomas A. C. (2011). Homophily and contagion are generically confounded in observational social network studies. Sociological Methods and Research 40 (2), 211-239.
- Simmel G., Wolff K. H. (1950). The Sociology of Georg Simmel . Simon and Schuster.
- Tiropanis T., Hall W., Crowcroft J., Contractor N., Tassiulas L. (2015). Network science, web science, and internet science. Commun. ACM 58 (8), 76-82.
- V´ azquez A. (2003). Growing network with local rules: Preferential attachment, clustering hierarchy, and degree correlations. Phys. Rev. E 67 (5), 056104. | 10.18713/JIMIS-140417-2-4 | [
"Jérôme Kunegis",
"Fariba Karimi",
"Jun Sun"
] | 2014-08-01T10:10:28+00:00 | 2017-04-24T09:51:54+00:00 | [
"cs.SI"
] | The Problem of Action at a Distance in Networks and the Emergence of Preferential Attachment from Triadic Closure | In this paper, we characterise the notion of preferential attachment in
networks as action at a distance, and argue that it can only be an emergent
phenomenon -- the actual mechanism by which networks grow always being the
closing of triangles. After a review of the concepts of triangle closing and
preferential attachment, we present our argument, as well as a simplified model
in which preferential attachment can be derived mathematically from triangle
closing. Additionally, we perform experiments on synthetic graphs to
demonstrate the emergence of preferential attachment in graph growth models
based only on triangle closing. |
1408.0120v1 | ## FAITHFUL TROPICALIZATION OF MUMFORD CURVES OF GENUS TWO
TILL WAGNER
Abstract. In the present paper, we investigate the question if the skeleton of a Mumford curve of genus two can be tropicalized faithfully in dimension three, i.e. if there exists an embedding of the curve in projective three space such that the tropicalization maps the skeleton of the curve isometrically to its image. Baker, Payne and Rabinoff showed that the skeleton of every analytic curve can be tropicalized faithfully. However the dimension of the ambient space in their proof can be quite large.
We will define a map from the skeleton to the tropicalization of the Jacobian, which is an isometry on the cycles. It allows us to find principal divisors and simultanously to determine the retractions of their support on the skeleton which is necessary to calculate their tropicalization.
It turns out that a Mumford curve of genus two whose cycles of its skeleton are either disjoint or share an edge of length at most half of the length of the cycles, can be tropicalized faithfully in dimension three.
## 1. Introduction
This paper is inspired by recent work of Baker, Payne and Rabinoff ([BPR1] and [BPR2]) which compares the analytic and tropical geometry of curves. Let K be a complete, non-archimedean field with a non-trivial absolute value, and let X be a smooth, proper and connected curve over K . Then the subset H ◦ ( X an ) of nonleaves in the Berkovich space X an carries a natural metric which is induced by skeletons of semistable models. If X is embedded in a toric variety and meets the dense torus T , the resulting tropicalization Trop( T ∩ X ) is a one-dimensional polyhedral complex. All its edges have rational slopes with respect to the cocharacter lattice of the torus. Hence Trop( T ∩ X ) can be endowed with a natural metric locally given by the lattice length on each edge. In general the tropicalization map ( X ∩ T ) an → Trop( X ∩ T ) is not injective and does not respect the metrics on both sides.
Among the main results in [BPR2] are Theorem 6.20 and 6.22, which say that for every skeleton Γ in H ◦ ( X an ) there exists a closed immersion of X in a quasiprojective toric variety such that X meets the dense torus T and Γ maps isometrically to its image under the induced tropicalization map on X ∩ T . In the terminology of [BPR2, 6.15.2] we say that in this case Γ is faithfully tropicalized.
Given a skeleton of an analytic curve, it is an interesting question to determine the minimal dimension necessary to tropicalize it faithfully. Using the construction in the proof of Theorem 6.22 in [BPR2], we may assume that the skeleton has at least two vertices and there are at least g + 1 edges. To tropicalize the skeleton faithfully they define two functions for each edge as well as one function for each pair of vertices. These functions may not define an embedding thus we have to add more rational functions (for example four additional functions since every curve
2000 Mathematics Subject Classification. 14T05, 14H30, 14H45.
Key words
and phrases.
Mumford
Curves,
Tropical
Geometry,
Tropicalization.
Berkovich spaces,
can be embedded in projective space of dimension three). This sums up to at least 2 g + 6 functions. Given a finite subset D ⊂ X K ( ) for every point p in D one needs two functions to tropicalize the ray leading to p faithfully. Hence we obtain an embedding of dimension at least 2( g + | D | ) + 5 that leads to a faithful tropicalization of a skeleton.
However, in special cases one can do much better. For example, for Tate curves, this bound would be 7, whereas by [BPR2, Theorem 7.2] there exists a faithful tropicalization in twodimensional projective space. Furthermore Chan and Sturmfels showed that after a change of coordinates every tropicalization of an elliptic curve is in so called honeycomb form which is a faithful tropicalization ([ChSt], Theorem 7).
In [BaRa, Theorem 8.2] Baker and Rabinoff defined for each curve X together with a skeleton Γ a rational morphism X /axisshort/axisshort/arrowaxisright P 3 whose tropicalization, when restricted to Γ, is an isometry onto its image. However this morphism may not be an embedding. In the present paper, we investigate this question for Mumford curves of genus two. There are two types of such curves: the cycles in the skeleton can share an edge or the cycles are disjoint. It turns out that for curves whose cycles are disjoint there exists an embedding in projective three-space such that the tropicalization is faithful (Theorem 5.3). This is also true for curves whose cycles share an edge if the cycles are at least twice as long as the shared edge.
Let D be a very ample divisor of degree five such that its support retracts to given points on the skeleton. We define two divisors as follows: Choose three points from the support of D (three poles) and one additional k -rational point on the curve (one zero). From general theory we know that there exist two k -rational points (zeros) so that the resulting degree zero divisor is principal, i.e. we obtain a rational function on the curve with three poles. However we do not know where the retractions of these new zeros lie on the skeleton. This is necessary to calculate the slopes of the tropicalization.
To solve this problem we will make use of the tropicalization of the Jacobian, which inherits a group structure from the Jacobian, and a map µ from the skeleton to the tropicalization of the Jacobian, which is an isometry on the cycles.
They will tells us where the new zeros of the function are retracting to (Lemma 5.1) and we are able to show that there exists a rational morphism from the curve to twodimensional projective space tropicalizing the skeleton faithfully.
Next we check if the rays from the extended skeleton are also tropicalized faithfully. We will see that two rays may intersect. To correct this we have to define a third function in the linear system L D ( ), linearly independent from the others. These three functions tropicalize the extended skeleton faithfully, and, since they are generators of L D ( ), they also define an embedding of the curve in projective threespace.
## 2. Skeletons and tropicalizations of curves
Let K be a algebraically closed field which is complete with respect to a nonArchimedean non-trivial absolute value | · | . As usual, we put K ◦ = { x ∈ K : | x | ≤ 1 } and K ◦◦ = { x ∈ K : | x | < 1 } and we denote by ˜ K = K /K ◦ ◦◦ the residue field of K .
For every K -scheme X of finite type we denote by X an the associated Berkovich analytic space, as defined in [Be]. If X is a smooth, projective and geometrically connected curve of positive genus, then X an is a special quasipolyhedron in the sense of [Be], Definition 4.1.1 and 4.1.5. Its Betti number is at most g by [Be], Theorem 4.3.2.
Let X be a smooth, projective curve over K with semistable reduction, and fix a semistable model X of X . This gives rise to a skeleton S ( X ) inside X an which is a deformation retract, see [Be, Chapter 4]. Let τ : X an → S ( X ) be the continuous retraction map .
Let D be a finite subset of X K ( ) and V be a finite set of type-2 points in X an . Set U = X \ D . Then U an \ V is a semistable decomposition in the sense of [BPR1, Definition 3.1] if it is the disjoint union of
- · infinitely many open balls,
- · finitely many open annuli,
- · finitely many punctured balls, each of them containing precisely one point of D .
The punctured balls can be seen as open annuli with infinite modulus. Their skeleton is a semi-infinite ray (see [BPR1], chapter 2.1).
For D as before set W = { τ ( x ) : x ∈ D } ∪ { vertices of S ( X ) } ⊂ X an . This is a semistable vertex set of X an in the sense of [BPR1], Definition 3.1. If two distinct points x, y of D lie in the same open ball B of X an \ W then there exists a smallest closed disc in B containing x and y . The Gauss point of this closed disc will be denoted by x ∨ y . If we adjoin all such points x ∨ y to W then it is still a semistable vertex set and U an \ W is a semistable decomposition. This follows from the proof of [BPR1, Lemma 3.13 (3)]. The path from x ∨ y to S ( X ) yields a new bounded edge. The skeleton associated to these data in [BPR1, Definition 3.3] is the union of S ( X ) with the new bounded edges, the vertices W and the rays leading to points in D . We denote it by S ( X , D ) and call it an extended skeleton. By [BPR1, Lemma 3.8] there exists a continuous retraction map τ : U an → S ( X , D ) from the open curve to the extended skeleton.
A skeleton carries a natural metric, the shortest-path metric. The distance between two points is the smallest length of all paths connecting the points, where the length of an edge is defined to be the logarithmic modulus of the corresponding annulus ([BPR1, Def. 3.10 and chapter 3.12]). This metric extends to rays giving the skeleton a degenerate metric.
We will use the following slope formula ([BPR1, Theorem 5.15]), see also Thuillier's thesis [Th, 3.3.15].
Theorem 2.1 (Slope formula) . Let f be a rational function on X and D be a finite subset of X K ( ) containing supp(div( f )). Set U = X \ D , and consider the retraction map τ : U an →S ( X , D ). Then the function log | f | : U an → R , mapping a point x to log | f ( x ) , | has the following properties:
- i) log | f | = log | f | ◦ τ , i.e. log | f | factors over the skeleton.
- ii) log | f | is piecewise affine-linear with integer slopes on each edge of the skeleton S ( X , D ).
- iii) Let x be a point in the skeleton and let d v ( x ) denote the outgoing slope of log | f | along an edge v . Then ∑ v d v ( x ) = 0 where only finitely many outgoing slopes are unequal to zero.
- iv) If v is a vertex in S and r a ray in v leading to a point x ∈ supp(div( f )), let d v be the outgoing slope of log | f | along r . If x has multiplicity m in div( f ), then d v ( x ) = -m .
If x is a point in the skeleton that is neither a vertex nor a retraction of a pole or zero then there are two edges of the skeleton emanating from x thus by iii) the slopes along theses edges have to be equal. Hence the slope of log | f | can only change at the retractions of the poles and zeros of f and the vertices of the skeleton. Let U be a connected K -scheme together with a closed immersion ϕ : U ↪ → G n m into a K -split torus. As a set, the associated tropical variety Trop( U ) = Trop ϕ ( U )
is the image of U an under the tropicalization map
↦
$$( \mathbb { G } _ { m } ^ { n } ) ^ { a n } = ( \text{Spec} K [ x _ { 1 } ^ { \pm }, \dots, x _ { n } ^ { \pm } ] ) ^ { a n } \longrightarrow \mathbb { R } ^ { n }, \ \ p \longmapsto ( \log | x _ { 1 } ( p ) |, \dots, \log | x _ { n } ( p ) | ).$$
Note that Trop ϕ ( U ) = Trop ϕ L ( U L ) for any base change by a non-Archimedean complete extension field L/K , see [Gu], Proposition 3.7. So if we start with a non-algebraically closed field we can perform a base change to apply the theory developed in this paper. The tropicalization Trop( U ) can be enriched with the structure of a balanced, weighted, integral polyhedral complex of pure dimension d = dim( U ), see e.g. [MaSt, Theorem 3.3.6]. Trop( U ) is called faithful if the restriction of the tropicalization map to the skeleton of the curve is an isometry. If we consider extended skeleta we call the tropicalization faithful if it is faithful on the skeleton, homeomorphic on the extended skeleton and the rays have slopes ± 1. Let ϕ : X an → ( P n ) an be an embedding in projective space given by rational functions f , . . . , f 0 n and let D = ⋃ i supp(div( f i )) be the union of the support of the corresponding principal divisors. We say that the curve is tropicalized faithfully with respect to ϕ if Trop( X D \ ) is a faithful tropicalization of the extended skeleton S ( X , D ).
## 3. Mumford curves
The present paper deals with analytic Mumford curves, for which the Betti number of X an is equal to the genus. Mumford curves are curves with totally degenerate stable reductions. In [Mu] Mumford shows that these are precisely the curves admitting a non-archimedean Schottky uniformization. Let us recall some facts about these uniformizations.
/negationslash
Let Γ be a subgroup of PGL(2 , K ). A point x ∈ P 1 ( K ) is called a limit point of Γ, if there exists some y ∈ P 1 ( K ) and an infinite subset { γ n : n ≥ 1 } of Γ such that γ n ( y ) → x . We denote by L = L Γ the set of all limit points. A subgroup Γ of PGL(2 , K ) is called a Schottky group if it is finitely generated, free and discontinuous, where the last property means that L /negationslash = P 1 ( K ) and that all orbit closures in P 1 ( K ) are compact. Every element γ = 1 of a Schottky group is hyperbolic, i.e. it has two different fixed points with different absolute values.
Let Γ be a Schottky group, and write Ω = ( P 1 K ) an \L , where ( P 1 K ) an is the Berkovich analytic space associated to the projective line over K . Then Γ acts freely and properly discontinuously on Ω, and the quotient Ω / Γ is a proper analytic curve over K , and hence the analytification of an algebraic curve X . Every curve over K with such a Schottky uniformization is called a Mumford curve.
It is shown in [GevP], section 1, paragraph 4, that every Schottky group has a good fundamental domain, i.e. for each Schottky group Γ of rank g there exist 2 g pairwise disjoint 'closed' discs B , . . . , B 1 g , C , . . . , C 1 g with centers in K and generators γ , . . . , γ 1 g of Γ such that
- · γ i ( P 1 ( K ) \ B ◦ i ) = C i and γ -1 i ( P 1 ( K ) \ B i ) = C ◦ i for all i = 1 , . . . , g .
- · F = P 1 ( K ) \ ( ⋃ i B i ∪ ⋃ i C ◦ i ) is a fundamental domain for the action of Γ on Ω
We denote the corresponding 'open' discs by B , C ◦ i ◦ i etc.
/negationslash
Note that we always choose our coordinates on P 1 so that 0 lies outside these discs. We fix centers b i of B i and c i of C i . Let r i be the radius of B i and R i the one of C i . Since 0 is not contained in any disc, the radii of B i and C i satisfy r i < b | i | and R < c i | i | . Furthermore, the absolute value of all points in B i is equal to | b i | and the absolute value of all points in C i is equal to | c i | . Since B i contains one fixed point of γ i and C i contains the other, and since the two fixed points of a hyperbolic element have different absolute values, we have | b i | = | c i | . Moreover, for every a ∈ B i and
b / B ∈ i we have | b - | a = | b -b i | . Similarly, for every a ∈ C i and b / C ∈ i , we have | b - | a = | b -c i | .
Now choose some a ∈ F and define for all i = 1 , . . . g
$$\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psilon \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi
u _ { i } ( z ) = \prod _ { \gamma \in \Gamma } \frac { z - \gamma a } { z } }.$$
By [GevP], section II.2, u i ( z ) is an analytic function without zeros on Ω which is independent of the choice of a . Moreover, the function u i ( z ) is an automorphic function with respect to Γ, i.e. the quotient c i ( γ ) = u i ( z /u ) i ( γz ) is a constant in K independent of z by [GevP], chapter VI, paragraph 2. This constant is multiplicative in γ and satisfies c i ( γ j ) = c j ( γ i ). We put q ij = c i ( γ j ). Then the matrix ( q ij ) ij is symmetric.
$$\mathbb { V } _ { 1 } / \mathbb { V } \circ \mathbb { Y } \text{mmcpy}. \\ \text{Proposition} \, 3. 1. \text{ For every } z \notin \bigcup _ { i = 1 } ^ { g } ( B _ { i } ^ { \circ } \cup C _ { i } ^ { \circ } ) \, \text{ we have } | u _ { i } ( z ) | = \left | \frac { z - b _ { i } } { z - c _ { i } } \right |. \\ \text{Proof}. \text{ Choose } a \in \mathbb { P } ^ { 1 } ( K ) \, \text{ inside the complement of the union of the discs } B _ { i }, C _ { i }. \\ \text{-} \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad........................................................................................................................................................................................................$$
/negationslash
/negationslash
/negationslash
Proof. Choose a ∈ P 1 ( K ) inside the complement of the union of the discs B , C i i . Let γ be in Γ such that γ = 1 and γ = γ i . Then γ = γ s m i m γ s m -1 i m -1 . . . γ s 1 i 1 for i 1 , . . . , i m ∈ { 1 , . . . , g } and signs s , . . . , s 1 m ∈ {-1 1 , } . We assume that this expression is reduced, i.e. that γ j and γ -1 j are never adjacent factors. Let us show by induction on m that the points γa and γγ a i are contained in the same disc. Since γ j maps the complement of B j to C ◦ j and γ -1 j maps the complement of C j to B ◦ j , the point γ a i is contained in C ◦ i which lies in the complement of all B j and in the complement of those C j with j = . Hence our claim holds for i m = 1.
/negationslash
/negationslash
/negationslash
Hence for all γ not equal to 1 or γ i we have | z -γγ a i | = | z -γa | , since z lies outside every open disc. This implies that
If γ is an element of length m > 1 in Γ, consider γ ′ = γ s m -1 i m -1 . . . γ s 1 i 1 . Then γ ′ = 1. If γ ′ = γ -1 i , then γ = γ γ s j -1 i , where s ∈ {-1 1 , } such that γ s j = γ i . In this case, the points γ -1 i a and a lie in the complement of B j (resp. C j ), hence they are mapped to the disc C ◦ j (resp. B ◦ j ) by γ s j , and our claim holds. Therefore we may assume that γ ′ is neither 1 nor γ i , in which case we conclude by induction hypothesis that γ a ′ and γ γ a ′ i are contained in C ◦ i m -1 (resp. B ◦ i m -1 ). Since γ s m i m = γ -s m -1 i m -1 , the element γ s m i m maps C i m -1 to B ◦ i m (resp. B i m -1 to C ◦ i m ) and our claim follows. -1
$$\text{every open disc. This implies that} \\ | u _ { i } ( z ) | = & \left | \prod _ { \gamma \in \Gamma } \frac { z - \gamma a } { z - \gamma \gamma _ { i } a } \right | = \frac { | z - \gamma _ { i } ^ { - 1 } a | } { | z - \gamma _ { i } a | } = \frac { | z - b _ { i } | } { | z - c _ { i } | }, \\ ^ { 1 } a \, \text{lies in } B _ { i } \text{ and } \gamma _ { i } a \, \text{ lies in } C _ { i }.$$
since γ -1 i a lies in B i and γ a i lies in C i .
/square
↦
$$\zeta _ { a, r } ( f ) = \max _ { n } \{ | c _ { n } | r ^ { n } \}.$$
Let us recall some facts about the Berkovich projective line ( P 1 ) an = ( A 1 ) an ∪{∞} . The points in the affine line ( A 1 ) an correspond to muliplicative seminorms on the polynomial ring K T [ ] extending the absolute value on K . These seminorms can be described explicitly and are classified into four types, see [Be], 1.4.4. Every point a in A 1 ( K ) induces a point of type one, i.e. the multiplicative seminorm f →| f ( a ) . | For every point a ∈ A 1 ( K ) and every positive real number r , there is a corresponding multiplicative seminorm ζ a,r ( f ) mapping f = ∑ n c n ( x -a ) n to
It can be described as a supremum norm over the disc in K around a with radius r . The point ζ a,r in ( A 1 ) an is called of type two, if the radius r lies in the value group | K ∗ | . Otherwise it is called of type three. Note that ζ a,r = ζ b,s if and only if | a - | ≤ b r = . s
The Berkovich projective line is an R -tree in the sense of [BaRu], Appendix B. It is uniquely arcwise connected. We denote the unique path between two elements x, y of ( P 1 ) an by [ x, y ]. For a, b ∈ A 1 ( K ) and r < s the path [ ζ a,r , ζ a,s ] consists of all points ζ a,t such that t ∈ [ r, s ]. To determine [ ζ a,r , ζ b,s ] in general, put R = max { r, s, | a - |} b and note that ζ a,R = ζ b,R . Then [ ζ a,r , ζ b,s ] = [ ζ a,r , ζ a,R ] ∪ [ ζ b,R , ζ b,s ]. The complement of the subset of points of type 1 in ( A 1 ) an can be endowed with a path distance metric, see [BaRu], section 2.7. For points x = ζ a,r and y = ζ b,s as above, it is equal to
$$\rho ( x, y ) = 2 \log R - \log r - \log s.$$
Set ζ + i = ζ b ,r i i and ζ -i = ζ c ,R i i . Note that γ i ( ζ -i ) = ζ + i . By the explicit description above, is easy to see that the path [ ζ -i , ζ + i [ is contained in the fundamental domain F .
The Berkovich curve X an contains the skeleton S ( X an ) of the semistable model of X constructed by Mumford [Mu], Theorem 3.3. The graph S ( X an ) is equal to the image under the natural map π : Ω → X an of the convex hull of all the points ζ + i , ζ -i in ( P 1 ) an . Note that this convex hull is contained in (Ω) an . The skeleton S ( X an ) can be endowed with a natural metric induced by the path distance metric on the projective line. It contains the g cycles Z i = π ([ ζ -i , ζ + i ]).
## Proposition 3.2.
- i) The cycle Z i has length -log | q ii | .
- ii) The intersection Z i ∩ Z j has length | log | q ij || .
Proof. i) After exchanging γ i with γ -1 i if necessary, we may assume that | b i | < c | i | . The length of Z i is equal to the path distance ρ ζ ( -i , ζ + i ). Since r , i R < c i | i | = | c i -b i | , we find
$$\rho ( \zeta _ { i } ^ { - }, \zeta _ { i } ^ { + } ) = 2 \log | c _ { i } | - \log r _ { i } - \log R _ { i }.$$
On the other hand, | q ii | = | u i ( z /u ) i ( γ z i ) | for any point z ∈ Ω. Let us choose a rational point z ∈ ∂B i . Then γ z i lies in ∂C i . Therefore we can apply Proposition 3.1 to z and γ z i to deduce
$$- \log | q _ { i i } | = - \log \frac { | z - b _ { i } | | \gamma _ { i } z - c _ { i } | } { | z - c _ { i } | | \gamma _ { i } z - b _ { i } | }.$$
Since by the choice of z we have | z -b i | = r i and | γ z i -c i | = R i and | z -c i | = | c i | as well as | γ z i -b i | = | γ z i | = | c i | , we deduce that
$$- \log | q _ { i i } | = 2 \log | c _ { i } | - \log r _ { i } - \log R _ { i }.$$
- ii) After exchanging γ i and γ -1 i if necessary, we may again assume that | b i | < c | i | . Similarly, we may assume that | b j | < c | j | . After exchanging i and j if necessary we also have | b i | ≤ | b j | .
Choose z ∈ ∂B j . Then γ z j ∈ ∂C j . Hence we can apply Proposition 3.1 to z and γ z j to deduce
By the choice of z we have | z -b i | = | b j -b i | and | z -c i | = | b j -c i | as well as | γ z j -b i | = | c j -b i | and | γ z j -c i | = | c j -c i | . Hence
$$\circ \text{deduce} \\ - \log | q _ { i j } | = - \log \left | \frac { u _ { i } ( z ) } { u _ { i } ( \gamma _ { j } z ) } \right | = - \log \frac { | z - b _ { i } | | \gamma _ { j } z - c _ { i } | } { | z - c _ { i } | | \gamma _ { j } z - b _ { i } | }. \\ \intertext { e choice of $z$ we have $|z-b_{i}|=|b_{j}-b_{i}|$ and $|z-c_{i}|=|b_{j}-c_{i}|$ as $w$} } - b _ { i } | = | c _ { i } - b _ { i } | $ \text{ and $|\gamma_{i}z-c_{i}|=|c_{i}-c_{i}|$. Hence}$$
$$- \log | q _ { i j } | & = \log \frac { | b _ { j } - c _ { i } | \, | c _ { j } - b _ { i } | } { | b _ { j } - b _ { i } | \, | c _ { j } - c _ { i } | }.$$
Recall that [ ζ + i , ζ -i ] = [ ζ + i , ζ b , c i | i | ] ∪ [ ζ c , c i | i | , ζ -i ]. The first part [ ζ + i , ζ b , c i | i | ] intersects [ ζ + j , ζ -j ] in all points ζ b ,r i satisfying | b i -b j | ≤ r ≤ min {| c i | , | c j |} . The second part [ ζ c , c i | i | , ζ -i ] intersects [ ζ + j , ζ -j ] in all points ζ c ,r i such that either | c j -c i | ≤ r ≤ min {| c i | , | c j |} or | b j -c i | ≤ r ≤ min {| c i | , | c j |} .
Now we can check our claim case by case.
Case 1: | c i | < b | j | . This implies | b i | < c | i | < b | j | < c | j | . In this case Z i ∩ Z j is empty and by formula (1) we have -log | q ij | = 0.
Case 2: | c i | = | b j | . This implies | b i | < c | i | = | b j | < c | j | . Here, Z i ∩ Z j is the image of [ ζ c , b i | j -c i | , ζ c , c i | i | ], which has length log( | c i || b j -c i | -1 ), which coincides with log | q ij | = |-log | q ij || by formula (1).
/negationslash
Case 3: | c i | > b | j | and | c i | = | c j | . Put m = min {| c i | , | c j |} . Then Z i ∩ Z j is the image of [ ζ b , b i | i -b j | , ζ b ,m i ], which has length log( mb | i -b j | -1 ). This coincides with -log | q ij | by formula (1).
Case 4: | c i | > b | j | and | c i | = | c j | . In this case, Z i ∩ Z j is the image of [ ζ b , b i | i -b j | , ζ b , c i | i | ] ∪ [ ζ c , c i | i | , ζ c , c i | i -c j | ], which has length
$$\log \frac { | c _ { i } | | c _ { i } | } { | b _ { i } - b _ { j } | | c _ { i } - c _ { j } | } = - \log | q _ { i j } |.$$
$$\begin{smallmatrix} \colon | q _ { i j } |. & \\ & & \Box \end{smallmatrix}$$
Note that part ii) of the preceding statement follows also from [vP], proof of Theorem 6.4 (2).
We can use the functions u i to give an explicit description of the embedding of X into its Jacobian.
Fix a ∈ Ω( K ) and consider the analytic morphism
↦
$$u & \colon \Omega \longrightarrow ( \mathbb { G } _ { m } ^ { g } ) ^ { \text{an} }, \quad z \mapsto \left ( \frac { u _ { 1 } ( z ) } { u _ { 1 } ( a ) }, \dots, \frac { u _ { g } ( z ) } { u _ { g } ( a ) } \right ).$$
Let Λ be the multiplicative lattice in ( G g m ) an generated by all λ i = ( q i 1 , . . . , q ig ). Then the quotient ( G g m ) an / Λ is isomorphic to the analytification J an of the Jacobian J of X , and the following uniformization diagram is commutative, where j is the embedding of X into its Jacobian associated to the point π a ( ) ∈ X K ( ).
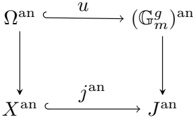
There exists a birational morphism j ( g ) : X ( g ) → J where X ( g ) denotes the g -th symmetric power of the curve sending ( z , . . . , z 1 g ) to j ( z 1 ) · · · j ( z g ). There is a natural tropicalization map
$$\text{rop} \colon ( \mathbb { G } _ { m } ^ { g } ) ^ { \text{an} } \longrightarrow \mathbb { R } ^ { g },$$
which maps a multiplicative seminorm x on the Laurent polynomial ring K T [ ± 1 1 , . . . , T ± 1 g ] to (log | T 1 ( x ) | , . . . , log | T g ( x ) ), | where | T i ( x ) | denotes the value of x on T i .
It induces a tropicalization map trop : J an -→ R g / log | Λ . | We will use this tropicalization map on the Jacobian to construct faithful tropicalizations.
## 4. Mumford curves of genus two
We study the situation of Mumford curves of genus g = 2. In this case, the skeleton S ( X an ) contains two cycles Z 1 and Z 2 . These cycles are either disjoint, meet in a point or meet in an edge (figure 1). We know from the proof of Proposition 3.2 that in the first two cases | q 12 | = | q 21 | = 1, and that in the third case the length of the shared edge is | log | q 12 || .
Figure 1. The three possible types of skeletons in genus two, from the left to the right: Skeleton with shared edge, connecting edge and connecting point.

Lemma 4.1. For a Schottky group Γ of rank two there exists an element γ ∈ PGL(2 , K ) such that γ Γ γ -1 has a good fundamental domain satisfying | b 1 | < c | 1 | < c | 2 | and | b 1 | < | b 2 | < | c 2 | . If the skeleton has a shared edge, we may also assume | b 2 | < c | 1 | .
Proof. Let γ , γ 1 2 be generators of Γ and B , B , C 1 2 1 , C 2 discs in P 1 providing a good fundamental domain. For i = 1 2 let , b i be the fixed point of Γ in B i , and let c i be the fixed point of Γ in C i . Recall that all elements in B i have absolute value | b i | , all elements in C i have absolute value | c i | , and the discs B , B , C 1 2 1 , C 2 are pairwise disjoint. We have
$$| c _ { 1 } - b _ { 1 } | \leq \max \{ | c _ { 1 } - c _ { 2 } |, | c _ { 2 } - b _ { 1 } | \}.$$
If | c 1 -c 2 | > c | 2 -b 1 | we exchange the generators γ 1 and γ -1 1 , and hence the pair of fixed points. Therefore we may assume that | c 1 -c 2 | ≤ | c 2 -b 1 | , which implies | c 1 -b 1 | ≤ | c 2 -b 1 | . Similarly, after exchanging γ 2 and γ -2 if necessary, we may assume that | b 1 -b 2 | ≤ | c 2 -b 1 | , which implies that | b 2 -c 2 | ≤ | c 2 -b 1 | . Since
$$| b _ { 1 } - b _ { 2 } | \leq \max \{ | b _ { 1 } - c _ { 2 } |, | c _ { 2 } - b _ { 2 } | \}$$
we have | b 1 -b 2 | ≤ | c 2 -b 1 | and similarly | c 1 -c 2 | ≤ | c 2 -b 1 | .
Thus
$$| c _ { 2 } - b _ { 1 } | \geq \max \{ | c _ { 1 } - b _ { 1 } |, | c _ { 2 } - b _ { 2 } |, | c _ { 2 } - c _ { 1 } |, | b _ { 2 } - b _ { 1 } | \}.$$
We find a point p ∈ K lying outside the closed disc B 1 such that | b 1 -p | < min {| b 1 -c 1 | , | b 1 -b 2 | , | c 2 -b 1 |} and there exists a point q ∈ K lying outside the closed disc C 2 satisfying | c 2 - | q < min {| c 2 -b 1 | , | c 2 -c 1 | , | c 2 -b 2 |} . Such points do exist since the discs are pairwise disjoint. This implies that
$$| c _ { 1 } - p | = | c _ { 1 } - b _ { 1 } |, | b _ { 2 } - p | = | b _ { 2 } - b _ { 1 } | \text{ and } | c _ { 2 } - p | = | c _ { 2 } - b _ { 1 } |,$$
as well as
$$| b _ { 1 } - q | = | b _ { 1 } - c _ { 2 } |, | c _ { 1 } - q | = | c _ { 1 } - c _ { 2 } | \text{ and } | b _ { 2 } - q | = | b _ { 2 } - c _ { 2 } |.$$
Hence p and q lie in the fundamental domain F .
$$\L \text{ by the element } \gamma ( z ) = \tilde { \frac { z } { z - q } } \text{ in } P \text{GL} ( 2, K ). \, \text{$1$ then } w \\ | \gamma ( b _ { 1 } ) | = \left | \frac { b _ { 1 } - p } { b _ { 1 } - q } \right | < \left | \frac { c _ { 1 } - p } { c _ { 1 } - q } \right | = | \gamma ( c _ { 1 } ) | \\ | c _ { 1 } - p | \text{ and } | c _ { 1 } - q | = | c _ { 2 } - c _ { 1 } | \leq | c _ { 2 } - b _ { 1 } | = | b _ { 1 } - \zeta \\ \text{ave}$$
We conjugate Γ by the element γ z ( ) = z -p z -q in PGL(2 , K ). Then we obtain since | b 1 - | p < c | 1 - | p and | c 1 - | q = | c 2 -c 1 | ≤ | c 2 -b 1 | = | b 1 - | q . Moreover, we have
since | c 2 - | q < c | 1 - | q and | c 1 - | p = | c 1 -b 1 | ≤ | c 2 -b 1 | = | c 2 - | p . This shows | γ b ( 1 ) | < γ c | ( 1 ) | < γ c | ( 2 ) . | We also find
$$& \text{ave} \\ & \left | \gamma ( c _ { 1 } ) \right | = \left | \frac { c _ { 1 } - p } { c _ { 1 } - q } \right | < \left | \frac { c _ { 2 } - p } { c _ { 2 } - q } \right | = | \gamma ( c _ { 2 } ) | \\ & \left | c _ { 1 } - q \right | \text{ and } | c _ { 1 } - p | = | c _ { 1 } - b _ { 1 } | \leq | c _ { 2 } - b _ { 1 } | = | c _ { 2 } - \gamma \\ & \frac { 1 } { 1 } ) | < | \gamma ( c _ { 1 } ) | < | \gamma ( c _ { 2 } ) |. \text{ We also find}$$
$$\iota _ { 1 } ) | < | \gamma ( c _ { 1 } ) | < | \gamma ( c _ { 2 } ) |. \text{ We also find} \\ | \gamma ( b _ { 1 } ) | = \left | \frac { b _ { 1 } - p } { b _ { 1 } - q } \right | < \left | \frac { b _ { 2 } - p } { b _ { 2 } - q } \right | = | \gamma ( b _ { 2 } ) |$$
since | b 1 - | p < b | 2 - | p and | b 1 - | q = | c 2 -b 1 | ≥ | b 2 -c 2 | = | b 2 - | q . Similarly, since | b 2 - | p = | b 2 -b 1 | ≤ | c 2 -b 1 | = | c 2 - | p and | b 2 - | q = | b 2 -c 2 | > c | 2 - | q . Thus we also get | γ b ( 1 ) | < γ b | ( 2 ) | < γ c | ( 2 ) . | Hence γ Γ γ -1 has a good fundamental domain satisfying the first claim of the lemma.
$$| b _ { 2 } - p | \text{ and } | b _ { 1 } - q | = | c _ { 2 } - b _ { 1 } | \geq | b _ { 2 } - c _ { 2 } | = | b _ { 2 } - \zeta \\ | \gamma ( b _ { 2 } ) | = \left | \frac { b _ { 2 } - p } { b _ { 2 } - q } \right | < \left | \frac { c _ { 2 } - p } { c _ { 2 } - q } \right | = | \gamma ( c _ { 2 } ) | \\ \quad \left | b _ { 2 } - b _ { 1 } \right | \leq | c _ { 2 } - b _ { 1 } | = | c _ { 2 } - p | \text{ and } | b _ { 2 } - q | = | b _ { 2 } - \text{ } \\ \text{t} \ | \gamma ( b _ { 1 } ) | < | \gamma ( b _ { 2 } ) | < | \gamma ( c _ { 2 } ) |.$$
In order to prove the second claim, we consider the case that the skeleton has a shared edge. By the first part of the proof we may assume that | b 1 | < c | 1 | < c | 2 | and | b 1 | < b | 2 | < c | 2 | hold. Recall from the proof of Proposition 3.2 that the inequality | b 2 | > c | 1 | implies that the cycles are disjoint. Hence we have | b 2 | ≤ | c 1 | . If the inequality is strict, our claim follows. Therefore we may assume that | c 1 | = | b 2 | . Note that in the case of a shared edge we have | c 1 -b 2 | < c | 1 | = | b 2 | . This follows from the discussion of Case 2 in the proof of Proposition 3.2.
There exists a point p ∈ K outside the disc C 1 such that
$$| c _ { 1 } - p | < \min \{ | c _ { 2 } - c _ { 1 } |, | b _ { 1 } - c _ { 1 } |, | b _ { 2 } - c _ { 1 } | \}$$
and a point q ∈ K outside C 2 such that
$$| c _ { 2 } - q | < \min \{ | c _ { 2 } - c _ { 1 } |, | c _ { 2 } - b _ { 2 } |, | c _ { 2 } - b _ { 1 } | \}.$$
A similar argument as in the proof of the first claim shows that p and q lie in the fundamental domain F . Let γ z ( ) = z -p z -q . We find since | c 1 -p | < | b 2 -c 1 | = | b 2 -p | and | c 1 -q | = | c 1 -c 2 | = | c 2 | as well as | b 2 - | q = | b 2 -c 2 | = | c 2 | . Similarly, we find
$$\text{unamental domain $\tilde{V}$} \cdot \text{Let $\gamma(z) = \frac{}{z-q}$}. \text{ we nnd} \\ | \gamma ( c _ { 1 } ) | = \left | \frac { c _ { 1 } - p } { c _ { 1 } - q } \right | = \frac { | c _ { 1 } - p | } { | c _ { 2 } | } < \frac { | b _ { 2 } - p | } { | c _ { 2 } | } = \left | \frac { b _ { 2 } - p } { b _ { 2 } - q } \right | = | \gamma ( b _ { 2 } ) | \\ \text{ince $|c_{1} - p|<|b_{2}-c_{1}|\, =\,|b_{2}-p|$ and $|c_{1}-q|\,=\,|c_{1}-c_{2}|\,=\,|c_{2}|$ as well as} \\ b _ { 2 } - q | = | b _ { 2 } - c _ { 2 } | = | c _ { 2 } |. \text{ Similarly, we find}$$
$$| b _ { 2 } - q | = | b _ { 2 } - c _ { 2 } | = | c _ { 2 } |. \text{ Similarly, we find} \\ | \gamma ( b _ { 2 } ) | = \left | \frac { b _ { 2 } - p } { b _ { 2 } - q } \right | = \frac { | b _ { 2 } - c _ { 1 } | } { | c _ { 2 } | } < \frac { | b _ { 1 } - c _ { 1 } | } { | b _ { 1 } - q | } = \left | \frac { b _ { 1 } - p } { b _ { 1 } - q } \right | = | \gamma ( b _ { 1 } ) | \\ \since { | b _ { 2 } - p | } = | b _ { 2 } - c _ { 1 } | < | c _ { 1 } | = | b _ { 1 } - c _ { 1 } | = | b _ { 1 } - p | \text{ and } | b _ { 2 } - q | = | b _ { 2 } - c _ { 2 } | = | c _ { 2 } | = \\ | c _ { 2 } - b _ { 1 } | = | b _ { 1 } - q |. \text{ Moreover, we have}$$
$$- b _ { 1 } | = | b _ { 1 } - q |. \text{ Moreover, we have} \\ | \gamma ( b _ { 1 } ) | = \left | \frac { b _ { 1 } - p } { b _ { 1 } - q } \right | = \frac { | c _ { 1 } | } { | c _ { 2 } | } < \frac { | c _ { 2 } | } { | c _ { 2 } - q | } = \left | \frac { c _ { 2 } - p } { c _ { 2 } - q } \right | = | \gamma ( c _ { 2 } ) | \\ \intertext { x } | b _ { 1 } - p | = | b _ { 1 } - c _ { 1 } | = | c _ { 1 } | < | c _ { 2 } | \text{ and } | c _ { 2 } - q | < | c _ { 2 } |. \\ \text{ is } | \gamma ( c _ { 1 } ) | < | \gamma ( b _ { 2 } ) | < | \gamma ( b _ { 1 } ) | < | \gamma ( c _ { 2 } ) |. \text{ Now exchange } \gamma _ { 1 } \text{ and } \gamma _ { 2 } ^ { - 1 } \text{ which}$$
since | b 2 - | p = | b 2 -c 1 | < c | 1 | = | b 1 -c 1 | = | b 1 - | p and | b 2 - | q = | b 2 -c 2 | = | c 2 | = | c 2 -b 1 | = | b 1 - | q . Moreover, we have since | b 1 - | p = | b 1 -c 1 | = | c 1 | < c | 2 | and | c 2 - | q < c | 2 | . Thus | γ c ( 1 ) | < γ b | ( 2 ) | < γ b | ( 1 ) | < γ c | ( 2 ) . | Now exchange γ 1 and γ -1 1 which exchanges c 1 and b 1 . This concludes the proof. /square
Let X be a Mumford curve of genus 2 over K obtained by a Schottky uniformization with a Schottky group Γ admitting a good fundamental domain. Since conjugation of the Schottky group by an element in PGL(2 , K ) amounts to a K -rational automorphism of the curve, we may assume by Lemma 4.1 that the set of generators of Γ satisfy the inequalities | b 1 | < c | 1 | < c | 2 | and | b 1 | < b | 2 | < c | 2 | with the additional inequality | b 2 | < c | 1 | in the case of a shared edge.
Every K -rational point in X (and hence every K -rational point of Ω) induces an embedding j : X ↪ → J into the Jacobian. Recall from the last section that the uniformization of J an by a two-dimensional torus gives rise to a tropicalization map trop : J an → R 2 / log | Λ . We consider the composition |
Note that µ is in general not injective.
$$& \mu \colon \mathcal { S } ( X ^ { \text{an} } ) \hookrightarrow X ^ { \text{an} } \stackrel { j ^ { \text{an} } } { \longleftrightarrow } J ^ { \text{an} } \stackrel { \text{top} } { \longrightarrow } \mathbb { R } ^ { 2 } \Big / \log | \Lambda | \\ \text{is in general not iniective}$$
Figure 2. The fundamental parallelepiped and the image of µ . Depicted on the left is the case of a connecting edge, on the right the case of a shared edge.
Theorem 4.2. Denote by e , e 1 2 the canonical basis of R 2 . There exists a point a ∈ Ω( K ) such that the map µ defined with the embedding j : X ↪ → J associated to a has the following image in a fundamental parallelepiped in R 2 / log | Λ : |
- (1) In the case of disjoint cycles or cycles meeting in a point we have
$$\lim ( \mu ) = [ 0, - \log | q _ { 1 1 } | [ e _ { 1 } \cup [ 0, - \log | q _ { 2 2 } | [ e _ { 2 }.$$
- (2) In the case of cycles sharing an edge, we put l = log | | q 12 || = log | | q 21 || and v = ( l, l ). Then we have
$$\lim ( \mu ) = [ 0, 1 [ v \cup v + [ 0, \log | q _ { 1 1 } | - l [ e _ { 1 } \cup v + [ 0, \log | q _ { 2 2 } | - l [ e _ { 2 }.$$
- (3) In the case of cycles sharing an edge, we have furthermore µ Z ( 1 \ Z 2 ) ⊂ v +[0 log , | q 11 | -l [ e 1 and µ Z ( 2 \ Z 1 ) ⊂ v +[0 log , | q 22 | -l [ e 2 .
- (4) µ maps the two cycles Z , Z 1 2 in S ( X an ) isometrically to their images µ Z ( 1 ) resp. µ Z ( 2 ) where we endow the fundamental parallelepiped with the metric induced from the maximum metric on R 2 .
Proof. Recall that by Proposition 3.1 | u i ( z ) | = | z -b i | | z -c i | on the fundamental domain. Hence we find for all x = ζ b 1 ,r with r 1 ≤ r ≤ | c 1 | :
$$\Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi } ^ { \Phi }, \Phi _ { \Phi \Phi } ^ { \Phi }, \Phi _ { \Phi \Phi } ^ { \Phi }, \Phi _ { \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi$$
For all x = ζ c 1 ,r with R 1 ≤ r ≤ | c 1 | we have
$$\zeta _ { c _ { 1 }, r } \text{ when } \kappa _ { 1 } \leq r \leq | c _ { 1 } | & \text{ we have} \\ \left ( | u _ { 1 } ( x ) |, | u _ { 2 } ( x ) | \right ) & = \left ( \frac { | c _ { 1 } | } { r }, \frac { \max \{ r, | c _ { 1 } - b _ { 2 } | \} } { \max \{ r, | c _ { 1 } - c _ { 2 } | \} } \right ) \\.. \quad. \quad. \quad. \quad.. \quad.. \quad..$$
Let us first discuss the case where the cycles are disjoint or share a point. By Proposition 3.2 this correponds to the case | b 1 | < c | 1 | < b | 2 | < c | 2 | or to the case | b 1 | < c | 1 | = | b 2 | < c | 2 | with | b 2 -c 1 | = | c 1 | . Choose a point a ∈ Ω( K ) such that | a | = | c 1 | = | c 1 -a | and | b 2 | = | b 2 -a | . Then ( | u 1 ( a ) | , | u 2 ( a ) ) | = (1 , | b 2 | / c | 2 | ). If we use π a ( ) to define the embedding j of X into its Jacobian, the associated map µ is given by µ x ( ) = (log | u 1 ( x ) | / u | 1 ( a ) | , log | u 2 ( x ) | / u | 2 ( a ) ) | mod log Λ | | on the fundamental domain. Hence the cycle Z 1 is mapped to
$$\left \{ \left ( \log r - \log | c _ { 1 } |, 0 \right ) \colon r \in [ r _ { 1 }, | c _ { 1 } | ] \right \} \cup \left \{ \left ( \log | c _ { 1 } | - \log r, 0 \right ) \colon r \in [ R _ { 1 }, | c _ { 1 } | ] \right \}.$$
Recall that in this case log | q 12 | = 0, so that we can add ( -log | q 11 | , 0) = (2 log | c 1 |-log r 1 -log R , 1 0) ∈ log | Λ | to the first subset. Therefore the image of Z 1 is [0 , -log | q 11 | [ e 1 . The second cycle Z 2 can be treated in the same way. This proves claim (1).
Now let us discuss the cases of cycles sharing an edge. In this case we have | b 1 | < | b 2 | < | c 1 | < | c 2 | . Choose a point a ∈ Ω( K ) such that | a | = | b 2 | =
| b 2 -a | . Then ( | u 1 ( a ) | , | u 2 ( a ) ) | = ( | b 2 | / c | 1 | , | b 2 | / c | 2 | ). If we use π a ( ) to define the embedding j of X into its Jacobian, the associated map µ is given by µ x ( ) = (log | u 1 ( x ) | / u | 1 ( a ) | , log | u 2 ( x ) | / u | 2 ( a ) ) | mod log Λ | | on the fundamental domain. Recall from the proof of Proposition 3.2 that the intersection Z 1 ∩ Z 2 corresponds to the line segment [ ζ b 1 , | b 2 | , ζ b 1 , | c 1 | ]. Hence Z 1 ∩ Z 2 is mapped to the line segment between (0 0) and (log , | c 1 | -log | b 2 | , log | c 1 | -log | b 2 | ) with slope one. Formula (1) in the proof of Proposition 3.2 implies that -log | q 12 | = log | c 1 | -log | b 2 | . Therefore the shared edge is mapped to [0 1] , v . Let us now look at Z 1 \ Z 2 . It corresponds to the union of the paths [ ζ b 1 ,r 1 , ζ b 1 , | b 2 | ] and [ ζ c 1 ,R 1 , ζ c 1 , | c 1 | ]. On the first path [ ζ b 1 ,r 1 , ζ b 1 , | b 2 | ] the map µ is given by
↦
$$\succeq \dots \tilde { \ } r \ r \, \sim \, \succeq \dots \tilde { \ } \lambda _ { J } \\ \zeta _ { b _ { 1 }, r } & \mapsto \left ( \log \frac { r } { | b _ { 2 } | }, 0 \right ).$$
Adding (log | q 11 | , log | q 12 | ) = ( -2 log | c 1 | + log r 1 + log R , 1 -log | c 1 | + log | b 2 | ) ∈ log | Λ we find that this is the line segment between (log | | c 1 | 2 R 1 | b 2 | , l ) and the lattice point (log | q 11 | , l ). On the second path [ ζ c 1 ,R 1 , ζ c 1 , | c 1 | ] the map µ is given by
↦
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \zeta _ { c _ { 1 }, r } & \mapsto \left ( \log \frac { | c _ { 1 } | ^ { 2 } } { r | b _ { 2 } | }, \log \frac { | c _ { 1 } | } { | b _ { 2 } | } \right ).$$
Its image is the line segment between v and (log | c 1 | 2 R 1 | b 2 | , l ). The cycle Z 2 can be treated similarly. Hence claims (2) and (3) hold. To show claim (4), write µ x ( ) = ( µ 1 ( x , µ ) 2 ( x )). Recall that on the first cycle µ 1 is of the form log r plus constant. In the case of a connecting edge µ 2 is equal to zero, which implies that µ is an isometry on this cycle. In the shared edge case there is also a change in µ 2 , but µ 1 will increase in the same way, so the maximum will be achieved in µ 1 . A similar argument holds for the second cycle.
/square
Lemma 4.3. Again let v = ( -log | q 12 | , -log | q 12 | ). If x = 2 v + αe 1 + βe 2 with 0 < α < -log | q 11 | + log | q 12 | and 0 < β < -log | q 22 | + log | q 12 | then there are exactly two points S and T in the skeleton such that µ S ( ) + µ T ( ) = x , namely S = µ -1 ( v + αe 1 ) and T = µ -1 ( v + βe 2 ).
Proof. If µ S ( ) = v + αe 1 and µ T ( ) = v + βe 2 then clearly µ S ( ) + µ T ( ) = x . So let us suppose there exist two other points U and V in the skeleton such that µ U ( ) + µ V ( ) = x . We have to handle several cases:
- (1) µ U ( ) = v + α e ′ 1 and µ V ( ) = v + β e ′ 2 with 0 < α ′ < -log | q 11 | +log | q 12 | and 0 < β ′ < -log | q 22 | +log | q 12 | . Then 2 v + αe 1 + βe 2 = 2 v + α e ′ 1 + β e ′ 2 so v + αe 1 + βe 2 = v + α e ′ 1 + β e ′ 2 . Since these points lie in the fundamental domain of the tropicalization of the Jacobian we obtain α ′ = α and β = β ′ , thus U and V coincide with S and T .
- (2) µ U ( ) = v + α e ′ 1 and µ V ( ) = v + α e ′′ 1 with 0 < α , α ′ ′′ < -log | q 11 | +log | q 12 | . Then µ U ( ) + µ V ( ) lies inside the image of the interior of the first cycle, but x does not. Thus such points U and V cannot exist. The same argument holds if both points lie on the other cycle.
- (3) µ U ( ) = v + α e ′ 1 and µ V ( ) = γv with 0 < α ′ < -log | q 11 | +log | q 12 | and γ ∈ [0 , 1]. Then 2 v + αe 1 + βe 2 = (1+ γ v ) + α e ′ 1 thus v + αe 1 + βe 2 = γv + α e ′ 1 . To satisfy this equality γv + α e ′ 1 cannot lie in the fundamental domain of the tropicalization of the Jacobian. Then (1+ γ v ) + α e ′ 1 -log | q 22 | e 2 lies in the fundamental domain, but this point is not equal to x = 2 v + αe 1 + βe 2 .
- (4) µ U ( ) = γv and µ V ( ) = γ v ′ with γ, γ ′ ∈ [0 , 1]. Then 2 v + αe 1 + βe 2 = ( γ ′ + ) γ v thus v + αe 1 + βe 2 = δv, δ ∈ -[ 1 1]. , This is not possible if δ ≥ 0.
So suppose δ < 0. We replace δv by an equivalent point:
δv = 2 v +( -log | q | +log | q | ) e +( -log | q | +log | q | ) e + δv
$$\delta v & = 2 v + ( - \log | q _ { 1 1 } | + \log | q _ { 1 2 } | ) e _ { 1 } + ( - \log | q _ { 2 2 } | + \log | q _ { 1 2 } | ) e _ { 2 } + \delta v \\ & = ( 1 + \delta ) v - \log | q _ { 1 1 } | e _ { 1 } - \log | q _ { 2 2 } | e _ { 2 }$$
Thus δv -log | q 11 | e 1 -log | q 22 | e 2 = αe 1 + βe 2 and we obtain α = -log | q 11 |-δ log | q 12 | . This contradicts α < -log | q 11 | +log | q 12 | .
The same argument holds for β thus the points U and V cannot exist.
/square
## 5. Faithful tropicalization in genus two
In this section we will always assume that the cycle lengths are at least twice as long as the length of the shared edge, i.e. | q 11 | < q | 12 | 2 and | q 22 | < q | 12 | 2 .
Lemma 5.1. Let A = -log | q 11 | +2log | q 12 | , B = -log | q 22 | +2log | q 12 | and v = ( -log | q 12 | , -log | q 12 | ). Then there exist points P , P 1 2 , P 3 , P 4 , S 1 , S 2 , S 3 , T 1 , T 2 , T 3 ∈ X K ( ) such that
- · µ ◦ τ ( P 1 ) = v + 1 4 Ae 1
- · µ ◦ τ ( P 3 ) = v + 1 4 Be 2
- · µ ◦ τ ( P 2 ) = v + 1 2 Ae 1
- · µ ◦ τ ( P 4 ) = v + 1 2 Be 2
- · µ ◦ τ ( T 1 ) = µ ◦ τ ( S 3 ) = v +( 3 4 A -log | q 12 | ) e 1
- · µ ◦ τ ( S 1 ) = µ ◦ τ ( T 3 ) = v +( 3 4 B -log | q 12 | ) e 2
- · µ ◦ τ ( S 2 ) = v -1 2 log | q 22 | e 2
- · j ( P 1 ) j ( P 2 ) j ( P 3 ) j ( S 1 ) j ( S 2 ) j ( S 3 ) , j ( P 1 ) j ( P 3 ) j ( P 4 ) j ( T 1 ) j ( T 2 ) j ( T 3 ) are trivial in J .
- · µ ◦ τ ( T 2 ) = v -1 2 log | q 11 | e 1
Proof. All points on the skeleton stated in the lemma are of type two thus there exist K -rational points P , P 1 2 , P 3 , P 4 , S 1 and T 1 as postulated. Since the map j (2) from X (2) to J is surjective there are points S , S 2 3 and T , T 2 3 in X K ( ) with
$$j ( S _ { 2 } ) j ( S _ { 3 } ) \, = \, \frac { j ( P _ { 1 } ) j ( P _ { 2 } ) j ( P _ { 3 } ) } { j ( S _ { 1 } ) } \, \text{and} \, j ( T _ { 2 } ) j ( T _ { 3 } ) \, = \, \frac { j ( P _ { 1 } ) j ( P _ { 3 } ) j ( P _ { 4 } ) } { j ( T _ { 1 } ) }$$
thus j ( P 1 ) j ( P 2 ) j ( P 3 ) j ( S 1 ) j ( S 2 ) j ( S 3 ) and j ( P 1 ) j ( P 3 ) j ( P 4 ) j ( T 1 ) j ( T 2 ) j ( T 3 ) are trivial in J . To determine the position of the retractions of S 2 and S 3 on the skeleton we use that
$$\mu \circ \tau ( S _ { 2 } ) + \mu \circ \tau ( S _ { 3 } ) = \mu \circ \tau ( P _ { 1 } ) + \mu \circ \tau ( P _ { 2 } ) + \mu \circ \tau ( P _ { 3 } ) - \mu \circ \tau ( S _ { 1 } ) \mod \log | \Lambda |.$$
.
Thus
$$\mu \circ \tau ( S _ { 2 } ) + \mu \circ \tau ( S _ { 3 } ) & = 2 v + \frac { 3 } { 4 } A e _ { 1 } - \left ( \frac { 1 } { 2 } B + \log | q _ { 1 2 } | \right ) e _ { 2 } \mod \log | \Lambda | \\ & = 2 v + \frac { 3 } { 4 } A e _ { 1 } + \frac { 1 } { 2 } \log | q _ { 2 2 } | e _ { 2 } \mod \log | \Lambda | \\ & = 3 v + \frac { 3 } { 4 } A e _ { 1 } + \left ( - \log | q _ { 2 2 } | + \log | q _ { 1 2 } | + \frac { 1 } { 2 } \log | q _ { 2 2 } | \right ) e _ { 2 } \mod \log | \Lambda | \\ \text{when we need to need to not need to not need to not need to not need to not need to not need to not need to be.}$$
$$- \left ( \frac { 1 } { 2 } B + \log | q _ { 1 2 } | \right ) e _ { 2 }$$
where we replaced the point 1 2 log | q 22 | e 2 by an equivalent one. Splitting one of the vectors v = -log | q 12 | e 1 -log | q 12 | e 2 yields
$$\nu \cos \nu & = \nu _ { 5 } | \gamma _ { 1 2 } | \nu _ { 1 } \quad \nu _ { 5 } | \gamma _ { 1 2 } | \nu _ { 2 } \, \nu \cos \\ \mu \circ \tau ( S _ { 2 } ) & + \mu \circ \tau ( S _ { 3 } ) = 2 v + \left ( \frac { 3 } { 4 } A - \log | q _ { 1 2 } | \right ) e _ { 1 } - \frac { 1 } { 2 } \log | q _ { 2 2 } | e _ { 2 }.$$
Figure 3. The extended skeletons.
Hence by Lemma 4.3
$$\text{leave by Lemma } 4. 0 \\ \mu \circ \tau ( S _ { 2 } ) & = v - \frac { 1 } { 2 } \log | q _ { 2 2 } | e _ { 2 } \text{ and } \mu \circ \tau ( S _ { 3 } ) = v + \left ( \frac { 3 } { 4 } A - \log | q _ { 1 2 } | \right ) e _ { 1 }.$$
µ ◦ τ ( T 2 ) and µ ◦ τ ( T 3 ) can be determined by a similar calculation.
/square
Theorem 5.2. Let P , P 1 2 , P 3 , P 4 ∈ X K ( ) be given as in the previous lemma and let D = P 1 + P 2 + P 3 + P 4 be the corresponding effective divisor. Then there exist functions f, g in the linear system L D ( ) such that the rational morphism (1 , f, g ) : X /axisshort/axisshort/arrowaxisright P 2 tropicalizes the skeleton faithfully.
Proof. By the previous lemma there exist points S , S 1 2 , S 3 , T 1 , T 2 , T 3 ∈ X K ( ) such that S 1 + S 2 + S 3 -P 1 -P 2 -P 3 = div( f ) and T 1 + T 2 + T 3 -P 2 -P 3 -P 4 = div( g ) are principal divisors. Both functions f and g are elements in the linear system L D ( ). Since µ is an isometry on the cycles by theorem 4.2 the points P , P 1 2 , P 3 , P 4 , S 1 , S 2 , S 3 , T 1 , T 2 , T 3 retract to the skeleton as shown in figure 3 where we label the edges on the first cycle by a, b, c, d, e, λ . Note that λ and c are not present in the connecting edge case. We orient all edges so that b, c, d, e, λ, a is the path τ ( P 1 ) → τ ( P 2 ) → τ ( T 2 ) → τ ( T 1 ) → τ ( P 1 ). Similarly we label the edges on the second cycle by α, β, γ, δ and λ , where again λ and γ are not present in the case of a connecting edge. We orient the cycle so that β, γ, δ, λ, α is the path τ ( P 3 ) → τ ( P 4 ) → τ ( S 2 ) → τ ( S 1 ) → τ ( P 3 ). In the connecting edge case the edge χ will be oriented from the first to the second cycle.
By | a | we mean the length of edge a , and we use similar notation for the other edges. By isometry of µ we obtain
$$( 2 ) \quad \ \ | c | + | d | = \frac { 3 } { 4 } A - \log | q _ { 1 2 } | - \frac { 1 } { 2 } A = \frac { 1 } { 4 } A - \log | q _ { 1 2 } | = | a | + | \lambda |$$
and
$$| \beta | + | \gamma | - | \epsilon | & = - \frac { 1 } { 2 } \log | q _ { 2 2 } | - \frac { 1 } { 4 } B - ( - \log | q _ { 2 2 } | + \log | q _ { 1 2 } | ) + ( \frac { 3 } { 4 } B - \log | q _ { 1 2 } | ) \\ & = \frac { 1 } { 2 } \log | q _ { 2 2 } | - 2 \log | q _ { 1 2 } | + \frac { 1 } { 2 } B = - \log | q _ { 1 2 } | = | \lambda | \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
where | c | = | γ | = | λ | = 0 in the connecting edge case.
We start by looking at log | f | . It suffices to calculate the slopes along a and α denoted by m a and m α resp. since the other slopes can be determined using the
slope formula (Theorem 2.1), e.g. the slope along edge b is m a -1. Since log | f | is piecewise linear by walking around the first cycle we get
$$m _ { \lambda } | \lambda | + m _ { a } | a | + ( m _ { a } - 1 ) | b | + ( m _ { a } - 2 ) ( | c | + | d | ) + ( m _ { a } - 1 ) | e | = 0.$$
Rearranging and making use of equation (2) leads us to
$$m _ { \lambda } | \lambda | + m _ { a } ( - \log | q _ { 1 1 } | - | \lambda | ) = - \log | q _ { 1 1 } |$$
Thus ( m λ -m a ) | λ | = (1 -m a ) log | q 11 | . If | λ | = 0, i.e. if we are in the connecting edge case, then m a = 1. If not then m λ -m a = m α by the slope formula. Thus
$$m _ { \alpha } | \lambda | & = ( 1 - m _ { a } ) \log | q _ { 1 1 } |.$$
Similarly since
$$m _ { \lambda } | \lambda | + m _ { \alpha } | \alpha | + ( m _ { \alpha } - 1 ) ( | \beta | + | \gamma | ) + m _ { \alpha } | \delta | + ( m _ { \alpha } + 1 ) | \epsilon | = 0$$
and | β | + | γ | = | /epsilon1 | + | λ | on the second cycle we obtain
$$m _ { \lambda } | \lambda | + m _ { \alpha } ( - \log | q _ { 2 2 } | - | \lambda | ) = | \lambda |$$
Thus
$$- m _ { \alpha } \log | q _ { 2 2 } | = ( m _ { \alpha } - m _ { \lambda } + 1 ) | \lambda |.$$
If | λ | = 0 then m α = 0. If not then m α -m λ = -m a thus
$$- m _ { \alpha } \log | q _ { 2 2 } | = ( 1 - m _ { a } ) | \lambda |.$$
Inserting m α = -(1 -m a ) | λ | log | q 22 | into (3) gives:
$$- ( 1 - m _ { a } ) \frac { | \lambda | ^ { 2 } } { \log | q _ { 2 2 } | } = ( 1 - m _ { a } ) \log | q _ { 1 1 } |$$
Since | λ | = -log | q 12 | and 0 < log | q 12 | 2 < log | q 11 | log | q 22 | this implies m a = 1 and hence m α = 0.
The calculation for log | g | is similiar to that of log | f | treating the second cycle first. Thus we obtain the following slope vectors for (log | f , | log | g | ):
$$m _ { a } = ( 1, 0 ), m _ { b } = ( 0, - 1 ), m _ { c } = ( - 1, - 1 ), m _ { d } = ( - 1, 0 ), m _ { e } = ( 0, 1 )$$
on the first cycle and
$$m _ { \alpha } = ( 0, 1 ), m _ { \beta } = ( - 1, 0 ), m _ { \gamma } = ( - 1, - 1 ), m _ { \delta } = ( 0, - 1 ), m _ { \epsilon } = ( 1, 0 )$$
on the second one. If the skeleton has a shared edge then by the slope formula (Theorem 2.1) the corresponding slope vector is m λ = (1 1). , If the skeleton has a connecting edge we obtain m χ = ( -1 1). , Hence the tropicalization maps the skeleton of the curve isometrically to its image, i.e. the tropicalization is faithful. See figure 4 for an illustration.
/square
Theorem 5.3. Let D ′ = D + S 3 . Then there exists a function h ∈ L D ( ′ ) such that (1 , f, g, h ) : X ↪ -→ P 3 is a closed immersion tropicalizing the extended skeleton faithfully.
Proof. Since deg( D ′ ) = 5 the divisor is very ample. By Riemann-Roch dim L D ( ′ ) = 3 thus a basis of the linear system defines an embedding into threedimensional projective space. The functions 1 , f and g are linearly independent in L D ( ′ ) so they can be completed to a basis by a function having a pole in S 3 . We already know that log | f | and log | g | tropicalize the skeleton faithfully.
First note that there can be up to two additional bounded edges on the extended skeleton with respect to D ′ : The rays to S 1 and T 3 (resp. T 1 and S 3 ) may meet
Figure 4. Tropicalization with respect to log | f | and log | g | of theorem 5.2 in the case of a shared edge resp. connecting edge where the possible intersection points are marked by a circle.
outside the skeleton. The slopes along these edges can be determined using the slope formula thus the slope vectors are ( -1 , -1) in both cases (oriented away from the skeleton). Hence these edges are mapped isometrically to their image in the tropicalization.
In the case of a connecting edge there are possibly two more bounded edges between the point where the rays leading to S 2 and P 4 meet and the skeleton resp. between the point where the rays leading to P 2 and T 2 meet and the skeleton. Again using
the slope formula we see that the slope vectors are ( -1 1) resp. , (1 , -1) so also these edges are going to be tropicalized faithfully.
The slope vector of the ray leading to P 1 is denoted by m P 1 similar notations for the other rays. By convention they are oriented away from the skeleton and are equal to the multiplicities of the poles resp. zeros of each function (Theorem 2.1).
Thus we obtain
$$m _ { P _ { 1 } } = ( 1, 1 ), \ m _ { P _ { 2 } } = ( 1, 0 ), \ m _ { T _ { 2 } } = ( 0, - 1 ), \ m _ { T _ { 1 } } = ( 0, - 1 ), \ m _ { S _ { 3 } } = ( - 1, 0 )$$
on the first cycle and
$$m _ { P _ { 3 } } = ( 1, 1 ), \ m _ { P _ { 4 } } = ( 0, 1 ), \ m _ { S _ { 2 } } = ( - 1, 0 ), \ m _ { S _ { 1 } } = ( - 1, 0 ), \ m _ { T _ { 3 } } = ( 0, - 1 )$$
on the second cycle.
Without loss of generality choose coordinates in R 2 such that via the tropicalization map one vertex of the connecting resp. shared edge lies in the origin. Let the plane be divided into two halfspaces by the line 〈 (1 , 1) . 〉 Then each cycle lies in one of the two halfspaces. Except for the rays leading to S 3 resp. T 3 all rays of one cycle lie in the same halfspace. This means these rays cannot intersect with rays from the other cycle. However the rays leading to S 3 and T 3 may well intersect, see figure 4. By arguments similar to that in the proof of lemma 5.1 there exists a rational function h having poles in S 3 , P 1 and P 3 as well as a zero in T 2 which implies that none of the other zeros will retract to τ ( S 3 ). Since h has a pole in S 3 the ray leading to this pole (and also a possible additional bounded edge) will be lifted into the third dimension as the ray leading to T 3 will not.
Thus log | h | separates the remaining rays, the tropicalization of the extended skeleton with respect to log | f , | log | g | and log | h | is faithful. /square
Acknowledgements This work has been supported by Deutsche Forschungsgemeinschaft (grant WE 4279). I would like to thank Annette Werner for numerous suggestions and corrections.
## References
[BaRa] Matt Baker, Joseph Rabinoff: The skeleton of the Jacobian, the Jacobian of the skeleton, and lifting meromorphic functions from tropical to algebraic curves , Preprint (2013), arXiv:1308.3864
[BPR1] Matthew Baker, Sam Payne, Joseph Rabinoff: On the structure of non-archimedean analytic curves . Contemp. Math. 605 (2013)
[BPR2] Matthew Baker, Sam Payne, Joseph Rabinoff: Nonarchimedean geometry, tropicalization, and metrics on curves . Preprint (2011), arXiv:1104.0320 .
[BaRu] Matthew Baker, Robert S. Rumely: Potential Theory and Dynamics on the Berkovich Projective Line . Volume 159 of Mathematical Surveys and Monographs , American Mathematical Soc. (2010)
[Be] Vladimir Berkovich: Spectral Theory and Analytic Geometry over non-Archimedean Fields . Vol. 33 of Mathematical Survey and Monographs , AMS (1990)
[ChSt] Melody Chan, Bernd Sturmfels: Elliptic curves in honeycomb form . Proceedings of the CIEM workshop in tropical geometry, Contemp. Math. 589 (2013) 87-107.
[Ge] Lothar Gerritzen: Zur nichtarchimedischen Uniformisierung von Kurven . Math. Ann. 210 (1974) 321-337
[GevP] Lothar Gerritzen, Marius van der Put: Schottky groups and Mumford curves . Lecture Notes in Mathematics 817 , Springer 1980.
[Gu] Walter Gubler: A guide to tropicalizations . In: Algebraic and Combinatorial Aspects of Tropical Geometry, AMS Contemporary Mathematics, 589 (2013) 125-189
[Ma] Yuri Manin: p -adic automorphic funtions . Itogi Nauki i Tekhniki, Sovremennye Problemy Matematiki 3 (1974) 5-92
[MaDr] Yuri Manin, Vladimir Drinfeld: Periods of p-adic Schottky groups. J. Reine Angew. Math. 262/263 (1973) 239-247
[MaSt] Diane Maclagan, Bernd Sturmfels: Introduction to Tropical Geometry . Version Feb 2014 http://homepages.warwick.ac.uk/staff/D.Maclagan/papers/TropicalBook.html
- [Mu] David Mumford: An analytic construction of degenerating curves over complete local rings . Compos. Math. 24 (1972) 129 - 174
- [Pa] Sam Payne: Analytification is the limit of all tropicalizations . Math. Res. Lett. 16 (2009) 543-556.
- [Th] Amaury Thuillier: Th´ eorie du potentiel sur les courbes en g´om´ etrie e analytique non archim´dienne. e Applications ` a la th´orie e d'Arakelov . Thesis (2005) http://tel.archives-ouvertes.fr/docs/00/04/87/50/PDF/tel-00010990.pdf
- [vP] Marius van der Put: Discrete groups, Mumford curves and Theta functions . Ann. Fac. Sci. Toulouse Math. (6) 1 (1992) 399 - 438
Goethe Universit¨t a Frankfurt, Institut f¨r Mathematik, u Robert-Mayer-Str. 6-10, 60325 Frankfurt am Main, Phone: 069 798 28281, Fax: 069 798 22302
E-mail address : [email protected] | null | [
"Till Wagner"
] | 2014-08-01T10:12:21+00:00 | 2014-08-01T10:12:21+00:00 | [
"math.AG",
"14T05, 14H30, 14H45"
] | Faithful Tropicalization of Mumford Curves of Genus Two | In the present paper, we investigate the question if the skeleton of a
Mumford curve of genus two can be tropicalized faithfully in dimension three,
i.e. if there exists an embedding of the curve in projective three space such
that the tropicalization maps the skeleton of the curve isometrically to its
image. Baker, Payne and Rabinoff showed that the skeleton of every analytic
curve can be tropicalized faithfully. However the dimension of the ambient
space in their proof can be quite large.
We will define a map from the skeleton to the tropicalization of the
Jacobian, which is an isometry on the cycles. It allows us to find principal
divisors and simultanously to determine the retractions of their support on the
skeleton which is necessary to calculate their tropicalization.
It turns out that a Mumford curve of genus two whose cycles of its skeleton
are either disjoint or share an edge of length at most half of the length of
the cycles, can be tropicalized faithfully in dimension three. |
1408.0121v3 | ## Thermally correlated states in Loop Quantum Gravity
Goffredo Chirco 1 2 , , Carlo Rovelli 1 2 , , Paola Ruggiero 3 4 ,
1 Aix Marseille Universit´, e CNRS, CPT, UMR 7332, 13288 Marseille, France. 2 Universit´ de e Toulon, CNRS, CPT, UMR 7332, 83957 La Garde, France. 3 Dipartimento di Fisica dell'Universit` di Pisa, a Largo Pontecorvo 3, I-56127 Pisa, Italy. 4 SISSA, Via Bonomea 265, 34136 Trieste, Italy.
(Dated: March 3, 2017)
We study a class of loop-quantum-gravity states characterized by (ultra-local) thermal correlations that reproduce some features of the ultraviolet structure of the perturbative quantum field theory vacuum. In particular, they satisfy an analog of the Bisognano-Wichmann theorem. These states are peaked on the intrinsic geometry and admit a semiclassical interpretation. We study how the correlations extend on the spin network beyond the ultra local limit.
## I. INTRODUCTION
The Bisognano-Wichmann theorem [1] states that the restriction of the vacuum of a Lorentz-invariant quantum field theory to the algebra of field operators with support on the Rindler wedge x > | t | is a KMS (Kubo-MartinSchwinger) state, that is, a thermal equilibrium state [2], with inverse temperature 2 π , with respect to the flow generated by the boost operator K in the x direction [3]. That is, it is described by the density matrix
$$\rho \in e ^ { - 2 \pi K }. \quad \quad \ \ ( 1 )$$
does not remain true in a quantum gravity theory (such as loop quantum gravity) where the Planck scale is a physical cut-off and there is no background metric defining the distance on the right hand side of this equation. Thus, (2) is not useful for characterising semiclassical states. On the other hand, as we shall see, (1) makes sense naturally in the theory. And it better hold true for semiclassical states, for these to yield the expected low energy phenomenology. 2 Here we explore the possibility of using (1) as a (partial) characterisation of 'good' semiclassical states in quantum gravity.
This fact is at the root of the thermal aspects of quantum field theory, such as the Unruh effect [4]. On a curved spacetime, quantum fields mimic flat space properties locally, and (a local version of) (1) can be argued to underpin the thermal properties of black holes [4-10]. 1
This effect derives from the quantum correlations in the field. This is particularly clear by considering states at fixed time. Eq. (1) can be obtained -at least formallyby tracing the state on the t = 0 surface over the degrees of freedom with support on x < 0. The resulting state is not pure because of the field correlations across x = 0. In general, we say that a state on a 3d spatial surface Σ has the Bisognano-Wichmann property if in any sufficient small patch of Σ a version of (1) holds locally for any 2d surface S , after tracing over the degrees of freedom on one side of S . (More precision below.) This property captures aspects of the field's local correlations.
This is of interest in quantum gravity for the following reason. The full background-independent nonperturbative theory must include states yielding conventional physics at low energy, including quantum field correlations. But the ultraviolet structure of these correlations which characterises theories defined on a background geometry
$$\langle 0 | \phi ( x ) \phi ( y ) | 0 \rangle \sim \frac { 1 } { | x - y | ^ { 2 } }, \quad \ \ ( 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
1 Hawking's black hole temperature is precisely equal to the Unruh temperature observed by a stationary observer near the horizon, red-shifted from this observer's location to infinity; see [11].
A similar suggestion has been recently put forward by two papers. In [10], Bianchi and Myers have suggested Bisognano-Wichmann-like correlations to characterize semiclassical states in any nonperturbative quantum theory of spacetime. The smooth structure of spacetime geometry at the classical level may be intimately related to the structure of correlations of the quantum gravitational state. A similar perspective has received attention in string theory, in the context of the gauge/gravity duality, where the entanglement of the boundary gauge field degrees of freedom has been associated to the connectivity of the bulk space-time dual [17-19]. In [20], the Bisognano-Wichmann property has been suggested as a possible replacement, in a background independent context, of the Hadamard condition that characterises the 'good' states in quantum field theory on curved space.
In loop quantum gravity, semiclassical states have been studied extensively [21-25]. Today we know how to write states where the expectation value of the the gravitational field appropriately matches a given smooth geometry. However, little is known so far about states where also the fluctuations of the gravitational field, and especially the nonlocal correlations, match the ones of conventional field theory. Here we construct and study states with a Bisognano-Wichmann-like property, as a step in this direction.
Notice that the main hypotheses of the BisognanoWichmann theorem are positivity of energy and Lorentz
2 Entanglement entropy due to short-scale quantum correlations has been studied in loop quantum gravity, especially in the context of black holes thermodynamics [12-16].
S
T
FIG. 1. A facet l separating two cells (a source cell S and a target cell T ) punctured by the link l that joins the two corresponding nodes.
invariance. The last is a dynamical property in the sense that a boost generates the change of a state from a given (spacelike) plane to a boosted one. Therefore the Bisognano-Wichmann property captures aspects of a state's evolution. As we will see, this is reflected in the states we define below: their definition depends on the (covariant [25-30]) definition of the loop quantum dynamics. Therefore they can also be viewed as a step towards fully physical dynamical quantum gravity states.
Section II recalls the covariant definition of loop quantum gravity states. In section III we define the thermally correlated link state, the fundamental brick of our construction. In Section III C we study the semiclassical properties of this state. In Section IV we construct the thermally correlated SU (2) spin network state. Section V shows how local correlations 'propagate' along the spin network. Results are summarised and discussed in the last section.
## II. LORENTZ COVARIANT LQG STATES
We start introducing the conventional loop quantum gravity space state, but using the SL (2 , C ) covariant language [31-33] adapted for what follows.
Consider an oriented three dimensional space-like hypersurface Σ embedded in a four dimensional space-time manifold M . Fix an oriented cellular decomposition of Σ. We call n (for 'node') the cells and l (for 'link') the facets separating two adjacent cells. Fix a dual graph Γ, with a node n in each cell and a link l connecting the nodes of neighbouring cells. We use the same notation, n and l for the nodes and links of the graph and the dual cells and facets of the triangulation. Each link l is oriented: we call n S (for 'source') and n T (for 'target') its initial and final nodes. The corresponding facet is equally oriented and separates a 'source' cell S from a 'target' cell T . See Figure 1.
Consider the spin connection ω of the Cartan formulation of general relativity, restricted to Σ. This describes aspects of the gravitational field on Σ. A quantum state can be expressed as a functional of ω . In particular, a quantum state on Γ is defined to be a (cylindrical 3 ) function Ψ[ ω ] = ψ g ( l [ ω ]) of the holonomy g l [ ω ] ∈ SL (2 , C ) of the spin connection along the L links l of the graph. These states, we assume, can be expanded in matrix elements of unitary representations of SL (2 , C ).
The SL (2 , C ) generators J IJ l = -J JI l , I, J = 0 , ..., 3 associated to each oriented link l play the role of the basic observables of the theory. They are the quantum operators representing the momentum conjugate to the spin connection, which on Σ is proportional to the Plebanski two-form e I ∧ e J , where e I is Cartan's tetrad one-form. More precisely, they are determined by the flux of this quantity across the facet l
$$J ^ { I J } _ { l, s } \sim \int _ { l } e ^ { I } \wedge e ^ { J },$$
parallel transported to the source node n S of l . The operator J IJ l, S acts on a function of g l as the left-invariant vector field. It is important for what follows to observe that the right -invariant vector ˜ J IJ l, T , related to J IJ l, S by the transformation defined by g l (in the adjoint representation), is a distinct operator. It represents the same flux, but parallel transported to the target node n T of the link l , namely in the frame of the adjacent cell. The relation between the two operators depends on the spin connection along the link.
It is convenient to pick the time gauge, which ties the normal to Σ to a direction t in the internal Minkowski space. Then J IJ l splits into rotation generators glyph[vector] L and boost generators glyph[vector] K . It is easy to see that (in a locally flat context [34]) the first is a vector normal to the facet l , with length proportional to the area of the facet [30].
The unitary representations of SL (2 , C ) are labelled by a positive real number p and non negative half-integer k [35]. At each node, the vector t determines a subgroup SU (2) ⊂ SL (2 , C ) that leaves it invariant. The Hilbert space H ( p,k ) that carries the ( p, k ) representation decomposes into irreducible representations of the subgroup as follows
$$\mathcal { H } _ { ( p, k ) } = \oplus _ { j = k } ^ { \infty } \mathcal { H } _ { j },$$
where H j is the (finite dimensional) SU (2) representation of spin j . Therefore H ( p,k ) admits a basis | ( p, k ); j, m 〉 , called the canonical basis, obtained by diagonalizing the total angular momentum L 2 and the L z = glyph[vector] L · glyph[vector] z component of the SU (2) subgroup. The states
$$\Psi _ { p _ { l } k _ { l } j _ { l } m _ { l } j _ { l } ^ { \prime } m _ { l } ^ { \prime } } [ \omega ] = \otimes _ { l } D _ { j _ { l } m _ { l }, j _ { l } ^ { \prime } m _ { l } ^ { \prime } } ^ { ( p _ { l }, k _ { l } ) } ( g _ { l } [ \omega ] ), \quad ( 5 )$$
where D ( p ,k l l ) are the representations matrices of the SL (2 , C ) unitary representations, span the space of the states on Γ.
3 A cylindrical function on an infinite dimensional space is a function depending on only on a finite number of coordinates on this space.
Within H ( p,k ) the physical subspace of the theory is determined (in a given Lorentz frame) by the linear simplicity condition
$$\vec { K } = \gamma \vec { L } \quad \quad \ \ ( 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
satisfied, in general relativity, by the momentum conjugate to the spin connection. Here γ ∈ R + is the BarberoImmirzi parameter [27, 30]. This relation determines a restriction on the set of the unitary representations and picks a subspace within each representation. Indeed, the relation (6) is weakly (in matrix elements) true [36] when restricted to states of the form
$$| p, k ; j, m \rangle = | \gamma ( j + 1 ), j ; j, m \rangle. \quad \ \ ( 7 ) \quad \ t o \ c$$
Accordingly, the physical subspace is formed by the states of the form
$$\Psi _ { j _ { l } m _ { l } m ^ { \prime } _ { l } } [ \omega ] = \otimes _ { l } D ^ { ( \gamma ( j _ { l } + 1 ), j _ { l } ) } _ { j _ { l } m _ { l }, j _ { l } m ^ { \prime } _ { l } } ( g _ { l } [ \omega ] ). \quad ( 8 ) \quad \text{A}.$$
This state space is naturally isomorphic to the space L 2 [ SU (2)] L , the conventional (non gauge invariant) Hilbert space of loop quantum gravity on the graph Γ. The isomorphism maps (8) into
$$\psi ( h _ { l } ) = \otimes _ { l } D _ { m _ { l }, m _ { l } ^ { \prime } } ^ { ( j ) } ( h _ { l } ) \quad \quad ( 9 )$$
where h l ∈ SU (2) and D j ( h ) are Wigner matrices, and is determined by the injection
$$Y _ { \gamma } \, \colon \, \ & \mathcal { H } _ { j } \quad \to \mathcal { H } _ { ( \gamma ( j + 1 ), j ) } \quad \quad ( 1 0 ) \quad \text{rota} \\ & \quad | j, m \rangle \mapsto | ( \gamma ( j + 1 ), j ) ; j, m \rangle.$$
L 2 [ SU (2)] L is a Hilbert space and this isomorphism endows the physical state space with the scalar product needed to define a quantum theory.
Let us now see how local gauge invariance affects this construction. In the Cartan formulation, general relativity is invariant under local SL (2 , C ) gauge transformations. Of these, only the Lorentz transformation Λ n at the nodes n of Γ affect the states on Γ (because only these affect the holonomies g l [ ω ]). Consider first gauge transformations where Λ n are rotations. These do not affect the local frame at each node, and transform physical states into themselves. The states invariant under these transformation are the well known spin network states
$$\psi ( h _ { l } ) = \bigotimes _ { l } D ^ { j _ { l } } ( h _ { l } ) \cdot \bigotimes _ { n } \iota _ { n } \quad \quad ( 1 1 ) \quad \underset { \text{rep} } { \text{$\text{$true$}$} }$$
where ι n is an SU (2) intertwiner at the node n and the contraction is determined by the structure of the graph. These gauge invariant states form the Hilbert space H Γ
$$\mathcal { H } _ { \Gamma } = L ^ { 2 } [ S U ( 2 ) ^ { L } / S U ( 2 ) ^ { N } ]$$
the standard loop quantum gravity state space on a graph. The states in this space have a direct interpretation as quantum geometry of the spatial section Σ of space-time.
More interesting are the Lorentz transformation that are not rotations. These act on the SL (2 , C ) states, changing (rotating) the class of physical states. Say t is a vector in the Minkowski representation, left invariant by SU (2); a generic Lorentz transformation boosts t into Λ , t which stabilises a different SU (2) subgroup, which in turn defines a different class of physical states. Therefore the spin network formalism is invariant under local rotations but is covariant under boosts. See [33] for a full discussion.
We are interested in the structure of correlations of these states. In other words. we are interested in the way different regions of a spin network can be correlated to one another.
## III. THERMAL LINK STATES
## A. Bisognano-Wichmann property on a single link
Let us begin by focusing on a single link, and disregarding, for now, gauge invariance. The states on a single link are given by functions ψ g ( ) on SL (2 , C ) satisfying the simplicity constraint, that is, linear combinations of the states of the form
$$\Psi _ { j m m ^ { \prime } } ( g ) \equiv \langle g | j m m ^ { \prime } \rangle = D _ { j m, j m ^ { \prime } } ^ { ( \gamma ( j + 1 ), j ) } ( g ). \quad ( 1 2 )$$
The operator glyph[vector] L S acts on this state as the generator of rotations on the first index
$$\langle j m m ^ { \prime } | \vec { L } _ { s } | j m ^ { \prime \prime } m ^ { \prime \prime \prime } \rangle = \vec { \tau } _ { m m ^ { \prime \prime } } ^ { j } \text{ \quad \ \ } ( 1 3 )$$
where glyph[vector] τ j is the generator of rotations in the spin j representation of SU (2) and summation over related indices is understood. The operator glyph[vector] L T acts on this state as the generator of rotations on the second index
$$\langle j m m ^ { \prime } | \vec { L } _ { \tau } | j m ^ { \prime \prime } m ^ { \prime \prime \prime } \rangle = \vec { \tau } _ { m ^ { \prime } m ^ { \prime \prime \prime } } ^ { j }. \quad \quad ( 1 4 )$$
The two boost generators, glyph[vector] K S and glyph[vector] K T restricted to this space, have the same matrix elements, multiplied by γ . This set of operators splits naturally into two groups: glyph[vector] L S and glyph[vector] K S act on the first magnetic index and represent observables living on the cell on the source side of the facet; while glyph[vector] L T and glyph[vector] K T act on the second magnetic index and represent operators living on the cell on the target side of the facet. Recall that they represent quantities parallel transported to two different nodes, and their difference measures the connection along the link. We can therefore split the observables into two groups, associated to the two cells on opposite sides of the facet l .
All operators considered here are diagonal in j (the boost operator mixes different j sectors of the same SL (2 , C ) irreducible, but not different SL (2 , C ) irreducibles, of course; also, states with different j belong to different irreducibles, because k = j ). It is therefore convenient to work at fixed quantum number j , namely
on a L 2 eigenspace (clearly | glyph[vector] L S | 2 = | glyph[vector] L T | 2 ). This space has the structure
$$\mathcal { H } = \mathcal { H } _ { j } ^ { s } \otimes \mathcal { H } _ { j } ^ { \mathcal { T } }. \quad \quad \ \ ( 1 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Given a state in this subspace, we can trace on one factor and define a density matrix over the other. Explicitly, tracing on the target factor, a state of the form
$$| \psi \rangle = \sum _ { m n } c _ { m n } | j m n \rangle \quad \quad ( 1 6 ) \quad \overset { \dots } { W _ { 1 } } \\ \underset { \dots } { \text{w} }$$
gives the density matrix
$$\rho = T r _ { \tau } | \psi \rangle \langle \psi | \equiv \sum _ { n } \overline { c _ { n m } } c _ { n m ^ { \prime } } | j, m \rangle \langle j, m ^ { \prime } | \quad ( 1 7 ) \quad \text{ with }$$
on H S j . Since the restriction of glyph[vector] K to H j is given by γ glyph[vector] L , because of the simplicity conditions, we can define the density matrix
$$e ^ { - 2 \pi \vec { K } \cdot \vec { z } } = \sum _ { m } e ^ { - 2 \pi \gamma m } | j, m \rangle \langle j, m |. \quad \ ( 1 8 )$$
where here | j, m 〉 is a basis of eigenstates of glyph[vector] L · glyph[vector] z . We now have the language for the following definition. We say that a link state ψ with spin j has the BisognanoWichmann property if there is a glyph[vector] n such that
$$\text{tr} _ { \tau } [ | \psi \rangle \langle \psi | ] = e ^ { - 2 \pi \vec { K } _ { S } \cdot \vec { n } }. \quad \quad ( 1 9 ) \quad \text{giv}$$
and there is a glyph[vector] n ′ such that
$$\ t r _ { s } [ | \psi \rangle \langle \psi | ] = e ^ { - 2 \pi \vec { K } _ { \tau } \cdot \vec { n } ^ { \prime } }. \quad \quad ( 2 0 ) \quad \text{No}$$
Armed with this definition, let us now see what are the states with this property.
## B. States
We want to find a class of states {| ψ 〉} satisfying (19) and (20).
For a given glyph[vector] z , we set glyph[vector] n = glyph[vector] n ′ ≡ glyph[vector] z . Sandwiching (19) between eigenstates of glyph[vector] K S · glyph[vector] z gives
$$\langle j m \, | \, \text{tr} _ { \tau } [ | \psi \rangle \langle \psi | ] \, | j m ^ { \prime } \rangle = e ^ { - 2 \gamma \pi m } \delta _ { m m ^ { \prime } } \quad ( 2 1 )$$
Using (17), this reads
$$\sum _ { n } \overline { c _ { n m } } c _ { n m ^ { \prime } } = e ^ { - 2 \gamma \pi m } \, \delta _ { m m ^ { \prime } }. \quad \quad ( 2 2 )$$
Let Λ be the diagonal matrix with entries e -γπm and c be the matrix with matrix elements c nm . Then the last equation can be written in the form
$$c c ^ { \dagger } = \Lambda \Lambda ^ { \dagger } \quad \quad \ \ ( 2 3 ) \quad \ t h$$
or equivalently
$$( c \Lambda ^ { - 1 } ) ( c \Lambda ^ { - 1 } ) ^ { \dagger } = \mathbb { I },$$
which is solved for any unitary matrix U by
$$c = \Lambda U \, \text{ \quad \ \ } \, ( 2 4 )$$
In components, our coefficients read
$$c _ { m n } = e ^ { - \pi \gamma m } \, U _ { m n } \, \text{ \quad \ \ } \text{(2.5)}$$
Moreover, recall that the definition of the BisognanoWichmann property demands the state to be thermal when traced on either side. Repeating the above derivation with source and target swapped yields
$$c _ { m n } = V _ { m n } e ^ { - \pi \gamma n }$$
with V mn also a unitary matrix.
Now, for two generic directions glyph[vector] n glyph[vector] , n ′ , it is easy to show that equations (25) and (26) generalize to
$$c _ { m n } = \sum _ { k } D ( \vec { n } ) _ { m k } e ^ { - \pi \gamma k } U _ { k n } \text{ \quad \ \ } ( 2 7 )$$
$$c _ { m n } = \sum _ { k } V _ { m k } e ^ { - \pi \gamma k } D ^ { \dagger } ( \vec { n } ^ { \prime } ) _ { k n } \text{ \quad \ \ } ( 2 8 )$$
where D glyph[vector] ( n ) and D glyph[vector] ( n ′ ) are the Wigner matrices (in the representation j ) corrisponding to the SU (2) elements rotating the glyph[vector] z into the glyph[vector] n and the glyph[vector] n ′ axes, respectively.
A wide class of states satisfying both (27) and (28) is given by
$$| \psi \rangle = \sum _ { m n l } D ( \vec { n } ) _ { l m } e ^ { - \pi \gamma m } D ^ { \dagger } ( \vec { n } ^ { \prime } ) _ { m n } | j, l, n \rangle \quad ( 2 9 )$$
Note that the effect of the Wigner matrices on the basis states | j, l, n 〉 = | j, l 〉 ⊗ | j, n 〉 † is simply to transform the L z eigenbasis | j, l 〉 into the eigenbasis | j, l 〉 glyph[vector] n of glyph[vector] L · glyph[vector] n for a generic vector glyph[vector] n . Therefore this class of (spin j ) states labelled by two arbitrary vectors and the SU (2) representation j , that satisfy the Bisognano-Wichmann property, has the compelling from
$$| \psi _ { j \tilde { n } \tilde { n } ^ { \prime } } \rangle = \sum _ { m } e ^ { - \pi \gamma m } | j, m \rangle _ { \tilde { n } } \otimes | j, m \rangle _ { \tilde { n } ^ { \prime } } \quad ( 3 0 )$$
These states are not normalised. Their norm is easily computed; it is the square root of
$$\mathcal { N } _ { j } = \langle \psi _ { j \bar { n } \bar { n } ^ { \prime } } | \psi _ { j \bar { n } \bar { n } ^ { \prime } } \rangle = \sum _ { k = - j } ^ { j } e ^ { - 2 \pi \gamma k } \quad \quad ( 3 1 )$$
These are the Bisognano-Wichmann link states.
## C. Semiclassicality
Before extending the Bisognano-Wichmann states to the full graph, let us study their properties. First of all, we have defined states at fixed spin j . Therefore we expect the corresponding conjugate momentum, namely the extrinsic curvature at the facet, to be fuzzy. We
leave open, for the moment, the task of combining these states into extrinsic [30] semiclassical states, and we concentrate on the properties of the intrinsic geometry they define.
For this, we estimate the mean value and the dispersion of the geometrical operators on the states (30). To begin with, consider the case with glyph[vector] n = glyph[vector] n ′ = glyph[vector] z . Choosing the basis that diagonalises L z we have immediately
$$\langle \vec { L } _ { s } \rangle & \equiv \langle \psi _ { j \vec { z } \vec { z } } | \vec { L } _ { s } | \psi _ { j \vec { z } \vec { z } } \rangle \\ & = \sum _ { m } e ^ { - 2 \gamma \i m } \langle j m | \begin{pmatrix} L _ { x } \\ L _ { y } \\ L _ { z } \end{pmatrix} | j m \rangle \,, \quad \text{ (3 2)}$$
where, we recall,
$$\begin{pmatrix} L _ { x } \\ L _ { y } \\ L _ { z } \end{pmatrix} | j m ^ { \prime } \rangle _ { s } = \begin{pmatrix} \frac { 1 } { 2 } ( c _ { 1 } | j, m ^ { \prime } - 1 \rangle _ { s } + c _ { 2 } | j, m ^ { \prime } + 1 \rangle _ { s } ) \\ \frac { 1 } { 2 } ( c _ { 1 } | j, m ^ { \prime } - 1 \rangle _ { s } - c _ { 2 } | j, m ^ { \prime } + 1 \rangle _ { s } ) \\ m ^ { \prime } | j m ^ { \prime } \rangle _ { s } \end{pmatrix} \quad \text{while} \quad \text{$$
the coefficients c 1 , c 2 being defined by
$$c _ { 1 } = \langle j, m - 1 | L _ { x } - i L _ { y } | j, m \rangle = \sqrt { ( j + m ) ( j - m + 1 ) }$$
c 2 = 〈 j, m +1 | L x + iL y | j, m 〉 = √ ( j + m +1)( j -m . )
Easily,
$$\langle \vec { L } _ { s } \rangle = \sum _ { m = - j } ^ { j } e ^ { - 2 \pi \gamma m } \begin{pmatrix} 0 \\ 0 \\ m \end{pmatrix} = \left ( \sum _ { m = - j } ^ { j } e ^ { - 2 \pi \gamma m } m \right ) \, \vec { z } \\ \text{The mean value number normalized reads} \quad \text{with} \quad \text{ }$$
The mean value, properly normalized, reads
$$\vec { L } _ { s } \equiv \frac { \langle \vec { L } _ { s } \rangle } { \mathcal { N } _ { j } } = \frac { \sum _ { m = - j } ^ { j } e ^ { - 2 \pi \gamma m } m } { \sum _ { m = - j } ^ { j } e ^ { - 2 \pi \gamma m } } \, \vec { z }. \quad \quad ( 3 4 )$$
The vector operator points in the direction identified by the state and, for large j , we have:
$$\frac { \vec { L } _ { s } } { ( - j ) } \xrightarrow { j \rightarrow \infty } 1$$
Therefore, glyph[vector] L S ∼ -j + O j ( ). The correction is actually a constant given by:
$$\vec { L } _ { s } \sim - j + \frac { 1 } { 2 ( e ^ { \pi \gamma } - 1 ) } \quad \quad ( 3 5 ) \quad \begin{array} { c } \text{th} \\ \text{sta} \\ \text{div} \end{array} \end{array}$$
In order to understand if the state become sharp for large j , we look to the relative dispersion of glyph[vector] L S in the plane orthogonal to the direction identified by the mean value. We saw above that
$$\langle L _ { x } \rangle = \langle L _ { y } \rangle = 0, \text{ \quad \ \ } ( 3 6 )$$
while, due to symmetry, we can write
$$\langle L _ { x } ^ { 2 } \rangle = \langle L _ { y } ^ { 2 } \rangle = \frac { 1 } { 2 } \langle ( L _ { x } ^ { 2 } + L _ { y } ^ { 2 } ) \rangle = \frac { 1 } { 2 } \langle ( \vec { L } ^ { 2 } - L _ { z } ^ { 2 } ) \rangle. \quad ( 3 7 ) \quad \text{$The$} \text{$can$}$$
The relative dispersions of the components L , L x y (the scale parameter is chosen to be the norm square of the vector itself) is given by
$$\frac { \sigma ( L _ { x } ) } { \langle \vec { L } ^ { 2 } \rangle } = \frac { \sigma ( L _ { y } ) } { \langle \vec { L } ^ { 2 } \rangle } = \frac { 1 } { 2 } \frac { \langle ( \vec { L } ^ { 2 } - L _ { z } ^ { 2 } ) \rangle } { \langle \vec { L } ^ { 2 } \rangle }. \quad \ \ ( 3 8 )$$
The expectation value of glyph[vector] L 2 is j ( j +1), while for L 2 z we get
$$L _ { z } ^ { 2 } = \frac { \sum _ { m = - j } ^ { j } m ^ { 2 } e ^ { - 2 \gamma \pi m } } { \sum _ { m = - j } ^ { j } e ^ { - 2 \gamma \pi m } }. \quad \quad \quad ( 3 9 )$$
The spread is then given by 4
$$\frac { \sigma ( L _ { y } ) } { \langle \vec { L } ^ { 2 } \rangle } = \frac { \sigma ( L _ { x } ) } { \langle \vec { L } ^ { 2 } \rangle } = \frac { 1 } { 2 } \frac { j ( j + 1 ) - \frac { \sum _ { m = - j } ^ { j } m ^ { 2 } e ^ { - 2 \gamma \pi m } } { \sum _ { m = - j } ^ { j } e ^ { - 2 \gamma \pi m } } } { j ( j + 1 ) },$$
which goes to zero in the limit j →∞ .
It is easy to generalize this result for a generic direction: the mean value of glyph[vector] L S on | ψ jglyph[vector] nglyph[vector] n ′ 〉 is given by
$$\vec { L } _ { s } = \frac { 1 } { \mathcal { N } _ { j } } \, \left ( \sum _ { m } e ^ { - 2 \pi m } m \right ) \, \vec { n }. \quad \quad ( 4 1 )$$
And the mean value of the right invariant vector field glyph[vector] L T is
$$\vec { L } _ { \tau } = \frac { 1 } { \mathcal { N } _ { j } } \, \left ( \sum _ { n } e ^ { - 2 \pi n } n \right ) \, \vec { n } ^ { \prime }. \, \quad \quad ( 4 2 )$$
with the same relative dispersion as above.
## D. Overcomplete basis
Finally an important property of the BisognanoWichmann link states is that they form an overcomplete basis for each j , in the Hilbert space H ⊗H j ∗ j . The resolution of the identity is
$$\mathbb { I } _ { j } = \frac { d _ { j } ^ { 2 } } { ( 4 \pi ) ^ { 2 } \mathcal { N } _ { j } } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } ^ { \prime } \ | \psi _ { j \vec { n } \vec { n } ^ { \prime } } \rangle \langle \psi _ { j \vec { n } \vec { n } ^ { \prime } } | \quad ( 4 3 )$$
The integration is over the two-sphere of the normalized vectors glyph[vector] n,glyph[vector] n ′ , with the standard R 3 measure restricted to the unit sphere. This property is crucial: it indicates that every state can be expressed as a superposition of states with semiclassical labels. The proof of (43) is given in Appendix A.
4 The calculation is easy to perform if one notes that all the quantities appearing are all of the form:
$$\sum _ { m = - j } ^ { j } m ^ { n } e ^ { - 2 \pi m } = \frac { d ^ { n } } { d \alpha ^ { n } } \sum _ { m = - j } ^ { j } e ^ { - \alpha m } | _ { \alpha = 2 \pi } \quad ( 4 0 )$$
The only sum one needs to perform is then ∑ j m = -j e -αm which can be split into two geometric sums.
## IV. THERMALLY CORRELATED SPIN NETWORK STATES
So far we have studied single link states. We now move to states defined on the full graph. The first step for this is to combine Bisognano-Wichmann states associated to the links that join on a single node n . To this aim, we simply take the tensor product of a Bisognano-Wichmann link state per each of the links meeting at n and project on the SU (2) gauge invariant subspace. The projection is performed by integrating over the local gauge group SU (2),
$$| \Psi ^ { ( n ) } _ { j _ { l }, \vec { n } _ { l }, \vec { n } ^ { \prime } _ { l } } \rangle = \int d h \bigotimes _ { l \in n } D ( h ) | \psi _ { j _ { l } \vec { n } _ { l } \vec { n } ^ { \prime } _ { l } } \rangle. \quad ( 4 4 ) \\ \tau \quad \tau \cdot \quad \tau \cdot \quad \tau \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \end{array}$$
The Bisognano-Wichmann graph state is then determined by a spin associated to each link and two vectors glyph[vector] n l and glyph[vector] n ′ l associated, respectively, to the source and the target of each link. The resulting gauge invariant state is
$$| \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \int \prod _ { n } d h _ { n } \bigotimes _ { l \equiv \langle n _ { l }, n _ { l } ^ { \prime } \rangle } D ^ { j _ { l } } ( h _ { n _ { l } } ) D ^ { j _ { l } \dagger } ( h _ { n _ { l } ^ { \prime } } ) | \psi _ { j _ { l } \vec { n } _ { l } \vec { n } _ { l } ^ { \prime } } \rangle \quad \text{with t} ] \quad \text{differef} \\ \text{where} \quad \text{general} \quad \text{(45)} \quad \text{This} \quad \text{array} \quad 1$$
where we identify each link with the two node at its endpoints, l ≡ 〈 n , n l ′ l 〉 .
These are the Bisognano-Wichmann states on the graph.
In the Schr¨dinger representation, namely on the group o element basis, they read
$$\Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } ( U _ { l } ) = \langle U _ { l } | \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \int \prod _ { n } d h _ { n } \quad \quad ( 4 6 )$$
$$\prod _ { l \equiv \langle n _ { l }, n _ { l } ^ { \prime } \rangle } \text{tr} _ { j _ { l } } [ D ( U _ { l } ) D ( h _ { n _ { l } } ) D ( \vec { n } _ { l } ) \, e ^ { - \pi L _ { z } } \, D ^ { \dagger } ( \vec { n } _ { l } ^ { \prime } ) D ^ { \dagger } ( h _ { n _ { l } ^ { \prime } } ) ].$$
These states resemble the common intrinsic LivineSpeziale states on the graph, but there is a crucial difference. The space of the states with fixed spin is the tensor product of one intertwined space per node, that is
$$\mathcal { H } _ { j _ { l } } = \bigotimes _ { n } \mathcal { H } _ { n } \quad \quad \quad ( 4 7 ) \quad \text{ an} \\ \quad \quad \quad \text{s}$$
where the intertwined space H n of the node n is the SU (2) invariant part of the tensor product of the representation spaces associated to the spins of the links joining in n :
$$\mathcal { H } _ { n } = I n v _ { S U ( 2 ) } [ \bigotimes _ { l } \mathcal { H } _ { j _ { l } } ].$$
where the product in l runs over the links joining in n . The Livine-Speziale states | j , glyph[vector] l n , glyph[vector] l n ′ l 〉 are tensor states with respect to this decomposition
$$| j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } \rangle = \bigotimes _ { n } | \iota _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } ^ { n } \rangle \quad \quad ( 4 8 ) \quad \text{$gat$} \\ \text{$sion$}$$
where ι n j ,glyph[vector] l n ,glyph[vector] l n ′ l is the Livine-Speziale intertwiner. On the contrary, the Bisognano-Wichmann states do not factorise. To see this, it is sufficient to consider the density matrix of the state defined in (44) and reduce it to the intertwined space H n , by tracing over the external representation spaces of the links. A straightforward calculation shows this to be
$$& \rho = \text{tr} [ | \Psi ^ { ( n ) } _ { j _ { l }, \vec { n } _ { l }, \vec { n } ^ { \prime } _ { l } } \rangle \langle \Psi ^ { ( n ) } _ { j _ { l }, \vec { n } _ { l }, \vec { n } ^ { \prime } _ { l } } | ] = \\ & = \bigotimes _ { l \in n } \int d h \int d \tilde { h } \quad [ D ( h ) e ^ { - 2 \pi \gamma \tilde { L } _ { l } \cdot \vec { n } _ { l } } D ^ { \dagger } ( \tilde { h } ) ]$$
where the tensor product is on the links that join at the node n and for simplicity we have assumed the node to be the source of these all. One may notice in this expression that [ D h e ( ) -2 π ∑ l glyph[vector] L glyph[vector] l · n l D † ( ˜ )] h does not act as a rotation of the vectors glyph[vector] n l , since the adjoint rapresentation acts with the same group element, whereas here we have two different SU (2) elements ( h, h ˜ ). This density matrix in general is not pure.
This indicates that the Bisognano-Wichmann states carry nontrivial quantum correlations between different nodes. In Appendix C we compute the correlations between two operators in a Bisognano-Wichmann state on a simple graph (the dipole graph), to verify explicitly that they are indeed non-vanishing (see also Appendix B for details on the observables).
This is the main property we were seeking.
## V. LONG DISTANCE CORRELATIONS
The Bisognano-Wichmann states defined in the previous section have non trivial quantum correlations across adjacent nodes. Do they also have correlations between nodes that are not adjacent? Here we show that the answer is yes and we give some preliminary elements of analysis of these correlations.
The simplest spin network we can use to try to address these questions, is an open spin network composed by a chain of N nodes, each pair sharing a single link. We start by writing the explicit form of the state for the special case N = 2 to understand the structure of the state itself. The non-gauge invariant state on the two node graph is given by
$$| \tilde { \Psi } _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle & = \sum _ { \{ k _ { l } \} } e ^ { - \pi \gamma \sum _ { l } k _ { l } } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } \rangle \times \\ & \times | j _ { 4 5 6 7 }, k _ { 4 5 6 7 } \vec { n } _ { 4 5 6 7 } ^ { \prime } \rangle ^ { \dagger } | | j _ { l }, k _ { l }, \vec { n } _ { l } ^ { ( ^ { \prime } ) } \rangle _ { i \neq 4 } ^ { ( \dagger ) }$$
glyph[negationslash]
gathering together the external half links into the espression || j , k , glyph[vector] l l n ( ) ′ l 〉 ( † ) l =4 . The projection to the gauge invari- glyph[negationslash]
ant subspace is given by
$$& | \Psi _ { j _ { l } }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } \rangle = \\ & \quad = \sum _ { \{ k _ { l } \} } e ^ { - \pi \gamma \sum _ { l } k _ { l } } \sum _ { \alpha \beta } \phi _ { \alpha } ( j _ { 1 2 3 4 } k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } ) \times \\ & \quad. \quad. \quad. \quad. \quad. \quad.. \quad. \quad. \quad. \quad. \quad. \quad. \, \quad \, \int \, \infty + \infty$$
$$\times \, \phi ^ { * } _ { \beta } ( j _ { 4 5 6 7 }, k _ { 4 5 6 7 } \vec { n } ^ { \prime } _ { 4 5 6 7 } ) \, | \iota _ { \alpha } \rangle | \iota _ { \beta } \rangle ^ { \dagger } | | j _ { l }, k _ { l }, \vec { n } ^ { ( ^ { \prime } ) } _ { l } \rangle ^ { ( \dagger ) } _ { l \neq 4 }$$
glyph[negationslash]
where the projector operator and the φ α,β coefficients are those defined in Appendix C. The generalization to a chain of N nodes is straightforward.
We have computed numerically the correlations on a chain of N = 7 nodes, fixing all j l = 1 2. / We have computed the following quantity
$$\langle P _ { i } ^ { ( 0 ) } P _ { j } ^ { ( 0 ) } \rangle - \langle P _ { i } ^ { ( 0 ) } \rangle \langle P _ { j } ^ { ( 0 ) } \rangle \, \text{ \quad \ \ } ( 4 9 )$$
for i, j = 1 , · · · , N , where P (0) i = | ι 0 〉〈 ι 0 | is the projector on the first element of the recoupling basis on the i -th node. The results of the numerical calculation are displayed in Figure 2.
The correlations that we find can be interpreted as the result the interplay between the thermal correlations on the single links, which correlate any two adjacent nodes, and the effect of gauge-invariance at nodes, which ties the links in quadruples and allows for the propagation of the those thermal correlations among far nodes.
## VI. SUMMARY AND DISCUSSION
We have defined a family of states in loop quantum gravity which are peaked on an (intrinsic) geometry and have non trivial correlations between distinct nodes. These correlations are such that tracing on one node yields, on a neighbouring node, a thermal state with respect to a flow related, via the simplicity conditions, to the boost generator. We have called these states Bisognano-Wichmann states, and this feature the Bisognano-Wichmann property. Correlations extend to non-neighbouring nodes.
We list in the following a number of questions which we think deserve to be investigated.
- · We have investigated in this paper states at fixed j . Extrinsic coherent states obtained relaxing the sharpness condition on j are of course interesting for physics.
- · The boost operator glyph[vector] K is the generator of internal boosts in the full covariant theory. In a gauge fixed formalism, as is implicitly the loop formalism which is formulated in the time gauge, this is related to a physical boost. The situation is analogous to the rotations of the tetrad in general relativity: if we describe a measuring apparatus gauge fixing the tetrad to its axes, then a rotation of the tetrad has the physical interpretation of a relative rotation
/Less
FIG. 2. Fit of the correlation function ( 〈 P N ( 1) P N ( 2) 〉 c = 〈 P N ( 1) P N ( 2) 〉 - 〈 P N ( 1) 〉〈 P N ( 2) 〉 ) as a function of the distance between nodes (∆ N = N 1 -N 2). The scale is linear logarithmic. Fit model: f (∆ N ) = a exp( -b ∆ N ). Fit results: a = 0 73; , b = 5 20. ,
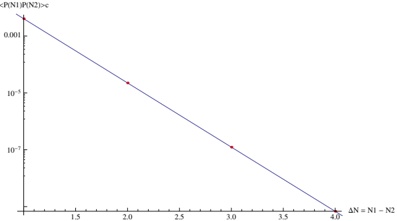
between the apparatus and its exterior. Similarly, the boost generator glyph[vector] K can also be interpreted as the generator of physical boosts: it evolves a state on a surface to the state on a boosted surface, which is to say to the surfaces of a boosted observer [37].
- · In the context of QFT, the restriction of the field vacuum state to the right Rindler wedge, automatically gives a restriction to the positive eigenvalues of the boost generator. In closer analogy, perhaps the restriction of states to those where glyph[vector] K · glyph[vector] n has positive eigenvalues is of physical interest. In particular, this aspect could turn out to be crucial for the normalizability of the states once the sum over the SU (2) representations ( j ) is considered. We leave this question open.
- · The spin-networks Hilbert space is the same as in a conventional SU (2) lattice Yang-Mills theory. In lattice gauge theory, nonlocal correlations have been studied by Donnelly in [38]. See also [39]. The construction here is related to these analyses, and the precise relation deserves to be better understood.
- · In the Bisognano-Wichmann states, the thermal correlations get mixed up by gauge invariance. The density matrix on a single node Hilbert space obtained by tracing the state on the rest of the nodes is not thermal, because the correlations defined on the links get mixed up by the gauge at the node. This is not in contradiction with the BisognanoWichmann property, which refers to a single surface (a single link), but deserves better understanding.
- · The 2 π in the Bisognano-Wichmann temperature is related to the Minkowski geometry and its complex extension, as well as the corner terms of the action on the spitting surface [40-42]. The role of these in the loop dynamics is strictly connected to the Bisognano-Wichmann property and is a tantalising issue, which still deserves clarification.
## ACKNOWLEDGEMENTS
Thanks to Aldo Riello and Hal Haggard for many exchanges. PR thanks the support of the Della Riccia Foundation.
## Appendix A: Resolution of identity
Here we derive explicitly the resolution of the identity given in the text. Starting from equation (43), we have
$$\text{ here we are explicitly the resolution or the identity} \text{ given in the text. Starting from equation (43), we have} \\ \mathbb { I } _ { j } & = \frac { 1 } { \mathcal { N } _ { j } } \frac { d _ { j } ^ { 2 } } { ( 4 \pi ) ^ { 2 } } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } ^ { \prime } | \psi _ { j } ( \vec { n }, \vec { n } ^ { \prime } ) } \rangle ( \psi _ { j } ( \vec { n }, \vec { n } ^ { \prime } ) | = \quad ( A 1 ) ^ { \ } _ { \ } a \text{ and } l _ { \ } & \text{(shaded} \, r \\ & = \frac { 1 } { \mathcal { N } _ { j } } \frac { d _ { j } ^ { 2 } } { ( 4 \pi ) ^ { 2 } } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } ^ { \prime } \sum _ { k } | j, k \rangle _ { s } D ( \vec { n } ) \, e ^ { - \pi \gamma k } \times \\ & \quad \times D ^ { \dagger } ( \vec { n } ^ { \prime } ) | j, k \rangle _ { s } ^ { \dagger } \sum _ { l } | j, l \rangle _ { \tau } D ( \vec { n } ^ { \prime } ) e ^ { - \pi \gamma l } D ^ { \dagger } ( \vec { n } ) | j, l \rangle _ { \tau } ^ { \dagger } \\ & = \frac { 1 } { \mathcal { N } _ { j } } \frac { d _ { j } ^ { 2 } } { ( 4 \pi ) ^ { 2 } } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } \int _ { S ^ { 2 } } d ^ { 2 } \vec { n } ^ { \prime } \sum _ { k, \alpha, \beta } | j, \alpha \rangle _ { s } D ( \vec { n } ) _ { \alpha, k } e ^ { - \pi \gamma k } \\ & D ^ { \dagger } ( \vec { n } ^ { \prime } ) _ { k, \beta } | j, \beta \rangle _ { \tau } ^ { \dagger } \sum _ { l, \tilde { \alpha }, \beta } | j, \tilde { \beta } \rangle _ { \tau } D ( \vec { n } ^ { \prime } ) _ { \tilde { \beta }, l } e ^ { - \pi \gamma l } D ^ { \dagger } ( \vec { n } ) _ { l, \tilde { \alpha } } | j, \tilde { \alpha } \rangle _ { s } ^ { \dagger }. \quad \text{number} [30]. Thus
\text{kerranging factors,}$$
Rearranging factors,
$$\mathbb { 1 }$$
$$& \iota _ {, \tilde { \alpha }, \tilde { \beta } } & & \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \julia \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota\iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ielta \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \uota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \\ & \quad \times e ^ { - \pi \gamma ( k + l ) } _ { j } \delta _ { \alpha, \beta } ^ { 2 } } \sum _ { k, \alpha, \beta } \sum _ { \alpha, \beta } | j, \alpha \rangle \langle j, \alpha \rangle | j, \beta \rangle \langle j, \beta | e ^ { - 2 \pi k } \\ & \quad \times e ^ { - \pi \gamma ( k + l ) } _ { k, \alpha, \beta } } \sum _ { k, \alpha, \beta } | j, \alpha \rangle \langle j, \alpha \rangle | \rangle, \beta \rangle \langle j, \beta | e ^ { - 2 \pi k } \\ & \quad \times \sum _ { \alpha } | j, \alpha \rangle \langle j, \alpha | \times \sum _ { \beta } | j, \beta \rangle \langle j, \beta | \times \frac { \sum _ { k } e ^ { - 2 \pi k } } { \sum _ { k } e ^ { - 2 \pi k } } } & \quad \text{$\interaction$ have} \\ & \quad = \mathbb { I } _ { s } \otimes \mathbb { I } _ { \tau } & & ( A 2 ) & & ( L ^ { i } \\ \text{which is the identity in $\mathcal{H}_{j} \otimes \mathcal{H}_{j}^{*}$}. & & = \\ & & k _ { 1, i }, \end{matrix}$$
which is the identity in H ⊗H j ∗ j .
## Appendix B: Node observables
To study correlations we need an observable to probe them. A good example of observable is the scalar product ( glyph[vector] L ( a ) · glyph[vector] L ( b ) ) A (where a and b are two links that meet at the node A ). Its geometrical interpretation is a measure
FIG. 3. Thetrahedron cell dual to the node A. The two links l a and l b meet at the node A . The observable given by the scalar product ( glyph[vector] L ( a ) · glyph[vector] L ( b ) ) A is a measure of the dihedral angle (shaded above) between the two facets of the cell A .
of the dihedral angle between the two facets of the cell A . Recall that the area of these facets is | L a | and | L b | . Here we assume for simplicity that all nodes are four-valent. See Figure 3.
This observable is diagonal in the appropriate recoupling basis, | ι α 〉 ≡ {| j 1 · · · j 4 , ι α 〉} , labelled by the spin number α of the 'virtual link' associated to the node [30]. This can be seen explicitly by looking at the operator ( glyph[vector] L ( a ) + glyph[vector] L ( b ) ) 2 first: consider the explicit form of the intertwiner state
$$| \iota _ { \alpha } \rangle & = | j _ { 1 } \cdots j _ { 4 }, \iota _ { \alpha } \rangle = & ( B 1 ) \\ & = \sum _ { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } } \iota _ { \alpha } ^ { k _ { 1 } k _ { 2 } k _ { 3 } k _ { 4 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle \\ \tilde { \beta }, \iota _ { \alpha } & = \sum _ { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } } \iota _ { ^ { k _ { 1 } k _ { 2 } m } } ^ { k _ { 1 } k _ { 2 } m } \iota _ { ^ { k _ { 3 } k _ { 4 } } } ^ { k _ { 1 } k _ { 1 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle. \\. &. &. &. &. \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \rightharpoonup \langle \rangle \rangle \rangle \rangle.$$
Acting with the operator ( glyph[vector] L ( a ) + glyph[vector] L ( b ) ), where a = 1 , b = 2 we have
$$( L ^ { i ( 1 ) } & + L ^ { i ( 2 ) } ) | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle = [ J ^ { i ( j _ { 1 } ) } + J ^ { i ( j _ { 2 } ) } ] | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle \\ \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
where J i are the generators of SU (2) in the rapresentation j . If we now use this for the full state (B1), we have
$$( A 2 ) \quad & ( L ^ { i \, ( 1 ) } + L ^ { i \, ( 2 ) } ) | \iota _ { \alpha } \rangle = & & ( B 3 ) \\ & = \sum _ { \substack { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } \\ m \\ \times | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | \iota _ { \alpha } | | } }$$
$$& \kappa _ { 1 }, \kappa _ { 2 }, \kappa _ { 3 }, \kappa _ { 4 } \\ & \quad \times | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle \\ & = \sum _ { \substack { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } \\ m, \bar { m } } } \iota ^ { k _ { 1 } k _ { 2 } } _ { \, m } [ - J ^ { i ( \alpha ) } ] \iota ^ { m k _ { 3 } k _ { 4 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle \\ \text{probe} \\ & \text{et at asure} \\ & \text{user} \\ & \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\rangle$$
where we used the definition of the intertwiner, D ( j 1 ) m n 1 1 D ( j 2 ) m n 2 2 D ( j 1 ) m n 3 3 ι n n n 1 2 3 = ι m m m 1 2 3 to get
$$& ( J ^ { ( j _ { 1 } ) } + J ^ { ( j _ { 2 } ) } + J ^ { ( j _ { 3 } ) } ) \, \iota ^ { n _ { 1 } n _ { 2 } n _ { 3 } } = 0 \\ \Rightarrow & \, ( J ^ { ( j _ { 1 } ) } + J ^ { ( j _ { 2 } ) } ) \, \iota ^ { n _ { 1 } n _ { 2 } n _ { 3 } } = - J ^ { ( j _ { 3 } ) } \iota ^ { n _ { 1 } n _ { 2 } n _ { 3 } }$$
Finally, applying the same operator a second time, we obtain
$$& ( L ^ { i ( 1 ) } + L ^ { i ( 2 ) } ) ( L ^ { i ( 1 ) } + L ^ { i ( 2 ) } ) | \iota _ { \alpha } \rangle = \\ & = \sum _ { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } } \iota ^ { k _ { 1 } k _ { 2 } } _ { m } [ - J ^ { i ( \alpha ) } ] ^ { 2 } \iota ^ { m k _ { 3 } k _ { 4 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle$$
$$& \langle \mathcal { L } ^ { \ } u \rightarrow \mathcal { L } ^ { \ } u \rangle \langle \mathcal { L } ^ { \ } u \rightarrow \mathcal { L } ^ { \ } u \rangle | \iota \alpha / - \\ & = \sum _ { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } } \iota ^ { k _ { 1 } k _ { 2 } } _ { m } [ - J ^ { i ( \alpha ) } ] ^ { 2 } \iota ^ { m k _ { 3 } k _ { 4 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle \\ & = \alpha ( \alpha + 1 ) \sum _ { k _ { 1 }, k _ { 2 }, k _ { 3 }, k _ { 4 } } \iota ^ { k _ { 1 } k _ { 2 } } _ { m } \iota ^ { m k _ { 3 } k _ { 4 } } | j _ { 1 } k _ { 1 } \rangle | j _ { 2 } k _ { 2 } \rangle | j _ { 3 } k _ { 3 } \rangle | j _ { 4 } k _ { 4 } \rangle \\ & = \alpha ( \alpha + 1 ) | \iota _ { \alpha } \rangle & & \text{Sharin} \\ & \sin e \, [ I ^ { i ( \alpha ) } ] ^ { 2 } \text{ is the Maximizer operator} \quad \text{Analogous} \, \text{with}$$
since [ J i ( α ) ] 2 is the Casimir operator. Analogously, the operator ( L i ( a ) L i ( b ) ) will be diagonal on this basis, as
$$L ^ { i ( 1 ) } \, L ^ { i ( 2 ) } = \frac { 1 } { 2 } [ ( L ^ { i ( 1 ) } + L ^ { i ( 2 ) } ) ^ { 2 } - ( L ^ { i ( 1 ) } ) ^ { 2 } - ( L ^ { i ( 2 ) } ) ^ { 2 } ] \\ _ { \dots \colon \colon \dots \dots \colon \dots \dots \colon \dots } \, \dots$$
with eigenvalues given by
$$C _ { \alpha } = \alpha ( \alpha + 1 ) - j _ { 1 } ( j _ { 1 } + 1 ) - j _ { 2 } ( j _ { 2 } + 1 ). \quad ( B 6 ) \quad \times \sum$$
In the recoupling basis, the operator takes the form
$$L ^ { i ( 1 ) } L ^ { i ( 2 ) } = \sum _ { \alpha } C _ { \alpha } | \iota _ { \alpha } \rangle \langle \iota _ { \alpha } |. \quad \ \ ( B 7 ) \quad \text{wh}$$
## Appendix C: Correlation in dipole graph
Here we show that the correlations between nodes are in fact non vanishing, by providing a detailed example for a simple graph. We consider the dipole graph ∆ : ∗ two four-valent nodes, A and B , sharing four links (Figure 4). We consider two operators acting on the two nodes: ( glyph[vector] L (1) S · glyph[vector] L (2) S ) A and ( glyph[vector] L (3) T · glyph[vector] L (4) T ) B , with glyph[vector] L S and glyph[vector] L T being respectively the left and right invariant vector fields. We want to measure the correlation between the two nodes.
We expand the state in the appropriate recoupling basis, where the chosen operators are diagonal:
$$\bullet \, | \iota _ { \alpha } \rangle \equiv | j _ { 1 }, j _ { 2 }, j _ { 3 }, j _ { 4 } \iota _ { \alpha } \rangle \, \text{s.t.} \quad \iota _ { \alpha } ^ { k 1 k _ { 2 } k _ { 3 } k _ { 4 } } = \iota ^ { k _ { 1 } k _ { 2 } a } \iota _ { a } ^ { k _ { 3 } k _ { 4 } }$$
$$\bullet \, | \iota _ { \beta } \rangle \equiv | j _ { 1 }, j _ { 2 }, j _ { 3 }, j _ { 4 } \iota _ { \beta } \rangle \text{ s.t.} \quad \iota _ { \beta } ^ { k _ { 1 } k _ { 2 } k _ { 3 } k _ { 4 } } = \iota ^ { k _ { 1 } k _ { 2 } b } \iota _ { b } ^ { k _ { 3 } k _ { 4 } } \quad \text{Now} \,.$$
Instead of integrating over the group for each node, we impose the gauge invariance through the projectors
$$P _ { A } = \sum _ { \alpha } | \iota _ { \alpha } \rangle \langle \iota _ { \alpha } | \text{ \ and \ } P _ { B } = \sum _ { \beta } | \iota _ { \beta } \rangle \langle \iota _ { \beta } |. \text{ \ \ (C1) }$$
The non-gauge invariant state is given by
$$& \cots \cots \circ \cots \circ \cots \cots \cots \cots \cots \cots \cots \cots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ & \quad | \tilde { \Psi } _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \\ & \quad = \sum _ { \{ k _ { l } \} } e ^ { - \pi \gamma \sum _ { l } k _ { l } } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } \rangle _ { s } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 } \vec { n } _ { 1 2 3 4 } ^ { \prime } \rangle _ { T } ^ { \dagger }$$
FIG. 4. Dipole graph ∆ : ∗ two four-valent nodes, A and B , sharing four links. We consider two operators acting on the two nodes: ( glyph[vector] L (1) S · glyph[vector] L (2) S ) A and ( glyph[vector] L (3) T · glyph[vector] L (4) T ) B
Projecting with (C1), we get its gauge invariant version
$$& \stackrel { \prime \ 1 } { ( B 5 ) } \quad & | \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \sum _ { \{ k _ { l } \} } e ^ { - \pi \gamma \sum _ { l } k _ { l } } \times \\ & ( B 6 ) \quad & \times \sum _ { \alpha \beta } \phi _ { \alpha } ( j _ { 1 2 3 4 } k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } ) \phi _ { \beta } ^ { * } ( j _ { 1 2 3 4 }, k _ { 1 2 3 4 } \vec { n } _ { 1 2 3 4 } ^ { \prime } ) | \iota _ { \alpha } \rangle | \iota _ { \beta } \rangle ^ { \dagger }$$
where we used the definition:
$$\phi _ { \alpha } ( j _ { 1 2 3 4 } k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } ) & = \langle \iota _ { \alpha } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } \rangle \ ( C 2 ) \\ \phi _ { \beta } ( j _ { 1 2 3 4 }, k _ { 1 2 3 4 } \vec { n } _ { 1 2 3 4 } ^ { \prime } ) & = \langle \iota _ { \beta } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } ^ { \prime } \rangle$$
We can write these coefficients explicitly. Consider first the case in which glyph[vector] n i ≡ glyph[vector] z . In this case we have
$$\langle \iota _ { \alpha } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 } \rangle = \iota _ { \alpha } ^ { k _ { 1 } k _ { 2 } k _ { 3 } k _ { 4 } } \text{ \quad \ \ } ( C 3 )$$
whose components can be calculated using the decomposition of this invariant tensor with { 3 j } symbols. If instead we keep generic directions glyph[vector] n i , we need to take into account a rotation matrix for each link:
$$\langle \iota _ { \alpha } | j _ { 1 2 3 4 }, k _ { 1 2 3 4 }, \vec { n } _ { 1 2 3 4 } \rangle = \sum D ^ { j _ { 1 } } _ { l _ { 1 } k _ { 1 } } ( \vec { n } _ { 1 } ) D ^ { j _ { 2 } } _ { l _ { 2 } k _ { 2 } } ( \vec { n } _ { 2 } ) \times \\ \times D ^ { j _ { 3 } } _ { l _ { 3 } k _ { 3 } } ( \vec { n } _ { 3 } ) D ^ { j _ { 4 } } _ { l _ { 4 } k _ { 4 } } ( \vec { n } _ { 4 } ) \iota _ { \alpha } ^ { l _ { 1 } l _ { 2 } l _ { 3 } l _ { 4 } }$$
Now we can take the expectation value of the operators. We obtain
$$\text{We obtain} \\ & \langle \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } | ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } | \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \\ & = \sum _ { \{ k _ { l } \}, \{ \vec { k } _ { l } \} } e ^ { - \pi \gamma \sum _ { l } ( k _ { l } + \vec { k } _ { l } ) } \times \\ & \quad \times \sum _ { \alpha, \tilde { \alpha } } \phi _ { \alpha } ^ { \{ k _ { l }, \vec { n } _ { l } \} } \phi _ { \tilde { \alpha } } ^ { * \{ \vec { k } _ { l } \, \vec { n } _ { l } \} } \langle \iota _ { \tilde { \alpha } } | ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } | \iota _ { \alpha } \rangle \times \\ & \quad \times \sum _ { \beta, \tilde { \beta } } \phi _ { \beta } ^ { * \{ k _ { l } \, \vec { n } _ { l } ^ { \prime } \} } \phi _ { \tilde { \beta } } ^ { \{ \vec { k } _ { l }, \vec { n } _ { l } ^ { \prime } \} } \langle \iota _ { \tilde { \beta } } | ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } | \iota _ { \beta } \rangle$$
$$= \sum _ { \{ k _ { l } \}, \{ \tilde { k } _ { l } \} } e ^ { - \pi \gamma \sum _ { l } ( k _ { l } + \tilde { k } _ { l } ) } \sum _ { \alpha, \tilde { \alpha } } \phi _ { \alpha } ^ { \{ k _ { l }, \tilde { n } _ { l } \} } \phi _ { \tilde { \beta } } ^ { * } \{ \tilde { k } _ { l }, \tilde { n } _ { l } \} } C _ { \alpha } \delta _ { \alpha, \tilde { \alpha } } \times \quad \text{We} \, v \, \\ \times \sum _ { \beta, \tilde { \beta } } \phi _ { \beta } ^ { * \{ k _ { l }, \tilde { n } _ { l } ^ { \prime } \} } \phi _ { \tilde { \beta } } ^ { \{ \tilde { k } _ { l }, \tilde { n } _ { l } ^ { \prime } \} } C _ { \beta } \delta _ { \beta, \tilde { \beta } } \\ = \sum _ { \{ k _ { l } \}, \{ \tilde { k } _ { l } \} } e ^ { - \pi \gamma \sum _ { l } ( k _ { l } + \tilde { k } _ { l } ) } \sum _ { \alpha, \tilde { \alpha } } \phi _ { \alpha } ^ { \{ k _ { l }, \tilde { n } _ { l } \} } \phi _ { \alpha } ^ { * \{ \tilde { k } _ { l }, \tilde { n } _ { l } \} } C _ { \alpha } \times \\ \times \sum _ { \beta, \tilde { \beta } } \phi _ { \beta } ^ { * \{ k _ { l }, \tilde { n } _ { l } ^ { \prime } \} } \phi _ { \beta } ^ { \{ \tilde { k } _ { l }, \tilde { n } _ { l } ^ { \prime } \} } C _ { \beta } \quad & \quad \text{Since} \, \text{can} \, \\ \text{Similarly},$$
Similarly,
$$\text{omma} y, & \stackrel { \_ } { \langle \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } | } ( \vec { L } ^ { ( 1 ) } _ { \varsigma } \cdot \vec { L } ^ { ( 2 ) } _ { \varsigma } ) _ { A } | \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \\ & = \sum _ { \{ k _ { l } \}, \{ \tilde { k } _ { l } \} } e ^ { - \pi \gamma \sum _ { l } ( k _ { l } + \tilde { k } _ { l } ) } \sum _ { \alpha, \tilde { \alpha } } \phi ^ { \{ k _ { l }, \vec { n } _ { l } \} } _ { \alpha } \phi ^ { * } _ { \alpha } \{ \tilde { k } _ { l }, \vec { n } _ { l } \} } C _ { \alpha } \times \\ & \quad \times \sum _ { \beta, \tilde { \beta } } \phi ^ { * \{ k _ { l }, \vec { n } _ { l } ^ { \prime } \} } _ { \beta } \phi ^ { \{ \tilde { k } _ { l }, \vec { n } _ { l } ^ { \prime } \} } _ { \beta } \\ \text{and}$$
and
$$& \text{and} \\ & \langle \Psi _ { j _ { i }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } | ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } | \Psi _ { j _ { l }, \vec { n } _ { l }, \vec { n } _ { l } ^ { \prime } } \rangle = \\ & \quad = \sum _ { \{ k _ { l } \}, \{ \vec { k } _ { l } \} } e ^ { - \pi \gamma \sum _ { l } ( k _ { l } + \vec { k } _ { l } ) } \sum _ { \alpha, \vec { \alpha } } \phi _ { \alpha } ^ { \{ k _ { l }, \vec { n } _ { l } \} } \phi _ { \alpha } ^ { * \{ \vec { k } _ { l }, \vec { n } _ { l } \} } \times \\ & \quad \times \sum _ { \beta, \vec { \beta } } \phi _ { \beta } ^ { * \{ k _ { l }, \vec { n } _ { l } ^ { \prime } \} } \phi _ { \beta } ^ { \{ \vec { k } _ { l }, \vec { n } _ { l } ^ { \prime } \} } C _ { \beta }.$$
- [1] J. J. Bisognano and E. H. Wichmann, 'On the Duality Condition for Quantum Fields,' J. Math. Phys. 17 (1976) 303-321.
- [2] R. Haag, N. M. Hugenholtz, and M. Winnink, 'On the equilibrium states in quantum statistical mechanics,' Comm. Math. Phys. 5 (1967). 215-236.
- [3] R. Haag, Local Quantum Physics: Fields, Particles, Algebras . Springer, 1996.
- [4] W. G. Unruh, 'Notes on black hole evaporation,' Phys. Rev. D 14 (1976) 870.
- [5] L. Bombelli, R. K. Koul, J. Lee, and R. D. Sorkin, 'Quantum source of entropy for black holes,' Phys. Rev. D 34 (1986) 373-383.
- [6] M. Srdnicki, 'Entropy and Area,' Phys. Rev. Lett. 71 (1993) 666-669.
- [7] T. Jacobson and R. Parentani, 'Horizon entropy,' Found. Phys. 33 (2003) 323-348, arXiv:0302099 .
- [8] S. N. Solodukhin, 'Entanglement entropy of black holes,' Living Rev. Relativity 14 (2011) 8.
- [9] E. Bianchi, 'Black hole entropy from graviton entanglement,' arXiv:1211.0522 .
- [10] E. Bianchi and R. C. Myers, 'On the Architecture of Spacetime Geometry,' arXiv:1212.5183 .
- [11] E. Frodden, A. Ghosh, and A. Perez, 'A local first law for black hole thermodynamics,' arXiv:1110.4055 .
- [12] A. Ashtekar, J. Baez, A. Corichi, and K. Krasnov, 'Quantum geometry and black hole entropy,' Phys. Rev.
We want to prove the following inequivalence
$$\langle ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } \rangle$$
$$\langle ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } \rangle \\ \div & \\ \langle ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } \rangle \langle ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } \rangle.$$
Since we know the explicit form of the coefficients, we can verify this statement in an explicit example. For semplicity, let us fix all j l = 1 2 on the links, so that the / intertwiner basis (recoupling basis) has only two elements {| ι 0 〉 , | ι 1 〉} , and consider glyph[vector] n l = glyph[vector] n ′ l = glyph[vector] z , for each l . We find
$$\langle ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } \rangle = \frac { 5 } { 4 }$$
$$\langle ( \vec { L } _ { s } ^ { ( 1 ) } \cdot \vec { L } _ { s } ^ { ( 2 ) } ) _ { A } \rangle = \langle ( \vec { L } _ { \tau } ^ { ( 3 ) } \cdot \vec { L } _ { \tau } ^ { ( 4 ) } ) _ { B } \rangle = - \frac { 1 } { 2 } \, \quad \ \ ( C 5 )$$
which implies glyph[negationslash]
$$\langle ( \vec { L } ^ { ( 1 ) } _ { s } \cdot \vec { L } ^ { ( 2 ) } _ { s } ) _ { A } ( \vec { L } ^ { ( 3 ) } _ { \tau } \cdot \vec { L } ^ { ( 4 ) } _ { \tau } ) _ { B } \rangle & - & ( \text{C6} ) \\ - & \langle ( \vec { L } ^ { ( 1 ) } _ { s } \cdot \vec { L } ^ { ( 2 ) } _ { s } ) _ { A } \rangle \langle ( \vec { L } ^ { ( 3 ) } _ { \tau } \cdot \vec { L } ^ { ( 4 ) } _ { \tau } ) _ { B } \rangle = \frac { 3 } { 4 } \neq 0$$
The conclusion is that the Bisognano-Wichmann states have correlations between neighbouring nodes.
Lett. 80 (1998) 904-907, arXiv:9710007 .
- [13] E. Bianchi, 'Entropy of Non-Extremal Black Holes from Loop Gravity,' arXiv:1204.5122 .
- [14] E. Frodden, A. Ghosh, and A. Perez, 'Black hole entropy in LQG: Recent developments,' AIP Conf. Proc. 1458 (2011) 100-115.
- [15] J. F. Barbero G., J. Lewandowski, and E. J. S. Villasenor, 'Quantum isolated horizons and black hole entropy,' arXiv:1203.0174 .
- [16] A. Ghosh, K. Noui, and A. Perez, 'Statistics, holography, and black hole entropy in loop quantum gravity,' arXiv:1309.4563 .
- [17] M. Van Raamsdonk, 'Building up spacetime with quantum entanglement,' arXiv:1005.3035 .
- [18] B. Czech, J. L. Karczmarek, F. Nogueira, and M. Van Raamsdonk, 'The Gravity Dual of a Density Matrix,' arXiv:1204.1330 .
- [19] B. Czech, J. L. Karczmarek, F. Nogueira, and M. Van Raamsdonk, 'Rindler Quantum Gravity,' arXiv:1206.1323 .
- [20] G. Chirco, H. M. Haggard, A. Riello, and C. Rovelli, 'Spacetime thermodynamics without hidden degrees of freedom,' arXiv:1401.5262 .
- [21] T. Thiemann, 'Complexifier coherent states for quantum general relativity,' Class. Quant. Grav. 23 (2006) 20632118, arXiv:0206037 .
- [22] E. R. Livine and S. Speziale, 'Physical boundary state
glyph[negationslash]
- for the quantum tetrahedron,' Class. Quant. Grav. 25 (2008) 85003, arXiv:0711.2455 .
- [23] E. Bianchi, E. Magliaro, and C. Perini, 'Coherent spin-networks,' Phys. Rev. D 82 (2010) 24012, arXiv:0912.4054 .
- [24] E. Bianchi, P. Don` a, and S. Speziale, 'Polyhedra in loop quantum gravity,' Phys. Rev. D 83 (2011) 44035, arXiv:1009.3402 .
- [25] A. Ashtekar, Quantum Gravity and Quantum Cosmology , Lecture Notes in Physics . Springer Berlin Heidelberg, Berlin, Heidelberg, (2013).
- [26] L. Freidel and K. Krasnov, 'A New Spin Foam Model for 4d Gravity,' Class. Quant. Grav. 25 (2008) 125018, arXiv:0708.1595 .
- [27] J. Engle, E. Livine, R. Pereira, and C. Rovelli, 'LQG vertex with finite Immirzi parameter,' Nucl. Phys. B 799 (2008) 136-149, arXiv:0711.0146 .
- [28] W. Kaminski, M. Kisielowski, and J. Lewandowski, 'Spin-Foams for All Loop Quantum Gravity,' Class. Quant. Grav. 27 (2010) 95006, arXiv:0909.0939 .
- [29] C. Rovelli, 'Zakopane lectures on loop gravity,' PoS ( QG -QG) (2011) 3, arXiv:1102.3660 .
- [30] C. Rovelli and F. Vidotto, Introduction to covariant loop quantum gravity . Cambridge University Press, to appear., 2015.
- [31] S. Alexandrov and E. R. Livine, 'SU(2) loop quantum gravity seen from covariant theory,' Phys. Rev. D 67 (2003) 44009, arXiv:0209105 .
- [32] M. Dupuis and E. R. Livine, 'Lifting SU(2) Spin Networks to Projected Spin Networks,' Phys. Rev. D 82
(2010) 64044.
- [33] C. Rovelli and S. Speziale, 'Lorentz covariance of loop quantum gravity,' Phys. Rev. D 83 (2011) 104029, arXiv:1012.1739 .
- [34] B. Dittrich and M. Geiller, 'A new vacuum for Loop Quantum Gravity,' arXiv:1401.6441 .
- [35] W. Ruhl, The Lorentz group and harmonic analysis . W.A. Benjamin, Inc, New York, 1970.
- [36] Y. Ding and C. Rovelli, 'The volume operator in covariant quantum gravity,' Class. Quant. Grav. 27 (2010) 165003, arXiv:0911.0543 .
- [37] C. Rovelli, 'What is observable in classical and quantum gravity?,' Class. Quant. Grav. 8 (1991) 297-316.
- [38] W. Donnelly, 'Decomposition of entanglement entropy in lattice gauge theory,' Physical Review D 85 (Apr., 2012) 085004, arXiv:1109.0036 .
- [39] P. Buividovich and M. Polikarpov, 'Entanglement entropy in gauge theories and the holographic principle for electric strings,' Physics Letters B 670 (Dec., 2008) 141145, arXiv:0806.3376 .
- [40] G. Hayward, 'Gravitational action for spacetimes with nonsmooth boundaries,' Physical Review D 47 (Apr., 1993) 3275-3280.
- [41] Y. Neiman, 'Parity and reality properties of the EPRL spinfoam,' Class.Quant.Grav. 29 (2012) 65008, arXiv:1109.3946 .
- [42] E. Bianchi and W. Wieland, 'Horizon energy as the boost boundary term in general relativity and loop gravity,' arXiv:1205.5325 . | 10.1088/0264-9381/32/3/035011 | [
"Goffredo Chirco",
"Carlo Rovelli",
"Paola Ruggiero"
] | 2014-08-01T10:21:18+00:00 | 2017-03-02T10:57:50+00:00 | [
"gr-qc",
"cond-mat.stat-mech",
"hep-th"
] | Thermally correlated states in Loop Quantum Gravity | We study a class of loop-quantum-gravity states characterized by
(ultra-local) thermal correlations that reproduce some features of the
ultraviolet structure of the perturbative quantum field theory vacuum. In
particular, they satisfy an analog of the Bisognano-Wichmann theorem. These
states are peaked on the intrinsic geometry and admit a semiclassical
interpretation. We study how the correlations extend on the spin-network beyond
the ultra local limit. |
1408.0123v1 | ## Optimization of indirect magnetoelectric effect in thin-film/substrate/piezoelectric-actuator heterostructure using polymer substrate
Mouhamadou Gueye, ∗ Fatih Zighem, † and Damien Faurie, Mohamed Belmeguenai and Silvana Mercone LSPM-CNRS, Université Paris XIII, Sorbonne Paris Cité, 93430 Villetaneuse, France (Dated: July 17 th 2014)
Indirect magnetoelectric effect has been studied in magnetostrictive-film/substrate/piezoelectricactuator heterostructures. Two different substrates have been employed: a flexible substrate (Young's modulus of 4 GPa) and a rigid one (Young's modulus of 180 GPa). A clear optimization of the indirect magnetoelectric coupling, studied by micro-strip ferromagnetic resonance, has been highlighted when using the polymer substrate. However, in contrast to the rigid substrate, the flexible substrate also leads to an a priori undesirable and huge uniaxial anisotropy which seems to be related to a non equibiaxial residual stress inside the magnetostrictive film. The 'strong' amplitude of this non equibiaxiallity is due to the large Young's modulus mismatch between the polymer and the magnetostrictive film which leads to a slight curvature along a given direction during the elaboration process and thus to a large magnetoelastic anisotropy.
Prospect of local magnetization control using an electric field or a pure voltage, for low power and ultrafast new electronics has resulted in an amount of new research domains mainly focused on artificial engineered materials[1-4]. Artificial magnetoelectric systems seems to be a promising route for such control. The easiest artificial architecture for a magnetization voltage control in those kinds of materials appears to be the piezoelectric/magnetostrictive bilayers presenting a good strainmediated coupling at the interface [4-12]. However, in these systems, clamping effects due to the substrate limits the strain applicable by the piezoelectric environment to the magnetization and therefore reduces perspective on applications. Indeed, in this kind of bilayers, a significant magnetoelectric coupling is obtained only in the presence of non negligible in-plane stresses in the magnetic media. Therefore, more the elastic strains are transferred at the interfaces of such systems, more this indirect magnetoelectric effect is optimized. Generally, the magnetic thin films are first deposited on a thick substrate ( ∼ hundreds of microns), which is then cemented on a piezoelectric actuator [9, 10, 13, 14]. This process limits the desired phenomenon, especially when the substrate is stiff such as for commonly used wafer (Si, GaAs, ...). This often reported limitation[14] (a few ten percents of losses in best cases) can be avoided by depositing the magnetic thin film on a compliant substrate such as polyimides [10] that are more and more used in flexible spintronics[16].
The present study presents a quantitative comparison of the obtained effective MagnetoElectric (ME) coupling in two different artificial magnetoelectric heterostructures characterized by the presence of a flexible or a rigid substrate between a ferromagnetic film and a piezoelectric actuator. The effective ME coupling will be deduced from in situ MicroStrip FerroMagnetic Resonance (MSFMR). The artificial ME heterostructures are composed
∗ Electronic address: [email protected]
† Electronic address: [email protected]
Figure 1: Schematics of the two studied heterostructures. The only difference comes from the substrate (either flexible (a) or rigid (b)) on which the Ni thin film has been deposited.
of a 200 nm Nickel film deposited by radio frequency sputtering either on a rigid substrate (Silicon of thickness 500 µ m) or on a flexible one (Kapton® of thickness 125 µ m) and then glued onto a piezoelectric actuator as presented on Figure 1. It is worth mentioning that Ni material has been chosen because of its well-known negative effective magnetostriction coefficients at saturation even in a polycrystalline film with no preferred orientations, which is closely the situation for both systems. In this condition, only one magnetostriction coefficient at saturation ( λ ) is sufficient to characterize the magnetoelastic anisotropy. Moreover, the two substrates have been chosen because of their Young's modulus ( ∼ 4 GPa for Kapton® as compared to ∼ 180 GPa for Si).
MS-FMR experiments have been performed at a fixed frequency by sweeping the applied magnetic field from 0 to 3 kOe [15]. The microwave driven frequency was fixed at 8 GHz in all the presented experiments, where the resonance fields are sufficiently higher than the inplane magnetic anisotropies fields present in the structures, avoiding undesirable magnetic and magnetoelastic hysteresis effects. The in situ applied voltage experiments have been done by varying the external voltage from 0V to 100V and back to 0V with step of around 5 V. Figure 2 shows typical MS-FMR spectra for two different applied voltages (0 and 100V). The magnetic field is applied along y direction which corresponds to a
Figure 2: Experimental spectra recorded at 8 GHz for an in-plane magnetic field at 90 degree with respect to the main positive strain axis of the actuator (along y -axis). The largest shift of the resonance is clearly put into evidence for the Ni film deposited onto Kapton®.
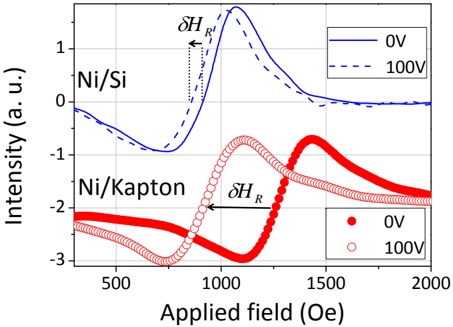
negative induced in-plane strains. Indeed, in the studied range of applied voltage [0-100V], the piezoelectric actuator presents a main positive in-plane strain along x direction ( ε xx > 0 ) and a smaller negative one along y direction ( ε yy < 0 with ε xx ∼ -2 ε yy ) [10]. We observed that in both structures the resonance field decreases as function of the applied voltage. This behavior is consistent with the negative magnetostriction coefficient at saturation of Ni material ( λ < 0 ). Indeed, in first approximation, the magnetoelastic anisotropy can be viewed as a voltage-induced uniaxial magnetoelastic anisotropy field glyph[vector] H ME ( V ) along y direction. Thus, since the in situ MSFMR experiments are performed along y , this y -axis will be easier (when increasing the applied voltage) for the magnetization direction leading to lower values of the resonance field. Figure 2 shows a clear shift of the resonance field δH R (defined as δH R = H R (0) -H R ( V ) ) between 0 V and 100 V for both heterostructures: it is close to 50 Oe for Si substrate and reaches a value around 350 Oe when a flexible substrate is used.
The complete δH R variations as function of the applied voltage are reported in Figure 3 where circles (resp. squares) refer to results obtained for Si (resp. Kapton®) substrate. A non linear and hysteretic variation is put into evidence when using Kapton® as a substrate whereas an almost linear dependence is found in the second structure indicating a difference of the strain transmission efficiency. This non linear and hysteretic behavior is due to the intrinsic properties of the ferroelectric material used during piezoelectric actuator fabrication [10]. However, in first approximation, if this non linear and hysteretic variation of δH R is neglected and adjusted by a linear fit, an effective magnetoelectric coupling α ME (in V.cm -1 .Oe -1 being given the width of the piezoelectric actuator ( 0 7 . cm)) can be estimated. The linear adjustments to the experimental data are presented in
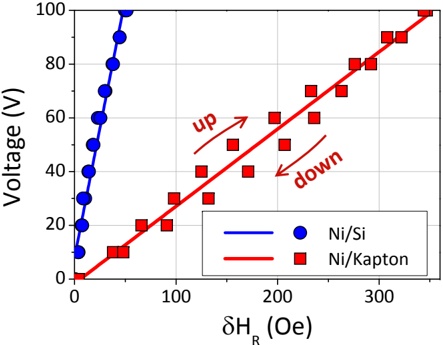
R
Figure 3: Resonance field shift ( δH R ) variations as function of the applied voltage for the two studied heterostructures. The lines correspond to linear fits of the experimental data. Arrows refer to up and down applied voltage sweeps (0 V to 100 V and 100 V to 0 V, respectively).
Figure 3. A strong magnetoelectric coupling is found for the Ni/Kapton®/Piezoelectric system with an effective magnetoelectric coefficient α ME ∼ 0 2 . V.cm -1 .Oe -1 . Interestingly, in the case of the Ni/Si/Piezoelectric system, it can be conclude that the magnetoelectric coupling is roughly seven times less efficient because of its higher magnetoelectric coefficient value ( α ME ∼ 1 35 . V.cm -1 .Oe -1 ). The relatively weak coupling found in the second system is due to a weaker transmission of the in-plane elastic stresses. The strain loss of a factor of almost 7 cannot be explained only by the stiffness of Silicon but also by the often reported imperfection of cementation of the epoxy glue[14]. Obviously these imperfections are insignificant when the substrate is highly stretchable like polymers.
However, depositing a magnetic thin film on a flexible substrate can lead to an a priori undesirable effects related to its possible anisotropic non-flatness during elaboration process. Moreover, because of the large contrast between the polymer and the Ni Young's modulus ( ∼ 4 GPa and ∼ 200 GPa, respectively), a more or less pronounced additional curvature due to growth stress develops during film deposition. These phenomenona lead to a stress state in the magnetic film with a possible in-plane non-equibiaxiallity[17]. This behavior is illustrated in Figure 4 showing in-plane angular dependencies (thereafter ϕ H is the angle between the in-plane applied magnetic field and x -axis) of the resonance field of the as-deposited structures. A huge uniaxial anisotropy (anisotropy field close to 300 Oe) characterized by a horizontal peanut shape of the resonance field variation is observed when the Ni film grown on Kapton® whereas a very weak one (anisotropy field around 30 Oe) is found when using the Si substrate. Since the present Ni films are polycrystalline with no preferential crystallographic
Figure 4: In-plane angular dependence of the resonance field at zero applied voltage for the two studied systems. Symbols refer to experimental data while lines are best fits to the experimental data by using equations 2 and 3. These fits allow an evaluation of the in-plane nonequibiaxial stress: ∣ ∣ σ residual xx -σ residual yy ∣ ∣ = 200 MPa and ∣ ∣ σ residual xx -σ residual yy ∣ ∣ = 15 MPa for the structures with a rigid and flexible substrate, respectively.
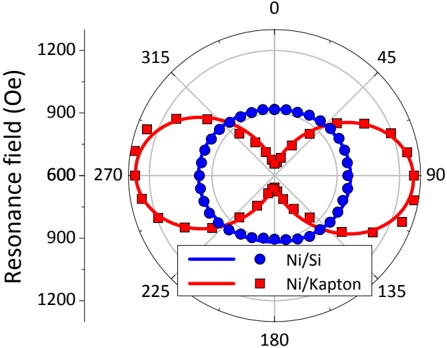
orientations, no in-plane macroscopic magnetocrystalline effects are expected in both cases. Thus this uniaxial anisotropy should have a magnetoelastic origin. The influence of the residual stresses on the magnetic properties of the as deposited films can be modeled using an isotropic magnetoelastic anisotropy energy term F ME :
$$F _ { M E } = - \frac { 3 } { 2 } \lambda \left ( \left ( \gamma _ { x } ^ { 2 } - \frac { 1 } { 3 } \right ) \sigma _ { x x } ^ { r e s i d u a l } + \left ( \gamma _ { y } ^ { 2 } - \frac { 1 } { 3 } \right ) \sigma _ { y y } ^ { r e s i d u a l } \right ) \begin{array} { c c } \text{the main} \\ \text{toelect} \\ \text{(1)} \\ \text{actuat} \\ \end{array} \text{,\quad\ } \text{$\text{$\text{$the main}_{\text{$the in}_{\text{$line}$ in}$}$}$} \cdot \end{array}$$
σ residual xx and σ residual yy being the in-plane principal residual stress tensor components while γ x and γ y correspond to the direction cosines of the in-plane magnetization. In this condition the resonance field expression can be written as H R = H 1 + H 2 with:
$$H _ { 1 } & = \left [ \left ( 2 \pi M _ { s } + \frac { 3 \lambda } { 2 M _ { S } } \left ( \sigma _ { x x } ^ { r e s i d u a l } \sin ^ { 2 } \varphi _ { H } & \quad \text{the two} \\ & + \sigma _ { y y } ^ { r e s i d u a l } \cos ^ { 2 } \varphi _ { H } \right ) \right ) ^ { 2 } + \left ( \frac { 2 \pi f } { \gamma } \right ) ^ { 2 } \right ] ^ { 0. 5 } - 2 \pi M _ { S } & \quad ( 2 ) & \quad \text{plicat}$$
$$H _ { 2 } = - \frac { 3 \lambda } { 4 M _ { S } } \left [ \sigma _ { x x } ^ { r e s i d u a l } ( 1 + 3 \cos 2 \varphi _ { H } )$$
$$\underset { \tau } { r e s i d u a l } & ( 1 + 3 \cos 2 \varphi _ { H } ) \\ & + \sigma _ { y y } ^ { r e s i d u a l } ( 1 - 3 \cos 2 \varphi _ { H } ) \Big | \quad ( 3 ) \quad \text{fi}$$
In the above expressions H 1 essentially represents a constant shift in the resonance field baseline because glyph[negationslash]
2 πM S ( M S being the saturation magnetization) and 2 πf γ ( γ is the gyromagnetic factor) are found to be larger than the equivalent magnetoelastic anisotropy field. The influence of in-plane residual stresses on the magnetic properties is included in H 2 term. It should be noted that this expression is obtained in the assumption of a uniform magnetization (macrospin approximation) aligned along the applied magnetic field. This assumption is well fulfilled at the 8 GHz driven frequency chosen for this study. It clearly appears that an equibiaxial residual stress ( σ residual xx = σ residual yy ) leads to an isotropic variation of the resonance field with a slight increase or decrease of the mean value depending on the sign of the residual stress. However, a non equibiaxial residual stress ( σ residual xx = σ residual yy ) leads to an anisotropic angular variation of the resonance field. Thanks to this model, the experimental angular variations of the resonance field have been fitted (see continuous lines in Figure 4) by using usual Ni material magnetic parameters: M S = 480 emu.cm -3 , γ = 1 885 . × 10 7 Hz.Oe -1 and λ = -26 × 10 -6 [10]. The deduced nonequibiaxiallity is ∣ ∣ σ residual xx -σ residual yy ∣ ∣ = 200 MPa and ∣ ∣ σ residual xx -σ residual yy ∣ ∣ = 15 MPa for the Ni film deposited onto flexible and rigid substrate, respectively. These results show that MS-FMR experiments can also be used for the determination of the non-equibiaxial residual stress in magnetostrictive films. It should be noted here that this kind of knowledge is not straightforward to get with standard techniques (sample deflection, X-ray diffraction), for which an equibiaxial stress state is generally assumed. Indeed, this parameter cannot be neglected since it determines the initial magnetization direction in the magnetic thin film being considered.
In conclusion, an optimization of the indirect magnetoelectric coupling in thin-film/substrate/piezoelectricactuator heterostructure has been performed by employing a polymer as a substrate. This optimization is due to a better strain transmission between the piezoelectric actuator and the Ni film which is due to the weak Young's modulus of the Kapton®. Furthermore, at zero applied voltage, a huge magnetoelastic anisotropy is evidenced in the Ni/Kapton®/Piezoelectric system. It is attributed to a 'residual' non-equibiaxial stress state due to a slight curvature along a given direction which generally appears when depositing a metallic film onto a flexible substrate. However, this effect could be a limitation for some applications where weak in-plane magnetic anisotropies are required.
## Acknowledgments
The authors gratefully acknowledge the CNRS for his financial support through the 'PEPS INSIS' program (FERROFLEX project). This work has been also partially supported by the Université Paris XIII through a 'Bonus Qualité Recherche' project.
- [1] Jing Ma , Jiamian Hu , Zheng Li and Ce-Wen Nan, Adv. Mater. 23 , 1062 (2011)
- [3] Pedro Martins and Senentxu Lanceros-Méndez, Adv. Funct. Mater., 23 , 3371 (2013)
- [2] Carlos A. F. Vaz , Jason Hoffman , Charles H. Ahn and Ramamoorthy Ramesh, Adv. Mater., 22 , 2900 (2010)
- [4] N. Lei, S. Park, P. Lecoeur, D. Ravelosona and Claude Chappert, Phys. Rev B 84 , 012404 (2011)
- [6] J. Lou, M. Liu, D. Reed, Y. Ren, and N. X. Sun, Adv. Mater. 21 , 4711 (2009)
- [5] M. Liu, O. Obi, Z. Cai, J. Lou, G. Yang, K. S. Ziemerand N. X. Sun, J. Appl. Phys. 107 , 073916 (2010)
- [7] Z. Wang, R. Viswan, B. Hu, J.-F. Li, V. G. Harris and D. Viehland, J. Appl. Phys. 111 , 034108 (2012)
- [9] C. Pettiford, J. Lou, L. Russell, and N. X. Sun, App. Phys. Lett. 92 , 122506 (2008)
- [8] Z. Li, J. Hu, L. Shu, Y. Gao, Y. Shen, Y. Lin and C. W. Nan , J. Appl. Phys. 111 , 033918 (2012)
- [10] F. Zighem, D. Faurie, S. Mercone, M. Belmeguenai and H. Haddadi, J. Appl. Phys. 114 , 073902 (2013)
- [11] M. Weiler, A. Brandlmaier, S. Geprägs, M. Althammer, M. Opel, C. Bihler, H. Huebl, M. S. Brandt, R.
- Grossand S. T. B. Goennenwein, New Journal of Physics 11, 013021 (2009)
- [13] C. Bihler, M. Althammer, A. Brandlmaier, S. Geprägs, M. Weiler, M. Opel, W. Schoch, W. Limmer, R. Gross, M. S. Brandt and S. T. B. Goennenwein, Phys. Rev. B 78 , 045203 (2008)
- [12] A. Brandlmaier, S. Geprägs, G. Woltersdorf, R. Gross and S. T. B. Goennenwein, J. Appl. Phys., 110 , 043913 (2011)
- [14] A. Brandlmaier, S. Geprägs, M. Weiler, A. Boger, M. Opel, H. Huebl, C. Bihler, M. S. Brandt, B. Botters, D. Grundler, R. Gross and S. T. B. Goennenwein, Phys. Rev. B 77 , 104445 (2008)
- [16] Amilcar Bedoya-Pinto, Marco Donolato, Marco Gobbi, Luis E. Hueso and Paolo Vavassori, App. Phys. Lett. 104 , 062412 (2014)
- [15] M. Belmeguenai, H. Tuzcuoglu, M. S. Gabor, T. Petrisor, Jr., C. Tiusan, D. Berling, F. Zighem, T. Chauveau, S. M. Ch!erif, and P. Moch, Phys. Rev. B 87 , 184431 (2013)
- [17] X. Zhang, Q. Zhan, G. Dai, Y. Liu, Z. Zuo, H. Yang, B. Chen, and R.-W. Li, J. Appl. Phys. 113 , 17A901 (2013) | 10.1063/1.4892579 | [
"Mouhamadou Gueye",
"Fatih Zighem",
"Damien Faurie",
"Mohamed Belmeguenai",
"Silvana Mercone"
] | 2014-08-01T10:31:42+00:00 | 2014-08-01T10:31:42+00:00 | [
"cond-mat.mtrl-sci"
] | Optimization of indirect magnetoelectric effect in thin-film/substrate/piezoelectric-actuator heterostructure using polymer substrate | Indirect magnetoelectric effect has been studied in
magnetostrictive-film/substrate/piezoelectric-actuator heterostructures. Two
different substrates have been employed: a flexible substrate (Young's modulus
of 4 GPa) and a rigid one (Young's modulus of 180 GPa). A clear optimization of
the indirect magnetoelectric coupling, studied by micro-strip ferromagnetic
resonance, has been highlighted when using the polymer substrate. However, in
contrast to the rigid substrate, the flexible substrate also leads to an a
priori undesirable and huge uniaxial anisotropy which seems to be related to a
non equibiaxial residual stress inside the magnetostrictive film. The strong
amplitude of this non equibiaxiallity is due to the large Young's modulus
mismatch between the polymer and the magnetostrictive film which leads to a
slight curvature along a given direction during the elaboration process and
thus to a large magnetoelastic anisotropy. |
1408.0124v1 | ## Mixed Gated/Exhaustive Service in a Polling Model with Priorities ∗
M.A.A. Boon †
[email protected]
I.J.B.F. Adan †
[email protected]
February, 2009
## Abstract
In this paper we consider a single-server polling system with switch-over times. We introduce a new service discipline, mixed gated/exhaustive service, that can be used for queues with two types of customers: high and low priority customers. At the beginning of a visit of the server to such a queue, a gate is set behind all customers. High priority customers receive priority in the sense that they are always served before any low priority customers. But high priority customers have a second advantage over low priority customers. Low priority customers are served according to the gated service discipline, i.e. only customers standing in front of the gate are served during this visit. In contrast, high priority customers arriving during the visit period of the queue are allowed to pass the gate and all low priority customers before the gate.
We study the cycle time distribution, the waiting time distributions for each customer type, the joint queue length distribution of all priority classes at all queues at polling epochs, and the steady-state marginal queue length distributions for each customer type. Through numerical examples we illustrate that the mixed gated/exhaustive service discipline can significantly decrease waiting times of high priority jobs. In many cases there is a minimal negative impact on the waiting times of low priority customers but, remarkably, it turns out that in polling systems with larger switch-over times there can be even a positive impact on the waiting times of low priority customers.
Keywords: Polling, priority levels, queue lengths, waiting times, mixed gated/exhaustive
## 1 Introduction
There are three ways in which one can introduce prioritisation into a polling model. The first type of priority is by changing the server routing such that certain queues are visited more frequently than other queues [6, 19]. This type of prioritisation is quite common in wireless network protocols. A second type of prioritisation is through differentiation of the number of customers that are served during each visit to a queue. This type of prioritisation is inflicted
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-FGI.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
through the usage of different service disciplines. For example, one can serve all customers in a queue before switching to the next queue (exhaustive service), or one can limit the amount of customers that are served to, e.g., only those customers present at the arrival of the server at the queue (gated service). Typically, this will have a negative impact on the waiting times of the customers in queues that are not served exhaustively. The third way of introducing priorities is by changing the order in which customers are served within a queue, which is a popular technique to improve performance of production systems, cf. [2, 22]. The present paper introduces a new service discipline, referred to as mixed gated/exhaustive service, that combines the last two types of prioritisation.
In the polling model considered in the present paper a single server visits N queues in a fixed, cyclic order. Some, or even all, of the queues contain two types of customers: high and low priority customers. For these queues we introduce a new service discipline, called mixed gated/exhaustive service based on the priority level of the customer. A polling system with high and low priority customers in a queue with purely gated or exhaustive service has been studied in [1, 2]. The mixed gated/exhaustive service discipline can be considered as a mixture of these two service disciplines where low priority customers receive gated service and high priority customers receive exhaustive service. A more detailed description is given in Section 2. Since the number of customers served during one visit in a queue with gated service is different from the number served during a visit with exhaustive service, the mixed gated/exhaustive service discipline introduced in the present paper combines the second and the third type of prioritisation. Avariation of the model under consideration, namely a polling system where low priority customers are served only if there are no high priority customers present in any of the queues , has been studied in [12].
Polling models have been studied for many years and because of their practical relevance many papers on polling systems have been written in a mixture of application areas. The survey of Takagi [21] on polling systems and their applications from 1991 is still very valuable, although the last couple of years interest in polling models has revived, partly triggered by many new applications. The motivation for the present paper is to present a service discipline that combines the benefits of the gated and exhaustive service disciplines for priority polling models. The specific application that attracted our attention is in the field of logistics. Consider a make-to-order production system with a single production capacity for multiple products. In many firms encountering this situation, the products are produced according to a fixed production sequence. The production capacity, where the production orders queue up, can be represented as a polling model by identifying each product with a queue and the demand process of a product with the arrival process at the corresponding queue. For a more detailed description of fixed-sequence strategies in the context of make-to-stock production situations, see [23]. In the context of this production setting, the situation with two or more priority levels - as studied in detail in the present paper - is oftentimes encountered in practice, where production departments have to supply both internal and external customers, the latter of which is commonly given a preferential treatment. A different application stems from production scheduling in flexible manufacturing systems where part types are often grouped with other types sharing (almost) similar characteristics, such that no change of machine configuration, i.e. setup time, is required when switching between these part types (see, e.g., [17]). Since no setup time is required to switch between these types, it can be seen as customers of different types being served in the same queue. The introduction of priorities can be useful to efficiently differentiate between different parts grouped within one queue.
These two applications make the practical relevance of the inclusion of multiple priority levels in the studied polling model evident. Finally, we should keep in the back of our mind that the results of the present paper are certainly not limited to these production settings, but may be used in many other fields where polling models arise, such as communication, transportation and health care (e.g., surgery procedures where an urgency parameter is assigned to each patient).
The present paper is structured as follows: first we discuss the model in more detail and we determine the generating functions (GFs) of the joint queue length distribution of all customers at visit beginnings and completions of each queue. In Section 4 we determine the Laplace-Stieltjes Transforms (LSTs) of the distributions of the cycle time, visit times and intervisit times. These distributions are used to determine the marginal queue length distributions and waiting time distributions of high and low priority customers in all queues. The LST of the waiting time distribution is used to compute the mean waiting time of each customer type. A pseudo-conservation law for these mean waiting times is presented in Section 7. Furthermore, we introduce some numerical examples to illustrate typical features of a polling model with mixed gated/exhaustive service. Finally we discuss possible extensions and future research on the topic.
## 2 Notation and model description
The model considered in the present paper is a polling model which consists of N queues, labelled Q , . . . , Q 1 N . Throughout the whole paper all indices are modulo N , so Q N +1 stands for Q 1 . The queues are visited by one server in a fixed, cyclic order: 1 2 , , . . . , N, 1 2 , , . . . . The switch-over time of the server from Q i to Q i +1 is denoted by S i with LST σ i ( ). · We assume that all switch-over times are independent and at least one switch-over time is strictly greater than zero. Each queue contains two customer types: high and low priority customers, although the analysis allows any number (greater than zero) of customer types per queue. High priority customers in Q i are called type iH customers and low priority customers in Q i are called iL customers, i = 1 , . . . , N . Type iH customers arrive at Q i according to a Poisson process with intensity λ iH , and type iL customers arrive at Q i according to a Poisson process with intensity λ iL . The service times of type iH and iL customers are denoted by B iH and B iL , with LSTs β iH ( ) and · β iL ( ). · All service times are assumed to be independent. We introduce the notation ρ iH = λ iH E B ( iH ) and similarly ρ iL = λ iL E B ( iL ). The total occupation rate of the system is ρ = ∑ N i =1 ρ i , where ρ i = ρ iH + ρ iL is the fraction of time that the server visits Q i . Service of the customers is gated for low priority customers and exhaustive for high priority customers. In more detail: each queue actually contains two lines of waiting customers: one for the low priority customers and one for the high priority customers. At the beginning of a visit to Q i , a gate is set behind the low priority customers to mark them eligible for service. High priority customers are always served exhaustively until no high priority customer is present. When no high priority customers are present in the queue, the low priority customers standing in front of the gate are served in order of arrival, but whenever a high priority customer enters the queue, he is served before any waiting low priority customers. Service is non-preemptive though, implying that service of a type iL customer is not interrupted by an arriving type iH customer. The visit to Q i ends when all type iL customers present at the beginning of this visit are served and no high
priority customers are present in the queue. Notice that if the arrival intensity λ iH equals 0, then Q i is served completely according to the gated service discipline. Similarly we can set λ iL = 0 to obtain a purely exhaustively served queue. Both the gated and the exhaustive service discipline fall into the category of branching-type service disciplines. These are service disciplines that satisfy the following property, introduced by Resing [16] and Fuhrmann [10].
Property 2.1 If the server arrives at Q i to find k i customers there, then during the course of the server's visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having probability generating function h i ( z , . . . , z 1 N ), which can be any N -dimensional probability generating function.
glyph[negationslash]
If Q i receives gated service, we have h i ( z , . . . , z 1 N ) = β i ( ∑ N j =1 λ j (1 -z j ) ) , where β i ( ) · denotes the service time LST of an arbitrary customer in Q i , and λ i denotes his arrival rate. For exhaustive service h i ( z , . . . , z 1 N ) = π i ( ∑ j = i λ j (1 -z j ) ) , where π i ( ) is the LST of a busy · period distribution in an M/G/ 1 system with only type i customers, so it is the root in (0 , 1] of the equation π i ( ω ) = β i ( ω + λ i (1 -π i ( ω ))), ω ≥ 0 (cf. [7], p. 250).
Property 2.1 is not satisfied if Q i receives mixed gated/exhaustive service, because the random population that replaces each of these customers depends on the priority level. In the next section we circumvent this problem by splitting each queue into two virtual queues, each of which has a branching-type service discipline. This equivalent polling system satisfies Property 2.1, so we can still use the methodology described in [16] to find, e.g., the joint queue length distribution at visit beginnings and completions. All other probability distributions that are derived in the present paper can be expressed in terms of (one of) these joint queue length distributions.
## 3 Joint queue length distribution at polling epochs
In the present section we analyse a polling system with all queues having two priority levels and receiving mixed gated/exhaustive service, but in fact each queue would be allowed to have any branching-type service discipline. Denote the GF of the joint queue length distribution of type 1 H, 1 L, . . . , N H, NL customers at the beginning and the completion of a visit to Q i by respectively V b i ( z 1 H , z 1 L , . . . , z NH , z NL ) and V c i ( z 1 H , z 1 L , . . . , z NH , z NL ). As discussed in the previous section, the polling model under consideration does not satisfy Property 2.1, which often means that an exact analysis is difficult or even impossible. For this reason we introduce a different polling system that does satisfy Property 2.1 and has the same joint queue length distribution at visit beginnings and endings. The equivalent system contains 2 N queues, denoted by Q 1 H ∗ , Q 1 L ∗ , . . . , Q NH ∗ , Q NL ∗ . The switch-over times S i , i = 1 , . . . , N , are incurred when the server switches from Q iL ∗ to Q ( +1) i H ∗ ; there are no switch-over times between Q iH ∗ and Q iL ∗ . Customers in this system are so-called 'smart customers', introduced in [4], meaning that the arrival rate of each customer type depends on the location of the server. Type iH ∗ customers arrive in Q iH ∗ according to arrival rate λ iH unless the server is serving Q iL ∗ . When the server is serving Q iL ∗ , the arrival rate of type iH ∗ customers is 0. The reason for this is that we incorporate the service times of all type iH customers that would have arrived during the service of a type iL customer, in the original polling model, into the service time of a type iL ∗ customer. In our alternative system, type iL ∗ customers arrive with
intensity λ iL and have service requirement B ∗ iL with LST β ∗ iL ( ). · There is a simple relation between B iL and B ∗ iL , expressed in terms of the LST:
$$\beta _ { i L } ^ { * } ( \omega ) = \beta _ { i L } ( \omega + \lambda _ { i H } ( 1 - \pi _ { i H } ( \omega ) ) ).$$
B ∗ iL is often called completion time in the literature, cf. [20], with mean E B ( ∗ iL ) = E B ( iL ) 1 -ρ iH . Service is exhaustive for Q 1 H ∗ , Q 2 H ∗ , . . . , Q NH ∗ and synchronised gated for Q 1 L ∗ , Q 2 L ∗ , . . . , Q NL ∗ , the gate of Q iL ∗ being set at the visit beginning of Q iH ∗ . The synchronised gated service discipline is introduced in [15] and does not strictly satisfy Property 2.1. However, it does satisfy a slightly modified version of Property 2.1 that still allows for straightforward analysis; see [3] for more details. During a visit to Q iL ∗ only those type iL ∗ customers are served that were present at the previous visit beginning to Q iH ∗ . The joint queue length distribution at a visit beginning of Q iH ∗ in this system is the same as the joint queue length distribution at a visit beginning of Q i in the original polling system. Similarly, the joint queue length distribution at a visit completion of Q iL ∗ is the same as the joint queue length distribution at a visit completion of Q i in the original polling system. In terms of the GFs:
$$V _ { b _ { i } } ( \mathbf z ) = V _ { b _ { i H ^ { * } } } ( \mathbf z ),$$
$$V _ { c _ { i } } ( { \mathbf z } ) = V _ { c _ { i L ^ { * } } } ( { \mathbf z } ),$$
$$\stackrel { \int _ { b _ { i H } * } ( z ) } { \int _ { c _ { i L } * } ( z ) },$$
where z is a shorthand notation for the vector ( z 1 H , z 1 L , . . . , z NH , z NL ). The GFs of the joint queue length distributions at a visit beginning and completion of Q iH ∗ are related in the following manner:
$$V _ { c _ { i H ^ { * } } } ( \mathbf z ) = V _ { b _ { i H ^ { * } } } ( z _ { 1 H }, z _ { 1 L }, \dots, h _ { i H } ( \mathbf z ), z _ { i L }, \dots, z _ { N H }, z _ { N L } ),$$
glyph[negationslash]
$$\text{with } h _ { i H } ( \mathbf z ) = \pi _ { i H } \left ( \lambda _ { i L } ( 1 - z _ { i L } ) + \sum _ { j \neq i } ( \lambda _ { j H } ( 1 - z _ { j H } ) + \lambda _ { j L } ( 1 - z _ { j L } ) ) \right ). \text{ Similarly} \text{:}$$
$$V _ { c _ { i L ^ { * } } } ( \mathbf z ) = V _ { b _ { i H ^ { * } } } \left ( z _ { 1 H }, z _ { 1 L }, \dots, h _ { i H } ( \mathbf z ), h _ { i L } ( \mathbf z ), \dots, z _ { N H }, z _ { N L } \right ),$$
glyph[negationslash]
where h iL ( z ) = β ∗ iL ( λ iL (1 -z iL ) + ∑ j = i ( λ jH (1 -z jH ) + λ jL (1 -z jL )) ) . Note that V c iH ∗ ( ) = · V b iL ∗ ( ) · since there is no switch-over time between Q iH ∗ and Q iL ∗ . There is a switch-over time between Q iL ∗ and Q ( +1) i H ∗ though:
$$V _ { b _ { ( i + 1 ) H ^ { * } } } ( { \mathbf z } ) = V _ { c _ { i L ^ { * } } } ( { \mathbf z } ) \sigma _ { i } \left ( \sum _ { j = 1 } ^ { N } ( \lambda _ { j H } ( 1 - z _ { j H } ) + \lambda _ { j L } ( 1 - z _ { j L } ) ) \right ).$$
Now that we can relate V b ( +1) i H ∗ ( ) to · V b iH ∗ ( ), we can repeat these steps · N times to obtain a recursive expression for V b iH ∗ ( ). · This recursive expression is sufficient to compute all moments of the joint queue length distribution at a visit beginning to Q iH ∗ by differentiation, but the expression can also be written as an infinite product which converges if and only if ρ < 1. We refer to [16] for more details.
## 4 Cycle time, visit time and intervisit time
We define the cycle time C i as the time between two successive visit beginnings to Q i , i = 1 , . . . , N . The LST of the distribution of C i , denoted by γ i ( ), · can be expressed in terms
of V b i ( ) · because the type iL customers that are present at the beginning of a visit to Q i are those type iL customers that have arrived during the previous cycle. It is convenient to introduce the notation ˜ V b i ( z iH , z iL ) = V b i (1 , . . . , 1 , z iH , z iL , 1 , . . . , 1), where z iH and z iL are the arguments that correspond respectively to type iH and iL customers. Using this notation we can write: ˜ V b i (1 , z ) = γ i ( λ iL (1 -z )). Hence, the LST of the cycle time distribution is:
$$\gamma _ { i } ( \omega ) = \widetilde { V } _ { b _ { i } } ( 1, 1 - \frac { \omega } { \lambda _ { i L } } ).$$
Note that E C ( i ) = E S ( 1 )+ ··· + E S ( N ) 1 -ρ , which does not depend on i . Higher moments of the cycle time distribution do depend on the cycle starting point.
We define the intervisit time I i as the time between a visit completion of Q i and the next visit beginning of Q i . The type iH customers present at the beginning of a visit to Q i are exactly those type iH customers that arrived during the previous intervisit time I i . Hence, ˜ V b i ( z, 1) = ˜ I i ( λ iH (1 -z )), where ˜ I ( ) · is the LST of the distribution of I i . This leads to the following expression for the LST of the intervisit time distribution of Q i :
$$\widetilde { I } _ { i } ( \omega ) = \widetilde { V } _ { b _ { i } } ( 1 - \frac { \omega } { \lambda _ { i H } }, 1 ).$$
It is intuitively clear that E I ( i ) = (1 -ρ i ) E C ( ).
The LSTs of the distributions of the cycle time and intervisit time are needed later in this paper. For the visit time of Q i , V i , we mention the LST here for completeness but it will not be used later:
$$E ( \mathrm e ^ { - \omega V _ { i } } ) = \widetilde { V } _ { b _ { i } } ( \pi _ { i H } ( \omega ), \beta _ { i L } ^ { * } ( \omega ) ).$$
It is easy to verify that E V ( i ) = ρ E C i ( ).
## 5 Waiting times and marginal queue lengths
## 5.1 High priority customers
Since high priority customers are served exhaustively, we can use the concept of delay-cycles, sometimes called T -cycles (cf. [21]), introduced by Kella and Yechiali [14] for vacation models to find the waiting time LST of a type iH customer, where waiting time is understood as the time between arrival of a customer into the system and the moment when the customer is taken into service. The waiting time plus service time will be called sojourn time of a customer. When it comes to computing waiting times in a polling system with priorities, one can use delay-cycles for any queue that is served exhaustively, cf. [1, 2]. A delay-cycle for a type iH customer is a cycle that starts with a certain initial delay at the moment that the last type iH customer in the system has been served. In our model this initial delay is either the service of a type iL customer, B iL , or (if no type iL customer is present) an intervisit period I i . The delay cycle ends at the first moment after the initial delay when no type iH customer is present in the system again. This is the moment that all type iH customers that have arrived during the delay, and all of their type iH descendants, have been served. In [1] delay-cycles have been applied to a polling system with two priority levels in an exhaustively served queue. For a type iH customer in the polling model in the present paper, the same
arguments can be used to compute the LST of the waiting time distribution. The fraction of time that the system is in a delay-cycle that starts with the service time B iL of a type iL customer is ρ iL 1 -ρ iH , and the fraction of time that the system is in a delay-cycle that starts with an intervisit period I i , is 1 -ρ iL 1 -ρ iH = 1 -ρ i 1 -ρ iH . We can use the Fuhrmann-Cooper decomposition [11] to obtain the LST of the waiting time distribution of a type iH customer, because from his perspective the system is an M/G/ 1 queue with server vacations. The vacation is the service time B iL of a type iL customer with probability ρ iL 1 -ρ iH , and an intervisit time I i with probability 1 -ρ i 1 -ρ iH . This leads to the following expression for the LST of the waiting time distribution of a type iH customer:
$$E [ e ^ { - \omega W _ { i H } } ] = \frac { ( 1 - \rho _ { i H } ) \omega } { \omega - \lambda _ { i H } ( 1 - \beta _ { i H } ( \omega ) ) } \cdot \left [ \frac { \rho _ { i L } } { 1 - \rho _ { i H } } \cdot \frac { 1 - \beta _ { i L } ( \omega ) } { \omega E ( B _ { i L } ) } + \frac { 1 - \rho _ { i } } { 1 - \rho _ { i H } } \cdot \frac { 1 - \widetilde { I } _ { i } ( \omega ) } { \omega E ( I _ { i } ) } \right ]. \quad ( 5. 1 )$$
Equation (5.1) is similar to the equation found in [1] for high priority customers in an exhaustive queue. Note that the intervisit time I i is different though, with LST ˜ I i ( ) as defined · in Equation (4.2).
The GF of the marginal queue length distribution of type iH customers can be found by applying the distributional form of Little's Law [13] to the sojourn time distribution:
$$E \left ( z ^ { N _ { i H } } \right ) = E \left ( \text{e} ^ { - \lambda _ { i H } ( 1 - z ) ( W _ { i H } + B _ { i H } ) } \right ).$$
This leads to the following expression:
$$E [ z ^ { N _ { i H } } ] = & \frac { ( 1 - \rho _ { i H } ) ( 1 - z ) \beta _ { i H } ( \lambda _ { i H } ( 1 - z ) ) } { \beta _ { i H } ( \lambda _ { i H } ( 1 - z ) ) - z } \\ & \cdot \left [ \frac { \rho _ { i L } } { 1 - \rho _ { i H } } \cdot \frac { 1 - \beta _ { i L } ( \lambda _ { i H } ( 1 - z ) ) } { ( 1 - z ) \lambda _ { i H } E ( B _ { i L } ) } + \frac { 1 - \rho _ { i } } { 1 - \rho _ { i H } } \cdot \frac { 1 - \widetilde { I } _ { i } ( \lambda _ { i H } ( 1 - z ) ) } { ( 1 - z ) \lambda _ { i H } E ( I _ { i } ) } \right ].$$
## 5.2 Low priority customers
In this subsection we determine the GF of the marginal queue length distribution of type iL customers, and the LST of the waiting time distribution of type iL customers. In order to obtain these functions, we regard the alternative system with 2 N queues as defined in Section 3. The number of type iL customers in the original polling system and their waiting time ( excluding the service time) have the same distribution as the number of type iL ∗ customers and their waiting time (again excluding the service time, which is different) in the alternative system. From the viewpoint of a type iL ∗ customer, the system is an ordinary polling system with synchronised gated service in Q iL ∗ .
We apply the Fuhrmann-Cooper decomposition to the alternative polling model with 2 N queues and type iL ∗ customers having completion time B ∗ iL . Using arguments similar as in the derivation of Equation (3.7) in [3], we find the general form of the GF of the marginal queue length distribution:
$$\text{pure region as uniform.} \\ E [ z ^ { N _ { i L } } ] & = \frac { ( 1 - \rho _ { i L } ^ { * } ) ( 1 - z ) \beta _ { i L } ^ { * } ( \lambda _ { i L } ( 1 - z ) ) } { \beta _ { i L } ^ { * } ( \lambda _ { i L } ( 1 - z ) ) - z } \\ & \quad \cdot \frac { V _ { c _ { i L } } ( 1, \dots, 1, z, 1, \dots, 1 ) - V _ { b _ { i L } } ( 1, \dots, 1, z, 1, \dots, 1 ) } { ( 1 - z ) ( E ( N _ { i L | I _ { e n d } } ^ { * } ) - E ( N _ { i L | I _ { b e g i n } } ^ { * } ) ) },$$
where ρ ∗ iL = ρ iL 1 -ρ iH and β ∗ iL ( ) · is given by (3.1). Furthermore, N ∗ iL I | end and N ∗ iL I | begin are the number of type iL ∗ customers at respectively the visit beginning and visit completion of Q iL ∗ . The visit beginning corresponds to the end of the intervisit period I iL , and the visit completion corresponds to the beginning of the intervisit period. Substitution into (5.3) leads to the following expression:
$$E [ z ^ { N _ { i L } } ] & = \frac { ( 1 - \frac { \rho _ { i L } } { 1 - \rho _ { i H } } ) ( 1 - z ) \beta _ { i L } ( \lambda _ { i L } ( 1 - z ) + \lambda _ { i H } ( 1 - \pi _ { i H } ( \lambda _ { i L } ( 1 - z ) ) ) ) } { \beta _ { i L } ( \lambda _ { i L } ( 1 - z ) + \lambda _ { i H } ( 1 - \pi _ { i H } ( \lambda _ { i L } ( 1 - z ) ) ) ) - z } \\ \cdot \frac { \widetilde { V } _ { b _ { i } } \left ( \pi _ { i H } ( \lambda _ { i L } ( 1 - z ) ), \beta _ { i L } ( \lambda _ { i L } ( 1 - z ) + \lambda _ { i H } ( 1 - \pi _ { i H } ( \lambda _ { i L } ( 1 - z ) ) ) ) \right ) - \widetilde { V } _ { b _ { i } } \left ( \pi _ { i H } ( \lambda _ { i L } ( 1 - z ) ), z \right ) } { ( 1 - z ) \lambda _ { i L } ( 1 - \frac { \rho _ { i L } } { 1 - \rho _ { i H } } ) E ( C ) },$$
where we use that E N ( ∗ iL I | end ) -E N ( ∗ iL I | begin ) = λ iL (1 -ρ ∗ iL ) E C ( ) = λ iL (1 -ρ iL 1 -ρ iH ) E C ( ), because this is the mean number of type iL ∗ customers that arrive during the intervisit time of Q iL ∗ .
Applying the distributional form of Little's Law to (5.4), we obtain the LST of the sojourn time distribution of a type iL customer. Since the sojourn time is W iL + B ∗ iL , the LST of the waiting time distribution immediately follows:
$$& \circ \cdots \cdots \cdots \cdots \\ & E [ e ^ { - \omega W _ { i L } } ] = & \frac { ( 1 - \frac { \rho _ { i L } } { 1 - \rho _ { i H } } ) \omega } { \omega - \lambda _ { i L } ( 1 - \beta _ { i L } ( \omega + \lambda _ { i H } ( 1 - \pi _ { i H } ( \omega ) ) ) ) } \\ & \quad \cdot \frac { \widetilde { V } _ { b _ { i } } \left ( \pi _ { i H } ( \omega ), \beta _ { i L } ( \omega + \lambda _ { i H } ( 1 - \pi _ { i H } ( \omega ) ) ) \right ) - \widetilde { V } _ { b _ { i } } \left ( \pi _ { i H } ( \omega ), 1 - \frac { \omega } { \lambda _ { i L } } \right ) } { \omega ( 1 - \frac { \rho _ { i L } } { 1 - \rho _ { i H } } ) E ( C ) }.$$
## 6 Moments
Differentiation of the waiting time LSTs derived in the previous section leads to the following mean waiting times:
$$E ( W _ { i H } ) = \frac { \rho _ { i H } E ( B _ { i H, r e s } ) + \rho _ { i L } E ( B _ { i L, r e s } ) } { 1 - \rho _ { i H } } + \frac { 1 - \rho _ { i } } { 1 - \rho _ { i H } } E ( I _ { i, r e s } ), \quad \quad ( 6. 1 )$$
$$E ( W _ { i L } ) = \left ( 1 + \frac { \rho _ { i L } } { 1 - \rho _ { i H } } \right ) \overset { \cdot \, \cdot \, \cdot } { E } ( C _ { i, r e s } ) + \frac { \rho _ { i H } } { 1 - \rho _ { i H } } \frac { \overset { \cdot \, \cdot \, \cdot } { E } ( \overset { \cdot \, \cdot } { X _ { i H } } X _ { i L } ) } { \lambda _ { i L } \lambda _ { i H } E ( C ) },$$
where B iH, res denotes a residual service time of a type iH customer, with E B ( iH, res ) = E B ( 2 iH ) 2 E B ( iH ) . We use a similar notation for the residual service time of a type iL customer, the residual intervisit time, and residual cycle time. Furthermore, X iH and X iL are respectively the number of type iH and type iL customers at the beginning of a visit to Q i , so E X ( iH X iL ) is obtained by differentiating ˜ V b i ( z iH , z iL ) with respect to z iH and z iL (and then setting z iH = z iL = 1).
We now present an alternative, direct way to obtain the mean waiting time for a type iL customer by conditioning on the event that an arrival takes place in a visit period, or in an
intervisit period.
$$\text{intervisit period.} \\ E ( W _ { i L } ) = & \frac { E ( V _ { i } ) } { E ( C ) } \left [ E ( V _ { i, r e s } ) + \frac { E ( V _ { i I } I _ { i } ) } { E ( V _ { i } ) } + \frac { \rho _ { i H } } { 1 - \rho _ { i H } } \frac { E ( V _ { i I } I _ { i } ) } { E ( V _ { i } ) } + \frac { \rho _ { i L } } { 1 - \rho _ { i H } } E ( V _ { i, p a s t ) } \right ] + \\ & \frac { E ( I _ { i } ) } { E ( C ) } \left [ E ( I _ { i, r e s } ) + \frac { \rho _ { i H } } { 1 - \rho _ { i H } } \left ( E ( I _ { i, p a s t } ) + E ( I _ { i, r e s } ) \right ) + \frac { \rho _ { i L } } { 1 - \rho _ { i H } } \left ( \frac { E ( V _ { i I } I _ { i } ) } { E ( I _ { i } ) } + E ( I _ { i, p a s t } ) \right ) \right ] \\ = & \frac { 1 } { E ( C ) } \left [ \frac { 1 } { 2 } E \left ( ( V _ { i } + I _ { i } ) ^ { 2 } \right ) + \frac { \rho _ { i L } } { 1 - \rho _ { i H } } E \left ( ( V _ { i } + I _ { i } ) ^ { 2 } \right ) + \frac { \rho _ { i H } } { 1 - \rho _ { i H } } \left ( E ( I _ { i } ^ { 2 } ) + E ( V _ { i I } I _ { i } ) \right ) \right ] \\ = & \left ( 1 + \frac { \rho _ { i L } } { 1 - \rho _ { i H } } \right ) \frac { E ( C _ { i } ^ { 2 } ) } { 2 E ( C ) } + \frac { \rho _ { i H } } { 1 - \rho _ { i H } } \left ( \frac { E ( I _ { i } ) } { E ( C ) } \left [ 2 \frac { E ( I _ { i } ^ { 2 } ) } { 2 E ( I _ { i } ) } \right ] + \frac { E ( V _ { i } ) } { E ( C ) } \frac { E ( I _ { i } V _ { i } ) } { E ( V _ { i } ) } \right ). \\ \text{In the above derivation, we use that both the past and residual intervisit time have expectation} \underset { \sim } { \sim }.$$
In the above derivation, we use that both the past and residual intervisit time have expectation E I ( 2 i ) 2 E I ( i ) , and that if a type iL customer arrives during the visit time (with probability E V ( i ) E C ( ) ), the mean length of the following intervisit time equals E I V ( i i ) E V ( i ) . The interpretation of (6.3) is that a type iL customer always has to wait for the residual cycle time, for the completion times of all type iL customers that have arrived during the past cycle time, and for the busy periods of all type iH customers that have arrived during the intervisit time of the cycle in which the type iL customer has arrived.
To show that (6.2) and (6.3) are equal, we can rewrite the last term in (6.2):
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \\ E ( X _ { i H } X _ { i L } ) & = E [ ( N _ { i L } ( V _ { i } ) + N _ { i L } ( I _ { i } ) ) N _ { i H } ( I _ { i } ) ] \\ & = E \Big ( E [ ( N _ { i L } ( V _ { i } ) + N _ { i L } ( I _ { i } ) ) N _ { i H } ( I _ { i } ) ] \, | \, I _ { i }, V _ { i } \Big ) \\ & = E [ ( \lambda _ { i L } V _ { i } + \lambda _ { i L } I _ { i } ) \lambda _ { i H } I _ { i } ] \\ & = \lambda _ { i L } \lambda _ { i H } E ( I _ { i } V _ { i } ) + \lambda _ { i L } \lambda _ { i H } E ( I _ { i } ^ { 2 } ), \\ \sqrt { \pi \vee } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
where N T j ( ) denotes the number of type j customers that have arrived during time T ( j = iH, iL ), and V i denotes the length of a visit of the server to Q i . Hence,
$$\cdot _ { \lambda } \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \delta \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dists \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \dots \, \delta \, \delta \, \delta \, \delta \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \dagma \, \d$$
which coincides with the last term in (6.3).
## 7 Pseudo-conservation law for priority polling systems
Boxma and Groenendijk [5] have shown that a so-called pseudo-conservation law holds for nonpriority polling systems. We do not discuss this law in detail in the present paper, but we mention that a generalised version of this law (cf. [18, 9]) holds for systems with multiple priority levels in each queue:
$$\underset { i = 1 } { \overset { N } { \sum } } \underset { k = 1 } { \overset { K _ { i } } { \sum } } \underset { i = 1 } { \overset { \rho } { \rho _ { i k } } E ( W _ { i k } ) } & = \frac { \rho } { 1 - \rho } \underset { i = 1 } { \overset { N } { \sum } } \underset { k = 1 } { \overset { K _ { i } } { \sum } } \underset { 2 E ( B _ { i k } ) } { \overset { E ( B _ { i k } ^ { 2 } ) } { 2 E ( B _ { i k } ) } } \\ & + \rho \frac { E ( S ^ { 2 } ) } { 2 E ( S ) } + \left [ \overset { N } { \rho ^ { 2 } } - \underset { i = 1 } { \overset { N } { \sum } } \underset { \rho _ { i k } } { \overset { N } { \sum } } \right ] \frac { E ( S ) } { 2 ( 1 - \rho ) } + \underset { i = 1 } { \overset { N } { \sum } } E ( Z _ { i i } ),$$
where S = ∑ N i =1 S i , and K i is the number of priority levels in Q i . In this expression Z ii is the amount of work at Q i when the server leaves this queue and depends on the service discipline. It is well-known that for gated service, E Z ( ii ) = ρ E C 2 i ( ) and for exhaustive service, E Z ( ii ) = 0. The pseudo-conservation law also holds for polling systems with mixed gated/exhaustive service in some or all of the queues. If Q i receives mixed gated/exhaustive service, we have K i = 2, and E Z ( ii ) = ρ iL ρ E C i ( ).
## 8 Numerical results
## Example 1
In order to illustrate the effect of using a mixed gated/exhaustive service discipline in a polling system with priorities, we compare it to the commonly used gated and exhaustive service disciplines. In this example we use a polling system which consists of two queues, Q 1 and Q 2 . Customers in Q 1 are divided into high priority customers, arriving with arrival rate λ 1 H = 2 10 , and low priority customers, with arrival rate λ 1 L = 4 10 . Customers in Q 2 all have the same priority level and arrive with arrival rate λ 2 = 2 10 . All service times are exponentially distributed with mean 1. The switch-over times S 1 and S 2 are also exponentially distributed with mean 1, which results in a mean cycle time of E C ( ) = 10. The service discipline in Q 2 is gated, the service discipline in Q 1 is varied: gated, exhaustive and mixed gated/exhaustive. Results for a queue with two priority levels and purely gated or exhaustive service are obtained in [1].
Table 1 displays the mean and the variance of the waiting times of the three customer types under the three service disciplines. We conclude that the mixed gated/exhaustive service is a major improvement for the high priority customers in Q 1 , whereas the mean waiting times of the low priority customers in Q 1 and the customers in Q 2 hardly deteriorate. Of course in systems where ρ 1 H is quite high, the negative impact can be bigger and one has to decide exactly how far one wants to go in giving extra advantages to customers that already receive high priority. When comparing the mixed gated/exhaustive strategy to a system with purely exhaustive service in Q 1 , we conclude that the improvement is not so much in the mean waiting time for high priority customers, but mostly in the mean and variance of the waiting time for customers in Q 2 .
Table 1: Numerical results for Example 1. The switch-over times S 1 and S 2 are exponentially distributed with mean 1. The mixed gated/exhaustive service discipline is compared to gated and exhaustive service.
| | Gated | Exhaustive | Mixed G/E |
|--------------|---------|--------------|-------------|
| E ( W 1 H ) | 9.578 | 2.52 | 2.338 |
| E ( W 1 L ) | 14.366 | 6.3 | 14.575 |
| E ( W 2 ) | 9.69 | 14.88 | 10.513 |
| Var( W 1 H ) | 56.739 | 9.29 | 6.496 |
| Var( W 1 L ) | 101.616 | 32.812 | 118.217 |
| Var( W 2 ) | 58.513 | 231.256 | 76.371 |
Table 2: Numerical results for Example 1. Switch-over times are deterministic: S 1 = S 2 = 10.
| | Gated | Exhaustive | Mixed G/E |
|--------------|---------|--------------|-------------|
| E ( W 1 H ) | 63.187 | 11.333 | 11.167 |
| E ( W 1 L ) | 94.781 | 28.333 | 90.417 |
| E ( W 2 ) | 63.251 | 68 | 64 |
| Var( W 1 H ) | 847.377 | 195.508 | 183.907 |
| Var( W 1 L ) | 894.173 | 315.823 | 850.199 |
| Var( W 2 ) | 853.777 | 1386.1 | 928.914 |
It is noteworthy that the mixed gated/exhaustive service discipline does not always have a negative effect on the mean waiting time of low priority customers in Q 1 , E W ( 1 L ), compared to the gated service discipline. If, for example, the switch-over times are taken to be deterministic with value 10, the mean waiting time for low priority customers is significantly less for the mixed gated/exhaustive service than for gated service, as can be seen in Table 2. Compared to gated service, type 1 H customers benefit strongly from the mixed gated/exhaustive service discipline, and even type 1 L customers benefit from it. The mean waiting time for customers in Q 2 has increased, but only marginally.
In order to get more understanding of this surprising behaviour of the waiting time of low priority customers as function of the arrival intensities λ 1 H and λ 1 L , we use a simplified model which leads to more insightful expressions, but displays the same characteristics as the model that was analysed in the previous paragraph. Instead of analysing a polling model, we analyse an M/G/ 1 queue with multiple server vacations. The queue, denoted by Q 1 to use familiar notation, contains high (type 1 H ) and low (type 1 L ) priority customers. Also here high priority customers are served before low priority customers. The service times of both customers types are exponentially distributed with mean 1. This is for notational reasons only, for this example we actually only require that both service times are identically distributed. One server vacation has a fixed length S . If the server does not find any customers waiting upon arrival from a vacation, he takes another vacation of length S and so on. In order to stay consistent with the notation used earlier, we denote the occupation rate of high and low priority customers by respectively ρ 1 H and ρ 1 L . The total occupation rate is ρ = ρ 1 = ρ 1 H + ρ 1 L . Note that in this example λ 1 H = ρ 1 H and λ 1 L = ρ 1 L . We now compare the mean waiting times of type 1 L customers in the system with purely gated service and the system with mixed gated/exhaustive service. For this simplified model, we can write down explicit expressions that have been obtained by differentiating the LSTs and solving the resulting equations. These expressions could also have been obtained by using Mean Value Analysis (MVA) for polling systems [22, 24].
Gated service:
$$E ( W _ { 1 L } ) = ( 1 + \rho + \rho _ { 1 H } ) \left ( \frac { S } { 2 ( 1 - \rho ) } + \frac { \rho } { 1 - \rho ^ { 2 } } \right ), \quad \quad ( 8. 1 )$$
$$\text{Mixed $G/E$ service:}$$
$$\text{vice} \colon \quad E ( W _ { 1 L } ) = \frac { \rho } { ( 1 - \rho ) ( 1 - \rho _ { 1 H } ) } + \frac { S ( 1 + \rho ( 1 - 2 \rho _ { 1 H } ) ) } { 2 ( 1 - \rho ) ( 1 - \rho _ { 1 H } ) }. \quad ( 8. 2 )$$
Now we analyse the behaviour of these waiting times as we vary λ 1 H between 0 and ρ , while keeping λ 1 H + λ 1 L = ρ constant. Substitution of λ 1 H = 0 shows that the mean waiting times
in the gated and mixed gated/exhaustive system are equal:
$$E ( W _ { 1 L } | \rho _ { 1 H } = 0 ) = \frac { S ( 1 + \rho ) } { 2 ( 1 - \rho ) } + \frac { \rho } { 1 - \rho }.$$
Letting λ 1 H → ρ leads to the following expressions:
$$\text{Gated service:}$$
$$E ( W _ { 1 L } | \rho _ { 1 H } \rightarrow \rho ) = \frac { \rho ( 1 + 2 \rho ) } { 1 - \rho ^ { 2 } } + \frac { S ( 1 + 2 \rho ) } { 2 ( 1 - \rho ) },$$
$$\text{Mixed } G / \text{E service} \colon \ \ E ( W _ { 1 L } | \rho _ { 1 H } \to \rho ) = \frac { \rho } { ( 1 - \rho ) ^ { 2 } } + \frac { S ( 1 + 2 \rho ) } { 2 ( 1 - \rho ) }.$$
Two interesting things can be concluded from these two equations for the case λ 1 H → ρ :
- · for fixed ρ , E W ( 1 L ) in a gated system is always less than E W ( 1 L ) in a mixed gated/exhaustive system,
- · the difference between E W ( 1 L ) in a gated system and E W ( 1 L ) in a mixed gated/exhaustive system does not depend on S .
Focussing on the mean waiting time of type 1 L customers only, we conclude that a gated system performs the same as a mixed gated/exhaustive system as ρ 1 L = ρ , and that a gated system always performs better when ρ 1 L → 0. For 0 < ρ 1 L < ρ the vacation time S determines which system performs better. By taking derivatives of (8.1) and (8.2) with respect to ρ 1 H and letting ρ 1 H → 0, one finds that the mean waiting time of a type 1 L customer in a mixed gated/exhaustive system is less than in a purely gated system when ρ 1 H → 0, if and only if S > 2 ρ 1+ ρ . Since a gated system always outperforms a mixed gated/exhaustive system when λ 1 H → ρ , for S > 2 ρ 1+ ρ there must be (at least) one value of λ 1 H for which the two systems perform the same. Further inspection of the derivatives gives the insight that in a gated system the relation between E W ( 1 L ) and λ 1 H is a straight line, which can also be seen immediately from Equation (8.1). In a mixed gated/exhaustive system, the relation between E W ( 1 L ) and λ 1 H is not a straight line, both the first and second derivative with respect to λ 1 H are strictly positive. This means that for S ≤ 2 ρ 1+ ρ the gated system always performs better than the mixed gated/exhaustive system for any value of λ 1 H > 0, and for S > 2 ρ 1+ ρ the mixed gated/exhaustive system performs better than the gated system for 0 < λ 1 H < λ ∗ 1 H . The value of λ ∗ 1 H can be determined analytically:
$$\lambda _ { 1 H } ^ { * } = \rho \frac { S - \frac { 2 \rho } { 1 + \rho } } { S + \frac { 2 \rho } { 1 + \rho } }.$$
From this expression we conclude that lim S →∞ λ ∗ 1 H = ρ . Although we have studied only the vacation model, the conclusions are also valid for more general settings, like polling models with non-deterministic switch-over times, but the expressions are by far not as appealing.
We visualise the findings of the present section in Figure 1, where we show three plots of the mean waiting time of type 1 L customers against λ 1 H . The model considered is the same as in the beginning of the present section (two queues, gated service in Q 2 ) except for the switch-over times S 1 and S 2 , which are now deterministic. We compare gated service in Q 1 to mixed gated/exhaustive service for three different switch-over times (notice that the scales of the three plots in Figure 1 are different).
6
6
6
Figure 1: Mean waiting time of type 1 L customers in the polling model discussed in Example 1. For gated and mixed gated/exhaustive service E W ( 1 L ) is plotted against λ 1 H while keeping λ 1 L + λ 1 H constant. The switch-over times S 1 = S 2 = S/ 2 are deterministic.
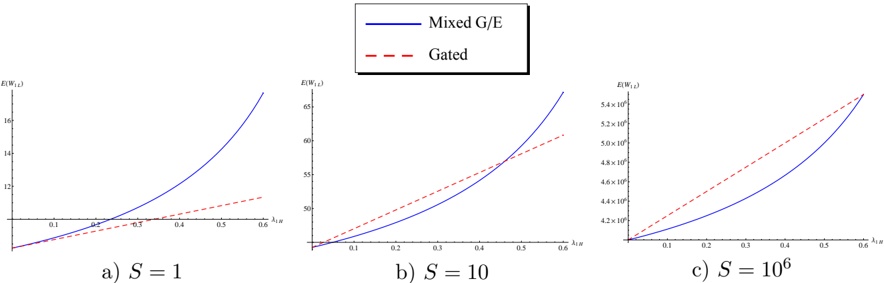
## Example 2
In the previous example we showed that the mixed gated/exhaustive service discipline does not necessarily have a negative impact on the mean waiting times of low priority customers. In this example we aim at giving a better comparison of the performance of the gated, exhaustive and mixed gated/exhaustive service disciplines in a polling system with priorities. The polling system considered consists of two queues, each having high and low priority customers. The switch-over times S 1 and S 2 are exponentially distributed with mean 10. Service times of all customer types are exponentially distributed with mean 1. The arrival rates of the various customer types are: λ 1 H = λ 1 L = 1 10 , and λ 2 H = λ 2 L = 7 20 . The total occupation rate of this polling system is ρ = 9 10 , and we deliberately choose a system where the occupation rates of the two queues are very different, and the switch-over times are relatively high compared to the service times. The reason is that we envision production systems as the main application for the present paper (see also Section 1). In these applications large setup times are very common (see, e.g., [23]).
Table 3 shows the mean and variance of the waiting times of all customer types of this polling system for all combinations of gated, exhaustive and mixed gated/exhaustive service. We leave it up to the reader to pick his favourite combination of service disciplines, but our preference goes out to the system with exhaustive service in Q 1 and mixed gated/exhaustive service in Q 2 because in our opinion the best combination of low mean waiting times and moderate variances is obtained in this system.
## 9 Possible extensions and variations
Many extensions or variations of the model discussed in the present paper can be thought of. In this section we discuss some of them.
A globally gated system. The globally gated service discipline has received quite some attention in polling systems. Instead of setting the gates at the beginning of a visit to
| Queue | Service discipline | E ( W iL ) | E ( W iH ) | Var( W iL ) | Var( W iH ) |
|---------|----------------------|--------------|--------------|---------------|---------------|
| 1 | gated | 141.81 | 119.99 | 5166.03 | 4660.09 |
| 2 | gated | 222.95 | 146.82 | 5917.7 | 3560.67 |
Queue
Service discipline
E W
(
iL
)
E W
(
iH
)
Var(
W
iL
)
Var(
W
iH
)
1
2
Queue
1
2
Queue
1
2
Queue
1
2
Queue
1
2
Queue
1
2
Queue
1
2
Queue
1
gated exhaustive
Service discipline gated
gatedexhaustive
Service discipline exhaustive
gated
Service discipline exhaustive
exhaustive
Service discipline exhaustive
gatedexhaustive
Service discipline gatedexhaustive
gated
Service discipline gatedexhaustive
exhaustive
Service discipline gatedexhaustive
165.49
59.45
E W
(
iL
)
147.38
209.86
E W
(
iL
)
97.63
224.00
E W
(
iL
)
119.80
61.62
E W
(
iL
)
102.18
211.90
E W
(
iL
)
140.95
223.45
E W
(
iL
)
166.85
60.39
E W
(
iL
)
146.87
140.03
17.83
E W
(
iH
)
124.71
16.98
E W
(
iH
)
78.10
147.51
E W
(
iH
)
95.84
18.49
E W
(
iH
)
81.75
17.27
E W
(
iH
)
77.96
147.15
E W
(
iH
)
94.38
18.12
E W
(
iH
)
81.41
11087.40
1862.57
Var(
W
iL
)
6406.11
6213.92
Var(
W
iL
)
4252.19
6186.88
Var(
W
iL
)
9516.58
2136.19
Var(
W
iL
)
5193.21
6722.53
Var(
W
iL
)
5140.20
6045.55
Var(
W
iL
)
11655.90
1978.87
Var(
W
iL
)
6452.48
9411.43
651.03
Var(
W
iH
)
5658.44
555.67
Var(
W
iH
)
3784.99
3690.81
Var(
W
iH
)
7952.09
728.97
Var(
W
iH
)
4533.58
586.84
Var(
W
iH
)
3756.12
3622.49
Var(
W
iH
)
7574.67
684.25
Var(
W
iH
)
4462.04
2
gatedexhaustive
210.82
17.10
6451.10
569.08
Table 3: Expectation and variance of the waiting times of the polling model discussed in Section 8, Example 2.
a certain queue, the globally gated service discipline states that all gates are set at the beginning of a cycle, which is the start of a visit to an arbitrarily chosen queue. The model under consideration can be analysed using similar techniques if high priority customers are served exhaustively, but low priority customers are served according to the globally gated service discipline. One would first have to build a similar model that contains 2 N queues
and determine the joint queue length distribution at visit beginnings and endings. The cycle time, starting at the moment that all gates are set, can be expressed in terms of the GF of the number of customers at the beginning of that cycle. Waiting times for high priority customers can be obtained using delay-cycles again, and waiting times for low priority customers can be obtained using the Fuhrmann-Cooper decomposition. The LST of the waiting time distribution of low priority customers gets more complicated as the queue gets served later in the cycle.
More than two priority levels. It is possible to analyse a similar model as the one of Section 2, but with more than two, say K i , priority levels in Q i . These K i priority levels still have to be divided into two categories: high priority levels 1 , . . . , k i that receive exhaustive service, and low priority levels k i + 1 , . . . , K i that receive gated service. The methodology from Section 5 can be used, combined with the techniques that are used to analyse a polling model with multiple priority levels, cf. [2].
A mixture of gated and exhaustive without priorities. One could think of a system where each queue contains two customer classes having respectively the exhaustive and gated service discipline, but service is First-Come-First-Served (FCFS). The model is similar to the model discussed in this paper, with the exception that no 'overtaking' takes place. Customers that are served exhaustively will not be served before any 'gated customers' standing in front of this gate, but they are allowed to pass the gate. The joint queue length distributions at polling epochs and the cycle times are the same as for the system considered in the present paper. Since no overtaking takes place, the waiting times can be found without the use of delay cycles. Nevertheless, analysis of the waiting times is quite tedious because a visit of a server to Q i consists of three parts. The third part is the service of exhaustive customers behind the gate, the first part is the service of the gated customers that have arrived during the 'previous third part' and the second part is the FCFS service of both gated and exhaustive customers that have arrived during the previous intervisit time of Q i . A combination of this non-priority mixture of gated and exhaustive, and the service discipline discussed in the present paper is discussed by Fiems et al. [8]. They introduce, albeit in the different setting of a vacation queue modelled in discrete time, a service discipline where high priority customers in front of the gate are served before low priority customers waiting in front of the gate. The difference with the model discussed in the present paper, is that high priority customers entering the queue while it is being visited can pass the gate, but are not allowed to overtake low priority customers standing in front of the gate.
## Acknowledgements
The authors wish to thank Erik Winands for his many helpful remarks and discussions. His contribution to the present paper is very much appreciated. Our gratitude also goes out to Jacques Resing who suggested the mixed gated/exhaustive service discipline. Finally, the authors thank Onno Boxma for valuable discussions and for useful comments on earlier drafts of the present paper.
## References
- [1] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A two-queue polling model with two priority levels in the first queue. ValueTools 2008 (Third International Conference on Performance Evaluation Methodologies and Tools, Athens, Greece, October 20-24, 2008) .
- [2] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A polling model with multiple priority levels. Eurandom report 2008-029, Eurandom , 2008.
- [3] S. C. Borst. Polling Systems , volume 115 of CWI Tracts . 1996.
- [4] O. J. Boxma. Polling systems. From universal morphisms to megabytes: A Baayen space odyssey. Liber amicorum for P.C. Baayen. CWI, Amsterdam , pages 215-230, 1994.
- [5] O. J. Boxma and W. P. Groenendijk. Pseudo-conservation laws in cyclic-service systems. Journal of Applied Probability , 24(4):949-964, 1987.
- [6] O. J. Boxma and J. A. Weststrate. Waiting times in polling systems with Markovian server routing. In Messung, Modellierung und Bewertung von Rechensystemen und Netzen , eds. G. Stiege and J. S. Lie, pages 89-105. Springer Verlag, Berlin, 1989.
- [7] J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982.
- [8] D. Fiems, S. De Vuyst, and H. Bruneel. The combined gated-exhaustive vacation system in discrete time. Performance Evaluation , 49:227-239, 2002.
- [9] L. Fournier and Z. Rosberg. Expected waiting times in polling systems under priority disciplines. Queueing Systems , 9(4):419-439, 1991.
- [10] S. W. Fuhrmann. Performance analysis of a class of cyclic schedules. Technical memorandum 81-59531-1, Bell Laboratories, March 1981.
- [11] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
- [12] J. Gianini and D. R. Manfield. An analysis of symmetric polling systems with two priority classes. Performance Evaluation , 8:93-115, 1988.
- [13] J. Keilson and L. D. Servi. The distributional form of Little's Law and the FuhrmannCooper decomposition. Operations Research Letters , 9(4):239-247, 1990.
- [14] O. Kella and U. Yechiali. Priorities in M/G/ 1 queue with server vacations. Naval Research Logistics , 35:23-34, 1988.
- [15] A. Khamisy, E. Altman, and M. Sidi. Polling systems with synchronization constraints. Annals of Operations Research , 35:231 - 267, 1992.
- [16] J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409 - 426, 1993.
- [17] M. Sharafali, H. C. Co, and M. Goh. Production scheduling in a flexible manufacturing system under random demand. European Journal of Operational Research , 158:89 - 102, 2004.
- [18] S. Shimogawa and Y. Takahashi. A pseudo-conservation law in a cyclic-service system with priority classes. IEICE Research Report , (IN88-86):13-18, 1988.
- [19] M. M. Srinivasan. Non-deterministic polling systems. Management Science , 37:667-681, 1991.
- [20] H. Takagi. Priority queues with setup times. Operations Research , 38(4):667-677, 1990.
- [21] H. Takagi. Queueing Analysis: A Foundation Of Performance Evaluation , volume 1: Vacation and Priority Systems, Part 1. North-Holland, Amsterdam, 1991.
- [22] A. Wierman, E. M. M. Winands, and O. J. Boxma. Scheduling in polling systems. Performance Evaluation , 64:1009-1028, 2007.
- [23] E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven University of Technology, 2007.
- [24] E. M. M. Winands, I. J. B. F. Adan, and G.-J. van Houtum. Mean value analysis for polling systems. Queueing Systems , 54:35-44, 2006. | 10.1007/s11134-009-9115-z | [
"Marko Boon",
"Ivo Adan"
] | 2014-08-01T10:42:45+00:00 | 2014-08-01T10:42:45+00:00 | [
"math.PR",
"cs.PF"
] | Mixed Gated/Exhaustive Service in a Polling Model with Priorities | In this paper we consider a single-server polling system with switch-over
times. We introduce a new service discipline, mixed gated/exhaustive service,
that can be used for queues with two types of customers: high and low priority
customers. At the beginning of a visit of the server to such a queue, a gate is
set behind all customers. High priority customers receive priority in the sense
that they are always served before any low priority customers. But high
priority customers have a second advantage over low priority customers. Low
priority customers are served according to the gated service discipline, i.e.
only customers standing in front of the gate are served during this visit. In
contrast, high priority customers arriving during the visit period of the queue
are allowed to pass the gate and all low priority customers before the gate.
We study the cycle time distribution, the waiting time distributions for each
customer type, the joint queue length distribution of all priority classes at
all queues at polling epochs, and the steady-state marginal queue length
distributions for each customer type. Through numerical examples we illustrate
that the mixed gated/exhaustive service discipline can significantly decrease
waiting times of high priority jobs. In many cases there is a minimal negative
impact on the waiting times of low priority customers but, remarkably, it turns
out that in polling systems with larger switch-over times there can be even a
positive impact on the waiting times of low priority customers. |
1408.0125v1 | ## EFFECT OF THE TECHNIQIE OF DRAWING WITH SHEAR ON THE STRUCTURE AND THE PROPERTIES OF LOW-CARBON WIRES
Donetsk Institute for Physics and Engineering named after А.А. Galkin NAS of Ukraine 72 R.Luxemburg Str., 83114, Donetsk, Ukraine
1 SPA «Donix», Donetsk, Ukraine
To obtain the materials of ultrafine grain (UFG) structure, different methods of severe plastic deformation (SPD) with shear in both cold and hot state are used: equal-channel angular pressing, twist extrusion, and combination of these methods with succeeding rolling, upset, drawing etc. The application of these methods allows substantial increase in the strength of the material at certain conserved reserve of plasticity.
However the mentioned combination of the methods can not be realized at wiredrawing production plants, whereas the last are very interested in new technological and operation characteristics of long-length wire products [1,2]. One of constraints imposed upon the production of UFG wire is that the total output of the materilas produced by the listed SPD methods is measured by tens of kilograms and tons but the required capacity of wiredrawing production is hundreds of thousand tons.
A possible solution of the problem of the long wire products can be application of drawing with shear. As may be supposed, an increase in the plasticity reserve of rods and wires allows cheapening and simplification of the production technique due to the abandonment of the intermediate anneal.
In [1-9], different methods of severe plastic deformation of long metal billets of varied configuration are described. The works [5,6,9] are of special interest here.
The authors of [5] analyze the application of sign-alternation twisting of cold-drawn furniture without an additional heating. The main advantages of the method are continuous operation and possible application to the production of long products with enhanced mechanical properties. In [6], a method of plastic structure formation in the material of long billets is tested, and a facility of the realization is presented that is based on sign-alternating deformation within intersecting channels. The deformation zone is formed within the billet due to a shift of the symmetry axes of the channels combined with uniaxial tension. The presented method is intermittent, and the finite billets of several meters in length can be produced. The advantage of the method is formation of a fine grain structure. But the deforming block is even more complex than that in the case of [5]. Both the methods [5,6] do not permit production of the wire of small diameter.
A drawing-based method of obtaining of UFG structure in long products is described in [9]. The main advantage is continuous operation and possible application to the large-scale drawing production. A drawback is labor intensity of drawing because a complex technical facility is used that requires disassembling and new installation in the course of replacement of wire drawing dies.
The present paper reports the developed technique of drawing with shear aimed at enhancement of technological plasticity of low-carbon steels without thermal treatment. The technology should provide definite physical and mechanical properties of the wire. It also should be cheap, simple and reliable in the course of operation.
3.9
5.0
5.3
## Experimental technique
The experiment was carried out with using the billet of steel ER70S-6 (Table 1). The drawing was realized at the plant АZТМ 7000/1 by the developed (experimental) technique (with shear dies) and by the classical one (with the standard round dies). The drawing routes of the both techniques are listed in Table 2.
Тable 1
Chemical composition of ER70S-6 steel, %
| C | Mn | Si | S | P | Cr | Ni | Cu | N |
|---------|---------|----------|-------|-------|--------|-------|-------|--------|
| 0.071 | 1.98 | 0.84 | 0.015 | 0.018 | 0.015 | 0.009 | 0.016 | 0.0055 |
| Ti | As | B | Al | V | Mo | W | Co | |
| < 0.005 | < 0.005 | < 0.0005 | 0.005 | 0.006 | < 0.01 | 0.024 | 0.01 | |
Тable 2 Drawing routes for the wires produced by the experimental and the standard techniques
| Technique | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm | Die diameter, mm |
|--------------|--------------------|--------------------|--------------------|--------------------|--------------------|--------------------|--------------------|--------------------|--------------------|--------------------|
| Experimental | 6.15 | 5.4 | 5.2 * | 5.0 | 4.30 | 3.90 | 3.5 | 3.06 | 2.70 | 2.39 |
| Conventional | | | 5.30 | | | | | | | |
Note . * - die with shear
The obtained samples from 6.15 tо 3.90 mm in diameter were subjected to mechanical tests, in particular, the ultimate tension strength and the contraction ratio were measured (Fig. 1).
The microstructures of the annealed sample and the deformed ones were studied at the 100-1000 power device «Neophot-32» after repetitive polishing and etching of the grain boundaries (the composition of the etching agent: 4% nitric acid, 97% alcohol). The photos were made by the optical microscope Axiovert 40 MAT.
0.8
824 838
766 807
2
0.6
6 0.2
642 642
Wire diameter, mm
6.15
а
Fig. 1. Mechanical properties of the ER70S-6 steel wire obtained by the conventional ( ■ ) and the experimental ( ) technique: а - the ultimate tensile strength σ uts , b - the contraction ratio
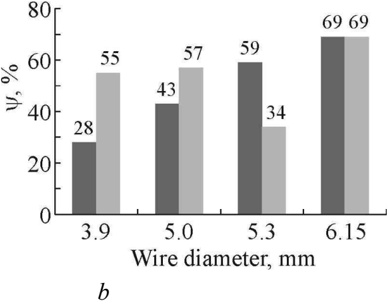
Тable 3
## Elongation ratio k of the ER70S-6 wire
| Technique | k | k | k |
|--------------|---------|---------|-------|
| | 6.5 | 5.0 | 3.9 |
| Experimental | 1 | 0.35 | 0.19 |
| Conventional | | 0.21 | 0.10 |
The estimation of the grain size and the fragment size was performed in the transversal and longitudinal directions of the samples. 100 measurements were made on every photo. The elongation ratio was calculated as
$$k = D _ { 1 } / D _ { 2 },$$
where D 1, D 2 were the lengths of the grain along the grain elongation and in the cross-section of the sample, respectively, mm.
Besides, Vickers hardness HV (loading of 200 g) and microhardness H μ (loading of 100 g) were measured. The measurement error was 5%. The density of the samples was measured by hydrostatic weighing. Strength tests were carried out with using UММ-50 test machine at the temperature of 293 K and the rate of loading of 10 mm/min according to GOST 25.601-80.
## Experiment results
The tests have demonstrated that when the diameter of the sample is reduced, the ultimate tensile strength remains at the same level irrespective of the conventional or experimental technique (Fig. 1, а ), and the contraction ratio of the sample processed by the experimental technique is higher as compared to the conventional drawing (Fig. 1, b ).
On the basis of the mean values, it is seen that the reduction of the diameter after the conventional technique is associated with the increase in the ultimate tensile strength by 380 N/mm , and the 2 experimental technique yields 240 N/mm . 2
After the conventional technique, the value of the contraction ratio is substantially decreased from 69 to 28%, and the drop after the experimental technique is from 69 to 55%.
One of the distinguishing features of the experimental technique is a decrease in the structure anisotropy in the longitudinal samples. An evidence of the fact is an increase in the elongation ratio (Table 3). The photos of microstructures confirm the calculated data (Fig. 2).

а
Fig. 2. Microstructure of the samples of the wire of ER70S-6 5.0 obtained by the experimental technique ( а ) and the conventional technique ( b ), 100. The scale represents 10 μm

The analysis of the structures revealed the following principal structure features.
1. The etchability of perlite colonies is higher at the conventional technique that is related to nonequilibrium of perlite after drawing. In the longitudinal section, along the section at the conventional technology is larger that of the experimental technique.
- 2. It has been established that the experimental technique results in decreased anisotropy of the grains, and the grain size is reduced as a whole, when the degree of deformation increases. But at certain stages, successive decrease and increase in the grain size is observed that is supposed to be related to the progress in competitive processes of fragmentation and dynamical polygonization.
For instance, in the tested samples of 5.2 and 5.0 in cross-section, the structure is enlarged: the ferrite grains and the sizes of perlite colonies grow as compared to the sample of 6.15. In the cross-section of the experimental sample, the structure was larger in comparison with the sample obtained by the conventional technique. The structure of the last sample contained more perlite phase.
- 3. In the cross-section of the samples of 3.9 obtained by the conventional technique, there is a surface zone of about 200-300 m that differs in etchability. This effect is not found after the experimental technique, the metal is homogeneous, the ferrite grains are lager, the size and the amount of perlite is much less than that after the conventional technique.
- 4. The samples of 2.39 by the conventional technique are etched better, so, the degree of nonequilibrium is higher. In the longitudinal section of the conventional samples, the anisotropy is more intensive, the ferrite grains are smaller, the perlite colonies are elongated as stripes (Fig. 3). The same effect is observed in the cross-section. Besides, healing of pores and microcracks is registered in the course of the experimental drawing (compare Fig. 3, c and d ).
## Conclusions
- 1. The application of the experimental dies allows improvement of the mechanical properties of the samples when the diameter is decreased after drawing: the contraction ratio of the wire is insignificantly reduced and stays at a relatively high level as compared to the conventional technique where the contraction ratio is halved.
- 2. The use of the experimental technique permits variation of the ferrite grain size (successive increase and decrease) in comparison with the conventional technique where the increase in the degree of deformation results in unambiguous grain reduction.
- 3. The application of the experimental technique generates pore healing in the wire of a small diameter.


а

b
- Fig. 3. Microstructure of the central zone of the ER70S-6 wire samples of 2.39 obtained by th4e conventional technique ( a , c ) and by the experimental technique ( b, d ) : а , b - the cross-section, c, d - the longitudinal section, 100. The scale is as in Fig. 2
- 4. To prevent the heating of the wire and the die, it is necessary to pass to the experimental drawing through two experimental dies with shear separated by a standard die. This configuration will result in enhanced fabricability and reduction of the drawing force.
- 1. E. Astafurova, G. Zakharova., E. Naydenkin., G. Raab., P. Odesskiy., S. Dobatkin , Materials letters 1. #4, 198 (2011).
- 2. E. Astafurova, G. Zakharova, E. Naydenkin, S. Dobatkin, G. Raab, FMM 110 , 275 (2010).
- 3. N. Kolbasnikov, O. Zotov., V.Duranichev, Metall treatment # 4, 25 (2009). ,
- 4. S. Yakovleva, S. Makharova, News of Samarian scientific centre of RAS, 12 , # 1(2), 589 (2010).
- 5. E. Kireev, M. Shulyak, A. Stolyarov, Steel # 3, 56 (2009).
- 6. Patent RF # 2440865, The method of structure of plastic material of long workpieces and device for its implementation, A. Matveev, R. Kazakov, Yu. Shumkina, V. Kurganskiy, application # 2010121631/02, 27.05.2010.
- 7. E. Astafurova, G. Zakharova., E. Naydenkin., G. Raab., S. Dobatkin Е.Г. , Астафурова, Physical mesomechanic 13 , № 4, 91 (2010).
- 8. A. Zakirova, R. Zaripova, V. Semenov, News UGATU, Engineering, materials science and thermal processing of metals 11 , № 2 (29), 123 (2008).
- 9. Patent RF # 2347633, A method for producing ultrafine semis drawing shift, G. Raab, A. Raab, application # 2007141899/02, 12.11.2007. | null | [
"E. G. Pashinskaya",
"V. N. Varyukhin",
"A. A. Maksakova",
"A. I. Maksakov1",
"A. A. Tolpa1",
"A. V. Zavdoveev"
] | 2014-08-01T10:44:07+00:00 | 2014-08-01T10:44:07+00:00 | [
"cond-mat.mtrl-sci"
] | Effect of the techniqie of drawing with shear on the structure and the properties of low-carbon wires | The technology of drawing with shear is developed. It allows increasing
technological plasticity of low carbon steel without heat treatment. It is
found that the use of experimental technology can improve mechanical properties
of wire samples with the diameter reduced during drawing: the relative
reduction of the wire decreases slightly and remains at high level compared
with the classical technology, where the relative reduction in the course of
drawing drops more than twice. It is shown that the use of experimental
technology allows varying the size of a ferrite grain (increase or decrease)
compared with the classical technology, where increasing of deformation degree
results in grain reduction. Furthermore, the experimental technology allows
reducing the number of pores in a wire of small diameter. To prevent heating of
the wire and the drawing dies, it is proposed to use experimental drawing
through two experimental dies with shear separated by an ordinary die. As a
result, the workability of the process will be enhanced and the efforts of
drawing will be reduced. |
1408.0126v1 | ## Jet formation in GRBs: A semi-analytic model of MHD flow in Kerr geometry with realistic plasma injection
Noemie Globus 1 and Amir Levinson 1
## ABSTRACT
We construct a semi-analytic model for MHD flows in Kerr geometry, that incorporates energy loading via neutrino annihilation on magnetic field lines threading the horizon. We compute the double-flow structure for a wide range of energy injection rates, and identify the different operation regimes. At low injection rates the outflow is powered by the spinning black hole via the Blandford-Znajek mechanism, whereas at high injection rates it is driven by the pressure of the plasma deposited on magnetic field lines. In the intermediate regime both processes contribute to the outflow formation. The parameter that quantifies the load is the ratio of the net power injected below the stagnation radius and the maximum power that can be extracted magnetically from the black hole.
## 1. Introduction
An issue of considerable interest in the theory of gamma-ray bursts (GRBs) is the nature of the gammaray emitting jet. The conventional wisdom has been that the jet is produced by a hyper-accreting black hole that results from a neutron star merger in case of short GRBs (Eichler et al. 1989), or the core-collapse of a massive star in case of long GRBs (MacFadyen, Woosley 1999). The black hole is likely to be immersed in a strong magnetic field ( B H /similarequal 10 15 G) seeded by the progenitor and advected inwards during the formation of the central engine. Feedback from a rapidly rotating black hole may dominate the torque experienced by the surrounding torus, leading to a state of suspended accretion in long GRBs (van Putten & Ostriker, 2001; van Putten & Levinson 2003), provided that mass loading of magnetic field lines anchored to the disk is, somehow, strongly suppressed (Komissarov & Barkov 2009; Globus & Levinson 2013; hereafter GL13). Rapid heating of the inner regions of the hyper-accretion disk, or the torus in the suspended accretion state if established, leads to prodigious emission of MeV neutrinos (and anti-neutrinos), with luminosities in the range L ν = 10 51 -10 54 erg s -1 , depending on accretion rate and specific angular momentum a of the black hole (e.g., Popham et al. 1999; Chen & Beloborodov 2007).
In the context of the picture outlined above, two competing jet formation mechanisms have been widely discussed in the literature; magnetic extraction of the spin down power of a Kerr black hole, and outflow formation via neutrino annihilation in the polar region, above the horizon (Paczy´ski 1990, Levinson & n Eichler 1993, Levinson 2006). These two processes are commonly treated under idealized conditions: models of Blandford-Znajek jets usually invoke the force-free limit and ignore loading of magnetic field lines (but c.f., Komissarov & Barkov 2009), whereas models of jets driven by νν ¯ annihilation (MacFadyen & Woosley 1999, Fryer & M´ esz´ros 2003) are usually constructed within the pure hydrodynamic limit. a In general, however, both processes might be at work, and it is desirable to characterize the interplay between them. The approach undertaken in this paper is to treat νν ¯ annihilation in the magnetosphere as external plasma load. It has been shown elsewhere (GL13) that injection of relativistically hot plasma on horizon threading field lines
1 School of Physics & Astronomy, Tel Aviv University, Tel Aviv 69978, Israel
always leads to the formation of a double-flow structure in the magnetosphere. The plasma inflowing into the black hole carries positive energy that tends to counteract the BZ process. The plasma outflowing to infinity contributes to the total asymptotic power. The question addressed in this paper is how the structure of the MHD flow depends on the details of the plasma injection process.
In a preliminary investigation (GL13), we considered the effect of the load on the activation of the BZ mechanism, assuming that the plasma source is confined to an infinitely thin layer, outside which the MHD flow is ideal and adiabatic. We derived solutions for the inflow section only, and evaluated the critical load above which the BZ process switches off. We then argued that this critical value differentiates magnetically extracted from pressure-driven flows when the injected plasma is relativistically hot. In this paper we extend our analysis to more realistic situations, and obtain solutions of the MHD equations for the entire double-flow structure. We focus on the conditions anticipated in GRBs, and employ a realistic injection profile computed recently by Zalamea & Beloborodov (2011, hereafter ZB11). We identify the different operation regimes, including the intermediate regime where the transition from magnetically extracted to pressure driven flows occurs. We also calculate overloaded solutions for which the BZ process is switch off and compare them with pure hydrodynamic flows derived in a previous study (Levinson & Globus 2013, hereafter LG13).
## 2. Model
The double-flow structure established in the magnetosphere is illustrated in Figure 1: plasma inflow into the black hole and outflow to infinity are ejected from a stagnation radius, r st , located between the inner and outer light surfaces. The plasma consists of relativistically hot e ± pairs created via annihilation of MeV neutrinos emitted from the surrounding accretion disk. The exact location of the stagnation surface depends, quite generally, on the energy injection profile, and is treated as an eigenvalue of the MHD equations. The double flow possesses six critical surfaces, corresponding to the characteristic phase speeds of the three MHD waves propagating in the medium: two slow magnetosonic, two Alfv´ enic and two fast magnetosonic. We consider an infinitely conducting, stationary and axisymmetric flow. In general, the flow is characterized by a stream function Ψ( r, θ ) that defines the geometry of magnetic flux surfaces, and by the following functionals of Ψ: the angular velocity of magnetic field lines Ω F (Ψ), the ratio of mass and magnetic fluxes η (Ψ), and the energy, angular momentum and entropy per baryon, denoted by E (Ψ), L (Ψ) and s (Ψ), respectively. These quantities are given explicitly in Equations (A7)-(A10).
The ideal MHD condition implies that Ω F (Ψ) is conserved along magnetic flux tubes, as usual. All other quantities change along streamlines, owing to plasma injection by the external source, according to Equations (A11)-(A14). We assume that in the acceleration zone the plasma is relativistically hot with a negligible baryonic content. We can therefore adopt the equation of state w = ρc h 2 ¯ = 4 p . To simplify the analysis we invoke a split monopole configuration for the magnetic field lines, described by a stream function of the form Ψ( r, θ ) = Ψ (1 0 -cos θ ). The energy, angular momentum and entropy fluxes, Equation (A6), then have only a radial component: /epsilon1 r = ρ E u r , l r = ρ L u r , s r = ρsu r . Note that E , L and s diverge in the limit ρ → 0 (baryon-free flow), whereas the corresponding fluxes, /epsilon1 r , l r and s r , remain finite and are well defined also in the baryon-free case. For the relativistic equation of state adopted above the entropy per unit volume is given by S = ρs = 4 p/kT ∝ p 3 / 4 , whereby s r ∝ u p r 3 / 4 , hence the pressure p can be used as a free variable instead of S . Since our analysis encompases the force-free limit, we find it convenient to use /epsilon1 r , l r and p as our free variables. With the above simplifications, Equations (A11)-(A13) reduce to:
$$\frac { 1 } { \sqrt { - g } } \partial _ { r } ( \sqrt { - g } \epsilon ^ { r } ) = - q _ { t },$$
$$\frac { 1 } { \sqrt { - g } } \partial _ { r } ( \sqrt { - g } l ^ { r } ) & = q _ { \varphi }, \\ 3 _ { \infty } \quad, \quad \partial _ { r } \quad \omega \quad u _ { \alpha } q ^ { \alpha } & \quad \omega \quad.$$
$$\frac { \ddot { 3 } } { 4 } \partial _ { r } \ln p = - \partial _ { r } \ln ( \Sigma u ^ { r } ) - \frac { u _ { \alpha } q ^ { \alpha } } { 4 p u ^ { r } },$$
here √ -g = Σsin θ , and Σ = r 2 + a 2 cos 2 θ . This set needs to be augmented by an equation of motion for the velocity u r . Instead of u r we use the poloidal velocity u p = √ u u r r = √ g rr u r . Its rate of change along streamlines is derived in appendix A and can be written in the form,
$$\partial _ { r } \ln u _ { p } = \frac { N _ { a d } + N _ { q } } { D },$$
where N ad , N q and D are functionals of /epsilon1 r , l r , p, u p , Ω , given explicitly by Equations (A23)-(A25). Equations F (1)-(4) form a complete set that governs the structure of the double MHD flow. The solutions for the radial profiles of the free variables /epsilon1 r , l r , p , and u p , depend on the particular choice of the angle θ that characterizes magnetic flux surfaces. The angular velocity Ω F ( θ ) is given as an input. The energy and angular momentum flow rates per solid angle (along a particular flux surface) are defined, respectively, as:
$$\dot { \mathcal { E } } ( r, \theta ) \equiv \Sigma \epsilon ^ { r }, \quad \dot { \mathcal { L } } ( r, \theta ) \equiv \Sigma l ^ { r }.$$
## 2.1. Source terms for the process νν ¯ → e + e -
The energy-momentum deposition rate by the reaction νν ¯ → e + e -was computed in a number of works, under different simplifying assumptions (Popham et al. 1999, Chen & Beloborodov 2007, ZB11). In what follows we use the recent analysis by ZB11 which includes general relativistic effects. Following ZB11 we denote by Q α νν ¯ the local energy-momentum deposition rate measured by a zero-angular-momentum observer (ZAMO). In general, those rates are functions of the Boyer-Lindquist coordinates r , θ and ϕ , as can be seen from Figures 2 and 3 in ZB11. In terms of the metric components defined in appendix A, g ϕϕ = /pi1 2 , g tϕ = -ωg ϕϕ , g tt = -α 2 + ω g 2 ϕϕ and g rr , we have the following relations between the ZAMO rates Q α νν ¯ and the source terms q α measured by a distant observer: αq t = Q t νν ¯ , /pi1q ϕ = Q ϕ νν ¯ + /pi1ωQ t νν ¯ /α , √ g rr q r = Q r νν ¯ . From that we obtain
$$- \, q _ { t } \ & = \ \alpha Q ^ { t } _ { \nu \bar { \nu } } + \varpi \omega Q ^ { \varphi } _ { \nu \bar { \nu } }, \\ \ \hat { \ } = \ \frac { } { } - \varpi \, & \quad \, \frac { } { } \, \nu \, \cdot$$
$$q _ { \varphi } \ = \ \varpi Q _ { \nu \bar { \nu } } ^ { \varphi },$$
$$u _ { \alpha } q ^ { \cdot ^ { \cdot } } \ = \ - \alpha u ^ { t } Q ^ { t } _ { \nu \bar { \nu } } + \varpi Q ^ { \varphi } _ { \nu \bar { \nu } } ( u ^ { \varphi } - \omega u ^ { t } ) + u _ { p } Q ^ { r } _ { \nu \bar { \nu } }.$$
The total power deposited in the magnetosphere can be expressed as,
$$\dot { E } ^ { t o t } _ { \nu \bar { \nu } } & = \int _ { r \geq r _ { H } } \left ( \alpha Q ^ { t } _ { \nu \bar { \nu } } + \varpi \omega Q ^ { \varphi } _ { \nu \bar { \nu } } \right ) \sqrt { - g } d r d \theta d \varphi \,. \\ \dots \dots \dots \dots \dots \pi \pi \pi \dots \dots \dots \dots \dots \pi \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{array}$$
A fit to the numerical results by ZB11 yields: ˙ E tot νν ¯ /similarequal 10 52 ˙ m 9 / 4 acc x -4 8 . mso erg s -1 for a black hole mass M BH = 3 M /circledot , and accretion rates (henceforth measured in units of M /circledot s -1 ) in the range 0 02 . < m ˙ acc < 1, where x mso is the radius of the marginally stable orbit in units of m = GM BH /c 2 .
Unfortunately, ZB11 do not exhibit results for the azimuthal term Q ϕ νν ¯ . It is also difficult to fit their result for Q r νν ¯ . We shall therefore set Q ϕ νν ¯ = Q r νν ¯ = 0. This should not alter much q t and u α q α , as the first term on the right hand side of Equations (6) and (8) dominates anyhow. However, for this choice q ϕ = 0,
implying that the angular momentum flow rate, ˙ ( L r, θ ) ≡ Σ l r , is conserved, as readily seen from Equation (2).
For our radial flow model it is sufficient to use the angle-averaged energy deposition rate. We adopt the form
$$Q ^ { t } _ { \nu \bar { \nu } } ( r ) = \dot { Q } _ { 0 } f ( x ),$$
where x = r/m is a fiducial radius, and f ( x ) is normalized such that f (1) = 1. From figures 2 and 3 in ZB11 we obtain the approximate profile f ( x ) /similarequal x -b , with b = 4 5 for a black hole spin parameter ˜ . a ≡ a/m = 0 95, . and b = 3 5 for ˜ = 0. The injected power per solid angle, from the horizon to a given radius . a x , is then given by
$$\dot { \mathcal { E } } _ { \nu \bar { D } } ( x, \theta ) = m ^ { 3 } \dot { Q } _ { 0 } \int _ { x _ { H } } ^ { x } \alpha \Sigma f ( x ^ { \prime } ) d x ^ { \prime }. \\ \text{information in to some hominom how to } \partial < \theta < \pi / \partial \text{i.s}$$
The cumulative power distribution in the upper hemisphere (0 ≤ θ ≤ π/ 2) is
$$\dot { E } _ { \nu \bar { \vartheta } } ( x ) & = 2 \pi \int _ { 0 } ^ { \pi / 2 } \dot { \mathcal { E } } _ { \nu \bar { \vartheta } } ( x, \theta ) \sin \theta d \theta. \\ \ddots \.$$
It is related to the total power through ˙ E tot νν ¯ = ˙ E νν ¯ ( x = ∞ ). The amount absorbed by the black hole along a particular field line equals the power per solid angle injected in the inflow section (between the horizon and the stagnation radius):
$$\i r a u s \} \colon & & \dot { \mathcal { E } } _ { \nu \bar { p } } ^ { i n } ( \theta ) = \dot { \mathcal { E } } _ { \nu \bar { p } } ( x _ { s t }, \theta ) = m ^ { 3 } \dot { Q } _ { 0 } \int _ { x _ { H } } ^ { x _ { s t } } \alpha \Sigma x ^ { - b } d x. & & ( 1 3 ) \\ \dot { \lambda } t o t ( \alpha ) \quad \dot { \lambda } i n ( \alpha ) \quad \dot { \lambda } t o t ( \alpha ) \ = \ \dot { \lambda } \ \ \partial _ { 0 } \quad \cdots \ e \ \cdots, \quad \tau \ \tau \ \cdots.$$
The rest, ˙ E out νν ¯ ( θ ) = ˙ E tot νν ¯ ( θ ) - E ˙ in νν ¯ ( θ ), where ˙ E tot νν ¯ ( θ ) ≡ E ˙ νν ¯ ( ∞ , θ ), emerges at infinity. The total power intercepted by the black hole in one hemisphere is
$$\dot { E } _ { \nu \bar { p } } ^ { i n } = 2 \pi \int _ { 0 } ^ { \pi / 2 } \dot { \mathcal { E } } _ { \nu \bar { p } } ^ { i n } ( \theta ) \sin \theta d \theta = \dot { E } _ { \nu \bar { p } } ( x _ { s t } ).$$
A plot of ˙ E νν ¯ ( x ) (Equation (12)), is exhibited in Figure 2. For our computations we use b = 4 5 for a spin . parameter ˜ = 0 95 (the solid line in Figure 2). a .
## 2.2. The load parameter κ θ ( )
Let us denote by ˙ E H ( θ ) = ˙ ( E r H , θ ), ˙ E st ( θ ) = ˙ ( E r st , θ ), and ˙ E ∞ ( θ ) = ˙ ( E ∞ , θ ) the angular distribution of the power at the horizon, stagnation radius and infinity, respectively, where ˙ ( E r, θ ) is defined in Equation (5). Integration of Equation (1) yields
$$\dot { \mathcal { E } } _ { H } ( \theta ) & = \dot { \mathcal { E } } _ { s t } ( \theta ) - \dot { \mathcal { E } } _ { \nu \bar { \mathcal { D } } } ^ { i n } ( \theta ), & ( 1 5 ) \\ \dot { \mathcal { C } } _ { \nu \lambda } & = \dot { \mathcal { C } } _ { \nu \lambda + \dot { \mathcal { C } } o u t } ( \theta ) & ( 1 \epsilon )$$
$$\dot { \mathcal { E } } _ { \infty } ( \theta ) = \dot { \mathcal { E } } _ { s t } ( \theta ) + \dot { \mathcal { E } } _ { \nu \bar { \mathcal { D } } } ^ { o u t } ( \theta ),$$
where Equations (6), (10) and (13) have been employed.
Now, the specific energy of the injected plasma is positive, hence ˙ E in νν ¯ ( θ ) ≥ 0, ˙ E out νν ¯ ( θ ) ≥ 0, as can be inferred from Equation (11). In the situations envisaged here ˙ E ∞ ( θ ) > 0, but ˙ E H ( θ ) can be negative or positive, depending on the load. In the force-free limit ˙ E tot νν ¯ ( θ ) → 0, whereby Equations (15) and (16) yield
˙ E ∞ ( θ ) = ˙ E H ( θ ) > 0. The extracted power per solid angle is given, in this limit, by (Blandford & Znajek, 1977):
$$\dot { \mathcal { E } } _ { H } ( \theta ) = P _ { B Z } ( \theta ) \equiv \frac { c } { 6 4 \pi ^ { 3 } } \alpha _ { \Omega } ( 1 - \alpha _ { \Omega } ) \left ( \frac { \tilde { a } } { m } \right ) ^ { 2 } \frac { ( x _ { H } ^ { 2 } + \tilde { a } ^ { 2 } ) \sin ^ { 2 } \theta } { x _ { H } ^ { 2 } ( x _ { H } ^ { 2 } + \tilde { a } ^ { 2 } \cos ^ { 2 } \theta ) } \Psi _ { 0 } ^ { 2 } \,, \quad \, ( 1 7 ) \intertext { m o f t h o b l a b o l a m i n } \ e n v { \ v t h o b l a b o l a m i n } \tilde { \ s u m i n o i o n o c o n o r o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o c o n o } = \Omega _ { s } / / \ s.$$
in terms of the black hole spin ˜, magnetic flux Ψ , and the dimensionless parameter a 0 α Ω = Ω F /ω H . In general ˙ E H ( θ ) < P BZ ( θ ), as readily seen from Equation (15).
Henceforth, we shall quantify the load on a specific streamline θ by the parameter
$$\kappa ( \theta ) \equiv \frac { \dot { \mathcal { E } } _ { \nu \bar { \mathcal { H } } } ^ { i n } ( \theta ) } { P _ { B Z } ( \theta ) }.$$
At κ θ ( ) << 1 the flow along the streamline θ is nearly force-free. At κ θ ( ) >> 1 the flow is nearly hydrodynamic, whereby ˙ E st ( θ ) /similarequal 0 and ˙ E H ( θ ) /similarequal -E ˙ in νν ¯ ( θ ) < 0, namely the energy injected below the stagnation radius on the flux surface θ is completely absorbed by the black hole. As shown below, the transition between the two regimes occurs, in general, at κ θ ( ) /similarequal 1.
## 3. Integration method
In general, the double flow must pass smoothly through 6 critical surfaces. Solutions that satisfy this requirement can be obtained, in principle, only if the trans-field equation is solved simultaneously with Equations (A11)-(A13), as the exact location of the critical surfaces is contingent upon the actual shape of the magnetic surfaces. Such an analysis is beyond the scope of this paper. Fixing the geometry of magnetic field lines renders the system of MHD equations, Eqs. (1)-(4), over constrained. The reason is that there are 4 regularity conditions (the regularity conditions at the inner and outer Alfv´n surfaces are automatically e satisfied), but only 3 adjustable parameters; the location of the stagnation point, r st , at which u p = 0, and the values of /epsilon1 r and p at r st , henceforth denoted by /epsilon1 r st , and p st , respectively. The value of the angular momentum flux at r st is related to /epsilon1 r st through the Bernoulli condition, Equation (A31): l r st = Ω -1 F /epsilon1 r st . Since we are interested in determining the energy flux on the horizon, we seek solutions that are regular on all 3 inner surfaces, and on the outer slow magnetosonic surface, but not necessarily on the outer fast magnetosonic surface. In practice we find that any solution that crosses the outer slow magnetosonic surface, is also regular on the outer Alfv´n surface. e
Our strategy is to start with some initial guess for the three adjustable parameters, r st , /epsilon1 r st , and p st , whereupon Equations (1)-(4) are integrated numerically from r st inwards to the horizon, and outwards to the outer Alfv´n surface, along a given field line e θ . The integration is repeated many times, where in each run the values r st , /epsilon1 r st , p st are readjusted until a solution that crosses the desired critical points smoothly is obtained. In all the examples presented below we neglected the change in linear and angular momentum owing to plasma injection, that is, we set Q ϕ νν ¯ = Q r νν ¯ = 0 in Equations (6)-(9). Equation (2) then readily yields ˙ L = Σ l r = const. The black hole spin ˜, angular velocity of the streamlines Ω a F , and load parameter κ are given as input parameters. In practice, however, κ cannot be determined a priori, since r st is unknown. We therefore use instead of κ the dimensionless parameter ˜ p B ≡ Ψ 2 0 c/ (32 π Q m 3 ˙ 0 5 ) as an indicator for the load. Once a solution is obtained and r st is determined, κ is computed by employing Equations (13), (17) and (18).
## 4. Results
The family of solutions can be divided into two classes that are distinguished by the sign of the energy flux on the horizon, /epsilon1 r H . This devision is dictated by the load parameter κ θ ( ), as discussed further below (Figure 4). We find that in case of underloaded solutions, defined as those for which κ θ ( ) << 1, the specific energy is negative in the entire region encompassed by the plasma inflow (below the stagnation radius), including the horizon, whereby /epsilon1 r H > 0. In case of overloaded solutions ( κ θ ( ) >> 1) we find /epsilon1 r H < 0. Interestingly, the energy flux of overloaded solutions changes sign at some radius below the stagnation point, implying that there is still a region where the specific energy of the plasma inflow is negative. Typical examples are shown in Figure 3, where the velocity profiles (left panel) and the corresponding energy fluxes (right panel) of underloaded ( κ = 10 -5 ) and overloaded ( κ = 20) equatorial flows are exhibited, for a black hole spin parameter ˜ = 0 95, and an energy deposition profile a . f ( x ) = x -4 5 . . In the right panel we also exhibit solutions with κ = 0 4, 1, 6, and . κ = ∞ (a purely hydrodynamic flow), that are not shown in the left panel for clarity. As seen, the energy flux of the underloaded solutions is positive everywhere, whereas that of overloaded solutions changes sign below the stagnation radius. The location r 0 at which ˙ ( E r 0 , θ ) = 0 approaches r st as κ θ ( ) → ∞ . We think that this peculiar behavior stems from the fact that in the regime Ω F < ω H the Poynting flux measured by a distant observer is always driven by the black hole (i.e., by frame dragging). To elucidate this point we employ Equation (A16) to obtain the Poynting flux on the horizon:
$$\left ( \frac { F ^ { r \theta } F _ { \theta t } } { 4 \pi } \right ) _ { H } = - \frac { \varpi _ { H } ^ { 2 } \Omega _ { F } ( \omega _ { H } - \Omega _ { F } ) } { M _ { H } ^ { 2 } + \varpi _ { H } ^ { 2 } ( \omega _ { H } - \Omega _ { F } ) ^ { 2 } } ( \epsilon _ { H } ^ { r } - \omega _ { H } l _ { H } ^ { r } ). \\ \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots$$
Now, /epsilon1 r H -ω H H l r = ρ H u r H ( E H -ω H L H ) is always negative, since the ZAMO energy is always positive, viz., E ZAMO = E ω L > 0, and u r H < 0. Thus, for any value of the load parameter, the electromagnetic flux on the horizon is positive if ω H > Ω . Note also that in the force-free limit F M 2 H → 0, and (19) reduces to the familiar result, /epsilon1 r H = ( F rθ F θt ) H / 4 π , whereas in the pure hydrodynamic case M 2 H → ∞ and the Poynting flux vanishes, as expected. Figure 4 shows the electric current, I = α/pi1B ϕ , for two overloaded solutions, and it is seen that it never changes sign. We find that this is true in general in the regime 0 < Ω F < ω H , implying that for any value of κ there is a continuous flow of Poynting energy from the horizon outwards, against the inflow of injected plasma. In particular, at the stagnation radius B ϕ ( r st ) < 0, and from Equation (A7) we obtain 1
$$\epsilon _ { s t } ^ { r } & = - \left ( \frac { \varpi \Omega _ { F } B _ { \varphi } B _ { r } } { 4 \pi \sqrt { g _ { r r } } } \right ) _ { s t } = \left ( \frac { F ^ { r \theta } F _ { \theta t } } { 4 \pi } \right ) _ { s t } > 0. \\ \intertext { a n d a t i n d } r & \leq \alpha \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{cases}$$
Since for overloaded solutions /epsilon1 r H < 0, it is evident that the energy flux must vanish at some radius r < r st , as seen in the right panel of Figure 3. Our interpretation is that the outward flow of electromagnetic energy driven by the black hole is counteracted by an inward flow of kinetic energy injected on magnetic flux tubes. When the latter exceeds the former the net energy flux becomes negative. For κ θ ( ) << 1 this never happens, implying energy extraction from the black hole. For κ θ ( ) >> 1 this happens close to the stagnation radius, and since /epsilon1 r H < 0 we infer that the black hole is being fed by the energy of the overloaded inflow (i.e., the energy injected below the stagnation radius).
Figure 5 displays the dependence of the outflow power on the load in the regime where rotational energy extraction is switched on, viz., /epsilon1 r H > 0. For reference, powers are normalized to the equatorial BZ power,
1 This point was not properly understood in GL13. The claim made there, that for overloaded solutions B ϕ must vanish at r st is incorrect. However, the conclusion regarding the activation of the BZ process remains valid, as confirmed in the present analysis.
P BZ ( π/ 2). The horizontal axis gives values of the parameter ˙ E in νν ¯ ( θ /P ) BZ ( π/ 2), which for the equatorial flow ( θ = π/ 2) is just the load parameter κ θ ( ) defined in Equation (18). For other streamlines, the load parameter is obtained by multiplying values on the horizontal axis by the factor P BZ ( π/ 2) /P BZ ( θ ). The dashed lines delineate the normalized power extracted from the black hole, ˙ E H ( θ /P ) BZ ( π/ 2), and the solid lines the asymptotic power at infinity, ˙ E ∞ ( θ /P ) BZ ( π/ 2). These lines are essentially the locus of solutions obtained from the numerical integration of Equations (1)-(4). Specific cases are indicated by the symbols; the circles correspond to solutions for which Ω F = ω H / 2 and the triangles to solutions for which Ω F = ω H / 4. As seen, the effect of the load is highly insensitive to the value of Ω F , even though the structure of the flow does depend on this parameter (see Figure 6 below). This analysis confirms that the transition from underloaded to overloaded flows occurs at κ θ ( ) /similarequal 1. We also computed solutions for different black hole spins, and found the same behavior (see, for example, Figure 4 in GL13). One caveat is the possibility of a nonlinear feedback of the load on the magnetic flux in the vicinity of the horizon. Such a feedback may, in principle, change somewhat the activation condition, but not in a drastic way. It may be possible to test it using numerical simulations.
As explained above, in our model the angular velocity Ω F is given as an input. In reality it is determined by global conditions. For nearly force-free flows numerical simulations indicate that Ω F /similarequal ω H / 2. We therefore used this value for the underloaded solutions. However, when the inertia of the injected plasma becomes important, it is likely to affect Ω F . To study how the properties of the flow depend on this parameter, we sought solutions with different values of Ω F ( θ ), but the same value of κ θ ( ). An example is presented in Figure 6, and it is seen that while the velocity profile depends on Ω F , the power profile is insensitive to the choice of this parameter. In particular, it does not affect at all the activation condition. We find this trend is quite general, and therefore conclude that the result exhibited in Figure 5 is robust.
## 5. Conclusion
We constructed a semi-analytic model for the double-transonic flow established in the magnetosphere of a Kerr black hole under conditions anticipated in GRBs, incorporating plasma deposition on magnetic field lines via annihilation of MeV neutrinos emitted by the surrounding hyper-accretion flow. We examined the effect of energy loading on the properties of the flow, and identified the different operation regimes. We find that magnetic extraction of the black hole spin energy ensues, as long as the power deposited below the stagnation radius separating the inflow and outflow sections is smaller than the force-free BZ power. The transition from underloaded flows that are powered by the black hole spin energy, to overloaded flows that are powered by the neutrino source is continuous, as seen in Figure 5.
To relate the load parameter derived in Equation (18) to the accretion rate ˙ m acc (henceforth measured in units of M /circledot s -1 ), we employ the scaling relation derived in ZB11. As mentioned above, their analysis, that exploit an advanced disk model, yields a total energy deposition rate of
$$\dot { E } _ { \nu \bar { \nu } } ^ { t o t } \simeq 1 0 ^ { 5 2 } \left ( M _ { B H } / 3 M _ { \odot } \right ) ^ { - 3 / 2 } \dot { m } _ { a c c } ^ { 9 / 4 } x _ { m s o } ^ { - 4. 8 } \ \text{erg s} ^ { - 1 },$$
for accretion rates in the range 0 02 . < m ˙ acc < 1, where x mso is the radius of the marginally stable orbit in units of m . Combining the latter result with the activation condition derived from Figure 5, and using the angle averaged energy deposition rate, yields a rough estimate for the accretion rate at which a transition from underloaded to overloaded solutions occurs:
$$\dot { m } _ { c } \simeq 1 \left ( \frac { M _ { B H } } { 3 M _ { \odot } } \right ) ^ { - 2 / 9 } \left ( \frac { \Psi _ { 0 } } { 1 0 ^ { 2 8 } \, G \, \text{cm} ^ { 2 } } \right ) ^ { 8 / 9 } f ( \tilde { a } ).$$
Here Ψ 0 is the magnetic flux accumulated in the vicinity of the horizon, and the function f (˜) is displayed a in Figure 7. According to this relation, when ˙ m acc < m ˙ c the outflow is powered by the BZ process, whereas for ˙ m acc > m ˙ c it is driven by the neutrino source. In reality, the magnetic flux Ψ 0 should also depend on the accretion rate, however, the sensitivity of this relation to the assumptions underlying the specific disk model adopted for its calculation renders it highly uncertain. Furtheremore, the presence of sufficiently strong magnetic field in the inner disk regions may affect the neutrino luminosity. For illustration, we use the disk model of Chen & Beloborodov (2007) to estimate the magnetic flux. Unfortunately, it is difficult to derive scaling relations from the results presented in this paper, but from Figures 1 and 2 there we obtained Ψ 0 ∼ 2 × 10 28 √ ξ B G cm 2 for a black hole mass M BH = 3 M /circledot , angular momentum ˜ = 0 95, viscosity a . parameter α vis = 0 1, and accretion rate . ˙ m acc = 0 2, assuming that the magnetic pressure in the inner . regions of the disk is a fraction ξ B of the total pressure. For this choice we infer that with ξ B on the order of a few percents, as naively expected, the transition from underloaded to overloaded flows may occur at accretion rates ˙ m acc > 0 1 or so. . We emphasize that this estimate is highly uncertain.
The above results may also have some implications for the jet structure. To be concrete, the dependence of the activation condition on the inclination angle θ of magnetic surfaces (see Figure 5), and the approximate uniformity of the angular distribution of the energy deposition rate indicated in Figures 2 and 3 of ZB11, suggest that for accretion rates ˙ m acc < ∼ ˙ m c , and unless the magnetic flux near horizon is extremely high, the outflow produced in the polar region may consist of an inner core inside which the power is dominated by the thermal energy of the hot plasma, and outside which it is dominated by the Poynting flux driven by frame dragging.
This research was supported by a grant from the Israel Science Foundation no. 1277/13
## A. Derivation of the flow equations
The stress-energy tensor of a magnetized fluid takes the form,
$$T ^ { \alpha \beta } & = \bar { h } \rho c ^ { 2 } u ^ { \alpha } u ^ { \beta } + p g ^ { \alpha \beta } + \frac { 1 } { 4 \pi } \left ( F ^ { \alpha \gamma } F ^ { \beta } _ { \gamma } - \frac { 1 } { 4 } g ^ { \alpha \beta } F ^ { 2 } \right ), \\ & \quad \quad \quad$$
here u α is the four-velocity measured in units of c, ¯ h = ( ρc 2 + e int + ) p /ρc 2 the dimensionless specific enthalpy, ρ the baryonic rest-mass density, p the pressure, and g µν the coefficients of the metric tensor of the Kerr spacetime. In the following we use geometrical units ( c = G = 1), unless otherwise stated, and express the Kerr metric in the regular Boyer-Lindquist coordinates, ds 2 ≡ g µν dx dx µ ν with the non-zero metric coefficients given by: g rr = Σ ∆, / g θθ = Σ, g ϕϕ ≡ /pi1 2 = A sin 2 θ/ Σ, g tt = -α 2 + ω g 2 φφ , g tφ = -ωg φφ , in terms of ∆ = r 2 + a 2 -2 mr , Σ = r 2 + a 2 cos 2 θ , A = ( r 2 + a 2 ) 2 -a 2 ∆sin 2 θ , α = √ Σ∆ /A , and ω = 2 mra/A . The parameters m and a are the mass and specific angular momentum per unit mass of the hole, α is the time lapse and ω the frame dragging potential between a zero-angular-momentum observer (ZAMO) and an observer at infinity. The angular velocity of the black hole is defined as the value of ω on the horizon, viz., ω H ≡ ω r ( = r H ) = a/ (2 mr H ), here r H = m + √ m 2 -a 2 is the radius of the horizon, obtained from the condition ∆ H = 0.
The dynamics of the flow is governed by the energy-momentum equations:
$$\frac { 1 } { \sqrt { - g } } ( \sqrt { - g } T ^ { \alpha \beta } ) _ {, \alpha } + \Gamma ^ { \beta } _ { \ \mu \nu } T ^ { \mu \nu } = q ^ { \beta },$$
mass conservation:
and Maxwell's equations:
$$\frac { 1 } { \sqrt { - g } } \partial _ { \alpha } ( \sqrt { - g } \rho u ^ { \alpha } ) = q _ { n },$$
$$F _ { ; \alpha } ^ { \beta \alpha } & = \frac { 1 } { \sqrt { - g } } ( \sqrt { - g } F ^ { \beta \alpha } ) _ {, \alpha } = 4 \pi j ^ { \beta }, \\ & F _ { \alpha \beta \cdot \gamma } + F _ { \beta \cdot \alpha } + F _ { \gamma \alpha \cdot \beta } = 0,$$
$$F _ { \alpha \beta, \gamma } + F _ { \beta \gamma, \alpha } + F _ { \gamma \alpha, \beta } = 0,$$
subject to the ideal MHD condition F µν u ν = 0. Here, q β denotes the source terms associated with energymomentum transfer by an external agent, q n is a particle source, and Γ β µν denotes the affine connection.
The energy, angular momentum and entropy fluxes, can be expressed explicitly as
$$\epsilon ^ { a } \equiv - T _ { t } ^ { a } = \rho u ^ { a } \mathcal { E }, \ \ l ^ { a } \equiv T _ { \varphi } ^ { a } = \rho u ^ { a } \mathcal { L }, \ \ s ^ { a } = ( \rho / m _ { N } ) u ^ { a } s,$$
in terms of the energy per baryon,
$$\mathcal { E } = - \bar { h } u _ { t } - \frac { \alpha \varpi \Omega _ { F } } { 4 \pi \eta } B _ { \varphi },$$
$$\mathcal { L } = \bar { h } u _ { \varphi } - \frac { \alpha \varpi B _ { \varphi } } { 4 \pi \eta },$$
and the entropy per baryon s , where
$$\alpha _ { F } = v ^ { \varphi } - \frac { v _ { p } B _ { \varphi } } { \varpi B _ { p } }$$
is the angular velocity of magnetic field lines,
$$\eta = \frac { \rho u _ { p } } { B _ { p } }$$
is the ratio of mass and magnetic fluxes, and the index a runs over r and θ . In the above equations u p = ± ( u u r r + u u θ θ ) 1 / 2 is the poloidal velocity, where the plus sign applies to outflow lines and the minus sign to inflow lines, v p = u /γ p , with γ = u α t being the Lorentz factor measured by a ZAMO, v ϕ = u ϕ /u t , B p = ( B 2 r + B 2 θ ) 1 / 2 /α is the redshifted poloidal magnetic field, and B r = F θϕ / √ A sin θ , B θ = √ ∆ F ϕr / √ A sin θ and B ϕ = √ ∆ F rθ / Σ the magnetic field components measured by a ZAMO (see van Putten and Levinson 2012 for details). Note that with our sign convention the value of η is defined to be positive on outflow lines and negative on inflow lines.
For a stationary and axisymmetric ideal MHD flow, Equations (A2)-(A5) can be reduced to (GL13)
$$\frac { 1 } { \sqrt { - g } } \partial _ { a } ( \sqrt { - g } \epsilon ^ { a } ) & = - q _ { t }, & ( \text{A11} ) \\ 1 \quad \sim \sim \frac { 1 } { 2 } \sim \frac { 1 } { 2 } \sim \frac { 1 } { 2 } \sim \cos$$
$$\stackrel { \kappa } { \frac { k T } { \sqrt { - g } } } \partial _ { a } ( \sqrt { - g } s ^ { a } ) & = - u _ { a } q ^ { \alpha }, & ( \text{A13} ) \\ \stackrel { w ^ { a } \lambda } { w ^ { a } \lambda } - \stackrel { u _ { p } q _ { n } } { \underline { u _ { p } q _ { n } } } & \text{$\ell \, \Lambda \, \Lambda$}$$
$$\frac { 1 } { \sqrt { - g } } \partial _ { a } ( \sqrt { - g } l ^ { a } ) & = q _ { \varphi }, & ( \text{A12} ) \\ k T \quad \sim \tilde { \sim } \longrightarrow \tilde { \sim } \tilde { \sim } \quad \tilde { \sim }$$
$$\begin{smallmatrix} \mathfrak { v } & \mathfrak { s } \\ u ^ { a } \partial _ { a } \eta = \frac { u _ { p } q _ { n } } { B _ { p } }, \\ \dots \dots \cdot \end{smallmatrix}$$
$$u ^ { a } \partial _ { a } \Omega ( \Psi ) & = 0.$$
angular momentum per baryon,
It can be readily seen that for q n = q µ = 0, the quantities Ω(Ψ), E (Ψ), L (Ψ), η (Ψ) and s (Ψ) are conserved on magnetic flux surfaces Ψ( r, θ ) =const, as is well known (e.g., Camenzind 1986).
From (A7)-(A10) we obtain the expressions:
$$B _ { \varphi } & = - \frac { 4 \pi \eta \mathcal { E } } { \alpha \varpi } \, \frac { \alpha ^ { 2 } \tilde { L } - \varpi ^ { 2 } ( \Omega _ { F } - \omega ) ( 1 - \tilde { L } \omega ) } { k _ { 0 } - M ^ { 2 } } \\, & \quad \mathcal { E } \, \alpha ^ { 2 } ( 1 - \Omega _ { F } \tilde { L } ) - M ^ { 2 } ( 1 - \omega \tilde { L } ) & \dots$$
$$u ^ { \varphi } = \frac { \cdot \cdot } { \overline { h } } \frac { \stackrel { \cdot \cdot } { \alpha } ^ { 2 } \Omega _ { F } ( 1 - \Omega _ { F } \tilde { L } ) - M ^ { 2 } \omega ( 1 - \omega \tilde { L } ) - M ^ { 2 } \tilde { L } \alpha ^ { 2 } \varpi ^ { - 2 } } { \alpha ^ { 2 } \left ( k _ { 0 } - M ^ { 2 } \right ) } \,, \quad \quad \quad$$
$$u ^ { t } & = \frac { \stackrel { \cdots } { \bar { h } } } { \bar { h } } \frac { \stackrel { \cdots } { \alpha ^ { 2 } ( 1 - \Omega _ { F } \tilde { L } ) - M ^ { 2 } ( 1 - \omega \tilde { L } ) } } { \alpha ^ { 2 } \left ( k _ { 0 } - M ^ { 2 } \right ) }, \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
here ˜ = L L E / , M as the poloidal Alfv´nic Mach number, defined through e M 2 ≡ 4 πhη c /ρ ¯ 2 2 = u /u 2 p 2 A , and u 2 A = B / 2 p (4 πhρc ¯ 2 ). Combining the latter relations with the normalization condition u α u α = -1 yields the Bernoulli equation (Camenzind, 1986; Takahashi et al. 1990):
$$u _ { p } ^ { 2 } + 1 = \left ( \frac { \mathcal { E } } { \bar { h } } \right ) ^ { 2 } \frac { k _ { 0 } k _ { 2 } - 2 k _ { 2 } M ^ { 2 } - k _ { 4 } M ^ { 4 } } { ( k _ { 0 } - M ^ { 2 } ) ^ { 2 } } \,,$$
where
$$k _ { 2 } \ = \ \begin{array} { c c } ( 1 - \tilde { L } \Omega ) ^ { 2 }, \\ \tilde { r } \, 2 \quad ( 1 - \tilde { r }, \lambda ^ { 2 } ) \end{array}$$
$$k _ { 0 } \ & = \ \alpha ^ { 2 } - \varpi ^ { 2 } \left ( \Omega _ { F } - \omega \right ) ^ { 2 }, \\ 1. \ & = \ \bar { \ t } 1 \quad \tilde { \ t } \, \varpi ^ { 2 } \quad \bar { \ t } \, \varpi ^ { 1 } \, \searrow$$
$$k _ { 4 } \ = \ \frac { \lambda } { \varpi ^ { 2 } } - \frac { \lambda ^ { \cdot } } { \alpha ^ { 2 } } \,.$$
In terms of the free variables, /epsilon1 r , l r , p , used in our integration we have: η E = √ Σ /epsilon1 r / ( √ ∆ B p ), and E /h ¯ = /epsilon1 r / (4 pu r ), ˜ = L l r //epsilon1 r .
The equation of motion (4) is obtained upon differentiating Equation (A19) along a given streamline, using Equations (A11)-(A13) with the source terms q t = -αQ f x ˙ 0 ( ), q φ = 0 and u α q α = u q t t , which are derived in section 2.1, and noting that in the split monopole geometry, the redshifted poloidal field reduces to B p = Ψ 0 / (2 π √ Σ∆), the poloidal velocity is u p = √ Σ ∆ / u r , and the convective derivative reduces to u α ∂ α = u ∂ r r = √ ∆ Σ / u ∂ p r . This yields the following expressions for the functionals D N , ad and N q in Equation (4):
$$u \, \psi _ { \alpha } - u \, \psi _ { r } - \, \sqcup \, \psi _ { d } \, \psi _ { r }. \, \ i m s y e s u n e \, \text{inowing expressions} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{incase} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in class} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in cases} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in Case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{inCase} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{inclass} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{in case} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing} \, \text{inclosing}$$
where the derivatives are defined by
$$\partial _ { x } k _ { 0 } \ = \ \underset { \mathfrak { g } _ { 0 } } { \partial _ { x } ( \alpha ^ { 2 } ) - ( \Omega _ { F } - \omega ) ^ { 2 } } \, \partial _ { x } ( \varpi ^ { 2 } ) + 2 \varpi ^ { 2 } \, ( \Omega _ { F } - \omega ) \, \partial _ { x } \omega, \\ \mathfrak { g } _ { 0 } \tilde { \tau } _ { 1 } \,,$$
$$\partial _ { x } k _ { a d } \ = \ \frac { 2 } { \alpha ^ { 2 } } ( 1 - \tilde { L } \omega ) ^ { 2 } \partial _ { x } \ln \alpha + \frac { 2 \tilde { L } \omega } { \alpha ^ { 2 } } ( 1 - \tilde { L } \omega ) \partial _ { x } \ln \omega - \frac { 2 \tilde { L } ^ { 2 } } { \varpi ^ { 2 } } \partial _ { x } \ln \varpi \,.$$
## A.1. The stagnation point
At the stagnation point x = x st , where u p = 0, Equations (1)-(4) with q ϕ = 0 yield:
$$\partial _ { x } u _ { p _ { | _ { x = x _ { s t } } } } \ = \ - \frac { ( \Sigma q _ { t } ) _ { s t } } { 4 p _ { s t } \alpha _ { s t } ( k _ { 0 s t } \, A _ { s t } ) ^ { 1 / 2 } },$$
$$= \ - \frac { ( \langle q _ { t } ) s t } { 4 p _ { s t } \alpha _ { s t } ( k _ { 0 s t } \, A _ { s t } ) ^ { 1 / 2 } }$$
$$( A 2 8 )$$
$$\partial _ { x } ( \Sigma \epsilon ^ { r } ) _ { | _ { x = x _ { s t } } } \ = \ - & ( \Sigma q _ { t } ) _ { s t } \,, \\ \intertext { a } \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \\ \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \\ \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \\ \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \begin{matrix} \partial _ { x } ( \Sigma q _ { t } ) _ { s t } \,, \end{matrix} \, \end{matrix}$$
$$\frac { 3 } { 4 } \partial _ { x } \ln ( p ) _ { | _ { x = x _ { s t } } } ^ { \mu ^ { \nu ^ { \nu ^ { \nu } } } } \ = \ - \frac { x _ { s t } - 1 } { \Delta _ { s t } } - \frac { x _ { s t } } { \Sigma _ { s t } } - \frac { \Sigma _ { s t } ^ { 2 } f ( x _ { s t } ) \epsilon _ { s t } ^ { r } ( 1 - \omega _ { s t } / \Omega _ { F } ) } { 8 p _ { s t } \alpha _ { s t } k _ { 0 s t } \tilde { p } _ { B } },$$
where -(Σ q t ) st = α st Σ st ˙ Q f x 0 ( st ), and the parameter ˜ p B ≡ Ψ 2 0 c/ (32 π Q m 3 ˙ 0 5 ) is an indicator for the load.
The Bernoulli condition can be rewritten
$$( 1 - \tilde { L } _ { s t } \Omega _ { F } ) \frac { \epsilon _ { s t } ^ { r } } { ( 4 p u ^ { r } ) _ { s t } } = \sqrt { k _ { 0 s t } } \,, & & ( A 3 1 ) \\ \otimes & \text{as we have shown. there is always extraction of angular momentum from the}$$
implying ˜ L st Ω F = 1, since as we have shown, there is always extraction of angular momentum from the black hole so that /epsilon1 r st > 0.
## A.2. The Alfv´ en surfaces
The location of the Alfv´n surfaces is defined by the roots of the denominator in Equations (A16)-(A18), e M 2 A = k 0 A = α 2 A -/pi1 2 A (Ω F -ω A ) 2 , here the subscript A denotes values on this surface. The latter equation has two roots, corresponding to the inner and outer Alfv´ en surfaces. The requirement that B ϕ , u t and u ϕ in Equations (A16)-(A18) are continuous there imposes a condition on the ratio of the ZAMO energy, E ZAMO = E ω L , and the energy E of an observer at infinity:
$$\left ( \frac { \mathcal { E } } { \mathcal { E } ^ { Z A M O } } \right ) _ { A } = 1 - \alpha _ { A } ^ { - 2 } \varpi _ { A } ^ { 2 } \omega _ { A } ( \omega _ { A } - \Omega _ { F } ). & ( A 3 2 ) \\ \intertext { t h D 7 } \text{when to attributed } \tilde { r } \, = \, \partial r \, \mathcal { C } \, \circ \, \text{and} \, \, \text{and} \, \text{and} \, \text{and} \, \text{when} \, \mathcal { C } \, \circ \, \text{and} \, \text{when} \, \text{below}$$
In the regime where the BZ process is activated, /epsilon1 r H = ρu r E > 0, and we must have E < 0 anywhere below the stagnation radius where u r < 0, and in particular at the inner Alfv´n point ( e IA ). Since the ZAMO energy is always positive, the latter condition, combined with Equation (A32), readily implies ω IA > Ω , F and defines the range of Alfv´n radii that are permitted for energy extraction: e
$$\alpha _ { I A } \, \frac { \alpha _ { I A } } { \sqrt { \omega _ { I A } ( \omega _ { I A } - \Omega _ { F } ) } } & < \varpi _ { I A }. & ( A 3 3 ) \\ \vdots \text{marks this range for solutions with } \Omega _ { F } = \omega _ { H } / 2. \text{ In the outflow section all} \\ \tilde { \Phi } _ { \Phi } \,. & > \, \Omega _ { \Phi } \,. & \text{ and}$$
The shaded area in Figure 8 marks this range for solutions with Ω F = ω H / 2. In the outflow section all energies are positive, yielding ω OA < Ω , and F
at the outer Alfv´n point ( e OA ).
$$\mathbb { m } { \omega } _ { O A } & \sim \mathbb { m } { F }, \, \Gamma _ { A } \\ & \quad \frac { \alpha _ { O A } } { \sqrt { \omega _ { O A } ( \omega _ { O A } - \Omega _ { F } ) } } > \varpi _ { O A }, & ( A 3 4 ) \\ \mathbb { m } { A } ).$$
## B. Pure hydrodynamic flows
The equations governing a purely hydrodynamic flow can be obtained formally from the MHD equations derived above upon taking the limit M 2 →∞ :
$$( u _ { p } ^ { 2 } - c _ { s } ^ { 2 } ) & \partial _ { x } \ln u _ { p } = N _ { a d } + N _ { q }, \\ / & \bullet \quad / \bullet 2 \circ \circ \bullet$$
$$N _ { q } = - \frac { 3 \, q _ { t } } { 2 \alpha ^ { 2 } \epsilon ^ { r } } ( 1 - \tilde { L } \omega ) \left ( \frac { \mathcal { E } } { \hbar } \right ) ^ { 2 } \left [ 1 + \left ( \frac { \mathcal { E } } { \hbar } \right ) ^ { 2 } \frac { 4 \, k _ { 4 } } { 3 } \right ] \,.$$
$$N _ { a d } = ( 1 + u _ { p } ^ { 2 } ) c _ { s } ^ { 2 } \left ( \frac { x } { \Sigma } + \frac { x - 1 } { \Delta } \right ) _ { \substack { \ell \\ \ell \lambda } } ^ { 2 } \left ( \frac { \mathcal { E } } { \bar { h } } \right ) ^ { 2 } \frac { 3 \partial _ { x } k _ { a d } } { 4 }, \\ \mathfrak { r } _ { \alpha }. \right ) _ { \substack { \ell \lambda } } ^ { 2 } \left [ \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \right ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \ \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \bottom ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \top ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left (
\left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \bar { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( { { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( ( { \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left ( \left \ \ {$$
$$\frac { 3 } { 4 } \partial _ { x } \ln \tilde { p } = - \partial _ { x } \ln u _ { p } - \frac { x } { \Sigma } - \frac { x - 1 } { \Delta } - \frac { q _ { t } ( 1 - \tilde { L } \omega ) } { \alpha ^ { 2 } \epsilon ^ { r } } \left ( \frac { \mathcal { E } } { \tilde { h } } \right ) ^ { 2 },$$
$$\partial _ { x } ( \Sigma \epsilon ^ { r } ) = - \Sigma q _ { t } \,, \quad \quad \quad$$
where now ˜ is a free parameter that describes the family of solutions, ˜ = L p p/Q t ˙ 0 d is the normalized pressure, with t d = GM BH /c 3 . The Bernoulli condition (A31) implies, in this limit, /epsilon1 r st = 0, as expected in the absence of magnetic fields. It can be readily shown that when M 2 → ∞ the slow-magnetosonic and Alfven speeds approach zero, whereas the fast-magnetosonic speed approaches the sound speed, c s = 1 / √ 2. Consequently, the above system of equations has critical points at u p = ± c s , as can be directly verified.
The regularity conditions at the sonic points, obtained from Equations (B2) and (B3), read:
$$2 \left ( \frac { x _ { c 1 } } { \Sigma _ { c 1 } } + \frac { x _ { c 1 } - 1 } { \Delta$$
$$2 \left ( \frac { x _ { c 2 } } { \Sigma _ { c 2 } } + \frac { x _ { c 2 } - 1 } { \Delta$$
/negationslash denoting the sonic point of the inflow (outflow) by x c 1 ( x c 2 ), and noting that u p = -1 / √ 2 at x c 1 , and u p = 1 / √ 2 at x c 2 . As seen, the existence of two sonic points, that is, x c 1 = x c 2 , is a consequence of energy injection. When f ( x ) = 0 the solutions of (B6) and (B7) merge, and the system has only one critical point, for either an inflow or an outflow, depending on the boundary conditions.
At the stagnation point, x = x st , the above equations yield
$$\tau \cdots \quad \partial _ { x } u _ { p _ { | x = \tilde { v } _ { s t } } } \ & = \$$
$$\partial _ { x } \ln ( \tilde { p } ) _ { | _ { x = x _ { s t } } } \ = \ \frac { 2 } {$$
$$\partial _ { x } u _ { p | _ { x = x _ { s t } } } & \ = \ \frac { \nu \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cd. } { 4 \tilde { p } _ { s t } \sqrt { \Delta _ { s t } } \alpha _ { s t } \sqrt { - k _ { 4, s t } } }, \\ \partial _ { x } ( \Sigma \epsilon ^ { r } ) _ { | _ { x = x _ { s t } } } & \ = \ \frac { - ( \Sigma q _ { t } ) _ { s t } \,, } { 2 \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots }$$
where ˜ p st = ˜( p x st ) is the normalized stagnation pressure. Thus, for a given choice of f ( x ) the solution is fully determined once x st and ˜ p st are known, since /epsilon1 r st = 0.
## REFERENCES
Blandford, R. D. & Znajek, R. L. 1977, MNRAS, 179, 433 Camenzind, M. 1986, ApJ, 162, 32 Chen, W-X. & Beloborodov, A. 2007, ApJ, 657, 383 Eichler, D., Livio, M., Piran, T. & Schramm, D. N. 1989, Nature, 340, 126 Fryer, C. L., & M´sz´ros, P. 2003, ApJ, 588, L25 e a Globus, N. & Levinson, A 2013, Phys. Rev. D, 88, 4046 Komissarov, S. & Barkov, M. 2009, MNRAS, 397, 1153 Levinson, A. 2006, ApJ, 648, 510 Levinson, A. & Eichler, D. 1993, ApJ, 418, 386 Levinson, A & Globus, N. 2013, ApJ, 770, 159 MacFadyen, A. I. & Woosley, S. E. 1999, ApJ, 524, 262 Paczy´ski, B. 1990, ApJ, 363, 218 n Popham, R., Woosley, S. E., & Fryer, C. 1999, ApJ, 518, 356 Takahashi, M., Nitta, S., Tatematsu, Y. & Tomimatsu, A. 1990, ApJ, 363, 206 van Putten, M. H. P. M. & Levinson, A. 2003, ApJ, 584, 937 van Putten, M. H. P. M. & Ostriker, E. C. 2001, ApJ, 552, 31
Thorne, K. S., MacDonald, D. A. & Price, R. H. 1986, Black Holes: The Membrane Paradigm (Yale University Press)
van Putten, M. H. P. M. & Levinson, A. 2012, Relativistic Astrophysics of the Transient Universe (Cambridge University Press)
Zalamea, I. & Beloborodov, A. 2011, MNRAS, 410, 2302
This preprint was prepared with the AAS L T E X macros v5.2. A
Fig. 1.- Illustration of the double-transonic flow model.
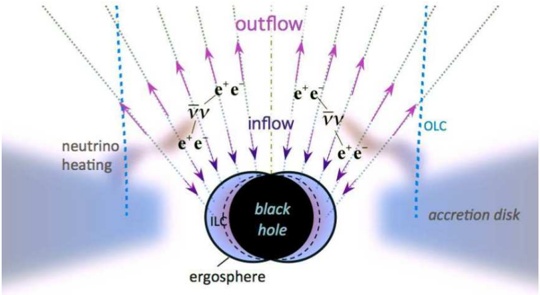
Fig. 2.- Net power deposited on magnetic field lines via neutrino annihilation as a function of radius x (Equation (12)), for two different injection profiles, f ( x ) = x -4 5 . and f ( x ) = x -3 5 . (˜ = 0 95). a .
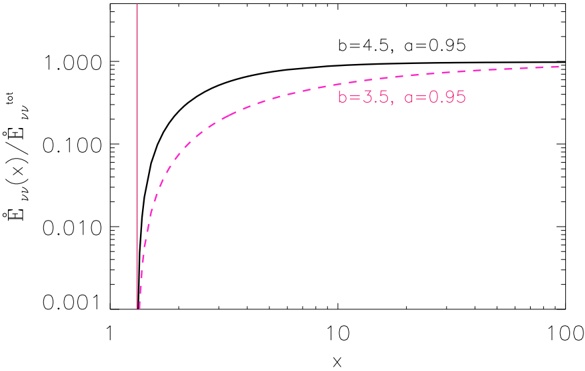
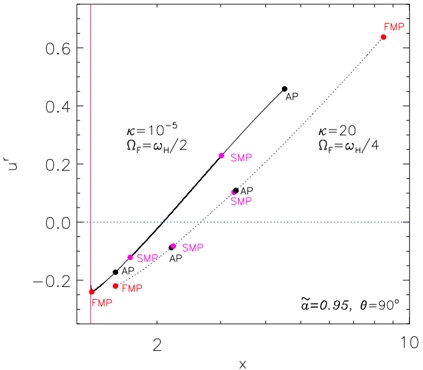
Fig. 3.- Left panel: velocity profiles of underloaded ( κ = 10 -5 ) and overloaded ( κ = 20) solutions, with f ( x ) = x -4 5 . , ˜ = 0 95, and a . θ = 90 . The region above (below) the horizontal dotted line ◦ u r = 0, corresponds to the outflow (inflow) sections. The inner and outer slow magnetosonic points (SMP), Alfv´n points (AP), e and fast magnetosonic points (FMP) are indicated. The vertical red line delineates the horizon. Right panel: profiles of the outflow power per solid angle for different values of the load parameter κ . The κ = 10 -5 and κ = 0 4 curves are rescaled for convenience. . The cross symbole on each curve marks the location of the stagnation radius. In the region of the inflow where the energy flux is positive (between the point of zero flux and the stagnation point) the specific energy is negative.
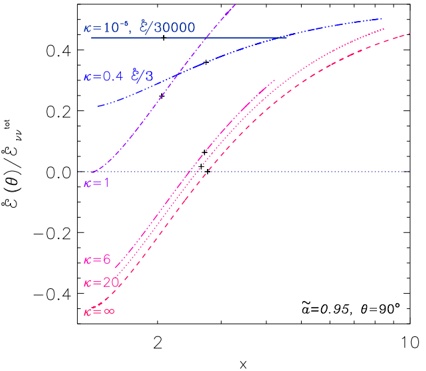
Fig. 4.- Electric current distribution, I ( x ) = B /pi1α ϕ , for equatorial flow solutions.
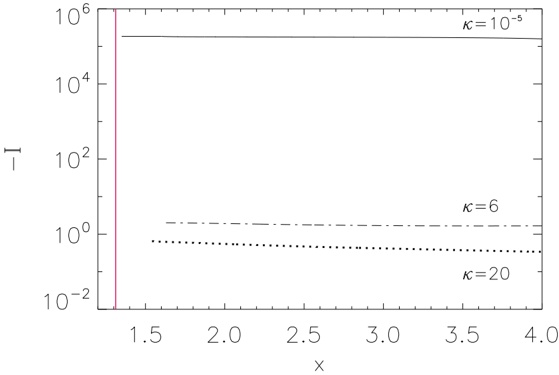
Fig. 5.- Dependence of the outflow power on the load for two different streamlines, θ = 90 , and ◦ θ = 30 . ◦ For reference, powers are normalized by the equatorial BZ power, P BZ ( π/ 2), given in Equation (17). The dashed line in each case gives the normalized power per solid angle on the horizon, ˙ E H ( θ /P ) BZ ( π/ 2), and the solid line the total power per solid angle, ˙ E ∞ ( θ /P ) BZ ( π/ 2). Specific cases are indicated by the symbols, with the circles corresponding to solutions for which Ω F = ω H / 2, and the triangles to solutions with Ω F = ω H / 4.
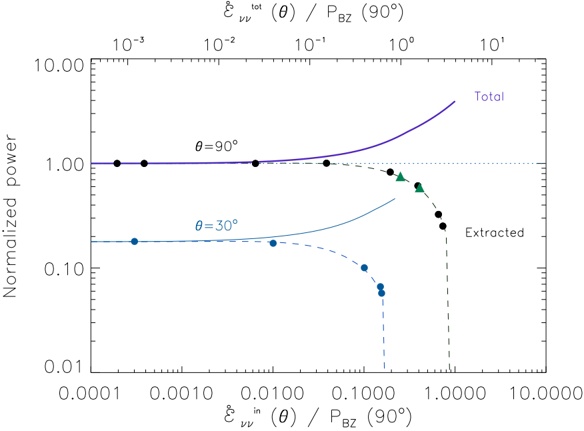
Fig. 6.- A comparison between two equatorial flow solutions with the same load parameter, κ = 0 4, and . different angular velocities Ω F , as indicated. The left panel displays the velocity profiles and the right panel the corresponding power profiles.
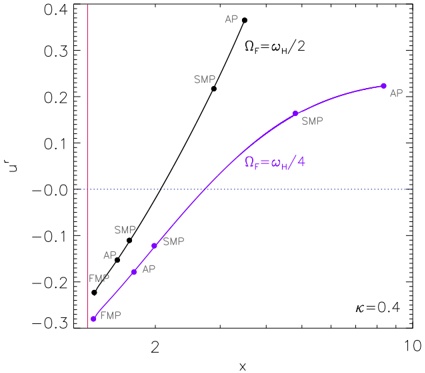
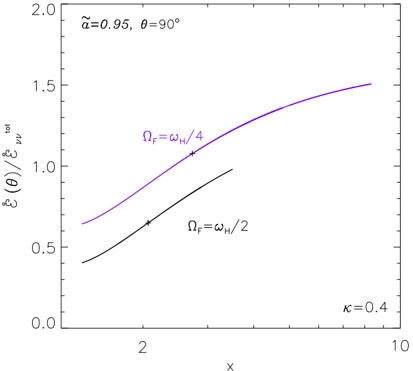
Fig. 7.- A plot of the function f (˜) defined in Equation (22). a
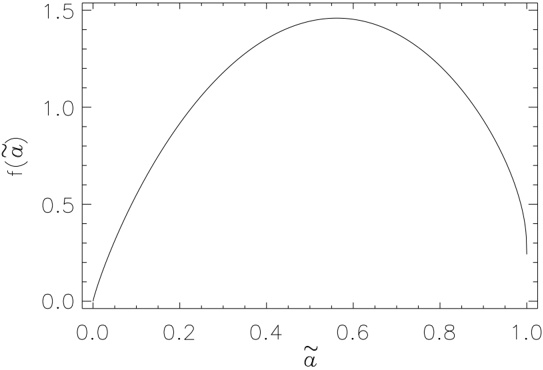
Fig. 8.- Effect of the loading efficiency on the position of the Alfv´n surfaces. The profile of e ˜ Ω L F is shown for 4 solutions corresponding to different values of κ , and ˜ = 0 95, Ω a . F = ω H / 2. The range of Alfv´n radii e that allows rotational energy extraction is delineated by the shaded area. In the force-free case ( κ → 0, ˙ E H = P BZ ) the Alfv´n points coincide with the light surfaces. e This result is in accord with that derived by Takahashi et al. (1990) for an adiabatic flow.
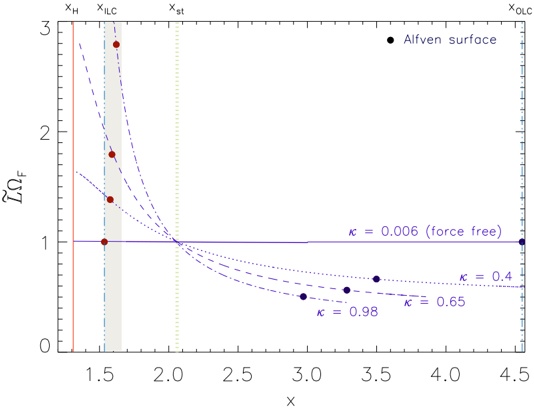 | 10.1088/0004-637X/796/1/26 | [
"Noemie Globus",
"Amir Levinson"
] | 2014-08-01T10:52:50+00:00 | 2014-08-01T10:52:50+00:00 | [
"astro-ph.HE"
] | Jet formation in GRBs: A semi-analytic model of MHD flow in Kerr geometry with realistic plasma injection | We construct a semi-analytic model for MHD flows in Kerr geometry, that
incorporates energy loading via neutrino annihilation on magnetic field lines
threading the horizon. We compute the double-flow structure for a wide range of
energy injection rates, and identify the different operation regimes. At low
injection rates the outflow is powered by the spinning black hole via the
Blandford-Znajek mechanism, whereas at high injection rates it is driven by the
pressure of the plasma deposited on magnetic field lines. In the intermediate
regime both processes contribute to the outflow formation. The parameter that
quantifies the load is the ratio of the net power injected below the stagnation
radius and the maximum power that can be extracted magnetically from the black
hole. |
1408.0127v1 | ## USING HOARE'S THEOREM TO FIND THE SIGNATURE OF A SUBGROUP OF AN NEC GROUP.
DAVID SINGERMAN AND PAUL WATSON
## 1. Introduction
There is a standard method, due to the first author, [6] of finding the signature of a subgroup Λ of a Fuchsian group Γ given the permutationn representation of Γ on the Λ -cosets. The structure of a non-Euclidean crystallographic (NEC) group is considerably more complicated, but a method of computing the signature of a subgroup was found by A. H. M. Hoare in [3] The purpose of this article is to explain how Hoare's Theorem is used and to give examples. Partial techniques to find the signature of a subgroup a are due to Gromadzki, [2].
The signature of a cocompact NEC group Γ has the form
$$( g ; \pm ; [ m _ { 1 }, \dots m _ { r } ] ; \{ ( n _ { 1 1 }, \dots n _ { 1 s _ { 1 } } ), \dots \{ ( n _ { k 1 }, \dots n _ { k s _ { k } } ) \} ) \quad \ ( 1 )$$
Here g is the genus of the quotient space H / Γ , ( H being the hyperbolic plane), m , . . . , m 1 r are the proper periods and the n ij are the link periods; the brackets ( n u 1 . . . n u su ) are called the period cycles.
Our problem is to find the signature of a subgroup Λ of finite index in Γ , given the permutation representation of Γ on the Λ cosets.
If Γ is a Fuchsian group then the result is in [6]. For Γ a proper NEC group the result follows from Hoare's theorem in [3]. This is rather more complicated to apply than for Fuchsian groups and the purpose of this note is to give a fairly algorithmic procedure to apply Hoare's result. (Much of this is derived from results in the second author's Southampton Ph.D. thesis,[8].)
The proper periods of the subgroup are computed in the same way as for Fuchsian groups. The major problem is to compute the link periods and the period cycles for Λ .
All reflections of Λ are conjugate to one of the generating reflections of Γ and so these correspond to fixed points of the generating reflections of Γ when acting on the right cosets of the subgroup by right multiplication. Thus if a reflection generator c i of Γ fixes a coset Λ g j then c ij = g c g j i -1 j ∈ Λ . We call c ij an induced reflection of Λ . Now
suppose that we have a period cycle ( n i 1 , n i 2 . . . n is i ) . This corresponds to a part of the presentation of Γ which has generators c i 0 , . . . c is i , e obeying the relations
$$c _ { i j - 1 } ^ { 2 } = c _ { i j } ^ { 2 } = ( c _ { i j - 1 } c _ { i j } ) ^ { n _ { i j } } = 1 = e _ { i } c _ { 0 } e _ { i } ^ { - 1 } c _ { s } = 1$$
We also have elliptic generators x i of orders m i so we have relations
$$x _ { j } ^ { m _ { j } } = 1$$
and also the long relations
$$x _ { 1 } \dots x _ { r } e _ { 1 } \dots e _ { k } a _ { 1 } b _ { 1 } a _ { 1 } ^ { - 1 } b _ { 1 } ^ { - 1 } \dots a _ { g } b _ { g } a _ { g } ^ { - 1 } b _ { g } ^ { - 1 } = 1$$
if H / Γ is orientable or
$$x _ { 1 } \dots x _ { r } e _ { 1 } \dots e _ { k } a _ { 1 } ^ { 2 } \dots a _ { g } ^ { 2 } = 1$$
if H / Γ is non-orientable.
The group Γ has a presentation which consists of the generators c , . . . , c 1 k , e 1 , . . . , e k , a 1 , b 1 , . . . , if H / Γ is orientable and c 1 . . . , c k , e 1 , . . . , e k , a 1 , . . . , a g
if H / Γ is non-orientable, and relations (2), (3),(4) if H / Γ is orientable and (2),(3), (5) if H / Γ is non-orientable.
The elements c i are reflections, x i elliptics, a , b i i hyperbolic in the orientable case and the a i are glide-reflections in the non-orientable case. The e i , called the connecting generators, are orientation-preserving and nearly always hyperbolic.
For these presentations see [5], [1].
Definition. Two reflections c and d of Γ are called linked with link period n if cd is an elliptic element of order n .
The following ideas come from Hoare's paper [3].
If c and d are linked reflection generators with link period n then c and d generate a dihedral group D n of order 2 n . Let σ be an orbit of the Λ -cosets under D n and let K be a coset in σ . If m is the least positive integer such that ( cd ) m ∈ K then either;
- a) σ contains no coset fixed by c or d in which case σ has length 2 m and gives an elliptic generator for Λ with period n/m , or
- b) σ contains two cosets fixed by c and d , one fixed by each if m is odd, two fixed by one and none by the other if m is even. Now σ has length m and the refection generators of Λ corresponding to the two fixed cosets are linked with period n/m . Each reflection generator of Λ appears in precisely two of these links, unless it is linked only to itself.
USING HOARE'S THEOREM TO FIND THE SIGNATURE OF A SUBGROUP OF AN NEC GROUP. 3
This gives the period cycles of Λ each coming from one of the period cycles of Γ .
- c) In a) above we find out how to get some proper periods of Λ . Other proper periods of Λ are just those induced by the proper periods of Γ . These are found in exactly the same way as in [6]. That is if x is an elliptic element of Γ of period n , then we let x act on the right Λ -cosets. by right multiplication. If we have an orbit (i.e. a cycle) of length m then there is an induced elliptic period equal to n/m in Λ . All elliptic periods of Λ are found in a) or c).
- d) The orientability of Λ is found by using [4]. If Γ is a group with generators Φ and Λ is a subgroup then the Schreier coset graph H (Γ Λ Φ) , , is the graph with vertices the cosets of Λ in Γ and directed edges at each vertex for each b ∈ Φ such that b : Λ g -→ Λ gb . If c is a reflection and if Λ gc = Λ g then the directed edge c : Λ g -→ Λ gc is a reflection loop . Let H be the Schreier graph with the reflection loops deleted. We call this the augmented Schreier graph. Each path in H corresponds to a word in Φ and hence to an element of Γ . A path is called positive (negative) if it corresponds to a orientation-preserving (orientation- reversing ) element of Γ . We label the edges of this graph with the generators of the group.
Then it was shown in [4] that H / Λ is orientable if and only if all circuits in H are positive, where H is the hyperbolic plane.
Finally, the genus of H / Λ is calculated using the Riemann-Hurwitz formula as usual. Usually, it is best to find the index | Γ + : Λ + | where Γ + (resp. Λ ) + is the canonical Fuchsian group of Γ , (resp. Λ ) the index two subgroups of orientation-preserving isometries. The signature of Γ + is found from [7].
## 2. The algorithm.
We suppose that Γ has a subgroup of index N and let the cosets be Λ g , 1 Λ g , . . . 2 Λ g N , which we represent in the usual way by 1 2 , , . . . .N . Then
Step 1. Write down the induced reflections.
- Step 2. Find all the links and link periods. Typically, c = c ij -1 and d = c ij are linked with link period n = n ij . Find the image of cd in the symmetric group S N and note the cycle lengths in this permutation. In particular the the lengths of the cycles containing fixed points of c or d will give the integers m above.
Step 3. Let c and d be two linked refections with link period n . Then c and d generate a dihedral group D n . Find the orbits of this D n in its action on the Λ -cosets. Let σ be an orbit and let K be a coset in σ (So K is just one of the integers 1 2 , , · · · , N .) Consider the cycles of cd . If there is a cycle of length m this just means that K cd ( ) m = K .
step 4 . Find the periods and link periods of the subgroup. If there are no cosets fixed by c or d in σ then Hoare's results in [3] tell us that σ has length 2 m and gives an elliptic period n/m in Λ .
If there are fixed cosets then
σ contains exactly two cosets fixed by c and d , one fixed by each if m is odd, two fixed by one and none by there other if m is even. Now σ has length m and the induced reflection generators of Λ are linked with link period n/m . We write c linked to d by c ∼ d . Each reflection generator of Λ occurs in exactly two of these links unless it is linked only to itself. This gives the period cycles of Λ , each coming from one of the period cycles of Γ .
Step 5. How to deal with the relation ec e 0 -1 c s = 1 .
Regard 〈 ec e 0 -1 , c s 〉 ∼ = D 1 . Now the orbits of 〈 ec e 0 -1 , c s 〉 ∼ = D 1 are the two-cycles of c s = ec e 0 -1 or the one-cycles, (fixed points). If we have a 2-cycle ( γ, δ ) then { γ, δ } is an orbit containing no fixed points of c s or ec e 0 -1 (= c s ) . Now ec e 0 -1 c s = 1 and so m = 1 and there is an elliptic period equal to 1 / 1 = 1 , that is no elliptic period at all. If c s = ec e 0 -1 fixes k then k ec e ( 0 -1 ) = k so c 0 fixes ke and we have a link c s ∼ c 0 ke with link period 1.
## Example 1
In our first examples we find all subgroups of index two in an extended triangle group. This is a group ∆ generated by three reflections in the sides of a triangle with angles π/n , π/n , π/n 1 2 3 . This has signature (0; +; [ ]; { n , n , n 1 2 3 } ) , which we usually denote by ( n , n , n 1 2 3 ) , which has presentation
$$\{ c _ { 1 }, c _ { 2 }, c _ { 3 } | c _ { 1 } ^ { 2 } = c _ { 2 } ^ { 2 } = c _ { 3 } ^ { 2 } = ( c _ { 1 } c _ { 2 } ) ^ { n _ { 1 } } = ( c _ { 2 } c _ { 3 } ) ^ { n _ { 2 } } = ( c _ { 3 } c _ { 1 } ) ^ { n _ { 3 } } = 1 \}.$$
There are 7 epimorphisms θ 1 : ∆ -→ C 2 = { e, t } , ( t 2 = 1 ).
- (1) θ 1 ( c i ) = t for i = 1 2 3 , , . Here the kernel (equal to the stabiliser of a point) is the canonical Fuchsian triangle group with signature (0; +; [ n , n , n 1 2 3 ]; { } ) usually denoted by [ n , n , n 1 2 3 ] .
- (2) θ 2 ( c 1 ) = θ c ( 2 ) = t = (1 2) , , θ c ( 3 ) = e = (1)(2) . Note that as θ c c ( 1 3 ) = θ c c ( 2 3 ) = t , n 2 and n 3 must be even.
USING HOARE'S THEOREM TO FIND THE SIGNATURE OF A SUBGROUP OF AN NEC GROUP. 5
We now use our algorithm to find Λ the stabiliser of a point.
Step 1. The induced reflections are c 31 , c 32 .
Step 2. Find the links and link periods. Here the links are c 1 ∼ c 2 with link period n 1 , c 2 ∼ c 3 with link period n 2 and c 3 ∼ c 1 with link period n 3 .
Step 3. Find the orbits of the dihedral subgroups. There are three dihedral subgroups here 〈 c , c 1 2 〉 ∼ = D l , 〈 c , c 2 3 〉 ∼ = D m , and 〈 c , c 3 1 〉 ∼ = D n . The orbits of all these three are { 1 2 , } . Also c c 1 2 = (1)(2) , and c c 2 3 = c c 3 1 = (1 2) , .
Step 4. We first notice that no coset is fixed by c , c 1 2 . The orbit σ of 〈 c , c 1 2 〉 has length 2 so that here m = 1 and so there is an elliptic period n 1 in Λ .
Now we consider the dihedral group 〈 c , c 2 3 〉 . Here the orbit has length 2 (which is even) and c 3 fixes two cosets 1 and 2 and c , 2 fixes no coset so c 31 ∼ c 32 . As c c 1 3 = (1 2) , , m = 2 and so the link period is n / 2 2 . Similarly , we also get c 31 ∼ c 32 from the orbit 〈 c , c 3 1 〉 . Here the link period is n / 3 2 . We get one chain c 3 ∼ c 2 ∼ c 3 and the period cycle is { n / 2 2 , n 3 / 2 } . As the augmented Schreier graph has two vertices, it cannot have any negative paths and so Λ has orientable quotient space. Thus the signature of Λ is of the form ( g ; +; [ n 1 ]; ( { n / 2 2 , n 3 / 2 } ) . We compute g using Riemann-Hurwitz. We pass to the canonical Fuchsian groups. ∆ + has Fuchsian signature (0; ( n , n , n 1 2 3 )) and Λ + has Fuchsian signature (2 g +1 -1; n , n , n 1 1 2 / 2 , n 3 / 2) . As the index of λ + in Γ + is two we apply Riemann-Hurwitz to get
$$4 g { - 2 } { + 1 } { - 1 } / n _ { 1 } { + 1 } { - 1 } / n _ { 1 } { + 1 } { - 2 } / n _ { 2 } { + 1 } { - 2 } / n _ { 3 } = 2 ( 1 { - 1 } / n _ { 1 } { - 1 } / n _ { 2 } { - 1 } / n _ { 3 } )$$
giving g = 0 . Thus the signature of the NEC group Λ is
$$( 0 ; + ; [ n _ { 1 } ] ; \{ ( n _ { 2 } / 2, n _ { 3 } / 2 ) \} ).$$
θ 2 ( c 1 ) = (1 2) , , θ 2 ( c 2 ) = θ c ( 3 ) = (1)(2) . Again we let Λ denote the stabiliser of a point.
Step 1. The induced reflections are c 21 , c 22 , c 31 , c 32
Step 2. The links are as in the previous example.
Step 3. The orbits of 〈 c , c 1 2 〉 and 〈 c , c 1 3 〉 are { 1 2 , } . The orbits of 〈 c , c 2 3 〉 are { } 1 and { } 2 . Also c c 1 2 = (1 2) ,
Step 4. The orbit of 〈 c , c 1 2 〉 contains two fixed points of c 2 and none of c 1 . As c c 1 2 = (1 2) , we find a link c 21 ∼ c 22 with link period n / 1 2 .
Now c c 2 3 = (1)(2) . By considering the two singleton orbits of 〈 c , c 2 3 〉 , we find that the orbit { } 1 contains 1 fixed point of c 2 and one fixed point of c 3 . Here c c 2 3 is the identity so m = 1 (odd!) so we get a link c 21 ∼ c 31 with link period n 2 . Similarly, by considering the orbit { } 2 we find a link c 22 ∼ c 32 with link period n 2 .
Also, the orbit of 〈 c , c 1 3 〉 contains two fixed points of c 3 and none of c 1 . (Note c c 1 3 = (1 2) , so m = 2 , (even!)). Thus c 31 ∼ c 32 with link period n / 3 2 . We thus have one chain
$$c _ { 2 1 } \sim c _ { 2 2 } \sim c _ { 3 2 } \sim c _ { 2 1 } \sim c _ { 3 1 } \sim c _ { 2 1 }$$
with link periods
$$n _ { 1 } / 2, n _ { 2 }, n _ { 3 } / 2, n _ { 2 }.$$
Thus Λ contains one period cycle ( n / 1 2 , n 2 , n 3 / 2 , n 2 ) .
As in the previous example, we show that we show that Λ has genus zero and orientable quotient space and so Λ has signature
$$( 0 ; + ; \{ ( n _ { 1 } / 2, n _ { 2 }, n _ { 3 } / 2, n _ { 2 } \} ).$$
By permuting n , n , n 1 2 3 we find the other possible subgroups of index two leading to the extended triangle group (0; +; [ ]; { n , n , n 1 2 3 ) } ) , to give
Theorem 1. The NEC triangle group ∆ of signature
$$( 0 ; + ; [ \ ] ; \{ n _ { 1 }, n _ { 2 }, n _ { 3 } ) \} )$$
has the Fuchsian triangle group [ n , n , n 1 2 3 ] as a subgroup of index two. If n , n 1 3 are even then the only other possible subgroups of index two in (0; +; [ ]; { n , n , n 1 2 3 ) } , have signatures
(0; +; [ n 2 ]; { ( n / 2 2 , n 3 / 2) }
$$( 0 ; + ; \, ; \, [ \, ] ; \{ ( n _ { 1 } / 2, n _ { 2 }, n _ { 3 } / 2, n _ { 2 } \} ) \,.$$
Similarly, if n , n 1 2 are even we get two other NEC subgroups of index 2 and if n , n 2 3 are even we get another two. Altogether this gives us our seven subgroups of index two in the extended triangle group, ( n , n , n 1 2 3 ) .
We now give other examples which illustrates all of the points used in Hoare's Theorem. The first one illustrates more fully how to find the period cycles and deal with empty period cycles.
## Example 2
USING HOARE'S THEOREM TO FIND THE SIGNATURE OF A SUBGROUP OF AN NEC GROUP. 7
Let Γ be an NEC group of signature
$$( 0 ; + ; [ \, ], \{ ( 2, 3 ), ( \, ) \} )$$
The canonical presentation of Γ is
$$\langle c _ { 0 }, c _ { 1 }, c _ { 2 }, d, e _ { 1 }, e _ { 2 } | c _ { 0 } ^ { 2 } = c _ { 1 } ^ { 2 } = ( c _ { 0 } c _ { 1 } ) ^ { 2 } = ( c _ { 1 } c _ { 2 } ) ^ { 3 } = d ^ { 2 } = 1, e _ { 1 } c _ { 0 } e _ { 1 } ^ { - 1 } = c _ { 2 }, e _ { 2 } d e _ { 2 } ^ { - 1 } = d, e _ { 1 } e _ { 2 } = 1 \rangle.$$
Consider the following permutation representation.
↦
c 0 -→ (1 , 2)(3)(4)
↦
c 1 -→ (1)(2)(3 , 4)
↦
$$c _ { 2 } \longmapsto ( 1, 3 ) ( 2 ) ( 4 )$$
↦
$$e _ { 1 } \longmapsto ( 1 ) ( 4 ) ( 2, 3 )$$
↦
$$e _ { 2 } \longmapsto ( 1 ) ( 4 ) ( 2, 3 )$$
↦
$$d \longmapsto ( 1 ) ( 4 ) ( 2, 3 )$$
We now follow our algorithm.
Step 1. The induced reflections are c 03 , c 04 , c 11 , c 12 , c 22 , c 24 , d 11 , d 14 .
Step 2. The links are c 0 ∼ c 1 with link period 2, c 1 ∼ c 2 with link period 3, e c e 1 0 -1 1 ∼ c 2 with link period 1 , e de 2 -1 2 ∼ d with link period 1.
Step 3. Find the orbits of the dihedral subgroups. These are 〈 c , c 0 1 〉 ∼ = D . 2 The orbits here are { 1 2 , } { , 3 4 , } , and c c 0 1 = (1 2)(3 4) , , .
〈 c , c 1 2 〉 ∼ = D 3 The orbits are { 1 3 4 , , } , { } 2 and c c 1 2 = (1 3 4)(2) , , .
〈 e c e 1 0 -1 1 , c 2 〉 ∼ = D 1 , The orbits are { 1 3 , } { , 2 } { , 4 } and ec e 0 -1 c 2 = (1)(2)(3)(4) .
〈 e de 2 -1 2 , d 〉 ∼ = D 1 . The orbits are { 1 3 , } { , 2 } { , 4 } and ede -1 d = (1)(2)(3)(4) .
Step 4. We have c c 0 1 = (1 2)(3 4) , , . In the cycle (1 , 2) we have two fixed points of c 1 and none of c 0 . (Note m = 2 here is even so we should have two fixed points of one generator and none of the other.) As n = 2 we have a link c 11 ∼ c 12 with link period 2 / 2 = 1
On the orbit { 3 4 , } of 〈 c , c 0 1 〉 we similarly get a link c 03 ∼ c 04 with link period equal to 1.
Now c c 1 2 = (1 3 4)(2) , , . In the cycle (1 , 3 4) , we have one fixed point 1 of c 1 and one fixed point 4 of c 2 so we get a link c 11 ∼ c 24 with link period 3 / 3 = 1 .
On the cycle { } 2 of 〈 c , c 1 2 〉 we have one fixed point of c 1 and one of c 2 , namely 2 in both cases and so we get a link c 12 ∼ c 22 with link period 3 / 1 = 3 .
Step 5. We now consider the dihedral group 〈 e c e 1 0 -1 1 , c 2 〉 ∼ = D 1 of order two. We have two fixed points of c , 0 namely 2 and 4. From step 5, we get links c 22 ∼ c 02 e 1 or c 22 ∼ c 03 with link period 1. Similarly we have the link c 24 ∼ c 04 with link period 1.
Putting all these links together we find that we only have one chain:
$$c _ { 1 1 } \sim c _ { 1 2 } \sim c _ { 2 2 } \sim c _ { 0 3 } \sim c _ { 0 4 } \sim c _ { 2 4 } \sim c _ { 1 1 }$$
All the link periods are equal to one except for the link period between c 24 and c 14 which is equal to 3. We can omit the link periods equal to one and so we are left with a single period cycle { (3) } .
We now find the number of period cycles induced by the empty period cycle of Γ . This empty period cycle corresponds to the reflection d , which gives two induced reflections d 1 and d 4 . This gives us two empty period cycles of Λ
We now consider the orientability of Λ . So we consider the augmented coset graph as described above. This graph has 4 vertices 1,2,3,4. We have an edge from 1 to 2, because of the reflection c 0 , an edge from 1 to 2 coming from the reflection c 1 and an edge from 1 to 3 because of the reflection d . Thus we have a triangle 1 -→ 2 -→ 3 -→ 1 . This gives an orientation-reversing loop and so Λ has non-orientable quotient space.
We now compute the genus of Λ . The group Γ has signature (8). Λ has a signature of the form ( g ; -[ ]; { (3) , ( ) , ( )) . By [[7] , Γ + has Fuchsian signature (1; 2 , 3) and Λ + has signature (g+2; 3). Riemann-Hurwitz now gives 2( g +2) -2 + 2 / 3 = 4 (7 . / 6) = 14 / 3 and thus g = 1 and so the signature of Λ is (1; [ ]; { (3) , ( ) , ( ) } ) .
The next example which comes from [8] illustrates more fully how to determine the proper periods of the subgroup.
## Example 3.
Let Γ be an NEC group of signature (0; +; [6 , 6]; { (5 , 8 12) , } ) and presentation with generators
$$x _ { 1 }, x _ { 2 }, e, c _ { 0 }, c _ { 1 }, c _ { 2 }, c _ { 3 },$$
USING HOARE'S THEOREM TO FIND THE SIGNATURE OF A SUBGROUP OF AN NEC GROUP. 9
and relations
$$x _ { 1 } ^ { 6 } = x _ { 2 } ^ { 6 } = c _ { 0 } ^ { 2 } = c _ { 1 } ^ { 2 } = c _ { 2 } ^ { 2 } = c _ { 3 } ^ { 2 } = ( c _ { 0 } c _ { 1 } ) ^ { 5 } = ( c _ { 1 } c _ { 2 } ) ^ { 8 } = ( c _ { 2 } c _ { 3 } ) ^ { 1 2 } = e c _ { 0 } e ^ { - 1 } = x _ { 1 } x _ { 2 } e = 1$$
Consider the following permutation representation of Γ
↦
$$x _ { 1 } \mapsto ( 1, 4 ) ( 2, 3, 6 ) ( 5 )$$
↦
$$x _ { 2 } \mapsto ( 1, 6, 2, 5, 4, 3 )$$
↦
$$e \mapsto ( 3, 2, 1 ) ( 6, 5, 4 ) )$$
↦
$$c _ { 0 } \mapsto ( 1, 2 ) ( 3, 4 ) ( 5 ) ( 6 )$$
↦
$$c _ { 1 } \mapsto ( 1, 3 ) ( 2, 6 ) ( 4 ) ( 5 )$$
↦
$$c _ { 2 } \mapsto ( 1, 4 ) ( 2, 6 ) ( 3, 5 )$$
↦
$$c _ { 3 } \mapsto ( 1, 5 ) ( 2, 3 ) ( 4 ) ( 6 )$$
Let Λ be the stabiliser of a point. We want to find the signature of Λ . We use our algorithm.
Step 1. The induced reflections are c 05 , c 06 , c 14 , c 15 , c 34 , c 36 .
Step 2. The links are c 0 ∼ c 1 with link period 5, c 1 ∼ c 2 with link period with link period 8, c 2 ∼ c 3 with link period 12, e -1 c e 0 ∼ c 3 with link period 1.
Step 3. Find the orbits of the dihedral subgroups.
〈 c , c 0 1 〉 ∼ = D 5 , The orbits are { 1 2 3 4 6 , , , , } { , 5 }
〈 c , c 1 2 〉 ∼ = D 8 , The orbits are { 1 3 4 5 , , , } { , 2 6 , }
〈 c , c 2 3 〉 ∼ = D 12 , Orbit { 1 2 3 4 5 6 , , , , , }
$$\langle e c _ { 0 } e ^ { - 1 }, c _ { 3 } \rangle \cong D _ { 1 }, \, \text{The orbits are } \{ 1, 5 \}, \{ 2, 3 \}, \{ 4 \}, \{ 6 \}$$
Step 4. On the orbit { 1 2 3 4 6 , , , , } of 〈 c , c 0 1 〉 we have one fixed point namely 6 of c 0 and one fixed point 5 of c 1 . This gives us a link c 06 ∼ c 15 with link period 5/5=1. On the orbit { } 5 we have one fixed point of both c 0 and c 1 This gives us a link c 05 ∼ c 15 with link period 5/1=5.
On the orbit { 1 3 4 5 , , , } of 〈{ c , c 1 2 }〉 we have two fixed points namely 4 and 5 of c 1 , giving the link c 14 ∼ c 15 . Here the period of the elliptic element is 8 and c c 1 2 has period 4 so that the link period is 8 / 4 = 2 .
Thus we have the following links, which give us one chain,
c 00 ∼ c 15 ∼ c 14 ∼ c 06 ∼ c 34 ∼ c 36 ∼ c 05 .
The link periods are 5 between c 05 and c 15 , 2 between c 15 and c 14 , 1 between c 14 and c 06 , 1 between c 06 and c 34 , 2 between c 34 and c 36 and 1 between c 36 and c 05 .
This gives us one period cycle { (2 , 2 5) , } .
The orbit { 2 6 , } of 〈 c , c 1 2 〉 contains no fixed points of c 1 or c 2 and so by step 4 of the algorithm this gives an elliptic period 8 / 1 = 8 on Λ . Also, the orbit { 2 3 , } of 〈 ec e 0 -1 , c 3 〉 contains no fixed points of c 3 and so gives an elliptic period 1 (which we can ignore).
Also, the elliptic elements x , x 1 2 induce elliptic periods on Λ of periods 2,3, and 6 from the permutation theorem for Fuchsian groups, [6].
Thus we have found that Λ has elliptic periods [2,3,6,8] and one period cycle { (2 , 2 5) , } .
For the orientability we draw the augmented Schreier coset graph. We find an edge labelled c 0 joining 1 and 2, an edge labelled c 3 joining 2 and 3 and an edge labelled c 1 joining 3 and 1. This gives us a triangle in the augmented Schreier graph and hence Λ has non-orientable quotient space, We now use the Riemann-Hurwitz formula as described above to find the genus of Λ . We find that it is 9, and so Λ has NEC signature
$$( 9 \, \colon - ; [ 2, 3, 6, 8 ] ; \{ ( 2, 2, 5 ) \} ).$$
## References
- [1] E. Bujalance, J. J. Etayo, J. M. Gamboa, G. Gromadzki, Automorphism groups of compact bordered Klein surfaces, Springer Lecture Notes in Mathematics 1439 (1990).
- [2] G. Gromadzki, On the Harnack-Natanzon Theorem for a family of real forms of Riemann surfaces, J.Pure Applied Algebra 121,253-269 (1997).
- [3] A. H. M. Hoare, Subgroups of NEC groups and finite permutation groups, Quart.J.Math,Oxford(2) 41 45-49 (1990).
- [4] A. H. M. Hoare and D.Singerman, Subgroups of plane groups, London Math. Soc. Lecture note series 71 (1982) 221-227
- [5] A. M. Macbeath, The classification of non-euclidean crystallographic groups. Can. J. Math 19 (1967) 1192-1205
- [6] D. Singerman, Subgroups of Fuchsian groups and finite permutation groups, Proc. London Math.Soc. (2) (1970),319-323.
- [7] D.Singerman, On the structure of non-Euclidean crystallographic groups, Proc. Camb. Phil. Soc. 76 (1974) 233-240.
- [8] P. D. Watson, Symmetries and automorphisms of compact Riemann surfaces, Ph.D. thesis, University of Southampton, (1995). | null | [
"David Singerman"
] | 2014-08-01T10:53:25+00:00 | 2014-08-01T10:53:25+00:00 | [
"math.GR",
"20H15, 30F35"
] | Using Hoare's Theorem to find the signature of a subgroup of an NEC group | We explain how to use Hoare's Theorem to find the signature of a subgroup of
an NEC group. We give several examples. |
1408.0128v3 | 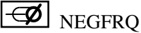
## Time and space, frequency and wavevector: or, what I talk about when I talk about propagation
## Paul Kinsler ∗
Blackett Laboratory, Imperial College London, Prince Consort Road, London SW7 2AZ, United Kingdom. (Dated: Tuesday 10 th December, 2019)
The existence of waves with negative frequency is a surprising and perhaps controversial claim which has recently been revisted in optics and for water waves. Here I explain a context within which to understand the meaning of the 'negative frequency' conception, and why it appears in some cases.
## Introduction
Claims or analyses involving negative frequency waves occur in a wide range of fields: quantum mechanics, optics & EM [1, 2], and acoustics and water waves [3]. However, some regard the notion of negative frequencies as unphysical. Here I describe four alternative views of the universe with a view to clarifying why negative frequencies might appear, and whether or not we should be worried: the omniscient , the traditional , the directed , and the causal .
The 'traditional' and the 'directed' pictures, involving propagation along time axis and one selected spatial axis respectively, have already been compared for a range of acoustic wave equations [4]. In particular, the convenience of spatial propagation in optics, and the additional utility of the unidirectional approximation has been widely studied (see e.g. [5] and references therein). Here I am most interested in comparing the traditional & directed views, and restrict notation to Cartesian coordinates for simplicity; although extension to alternate systems is of course possible [6]. It is important to note that in practical terms, utilising spatial propagation amounts to making an approximation, since not only the initial conditions but the ongoing propagation require a knowledge of the future which we rarely have.
It is useful to mention two ideas before we start: first, the standard notion of the casual past of a point in time and space, generally called the past light cone; and second, the computational past of that point. This notion of computational past applies primarily to numerical simulations, but can also be useful from more abstract perspective. It consists of both the set of initial conditions and/or computed data which might have affected the calculated state of that chosen point.
In what follows I will denote the profile of the wave field under discussion as F , but rather than festooning it with a plethora of typographical tics (bars, tildes, primes, and the like) to indicate what arguments may or may not have been transformed, I use its arguments alone to define F 's meaning - whether time t or space r =( x y z , , ) , whether it is a spectra with frequency w or wavevector k = ( kx , ky , kz ) , and so on. Further, I will not consider any specifics as to why a specified wave field might develop a certain character or characteristics - pulses, oscillations, spectral features and the like - just what we can say about the wave given the available knowledge.
∗ Electronic address: [email protected]
In addition to the four sections addressing each of the omniscient, traditional, directed, and causal pictures in turn, along with a brief conclusion, there are appendices which address some issues relevant in particular to the field of nonlinear optics: the handling of time-response models, and the appearance of negative frequency terms.
## I. OMNISCIENT: ALL TIME AND ALL SPACE
The omniscient position is taken when we claim all possible knowledge about how some wave has and will move through its environment. Here we might express our knowledge of some wave-field F by writing it with full space and time arguments: i.e. F t ( , r ) . Most likely, this view is a result of us having an analytic solution to some specific case of the physical model we are interested in.
Given this fully known wave field solution F t ( , r ) , we are at liberty to Fourier transform in either time or space (or both) as we see fit. In the resulting double spectrum F ( w , k ) , we will quite naturally see not only positive and negative frequency components, but also forward and backward wavevector components along each spatial coordinate axes.
Since the spectrum of some function is closely related to the complex conjugate of that spectrum for negative frequencies, we know for the doubly transformed F ( w , k ) that F ( w , k ) = F ( -w , -k ) . Notably, in this case there is no obvious distinction between a positive frequency disturbance evolving in one direction and a negative frequency disturbance evolving in the opposite direction. We therefore need not be troubled by the presence of negative frequencies, since we can reinterpret them as oppositely directed positive ones - we might, for example, refer to the idea that a positron is only an electron travelling backwards in time 1 .
It is also possible to consider a 'limited omniscience' position, where we claim complete knowledge of the wave behaviour in some defined region of space and time. This might be from some (past) experimental results, or be a numerical or analytic solution valid over that limited extent. In such a case, both time and space can be Fourier transformed, and the remarks above about handling and/or interpreting negative frequencies still hold. However, whilst such after-the-fact
1 Of course the handling of most particles is complicated by their mass, whereas photons, being massless, can be their own antiparticle.
FIG. 1: Temporal propagation of waves, where disturbances (or pulses) evolve either forward or backward in space. At any point in the propagation, we know the spatial behaviour of our wave field at all points in space, as indicated by the pale green vertical lines. The pale green shaded triangles indicate the past light cones (i.e. the causal past) of a wave element (black circles) at selected times along the path of the disturbance. In a temporally propagated numerical simulation which has a maximum wave speed, the causal past matches the computational past. A notional interface has been added to the diagram to show how a reflection would behave.
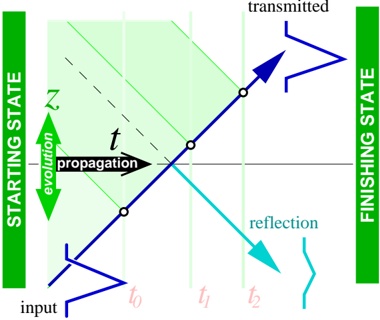
analysis is typically very useful, caution should be taken when applying the conclusions to an on-going propagation: in such inescapably dynamical situations, the alternatives discussed in the next three sections are more applicable.
## II. TRADITIONAL: TEMPORAL PROPAGATION
The traditional position is taken when we claim all knowledge about how the wave has moved through its environment up until now. This picture is shown on fig. 1, and assumes the normal preferred direction of propagation along the time axis, which is usually from t = -¥ , through t = 0, and towards t =+ ¥ .
Here we might express our knowledge of the wave-field F by writing it at the current time t 0 with full space arguments: i.e. Ft 0 ( r ) ; and where is is implied that we also knew Ft ( r ) at all past times t < t 0 also. The starting state of our propagation matches the early-time boundary conditions - i.e. what would normally be considered to be the initial conditions. An electromagnetic FDTD simulation [7, 8], along with many other finite element approaches, uses this traditional approach; it is also possible to apply factorization methods to get unidirectional versions of temporally propagated wave equations [9]. In this sense the starting state for some temporally propagated simulation - the 'computational initial conditions' - are the same as the traditional physical initial conditions 2 .
2 However, if we were to decide to propagate backwards in time from t =+ ¥
Given some wave field state Ft ( r ) known over all space r at some specified time t = t 0, we are at liberty to Fourier transform in space, but not time. The spatial transform will give us the wavevector or momentum-like properties of the wave field, in a spectrum Ft 0 ( k ) . This will contain both forward and backward wavevector components along each spatial coordinate axis, and we can calculate it not only at the current time t 0, but also all past times t < t 0.
For simplicity, imagine we are following some trajectory through time and space, while counting interesting events that occur locally. Time is always increasing but we might travel any direction through space, although it is easier to think of the case where our position is fixed. Naturally, our count of interesting events will only ever increase, thus any estimate of the time period T between events would be a positive number; as would any frequency estimation f in events-per-second. However, the events themselves may have different spatial characteristics: notably, we may see objects that pass us travelling left, or perhaps travelling right. The differing character of events, accessible to us through our spatial knowledge Ft ( r ) , allows us to impose a sign (or signs) when adjusting our counting total - perhaps +1 for left-going objects, and -1 for right-going ones.
Having discussed how a counting/timing argument that gives us a strictly positive frequency estimate can be converted into a signed count using spatial information, let us revist the temporally propagated spatial spectrum Ft 0 ( k ) of our notional wave field. As already noted, the spatial spectrum of the wave has both positive and negative wavevector components. Starting with the well known velocity relation for waves v = w / k , we can use this to claim that the positive wavevector part of the spectrum represents forward evolving waves (with v > 0), while the negative wavevector part represents backward evolving waves (with v < 0). However, we have to be careful: even a static field profile will have positive and negative wavevector components, since for real-valued Ft ( ) z , Ft ( -k ) = F t ∗ ( k ) . It is the changing complex phase(s) of Ft ( k ) that represents the shift in Ft ( ) z profile from one position to another.
Note that I have so far only discussed frequency estimates . Strictly speaking, in this picture, any system state exists only at an instant in time, so of itself that state has no frequency content at all. Further, even given our knowledge of past states, we cannot calculate a true frequency dependence, because we do not have the entire wave history to hand: we have the past but not the future. The best we might do in getting an up-to-date idea of the spectrum is apply a Laplace transform 3 over the known past information, converting t into a Laplacespectral s , and get a hybrid spectrum F t ′ 0 ( s , k ) . Nevertheless,
to t = -¥ , as is sometimes done when we have preferred final-time boundary conditions, note that those become the computational initial conditions, and that the computational past of any point in the propagation will be its future light cone. The interested reader might try drawing a suitable counterpart to fig. 1 themselves.
3 Although any one-sided transform that seemed appropriate, if applied over past (known) data, would also be fine.

it may be possible to characterise the dominant frequencylike properties of the propagation as a function of the know wavevector; and so be able to use a reference frequency W ( k ) [4] as a basis on which to simplify the propagation - perhaps by assuming it to be unidirectional.
However, if we judge that omitting the future behaviour will have a negligible effect, or that it is irrelevant since we only care about an experiment or computation that has already finished, we can simply take data from the appropriate past time interval, and calculate the frequency spectrum of that. This after-the-fact analysis of past data returns us to a version of the omniscient position, albeit one limited in scope, so that the same view of negative frequencies as there can be applied. This is what is usually done (either implicitly or explicitly), which is of course the reason why so many frequency responses & spectra appear in the literature, textbooks, and on datasheets.
So in this traditional picture, we need not be overly troubled by negative frequencies. Either we are being very rigorous, and so deny that a true frequency spectrum exists at all, or we have a spectrum calculated from known historical data, which has negative frequencies reinterpretable as positive ones, just as in the omniscient picture. As a final note, and as a result of the considerations above, the spectroscopists habit of giving spatial (wavevector, or momentumlike) spectra rather than temporal (frequency, or energy-like) ones makes sense from a theoretical perspective, as well as from a practical experimental one.
## III. DIRECTED: SPATIAL PROPAGATION
The directed position is taken when we claim all knowledge about how the wave the wave has moved in a preferred direction along some chosen path through its environment. This picture is shown on fig. 2, where the path is along the z axis from z = -¥ , through z = 0, and towards z =+ ¥ . Here we might express our knowledge of the wave-field F by writing it at the current position (e.g. z = z 0) with full time and transverse space arguments: i.e. Fz 0 ( t , x y , ) ; and where it is implied that we also knew Fz ( t , x y , ) at all prior positions z < z 0 along that path also. This often seems a very natural thing to do, especially when considering unidirectional beam propagation in waveguides or optical fibres. In particular, this position is made most explicit in the PSSD (pseudospectral spatial domain) method for propagating electromagnetic pulses, but also in many others [5, 10-13]. Here, the starting state at z = zi for some spatially propagated simulation - the 'computational initial conditions' - could be written Fzi ( t , x y , ) , and are emphatically not the same as the traditional physical initial conditions at a time t = t i (written as e.g. Fti ( x y z , , ) ). Contrast, for example, the starting states on figs. 1 and 2.
Given some wave field state Fz ( t , x y , ) known at some specified path position z 0, we are at liberty to Fourier transform in x and y space, and over time t , but not along the propgation axis z . The result will be a mixed spectrum Fz ( w , kx , ky ) as calculable for the current position z 0, as well as prior locations z < z 0. The spatial transform of this will give us the trans-
FIG. 2: Spatial propagation of waves, where disturbances (or pulses) evolve either forward or backward in time. At any point in the propagation, we know the full time behaviour of our wave field - both history and future, as indicated by the pale pink horizontal lines.. The light pink shaded triangles indicates the computational past of a wave element at particular points (black circles) along the path of the disturbance. Note that unlike the temporally propagated case shown in fig. 1, the computational past of a spatially propagated system is not the same as the causal past. A notional interface has been added to the diagram to show how reflections behave - i.e. in an unexpected way [4]. This is because a reflection should have been put in the initial conditions, but was not due to an (assumed) lack of knowledge of that future behaviour.
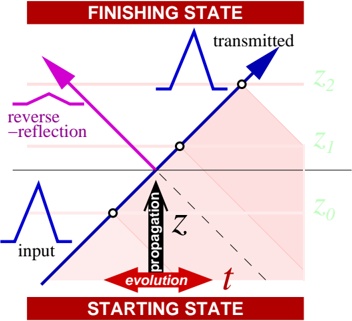
verse wavevector spectrum of the wave field, which will contain both positive and negative wavevector components along each transverse coordinate axes. The temporal transform, using the known full past-and-future history of that transverse behaviour, will contain both positive and negative frequency components. This outcome is particularly convenient because (assumed) knowledge of the full time behaviour enables a frequency spectrum to be calculated, and arbitrary temporal material response (dispersion) to be implemented in a numerically efficient way using (see commentary in e.g. [4, 5, 14] and references therein).
For simplicity, and in analogy to the comparable discussion for the traditional picture, imagine we are following some trajectory through space and time, while counting interesting events that occur locally along that path. In this picture, the spatial coordinate along our propagation axis (e.g. z ) is always increasing but our trajectory can move forward or back along the other spatial axes ( x , y ), and even forward of back in time; although it is easier to think of the case where our x , y position is fixed, as is time t . Naturally, our count of interesting events will only ever increase, but rather than measuring second between events (or events per second), it would be in meters between events (or events per meter) - not a temporal period (or frequency), but a spatial interval l or spatial recurrence rate (wavevector) kz = 2 p / l . Consquently, any l (or kz ) estimation we might make would be a positive number. However, the events themselves may have different characteristics: notably, we may see objects that pass us travelling along a transverse spatial axis in either direction. Further, since Fz ( t , x y , )

contains a full time history, this picture can even encode objects travelling forward or backward in time! The differing character of events, accessible to us through the spatial and temporal knowledge in Fz ( t , x y , ) , allows us to impose a sign (or signs) when adjusting our counting total - perhaps +1 for future-going objects, and -1 for past-going ones.
Having discussed how a counting/distance argument that gives us a strictly positive wavevector estimate can be converted into a signed count using temporal information, let us revist the spatially propagated frequency spectrum Fz 0 ( w ) of our notional wave field. As already noted, the frequency spectrum of the wave has both positive and negative frequency components. Again using the well known velocity relation for waves v = w / k , we can now claim that the positive frequency part of the spectrum represents forward (in time) evolving waves (with v > 0), while the negative wavevector part represents backward (in time) evolving waves (with v < 0). However, we have to be careful: even a static wave will have positive and negative frequency components, since for real-valued F t ( ) , F ( -w ) = F ∗ ( w ) . It is the changing complex phase of F ( w ) that represents the shift in F t ( ) profile from one time to another.
Note that I have so far only discussed estimates of the propagation axis wavevector kz . In this picture, any system state exists only at a specific location (e.g. z = z 0) along its path, and so of itself that state provides no information about a kz at all. Further, even given our knowledge of previous states on the path, we cannot calculate a true kz , because we only know about where we have been ( z ≤ z 0), not where we are yet to go ( z > z 0). The best we might do is apply a Laplace transform over the data from behind us along our path, converting z into a Laplace-spectral qz , and get hybrid spectrum F z ′ 0 ( w , kx , ky , qz ) . Nevertheless, it is usually extremely advantageous to characterise the dominant kz -like properties of the propagation as a function of the known frequency and so be able to use a reference kz ( w ) [4, 5] as a basis on which to simplify the propagation - perhaps by assuming it to be unidirectional.
So in the directed picture, we can directly obtain a true frequency spectrum at any point in our propagation, and that spectrum will have negative components. These negative frequencies have a precise and well-defined meaning, but that meaning results from the convenient (but physically approximate) decision to treat propagation as if it were along a spatial path, rather than forward in time.
## IV. CAUSAL: THE PAST LIGHT CONE
The causal position taken when we claim all knowledge allowed by causal signalling about how the wave has moved through its environment. Here we might express our knowledge of some wave-field F by writing it F ( t , B ) ; where t and B are the proper time interval into the past and B the vector 'rapidity' needed for a signal to travel from the past to our current location. These t and B are constructed in a similar way to Rindler coordinates, and quite naturally respect the light cone. This has been discussed in more detail elsewhere
FIG. 3: Causal propagation, where our knowledge only advances with the edge of a single point's (observer's) lightcone; here I show the point travelling at slightly less than the maximum speed (i.e. of that of light) for clarity. At any point in the propagation, we know only the behaviour in our past lightcone; we show three such past lightcones, one being inscribed with curves showing how the rapidity B varies at a selection of fixed proper time t intervals. The initial conditions are a single point, and the final state the lightcone border. A notional interface has been added to the diagram to show how reflections behave.
[15].
Since here our frequency-like quantity relates to the proper time t and not t , and because our wavevector-like quantity relates to B and not r , I leave any more systematic analysis to later work. However, note that t is like time t in the sense that it is one sided - we only know the past; and that B is like r in that spans all (allowed) points in space.
On fig. 3 I indicate in diagram form how a strictly causal simulation might proceed if we consider the knowledge of (an observer) at a single point e.g. one co-moving with a point on the wave profile. The starting state of this causal propagation matches what would we would know the instant we switched on some sensors - i.e. only that of the observer's current location. Here, the starting state for some causally propagated simulation - the 'computational initial conditions' - are a limited (single point) subset of the traditional physical initial conditions, which tend to assume a much greater knowledge of the environment. If desired, these causal initial conditions could be expanded to cover the past light cone of the initial point. This initial knowledge would then expand, because as we propagate, we would integrate our model of the system to add a 'new layer' to the outside of our prior past light cone to get our new (updated) past light cone.
It is debatable whether this rather purist causal picture is of much use in a scientific setting, except perhaps as part of a thought experiment. Nevertheless, it could be invaluable when considering cause and effect or the dynamical responses in specific situations, such as a metamaterial element being driven in the ultrafast and nanoscopic regime. On a more colourful level, for those engaged in spaceship combat at relativistic velocities - or more likely, those science fiction authors writing about such things - it is the only view of the
known environment that makes sense.
## V. SUMMARY
The above discussion shows that negative frequencies can have a well grounded and physical basis - as long as we either are sufficiently omniscient and have a complete knowledge of the behaviour we consider relevant, or if we start from the premise that choosing spatial propagation is reasonable. In such cases we cannot object to the appearance of negative frequency components, but it is worth noting that that we are not omniscient, and that spatial propagation - however useful -
- [1] E. Rubino, J. McLenaghan, S. C. Kehr, F. Belgiorno, D. Townsend, S. Rohr, C. E. Kuklewicz, U. Leonhardt, F. König, and D. Faccio, Phys. Rev. Lett. 108 , 253901 (2012), doi:10.1103/PhysRevLett.108.253901.
- [2] M. Conforti, N. Westerberg, F. Baronio, S. Trillo, D. Faccio, Phys. Rev. A 88 , 013829 (2013), doi:10.1103/PhysRevA.88.013829.
- [3] G. Rousseaux, C. Mathis, P. Maïssa, T. G. Philbin, U. Leon-
- hardt, New J. Phys. 10 , 053015 (2008), doi:10.1088/1367-2630/10/5/053015.
- J. Phys. Commun. 10 , 025011 (2018), doi:10.1088/2399-6528/aaa85c,
- [4] P. Kinsler, arXiv:1202.0714.
- [5] P. Kinsler,
- Phys. Rev. A 81 , 013819 (2010), doi:10.1103/PhysRevA.81.013819, arXiv:0810.5689.
- [6] P. Kinsler,
- Directional pulse propagation in beam, rod, pipe, and disk geometries (2012),
- arXiv:1210.6794.
- [7] K. S. Yee,
IEEE Trans. Antennas Propagat.
14
, 302 (1966), doi:10.1109/TAP.1966.1138693
- [8] A. F. Oskooi, D. Roundy, M. Ibanescu, P. Bermel, J. D. Joannopoulos, and S. G. Johnson, Comput. Phys. Commun. 181 , 687 (2010), doi:10.1016/j.cpc.2009.11.008.
- [9]
- P. Kinsler, J. Opt. 20 , 025502 (2018),
- doi:10.1088/2040-8986/aaa0fc, arXiv:1501.05569.
- [10] K. J. Blow and D. Wood, IEEE J. Quantum Electronics 25 , 2665 (1989), doi:10.1109/3.40655.
- [11] M. Kolesik, J. V. Moloney, and M. Mlejnek, Phys. Rev. Lett. 89 , 283902 (2002), doi:10.1103/PhysRevLett.89.283902.
- [12] G. Genty, P. Kinsler, B. Kibler, and J. M. Dudley, Opt. Express 15 , 5382 (2007), doi:10.1364/OE.15.005382.
is (in practice) an approximation of reality. This means that the concept of negative frequencies must be treated with some caution in any kind of dynamical situation.
## Acknowledgments
I would like to acknowledge the role of the recent 'The Nonlinear Meeting 2014' in Edinburgh (May 2014), funded by the Max Planck Society, in helping crystallize some of my thoughts on this topic, and motivating me to write them up. I also acknowledge financial support from EPSRC [17].
[13] P. Kinsler, S. B. P. Radnor, and G. H. C. New, Phys. Rev. A 72 , 063807 (2005), doi:10.1103/PhysRevE.75.066603, arXiv:physics/0611215.
[14] J. C. A. Tyrrell, P. Kinsler, G. H. C. New, J. Mod. Opt. 52 , 973 (2005), doi:10.1080/09500340512331334086.
[15] P. Kinsler,
Eur. J. Phys.
32
, 1687 (2011),
doi:10.1088/0143-0807/32/6/022,
arXiv:1106.1792 (a longer and updated version).
[16] P. Kinsler, G. H. C. New, and J. C. A. Tyrrell, (2006),
arXiv:physics/0611213.
[17]
M. W. McCall, P. Kinsler, EPSRC grant number EP/K003305/1.
[18] J. R. Gulley and W. M. Dennis, Phys. Rev. A 81 , 033818 (2010), doi:10.1103/PhysRevA.81.033818.
[19] P. Kinsler and G. H. C. New, Phys. Rev. A 72 , 033804 (2005), doi:10.1103/PhysRevA.72.033804, arXiv:physics/0606111.
[20] R. H. Stolen, J. P. Gordon, W. J. Tomlinson, and H. A. Haus, J. Opt. Soc. Am. B 6 , 1159 (1989), doi:10.1364/JOSAB.6.001159.
[21] P. Kinsler, Phys. Rev. A 82 , 055804 (2010), doi:10.1103/PhysRevA.81.013819, arXiv:1008.2088.
[22]
P. Kinsler, An introduction to spatial dispersion (2019),
arXiv:1904.11957.
## Appendix: Time response models
The time response of a propagation medium is handled rather differently in the temporal and spatial propagation approaches. Consider a set of material properties ni that follow some kind of dynamical (temporal) response models defined by a differential equation. The differential equations for each ni will depends on both the local material states and that of the
local field:
$$\partial _ { t } ^ { k } n _ { i } = r _ { i } ( \{ n _ { j } \}, F ). \quad \quad \ ( 5. 1 ) \quad \partial _ { i }$$
Typical examples might be nonlinear response delays [10], a free carrier density model [18], a Raman response [19, 20], or even just a Drude or Lorentz oscillator [15] giving rise to dispersion. The requirement here for the model to be properly causal is that the order of the time derivative k is greater than any other time derivative parts present in the response function (or operator) ri [21].
- glyph[trianglerightsld] In the traditional time propagated picture, each spatial location needs to not only know its field state F ( r ) , but also its material property state(s) ni ( r ) . In some situations, values of F or ni from earlier times - i.e. values from the computational past of the simulation - may need to be stored for use in subsequent computations. Further, as the propagation proceeds step-by-step in time, both the field F ( r ) and current material properties ni ( r ) need to be updated.
- glyph[trianglerightsld] In the (directed) space propagated picture, each currently held state of the field holds the time history of each point. This means that it is never necessary to store the computational past of the simulation, since the values for earlier times are already incorporated into the current computational state F t ( , x y , ) . We can simply solve equations such as eqn. (5.1) by directly integrating them from the distant past up to the desired time, using only that current state information. And, as already mentioned, if the response model is linear and has a known frequency response, as in the case of typical dispersive behaviours, it can be applied quickly and efficiently as a simple pahse shift applied to the frequency spectrum - a process requiring only two Fourier transforms and a multiplication.
## Appendix: Nonlinear optics and negative frequencies
There are some specific issues relating to nonlinear optics (NLO) and negative frequencies which bear additional examination. Consider the nonlinear Schrödinger equation (NLSE) as derived from Maxwell's equations in the 1+1D regime of ( t , z ) , with some sources of dispersion and a perturbative third order (Kerr) nonlinearity. Generally in NLO it is written in the convenient (i.e. directed) spatially propagated picture, in a unidirectional approximation with fields evolving forward in time only, as the zNLSE [5]
$$\partial _ { z } E ^ { + } ( t ) = \imath K E ^ { + } ( t ) + \sum _ { j } \beta _ { j } \partial _ { t } ^ { j } E ^ { + } ( t ) + \imath \chi _ { z } \left | E ^ { + } ( t ) \right | ^ { 2 } E ^ { + } ( t ), \quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
but note that it is also possible to derive a temporally propagated version, for the case of a unidirectional field evolving forward in space only, as the tNLSE 4
$$( 5. 1 ) \quad \partial _ { t } D _ { + } ( z ) = \imath \Omega D _ { + } ( z ) + \sum _ { j } \gamma _ { j } \partial _ { z } ^ { j } D _ { + } ( z ) + \imath \chi _ { t } | D _ { + } ( z ) | ^ { 2 } D _ { + } ( z ). \\ 0 1. \text{ a}$$
Note that in the 'directed' spatial zNLSE eqn. (5.2) all sources of dispersion - whether due to time-dependent material response or the geometric properties of a confining waveguide - are treated as if they were solely due to a timedependent response (by means of the power series in time derivatives). In contrast, in the 'traditional' temporal zNLSE eqn. (5.3), all sources of dispersion in the tNLSE are treated as if they were solely due to the local geometric properties of that material i.e. by spatial dispersion [22]; typically this is expressed as a power series in either spatial derivatives or wavevector. However, given that most dispersions are rather weak in applications NLSE propagation, either picture can plausibly be assumed to be able to treat dispersion accurately enough for such purposes (although see [9]).
In both these cases we can see that it would be useful to Fourier transform the field to get temporal and spatial spectra ˜ E + ( w ) and ¯ D +( ) k respectively, because then the dispersion model can be directly applied as a simple polynomial phase shift, i.e. either of
$$\beta ( \omega ) = \sum _ { j } \beta _ { j }. \, ( - \imath \omega ) ^ { j } \, \text{ \quad \ \ } \text{(5.4)}$$
$$\gamma ( k ) = \sum _ { j } \gamma _ { j }. \, ( \imath k ) ^ { j }$$
It is often stated that a Kerr nonlinearity causes third harmonic generation, but we now also need to consider what this generation is a 'third harmonic' of. In the usual zNLSE model of eqn. (5.2), an existing harmonic field E + ( ) t glyph[similarequal] E + 0 e -ı w 1 t + c.c. leads to not only some self phase modulation (SPM) but also third harmonic frequency generation at w 3 = 3 w 1. In the tNLSE model of eqn. (5.3), an existing harmonic field D +( ) z glyph[similarequal] D e ık z 0 + 1 + c.c. leads to not only some self phase modulation (SPM) but also third harmonic wavevector generation at k 3 = 3 k 1.
For clarity, let us write this out as carefully as possible, in the case where we spilt the real-valued fields E + or D + into complex conjugate halves, in the style of [16]. With E + ( ) = t E ′ ( ) t e -ı w 1 t + E ′∗ ( ) t e + ı w 1 t , the zNLSE equation can be partitioned into two complex conjugate halves. We can also dispense with the exponential oscillation by setting w 1 = 0 although it is often useful to include such carrier oscillations when the fields are narrow band, having them written explicitly rather than implicitly is not required. The two complex
4 Author's derivation, unpublished

conjugate zNLSE equations are
$$\partial _ { z } E ^ { \prime } ( t ) e ^ { - i \omega _ { 1 } t } = & \, \imath K E ^ { \prime } ( t ) e ^ { - i \omega _ { 1 } t } + \sum _ { j } \beta _ { j } \, \partial _ { t } ^ { j } E ^ { \prime } ( t ) e ^ { - i \omega _ { 1 } t } \\ & + \imath \chi _ { z } \left [ E ^ { \prime } ( t ) ^ { 3 } e ^ { - 3 i \omega _ { 1 } t } + 3 E ^ { \prime } ( t ) ^ { 2 } \left [ E ^ { \prime } ( t ) \right ] ^ { * } e ^ { - i \omega _ { 1 } t } \right ], \quad \text{ might } \, \imath \, \text{ be to } \, \i \, \text{struct t} \, \i }$$
$$\begin{matrix} \end{matrix}$$
$$\partial _ { z } E ^ { \prime * } ( t ) e ^ { + \imath \omega _ { 1 } t } = \imath K E ^ { \prime * } ( t ) e ^ { + \imath \omega _ { 1 } t } + \sum _ { j } \beta _ { j } \partial _ { t } ^ { j } E ^ { \prime * } ( t ) e ^ { + \imath \omega _ { 1 } t }$$
$$+ \imath \chi _ { z } \left [ E ^ { \prime * } ( t ) ^ { 3 } e ^ { + 3 \imath \omega _ { 1 } t } + 3 E ^ { \prime * } ( t ) ^ { 2 } \left [ E ^ { \prime * } ( t ) \right ] ^ { * } e ^ { + \imath \omega _ { 1 } t } \right ] \underset { \substack { \text{num} \\ ( 5. 7 ) } } { \text{num} }.$$
The sum of these two equations is just eqn. (5.2). Further, since they are exact complex conjugates of one another, we can solve just one version, which automatically gives us a solution to the other, and hence the solution to the real valued field E + ( ) t .
Note in particular that the nonlinearity in this exact mathematical re-expression of the zNLSE equation drives only resonant or third-harmonic frequencies. There is no explicit coupling to negative frequencies, which can be seen most clearly when assuming finite w 1 and a constant E ′ ; then, eqn. (5.6) does not drive negative frequencies of itself. Nevertheless, although the complex E ′ ( w ) might start with content solely in positive frequencies, its frequency bandwidth is not restricted. Consequently after propagating some distance it may well have evolved into a field whose spectrum is very wide, perhaps even extending past the origin. In this state, multifrequency interactions that drive the field at negative frequencies could indeed occur as a result of the nonlinearity - remember that if represented in the frequency domain, the cubic nonlinear term transforms into a double convolution over the entire frequency spectra.
However, we could, if we wanted, make such 'negative frequency' driving terms appear explicitly by repartitioning the whole nonlinear term into different complex conjugate halves, e.g. by writing not eqn. (5.6) but
$$\partial _ { z } E ^ { \prime } ( t ) e ^ { - \imath \omega _ { 1 } t } = \imath K E ^ { \prime } ( t ) e ^ { - \imath \omega _ { 1 } t } + \sum _ { \colon } \beta _ { j } \partial _ { t } ^ { j } E ^ { \prime } ( t ) e ^ { - \imath \omega _ { 1 } t }$$
$$+ \imath \chi _ { z } \left [ E ^ { \prime } ( t ) ^ { 3 } e ^ { - 3 \imath \omega _ { 1 } t } + \frac { 3 } { 2 } E ^ { \prime } ( t ) ^ { 2 } \left [ E ^ { \prime } ( t ) \right ] ^ { * } e ^ { - \imath \imath \omega _ { 1 } t } \quad \text{As} \\ + \frac { 3 } { 2 } \left [ E ^ { \prime } ( t ) \right ] ^ { * 2 } E ^ { \prime } ( t ) e ^ { + \imath \imath \omega _ { 1 } t } \right ], \quad \text{of} \ \imath \\ \quad \text{$\quad \text{$\quad \colon c.}$}$$
$$& \stackrel { | t } { \L } + \sum _ { j } \beta _ { j } \, \partial _ { t } ^ { J } \, E ^ { \prime } ( t ) e ^ { - \iota \omega _ { 1 } t } \\ & e ^ { - 3 \iota \omega _ { 1 } t } + \frac { 3 } { 2 } E ^ { \prime } ( t ) ^ { 2 } \left [ E ^ { \prime } ( t ) \right ] ^ { * } e ^ { - \iota \omega _ { 1 } t } \\ & + \frac { 3 } { 2 } \left [ E ^ { \prime } ( t ) \right ] ^ { * 2 } E ^ { \prime } ( t ) e ^ { + \iota \omega _ { 1 } t } \right ], \quad \, \stackrel { | t } { \L } \\ & \quad ( 5. 8 ) \quad \, \text{$1$}$$
]
. and there is of course also a matching complex congugate counterpart of eqn. (5.7), and the sum of both will be equal to the original zNLSE equation. Whether or not this representation containing explicit driving of negative frequencies might be useful is another matter, but it is certainly possible to (re)express the mathematical model in order to construct them. But, apart from specific numerical difficulties that might occur when solving these propagation equations, the solutions gained from either form should be identical: both are just different ways of representing the same physical model .
Naturally one can apply the same method to the tNLSE as well, setting D +( ) = z D z e ık t ′ ( ) 1 + D ′∗ ( ) z e -ık 1 z , and arriving at two complex conjugate equations
$$\underset { \text{re} - } { \text{ley} } \quad \partial _ { z } D ^ { \prime } ( z ) e ^ { + \imath k _ { 1 } z } = \imath K D ^ { \prime } ( z ) e ^ { + \imath k _ { 1 } z } + \sum _ { z } \gamma _ { j } \partial _ { z } ^ { j } D ^ { \prime } ( z ) e ^ { + \imath k _ { 1 } z }$$
$$\frac { \Gamma \cos ^ { - } } { - \underset { \dots } { \mathfrak { e } } ^ { - } } \partial _ { z } D ^ { \prime * } ( z ) e ^ { - \imath k _ { 1 } z } = \imath K D ^ { \prime * } ( z ) e ^ { - \imath k _ { 1 } z } + \sum _ { \imath } \gamma _ { j } \partial _ { z } ^ { j } D ^ { \prime * } ( z ) e ^ { - \imath k _ { 1 } z }$$
$$+ \imath \chi _ { t } \left [ D ^ { \prime * } ( z ) ^ { 3 } e ^ { - 3 t k _ { 1 } z } + 3 D ^ { \prime * } ( z ) ^ { 2 } \left [ D ^ { \prime * } ( z ) \right ] ^ { * } e ^ { - t k _ { 1 } z } \right ].$$
$$\L \L e ^ { + t k _ { 1 } z } & = \imath K D ^ { \prime } ( z ) e ^ { + t k _ { 1 } z } + \sum _ { j } \gamma _ { j } \partial _ { z } ^ { j } D ^ { \prime } ( z ) e ^ { + t k _ { 1 } z } \\ & \quad + \imath \chi _ { t } \left [ D ^ { \prime } ( z ) ^ { 3 } e ^ { + 3 t k _ { 1 } z } + 3 D ^ { \prime } ( z ) ^ { 2 } \left [ D ^ { \prime } ( z ) \right ] ^ { * } e ^ { + t k _ { 1 } z } \right ], \\ \L \L e ^ { - t k _ { 1 } z } & = \imath K D ^ { \prime * } ( z ) e ^ { - t k _ { 1 } z } + \sum _ { j } \gamma _ { j } \partial _ { z } ^ { j } D ^ { \prime * } ( z ) e ^ { - t k _ { 1 } z } \\ & \quad + \imath \chi _ { t } \left [ D ^ { \prime * } ( z ) ^ { 3 } e ^ { - 3 t k _ { 1 } z } + 3 D ^ { \prime * } ( z ) ^ { 2 } \left [ D ^ { \prime * } ( z ) \right ] ^ { * } e ^ { - t k _ { 1 } z } \right ].$$
As we should expect, these two equations sum to eqn. (5.3). Also, here there again is no explicit coupling to opposite parts of the wavevector spectra D k ′ ( ) in each equation, although (as before) we might repartition the nonlinear term to construct it, if we so desired. | null | [
"Paul Kinsler"
] | 2014-08-01T10:53:57+00:00 | 2019-12-09T16:09:59+00:00 | [
"physics.optics"
] | Time and space, frequency and wavevector: or, what I talk about when I talk about propagation | The existence of waves with negative frequency is a surprising and perhaps
controversial claim which has recently been revisted in optics and for water
waves. Here I explain a context within which to understand the meaning of the
"negative frequency" conception, and why it appears in some cases. |
1408.0129v1 | ## A Polling Model with Smart Customers ∗
M.A.A. Boon †
[email protected]
A.C.C. van Wijk ‡ [email protected]
I.J.B.F. Adan † [email protected]
O.J. Boxma † [email protected]
September, 2010
## Abstract
In this paper we consider a single-server, cyclic polling system with switch-over times. A distinguishing feature of the model is that the rates of the Poisson arrival processes at the various queues depend on the server location. For this model we study the joint queue length distribution at polling epochs and at server's departure epochs. We also study the marginal queue length distribution at arrival epochs, as well as at arbitrary epochs (which is not the same in general, since we cannot use the PASTA property). A generalised version of the distributional form of Little's law is applied to the joint queue length distribution at customer's departure epochs in order to find the waiting time distribution for each customer type. We also provide an alternative, more efficient way to determine the mean queue lengths and mean waiting times, using Mean Value Analysis. Furthermore, we show that under certain conditions a Pseudo-Conservation Law for the total amount of work in the system holds. Finally, typical features of the model under consideration are demonstrated in several numerical examples.
Keywords: Polling, smart customers, varying arrival rates, queue lengths, waiting times, pseudo-conservation law
## 1 Introduction
The classical polling system is a queueing system consisting of multiple queues, visited by a single server. Typically, queues are served in cyclic order, and switching from one queue to the next queue requires a switch-over time, but these assumptions are not essential to the analysis. The decision at what moment the server should start switching to the next queue is important to the analysis, though. Polling systems satisfying a so-called branching property
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-NF.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
‡ Eurandom , Department of Industrial Engineering & Innovation Sciences and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
generally allow for an exact analysis, whereas polling systems that do not satisfy this property rarely can be analysed in an exact way. See Resing [24], or Fuhrmann [14], for more details on this branching property.
There is a huge literature on polling systems, mainly because of their practical relevance. Applications are found, among others, in production environments, transportation, and data communication. The surveys of Takagi [27], Levy and Sidi [21], and Vishnevskii and Semenova [29] provide a good overview of applications of polling systems. These surveys, and [30], Chapters 2 2 . and 3, are also excellent references to find more information about various analysis techniques, such as the Buffer Occupancy method, the Descendant Set approach, and Mean Value Analysis (MVA) for polling systems. The vast majority of papers on polling models assumes that the arrival rate stays constant throughout a cycle, although it may vary per queue. The polling model considered in the present paper, allows the arrival rate in each queue to vary depending on the server location. This model was first considered by Boxma [5], who refers to this model as a polling model with smart customers , because one way to look at this system is to regard it as a queueing system where customers choose which queue to join, based on the current server position. Note that Boxma's definition of smart customers is different from the definition used by Mandelbaum and Yechiali [22], who study an M/G/ 1 queue where smart customers may decide upon arrival to join the queue, not to enter the system at all, or to wait for a while and postpone the decision.
A relevant application can be found in [16], where a polling model is used to model a dynamic order picking system (DPS). In a DPS, a worker picks orders arriving in real time during the picking operations and the picking information can dynamically change in a picking cycle. One of the challenging questions that online retailers now face, is how to organise the logistic fulfillment processes during and after order receipt. In traditional stores, purchased products can be taken home immediately. However, in the case of online retailers, the customer must wait for the shipment to arrive. In order to reduce throughput times, an efficient enhancement to an ordinary DPS is to have products stored at multiple locations. The system can be modelled as a polling system with queues corresponding to each of the locations, and customers corresponding to orders. The location of the worker determines in which of the queues an order is being placed. In this system arrival rates of the orders depend on the location of the server (i.e. the worker), which makes it a typical smart customers example. A graphical illustration is given in Figure 1. We focus on one specific order type, which is placed in two locations, say Q i and Q j . While the picker is on its way to Q i , say at location 1, all of these orders are routed to Q i and the arrival rate at Q j is zero. If the picker is between Q i and Q j , say at location 2, the situation is reversed and Q j receives all of these orders.
Besides practical relevance, the smart customers model also provides a powerful framework to analyse more complicated polling models. For example, a polling model where the service discipline switches each cycle between gated and exhaustive, can be analysed constructing an alternative polling model with twice the number of queues and arrival rates being zero during specific visit periods [8]. The idea of temporarily setting an arrival rate to zero is also used in [2] for the analysis of a polling model with multiple priority levels. Time varying arrival rates also play a role in the analysis of a polling model with reneging at polling instants [1].
Concerning state dependent arrival rates, more literature is available for systems consisting of only one queue, often assuming phase-type distributions for vacations and/or service times. A system consisting of a single queue with server breakdowns and arrival rates depending on
Figure 1: A dynamic order picking system. Orders are placed in queues Q , . . . , Q 1 N .
1 the server status is studied in [26]. A difference with the system studied in the present paper, besides the number of queues, is that the machine can break down at arbitrary moments during the service of customers. Polling systems with breakdowns have been studied as well, cf. [9, 17, 20, 23]. However, only Nakdimon and Yechiali [23] consider a model where the arrival process stops temporarily during a breakdown. Shanthikumar [25] discusses a stochastic decomposition for the queue length in an M/G/ 1 queue with server vacations under less restrictive assumptions than Fuhrmann and Cooper [15]. One of the relaxations is that the arrival rate of customers may be different during visit periods and vacations. Another system, with so-called working vacations and server breakdowns is studied in [18]. During these working vacations, both the service and arrival rates are different. Mean waiting times are found using a matrix analytical approach. For polling systems, a model with arrival rates that vary depending on the location of the server has not been studied in detail yet. Boxma [5] studies the joint queue length distribution at the beginning of a cycle, but no waiting times or marginal queue lengths are discussed. In a recent paper [11], a polling system with L´ evy-driven, possibly correlated input is considered. Just as in the present paper, the arrival process may depend on the location of the server. In [11] typical performance measures for L´ evy processes are determined, such as the steady-state distribution of the joint amount of fluid at an arbitrary epoch, and at polling and switching instants. The present paper studies a similar setting, but assumes Poisson arrivals of individual customers. This enables us to find the probability generating functions (PGFs) of the joint queue length distributions at polling instants and customer's departure epochs, and the marginal queue length distributions at customer's arrival epochs and at arbitrary epochs (which are not the same, because PASTA cannot be used). The introduction of customer subtypes, categorised by their moment of arrival, makes it possible to generalise the distributional form of Little's law (see, e.g., [19]), and apply it to the joint queue length distribution at departure epochs to find the LaplaceStieltjes Transform (LST) of the waiting time distribution.
The present paper is structured as follows: Section 2 gives a detailed model description and introduces the notation used in this paper. In Section 3 the PGFs of the joint queue length distributions of all customer types at polling instants are derived. The marginal queue length distribution is also studied in this section, but we show in Section 4 that the derivation of
the waiting time LST for each customer type requires a more complicated analysis, based on customer subtypes. In Sections 3 and 4 we need information on the lengths of the cycle time and all visit times, which are studied in Section 5. In Section 6 we adapt the MVA framework for polling systems, introduced in [31], to our model. This results in a very efficient method to compute the mean waiting time of each customer type. For polling systems with constant arrival rates, a Pseudo-Conservation Law (PCL) is studied in [6]. In Section 7 we show that, under certain conditions, a PCL is satisfied by our model. Finally, we give numerical examples that illustrate some typical features and advantages of the model under consideration.
## 2 Model description and notation
The polling model in the present paper contains N queues, Q , . . . , Q 1 N , visited in cyclic order by one server. Switching from Q i to Q i +1 ( i = 1 , . . . , N , where Q N +1 is understood to be Q 1 , etc.) requires a switch-over time S i , with LST σ i ( ). · We assume that at least one switch-over time is strictly greater than zero, otherwise the mean cycle length in steady-state becomes zero and the analysis changes slightly. See, e.g., [4] for a relation between polling systems with and without switch-over times. Switch-over times are assumed to be independent. The cycle time C i is the time that elapses between two successive visit beginnings to Q i , and C ∗ i is the time that elapses between two successive visit endings to Q i . The mean cycle time does not depend on the starting point of the cycle, so E [ C i ] = E [ C ∗ i ] = E [ C ]. The visit time V i of Q i is the time between the visit beginning and visit ending of Q i . The intervisit time I i of Q i is the time between a visit ending to Q i and the next visit beginning at Q i . We have C i = V i + I i , and I i = S i + V i +1 + · · · + S i + N -1 , i = 1 , . . . , N . Customers arriving at Q i , i.e. type i customers, have a service requirement B i , with LST β i ( ). · We also assume independence of service times, and first-come-first-served (FCFS) service order.
The service discipline of each queue determines the moment at which the server switches to the next queue. In the present paper we study the two most popular service disciplines in polling models, exhaustive service (the server switches to the next queue directly after the last customer in the current queue has been served) and gated service (only visitors present at the server's arrival at the queue are served). The reason why these two service disciplines have become the most popular in polling literature, lies in the fact that they are from a practical point of view the most relevant service disciplines that allow an exact analysis. In this respect the following property, defined by Resing [24] and also Fuhrmann [14], is very important.
Property 2.1 (Branching Property) If the server arrives at Q i to find k i customers there, then during the course of the server's visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having probability generating function h i ( z , . . . , z 1 N ), which can be any N -dimensional probability generating function.
In most cases, a polling model can only be analysed exactly, if the service discipline at each queue satisfies Property 2.1, or some slightly weaker variant of this property, because in this case the joint queue length process at visit beginnings to a fixed queue constitutes a MultiType Branching Process, which is a nicely structured and well-understood process. Gated and exhaustive service both satisfy this property, whereas a service discipline like k -limited service (serve at most k customers during each visit) does not.
The feature that distinguishes the model under consideration from commonly studied polling models, is the arrival process. This arrival process is a standard Poisson process, but the rate depends on the location of the server. The arrival rate at Q i is denoted by λ ( P ) i , where P denotes the position of the server, which is either serving a queue, or switching from one queue to the next: P ∈ { V , S 1 1 , . . . , V N , S N } . One of the consequences is that the PASTA property does not hold for an arbitrary arrival, but as we show in Section 3, a conditional version of PASTA does hold. Another difficulty that arises, is that the distributional form of Little's law cannot be applied to the PGF of the marginal queue length distribution to obtain the LST of the waiting time distribution anymore. We explain this in Section 4, where we also derive a generalisation of the distributional form of Little's law.
## 3 Queue length distributions
## 3.1 Joint queue length distribution at visit beginnings/endings
The two main performance measures of interest, are the steady-state queue length distribution and the waiting time distribution of each customer type. In this section we focus on queue lengths rather than waiting times, because the latter requires a more complex approach that is discussed in the next section. We restrict ourselves to branching-type service disciplines, i.e., service disciplines satisfying Property 2.1. Boxma [5] follows the approach by Resing [24], defining offspring and immigration PGFs to determine the joint queue length distribution at the beginning of a cycle. We take a slightly different approach that gives the same result, but has the advantage that it gives expressions for the joint queue length PGF at all visit beginnings and endings as well. Denote by ˜ LB ( P ) ( z , . . . , z 1 N ) the PGF of the steady-state joint queue length distribution at beginnings of period P ∈ { V , S 1 1 , . . . , V N , S N } . The relation between these PGFs, also referred to as laws of motion in the polling literature, is obtained by application of Property 2.1 to ˜ LB ( V i ) ( z ), where z is a shorthand notation for the vector ( z , . . . , z 1 N ). This property states that each type i customer present at the visit beginning to Q i will be replaced during this visit by a random population having PGF h i ( z ), which depends on the service discipline. The only difference between conventional polling models and the model under consideration in the present paper, is that the arrival rates depend on the server location. The relations between ˜ LB ( V i ) ( z ) , ˜ LB ( S i ) ( z ), and ˜ LB ( V i +1 ) ( z ) are given by:
$$\widetilde { L B } ^ { ( S _ { i } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( V _ { i } ) } ( z _ { 1 }, \dots, z _ { i - 1 }, h _ { i } ( \mathbf z ), z _ { i + 1 }, \dots, z _ { N } ),$$
$$\widetilde { L } B ^ { ( V _ { i + 1 } ) } ( { \mathbf z } ) = \widetilde { L } B ^ { ( S _ { i } ) } ( { \mathbf z } ) \, \sigma _ { i } \left ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( S _ { i } ) } ( 1 - z _ { j } ) \right ),$$
glyph[negationslash]
where h i ( z ) is the PGF mentioned in Property 2.1. It is discussed in the context of a polling model with smart customers in [5]. For gated service, h i ( z ) = β i ( ∑ N j =1 λ ( V i ) j (1 -z j ) ) . For exhaustive service, h i ( z ) = π i ( ∑ j = i λ ( V i ) j (1 -z j ) ) , where π i ( ) · is the LST of a busy period distribution in an M/G/ 1 system with only type i customers, so it is the root in (0 , 1] of the equation π i ( ω ) = β i ( ω + λ ( V i ) i (1 -π i ( ω )) ) , ω ≥ 0 (cf. [12], p. 250). Now that we can relate ˜ LB ( V i +1 ) ( z ) to ˜ LB ( V i ) ( z ), we can repeat this and finally obtain a recursion for ˜ LB ( V i ) ( z ). This
recursive expression is sufficient to compute all moments of the joint queue length distribution at a visit beginning to Q i by differentiation, but iteration of the expression leads to the steadystate queue length distribution at polling epochs, written as an infinite product. We refer to [24] for more details regarding this approach, and for rigorous proofs of the laws of motion. Stability conditions are studied in more detail in [11], where it is shown that a necessary and sufficient condition for ergodicity is that the Perron-Frobenius eigenvalue of the matrix R -I N should be less than 0, where I N is the N × N identity matrix, and R is an N × N matrix containing elements ρ ij := λ ( V j ) i E [ B i ]. This holds under the assumption that E [ V i ] > 0 for all i = 1 , . . . , N .
## 3.2 Marginal queue length distribution
Common techniques in polling systems (see, e.g. [3, 13]) to determine the PGF of the steadystate marginal queue length distribution of each customer type, are based on deriving the queue length distribution at departure epochs. A level-crossing argument implies that the marginal queue length distribution at arrival epochs must be the same as the one at departure epochs, and, finally, because of PASTA this distribution is the same as the marginal queue length distribution at an arbitrary point in time. In our model, the marginal queue length distributions at arrival and departure epochs are also the same, but the distribution at arbitrary moments is different because of the varying arrival rates during a cycle. We can circumvent this problem by conditioning on the location P of the server ( P ∈ { V , S 1 1 , . . . , V N , S N } ) and use conditional PASTA to find the PGF of the marginal queue length distribution at an arbitrary point in time. Let L i denote the steady-state queue length of type i customers at an arbitrary moment, and let L ( V j ) i and L ( S j ) i denote the queue length of type i customers at an arbitrary time point during V j and S j respectively ( i, j = 1 , . . . , N ). The following relation holds:
$$\text{max} \colon \\ \mathbb { E } [ z ^ { L _ { i } } ] = \sum _ { j = 1 } ^ { N } \left ( \frac { \mathbb { E } [ V _ { j } ] } { \mathbb { E } [ C ] } \mathbb { E } \left [ z ^ { L _ { i } ^ { ( V _ { j } ) } } \right ] + \frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ C ] } \mathbb { E } \left [ z ^ { L _ { i } ^ { ( S _ { j } ) } } \right ] \right ), \quad i = 1, \dots, N.$$
glyph[negationslash]
Note that, at this moment, E [ V j ] and E [ C ] are still unknown. In Sections 5 and 6 we illustrate two different ways to compute them. Since S j , for j = 1 , . . . , N , and V j , for j = , are i nonserving intervals for customers of type i , we use a standard result (see, e.g., [3]) to find the PGFs of L ( V j ) i and L ( S j ) i respectively:
glyph[negationslash]
$$\mathbb { E } \left [ z ^ { L _ { i } ^ { ( V _ { j } ) } } \right ] = \frac { \mathbb { E } [ z ^ { L B _ { i } ^ { ( V _ { j } ) } } ] - \mathbb { E } [ z ^ { L B _ { i } ^ { ( S _ { j } ) } } ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( S _ { j } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( V _ { j } ) } ] \right ) }, \quad \quad i = 1, \dots, N ; j \neq i, \quad \ ( 3. 4 )$$
$$\mathbb { E } \left [ z ^ { L _ { i } ^ { ( S _ { j } ) } } \right ] = \frac { \overset { \bullet } { \mathbb { E } [ z ^ { L B _ { i } ^ { ( S _ { j } ) } } ] - \mathbb { E } [ z ^ { L B _ { i } ^ { ( V _ { j + 1 } ) } } ] } } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { j + 1 } ) _ { j } } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { j } ) _ { j } } ] \right ) }, \quad \quad \ \ i, j = 1, \dots, N,$$
where LB ( P ) i , for i = 1 , . . . , N , are the number of type i customers at the beginning of period P ∈ { V , S 1 1 , . . . , V N , S N } . Their PGFs can be expressed in terms of ˜ LB ( V 1 ) ( z ) using the relations (3.2) and (3.1), and replacing argument z by the vector (1 , . . . , 1 , z, 1 , . . . , 1) where z is the element at position i . Using branching theory from [24], an explicit expression for
˜ LB ( V 1 ) ( z ) is given in [5]. The mean values, E [ LB ( V j ) i ] and E [ LB ( S j ) i ], can be obtained by differentiation of the corresponding PGFs and substituting z = 1.
It remains to compute E [ z L ( V i ) i ] , i = 1 , . . . , N , i.e., the PGF of the number of type i customers at an arbitrary point within V i . As far as the marginal queue length of type i customers is concerned, the system can be viewed as a vacation queue with the intervisit time I i corresponding to the server vacation. We can use the Fuhrmann-Cooper decomposition [15], but we have to be careful here. In a polling system where type i customers arrive with constant arrival rate λ ( V i ) i , the Fuhrmann-Cooper decomposition states that
$$\mathbb { E } [ z ^ { L _ { i } } ] = \frac { ( 1 - \lambda _ { i } ^ { ( V _ { i } ) } \mathbb { E } [ B _ { i } ] ) ( 1 - z ) \beta _ { i } \left ( \lambda _ { i } ^ { ( V _ { i } ) } ( 1 - z ) \right ) } { \beta _ { i } \left ( \lambda _ { i } ^ { ( V _ { i } ) } ( 1 - z ) \right ) - z } \times \frac { \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( S _ { i } ) } } \right ] - \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { i } ) } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { i } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { i } ) } ] \right ) }. \quad ( 3. 6 )$$
The two parts in this decomposition can be recognised as the PGFs of the number of type i customers respectively at an arbitrary moment in an M/G/ 1 queue, and at an arbitrary point during the intervisit time I i . Of course, the following relation also holds:
$$\mathbb { E } [ z ^ { L _ { i } } ] & = \frac { \mathbb { E } [ V _ { i } ] } { \mathbb { E } [ C ] } \mathbb { E } [ z ^ { L _ { i } ^ { ( V _ { i } ) } } ] + \frac { \mathbb { E } [ I _ { i } ] } { \mathbb { E } [ C ] } \mathbb { E } [ z ^ { L _ { i } ^ { ( I _ { i } ) } } ].$$
Combining (3.6) with (3.7), results in:
$$\mathbb { E } [ z ^ { L ^ { ( V _ { i } ) } _ { i } } ] = \frac { 1 - \lambda ^ { ( V _ { i } ) } _ { i } \mathbb { E } [ B _ { i } ] } { \lambda ^ { ( V _ { i } ) } _ { i } \mathbb { E } [ B _ { i } ] } \frac { z \left ( 1 - \beta _ { i } ( \lambda ^ { ( V _ { i } ) } _ { i } ( 1 - z ) ) \right ) } { \beta _ { i } ( \lambda ^ { ( V _ { i } ) } _ { i } ( 1 - z ) ) - z } \times \frac { \mathbb { E } \left [ z ^ { L B ^ { ( S _ { i } ) } _ { i } } \right ] - \mathbb { E } \left [ z ^ { L B ^ { ( V _ { i } ) } _ { i } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B ^ { ( V _ { i } ) } _ { i } ] - \mathbb { E } [ L B ^ { ( S _ { i } ) } _ { i } ] \right ) }, \ \ ( 3. 8 )$$
for i = 1 , . . . , N . The second part of this decomposition is, again, the PGF of the number of customers at an arbitrary point during the intervisit time I i . The first part can be recognised as the PGF of the queue length of an M/G/ 1 queue with type i customers at an arbitrary point during a busy period.
Now we return to the model with varying arrival rates. The key observation is that the behaviour of the number of type i customers during a visit period of Q i , is exactly the same in this system as in a polling system with constant arrival rates λ ( V i ) i for type i customers. Equation (3.8) no longer depends on anything that happens during the intervisit time, because this is all captured in LB ( V i ) i , the number of type i customers at the beginning of a visit to Q i . This implies that, for a polling model with smart customers, the queue length PGF of Q i at a random point during V i is also given by (3.8). The only difference lies in the interpretation of (3.8). Obviously, the first part in (3.8) is still the PGF of the queue length distribution of an M/G/ 1 queue at an arbitrary point during a busy period. However, the last term can no longer be interpreted as the PGF of the distribution of the number of type i customers at an arbitrary point during the intervisit time I i .
Substitution of (3.4), (3.5), and (3.8) in (3.3) gives the desired expression for the PGF of the marginal queue length in Q i .
Remark 3.1 The marginal queue length PGF (3.3) has been obtained by conditioning on the position of the server at an arbitrary epoch in a cycle, which explains the probabilities E [ V j ] E [ C ] (server is serving Q j ) and E [ S j ] E [ C ] (server is switching to Q j +1 ). It is easy now
to obtain the marginal queue length PGF at an arrival epoch , simply by conditioning on the position of the server at an arbitrary arrival epoch . The probability that the server is at position P ∈ { V , S 1 1 , . . . , V N , S N } at the arrival of a type i customer, is λ ( P ) i E [ P ] λ i E [ C ] , with λ i = 1 E [ C ] ∑ N j =1 ( λ ( V j ) i E [ V j ] + λ ( S j ) i E [ S j ] ) . This results in the following expression for the PGF of the distribution of the number of type i customers at the arrival of a type i customer:
$$\mathbb { E } [ z ^ { L _ { i } } | \text{arrival type } i ] = \sum _ { j = 1 } ^ { N } \left ( \frac { \lambda _ { i } ^ { ( V _ { j } ) } \mathbb { E } [ V _ { j } ] } { \bar { \lambda } _ { i } \mathbb { E } [ C ] } \mathbb { E } \left [ z ^ { L _ { i } ^ { ( V _ { j } ) } } \right ] + \frac { \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] } { \bar { \lambda } _ { i } \mathbb { E } [ C ] } \mathbb { E } \left [ z ^ { L _ { i } ^ { ( S _ { j } ) } } \right ] \right ),$$
for i = 1 , . . . , N . A standard up-and-down crossing argument can be used to argue that (3.9) is also the PGF of the distribution of the number of type i customers at the departure of a type i customer. As stated before, it is different from the PGF of the distribution of the number of type i customers at an arbitrary epoch, unless λ ( V j ) i = λ ( S j ) i = λ i for all i, j = 1 , . . . , N (as is the case in polling models without smart customers).
Remark 3.2 Equations (3.4) and (3.5) rely heavily on the PASTA property and are only valid if type i arrivals take place during the non-serving interval. If no type i arrivals take place (i.e. λ ( P ) i = 0 for the non-serving interval P ), both the numerator and the denominator become 0. This situation has to be analysed differently. Now assume that λ ( P ) i = 0 for a specific customer type i = 1 , . . . , N , during a non-serving interval P ∈ { V , S 1 1 , . . . , V N , S N }\ V i . We now distinguish between visit periods and switch-over periods. Let us first assume that P is a switch-over time, say S , j j = 1 , . . . , N . The length of a switch-over time is independent from the number of customers in the system, so the distribution of the number of type i customers at an arbitrary point in time during S j is the same as at the beginning of S j :
$$\mathbb { E } \left \lceil z ^ { L _ { i } ^ { ( S _ { j } ) } } \right \rceil = \mathbb { E } \left \lceil z ^ { L B _ { i } ^ { ( S _ { j } ) } } \right \rceil, \quad i, j = 1, \dots, N.$$
glyph[negationslash]
The case where P is a visit time, say P = V j for some j = , requires more attention, because i the length of V j depends on the number of type j customers present at the visit beginning. Since this number is positively correlated with the number of customers in the other queues, we have to correct for the fact that it is more likely that a random point during an arbitrary V j , falls within a long visit period (with more customers present at its beginning) than in a short visit period. The first step, is to determine the probability that the number of type i customers at an arbitrary point during V j is k . Since we consider the case where λ ( V j ) i = 0, this implies that we need the probability that the number of customers at the beginning of V j is k . Standard renewal arguments yield
$$\mathbb { P } [ L _ { i } ^ { ( V _ { j } ) } = k ] & = \frac { \mathbb { P } [ L B _ { i } ^ { ( V _ { j } ) } = k ] \, \mathbb { E } [ V _ { j } | L B _ { i } ^ { ( V _ { j } ) } = k ] } { \sum _ { l = 0 } ^ { \infty } \mathbb { P } [ L B _ { i } ^ { ( V _ { j } ) } = l ] \, \mathbb { E } [ V _ { j } | L B _ { i } ^ { ( V _ { j } ) } = l ] } \\ & = \frac { \mathbb { E } [ V _ { j } \, \mathbf 1 _ { [ L B _ { i } ^ { ( V _ { j } ) } = k ] } ] } { \mathbb { E } [ V _ { j } ] },$$
where 1 [ A ] is the indicator function for event A . The first line in (3.10) is based on the fact that the probability is proportional to the length of visit periods V j that start with k
type i customers, and to the number of such visit periods V j . The denominator is simply a normalisation factor.
Now we can write down the expression for the number of type i customers at an arbitrary point during V j if λ ( V j ) i = 0:
$$\mathfrak { g } V _ { j } \, \text{if } \lambda _ { i } ^ { ( v _ { j } ) } = 0 \colon \\ \mathbb { E } \left [ z ^ { L _ { i } ^ { ( v _ { j } ) } } \right ] & = \sum _ { k = 0 } ^ { \infty } z ^ { k } \mathbb { P } [ L _ { i } ^ { ( V _ { j } ) } = k ] \\ & = \frac { 1 } { \mathbb { E } [ V _ { j } ] } \sum _ { k = 0 } ^ { \infty } z ^ { k } \mathbb { E } [ V _ { j } \, \mathbf 1 _ { [ L B _ { i } ^ { ( V _ { j } ) } = k ] } ] \\ & = \frac { 1 } { \mathbb { E } [ V _ { j } ] } \mathbb { E } [ V _ { j } \sum _ { k = 0 } ^ { \infty } z ^ { k } \, \mathbf 1 _ { [ L B _ { i } ^ { ( V _ { j } ) } = k ] } ] \\ & = \frac { 1 } { \mathbb { E } [ V _ { j } ] } \mathbb { E } [ V _ { j } \, z ^ { L B _ { i } ^ { ( V _ { j } ) } } ] \\ & = - \frac { 1 } { \mathbb { E } [ V _ { j } ] } \frac { \partial } { \partial \omega } \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { j } ) } } e ^ { - \omega V _ { j } } \right ] \right | _ { \omega = 0 }, \\., N \, \text{and } j \neq i. \\ \quad, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
., N \, \text{and } j \neq i.$$
glyph[negationslash]
for i = 1 , . . . , N and j = . i
Now we only need to determine E [ z LB ( V j ) i e -ωV j ]. We use the joint queue length distribution of all customers present at the beginning of V j , which is given implicitly by (3.2). Define Θ j as the time that the server spends at Q j due to the presence of one customer there, with LST θ j ( ). · For gated service θ j ( ) · = β j ( ), · and for exhaustive service θ j ( ) · = π j ( ). · The length of V j , given that l j type j customers are present at the visit beginning, is the sum of l j independent random variables with the same distribution as Θ , denoted by Θ j j, 1 , . . . , Θ j,l j . The joint distribution of the number of type i customers present at the beginning of V j and the length of V j is given by:
$$\tilde { \text{the length of } V _ { j } \text{ is given by: } } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { j } ) } } e ^ { - \omega V _ { j } } \right ] & = \sum _ { l _ { i } = 0 } ^ { \infty } \sum _ { l _ { j } = 0 } ^ { \infty } \mathbb { E } \left [ z ^ { l _ { i } } e ^ { - \omega ( \Theta _ { j, 1 } + \cdots + \Theta _ { j, l _ { j } } ) } \right ] \mathbb { P } \left [ L B _ { i } ^ { ( V _ { j } ) } = l _ { i }, L B _ { j } ^ { ( V _ { j } ) } = l _ { j } \right ] \\ & = \sum _ { l _ { i } = 0 } ^ { \infty } \sum _ { l _ { j } = 0 } ^ { \infty } z ^ { l _ { i } } \mathbb { E } \left [ z ^ { - \omega \Theta _ { j, 1 } } \right ] \mathbb { P } \left [ L B _ { i } ^ { ( V _ { j } ) } = l _ { i }, L B _ { j } ^ { ( V _ { j } ) } = l _ { j } \right ] \\ & = \sum _ { l _ { i } = 0 } ^ { \infty } \sum _ { l _ { j } = 0 } ^ { \infty } z ^ { l _ { i } } \theta _ { j } ( \omega ) ^ { l _ { j } } \mathbb { P } \left [ L B _ { i } ^ { ( V _ { j } ) } = l _ { i }, L B _ { j } ^ { ( V _ { j } ) } = l _ { j } \right ] \\ & = \widetilde { L } \mathbb { B } ^ { ( V _ { j } ) } ( 1, \dots, 1, z, 1, \dots, 1, \theta _ { j } ( \omega ), 1, \dots, 1 ), \\ \text{where } z \text{ corresponds to customers in } Q _ { i }, \text{ and } \theta _ { j } ( \omega ) \text{ corresponds to customers in } Q _ { j }. \text{ Subst} \text{-}$$
where z corresponds to customers in Q i , and θ j ( ω ) corresponds to customers in Q j . Substitution of (3.12) in (3.11) gives the desired result.
## 4 Waiting time distribution
In the previous section we gave an expression for the PGF of the distribution of the steadystate queue length of a type i customer at an arbitrary epoch, L i . If the arrival rates do not
depend on the server position, i.e. λ ( V j ) i = λ ( S j ) i = λ i for all i, j = 1 , . . . , N , we can use the distributional form of Little's law (see, e.g., [19]) to obtain the LST of the distribution of the waiting time of a type i customer, W i , i = 1 , . . . , N . Because of the varying arrival rates, there is no λ i for which the relation E [ z L i ] = E [ e -λ i (1 -z )( W i + B i ) ] holds (even if we choose λ i = λ i ). In the present section, we introduce subtypes of each customer type. Each subtype is identified by the position of the server at its arrival in the system. We show that one can use a generalised version of the distributional form of Little's law that leads to the LST of the waiting time distribution of a type i customer, when applied to the PGF of the joint queue length distribution of all subtypes of a type i customer. Determining this PGF requires a separate treatment of exhaustive and gated service, so results in this section do not apply to any arbitrary branching-type service discipline.
## 4.1 Joint queue length distribution at visit beginnings/endings for all subtypes
In the present section we distinguish between subtypes of type i customers, arriving during different visit/switch-over periods. We define a type i ( P ) customer to be a customer arriving at Q i during P ∈ { V , S 1 1 , . . . , V N , S N } . Therefore, only in this section, we define z in the following way:
$$\mathbf z = ( z _ { 1 } ^ { ( V _ { 1 } ) }, \dots, z _ { 1 } ^ { ( S _ { N } ) }, \dots, z _ { N } ^ { ( V _ { 1 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } ).$$
Note that z has 2 N 2 components: N customer types times 2 N subperiods within a cycle ( N visit times plus N switch-over times). Let ˜ VB ( P ) i ( z ) be the PGF of the joint queue length distribution of all these customer types at the moment that the server starts serving type i customers that have arrived when the server was located at position P . ˜ VC ( P ) i ( z ) is defined equivalently for the moment that the server completes service of type i ( P ) customers.
For exhaustive service, the visit period V i can be divided into the following subperiods: V i = V ( S i ) i + V ( V i +1 ) i + · · · + V ( S i + N -1 ) i + V ( V i ) i . First the type i ( S i ) customers that were present at the visit beginning are served, followed by the type i ( V i +1 ) customers, and so on. Note that during these services only type j ( V i ) customers arrive in Q j , j = 1 , . . . , N . Visit period V i ends with V ( V i ) i , i.e., the exhaustive service of all type i ( V i ) customers that have arrived during V i so far. The joint queue length process at polling instants of each of the subperiods is still a Multi-Type Branching Process, because the service discipline in each subperiod satisfies the Branching Property. Hence, the laws of motion can be obtained by applying this property successively. As an example, we show the relations for the PGFs of the joint queue length
distributions at beginnings and endings of the subperiods of V 1 :
$$& \quad \text{www.w3.com/w3-v-2.5.0.1} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \quad \text{$2\pi$} \\ & \quad \widetilde { V B } _ { 1 } ^ { ( V _ { 2 } ) } ( z ) = \widetilde { V C } _ { 1 } ^ { ( V _ { 2 } ) } ( z ) = \widetilde { V B } _ { 1 } ^ { ( V _ { 2 } ) } \left ( z _ { 1 } ^ { ( V _ { 1 } ) }, 1, \beta _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), z _ { 1 } ^ { ( S _ { 2 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ), \\ &.$$
.
.
.
glyph[negationslash]
$$\begin{array} { c } \colon \\ \widetilde { V B } _ { 1 } ^ { ( V _ { 1 } ) } ( z ) = \widetilde { V C } _ { 1 } ^ { ( S _ { N } ) } ( z ) = \widetilde { V B } _ { 1 } ^ { ( S _ { N } ) } \left ( z _ { 1 } ^ { ( V _ { 1 } ) }, 1, \dots, 1, \beta _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), z _ { 2 } ^ { ( V _ { 1 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ), \\ \widetilde { V C } _ { 1 } ^ { ( V _ { 1 } ) } ( z ) = \widetilde { V B } _ { 1 } ^ { ( V _ { 1 } ) } \left ( \pi _ { 1 } ( \sum _ { j \neq 1 } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), 1, \dots, 1, z _ { 2 } ^ { ( V _ { 1 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ). \\ _ { - } \quad. \quad _ { - } \quad _ { - } \quad _ { \ell c \, \dots } \quad _ { - } \, \quad _ { - } \, \end{array} \,.$$
During a switch-over time S j only type i ( S j ) customers arrive, i, j = 1 , . . . , N . We can relate the PGF of the joint queue length distribution at the beginning of a visit to Q 2 (starting with the service of type 2 ( S 2 ) customers) to ˜ VC ( V 1 ) 1 ( z ):
$$\widetilde { V B } _ { 2 } ^ { ( S _ { 2 } ) } ( { \mathbf z } ) = \widetilde { V C } _ { 1 } ^ { ( V _ { 1 } ) } ( { \mathbf z } ) \, \sigma _ { 1 } \Big ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( S _ { 1 } ) } ( 1 - z _ { j } ^ { ( S _ { 1 } ) } ) \Big ).$$
The above expressions can be used to express ˜ VB ( S 2 ) 2 ( ) · in terms of ˜ VB ( S 1 ) 1 ( ), · and this can be repeated to obtain a recursion for ˜ VB ( S 1 ) 1 ( ). ·
Remark 4.1 For gated service we take similar steps, but they are slightly different because arriving customers will always be served in the next cycle. This means that a visit to Q i starts with the service of all type i ( V i ) customers present at that polling instant: V i = V ( V i ) i + V ( S i ) i + V ( V i +1 ) i + · · · + V ( S i + N -1 ) i . The relations for the PGF of the joint queue length distribution at beginnings and endings of the subperiods of V 1 are:
$$& \varkappa \text{gmingo and running on one or more or more } \ v _ { 1 } \ a r. \\ & \widetilde { V } B _ { 1 } ^ { ( S _ { 1 } ) } ( z ) = \widetilde { V C } _ { 1 } ^ { ( V _ { 1 } ) } ( z ) = \widetilde { V B } _ { 1 } ^ { ( V _ { 1 } ) } \left ( \beta _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), z _ { 1 } ^ { ( S _ { 1 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ), \\ & \widetilde { V } B _ { 1 } ^ { ( V _ { 2 } ) } ( z ) = \widetilde { V C } _ { 1 } ^ { ( S _ { 1 } ) } ( z ) = \widetilde { V B } _ { 1 } ^ { ( S _ { 1 } ) } \left ( z _ { 1 } ^ { ( V _ { 1 } ) }, \beta _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), z _ { 1 } ^ { ( V _ { 2 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ), \\ &.$$
.
.
.
$$\widetilde { V C } _ { 1 } ^ { ( S _ { N } ) } ( \mathbf z ) = \widetilde { V B } _ { 1 } ^ { ( S _ { N } ) } \left ( z _ { 1 } ^ { ( V _ { 1 } ) }, 1, \dots, 1, \beta _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { 1 } ) } ( 1 - z _ { j } ^ { ( V _ { 1 } ) } ) ), z _ { 2 } ^ { ( V _ { 1 } ) }, \dots, z _ { N } ^ { ( S _ { N } ) } \right ).$$
The remainder of this section is valid for any branching-type service discipline treating customers in order of arrival in each queue, such as, e.g., exhaustive, gated, globally gated and
multi-stage gated [28]. Having determined the joint queue length distribution at beginnings and endings of all subperiods within each visit period, we are ready to determine the joint queue length distribution at departure epochs of all customer subtypes. We follow the approach in [3, 4], which itself is based on Eisenberg's approach [13], developing a relation between joint queue lengths at service beginnings/completions and visit beginnings/endings. In [3], for conventional polling systems, the joint distribution of queue length vector and server position at service completions leads to the marginal queue length distribution. Developing an equivalent for our model, requires distinguishing between customer subtypes. Firstly, the queue length vector z contains all customer subtypes. Secondly, the type of service completion is not just defined by the location i of the server, but also by the subtype P of the customer that has been served. Therefore, let M ( P ) i ( z ) denote the PGF of the joint distribution of the subtypes of customers being served (combination of i = 1 , . . . , N and P ∈ { V , S 1 1 , . . . , V N , S N } ) and queue length vector of all customer subtypes at service completions. Equation (3.4) in [3], applied to our model, gives:
$$M _ { i } ^ { ( P ) } ( \mathbf z ) = \frac { 1 } { \overline { \lambda } \mathbb { E } [ C ] } \, \frac { \beta _ { i } \left ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { i } ) } ( 1 - z _ { j } ^ { ( V _ { i } ) } ) \right ) } { z _ { i } ^ { ( P ) } - \beta _ { i } \left ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ^ { ( V _ { i } ) } ( 1 - z _ { j } ^ { ( V _ { i } ) } ) \right ) } \, \left [ \widetilde { V B } _ { i } ^ { ( P ) } ( \mathbf z ) - \widetilde { V C } _ { i } ^ { ( P ) } ( \mathbf z ) \right ], \quad \, ( 4. 1 )$$
for i = 1 , . . . , N ; P ∈ { V , S 1 1 , . . . , V N , S N } , and λ = ∑ N i =1 λ i . Thus, M ( P ) i ( z ) is the generating function of the probabilities that, at an arbitrary departure epoch, the departing customer is a type i ( P ) customer and the number of customers left behind by this departing customer is l ( V 1 ) 1 , . . . , l ( S N ) N . We now focus on the queue length vector of subtypes of type i customers only, given that the departure takes place at Q i . The probability that an arbitrary service completion (regardless of the subtype of the customer) takes place at Q i , is λ /λ i . It is convenient to introduce the notation z i = (1 , . . . , 1 , z ( V 1 ) i , . . . , z ( S N ) i , 1 , . . . , 1). The PGF of the joint queue length distribution of all subtypes of type i customers at an arbitrary departure from Q i is:
$$\mathbb { E } \left [ \left ( z _ { i } ^ { ( V _ { 1 } ) } \right ) ^ { D _ { i } ^ { ( V _ { 1 } ) } } \cdots \left ( z _ { i } ^ { ( S _ { N } ) } \right ) ^ { D _ { i } ^ { ( S _ { N } ) } } \right ] = \frac { \bar { \lambda } } { \bar { \lambda } _ { i } } \sum _ { j = 1 } ^ { N } \left ( M _ { i } ^ { ( V _ { j } ) } ( \mathbf z _ { 1 } ) + M _ { i } ^ { ( S _ { j } ) } ( \mathbf z _ { 1 } ) \right )$$
where D ( P ) i is the number of type i ( P ) customers left behind at a departure from Q i (which should not be confused with L ( P ) i , the number of type i customers at an arbitrary moment while the server is at position P ).
Remark 4.2 Substitution of z ( P ) i = z for all P ∈ { V , S 1 1 , . . . , V N , S N } in (4.2) gives the marginal queue length distribution of type i customers at departure epochs, which is equal to (3.9), the marginal queue length distribution at arrival epochs of a type i customer.
## 4.2 Waiting times
Now we present a generalisation of the distributional form of Little's law that can be applied to the joint queue length distribution of all subtypes of a type i customer at departure epochs from Q i , to obtain the waiting time LST of a type i customer.
Theorem 4.3 The LST of the distribution of the waiting time W i of a type i customer, i = 1 , . . . , N , is given by:
$$\mathbb { E } \left [ e ^ { - \omega W _ { i } } \right ] = \frac { 1 } { \beta _ { i } ( \omega ) } \mathbb { E } \left [ \left ( 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } } \right ) ^ { D _ { i } ^ { ( V _ { 1 } ) } } \cdots \left ( 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } } \right ) ^ { D _ { i } ^ { ( S _ { N } ) } } \right ].$$
Proof Wefocus on the departure of a type i customer that arrived during P A ∈ { V , S 1 1 , . . . , V N , S N } . We make use of the fact that the sojourn time (i.e., waiting time plus service time) of this tagged type i ( P A ) customer can be determined by studying the subtypes of all type i customers that he leaves behind on his departure. We need to distinguish between two cases, which can be treated simultaneously, but require different notations. Firstly, the case where a customer arrives in the system and departs during another period. In the second case, the customer departs during the same period in which he arrived. Obviously, in our model the second case can only occur if a customer arrives at a queue with exhaustive service while it is being visited by the server.
glyph[negationslash]
Case 1: departure in a different period. In this case we have that P A = V i , or P A = V i but the cycle in which the arrival took place is not the same as the cycle in which the departure takes place (this situation cannot occur with exhaustive service). All type i customers that are left behind, have arrived during the residual period P A , all periods between P A and V i (if any), and during the elapsed part of V i . Denote by P I the set of visit periods and switch-over periods that lie between P A and V i . Furthermore, let P A, res be the residual period P A . Finally denote by V i, past the age of V i at the departure instant of the tagged type i customer.
Case 2: departure during the period of arrival. If the customer arrived during the same visit period in which his departure takes place, take P A, res = 0 , P I = ∅ , and V i, past is the time that elapsed since the arrival of the tagged type i ( V i ) customer.
In both cases, the joint queue length distribution of all customer i subtypes at this departure instant is given by (4.2). Since we assume FCFS service, at such a departure instant no type i customers are present anymore that have arrived before the arrival epoch of the tagged type i customer. This results in:
$$\mathbb { E } \left [ \left ( z _ { i } ^ { ( V _ { 1 } ) } \right ) ^ { D _ { i } ^ { ( V _ { 1 } ) } } \cdots \left ( z _ { i } ^ { ( S _ { N } ) } \right ) ^ { D _ { i } ^ { ( S _ { N } ) } } \right ] = \mathbb { E } \left [ e ^ { - \lambda _ { i } ^ { ( P _ { A } ) } ( 1 - z _ { i } ^ { ( P _ { A } ) } ) P _ { A, r e s } - \sum _ { p \in P _ { I } } \lambda _ { i } ^ { ( p ) } ( 1 - z _ { i } ^ { ( p ) } ) p - \lambda _ { i } ^ { ( V _ { i } ) } ( 1 - z _ { i } ^ { ( V _ { i } ) } ) V _ { i, p a s t } } \right ].$$
(4.4)
Equation (4.3) follows from the relation W i + B i = P A, res + ∑ p ∈ P I p + V i, past and substitution of z ( P ) i = 1 -ω λ ( P ) i for all P ∈ { V , S 1 1 , . . . , V N , S N } in (4.4). glyph[square]
Remark 4.4 Theorem 4.3 only holds if λ ( P ) i > 0 for all i = 1 , . . . , N , and P ∈ { V , S 1 1 , . . . , V N , S N } . If λ ( P ) i = 0 for a certain i and P , we can still find an expression for E [ e -ωW i ] , but we might have to resort to some 'tricks'. In Section 8, Example 2, we show how the introduction of an extra (virtual) customer type can help to resolve this problem.
## 5 Cycle time, intervisit time and visit times
In the previous sections we repeatedly needed the mean cycle time E [ C ] and the mean visit times E [ V i ] , i = 1 , . . . , N . In this section we study the LSTs of the cycle time distribution and visit time distributions, which can be used to obtain the mean and higher moments. The LSTs of the distributions of the visit times V , i i = 1 , . . . , N , can easily be determined for any branching-type service discipline using the function θ i ( ), · introduced in Remark 3.2, and the joint queue length distribution at the visit beginning of Q i (not taking subtypes into account):
$$\mathbb { E } [ \mathrm e ^ { - \omega V _ { i } } ] = \widetilde { L B } ^ { ( V _ { i } ) } ( 1, \dots, 1, \theta _ { i } ( \omega ), 1, \dots, 1 ).$$
The cycle time C i is defined as the time that elapses between two consecutive visit beginnings to Q i . We consider branching-type service disciplines only, i.e., service disciplines for which Property 2.1 holds. The cycle time LST for polling models with branching-type service disciplines and arrival rates independent of the server position, has been established in [10]. We adapt their approach to the model with arrival rates depending on the server location. Using θ i ( ), · i = 1 , . . . , N , we define the following functions in a recursive way:
$$\psi ^ { ( V _ { N } ) } ( \omega ) & = \omega, \\ \psi ^ { ( V _ { i } ) } ( \omega ) & = \omega + \sum _ { k = i + 1 } ^ { N } \lambda _ { k } ^ { ( V _ { i } ) } \left ( 1 - \theta _ { k } ( \psi ^ { ( V _ { k } ) } ( \omega ) ) \right ), \quad i = N - 1, \dots, 1.$$
Similarly, define:
$$\psi ^ { ( S _ { N } ) } ( \omega ) = \omega,$$
$$\psi ^ { ( S _ { i } ) } ( \omega ) = \omega + \sum _ { k = i + 1 } ^ { N } \lambda _ { k } ^ { ( S _ { i } ) } \left ( 1 - \theta _ { k } ( \psi ^ { ( V _ { k } ) } ( \omega ) ) \right ), \quad i = N - 1, \dots, 1.$$
Theorem 5.1 The LST of the distribution of the cycle time C 1 is:
$$\mathbb { E } \left [ \mathrm e ^ { - \omega C _ { 1 } } \right ] = \widetilde { L B } ^ { ( V _ { 1 } ) } \left ( \theta _ { 1 } ( \psi ^ { ( V _ { 1 } ) } ( \omega ) ), \dots, \theta _ { N } ( \psi ^ { ( V _ { N } ) } ( \omega ) ) \right ) \prod _ { i = 1 } ^ { N } \sigma _ { i } \left ( \psi ^ { ( S _ { i } ) } ( \omega ) \right ).$$
Proof Similar to the proof of Theorem 3.1 in [10], by giving an expression for the cycle time LST conditioned on the numbers of customers in all queues at the beginning of a cycle, and then by subsequently unconditioning one queue at a time. glyph[square]
The LST of the distribution of the intervisit time I 1 can be found in a similar way:
$$\mathbb { E } \left [ e ^ { - \omega I _ { 1 } } \right ] = \widetilde { L B } ^ { ( S _ { 1 } ) } \left ( 1, \theta _ { 2 } ( \psi ^ { ( V _ { 2 } ) } ( \omega ) ), \dots, \theta _ { N } ( \psi ^ { ( V _ { N } ) } ( \omega ) ) \right ) \prod _ { i = 1 } ^ { N } \sigma _ { i } \left ( \psi ^ { ( S _ { i } ) } ( \omega ) \right ).$$
Equations (5.2) and (5.3) hold for general branching-type service disciplines. For gated and exhaustive service we can give expressions that are more compact and easier to interpret, using the joint queue length distribution of all customer subtypes at visit beginnings, as given in Subsection 4.1.
Theorem 5.2 If Q i receives exhaustive service , the LST of the distribution of the cycle time C ∗ i , starting at a visit ending to Q i , and the LST of the distribution of the intervisit time I i , are given by:
$$\mathbb { E } [ e ^ { - \omega C _ { i } ^ { * } } ] = \widetilde { V B } _ { i } ^ { ( S _ { i } ) } ( 1, \dots, 1, \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ), \quad \ \ ( 5. 4 )$$
$$\mathbb { E } [ \mathrm e ^ { - \omega I _ { i } } ] = \widetilde { V B _ { i } } ^ { ( S _ { i } ) } ( 1, \dots, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ),$$
glyph[negationslash]
glyph[negationslash]
provided that λ ( P ) i = 0 for all P ∈ { V , S 1 1 , . . . , V N , S N } . In the right hand sides of (5.4) and (5.5), the components z ( P ) j with j = i are 1.
If Q i receives gated service , the LST of the distribution of the cycle time C i , and the LST of the distribution of the intervisit time I i , are given by:
$$& \text{$w$ unwra$or $or $var$or $var$or $my$} _ { i }, \text{$w$} _ { i }, \text{$w$} _ { i }, \text{$w$} _ { i }, \text{$w$} _ { i }, \text{$w$} _ { i }, \\ & \mathbb { E } [ e ^ { - \omega C _ { i } } ] = \widetilde { \ V B } _ { i } ^ { ( V _ { i } ) } ( 1, \dots, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ), \\ & \mathbb { E } [ e ^ { - \omega I _ { i } } ] = \widetilde { \ V B } _ { i } ^ { ( V _ { i } ) } ( 1, \dots, 1, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { i - 1 } ) } }, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { i } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ), \\ & \dots$$
glyph[negationslash]
again provided that λ ( P ) i = 0 for all P ∈ { V , S 1 1 , . . . , V N , S N } . Note that z ( V i ) i = 1 in (5.6).
Proof We prove the exhaustive case only, the proof for gated service proceeds along the same lines. Using I i = S i + V i +1 + S i +1 + · · · + S i + N -1 , and the fact that no type i ( V i ) customers are present at the beginning of the intervisit period (and hence also at the beginning of a cycle C ∗ i ), we obtain:
$$\widetilde { V } _ { i } ^ { ( S _ { i } ) } \left ( 1, \dots, 1, z _ { i } ^ { ( V _ { 1 } ) }, \dots, z _ { i } ^ { ( S _ { N } ) }, 1, \dots, 1 \right ) = \mathbb { E } \left [ e ^ { - \lambda _ { i } ^ { ( S _ { i } ) } ( 1 - z _ { i } ^ { ( S _ { i } ) } ) S _ { i } - \dots - \lambda _ { i } ^ { ( S _ { i + N - 1 } ) } ( 1 - z _ { i } ^ { ( S _ { i + N - 1 } ) } ) S _ { i + N - 1 } } \right ]. \\ \hat { \ }. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.. \.. \........................................................................................................................................................................................................$$
Substitution of z ( P ) i = 1 -ω λ ( P ) i for all P ∈ { V , S 1 1 , . . . , V N , S N } proves (5.5). Equation (5.4) follows by using the relation C ∗ i = I i + V i , and noting that V i is the sum of the busy periods initiated by all type i customers that have arrived during I i . In terms of LSTs:
$$& \text{ initiated by all type $i$ customers that have arrived during $I_{i}$. In terms of LS1$} \text{s} \text{:} \\ & \mathbb { E } \left [ e ^ { - \omega C _ { i } ^ { * } } \right ] = \mathbb { E } \left [ e ^ { - \left ( \omega + \lambda _ { i } ^ { ( S _ { i } ) } ( 1 - \pi _ { i } ( \omega ) ) \right ) S _ { i } - \dots - \left ( \omega + \lambda _ { i } ^ { ( S _ { i } + N - 1 ) } ( 1 - \pi _ { i } ( \omega ) ) \right ) S _ { i + N - 1 } } \right ] \\ & \quad = \mathbb { E } \left [ e ^ { - \lambda _ { i } ^ { ( S _ { i } ) } \left ( 1 - \left ( \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( S _ { i } ) } } \right ) } \right ) S _ { i } - \dots - \lambda _ { i } ^ { ( S _ { i } + N - 1 ) } \left ( 1 - \left ( \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( S _ { i } + N - 1 ) } } \right ) \right ) S _ { i + N - 1 } } \right ], \\ & \text{which, by } ( 5. 7 ), \text{reduces to } ( 5. 4 ).$$
which, by (5.7), reduces to (5.4).
Differentiation of the LSTs of C i and C ∗ i for i = 1 , . . . , N , shows that, just like in polling models with constant arrival rates, the mean cycle time does not depend on the starting point of the cycle, i.e. E [ C i ] = E [ C ∗ i ] = E [ C ]. The mean cycle time E [ C ] and mean visit times E [ V i ] can be obtained by differentiating the corresponding LSTs. In the next section a more efficient method is described to compute them.
## 6 Mean Value Analysis
In this section we extend the Mean Value Analysis (MVA) framework for polling models, originally developed by Winands et al. [31], to suit the concept of smart customers. For this purpose, we first outline the main ideas of MVA for polling systems. Subsequently, we determine the mean visit times and the mean cycle time in a numerically more efficient way than in the previous section, and, finally, we present the MVA equations for a polling system with smart customers.
## 6.1 Main idea MVA
For 'ordinary' polling models, where the arrival rates at a queue do not depend on the position of the server, in [31] an approach is described for deriving the steady-state mean waiting times at each of the queues, E [ W i ] for i = 1 , . . . , N , by setting up a system of linear equations, where each equation has a probabilistic and intuitive explanation. We sketch the main ideas of MVA for exhaustive service; the cases of gated or mixed service disciplines require only minor changes.
The mean waiting time E [ W i ] of a type i customer, excluding his service time, can be expressed in the following way: upon arrival of a (tagged) type i customer, he has to wait for the (remaining) time it takes to serve all type i customers already present in the system, plus possibly the time before the server arrives at Q i . By PASTA, the arriving customer finds in expectation E [ ˆ ] L i waiting type i customers in queue, each having an expected service time E [ B i ]. Note that we use ˆ L i to denote the queue lengths excluding customers in service. The expected time until the server returns to Q i , is denoted by E [ T i ] (which depends on the service discipline of all queues). A fraction ρ i := λ i E [ B i ] of the time, the server is serving Q i , and hence, with probability ρ i , an arriving customer has to wait for a mean residual service time, denoted by E [ R B i ]; otherwise he has to wait until the server returns. This gives, for i = 1 , . . . , N :
$$\mathbb { E } [ W _ { i } ] = \mathbb { E } [ \hat { L } _ { i } ] \, \mathbb { E } [ B _ { i } ] + \rho _ { i } \, \mathbb { E } [ R _ { B _ { i } } ] + ( 1 - \rho _ { i } ) \, \mathbb { E } [ T _ { i } ].$$
Little's law gives E [ ˆ ] = L i λ i E [ W i ], for i = 1 , . . . , N , and so it remains to derive E [ T i ]. For this, first a system of equations is composed for the conditional mean queue lengths, which can be expressed in mean residual durations of (sums of) visit and switch-over times. The solution of this system of equations can be used to determine E [ T i ], and hence E [ ˆ ] L i and E [ W i ] follow.
## 6.2 Mean visit times and mean cycle time
For the case of smart customers, the visit times to a queue depend on all arrival rates λ ( V j ) i and λ ( S j ) i . In order to extend MVA to this case, we first derive the mean visit times to each of the queues, E [ V i ], for i = 1 , . . . , N . We set up a system of N linear equations where the mean visit time of a queue is expressed in terms of the other mean visit times. We again focus on the exhaustive service discipline.
At the moment the server finishes serving Q i , there are no type i customers present in the system any more. From this point on, the number of type i customers builds up at rates
λ ( S i ) , λ ( V i +1 ) , . . . , λ ( S i + N -1 ) (depending on the position of the server), until the server starts working on Q i again. Each of these customers initiates a busy period, with mean E [ BP i ] := E [ B / i ] (1 -λ ( V i ) i E [ B i ]). This gives:
$$\mathbb { E } [ V _ { i } ] = \mathbb { E } [ B P _ { i } ] \left ( \lambda _ { i } ^ { ( S _ { i } ) } \mathbb { E } ( S _ { i } ) + \sum _ { j = i + 1 } ^ { i + N - 1 } \left ( \lambda _ { i } ^ { ( V _ { j } ) } \mathbb { E } [ V _ { j } ] + \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] \right ) \right ),$$
for i = 1 , . . . , N . The E [ V i ] follow from solving this set of equations. This method is computationally faster than determining (and differentiating) the LSTs of the visit time distributions (5.1). Once the mean visit times have been obtained, the mean cycle time follows from E [ C ] = ∑ N i =1 ( E [ V i ] + E [ S i ]).
## 6.3 MVA equations
We extend the MVA approach to polling systems with smart customers. First, we briefly introduce some extra notation, then we give expressions for the mean waiting times, and the mean conditional and unconditional queue lengths. After eliminating variables, we end up with a system of linear equations. The system can (numerically) be solved in order to find the unknowns, in particular, the mean unconditional queue lengths and the mean waiting times. Although all equations are discussed in the present section, for the sake of brevity of this section, some of them are presented in Appendix A.
The fraction of time the system is in a given period P ∈ { V , S 1 1 , . . . , V N , S N } is denoted by q ( P ) := E [ P ] E [ C ] . The mean residual duration of a period P , at an arbitrarily chosen point in this period, is denoted by E [ R P ] = E [ P 2 ] 2 E [ P ] . The mean conditional number of type j customers in the queue during a random point in P is denoted by E [ ˆ L ( P ) j ], and the mean (unconditional) number of type j customers in queue is denoted by E [ ˆ L j ]. Note that ˆ L j and ˆ L ( P ) j do not include a potential customer in service, whereas L j and L ( P ) j , introduced in Section 3, denote queue lengths including customers being served.
We define an interval , e.g. ( V i : S j ), as the consecutive periods from the first mentioned period on, until and including the last mentioned period, here consisting of the periods V , S , V i i i +1 , S i +1 , . . . , V , S j j . The mean residual duration of an interval, e.g. ( V i : S j ), is denoted by E [ R V i : S j ]. Analogously, we define E [ R V i : V j ], E [ R S i : V j ] and E [ R S i : S j ].
An important concept in the remainder of the analysis is the concept of conditional durations of a period. This is an extension of the well-known residual duration, or the age of a period. It deals with the length of a period within the cycle (i.e., a visit time or a switch-over time), given that the system is being observed from another period. Before we proceed, we clarify this important concept by a simple example. Consider a vacation system, i.e., a polling system with N = 1. A cycle consists of a switch-over time (or: vacation) S 1 , followed by a visit time V 1 , during which the queue is served exhaustively. Now assume that the system is being observed at a random epoch during the switch-over time S 1 . We derive an expression for E [ - → V 1 ( S 1 ) ], which is the conditional mean visit time following the switch-over time, given that the system is being observed during S 1 . Since service is exhaustive, the visit time consists of the busy periods of the customers that arrived during the elapsed part of S 1 , denoted by
S 1 past , , plus the busy periods of the customers that will arrive during the residual switch-over time, denoted by S 1 res , . Hence, it can be seen that in this system
$$\mathbb { E } [ \overrightarrow { V _ { 1 } } ^ { ( S _ { 1 } ) } ] = \frac { \lambda _ { 1 } ^ { ( S _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } { 1 - \lambda _ { 1 } ^ { ( V _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } \left ( \mathbb { E } [ S _ { 1, \text{past} } ] + \mathbb { E } [ S _ { 1, \text{res} } ] \right ) = \frac { \lambda _ { 1 } ^ { ( S _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } { 1 - \lambda _ { 1 } ^ { ( V _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } \frac { \mathbb { E } [ S _ { 1 } ^ { 2 } ] } { \mathbb { E } [ S _ { 1 } ] }.$$
Instead of studying the mean visit time following the switch-over time during which the system is observed, we can also study the mean visit time preceding this particular switchover time, denoted by E [ ← -V 1 ( S 1 ) ]. Now the expression is easier, because a switch-over time is independent of the preceding visit time, so
$$\mathbb { E } [ \overleftarrow { V _ { 1 } } ^ { ( S _ { 1 } ) } ] = \mathbb { E } [ V _ { 1 } ] = \frac { \lambda _ { 1 } ^ { ( S _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } { 1 - \lambda _ { 1 } ^ { ( V _ { 1 } ) } \mathbb { E } [ B _ { 1 } ] } \mathbb { E } [ S _ { 1 } ].$$
Similarly, we denote by E [ - → S 1 ( V 1 ) ] and E [ ← -S 1 ( V 1 ) ] the mean switch-over times following , respectively preceding , the visit period V 1 during which the system is observed. Because of the independence between S 1 and the preceding V 1 , it is immediately clear that
$$\mathbb { E } [ \overrightarrow { S _ { 1 } } ^ { ( V _ { 1 } ) } ] = \mathbb { E } [ S _ { 1 } ].$$
Unfortunately, E [ ← -S 1 ( V 1 ) ] cannot be determined this easily, since V 1 is positively correlated with the preceding switch-over time. However, it plays a role in the set of MVA equations developed later in this section, relating the conditional mean queue lengths, the conditional mean waiting times and the conditional durations of the periods in a cycle. We leave it up to the reader to verify that Equation (6.8) reduces to E [ ← -S 1 ( V 1 ) ] = E [ S 2 1 ] / E [ S 1 ] in the exhaustive vacation model. This example simply serves the purpose of illustrating the concept of these conditional durations. In a polling system consisting of multiple queues, these expressions become more complicated and can only be found by solving sets of equations, as will be shown in the remainder of this section. Note that, because of conditional PASTA, an arbitrary customer arriving during S 1 finds the system in the same state as an observer who observes the system at an arbitrary epoch during S 1 . Hence, the conditional durations of periods play an important role in determining the mean waiting times.
glyph[negationslash]
glyph[negationslash]
For the mean conditional durations of a period, we have the following: E [ ← -V i ( V j ) ] denotes the mean duration of the previous period V i , seen from an arbitrary point in V j (i.e., V i seen backwards in time from the viewpoint of V j ), and E [ -→ V i ( V j ) ] denotes the mean duration of the next period V i (i.e., V i seen forwards in time from the viewpoint of V j ). For i = j they both coincide, and represent the mean age, resp. the mean residual duration of V i . Since the distribution of the age of a period is the same as the distribution of the residual period, we have E [ ← -V i ( V i ) ] = E [ -→ V i ( V i ) ] = E [ R V i ]. Generally, however, E [ ← -V i ( V j ) ] = E [ -→ V i ( V j ) ] for i = j , because of the dependencies between the durations of periods. Analogously, we define E [ ← -V i ( S j ) ], E [ -→ V i ( S j ) ], E [ ← -S i ( V j ) ] and E [ -→ S i ( V j ) ]. Note that, e.g., E [ -→ S i ( V j ) ] = E [ S i ], but E [ ← -S i ( V j ) ] = E [ S i ]. As switch-over times are independent, the following quantities directly simplify:
glyph[negationslash]
glyph[negationslash]
$$\mathbb { E } [ \overleftarrow { S _ { i } } ( S _ { j } ) ] = \mathbb { E } [ \overrightarrow { S _ { i } } ( S _ { j } ) ] = \begin{cases} \mathbb { E } [ S _ { i } ] & \text{for $i\neq j$}, \\ \mathbb { E } [ R _ { S _ { i } } ] & \text{for $i=j$}. \end{cases}$$
Having introduced the required notation, we now present the main theorem of this section, which gives a set of equations that can be solved to find the mean waiting times of customers in the system.
Theorem 6.1 The mean waiting times, E [ W i ], for i = 1 , . . . , N , and the mean queue lengths, E [ ˆ ], satisfy the following equations: L i
$$\mathbb { E } [ L _ { i } ], & \text{satisfy the following equations:} \\ \mathbb { E } [ W _ { i } ] & = \frac { q ^ { ( V _ { i } ) } \lambda _ { i } ^ { ( V _ { i } ) } } { \bar { \lambda } _ { i } } \left ( \mathbb { E } [ \tilde { L } _ { i } ^ { ( V _ { i } ) } ] \mathbb { E } [ B _ { i } ] + \mathbb { E } [ R _ { B _ { i } } ] \right ) \\ & \quad + \sum _ { j = i + 1 } ^ { i + N - 1 } \frac { q ^ { ( V _ { j } ) } \lambda _ { i } ^ { ( V _ { j } ) } } { \bar { \lambda } _ { i } } \left ( \mathbb { E } [ \tilde { L } _ { i } ^ { ( V _ { j } ) } ] \mathbb { E } [ B _ { i } ] + \sum _ { k = j } ^ { i + N - 1 } \left ( \mathbb { E } [ S _ { k } ] + \mathbb { E } [ \vec { V } _ { k } ^ { ( V _ { j } ) } ] \right ) \right ) \\ & \quad + \sum _ { j = i } ^ { i + N - 1 } \frac { q ^ { ( S _ { j } ) } \lambda _ { i } ^ { ( S _ { j } ) } } { \bar { \lambda } _ { i } } \left ( \mathbb { E } [ \tilde { L } _ { i } ^ { ( S _ { j } ) } ] \mathbb { E } [ B _ { i } ] + \mathbb { E } [ R _ { S _ { j } } ] + \sum _ { k = j + 1 } ^ { i + N - 1 } \left ( \mathbb { E } [ S _ { k } ] + \mathbb { E } [ \vec { V } _ { k } ^ { ( S _ { j } ) } ] \right ) \right ), \ \ ( 6. 1 ) \\ \mathbb { E } [ \tilde { L } _ { i } ] & = \bar { \lambda } _ { i } \mathbb { E } [ W _ { i } ],$$
$$\mathbb { E } [ \hat { L } _ { i } ] = \overline { \lambda } _ { i } \mathbb { E } [ W _ { i } ],$$
$$\mathbb { E } [ \hat { L } _ { i } ] = \sum _ { j = i + 1 } ^ { i + N } \left ( q ^ { ( V _ { j } ) } \mathbb { E } [ \hat { L } _ { i } ^ { ( V _ { j } ) } ] + q ^ { ( S _ { j } ) } \mathbb { E } [ \hat { L } _ { i } ^ { ( S _ { j } ) } ] \right ),$$
where the conditional mean queue lengths E [ ˆ L ( V j ) i ] and E [ ˆ L ( S j ) i ], for j = i +1 , . . . , i + N -1, are given by
$$\mathbb { E } [ \hat { L } _ { i } ^ { ( V _ { j } ) } ] = \sum _ { k = i + 1 } ^ { j } \lambda _ { i } ^ { ( V _ { k } ) } \mathbb { E } [ \overleftarrow { V _ { k } } ^ { ( V _ { j } ) } ] + \sum _ { k = i } ^ { j - 1 } \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ \overleftarrow { S _ { k } } ^ { ( V _ { j } ) } ],$$
$$\mathbb { E } [ \hat { L } _ { i } ^ { ( S _ { j } ) } ] = \sum _ { k = i + 1 } ^ { j } \lambda _ { i } ^ { ( V _ { k } ) } \mathbb { E } [ \overleftarrow { V _ { k } } ^ { ( S _ { j } ) } ] + \sum _ { k = i } ^ { j } \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ \overleftarrow { S _ { k } } ^ { ( S _ { j } ) } ],$$
and where all E [ ← -P 1 ( P 2 ) ] and E [ - → P 1 ( P 2 ) ], for P , P 1 2 ∈ { V , S 1 1 , . . . , V N , S N } , satisfy the set of equations (6.6) - (6.8) below, and (A.2)-(A.7) in Appendix A.
glyph[negationslash]
Proof In order to derive the mean waiting time E [ W i ], we condition on the period in which a type i customer arrives. A fraction q ( V j ) λ ( V j ) i /λ i , and q ( S j ) λ ( S j ) i /λ i respectively, of the type i customers arrives during period V j , and during period S j respectively. If a tagged type i customer arrives during period V i (i.e., while his queue is being served), he has to wait for a residual service time, plus the service times of all type i customers present in the system upon his arrival, which is (by conditional PASTA), E [ ˆ L ( V i ) i ]. As a fraction q ( V i ) λ ( V i ) i /λ i of the customers arrives during V i , this explains the first line of (6.1). If the customer arrives in any other period, he has to wait until the server returns to Q i again. For this, we condition on the period in which he arrives. If the arrival period is a visit to Q j , say V j for j = , he has i to wait for the residual duration of V j and the interval ( S j : S i -1 ), and for the service of the type i customers present in the system upon his arrival. This gives the second line of (6.1). The third line, the case where the customer arrives during the switch-over time from Q j to Q j +1 (period S j ), can be interpreted along the same lines as the case V j .
Equation (6.3) is obtained by unconditioning the conditional queue lengths E [ ˆ L ( P ) i ]. The mean number of type i customers in the queue at an arbitrary point during V j , given by
(6.4), is the mean number of customers built up from the last visit to Q i (when Q i became empty) until and including a residual duration of V j (as the mean residual duration of V j is equal to the mean age of that period), taking into account the varying arrival rates. The mean number of type i customers queueing in the system during period S j , given by (6.5), can be found similarly. Equations (6.4) and (6.5) show one of the difficulties in adapting the 'ordinary' MVA approach to that of smart customers. If the arrival rates remain constant during a cycle, these expressions would reduce to λ i multiplied by the mean time passed since the server has left Q i . However, for the smart customers case, we have to keep track of the duration of all the intermediate periods, from the viewpoint of period V j respectively S j .
glyph[negationslash]
As indicated in Theorem 6.1, at this point, the number of equations is insufficient to find all the unknowns, E [ ← -P 1 ( P 2 ) ] and E [ - → P 1 ( P 2 ) ], for P , P 1 2 ∈ { V , S 1 1 , . . . , V N , S N } . In the remainder of the proof, we develop additional relations for these quantities to complete the set of equations. We start by considering E [ -→ V i ( V j ) ], which is the mean duration of the next period V i , when observed from an arbitrary point in V j . For i = j this is just the residual duration of V i , consisting of a busy period induced by a customer with a residual service time left, and the busy periods of all type i customers in the queue. The cases i = j need some more attention. The duration of V i now consists of the busy period induced by the type i customers in the queue, which are in expectation E [ ˆ L ( V j ) i ] customers. During the periods V , S , . . . , S j j i -1 , however, new type i customers are arriving, each contributing a busy period to the duration of V i . Hence, summing over these periods and taking into account the varying arrival rates, we get the mean total of newly arriving customers in this interval. This yields, for i = 1 , . . . , N and j = i +1 , . . . , i + N -1:
$$\mathbb { E } [ \overrightarrow { V } _ { i } ^ { ( V _ { i } ) } ] = \mathbb { E } [ B P _ { i } ] \, \mathbb { E } [ \hat { L } _ { i } ^ { ( V _ { i } ) } ] + \mathbb { E } [ R _ { B _ { i } } ] / \left ( 1 - \lambda _ { i } ^ { ( V _ { i } ) } \mathbb { E } [ B _ { i } ] \right ),$$
$$\mathbb { E } [ \overrightarrow { V _ { i } } ( V _ { j } ) ] = \mathbb { E } [ B P _ { i } ] \left ( \mathbb { E } [ \hat { L } _ { i } ^ { ( V _ { j } ) } ] + \sum _ { k = j } ^ { i + N - 1 } \left ( \lambda _ { i } ^ { ( V _ { k } ) } \mathbb { E } [ \overrightarrow { V _ { k } } ( V _ { j } ) ] + \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ S _ { k } ] \right ) \right ).$$
Analogously E [ -→ V i ( S j ) ] denotes the mean duration of the next period V i , when observed from an arbitrary point in S j . The explanation of its expression is along the same lines as that of E [ -→ V i ( V j ) ], although it should be noted that i = j is not a special case. See (A.1) in Appendix A.
The last step in the proof of Theorem 6.1, needs the following lemma to find the final relations between E [ ← -P 1 ( P 2 ) ] and E [ - → P 1 ( P 2 ) ]:
Lemma 6.2 For i = 1 , . . . , N , and j = i +1 , . . . , i + N :
$$\text{Lemma } 6. 2 \text{ For } i = 1, \dots, N, \text{ and } j = i + 1, \dots, i + N \colon \\ \sum _ { k = i } ^ { j - 1 } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( S _ { i } \cdot V _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { S } _ { i } ^ { ( S _ { k } ) } ] + \sum _ { l = i + 1 } ^ { k } \left ( \mathbb { E } [ \widetilde { S } _ { l } ^ { ( S _ { k } ) } ] + \mathbb { E } [ \widetilde { V } _ { l } ^ { ( S _ { k } ) } ] \right ) \\ - \mathbb { E } [ R _ { S _ { k } } ] - \mathbb { E } [ \widetilde { V } _ { j } ^ { ( S _ { k } ) } ] - \sum _ { l = k + 1 } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \widetilde { V } _ { l } ^ { ( S _ { k } ) } ] \right ) \right ) \\ = \sum _ { k = i + 1 } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( S _ { i } \cdot V _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { V } _ { j } ^ { ( V _ { k } ) } ] + \sum _ { l = k } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \widetilde { V } _ { l } ^ { ( V _ { k } ) } ] \right ) \\ - \mathbb { E } [ \widetilde { S } _ { i } ^ { ( V _ { k } ) } ] - \mathbb { E } [ \widetilde { V } _ { k } ^ { ( V _ { k } ) } ] - \sum _ { l = i + 1 } ^ { k - 1 } \left ( \mathbb { E } [ \widetilde { S } _ { l } ^ { ( V _ { k } ) } ] + \mathbb { E } [ \widetilde { V } _ { l } ^ { ( V _ { k } ) } ] \right ) \right ). \quad \text{(6.8)} \\ \text{Proof } \text{ }
0.8) can be proven by studying all mean residual interval lengths 1.8 2.8 1.9 3.8 0.9 0.5 - 6.8 3.9 3.5 0.4 7.5$$
Proof Equation (6.8) can be proven by studying all mean residual interval lengths E [ R S i : V j ], E [ R S i : S j ], E [ R V i : V j ] and E [ R V i : S j ]. Consider E [ R S i : V j ], the mean residual duration of the interval S , V i i +1 , . . . , V j . We condition on the period in which the interval is observed. As the mean duration of the interval is given by E [( S i : V j )], it follows that E [ S k ] / E [( S i : V j )] is the probability that the interval is observed in period S k . The remaining duration of the interval consists of the remaining duration of S k plus the mean durations of the (coming) periods V k +1 , S k +1 , . . . , V j , when observed from period S k . When observing E [( S i : V j )] from V k , a similar way of reasoning is used. This gives, for i = 1 , . . . , N , and j = i +1 , . . . , i + N :
$$\mathbb { E } [ R _ { S _ { i } V _ { j } } ] & = \sum _ { k = i } ^ { j - 1 } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( S _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ R _ { S _ { k } } ] + \mathbb { E } [ \overrightarrow { V _ { j } } ( S _ { k } ) ] + \sum _ { l = k + 1 } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ( S _ { k } ) ] \right ) \right ) \\ & \quad + \sum _ { k = i + 1 } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( S _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ \overrightarrow { V _ { j } } ( V _ { k } ) ] + \sum _ { l = k } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ( V _ { k } ) ] \right ) \right ). \\ \mathbb { V } \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \text{$\mathbb{V}$} \, \colon$}$$
We now use that the distribution of the residual length of an interval is the same as the distribution of the age of this interval. Again, focus on E [ R S i : V j ], conditioning on the period in which the interval is observed, but now looking forwards in time. Consider all the periods in ( S i : V j ) that have already passed when observing during S k . The interval has lasted for the sum of these periods, plus the age of S k . The same can be done for an arbitrary point in V k . This gives, for i = 1 , . . . , N , j = i +1 , . . . , i + N :
$$v _ { k } \colon \ 1 i n s \ g i v e s, \ \text{or } \imath = 1, \dots, \imath \imath, \, j = \imath + 1, \dots, \imath + \imath \imath \colon \\ \mathbb { E } [ R _ { S _ { i } } v _ { j } ] = & \sum _ { k = i } ^ { j - 1 } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( S _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { S _ { i } } ( S _ { k } ) ] + \sum _ { l = i + 1 } ^ { k } \left ( \mathbb { E } [ \widetilde { S _ { l } } ( S _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { l } } ( S _ { k } ) ] \right ) \right ) \\ & + \sum _ { k = i + 1 } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( S _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { S _ { i } } ( V _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { k } } ( V _ { k } ) ] + \sum _ { l = i + 1 } ^ { k - 1 } \left ( \mathbb { E } [ \widetilde { S _ { l } } ( V _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { l } } ( V _ { k } ) ] \right ) \right ). \\ \intertext { T h o w o w e f o f $ I $ o m o $ o $ i n o m o t o d h r o m o t i n o t o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t O m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t O $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m O $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o $ T o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ T o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o $ t o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o$ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o$ t o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o s t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o 0 $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m 0 $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t om o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t om 0 $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o $ s t $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t o m o $ t$$
The proof of Lemma 6.2 is completed by equating (6.9) and (6.10) and rearranging the terms. glyph[square]
Similar to the proof of Lemma 6.2, we can develop two different expressions for each of the terms E [ R S i : S j ] , E [ R V i : V j ] and E [ R V i : S j ]. For the sake of brevity of this section, they are
presented in Appendix A, Equations (A.2)-(A.7). Equating each pair of these expressions, completes the set of (linear) equations for the mean waiting times and mean queue lengths. This concludes the proof of Theorem 6.1. glyph[square]
## 7 Pseudo-Conservation Law
In this section we derive a so-called Pseudo-Conservation Law (PCL), which gives an expression for the weighted sum of the mean waiting times at each of the queues. For 'ordinary' cyclic polling systems, Boxma and Groenendijk [6] derive a PCL under various service disciplines. This PCL, in commonly used notation ρ i = λ i E [ B ,ρ i ] = ∑ N i =1 ρ , S i = ∑ N i =1 S i , states that:
$$\sum _ { i = 1 } ^ { N } \rho _ { i } \mathbb { E } [ W _ { i } ] = \rho \frac { \sum _ { i = 1 } ^ { N } \rho _ { i } \mathbb { E } [ R _ { B _ { i } } ] } { 1 - \rho } + \rho \mathbb { E } [ R _ { S } ] + \frac { \mathbb { E } [ S ] } { 2 ( 1 - \rho ) } \left ( \rho ^ { 2 } - \sum _ { i = 1 } ^ { N } \rho _ { i } ^ { 2 } \right ) + \sum _ { i = 1 } ^ { N } \mathbb { E } [ Z _ { i i } ], \quad ( 7. 1 )$$
with Z ii denoting the amount of work left behind by the server at Q i at the ending of a visit. For exhaustive service at Q i , we have E [ Z ii ] = 0, and for gated service E [ Z ii ] = ρ 2 i E [ S ] 1 -ρ .
We base our approach on [6], and adapt their ideas to derive a PCL for a polling model with smart customers. The approach focusses on the mean amount of work in the system at an arbitrary point in time. A required restriction for our approach in this section, is that the Poisson process according to which work arrives in the system, has a fixed arrival rate during all visit periods . We also require that the amounts of work brought by an individual arrival are identically distributed for all visit periods. We mention two typical cases where this requirement is satisfied. Firstly, the case when the arrival rate at a given queue stays constant during different visit times, and secondly when the total arrival rate remains constant during visit times and the service times are identically distributed:
$$\text{Case 1} \colon \quad \lambda _ { i } ^ { ( V _ { 1 } ) } = \lambda _ { i } ^ { ( V _ { 2 } ) } = \dots = \lambda _ { i } ^ { ( V _ { N } ) } = \colon \lambda _ { i } ^ { ( V ) }, \quad \quad \ \ i = 1, \dots, N, \quad \ \ ( 7. 2 )$$
$$\text{Case 2} \colon \quad \sum _ { i = 1 } ^ { N } \lambda _ { i } ^ { ( V _ { j } ) } = \colon \Lambda ^ { ( V ) }, \text{ and } B _ { 1 } \stackrel { d } { = } \dots \stackrel { d } { = } B _ { N }, \text{ \quad \ \ } j = 1, \dots, N. \quad \ \ \ \ ( 7. 3 )$$
Note that Case 1 does allow for different arrival rates during switch-over times . During visit periods, let Λ ( V ) be the total arrival rate of all customer types, and let B ( V ) denote the generic service time of an arbitrary customer entering the system. In particular, this means for Case 1 that Λ ( V ) = ∑ N i =1 λ ( V ) i and B ( V ) d = B i with probability λ ( V ) i / Λ ( V ) for i = 1 , . . . , N . We introduce ρ ( V ) to denote the mean amount of work entering the system per time unit during a visit period, so ρ ( V ) = Λ ( V ) E [ B ( V ) ].
Denote by Y the amount of work in the polling system at an arbitrary point in time, and by Y ( V ) and Y ( S ) the amount of work at an arbitrary point during respectively a visit period, and a switch-over period. Then
$$Y \stackrel { d } { = } \begin{cases} Y ^ { ( V ) } & \text{w.p. } \bar { \rho }, \\ Y ^ { ( S ) } & \text{w.p. } 1 - \bar { \rho }, \end{cases}$$
where ρ := ∑ N i =1 ρ i = ∑ N i =1 λ i E [ B i ] is the mean offered amount of work per time unit. Hence,
$$\mathbb { E } [ Y ] = \bar { \rho } \, \mathbb { E } [ Y ^ { ( V ) } ] + ( 1 - \bar { \rho } ) \mathbb { E } [ Y ^ { ( S ) } ].$$
Another way to obtain the mean total amount of work in the system, is by taking the sum of the mean workloads. The mean workload in Q i is the mean amount of work of all customers in the queue, plus, with probability ρ i = λ i E [ B i ], the mean remaining amount of work of a customer in service at Q i :
$$\mathbb { E } [ Y ] = \sum _ { i = 1 } ^ { N } \left ( \mathbb { E } [ \hat { L } _ { i } ] \mathbb { E } [ B _ { i } ] + \bar { \rho } _ { i } \mathbb { E } [ R _ { B _ { i } } ] \right ).$$
In the next subsections we show that equating (7.5) and (7.6), and applying Little's law, E [ ˆ ] = L i λ i E [ W i ], gives a PCL for the mean waiting times in the system. But first we have to find E [ Y ( V ) ] and E [ Y ( S ) ]. We start with the latter.
## 7.1 Work during switch-over periods
The term E [ Y ( S ) ] denotes the mean amount of work in the system when observed at a random point in a switch-over interval. Denoting by E [ Y ( S i ) ] the mean amount of work in the system at an arbitrary moment during S i , we can condition on the switch-over interval in which the system is observed:
$$\mathbb { E } [ Y ^ { ( S ) } ] = \sum _ { i = 1 } ^ { N } \frac { \mathbb { E } [ S _ { i } ] } { \mathbb { E } [ S ] } \mathbb { E } [ Y ^ { ( S _ { i } ) } ].$$
We can split E [ Y ( S i ) ] into two parts: the mean amount of work present at the start of S i , plus the mean amount of work built up since the start of the switch-over time. In expectation, a duration E [ R S i ] has passed since the beginning of the switch-over time, in which work arrived at rate λ ( S i ) j E [ B j ] at Q j . Hence, this gives a contribution to E [ Y ( S i ) ] of ∑ N j =1 λ ( S i ) j E [ B j ] E [ R S i ]. For the work present at the start of the switch-over period, we start looking at the moment that the server left Q j , leaving a mean amount of work E [ Z jj ] behind in this queue. For exhaustive service, E [ Z jj ] = 0, for gated service E [ Z jj ] = λ ( V j ) j E [ B j ] E [ V j ]. Since then, the interval ( S j : V i + N ) has passed, for j = i +1 , . . . , i + N -1. In this interval the amount of type j work increased at rates λ ( S j ) j E [ B ,λ j ] ( V j +1 ) j E [ B ,..., λ j ] ( S i -1 ) j E [ B ,λ j ] ( V i ) j E [ B j ] during the various periods. This leads to the following expression for E [ Y ( S i ) ]:
$$\mathbb { E } [ Y ^ { ( S _ { i } ) } ] = \sum _ { j = 1 } ^ { N } \left ( \lambda _ { j } ^ { ( S _ { i } ) } \mathbb { E } [ B _ { j } ] \mathbb { E } [ R _ { S _ { i } } ] + \mathbb { E } [ Z _ { j j } ] \right ) + \sum _ { j = i + 1 } ^ { i + N - 1 } \sum _ { k = j } ^ { i + N - 1 } \left ( \lambda _ { j } ^ { ( S _ { k } ) } \mathbb { E } [ B _ { j } ] \mathbb { E } [ S _ { k } ] + \lambda _ { j } ^ { ( V _ { k + 1 } ) } \mathbb { E } [ B _ { j } ] \mathbb { E } [ V _ { k + 1 } ] \right ).$$
## 7.2 Work during visit periods
The key observation in the proof of [6] is the work decomposition property in a polling system. This property states that the amount of work at an arbitrary epoch in a visit period is distributed as the sum of two independent random variables: the amount of work in the 'corresponding' M/G/ 1 queue at an arbitrary epoch during a busy period, denoted by Y ( V ) M/G/ 1 , and the amount of work in the polling system at an arbitrary epoch during a switch-over time, Y ( S ) . In a polling model with smart customers, this decomposition does not typically hold, but a minor adaptation is required. We follow the proof in [6] as closely as possible, meaning
that we use the concepts of ancestral line and offspring of a customer, as introduced in [15]. We also copy the idea of comparing the polling system to an M/G/ 1 queue with vacations and Last-Come-First-Served (LCFS) service. The traffic process offered to this M/G/ 1 queue is identical to the traffic process of the polling system. The server of the M/G/ 1 queue takes vacations exactly during the switching periods of the polling system. These vacations might interrupt the service of a customer in the M/G/ 1 queue. This service is not resumed until all customers that have arrived during the vacation and their offspring have been served (in LCFS order).
glyph[negationslash]
We now focus on the amount of work in this M/G/ 1 system at an arbitrary moment during a visit (busy) period . Let K be the customer being served at this observation moment, and let K A be his ancestor. By definition, K A has arrived during a vacation period (or: switch-over period in the corresponding polling system). Denote by Y K A the amount of work present in the system at the moment that K A enters the system. An important difference with the situation studied in [6] is that we cannot use the PASTA property, so in general Y K A = Y ( S ) . We now condition on the customer type of K A . The mean duration of the service of a type i ancestor and his entire ancestral line is E [ B / i ] (1 -ρ ( V ) ). This can be regarded as the mean busy period commencing with the service of an exceptional first customer (namely a type i customer). Each type i customer arriving during S j , with arrival rate λ ( S j ) i , i, j = 1 , . . . , N , starts such a busy period, so the probability that K A is a type i customer is:
$$p _ { i } = \frac { \sum _ { j = 1 } ^ { N } \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] \mathbb { E } [ B _ { i } ] / ( 1 - \rho ^ { ( V ) } ) } { \sum _ { k = 1 } ^ { N } \sum _ { j = 1 } ^ { N } \lambda _ { k } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] \mathbb { E } [ B _ { k } ] / ( 1 - \rho ^ { ( V ) } ) } = \frac { \sum _ { j = 1 } ^ { N } \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] \mathbb { E } [ B _ { i } ] } { \sum _ { k = 1 } ^ { N } \sum _ { j = 1 } ^ { N } \lambda _ { k } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] \mathbb { E } [ B _ { k } ] }.$$
Given that K A is a type i customer, we again pick up the proof of the work decomposition in [6]. Denote by B K A the service requirement of K A . Then, because of the LCFS service discipline of the M/G/ 1 queue, the amount of work when K A goes into service is exactly Y K A + B K A , and the amount of work when the last descendant of K A has been served equals Y K A again (for the first time, since the arrival of K A ). Ignoring the amount of work present at K A 's arrival, the residual amount of work evolves just as during a busy period in an M/G/ 1 queue with an exceptional first customer (having generic service requirement B i ). The only exception is caused by the vacations (or switch-over times in the polling model), during which the work remains constant or may increase because of new arrivals. However, just as in [6], if we ignore these vacations and the (LCFS) service of the ancestral lines of the customers that arrive during these vacations, what remains is the workload process during a busy period initiated by a type i customer. Denote by Y ( V ) M/G/ 1 | i the amount of work at an arbitrary moment during this busy period, and denote by Y ( S ) A i the amount of work present in the polling system at an arbitrary arrival epoch of a type i customer during a switch-over time . Note that Y K A is distributed like Y ( S ) A i . Then we have the following decomposition:
$$Y ^ { ( V ) } \stackrel { d } { = } Y ^ { ( V ) } _ { M / G / 1 | i } + Y ^ { ( S ) } _ { A _ { i } } \quad \text{ w.p.} \ p _ { i }, \quad i = 1, \dots, N,$$
with p i as given in (7.9), and Y ( V ) M/G/ 1 | i and Y ( S ) A i being independent. This leads to
$$\mathbb { E } [ Y ^ { ( V ) } ] & = \sum _ { i = 1 } ^ { N } p _ { i } \left ( \mathbb { E } [ Y ^ { ( V ) } _ { M / G / 1 | i } ] + \mathbb { E } [ Y ^ { ( S ) } _ { A _ { i } } ] \right ),$$
with
$$\mathbb { E } [ Y _ { M / G / 1 | i } ^ { ( V ) } ] & = \mathbb { E } [ R _ { B _ { i } } ] + \frac { \rho ^ { ( V ) } } { 1 - \rho ^ { ( V ) } } \mathbb { E } [ R _ { B ^ { ( V ) } } ],$$
$$\mathbb { E } [ Y _ { A _ { i } } ^ { ( S ) } ] = \sum _ { j = 1 } ^ { N } \frac { \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] } { \sum _ { k = 1 } ^ { N } \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ S _ { k } ] } \mathbb { E } [ Y ^ { ( S _ { j } ) } ].$$
For (7.12) we use standard theory on an M/G/ 1 queue with an exceptional first customer (cf. [32]), and (7.13) is established by conditioning on the switch-over period in which a type i customer arrives.
## 7.3 PCL for smart customers
We are now ready to state the PCL.
Theorem 7.1 Provided that (7.2) or (7.3) is valid, the following Pseudo-Conservation Law holds:
$$\sum _ { i = 1 } ^ { N } \bar { \rho } _ { i } \, \mathbb { E } [ W _ { i } ] & = ( 1 - \bar { \rho } ) \sum _ { i = 1 } ^ { N } \frac { \mathbb { E } [ S _ { i } ] } { \mathbb { E } [ S ] } \mathbb { E } [ Y ^ { ( S _ { i } ) } ] - \sum _ { i = 1 } ^ { N } \bar { \rho } _ { i } \mathbb { E } [ R _ { B _ { i } } ] \\ & \quad + \bar { \rho } \sum _ { i = 1 } ^ { N } p _ { i } \left ( \sum _ { j = 1 } ^ { N } \frac { \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ S _ { j } ] } { \sum _ { k = 1 } ^ { N } \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ S _ { k } ] } \mathbb { E } [ Y ^ { ( S _ { j } ) } ] + \mathbb { E } [ R _ { B _ { i } } ] + \frac { \rho ^ { ( V ) } } { 1 - \rho ^ { ( V ) } } \mathbb { E } [ R _ { B ^ { ( V ) } } ] \right ), \\ \quad \,. \quad \, \frac { \lambda \cdot \dots } { \lambda \cdot \dots }$$
where E [ Y ( S i ) ] are as in (7.8), and p i as in (7.9).
Proof We have two equations, (7.5) and (7.6), for the mean total amount of work in the system. Combining these two equations, and plugging in (7.7) and (7.11), we find
$$\sum _ { i = 1 } ^ { N } \left ( \mathbb { E } [ \hat { L } _ { i } ] \mathbb { E } [ B _ { i } ] + \bar { \rho } _ { i } \mathbb { E } [ R _ { B _ { i } } ] \right ) = ( 1 - \bar { \rho } ) \sum _ { j = 1 } ^ { N } \frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ S ] } \mathbb { E } [ Y ^ { ( S _ { j } ) } ] + \bar { \rho } \sum _ { i = 1 } ^ { N } p _ { i } \left ( \mathbb { E } [ Y ^ { ( V ) } _ { M / G / 1 | i } ] + \mathbb { E } [ Y ^ { ( S ) } _ { A _ { i } } ] \right ).$$
By application of Little's law, E [ ˆ ] = L i λ i E [ W i ], using that ρ i = λ i E [ B i ], plugging in (7.12) and (7.13), after some rewriting we obtain (7.14), which is a PCL for a polling model with smart customers. glyph[square]
Remark 7.2 When λ ( S 1 ) i = λ ( S 2 ) i = . . . = λ ( S N ) i = λ ( V 1 ) i = · · · = λ ( V N ) i = λ i , for all i = 1 , . . . , N , Equation (7.14) reduces to (7.1). E.g., because of PASTA, E [ Y ( S ) A i ] = E [ Y ( S ) ], and p i = λ / i Λ for all i .
Case 2, where assumptions (7.3) hold, has a nice practical interpretation if we add the additional requirement that ∑ N i =1 λ ( S j ) i = ∑ N i =1 λ ( V j ) i =: Λ for all j = 1 , . . . , N . Now, the model can be interpreted as a polling system with customers arriving in one Poisson stream with constant arrival rate Λ, and generic service requirement B , but joining a certain queue with a fixed probability that may depend on the location of the server at the arrival epoch. In
Section 8, we discuss an example on how these probabilities may be chosen to minimise the mean waiting time of an arbitrary customer. The PCL (7.14) can be simplified considerably in this situation.
Corollary 7.3 If (7.3) is valid, the PCL (7.14) reduces to:
$$\sum _ { i = 1 } ^ { N } \bar { \rho } _ { i } \, \mathbb { E } [ W _ { i } ] = \sum _ { i = 1 } ^ { N } \frac { \mathbb { E } [ S _ { i } ] } { \mathbb { E } [ S ] } \mathbb { E } [ Y ^ { ( S _ { i } ) } ] + \frac { \rho ^ { 2 } } { 1 - \rho } \mathbb { E } [ R _ { B } ].$$
Proof This is a direct consequence of assumptions (7.3). E.g., in the computation of (7.12) there is no need to condition on a special first customer, and hence the term E [ Y M/G/ 1 | i ] does not depend on i anymore:
$$\mathbb { E } [ Y _ { M / G / 1 | i } ] = \frac { \mathbb { E } [ R _ { B } ] } { 1 - \rho },$$
where ρ = Λ E [ B ]. Additionally, the term ∑ N i =1 p i E [ Y ( S ) A i ] also simplifies considerably:
$$\sum _ { i = 1 } ^ { N } p _ { i } \mathbb { E } [ Y _ { A _ { i } } ^ { ( S ) } ] = \sum _ { i = 1 } ^ { N } \frac { \mathbb { E } [ S _ { i } ] } { \mathbb { E } [ S ] } \mathbb { E } [ Y ^ { ( S _ { i } ) } ].$$
Combining this, multiple terms cancel out and (7.15) follows. It is easily seen that (7.15) is in line with (7.1), when the arrival rates do not change during various visit and switch-over times. glyph[square]
## 8 Numerical examples
## 8.1 Example 1: smart customers
In the first numerical example, we study a polling system where arriving customers choose which queue they join, based on the current position of the server. In [5, 7] a fully symmetric case is studied with gated service, and it is proven that the mean sojourn time of customers is minimised if customers join the queue that is being served directly after the queue that is currently being served. Although the exhaustive case is not studied, it is intuitively clear that in this situation smart customers join the queue that is currently being served. Or, in case an arrival takes place during a switch-over time, join the next queue that is visited. In this example, we study this situation in more detail by adding an extra parameter that can be varied. The polling model is fully symmetric, except for the service time of customers in Q 1 , which is varied. The practical interpretation is the following: as in the previously described examples, customers arrive with a fixed arrival intensity, say Λ, and choose which queue they join. This does not affect their service time, except when they choose Q 1 . In this case the service time has a different distribution. To illustrate the dynamics of this system, we choose the following setting. The system consists of three queues with exhaustive service. The switch-over times are all exponentially distributed with mean 1. The service times are also exponentially distributed with E [ B 2 ] = E [ B 3 ] = 1, and E [ B 1 ] is varied between 0 and 2. Arriving customers choose one queue which they want to join. This queue is the same for all customers, so there is no randomness involved in the selection, which is only based on
the location of the server at their arrival epochs. We intend to find the optimal queue for customers to join. In terms of the model parameters: we seek to find values for λ ( V j ) i and λ ( S j ) i , i, j = 1 2 3, that minimise the mean sojourn time of an arbitrary customer, under the , , restriction that for each value of j , exactly one λ ( V j ) i and exactly one λ ( S j ) i is equal to Λ, and all the other values are 0. A valid combination of these arrival intensities is called a strategy , and we introduce the short notation for a strategy by the indices of the queues that are joined in respectively ( V , S 1 1 , V 2 , S 2 , V 3 , S 3 ). E.g., for the fully symmetric case, with E [ B 1 ] = 1, it is intuitively clear that the optimal strategy is to join Q i , if the arrival takes place during V i , and to join Q i +1 if the arrival takes place during S i . This strategy is denoted by (1 2 2 3 3 1), , , , , , and corresponds to λ ( V 1 ) 1 = λ ( V 2 ) 2 = λ ( V 3 ) 3 = Λ, and λ ( S 1 ) 2 = λ ( S 2 ) 3 = λ ( S 3 ) 1 = Λ. The other arrival intensities are 0. As stated before, we vary E [ B 1 ] between 0 and 2, and focus on the overall mean sojourn time. It is clear that making E [ B 1 ] smaller, makes it more attractive to join Q 1 (even if another queue is served), whereas making E [ B 1 ] larger, makes it less attractive to join Q 1 . In order to obtain numerical results, we choose the (arbitrary) value Λ = 3 5 . It turns out that as much as seven different strategies can be optimal, depending on the value of E [ B 1 ]. We refer to these strategies as I through VII, listed in Table 1, along with their region of optimality. For each of these strategies, the mean sojourn time of an arbitrary customer is plotted versus E [ B 1 ] in Figure 2.
Table 1: The seven smartest strategies in Example 1 that minimise the mean waiting time of an arbitrary customer who can choose the queue in which he wants to be served. An 'X' means that the length of the corresponding visit time equals 0 because customers never join this queue.
| Strategy | Queue to join during Region of optimality | Queue to join during Region of optimality |
|------------|---------------------------------------------|---------------------------------------------|
| Strategy | V 1 S 1 V 2 S 2 V 3 | |
| I | 1 1 X 1 X | 1 0 . 00 ≤ E [ B 1 ] ≤ 0 . 41 |
| II | 1 2 1 1 X | 1 0 . 41 ≤ E [ B 1 ] ≤ 0 . 66 |
| III | 1 2 2 1 X | 1 0 . 66 ≤ E [ B 1 ] ≤ 0 . 73 |
| IV | 1 2 2 3 1 | 1 0 . 73 ≤ E [ B 1 ] ≤ 0 . 84 |
| V | 1 2 2 3 3 | 1 0 . 84 ≤ E [ B 1 ] ≤ 1 . 10 |
| VI | 2 2 2 3 3 | 1 1 . 10 ≤ E [ B 1 ] ≤ 1 . 16 |
| VII | X 2 2 3 3 | 2 1 . 16 ≤ E [ B 1 ] |
As expected, Q 1 is most popular if E [ B 1 ] is very small. In particular, for very small values of E [ B 1 ], customers always join this queue (Strategy I). As E [ B 1 ] becomes larger, Q 2 and later also Q 3 are chosen in more and more situations (Strategies II-V). Strategy V, which is optimal if the system is (nearly) symmetric, is the one where customers join the queue that is being served, or is going to be served next if the arrival takes place during a switch-over time. Strategy VI, which is optimal in only a very small range of values of E [ B 1 ], states that customers only join Q 1 during the switch-over time S 3 . Strategy VII, in which customers never join Q 1 , is optimal for large values of E [ B 1 ]. The ergodicity constraint, considering all parameters are fixed except for E [ B 1 ], for the different strategies is also interesting to mention. For strategies I-V, the necessary and sufficient condition for stability is E [ B 1 ] < 5 3 . Strategies VI and VII always result in a stable system, regardless of E [ B 1 ]. For illustration purposes, we show how to compute the ergodicity constraint for Strategy V. As indicated
/RBracket1
Figure 2: The mean sojourn time of an arbitrary customer for the seven smartest strategies in Example 1, against the mean service time in Q 1 .
in Section 3, the ergodicity constraint requires computation of the eigenvalues of the matrix R -I N , where I N is the N × N identity matrix, and R is an N × N matrix containing elements ρ ij := λ ( V j ) i E [ B i ]. For Strategy V, we find
$$R - I _ { 3 } = \begin{pmatrix} \Lambda \mathbb { E } [ B _ { 1 } ] - 1 & 0 & 0 \\ 0 & \Lambda - 1 & 0 \\ 0 & 0 & \Lambda - 1 \end{pmatrix}.$$
The eigenvalues of this matrix are Λ E [ B 1 ] -1 Λ , -1, and again Λ -1. The ergodicity constraint in this situation states that the largest (and, hence, all) of these eigenvalues should be negative. This means that E [ B 1 ] < 1 Λ is a sufficient and necessary condition for stability of this system, given that Λ < 1. The ergodicity constraints of the other strategies are computed similarly, but all rows and columns corresponding to visit times that are zero should be deleted from the matrix R -I 3 (cf. [11]). For Strategies VI and VII this implies that the first row and the first column should be deleted. Since the first row is the only row which contains E [ B 1 ], these strategies always result in a stable system. Note that the arrival rates during switch-over times do not play a role in the ergodicity constraint.
It is also interesting to discuss what stupid customers would do in this system. Stupid customers choose the worst possible strategy, in order to maximise the mean sojourn time of an arbitrary customer. We do not go into details and do not mention exactly which strategy is worst for each value of E [ B 1 ], but we pick out some interesting cases. Obviously, when E [ B 1 ] = 0, the worst possible thing to do is never to join Q 1 . The worst strategy in this case is ( X, 3 3 2 2 3), where , , , , X means that any queue can be chosen (because the length of the corresponding visit time equals 0, since customers never join this queue). This strategy leads to an overall mean sojourn time of 7 48. . As E [ B 1 ] grows larger, Q 1 gradually will be chosen more frequently. In the symmetric case, E [ B 1 ] = 1, customers arriving during V i choose Q i -1 , and customers arriving during S i choose Q i , resulting in a mean sojourn time of 8 5. . For large E [ B 1 ], the worst possible strategy might be a bit surprising. It is not simply to always join Q 1 , but it is (1 , 1 1 2 1 3). , , , , During visit periods, customers always join Q 1 , but during
S i customers join Q i . For E [ B 1 ] ↑ 5 3 , this strategy results in the highest mean sojourn time of an arbitrary customer. For the situation E [ B 1 ] ≥ 5 3 , there are many strategies for which the system becomes unstable and sojourn times become infinite. The worst possible strategy for E [ B 1 ] ≥ 5 3 that still results in a stable system, is (3 , 1 , X, 1 1 1). , ,
## 8.2 Example 2: no arrivals during a specific period
In this example we illustrate how to deal with polling models with arrival rates being zero during certain periods. For MVA, this is no problem. The equations presented in Section 6 still give the correct solution if some of the arrival rates during periods are zero. The problem arises when determining the LST of the waiting time distribution (4.3) and can only be circumvented by a work-around, which is explained using a simple example. The polling model in this example contains two queues, Q 1 and Q 2 , which are served exhaustively. All switch-over times and all service times are exponentially distributed with parameter 1. All arrival rates are 1 2 , except for the arrival rate of type 1 customers arriving during the service of type 2 customers: λ ( V 2 ) 1 = 0. This brings along some complications. First of all, (5.4) cannot be used to determine the cycle time LST. This is no real problem, because (5.2) can be used instead. Because of λ ( V 2 ) 1 being zero, we should use (3.11) instead of (3.4) for type 1 ( V 2 ) customers to determine the PGF of the steady-state queue length of Q 1 . Again, no real problem but just something to be careful about. Determining the waiting time LST for type 1 customers does raise some issues, though. The (generalisation of the) distributional form of Little's law, given by (4.3), uses the joint distribution of customers left behind by a departing type i customer to determine his time spent in the system. As can be seen in the proof of Theorem 4.3, this technique requires that type i customers may arrive during each period within a cycle. In our model this is not the case, because no type 1 customers arrive during V 2 . This implies that the number of customers left behind by a departing type 1 customer, does not give any information about the waiting time of type 1 customers (more specifically, of those that arrived during S 1 ), because a departing type 1 customer does not leave behind any customers (of any type) that have arrived during V 2 .
A work-around for this problem, is to introduce an extra queue , Q X , with type X customers that have no service requirement ( B X = 0), and λ ( V 2 ) X > 0. Customers in this queue are served exhaustively somewhere between the end of V 1 and the beginning of V 2 , because type X ( V 2 ) customers have to be present at departure epochs of type 1 customers. In our approach, we choose to treat Q X as a regular queue between Q 1 and Q 2 with no switch-over time from Q X to Q 2 because this gives us a 'normal', three-queue polling system. Determining the waiting time LST of type 1 customers, requires a careful application of the distributional form of Little's law to the various customer subtypes in Equation (4.2). For convenience, we introduce the following two vectors, where the elements correspond to customer subtypes (1 ( V 1 ) , . . . , 1 ( S 2 ) , X ( V 1 ) , . . . , X ( S 2 ) , 2 ( V 1 ) , . . . , 2 ( S 2 ) ):
$$\lambda ^ { \bullet \prime }, \dots, 1 \wedge ^ { \bullet } _ { \bullet }, \Lambda ^ { \bullet \prime }, \dots, \Lambda ^ { \bullet \prime }, \Lambda ^ { \bullet \prime }, \dots, \Lambda ^ { \bullet \prime } ) \colon \\ \omega _ { 1 } & = ( 1 - \frac { \omega } { \lambda _ { 1 } ^ { ( V _ { 1 } ) } }, 1 - \frac { \omega } { \lambda _ { 1 } ^ { ( S _ { 1 } ) } }, 1, 1, 1, 1, 1, 1, 1, 1 ), \\ \omega _ { 1 } ^ { * } & = ( 1 - \frac { \omega } { \lambda _ { 1 } ^ { ( V _ { 1 } ) } }, 1 - \frac { \omega } { \lambda _ { 1 } ^ { ( S _ { 1 } ) } }, 1, 1 - \frac { \omega } { \lambda _ { 1 } ^ { ( S _ { 2 } ) } }, 1, 1, 1 - \frac { \omega } { \lambda _ { X } ^ { ( V _ { 2 } ) } }, 1, 1, 1, 1, 1 ), \\ \intertext { a diforando hámá in t h a alomntar c o r a c r o n d i n z t o t h a t r a v i o d i n v }$$
the difference being in the element corresponding to the type X customers that arrive during V 2 . Note that we do not introduce customer subtypes that arrive during V X or S X , because the
lengths of these periods are 0. The LST of the waiting time distribution of type 1 customers is given by:
$$\mathbb { E } \left [ \mathrm e ^ { - \omega W _ { 1 } } \right ] = \frac { 1 } { \beta _ { 1 } ( \omega ) } \frac { \bar { \lambda } } { \bar { \lambda } _ { 1 } } \left ( M _ { 1 } ^ { ( V _ { 1 } ) } ( \omega _ { 1 } ) + M _ { 1 } ^ { ( S _ { 1 } ) } ( \omega _ { 1 } ^ { * } ) + M _ { 1 } ^ { ( V _ { 2 } ) } ( \omega _ { 1 } ) + M _ { 1 } ^ { ( S _ { 2 } ) } ( \omega _ { 1 } ) \right ).$$
The interpretation is that we use the type X ( V 2 ) customers left behind by a departing 1 ( S 1 ) customer to determine the length of V 2 , which is part of the total waiting time of a type 1 ( S 1 ) customer. The other type 1 customers arrive after the visit to Q 2 and can be handled in the regular way. The numerical results of this example are shown in Table 2.
Table 2: Numerical results for the polling model discussed in Example 2.
| | Q 1 | Q 2 |
|---------------------------------------|-------|-------|
| Mean queue length at arrival epochs | 1.75 | 3.375 |
| Mean queue length at departure epochs | 1.75 | 3.375 |
| Mean queue length at arbitrary epochs | 1.188 | 3.375 |
| Mean waiting time | 3.75 | 5.75 |
| Standard deviation waiting time | 5.093 | 6.28 |
We can modify (5.4) and (5.5) accordingly to obtain the LSTs of the cycle time distribution C ∗ 1 , starting at a visit ending to Q 1 , and the intervisit time distribution I 1 :
$$\mathbb { E } [ e ^ { - \omega C _ { 1 } ^ { * } } ] = \widetilde { \ V B } _ { 1 } ^ { ( S _ { 1 } ) } ( \pi _ { 1 } ( \omega ) - \frac { \omega } { \lambda _ { 1 } ^ { ( V _ { 1 } ) } }, \pi _ { 1 } ( \omega ) - \frac { \omega } { \lambda _ { 1 } ^ { ( S _ { 1 } ) } }, 1, \pi _ { 1 } ( \omega ) - \frac { \omega } { \lambda _ { 1 } ^ { ( S _ { 2 } ) } }, 1, 1, 1 - \frac { \omega } { \lambda _ { X } ^ { ( V _ { 2 } ) } }, 1, 1, 1, 1, 1 ),$$
$$\Phi _ { 1 } ^ { \quad } \Phi _ { 2 } ^ { \quad } \Phi _ { 3 } ^ { \quad } \Phi _ { 4 } ^ { \quad } \Phi _ { 5 } ^ { \quad } \Phi _ { 6 } ^ { \quad } \Phi _ { 7 } ^ { \quad } \Phi _ { 8 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Phi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { 0 \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \ \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ { 9 } ^ { \quad } \Psi _ [ \mathrm e ^ { - \omega I _ { 1 } ] } = \widetilde { V B } _ { 1 } ^ { ( S _ { 1 } ) } ( \omega _ { 1 } ^ { * } ).$$
## Appendix
## A MVA equations
In this appendix we present all MVA equations that have been omitted in Section 6.
glyph[negationslash]
The mean duration of the next period V i , when in S j is denoted by E [ -→ V i ( S j ) ]. A difference with E [ -→ V i ( V j ) ], is that E [ -→ V i ( S i ) ] is not different from E [ -→ V i ( S j ) ] for j = . Similar to (6.7), we i have for i = 1 , . . . , N , j = i, . . . , i + N -1:
$$\mathbb { E } [ \overrightarrow { V _ { i } } ( S _ { j } ) ] = \mathbb { E } [ B P _ { i } ] \left ( \mathbb { E } [ \hat { L } _ { i } ^ { ( S _ { j } ) } ] + \lambda _ { i } ^ { ( S _ { j } ) } \mathbb { E } [ R _ { S _ { j } } ] + \sum _ { k = j + 1 } ^ { i + N - 1 } \left ( \lambda _ { i } ^ { ( V _ { k } ) } \mathbb { E } [ \overrightarrow { V _ { k } } ( S _ { j } ) ] + \lambda _ { i } ^ { ( S _ { k } ) } \mathbb { E } [ S _ { k } ] \right ) \right ). \ \ ( A. 1 )$$
Equation (6.9) for E [ R S i : V j ], the mean residual duration of the interval S , V i i +1 , . . . , V j , is obtained by conditioning on the period in which the interval is observed, looking forwards in time. Similarly, we find expressions for E [ R S i : S j ] , E [ R V i : V j ], and E [ R V i : S j ]. For i = 1 , . . . , N , j = i +1 , . . . , i + N -1:
$$\L _ { \L } & \quad. \quad \L _ { \L } [ R _ { S _ { i } ; S _ { j } } ] = \sum _ { k = i } ^ { j } \frac { \L E [ S _ { k } ] } { \L E [ ( S _ { i } \colon S _ { j } ) ] } \left ( \L E [ R _ { S _ { k } } ] + \sum _ { l = k + 1 } ^ { j } \left ( \L E [ S _ { l } ] + \L E [ \overrightarrow { V _ { l } } ( S _ { k } ) ] \right ) \right ) \\ & \quad + \sum _ { k = i + 1 } ^ { j } \frac { \L E [ V _ { k } ] } { \L E [ ( S _ { i } \colon S _ { j } ) ] } \left ( \sum _ { l = k } ^ { j } \left ( \L E [ S _ { l } ] + \L E [ \overrightarrow { V _ { l } } ( V _ { k } ) ] \right ) \right ). \\ \Sigma \quad \cdot \quad \L _ { \L } \quad \L _ { \L } \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
For i = 1 , . . . , N , j = i +1 , . . . , i + N -1:
$$\mathbb { E } [ R _ { V _ { i } ; V _ { j } } ] & = \sum _ { k = i } ^ { j - 1 } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ R _ { S _ { k } } ] + \mathbb { E } [ \overrightarrow { V _ { j } } ^ { ( S _ { k } ) } ] + \sum _ { l = k + 1 } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ^ { ( S _ { k } ) } ] \right ) \right ) \\ & \quad + \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon V _ { j } ) ] } \left ( \mathbb { E } [ \overrightarrow { V _ { j } } ^ { ( V _ { k } ) } ] + \sum _ { l = k } ^ { j - 1 } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ^ { ( V _ { k } ) } ] \right ) \right ). \\ \mathbb { m } = \cdot \cdot \cdot \mathbb { m } \, \mathbb { m } \, + \cdot \cdot \cdot \cdot \cdot \cdot \mathbb { m } \, + \cdot \cdot \cdot$$
For i = 1 , . . . , N , j = i +1 , . . . , i + N -1:
$$\mathbb { E } [ R _ { V _ { i } ; S _ { j } } ] & = \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon S _ { j } ) ] } \left ( \mathbb { E } [ R _ { S _ { k } } ] + \sum _ { l = k + 1 } ^ { j } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ^ { ( S _ { k } ) } ] \right ) \right ) \\ & \quad + \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon S _ { j } ) ] } \left ( \sum _ { l = k } ^ { j } \left ( \mathbb { E } [ S _ { l } ] + \mathbb { E } [ \overrightarrow { V _ { l } } ^ { ( V _ { k } ) } ] \right ) \right ). \\ \nu \quad \varepsilon \quad.. \quad \varepsilon \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad.. \quad... \quad....$$
In Section 6, a second set of equations is discussed for E [ R S i : V j ] , E [ R S i : S j ] , E [ R V i : V j ], and E [ R V i : S j ]. This set is obtained by conditioning on the period in which the interval is observed, but now looking backwards in time. We use that the residual length of an interval has the same distribution as the elapsed time of this interval. The equation for E [ R S i : V j ] is given by (6.10). The other equations are given below. For i = 1 , . . . , N , j = i +1 , . . . , i + N -1:
$$\dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \mathbb { E } [ R _ { S _ { i } ; S _ { j } } ] = & \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( S _ { i } \cdot S _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { S _ { i } } ( S _ { k } ) ] + \sum _ { l = i + 1 } ^ { k } \left ( \mathbb { E } [ \widetilde { S _ { l } } ( S _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { l } } ( S _ { k } ) ] \right ) \right ) \\ & + \sum _ { k = i + 1 } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( S _ { i } \cdot S _ { j } ) ] } \left ( \mathbb { E } [ \widetilde { S _ { i } } ( V _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { k } } ( V _ { k } ) ] + \sum _ { l = i + 1 } ^ { k - 1 } \left ( \mathbb { E } [ \widetilde { S _ { l } } ( V _ { k } ) ] + \mathbb { E } [ \widetilde { V _ { l } } ( V _ { k } ) ] \right ) \right ). \\ \vdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
For i = 1 , . . . , N , j = i +1 , . . . , i + N -1:
$$\mathbb { E } [ R _ { V _ { i } ; V _ { j } } ] & = \sum _ { k = i } ^ { j - 1 } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( V _ { i } \cdot V _ { j } ) ] } \left ( \sum _ { l = i } ^ { k } \left ( \mathbb { E } [ \overleftarrow { S _ { l } } ( S _ { k } ) ] + \mathbb { E } [ \overleftarrow { V _ { l } } ( S _ { k } ) ] \right ) \right ) \\ & \quad + \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( V _ { i } \cdot V _ { j } ) ] } \left ( \mathbb { E } [ \overleftarrow { V _ { k } } ( V _ { k } ) ] + \sum _ { l = i } ^ { k - 1 } \left ( \mathbb { E } [ \overleftarrow { S _ { l } } ( V _ { k } ) ] + \mathbb { E } [ \overleftarrow { V _ { l } } ( V _ { k } ) ] \right ) \right ).$$
For i = 1 , . . . , N , j = i, . . . , i + N -1:
$$\mathbb { E } [ R _ { V _ { i } ; S _ { j } } ] = & \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ S _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon S _ { j } ) ] } \left ( \sum _ { l = i } ^ { k } \left ( \mathbb { E } [ \overleftarrow { S _ { l } } ^ { ( S _ { k } ) } ] + \mathbb { E } [ \overleftarrow { V _ { l } } ^ { ( S _ { k } ) } ] \right ) \right ) \\ & + \sum _ { k = i } ^ { j } \frac { \mathbb { E } [ V _ { k } ] } { \mathbb { E } [ ( V _ { i } \colon S _ { j } ) ] } \left ( \mathbb { E } [ \overleftarrow { V _ { k } } ^ { ( V _ { k } ) } ] + \sum _ { l = i } ^ { k - 1 } \left ( \mathbb { E } [ \overleftarrow { S _ { l } } ^ { ( V _ { k } ) } ] + \mathbb { E } [ \overleftarrow { V _ { l } } ^ { ( V _ { k } ) } ] \right ) \right ).$$
## References
- [1] M. A. A. Boon. A polling model with reneging at polling instants. To appear in Annals of Operations Research , 2010. DOI: 10.1007/s10479-010-0758-2.
- [2] M. A. A. Boon and I. J. B. F. Adan. Mixed gated/exhaustive service in a polling model with priorities. Queueing Systems , 63:383-399, 2009.
- [3] S. C. Borst. Polling Systems , volume 115 of CWI Tracts . 1996.
- [4] S. C. Borst and O. J. Boxma. Polling models with and without switchover times. Operations Research , 45(4):536 - 543, 1997.
- [5] O. J. Boxma. Polling systems. In: From universal morphisms to megabytes: A Baayen space odyssey. Liber amicorum for P.C. Baayen. CWI, Amsterdam , pages 215-230, 1994.
- [6] O. J. Boxma and W. P. Groenendijk. Pseudo-conservation laws in cyclic-service systems. Journal of Applied Probability , 24(4):949-964, 1987.
- [7] O. J. Boxma and M. Kelbert. Stochastic bounds for a polling system. Annals of Operations Research , 48:295-310, 1994.
- [8] O. J. Boxma, A. C. C. van Wijk, and I. J. B. F. Adan. Polling systems with a gatedexhaustive discipline. ValueTools 2008 (Third International Conference on Performance Evaluation Methodologies and Tools, Athens, Greece, October 20-24, 2008) .
- [9] O. J. Boxma, J. A. Weststrate, and U. Yechiali. A globally gated polling system with server interruptions, and applications to the repairman problem. Probability in the Engineering and Informational Sciences , 7:187-208, 1993.
- [10] O. J. Boxma, J. Bruin, and B. H. Fralix. Waiting times in polling systems with various service disciplines. Performance Evaluation , 66:621-639, 2009.
- [11] O. J. Boxma, J. Ivanovs, K. Kosi´ski, and M. Mandjes. L´vy-driven polling systems and n e continuous-state branching processes. Eurandom report 2009-026, Eurandom , 2009.
- [12] J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982.
- [13] M. Eisenberg. Queues with periodic service and changeover time. Operations Research , 20(2):440-451, 1972.
- [14] S. W. Fuhrmann. Performance analysis of a class of cyclic schedules. Technical memorandum 81-59531-1, Bell Laboratories, March 1981.
- [15] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
- [16] Y. Gong and R. de Koster. A polling-based dynamic order picking system for online retailers. IIE Transactions , 40:1070-1082, 2008.
- [17] O. C. Ibe and K. S. Trivedi. Two queues with alternating service and server breakdown. Queueing Systems , 7:253-268, 1990.
- [18] M. Jain and A. Jain. Working vacations queueing model with multiple types of server breakdowns. Applied Mathematical Modelling , 34(1):1-13, 2010.
- [19] J. Keilson and L. D. Servi. The distributional form of Little's Law and the FuhrmannCooper decomposition. Operations Research Letters , 9(4):239-247, 1990.
- [20] D. Kofman and U. Yechiali. Polling systems with station breakdowns. Performance Evaluation , 27-28:647-672, 1996.
- [21] H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990.
- [22] A. Mandelbaum and U. Yechiali. Optimal entering rules for a customer with wait option at an M/G/ 1 queue. Management Science , 29(2):174-187, 1983.
- [23] O. Nakdimon and U. Yechiali. Polling systems with breakdowns and repairs. European Journal of Operational Research , 149:588613, 2003.
- [24] J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409 - 426, 1993.
- [25] J. G. Shanthikumar. On stochastic decomposition in M/G/ 1 type queues with generalized server vacations. Operations Research , 36(4):566-569, 1988.
- [26] A. W. Shogan. A single server queue with arrival rate dependent on server breakdowns. Naval Research Logistics Quarterly , 26(3):487-497, 1979.
- [27] H. Takagi. Queuing analysis of polling models. ACM Computing Surveys (CSUR) , 20: 5-28, 1988.
- [28] R. D. van der Mei and J. A. C. Resing. Analysis of polling systems with two-stage gated service: fairness versus efficiency. In L. Mason, T. Drwiega, and J. Yan, editors, Proc. ITC-20 - Managing traffic performance in converged networks: the interplay between convergent and divergent forces , pages 544-555. Berlin: Springer-Verlag, 2007.
- [29] V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006.
- [30] E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven University of Technology, 2007.
- [31] E. M. M. Winands, I. J. B. F. Adan, and G.-J. van Houtum. Mean value analysis for polling systems. Queueing Systems , 54:35-44, 2006.
- [32] R. Wolff. Stochastic Modeling and the Theory of Queues . Prentice-Hall, Englewood Cliffs (NJ), 1989. | 10.1007/s11134-010-9191-0 | [
"Marko Boon",
"Sandra van Wijk",
"Ivo Adan",
"Onno Boxma"
] | 2014-08-01T11:02:26+00:00 | 2014-08-01T11:02:26+00:00 | [
"math.PR"
] | A Polling Model with Smart Customers | In this paper we consider a single-server, cyclic polling system with
switch-over times. A distinguishing feature of the model is that the rates of
the Poisson arrival processes at the various queues depend on the server
location. For this model we study the joint queue length distribution at
polling epochs and at server's departure epochs. We also study the marginal
queue length distribution at arrival epochs, as well as at arbitrary epochs
(which is not the same in general, since we cannot use the PASTA property). A
generalised version of the distributional form of Little's law is applied to
the joint queue length distribution at customer's departure epochs in order to
find the waiting time distribution for each customer type. We also provide an
alternative, more efficient way to determine the mean queue lengths and mean
waiting times, using Mean Value Analysis. Furthermore, we show that under
certain conditions a Pseudo-Conservation Law for the total amount of work in
the system holds. Finally, typical features of the model under consideration
are demonstrated in several numerical examples. |
1408.0130v1 | ## A TOPOLOGICAL APPROACH TO PERIODIC OSCILLATIONS RELATED TO THE LIEBAU PHENOMENON
J. A. CID, G. INFANTE, M. TVRD ´ , AND M. ZIMA Y
Abstract. We give some sufficient conditions for existence, non-existence and localization of positive solutions for a periodic boundary value problem related to the Liebau phenomenon. Our approach is of topological nature and relies on the Krasnosel'ski˘ ı-Guo theorem on cone expansion and compression. Our results improve and complement earlier ones in the literature.
## 1. Introduction
In the 1950's the physician G. Liebau developed some experiments dealing with a valveless pumping phenomenon arising on blood circulation and that has been known for a long time: roughly speaking, Liebau showed experimentally that a periodic compression made on an asymmetric part of a fluid-mechanical model could produce the circulation of the fluid without the necessity of a valve to ensure a preferential direction of the flow [1, 12, 13]. After his pioneering work this effect has been known as the Liebau phenomenon.
In [14] G. Propst, with the aim of contributing to the theoretical understanding of the Liebau phenomenon, presented some differential equations modeling a periodically forced flow through different pipe-tank configurations. He was able to prove the presence of pumping effects in some of them, but the apparently simplest model, the 'one pipe-one tank' configuration, skipped his efforts due to a singularity in the corresponding differential equation model, namely
$$\overbrace { \overbrace { \infty } } ^ { \overbrace { \sim } } \quad ( 1 ) & \quad \begin{cases} \ u ^ { \prime \prime } ( t ) + a \, u ^ { \prime } ( t ) = \frac { 1 } { u } \left ( e ( t ) - b \left ( u ^ { \prime } ( t ) \right ) ^ { 2 } \right ) - c, & t \in [ 0, T ], \\ u ( 0 ) = u ( T ), & u ^ { \prime } ( 0 ) = u ^ { \prime } ( T ), \end{cases}$$
being a ≥ 0 , b > 1 , c > 0 and e t ( ) continuous and T -periodic on R .
The singular periodic problem (1) was studied in [4], where the authors gave general results for the existence and asymptotic stability of positive solutions by performing the change of variables u = x µ , where µ = 1 b +1 , which transforms the singular problem (1) into the regular
2010 Mathematics Subject Classification. Primary 34B18, secondary 34B27, 34B60.
Key words and phrases. Valveless pumping; Periodic boundary value problem; Krasnosel'ski˘ ı-Guo fixed point theorem; Green's function.
$$\begin{cases} \ x ^ { \prime \prime } ( t ) + a \, x ^ { \prime } ( t ) = \frac { e ( t ) } { \mu } \, x ^ { 1 - 2 \, \mu } ( t ) - \frac { c } { \mu } \, x ^ { 1 - \mu } ( t ), \quad t \in [ 0, T ], \\ x ( 0 ) = x ( T ), \quad x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ). \end{cases}$$
Then the existence and stability of positive solutions for (2) were obtained by means of the lower and upper solution technique [5] and using tricks analogous to those used in [15].
In this paper we deal with the existence of positive solutions for the following generalization of the problem (2)
$$\begin{cases} \ x ^ { \prime \prime } ( t ) + a x ^ { \prime } ( t ) = r ( t ) x ^ { \alpha } ( t ) - s ( t ) x ^ { \beta } ( t ), & t \in [ 0, T ], \\ \ x ( 0 ) = x ( T ), & x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ), \end{cases}$$
where we assume
$$( \text{H0} ) \ a \geq 0, \, r, s \in \mathcal { C } [ 0, T ], \, 0 < \alpha < \beta < 1.$$
Note that, by defining r t ( ) = e t ( ) µ , s t ( ) = c µ , α = 1 -2 µ and β = 1 -µ , the problem (2) fits within (3).
Our approach is essentially of topological nature: in Section 2 we rewrite problem (3) as an equivalent fixed point problem suitable to be treated by means of the Krasnosel'ski˘ ı-Guo cone expansion/compression fixed point theorem. A careful analysis of the related Green's function, necessary in our approach, is postponed to a final Appendix. In Section 3 we present our main results: existence, non-existence and localization criteria for positive solutions of the problem (3). Some corollaries with more ready-to-use results are also addressed. We point out that our results are valid not only for the more general problem (3), but also when applied to the singular model problem (1) we improve previous results of [4].
## 2. A fixed point formulation
First of all, by means of a shifting argument, we rewrite the problem (3) in the equivalent form
$$( 4 ) \quad \begin{cases} \ x ^ { \prime \prime } ( t ) + a x ^ { \prime } ( t ) + m ^ { 2 } x ( t ) = r ( t ) x ^ { \alpha } ( t ) - s ( t ) x ^ { \beta } ( t ) + m ^ { 2 } x ( t ) \coloneqq f _ { m } ( t, x ( t ) ), \ t \in [ 0, T ], \\ x ( 0 ) = x ( T ), \ \ x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ), \end{cases}$$
with m ∈ R . A similar approach has been used, under a variety of boundary conditions in [7, 9, 16, 17].
We say that problem (4) is non-resonant if zero is the unique solution of the homogeneous linear problem
$$\begin{cases} \ x ^ { \prime \prime } ( t ) + a x ^ { \prime } ( t ) + m ^ { 2 } x ( t ) = 0, \quad t \in [ 0, T ], \\ \ x ( 0 ) = x ( T ), \quad x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ). \end{cases}$$
In this case the non-homogeneous linear problem
$$\begin{cases} \ x ^ { \prime \prime } ( t ) + a x ^ { \prime } ( t ) + m ^ { 2 } x ( t ) = h ( t ), & t \in [ 0, T ], \\ \ x ( 0 ) = x ( T ), & x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ), \end{cases}$$
is also uniquely solvable and its unique solution is given by
$$\mathcal { K } h ( t ) = \int _ { 0 } ^ { T } G _ { m } ( t, s ) h ( s ) d s,$$
where G m ( t, s ) is the related Green's function (see [2, 3]).
In particular, if m> 0 and m < 2 ( π T ) 2 + ( a 2 ) 2 then the problem (4) is non-resonant and moreover G m ( t, s ) satisfies the following properties (see the Appendix for the details):
- i) G m ( t, s ) > 0 , for all ( t, s ) ∈ [0 , T ] × [0 , T ].
- ii) ∫ T G m ( t, s ) ds = 1 m . 2
- 0 iii) There exists a constant c m ∈ (0 , 1) such that
$$G _ { m } ( t, s ) \geq G _ { m } ( s, s ) \geq c _ { m } G _ { m } ( t, s ), \text{ for all } ( t, s ) \in [ 0, T ] \times [ 0, T ].$$
A cone in a Banach space X is a closed, convex subset of X such that λx ∈ K for x ∈ K and λ ≥ 0 and K ∩ -( K ) = { } 0 . Here we work in the space X = C [0 , T ] endowed with the usual maximum norm ‖ x ‖ = max {| x t ( ) | : t ∈ [0 , T ] } and use the cone
$$P = \{ x \in X \, \colon x ( t ) \geq c _ { m } \| x \| \text{ on } [ 0, T ] \},$$
a type of cone firstly used by Krasnosel'ski˘ ı, see for example [10], and D. Guo, see for example [6]. The cone P is particularly useful when dealing with singular nonlinearities (see [11]), or for localizing the solutions (see for example [8]).
Let us define the operator F : P → X
$$F x ( t ) = \int _ { 0 } ^ { T } G _ { m } ( t, s ) f _ { m } ( s, x ( s ) ) d s.$$
Note that a fixed point of F in P is a non-negative solution of the problem (4). In order to get such a fixed point we employ the following well-known Krasnosel'ski˘ ı-Guo cone compression/expansion theorem.
Theorem 2.1. [6] Let P be a cone in X and suppose that Ω 1 and Ω 2 are bounded open sets in X such that 0 ∈ Ω 1 and Ω 1 ⊂ Ω 2 . Let F : P ∩ (Ω 2 \ Ω ) 1 → P be a completely continuous operator such that one of the following conditions holds:
- (i) ‖ Fx ‖ ≥ ‖ x ‖ for x ∈ P ∩ ∂ Ω 1 and ‖ Fx ‖ ≤ ‖ x ‖ for x ∈ P ∩ ∂ Ω 2 ,
- (ii) ‖ Fx ‖ ≤ ‖ x ‖ for x ∈ P ∩ ∂ Ω 1 and ‖ Fx ‖ ≥ ‖ x ‖ for x ∈ P ∩ ∂ Ω 2 .
Then F has a fixed point in the set P ∩ (Ω 2 \ Ω ) 1 .
In the sequel, for a given continuous function h : [0 , T ] → R we use the notation
$$h _ { * } = \min \{ h ( t ) \, \colon t \in [ 0, T ] \} \quad \text{and} \quad h ^ { * } = \max \{ h ( t ) \, \colon t \in [ 0, T ] \}.$$
## 3. Main results
Integrating on [0 , T ] the differential equation in the problem (3), and taking into account the boundary conditions, we get a necessary condition for the existence of positive solutions, namely
$$0 = \int _ { 0 } ^ { T } [ r ( t ) x ^ { \alpha } ( t ) - s ( t ) x ^ { \beta } ( t ) ] d t.$$
So it is easy to arrive to the following non-existence result.
Theorem 3.1. If one of the following conditions holds,
- (1) r ∗ ≥ 0 and s ∗ < 0 ,
- (2) r ∗ > 0 and s ∗ ≤ 0 ,
- (3) r ∗ ≤ 0 and s ∗ > 0 ,
- (4) r ∗ < 0 and s ∗ ≥ 0 ,
then problem (3) does not have positive solutions.
Our main result, concerning not only the existence but also the localization of positive solutions, is the following one.
Theorem 3.2. Assume that (H0) and the following condition hold:
$$( \text{H1} ) \text{ There exist } m > 0 \text{ and } 0 < R _ { 1 } < R _ { 2 } \text{ such that } m ^ { 2 } < \left ( \frac { \pi } { T } \right ) ^ { 2 } + \left ( \frac { a } { 2 } \right ) ^ { 2 },$$
$$( 7 ) \quad \ f _ { m } ( t, x ) = r ( t ) x ^ { \alpha } - s ( t ) x ^ { \beta } + m ^ { 2 } x \geq 0 \quad \text{for} \, t \in [ 0, T ] \text{ and } x \in [ c _ { m } R _ { 1 }, R _ { 2 } ],$$
$$f _ { m } ( t, x ) \geq m ^ { 2 } R _ { 1 } \ \text{ for } t \in [ 0, T ] \ a n d \ x \in [ c _ { m } R _ { 1 }, R _ { 1 } ]$$
and
$$f _ { m } ( t, x ) \leq m ^ { 2 } R _ { 2 } \ \ \text{ for } t \in [ 0, T ] \ \text{ and } x \in [ c _ { m } R _ { 2 }, R _ { 2 } ].$$
Then, the problem (3) has a positive solution x t ( ) such that
$$c _ { m } R _ { 1 } \leq x ( t ) \leq R _ { 2 }.$$
Proof. The problem (4) with the value of m given by (H1) is non-resonant and its Green's function G m ( t, s ) satisfies the properties i), ii) and iii) stated in the Introduction. Let us define
$$\Omega _ { j } = \{ x \in X \, \colon \| x \| < R _ { j } \} \ \ j = 1, 2.$$
Then by (7) we have f m ( t, x ( )) t ≥ 0 for x ∈ P ∩ (Ω 2 \ Ω ). Now, for every 1 x ∈ P ∩ (Ω 2 \ Ω ) 1 and for every t ∈ [0 , T ], we have that
$$\int _ { 0 } ^ { T } G _ { m } ( s, s ) f _ { m } ( s, x ( s ) ) d s \leq F x ( t ) = \int _ { 0 } ^ { T } G _ { m } ( t, s ) f _ { m } ( s, x ( s ) ) d s \leq \int _ { 0 } ^ { T } \frac { G _ { m } ( s, s ) } { c _ { m } } f _ { m } ( s, x ( s ) ) d s,$$
and therefore F P ( ∩ (Ω 2 \ Ω )) 1 ⊂ P . A standard argument shows that F is a completely continuous operator.
Now, we check that condition (i) in Theorem 2.1 is fulfilled.
Claim 1. ‖ Fx ‖ ≥ ‖ x ‖ for x ∈ P ∩ ∂ Ω 1 .
Let x ∈ P ∩ ∂ Ω , that is, 1 x ∈ P and ‖ x ‖ = R 1 . Then we have that c m R 1 ≤ x t ( ) ≤ R 1 for all t ∈ [0 , T ] and hence
$$\L ^ { \cdot } _ { \cdot } F x ( t ) \ & = \ \int _ { 0 } ^ { T } G _ { m } ( t, s ) f _ { m } ( s, x ( s ) ) d s \geq \int _ { 0 } ^ { T } G _ { m } ( t, s ) m ^ { 2 } R _ { 1 } d s \\ & = \ m ^ { 2 } R _ { 1 } \int _ { 0 } ^ { T } G _ { m } ( t, s ) d s = m ^ { 2 } R _ { 1 } \frac { 1 } { m ^ { 2 } } = R _ { 1 } = \| x \|. \\ \L _ { \cdot } \ \L _ { \cdot } \ \L _ { \cdot } \ \L _ { \cdot } \ \L _ { \cdot } \ \L _ { \cdot } \ \L _ { \cdot }$$
$$0$$
Claim 2. ‖ Fx ‖ ≤ ‖ x ‖ for x ∈ P ∩ ∂ Ω 2 .
Let x ∈ P ∩ ∂ Ω , that is, 2 x ∈ P and ‖ x ‖ = R 2 . Then c m R 2 ≤ x t ( ) ≤ R 2 for all t ∈ [0 , T ] and hence
$$F x ( t ) \ & = \ \int _ { 0 } ^ { T } G _ { m } ( t, s ) f _ { m } ( s, x ( s ) ) d s \leq \int _ { 0 } ^ { T } G _ { m } ( t, s ) m ^ { 2 } R _ { 2 } d s \\ & = \ m ^ { 2 } R _ { 2 } \int _ { 0 } ^ { T } G _ { m } ( t, s ) d s = m ^ { 2 } R _ { 2 } \frac { 1 } { m ^ { 2 } } = R _ { 2 } = \| x \|. \\ \cdots \cdots \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{array}$$
Thefore by Theorem 2.1 the existence of a solution of the problem (3) with the desired localization property immediately follows. glyph[square]
The following result is a consequence of Theorem 3.2.
Theorem 3.3. Assume that (H0) and the following conditions hold:
$$\text{(H2)} \ T h e r e \ e x i s t s \ m > 0 \ s u c h \ t h a t \ m ^ { 2 } < \left ( \frac { \pi } { T } \right ) ^ { 2 } + \left ( \frac { a } { 9 } \right ) ^ { 2 } \ a n d$$
$$\left ( \text{H2} \right ) \text{ Theme exists } m > 0 \text{ such that } m ^ { 2 } < \left ( \frac { n } { T } \right ) ^ { \kappa } + \left ( \frac { u } { 2 } \right ) ^ { \kappa } \text{ and }$$
$$f _ { m } ( t, x ) = r ( t ) x ^ { \alpha } - s ( t ) x ^ { \beta } + m ^ { 2 } x \geq 0 \ \ \text{ for } t \in [ 0, T ] \text{ and } x \geq 0.$$
(H3) r ∗ > 0 and s ∗ > 0 .
Then the problem (3) has a positive solution.
Proof. We are going to prove that assumption (H1) in Theorem 3.2 is satisfied. By (H0), (H3) and since c m ∈ (0 , 1) we can choose 0 < R 1 < R 2 such that
$$( 1 - c _ { m } ) m ^ { 2 } R _ { 1 } ^ { 1 - \alpha } + s ^ { * } R _ { 1 } ^ { \beta - \alpha } \leq r _ { * } c _ { m } ^ { \alpha }$$
and
$$r ^ { * } \leq s _ { * } c _ { m } ^ { \beta } R _ { 2 } ^ { \beta - \alpha }.$$
Note that the inequality (7) follows from (H2) so it only remains to check the inequalities (8) and (9).
$$\text{If } t \in [ 0, T ] \text{ and } x \in [ c _ { m } R _ { 1 }, R _ { 1 } ] \text{ then, taking into account (H3) and (10), we have that} \\ f _ { m } ( t, x ) \geq r _ { * } ( c _ { m } R _ { 1 } ) ^ { \alpha } - s ^ { * } R _ { 1 } ^ { \beta } + m ^ { 2 } c _ { m } R _ { 1 } \geq m ^ { 2 } R _ { 1 },$$
so the inequality (8) is fulfilled.
$$\text{If } t \in [ 0, T ] \text{ and } x \in [ c _ { m } R _ { 2 }, R _ { 2 } ] \text{ then, taking into account (H3) and (11), we have that } \\ f _ { m } ( t, x ) \leq r ^ { * } R _ { 2 } ^ { \alpha } - s _ { * } ( c _ { m } R _ { 2 } ) ^ { \beta } + m ^ { 2 } R _ { 2 } \leq m ^ { 2 } R _ { 2 },$$
so the inequality (9) is also fulfilled.
glyph[square]
Remark 3.4. Note that (H0) and (H2) imply that r ∗ > 0, thus the first part of condition (H3) is redundant but we have included it for the sake of clarity. On the other hand, notice that condition (7) in Theorem 3.2 could be satisfied even if r t ( ) assumes negative values.
Next, we present an explicit condition sufficient in order to get the condition (H2) in Theorem 3.3.
Corollary 3.5. Assume that (H0) and (H3) hold and, moreover, that
$$s ^ { * } < \min \{ \left ( \frac { \pi } { T } \right ) ^ { 2 } + \left ( \frac { a } { 2 } \right ) ^ { 2 }, r _ { * } \}.$$
Then the problem (3) has a positive solution.
Proof. It is enough to show that condition (12) implies (H2). Indeed, by (12) we can choose m> 0 such that
$$s ^ { * } < m ^ { 2 } < \left ( \frac { \pi } { T } \right ) ^ { 2 } + \left ( \frac { a } { 2 } \right ) ^ { 2 }.$$
Now, we are going to prove that for such m we have that f m ( t, x ) ≥ 0 for all t ∈ [0 , T ] and all x ≥ 0.
Step 1. We show that f m ( t, x ) ≥ 0 for all t ∈ [0 , T ] and all x ∈ [0 , 1] .
Since 0 < α < β < 1 we have x β ≤ x α for 0 ≤ x ≤ 1. Moreover s ∗ < r ∗ by (12) and then
$$f _ { m } ( t, x ) \ & = \ r ( t ) x ^ { \alpha } - s ( t ) x ^ { \beta } + m ^ { 2 } x \geq r _ { * } x ^ { \alpha } - s ^ { * } x ^ { \beta } + m ^ { 2 } x \\ & \geq \ r _ { * } x ^ { \beta } - s ^ { * } x ^ { \beta } + m ^ { 2 } x = ( r _ { * } - s ^ { * } ) x ^ { \beta } + m ^ { 2 } x > 0.$$
Step 2. We show that f m ( t, x ) ≥ 0 for all t ∈ [0 , T ] and all x ≥ 1 . Since 0 < β < 1 we have x β ≤ x for x ≥ 1 and therefore
$$f _ { m } ( t, x ) \ & = \ r ( t ) x ^ { \alpha } - s ( t ) x ^ { \beta } + m ^ { 2 } x \geq r _ { * } x ^ { \alpha } - s ^ { * } x ^ { \beta } + m ^ { 2 } x \\ & \geq \ r _ { * } x ^ { \alpha } - s ^ { * } x ^ { \beta } + m _ { \substack { \epsilon \\ \epsilon } } ^ { 2 } x ^ { \beta } = r _ { * } x ^ { \alpha } + ( m ^ { 2 } - s ^ { * } ) x ^ { \beta } \geq 0.$$
glyph[square]
In the particular case of problem (2) we recover [4, Theorem 1.8].
Corollary 3.6. Assume that a ≥ 0 , b > 1 , c > 0 and e ∗ > . 0 Then problem (2) has a positive solution provided that
$$\frac { \left ( b + 1 \right ) c ^ { 2 } } { 4 \, e _ { * } } < \left ( \frac { \pi } { T } \right ) ^ { 2 } + \frac { a ^ { 2 } } { 4 } \,.$$
Proof. We recall that the problem (2) is of the form (3) with
$$\mu = \frac { 1 } { b + 1 }, \, r ( t ) = \frac { e ( t ) } { \mu }, \, s ( t ) = \frac { c } { \mu }, \, \alpha = 1 - 2 \, \mu, \ \beta = 1 - \mu.$$
From our assumptions it follows immediately that the conditions (H0) and (H3) of Theorem 3.3 hold. Thus it only remains to check the condition (H2). By (13) we can choose m > 0 such that
$$\frac { \left ( b + 1 \right ) c ^ { 2 } } { 4 \, e _ { * } } < m ^ { 2 } < \left ( \frac { \pi } { T } \right ) ^ { 2 } + \frac { a ^ { 2 } } { 4 } \,.$$
Then for all t ∈ [0 , T ] and x ≥ 0 we have
$$f _ { m } ( t, x ) \ & = \ \frac { e ( t ) } { \mu } \, x ^ { 1 - 2 \mu } - \frac { c } { \mu } \, x ^ { 1 - \mu } + m ^ { 2 } x \geq \frac { e _ { * } } { \mu } \, x ^ { 1 - 2 \mu } - \frac { c } { \mu } \, x ^ { 1 - \mu } + m ^ { 2 } x \\ & = \ \frac { x ^ { 1 - 2 \mu } } { \mu } \left ( e _ { * } - c x ^ { \mu } + m ^ { 2 } \, \mu \, x ^ { 2 \mu } \right ) \geq 0, \\. \. \. \. \ \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \partial _ { \lambda } \quad \odot.$$
because e ∗ -cx µ + m µx 2 2 µ > 0 (it is a parabola in the variable x µ which has by (14) negative discriminant c 2 -4 m µe 2 ∗ < 0, so it has constant sign, and positive independent term e ∗ > 0). glyph[square]
The following example shows that Theorem 3.2 is in fact more general than Corollary 3.6. Therefore, even in the case of the model problem (2), Theorem 3.2 is a true extension of [4, Theorem 1.8]. Moreover, notice that we also obtain information about the localization of the solution which was not provided in [4]. Some computations here were made with MAPLE.
Example 3.7. Consider the problem (2), that is,
$$\begin{cases} \ x ^ { \prime \prime } ( t ) + a \, x ^ { \prime } ( t ) = \frac { e ( t ) } { \mu } \, x ^ { 1 - 2 \, \mu } - \frac { c } { \mu } \, x ^ { 1 - \mu }, \quad t \in [ 0, T ], \\ \ x ( 0 ) = x ( T ), \quad x ^ { \prime } ( 0 ) = x ^ { \prime } ( T ), \end{cases}$$
with the parameter values a = 1 6, . e t ( ) ≡ 1 54, . µ = 0 01, . c = 1 49 and . T = 1.
Therefore we have
$$b = 9 9 \, ( \text{recall that } \mu \coloneqq \frac { 1 } { b + 1 } ), \, r ( t ) \coloneqq \frac { e ( t ) } { \mu } \equiv 1 5 4, \, s ( t ) \coloneqq \frac { c } { \mu } \equiv 1 4 9, \\ \alpha \coloneqq 1 - 2 \mu = 0. 9 8 \quad \text{and} _ { 7 } \quad \beta \coloneqq 1 - \mu = 0. 9 9.$$
Thus, condition (13) in Corollary 3.6 is not satisfied because
$$\frac { \left ( b + 1 \right ) c ^ { 2 } } { 4 \, e _ { * } } \approx 3 6. 0 4 0 6 > 1 0. 5 0 9 6 \approx \left ( \frac { \pi } { T } \right ) ^ { 2 } + \frac { a ^ { 2 } } { 4 }.$$
Notice that neither condition (12) in Corollary 3.5 is satisfied since
$$s ^ { * } = 1 4 9 > 1 0. 5 0 9 6 \approx \left ( \frac { \pi } { T } \right ) ^ { 2 } + \frac { a ^ { 2 } } { 4 }.$$
However, the condition (H0) in Theorem 3.2 is clearly satisfied and if we define m := 0 7, . R 1 := 27 and R 2 := 29 then (H1) is also fulfilled (notice that c m ≈ 0 9414 as it is given by . (20)).
Thus, Theorem 3.2 ensures the existence of a solution x t ( ) of this problem such that
$$2 5. 4 1 8 9 \approx c _ { m } R _ { 1 } \leq x ( t ) \leq R _ { 2 } = 2 9.$$
Observe that f m is not positive for all x ≥ 0.
Remark 3.8. From a careful reading of the proof of [4, Theorem 1.8] it follows that the existence of a positive periodic solution to problem (2) is ensured if condition (13) in Corollary 3.6 is replaced by the more general one:
- (H) There is δ 0 > 0 such that f ( t, x ) < 0 for all t ∈ [0 , T ] and all x ∈ (0 , δ 0 ) and λ x ∗ -f ( t, x ) > 0 for all t ∈ [0 , T ] and all x > 0, where λ ∗ = ( π T ) 2 + a 2 4 .
However, condition (H) is neither satisfied for the problem presented in Example 3.7 because in that case
$$\lambda ^ { * } x - f ( t, x ) \approx 1 0. 5 0 9 6 x - 1 4 9 x ^ { 0. 9 9 } + 1 5 4 x ^ { 0. 9 8 },$$
which is a sing-changing nonlinearity on the positive real line. Indeed, dividing by x 0 98 . and making the change y = x 0 01 . , it is clear that λ x ∗ -f ( t, x ) is negative on ( r , r 1 2 ) and positive on (0 , r 1 ) ∪ ( r , 2 ∞ ), being r 1 ≈ 103620 4135 and . r 2 ≈ 3 7845 . ∗ 10 111 .
$$4. \ A P P E N D I X \colon \text{THE GREEN'S FUNCTION}$$
4.1. The case 0 < m < a 2 . The Green's function related to problem (5) is given by
$$G _ { m } ( t, s ) = \frac { 1 } { \lambda _ { 2 } - \lambda _ { 1 } } \begin{cases} \frac { e ^ { \lambda _ { 2 } ( t - s ) } } { 1 - e ^ { \lambda _ { 2 } T } } - \frac { e ^ { \lambda _ { 1 } ( t - s ) } } { 1 - e ^ { \lambda _ { 1 } T } }, \quad & 0 \leq s \leq t \leq T, \\ \frac { e ^ { \lambda _ { 2 } ( t - s + T ) } } { 1 - e ^ { \lambda _ { 2 } T } } - \frac { e ^ { \lambda _ { 1 } ( t - s + T ) } } { 1 - e ^ { \lambda _ { 1 } T } }, \quad 0 \leq t \leq s \leq T, \end{cases} \\ \text{where $\lambda$} \text{ and $\lambda$} \text{ are the characteristic roots of the homogeneous equation}$$
where λ 1 and λ 2 are the characteristic roots of the homogeneous equation
$$x ^ { \prime \prime } ( t ) + a x ^ { \prime } ( t ) + m ^ { 2 } x ( t ) = 0,$$
that is,
$$\lambda _ { 1 } = \frac { - a - \sqrt { a ^ { 2 } - 4 m ^ { 2 } } } { 2 }, \ \lambda _ { 2 } = \frac { - a + \sqrt { a ^ { 2 } - 4 m ^ { 2 } } } { 2 }.$$
Note that λ 1 < λ 2 < 0.
Remark 4.1. G m ( s, s ) is constant for s ∈ [0 , T ],
$$G _ { m } ( s, s ) = \frac { 1 } { \lambda _ { 2 } - \lambda _ { 1 } } \left ( \frac { 1 } { 1 - e ^ { \lambda _ { 2 } T } } - \frac { 1 } { 1 - e ^ { \lambda _ { 1 } T } } \right ),$$
and
$$\int _ { 0 } ^ { T } G _ { m } ( t, s ) d s = \frac { 1 } { \lambda _ { 1 } \lambda _ { 2 } } = \frac { 1 } { m ^ { 2 } }.$$
The Green's function (15) satisfies
$$G _ { m } ( t, s ) \geq G _ { m } ( s, s ) > 0,$$
and
$$G _ { m } ( s, s ) \geq \underset { 9 } { c } _ { m } G _ { m } ( t, s ),$$
for all ( t, s ) ∈ [0 , T ] × [0 , T ], where
$$c _ { m } = \frac { G _ { m } ( s, s ) } { \max \{ G _ { m } ( t, s ) \, \colon t, s \in [ 0, T ] \} },$$
that is,
$$c _ { m } = - \frac { \lambda _ { 2 } } { \lambda _ { 2 } - \lambda _ { 1 } } \frac { e ^ { \lambda _ { 2 } T } - e ^ { \lambda _ { 1 } T } } { ( 1 - e ^ { \lambda _ { 2 } T } ) \left ( \frac { ( 1 - e ^ { \lambda _ { 2 } T } ) \lambda _ { 1 } } { ( 1 - e ^ { \lambda _ { 1 } T } ) \lambda _ { 2 } } \right ) ^ { \frac { \lambda _ { 1 } } { \lambda _ { 2 } - \lambda _ { 1 } } } }.$$
4.2. The case m = a 2 . The Green's function related to the problem (5) is given by
$$G _ { m } ( t, s ) & = \frac { 1 } { e ^ { m T } - 1 } \begin{cases} e ^ { m ( t - s ) } \left [ \frac { T e ^ { m T } } { e ^ { m T } - 1 } + s - t \right ], & 0 \leq s \leq t \leq T, \\ e ^ { m ( T - s + t ) } \left [ \frac { T } { e ^ { m T } - 1 } + s - t \right ], & 0 \leq t \leq s \leq T. \end{cases}$$
Then we have
$$\int _ { 0 } ^ { T } G _ { m } ( t, s ) d s = \frac { 1 } { m ^ { 2 } }, \\ G _ { m } ( t, s ) \geq G _ { m } ( s, s ) > 0,$$
and
$$G _ { m } ( s, s ) \geq c _ { m } \, G _ { m } ( t, s ),$$
for all ( t, s ) ∈ [0 , T ] × [0 , T ], where
$$c _ { m } = \frac { G _ { m } ( s, s ) } { \max \{ G _ { m } ( t, s ) \colon t, s \in [ 0, T ] \} },$$
that is,
$$c _ { m } = \kappa e ^ { 1 - \kappa },$$
with
$$\kappa = \frac { m T } { e ^ { m T } - 1 }.$$
4.3. The case m> a 2 and m < 2 ( π T ) 2 + ( a 2 ) 2 . We use the following notation:
$$& 2 & \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \quad \quad$$
The Green's function related to the problem (5) is given by
(22)
$$G _ { m } ( t, s ) = \frac { 1 } { \delta D } \begin{cases} e ^ { \gamma ( T + t - s ) } \sin ( \delta ( T + s - t ) ) + e ^ { \gamma ( t - s ) } \sin ( \delta ( t - s ) ), \quad & 0 \leq s \leq t \leq T, \\ e ^ { \gamma ( T + t - s ) } \sin ( \delta ( T + t - s ) ) + e ^ { \gamma ( 2 T + t - s ) } \sin ( \delta ( s - t ) ), \quad 0 \leq t \leq s \leq T. \end{cases}$$
Then we have and
$$G _ { m } ( s, s ) \geq c _ { m } \, G _ { m } ( t, s ),$$
for all ( t, s ) ∈ [0 , T ] × [0 , T ], where
$$c _ { m } = \frac { G _ { m } ( s, s ) } { \max \{ G _ { m } ( t, s ) \, \colon t, s \in [ 0, T ] \} } = \frac { \frac { 1 } { \delta D } e ^ { \gamma T } \sin ( \delta T ) } { \max \{ G _ { m } ( t, s ) \, \colon t, s \in [ 0, T ] \} }.$$
If a = 0 then γ = 0 , δ = m, D = 2(1 -cos mT ) and it is known that max { G m ( t, s ) : t, s ∈ [0 , T ] } = 1 2 m sin mT 2 , see [16]. Therefore we have c m = cos mT 2 .
On the other hand, if a > 0 it is difficult to find exactly the maximum of G m ( t, s ), but we are able to get an upper bound in the following way: since 0 < δT < π we have for 0 ≤ s ≤ t ≤ T (the case 0 ≤ t ≤ s ≤ T is analogous)
$$e ^ { \gamma ( T + t - s ) } \sin ( \delta ( T + s - t ) ) & + e ^ { \gamma ( t - s ) } \sin ( \delta ( t - s ) ) \leq \sin ( \delta ( T + s - t ) ) + \sin ( \delta ( t - s ) ) \\ & = 2 \sin \frac { \delta T } { 2 } \cos \left ( \delta ( \frac { T } { 2 } - ( t - s ) ) \right ) \leq 2 \sin \frac { \delta T } { 2 }.$$
So, max { G m ( t, s ) : t, s ∈ [0 , T ] } ≤ 2 δD sin δT 2 which yields c m ≥ e γT cos δT 2 .
$$\text{Remark } 4. 2. \text{ If } m ^ { 2 } = \left ( \frac { \pi } { T } \right ) ^ { 2 } + \left ( \frac { a } { 2 } \right ) ^ { 2 } \text{ then } G _ { m } ( s, s ) = 0.$$
## Acknowledgements
J. A. Cid was partially supported by Ministerio de Educaci´n y Ciencia, o Spain, and FEDER, Project MTM2010-15314, G. Infante was partially supported by G.N.A.M.P.A. -INdAM (Italy), M. Tvrd´ was supported by GA CR Grant P201/14-06958S and RVO: y ˇ 67985840 and M. Zima was partially supported by the Centre for Innovation and Transfer of Natural Science and Engineering Knowledge of University of Rzesz´w. o
## References
[1] A. Borz` ı and G. Propst, Numerical investigation of the Liebau phenomenon, Z. Angew. Math. Phys. 54 (2003) 1050-1072.
[2] A. Cabada, Green's Functions in the Theory of Ordinary Differential Equations, SpringerBriefs in Mathematics, 2014.
[3] A. Cabada, J. A. Cid and B. M´quez-Villamar´ ın, Computation of Green's functions for boundary value a problems with Mathematica, Appl. Math. Comput. 219 (2012), 1919-1936.
[4] J. A. Cid, G. Propst and M. Tvrd´, On the pumping effect in a pipe/tank flow configuration with y friction, Phys. D 273-274 (2014) 28-33.
$$\int _ { 0 } ^ { T } G _ { m } ( t, s ) d s = \frac { 1 } { m ^ { 2 } }, \\ G _ { m } ( t, s ) \geq G _ { m } ( s, s ) > 0,$$
$$\dots$$
| [5] | C. de Coster and P. Habets, Two-point Boundary Value Problems. Lower and Upper Solutions , Elsevier, Amsterdam (2006). |
|------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [6] | D. Guo and V. Lakshmikantham, Nonlinear problems in abstract cones , Academic Press, Boston, 1988. |
| [7] | X. Han, Positive solutions for a three-point boundary value problems at resonance, J. Math. Anal. Appl. 336 (2007), 556-568. |
| [8] | G. Infante, P. Pietramala and M. Tenuta, Existence and localization of positive solutions for a nonlocal BVP arising in chemical reactor theory, Commun. Nonlinear Sci. Numer. Simulat. , 19 (2014), 2245- 2251. |
| [9] | G. Infante, P. Pietramala and F. A. F. Tojo, Nontrivial solutions of local and nonlocal Neumann boundary value problems, arXiv:1404.1390 (2014). |
| [10] | M. A. Krasnosel'skii ˘ and P. P. Zabreiko, ˘ Geometrical methods of nonlinear analysis , Springer-Verlag, Berlin, (1984). |
| [11] | K. Q. Lan, Multiple positive solutions of Hammerstein integral equations and applications to periodic boundary value problems, Appl. Math. Comput. , 154 (2004), 531-542. |
| [12] | G. Liebau, ¨ Uber ein ventilloses Pumpprinzip, Naturwissenschaften 41 (1954), 327. |
| [13] | M. Moser, J. W. Huang, G. S. Schwarz, T. Kenner and A. Noordergraaf, Impedance defined flow. Generalisation of William Harvey's concept of the circulation-370 years later, Int. J. Cardiovasc. Med. Sci. 1 (1998), 205-211. |
| [14] | G. Propst, Pumping effects in models of periodically forced flow configurations, Phys. D 217 (2006), 193-201. |
| [15] | I. Rach˚nkov´, u a M Tvrd´ y and I. Vrkoˇ, c Existence of nonnegative and nonpositive solutions for second order periodic boundary value problems, J. Differential Equations 176 (2001), 445-469. |
| [16] | P. J. Torres, Existence of one-signed periodic solutions of some second-order differential equations via a Krasnoselskii fixed point theorem, J. Differential Equations , 190 (2003), 643-662. |
| [17] | J. R. L. Webb and M. Zima, Multiple positive solutions of resonant and non-resonant nonlocal boundary value problems, Nonlinear Anal. 71 (2009), 1369-1378. |
| Jos´ e ´ Angel Cid, Departamento de Matem´ticas, a Universidade de Vigo, 32004, Pabell´n o 3, Campus de Ourense, Spain | Jos´ e ´ Angel Cid, Departamento de Matem´ticas, a Universidade de Vigo, 32004, Pabell´n o 3, Campus de Ourense, Spain |
| Gennaro Infante, Dipartimento di Matematica e Informatica, Universit` a della Calabria, 87036 Arcavacata di Rende, Cosenza, Italy | Gennaro Infante, Dipartimento di Matematica e Informatica, Universit` a della Calabria, 87036 Arcavacata di Rende, Cosenza, Italy |
| Milan Tvrd´, y Mathematical Institute, Academy of Sciences of the Czech Republic, CZ 115 | Milan Tvrd´, y Mathematical Institute, Academy of Sciences of the Czech Republic, CZ 115 |
| E-mail address : [email protected] Mirosglyph[suppress] lawa Zima, Department of Differential Equations and Statistics, Faculty of | E-mail address : [email protected] Mirosglyph[suppress] lawa Zima, Department of Differential Equations and Statistics, Faculty of |
| and Natural Sciences, University of Rzesz´w, o Pigonia 1, 35-959 Rzesz´w, o Poland. | and Natural Sciences, University of Rzesz´w, o Pigonia 1, 35-959 Rzesz´w, o Poland. |
| E-mail address : [email protected] | E-mail address : [email protected] |
| ematics | ematics |
| Praha 1, a 25, Czech Republic | Praha 1, a 25, Czech Republic |
| Zitn´ | Zitn´ |
| ˇ | ˇ |
| E-mail address : [email protected] | E-mail address : [email protected] |
| | Math- | | 10.1016/j.jmaa.2014.10.054 | [
"José Ángel Cid",
"Gennaro Infante",
"Milan Tvrdý",
"Mirosława Zima"
] | 2014-08-01T11:12:58+00:00 | 2014-08-01T11:12:58+00:00 | [
"math.CA",
"34B18 (Primary), 34B27 (Secondary), 34B60"
] | A topological approach to periodic oscillations related to the Liebau phenomenon | We give some sufficient conditions for existence, non-existence and
localization of positive solutions for a periodic boundary value problem
related to the Liebau phenomenon. Our approach is of topological nature and
relies on the Krasnosel'ski\u\i{}-Guo theorem on cone expansion and
compression. Our results improve and complement earlier ones in the literature. |
1408.0131v1 | ## A Polling Model with Reneging at Polling Instants ∗
## M.A.A. Boon †
[email protected]
April, 2010
## Abstract
In this paper we consider a single-server, cyclic polling system with switch-over times and Poisson arrivals. The service disciplines that are discussed, are exhaustive and gated service. The novel contribution of the present paper is that we consider the reneging of customers at polling instants. In more detail, whenever the server starts or ends a visit to a queue, some of the customers waiting in each queue leave the system before having received service. The probability that a certain customer leaves the queue, depends on the queue in which the customer is waiting, and on the location of the server. We show that this system can be analysed by introducing customer subtypes, depending on their arrival periods, and keeping track of the moment when they abandon the system. In order to determine waiting time distributions, we regard the system as a polling model with varying arrival rates, and apply a generalised version of the distributional form of Little's law. The marginal queue length distribution can be found by conditioning on the state of the system (position of the server, and whether it is serving or switching).
Keywords: Polling, reneging, varying arrival rates, queue lengths, waiting times
## 1 Introduction
A polling system is a queueing system that consists of multiple queues being served by one server, generally in a fixed, cyclic, order. There is a vast literature on polling systems, motivated by many real-life applications. These applications are frequently found in production environments, where one machine produces different part types. Typically, after the production of several parts of the same type, the machine is reconfigured and starts producing parts of the next type. The performance measures of interest are, e.g., the mean throughput of the machine, the number of different product orders that are waiting to be processed, and the mean order lead time (i.e., the time between the placement of the order and the completion of the last item in the order). Other typical application areas of polling systems are telecommunications, where several protocols use a round-robin principle for the communication of data packets between multiple devices, and transportation. We recommend surveys of, e.g.,
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-NF.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
Takagi [24], Levy and Sidi [18] and Vishnevskii and Semenova [25], for a better overview of applications of polling systems, and techniques to analyse them.
In queueing systems, waiting is an inevitable nuisance. When waiting times become too large, the impatience grows and customers might decide to leave the queue and possibly return another time. This phenomenon, which occurs in many real-life situations, is referred to in queueing literature as reneging . Alternatively, the terms abandonment or impatience are used. The first paper on the subject of abandonment due to impatience, has been written by Palm [21] who studies annoyance of customers in telecommunications. In [21], as in most of the literature on reneging, impatience is modelled as a timer that starts running at the moment that a customer joins the queue. When this timer reaches a certain (usually random) value while the customer is still waiting in the queue, he abandons the system immediately. The system studied in [21] is an M/M/n queue with exponentially distributed customer patience, which is used frequently to model call centers, and is referred to as the Erlang-A ( M/M/n + M ) queueing system. This model, and generalisations to other patience distributions, are studied in more detail in by, e.g., Riordan [23], Haugen and Skogan [15], Baccelli and Hebuterne [4], and Boxma and De Waal [8]. The vast majority of papers on reneging focusses on the application to call centers, studying the loss probability and comparing different staffing rules. See [17, 20, 28] for some recent developments in reneging in queueing models for call centers. In the application area of computer systems, processor sharing is an important discipline and reneging has been studied in this context as well. Assaf and Haviv [3] consider a model where customers may decide to abandon the system, depending on the number of customers that are in service simultaneously. Gromoll et al. [14] consider an overloaded processor sharing queue with impatient customers, and find a scaling procedure that makes the model analytically tractable.
One common aspect of all models considered in the aforementioned literature, is that whenever customers are available in the system, (at least) one of them is in service. In polling models, customer impatience might be increased by absence of the server at the queue of arrival. This kind of behaviour has been studied in single-queue systems by Altman and Yechiali [2], who discuss M/G/ 1 and M/M/c queues with server vacations, and customers growing impatient while the server is away. Zhang et al. [29] study a similar system, but with an M/M/ /N 1 queue. Their model also includes balking, which means that customers may decide not to enter the system at all, depending on the number of customers present in the queue. Madan [19] studies a system where server vacations may start at arbitrary moments, even when customers are being served or when the system is idle. Whenever a vacation starts, a random number of customers abandons the system immediately. The fact that more than one customer can leave the system at the same time, and only at specified moments (in this case the beginning of a vacation) makes this model quite different from most of the other papers dealing with customer impatience. We refer to this kind of abandonment as synchronised reneging , a term that is introduced by Adan et al. [1], who consider a model where each customer has the same probability of abandoning the system at synchronised reneging epochs. They consider a queueing system with server vacations that start as soon as the queue becomes empty, distinguishing between two cases. In the first case, which is called the Unique Abandonment Epoch (UAE) model, customers leave the queue at visit beginnings only. In the second case, referred to as the Multiple Abandonment Epochs (MAE) model, impatient customers also abandon at (randomly) specified, synchronised moments during the server vacation.
In the present paper we study synchronised reneging in polling systems , with abandonments taking place at visit beginnings and endings. Basically, this means that we extend the UAE model of [1] to systems with multiple queues, thereby increasing the number of synchronised reneging epochs. The higher frequency of abandonment epochs significantly increases the complexity of the analysis. Although the reneging policy considered in the current paper is based on [1], the analysis is different. It is based on new techniques, developed in a recent paper on polling models with so-called smart customers , cf. [5], to find waiting time and queue length distributions in polling systems with varying arrival rates. In the present paper we use and extend these techniques, so they can be applied to a polling model with synchronised reneging. This makes it possible to extend the results of [1] in three new directions. Firstly, this allows us to study systems with multiple queues. Secondly, we can consider other service disciplines than exhaustive service (i.e., serve customers in a queue until it is empty). In the present paper we discuss not only exhaustive, but also gated service (i.e., serve all customers present at the server's arrival at the queue). The third new contribution of the present paper is that we can compute other relevant performance measures as well, like the distributions of the cycle times and the waiting times. These extensions provide the main motivation to study this model, which is one of the first attempts to introduce reneging in polling systems. The only related work is by Vishnevsky and Semenova [26] who study a two-queue polling system with exponential service times and exhaustive service, with the more conventional timer to model the patience of the customer. They illustrate how the Power-series algorithm can be used to find the equilibrium state probabilities, but no explicit performance measures are computed.
Since the analysis in the present paper relies heavily on [5], we briefly summarise their results. In a polling system with smart customers, the arrival rates of the different customer types depend on the state of the server, where state is defined as a combination of its location, and whether it is working or switching. In this situation, it is no longer possible to apply the distributional form of Little's law in its standard form (see, for example, [16]), but it requires a generalization, developed in [5]. In the present paper we apply this model with smart customers to determine the Laplace-Stieltjes Transform (LST) of the waiting time distribution of each customer type. This generalised version of the distributional form of Little's law is applied to the joint queue length distribution at departure epochs of customers that have not abandoned the system prematurely, which means that this waiting time is determined only for customers that are actually served. To determine the Probability Generating Function (PGF) of the marginal queue length distribution of each customer type, we do need to take into account the impatient customers that abandon the system before being served. This requires a different approach, as will be shown later in this paper.
The structure of the present paper is as follows. In the next section we describe the model and the notation in more detail. In Section 3 we introduce an alternative model with smart customers that is used to determine the cycle time and waiting time of served customers in the original model. The stability condition is also presented in this section. The marginal queue length distributions are studied in Section 4, because this requires a different approach. Section 5 discusses a special case of the model under consideration, a polling system with only one queue and exhaustive service. This queueing system with server vacations, has been studied in [1]. We show that the queue length PGF obtained in Section 4 agrees with their result, and we mention some further results that have not been discussed in [1], like the cycle time and sojourn times of all customers, which reduce to elegant expressions when the system
consists of only one queue. The last section discusses a numerical example to illustrate typical features of a polling model with synchronised reneging at polling instants.
## 2 Model and notation
The polling model under consideration contains N queues, Q , . . . , Q 1 N . These queues are served by one server in a fixed, cyclic order. The time that is required to switch from Q i to Q i +1 is denoted by S i , which is called a switch-over time, with LST σ i ( ). · Throughout the paper, all indices are modulo N , so Q N +1 refers to Q 1 and so on. The arrival process of customers in Q i , denoted by type i customers, is a Poisson process with parameter λ i . The service time of a type i customer is denoted by B i , with LST β i ( ). · The switch-over times, interarrival times and service times are all assumed to be independent of each other. The service discipline of each queue determines when the server switches to the next queue. The following property, which is defined in [22] and [12], plays a key role in the analysis of polling systems.
Property 2.1 (Branching Property) If the server arrives at Q i to find k i customers there, then during the course of the server's visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having probability generating function h i ( z , . . . , z 1 N ), which can be any N -dimensional probability generating function.
glyph[negationslash]
Performance measures, like queue length distributions and waiting times, can be determined for polling systems with all queues satisfying Property 2.1, whereas only very few, exceptional, polling systems can be analysed if the service disciplines do not satisfy this property. In the present paper we discuss the two most common service disciplines satisfying this branching property , exhaustive and gated service. A queue with exhaustive service is served until it is completely empty. In a queue with gated service only those customers are served, that are present at the beginning of a visit to this queue. The PGF h i ( z , . . . , z 1 N ) in Property 2.1 is β i ( ∑ N j =1 λ j (1 -z j ) ) for gated service, and π i ( ∑ j = i λ j (1 -z j ) ) for exhaustive service, where π i ( ) is the LST of a busy period distribution in an · M/G/ 1 system with only type i customers, so it is the root in (0 , 1] of the equation π i ( ω ) = β i ( ω + λ i (1 -π i ( ω ))), ω ≥ 0 (cf. [10], p. 250). Define θ i ( ) as the LST of the time that the server spends at · Q i due to the presence of one customer there. For gated service θ i ( ) = · β i ( ), and for exhaustive service · θ i ( ) = · π i ( ). ·
A cycle consists of the visit times of all queues, denoted by V , . . . , V 1 N , and the switch-over times S , . . . , S 1 N . The distribution of the length of one cycle depends on the starting point of this cycle. We use the notation C i for the time between two successive visit beginnings to Q i , with LST γ i ( ), and · C ∗ i for the time between two successive visit completions to Q i , with LST γ ∗ i ( ). · When studying a queue with gated service, it turns out that C i plays an important role, whereas C ∗ i is used in the analysis of queues receiving exhaustive service. The intervisit time I i is the time between a visit completion of Q i and the next visit beginning at Q i .
The model discussed in the present paper is different from models in existing literature because customers grow impatient and may decide to leave the waiting line before actually being served. This is called reneging . The moments at which customers are allowed to leave the system, are only those moments when a new visit or switch-over time starts. For this reason, we refer to this model as a polling model with synchronised reneging at polling instants .
Now we give a more formal description. As stated before, a cycle consists of the periods V , S 1 1 , . . . , V N , S N . Now let P ∈ { V , S 1 1 , . . . , V N , S N } . At the moment that P starts, each customer waiting in Q i immediately leaves the system with probability p ( P ) i , i = 1 , . . . , N . We denote the probability that a customer stays by q ( P ) i = 1 -p ( P ) i . The difficulty in the analysis of this model, is that customers in a certain queue may leave the system at more than just one occasion. We use different ways to circumvent this problem in order to find the performance measures of interest. An important part in the analysis, is the fact that we artificially split each visit time and switch-over time into two parts, a and b . Visit time V i is split into V ia and V ib . We consider V ia as the subperiod in which all the customers abandon the system, right before the start of the actual service of the type i customers, which takes place during V ib . So during V ia , first each type 1 customer abandons the system with probability p ( V i ) 1 , followed by the type 2 customers, and so on, until the reneging of the type N customers. This requires no time, so E [ V ia ] = 0. During V ib the service of the type i customers that remain in the system takes place, so E [ V ib ] = E [ V i ]. Similarly, the switch-over time S i is also split into S ia and S ib , with E [ S ia ] = 0, and E [ S ib ] = E [ S i ]. During S ia the reneging of the customers that abandon the system before the beginning of S i takes place. We need this way of looking at the system, because the queue lengths at the beginning of V ia are different from the queue lengths at the beginning of V ib (and the same holds for the switch-over times). In fact, one can regard V ia , for i = 1 , . . . , N , as separate visit periods during which subsequently type 1 , . . . , N customers are served with probability p ( V i ) 1 , . . . , p ( V i ) N (or probability p ( S i ) 1 , . . . , p ( S i ) N for S ia ), with all service times equal to 0.
## 3 Cycle time, visit times and waiting time distributions
In the present section we study the LSTs of the cycle time distribution, visit time distributions, and of the waiting time distribution of each customer type. The section ends with a note on the stability condition of the model. The waiting time of a customer is the time between the moment of arrival, and the moment that the customer is taken into service. The waiting time is only determined for customers that have not prematurely abandoned the system. The time that all , including reneging, customers spend in the system, requires a different approach and is not discussed in detail in the present paper. We only show in an example in Section 5 how this can be done.
In this section we introduce a different way of looking at the system. Obviously, the length of a visit V i is solely determined by those type i customers that have not abandoned the system at any of the moments where this had been possible. A logical consequence is that only customers that are eventually served, contribute to the cycle time and determine whether the system is stable or not. This observation forms the basis of the analysis in this section. If we remove reneging customers from the system and focus on the remaining customers only, we can show that the system can be viewed as a polling system where the arrival rates of the N customer types depend on the state of the server, i.e., its location and whether it is serving or switching. This type of model is called a polling system with smart customers, introduced in [7], and analysed in more detail in [5]. The present section uses results from these papers and applies them to a polling model with reneging at polling instants.
Westart by introducing the joint queue length PGF at the beginning of all subperiods, denoted
by ˜ LB ( P ) ( z , . . . , z 1 N ), where subperiod P ∈ { V 1 a , V 1 b , S 1 a , S 1 b , . . . , V Na , V Nb , S Na , S Nb } . The PGFs of the joint queue length distributions at the beginnings of the various subperiods in the cycle can be related to each other in the following way:
$$\widetilde { L B } ^ { ( V _ { i b } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( V _ { i a } ) } ( q _ { 1 } ^ { ( V _ { i } ) } z _ { 1 } + p _ { 1 } ^ { ( V _ { i } ) }, \dots, q _ { N } ^ { ( V _ { i } ) } z _ { N } + p _ { N } ^ { ( V _ { i } ) } ),$$
$$\widetilde { L } B ^ { ( S _ { i a } ) } ( \mathbf z ) = \widetilde { L } B ^ { ( V _ { i b } ) } ( z _ { 1 }, \dots, z _ { i - 1 }, h _ { i } ( \mathbf z ), z _ { i + 1 }, \dots, z _ { N } ),$$
$$\widetilde { L } B ^ { ( S _ { i b } ) } ( { \mathbf z } ) = \widetilde { L } B ^ { ( S _ { i a } ) } ( q _ { 1 } ^ { ( S _ { i } ) } z _ { 1 } + p _ { 1 } ^ { ( S _ { i } ) }, \dots, q _ { N } ^ { ( S _ { i } ) } z _ { N } + p _ { N } ^ { ( S _ { i } ) } ),$$
$$\widetilde { L B } ^ { ( V _ { ( i + 1 ) a ) } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( S _ { i b ) } ) } ( \mathbf z ) \, \sigma _ { i } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ) ),$$
where we use the shorthand notation z for the vector ( z , . . . , z 1 n ). Successive substitution leads to a recursive expression for the joint queue length PGF at an arbitrary polling epoch. In, e.g., [22] it is discussed how this recursive expression leads to the PGF of the joint queue length distribution at polling epochs, written as an infinite product. The recursive equation itself can be used to compute the moments of this joint queue length distribution explicitly. For now, we are more interested in a nice property of the Poisson arrival processes. During the actual visit period V ib , the type i customers that have not abandoned the system are served. For the moment, assuming exhaustive service, we focus on the end of V i , when there are no type i customers present in the system. Then the PGF of the number of type i customers present at the end of S i (which coincides with the beginning of V i +1 ) is
$$\widetilde { L B } ^ { ( V _ { ( i + 1 ) a } ) } ( 1, \dots, 1, z _ { i }, 1, \dots, 1 ) = \sigma _ { i } \left ( \lambda _ { i } ( 1 - z _ { i } ) \right ).$$
Each of these customers abandons the system before the start of V i +1 with probability p ( V i +1 ) i , so the PGF of the number of type i customers that are still in the system at the beginning of V i +1 is:
$$\widetilde { L B } ^ { ( V _ { ( i + 1 ) b ) } ) } ( 1, \dots, 1, z _ { i }, 1, \dots, 1 ) & = \widetilde { L B } ^ { ( V _ { ( i + 1 ) a ) } } ( 1, \dots, 1, q _ { i } ^ { ( V _ { i + 1 } ) } z _ { i } + p _ { i } ^ { ( V _ { i + 1 } ) }, 1, \dots, 1 ) \\ & = \sigma _ { i } \left ( \lambda _ { i } ( 1 - q _ { i } ^ { ( V _ { i + 1 } ) } z _ { i } - p _ { i } ^ { ( V _ { i + 1 } ) } ) \right ) \\ & = \sigma _ { i } \left ( \lambda _ { i } q _ { i } ^ { ( V _ { i + 1 } ) } ( 1 - z _ { i } ) \right ).$$
This short example illustrates that, as far as the joint queue lengths at polling epochs is concerned, and only focussing on the customers that did not abandon the system prematurely, we can view the system as a polling model with Poisson arrivals, but with varying arrival rates (in the example, we have that the new arrival rate is λ q i ( V i +1 ) i during S i ). Just before the start of S i +1 each type i customer in the system reneges with probability p ( S i +1 ) i . This implies that a customer that arrived during S i is still in the system at the beginning of S i +1 with probability q ( V i +1 ) i q ( S i +1 ) i . Hence, the number of type i customers present at the beginning of S i +1 is the same as in a polling system without reneging, but with arrival rates q ( V i +1 ) i q ( S i +1 ) i λ i during S i , and q ( S i +1 ) i λ i during V i +1 . This observation makes it possible to analyse the polling system with reneging by regarding a dual system, without reneging but with varying arrival rates. For the remainder of this section, we consider this dual system. A system with arrival rates that depend on the location of the server, is studied in [5], where it is referred to as a
polling system with smart customers. We apply their results and adopt their notation. Let λ ( P ) i denote the arrival intensity of type i customers during period P ∈ { V , S 1 1 , . . . , V N , S N } . In order to create a similar system as the original polling system with reneging, we define these arrival intensities in the following way:
$$\text{these arrival intensities in the following way:} \\ \lambda _ { i } ^ { ( S _ { i - 1 } ) } & = \lambda _ { i } q _ { i } ^ { ( V _ { i } ) }, \\ \lambda _ { i } ^ { ( V _ { i - 1 } ) } & = \lambda _ { i } q _ { i } ^ { ( S _ { i - 1 } ) } q _ { i } ^ { ( V _ { i } ) }, \\ \lambda _ { i } ^ { ( S _ { i - 2 } ) } & = \lambda _ { i } q _ { i } ^ { ( V _ { i - 1 } ) } q _ { i } ^ { ( S _ { i - 1 } ) } q _ { i } ^ { ( V _ { i } ) }, \\ & \quad \vdots & & & & ( 3. 5 ) \\ \lambda _ { i } ^ { ( S _ { i - N } ) } & = \lambda _ { i } q _ { i } ^ { ( V _ { i } ) } \prod _ { j = 1 } ^ { N - 1 } q _ { i } ^ { ( V _ { i - j } ) } q _ { i } ^ { ( S _ { i - j } ) }, \\ \lambda _ { i } ^ { ( V _ { i - N } ) } & = \begin{cases} \lambda _ { i } \prod _ { j = 1 } ^ { N } q _ { i } ^ { ( V _ { i - j } ) } q _ { i } ^ { ( S _ { i - j } ) }, & \text{ if } Q _ { i } \text{ receives gated service,} \\ \lambda _ { i }, & & & & \text{ if } Q _ { i } \text{ receives exhaustive service.} \end{cases} \\ \text{The only difference for gated service, compared to exhaustive service, is that type } i \text{ customers}$$
The only difference for gated service, compared to exhaustive service, is that type i customers arriving during V i have to wait until the next visit period of type i customers before they are served. Thus, type i customers that arrive during V i , abandon the system before the start of S i with probability p ( S i ) i , whereas for exhaustive service all of these customers would be served during the visit period in which they arrive.
## Cycle time
The cycle time distribution of this dual system is the same as in the original system with reneging. Theorem 5 1 from [5], applied to the dual system with arrival intensities as defined . in (3.5), gives the LSTs of distributions of the cycle time C 1 and the intervisit time I 1 :
$$\mathbb { E } \left [ e ^ { - \omega C _ { 1 } } \right ] & = \widetilde { L B } ^ { ( V _ { 1 b } ) } \left ( \theta _ { 1 } ( \psi ^ { ( V _ { 1 } ) } ( \omega ) ), \dots, \theta _ { N } ( \psi ^ { ( V _ { N } ) } ( \omega ) ) \right ) \prod _ { i = 1 } ^ { N } \sigma _ { i } \left ( \psi ^ { ( S _ { i } ) } ( \omega ) \right ), \\ \mathbb { E } \left [ e ^ { - \omega I _ { 1 } } \right ] & = \widetilde { L B } ^ { ( S _ { 1 b } ) } \left ( 1, \theta _ { 2 } ( \psi ^ { ( V _ { 2 } ) } ( \omega ) ), \dots, \theta _ { N } ( \psi ^ { ( V _ { N } ) } ( \omega ) ) \right ) \prod _ { i = 1 } ^ { N } \sigma _ { i } \left ( \psi ^ { ( S _ { i } ) } ( \omega ) \right ), \\ & \quad \text{--}.$$
where the functions ψ ( P ) ( ω ) are defined in the following, recursive way:
$$\text{where} \, \text{$\psi^{\prime}\nu$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$ } \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \ \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \ text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{ $\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\ varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi`} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$} \, \text{$\varphi$}$$
$$k = i + 1$$
Remark 3.1 Specifically for exhaustive and gated service, more compact expressions for the LSTs of the cycle time and intervisit time distributions are found in Theorem 5 2 in [5]. . These expressions follow from an analysis based on subtypes of customers, where arrivals during the different periods within a cycle mark the customer subtypes. E.g., a type i ( V j ) customer is a type i customer that arrives during V j . Using the analysis based on customer subtypes, we can express the LSTs of the cycle time and intervisit time in terms of the PGF of the joint queue length distribution at polling instants of all customer subtypes, which we denote here as ˜ LB ( V i ) ( z ( V 1 ) 1 , . . . , z ( S N ) 1 , . . . , z ( V 1 ) N , . . . , z ( S N ) N ) . We do not repeat the complete analysis on how to obtain this PGF, but instead refer to Section 5 of [5].
For exhaustive service, the LSTs of the distributions of C ∗ i and I i are:
$$\mathbb { E } [ \mathrm e ^ { - \omega C _ { i } ^ { \ast } } ] = \widetilde { L B } ^ { ( V _ { i } ) } ( 1, \dots, 1, \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, \pi _ { i } ( \omega ) - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ), \quad \ ( 3. 6 )$$
$$\mathbb { E } [ e ^ { - \omega I _ { i } } ] = \widetilde { L } B ^ { ( V _ { i } ) } ( 1, \dots, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ).$$
If Q i receives gated service , the LST of the cycle time distribution C i , and the LST of the intervisit time distribution I i , are given by:
$$\Phi \left [ e ^ { - \omega C _ { i } } \right ] & = \widetilde { L } B ^ { ( V _ { i } ) } ( 1, \dots, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( V _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ), \\ \mathbb { E } \left [ e ^ { - \omega I _ { i } } \right ] & = \widetilde { L } B ^ { ( V _ { i } ) } ( 1, \dots, 1, 1, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { 1 } ) } }, \dots, 1 - \frac { \omega } { \lambda _ { i } ^ { ( S _ { N } ) } }, 1, \dots, 1 ).$$
$$\cdot$$
## Visit time
The LSTs of the distributions of the visit times V , i i = 1 , . . . , N , can directly be determined for any branching-type service discipline using the function θ i ( ), · and the joint queue length distribution (without subtypes) at the beginning of subperiod V ib :
$$\mathbb { E } [ \mathrm e ^ { - \omega V _ { i } } ] = \widetilde { L B } ^ { ( V _ { i b } ) } ( 1, \dots, 1, \theta _ { i } ( \omega ), 1, \dots, 1 ).$$
The mean cycle time E [ C ] and mean visit times E [ V i ], which are needed later in this paper, can be obtained by differentiating the corresponding LSTs. A numerically more efficient way to compute them, is using MVA for polling systems with smart customers, which is described in more detail in [5].
## Waiting time
The waiting time of customers in the dual system also has the same distribution as the time that customers in the original system have to wait before being taken into service (not taking the impatient customers into account). Note that the marginal queue length distribution at departure epochs of customers that did not renege, is not the same as the marginal queue length distribution at arbitrary epochs , because the arrival intensities change during the cycle. This implies that we cannot use PASTA, and the standard distributional form of Little's law, as discussed by, e.g., Keilson and Servi [16], cannot be used to obtain the waiting time
distribution from the queue length distribution. What we can use though, is a slightly generalised version of the distributional form of Little's law, that can be applied to the joint queue length distribution at departure epochs, as discussed in the proof of Theorem 4 3 in [5]. . We mention the result here, but refer to [5], Section 4, for details on how to obtain the PGF of the joint queue length distributions of all type i customer subtypes at a departure epoch from
$$\begin{array} { l l$$
The LST of the distribution of the waiting time W i of a type i customer, i = 1 , . . . , N , is:
$$\mathbb { E } \left [ e ^ { - \omega W _ { i } } \$$
In the next section we study the queue lengths of all customers that enter the system, including those that renege before the start of their service.
## Stability condition
The stability condition of a polling model with reneging at polling instants, is the same as in the model with smart customers, discussed in the present section. It is clear that customers leaving the system without being served, do not contribute to the workload of the server. The stability condition of a model with smart customers is discussed in [5, 9]. In [9] it is shown that a necessary and sufficient condition for ergodicity is that the Perron-Frobenius eigenvalue of the matrix R -I N should be less than 0, where I N is the N × N identity matrix, and R is an N × N matrix containing elements ρ ij := λ ( V j ) i E [ B i ].
## Proportion of customers served
In queueing models with reneging, the expected proportion of customers that do not abandon the system prematurely, denoted by r , is an important quality measure of the system. In some systems, this might be difficult to compute. In the model considered in the present paper, this quantity is relatively easily obtained. The probability that an arbitrary customer is of type i , is obviously λ / i Λ, where Λ = ∑ N j =1 λ j . The fraction of customers arriving during period P ∈ { V , S 1 1 , . . . , V N , S N } is E [ P / ] E [ C ]. Conditioning on the type of an arbitrary arriving customer, and the location of the server upon his arrival, one can determine the probability that he will not abandon the system prematurely similarly to determining the arrival intensities (3.5). Denote by r i the probability that an arbitrary type i customer is eventually served. Then it is easily seen that
$$\Phi _ { i } & = \sum _ { j = 1 } ^ { N } \left$$
## 4 Queue length distributions
In the previous section, we divided each visit period and switch-over period into two subperiods, part a where impatient customers decide to abandon the system, and part b , where the server is actually serving (or switching in the case of a switch-over period). The PGFs of the joint queue length distributions at the beginnings of all these subperiods are given implicitly by (3.1)-(3.4). In the present section we show how the marginal queue length distribution at an arbitrary epoch can be expressed in terms of these PGFs. We denote the marginal queue length of a type i customer by L i , i = 1 , . . . , N . The PGF of the distribution of L i is determined by conditioning on the subperiod during which the queue is observed. The number of type i customers at an arbitrary moment in subperiod P ∈ { V 1 a , V 1 b , S 1 a , S 1 b , . . . , V Na , V Nb , S Na , S Nb } is denoted by L ( P ) i . By conditioning on P , we have
$$\Re [ z ^ { L _ { i } } ] = \sum _ { j = 1 } ^$$
where we used that E [ V ja ] = E [ S ja ] = 0, E [ V jb ] = E [ V j ], and E [ S jb ] = E [ S j glyph[negationslash]
]. i i
Since S , j j = 1 , . . . , N and V , j j = , are i non-serving intervals for customers of type i , we use a standard result (see, e.g., [6]) to find the PGFs of L ( V jb ) and L ( S jb ) respectively:
glyph[negationslash]
$$\mathbb { E } \left [ z ^ { L _ { i } ^ { ( V _ {$$
$$\mathbb { E } \left [ z ^ { L _ { i } ^ { ( S _ { j b } ) } } \right ] = \frac { \overset { \cdot } { \mathbb { E } } \left [ z ^ { L B _ { i } ^ { ( S _ { j b } ) } } \right ] - \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { ( j + 1 ) a } ) } } \right ] ^ { \cdot } } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { ( j + 1 ) a } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { j b } ) } ] \right ) }, \quad \ \ i, j = 1, \dots, N,$$
$$\mathbb { E } \left [ z ^ { L _ { i } ^ { ( V _ { j b } ) } } \right ] & = \frac { \mathbb { E } \left [ z ^ { \cdot \cdot \cdot } \right ] ^ { z } \right ] ^ { z } \right ] ^ { z } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( S _ { j a } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( V _ { j b } ) } ] \right ) }, & i = 1, \dots, N ; j \neq i, \quad ( 4. 2 ) \\ \mathbb { E } \left [ z ^ { L _ { i } ^ { ( S _ { j b } ) } } \right ] & = \frac { \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( S _ { j b } ) } } \right ] - \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { j + 1 } ) a } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { ( j + 1 ) a } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { j b } ) } ] \right ) }, & i, j = 1, \dots, N,$$
where LB ( V jb ) i and LB ( S ja ) i are the number of type i customers at respectively a visit beginning and completion at Q j . Their PGFs are given by ˜ LB ( V jb ) (1 , . . . , 1 , z, 1 , . . . , 1) and ˜ LB ( S ja ) (1 , . . . , 1 , z, 1 , . . . , 1), where z is the element at position i . Differentiation of these PGFs and substituting z = 1 gives the mean values. Similarly, LB ( S jb ) i and LB ( V ( j +1) a ) i are the number of type i customers at respectively the beginning and ending of S j .
It remains to compute E [ z L ( V i ) i ] , i = 1 , . . . , N , i.e. the PGF of the number of type i customers at an arbitrary epoch within V i . In order to do this, we temporarily look at a polling system without reneging, and focus on type i customers. As far as the marginal queue length of type i customers is concerned, the system can be viewed as a vacation queue where the intervisit time I i corresponds to the server vacation. In this 'ordinary' polling model, we can use the Fuhrmann-Cooper decomposition [13], which states that
$$\mathbb { E } [ z ^ { L _ { i } } ] = \frac { ( 1 - \lambda _ { i } \mathbb { E } [ B _ { i } ] ) ( 1 - z ) \beta _ { i } \left ( \lambda _ { i } ( 1 - z ) \right ) } { \beta _ { i } \left ( \lambda _ { i } ( 1 - z ) \right ) - z } \times \frac { \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( S _ { i } ) } } \right ] - \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { i } ) } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { i } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { i } ) } ] \right ) }, \quad ( 4. 4 )$$
where LB ( V i ) i and LB ( S i ) i denote the number of type i customers at respectively the beginning and completion of V i . The first part in this decomposition is the PGF of the marginal queue
length of an M/G/ 1 queue with type i customers only. The second part, which is independent of the first, is the PGF of the number of type i customers at an arbitrary epoch during the intervisit time I i , which we denote by E [ z L ( I i ) i ]. Now we focus on the visit and intervisit time of Q i separately, using the relation E [ z L i ] = E [ V i ] E [ C ] E [ z L ( V i ) i ] + E [ I i ] E [ C ] E [ z L ( I i ) i ]. Plugging this relation into (4.4), leads to:
$$\mathbb { E } [ z ^ { L _ { i } ^ { ( V _ { i } ) } } ] = \frac { 1 - \lambda _ { i } \mathbb { E } [ B _ { i } ] } { \lambda _ { i } \mathbb { E } [ B _ { i } ] } \frac { z \left ( 1 - \beta _ { i } ( \lambda _ { i } ( 1 - z ) ) \right ) } { \beta _ { i } ( \lambda _ { i } ( 1 - z ) ) - z } \times \frac { \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( S _ { i } ) } } \right ] - \mathbb { E } \left [ z ^ { L B _ { i } ^ { ( V _ { i } ) } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { i } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { i } ) } ] \right ) }.$$
The second part of this decomposition is, again, the PGF of the number of customers at an arbitrary moment during the intervisit time I i . The first part can be recognised as the PGF of the queue length of an M/G/ 1 queue with type i customers only, at an arbitrary epoch during a busy period.
Now we return to the model with synchronised reneging. The key observation is that during a visit period , this system behaves exactly as a polling system without reneging. Equation (4.5) no longer depends on anything that happens during the intervisit time, because this is all captured in LB ( V i ) i , the number of type i customers at the beginning of a visit to Q i . This implies that (4.5) also holds for the system considered in the present paper. The only difference is that the interpretation of (4.5) is different. Obviously, the first part in (4.5) still is the PGF of the queue length of an M/G/ 1 queue at an arbitrary epoch during a busy period. However, the last term can no longer be interpreted as the PGF of the distribution of the number of type i customers at an arbitrary moment during the intervisit time I i . For this reason, the Fuhrmann-Cooper decomposition does not hold in a polling model with synchronised reneging. The condition that has to be satisfied for the Fuhrmann-Cooper decomposition, is:
glyph[negationslash]
$$\sum _ { j \neq i } \left ( \frac { \mathbb { E } [ V _ { j } ] } { \mathbb { E } [ C ] } \mathbb { E } \left [ z _ { i } ^ { ( V _ { j } b ) } \right ] \right ) + \sum _ { j = 1 } ^ { N } \left ( \frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ C ] } \mathbb { E } \left [ z _ { i } ^ { ( S _ { j } b ) } \right ] \right ) = \frac { \mathbb { E } [ I _ { i } ] } { \mathbb { E } [ C ] } \frac { \mathbb { E } \left [ z _ { i } ^ { L B _ { i } ^ { ( S _ { i } ) } } \right ] - \mathbb { E } \left [ z _ { i } ^ { L B _ { i } ^ { ( V _ { i } ) } } \right ] } { ( 1 - z ) \left ( \mathbb { E } [ L B _ { i } ^ { ( V _ { i } ) } ] - \mathbb { E } [ L B _ { i } ^ { ( S _ { i } ) } ] \right ) }, \\. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
the left-hand side of (4.6) being E [ I i ] E [ C ] E [ z L ( I i ) i ]. However, substitution of (4.2) and (4.3) in (4.6), and using (3.5), shows that (4.6) is only true if q ( P ) i = 1 for all P ∈ { V , S 1 1 , . . . , V N , S N } , because only in that case all terms in the numerator, except for E [ z LB ( S i ) i ] and E [ z LB ( V i ) i ] cancel out.
Substitution of (4.2), (4.3), and (4.5) in (4.1) gives the desired expression for the PGF of the marginal queue length in Q i .
## Additional remarks
The marginal queue length distribution at an arbitrary epoch is given by (4.1). It is noteworthy that, unlike in Section 3, we can use PASTA now because we focus on all customers - including the impatient ones. This implies that the marginal queue length distribution at arrival and departure epochs of type i customers is also given by (4.1). It should be noted that, when studying the queue length at departure epochs, we assume that reneging customers leave the
system in order of arrival, even though several of them might leave at the same reneging epoch. When looking at it this way, we do not really have group departures, but consecutive departures that might take place during an interval of zero length. Determining the LST of the sojourn time distribution of type i customers, including those that abandon the system before being served, remains difficult. One cannot use the distributional form of Little's law, because there are multiple occasions within a cycle during which a type i customer might leave the system. In the present paper we do not show exactly how to compute the sojourn time distribution of an arbitrary customer, because it requires a lot of bookkeeping. For each customer type, one needs to keep track of when a customer entered the system, and at which point he is going to leave the system. There are N customer types, entering the system during 2 N subperiods, and leaving the system at 2 N + 1 occasions (2 N reneging moments plus one visit period). This gives a maximum of 2(2 N +1) N 2 customer subtypes, although it is determined by the service disciplines in the different queues, which of these subtypes are actually needed. For all customer subtypes, the joint queue lengths at departure moments have to be determined in order to find the sojourn time distributions. We only show how this is done for a vacation model, in Section 5. Although not applicable in its distributional form, Little's law can still be used to determine the mean sojourn time of a type i customer, T i , for i = 1 , . . . , N :
$$\mathbb { E } [ T _ { i } ] = \mathbb { E } [ L _ { i } ] / \lambda _ { i }.$$
## 5 Vacation system with exhaustive service
This section discusses the special case N = 1 and exhaustive service in more detail. The results obtained in the previous sections reduce to nice, compact expressions. When N = 1, there is only one queue being served, and the switch-over time between successive visits is called a server vacation . This model is studied in Adan et al. [1], where it is referred to as the Unique Abandonment Epoch (UAE) model. In [1] only the queue length PGF is determined. The methods used in the present paper also make it possible to find the LSTs of the cycle time and the waiting time distribution. Although it is not discussed explicitly in this section, of course it is also possible to analyse the vacation system with gated service.
We use the same notation as in the rest of the paper, which is slightly different from common notation in vacation models. Since there is only one queue, the indices i = 1 , . . . , N , are dropped. A vacation is the switch-over period S with LST σ ( ), · whereas V denotes the visit period. The analysis in the present section is a slightly more extended version of the one in the previous sections, because we aim at finding the sojourn time of an arbitrary customer, including those that renege, as well. This requires distinguishing not only between moments at which customers abandon the system, but also between their arrival (sub)periods. Therefore, the cycle is divided into four subperiods: V , V a ( S ) b , V ( V ) b and S . During V a the impatient customers abandon the system. All of these customers have arrived during S . The remaining customers, that have also arrived during S , are served during V ( S ) b . During V ( V ) b , all customers that have entered the system during V ( S ) b , and newly arriving customers, are served until the system is empty. Since the system is empty at the beginning of S , we do not split S into subperiods, and we use the notation p for the probability that a customer abandons the system before being served, and q = 1 -p . The astute reader has noticed that we distinguish between three customer types. Type a customers are those that abandon the system during V a , type
b ( S ) customers are those that enter during the vacation S without abandoning the system, type b ( V ) customers enter during the visit period and are always served. The advantage of considering both the arrival epoch and the departure epoch of each customer type, is that it enables us to combine the techniques from Sections 3 and 4. The PGFs of the joint queue length distributions, at the start of the four subperiods, follow from (3.1)-(3.4), and the LST of the cycle time C ∗ follows from (3.6). In this vacation model, it reduces to:
$$\gamma ^ { * } ( \omega ) = \widetilde { L B } ^ { ( V _ { b } ^ { ( S ) } ) } ( 1, \pi ( \omega ) - \frac { \omega } { q \lambda }, 1 ) = \sigma ( \omega + q \lambda ( 1 - \pi ( \omega ) ) ).$$
The mean cycle time and the mean visit time are:
$$\mathbb { E } [ C ] & = \frac { 1 - p \rho } { 1 - \rho } \mathbb { E } [ S ], & \mathbb { E } [ V ] & = \frac { q \rho } { 1 - \rho } \mathbb { E } [ S ],$$
where ρ = λ E [ B ]. In [1], the PGF of the marginal queue length distribution is obtained using similar techniques as in Section 4. In this section we use a different approach, based on the joint queue length distribution at departure epochs. This approach is similar to the one used in Section 3, but now including the customers that renege from the system. We follow the steps taken by Borst [6], who extends an idea of Eisenberg [11], to find the PGF of the joint distribution of the queue lengths and state of the server at departure epochs, M ( P ) ( z , z a ( S ) b , z ( V ) b ). The state of the server is identified by the subperiod P , which can be any of the three periods during which customers depart from the system, V , V a ( S ) b and V ( V ) b .
$$\text{any of the three periods during which customers depart from the system, V} _ { a }, V _ { b } ^ { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \\ M ^ { ( V _ { a } ) } ( z _ { a }, z _ { b } ^ { ( S ) }, z _ { b } ^ { ( V ) } ) = & \frac { 1 } { \Lambda \mathbb { E } [ C ] } \frac { 1 } { z _ { a } - 1 } \left ( \widetilde { L B } ^ { ( V _ { a } ) } ( z _ { a }, z _ { b } ^ { ( S ) }, z _ { b } ^ { ( V ) } ) - \widetilde { L B } ^ { ( V _ { b } ^ { ( S ) } ) } ( z _ { a }, z _ { b } ^ { ( S ) }, z _ { b } ^ { ( V ) } ) \right ), \\ M ^ { ( V _ { b } ^ { ( S ) } ) } ( z _ { a }, z _ { b } ^ { ( S ) }, z _ { b } ^ { ( V ) } ) = & \frac { 1 } { \Lambda \mathbb { E } [ C ] } \frac { \beta \left ( \lambda ( 1 - z _ { b } ^ { ( V ) } ) \right ) } { z _ { b } ^ { ( V ) } - \beta \left ( \lambda ( 1 - z _ { b } ^ { ( V ) } ) \right ) } \left ( \widetilde { L B } ^ { ( V _ { b } ^ { ( V ) } ) } ( z _ { a }, z _ { b } ^ { ( S ) }, z _ { b } ^ { ( V ) } ) \right ), \\ \text{The PGF of the joint queue length distribution at an arbitrary departure epoch is simply}$$
The PGF of the joint queue length distribution at an arbitrary departure epoch is simply the sum of these three PGFs. Using PASTA and an up-and-down crossing argument, we find that the marginal queue length distribution at an arbitrary moment is:
$$\mathbb { E } [ z ^ { L } ] = M ^ { ( V _ { a } ) } ( z, z, z ) + M ^ { ( V _ { b } ^ { ( S ) } ) } ( z, z, z ) + M ^ { ( V _ { b } ^ { ( V ) } ) } ( z, z, z ).$$
The sojourn time of an arbitrary customer in a polling model with synchronised reneging has not been discussed in the present paper because of the effort it takes to keep track of all customers and their arrival and departure moments. For this vacation model, it is not too complicated though. It requires applying the generalised distributional form of Little's law, as discussed in [5], to the joint queue length distribution at departure epochs. This leads to
the following LST of the distribution of the sojourn time T of an arbitrary customer:
$$\intertext { n o w o n v e n t o n o f t o n e s o j o u r m e i o f o n a n a r o u r y c u s t o m e r $ } \mathbb { E } [ e ^ { - \omega T } ] & = M ^ { ( \nu _ { \omega } ) } ( 1 - \frac { \omega } { p \lambda }, 1, 1 ) + M ^ { ( \nu _ { b } ^ { ( S ) } ) } ( 1, 1 - \frac { \omega } { q \lambda }, 1 - \frac { \omega } { \lambda } ) + M ^ { ( \nu _ { b } ^ { ( V ) } ) } ( 1, 1 - \frac { \omega } { q \lambda }, 1 - \frac { \omega } { \lambda } ) \\ & = \frac { p ( 1 - \rho ) } { 1 - p \rho } \frac { 1 - \sigma ( \omega ) } { \omega \mathbb { E } [ S ] } + \frac { q ( 1 - \rho ) } { 1 - p \rho } \frac { \sigma ( \omega ) - \sigma ( q \lambda ( 1 - \beta ( \omega ) ) ) } { ( q \lambda ( 1 - \beta ( \omega ) ) - \omega ) \mathbb { E } [ S ] } \beta ( \omega ) \\ & \quad + \frac { 1 - \rho } { 1 - p \rho } \frac { \sigma ( q \lambda ( 1 - \beta ( \omega ) ) ) - 1 } { ( \lambda ( 1 - \beta ( \omega ) ) - \omega ) \mathbb { E } [ S ] } \beta ( \omega ).$$
The waiting time of customers that did not renege the system, is obtained in the same way, but without taking into account the type a customers:
$$\mathbb { E } [ e ^ { - \omega W _ { b } } ] = \frac { \lambda \mathbb { E } [ C ] } { q \lambda \mathbb { E } [ S ] + \lambda \mathbb { E } [ V ] } \left ( M ^ { ( V _ { b } ^ { ( s ) } ) } ( 1, 1 - \frac { \omega } { q \lambda }, 1 - \frac { \omega } { \lambda } ) + M ^ { ( V _ { b } ^ { ( V ) } ) } ( 1, 1 - \frac { \omega } { q \lambda }, 1 - \frac { \omega } { \lambda } ) \right ) \frac { 1 } { \beta ( \omega ) }.$$
## 6 Numerical example
In this section we study the impact of the reneging probabilities on the mean queue lengths in a two-queue polling system. The service times of all customers, in both queues, are exponentially distributed with mean 1. The arrival processes are Poisson with rates 1 10 for Q 1 and 7 10 for Q 2 . We deliberately choose an imbalanced system to study differences between a heavily and a lightly loaded queue. The switch-over times are also exponentially distributed. We compare a system with small switch-over times, E [ S i ] = 1, with a system having larger switch-over times, E [ S i ] = 10. Finally, two different combinations of reneging probabilities are taken:
$$\text{Case } 1 \colon \quad \ p _ { i } ^ { ( V _ { j } ) } = p _ { i } ^ { ( S _ { j } ) } = p _ { i },$$
$$\text{Case 2} \colon \quad \ p _ { i } ^ { ( S _ { i } ) } = \frac { 8 } { 1 0 } p _ { i }, p _ { i } ^ { ( V _ { i + 1 } ) } = \frac { 6 } { 1 0 } p _ { i }, p _ { i } ^ { ( S _ { i + 1 } ) } = \frac { 4 } { 1 0 } p _ { i }, p _ { i } ^ { ( V _ { i } ) } = \frac { 2 } { 1 0 } p _ { i },$$
for i, j = 1 2. , In Case 1, the reneging probabilities per customer type are the same for all reneging moments. In Case 2, which might be considered as more realistic, the probabilities of reneging decrease as the moment of being served comes nearer. The parameters p i are varied, independently for i = 1 2, , between 0 and 1. Furthermore, we study all possible combinations of gated and exhaustive service for each queue. The results are depicted in Figures 1 - 4, where the mean queue lengths E [ L 1 ] and E [ L 2 ] are plotted against p 1 and p 2 . As expected, Q 2 dominates the behaviour of the system, because of its heavy load compared to Q 1 . For this reason, results are omitted for Q 1 receiving exhaustive service, because they hardly deviate from the results where Q 1 receives gated service. A conclusion that can be drawn from a comparison between Figures 2 and 4, is that the lengths of the switch-over times hardly influence the impact of p 1 and p 2 on the mean queue lengths if the reneging probabilities are decreasing as in Case 2. For constant reneging probabilities, as in Case 1, the behaviour of the mean queue lengths changes when the mean switch-over times become larger. The non-monotonic behaviour that was noted in one of the examples studied in [1], is also visible in Figure 3. If switch-over times are relatively large, higher values of p 2 may result in an increase in the mean number of customers in Q 2 , but also in Q 1 if Q 2 receives
gated service. Furthermore, it is interesting to observe in Figures 2 and 4 that in Case 2, both p 1 and p 2 have a high impact on E [ L 1 ] and E [ L 2 ]. In contrast, for Case 1, the influence of p 1 and p 2 varies per queue. E.g., Figures 1 and 3 illustrate that E [ L 2 ] is mainly influenced by p 2 , whereas E [ L 1 ] is influenced by both parameters.
Figure 1: Mean queue lengths in the polling system in Case 1 of Example 2, versus p 1 and p 2 . The reneging probabilities are constant, E [ S i ] = 1.
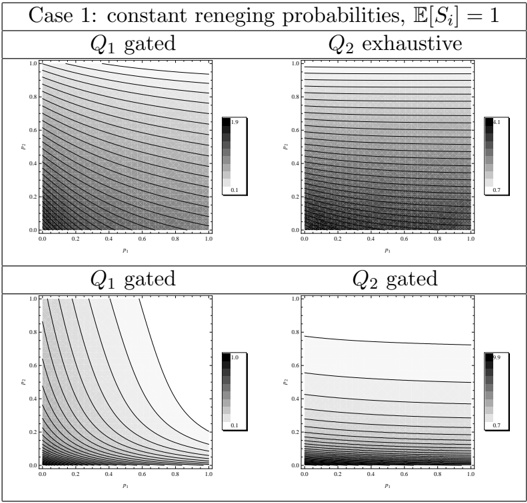
## 7 Conclusions and topics for future research
In the present section we summarise our findings and conclusions, and discuss possible future extensions of the model under consideration. We have extended some results on a vacation model with synchronised reneging, as presented in [1], to a polling system consisting of multiple queues. Using techniques from a polling model with varying arrival rates, depending on the server location (cf. [5]) we have been able to find the LST of the cycle time distribution, visit and intervisit time distributions, and of the waiting time distribution of customers that get served eventually. An adaptation of these techniques leads to the PGF of the marginal queue length distribution of all customers in each queue. It also leads to the sojourn time distribution, but this requires lengthy, cumbersome computations that have only been discussed for a system consisting of one queue.
When comparing the model of the present paper with existing literature, one of the most striking differences is the non-monotonic behaviour of the mean queue lengths that might occur in polling (or vacation) models. As illustrated in the numerical example, the presence of large switch-over times might cause the mean queue lengths to increase if reneging probabilities increase. Another notable difference is that it is relatively easy to compute the
Figure 2: Mean queue lengths in the polling system in Case 2 of Example 2, versus p 1 and p 2 . The reneging probabilities are decreasing, E [ S i ] = 1.
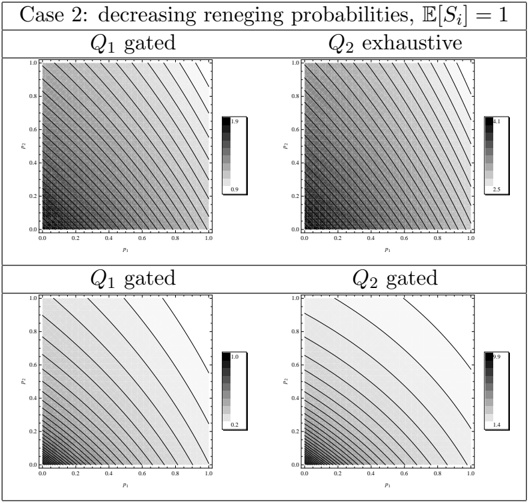
Figure 3: Mean queue lengths in the polling system in Case 1 of Example 2, versus p 1 and p 2 . The reneging probabilities are constant, E [ S i ] = 10.
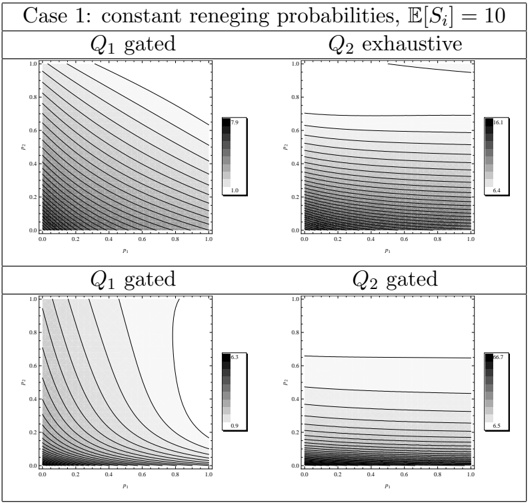
Figure 4: Mean queue lengths in the polling system in Case 2 of Example 2, versus p 1 and p 2 . The reneging probabilities are decreasing, E [ S i ] = 10.
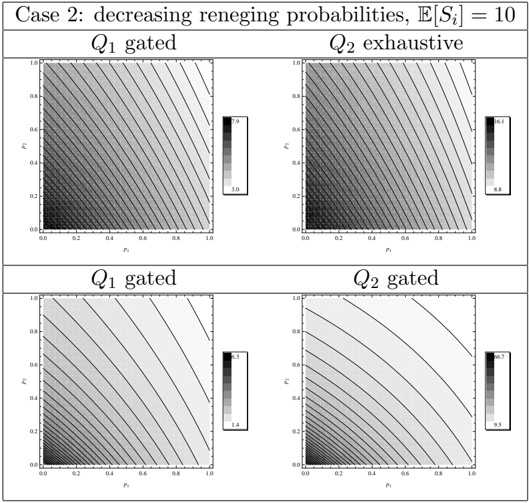
proportion of customers served. This metric is a relevant quantity in reneging literature. In our model, given the customer type and server location upon his arrival, one knows exactly how many possibilities this customer will have to abandon the system, and the corresponding reneging probabilities.
Several research topics, beyond the scope of the present paper, are worth studying. An interesting extension is to allow (synchronised) reneging at various epochs during switch-over and visit periods. Possibly, the analysis of the Multiple Abandonment Epochs (MAE) model in [1] (synchronised reneging), and the analysis of Altman and Yechiali [2] (customers growing impatient during vacations) might be extended to polling models. Another extension, relevant from a practical point of view, is to develop numerically more efficient algorithms to compute performance measures of interest. In the present paper, we use the buffer occupancy method, but it would be more efficient to extend the Mean Value Analysis (MVA) framework for polling systems (cf. [27]) to a polling model with reneging at polling instants. In [1], as well as in [5], MVA has been used to find the mean queue lengths. These two implementations should give a good indication of how to implement MVA for the model discussed in the present paper. Note that difficulties in finding the sojourn time distribution do not occur when studying the mean sojourn time, which can simply be found using Little's law.
## Acknowledgements
The author wishes to thank Ivo Adan and Onno Boxma for their valuable comments on earlier drafts of the present paper.
## References
- [1] I. J. B. F. Adan, A. Economou, and S. Kapodistria. Synchronized reneging in queueing systems with vacations. Queueing Systems , 62:1-33, 2009.
- [2] E. Altman and U. Yechiali. Analysis of customers' impatience in queues with server vacations. Queueing Systems , 52(4):261-279, 2006.
- [3] D. Assaf and M. Haviv. Reneging from processor sharing systems and random queues. Mathematics of Operations Research , 15(1):129-138, 1990.
- [4] F. Baccelli and G. Hebuterne. On queues with impatient customers. In F. Kylstra, editor, Performance '81 , pages 159-179. North-Holland, Amsterdam, 1981.
- [5] M. A. A. Boon, A. C. C. van Wijk, I. J. B. F. Adan, and O. J. Boxma. A polling model with smart customers. Eurandom report 2009-038, Eurandom , 2009.
- [6] S. C. Borst. Polling Systems , volume 115 of CWI Tracts . 1996.
- [7] O. J. Boxma. Polling systems. In From universal morphisms to megabytes: A Baayen space odyssey. Liber amicorum for P.C. Baayen , pages 215-230. CWI, Amsterdam, 1994.
- [8] O. J. Boxma and P. R. de Waal. Multiserver queues with impatient customers. In J. Labetoulle and J. W. Roberts, editors, The Fundamental Role of Teletraffic in the Evolution of Telecommunications Networks , Proceedings 14th International Teletraffic Congress (ITC 14) Antibes Juan-les-Pins, France, June 6-10, 1994, pages 743-756. Elsevier, Amsterdam, 1994.
- [9] O. J. Boxma, J. Ivanovs, K. Kosi´ski, and M. Mandjes. L´vy-driven polling systems and n e continuous-state branching processes. Eurandom report 2009-026, Eurandom , 2009.
- [10] J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982.
- [11] M. Eisenberg. Queues with periodic service and changeover time. Operations Research , 20(2):440-451, 1972.
- [12] S. W. Fuhrmann. Performance analysis of a class of cyclic schedules. Technical memorandum 81-59531-1, Bell Laboratories, March 1981.
- [13] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
- [14] H. C. Gromoll, P. Robert, A. P. Zwart, and R. F. Bakker. The impact of reneging in processor sharing queues. ACM SIGMETRICS Performance Evaluation Review , 34(1): 87-96, 2006.
- [15] S. E. Haugen, R. B. Queueing systems with stochastic time out. IEEE Transactions on Communications , 28(12):1984-1989, 1980.
- [16] J. Keilson and L. D. Servi. The distributional form of Little's Law and the FuhrmannCooper decomposition. Operations Research Letters , 9(4):239-247, 1990.
- [17] G. Koole and A. Mandelbaum. Queueing models of call centers: An introduction. Annals of Operations Research , 113:41-59, 2002.
- [18] H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990.
- [19] K. C. Madan. On a vacation queue with instantaneous customer loss. Microelectronics and Reliability , 36(2):179-188, 1996.
- [20] A. Mandelbaum and S. Zeltyn. The impact of customers patience on delay and abandonment: some empirically-driven experiments with the M/M/n + G queue. OR Spectrum , 26:377-411, 2004.
- [21] C. Palm. Methods of judging the annoyance caused by congestion. Tele. , 4:189-208, 1953.
- [22] J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409 - 426, 1993.
- [23] J. Riordan. Stochastic service systems . Wiley, New York, 1962.
- [24] H. Takagi. Queuing analysis of polling models. ACM Computing Surveys (CSUR) , 20: 5-28, 1988.
- [25] V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006.
- [26] V. M. Vishnevsky and O. V. Semenova. The power-series algorithm for two-queue polling system with impatient customers. In International Conference on Telecommunications 2008 (ICT 2008) , pages 1-3, 2008.
- [27] E. M. M. Winands, I. J. B. F. Adan, and G.-J. van Houtum. Mean value analysis for polling systems. Queueing Systems , 54:35-44, 2006.
- [28] S. Zeltyn and A. Mandelbaum. Call centers with impatient customers: Many-server asymptotics of the M/M/n + G queue. Queueing Systems , 51:361-402, 2005.
- [29] Y. Zhang, D. Yue, and W. Yue. Analysis of an M/M/ /N 1 queue with balking, reneging and server vacations. Proc. of the 5th International Symposium on Operations Research and its Applications (ISORA'05) , pages 37-47, 2005. | 10.1007/s10479-010-0758-2 | [
"Marko Boon"
] | 2014-08-01T11:16:27+00:00 | 2014-08-01T11:16:27+00:00 | [
"math.PR",
"cs.PF"
] | A Polling Model with Reneging at Polling Instants | In this paper we consider a single-server, cyclic polling system with
switch-over times and Poisson arrivals. The service disciplines that are
discussed, are exhaustive and gated service. The novel contribution of the
present paper is that we consider the reneging of customers at polling
instants. In more detail, whenever the server starts or ends a visit to a
queue, some of the customers waiting in each queue leave the system before
having received service. The probability that a certain customer leaves the
queue, depends on the queue in which the customer is waiting, and on the
location of the server. We show that this system can be analysed by introducing
customer subtypes, depending on their arrival periods, and keeping track of the
moment when they abandon the system. In order to determine waiting time
distributions, we regard the system as a polling model with varying arrival
rates, and apply a generalised version of the distributional form of Little's
law. The marginal queue length distribution can be found by conditioning on the
state of the system (position of the server, and whether it is serving or
switching). |
1408.0133v3 | ## THE HOMOTOPY GROUPS OF THE ALGEBRAIC K -THEORY OF THE SPHERE SPECTRUM
ANDREW J. BLUMBERG AND MICHAEL A. MANDELL
Abstract. We calculate π K ∗ ( S ) ⊗ Z [1 / 2], the homotopy groups of K ( S ) away from 2, in terms of the homotopy groups of K ( Z ), the homotopy groups of C P ∞ -1 , and the homotopy groups of S . This builds on work of Waldhausen, who computed the rational homotopy groups (building on work of Quillen and Borel) and Rognes, who calculated the groups at odd regular primes in terms of the homotopy groups of C P ∞ -1 , and the homotopy groups of S .
## 1. Introduction
The algebraic K -theory of the sphere spectrum K ( S ) is Waldhausen's A ( ∗ ), the algebraic K -theory of the one-point space. The underlying infinite loop space of K ( S ) splits as a copy of the underlying infinite loop space of S and the smooth Whitehead space of a point Wh Diff ( ∗ ). For a highly-connected compact manifold M , the second loop space of Wh Diff ( ∗ ) approximates the stable concordance space of M , and the loop space of Wh Diff ( ∗ ) parametrizes stable h -cobordisms [32]. As a consequence, computation of the algebraic K -theory of the sphere spectrum is a fundamental problem in algebraic and differential topology.
Early efforts in this direction were carried out by Waldhausen in the 1980s using the 'linearization' map K ( S ) → K ( Z ) from the K -theory of the sphere spectrum to the K -theory of the integers. This is induced by the map of (highly structured) ring spectra S → Z . Waldhausen showed that because the map S → Z is an isomorphism on homotopy groups in degree zero (and below) and a rational equivalence on higher homotopy groups, the map K ( S ) → K ( Z ) is a rational equivalence. Borel's computation of the rational homotopy groups of K ( Z ) then applies to calculate the rational homotopy groups of K ( S ): π K q ( Z ) ⊗ Q is rank 1 when q = 0 or q = 4 k +1 for k > 1 and is zero for all other q .
In the 1990s, work of B¨kstedt, Carlsson, Cohen, Goodwillie, Hsiang, and Mado sen revolutionized the computation of algebraic K -theory with the introduction and study of topological cyclic homology TC , an analogue of negative cyclic homology that can be computed using the methods of equivariant stable homotopy theory. TC is the target of the cyclotomic trace , a natural transformation K → TC . For a
2010 Mathematics Subject Classification. Primary 19D10.
Key words and phrases. Algebraic K -theory of spaces, stable pseudo-isotopy theory, Whitehead space, cyclotomic trace.
This is substantially the same as the work with identical title and authors first published in Geometry & Topology 23(1) (2019), published by Mathematical Sciences Publishers.
© 2019 Mathematical Sciences Publishers.
map of highly structured ring spectra such as S → Z , naturality gives a diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
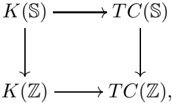
/d47
the linearization/cyclotomic trace square . A foundational theorem of Dundas [8] (building on work of McCarthy [21] and Goodwillie [11]) states that the square above becomes homotopy cartesian after p -completion, which means that the maps of homotopy fibers become weak equivalences after p -completion.
In the 2000s, Rognes [29] used the linearization/cyclotomic trace square to compute the homotopy groups of K ( S ) at odd regular primes in terms of the homotopy groups of S and the homotopy groups of C P ∞ -1 (assuming the now affirmed QuillenLichtenbaum conjecture). The answer is easiest to express in terms of the torsion subgroups: Because π K n ( S ) is finitely generated, it is the direct sum of a free part and a torsion part, the free part being Z when n = 0 or n ≡ 1 mod 4, n > 1, and 0 otherwise. The main theorem of Rognes [29] is that for p an odd regular prime the p -torsion of π K ∗ ( S ) is
$$\text{tor} _ { p } ( \pi _ { * } K ( \mathbb { S } ) ) \cong \text{tor} _ { p } ( \pi _ { * } \mathbb { S } \oplus \pi _ { * - 1 } c \oplus \pi _ { * - 1 } \overline { \mathbb { C } P } _ { - 1 } ^ { \infty } ).$$
(which can be made canonical, as discussed below). Here c denotes the additive p -complete cokernel of J spectrum (the connected cover of the homotopy fiber of the map S ∧ p → L K (1) S ); its homotopy groups are all torsion and are direct summands of π ∗ S . The spectrum C P ∞ -1 is a wedge summand of ( C P ∞ -1 ) ∧ p [19, (1.3)], [29, p.166], ( C P ∞ -1 ) ∧ p /similarequal C P ∞ -1 ∨ S ∧ p ; using unpublished work of Knapp, Rognes [29, 4.7] calculates the order of these torsion groups in degrees ≤ 2(2 p +1)( p -1) -4.
The description of tor p ( π K ∗ ( S )) above uses an identification of the homotopy type of TC ( S ) ∧ p as S ∧ p ∨ Σ C P ∞ -1 due to B¨kstedt-Hsiang-Madsen [4, 5.15,5.17]. Unforo tunately, there does not seem to be a canonical map realizing this weak equivalence, and so the isomorphism above is not canonical. We do have a canonical splitting TC ( S ) /similarequal S ∨ Cu where Cu is the homotopy cofiber of the unit map S → TC ( S ), or equivalently, the homotopy fiber of the map TC ( S ) → THH ( S ). As we discuss below, the splitting of the p -completion Cu ∧ p ,
$$C u _ { p } ^ { \wedge } \simeq \overline { C u } \vee \Sigma \mathbb { S } _ { p } ^ { \wedge }$$
corresponding to the splitting ( C P ∞ -1 ) ∧ p /similarequal C P ∞ -1 ∨ S ∧ p turns out to be canonical. Rognes' canonical identification of the p -torsion of π K ∗ ( S ) is then
$$\text{tor} _ { p } ( \pi _ { * } K ( \mathbb { S } ) ) \cong \text{tor} _ { p } ( \pi _ { * } \mathbb { S } \oplus \pi _ { * - 1 } c \oplus \pi _ { * } \overline { C u } ).$$
This paper computes π K ∗ ( S ) ∧ p in the case of irregular primes, thereby completing the computation of the homotopy groups of the algebraic K -theory of the sphere spectrum away from the prime 2. As a first step, we prove the following splitting theorem in Section 4.
Theorem 1.1. Let p be an odd prime. The long exact sequence on homotopy groups induced by the p -completed linearization/cyclotomic trace square breaks up into non-canonically split short exact sequences
$$0 \longrightarrow \pi _ { * } K ( \mathbb { S } ) _ { p } ^ { \wedge } \longrightarrow \pi _ { * } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \oplus \pi _ { * } K ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \pi _ { * } T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow 0.$$
Choosing appropriate splittings in the previous theorem, we can identify the p -torsion groups. The identification is again in terms of π ∗ S and π Cu ∗ (or noncanonically, π ∗ Σ C P ∞ -1 ) but now involves also π K ∗ ( Z ), which is not fully understood at irregular primes. In the statement, K red ( Z ) denotes the wedge summand of K ( Z ) ∧ p complementary to j [9, 2.1,9.7], K ( Z ) ∧ p /similarequal j ∨ K red ( Z ), where j is the p -complete additive image of J spectrum, the connective cover of L K (1) S . (As discussed below, this splitting is canonical.)
Theorem 1.2. Let p be an odd prime. The p -torsion in π K ∗ ( S ) admits canonical isomorphisms
$$( \mathbf a ) \quad \text{ tor} _ { p } ( \pi _ { * } K ( \mathbb { S } ) ) \cong \text{tor} _ { p } ( \pi _ { * } c \oplus \pi _ { * - 1 } c \oplus \pi _ { * } \overline { C u } \oplus \pi _ { * } K ( \mathbb { Z } ) )$$
$$\cong \text{tor} _ { p } ( \pi _ { * } \mathbb { S } \oplus \pi _ { * - 1 } c \oplus \pi _ { * } \overline { C u } \oplus \pi _ { * } K ^ { \text{red} } ( \mathbb { Z } ) ).$$
In Formula (a), the map tor ( p π K ∗ ( S )) → tor p ( π ∗ ( K ( Z ))) is induced by the linearization map and the map
$$\text{tor} _ { p } ( \pi _ { * } K ( \mathbb { S } ) ) \longrightarrow \text{tor} _ { p } ( \pi _ { * } c \oplus \pi _ { * - 1 } c \oplus \pi _ { * } \overline { C u } )$$
is induced by the composite of the cyclotomic trace map K ( S ) → TC ( S ) and a canonical splitting (2.3) of the homotopy groups π TC ∗ ( S ) ∧ p as
$$\pi _ { * } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \cong \pi _ { * } ( j ) \oplus \pi _ { * } ( c ) \oplus \pi _ { * } ( \Sigma j ) \oplus \pi _ { * } ( \Sigma c ) \oplus \pi _ { * } ( \overline { C u } )$$
explained in the first part of Section 2, followed by the projection onto the nonj summands.
In formula (b), the map tor p ( π K ∗ ( S )) → tor p ( π K ∗ red ( Z )) is induced by the linearization map and the canonical map π K ∗ ( Z ) → π K ∗ red ( Z ) which is the quotient by the image of the unit map π ∗ S → π K ∗ ( Z ). The map
$$\text{tor} _ { p } ( \pi _ { * } K ( \mathbb { S } ) ) \longrightarrow \text{tor} _ { p } ( \pi _ { * } \mathbb { S } \oplus \pi _ { * - 1 } c \oplus \pi _ { * } \overline { C u } )$$
is induced by the composite of the cyclotomic trace map K ( S ) → TC ( S ) and the canonical splitting of homotopy groups
$$\pi _ { * } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \cong \pi _ { * } ( \mathbb { S } _ { p } ^ { \wedge } ) \oplus \pi _ { * } ( \Sigma j ) \oplus \pi _ { * } ( \Sigma c ) \oplus \pi _ { * } ( \overline { C u } )$$
followed by projection away from the Σ j summand. (The splitting of π TC ∗ ( S ) ∧ p here is related to the splitting above by the canonical splitting on homotopy groups π ∗ S ∧ p ∼ = π ∗ ( j ) ⊕ π ∗ ( c ).)
Formula (b) generalizes the computation of Rognes [29] at odd regular primes because K red ( Z ) is torsion free if (and only if) p is regular (see for example [36, § VI.10]). Part of the argument for the theorems above involves making certain splittings in prior K -theory and TC computations canonical and canonically identifying certain maps (or at least their effect on homotopy groups). Although we construct the splittings and prove their essential uniqueness calculationally, we offer in Section 5 a theoretical explanation in terms of a conjectural extension of Adams operations on algebraic K -theory to an action of the p -adic units and a conjecture on the consistency of Adams operations on K -theory and Adams operations on TC . This perspective leads to a splitting of K ( S ) ∧ p and the linearization/cyclotomic trace square into p -1 summands (which is independent of the conjectures), expanding on certain splittings discovered by Rognes [29, § 3] (in the case of regular primes); see Theorem 5.1.
The identification of the maps in Section 3 allows us to prove the following theorem, which slightly sharpens Theorem 1.2.
Theorem 1.3. Let p be an odd prime. Let α : π TC ∗ ( S ) → π j ∗ be the induced map on homotopy groups given by the composite of the canonical maps TC ( S ) → THH ( S ) /similarequal S and S → j ; let β : π K ∗ ( Z ) → π j ∗ be the canonical splitting; and let γ : π TC ∗ ( S ) → π ∗ Σ S 1 → π ∗ Σ j be the map induced by the splitting of (2.3) below. Then the p -torsion subgroup of π K ∗ ( S ) maps isomorphically to the subgroup of the p -torsion subgroup of π TC ∗ ( S ) ⊕ π K ∗ ( Z ) where the appropriate projections composed with α and β agree and the appropriate projection composed with γ is zero.
Theorems 1.2 and 1.3 provide a good understanding of what the linearization/cyclotomic trace square does on the odd torsion part of the homotopy groups. In contrast, the maps on mod torsion homotopy groups are not fully understood. We have that π K n ( S ) and π K n ( Z ) mod torsion are rank one for n = 0 and n ≡ 1 mod 4, n > 1; the map K ( S ) → K ( Z ) is a rational equivalence and an isomorphism in degree zero, but is not an isomorphism on mod torsion homotopy groups in degrees congruent to 1 mod 2( p -1) by the work of Klein-Rognes (see the proof of [14, 6.3.(i)]). The mod torsion homotopy groups of TC ( S ) ∧ p are rank one in degree zero and odd degrees ≥ -1; the map K ( S ) ∧ p → TC ( S ) ∧ p on mod torsion homotopy groups is an isomorphism in degree zero, by necessity zero in degrees not congruent to 1 mod 4, and for odd regular primes an isomorphism in degrees congruent to 1 mod 4. For irregular primes, the map is not fully understood.
In principle, we can use Theorem 1.2 to calculate π K ∗ ( S ) in low degrees. In practice, we are limited by a lack of understanding of π ∗ C P ∞ -1 and π K ∗ ( Z ); we know π ∗ S and π c ∗ in a comparatively larger range. The calculations of π ∗ C P ∞ -1 for ∗ < β | 2 | -1 = (2 p +1)(2 p -2) -3 in [29, 4.7] work for irregular primes as well as odd regular primes; although they only give the order of the torsion rather than the torsion group, in many cases the order is either 1 or p , and the group structure is also determined. At primes that satisfy the Kummer-Vandiver conjecture, we know π K ∗ ( Z ) in terms of Bernoulli numbers; at other primes we know π K ∗ ( Z ) in odd degrees, but do not know K 4 n Z at all (except n = 0 1) and only know the order , of π 4 n +2 K ( Z ) and again only in terms of Bernoulli numbers. As the formula [29, 4.7] for π ∗ C P ∞ -1 is somewhat messy, we do not summarize the answer here, but for convenience, we have included it in Section 6.
As a consequence of the work of Rognes [29, 3.6,3.8], the cyclotomic trace
$$\ t r c _ { p } \colon K ( \mathbb { S } ) _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { S } ) _ { p } ^ { \wedge }$$
is injective on homotopy groups at odd regular primes. In Theorem 1.2 above, the contribution in tor p ( π K ∗ ( S )) of p -torsion from tor p ( π K ∗ red ( Z )) maps to zero in π TC ∗ ( S ) under the cyclotomic trace. This then gives the following complete answer to the question the authors posed in [3]:
Corollary 1.4. For an odd prime p , the cyclotomic trace trc p : K ( S ) ∧ p → TC ( S ) ∧ p is injective on homotopy groups if and only if p is regular.
Theorem 1.1 contains the following more general injectivity result.
Corollary 1.5. For an odd prime p , the map of ring spectra
$$K ( \mathbb { S } ) _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { S } ) _ { p } ^ { \wedge } \times K ( \mathbb { Z } ) _ { p } ^ { \wedge }$$
is injective on homotopy groups.
Conventions. Throughout this paper p denotes an odd prime. For a ring R , we write R × for its group of units.
Acknowledgments. The authors especially thank Lars Hesselholt for many helpful conversations and for comments on a previous draft that led to substantial sharpening of the results. We are grateful to an anonymous referee who wrote an extremely careful and detailed report, which led to many improvements and corrections. The authors also thank Mark Behrens, Bill Dwyer, Tom Goodwillie, John Greenlees, Mike Hopkins, Thomas Kragh, Tyler Lawson, and Birgit Richter for helpful conversations, John Rognes for useful comments, and the IMA and MSRI for their hospitality while some of this work was done.
The first author was supported in part by NSF grant DMS-1151577; the second author was supported in part by NSF grants DMS-1105255, DMS-1505579.
## 2. The spectra in the linearization/cyclotomic trace square
We begin by reviewing the descriptions of the spectra TC ( S ) ∧ p , K ( Z ) ∧ p , and TC ( Z ) ∧ p in the p -completed linearization/cyclotomic trace square
/d47
/d47
/d15
/d15
/d15
/d15
/d47
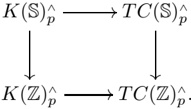
/d47
These three spectra have been identified in more familiar terms up to weak equivalence. We discuss how canonical these weak equivalences are. Often this will involve studying splittings of the form X /similarequal Y ∨ Z (or with additional summands). We will say that the splitting is canonical when we have a canonical isomorphism in the stable category X /similarequal X ′ ∨ X ′′ with X ′ and X ′′ (possibly non-canonically) isomorphic in the stable category to Y and Z ; we will say that the identification of the summand Y is canonical when further the isomorphism in the stable category X ′ /similarequal Y is canonical.
To illustrate the above terminology, and justify its utility, consider the example when X is non-canonically weakly equivalent to Y ∨ Z and [ Y, Z ] = 0 = [ Z, Y ] (where [ - -, ] denotes maps in the stable category). In the terminology above, this gives an example of a canonical splitting X /similarequal Y ∨ Z without canonical identification of the summands. As another example, if we have a canonical map Y → X in the stable category and a canonical map X → Y in the stable category giving a retraction, then we have a canonical splitting with canonical identification of summands X /similarequal Y ∨ F where F is the homotopy fiber of the retraction map X → Y . In this second example if we also have a non-canonical weak equivalence Z → F , we then have a canonical splitting X /similarequal Y ∨ Z with a canonical identification of the summand Y (but not the summand Z ).
The splitting of TC ( S ) ∧ p . Historically, TC ( S ) ∧ p was the first of the terms in the linearization/cyclotomic trace square to be understood. Work of B¨kstedt-Hsiango Madsen [4, 5.15,5.17] identifies the homotopy type of TC ( S ) ∧ p as
$$T C ( \mathbb { S } ) _ { p } ^ { \wedge } \simeq \mathbb { S } _ { p } ^ { \wedge } \vee \Sigma ( \mathbb { C } P _ { - 1 } ^ { \infty } ) _ { p } ^ { \wedge }.$$
The inclusion of the S summand is the unit of the ring spectrum structure and is split by the canonical map TC ( S ) ∧ p → THH ( S ) ∧ p and canonical identification
S ∧ p /similarequal THH ( S ) ∧ p (also induced by the ring spectrum structure). We therefore get a canonical isomorphism in the stable category between TC ( S ) ∧ p and S ∧ p ∨ Cu ∧ p where Cu ∧ p is the homotopy cofiber of the map S ∧ p → TC ( S ) ∧ p ; in the terminology at the beginning of the section, this is a canonical splitting with canonical identification
$$T C ( \mathbb { S } ) _ { p } ^ { \wedge } \simeq \mathbb { S } _ { p } ^ { \wedge } \vee C u _ { p } ^ { \wedge }.$$
We have a canonical splitting with non-canonical identification TC ( S ) ∧ p /similarequal S ∧ p ∨ Σ( C P ∞ -1 ) ∧ p .
As already indicated, we make use of a further splitting from [29, § 3] (see also the remarks preceding [19, (1.3)]),
$$( \mathbb { C } P _ { - 1 } ^ { \infty } ) _ { p } ^ { \wedge } \simeq \mathbb { S } _ { p } ^ { \wedge } \vee \overline { \mathbb { C } P } _ { - 1 } ^ { \infty },$$
induced by the splitting Σ ∞ + C P ∞ /similarequal Σ ∞ C P ∞ ∨ S . The splitting exists after inverting 2, but for notational convenience, we use it only after p -completion. It follows that there exists an analogous splitting
$$C u _ { p } ^ { \wedge } \simeq \Sigma \mathbb { S } _ { p } ^ { \wedge } \vee \overline { C u }.$$
There is a canonical map Σ S ∧ p → TC ( S ) ∧ p in the stable category arising from [4, 5.15-17], which in particular gives a canonical isomorphism
$$\pi _ { 1 } ( T C ( \mathbb { S } ) _ { p } ^ { \wedge } ) \cong \lim \mathbb { Z } / p ^ { n }.$$
Ravenel's calculation [22, 1.11.(iii)] reveals that [ C P ∞ -1 , S ∧ p ] ∼ = Z ∧ p , so there is a unique map Cu ∧ p → Σ S ∧ p in the stable category such that the composite self-map of Σ S ∧ p is the identity.
Finally, we have a canonical isomorphism of homotopy groups π ∗ S ∧ p ∼ = π ∗ ( j ) ⊕ π ∗ ( c ) from classical work in homotopy theory on Whitehead's J -homomorphism and Bousfield's work on localization of spectra [7, § 4]. As above, j denotes the connective cover of the K (1)-localization of the sphere spectrum and c denotes the homotopy fiber of the map S ∧ p → j . The map S ∧ p → j induces an isomorphism from the p -Sylow subgroup of the image-ofJ subgroup of π q S ∧ p to π j q .
Putting this all together, we have a canonical isomorphism
$$\pi _ { * } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \cong \pi _ { * } ( j ) \oplus \pi _ { * } ( c ) \oplus \pi _ { * } ( \Sigma j ) \oplus \pi _ { * } ( \Sigma c ) \oplus \pi _ { * } ( \overline { C u } ).$$
The splitting of TC ( Z ) ∧ p . Next up historically is TC ( Z ), which was first identified by B¨ okstedt-Madsen [5, 6] and Rognes [26]. They expressed the answer on the infinite-loop space level and (equivalently) described the connective cover spectrum TC ( Z ) ∧ p [0 , ∞ ) as having the homotopy type of
$$j \vee \Sigma j \vee \Sigma ^ { 3 } k u _ { p } ^ { \wedge } \simeq j \vee \Sigma j \vee \Sigma ^ { 3 } \ell \vee \Sigma ^ { 5 } \ell \vee \cdots \vee \Sigma ^ { 3 + 2 ( p - 2 ) } \ell$$
(non-canonical isomorphism in the stable category). Here ku denotes connective complex topological K -theory (the connective cover of periodic complex topological K -theory KU ), and /lscript denotes the Adams summand of ku ∧ p (the connective cover of the Adams summand L of KU ∧ p ). A standard calculation (e.g., see [18, 2.5.7]) shows that before taking the connective cover π -1 ( TC ( Z ) ∧ p ) is free of rank one over Z ∧ p , and as we explain in the subsection on the homotopy type of TC ( Z ) ∧ p below, the argument for [29, 3.3] extends to show that summand Σ 3+2( p -3) /lscript above becomes Σ -1 /lscript in TC ( Z ) ∧ p .
The non-canonical splitting above rigidifies into a canonical splitting and canonical identification
$$( 2. 4 ) \ T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \simeq j \vee \Sigma j ^ { \prime } \vee \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \vee \Sigma ^ { - 1 } \ell _ { T C } ( p ) \vee \Sigma ^ { - 1 } \ell _ { T C } ( 2 ) \vee \cdots \vee \Sigma ^ { - 1 } \ell _ { T C } ( p - 2 ).$$
Here the numbering replaces 1 with p but otherwise numbers sequentially 0,. . . , p -2. Each Σ -1 /lscript TC ( ) is i a spectrum that is non-canonically weakly equivalent to Σ 2 i -1 /lscript ∼ = Σ 2 i (Σ -1 /lscript ) but that admits a canonical description by work of Hesselholt-Madsen [12, Th. D] and Dwyer-Mitchell [9, § 13] in terms of units of cyclotomic extensions of Q ∧ p ; we omit a detailed description of the identification as we do not use it. The spectrum j ′ is the connective cover of the K (1)-localization of the ( Z ∧ p ) × -Moore spectrum M ( Z ∧ × p ) , or equivalently, the p -completion of j ∧ M ( Z ∧ × p ) . Since the p -completion of ( Z ∧ p ) × is non-canonically isomorphic to Z ∧ p , we have that j ′ is non-canonically weakly equivalent to j but with π j 0 ′ canonically isomorphic to (( Z ∧ p ) × ) ∧ p (and isomorphisms in the stable category from j to j ′ are in canonical bijection with isomorphisms Z ∧ p → (( Z ∧ p ) × ) ∧ p ). Much of the canonical splitting in (2.4) follows by a calculation of maps in the stable category. Temporarily writing x (0) = j ∨ Σ -1 /lscript , x (1) = Σ j ∨ Σ 2 p -1 /lscript , and x i ( ) = Σ 2 i -1 /lscript for i = 2 , . . . , p -2, the results above give us a canonical splitting without canonical identification (see the start of this section for an explanation of this terminology)
$$T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \simeq x ( 0 ) \vee \dots \vee x ( p - 2 )$$
/negationslash because for i = i ′ , we have [ x i , x i ( ) ( ′ )] = 0; we provide a detailed computation as Proposition 2.14 at the end of the section. The canonical map S → j induces an isomorphism [ j, T C ( Z ) ∧ p ] ∼ = π 0 ( TC ( Z ) ∧ p ) and so we have a canonical map η : j → TC ( Z ) ∧ p coming from the unit of the ring spectrum structure. Likewise, the canonical map M ( Z ∧ × p ) → j ′ induces an isomorphism
$$[ \Sigma j ^ { \prime }, T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ] \cong [ \Sigma M _ { ( \mathbb { Z } _ { p } ^ { \wedge } ) ^ { \times } }, T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ] \cong \text{Hom} ( ( ( \mathbb { Z } _ { p } ^ { \wedge } ) ^ { \times } ) _ { p } ^ { \wedge }, \pi _ { 1 } T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ).$$
The canonical isomorphism π TC 1 ( Z ) ∧ p ∼ = (( Z ∧ p ) × ) ∧ p [12, Th. D], then gives a canonical map u : Σ j ′ → TC ( Z ) ∧ p . The restriction along η and u induce bijections
$$[ T C ( \mathbb { Z } ) _ { p } ^ { \wedge }, j ] \cong [ j, j ] \quad \text{and} \quad [ T C ( \mathbb { Z } ) _ { p } ^ { \wedge }, \Sigma j ^ { \prime } ] \cong [ \Sigma j ^ { \prime }, \Sigma j ^ { \prime } ]$$
(q.v. Proposition 2.15 below), giving retractions to η and u that are unique in the stable category. This gives a canonical splitting and identification of the j and Σ j ′ summands in (2.4).
The splitting of K ( Z ) ∧ p . The homotopy type of K ( Z ) ∧ p is still not fully understood at irregular primes even in light of the confirmation of the Quillen-Lichtenbaum conjecture. The Quillen-Lichtenbaum conjecture implies that K ( Z ) ∧ p can be understood in terms of its K (1)-localization L K (1) K ( Z ), and work of Dwyer-Friedlander [10] or Dwyer-Mitchell [9, 12.2] identifies the homotopy type of K ( Z ) ∧ p at regular odd primes as j ∨ Σ 5 ko ∧ p (non-canonically). At any prime, Quillen's Brauer induction and reduction mod r (for r prime a generator of ( Z /p 2 ) × ) induce a splitting
$$K ( \mathbb { Z } ) _ { p } ^ { \wedge } \simeq j \vee K ^ { \text{red} } ( \mathbb { Z } )$$
for some p -complete spectrum we denote as K red ( Z ) (see for example, [9, 2.1,5.4,9.7]). We argue in Proposition 2.17 at the end of this section (once we have reviewed more about K red ( Z )) that [ j, K red ( Z )] = 0 and [ K red ( Z ) , j ] = 0, and it follows that the
splitting in (2.5) is canonical; the identification of the summand j is also canonical, as the map j → K ( Z ) described is then the unique one taking the canonical generator of π j 0 to the unit element of π K 0 ( Z ) in the ring spectrum structure.
The splitting K ( Z ) ∧ p /similarequal j ∨ K red ( Z ) corresponds to a splitting
$$L _ { K ( 1 ) } K ( \mathbb { Z } ) \simeq J \vee L _ { K ( 1 ) } K ^ { \text{red} } ( \mathbb { Z } )$$
where J = L K (1) S is the K (1)-localization of S . We have that K red ( Z ) is 4connected [16, 17, 27] and the Quillen-Lichtenbaum conjecture (as reformulated by Waldhausen [34, § 4]) implies that K ( Z ) ∧ p → L K (1) K ( Z ) induces an isomorphism on homotopy groups in degrees 2 and above. Thus, K red ( Z ) is the 4-connected cover of L K (1) K red ( Z ). This makes it straightforward to convert statements about the homotopy type of L K (1) K red ( Z ) into statements about the homotopy type of K red ( Z ) ∧ p .
A lot about L K (1) K ( Z ) is known by work of Dwyer-Mitchell [9], which studies L K (1) K R ( F ) where R F = O F [1 /p ] is the ring of p -integers in a number field; in the case F = Q , R F = Z [1 /p ]. By Quillen's localization theorem (and the triviality of L K (1) K ( F p ) /similarequal L K (1) H Z ∧ p ),
$$L _ { K ( 1 ) } K ( \mathbb { Z } ) \simeq L _ { K ( 1 ) } K ( \mathbb { Z } [ 1 / p ] )$$
and [9, 1.7] in particular computes ( KU ∧ p ) ∗ ( K red ( Z )) together with the action of ( KU ∧ p ) 0 ( KU ∧ p ) in number theoretic terms in terms of the Iwasawa module M . Let µ p n denote the p n th roots of unity and let µ p ∞ = ⋃ µ p n . The Iwasawa module M is then the Galois group of the maximal abelian p -extension of Q ( µ p ∞ ) unramified except at p . It comes with an action of Γ ′ = Gal( Q ( µ p ∞ ) / Q ) and its completed group ring, typically denoted as Λ ′ in Iwasawa theory. The canonical isomorphism Γ = ( ′ ∼ Z ∧ p ) × (induced by the canonical isomorphisms Aut( µ p n ) = ( ∼ Z /p n ) × ) and the interpolation of Adams operations on KU ∧ p to p -adic units gives an isomorphism between Γ ′ and this group of p -adically interpolated Adams operations, and induces an isomorphism of Z ∧ p -algebras Λ ′ ∼ = ( KU ∧ p ) 0 ( KU ∧ p ). From here on, we identify these two algebras via this isomorphism, the utility of which is explained in [9, § 4, § 6]. The main result of Dwyer-Mitchell [9, 1.7] proves
$$( K U _ { p } ^ { \wedge } ) ^ { 0 } ( K ^ { \text{red} } ( \mathbb { Z } ) ) & = 0 \\ ( K U _ { p } ^ { \wedge } ) ^ { - 1 } ( K ^ { \text{red} } ( \mathbb { Z } ) ) & \cong M$$
as Λ -algebras. As discussed in [9, ′ § 8], M is finitely generated projective dimension one as a Λ -module. Working in terms of ′ L , the Adams summand of KU ∧ p , it follows that L ∗ ( K red ( Z )) is concentrated in odd degrees where it is a finitely generated projective dimension one L L 0 -module in each degree. In particular, L K (1) K red ( Z ) splits
$$L _ { K ( 1 ) } K ^ { \text{red} } ( \mathbb { Z } ) \simeq Y _ { 0 } \vee \dots \vee Y _ { p - 2 }$$
where Y i is the fiber of a map from a finite wedge of copies of Σ 2 i -1 L to a finite wedge of copies of Σ 2 i -1 L , giving an L L 0 -resolution of the module L 2 i -1 Y i . We note that [ Y , Y i i ′ ] = 0 unless i = i ′ .
/negationslash
Letting y i be the 4-connected cover of Y i , we show below in Proposition 2.18 that [ y , y i i ′ ] = 0 for i = i ′ and so obtain a canonical splitting and canonical identification of summands
$$K ( \mathbb { Z } ) _ { p } ^ { \wedge } \simeq j \vee y _ { 0 } \vee \dots \vee y _ { p - 2 }.$$
Dwyer-Mitchell [9, 8.10] relates the L L 0 -modules L 2 i -1 Y i to class groups of cyclotomic fields. Write A m for the p -Sylow subgroup of the ideal class group of the cyclotomic field Q ( µ p m +1 ), and let A ∞ denote the inverse limit of A m over the norm maps, with its natural structure of a Λ -module. ′ Usual notation is to write Γ for the subgroup of Γ ′ given by Gal( Q ( µ p ∞ ) / Q ( µ p )), or equivalently, the subgroup of ( Z ∧ p ) × of p -adic units that are congruent to 1 mod p . Writing ∆ for Gal( Q ( µ p ) / Q ), or equivalently, ( Z /p ) × , the Teichm¨ller character u ω : ∆ → ( Z ∧ p ) × then induces a splitting Γ ′ ∼ = Γ × ∆, which in turn induces an isomorphism Λ ′ = Λ[∆], for a certain subring Λ of Λ . ′ In these terms, [9, 8.10] gives an exact sequence
$$( 2. 7 ) \ \ 0 \longrightarrow \text{Ext} _ { \Lambda } ^ { 1 } ( A _ { \infty }, \Lambda ) \longrightarrow ( K U _ { p } ^ { \hat { \jmath } } ) ^ { 1 } ( K ^ { \text{red} } ( \mathbb { Z } ) ) \longrightarrow \text{Hom} _ { \Lambda } ( E _ { \infty } ^ { \prime } ( \text{red} ), \Lambda ) \longrightarrow \\ \text{Ext} _ { \Lambda } ^ { 2 } ( A _ { \infty }, \Lambda ) \longrightarrow 0.$$
(Note that in the case under consideration here, A ∞ ′ is also isomorphic to the Λ -′ modules denoted L ∞ and A ′ ∞ in [9], q.v. § 12.) Here E ∞ (red) is a certain Λ -module ′ defined in terms of cyclotomic units, the details of which will not come into play here, except to note that by [9, 9.10], E ′ ∞ (red) is non-canonically isomorphic to ( KU ∧ p ) 0 ( KO ∧ p ) as a Λ -module. ′
To decompose (2.7) in terms of the Y i , we employ the 'Adams splitting' or 'eigensplitting' of ∆-equivariant Z ∧ p -modules. Any Z ∧ p [∆]-module X decomposes as a direct sum of pieces corresponding to the powers ω j of the Teichm¨ller character u ω : ∆ → ( Z ∧ p ) × . The ω j -character piece /epsilon1 j X is the submodule where the element α of ∆ acts by multiplication by ω j ( α ) ∈ Z ∧ p (for all α ∈ ∆). (For Λ ′ = Λ[∆]-modules, the ω j character piece is the summand where ψ ω α ( ) acts by ω j ( α ) for all α ∈ ∆.) This relates to the Adams decomposition of KU ∧ p as
$$\epsilon _ { j } ( ( K U _ { p } ^ { \wedge } ) ^ { q } ( Z ) ) \cong L ^ { 2 j + q } ( Z )$$
for any spectrum Z , and
$$( \Sigma ^ { 2 j } L ) ^ { 0 } ( \Sigma ^ { 2 j } L ) \xrightarrow { \cong } ( K U _ { p } ^ { \wedge } ) ^ { 0 } ( \Sigma ^ { 2 j } L ) \longrightarrow ( K U _ { p } ^ { \wedge } ) ^ { 0 } ( K U _ { p } ^ { \wedge } ) = \Lambda ^ { \prime }$$
is reasonably interpreted as the inclusion of /epsilon1 j Λ . ′ (The projection ( KU ∧ p ) 0 ( KU ∧ p ) → (Σ 2 j L ) 0 (Σ 2 j L ) induces an isomorphism of rings from Λ to (Σ 2 j L ) 0 (Σ 2 j L ).) In ∆equivariant terms, the exact sequence (2.7) is better written as
$$0 \longrightarrow \text{Ext} _ { \Lambda } ^ { 1 } ( A _ { \infty }, L ^ { 0 } L ) \longrightarrow ( K U _ { p } ^ { \wedge } ) ^ { 1 } ( K ^ { \text{red} } ( \mathbb { Z } ) ) \longrightarrow \text{Hom} _ { \Lambda } ( E _ { \infty } ^ { \prime } ( \text{red} ), L ^ { 0 } L ) \longrightarrow \\ \text{Ext} _ { \Lambda } ^ { 2 } ( A _ { \infty }, L ^ { 0 } L ) \longrightarrow 0.$$
(q.v. [9, 8.11]) with the canonical action of ∆ on Hom and Ext . i Taking the /epsilon1 j piece of the ∆-eigensplitting of this sequence, we get exact sequences
$$0 \longrightarrow \text{Ext} _ { \Lambda } ^ { 1 } ( \epsilon _ { - j } A _ { \infty }, L ^ { 0 } L ) \longrightarrow L ^ { 2 j + 1 } Y _ { j + 1 } \longrightarrow \text{Hom} _ { \Lambda } ( \epsilon _ { - j } E _ { \infty } ^ { \prime } ( \text{red} ), L ^ { 0 } L ) \longrightarrow \\ \text{Ext} _ { \Lambda } ^ { 2 } ( \epsilon _ { - j } A _ { \infty }, L ^ { 0 } L ) \longrightarrow 0$$
/negationslash since L 2 +1 j Y k = 0 for k = j + 1 (where we understand Y p -1 = Y 0 ). Now Hom ( Λ /epsilon1 -j E ′ ∞ (red) , L 0 L ) is zero when j is odd and a free Λ-module of rank 1 when j is even. Specifically, Y i is closely related to /epsilon1 j A ∞ for i + j ≡ 1 mod ( p -1).
For fixed p , several of the ω j -character pieces of A ∞ are always zero. In particular, /epsilon1 0 A 0 = 0 (because it is canonically isomorphic to the p -Sylow subgroup of the projective class group of Z ) and [35, 10.7] then implies that /epsilon1 0 A ∞ = 0. From the
exact sequence above, L Y 1 1 ∼ = L L 0 (non-canonically) and so Y 1 is non-canonically weakly equivalent to Σ L . It follows that y 1 is non-canonically weakly equivalent to Σ 1+2( p -1) /lscript . In terms of K ( Z ) ∧ p , we obtain a further canonical splitting (without canonical identification) K red ( Z ) /similarequal Σ 2 p -1 /lscript ∨ K red# ( Z ) for some p -complete spectrum K red# ( Z ). We use the identification of y 1 as a key step in the proof of Theorem 1.1 in Section 4.
Another useful vanishing result is /epsilon1 1 A 0 = 0 [35, 6.16]. As a consequence, we see that
$$Y _ { 0 } & \simeq *.$$
This simplifies some formulas and arguments.
/negationslash
/negationslash
Although these are the only results we use, other vanishing results for /epsilon1 j A give other vanishing results for the summands Y i . Herbrand's Theorem [35, 6.17] and Ribet's Converse [24], [35, 15.8] state that for 3 ≤ j ≤ p -2 odd, /epsilon1 j A 0 = 0 if and only if p B | p -j where B n denotes the Bernoulli number, numbered by the convention t e t -1 = ∑ B n n t n ! . We see that for p -3 ≥ i ≥ 2 even, Y i /similarequal ∗ when p does not divide B i +1 . In particular, Y 2 , Y 4 , Y 6 , Y 8 , and Y 10 are trivial, Y 12 is trivial for p = 691, and for every even i , Y i is only nontrivial for finitely many primes.
Aprime p is regular precisely when p does not divide the class number of Q ( ζ p ), or in other words, when A 0 = 0 and therefore A ∞ = 0. Then for an odd regular prime, we have that Y 2 k is trivial for all k and Y 2 k +1 is non-canonically weakly equivalent to Σ 4 k +1 L . It follows that L K (1) K red ( Z ) is non-canonically weakly equivalent to Σ KO ∧ p and K red ( Z ) is non-canonically weakly equivalent to Σ 5 ko ∧ p , since K red ( Z ) is the 4-connected cover of L K (1) K red ( Z ). This leads precisely to the description of K ( Z ) ∧ p as non-canonically weakly equivalent to j ∨ Σ 5 ko ∧ p , as indicated above.
Now consider the case when p satisfies the Kummer-Vandiver condition. This means that p does not divide the class number of Q ( ζ p + ζ -1 p ) (the fixed field of Q ( ζ p ) under complex conjugation). The p -Sylow subgroup is precisely the subgroup of A 0 fixed by complex conjugation, which is the internal direct sum of /epsilon1 j A 0 for 0 ≤ j < p -1 even. It follows that /epsilon1 j A 0 = 0 for j even, and so again Y 2 k +1 is non-canonically weakly equivalent to Σ 4 k +1 L ; this splits a copy of Σ KO ∧ p (with non-canonical identification) off L K (1) K red as in [9, 12.2]. Now the even summands Y 2 k may be non-zero, but the Λ-modules /epsilon1 j A ∞ are cyclic for j odd (see for example, [35, 10.16]) and Y 2 k is (non-canonically) weakly equivalent to the homotopy fiber of a map Σ 4 k -1 L → Σ 4 k -1 L determined by the p -adic L -function L p ( s ω ; 2 k ) [9, 12.2]. As above, Y 0 /similarequal ∗ and in the other cases, for n > 0, n ≡ 2 k -1 mod ( p -1),
$$\pi _ { 2 n } Y _ { 2 k } & \cong \mathbb { Z } _ { p } ^ { \wedge } / L _ { p } ( - n, \omega ^ { 2 k } ) = \mathbb { Z } _ { p } ^ { \wedge } / \left ( \frac { B _ { n + 1 } } { n + 1 } \right ) \\ \pi _ { 2 n + 1 } Y _ { 2 k } & = 0$$
/negationslash
(non-canonical isomorphisms). The groups are of course zero for n ≡ 2 k -1 mod ( p -1). (For n < 0, n ≡ 2 k -1 mod ( p -1), the L -function formula for π 2 n Y 2 k still holds, and π 2 n +1 Y 2 k = 0 still holds provided the value of the L -function is non-zero. If the value of the L -function is zero, then π 2 n +1 Y 2 k ∼ = Z ∧ p , though it is conjectured [30, 15] that this case never occurs.)
For p not satisfying the Kummer-Vandiver condition, the odd summands satisfy
$$\pi _ { 2 n } Y _ { 2 k + 1 } = \text{finite}$$
$$\pi _ { 2 n } Y _ { 2 k + 1 } = \text{finite} \\ \pi _ { 2 n + 1 } Y _ { 2 k + 1 } \cong \mathbb { Z } _ { p } ^ { \wedge }$$
(non-canonical isomorphism) for ∗ n ≡ 2 k mod ( p -1) (and zero otherwise) with the finite group unknown. As always Y 0 /similarequal ∗ , and the Mazur-Wiles theorem [20], [35, 15.14] implies that in the even summands,
$$& \# ( \pi _ { 2 n } Y _ { 2 k } ) = \# \left ( \mathbb { Z } _ { p } ^ { \wedge } / \left ( \frac { B _ { n + 1 } } { n + 1 } \right ) \right ) \\ & \pi _ { 2 n + 1 } Y _ { 2 k } = 0$$
/negationslash for n > 0, n ≡ 2 k -1 mod ( p -1) (and π 2 n Y 2 k = 0 for n ≡ 2 k -1 mod ( p -1)), although the precise group in the first case is unknown. (In this case, for n < 0, n ≡ 2 k -1 mod ( p -1), it is known that #( π 2 n Y 2 k ) = #( Z ∧ p /L p ( -n, ω 2 k )) and π 2 n +1 Y 2 k = 0, provided L p ( -n, ω 2 k ) is non-zero. If L p ( -n, ω 2 k ) = 0, then π 2 n Y 2 k ∼ = Z ∧ p ⊕ finite and π 2 n +1 Y 2 k ∼ = Z ∧ p , non-canonically.) For more on the homotopy groups of K ( Z ), see for example [36, § VI.10].
Supporting calculations. In several places above, we claimed (implicitly or explicitly) that certain hom sets in the stable category were zero. Here we review some calculations and justify these claims. All of these computations follow from well-known facts about the spectrum L together with standard facts about maps in the stable category. In particular, in several places, we make use of the fact that for a K (1)-local spectrum Z , the localization map X → L K (1) X induces an isomorphism [ L K (1) X,Z ] → [ X,Z ]; also, several times we make use of the fact that if X is ( n -1)-connected, then the ( n -1)-connected cover map Z n, [ ∞ → ) Z induces an isomorphism [ X,Z n, [ ∞ → )] [ X,Z ]. We begin with results on [ /lscript, Σ q /lscript ].
Proposition 2.9. The map [ /lscript, Σ q /lscript ] → [ /lscript, Σ q L ] ∼ = [ L, Σ q L ] is an injection for q ≤ 2(2 p -2). In particular, [ /lscript, Σ q /lscript ] = 0 if q ≡ 0 mod (2 p -2) and q < 2(2 p -2).
/negationslash
Proof. We have a cofiber sequence
$$\Sigma ^ { q - 1 - ( 2 p - 2 ) } H \mathbb { Z } _ { p } ^ { \wedge } \longrightarrow \Sigma ^ { q } \ell \longrightarrow \Sigma ^ { q - ( 2 p - 2 ) } \ell \longrightarrow \Sigma ^ { q - ( 2 p - 2 ) } H \mathbb { Z } _ { p } ^ { \wedge },$$
and a corresponding long exact sequence
$$\cdots \longrightarrow [ \ell, \Sigma ^ { q - 1 - ( 2 p - 2 ) } H \mathbb { Z } _ { p } ^ { \wedge } ] \longrightarrow [ \ell, \Sigma ^ { q } \ell ] \longrightarrow [ \ell, \Sigma ^ { q - ( 2 p - 2 ) } \ell ] \longrightarrow \cdots.$$
First we note that the map [ /lscript, Σ q /lscript ] → [ /lscript, Σ q -(2 p -2) /lscript ] is injective for q ≤ 2(2 p -2): When q = (2 p -2) + 1 this follows from the fact that
/negationslash
$$[ \ell, \Sigma ^ { q - 1 - ( 2 p - 2 ) } H \mathbb { Z } _ { p } ^ { \wedge } ] = H ^ { q - 1 - ( 2 p - 2 ) } ( \ell ; \mathbb { Z } _ { p } ^ { \wedge } ) = 0$$
for q - -1 (2 p -2) < (2 p -2) unless q - -1 (2 p -2) = 0. In the case q = (2 p -2)+1, the image of [ /lscript, Σ 0 H Z ∧ p ] in [ /lscript, Σ q /lscript ] in the long exact sequence is still zero because the map [ /lscript, /lscript ] → [ /lscript, H Z ∧ p ] ∼ = Z ∧ p is surjective. Now when q -(2 p -2) < p 2 -2,
$$[ \ell, \Sigma ^ { q - ( 2 p - 2 ) } \ell ] \cong [ \ell, \Sigma ^ { q - ( 2 p - 2 ) } L ] \cong [ L, \Sigma ^ { q - ( 2 p - 2 ) } L ]$$
since then Σ q -(2 p -2) /lscript → Σ q -(2 p -2) L is a weak equivalence on connective covers. For the remaining case q = 2(2 p -2), we have seen that the map [ /lscript, Σ q /lscript ] →
∗ The published version has 2 k +1 here, which is incorrect
[ /lscript, Σ q -(2 p -2) /lscript ] is an injection and the map [ /lscript, Σ q -(2 p -2) /lscript ] → [ /lscript, Σ q -(2 p -2) L ] is an injection. /square
Next, using the cofiber sequence
$$\Sigma ^ { - 1 } \ell \longrightarrow \Sigma ^ { ( 2 p - 2 ) - 1 } \ell \longrightarrow j \longrightarrow \ell$$
and applying the previous result, we obtain the following calculation.
Proposition 2.10. [ j, Σ q /lscript ] = 0 if q ≡ 0 mod (2 p -2) and q < 2(2 p -2).
/negationslash
Proof. Looking at the long exact sequence
$$\cdots \longrightarrow [ \ell, \Sigma ^ { q } \ell ] \longrightarrow [ j, \Sigma ^ { q } \ell ] \longrightarrow [ \Sigma ^ { ( 2 p - 2 ) - 1 } \ell, \Sigma ^ { q } \ell ] \longrightarrow [ \Sigma ^ { - 1 } \ell, \Sigma ^ { q } \ell ] \longrightarrow \cdots$$
/negationslash and using the isomorphism [Σ (2 p -2) -1 /lscript, Σ q /lscript ] ∼ = [ /lscript, Σ q +1 -(2 p -2) /lscript ] we have that both [ /lscript, Σ q /lscript ] and [Σ (2 p -2) -1 /lscript, Σ q /lscript ] are 0 when q ≡ 0 , -1 mod (2 p -2) and q ≤ 2(2 p -2). In the case when q ≡ -1 mod (2 p -2), using also the isomorphism [Σ -1 /lscript, Σ q /lscript ] ∼ = [ /lscript, Σ q +1 /lscript ], we have a commutative diagram
/d47
/d47
/d15
/d15
/d15
/d15
$$[ \ell, \Sigma ^ { q + 1 - ( 2 p - 2 ) } \ell ] \xrightarrow { \coprod } [ \ell, \Sigma ^ { q + 1 } \ell ] \\ [ L, \Sigma ^ { q + 1 - ( 2 p - 2 ) } L ] \xrightarrow { \coprod } [ L, \Sigma ^ { q + 1 } L ]$$
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
where the feathered arrows are known to be injections. The statement now follows in this case as well. /square
For maps the other way, we have the following result. The proof is similar to the proof of the previous proposition.
Proposition 2.11. [Σ q /lscript, j ] = 0 if q ≡ -1 mod (2 p -2) and q ≥ -(2 p -2).
/negationslash
We also have the following result for q = -1.
Proposition 2.12. [Σ -1 /lscript, j ] = 0
Proof. Let j -1 = J [ -1 , ∞ ) where J = L K (1) S /similarequal L K (1) j . Then we have a cofiber sequence Σ -2 Hπ -1 J → j → j -1 → Σ -1 Hπ -1 J and a long exact sequence
$$\cdots \rightarrow [ \Sigma ^ { - 1 } \ell, \Sigma ^ { - 2 } H \pi _ { - 1 } J ] \rightarrow [ \Sigma ^ { - 1 } \ell, j ] \rightarrow [ \Sigma ^ { - 1 } \ell, j _ { - 1 } ] \rightarrow [ \Sigma ^ { - 1 } \ell, \Sigma ^ { - 1 } H \pi _ { - 1 } J ] \rightarrow \cdots.$$
Since Σ -1 /lscript is ( -2)-connected, the inclusion of j -1 in J induces a bijection
$$[ \Sigma ^ { - 1 } \ell, j _ { - 1 } ] \longrightarrow [ \Sigma ^ { - 1 } \ell, J ] \cong [ \Sigma ^ { - 1 } L, J ].$$
It follows that a map Σ -1 /lscript → j -1 is determined by the map on π -1 , and therefore that the image of [Σ -1 /lscript, j ] in [Σ -1 /lscript, j -1 ] is zero. But H -2 (Σ -1 /lscript ; π -1 J ) = 0, so [Σ -1 /lscript, j ] = 0. /square
In the case of maps between suspensions of j , we only need to consider two cases:
Proposition 2.13. [ j, Σ ] = 0 and [Σ j j, j ] = 0.
Proof. As in the previous proof, we let j -1 = J [ -1 , ∞ ), and we use the cofiber sequence Σ -1 Hπ -1 J → Σ j → Σ j -1 → Hπ -1 J and the induced long exact sequence
$$\cdots \longrightarrow [ j, \Sigma ^ { - 1 } H \pi _ { - 1 } J ] \longrightarrow [ j, \Sigma j ] \longrightarrow [ j, \Sigma j _ { - 1 } ] \longrightarrow [ j, H \pi _ { - 1 } J ] \longrightarrow \cdots.$$
Since the connective cover of Σ J is Σ j -1 , we have that the map [ j, Σ j -1 ] → [ j, Σ ] J is a bijection, and the maps
$$[ J, \Sigma J ] \longrightarrow [ j, \Sigma J ] \longrightarrow [ \mathbb { S }, \Sigma J ] \cong \pi _ { - 1 } J$$
are isomorphisms. It follows that the map [ j, Σ j -1 ] → [ j, Hπ -1 J ] is an isomorphism. Since [ j, Σ -1 Hπ -1 J ] = 0, this proves [ j, Σ ] = 0. For the other calculation, j the map j → J induces a weak equivalence of 1-connected covers, and the induced map
$$[ \Sigma j, j ] \longrightarrow [ \Sigma j, J ] \cong [ \Sigma J, J ] \cong [ \Sigma \mathbb { S }, J ] = \pi _ { 1 } J = 0$$
is a bijection.
$$\Box$$
The following propositions are now clear.
Proposition 2.14. In the notation above, the summands x i ( ) of TC ( Z ) ∧ p satisfy [ x i , x i ( ) ( ′ )] = 0 for i = i ′ .
/negationslash
/negationslash
Proposition 2.15. Let k = 0 1. , In the notation above, [ x i , ( ) Σ k j ] = 0 for i = k and the inclusion of Σ k j in x k ( ) induces a bijection [ x k , ( ) Σ k j ] → [Σ k j, Σ k j ].
Eliminating the summands where maps out of j or Σ j are trivial, and looking at the connective and 0-connected covers of K (1)-localizations, we get the following proposition.
Proposition 2.16. The map S → j induces isomorphisms [ j, T C ( Z ) ∧ p ] ∼ = π TC 0 ( Z ) ∧ p and [Σ j, T C ( Z ) ∧ p ] ∼ = π TC 1 ( Z ) ∧ p .
For the summands of K ( Z ) ∧ p , we first consider the splitting of j .
$$\text{Proposition 2.17.} \ [ j, K ^ { \text{red} } ( \mathbb { Z } ) ] = 0 \text{ and } [ K ^ { \text{red} } ( \mathbb { Z } ), j ] = 0$$
Proof. As indicated above K red ( Z ) /similarequal y 0 ∨ · · · ∨ y p -2 . We have that y 1 is (noncanonically) weakly equivalent to Σ 2 p -1 /lscript , and applying Propositions 2.10, 2.11, we see that [ j, y 1 ] = 0 and [ y , j 1 ] = 0. In addition, y 2 /similarequal ∗ and y 0 /similarequal ∗ . For 2 < i ≤ p -2, y i is the fiber of a map from a finite wedge of copies of Σ 2 i -1 /lscript to a finite wedge of copies of Σ 2 i -1 /lscript . Looking at the long exact sequences
$$\cdots & \longrightarrow \bigoplus [ j, \Sigma ^ { 2 i - 2 } \ell ] \longrightarrow [ j, y _ { i } ] \longrightarrow \bigoplus [ j, \Sigma ^ { 2 i - 1 } \ell ] \longrightarrow \cdots \\ \cdots & \longrightarrow \prod [ \Sigma ^ { 2 i - 1 } \ell, j ] \longrightarrow [ y _ { i }, j ] \longrightarrow \prod [ \Sigma ^ { 2 i - 2 } \ell, j ] \longrightarrow \cdots, \\ \cdots \text{again see from Propositions 2.10 and 2.11 that } [ j, y _ { i } ] = 0 \text{ and } [ y _ { i }, j ] = 0.$$
we again see from Propositions 2.10 and 2.11 that [ j, y i ] = 0 and [ y , j i ] = 0. /square
/negationslash
Finally, the spectra Y i clearly satisfy [ Y , Y i i ′ ] = 0 for i = i ′ ; we now verify that the same holds for the covers y i .
/negationslash
Proposition 2.18. In the notation above, the summands y i of K red ( Z ) satisfy [ y , y i i ′ ] = 0 for i = i ′ .
Proof. Each y i is the fiber of a map from a finite wedge of copies of Σ 2 i -1 /lscript to a finite wedge of copies of Σ 2 i -1 /lscript except that y 1 /similarequal Σ 2 p -1 /lscript (non-canonically), y 0 /similarequal ∗ , and y 2 /similarequal ∗ . First, for i > 2, looking at the long exact sequence
$$\cdots \longrightarrow \prod [ \Sigma ^ { 2 i - 1 } \ell, \Sigma ^ { q } \ell ] \longrightarrow [ y _ { i }, \Sigma ^ { q } \ell ] \longrightarrow \prod [ \Sigma ^ { 2 i - 2 } \ell, \Sigma ^ { q } \ell ] \longrightarrow \cdots,$$
/negationslash we see from Proposition 2.9 that [ y , i Σ q /lscript ] = 0 when q ≡ 2 i -1 2 , i -2 mod (2 p -2) and q ≤ 2(2 p -2) + 2 i -3. In particular, [ y , y i 1 ] = 0 for i > 2. For i ′ > 2, looking at the long exact sequence
$$\cdots \longrightarrow \bigoplus [ y _ { i }, \Sigma ^ { 2 i ^ { \prime } - 2 } \ell ] & \longrightarrow [ y _ { i }, y _ { i ^ { \prime } } ] \longrightarrow \bigoplus [ y _ { i }, \Sigma ^ { 2 i ^ { \prime } - 1 } \ell ] \longrightarrow \cdots, \\ \intertext { w o c o n t h t a t. a.. } \cap \, \text{$\Gamma$} \, i \sim i ^ { \prime } \text{ in the common in} \, \text{accoc} \quad \bigcap }$$
we see that [ y , y i i ′ ] = 0 for i = i ′
/negationslash in the remaining cases. /square
The homotopy type of TC ( Z ) ∧ p . To determine the homotopy type of TC ( Z ) ∧ p from that of TC ( Z ) ∧ p [0 , ∞ ), we need to study the cofiber sequence
$$\Sigma ^ { - 2 } H \mathbb { Z } _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \Sigma ^ { - 1 } H \mathbb { Z } _ { p } ^ { \wedge }.$$
The argument of [29, 3.3] studies the induced cofiber sequence on the cofiber of the inclusion of j ,
$$\Sigma ^ { - 2 } H \mathbb { Z } _ { p } ^ { \wedge } & \longrightarrow C ( j \to T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ( 0, \infty ) ) \longrightarrow C ( j \to T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ) \longrightarrow \Sigma ^ { - 1 } H \mathbb { Z } _ { p } ^ { \wedge }, \\ \text{and shows that } C ( i \to T C ( \mathbb { Z } ) _ { \wedge } ^ { \wedge } ) \text{ has the homotonv tvne of}$$
$$\Sigma j \vee \Sigma ^ { 3 } \ell \vee \cdots \vee \Sigma ^ { 2 p - 5 } \ell \vee \Sigma ^ { - 1 } \ell \vee \Sigma ^ { 2 p - 1 } \ell.$$
and shows that C j ( → TC ( Z ) ∧ p ) has the homotopy type of
In terms of the non-canonical weak equivalence
$$C ( j \to T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) ) \simeq \Sigma j \vee \Sigma ^ { 3 } k u _ { p } ^ { \wedge }, \\ \mathbb { Z } _ { \wedge } \to C ( i \to T C ( \mathbb { Z } ) _ { \wedge } [ 0, \infty ) ] \text{ factors through a man}$$
$$\Sigma ^ { - 2 } H \mathbb { Z } _ { p } ^ { \wedge } \xrightarrow { \lambda } \Sigma ^ { 2 p - 3 } \ell \xrightarrow { \alpha } \Sigma ^ { 3 } k u _ { p } ^ { \wedge }$$
the map Σ -2 H Z ∧ p → C j ( → TC ( Z ) ∧ p [0 , ∞ ) ) factors through a map where α : Σ 2 p -3 /lscript → Σ 3 ku ∧ p is the inclusion of an Adams summand and the map λ : Σ -2 H Z ∧ p → Σ 2 p -3 /lscript is a generator of [Σ -2 H Z ∧ p , Σ 2 p -3 /lscript ] ∼ = Z ∧ p . It follows in particular that pulling back along λ induces an isomorphism [Σ 2 p -3 /lscript, j ] → [Σ -2 H Z ∧ p , j ]. The splitting
$$T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) \simeq j \vee C \left ( j \to T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) \right ) \\ \text{ical. determined by a choice of map $T C ( \mathbb { Z } ) _ { \wedge } [ 0. \infty ) \to i$ (i}$$
is non-canonical, determined by a choice of map TC ( Z ) ∧ p [0 , ∞ → ) j (in the stable category) such that the composite map j → j is the identity; choosing an arbitrary such map, we can alter it by a map Σ 2 p -3 /lscript → j to get a splitting where the composite map
$$\Sigma ^ { - 2 } H \mathbb { Z } _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) \longrightarrow j$$
is the zero map. It follows that TC ( Z ) ∧ p is non-canonically weakly equivalent to
$$j \vee \Sigma j \vee \Sigma ^ { 3 } \ell \vee \cdots \vee \Sigma ^ { 2 p - 5 } \ell \vee \Sigma ^ { - 1 } \ell \vee \Sigma ^ { 2 p - 1 } \ell.$$
## 3. The maps in the linearization/cyclotomic trace square
The previous section discussed the corners of the linearization/cyclotomic trace square; in this section, we discuss the edges. The main observation is that with respect to the canonical splittings of the previous section, the cyclotomic trace is diagonal and the linearization map is diagonal on the p -torsion part of the homotopy groups.
Theorem 3.1. In terms of the splittings (2.4) and (2.6) of the previous section, the cyclotomic trace K ( Z ) ∧ p → TC ( Z ) ∧ p splits as the wedge of the identity map j → j and maps
$$y _ { 0 } & \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \\ y _ { 1 } & \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( p ) \\ y _ { 2 } & \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( 2 ) \\ \vdots & \vdots \\ \wedge & \longrightarrow \Sigma ^ { - 1 } \ell _ { \varpi \varpi l n } = 0$$
$$y _ { p - 2 } \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( p - 2 ).$$
Proof. We have that each y i fits into a fiber sequence of the form
$$y _ { i } & \longrightarrow \bigvee \Sigma ^ { 2 i - 1 } \ell \longrightarrow \bigvee \Sigma ^ { 2 i - 1 } \ell \\ = 1 \text{ where theenson is } \Sigma ^ { 2 p - 1 } \ell \text{ ratio}$$
except in the case i = 1 where the suspension is Σ 2 p -1 /lscript rather than Σ 1 /lscript (and the cases i = 0 and i = 2, where y i = ∗ anyway). Choosing a non-canonical weak equivalence Σ 2 q -1 /lscript /similarequal Σ -1 /lscript TC ( q ), and looking at the long exact sequences of maps into Σ 2 q -1 /lscript , Proposition 2.9 implies [ y , i Σ -1 /lscript TC ( q )] = 0 unless q ≡ i mod ( p -1). Likewise, [ j, Σ -1 /lscript TC ( q )] = 0 for all q by Proposition 2.10. /square
Next, we turn to the linearization map.
Theorem 3.2. In terms of the splittings (2.1) , (2.2) , and (2.4) of the previous section, the linearization map TC ( S ) ∧ p → TC ( Z ) ∧ p admits factorizations as follows:
- (i) The map S ∧ p → TC ( Z ) ∧ p factors through the canonical map S ∧ p → j , which is a canonically split surjection on homotopy groups in all degrees.
- (ii) The map Σ S ∧ p → TC ( Z ) ∧ p factors through a map Σ S ∧ p → Σ j ′ that is an isomorphism on π 1 and is a split surjection on homotopy groups in all degrees.
- (iii) The map Cu → TC ( Z ) ∧ p factors through j ∨ ∨ Σ -1 /lscript TC ( ) i (for i = 0 , p , 2 ,. . . , p -2 ). On p -torsion, the map tor p ( π ∗ ( Cu )) → tor p ( π ∗ ( TC ( Z ) ∧ p )) is zero.
Proof. The statement (i) is clear from the construction of the map j → TC ( Z ) ∧ p since the linearization map is a map of ring spectra. For (ii), the composite map Σ S ∧ p → TC ( Z ) ∧ p is determined by where the generator goes in π TC 1 ( Z ) ∧ p , but the inclusion of Σ j ′ in TC ( Z ) ∧ p induces an isomorphism on π 1 , and so Σ S ∧ p factors through Σ j ′ . The map TC ( S ) ∧ p → TC ( Z ) ∧ p is a (2 p -3)-equivalence [5, 9.10]; the map Σ S → Σ j ′ is therefore an isomorphism on π 1 . Using the image of the generator of π 1 Σ S as a generator for π 1 Σ j ′ gives a weak equivalence Σ j → Σ j ′ such that the map Σ S → Σ j ′ → Σ j obtained by composing with the inverse is the suspension of the canonical map S → j . This completes the proof of (ii).
To show the factorization of Cu → TC ( Z ) ∧ p for (iii), it suffices to check that the composite map
$$\overline { C u } \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \Sigma j ^ { \prime }$$
is trivial. Using the non-canonical weak equivalence Cu /similarequal Σ C P ∞ -1 , the AtiyahHirzebruch spectral sequence to calculate (Σ j ) ∗ (Σ C P ∞ -1 ) with
$$E _ { 2 } ^ { s, t } = H ^ { s + t } ( \Sigma \overline { \mathbb { C } P } _ { - 1 } ^ { \infty } ; \pi _ { - t } ( \Sigma j ^ { \prime } ) ) \cong H ^ { s + t } ( \overline { \mathbb { C } P } _ { - 1 } ^ { \infty } ; \pi _ { - t } ( j ) )$$
is zero along the line of total degree zero, and so [ Cu, Σ j ′ ] = 0.
Finally, to see that the map Cu → TC ( Z ) ∧ p is zero on the torsion subgroup of π Cu ∗ , it suffices to note that the composite map
$$\Sigma \overline { \mathbb { C } P } ^ { \infty } _ { - 1 } \simeq \overline { C u } \longrightarrow T C ( \mathbb { Z } ) ^ { \wedge } _ { p } \longrightarrow j$$
is zero on the torsion subgroup of π ∗ Σ C P ∞ -1 , or equivalently that the composite map to J is zero on the torsion subgroup of π ∗ Σ C P ∞ -1 . Post-composing with the (canonical) map J → L in the fiber sequence
$$\Omega L \longrightarrow J \longrightarrow L \longrightarrow L,$$
the map Σ C P ∞ -1 → L is trivial (since L ∗ (Σ C P ∞ -1 ) is concentrated in odd degrees). It follows that the map Σ C P ∞ -1 → J factors through the map Ω L → J , and therefore is zero on torsion. /square
It would be reasonable to expect that the augmentations TC ( S ) ∧ p → S ∧ p and TC ( Z ) ∧ p → j are compatible, although we see no K -theoretic, THH -theoretic, or calculational reasons why this should hold. Such a compatibility would imply that the map Cu → TC ( Z ) ∧ p factors through ∨ Σ -1 /lscript TC ( ) i and would then (combined with the observations in Section 5) say that the linearization map is fully diagonal with respect to the splittings of the previous section.
## 4. Proof of main results
We now apply the work of the previous two sections to prove the theorems stated in the introduction. We begin with Theorem 1.1, which is an immediate consequence of the following theorem.
Theorem 4.1. The map
$$\pi _ { n } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \oplus \pi _ { n } K ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \pi _ { n } T C ( \mathbb { Z } ) _ { p } ^ { \wedge }$$
is (non-canonically) split surjective.
We apply the splittings of TC ( S ) ∧ p , TC ( Z ) ∧ p , and K ( Z ) ∧ p and the maps on homotopy groups to prove the previous theorem by breaking it into pieces and showing that different pieces in the splitting induce surjections on homotopy groups. Theorem 3.2.(i) and (ii) provide two surjection results; we write two more in Lemmas 4.2 and 4.4. The first of these is essentially due to Klein-Rognes [14].
Lemma 4.2. Under the splittings (2.1) , (2.2) , and (2.4) , the composite map
$$\overline { C u } \rightarrow T C ( \mathbb { S } ) _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \vee \cdots \vee \Sigma ^ { - 1 } \ell _ { T C } ( p - 2 )$$
/negationslash induces a split surjection on π 2 +1 q for q ≡ 0 mod ( p -1)
Proof. Klein and Rognes [14, 5.8,(17)] (and independently Madsen and Schlichtkrull [19, 1.1]) construct a space-level map
$$S U _ { p } ^ { \wedge } \longrightarrow \Omega ^ { \infty } ( \Sigma \mathbb { C } P _ { - 1 } ^ { \infty } ) _ { p } ^ { \wedge }.$$
They study the composite map
$$S U _ { p } ^ { \wedge } \longrightarrow \Omega ^ { \infty } ( \Sigma \mathbb { C } P _ { - 1 } ^ { \infty } ) _ { p } ^ { \wedge } \longrightarrow \Omega ^ { \infty } ( T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ) \longrightarrow S U _ { p } ^ { \wedge }$$
induced by the linearization map TC ( S ) ∧ p → TC ( Z ) ∧ p , the projection map
$$T C ( \mathbb { Z } ) _ { p } ^ { \wedge } [ 0, \infty ) \longrightarrow \Sigma ^ { 3 } k u _ { p } ^ { \wedge },$$
and the Bott periodicity isomorphism Ω ∞ Σ 3 ku /similarequal SU . In [14, 6.3.(i)], Klein and Rognes show that their map (4.3) induces an isomorphism of homotopy groups in all degrees except those congruent to 1 mod 2( p -1). This proves the statement except in degree -1, where it follows from the fact that the linearization map TC ( S ) ∧ p → TC ( Z ) ∧ p is a (2 p -3)-equivalence [5, 9.10]. /square
The other lemma constructs a split surjection onto π TC ∗ ( Z ) ∧ p in degrees congruent to 1 mod 2( p -1). We give a direct argument for the following lemma, but it can also be proved using the vanishing results in [3].
Lemma 4.4. Under the splittings of (2.4) and (2.6) , the composite map
$$y _ { 1 } \longrightarrow K ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( p )$$
is a weak equivalence.
Proof. Since y 1 and Σ -1 /lscript TC ( p ) are both (non-canonically) weakly equivalent to Σ 2 p -1 /lscript , it suffices to show that the map becomes a weak equivalence after K (1)localization. Indeed, by v 1 periodicity, it suffices to show that the map on K (1)localizations is an isomorphism on any homotopy group in degree congruent to 1 mod (2 p -2). We check this on π 1 . Consider the commutative diagram
/d47
/d47
/d55
/d55
/d55
/d55
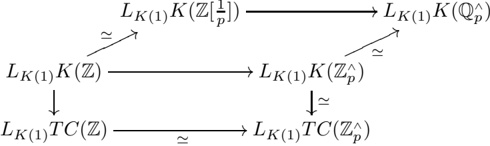
/d15
/d15
/d15
/d15
/d47
/d47
where the vertical maps are induced by the cyclotomic trace and the indicated maps are weak equivalences, for the diagonal maps by Quillen's localization sequence, for the indicated horizontal map by [12, Add. 6.2], and for the indicated vertical map by [12, Th. D]. On π 1 , the canonical maps
$$\mathbb { Z } [ \frac { 1 } { p } ] ^ { \times } & \longrightarrow \pi _ { 1 } ( K ( \mathbb { Z } [ \frac { 1 } { p } ] ) ) \longrightarrow \pi _ { 1 } ( L _ { K ( 1 ) } K ( \mathbb { Z } [ \frac { 1 } { p } ] ) ) \\ ( \mathbb { Q } _ { p } ^ { \wedge } ) ^ { \times } & \longrightarrow \pi _ { 1 } ( K ( \mathbb { Q } _ { p } ^ { \wedge } ) ) \longrightarrow \pi _ { 1 } ( L _ { K ( 1 ) } K ( \mathbb { Q } _ { p } ^ { \wedge } ) )$$
induce isomorphims
$$( \mathbb { Z } [ \frac { 1 } { p } ] ^ { \times } ) _ { p } ^ { \wedge } & \cong \pi _ { 1 } ( L _ { K ( 1 ) } K ( \mathbb { Z } ) ) \cong \pi _ { 1 } ( Y _ { 1 } ) \\ ( ( \mathbb { Q } _ { p } ^ { \wedge } ) ^ { \times } ) _ { p } ^ { \wedge } & \cong \pi _ { 1 } ( L _ { K ( 1 ) } T C ( \mathbb { Z } ) ) \cong \pi _ { 1 } ( L _ { K ( 1 ) } \Sigma j ^ { \prime } ) \oplus \pi _ { 1 } ( L _ { K ( 1 ) } \Sigma ^ { - 1 } \ell _ { T C } ( p ) ),$$
under which the map π 1 ( Y 1 ) → π 1 ( L K (1) TC ( Z ∧ p )) corresponds to the map induced by the inclusion of Z [ 1 p ] in Q ∧ p . By construction, the map Σ j ′ → TC ( Z ) ∧ p sends π 1 ( j ′ ) isomorphically onto the subgroup (( Z ∧ p ) × ) ∧ p of (( Q ∧ p ) × ) ∧ p under the isomorphism above. The map
$$( \mathbb { Z } [ \frac { 1 } { p } ] ^ { \times } ) _ { p } ^ { \wedge } \longrightarrow ( ( \mathbb { Q } _ { p } ^ { \wedge } ) ^ { \times } ) _ { p } ^ { \wedge } / ( ( \mathbb { Z } _ { p } ^ { \wedge } ) ^ { \times } ) _ { p } ^ { \wedge }$$
is an isomorphism of free Z ∧ p -modules of rank 1.
We now have everything we need for the proof of Theorem 4.1.
/square
/d47
/d47
Proof of Theorem 4.1. Combining previous results, we have two families of (noncanonical) splittings
$$\pi _ { * } ( \mathbb { S } \vee \Sigma \S \vee \overline { C u } \vee j \vee y _ { 0 } \vee \dots \vee y _ { p - 2 } ) \\ & \longrightarrow \pi _ { * } ( j \vee \Sigma j ^ { \prime } \vee \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \vee \dots \vee \Sigma ^ { - 1 } \ell _ { T C } ( p - 2 ).$$
For both splittings we use Lemma 4.4 to split the Σ -1 /lscript TC ( p ) summand in the codomain (canonically) using the y 1 summand of the domain, we use Theorem 3.2.(ii) to split the π ∗ Σ j ′ summand in the codomain (canonically) using the Σ S 1 summand in the domain, and we use Lemma 4.2 to split the
$$\pi _ { * } ( \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \vee \Sigma ^ { - 1 } \ell _ { T C } ( 2 ) \vee \cdots \vee \Sigma ^ { - 1 } \ell _ { T C } ( p - 2 ) )$$
summands in the codomain (non-canonically) using the π Cu ∗ summand in the domain. We then have a choice on the remaining summand of the codomain, π j ∗ . We can use Theorem 3.1 to split this (canonically) using the π j ∗ summand in the domain or use Theorem 3.2 to split this (canonically) using the π ∗ S summand in the domain. /square
This completes the proof of Theorem 1.1. We now prove the remaining theorems from the introduction.
Proof of Theorems 1.2 and 1.3. Since the long exact sequence of the homotopy cartesian linearization/cyclotomic trace square breaks into split short exact sequences, we get split short exact sequences on p -torsion subgroups
$$0 \to \text{tor} _ { p } ( \pi _ { n } K ( \mathbb { S } ) ) \longrightarrow \text{tor} _ { p } ( \pi _ { n } T C ( \mathbb { S } ) _ { p } ^ { \wedge } \oplus \pi _ { n } K ( \mathbb { Z } ) ) \longrightarrow \text{tor} _ { p } ( \pi _ { n } T C ( \mathbb { Z } ) _ { p } ^ { \wedge } ) \longrightarrow 0.$$
Using the splittings of (2.1), (2.4), and (2.5), leaving out the non-torsion summands, we can identify tor p ( π K n ( S )) as the kernel of a map
$$\text{tor} _ { p } ( \pi _ { n } \mathbb { S } \oplus \pi _ { n - 1 } \mathbb { S } \oplus \pi _ { n } \overline { C u } \oplus \pi _ { n } j \oplus \pi _ { n } K ^ { \text{red} } ( \mathbb { Z } ) ) \longrightarrow \text{tor} _ { p } ( \pi _ { n } j \oplus \pi _ { n - 1 } j ^ { \prime } )$$
which by Theorems 3.1 and 3.2 is mostly diagonal: It is the direct sum of the canonical maps
$$\text{tor} _ { p } ( \pi _ { n } \mathbb { S } ) & \oplus \text{tor} _ { p } ( \pi _ { n } j ) \longrightarrow \text{tor} _ { p } ( \pi _ { n } j ) \\ \text{tor} _ { p } ( \pi _ { n - 1 } \mathbb { S } ) & \longrightarrow \text{tor} _ { p } ( \pi _ { n - 1 } j ^ { \prime } )$$
and the zero maps on tor p ( π Cu n ) and tor p ( π K n red ( Z )). The isomorphism (a) uses the canonical splitting π j n → π n S on the π n S summand, while the isomorphism (b) uses the identity of π j n on the π j n summand. /square
## 5. Conjecture on Adams Operations
In Section 2 we produced canonical splittings on K ( Z ) ∧ p and TC ( Z ) ∧ p and in Section 3, we showed that the cyclotomic trace is diagonal with respect to these splittings. The purpose of this section is to prove the following splitting of the linearization/cyclotomic trace square and relate it to conjectures on Adams operations.
Theorem 5.1. The spectrum K ( S ) ∧ p splits into p -1 summands, K ( S ) ∧ p /similarequal K ∨ 0 · · · ∨ K p -2 , and the linearization/cyclotomic trace square splits into the wedge sum of p -1 homotopy cartesian squares
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
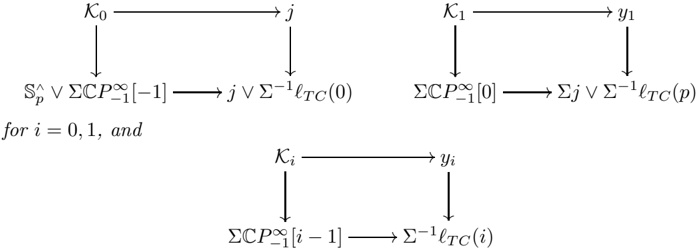
/d47
/d47
for i = 2 , . . . p -2 .
We are using the notation from Section 2 for the summands y i and Σ -1 /lscript TC ( ) of i K ( Z ) ∧ p and TC ( Z ) ∧ p . The spectra C P ∞ -1 [ i ] are the wedge summands of the 'Adams splitting' previously used by Rognes [29, § 5]
$$\mathbb { C } P _ { - 1 } ^ { \infty } \simeq \mathbb { C } P _ { - 1 } ^ { \infty } [ - 1 ] \vee \mathbb { C } P _ { - 1 } ^ { \infty } [ 0 ] \vee \cdots \vee \mathbb { C } P _ { - 1 } ^ { \infty } [ p - 3 ].$$
Here we are following the numbering of Rognes [29, p. 169], which has its rationale in that the [ ] piece has its ordinary cohomology concentrated in degrees 2 i i mod 2 p -2 and starts in degree 2 . i Note that the splitting of the theorem fails to be canonical because of problems with the identification of TC ( S ) ∧ p as S ∧ p ∨ Σ C P ∞ -1 .
In the theorem, for the i = 0 square, we have used that y 0 = ∗ as noted in Section 2. In using these squares to study the homotopy type of K i , we can simplify the i = 0 square to a cofiber sequence
$$\mathcal { K } _ { 0 } \longrightarrow \mathbb { S } _ { p } ^ { \wedge } \vee \Sigma \mathbb { C } P _ { - 1 } ^ { \infty } [ - 1 ] \longrightarrow \Sigma ^ { - 1 } \ell _ { T C } ( 0 ) \longrightarrow \Sigma \mathcal { K } _ { 0 }$$
since Theorem 3.1 indicates that the map j → j ∨ Σ -1 /lscript TC (0) factors through the identity map j → j . For the i = 1 square, the splitting of C P ∞ -1 fits into a fiber sequence with the splitting of
$$( \Sigma ^ { \infty } \mathbb { C } P ^ { \infty } ) _ { p } ^ { \wedge } \simeq \Sigma ^ { \infty } K ( \mathbb { Z } _ { p } ^ { \wedge }, 2 ) ) \simeq \mathbb { C } P ^ { \infty } [ 1 ] \vee \cdots \vee \mathbb { C } P ^ { \infty } [ p - 1 ],$$
which identifies C P ∞ -1 [0] as S ∧ p ∨ C P ∞ [ p -1]. Theorem 3.1 and Lemma 4.4 indicate that the map y 1 → Σ j ∨ Σ -1 /lscript TC ( p ) factors through a weak equivalence y 1 → Σ -1 /lscript TC ( p ), and we get a weak equivalence
$$\mathcal { K } _ { 1 } \simeq \Sigma c \vee \mathbb { C } P ^ { \infty } [ p - 1 ],$$
where by definition c is the homotopy fiber of the canonical map S → j .
Proof of Theorem 5.1. Let /epsilon1 i TC ( S ) ∧ p , /epsilon1 i TC ( Z ) ∧ p , and /epsilon1 i K ( Z ) ∧ p be the summands of TC ( S ) ∧ p , TC ( Z ) ∧ p , and K ( Z ) ∧ p , respectively, specified in the i th square in the statement of the theorem. Our work in Section 3 shows that the map K ( Z ) ∧ p → TC ( Z ) ∧ p restricts to a sum of maps /epsilon1 i K ( Z ) ∧ p → /epsilon1 i TC ( Z ) ∧ p . The Atiyah-Hirzebruch spectral sequence implies that the C P ∞ -1 [ i -1] summand of /epsilon1 i TC ( S ) ∧ p factors uniquely through /epsilon1 i TC ( Z ) ∧ p as there are no essential maps to the other summands; Theorem 3.2 then implies that the map TC ( S ) ∧ p → TC ( Z ) ∧ p decomposes as a wedge sum of maps /epsilon1 i TC ( S ) ∧ p → /epsilon1 i TC ( Z ) ∧ p . /square
/d47
/d47
/d15
/d15
/d47
/d47
/d15
/d15
/d47
/d47
In the proof above, we argued calculationally using the paucity of maps in the stable category between the summands; however, there is a conceptual reason to expect much of this behavior based on p -adically interpolated of Adams operations. In [1, 10.7], we showed that the splitting of C P ∞ -1 arises from a p -adic interpolation of the Adams operations on TC ( S ) ∧ p (constructed there). Such a p -adic interpolation is an extension to ( Z ∧ p ) × of the action of the monoid Z × ( p ) ∩ Z on TC ( -; p ) (in the p -complete stable category) acting by Adams operations. Using the Teichm¨ller u character ω to embed ( Z /p ) × in ( Z ∧ p ) × , we then get an action of the ring Z ∧ p [( Z /p ) × ], which then produces an eigensplitting of TC ( S ) ∧ p into the p -1 summands corresponding to the powers of the Teichm¨ller character. u The wedge summand /epsilon1 i TC ( S ) ∧ p in the proof of Theorem 5.1 corresponds to the character ω i in the sense that the p -adically interpolated Adams operation ψ ω α ( ) acts on it by multiplication by ω i ( α ) ∈ Z ∧ p for all α ∈ ( Z /p ) × .
We can imagine that p -adically interpolated Adams operations act on the whole linearization/cyclotomic trace square; we would then obtain an eigensplitting into p -1 squares exactly as in the statement of Theorem 5.1. We regard this as providing evidence for the following pair of conjectures, which together would give a conceptual (as opposed to calculational) proof of Theorem 5.1.
Conjecture 5.3. Let R be an E ∞ ring spectrum. There exists a homomorphism from ( Z ∧ p ) × to the composition monoid [ K R ( ) ∧ p , K ( R ) ∧ p ] , which is natural in the obvious sense and satisfies the following properties.
- (i) When R is a ring, the restriction to Z ∩ ( Z ∧ p ) × gives Quillen's Adams operations on the zeroth space.
- (ii) The induced map ( Z ∧ p ) × → Hom( π K R ∗ ( ) ∧ p , π ∗ K R ( ) ∧ p ) is continuous where the target is given the p -adic topology.
Conjecture 5.4. For R a connective E ∞ ring spectrum, the cyclotomic trace K R ( ) ∧ p → TC R ( ) ∧ p commutes with the (conjectural) p -adically interpolated Adams operations.
The preceding conjecture on p -adic interpolation of the Adams operations in p -completed algebraic K -theory is weaker than the (known) results in the case of topological K -theory in that we are only asking for continuity on homotopy groups rather than continuity for (some topology on) endomorphisms. Nevertheless, it implies a natural action of Z ∧ p [( Z /p ) × ] (in the stable category) on p -completed algebraic K -theory spectra (of connective ring spectra), which is all that is needed for the eigensplitting. To compare to the splitting used in Theorem 5.1, note that for an algebraically closed field of characteristic prime to p or a strict Henselian ring A with p invertible, the Adams operation ψ k acts on π 2 s L K (1) K A ( ) by multiplication by k s . As a consequence, for any scheme satisfying the hypotheses for Thomason's spectral sequence [31, 4.1], the eigensplitting on homotopy groups is compatible with the filtration from E ∞ in the sense that the subquotient of H s ( R ; Z /p n ( )) i comes from the ω i summand. For R = Z [1 /p ], we see that the ω i summand of L K (1) K R ( ) has homotopy groups only in degrees congruent to 2 i -1 and 2 i -2 mod 2( p -1) except when i = 0 where the unit of π L 0 K (1) ( R ) is also in the trivial character summand. As a consequence, we see that this splitting agrees with the splitting described above for L K (1) K ( Z [1 /p ]) /similarequal L K (1) K ( Z ). Specifically, the summand corresponding to trivial character is J and the summand corresponding to ω i is Y i for i = 1 , . . . , p -2.
The preceding conjectures also leads to the same splitting of TC ( Z ) ∧ p . HesselholtMadsen [12, Th. D,Add. 6.2] shows that the completion map and cyclotomic trace
$$T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow T C ( \mathbb { Z } _ { p } ^ { \wedge } ) _ { p } ^ { \wedge } \longleftarrow K ( \mathbb { Z } _ { p } ^ { \wedge } ) _ { p } ^ { \wedge }$$
are weak equivalences after taking the connective cover and so in particular induce weak equivalences after K (1)-localization. The Quillen localization sequence identifies the homotopy fiber of the map K ( Z ∧ p ) → K ( Q ∧ p ) as K ( F p ). Since the p -completion of K ( F p ) is weakly equivalent to H Z ∧ p , its K (1)-localization is trivial. Combining these maps, we obtain a canonical isomorphism in the stable category from L K (1) TC ( Z ) to L K (1) K ( Q ∧ p ). The Hesselholt-Madsen proof of the QuillenLichtenbaum conjecture for certain local fields [13, Th. A] (or in this case, inspection from the calculation of TC ( Z ) ∧ p ), shows that the map
$$T C ( \mathbb { Z } ) _ { p } ^ { \wedge } \longrightarrow L _ { K ( 1 ) } T C ( \mathbb { Z } ) \simeq L _ { K ( 1 ) } K ( \mathbb { Q } _ { p } ^ { \wedge } )$$
becomes a weak equivalence after taking 1-connected covers. Again looking at Thomason's spectral sequence, we see that the conjectural Adams operations would then split L K (1) K ( Q ∧ p ) into summands as follows. The summand corresponding to the trivial character is J ∨ Σ -1 L TC (0), the summand corresponding to ω is Σ J ∨ Σ -1 L TC (1), and the summand corresponding to ω i is Σ -1 L TC ( ) i for i = 2 , . . . , p -2. A short argument now shows that the eigensplitting gives the splitting of TC ( Z ) ∧ p used in Theorem 5.1.
We have proposed relatively strong conjectures in 5.3 and 5.4; for a proof of Theorem 5.1, it would be enough for the operations to exist and be compatible just for regular rings. The work of Riou [25] makes the existence of such operations plausible. But given the work of Dundas [8], the more general conjectures above (at least for connective ring spectra R with π R 0 regular) are not far removed from the corresponding conjectures for rings. We do also note that work on non-existence of determinants [2, 2.3] and [33, Proof of 3.7] is often cited as evidence against the existence of Adams operations on the algebraic K -theory of ring spectra.
## 6. Low degree computations
Theorem 1.2 describes the p -torsion in K ( S ) in terms of the p -torsion in various pieces. For convenience, we review in Proposition 6.1 below what is known about the homotopy groups of these pieces at least up to the range in which [29] describes the homotopy groups of C P ∞ -1 /similarequal Σ -1 Cu . As a consequence of Theorem 1.2, irregular primes potentially contribute in degrees divisible by 4 but otherwise make no contribution to the torsion of K ( S ) until degree 22. Thus, π K ∗ ( S ) in degrees ≤ 21 not divisible by 4 is fully computed (up to some 2-torsion extensions) by the work of Rognes [28, 29]. For convenience, we assemble the computation of π K ∗ ( S ) for ∗ ≤ 22 in Table 1 on page 24.
Proposition 6.1. The p -torsion groups tor p ( π ∗ S ), tor p ( π c ∗ ), tor p ( π K ∗ red ( Z )), and tor p ( π Cu ∗ ) are known in at least the following ranges, as follows.
- (i) π ∗ S , π j ∗ , see for example [23, 1.1.13]. π ∗ S splits as
$$\pi _ { * } \mathbb { S } = \pi _ { * } j \oplus \pi _ { * } c.$$
tor p ( π j k ) is zero unless 2( p -1) divides k + 1, in which case it is cyclic of order p s +1 where k +1 = 2( p -1) p m s for m relatively prime to p . See below for π c ∗ .
- (ii) π c ∗ , see for example [23, 1.1.14]. In degrees ≤ 6 p p ( -1) -6, tor p ( π c ∗ ) is Z /p in the following degrees and zero in all others. (In the table, α 1 ∈ π 2 p -3 j .)
- (iii) π K ∗ red ( Z ), see for example [36, § VI.10] or Section 2. tor p ( π K ∗ red ( Z )) is zero in odd degrees. If p is regular, then tor p ( π 2 k K red ( Z )) = 0. If p satisfies the Kummer-Vandiver condition, then
| Generator | Degree |
|-----------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------|
| β 1 α 1 β 1 β 2 1 α 1 β 2 1 β 2 α 1 β 2 β 3 1 | 2 p ( p - 1) - 2 2( p +1)( p - 1) - 3 4 p ( p - 1) - 4 2(2 p +1)( p - 1) - 5 2(2 p +1)( p - 1) - 2 4( p +1)( p - 1) - 3 6 p ( p - 1) - 6 |
$$\text{tor} _ { p } ( \pi _ { 4 k } K ^ { \text{red} } ( \mathbb { Z } ) ) = 0 \text{ \ and \ } \text{tor} _ { p } ( \pi _ { 4 k + 2 } K ^ { \text{red} } ( \mathbb { Z } ) ) = \mathbb { Z } _ { p } ^ { \wedge } / ( \frac { B _ { 2 k + 2 } } { 2 k + 2 } ),$$
where B n denotes the Bernoulli number, numbered by the convention t e t -1 = ∑ B n n t n ! . If p does not satisfy the Kummer-Vandiver condition then tor p ( π 4 k K red ( Z )) = 0 for k = 1 and is an unknown finite group for k > 1, while tor p ( π 4 k +2 K red ( Z )) is an unknown group of order #( Z ∧ p / B ( 2 k +2 / (2 k +2)) for all k .
- (iv) π Cu ∗ , see [29, 4.7].
- · In odd degrees ≤ | β 2 | -2 = 2(2 p +1)( p -1) -4,
$$\text{tor} _ { p } ( \pi _ { 2 n + 1 } \overline { C u } ) = \mathbb { Z } / p$$
in degrees n = p 2 - -p 1+ m or n = 2 p 2 -2 p -2+ m for 1 ≤ m ≤ p -3 and zero otherwise.
- · In even degrees ≤ 2 p p ( -1),
$$\text{tor} _ { p } ( \pi _ { 2 n } \overline { C u } ) = \mathbb { Z } / p$$
for m p ( -1) < n < mp for 2 ≤ m ≤ p -1 and zero otherwise except that
$$\text{tor} _ { p } ( \pi _ { 2 ( p ( p - 1 ) - 1 ) } \overline { C u } ) = 0.$$
Beyond this range, [29, 4.7] only describes the size of the group. In all even degrees ≤ | β 2 | -2 = 2(2 p +1)( p -1) -4, the size of tor p ( π 2 n Cu ) is
$$\# ( \text{tor} _ { p } ( \pi _ { 2 n } \overline { C u } ) ) = p ^ { a ( n ) + b ( n ) - c ( n ) - d ( n ) + e ( n ) }$$
where
$$a ( n ) & = \lfloor ( n - 1 ) / ( p - 1 ) \rfloor \\ b ( n ) & = \lfloor ( n - 1 ) / ( p ( p - 1 ) ) \rfloor \\ c ( n ) & = \lfloor n / p \rfloor \\ d ( n ) & = \lfloor n / p ^ { 2 } \rfloor$$
and
$$\text{and} \\ e ( n ) = \begin{cases} + 1, & \text{if $n=p^{2}-2+mp$ for $1\leq m\leq p-3$,} \\ - 1, & \text{if $n=p-1+mp$ for $m\geq p-2$} \\ 0, & \text{otherwise.} \end{cases} \\ \text{Here } \left [ x \right ] \text{ denotes the greatest integer $\leq x$}. \quad \text{The formulas $a$,} \\ \cdots \dots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots + \cdots \dots \dots \dots \dots \dots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots + \cdots \delta \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \delta \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \delta \cdots \delta \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
Here /floorleft x /floorright denotes the greatest integer ≤ x . The formulas a, b, c, d above count the number of positive integers < n (in a and b ) or ≤ n (in c and d ) that are divisible by the denominator.
The formula above shows that for p = 3, π 14 ( Cu ) has order 9. Rognes [29, 4.9(b)] shows that this group is Z / 9.
Table 1. The homotopy groups of K ( S ) in low degrees
| n | | π n K ( S ) | | | | | | | |
|-----------|-----|-------------------------------------------------|---------------------------|--------------|-------|-------------|-------|----|------------|
| 0 1 2 3 4 | Z 0 | Z / 2 Z / 2 Z / 8 × Z / 3 | ⊕ Z / 2 | 2 | | | | ⊕ | K 8 ( Z ) |
| 11 12 | | Z / 8 × Z / 9 × Z / 7 | ⊕ Z / 2 ⊕ Z / 4 | | Z / 3 | | | ⊕ | K 12 ( Z ) |
| 13 14 15 | Z ⊕ | Z / 3 ( Z / 2) 2 Z / 32 × Z / 2 × Z / 3 × Z / 5 | ⊕ Z / 4 ⊕ Z | 2 | Z / 3 | ⊕ | Z / 9 | ⊕ | K 16 ( Z ) |
| 16 17 | Z ⊕ | ( Z / 2) 2 ( Z / 2) 4 | ( / 2) ⊕ Z / 8 ⊕ ( Z / 2) | × Z / 2 2 | ⊕ ⊕ | Z / 3 | | | |
| 18 19 20 | | Z / 8 × Z / 2 Z / 8 × Z / 2 × Z / 3 × Z / 11 | ⊕ Z / 32 ⊕ [64] ⊕ [128] | × ( Z / 2) 3 | | Z / ⊕ Z / 3 | 3 × Z | ⊕ | K 20 ( Z ) |
| 21 | | Z / 8 × Z / 3 ( Z / 2) 2 | [16] | | Z / 3 | | | | Z / 691 |
| 22 | Z ⊕ | ( Z / 2) 2 | ⊕ ⊕ [2 ? ] | | ⊕ | Z / | 3 | ⊕ | |
| | 1 ○ | 2 ○ | 3 ○ | | 4 ○ | 5 ○ | | | 6 ○ |
The table compiles the results reviewed in Proposition 6.1 (q.v. for sources) and [28, 5.8] into the computation of π K n ( S ) for n ≤ 22. The description of π K n ( S ) is divided into columns:
- 1. The non-torsion part
- 2. The contribution from the torsion of S
- 3. The remaining 2-torsion (from [28])
- 4. The contribution from Σ c for odd primes
- 5. The torsion contribution from Cu for odd primes
- 6. The torsion contribution from K red ( Z ) for odd primes
Presently K 4 n ( Z ) is unknown for n > 1, conjectured to be 0 (the Kummer-Vandiver conjecture) and if non-zero is a finite group with order a product of irregular primes, each of which is > 10 . 8
Summands denoted as [ m ] are finite groups of order m whose isomorphism class is not known.
## References
- [1] Vigleik Angeltveit, Andrew J. Blumberg, Teena M. Gerhardt, Michael A. Hill, Tyler Lawson, and Michael A. Mandell. Topological cyclic homology via the norm. Preprint, arXiv:1401.5001, 2014.
- [2] Christian Ausoni, Bjørn Ian Dundas, and John Rognes. Divisibility of the Dirac magnetic monopole as a two-vector bundle over the three-sphere. Doc. Math. , 13:795-801, 2008.
- [3] Andrew J. Blumberg and Michael A. Mandell. The nilpotence theorem for the algebraic K -theory of the sphere spectrum. Geom. Topol. , 21(6):3453-3466, 2017.
- [4] M. B¨ okstedt, W. C. Hsiang, and I. Madsen. The cyclotomic trace and algebraic K -theory of spaces. Invent. Math. , 111(3):465-539, 1993.
- [5] M. B¨ okstedt and I. Madsen. Topological cyclic homology of the integers. Ast´risque e , (226):57143, 1994. K -theory (Strasbourg, 1992).
- [6] M. B¨ okstedt and I. Madsen. Algebraic K -theory of local number fields: the unramified case. In Prospects in topology (Princeton, NJ, 1994) , volume 138 of Ann. of Math. Stud. , pages 28-57. Princeton Univ. Press, Princeton, NJ, 1995.
- [7] A. K. Bousfield. The localization of spectra with respect to homology. Topology , 18(4):257281, 1979.
- [8] Bjørn Ian Dundas. Relative K -theory and topological cyclic homology. Acta Math. , 179(2):223-242, 1997.
- [9] W. G. Dwyer and S. A. Mitchell. On the K -theory spectrum of a ring of algebraic integers. K -Theory , 14(3):201-263, 1998.
- [10] William G. Dwyer and Eric M. Friedlander. Topological models for arithmetic. Topology , 33(1):1-24, 1994.
[11]
Thomas G. Goodwillie. Relative algebraic
K
-theory and cyclic homology.
Ann. of Math. (2)
,
124(2):347-402, 1986.
- [12] Lars Hesselholt and Ib Madsen. On the K -theory of finite algebras over Witt vectors of perfect fields. Topology , 36(1):29-101, 1997.
- [13] Lars Hesselholt and Ib Madsen. On the K -theory of local fields. Ann. of Math. (2) , 158(1):1113, 2003.
- [14] John R. Klein and John Rognes. The fiber of the linearization map A ( ∗ ) → K ( Z ). Topology , 36(4):829-848, 1997.
- [15] Manfred Kolster, Thong Nguyen Quang Do, and Vincent Fleckinger. Twisted S -units, p -adic class number formulas, and the Lichtenbaum conjectures. Duke Math. J. , 84(3):679-717, 1996.
- [16] Ronnie Lee and R. H. Szczarba. The group K 3 ( Z ) is cyclic of order forty-eight. Ann. of Math. (2) , 104(1):31-60, 1976.
- [17] Ronnie Lee and R. H. Szczarba. On the torsion in K 4 ( Z ) and K 5 ( Z ). Duke Math. J. , 45(1):101-129, 1978.
- [18] Ib Madsen. Algebraic K -theory and traces. In Current developments in mathematics, 1995 (Cambridge, MA) , pages 191-321. Int. Press, Cambridge, MA, 1994.
- [19] Ib Madsen and Christian Schlichtkrull. The circle transfer and K -theory. In Geometry and topology: Aarhus (1998) , volume 258 of Contemp. Math. , pages 307-328. Amer. Math. Soc., Providence, RI, 2000.
- [20] B. Mazur and A. Wiles. Class fields of abelian extensions of Q . Invent. Math. , 76(2):179-330, 1984.
[21]
Randy McCarthy. Relative algebraic
K
-theory and topological cyclic homology.
Acta Math.
,
179(2):197-222, 1997.
- [22] Douglas C. Ravenel. The Segal conjecture for cyclic groups and its consequences. Amer. J. Math. , 106(2):415-446, 1984. With an appendix by Haynes R. Miller.
- [23] Douglas C. Ravenel. Nilpotence and periodicity in stable homotopy theory , volume 128 of Annals of Mathematics Studies . Princeton University Press, Princeton, NJ, 1992. Appendix C by Jeff Smith.
- [24] Kenneth A. Ribet. A modular construction of unramified p -extensions of Q µ ( p ). Invent. Math. , 34(3):151-162, 1976.
- [25] Jo¨ el Riou. Algebraic K -theory, A 1 -homotopy and Riemann-Roch theorems. J. Topol. , 3(2):229-264, 2010.
- [26] John Rognes. Characterizing connected K -theory by homotopy groups. Math. Proc. Cambridge Philos. Soc. , 114(1):99-102, 1993.
- [27] John Rognes. K 4 ( Z ) is the trivial group. Topology , 39(2):267-281, 2000.
- [28] John Rognes. Two-primary algebraic K -theory of pointed spaces. Topology , 41(5):873-926, 2002.
- [29] John Rognes. The smooth Whitehead spectrum of a point at odd regular primes. Geom. Topol. , 7:155-184 (electronic), 2003.
- [30] Peter Schneider. Uber gewisse Galoiscohomologiegruppen. ¨ Math. Z. , 168(2):181-205, 1979.
- [31] R. W. Thomason. Algebraic K -theory and ´tale cohomology. e Ann. Sci. Ecole Norm. Sup. ´ (4) , 18(3):437-552, 1985.
- [32] F. Waldhausen, B. Jahren, and J. Rognes. Spaces of PL manifolds and categories of simple maps , volume 186 of Annals of Mathematics Studies . Princeton University Press, Princeton, 2013.
- [33] Friedhelm Waldhausen. Algebraic K -theory of spaces, a manifold approach. In Current trends in algebraic topology, Part 1 (London, Ont., 1981) , volume 2 of CMS Conf. Proc. , pages 141184. Amer. Math. Soc., Providence, R.I., 1982.
- [34] Friedhelm Waldhausen. Algebraic K -theory of spaces, localization, and the chromatic filtration of stable homotopy. In Algebraic topology, Aarhus 1982 (Aarhus, 1982) , volume 1051 of Lecture Notes in Math. , pages 173-195. Springer, Berlin, 1984.
- [35] Lawrence C. Washington. Introduction to cyclotomic fields , volume 83 of Graduate Texts in Mathematics . Springer-Verlag, New York, second edition, 1997.
- [36] Charles A. Weibel. The K -book , volume 145 of Graduate Studies in Mathematics . American Mathematical Society, Providence, RI, 2013. An introduction to algebraic K -theory.
Department of Mathematics, The University of Texas, Austin, TX 78712 Email address : [email protected]
Department of Mathematics, Indiana University, Bloomington, IN 47405 Email address : [email protected] | 10.2140/gt.2019.23.101 | [
"Andrew J. Blumberg",
"Michael A. Mandell"
] | 2014-08-01T11:24:42+00:00 | 2020-12-14T21:23:35+00:00 | [
"math.KT",
"math.AT",
"19D10"
] | The homotopy groups of the algebraic K-theory of the sphere spectrum | We calculate $\pi_*K(\mathbb S)[1/2]$, the homotopy groups of $K(\mathbb S)$
away from 2, in terms of the homotopy groups of $K(\mathbb Z)$, the homotopy
groups of ${\mathbb C}P^\infty_{-1}$, and the homotopy groups of $\mathbb S$.
This builds on the work of Waldhausen, who computed the rational homotopy
groups (building on work of Quillen and Borel) and Rognes, who calculated the
groups at regular primes in terms of the homotopy groups of ${\mathbb
C}P^\infty_{-1}$, and the homotopy groups of $\mathbb S$. |
1408.0134v1 | ## Closed-Form Waiting Time Approximations for Polling Systems ∗
M.A.A. Boon †
[email protected]
E.M.M. Winands [email protected]
‡
I.J.B.F. Adan †
[email protected]
A.C.C. van Wijk § [email protected]
December, 2010
## Abstract
A typical polling system consists of a number of queues, attended by a single server in a fixed order. The vast majority of papers on polling systems focusses on Poisson arrivals, whereas very few results are available for general arrivals. The current study is the first one presenting simple closed-form approximations for the mean waiting times in polling systems with renewal arrival processes, performing well for all workloads. The approximations are constructed using heavy traffic limits and newly developed light traffic limits. The closed-form approximations may prove to be extremely useful for system design and optimisation in application areas as diverse as telecommunication, maintenance, manufacturing and transportation.
Keywords: Polling, waiting times, queue lengths, approximation
## 1 Introduction
Polling systems are queueing systems consisting of multiple queues, visited by a single server -typically in a fixed, cyclic order. They find their origin in many real-life applications, e.g. (computer) communication, production and manufacturing environments, traffic and transportation. For a good literature overview of polling systems and their applications, we refer to surveys of, e.g., Takagi [21], Levy and Sidi [14], and Vishnevskii and Semenova [24]. When studying literature on polling systems, it rapidly becomes apparent that the computation of the distributions and moments of the waiting times and marginal queue lengths is very cumbersome. Closed form expressions do not exist, and even when one specifies the number of queues and solves the set of equations that leads to the mean waiting times, the obtained
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-NF.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
‡ Department of Mathematics, Section Stochastics, VU University, De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands
§ Department of Industrial Engineering & Innovation Sciences and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
expressions are still too lengthy and complicated to interpret directly. Numerical procedures, both approximate and exact, have been developed in the past to compute these performance measures. However, these methods have several drawbacks. Firstly, they are not transparent and act as a kind of black box. It is, for instance, rather difficult to study the impact of parameters like the occupation rate and the service level. Secondly, these procedures are computationally complex and hard, if not impossible, to implement in a standard spreadsheet program commonly used on the work floor. Finally, the vast majority of standard methods focusses on Poisson arrival processes, which may not be very realistic in many application areas. In the present paper we study polling systems in which the arrival streams are not (necessarily) Poisson, i.e., the interarrival times follow a general distribution. The goal is to derive closed-form approximate solutions for the mean waiting times and mean marginal queue lengths, which can be computed by simple spreadsheet calculations.
Our approach in developing an approximation for the mean waiting times uses novel developments in polling literature. Recently, a heavy traffic (HT) limit has been developed for the mean waiting times as the system becomes saturated [6, 17, 23]. In the present paper we derive an approximation for the light traffic (LT) limit, i.e. as the load decreases to zero, which is exact for Poisson arrivals. The main idea is to create an interpolation between the LT limit and the HT limit. This interpolation yields good results, and has several nice properties, like satisfying the Pseudo Conservation Law (PCL), and being exact for symmetric systems with Poisson arrivals and in many limiting cases. These properties are described in more detail in the present paper. In polling literature, several alternative approximations have been developed before, most of which assume Poisson arrivals. For polling systems with Poisson arrivals and gated or exhaustive service, the best results, by far, are obtained by an approximation based on the PCL (see, e.g., [3, 7, 11]). Fischer et al. [8] study an approximation for the mean waiting times in polling systems, which is also based on an interpolation between (approximate) LT and HT limits. Their approach, however, is applied to a system with Poisson arrivals and time-limited service. Hardly any closed-form approximations exist for non-Poisson arrivals. The few that exist, perform well in specific limiting cases, e.g., under HT conditions [17, 23], or if switch-over times become very large [27, 28], but performance deteriorates rapidly if these limiting conditions are abandoned, in contrast to the approximation developed in the present paper. We show in an extensive numerical study that the quality of our approximation can be compared to the PCL approximation for systems with Poisson arrivals, but provides good results as well for systems with renewal arrivals.
Because of its simple form, the approximation function is very suitable for optimisation purposes and implementation in a spreadsheet. Although only the mean waiting times of systems with exhaustive or gated service are studied, the results can be extended to higher moments and general branching-type service disciplines. Polling systems with polling tables and/or batch service can also be analysed in a similar manner.
The structure of the present paper is as follows: the next section introduces the model and the required notation, and states the main result. Section 3 illustrates how this main result is obtained, while Section 4 provides results on the accuracy of the approximation for a large set of combinations of input parameter values. The last section discusses further research topics and possible extensions of the model.
## 2 Model description and main result
The model under consideration is a polling system consisting of N queues, Q , . . . , Q 1 N , with renewal arrival processes. Indices throughout the present paper are understood to be modulo N : Q N +1 actually refers to Q 1 . Whenever a server switches from Q i to Q i +1 , a random switch-over time S i is incurred. The generic service requirement of a customer arriving in Q i , also referred to as a type i customer, is denoted by the random variable B i . We make the usual independence assumptions for polling systems; the interarrival times, service times and switch-over times are all independent. The moment at which the server switches from one queue to the next queue, is determined by the service discipline of the queue that is being served. In the present paper we focus on polling systems in which each queue is either served according to the gated service discipline, which states that during the course of a visit of the server to Q i , only those type i customers are served that were present at the beginning of that visit, or according to the exhaustive service discipline, which means that the server keeps on serving type i customers until Q i is empty, before switching to Q i +1 .
We regard several variables as a function of the load ρ in the system. Scaling is done by keeping the service time distributions fixed, and varying the interarrival times. For each variable x that is a function of the load in the system, ρ , its value evaluated at ρ = 1 is denoted by ˆ. x For ρ = 1, the generic interarrival time of the stream in Q i is denoted by ˆ . A i Reducing the load ρ is done by scaling the interarrival times, i.e., taking the random variable A i := ˆ A /ρ i as generic interarrival time at Q i . After scaling, the load at Q i becomes ρ i = ρ E [ B i ] E [ ˆ ] A i . The (scaled) rate of the arrival stream at Q i is defined as λ i = 1 / E [ A i ]. Similarly, we define arrival rates ˆ λ i = 1 / E [ ˆ ], A i and proportional load at Q i , ˆ ρ i = ρ i ρ ('proportional' because ∑ N i =1 ˆ ρ i = 1). The system is assumed to be stable, so ρ is varied between 0 and 1. We use B to denote the generic service requirement of an arbitrary customer entering the system, with E [ B k ] = ∑ N i =1 ˆ λ i E [ B k i ] ∑ N j =1 ˆ λ j for any integer k > 0, and S = ∑ N i =1 S i denotes the total switch-over time in a cycle. Finally, the (equilibrium) residual length of a random variable X is denoted by X res , with E [ X res ] = 1 E [ X / 2 ] E [ X ].
2
We now present the main result of this paper, which is a closed-form approximation formula for the mean waiting time E [ W i ] of a type i customer as a function of ρ :
$$\mathbb { E } [ W _ { i, a p p } ] = \frac { K _ { 0, i } + K _ { 1, i } \rho + K _ { 2, i } \rho ^ { 2 } } { 1 - \rho }, \quad i = 1, \dots, N.$$
The constants K 0 ,i , K 1 ,i , and K 2 ,i depend on the input parameters and the service discipline. If all queues receive exhaustive service, the constants become:
$$K _ { 0, i } = \mathbb { E } [ S ^ { \text{res} } ],$$
$$\nu, \quad \Gamma ^ { \nu } _ { 1, i } = & \hat { \rho } _ { i } ( \mathbb { E } [ \hat { A } _ { i } ] \hat { \rho } _ { i } ( 0 ) - 1 ) \mathbb { E } [ B _ { i } ^ { r e s } ] + \mathbb { E } [ B ^ { r e s } ] + \hat { \rho } _ { i } ( \mathbb { E } [ S ^ { r e s } ] - \mathbb { E } [ S ] ) - \frac { 1 } { \mathbb { E } [ S ] } \sum _ { j = 0 } ^ { N - 1 } \sum _ { k = 0 } ^ { j } \hat { \rho } _ { i + k } \mathbb { V } \tilde { \Gamma } [ S _ { i + j } ], \\ & \quad \,. \,. \,. \,. \,. \,.$$
$$K _ { 2, i } = & \frac { 1 - \hat { \rho } _ { i } } { 2 } \left ( \frac { \sum _ { j = 1 } ^ { N } \hat { \lambda } _ { j } \left ( \mathbb { V } { \text{ar} } [ B _ { j } ] + \hat { \rho } _ { j } ^ { 2 } \mathbb { V } { \text{ar} } [ \hat { A } _ { j } ] \right ) } { \sum _ { j = 1 } ^ { N } \hat { \rho } _ { j } ( 1 - \hat { \rho } _ { j } ) } + \mathbb { E } [ S ] \right ) - K _ { 0, i } - K _ { 1, i }.$$
If all queues receive gated service, we get:
$$K _ { 0, i } = \mathbb { E } [ S ^ { \text{res} } ],$$
$$\Phi _ { 1, i } = & \hat { \rho } _ { i } ( \mathbb { E } [ \hat { A } _ { i } ] \hat { \rho } _ { i } ( 0 ) - 1 ) \mathbb { E } [ B _ { i } ^ { r e s } ] + \mathbb { E } [ B ^ { r e s } ] + \hat { \rho } _ { i } \mathbb { E } [ S ^ { r e s } ] - \frac { 1 } { \mathbb { E } [ S ] } \sum _ { j = 0 } ^ { N - 1 } \sum _ { k = 0 } ^ { j } \hat { \rho } _ { i + k } \text{Var} [ S _ { i + j } ], \\ & \quad \Phi _ { 1, i } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phis _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j } \Phi _ { j + k } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psi _ { j } \Psigma _ { j } \Psi _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j + k } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psi _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j + k } \Psigma _ { j } \Psigma _ _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j} \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma _ { j } \Psigma }$$
$$K _ { 2, i } = & \frac { 1 + \hat { \rho } _ { i } } { 2 } \left ( \frac { \sum _ { j = 1 } ^ { N } \hat { \lambda } _ { j } \left ( \mathbb { V } { \text{ar} [ B _ { j } ] } + \hat { \rho } _ { j } ^ { 2 } \mathbb { V } { \text{ar} [ \hat { A } _ { j } ] } \right ) } { \sum _ { j = 1 } ^ { N } \hat { \rho } _ { j } ( 1 + \hat { \rho } _ { j } ) } + \mathbb { E } [ S ] \right ) - K _ { 0, i } - K _ { 1, i }.$$
The term ˆ ( ) is the density of g i t ˆ , the interarrival times at A i ρ = 1. This term is discussed in more detail in the next section, but for practical purposes it is useful to know that E [ ˆ ]ˆ (0) A g i i can be very well approximated by
$$\mathbb { E } [ \hat { A } _ { i } ] \hat { g } _ { i } ( 0 ) \approx \begin{cases} 2 \frac { c v _ { A _ { i } } ^ { 2 } } { c v _ { A _ { i } } ^ { 2 } + 1 } & \quad \text{ if } c v _ { A _ { i } } ^ { 2 } > 1, \\ \left ( c v _ { A _ { i } } ^ { 2 } \right ) ^ { 4 } & \quad \text{ if } c v _ { A _ { i } } ^ { 2 } \leq 1, \end{cases}$$
where cv 2 A i is the squared coefficient of variation (SCV) of A i (and, hence, also of ˆ ). A i Note that this simplification results in an approximation that requires only the first two moments of each input variable (i.e., service times, switch-over times, and interarrival times).
Remark 2.1 In case of Poisson arrivals, the constants K 1 ,i and K 2 ,i simplify considerably. E.g., for exhaustive service they simplify to:
$$K _ { 1, i } ^ { P o i s s o n } = & \mathbb { E } [ B ^ { r e s } ] + \hat { \rho } _ { i } \left ( \mathbb { E } [ S ^ { r e s } ] - \mathbb { E } [ S ] \right ) - \frac { 1 } { \mathbb { E } [ S ] } \sum _ { j = 0 } ^ { N - 1 } \sum _ { k = 0 } ^ { j } \hat { \rho } _ { i + k } \mathbb { V } \text{ar} [ S _ { i + j } ],$$
$$K _ { 2, i } ^ { P o i s s o n } = & ( 1 - \hat { \rho } _ { i } ) \left ( \frac { \mathbb { E } [ B ^ { r e s } ] } { \sum _ { j = 1 } ^ { N } \hat { \rho } _ { j } ( 1 - \hat { \rho } _ { j } ) } + \frac { \mathbb { E } [ S ] } { 2 } \right ) ^ { \cdot } - K _ { 0, i } - K _ { 1, i } ^ { P o i s s o n }.$$
$$\AA _ { i + j }, \\ \AA _ { i + j },$$
The derivation of this approximative formula for the mean waiting time is the topic of the next section. An approximation for the mean queue length at Q i , E [ L i ] is obtained by application of Little's Law to the sojourn time of type i customers, i.e. the waiting time plus the service time. As a function of ρ , we have
$$\mathbb { E } [ L _ { i, a p p } ] = \rho \frac { \mathbb { E } [ W _ { i, a p p } ] + \mathbb { E } [ B _ { i } ] } { \mathbb { E } [ \hat { A } _ { i } ] }.$$
## 3 Derivation of the approximation
Approximation (2.1) is an interpolation approximation based on LT and HT limits. In the next subsection we first provide a motivation for this approach.
## 3.1 Generic interpolation function
In its generic form, the interpolation approximation proceeds as follows; see [18, 20]. Consider an open queueing system with load ρ . Let f ( ρ ), 0 ≤ ρ < 1, be some function of the queueing system (such as the mean waiting time), which is assumed to be analytic on [0 1), i.e., by , Taylor's Theorem f ( ρ ) can be expressed as
$$f ( \rho ) = \sum _ { n = 0 } ^ { \infty } \frac { f ^ { ( n ) } ( 0 ) } { n! } \rho ^ { n }, \ \ 0 \leq \rho < 1,$$
where f ( n ) ( ρ ) denotes the n th derivative f ( ρ ). Usually, f ( ρ ) is intractable, but it may be possible to derive partial information about f ( ρ ), such as the light traffic limits f ( n ) (0) for n = 0 1 , , . . . , k and the 'canonical' heavy traffic limit h = lim ρ → 1 (1 -ρ f ) ( ρ ). For examples, see [9, 18, 25], where based on the partial information, an approximation for f ( ρ ) is constructed of the form
$$\tilde { f } ( \rho ) = \frac { q ( \rho ) } { 1 - \rho },$$
where q ρ ( ) is the ( k +1)st degree polynomial, uniquely determined by the requirement that ˜ ( f ρ ) has to match everything that is known about f ( ρ ), i.e., ˜ f ( n ) (0) = f ( n ) (0) for n = 0 1 , , . . . , k and lim ρ → 1 (1 -ρ f ) ˜ ( ρ ) = h . The heavy traffic limit implies (see Prop. 1 in [20]),
$$\lim _ { n \to \infty } \frac { f ^ { ( n ) } ( 0 ) } { n! } = h.$$
This suggests that, in the Taylor series, f ( n ) (0) for n > k can be approximated by n h ! . Thus, combined with knowledge of the light traffic limits f ( n ) (0) for n = 0 1 , , . . . , k , the following new approximation can be produced,
$$\bar { f } ( \rho ) = \sum _ { n = 0 } ^ { k } \frac { f ^ { ( n ) } ( 0 ) } { n! } \rho ^ { n } + h \frac { \rho ^ { k + 1 } } { 1 - \rho }.$$
Interestingly, this seemingly different approximation ¯ ( f ρ ) is identical to the interpolation approximation ˜ ( f ρ ), confirming the notion that they are the 'natural' approximation for f ( ρ ), given the partial information. In [18] the interpolation approximation (3.1) is shown to work extremely well for several examples. The present paper applies approximation (3.1) to the new setting of polling systems with general renewal arrivals, for which no analytic expressions are known for the mean waiting times. Choosing f ( ρ ) as the mean waiting time of a type i customer, we derive new (approximations for the) light traffic limits f (0) and the first derivative f ′ (0), which together with the heavy traffic limit, yield an interpolation with a quadratic polynomial q ρ ( ); see (2.1).
In Sections 3.2 and 3.3 we derive the LT and HT limits, respectively. The interpolation approximation, matching these limits, is presented in Section 3.4. Finally, in Section 3.5, we show that the interpolation approximation also matches known exact results for mean waiting times in polling systems. In particular, we prove that the form (3.1) is crucial for satisfying the pseudo-conservation law for all loads ρ . An extensive numerical validation is the topic of Section 4, showing that the interpolation approximation works extremely well for polling systems.
## 3.2 Light traffic
The mean waiting times in the polling model under consideration in light-traffic, have been studied in Blanc and Van der Mei [2], under the assumption of Poisson arrivals. They obtain expressions for the mean waiting times in light traffic that are exact up to (and including) firstorder terms in ρ . These expressions have been found by carefully inspecting numerical results obtained with the Power-Series Algorithm, but no proof is provided. In the present section we shall not only prove the correctness of the light-traffic results in a system with Poisson arrivals, but also use them as base for an approximation for the mean waiting times in polling systems with renewal interarrival times. The key ingredient to the LT analysis of a polling system, is the well-known Fuhrmann-Cooper decomposition [10]. It states that in a vacation system with Poisson arrivals the queue length of a customer is the sum of two independent random variables: the number of customers in an isolated M/G/ 1 queue, and the number of customers during an arbitrary moment in the vacation period. The distributional form of Little's Law [12] can be used to translate this result to waiting times. Since no independence is required between the length of a vacation and the length of the preceding visit period, this decomposition also holds for polling systems with Poisson arrivals. We introduce V i to denote the length of a visit period to Q i , and I i to denote the length of the intervisit period, i.e. the time that the server is away between two successive visits to Q i . Using C i to denote the cycle time, starting at a visit beginning to Q i , we have E [ V i ] = ρ i E [ C i ] and E [ I i ] = (1 -ρ i ) E [ C i ]. It is well-known that the mean cycle time in polling systems, unlike higher moments, does not depend on the starting point: E [ C i ] = E [ C ] = E [ S ] 1 -ρ .
The Fuhrmann-Cooper decomposition, applied to the mean waiting time, results in:
$$\text{exhaustive} \colon & & \mathbb { E } [ W _ { i } ] = \mathbb { E } [ W _ { i, M / G / 1 } ] + \mathbb { E } [ I _ { i } ^ { r e s } ], & & ( 3. 2 )$$
$$\mathbb { E } [ W _ { i } ] = \mathbb { E } [ W _ { i, M / G / 1 } ] + \mathbb { E } [ I _ { i } ^ { r e s } ],$$
gated:
$$\mathbb { E } [ W _ { i } ] = \mathbb { E } [ W _ { i, M / G / 1 } ] + \mathbb { E } [ I _ { i } ^ { r e s } ] + \frac { \mathbb { E } [ V _ { i } I _ { i } ] } { \mathbb { E } [ I _ { i } ] }. \quad \quad ( 3. 3 )$$
For our approximation, we assume that this decomposition also holds for renewal arrival processes in light traffic. Determining the LT limit of the mean waiting time, E [ W LT i ], in a polling system with exhaustive or gated service is based on the following two-step approach. The first step is to find the LT limit of E [ W i,GI/G/ 1 ], the mean waiting time of a GI/G/ 1 queue with only type i customers in isolation, i = 1 , . . . , N . The second step is determining E [ I res i ], the mean residual intervisit time of Q i , and E [ V I i i ] E [ I i ] , the mean visit time of Q i given that it is being observed at a random epoch during the following intervisit time.
Remark 3.1 Bertsimas and Mourtzinou [1] state that the decompositions (3.2) and (3.3) also hold for polling systems with Mixed Generalised Erlang arrivals. However, simulation and exact analysis of some simple cases indicate that the decomposition result is not valid for the mean waiting times.
For the LT limit of the mean waiting time in a GI/G/ 1 queue, we use Whitt's result (Equation (16) in [25]), which gives:
$$\lim _ { \rho _ { i } \downarrow 0 } \frac { \mathbb { E } [ W _ { i, G I / G / 1 } ] } { \rho _ { i } } = \frac { 1 + c \upsilon _ { B _ { i } } ^ { 2 } } { 2 } \mathbb { E } [ \hat { A } _ { i } ] \hat { g } _ { i } ( 0 ) \mathbb { E } [ B _ { i } ],$$
where cv 2 B i is the SCV of the service times, and ˆ ( ) is the density of the interarrival times g i t ˆ . A i For practical purposes, it may be more convenient to express ˆ (0) in terms of the density of g i
A i , the generic interarrival time of Q i in the scaled situation.The relation between the density of the scaled interarrival times A i (= ˆ A /ρ i ), denoted by g i ( ), and the density of t ˆ , A i ˆ ( ), is g i t simply: g i ( ) = t ρg ˆ ( i ρt ). This means that the term E [ ˆ ]ˆ (0) can be rewritten as A g i i
$$\mathbb { E } [ \hat { A } _ { i } ] \hat { g } _ { i } ( 0 ) = \mathbb { E } [ A _ { i } ] g _ { i } ( 0 ).$$
Because of this equality, in the remainder of the paper we might use either notation. Since determining E [ ˆ ]ˆ (0) is a required step in the computation of our approximation for A g i i E [ W i ], we give some practical examples.
Example 1 If the scaled interarrival times A i are exponentially distributed with parameter λ i := 1 / E [ A i ], we have g i ( ) = t λ i e -λ t i . This implies that E [ A g i ] i (0) = 1.
Example 2 In this example we assume that A i follows a H 2 distribution with balanced means. The SCV of A i is denoted by cv 2 A i . The density of this hyper-exponential distribution is (see, e.g., [22])
$$g _ { i } ( t ) = p \mu _ { 1 } \text{e} ^ { - \mu _ { 1 } t } + ( 1 - p ) \mu _ { 2 } \text{e} ^ { - \mu _ { 2 } t },$$
with
$$p \ & = \ \frac { 1 } { 2 } \left ( 1 + \sqrt { \frac { c v _ { A _ { i } } ^ { 2 } - 1 } { c v _ { A _ { i } } ^ { 2 } + 1 } } \right ), \\ \mu _ { 1 } \ & = \ \frac { 1 } { \mathbb { E } \left [ A _ { i } \right ] } \left ( 1 + \sqrt { \frac { c v _ { A _ { i } } ^ { 2 } - 1 } { c v _ { A _ { i } } ^ { 2 } + 1 } } \right ), \\ \mu _ { 2 } \ & = \ \frac { 1 } { \mathbb { E } \left [ A _ { i } \right ] } \left ( 1 - \sqrt { \frac { c v _ { A _ { i } } ^ { 2 } - 1 } { c v _ { A _ { i } } ^ { 2 } + 1 } } \right ). \\ \dots ^ { 2 } \ \, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
This leads to E [ A g i ] i (0) = 1 + cv 2 A -1 cv 2 A +1 = 2 cv 2 A cv 2 A +1 .
Example 3 Now we assume that the interarrival times follow a mixed Erlang distribution. The density of the scaled interarrival times is:
$$g _ { i } ( t ) = p \frac { \mu ^ { k - 1 } t ^ { k - 2 } } { ( k - 2 )! } \text{e} ^ { - \mu t } + ( 1 - p ) \frac { \mu ^ { k } t ^ { k - 1 } } { ( k - 1 )! } \text{e} ^ { - \mu t },$$
i.e., a mixture of an Erlang( k -1) and an Erlang( k ) distribution with
$$\Pi \text{Elam} ( \varkappa - 1 ) \text{ and } \Pi \text{Elam} ( \varkappa ) \text{ using the output} \, \text{ with} \, \\ k \quad = \quad \left \lceil \frac { 1 } { c v _ { A _ { i } } ^ { 2 } } \right \rceil, \\ p \quad = \quad \frac { k \, c v _ { A _ { i } } ^ { 2 } - \sqrt { k ( 1 + c v _ { A _ { i } } ^ { 2 } ) - k ^ { 2 } \, c v _ { A _ { i } } ^ { 2 } } } { 1 + c v _ { A _ { i } } ^ { 2 } }, \\ \mu \quad = \quad \frac { k - p } { \mathbb { E } [ A _ { i } ] }. \\ \text{to $\mathbb{F} [ A ] } a ( 0 ) = 0$$
If k > 2, this leads to E [ A i ] g i (0) = 0.
The distributions in Examples 1 -3 are typical distributions to be used in a two-moment fit if the SCV of the interarrival times is respectively 1, greater than 1, and less than 1 (cf. [22]). The examples illustrate how E [ A g i ] i (0) can be computed if the density of the (scaled) interarrival times is known. If no information is available about the complete density, but the first two moments of A i are known, Whitt suggests to use the following approximation for E [ A g i ] i (0):
$$\mathbb { E } [ A _ { i } ] g _ { i } ( 0 ) = \begin{cases} 2 \frac { c v _ { A _ { i } } ^ { 2 } } { c v _ { A _ { i } } ^ { 2 } + 1 } & \quad \text{ if } c v _ { A _ { i } } ^ { 2 } > 1, \\ \left ( c v _ { A _ { i } } ^ { 2 } \right ) ^ { 4 } & \quad \text{ if } c v _ { A _ { i } } ^ { 2 } \leq 1, \end{cases}$$
where cv 2 A i is the squared coefficient of variation of the interarrival times of Q i . This approximation is exact for cv 2 A i > 1, if the interarrival time distribution is a hyper-exponential distribution as discussed in Example 2. For cv 2 A i ≤ 1, the approximation is rather arbitrary, but Example 3 shows that E [ A g i ] i (0) becomes small (or even zero) very rapidly as cv 2 A i gets smaller.
Summarising, the LT limit of a GI/G/ 1 queue (ignoring O ( ρ 2 i ) terms and higher) is:
$$\mathbb { E } [ W _ { i, G I / G / 1 } ^ { L T } ] = \rho _ { i } \mathbb { E } [ A _ { i } ] g _ { i } ( 0 ) \mathbb { E } [ B _ { i } ^ { r e s } ].$$
For Poisson arrivals ( E [ A g i ] i (0) = 1), it is known that E [ W i,M/G/ 1 ] = ρ i 1 -ρ i E [ B res i ] = ρ i E [ B res i ]+ O ( ρ 2 i ), which is consistent with our approximation.
The second step in determining the LT limit of the mean waiting time of a type i customer in a polling system, is finding the LT limits of E [ I res i ], the mean residual intervisit time of Q i , and (for gated service only) E [ V I i i ] E [ I i ] , the mean visit time V i given that it is observed from the following intervisit time I i . In this LT analysis we need to focus on first order terms only. Noting the fact that I i = S i + V i +1 + S i +1 + · · · + V i + N -1 + S i + N -1 , we condition on the moment at which I i is observed. We distinguish between two cases. The moment of observation either takes place during a visit time, or during a switch-over time:
$$\Phi _ { \Phi } \Phi _ { i } ^ { \Phi } & = \sum _ { j = 1 } ^ { N - 1 } \frac { \mathbb { E } [ V _ { i + j } ] } { \mathbb { E } [ I _ { i } ] } \mathbb { E } [ I _ { i } ^ { L T, r e s } | \text{observed during } V _ { i + j } ] \\ & \quad + \sum _ { j = 0 } ^ { N - 1 } \frac { \mathbb { E } [ S _ { i + j } ] } { \mathbb { E } [ I _ { i } ] } \mathbb { E } [ I _ { i } ^ { L T, r e s } | \text{observed during } S _ { i + j } ].$$
glyph[negationslash]
Observation during visit time. The probability that a random observation epoch takes place during a visit time, say V j , is E [ V j ] E [ I i ] , for any j = . However, we are only interested in i order ρ terms, so this probability simplifies to
$$\frac { \mathbb { E } [ V _ { j } ] } { \mathbb { E } [ I _ { i } ] } = \frac { \rho _ { j } \mathbb { E } [ C ] } { ( 1 - \rho _ { i } ) \mathbb { E } [ C ] } = \rho _ { j } + \mathcal { O } ( \rho ^ { 2 } ).$$
The fact that this probability is O ( ρ ), implies that all further O ( ρ ) terms can be ignored in E [ I LT,res i | observed during V j ], because in LT we focus on first order terms only.
The length of the residual intervisit time is the length of the residual visit period of type j customers, V res j , plus all switch-over times S j + · · · + S i -1 , plus all visit times V j +1 + · · · + V i -1 .
The first term simplifies to E [ V res j ] = E [ B res j ] + O ( ρ ). The terms E [ V k | observed from V j ] , k = j + 1 , . . . , i -1, in light traffic, are all O ( ρ ). Summarising, the mean residual intervisit period when observed during V j is simply a mean residual service time E [ B res j ], plus all mean switch-over times E [ S j + · · · + S i -1 ], plus O ( ρ ) terms:
$$\mathbb { E } [ I _ { i } ^ { L T, r e s } | \text{observed during } V _ { j } ] = \mathbb { E } [ B _ { j } ^ { r e s } ] + \sum _ { k = j } ^ { i - 1 } \mathbb { E } [ S _ { k } ] + \mathcal { O } ( \rho ).$$
The intuition behind this equation is that, in light traffic, the probability of having another service during the residual cycle is negligible, i.e., O ( ρ ). Hence, the length of the residual intervisit time is solely determined by the residual service time and the remaining switch-over times in the cycle.
Observation during switch-over time. We continue by determining the mean residual intervisit period, conditioned on a random observation epoch during a switch-over time, say S j , j = 1 , . . . , N . The probability that such an epoch takes place during S j , is
$$\frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ I _ { i } ] } = \frac { \mathbb { E } [ S _ { j } ] } { ( 1 - \rho _ { i } ) \mathbb { E } [ C ] } = \frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ S ] } \frac { 1 - \rho } { 1 - \rho _ { i } } = \frac { \mathbb { E } [ S _ { j } ] } { \mathbb { E } [ S ] } ( 1 - \rho + \rho _ { i } ) + \mathcal { O } ( \rho ^ { 2 } ).$$
It becomes apparent from this expression that things get slightly more complicated now, because order ρ terms in the conditional residual intervisit time may no longer be neglected. The residual intervisit time now consists of the residual switch-over time S res j , plus the switchover times S j +1 + · · · + S i -1 , plus all visit periods V j +1 + · · · + V i -1 . The length of a visit period V k , for k > j , is the sum of the busy periods of all type k customers that have arrived during S k -N , . . . , S j -1 , S past j , S res j , and S j +1 , . . . , S k -1 . By S past j we denote the elapsed switch-over time during which the intervisit period is observed, which has the same distribution as the residual switch-over time S res j . Compared to an observation during a visit time, it is more difficult to determine the conditional mean length of a busy period E [ V k | observed during S j ] under LT. We use a heuristic approach, which is exact if the arrival process of type k customers is Poisson, and approximate it by:
glyph[negationslash]
$$\mathbb { E } [ V _ { k } | \text{observed during } S _ { j } ] \approx \rho _ { k } \left ( \sum _ { l \neq j } \mathbb { E } [ S _ { l } ] + \mathbb { E } [ S _ { j } ^ { p a s t } ] + \mathbb { E } [ S _ { j } ^ { r e s } ] \right ) + \mathcal { O } ( \rho ^ { 2 } ), \quad k = j + 1, \dots, i - 1.$$
If A k is exponentially distributed, the above expression is exact. Nevertheless, numerical experiments have shown that this approximative assumption has no or at least negligible impact on the accuracy of the approximated mean waiting times. Summarising:
$$\ell [ I _ { i } ^ { L T, r e s } | \text{observed during } S _ { j } ] & \approx \sum _ { k = i } ^ { j - 1 } \mathbb { E } [ S _ { k } ] ( \sum _ { l = j + 1 } ^ { i + N - 1 } \rho _ { l } ) + \mathbb { E } \left ( S _ { j } ^ { p a s t } \right ) ( \sum _ { k = j + 1 } ^ { i + N - 1 } \rho _ { k } ) \\ & \quad + \mathbb { E } \left ( S _ { j } ^ { r e s } \right ) ( 1 + \sum _ { k = j + 1 } ^ { i + N - 1 } \rho _ { k } ) + \sum _ { k = j + 1 } ^ { i + N - 1 } \mathbb { E } [ S _ { k } ] ( 1 + \sum _ { l = j + 1 } ^ { i + N - 1 } \rho _ { l } ) + \mathcal { O } ( \rho ^ { 2 } ).$$
$$( 3. 8 )$$
The expression for I res i under light traffic conditions now follows from substituting (3.7) and (3.8) in (3.6). The result can be rewritten to:
$$& \text{The expression for } I _ { i } ^ { r e s } \text{ under light traffic conditions now follows from substituting (3.7) and } ( 3. 8 ) \text{ in (3.6). The result can be rewritten to: } \\ & \text{[T](I_T, r e s ] } \approx \sum _ { j = i + 1 } ^ { i + N - 1 } \rho _ { j } \text{E[B]} ^ { r e s ] } + \sum _ { j = i + 1 } ^ { i + N - 1 } \rho _ { j } \sum _ { k = j } ^ { \text{E[S,k]} } \\ & \quad \quad \quad + \sum _ { j = i } ^ { i + N - 1 } \frac { 1 } { 2 \text{E[S] } } \left [ \begin{array} { c } \text{$E(S_{j})$ (1 - \rho + \rho_{i}+2 \sum _ { k=j+1})$ } \rho _ { k}) \end{array} \right ] \\ & \quad \quad + \sum _ { j = i + 1 } ^ { i + N - 1 } \left [ \begin{array} { c } j - 1 \\ j - 1 \\ \sum _ { j = i } ^ { \text{E[S,j]}$\text{E[S,k]}$( \sum _ { j = i + 1 } ^ { i + N - 1 } \frac { i + N - 1 } { 2 \text{E[S,j]}$\text{E[S,k]}$(1 - \rho + \rho_{i}+2 \sum _ { l=j+1})$ } \rho _ { l=j+1 } \end{array} \right ] \\ & \quad \quad + \overline { \text{E[S] } } \sum _ { j = i + 1 } ^ { i + N - 1 } \left [ \begin{array} { c } j - 1 \\ j - 1 \\ \sum _ { k = j + 1 } ^ { \text{E[S,j]}$\text{E[S,k]}$( \sum _ { j = i + 1 } ^ { i + N - 1 } \frac { i + N - 1 } { 2 \text{E[S,j]}$\text{E[S,k]}$(1 - \rho + \rho_{i}+2 \sum _ { l=j+1})$ } \rho _ { l=j+1 } \end{array} \right ] \\ & \quad \quad + \overline { \text{O(r}^{2)}$} \\ & \quad \quad \quad$$
for i = 1 , . . . , N . The last step in (3.9) follows after some straightforward (but tedious) rewriting.
The Fuhrmann-Cooper decomposition of the mean waiting time for customers in a polling system with gated service (3.3), also requires the computation of E [ V I i i ] E [ I i ] under LT conditions.
Here, again, we have to resort to using a heuristic and use E [ V I i i ] E [ I i ] = ρ i E [ S ] + O ( ρ 2 ), because this value is exact in the case of Poisson arrivals. This term is the mean length of the visit time V i given that it is observed during the following intervisit time I i . The term appears because, contrary to exhaustive service, type i customers arriving during V i are not served until the next cycle. However, it is easier to consider E [ V I i i ] / E [ V i ] instead, and to use the relation
$$\frac { \mathbb { E } [ V _ { i } I _ { i } ] } { \mathbb { E } [ I _ { i } ] } = \frac { \mathbb { E } [ V _ { i } I _ { i } ] } { \mathbb { E } [ V _ { i } ] } \times \frac { \mathbb { E } [ V _ { i } ] } { \mathbb { E } [ I _ { i } ] }.$$
The term E [ V I i i ] / E [ I i ] is the mean length of the intervisit time I i following V i , given that it is observed during this visit time V i . Firstly, we note that
$$\frac { \mathbb { E } [ V _ { i } ] } { \mathbb { E } [ I _ { i } ] } = \frac { \rho _ { i } } { 1 - \rho _ { i } } = \rho _ { i } + \mathcal { O } ( \rho ^ { 2 } ).$$
This implies that we can ignore all O ( ρ ) terms in E [ V I i i ] / E [ V i ], which means that only the switch-over times play a role,
$$\frac { \mathbb { E } [ V _ { i } I _ { i } ] } { \mathbb { E } [ V _ { i } ] } = \mathbb { E } [ S ] + \mathcal { O } ( \rho ).$$
Concluding, we have
$$\frac { \mathbb { E } [ V _ { i } I _ { i } ] } { \mathbb { E } [ I _ { i } ] } = \rho _ { i } \mathbb { E } [ S ] + \mathcal { O } ( \rho ^ { 2 } ),$$
in the case of Poisson arrivals. If the arrival process is not Poisson, this is not exact, but we use it as an approximation.
Having made all required preparations, we are ready to formulate the main result of the present subsection. Under light traffic, an approximation for the mean waiting time of a type i customer in a polling model with general arrivals and respectively exhaustive and gated service in Q i , is:
$$\mathbb { E } [ W _ { i } ^ { L T, e x h } ] & \approx \mathbb { E } [ S ^ { r e s } ] + \rho _ { i } ( \mathbb { E } [ \hat { A } _ { i } ] \hat { g } _ { i } ( 0 ) - 1 ) \mathbb { E } [ B _ { i } ^ { r e s } ] + \rho \mathbb { E } [ B ^ { r e s } ] + ( \rho - \rho _ { i } ) \left ( \mathbb { E } [ S ] - \mathbb { E } [ S ^ { r e s } ] \right ) \\ & + \frac { 1 } { \mathbb { E } [ S ] } \sum _ { k = i + 1 } ^ { i + N - 1 } \rho _ { k } \sum _ { j = i } ^ { k - 1 } \mathbb { V } \text{ar} [ S _ { j } ] + \mathcal { O } ( \rho ^ { 2 } ), \quad i = 1, \dots, N, \\ \mathbb { w } \colon \colon L T. \text{atched} \quad \mathbb { w } \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \col. \end{matrix}$$
$$\mathbb { E } [ W _ { i } ^ { L T, g a t e d _ { i } } ] \approx \mathbb { E } [ W _ { i } ^ { L T, e x h _ { i } } ] + \rho _ { i } \mathbb { E } [ S ],$$
where ˆ ( ) is the density of the interarrival times of type g i t i customers at ρ = 1. Equation (3.11) follows from substitution of (3.5) and (3.9) in
$$\mathbb { E } [ W _ { i } ] \approx \mathbb { E } [ W _ { i, G I / G / 1 } ] + \mathbb { E } [ I _ { i } ^ { r e s } ], \quad i = 1, \dots, N.$$
For Poisson arrivals, (3.11) and (3.12) are exact. The LT limit for polling systems with Bernoulli service (and Poisson arrivals) has been experimentally found in [2] and, indeed, it can be shown that their result for exhaustive service, which is a special case of Bernoulli service, agrees with our result after substituting E [ ˆ ]ˆ (0) = 1 in (3.11). A g i i
## 3.3 Heavy traffic
Heavy traffic limits in polling systems have been studied by Coffman et al. [5, 6], and by Olsen and Van der Mei [16, 17]. In these papers, the HT limits of the waiting time distributions are found under the assumption of Poisson arrivals. For general renewal arrivals, a proof is given for the special case N = 2 (cf. [5, 6]), and a strong conjecture for larger values of N (cf. [17]). In [23], the following result for the mean waiting time is proven rigorously for polling systems with renewal arrivals:
$$\mathbb { E } [ W _ { i } ^ { H T } ] = \frac { \omega _ { i } } { 1 - \rho } + o ( ( 1 - \rho ) ^ { - 1 } ), \quad \rho \uparrow 1.$$
Obviously, in HT, all queues become unstable and, thus, E [ W i ] tends to infinity for all i . The rate at which E [ W i ] tends to infinity as ρ ↑ 1 is indicated by ω i , which is referred to as the mean asymptotic scaled delay at queue i , and depends on the service discipline. For exhaustive service,
$$\omega _ { i } = \frac { 1 - \hat { \rho } _ { i } } { 2 } \left ( \frac { \sigma ^ { 2 } } { \sum _ { j = 1 } ^ { N } \hat { \rho } _ { j } ( 1 - \hat { \rho } _ { j } ) } + \mathbb { E } [ S ] \right ), \quad i = 1, \dots, N,$$
with
$$\sigma ^ { 2 } \coloneqq \sum _ { i = 1 } ^ { N } \hat { \lambda } _ { i } \left ( \mathbb { V } \arho [ B _ { i } ] + \hat { \rho } _ { i } ^ { 2 } \mathbb { V } \arho [ \hat { A } _ { i } ] \right ).$$
Here, the limits are taken such that the arrival rates are increased, while keeping the servicetime distributions fixed, and keeping the distributions of the interarrival times A i ( i = 1 , . . . , N ) fixed up to a common scaling constant ρ . Notice that in the case of Poisson arrivals we have σ 2 = E [ B 2 ] / E [ B ].
For gated service, we have
$$\omega _ { i } = \frac { 1 + \hat { \rho } _ { i } } { 2 } \left ( \frac { \sigma ^ { 2 } } { \sum _ { j = 1 } ^ { N } \hat { \rho } _ { j } ( 1 + \hat { \rho } _ { j } ) } + \mathbb { E } [ S ] \right ).$$
## 3.4 Interpolation
Now that we have the expressions for the mean delay in both LT and HT, we can determine the constants K 0 ,i , K 1 ,i , and K 2 ,i in approximation formula (2.1). We simply impose the requirements that approximation (2.1) results in the same mean waiting time for ρ = 0 as the LT limit, and for ρ ↑ 1 as the HT limit. Since (3.11) (and (3.12) for gated service) has been determined up to the first order of ρ terms, we also add the requirement that the derivative with respect to ρ , taken at ρ = 0, of our approximation is equal to the derivative of the LT limit. A more formal definition of these requirements is presented below:
$$\mathbb { E } [ W _ { i, a p p } ] \Big | _ { \rho = 0 } & = \mathbb { E } [ W _ { i } ] \Big | _ { \rho = 0 }, \\ \frac { d } { d \rho } \mathbb { E } [ W _ { i, a p p } ] \Big | _ { \rho = 0 } & = \frac { d } { d \rho } \mathbb { E } [ W _ { i } ] \Big | _ { \rho = 0 }, \\ ( 1 - \rho ) \mathbb { E } [ W _ { i, a p p } ] \Big | _ { \rho = 1 } & = ( 1 - \rho ) \mathbb { E } [ W _ { i } ] \Big | _ { \rho = 1 }.$$
This leads to (2.1) as approximation for E [ W i ] in a polling system with general arrivals. Constants K 0 ,i , K 1 ,i , and K 2 ,i are defined in (2.2)-(2.4) for systems with exhaustive service, or (2.5)-(2.7) for gated service.
## 3.5 Matching properties
A desirable property of an approximation is that it matches known exact results. In the present section we discuss several cases where the interpolation approximation yields exact results. Most cases require Poisson arrivals, but it is shown that also in two limiting cases where exact results are available for general arrivals, i.e., heavy traffic and large switch-over times, the approximation is exact. It further turns out that, in case of Poisson arrivals, the approximated mean waiting times satisfy the pseudo-conservation law , implying that the weighted sum ∑ N i =1 ρ i E [ W i, app ] is exact for each load 0 ≤ ρ < 1. In fact, this appears to be true for any interpolation approximation for the mean waiting times of the form (3.1) matching the HT limit and the LT limits of order 0 up to order k , provided k > 0. These properties of the interpolation approximation indicate that it is the 'natural' approximation, given the HT and LT limits.
Light and heavy traffic. The light traffic limit of E [ W i ], given by (3.11) for exhaustive service and by (3.12) for gated service, is exact for Poisson arrivals. The heavy traffic limit (3.14) of E [ W i ] is even exact for renewal arrivals. An appropriate choice of constants K 0 ,i , K 1 ,i
and K 2 ,i can reduce (2.1) to either (3.11), (3.12), or (3.14). Since the LT and HT limits have been used in the set of equations that determine the coefficients of the approximation, it goes without saying that E [ W i, app ] is equal to (3.11) (or (3.12) for gated service) and (3.14), for ρ ↓ 0 and ρ ↑ 1 respectively. This implies that the LT limit of our approximation is exact for Poisson arrivals, and the HT limit is exact for general arrivals.
Symmetric system. If ˆ ρ i = 1 N for all i = 1 , . . . , N , all B i have the same distribution, and the variances V ar[ S i ] of all switch-over times are equal, then our approximation is exact if all interarrival distributions are exponential. For exhaustive service, we obtain
$$K _ { 1, i } = & \mathbb { E } [ B ^ { r e s } ] + \frac { N - 1 } { N } \mathbb { E } [ S ] - \left ( 2 - \frac { 1 } { N } \right ) \mathbb { E } [ S ^ { r e s } ] + \frac { 1 } { \mathbb { E } [ S ] } \sum _ { k = i + 1 } ^ { i + N - 1 } \hat { \rho } _ { k } \sum _ { j = i } ^ { k - 1 } \mathbb { V } _ { \ } [ S _ { j } ] \\ = & \mathbb { E } [ B ^ { r e s } ] + \frac { N - 1 } { N } \mathbb { E } [ S ] - \left ( 2 - \frac { 1 } { N } \right ) \mathbb { E } [ S ^ { r e s } ] + \frac { N - 1 } { N } \frac { \text{Var} [ S ] } { 2 \mathbb { E } [ S ] } \\ = & \mathbb { E } [ B ^ { r e s } ] + \left ( 1 - \frac { 1 } { N } \right ) \frac { \mathbb { E } [ S ] } { 2 } - \mathbb { E } [ S ^ { r e s } ], \\ \dots \pi \nu \quad \partial \, \text{Tr.\colon \dots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \ddots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \vdots \pi \cup \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \}$$
and K 2 ,i = 0. This implies that E [ W i, app ] = E [ W i, symm ], since
$$\mathbb { E } [ W _ { i, s y m m } ] = \frac { \rho } { 1 - \rho } \mathbb { E } [ B ^ { r e s } ] + \mathbb { E } [ S ^ { r e s } ] + \frac { \rho ( 1 - \frac { 1 } { N } ) } { 1 - \rho } \frac { \mathbb { E } [ S ] } { 2 }.$$
Note that E [ W i, symm ] is of the form (3.1) with q ρ ( ) being a linear polynomial. In fact, this immediately implies that the interpolation is exact, given the (exact) LT and HT limits. Further, we do not require that the mean switch-over times E [ S i ] are equal. One can verify that the same holds for gated service.
Single queue (vacation model). An immediate consequence of the fact that our approximation is exact in symmetric polling systems with Poisson arrivals, is that it also gives exact results for the mean waiting time of customers in a single-queue polling system with Poisson arrivals. A polling system consisting of only one queue, but with a switch-over time between successive visits to this queue, is generally referred to as a queueing system with multiple server vacations.
Large switch-over times. For S deterministic, S →∞ , and, again, under the assumption of Poisson arrivals, it is proven in [27, 28] that E [ W i ] S → 1 -ρ i 2(1 -ρ ) for exhaustive service. It can easily be verified that our approximation has the same limiting behaviour:
$$\lim _ { S \to \infty } \frac { \mathbb { E } [ W _ { i, a p p } ] } { S } = \frac { 1 - \rho _ { i } } { 2 ( 1 - \rho ) }.$$
For gated service, E [ W i, app ] S → 1+ ρ i 2(1 -ρ ) , which is also the exact limit (see, e.g., [26]).
Olsen [15] studies the effects of large switch-over times in polling systems operating under HT conditions. She discovers that, under these conditions, the limiting behaviour (3.15) is also exhibited in polling systems with general renewal arrivals .
Miscellaneous other exact results. The approximation is also exact in several other cases, all with Poisson arrivals, when the parameter values are carefully chosen. The relations between the input parameters that yield exact approximation results become very complicated, especially in polling systems with more than two queues. We only mention one interesting example here: our approximation gives exact results for a two-queue polling system with exhaustive service and
$$\mathbb { E } [ B _ { 1 } ] = \mathbb { E } [ B _ { 2 } ], \mathbb { E } [ S _ { 1 } ] = \mathbb { E } [ S _ { 2 } ], c \nu _ { A _ { 1 } } ^ { 2 } = c \nu _ { A _ { 2 } } ^ { 2 }, c \nu _ { B _ { 1 } } ^ { 2 } = c \nu _ { B _ { 2 } } ^ { 2 }, c \nu _ { S _ { 1 } } ^ { 2 } = c \nu _ { S _ { 2 } } ^ { 2 },$$
if the following constraint is satisfied:
$$\rho = \frac { 1 + I _ { A _ { i } } ^ { 2 } } { 2 I _ { A _ { i } } } - \frac { c v _ { S _ { i } } ^ { 2 } } { 1 + c v _ { B _ { i } } ^ { 2 } } \cdot \frac { \mathbb { E } [ S _ { i } ] } { \mathbb { E } [ B _ { i } ] },$$
where I A i = ˆ ρ 1 ˆ ρ 2 is the ratio of the loads of the two queues. Obviously, if I A i = 1, the system is symmetric and our approximation gives exact results regardless of the other parameter settings.
Pseudo-conservation law. Awell-known result in polling literature, is the so-called pseudoconservation law , derived by Boxma and Groenendijk [4] using the concept of work decomposition. This law gives the following exact expression for the weighted sum of the mean waiting times in a polling system with Poisson arrivals:
$$\sum _ { i = 1 } ^ { N } \rho _ { i } \mathbb { E } [ W _ { i } ] = \frac { \rho ^ { 2 } } { 1 - \rho } \mathbb { E } [ B ^ { r e s } ] + \rho \mathbb { E } [ S ^ { r e s } ] + \frac { \mathbb { E } [ S } { 2 } \frac { \rho ^ { 2 } - \sum _ { j = 1 } ^ { N } \rho _ { j } ^ { 2 } } { 1 - \rho } + \sum _ { j = 1 } ^ { N } \mathbb { E } [ Z _ { j j } ], \quad \ ( 3. 1 8 )$$
where E [ Z jj ] denotes the mean amount of work left behind in Q j at the completion of a visit of the server to Q j . It is shown in [4] that E [ Z jj ] is the only term that depends on the service discipline. For exhaustive service E [ Z jj ] = 0, for gated service E [ Z jj ] = ρ 2 j E [ S ] 1 -ρ . It can be shown that the interpolation approximation (2.1) satisfies the pseudo-conservation law in the case of Poisson arrivals: if E [ ˆ ]ˆ (0) = 1 for A g i i i = 1 , . . . , N , then ∑ N i =1 ρ i E [ W i, app ] equals the right-hand side of (3.18). In fact, in case of Poisson arrivals, any interpolation approximation for the mean waiting times of the form (3.1), matching the HT limit and the LT limits of order 0 up to order k , satisfies (3.18), provided k > 0. To establish this result, we first rewrite (3.18) in the form Q ρ ( ) = 0, by moving the terms at right-hand side of (3.18) to the left. Now let ˜ ( Q ρ ) denote the version of Q ρ ( ) where the mean waiting times have been replaced by their interpolation approximation. Clearly, the interpolation approximation and the right-hand side of (3.18) are both of the form (3.1), and thus ˜ ( Q ρ ) is also of the form
$$\tilde { Q } ( \rho ) = \frac { \tilde { q } ( \rho ) } { 1 - \rho },$$
where ˜( q ρ ) is a polynomial of degree k +2. Since the interpolation approximation matches the LT limits of order 0 up to order k , it follows that ˜ Q ( n ) (0) = Q ( n ) (0) = 0, and hence, ˜ q ( n ) (0) = 0 for all n = 0 1 , , . . . , k +1. Further, by the HT limit, ˜(1) = lim q ρ → 1 (1 -ρ Q ρ ) ˜ ( ) = lim ρ → 1 (1 -ρ Q ρ ) ( ) = 0. This implies that ˜( q ρ ) = 0, and thus ˜ ( Q ρ ) = 0 for all ρ .
## 4 Numerical study
## 4.1 Initial glance at the approximation
Before we study the accuracy of the approximation to a large test bed of polling systems, we just pick a rather arbitrary, simple system to compare the approximation with exact results in order to get some initial insights. Consider a three-queue polling system with loads of Q 1 , Q 2 , and Q 3 divided as follows: ˆ ρ 1 = 0 1 . , ρ ˆ 2 = 0 3, and . ˆ ρ 3 = 0 6. . All service times and switch-over times are exponentially distributed, with mean 1. The interarrival times have SCV cv 2 A i = 3 for i = 1 2 3. In Figure 1 we plot the approximated mean waiting time of , , Q 2 , E [ W 2 , app ], versus the load of the system ρ . Since this system cannot be analysed analytically, we compare the approximated values with simulated values. Both in the approximation and in the simulation we fit a H 2 distribution as described in Example 2.
The errors are largest for Q 2 , which is the reason why we chose this queue in particular in Figure 1. The most important information that this figure reveals, is that even though the accuracy of the approximation is worst for this queue (a relative error of -4 47% for . ρ = 0 7), . the shape of the approximation function is very close to the shape of the exact function, which makes it very suitable for optimisation purposes. The maximum relative errors of Q 1 and Q 3 are 3 10% and 2 90% respectively. . .
In order to get more insight in the numerical accuracy of the approximation for a wide variety of different parameter settings, we create a large test bed in the next subsection and compare the approximation with exact or simulated results. It turns out that the maximum relative errors for most of the polling systems are smaller than the one selected in the above example.
Figure 1: Approximated and simulated mean waiting time E [ W 2 ] of Q 2 of the example in subsection 4.1.
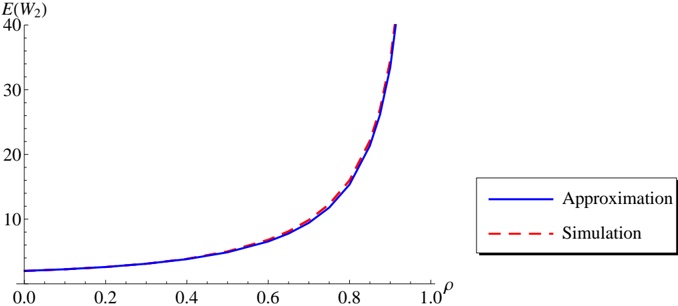
## 4.2 Accuracy of the approximation
In the present section we study the accuracy of our approximation. We compare the approximated mean waiting times of customers in various polling systems to the exact values. The complete test bed of polling systems that are analysed, contains 2304 different combinations of parameter values, all listed in Table 1. We show detailed results for exhaustive service first, and discuss polling systems with gated service at the end of this section. We have varied
Table 1: Test bed used to compare the approximation to exact results.
| Parameter | Notation | Values |
|-------------------------------------|------------|------------------------------------------------|
| Number of queues | N | 2 , 3 , 4 , 5 |
| Load | ρ | 0 . 1 , 0 . 3 , 0 . 5 , 0 . 7 , 0 . 9 , 0 . 99 |
| SCV interarrival times | cv 2 A i | 0 . 25 , 1 , 2 |
| SCV service times | cv 2 B i | 0 . 25 , 1 |
| SCV switch-over times | cv 2 S i | 0 . 25 , 1 |
| Imbalance interarrival times | I A i | 1 , 5 |
| Imbalance service times | I B i | 1 , 5 |
| Ratio service and switch-over times | I S i /B i | 1 , 5 |
glyph[negationslash]
the load between 0 1 and 0 9 with steps of 0 2, and included . . . ρ = 0 99 to analyse the limiting . behaviour of our approximation when the load tends to 1. The SCV of the interarrival times, cv 2 A i , is varied between 0 25 and 2. . In case of non-Poisson arrivals, i.e. cv 2 A i = 1, the exact values have been established through extensive simulation because they cannot be obtained in an analytic way. In these simulations we fit a phase-type distribution to the first two moments of the interarrival times, as described in Examples 2 and 3. For service times and switch-over times, only SCVs of 0 25 and 1 are considered. . SCVs greater than 1 are less common in practice and are discussed separately from the test bed later in this section. The imbalance in interarrival times and service times, I A i and I B i , is the ratio between the largest and the smallest mean interarrival/service time. The interarrival times are determined in such a way, that the overall mean is always 1, λ 1 is the largest and λ N the smallest, and the steps between the λ i are linear. E.g., for N = 5 and I A i = 5 we get λ i = 2 -i/ 3 , i = 1 , . . . , 5. The mean service times E [ B i ] increase linearly in i = 1 , . . . , N , with E [ B N ] = I B i E [ B 1 ] (so E [ B 1 ] is the smallest mean service time). They follow from the relation ∑ N i =1 λ i E [ B i ] = ρ . E.g., for N = 5, and I A i = I B i = 5 we get E [ B /ρ i ] = 3 i/ 35. The last parameter that is varied in the test bed, is the ratio between the mean switch-over times and the mean service times, I S /B i i = E [ S i ] E [ B i ] . The total number of systems analysed is 4 × 6 × 3 × 2 5 = 2304. A system consisting of N queues results N mean waiting times, E [ W ,..., 1 ] E [ W N ], so in total these 2304 systems yield 8064 mean waiting times. The absolute relative errors, defined as | o - | e /e , where o stands for observed (approximated) value, and e stands for expected (exact) value, are computed for all these 8064 queues. Table 2 shows these relative errors (times 100%) categorised in bins of 5%. In this table, and in all other tables, results for systems with a different number of queues are displayed in separate rows. The reader should keep in mind that the statistics in each row are based on 1 4 × 2304 × N absolute relative errors, where N is the number of queues used in the specified row. Table 2 shows that, e.g., 98 84% of the approximated mean . waiting times in polling systems consisting of 3 queues deviate less than 5% from their true
values. From Table 2 it can be concluded that the approximation accuracy increases with the number of queues in a polling system. More specifically, for systems with more than 2 queues, no approximation errors are greater than 10%, and the vast majority is less than 5%. The mean relative errors for N = 2 , . . . , 5 are respectively 2 18% 0 93% 0 70% and 0 57%. . , . , . . It is also noteworthy, that 193 out of the 2304 systems yield exact results. All of these 193 systems have Poisson input, and all of them - except for one - are symmetric. The only asymmetric case for which our approximation yields an exact result, happens to satisfy constraints (3.16) and (3.17).
In Table 3 the mean relative error percentages are shown for a combination of input parameter settings. The number of queues is always varied per row, while per column another input parameter is varied. This way we can find in more detail which (combinations of) parameter settings result in large approximation errors. In Table 3(a) the load ρ is varied, and it can be seen that for a load of ρ = 0 7 the approximation is least accurate. . E.g., the mean relative error of all approximated waiting times in polling systems consisting of 3 queues with a load of ρ = 0 7 is 1 69%. . . Table 3(b) shows the impact of the SCV of the interarrival times on the accuracy. Especially for systems with more than 2 queues the accuracy is very satisfactory, in particular for the case cv 2 A i = 1. In Table 3(c) the impact of imbalance in a polling system on the accuracy is depicted, and, as could be expected, it can be concluded that a high imbalance in either service or interarrival times has a considerable, negative, impact on the approximation accuracy. Polling systems with more than 2 queues are much less bothered by this imbalance than polling systems with only 2 queues.
Table 2: Errors of the approximation applied to the 2304 test cases with exhaustive service, as described in Section 4, categorised in bins of 5%.
| N | 0 - 5% | 5 - 10% | 10 - 15% | 15 - 20% |
|-----|----------|-----------|------------|------------|
| 2 | 86 . 46 | 10 . 24 | 2 . 78 | 0 . 52 |
| 3 | 98 . 84 | 1 . 16 | 0 . 00 | 0 . 00 |
| 4 | 99 . 78 | 0 . 22 | 0 . 00 | 0 . 00 |
| 5 | 99 . 93 | 0 . 07 | 0 . 00 | 0 . 00 |
## 4.3 Miscellaneous other cases
In this subsection we discuss several cases that are left out of the test bed because they might not give any new insights, or because the combination of parameter values might be rarely found in practice.
More queues. Firstly, we discuss polling systems with more than 5 queues briefly. Without listing the actual results, we mention here that the approximations become more and more accurate when letting N grow larger, and still varying the other parameters in the same way as is described in Table 1. For N = 10 already, all relative errors are less than 5%, with an average of less than 0 5% and it only gets smaller as . N grows further.
More variation in service times and switch-over times. In the test bed we only use SCVs 0 25 and 1 for the service times and switch-over times, because these seem more relevant .
| N | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) |
|----------|--------------|--------------|--------------|--------------|--------------|
| 0 . 10 | 0 . 30 | 0 . 50 | 0 . 70 | 0 . 90 | 0 . 99 |
| 2 0 . 31 | 1 . 81 | 3 . 41 | 4 . 17 | 2 . 70 | 0 . 67 |
| 3 0 . 16 | 0 . 84 | 1 . 44 | 1 . 69 | 1 . 07 | 0 . 39 |
| 4 0 . 13 | 0 . 68 | 1 . 14 | 1 . 28 | 0 . 73 | 0 . 25 |
| 5 0 . 11 | 0 . 57 | 0 . 94 | 1 . 03 | 0 . 57 | 0 . 22 |
(a)
| N | SCV interarrival 0 . 25 | 1 | times ( cv A 2 |
|-----|---------------------------|--------|------------------|
| 2 | 2 . 27 | 1 . 76 | 2 . 50 |
| 3 | 1 . 36 | 0 . 52 | 0 . 92 |
| 4 | 1 . 13 | 0 . 29 | 0 . 69 |
| 5 | 0 . 97 | 0 . 19 | 0 . 56 |
| | | (b) | |
| N | Imbalance interarrival and service times | Imbalance interarrival and service times | Imbalance interarrival and service times | Imbalance interarrival and service times |
|-----|--------------------------------------------|--------------------------------------------|--------------------------------------------|--------------------------------------------|
| | I A i = 1 , I B i = 1 | I A i = 1 , I B i = 5 | I A i = 5 , I B i = 1 | I A i = 5 , I B i = 5 |
| 2 | 0 . 69 | 2 . 92 | 2 . 80 | 2 . 30 |
| 3 | 0 . 65 | 1 . 27 | 0 . 75 | 1 . 06 |
| 4 | 0 . 56 | 0 . 89 | 0 . 62 | 0 . 73 |
| 5 | 0 . 49 | 0 . 69 | 0 . 53 | 0 . 59 |
(c)
Table 3: Mean relative approximation error, categorised by number of queues ( N ) and total load of the system (a), SCV interarrival times (b), and imbalance of the interarrival and service times (c).
from a practical point of view. As the coefficient of variation grows larger, our approximation will become less accurate. E.g., for Poisson arrivals we took cv 2 B i ∈ { 2 5 , } , cv 2 S i ∈ { 2 5 , } , and varied the other parameters as in our test bed (see Table 1). This way we reproduced Table 2. The result is shown in Table 4 and indicates that the quality of our approximation deteriorates in these extreme cases. The mean relative errors for N = 2 , . . . , 5 are respectively 3 58%, 1 78%, 1 07%, and 0 77%, which is still very good for systems with such high variation . . . . in service times and switch-over times. For non-Poisson input, no investigations were carried out because the results are expected to show the same kind of behaviour.
Table 4: Errors of the approximation applied to the 768 test cases with Poisson arrival processes and high SCVs of the service times and switch-over times, categorised in bins of 5%.
| N | 0 - 5% | 5 - 10% | 10 - 15% | 15 - 20% |
|-----|----------|-----------|------------|------------|
| 2 | 74 . 22 | 14 . 84 | 6 . 51 | 2 . 08 |
| 3 | 89 . 76 | 7 . 29 | 2 . 08 | 0 . 69 |
| 4 | 94 . 53 | 4 . 56 | 0 . 91 | 0 . 00 |
| 5 | 97 . 71 | 2 . 19 | 0 . 10 | 0 . 00 |
Small switch-over times. Systems with small switch-over times, in particular smaller than the mean service times, also show a deterioration of approximation accuracy - especially in systems with 2 queues. In Figure 2 we show an extreme case with N = 2, service times and switch-over times are exponentially distributed with E [ B i ] = 9 40 and E [ S i ] = 9 200 for i = 1 2, which makes the mean switch-over times 5 times , smaller than the mean service times. Furthermore, the interarrival times are exponentially distributed with λ 1 = 5 λ 2 . In Figure 2 the mean waiting times of customers in both queues are plotted versus the load of the system. Both the approximation and the exact values are plotted. For customers in Q 1 the mean waiting time approximations underestimate the true values, which leads to a maximum relative error of -11 2% for . ρ = 0 7 ( . E [ W 1 , app ] = 0 43, whereas . E [ W 1 ] = 0 49). . The approximated mean waiting time for customers in Q 2 is systematically overestimating the true value. The maximum relative error is attained at ρ = 0 5 and is 28 8% ( . . E [ W 1 , app ] = 0 41, . whereas E [ W 1 ] = 0 52). . Although the relative errors are high in this situation, the absolute errors are still rather small compared to the mean service time of an individual customer. This implies that the mean sojourn time is already much better approximated. Nevertheless, this example illustrates one of the situations where our approximation gives unsatisfactory results.
Figure 2: Approximated and exact mean waiting times for a two-queue polling system with small switch-over times.
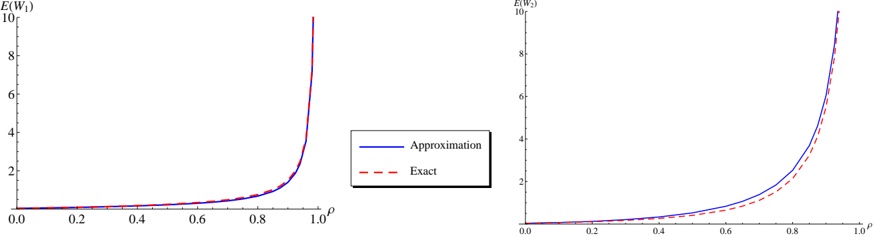
## 4.4 Comparison with existing approximations
The only alternative approximations that exist for polling systems with non-exponential interarrival times, only perform well under extreme, limiting conditions. In [17, 23] it is suggested to use the HT limit (3.14) as an approximation, but the accuracy is only found to be acceptable for ρ > 0 8. . Another approximation for the mean waiting time in polling systems with non-exponential interarrival times uses the limit for S →∞ [27, 28]. This approximation is usable if either the total switch-over time in the system is large and the switch-over times have low variance, or if the total switch-over time in the system is large and the system is in heavy traffic. For completeness, we mention that it is also possible to construct an approximation that is purely based on the LT limit, developed in the present paper:
$$\mathbb { E } [ W _ { i } ^ { L T } ] \approx \frac { K _ { 0, i } + ( K _ { 1, i } - K _ { 0, i } ) \rho } { 1 - \rho }.$$
We do not wish to go into further details on this topic, because the accuracy of (4.1) turns out to be worse for high loads. This makes our approximation, which is exact in all these
limiting cases, the only one which can be applied under all circumstances. We support this statement by reproducing Table 3(a) for the three alternative approximations, based on HT limit, large switch-over times, and LT limit. A comparison of Table 5, which displays these results, to Table 3(a), clearly indicates the drawbacks of using approximations based on one limiting case only.
| N | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) |
|-----------|--------------|--------------|--------------|--------------|--------------|
| 0 . 10 | 0 . 30 | 0 . 50 | 0 . 70 | 0 . 90 | 0 . 99 |
| 2 58 . 97 | 51 . 03 | 40 . 34 | 27 . 47 | 11 . 34 | 1 . 46 |
| 3 30 . 62 | 25 . 66 | 19 . 63 | 12 . 61 | 4 . 56 | 0 . 62 |
| 4 22 . 49 | 18 . 61 | 14 . 02 | 8 . 80 | 3 . 08 | 0 . 42 |
| 5 18 . 06 | 14 . 83 | 11 . 10 | 6 . 88 | 2 . 36 | 0 . 37 |
(a)
(b)
| N | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) |
|-----|--------------|--------------|--------------|--------------|--------------|--------------|
| | 0 . 10 | 0 . 30 | 0 . 50 | 0 . 70 | 0 . 90 | 0 . 99 |
| 2 | 27 . 13 | 31 . 08 | 35 . 95 | 41 . 32 | 46 . 78 | 49 . 23 |
| 3 | 19 . 28 | 21 . 68 | 24 . 51 | 27 . 52 | 30 . 33 | 31 . 44 |
| 4 | 15 . 05 | 16 . 75 | 18 . 76 | 20 . 92 | 22 . 93 | 23 . 67 |
| 5 | 12 . 37 | 13 . 67 | 15 . 24 | 16 . 96 | 18 . 56 | 19 . 17 |
Table 5: Mean relative approximation error, categorised by number of queues ( N ) and total load of the system, for three alternative approximations: based on the HT limit (a), based on large switch-over times (b), and based on the LT limit (c).
| N Load ( ρ ) | N Load ( ρ ) | N Load ( ρ ) | N Load ( ρ ) | N Load ( ρ ) | N Load ( ρ ) |
|----------------|----------------|----------------|----------------|----------------|----------------|
| | 0 . 10 | 0 . 30 | 0 . 50 0 . 70 | 0 . 90 | 0 . 99 |
| 2 | 0 . 34 2 . 65 | 7 . 00 | 13 . 42 | 21 . 90 | 26 . 82 |
| 3 | 0 . 24 1 . 68 | 3 . 90 | 6 . 70 | 9 . 62 | 10 . 82 |
| 4 | 0 . 19 1 . 31 | 2 . 97 | 4 . 87 | 6 . 75 | 7 . 46 |
| 5 | 0 . 16 1 . 09 | 2 . 45 | 4 . 02 | 5 . 54 | 6 . 12 |
For polling systems with Poisson arrivals, several alternative approximations have been developed in existing literature. The best one among them (see, e.g., [3, 7, 11]) uses the relation E [ W i ] = (1 ± ρ i ) E [ C res i ], where C i is the cycle time, starting at a visit completion to Q i when service is exhaustive, and starting at a visit beginning for gated service. By ± we mean -for exhaustive service, and + for gated service. The mean residual cycle time, E [ C res i ], is assumed to be equal for all queues, i.e. E [ C res i ] ≈ E [ C res ], and can be found by substituting E [ W i ] ≈ (1 ± ρ i ) E [ C res ] in the pseudo-conservation law (3.18). We have used this PCL-based approximation to estimate the mean waiting times of all queues in the test bed described in Table 1, but taking only the 768 cases where cv 2 A i = 1. Table 6 shows the mean relative
errors for our approximation (a) and the PCL approximation (b), categorised in bins of 5% as was done before in Table 2. From these tables (and from other performed experiments that are not mentioned for the sake of brevity) it can be concluded that for N > 2 both approximations have almost the same accuracy, our approximation being slightly better for small values of ρ , and the PCL approximation being slightly better for high values of ρ (both methods are asymptotically exact as ρ ↑ 1). However, for N = 2 our method suffers greatly from imbalance in the system, whereas the PCL approximation proves to be more robust.
Table 6: Errors of the approximation applied to the 768 test cases with Poisson input, categorised in bins of 5%. In (a) the percentages of mean relative errors in each bin are shown for our approximation, in (b) results are shown for the PCL approximation.
| N | 0 - 5% | 5 - 10% | 10 - 15% |
|-----|----------|-----------|------------|
| 2 | 89 . 32 | 9 . 11 | 1 . 56 |
| 3 | 100 . 00 | 0 . 00 | 0 . 00 |
| 4 | 100 . 00 | 0 . 00 | 0 . 00 |
| 5 | 100 . 00 | 0 . 00 | 0 . 00 |
| | | (a) | |
| N | 0 - 5% | 5 - 10% | 10 - 15% |
|-----|----------|-----------|------------|
| 2 | 96 . 09 | 2 . 86 | 1 . 04 |
| 3 | 99 . 31 | 0 . 69 | 0 . 00 |
| 4 | 100 . 00 | 0 . 00 | 0 . 00 |
| 5 | 100 . 00 | 0 . 00 | 0 . 00 |
| | | (b) | |
## 4.5 Gated service
glyph[negationslash]
Until now we have only shown and discussed approximation results for polling systems with exhaustive service. The complete test bed described in Table 1 has also been analysed for polling systems where each queue receives gated service. As can be seen in Table 7, the overall quality of the approximation is good, but worse than for polling systems with exhaustive service. More details on the reason for these inaccuracies can be found in Table 8, which is the equivalent of Table 3 for gated service. Table 8(b) illustrates that there is now a huge difference between systems with Poisson arrivals, and systems with non-Poisson arrivals. For the cases with cv 2 A i = 1, the approximation is extremely accurate, even for two-queue polling systems. The accuracy in cases with cv 2 A i = 1 is worse, which is caused by the assumptions that are made to approximate the LT limit (3.12). Firstly, the decomposition (3.3) does not hold for non-Poisson arrivals, and secondly, the terms E [ I res i ] and E [ V I i i ] E [ I i ] in this decomposition have only been approximated. For exhaustive service, these assumptions do not have much negative impact on the accuracy, but apparently, for gated service, they do. The mean relative errors for N = 2 , . . . , 5 queues are respectively 2 70%, 2 25%, 1 90%, and 1 63%. The . . . . imbalance of the mean interarrival and service times hardly influences the accuracy of the approximation, as can be concluded from Table 8(c).
If we consider the 768 cases with Poisson arrivals only, the mean relative errors of our approximation for N = 2 , . . . , 5 are respectively 0 34% . , 0 17% 0 10%, and 0 08%. This accuracy . , . . is even better than the one achieved by the PCL approximation.
| N | 0 - 5% | 5 - 10% | 10 - 15% | 15 - 20% |
|-----|----------|-----------|------------|------------|
| 2 | 82 . 55 | 12 . 33 | 2 . 95 | 1 . 56 |
| 3 | 85 . 42 | 10 . 53 | 3 . 13 | 0 . 81 |
| 4 | 88 . 85 | 8 . 46 | 2 . 43 | 0 . 26 |
| 5 | 92 . 22 | 6 . 60 | 1 . 15 | 0 . 03 |
Table 7: Errors of the approximation applied to the 2304 test cases with gated service, as described in Subsection 4.5, categorised in bins of 5%.
| N | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) | Load ( ρ ) |
|----------|--------------|--------------|--------------|--------------|--------------|
| 0 | . 10 0 . 30 | 0 . 50 | 0 . 70 | 0 . 90 | 0 . 99 |
| 2 2 . | 64 4 . 55 | 4 . 31 | 3 . 10 | 1 . 25 | 0 . 37 |
| 3 2 . 03 | 3 . 78 | 3 . 68 | 2 . 68 | 1 . 04 | 0 . 30 |
| 4 1 . 62 | 3 . 14 | 3 . 13 | 2 . 32 | 0 . 92 | 0 . 28 |
| 5 1 . | 35 2 . 67 | 2 . 71 | 2 . 03 | 0 . 81 | 0 . 21 |
(a)
Table 8: For gated service: mean relative approximation error, categorised by number of queues ( N ) and total load of the system (a), SCV interarrival times (b), and imbalance of the interarrival and service times (c).
| N | SCV interarrival times ( cv 2 A i ) | SCV interarrival times ( cv 2 A i ) | SCV interarrival times ( cv 2 A i ) |
|-----|---------------------------------------|---------------------------------------|---------------------------------------|
| | 0 . 25 | 1 | 2 |
| 2 | 4 . 72 | 0 . 34 | 3 . 05 |
| 3 | 4 . 06 | 0 . 17 | 2 . 53 |
| 4 | 3 . 45 | 0 . 10 | 2 . 16 |
| 5 | 2 . 98 | 0 . 08 | 1 . 84 |
| | | (b) | |
| N | Imbalance interarrival and service times | Imbalance interarrival and service times | Imbalance interarrival and service times | Imbalance interarrival and service times |
|-----|--------------------------------------------|--------------------------------------------|--------------------------------------------|--------------------------------------------|
| | I A i = 1 , I B i = | 1 I A i = 1 , I B i = 5 | I A i = 5 , I B i = 1 | I A i = 5 , I B i = 5 |
| 2 | 2 . 76 | 2 . 64 | 2 . 81 | 2 . 59 |
| 3 | 2 . 28 | 2 . 25 | 2 . 27 | 2 . 21 |
| 4 | 1 . 93 | 1 . 91 | 1 . 90 | 1 . 87 |
| 5 | 1 . 64 | 1 . 66 | 1 . 64 | 1 . 58 |
| (c) | (c) | (c) | (c) | (c) |
## 5 Further research topics
The research that is done in the present paper can be extended in many different directions. In this section we discuss some possibilities that we find most relevant.
Higher moments. Firstly, a logical follow-up step would be to use the same approach to find approximations for higher moments of the waiting time distribution as well. This might prove to be a hard exercise, since the LT limit of E [ W 2 i ] is unknown and, although its derivation might follow the same lines as in Section 3, it probably requires substantially more effort. In [13], explicit expressions for the second moments of the waiting time distributions are given, but only for symmetric systems with N = 2 3 , , and 4, and under the assumption of Poisson arrivals. Also, the HT limit of E [ W 2 i ] is unknown, although some research in this area
has already been done and in [17] a strong conjecture is given for the limiting distribution of W i as ρ ↑ 1.
Another question that remains to be investigated, is the required form of the interpolation, as (2.1) is surely not adequate to approximate higher moments of E [ W i ].
Other service disciplines. In the present paper, only exhaustive and gated service are discussed. In order to obtain results for polling systems with some queues receiving exhaustive service, and others receiving gated service, only minor modifications should be made, but we leave this to the reader. It would be more challenging to generalise the approximation to a wider variety of service disciplines. In particular, it would be nice to have one expression for the mean waiting time of customers in a queue with an arbitrary branching-type service discipline (cf. [19]). The exhaustiveness of a branching-type service discipline (cf. [26]) might appear in this expression. Gated and exhaustive are both branching type service disciplines, but are discussed separately in the present paper. The HT limit can most likely be established for arbitrary branching type service disciplines (see conjectures in [17]), so the question that remains is whether the LT limit can be found in a similar way.
Optimisation. One of the main reasons to choose (2.1) as form of the interpolation, besides its asymptotic correctness, is its simplicity. Having this exact and simple expression for the approximate mean waiting times, makes it very useful for optimisation purposes. In production environments, one can, for example, determine what the optimal strategy is to combine orders of different types (i.e., determine what queue customers should join). Because general arrivals are supported, one can determine optimal sizes of batches in which items are grouped and sent to a specific machine. The simplicity of (2.1) makes it possible for a manager to create a handy Excel sheet that can be used by operators to compute all kind of optimal parameter settings. No difficult computations are required at all, so a large variety of users can use the approximation.
In the present paper the accuracy of the approximation has been investigated and has been found to be very good in most situations. Another advantage of our approximation regarding optimisation purposes, is that the general shape of the approximated curve follows the exact curve very closely. Even in cases where the relative errors are rather large, like in Figure 1, the shape of the actual curves is still very well approximated. This means that plugging our approximation, instead of an exact expression if it had been available, in an optimisation function yields an optimum that should be close to the true optimum.
Polling Table. The interpolation based approximation can also be extended to polling systems where the visiting order of the queues is not cyclic. Waiting times in polling systems with so-called polling tables can be obtained in the same way as shown in the present paper. Both the LT and HT limits are not difficult to determine in this situation, and the interpolation follows directly from these limits.
Model. The form of the interpolation might be changed to improve the accuracy of approximations for cases that give less satisfactory results in the present form. E.g., one could try other functions than a second-order polynomial as numerator of (2.1). Alternatively, one
could try to find a correction term which could be added to (2.1) to obtain better results for, e.g., two-queue polling systems. But most of all, if an exact LT limit of the mean waiting time in a polling system with non-Poisson arrivals could be found, the accuracy of the approximation in the case of gated service might be improved.
## Acknowledgements
The authors wish to thank Onno Boxma for valuable discussions and for useful comments on earlier drafts of the present paper.
## References
- [1] D. Bertsimas and G. Mourtzinou. Decomposition results for general polling systems and their applications. Queueing Systems , 31:295-316, 1999.
- [2] J. P. C. Blanc and R. D. van der Mei. Optimization of polling systems with Bernoulli schedules. Performance Evaluation , 22:139-158, 1995.
- [3] O. J. Boxma. Workloads and waiting times in single-server systems with multiple customer classes. Queueing Systems , 5:185-214, 1989.
- [4] O. J. Boxma and W. P. Groenendijk. Pseudo-conservation laws in cyclic-service systems. Journal of Applied Probability , 24(4):949-964, 1987.
- [5] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems with zero switchover times: A heavy-traffic averaging principle. The Annals of Applied Probability , 5(3):681-719, 1995.
- [6] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems in heavy-traffic: A Bessel process limit. Mathematics of Operations Research , 23:257-304, 1998.
- [7] D. Everitt. Simple approximations for token rings. IEEE Transactions on Communications , COM-34(7):719-721, 1986.
- [8] M. J. Fischer, C. M. Harris, and J. Xie. An interpolation approximation for expected wait in a time-limited polling system. Computers & Operations Research , 27:353-366, 2000.
- [9] P. J. Fleming and B. Simon. Interpolation approximations of sojourn time distributions. Operations Research , 39(2):251-260, 1991.
- [10] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
- [11] W. P. Groenendijk. Waiting-time approximations for cyclic-service systems with mixed service strategies. In Proc. 12th ITC , pages 1434-1441. North-Holland Publ. Co., Amsterdam, 1989.
| [12] | J. Keilson and L. D. Servi. The distributional form of Little's Law and the Fuhrmann- Cooper decomposition. Operations Research Letters , 9(4):239-247, 1990. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [13] | S. Kudoh, H. Takagi, and O. Hashida. Second moments of the waiting time in symmetric polling systems. Journal of the Operations Research Society of Japan , 43(2):306-316, 1996. |
| [14] | H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990. |
| [15] | T. L. Olsen. Limit theorems for polling models with increasing setups. Probability in the Engineering and Informational Sciences , 15(1):35-55, 2001. |
| [16] | T. L. Olsen and R. D. van der Mei. Polling systems with periodic server routeing in heavy traffic: distribution of the delay. Journal of Applied Probability , 40:305-326, 2003. |
| [17] | T. L. Olsen and R. D. van der Mei. Polling systems with periodic server routing in heavy traffic: renewal arrivals. Operations Research Letters , 33:17-25, 2005. |
| [18] | M. I. Reiman and B. Simon. An interpolation approximation for queueing systems with Poisson input. Operations Research , 36(3):454-469, 1988. |
| [19] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409 - 426, 1993. |
| [20] | B. Simon. A simple relationship between light and heavy traffic limits. Operations Research , 40(Supplement 2):S342-S345, 1992. |
| [21] | H. Takagi. Queuing analysis of polling models. ACM Computing Surveys (CSUR) , 20: 5-28, 1988. |
| [22] | H. C. Tijms. Stochastic models: an algorithmic approach . Wiley, Chichester, 1994. |
| [23] | R. D. van der Mei and E. M. M. Winands. A note on polling models with renewal arrivals and nonzero switch-over times. Operations Research Letters , 36:500-505, 2008. |
| [24] | V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006. |
| [25] | W. Whitt. An interpolation approximation for the mean workload in a GI/G/ 1 queue. Operations Research , 37(6):936-952, 1989. |
| [26] | E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven University of Technology, 2007. |
| [27] | E. M. M. Winands. On polling systems with large setups. Operations Research Letters , 35:584-590, 2007. |
| [28] | E. M. M. Winands. Branching-type polling systems with large setups. To appear in OR Spectrum , 2009. | | 10.1016/j.peva.2010.12.004 | [
"Marko Boon",
"Erik Winands",
"Ivo Adan",
"Sandra van Wijk"
] | 2014-08-01T11:24:42+00:00 | 2014-08-01T11:24:42+00:00 | [
"math.PR",
"cs.PF"
] | Closed-Form Waiting Time Approximations for Polling Systems | A typical polling system consists of a number of queues, attended by a single
server in a fixed order. The vast majority of papers on polling systems
focusses on Poisson arrivals, whereas very few results are available for
general arrivals. The current study is the first one presenting simple
closed-form approximations for the mean waiting times in polling systems with
renewal arrival processes, performing well for ALL workloads. The
approximations are constructed using heavy traffic limits and newly developed
light traffic limits. The closed-form approximations may prove to be extremely
useful for system design and optimisation in application areas as diverse as
telecommunication, maintenance, manufacturing and transportation. |
1408.0135v1 | Paper published in El profesional de la información , vol. 23, n.4, pp. 359-366 doi:10-3145/epi.2014.jul.03
## New data, new possibilities: Exploring the insides of Altmetric.com
Nicolás Robinson-García , Daniel Torres-Salinas , Zohreh Zahedi and Rodrigo Costas 1 2 3 3
1 EC3: Evaluación de la Ciencia y de la Comunicación Científica, Departamento de Información y Documentación, Universidad de Granada, Spain
2 EC3Metrics, Granada, Spain
3 Centre for Science and Technology Studies, Leiden University, The Netherlands
## Abstract
This paper analyzes Altmetric.com, one of the most important altmetric data providers currently used. We have analyzed a set of publications with DOI number indexed in the Web of Science during the period 2011-2013 and collected their data with the Altmetric API. 19% of the original set of papers was retrieved from Altmetric.com including some altmetric data. We identified 16 different social media sources from which Altmetric.com retrieves data. However five of them cover 95.5% of the total set. Twitter (87.1%) and Mendeley (64.8%) have the highest coverage. We conclude that Altmetric.com is a transparent, rich and accurate tool for altmetric data. Nevertheless, there are still potential limitations on its exhaustiveness as well as on the selection of social media sources that need further research.
Keywords: Altmetric.com; Twitter; Mendeley; altmetrics; social impact; coverage; Web 2.0
Título: Nuevos datos, nuevas posibilidades: Revelando el interior de Altmetric.com
## Resumen
Este trabajo analiza Altmetric.com, una de las fuentes de datos altmétricos más usadas actualmente. Para ello hemos cruzado un set de publicaciones con DOI indexadas en la Web of Science para el periodo 2011-2013 con la API de Altmetric.com. Solo el 19% de las publicaciones de nuestro set estaban indexadas en Altmetric.com. Este recurso obtiene datos altmétricos de 16 redes sociales distintas. No obstante, cinco de ellas representan el 95.5% del set de datos recuperado. Twitter (87.1%) y Mendeley (64.8%) cubren un mayor número de publicaciones. Concluimos destacando Altmetric.com como una herramienta rica, transparente y precisa en sus datos altmétricos. No obstante, ofrece aún algunas dudas acerca de la exhaustividad de la recuperación así como de la selección de fuentes que requieren más investigación.
Palabras clave: Altmetric.com; Twitter; Mendeley; indicadores altmétricos; impacto social; cobertura; Web 2.0
## Introduction
Citation analysis has been traditionally confronted with different and opposed views as to its suitability to quantitatively measure the 'scientific impact' of publications. In brief, these have to do with citation biases, publication delays or process biases derived from peer review limitations ( Bollen; van de Sompel , 2006). Several alternatives have been proposed, especially since the 1990s and the expansion of the Internet and the digital media. Among others here we highlight the use of acknowledgments or influmetrics ( Cronin; Weaver , 1995), web links or webometrics ( Almind; Ingwersen , 1997) and usage metrics ( Kurz; Bollen , 2010). However, the most recent proposal as an alternative to traditional citation analysis has become a hot topic within the bibliometric community. Altmetrics or the use of social media-based indicators to quantify the social impact of scholarly information was first proposed by Priem et al. (2010). Since then it has become a research front of itself producing its own scientific corpus as it has been received by the research community.
Altmetric proponents claim that such indicators have the potential to complement or improve the more traditional scientific evaluation systems ( Priem , et al , 2010). They base their arguments stating that almetric indicators provide a wider picture of the relevance and impact of scientific contributions (or 'research products') ( Piwowar , 2013); also, they are produced at greater speed than citations and end with the monopoly exerted by citation indexes as they come from open sources. However, their strongest claim is that they can capture other aspects of impact different from those derived from citation counting. However, the reality is that they are still under-developed and much study is needed before confirming such arguments, which are currently either questionable or simple promises ( Wouters; Costas , 2012).
Hence, there are still serious concerns as to the meaning of these indicators ( Torres; Cabezas; Jiménez , 2013; Torres-Salinas; Cabezas-Clavijo , 2013) and the suitability of the sources ( Thelwall et al., 2013). So far, studies have reported 1) a relatively weak correlation with citations (i.e., Thelwall et al., 2013; Costas; Zahedi; Wouters , 2014), 2) their potential to offer complement aspects of impact remains unknown and 3) Twitter, blogs mentions, Mendeley readers, F1000 recommendations or news outlets seem to be among the most relevant sources ( Li; Thelwall , 2012; Li; Thelwall; Giustini , 2012; Haustein et al., 2013; Costas; Zahedi; Wouters , 2014; Zahedi; Costas; Wouters , in press). Regarding this latter issue, many tools have appeared in the last few years recollecting and providing these metrics. The main ones are ImpactStory.org , Plum Analytics and Altmetric.com . 1 2 3
Altmetric.com is currently one of the most important altmetric data providers. It captures information regarding the impact of a paper from various social media sources developing a weighted score. In order to do so it disambiguates links to articles, unifying links to PubMed records, Arxiv identifiers, DOI numbers or publisher's sites. Although some have warned against the use of aggregated altmetric scores ( Davis , 2013), there has been less debate about the richness and diversity of the data provided. One of the major problems potential users face when dealing with this source is that such diversity and richness of data is actually difficult to grasp. Although the web company provides extensive information of its contents ( http://support.altmetric.com ) one would still have difficulties in understanding the broadness of the data and possibilities that this source could provide.
The aim of this paper is to explore Altmetric.com as a source for developing altmetric indicators. In order to unveil the potential use of this tool, we provide a comprehensive and practical view on the contents available in Altmetric.com. Specifically, we will answer the following research questions:
- 1. Which data sources are included in Altmetric.com and how are they structured?
- 2. What is the coverage of Altmetric.com and which data sources cover more altmetric impact of publications?
For this we have performed a practical extraction of data from Altmetric.com and carried out a detailed analysis of the data provided by this tool.
## Material and methods
In order to explore Altmetric.com, we selected all publications between 2011 and 2013 4 indexed in the Web of Science database using the CWTS (University of Leiden) in-house version. From this set of papers we selected only those which included a DOI number. In January 2014 we matched a total of 2,792,706 DOI numbers with the Altmetric API ( https://api.altmetric.com/ ). We retrieved a total of 516,150 records from the Altmetric API. This means that roughly 19% of all publication with DOI number during the study time period had received some kind of social media attention. However, we most note that there are errors on some of the unique DOIs present in Altmetric.com. Also, not all papers in Altmetric.com include DOI information. For each record we obtained a file on Javascript Object Notation format (JSON) . The JSON files include raw data collected by Altmetric.com for each 5 publication. Table 1 shows the structure of each file indicating the type of information provided for each section.
Table 1. Disaggregated structure from a record provided by the Altmetric API
| Description | Example of fields extracted |
|--------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Summary of metrics as shown in the Altmetric.com bookmarklet | "counts":{"readers":{"mendeley","citeulike","connotea"},"facebook":{"unique_users_count ","unique_users":[],"posts_count"},"blogs":{"unique_users_count","unique_users":[],"posts _count"},"news":{"unique_users_count","unique_users":[],"posts_count"},"pinterest":{"uni que_users_count","unique_users":[],"posts_count"},"reddit":{"unique_users_count","uniqu e_users":[],"posts_count"},"twitter":{"unique_users_count","unique_users":[],"posts_coun t"},"video":{"unique_users_count","unique_users":[],"posts_count"}},"linkedin":{"unique_u sers_count","unique_users":[]',"posts_count","total":[]"... |
| Bibliographic description of the paper | "citation":{"title","authors":[],"pubdate","volume","issue","startpage","endpage","doi","P MID","arxiv_id","journal","altmetric_jid","links":[],"first_seen_on"} "altmetric_score":{"score","score_history":{"1d","2d","3d","4d","5d","6d","1w","1m","3m", |
| Comparison and evolution of the aggregated Altmetric score | ne","total_number_of_other_articles","this_scored_higher_than","this_scored_higher_tha n_pct","percentile","rank_type":"approximate"},"similar_age_3m":{"rank","mean","median ","sample_size","sparkline","total_number_of_other_articles","this_scored_higher_than"," this_scored_higher_than_pct","percentile","rank_type":"approximate"},... |
| Demographics (Twitter): Public type and country | "demographics":{"poster_types":{"member_of_the_public","researcher","practitioner","sci ence_communicator"},"geo":{"twitter":{"*Country*":"*number of users*"}}} "posts":{"twitter":[{{"url","posted_on","license","summary","author":{"name","image","id_ on_source","followers"},"tweet_id"}],"blogs":[{"title"{"title","url","posted_on","summary", |
| Altmetric data disaggregated by provider | "author":{"name","url","description"}}],"facebook":[{"title","url","posted_on","summary"," author":{"name","url","facebook_wall_name","image"","id_on_source"}},{"url","posted_on ","summary","author":{"name","url","facebook_wall_name","image","id_on_source"}}],"go ogleplus":[{{"title","url","posted_on","summary","author":{"name","url","image","id_on_so urce"}}],... |
As observed, five distinctive parts were identified. The first section is a summary with the global scores by source from which counts have been retrieved. Secondly, a brief description
of the scientific paper is given including not only the bibliographic reference but also information such as the date when the paper was first included in the system or alternative links to the paper. The third part of the file offers a temporal evolution of the aggregated altmetric score for different time periods, along with comparisons with the journal's scores. Forth, a demographic display is shown by country and public type. This information is based on the Twitter account of users mentioning the paper. Finally, the last section includes a display with all the information and fields recorded in the system derived from each of the sources from which Altmetric.com retrieves the data.
## Description of sources collected by Altmetric.com
16 sources were identified in Altmetric.com. In table 2 we display each source including a brief description, the type of metric they measure and the data fields retrieved by Altmetric.com. Each record keeps a historical track of all metrics recorded since 2011 or since the inclusion of the paper in the system. In order to capture this data, Altmetric.com identifies mentions through link recognition. The only exception is done with blogs and news, where they also employ a tracker mechanism using text-mining techniques in order to capture those mentions which do not link to the publication. Such techniques are employed only for English language sources.
As observed, the most common type of metrics collected are discussions and mentions (four sources for each metric), followed by readership counts (Mendeley, Connotea and Citeulike). Then, other similar metrics to these can be seen such as videos, reviews or 'Question and Answer' discussion threads. As observed, with the exception of Research Highlights, which includes citation data retrieved from the highlights section of Nature magazine, all sources are of a 2.0 nature. Also, some of these sources may be biased towards certain fields. For instance, F1000 is a post-publication peer review service of Biomedical and Medicine research ( Waltman; Costas 2014). Also, Stack Exchange is especially used by researchers from Computer and Natural Sciences.
| Source | Description | Type of metrics | Data elements |
|----------------|------------------------------------|-------------------|--------------------------------------------------------------------------------------------------------------------------------------|
| Blogs | Manually-curated RSS list | Discussion | Blog title; post title; post URL; publication date and time; summary; author name; author URL; author description |
| News | Manually-curated RSS list | Discussion | News title; news URL; publication date and time; license; summary; news media name; news media URL; news media id; news media image |
| Reddit | News provider | Discussion | News title; reddit URL; publication date and time; author name; author URL; author id; followers; subreddit |
| Facebook | Social network | Mentions | Mention title; URL mention; publication date and time; summary; author name; author URL; Facebook wall name; author image; author id |
| Google Plus | Social network | Mentions | Mention title; URL mention; publication date and time; summary; author name; author URL; author image; author id |
| Pinterest | Social network | Mentions | Mention URL; mention image; publication date and time; summary; author name; pinboard |
| Twitter | Microblogging | Mentions | URL; publication date and time; license; summary; author name; author image; number of followers, tweet id; type of public; country |
| Stack Exchange | Question & Answer site | Discussion | Thread title; thread URL; publication date and time; summary; author id |
| Citeulike | Social bookmarking | Readers | Total count of bookmarks |
| Connotea | Social bookmarking (discontinued) | Readers | Total count of bookmarks |
| Mendeley | Social bookmarking | Readers | Total count of bookmarks |
| F1000 | Pospublication peer review service | Reviews | Recommended in F1000; publication date (probably of the last update); type of recommendation |
| YouTube | Video sharing site | Video | Video title; video URL; video image; publication date and time; license; summary; embed type; YouTube id; author name; author id |
## Paper published in El profesional de la información , vol. 23, n.4, pp. 359-366 doi:10-3145/epi.2014.jul.03
Table 2. Summary of data elements provided by Altmetric.com by data sources
| Source | Description | Type of metrics | Data elements |
|---------------------|-----------------------------|-------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| LinkedIn Groups | Professional social network | Mentions | Total unique users; unique users name; total posts; post title; summary; publication date and time; author name; author description; post URL; group logo URL; group name; group description |
| Research Highlights | Nature highlights | Citations | Highlight URL; date added to Altmetric.com; highlight title; total highlights; bibliographic description of highlight; first seen |
| Misc | Others | Others | This field includes data from different social media sources which are added on authors' request ( Adie , 2014) |
With the exception of the Misc field which is devoted to other media sources not included in the original set of Altmetric.com, all are included when calculating the aggregated Altmetric score of each paper. Most of this information can be displayed through the Altmetric.com bookmarklet ( Figure 1 ). However, some differences have been noted between the records retrieved from the Altmetric API and those displayed in the Altmetric bookmarklet: some indicators and data elements are not displayed in the breakup of the bookmarklet (e.g. all tweets and retweets) or discrepancies between the information provided between the sources (e.g. occasional errors in the Q&A threads).
Figure 1. Example of data provided by the Altmetric.com bookmarklet
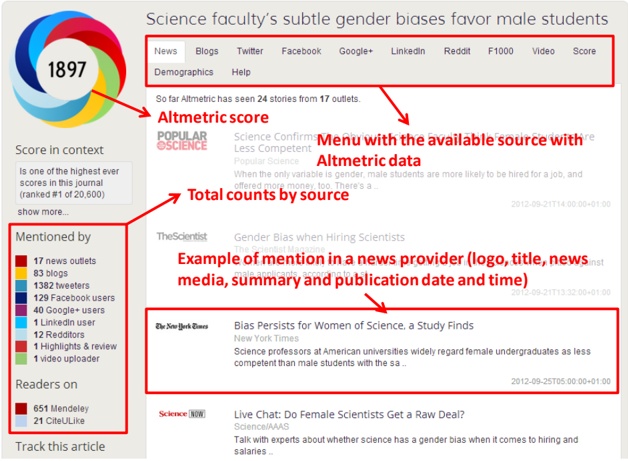
## Coverage of Altmetric.com for WoS publications with DOI in 2011-2013 4
From the total of publications in the original sample, only 19% were included in Altmetric.com reporting some type of altmetric impact ( Figure 2 ). Twitter is the source providing more altmetric data (87.1%) followed by Mendeley (64.8%). None of the other social media reaches values higher than 20% of the total share of papers with altmetric indicators associated, although Facebook reaches a total share of 19.9% of papers included in Altmetric.com.
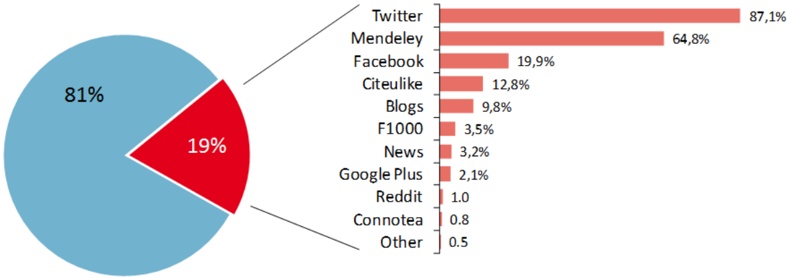

WoS publications with DOI not included in Altmetric.com

WoS publications with DOl included in Altmetric.com
Figure 3. Coverage of WoS papers in Altmetric.com by social media for the period 2011-2103 4
In table 3 we include further information on the number of papers including metrics, total counts of each metric and unique users for the five top sources (Twitter, Mendeley, Facebook, Citeulike and blogs). These sources are present in 95.5% of the total share of papers retrieved from Altmetric.com. Although Twitter is the social media with the most mentions, Mendeley includes a higher number of users bookmarking scientific papers. These two data sources are the most expanded social media among all the altmetric sources analyzed. Indeed, the presence of mentions to scientific papers from social media such as Facebook, Citeulike or even blogs, never reaches 5% of the total papers with DOI indexed in the Web of Science during the studied time period.
Table 3. Coverage of Altmetric.com by social media to papers indexed in Web of Science for the 20112013 time period 4
| Social media | Papers | Total counts | Unique users | %Papers in WoS |
|----------------|----------|----------------|----------------|------------------|
| Twitter | 449,493 | 1,819,194 | 1,621,396 | 16.1 |
| Mendeley | 334,616 | 2,631,396 | 2,631,396 | 12 |
| Facebook | 102,923 | 197,449 | 182,422 | 3.7 |
| Citeulike | 65,799 | 130,756 | 130,756 | 2.4 |
| Blogs | 50,529 | 84,927 | 75,946 | 1.8 |
## Discussion and concluding remarks
In this paper we analyzed Altmetric.com as an altmetric data provider for analyzing the altmetric impact of scientific publications. The main issue this type of sources have is the difficulties that entail identifying mentions to scientific papers, similarly to the shortcomings found when using webometric techniques ( Thelwall , 2011). Although Altmetric.com states that they do serious efforts on link disambiguation ( http://support.altmetric.com ), there is still an important lack of research on the exhaustiveness, precision and correctness of the information retrieved by these tools (e.g. How many mentions is Altmetric.com missing from
the covered sources?). This is specially relevant when analyzing the retrieval method for identifying mentions to scientific papers in more problematic sources such as blogs or news media. Here, a tracker mechanism based on text-mining techniques is applied as a complement to the link recognition method. However, it is applied to a manually-curated list of resources, not being evident the criteria followed for selecting them ( http://www.altmetric.com/sources-blogs.php ). Also, this technique is applied only for English language sources while for non-English sources only direct links to publications are considered ( http://www.altmetric.com/sources-news.php ), which inserts an important language bias that needs to be considered when studying publications from different languages.
Conceptually speaking, a very serious limitation is related to the sources covered by Altmetric.com. The reasons why these and no other sources are covered is a relevant question. Particularly in an environment of increasingly growing social media tools. In fact, this shortcoming applies to all altmetric providers as they do not always empirically or conceptually justify their selected sources. As such, one could argue that if Facebook is included, why not the Spanish Tuenti? If Twitter is covered, why not Tumblr, or the Spanish 'Menéame' along with Reddit? In the same line, related with scientific research it is worth mentioning the omission of scientific social networks such as Academia.edu or ResearchGate which seem to be used by many researchers ( Mas-Bleda; Thelwall; Kousha; Aguillo , 2014). In this sense, some improvements have been reported, and on April 7, 2014, Altmetric.com reported the inclusion of the Chinese Weibo as a new source ( Adie , 2014).
Probably, the reason for the selection of the current sources is more practical than conceptual (these sources are popular, have public APIs, are international, etc.) and although with limitations, finding and scanning mentions to research outputs across them is relatively feasible. However, technical issues should not avoid a more conceptual and theoretical discussion on what should be covered and the possible limitations or biases of the current sources, similarly to the analyses on coverage and limitations of other bibliometric databases such as the Web of Science, Scopus or Google Scholar (e.g. Jacso , 2009).
Our results show that from the 16 sources covered by Altmetric.com only 5 represent 95.5% of the total share of publications with altmetrics. This opens the question of the relevance of the sources and whether the smaller ones can really provide a meaningful evidence of impact. Indeed such concentration in a small number of social media has already been discussed elsewhere ( Priem et al. , 2012; Cabezas-Clavijo; Torres-Salinas , 2010). The most important sources are Twitter and Mendeley ( Figure 2 ). These sources are the ones that seem more promising for determining the type of impact altmetric data provide, as they show a higher density and therefore more reliable metrics could be extracted from them. As observed in our results, while Twitter seems to show data related to a larger number of publications, Mendeley shows higher figures ( Table 2 ), including a larger number of counts and users. In this sense, this latter tool seems to have expanded much among the scientific community ( Haustein et al. , 2014). Surprisingly, Altmetric.com does not collect readership data (i.e., Mendeley data) unless other bibliometric indicators are collected ( Costas; Zohedi; Wouters , 2014).
## Paper published in El profesional de la información , vol. 23, n.4, pp. 359-366 doi:10-3145/epi.2014.jul.03
All in all, Altmetric.com is indeed a very relevant open tool and data provider, which shows high quality and transparent data related to mentions in social media to scientific publications. The recent partnership established between ImpactStory (another important altmetric tool) and Altmetric.com ( Piwowar , 2014) is a clear recognition of the value of this tool. Our study highlights the richness of the data collected. This richness is reflected in the fact that not only metrics about the counts and mentions on the different social media tools are recorded, but also data elements about their users and their origin or the dates of their mentions, for instance. As it stands, this data collection has two important positive implications. First, the fact that the data are stored and recorded permanently allows the reproducibility of the results and retrospective analysis, thus giving a solution to the problem of volatility of altmetric data ( Wouters; Costas , 2012). Secondly, the abundance of data elements recorded opens the possibilities for further analyses that go beyond the simple counting of mentions. For example, the possibility of analyzing types of audience, the interests of these audiences, their relationships, etc. are new possibilities not yet explored.
Finally, our study shows that there are still important issues that need to be resolved to fully understand altmetric data. Our results indicate that more research is needed for understanding the methodologies for retrieving valid and reliable altmetric data. In the same line, the selection of social media sources must be rigorous and critical, attending to its use within the different communities and audiences and avoiding potential discipline or language biases.
## Acknowledgments
The authors would like to thank Erik van Wijk from CWTS for helping in the retrieval of the data. Euan Adie from Altmetric.com clarified some of our concerns on the data. Stefanie Haustein contributed with her comments which improved the final version of the manuscript. Nicolás Robinson-García is currently supported with a FPU grant from the Spanish Ministerio de Economía y Competitividad.
## Notes
- 1 http://impactstory.org. Founded by Jason Priem and Heather Piwowar in 2011, it was originally called Total-Impact.
- 2 http://www.plumanalytics.com/. Founded in late 2011 by Andrea Michalek and Mike Buschman, it has recently been acquired by EBSCO Publishing.
- 3 http://www.altmetric.com/. Founded by Euan Audie in 2011, it has become one of the main altmetric providers.
- 4 The publication year 2013 is not complete. Only one third of the publications were uploaded in the system at that time. In any case, this is not problematic for our analysis as we are just doing a descriptive analysis of the presence of Altmetric.com covered mentions across available scientific publications.
- 5 For more information about the JSON format the reader is referred to http://en.wikipedia.org/wiki/JSON
## References
Adie, E. (2014). "Announcing Sina Weibo support". http://www.altmetric.com/blog/announcing-sina-weibo-support/
Adie, E. (2014) "Personal communication".
Almind, T.; Ingwersen, P. (1997). "Informetric analyses on the world wide web: Methodological approaches to 'webometrics'". Journal of Documentation, vol. 53, n. 4, pp. 404-426. http://dx.doi.org/10.1108/EUM0000000007205
Altmetric.com. "Knowledge Base". http://support.altmetric.com/knowledgebase
Bollen, J.; Van de Sompel, H. (2006). "Mapping the structure of science through usage". Scientometrics , vol. 69, n. 2, pp. 227-258. http://dx.doi.org/10.1007/s11192-006-0151-8
Cabezas-Clavijo, Á.; Torres-Salinas, D. (2010). "Los investigadores en la ciencia 2.0: El caso de PLOS One". El profesional de la información , vol. 19, n. 4, 431-434.
Costas, R.; Zahedi, Z.; Wouters, P. (2014). "Do 'altmetrics' correlate with citations? Extensive comparison of altmetric indicators with citations from a multidisciplinary perspective". http://arxiv.org/abs/1401.4321
Cronin, B.; Weaver, S. (1995). "The praxis of acknowledgement: From bibliometrics to Influmetrics". Revista Española de Documentación Científica, vol. 18, n. 2, pp. 172-177. http://dx.doi.org/10.3989/redc.1995.v18.i2.654
Davis, P. (2013). "Visualizing article performance - Altmetric searches for appropriate display". The Scholarly Kitchen . http://scholarlykitchen.sspnet.org/2013/09/30/visualizing-articleperformance-altmetrics-searches-for-appropriate-display/
Jacso, P. (2009). "Testing the Calculation of a Realistic h-index in Google Scholar, Scopus, and Web of Science for F.W. Lancaster". Library Trends , vol. 56, n. 4, pp. 784-815.
Haustein, S.; Peters, I.; Bar-Ilan, J.; Priem, J.; Shema, H.; Tersliener, J. (2014). "Coverage and adoption of altmetrics in the bibliometric community". Scientometrics . http://dx.doi.org/10.1007/s11192-013-1221-3
Haustein, S.; Peters, I.; Sugimoto, C.; Thelwall, M.; Larivière, V. (2013). "Tweeting biomedicine: An analysis of tweets and citations in the biomedical literature". Journal of the American Society for Information Science and Technology. http://dx.doi.org/10.1002/asi.23101
Kurz, M.J.; Bollen, J. (2010). "Usage bibliometrics". Annual Review of Information Science and Technology, vol. 44, pp. 1-64. http://dx.doi.org/10.1002/aris.2010.1440440108
Li, X.; Thelwall, M. (2012). "F1000 , Mendeley and Traditional Bibliometric Indicators". In 17th International Conference on Science and Technology Indicators , vol. 3, pp. 1-11. http://2012.sticonference.org/Proceedings/vol2/Li\_F1000\_541.pdf
Li, X.; Thelwall, M.; Giustini, D. (2012). "Validating online reference managers for scholarly impact measurement". Scientometrics, vol. 91, n. 2, pp. 461-471. http://dx.doi.org/10.1007/s11192-011-0580-x
Mas-Bleda, A.; Thelwall, M.; Kousha, K.; Aguillo, I.F. (2014). "Successful researchers publicizing research online: An outlink analysis of European highly cited scientists' personal websites". Journal of Documentation , vol. 70, n. 1, 148-172. http://dx.doi.org/10.1108/JD-122012-0156
Piwowar, H.A. (2013). "Altmetrics: Value all research products". Nature , vol. 493, n. 7431, 159. http://dx.doi.org/10.1038/493159a
Piwowar, H.A. (2014). "Impactstory partners with Altmetric.com". ImpactStory blog . http://blog.impactstory.org/2014/01/28/altmetric\_com/
Priem, J.; Piwowar, H.A.; Hemminger, B.M. (2012). "Altmetrics in the wild: Using social media to explore scholarly impact". http://arxiv.org/html/1203.4745
Priem, J.; Taraborelli, D.; Groth, P.; Neylon, C. (2010). "Altmetrics: A manifestoaltmetrics.org". http://altmetrics.org/manifesto
Thelwall, M. (2011). "A comparison of link and URL citation counting". Aslib Proceedings , vol. 63, n. 4, 419-425. http://dx.doi.org/10.1108/00012531111148985
Thelwall, M.; Haustein, S.; Larivière, V.; Sugimoto, C. (2013). "Do Altmetrics work? Twitter and ten other social web services". PLoS ONE , vol. 8, n. 5, e64841. http://dx.doi.org/10.1371/journal.pone.0064841
Torres, D.; Cabezas, Á.; Jiménez, E. (2013). "Altmetrics: New indicators for scientific communication in web 2.0". Comunicar , vol. 21, n. 41, pp. 53-60. http://dx.doi.org/10.3916/C41-2013-05
Torres-Salinas, D.; Cabezas-Clavijo, Á. (2013). "Altmetrics: no todo lo que se puede contar, cuenta". Anuario ThinkEPI , vol. 7, pp. 114-117.
Waltman, L.; Costas, R. (2014). "F1000 Recommendations as a Potential New Data Source for Research Evaluation : A Comparison With Citations". Journal of the Association for Information Science and Technology , vol. 65, n. 3, 433-445.
Wouters, P.; Costas, R. (2012). "Users, narcissism and control - Tracking the impact of scholarly publications in the 21st Century". In: Proceedings of 17th International Conference on Science and Technology Indicators , vol. 2, pp. 847-857. http://2012.sticonference.org/Proceedings/vol2/Wouters\_Users\_847.pdf
Zahedi, Z.; Costas, R. ; Wouters, P. (in press). "How well developed are altmetrics? Cross disciplinary analysis of the presence of 'alternative metrics' in scientific publications". Scientometrics . http://dx.doi.org/10.1007/s11192-014-1264-0 | 10.3145/epi.2014.jul.03 | [
"Nicolás Robinson-García",
"Daniel Torres-Salinas",
"Zohreh Zahedi",
"Rodrigo Costas"
] | 2014-08-01T11:27:47+00:00 | 2014-08-01T11:27:47+00:00 | [
"cs.DL"
] | New data, new possibilities: Exploring the insides of Altmetric.com | This paper analyzes Altmetric.com, one of the most important altmetric data
providers currently used. We have analyzed a set of publications with DOI
number indexed in the Web of Science during the period 2011-2013 and collected
their data with the Altmetric API. 19% of the original set of papers was
retrieved from Altmetric.com including some altmetric data. We identified 16
different social media sources from which Altmetric.com retrieves data. However
five of them cover 95.5% of the total set. Twitter (87.1%) and Mendeley (64.8%)
have the highest coverage. We conclude that Altmetric.com is a transparent,
rich and accurate tool for altmetric data. Nevertheless, there are still
potential limitations on its exhaustiveness as well as on the selection of
social media sources that need further research. |
1408.0136v1 | ## Applications of polling systems
M.A.A. Boon [email protected]
∗
R.D. van der Mei † ‡ [email protected]
E.M.M. Winands †
[email protected]
February, 2011
## Abstract
Since the first paper on polling systems, written by Mack in 1957, a huge number of papers on this topic has been written. A typical polling system consists of a number of queues, attended by a single server. In several surveys, the most notable ones written by Takagi, detailed and comprehensive descriptions of the mathematical analysis of polling systems are provided. The goal of the present survey paper is to complement these papers by putting the emphasis on applications of polling models. We discuss not only the capabilities, but also the limitations of polling models in representing various applications. The present survey is directed at both academicians and practitioners.
Keywords : Polling systems, applications, survey
## 1 Introduction
A typical polling system consists of a number of queues, attended by a single server in a fixed order. There is a huge body of literature on polling systems that has developed since the late 1950s, when the papers of Mack et al. [117, 118] concerning a patrolling repairman model for the British cotton industry were published. The term 'polling' originates from the socalled polling data link control scheme, in which a central computer (server) interrogates each terminal (queue) on a communication line to find whether it has any information (customers) to transmit. The addressed terminal transmits information and the computer then switches to the next terminal to check whether that terminal has any information to transmit. In a broader perspective, polling models are applicable in situations in which several types of users compete for access to a common resource which is available to only one type of user at a time. The ubiquity of polling systems can be observed in many applications, e.g., in computer-communication, production, transportation and maintenance systems. The present paper discusses the main application areas of polling systems along with an extensive list of references, examines how these various applications can be represented and analyzed via
∗ Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
† Department of Mathematics, Section Stochastics, VU University, De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands
‡ Centre for Mathematics and Computer Science (CWI), Department of Probability and Stochastic Networks, 1098 SJ Amsterdam, The Netherlands
polling models and outlines several topics for future research inside and outside the described areas.
To illustrate the fact that polling systems have become a powerful tool for the performance analysis of a wide variety of important applications, we would like to cite Hideaki Takagi, one of the fathers of the success of polling models [152]: The analysis of polling models gained momentum as queueing systems that are easy to understand, analyze, and extend. The study has been accelerated largely by applications to the modeling of communication, manufacturing and transportation systems. I believe that it is one of the few successful theoretical performance evaluation models developed in the last decades. The fact that nowadays polling systems are still fully alive can be illustrated by observing that the recent application-oriented conferences Performance 2007, Informs Applied Probability 2007 and 2009, and ValueTools 2008 all scheduled a dedicated session for polling systems. Very recently, Annals of Operations Research dedicated a special issue to polling systems.
Until the mid nineties, Takagi maintained a fairly complete bibliography on polling models, which contained over 700 publications, including journal and conference papers, books, theses, and technical reports. Since research on polling models has continued in the past years (although not at as high a pace as in the years around 1990), the number of papers might now well be above 1000. The main reason for this tidal wave of papers on polling models in the past 50 years can be found in the diversity of applications, which have led to innumerable enhancements of the basic cyclical polling system. Such enhancements gave rise to interesting new queueing theoretic problems which in turn stimulated research in various directions.
In this respect one of the most remarkable mathematical results in the polling literature is the striking dichotomy in the complexity of the analysis of polling systems, which has been independently illuminated by Fuhrmann [74] and Resing [135] via the use of a multitype branching approach. That is, if the service discipline (i.e., the criterion which determines how many customers are served during a visit of the server to a queue) satisfies a certain branching property, in many cases the polling system allows for an exact analysis by rather standard methods. If this branching property is, however, violated, the corresponding polling system defies an exact analysis except for some special (two-queue or symmetric) cases.
The most important members of the class of policies satisfying the branching property are the exhaustive service discipline, under which the server continues to work until the queue has become empty, the gated service discipline, under which exactly those customers are served who were present at the queue at the beginning of the visit, and globally gated service, which states that only those customers are served that were present at the server's arrival epoch at some predetermined 'parent queue'. (Actually the globally gated service discipline does not strictly satisfy the branching property as defined in [135], but a weaker variant that still allows an exact analysis.) Unfortunately, the k -limited service policy, under which the server continues working at a queue until either a predefined number of k customers is served or until the queue becomes empty, is on the wrong side of the borderline implying that even mean queue lengths are in general not known.
In the past various survey papers dedicated to polling systems have appeared in the open literature (see, e.g., [115, 149, 151, 152, 168, 182]) which give detailed and comprehensive descriptions of the mathematical analysis of polling systems. Although we present a brief overview of the basic mathematical analysis techniques, the main goal of the present survey paper is to complement these papers by putting the emphasis on applications of polling
models. We unearth not only the capabilities, but also the limitations of polling models in representing various applications. Moreover, since the publication of the previous survey papers around 10 till 15 years ago, a large number of papers on polling models have been published. The present survey is directed at both academicians and practitioners. The list of references is relatively recent, but deliberately far from exhaustive. The reader who is interested in going deeper into specific mathematical details of polling systems will find references to the aforementioned survey papers aimed at that objective. In selecting the literature to cite in this survey, a preference has been given to current papers and research on applications of polling systems.
The rest of the present paper is organized as follows. Section 2 gives a global overview of various aspects of polling systems, and gives an illustration of how one can analyze a typical polling system. In Section 3 we describe the main applications of polling systems in communication networks, production systems, traffic and transportation problems and various other fields of engineering. Finally, the last section indicates some possible directions for further research.
## 2 Polling systems
A polling model consists of a number of queues, attended by a single server who visits the queues in some order to render service to the customers waiting at the queues, typically incurring some switch-over time while moving from one queue to the next. In Section 2.1 we give a structural overview of the variety of polling models considered in the literature, successively discussing model variants with respect to the arrival process, the buffer size, the service process, the switch-over process, the server routing, the service discipline and the queueing discipline. In Section 2.2 we briefly illustrate how polling systems may be analyzed.
## 2.1 Typical features
Arrival process. In most polling models, customers arrive at the queues according to mutually independent homogeneous single Poisson arrival processes. In many cases arrival processes can indeed be described adequately by Poisson processes, e.g., in the case of telephone calls and traffic accidents. Moreover, due to the memorylessness property of the Poisson process, polling models with Poisson arrivals often allow for a tractable analysis.
Yet, in many situations the assumption of Poisson arrivals is unrealistic, e.g., in case of bursty traffic (voice, video) and several production applications. Only very recently, variations of Poisson arrival processes have been considered. Van Vuuren and Winands [167] have presented an approximate algorithm for polling systems with k -limited service and Markovian Arrival Processes (MAPs). Boxma et al. [32] consider polling systems with L´ evy-driven input. Bertsimas and Mourtzinou [15] study polling systems with Mixed General Erlang arrival processes. Slightly more general arrival processes are discussed by Saffer and Telek [136] who consider BMAPs (Batch Markov Arrival Processes). Some limiting cases lead to closed-form expressions for, e.g., queue lengths or waiting time distributions, even under the assumption of general renewal arrivals. For example, Van der Mei and Winands [162, 163] derive the distribution of the scaled waiting time under heavy traffic conditions, i.e., when the load tends to one. For switch-over times tending to infinity, the scaled waiting time distribution
is conjectured in [175], but the proof is still an open problem. Closed-form approximations for waiting times in polling systems with general renewal arrivals are constructed in [24, 57] using an interpolation between light-traffic and heavy-traffic limits.
In polling models it is almost exclusively assumed that customers arrive from some external infinite population. In some applications this assumption is unrealistic, e.g., in maintenance environments where customers represent machine breakdowns. Altman and Yechiali [7] study a closed polling model in which customers, after having received service at a queue, proceed to another (possibly the same) queue. This model is extended in [8] where a model with transient as well as permanent customers is considered. Sidi and Levy [143] consider a system in which (external) customers arrive at a queue according to a Poisson process, and in which a customer, after having received service at a queue, either leaves the system or moves to another queue (with some given probability). Applications of this type of customer routing can be found, for example, in manufacturing when products undergo service in a number of stages or in the context of rework. Finally, we mention work of Levy and Sidi [116] in which they study a polling model with simultaneous arrivals at the queues.
A final remark regarding arrival processes, is that some papers study discrete-time arrival processes. For some applications, it is natural to divide time into slots. In communication systems discrete-time models are used by, e.g., Kleinrock and Scholl [99] for the analysis of the Minislotted Alternating Priorities (MSAP) multiple-access scheme, by Kleinrock and Levy [98] for the analysis of polling systems with random server routing to model the Slotted ALOHA system, and by Beekhuizen [11] to model networks on chips. An example in a completely different application area, is provided by Van Leeuwaarden [166] who analyses the Fixed Cycle Traffic Light queue in discrete time.
Buffer size. In most polling models the buffer size is assumed to be infinite. In a number of applications the buffer capacities are obviously finite, e.g., transportation and manufacturing. In some applications it is natural to assume that the buffers are unit sized, i.e., each queue can only accommodate one customer at a time. Applications of polling models with unit-sized buffers are found, e.g., in the area of maintenance. If one would like to study a multi-item production system which produces products in a make-to-order fashion, a polling system with finite buffers appears naturally as well. For an analysis of polling models with finite buffers, see, e.g., Takagi [150], or Browne and Yechiali [39].
Service process. The service times at a queue are typically assumed to be samples from a probability distribution which is characteristic for that queue. The service times are usually assumed to be mutually independent and independent of the actual state of the system. Polling models with batch service are studied in [164] and [35]. Van der Wal and Yechiali [164] study a model where, at the beginning of each cycle, the server determines a tour along each of the non-empty queues. This model, with customers being served in one batch, has applications to videotex, telex, and time-division multiple access (TDMA) systems, as well as for central database systems and Automated Guided Vehicles (AGVs). Boxma et al. [35] study a polling model with batch service. Server routing is either strictly cyclic, or the server visits the queue with the oldest customer first.
The usual assumption in the polling literature is that a single server is visiting all the queues. Only few results have been obtained on multiple -server polling systems. For example, some
numerical results are obtained by Ajmone Marsan et al. [1], who perform several numerical studies using generalized stochastic Petri nets (GSPNs). Analytical approximative results have been obtained by Morris and Wang [125], and also in [29, 157]. Morris and Wang observe the interesting phenomenon that the servers tend to cluster if they follow identical routes, deteriorating the system performance. Because the methods used in all of these papers are based on approximations, many challenges remain for future research. However, some interesting exact results are found for a polling system with multiple coupled servers, visiting the queues always together [25].
Switch-over process. The switch-over times needed by the server to move from one queue to another queue are typically assumed to be samples from some prespecified probability distribution which is characteristic for that couple of queues. In a few cases the switch-over times are assumed to be decomposed into switch-out times (which are characteristic for the queue being departed from) and switch-in times (which are characteristic for the queue being switched to), putting a special structure on the switch-over times.
Nearly all of the existing literature on polling systems makes the assumption of state-independent switch-overs, i.e., switch-overs are assumed to be independent of the current state of the system. Notable exceptions are the recent studies of Altman et al. [3], G¨nalay and Gupta [86], u Gupta and Srinivasan [87], Singh and Srinivasan [144] and Winands et al. [177]. The choice of modeling state-independent setups is generally not motivated by an application but by the tractability of the resulting analysis.
Altman and Fiems [4] allow correlation between switch-over times in the polling model. That is, they assume that the switch-over times constitute a stationary ergodic series of random variables. A wireless LAN, where an access point polls mobiles, is one of the applications of this type of switch-over process.
Server routing. The order in which the server visits the queues is determined by some routing mechanism. Such a mechanism may depend on the actual state of the system (dynamic) or may be independent of the state of the system (static).
We first discuss static routing mechanisms. The traditional routing mechanism is the cyclic server routing. To model systems in which particular queues are visited more frequently than others, cyclic polling has been extended to periodic polling, in which the server visits the queue periodically according to some service order table of finite length, cf. [9]. Alternatively, the server may be routed along the queues according to some probabilistic routing mechanism. Kleinrock and Levy [98] introduce the so-called random polling mechanism in which, after a departure from a queue, the server proceeds to queue j with some given probability p j .
Boxma and Weststrate [36] and Srinivasan [146] generalize the random polling scheme to the so-called Markovian routing scheme in which the server, after a departure of the server from queue i , proceeds to queue j with given probability p i,j .
Under dynamic server routing, the decision of the server as to the order in which the queues are visited may depend on a certain amount of information available to the server, such as the queue lengths. For instance, it might not make sense to move to an empty queue while customers are waiting at other queues (cf., e.g., [91]). An example of dynamic server routing in systems with full information about the buffer contents is the 'serve-longest-queue' policy.
Yechiali [181] has introduced the so-called semi-dynamic server routing, in which the server, at the end of each tour along the queues, receives information about the queue lengths. Based on this information, the server makes a decision as to the order in which it will visit the queues in the next tour. This order cannot be changed during the course of that visit tour.
Service discipline. The service discipline specifies the number of customers that is served during one visit of the server to a queue. In the literature, a whole abundance of service disciplines has been proposed by putting some cut-off mechanism (which eventually depends on the evolution of the queue length during the server visit) on the classical exhaustive and gated service disciplines. The service disciplines can be classified into the class of customerlimited service disciplines, in which restrictions are put on the number of customers served during a visit of the server to a queue, and the class of time-limited service strategies, putting restrictions on the amount of time spent by the server during one visit of the server to a queue.
Alternatively, service disciplines can be classified into the so-called exhaustive-type policies and the gated-type policies, depending on whether customers who arrive at a queue while the server is working at that queue are candidates for service during the same visit of the server to that queue, e.g., [115]. Under an exhaustive-type policy the customers arriving at a queue in service are candidates for service in the same visit period, whereas under a gated-type policy they are not. The best known variant of the gated service discipline is globally gated , which also allows for an exact analysis [34]. This service discipline states that only those customers are served who were present at the beginning of a visit to one fixed 'parent-queue'. Numerous hybrid variants of service disciplines can be conceived by combining the various types of cut-off mechanisms. A number of these service disciplines has been studied in the literature, such as customer-limited type service policies like the k -limited service, Bernoulli service [94], probabilistically-limited service [112], binomial-gated service [114], binomial-exhaustive, Bernoulli-gated and Bernoulli-exhaustive service [38], fractionalexhaustive service [113], mixed gated/exhaustive service based on customer priority levels [20], Bernoulli-type service [135], and time-limited service disciplines with exponential time limits [44, 111], and with constant time limits [55]. A gated-type service discipline with multiple gates is studied in [159-161].
Queueing discipline. The queueing discipline specifies the order in which the customers present at the same queue are served. The most common queueing discipline is the classical First-Come-First-Served (FCFS) discipline. Very recently, Wierman et al. [173] showed that optimization of the queueing discipline in a polling system can improve the performance of the system significantly without having to purchase additional resources. Other recent papers in this direction are, for example, [21, 22, 30]. It is important to note that the queue length distribution is independent of the service order, and so are, by Little's law, the mean waiting times (provided the queueing discipline does not depend on the service times). However, the distribution of the waiting time does depend on the queueing discipline.
## 2.2 Mathematical analysis
In this subsection we give a brief impression of how polling systems can be analyzed. As stated in the introduction, the present paper surveys the application areas of polling systems, where it is not our intention to present an encyclopedic overview of all available mathematical results. Consequently, we have chosen to discuss only one (frequently used) analysis method, studying the marginal queue length and waiting time distributions. The reader should bear in mind that several alternatives exist. For detailed and comprehensive surveys of the analysis methodology of polling systems, we refer to Takagi's surveys [149, 151, 152], and furthermore to [115, 168, 182]. Moreover, Takagi's seminal book 'Analysis of polling systems' [148] should definitely be mentioned here.
The model studied in the present subsection can be considered as the basic, standard polling model. We assume that the polling model consists of N queues ( N ≥ 1), denoted by Q , . . . , Q 1 N , attended by one server in cyclic order. Whenever the server switches from Q i to Q i +1 , a switch-over time S i is incurred ( i = 1 , . . . , N ; since the system is cyclic, Q N +1 actually refers to Q 1 etc.). The switch-over times are independent random variables. In [28] an adaptation of the analysis is given for polling models without switch-over times. The arrival processes to the different queues are independent Poisson processes with intensities λ i , i = 1 , . . . , N . The service times of customers arriving in Q i are independent random variables denoted by B i . At the end of this section we will briefly mention some alternative techniques that may be required if the polling model of interest does not satisfy all of these assumptions.
The individual loads of the queues are denoted by ρ i = λ i E [ B i ], for i = 1 , . . . , N , and the total load of the system is denoted by ρ = ∑ N i =1 ρ i . The Laplace-Stieltjes transform (LST) of a continuous, positive random variable X is denoted by ˜ X ( ). · We use the same notation for the probability generating function (PGF) in case X is a discrete random variable.
Cycle times, visit times and intervisit times. The distribution of the length of one cycle depends on its starting point. For this reason we denote by C i the time between two successive visit beginnings to Q i , and by C ∗ i the time between two consecutive visit completions to Q i . The intervisit time of Q i , denoted by I i , is the time between the visit completion of Q i and the next visit beginning to this queue. The mean cycle time and the mean visit times can easily be computed in a cyclic polling system. The first obvious, but important, observation is that the mean cycle time does not depend on the starting point of the cycle. For this reason, we denote the mean cycle time by E [ C ] = E [ C i ] = E [ C ∗ i ] for all i = 1 , . . . , N . Since each customer arriving in the system gets served eventually, the server must be working a fraction ρ of the time, and is switching between queues a fraction 1 -ρ of the time. This leads to the simple relation E [ S ] = (1 -ρ ) E [ C ], where S = ∑ N i =1 S i . A similar way of reasoning can be applied to the workload of the individual queues, yielding expressions for the mean visit and intervisit times.
$$\mathbb { E } [ C ] & = \frac { \mathbb { E } [ S ] } { 1 - \rho }, \\ \mathbb { E } [ V _ { i } ] & = \rho _ { i } \mathbb { E } [ C ], \\ \mathbb { E } [ I _ { i } ] & = ( 1 - \rho _ { i } ) \mathbb { E } [ C ]. \\. \quad \dots \quad \dots.$$
The stability condition of the system depends on the service disciplines in the various queues. For exhaustive, gated, and globally gated service (and many other disciplines as well) the
stability condition is simply ρ < 1, yielding E [ C < ] ∞ . Note that for these service disciplines the switch-over times do not play a role in the stability condition, as they become negligible compared to the visit times, as ρ → 1.
Queue lengths and waiting times. The key performance measures of a polling system are the queue lengths and the waiting times. One of the most remarkable results regarding the marginal queue length distribution, denoted by L i , has been obtained by Fuhrmann and Cooper [75]. They observed that the marginal queue length distribution can be decomposed as the sum of two independent random variables:
$$L _ { i } \stackrel { d } { = } L _ { i } ^ { ( M / G / 1 ) } + L _ { i } ^ { ( I _ { i } ) },$$
where L ( M/G/ 1) i is the queue length of an M/G/ 1 queue with only type i customers in isolation, often referred to as 'the corresponding M/G/ 1 queue', and L ( I i ) i is the queue length at an arbitrary moment during the intervisit period I i . This results in the following PGF of the marginal queue length distribution:
$$\widetilde { L } _ { i } ( z ) = \frac { ( 1 - \rho _ { i } ) ( 1 - z ) \widetilde { B } _ { i } \left ( \lambda _ { i } ( 1 - z ) \right ) } { \widetilde { B } _ { i } \left ( \lambda _ { i } ( 1 - z ) \right ) - z } \times \frac { \widetilde { L } _ { i } ^ { ( V _ { c _ { i } } ) } ( z ) - \widetilde { L } _ { i } ^ { ( V _ { b _ { i } } ) } ( z ) } { \lambda _ { i } \mathbb { E } [ I _ { i } ] ( 1 - z ) },$$
for i = 1 , . . . , N . In (1) we have used L ( V b i ) i and L ( V c i ) i to denote the number of customers in Q i at, respectively, the beginning and completion of a visit to Q i . An important observation is that one only needs the queue length distribution at the beginnings and completions of a visit to each queue, in order to find the marginal queue length distributions. Moreover, Keilson and Servi show that the LSTs of the waiting time distributions follow directly from ˜ L i ( ) by applying the distributional form of Little's Law [95]: ·
$$\widetilde { W } _ { i } ( \omega ) = \frac { \widetilde { L } _ { i } ( 1 - \omega / \lambda _ { i } ) } { \widetilde { B } _ { i } ( \omega ) },$$
where ˜ W i ( ) · is the LST of the waiting time distribution of type i customers, excluding the service time B i .
Joint queue length at polling epochs. Determining the marginal queue length distributions at visit beginnings and completions, requires studying the joint queue length distributions at these embedded epochs. It turns out that, a few exceptions aside, an exact analysis is only possible if all service disciplines in the polling system satisfy the following branching property , described by Fuhrmann [74] and Resing [135].
Property 2.1 (Branching Property) . If the server arrives at Q i to find k i customers there, then during the course of the server's visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having PGF h i ( z , . . . , z 1 N ) , which can be any N -dimensional PGF.
The PGF mentioned in the branching property depends on the service discipline. As an example, we give the expressions for exhaustive and gated service.
glyph[negationslash]
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \\ \text{Gated:} & & h _ { i } ( z _ { 1 }, \dots, z _ { N } ) = \widetilde { B } _ { i } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ) ), \\ \text{Exhaustive:} & & h _ { i } ( z _ { 1 }, \dots, z _ { N } ) = \pi _ { i } ( \sum _ { j \neq i } \lambda _ { j } ( 1 - z _ { j } ) ), \\ / \vee \cdot \cdot \cdot \cdot \, \underbrace { \pi } \, \underbrace { \pi } \, \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
where π i ( ) · is the LST of a busy period distribution in an M/G/ 1 system with only type i customers, so it is the root in (0 , 1] of the equation π i ( ω ) = ˜ B i ( ω + λ i (1 -π i ( ω )) ) , ω ≥ 0 (cf. [45], p. 250).
Recall that the globally gated service discipline does not strictly satisfy Property 2.1, but still allows for an exact analysis. Borst [26] defines a generalization of the branching property that still ensures mathematical tractability. The globally gated discipline satisfies this weaker property.
Assuming that each queue satisfies the branching property, the PGF of the joint queue length distribution at visit completions, denoted by ˜ L ( V c i ) ( z , . . . , z 1 N ), can be expressed in terms of the joint queue length distribution at visit beginnings, denoted by ˜ L ( V b i ) ( z , . . . , z 1 N ). The following relations, which are commonly referred to as the laws of motion , hold:
$$\widetilde { L } ^ { ( V _ { c _ { 1 } } ) } ( z _ { 1 }, \dots, z _ { N } ) = \widetilde { L } ^ { ( V _ { b _ { 1 } } ) } ( h _ { 1 } ( z _ { 1 }, \dots, z _ { N } ), z _ { 2 }, \dots, z _ { N } ),$$
$$\widetilde { L } ^ { ( V _ { b _ { 2 } } ) } ( z _ { 1 }, \dots, z _ { N } ) = \widetilde { L } ^ { ( V _ { c _ { 1 } } ) } ( z _ { 1 }, \dots, z _ { N } ) \, \widetilde { S } _ { 1 } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ) ),$$
.
.
.
$$\widetilde { L } ^ { ( V _ { e _ { N } } ) } ( z _ { 1 }, \dots, z _ { N } ) = \widetilde { L } ^ { ( V _ { b _ { N } } ) } ( z _ { 1 }, z _ { 2 }, \dots, z _ { N - 1 }, h _ { N } ( z _ { 1 }, \dots, z _ { N } ) ),$$
$$\widetilde { L } ^ { ( V _ { b _ { 1 } } ) } ( z _ { 1 }, \dots, z _ { N } ) = \widetilde { L } ^ { ( V _ { c _ { N } } ) } ( z _ { 1 }, \dots, z _ { N } ) \, \widetilde { S } _ { N } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ) ).$$
The recursive equation for ˜ L ( V b 1 ) ( z , . . . , z 1 N ) itself can be used to compute the moments of this joint queue length distribution. An explicit expression for ˜ L ( V b 1 ) ( z , . . . , z 1 N ) can be found by clever definition of offspring generating functions and immigration generating functions . We refer to [135] for more details.
Mean waiting times. By differentiation of the LSTs of the waiting time distributions, the following expressions for E [ W i ] are found for exhaustive, gated, and globally gated service respectively:
$$\text{Exhaustive} \colon$$
$$\mathbb { E } [ W _ { i } ] = \, ( 1 - \rho _ { i } ) \frac { \mathbb { E } [ C _ { i } ^ { * 2 } ] } { 2 \mathbb { E } [ C ] },$$
$$\text{Gated} & \mathbb { E } [ W _ { i } ] = ( 1 + \rho _ { i } ) \frac { \mathbb { E } _ { [ } C ^ { \ast } _ { i } ] } { 2 \mathbb { E } [ C ] },$$
$$\mathbb { m } { \hat { \frac { \mathbb { E } [ \dot { C } _ { i } ^ { 2 } ] } } { 2 \mathbb { E } [ C ] } },$$
$$\text{Globally gated: } & \mathbb { E } [ W _ { i } ] = \sum _ { j = 1 } ^ { i - 1 } \mathbb { E } [ S _ { j } ] + ( 1 + 2 \sum _ { j = 1 } ^ { i - 1 } \rho _ { j } + \rho _ { i } ) \frac { \mathbb { E } [ C _ { 1 } ^ { 2 } ] } { 2 \mathbb { E } [ C ] }. & & ( 8 )$$
$$( 8 )$$
For a polling system with globally gated service, we have assumed that the server's arrival epoch at Q 1 determines which customers (in all queues) are eligible for service. Although the expressions (6)-(8) seem quite simple at first sight, it should be noted that the computation of the second moments of C ∗ i and C i is not straightforward. Although they can be obtained by solving the set of equations resulting from differentiation of the recursive expression for ˜ L ( V b 1 ) ( z , . . . , z 1 N ), obtained from the laws of motion, with respect to z , . . . , z 1 N , more efficient methods have been developed. The two most frequently used alternatives to find mean waiting times are the descendant set approach , developed by Konheim et al. [101], and mean value analysis for polling systems, developed by Winands et al. [176].
Pseudo-conservation law. Boxma and Groenendijk [31] derive a so-called pseudo-conservation law (PCL) for the mean waiting times under various service disciplines. This PCL states that
$$\sum _ { i = 1 } ^ { N } \rho _ { i } \mathbb { E } [ W _ { i } ] = \rho \frac { \sum _ { i = 1 } ^ { N } \lambda _ { i } \mathbb { E } [ B _ { i } ^ { 2 } ] } { 2 ( 1 - \rho ) } + \rho \frac { \mathbb { E } [ S ^ { 2 } ] } { 2 \mathbb { E } [ S ] } + \frac { \mathbb { E } [ S ] } { 2 ( 1 - \rho ) } \left ( \rho ^ { 2 } - \sum _ { i = 1 } ^ { N } \rho _ { i } ^ { 2 } \right ) + \sum _ { i = 1 } ^ { N } \mathbb { E } [ Z _ { i i } ], \quad ( 9 )$$
where Z ii denotes the amount of work left behind by the server at Q i at the completion of a visit, which solely depends on the service discipline of Q i . For exhaustive service at Q i , we have E [ Z ii ] = 0, and for gated service E [ Z ii ] = ρ 2 i E [ S / ] (1 -ρ ).
Other models and/or techniques In the present section we have described only one technique, often referred to as the buffer occupancy method , first used by Cooper and Murray [47] and Cooper [46]. An advantage of this technique is its applicability to several variations of the basic polling model, described in the current subsection, such as polling systems with other service disciplines than exhaustive and/or (globally) gated service, systems with simultaneous arrivals [116], or fluid polling systems [49]. However, if the assumptions stated in the beginning of this subsection are not all valid, one might have to resort to alternative ways to analyze the system. For example, if the arrival processes are not Poisson, but BMAPs, a generalization of the buffer occupancy method using Kronecker product notation can be used [136]. Altman and Fiems [4] show how stochastic recursive equations can be used to analyse a polling model with correlated switch-over times. If the service disciplines do not satisfy the branching property, one may have to resort to different techniques, or even approximations. For example, a twoqueue polling system with Bernoulli service (a generalization of 1-limited as well as exhaustive service) has been analyzed by Lee [109] by formulating the model as a Riemann boundary value problem with a shift. Unfortunately, to analyze polling systems with non-branching service disciplines consisting of more than two queues, one may have to use approximations or numerical methods. Van Houdt [165] uses a numerical algorithm based on the power method, Kronecker matrix representations, and the shuffle algorithm, to analyze discrete-time polling systems for networks on chips (which will be discussed later in this paper). This algorithm can also be used for general polling systems with branching-type or non-branching-type service disciplines.
## 3 Applications
In this section, we will first describe the three most successful application areas of polling models within the classical fields of engineering of communication systems, production sys-
tems, traffic and transportation systems. Subsequently, the last subsection summarizes a variety of miscellaneous applications of polling systems.
## 3.1 Computer-communication systems
Polling systems find a wealth of applications in the area of computer-communication systems, where resources (e.g., bandwidth, CPU power) are shared among different users. The reader is referred to surveys by Grillo [85], Levy and Sidi [115], Takagi [152] and Weststrate [172] for overviews of applications up until the early 1990s. For completeness, the main applications cited in these survey papers are outlined below, and supplemented with more recent applications of polling models in communication systems.
Time-sharing computer systems. Classical applications of polling models are timesharing computer systems [100], consisting of a number of terminals connected by multi-drop lines to a central computer. The data transfer from the terminals to the computer - and back - is controlled via a polling scheme in which the computer polls the terminals, requesting their data, one terminal at a time. In such applications of polling models, the server represents the central computer, the queues represent the terminals and customers represent the data.
In communication networks different terminals compete for access to a shared medium. If multiple terminals transmit or receive data over the medium at the same time, packet collisions and interference problems may occur. Motivated by this many medium access control (MAC) protocols have been proposed for different network technologies, in many cases leading to polling models.
Token-ring networks. Bux [42] uses polling models to study the performance of tokenpassing schemes in Local Area Networks (LANs) where a token - representing the right for transmission - is circulated among the different users. In such cases, the token-passing scheme is usually configured in a ring or a bus topology. A token-ring network can be characterized as a set of stations connected to a common transmission medium in a ring topology. All messages travel over a fixed route from station to station around the loop. A token can be in two states: occupied or free. A station with data to transmit reads the free token and changes it to the occupied state before retransmitting it. The occupied token is then incorporated as part of the header of the data transmitted on the ring by the station. Thus, other stations on the ring can read the header, note the occupied token and refrain from transmission. When the token is back at the station that changed it to the occupied state and the station decides to transfer the right for transmission to another station, it changes the token to the free state. The token-ring network allows the transmission of packets in a conflict-free manner. However, transmission of packets may still fail due to errors and distortions on the ring itself. Typically, these errors are rare and a so-called Selective-Repeat ARQ (SR-ARQ) could be used to recover these errors. In such a scheme, a station that receives an erroneous message transmits a negative acknowledgment to the transmitting station to indicate that the message has to be retransmitted. To analyze the performance of SR-ARQ schemes, Levy and Sidi [115] use a polling model in which each station is represented by two queues, one for messages that need to be sent out and one for negative acknowledgments to be sent back when erroneous messages are received. Altman and Kofman [6] propose a solution to deal with the irregular,
bursty, correlated arrival processes in token-ring networks. To this end, they use a polling model with so-called Cruz-type traffic, filtering the arrival streams by leaky buckets.
Token-bus networks. The token-bus network consists of a set of stations connected to each other in a bus topology. The intention behind this technique is to combine the attractive features of the bus topology with those of a conflict-free medium-access protocol. In a token bus, as the token is passed, a logical ring is formed. Since the bus topology does not impose any sequential ordering of the stations, the logical ring is defined by a sequence of station addresses. Conceptually, token passing on buses and rings is very similar and the same type of performance model can be used to describe these techniques. The difference between a token ring and a token bus from a modeling point of view is that the server in the token ring network visits the queues in a cyclic manner, whereas in the token-bus model the server moves along the queues in a non-cyclic periodic manner, which can be modeled by a polling table. An example of a token-bus network is presented by Manfield [119], where a communication network constitutes the transmission medium between a master processor and a set of peripheral processors. The operation of these systems works as follows: the master processor polls each of the peripheral processors in turn. Subsequently, it receives a response which indicates whether the peripheral processor has any packet to send. If it has, the packet at the head of that queue is sent to the master processor. After polling a peripheral incoming queue, the master processor checks its own queue for outgoing packets, and if the queue is not empty, seizes control of the bus. The advantage of this system, is that it ensures that outgoing messages are rapidly sent and it avoids message deadlocks in the central control facility (i.e., the master processor). This polling scheme is called star polling in the literature.
Slotted-ring networks. Another class of communication protocols for networks with a ring topology is a so-called slotted-ring network. In a slotted-ring network one or more slots circulate along the stations. If there is a packet at a station ready for transmission and an empty slot comes along, the packet is put into the slot, together with the address of the destination station. That slot is then examined by each of the other stations in turn, until the destination station recognizes it and copies its content. There are two possibilities to empty the slot: either it is emptied by the source station (this is called the Cambridge Ring Protocol), or by the destination system (this is called the Orwell Ring Protocol). We refer to Bux [42] for a polling model with source release, and to Van Arem [153] for a polling model of a slotted-ring protocol with destination release.
Fibre Distributed Data Interface networks. The FDDI is a token-passing protocol for LANs with a ring topology in which the access to the ring for transmission is controlled via a so-called timed-token protocol, i.e. where the transmission time for each station is bounded. This type of models leads to the formulation of polling models with time-limited service policies [141].
Distributed Queue Dual Bus networks. The DQDB protocol is a multiple access protocol for communication networks consisting of two unidirectional buses carrying information in the opposite directions. The stations are distributed along the two buses and have the
capability to transmit/receive information to/from both buses. The DQDB protocol is intended to integrate data, voice and video traffic in a single communication network. Bisdikian [17] uses a polling model to study medium access mechanisms of a single station in a DQDB network.
Random access schemes. Opposite to the scheduled multiple access protocols are the random multiple access protocols, where an entity with a message will transmit it regardless of potential collisions. The ALOHA access scheme is an example of a random access scheme. As soon as a packet arrives at a station it is transmitted. When the transmission fails, for example because other packets were transmitted at the same time causing a collision, the packet is scheduled for transmission after a random period of time. An alternative for this scheme is the so-called reservation ALOHA access scheme. In this scheme, a station is granted the exclusive right to transmit, without being interfered by any other station, for a certain amount of time. When a transmitting station no longer reserves the channel, some - or all -stations of the system start contending in order to seize the channel. The length of the contention period is random and the next station that will seize the channel is also random. This type of protocols naturally leads to the formulation of polling models with random routing [36, 98]. A detailed comparison of various multi-access schemes, including random access schemes like ALOHA and CSMA, is given by Kleinrock [97].
Optical networks. Polling models also find applications in the area of Ethernet Passive Optical networks (EPONs), where packets from different Optical Network Units (ONUs) share channel capacity in the upstream direction. An EPON is a point-to-multipoint network in the downstream direction and a multipoint-to-point network in the upstream direction. The Optical Line Terminal (OLT) resides in the local office, connecting the access network to the Internet. The OLT allocates the bandwidth to the Optical Network Units (ONUs) located at the customer premises, providing interfaces between the OLT and end-user network to send voice, video and data traffic. In an EPON the process of transmitting data downstream from the OLT to the ONUs is broadcast in variable-length packets according to the 802.3 protocol [104]. However, in the upstream direction the ONUs share capacity, and various polling-based bandwidth allocation schemes can be implemented. Simple time-division multiple access (TDMA) schemes based on fixed time-slot assignment suffer from the lack of statistical multiplexing, making inefficient use of the available bandwidth, which raises the need for dynamic bandwidth allocation (DBA) schemes. A dynamic scheme that reduces the time-slot size when there are no data to transmit would allow excess bandwidth to be used by other ONUs. Kramer et al. [103, 105] propose an OLT-based interleaved polling scheme similar to hub-polling to support dynamic bandwidth allocation. To avoid monopolization of bandwidth usage of ONUs with high data volumes they propose an interleaved DBA scheme with a maximum transmission window size limit.
Bluetooth. Bluetooth is a wireless technology standard, used for exchanging data between mobile devices such as mobile phones, laptops, and headsets. These devices form small networks, referred to as Wireless Personal Area Networks (WPANs). The basic Bluetooth network topology is called a piconet , consisting of one master device and up to seven slave devices. Miorandi et al. [124] observe that the structure of a piconet consisting of N slaves,
can be modeled adequately using a polling system consisting of 2 N queues. One queue is used for each master-to-slave communication link, and one additional queue is required for each slave-to-master link. Approximations of the mean delays are found for the Pure Round-Robin (corresponding to 1-limited service), gated, and exhaustive disciplines. Zussman et al. [185] study the same model, deriving exact results regarding the packet delays.
I/O subsystems. Polling models occur in the context of I/O-subsystems of file servers or database management systems as well. File servers are expected to handle large volumes of information-retrieval requests within a reasonable amount of time. After the requested information (either static or dynamic) has been gathered, the information is ready for transmission to the client over the communication network that connects the client to the server. To this end, the information is placed in an I/O-subsystem, where it is ready to be drained to the client over the network. This can be done for example via the Transport Control Protocol (TCP), implementing a window-based control mechanism. The I/O-subsystem will typically consist of a number of parallel TCP-buffers. The draining of the different buffers is managed by an I/O-controller that controls the access of the buffer content to the network. To this end, the I/O controller 'visits' the buffers in some order to check whether a buffer has information to be drained, and if so, whether the corresponding TCP-window is open, allowing for transmission of data segments residing in the buffer via the network to the client. We refer to [89, 158] for performance models of Web servers including I/O-controlled buffers. This type of I/O-control leads to the formulation of polling models where the service discipline represents the complicated dynamics of TCP-window control. In [48], Czerniak et al. analyze TCP systems using polling models to describe the different transmission methods.
Mobile networks. Polling models can also be found in the area of mobile networks, where different users compete for access to the shared scarce radio resources. In such environments, the base station is typically in charge of assigning time slots to the different users in some way. In this context, the server represents the right for transmission and the customers represent data packets to be transmitted. Typical examples of polling mechanisms occur in the context of the Code Division Multiple Access (CDMA) based High Speed Packet Access (HSPA), where the base station controller grants access to the medium in a per-timeslot basis. There are different scheduling mechanisms for deciding which of the terminals gets access to the medium for the duration of a single time slot. A common implementation is simple RoundRobin (RR) scheduling, where medium-access is circulated among the terminals, independent of the quality of the signal [154]. This immediately leads to polling models with limited service policies and cyclic server routing. A straightforward extension of RR scheduling is Weighted Round-Robin (WRR), which leads to the formulation of polling models with periodic server routing. To enhance the efficiency of medium access for HSPA-networks, highly sophisticated channel-aware scheduling mechanisms have been proposed, granting time slots to terminals based on the measured instantaneous (possibly relative) Signal-to-Noise Ratios (SINRs) of each of the terminals [18, 27]. The inherent randomness in the channel conditions, and hence in the order in which the stations are granted access to the medium naturally leads to the formulation of polling models with random or Markovian server routing [36, 98].
Ferry-based Wireless LANs. Polling models are applicable in the context of designing message ferry routes in Ferry-based Wireless LANs. In such FWLANs, a number of isolated nodes are scattered over some geographical area where communication between a node and the outer world, or communication between nodes, is made possible via a message ferry. The ferry follows a predetermined cyclic path, collecting messages from and delivering messages to nodes whenever it is in the vicinity of the node (implying that the routes do not have to pass through all the points in space). The transmission and reception range is flexible: assuming a fixed transmission power, the range can be increased at the cost of decreasing throughput. Taking into account the relation between the range and the throughput, one can design an optimal cyclic route of the ferry. We refer to Kavitha and Altman [93] (and references therein) for results in FWLANs.
Mobile adhoc networks. Polling models occur naturally in the modeling of mobile ad-hoc networks (MANETs), consisting of both mobile and fixed wireless terminals. A typical feature of these kind of networks, is that wireless devices create their own wireless network in a distributional fashion. Mobile users can change location and thereby change communication links in the network. Examples of MANETs are animal-monitoring systems, collaborative conference computing, vehicular networks, peer-to-peer file-sharing systems and disaster-relief networks. Unlike most classical wireless networks, MANETs allow for multi-hop communication. Communication links appear and break down dynamically. Their lifetimes are random and independent of the amount of traffic offered to or transmitted over such links. To capture this phenomenon, De Haan [54] proposes the so-called pure time-limited service policy, where the server visits a queue for a random amount of time, independent of anything else in the system; note that this policy is not work conserving. The reader is referred to [53] (Chapter 1) for an overview of applications of polling models in MANETs.
Networks on chips. Another interesting application area of polling models is networks on chips (NOCs), which have been proposed as a solution for the inefficiency caused by traditional bus connections [12, 51]. In NOCs, intellectual property blocks (a general term for on-chip modules) are not connected to a single shared link, but to network interfaces that implement communication protocols. Data is transmitted using switches that consist of input and output ports. If multiple ports have data for the same output port, only one input port can transmit its data, and the switch selects which one. Data that is not transmitted immediately is stored in buffers and will be transmitted later. We refer to [11] for overview of the applicability and the state-of-the-art on analysis of polling models for networks on chips, and to [165] for an efficient numerical algorithm.
## 3.2 Production systems
Acompletely different application area of polling systems can be found in the so-called stochastic economic lot scheduling problem (SELSP). The SELSP deals with the make-to-stock production of multiple standardized products on a single machine with limited capacity under random demands , possibly random setup times and possibly random production times . The SELSP is a common problem in practice, e.g., in glass and paper production, injection molding, metal stamping and semi-continuous chemical processes, but also in bulk production of
/G64
/G64
/G65
/G6D
/G61
/G6E
/G64
/G20
/G70
/G72
/G6F
/G63
/G65
/G73
/G73
/G72
/G65
/G70
/G6C
/G65
/G6E
/G69
/G73
/G68
/G6D
/G65
/G6E
/G74
/G6F
/G63
/G65
/G73
/G73
/G72
/G65
/G70
/G6C
/G65
/G6E
/G69
/G73
/G68
/G6D
/G65
/G6E
/G74
/G70
/G72
/G6F
/G63
/G65
/G73
/G73
/G70
/G6C
/G65
/G6E
/G69
/G73
/G68
/G6D
/G65
/G6E
/G74
/G70
/G72
/G6F
/G63
/G65
/G73
/G73
/G72
/G65
/G70
/G6C
/G65
/G6E
/G69
/G73
/G68
/G6D
/G65
/G6E
/G74
/G70
/G72
/G6F
/G63
/G65
/G73
/G73
Figure 1: The fixed-sequence base-stock system.
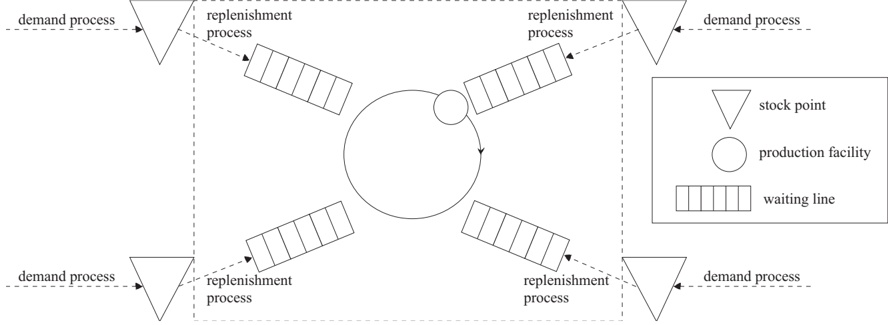
consumer products such as detergents and beers.
In many firms encountering the SELSP, the following class of fixed-sequence base-stock policies is used for the control of the inventory of each product. We distinguish N products, which are numbered 1 2 , , . . . , N . Subsequently, to each individual product a stock point is assigned which is controlled by a base-stock inventory policy. Under such a policy, for each product there exists a pre-defined desired number of items in stock, the base-stock level b i , i = 1 2 , , . . . , N . When demand arrives at a stock point and the requested product is on stock, the demand is immediately fulfilled. Otherwise, demand is backlogged and fulfilled as soon as the product becomes available after production. A production order, also called replenishment order, is placed immediately after demand for the corresponding product has arrived. These production orders queue up at the production facility, where each product has its own designated queue.
On the strategy deployed by the production facility, the following two restrictions are imposed,
- 1. The products are produced according to a fixed production sequence;
- 2. When the machine starts production of a product, it will continue production until either the base-stock level has been reached or a second local criterion, i.e., only dependent on the stock level of the product currently setup, has been fulfilled.
The combination of stock points and production facility is visualized in Figure 1.
For given values of the base-stock levels b i the steady-state net stock level N i for product i is given by, for i = 1 2 , , . . . , N ,
$$N _ { i } = b _ { i } - L _ { i },$$
where L i denotes the steady-state shortfall (the number of outstanding production orders at the production facility) of product i . Notice that the net stock level of a product becomes negative, when the shortfall of this product is larger than its base-stock level. One can verify that the shortfall of a product is independent of the base-stock levels implying that the performance of the production facility can be analyzed independently of these base-stock levels. Moreover, the shortfall distribution of a product at the production facility is identical
/G65
/G6D
/G61
/G6E
/G64
/G20
/G70
/G72
/G6F
/G63
/G65
/G73
/G73
/G72
/G70
/G65
/G72
/G64
/G64
/G65
/G65
/G6D
/G6D
/G61
/G61
/G6E
/G6E
/G64
/G64
/G20
/G20
/G70
/G70
/G73
/G70
/G72
/G72
/G77
/G74
/G72
/G6F
/G6F
/G6F
/G6F
/G61
/G63
/G63
/G63
/G64
/G69
/G65
/G65
/G6B
/G74
/G75
/G73
/G73
/G69
/G20
/G6E
/G73
/G73
/G63
/G70
/G74
/G67
/G6F
/G69
/G20
/G6F
/G69
/G6C
/G6E
/G69
/G6E
/G6E
/G74
/G20
/G66
/G65
/G61
/G63
/G69
/G6C
/G69
/G74
/G79
to the queue length distribution in a polling system. The interarrival, service and setup time processes in such a polling system are identical to the demand, processing and setup time processes in the SELSP, respectively. For given base-stock levels, the evaluation of a fixedsequence base-stock policy is, therefore, tantamount to evaluation of the corresponding polling system .
Literature on the SELSP. Seminal papers analyzing the above fixed-sequence base-stock policy via polling systems are by Federgruen and Katalan [67, 69, 70]. Besides the basic assumptions for the SELSP, products are produced by an exhaustive or a gated base-stock policy. The production manager is allowed to insert a fixed idle time prior to the setup for a product in order to reduce the setup frequencies and, hence, the average setup costs.
Grasman et al. [83] extend the exhaustive base-stock model of Federgruen and Katalan by adding random yields for the cases of backlogging, lost sales and expediting. In case of backlogging they derive similar newsboy equations in order to obtain optimal base-stock levels. In case of lost sales or expediting they have to resort to a heuristic for computing the (approximate) optimal base-stock levels. Krieg and Kuhn [106, 107] introduce continuoustime models for single-stage multi-product Kanban systems , which are completely identical to the SELSP with lost sales. In Krieg and Kuhn [106], a system is analyzed with stateindependent setups, whereas in Krieg and Kuhn [107] state-dependent setups are modeled, i.e., no setup for a product is incurred when there is no shortfall. Production quantities are in both models determined by an exhaustive base-stock policy.
Winands et al. [177] analyze a two-product system, in which a high-priority product is produced exhaustively and a low-priority product according to the k -limited service strategy. Chapter 4 of [174] is devoted to a numerical simulation study which shows that the k -limited lot-sizing policy outperforms the standard exhaustive policy for a wide variety of environments. In particular, the k -limited policy proves its worth in asymmetric production systems.
In most applications, the service discipline determines how many items are produced, and, hence, what the (random) duration of a cycle in the polling system is. In some cases, however, the cycle length is fixed implying that the corresponding analysis often reduces to a onedimensional problem. See [81] for a case study of a chemical plant, for which a fixed production sequence strategy in combination with a fixed cycle length has been developed under the assumption of deterministic production and setup times. Erkip et al. [66] introduce a discretetime model under the assumption of backlogging, in which the production and setup times are deterministic. Other work in this direction is by Bruin [40], who presents a generating function approach for the fixed cycle strategy under general traffic settings, and by Dellaert [56], who develops a heavy-traffic approximation for the optimal base-stock levels.
Make-to-order. Summarizing, we can say that the SELSP is an extension of a standard polling system by an additional inventory dimension. The make-to-order scheduling counterpart (in which no stock is kept for a product and thus the base-stock levels equal 0) is, however, precisely equivalent to a standard polling model. The polling system again consists of a server, mostly referred to as machine, and multiple customer classes, which will be referred to as products.
In the literature, one can notice that (almost) all modeling variants as discussed in Section 2
have been studied in the context of such a make-to-order production situation. This implies that an enormous amount of papers on polling systems have appeared motivated by make-toorder manufacturing applications. Since the primary goal of the present paper is to give an overview of the various application areas of polling systems - and not to give an exhaustive list of papers within each area - we only give a small subset of recent papers on make-to-order polling systems (i.e., [13, 59, 60, 108, 127, 132, 142, 145]).
Finally, in Markowitz et al. [120, 121] heavy traffic polling results are applied to all kinds of related stochastic multi-product single-machine scheduling problems.
The impact of setup times. Besides papers on the performance analysis of polling systems in the context of production environments, much research has been published on the impact of setup times (see [58, 80, 122, 139, 183, 184]). In these papers, it is shown that reduction of setup times can, counterintuitively, increase the mean queue lengths in polling systems and cyclic production systems for a variety of settings. Furthermore, the conditions are studied under which mean queue lengths increase when setup times are reduced [68, 69, 137, 138, 174].
## 3.3 Traffic and transportation systems
The third important area in which polling systems are frequently applied in practice are traffic and transportation systems. In road traffic a polling system is the natural way to model a situation where queues arise due to the fact that multiple flows of traffic have to share one single lane. The plainest form is a two-way road which is partly blocked because of an accident or road maintenance, but any common traffic intersection also qualifies. Besides road traffic, polling models are employed in transportation systems consisting of driverless electric vehicles that follow a predetermined track. The actual transportation is performed by so-called Automated Guided Vehicles (AGVs). AGV systems are used in warehouses and container terminals, but also in other application areas like, e.g., health care.
## Traffic signals
We discuss applications of polling systems in road traffic first. Queues are formed by the lines of cars waiting before a red traffic signal. The time that is required for one vehicle to pass the traffic signal can be viewed as service time, while the times that all queues face a red light simultaneously, i.e. the clearance times of the intersection, can be considered as switchover times. There are several aspects that make polling models for signalized intersections different from the models in other application areas. Firstly, the assumption of independent, identically distributed service times is in practice not valid. When a green period commences, a certain time elapses while vehicles are accelerating to normal speed. After this time, which typically lasts a few seconds, the queue discharges at a more or less constant rate, which is called the saturation flow. In practice the saturation flow may vary within a cycle and between cycles, but Webster [171] finds that the assumption of a constant saturation flow agrees well with values observed over a fairly large number of cycles. A typical feature of the traffic light queue is that cars approaching an empty intersection while facing a green light do not slow down and require almost no service time at all, especially if they do not have to take a turn. The second difference between traffic intersections and many other polling applications
is the arrival process. The assumption of Poisson arrivals might be realistic for an isolated traffic intersection, but many intersections are part of an arterial system, which means that an output process of the first intersection forms an input process for the next intersection. Only few papers deal with these so-called platooned arrivals. The third difference that we discuss is that most traffic intersections are divided into groups of flows that face a green light simultaneously. In the polling system this can be modeled as a (possibly varying) number of multiple coupled servers serving queues simultaneously. The moment at which a switch-over is incurred depends on the service discipline that is used for the intersection. The best known discipline is the Fixed Cycle Traffic Light discipline, which uses deterministic green, red and amber times. The obvious disadvantage of fixed settings is that the system does not respond to the current situation, which might be less efficient because traffic lights remain green even when no cars are waiting in the corresponding queue. An alternative to fixed settings that is very commonly used is an adaptive control mechanism for traffic signals. This is a mechanism that detects the presence of vehicles and makes decisions on whether or not to switch a signal based upon this information. A typical policy is to wait until all traffic flows that face a green light are empty before switching to red. For some intersections, a time limited policy might be more suitable. See [130] for a discussion on this topic. We discuss literature on polling models for traffic intersections in more detail by splitting it into two groups: papers concerning the fixed cycle traffic light queue, and papers on vehicle-actuated signals.
Literature on the Fixed Cycle Traffic Light queue. A traffic intersection with fixed green, amber and red times can be viewed as a polling model with deterministic visit times and switch-over times. One may argue whether this system should be considered a real polling system, since the analysis of delays is a one-dimensional problem and one can focus on one queue in particular. One of the most influential papers on the fixed cycle traffic light queue is [171], in which Webster describes a procedure to find optimal settings (i.e., green and red times for all traffic flows) for traffic lights. He derives an approximate expression for the optimal cycle length and an expression for the average delay per vehicle. His expressions are partly based on theoretical grounds, and partly on simulation results. Although more sophisticated methods have been developed ever since, his results are still quite popular in practice. Few years later, Miller [123], under the assumption of Poisson arrivals, and Newell [128], for general arrivals, develop approximations for the distributions of the delay and the queue length. Exact expressions for these distributions have been obtained by Heidemann [90], but again under the assumption of Poisson arrivals. In a recent paper Van Leeuwaarden [166] derives the queue length and the waiting time distribution for general arrival processes. Van den Broek et al. [155] derive approximations for the mean overflow, i.e., the mean queue length at the end of a green period, that are easier to compute and provide more intuitive insight.
In practice, intersections are often part of an arterial system and interarrival times are correlated. Alfa and Neuts [2] regard a model with platooned arrivals, which allows for distinguishing between interarrival times between cars within a platoon, and interplatoon interarrival times. The number of cars within one platoon can have any discrete phase probability distribution. The platooned arrival process is applied to road traffic, and to the fixed cycle traffic light queue. Through a numerical example they conclude that ignoring correlation in the arrival process leads to an underestimation of the mean queue length at high traffic intensities.
Literature on vehicle-actuated traffic signal control. Nowadays fixed cycles are less and less frequently implemented at traffic intersections, but it might still be a realistic assumption when the intersection is congested during rush-hour. Most traffic signal systems are vehicle-actuated, which means that the system contains detectors that gather information about the number of cars present at each flow and regulate the green and red times based on this information. In particular, when a queue becomes empty, the corresponding traffic light turns red and the traffic light of the next group of flows becomes green. This situation corresponds to a polling model with exhaustive service. However, in general, vehicle-actuated systems are designed to have minimum and maximum green times for each flow. This makes them very suitable to model as a polling system with time-limited service, but it also makes them difficult to analyse. Frigui and Alfa [72, 73] propose an iterative algorithm to approximate waiting times in a discrete-time polling system with time-limited service. Their papers focus on applications in communication systems, but in [71] the model is also applied to traffic intersections.
The earliest literature on vehicle-actuated systems dates from the early 1960s when Darroch et al. [52] analyze a system that consists of two intersecting traffic streams that are served exhaustively. A model with two lanes that does not assume Poisson input has been studied by Lehoczky [110], who uses an alternating priority queueing model. Newell [129] analyzes an intersection with two one-way streets using fluid and diffusion queueing approximations. Daganzo [50] studies a polling system with more general arrival and service processes, with applications in traffic and transportation systems (as long as only one flow of traffic is served at a time). In [131], Newell and Osuna study a four-lane intersection where two opposite flows face a green light simultaneously. A variation of the two-lane intersection is introduced by Greenberg et al. [84], who analyse mean delays on a single rail line that has to be shared by trains arriving from opposite directions. This model is extended by Yamashita et al. [180], who study alternating traffic crossing a narrow one-lane bridge on a two-lane road. In many of the discussed papers traffic is modeled as fluid passing through the road. This approximation is fairly accurate when the traffic intensity is relatively high. Vlasiou and Yechiali [170] use a different approach, modeling a traffic intersection as a polling system with an infinite number of servers visiting each queue simultaneously.
All in all it is rather surprising how few mathematical models have been developed that deal with intersections where multiple flows face a green light simultaneously. In [22] a two-queue polling model is analyzed with two priority levels in one queue. This model can be applied to an intersection where two conflicting traffic flows share the same green slot. In [88] a Markov Decision Problem (MDP) decomposition approach is used to find optimal traffic signal settings at intersections with larger numbers of combined flows.
## Automated guided vehicles
Next to traffic intersections, a large transportation related application area of polling systems are Automated Guided Vehicles. The first AGV system was simply a tow truck that followed a wire in the floor instead of a rail, nowadays AGVs are mostly laser navigated. AGVs are mostly used for the transport of materials in manufacturing systems, but also in other areas like public transportation systems at airports. Not all AGV systems can be modeled as a polling system, but we discuss some exceptions. In a conventional AGV system, each vehicle can pick up a load from any station and deliver it to any other station. In order to
avoid collisions between vehicles, most systems use the zone blocking concept where the entire system is divided into zones. The control system allows only one vehicle in each zone at a time. Whenever an AGV system consists of a single loop, it can be modeled as a polling system. The vehicle corresponds to the server in the polling system, and the stations form the queues of the system. In some cases each station is modeled as two queues, one for the picking-up, and one for the drop-off. The inter-station travel times are modelled as switch-over times in the polling model. AGV systems with multiple vehicles can be modeled as a polling system with multiple, independently moving servers, but it is more common to approximate this situation by modeling it as a system with one vehicle that moves at a higher speed (see, e.g., [61]). It is typical for AGV systems that the vehicle in general does not visit the stations in a deterministic order. Although most papers concerning polling systems focus on a fixed visiting order of the queues, several papers discuss an alternative server routing. Srinivasan [146] uses a polling system with Markovian server routing to model AGV systems. In [33] and [16] optimization of server routing in polling systems is discussed. In AGV systems the visit order is generally determined by a decentralized cargo dispatching rule. The most commonly used cargo dispatching rule in AGV systems is First-Encountered-First-Served (FEFS) rule. The FCFS rule is less efficient, because it leads to unnecessary empty travel. Note that FCFS in the context of AGV systems generally does not refer to the order in which items are picked up within a queue, but to the route that the vehicle takes. In terms of queues, it travels towards the queue with the oldest waiting customer. The FEFS rule is presented for singleloop AGV systems in [10] and states that an empty vehicle continues to travel along the loop until it finds some load to pick up at some station. If it has available space, it picks up the load and drops it off at its destination. The number of packages that are picked up depends on the service discipline and may vary per station.
Bozer and Srinivasan [37] discuss an AGV system with tandem configurations. The original AGV system is divided into non-overlapping, single vehicle closed loops with load transfer stations in between (see Figure 2). Each loop can be modeled as a single server polling system. An advantage of a tandem AGV system is that each vehicle is dispatched over a smaller number of stations. Another advantage is that traffic management problems within each loop are completely eliminated. In [37] the mean throughput capacity for the loop is estimated under the FEFS rule. Srinivasan et al. [147] study this rule as well, and also introduce a modified FCFS dispatching rule, under which a vehicle deposits a load at a station and then checks that station for a new load-transfer request. If there is one, the vehicle serves this request; otherwise, it travels empty to other stations based on the FCFS dispatching rule. Xu et al. [179] focus on the loop configuration rather than on the cargo dispatching rule. Ganesharajah et al. [79] consider both simultaneously. Van der Heijden et al. [156] study an underground transportation system that contains a single traffic lane which has to be shared by AGVs from opposite directions. The system has similarities with a road traffic situation, but the extremely long clearance times require a more dedicated approach. The research is continued in [62] where more intelligent, adaptive control rules and dynamic programming algorithms are used to minimize vehicle waiting times.
## 3.4 Miscellaneous
The present subsection provides an overview of miscellaneous applications of polling systems observed in the open literature.
Figure 2: A conventional AGV system (left) and a tandem AGV system (right) as proposed by Bozer and Srinivasan [37]. The dots represent stations with pick-and-drop points. In the tandem AGV system, each loop is modeled as a single server polling system, and additional pick-and-drop points are placed as interface between adjacent loops. This figure appeared originally in [37].
Health care. In [43] a medical emergency room is modeled via a multi-server polling model. At the emergency room different types of patients arrive and are placed in queues depending on the type of surgical procedure required. Each emergency surgical procedure has a separate queue of infinite buffer capacity. The number of emergency room theatres is limited, and each emergency room theatre is modeled by a server in the polling model. Since setting up for surgery procedures takes longer than the actual procedures themselves, the service times within the polling model are much smaller than the switch-over times. Finally, an urgency parameter in terms of average waiting time is assigned to each patient which dictates the existence of (local) priority levels within each queue. From the application point of view, Cicin-Sain offers, albeit in a highly idealized mathematical setting, a preliminary exploration of how to design emergency rooms such that the most urgent patients have the shortest waiting times [43]. Another application in health care is depicted in [169], where a polling model, consisting of two queues with infinite supply, is used to model scheduling strategies by surgeons performing eye surgeries.
Mail delivery. Another polling application is an internal mail delivery system, which was modeled via a continuous polling system (a system with an infinite number of queues) by Nahmias and Rothkopf [126]. In their model, a clerk traverses at a constant rate a cyclic route along which mail is generated according to a Poisson process. The clerk picks up the mail that has been generated since the last traversal and delivers the mail (that was previously picked up and sorted) to locations distributed uniformly along the route. At the end of the route, the clerk sorts the mail just picked up. Then, the clerk again traverses the route, delivers the mail that has just been sorted and picks up the new mail and so on. In [126] also the extension is studied in which there are several independent routes for a couple of clerks and a single room where sorting takes place.
Sarkar and Zangwill [140] discuss a finite-queue variant of the above problem. That is, they study a polling system where the workload at a queue either comes from outside the system or from another queue within the system. In terms of the above mail delivery application the sorting of the clerk would be done at one designated queue N , whereas at the other queues
the mail is generated by exogenous Poisson processes. The sorting work done by the clerk at queue N obviously depends upon the amount of mail generated at the other queues. Besides the mail delivery application, Sarkar and Zangwill also describe applications of this model related to rework in manufacturing systems, computer file transfers and buses circulating at airports.
Snow blowing. Eliazar [64, 65] studies a so-called snowblower problem. That is, on a closed-loop racetrack snow is falling randomly and a snowblower machine is continuously circling this racetrack and clearing off the snow. This snowy racetrack can be modeled by a continuous polling system by drawing the following analogies: server ↔ snowblower; job arrivals ↔ snowfall; workload ↔ snowload.
Shipyard loading. Another application of a polling system is a shipyard loading problem in which containers arrive by truck to the port. Trucks drive the containers up to their destination and the receiving yard crane transfers them to their assigned position. The crane represents the server of a polling system, whereas the trucks arriving for a specific destination are customers of a specific type. As stated by Daganzo [50], storage room (or: queue lengths) is the most critical performance measure for transportation problems dealing with freight. For transportation problems dealing with passengers, the waiting time is the most commonly used performance measure. In the aforementioned shipyard loading problem, one is especially interested in the characteristics of the total queue length in the polling system. That is, early arriving trucks wait in a common area until they are due for service. To dimension up this common area, information on the total queue length is needed.
Dynamic Picking Systems. Gong and De Koster [82] use a polling model to describe a dynamic order picking system (DPS). In a DPS, a worker picks orders that arrive in real time during the picking operations and the picking information can dynamically change in a picking cycle. It is very important to achieve short delivery times, especially for online retailers. One of the challenging questions that online retailers now face is how to organize the logistic fulfillment processes during and after order receipt. In traditional stores, purchased products can be taken home immediately. However, in the case of online retailers, the customer must wait for the shipment to arrive. In [82] polling models are used to describe and identify a DPS for online retailers. Polling-based picking systems can lead to shorter throughput times than traditional batch picking systems, particularly for high order arrival rates.
Elevators. A (multi-server) polling model has been studied by Gamse and Newell [76, 77] for an application of elevators in a building. In the model assumptions are made pertaining to the relative movements of servers within the system, with the assumptions being formed based on the nature of the specific application of elevators. In this context it is also interesting to spend some words on the so-called elevator server routing scheme. In such a system, the server first serves queues in the 'up' direction, i.e., in the order 1 2 , , . . . , N -1 , N , and subsequently serves these queues in the opposite ('down') direction, i.e., visiting them in the order N,N -1 , . . . , 2 1 (see, , e.g., Altman et al. [5]). It turns out that the globally gated service discipline in combination with elevator-type server movement results in equal mean waiting times for customers in all queues, establishing a perfectly fair polling system.
Another way of modeling an elevator system using a polling model can be found in [78]. In this paper an MDP approach is used to dynamically schedule elevators in a building. However, the model under consideration is only suitable for a limited amount of practical purposes, because all customers are assumed to have one common destination, which is the ground floor.
Besides the different routing scheme, another difficulty in modeling elevator systems is the fact that each idle elevator should return to the floor that is its home base. In polling literature some work has been done on this topic, which is called a stopping or dormant server, cf., [26, 63].
Maintenance. We would like to end this survey with actually the first application of a polling system which appeared in the open literature, i.e., in the area of maintenance. That is, Mack et al. [117, 118] use a polling model to describe a patrolling repairman who inspects a number of machines to check whether a breakdown has occurred and if so, eliminates such breakdowns. Evidently, in a polling model the repairman is represented by the server, the breakdowns are represented by the customers and the times needed by the repairman to travel from one machine to the next are represented by the switch-over times. In [102] a similar model is studied in which an operator at a fixed position serves a number of storage locations on a rotating carousel conveyor. Models with several independent rotating carousels have also been considered, cf. [41, 96]. Weststrate [172] studies a polling model which captures the behavior of a single repairman who is not only concerned with corrective maintenance, i.e., maintenance after a breakdown has occurred, but who can also perform preventive maintenance.
## 4 Outlook
Let us conclude the present survey with some personal views on possible future research directions related to applications and practical considerations. The present section is structured identically to the preceding section.
## 4.1 Communication systems
The technological advances in information and communication technology lead to the formulation of polling models with features that are not included in the classical polling models framework for which results are known today, and as such will lead to a variety of scientific challenges in the years to come. In this subsection we address a number of such open research problems.
The applicability of the results on polling models that are known today is strongly limited by the usual Poisson assumption , often needed to obtain exact results. Despite the fact that the packet-level dynamics on communication networks are well-known to be highly complicated and often far from Poisson, the vast majority of research results explicitly rely on the Poisson assumptions, or some straightforward relaxation of that. Extension of Poisson-based results to non-Poisson and/or dependent arrival processes raises tremendous scientific challenges, requiring new queueing-theoretical analysis methods. The development of such methods would strongly enhance the applicability of queueing-theoretical results on polling models. In
this context, encouraging results (but still only for renewal arrivals) have been obtained in [14, 133, 162, 163].
Another aspect that limits the applicability of results on polling models is inflexibility with respect to the service policies . In fact, the modeling of many computer-communication networks often leads to polling models where the service policies, typically representing the right for transmission/receipt of data to a shared medium, are of limited-type, and as such do not possess the convenient branching structure that allows for exact analysis. This raised the great need for the development of techniques to handle limited-type service policies, although there is not much hope for detailed exact analysis of such models. This stresses the importance of the development of asymptotic results (e.g., asymptotics on heavy traffic, large numbers of queues, heavy tails), a direction of research that has been highly successful in analyzing many queueing models in the past couple of years. Development of asymptotic results on polling models with limited-type service policies will continue to form a challenging area of research in the years to come.
The assumption of having a single server serving multiple queues is also an important limitation for many real applications. As mentioned before, only few results exist on polling models consisting of multiple servers.
In the area of mobile and wireless networks, a promising means to increase bandwidth, and to enhance robustness of the user-perceived service quality, is to make use of multiple antennas, enabling users to simultaneously utilize multiple networks (e.g., MIMO). In such environments, packet streams can be split over multiple parallel networks, each of which can be modeled as a polling model, where the packet routing may depend on the actual state of these networks. The packet-level analysis of such multi-network scenarios using this type of concurrent-access techniques will lead to the development of coupled polling models, where the arrival processes at the different polling models are correlated and state dependent. For this type of models, only few results are known today. Possibly, results from [116] (correlated arrivals) and [32] (correlated and state dependent arrivals) could be used to model these kind of networks.
## 4.2 Production systems
Although polling models appear naturally as a modeling tool in a wide variety of production applications, one can certainly observe common characteristics among these applications. The first similarity is the fact that a high utilization of capacity is typically prevalent due to either the magnitude of the setup times or the customer demands.
Secondly, in [92, 178] it is shown that assuming exponential interarrival times is not appropriate, whereas the independence assumptions do appear to be valid. Although these studies represent only a minuscule sample of production systems, they do show that the analysis of queueing systems with general (renewal) arrival processes is of practical interest for production applications.
Thirdly, in many other production systems the single most important performance measure is not an aggregate measure like the mean queue length, rather the probability that the queue length exceeds a pre-defined threshold.
In view of these three observations, the importance of explicit expressions of the complete
queue length distribution in the asymptotic regimes of high utilization of capacity (due to either the presence of setup times or the customer demands) for general arrival processes is evident.
## 4.3 Traffic and transportation systems
Although traffic intersections with vehicle actuated signals are typical examples of polling systems, there is still a lot of research to be done in this area before a realistic model is obtained. In traffic and transportation systems the assumption of independent interarrival times is reasonable for isolated intersections, but not for intersections that are part of an arterial system. Just like in the area of communication and production systems, it is necessary to develop techniques to analyse polling systems with other arrival assumptions, in particular platooned arrivals. For practical purposes there is a great need of good models for intersections that are part of an arterial system, i.e., the output of a certain queue forms the input process of a queue in a neighboring polling system. The assumption of independent interarrival times is strongly violated in such systems. One could consider the study of Reiman and Wein [134] as an important first step in this direction. They study waiting times of customers in a sequence of two-queue, exhaustive polling systems under heavy traffic conditions. Obviously, the analysis of networks of polling systems would not only be of interest for traffic and transportation systems, but also for other application areas.
The assumption of independent service times is not realistic either in most cases. It is also of great importance that models are developed for situations where multiple (conflicting and/or non-conflicting) traffic flows face a green light simultaneously. Some initial results on this topic are obtained in [19, 23], but (also here) many challenges remain for future research. Finally, and also this is not just important in the area of transportation, it is important to obtain good waiting-time approximations for time-limited systems.
Another area in transportation systems where few results have been obtained, is a system with one or multiple elevators. It would be of much practical relevance to have a realistic (polling) model that can be used to find optimal settings for the visiting policies of elevators. Difficulties that have to be addressed in elevator polling are the different routing schemes, but also the fact that each idle elevator returns to the floor that is its home base.
## Acknowledgments
The authors are very grateful to Ivo Adan and Onno Boxma for providing valuable comments on earlier drafts of the present paper.
## References
- [1] M. Ajmone Marsan, S. Donatelli, F. Neri, and G. Fantini. Some numerical results on finite-buffer markovian multiserver polling systems. In: IEEE International Telecommunications Symposium, Rio de Janeiro, Brazil , 1994.
- [2] A. S. Alfa and M. F. Neuts. Modelling vehicular traffic using the discrete time Markovian arrival process. Transportation Science , 29(2):109-117, 1995.
- [3] E. Altman, J. P. C. Blanc, A. Khamisy, and U. Yechiali. Gated-type polling systems with walking and switch-in times. Stochastic Models , 10:741-763, 1994.
- [4] E. Altman and D. Fiems. Expected waiting time in symmetric polling systems with correlated walking times. Queueing Systems , 56(3-4):241-253, 2007.
- [5] E. Altman, A. Khamisy, and U. Yechiali. On Elevator polling with globally gated regime. Queueing Systems , 11:85-90, 1992.
- [6] E. Altman and D. Kofman. Bounds for performance measures of token rings. IEEE/ACM Transactions on Networking , 4(2):292-299, 1996.
- [7] E. Altman and U. Yechiali. Polling in a closed network. Probability in the Engineering and Informational Sciences , 8(3):327-343, 1994.
- [8] R. Armony and U. Yechiali. Polling systems with permanent and transient jobs. Stochastic Models , 15(3):395-427, 1999.
- [9] J. E. Baker and I. Rubin. Polling with a general-service order table. IEEE Transactions on Communications , 35(3):283-288, 1987.
- [10] J. J. Bartholdi, III and L. K. Platzman. Decentralized control of Automated Guided Vehicles on a simple loop. IIE Transactions , 21:76-81, 1989.
- [11] P. Beekhuizen. Performance Analysis of Networks on Chips . PhD thesis, Eindhoven University of Technology, 2010.
- [12] L. Benini and G. De Micheli. Networks on chips: a new SoC paradigm. Computer , 35(1):70-78, 2002.
- [13] S. Benjaafar and D. Gupta. Workload allocation in multi-product, multi-facility production systems. IIE Transactions , 31(4):339-352, 1999.
- [14] D. Bertsimas and G. Mourtzinou. Multiclass queueing systems in heavy traffic: an asymptotic approach based on distributional and conservation laws. Operations Research , 45:470-487, 1997.
- [15] D. Bertsimas and G. Mourtzinou. Decomposition results for general polling systems and their applications. Queueing Systems , 31:295-316, 1999.
- [16] D. Bertsimas and H. Xu. Optimization of polling systems and dynamic vehicle routing problems on networks. Working paper, Operations Research Center, MIT, 1993.
- [17] C. Bisdikian. A queueing model for a data station within the IEEE 802.6 MAN. In: Proceedings 17th Conference on Local Computer Networks, 1992 , pages 52-61, 1992.
- [18] T. Bonald and A. Prouti` ere. Wireless downlink data channels: user performance and cell dimensioning. In: Proceedings Mobicom '03 , San Diego, USA, 2003.
- [19] M. A. A. Boon. Polling Models - From Theory to Traffic Intersections . PhD thesis, Eindhoven University of Technology, 2011.
- [20] M. A. A. Boon and I. J. B. F. Adan. Mixed gated/exhaustive service in a polling model with priorities. Queueing Systems , 63:383-399, 2009.
- [21] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A polling model with multiple priority levels. Performance Evaluation , 67:468-484, 2010.
| [22] | M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A two-queue polling model with two priority levels in the first queue. Discrete Event Dynamic Systems , 20(4):511-536, 2010. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [23] | M. A. A. Boon, I. J. B. F. Adan, E. M. M. Winands, and D. G. Down. Delays at signalised intersections with exhaustive traffic control. Eurandom report 2010-043, Eurandom , 2010. |
| [24] | M. A. A. Boon, E. M. M. Winands, I. J. B. F. Adan, and A. C. C. van Wijk. Closed-form waiting time approximations for polling systems. Performance Evaluation , 68:290-306, 2011. |
| [25] | S. C. Borst. Polling systems with multiple coupled servers. Queueing Systems , 20:369-393, 1995. |
| [26] | S. C. Borst. Polling Systems , volume 115 of CWI Tracts . 1996. |
| [27] | S. C. Borst. User-level performance of channel-aware scheduling algorithms in wireless data networks. In: Proceedings Infocom '03 , San Francisco, USA, 2003. |
| [28] | S. C. Borst and O. J. Boxma. Polling systems with and without switch-over times. Operations Research , 45:536-543, 1997. |
| [29] | S. C. Borst and R. D. van der Mei. Waiting-time approximations for multiple-server polling systems. Performance Evaluation , 31:163-182, 1998. |
| [30] | O. J. Boxma, J. Bruin, and B. H. Fralix. Waiting times in polling systems with various service disciplines. Performance Evaluation , 66:621-639, 2009. |
| [31] | O. J. Boxma and W. P. Groenendijk. Pseudo-conservation laws in cyclic-service systems. Journal of Applied Probability , 24(4):949-964, 1987. |
| [32] | O. J. Boxma, J. Ivanovs, K. Kosi´ski, n and M. Mandjes. L´vy-driven e polling systems and continuous-state branching processes. Eurandom report 2009-026, Eurandom , 2009. |
| [33] | O. J. Boxma, H. Levy, and J. A. Weststrate. Optimization of polling systems. In: P. J. B. King, I. Mitrani, and R. J. Pooley (Eds.), Proceedings Performance '90 . North-Holland, Amsterdam, 1990. |
| [34] | O. J. Boxma, H. Levy, and U. Yechiali. Cyclic reservation schemes for efficient operation of multiple-queue single-server systems. Annals of Operations Research , 35(3):187-208, 1992. |
| [35] | O. J. Boxma, J. van der Wal, and U. Yechiali. Polling with batch service. Stochastic Models , 24(4):604-625, 2008. |
| [36] | O. J. Boxma and J. A. Weststrate. Waiting times in polling systems with Markovian server routing. In: G. Stiege and J. S. Lie (Eds.), Messung, Modellierung und Bewertung von Rechen- systemen und Netzen , pages 89-105. Springer Verlag, Berlin, 1989. |
| [37] | Y. A. Bozer and M. M. Srinivasan. Tandem configurations for Automated Guided Vehicle systems and the analysis of single vehicle loops. IIE Transactions , 23:72-82, 1991. |
| [38] | S. Browne and U. Yechiali. Dynamic server routing in binomial-gated, binomial-exhaustive, bernoulli-gated, bernoulli exhaustive and mixed polling systems. Technical report, Dept. of Statistics & Operations Research, Tel-Aviv University, 1990. |
| [39] | S. Browne and U. Yechiali. Dynamic scheduling in single server multi-class service systems with unit buffers. Naval Research Logistics , 38:383-396, 1991. |
| [40] | J. Bruin. Cyclic multi-item production systems. In: Proceedings of Analysis of Manufacturing Systems , pages 99-104, 2007. |
| [41] | B. D. Bunday and W. K. El-Badri. The efficiency of M groups of N machines served by a travelling robot: comparison of two models. International Journal of Production Research , 26:299-308, 1988. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [42] | W. Bux. Local-area subnetworks: a performance comparison. IEEE Transactions on Commu- nications , 29(10):1465-1473, 1981. |
| [43] | M. Cicin-Sain, C. E. M. Pearce, and J. Sunde. On the application of a polling model with non- zero walk times and priority processing to a medical emergency-room environment. Proceedings 23rd International Conference on Information Technology Interfaces, 2001 , 1:49-56, 2001. |
| [44] | E. G. Coffman Jr., G. Fayolle, and I. Mitrani. Two queues with alternating service periods. In: Proceedings 12th IFIP WG 7.3 International Symposium on Computer Performance Modelling, Measurement and Evaluation , pages 227-239. North-Holland, Amsterdam, 1987. |
| [45] | J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982. |
| [46] | R. B. Cooper. Queues served in cyclic order: waiting times. The Bell System Technical Journal , 49(3):399-413, 1970. |
| [47] | R. B. Cooper and G. Murray. Queues served in cyclic order. The Bell System Technical Journal , 48(3):675-689, 1969. |
| [48] | O. Czerniak, E. Altman, and U. Yechiali. Analysis of a TCPsystem under polling-type reduction- signal procedures. In: Proceedings of ValueTools 2009, Pisa, Italy , 2009. |
| [49] | O. Czerniak and U. Yechiali. Fluid polling systems. Queueing Systems , 63:401-435, 2009. |
| [50] | C. Daganzo. Some properties of polling systems. Queueing Systems , 6(2):137-154, 1990. |
| [51] | W. J. Dally and B. Towles. Route packets, not wires: on-chip interconnection networks. In: Proceedings of the Design Automation Conference , pages 684-689, 2001. |
| [52] | J. N. Darroch, G. F. Newell, and R. W. J. Morris. Queues for a vehicle-actuated traffic light. Operations Research , 12(6):882-895, 1964. |
| [53] | R. de Haan. Queueing Models for Mobile Adhoc Networks . PhD thesis, University of Twente, 2009. |
| [54] | R. de Haan, R. J. Boucherie, and J.-K. van Ommeren. A polling model with an autonomous server. Queueing Systems , 62(3):279-308, 2009. |
| [55] | E. De Souza e Silva, H. R. Gail, and R. R. Muntz. Polling systems with server timeouts and their application to token passing networks. IEEE/ACM Transactions on Networking , 3(5):560-575, 1995. |
| [56] | N. P. Dellaert. Production To Order: Models and Rules for Production Planning , volume 333 of Lecture Notes in Economics and Mathematical Systems . Springer Verlag, Berlin, 1989. |
| [57] | J. L. Dorsman, R. D. van der Mei, and E. M. M. Winands. A new method for deriving waiting- time approximations in polling systems with renewal arrivals. To appear in Stochastic Models , 2011. |
| [58] | I. M. Duenyas. The limitations of suboptimal policies. Interfaces , 24(5):77-84, 1994. |
| [59] | I. M. Duenyas and P. Van Oyen. Multi-product systems with both setup times and costs: Fluid bounds and schedules. Queueing Systems , 19:421-444, 1995. |
| [60] | I. M. Duenyas and P. Van Oyen. Heuristic scheduling of parallel heterogeneous queues with setups. Management Science , 42:814-829, 1996. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [61] | I. M. Dukhovnyy. An approximate model of motion of urban passenger transportation over annular routes. Engineering Cybernetics , 17:161-162, 1979. |
| [62] | M. Ebben, D.-J. van der Zee, and M. van der Heijden. Dynamic one-way traffic control in automated transportation systems. Transportation Research Part B , 38:441-458, 2004. |
| [63] | M. Eisenberg. The polling system with a stopping server. Queueing Systems , 18(3):387-431, 1994. |
| [64] | I. Eliazar. The snowblower problem. Queueing Systems , 45(4):357-380, 2003. |
| [65] | I. Eliazar. From polling to snowplowing. Queueing Systems , 51(1-2):115-133, 2005. |
| [66] | N. Erkip, R. G¨ll¨, u u and A. Kocabiyikoglu. A quasi-birth-and-death model to evaluate fixed cycle time policies for stochastic multi-item production/inventory problem. In: Proceedings of MSOM conference , 2000. |
| [67] | A. Federgruen and Z. Katalan. Customer waiting-time distributions under base-stock policies in single-facility multi-item production systems. Naval Research Logistics , 43:533-548, 1996. |
| [68] | A. Federgruen and Z. Katalan. The impact of setup times on the performance of multiclass service and production systems. Operations Research , 44:989-1001, 1996. |
| [69] | A. Federgruen and Z. Katalan. The stochastic Economic Lot Scheduling Problem: cyclical base-stock policies with idle times. Management Science , 42(6):783-796, 1996. |
| [70] | A. Federgruen and Z. Katalan. Determining production schedules under base-stock policies in single facility multi-item production systems. Operations Research , 46(6):883-898, 1998. |
| [71] | I. Frigui. Analysis of a time-limited polling system with Markovian Arrival Process and phase type service . PhD thesis, University of Manitoba, Winnipeg, 1997. |
| [72] | I. Frigui and A. S. Alfa. Analysis of a time-limited polling system. Computer Communications , 21:558-571, 1998. |
| [73] | I. Frigui and A. S. Alfa. Analysis of a discrete time table polling system with MAP input and time-limited service discipline. Telecommunication Systems , 12:51-77, 1999. |
| [74] | S. W. Fuhrmann. Performance analysis of a class of cyclic schedules. Technical Memorandum 81-59531-1, Bell Laboratories, 1981. |
| [75] | S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985. |
| [76] | B. Gamse and G. F. Newell. An analysis of elevator operations in moderate high buildings - I. single elevator. Transportation Research Part B , 16(4):303-319, 1982. |
| [77] | B. Gamse and G. F. Newell. An analysis of elevator operations in moderate high buildings - II. multiple elevators. Transportation Research Part B , 16(4):321-335, 1982. |
| [78] | A. D. Gandhi and C. G. Cassandras. Optimal control of polling models for transportation applications. Mathematical and Computer Modelling , 23(11-12):1-23, 1996. |
| [79] | T. Ganesharajah, N. G. Hall, and C. Sriskandarajah. Design and operational issues in AGV- served manufacturing systems. Annals of Operations Research , 76:109-154, 1998. |
| [80] | Y. Gerchak and Z. Zhang. The cheaper/faster-yet-more-expensive phenomenon: are Zangwill's 'paradoxes' indeed paradoxical? Interfaces , 24(5):84-87, 1994. |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [81] | R. B. L. M. Giezenaar. Ontwerp voor een productie- en voorraadstrategie voor de productieplant Laurox bij AKZONobel Chemicals te Deventer. Master's thesis, University of Twente (in Dutch), 1997. |
| [82] | Y. Gong and R. de Koster. A polling-based dynamic order picking system for online retailers. IIE Transactions , 40:1070-1082, 2008. |
| [83] | S. E. Grasman, T. L. Olsen, and J. R. Birge. Setting basestock levels in multi-product systems with setups and random yield. IIE Transactions , 40(12):1158-1170, 2008. |
| [84] | B. S. Greenberg, R. C. Leachman, and R. W. Wolff. Predicting dispatching delays on a low speed, single track railroad. Transportation Science , 22:31-38, 1988. |
| [85] | D. Grillo. Polling mechanism models in communication systems - some application examples. In: H. Takagi (Ed.), Stochastic Analysis of Computer and Communication Systems , pages 659-699. North-Holland, Amsterdam, 1990. |
| [86] | Y. G¨nalay u and D. Gupta. A polling system with a patient server and state-dependent setup times. IIE Transactions , 29:479-480, 1997. |
| [87] | D. Gupta and M. M. Srinivasan. Polling systems with state-dependent setup times. Queueing Systems , 22:403-423, 1996. |
| [88] | R. Haijema and J. van der Wal. An MDP decomposition approach for traffic control at isolated signalized intersections. Probability in the Engineering and Informational Sciences , 22:587-602, 2007. |
| [89] | R. Hariharan, W. K. Ehrlich, P. K. Reeser, and R. D. van der Mei. Performance of web servers in a distributed computing environment. In: J. M. de Souza, N. L. S. da Fonseca, and E. D. de Souza e Silva (Eds.), Teletraffic Engineering in the Internet Era , pages 137-148, 2001. |
| [90] | D. Heidemann. Queue length and delay distributions at traffic signals. Transportation Research Part B , 28(5):377-389, 1994. |
| [91] | M. Hofri and K. W. Ross. On the optimal control of two queues with server setup times and its analysis. SIAM Journal on Computing , 16(2):399-42, 1987. |
| [92] | R. R. Inman. Empirical evaluation of exponential and independence assumptions in queueing models of manufacturing systems. Production and Operations Management , 8(4):409-432, 1999. |
| [93] | V. Kavitha and E. Altman. Queueing in space: design of message ferry routes in static adhoc networks. In: Proceedings ITC21 , 2009. |
| [94] | J. Keilson and L. D. Servi. Oscillating random walk models for GI/G/I vacation systems with Bernoulli schedules. Journal of Applied Probability , 23:790-802, 1986. |
| [95] | J. Keilson and L. D. Servi. The distributional form of Little's Law and the Fuhrmann-Cooper decomposition. Operations Research Letters , 9(4):239-247, 1990. |
| [96] | W. B. Kim and E. K¨nigsberg. o The efficiency of two groups of N machines derved by a single robot. The Journal of the Operational Research Society , 38(6):523-538, 1987. |
| [97] | L. Kleinrock. Performance evaluation of distributed computer-communication systems. In: O. J. Boxma and R. Syski (Eds.), Queueing Theory and its Applications - Liber Amicorum for J.W. Cohen , pages 1-57. North-Holland, Amsterdam, 1988. |
| [98] | L. Kleinrock and H. Levy. The analysis of random polling systems. Journal of Operations Research , 36(5):716-732, 1988. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [99] | L. Kleinrock and M. O. Scholl. Packet switching in radio channels: New conflict-free access schemes. IEEE Transactions on Communication , 28(7):1015-1029, 1980. |
| [100] | G. P. Klimov. Time-sharing service systems I. Theory of Probability and its Applications 19:532-551, 1974. |
| [101] | A. G. Konheim, H. Levy, and M. M. Srinivasan. Descendant set: an efficient approach for the analysis of polling systems. IEEE Transactions on Communications , 42(2-4):1245-1253, 1994. |
| [102] | E. K¨nigsberg o and J. Mamer. The analysis of production systems. International Journal of Production Research , 20:1-16, 1982. |
| [103] | G. Kramer, B. Mukherjee, S. Dixit, Y. Yinghua, and R. Hirth. Supporting differentiated classes of services in ethernet passive optical networks. Journal of Optical Networking , 1(9):280-290, 2002. |
| [104] | G. Kramer, B. Mukherjee, and G. Pesavento. Ethernet PON (ePON): design and analysis of an optical access network. Photonic Network Communications , 3:307-319, 2001. |
| [105] | G. Kramer, B. Mukherjee, and G. Pesavento. Interleaved polling with adaptive cycle time (IPACT): a dynamic bandwidth allocation scheme in an optical access network. Photonic Net- work Communications , 4:89-107, 2002. |
| [106] | G. N. Krieg and H. Kuhn. A decomposition method for multi-product kanban systems with setup times and lost sales. IIE Transactions , 34(7):613-625, 2002. |
| [107] | G. N. Krieg and H. Kuhn. Analysis of multi-product kanban systems with state-dependent setups and lost sales. Annals of Operations Research , 125:141-166, 2004. |
| [108] | W.-M. Lan and T. L. Olsen. Multiproduct systems with both setup times and costs: Fluid bounds and schedules. Operations Research , 54(3):505-522, 2006. |
| [109] | D.-S. Lee. Analysis of a two-queue model with Bernoulli schedules. Journal of Applied Probability 34:176-191, 1997. |
| [110] | J. P. Lehoczky. Traffic intersection control and zero-switch queues under conditions of Markov chain dependence input. Journal of Applied Probability , 9(2):382-395, 1972. |
| [111] | K. Leung. Cyclic service systems with non-preemptive, time-limited service. IEEE Transactions on Communication , 42(8):2521-2524, 1994. |
| [112] | K. K. Leung. Cyclic-service systems with probabilistically-limited service. IEEE Journal on Selected Areas in Communications , 9(2):185-193, 1991. |
| [113] | H. Levy. Optimization of polling systems: the fractional exhaustive service method. Report, Tel-Aviv University, 1988. |
| [114] | H. Levy. Analysis of cyclic polling systems with binomial gated service. In: T. Hasegawa, H. Takagi, and Y. Takahashi (Eds.), Performance of Distributed and Parallel Systems , pages 127-139. North-Holland, Amsterdam, 1989. |
| [115] | H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Trans- actions on Communications , 38:1750-1760, 1990. |
| [116] | H. Levy and M. Sidi. Polling systems with simultaneous arrivals. IEEE Transactions on Com- munications , 39(6):823-827, 1991. |
|---------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [117] | C. Mack. The efficiency of N machines uni-directionally patrolled by one operative when walking time is constant and repair times are variable. Journal of the Royal Statistical Society Series B , 19(1):173-178, 1957. |
| [118] | C. Mack, T. Murphy, and N. L. Webb. The efficiency of N machines uni-directionally patrolled by one operative when walking time and repair times are constants. Journal of the Royal Statistical Society Series B , 19(1):166-172, 1957. |
| [119] | D. R. Manfield. Analysis of a priority polling system for two-way traffic. IEEE Transactions on Communications , 33:1001-1006, 1985. |
| [120] | D. M. Markowitz, M. I. Reiman, and L. M. Wein. The stochastic economic lot scheduling problem: heavy traffic analysis of dynamic cyclic policies. Operations Research , 48(1):136-154, 2000. |
| [121] | D. M. Markowitz and L. M. Wein. Heavy traffic analysis of dynamic cyclic policies: a unified treatment of the single machine scheduling problem. Operations Research , 49(2):246-270, 2001. |
| [122] | B. McIntyre. A comment on Zangwill's 'the limits of Japanese production theory'. Interfaces , 24(5):87-89, 1994. |
| [123] | A. J. Miller. Settings for fixed-cycle traffic signals. Operational Research Quarterly , 14:373-386, 1963. |
| [124] | D. Miorandi, A. Zanella, and G. Pierobon. Performance evaluation of bluetooth polling schemes: An analytical approach. Mobile Networks and Applications , 9:63-72, 2004. |
| [125] | R. J. T. Morris and Y. T. Wang. Some results for multi-queue systems with multiple cyclic servers. In: W. Bux and H. Rudin (Eds.), Performance of Computer-Communication Systems , pages 245-258. North-Holland, Amsterdam, 1984. |
| [126] | S. Nahmias and M. H. Rothkopf. Stochastic models of internal mail delivery systems. Manage- ment Science , 30(9):1113-1120, 1984. |
| [127] | K. B. Narasimha and S. Bhattacharya. Lead time minimization of a multi-product, single- processor system: A comparison of cyclic policies. International Journal of Production Eco- nomics , 106(1):28-40, 2007. |
| [128] | G. F. Newell. Approximation methods for queues with application to the fixed-cycle traffic light. SIAM Review , 7(2):223-240, 1965. |
| [129] | G. F. Newell. Properties of vehicle-actuated signals: I. one-way streets. Transportation Science , 3(2):31-52, 1969. |
| [130] | G. F. Newell. The rolling horizon scheme of traffic signal control. Transportation Research Part A , 32(1):39-44, 1998. |
| [131] | G. F. Newell and E. E. Osuna. Properties of vehicle-actuated signals: II. two-way streets. Transportation Science , 3(2):99-125, 1969. |
| [132] | T. L. Olsen. A practical scheduling method for multiclass production systems with setups. Management Science , 45(1):116-130, 1999. |
| [133] | T. L. Olsen and R. D. van der Mei. Periodic polling systems in heavy-traffic: renewal arrivals. Operations Research Letters , 33:17-25, 2005. |
| [134] | M. I. Reiman and L. M. Wein. Heavy traffic analysis of polling systems in tandem. Operations Research , 47(4):524-534, 1999. |
|---------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [135] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409- 426, 1993. |
| [136] | Z. Saffer and M. Telek. Unified analysis of BMAP/G/ 1 cyclic polling models. Queueing Systems , 64(1):69-102, 2010. |
| [137] | S. Samaddar and C. A. Hill. Controlling adverse effect on work in process inventory while reducing machine setup time. European Journal of Operational Research , 180(1):249-261, 2007. |
| [138] | S. Samaddar and T. Whalen. Improving performance in cyclic production systems by using forced variable idle setup time. Manufacturing & Service Operations Management , 10(2):173- 180, 2008. |
| [139] | D. Sarkar and W. I. Zangwill. Variance effects in cyclic production systems. Management Science , 37:444-453, 1991. |
| [140] | D. Sarkar and W. I. Zangwill. File and work transfers in cyclic queue systems. Management Science , 38(10):1510-1523, 1992. |
| [141] | K. C. Sevcik and M. J. Johnson. Cycle time properties of the FDDI token ring protocol. IEEE Transactions on Software Engineering , 13:376-385, 1987. |
| [142] | M. Sharafali, H. C. Co, and M. Goh. Production scheduling in a flexible manufacturing system under random demand. European Journal of Operational Research , 158(1):89-102, 2004. |
| [143] | M. Sidi and H. Levy. Customer routing in polling systems. In: P. King, I. Mitrani, and R. Pooley (Eds.), Proceedings Performance '90 , pages 319-331. North-Holland, Amsterdam, 1990. |
| [144] | M. P. Singh and M. M. Srinivasan. Exact analysis of the state dependent polling model. Queueing Systems , 41:371-399, 2002. |
| [145] | M. P. Singh and M. M. Srinivasan. Performance bounds for flexible systems requiring setups. Management Science , 53(6):991-1004, 2007. |
| [146] | M. M. Srinivasan. Non-deterministic polling systems. Management Science , 37:667-681, 1991. |
| [147] | M. M. Srinivasan, Y. A. Bozer, and M. Cho. Trip-based material handling systems: throughput capacity analysis. IIE Transactions , 26:70-89, 1994. |
| [148] | H. Takagi. Analysis of polling systems . MIT Press (Cambridge, Mass.), 1986. |
| [149] | H. Takagi. Queueing analysis of polling models: an update. In: H. Takagi (Ed.), Stochastic Analysis of Computer and Communication Systems , pages 267-318. North-Holland, Amsterdam, 1990. |
| [150] | H. Takagi. Analysis of finite-capacity polling systems. Advances in Applied Probability , 23(2):373-387, 1991. |
| [151] | H. Takagi. Queueing analysis of polling models: progress in 1990-1994. In: J. H. Dshalalow (Ed.), Frontiers in Queueing: Models, Methods and Problems , pages 119-146. CRC Press, Boca Raton, 1997. |
| [152] | H. Takagi. Analysis and application of polling models. In: G. Haring, C. Lindemann, and M. Reiser (Eds.), Performance Evaluation: Origins and Directions , volume 1769 of Lecture Notes in Computer Science , pages 424-442. Springer, Berlin, 2000. |
| [153] | B. van Arem. Queueing Network Models for Slotted Transmission Systems . PhD thesis, Univer- sity of Twente, The Netherlands, 1990. |
|---------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [154] | J. L. van den Berg, R. Litjens, and J. Laverman. HSDPA flow level performance: the impact of key system and traffic aspects. In: Proceedings MSWiM '04 (Venice, Italy) , 2004. |
| [155] | M. S. van den Broek, J. S. H. van Leeuwaarden, I. J. B. F. Adan, and O. J. Boxma. Bounds and approximations for the fixed-cycle traffic-light queue. Transportation Science , 40(4):484-496, 2006. |
| [156] | M. van der Heijden, A. van Harten, and M. Ebben. Waiting times at periodically switched one-way traffic lanes. Probability in the Engineering and Informational Sciences , 15:495-517, 2001. |
| [157] | R. D. van der Mei and S. C. Borst. Analysis of multiple-server polling systems by means of the power-series algorithm. Communications in Statistics - Stochastic Models , 13(2):339-369, 1997. |
| [158] | R. D. van der Mei, R. Hariharan, and P. K. Reeser. Web server performance modeling. Telecom- munication Systems , 16:361-378, 2001. |
| [159] | R. D. van der Mei and J. A. C. Resing. Analysis of polling models with two-stage gated service: fairness versus efficiency. In: L. Mason, T. Drwiega, and J. Yan (Eds.), Managing Traffic Performance in Converged Networks - the Interplay between Convergent and Divergent Forces , ITC2007, Lecture Notes in Computer Science 4516, pages 544-555, 2007. |
| [160] | R. D. van der Mei and J. A. C. Resing. Polling models with two-phase gated service: heavy- traffic results for the waiting-time distributions. Probability in the Engineering and Informational Sciences , 22:623-651, 2008. |
| [161] | R. D. van der Mei and A. Roubos. Polling models with multi-phase gated service. To appear in Annals of Operations Research , 2011. |
| [162] | R. D. van der Mei and E. M. M. Winands. Polling models with renewal arrivals: A new method to derive heavy-traffic asymptotics. Performance Evaluation , 64(9-12):1029-1040, 2007. |
| [163] | R. D. van der Mei and E. M. M. Winands. A note on polling models with renewal arrivals and nonzero switch-over times. Operations Research Letters , 36:500-505, 2008. |
| [164] | J. van der Wal and U. Yechiali. Dynamic visit-order rules for batch-service polling. Probability in the Engineering and Informational Sciences , 17:351-367, 2003. |
| [165] | B. van Houdt. Numerical solution of polling systems for analyzing networks on chips. In: Proceedings of NSMC 2010, Williamsburg (USA) , pages 90-93, 2010. |
| [166] | J. S. H. van Leeuwaarden. Delay analysis for the fixed-cycle traffic-light queue. Transportation Science , 40(2):189-199, 2006. |
| [167] | M. van Vuuren and E. M. M. Winands. Iterative approximation of k -limited polling systems. Queueing Systems , 55(3):161-178, 2007. |
| [168] | V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006. |
| [169] | M. Vlasiou, I. J. B. F. Adan, and O. J. Boxma. A two-station queue with dependent preparation and service times. European Journal of Operations Research , 195:104-116, 2009. |
| [170] | M. Vlasiou and U. Yechiali. M/G/ ∞ polling systems with random visit times. Probability in the Engineering and Informational Sciences , 22:81-106, 2008. |
| [171] | F. V. Webster. Traffic signal settings. Technical Paper 39, Road Research Laboratory, 1958. |
|---------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [172] | J. A. Weststrate. Analysis and Optimization of Polling Systems . PhD thesis, Tilburg University, 1992. |
| [173] | A. Wierman, E. M. M. Winands, and O. J. Boxma. Scheduling in polling systems. Performance Evaluation , 64:1009-1028, 2007. |
| [174] | E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven University of Technology, 2007. |
| [175] | E. M. M. Winands. Branching-type polling systems with large setups. OR Spectrum , 33(1):77-97, 2011. |
| [176] | E. M. M. Winands, I. J. B. F. Adan, and G.-J. van Houtum. Mean value analysis for polling systems. Queueing Systems , 54:35-44, 2006. |
| [177] | E. M. M. Winands, I. J. B. F. Adan, G. J. van Houtum, and D. G. Down. A state-dependent polling model with k -limited service. Probability in the Engineering and Informational Sciences , 23(2):385-408, 2009. |
| [178] | E. M. M. Winands, A. G. de Kok, and C. Timpe. Case study of a batch-production/inventory system. Interfaces , 39(6):552-554, 2009. |
| [179] | D. Xu, N. Shi, and R. K. Cheung. Heavy traffic analysis of a single vehicle loop in an automated storage and retrieval system. OR Spectrum , 29(3):489-512, 2007. |
| [180] | H. Yamashita, Y. Ishizuka, and S. Suzuki. Mean and variance of waiting time and their opti- mization for alternating traffic control systems. Mathematical Programming , 108(2-3):419-433, 2006. |
| [181] | U. Yechiali. Optimal dynamic control of polling systems. In: J. W. Cohen and C. D. Pack (Eds.), Proceedings ITC13, Workshop: Queueing, Performance and Control in ATM , pages 205-218. North-Holland, Amsterdam, 1991. |
| [182] | U. Yechiali. Analysis and control of poling systems. In: L. Donatiello and R. Nelson (Eds.), Performance Evaluation of Computer and Communication Systems , pages 630-650. Springer Verlag, 1993. |
| [183] | W. I. Zangwill. The limits of Japanese production theory. Interfaces , 22(5):14-25, 1992. |
| [184] | W. I. Zangwill. Response to comments on our work by Duenyas, by Gerchak and Zhang, and by McIntyre. Interfaces , 24(5):90-94, 1994. |
| [185] | G. Zussman, A. Segall, and U. Yechiali. On the analysis of the bluetooth time division duplex mechanism. IEEE Transactions on Wireless Communications , 6(6):2149-2161, 2007. | | 10.1016/j.sorms.2011.01.001 | [
"Marko Boon",
"Rob van der Mei",
"Erik Winands"
] | 2014-08-01T11:35:14+00:00 | 2014-08-01T11:35:14+00:00 | [
"math.PR",
"cs.PF"
] | Applications of polling systems | Since the first paper on polling systems, written by Mack in 1957, a huge
number of papers on this topic has been written. A typical polling system
consists of a number of queues, attended by a single server. In several
surveys, the most notable ones written by Takagi, detailed and comprehensive
descriptions of the mathematical analysis of polling systems are provided. The
goal of the present survey paper is to complement these papers by putting the
emphasis on \emph{applications} of polling models. We discuss not only the
capabilities, but also the limitations of polling models in representing
various applications. The present survey is directed at both academicians and
practitioners. |
1408.0137v1 | ## Delays at signalised intersections with exhaustive traffic control ∗
M.A.A. Boon † [email protected]
I.J.B.F. Adan †
‡
[email protected]
E.M.M. Winands [email protected]
D.G. Down §
[email protected]
July, 2011
## Abstract
In this paper we study a traffic intersection with vehicle-actuated traffic signal control. Traffic lights stay green until all lanes within a group are emptied. Assuming general renewal arrival processes, we derive exact limiting distributions of the delays under Heavy Traffic (HT) conditions. Furthermore, we derive the Light Traffic (LT) limit of the mean delays for intersections with Poisson arrivals, and develop a heuristic adaptation of this limit to capture the LT behaviour for other interarrival-time distributions. We combine the LT and HT results to develop closed-form approximations for the mean delays of vehicles in each lane. These closed-form approximations are quite accurate, very insightful and simple to implement.
Keywords: delays, intersection, vehicle-actuated traffic signals, polling, light traffic, heavy traffic, approximation
## 1 Introduction
Traffic signals play an important part in the infrastructure of towns and cities all over the world, and waiting before a red traffic light has become an unavoidable nuisance in everyday life. It is obvious that it is important to find optimal settings, i.e. green and red times, for signalised intersections. When evaluating the quality of traffic signal settings, the most commonly used criterion for optimality is a weighted average of the expected vehicle delays. Surprisingly, however, the most commonly used formulas for calculating the mean delays are based on major simplifications of the actual situation encountered in reality (see, e.g., [8, 33]). On the other hand, for most realistic cases hardly any good alternatives exist. Typical traffic
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-NF.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
‡ Department of Mathematics, Section Stochastics, VU University, De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands
§ McMaster University, 1280 Main Street West, Hamilton, ON L8S 4L7, Canada.
lights settings can be divided into three strategies: fixed cycle, vehicle-actuated, and trafficactuated signals. The fixed-cycle policy for signalised intersections is the oldest strategy, defining fixed red, amber and green times. Vehicle-actuated traffic signals have flexible green phases with minimum and maximum green times. Detectors gather information about the presence of vehicles at the different traffic flows and use this information to determine whether the best option is to stay green, or switch to an all-red phase. Traffic-actuated signals are much like vehicle-actuated signals, with the additional possibility that actual queue lengths are determined. The combined information about all queue lengths can be used to create more sophisticated traffic signal settings. In the present paper we study a signalised intersection with vehicle-actuated, exhaustive traffic control. The policy is exhaustive, because a green phase ends as soon as no vehicle is present in any flow that faces a green light. The main advantage of an exhaustive control policy is its efficiency, due to the fact that the traffic lights do not turn red until all vehicles in the corresponding flows have left. This implies that the exhaustive policy minimises the mean total amount of unprocessed work in the system, i.e., the total time required by all vehicles present at the intersection to discharge at the corresponding saturation flow rates. Newell [26] argues that, for isolated intersections, an exhaustive control policy should be preferred over alternative strategies. Nevertheless, a wellknown disadvantage of the exhaustive control policy is its unfairness with respect to vehicles in flows where relatively few vehicles arrive. For this reason, in practice often time-limited control policies are used.
Although the model in the present paper is vehicle-actuated, we will give a short literature review about fixed-cycle traffic signals first. Intersections based on a fixed cycle have been studied since a long time. One of the first, and perhaps still the most influential and practically applied papers, is written by Webster [40] who analyses a fixed-cycle traffic-light queue. Although more sophisticated analyses have appeared throughout the years (cf. [18, 23, 24, 37]), his formula for the mean delay is still used in most traffic engineering manuals. The present paper does not focus on settings based on a fixed cycle or on traffic-actuated signals, but on vehicle-actuated traffic signal control. Considering this is the most commonly used control type nowadays, it is surprising how little mathematical literature is available to analyse a typical, realistic vehicle-actuated signalised intersection. The earliest literature on vehicleactuated systems dates from the early 1960s when Darroch et al. [12] analysed a system consisting of two intersecting Poisson traffic streams that are served exhaustively. A model with two lanes that does not assume Poisson input has been studied by Lehoczky [19], who uses an alternating priority queueing model. Newell [25] analyses an intersection with two one-way streets using fluid and diffusion queueing approximations. In [27], Newell and Osuna study a four-lane intersection where two opposite flows face a green light simultaneously. A variation of the two-lane intersection is introduced by Greenberg et al. [16], who analyse mean delays on a single rail line that has to be shared by trains arriving from opposite directions. This model is extended by Yamashita et al. [42], who study alternating traffic crossing a narrow one-lane bridge on a two-lane road. In many of the discussed papers traffic is modelled as fluid passing through the road. These types of approximations are fairly accurate when the traffic intensity is relatively high, but do not perform very well if there is a lot of variation in the arrival or departure processes. Vlasiou and Yechiali [39] use a different approach, modelling a traffic intersection as a polling system, consisting of multiple queues with an infinite number of servers visiting each queue simultaneously. A disadvantage that all of the aforementioned papers have in common, is that the methods can be applied only to situations
that are significant simplifications of modern intersections encountered in practice. Most of the papers focus on two or four lanes only, and Newell and Osuna [27] have written one of the few papers studying an intersection where multiple flows of vehicles can receive a green light simultaneously. Haijema and Van der Wal [17] study a model that allows for multiple groups of different flows, but their approach uses a Markov Decision Problem (MDP) formulation, which does not lead to closed-form, transparent expressions for the mean delay that can be used for optimisation purposes. Summarising, in the literature on vehicle-actuated traffic signals, either the models are very simplified versions of reality, or the resulting algorithm or expression to determine the mean delays is so complex that it cannot be implemented for real-life intersections. Additional advantages, apart from the comprehensiveness, of a closedform expression for the mean delay, is that it is perfectly suitable for optimisation purposes, and that it can easily be adapted to extensions of the model discussed in the present paper.
The goal of this paper is to provide a comprehensive, novel analysis for traffic intersections with a vehicle-actuated, exhaustive control policy. The model in the present paper is more realistic than most vehicle-actuated models, in the sense that we allow combinations of multiple flows to receive a green light simultaneously, we take more types of randomness into account (e.g., in interarrival times and interdeparture times), and we do not limit ourselves to Poisson arrivals. The main contribution of the paper is twofold. Firstly, we capture the limiting behaviour of the model under Light Traffic (LT) and Heavy Traffic (HT) conditions. The HT results give insight into the system behaviour when the intersection becomes saturated, which makes them very usable by themselves. The LT results describe the system when it is hardly exposed to any traffic at all. These results are mostly interesting because they form an essential building block for the second main contribution of the paper, a closed-form approximation for the mean delay. This approximation is created using an interpolation between the LT and HT limits, which results in a comprehensive expression that is very insightful, simple to implement, and suitable for optimisation purposes.
We use a polling model to describe the traffic intersection. A polling model is a queueing system with multiple queues of customers, served by a single server in a cyclic order. The switch of the server from one queue to the next requires some (possibly random) time, and is called a switch-over time. An advantage of using a polling model, with customers representing the vehicles, is that we can model randomness in the interarrival times, but also in the service times, corresponding to the times between two successive vehicles as they pass the stop line. When considering the features of a polling model, it seems like the natural way to model a traffic intersection. However, traffic intersections do exhibit features that have not been studied in the polling literature before, which impels us to considerably extend the queueing analysis of these systems. In particular, the feature that multiple queues (corresponding to the different traffic flows) should be allowed to receive service simultaneously has not been investigated yet in the huge literature on polling systems (for good surveys on polling systems and their applications, see, for example, [3, 20, 31, 38]). The main reason why it is difficult to analyse a polling system with simultaneous service of multiple queues, is that the system loses the so-called branching-property . We do not discuss this property in more detail here, but we just mention that Resing [30] and Fuhrmann [14] have shown that for polling models satisfying this property, performance measures like cycle time distribution and waiting time distributions can be obtained. If this branching property is, however, not satisfied, the corresponding polling model defies an exact analysis except for some special (two-queue or symmetric) cases. In the present paper we show that, despite the fact that
the branching property is not satisfied, the delays can still be studied under LT and HT conditions. Furthermore, using these LT and HT results we propose an accurate closedform approximation of the mean delay for a signalised intersection with vehicle-actuated, exhaustive traffic control.
The structure of the present paper is as follows. In the next section we present an outline of the model and describe in more detail how a traffic intersection can be modelled using a polling model with simultaneous service of multiple queues. The notation required for the remainder of the paper is also introduced in Section 2. In Section 3 we study the distribution of the delays under Heavy Traffic conditions. This means that we increase the arrival intensities and, hence, the load of the system until it reaches the point of saturation. In Section 4 we study the behaviour of the system under Light Traffic conditions. It goes without saying that this situation is rather opposite to the previous section, and mean delays of vehicles in an (almost) empty system are analysed. Using the mean delays under LT conditions, and the mean delays under HT conditions, we develop interpolations between these two limits in Section 5. These interpolations can be used as approximations for the mean delay under any system load. In Section 6 we discuss the accuracy of the approximations and show numerical results for three intersections, located in The Netherlands. We finish with some conclusions and topics for further research.
## 2 Model description and notation
We model the traffic intersection as a polling system. A typical polling system consists of N queues attended by a single server in a cyclic order. Each flow of vehicles, sometimes referred to as stream, corresponds to a queue in the polling system. Note that traffic approaching the intersection from the same direction, sharing one lane, but with different destinations (e.g., flow 9 in Figure 1), is modelled as one single queue, whereas the same situation with two different lanes (e.g., flows 1 and 2) is modelled as two separate queues. The main contribution
1
3
5/.notdef4
Figure 1: An example of an intersection with traffic approaching from four directions.
of the present paper is that we extend the standard polling model by dividing the queues into groups that are served simultaneously, which turns out to complicate the queueing analysis significantly. We impose the restriction that each flow can be part of only one group. Note
that the Highway Capacity Manual 2000 (HCM, [33]) often does not use the terms 'flow' or 'stream', but prefers lane group , defined as a set of lanes established at an intersection approach for separate capacity and level-of-service analysis. We will not adopt this terminology, except for a few times in this section, because it might be confused with a group (or combination) of non-conflicting flows that receive a green light simultaneously. A cycle consists of multiple phases, where groups of non-conflicting flows receive the right-of-way simultaneously. The switch-over times in the polling model correspond to the all-red times of a traffic intersection. Adopting the terminology used in the polling literature, we refer to the green periods as visit times , i.e., the times that the server visits a group of queues. Similarly, the red period of a group of flows may be referred to as intervisit time of that group. In the present paper we assume that the control policy, which is called service discipline in polling literature, is exhaustive service. Since multiple queues are served simultaneously, exhaustive service implies that a green period only ends when all queues in the corresponding group are empty. The N flows of the intersection are divided into a number of groups, denoted by M . Each group, say group g = 1 , . . . , M , consists of N g nonconflicting flows of vehicles. We assume that each flow belongs to exactly one group, so ∑ M g =1 N g = N . Denote by R g the all-red time starting at the end of the green period of group g , denoted by G g . The total all-red time in a cycle, denoted by R , equals R = ∑ M g =1 R g . Throughout this paper, we assume that the all-red times R g are independent random variables. In reality, all-red times are generally deterministic, which simplifies many results obtained in this paper.
The times between two consecutive vehicles (in the same flow) crossing the stop line are generally called departure headways and will be denoted by B i , i = 1 , . . . , N . In the polling model, these headways correspond to service times of customers, but in the literature on traffic signals it is more common to use the reciprocal, 1 / E [ B i ], which is referred to as discharge rate or saturation flow rate. An advantage of adopting a polling model, is that it allows for randomness in the headways, which is generally ignored in the literature on traffic signals. This randomness enables us to distinguish between slow and fast, or between big and small vehicles. An important aspect of our model, is that we make a distinction between the headways of queued vehicles, and vehicles approaching the intersection without queue in front of them. If a queue clears before the green period terminates, all vehicles that arrive during the remainder of this visit period pass through the system and experience no delay whatsoever. This assumption is quite common in the literature on traffic light queues to distinguish between headways of cars that need to accelerate and cars that arrive at full speed (see, e.g., [34, 37]), but it is not common in the polling literature. Furthermore, we assume that the headways B i are independent of each other and of all other random variables in the model. This assumption is generally not satisfied in practice, because the first few vehicles might require a slightly longer time to accelerate. However, this can be circumvented by incorporating any systematic, additional delay of the first cars crossing the intersection after an all-red phase in the preceding all-red time ( R g -1 for vehicles belonging to group g = 1 , . . . , M ).
We assume that the interarrival times of vehicles, corresponding to customers in the polling system, are independent, generally distributed random variables A i , i = 1 , . . . , N . The arrival rates are denoted by λ i = 1 / E [ A i ], i = 1 , . . . , N . The main performance measures of interest in the present paper are the delays W i of vehicles in flow i . Note that for a queued vehicle, the delay is the waiting time plus B i , whereas vehicles approaching a clear intersection during a green period experience no delay at all. We study the delay as a function of the total traffic
load offered to the system, denoted by ρ . The load of a particular flow, say flow i , is the product of the arrival rate and the mean departure headway: ρ i = λ i E [ B i ]. The total load is the sum of the loads of the different flows: ρ = ∑ N i =1 ρ i . The HCM refers to ρ i as the flow ratio of lane group i , being the ratio of the actual flow rate ( λ i ) to the saturation flow rate (1 / E [ B i ]) for lane group i at an intersection. Since, starting from the next section, we consider the delay as a function of ρ , the total amount of traffic offered to the system, we have to specify in more detail how the scaling takes place. The traffic intensity is varied by keeping the headways B i fixed, and scaling the interarrival times A i (or arrival rates λ i ). We denote unscaled quantities by putting a hat on the scaled quantities. The settings that we call 'unscaled' correspond to the situation where ˆ = ρ ∑ N i =1 ˆ ρ i = 1, which has the advantage that ˆ ρ i can be interpreted as the fraction of the total traffic load that is routed to flow i . This means that, if the total load equals ρ , the actual flow ratio of flow i is ρ i = ˆ ρ i × ρ . Hence, the unscaled interarrival times ˆ A i are the interarrival times that lead to a system with load 1:
$$\sum _ { i = 1 } ^ { N } \hat { \rho } _ { i } = \sum _ { i = 1 } ^ { N } \hat { \lambda } _ { i } \mathbb { E } [ B _ { i } ] = \sum _ { i = 1 } ^ { N } \frac { \mathbb { E } [ B _ { i } ] } { \mathbb { E } [ \hat { A } _ { i } ] } = 1. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{array}$$
The other scaled/unscaled quantities follow from the relation A i = ˆ A /ρ i . Another interesting quantity is the departure headway of an arbitrary vehicle (in any flow), denoted by B . Since an arbitrary vehicle arrives in flow i with probability λ / i ∑ N j =1 λ j , we have
In the remainder of the paper, we use the subscripts { g, j } for flow j within group g . Without loss of generality, we order the flows within a group according to their flow ratios: ρ g, 1 > ρ g, 2 ≥ · · · ≥ ρ g,N g . For example, supposing that in Figure 1 flows 4 and 9 are part of group 1, and flow 4 has a higher flow ratio than flow 9, we use the notation B 1 1 , = B 4 , and B 1 2 , = B 9 . The flows with the highest flow ratios, flows { g, 1 } for g = 1 , . . . , M , are called dominant flows , or critical lane groups in the HCM. Since we study the limiting behaviour of the intersection as it becomes saturated, the stability condition is an important issue for our analysis.
$$\mathbb { E } [ B ] = \frac { 1 } { \sum _ { j = 1 } ^ { N } \lambda _ { j } } \sum _ { i = 1 } ^ { N } \lambda _ { i } \mathbb { E } [ B _ { i } ] = \frac { \rho } { \sum _ { j = 1 } ^ { N } \lambda _ { j } } = \frac { 1 } { \sum _ { i = 1 } ^ { N } \hat { \lambda } _ { i } }. \\ \intertext {. under of the paper, we use the subscripts } \{ g, j \} \text{ for flow } j \text{ with in group } \dots \dots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
Theorem 2.1 The system is stable (i.e., the intersection is undersaturated) if and only if
$$\sum _ { g = 1 } ^ { M } \rho _ { g, 1 } < 1.$$
## Proof:
The proof is provided in Appendix A.
glyph[square]
Note that only the dominant flows play a role in this stability condition. We study the steady-state of stable systems only, so throughout the paper we assume that
$$0 \leq L \rho < 1,$$
where L = ∑ M g =1 ˆ ρ g, 1 , i.e., the total relative load of the dominant flows. The quantity Lρ is called the critical volume-to-capacity ratio in the HCM, defined as the proportion of available
intersection capacity used by vehicles in critical lane groups. Sometimes it is more comprehensive to use Lρ instead of ρ , because its value is always between 0 and 1, for all stable intersections. It turns out to be convenient to introduce ρ g, · = ∑ N g j =1 ρ g,j as the load of group g , and λ g, · = ∑ N g j =1 λ g,j as the total arrival rate of group g .
Finally, the (equilibrium) residual length of a random variable X is denoted by X res , with E [ X res ] = E [ X / 2 ] 2 E [ X ]. See, e.g., [7], pp. 108 - 115, for more information.
## 3 Heavy traffic
In the present section we study an intersection with exhaustive control policy under Heavy Traffic conditions. This means that we increase the load of the system until it reaches the point of saturation. From Theorem 2.1 we learn that the critical load for which the point of saturation is reached, is completely determined by the dominant flows in each group: the system becomes saturated as ∑ M g =1 ρ g, 1 → 1, which is equivalent to Lρ → 1. As the total load of the system, ρ , increases, the green times, the cycle times and waiting times become larger and will eventually grow to infinity. For this reason, we scale them appropriately and consider the scaled versions. Since we consider finite all-red times, they become negligible compared to the waiting times as the load is increased. Polling systems under HT conditions have been studied by Coffman et al. [5, 6], and by Olsen and Van der Mei [28, 29]. The key observation in these papers, is the occurrence of a so-called Heavy Traffic Averaging Principle (HTAP). When a polling system becomes saturated, two limiting processes take place. Let V denote the total workload of the system. As the load offered to the system, ρ , tends to 1, the scaled total workload (1 -ρ V ) tends to a Bessel-type diffusion. However, the work in each queue is emptied and refilled at a faster rate than the rate at which the total workload is changing. This implies that during the course of a cycle, the total workload can be considered as constant, while the loads of the individual queues fluctuate like a fluid model. The HTAP relates these two limiting processes and provides expressions for the stationary distributions of the scaled cycle times, switch-over times, and waiting times. In order to derive the HT limits for traffic intersections, we introduce and analyse a novel fluid model . Subsequently, we adapt and extend the HTAP to relate the results of this fluid model with the original traffic intersection model.
We introduce a fluid model, with work flowing in at constant rate lim ρ → 1 /L ρ g,j = ˆ ρ g,j /L for flow { g, j } . The all-red times are not considered in the fluid model, because under HT conditions they become negligible. A graphical illustration of the fluid model is presented in Figure 2. On the horizontal axis, the course of a cycle with length c is plotted. On the vertical axis, the scaled workloads in flows { g, 1 } and { g, 2 } are plotted. Because the length of the green periods is determined by the dominant flows, the system becomes saturated as ∑ M g =1 ρ g, 1 = Lρ → 1. A formal proof of this statement is provided in Appendix A. For the total load offered to the system, this translates to ρ → 1 L . We (arbitrarily) start the cycle at the moment that the traffic lights for the flows in group g turn green. For now, during the first part of the analysis, we assume that the amount of work at the beginning of a cycle is fixed. This implies that the length of a cycle, denoted by c , is also fixed because it is determined by the amount of work present at the beginning of the cycle. Throughout the cycle, work arrives with intensity 1 /L and a fraction ˆ ρ g,j is directed to flow { g, j } . During
︸
︷︷
︸
c
Figure 2: Heavy traffic fluid limits.
the green periods, work flows out of each stream at rate 1 as long as it is not empty. As soon as the stream is empty, it stays empty (hence, the work flows out at rate ˆ ρ g,j /L ) until the end of the green period. As a consequence, although the total amount of work in the system at the end of a cycle is back to the level of the beginning of a cycle, it varies throughout the cycle. However, if we consider the workload in dominant flows only, the total workload remains constant, because it flows out at rate 1, and flows in at rate ∑ g ˆ ρ g, 1 /L = 1. This result follows directly from the observation that in the fluid model, the non-dominant flows do not contribute to the cycle length and, hence, do not influence the total workload in the dominant flows.
From the viewpoint of fluid in flow { g, j } , a cycle of length c consists of three parts. During the first part, starting at the moment that the lights turn green, fluid starts to drain out of the system until flow { g, j } is empty. The second part is the time between the emptying of flow { g, j } and the moment that the dominant flow of the group, { g, 1 } becomes empty and traffic lights turn red. The third part is the red period of group g . It is easily seen that the length of this third part is ( 1 -ˆ ρ g, 1 /L c ) , and the length of the first two parts together (the green period of group g ) is ˆ ρ g, 1 L c . Using Figure 2 we see that the length of the first part, with flow { g, j } being non-empty, is ˆ ρ g,j L 1 -ˆ ρ g, 1 /L 1 -ˆ ρ g,j /L c . We denote the lengths of the three parts respectively by P , P j 1 , and P R . The probability distribution of the delay of an arbitrary fluid particle arriving in flow { g, j } , denoted by W fluid g,j , can now be computed.
## Theorem 3.1
$$W _ { g, j } ^ { \ f l u i d } \stackrel { d } { = } \begin{cases} 0 & w. p. \ P _ { 1 } / c, \\ U \times P _ { R }, & w. p. \ ( P _ { j } + P _ { R } ) / c, \end{cases} \\ \intertext { a uniformly distributed random variable on the interval } \, \text{$10$}$$
where U is a uniformly distributed random variable on the interval [0 , 1].
## Proof:
We condition on the arrival epoch of an arbitrary fluid particle in flow { g, j } . With probability P /c R , the arrival takes place during the red period. The probability that the arrival takes
place during the first part of the green period, when there is still other fluid present in flow { g, j } , is P /c j . If the particle arrives during the second part of the green period, when there is no fluid present in flow { g, j } , its delay is 0. This happens with probability P /c 1 . So we can write:
$$W _ { g, j } ^ { \text{fluid} } \underline { d } = \begin{cases} 0 & w. p. \ P _ { 1 } / c, \\ W _ { g, j } ^ { \text{green} } & w. p. \ P _ { j } / c, \\ W _ { g, j } ^ { \text{red} } & w. p. \ P _ { R } / c. \end{cases} \\ \text{ing the first part of the green period (with lengt} \\ \text{if it has left the system. Let the uniform rando}$$
$$W _ { g, j } ^ { g r e e n } \stackrel { d } { = } \frac { \hat { \rho } _ { g, j } } { L } ( 1 - U _ { G } ) \left ( 1 - \hat { \rho } _ { g, 1 } / L \right ) c.$$
A particle arriving during the first part of the green period (with length P j ) has to wait until all the fluid in front of it has left the system. Let the uniform random variable U G denote the fraction of P j that has elapsed at the arrival epoch of this particle. Then the amount of fluid left in flow { g, j } is (1 -ˆ ρ g,j /L ) × (1 -U G ) P j = ˆ ρ g,j L ( 1 -ˆ ρ g, 1 /L ) (1 -U G ) c . Hence,
The delay of a particle arriving during the red period can be analysed similarly. Let the uniform random variable U R denote the fraction of the red period that has elapsed at the arrival epoch of this particle. Then the amount of fluid present in flow { g, j } is ˆ ρ g,j L × U P R R . The arriving particle has to wait for this amount of fluid to drain, after it has waited for the residual red period (1 -U R ) P R . Hence, we have
If we study (3.2) and (3.3) more carefully, we see that W green g,j is uniformly distributed on the interval [0 , ˆ ρ g,j L P R ] and W red g,j is uniformly distributed on the interval [ ˆ ρ g,j L P ,P R R ]. Recall that W fluid g,j d = W green g,j with probability P /c j = ˆ ρ g,j /L 1 -ˆ ρ g,j /L P /c R = ˆ ρ g,j L ( P j + P R ) /c , and W fluid g,j d = W red g,j with probability P /c R = ( 1 -ˆ ρ g,j L ) ( P j + P R ) /c . This implies that W fluid g,j is uniformly distributed on [0 , P R ] with probability ( P j + P R ) /c , and it is 0 otherwise. glyph[square]
$$\text{p.m. } \colon & = \cup _ { R } \nmid \colon = \cup _ { R } \nmid \colon = \colon \\ & W _ { g, j } ^ { r e d } \frac { d } { } = \left ( \frac { \hat { \rho } _ { g, j } } { L } U _ { R } + ( 1 - U _ { R } ) \right ) \left ( 1 - \hat { \rho } _ { g, 1 } / L \right ) c. \\ & \text{(3.2)} \text{ and (3.3)} \text{ more carefully, we see that } W _ { a } ^ { g r e e n } \text{ is uniformly distributed on the}$$
Now that we have established the distribution of the delay of a particle in the fluid model, we can find the distribution of the scaled delay of a vehicle in the original model for the traffic intersection, under HT conditions.
Original model. For ordinary polling models, the link between the fluid model and the polling model under HT conditions is the Heavy Traffic Averaging Principle. This principle states that the work in each queue is emptied and refilled at a rate that is so much faster than the rate at which the total workload is changing, that during the course of a cycle, the total workload can be considered as constant, while the loads of the individual queues fluctuate like a fluid model. A novel contribution of the present paper is the adaptation and extension of the HTAP for polling systems to the traffic intersection model. Also in this model, when the system becomes saturated, the diffusion limits of the total workload process and the workload in the individual flows can be related using the HTAP. The main difference is that in the fluid model for the traffic intersection, the total workload does not remain constant, but the total workload in the dominant flows does. From the fluid model it has become clear
that the non-dominant flows do not play a role in the length of the green periods, because the dominant flow in each group will always be the last flow that becomes empty. For this reason, we can ignore the non-dominant flows temporarily and focus on the workload in the dominant flows only. This turns our traffic light model into an ordinary polling model with exhaustive service. First, we define a random variable with a Gamma distribution as a random variable with probability density function
$$f ( t ) = \frac { 1 } { \Gamma ( \alpha ) } \mathrm e ^ { - \mu t } \mu ^ { \alpha } t ^ { \alpha - 1 }, \quad t \geq 0,$$
where Γ( α ) = ∫ ∞ -0 e t t α -1 d . t The positive parameters α and µ are respectively the scale and rate parameter.
When the load ρ approaches 1 /L , the system becomes overloaded and the queue lengths and waiting times tend to infinity. For this reason, we consider the scaled delay (1 -Lρ W ) g,j , which stays finite for ρ → 1 /L . Before we can formulate the main result of this section, the distribution of the scaled delay as the HT limit is approached, we need some lemmas. Note that the proofs of these lemmas all rely on the conjectures posed in [29]. Although these conjectures are widely accepted to be true, they have only been proven for systems consisting of two queues (cf. [5, 6]), systems with Poisson arrivals (cf. [28]), or for the means rather than the complete distributions (cf. [36]).
Lemma 3.2 Denote by V · , 1 the amount of work in the dominant flows of the intersection, at the beginning of a cycle. For ρ → 1 /L , (1 -Lρ V ) · , 1 has a Gamma distribution with parameters α = 2 E [ R δ/σ ] 2 + 1 and µ = 2 /σ 2 , where δ = ∑ M g =1 ˆ ρ g, 1 L (1 -ˆ ρ g, 1 L ) / 2, and σ 2 = ∑ M g =1 ˆ λ g, 1 L ( V ar[ B g, 1 ] + ˆ ρ 2 g, 1 V ar[ ˆ A g, 1 ] ) . Proof:
By the HTAP, the total workload in the dominant flows of the system may be regarded as unchanged over the course of a cycle. So if we regard the system with dominant flows only, Lemma 3.2 follows directly from Olsen and Van der Mei [29], Conjecture 1. More specifically, we use the special case of cyclic, exhaustive service to obtain the distribution of the scaled amount of work in the dominant flows. glyph[square]
Before continuing, it is important to realise the interpretation of δ . Assume, just like in Figure 2, that c is the length of a cycle, starting at the beginning of green period G g . Then the workload in flow { g, 1 } at the beginning of the cycle is ˆ ρ g, 1 L ( 1 -ˆ ρ g, 1 L ) c . The flow is empty at the moment that a fraction ˆ ρ g, 1 L of the cycle has passed, and at the end of the cycle it has reached the same level as at the beginning. The mean workload in flow { g, 1 } during this cycle is 1 ˆ 2 ρ g, 1 L ( 1 -ˆ ρ g, 1 L ) c . A summation over all dominant flows shows that δc is the mean total workload of the dominant flows during the course of one cycle of length c
Given the scaled amount of work in the dominant queues at the start of a green period of group g , we can derive the distribution of the scaled cycle time (1 -Lρ C ) . In fact, we consider the length-biased (or time-averaged) scaled cycle time (1 -Lρ ) C . If a random variable X has probability density function F X ( x ), then we define the length-biased random variable X as a random variable with probability density function f X ( x ) = xf X ( x / ) E [ X ]. From renewal theory, we know that the length-biased cycle length accounts for the fact that an arbitrary arriving vehicle arrives with a higher probability during a long cycle, than during a short one.
The length of a cycle depends on the amount of work at the beginning of that cycle. Denote by C x ( ) the length of a cycle, given that a total amount of x work is present in the dominant flows. We are now ready to formulate the second lemma, needed to find the distributions of the scaled delays under HT conditions.
Lemma 3.3 Denote by I g the length-biased red-time (or intervisit time) of group g , g = 1 , . . . , M . For ρ → 1 /L , we find that (1 -Lρ ) I g converges in distribution to a random variable having a Gamma distribution with parameters α = 2 E [ R δ/σ ] 2 + 1 and µ g := 2 δ/ σ ( 2 (1 -ˆ ρ g, 1 /L ) ) . Proof:
The proof proceeds along the same lines as the argument given to support Conjecture 2 in [29]. It uses Lemma 3.2 and the fact that, due to the averaging principle, the scaled workload in the dominant flows remains effectively constant. In steady-state, we have the following relation:
$$\delta C ( x ) = x.$$
This relation can easily be verified graphically from Figure 2, because the total amount of work in the dominant queues remains constant throughout the course of a cycle. Given a cycle length of c , the total amount of work in the dominant queues is ∑ M g =1 ˆ ρ g, 1 L ( 1 -ˆ ρ g, 1 L ) c/ 2 = δc . Hence, given an amount of work x in the dominant flows, the cycle time is C x ( ) = x/δ . Now we use Lemma 3.2, which states that, in the HT limit, the scaled workload in the dominant flows has a Gamma distribution with parameters α and µ . This implies that for ρ → 1 /L , the scaled, length-biased cycle time (1 -Lρ ) C follows a Gamma distribution with, again, scale parameter α , but with rate parameter µδ . The distributions of the scaled length-biased intervisit times, denoted by (1 -Lρ ) I g for group g = 1 , . . . , M , can now be determined. The intervisit time of group g is the time that the signals in group g are red. Given that x is the amount of work present at the dominant queues at the beginning of a cycle, the intervisit time conditioned on x is obviously
$$I _ { g } ( x ) = C ( x ) ( 1 - \frac { \hat { \rho } _ { g, 1 } } { L } ). \\. - L \rho ) I _ { g } \text{ now readily follows frc}$$
The limiting distribution of (1 -Lρ ) I g now readily follows from the limiting distribution of (1 -Lρ ) C . glyph[square]
Finally, we formulate the main result of the present section.
Theorem 3.4 As ρ ↑ 1 /L , the scaled delay is 0 with probability ˆ ρ g, 1 -ˆ ρ g,j L -ˆ ρ g,j , and it is the product of a uniformly distributed random variable on [0 1], denoted by , U , and a random variable Γ I having the same distribution as the limiting distribution of (1 -Lρ ) I g , with probability 1 -ˆ ρ g, 1 /L 1 -ˆ ρ g,j /L :
$$\Gamma _ { 1 } - \Gamma _ { g, j / 2 } & \Gamma _ { 2 } & & & \\ & ( 1 - L \rho ) W _ { g, j } \stackrel { d } { \rightarrow } \begin{cases} 0 & \text{w.p. } \frac { \hat { \rho } _ { g, 1 } - \hat { \rho } _ { g, j } } { L - \hat { \rho } _ { g, j } }, \\ U \times \Gamma _ { I }, & \text{w.p. } \frac { 1 - \hat { \rho } _ { g, 1 } / L } { 1 - \hat { \rho } _ { g, j } / L }, \end{cases} & & ( 3. 4 ) \\ \Gamma _ { 1 } & & & &$$
for ρ → 1 /L .
## Proof:
A combination of Theorem 3.1 and Lemma 3.3 yields the desired result. The scaled intervisit
time (1 -Lρ ) I g converges in distribution to a random variable having a Gamma distribution with parameters α and µ g . The HTAP states that we can simply replace P R , the deterministic red time in the fluid model, in (3.1) by the scaled, length-biased red time in the original model, (1 -Lρ ) I g , because the random variables U and I g are independent. glyph[square]
For the approximations developed in Section 5, the mean scaled delay for ρ → 1 /L will be used.
## Corollary 3.5
$$\tilde { \nu } \cdot \cdot \\ \lim _ { \rho \to \frac { 1 } { L } } ( 1 - L \rho ) \mathbb { E } [ W _ { g, j } ] = \frac { ( 1 - \hat { \rho } _ { g, 1 } / L ) ^ { 2 } } { 1 - \hat { \rho } _ { g, j } / L } \left ( \frac { \mathbb { E } [ R ] } { 2 } + \frac { \sigma ^ { 2 } } { \delta } \right ), \\ \cdot$$
## where δ = ∑ M g =1 ˆ ρ g, 1 L (1 -ˆ ρ g, 1 L ) / 2, and σ 2 = ∑ M g =1 ˆ λ g, 1 ( V ar[ B g, 1 ] + ˆ ρ 2 g, 1 V ar[ ˆ A g, 1 ] ) . Proof:
The result immediately follows from (3.4).
glyph[square]
Note that any possible variations in the all-red times R g have no influence on the mean scaled delay under HT conditions.
Remark 3.6 For Poisson arrivals σ 2 can be simplified to σ 2 = E [ B 2 · , 1 ] E [ B · , 1 ] , where B · , 1 = ∑ M g =1 ˆ λ g, 1 B g, 1 ∑ M g =1 ˆ λ g, 1 is the headway of an arbitrary vehicle arriving in a dominant flow.
Remark 3.7 (Convergence to the HT limit) Although the distribution of the scaled delay in the HT limit ρ ↑ 1 /L is exact, it is interesting to know how fast this limiting distribution is approached. Unfortunately, the analysis does not provide any insight in the speed at which the scaled delay converges to this limiting distribution, so we have to resort to simulations. Denote by p g,j the steady-state probability that flow { g, j } is the flow from which the last departure takes place before the corresponding green phase G g ends. This probability depends on ρ , the total load of the system. We have shown in this section that, in the limiting situation, the dominant flow of each group is always the last flow to become empty in this group. For ρ < 1 /L , the fraction of green periods in which the last departure indeed takes place from the dominant flow becomes smaller. In fact, in the LT limit one can easily calculate the exact value of p g,j . In LT, the probability that the last vehicle in group g departs from flow { g, j } is proportional to the arrival rates of the flows in this group. Summarising:
$$\text{to the arrival rates of the flows in this } g \\ \lim _ { \rho \uparrow 1 / L } p _ { g, j } & = \begin{cases} 1 & \text{if } j = 1, \\ 0 & \text{if } j > 1, \end{cases} \\ \lim _ { \rho \downarrow 0 } p _ { g, j } & = \frac { \hat { \lambda } _ { g, j } } { \hat { \lambda } _ { g, \bullet } }. \\ \text{, \quad \ e \ \, \quad \. \end{cases}$$
This implies that we can regard p g,j as a measure for how close the distribution of the scaled delay is to the limiting distribution. In Figure 3 we show an example that illustrates how p g,j might depend on ρ . The specific intersection chosen for this figure, has two groups of three flows each. The traffic intensities of the flows within each group are relatively close to each other. In this situation, it takes rather long before the probabilities p g,j converge to
their limiting values for ρ → 1 /L . For example, in Figure 3 one can see that at Lρ = 0 9, . the probability p 2 1 , (corresponding to flow 6) is less than 0 7. . The fact that this value is still quite different from its limiting value 1, has a direct impact on the distribution of the scaled delay. The (simulated) mean scaled delay (1 -Lρ ) E [ W 2 1 , ] at Lρ = 0 9 is 4 5, whereas . . lim Lρ ↑ 1 (1 -Lρ ) E [ W 2 1 , ] = 3 5. For this reason, one has to be careful when applying the results . for ρ ≈ 1 /L to situations with smaller loads. In Section 6, we continue the discussion on the numerical accuracy. For more information about the intersection which is used for Figure 3, see Scenario V in Example 1.
Figure 3: Simulated fractions of the green periods where the corresponding flows have been the last in their groups from which a vehicle departs before the traffic lights turn red.
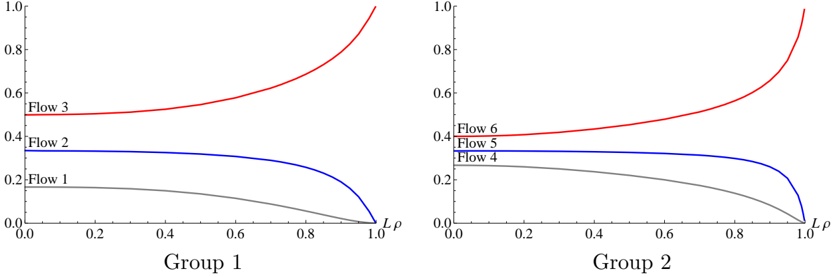
## 4 Light traffic
In the present section we study the delay of vehicles arriving at the traffic intersection under Light Traffic conditions, i.e., for ρ ↓ 0. In the first part of the section, we find an expression for the mean delay of vehicles, assuming Poisson arrivals. Subsequently, we heuristically adapt this expression to find an approximation for the mean delay for intersections with general renewal arrivals. The analysis of the present section follows the lines of [4], where the derivation of the LT limit of mean waiting times for polling systems is discussed, with modifications for the specific traffic intersection model.
For the first part in this section we assume that the arrival processes in all flows are Poisson. Under this assumption, the LT limit of the mean delay can be determined by conditioning on the arrival epoch of an arbitrary vehicle in, say, flow { g, j } . By the LT limit of E [ W g,j ], we mean the expression for E [ W g,j ] as a function of the load in the system, ρ , up to O ( ρ ) terms for ρ ↓ 0. In the following theorem we formulate the main result for the system with Poisson arrivals.
Theorem 4.1 Under the assumption of Poisson arrivals, the LT limit of the mean delay of
an arbitrary type { g, j } vehicle is
$$\text{an arbitrary type } \{ g, j \} \text{ vehicle is} \\ \mathbb { E } [ W _ { g, j } ^ { L T, P o i s o m } ] & = \rho _ { g, j } \left ( \mathbb { E } [ B _ { g, j } ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] \right ) + \sum _ { m = g - M + 1 } ^ { g - 1 } \sum _ { k = 1 } ^ { N _ { m } } \rho _ { m, k } \left ( \mathbb { E } [ B _ { m, k } ^ { r e s } ] + \sum _ { l = m } ^ { g - 1 } \mathbb { E } [ R _ { l } ] + \mathbb { E } [ B _ { g, j } ] \right ) \\ & + \sum _ { m = g - M } ^ { g - 1 } \frac { \mathbb { E } [ R _ { m } ] } { \mathbb { E } [ R ] } \left ( E [ R _ { m } ^ { r e s } \right ) \left ( 1 - \rho + 2 \sum _ { k = m + 1 } ^ { g - 1 } \rho _ { k, \bullet } + \rho _ { g, j } \right ) + \\ & \sum _ { k = g - M } ^ { m - 1 } \mathbb { E } [ R _ { k } ] \left ( \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) + \sum _ { k = m + 1 } ^ { g - 1 } \mathbb { E } [ R _ { k } ] \left ( 1 - \rho + \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } \right ) + \left ( 1 - \rho \right ) \mathbb { E } [ B _ { g, j } ] \right ) \\ & + O ( \rho ^ { 2 } ). \\ \text{Proof} \text{:} \text{$r$} \text{:} \text{$r$} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{\end{:} } \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{::} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{:} \text{\end{:} }$$
## Proof:
The proof is essentially a Mean Value Analysis (MVA) that ignores all O ( ρ 2 ) terms, and focusses mainly on the amount of work instead of number of vehicles. The first step is to condition on the arrival epoch of a vehicle in flow { g, j } . A cycle consists of the green phases G g and all-red phases R g , for g = 1 , . . . , M . At the beginning of green time G g , the probability that one vehicle has arrived in any of the flows in group g during the preceding red time (or: intervisit time) I g , is λ g, · E [ I g ] + O ( λ 2 g, · ). The probability that more than one vehicle has arrived in any flow of group g is O ( λ 2 g, · ) and therefore negligible in LT analysis. Therefore, we have that
$$\text{ve that} \\ \text{ean cycle time is}$$
The mean cycle time is
$$\mathbb { E } [ C ] & = \sum _ { g = 1 } ^ { M } \mathbb { E } [ G _ { g } ] + \mathbb { E } [ R ] = \mathbb { E } [ R ] \left ( 1 + \rho \right ) + \mathcal { O } ( \rho ^ { 2 } ). & ( 4. 3 ) \\ \mathcal { e } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
Now we can find the LT limit of E [ W g,j ] by conditioning on the arrival epoch of an arbitrary customer. The probability that an arbitrary vehicle arrives during the all-red phase R k , for k = 1 , . . . , M , is
$$\mathbb { P } ( \text{arrival during } R _ { k } ) = \frac { \mathbb { E } [ R _ { k } ] } { \mathbb { E } [ C ] } = \frac { \mathbb { E } [ R _ { k } ] } { \mathbb { E } [ R ] } ( 1 - \rho ) + \mathcal { O } ( \rho ^ { 2 } ).$$
The probability that an arbitrary vehicle arrives during the green phase G k , for k = 1 , . . . , M , is
If a vehicle arrives during G k , the vehicle crossing the intersection at that moment is a type { k, l } vehicle with probability ρ k,l ρ k, · , for l = 1 , . . . , N k . This means that we can formulate the mean delay of a type { g, j } vehicle as follows.
$$\mathbb { P } ( \text{arrival during } G _ { k } ) = \frac { \mathbb { E } [ G _ { k } ] } { \mathbb { E } [ C ] } = \frac { \mathbb { E } [ G _ { k } ] } { \mathbb { E } [ R ] } ( 1 - \rho ) + \mathcal { O } ( \rho ^ { 2 } ) = \sum _ { l = 1 } ^ { N _ { k } } \rho _ { k, l } + \mathcal { O } ( \rho ^ { 2 } ). \\ \text{If a vehicle arrives during } G _ { k }, \text{ the vehicle crossing the intersection at that moment is a type}$$
$$\mathbb { E } [ W _ { g, j } ] & = \sum _ { k = 1 } ^ { M } \left ( \frac { \mathbb { E } [ R _ { k } ] } { \mathbb { E } [ R ] } ( 1 - \rho ) \mathbb { E } [ W _ { g, j } ^ { ( R _ { k } ) } ] + \sum _ { l = 1 } ^ { N _ { k } } \rho _ { k, l } \mathbb { E } [ W _ { g, j } ^ { ( G _ { k, l } ) } ] \right ) + \mathcal { O } ( \rho ^ { 2 } ), \quad \ ( 4. 4 )$$
where E [ W ( R k ) g,j ] is the mean delay of a { g, j } vehicle that arrives during R k , and E [ W ( G k,l ) g,j ] is the mean delay of a { g, j } vehicle that arrives during the service of a { k, l } vehicle. We will study these conditional mean delays in more detail.
Firstly, we note that the mean delay of a { g, j } vehicle arriving while another vehicle of the same type is crossing the intersection, is simply the residual headway of the crossing vehicle, plus the departure headway of the vehicle itself:
$$\mathbb { E } [ W _ { g, j } ^ { ( G _ { g, j } ) } ] = \mathbb { E } [ B _ { g, j } ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] + \mathcal { O } ( \rho ), \quad g = 1, \dots, M ; j = 1, \dots, N _ { g }. \quad ( 4. 5 )$$
The O ( ρ ) terms are of no interest in (4.5), because the probability of an arrival during a green period is an O ( ρ ) term itself. Secondly, a { g, j } vehicle arriving while another vehicle of the same group, but not of the same flow, is crossing the intersection experiences no delay at all, because the probability that another vehicle of the same type is present at the intersection is O ( ρ ):
$$\mathbb { E } [ W _ { g, j } ^ { ( G _ { g, l } ) } ] = 0 + \mathcal { O } ( \rho ), \quad g = 1, \dots, M ; j = 1, \dots, N _ { g } ; l \neq j.$$
glyph[negationslash]
The mean delay of a { g, j } vehicle arriving while a vehicle of another group is crossing the intersection, is composed of the mean residual headway of that other vehicle, plus all subsequent all-red times until the vehicle itself can start crossing the intersection, plus its own headway. Note that the intermediate green times are negligible, because their total length is O ( ρ ).
glyph[negationslash]
$$\mathbb { E } [ W ^ { ( G _ { k, l } ) } _ { g, j } ] = \mathbb { E } [ B ^ { r e s } _ { k, l } ] + \sum _ { i = k } ^ { g - 1 } \mathbb { E } [ R _ { i } ] + \mathbb { E } [ B _ { g, j } ] + \mathcal { O } ( \rho ), \quad g \neq k. \quad \quad ( 4. 7 ) \\.. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
Note that the sum in (4.7) has to be taken cyclic over the all-red periods between the green times of groups k and g . The mean delay of vehicles arriving during all-red times is slightly more complicated. We have to include all O ( ρ ) terms now, because the probability of an arrival during an all-red period is not O ( ρ ). The mean delay of a { g, j } vehicle arriving during all-red period R m consists of the residual all-red period R res m , plus the green and allred periods between group m and group g . In more detail, the mean delay is composed of:
- 1. The departure headways of all vehicles that arrive in groups m +1 , . . . , g -1 and in flow { g, j } during the all-red times R , . . . , R g m -1 , and the elapsed part of R m at the arrival epoch, denoted by R past m ;
- 2. The residual red time R m , denoted by R res m , plus the headways of all vehicles arriving in groups m +1 , . . . , g -1 during this residual red time;
- 3. The all-red times R m +1 , . . . , R g -1 plus the headways of the vehicles that arrive during these all-red times and will be served between R m and the green period of group g ;
- 4. The headway of the arriving vehicle itself.
Note that R past m is the same, in distribution, as R res m . This leads to the following expression
for E [ W ( R m ) g,j ], where the terms (4.8) -(4.11) correspond to items 1 -4:
$$& \bigvee _ { k = g - M } \quad \int _ { \substack { k = m + 1 \\ + E [ R _ { m } ^ { r e s } ] \left ( 1 + \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } \right ) \\ \frac { g - 1 } { \longrightarrow } \quad \int _ { \substack { g - 1 \\ \longrightarrow } } ^ { g - 1 } \quad \cdot$$
$$\lambda _ { ( } \cdots g, j ), \quad \lambda _ { ( } \cdots \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \% \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \imes \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \null } \Phi ( R _ { g, j } ^ { r e s } ) & = \left ( \sum _ { k = g - M } ^ { m - 1 } \mathbb { E } [ R _ { k } ] + E [ R _ { m } ^ { p a s t } ] \right ) \left ( \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l = m + 1 } ^ { m - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) & = \left ( \sum _ { l \cdots \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \raysetcdots \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \raysetclots \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times \times$$
$$& + \sum _ { k = m + 1 } ^ { g - 1 } \mathbb { E } [ R _ { k } ] \Big ( 1 + \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } \Big ) \\ & + \mathbb { E } [ B _ { a } \, _ { i } ].$$
$$+ \mathbb { E } [ B _ { g, j } ].$$
Combining Equations (4.2)-(4.11) completes the proof of Theorem 4.1. glyph[square]
glyph[negationslash]
Remark 4.2 Equation (4.6) will turn out to be the only place in the LT analysis where the assumption that an empty flow stays empty during the remainder of the green period plays a role. Without this assumption, we would have that E [ W ( G g,l ) g,j ] = E [ B g,j ] + O ( ρ ) for l = j . The HT analysis in the previous section would not change at all. This means that the assumption, perhaps surprisingly, does not have much impact at all on the real and the approximated mean delays. In Section 6, Example 3, we discuss in more detail the impact of the assumption that vehicles arriving at an empty flow during a green phase do not experience any delay.
The main result of this section is an adaptation of (4.1), which can be used as an approximation for the LT limit of the mean delay for general renewal arrivals.
Corollary 4.3 An approximation for the LT limit of the mean delay for vehicles in flow { g, j } for a traffic intersection with general renewal arrivals and deterministic all-red times is:
glyph[negationslash]
$$+ \, \frac { 1 } { 2 } ( 1 + \rho + \rho _ { g, j } - 2 \rho _ { g, \bullet } ) R.$$
$$& \{ y, j \} \text{ for a main line section with given real rewrite with any use of use is.} \\ & \mathbb { E } [ W _ { g, j } ^ { L T } ] & \approx \rho _ { g, j } \left ( \mathbb { E } [ \hat { A } _ { g, j } ] \hat { g } _ { g, j } ( 0 ) - 1 \right ) \mathbb { E } [ B _ { g, j } ^ { r e s } ] ) + \rho \mathbb { E } [ B ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] - \sum _ { k \neq j } \rho _ { g, k } \left ( \mathbb { E } [ B _ { g, k } ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] \right ) \\ & \quad + \frac { 1 } { 2 } ( 1 + \rho + \rho _ { g, j } - 2 \rho _ { g, \bullet } ) R.$$
We derive approximation (4.12) by adapting (4.1) to create an LT approximation for the case of general renewal arrivals. This adaptation is similar as in [4], based on the observation that the first term in (4.1), ρ g,j E [ B res g,j ], is the LT limit of the mean waiting time (excluding the service time) in an M/G/ 1 queue in isolation:
$$\mathbb { E } [ W _ { M / G / 1 } ] = \rho \mathbb { E } [ B ^ { r e s } ] + \mathcal { O } ( \rho ^ { 2 } ).$$
We obtain an approximation for the mean waiting time for general renewal arrivals by replacing this term with the LT limit for the GI/G/ 1 queue from Whitt [41]:
$$\lim _ { \rho \downarrow 0 } \frac { \mathbb { E } [ W _ { G I / G / 1 } ] } { \rho } = \frac { 1 + c v _ { B } ^ { 2 } } { 2 } \mathbb { E } [ \hat { A } ] \hat { g } ( 0 ) \mathbb { E } [ B ],$$
where cv 2 B is the Squared Coefficient of Variation (SCV) of the service times, and ˆ( ) is the g t density of the interarrival times ˆ at A ρ = 1. Our approximation is based on the approximative assumption that the Fuhrmann-Cooper decomposition (cf. [15]) holds for our system with general renewal arrivals. The Fuhrmann-Cooper decomposition for the waiting times of customers in queue i of a polling system with Poisson arrivals and exhaustive service in queue i states that the waiting time of an arbitrary type i customer is the sum of two independent random variables. One of these random variables is the waiting time of a customer in the corresponding M/G/ 1 queue in isolation (as if it would not have been part of a polling system), and the other random variable is the residual intervisit time of queue i :
$$W _ { i } \stackrel { d } { = } W _ { i, M / G / 1 } + I _ { i } ^ { r e s }.$$
If we combine this Fuhrmann-Cooper decomposition with (4.1), (4.13), and (4.14), we obtain the following approximation for the mean delay (i.e., waiting time plus headway) of a vehicle in flow { g, j } for an intersection with general renewal arrivals:
$$\mathbb { E }$$
$$& \text{the following approximation for the mean delay} ( 1. e., \text{ waiting time plus headway} ) \text{ of a vehicle} \\ & \mathbb { E } [ W ^ { L T } _ { g, j } ] \approx \rho _ { g, j } \left ( \mathbb { E } [ \hat { A } _ { g, j } ] \hat { g } _ { g, j } ( 0 ) \mathbb { E } [ B ^ { r e s } _ { g, j } ] + \mathbb { E } [ B _ { g, j } ] \right ) + \sum _ { m = g - M + 1 } ^ { g - 1 } \sum _ { \substack { N _ { m } } } \rho _ { m, k } \left ( \mathbb { E } [ B ^ { r e s } _ { m, k } ] + \sum _ { l = m } ^ { g - 1 } \mathbb { E } [ R _ { l } ] + \mathbb { E } [ B _ { g, j } ] \right ) \\ & \quad + \sum _ { m = g - M } ^ { g - 1 } \frac { \mathbb { E } [ R _ { m } ] } { \mathbb { E } [ R ] } \left ( E [ R ^ { r e s } _ { m } ] \left ( 1 - \rho + 2 \sum _ { k = m + 1 } ^ { g - 1 } \rho _ { k, \bullet } + \rho _ { g, j } \right ) + \\ & \quad \sum _ { k = g - M } ^ { m - 1 } \mathbb { E } [ R _ { k } ] \left ( \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } + \rho _ { g, j } \right ) + \sum _ { k = m + 1 } ^ { g - 1 } \mathbb { E } [ R _ { k } ] \left ( 1 - \rho + \sum _ { l = m + 1 } ^ { g - 1 } \rho _ { l, \bullet } \right ) + ( 1 - \rho ) \mathbb { E } [ B _ { g, j } ] \right ) \\ & \text{This expression can be written into a more compact form. After some straightforward (but}$$
This expression can be written into a more compact form. After some straightforward (but tedious) rewriting, it can be shown that (4.15) reduces to:
glyph[negationslash]
$$\text{redious} \right ) & \text{ rewriting, it can be shown that } ( 4. 1 5 ) & \text{reduces to} \colon \\ \mathbb { E } [ W _ { g, j } ^ { L T } ] & \approx \rho _ { g, j } \left ( \mathbb { E } [ \tilde { A } _ { g, j } ] \tilde { g } _ { g, j } ( 0 ) - 1 \right ) \mathbb { E } [ B _ { g, j } ^ { r e s } ] + \rho \mathbb { E } [ B ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] - \sum _ { k \neq j } \rho _ { g, k } \left ( \mathbb { E } [ B _ { g, k } ^ { r e s } ] + \mathbb { E } [ B _ { g, j } ] \right ) \\ & \quad + ( 1 - \rho + \rho _ { g, j } ) \mathbb { E } [ R ^ { r e s } ] + ( \rho - \rho _ { g, \bullet } ) \mathbb { E } [ R ] + \frac { 1 } { \mathbb { E } [ R ] } \sum _ { m = g - M } ^ { g - 1 } \left ( \sum _ { k = m + 1 } ^ { g - 1 } \rho _ { k, \bullet } \right ) \text{Var} [ R _ { m } ]. \\ \mathbb { E } \text{Are\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\} } \text{and\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\ } } \text{and\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \,\,\} } \text{and\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\} } \text{and\,\, \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\} } \text{end}$$
For deterministic all-red times, we have E [ R res ] = R/ 2 and V ar[ R g ] = 0 for g = 1 , . . . , M . Carrying out these substitutions in (4.16) leads to expression (4.12).
Remark 4.4 A simplification can be made to replace the expression E [ ˆ A g,j ]ˆ g g,j (0). In [4, 41] it is shown that a good approximation for this term is
$$\text{good approximation for this term is} \\ \mathbb { E } [ \hat { A } _ { i } ] \hat { g } _ { i } ( 0 ) \approx \begin{cases} 2 \frac { c v _ { A _ { i } } ^ { 2 } } { c v _ { A _ { i } } ^ { 2 } + 1 } & \text{if $cv_{A_{i}}^{2}>1$}, \\ \left ( c v _ { A _ { i } } ^ { 2 } \right ) ^ { 4 } & \text{if $cv_{A_{i}}^{2} \leq 1$}, \end{cases} \\ \text{quared coefficient of variation of $A_{i}$ (and, hence, also of $z$} \\ \text{lts in an approximation that requires only the first twc}$$
where cv 2 A i is the squared coefficient of variation of A i (and, hence, also of ˆ ). A i Note that this simplification results in an approximation that requires only the first two moments of each input variable (i.e., headways, all-red times, and interarrival times).
$$\cdot$$
Remark 4.5 (Convergence to the LT limit) In this paragraph we study the convergence of the mean delays to their LT limiting values, similarly to what we have done for the HT limit in the previous section. Although the LT limit of the mean delay (4.15) has been obtained in a rather heuristical way, it turns out to be very accurate. In contrast to the HT limit, expression (4.15) is not exact when the arrival processes are not Poisson, because the correction term ρ g,j ( E [ ˆ A g,j ]ˆ g g,j (0) -1 ) E [ B res g,j ]) is based on a decomposition of the mean delay (see [4] for more details) which is known not be true in general. Nevertheless, when comparing the approximated delays with simulated delays, results show that the approximation is very accurate (see Section 6). We have also been able to test the accuracy of the LT limit for small intersections (4 flows) by comparing it to exact results under the assumption that all the departure headways, interarrival times and switch-over times are exponentially distributed. This has provided much insight in the behaviour of the delay as a function of the load ρ . Expression (4.15) captures the LT behaviour very well, except for some cases where the behaviour exposes more curvature. To illustrate this, we consider a simple intersection with four flows, divided into two groups, each having a saturation flow rate of 1800 vehicles per hour. The mean all-red times are 6 seconds each. The relative loads are ˆ ρ 1 = ˆ ρ 3 = 0 1, . and ˆ ρ 2 = ˆ ρ 4 = 0 4. . We assume exponentially distributed headways, interarrival times and all-red times, because this enables us to model this system as a Markov chain. In order to solve this system numerically, we need a finite state space, so we take a maximum queue length of 6 vehicles per flow. This is sufficient since we are only focussing on LT behaviour. Figure 4 shows the mean delays for flows 1 and 2 (and, because of symmetry, also of flows 3 and 4) as a function of ρ , the total load in the system. These pictures illustrate that the derivative at ρ = 0 of the mean delay indeed equals the LT expression. But Figure 4(a) also illustrates that the actual behaviour may be non-linear, which can lead to deviations between the approximation, developed in the next section, and the actual mean delay.
Figure 4: The exact mean delays of flow 1 (left) and flow 2 (right) and the LT limits of the example in Section 4.
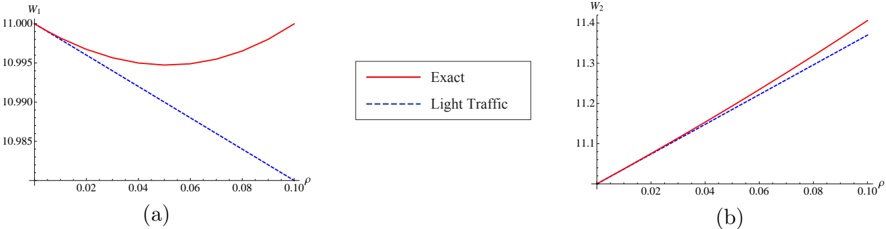
## 5 Interpolations
In the previous two sections we have given expressions for the mean delay in the extreme cases where the system is either hardly exposed to traffic, or completely saturated. In the present section we use these results to develop interpolations between these two cases that give an
approximation for the mean delay for any load, as long as the system is not oversaturated (cf. [4]). In fact, we develop two different interpolations. At the end of this section we discuss the conditions under which each interpolation should be preferred.
$$& \mathbb { E } [ W _ { g, j } ^ { a p p t } ] = \frac { K _ { 0, g, j } ^ { \prime } + K _ { 1, g, j } ^ { \prime } \rho } { 1 - L \rho }, & g = 1, \dots, M ; j = 1, \dots, N _ { g }. \quad \ \ ( 5. 1 ) \\ & \quad \ w w w w a n n 2 \, \quad K _ { 0. a. i } + K _ { 1. a. i } \rho + K _ { 2. a. i } \rho ^ { 2 } \quad \ \. \quad \. \quad \. \quad \ w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w h w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w k w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w w x x y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y z y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y yy y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y x y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y y z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z zz z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z Z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z zgz z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z cz z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z z | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 100 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 \ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0$$
De denominator 1 -Lρ is required to capture the HT behaviour of the system, as discussed in Section 3. The numerator is a polynomial of first or second degree. The constants K ′ 0 ,g,j and K 0 ,g,j (which will turn out to be the same) follow from the requirement that (5.1) and (5.2) should result in the same mean delay for ρ = 0 as the LT limit (4.15). We find K ′ 1 ,g,j and K 2 ,g,j by imposing that the HT limit of the approximation is equal to the HT limit of the exact mean delay. Finally, the constant K 1 ,g,j is found by adding the requirement that also the derivative with respect to ρ , taken at ρ = 0, of our approximation is equal to the derivative of the LT limit. A more formal definition of these requirements is presented below:
$$\mathbb { E } [ W _ { g, j } ^ { a p p 2 } ] & = \frac { \stackrel { \ell } { r } } { 1 - L \rho } + K _ { 0, g, j } + K _ { 1, g, j } \rho + K _ { 2, g, j } \rho ^ { 2 } } { 1 - L \rho }, \quad \ g = 1, \dots, M ; j = 1, \dots, N _ { g }. \quad \ ( 5. 2 ) \\ \text{De denominator } 1 - L o \text{ is required to continue the HT behavior of the system as dismissed}$$
$$\mathbb { E } [ W _ { g, j } ^ { a p p 1 } ] | _ { \rho = 0 } & = \mathbb { E } [ W _ { g, j } ^ { L T } ] | _ { \rho = 0 }, \\ \lim _ { \rho \uparrow 1 / L } ( 1 - L \rho ) \mathbb { E } [ W _ { g, j } ^ { a p p 1 } ] & = \lim _ { \rho \rightarrow 1 / L } ( 1 - L \rho ) \mathbb { E } [ W _ { g, j } ],$$
and for approximation (5.2),
$$\text{imation (5.2)}, \\ \mathbb { E } [ W _ { g, j } ^ { a p p 2 } ] | _ { \rho = 0 } &$$
using (4.12) for E [ W LT g,j ] and (3.5) for lim ρ → 1 /L (1 -Lρ ) E [ W g,j ]. This leads to the following constants:
$$K _ { 0, g, j } ^ { \prime } = \frac { R } { 2 } + \mathbb { E } [ B _ { g, j } ], \quad \$$
$$\mathfrak { R } _ { 0, g, j } & = \frac { } { 2 } + \mathbb { E } _ { \{ } \mathfrak { B }$$
$$K _ { 0, g, j } = \frac { R } { 2 } + \mathbb { E } [ B _ { g, j } ], \quad \quad \quad$$
glyph[negationslash]
$$+ \, \frac { 1 } { 2 } ( 1 - L + \hat { \rho } _ { g, j } - 2 \hat { \rho } _ { g, \$$
$$\mathfrak { A } _ { 0, g, j } & = \frac { } { 2 } + \mathbb { E } _ { [ D _ { g, j } ] }, & \log \log \\ K _ { 1, g, j } &$$
$$& + \frac { } { 2 } \left ( 1 - L + \rho _ { g, j } - 2 \rho _ { g, \bullet } \right ) \mathcal { N }, \\ K _ { 2, g, j } & =$$
where δ = ∑ M g =1 ˆ ρ g, 1 L (1 -ˆ ρ g, 1 L ) / 2, and σ 2 = ∑ M g =1 ˆ λ g, 1 ( V ar[ B g, 1 ] + ˆ ρ 2 g, 1 V ar[ ˆ A g, 1 ] ) . In the above expressions, we have assumed that the all-red times are deterministic, as is usually the case. Sections 3 and 4 give insight in how to adapt these constants if randomness is involved in (some of) the all-red times.
An obvious question that arises now, is which of the two approximations, (5.1) or (5.2), should be preferred. We can give some (heuristic) arguments, obtained by studying many numerical examples. It can be shown that the two approximations, (5.1) or (5.2), are both exact for the limiting cases ρ → 0, ρ → 1 /L and E [ R ] →∞ . The difference between the two interpolation functions, respectively having a first and second order polynomial in the numerator, is the additional requirement that the derivative in ρ = 0 of the approximated mean waiting time should be equal to the derivative of the LT expression (4.15). Since the LT expression is very accurate, using this additional information generally leads to more accurate approximations. For this reason, (5.2) should be preferred in most practical cases. However, there are some circumstances under which (5.1) should be preferred, despite resulting in a derivative at ρ = 0 which is not exact. In more detail, if the actual delay displays a strong non-linear behaviour for small loads, using the second-order interpolation leads to bigger inaccuracies for loads around Lρ = 0 7. . In most cases, this happens if the derivative in ρ = 0 is very small, or even negative (see also Figure 4(a)). Studying the LT expression (4.15) shows that the most natural way for a negative derivative to appear, is when the combined load in all other groups is smaller than the load of the other flows within the group. In terms of the model parameters: if, for a certain flow { g, i } , the criterion glyph[negationslash]
$$\sum _ { m \neq g } \hat { \rho } _ { m, \bullet } - \sum _ { j \neq i } \hat { \rho } _ { g, j } < 0, \quad \quad \quad$$
glyph[negationslash]
is satisfied, the first-order interpolation (5.1) is preferred over the second-order interpolation (5.2). Note that this is just a rule of thumb. We show the effect of choosing the wrong interpolation at the end of Example 2 in the next section.
Remark 5.1 Anegative slope at ρ = 0 is possible because of the assumption that the delay of vehicles approaching an empty flow during a green period experience no delay at all. Under some circumstances, mostly when Condition 5.8 is satisfied, an increase in traffic may be beneficial for certain flows that hardly receive any traffic at all. The increase in traffic results in an increase of the mean green period, which results in a larger number of vehicles that benefit from the green light while their flow is empty. This might have a positive effect on the mean delay for vehicles in this flow, although the effect disappears when the load increases further.
## 6 Numerical results
In the present section, we study typical features of the approximations and assess their accuracies. In Example 1 we do this by taking an imaginary intersection and simulating several scenarios. For each scenario we compare the simulated delays to the approximated delays. In Example 2 we take three real, existing intersections.
## Example 1: Accuracy of the approximations
In this example, we analyse an (imaginary) intersection with 6 traffic flows. The ratios of the arrival rates of the six flows are 1 : 2 : 3 : 4 : 5 : 6. The discharge rates are all equal, 1800 vehicles per hour, hence E [ B i ] = 2 seconds. For now, we assume that the SCV of the departure headways is 1. In our simulation we have used exponentially distributed random variables to achieve this. We will have a short discussion at the end of this example about other probability distributions. Note that ˆ ρ i = i 21 , because the mean headways are all equal. The total all-red time R in a cycle is 12 seconds, divided equally among the individual all-red times. We compare several different scenarios to get insight into the accuracy of the approximations. The first seven scenarios, shown in Table 1, differ in the choice of which flows to combine in one group. For each scenario, the mean delays for all queues have been obtained by simulation, and are being compared to the approximated mean delays (5.1) or (5.2), using Criterion (5.8) to decide which of the two interpolations is used. The mean delay of each queue, in each scenario, is obtained for 11 different loads: Lρ = { 0 001 0 1 0 2 . , . , . , . . . , 0 8 . , 0 9 . , 0 99 . } . Note that it is convenient to use Lρ instead of ρ , because Lρ takes values between 0 and 1. Furthermore, Lρ can be interpreted as the level of saturation of the intersection. By comparing all approximated mean delays to the corresponding simulated values, the relative errors are calculated:
$$\text{alculated} \colon \\ e _ { i } ( L \rho ) = \left | \frac { W _ { i } ^ { a p p } - W _ { i } ^ { s i m } } { W _ { i } ^ {$$
In order to compare the scenarios, we introduce two quality measures. The first quality measure, QM1 , which gives insight in the worst performance, is the largest relative error (and the corresponding queue, and the load at which this error is obtained). The second quality measure, QM2 , which provides a better insight in the overall performance, is the weighted mean relative error. This is computed by averaging the 11 relative errors for each flow, e i , and subsequently taking the weighted average proportional to the arrival rates. In more detail:
$$Q M 1 & = \max _ { i, L \rho } e _ { i } ( L \rho ), \\ Q M 2 & = \sum _ { i = 1 } ^ { 6 } \frac { \hat { \lambda } _ { i } }$$
Table 1 displays these two quality measures for scenarios I -VII .
We discuss the scenarios I -VII first, later we add some extra scenarios. Scenario I divides the six signals into six separate groups. This reduces the model to an ordinary polling model with exhaustive service and Poisson arrivals. Exact results are known for this model, and the approximation developed in the present paper simplifies to the expression found in [4]. In [4], this approximation is discovered to perform very well, especially for systems with more than two queues. Therefore, it is no surprise that scenario I results in the best approximation accuracy: an average mean error of only 0.06%, and the worst relative error, 0.3%, is obtained for flow 1 (with the smallest load) at Lρ = 0 7. The next scenario, Scenario . II , has the lowest accuracy, illustrating the greatest drawbacks of the approximation. The six flows are divided into three groups. The reason why this scenario performs so poorly, is that the flows in each
| Scenario | Groups | cv 2 A i | cv 2 B | Interpolation | QM1 | QM1 | QM1 | QM2 |
|------------|-----------------------------------------------|------------|----------|-----------------|-------|-------|-------|-------|
| | | | | orders | error | flow | Lρ | |
| I | { 1 } , { 2 } , { 3 } , { 4 } , { 5 } , { 6 } | 1 | 1 | 2 2 2 2 2 2 | 0.3% | 1 | 0.7 | 0.06% |
| II | { 1 , 2 } , { 3 , 4 } , { 5 , 6 } | 1 | 1 | 2 2 2 2 2 2 | 21.9% | 6 | 0.9 | 8.17% |
| III | { 1 , 4 } , { 2 , 5 } , { 3 , 6 } | 1 | 1 | 2 2 2 2 2 2 | 4.4% | 6 | 0.7 | 1.29% |
| IV | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 1 | 1 | 2 2 2 2 2 2 | 10.3% | 5 | 0.9 | 3.29% |
| V | { 1 , 2 , 3 } , { 4 , 5 , 6 } | 1 | 1 | 2 2 2 1 1 1 | 12.3% | 6 | 0.9 | 4.14% |
| VI | { 1 , 2 , 5 } , { 3 , 4 , 6 } | 1 | 1 | 2 2 1 1 2 2 | 11.8% | 6 | 0.7 | 3.79% |
| VII | 1 , 3 , 5 , 2 , 4 , 6 | 1 | 1 | 2 1 2 2 2 2 | 9.5% | 6 | 0.7 | 3.22% |
{
} {
}
Table 1: Scenarios I -VII used in Example 1, and the corresponding quality measures QM1 and QM2 .
group have rather similar loads. When the HT limit is reached, the system behaviour is such that the heaviest loaded flows dominate the groups and determine the lengths of the green periods. As a result, the approximation converges to the HT limit only very slowly. For Lρ = 0 9 the relative errors . e i are approximately 21% for all flows, whereas the errors are back to 7% for Lρ = 0 99. . The overall mean relative error of 8.17% is reasonable, but in the range 0 8 . ≤ Lρ ≤ 0 97 all relative errors are greater than 15%. . We will have some further discussion on this issue later in this paper. In Scenario III , the flows are also divided into three groups, but now the best possible choice (for our approximation) is made, avoiding groups with two flows having similar loads. Therefore, the results are excellent now, with QM1 = 4 4% and . QM2 = 1 29%. Scenario . IV might be the most interesting from a practical point of view, combining good and bad combinations of flows in the groups. As expected, the performance is better than Scenario II , and worse than Scenario III , with QM1 = 10 3% and . QM2 = 3 29%. Because there is one group (with flows 3 and 4) having loads relatively close . to each other, the relative errors are relatively large for Lρ = 0 9, ranging from 7 5% . . -10%, but since the other groups have better combinations of flows, the results are much better than for Scenario II . We will return to Scenario IV later in this section, when we vary several other parameters of the model.
glyph[negationslash]
Now, we discuss Scenarios V VII -briefly. These scenarios have only two groups, each containing three flows. Scenario V can be compared to Scenario II , having the worst possible division into groups. An interesting aspect of this scenario, is that the mean delays of all flows in group 1 are approximated using the second-order approximation (5.2), whereas the mean delays in group 2 use the first-order approximation (5.1). The reason to do this, is that the Criterion (5.8) is satisfied for the flows in group 2, because this group contains the three heaviest loaded flows of the intersection. This implies that the total relative load of group 1, ˆ ρ 1 , · , is much smaller than the relative load of any pair of flows in group 2, ∑ j = i ˆ ρ 2 ,j , for i = 1 2 3. , , Since Criterion (5.8) is satisfied, second order interpolations would severely underestimate the mean delays in group 2. In fact, if one would take (5.2) instead of (5.1) for group 2, the mean relative error for flows in this group would be increased from 4 07% to . 15 9%. . Figure 5 shows the approximated and simulated mean delays for flow 1 (typical for group 1) and for flow 6 (typical for group 2) against Lρ . It can be seen that the derivative in Lρ = 0 of the approximated mean delay for flow 1 is not correct (it is slightly greater than the actual value), but it does lead to an overall better accuracy. In Scenarios VI and VII ,
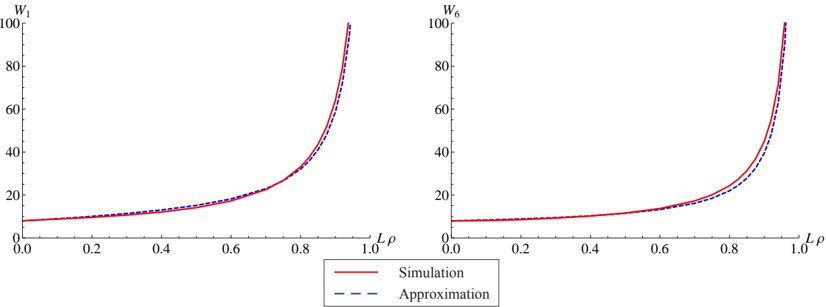
0
0.0
0.2
0.4
0.6
0.8
1.0
L
Figure 5: Simulated and approximated mean delays for flow 1 (left) and flow 6 (right) in Scenario V.
the division into groups is better, resulting in more favourable results.
Scenarios I -VII illustrate how the accuracy of the approximation depends on the distribution of the loads among the groups. Numerical experiments indicate that this is the biggest source of variation in the accuracy. For completeness, we show the effects of different interarrivaltime distributions, and different distributions of the departure headways in Scenario IV . In our simulations we have fitted phase-type distributions, as suggested in [32], matching the specified SCVs. We can be brief in discussing the results, displayed in Table 2. The variation in the interarrival times and headways does not have a major impact on the accuracy of the approximation, but in general it can be concluded that an increase (decrease) in variation results in a decrease (increase) in the accuracy.
| Scenario | Groups | cv 2 A i | cv 2 B | QM1 | QM1 | QM1 | QM2 |
|------------|-----------------------------------|------------|----------|-------|-------|-------|--------|
| | | | | error | flow | Lρ | |
| IV | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 1 | 1 | 10.3% | 5 | 0.9 | 3.29% |
| VIII | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 0.5 | 1 | 7.8% | 5 | 0.9 | 1.91 % |
| IX | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 2 | 1 | 14.7% | 5 | 0.9 | 5.70% |
| X | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 1 | 0 | 5.6% | 4 | 0.9 | 1.57% |
| XI | { 1 , 6 } , { 2 , 5 } , { 3 , 4 } | 1 | 0.5 | 8.2% | 5 | 0.9 | 2.50% |
| XII | 1 , 6 , 2 , 5 , 3 , 4 | 1 | 2 | 13.1% | 5 | 0.9 | 4.45% |
{
} {
} {
}
Table 2: Scenarios IV , VIII -XII used in Example 1, and the corresponding quality measures QM1 and QM2 .
## Example 2: Real-life examples
In the present subsection we test the approximation on three real-life situations. We take three intersections, graphically displayed in Figure 6, and compare approximated mean delays with the simulated values. The first two intersections are located in Eindhoven, The Netherlands,
Figure 6: The intersections discussed in Example 2.
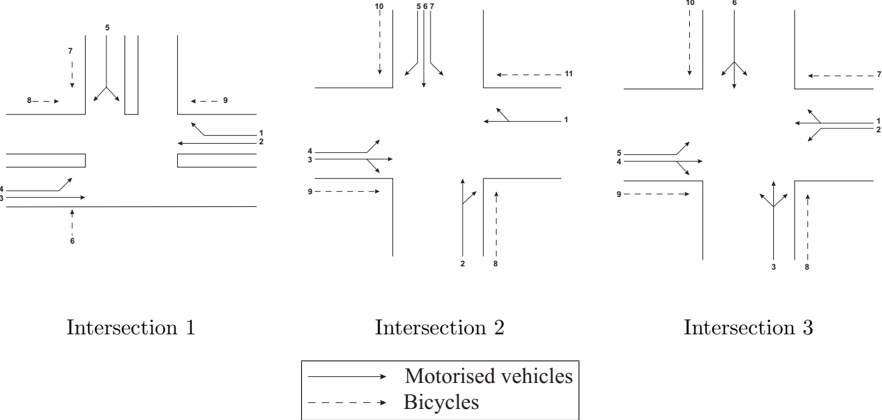
and data have been obtained from the local city council. The data for the third intersection are taken from the Dutch manual for configuration of traffic intersections [8]. Each of these intersections contains several flows for motorised vehicles, and four bicycle lanes. The exact settings for each intersection can be found in Appendix B. Table 3 shows the numerical results of the approximated and simulated delays for the three different intersections. For
Table 3: Performance measures QM1 and QM2 for the intersections in Section 6, Example 2.
| Intersection | QM1 | QM1 | QM1 | QM2 |
|----------------|-------|-------|-------|--------|
| Intersection | error | flow | Lρ | |
| 1 | 21.3% | 2 | 0.99 | 6.60% |
| 2 | 13.6% | 6 | 0.9 | 4.65 % |
| 3 | 30.4% | 4 | 0.9 | 11.62% |
all of the intersections, but especially for Intersections 1 and 2, the overall accuracy is quite good, considering the overall mean relative error percentage QM2 . But at the same time, one of the drawbacks becomes apparent. In practice, these intersections have maximum green times, which are chosen such that the cycle time cannot exceed a specified value. In order to minimise the maximum cycle time, flows are generally divided into groups such that the busiest streams are put together in the same group, as long as no conflicts arise. As discussed in the first example, our approximation gives very accurate results, as long the loads of the busiest flows in a group are not too close to each other. However, some of these examples have at least one group with two busy flows with similar relative loads. In Intersection 1, in group 4, we have ˆ ρ 4 1 , = 0 12 and ˆ . ρ 4 2 , = 0 11. In Intersection 3, the highest two relative loads . in group 3 are ˆ ρ 3 1 , = 0 15 and ˆ . ρ 3 2 , = 0 14. This means that the mean waiting time converges .
to its HT limit (3.5) only very slowly. This explains that for these two intersections, the approximation gives rather high relative errors (sometimes more than 20%) for high loads ( Lρ = 0 9 . , . . . , 0 98). .
We end this example with a final note on the accuracy of the approximations (5.1) and (5.2). As stated before, the second-order interpolation (5.2) generally gives better results, unless Criterion (5.8) is satisfied. In Figure 7(a) the mean simulated delay for flow 8 of Intersection 2 is plotted, as well as the approximations (5.1) and (5.2). We have chosen this particular example, because in Intersection 2 none of the flows satisfy Criterion (5.8), and no group contains more than one flow with a very high flow ratio. In this situation there is no need to use the first-order interpolation, because it only gives worse results, as can be seen in Figure 7(a). Figure 7(b) shows the scaled mean delay (1 -Lρ W ) i , also for the simulated delay and the two approximations. Clearly, the first-order interpolation should not be used here. For flow 3 in Intersection 1, Criterion (5.8) is satisfied. In Figure 7(c) and 7(d) we see that the non-linearity for small values of Lρ results in an underestimation of the actual delay by the second-order interpolation. The first-order interpolation is more suitable here. Finally, Figures 7(e) and 7(f) show why it is sometimes impossible to find a simple polynomial that describes the behaviour of the scaled delay well. These figures, taken from Intersection 3, show that the HT limit is reached only extremely late ( Lρ > 0 99) for . flow 2. In fact, for Lρ = 0 99 there is still . a gap between the simulated value and the HT limit. Due to the fact that the HT limit is being approached so slowly, the approximations are not very accurate in the range 0 8 . < Lρ < 0 99, . with relative errors greater than 20% for all flows. Neither the first-order interpolation, nor the second-order interpolation is complex enough to describe the behaviour of (1 -Lρ W ) i . These pictures also indicate that a fitting function more sophisticated that a first or second order polynomial is required if one wants to obtain a more accurate closed-form approximation.
## Example 3: The impact of the stay-empty assumption
glyph[negationslash]
Throughout the paper we have assumed that vehicles arriving during a green period while their flow is already empty, experience no delay at all because they do not have to accelerate and cross the intersection at normal speed. This assumption, which we refer to as the 'stayempty assumption', has been made because it makes the model more realistic than a standard queueing model with queues emptying and possibly refilling during the same green period. In this example we study the impact of this assumption by comparing delays found in the previous example to delays of vehicles in the same intersections, but assuming that queues do not stay empty. Before we carry out the numerical analysis, we discuss the model with refilling queues in more detail. The derivation of the LT limit (4.15) uses the stay-empty assumption only in Equation (4.6). The LT limit of the model with refilling queues is obtained by replacing (4.6) with E [ W ( G g,l ) g,j ] = E [ B g,j ] + O ( ρ ) for l = j . This would, by the way, slightly simplify the LT limit (4.15) and, hence, also simplify the second-order interpolation (5.2). Another interesting observation is that the distributions of the scaled delays under HT conditions do not change at all. Without providing a rigorous proof here, we argue that the HT fluid limits remain exactly the same if the stay-empty assumption is abandoned. Consequently, the stability condition ∑ M g =1 ρ g, 1 < 1 does not change, which can also be proven by making minor modifications to the proof in Appendix A. Note that the first-order interpolation for the stay-empty model is exactly the same as for the model with refilling queues. This means that
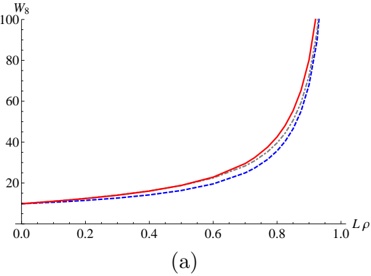
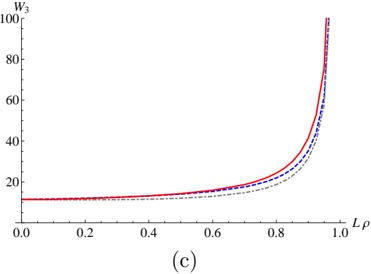
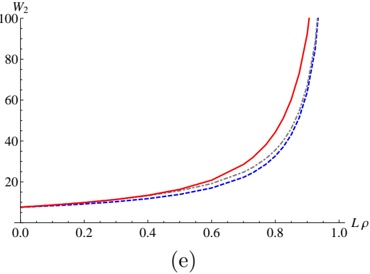
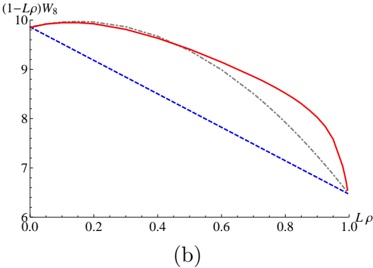
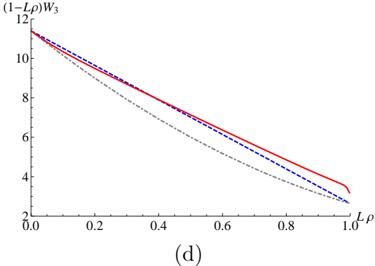
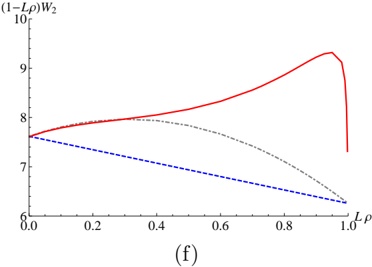
7.5
7.0
6.5
6.0

0.2
0.4
0.6
0.8
1.0
L
Figure 7: Three plots of mean waiting times W i and scaled mean waiting times (1 -Lρ W ) i , taken from Example 2 in Section 6. Figures (a) and (b) correspond to flow 8 of Intersection 2. Figures (c) and (d) correspond to flow 3 of Intersection 1. Figures (e) and (f) correspond to flow 2 of Intersection 3.
the stay-empty assumption, perhaps surprisingly, does not have much impact at all on the simulated and the approximated mean delays. We show one example of how close the mean delays for the two different models are. In Figure 8 we study the mean delays of vehicles in flow 3 of Intersection 1 again, just like in Figure 7(c). In Figure 8 the mean delays are plotted against Lρ for the model with and without the stay-empty assumption. As a reference, the approximated mean values are also shown in the same figure. Since we used a first-order interpolation for this example, the approximations for the model with and without the stayempty assumption are the same. The relative difference between the simulated values for the two models is at most 7%, for Lρ = 0 98. . Summarising, the approximation for the mean delay can be used for models with and without the stay-empty assumption, although it is recommended to adapt the LT limit slightly as stated before. However, one should keep in mind that scaled mean delay for the model with refilling queues converges to the HT limit slower than for the model with flows that stay empty.
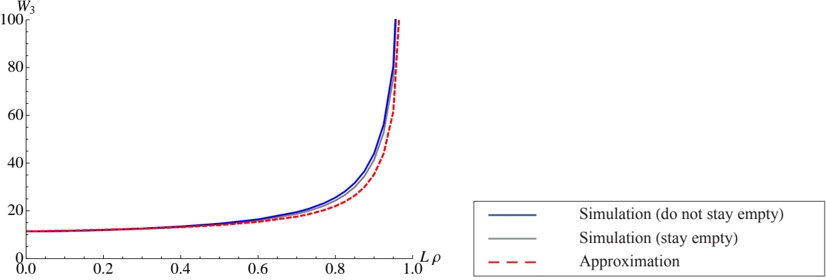
0.0 .2 4 6 8 0
0 ....
001
Figure 8: The mean delays for flow 3 of Intersection 1, for the model with and without the stay-empty assumption, compared to the approximated mean delay.
## 7 Conclusions and topics for future research
Under LT and HT conditions, we managed to accurately describe the behaviour of delay of vehicles approaching a traffic intersection with an exhaustive control policy. Based on these limiting situations, mean delay approximations have been established for any workload. These approximations are easy to implement, and have been tested on real-life situations. The performance of the approximations is good, except when the two greatest flow ratios within a group are very close.
Several extensions of the model considered in the present paper are interesting to study.
- · In order to build a better model for intersections that are part of an arterial system, it would be interesting to allow correlated batch arrivals: groups of vehicles arriving simultaneously. The studies by Levy and Sidi [21] and Van der Mei [35] on polling systems with correlated batch arrivals might prove useful in this respect.
- · Furthermore, using results on polling systems with priorities (see, e.g., [1, 2]), one could also analyse conflicting flows receiving a green light simultaneously. The conflicting
flows should be placed in the same lane group and by assigning priority levels to each of the conflicting flows, the right of way rules can be implemented. Only minor adaptations to the LT and HT limits are required to introduce the priority levels.
- · It may also be possible to extend the distributional approximations for polling systems developed by Dorsman et al. [13] to traffic intersections. The two required ingredients of such a distributional approximation are both derived in the present paper. That is, we need an HT approximation for the waiting-time distribution (as derived in Section 3) in conjunction with a mean waiting-time approximation for general load (as obtained in Section 5). Subsequently, the HT distributional approximation should be refined such that its mean coincides with the mean waiting-time approximation, while the resulting distributional approximation keeps the correct limiting behavior in HT after refinement.
- · From a practical point of view, it would be desirable to have a model that allows flows to be part of multiple groups, instead of just one. However, this would complicate the analysis considerably at some points, because it is not straightforward anymore to determine which flows are dominant in each group.
- · Finally, possibly the greatest challenge, is the analysis of intersections with time-limited service. Although these are by far the most commonly used intersections in practice, hardly any detailed results are known to reliably estimate the expected delays.
## Acknowledgements
The authors wish to thank Onno Boxma for valuable discussions and for useful comments on earlier drafts of the present paper.
## Appendix
## A Proof of stability
In this appendix, we provide a rigorous proof of Theorem 2.1. This theorem states that the stability condition of an intersection with exhaustive traffic control only depends on the flow ratios of the dominant flows in each group.
## A.1 Model
For each flow { g, j } , g = 1 , . . . , M and j = 1 , . . . , N g , there is an i.i.d. sequence of interarrival times { A g,j,k } and an i.i.d. sequence of headways { B g,j,k } . All sequences are mutually independent. We assume that each sequence has a finite first moment and define the appropriate rates:
$$\lambda _ { g, j } \ & = \ 1 / \mathbb { E } [ A _ { g, j, 1 } ], \\ \mu _ { g, j } \ & = \ 1 / \mathbb { E } [ B _ { g, j, 1 } ].$$
We assume that the interarrival time distribution is unbounded and spread-out, in other words P ( A g,j, 1 > T ) > 0 for all T > 0, and for some integer glyph[lscript] ,
$$\mathbb { P } ( A _ { g, j, 1 } + \dots + A _ { g, j, \ell } \in \mathrm d x ) \geq q ( x ) \mathrm d x$$
where
$$\int _ { 0 } ^ { \infty } q ( x ) \, \mathrm d x & > 0. \\ \tilde { \ }. \quad \tilde { \ }. \quad \tilde { \ }. \quad \tilde { \ }.$$
The control policy is to allow flows { 1 1 , } , . . . , { 1 , N 1 } to operate until all of them are empty, then allow flows { 2 1 , } , . . . , { 2 , N 2 } to operate until they are all empty and so on, until flows { M, 1 } , . . . , { M,N M } have operated. Then, this cycle is repeated. We assume that when switching for the m th time from group 1 to group 2, there is an all-red period of R 1 ,m . In general, for the m th switch from group g to group g +1 (all group indices are modulo M ), the all-red time is given by R g,m . We assume that for g = 1 , . . . , M , { R g,m } are i.i.d. sequences with E [ R g, 1 ] < ∞ .
Let E g,j ( ) be the number of vehicles arriving to flow t { g, j } in (0 , t ]. Let S g,j ( ) be the t potential number of service completions by flow { g, j } in (0 , t ], i.e. S g,j ( ) is the number of vehicles that t would have departed from flow { g, j } between times 0 and t if there were no idling of server { g, j } . Let A res g,j ( ) be the residual interarrival time at time t t for stream { g, j } and let B res g,j ( ) t be the residual headway of the vehicle crossing at flow { g, j } . We assume that A res g,j ( ) t and B res g,j ( ) are right continuous. t Thus we have
$$E _ { g, j } ( t ) \ = \ \max \{ n \geq 0 \, \colon A _ { g, j } ^ { r e s } ( 0 ) + A _ { g, j, 1 } + \dots + A _ { g, j, n - 1 } \leq t \},$$
$$S _ { g, j } ( t ) \ = \ \max \{ n \geq 0 \, \colon B _ { g, j } ^ { r e s } ( 0 ) + B _ { g, j, 1 } + \dots + B _ { g, j, n - 1 } \leq t \}.$$
$$& = \max \{ n \geq 0 \, \colon A _ { g, j } ^ { r e s } ( 0 ) + A _ { g, j, 1 } + \dots + A _ { g, j, n - 1 } \leq t \}, \\ & = \max \{ n \geq 0 \, \colon B _ { g, j } ^ { r e s } ( 0 ) + B _ { g, j, 1 } + \dots + B _ { g, j, n - 1 } \leq t \}.$$
where the maximum of an empty set is defined to be zero. Let T g,j ( ) be the cumulative busy t time for server { g, j } in (0 , t ]. Then the number at server { g, j } , Q g,j ( ) at time t t , is
$$Q _ { g, j } ( t ) & = Q _ { g, j } ( 0 ) + E _ { g, j } ( t ) - S _ { g, j } ( T _ { g, j } ( t ) ), & ( \text{A.1} )$$
where T g,j ( ) is determined by the control policy. t Define
$$X ( t ) = ( Q _ { g, j } ( t ), A _ { g, j } ( t ), B _ { g, j } ( t ), I ( t ) \, \colon g = 1, \dots, M, \ j = 1, \dots, N _ { g } ),$$
where I ( ) is the group number (1 t , . . . , M ) that receives a green light at time t (it can be set to an arbitrary value during the all-red times). Then it is not difficult to see that X = { X t ( ) } is a Markov process and has the strong Markov property. The assumption that the interarrival time distribution is unbounded and spread-out allows us to conclude that the states where Q g,j ( ) t = 0 are reachable and to show the existence of a continuous component for X , see Meyn and Down [22].
## A.2 Stability of fluid models
Let q = ∑ M g =1 ∑ N g j =1 Q g,j (0). Suppose that the function ( ¯ Q g,j ( ) · , T ¯ g,j ( ) · : g = 1 , . . . , M, j = 1 , . . . , N g ) is a limit point of
$$( q ^ { - 1 } Q _ { g, j } ( q t ), q ^ { - 1 } T _ { g, j } ( q t ) \colon g = 1, \dots, M, \, j = 1, \dots, N _ { g } ),$$
when q → ∞ . When it exists ( ¯ Q g,j ( ) t , T ¯ g,j ( ) t : g = 1 , . . . , M, j = 1 , . . . , N g ) is called a fluid limit of the system. Since we have been able to describe the system dynamics in the form (A.1), Dai [10, Theorem 2.3.2] yields that a fluid limit exists (it may not be unique). Furthermore, each of the fluid limits is a solution of the following set of conditions, known as the fluid model .
$$\bar { Q } _ { a. i } ( t ) \ = \ \bar { Q } _ { a. i } ( 0 ) + \lambda _ { a. i } ( t ) - \mu _ { a. i } \bar { T } _ { a. i } ( t )$$
$$\bar { T } _ { g, j } ( \cdot ) & \text{ is non-decreasing} \\. &. &. &. &.$$
$$\begin{array} { r c l } \bar { Q } _ { g, j } ( t ) & = & \bar { Q } _ { g, j } ( 0 ) + \lambda _ { g, j } ( t ) - \mu _ { g, j } \bar { T } _ { g, j } ( t ) \\ \bar { Q } _ { g, j } ( t ) & \geq & 0 \\ \bar { T } _ { g, j } ( 0 ) & = & 0 \text{ and } \bar { T } _ { g, j } ( \cdot ) \text{ is non-decreasing} \\ \end{array}$$
plus additional conditions on ¯ T g,j ( ) · due to the control policy. This last condition is usually the most important, even though it is vague at this point.
glyph[negationslash]
The connections between the Markov process and the fluid model are as follows: if the fluid model is stable, there exists a unique invariant probability for X (Theorem 4.2 of Dai [9]). If the fluid model is unstable, then X is transient (Theorem 2.5.1 of Dai [10]). If one is interested in finiteness of moments, then under corresponding assumptions on the underlying random variables, stability of the fluid model yields finiteness of moments, see Dai and Meyn [11]. For example, assuming finite second moments on the underlying random variables, stability of the fluid model implies the existence of an invariant probability and finite mean queue lengths.
The fluid model is said to be stable if there exists a fixed time t 0 such that ∑ M g =1 ∑ N g j =1 ¯ Q g,j ( ) = t 0, for all t ≥ t 0 , for any solution of the fluid model. The fluid model is said to be unstable if for every solution of the fluid model with ∑ M g =1 ∑ N g j =1 ¯ Q g,j (0) = 0, there exists a δ > 0 such that ∑ M g =1 ∑ N g j =1 ¯ Q g,j ( δ ) = 0. Thus, stability of the fluid model states that eventually all flows will drain, and once drained, they remain empty.
For the model under consideration, let ρ g,j = λ g,j /µ g,j and assume without loss of generality that ρ g, 1 > ρ g, 2 > · · · > ρ g,N g for all g = 1 , . . . , M . Then we have the following result.
(ii) If ∑ M g =1 ρ g, 1 > 1, then the fluid model is unstable and X is transient.
Proposition A.1 (i) If ∑ M g =1 ρ g, 1 < 1, the fluid model is stable and, thus, an invariant probability ϕ exists for X .
## Proof:
(i) First, we show that the all-red periods can be ignored in the stability analysis. Suppose that at time 0, group g has just completed and group g ′ = ( g +1) mod M +1 begins service, where g ′ is such that ¯ Q g ,j ′ (0) > 0 for some j ∈ { 1 , . . . , N g ′ } . We then have that there exists δ > 0 such that ¯ Q g ,j ′ ( s ) > 0 for s ∈ [0 , δ ]. In this case, we have
$$> 0 & \text{ for } s \in [ 0, \delta ]. \text{ in this case, we have } \\ & \lim _ { q \to \infty } \frac { T _ { g, j } ( \delta q ) } { q } \\ & = \lim _ { q \to \infty } \frac { \max ( \delta q - R _ { g }, 0 ) } { q } \\ & = \lim _ { q \to \infty } \left ( \max \left ( \delta - \frac { R _ { g } } { q }, 0 \right ) \right ) \\ & = \delta \\. & ( t ) | _ { \varepsilon = 0 } = 1 \text{ and thus without loss of gener}$$
from which we have d dt ¯ T g,j ( ) t | t =0 = 1 and thus without loss of generality we can assume that the all-red times are zero.
Next, we show that if we are serving group g at time t and ¯ Q g,j ( ) = 0 for all t j ∈ { 1 , . . . , N g } , then for any fluid limit, we immediately switch to a new group (unless for all g, j , ¯ Q g,j ( ) = 0). t Note that for group g , queues 1 , . . . , N g operate as N g stable queues in parallel (until all queues are simultaneously empty), which is a special case of a stable generalized Jackson network (as ρ g,j < 1 for all j ). Denote by T ( n ,...,n 1 Ng ) 0 the time to reach the state when all queues are empty, starting from the initial condition is that there are n i jobs at queue i . Theorem 3.8 of [22] implies that all queues being empty is reachable and as
$$\frac { Q _ { g, j } ( q t ) } { q } \rightarrow 0,$$
then
$$0, \\ \frac {, _ { N _ { g } } ( q t ) ) } { } \rightarrow 0$$
$$\frac { T _ { 0 } ^ { ( Q _ { g, 1 } ( q t ), Q _ { g, 2 } ( q t ), \dots, Q _ { g, N _ { g } } ( q t ) ) } } { q } \to 0$$
and thus on the fluid scale, switching away from group g is immediate when all of the queues are empty (on the fluid scale).
Next, we show that from an arbitrary initial condition for the fluid model (i.e. ¯ Q g,j (0) = x g,j ≥ 0) and with the server initially at group 1, we have that group i is switched away from for the first time at time t i , where t i is given by:
$$\text{$num\,occur\,memory\,\omega$ group $1$, we move down group $2$ as otherwise} \text{$ne at time $t_{i}$, where $t_{i}$ is given by} \text{:} \\ t _ { 1 } \ \ = \ \max _ { 1 \leq j \leq N _ { 1 } } \left \{ \frac { x _ { 1, j } } { \mu _ { 1, j } - \lambda _ { 1, j } } \right \} \\ t _ { 2 } \ \ = \ \ t _ { 1 } + \max _ { 1 \leq j \leq N _ { 2 } } \left \{ \frac { x _ { 2, j } + \lambda _ { 2, j } t _ { 1 } } { \mu _ { 2, j } - \lambda _ { 2, j } } \right \} \\ \vdots \\ t _ { M } \ \ = \ \ t _ { M - 1 } + \max _ { 1 \leq j \leq N _ { M } } \left \{ \frac { x _ { M, j } + \lambda _ { M, j } t _ { M - 1 } } { \mu _ { M, j } - \lambda _ { M, j } } \right \}. \\ \slash \mu _ { g, j } < 1 \text{ for all $g,j$, then $t_{M} < \infty$. However, at this point, by} \text{.}$$
Clearly, if λ g,j /µ g,j < 1 for all g, j , then t M < ∞ . However, at this point, by definition, it is clear that for t ≥ t M ,
$$\frac { \bar { Q } _ { g, 1 } ( t ) } { \mu _ { g, 1 } } \geq \frac { \bar { Q } _ { g, j } ( t ) } { \mu _ { g, j } }$$
for all g and j ∈ { 2 , . . . , N g } .
Now, consider
$$V ( t ) = \sum _ { g = 1 } ^ { M } \frac { \bar { Q } _ { g, 1 } ( t ) } { \mu _ { g, 1 } }. \\ \mu \cdots \colon & \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{array}$$
This completes the proof of (i).
We trivially see that ∑ M g =1 d dt ¯ T g, 1 ( ) = 1 if t V ( ) t > 0, and thus for t ≥ t M and if V ( ) t > 0, using (A.2), d dt V ( ) = t ∑ M g =1 ρ g, 1 -1 < 0. Therefore, there exists a T < ∞ such that V ( ) = 0 t for all t ≥ T and again using (A.2), we conclude that for all g, j ¯ Q g,j ( ) = 0 for all t t ≥ T .
To show (ii), as ∑ M g =1 d dt ¯ T g, 1 ( ) t ≤ 1, we see that d dt V ( ) t ≥ ∑ M g =1 ρ g, 1 -1, which is strictly positive and thus the fluid model is unstable. glyph[square]
## B Input settings for Example 2
In this appendix we give the input settings for the intersections discussed in Section 6, Example 2.
| Intersection 1 | Intersection 1 |
|---------------------------------------------|------------------------------------------------------------------------|
| N | 9 |
| Vehicle types | 5 flows for cars (1 , . . . , 5), 4 flows for bicycles (6 , . . . , 9) |
| Arrival processes | Poisson |
| Arrival intensities (cars/bikes per hour) | 280, 930, 700, 120, 240, 60, 60, 60, 60 |
| Saturation flow rates (cars/bikes per hour) | 1800, 1900, 1900, 1700, 1700, 10000, 10000, 10000, 10000 |
| SCVs of the headways | cv 2 B i = 1 for cars ( i ≤ 5), and cv 2 B i = 0 for bikes ( i ≥ 6) |
| Groups | { 2 , 3 , 8 , 9 } , { 4 } , { 6 , 7 } , { 1 , 5 } |
| All-red times | 2 , 8 , 4 , 5 |
| Intersection 2 | Intersection 2 |
|---------------------------------------------|-------------------------------------------------------------------------|
| N | 11 |
| Vehicle types | 7 flows for cars (1 , . . . , 7), 4 flows for bicycles (8 , . . . , 11) |
| Arrival processes | Poisson |
| Arrival intensities (cars/bikes per hour) | 263, 344, 332, 381, 148, 442, 258, 60, 60, 60, 60 |
| Saturation flow rates (cars/bikes per hour) | 1950, 1950, 1950, 1800, 1700, 1950, 1700, 10000, 10000, 10000, 10000 |
| SCVs of the headways | cv 2 B i = 1 for cars ( i ≤ 7), and cv 2 B i = 0 for bikes ( i ≥ 8) |
| Groups | { 1 , 3 , 9 , 11 } , { 2 , 5 } , { 4 , 8 } , { 6 , 7 , 10 } |
| All-red times | 8 , 1 , 4 , 6 |
| Intersection 3 | Intersection 3 |
|---------------------------------------------|-------------------------------------------------------------------------|
| N | 10 |
| Vehicle types | 6 flows for cars (1 , . . . , 6), 4 flows for bicycles (7 , . . . , 10) |
| Arrival processes | Poisson |
| Arrival intensities (cars/bikes per hour) | 680, 150, 390, 860, 280, 430, 100, 100, 100, 100 |
| Saturation flow rates (cars/bikes per hour) | 1950, 1700, 1850, 1950, 1700, 1850, 10000,10000,10000, 10000 |
| SCVs of the headways | cv 2 B i = 1 for cars ( i ≤ 6), and cv 2 B i = 0 for bikes ( i ≥ 7) |
| Groups | { 1 , 4 , 8 , 10 } , { 2 , 5 } , { 3 , 6 , 7 , 9 } |
| All-red times | 4 , 2 , 5 |
## References
- [1] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A two-queue polling model with two priority levels in the first queue. Discrete Event Dynamic Systems , 20(4):511-536, 2010.
- [2] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A polling model with multiple priority levels. Performance Evaluation , 67:468-484, 2010.
- [3] M. A. A. Boon, R. D. van der Mei, and E. M. M. Winands. Applications of polling systems. Surveys in Operations Research and Management Science , 16:67-82, 2011.
- [4] M. A. A. Boon, E. M. M. Winands, I. J. B. F. Adan, and A. C. C. van Wijk. Closed-form waiting time approximations for polling systems. Performance Evaluation , 68:290-306, 2011.
- [5] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems with zero switchover times: A heavy-traffic averaging principle. The Annals of Applied Probability , 5(3):681-719, 1995.
- [6] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems in heavy-traffic: A Bessel process limit. Mathematics of Operations Research , 23:257-304, 1998.
- [7] J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982.
- [8] CROW. Handboek verkeerslichtenregelingen . Publicatie 213. CROW kenniscentrum voor verkeer, vervoer en infrastructuur, Ede, 2006. ISBN 90 6628 444 7.
- [9] J. G. Dai. On positive Harris recurrence of multiclass queueing networks: a unified queue via fluid limit models. Annals of Applied Probability , 5:49-77, 1995.
- [10] J. G. Dai. Stability of fluid and stochastic processing networks. Miscellanea Publication, No. 9. Centre for Mathematical Physics and Stochastics, Aarhus, Denmark. http://www.maphysto.dk/ , 1999.
- [11] J. G. Dai and S. P. Meyn. Stability and convergence of moments for multiclass queueing networks via fluid models. IEEE Transactions on Automatic Control , 40:1889-1904, 1995.
- [12] J. N. Darroch, G. F. Newell, and R. W. J. Morris. Queues for a vehicle-actuated traffic light. Operations Research , 12(6):882-895, 1964.
- [13] J. L. Dorsman, R. D. van der Mei, and E. M. M. Winands. A new method for deriving waiting-time approximations in polling systems with renewal arrivals. Stochastic Models , 27(2):318-332, 2011.
- [14] S. W. Fuhrmann. Performance analysis of a class of cyclic schedules. Technical memorandum 81-59531-1, Bell Laboratories, March 1981.
- [15] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
| [16] | B. S. Greenberg, R. C. Leachman, and R. W. Wolff. Predicting dispatching delays on a low speed, single track railroad. Transportation Science , 22:31-38, 1988. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [17] | R. Haijema and J. van der Wal. An MDP decomposition approach for traffic control at isolated signalized intersections. Probability in the Engineering and Informational Sciences , 22:587-602, 2007. |
| [18] | D. Heidemann. Queue length and delay distributions at traffic signals. Transportation Research Part B , 28(5):377-389, 1994. |
| [19] | J. P. Lehoczky. Traffic intersection control and zero-switch queues under conditions of Markov chain dependence input. Journal of Applied Probability , 9(2):382-395, 1972. |
| [20] | H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990. |
| [21] | H. Levy and M. Sidi. Polling systems with simultaneous arrivals. IEEE Transactions on Communications , 39:823-827, 1991. |
| [22] | S. P. Meyn and D. Down. Stability of generalized jackson networks. Annals of Applied Probability , 4:124-148, 1994. |
| [23] | A. J. Miller. Settings for fixed-cycle traffic signals. Operational Research Quarterly , 14: 373-386, 1963. |
| [24] | G. F. Newell. Approximation methods for queues with application to the fixed-cycle traffic light. SIAM Review , 7(2):223-240, 1965. |
| [25] | G. F. Newell. Properties of vehicle-actuated signals: I. one-way streets. Transportation Science , 3(2):31-52, 1969. |
| [26] | G. F. Newell. The rolling horizon scheme of traffic signal control. Transportation Research Part A , 32(1):39-44, 1998. |
| [27] | G. F. Newell and E. E. Osuna. Properties of vehicle-actuated signals: II. two-way streets. Transportation Science , 3(2):99-125, 1969. |
| [28] | T. L. Olsen and R. D. van der Mei. Polling systems with periodic server routeing in heavy traffic: distribution of the delay. Journal of Applied Probability , 40:305-326, 2003. |
| [29] | T. L. Olsen and R. D. van der Mei. Polling systems with periodic server routing in heavy traffic: renewal arrivals. Operations Research Letters , 33:17-25, 2005. |
| [30] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409 - 426, 1993. |
| [31] | H. Takagi. Queuing analysis of polling models. ACM Computing Surveys (CSUR) , 20: 5-28, 1988. |
| [32] | H. C. Tijms. Stochastic models: an algorithmic approach . Wiley, Chichester, 1994. |
| [33] | TRB. Highway Capacity Manual 2000 . Transportation Research Board, 2000. |
- [34] M. S. van den Broek, J. S. H. van Leeuwaarden, I. J. B. F. Adan, and O. J. Boxma. Bounds and approximations for the fixed-cycle traffic-light queue. Transportation Science , 40(4):484-496, 2006.
- [35] R. D. van der Mei. Polling systems with simultaneous batch arrivals. Stochastic Models , 17(3):271-292, 2001.
- [36] R. D. van der Mei and E. M. M. Winands. A note on polling models with renewal arrivals and nonzero switch-over times. Operations Research Letters , 36:500-505, 2008.
- [37] J. S. H. van Leeuwaarden. Delay analysis for the fixed-cycle traffic-light queue. Transportation Science , 40(2):189-199, 2006.
- [38] V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006.
- [39] M. Vlasiou and U. Yechiali. M/G/ ∞ polling systems with random visit times. Probability in the Engineering and Informational Sciences , 22:81-106, 2008.
- [40] F. V. Webster. Traffic signal settings. Technical Paper 39, Road Research Laboratory, 1958.
- [41] W. Whitt. An interpolation approximation for the mean workload in a GI/G/ 1 queue. Operations Research , 37(6):936-952, 1989.
- [42] H. Yamashita, Y. Ishizuka, and S. Suzuki. Mean and variance of waiting time and their optimization for alternating traffic control systems. Mathematical Programming , 108 (2-3):419-433, 2006. | 10.1017/S0269964812000058 | [
"Marko Boon",
"Ivo Adan",
"Erik Winands",
"Doug Down"
] | 2014-08-01T11:48:04+00:00 | 2014-08-01T11:48:04+00:00 | [
"math.PR",
"cs.PF"
] | Delays at signalised intersections with exhaustive traffic control | In this paper we study a traffic intersection with vehicle-actuated traffic
signal control. Traffic lights stay green until all lanes within a group are
emptied. Assuming general renewal arrival processes, we derive exact limiting
distributions of the delays under Heavy Traffic (HT) conditions. Furthermore,
we derive the Light Traffic (LT) limit of the mean delays for intersections
with Poisson arrivals, and develop a heuristic adaptation of this limit to
capture the LT behaviour for other interarrival-time distributions. We combine
the LT and HT results to develop closed-form approximations for the mean delays
of vehicles in each lane. These closed-form approximations are quite accurate,
very insightful and simple to implement. |
1408.0139v1 | ## On the possibility of rho-meson condensation in neutron stars
Ritam Mallick ∗ and Stefan Schramm † Frankfurt Institute for Advanced Studies, 60438 Frankfurt am Main, Germany
Veronica Dexheimer ‡
Department of Physics, Kent State University, Kent, Ohio 44242, USA
Abhijit Bhattacharyya §
Department of Physics, University of Calcutta, 700009 Kolkata, India
(Dated: August 4, 2014)
## Abstract
The possibility of meson condensation in stars and in heavy-ion collisions has been discussed in the past. Here, we study whether rho meson condensation ( ρ -) can occur in very dense matter and determine the effect of strong magnetic fields on this condensation. We find that rho meson condensates can appear in the core of the neutron star assuming a rho mass which is reduced due to in-medium effects. We find that the magnetic field has a non-negligible effect in triggering condensation.
PACS numbers: 26.60.Kp, 52.35.Tc, 97.10.Cv
Keywords: dense matter, stars: neutron, stars : magnetic field, equation of state
The study of strongly interacting matter at high densities and/or temperatures is a central topic of modern nuclear physics. From the experimental side the main approaches to learn about matter under these conditions are the study of relativistic heavy-ion collisions (HIC) and observations of neutron stars, where the former approach aims at studying hightemperature and the latter one high-density and low-temperature matter. In addition, the future experiments at GSI/ FAIR with beam energies ≤ 30 GeV per nucleon and the beam energy scan at RHIC aim to study the properties of matter not only at high temperature but also at comparatively high densities.
Increasing the density of the nuclear matter it is expected that the spontaneously broken chiral symmetry, characterized by a large quark condensate, is at least partially restored. However, a clear observable signature of this effect is still not well established. From the theory side, an early conjecture suggested by Brown and Rho [1], argued that hadrons (except for the pseudo-Goldstone bosons like pions) experience a mass reduction in nuclear matter, which is proportional to the in-medium quark condensate. More recent calculations, using QCD sum rules [2], quark-meson models [3] and hadronic models of vacuum polarization [4] also suggest such mass reduction. However, a full understanding of the restoration of chiral symmetry in dense matter remains an open and much-discussed topic.
More direct evidence of a potential mass reduction of vector mesons, the enhancement in the production of low invariant-mass dileptons in heavy-ion collisions has been investigated extensively, following such observations for an invariant mass around 400 -500 MeV, as measured by the CERES experiment at the CERN-SPS [5]. Various model studies ranging from simple thermal models to more detailed transport calculations, predicted enhanced dilepton production [6-9]. One of the conjectures which explains such enhanced dilepton production in HIC, suggested the reduction of the in-medium masses of the vector mesons. The theoretical results were consistent with experimental data. However, later dynamical studies hinted that the earlier studies overestimated the effect [10]. The enhancement in dilepton production due to vector meson mass reduction also differed from experiment to experiment (consistent at SPS energies but not with DLS results [11]). Overall the situation with respect to dilepton enhancement is still not unambiguously resolved.
More recent experiments of γ -A [12] reactions provided s clearer signature of an inmedium ω mass reduction. In the experiment by the TAPS collaboration [12] the modification of the ω in nuclei was measured in photo-production experiments, where its mass
was found to be m ∗ ω = 722 ± 4 MeV at 0 6 . n 0 . Similar numbers were also found in 12 GeV photon-nuclear reaction by Naruki et al. [13]. The ω meson mass and quark-condensate were studied in more recent NJL model calculations [14], where they approximately recovered the B-R scaling law using constraints from the TAPS experiment. However, for the ρ meson the picture is still not clear.
At the other extreme QCD exhibits exciting physics in a strong background magnetic field, since quarks are electrically charged and can be strongly affected by the field [15]. It changes the chiral symmetry breaking by increasing the quark-condensate [16, 17]. However, the strength of the magnetic field which typically can influence QCD effects is about eB ∼ m 2 π ∼ 3 × 10 18 G, where e is the charge of the electron, B is the magnetic field and m π denotes the mass of pion. Quarks and antiquarks can form condensates in the presence of strong magnetic fields. For the quark-antiquark bound state with light quarks, i.e. for the ρ meson, strong magnetic fields can enhance the formation of a condensate.
As will be discussed further below, the key idea lies in the fact that a sufficiently strong magnetic field can trigger an instability in the vacuum leading to condensates in specific quark channels, especially with respect to the charged vector mesons generating non-zero ρ condensates [15, 17]. Huge magnetic fields are generated at the periphery of heavy-ion collisions, where the large nuclear charges and momenta magnify the magnetic field [18]. At LHC energies of 3 5 TeV, the strength of the magnetic field could be as high as 10 . 20 -10 21 G [19]. However, such a field only exists for a very short time and is restricted to a small volume.
On the other hand, the extreme conditions discussed above can occur naturally in neutron stars (NS), where the nuclear density is several times the nuclear saturation density ( n 0 ) and the magnetic field can be as high as 10 18 -10 19 G in their cores [20, 21]. The high density might reduce the ρ meson mass due to in-medium effects and with the aid of strong magnetic field, a condensate could subsequently form.
The possibility of pion and/or kaon condensation in neutron stars has been investigated in numerous studies in the past. Since it was first suggested by Migdal [22, 23], pion condensation and its impact on NS physics became the focus of intense discussion. There were calculations, both supporting and challenging a condensed state in the dense cores of compact stars. Similarly, for kaon ( K -) condensation [24], it was argued that as the electron chemical potential is an increasing function of density, whereas the effective (anti-
)kaon mass decreases with density, condensation sets in at some density. Depending on the kaon-nucleon sigma term and the specific model, kaon condensation might occur already at about 3 -4 times saturation density, when the kaon energy becomes equal to the electron chemical potential, and above this density it is favourable for neutrons to decay to protons and kaons rather than protons and electrons, giving rise to a kaon condensate. Such densities can easily be achieved in the cores of neutron stars and, therefore, condensation can take place. However, non-linear terms and the occurrence of hyperons tend to shift the onset of kaon condensation to higher densities [25], beyond values reached in neutron stars.
One general problem for all condensate studies is their effect on the maximum possible neutron star masses. Since the discovery of pulsars PSR J1614-2230 and PSR J0348+0432 [26, 27] with masses approximately 2 M /circledot puts severe constraints on the stiffness of the equation of state (EoS) of the core region of stellar matter. Therefore, a potential onset of a condensate is important since (zero-momentum) condensates soften the equation of state thereby reducing maximum star masses.
In this Letter, we study the possibility of rho meson ( ρ -) condensation occurring inside a NS and look into the conditions which might make rho condensation possible. There are various aspects that increase the possibility of condensation in a neutron star environment. Firstly, in the core of the star extreme densities exist, which could strongly amplify a potential density-dependence of the meson mass. Secondly, as the neutron star is in a charge-neutral state, condensation of negatively charged particles set in when their mass drops below the lepton Fermi energy, in striking contrast to the situation in a heavy-ion collision, where there is no such effect. Finally, there is a possibility of strong extended magnetic fields in at least certain classes of neutron stars like magnetars, which can generate a substantial effect for a charged spin-1 particle.
We use a standard relativistic mean field approach to study the possibility of rho-meson condensation. Within this approach the nucleons interact through meson exchange represented by their mean field values. The scalar meson ( σ ) provides the attractive force, whereas the vector mesons ( ω, ρ ) generate repulsion. In order to investigate whether the rho meson will condense in a neutron star we assume a simple relation for the medium-dependent ρ mass. Certainly, in more extensive calculations a fuller study of density- (or field-) dependent masses of all involved hadrons should be performed. Here, in order to determine whether such a condensation could take place in principle, for simplicity we adopt a linear
dependence of the rho mass on the scalar field
$$m _ { \rho } ^ { * } = m _ { \rho } - g \sigma$$
where g is a dimensionless constant and m ρ = 776 MeV is the vacuum mass of the rho meson. This term effectively introduces a coupling between the vector and scalar fields.
In the presence of a background magnetic field of strength B , the energy level E n,S x of a particle of mass m , charge e , and spin s in the Landau level n is given by [15, 19, 28-30]
$$E _ { n, S _ { x } } = \sqrt { p ^ { 2 } + m ^ { 2 } + ( 2 n - g _ { B } S _ { x } + 1 ) e B }$$
where S x is the spin projection onto the magnetic field axis, and g B is gyromagnetic ratio of the particle which is taken to be 2 for the ρ meson [31-33]. Therefore, the energy squared of the lowest state for a charged rho meson corresponding to p = 0 , n = 0 and S x = 1 is
$$m _ { \rho ^ { - } } ^ { 2 } \, ^ { * } = m _ { \rho ^ { - } } ^ { 2 } - e B.$$
The upper equations point to the fact that in principle, if the in-medium effect or magnetic field is high enough, the effective mass squared of the ρ meson can be negative and condensation can take place. However, for neutron stars the situation is less restrictive as mentioned above, since the mass of the ρ -only has to fall below the electron chemical potential, so that electrons can be replaced by negative rho mesons for generating a charge-neutral system. In this case, we obtain a neutron star with rho meson condensation.
To have a better idea about if and how the rho meson condensation takes place in a neutron star, we have to adopt a specific relativistic mean field description including electrons to ensure charge neutrality of the matter. We choose the GM3 model for our calculation as its equation of state (EoS) has frequently been used in the literature to describe nuclear matter in NSs [34]. This EoS can generate 2 solar mass NSs, which is an important criterion. We solve the mean field equations at finite density including the additional term Eq. (1). As this term does not affect isospin symmetric matter the isospin-independent quantities of saturated matter for the GM3 parameters do not change. However, the GM3 value of the asymmetry energy ( a sym = 32 5 MeV) changes. . Therefore, while varying the fielddependence of the meson mass with the coupling g from Eq. (1), we accordingly adjust the g Nρ coupling of the nucleon to the rho meson in order to maintain the original value of a sym .
The results for stellar matter calculations are shown in Fig 1. We plot the variation of the electron chemical potential and the effective mass of the rho meson as a function of
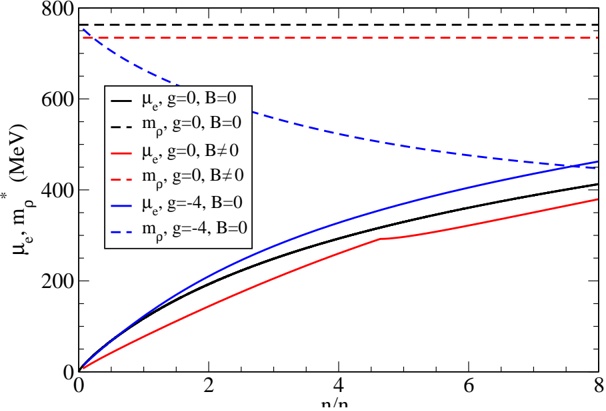
n/n
0
(a)
FIG. 1. (Color online) The electron chemical potential (solid lines) and effective ρ -mass (dashed lines) are plotted as functions of normalized density. The crossing points mark the density at which the condensation appears.
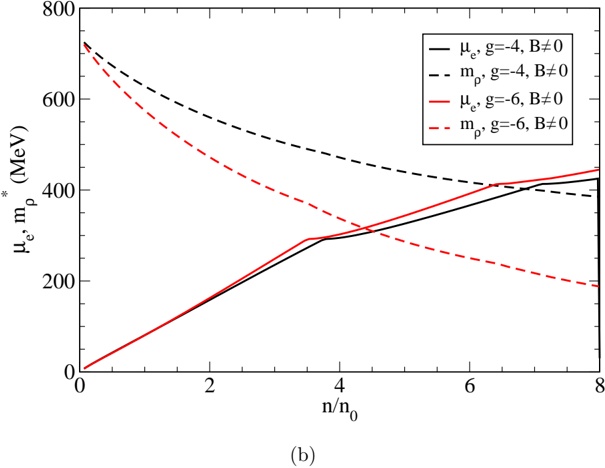
normalized baryon density. The dashed lines represent the rho meson effective mass and the solid lines depict the electron chemical potential. In Fig. 1a the black lines shows the respective values without any in-medium effect or magnetic field ( g = 0, B = 0). In this case, we find that there is no crossing point between the lines, which means the rho meson
/negationslash does not condense in this environment for any reasonable density value. The inclusion of the magnetic field ( B = 0) shifts the curves but is still not able to generate a crossing (red lines), which points to the fact that the magnetic field alone cannot give rise to condensation in a compact star. In order to investigate the maximum size of the effect with some reasonable assumptions, we considered a magnetic field of a strength of 7 1 . × 10 18 G (5 × 10 5 MeV ). In 2 order to produce rho condensation solely due to a strong magnetic field, much higher values for the magnetic field is required (3 -4 × 10 19 G). However, studies suggest that such high magnetic fields are difficult, if not impossible, to realize in a NS; however, they may locally appear for a short time during heavy ion collisions. For the crossing to take place, the rho mass modification due to in-medium effect must be included. Taking this effect into account we find that the blue lines cross each other at about 7 6 times nuclear saturation density. . For such variation, we have assumed a vector-scalar coupling g = -4. We have checked the parameter setting with nuclear matter constraints, and all are well within the accepted values. Recent measurements of pulsar masses suggest that the central energy density of neutron stars might lie around 5 -6 times nuclear saturation values [26]. In order for condensation to occur at such densities one must consider the effects of density-dependence of the mass and the effect of magnetic fields simultaneously.
In Fig 1b. we plot curves for the case in which both (in-medium and magnetic) effects are taken into account. With the above mentioned values of B and g the condensate sets in at approximately 6 9 times saturation density. . However, if we now increase the value of g , i.e. assuming a larger rho mass modification due to in-medium effects, the condensate sets in at smaller densities. For g = -6, the condensate appears around 4 4 times nuclear . saturation density. Therefore, for a neutron star with a central density of 6 times nuclear density, a rho meson condensate appears in the core of the star and extends up to the radius where the nuclear density is 4 4 times nuclear density. .
To study how rho condensation impacts the properties of a neutron star, we solve the Tolman-Oppenheimer-Volkov equation. In Fig. 2, we plot the sequence of stars obtained using the GM3 EoS. The black line represents the results for a NS where there is no ρ -condensate. The maximum mass achieved is about 2 05 . M /circledot . The red and blue curves show the sequences where rho meson condensation takes place. The solid lines in the curve represent stars which do not contain rho condensate, whereas the dotted points of the curve indicate stars that have some amount of ρ -condensate in their cores. For these curves the
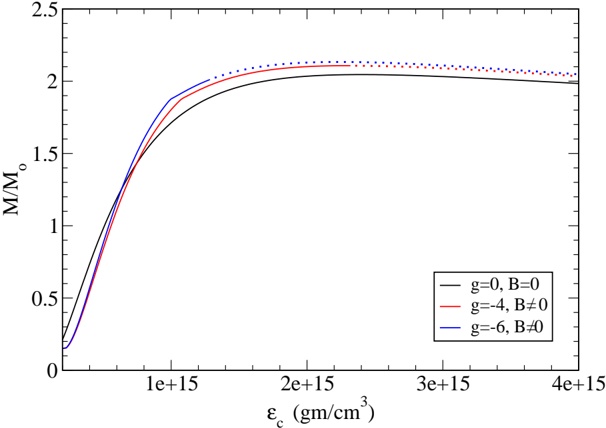
c
/negationslash
FIG. 2. (Color online) Sequence of stars for the GM3 EoS. The mass is shown as function of the central energy density. When both g and B are set to zero there is no rho condensate inside the stars and the maximum mass achieved is 2 05 solar mass. When . g, B = 0 the condensate appears. The dotted lines indicate stars that contain some amount of rho condensate.
magnetic field is kept constant at B = 7 1 . × 10 15 G. We find that as we increase g , the condensate appears much earlier i.e. more and more stars of the sequence have a condensate region in their cores. At this point we have determined the onset of condensation but so far have not performed a full calculation of the star structure including a condensate. However, assuming a drastic softening of the equation of state, the biggest possible shift of the maximum mass is given by the star mass when condensation starts to set in, which, for this specific model, yields a shift downward by about 0 2 . M /circledot for a coupling of g = -6 and including magnetic fields as can be inferred from Fig. 2.
To summarize, we studied the possibility of rho meson condensation within a standard relativistic mean field approach. While not rigorously proving the existence of the condensate, we have shown that such a state can be achieved, especially in a stellar environment, using quite reasonable assumptions. We conclude that the appearance of the condensate requires a modification of rho meson mass in the dense medium. In addition, magnetic fields have a non-negligible effect in reducing the threshold for condensation further. For that the magnetic field has to be quite large, at least in the high-density core region of the
star; however, the exact upper limit of potential magnetic fields in the interior of a neutron star is still an open discussion.
Note that although we had to use a specific model for obtaining numerical results all the arguments are quite generic and hold as well for other models. The actual numbers (condensation critical density, maximum mass shift due to condensation) will vary somewhat, but the qualitative nature of our result remains the same. One interesting consequence of the condensate would be the modification of the neutron star cooling, which has to be studied in more detail in the future. On the modelling side of this work more general and microscopic, quark-level based calculations of possible vector meson mass changes with density and their effects on the equation of state will be presented in subsequent publications.
- ∗ [email protected]
- † [email protected]
- ‡ [email protected]
- § [email protected]
- [1] Brown, G. E., & Rho, M., Phys. Rev. Lett. 66, 2720 (1991)
- [2] Hatsuda, T., & Lee, S. H., Phys. Rev. C 46, R34 (1992)
- [3] Saito, K., & Thomas, A. W., Phys. lett. B 327, 9 (1994)
- [4] Jean, H. C., Piekarewicz, J., & Williams, A. G., Phys. Rev. C 49, 1981 (1994)
- [5] Agakichiev, G. et al., Phys. Rev. Lett. 75, 1272 (1995)
- [6] Cassing, W., Ehehalt, W., & ko, C. M., Phys. lett. B 363, 35 (1995)
- [7] Srivastava, M. K., Sinha, B., & Gale, C., Phys. Rev. C 53, R567 (1996)
- [8] Koch, V., & Song, C., Phys. Rev. C 54, 1903 (1996)
- [9] Bratkovskaya, E. L., & Cassing, W., Nucl. Phys. A 619, 413 (1997)
- [10] Cassing, W., Bratkovskaya, E. L., Rapp, R., & Wambach, J., Phys. Rev. C 57, 916 (1998)
- [11] Bratkovskaya, E. L., Ko, C. M., Phys. Lett. B 445, 265 (1999)
- [12] Trnka, D. et al., Phys. Rev. Lett. 94, 192303 (2005)
- [13] Naruki, M. et al., Phys. Rev. Lett 96, 092301 (2006)
- [14] Huguet, R., Caillon, J. C., & Labarsouque, J., Phys. Rev. C 75, 048201 (2007)
- [15] Chernodub, M. N., Lect.Notes Phys. 871, 143 (2013)
- [16] Gusynin, V. P., Miransky, V. A., & Shovkovy, I. A., Phys. Rev. Lett. 73, 3499 (1994)
- [17] Schramm, S., Mueller, B., & Schramm, A. J., Mod. Phys. lett. A 7, 973 (1992)
- [18] Skokov, V., Illarionov, A. Y., & Toneev, V., Int. J. Mod. Phys. a 24, 5925 (2009)
- [19] Schramm, S., Mueller, B., & Schramm, A. J., Phys. lett. B 277, 512 (1992)
- [20] Ferrer, E. J., de la Incera, V., Keith, J. P., Portillo, I., & Springsteen, P. P., Phys. Rev. C 82, 065802 (2010)
- [21] Dexheimer, V., Negreiros, R., & Schramm, S., Eur. Phys. J. A, 48, 189 (2012)
- [22] Migdal, A. B., Soviet Phys. JETP 61, 2209 (1971)
- [23] Migdal, A. B., Phys. Lett. 45B, 448 (1973)
- [24] Kaplan, D. B., & Nelson, A. E., Phys. Lett. B 175, 57 (1986)
- [25] A. Mishra, A. Kumar, S. Sanyal, V. Dexheimer and S. Schramm, Eur. Phys. J. A 45 (2010) 169
- [26] Demorest, P., Pennucci, T., Ransom, S., Roberts, M., & Hessels, J., Nature, 467, 1081 (2010)
- [27] Antonidis, J., Freire, P. C. C., Wex, N. et. al., Science, 340, 448 (2013)
- [28] Skalozub, V. V., Sov. J. Nucl. Phys. 41, 1044 (1985)
- [29] Ambjorn, J., & Olsen, P., Phys. Lett. B 257, 201 (1991)
- [30] Chernodub, M. N., Phys. Rev. D 82, 085011 (2010)
- [31] Samsonov, A., JHEP 0312, 061 (2003)
- [32] Bhagwat, M. S., & Maris, P., Phys. Rev. C 77, 025203 (2008)
- [33] Hedditch, J. N., Kamleh, W., Lasscock, B. G. et al., Phys. Rev. D 75, 094504 (2007)
- [34] Glendenning, N. K., & Moszkowski, Phys. Rev. Lett. 67 , 2414 (1991) | 10.1093/mnras/stv402 | [
"Ritam Mallick",
"Stefan Schramm",
"Veronica Dexheimer",
"Abhijit Bhattacharyya"
] | 2014-08-01T11:55:40+00:00 | 2014-08-01T11:55:40+00:00 | [
"astro-ph.HE",
"nucl-th"
] | On the possibility of rho-meson condensation in neutron stars | The possibility of meson condensation in stars and in heavy-ion collisions
has been discussed in the past. Here, we study whether rho meson condensation
($\rho^{-}$) can occur in very dense matter and determine the effect of strong
magnetic fields on this condensation. We find that rho meson condensates can
appear in the core of the neutron star assuming a rho mass which is reduced due
to in-medium effects. We find that the magnetic field has a non-negligible
effect in triggering condensation. |
1408.0140v1 | ## Shocks in dense clouds
## IV. Effects of grain-grain processing on molecular line emission
S. Anderl, 1 V. Guillet, 2 G. Pineau des Forˆ ets 2 3 ; and D. R. Flower 4
- 1 Argelander-Institut f¨r Astronomie, Universit¨ at Bonn, Auf dem H¨gel 71, 53121 Bonn, Germany u u e-mail: [email protected]
- 2 Institut d'Astrophysique Spatiale (IAS), UMR 8617, CNRS, Bˆ atiment 121, Universit´ e Paris Sud 11, 91405 Orsay, France
- 3 LERMA (UMR 8112 du CNRS), Observatoire de Paris, 61 Avenue de l'Observatoire, 75014 Paris, France
- 4 Physics Department, The University of Durham, Durham DH1 3LE, UK
Received 4 March 2013; accepted 19 June 2013
## ABSTRACT
Context. Grain-grain processing has been shown to be an indispensable ingredient of shock modelling in high density environments. For densities higher than GLYPH<24> 10 5 cm 3 , shattering becomes a self-enhanced process that imposes severe chemical and dynamical conGLYPH<0> sequences on the shock characteristics. Shattering is accompanied by the vaporization of grains, which can, in addition to sputtering, directly release SiO to the gas phase. Given that SiO rotational line radiation is used as a major tracer of shocks in dense clouds, it is crucial to understand the influence of vaporization on SiO line emission.
Aims. We extend our study of the impact of grain-grain processing on C-type shocks in dense clouds. Various values of the magnetic field are explored. We study the corresponding consequences for molecular line emission and, in particular, investigate the influence of shattering and related vaporization on the rotational line emission of SiO.
Methods. We have developed a recipe for implementing the e GLYPH<11> ects of shattering and vaporization into a 2-fluid shock model, resulting in a reduction of computation time by a factor GLYPH<24> 100 compared to a multi-fluid modelling approach. This implementation was combined with an LVG-based modelling of molecular line radiation transport. Using this combined model we calculated grids of shock models to explore the consequences of di GLYPH<11> erent dust-processing scenarios.
Results. Grain-grain processing is shown to have a strong influence on C-type shocks for a broad range of magnetic fields: the shocks become hotter and thinner. The reduction in column density of shocked gas lowers the intensity of molecular lines, at the same time as higher peak temperatures increase the intensity of highly excited transitions compared to shocks without grain-grain processing. For OH the net e GLYPH<11> ect is an increase in line intensities, while for CO and H2O it is the contrary. The intensity of H2 emission is decreased in low transitions and increased for highly excited lines. For all molecules, the highly excited lines become sensitive to the value of the magnetic field. Although vaporization increases the intensity of SiO rotational lines, this e GLYPH<11> ect is weakened by the reduced shock width. The release of SiO early in the hot shock changes the excitation characteristics of SiO radiation, although it does not yield an increase in width for the line profiles. To significantly increase the intensity and width of SiO rotational lines, SiO needs to be present in grain mantles.
Key words. shock waves - magnetohydrodynamics (MHD) - dust, extinction - ISM: clouds - ISM: jets and outflows - ISM: kinematics and dynamics
## 1. Introduction
Shocks are ubiquitous in the interstellar medium, occurring when matter moves into a more rarefied medium at a velocity that exceeds the local sound speed. Depending on the value of the local magnetosonic speed, di GLYPH<11> erent types of shocks can be distinguished. The classical shocks are faster than any signal speed in the shocked medium, so the preshock medium is not able to dynamically respond to the shockwave before it arrives. This type of shock is called 'J-type' (see e.g. Hollenbach &McKee (1979); McKee & Hollenbach (1980)). A di GLYPH<11> erent situation can occur if a low degree of ionization and the presence of a magnetic field allow magnetosonic waves to precede the shock. Ions then decouple from the neutrals and are already accelerated in the preshock gas, so that there is no longer a discontinuity in the flow of the ion fluid. In the preshock gas, the ions heat and accelerate the neutrals and broaden the heating region, so that heating and cooling take place simultaneously. The shock transition can then become continuous in the neutral fluid ('C- type shocks') also. Shocks of this type are thicker and less hot than J-type shocks (see Draine 1980; Draine & McKee 1993). Observations often reveal shocks as bow-shaped structures, with the ambient material being compressed and pushed aside (e.g. Nissen et al. 2007; Davis et al. 2009).
Shocks play an important role in the energy budget of the interstellar medium by determining the energetic feedback of events such as supernovae, stellar winds, cloud-cloud collisions, or expanding HII regions. On the other hand, shocks have a major influence on the chemistry of the interstellar medium. Among the most characteristic chemical tracers of shock waves are species that are typically heavily depleted on dust grains, such as Fe, Mg, or Si. Dust processing occurring in the violent environment of shocked media is able to release these species into the gas phase (e.g. Li GLYPH<11> man & Clayton 1989; O'Donnell & Mathis 1997). The understanding of dust processing in shocks is therefore intimately linked with the theoretical interpretation of characteristic emission lines in environments where shocks occur.
The processing of dust in shocks can have two di GLYPH<11> erent consequences. It either changes the dust-to-gas mass ratio or alters the dust size distribution. The former occurs in the processes of sputtering and vaporization, while the latter is also found with shattering. Sputtering denotes energetic impacts of gas particles on grains that can release species from the grain surfaces into the gas phase. This can happen either at very high temperatures (thermal sputtering) or at high relative gas-grain velocities (inertial sputtering). Sputtering of dust grains has been the subject of many theoretical studies (Barlow 1978; Tielens et al. 1994; Jones et al. 1994; May et al. 2000; Van Loo et al. 2013) and has become an established ingredient of shock models. Shattering, which is the fragmentation of grains due to grain-grain collisions, has been identified as a crucial process for determining the grain-size spectrum of interstellar grains (Biermann & Harwit 1980; Borkowski & Dwek 1995). Together with vaporization, which describes the return of grain material to the gas phase following grain-grain collisions, shattering needs to be included in order to account for UV extinction curves (Seab & Shull 1983). Moreover, recent infrared and sub-mm observations hint at an overabundance of small dust grains relative to the expected sizedistribution in parts of the interstellar medium and thereby stress the importance of dust processing (Andersen et al. 2011; Planck Collaboration 2011), which has also been associated with MHD turbulence acceleration of dust grains or charge-fluctuation induced acceleration (e.g. Ivlev et al. 2010; Hirashita 2010).
A rigorous theoretical description of grain-grain collisions requires a detailed description of shock waves in solids, which had not been undertaken before the work of Tielens et al. (1994), earlier studies having relied on much simplified models (e.g. Seab & Shull 1983). The e GLYPH<11> ect of the microphysics of grain shattering and its e GLYPH<11> ects on the grain size distribution in J-type shocks in the warm intercloud medium was studied by Jones et al. (1996). Slavin et al. (2004) extended this work by explicitly following individual trajectories of the grains, considered as test particles.
In a series of papers, Guillet et al. (2007, 2009, 2011, hereafter Papers I, II and III) have shown that a multi-fluid approach to the dust dynamics, together with a detailed calculation of the grain charge distribution, shows shattering and the accompanying vaporization to be indispensable ingredients of shock models. For C-type shocks at preshock densities higher than GLYPH<24> 10 5 cm GLYPH<0> 3 , shattering becomes dramatically self-enhanced, due to feedback processes: electrons are heavily depleted on to small grain fragments, and the lack of electrons in the gas phase affects the grain dynamics, resulting in even more shattering and production of small grains. Owing to the increase of the total geometrical grain cross-section, these shocks become much hotter and narrower, and vaporization becomes important for the release of depleted species into the gas phase. Both the dynamical and the chemical consequences of shattering a GLYPH<11> ect the predicted observational characteristics, compared with models in which shattering and vaporization are neglected. Given that conditions favoring C-shocks are frequently found in dense clouds and Bok globules, it is necessary to evaluate the observational consequences of shock models including grain-grain processing for a proper understanding of massive star formation and interactions of supernova remnants with molecular cloud cores (Cabrit et al. 2012).
The aforementioned studies leave open a series of issues that we aim to address in this paper. The three main questions are:
- -How do the e GLYPH<11> ects of shattering and vaporization change if the magnetic field strength is varied?
- -What are the consequences of shattering for molecular line emission?
- -How do shattering and associated vaporization of SiO and C influence the SiO and atomic carbon line emission?
In order to answer the last two questions, it is necessary to introduce a detailed treatment of radiative transport. However, due to the numerical complexity of the multifluid treatment of Papers I-III, a self-consistent merging of this multifluid model with an LVG treatment of molecular line emission would be technically di GLYPH<14> cult. It would also prevent the resulting model from being a practical analysis tool whenever large grids of models are required. Therefore, we have developed a method for implementing the e GLYPH<11> ects of shattering and vaporization into a 2-fluid shock model that is su GLYPH<14> ciently general to be applied to any similar model. We incorporated the main features, neglecting all the minor details of grain-grain processing; the resulting saving in computation time amounts to a factor of GLYPH<24> 100. With this model, the consequences of shattering and vaporization on the molecular line emission of C-type shocks can be studied in detail, using a self-consistent treatment of the line transfer (Flower & Pineau des Forˆ ets 2010). In the context of the emission of SiO from Ctype shocks (Schilke et al. 1997; Gusdorf et al. 2008b,a), the inclusion of grain shattering and vaporization, along with the line transfer, should improve significantly our ability to interpret the observations correctly.
Our paper is structured as follows. In Sect. 2, we introduce our model, which extends the work of Flower & Pineau des Forˆ ets (2010) by including the shattering and vaporization of grains and molecular line transfer. We use this model to demonstrate the e GLYPH<11> ect of shattering on the shock structure for di GLYPH<11> erent values of the magnetic field in the preshock gas (Sect. 3). In Sect. 4, we consider observational diagnostics, with the main emphasis being on the rotational line emission of SiO. In addition, we investigate the influence of vaporization on the [C I] emission lines. The results are discussed and summarized in Sect. 5.
## 2. Our model
In order to study the e GLYPH<11> ect of shattering and vaporization on molecular line emission, we have built on the findings of Papers I - III, where shattering and vaporization are described within a multi-fluid formalism for the dust grains. These results needed to be transferred to a 2-fluid formulation, as used in the model of Flower & Pineau des Forˆ ets 2010 (hereafter FPdF10), whose model includes a detailed treatment of molecular line radiative transfer, in the presence of the cosmic microwave background radiation. In the present Section, we first describe the treatment of dust in the model of FPdF10 and then summarize the multifluid treatment of dust and its implications, finally outlining how we introduced the e GLYPH<11> ects of shattering and vaporization into the model of FPdF10.
## 2.1. Two-fluid treatment of dust
The way in which dust is treated in the LVG-model of FPdF10 derives from the work of Flower & Pineau des Forˆ ets 2003 (hereafter FPdF03). This one-dimensional, steady-state, 2-fluid model 1 of plane-parallel C-type shocks solves the magnetohydrodynamical equations in parallel with a large chemical network, comprising more than 100 species and approximately
1 Although electrons and ions are treated as one dynamical fluid, their temperatures are calculated separately.
1000 reactions, including ion-neutral and neutral-neutral reactions, charge transfer, radiative and dissociative recombination. Furthermore the populations of the H2 ro-vibrational levels are computed at each integration step, along with the populations of the rotational levels of other important coolants, such as CO, OH and H2O. In these cases, the molecular line transfer is treated by means of the large velocity gradient approximation (see also Sect. 4). 'Dust' is included in the forms of polycyclic aromatic hydrocarbons (PAHs), represented by C54H18, and large grains from bulk carbonaceous material and silicates (specifically olivine, MgFeSiO4). The large grains are assumed to have a power law size distribution, d n g ( a ) = d a / a GLYPH<0> 3 5 : (Mathis et al. 1977), and radii in the range 100 to 3000 Å (0.3 GLYPH<22> m). In the preshock medium, the grain cores are covered by ice mantles, consisting of the chemical species listed in Table 2 of FPdF03 and including H2O, CO and CO2. Both PAHs and large grains exist as neutral, singly positively and singly negatively charged species. The physical treatment of dust comprises:
- -determination of the grain charge distribution, limited to Z = GLYPH<0> 1 0 1; ; ;
- -sputtering of grain cores and mantles due to grain-gas collisions;
- -removal of mantles by cosmic ray desorption;
- -build-up of mantles by adsorption of gas-phase species in the postshock gas.
## 2.2. Multi-fluid treatment of dust
To properly account for the e GLYPH<11> ects of grain-grain collisions in shocks, it is necessary to introduce a multi-fluid description of the dust dynamics, in which dust grains are treated as test particles. In Papers I-III the dust size distribution was modeled by the use of discrete bins, with grain sizes ranging from 5 to 3000 Å. PAHs were not included as separate species, distinct from the dust grains (as in the two-fluid model), but were incorporated into the dust size distribution. The equations describing the 2-D grain dynamics and complete charge distribution were integrated for each individual bin size, independently for silicate and carbon grains.
While the shock structure is not much a GLYPH<11> ected by this more accurate treatment of the grain dynamics and charging (Paper I, Appendix D 2 ), the introduction of dust shattering in grain-grain collisions and the corresponding changes to the grain size distribution have major e GLYPH<11> ects on shocks in dense clouds with a low degree of ionization (Paper III). When grains collide with a velocity greater than 1.2 km s GLYPH<0> 1 (carbon grains) or 2.7 km s GLYPH<0> 1 (silicate grains), a fraction of their mass, which increases with velocity, is shattered into smaller fragments. At higher velocities, another fraction is vaporized and released into the gas phase (the numerical treatment follows the models of Tielens et al. (1994) and Jones et al. (1996), where the vaporization threshold is GLYPH<24> 19 km s GLYPH<0> 1 ).
Paper III demonstrated that there is a marked shift of the dust size distribution towards smaller grains when the grain dynamics, charging and evolution are coupled self-consistently with the shock dynamics and chemistry. The most dramatic consequence is an increase of the total geometrical grain cross-section - which governs the coupling between the neutral and charged fluids -
2 Although changes to the re-accretion of mantle species in the multifluid treatment give rise to a slightly di GLYPH<11> erent temperature profile in the postshock gas.
Fig. 1. Temperature and density (upper panel) and velocity profiles in the shock frame (lower panel) for a 30 km s GLYPH<0> 1 C-type shock with a magnetic field parameter b = 1 5 and a preshock : density of n H = 10 5 cm GLYPH<0> 3 . The full curves show the results obtained when grain-grain processing is treated as in Paper III; the broken curves are obtained by following the approach of FPdF03.
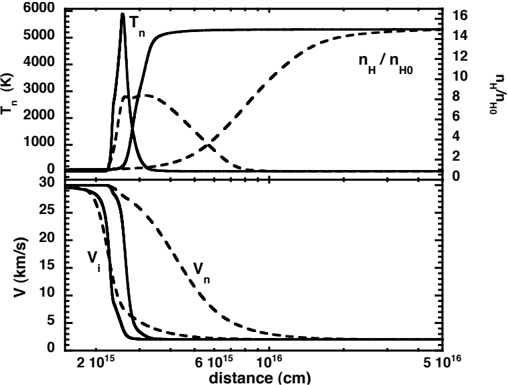
by a factor 3 of GLYPH<24> 10. The shock becomes narrower by a factor of GLYPH<24> 4, and the peak temperature increases by a factor of 1.5-2 (see Fig. 1). The small grain fragments deplete ions and electrons from the gas until grains become the dominant charge carriers, a situation known as a dusty plasma (Fortov et al. 2005). The strong e GLYPH<11> ect of shattering, for preshock densities of 10 5 cm GLYPH<0> 3 and higher, can be understood in terms of the feedback processes described in Paper III. At these high preshock densities, it turns out that vaporization related to shattering becomes important, if not dominant, compared to sputtering.
## 2.3. Implementation of shattering
As described in Sect. 2.2, there are two ways in which shattering a GLYPH<11> ects the shock wave: first it increases the collisional dust cross-section, and second it lowers the degree of ionization of the gas. In the model of FPdF10, dust as a dynamical species and dust as a chemically reacting species were treated separately. Our implementation and validation of shattering in the FPdF10 model are described in Appendix A.1. Here we only summarize our basic approach.
- -The dynamical e GLYPH<11> ects of shattering can be simulated by incorporating the change in the total grain cross section h n GLYPH<27> i , computed with the model of Paper III; this is done by multiplying h n GLYPH<27> i by an additional factor that varies with the spatial coordinate, z , through the shock wave. This factor is modelled as an implicit function of the compression of the ionized fluid; its value is 1 in the preshock gas, and its maximumvalue - derived from the multi-fluid model - is attained
3 This factor refers to the total cross-section of grain cores. The reaccretion of grain mantles in the postshock gas leads to a much larger increase in the total cross-section, by a factor of GLYPH<24> 100 (see. Fig. A.1). However, this large increase is irrelevant to the shock dynamics, as it happens where the momentum transfer between the ionized and the neutral fluids is almost complete ( T GLYPH<24> 100 K).
Fig. 2. Peak temperature of the neutral fluid and the shock width (in cm), to T = 100 K in the cooling flow, for the grid of models without (broken lines) and with (full lines) grain-grain processing. The preshock density is 10 5 cm GLYPH<0> 3 , and the shock velocities are 20 km s GLYPH<0> 1 (blue), 30 km s GLYPH<0> 1 (green) and 40 km s GLYPH<0> 1 (red) for various values of the magnetic field parameter, b , in B ( GLYPH<22> G) = b p n H(cm GLYPH<0> 3 ).
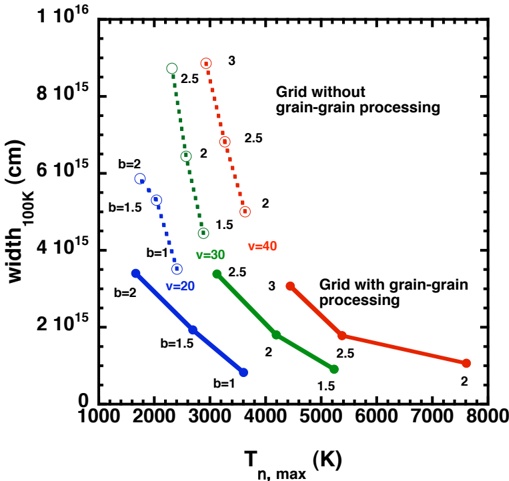
when shattering is completed. It is possible to use linear fits of the parameters that are required.
- -The chemical e GLYPH<11> ects of shattering, i.e. the consequences for grains as charged species, as determined by grain-charging reactions, need to be considered separately. In order to model the influence of shattering on the abundances of charged grains, a shattering source-term is introduced, whose value is consistent with h n GLYPH<27> i .
## 2.4. Implementation of vaporization
Grain-grain collisions lead not only to shattering of grains, and consequent changes in the shock structure and degree of ionization, but also to their vaporization, when the impact velocity is higher than the vaporization threshold of GLYPH<24> 19 kms GLYPH<0> 1 . We assume that the silicon released through vaporization is in the form of SiO (Nagahara & Ozawa 1996; Wang et al. 1999). We have implemented the e GLYPH<11> ect of SiO vaporization in a similar way as for shattering 4 ; the details are given in Appendix A.2. Our procedure involves introducing an additional term in the rate of creation of gas-phase SiO from Si and O in the grain cores. Thus, vaporization is incorporated as a new type of pseudo-chemical reaction. The rate of creation of SiO through vaporization is determined by parameterizing the results of the multi-fluid models.
Another modification of the FPdF10 model concerns the mantle thickness, which is now calculated as described in Paper I, Appendix B. Our simplified, but self-consistent, treatment of shattering and vaporization reduces the computation time by a factor of more than 100.
4 We emphasize the e GLYPH<11> ects of SiO vaporization because the finestructure lines of atomic carbon are optically thin and do not require an LVG treatment.
## 3. The influence of grain-grain processing on the shock structure
## 3.1. The grid of models
Having implemented shattering and vaporization in the model of FPdF10, we first study the dependence of grain-grain processing and feedback on the strength of the transverse magnetic field. The analysis of Paper III was restricted to shocks propagating at the critical velocity, which defines the fastest possible C-type shock for a given magnetic field (or, conversely, the lowest value of the magnetic field possible for a given shock velocity). This critical velocity is determined by the condition that the shock velocity should be only slightly smaller than the velocity of magnetosonic waves,
$$V _ { \text{ms} } = \frac { B } { \sqrt { 4 \pi \rho _ { \text{c} } } }$$
where GLYPH<26> c is the mass density of matter that is strongly coupled to the magnetic field. We assumed that the magnetic field strength, B , in dense clouds scales with the total proton density, n H, as B ( GLYPH<22> G) = b p n H(cm GLYPH<0> 3 ) (Crutcher 1999), which implies that the magnetic energy density is proportional to n H. The assumed power-law exponent of 0.5 is somewhat lower than the more recent value of 0.65 GLYPH<6> 0.05, given by Crutcher (2012), but is probably consistent with the uncertainties associated with its deduction from measurements of Zeeman splitting. The restriction to critical shocks was justified in Paper III by the fact that the observations will be dominated by the fastest shocks, if present. However, to assess the importance of shattering in the dense interstellar medium, it is necessary to establish whether shattering is still a relevant factor when the magnetic field is higher and the (charged) grains are better protected by their coupling to the magnetic field. Shattering is sensitive to the preshock density because the drag force becomes more important, relative to the Lorentz force, as the density increases. At high densities, large grains decouple from the magnetic field and exhibit a large velocity dispersion in the initial part of the shock wave, where they undergo destruction. Furthermore, the degree of ionization is lower in higher density gas, so the feedback due to the depletion of electrons is enhanced.
Wehave studied shocks with a preshock density of 10 5 cm GLYPH<0> 3 . We consider only this value because, on the one hand, it was shown that the change in the grain size distribution due to shattering is negligible for a preshock density of 10 4 cm GLYPH<0> 3 , and, on the other hand, the strength of the feedback from shattering at higher densities prevents the multi-fluid model of Paper III from converging at a preshock density of 10 6 cm GLYPH<0> 3 , and hence there are no results with which to compare at this density. We have restricted our calculations to shocks that do not fully dissociate H2 (shock velocity V s GLYPH<20> 50kms GLYPH<0> 1 ), in practice to 20, 30 and 40 kms GLYPH<0> 1 .
The values of the magnetic field that we considered were determined by two considerations. First, in order to study critical shocks, we adopted the corresponding (minimum) values of b (see Paper III); and, second, we varied b for a given shock velocity in order to study the influence of variations in the magnetic field strength. Thus, we consider three values of the b parameter for each velocity, in steps of 0.5, where the lowest value is close to that for a critical shock; the lowest values are b = 1 0 for 20 : kms GLYPH<0> 1 , b = 1 5 for 30 km s : GLYPH<0> 1 , and b = 2 0 for 40 km s : GLYPH<0> 1 . The corresponding grid of nine models is summarized in Table 1. We note that a comparison of models with di GLYPH<11> erent shock velocities and the same magnetic field is possible for the case b = 2 0. :
Table 1. Parameters defining our grid of models.
| V s [kms GLYPH<0> 1 ] | b | B [ GLYPH<22> G] | n H [cm GLYPH<0> 3 ] |
|-------------------------|-----|--------------------|------------------------|
| 20 | 1 | 316 | 10 5 |
| 20 | 1.5 | 474 | 10 5 |
| 20 | 2 | 632 | 10 5 |
| 30 | 1.5 | 474 | 10 5 |
| 30 | 2 | 632 | 10 5 |
| 30 | 2.5 | 791 | 10 5 |
| 40 | 2 | 632 | 10 5 |
| 40 | 2.5 | 791 | 10 5 |
| 40 | 3 | 949 | 10 5 |
## 3.2. Hotter and thinner
The most dramatic e GLYPH<11> ect of shattering is the change in the overall shock structure, owing to the increase in the collision crosssection of the dust and the corresponding increase in the coupling between the neutral and charged fluids. Figure 2 shows the peak temperature of the neutral fluid and the shock width (up to the point at which the temperature has fallen to 100 K) for our grid of nine models, as compared with the results obtained without grain-grain processing.
The peak temperature of the models that include shattering increases by a factor of 1.5-2 for the shocks closest to the critical velocity, as in Paper III. Our models show that this increase is smaller for slower shocks, and for shocks with higher magnetic field strengths, because the charged grains are more strongly bound to and protected by the magnetic field. Thus, shocks with V s = 20 kms GLYPH<0> 1 and b = 2 have a peak temperature comparable to that found without grain-grain processing. However, the shock width, as determined at the point in the cooling flow at which the gas temperature has fallen to 100 K, is always much smaller for models in which grain-grain processing is included. For the shocks closest to the critical velocity, the width is reduced by a factor of 4-5. The trend is the same as for the peak temperature: the shock widths, as computed with and without grain-grain processing, are most similar for lower velocities and higher magnetic fields, di GLYPH<11> ering by a factor of only 1.7 for V s = 20 kms GLYPH<0> 1 and b = 2.
It is interesting to see the dependence of the shock structure on the transverse magnetic field strength. In models that neglect grain-grain processing, a change in the magnetic field modifies the shock width at almost constant peak temperature, whereas, when grain-grain processing is included, a variation in the magnetic field has a strong a GLYPH<11> ect on the peak temperature. We return to this point in Sect. 4, where we consider the di GLYPH<11> erences between the spectra predicted by these two categories of model; but it is already clear that shattering is significant, even for noncritical shocks, and should be included in steady-state C-type shock models with high preshock densities ( nH GLYPH<21> 10 5 cm GLYPH<0> 3 ).
## 4. Observational consequences
In our model, the molecular line transfer is treated using the large velocity gradient (LVG) approximation (e.g. Surdej 1977), allowing for self-absorption via the escape probability formalism. The LVG method is well adapted to the conditions of shocks, where flow velocities change rapidly. The computation of the molecular energy level populations is performed in parallel with the integration of the chemical and dynamical rate equations, as introduced for CO by Flower & Gusdorf (2009). The molecular line transfer of H2O, CH3OH, NH3, OH and SiO has since been added (Flower et al. 2010; Flower & Pineau des Forˆ ets 2010, 2012.
The modelling of interstellar shock waves requires many molecular energy levels to be considered. As described in FPdF10, we include levels of H2O up to an energy of approximately 2000 K above ground. Although this is less than the maximum temperatures that are attained, the high values of the radiative (electric dipole) transition probabilities ensure that the populations of higher, neglected levels remain small, and hence the associated errors in the computed line intensities are modest. Above the maximum temperatures for which the rotational deexcitation coe GLYPH<14> cients have been calculated, their values are assumed to remain constant (cf. Flower & Pineau des Forˆ ets 2012, Appendix A). Rate coe GLYPH<14> cients for excitation are obtained from the detailed balance relation.
The consequences of grain-grain processes for the molecular line radiation of H2, H2O and OH for representative shocks of V s = 30 kms GLYPH<0> 1 are briefly discussed in Sect. 4.1 and in more detail in Appendix B. In Sect. 4.2, we consider the rotational line emission of SiO and, in Sect. 4.3, the vaporization of carbon.
## 4.1. Molecular line emission
We have seen that including grain-grain processing leads to an increase in the peak shock temperature; this a GLYPH<11> ects the chemistry and gives rise to higher fractional abundances of molecules in excited states. The intensities of lines emitted by highly excited states are thereby enhanced. At the same time, the column density of shocked gas decreases, which tends to reduce the intensity of molecular line emission. The net e GLYPH<11> ect depends on the chemical and spectroscopic properties of the individual molecules.
In Appendix B, we show that the intensities of all transitions of OH increase in shocks faster than 30 km s GLYPH<0> 1 that incorporate grain-grain processing; this is due to the temperature sensitivity of OH formation. On the other hand, the intensities of the emission lines of H2, CO, and H2O decrease because of the reduction in the column density of shocked material. Furthermore, the inclusion of grain-grain processing introduces a dependence of the intensities of lines from highly excited states on the magnetic field, owing to the variation of the peak shock temperature with the field strength (see Sect. 3.2 and Fig. 2).
## 4.2. The effect of vaporization on SiO emission
SiO is a prominent indicator of shock processing in dense clouds associated with jets and molecular outflows (e.g. Bachiller et al. 1991; Martin-Pintado et al. 1992; Gueth et al. 1998; Nisini et al. 2007; Cabrit et al. 2007). The first chemically adequate theoretical study of SiO production by sputtering in C-type shocks was conducted by Schilke et al. (1997); this work was pursued subsequently by Gusdorf et al. (2008b,a). These studies considered the release, by sputtering, of Si from grain cores and SiO from grain mantles, but not the process of vaporization, which could modify the predicted SiO rotational line profiles. We note that Cabrit et al. (2012) found that, in the protostellar jet HH212, at least 10% of elemental Si could be present as gas-phase SiO, if the wind is dusty. To explain such a high value, they hint at the possible importance of grain-grain processing and the release of SiO by vaporization. The sputtering of Si from the grain cores seems unable to account for the observations in this case, as the dynamical timescale of 25 yr is too short for the chemical conversion, in the gas phase, of the sputtered Si into SiO.
Fig. 3. The fractions of Si (left panel) and C (right panel) released from grain cores in model M1 of Table 2 by vaporization (full lines) and sputtering (broken lines), for V s = 20 kms GLYPH<0> 1 (blue), V s = 30 kms GLYPH<0> 1 (green), and V s = 40 kms GLYPH<0> 1 (red), as functions of the magnetic field parameter, b , in B ( GLYPH<22> G) = b p n H(cm GLYPH<0> 3 ).
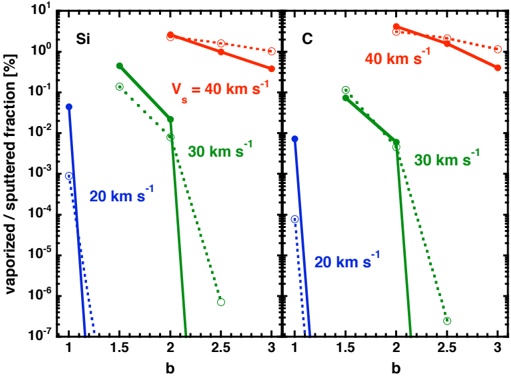
Table 2. Summary of the three dust processing scenarios investigated in order to study the release of SiO into the gas phase. The percentage refers to elemental silicon in the form of SiO in the mantles.
| Scenario | Si in cores | SiO in mantles | Grain-grain processing |
|------------|---------------|------------------|--------------------------|
| M1 | yes | no | yes |
| M2 | yes | no | no |
| M3 | yes | 10% | no |
The influence of grain-grain processing on the SiO line emission is twofold. On the one hand, vaporization strongly increases the amount of SiO released from grain cores, at su GLYPH<14> ciently high shock speeds. On the other hand, as the process of vaporization is necessarily related to shattering of dust grains, shocks with grain-grain processing have a di GLYPH<11> erent structure (cf. Sect. 3.2). The consequences of the latter e GLYPH<11> ect for the emission by molecules whose abundances are not directly influenced by vaporization are summarized in Sect. 4.1.
In order to address the question of how the related e GLYPH<11> ects of shattering and vaporization a GLYPH<11> ect the emission of SiO in C-type shocks, we compare results of shock models, obtained including and excluding grain-grain processing, for three di GLYPH<11> erent scenarios, summarized in Table 2. Models corresponding to scenario 1 (M1) were calculated using the implementation of shattering and vaporization described in Sect. 2.3 and 2.4 with the parameters of Table A.1. Models corresponding to scenario 2 (M2) do not include grain-grain processing, but Si is still released by the sputtering of grain cores. Scenario 3 (M3) di GLYPH<11> ers from M2 in that 10% of the elemental Si is assumed to be in the form of SiO in the grain mantles. In total, there are 9 GLYPH<2> 3 = 27 individual models to be computed.
Fig. 4. Upper panel: Evolution of the fractional abundance of SiO in the gas phase (left ordinate, full curves) and temperature of the neutral fluid (right ordinate, broken curves). From left to right: dust modelling scenarios M1, M2, and M3. The models shown in all three panels are for V s = 20 kms GLYPH<0> 1 with b = 1.0 (blue), V s = 30 kms GLYPH<0> 1 with b = 1.5 (green), and V s = 40 kms GLYPH<0> 1 with b = 2.0 (red). The fractional abundance of SiO in the gas phase is negligible for V s = 20 kms GLYPH<0> 1 with b = 1.0 in scenario M2. Lower panel: variation through the shock wave of the gas-phase fractional abundances of O2 (left ordinate, full blue curves) and OH (left ordinate, full red curves), together with the temperature of the neutral fluid (right ordinate, black broken curves), for V s = 30 km s GLYPH<0> 1 and b = 1.5 and each of the dust models M1, M2 and M3 (from left to right).
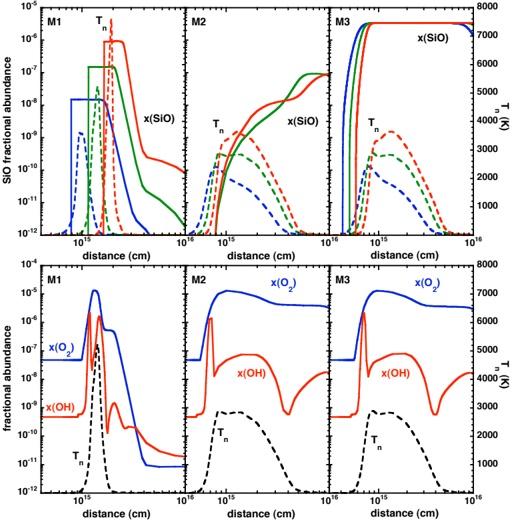
## 4.2.1. The release of SiO through dust processing
In order to compare the relative importance of vaporization and sputtering, we investigate the release of the Si in grain cores into the gas phase by each of these processes during the passage of a shock wave. The left-hand panel of Figure 3 shows the fraction of Si eroded from grain cores through sputtering and vaporization in model M1. There is negligible sputtering for V s GLYPH<20> 20 kms GLYPH<0> 1 , because the adopted sputtering threshold for refractory grain material is GLYPH<24> 25 km s GLYPH<0> 1 (May et al. 2000). Both the sputtering of Si and the vaporization of SiO are inhibited by the magnetic field. In the case of sputtering, the maximum ion-neutral drift velocity decreases with increasing field strength, whereas, for vaporization, the charged grains are more strongly coupled to the field and hence to the charged fluid (we assume that the magnetic field is 'frozen' in the charged fluid). For models M3 (SiO in mantles) with velocities su GLYPH<14> cient for mantle sputtering, all the SiO initially in the mantles is released into the gas phase. The rotational line emission of SiO depends not only on the amount of silicon released from the grains but also on the location of its release and the physical conditions prevailing where SiO is present within the shock wave.
The upper panel of Figure 4 shows the fractional abundance of SiO in the gas phase, for dust models M1-3 of Table 2 and
three di GLYPH<11> erent values of the shock speed. In model M1, vaporization releases SiO directly into the gas phase in the region where the temperature of the neutral fluid is rising steeply. The higher the shock speed, the more SiO is produced. The large increase in the total grain cross section in the postshock gas enhances the rate of formation of mantles and removes SiO from the gas phase.
The variation of the fractional abundance of SiO is very different if only the sputtering of grain cores is considered (M2), because the Si that is released by sputtering has to be transformed into SiO by gas-phase chemical reactions, predominantly oxidation by O2 and OH. The corresponding reactions are
$$\text{Si} + 0 _ { 2 } \rightarrow \text{Si} 0 + 0$$
$$S i + O H \longrightarrow S i O + H.$$
For reaction (1) the rate coe GLYPH<14> cient (cm 3 s GLYPH<0> 1 )
$$k = 1. 7 2 \times 1 0 ^ { - 1 0 } ( T / 3 0 0 ) ^ { - 0. 5 3 } \exp ( - 1 7 / T )$$
was measured by Le Picard et al. (2001). The rate coe GLYPH<14> cient for reaction (2), which is not measured, was adopted to be the same.
Thus, the fractional abundance of SiO in the gas phase depends not only on the amount of Si sputtered from the grain cores but also on the abundances of O2 and OH, displayed in the lower panel of Fig. 4. The chemical delay in SiO production is apparent in the upper panel of Fig. 4; the abundance of SiO peaks in the cool and dense postshock region. If SiO is initially in the grain mantles (M3), its release is rapid and complete even before the temperature of the neutral fluid rises significantly. 5 For the shock models considered, all the SiO in the mantles is released into the gas phase. We have assumed that 10% of elemental silicon is initially in the form SiO in the mantles; this is the largest of the values considered by Gusdorf et al. (2008b). If the same fraction of silicon is initially in the form of SiH4 in the mantles, there occurs the same chemical delay in the production of SiO in the gas phase as in models M2.
## 4.2.2. Excitation of the SiO rotational lines
The di GLYPH<11> erences in the SiO abundance profiles in the three cases M1-3 - specifically, whether SiO is already present in the hot gas, early in the shock wave, or only in the cold postshock gas - have consequences for the relative intensities of the SiO rotational lines. To illustrate this point, we compare, in Fig. 5, the peak temperatures of the rotational lines of SiO, relative to the J = 5-4 transition, calculated for each of these three cases. The results in Fig. 5 may be better understood by referring to the line profiles, shown for the V s = 30 km s GLYPH<0> 1 shock in Fig. 7.
The first thing to note is the similarity of the relative peak line temperatures for the V s = 30 kms GLYPH<0> 1 and V s = 40 kms GLYPH<0> 1 models with only core sputtering (M2); this can be ascribed to the chemical delay in SiO formation. The rotational lines up to the 8-9 transition in these models mostly stem from the cold postshock gas, where almost maximum compression is reached. Therefore, the lines have large optical depths and near-LTE excitation conditions, which makes the relative peak temperatures of the transitions displayed independent of the shock velocity. The models with vaporization (M1), on the other hand, show a clear variation of excitation conditions with shock speed. The lines are
5 The threshold velocity for sputtering of the mantles is GLYPH<24> 10 GLYPH<22> GLYPH<0> 1 2 kms 1 , where GLYPH<0> GLYPH<22> is the reduced mass of the colliding species, relative to atomic hydrogen (Barlow 1978).
Fig. 5. The peak temperatures (K) of the rotational emission lines of SiO, relative to the J = 5-4 transition, as functions of the rotational quantum number of the upper level of the transition J up . Displayed are the shock models in our grid that are most strongly influenced by vaporization, i.e. V s = 20 km s GLYPH<0> 1 with b = 1 (blue), V s = 30 km s GLYPH<0> 1 with b = 1.5 (green), and V s = 40 km s GLYPH<0> 1 with b = 2 (red). Full lines: M1; dotted lines: M2; broken lines: M3.
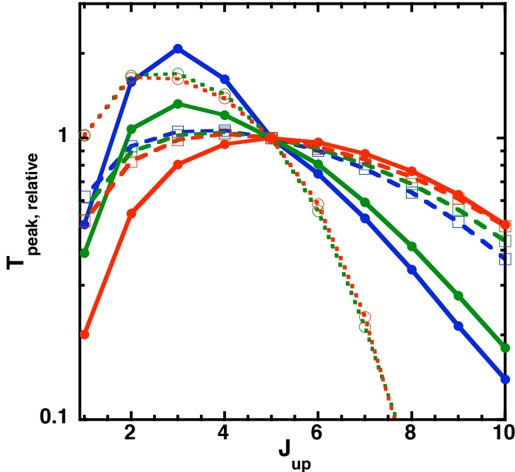
formed mainly in the cooling flow, where the temperature of the neutral fluid is a few hundred K (the case for V s = 30 km s GLYPH<0> 1 , J up > 4 and for V s = 40 kms GLYPH<0> 1 , J up > 2), and are sensitive to the velocity dependence of both the temperature in the cooling flow and the amount of SiO that is produced by vaporization.
For the models with SiO in the mantles (M3), the di GLYPH<11> erences in the relative peak line temperatures are much less between shocks of di GLYPH<11> erent velocities than is the case for models with vaporization. The same amount of SiO is released for both velocities and the column density of the cooling gas is greater than in models that include vaporization. Most of the radiation arises in the cooling flow, where the temperature profiles are very similar and the optical depths are large: for model M2, with V s = 30 km s GLYPH<0> 1 and b = 1.5, the transitions up to J = 7-6 become optically thick, with optical depths at the line centres reaching 1 GLYPH<24> < GLYPH<28> GLYPH<24> < 6, depending on the transition. We conclude that clear variations of the relative line intensities with the shock velocity are characteristic of those models in which grain vaporization occurs.
## 4.2.3. SiO rotational line profiles
Given that the excitation conditions of the SiO lines di GLYPH<11> er in the three scenarios M1-3, we expect the SiO spectral line profiles di GLYPH<11> er also, with respect to line width, location of the peak, and integrated flux. Line profiles for V s = 30 kms GLYPH<0> 1 , divided by the peak temperature of the J = 5-4 transition (except for the 5-4 transition itself), are shown in Fig. 6. Model M1 predicts narrower lines for lowJ transitions, but similar widths for highJ transitions, as model M2, and much narrower lines than model M3. There is a weak variation with J up of the location of the line peak in models M1 and M2. For M1, the peak in the profile of
Fig. 6. Profiles of the SiO rotational transitions (2-1), (3-2), (5-4), (6-5), (9-8), and (10-9), for V s = 30 kms GLYPH<0> 1 and b = 1.5. The line temperatures have been divided by the peak temperature of the (5-4) transition, except for the (5-4) transition itself, for which the absolute line profiles are given (for models M1 and M2; for model M3, the line temperature has been divided by a factor of 7 for the purposes of presentation). Full lines: M1; dotted lines: M2; broken lines: M3.
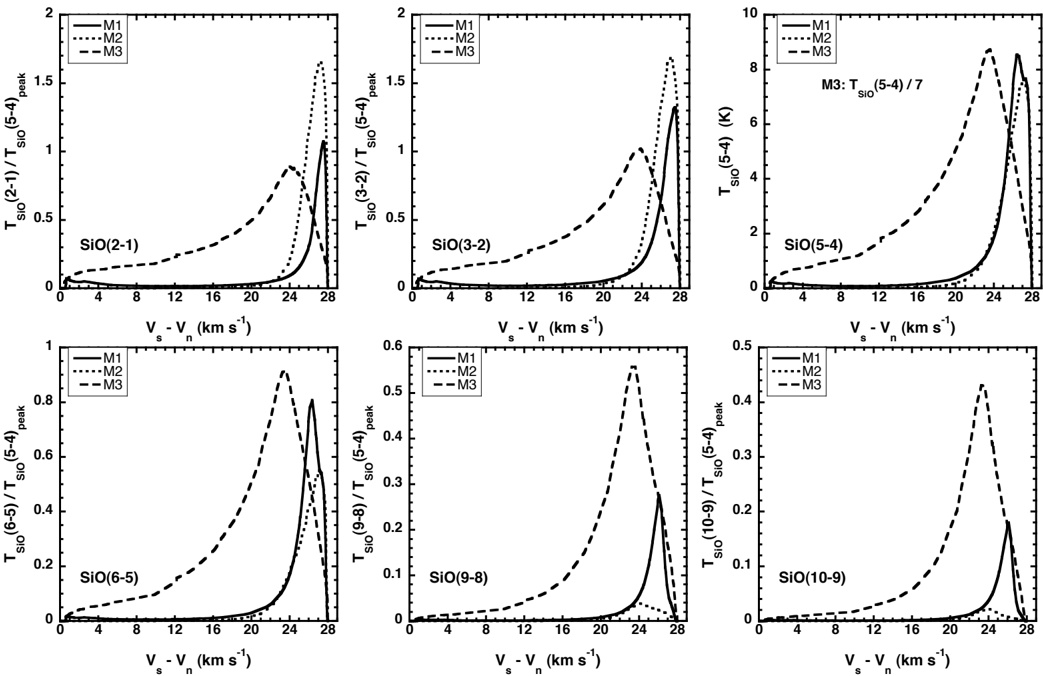
Fig. 7. Temperature profiles of the neutral fluid (left ordinate, broken curves) and SiO line temperatures (right ordinate, full curves) of the rotational transitions J = 2-1 (blue), 5-4 (green), and 9-8 (red) for V s = 30 kms GLYPH<0> 1 , b = 1.5; models M1 (left panel), M2 (centre panel), and M3 (right panel). The abscissa is the distance through the shock wave.
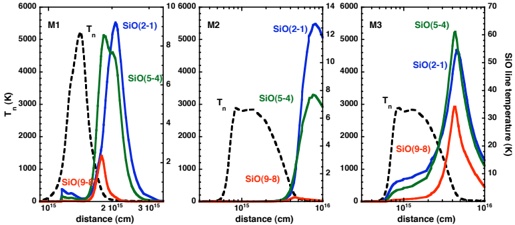
the lowest transition occurs in the cold posthock gas, where the neutral fluid is moving at a velocity V n GLYPH<24> 3 kms GLYPH<0> 1 , whereas, for higher transitions, the peak moves to hotter gas, at V n GLYPH<24> 4 km s GLYPH<0> 1 . A similar trend is seen for model M2, but, in this case, it is only the highest (and very weak) transitions that peak earlier in the shock wave. In contrast, the line peaks for model M3 are always located at the same velocity of V n GLYPH<24> 24 kms GLYPH<0> 1 . Thus, the di GLYPH<11> erences in shock structure and spatial distribution of SiO between models M1 and M2 do not have a strong e GLYPH<11> ect on the SiO rotational line profiles. In particular, the release of SiO through vaporization early in the shock wave does not lead to significant broadening of the lines . However, the lines are strongly broadened if SiO is present in the grain mantles (scenario M3), and this seems to be the only way of accounting for observed line widths of several tens of km s GLYPH<0> 1 if they are to be explained by one single shock. Alternatively, broad SiO lines can be explained by the existence of several shocks inside the telescope beam, such that the individual narrow line profiles appear spread out in radial velocity due to di GLYPH<11> erent velocities and inclination angles, in the observer's frame. Similarly, the lines would be broadened by the velocity profile associated with a bow shock (e.g. Brand et al. 1989).
## 4.2.4. Integrated SiO rotational line intensities
An interesting question is whether the release of SiO due to vaporization significantly increases the integrated (along the z -direction) SiO rotational line intensities. Fig. 8 shows, that indeed there is an increase in the intensities of the highly excited transitions. Furthermore, the slope of the integrated intensity curves di GLYPH<11> ers between models M1 and M2 for transitions 3 GLYPH<20> J up GLYPH<20> 10.
The integrated intensities of the lowest transitions -up to J up GLYPH<24> 7 - are dependent on the timescale for accretion of gas-phase species on to grains in the cooling flow; this
Fig. 8. Integrated intensities of the rotational transitions J up ! J up GLYPH<0> 1 of SiO for shocks with V s = 20 kms GLYPH<0> 1 , b = 1 (blue), V s = 30 kms GLYPH<0> 1 , b = 1.5 (green), and V s = 40 kms GLYPH<0> 1 , b = 2 (red). Full lines: model M1; dotted lines: model M2; broken lines: model M3.
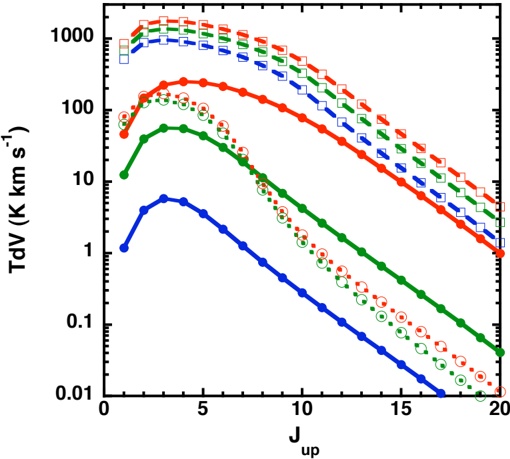
Fig. 9. Integrated intensities of the rotational transitions J up ! J up GLYPH<0> 1 of SiO, relative to the intensity of the transition with Jup = 5. The shock velocity is V s = 30 kms GLYPH<0> 1 , with values of the magnetic field parameter b = 1.5 (red), b = 2.0 (green) and b = 2.5 (blue). Full curves denote model M1, dotted curves model M2.
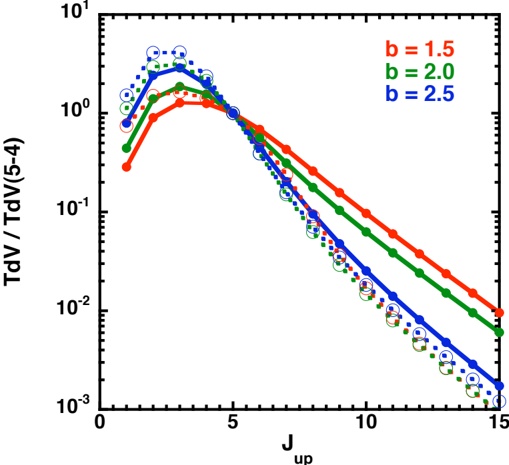
timescale depends on the (uncertain) accretion rates. In addition, 1-dimensional models tend to overestimate the compression of the postshock gas. Previous studies (Gusdorf et al. 2008a) have found the accretion timescale to be unimportant for the molecular line emission. However, owing to the large increase in the total grain cross-section, induced by vaporization, we see, for the first time, an observational consequence that may be related to this timescale.
Independent of the accretion timescale, the integrated intensities of, in particular, the lowest transitions increase significantly for model M3; but we recall that the amount of SiO in the mantles is treated as a free parameter, and the absolute intensities can be varied accordingly. The intensity curves corresponding to model M3 have similar slopes to the curves of model M1, for transitions from J up GLYPH<24> > 10; they peak at J up = 3. On the other hand, the peak of the curve corresponding to model M1 at V s = 40 km s GLYPH<0> 1 is displaced to J up = 4, owing to the higher maximum temperature. As may be seen from Fig. 8, the integrated line intensities decrease by a factor GLYPH<24> 100 between 5 GLYPH<20> J up GLYPH<20> 10 for model M2, which sets it apart from models M1 and M3.
Fig. 9 shows the e GLYPH<11> ect of variations in the magnetic field on the integrated SiO rotational line intensities. In this Figure, the integrated intensities are expressed relative to the 5-4 transition, in order to focus attention on the excitation conditions, rather than the release of SiO into the gas phase. For model M1, there is a clear variation with magnetic field strength, which is not present for model M2. This di GLYPH<11> erence can be understood from Fig. 2, which shows that the maximum temperature of the neutral fluid hardly varies with the magnetic field strength for model M2, whereas the maximum value changes for model M1. Thus, Fig. 9 demonstrates that the excitation conditions vary with the strength of the magnetic field when the e GLYPH<11> ects of grain-grain collisions are incorporated.
## 4.3. The effect of vaporization on [C I] emission
Our model, and the models of Papers I-III, includes two di GLYPH<11> erent populations of dust grains: silicate and carbon grains. While emission of SiO could be used as a tracer of vaporization in shocks because of the strong depletion of Si and SiO in quiescent gas, the e GLYPH<11> ects of vaporization on [C I] emission will not be seen as clearly. Nonetheless, the vaporization of graphite grains modifies the emission of atomic carbon. In order to predict the magnitude of this e GLYPH<11> ect, we have used the multi-fluid model of Paper III.
Fig. 3 (right-hand panel) shows the fraction of carbon released from grain cores by sputtering (M2) and vaporization (M1). At low velocities, the destruction of carbon grains is less than for silicates because the gyration of large carbon grains is damped more rapidly, owing to their lower specific density. At higher velocities, for which small grains also contribute significantly to vaporization, the fraction of carbon released from graphite grains is higher than the fraction of silicon from silicates; graphite grains are more strongly a GLYPH<11> ected by shattering. Table B.1 shows the intensities of two [C I] forbidden lines, at 609.8 GLYPH<22> mand 370.4 GLYPH<22> m. The values in these Tables confirm that the e GLYPH<11> ect of vaporization on the [C I] lines is less than on the SiO rotational transitions.
## 5. Concluding remarks
In this series of papers, the consequences of grain-grain collisions in shock waves have been investigated; such processes had been ignored in previous studies of C-type shocks. Shattering is a key factor in the production of the large populations of very small grains (mostly carbonaceous: see, for example, Draine & Lee 1984) in the turbulent ISM (Hirashita 2010). It has been shown, in earlier papers in the series, that C-type shock waves provide similar dynamical conditions to turbulence, and so shattering needs to be included in shock models.
Our study relies on the shattering model that was developed in Paper III, and our results inherit the dependence of this model on parameters such as the size of the smallest fragments (5Å in Paper III), the slope of the size distribution of the fragments, their charge distribution, and the composition of the dust grains. Whilst shattering almost certainly occurs in the ISM, as a direct consequence of the weak coupling of large grains to the magnetic field in high density clouds, the threshold density at which shattering starts to have a significant e GLYPH<11> ect on the shock dynamics is more uncertain.
In our model, the processes of shattering and vaporization are linked, so that the threshold density for shattering applies also to vaporization. The parameters of the shattering model in Paper III were chosen to minimize the amount of shattering and thereby yield a conservative estimate of the threshold density. It was shown that strong feedback on the shock dynamics was expected only for densities higher than GLYPH<24> 10 5 cm GLYPH<0> 3 . The results of the present paper include some observational predictions that should help to constrain the grain-shattering model. The main conclusions of our study are as follows:
- 1. The influence of grain-grain processing on the overall shock structure was found to be significant for the full range of magnetic field strengths that we studied. The maximum temperature increases by a factor of 1.5-2, and the shock width is reduced by a factor 4-5. The inclusion of grain-grain processing changes the dependence of the shock structure on the magnetic field strength. While for shocks without graingrain processing there is only a weak dependence of the peak temperature on the magnetic field, the peak temperature becomes strongly dependent on the magnetic field when grainshattering and vaporization are incorporated. Consequently, the intensities of, in particular, highly excited molecular transitions become dependent on the strength of the magnetic field. While shattering is shown to be important for all models of our grid, the vaporization of SiO from silicate grain cores is significant only for fast shocks and low magnetic fields.
- 2. There are two consequences of grain-grain processing for the molecular line emission: the reduced shock width results in a lower column density of shock-heated gas, whereas the higher peak temperature can modify the chemistry and enhance the fractional abundances of molecules in highly excited states. Which of these tendencies prevails is decided by the chemical and physical properties of the individual molecules and their transitions. The intensities of all lines of OHincrease in shocks with velocities greater than 30 km s GLYPH<0> 1 , when grain-grain processing is included, owing to the temperature sensitivity of OH formation. On the other hand, the intensities of the emission of CO and H2O decrease because of the reduced column density of shocked material. In the case of H2, the intensities of highly-excited transitions increase, whilst the intensities of lines of lower excitation decrease.
- 3. The release of SiO through collisional vaporization of silicate grain cores enhances the integrated intensities of SiO rotational lines, mainly from highly-excited levels. However, this e GLYPH<11> ect is counteracted by the reduction in shock width. To obtain significantly higher line intensities, it is necessary to introduce SiO into the grain mantles. The situation is similar with respect to the widths of the SiO rotational lines. Although vaporizations releases SiO early, in the hot part of the shock wave, the reduction in the shock width prevents the lines from becoming significantly broader than in mod-
els that neglect grain-grain processing. Therefore, vaporization alone cannot account for broad lines if only one single shock is considered. To obtain broad profiles, it seems necessary that SiO should be present in the grain mantles, such that mantle sputtering releases SiO, also in the early part of the shock wave. It is essential that SiO is released directly, thereby eliminating the chemical delay that would be associated with its production, in gas-phase reactions, from Si or SiH4.
Due to the fact, that most of the SiO emission stems from the early part of the shock, where the temperature profile depends on the shock velocity, the SiO rotational line ratios vary with the shock velocity; this variation is not present if vaporization is ignored. The e GLYPH<11> ect of vaporization on [C I] emission lines was found to be less than for the SiO rotational lines.
Acknowledgements. We are grateful to an anonymous referee for useful comments that helped to strengthen the paper. S. Anderl acknowledges support by the DFG SFB 956, the International Max Planck Research School (IMPRS) for Astronomy and Astrophysics, and the Bonn-Cologne Graduate School of Physics and Astronomy.
## References
- Andersen, M., Rho, J., Reach, W. T., Hewitt, J. W., & Bernard, J. P. 2011, ApJ, 742, 7
- Bachiller, R., Martin-Pintado, J., & Fuente, A. 1991, A&A, 243, L21
- Barlow, M. J. 1978, MNRAS, 183, 367
- Biermann, P. & Harwit, M. 1980, ApJ, 241, L105
- Borkowski, K. J. & Dwek, E. 1995, ApJ, 454, 254
- Brand, P. W. J. L., Toner, M. P., Geballe, T. R., & Webster, A. S. 1989, MNRAS, 237, 1009
- Cabrit, S., Codella, C., Gueth, F., & Gusdorf, A. 2012, A&A, 548, L2
- Cabrit, S., Codella, C., Gueth, F., et al. 2007, A&A, 468, L29
- Crutcher, R. M. 1999, ApJ, 520, 706
- Crutcher, R. M. 2012, ARA&A, 50, 29
- Davis, C. J., Froebrich, D., Stanke, T., et al. 2009, A&A, 496, 153
- Draine, B. T. 1980, ApJ, 241, 1021
- Draine, B. T. & Lee, H. M. 1984, ApJ, 285, 89
- Draine, B. T. & McKee, C. F. 1993, ARA&A, 31, 373
Flower, D. R. & Gusdorf, A. 2009, MNRAS, 395, 234
- Flower, D. R. & Pineau des Forˆ ets, G. 2003, MNRAS, 343, 390, (FPdF03)
Flower, D. R. & Pineau des Forˆ ets, G. 2010, MNRAS, 406, 1745, (FPdF10)
- Flower, D. R. & Pineau des Forˆ ets, G. 2012, MNRAS, 421, 2786
- Flower, D. R., Pineau des Forˆ ets, G., & Rabli, D. 2010, MNRAS, 409, 29
- Fortov, V. E., Ivlev, A. V., Khrapak, S. A., Khrapak, A. G., & Morfill, G. E. 2005, Phys. Rep., 421, 1
- Gueth, F., Guilloteau, S., & Bachiller, R. 1998, A&A, 333, 287
- Guillet, V., Jones, A. P., & Pineau des Forˆ ets, G. 2009, A&A, 497, 145, (Paper II)
- Guillet, V., Pineau des Forˆts, G., & Jones, A. P. 2007, A&A, 476, 263, (Paper I) e Guillet, V., Pineau des Forˆ ets, G., & Jones, A. P. 2011, A&A, 527, 123, (Paper III)
- Gusdorf, A., Cabrit, S., Flower, D. R., & Pineau des Forˆ ets, G. 2008a, A&A, 482, 809
- Gusdorf, A., Pineau des Forˆ ets, G., Cabrit, S., & Flower, D. R. 2008b, A&A, 490, 695
- Hirashita, H. 2010, MNRAS, 407, L49
- Hollenbach, D. & McKee, C. F. 1979, ApJS, 41, 555
- Ivlev, A. V., Lazarian, A., Tsytovich, V. N., et al. 2010, ApJ, 723, 612
- Jones, A. P., Tielens, A. G. G. M., & Hollenbach, D. J. 1996, ApJ, 469, 740
- Jones, A. P., Tielens, A. G. G. M., Hollenbach, D. J., & McKee, C. F. 1994, ApJ, 433, 797
- Le Picard, S. D., Canosa, A., Pineau des Forˆ ets, G., Rebrion-Rowe, C., & Rowe, B. R. 2001, A&A, 372, 1064
- Li GLYPH<11> man, K. & Clayton, D. D. 1989, ApJ, 340, 853
- Martin-Pintado, J., Bachiller, R., & Fuente, A. 1992, A&A, 254, 315 May, P. W., Pineau des Forˆ ets, G., Flower, D. R., et al. 2000, MNRAS, 318, 809 McKee, C. F. & Hollenbach, D. J. 1980, ARA&A, 18, 219 Nagahara, H. & Ozawa, K. 1996, GeCoA, 60, 1445 Nisini, B., Codella, C., Giannini, T., et al. 2007, A&A, 462, 163 Nissen, H. D., Gustafsson, M., Lemaire, J. L., et al. 2007, A&A, 466, 949
- O'Donnell, J. E. & Mathis, J. S. 1997, ApJ, 479, 806
Planck Collaboration. 2011, A&A, 536, 24 Schilke, P., Walmsley, C. M., Pineau des Forets, G., & Flower, D. R. 1997, A&A, 321, 293 Seab, C. G. & Shull, J. M. 1983, ApJ, 275, 652 Slavin, J. D., Jones, A. P., & Tielens, A. G. G. M. 2004, ApJ, 614, 796 Surdej, J. 1977, A&A, 60, 303 Tielens, A. G. G. M., McKee, C. F., Seab, C. G., & Hollenbach, D. J. 1994, ApJ, 431, 321 Van Loo, S., Ashmore, I., Caselli, P., Falle, S. A. E. G., & Hartquist, T. W. 2013, MNRAS, 428, 381 Wang, J., Davis, A. M., Clayton, R. N., & Hashimoto, A. 1999, Geochim. Cosmochim. Acta, 63, 953 Wilgenbus, D., Cabrit, S., Pineau des Forˆ ets, G., & Flower, D. R. 2000, A&A, 356, 1010
## Appendix A: Shattering and vaporization: their implementation and validation
A.1. Shattering
## A.1.1. Dynamical effects of shattering
The dynamical e GLYPH<11> ects of shattering on the shock structure can be simulated by ensuring that the total grain cross section, h n GLYPH<27> i , changes in accord with the results of Paper III. We found that it is possible to model the increase of h n GLYPH<27> i due to shattering by multiplying the total grain cross section, in the absence of graingrain processing, by an additional factor, which varies with the spatial coordinate, z , through the shock wave. This factor is modelled as an intrinsic function of the compression of the ion fluid, normalized to the theoretical postshock compression at infinity, as predicted by the Rankine-Hugoniot relations. This normalized ion compression parameter constitutes a function, GLYPH<17> ( z ), varying from 0 in the preshock to 1 in the postshock medium.
The preshock (medium 1) and postshock (medium 2) kinetic temperatures are approximately equal in the C-type shock models of our grid. Thus, the Rankine-Hugoniot continuity relations may be applied across the shock wave, replacing the relation of conservation of energy flux by the isothermal condition, T 1 = T 2 . Then, setting the ratio of specific heats GLYPH<13> = 1, the expression for the compression ratio, GLYPH<26> 2 =GLYPH<26> 1 , across the shock wave may be derived (cf. Draine & McKee 1993). Under the conditions of our models, which are such that Ms = V s = c 1 GLYPH<29> MA = V s = V A GLYPH<29> 1, where Ms is the sonic Mach number of the flow, evaluated in the preshock gas, c 1 is the sound speed, and MA is the Alfv´nic e Mach number, also in the preshock gas, the compression ratio reduces to GLYPH<26> 2 =GLYPH<26> 1 GLYPH<25> p 2MA, whence
$$V _ { \text{postshock} } & = \frac { V _ { A } } { \sqrt { 2 } } = \frac { B } { \sqrt { 2 \times 4 \pi \, 1. 4 \, m _ { H } n _ { H } } } \, & ( A. 1 ) \quad \text{information} \\ & \quad \text{of both 1} \\ & \quad \text{with $1w$}.$$
where V postshock is the flow speed in the postshock gas, m H the proton mass and n H = n (H) + 2 n (H2) the proton density in the preshock gas. Using
$$\eta ( z ) & = \frac { V _ { s } / V _ { i } ( z ) - 1 } { V _ { s } / V _ { \text{postshock} } - 1 } & & ( A. 2 ) & \text{The char} \\ & & & \text{tering, h}$$
(where V s is the shock velocity and V i the velocity of the ion fluid in the shock frame, respectively), the factor by which the total grain cross section is enhanced is given by
$$\Sigma ( z ) & = \eta ( z ) \cdot ( \Sigma _ { \max } - 1 ) + 1 \,. & ( A. 3 ) \quad \text{known } \varepsilon$$
The extent of the increase of h n GLYPH<27> i due to shattering is given by the final value of the shattering-factor, GLYPH<6> max. This value depends on the shock velocity and the magnetic field and is an external parameter, which needs to be extracted from the multifluid models. However, this simple functional form did not reproduce satisfactorily the onset of shattering in the shock. We therefore propose the following refined expression
$$\prod _ { \text{$1.w. } 2 0 1 3, } ^ { 1 9 9 4, \, \text{APJ}, } \ \Sigma = \left ( \eta ^ { \beta } - \frac { \sin { ( 2 \pi \, \eta ^ { \beta } ) } } { 2 \pi } \right ) \cdot \left ( \Sigma _ { m a x } - 1 \right ) + 1 \quad & \quad ( A. 4 )$$
that introduces another parameter, GLYPH<12> , which needs to be extracted from the corresponding multi-fluid model. GLYPH<12> describes the delay in the shattering feedback, relative to the ion compression, and is only weakly dependent on the shock velocity. The parameters, GLYPH<12> and GLYPH<6> max, which correspond to the grid of models introduced in Section 3.1, are listed in Table A.1. Linear fits in the shock velocity V s and the magnetic field parameter b are
$$\Sigma _ { m a x } = 9. 5 + 0. 4 \cdot V _ { s } - 4. 6 \cdot b & & ( A. 5 )$$
and
$$\omega _ { s } \, \infty \, \begin{array} { c } \beta = 0. 9 5 - 0. 0 2 5 \cdot V _ { s } + 0. 4 \cdot b \end{array}.$$
The increase of the total grain collisional cross-section needs to be consistent with the mean square radius of the grains and with their total number density, following the compression of the ions. Analyzing the multi-fluid computations corresponding to Paper III, we find a reasonable approximation to the behaviour of the total grain number density, n G, and the mean square radius, h GLYPH<27> i G: the former increases as GLYPH<6> 4 , the latter decreases as GLYPH<6> GLYPH<0> 3 , relative to the corresponding values without shattering. These changes affect the rates of grain-catalyzed reactions, adsorption to the grain mantles, excitation of H2 in collisions with grains, and transfer of momentum and thermal and kinetic energy between the neutral and the charged fluids.
Figure A.1 shows a comparison between the multi-fluid model of Paper III and our current model 6 for a representative shock for which n H = 10 5 cm GLYPH<0> 3 , V s = 30 km s GLYPH<0> 1 and b = 1.5. The temperature profiles of the neutral fluid agree well. Furthermore, the variation of the total grain-core cross-section is reproduced by our simulation, as may be seen from the lower panel of Figure A.1. The total grain cross-section (including mantles) increases somewhat later in our current model, due to small differences - independent of grain shattering -with the model of Paper III. The discrepancy in the value of the grain cross-section in the postshock medium arises because our simplified treatment of shattering tends to underestimate the final number density of small grains. However, this simplification introduces only small deviations in the hydrodynamic parameters, such that the values of both the peak temperature of the neutral fluid and the shock width (up to 100 K in the cooling flow) agree to within GLYPH<6> GLYPH<24> 15 % for the entire grid of models incorporating shattering.
## A.1.2. Chemical effect of shattering
The change in the total grain cross-section, h n GLYPH<27> i , owing to shattering, has consequences for the rates of grain-charging reactions. In order to model the e GLYPH<11> ect of shattering on the abundances of charged grains, the corresponding chemical source term needs to be introduced.
The charge distribution of the fragments is essentially unknown and cannot be numerically integrated separately from
6 In order to make a direct comparison with the results of Paper III, it is necessary to disable the LVG treatment of molecular line transfer in our current model.
Fig. A.1. Upper panel: temperature profiles of the neutral fluid for a shock with n H = 10 5 cm GLYPH<0> 3 , V s = 30 kms GLYPH<0> 1 and b = 1.5 corresponding to Paper III (in blue) and our current model (in red). Lower panel: evolution of the total grain cross section, h n GLYPH<27> i , for the same shock models, with and without taking into account the grain mantles and normalized to the preshock values of h n GLYPH<27> i .
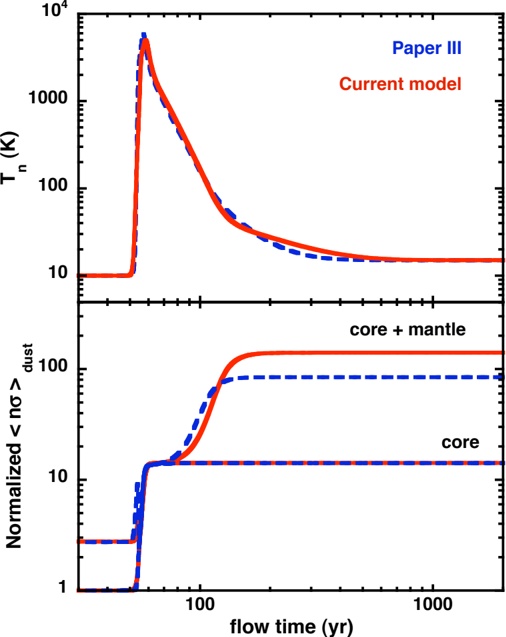
Table A.1. Parameters relating to the modification by shattering of the total grain cross-section, h n GLYPH<27> i and to SiO vaporization, for the grid of multi-fluid models introduced in Section 3.1.
| V s [kms GLYPH<0> 1 ] | b | B [ GLYPH<22> G] | GLYPH<6> max | GLYPH<12> | x (SiO peak ) |
|-------------------------|-----|--------------------|----------------|-------------|------------------------------|
| 20 | 1 | 316 | 11.7 | 0.8 | 1.53 GLYPH<1> 10 GLYPH<0> 8 |
| 20 | 1.5 | 474 | 10.5 | 1.1 | 1.99 GLYPH<1> 10 GLYPH<0> 17 |
| 20 | 2 | 632 | 8.5 | 2 | 2.16 GLYPH<1> 10 GLYPH<0> 19 |
| 30 | 1.5 | 474 | 14.2 | 0.8 | 1.55 GLYPH<1> 10 GLYPH<0> 7 |
| 30 | 2 | 632 | 11.7 | 0.9 | 7.92 GLYPH<1> 10 GLYPH<0> 9 |
| 30 | 2.5 | 791 | 10.5 | 1.2 | 5.63 GLYPH<1> 10 GLYPH<0> 13 |
| 40 | 2 | 632 | 18.4 | 0.8 | 9.13 GLYPH<1> 10 GLYPH<0> 7 |
| 40 | 2.5 | 791 | 13.7 | 0.9 | 3.43 GLYPH<1> 10 GLYPH<0> 7 |
| 40 | 3 | 949 | 11.4 | 1.1 | 1.34 GLYPH<1> 10 GLYPH<0> 7 |
that of grains already present in the medium. In the present paper , the charge distribution of fragments is designed to ensure 7
7 The situation was more complicated in Paper III, which dealt with a full grain size distribution. Fragments were allocated to the size bins corresponding to their individual mass, while the corresponding mass was removed from the projectile and target size bins. This procedure does not allow for charge conservation, because small grains carry much more (negative) charge per unit mass than large grains. To compensate for this charge excess, the charge distributions of all grain sizes was
charge conservation. We fitted the fragment charge distribution by aligning the shock widths (see Fig. A.1, upper panel). This procedure yielded a charge distribution in which 1 2 of the frag-/ ments were neutral, and 1 4 were positively and 1 4 negatively / / charged, following shattering. Subsequently, the grain charge distribution evolved on a timescale that can be long - of the order of the flow time through the shock wave when the mean grain size becomes very small.
The source term for the creation of grains through shattering can be derived from the equation of conservation of the total flux of grains, in the absence of shattering,
$$\overline { \longrightarrow } \sum _ { j \in [ G 0, G +, G - \} } n _ { j } \cdot V _ { j } \cdot \Sigma ^ { - 4 } ( z ) = \text{constant}$$
where n G0 is the number density of neutral grains, n G + ; G GLYPH<0> are the number densities of positively and negatively charged grains, respectively, V G0 = V n is the velocity of the neutral grains, in the shock frame, and V G + ; G GLYPH<0> = V i is the velocity of the charged grains, in the shock frame. Di GLYPH<11> erentiation of (A.7), subject to the charge distribution of the fragments, then yields
$$\frac { d n _ { G 0 } } { d z } \Big | _ { \text{shat} } = \frac { 1 } { 2 } \cdot 4 \cdot n _ { G, \text{preshock} } \frac { V _ { s } } { V _ { n } } \cdot \Sigma ^ { 3 } \cdot \frac { d \Sigma } { d z }$$
for the neutral grains, and
$$\overline { 0 } \quad \frac { d n _ { G +, G - } } { d z } \Big | _ { \text{shat} } = \frac { 1 } { 4 } \cdot 4 \cdot n _ { G, \text{preshock} } \frac { V _ { s } } { V _ { i } } \cdot \Sigma ^ { 3 } \cdot \frac { d \Sigma } { d z }$$
for the charged grains, where n G preshock ; is the total (charged and neutral) number density of grains in the preshock gas. The derivative of GLYPH<6> is given by
$$\inf _ { k \text{ values} } \frac { d \Sigma } { d z } = \left ( \frac { d } { d z } \eta ^ { \beta } - \cos \left ( 2 \pi \eta ^ { \beta } \right ) \frac { d } { d z } \eta ^ { \beta } \right ) \left ( \Sigma _ { \max } - 1 \right ) \quad \text{(A.10)}$$
where
$$\text{attering} \quad \frac { d } { d z } \eta = \beta \, \eta ^ { ( \beta - 1 ) } \frac { d \eta } { d z }$$
and
$$\frac { 1 } { 8 } \frac { 1 } { d z } = - \frac { 1 } { ( V _ { s } / V _ { \text{postshock} } - 1 ) } \frac { V _ { s } } { V _ { i } ^ { 2 } } \frac { d V _ { i } } { d z }.$$
With these parameters, our model is able to reproduce the main e GLYPH<11> ects of the increase in the grain cross section, reported in Paper III: the e GLYPH<11> ective rate of recombination of electrons and ions is enhanced; the fractional abundance of free electrons falls by three orders of magnitude; and dust grains become the dominant charge carriers, with equal numbers of positively and negatively charged grains being produced.
## A.2. Vaporization
The e GLYPH<11> ect of vaporization is modelled as an additional term in the creation rate of gas-phase SiO, from Si and O in grain cores (denoted by **), corresponding to a new type of pseudochemical reaction:
$$\underset { \cdot } { \text{ure} } \ \ S i ^ { * * } \ + \ 0 ^ { * * } \ = \ S i 0 \ + \ GRAIN$$
shifted infinitesimally at each shattering event to ensure charge conservation.
Because vaporization sets in suddenly, when the vaporization threshold is reached, the function
$$\Omega ( z ) = \frac { 1 } { 1 + \exp \left ( - 1 0 ^ { 3 } \cdot \left ( V _ { s } / V _ { 1 } ( z ) - V _ { s } / 6 V _ { \text{postshock} } \right ) \right ) } \quad ( A. 1 3 )$$
can be used to approximate the rate of creation of SiO. The function GLYPH<10> ( z ) is centred at the point where the compression of the charged fluid reaches 1 = 6 of its final value, as determined by our fitting procedure. Similarly, the factor 10 3 in the exponent, which determines the steepness of the function, derives from a fit to the numerical results of Paper III. Using this function, the creation rate (cm GLYPH<0> 3 s GLYPH<0> 1 ) can be expressed as
$$\frac { d n ( \text{SiO} ) } { d t } \Big | _ { \text{vapo} } \, = \, \frac { d \Omega ( z ) } { d t } \cdot n _ { \text{H} } \cdot x ( \text{SiO} ) _ { \text{peak} }$$
$$= \, \frac { d \Omega ( z ) } { d z } \cdot V _ { s } \cdot n _ { H, p r e s h o c k } \cdot x ( S i O ) _ { p e a k } \,, \quad ($$
$$\frac { d n ( S i O ) } { d t } \Big | _ { \varphi o } & = \ \frac { d \Omega ( z ) } { d t } \cdot n _ { H } \cdot x ( S i O ) _ { \text{peak} } & ( A. 1 4 ) & \quad 1 0 \cdot \\ & = \ \frac { d \Omega ( z ) } { d z } \cdot V _ { n } \cdot n _ { H } \cdot x ( S i O ) _ { \text{peak} } & ( A. 1 5 ) & \quad 1 0 \cdot \\ & = \ \frac { d \Omega ( z ) } { d z } \cdot V _ { s } \cdot n _ { H, \text{preshock} } \cdot x ( S i O ) _ { \text{peak} } \, & ( A. 1 6 ) & \quad \text{Fig. A.}$$
where use is made of the conservation of the flux of n H, and where
$$\frac { d } { d z } \Omega ( z ) = - \Omega ( z ) \cdot \left ( 1 - \Omega ( z ) \right ) \cdot 1 0 ^ { 3 } \frac { V _ { s } } { V _ { i } ^ { 2 } } \cdot \frac { d V _ { i } } { d z } \,. \quad \quad ( A. 1 7 ) \quad = 1. 5. \, T I \\ \text{curves} ; \, \imath$$
The spatial change in number density of SiO, owing to vaporization, is then given by
$$\frac { d n ( S i O ) } { d z } \Big | _ { \text{vapo} } = \left ( \frac { d n ( S i O ) } { d t } \Big | _ { \text{vapo} } - n ( S i O ) \frac { d V _ { n } } { d z } \right ) \frac { 1 } { V _ { n } } \, \quad \quad ( A. 1 8 )$$
The peak fractional abundance x (SiO)peak needs to be computed with the multi-fluid model and constitutes a free parameter, given in Table A.1 for our grid of models. As can be seen in Table A.1, vaporization of SiO is relevant only for the shocks with high velocity and low magnetic field; it can be neglected for the shocks with V s = 20 kms GLYPH<0> 1 and b = 1.5, b = 2, as well as for the model with V s = 30 km s GLYPH<0> 1 and b = 2.5 .
Figure A.2 shows the result of our implementation of vaporization. We assume that, initially (in the preshock medium), there are no Si-bearing species, either in the gas phase or in the grain mantles; all the Si is contained in olivine (MgFeSiO4) grain cores. This Figure compares the fractional abundance of SiO, as computed with our current model (incorporating grain-grain processing) and as predicted by the multi-fluid model of Paper III. By construction, the peaks of the fractional abundance of SiO agree, whereas the timescale for its accretion on to grains di GLYPH<11> ers between the two models, as is visible in the plot; this discrepancy relates to the imperfect agreement of the total crosssection, h n GLYPH<27> i , in the postshock medium (see Fig. A.1). However, we have verified that the timescale for SiO accretion is not critical to our analysis: the complete neglect of accretion on to grains leads to increases in the integrated intensities of the lowest rotational transitions of SiO and CO, by factors of GLYPH<24> 2 and GLYPH<24> 3, respectively. We note that the intensities of these transitions are, in any case, a GLYPH<11> ected by the foreground emission of ambient, nonshocked gas.
## Appendix B: Molecular line emission
The introduction of shattering leads to a reduction of the shock width, and hence to lower column densities of shocked material,
Fig. A.2. The fractional abundance of SiO (full curves), as determined when including grain-grain processing, using the present model (in red) and the multi-fluid model of Paper III (in blue); the shock parameters are n H = 10 5 cm GLYPH<0> 3 , V s = 30 km s GLYPH<0> 1 and b = 1.5. The temperature of the neutral fluid is shown also (broken curves; right-hand ordinate).
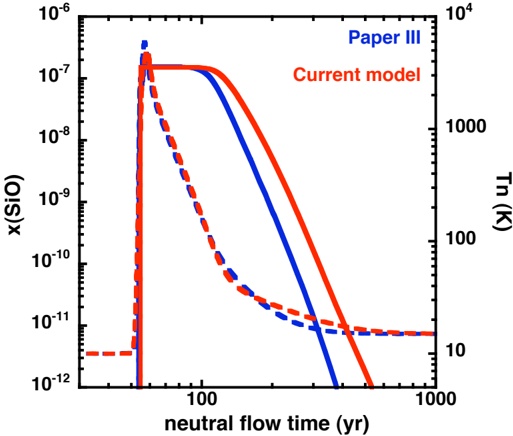
Fig. B.1. Computed H2 excitation diagrams for rovibrational levels with energies E v ; J GLYPH<20> 10 000 K and for shocks with n H = 10 5 cm GLYPH<0> 3 , V s = 30 kms GLYPH<0> 1 and b = 1.5 (red), b = 2.0 (green) and b = 2.5 (blue). Full lines: model M1; dotted lines: model M2.
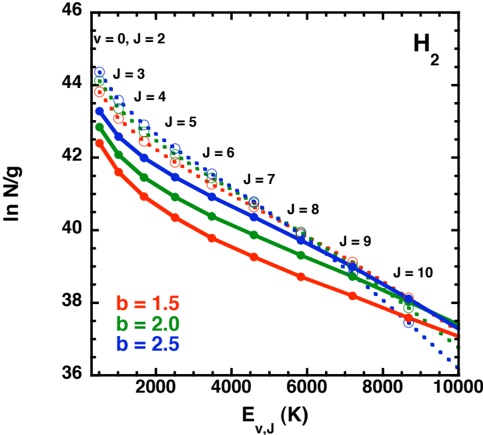
and to higher peak temperatures, which a GLYPH<11> ect the chemistry and enhance the fractional abundances of molecules in excited states. Which of these e GLYPH<11> ects prevails is determined by the chemical and spectroscopic properties of the individual molecular species.
## B.1. H 2
The intensities of pure rotational and ro-vibrational lines of H2 contain key information on the structure of C-type shock waves,
Fig. B.2. Integrated intensities of the rotational transitions J up ! J up GLYPH<0> 1 of CO for shocks with n H = 10 5 cm GLYPH<0> 3 , V s = 30 kms GLYPH<0> 1 and b = 1.5 (red), b = 2.0 (green) and b = 2.5 (blue). Full lines: model M1; dotted lines: model M2.
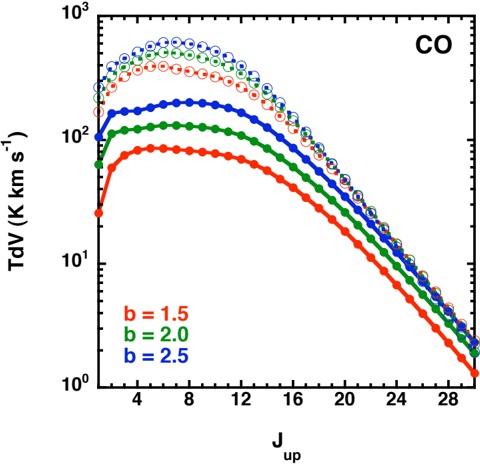
Fig. B.3. Integrated intensities of selected rotational transitions of ortho-H2O plotted against the excitation energy of the emitting level, expressed relative to the energy of the J = 0 = K ground state of para-H2O. Results are shown for shocks with n H = 10 5 cm GLYPH<0> 3 , V s = 30 kms GLYPH<0> 1 and b = 1.5 (red), b = 2.0 (green) and b = 2.5 (blue). Full circles: model M1; open circles: model M2.
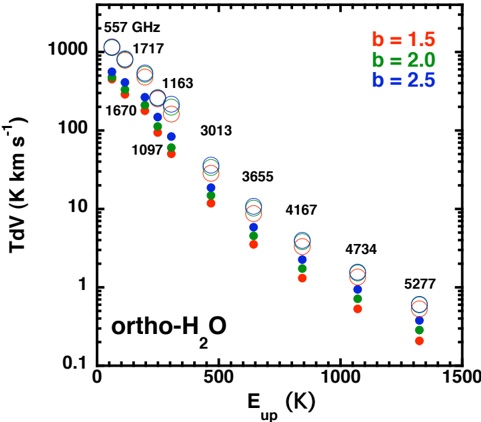
as was demonstrated, for example, by Wilgenbus et al. (2000). These lines are optically thin, and their intensities are integrated in parallel with the shock structure, neglecting radiative transfer.
As may be seen from Fig. B.1, the introduction of shattering leads to a reduction in the computed column densities of the lowest rotational levels of H2, by approximately an order of magnitude. With increasing energy of the emitting level, the effect of the decrease in the shock width is compensated by the
Fig. B.4. Integrated intensities of the rotational transitions of OH for emitting levels of negative parity, plotted against the excitation energy of the upper level. Results are shown for shocks with V s = 30 kms GLYPH<0> 1 and b = 1.5 (red), b = 2.0 (green) and b = 2.5 (blue). Full circles: model M1; open circles: model M2.
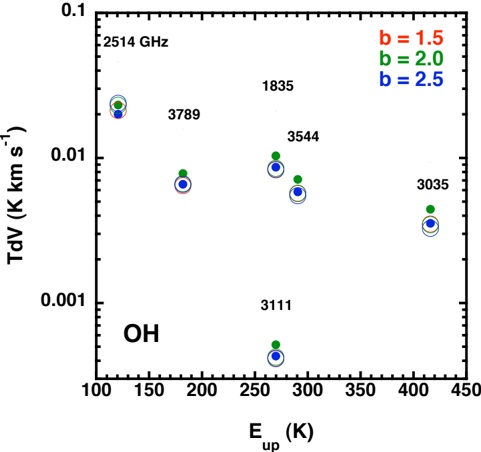
higher peak temperature, and the column densities predicted by the models that include shattering eventually exceed those calculated neglecting shattering. The change-over occurs at energies of the emitting level of GLYPH<24> > 6000 K for V s = 20 kms GLYPH<0> 1 , GLYPH<24> > 7000 K for V s = 30 km s GLYPH<0> 1 , and GLYPH<24> > 10,000 K for V s = 40 km s GLYPH<0> 1 , with the exact values depending on the magnetic field strength. The computed intensities of selected lines of H2 are given in Table B.1, together with the intensities of forbidden lines of atomic oxygen (63 GLYPH<22> m and 147 GLYPH<22> m), of atomic sulfur (25 GLYPH<22> m) and of [C I] (610 GLYPH<22> mand 370 GLYPH<22> m).
## B.2. CO, H O and OH 2
Figure B.2 shows the integrated line intensities, TdV , of the rotational transitions of CO, plotted against the rotational quantum number, J , of the emitting level for shocks with n H = 10 5 cm GLYPH<0> 3 and V s = 30 km s GLYPH<0> 1 . The line intensities, which are listed in Tables B.2-B.4, are lower when shattering is included, owing to the reduction in the shock width; this e GLYPH<11> ect is most pronounced at low magnetic field strengths. While the intensities computed with models M2 peak at around J up = 7, those of models M1 peak at higher values of J up and exhibit a plateau extending to J up GLYPH<25> 12. These di GLYPH<11> erences reflect the corresponding excitation conditions. As in the case of SiO (see Sect. 4.2), the peak temperature shows a stronger dependence on the strength of the magnetic field in models that include grain-grain processing. Accordingly, the integrated intensities of highly excited transitions vary with b for models M1.
Similarly to CO, the intensities of lines of H2O also become weaker when shattering is included, owing to the reduced shock width. Figure B.3 shows the computed intensities of the lines of ortho-H2O as a function of the excitation energy of the emitting level. The intensities of all the lines of ortho- and para-H2O that fall in the Herschel PACS HIFI bands are listed in Tables B.6-/ / B.11.
Fig. B.5. The rate of cooling by the principal molecular coolants, H2 (mauve), H2O (green), CO (blue) and OH (red) for V s = 40 km s GLYPH<0> 1 and b = 2 for model M1 (left panel) and M2 M3 / (right panel), which are shown together because the presence of SiO in grain mantles does not a GLYPH<11> ect the cooling of the shock wave. Note the di GLYPH<11> erent distance intervals on the x -axes.
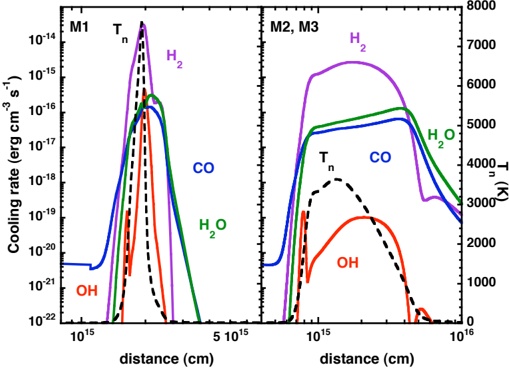
Contrary to the behaviour of CO and H2O, the line intensities of OH become stronger for the 30 km s GLYPH<0> 1 and 40 km s GLYPH<0> 1 shocks when shattering is included, as may be seen for V s = 30 kms GLYPH<0> 1 in Figure B.4. The lines displayed fall within the Herschel PACS / band; their emitting levels have negative parity. The intensities of all transitions of OH observable with Herschel are listed in Table B.5. The increase in the integrated intensities in models M1 is due to the higher peak temperatures, which favour the conversion of the gas-phase oxygen that is not bound in CO into OH. Again, we see a variation of the integrated line intensities with the magnetic field strength in models M1, associated with the temperature-dependent rate of OH formation.
On the basis of these findings, it is interesting to ask how the allowance for grain-grain processing a GLYPH<11> ects the radiative cooling of the medium. Although the narrower shock width, and hence larger velocity gradients, in scenario M1 might be expected to modify the optical thickness of the lines, and thereby their rate of cooling, we do not detect such an e GLYPH<11> ect in our models, as is demonstrated by Fig. B.5. Instead, we see an increase in the contribution of OH to the rate of cooling, owing to the enhanced abundance of gas-phase OH in the hot shocked medium (see the lower panel of Fig. 4).
Table B.1. Selected H2, [OI], [CI], and [SI] line intensities (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ), for shocks with velocities V s = 20 kms GLYPH<0> 1 (top), V s = 30 kms GLYPH<0> 1 (middle), and V s = 40 kms GLYPH<0> 1 (bottom) and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | v20b1, M1 | (v20b1, M2) | v20b1.5, M1 | (v20b1.5, M2) | v20b2, M1 | (v20b2, M2) |
|----------------------------|----------------------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| H 2 0-0 S(0) | 28.22 | 1.87e-06 | (6.80e-06) | 3.33e-06 | (9.44e-06) | 5.98e-06 | (1.01e-05) |
| H 2 0-0 S(1) | 17.04 | 9.59e-05 | (3.48e-04) | 0.000174 | (4.50e-04) | 0.000331 | (4.84e-04) |
| H 2 0-0 S(2) | 12.28 | 0.000169 | (5.85e-04) | 0.000306 | (6.96e-04) | 0.000588 | (7.45e-04) |
| H 2 0-0 S(3) | 9.66 | 0.00155 | (4.79e-03) | 0.00273 | (5.17e-03) | 0.00492 | (5.46e-03) |
| H 2 0-0 S(4) | 8.02 | 0.00111 | (2.89e-03) | 0.00185 | (2.79e-03) | 0.00293 | (2.85e-03) |
| H 2 0-0 S(5) | 6.91 | 0.00564 | (1.14e-02) | 0.00848 | (9.63e-03) | 0.0107 | (9.23e-03) |
| H 2 0-0 S(6) | 6.11 | 0.00257 | (3.65e-03) | 0.00333 | (2.66e-03) | 0.00297 | (2.26e-03) |
| H 2 0-0 S(7) | 5.51 | 0.00875 | (7.71e-03) | 0.00909 | (4.78e-03) | 0.0049 | (3.35e-03) |
| H 2 1-0 S(1) | 2.12 | 0.00102 | (2.17e-04) | 0.000412 | (1.00e-04) | 8.82e-05 | (5.43e-05) |
| OI 2p 4 3 P 1 ! 2p 4 3 P 2 | 63.1 | 3.72e-06 | (3.93e-06) | 1.03e-05 | (7.57e-06) | 2.02e-05 | (1.27e-05) |
| OI 2p 4 3 P 0 ! 2p 4 3 P 1 | 145.5 | 2.66e-07 | (2.74e-07) | 7.44e-07 | (5.32e-07) | 1.45e-06 | (9.06e-07) |
| CI 3 P 1 ! 3 P 0 | 609.75 | 4.84e-11 | (1.11e-10) | 2.21e-10 | (3.36e-10) | 4.68e-10 | (6.45e-10) |
| CI 3 P 2 ! 3 P 1 | 370.37 | 4.05e-11 | (3.40e-10) | 1.23e-10 | (7.04e-10) | 3.12e-10 | (1.24e-09) |
| SI 3P J = 1 ! 3P J = 2 | 25.25 | 2.81e-05 | (7.03e-05) | 3.71e-05 | (9.61e-05) | 8.44e-05 | (1.21e-04) |
| Transition | GLYPH<21> ( GLYPH<22> m) | v30b1.5, M1 | (v30b1.5, M2) | v30b2, M1 | (v30b2, M2) | v30b2.5, M1 | (v30b2.5, M2) |
|----------------------------|----------------------------|---------------|-----------------|-------------|---------------|---------------|-----------------|
| H 2 0-0 S(0) | 28.22 | 2.13e-06 | (8.83e-06) | 3.34e-06 | (1.19e-05) | 5.19e-06 | (1.52e-05) |
| H 2 0-0 S(1) | 17.04 | 0.000108 | (4.77e-04) | 0.000176 | (6.31e-04) | 0.00029 | (7.91e-04) |
| H 2 0-0 S(2) | 12.28 | 0.00019 | (8.79e-04) | 0.000324 | (1.13e-03) | 0.000554 | (1.38e-03) |
| H 2 0-0 S(3) | 9.66 | 0.00177 | (8.14e-03) | 0.00313 | (1.01e-02) | 0.00543 | (1.19e-02) |
| H 2 0-0 S(4) | 8.02 | 0.00129 | (5.68e-03) | 0.00234 | (6.78e-03) | 0.00403 | (7.57e-03) |
| H 2 0-0 S(5) | 6.91 | 0.00687 | (2.71e-02) | 0.0126 | (3.04e-02) | 0.0206 | (3.15e-02) |
| H 2 0-0 S(6) | 6.11 | 0.00331 | (1.10e-02) | 0.00596 | (1.13e-02) | 0.00899 | (1.06e-02) |
| H 2 0-0 S(7) | 5.51 | 0.0127 | (3.20e-02) | 0.0215 | (2.88e-02) | 0.0283 | (2.32e-02) |
| H 2 1-0 S(1) | 2.12 | 0.00692 | (3.42e-03) | 0.00482 | (2.32e-03) | 0.00293 | (1.40e-03) |
| OI 2p 4 3 P 1 ! 2p 4 3 P 2 | 63.1 | 4e-06 | (4.40e-06) | 8.05e-06 | (7.18e-06) | 1.4e-05 | (1.13e-05) |
| OI 2p 4 3 P 0 ! 2p 4 3 P 1 | 145.5 | 2.87e-07 | (2.79e-07) | 5.76e-07 | (4.67e-07) | 1.01e-06 | (7.37e-07) |
| CI 3 P 1 ! 3 P 0 | 609.75 | 1.88e-10 | (1.24e-10) | 1.85e-10 | (3.04e-10) | 3.66e-10 | (5.24e-10) |
| CI 3 P 2 ! 3 P 1 | 370.37 | 1.18e-09 | (3.98e-10) | 1.09e-10 | (6.58e-10) | 2.01e-10 | (9.67e-10) |
| SI 3P J = 1 ! 3P J = 2 | 25.25 | 0.000393 | (6.10e-04) | 0.000256 | (7.34e-04) | 0.000156 | (8.24e-04) |
| Transition | GLYPH<21> ( GLYPH<22> m) | v40b2, M1 | (v40b2, M2) | v40b2.5, M1 | (v40b2.5, M2) | v40b3, M1 | (v40b3, M2) |
|----------------------------|----------------------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| H 2 0-0 S(0) | 28.22 | 3.54e-06 | (1.08e-05) | 3.6e-06 | (1.35e-05) | 5.02e-06 | (1.65e-05) |
| H 2 0-0 S(1) | 17.04 | 0.000146 | (5.81e-04) | 0.000181 | (7.26e-04) | 0.000273 | (8.79e-04) |
| H 2 0-0 S(2) | 12.28 | 0.000203 | (1.07e-03) | 0.000321 | (1.34e-03) | 0.000521 | (1.62e-03) |
| H 2 0-0 S(3) | 9.66 | 0.00159 | (1.02e-02) | 0.00304 | (1.27e-02) | 0.000521 | (1.51e-02) |
| H 2 0-0 S(4) | 8.02 | 0.00109 | (7.27e-03) | 0.00225 | (9.10e-03) | 0.004 | (1.07e-02) |
| H 2 0-0 S(5) | 6.91 | 0.00578 | (3.65e-02) | 0.0123 | (4.54e-02) | 0.022 | (5.19e-02) |
| H 2 0-0 S(6) | 6.11 | 0.00297 | (1.59e-02) | 0.00603 | (1.95e-02) | 0.0106 | (2.14e-02) |
| H 2 0-0 S(7) | 5.51 | 0.0124 | (5.21e-02) | 0.0236 | (6.15e-02) | 0.0392 | (6.35e-02) |
| H 2 1-0 S(1) | 2.12 | 0.0134 | (1.58e-02) | 0.0159 | (1.15e-02) | 0.0131 | (8.75e-03) |
| OI 2p 4 3 P 1 ! 2p 4 3 P 2 | 63.1 | 3.72e-05 | (3.48e-06) | 7.41e-06 | (5.98e-06) | 1.17e-05 | (9.20e-06) |
| OI 2p 4 3 P 0 ! 2p 4 3 P 1 | 145.5 | 1.36e-06 | (2.44e-07) | 5.34e-07 | (3.96e-07) | 8.42e-07 | (5.97e-07) |
| CI 3 P 1 ! 3 P 0 | 609.75 | 5.5e-08 | (6.66e-10) | 1.04e-08 | (4.27e-10) | 5.34e-10 | (5.95e-10) |
| CI 3 P 2 ! 3 P 1 | 370.37 | 4.73e-07 | (2.26e-09) | 8.16e-08 | (1.04e-09) | 1.83e-09 | (1.27e-09) |
| SI 3P J = 1 ! 3P J = 2 | 25.25 | 0.00135 | (1.43e-03) | 0.000707 | (1.37e-03) | 0.000597 | (1.40e-03) |
Table B.2. Intensities of CO lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) for shocks with velocity V s = 20 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | Freq. (GHz) | GLYPH<21> ( GLYPH<22> m) | v20b1, M1 | (v20b1, M2) | v20b1.5, M1 | (v20b1.5, M2) | v20b2, M1 | (v20b2, M2) |
|-----------------------|---------------|----------------------------|-------------------|-----------------------|-------------------|-----------------------|-------------------|-----------------------|
| CO (1-0) | 115.27 | 2600.7 | 3.47e-08 | (1.85e-07) | 9.49e-08 | (2.63e-07) | 1.47e-07 | (2.69e-07) |
| CO (2-1) | 230.54 | 1300.4 | 6.39e-07 | (2.41e-06) | 1.28e-06 | (3.23e-06) | 1.76e-06 | (3.14e-06) |
| CO (3-2) | 345.80 | 866.96 | 2.72e-06 | (1.01e-05) | 4.69e-06 | (1.30e-05) | 6.33e-06 | (1.22e-05) |
| CO (4-3) | 461.04 | 650.25 | 7.01e-06 | (2.73e-05) | 1.15e-05 | (3.50e-05) | 1.57e-05 | (3.24e-05) |
| CO (5-4) | 576.27 | 520.23 | 1.41e-05 | (5.78e-05) | 2.36e-05 | (7.55e-05) | 3.40e-05 | (7.07e-05) |
| CO (6-5) | 691.47 | 433.55 | 2.42e-05 | (1.00e-04) | 4.22e-05 | (1.36e-04) | 6.46e-05 | (1.30e-04) |
| CO (7-6) | 806.65 | 371.65 | 3.76e-05 | (1.51e-04) | 6.71e-05 | (2.09e-04) | 1.09e-04 | (2.06e-04) |
| CO (8-7) | 921.80 | 325.22 | 5.51e-05 | (2.13e-04) | 9.84e-05 | (2.91e-04) | 1.66e-04 | (2.94e-04) |
| CO (9-8) | 1036.9 | 289.12 | 7.68e-05 | (2.83e-04) | 1.36e-04 | (3.76e-04) | 2.32e-04 | (3.86e-04) |
| CO (10-9) | 1152.0 | 260.24 | 1.02e-04 | (3.54e-04) | 1.76e-04 | (4.52e-04) | 3.01e-04 | (4.70e-04) |
| CO (11-10) | 1267.0 | 236.61 | 1.29e-04 | (4.16e-04) | 2.17e-04 | (5.09e-04) | 3.63e-04 | (5.31e-04) |
| CO (12-11) | 1382.0 | 216.93 | 1.56e-04 | (4.57e-04) | 2.52e-04 | (5.38e-04) | 4.09e-04 | (5.62e-04) |
| CO (13-12) | 1496.9 | 200.27 | 1.78e-04 | (4.72e-04) | 2.75e-04 | (5.33e-04) | 4.32e-04 | (5.58e-04) |
| CO (14-13) | 1611.8 | 186.00 | 1.94e-04 | (4.64e-04) | 2.87e-04 | (5.03e-04) | 4.34e-04 | (5.25e-04) |
| CO (15-14) | 1726.6 | 173.63 | 2.00e-04 | (4.29e-04) | 2.83e-04 | (4.47e-04) | 4.11e-04 | (4.65e-04) |
| CO (16-15) | 1841.3 | 162.81 | 2.02e-04 | (3.94e-04) | 2.75e-04 | (3.95e-04) | 3.84e-04 | (4.10e-04) |
| CO (17-16) | 1956.0 | 153.27 | 1.98e-04 | (3.52e-04) | 2.59e-04 | (3.42e-04) | 3.49e-04 | (3.52e-04) |
| CO (18-17) | 2070.6 | 144.78 | 1.89e-04 | (3.09e-04) | 2.39e-04 | (2.91e-04) | 3.09e-04 | (2.97e-04) |
| CO (19-18) | 2185.1 | 137.20 | 1.78e-04 | (2.67e-04) | 2.17e-04 | (2.44e-04) | 2.70e-04 | (2.48e-04) |
| CO (20-19) | 2299.6 | 130.37 | 1.64e-04 | (2.28e-04) | 1.94e-04 | (2.03e-04) | 2.32e-04 | (2.04e-04) |
| CO (21-20) | 2413.9 | 124.19 | 1.47e-04 | (1.91e-04) | 1.70e-04 | (1.66e-04) | 1.96e-04 | (1.65e-04) |
| CO (22-21) | 2528.2 | 118.58 | 1.31e-04 | (1.59e-04) | 1.47e-04 | (1.34e-04) | 1.63e-04 | (1.33e-04) |
| CO (23-22) | 2642.3 | 113.46 | 1.15e-04 | (1.31e-04) | 1.26e-04 | (1.08e-04) | 1.34e-04 | (1.06e-04) |
| CO (24-23) | 2756.4 | 108.76 | 9.98e-05 | (1.07e-04) | 1.07e-04 | (8.63e-05) | 1.09e-04 | (8.34e-05) |
| CO (25-24) | 2870.3 | 104.44 | 8.58e-05 | (8.66e-05) | 8.98e-05 | (6.85e-05) | 8.83e-05 | (6.54e-05) |
| CO (26-25) | 2984.2 | 100.46 | 7.32e-05 | (6.98e-05) | 7.50e-05 | (5.41e-05) | 7.08e-05 | (5.10e-05) |
| CO (27-26) | 3097.9 | 96.772 | 6.20e-05 | (5.60e-05) | 6.23e-05 | (4.25e-05) | 5.63e-05 | (3.95e-05) |
| CO (28-27) | 3211.5 | 93.348 | 5.21e-05 | (4.46e-05) | 5.13e-05 | (3.32e-05) | 4.44e-05 | (3.04e-05) |
| CO (29-28) | 3325.0 | 90.162 | 4.35e-05 | (3.53e-05) | 4.20e-05 | (2.58e-05) | 3.48e-05 | (2.33e-05) |
| CO (30-29) | 3438.4 | 87.190 | 3.59e-05 | (2.78e-05) | 3.40e-05 | (1.99e-05) | 2.70e-05 | (1.77e-05) |
| CO (31-30) | 3551.6 | 84.410 | 2.95e-05 | (2.17e-05) | 2.74e-05 | (1.52e-05) | 2.08e-05 | (1.33e-05) |
| CO (32-31) | 3664.7 | 81.805 | 2.40e-05 | (1.68e-05) | 2.19e-05 | (1.16e-05) | 1.58e-05 | (9.96e-06) |
| CO (33-32) | 3777.6 | 79.359 | 1.92e-05 | (1.29e-05) | 1.72e-05 | (8.71e-06) | 1.19e-05 | (7.37e-06) |
| CO (34-33) | 3890.4 | 77.058 | 1.52e-05 | (9.72e-06) | 1.34e-05 | (6.48e-06) | 8.87e-06 | (5.39e-06) |
| CO (35-34) | 4003.1 | 74.889 | 1.18e-05 | (7.21e-06) | 1.02e-05 | (4.73e-06) | 6.46e-06 | (3.87e-06) |
| CO (36-35) | 4115.6 | 72.842 | 8.96e-06 | (5.22e-06) | 7.60e-06 | (3.37e-06) | 4.60e-06 | (2.71e-06) |
| CO (37-36) | 4228.0 | 70.907 | 6.52e-06 | (3.64e-06) | 5.43e-06 | (2.32e-06) | 3.15e-06 | (1.84e-06) |
| CO (38-37) | 4340.1 | 69.074 | 4.46e-06 | (2.39e-06) | 3.65e-06 | (1.50e-06) | 2.03e-06 | (1.17e-06) |
| CO (39-38) CO (40-39) | 4452.2 4564.0 | 67.336 65.686 | 2.72e-06 1.25e-06 | (1.41e-06) (6.22e-07) | 2.19e-06 9.89e-07 | (8.72e-07) (3.81e-07) | 1.17e-06 5.10e-07 | (6.69e-07) (2.88e-07) |
Table B.3. Intensities of CO lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) for shocks with velocity V s = 30 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | Freq. (GHz) | GLYPH<21> ( GLYPH<22> m) | v30b1.5, M1 | (v30b1.5, M2) | v30b2, M1 | (v30b2, M2) | v30b2.5, M1 | (v30b2.5, M2) |
|--------------|---------------|----------------------------|---------------|-----------------|-------------------|-----------------------|-------------------|-----------------|
| CO (1-0) | 115.27 | 2600.7 | 4.01e-08 | (2.64e-07) | 9.93e-08 | (3.42e-07) | 1.65e-07 | (4.14e-07) |
| CO (2-1) | 230.54 | 1300.4 | 7.45e-07 | (3.35e-06) | 1.41e-06 | (4.14e-06) | 2.05e-06 | (4.88e-06) |
| CO (3-2) | 345.8 | 866.96 | 3.19e-06 | (1.37e-05) | 5.06e-06 | (1.65e-05) | 7.19e-06 | (1.92e-05) |
| CO (4-3) | 461.04 | 650.25 | 8.29e-06 | (3.68e-05) | 1.22e-05 | (4.39e-05) | 1.72e-05 | (5.12e-05) |
| CO (5-4) | 576.27 | 520.23 | 1.68e-05 | (7.71e-05) | 2.49e-05 | (9.47e-05) | 3.57e-05 | (1.12e-04) |
| CO (6-5) | 691.47 | 433.55 | 2.89e-05 | (1.33e-04) | 4.42e-05 | (1.71e-04) | 6.54e-05 | (2.07e-04) |
| CO (7-6) | 806.65 | 371.65 | 4.49e-05 | (2.01e-04) | 7.03e-05 | (2.69e-04) | 1.07e-04 | (3.30e-04) |
| CO (8-7) | 921.8 | 325.22 | 6.56e-05 | (2.86e-04) | 1.04e-04 | (3.88e-04) | 1.61e-04 | (4.79e-04) |
| CO (9-8) | 1036.9 | 289.12 | 9.13e-05 | (3.90e-04) | 1.44e-04 | (5.26e-04) | 2.26e-04 | (6.46e-04) |
| CO (10-9) | 1152 | 260.24 | 0.000122 | (5.06e-04) | 1.92e-04 | (6.74e-04) | 3.00e-04 | (8.15e-04) |
| CO (11-10) | 1267 | 236.61 | 0.000155 | (6.22e-04) | 2.43e-04 | (8.13e-04) | 3.77e-04 | (9.65e-04) |
| CO (12-11) | 1382 | 216.93 | 0.000188 | (7.22e-04) | 2.93e-04 | (9.23e-04) | 4.48e-04 | (1.07e-03) |
| CO (13-12) | 1496.9 | 200.27 | 0.000218 | (7.91e-04) | 3.35e-04 | (9.86e-04) | 5.03e-04 | (1.12e-03) |
| CO (14-13) | 1611.8 | 186 | 0.000242 | (8.26e-04) | 3.66e-04 | (1.00e-03) | 5.40e-04 | (1.12e-03) |
| CO (15-14) | 1726.6 | 173.63 | 0.000255 | (8.14e-04) | 3.80e-04 | (9.65e-04) | 5.50e-04 | (1.05e-03) |
| CO (16-15) | 1841.3 | 162.81 | 0.000263 | (7.89e-04) | 3.86e-04 | (9.15e-04) | 5.49e-04 | (9.77e-04) |
| CO (17-16) | 1956 | 153.27 | 0.000262 | (7.45e-04) | 3.81e-04 | (8.46e-04) | 5.34e-04 | (8.86e-04) |
| CO (18-17) | 2070.6 | 144.78 | 0.000255 | (6.87e-04) | 3.68e-04 | (7.65e-04) | 5.07e-04 | (7.87e-04) |
| CO (19-18) | 2185.1 | 137.2 | 0.000243 | (6.23e-04) | 3.48e-04 | (6.81e-04) | 4.73e-04 | (6.89e-04) |
| CO (20-19) | 2299.6 | 130.37 | 0.000227 | (5.57e-04) | 3.24e-04 | (5.98e-04) | 4.35e-04 | (5.96e-04) |
| CO (21-20) | 2413.9 | 124.19 | 0.000207 | (4.88e-04) | 2.94e-04 | (5.16e-04) | 3.91e-04 | (5.06e-04) |
| CO (22-21) | 2528.2 | 118.58 | 0.000186 | (4.23e-04) | 2.64e-04 | (4.40e-04) | 3.47e-04 | (4.25e-04) |
| CO (23-22) | 2642.3 | 113.46 | 0.000165 | (3.62e-04) | 2.34e-04 | (3.72e-04) | 3.05e-04 | (3.54e-04) |
| CO (24-23) | 2756.4 | 108.76 | 0.000145 | (3.08e-04) | 2.05e-04 | (3.11e-04) | 2.65e-04 | (2.93e-04) |
| CO (25-24) | 2870.3 | 104.44 | 0.000125 | (2.60e-04) | 1.78e-04 | (2.59e-04) | 2.28e-04 | (2.40e-04) |
| CO (26-25) | 2984.2 | 100.46 | 0.000108 | (2.18e-04) | 1.54e-04 | (2.14e-04) | 1.95e-04 | (1.96e-04) |
| CO (27-26) | 3097.9 | 96.772 | 9.19e-05 | (1.81e-04) | 1.32e-04 | (1.76e-04) | 1.66e-04 | (1.58e-04) |
| CO (28-27) | 3211.5 | 93.348 | 7.78e-05 | (1.50e-04) | 1.12e-04 | (1.43e-04) | 1.39e-04 | (1.27e-04) |
| CO (29-28) | 3325 | 90.162 | 6.53e-05 | (1.23e-04) | 9.40e-05 | (1.16e-04) | 1.17e-04 | (1.02e-04) |
| CO (30-29) | 3438.4 | 87.19 | 5.43e-05 | (1.00e-04) | 7.85e-05 | (9.33e-05) | 9.66e-05 | (8.07e-05) |
| CO (31-30) | 3551.6 | 84.41 | 4.49e-05 | (8.08e-05) | 6.51e-05 | (7.44e-05) | 7.94e-05 | (6.35e-05) |
| CO (32-31) | 3664.7 | 81.805 | 3.67e-05 | (6.47e-05) | 5.34e-05 | (5.89e-05) | 6.46e-05 | (4.95e-05) |
| CO (33-32) | 3777.6 | 79.359 | 2.97e-05 | (5.12e-05) | 4.33e-05 | (4.60e-05) | 5.19e-05 | (3.81e-05) |
| CO (34-33) | 3890.4 | 77.058 | 2.37e-05 | (4.00e-05) | 3.45e-05 | (3.55e-05) | 4.11e-05 | (2.90e-05) |
| CO (35-34) | 4003.1 | 74.889 | 1.85e-05 | (3.06e-05) | 2.70e-05 | (2.68e-05) | 3.19e-05 | (2.16e-05) |
| CO (36-35) | 4115.6 | 72.842 | 1.41e-05 | (2.29e-05) | 2.06e-05 | (1.98e-05) | 2.42e-05 | (1.57e-05) |
| CO (37-36) | 4228 | 70.907 | 1.03e-05 | (1.64e-05) | 1.51e-05 | (1.40e-05) | 1.76e-05 | (1.10e-05) |
| CO (38-37) | 4340.1 | 69.074 | 7.11e-06 | (1.11e-05) | | | | (7.26e-06) |
| CO (39-38) | 4452.2 | 67.336 | 4.37e-06 | (6.68e-06) | 1.04e-05 6.39e-06 | (9.36e-06) (5.58e-06) | 1.20e-05 7.31e-06 | (4.27e-06) |
Table B.4. Intensities of CO lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) for shocks with velocity V s = 40 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | Freq. (GHz) | GLYPH<21> ( GLYPH<22> m) | v40b2, M1 | (v40b2, M2) | v40b2.5, M1 | (v40b2.5, M2) | v40b3, M1 | (v40b3, M2) |
|--------------|---------------|----------------------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| CO (1-0) | 115.27 | 2600.7 | 3.42e-08 | (3.41e-07) | 1e-07 | (4.18e-07) | 1.73e-07 | (4.86e-07) |
| CO (2-1) | 230.54 | 1300.4 | 6.14e-07 | (4.33e-06) | 1.45e-06 | (5.02e-06) | 2.22e-06 | (5.69e-06) |
| CO (3-2) | 345.8 | 866.96 | 2.73e-06 | (1.76e-05) | 5.3e-06 | (1.98e-05) | 7.52e-06 | (2.21e-05) |
| CO (4-3) | 461.04 | 650.25 | 7.9e-06 | (4.67e-05) | 1.3e-05 | (5.22e-05) | 1.76e-05 | (5.82e-05) |
| CO (5-4) | 576.27 | 520.23 | 1.81e-05 | (9.75e-05) | 2.68e-05 | (1.11e-04) | 3.63e-05 | (1.25e-04) |
| CO (6-5) | 691.47 | 433.55 | 3.51e-05 | (1.68e-04) | 4.79e-05 | (1.99e-04) | 6.58e-05 | (2.30e-04) |
| CO (7-6) | 806.65 | 371.65 | 6.04e-05 | (2.53e-04) | 7.7e-05 | (3.11e-04) | 0.000107 | (3.66e-04) |
| CO (8-7) | 921.8 | 325.22 | 9.53e-05 | (3.58e-04) | 0.000114 | (4.49e-04) | 0.000161 | (5.35e-04) |
| CO (9-8) | 1036.9 | 289.12 | 0.00014 | (4.91e-04) | 0.000159 | (6.17e-04) | 0.000227 | (7.36e-04) |
| CO (10-9) | 1152 | 260.24 | 0.000193 | (6.46e-04) | 0.000211 | (8.08e-04) | 0.000303 | (9.57e-04) |
| CO (11-10) | 1267 | 236.61 | 0.000251 | (8.09e-04) | 0.000267 | (1.00e-03) | 0.000384 | (1.18e-03) |
| CO (12-11) | 1382 | 216.93 | 0.000311 | (9.61e-04) | 0.000323 | (1.18e-03) | 0.000464 | (1.37e-03) |
| CO (13-12) | 1496.9 | 200.27 | 0.000366 | (1.08e-03) | 0.000371 | (1.31e-03) | 0.000532 | (1.50e-03) |
| CO (14-13) | 1611.8 | 186 | 0.000412 | (1.15e-03) | 0.000409 | (1.38e-03) | 0.000584 | (1.56e-03) |
| CO (15-14) | 1726.6 | 173.63 | 0.000439 | (1.17e-03) | 0.000429 | (1.38e-03) | 0.000609 | (1.54e-03) |
| CO (16-15) | 1841.3 | 162.81 | 0.000457 | (1.16e-03) | 0.00044 | (1.36e-03) | 0.000622 | (1.50e-03) |
| CO (17-16) | 1956 | 153.27 | 0.000461 | (1.11e-03) | 0.000439 | (1.30e-03) | 0.000617 | (1.42e-03) |
| CO (18-17) | 2070.6 | 144.78 | 0.000452 | (1.04e-03) | 0.000426 | (1.21e-03) | 0.000598 | (1.31e-03) |
| CO (19-18) | 2185.1 | 137.2 | 0.000433 | (9.61e-04) | 0.000405 | (1.11e-03) | 0.000568 | (1.19e-03) |
| CO (20-19) | 2299.6 | 130.37 | 0.000407 | (8.71e-04) | 0.000379 | (1.00e-03) | 0.000531 | (1.07e-03) |
| CO (21-20) | 2413.9 | 124.19 | 0.000374 | (7.73e-04) | 0.000346 | (8.86e-04) | 0.000485 | (9.36e-04) |
| CO (22-21) | 2528.2 | 118.58 | 0.000337 | (6.76e-04) | 0.000311 | (7.74e-04) | 0.000437 | (8.13e-04) |
| CO (23-22) | 2642.3 | 113.46 | 0.000301 | (5.86e-04) | 0.000276 | (6.69e-04) | 0.000389 | (6.99e-04) |
| CO (24-23) | 2756.4 | 108.76 | 0.000265 | (5.02e-04) | 0.000242 | (5.74e-04) | 0.000343 | (5.96e-04) |
| CO (25-24) | 2870.3 | 104.44 | 0.00023 | (4.27e-04) | 0.000211 | (4.88e-04) | 0.000299 | (5.04e-04) |
| CO (26-25) | 2984.2 | 100.46 | 0.000199 | (3.61e-04) | 0.000182 | (4.12e-04) | 0.000259 | (4.23e-04) |
| CO (27-26) | 3097.9 | 96.772 | 0.00017 | (3.03e-04) | 0.000156 | (3.45e-04) | 0.000223 | (3.53e-04) |
| CO (28-27) | 3211.5 | 93.348 | 0.000145 | (2.52e-04) | 0.000132 | (2.88e-04) | 0.00019 | (2.93e-04) |
| CO (29-28) | 3325 | 90.162 | 0.000122 | (2.08e-04) | 0.000111 | (2.38e-04) | 0.000161 | (2.41e-04) |
| CO (30-29) | 3438.4 | 87.19 | 0.000103 | (1.71e-04) | 9.31e-05 | (1.95e-04) | 0.000135 | (1.97e-04) |
| CO (31-30) | 3551.6 | 84.41 | 8.53e-05 | (1.39e-04) | 7.72e-05 | (1.59e-04) | 0.000112 | (1.60e-04) |
| CO (32-31) | 3664.7 | 81.805 | 7.03e-05 | (1.12e-04) | 6.34e-05 | (1.28e-04) | 9.22e-05 | (1.28e-04) |
| CO (33-32) | 3777.6 | 79.359 | 5.73e-05 | (8.96e-05) | 5.15e-05 | (1.02e-04) | 7.5e-05 | (1.02e-04) |
| CO (34-33) | 3890.4 | 77.058 | 4.61e-05 | (7.05e-05) | 4.12e-05 | (8.06e-05) | 6.01e-05 | (7.99e-05) |
| CO (35-34) | 4003.1 | 74.889 | 3.63e-05 | (5.44e-05) | 3.23e-05 | (6.22e-05) | 4.72e-05 | (6.13e-05) |
| CO (36-35) | 4115.6 | 72.842 | 2.79e-05 | (4.09e-05) | 2.47e-05 | (4.68e-05) | 3.61e-05 | (4.59e-05) |
| CO (37-36) | 4228 | 70.907 | 2.06e-05 | (2.96e-05) | 1.82e-05 | (3.38e-05) | 2.66e-05 | (3.31e-05) |
Table B.5. Intensities of OH lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS instrument on the Herschel Space Observatory, for shocks with velocities V s = 20 km s GLYPH<0> 1 (top), V s = 30 km s GLYPH<0> 1 (middle), and V s = 40 km s GLYPH<0> 1 (bottom) and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v20b1, M1 | (v20b1, M2) | v20b1.5, M1 | (v20b1.5, M2) | v20b2, M1 | (v20b2, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 1834.8 GHz | 163.39 | 269.8 | 1.65e-08 | (1.76e-08) | 2.58e-08 | (2.51e-08) | 3.92e-08 | (3.03e-08) |
| 1839.0 GHz | 163.01 | 270.2 | 2.42e-08 | (2.54e-08) | 3.75e-08 | (3.58e-08) | 5.65e-08 | (4.35e-08) |
| 2510.0 GHz | 119.44 | 120.5 | 1.79e-07 | (2.71e-07) | 2.88e-07 | (4.89e-07) | 4.38e-07 | (4.20e-07) |
| 2514.0 GHz | 119.23 | 120.7 | 9.78e-08 | (1.65e-07) | 1.6e-07 | (3.14e-07) | 2.44e-07 | (2.50e-07) |
| 3035.0 GHz | 98.76 | 415.9 | 3.11e-08 | (3.08e-08) | 4.61e-08 | (4.01e-08) | 6.78e-08 | (5.11e-08) |
| 3036.0 GHz | 98.74 | 415.5 | 1e-08 | (1.00e-08) | 1.5e-08 | (1.31e-08) | 2.22e-08 | (1.68e-08) |
| 3111.0 GHz | 96.36 | 269.8 | 4.01e-09 | (4.28e-09) | 6.28e-09 | (6.11e-09) | 9.54e-09 | (7.36e-09) |
| 3114.0 GHz | 96.27 | 270.2 | 5.86e-09 | (6.16e-09) | 9.07e-09 | (8.67e-09) | 1.37e-08 | (1.05e-08) |
| 3544.0 GHz | 84.6 | 290.5 | 8.1e-08 | (8.30e-08) | 1.24e-07 | (1.13e-07) | 1.86e-07 | (1.41e-07) |
| 3551.0 GHz | 84.42 | 291.2 | 1.94e-08 | (2.01e-08) | 3e-08 | (2.76e-08) | 4.52e-08 | (3.44e-08) |
| 3786.0 GHz | 79.18 | 181.7 | 1.01e-07 | (1.19e-07) | 1.61e-07 | (1.88e-07) | 2.47e-07 | (2.03e-07) |
| 3789.0 GHz | 79.12 | 181.9 | 1.11e-07 | (1.27e-07) | 1.76e-07 | (1.96e-07) | 2.68e-07 | (2.17e-07) |
| 4210.0 GHz | 71.22 | 617.9 | 1.51e-08 | (1.45e-08) | 2.13e-08 | (1.81e-08) | 3.04e-08 | (2.31e-08) |
| 4212.0 GHz | 71.17 | 617.6 | 2.92e-09 | (2.81e-09) | 4.17e-09 | (3.53e-09) | 5.96e-09 | (4.52e-09) |
| 4592.0 GHz | 65.28 | 510.9 | 2.78e-08 | (2.71e-08) | 4.05e-08 | (3.46e-08) | 5.87e-08 | (4.43e-08) |
| 4603.0 GHz | 65.13 | 512.1 | 4.03e-09 | (3.94e-09) | 5.9e-09 | (5.05e-09) | 8.58e-09 | (6.47e-09) |
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v30b1.5, M1 | (v30b1.5, M2) | v30b2, M1 | (v30b2, M2) | v30b2.5, M1 | (v30b2.5, M2) |
|--------------|----------------------------|------------|---------------|-----------------|-------------|---------------|---------------|-----------------|
| 1834.8 GHz | 163.39 | 269.8 | 1.33e-07 | (5.28e-08) | 6.54e-08 | (5.38e-08) | 5.46e-08 | (5.24e-08) |
| 1839.0 GHz | 163.01 | 270.2 | 1.98e-07 | (7.76e-08) | 9.67e-08 | (7.86e-08) | 8e-08 | (7.62e-08) |
| 2510.0 GHz | 119.44 | 120.5 | 4.38e-07 | (6.17e-07) | 6.95e-07 | (6.58e-07) | 5.94e-07 | (6.68e-07) |
| 2514.0 GHz | 119.23 | 120.7 | 7.47e-07 | (3.46e-07) | 3.77e-07 | (3.76e-07) | 3.26e-07 | (3.88e-07) |
| 3035.0 GHz | 98.76 | 415.9 | 2.66e-07 | (1.00e-07) | 1.27e-07 | (9.94e-08) | 1.02e-07 | (9.38e-08) |
| 3036.0 GHz | 98.74 | 415.5 | 8.54e-08 | (3.23e-08) | 4.08e-08 | (3.21e-08) | 3.28e-08 | (3.04e-08) |
| 3111.0 GHz | 96.36 | 269.8 | 3.24e-08 | (1.28e-08) | 1.59e-08 | (1.31e-08) | 1.34e-08 | (1.27e-08) |
| 3114.0 GHz | 96.27 | 270.2 | 4.8e-08 | (1.88e-08) | 2.34e-08 | (1.90e-08) | 1.94e-08 | (1.84e-08) |
| 3544.0 GHz | 84.6 | 290.5 | 6.69e-07 | (2.59e-07) | 3.24e-07 | (2.61e-07) | 2.66e-07 | (2.50e-07) |
| 3551.0 GHz | 84.42 | 291.2 | 1.59e-07 | (6.20e-08) | 7.73e-08 | (6.26e-08) | 6.38e-08 | (6.04e-08) |
| 3786.0 GHz | 79.18 | 181.7 | 7.87e-07 | (3.27e-07) | 3.93e-07 | (3.40e-07) | 3.34e-07 | (3.39e-07) |
| 3789.0 GHz | 79.12 | 181.9 | 8.78e-07 | (3.59e-07) | 4.36e-07 | (3.71e-07) | 3.67e-07 | (3.67e-07) |
| 4210.0 GHz | 71.22 | 617.9 | 1.37e-07 | (4.97e-08) | 6.34e-08 | (4.83e-08) | 4.89e-08 | (4.45e-08) |
| 4212.0 GHz | 71.17 | 617.6 | 2.64e-08 | (9.61e-09) | 1.22e-08 | (9.35e-09) | 9.5e-09 | (8.65e-09) |
| 4592.0 GHz | 65.28 | 510.9 | 2.45e-07 | (9.07e-08) | 1.15e-07 | (8.90e-08) | 9.07e-08 | (8.31e-08) |
| 4603.0 GHz | 65.13 | 512.1 | 3.53e-08 | (1.31e-08) | 1.66e-08 | (1.29e-08) | 1.31e-08 | (1.21e-08) |
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v40b2, M1 | (v40b2, M2) | v40b2.5, M1 | (v40b2.5, M2) | v40b3, M1 | (v40b3, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 1834.8 GHz | 163.39 | 269.8 | 6.25e-06 | (2.49e-07) | 4.66e-07 | (1.67e-07) | 2.05e-07 | (1.36e-07) |
| 1839.0 GHz | 163.01 | 270.2 | 9.23e-06 | (3.69e-07) | 6.95e-07 | (2.47e-07) | 3.05e-07 | (2.01e-07) |
| 2510.0 GHz | 119.44 | 120.5 | 6.49e-05 | (2.67e-06) | 4.84e-06 | (1.86e-06) | 2.15e-06 | (1.58e-06) |
| 2514.0 GHz | 119.23 | 120.7 | 3.68e-05 | (1.45e-06) | 2.60e-06 | (1.02e-06) | 1.16e-06 | (8.84e-07) |
| 3035.0 GHz | 98.76 | 415.9 | 1.23e-05 | (4.90e-07) | 9.37e-07 | (3.25e-07) | 4.06e-07 | (2.60e-07) |
| 3036.0 GHz | 98.74 | 415.5 | 4.21e-06 | (1.57e-07) | 3.01e-07 | (1.04e-07) | 1.3e-07 | (8.37e-08) |
| 3111.0 GHz | 96.36 | 269.8 | 1.52e-06 | (6.06e-08) | 1.13e-07 | (4.07e-08) | 4.99e-08 | (3.32e-08) |
| 3114.0 GHz | 96.27 | 270.2 | 2.24e-06 | (8.94e-08) | 1.68e-07 | (5.99e-08) | 7.38e-08 | (4.87e-08) |
| 3544.0 GHz | 84.6 | 290.5 | 3.11e-05 | (1.24e-06) | 2.35e-06 | (8.30e-07) | 1.03e-06 | (6.70e-07) |
| 3551.0 GHz | 84.42 | 291.2 | 7.93e-06 | (2.96e-07) | 5.59e-07 | (1.98e-07) | 2.44e-07 | (1.60e-07) |
| 3786.0 GHz | 79.18 | 181.7 | 3.54e-05 | (1.49e-06) | 2.74e-06 | (1.02e-06) | 1.22e-06 | (8.42e-07) |
| 3789.0 GHz | 79.12 | 181.9 | 3.9e-05 | (1.66e-06) | 3.06e-06 | (1.12e-06) | 1.36e-06 | (9.26e-07) |
| 4210.0 GHz | 71.22 | 617.9 | 6.52e-06 | (2.48e-07) | 4.85-07 | (1.63e-07) | 2.07e-07 | (1.29e-07) |
| 4212.0 GHz | 71.17 | 617.6 | 1.29e-06 | (4.79e-08) | 9.34e-08 | (3.15e-08) | 4e-08 | (2.50e-08) |
| 4592.0 GHz | 65.28 | 510.9 | 1.18e-05 | (4.79e-08) | 8.66e-07 | (2.96e-07) | 3.73e-07 | (2.36e-07) |
| 4603.0 GHz | 65.13 | 512.1 | 1.79e-06 | (6.46e-08) | 1.25e-07 | (4.27e-08) | 5.37e-08 | (3.40e-08) |
Table B.6. Intensities of ortho-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 20 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v20b1, M1 | (v20b1, M2) | v20b1.5, M1 | (v20b1.5, M2) | v20b2, M1 | (v20b2, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 5500.1 GHz | 54.506 | 732.1 | 1.31e-06 | (2.25e-06) | 1.56e-06 | (2.12e-06) | 1.38e-06 | (1.44e-06) |
| 5437.8 GHz | 55.131 | 1274 | 5.49e-06 | (8.49e-06) | 6.44e-06 | (7.07e-06) | 5.49e-06 | (4.75e-06) |
| 5276.5 GHz | 56.816 | 1324 | 1.97e-05 | (3.03e-05) | 2.3e-05 | (2.43e-05) | 1.95e-05 | (1.64e-05) |
| 5107.3 GHz | 58.699 | 550.4 | 0.00011 | (1.98e-04) | 0.000129 | (1.94e-04) | 0.000116 | (1.33e-04) |
| 4764.0 GHz | 62.928 | 1553 | 2.74e-07 | (4.08e-07) | 3.2e-07 | (3.36e-07) | 2.67e-07 | (2.24e-07) |
| 4734.3 GHz | 63.323 | 1071 | 3.62e-05 | (5.86e-05) | 4.26e-05 | (4.87e-05) | 3.72e-05 | (3.32e-05) |
| 4600.4 GHz | 65.166 | 795.5 | 2.57e-05 | (4.19e-05) | 3.03e-05 | (3.89e-05) | 2.61e-05 | (2.61e-05) |
| 4535.9 GHz | 66.092 | 1013 | 9.11e-06 | (1.44e-05) | 1.07e-05 | (1.29e-05) | 9.17e-06 | (8.64e-06) |
| 4512.4 GHz | 66.437 | 410.7 | 0.000154 | (2.99e-04) | 0.000176 | (2.47e-04) | 0.000174 | (1.85e-04) |
| 4456.6 GHz | 67.268 | 410.7 | 7.77e-06 | (1.24e-05) | 1.08e-05 | (2.21e-05) | 6.45e-06 | (1.24e-05) |
| 4240.2 GHz | 70.702 | 1274 | 7.4e-07 | (1.14e-06) | 8.68e-07 | (9.53e-07) | 7.39e-07 | (6.40e-07) |
| 4166.9 GHz | 71.946 | 843.5 | 6.01e-05 | (9.94e-05) | 7.09e-05 | (8.79e-05) | 6.23e-05 | (5.96e-05) |
| 4000.2 GHz | 74.944 | 1126 | 2.34e-06 | (3.70e-06) | 2.75e-06 | (3.13e-06) | 2.36e-06 | (2.11e-06) |
| 3977.0 GHz | 75.38 | 305.3 | 0.00029 | (4.45e-04) | 0.000337 | (4.79e-04) | 0.000263 | (3.07e-04) |
| 3971.0 GHz | 75.495 | 1806 | 3.32e-07 | (4.91e-07) | 3.83e-07 | (3.59e-07) | 3.2e-07 | (2.45e-07) |
| 3807.3 GHz | 78.742 | 432.2 | 0.00013 | (2.33e-04) | 0.000153 | (2.21e-04) | 0.000136 | (1.53e-04) |
| 3654.6 GHz | 82.031 | 643.5 | 0.000107 | (1.81e-04) | 0.000126 | (1.70e-04) | 0.000111 | (1.15e-04) |
| 3536.7 GHz | 84.766 | 1013 | 1.61e-06 | (2.56e-06) | 1.9e-06 | (2.29e-06) | 1.62e-06 | (1.53e-06) |
| 3167.6 GHz | 94.643 | 795.5 | 3.28e-06 | (5.34e-06) | 3.87e-06 | (4.97e-06) | 3.34e-06 | (3.33e-06) |
| 3165.5 GHz | 94.704 | 702.3 | 1.26e-06 | (2.24e-06) | 1.51e-06 | (2.23e-06) | 1.34e-06 | (1.50e-06) |
| 3013.2 GHz | 99.492 | 468.1 | 0.000197 | (3.45e-04) | 0.000233 | (3.41e-04) | 0.000204 | (2.31e-04) |
| 2970.8 GHz | 100.91 | 574.7 | 2.8e-05 | (4.71e-05) | 3.32e-05 | (4.70e-05) | 2.84e-05 | (3.13e-05) |
| 2774.0 GHz | 108.07 | 194.1 | 0.000617 | (1.30e-03) | 0.000725 | (1.52e-03) | 0.000604 | (1.00e-03) |
| 2664.6 GHz | 112.51 | 1340 | 3.64e-07 | (5.72e-07) | 4.24e-07 | (4.42e-07) | 3.66e-07 | (3.04e-07) |
| 2640.5 GHz | 113.54 | 323.5 | 0.000432 | (7.79e-04) | 0.000514 | (8.34e-04) | 0.000439 | (5.55e-04) |
| 2462.9 GHz | 121.72 | 550.4 | 5.88e-06 | (9.46e-06) | 7.77e-06 | (1.16e-05) | 5.79e-06 | (7.11e-06) |
| 2344.3 GHz | 127.88 | 1126 | 7.24e-07 | (1.14e-06) | 8.51e-07 | (9.68e-07) | 7.3e-07 | (6.52e-07) |
| 2264.1 GHz | 132.41 | 432.2 | 2.81e-05 | (4.18e-05) | 3.53e-05 | (6.21e-05) | 2.45e-05 | (3.65e-05) |
| 2221.8 GHz | 134.93 | 574.7 | 1.01e-05 | (1.70e-05) | 1.2e-05 | (1.70e-05) | 1.03e-05 | (1.13e-05) |
| 2196.3 GHz | 136.49 | 410.7 | 2.79e-05 | (4.79e-05) | 3.62e-05 | (8.13e-05) | 2.36e-05 | (4.71e-05) |
| 1918.5 GHz | 156.26 | 642.4 | 6.92e-07 | (1.17e-06) | 8.33e-07 | (1.13e-06) | 7.12e-07 | (7.49e-07) |
| 1867.7 GHz | 160.51 | 732.1 | 9.5e-07 | (1.63e-06) | 1.13e-06 | (1.54e-06) | 9.99e-07 | (1.04e-06) |
| 1716.8 GHz | 174.62 | 196.8 | 0.000614 | (1.34e-03) | 0.000721 | (1.31e-03) | 0.000677 | (9.16e-04) |
| 1669.9 GHz | 179.53 | 114.4 | 0.000957 | (2.22e-03) | 0.00109 | (2.06e-03) | 0.00105 | (1.49e-03) |
| 1661.0 GHz | 180.49 | 194.1 | 0.000193 | (4.63e-04) | 0.00023 | (5.06e-04) | 0.000203 | (3.41e-04) |
| 1162.9 GHz | 257.79 | 305.3 | 5.65e-05 | (1.39e-04) | 7.12e-05 | (1.64e-04) | 6.68e-05 | (1.11e-04) |
| 1153.1 GHz | 259.98 | 249.4 | 0.000122 | (2.54e-04) | 0.000149 | (3.43e-04) | 0.000112 | (2.17e-04) |
| 1097.4 GHz | 273.19 | 249.4 | 8.72e-05 | (1.96e-04) | 0.000104 | (1.71e-04) | 0.000107 | (1.25e-04) |
| 556.94 GHz | 538.28 | 61 | 5.61e-05 | (1.32e-04) | 6.01e-05 | (1.21e-04) | 5.73e-05 | (8.89e-05) |
Table B.7. Intensities of ortho-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 30 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v30b1.5, M1 | (v30b1.5, M2) | v30b2, M1 | (v30b2, M2) | v30b2.5, M1 | (v30b2.5, M2) |
|--------------|----------------------------|------------|---------------|-----------------|-------------|---------------|---------------|-----------------|
| 5500.1 GHz | 54.506 | 732.1 | 2.16e-06 | (5.36e-06) | 2.8e-06 | (6.34e-06) | 3.6e-06 | (6.74e-06) |
| 5437.8 GHz | 55.131 | 1274 | 8.87e-06 | (2.26e-05) | 1.21e-05 | (2.60e-05) | 1.6e-05 | (2.68e-05) |
| 5276.5 GHz | 56.816 | 1324 | 3.13e-05 | (8.00e-05) | 4.3e-05 | (8.99e-05) | 5.69e-05 | (9.14e-05) |
| 5107.3 GHz | 58.699 | 550.4 | 0.000175 | (4.39e-04) | 0.000213 | (4.97e-04) | 0.000272 | (5.15e-04) |
| 4764.0 GHz | 62.928 | 1553 | 4.44e-07 | (1.13e-06) | 6.15e-07 | (1.32e-06) | 8.16e-07 | (1.36e-06) |
| 4734.3 GHz | 63.323 | 1071 | 5.78e-05 | (1.47e-04) | 7.78e-05 | (1.66e-04) | 0.000102 | (1.70e-04) |
| 4600.4 GHz | 65.166 | 795.5 | 4.28e-05 | (1.05e-04) | 5.6e-05 | (1.25e-04) | 7.23e-05 | (1.33e-04) |
| 4535.9 GHz | 66.092 | 1013 | 1.5e-05 | (3.76e-05) | 2e-05 | (4.43e-05) | 2.62e-05 | (4.65e-05) |
| 4512.4 GHz | 66.437 | 410.7 | 0.000235 | (5.69e-04) | 0.000282 | (5.97e-04) | 0.00036 | (5.97e-04) |
| 4456.6 GHz | 67.268 | 410.7 | 1.89e-05 | (3.95e-05) | 2.66e-05 | (6.85e-05) | 3.09e-05 | (8.70e-05) |
| 4240.2 GHz | 70.702 | 1274 | 1.2e-06 | (3.04e-06) | 1.64e-06 | (3.51e-06) | 2.16e-06 | (3.62e-06) |
| 4166.9 GHz | 71.946 | 843.5 | 9.74e-05 | (2.45e-04) | 0.000129 | (2.83e-04) | 0.000168 | (2.95e-04) |
| 4000.2 GHz | 74.944 | 1126 | 3.76e-06 | (9.59e-06) | 5.09e-06 | (1.10e-05) | 6.71e-06 | (1.13e-05) |
| 3977.0 GHz | 75.38 | 305.3 | 0.000548 | (1.11e-03) | 0.000656 | (1.35e-03) | 0.000745 | (1.49e-03) |
| 3971.0 GHz | 75.495 | 1806 | 5.24e-07 | (1.32e-06) | 7.29e-07 | (1.42e-06) | 9.63e-07 | (1.41e-06) |
| 3807.3 GHz | 78.742 | 432.2 | 0.000222 | (5.14e-04) | 0.00028 | (6.19e-04) | 0.000349 | (6.68e-04) |
| 3654.6 GHz | 82.031 | 643.5 | 0.000176 | (4.35e-04) | 0.000227 | (5.11e-04) | 0.000292 | (5.41e-04) |
| 3536.7 GHz | 84.766 | 1013 | 2.65e-06 | (6.66e-06) | 3.55e-06 | (7.86e-06) | 4.64e-06 | (8.23e-06) |
| 3167.6 GHz | 94.643 | 795.5 | 5.47e-06 | (1.35e-05) | 7.15e-06 | (1.60e-05) | 9.23e-06 | (1.69e-05) |
| 3165.5 GHz | 94.704 | 702.3 | 2.11e-06 | (5.21e-06) | 2.69e-06 | (6.29e-06) | 3.43e-06 | (6.79e-06) |
| 3013.2 GHz | 99.492 | 468.1 | 0.000331 | (7.96e-04) | 0.000416 | (9.46e-04) | 0.000523 | (1.01e-03) |
| 2970.8 GHz | 100.91 | 574.7 | 4.87e-05 | (1.14e-04) | 6.22e-05 | (1.40e-04) | 7.79e-05 | (1.52e-04) |
| 2774.0 GHz | 108.07 | 194.1 | 0.00101 | (2.62e-03) | 0.00115 | (3.14e-03) | 0.00139 | (3.42e-03) |
| 2664.6 GHz | 112.51 | 1340 | 5.73e-07 | (1.46e-06) | 7.81e-07 | (1.58e-06) | 1.03e-06 | (1.58e-06) |
| 2640.5 GHz | 113.54 | 323.5 | 0.000737 | (1.76e-03) | 0.000896 | (2.12e-03) | 0.00111 | (2.29e-03) |
| 2462.9 GHz | 121.72 | 550.4 | 1.3e-05 | (2.68e-05) | 1.89e-05 | (4.43e-05) | 2.29e-05 | (5.58e-05) |
| 2344.3 GHz | 127.88 | 1126 | 1.16e-06 | (2.96e-06) | 1.57e-06 | (3.39e-06) | 2.07e-06 | (3.49e-06) |
| 2264.1 GHz | 132.41 | 432.2 | 5.71e-05 | (1.27e-04) | 7.08e-05 | (1.80e-04) | 8.42e-05 | (2.07e-04) |
| 2221.8 GHz | 134.93 | 574.7 | 1.76e-05 | (4.13e-05) | 2.24e-05 | (5.05e-05) | 2.81e-05 | (5.47e-05) |
| 2196.3 GHz | 136.49 | 410.7 | 5.57e-05 | (1.36e-04) | 6.77e-05 | (1.98e-04) | 7.99e-05 | (2.33e-04) |
| 1918.5 GHz | 156.26 | 642.4 | 1.23e-06 | (2.87e-06) | 1.66e-06 | (3.67e-06) | 2.08e-06 | (4.13e-06) |
| 1867.7 GHz | 160.51 | 732.1 | 1.57e-06 | (3.89e-06) | 2.03e-06 | (4.60e-06) | 2.62e-06 | (4.90e-06) |
| 1716.8 GHz | 174.62 | 196.8 | 0.000924 | (2.48e-03) | 0.00109 | (2.70e-03) | 0.00137 | (2.79e-03) |
| 1669.9 GHz | 179.53 | 114.4 | 0.00138 | (3.73e-03) | 0.00158 | (3.81e-03) | 0.00196 | (3.89e-03) |
| 1661.0 GHz | 180.49 | 194.1 | 0.000293 | (8.45e-04) | 0.000341 | (9.58e-04) | 0.000419 | (1.03e-03) |
| 1162.9 GHz | 257.79 | 305.3 | 8.11e-05 | (2.61e-04) | 9.72e-05 | (3.20e-04) | 0.000135 | (3.48e-04) |
| 1153.1 GHz | 259.98 | 249.4 | 0.000209 | (5.63e-04) | 0.000244 | (7.36e-04) | 0.000297 | (8.35e-04) |
| 1097.4 GHz | 273.19 | 249.4 | 0.000127 | (3.43e-04) | 0.000152 | (3.55e-04) | 0.0002 | (3.50e-04) |
| 556.94 GHz | 538.28 | 61 | 7.98e-05 | (2.06e-04) | 8.45e-05 | (2.00e-04) | 9.89e-05 | (2.04e-04) |
Table B.8. Intensities of ortho-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 40 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v40b2, M1 | (v40b2, M2) | v40b2.5, M1 | (v40b2.5, M2) | v40b3, M1 | (v40b3, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 5500.1 GHz | 54.506 | 732.1 | 5.58e-06 | (9.15e-06) | 3.78e-06 | (1.08e-05) | 4.89e-06 | (1.19e-05) |
| 5437.8 GHz | 55.131 | 1274 | 1.47e-05 | (3.87e-05) | 1.53e-05 | (4.56e-05) | 2.14e-05 | (4.94e-05) |
| 5276.5 GHz | 56.816 | 1324 | 4.82e-05 | (1.35e-04) | 5.37e-05 | (1.56e-04) | 7.51e-05 | (1.67e-04) |
| 5107.3 GHz | 58.699 | 550.4 | 0.000339 | (7.11e-04) | 0.000275 | (7.70e-04) | 0.000344 | (8.04e-04) |
| 4764.0 GHz | 62.928 | 1553 | 7.07e-07 | (1.96e-06) | 7.73e-07 | (2.35e-06) | 1.09e-06 | (2.55e-06) |
| 4734.3 GHz | 63.323 | 1071 | 9.55e-05 | (2.46e-04) | 9.84e-05 | (2.83e-04) | 0.000135 | (3.03e-04) |
| 4600.4 GHz | 65.166 | 795.5 | 9.22e-05 | (1.83e-04) | 7.4e-05 | (2.17e-04) | 9.76e-05 | (2.37e-04) |
| 4535.9 GHz | 66.092 | 1013 | 2.84e-05 | (6.51e-05) | 2.59e-05 | (7.73e-05) | 3.51e-05 | (8.41e-05) |
| 4512.4 GHz | 66.437 | 410.7 | 0.000535 | (8.84e-04) | 0.00038 | (9.42e-04) | 0.000463 | (9.85e-04) |
| 4456.6 GHz | 67.268 | 410.7 | 0.000127 | (8.96e-05) | 4.9e-05 | (1.41e-04) | 5.51e-05 | (1.74e-04) |
| 4240.2 GHz | 70.702 | 1274 | 1.98e-06 | (5.21e-06) | 2.07e-06 | (6.15e-06) | 2.88e-06 | (6.65e-06) |
| 4166.9 GHz | 71.946 | 843.5 | 0.000183 | (4.15e-04) | 0.000166 | (4.81e-04) | 0.000222 | (5.19e-04) |
| 4000.2 GHz | 74.944 | 1126 | 6.26e-06 | (1.62e-05) | 6.44e-06 | (1.89e-05) | 8.87e-06 | (2.03e-05) |
| 3977.0 GHz | 75.38 | 305.3 | 0.00164 | (2.05e-03) | 0.000985 | (2.40e-03) | 0.0011 | (2.62e-03) |
| 3971.0 GHz | 75.495 | 1806 | 7.12e-07 | (2.20e-06) | 8.98e-07 | (2.48e-06) | 1.27e-06 | (2.62e-06) |
| 3807.3 GHz | 78.742 | 432.2 | 0.000695 | (8.97e-04) | 0.000406 | (1.09e-03) | 0.000495 | (1.21e-03) |
| 3654.6 GHz | 82.031 | 643.5 | 0.000382 | (7.41e-04) | 0.000301 | (8.65e-04) | 0.00039 | (9.37e-04) |
| 3536.7 GHz | 84.766 | 1013 | 5.03e-06 | (1.15e-05) | 4.58e-06 | (1.37e-05) | 6.22e-06 | (1.49e-05) |
| 3167.6 GHz | 94.643 | 795.5 | 1.18e-05 | (2.34e-05) | 9.46e-06 | (2.78e-05) | 1.25e-05 | (3.02e-05) |
| 3165.5 GHz | 94.704 | 702.3 | 5.9e-06 | (8.94e-06) | 3.7e-06 | (1.07e-05) | 4.67e-06 | (1.18e-05) |
| 3013.2 GHz | 99.492 | 468.1 | 0.000828 | (1.36e-03) | 0.00057 | (1.59e-03) | 0.000708 | (1.73e-03) |
| 2970.8 GHz | 100.91 | 574.7 | 0.000147 | (2.03e-04) | 8.82e-05 | (2.48e-04) | 0.00011 | (2.76e-04) |
| 2774.0 GHz | 108.07 | 194.1 | 0.00217 | (4.21e-03) | 0.00156 | (4.71e-03) | 0.00179 | (5.06e-03) |
| 2664.6 GHz | 112.51 | 1340 | 8.39e-07 | (2.40e-06) | 9.72e-07 | (2.69e-06) | 1.35e-06 | (2.85e-06) |
| 2640.5 GHz | 113.54 | 323.5 | 0.00178 | (3.00e-03) | 0.00124 | (3.45e-03) | 0.00148 | (3.73e-03) |
| 2462.9 GHz | 121.72 | 550.4 | 7.19e-05 | (6.04e-05) | 3.27e-05 | (9.70e-05) | 3.95e-05 | (1.21e-04) |
| 2344.3 GHz | 127.88 | 1126 | 1.94e-06 | (5.02e-06) | 1.99e-06 | (5.84e-06) | 2.74e-06 | (6.28e-06) |
| 2264.1 GHz | 132.41 | 432.2 | 0.000194 | (2.46e-04) | 0.000106 | (3.13e-04) | 0.000123 | (3.53e-04) |
| 2221.8 GHz | 134.93 | 574.7 | 5.05e-05 | (7.31e-05) | 3.16e-05 | (8.86e-05) | 3.94e-05 | (9.80e-05) |
| 2196.3 GHz | 136.49 | 410.7 | 0.00016 | (2.56e-04) | 9.58e-05 | (3.20e-04) | 0.00011 | (3.57e-04) |
| 1918.5 GHz | 156.26 | 642.4 | 5.16e-06 | (5.30e-06) | 2.55e-06 | (7.21e-06) | 3.22e-06 | (8.64e-06) |
| 1867.7 GHz | 160.51 | 732.1 | 4.07e-06 | (6.64e-06) | 2.75e-06 | (7.87e-06) | 3.55e-06 | (8.66e-06) |
| 1716.8 GHz | 174.62 | 196.8 | 0.00162 | (3.74e-03) | 0.00139 | (3.94e-03) | 0.00169 | (4.10e-03) |
| 1669.9 GHz | 179.53 | 114.4 | 0.00215 | (5.35e-03) | 0.00198 | (5.35e-03) | 0.00238 | (5.47e-03) |
| 1661.0 GHz | 180.49 | 194.1 | 0.000539 | (1.28e-03) | 0.000443 | (1.37e-03) | 0.00052 | (1.45e-03) |
| 1162.9 GHz | 257.79 | 305.3 | 0.000137 | (3.89e-04) | 0.00012 | (4.39e-04) | 0.000152 | (4.74e-04) |
| 1153.1 GHz | 259.98 | 249.4 | 0.000507 | (9.47e-04) | 0.000338 | (1.12e-03) | 0.000389 | (1.24e-03) |
| 1097.4 GHz | 273.19 | 249.4 | 0.00022 | (5.04e-04) | 0.000197 | (5.22e-04) | 0.000242 | (5.29e-04) |
| 556.94 GHz | 538.28 | 61 | 0.000114 | (2.84e-04) | 0.000106 | (2.71e-04) | 0.00012 | (2.74e-04) |
Table B.9. Intensities of para-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 20 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v20b1, M1 | (v20b1, M2) | v20b1.5, M1 | (v20b1.5, M2) | v20b2, M1 | (v20b2, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 5322.5 GHz | 56.325 | 552.3 | 2.46e-05 | (4.10e-05) | 2.91e-05 | (4.81e-05) | 2.37e-05 | (3.10e-05) |
| 5280.7 GHz | 56.771 | 1324 | 4.69e-06 | (7.15e-06) | 5.49e-06 | (5.91e-06) | 4.63e-06 | (3.96e-06) |
| 5201.4 GHz | 57.636 | 454.3 | 6.05e-05 | (1.10e-04) | 7.08e-05 | (1.04e-04) | 6.41e-05 | (7.16e-05) |
| 5194.9 GHz | 57.709 | 1270 | 9.33e-07 | (1.41e-06) | 1.09e-06 | (1.25e-06) | 9.06e-07 | (8.23e-07) |
| 4997.6 GHz | 59.987 | 1021 | 1.76e-06 | (2.71e-06) | 2.06e-06 | (2.59e-06) | 1.71e-06 | (1.69e-06) |
| 4850.3 GHz | 61.808 | 552.3 | 3.85e-07 | (6.35e-07) | 4.6e-07 | (7.56e-07) | 3.68e-07 | (4.84e-07) |
| 4724.0 GHz | 63.457 | 1070 | 8.78e-06 | (1.40e-05) | 1.03e-05 | (1.18e-05) | 8.87e-06 | (8.00e-06) |
| 4468.6 GHz | 67.089 | 410.4 | 6.05e-05 | (1.16e-04) | 7.04e-05 | (1.13e-04) | 6.54e-05 | (7.90e-05) |
| 4218.4 GHz | 71.067 | 598.8 | 1.54e-05 | (2.56e-05) | 1.82e-05 | (2.67e-05) | 1.54e-05 | (1.76e-05) |
| 4190.6 GHz | 71.539 | 843.8 | 1.76e-05 | (2.95e-05) | 2.08e-05 | (2.53e-05) | 1.85e-05 | (1.73e-05) |
| 3798.3 GHz | 78.928 | 781.1 | 3.35e-06 | (5.31e-06) | 3.95e-06 | (5.66e-06) | 3.27e-06 | (3.66e-06) |
| 3691.3 GHz | 81.215 | 1021 | 2.36e-07 | (3.63e-07) | 2.77e-07 | (3.48e-07) | 2.29e-07 | (2.27e-07) |
| 3599.6 GHz | 83.283 | 642.7 | 3.16e-05 | (5.37e-05) | 3.74e-05 | (5.04e-05) | 3.29e-05 | (3.40e-05) |
| 3331.5 GHz | 89.988 | 296.8 | 5.73e-05 | (9.59e-05) | 6.85e-05 | (1.03e-04) | 5.74e-05 | (6.87e-05) |
| 3182.2 GHz | 94.209 | 877.8 | 2.05e-07 | (3.32e-07) | 2.44e-07 | (3.57e-07) | 2.05e-07 | (2.32e-07) |
| 3135.0 GHz | 95.626 | 469.9 | 5.68e-05 | (9.94e-05) | 6.73e-05 | (1.01e-04) | 5.86e-05 | (6.75e-05) |
| 2968.7 GHz | 100.98 | 195.9 | 0.000186 | (3.60e-04) | 0.000214 | (4.13e-04) | 0.000168 | (2.66e-04) |
| 2884.3 GHz | 103.94 | 781.1 | 7.63e-07 | (1.21e-06) | 9.01e-07 | (1.29e-06) | 7.45e-07 | (8.34e-07) |
| 2685.6 GHz | 111.63 | 598.8 | 1.77e-06 | (2.94e-06) | 2.09e-06 | (3.08e-06) | 1.77e-06 | (2.02e-06) |
| 2631.0 GHz | 113.95 | 725.1 | 1.35e-06 | (2.40e-06) | 1.6e-06 | (1.98e-06) | 1.47e-06 | (1.40e-06) |
| 2391.6 GHz | 125.35 | 319.5 | 0.000112 | (2.04e-04) | 0.000133 | (2.18e-04) | 0.000114 | (1.46e-04) |
| 2365.9 GHz | 126.71 | 410.4 | 3.25e-06 | (5.59e-06) | 4.66e-06 | (8.41e-06) | 3.33e-06 | (4.95e-06) |
| 2164.1 GHz | 138.53 | 204.7 | 0.000283 | (5.69e-04) | 0.000336 | (6.40e-04) | 0.000282 | (4.21e-04) |
| 2074.4 GHz | 144.52 | 396.4 | 1.1e-05 | (1.84e-05) | 1.31e-05 | (2.17e-05) | 1.04e-05 | (1.39e-05) |
| 2040.5 GHz | 146.92 | 552.3 | 5.41e-07 | (8.92e-07) | 6.47e-07 | (1.06e-06) | 5.18e-07 | (6.80e-07) |
| 1919.4 GHz | 156.19 | 296.8 | 2.97e-05 | (5.47e-05) | 3.59e-05 | (7.92e-05) | 2.5e-05 | (4.86e-05) |
| 1794.8 GHz | 167.03 | 867.3 | 1.81e-07 | (3.03e-07) | 2.16e-07 | (3.08e-07) | 1.87e-07 | (2.04e-07) |
| 1602.2 GHz | 187.11 | 396.4 | 9.43e-06 | (1.59e-05) | 1.12e-05 | (1.86e-05) | 8.99e-06 | (1.20e-05) |
| 1228.8 GHz | 243.97 | 195.9 | 3.48e-05 | (9.50e-05) | 4.45e-05 | (9.36e-05) | 4.62e-05 | (6.63e-05) |
| 1113.3 GHz | 269.27 | 53.4 | 0.000264 | (6.40e-04) | 0.000297 | (5.82e-04) | 0.000289 | (4.25e-04) |
| 987.93 GHz | 303.45 | 100.8 | 0.00021 | (5.15e-04) | 0.000242 | (4.97e-04) | 0.000233 | (3.55e-04) |
| 752.03 GHz | 398.64 | 136.9 | 6.59e-05 | (1.75e-04) | 7.72e-05 | (1.71e-04) | 7.54e-05 | (1.21e-04) |
Table B.10. Intensities of para-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 30 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v30b1.5, M1 | (v30b1.5, M2) | v30b2, M1 | (v30b2, M2) | v30b2.5, M1 | (v30b2.5, M2) |
|--------------|----------------------------|------------|---------------|-----------------|-------------|---------------|---------------|-----------------|
| 5322.5 GHz | 56.325 | 552.3 | 4.33e-05 | (1.03e-04) | 5.31e-05 | (1.34e-04) | 6.64e-05 | (1.48e-04) |
| 5280.7 GHz | 56.771 | 1324 | 7.51e-06 | (1.93e-05) | 1.03e-05 | (2.21e-05) | 1.38e-05 | (2.26e-05) |
| 5201.4 GHz | 57.636 | 454.3 | 9.73e-05 | (2.39e-04) | 0.000119 | (2.65e-04) | 0.00015 | (2.74e-04) |
| 5194.9 GHz | 57.709 | 1270.3 | 1.54e-06 | (3.88e-06) | 2.08e-06 | (4.62e-06) | 2.74e-06 | (4.84e-06) |
| 4997.6 GHz | 59.987 | 1021 | 2.97e-06 | (7.39e-06) | 3.94e-06 | (9.09e-06) | 5.15e-06 | (9.70e-06) |
| 4850.3 GHz | 61.808 | 552.3 | 7.05e-07 | (1.62e-06) | 8.95e-07 | (2.20e-06) | 1.11e-06 | (2.51e-06) |
| 4724.0 GHz | 63.457 | 1070 | 1.41e-05 | (3.60e-05) | 1.9e-05 | (4.10e-05) | 2.51e-05 | (4.21e-05) |
| 4468.6 GHz | 67.089 | 410.4 | 9.46e-05 | (2.37e-04) | 0.000112 | (2.61e-04) | 0.000142 | (2.70e-04) |
| 4218.4 GHz | 71.067 | 598.8 | 2.62e-05 | (6.37e-05) | 3.32e-05 | (7.92e-05) | 4.23e-05 | (8.59e-05) |
| 4190.6 GHz | 71.539 | 843.8 | 2.82e-05 | (7.16e-05) | 3.73e-05 | (8.08e-05) | 4.87e-05 | (8.35e-05) |
| 3798.3 GHz | 78.928 | 781.1 | 5.73e-06 | (1.41e-05) | 7.39e-06 | (1.81e-05) | 9.56e-06 | (1.97e-05) |
| 3691.3 GHz | 81.215 | 1021 | 3.98e-07 | (9.91e-07) | 5.29e-07 | (1.22e-06) | 6.91e-07 | (1.30e-06) |
| 3599.6 GHz | 83.283 | 642.7 | 5.17e-05 | (1.29e-04) | 6.68e-05 | (1.51e-04) | 8.63e-05 | (1.60e-04) |
| 3331.5 GHz | 89.988 | 296.8 | 0.000109 | (2.28e-04) | 0.000133 | (2.99e-04) | 0.00016 | (3.30e-04) |
| 3182.2 GHz | 94.209 | 877.8 | 3.47e-07 | (8.74e-07) | 4.48e-07 | (1.12e-06) | 5.89e-07 | (1.22e-06) |
| 3135.0 GHz | 95.626 | 469.9 | 9.47e-05 | (2.32e-04) | 0.000119 | (2.78e-04) | 0.000151 | (2.99e-04) |
| 2968.7 GHz | 100.98 | 195.9 | 0.000321 | (7.66e-04) | 0.000369 | (8.96e-04) | 0.000419 | (9.80e-04) |
| 2884.3 GHz | 103.94 | 781.1 | 1.31e-06 | (3.23e-06) | 1.69e-06 | (4.12e-06) | 2.18e-06 | (4.49e-06) |
| 2685.6 GHz | 111.63 | 598.8 | 3.02e-06 | (7.33e-06) | 3.83e-06 | (9.14e-06) | 4.87e-06 | (9.91e-06) |
| 2631.0 GHz | 113.95 | 725.1 | 2.11e-06 | (5.34e-06) | 2.74e-06 | (5.74e-06) | 3.55e-06 | (5.85e-06) |
| 2391.6 GHz | 125.35 | 319.5 | 0.000192 | (4.57e-04) | 0.000234 | (5.55e-04) | 0.000289 | (6.03e-04) |
| 2365.9 GHz | 126.71 | 410.4 | 7.21e-06 | (1.60e-05) | 1.03e-05 | (2.66e-05) | 1.25e-05 | (3.32e-05) |
| 2164.1 GHz | 138.53 | 204.7 | 0.000471 | (1.19e-03) | 0.000554 | (1.42e-03) | 0.000674 | (1.54e-03) |
| 2074.4 GHz | 144.52 | 396.4 | 2.05e-05 | (4.55e-05) | 2.57e-05 | (6.10e-05) | 3.1e-05 | (6.94e-05) |
| 2040.5 GHz | 146.92 | 552.3 | 9.9e-07 | (2.28e-06) | 1.26e-06 | (3.10e-06) | 1.56e-06 | (3.54e-06) |
| 1919.4 GHz | 156.19 | 296.8 | 5.46e-05 | (1.33e-04) | 6.41e-05 | (1.80e-04) | 7.51e-05 | (2.08e-04) |
| 1794.8 GHz | 167.03 | 867.3 | 3.01e-07 | (7.63e-07) | 3.89e-07 | (9.46e-07) | 5.08e-07 | (1.02e-06) |
| 1602.2 GHz | 187.11 | 396.4 | 1.72e-05 | (3.89e-05) | 2.11e-05 | (5.08e-05) | 2.56e-05 | (5.67e-05) |
| 1228.8 GHz | 243.97 | 195.9 | 4.9e-05 | (1.61e-04) | 5.99e-05 | (1.80e-04) | 8.46e-05 | (1.84e-04) |
| 1113.3 GHz | 269.27 | 53.4 | 0.000372 | (1.03e-03) | 0.00042 | (1.01e-03) | 0.000513 | (1.02e-03) |
| 987.93 GHz | 303.45 | 100.8 | 0.000297 | (8.56e-04) | 0.00034 | (8.95e-04) | 0.000431 | (9.18e-04) |
| 752.03 GHz | 398.64 | 136.9 | 9.1e-05 | (2.81e-04) | 0.000103 | (2.98e-04) | 0.000135 | (3.04e-04) |
Table B.11. Intensities of para-H2O lines (erg cm GLYPH<0> 2 s GLYPH<0> 1 sr GLYPH<0> 1 ) observable with the PACS (top) and HIFI (bottom) instruments on the Herschel Space Observatory, for shocks with velocity V s = 40 kms GLYPH<0> 1 and the magnetic field strengths listed in Table 1. Results are given for models M1, which include grain-grain processing, and M2 (in parentheses), which neglect grain-grain processing. The preshock density is n H = 10 5 cm GLYPH<0> 3 .
| Transition | GLYPH<21> ( GLYPH<22> m) | E up (K) | v40b2, M1 | (v40b2, M2) | v40b2.5, M1 | (v40b2.5, M2) | v40b3, M1 | (v40b3, M2) |
|--------------|----------------------------|------------|-------------|---------------|---------------|-----------------|-------------|---------------|
| 5322.5 GHz | 56.325 | 552.3 | 0.000119 | (1.86e-04) | 7.42e-05 | (2.27e-04) | 9.05e-05 | (2.50e-04) |
| 5280.7 GHz | 56.771 | 1324 | 1.25e-05 | (3.28e-05) | 1.3e-05 | (3.84e-05) | 1.82e-05 | (4.14e-05) |
| 5201.4 GHz | 57.636 | 454.3 | 0.000194 | (3.86e-04) | 0.000155 | (4.16e-04) | 0.000193 | (4.33e-04) |
| 5194.9 GHz | 57.709 | 1270.3 | 2.91e-06 | (6.81e-06) | 2.67e-06 | (8.18e-06) | 3.68e-06 | (8.93e-06) |
| 4997.6 GHz | 59.987 | 1021 | 6.42e-06 | (1.32e-05) | 5.17e-06 | (1.61e-05) | 6.97e-06 | (1.77e-05) |
| 4850.3 GHz | 61.808 | 552.3 | 3.27e-06 | (3.06e-06) | 1.4e-06 | (4.07e-06) | 1.68e-06 | (4.80e-06) |
| 4724.0 GHz | 63.457 | 1070 | 2.47e-05 | (6.05e-05) | 2.4e-05 | (7.00e-05) | 3.29e-05 | (7.51e-05) |
| 4468.6 GHz | 67.089 | 410.4 | 0.000196 | (3.74e-04) | 0.000146 | (3.99e-04) | 0.000179 | (4.15e-04) |
| 4218.4 GHz | 71.067 | 598.8 | 6.55e-05 | (1.12e-04) | 4.51e-05 | (1.35e-04) | 5.73e-05 | (1.49e-04) |
| 4190.6 GHz | 71.539 | 843.8 | 5.1e-05 | (1.19e-04) | 4.78e-05 | (1.36e-04) | 6.4e-05 | (1.46e-04) |
| 3798.3 GHz | 78.928 | 781.1 | 1.37e-05 | (2.56e-05) | 9.94e-06 | (3.15e-05) | 1.3e-05 | (3.48e-05) |
| 3691.3 GHz | 81.215 | 1021 | 8.61e-07 | (1.77e-06) | 6.94e-07 | (2.16e-06) | 9.36e-07 | (2.38e-06) |
| 3599.6 GHz | 83.283 | 642.7 | 0.000107 | (2.19e-04) | 8.77e-05 | (2.54e-04) | 0.000114 | (2.75e-04) |
| 3331.5 GHz | 89.988 | 296.8 | 0.000409 | (4.30e-04) | 0.00021 | (5.44e-04) | 0.000238 | (6.11e-04) |
| 3182.2 GHz | 94.209 | 877.8 | 8.47e-07 | (1.57e-06) | 5.99e-07 | (1.93e-06) | 7.86e-07 | (2.14e-06) |
| 3135.0 GHz | 95.626 | 469.9 | 0.000228 | (3.96e-04) | 0.000161 | (4.63e-04) | 0.000202 | (5.04e-04) |
| 2968.7 GHz | 100.98 | 195.9 | 0.00076 | (1.28e-03) | 0.00053 | (1.41e-03) | 0.000583 | (1.52e-03) |
| 2884.3 GHz | 103.94 | 781.1 | 3.14e-06 | (5.83e-06) | 2.27e-06 | (7.18e-06) | 2.96e-06 | (7.95e-06) |
| 2685.6 GHz | 111.63 | 598.8 | 7.73e-06 | (1.30e-05) | 5.23e-06 | (1.57e-05) | 6.63e-06 | (1.72e-05) |
| 2631.0 GHz | 113.95 | 725.1 | 3.67e-06 | (8.53e-06) | 3.51e-06 | (9.32e-06) | 4.6e-06 | (9.83e-06) |
| 2391.6 GHz | 125.35 | 319.5 | 0.000505 | (7.82e-04) | 0.000329 | (9.15e-04) | 0.000392 | (9.97e-04) |
| 2365.9 GHz | 126.71 | 410.4 | 3.46e-05 | (3.41e-05) | 1.72e-05 | (5.11e-05) | 2e-05 | (6.20e-05) |
| 2164.1 GHz | 138.53 | 204.7 | 0.00105 | (1.96e-03) | 0.00076 | (2.20e-03) | 0.000884 | (2.36e-03) |
| 2074.4 GHz | 144.52 | 396.4 | 8.42e-05 | (8.54e-05) | 4.01e-05 | (1.11e-04) | 4.69e-05 | (1.29e-04) |
| 2040.5 GHz | 146.92 | 552.3 | 4.64e-06 | (4.30e-06) | 1.96e-06 | (5.72e-06) | 2.37e-06 | (6.76e-06) |
| 1919.4 GHz | 156.19 | 296.8 | 0.000161 | (2.38e-04) | 9.42e-05 | (2.91e-04) | 0.000105 | (3.26e-04) |
| 1794.8 GHz | 167.03 | 867.3 | 6.52e-07 | (1.33e-06) | 5.12e-07 | (1.60e-06) | 6.72e-07 | (1.75e-06) |
| 1602.2 GHz | 187.11 | 396.4 | 5.1e-05 | (7.11e-05) | 3.06e-05 | (8.73e-05) | 3.6e-05 | (9.67e-05) |
| 1228.8 GHz | 243.97 | 195.9 | 8.03e-05 | (2.34e-04) | 7.51e-05 | (2.53e-04) | 9.65e-05 | (2.63e-04) |
| 1113.3 GHz | 269.27 | 53.4 | 0.00053 | (1.43e-03) | 0.000521 | (1.39e-03) | 0.000621 | (1.40e-03) |
| 987.93 GHz | 303.45 | 100.8 | 0.000452 | (1.22e-03) | 0.00042 | (1.24e-03) | 0.00051 | (1.27e-03) |
| 752.03 GHz | 398.64 | 136.9 | 0.000137 | (3.95e-04) | 0.000126 | (4.05e-04) | 0.000154 | (4.15e-04) | | 10.1051/0004-6361/201321399 | [
"S. Anderl",
"V. Guillet",
"G. Pineau des Forêts",
"D. R. Flower"
] | 2014-08-01T11:55:58+00:00 | 2014-08-01T11:55:58+00:00 | [
"astro-ph.GA",
"astro-ph.SR"
] | Shocks in dense clouds. IV. Effects of grain-grain processing on molecular line emission | Grain-grain processing has been shown to be an indispensable ingredient of
shock modelling in high density environments. For densities higher than
\sim10^5 cm-3, shattering becomes a self-enhanced process that imposes severe
chemical and dynamical consequences on the shock characteristics. Shattering is
accompanied by the vaporization of grains, which can directly release SiO to
the gas phase. Given that SiO rotational line radiation is used as a major
tracer of shocks in dense clouds, it is crucial to understand the influence of
vaporization on SiO line emission. We have developed a recipe for implementing
the effects of shattering and vaporization into a 2-fluid shock model,
resulting in a reduction of computation time by a factor \sim100 compared to a
multi-fluid modelling approach. This implementation was combined with an
LVG-based modelling of molecular line radiation transport. Using this model we
calculated grids of shock models to explore the consequences of different
dust-processing scenarios. Grain-grain processing is shown to have a strong
influence on C-type shocks for a broad range of magnetic fields: they become
hotter and thinner. The reduction in column density of shocked gas lowers the
intensity of molecular lines, at the same time as higher peak temperatures
increase the intensity of highly excited transitions compared to shocks without
grain-grain processing. For OH the net effect is an increase in line
intensities, while for CO and H2O it is the contrary. The intensity of H2
emission is decreased in low transitions and increased for highly excited
lines. For all molecules, the highly excited lines become sensitive to the
value of the magnetic field. Although vaporization increases the intensity of
SiO rotational lines, this effect is weakened by the reduced shock width. The
release of SiO early in the hot shock changes the excitation characteristics of
SiO radiation. |
1408.0141v1 | ## Microscopic Origin of Shear Relaxation in Strongly Coupled Yukawa Liquids
∗
Ashwin J. and Abhijit Sen Institute for Plasma Research, Bhat, Gandhinagar-382428, India. (Dated: August 4, 2014)
We report accurate molecular dynamics calculations of the shear stress relaxation in a twodimensional strongly coupled Yukawa liquid over a wide range of the Coulomb coupling strength Γ and the Debye screening parameter κ . Our data on the relaxation times of the ideal- , excess- and total shear stress auto-correlation ( τ id M , τ ex M , τ M respectively) along with the lifetime of local atomic connectivity τ LC leads us to the following important observation. Below a certain crossover Γ ( c κ ), τ LC → τ ex M , directly implying that here τ LC is the microscopic origin of the relaxation of excess shear stress unlike the case for ordinary liquids where it is the origin of the relaxation of the total shear stress. At Γ >> Γ ( c κ ) i.e. in the potential energy dominated regime, τ ex M → τ M meaning that τ ex M can fully account for the elastic or 'solid like' behavior.
PACS numbers: 52.27.Lw,51.35.+a,52.65.Yy
The Yukawa liquid is routinely used to model a wide variety of strongly coupled systems such as laboratory and astrophysical dusty plasma systems, charged colloids and liquid metals [1, 2]. The particle interaction potential used in this liquid has the form φ r ( ) = Q 2 4 πglyph[epsilon1] 0 r e -r λ D . Here Q and λ D refer to the particle charge and Debye shielding distance respectively. The thermodynamic state point of the Yukawa liquid is completely characterized by two dimensionless quantities namely, the screening parameter κ = a λ D and the coupling strength Γ = Q 2 4 πglyph[epsilon1] 0 ak B T . Here a is the Wigner-Seitz radius such that πa n 2 = 1 with n being the areal number density. In a strongly coupled Yukawa liquid (SCYL), the average Coulomb interaction energy can exceed the average kinetic energy per particle thus leading to Γ > 1. A direct consequence of this is the emergence of solid-like features such as sustaining low frequency shear modes [3] originally predicted in theoretical works [4, 5] and later realized in laboratory experiments [6]. This makes SCYL a good model system to study a range of collective phenomena in dusty plasma systems. SCYL's have also been shown to be excellent test-beds for modeling hydrodynamic flows [79], self-organization phenomena such as clustering [10] and lane formation [11] in complex plasmas. A significant amount of numerical work has also been done on the viscosity measurements in SCYL using both equilibrium [12-14] and non-equilibrium molecular dynamics simulations [15, 16] . These studies have confirmed the existence of a viscosity minimum at some crossover value Γ ( c κ ). The minimum arises due to the competition between ideal and the excess part of the stress tensor. In later works, visco-elasticity was also quantified using both experiments [17, 18] and numerical simulations [19] where the crossover frequency for the real and imaginary parts of the complex viscosity was shown to be empirically related to the inverse Maxwell time. It was shown in Ref [19] that this crossover frequency develops a maximum at some Γ ( c κ ) implying a minimum in the Maxwell time τ M at the same Γ ( c κ ). However, a systematic study of the microscopic origin of shear relaxation and Maxwell time in these liquids at various (Γ , κ ) values is still lacking. The aim of this letter is to fill this gap and provide from first principles, an atomistic study that would provide answers to the following two fundamentally important questions: (a) What is the connection between the microscopic world and the macroscopic shear relaxation in these SCYL? (b) Is τ M the duration of dominant elastic response for these liquids especially at Γ glyph[lessmuch] Γ ( c κ )? To address the first question, we have calculated the lifetime of local atomic connectivity τ LC [20] and found that it converges to the relaxation of the excess part of shear stress auto-correlation τ ex M at Γ < Γ ( c κ ). Since τ LC corresponds to the time duration where the topology of nearest neighbors remains intact, the fact that τ ex M → τ LC for Γ < Γ ( c κ ) directly indicates that τ ex M is the duration of dominant elastic response at these temperatures. This is different from the results reported in Ref [19] where τ LC was shown to converge to τ M below the cross-over temperature for a range of ordinary liquids. It is important to note that none of those liquids showed a nonmonotonous behavior in τ M with temperature. We also show that at Γ > Γ ( c k ), τ LC deviates from τ ex M directly indicating a crossover from a kinetic regime to potential energy dominated regime. Our study further shows that the infinite frequency shear modulus G ∞ does not have a minimum at any temperature as opposed to the viscosity data which has a well known minimum at Γ = Γ ( c κ ). In the following we provide the details of our numerical work and also explain the procedure used to extract quality data.
Numerical simulations: We have performed molecular dynamics (MD) simulations on a two-dimensional (2D) Yukawa liquid in a canonical ensemble under periodic boundary conditions. All distances are normalized to Wigner-Seitz radius a , energies are normalized to Q 2 4 πglyph[epsilon1] 0 a and times are normalized to ω -1 pd . Here ω pd is the 2D nominal plasma frequency given by ω pd = √ Q 2 2 πglyph[epsilon1] 0 ma 3 .
The simulation box contains 5016 particles at a reduced number density n = π -1 . The dimensions of rectangular box were chosen to be 125.705291 × 125.358517 which allows for the formation of a perfect triangular lattice below the freezing transition. The interaction potential is truncated smoothly to zero along with its first two derivatives by employing a fifth order polynomial as a switching function in the range ( r m < r < r c ) where r m and r c are the inner and the outer cutoff respectively. We chose r m and r c subject to the criteria: φ r ( m ) ≈ 2 27 . × 10 -6 and φ r ( c ) ≈ 1 49 . × 10 -7 thus ensuring negligible perturbation to the bare Yukawa potential. A Nose-Hoover thermostat [21] with a time constant of 1 √ 2 is employed to maintain the temperature at a desired Γ. To improve statistics, we have averaged our data over an ensemble of 3200 independent realizations. This was necessary to reduce the fluctuations present in the long time tail of the stress relaxation function originating from the long range nature of the interaction potential. We now proceed to explain the computation of various dynamical quantities reported in this paper.
The stress relaxation function used in our work is the auto-correlation of the shear stress tensor and is given as
$$G ( t ) = \frac { 1 } { A k \cap T } \langle \sigma _ { x y } ( t ) \sigma _ { x y } ( 0 ) \rangle$$
$$\L ^ { ( t ) } = \frac { 1 } { A k _ { B } T } \langle \sigma _ { x y } ( t ) \sigma _ { x y } ( 0 ) \rangle \quad \quad ( 1 )$$
with initial value of this auto-correlation giving the infinite frequency shear modulus G ∞ = G (0). The angular brackets here denote the average over the entire ensemble, with A being the area and σ xy ( ) t the microscopic stress tensor being defined as
$$\sigma _ { x y } ( t ) = \sum _ { i = 1 } ^ { N } m _ { i } v _ { i } ^ { x } ( t ) v _ { i } ^ { y } ( t ) - \sum _ { i = 1 } ^ { N } \sum _ { j > i } ^ { N } x _ { i j } ( t ) y _ { i j } ( t ) \frac { \phi ^ { \prime } ( r _ { i j }, t ) } { r _ { i j } ( t ) } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
T h o \ f o w t \text{ to the thead} \text{ in and thead} \text{ in to}$$
The first term on the right hand side has purely kinetic origins and is the dominating term at high temperatures whereas the second term is the excess part and has its origins in particle interactions. The second term is named excess as it would be absent in an ideal gas (gas of 'hard spheres' ) and arises only in a real gas. Figure 1 shows the normalized stress relaxation function G t ( ) of a 2D Yukawa liquid at various coupling strengths Γ > Γ ( c κ ). It is clear that at short times, G t ( ) has a zero slope meaning that liquid response is dominantly elastic. This is followed by a region of fast decay where both the elastic and viscous effects are comparable. At large times, G t ( ) has become much smaller (within statistical noise) indicating a regime dominated by viscous response and negligible elastic effects. It is also seen from the figure that the relaxation time increases with Γ implying that elastic response will dominate for longer times as Γ increases. This is mainly due to growing structural order as shown in the inset of Figure 1. Next we turn our attention to the hydrodynamic (or zero frequency) shear viscosity η which is an important dynamical property responsible for viscous dissipation in liquids.
FIG. 1. (color online). Normalized stress relaxation function G t ( ) for a Yukawa liquid at various Γ. The dashed line shows the location of 1 /e falling time. It is clear from the figure that the relaxation time increases with Γ for Γ > Γ ( c κ ). Note that the relaxation time (or e-folding time) increases with Γ. [Inset: shows the growing hexagonal order in the liquid with Γ.]
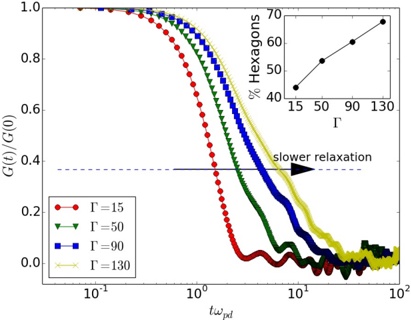
All liquids tend to gradually resist the deformation imposed by an external shear stress. A measure of this resistance is the hydrodynamic shear viscosity η (bulk viscosity in case of a compressive external force). For a liquid at thermal equilibrium, this shear viscosity can be obtained by the long time integral of the stress relaxation function -a procedure well known as the Green-Kubo formula [22].
$$\eta = \int _ { 0 } ^ { \infty } G ( t ) d t$$
In calculating η from Eq. (3), the upper limit of the integral is set to the first zero crossing time of the ensemble averaged shear relaxation function G t ( ). In Figure 2, we have shown our data on the shear viscosity measurement at three different values of κ . Our results for η are both qualitatively and quantitatively similar to the existing report on 2D equilibrium simulations [14]. Next we show our data on the G ∞ calculation in Figure 3 at various κ . It is interesting to see that unlike shear viscosity, G ∞ does not have a minimum at any temperature. The contributions coming from both the ideal and excess part of G ∞ are shown in the inset of Figure 3. At high temperatures (low Γ), kinetic effects are dominant and the ideal part G id ∞ is the dominating term and becomes a major contributor to the overall G ∞ . At low temperatures (high Γ) the excess term G ex ∞ begins to dominate and the ideal term becomes very small. It is interesting to note that the excess part G ex ∞ saturates as Γ increases.
FIG. 2. (color online). Hydrodynamic viscosity (normalized to η 0 = a nmω 2 pd ) computed from Eq. (3) at various κ . The minimum at Γ = Γ ( c κ ) is due to the competition of the ideal part and the excess part of the stress tensor and is well known in the literature [12, 14].
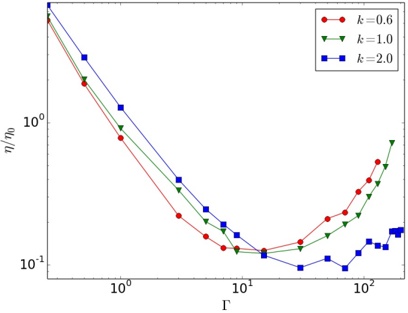
FIG. 3. (color online). Infinite frequency shear modulus G ∞ vs. Γ at various κ . Unlike viscosity which has a minimum, G ∞ does not have a minimum at any temperature. [Inset: The total, ideal and excess contributions for the case κ = 0 6 . only. It is clear that at low Γ, the entire contribution comes from the ideal term whereas at high Γ, the excess term is responsible for the entire G ∞ .]
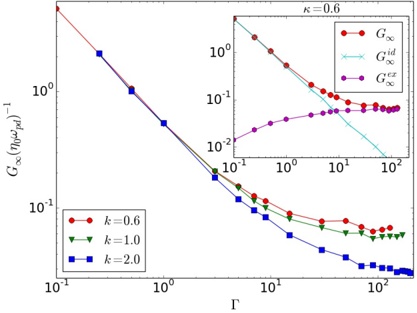
In the following, we will show the effect of quantities addressed so far in the determining the Maxwell shear stress relaxation time τ M .
It is generally accepted that all liquids are visco-elastic in nature meaning that their mechanical response to an external force will be both viscous and elastic at the same time. This can be explained through the concept of the Maxwell relaxation time scale τ M such that at times t << τ M , the response of the liquid will be dominantly elastic ( reversible ) and at t >> τ M the response will be dominantly viscous ( irreversible ). At intermediate time
FIG. 4. (color online). Maxwell relaxation time τ M as calculated from Eq. (4). The data shows a clear minimum around a crossover Γ ( c κ ) as previously shown in Ref [19]. We explain this non-monotonous behavior by measuring independently the relaxation times of the ideal and excess parts of the shear stress auto-correlation function [See text and also Fig. 5 for details].
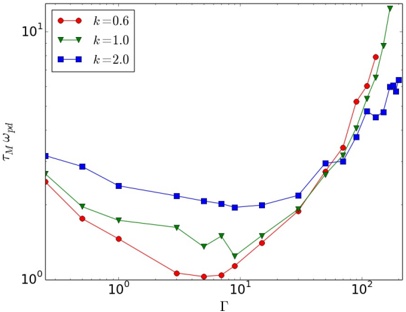
scales, both elastic and viscous features will be comparable. The ratio of the hydrodynamic shear viscosity η to the infinite frequency shear modulus G ∞ defines an average shear relaxation time or the Maxwell time [23],
$$\tau _ { M } = \frac { \eta } { G _ { \infty } } = \frac { \int _ { 0 } ^ { \infty } G ( t ) d t } { G _ { \infty } } \, \quad \quad \quad ( 4 )$$
FIG. 5. (color online). The relaxation times of the stress relaxation function G t ( ) along with its ideal G id ( ) and excess t parts G ex ( ) for the case of t κ = 0 6. . It is interesting to note that while the excess term τ ex M continues to rise all the way to the freezing transition, the ideal part saturates to a constant value around Γ ( c κ ) indicating the onset of potential energy influenced regime. [Inset: Data plotted on a log-linear axis. A dashed exponential is drawn to aid the eye of the reader.]
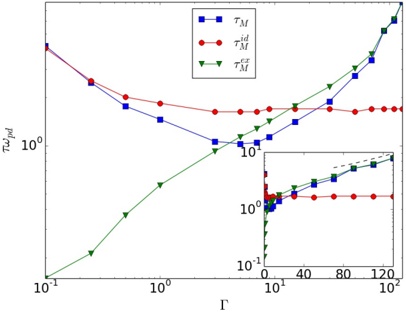
FIG. 6. (color online). Comparison of τ LC with time scales τ M , τ ex M and τ id M for the cases (a) κ = 0 6, (b) . κ = 1 0, (c) . κ = 2 0. . At Γ < Γ ( c κ ), τ ex M becomes equal to the lifetime of atomic connectivity τ LC . At Γ > Γ ( c κ ) these two time scales deviate as the liquid enters a landscape dominated regime where the interaction between local networks becomes significant and leads to cancellation of long range elastic fields [20]
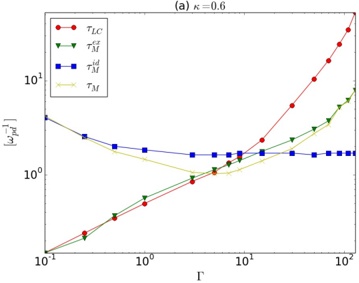
.
The normalized integral given above provides the duration of the auto-correlation and is hence a good measure of the time duration of G t ( ). Figure 4 shows a plot of τ M vs. coupling strength Γ for three values of κ . Our data shows the minimum in τ M at Γ = Γ ( c κ ) similar to the results reported in Ref [19]. This means that if one considers τ M (the relaxation of the total stress auto-correlation) as a measure of elastic response then it would imply that elasticity will persist for longer times as the weakly coupled limit or Γ → 0 is approached. We thus propose that τ M would be an incorrect measure of elasticity in these liquids as Γ → 0. To seek for an appropriate measure of elasticity we turn our attention to the components of the total stress auto-correlation G t ( ) namely the ideal part G id ( ) and the excess part t G ex ( ). t There is a cross term as well but its value is negligible at all values of ( κ, Γ). In figure 5 we show the relaxation times of the total total stress auto-correlation and its two components over the range of Γ that spans from the very weakly coupled fluid limit Γ = 0 25 to the highest Γ just below freez-. ing transition. As the liquid nears freezing (Γ → Γ m ), τ ex M → τ M and the shear relaxation is dominantly due to the particle interactions. We find that the relaxation time of the G ex ( ) denoted here by t τ ex M serves as a good measure of elasticity as it goes to zero monotonically as Γ → 0. On the high Γ side, it rises exponentially with Γ (see inset: Figure 5) as the liquid approaches the freezing transition. On the other hand, as Γ → 0, relaxation time of G id ( ) denoted here as t τ id M becomes dominant and is entirely responsible for the origin of τ M . This means that in the weakly coupled fluid limit, stress relaxation is purely kinetic and has very little contribution coming from particle interactions. It is very important to note here that our assertion on τ ex M being the right indicator for elasticity is not just based on the right asymptotic behavior with Γ but also due to its convergence to the lifetime of local atomic connectivity τ LC as explained in the following section.
In solids, phonons are weakly scattered (long lived) and hence they are the microscopic origin for vibrations. In liquids however, they exhibit highly marginalized behavior as they are strongly scattered due to lack of any underlying long range structural order. As a result phonons cannot be used to explain the microscopic origins of viscosity and the infinite frequency shear modulus. One is thus led to the following fundamentally important question: What is the microscopic origin for shear relaxation in SCYL? To answer this question, we measure the lifetime of the local atomic connectivity τ LC [20] in SCYL. To calculate τ LC one first assigns a set of bonds between a central atom and its nearest neighbors at some reference time t 0 . The nearest neighbors here correspond to atoms situated at a distance lesser than the location of the first minima in the radial distribution function. Once a reference state is assigned we track the change in local atomic connectivity i.e. the central atoms losing or gaining some neighbors. As the simulation proceeds the average coordination number will reduce and τ LC is extracted as the time duration (elapsed since t 0 ) in which the average coordination falls by 1. To improve statistics, we averaged our data over several independent realizations. In this sense, τ LC is the average time during which any atom will lose one neighbor. It was shown in Ref [20] that above a certain crossover temperature, τ LC
converges to the Maxwell time τ M and is thus the microscopic origin of shear relaxation in a range of liquids. It should be noted that none of the liquids used in that work showed a non-monotonic behavior in τ M . In Figure 6 we show our data on τ LC calculated at various values (Γ , κ ) and make the following interesting observation. At Γ < Γ ( c κ ), τ LC → τ ex M making τ LC the microscopic origin of excess part of stress at these temperatures. Since τ LC corresponds to the time duration where the topology of nearest neighbors remains intact it is also the duration of the dominant elastic or 'solid like' response. These observations directly imply that the relevant shear relaxation time scale which quantifies the elastic response in these liquids is τ ex M which becomes equal to τ LC at Γ < Γ ( c κ ) and approaches the value of τ M at Γ > Γ ( c κ ). The reader should also note that at Γ > Γ ( c k ), τ LC deviates from τ ex M directly indicating a crossover from a kinetic regime to potential energy dominated regime. This is a regime where interaction between local networks becomes significant and leads to cancellation of long range elastic fields [20].
Summary: We have calculated the infinite frequency shear modulus G ∞ , Maxwell relaxation times ( τ M , τ id M and τ ex M ) and the lifetime of the local atomic connectivity τ LC of a 2D SCYL using accurate MD simulations. The simulations were done under a canonical ensemble and quality data is obtained by averaging the runs over 3200 independent realizations. Our major finding is the microscopic origin of shear relaxation in SCYL. We find that the lifetime of topology of nearest neighbors τ LC is responsible for the relaxation of the excess part of the shear stress relaxation τ ex M . Wealso provide a solution to the riddle concerning the minimum in τ M which renders it unsuitable to quantify the elastic properties of a SCYL approaching the weakly coupled fluid limit Γ → 0. We resolve this issue by proposing that the correct object that quantifies elastic response of such strongly coupled liquids is the relaxation time of the excess part of the shear stress auto-correlation τ ex M which goes to zero as Γ → 0 and becomes exponential as the liquid nears the freezing transition. Our assertion is backed by careful measurements of the lifetime of the local atomic connectivity τ LC which clearly shows that τ ex M → τ LC below the crossover Γ ( c κ ) directly indicating that τ ex M is the duration of dominant elastic response. The relaxation of the ideal part of shear stress auto-correlation τ id saturates with Γ > Γ ( c κ ) implying a crossover from the kinetic regime to the potential energy regime. We also find that the infinite frequency shear modulus G ∞ does not have a minimum at any temperature as opposed to the viscosity data which has a well known minimum around Γ ( c κ ).
We believe the present work is fundamentally important as it provides the microscopic origin of shear relaxation time scales in a SCYL. The results presented here may also apply to other models of visco-elastic liquids exhibiting a non-monotonic behavior of Maxwell time with temperature. It will be very interesting to extend the present study to the binary super-cooled Yukawa liquids.
Discussions with P.K. Kaw and R. Ganesh are gratefully acknowledged. This work was supported under the INSPIRE faculty program, Department of Science and Technology, Ministry of Science and Technology, Government of India.
- ∗ [email protected]
- [1] G. E. Morfill and A. V. Ivlev, Rev. Mod. Phys. 81 , 1353 (2009).
- [2] V. Fortov, A. Ivlev, S. Khrapak, A. Khrapak, and G. Morfill, Physics Reports 421 , 1 (2005).
- [3] H. Ohta and S. Hamaguchi, Phys. Rev. Lett. 84 , 6026 (2000).
- [4] P. K. Kaw and A. Sen, Physics of Plasmas 5 , 3552 (1998).
- [5] G. Kalman, M. Rosenberg, and H. E. DeWitt, Phys. Rev. Lett. 84 , 6030 (2000).
- [6] J. Pramanik, G. Prasad, A. Sen, and P. K. Kaw, Phys. Rev. Lett. 88 , 175001 (2002).
- [7] Ashwin J. and R. Ganesh, Phys. Rev. Lett. 104 , 215003 (2010).
- [8] Ashwin J. and R. Ganesh, Phys. Rev. Lett. 106 , 135001 (2011).
- [9] Ashwin J. and R. Ganesh, Physics of Fluids (1994present) 24 , 092002 (2012).
- [10] H. Totsuji, C. Totsuji, and K. Tsuruta, Phys. Rev. E 64 , 066402 (2001).
- [11] A. Wysocki and H. L¨ owen, Phys. Rev. E 79 , 041408 (2009).
- [12] T. Saigo and S. Hamaguchi, Physics of Plasmas 9 , 1210 (2002).
- [13] G. Salin and J.-M. Caillol, Phys. Rev. Lett. 88 , 065002 (2002).
- [14] B. Liu and J. Goree, Phys. Rev. Lett. 94 , 185002 (2005).
- [15] K. Y. Sanbonmatsu and M. S. Murillo, Phys. Rev. Lett. 86 , 1215 (2001).
- [16] Z. Donk´ o, J. Goree, P. Hartmann, and K. Kutasi, Phys. Rev. Lett. 96 , 145003 (2006).
- [17] Y. Feng, J. Goree, and B. Liu, Phys. Rev. Lett. 105 , 025002 (2010).
- [18] Y. Feng, J. Goree, and B. Liu, Phys. Rev. E 85 , 066402 (2012).
- [19] J. Goree, Z. Donk´, o and P. Hartmann, Phys. Rev. E 85 , 066401 (2012).
- [20] T. Iwashita, D. M. Nicholson, and T. Egami, Phys. Rev. Lett. 110 , 205504 (2013).
- [21] W. G. Hoover, Phys. Rev. A 31 , 1695 (1985).
- [22] J. P. Hansen and I. McDonald, Theory of Simple Liquids: with applications to soft matter , 4th ed. (Academic, Oxford, 2013).
- [23] R. D. Mountain and R. Zwanzig, The Journal of Chemical Physics 44 (1966). | 10.1103/PhysRevLett.114.055002 | [
"Ashwin J.",
"Abhijit Sen"
] | 2014-08-01T11:57:26+00:00 | 2014-08-01T11:57:26+00:00 | [
"cond-mat.soft",
"physics.plasm-ph"
] | Microscopic Origin of Shear Relaxation in Strongly Coupled Yukawa Liquids | We report accurate molecular dynamics calculations of the shear stress
relaxation in a two-dimensional strongly coupled Yukawa liquid over a wide
range of the Coulomb coupling strength $\Gamma$ and the Debye screening
parameter $\kappa$. Our data on the relaxation times of the ideal- , excess-
and total shear stress auto-correlation ($\tau^{id}_M, \tau^{ex}_M, \tau_M$
respectively) along with the lifetime of local atomic connectivity $\tau_{LC}$
leads us to the following important observation. Below a certain crossover
$\Gamma_c(\kappa)$, $\tau_{LC} \rightarrow \tau^{ex}_M$, directly implying that
here $\tau_{LC}$ is the microscopic origin of the relaxation of excess shear
stress unlike the case for ordinary liquids where it is the origin of the
relaxation of the total shear stress. At $\Gamma >> \Gamma_c(\kappa)$ i.e. in
the potential energy dominated regime, $\tau^{ex}_M\rightarrow \tau_M$ meaning
that $\tau^{ex}_M$ can fully account for the elastic or "solid like" behavior. |
1408.0142v1 | ## On open problems in polling systems ∗
Marko Boon † [email protected]
O.J. Boxma † [email protected]
E.M.M. Winands ‡ [email protected]
January, 2011
## Abstract
In the present paper we address two open problems concerning polling systems, viz., queueing systems consisting of multiple queues attended by a single server that visits the queues one at a time. The first open problem deals with a system consisting of two queues, one of which has gated service, while the other receives 1-limited service. The second open problem concerns polling systems with general (renewal) arrivals and deterministic switchover times that become infinitely large. We discuss related, known results for both problems, and the difficulties encountered when trying to solve them.
Keywords: Polling, gated, one-limited, branching-class, switch-over time asymptotics
## 1 Introduction
Apolling system is a queueing system consisting of multiple queues attended by a single server that visits the queues one at a time. Polling systems naturally arise in a large number of application areas, like
- · maintenance: a patrolling repairman visits various sites;
- · manufacturing: a machine successively produces items of various types;
- · computer-communication systems: a central computer cyclically polls the terminals on a common link to inquire whether they have any data to transmit;
- · road traffic: traffic lights determine which traffic streams may proceed.
In many of these applications, the server incurs a non-negligible switch-over time when switching between queues.
There is a huge body of literature on polling systems, in which the basic cyclic polling system and many enhancements have been studied. Extensive surveys on polling systems and their applications may be found in [13, 20, 24]. In this note we present two challenging open problems motivated by two of the aforementioned application areas. By doing so, we want to stimulate research and new collaborations in these directions. The first problem is motivated by a computer-communication system application and seems to lead to a boundary value problem with a rather complicated shift. The second problem requires an asymptotic analysis of the waiting-time distribution and stems from a manufacturing application.
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-NF.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
‡ Department of Mathematics, Section Stochastics, VU University, De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands
## 2 Model and notation
In the present paper (and in almost the whole polling literature), the server visits the N queues in cyclic order Q , Q , . . . , Q 1 2 N , Q 1 , . . . , and the arrival processes of customers at the various queues are assumed to be independent Poisson processes, with rate λ i at Q i , i = 1 , . . . , N . The service requirements at Q i , denoted by B i , are independent, identically distributed random variables with LST (Laplace-Stieltjes transform) β i ( ), · i = 1 , . . . , N . Similarly, the switch-over times between Q i and Q i +1 , denoted by S i , are independent, identically distributed with LST σ i ( ), · i = 1 , . . . , N . The sum of the switch-over times is denoted by S . We furthermore assume that all arrival, service and switch-over processes are independent, and that the various parameters are such that the joint steady-state queue-length distributions at server visit epochs, server departure epochs and arbitrary epochs exist. We also introduce the notation ρ i = λ i E [ B i ], and ρ = ∑ N i =1 ρ i .
A key aspect of polling systems is the service discipline at each queue. The three most important service disciplines are exhaustive (E): a queues is served until it is empty; gated (G): the server only serves those customers which were present at the start of the visit; and 1-limited (1-L): the server serves only one customer - if any is present. In a seminal paper, Resing [18] has shown that the PGF (Probability Generating Function) of the joint steady-state queue-length distribution at epochs at which the server arrives at, say, Q 1 can be obtained explicitly for those polling systems in which the service discipline at each queue is of a branching-type, viz., the following holds for i = 1 , . . . , N :
If there are k i customers present at Q i at the start of a visit, then during the course of the visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having PGF h i ( z , . . . , z 1 N ) , which may be any N -dimensional PGF.
/negationslash
The joint queue-length process at visit epochs then becomes an N -class branching process with immigration (the immigration corresponding to arrivals during switch-over times). One may easily verify that exhaustive and gated are branching-type disciplines, whereas 1-limited is not. In the gated case, h i ( z , . . . , z 1 N ) = β i ( ∑ N j =1 λ j (1 -z j )), and in the exhaustive case, h i ( z , . . . , z 1 N ) = π i ( ∑ N j = i λ j (1 -z j )), where π i ( ) · denotes the LST of the busy period distribution at Q i , when viewed as an M/G/ 1 queue in isolation.
A key element in the analysis of such branching-type polling systems is that the following relation holds between the PGF G z ,... , z i ( 1 N ) of the joint queue-length distribution at the end of a visit to Q i and the PGF F i ( z , . . . , z 1 N ) of the joint queue-length distribution at the start of that visit:
$$G _ { i } ( z _ { 1 }, \dots, z _ { N } ) = F _ { i } ( z _ { 1 }, \dots, z _ { i - 1 }, h _ { i } ( z _ { 1 }, \dots, z _ { N } ), z _ { i + 1 }, \dots, z _ { N } ). \quad \ ( 1 )$$
Moreover, it is easily seen that
$$F _ { i + 1 } ( z _ { 1 }, \dots, z _ { N } ) = \sigma _ { i } ( \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ) ) G _ { i } ( z _ { 1 }, \dots, z _ { N } ).$$
Successively applying each of these equations once for i = 1 , . . . , N , one may now express F 1 ( z , . . . , z 1 N ) into itself. After iteration this yields an expression for F 1 ( z , . . . , z 1 N ) in the form of an infinite sum of products.
In the next two sections we formulate two open problems for polling systems with a partial, respectively full, branching-type service discipline.
## 3 Open problem 1: gated plus 1-limited
In this section we restrict ourselves to the case of N = 2 queues. We are interested in determining F 1 ( z , z 1 2 ) and F 2 ( z , z 1 2 ). After briefly discussing known results in Subsection 3.1, we formulate in Subsection 3.2 an open problem regarding the polling model with a gated and a 1-limited queue.
## 3.1 Known results for two-queue polling systems
The polling models with discipline E/E (Exhaustive/Exhaustive), G/G and E/G fall in the class of multi-type branching, and are easily solved; E/E was already solved by Tak´cs [19] in 1968. a We refer to the survey [20] and to [18] for the other cases and for extensions to a general number of queues N . The 1-L/1-L model was solved by using the theory of boundary value problems; see [6] for the case of zero switch-over times, and [5] for the case of non-zero switch-over times. Now let us turn to E/1-L and G/1-L. First observe that, with Q 2 having 1-L:
$$G _ { 2 } ( z _ { 1 }, z _ { 2 } ) = \frac { \beta _ { 2 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ) } { z _ { 2 } } [ F _ { 2 } ( z _ { 1 }, z _ { 2 } ) - F _ { 2 } ( z _ { 1 }, 0 ) ] + F _ { 2 } ( z _ { 1 }, 0 ).$$
Combination of (1), (2) and (3) yields, after having introduced β i ( z , z 1 2 ) := β i ( λ 1 (1 -z 1 ) + λ 2 (1 -z 2 )) and σ i ( z , z 1 2 ) := σ i ( λ 1 (1 -z 1 ) + λ 2 (1 -z 2 )), i = 1 2: ,
$$F _ { 1 } ( z _ { 1 }, z _ { 2 } ) \ & = \ \frac { \beta _ { 2 } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 2 } ( z _ { 1 }, z _ { 2 } ) } { z _ { 2 } } [ \sigma _ { 1 } ( z _ { 1 }, z _ { 2 } ) F _ { 1 } ( h _ { 1 } ( z _ { 1 }, z _ { 2 } ), z _ { 2 } ) - \sigma _ { 1 } ( z _ { 1 }, 0 ) F _ { 1 } ( h _ { 1 } ( z _ { 1 }, 0 ), 0 ) ] \\ & + \ \sigma _ { 2 } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 1 } ( z _ { 1 }, 0 ) F _ { 1 } ( h _ { 1 } ( z _ { 1 }, 0 ), 0 ).$$
The E/1-L model with zero switch-over times is simply a two-class nonpreemptive priority model. Ibe [10] considers the case of non-zero switch-over times, obtaining the marginal queue-length distribution in Q 1 at polling instants of that queue. It is less well-known that the joint queuelength distributions at polling instants of a queue can also be found in a quite straightforward manner. This is accomplished by substituting h 1 ( z , z 1 2 ) = π 1 ( λ 2 (1 -z 2 )) into (4), calling this function g z ( 2 ), and observing that F 1 ( h 1 ( z , 1 0) 0) = , F 1 ( g (0) , 0) is a constant, say C , not depending on z 1 :
$$F _ { 1 } ( z _ { 1 }, z _ { 2 } ) \ & = \ \frac { \beta _ { 2 } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 2 } ( z _ { 1 }, z _ { 2 } ) } { z _ { 2 } } [ \sigma _ { 1 } ( z _ { 1 }, z _ { 2 } ) F _ { 1 } ( g ( z _ { 2 } ), z _ { 2 } ) - C \sigma _ { 1 } ( z _ { 1 }, 0 ) ] \\ & + \ C \sigma _ { 2 } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 1 } ( z _ { 1 }, 0 ).$$
The substitution z 1 = g z ( 2 ) finally solves the problem. Details may be found in Section 6.3 of the PhD thesis of Groenendijk [9]. E/1-L appears to be conceptually easier than E/E or any other known polling model, not requiring a branching-type sum-of-infinite-products solution, and neither the solution of a boundary value problem.
Remark 3.1. Our sketch of the analysis of E/1-L reveals that one can extend that analysis to the case in which h 1 ( z , z 1 2 ), which above equals π 1 ( λ 2 (1 -z 2 )), is some arbitrary PGF g z ( 2 ). For example, when the server is at Q 1 , one could have Poisson arrivals with rate λ ∗ 2 , or batch Poisson arrivals, at Q 2 .
Remark 3.2. For general k , an exact evaluation for the queue-length distribution is known in two-queue exhaustive/ k -limited systems with zero setup times (see Lee [11] and Ozawa [15, 16]) and with state-dependent switch-over times (see [28]).
Remark 3.3. As discussed in various polling studies, one can readily derive the waiting-time LST at Q i from F i ( z , z 1 2 ). Furthermore, there exists a simple relation between the mean waiting times E [ W i ] (at Q i ), i = 1 2 , , . . . , N in polling systems, a so-called pseudo-conservation law (cf. [4]). In the G/1-L case, this pseudo-conservation law reduces to:
$$\rho _ { 1 } \mathbb { E } [ W _ { 1 } ] + \rho _ { 2 } \left ( 1 - \frac { \lambda _ { 2 } \mathbb { E } [ S ] } { 1 - \rho } \right ) \mathbb { E } [ W _ { 2 } ] = \rho \sum _ { i = 1 } ^ { 2 } \frac { \lambda _ { i } \mathbb { E } [ B _ { i } ^ { 2 } ] } { 2 ( 1 - \rho ) } + \rho \frac { \mathbb { E } [ S ^ { 2 } ] } { 2 \mathbb { E } [ S ] } + \frac { \mathbb { E } [ S ] } { 2 ( 1 - \rho ) } [ \rho ^ { 2 } + \rho _ { 1 } ^ { 2 } + \rho _ { 2 } ^ { 2 } ], \quad ( 6 )$$
## 3.2 An unsolved two-queue polling model: G/1-L
Throughout the polling literature, G and E seem to have comparable complexity. Their role in the branching-type polling models, and in (pseudo-)conservation laws, is similar. In view of this,
and of the simplicity of E/1-L, it is remarkable that G/1-L has remained unsolved for the past twenty years, despite the fact that it is a quite relevant model (cf. Bisdikian [1], who introduces a variant of G/1-L as a model for communication networks with bridge-stations and suggests an approximative approach). Hence we state
Open problem 1. Determine the joint queue-length PGF at polling instants in the two-queue G/1-L polling system.
In the G/1-L case, (4) holds with h 1 ( z , z 1 2 ) = β 1 ( z , z 1 2 ). Obvious attempts to obtain F 1 ( z , z 1 2 ) from (4) include substituting z 1 = 0 (which yields a derivative), and substituting z 1 = h 1 ( z , z 1 2 ) into the lefthand side of (4). In the latter case, one obtains terms F 1 ( h 1 ( h 1 ( z , z 1 2 ) , z 2 ) , z 2 ) and F 1 ( h 1 ( h 1 ( z , z 1 2 ) , 0) 0) in the righthand side, and iteration does not seem to lead to a solution. ,
Our feeling is that (4), in combination with obvious analyticity conditions of F 1 ( · , · ) inside the product of unit circles, leads to a boundary value problem (cf. [7]), but one with a rather complicated shift introduced by the function h 1 ( · , · ). Boundary value problems with a shift have been studied in the Riemann-Hilbert framework (cf. [8], Section 17), and even in the setting of polling systems (cf. [12], which studies a two-queue polling model with Bernoulli service at both queues), but the present problem seems particularly challenging.
## 4 Open problem 2: switch-over time asymptotics
The next open problem considers the class of polling systems, with N queues, that allow a multitype branching process interpretation. We are interested in the behaviour of the polling system (under proper scaling conditions), when the deterministic switch-over times tend to infinity. This large switch-over time problem is relevant from a practical point of view, since systems with large switch-over times find a wide variety of applications in manufacturing environments (see [26]). Firstly, Subsection 4.1 summarises known results for switch-over time asymptotics in polling systems with Poisson arrivals. Subsequently, we pose a conjecture for the behaviour of systems in which the arrival process at each of the queues is a general (renewal) process (see Subsection 4.2). Finally, the rigourous proof of this conjecture is stated as an open problem.
## 4.1 Known result for Poisson arrival processes
Under the assumption of Poisson arrival processes , Winands [27] presents an exact asymptotic analysis of the waiting-time distribution in branching-type polling systems with deterministic switch-over times when the switch-over times tend to infinity. The results of [27] generalise those derived in [14, 22, 25] for the special case of exhaustive and gated service. Since the waiting time grows to infinity in the limiting case, [27] focusses on the asymptotic scaled waiting time W /S i as S → ∞ while keeping the ratios of the switch-over times constant. We introduce Φ i as the 'exhaustiveness' of the service discipline in Q i , defined as Φ i = 1 -∂ ∂z i h i ( z , . . . , z 1 N ) ∣ ∣ z 1 =1 ,...,z N =1 . Its interpretation is, that each customer present at the start of a visit to Q i will be replaced by a number of type i customers with mean 1 -Φ . If i Q i receives exhaustive service, the exhaustiveness is 1; for gated service, it is 1 -ρ i . In case of Poisson arrivals and deterministic switch-over times, the distribution of the asymptotic scaled waiting time is given by
$$\frac { W _ { i } } { S } \stackrel { d } { \rightarrow } \frac { 1 - \rho _ { i } } { 1 - \rho } U _ { i }, \quad ( S \rightarrow \infty ),$$
where U i is uniformly distributed on [ 1 -Φ i Φ i , 1 Φ i ].
The closed-form expression of the scaled delay distribution has an intuitively appealing interpretation. That is, in the case of increasing deterministic switch-over times the polling system converges to a deterministic cyclic system with continuous deterministic service rates 1 / E [ B i ] and
continuous demand rates λ i , i = 1 2 , , . . . , N , which reveals itself, for example, in the fact that the scaled number of customers at Q i at a polling instant of Q i becomes deterministic in the limit as shown in [27]. This means that in the limit the customers arrive to the system and are served at constant rates with no statistical fluctuation whatsoever and that the scaled queue lengths can be seen as continuous quantities. Therefore, the uniform distribution emerging in the limiting theorems can be explained by the fact that it represents the position of the server in the cycle on arrival of a tagged customer.
Remark 4.1. In [23] it is shown that in heavy traffic (HT), i.e., if the load tends to one, the impact of higher moments of the switch-over times on the waiting-time distribution vanishes. Consequently, the scaled asymptotic waiting time depends on the marginal switch-over time distributions only through the first moment of the total switch-over time in a cycle. Building upon this observation, [27] analyses the scaled asymptotic waiting time in branching-type polling systems with generally distributed switch-over times under heavy traffic when the switch-over times tend to infinity. The behaviour of the polling system then becomes deterministic, just like in polling systems with deterministic switch-over times, which are not necessarily operating in HT.
## 4.2 Conjecture for general renewal arrival processes
Until now, we have assumed that the arrival processes are Poisson processes. This assumption is used in [27] to derive the asymptotics presented in the previous subsection, building upon a result of [3] which derives a strong relation between the waiting-time distributions in models with and without switch-over times. This relation is established by relating the similarities in the offspring generating functions of the underlying branching processes and by expressing the differences between the underlying immigration functions. These results for polling systems with finite switch-over times are exploited and, subsequently, it is shown that significant simplifications result as the switch-over times tend to infinity . Unfortunately, the techniques used throughout [27] rely heavily on the Poisson assumption, and corresponding results for polling systems with general arrival processes are not known. Taking a second look at the intuitive interpretation of the aforementioned results, one would expect that the Poisson assumption is not essential for this kind of behaviour. That is, if the scaled number of arrivals during an intervisit period becomes deterministic, then the length of the scaled visit period (generated by these arrivals) converges to a constant as well. Since the intervisit period is the sum of individual visit periods and switch-over times, based on strong law of large numbers arguments the scaled number of arrivals subsequently indeed tends to become deterministic. This circular intuitive reasoning (ignoring the interdependence between the visit periods) is independent of the precise characteristics of the renewal arrival process chosen. We now pose this statement as a conjecture (see, also, [27]).
Conjecture 4.2. A cyclic polling system with general (renewal) arrival processes converges to a deterministic cyclic system when the deterministic switch-over times tend to infinity.
To numerically test this conjecture for general arrival processes, we have performed a couple of simulation experiments of exhaustive polling systems with general renewal arrivals. In Table 1, we show results for a symmetric polling system with 3 queues, where the service times are exponential with mean 0 25. . Interarrival times have mean 1 and the corresponding squared coefficient of variation (SCV), c 2 A i , is varied between 0 25, 0 5, 1 and 2. . . In order to obtain a distribution for these interarrival times, we fit a phase-type distribution on the first two moments (cf., e.g., [21]). For the cases where the SCV equals 1, Poisson processes are used for the arrival processes in order to obtain exact results, and this case is included as benchmark.
Table 1 shows c 2 P 1 , the SCV of the scaled number of customers at Q 1 at a polling instant of Q 1 for varying values of the marginal switch-over times S i in a cycle. From Table 1, we clearly see that the coefficient of variation approaches zero when the switch-over times tend to infinity. For polling systems with deterministic switch-over times and Poisson arrivals, it can actually be shown analytically that the SCV of the number of customers in a queue, at the beginning of a visit to
Table 1: Squared coefficient of variation of the scaled number of customers at Q 1 at a polling instant of Q 1 . Values in italic are not obtained by simulation, but are computed analytically.
| Cyclic | Cyclic | Cyclic | Cyclic | Cyclic |
|-----------|------------------|-----------------|-------------|-------------|
| | c 2 A i = 0 . 25 | c 2 A i = 0 . 5 | c 2 A i = 1 | c 2 A i = 2 |
| S i = 1 | 0 . 121 | 0 . 167 | 0.259 | 0 . 444 |
| S i = 10 | 0 . 012 | 0 . 017 | 0.026 | 0 . 044 |
| S i = 100 | 0 . 001 | 0 . 002 | 0.003 | 0 . 004 |
this queue, is inversely proportional to the total switch-over time S . Table 1 seems to suggest that this also holds for other arrival processes. It goes without saying that a highly variable arrival process has a negative impact on how 'fast' the limiting behaviour is approached. Via Chebyshev's inequality (see, e.g., [17]) we know that a random variable with zero variance follows a deterministic distribution and, therefore, this observation provides empirical evidence for the fact that the scaled number of customers at Q 1 at a polling instant of Q 1 becomes deterministic. Therefore, it confirms the validity of our conjecture that the polling system converges to a deterministic cyclic system as the switch-over times increase to infinity.
We have run tests for asymmetric polling systems as well, as shown in Table 2. The first three columns show the input parameters: the SCV of the interarrival time distributions, c 2 A i , the imbalance of the interarrival times, I A , and the imbalance of the service times, I B . The imbalance is the ratio between the largest and the smallest mean interarrival/service time. The arrival rates and mean service times are chosen such that the differences λ i -λ i +1 and E [ B i +1 ] -E [ B i ] are kept constant for i = 1 , . . . , N -1. Furthermore, we have chosen the normalisation constraint ∑ N i =1 λ /N i = 1, implying that the actual arrival rates and mean service times (for fixed ρ ) follow from the relation ρ = ∑ N i =1 λ i E [ B i ]. See [2] for a more elaborate description and some examples of how the arrival rates and mean service times can be computed from this definition of imbalance. The last two columns of Table 2 contain the SCVs of the waiting times of customers in Q 1 , c 2 W 1 , and the SCVs of the numbers of customers at Q 1 at a polling instant, c 2 P 1 , for a cyclic polling system with ρ = 0 75 and deterministic switch-over times . S i = 100, for i = 1 2 3. , , The SCVs of the waiting times approach the limiting value 1 3 , which is the SCV of a uniform distribution, quite rapidly. Furthermore, c 2 P 1 becomes negligibly small, illustrating that the behaviour of the system becomes deterministic.
Table 2: Squared coefficient of variation of the waiting time and the number of customers at Q 1 at a polling instant of Q 1 . Values in italic are not obtained by simulation, but are computed analytically.
| Cyclic | Cyclic | Cyclic | Cyclic | Cyclic |
|----------|----------|----------|----------|----------|
| c 2 A i | I A | I B | c 2 W 1 | c 2 P 1 |
| 0 . 25 | 1 | 1 | 0 . 335 | 0 . 001 |
| 0 . 25 | 1 | 3 | 0 . 335 | 0 . 002 |
| 0 . 25 | 3 | 1 | 0 . 334 | 0 . 001 |
| 0 . 25 | 3 | 3 | 0 . 335 | 0 . 001 |
| 1 | 1 | 1 | 0.335 | 0.003 |
| 1 | 1 | 3 | 0.336 | 0.003 |
| 1 | 3 | 1 | 0.335 | 0.002 |
| 1 | 3 | 3 | 0.336 | 0.003 |
| 2 | 1 | 1 | 0 . 336 | 0 . 004 |
| 2 | 1 | 3 | 0 . 337 | 0 . 005 |
| 2 | 3 | 1 | 0 . 336 | 0 . 004 |
| 2 | 3 | 3 | 0 . 337 | 0 . 004 |
Summarising, we state the second open problem for polling systems.
Open problem 2. Provide a rigourous proof of Conjecture 4.2, which states that a cyclic polling system with general (renewal) arrival processes converges to a deterministic cyclic system when the deterministic switch-over times tend to infinity.
We wish to end the present paper with stating a related open problem given in [14]. That is, [14] shows via numerical testing that similar limit theorems as presented here carry over to systems with Poisson arrivals and dynamic visit orders (i.e., there exists no pre-determined order in which the queues are served). This phenomenon is intuitively explained via heuristic strong law reasoning in [14] and it is conjectured that the limit theorems hold so long as the switch-overs perform a regulating effect . As an example, we show simulation results in Table 3 for the same symmetric polling systems as studied in Table 1, but now the server switches to the longest queue at the end of a visit. We can see clearly, that the system becomes deterministic as well. A resulting open problem is, therefore, the classification of polling systems in terms of service, visit and scheduling disciplines, which exhibit the discussed behaviour.
Table 3: Squared coefficient of variation of the scaled number of customers at Q 1 at a polling instant of Q 1 .
| Longest queue | Longest queue | Longest queue | Longest queue | Longest queue |
|-----------------|------------------|-----------------|-----------------|-----------------|
| | c 2 A i = 0 . 25 | c 2 A i = 0 . 5 | c 2 A i = 1 | c 2 A i = 2 |
| S i = 1 | 0.125 | 0.170 | 0.254 | 0.434 |
| S i = 10 | 0.012 | 0.017 | 0.026 | 0.044 |
| S i = 100 | 0.001 | 0.002 | 0.003 | 0.004 |
## 5 Conclusions
There is a huge literature on polling systems, due to their great applicability in real-life situations. In this paper we have described two problems that have remained unsolved in the polling literature, despite their practical relevance, and despite the fact that seemingly minor adaptations of these problems can be solved explicitly. For the first problem, which is the exact analysis of a twoqueue polling system with respectively gated and 1-limited service, we pinpoint the difficulties one runs into when applying standard techniques. The second problem is the analysis of a polling system with general renewal arrivals under the limiting situation where the (deterministic) switchover times tend to infinity. For this problem we have posed a strong conjecture stating that the (known) results for Poisson arrivals carry over to the system with general renewal arrivals. By posing these open problems we hope to provide a motivation to search for alternative ways to study and hopefully even solve them.
## References
- [1] C. Bisdikian. A queueing model with applications to bridges and the DQDB (IEEE 802.6) MAN. Computer Networks and ISDN Systems , 25(12):1279-1289, 1993.
- [2] M. A. A. Boon, E. M. M. Winands, I. J. B. F. Adan, and A. C. C. van Wijk. Closed-form waiting time approximations for polling systems. Performance Evaluation , 68:290-306, 2011.
- [3] S. C. Borst and O. J. Boxma. Polling models with and without switchover times. Operations Research , 45(4):536 - 543, 1997.
- [4] O. Boxma. Workload and waiting times in single-server systems with multiple customer classes. Queueing Systems , 5:185 - 214, 1989.
| [5] | O. J. Boxma and W. P. Groenendijk. Two queues with alternating service and switching times. In O. J. Boxma and R. Syski, editors, Queueing Theory and its Applications - Liber Amicorum for J.W. Cohen , pages 261-282. North-Holland Publishing Company, Amsterdam, 1988. |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [6] | J. W. Cohen and O. J. Boxma. The M/G/ 1 queue with alternating service formulated as a Riemann-Hilbert boundary value problem. In F. J. Kylstra, editor, Proc. Performance '81 , pages 181-199. North-Holland Publishing Company, Amsterdam, 1981. |
| [7] | J. W. Cohen and O. J. Boxma. Boundary Value Problems in Queueing System Analysis . North-Holland Publishing Company, Amsterdam, 1983. |
| [8] | F. D. Gakhov. Boundary Value Problems . Pergamon Press, Oxford, 1966. |
| [9] | W. P. Groenendijk. Conservation Laws in Polling Systems . PhD thesis, University of Utrecht, 1990. |
| [10] | O. C. Ibe. Analysis of polling systems with mixed service disciplines. Stochastic Models , 6 (4):667-689, 1990. |
| [11] | D.-S. Lee. A two-queue model with exhaustive and limited service disciplines. Stochastic Models , 12(2):285-305, 1996. |
| [12] | D.-S. Lee. Analysis of a two-queue model with Bernoulli schedules. Journal of Applied Probability , 34:176-191, 1997. |
| [13] | H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990. |
| [14] | T. Olsen. Limit theorems for polling models with increasing setups. Probability in the Engi- neering and Informational Sciences , 15:35-55, 2001. |
| [15] | T. Ozawa. Alternating service queues with mixed exhaustive and K -limited services. Perfor- mance Evaluation , 11(3):165-175, 1990. |
| [16] | T. Ozawa. Waiting time distributions in a two-queue model with mixed exhaustive and gated- type K -limited services. In Proceedings of International Conference on the Performance and Management of Complex Communication Networks , pages 231-250, Tsukuba, 1997. |
| [17] | A. Papoulis. Probability, Random Variables, and Stochastic Processes . McGraw-Hill, New York, 2 nd edition, 1984. |
| [18] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13: 409 - 426, 1993. |
| [19] | L. Tak´cs. a Two queues attended by a single server. Operations Research , 16(3):639-650, 1968. |
| [20] | H. Takagi. Queuing analysis of polling models. ACM Computing Surveys (CSUR) , 20:5-28, 1988. |
| [21] | H. C. Tijms. Stochastic Models: An Algorithmic Approach . Wiley, Chichester, 1994. |
| [22] | R. D. van der Mei. Delay in polling systems with large switch-over times. Journal of Applied Probability , 36:232-243, 1999. |
| [23] | R. D. van der Mei. Towards a unifying theory on branching-type polling models in heavy traffic. Queueing Systems , 57:29-46, 2008. |
| [24] | V. M. Vishnevskii and O. V. Semenova. Mathematical methods to study the polling systems. Automation and Remote Control , 67(2):173-220, 2006. |
- [25] E. M. M. Winands. On polling systems with large setups. Operations Research Letters , 35: 584-590, 2007.
- [26] E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven University of Technology, 2007.
- [27] E. M. M. Winands. Branching-type polling systems with large setups. OR Spectrum , 33(1): 77-97, 2011.
- [28] E. M. M. Winands, I. J. B. F. Adan, G. J. van Houtum, and D. G. Down. A state-dependent polling model with k -limited service. Probability in the Engineering and Informational Sciences , 23(2):385-408, 2009. | 10.1007/s11134-011-9247-9 | [
"Marko Boon",
"Onno Boxma",
"Erik Winands"
] | 2014-08-01T12:00:03+00:00 | 2014-08-01T12:00:03+00:00 | [
"math.PR",
"cs.PF"
] | On open problems in polling systems | In the present paper we address two open problems concerning polling systems,
viz., queueing systems consisting of multiple queues attended by a single
server that visits the queues one at a time. The first open problem deals with
a system consisting of two queues, one of which has gated service, while the
other receives 1-limited service. The second open problem concerns polling
systems with general (renewal) arrivals and deterministic switch-over times
that become infinitely large. We discuss related, known results for both
problems, and the difficulties encountered when trying to solve them. |
1408.0143v1 | ## Billiard Arrays and finite-dimensional irreducible Uq ( sl 2 ) -modules
## Paul Terwilliger
## Abstract
We introduce the notion of a Billiard Array. This is an equilateral triangular array of one-dimensional subspaces of a vector space V , subject to several conditions that specify which sums are direct. We show that the Billiard Arrays on V are in bijection with the 3-tuples of totally opposite flags on V . We classify the Billiard Arrays up to isomorphism. We use Billiard Arrays to describe the finite-dimensional irreducible modules for the quantum algebra U q ( sl 2 ) and the Lie algebra sl 2 .
Keywords . Quantum group, quantum enveloping algebra, Lie algebra, flag. 2010 Mathematics Subject Classification . Primary: 17B37. Secondary: 15A21.
## 1 Introduction
Our topic is informally described as follows. As in the game of Billiards, we start with an array of billiard balls arranged to form an equilateral triangle. We assume that there are N + 1 balls along each boundary, with N ≥ 0. For N = 3 the balls are centered at the following locations:
•
•

•
•
•
For us, each ball in the array represents a one-dimensional subspace of an ( N +1)-dimensional vector space V over a field F .
We impose two conditions on the array, that specify which sums are direct. The first condition is that, for each set of balls on a line parallel to a boundary, their sum is direct. The second condition is described as follows. Three mutually adjacent balls in the array are said to form a 3-clique. There are two kinds of 3-cliques: ∆ (black) and ∇ (white). The second condition is that, for any three balls in the array that form a black 3-clique, their sum is not direct.
Whenever the above two conditions are met, our array is called a Billiard Array on V . We say that the Billiard Array is over F , and call N the diameter.
We have some remarks about notation. For 1 ≤ i ≤ N + 1 let P i ( V ) denote the set of subspaces of V that have dimension i . Recall the natural numbers N = { 0 1 2 , , , . . . } . Let ∆ N denote the set consisting of the 3-tuples of natural numbers whose sum is N . Thus
$$\Delta _ { N } = \{ ( r, s, t ) \ | \ r, s, t \in \mathbb { N }, \ r + s + t = N \}.$$
We arrange the elements of ∆ N in a triangular array. For N = 3, the array looks as follows after deleting all punctuation:
$$\begin{smallmatrix} 0 3 0 \\ 1 2 0 & 0 2 1 \\ 2 1 0 & 1 1 1 & 0 1 2 \\ 3 0 0 & 2 0 1 & 1 0 2 & 0 0 3 \end{smallmatrix}$$
↦
An element in ∆ N is called a location. We view our Billiard Array on V as a function B : ∆ N →P 1 ( V ) , λ → B λ . For λ ∈ ∆ , N B λ is the billiard ball/subspace at location λ .
In this paper we obtain three main results, which are summarized as follows: (i) we show that the Billiard Arrays on V are in bijection with the 3-tuples of totally opposite flags on V ; (ii) we classify the Billiard Arrays up to isomorphism; (iii) we use Billiard Arrays to describe the finite-dimensional irreducible modules for the quantum algebra U q ( sl 2 ) and the Lie algebra sl 2 .
We now describe our results in more detail. By a flag on V we mean a sequence { U i } N i =0 such that U i ∈ P i +1 ( V ) for 0 ≤ i ≤ N and U i -1 ⊆ U i for 1 ≤ i ≤ N . Suppose we are given three flags on V , denoted
$$\{ U _ { i } \} _ { i = 0 } ^ { N }, \quad \{ U _ { i } ^ { \prime } \} _ { i = 0 } ^ { N }, \quad \{ U _ { i } ^ { \prime \prime } \} _ { i = 0 } ^ { N }.$$
These flags are called totally opposite whenever U N -r ∩ U ′ N -s ∩ U ′′ N -t = 0 for all r, s, t (0 ≤ r, s, t ≤ N ) such that r + s + t > N . Assume that the flags in line (1) are totally opposite. Using these flags we now construct a Billiard Array on V . For each location λ = ( r, s, t ) in ∆ N define
$$B _ { \lambda } = U _ { N - r } \cap U _ { N - s } ^ { \prime } \cap U _ { N - t } ^ { \prime \prime }.$$
↦
We will show that B λ has dimension one, and the map B : ∆ N →P 1 ( V ), λ → B λ is a Billiard Array on V . We just went from flags to Billard Arrays; we now reverse the direction. Let B denote a Billiard Array on V . Using B we now construct a 3-tuple of totally opposite flags on V . By the 1-corner of ∆ N we mean the location ( N, 0 0). , The 2-corner and 3-corner of ∆ N are similarly defined. For 0 ≤ i ≤ N let U i (resp. U ′ i ) (resp. U ′′ i ) denote the sum of the balls in B that are at most i balls over from the 1-corner (resp. 2-corner) (resp. 3-corner). We will show that
$$\{ U _ { i } \} _ { i = 0 } ^ { N }, \quad \{ U _ { i } ^ { \prime } \} _ { i = 0 } ^ { N }, \quad \{ U _ { i } ^ { \prime \prime } \} _ { i = 0 } ^ { N }$$
are totally opposite flags on V . Consider the following two sets:
- (i) the Billiard Arrays on V ;
- (ii) the 3-tuples of totally opposite flags on V .
We just described a function from (i) to (ii) and a function from (ii) to (i). We will show that these functions are inverses, and hence bijections.
↦
We now describe our classification of Billiard Arrays up to isomorphism. Let B denote a Billiard Array on the above vector space V . Let V ′ denote a vector space over F with dimension N +1, and let B ′ denote a Billiard Array on V ′ . The Billiard Arrays B,B ′ are called isomorphic whenever there exists an F -linear bijection V → V ′ that sends B λ → B ′ λ for all λ ∈ ∆ . By a value function on ∆ N N we mean a function ∆ N → \{ } F 0 . For N ≤ 1, up to isomorphism there exists a unique Billiard Array over F that has diameter N . For N ≥ 2 we will obtain a bijection between the following two sets:
- (i) the isomorphism classes of Billiard Arrays over F that have diameter N ;
- (ii) the value functions on ∆ N -2 .
/negationslash
↦
We now describe the bijection. Let V denote a vector space over F with dimension N +1, and let B denote a Billiard Array on V . Given adjacent locations λ, µ in ∆ N , we define an F -linear map ˜ B λ,µ : B λ → B µ as follows. There exists a unique location ν ∈ ∆ N such that λ, µ, ν form a black 3-clique. Pick 0 = u ∈ B λ . There exists a unique v ∈ B µ such that u + v ∈ B ν . The map ˜ B λ,µ sends u → v . By construction the maps ˜ B λ,µ : B λ → B µ and ˜ B µ,λ : B µ → B λ are inverses. Let λ, µ, ν denote locations in ∆ N that form a 3-clique, either black or white. Consider the composition of maps around the clique:
$$B _ { \lambda } \, \underset { \tilde { B } _ { \lambda, \mu } } { \longrightarrow } \, B _ { \mu } \, \underset { \tilde { B } _ { \mu, \nu } } { \longrightarrow } \, B _ { \nu } \, \underset { \tilde { B } _ { \nu, \lambda } } { \longrightarrow } \, B _ { \lambda }.$$
This composition is a nonzero scalar multiple of the identity map on B λ . First assume that the 3-clique is black. Then the scalar is 1. Next assume that the 3-clique is white. Then the scalar is called the clockwise B -value (resp. counterclockwise B -value) of the 3-clique whenever the sequence λ, µ, ν runs clockwise (resp. counterclockwise) around the clique. The clockwise B -value and counterclockwise B -value are reciprocal. By the B -value of the 3-clique, we mean its clockwise B -value. For N ≤ 1 the set ∆ N has no white 3-clique. For N ≥ 2 we now give a bijection from ∆ N -2 to the set of white 3-cliques in ∆ N . The bijection sends each element ( r, s, t ) in ∆ N -2 to the white 3-clique in ∆ N consisting of the locations
$$( r, s + 1, t + 1 ), \quad ( r + 1, s, t + 1 ), \quad ( r + 1, s + 1, t ).$$
↦
Using B we define a function ˆ B : ∆ N -2 → F as follows: ˆ B sends each element ( r, s, t ) in ∆ N -2 to the B -value of the corresponding white 3-clique in ∆ N . By construction ˆ is a B value function on ∆ N -2 . The map B → ˆ induces our bijection, from the set of isomorphism B classes of Billiard Arrays over F that have diameter N , to the set of value functions on ∆ N -2 .
We now use Billiard Arrays to describe the finite-dimensional irreducible U q ( sl 2 )-modules. We recall U q ( sl 2 ). We will use the equitable presentation, which was introduced in [11]. See
/negationslash also [1, 3, 5, 7-10, 14-17]. Fix a nonzero q ∈ F such that q 2 = 1. By [11, Theorem 2.1] the equitable presentation of U q ( sl 2 ) has generators x, y ± 1 , z and relations yy -1 = 1, y -1 y = 1,
$$\frac { q x y - q ^ { - 1 } y x } { q - q ^ { - 1 } } = 1, \quad \frac { q y z - q ^ { - 1 } z y } { q - q ^ { - 1 } } = 1, \quad \frac { q z x - q ^ { - 1 } x z } { q - q ^ { - 1 } } = 1.$$
Following [15, Definition 3.1] define
$$\nu _ { x } = q ( 1 - y z ), \quad \nu _ { y } = q ( 1 - z x ), \quad \nu _ { z } = q ( 1 - x y ).$$
By [15, Lemma 3.5],
$$x \nu _ { y } & = q ^ { 2 } \nu _ { y } x, \quad \ x \nu _ { z } = q ^ { - 2 } \nu _ { z } x, \\ y \nu _ { z } & = q ^ { 2 } \nu _ { z } y, \quad \ y \nu _ { x } = q ^ { - 2 } \nu _ { x } y, \\ z \nu _ { x } & = q ^ { 2 } \nu _ { x } z, \quad \ z \nu _ { y } = q ^ { - 2 } \nu _ { y } z.$$
For the moment, assume that q is not a root of unity. Pick N ∈ N and let V denote an irreducible U q ( sl 2 )-module of dimension N +1. By [16, Lemma 8.2] each of ν N +1 x , ν N +1 y , ν N +1 z is zero on V . Moreover by [16, Lemma 8.3], each of the following three sequences is a flag on V :
$$\{ \nu _ { x } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { y } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { z } ^ { N - i } V \} _ { i = 0 } ^ { N }.$$
We will show that these three flags are totally opposite. We will further show that for the corresponding Billiard Array on V , the value of each white 3-clique is q -2 .
We just obtained a Billiard Array from each finite-dimensional irreducible U q ( sl 2 )-module, under the assumption that q is not a root of unity. Similarly, for the Lie algebra sl 2 over F , we will obtain a Billiard Array from each finite-dimensional irreducible sl 2 -module, under the assumption that F has characteristic 0. We will show that for these Billiard Arrays, the value of each white 3-clique is 1.
We have been discussing Billiard Arrays. Later in this paper we will introduce the concept of a Concrete Billiard Array and an edge-labelling of ∆ N . These concepts help to clarify the Billiard Array theory, and will be used in our proofs. They may be of independent interest.
This paper is organized as follows. Section 2 contains some preliminaries. In Sections 3-5 we consider the set ∆ N from various points of view. Section 6 is about flags. Section 7 contains the definition and basic facts about Billiard Arrays. Section 8 contains a similar treatment for Concrete Billiard Arrays. Sections 9-12 are devoted to the correspondence between Billiard Arrays and 3-tuples of totally opposite flags. Sections 13-19 are devoted to our classification of Billiard Arrays up to isomorphism. Section 20 contains some examples of Concrete Billiard Arrays. In Section 21 we use Billiard Arrays to describe the finite-dimensional irreducible modules for U q ( sl 2 ) and sl 2 .
## 2 Preliminaries
We now begin our formal argument. Let R denote the field of real numbers. We will be discussing the vector space R 3 (row vectors). We will refer to the basis
$$e _ { 1 } = ( 1, 0, 0 ), \quad e _ { 2 } = ( 0, 1, 0 ), \quad e _ { 3 } = ( 0, 0, 1 ).$$
Define a subset Φ ⊆ R 3 by
/negationslash
$$\Phi = \{ e _ { i } - e _ { j } \ | \ 1 \leq i, j \leq 3, \ i \neq j \}.$$
The set Φ is often called the root system A 2 . For notational convenience define
$$\alpha = e _ { 1 } - e _ { 2 }, \quad \quad \beta = e _ { 2 } - e _ { 3 }, \quad \quad \gamma = e _ { 3 } - e _ { 1 }.$$
Note that
$$\Phi = \{ \pm \alpha, \pm \beta, \pm \gamma \}, \quad \ \alpha + \beta + \gamma = 0.$$
An element ( r, s, t ) ∈ R 3 will be called nonnegative whenever each of r, s, t is nonnegative. Define a partial order ≤ on R 3 such that for λ, µ ∈ R 3 , µ ≤ λ if and only if λ -µ is nonnegative.
Let { u i } n i =0 denote a finite sequence. We call u i the i -component or i -coordinate of the sequence. By the inversion of the sequence { u i } n i =0 we mean the sequence { u n -i } n i =0 .
## 3 The set ∆ N
Throughout this section fix N ∈ N .
Definition 3.1. Let ∆ N denote the subset of R 3 consisting of the three-tuples of natural numbers whose sum is N . Thus
$$\Delta _ { N } = \{ ( r, s, t ) \ | \ r, s, t \in \mathbb { N }, \ r + s + t = N \}.$$
We arrange the elements of ∆ N in a triangular array, as discussed in Section 1. An element in ∆ N is called a location . For notational convenience define ∆ -1 = ∅ .
Definition 3.2. For η ∈ { 1 2 3 , , } the η -corner of ∆ N is the location in ∆ N that has η -coordinate N and all other coordinates 0. By a corner of ∆ N we mean the 1-corner or 2-corner or 3-corner. The corners in ∆ N are listed below.
$$N e _ { 1 } = ( N, 0, 0 ), \quad N e _ { 2 } = ( 0, N, 0 ), \quad N e _ { 3 } = ( 0, 0, N ).$$
Definition 3.3. For η ∈ { 1 2 3 , , } the η -boundary of ∆ N is the set of locations in ∆ N that have η -coordinate 0.
Example 3.4. The 1-boundary of ∆ N consists of the locations
$$( 0, N - i, i ) \quad \ \ i = 0, 1, \dots, N.$$
Definition 3.5. The boundary of ∆ N is the union of its 1-boundary, 2-boundary, and 3boundary. By the interior of ∆ N we mean the set of locations in ∆ N that are not on the boundary.
Definition 3.6. For η ∈ { 1 2 3 , , } we define a binary relation on ∆ N called η -collinearity. By definition, locations λ, λ ′ in ∆ N are η -collinear whenever the η -coordinate of λ -λ ′ is 0. Note that η -collinearity is an equivalence relation. Each equivalence class will be called an η -line .
Example 3.7. Pick η ∈ { 1 2 3 , , } . For 0 ≤ i ≤ N there exists a unique η -line of ∆ N that has cardinality i +1. For i = 0 (resp. i = N ) this η -line is the η -corner (resp. η -boundary) of ∆ N .
Example 3.8. For 0 ≤ i ≤ N the following locations make up the unique 1-line of ∆ N that has cardinality i +1:
$$( N - i, i - j, j ) \quad \ \ j = 0, 1, \dots, i.$$
Definition 3.9. Locations λ, λ ′ in ∆ N are called collinear whenever they are 1-collinear or 2-collinear or 3-collinear. By a line in ∆ N we mean a 1-line or 2-line or 3-line.
## 4 ∆ N as a graph
Throughout this section fix N ∈ N . In this section we describe ∆ N using notions from graph theory. For each result that we mention, the proof is routine and omitted.
Definition 4.1. Locations λ, µ in ∆ N are called adjacent whenever λ -µ ∈ Φ.
Example 4.2. Assume N ≥ 1, and pick a location λ ∈ ∆ . N
- (i) Assume that λ is a corner. Then λ is adjacent to exactly 2 locations in ∆ N .
- (ii) Assume that λ is on the boundary, but not a corner. Then λ is adjacent to exactly 4 locations in ∆ N .
- (iii) Assume that λ is in the interior. Then λ is adjacent to exactly six locations in ∆ N .
Definition 4.3. By an edge in ∆ N we mean a set of two adjacent locations.
/negationslash
Definition 4.4. For n ∈ N , by a walk of length n in ∆ N we mean a sequence of locations { λ i } n i =0 in ∆ N such that λ i -1 , λ i are adjacent for 1 ≤ i ≤ n . This walk is said to be from λ 0 to λ n . By a path of length n in ∆ N we mean a walk { λ i } n i =0 in ∆ N such that λ i -1 = λ i +1 for 1 ≤ i ≤ n -1. By a cycle in ∆ N we mean a path { λ i } n i =0 in ∆ N of length n ≥ 3 such that λ , λ , . . . , λ 0 1 n -1 are mutually distinct and λ 0 = λ n .
Definition 4.5. For locations λ, λ ′ ∈ ∆ N let ∂ λ, λ ( ′ ) denote the length of a shortest path from λ to λ ′ . We call ∂ λ, λ ( ′ ) the distance between λ and λ ′ .
Example 4.6. A location λ = ( r, s, t ) in ∆ N is at distance N -r (resp. N -s ) (resp. N -t ) from the 1-corner (resp. 2-corner) (resp. 3-corner) of ∆ N .
Definition 4.7. For a location λ ∈ ∆ N and a nonempty subset S ⊆ ∆ , define N
$$\partial ( \lambda, S ) = \min \{ \partial ( \lambda, \lambda ^ { \prime } ) \ | \ \lambda ^ { \prime } \in S \}.$$
We call ∂ λ, S ( ) the distance between λ and S .
Example 4.8. A location λ = ( r, s, t ) in ∆ N is at distance r (resp. s ) (resp. t ) from the 1-boundary (resp. 2-boundary) (resp. 3-boundary) of ∆ N .
Lemma 4.9. For η ∈ { 1 2 3 , , } and 0 ≤ n ≤ N the following sets coincide:
- (i) the locations in ∆ N that have η -coordinate n ;
- (ii) the locations in ∆ N at distance n from the η -boundary;
- (iii) the locations in ∆ N at distance N -n from the η -corner;
- (iv) the η -line of cardinality N -n +1 .
We now consider the distance function ∂ in more detail.
Lemma 4.10. Let λ and λ ′ denote locations in ∆ N , written λ = ( r, s, t ) and λ ′ = ( r , s , t ′ ′ ′ ) . Then ∂ λ, λ ( ′ ) is equal to the maximum of the absolute values
$$| r - r ^ { \prime } |, \quad | s - s ^ { \prime } |, \quad | t - t ^ { \prime } |.$$
Lemma 4.11. Given locations ( r, s, t ) and ( r , s , t ′ ′ ′ ) in ∆ N , consider the three quantities in line (5) . Let d , d 1 2 , d 3 denote an ordering of these quantities such that d 1 ≤ d 2 ≤ d 3 . Then d 1 + d 2 = d 3 .
Lemma 4.12. For locations λ, λ ′ in ∆ N we have ∂ λ, λ ( ′ ) ≤ N . Moreover the following are equivalent:
- (i) ∂ λ, λ ( ′ ) = N ;
- (ii) there exists η ∈ { 1 2 3 , , } such that one of λ, λ ′ is the η -corner of ∆ N , and the other one is on the η -boundary of ∆ N .
We mention several types of paths in ∆ N .
Definition 4.13. Pick η ∈ { 1 2 3 , , } . A path { λ i } n i =0 in ∆ N is called an η -boundary path whenever λ i is on the η -boundary for 0 ≤ i ≤ n . The path { λ i } n i =0 is called η -linear whenever there exists an η -line that contains λ i for 0 ≤ i ≤ n .
Definition 4.14. Pick η ∈ { 1 2 3 , , } . A subset S of ∆ N is called η -geodesic whenever distinct elements in S do not have the same η -coordinate.
Lemma 4.15. Pick η ∈ { 1 2 3 , , } . For a path { λ i } n i =0 in ∆ N the following are equivalent:
- (i) the path { λ i } n i =0 is η -geodesic;
- (ii) there exists ε ∈ { 1 , - } 1 such that for 1 ≤ i ≤ n , the η -coordinate of λ i is equal to ε plus the η -coordinate of λ i -1 .
Lemma 4.16. Pick η ∈ { 1 2 3 , , } . For a path { λ i } n i =0 in ∆ N the following are equivalent:
- (i) the path { λ i } n i =0 is η -linear;
- (ii) the path { λ i } n i =0 is ξ -geodesic for each ξ ∈ { 1 2 3 , , } other than η .
Definition 4.17. A path { λ i } n i =0 in ∆ N is said to be geodesic whenever ∂ λ , λ ( 0 n ) = n .
Lemma 4.18. For a path { λ i } n i =0 in ∆ N the following are equivalent:
- (i) the path { λ i } n i =0 is geodesic;
- (ii) there exists η ∈ { 1 2 3 , , } such that the path { λ i } n i =0 is η -geodesic.
Lemma 4.19. Let λ and λ ′ denote locations in ∆ N , written λ = ( r, s, t ) and λ ′ = ( r , s , t ′ ′ ′ ) . Then the number of geodesic paths in ∆ N from λ to λ ′ is equal to the binomial coefficient ( d 1 + d 2 d 1 ) with d , d 1 2 from Lemma 4.11.
Lemma 4.20. For locations λ, λ ′ in ∆ N the following are equivalent:
- (i) the locations λ, λ ′ are collinear;
- (ii) there exists a unique geodesic path in ∆ N from λ to λ ′ .
Assume that (i), (ii) hold. Define η ∈ { 1 2 3 , , } such that λ, λ ′ are η -collinear. Then the geodesic path mentioned in (ii) is η -linear.
To motivate the next definition we make some comments. Let λ, λ ′ denote distinct corner locations in ∆ N . Then λ, λ ′ are collinear, and ∂ λ, λ ( ′ ) = N . There exists a unique geodesic path in ∆ N from λ to λ ′ . This is a boundary path.
Definition 4.21. For distinct η, ξ ∈ { 1 2 3 , , } let [ η, ξ ] denote the unique geodesic path in ∆ N from the η -corner of ∆ N to the ξ -corner of ∆ N .
Lemma 4.22. For distinct η, ξ ∈ { 1 2 3 , , } the path [ η, ξ ] is the inversion of the path [ ξ, η ] .
Lemma 4.23. Pick distinct η, ξ ∈ { 1 2 3 , , } and let { λ i } N i =0 denote the path [ η, ξ ] . For 0 ≤ i ≤ N the location λ i is described in the table below:
$$\frac { [ \eta, \xi ] } { [ 1, 2 ] } \left | \left ( N - i, i, 0 \right ) \right ) } \frac { ( N - i, i, 0 ) } { [ 2, 1 ] } \left | \left ( i, N - i, 0 \right ) \right ) } \frac { ( 0, N - i, i ) } { [ 2, 3 ] } \left | \left ( 0, i, N - i \right ) } \frac { ( 0, i, N - i ) } { [ 3, 1 ] } \left | \left ( i, 0, N - i \right ) } \frac { ( i, 0, N - i ) } { [ 1, 3 ] } \left | \left ( N - i, 0, i \right ) }$$
Definition 4.24. A subset S of ∆ N is said to be geodesically closed whenever for each geodesic path { λ i } n i =0 in ∆ N , if S contains λ , λ 0 n then S contains λ i for 0 ≤ i ≤ n .
Example 4.25. For η ∈ { 1 2 3 , , } and 0 ≤ n ≤ N , the set of locations in ∆ N that have η -coordinate at least n is geodesically closed.
Lemma 4.26. Let S and S ′ denote geodesically closed subsets of ∆ N . Then S ∩ S ′ is geodesically closed.
Definition 4.27. By a spanning tree of ∆ N we mean a set T of edges for ∆ N that has the following property: for any two distinct locations λ, λ ′ in ∆ N there exists a unique path in ∆ N from λ to λ ′ that involves only edges in T .
Note 4.28. Let T denote a spanning tree of ∆ N . Then the cardinality of T is one less than the cardinality of ∆ N .
Definition 4.29. By a 3-clique in ∆ N we mean a set of three mutually adjacent locations in ∆ N . There are two kinds of 3-cliques: ∆ (black) and ∇ (white).
Example 4.30. Assume N = 0. Then ∆ N does not contain a 3-clique. Assume N = 1. Then ∆ N contains a unique black 3-clique and no white 3-clique. Assume N = 2. Then ∆ N contains three black 3-cliques and a unique white 3-clique.
Lemma 4.31. Assume N ≥ 1 . We describe a bijection from ∆ N -1 to the set of black 3cliques in ∆ N . The bijection sends each ( r, s, t ) ∈ ∆ N -1 to the black 3-clique consisting of the locations
$$( r + 1, s, t ), \quad ( r, s + 1, t ), \quad ( r, s, t + 1 ).$$
Lemma 4.32. Assume N ≥ 2. We describe a bijection from ∆ N -2 to the set of white 3-cliques in ∆ N . The bijection sends each ( r, s, t ) ∈ ∆ N -2 to the white 3-clique consisting of the locations
$$( r, s + 1, t + 1 ), \quad ( r + 1, s, t + 1 ), \quad ( r + 1, s + 1, t ).$$
Lemma 4.33. For ∆ N , each edge is contained in a unique black 3-clique and at most one white 3-clique.
## 5 The poset ∆ ≤ N
Throughout this section fix N ∈ N . We now describe ∆ N using notions from the theory of posets. We will follow the notational conventions from [13].
Definition 5.1. Let ∆ ≤ N denote the poset consisting of the set ∪ N n =0 ∆ together with the n partial order ≤ from Section 2. An element λ in the poset is said to have rank n whenever λ ∈ ∆ . n
We mention some facts about the poset ∆ ≤ N . Pick elements λ, µ in the poset. Then λ covers µ if and only if λ -µ is one of e , e 1 2 , e 3 . In this case rank( λ ) = 1 + rank( µ ). For 0 ≤ n ≤ N -1, each element in ∆ n is covered by precisely three elements in the poset. An element in ∆ N is not covered by any element in the poset. For 1 ≤ n ≤ N , each element in ∆ covers at least one element in the poset. n The element in ∆ 0 does not cover any element in the poset.
Given elements λ, µ in ∆ ≤ N we define an element λ ∧ µ in ∆ ≤ N as follows: for η ∈ { 1 2 3 , , } the η -coordinate of λ ∧ µ is the minimum of the η -coordinates for λ and µ . Note that λ ∧ µ ≤ λ and λ ∧ µ ≤ µ . Moreover ν ≤ λ ∧ µ for all elements ν in ∆ ≤ N such that ν ≤ λ and ν ≤ µ .
Given elements λ, µ in ∆ ≤ N we define an element λ ∨ µ in R 3 as follows: for η ∈ { 1 2 3 , , } the η -coordinate of λ ∨ µ is the maximum of the η -coordinates for λ and µ . Note that λ ∨ µ is contained in ∆ ≤ N if and only if the sum of its coordinates is at most N . In this case we say that λ ∨ µ exists in ∆ ≤ N . Assume that λ ∨ µ exists in ∆ ≤ N . Then λ ≤ λ ∨ µ and µ ≤ λ ∨ µ . Moreover λ ∨ µ ≤ ν for all elements ν in ∆ ≤ N such that λ ≤ ν and µ ≤ ν . Now assume that λ ∨ µ does not exist in ∆ ≤ N . Then ∆ ≤ N does not contain an element ν such that λ ≤ ν and µ ≤ ν .
Lemma 5.2. For locations λ, µ in ∆ N the rank of λ ∧ µ is equal to N -∂ λ, µ ( ) .
Proof. Write λ = ( r, s, t ) and µ = ( r , s , t ′ ′ ′ ). By construction r + + = s t N and r ′ + s ′ + t ′ = N . The sum of r -r , s ′ -s , t ′ -t ′ is zero. Permuting the coordinates of R 3 and interchanging λ, µ if necessary, we may assume without loss that each of r -r , s ′ ′ -s, t ′ -t is nonnegative. By Lemma 4.10 ∂ λ, µ ( ) = r -r ′ . By construction λ ∧ µ = ( r , s, t ′ ) has rank r ′ + s + . The t result follows.
For µ ∈ ∆ ≤ N we now describe the set
$$\{ \lambda \in \Delta _ { N } \ | \ \mu \leq \lambda \}.$$
Lemma 5.3. For µ = ( r, s, t ) ∈ ∆ ≤ N and λ ∈ ∆ N , the following are equivalent:
- (i) µ ≤ λ ;
- (ii) the 1 -coordinate (resp. 2 -coordinate) (resp. 3 -coordinate) of λ is at least r (resp. s ) (resp. t );
- (iii) λ is at distance at least r (resp. s ) (resp. t ) from the 1 -boundary (resp. 2 -boundary) (resp. 3 -boundary) of ∆ N ;
- (iv) λ is at distance at most N -r (resp. N -s ) (resp. N -t ) from the 1 -corner (resp. 2 -corner) (resp. 3 -corner) of ∆ N ;
- (v) the 1 -line (resp. 2 -line) (resp. 3 -line) of ∆ N that contains λ has cardinality at most N -r +1 (resp. N -s +1 ) (resp. N -t +1 ).
Proof. (i) ⇔ (ii) By the definition of the partial order ≤ in Section 2. (ii) ⇔ (iii) ⇔ (iv) ⇔ (v) By Lemma 4.9.
Lemma 5.4. For 0 ≤ n ≤ N and µ ∈ ∆ N -n the set (6) is equal to ∆ + n µ .
Proof. By construction.
Lemma 5.5. For µ ∈ ∆ ≤ N the set (6) is geodesically closed.
Proof. By Example 4.25 and Lemma 4.26, along with Lemma 5.3(i),(ii).
We have been discussing the set (6). We now consider a special case.
Definition 5.6. Pick η ∈ { 1 2 3 , , } . Note by Definition 3.2 that for 0 ≤ n ≤ N the element ne η is the η -corner of ∆ n . By an η -corner of ∆ ≤ N we mean one of { ne η } N n =0 . By a corner of ∆ ≤ N we mean a 1-corner or 2-corner or 3-corner of ∆ ≤ N .
Referring to Lemma 5.3, we now consider the case in which µ is a corner of ∆ ≤ N .
Lemma 5.7. For η ∈ { 1 2 3 , , } and 0 ≤ n ≤ N and λ ∈ ∆ N , the following are equivalent:
- (i) µ ≤ λ , where µ is the η -corner of ∆ N -n ;
- (ii) the η -coordinate of λ is at least N -n ;
- (iii) λ is at distance at least N -n from the η -boundary of ∆ N ;
- (iv) λ is at distance at most n from the η -corner of ∆ N ;
- (v) the η -line containing λ has cardinality at most n +1 .
Proof. For the η -corner µ of ∆ N -n , the η -coordinate is N -n and the other two coordinates are 0. The result follows in view of Lemma 5.3.
Definition 5.8. By a flag in ∆ ≤ N we mean a sequence { λ n } N n =0 such that λ n ∈ ∆ n for 0 ≤ n ≤ N and λ n -1 ≤ λ n for 1 ≤ n ≤ N .
Definition 5.9. Pick η ∈ { 1 2 3 , , } . Observe that the sequence of η -corners { ne η } N n =0 is a flag in ∆ ≤ N . We denote this flag by [ η ].
## 6 The vector space V and the poset P ( V )
From now on, let F denote a field. Fix N ∈ N , and let V denote a vector space over F with dimension N +1. Let End( V ) denote the F -algebra consisting of the F -linear maps from V to V . Let I ∈ End( V ) denote the identity map on V . By a decomposition of V we mean a sequence { V i } N i =0 consisting of one-dimensional subspaces of V such that V = ∑ N i =0 V i (direct sum). For a decomposition of V , its inversion is a decomposition of V . Let { v i } N i =0 denote a basis for V and let { V i } N i =0 denote a decomposition of V . We say that { v i } N i =0 induces { V i } N i =0 whenever v i ∈ V i for 0 ≤ i ≤ N .
Let P ( V ) denote the set of nonzero subspaces of V . The containment relation ⊆ is a partial order on P ( V ). For 1 ≤ i ≤ N +1 let P i ( V ) denote the set of i -dimensional subspaces of V . This yields a partition P ( V ) = ∪ N +1 i =1 P i ( V ).
By a flag in P ( V ) we mean a sequence { U i } N i =0 such that U i ∈ P i +1 ( V ) for 0 ≤ i ≤ N and U i -1 ⊆ U i for 1 ≤ i ≤ N . For notational convenience, a flag in P ( V ) is said to be on V . The following construction yields a flag on V . Let { V i } N i =0 denote a decomposition of V . For 0 ≤ i ≤ N define U i = V 0 + · · · + V i . Then the sequence { U i } N i =0 is a flag on V . This flag is said to be induced by the decomposition { V i } N i =0 . Suppose we are given two flags on V , denoted { U i } N i =0 and { U ′ i } N i =0 . Then the following are equivalent: (i) U i ∩ U ′ j = 0 if i + j < N (0 ≤ i, j ≤ N ); (ii) there exists a decomposition { V i } N i =0 of V that induces { U i } N i =0 and whose inversion induces { U ′ i } N i =0 . The flags are called opposite whenever (i), (ii) hold. In this case V i = U i ∩ U ′ N -i for 0 ≤ i ≤ N .
We mention a result for later use.
Lemma 6.1. Let { U i } N i =0 and { U ′ i } N i =0 denote opposite flags on V . Pick integers r, s (0 ≤ r, s ≤ N ) such that r + s ≥ N . Then U r ∩ U ′ s has dimension r + s -N +1 .
Proof. There exists a decomposition { V i } N i =0 of V that induces { U i } N i =0 and whose inversion induces { U ′ i } N i =0 . Observe that U r ∩ U ′ s = ∑ r i = N -s V i . The sum is direct, so it has dimension r + s -N +1.
## 7 Billiard Arrays
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1.
↦
- (i) for each line L in ∆ N the sum ∑ λ ∈ L B λ is direct;
Definition 7.1. By a Billiard Array on V we mean a function B : ∆ N →P 1 ( V ), λ → B λ that satisfies the following conditions:
- (ii) for each black 3-clique C in ∆ N the sum ∑ λ ∈ C B λ is not direct.
We say that B is over F . We call V the underlying vector space . We call N the diameter of B .
Note 7.2. We will show that the Billiard Array B in Definition 7.1 is injective.
Let B denote a Billiard Array on V , as in Definition 7.1. We view B as an arrangement of one-dimensional subspaces of V into a triangular array, with B λ at location λ for all λ ∈ ∆ . N For U ∈ P 1 ( V ) and λ ∈ ∆ , we say that N U is included in B at location λ whenever U = B λ .
Lemma 7.3. Let B denote a Billiard Array on V . Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then the subspace B λ + B µ + B ν is equal to each of
$$B _ { \lambda } + B _ { \mu }, \quad B _ { \mu } + B _ { \nu }, \quad B _ { \nu } + B _ { \lambda }.$$
Moreover, in line (7) each sum is direct.
Proof. Any two of λ, µ, ν are collinear, so in line (7) each sum is direct by Definition 7.1(i). The sum B λ + B µ + B ν is not direct by Definition 7.1(ii). The result follows.
Corollary 7.4. Let B denote a Billiard Array on V . Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then each of B , B , B λ µ ν is contained in the sum of the other two.
Lemma 7.5. Let B denote a Billiard Array on V . Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. Then the sum B λ + B µ + B ν is direct.
Proof. Permuting λ, µ, ν if necessary, we may assume that
$$\mu - \lambda = \alpha, \quad \ \nu - \mu = \beta, \quad \ \lambda - \nu = \gamma,$$
where α, β, γ are from (2). Consider the locations µ + γ, µ, µ -γ in ∆ N . These locations are collinear, so by Definition 7.1(i) the sum B µ + γ + B µ + B µ -γ is direct. The locations λ, µ, µ + γ form a black 3-clique, so B µ + γ is contained in B λ + B µ by Corollary 7.4. The locations µ, ν, µ -γ form a black 3-clique, so B µ -γ is contained in B µ + B ν by Corollary 7.4. By these comments B µ + γ + B µ + B µ -γ is contained in B λ + B µ + B ν . The result follows.
Lemma 7.6. Let B denote a Billiard Array on V . Pick η ∈ { 1 2 3 , , } and let L denote the η -boundary of ∆ N . Then the sum V = ∑ λ ∈ L B λ is direct.
Proof. The sum ∑ λ ∈ L B λ is direct by Definition 7.1(i) and since L is a line. The sum is equal to V , since L has cardinality N +1 and V has dimension N +1.
Corollary 7.7. Let B denote a Billiard Array on V . Then V is spanned by { B λ } λ ∈ ∆ N .
Proof. By Lemma 7.6.
We now describe the Billiard Arrays of diameter 0 and 1.
Example 7.8. Let B : ∆ N →P 1 ( V ) denote any function.
- (i) Assume N = 0 , so that ∆ N and P 1 ( V ) each have cardinality 1. Then B is a Billiard Array on V .
- (ii) Assume N = 1 . Then B is a Billiard Array on V if and only if B is injective.
↦
Definition 7.9. Let V ′ denote a vector space over F with dimension N + 1. Let B (resp. B ′ ) denote a Billiard Array on V (resp. V ′ ). By an isomorphism of Billiard Arrays from B to B ′ we mean an F -linear bijection σ : V → V ′ that sends B λ → B ′ λ for all λ ∈ ∆ . N The Billiard Arrays B and B ′ are called isomorphic whenever there exists an isomorphism of Billiard Arrays from B to B ′ .
Example 7.10. For N = 0 or N = 1 , any two Billiard Arrays over F of diameter N are isomorphic.
## 8 Concrete Billiard Arrays
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1.
↦
Definition 8.1. By a Concrete Billiard Array on V we mean a function B : ∆ N → V , λ →B λ that satisfies the following conditions:
- (i) for each line L in ∆ N the vectors {B } λ λ ∈ L are linearly independent;
- (ii) for each black 3-clique C in ∆ N the vectors {B } λ λ ∈ C are linearly dependent.
We say that B is over F . We call V the underlying vector space . We call N the diameter of B .
/negationslash
Lemma 8.2. Let B denote a Concrete Billiard Array on V . Then B λ = 0 for all λ ∈ ∆ N .
Proof. There exists a line L in ∆ N that contains λ . The result follows in view of Definition 8.1(i).
↦
↦
Billiard Arrays and Concrete Billiard Arrays are related as follows. Let B denote a Billiard Array on V . For λ ∈ ∆ N let B λ denote a nonzero vector in B λ . Then the function B : ∆ N → V , λ →B λ is a Concrete Billiard Array on V . Conversely, let B denote a Concrete Billiard Array on V . For λ ∈ ∆ N let B λ denote the subspace of V spanned by B λ . Note that B λ ∈ P 1 ( V ) by Lemma 8.2. The function B : ∆ N →P 1 ( V ), λ → B λ is a Billiard Array on V .
Definition 8.3. Let B denote a Billiard Array on V , and let B denote a Concrete Billiard Array on V . We say that B, B correspond whenever B λ spans B λ for all λ ∈ ∆ . N
Let B denote a Concrete Billiard Array on V . For v ∈ V and λ ∈ ∆ , we say that N v is included in B at location λ whenever v = B λ .
Lemma 8.4. Let B denote a Concrete Billiard Array on V . Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then B λ , B µ , B ν span a 2-dimensional subspace of V . Any two of B λ , B µ , B ν form a basis for this subspace.
Proof. Use Lemma 7.3.
Lemma 8.5. Let B denote a Concrete Billiard Array on V . Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. Then the vectors B λ , B µ , B ν are linearly independent.
Proof. Use Lemma 7.5.
Lemma 8.6. Let B denote a Concrete Billiard Array on V . Pick η ∈ { 1 2 3 , , } and let L denote the η -boundary of ∆ N . Then the vectors {B } λ λ ∈ L form a basis for V .
Proof. Use Lemma 7.6.
Corollary 8.7. Let B denote a Concrete Billiard Array on V . Then V is spanned by the vectors {B } λ λ ∈ ∆ N .
Proof. By Corollary 7.7 or Lemma 8.6.
We now describe the Concrete Billiard Arrays of diameter 0 and 1.
Example 8.8. Let B : ∆ N → V denote any function.
/negationslash
- (i) Assume N = 0 , so that ∆ N contains a unique element λ . Then B is a Concrete Billiard Array on V if and only if B λ = 0 .
- (ii) Assume N = 1 . Then B is a Concrete Billiard Array on V if and only if any two of {B } λ λ ∈ ∆ N are linearly independent.
↦
Lemma 8.9. Let B denote a Concrete Billiard Array on V . For all λ ∈ ∆ N let κ λ denote a nonzero scalar in F . Then the function B ′ : ∆ N → V , λ → κ λ B λ is a Concrete Billiard Array on V .
Definition 8.10. Let B B , ′ denote Concrete Billiard Arrays on V . We say that B B , ′ are associates whenever there exist nonzero scalars { κ λ } λ ∈ ∆ N in F such that B ′ λ = κ λ B λ for all λ ∈ ∆ . The relation of being associates is an equivalence relation. N
Lemma 8.11. Let B B , ′ denote Concrete Billiard Arrays on V . Then B B , ′ are associates if and only if they correspond to the same Billiard Array.
Proof. By Definitions 8.3, 8.10.
Example 8.12. Referring to Definition 8.10, if N = 0 then B B , ′ are associates.
/negationslash
Definition 8.13. Let B B , ′ denote Concrete Billiard Arrays on V . Then B B , ′ are called relatives whenever there exists 0 = κ ∈ F such that B ′ λ = κ B λ for all λ ∈ ∆ . The relation N of being relatives is an equivalence relation.
Example 8.14. Referring to Definition 8.13, if N = 0 then B B , ′ are relatives.
↦
Definition 8.15. Let V ′ denote a vector space over F with dimension N +1. Let B (resp. B ′ ) denote a Concrete Billiard Array on V (resp. V ′ ). By an isomorphism of Concrete Billiard Arrays from B to B ′ we mean an F -linear bijection σ : V → V ′ that sends B λ →B ′ λ for all λ ∈ ∆ . We say that N B B , ′ are isomorphic whenever there exists an isomorphism of Concrete Billiard Arrays from B to B ′ . In this case the isomorphism is unique. Isomorphism is an equivalence relation.
Example 8.16. Referring to Definition 8.15, if N = 0 then B B , ′ are isomorphic.
Definition 8.17. Let V ′ denote a vector space over F with dimension N +1. Let B (resp. B ′ ) denote a Concrete Billiard Array on V (resp. V ′ ). Then B B , ′ are called similar whenever their corresponding Billiard Arrays are isomorphic in the sense of Definition 7.9. Similarity is an equivalence relation.
Example 8.18. Referring to Definition 8.17, assume N = 0 or N = 1. Then B B , ′ are similar.
In each of the last four definitions we gave an equivalence relation for Concrete Billiard Arrays.
Lemma 8.19. The above equivalence relations obey the following logical implications:
Proof. This is routinely verified.
We have a few comments.
Proposition 8.20. Let V ′ denote a vector space over F with dimension N +1 . Let B ′ ′
(resp.
- B ) denote a Concrete Billiard Array on V (resp. V ). Then the following are equivalent:
- (i) B and B ′ are similar;
- (ii) B is isomorphic to a Concrete Billiard Array associated with B ′ ;
- (iii) B is associated with a Concrete Billiard Array isomorphic to B ′ .
Proof. Let B (resp. B ′ ) denote the Billiard Array on V (resp. V ′ ) that corresponds to B (resp. B ′ ).
↦
- (i) ⇒ (ii) By Definition 8.17 B,B ′ are isomorphic. Let σ : V → V ′ denote an isomorphism of Billiard Arrays from B to B ′ . Define a function B ′′ : ∆ N → V , λ ′ → σ ( B λ ). By construction, B ′′ is a Concrete Billiard Array that is isomorphic to B and corresponds to B ′ . Note that B ′ , B ′′ are associates since they both correspond to B ′ .
- (ii) ⇒ (i) Let B ′′ denote a Concrete Billiard Array that is isomorphic to B and associated with B ′ . Since B ′ , B ′′ are associates, B ′′ must correspond to B ′ . Let σ denote an isomorphism of Concrete Billiard Arrays from B to B ′′ . Then σ is an isomorphism of Billiard Arrays from B to B ′ . Therefore B,B ′ are isomorphic so B B , ′ are similar.
- (i) ⇔ (iii) Interchange the roles of B B , ′ in the proof of (i) ⇔ (ii).
Lemma 8.21. Consider the map which takes a Concrete Billiard Array to the corresponding Billiard Array. This map induces a bijection between the following two sets:
- (i) the similarity classes of Concrete Billiard Arrays over F that have diameter N ;
- (ii) the isomorphism classes of Billiard Arrays over F that have diameter N .
Proof. By Definition 8.17 the given map induces an injective function from set (i) to set (ii). The function is surjective by the comments above Definition 8.3. Therefore the function is a bijection.
## 9 Billiard Arrays and the poset ∆ ≤ N
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1. Let B denote a Billiard Array on V .
By definition, B is a function ∆ N → P 1 ( V ). We now extend B to a function B : ∆ ≤ N → P ( V ).
Definition 9.1. For µ ∈ ∆ ≤ N define
$$\cdot \cdot \\ B _ { \mu } = \sum _ { \stackrel { \lambda \in \Delta _ { N } } { \mu \leq \lambda } } B _ { \lambda }.$$
Thus B µ ∈ P ( V ).
Pick µ ∈ ∆ ≤ N . Let n = N -rank( µ ), so that µ ∈ ∆ N -n . Evaluating (8) using Lemma 5.4 we obtain
$$\cdot \cdot \cdot \\ B _ { \mu } = \sum _ { \nu \in \Delta _ { n } } B _ { \mu + \nu }.$$
↦
Our next goal is to show that the function ∆ n →P 1 ( B µ ), ν → B µ + ν is a Billiard Array on B µ . To this end, we show that B µ has dimension n +1.
Lemma 9.2. With the above notation, pick ξ ∈ { 1 2 3 , , } and let K denote the ξ -boundary of ∆ n . Then the sum
$$B _ { \mu } = \sum _ { \nu \in K } B _ { \mu + \nu }$$
is direct. Moreover B µ has dimension n +1 .
Proof. Define B ′ µ = ∑ ν ∈ K B µ + ν . The preceding sum is direct, by Definition 7.1(i) and since { µ + ν } ν ∈ K are collinear locations in ∆ N . We show B µ = B ′ µ . We have B ′ µ ⊆ B µ by (9). To obtain B µ ⊆ B ′ µ , for ν ∈ ∆ use Corollary 7.4 and induction on the n ξ -coordinate of ν to obtain B µ + ν ⊆ B ′ µ . This and (9) yield B µ ⊆ B ′ µ , and therefore B µ = B ′ µ . We have shown that the sum (10) is direct. The set K has cardinality n +1, so B µ has dimension n +1.
We emphasize one aspect of Lemma 9.2.
Lemma 9.3. For µ ∈ ∆ ≤ N we have B µ ∈ P n +1 ( V ) , where n = N -rank( µ ) .
↦
Proposition 9.4. For 0 ≤ n ≤ N and µ ∈ ∆ N -n , the function ∆ n →P 1 ( B µ ) , ν → B µ + ν is a Billiard Array on B µ .
Proof. We verify that the given function satisfies the conditions of Definition 7.1. Let L denote a line in ∆ n . Then the elements { µ + ν } ν ∈ L are collinear locations in ∆ N . Consequently the given function satisfies Definition 7.1(i). Let C denote a black 3-clique in ∆ n . Then the locations { µ + ν } ν ∈ C form a black 3-clique in ∆ N . Therefore the given function satisfies Definition 7.1(ii). The result follows.
As we work with the elements B µ from Definition 9.1, we often encounter the case in which µ is a corner of ∆ ≤ N . We now consider this case.
Lemma 9.5. Pick η ∈ { 1 2 3 , , } and 0 ≤ n ≤ N . Let µ denote the η -corner of ∆ N -n . Then B µ is described as follows.
- (i) We have B µ = ∑ λ B λ , where the sum is over the locations λ in ∆ N at distance ≤ n from the η -corner of ∆ N .
- (ii) The sum B µ = ∑ λ B λ is direct, where the sum is over the locations λ in ∆ N at distance n from the η -corner of ∆ N .
- (iii) Pick ξ ∈ { 1 2 3 , , } other than η . Then the sum B µ = ∑ λ B λ is direct, where the sum is over the locations λ on the ξ -boundary of ∆ N at distance ≤ n from the η -corner of ∆ N .
Proof. (i) By Lemma 5.7(i),(iv) and Definition 9.1. (ii), (iii) In Lemma 9.2, take µ to be the η -corner of ∆ N -n
.
At the end of Section 5 we discussed the flags in the poset ∆ ≤ N . In Section 6 we discussed the flags in the poset P ( V ). We now consider how the flags in these two posets are related.
Lemma 9.6. Let µ, ν denote elements in ∆ ≤ N such that µ ≤ ν . Then B ν ⊆ B µ .
Proof. Use Definition 9.1.

Lemma 9.7. Let { λ n } N n =0 denote a flag in ∆ ≤ N . Define U i = B λ N -i for 0 ≤ i ≤ N . Then the sequence { U i } N i =0 is a flag on V .
Proof. By Lemma 9.6 U i -1 ⊆ U i for 1 ≤ i ≤ N . By Lemma 9.3 the subspace U i has dimension i +1 for 0 ≤ i ≤ N . The result follows.
Definition 9.8. Referring to Lemma 9.7, the flag { U i } N i =0 is called the B -flag induced by { λ n } N n =0 .
Definition 9.9. Pick η ∈ { 1 2 3 , , } . Recall from Definition 5.9 the flag [ η ] in ∆ ≤ N . The B -flag induced by [ η ] will be called the B -flag [ η ]. This is a flag on V .
The next result is meant to clarify Definition 9.9.
Lemma 9.10. Pick η ∈ { 1 2 3 , , } . Let { U n } N n =0 denote the B -flag [ η ] . Then for 0 ≤ n ≤ N , U n is equal to the space B µ from Lemma 9.5.
Proof. By Lemma 9.7 and Definitions 9.8, 9.9.
Lemma 9.11. Pick η ∈ { 1 2 3 , , } . Let { U n } N n =0 denote the B -flag [ η ] . Then for 1 ≤ n ≤ N the sum U n = U n -1 + B λ is direct, where λ is any location in ∆ N at distance n from the η -corner.
/negationslash
Proof. We first show that U n -1 + B λ is independent of the choice of λ . Let L denote the set of locations in ∆ N that are at distance n from the η -corner. By Lemma 4.9, L is the η -line with cardinality n +1. By construction λ ∈ L . Let µ ∈ L be adjacent to λ . By Lemma 4.33 there exists a unique ν ∈ ∆ N such that λ, µ, ν form a black 3-clique. The location ν is at distance n -1 from the η -corner of ∆ N , so B ν ⊆ U n -1 in view of Lemmas 9.5(i), 9.10. By Lemma 7.3 we have B λ + B ν = B µ + B ν . By these comments U n -1 + B λ = U n -1 + B µ . It follows that U n -1 + B λ is independent of the choice of λ . So we may assume that λ is on the boundary of ∆ N . Now there exists ξ ∈ { 1 2 3 , , } such that ξ = η and λ is on the ξ -boundary of ∆ N . By Lemmas 9.5(iii), 9.10 we have a direct sum U n -1 = ∑ ζ B ζ , where the sum is over the locations ζ on the ξ -boundary of ∆ N at distance ≤ n -1 from the η -corner. Similarly we have a direct sum U n = ∑ ζ B ζ , where the sum is over the locations ζ on the ξ -boundary of ∆ N at distance ≤ n from the η -corner. By assumption λ is on the ξ -boundary of ∆ N at distance n from the η -corner. By these comments the sum U n = U n -1 + B λ is direct.
Proposition 9.12. Pick η ∈ { 1 2 3 , , } . Let S denote a subset of ∆ N that is η -geodesic in the sense of Definition 4.14. Then the sum ∑ λ ∈ S B λ is direct.
Proof. We assume that the assertion is false, and get a contradiction. By assumption there exists a counterexample S . Without loss, we may assume that among all the counterexamples, the cardinality of S is minimal. This cardinality is at least 2. Let µ denote the location in S that has minimal η -coordinate, and abbreviate R = S \{ µ } . By construction the sum ∑ λ ∈ S B λ is not direct, and the sum ∑ λ ∈ R B λ is direct. By Definition 7.1 B µ has dimension 1. By these comments B µ ⊆ ∑ λ ∈ R B λ . Denote the η -coordinate of µ by N -n , and observe n ≥ 1. By construction µ is at distance n from the η -corner of ∆ N , and each element of R is at distance ≤ n -1 from the η -corner of ∆ N . Let { U i } N i =0 denote the B -flag [ η ]. By Lemma 9.11 the sum U n = U n -1 + B µ is direct. Using Lemmas 9.5(i), 9.10 we obtain B λ ⊆ U n -1 for all λ ∈ R . Therefore B µ ⊆ U n -1 , for a contradiction. The result follows.
Corollary 9.13. The function B is injective.
Proof. Let λ, µ denote locations in ∆ N such that B λ = B µ . By Proposition 9.12 the locations λ, µ have the same η -coordinate for all η ∈ { 1 2 3 , , } . Therefore λ = µ .
The following definition is for notational convenience.
Definition 9.14. Let B denote a Billiard Array on V . Define B λ = 0 for all λ ∈ R 3 such that λ / ∈ ∆ ≤ N .
## 10 Bases, decompositions, and flags
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N + 1. Let B denote a Concrete Billiard Array on V , and let B denote the corresponding Billiard Array on V .
Lemma 10.1. Let { λ i } n i =0 denote a geodesic path in ∆ N , and define µ = λ 0 ∧ λ n . Then the following (i)-(iii) hold:
- (i) µ ≤ λ i for 0 ≤ i ≤ n ;
- (ii) the sequence { B λ i } n i =0 is a decomposition of B µ ;
- (iii) the sequence {B λ i } n i =0 is a basis for B µ .
Proof. (i) The set { λ ∈ ∆ N | µ ≤ λ } is geodesically closed by Lemma 5.5. By construction µ ≤ λ 0 and µ ≤ λ n . Now by Definition 4.24, µ ≤ λ i for 0 ≤ i ≤ n . (ii) By Definition 9.1 and (i) above, B λ i ⊆ B u for 0 ≤ i ≤ n . Observe that n = ∂ λ , λ ( 0 n ) by Definition 4.17, so µ ∈ ∆ N -n by Lemma 5.2. Now B µ has dimension n +1 by Lemma 9.3. It remains to show that the sum ∑ n i =0 B λ i is direct. This sum is direct by Lemma 4.18 and Proposition 9.12.
- (iii) By (ii) and since B λ spans B λ for all λ ∈ ∆ . N
Definition 10.2. Referring to Lemma 10.1, the decomposition { B λ i } n i =0 (resp. basis {B λ i } n i =0 ) is said to be B -induced (resp. B -induced ) by the path { λ i } n i =0 .
Definition 10.3. For distinct η, ξ ∈ { 1 2 3 , , } we define a decomposition of V called the B -decomposition [ η, ξ ]. This decomposition is B -induced by the path [ η, ξ ] in ∆ N from Definition 4.21. Similarly, we define a basis of V called the B -basis [ η, ξ ]. This basis is B -induced by the path [ η, ξ ] in ∆ . N By construction, the B -basis [ η, ξ ] of V induces the B -decomposition [ η, ξ ] of V , in the sense of the first paragraph of Section 6.
Lemma 10.4. For distinct η, ξ ∈ { 1 2 3 , , } consider the B -decomposition (resp. B -basis) [ η, ξ ] of V . For 0 ≤ i ≤ N the i -component of this decomposition (resp. basis) is included in B (resp. B ) at the location λ i given in Lemma 4.23.
Proof. By Lemma 4.23 and Definitions 10.2, 10.3.

Lemma 10.5. For distinct η, ξ ∈ { 1 2 3 , , } the B -decomposition (resp. B -basis) [ η, ξ ] is the inversion of the B -decomposition (resp. B -basis) [ ξ, η ] .
Proof. By Lemma 4.22 or Lemma 10.4.
Lemma 10.6. For distinct η, ξ ∈ { 1 2 3 , , } the B -decomposition [ η, ξ ] of V induces the B -flag [ η ] on V .
Proof. By Lemmas 9.5(iii), 9.10.
Lemma 10.7. The B -flags [1] , [2] , [3] on V are mutually opposite.
Proof. Pick distinct η, ξ ∈ { 1 2 3 , , } . By Lemma 10.6, the B -decomposition [ η, ξ ] induces the B -flag [ η ], and the B -decomposition [ ξ, η ] induces the B -flag [ ξ ]. Now the B -flags [ η ], [ ξ ] are opposite in view of Lemma 10.5.
Lemma 10.8. For distinct η, ξ ∈ { 1 2 3 , , } and 0 ≤ i ≤ N , the i -component of the B -decomposition [ η, ξ ] is equal to the intersection of the following two subspaces of V :
- (i) component i of the B -flag [ η ] ;
- (ii) component N -i of the B -flag [ ξ ] .
Proof. The B -decomposition [ η, ξ ] induces the B -flag [ η ], and the inversion of this decomposition induces the B -flag [ ξ ].
## 11 More on flags
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1. Let B denote a Billiard Array on V .
Proposition 11.1. Pick integers r, s, t (0 ≤ r, s, t ≤ N ) and consider the intersection of the following three sets:
- (i) component N -r of the B -flag [1] ;
- (ii) component N -s of the B -flag [2] ;
- (iii) component N -t of the B -flag [3] .
If r + s + t > N then the intersection is zero. If r + s + t ≤ N then the intersection is B µ , where µ = ( r, s, t ) .
Proof. Denote the sets in (i), (ii), (iii) by S , S , S 1 2 3 respectively. Let L denote the set of locations in ∆ N at distance N -s from the 2-corner of ∆ N . Thus L is the 2-line with cardinality N -s +1. The set L consists of the locations { λ i } N -s i =0 where λ i = ( N - -s i, s, i ) for 0 ≤ i ≤ N -s . By Lemmas 9.5(ii), 9.10 the sequence { B λ i } N -s i =0 is a decomposition of S 2 . We now describe S 1 ∩ S 2 . By Lemma 10.7 the B -flags [1] , [2] are opposite. For the moment assume r + s > N . Then S 1 ∩ S 2 = 0, so S 1 ∩ S 2 ∩ S 3 = 0 and we are done. Next assume r + s ≤ N . Then S 1 ∩ S 2 has dimension N -r -s +1 by Lemma 6.1. For 0 ≤ i ≤ N -s
the location λ i is at distance s + i from the 1-corner of ∆ N . For 0 ≤ i ≤ N -r -s this distance is at most N -r , so B λ i ⊆ S 1 by Lemmas 9.5(i), 9.10, so B λ i ⊆ S 1 ∩ S 2 . Therefore ∑ N - -r s i =0 B λ i ⊆ S 1 ∩ S 2 . In this inclusion each side has dimension N -r -s +1, so equality holds. In other words
$$S _ { 1 } \cap S _ { 2 } = \sum _ { i = 0 } ^ { N - r - s } B _ { \lambda _ { i } }.$$
We now describe S 2 ∩ S 3 . By Lemma 10.7 the B -flags [2] , [3] are opposite. For the moment assume s + t > N . Then S 2 ∩ S 3 = 0, so S 1 ∩ S 2 ∩ S 3 = 0 and we are done. Next assume s + t ≤ N . Then S 2 ∩ S 3 has dimension N -s -t +1 by Lemma 6.1. For 0 ≤ i ≤ N -s the location λ i is at distance N -i from the 3-corner of ∆ N . For t ≤ i ≤ N -s this distance is at most N -t , so B λ i ⊆ S 3 by Lemmas 9.5(i), 9.10, so B λ i ⊆ S 2 ∩ S 3 . Therefore ∑ N -s i = t B λ i ⊆ S 2 ∩ S 3 . In this inclusion each side has dimension N -s -t + 1, so equality holds. In other words
$$S _ { 2 } \cap S _ { 3 } = \sum _ { i = t } ^ { N - s } B _ { \lambda _ { i } }.$$
Combining (11), (12) we obtain
$$S _ { 1 } \cap S _ { 2 } \cap S _ { 3 } = \sum _ { i = t } ^ { N - r - s } B _ { \lambda _ { i } }.$$
Consider the sum on the right in (13). First assume r + s + t > N . Then the sum is empty, so S 1 ∩ S 2 ∩ S 3 = 0. Next assume r + s + t ≤ N , and define n = N -r -s -t . Then 0 ≤ n ≤ N and µ = ( r, s, t ) is contained in ∆ N -n . Let K denote the 2-boundary of ∆ n , and consider the set K + µ . This set consists of the locations { λ i } N - -r s i = t . Now by Lemma 9.2 we obtain B µ = ∑ N - -r s i = t B λ i . By this and (13) we obtain S 1 ∩ S 2 ∩ S 3 = B µ .
Corollary 11.2. Pick a location λ = ( r, s, t ) in ∆ N . Then B λ is equal to the intersection of the following three sets:
- (i) component N -r of the B -flag [1] ;
- (ii) component N -s of the B -flag [2] ;
- (iii) component N -t of the B -flag [3] .
Proof. In Proposition 11.1, assume r + s + t = N .
By Corollary 11.2 the Billiard Array B is uniquely determined by the B -flags [1] , [2] , [3]. This idea will be pursued further in Section 12. In the meantime we have a few comments.
Proposition 11.3. Let µ, ν denote elements in ∆ ≤ N .
- (i) Assume that µ ∨ ν exists in ∆ ≤ N . Then B µ ∩ B ν = B µ ∨ ν .
- (ii) Assume that µ ∨ ν does not exist in ∆ ≤ N . Then B µ ∩ B ν = 0 .
Proof. This is a routine application of Proposition 11.1.

Proposition 11.4. Let µ, ν denote elements in ∆ ≤ N . Then µ ≤ ν if and only if B ν ⊆ B µ .
/negationslash
Proof. First assume that µ ≤ ν . Then B ν ⊆ B µ by Lemma 9.6. Next assume that B ν ⊆ B µ . Then B ν = B µ ∩ B ν , so B µ ∩ B ν = 0. Now by Proposition 11.3 we see that µ ∨ ν exists in ∆ ≤ N , and B µ ∩ B ν = B µ ∨ ν . Therefore B ν = B µ ∨ ν . By this and Lemma 9.3, ν and µ ∨ ν have the same rank. By construction ν ≤ µ ∨ ν . By these comments ν = µ ∨ ν , so µ ≤ ν .
## 12 A characterization of Billiard Arrays using totally opposite flags
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1.
In Lemma 10.7 we encountered three flags on V that are mutually opposite. We now introduce a stronger condition involving three flags.
Definition 12.1. Suppose we are given three flags on V , denoted { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 . These flags are said to be totally opposite whenever U N -r ∩ U ′ N -s ∩ U ′′ N -t = 0 for all r, s, t (0 ≤ r, s, t ≤ N ) such that r + s + t > N .
Lemma 12.2. Referring to Definition 12.1, assume that { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 are totally opposite. Then they are mutually opposite.
Proof. Setting r = 0 (resp. s = 0) (resp. t = 0) in Definition 12.1, we find that the flags { U ′ i } N i =0 and { U ′′ i } N i =0 (resp. { U ′′ i } N i =0 and { U i } N i =0 ) (resp. { U i } N i =0 and { U ′ i } N i =0 ) are opposite.
Lemma 12.3. Referring to Definition 12.1, the following are equivalent:
- (i) the flags { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 are totally opposite;
- (ii) for 0 ≤ n ≤ N the sequences
$$\{ U _ { i } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } \cap U _ { n + i } ^ { \prime } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } \cap U _ { n + i } ^ { \prime \prime } \} _ { i = 0 } ^ { N - n } \quad \quad ( 1 4 )$$
are mutually opposite flags on U N -n ;
- (iii) for 0 ≤ n ≤ N the sequences
$$\{ U _ { i } ^ { \prime } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } ^ { \prime } \cap U _ { n + i } ^ { \prime \prime } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } ^ { \prime } \cap U _ { n + i } \} _ { i = 0 } ^ { N - n }$$
are mutually opposite flags on U ′ N -n ;
- (iv) for 0 ≤ n ≤ N the sequences
$$\{ U _ { i } ^ { \prime \prime } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } ^ { \prime \prime } \cap U _ { n + i } \} _ { i = 0 } ^ { N - n }, \quad \{ U _ { N - n } ^ { \prime \prime } \cap U _ { n + i } ^ { \prime } \} _ { i = 0 } ^ { N - n }$$
are mutually opposite flags on U ′′ N -n .
Proof. (i) ⇒ (ii) We first show that each sequence in (14) is a flag on U N -n . For the first sequence this is clear, so consider the second sequence. By construction, the subspaces { U N -n ∩ U ′ n + i } N -n i =0 are nested and contained in U N -n . For 0 ≤ i ≤ N -n the subspace U N -n ∩ U ′ n + i has dimension i + 1 by Lemmas 6.1, 12.2. Therefore the sequence { U N -n ∩ U ′ n + i } N -n i =0 is a flag on U N -n . Similarly the sequence { U N -n ∩ U ′′ n + i } N -n i =0 is a flag on U N -n . We have shown that each sequence in (14) is a flag on U N -n . We check that these three flags are mutually opposite. We show that the flags { U i } N -n i =0 and { U N -n ∩ U ′ n + i } N -n i =0 are opposite. For 0 ≤ i, j ≤ N -n such that i + j < N -n , the intersection of U i and U N -n ∩ U ′ n + j is equal to U i ∩ U ′ n + j , which is zero by Lemma 12.2. Therefore the flags { U i } N -n i =0 and { U N -n ∩ U ′ n + i } N -n i =0 are opposite. Similarly the flags { U i } N -n i =0 and { U N -n ∩ U ′′ n + i } N -n i =0 are opposite. We now show that the flags { U N -n ∩ U ′ n + i } N -n i =0 and { U N -n ∩ U ′′ n + i } N -n i =0 are opposite. For 0 ≤ i, j ≤ N -n such that i + j < N -n , the intersection of U N -n ∩ U ′ n + i and U N -n ∩ U ′′ n + j is equal to U N -n ∩ U ′ n + i ∩ U ′′ n + j , which is zero by Definition 12.1. Therefore the flags { U N -n ∩ U ′ n + i } N -n i =0 and { U N -n ∩ U ′′ n + i } N -n i =0 are opposite. By these comments the three flags in (14) are mutually opposite.
(ii) ⇒ (i) Setting n = 0 in (14) we see that the flags { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 are mutually opposite. Pick integers r, s, t (0 ≤ r, s, t ≤ N ) such that r + s + t > N . We show that U N -r ∩ U ′ N -s ∩ U ′′ N -t = 0. We may assume that r + s ≤ N (resp. s + t ≤ N ) (resp. t + r ≤ N ); otherwise U N -r ∩ U ′ N -s = 0 (resp. U ′ N -s ∩ U ′′ N -t = 0) (resp. U ′′ N -t ∩ U N -r = 0) and we are done. Define i = N - -r s and j = N - -r t . By construction 0 ≤ i, j ≤ N -r and i + j < N -r . Observe that U ′ N -s = U ′ r + i and U ′′ N -t = U ′′ r + j . Therefore U N -r ∩ U ′ N -s ∩ U ′′ N -t is the intersection of U N -r ∩ U ′ r + i and U N -r ∩ U ′′ r + j , which is zero by assumption.
The implications (i) ⇔ (iii) and (i) ⇔ (iv) are similarly obtained.
Theorem 12.4. Let B denote a Billiard Array on V , and recall the B -flags [1] , [2] , [3] on V from Definition 9.9. These flags are totally opposite.
Proof. By Proposition 11.1 and Definition 12.1.
Lemma 12.5. Suppose we are given three totally opposite flags on V , denoted { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 . Then U N -r ∩ U ′ N -s ∩ U ′′ N -t has dimension N -r -s -t + 1 for all ( r, s, t ) ∈ ∆ ≤ N .
Proof. The given flags satisfy Lemma 12.3(i), so they satisfy Lemma 12.3(ii). Therefore the sequences { U N -r ∩ U ′ r + i } N -r i =0 and { U N -r ∩ U ′′ r + i } N -r i =0 are opposite flags on U N -r . Define i = N - -r s and j = N - -r t . By construction 0 ≤ i, j ≤ N -r and i + j ≥ N -r . Observe that U ′ N -s = U ′ r + i and U ′′ N -t = U ′′ r + j . Therefore U N -r ∩ U ′ N -s ∩ U ′′ N -t is the intersection of U N -r ∩ U ′ r + i and U N -r ∩ U ′′ r + j . By Lemma 6.1 this intersection has dimension i + + j r -N +1, which is equal to N -r -s -t +1.
Corollary 12.6. Suppose we are given three totally opposite flags on V , denoted { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 . Then U N -r ∩ U ′ N -s ∩ U ′′ N -t has dimension one for all ( r, s, t ) ∈ ∆ . N
Proof. In Lemma 12.5, assume r + s + t = N
.
Theorem 12.7. Suppose we are given three totally opposite flags on V , denoted { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 . For each location λ = ( r, s, t ) in ∆ N define
$$B _ { \lambda } = U _ { N - r } \cap U _ { N - s } ^ { \prime } \cap U _ { N - t } ^ { \prime \prime }.$$
↦
Then the map B : ∆ N →P 1 ( V ) , λ → B λ is a Billiard Array on V .
Proof. The map B is well defined by Corollary 12.6. We check that B satisfies the conditions of Definition 7.1. We show that B satisfies Definition 7.1(i). Let L denote a line in ∆ N . We show that the sum ∑ λ ∈ L B λ is direct. For notational convenience, assume that L is a 1-line. Denote the cardinality of L by N -n + 1. The sum ∑ λ ∈ L B λ is direct, since the summands make up the decomposition of U N -n associated with the last two flags in (14). We have shown that B satisfies Definition 7.1(i). Next we show that B satisfies Definition 7.1(ii). Assume N ≥ 1; otherwise we are done. Pick ( r, s, t ) ∈ ∆ N -1 and let C denote the corresponding black 3-clique in ∆ N from Lemma 4.31. By construction, for all λ ∈ C the subspace B λ is contained in U N -r ∩ U ′ N -s ∩ U ′′ N -t . This space has dimension 2 by Lemma 12.5. Therefore the sum ∑ λ ∈ C B λ is not direct. We have shown that B satisfies Definition 7.1(ii). By the above comments B is a Billiard Array on V .
Proposition 12.8. Referring to Theorem 12.7, the B -flags [1] , [2] , [3] coincide with { U i } N i =0 , { U ′ i } N i =0 , { U ′′ i } N i =0 respectively.
Proof. We show that the B -flag [1] coincides with { U i } N i =0 . Denote the B -flag [1] by {U } i N i =0 . We show that U i = U i for 0 ≤ i ≤ N . Let i be given. By Lemmas 9.5(i), 9.10 the subspace U i is spanned by the subspaces B λ such that λ is a location in ∆ N at distance ≤ i from the 1-corner of ∆ N . Each such B λ is contained in U i by (15), so U i ⊆ U i . Each of U i , U i has dimension i +1 by the definition of a flag. Therefore U i = U i . We have shown that the B -flag [1] coincides with { U i } N i =0 . The remaining assertions are similarly shown.
Consider the following two sets:
- (i) the Billiard Arrays on V ;
- (ii) the 3-tuples of totally opposite flags on V .
Theorem 12.4 describes a function from (i) to (ii). Theorem 12.7 describes a function from (ii) to (i).
Theorem 12.9. The above functions are inverses. Moreover they are bijections.
Proof. The functions are inverses by Corollary 11.2 and Proposition 12.8. It follows that they are bijections.
## 13 The braces for a Billiard Array
Our next general goal is to classify the Billiard Arrays up to isomorphism. This goal will be completed in Secton 19. Throughout the present section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N + 1. Let B denote a Billiard Array on V .
Definition 13.1. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. By an affine brace (or abrace ) for this clique, we mean a set of vectors
$$u \in B _ { \lambda }, \quad \ \ v \in B _ { \mu }, \quad \ \ w \in B _ { \nu }$$
that are not all zero, and u + v + w = 0.
Example 13.2. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Pick any nonzero vectors
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }, \quad \ w \in B _ { \nu }.$$
The vectors u, v, w are linearly dependent by Definition 7.1(ii). So there exist scalars a, b, c in F that are not all zero and au + bv + cw = 0. The vectors au, bv, cw form an abrace for the clique.
We have a few comments about abraces.
Lemma 13.3. Referring to Definition 13.1, assume that u, v, w form an abrace. Then each of u, v, w is nonzero. Moreover any two of u, v, w are linearly independent.
Proof. If at least one of u, v, w is zero then the other two are opposite and nonzero, contradicting the last assertion of Lemma 7.3. Therefore each of u, v, w is nonzero. By this and the last assertion of Lemma 7.3, we find that any two of u, v, w are linearly independent.
Lemma 13.4. Referring to Definition 13.1, assume that u, v, w form an abrace. Let a, b, c denote scalars in F such that au + bv + cw = 0 . Then a = b = c .
Proof. Using u + v + w = 0 we obtain ( b -a v ) +( c -a w ) = 0. The vectors v, w are linearly independent so b -a and c -a are zero.
/negationslash
Lemma 13.5. Referring to Definition 13.1, assume that u, v, w form an abrace. Then for 0 = δ ∈ F the vectors δu, δv, δw form an abrace.
Proof. By Definition 13.1.
Lemma 13.6. Referring to Definition 13.1, assume that u, v, w form an abrace. Then for any abrace
$$u ^ { \prime } \in B _ { \lambda }, \quad \ v ^ { \prime } \in B _ { \mu }, \quad \ w ^ { \prime } \in B _ { \nu }$$
/negationslash there exists 0 = δ ∈ F such that
$$u ^ { \prime } = \delta u, \quad \ v ^ { \prime } = \delta v, \quad \ w ^ { \prime } = \delta w.$$
Proof. By (16) and since u, v, w are nonzero, we see that u, v, w are bases for B λ , B µ , B ν respectively. Therefore there exist scalars a, b, c in F such that
$$u ^ { \prime } = a u, \quad \ v ^ { \prime } = b v, \quad \ w ^ { \prime } = c w.$$
Now au + bv + cw = u ′ + v ′ + w ′ = 0 so a = b = c by Lemma 13.4. Let δ denote this common value and observe that δ satisfies the requirements of the lemma.
Lemma 13.7. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then each nonzero u ∈ B λ is contained in a unique abrace for this clique.
Proof. Concerning existence, pick nonzero vectors v ∈ B µ and w ∈ B ν . By Example 13.2 there exist scalars a, b, c in F such that au, bv, cw is an abrace. The scalars a, b, c are nonzero by Lemma 13.3. Now by construction the vectors u, ba -1 v, ca -1 w form an abrace that contains u . The abrace containing u is unique by Lemma 13.6.
Definition 13.8. Let λ, µ denote locations in ∆ N that form an edge. By Lemma 4.33 there exists a unique location ν ∈ ∆ N such that λ, µ, ν form a black 3-clique. We call ν the completion of the edge.
Definition 13.9. Let λ, µ denote locations in ∆ N that form an edge. By a brace for this edge, we mean a set of nonzero vectors
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }$$
such that u + v ∈ B ν . Here ν denotes the completion of the edge.
Lemma 13.10. Referring to Definition 13.1, assume that u, v, w form an abrace. Then u, v form a brace for the edge λ, µ .
Proof. The vectors u, v are nonzero by Lemma 13.3. Moreover u + v = -w ∈ B ν . The result follows in view of Definition 13.9.
Lemma 13.11. Referring to Definition 13.9, assume that u, v form a brace, and define w = -u -v . Then u, v, w form an abrace for the black 3-clique λ, µ, ν .
Proof. By Definitions 13.1 and 13.9.
Lemma 13.12. Let λ, µ denote locations in ∆ N that form an edge. Each nonzero u ∈ B λ is contained in a unique brace for this edge.
Proof.
By Lemmas 13.10, 13.11 together with Lemma 13.7.
## 14 The maps ˜ Bλ,µ and the value function ˆ B
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1. Let B denote a Billiard Array on V .
Definition 14.1. Let λ, µ denote adjacent locations in ∆ . N We define an F -linear map ˜ B λ,µ : B λ → V as follows. For each brace
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }$$
↦
the map ˜ B λ,µ sends u → v . The map ˜ B λ,µ is well defined by Lemma 13.12.
Note 14.2. Let λ, µ denote adjacent locations in ∆ N . By Definition 14.1, B µ is the image of B λ under ˜ B λ,µ . Consequently we sometimes view ˜ B λ,µ as a bijection ˜ B λ,µ : B λ → B µ .
The following definition is for notational convenience.
Definition 14.3. Define ˜ B λ,µ = 0 for all λ, µ ∈ R 3 such that λ / ∈ ∆ N or µ / ∈ ∆ . N
Lemma 14.4. Let λ, µ denote adjacent locations in ∆ N . For vectors u ∈ B λ and v ∈ B µ the following are equivalent:
- (i) the vectors u, v form a brace;
/negationslash
- (ii) the vector u = 0 and the map ˜ B λ,µ sends u → v ;
↦
/negationslash
- (iii) the vector v = 0 and the map ˜ B µ,λ sends v → u .
↦
Proof. By Definition 14.1.
Lemma 14.5. Let λ, µ denote adjacent locations in ∆ N . Then the maps ˜ B λ,µ : B λ → B µ and ˜ B µ,λ : B µ → B λ are inverses.
$$P r o o f. \text{ Compare parts (ii), (iiii) of Lemma 14.4.}$$
Lemma 14.6. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Pick an abrace
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }, \quad \ w \in B _ { \nu }.$$
Then
↦
$$\frac { \text{ the map} } { \text{sends} } \left | \begin{array} { c c } \tilde { B } _ { \lambda, \mu } & \tilde { B } _ { \mu, \lambda } \\ u \mapsto v & v \mapsto u \end{array} \right | \begin{array} { c c } \tilde { B } _ { \mu, \nu } & \tilde { B } _ { \nu, \mu } \\ v \mapsto w & w \mapsto v \end{array} \right | \begin{array} { c c } \tilde { B } _ { \nu, \lambda } & \tilde { B } _ { \lambda, \nu } \\ w \mapsto u & u \mapsto w \end{array} \right |$$
↦
↦
↦
↦
↦
Proof. By Lemma 13.10 and Lemma 14.4.
Lemma 14.7. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then on B λ ,
$$I + \tilde { B } _ { \lambda, \mu } + \tilde { B } _ { \lambda, \nu } = 0.$$
Proof. Use Definition 13.1 and Lemma 14.6.
Lemma 14.8. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then the composition
$$B _ { \lambda } \, \underset { \tilde { B } _ { \lambda, \mu } } { \longrightarrow } \, B _ { \mu } \, \underset { \tilde { B } _ { \mu, \nu } } { \longrightarrow } \, B _ { \nu } \, \underset { \tilde { B } _ { \nu, \lambda } } { \longrightarrow } \, B _ { \lambda }$$
is equal to the identity map on B λ .
Proof. Use Lemma 14.6.
Definition 14.9. Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. Then the composition
$$B _ { \lambda } \, \xrightarrow { \tilde { B } _ { \lambda, \mu } } \, B _ { \mu } \, \xrightarrow { \tilde { B } _ { \mu, \nu } } \, B _ { \nu } \, \xrightarrow { \tilde { B } _ { \nu, \lambda } } \, B _ { \lambda }$$
is a nonzero scalar multiple of the identity map on B λ . The scalar is called the clockwise B -value (resp. counterclockwise B -value ) of the clique whenever the sequence λ, µ, ν runs clockwise (resp. counterclockwise) around the clique.
Lemma 14.10. For each white 3-clique in ∆ N , its clockwise B -value and counterclockwise B -value are reciprocal.
Proof. By Lemma 14.5 and Definition 14.9.
Definition 14.11. For each white 3-clique in ∆ N , by its B -value we mean its clockwise B -value.
Definition 14.12. By a value function on ∆ N we mean a function ψ : ∆ N → \{ } F 0 .
Definition 14.13. Assume N ≥ 2. We define a function ˆ B : ∆ N -2 → F as follows. Pick ( r, s, t ) ∈ ∆ N -2 . To describe the image of ( r, s, t ) under ˆ , B consider the corresponding white 3-clique in ∆ N from Lemma 4.32. The B -value of this 3-clique is the image of ( r, s, t ) under ˆ . B Observe that ˆ is a value function on ∆ B N -2 , in the sense of Definition 14.12. We call ˆ B the value function for B .
↦
We are going to show that for N ≥ 2 the map B → ˆ B induces a bijection from the set of isomorphism classes of Billiard Arrays over F that have diameter N , to the set of value functions on ∆ N -2 . The proof of this result will be completed in Section 19.
## 15 The scalars ˜ B λ,µ
Throughout this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N + 1. Let B denote a Concrete Billiard Array on V . Let B denote the corresponding Billiard Array on V , from Definition 8.3.
↦
Definition 15.1. Let λ, µ denote adjacent locations in ∆ N . Recall the bijection ˜ B λ,µ : B λ → B µ . Recall that B λ is a basis for B λ and B µ is a basis for B µ . Define a scalar ˜ B λ,µ ∈ F such that ˜ B λ,µ sends B λ →B ˜ λ,µ B µ . Note that ˜ B λ,µ = 0.
/negationslash
↦
Lemma 15.2. For all λ ∈ ∆ N let κ λ denote a nonzero scalar in F . Consider the Concrete Billiard Array B ′ : ∆ N → V , λ → κ λ B λ . Then for all adjacent λ, µ in ∆ N ,
$$\tilde { \mathcal { B } } _ { \lambda, \mu } \kappa _ { \lambda } = \tilde { \mathcal { B } } ^ { \prime } _ { \lambda, \mu } \kappa _ { \mu }.$$
↦
Proof. By Definition 15.1 the map ˜ B λ,µ sends B λ → B ˜ λ,µ B µ and B ′ λ → B ˜ ′ λ,µ B ′ µ . Compare these using B ′ λ = κ λ B λ and B ′ µ = κ µ B µ .
↦
We mention a special case of Lemma 15.2.
/negationslash
↦
Lemma 15.3. Pick 0 = κ ∈ F and consider the Concrete Billiard Array B ′ : ∆ N → V , λ → B κ λ . Then ˜ B λ,µ = ˜ B ′ λ,µ for all adjacent λ, µ in ∆ N .
Lemma 15.4. Let λ, µ denote adjacent locations in ∆ N . Then the scalars ˜ B λ,µ and ˜ B µ,λ are reciprocal.
Proof. By Lemma 14.5 and Definition 15.1.
Lemma 15.5. Let λ, µ denote adjacent locations in ∆ N . Then the following are equivalent:
- (i) the vectors B λ , B µ form a brace for B ;
- (ii) ˜ B λ,µ = 1;
$$( \text{ii} ) \ \tilde { \mathcal { B } } _ { \mu, \lambda } = 1.$$
Proof.
$$P r o o f. \ B y \, L e m m a \, 1 4. 4 \, \text{ and Definition } 1 5. 1.$$
Lemma 15.6. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then
$$\mathcal { B } _ { \lambda } + \tilde { \mathcal { B } } _ { \lambda, \mu } \mathcal { B } _ { \mu } + \tilde { \mathcal { B } } _ { \lambda, \nu } \mathcal { B } _ { \nu } = 0.$$
Proof. Use Lemma 14.7 and Definition 15.1.
We now consider the linear dependency (18) from a slightly more general point of view. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. By Definition 8.1(ii) the vectors B λ , B µ , B ν are linearly dependent. Therefore there exist scalars a, b, c in F that are not all zero, and
$$a \mathcal { B } _ { \lambda } + b \mathcal { B } _ { \mu } + c \mathcal { B } _ { \nu } = 0.$$
By Definition 13.1 the vectors a B λ , b B µ , c B ν form an abrace for the given black 3-clique. Each of a, b, c is nonzero by Lemma 13.3.
Lemma 15.7. With the above notation,
$$\tilde { \mathcal { B } } _ { \lambda, \mu } & = b / a, \quad \tilde { \mathcal { B } } _ { \mu, \nu } = c / b, \quad \tilde { \mathcal { B } } _ { \nu, \lambda } = a / c, \\ \tilde { \mathcal { B } } _ { \mu, \lambda } & = a / b, \quad \tilde { \mathcal { B } } _ { \nu, \mu } = b / c, \quad \tilde { \mathcal { B } } _ { \lambda, \nu } = c / a.$$
Proof. To obtain the first and last equation, compare (18), (19) in light of Lemma 8.4. The remaining equations are obtained from these by cyclically permuting the roles of λ, µ, ν .
Lemma 15.8. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then
$$\tilde { \mathcal { B } } _ { \lambda, \mu } \tilde { \mathcal { B } } _ { \mu, \nu } \tilde { \mathcal { B } } _ { \nu, \lambda } = 1.$$
Proof. Use Lemma 14.8 and Definition 15.1, or use Lemma 15.7.
Lemma 15.9. Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. Then the clockwise (resp. counterclockwise) B -value of the clique is equal to
$$\tilde { \mathcal { B } } _ { \lambda, \mu } \tilde { \mathcal { B } } _ { \mu, \nu } \tilde { \mathcal { B } } _ { \nu, \lambda }$$
whenever the sequence λ, µ, ν runs clockwise (resp. counterclockwise) around the clique.
$$P r o o f. \ U s e \ D e f i n i t i o n s \, 1 4. 9, \, 1 5. 1.$$
## 16 Edge-labellings of ∆ N
Throughout this section fix N ∈ N .
Definition 16.1. By an edge-labelling of ∆ N we mean a function β that assigns to each ordered pair λ, µ of adjacent locations in ∆ N a scalar β λ,µ ∈ F such that:
- (i) for adjacent locations λ, µ in ∆ N ,
$$\beta _ { \lambda, \mu } \beta _ { \mu, \lambda } = 1 ;$$
- (ii) for locations λ, µ, ν in ∆ N that form a black 3-clique,
$$\beta _ { \lambda, \mu } \beta _ { \mu, \nu } \beta _ { \nu, \lambda } = 1.$$
Lemma 16.2. Let B denote a Concrete Billiard Array over F that has diameter N . Define a function ˜ B that assigns to each ordered pair λ, µ of adjacent locations in ∆ N the scalar ˜ B λ,µ from Definition 15.1. Then ˜ B is an edge-labelling of ∆ N .
Proof. The function ˜ satisfies B the conditions (i), (ii) of Definition 16.1 by Lemmas 15.4, 15.8, respectively.
For the rest of this section the following notation is in effect. Let β denote an edge-labelling of ∆ N . Let V denote a vector space over F that has dimension N +1.
Our next goal is to describe the Concrete Billiard Arrays B on V such that β = ˜ . B
/negationslash
Lemma 16.3. For adjacent locations λ, µ in ∆ N we have β λ,µ = 0 .
Proof.
$$\L o f. \ B y \text{ Definition } 1 6. 1 ( i ).$$
↦
Definition 16.4. A function B : ∆ N → V , λ →B λ is said to be β -dependent whenever
$$\mathcal { B } _ { \lambda } + \beta _ { \lambda, \mu } \mathcal { B } _ { \mu } + \beta _ { \lambda, \nu } \mathcal { B } _ { \nu } = 0$$
for all locations λ, µ, ν in ∆ N that form a black 3-clique.
Lemma 16.5. Let B denote a Concrete Billiard Array on V . Then B is β -dependent if and only if β = ˜ B .
Proof. Compare (18), (20) in light of Lemma 8.4.
↦
Let B : ∆ N → V , λ →B λ denote a β -dependent function. Let λ, µ, ν denote locations in ∆ N that form a black 3-clique. Then the vectors B λ , B µ , B ν satisfy (20). Cyclically permuting the roles of λ, µ, ν we obtain
$$\mathcal { B } _ { \lambda } + \beta _ { \lambda, \mu } \mathcal { B } _ { \mu } + \beta _ { \lambda, \nu } \mathcal { B } _ { \nu } = 0,$$
$$\beta _ { \mu, \lambda } \mathcal { B } _ { \lambda } + \mathcal { B } _ { \mu } + \beta _ { \mu, \nu } \mathcal { B } _ { \nu } = 0,$$
$$\beta _ { \nu, \lambda } \mathcal { B } _ { \lambda } + \beta _ { \nu, \mu } \mathcal { B } _ { \mu } + \mathcal { B } _ { \nu } = 0.$$
The linear dependencies (21)-(23) are essentially the same. To see this, consider the coefficient matrix
$$\vdots \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nolimits \\ \vdots \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \Delta \nu \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \gamma \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \coprod \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \colon \alpha \coprod \colon \colon \colon \colon \colon \colon \colon \colon \col. \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \beta \colon \gamma \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \tag \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \exponent \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \exponent \colon \colon \colon \colon \colon \colon \colon \colon \colon \exponent \colon \colon \colon \colon \colon \colon \exponent \colon \colon \colon \exponent \colon \colon \colon \exponent \colon \colon \exponent \colon \colon \exponent \colon \colon \exponent \colon \exponent \colon \exponent \colon \colon \exponent \colon \exponent \colon \colon \exponent \colon \colon \exponent \colon \exponent \colon \colon \exponent \colon \colon \exponent \colon \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \clon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \exponent \colon \$$
Using Definition 16.1 one checks that this matrix has rank 1.
↦
Lemma 16.6. Assume N ≥ 1 . For a function B : ∆ N → V , λ →B λ the following (i), (ii) are equivalent:
- (i) B is β -dependent;
- (ii) for all ( r, s, t ) ∈ ∆ N -1 we have
$$\mathcal { B } _ { \lambda } + \beta _ { \lambda, \mu } \mathcal { B } _ { \mu } + \beta _ { \lambda, \nu } \mathcal { B } _ { \nu } = 0,$$
where
$$\lambda = ( r + 1, s, t ), \quad \mu = ( r, s + 1, t ), \quad \nu = ( r, s, t + 1 ).$$
Proof. By Lemma 4.31 and Definition 16.4, along with the discussion around (24).
Given a β -dependent function B : ∆ N → V, λ → B λ , using the dependencies (25) we can solve for {B } λ λ ∈ ∆ N in terms of {B } λ λ ∈ L , where L denotes the 1-boundary of ∆ N . We give the details after a few definitions.
/negationslash
Definition 16.7. For each walk ω = { λ i } n i =0 in ∆ N we define the scalar β ω = ∏ n i =1 β λ i -1 ,λ i called the β -value of ω . Note that β ω = 0 by Lemma 16.3. We interpret β ω = 1 if n = 0.
Lemma 16.8. For any walk ω in ∆ N the following scalars are reciprocal:
- (i) the β -value for ω ;
- (ii) the β -value for the inversion of ω .
Proof. By Definition 16.1(i) and Definition 16.7.
Definition 16.9. For λ, µ ∈ ∆ N we define the scalar
$$\beta _ { \lambda, \mu } = \sum _ { \omega } \beta _ { \omega },$$
where the sum is over all geodesic paths ω in ∆ N from λ to µ .
/negationslash
Note 16.10. Let λ, µ denote collinear locations in ∆ N . By Lemma 4.20 there exists a unique geodesic path ω in ∆ N from λ to µ . Now β λ,µ = β ω in view of Definition 16.9. In this case β λ,µ = 0.
Recall the path [2 , 3] in ∆ N , from Definition 4.21 and Lemma 4.23. This path runs along the 1-boundary of ∆ N , from the 2-corner to the 3-corner.
↦
↦
Proposition 16.11. Let { λ i } N i =0 denote the path [2 , 3] in ∆ N . Let { v i } N i =0 denote arbitrary vectors in V . Then there exists a unique β -dependent function B : ∆ N → V, λ → B λ that sends λ i → v i for 0 ≤ i ≤ N . For λ = ( r, s, t ) in ∆ N we have
$$\mathcal { B } _ { \lambda } = ( - 1 ) ^ { r } \sum _ { i = t } ^ { r + t } \beta _ { \lambda, \lambda _ { i } } v _ { i }.$$
↦
↦
↦
Proof. We first show that B exists. We define the vectors {B } λ λ ∈ ∆ N in the following recursive way. For ξ = 0 1 , , . . . , N we define B λ for those locations λ ∈ ∆ N that have 1-coordinate ξ . Let ξ and λ be given. First assume ξ = 0, so that λ is on the 1-boundary of ∆ N . Define B λ = v i where λ = λ i . Next assume 1 ≤ ξ ≤ N . For notational convenience define r = ξ -1 and write λ = ( r +1 , s, t ). Consider the locations µ = ( r, s +1 , t ) and ν = ( r, s, t +1) in ∆ N . The locations λ, µ, ν form a black 3-clique. Each of µ, ν has 1-coordinate r , so the vectors B µ and B ν were defined earlier in the recursion. Define B λ so that (25) holds. The vectors {B } λ λ ∈ ∆ N are now defined. Consider the function B : ∆ N → V , λ →B λ . By construction B satisfies condition (ii) of Lemma 16.6, so by that lemma B is β -dependent. By construction B sends λ i → v i for 0 ≤ i ≤ N . We have shown that B exists. Now let B : ∆ N → V, λ →B λ denote any β -dependent function that sends λ i → v i for 0 ≤ i ≤ N . Then B satisfies the equivalent conditions (i), (ii) of Lemma 16.6. In condition (ii) there is a parameter r ; using condition (ii) and induction on r one routinely obtains (27). It follows from (27) that B is unique.
Proposition 16.12. With reference to Proposition 16.11, the following are equivalent:
- (i) B is a Concrete Billiard Array;
- (ii) the vectors { v i } N i =0 are linearly independent.
Proof. (i) ⇒ (ii) By Definition 8.1(i) and since { λ i } N i =0 form a line in ∆ N .
(ii) ⇒ (i) We show that B satisfies the conditions of Definition 8.1. Concerning Definition 8.1(i), let L denote a line in ∆ N . Pick a location λ = ( r, s, t ) in L and consider the sum in line (27). In that sum, by Note 16.10 the coefficient of v i is nonzero for i = t and i = r + . t Therefore the vectors {B } λ λ ∈ L are linearly independent. We have shown that B satisfies Definition 8.1(i). The function B satisfies Definition 8.1(ii), since for each black 3-clique C in ∆ N the vectors {B } λ λ ∈ C are linearly dependent by (20). We have shown that B satisfies the conditions of Definition 8.1, so B is a Concrete Billiard Array.
We give two variations on Propositions 16.11, 16.12.
↦
Proposition 16.13. Let { λ i } N i =0 denote the path [2 , 3] in ∆ N . Then for any function B : ∆ N → V , λ →B λ the following (i), (ii) are equivalent:
- (i) B is a Concrete Billiard Array and β = ˜ B ;
- (ii) B is β -dependent and {B λ i } N i =0 are linearly independent.
Proof. (i) ⇒ (ii) The function B is β -dependent by Lemma 16.5. The vectors {B λ i } N i =0 are linearly independent by Definition 8.1(i).
↦
- (ii) ⇒ (i) Define v i = B λ i for 0 ≤ i ≤ N . By assumption, the function B is β -dependent and sends λ i → v i for 0 ≤ i ≤ N . Therefore B meets the requirements of Proposition 16.11. By assumption, the vectors { v i } N i =0 are linearly independent. Now B is a Concrete Billiard Array in view of Proposition 16.12. We have β = ˜ by Lemma 16.5. B
Proposition 16.14. Let { v i } N i =0 denote a basis for V . Then there exists a unique Concrete Billiard Array B on V such that β = ˜ B and { v i } N i =0 is the B -basis [2 , 3] .
↦
↦
↦
↦
Proof. Let { λ i } N i =0 denote the path [2 , 3] in ∆ N . We first show that B exists. By Proposition 16.11 there exists a β -dependent function B : ∆ N → V , λ → B λ that sends λ i → v i for 0 ≤ i ≤ N . By construction B satisfies condition (ii) of Proposition 16.13. By that proposition B is a Concrete Billiard Array and β = ˜ . B By construction { v i } N i =0 is the B -basis [2 , 3]. We have shown that B exists. Concerning uniqueness, let B denote any Concrete Billiard Array on V such that β = ˜ and B { v i } N i =0 is the B -basis [2 , 3]. Then B is β -dependent by Proposition 16.13. By construction the function B sends λ i → v i for 0 ≤ i ≤ N . Therefore B meets the requirements of Proposition 16.11. By that proposition B is unique.
↦
Corollary 16.15. Let B : ∆ N → V, λ → B λ denote a β -dependent function. Then B is a Concrete Billiard Array if and only if the vectors {B } λ λ ∈ ∆ N span V .
Proof. First assume that B is a Concrete Billiard Array. Then the vectors {B } λ λ ∈ ∆ N span V by Corollary 8.7. Conversely, assume that the vectors {B } λ λ ∈ ∆ N span V . Let { λ i } N i =0 denote the path [2 , 3] in ∆ N and define v i = B λ i for 0 ≤ i ≤ N . By Proposition 16.11 the vectors {B } λ λ ∈ ∆ N are contained in the span of { v i } N i =0 . Therefore the vectors { v i } N i =0 span V . The dimenension of V is N +1 so { v i } N i =0 are linearly independent. Now B is a Concrete Billiard Array by Proposition 16.12.
## 17 Concrete Billiard Arrays and edge-labellings
Throughout this section fix N ∈ N .
Let B denote a Concrete Billiard Array over F that has diameter N . Recall from Lemma 16.2 the edge-labelling ˜ of ∆ B N .
Proposition 17.1. With the above notation, the map B ↦→ B ˜ induces a bijection between the following two sets:
- (i) the isomorphism classes of Concrete Billiard Arrays over F that have diameter N ;
- (ii) the edge-labellings of ∆ N .
↦
↦
Proof. The map B ↦→ B ˜ induces a function from set (i) to set (ii), and this function is surjective by Proposition 16.14. We now show that the function is injective. Let B B , ′ denote Concrete Billiard Arrays over F that have diameter N and ˜ = B ˜ . B ′ We show that B B , ′ are isomorphic. Let V (resp. V ′ ) denote the vector space underlying B (resp. B ′ ). Let { v i } N i =0 denote the B -basis [2 , 3] for V , and let { v ′ i } N i =0 denote the B ′ -basis [2 , 3] for V ′ . Consider the F -linear bijection σ : V → V ′ that sends v i → v ′ i for 0 ≤ i ≤ N . For λ = ( r, s, t ) in ∆ N the vector B λ satisfies (27), where β = ˜ = B ˜ . B ′ Applying σ to each side of (27) we see that σ sends B λ →B ′ λ . So by Definition 8.15, σ is an isomorphism of Concrete Billiard Arrays from B to B ′ . Consequently B B , ′ are isomorphic, as desired. The result follows.
Lemma 17.2. Let β denote an edge-labelling of ∆ N . Let { κ λ } λ ∈ ∆ N denote nonzero scalars in F . Then there exists an edge-labelling β ′ of ∆ N such that β λ,µ κ λ = β ′ λ,µ κ µ for all adjacent λ, µ in ∆ N .
Proof. For all adjacent λ, µ ∈ ∆ N define β ′ λ,µ = β λ,µ κ /κ λ µ . One checks that β ′ is an edgelabelling of ∆ N with the required features.
Definition 17.3. Edge-labellings β, β ′ of ∆ N are called similar whenever there exist nonzero scalars { κ λ } λ ∈ ∆ N in F such that β λ,µ κ λ = β ′ λ,µ κ µ for all adjacent λ, µ in ∆ N . This similarity relation is an equivalence relation.
Example 17.4. Assume N = 1. Then any two edge-labellings of ∆ N are similar.
Lemma 17.5. Let B and B ′ denote Concrete Billiard Arrays over F that have diameter N . Then the following are equivalent:
- (i) B and B ′ are similar in the sense of Definition 8.17;
- (ii) the edge-labellings ˜ B and ˜ B ′ are similar in the sense of Definition 17.3.
↦
Proof. (i) ⇒ (ii) By Proposition 8.20 there exists a Concrete Billiard Array B ′′ over F that is associated with B and isomorphic to B ′ . By Definition 8.10 there exist nonzero scalars { κ λ } λ ∈ ∆ N in F such that B ′′ λ = κ λ B λ for all λ ∈ ∆ . N For all adjacent λ, µ ∈ ∆ N we have ˜ B λ,µ κ λ = ˜ B ′′ λ,µ κ µ by Lemma 15.2, and ˜ B ′′ λ,µ = ˜ B ′ λ,µ by Proposition 17.1, so ˜ B λ,µ κ λ = ˜ B ′ λ,µ κ µ . Now ˜ and B ˜ B ′ are similar in the sense of Definition 17.3. (ii) ⇒ (i) By Definition 17.3 there exist nonzero scalars { κ λ } λ ∈ ∆ N in F such that ˜ B λ,µ κ λ = ˜ B ′ λ,µ κ µ for all adjacent λ, µ in ∆ N . Let B ′′ denote the Concrete Billiard Array over F that sends λ → κ λ B λ for all λ ∈ ∆ . Then N B ′′ is associated with B . For all adjacent λ, µ ∈ ∆ N we have ˜ B λ,µ κ λ = ˜ B ′′ λ,µ κ µ by Lemma 15.2, so ˜ B ′ λ,µ = ˜ B ′′ λ,µ . Therefore B ′ , B ′′ are isomorphic by Proposition 17.1. The Concrete Billiard Array B ′′ is associated with B and isomorphic to B ′ . Now by Proposition 8.20, B and B ′ are similar in the sense of Definition 8.17.
The following result is a variation on Proposition 17.1.
Proposition 17.6. The map B ↦→ B ˜ induces a bijection between the following two sets:
- (i) the similarity classes of Concrete Billiard Arrays over F that have diameter N ;
- (ii) the similarity classes of edge-labellings for ∆ N .
Proof. By Proposition 17.1 and Lemma 17.5.
## 18 Edge-labellings and value functions
Throughout this section fix N ∈ N .
For this section our goal is to describe the similarity classes of edge-labellings for ∆ N . Note that if N = 0 then ∆ N has no edges. If N = 1 then by Example 17.4, any two edge-labellings of ∆ N are similar. For N ≥ 2 we will display a bijection between the following two sets: (i) the similarity classes of edge-labellings for ∆ N ; (ii) the value functions on ∆ N -2 .
Definition 18.1. Let β denote an edge-labelling of ∆ N . Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. Then the scalar
$$\beta _ { \lambda, \mu } \beta _ { \mu, \nu } \beta _ { \nu, \lambda }$$
is called the clockwise β -value (resp. counterclockwise β -value ) of the clique whenever the sequence λ, µ, ν runs clockwise (resp. counterclockwise) around the clique.
Lemma 18.2. Let β denote an edge-labelling of ∆ N . For each white 3-clique in ∆ N , its clockwise β -value and counterclockwise β -value are reciprocal.
Proof.
$$P r o o f. \text{ By Definition 16.1(i) and Definition 18.1.}$$
Definition 18.3. Let β denote an edge-labelling of ∆ N . For each white 3-clique in ∆ N , by its β -value we mean its clockwise β -value.
Definition 18.4. Assume N ≥ 2, and let β denote an edge-labelling of ∆ N . We define a function ˆ : ∆ β N -2 → F as follows. Pick ( r, s, t ) ∈ ∆ N -2 . To describe the image of ( r, s, t ) under ˆ , β consider the corresponding white 3-clique in ∆ N from Lemma 4.32. The β -value of this 3-clique is the image of ( r, s, t ) under ˆ . β Note that ˆ is a value function on ∆ β N -2 , in the sense of Definition 14.12. We call ˆ the β value function for β .
Lemma 18.5. Let B denote a Concrete Billiard Array over F that has diameter N . Let B denote the corresponding Billiard Array. Then for each white 3-clique in ∆ N the B -value is equal to the ˜ B -value. In other words, B and ˜ B have the same value function.
Proof. Compare Lemma 15.9 and Definition 18.1.
Proposition 18.6. Let β denote an edge-labelling of ∆ N . Given a cycle in ∆ N that runs clockwise (resp. counterclockwise), consider the white 3-cliques that are surrounded by the cycle. Then the following scalars coincide:
- (i) the β -value of the cycle, in the sense of Definition 16.7;
- (ii) the product of the clockwise (resp. counterclockwise) β -values for these white 3-cliques.
Proof. Use Definitions 16.1, 16.7, 18.1.
Let β denote an edge-labelling of ∆ N . Let T denote a spanning tree of ∆ N , as in Definition 4.27. Consider the scalars
$$\beta _ { \lambda, \mu } \quad \lambda, \mu \in \Delta _ { N }, \quad \lambda, \mu \text{ form an edge in } T.$$
For adjacent λ, µ ∈ ∆ N we now compute β λ,µ in terms of (28) and the value function ˆ . β First assume that the edge formed by λ, µ is in T . Then β λ,µ is included in (28), so we are done. Next assume that the edge formed by λ, µ is not in T . There exists a unique path in ∆ N from µ to λ that involves only edges in T . Denote this path by { λ i } n i =1 . By construction λ 1 = µ and λ n = λ . Define λ 0 = λ and note that { λ i } n i =0 is a cycle in ∆ N . Apply Proposition 18.6 to this cycle. For this cycle, the scalar in Proposition 18.6(i) is equal to ∏ n i =1 β λ i -1 ,λ i , and
the scalar in Proposition 18.6(ii) is determined by ˆ . β Therefore ∏ n i =1 β λ i -1 ,λ i is determined by ˆ . β In the product ∏ n i =1 β λ i -1 ,λ i consider the i -factor for 1 ≤ i ≤ n . This i -factor is β λ,µ for i = 1, and is included in (28) for 2 ≤ i ≤ n . Using these comments we routinely solve for β λ,µ in terms of (28) and ˆ . β
The scalars (28) are 'free' in the following sense.
Proposition 18.7. Assume N ≥ 2 , and let ψ denote a value function on ∆ N -2 . Let T denote a spanning tree of ∆ N . Consider a collection of scalars
$$b _ { \lambda, \mu } \in \mathbb { F }, \quad \lambda, \mu \in \Delta _ { N }, \quad \lambda, \mu \text{ form an edge in } T$$
such that b λ,µ b µ,λ = 1 for all λ, µ ∈ ∆ N that form an edge in T . Then there exists a unique edge-labelling β of ∆ N that has value function ψ and β λ,µ = b λ,µ for all λ, µ ∈ ∆ N that form an edge in T .
Proof. We first show that β exists. To do this we mimic the argument from below (28). For adjacent λ, µ ∈ ∆ N we define a scalar β λ,µ as follows. First assume that the edge formed by λ, µ is in T . Define β λ,µ = b λ,µ . Next assume that the edge formed by λ, µ is not in T . There exists a unique path in ∆ N from µ to λ that involves only edges in T . Denote this path by { λ i } n i =1 . By construction λ 1 = µ and λ n = λ . Define λ 0 = λ and note that { λ i } n i =0 is a cycle in ∆ N . Define ε = 1 (resp. ε = -1) if this cycle is clockwise (resp. counterclockwise). Define β λ,µ = c /d ε where d = ∏ n i =2 b λ i -1 ,λ i and c is the product of the ψ -values of the white 3-cliques surrounded by the cycle. We have defined the scalar β λ,µ for all adjacent λ, µ ∈ ∆ . N One checks that these scalars satisfy the conditions of Definition 16.1. This gives an edgelabelling β of ∆ N . By construction β has value function ψ and β λ,µ = b λ,µ for all λ, µ ∈ ∆ N that form an edge in T . We have shown that β exists. The edge-labelling β is unique by the discussion below (28).
Corollary 18.8. Assume N ≥ 2 , and let ψ denote a value function on ∆ N -2 . Let T denote a spanning tree of ∆ N . Then there exists a unique edge-labelling β of ∆ N that has value function ψ and β λ,µ = 1 for all λ, µ ∈ ∆ N that form an edge in T .
Proof. Apply Proposition 18.7, with b λ,µ = 1 for all λ, µ ∈ ∆ N that form an edge in T .
↦
Assume N ≥ 2. By Definition 18.4 we get a map β → ˆ from the set of edge-labellings of β ∆ , to the set of value functions on ∆ N N -2 . This map is surjective by Corollary 18.8. We now consider the issue of injectivity.
Lemma 18.9. Assume N ≥ 2 . Let β and β ′ denote edge-labellings of ∆ N . Then the following are equivalent:
- (i) β and β ′ are similar;
- (ii) β and β ′ have the same value function.
Proof. (i) ⇒ (ii) Let λ, µ, ν denote locations in ∆ N that form a white 3-clique. We show that
$$\beta _ { \lambda, \mu } \beta _ { \mu, \nu } \beta _ { \nu, \lambda } = \beta ^ { \prime } _ { \lambda, \mu } \beta ^ { \prime } _ { \mu, \nu } \beta ^ { \prime } _ { \nu, \lambda }.$$
By Definition 17.3 there exist nonzero κ , κ λ µ , κ ν ∈ F such that
$$\beta _ { \lambda, \mu } \kappa _ { \lambda } = \beta ^ { \prime } _ { \lambda, \mu } \kappa _ { \mu }, \quad \beta _ { \mu, \nu } \kappa _ { \mu } = \beta ^ { \prime } _ { \mu, \nu } \kappa _ { \nu }, \quad \beta _ { \nu, \lambda } \kappa _ { \nu } = \beta ^ { \prime } _ { \nu, \lambda } \kappa _ { \lambda }.$$
Line (30) is routinely verified using (31).
/negationslash
(ii) ⇒ (i) Let T denote a spanning tree of ∆ N . Fix a location ν ∈ ∆ . For N λ ∈ ∆ N (and with reference to Definition 16.7) define κ λ = β /β ′ ω ω where ω denotes the unique path in ∆ N from λ to ν that involves only edges in T . Note that κ λ = 0. Using Proposition 18.6 one checks that β λ,µ κ λ = β ′ λ,µ κ µ for all adjacent λ, µ in ∆ N . Therefore β, β ′ are similar in view of Definition 17.3.
Assume N ≥ 2, and let β denote an edge-labelling of ∆ N . Recall from Definition 18.4 the value function ˆ on ∆ β N -2 .
↦
Proposition 18.10. With the above notation, the map β → ˆ β induces a bijection between the following two sets:
- (i) the similarity classes of edge-labellings for ∆ N ;
- (ii) the value functions on ∆ N -2 .
↦
Proof. By Lemma 18.9 the map β → ˆ induces an injective function from set (i) to set (ii). β The function is surjective by Corollary 18.8. Therefore the function is a bijection.
## 19 Billiard Arrays and value functions
From now until Proposition 19.3, fix an integer N ≥ 2.
↦
To motivate the next result, we review a few points. Let BA N ( F ) denote the set of isomorphism classes of Billiard Arrays over F that have diameter N . Let CBA N ( F ) denote the set of similarity classes of Concrete Billiard Arrays over F that have diameter N . Let EL N ( F ) denote the set of similarity classes of edge-labellings on ∆ N . Let VF N ( F ) denote the set of value functions on ∆ N . The map B → ˆ B induces a function BA N ( F ) → VF N -2 ( F ) which we will denote by θ . In Lemma 8.21 we displayed a bijection CBA N ( F ) → BA ( ) which we N F will denote by f . In Proposition 17.6 we displayed a bijection CBA N ( F ) → EL N ( F ) which we will denote by g . In Proposition 18.10 we displayed a bijection EL N ( F ) → VF N -2 ( F ) which we will denote by h .
Lemma 19.1. With the above notation, the following diagram commutes:
$$\text{CBA} _ { N } ( \mathbb { F } ) & \xrightarrow { f } \text{ BA} _ { N } ( \mathbb { F } ) \\ \g \Big { \downarrow } & \quad \Big { \downarrow } ^ { \theta } \\ \text{EL} _ { N } ( \mathbb { F } ) & \xrightarrow { f } \text{ VF} _ { N - 2 } ( \mathbb { F } )$$
Moreover θ is a bijection.
Proof. The diagram commutes by Lemma 18.5. It follows that θ is a bijection.

We emphasize one aspect of Lemma 19.1.
↦
Corollary 19.2. The map B → ˆ B induces a bijection between the following two sets:
- (i) the isomorphism classes of Billiard Arrays over F that have diameter N ;
- (ii) the value functions on ∆ N -2 .
Proof. The map θ in Lemma 19.1 is a bijection.
Summarizing the above discussion, we obtain a bijection between any two of the following sets:
- · the isomorphism classes of Billiard Arrays over F that have diameter N ;
- · the similarity classes of Concrete Billiard Arrays over F that have diameter N ;
- · the similarity classes of edge-labellings for ∆ N ;
- · the value functions on ∆ N -2 .
We have some remarks. For the rest of this section fix N ∈ N . Let V denote a vector space over F with dimension N +1.
Proposition 19.3. Let B and B ′ denote Concrete Billiard Arrays on V . Then the following are equivalent:
- (i) B and B ′ are relatives;
- (ii) B and B ′ are associates and isomorphic.
/negationslash
Proof. (i) ⇒ (ii) By Lemma 8.19. (ii) ⇒ (i) By Definition 8.10 and since B B , ′ are associates, there exist nonzero scalars { κ λ } λ ∈ ∆ N in F such that B ′ λ = κ λ B λ for all λ ∈ ∆ . N For all adjacent λ, µ ∈ ∆ N we have ˜ B λ,µ κ λ = ˜ B ′ λ,µ κ µ by Lemma 15.2, and ˜ B λ,µ = ˜ B ′ λ,µ since B B , ′ are isomorphic, so κ λ = κ µ . Consequently there exists 0 = κ ∈ F such that κ λ = κ for all λ ∈ ∆ . Now N B and B ′ are relatives by Definition 8.13.
Proposition 19.4. Let B denote a Billiard Array on V . For an F -linear map σ : V → V the following are equivalent:
- (i) the map σ is an isomorphism of Billiard Arrays from B to B ;
/negationslash
- (ii) there exists 0 = κ ∈ F such that σ = κI .
↦
Proof. (i) ⇒ (ii) Let B denote a Concrete Billiard Array on V that corresponds to B . Consider the Concrete Billiard Array B ′ : ∆ N → V , λ → σ ( B λ ). By construction σ is an isomorphism of Concrete Billiard Arrays from B to B ′ ; therefore B and B ′ are isomorphic. By construction B ′ corresponds to B ; therefore B and B ′ are associates. Now B and B ′ are relatives by Proposition 19.3. By Definition 8.13 there exists 0 = κ ∈ F such that B ′ λ = κ B λ for all λ ∈ ∆ . N Now κI is an isomorphism of Concrete Billiard Arrays from B to B ′ . By Definition 8.15, there does not exist another isomorphism of Concrete Billiard Arrays from B to B ′ . Therefore σ = κI .
/negationslash
- (ii) ⇒ (i) Clear.

We make a definition for later use.
Definition 19.5. Let B denote a Concrete Billiard Array on V , and let B denote the corresponding Billiard Array on V . Let C denote a white 3-clique in ∆ N . By the B -value of C we mean the B -value of C , which is the same as the ˜ -value of B C by Lemma 18.5.
## 20 Examples of Concrete Billiard Arrays
Throughout this section the following notation is in effect. Let x, y, z denote mutually commuting indeterminates. Let P = F [ x, y, z ] denote the F -algebra consisting of the polynomials in x, y, z that have all coefficients in F . For n ∈ N let P n denote the subspace of P consisting of the homogeneous polynomials that have total degree n . The sum P = ∑ n ∈ N P n is direct. Fix an integer N ≥ 1. In this section we give some examples of Concrete Billiard Arrays of diameter N . For these examples, the underlying vector space will be a subspace of P N .
We now describe our first example.
Definition 20.1. For each location λ = ( r, s, t ) in ∆ N define
$$\mathcal { B } _ { \lambda } = ( x - y ) ^ { r } ( y - z ) ^ { s } ( z - x ) ^ { t }.$$
We will show that the function B from Definition 20.1 is a Concrete Billiard Array.
Lemma 20.2. Let λ , µ , ν denote locations in ∆ N that form a black 3-clique. Then
$$\mathcal { B } _ { \lambda } + \mathcal { B } _ { \mu } + \mathcal { B } _ { \nu } = 0.$$
Proof. By Lemma 4.31 we may take
$$\lambda = ( r + 1, s, t ), \quad \mu = ( r, s + 1, t ), \quad \nu = ( r, s, t + 1 )$$
with ( r, s, t ) ∈ ∆ N -1 . By Definition 20.1,
$$\mathcal { B } _ { \lambda } & = ( x - y ) ^ { r + 1 } ( y - z ) ^ { s } ( z - x ) ^ { t }, \\ \mathcal { B } _ { \mu } & = ( x - y ) ^ { r } ( y - z ) ^ { s + 1 } ( z - x ) ^ { t }, \\ \mathcal { B } _ { \nu } & = ( x - y ) ^ { r } ( y - z ) ^ { s } ( z - x ) ^ { t + 1 }.$$
From this we routinely obtain (32).
Lemma 20.3. The function B from Definition 20.1 is a Concrete Billiard Array.
Proof. We show that B satisfies the two conditions in Definition 8.1. Concerning Definition 8.1(i), let L denote a line in ∆ N and consider the locations in L . We show that their images under B are linearly independent. Without loss we may assume that L is a 1-line. Denote the cardinality of L by i +1. The locations in L are listed in (4). For these locations their images under B are
$$( x - y ) ^ { N - i } ( y - z ) ^ { i - j } ( z - x ) ^ { j } \quad \quad \ 0 \leq j \leq i.$$
We show that the vectors (33) are linearly independent. The vectors
$$( y - z ) ^ { i - j } ( z - x ) ^ { j } \text{ \quad \ \ } 0 \leq j \leq i$$
are linearly independent; to see this set z = 0 in (34) and note that x, y are algebraically independent. It follows that the vectors (33) are linearly independent. We have shown that B satisfies Definition 8.1(i). The function B satisfies Definition 8.1(ii) by Lemma 20.2.
For the Concrete Billiard Array B in Definition 20.1 we now compute the corresponding edge labelling and value function.
Lemma 20.4. Let B denote the Concrete Billiard Array from Definition 20.1. For adjacent locations λ, µ in ∆ N we have ˜ B λ,µ = 1 .
Proof. By Lemma 4.33 there exists a location ν ∈ ∆ N such that λ µ ν , , form a black 3-clique. Now B λ + B µ + B ν = 0 by Lemma 20.2. Comparing this with (18) we find that in (18) the terms B µ and B ν have coefficient 1. Therefore ˜ B λ,µ = 1.
Proposition 20.5. Let B denote the Concrete Billiard Array from Definition 20.1. Then each white 3-clique in ∆ N has B -value 1.
Proof. By Lemmas 15.9, 20.4 along with Definition 19.5.
We are done with our first example. We now describe our second example.
/negationslash
We will use the following notation. Fix 0 = q ∈ F such that q = 1. For elements a, b in any F -algebra, define
/negationslash
$$( a, b ; q ) _ { n } = ( a - b ) ( a - b q ) ( a - b q ^ { 2 } ) \cdots ( a - b q ^ { n - 1 } ) \quad \quad n = 0, 1, 2, \dots$$
We interpret ( a, b ; q ) 0 = 1.
Definition 20.6. Pick three scalars x , y , z in F such that xy z = q N -1 . For each location λ = ( r, s, t ) in ∆ N define
$$\mathcal { B } _ { \lambda } = ( x \overline { x }, y ; q ) _ { r } ( y \overline { y }, z ; q ) _ { s } ( z \overline { z }, x ; q ) _ { t }.$$
We are going to show that the function B from Definition 20.6 is a Concrete Billiard Array. Pick a location ( r, s, t ) ∈ ∆ N -1 and consider the corresponding black 3-clique in ∆ N from Lemma 4.31:
$$\lambda = ( r + 1, s, t ), \quad \mu = ( r, s + 1, t ), \quad \nu = ( r, s, t + 1 ).$$
Lemma 20.7. With the above notation,
$$a \mathcal { B } _ { \lambda } + b \mathcal { B } _ { \mu } + c \mathcal { B } _ { \nu } = 0$$
where each of a, b, c is nonzero and
$$b / a = q ^ { r } / \overline { y }, \quad \ \ c / b = q ^ { s } / \overline { z }, \quad \ \ a / c = q ^ { t } / \overline { x }.$$
Proof. By Definition 20.6 and the construction,
$$\mathcal { B } _ { \lambda } & = ( x \overline { x }, y ; q ) _ { r + 1 } ( y \overline { y }, z ; q ) _ { s } ( z \overline { z }, x ; q ) _ { t }, \\ \mathcal { B } _ { \mu } & = ( x \overline { x }, y ; q ) _ { r } ( y \overline { y }, z ; q ) _ { s + 1 } ( z \overline { z }, x ; q ) _ { t }, \\ \mathcal { B } _ { \nu } & = ( x \overline { x }, y ; q ) _ { r } ( y \overline { y }, z ; q ) _ { s } ( z \overline { z }, x ; q ) _ { t + 1 }.$$
Define so
$$\mathcal { B } _ { \lambda } = F ( x \overline { x } - y q ^ { r } ), \quad \ \mathcal { B } _ { \mu } = F ( y \overline { y } - z q ^ { s } ), \quad \ \mathcal { B } _ { \nu } = F ( z \overline { z } - x q ^ { t } ). \quad \ \ \ ( 3 7 )$$
Using (36) along with r + s + t = N -1 and xy z = q N -1 , we obtain
$$a ( x \overline { x } - y q ^ { r } ) + b ( y \overline { y } - z q ^ { s } ) + c ( z \overline { z } - x q ^ { t } ) = 0.$$
Equation (35) follows from (37) and (38).
Lemma 20.8. The function B from Definition 20.6 is a Concrete Billiard Array.
Proof. We show that B satisfies the two conditions in Definition 8.1. Concerning Definition 8.1(i), let L denote a line in ∆ N and consider the locations in L . We show that their images under B are linearly independent. Without loss we may assume that B is a 1-line. Denote the cardinality of L by i +1. The locations in L are listed in (4). For these locations their images under B are
$$( x \overline { x }, y ; q ) _ { N - i } ( y \overline { y }, z ; q ) _ { i - j } ( z \overline { z }, x ; q ) _ { j } \quad \quad 0 \leq j \leq i.$$
We show that the vectors (39) are linearly independent. The vectors
$$( y \overline { y }, z ; q ) _ { i - j } ( z \overline { z }, x ; q ) _ { j } \quad \quad 0 \leq j \leq i$$
are linearly independent; to see this set z = 0 in (40) and note that x, y are algebraically independent. It follows that the vectors (39) are linearly independent. We have shown that B satisfies Definition 8.1(i). The function B satisfies Definition 8.1(ii) by Lemma 20.7.
For the Concrete Billiard Array B in Definition 20.6 we now compute the corresponding edge labelling and value function.
Lemma 20.9. With the notation from above Lemma 20.7,
$$\tilde { \mathcal { B } } _ { \lambda, \mu } & = q ^ { r } / \overline { y }, \quad \tilde { \mathcal { B } } _ { \mu, \nu } = q ^ { s } / \overline { z }, \quad \tilde { \mathcal { B } } _ { \nu, \lambda } = q ^ { t } / \overline { x }, \\ \tilde { \mathcal { B } } _ { \mu, \lambda } & = \overline { y } / q ^ { r }, \quad \tilde { \mathcal { B } } _ { \nu, \mu } = \overline { z } / q ^ { s }, \quad \tilde { \mathcal { B } } _ { \lambda, \nu } = \overline { x } / q ^ { t }.$$
Proof. Compare Lemma 15.7 and Lemma 20.7.
Proposition 20.10. Let B denote the Concrete Billiard Array from Definition 20.6. Then each white 3-clique in ∆ N has B -value q .
$$F = ( x \overline { x }, y ; q ) _ { r } ( y \overline { y }, z ; q ) _ { s } ( z \overline { z }, x ; q ) _ { t },$$
Proof. Assume N ≥ 2; otherwise ∆ N has no white 3-clique. Let ( r, s, t ) ∈ ∆ N -2 and consider the corresponding white 3-clique in ∆ N from Lemma 4.32. This 3-clique consists of the locations
$$\lambda = ( r, s + 1, t + 1 ), \quad \ \mu = ( r + 1, s, t + 1 ), \quad \ \nu = ( r + 1, s + 1, t ).$$
Using Lemma 20.9,
$$\tilde { \mathcal { B } } _ { \lambda, \mu } = \overline { y } / q ^ { r }, \quad \tilde { \mathcal { B } } _ { \mu, \nu } = \overline { z } / q ^ { s }, \quad \tilde { \mathcal { B } } _ { \nu, \lambda } = \overline { x } / q ^ { t }.$$
By Lemma 15.9 and Definition 19.5 the B -value of the above white 3-clique is ˜ B λ,µ ˜ B µ,ν ˜ B ν,λ which is equal to
$$\frac { \overline { x } \, \overline { y } \, \overline { z } } { q ^ { r + s + t } } = \frac { q ^ { N - 1 } } { q ^ { N - 2 } } = q.$$
Corollary 20.11. For the Concrete Billiard Array B from Definition 20.6, the similarity class is independent of the choice of x , y , z and depends only on q , N .
Proof. By Lemma 19.1 and Proposition 20.10.
Corollary 20.12. For the Concrete Billiard Array B from Definition 20.6, the isomorphism class of the corresponding Billiard Array is independent of the choice of x , y , z and depends only on q , N .
Proof.
$$P r o o f. \, \text{By Corollary 19.2 and Proposition 20.10}.$$
## 21 The Lie algebra sl 2 and the quantum algebra Uq ( sl 2 )
In this section we use Billiard Arrays to describe the finite-dimensional irreducible modules for the Lie algebra sl 2 and the quantum algebra U q ( sl 2 ). We now recall sl 2 . We will use the equitable basis, which was introduced in [4] and comprehensively described in [2]. Until the end of Corollary 21.15, assume that the characteristic of F is not 2.
Definition 21.1. [4, Lemma 3.2] Let sl 2 denote the Lie algebra over F with basis x, y, z and Lie bracket
$$[ x, y ] = 2 x + 2 y, \quad [ y, z ] = 2 y + 2 z, \quad [ z, x ] = 2 z + 2 x.$$
Until the end of Corollary 21.15 the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1. Let B denote a Billiard Array on V . Assume that each white 3-clique in ∆ N has B -value 1. Using B we will turn V into a sl 2 -module. We acknowledge that our construction is essentially the same as the one in [2, Proposition 8.17]; the details given here are meant to illuminate the role played by the maps ˜ B λ,µ . Recall the B -decompositions [ η, ξ ] of V from Definition 10.3.
Definition 21.2. Define X,Y,Z in End( V ) such that for 0 ≤ i ≤ N X , -(2 i -N I ) (resp. Y -(2 i -N I ) ) (resp. Z -(2 i -N I ) ) vanishes on component i of the B -decomposition [2 , 3] (resp. [3 , 1]) (resp. [1 , 2]).
The next result is meant to clarify Definition 21.2.
Lemma 21.3. Pick a location λ = ( r, s, t ) on the boundary of ∆ N . Then on B λ ,
$$X & = ( 2 t - N ) I = ( N - 2 s ) I \quad \quad \text{ if } r = 0 ; \\ Y & = ( 2 r - N ) I = ( N - 2 t ) I \quad \quad \text{ if } s = 0 ; \\ Z & = ( 2 s - N ) I = ( N - 2 r ) I \quad \quad \text{ if } t = 0.$$
Proof. By Lemma 10.4 and Definition 21.2.
Pick ( r, s, t ) ∈ ∆ N -1 and consider the corresponding black 3-clique in ∆ N from Lemma 4.31:
$$\lambda = ( r + 1, s, t ), \quad \mu = ( r, s + 1, t ), \quad \nu = ( r, s, t + 1 ).$$
Proposition 21.4. With the above notation, for each abrace
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }, \quad \ w \in B _ { \nu }$$
we have
$$X u & = ( N - 2 t ) v + ( 2 s - N ) w, \\ Y v & = ( N - 2 r ) w + ( 2 t - N ) u, \\ Z w & = ( N - 2 s ) u + ( 2 r - N ) v.$$
Proof. We verify (42). Our proof is by induction on r . First assume r = 0, so that s + t = N -1. By construction µ = (0 , N -t, t ) and ν = (0 , s, N -s ). So Xv = (2 t -N v ) and Xw = ( N -2 ) s w in view of Lemma 21.3. To obtain (42), in the equation u + + v w = 0 apply X to each term and evaluate the result using the above comments. We have verified (42) for r = 0. Next assume r ≥ 1. For the location ( r -1 , s, t +1) ∈ ∆ N -1 the corresponding black 3-clique in ∆ N is
$$\lambda ^ { \prime } = ( r, s, t + 1 ), \quad \mu ^ { \prime } = ( r - 1, s + 1, t + 1 ), \quad \nu ^ { \prime } = ( r - 1, s, t + 2 ).$$
/negationslash
Observe λ ′ = ν . By Lemma 13.7 and since 0 = w ∈ B ν = B λ ′ there exists a unique abrace
$$u ^ { \prime } \in B _ { \lambda ^ { \prime } }, \quad \ v ^ { \prime } \in B _ { \mu ^ { \prime } }, \quad \ w ^ { \prime } \in B _ { \nu ^ { \prime } }$$
such that u ′ = w . By Definition 13.1 u ′ + v ′ + w ′ = 0. By induction
$$X u ^ { \prime } = ( N - 2 t - 2 ) v ^ { \prime } + ( 2 s - N ) w ^ { \prime }.$$
For the location ( r -1 , s +1 , t ) ∈ ∆ N -1 the corresponding black 3-clique in ∆ N is
$$\lambda ^ { \prime \prime } = ( r, s + 1, t ), \quad \mu ^ { \prime \prime } = ( r - 1, s + 2, t ), \quad \nu ^ { \prime \prime } = ( r - 1, s + 1, t + 1 ).$$
/negationslash
Observe λ ′′ = µ . By Lemma 13.7 and since 0 = v ∈ B µ = B λ ′′ there exists a unique abrace
$$u ^ { \prime \prime } \in B _ { \lambda ^ { \prime \prime } }, \quad \ v ^ { \prime \prime } \in B _ { \mu ^ { \prime \prime } }, \quad \ w ^ { \prime \prime } \in B _ { \nu ^ { \prime \prime } }$$
such that u ′′ = v . By Definition 13.1 u ′′ + v ′′ + w ′′ = 0. By induction
$$X u ^ { \prime \prime } = ( N - 2 t ) v ^ { \prime \prime } + ( 2 s + 2 - N ) w ^ { \prime \prime }.$$
We claim that w ′′ = v ′ . We now prove the claim. Observe µ ′ = ν ′′ . The three locations
$$\mu ^ { \prime } = \nu ^ { \prime \prime }, \quad \ \lambda ^ { \prime } = \nu, \quad \ \lambda ^ { \prime \prime } = \mu$$
↦
↦
run clockwise around a white 3-clique in ∆ N , which we recall has B -value 1. By construction v , u ′ ′ is a brace for the edge µ , λ ′ ′ so ˜ B µ ,λ ′ ′ sends v ′ → u ′ . Similarly w, v is a brace for the edge ν, µ so ˜ B ν,µ sends w → v . Similarly u , w ′′ ′′ is a brace for the edge λ , ν ′′ ′′ so ˜ B λ ,ν ′′ ′′ sends u ′′ → w ′′ . Consider the composition
↦
$$B _ { \mu ^ { \prime } } \ \xrightarrow { \tilde { B } _ { \mu ^ { \prime }, \lambda ^ { \prime } } } \ B _ { \lambda ^ { \prime } } = B _ { \nu } \ \xrightarrow { \tilde { B } _ { \nu, \mu } } \ B _ { \mu } = B _ { \lambda ^ { \prime \prime } } \ \xrightarrow { \tilde { B } _ { \lambda ^ { \prime \prime }, \nu ^ { \prime \prime } } } \ B _ { \nu ^ { \prime \prime } } = B _ { \mu ^ { \prime } }.$$
On one hand, this composition sends
↦
$$v ^ { \prime } \mapsto u ^ { \prime } = w \mapsto v = u ^ { \prime \prime } \mapsto w ^ { \prime \prime }.$$
↦
↦
On the other hand, by Definition 14.9 this composition is equal to the identity map on B ′ µ . Therefore w ′′ = v ′ and the claim is proved. Now to obtain (42), in the equation u + + v w = 0 apply X to each term and evaluate the result using (43), (44) and nearby comments. We have verified equation (42). The remaining two equations are similarly verified.
We now reformulate Proposition 21.4.
Corollary 21.5. Referring to the notation above Proposition 21.4, the following (i)-(iii) hold.
$$( \begin{matrix} i \end{matrix} ) & O n \ B _ { \lambda }, & X & = ( N - 2 t ) \tilde { B } _ { \lambda, \mu } + ( 2 s - N ) \tilde { B } _ { \lambda, \nu }.$$
- (ii) On B µ
- (iii)
$$( \text{ii} ) & \ O n \ B _ { \mu }, \\ & Y = ( N - 2 r ) \tilde { B } _ { \mu, \nu } + ( 2 t - N ) \tilde { B } _ { \mu, \lambda }. \\ \\ ( \text{iii} ) & \ O n \ B _ { \nu }, \\ & Z = ( N - 2 s ) \tilde { B } _ { \nu, \lambda } + ( 2 r - N ) \tilde { B } _ { \nu, \mu }.$$
Proof. Use Lemma 14.6 and Proposition 21.4.
Recall the vectors α, β, γ from line (2).
Proposition 21.6. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$X - ( N - 2 s ) I & = 2 r \tilde { B } _ { \lambda, \lambda - \alpha }, \quad \quad X - ( 2 t - N ) I = - 2 r \tilde { B } _ { \lambda, \lambda + \gamma }, \\ Y - ( N - 2 t ) I & = 2 s \tilde { B } _ { \lambda, \lambda - \beta }, \quad \quad Y - ( 2 r - N ) I = - 2 s \tilde { B } _ { \lambda, \lambda + \alpha }, \\ Z - ( N - 2 r ) I & = 2 t \tilde { B } _ { \lambda, \lambda - \gamma }, \quad \quad Z - ( 2 s - N ) I = - 2 t \tilde { B } _ { \lambda, \lambda + \beta }.$$
Proof. We verify the equations in the top row. First assume r = 0, so that s + t = N . In each equation the left-hand side is zero by Lemma 21.3. In each equation the right-hand side is zero since r = 0. Next assume r ≥ 1. Define
$$\mu = ( r - 1, s + 1, t ) = \lambda - \alpha, \quad \nu = ( r - 1, s, t + 1 ) = \lambda + \gamma.$$
The locations λ, µ, ν form a black 3-clique in ∆ N that corresponds to the location ( r -1 , s, t ) in ∆ N -1 under the bijection of Lemma 4.31. Apply Corollary 21.5(i) to this 3-clique and in the resulting equation (45) eliminate ˜ B λ,µ or ˜ B λ,ν using (17). We have verified the equations in the top row. The other equations are similarly verified.
Corollary 21.7. For each location λ = ( r, s, t ) in ∆ N ,
$$& ( X - ( N - 2 s ) I ) B _ { \lambda } \subseteq B _ { \lambda - \alpha }, \quad \quad ( X - ( 2 t - N ) I ) B _ { \lambda } \subseteq B _ { \lambda + \gamma }, \\ & ( Y - ( N - 2 t ) I ) B _ { \lambda } \subseteq B _ { \lambda - \beta }, \quad \quad ( Y - ( 2 r - N ) I ) B _ { \lambda } \subseteq B _ { \lambda + \alpha }, \\ & ( Z - ( N - 2 r ) I ) B _ { \lambda } \subseteq B _ { \lambda - \gamma }, \quad \quad ( Z - ( 2 s - N ) I ) B _ { \lambda } \subseteq B _ { \lambda + \beta }.$$
Moreover, equality holds in each inclusion provided that the characteristic of F is 0 or greater than N .
Proof. By Note 14.2 and Proposition 21.6.
Our next goal is to show that the elements X,Y,Z from Definition 21.2 satisfy the defining relations for sl 2 given in (41).
Lemma 21.8. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$X Y - 2 Y & = X ( 2 r - N ) + Y ( N - 2 s ) + ( N + 2 ) ( 2 t - N ) I = Y X + 2 X, \\ Y Z - 2 Z & = Y ( 2 s - N ) + Z ( N - 2 t ) + ( N + 2 ) ( 2 r - N ) I = Z Y + 2 Y, \\ Z X - 2 X & = Z ( 2 t - N ) + X ( N - 2 r ) + ( N + 2 ) ( 2 s - N ) I = X Z + 2 Z.$$
Proof. We verify the equation on the left in the bottom row. For this equation let M denote the left-hand side minus the right-hand side. We show M = 0 on B λ . First assume r = 0, so that s + t = N . By Lemma 21.3 X = (2 t -N I ) on B λ . By these comments we routinely obtain M = 0 on B λ . Next assume r ≥ 1. Observe λ + γ = ( r -1 , s, t +1) ∈ ∆ . By Lemma N 14.5 the maps ˜ B λ,λ + γ : B λ → B λ + γ and ˜ B λ + γ,λ : B λ + γ → B λ are inverses. Using Proposition 21.6 we find that on B λ ,
$$X - ( 2 t - N ) I = - 2 r \tilde { B } _ { \lambda, \lambda + \gamma },$$
and on B λ + γ ,
$$Z - ( N - 2 r + 2 ) I = 2 ( t + 1 ) \tilde { B } _ { \lambda + \gamma, \lambda }.$$
Therefore on B λ ,
$$( Z - ( N - 2 r + 2 ) I ) ( X - ( 2 t - N ) I ) = - 4 r ( t + 1 ) I.$$
Evaluating (46) using r + + s t = N we find that M = 0 on B λ . We have verified the equation on the left in the bottom row. The remaining equations are similarly verified.
## Proposition 21.9. The elements X,Y,Z from Definition 21.2 satisfy
$$X Y - Y X = 2 X + 2 Y, \quad Y Z - Z Y = 2 Y + 2 Z, \quad Z X - X Z = 2 Z + 2 X.$$
Proof. By Lemma 21.8 these equations hold on B λ for all λ ∈ ∆ . The result holds in view N of Corollary 7.7.
Theorem 21.10. Let V denote a vector space over F with dimension N +1 . Let B denote a Billiard Array on V . Assume that each white 3-clique in ∆ N has B -value 1 . Then there exists a unique sl 2 -module structure on V such that for 0 ≤ i ≤ N , x -(2 i -N I ) (resp. y -(2 i -N I ) ) (resp. z -(2 i -N I ) ) vanishes on component i of the B -decomposition [2 , 3] (resp. [3 , 1] ) (resp. [1 , 2] ). The sl 2 -module V is irreducible, provided that the characteristic of F is 0 or greater than N .
Proof. The sl 2 -module structure exists by Proposition 21.9. It is unique by construction. The last assertion of the theorem is readily checked.
Definition 21.11. [2, Section 2] Define ν , ν x y , ν z in sl 2 by
$$- 2 \nu _ { x } = y + z, \quad - 2 \nu _ { y } = z + x, \quad - 2 \nu _ { z } = x + y.$$
Our next goal is to describe the actions of ν , ν x y , ν z on { B λ } λ ∈ ∆ N .
Proposition 21.12. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$\nu _ { x } = s \tilde { B } _ { \lambda, \lambda + \alpha } - t \tilde { B } _ { \lambda, \lambda - \gamma }, \quad \nu _ { y } = t \tilde { B } _ { \lambda, \lambda + \beta } - r \tilde { B } _ { \lambda, \lambda - \alpha }, \quad \nu _ { z } = r \tilde { B } _ { \lambda, \lambda + \gamma } - s \tilde { B } _ { \lambda, \lambda - \beta }.$$
Proof.
Evaluate the equations in Definition 21.11 using Proposition 21.6.
Corollary 21.13. For each location λ ∈ ∆ N ,
$$\nu _ { x } B _ { \lambda } \subseteq B _ { \lambda + \alpha } + B _ { \lambda - \gamma }, \quad \nu _ { y } B _ { \lambda } \subseteq B _ { \lambda + \beta } + B _ { \lambda - \alpha }, \quad \nu _ { z } B _ { \lambda } \subseteq B _ { \lambda + \gamma } + B _ { \lambda - \beta }.$$
Proof. By Note 14.2 and Proposition 21.12.
Recall the B -flags [1] , [2] , [3] from Definition 9.9.
Proposition 21.14. Assume that the characteristic of F is 0 or greater than N . Then the B -flags [1] , [2] , [3] are, respectively,
$$\{ \nu _ { x } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { y } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { z } ^ { N - i } V \} _ { i = 0 } ^ { N }.$$
Proof. Consider the B -flag [1]. Denote this by { U i } N i =0 . Denote the B -decomposition [1 2] , by { V i } N i =0 . Recall from Lemma 10.4 that for 0 ≤ i ≤ N , V i is included in B at location ( N -i, i, 0). Recall from Lemma 10.6 that U i = V 0 + · · · + V i for 0 ≤ i ≤ N . By Corollary 21.13 we find ν V x i ⊆ V i -1 for 1 ≤ i ≤ N and ν V x 0 = 0. Going back to Proposition 21.12 and invoking our assumption about the characteristic of F , we see that in fact ν V x i = V i -1 for 1 ≤ i ≤ N . By the above comments ν U x i = U i -1 for 1 ≤ i ≤ N . Now since U N = V we obtain U i = ν N -i x V for 0 ≤ i ≤ N . We have shown that the B -flag [1] is equal to { ν N -i x V } N i =0 . The remaining assertions are similarly shown.
Corollary 21.15. Assume that F has characteristic 0 . Let V denote an irreducible sl 2 -module of dimension N +1 . Then
- (i) the following are totally opposite flags on V :
$$\{ \nu _ { x } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { y } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { z } ^ { N - i } V \} _ { i = 0 } ^ { N }.$$
- (ii) for the corresponding Billiard Array on V , the value of each white 3-clique is 1 .
Proof. By [6, Theorem 7.2], up to isomorphism there exists a unique irreducible sl 2 -module with dimension N + 1. The sl 2 -module from Theorem 21.10 is irreducible with dimension N +1. Therefore the sl 2 -module V is isomorphic to the sl 2 -module from Theorem 21.10. Via the isomorphism we identify these sl 2 -modules. Consider the Billiard Array B on V from Theorem 21.10. By Theorem 12.4 and Proposition 21.14, the three sequences in line (47) are totally opposite flags on V , and B is the corresponding Billiard Array. By the assumption of Theorem 21.10, the B -value of each white 3-clique is 1.
/negationslash
We are done discussing sl 2 . For the rest of this section assume the field F is arbitrary. Fix a nonzero q ∈ F such that q 2 = 1. We recall the quantum algebra U q ( sl 2 ). We will use the equitable presentation, which was introduced in [11].
Definition 21.16. [11, Theorem 2.1] Let U q ( sl 2 ) denote the associative F -algebra with generators x, y ± 1 , z and relations yy -1 = 1, y -1 y = 1,
$$\frac { q x y - q ^ { - 1 } y x } { q - q ^ { - 1 } } = 1, \quad \frac { q y z - q ^ { - 1 } z y } { q - q ^ { - 1 } } = 1, \quad \frac { q z x - q ^ { - 1 } x z } { q - q ^ { - 1 } } = 1.$$
For the rest of this section the following notation is in effect. Fix N ∈ N . Let V denote a vector space over F with dimension N +1. Let B denote a Billiard Array on V . Assume that each white 3-clique in ∆ N has B -value q -2 . Using B we will turn V into a U q ( sl 2 )-module. Recall the B -decompositions [ η, ξ ] of V from Definition 10.3.
Definition 21.17. Define X,Y,Z in End( V ) such that for 0 ≤ i ≤ N X , -q N -2 i I (resp. Y -q N -2 i I ) (resp. Z -q N -2 i I ) vanishes on component i of the B -decomposition [2 , 3] (resp. [3 , 1]) (resp. [1 , 2]). Note that each of X,Y,Z is invertible.
The next result is meant to clarify Definition 21.17.
Lemma 21.18. Pick a location λ = ( r, s, t ) on the boundary of ∆ N . Then on B λ ,
$$X & = q ^ { N - 2 t } I = q ^ { 2 s - N } I \quad \quad \text{ if } r = 0 ; \\ Y & = q ^ { N - 2 r } I = q ^ { 2 t - N } I \quad \quad \text{ if } s = 0 ; \\ Z & = q ^ { N - 2 s } I = q ^ { 2 r - N } I \quad \quad \text{ if } t = 0.$$
Proof. By Lemma 10.4 and Definition 21.17.
Pick ( r, s, t ) ∈ ∆ N -1 and consider the corresponding black 3-clique in ∆ N from Lemma 4.31:
$$\lambda = ( r + 1, s, t ), \quad \mu = ( r, s + 1, t ), \quad \nu = ( r, s, t + 1 ).$$
Proposition 21.19. With the above notation, for each abrace
$$u \in B _ { \lambda }, \quad \ v \in B _ { \mu }, \quad \ w \in B _ { \nu }$$
we have
$$X u & = - q ^ { N - 2 t } v - q ^ { 2 s - N } w, \\ Y v & = - q ^ { N - 2 r } w - q ^ { 2 t - N } u, \\ Z w & = - q ^ { N - 2 s } u - q ^ { 2 r - N } v.$$
Proof. Our proof is similar to the proof of Proposition 21.4; we give the details for the sake of clarity. We verify (49). Our proof is by induction on r . First assume r = 0, so that s + t = N -1. By construction µ = (0 , N -t, t ) and ν = (0 , s, N -s ). So Xv = q N -2 t v and Xw = q 2 s -N w in view of Lemma 21.18. To obtain (49), in the equation u + v + w = 0 apply X to each term and evaluate the result using the above comments. We have verified (49) for r = 0. Next assume r ≥ 1. For the location ( r -1 , s, t +1) ∈ ∆ N -1 the corresponding black 3-clique in ∆ N is
$$\lambda ^ { \prime } = ( r, s, t + 1 ), \quad \mu ^ { \prime } = ( r - 1, s + 1, t + 1 ), \quad \nu ^ { \prime } = ( r - 1, s, t + 2 ).$$
/negationslash
Observe λ ′ = ν . By Lemma 13.7 and since 0 = w ∈ B ν = B λ ′ there exists a unique abrace
$$u ^ { \prime } \in B _ { \lambda ^ { \prime } }, \quad \ v ^ { \prime } \in B _ { \mu ^ { \prime } }, \quad \ w ^ { \prime } \in B _ { \nu ^ { \prime } }$$
such that u ′ = w . By Definition 13.1 u ′ + v ′ + w ′ = 0. By induction
$$X u ^ { \prime } = - q ^ { N - 2 t - 2 } v ^ { \prime } - q ^ { 2 s - N } w ^ { \prime }.$$
For the location ( r -1 , s +1 , t ) ∈ ∆ N -1 the corresponding black 3-clique in ∆ N is
$$\lambda ^ { \prime \prime } = ( r, s + 1, t ), \quad \mu ^ { \prime \prime } = ( r - 1, s + 2, t ), \quad \nu ^ { \prime \prime } = ( r - 1, s + 1, t + 1 ).$$
/negationslash
Observe λ ′′ = µ . By Lemma 13.7 and since 0 = v ∈ B µ = B λ ′′ there exists a unique abrace
$$u ^ { \prime \prime } \in B _ { \lambda ^ { \prime \prime } }, \quad \ v ^ { \prime \prime } \in B _ { \mu ^ { \prime \prime } }, \quad \ w ^ { \prime \prime } \in B _ { \nu ^ { \prime \prime } }$$
such that u ′′ = v . By Definition 13.1 u ′′ + v ′′ + w ′′ = 0. By induction
$$X u ^ { \prime \prime } = - q ^ { N - 2 t } v ^ { \prime \prime } - q ^ { 2 s + 2 - N } w ^ { \prime \prime }.$$
We claim that w ′′ = q -2 v ′ . We now prove the claim. Observe µ ′ = ν ′′ . The three locations
$$\mu ^ { \prime } = \nu ^ { \prime \prime }, \quad \ \lambda ^ { \prime } = \nu, \quad \ \ \lambda ^ { \prime \prime } = \mu$$
↦
↦
run clockwise around a white 3-clique in ∆ N , which we recall has B -value q -2 . By construction v , u ′ ′ is a brace for the edge µ , λ ′ ′ so ˜ B µ ,λ ′ ′ sends v ′ → u ′ . Similarly w, v is a brace for the edge ν, µ so ˜ B ν,µ sends w → v . Similarly u , w ′′ ′′ is a brace for the edge λ , ν ′′ ′′ so ˜ B λ ,ν ′′ ′′ sends u ′′ → w ′′ . Consider the composition
↦
$$B _ { \mu ^ { \prime } } \xrightarrow { \longrightarrow } \ B _ { \lambda ^ { \prime } } = B _ { \nu } \xrightarrow { \longrightarrow } \ B _ { \mu } = B _ { \lambda ^ { \prime \prime } } \xrightarrow { \longrightarrow } \ B _ { \nu ^ { \prime \prime } } = B _ { \mu ^ { \prime } }.$$
On one hand, this composition sends
↦
$$v ^ { \prime } \mapsto u ^ { \prime } = w \mapsto v = u ^ { \prime \prime } \mapsto w ^ { \prime \prime }.$$
↦
↦
On the other hand, by Definition 14.9 this composition is equal to q -2 times the identity map on B ′ µ . Therefore w ′′ = q -2 v ′ and the claim is proved. Now to obtain (49), in the equation u + v + w = 0 apply X to each term and evaluate the result using (50), (51) and nearby comments. We have verified equation (49). The remaining two equations are similarly verified.
We now reformulate Proposition 21.19.
Corollary 21.20. Referring to the notation above Proposition 21.19, the following (i)-(iii) hold.
$$\left ( \begin{matrix} 0 & 0 n & B _ { \lambda }, \\ & & X = - q ^ { N - 2 t } \tilde { B } _ { \lambda, \mu } - q ^ { 2 s - N } \tilde { B } _ { \lambda, \nu }. \end{matrix} \right )$$
- (ii) On B µ
- (iii)
$$( \text{i} ) & \ O n \ B _ { \lambda }, \\ & X = - q ^ { N - 2 t } \tilde { B } _ { \lambda, \mu } - q ^ { 2 s - N } \tilde { B } _ { \lambda, \nu }. \\ & ( \text{ii} ) & \ O n \ B _ { \mu }, \\ & Y = - q ^ { N - 2 r } \tilde { B } _ { \mu, \nu } - q ^ { 2 t - N } \tilde { B } _ { \mu, \lambda }. \\ & ( \text{ii} ) & \ O n \ B _ { \nu }, \\ & Z = - q ^ { N - 2 s } \tilde { B } _ { \nu, \lambda } - q ^ { 2 r - N } \tilde { B } _ { \nu, \mu }.$$
$$Z = - q ^ { N - 2 s } \tilde { B } _ { \nu, \lambda } - q ^ { 2 r - N } \tilde { B } _ { \nu, \mu }.$$
Proof. Use Lemma 14.6 and Proposition 21.19.
Proposition 21.21. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$X - q ^ { 2 s - N } I & = ( q ^ { 2 s - N } - q ^ { N - 2 t } ) \tilde { B } _ { \lambda, \lambda - \alpha }, \quad & X - q ^ { N - 2 t } I = ( q ^ { N - 2 t } - q ^ { 2 s - N } ) \tilde { B } _ { \lambda, \lambda + \gamma }, \\ Y - q ^ { 2 t - N } I & = ( q ^ { 2 t - N } - q ^ { N - 2 r } ) \tilde { B } _ { \lambda, \lambda - \beta }, \quad & Y - q ^ { N - 2 r } I = ( q ^ { N - 2 r } - q ^ { 2 t - N } ) \tilde { B } _ { \lambda, \lambda + \alpha }, \\ Z - q ^ { 2 r - N } I & = ( q ^ { 2 r - N } - q ^ { N - 2 s } ) \tilde { B } _ { \lambda, \lambda - \gamma }, \quad & Z - q ^ { N - 2 s } I = ( q ^ { N - 2 s } - q ^ { 2 r - N } ) \tilde { B } _ { \lambda, \lambda + \beta }.$$
Proof. We verify the equations in the top row. First assume r = 0, so that s + t = N . In each equation the left-hand side is zero by Lemma 21.18. In each equation the right-hand side is zero since 2 s -N = N -2 . t Next assume r ≥ 1. Define
$$\mu = ( r - 1, s + 1, t ) = \lambda - \alpha, \quad \nu = ( r - 1, s, t + 1 ) = \lambda + \gamma.$$
The locations λ, µ, ν form a black 3-clique in ∆ N that corresponds to the location ( r -1 , s, t ) in ∆ N -1 under the bijection of Lemma 4.31. Apply Corollary 21.20(i) to this 3-clique and in the resulting equation (52) eliminate ˜ B λ,µ or ˜ B λ,ν using (17). We have verified the equations in the top row. The other equations are similarly verified.
Corollary 21.22. For each location λ = ( r, s, t ) in ∆ N ,
$$( X - q ^ { 2 s - N } I ) B _ { \lambda } & \subseteq B _ { \lambda - \alpha }, \quad \quad ( X - q ^ { N - 2 t } I ) B _ { \lambda } \subseteq B _ { \lambda + \gamma }, \\ ( Y - q ^ { 2 t - N } I ) B _ { \lambda } & \subseteq B _ { \lambda - \beta }, \quad \quad ( Y - q ^ { N - 2 r } I ) B _ { \lambda } \subseteq B _ { \lambda + \alpha }, \\ ( Z - q ^ { 2 r - N } I ) B _ { \lambda } & \subseteq B _ { \lambda - \gamma }, \quad \quad ( Z - q ^ { N - 2 s } I ) B _ { \lambda } \subseteq B _ { \lambda + \beta }.$$
/negationslash
Moreover, equality holds in each inclusion provided that q 2 i = 1 for 1 ≤ i ≤ N .
Proof. By Note 14.2 and Proposition 21.21.
Our next goal is to show that the elements X,Y,Z from Definition 21.17 satisfy the defining relations for U q ( sl 2 ) given in (48).
Lemma 21.23. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$q ( I - X Y ) & = - q ^ { N - 2 r + 1 } ( X - q ^ { N - 2 t } I ) - q ^ { 2 s - N - 1 } ( Y - q ^ { 2 t - N } I ) = q ^ { - 1 } ( I - Y X ), \\ q ( I - Y Z ) & = - q ^ { N - 2 s + 1 } ( Y - q ^ { N - 2 r } I ) - q ^ { 2 t - N - 1 } ( Z - q ^ { 2 r - N } I ) = q ^ { - 1 } ( I - Z Y ), \\ q ( I - Z X ) & = - q ^ { N - 2 t + 1 } ( Z - q ^ { N - 2 s } I ) - q ^ { 2 r - N - 1 } ( X - q ^ { 2 s - N } I ) = q ^ { - 1 } ( I - X Z ).$$
Proof. We verify the equation on the left in the bottom row. For this equation let M denote the left-hand side minus the right-hand side. We show M = 0 on B λ . First assume r = 0, so that s + t = N . By Lemma 21.18 X = q N -2 t I on B λ . By these comments we routinely obtain M = 0 on B λ . Next assume r ≥ 1. Observe λ + γ = ( r -1 , s, t +1) ∈ ∆ . By Lemma N 14.5 the maps ˜ B λ,λ + γ : B λ → B λ + γ and ˜ B λ + γ,λ : B λ + γ → B λ are inverses. Using Proposition 21.21 we find that on B λ ,
$$X - q ^ { N - 2 t } I = ( q ^ { N - 2 t } - q ^ { 2 s - N } ) \tilde { B } _ { \lambda, \lambda + \gamma },$$
and on B λ + γ ,
$$Z - q ^ { 2 r - 2 - N } I = ( q ^ { 2 r - 2 - N } - q ^ { N - 2 s } ) \tilde { B } _ { \lambda + \gamma, \lambda }.$$
Therefore on B λ ,
$$( Z - q ^ { 2 r - 2 - N } I ) ( X - q ^ { N - 2 t } I ) = ( q ^ { 2 r - 2 - N } - q ^ { N - 2 s } ) ( q ^ { N - 2 t } - q ^ { 2 s - N } ) I.$$
Evaluating (53) using r + + s t = N we find that M = 0 on B λ . We have verified the equation on the left in the bottom row. The remaining equations are similarly verified.
Lemma 21.24. The elements X,Y,Z from Definition 21.17 satisfy
$$q ( I - X Y ) & = q ^ { - 1 } ( I - Y X ), \\ q ( I - Y Z ) & = q ^ { - 1 } ( I - Z Y ), \\ q ( I - Z X ) & = q ^ { - 1 } ( I - X Z ).$$
Proof. By Lemma 21.23 these equations hold on B λ for all λ ∈ ∆ . The result holds in view N of Corollary 7.7.
Proposition 21.25. The elements X,Y,Z from Definition 21.17 satisfy
$$\frac { q X Y - q ^ { - 1 } Y X } { q - q ^ { - 1 } } = I, \quad \frac { q Y Z - q ^ { - 1 } Z Y } { q - q ^ { - 1 } } = I, \quad \frac { q Z X - q ^ { - 1 } X Z } { q - q ^ { - 1 } } = I.$$
Proof.
These equations are a reformulation of the equations in Lemma 21.24.
/negationslash
Theorem 21.26. Let V denote a vector space over F with dimension N +1 . Let B denote a Billiard Array on V . Assume that each white 3-clique in ∆ N has B -value q -2 . Then there exists a unique U q ( sl 2 ) -module structure on V such that for 0 ≤ i ≤ N , x -q N -2 i I (resp. y -q N -2 i I ) (resp. z -q N -2 i I ) vanishes on component i of the B -decomposition [2 , 3] (resp. [3 , 1] ) (resp. [1 , 2] ). The U q ( sl 2 ) -module V is irreducible, provided that q 2 i = 1 for 1 ≤ i ≤ N .
Proof. The U q ( sl 2 )-module structure exists by Proposition 21.25. It is unique by construction. The last assertion of the theorem is readily checked.
Definition 21.27. [15, Definition 3.1] Let ν , ν x y , ν z denote the following elements in U q ( sl 2 ):
$$\begin{array} { c } s _ { 1 } ( x _ { 1 } ) y _ { 2 } ( x _ { 2 } ) \\ \nu _ { x } = q ( 1 - y z ) = q ^ { - 1 } ( 1 - z y ), \\ \nu _ { y } = q ( 1 - z x ) = q ^ { - 1 } ( 1 - x z ), \\ \nu _ { z } = q ( 1 - x y ) = q ^ { - 1 } ( 1 - y x ). \\........................................................................................................................................................................................................
....................................................................................................................................................................................................... \end{array}$$
Our next goal is to describe the actions of ν , ν x y , ν z on { B λ } λ ∈ ∆ N .
Proposition 21.28. For each location λ = ( r, s, t ) in ∆ N the following hold on B λ :
$$\ast$$
$$\nu _ { x } & = q ^ { t - 2 s - 1 } ( q ^ { t } - q ^ { - t } ) \tilde { B } _ { \lambda, \lambda - \gamma } - q ^ { 2 t - s + 1 } ( q ^ { s } - q ^ { - s } ) \tilde { B } _ { \lambda, \lambda + \alpha }, \\ \nu _ { y } & = q ^ { r - 2 t - 1 } ( q ^ { r } - q ^ { - r } ) \tilde { B } _ { \lambda, \lambda - \alpha } - q ^ { 2 r - t + 1 } ( q ^ { t } - q ^ { - t } ) \tilde { B } _ { \lambda, \lambda + \beta }, \\ \nu _ { z } & = q ^ { s - 2 r - 1 } ( q ^ { s } - q ^ { - s } ) \tilde { B } _ { \lambda, \lambda - \beta } - q ^ { 2 s - r + 1 } ( q ^ { r } - q ^ { - r } ) \tilde { B } _ { \lambda, \lambda + \gamma }. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
Proof. Evaluate the equations in Lemma 21.23 using Proposition 21.21 and Definition 21.27.
Corollary 21.29. For each location λ ∈ ∆ N ,
$$\nu _ { x } B _ { \lambda } \subseteq B _ { \lambda + \alpha } + B _ { \lambda - \gamma }, \quad \nu _ { y } B _ { \lambda } \subseteq B _ { \lambda + \beta } + B _ { \lambda - \alpha }, \quad \nu _ { z } B _ { \lambda } \subseteq B _ { \lambda + \gamma } + B _ { \lambda - \beta }.$$
Proof. By Note 14.2 and Proposition 21.28.
Recall the B -flags [1] , [2] , [3] from Definition 9.9.
/negationslash
Proposition 21.30. Assume that q 2 i = 1 for 1 ≤ i ≤ N . Then the B -flags [1] , [2] , [3] are, respectively,
$$\{ \nu _ { x } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { y } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { z } ^ { N - i } V \} _ { i = 0 } ^ { N }.$$
Proof. Similar to the proof of Proposition 21.14.
Corollary 21.31. Assume that q is not a root of unity. Let V denote an irreducible U q ( sl 2 ) -module with dimension N +1 . Then
- (i) the following are totally opposite flags on V :
$$\{ \nu _ { x } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { y } ^ { N - i } V \} _ { i = 0 } ^ { N }, \quad \{ \nu _ { z } ^ { N - i } V \} _ { i = 0 } ^ { N }.$$
- (ii) for the corresponding Billiard Array on V , the value of each white 3-clique is q -2 .
Proof. By [11, Theorem 2.1] and [12, Theorem 2.6], each of x, y, z is diagonalizable on V . Moreover by [11, Theorem 2.1] and [12, Theorem 2.6], there exists ε ∈ { 1 , - } 1 such that for each of x, y, z the eigenvalues on V are { εq N -2 i } N i =0 . The U q ( sl 2 )-module V has type ε in the sense of [12, Section 5.2]. Replacing x, y, z by εx, εy, εz respectively, the type becomes 1 and ν , ν x y , ν z are unchanged. By [12, Theorem 2.6], up to isomorphism there exists a unique irreducible U q ( sl 2 )-module with type 1 and dimension N + 1. The U q ( sl 2 )-module from Theorem 21.26 is irreducible, with type 1 and dimension N +1. Therefore the U q ( sl 2 )-module V is isomorphic to the U q ( sl 2 )-module from Theorem 21.26. Via the isomorphism we identify these U q ( sl 2 )-modules. Consider the Billiard Array B on V from Theorem 21.26. By Theorem 12.4 and Proposition 21.30, the three sequences in line (54) are totally opposite flags on V , and B is the corresponding Billiard Array. By the assumption of Theorem 21.26, the B -value of each white 3-clique is q -2 .
$$\cdot$$
## 22 Acknowledgments
The author thanks Jae-ho Lee and Kazumasa Nomura for giving this paper a close reading and offering valuable suggestions.
## References
- [1] H. Alnajjar. Leonard pairs associated with the equitable generators of the quantum algebra U q ( sl 2 ). Linear Multilinear Algebra 59 (2011) 1127-1142.
- [2] G. Benkart and P. Terwilliger. The equitable basis for sl 2 . Math. Z. 268 (2011) 535-557. arXiv:0810.2066 .
- [3] D. Funk-Neubauer. Bidiagonal pairs, the Lie algebra sl 2 , and the quantum group U q ( sl 2 ). J. Algebra Appl . 12 (2013) 1250207, 46 pp. arXiv:1108.1219 .
- [4] B. Hartwig and P. Terwilliger. The tetrahedron algebra, the Onsager algebra, and the s l 2 loop algebra. J. Algebra 308 (2007) 840-863. arXiv:math-ph/0511004 .
- [5] H. Huang. The classification of Leonard triples of QRacah type. Linear Algebra Appl. 436 (2012) 1442-1472. arXiv:1108.0458 .
- [6] J. E. Humphreys. Introduction to Lie Algebras and Representation Theory . Graduate Texts in Math. 9, Springer, New York, 1972.
- [7] T. Ito, H. Rosengren, P. Terwilliger. Evaluation modules for the q -tetrahedron algebra. Linear Algebra Appl. 451 (2014) 107-168. arXiv:1308.3480 .
- [8] T. Ito and P. Terwilliger. Tridiagonal pairs and the quantum affine algebra U q ( ̂ s l 2 ). Ramanujan J. 13 (2007) 39-62. arXiv:math/0310042 .
- [9] T. Ito and P. Terwilliger. Two non-nilpotent linear transformations that satisfy the cubic q -Serre relations. J. Algebra Appl. 6 (2007) 477-503. arXiv:math/0508398 .
- [10] T. Ito and P. Terwilliger. The q -tetrahedron algebra and its finite-dimensional irreducible modules. Comm. Algebra 35 (2007) 3415-3439. arXiv:math/0602199 .
- [11] T. Ito, P. Terwilliger, C. Weng. The quantum algebra U q ( sl 2 ) and its equitable presentation. J. Algebra 298 (2006) 284-301. arXiv:math/0507477 .
- [12] J. Jantzen. Lectures on quantum groups . Graduate Studies in Mathematics, 6. Amer. Math. Soc., Providence, RI, 1996.
- [13] S. Roman. Lattices and ordered sets. Springer, New York, 2008.
- [14] P. Terwilliger. The equitable presentation for the quantum group U q ( g ) associated with a symmetrizable Kac-Moody algebra g . J. Algebra 298 (2006) 302-319. arXiv:math/0507478 .
- [15] P. Terwilliger. The universal Askey-Wilson algebra and the equitable presentation of U q ( sl 2 ). SIGMA 7 (2011) 099, 26 pp. arXiv:1107.3544 .
- [16] P. Terwilliger. Finite-dimensional irreducible U q ( sl 2 )-modules from the equitable point of view. Linear Algebra Appl. 439 (2013) 358-400. arXiv:1303.6134 .
- [17] C. Worawannotai. Dual polar graphs, the quantum algebra U q ( sl 2 ), and Leonard systems of dual q -Krawtchouk type. Linear Algebra Appl. 438 (2013) 443-497. arXiv:1205.2144.
Paul Terwilliger Department of Mathematics University of Wisconsin 480 Lincoln Drive Madison, WI 53706-1388 USA email: [email protected] | null | [
"Paul Terwilliger"
] | 2014-08-01T12:03:45+00:00 | 2014-08-01T12:03:45+00:00 | [
"math.QA",
"math.RT",
"17B37"
] | Billiard Arrays and finite-dimensional irreducible $U_q(\mathfrak{sl}_2)$-modules | We introduce the notion of a Billiard Array. This is an equilateral
triangular array of one-dimensional subspaces of a vector space $V$, subject to
several conditions that specify which sums are direct. We show that the
Billiard Arrays on $V$ are in bijection with the 3-tuples of totally opposite
flags on $V$. We classify the Billiard Arrays up to isomorphism. We use
Billiard Arrays to describe the finite-dimensional irreducible modules for the
quantum algebra $U_q(\mathfrak{sl}_2)$ and the Lie algebra $\mathfrak{sl}_2$. |
1408.0144v3 | ## Cutting down p
## -trees and
## inhomogeneous continuum random trees
Nicolas Broutin ∗
Minmin Wang †
## Abstract
Westudy a fragmentation of the p -trees of Camarri and Pitman [ Elect. J. Probab. , vol. 5, pp. 1-18, 2000]. We give exact correspondences between the p -trees and trees which encode the fragmentation. We then use these results to study the fragmentation of the ICRTs (scaling limits of p -trees) and give distributional correspondences between the ICRT and the tree encoding the fragmentation. The theorems for the ICRT extend the ones by Bertoin and Miermont [ Ann. Appl. Probab. , vol. 23(4), pp. 1469-1493, 2013] about the cut tree of the Brownian continuum random tree.
## 1 Introduction
The study of random cutting of trees has been initiated by Meir and Moon [40] in the following form: Given a (graph theoretic) tree, one can proceed to chop the tree into pieces by iterating the following process: choose a uniformly random edge; removing it disconnects the tree into two pieces; discard the part which does not contain the root and keep chopping the portion containing the root until it is reduced to a single node. In the present document, we consider the related version where the vertices are chosen at random and removed (until one is left with an empty tree); each such pick is referred to as a cut . We will see that this version is actually much more adapted than the edge cutting procedure to the problems we consider here.
The main focus in [40] and in most of the subsequential papers has been put on the study of some parameters of this cutting down process, and in particular on how many cuts are necessary for the process to finish. This has been studied for a number of different models of deterministic and random trees such as complete binary trees of a given height, random trees arising from the divide-and-conquer paradigm [24, 32-34] and the family trees of finite-variance critical Galton-Watson processes conditioned on the total progeny [29, 36, 42]. The latter model of random trees turns out to be far more interesting, and it provides an a posteriori motivation for the cutting down process. As we will see shortly, the cutting down process provides an interesting way to investigate some of the structural properties of random trees by partial destruction and re-combination, or equivalently as partially resampling the tree.
Let us now be more specific: if L n denotes the number of cuts required to completely cut down a uniformly labelled rooted tree (random Cayley tree, or equivalently condition Galton-Watson tree with Poisson offspring distribution) on n nodes, then n -1 2 / L n converges in distribution to a Rayleigh distribution which has density xe -x / 2 2 on R + . Janson [36] proved that a similar result holds for any Galton-Watson tree with a finite-variance offspring distribution conditioned on the total progeny to be n . This is the parameter point of view. Addario-Berry, Broutin, and Holmgren [3] have shown that for the random Cayley trees, L n actually has the same distribution as the number of nodes on the path between two uniformly random nodes. Their method relies on an 'objective' argument based on a coupling that
∗ Inria Paris-Rocquencourt, Domaine de Voluceau, 78153 Le Chesnay - France. Email: [email protected]
† Universit´ e Pierre et Marie Curie, 4 place Jussieu, 75005 Paris - France. Email: [email protected]
associates with the cutting procedure a partial resampling of the Cayley tree of the kind mentioned earlier: if one considers the (ordered) sequence of subtrees which are discarded as the cutting process goes on, and adds a path linking their roots, then the resulting tree is a uniformly random Cayley tree, and the two extremities of the path are independent uniform random nodes. So the properties of the parameter L n follow from a stronger correspondence between the combinatorial objects themselves.
This strong connection between the discrete objects can be carried to the level of their scaling limit, namely Aldous' Brownian continuum random tree (CRT) [5]. Without being too precise for now, the natural cutting procedure on the Brownian CRT involves a Poisson rain of cuts sampled according to the length measure. However, not all the cuts contribute to the isolation of the root. As in the partial resampling of the discrete setting, we glue the sequence of discarded subtrees along an interval, thereby obtaining a new CRT. If the length of the interval is well-chosen (as a function of the cutting process), the tree obtained is distributed like the Brownian CRT and the two ends of the interval are independently random leaves. This identifies the distribution of the discarded subtrees from the cutting procedure as the distribution of the forest one obtains from a spinal decomposition of the Brownian CRT. The distribution of the latter is intimately related to Bismut's [18] decomposition of a Brownian excursion. See also [25] for the generalization to the L´ evy case. Note that a similar identity has been proved by Abraham and Delmas [2] for general L´ evy trees without using a discrete approximation. A related example is that of the subtree prune and re-graft dynamics of Evans et al. [28] [See also 26], which is even closer to the cutting procedure and truly resamples the object rather than giving a 'recursive' decomposition.
The aim of this paper is two-fold. First we prove exact identities and give reversible transformations of p -trees similar to the ones for Cayley trees in [3]. The model of p -trees introduced by Camarri and Pitman [21] generalizes Cayley trees in allowing 'weights' on the vertices. In particular, this additional structure of weights introduces some inhomogeneity. We then lift these results to the scaling limits, the inhomogeneous continuum random trees (ICRT) of Aldous and Pitman [8], which are closely related to the general additive coalescent [8, 13, 14]. Unlike the Brownian CRT or the stable trees (special cases of L´ evy trees), a general ICRT is not self-similar. Nor does it enjoy a 'branching property' as the L´vy trees e do [37]. This lack of 'recursivity' ruins the natural approaches such as the one used in [1, 2] or the ones which would argue by comparing two fragmentations with the same dislocation measure but different indices of self-similarity [15]. This is one of the reasons why we believe these path transformations at the level of the ICRT are interesting. Furthermore, a conjecture of Aldous, Miermont, and Pitman [10, p. 185] suggests that the path transformations for ICRTs actually explain the result of Abraham and Delmas [2] for L´ evy trees by providing a result 'conditional on the degree distribution'.
Second, rather than only focusing on the isolation of the root we also consider the genealogy of the entire fragmentation as in the recent work of Bertoin and Miermont [16] and Dieuleveut [23] (who examine the case of Galton-Watson trees). In some sense, this consists in obtaining transformations corresponding to tracking the effect of the cutting down procedure on the isolation of all the points simultaneously. Tracking finitely many points is a simple generalization of the one-point results, but the 'complete' result requires additional insight. The results of the present document are used in a companion paper [20] to prove that the 'complete' cutting procedure in which one tries to isolate every point yields a construction of the genealogy of the fragmentation on ICRTs which is reversible in the case of the Brownian CRT. More precisely, the genealogy of Aldous-Pitman's fragmentation of a Brownian CRT is another Brownian CRT, say G , and there exists a random transformation of G into a real tree T such that in the pair ( T , G ) the tree G is indeed distributed as the genealogy of the fragmentation on T , conditional on T . The proof there relies crucially on the 'bijective' approach that we develop here.
Plan of the paper. In the next section, we introduce the necessary notation and relevant background. We then present more formally the discrete and continuous models we are considering, and in which sense the inhomogeneous continuum random trees are the scaling limit of p -trees. In Section 3 we introduce the cutting down procedures and state our main results. The study of cutting down procedure for p -trees
is the topic of Section 4. The results are lifted to the level of the scaling limits in Section 5.
## 2 Notation, models and preliminaries
Although we would like to introduce our results earlier, a fair bit of notation and background is in order before we can do so properly. This section may safely be skipped by the impatient reader and referred to later on.
## 2.1 Aldous-Broder Algorithm and p -trees
Let A be a finite set and p = ( p , u u ∈ A ) be a probability measure on A such that min u ∈ A p u > 0 ; this ensures that A is indeed the support of p . Let T A denote the set of rooted trees labelled with (all the) elements of A (connected acyclic graphs on A , with a distinguished vertex). For t ∈ T A , we let r = ( ) r t denote its root vertex. For u, v ∈ A , we write { u, v } to mean that u and v are adjacent in t . We sometimes write 〈 u, v 〉 to mean that { u, v } is an edge of t , and that u is on the path between r and v (we think of the edges as pointing towards the root). For a tree t ∈ T A (rooted at r , say) and a node v ∈ A , we let t v denote the tree re-rooted at v .
We usually abuse notation, but we believe it does not affect the clarity or precision of our statements. For instance, we refer to a node u in the vertex set v ( ) t of a tree t using u ∈ t . Depending on the context, we sometimes write t \{ u } to denote the forest induced by t on the vertex set v ( ) t \{ u } . The (in-)degree C u ( ) t of a vertex u ∈ A is the number of edges of the form 〈 u, v 〉 with v ∈ A . For a rooted tree t , and a node u of t , we write Sub( t, u ) for the subtree of t rooted at u (above u ). For t ∈ T A and V ⊆ A , we write Span( ; t V ) for the subtree of t spanning V and the root of r t ( ) . So Span( ; t V ) is the subtree induced by t on the set
$$\bigcup _ { u \in \mathbf V } \left [ r ( t ), u \right ],$$
where J u, v K denotes collection of nodes on the (unique) path between u and v in t . When V = { v , v 1 2 , . . . , v k } , we usually write Span( ; t v , . . . , v 1 k ) instead of Span( ; t { v , . . . , v 1 k } ) . We also write
$$\text{Span} ^ { * } ( t ; \mathbf V ) \coloneqq \text{Span} ( t ; \mathbf V ) \, \langle \, \{ r ( t ) \}.$$
As noticed by Aldous [12] and Broder [19], one can generate random trees on A by extracting a tree from the trace of a random walk on A , where the sequence of steps is given by a sequence of i.i.d. vertices distributed according to p .
Algorithm 2.1 (Weighted version of Aldous-Broder Algorithm) . Let Y = ( Y , j j ≥ 0) be a sequence of independent variables with common distribution p ; further on, we say that Y j are i.i.d. p -nodes. Let T ( Y ) be the graph rooted at Y 0 with the set of edges
$$\{ \langle Y _ { j - 1 }, Y _ { j } \rangle \colon Y _ { j } \notin \{ Y _ { 0 }, \cdots, Y _ { j - 1 } \}, j \geq 1 \}.$$
The sequence Y defines a random walk on A , which eventually visits every element of A with probability one, since A is the support of p . So the trace {〈 Y j -1 , Y j 〉 : j ≥ 1 } of the random walk on A is a connected graph on A , rooted at Y 0 . Algorithm 2.1 extracts the tree T ( Y ) from the trace of the random walk. To see that T ( Y ) is a tree, observe that the edge 〈 Y j -1 , Y j 〉 is added only if Y j has never appeared before in the sequence. It follows easily that T ( Y ) is a connected graph without cycles, hence a tree on A . Let π denote the distribution of T ( Y ) .
Lemma 2.2 ([12, 19, 27]) . For t ∈ T A , we have
$$\pi ( t ) \coloneqq \pi ^ { ( p ) } ( t ) = \prod _ { u \in A } p _ { u } ^ { C _ { u } ( t ) }.$$
Note that π is indeed a probability distribution on T A , since by Cayley's multinomial formula ([22, 43]), we have
$$\sum _ { t \in \mathbb { T } _ { A } } \pi ( t ) = \sum _ { t \in \mathbb { T } _ { A } } \prod _ { u \in A } p _ { u } ^ { C _ { u } ( t ) } = \left ( \sum _ { u \in A } p _ { u } \right ) ^ { | A | - 1 } = 1. \quad \quad ( 2. 3 )$$
Arandom tree on A distributed according to π as specified by (2.2) is called a p -tree . It is also called the birthday tree in the literature, for its connection with the general birthday problem (see [21]). Observe that when p is the uniform distribution on [ n ] := { 1 2 , , . . . , n } , a p -tree is a uniformly random rooted tree on [ n ] (a Cayley tree). So the results we are about to present generalize the exact distributional results in [3]. However, we believe that the point of view we adopt here is a little cleaner, since it permits to make the transformation exactly reversible without any extra anchoring nodes (which prevent any kind duality at the discrete level).
From now on, we consider n ≥ 1 and let [ n ] denote the set { 1 2 , , · · · , n } . Wewrite T n as a shorthand for T [ n ] , the set of the rooted trees on [ n ] . Let also p = ( p , i 1 ≤ i ≤ n ) be a probability measure on [ n ] satisfying min i ∈ [ n ] p i > 0 . For a subset A ⊆ [ n ] such that p ( A > ) 0 , we let p | A ( · ) = p ( · ∩ A / ) p ( A ) denote the restriction of p on A , and write π | A := π ( p | A ) . The following lemma says that the distribution of p -trees is invariant by re-rooting at an independent p -node and 'recursive' in a certain sense. These two properties are one of the keys to our results on the discrete objects. (For a probability distribution µ , we write X ∼ µ to mean that µ is the distribution of the random variable X .)
## Lemma 2.3. Let T be a p -tree on [ n ] .
- i) If V is an independent p -node. Then, T V ∼ π .
glyph[negationslash]
- ii) Let N be set of neighbors of the root in T . Then, for u ∈ N , conditional on v (Sub( T, u )) = V , Sub( T, u ) ∼ π | V independent of { Sub( T, w ) : w ∈ N,w = u } .
The first claim can be verified from (2.2), the second is clear from the product form of π .
## 2.2 Measured metric spaces and the Gromov-Prokhorov topology
If ( X,d ) is a metric space endowed with the Borel σ -algebra, we denote by M f ( X ) the set of finite measures on X and by M 1 ( X ) the subset of probability measures on X . If m ∈ M f ( X ) , we denote by supp( m ) the support of m on X , that is the smallest closed set A such that m A ( c ) = 0 . If f : X → Y is a measurable map between two metric spaces, and if m ∈ M f ( X ) , then the push-forward of m is an element of M f ( Y ) , denoted by f m ∗ ∈ M f ( Y ) , and is defined by ( f m ∗ )( A ) = m f ( -1 ( A )) for each Borel set A of Y . If m ∈ M f ( X ) and A ⊆ X , we denote by m glyph[harpoonupright] A the restriction of m to A : m glyph[harpoonupright] A ( B ) = m A ( ∩ B ) for any Borel set B . This should not be confused with the restriction of a probability measure, which remains a probability measure and is denoted by m | A .
We say a triple ( X,d,µ ) is a measured metric space (or sometimes a metric measure space ) if ( X,d ) is a Polish space (separable and complete) and µ ∈ M 1 ( X ) . Two measured metric spaces ( X,d,µ ) and ( X , d , µ ′ ′ ′ ) are said to be weakly isometric if there exists an isometry φ between the supports of µ on X and of µ ′ on X ′ such that ( φ ) ∗ µ = µ ′ . This defines an equivalence relation between the measured metric spaces, and we denote by M the set of equivalence classes. Note that if ( X,d,µ ) and ( X , d , µ ′ ′ ′ ) are weakly isometric, the metric spaces ( X,d ) and ( X , d ′ ′ ) may not be isometric.
We can define a metric on M by adapting Prokhorov's distance. Consider a metric space ( X,d ) and for glyph[epsilon1] > 0 , let A glyph[epsilon1] := { x ∈ X : d x, A ( ) < glyph[epsilon1] } . Then, given two (Borel) probability measures µ, ν ∈ M 1 ( X ) , the Prokhorov distance d P between µ and ν is defined by
$$\text{dp} ( \mu, \nu ) \coloneqq \inf \{ \epsilon > 0 \, \colon \mu ( A ) \leq \nu ( A ^ { \epsilon } ) + \epsilon \, \text{and} \, \nu ( A ) \leq \mu ( A ^ { \epsilon } ) + \epsilon, \text{ for all Borel sets } A \}. \quad ( 2. 4 )$$
Note that the definition of the Prokhorov distance (2.4) can be easily extended to a pair of finite (Borel) measures on X . Then, for two measured metric spaces ( X,d,µ ) and ( X , d , µ ′ ′ ′ ) the Gromov-Prokhorov
(GP) distance between them is defined to be
$$\text{d} _ { \text{GP} } ( ( X, d, \mu ), ( X ^ { \prime }, d ^ { \prime }, \mu ^ { \prime } ) ) = \inf _ { Z, \phi, \psi } \text{d} _ { \text{GP} } ( \phi _ { * } \mu, \psi _ { * } \mu ^ { \prime } ),$$
where the infimum is taken over all metric spaces Z and isometric embeddings φ : supp( µ ) → Z and ψ : supp( µ ′ ) → Z . It is clear that d GP depends only on the equivalence classes containing ( X,d,µ ) and ( X , d , µ ′ ′ ′ ) . Moreover, the Gromov-Prokhorov distance turns M in a Polish space.
There is another more convenient characterization of the GP topology (the topology induced by d GP ) that relies on convergence of distance matrices between random points. Let X = ( X,d,µ ) be a measured metric space and let ( ξ , i i ≥ 1) be a sequence of i.i.d. points of common distribution µ . In the following, we will often refer to such a sequence as ( ξ , i i ≥ 1) as an i.i.d. µ -sequence. We write ρ X = ( ( d ξ , ξ i j ) , 1 ≤ i, j < ∞ ) for the distance matrix associated with this sequence. One easily verifies that the distribution of ρ X does not depend on the particular element of an equivalent class of M . Moreover, by Gromov's reconstruction theorem [30, 3 1 2 ], the distribution of ρ X characterizes X as an element of M .
Proposition 2.4 (Corollary 8 of [38]) . If X is some random element taking values in M and for each n ≥ 1 , X n is a random element taking values in M , then X n converges to X in distribution as n →∞ if and only if ρ X n converges to ρ X in the sense of finite-dimensional distributions.
Pointed Gromov-Prokhorov topology. The above characterization by matrix of distances turns out to be quite handy when we want to keep track of marked points. Let k ∈ N . If ( X,d,µ ) is a measured metric space and x = ( x , x 1 2 , · · · , x k ) ∈ X k is a k -tuple, then we say ( X,d,µ, x ) is a k -pointed measured metric space , or simply a pointed measured metric space. Two pointed metric measure spaces ( X,d,µ, x ) and ( X , d , µ , ′ ′ ′ x ′ ) are said to be weakly isometric if there exists an isometric bijection
$$\phi \colon \text{supp} ( \mu ) \cup \{ x _ { 1 }, x _ { 2 }, \cdots, x _ { k } \} \to \text{supp} ( \mu ^ { \prime } ) \cup \{ x _ { 1 } ^ { \prime }, x _ { 2 } ^ { \prime }, \cdots, x _ { k } ^ { \prime } \}$$
such that ( φ ) ∗ µ = µ ′ and φ x ( i ) = x ′ i , 1 ≤ i ≤ k , where x = ( x , x 1 2 , · · · , x k ) and x ′ = ( x , x ′ 1 ′ 2 , · · · , x ′ k ) . We denote by M ∗ k the space of weak isometry-equivalence classes of k -pointed measured metric spaces. Again, we emphasize the fact that the underlying metric spaces ( X,d ) and ( X , d ′ ′ ) do not have to be isometric. The space M ∗ k equipped with the following pointed Gromov-Prokhorov topology is a Polish space.
A sequence ( X ,d ,µ , n n n x n n ) ≥ 1 of k -pointed measured metric spaces is said to converge to some pointed measured metric space ( X,d,µ, x ) in the k -pointed Gromov-Prokhorov topology if for any m ≥ 1 ,
$$\left ( d _ { n } ( \xi _ { n, i } ^ { * }, \xi _ { n, j } ^ { * } ), 1 \leq i, j \leq m \right ) \overset { n \rightarrow \infty } { \longrightarrow } \left ( d ( \xi _ { i } ^ { * }, \xi _ { j } ^ { * } ), 1 \leq i, j \leq m \right ),$$
where for each n ≥ 1 and 1 ≤ i ≤ k , ξ ∗ n,i = x n,i if x n = ( x n, 1 , x n, 2 , · · · , x n,k ) and ( ξ ∗ n,i , i ≥ k +1) is a sequence of i.i.d. µ n -points in X n . Similarly, ξ ∗ i = x i for 1 ≤ i ≤ k and ( ξ ∗ i , i ≥ k +1) is a sequence of i.i.d. µ -points in X . This induces the k -pointed Gromov-Prokhorov topology on M ∗ k .
## 2.3 Compact metric spaces and the Gromov-Hausdorff metric
Gromov-Hausdorff metric. Two compact subsets A and B of a given metric space ( X,d ) are compared using the Hausdorff distance d H .
$$d _ { H } ( A, B ) \coloneqq \inf \{ \epsilon > 0 \, \colon A \subseteq B ^ { \epsilon } \, \text{and} \, B \subseteq A ^ { \epsilon } \}.$$
To compare two compact metric spaces ( X,d ) and ( X , d ′ ′ ) , we first embed them into a single metric space ( Z, δ ) via isometries φ : X → Z and ψ : X ′ → Z , and then compare the images φ X ( ) and ψ X ( ′ ) using the Hausdorff distance on Z . One then defines the Gromov-Hausdoff (GH) distance d GH by
$$d _ { \text{GH} } ( ( X, d ), ( X ^ { \prime }, d ^ { \prime } ) ) \coloneqq \inf _ { Z, \phi, \psi } d _ { \text{H} } ( \phi ( X ), \psi ( X ^ { \prime } ) ),$$
where the infimum ranges over all choices of metric spaces Z and isometric embeddings φ : X → Z and ψ : X ′ → Z . Note that, as opposed to the case of the GP topology, two compact metric spaces that are at GH distance zero are isometric.
Gromov-Hausdorff-Prokhorov metric. Now if ( X,d ) and ( X , d ′ ′ ) are two compact metric spaces and if µ ∈ M f ( X ) and µ ′ ∈ M f ( X ′ ) , one way to compare simultaneously the metric spaces and the measures is to define
$$d _ { \text{GHP} } \left ( ( X, d, \mu ), ( X ^ { \prime }, d ^ { \prime }, \mu ^ { \prime } ) \right ) \coloneqq \inf _ { Z, \phi, \psi } \left \{ d _ { \text{H} } \left ( \phi ( X ), \psi ( X ^ { \prime } ) \right ) \vee d _ { \text{P} } ( \phi _ { * } \mu, \psi _ { * } \mu ^ { \prime } ) \right \},$$
where the infimum ranges over all choices of metric spaces Z and isometric embeddings φ : X → Z and ψ : X ′ → Z . If we denote by M c the set of equivalence classes of compact measured metric spaces under measure-preserving isometries, then M c is Polish when endowed with d GHP .
Pointed Gromov-Hausdorff metric. We fix some k ∈ N . Given two compact metric spaces ( X,d X ) and ( Y, d Y ) , let x = ( x , x 1 2 , · · · , x k ) ∈ X k and y = ( y , y 1 2 , · · · , y k ) ∈ Y k . Then the pointed GromovHausdorff metric between ( X,d X , x ) and ( Y, d Y , y ) is defined to be
$$d _ { p G H } \left ( ( X, d _ { X }, \mathbf x ), ( Y, d _ { Y }, \mathbf y ) \right ) \coloneqq \inf _ { Z, \phi, \psi } \left \{ d _ { H } \left ( \phi ( X ), \psi ( Y ) \right ) \vee \max _ { 1 \leq i \leq k } d _ { Z } \left ( \phi ( x _ { i } ), \psi ( y _ { i } ) \right ) \right \},$$
where the infimum ranges over all choices of metric spaces Z and isometric embeddings φ : X → Z and ψ : X ′ → Z . Let M k c denote the isometry-equivalence classes of those compact metric spaces with k marked points. It is a Polish space when endowed with d pGH .
## 2.4 Real trees
A real tree is a geodesic metric space without loops. More precisely, a metric space ( X,d,r ) is called a (rooted) real tree if r ∈ X and
- · for any two points x, y ∈ X , there exists a continuous injective map φ xy : [0 , d ( x, y )] → X such that φ xy (0) = x and φ xy ( d x, y ( )) = y . The image of φ xy is denoted by J x, y K ;
- · if q : [0 , 1] → X is a continuous injective map such that q (0) = x and q (1) = y , then q ([0 , 1]) = J x, y K .
As for discrete trees, when it is clear from context which metric we are talking about, we refering to metric spaces by the sets. For instance ( T , d ) is often referred to as T .
A measured (rooted) real tree is a real tree ( X,d,r ) equipped with a finite (Borel) measure µ ∈ M ( X ) . We always assume that the metric space ( X,d ) is complete and separable. We denote by T w the set of the weak isometry equivalence classes of measured rooted real trees, equipped with the pointed Gromov-Prokhorov topology. Also, let T c w be the set of the measure-preserving isometry equivalence classes of those measured rooted real trees ( X,d,r, µ ) such that ( X,d ) is compact. We endow T c w with the pointed Gromov-Hausdorff-Prokhorov distance. Then both T w and T c w are Polish spaces. However in our proofs, we do not always distinguish an equivalence class and the elements in it.
Let ( T, d, r ) be a rooted real tree. For u ∈ T , the degree of u in T , denoted by deg( u, T ) , is the number of connected components of T \ { u } . We also denote by
$$\text{Lf} ( T ) = \{ u \in T \, \colon \deg ( u, T ) = 1 \} \quad \text{and} \quad \text{Br} ( T ) = \{ u \in T \, \colon \deg ( u, T ) \geq 3 \}$$
the set of the leaves and the set of branch points of T , respectively. The skeleton of T is the complementary set of Lf( T ) in T , denoted by Sk( T ) . For two points u, v ∈ T , we denote by u ∧ v the closest common ancestor of u and v , that is, the unique point w of r, u ∩ r, v such that d u, v ( ) = d u, w ( ) + d w, v ( ) .
J K J K For a rooted real tree ( T, r ) , if x ∈ T then the subtree of T above x , denoted by Sub( T, x ) , is defined to be
$$\text{Sub} ( T, x ) \coloneqq \{ u \in T \colon x \in \mathbb { [ } r, u \mathbb { ] } \}.$$
Spanning subtree. Let ( T, d, r ) be a rooted real tree and let x = ( x , 1 · · · , x k ) be k points of T for some k ≥ 1 . We denote by Span( T ; x ) the smallest connected set of T which contains the root r and x , that is, Span( T ; x ) = ∪ 1 ≤ ≤ i k J r, x i K . We consider Span( T ; x ) as a real tree rooted at r and refer to it as a spanning subtree or a reduced tree of T .
If ( T, d, r ) is a real tree and there exists some x = ( x , x 1 2 , · · · , x k ) ∈ T k for some k ≥ 1 such that T = Span( T ; x ) , then the metric aspect of T is rather simple to visualize. More precisely, if we write x 0 = r and let ρ x = ( d x , x ( i j ) , 0 ≤ i, j ≤ k ) , then ρ x determines ( T, d, r ) under an isometry.
Gluing. If ( T , d i i ) , i = 1 2 , are two real trees with some distinguished points x i ∈ T i , i = 1 2 , , the result of the gluing of T 1 and T 2 at ( x , x 1 2 ) is the metric space ( T 1 ∪ T , δ 2 ) , where the distance δ is defined by
$$\delta ( u, v ) = \begin{cases} \ d _ { i } ( u, v ), & \text{if } ( u, v ) \in T _ { i } ^ { 2 }, i = 1, 2 ; \\ \ d _ { 1 } ( u, x _ { 1 } ) + d _ { 2 } ( v, x _ { 2 } ), & \text{if } u \in T _ { 1 }, v \in T _ { 2 }. \end{cases}$$
It is easy to verify that ( T 1 ∪ T , δ 2 ) is a real tree with x 1 and x 2 identified as one point, which we denote by T 1 glyph[circleasterisk] x 1 = x 2 T 2 in the following. Moreover, if T 1 is rooted at some point r , we make the convention that T 1 glyph[circleasterisk] x 1 = x 2 T 2 is also rooted at r .
## 2.5 Inhomogeneous continuum random trees
The inhomogeneous continuum random tree (abbreviated as ICRT in the following) has been introduced in [21] and [8]. See also [7, 10, 11] for studies of ICRT and related problems.
Let Θ (the parameter space ) be the set of sequences θ = ( θ , θ 0 1 , θ 2 , · · · ) ∈ R ∞ + such that θ 1 ≥ θ 2 ≥ θ 3 · · · ≥ 0 , θ 0 ≥ 0 , ∑ i ≥ 0 θ 2 i = 1 , and either θ 0 > 0 or ∑ i ≥ 1 θ i = ∞ .
Poisson point process construction. For each θ ∈ Θ , we can define a real tree T in the following way.
- · If θ 0 > 0 , let P 0 = { ( u , v j j ) , j ≥ 1 } be a Poisson point process on the first octant { ( x, y ) : 0 ≤ y ≤ x } of intensity measure θ dxdy 2 0 , ordered in such a way that u 1 < u 2 < u 3 < · · · .
- · For every i ≥ 1 such that θ i > 0 , let P = i { ξ i,j , j ≥ } 1 be a homogeneous Poisson process on R + of intensity θ i under P , such that ξ i, 1 < ξ i, 2 < ξ i, 3 < · · · .
All these Poisson processes are supposed to be mutually independent and defined on some common probability space (Ω , F , P ) . We consider the points of all these processes as marks on the half line R + , among which we distinguish two kinds: the cutpoints and the joinpoints . Acutpoint is either u j for some j ≥ 1 or ξ i,j for some i ≥ 1 and j ≥ 2 . For each cutpoint x , we associate a joinpoint x ∗ as follows: x ∗ = v j if x = u j for some j ≥ 1 and x ∗ = ξ i, 1 if x = ξ i,j for some i ≥ 1 and j ≥ 2 . One easily verifies that the hypotheses on θ imply that the set of cutpoints is a.s. finite on each compact set of R + , while the joinpoints are dense a.s. everywhere. (See for example [8] for a proof.) In particular, we can arrange the
cutpoints in increasing order as 0 < η 1 < η 2 < η 3 < · · · . This splits R + into countaly intervals that we now reassemble into a tree. We write η ∗ k for the joinpoint associated to the k -th cutpoint η k . We define R 1 to be the metric space [0 , η 1 ] rooted at 0 . For k ≥ 1 , we let
$$R _ { k + 1 } \coloneqq R _ { k } \underset { \eta _ { k } ^ { * } = \eta _ { k } } { \diamondsuit } [ \eta _ { k }, \eta _ { k + 1 } ].$$
In words, we graft the intervals [ η , η k k +1 ] by gluing the left end at the joinpoint η ∗ k . Note that we have η ∗ k < η k a.s., thus η ∗ k ∈ R k and the above grafting operation is well defined almost surely. It follows from this Poisson construction that ( R k ) k ≥ 1 is a consistent family of 'discrete' trees which also verifies the 'leaf-tight' condition in Aldous [5]. Therefore by [5, Theorem 3], the complete metric space T := ∪ k ≥ 1 R k is a real tree and almost surely there exists a probability measure µ , called the mass measure , which is concentrated on the leaf set of T . Moreover, if conditional on T , ( V , k k ≥ 1) is a sequence of i.i.d. points sampled according to µ , then for each k ≥ 1 , the spanning tree Span( T V , V , ; 1 2 · · · , V k ) has the same unconditional distribution as R k . The distribution of the weak isometry equivalence class of ( T , µ ) is said to be the distribution of an ICRT of parameter θ , which is a probability distribution on T w . The push-forward of the Lebesgue measure on R + defines a σ -finite measure glyph[lscript] on T , which is concentrated on Sk( T ) and called the length measure of T . Furthermore, it is not difficult to deduce the distribution of glyph[lscript] ( R 1 ) from the above construction of T :
$$\mathbb { P } \left ( \ell ( R _ { 1 } ) > r \right ) = \mathbb { P } \left ( \eta _ { 1 } > r \right ) = e ^ { - \frac { 1 } { 2 } \theta _ { 0 } ^ { 2 } r ^ { 2 } } \prod _ { i \geq 1 } ( 1 + \theta _ { i } r ) e ^ { - \theta _ { i } r }, \quad r > 0.$$
In the important special case when θ = (1 0 0 , , , · · · ) , the above construction coincides with the linebreaking construction of the Brownian CRT in [4, Algorithm 3], that is, T is the Brownian CRT. This case will be referred as the Brownian case in the sequel. We notice that whenever there is an index i ≥ 1 such that θ i > 0 , the point, denoted by β i , which corresponds to the joinpoint ξ i, 1 is a branch point of infinite degree. According to [10, Theorem 2]), θ i is a measurable function of ( T , β i ) , and we refer to it as the local time of β i in what follows.
ICRTs as scaling limits of p -trees. Let p n = ( p n 1 , p n 2 , · · · , p nn ) be a probability measure on [ n ] such that p n 1 ≥ p n 2 ≥ · · · ≥ p nn > 0 , n ≥ 1 . Define σ n ≥ 0 by σ 2 n = ∑ n i =1 p 2 ni and denote by T n the corresponding p n -tree, which we view as a metric space on [ n ] with graph distance d T n . Suppose that the sequence ( p n , n ≥ 1) verifies the following hypothesis: there exists some parameter θ = ( θ , i i ≥ 0) such that
$$\text{hat} \\ \lim _ { n \to \infty } \sigma _ { n } = 0, \quad \text{ and } \quad \lim _ { n \to \infty } \frac { p _ { n i } } { \sigma _ { n } } = \theta _ { i }, \quad \text{for every } i \geq 1.$$
Then, writing σ T n n for the rescaled metric space ([ n , σ ] n d T n ) , Camarri and Pitman [21] have shown that
$$( \sigma _ { n } T ^ { n }, p _ { n } ) \stackrel { n \to \infty } { \overrightarrow { d, \text{GP} } } ( \mathcal { T }, \mu ),$$
where → d, GP denotes the convergence in distribution with respect to the Gromov-Prokhorov topology.
## 3 Main results
## 3.1 Cutting down procedures for p -trees and ICRT
Consider a p -tree T . We perform a cutting procedure on T by picking each time a vertex according to the restriction of p to the remaining part; however, it is more convenient for us to retain the portion of the tree that contains a random node V sampled according to p rather than the root. We denote by L T ( ) the number of cuts necessary until V is finally picked, and let X i , 1 ≤ i ≤ L T ( ) , be the sequence of
nodes chosen. The following identity in distribution has been already shown in [3] in the special case of the uniform Cayley tree:
$$L ( T ) \stackrel { d } { = } \text{Card} \{ \text{vertices on the path from the root to } V \}.$$
In fact, (3.1) is an immediate consequence of the following result. In the above cutting procedure, we connect the rejected parts, which are subtrees above X i just before the cutting, by drawing an edge between X i and X i +1 , i = 1 2 , , · · · , L ( T ) -1 (see Figure 1 in Section 4). We obtain another tree on the same vertex set, which contains a path from the first cut X 1 to the random node V that we were trying to isolate. We denote by cut( T, V ) this tree which (partially) encodes the isolating process of V . We prove in Section 4 that we have
$$( \text{cut} ( T, V ), V ) \stackrel { d } { = } ( T, V ).$$
This identity between the pairs of trees contains a lot of information about the distributional structure of the p -trees, and our aim is to obtain results similar to (3.2) for ICRTs. The method we use relies on the discrete approximation of ICRT by p -trees, and a first step consists in defining the appropriate cutting procedure for ICRT.
In the case of p -trees, one may pick the nodes of T in the order in which they appear in a Poisson random measure. We do not develop it here but one should keep in mind that the cutting procedure may be obtained using a Poisson point process on R + × T with intensity measure dt ⊗ p . In particular, this measure has a natural counterpart in the case of ICRTs, and it is according to this measure that the points should be sampled in the continuous case.
glyph[negationslash]
So consider now an ICRT T . Recall that for θ = (1 0 , , . . . ) , for each θ i > 0 with i ≥ 1 , there exists a unique point, denoted by β i , which has infinite degree. Let L be the measure on T defined by
$$\mathcal { L } ( d x ) \coloneqq \theta _ { 0 } ^ { 2 } \ell ( d x ) + \sum _ { i \geq 1 } \theta _ { i } \delta _ { \beta _ { i } } ( d x ),$$
which is almost surely σ -finite (Lemma 5.1). Proving that L is indeed the relevant cutting measure (in a sense made precise in Proposition 5.2) is the topic of Section 7. Conditional on T , let P be a Poisson point process on R + × T of intensity measure dt ⊗ L ( dx ) and let V be a µ -point on T . We consider the elements of P as the successive cuts on T which try to isolate the random point V . For each t ≥ 0 , define
$$\mathcal { P } _ { t } = \{ x \in \mathcal { T } \, \colon \exists \, s \leq t \, \text{such that } ( s, x ) \in \mathcal { P } \},$$
and let T t be the part of T still connected to V at time t , that is the collection of points u ∈ T for which the unique path in T from V to u does not contain any element of P t . Clearly, T t ′ ⊂ T t if t ′ ≥ t . We set C := { t > 0 : µ ( T t -) > µ ( T t ) } . Those are the cuts which contribute to the isolation of V .
## 3.2 Tracking one node and the one-node cut tree
We construct a tree which encodes this cutting process in a similar way that the tree H = cut( T, V ) encodes the cutting procedure for discrete trees. First we construct the 'backbone', which is the equivalent of the path we add in the discrete case. For t ≥ 0 , we define
$$L _ { t } \coloneqq \int _ { 0 } ^ { t } \mu ( \mathcal { T } _ { s } ) d s,$$
and L ∞ the limit as t → ∞ (which might be infinite). Now consider the interval [0 , L ∞ ] , together with its Euclidean metric, that we think of as rooted at 0 . Then, for each t ∈ C we graft T t -\ T t , the portion of the tree discarded at time t , at the point L t ∈ [0 , L ∞ ] (in the sense of the gluing introduced in Section 2.5). This creates a rooted real tree and we denote by cut( T , V ) its completion. Moreover, we
can endow cut( T , V ) with a (possibly defective probability) measure ˆ µ by taking the push-forward of µ under the canonical injection φ from ∪ t ∈C ( T t -\ T t ) to cut( T , V ) . We denote by U the endpoint L ∞ of the interval [0 , L ∞ ] . We show in Section 5 that
Theorem 3.1. We have L ∞ < ∞ almost surely. Moreover, under (H) we have
$$( \sigma _ { n } \, \text{cut} ( T ^ { n }, V ^ { n } ), \boldsymbol p _ { n }, V ^ { n } ) \underset { d, \text{GP} } { \longrightarrow } ( \text{cut} ( \mathcal { T }, V ), \hat { \mu }, U ),$$
jointly with the convergence in (2.6) .
Combining this with (3.2), we show in Section 5 that
Theorem 3.2. Conditional on T , U has distribution ˆ µ , and the unconditional distribution of (cut( T , V ) , µ ˆ) is the same as that of ( T , µ ) .
Theorems 3.1 and 3.2 immediately entail that
Corollary 3.3. Suppose that (H) holds. Then
$$\sigma _ { n } L ( T ^ { n } ) \stackrel { n \rightarrow \infty } { \longrightarrow } L _ { \infty },$$
jointly with the convergence in (2.6) . Moreover, the unconditional distribution of L ∞ is the same as that of the distance in T between the root and a random point V chosen according to µ , given in (2.5) .
## 3.3 The complete cutting procedure
In the procedure of the previous section, the fragmentation only takes place on the portions of the tree which contain the random point V . Following Bertoin and Miermont [16], we consider a more general cutting procedure which keeps splitting all the connected components. The aim here is to describe the genealogy of the fragmentation that this cutting procedure produces. For each t ≥ 0 , P t induces an equivalence relation ∼ t on T : for x, y ∈ T we write x ∼ t y if J x, y K ∩ P t = ∅ . We denote by T x ( ) t the equivalence class containing x . In particular, we have T V ( ) t = T t . Let ( V i ) i ≥ 1 be a sequence of i.i.d. µ -points in T . For each t ≥ 0 , define µ i ( ) = t µ ( T V i ( )) t . We write µ ↓ ( ) t for the sequence ( µ i ( ) t , i ≥ 1) rearranged in decreasing order. In the case where T is the Brownian CRT, the process ( µ ↓ ( )) t t ≥ 0 is the fragmentation dual to the standard additive coalescent [8]. In the other cases, however, it is not even Markov because of the presence of those branch points β i with fixed local times θ i .
As in [16], we can define a genealogical tree for this fragmentation process. For each i ≥ 1 and t ≥ 0 , let
$$L _ { t } ^ { i } \coloneqq \int _ { 0 } ^ { t } \mu _ { i } ( s ) d s,$$
and let L i ∞ ∈ [0 , ∞ ] be the limit as t → ∞ . For each pair ( i, j ) ∈ N 2 , let τ ( i, j ) = τ ( j, i ) be the first moment when J V , V i j K contains an element of P (or more precisely, its projection onto T ), which is almost surely finite by the properties of T and P . It is not difficult to construct a sequence of increasing real trees S 1 ⊂ S 2 ⊂ · · · such that S k has the form of a discrete tree rooted at a point denoted ρ ∗ with exactly k leaves { U , U , 1 2 · · · , U k } satisfying
$$d ( \rho _ { * }, U _ { i } ) = L ^ { i } _ { \infty }, \ \ d ( U _ { i }, U _ { j } ) = L ^ { i } _ { \infty } + L ^ { j } _ { \infty } - 2 L ^ { i } _ { \tau ( i, j ) }, \ \ 1 \leq i < j \leq k ;$$
where d denotes the distance of S k , for each k ≥ 1 . Then we define
$$\text{cut} ( \mathcal { T } ) \coloneqq \overline { \cup _ { k \geq 1 } S _ { k } },$$
the completion of the metric space ( ∪ k S , d k ) , which is still a real tree. In the case where T is the Brownian CRT, the above definition of cut( T ) coincides with the tree defined by Bertoin and Miermont [16].
Similarly, for each p n -tree T n , we can define a complete cutting procedure on T n by first generating a random permutation ( X n 1 , X n 2 , · · · , X nn ) on the vertex set [ n ] and then removing X ni one by one. Here the permutation ( X n 1 , X n 2 , . . . , X nn ) is constructed by sampling, for i ≥ 1 , X ni according to the restriction of p n to [ n ] \ { X nj , j < i } . We define a new genealogy on [ n ] by making X ni an ancestor of X nj if i < j and X nj and X ni are in the same connected component when X ni is removed. If we denote by cut( T n ) the corresponding genealogical tree, then the number of vertices in the path of cut( T n ) between the root X n 1 and an arbitrary vertex v is precisely equal to the number of cuts necessary to isolate this vertex v . We have
Theorem 3.4. Suppose that (H) holds. Then, we have
$$\left ( \sigma _ { n } \cut ( T ^ { n } ), p _ { n } \right ) \underset { d, \text{GP} } { \longrightarrow } \left ( \cut ( \mathcal { T } ), \nu \right ),$$
jointly with the convergence in (2.6) . Here, ν is the weak limit of the empirical measures 1 k ∑ k -1 i =0 δ U i , which exists almost surely conditional on T .
From this, we show that
Theorem 3.5. Conditionally on T , ( U , i i ≥ 0) has the distribution as a sequence of i.i.d. points of common law ν . Furthermore, the unconditioned distribution of the pair (cut( T ) , ν ) is the same as ( T , µ ) .
In general, the convergence of the p n -trees to the ICRT in (2.6) cannot be improved to GromovHausdorff (GH) topology, see for instance [9, Example 28]. However, when the sequence ( p n n ) ≥ 1 is suitably well-behaved, one does have this stronger convergence. (This is the case for example with p n the uniform distribution on [ n ] , which gives rise to the Brownian CRT, see also [10, Section 4.2].) In such cases, we can reinforce accordingly the above convergences of the cut trees in the Gromov-Hausdorff topology. Note however that a 'reasonable' condition on p ensuring the Gromov-Hausdorff convergence seems hard to find. Let us mention a related open question in [10, Section 7], which is to determine a practical criterion for the compactness of a general ICRT. Writing → d, GHP for the convergence in distribution with respect to the Gromov-Hausdorff-Prokhorov topology (see Section 2), we have
Theorem 3.6. Suppose that T is almost surely compact and suppose also as n →∞ ,
$$( \sigma _ { n } T ^ { n }, p _ { n } ) \underset { d, \text{CHP} } { \underset { n \rightarrow \infty } { \longrightarrow } } ( \mathcal { T }, \mu ).$$
Then, jointly with the convergence in (3.5) , we have
$$( \sigma _ { \sim } \, \text{cut} ( T ^ { n }. V ^ { n } ). \, \text{n} _ { \sim } ) \stackrel { n \to \infty } { \longrightarrow } ( \, \text{em}$$
$$\left ( \sigma _ { n } \, & \text{cut} ( T ^ { n }, V ^ { n } ), \boldsymbol p _ { n } \right ) \underset { d, \text{GHP} } { \underset { d, \text{GHP} } { \longrightarrow } } \left ( \, \text{cut} ( \mathcal { T }, V ), \hat { \mu } \right ), \\ \left ( \sigma _ { n } \, & \text{cut} ( T ^ { n } ), \boldsymbol p _ { n } \right ) \underset { d, \text{GHP} } { \underset { d, \text{GHP} } { \longrightarrow } } \left ( \, \text{cut} ( \mathcal { T } ), \nu \right ).$$
## 3.4 Reversing the cutting procedure
Wealso consider the transformation that 'reverses' the construction of the trees cut( T , V ) defined above. Here, by reversing we mean to obtain a tree distributed as the primal tree T , conditioned on the cut tree being the one we need to transform. So for an ICRT ( H , d H , µ ˆ) and a random point U sampled according to its mass measure ˆ µ , we should construct a tree shuff( H , U ) such that
$$( \mathcal { T }, \text{cut} ( \mathcal { T }, V ) ) \stackrel { d } { = } ( \text{shuff} ( \mathcal { H }, U ), \mathcal { H } ).$$
This reverse transformation is the one described in [3] for the Brownian CRT. For H rooted at r ( H ) , the path between J r ( H ) , U K that joins r ( H ) to U in H decomposes the tree into countably many subtrees of positive mass
$$F _ { x } = \{ y \in \mathcal { H } \, \colon U \wedge y = x \},$$
where U ∧ y denotes the closest common ancestor of U and y , that is the unique point a such that J r ( H ) , U K ∩ J r ( H ) , y K = J r ( H ) , a K . Informally, the tree shuff( H , U ) is the metric space one obtains from H by attaching each F x of positive mass at a random point A x , which is sampled proportionally to ˆ µ in the union of the F y for which d H ( U, y ) < d H ( U, x ) . We postpone the precise definition of shuff( H , U ) until Section 6.1.
The question of reversing the complete cut tree cut( T ) is more delicate and is the subject of the companion paper [20]. There we restrict ourselves to the case of a Brownian CRT: for T and G Brownian CRT we construct a tree shuff( G ) such that
$$( \mathcal { T }, \text{cut} ( \mathcal { T } ) ) \stackrel { d } { = } ( \text{shuff} ( \mathcal { G } ), \mathcal { G } ).$$
We believe that the construction there is also valid for more general ICRTs, but the arguments we use there strongly rely on the self-similarity of the Brownian CRT.
Remarks. i. Theorem 3.2 generalizes Theorem 1.5 in [3], which is about the Brownian CRT. The special case of Theorem 3.1 concerning the convergence of uniform Cayley trees to the Brownian CRT is also found there.
ii. When T is the Brownian CRT, Theorem 3.5 has been proven by Bertoin and Miermont [16]. Their proof relies on the self-similar property of the Aldous-Pitman's fragmentation. They also proved a convergence similar to the one in Theorem 3.4 for the conditioned Galton-Watson trees with finitevariance offspring distributions. Let us point out that their definition of the discrete cut trees is distinct from ours, and there is no 'duality' at the discrete level for their definitions. Very recently, a result related to Theorem 3.4 has been proved for the case of stable trees [23] (with a different notion of discrete cut tree). Note also that the convergence of the cut trees proved in [16] and [23] is with respect to the Gromov-Prokhorov topology, so is weaker than the convergence of the corresponding conditioned Galton-Watson trees, which holds in the Gromov-Hausdorff-Prokhorov sense. In our case, the identities imply that the convergence of the cut trees is as strong as that of the p n -trees (Theorem 3.6).
iii. Abraham and Delmas [2] have shown an analog of Theorem 3.2 for the L´ evy tree, introduced in [37]. In passing Aldous et al. [10] have conjured that a L´ evy tree is a mixture of the ICRTs where the parameters θ are chosen according to the distribution of the jumps in the bridge process of the associated L´ evy process. Then the similarity between Theorem 3.2 and the result of Abraham and Delmas may be seen as a piece of evidence supporting this conjecture.
## 4 Cutting down and rearranging a p -tree
As we have mentioned in the introduction, our approach to the theorems about continuum random trees involves taking limits in the discrete world. In this section, we prove the discrete results about the decomposition and the rearrangement of p -trees that will enable us to obtain similar decomposition and rearrangement procedures for inhomogeneous continuum random trees.
## 4.1 Isolating one vertex
As a warm up, and in order to present many of the important ideas, we start by isolating a single node. Let T be a p -tree and let V be an independent p -node. We isolate the vertex V by removing each time a random vertex of T and preserving only the component containing V until the time when V is picked.
THE 1-CUTTING PROCEDURE AND THE 1 -CUT TREE. Initially, we have T 0 = T , and an independent vertex V . Then, for i ≥ 1 , we choose a node X i according to the restriction of p to the vertex set v ( T i -1 ) of T i -1 . We define T i to be the connected component of the forest induced by T i -1 on v ( T i -1 ) \ { X i } which contains V . If T i = ∅ , or equivalently X i = V , the process stops and we set L = L T ( ) = i . Since at least one vertex is removed at every step, the process stops in time L ≤ n .
As we destruct the tree T to isolate V by iteratively pruning random nodes, we construct a tree which records the history of the destruction, that we call the 1 -cut tree. This 1 -cut tree will, in particular, give some information about the number of cuts which were needed to isolate V . However, we remind the reader that this number of cuts is not our main objective, and that we are after a more detailed correspondence between the initial tree and its 1 -cut tree. We will prove that these two trees are dual in a sense that we will make precise shortly.
glyph[negationslash]
J K When the procedure stops, we have a vector ( F , i 1 ≤ i ≤ L ) of subtrees of T which together span all of [ n ] . We may re-arrange them into a new tree, the 1 -cut tree corresponding to the isolation of V in T . We do this by connecting their roots X ,X ,..., X 1 2 L into a path (in this order). The resulting tree, denoted by H is seen as rooted at X 1 , and carries a distinguished path or backbone J X ,V 1 K , which we denote by S , and distinguished points U , . . . , U 1 L -1 .
By construction, ( T , i 0 ≤ i < L ) is a decreasing sequence of nonempty trees which all contain V , and ( X , i 0 ≤ i < L ) is a sequence of distinct vertices of T = T 0 . Removing X i from T i -1 disconnects it into a number of connected components. Then T i is the one of these connected components which contains V , or T i = ∅ if X i = V . If X i = V we set F i = T i -1 , which we see as a tree rooted at X i = V . Otherwise X i = V and there is a neighbor U i of X i on the path between X i and V in T i -1 . Then U i ∈ T i and we see T i as rooted at U i ; furthermore, we let F i be the subtree of T i -1 \ { U i } which contains X i , seen as rooted at X i . In other words, T i is the subtree with vertex set { u ∈ T i -1 : X / i ∈ J u, V K } rooted at U i and F i is the subtree with vertex set { u ∈ T i -1 : X i ∈ u, V } rooted at X i .
Note that for i = 1 , . . . , L -1 , we have U i ∈ T i . Equivalently, U i lies in the subtree of H rooted at X i +1 . In general, for a tree t ∈ T n and v ∈ [ n ] , let x , . . . , x 1 glyph[lscript] = v be the nodes of Span( ; t v ) . We define U ( t, v ) as the collection of vectors ( u , . . . , u 1 glyph[lscript] -1 ) of nodes of [ n ] such that u i ∈ Sub( t, x i +1 ) , for 1 ≤ i < glyph[lscript] . Then by construction, for a h ∈ T n , conditional on H = h and V = v , we have L equal to the number of the nodes in Span( h v ; ) and ( U , . . . , U 1 L -1 ) ∈ U ( h, v ) with probability one. For A ⊆ [ n ] , we write p ( A ) := ∑ i ∈ A p i .
Lemma 4.1. Let T be a p -tree on [ n ] , and V be an independent p -node. Let h ∈ T n , and v ∈ [ n ] for which Span( h v ; ) is the path made of the nodes x , x 1 2 , . . . , x glyph[lscript] -1 , x glyph[lscript] = v . Let ( u , . . . , u 1 glyph[lscript] -1 ) ∈ U ( h, v ) and w ∈ [ n ] . Then we have
$$\mathbb { P } \left ( H = h ; V = v ; r ( T ) = w ; U _ { i } = u _ { i }, 1 \leq i < \ell \right ) = \pi ( h ) \cdot \prod _ { 1 \leq i < \ell } \frac { p _ { u _ { i } } } { p ( \text{Sub} ( h, x _ { i + 1 } ) ) } \cdot p _ { v } \cdot p _ { w }.$$
In particular, ( H,V ) ∼ π ⊗ p .
As a direct consequence of our construction of H L , is the number of nodes of the subtree Span( H,V ) , which we write #Span( H,V ) . So Lemma 4.1 entails immediately that
Proposition 4.2. Let T be a p -tree and V be an independent p -node. Then
$$L \stackrel { d } { = } \# \text{Span} ( T, V ).$$
Proof of Lemma 4.1. By construction, we have
$$\{ H = h ; V = v \} \subset \{ X _ { 1 } = x _ { 1 }, \cdots, X _ { \ell - 1 } = x _ { \ell - 1 }, X _ { \ell } = v ; L = \ell \},$$
Figure 1: The re-organization of the tree in the one-cutting procedure: on the left the initial tree T , on the right H and the marked nodes U , . . . , U 1 4 where to reattach X ,. . . , X 1 4 in order to recover T .
and the sequence ( F , i 1 ≤ i ≤ glyph[lscript] ) is precisely the sequence of subtrees f i , of h rooted at x i , 1 ≤ i ≤ glyph[lscript] , that are obtained when one removes the edges { x , x i i +1 } , 1 ≤ i < glyph[lscript] (the edges of the subgraph Span( h v ; ) ). Furthermore, given that L = glyph[lscript] and the sequence of cut vertices X i = x i , 1 ≤ i < glyph[lscript] , in order to recover the initial tree T it suffices to identify the vertices U i , 1 ≤ i < glyph[lscript] , for which there used to be an edge { X , U i i } (which yields the correct adjacencies) and the root of T . Note that U i is a node of T i , 1 ≤ i < glyph[lscript] . However, by construction, given that H = h and V = v , the set of nodes of T i is precisely the set of nodes of Sub( h, x i +1 ) , the subtree of h rooted at x i +1 .
For u = ( u , 1 · · · , u glyph[lscript] -1 ) ∈ U ( h, v ) , define τ ( h, v ; u ) as the tree obtained from h by removing the edges of Span( h v ; ) , and reconnecting the pieces by adding the edges { x , u i i } , for all the edges 〈 x , x i i +1 〉 in Span( h, v ) . (In particular, the number of edges is unchanged.) We regard τ ( h, v ; u ) as a tree rooted at r = x 1 , the root of h . The the tree T may be recovered by characterizing T r , the tree T rerooted at r , and the initial root r T ( ) . We have:
$$\{ H = h ; V = v ; r ( T ) = w ; U _ { i } = u _ { i }, 1 \leq i < \ell \} = \{ T ^ { r } = \tau ( h, v ; \mathbf u ) ; r ( T ) = w ; X _ { i } = x _ { i }, 1 \leq i \leq \ell \}.$$
It follows that, for any nodes u , u 1 2 , . . . , u glyph[lscript] -1 as above, we have
$$\mathbb { P } \left ( H = h ; V = v ; \tau ( T ) = w ; U _ { i } = u _ { i }, 1 \leq i < \ell \right ) & = \mathbb { P } \left ( T = \tau ( h, v ; \mathbf u ) ^ { w } ; V = v ; X _ { i } = x _ { i } ; 1 \leq i \leq \ell \right ) \\ & = \pi ( \tau ( h, v ; \mathbf u ) ^ { w } ) \cdot p _ { v } \cdot \prod _ { 1 \leq i \leq \ell } \frac { p _ { x _ { i } } } { p ( \text{Sub} ( h, x _ { i } ) ) }.$$
Now, by definition, the only nodes that get their (in-)degree modified in the transformation from h to τ ( h, v ; u ) are u i , x i +1 , 1 ≤ i < glyph[lscript] : every such x i +1 gets one less in-edge while u i gets one more. The re-rooting at w then only modifies the in-degrees of the extremities of the path that is reversed, namely x 1 = r and w . It follows that
$$\pi ( \tau ( h, v ; \mathbf u ) ^ { w } ) = \pi ( h ) \cdot \prod _ { 1 \leq i < \ell } \frac { p _ { u _ { i } } } { p _ { x _ { i + 1 } } } \cdot \frac { p _ { w } } { p _ { x _ { 1 } } }.$$
Since p (Sub( h, x 1 )) = 1 , we have
$$\mathbb { P } \left ( H = h ; V = v ; r ( T ) = w ; U _ { i } = u _ { i }, 1 \leq i < \ell \right ) = \pi ( h ) \cdot \prod _ { 1 \leq i < \ell } \frac { p _ { u _ { i } } } { p ( \text{Sub} ( h, x _ { i + 1 } ) ) } \cdot p _ { v } \cdot p _ { w },$$
which proves the first claim. Summing over all the choices for u = ( u , u 1 2 , . . . , u glyph[lscript] -1 ) ∈ U ( h, v ) , and w ∈ [ n ] , we obtain
$$w \in [ n ], \, \text{we obtain} \\ \mathbb { P } \left ( H = h ; V = v \right ) & = \sum _ { w \in [ n ] } \sum _ { \mathfrak { u } \in U ( h, v ) } \pi ( h ) \cdot \prod _ { 1 \leq i < \ell } \frac { p _ { u _ { i } } } { p ( \text{Sub} ( h, x _ { i + 1 } ) ) } \cdot p _ { v } \cdot p _ { w } \\ & = \pi ( h ) \cdot p _ { v } \cdot \sum _ { \substack { u = ( u _ { 1 }, \cdots, u _ { \ell - 1 } ) \colon \\ u _ { i } \in \text{Sub} ( h, x _ { i + 1 } ), 1 \leq i < \ell } } \frac { p _ { u _ { 1 } } } { p ( \text{Sub} ( h, x _ { 2 } ) ) } \cdots \frac { p _ { u _ { \ell - 1 } } } { p ( \text{Sub} ( h, x _ { \ell } ) ) } \\ & = \pi ( h ) \cdot p _ { v }, \\ \dots \dots \dots \dots \dots \ell & \sqcup \cdots \dots \ell$$
which completes the proof.
THE REVERSE 1-CUTTING PROCEDURE. We have transformed the tree T into the tree H , by somewhat 'knitting' a path between the first picked random p -node X 1 and the distinguished node V . This transform is reversible. Indeed, it is possible to 'unknit' the path between V and the root of H , and reshuffle the subtrees thereby created in order to obtain a new tree ˜ T , distributed as T and in which V is an independent p -node. Knowing the U i , one could do this exactly, and recover the adjacencies of T (recovering T also requires the information about the root r T ( ) which has been lost). Defining a reverse transformation reduces to finding the joint distribution of ( U i ) and r T ( ) , which is precisely the statement of Lemma 4.1, so that the following reverse construction is now straightforward.
Let h ∈ T n , rooted at r and let v be a node in [ n ] . We think of h as the tree that was obtained by the 1 -cutting procedure cut( T, v ) , for some initial tree T . Suppose that Span( h, v ) consists of the vertices r = x , x 1 2 , . . . , x glyph[lscript] = v . Removing the edges of Span( h, v ) from h disconnects it into glyph[lscript] connected components which we see as rooted at x i , 1 ≤ i ≤ glyph[lscript] . For w ∈ Span ( ∗ h, v ) = Span( h, v ) \ { r } , sample a node U w according to the restriction of p to Sub( h, w ) . Let U = ( U ,w w ∈ Span ( ∗ h, v )) be the obtained vector. Then U ∈ U ( h, v ) . We then define shuff( h, v ) to be the rooted tree which has the adjacencies of τ ( h, v ; U ) , but that is re-rooted at an independent p -node.
It should now be clear that the 1 -cutting procedure and the reshuffling operation we have just defined are dual in the following sense.
Proposition 4.3 (1-cutting duality) . Let T be p -tree on [ n ] and V be an independent p -node. Then,
$$( \text{shuff} ( T, V ), T, V ) \stackrel { d } { = } ( T, \text{cut} ( T, V ), V ).$$
In particular, (shuff( T, V ) , V ) ∼ π ⊗ p .
Note that for the joint distribution in Proposition 4.3, it is necessary to re-root at another independent p -node in order to have the claimed equality. Indeed, T and τ ( T, V ; U ) have the same root almost surely, while T and cut( T, V ) do not (they only have the same root with probability ∑ i ≥ 1 p 2 i < 1 ).
Proof of Proposition 4.3. Let H = cut( T, V ) be the tree resulting from the cutting procedure. Let L = #Span( H V ; ) . For 1 ≤ i < L , we defined nodes U i , which used to be the neighbors of X i in T . For w ∈ Span ( ∗ H V ; ) , we let U w = U i if w = X i +1 , and let U be the corresponding vector. Then writing ˆ = r r T ( ) , with probability one, we have
$$T = \tau ( H, V ; \mathbf U ) ^ { \hat { r } }.$$
By Lemma 4.1, U ∈ U ( H,V ) and conditional on H and V , U w , w ∈ Span ( ∗ H,V ) and ˆ = r r T ( ) are independent and distributed according to the restriction of p to Sub( H,w ) and p , respectively. So this coupling indeed gives that T = τ ( H,V ; U ) ˆ r is distributed as shuff( H,V ) , conditional on H . Since in this coupling (shuff( H,V ,T,V ) ) is almost surely equal to ( T, H, V ) , the proof is complete.
Figure 2: The decomposition of the tree when removing the point X i from the connected component of Γ i which contains V , V 1 2 and V 3 .
Remark. Note that the shuffle procedure would permit to obtain the original tree T exactly if we were to use some information that might be gathered as the cutting procedure goes on. In this discrete case, this is rather clear that one could do this, since the shuffle construction only consists in replacing some edges with others but the vertex set remains the same. This observation will be used in Section 6 to prove a similar statement for the ICRT. There it is much less clear and the result is slightly weaker: it is possible to couple the shuffle in such a way that the tree obtained is measure-isometric to the original one.
## 4.2 Isolating multiple vertices
We define a cutting procedure analogous to the one described in Section 4.1, but which continues until multiple nodes have been isolated. Again, we let T be a p -tree and, for some k ≥ 1 , let V , V 1 2 , · · · , V k be k independent vertices chosen according to p (so not necessarily distinct).
THE k -CUTTING PROCEDURE AND THE k -CUT TREE. We start with Γ 0 = T . Later on, Γ i is meant to be the forest induced by T on the nodes that are left. For each time i ≥ 1 , we pick a random vertex X i according to p restricted to v (Γ i -1 ) , the set of the remaining vertices, and remove it. Then among the connected components of T \ { X , 1 · · · , X i } , we only keep those containing at least one of V , 1 · · · , V k . We stop at the first time when all k vertices V , . . . , V 1 k have been chosen, that is at time
$$L ^ { k } \coloneqq \inf \{ i \geq 1 \colon \{ V _ { 1 }, \dots, V _ { k } \} \subseteq \{ X _ { 1 }, \dots, X _ { i } \} \}.$$
For 1 ≤ glyph[lscript] ≤ k and for i ≥ 0 , we denote by T glyph[lscript] i the connected component of T \ { X ,X , 1 2 · · · , X i } containing V glyph[lscript] at time i , or T glyph[lscript] i = ∅ if V glyph[lscript] ∈ { X ,. . . , X 1 i } . Then Γ i is the graph consisting of the connected components T glyph[lscript] i , glyph[lscript] = 1 , . . . , k .
glyph[negationslash]
glyph[negationslash]
Fix some glyph[lscript] ∈ { 1 2 , , . . . , k } , and suppose that at time i ≥ 1 , we have X i ∈ T glyph[lscript] i -1 . If X i = V glyph[lscript] , then T glyph[lscript] i = ∅ and we define F i = T glyph[lscript] i -1 , re-rooted at X i = V glyph[lscript] . Otherwise, X i = V glyph[lscript] and there is a first node U glyph[lscript] i on the path between X i and V glyph[lscript] in T glyph[lscript] i -1 . Then U glyph[lscript] i ∈ T glyph[lscript] i , and we see T glyph[lscript] i as rooted at U glyph[lscript] i . Note that it is possible that T j i -1 = T glyph[lscript] i -1 , for j = glyph[lscript] , and that removing X i may separate V glyph[lscript] from V j . Removing from Γ i -1 the edges { X , U i glyph[lscript] i } , for 1 ≤ glyph[lscript] ≤ k such that T glyph[lscript] i glyph[owner] X i , isolates X i from the nodes V , . . . , V 1 k , and we define F i as the subtree of T induced on the nodes in Γ i -1 \ Γ i , so that F i is the portion of the forest Γ i -1 which gets discarded at time i , which we see as rooted at X i .
Consider the set of effective cuts which affect the size of T glyph[lscript] i :
$$\mathcal { E } _ { \ell } ^ { k } = \{ x \in [ n ] \, \colon \text{there exists $i\geq 1$, such that $X_{i}=x\in T_{i-1}^{\ell}$} \},$$
and note that E k 1 ∪ E k 2 ∪ · · · ∪ E k k = { X i : 1 ≤ i ≤ L k } . Let S k , the k -cutting skeleton , be a tree on E k 1 ∪ · · · ∪ E k k that is rooted at X 1 , and such that the vertices on the path from X 1 to V glyph[lscript] in S k
are precisely the nodes of E k glyph[lscript] , in the order given by the indices of the cuts. So if we view S k as a genealogical tree, then in particular, for 1 ≤ j, glyph[lscript] ≤ k , the common ancestors of V j and V glyph[lscript] are exactly the ones in E k j ∩ E k glyph[lscript] . The tree S k constitutes the backbone of a tree on [ n ] which we now define. For every x ∈ S k , there is a unique i = ( ) i x ≥ 1 such that x = X i . For that integer i we have defined a subtree F i which contains X i = x . We append F i to S k at x . Formally, we consider the tree on [ n ] whose edge set consists of the edges of S k together with the edges of all F i , 1 ≤ i ≤ L k . Furthermore, the tree is considered as rooted at X 1 . Then this tree is completely determined by T , V , . . . , V 1 k , and the sequence X := ( X , i i = 1 , . . . , L k ) , and we denote this tree by κ T ( ; V , . . . , V 1 k ; X ) when we want to emphasize the dependence in X , or more simply cut( T, V 1 , . . . , V k ) (in which it is implicit that the cutting sequence used in the transformation is such that for every i ≥ 1 , X i is a p -node in Γ i -1 ). Clearly, if H k = cut( T, V 1 , . . . , V k ) then S k = Span( H k ; V , . . . , V 1 k ) .
glyph[negationslash]
It is convenient to define a canonical (total) order glyph[precedesequal] on the vertices of S k . It will be needed later on in order to define the reverse procedure. For two nodes u, v in S k , we say that u glyph[precedesequal] v if either u ∈ J X ,v 1 K , or if there exists glyph[lscript] ∈ { 1 , . . . , k } such that u ∈ Span( S k ; V , . . . , V 1 glyph[lscript] ) but v ∈ Span( S k ; V , . . . , V 1 glyph[lscript] ) .
A USEFUL COUPLING. It is useful to see all the trees cut( T V , . . . , V ; 1 k ) on the same probability space, and provide a natural but crucial coupling for which the sequence ( S k ) is increasing in k . Let Y i , i ≥ 1 , be a sequence of i.i.d. p -nodes. For k ≥ 1 , we define an increasing sequence σ k as follows. Let σ k (1) = 1 . Suppose that we have already defined X ,... , X k 1 k i -1 . Let Γ k i -1 be the collection of connected components of T \ { X ,... , X k 1 k i -1 } which contain at least one of V , . . . , V 1 k . Let
$$\sigma _ { k } ( i ) = \inf \{ j > \sigma _ { k } ( i - 1 ) \, \colon Y _ { j } \in \Gamma _ { i - 1 } ^ { k } \},$$
and define X k i = Y σ k ( ) i . Then, for every k , X k i , i ≥ 1 , is a sequence of nodes sampled according to the restriction of p to Γ k i -1 , so that X k := ( X ,i k i ≥ 1) can be used to define cut( T, V 1 , . . . , V k ) , k ≥ 1 , in a consistent way by setting
$$\text{cut} ( T, V _ { 1 }, \dots, V _ { k } ) = \kappa ( T, V _ { 1 }, \dots, V _ { k } ; \mathbf X ^ { k } ).$$
Suppose that the trees H k := cut( T V , . . . , V ; 1 k ) , k ≥ 1 , are constructed using the coupling we have just described. By convention let H 0 = T and Span( T ; ∅ ) = ∅ .
Lemma 4.4. Let S k = Span( H k ; V , . . . , V 1 k ) . Then, S k ⊆ S k +1 and
$$S _ { k } = \text{Span} ( S _ { k + 1 } ; V _ { 1 }, \dots, V _ { k } ).$$
Proof. Let T glyph[lscript] i be the connected component of Γ k i which contains V glyph[lscript] . Let ˆ T glyph[lscript] j be the connected component of T \ { Y , Y 1 2 , . . . , Y j } which contains V glyph[lscript] . Then, for glyph[lscript] ≤ k , we have
$$\mathcal { E } _ { \ell } ^ { k } = \{ x \, \colon \exists i \geq 1, x = X _ { i } ^ { k } \in T _ { i - 1 } ^ { \ell } \} = \{ y \, \colon \exists j \geq 1, y = Y _ { j } \in \hat { T } _ { j - 1 } ^ { \ell } \},$$
so that E k glyph[lscript] does not depend on k . Then S k is the tree on E k 1 ∪ · · · ∪ E k k such that the nodes on the path Span( S k ; V glyph[lscript] ) are precisely the nodes of E k glyph[lscript] , in the order given by the cut sequence X k . It follows that S k ⊆ S k +1 and more precisely that S k = Span( S k +1 ; V , . . . , V 1 k ) .
Remark. The coupling we have just defined justifies an ordered cutting procedure which is very similar to the one defined in [3]. Suppose that, for some j, glyph[lscript] ∈ { 1 , . . . , k } we have x ∈ E k j \ E k glyph[lscript] and y ∈ E k glyph[lscript] \ E k j . Write ( ˜ X , i i ≥ 1) for the sequence in which we have exchanged the positions of x and y . Then the trees T k i , i ≥ max { m : X m = x or y } are unaffected if we replace ( X , i i ≥ 1) by ( ˜ X , i i ≥ 1) in the cutting procedure. In particular, if we are only interested in the final tree H k , we can always suppose that there
glyph[negationslash]
exist numbers 0 = m < m 0 1 < m 2 < · · · < m k ≤ n such that, for 1 ≤ glyph[lscript] ≤ k , and if V glyph[lscript] ∈ { V , . . . , V 1 j } , we have
$$\mathcal { E } _ { \ell } ^ { k } \, \smallsetminus \bigcup _ { 1 \leq j < \ell } \mathcal { E } _ { j } ^ { k } = \{ X _ { i } \colon m _ { \ell - 1 } < i \leq m _ { \ell } \}.$$
However, we prefer the coupling over the reordering of the sequence since it does not involve any modification of the distribution of the cutting sequences.
Let ˜ T k be the subtree of H k -1 \ Span( H k -1 ; V , . . . , V 1 k -1 ) = H k -1 \ S k -1 which contains V k ; we agree that ˜ T k = ∅ if V k ∈ Span( H k -1 ; V , . . . , V 1 k -1 ) .
Lemma 4.5. Let T be a p -tree and let V k , k ≥ 1 , be a sequence of i.i.d. p -nodes. Then, for each k ≥ 1 :
glyph[negationslash]
- i. Let V ⊆ [ n ] with V = ∅ , then conditional on V glyph[lscript] ∈ v ( ˜ T k ) = V , the pair ( ˜ T , V k glyph[lscript] ) is distributed as π | V ⊗ p | V , and is independent of ( H k -1 \ V , V 1 , · · · , V k -1 ) .
- ii. The joint distribution of ( H ,V , k 1 · · · , V k ) is given by π ⊗ p ⊗ k .
Proof. We proceed by induction on k ≥ 1 . Let ˜ R k denote the tree induced by H k on the vertex set [ n ] \ v ( ˜ T k ) . For the base case k = 1 , the first claim is trivial since ˜ T 1 = T , and the second is exactly the statement of Lemma 4.1.
Given the two subtrees ˜ T k and ˜ R k , it suffices to identify where the tree ˜ T k is grafted on ˜ R k in order to recover the tree H k -1 . By construction, the edge connecting ˜ T k and ˜ R k in H k -1 binds the root of ˜ T k to a node of Span( ˜ R k ; V , . . . , V 1 k -1 ) . Let t ∈ T V , r ∈ T [ n ] \ V , v k ∈ V and v i ∈ [ n ] \ V for 1 ≤ i < k . Write v k -1 = { v , . . . , v 1 k -1 } . For a given node x ∈ Span( ; r v k -1 ) , let j x ( r, t ) (the joint of r and t at x ) be the tree obtained from t and r by adding an edge between x and the root of t . By the induction hypothesis, ( H k -1 , V 1 , · · · , V k -1 ) is distributed like a p -tree together with k -1 independent p -nodes. Furthermore V k is independent of ( H k -1 , V 1 , · · · , V k -1 ) . It follows that
$$\mathbb { P } ( \tilde { T } _ { k } = t ; \tilde { R } _ { k } = r ; V _ { i } = v _ { i }, 1 \leq i \leq k ) = \sum _ { x \in \text{Span} ( r ; \nu _ { k - 1 } ) } \mathbb { P } ( H _ { k - 1 } = j _ { x } ( r, t ) ; V _ { i } = v _ { i }, 1 \leq i \leq k )$$
$$& = \sum _ { x \in \text{Span} ( r ; \mathbf v _ { k - 1 } ) } \prod _ { i \in \mathbf V } p _ { i } ^ { C _ { i } ( t ) } \cdot \prod _ { j \in [ n ] \mathbf V } p _ { j } ^ { C _ { j } ( r ) } \cdot p _ { x } \cdot \prod _ { 1 \leq i \leq k } p _ { v _ { i } } \\ & = \prod _ { i \in \mathbf V } p _ { i } ^ { C _ { i } ( t ) } \cdot p _ { v _ { k } } \cdot \prod _ { j \in [ n ] \mathbf V } p _ { j } ^ { C _ { j } ( r ) } \cdot p ( \text{Span} ( r ; \mathbf v _ { k - 1 } ) ) \cdot \prod _ { 1 \leq i < k } p _ { v _ { i } }.$$
$$& \overset { \cdot } { \sum } _ { i \in \text{Span} ( r ; \mathbf v _ { k - 1 } ) } \mathbb { P } ( H _ { k - 1 } = j _ { x } ( r, t ) ; V _ { i } = v _ { i }, 1 \leq i \leq k ) \\ & \sum _ { i \in \text{Span} ( r ; \mathbf v _ { k - 1 } ) } \prod _ { i \in \mathbf V } p _ { i } ^ { C _ { i } ( t ) } \cdot \prod _ { j \in [ n ] \mathbf V } p _ { j } ^ { C _ { j } ( r ) } \cdot p _ { x } \cdot \prod _ { 1 \leq i \leq k } p _ { v _ { i } } \\ & \prod _ { \in \mathbf V } p _ { i } ^ { C _ { i } ( t ) } \cdot p _ { v _ { k } } \cdot \prod _ { j \in [ n ] \mathbf V } p _ { j } ^ { C _ { j } ( r ) } \cdot p ( \text{Span} ( r ; \mathbf v _ { k - 1 } ) ) \cdot \prod _ { 1 \leq i < k } p _ { v _ { i } }.$$
glyph[negationslash]
By summing over t and r and applying Cayley's multinomial formula, we deduce that conditional on v T ( ˜ k ) = V = ∅ , ( ˜ T , V k k ) is independent of ( ˜ R , V , . . . , V k 1 k -1 ) and distributed according to π | V ⊗ | p V , which establishes the first claim for k .
Now, conditional on the event { V k ∈ S k -1 } , the vertex V k is distributed according to the restriction of p to S k -1 . In this case, H k = H k -1 so that by the induction hypothesis
$$\text{on} \ \{ V _ { k } \in S _ { k = 1 } \}, \quad ( H _ { k }, V _ { 1 }, \dots, V _ { k } ) \sim \pi \otimes p ^ { k - 1 } \otimes p | _ { S _ { k - 1 } }.$$
glyph[negationslash]
On the other hand, if V k ∈ S k -1 , then v ( ˜ T k ) = ∅ and conditional on v ( ˜ T k ) = V , we have ( ˜ T , V k k ) ∼ π | V ⊗ p | V . In that case, H k is obtained from H k -1 by replacing ˜ T k by cut( ˜ T , V k k ) . We have already proved that, in this case, ( ˜ T , V k k ) is independent of ˜ R k , and Lemma 4.1 ensures that the replacement does not alter the distribution. In other words, glyph[negationslash]
glyph[negationslash]
$$\text{on} \ \{ V _ { k } \not \in S _ { k - 1 } \}, \quad ( H _ { k }, V _ { 1 }, \dots, V _ { k } ) \sim \pi \otimes \mathbf p ^ { k - 1 } \otimes \mathbf p | _ { [ n ] \langle S _ { k - 1 } }.$$
Since V k ∼ p is independent of everything else, conditional on S k -1 , the event { V k ∈ S k -1 } occurs precisely with probability p ( S k -1 ) , so that putting (4.1) and (4.2) together completes the proof of the induction step.
Figure 3: In order to obtain cut( T, V 1 , . . . , V k ) from cut( T, V 1 , . . . , V k -1 ) , it suffices to transform the subtree ˜ T k of cut( T, V 1 , . . . , V k -1 ) \ S k -1 which contains V k .
Figure 4: The 3 -cut tree and the marked points U 1 3 , U 3 3 corresponding to the cut node X 3 . The backbone is represented by the subtree in thick blue.
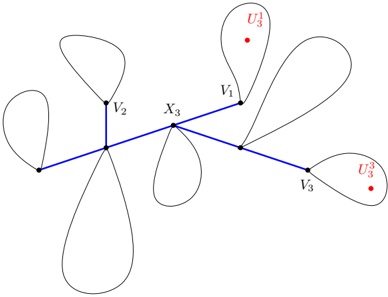
Corollary 4.6. Suppose that T is a p -tree and that V , . . . , V 1 k are k ≥ 1 independent p -nodes, also independent of T . Then,
$$S _ { k } \stackrel { d } { = } \text{Span} ( T ; V _ { 1 }, \dots, V _ { k } ).$$
In particular, the total number of cuts needed to isolate V , . . . , V 1 k in T is distributed as the number of vertices of Span( T V , . . . , V ; 1 k ) .
REVERSE k -CUTTING AND DUALITY. As when we were isolating a single node V in Section 4.1, the transformation that yields H k = cut( T, V 1 , . . . , V k ) is reversible. To reverse the 1 -cutting procedure, we 'unknitted' the path between X 1 and V . Similarly, to reverse the k -cutting procedure, we 'unknit' the backbone S k and by doing this obtain a collection of subtrees; then we re-attach these pendant subtrees at random nodes, which are chosen in suitable subtrees in order to obtain a tree distributed like the initial tree T .
For every i , the subtree F i , rooted at X i , was initially attached to the set of nodes
$$\mathcal { U } _ { i } \coloneqq \{ U _ { i } ^ { j } \, \colon 1 \leq j \leq k \, \text{such that} \, T _ { i - 1 } ^ { j } \ni X _ { i } \}.$$
The corresponding edges have been replaced by some edges which now lie in the backbone S k . So, to reverse the cutting procedure knowing the sets U i , it suffices to remove all the edges of S k , and to re-attach X i to every node in U i . In other words, defining a reverse k -cutting transformation knowing
only the tree H k and the distinguished nodes V , . . . , V 1 k reduces to characterizing the distribution of the sets U i .
Consider a tree h ∈ T n , and k nodes v , v 1 2 , . . . , v k not necessarily distinct. Removing the edges of Span( h v , . . . , v ; 1 k ) from h disconnects it into connected components f x , each containing a single vertex x of Span( h v , . . . , v ; 1 k ) . For a given edge 〈 x, w 〉 of Span( h v , . . . , v ; 1 k ) , let u w be a node in Sub( h, w ) . Let u be the vector of the u w , sorted according to the canonical order of w on Span( h v , . . . , v ; 1 k ) (see p. 17). For a given tree h and v , . . . , v 1 k , we let U ( h, v 1 , . . . , v k ) be the set of such vectors u . For u ∈ U ( h, v 1 , . . . , v k ) , define τ ( h, v 1 , . . . , v k ; u ) as the graph obtained from h by removing every edge 〈 x, w 〉 of Span( h v , . . . , v ; 1 k ) and replacing it by { x, u w } . We regard τ ( h, v 1 , . . . , v k ; u ) as rooted at the root of h .
Lemma 4.7. Suppose that h ∈ T n , and that v , v 1 2 , . . . , v k are k nodes of [ n ] , not necessarily distinct. Then for every u ∈ U ( h, v 1 , . . . , v k ) , τ ( h, v 1 , . . . , v k ; u ) is a tree on [ n ] .
Proof. Write t := τ ( h, v 1 , . . . , v k ; u ) . We proceed by induction on n ≥ 1 . For n = 1 , t = h is reduced to a single node; so t is a tree.
glyph[negationslash]
glyph[negationslash]
Suppose now that for any tree t ′ of size at most n -1 , any k ≥ 1 , any nodes v , v 1 2 , . . . , v k ∈ v ( t ′ ) , and any u ′ ∈ U ( t , v ′ 1 , . . . , v k ) , the graph τ ( t , v ′ 1 , . . . , v k ; u ′ ) is a tree. Let N be the set of neighbors of the root x 1 of h . For y ∈ N , define v y the subset of { v , . . . , v 1 k } containing the vertices which lie in Sub( h, y ) . If v y = ∅ , let also u y ∈ U (Sub( h, y ) , v y ) be obtained from u by keeping only the vertices u w for w ∈ Span (Sub( ∗ h, y ) , v y ) , still in the canonical order. Then, by construction, the subtrees Sub( h, y ) , with y ∈ N such that v y = ∅ are transformed regardless of one another, and the others, for which v y = ∅ , are left untouched. So the graph τ ( h, v 1 , . . . , v k ; u ) induced on [ n ] \ { x 1 } consists precisely of τ (Sub( h, y ) , v y ; u y ) , y ∈ N . By the induction hypothesis, these subgraphs are actually trees. Then τ ( h, v 1 , . . . , v k ; u ) is simply obtained by adding the node x 1 together with the edges { x , u 1 y } , for y ∈ N , where u y ∈ Sub( h, y ) . In other words, each such edge connects x 1 to a different tree τ (Sub( h, y ) , v y ; u y ) so that the resulting graph is also a tree.
For a given tree h and v , . . . , v 1 k ∈ [ n ] let U ∈ U ( h, v 1 , . . . , v k ) be obtained by sampling U w according to the restriction of p to Sub( h, w ) , for every w ∈ Span ( ∗ h, v 1 , . . . , v k ) . Finally, we define the k -shuffled tree shuff( h v , . . . , v ; 1 k ) to be the tree τ ( h, v 1 , . . . , v k ; U ) re-rooted at an independent p -node.
We have the following result, which expresses the fact that the k -cutting and k -shuffling procedures are truly reverses of one another.
Proposition 4.8 ( k -cutting duality) . Let T be a p -tree and let V , . . . , V 1 k be k independent p -nodes, also independent of T . Then, we have the following duality
$$( \text{shuff} ( T, V _ { 1 }, \dots, V _ { k } ), T, V _ { 1 }, \dots, V _ { k } ) \stackrel { d } { = } ( T, \text{cut} ( T, V _ { 1 }, \dots, V _ { k } ), V _ { 1 }, \dots, V _ { k } ).$$
In particular, (shuff( T, V 1 , . . . , V k ) , V 1 , . . . , V k ) ∼ π ⊗ p ⊗ k .
Proof. We consider the coupling we have defined on page 17: We let H k = cut( T, V 1 , . . . , V k ) for a p -tree T rooted at ˆ = r r T ( ) , and for every edge 〈 x, w 〉 of Span( H k ; V , . . . , V 1 k ) we let U w be the unique node of Sub( H ,w k ) which used to be connected to x in the initial tree T . This defines the vector U = ( U ,w w ∈ Span ( ∗ H k ; V , . . . , V 1 k )) . We show by induction on k ≥ 1 that τ ( H ,V ,. . . , V k 1 k ; U ) ˆ r = T and that the joint distribution of ( H ,r, V , . . . , V k ˆ 1 k , U ) is that required by the construction above, so that
$$( \tau ( H _ { k }, V _ { 1 }, \dots, V _ { k } ; \mathbf U ) ^ { \hat { r } }, H _ { k }, V _ { 1 }, \dots, V _ { k } ) \stackrel { d } { = } ( \text{shuff} ( H _ { k }, V _ { 1 }, \dots, V _ { k } ), H _ { k }, V _ { 1 }, \dots, V _ { k } ).$$
Since H k d = T , this would complete the proof.
For k = 1 , the statement corresponds precisely to the construction of the proof of Proposition 4.3. As before, for glyph[lscript] ≤ k , we let S glyph[lscript] = Span( H k ; V , . . . , V 1 glyph[lscript] ) . If k ≥ 2 , let ˜ R k be the connected component of H k \ S k -1 which contains V k , or ˜ R k = ∅ if V k ∈ S k -1 . In the latter case, T = τ ( H ,V ,. . . , V k 1 k -1 , U ) ˆ r and the joint distribution of ( H ,r, V , . . . , V k ˆ 1 k -1 , U ) is correct by the induction hypothesis. Otherwise, let U k denote the sub-vector of U consisting of the components U w for w ∈ Span ( ˜ ∗ R , V k k ) , and let U 1 ,k -1 = ( U ,w w ∈ Span ( ∗ H k ; V , . . . , V 1 k -1 )) . If θ ∈ S k is the unique point such that ˜ R k = Sub( H ,θ k ) (that is, θ is the root of ˜ R k ), then removing ˜ R k from H k and replacing it by τ ( ˜ R , V k k ; U k ) U θ yields precisely the tree H k -1 := cut( T V , . . . , V ; 1 k -1 ) . Also, the distribution of ( ˜ R , U , V k θ k , U k ) is correct, since conditional on the vertex set ˜ R k is distributed as π | v ( ˜ R k ) (Lemma 4.5i). Note that this transformation does not modify the distribution of U 1 ,k -1 . By the induction hypothesis, T = τ ( H k -1 , V 1 , . . . , V k -1 ; U 1 ,k -1 ) ˆ r . Since conditionally on S k -1 = Span( H k ; V , . . . , V 1 k -1 ) we have V k ∈ S k -1 with probability p ( S k -1 ) , the proof is complete.
## 4.3 The complete cutting and the cut tree.
For n a natural number, we may also easily apply the previous procedure until all n nodes have been chosen. In this case, the cutting procedure continues recursively in all the connected components. The number of cuts is now completely irrelevant (it is a.s. equal to n ), and we define the forward transform as follows. Let T be a p -tree and let ( X , i i ≥ 1) be a sequence of elements of [ n ] such that X i is sampled according to the restriction of p to [ n ] \ { X ,. . . , X 1 i -1 } . Let Γ = i T \ { X ,. . . , X 1 i } ; we stop precisely at time n , when { X ,. . . , X 1 n } = [ n ] and Γ n = ∅ .
For every k ∈ [ n ] , define T 〈 k 〉 i as the connected component of Γ i which contains the vertex k , or T 〈 k 〉 i = ∅ if k ∈ { X ,. . . , X 1 i } . For each i = 1 , . . . , n , let U i denote the set of neighbors of X i in Γ i -1 . Then we can write U i = { U 〈 k 〉 i : 1 ≤ k ≤ n such that T 〈 k 〉 i -1 glyph[owner] X i } where U 〈 k 〉 i is the unique element of U i which lies in T 〈 k 〉 i . The cuts which affect the connected component containing k are
$$\mathcal { E } _ { \langle k \rangle } \coloneqq \{ x \in [ n ] \, \colon \exists i \geq 1, X _ { i } = x \in T _ { i - 1 } ^ { \langle k \rangle } \}.$$
We claim that there exists a tree G such that for every k ∈ [ n ] , the path J X ,k 1 K in G is precisely made of the nodes in E 〈 k 〉 , in the order in which they appear in the permutation ( X ,X ,..., X 1 2 n ) . In the following, we write cut( T ) := G . The following proposition justifies the claim.
Proposition 4.9. Let T be a p -tree, and let V k , k ≥ 1 , be i.i.d. p -nodes, independent of T . Then, as k →∞ ,
$$\text{cut} ( T, V _ { 1 }, \dots, V _ { k } ) \stackrel { d } { \rightarrow } \text{cut} ( T ).$$
Proof. We rely on the coupling we introduced in Section 4.2. Since, for k ≥ 1 , we have V , . . . , V 1 k ∈ S k and S k ⊆ S k +1 , the tree S k converges almost surely to a tree on [ n ] , so that lim k →∞ cut( T V , . . . , V ; 1 k ) indeed exists with probability one. In particular, although cut( T V , . . . , V ; 1 k ) certainly depends on V , . . . , V 1 k , the limit only depends on the sequence ( X , i i ≥ 1) . Indeed, K := inf { k ≥ 1 : [ n ] = { V , . . . , V 1 k }} is a.s. finite, and for every k ≥ K , one has cut( T V , . . . , V ; 1 k ) = cut( T X ,... , X ; 1 n ) . We then write cut( T ) := cut( T X ,... , X ; 1 n ) .
Theorem 4.10 (Cut tree) . Let T be a p -tree on [ n ] . Then, we have cut( T ) ∼ π .
Proof. In the coupling defined in Section 4.2, we have
$$S _ { k } = \text{Span} ( \text{cut} ( T ) ; V _ { 1 }, V _ { 2 }, \dots, V _ { k } ) \rightarrow \text{cut} ( T )$$
almost surely as k →∞ . However, by Corollary 4.6, S k is distributed like Span( T V , . . . , V ; 1 k ) , so that S k → T in distribution, as k →∞ , which completes the proof.
SHUFFLING TREES AND THE REVERSE TRANSFORMATION. Given a tree g ∈ T n that we know is cut( ) t for some tree t ∈ T n , and the collections of sets U x , x ∈ [ n ] , we cannot recover the initial tree t exactly, for the information about the root has been lost. However, the structure of t as an unrooted tree is easily (in this case, trivially) recovered by connecting every node x to all the nodes in U x . We now define the reverse operation, which samples the sets U x with the correct distribution conditional on g , and produces a tree ˜ T distributed as T conditionally on cut( T ) = g .
Consider a tree g ∈ T n , rooted at r ∈ [ n ] . For each edge 〈 x, w 〉 of the tree g , let U w be a random element sampled according to the restriction of p to Sub( g, w ) . Let U ∈ U ( g ) := U ( g, 1 2 , , . . . , n ) be the vector of the U w , sorted using the canonical order on g with distinguished nodes 1 2 , , . . . , n . Let τ ( g, [ n ]; U ) denote the graph on [ n ] whose edges are { x, U w } , for 〈 x, w 〉 edges of g . Then, τ ( g, [ n ]; U ) is a tree (Lemma 4.7) and we write shuff( g ) for the random rerooting of τ ( g, [ n ]; U ) at an independent p -node.
Proposition 4.11. Let G be a p -tree, and ( V , k k ≥ 1) a sequence of i.i.d. p -nodes. Then, as k →∞ ,
$$\text{shuff} ( G ; V _ { 1 }, \dots, V _ { k } ) \stackrel { d } { \rightarrow } \text{shuff} ( G ).$$
glyph[negationslash]
Proof. We prove the claim using a coupling which we build using the random variables U w , w = r . For k ≥ 1 , we let U k be the subset of U containing the U w for which w ∈ Span ( ∗ G V , . . . , V ; 1 k ) , in the canonical order on Span ( ∗ G V , . . . , V ; 1 k ) . Then for k ≥ 1 , U k ∈ U ( G,V , . . . , V 1 k ) and since Span( G V , . . . , V ; 1 k ) increases to T , the number of edges of τ ( G V , . . . , V ; 1 k ; U k ) which are constrained by the choices in U k increases until they are all constrained. It follows that
$$\tau ( G ; V _ { 1 }, \dots, V _ { k } ; \mathbf U _ { k } ) \to \tau ( G ; 1, 2, \dots, n ; \mathbf U )$$
almost surely, as k →∞ . Re-rooting all the trees at the same random p -node proves the claim.
We can now state the duality for the complete cutting procedure. It follows readily from the distributional identity in Proposition 4.8
$$( T, \text{cut} ( T, V _ { 1 }, \dots, V _ { k } ) ) \stackrel { d } { = } ( \text{shuff} ( T, V _ { 1 }, \dots, V _ { k } ), T ).$$
and the fact that cut( T V , . . . , V ; 1 k ) → cut( T ) and shuff( T V , . . . , V ; 1 k ) → shuff( T ) in distribution as k →∞ (Propositions 4.9 and 4.11).
Proposition 4.12 (Cutting duality) . Let T be a p -tree. Then, we have the following duality in distribution
$$( T, \text{cut} ( T ) ) \stackrel { d } { = } ( \text{shuff} ( T ), T ).$$
In particular, shuff( T ) ∼ π .
## 5 Cutting down an inhomogeneous continuum random tree
From now on, we fix some θ = ( θ , θ 0 1 , θ 2 , · · · ) ∈ Θ . We denote by I = { i ≥ 1 : θ i > 0 } the index set of those θ i with nonzero values. Let T be the real tree obtained from the Poisson point process construction in Section 2.5. We denote by µ and glyph[lscript] its respective mass and length measures. Recall the measure L defined by
$$\mathcal { L } ( d x ) = \theta _ { 0 } ^ { 2 } \ell ( d x ) + \sum _ { i \in I } \theta _ { i } \delta _ { \beta _ { i } } ( d x ),$$
where β i is the branch point of local time θ i for i ∈ I . The hypotheses on θ entail that L has infinite total mass. On the other hand, we have
Lemma 5.1. Almost surely, L is a σ -finite measure concentrated on the skeleton of T . More precisely, if ( V , i i ≥ 1) is a sequence of independent points sampled according to µ , then for each k ≥ 1 , we have P -almost surely
$$\mathcal { L } ( \text{Span} ( \mathcal { T } ; V _ { 1 }, V _ { 2 }, \cdots, V _ { k } ) ) < \infty.$$
Proof. We consider first the case k = 1 . Recall the Poisson processes (P j , j ≥ 0) in the Section 2.5 and the notations there. We have seen that Span( T ; V 1 ) and R 1 have the same distribution. Then we have
$$\mathcal { L } ( \text{Span} ( \mathcal { T } ; V _ { 1 } ) ) \stackrel { d } { = } \theta _ { 0 } ^ { 2 } \, \eta _ { 1 } + \sum _ { i \geq 1 } \theta _ { i } \, \delta _ { \xi _ { i, 1 } } ( [ 0, \eta _ { 1 } ] ).$$
By construction, η 1 is either ξ j, 2 for some j ≥ 1 or u 1 . This entails that on the event { η 1 ∈ P j } , we have η 1 < ξ i, 2 for all i ∈ N \ { j } . Then,
$$\mathbb { E } \left [ \sum _ { i \geq 1 } \theta _ { i } \, \delta _ { \xi _ { i, 1 } } ( [ 0, \eta _ { 1 } ] ) \right ] = \sum _ { j \geq 1 } \mathbb { E } \left [ \sum _ { i \geq 1 } \theta _ { i } \cdot 1 _ { \{ \xi _ { i, 1 } \leq \eta _ { 1 } \} } 1 _ { \{ \eta _ { 1 } = \xi _ { j, 2 } \} } \right ] + \mathbb { E } \left [ \sum _ { i \geq 1 } \theta _ { i } \cdot 1 _ { \{ \xi _ { i, 1 } < \eta _ { 1 } \} } 1 _ { \{ \eta _ { 1 } = u _ { 1 } \} } \right ].$$
glyph[negationslash]
Note that the event { ξ j, 1 ≤ η 1 } ∩ { η 1 = ξ j, 2 } always occurs. By breaking the first sum on i into θ j + ∑ i = j θ i 1 { ξ i, 1 <η <ξ 1 i, 2 } and re-summing over j , we obtain glyph[negationslash]
glyph[negationslash]
$$\Lambda \leq \iota \neq j \nu \cdot \lambda _ { 1 } \lq \xi _ { i, 1 } \lq \eta _ { 1 } \lq \xi _ { i, 2 } \rq \dots \cdots \cdots \cdots \cdots \\ \mathbb { E } \left [ \sum _ { i \geq 1 } \theta _ { i } \, \delta _ { \xi _ { i, 1 } } ( [ 0, \eta _ { 1 } ] ) \right ] & = \sum _ { j \geq 1 } \theta _ { j } \, \mathbb { P } \, ( \eta _ { 1 } \in P _ { j } ) + \sum _ { j \geq 0 } \mathbb { E } \left [ \sum _ { i \geq 1, i \neq j } \theta _ { i } \cdot 1 _ { \{ \xi _ { i, 1 } < \eta _ { 1 } < \xi _ { i, 2 } \} } 1 _ { \{ \eta _ { 1 } \in P _ { j } \} } \right ] \\ & = \sum _ { j \geq 1 } \theta _ { j } \, \mathbb { P } \, ( \eta _ { 1 } \in P _ { j } ) + \sum _ { j \geq 0 } \sum _ { i \neq j } \mathbb { E } [ \theta _ { i } ^ { 2 } \eta _ { 1 } e ^ { - \theta _ { i } \eta _ { 1 } } 1 _ { \{ \eta _ { 1 } \in P _ { j } \} } ] \\ & \leq 1 + \sum _ { i \geq 1 } \theta _ { i } ^ { 2 } \cdot \mathbb { E } [ \eta _ { 1 } ], \\ \intertext { m a n a n d } \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n D \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d \ m a n d$$
where we have used the independence of (P j , j ≥ 0) in the second equality. The distribution of η 1 is given by (2.5). If θ 0 > 0 , we have P ( η 1 > r ) ≤ exp( -θ r 2 0 2 / 2) ; otherwise, we have P ( η 1 > r ) ≤ (1 + θ r e 1 ) -θ 1 r . In either case, we are able to show that E [ η 1 ] < ∞ . Therefore,
$$\mathbb { E } \left [ \mathcal { L } ( \text{Span} ( \mathcal { T } ; V _ { 1 } ) ) \right ] = \theta _ { 0 } ^ { 2 } \mathbb { E } [ \eta _ { 1 } ] + \mathbb { E } \left [ \sum _ { i \geq 1 } \theta _ { i } \, \delta _ { \xi _ { i, 1 } } ( [ 0, \eta _ { 1 } ] ) \right ] < \infty.$$
In general, the variables V , V 1 2 , · · · , V k are exchangeable, therefore
$$\mathbb { E } \left [ \mathcal { L } ( \text{Span} ( \mathcal { T } ; V _ { 1 }, V _ { 2 }, \cdots, V _ { k } ) ) \right ] \leq k \mathbb { E } \left [ \mathcal { L } ( \text{Span} ( \mathcal { T } ; V _ { 1 } ) ) \right ] < \infty,$$
which proves that L is almost surely finite on the trees spanning finitely many random leaves. Finally, with probability one, ( V , i i ≥ 1) is dense in T , thus Sk( T ) = ∪ k ≥ 1 K r ( T ) , V i J (see for example [5, Lemma 5]). This concludes the proof.
We recall the Poisson point process P of intensity measure dt ⊗ L ( dx ) , whose points we have used to define both the one-node-isolation procedure and the complete cutting procedure. As a direct consequence of Lemma 5.1, P has finitely many atoms on [0 , t ] × Span( T ; V , V 1 2 , · · · , V k ) for all t > 0 and k ≥ 1 , almost surely. This fact will be implicitly used in the sequel.
## 5.1 An overview of the proof
Recall the hypothesis (H) on the sequence of the probability measures ( p n , n ≥ 1) :
$$\sigma _ { n } = \left ( \sum _ { i = 1 } ^ { n } p _ { n i } ^ { 2 } \right ) ^ { 1 / 2 } \stackrel { n \to \infty } { \longrightarrow } 0, \quad \text{and} \quad \lim _ { n \to \infty } \frac { p _ { n i } } { \sigma _ { n } } = \theta _ { i }, \quad \text{for every $i\geq 1$.}$$
Recall the notation T n for a p n -tree, which, from now on, we consider as a measured metric space, equipped with the graph distance and the probability measure p n . Camarri-Pitman [21] have proved that under hypothesis (H),
$$( \sigma _ { n } T ^ { n }, p _ { n } ) \xrightarrow { n \to \infty } _ { d, \text{GP} } ( \mathcal { T }, \mu ).$$
This is equivalent to the convergence of the reduced subtrees: For each n ≥ 1 and k ≥ 1 , write R n k = Span( T n ; ξ n 1 , · · · , ξ n k ) for the subtree of T n spanning the points { ξ n 1 , · · · , ξ n k } , which are k random points sampled independently with distribution p n . Similarly, let R k = Span( T ; ξ , . . . , ξ 1 k ) be the subtree of T spanning the points { ξ , 1 · · · , ξ k } , where ( ξ , i i ≥ 1) is an i.i.d. sequence of common law µ . Then (5.1) holds if and only if for each k ≥ 1 ,
$$\sigma _ { n } R _ { k } ^ { n } \xrightarrow { n \to \infty } R _ { k }.$$
However, even if the trees converge, one expects that for the cut trees to converge, one at least needs that the measures which are used to sample the cuts also converge in a reasonable sense. Observe that L has an atomic part, which, as we shall see, is the scaling limit of large p n -weights. Recall that p n is sorted: p n 1 ≥ p n 2 ≥ · · · p nn . For each m ≥ 1 , we denote by B n m = (1 2 , , · · · , m ) the vector of the m p n -heaviest points of T n , which is well-defined at least for n ≥ m . Recall that for i ≥ 1 , β i denotes the branch point in T of local time θ i , and write B m = ( β , β 1 2 , · · · , β m ) . Then Camarri and Pitman [21] also proved that
$$\left ( \sigma _ { n } T ^ { n }, p _ { n }, \mathfrak { B } _ { m } ^ { n } \right ) \overset { n \to \infty } { \longrightarrow } \left ( \mathcal { T }, \mu, \mathfrak { B } _ { m } \right )$$
with respect to the m -pointed Gromov-Prokhorov topology, which will allow us to prove the following convergence of the cut-measures. Let
$$\mathcal { L } _ { n } = \sum _ { i \in [ n ] } \frac { p _ { n i } } { \sigma _ { n } } \cdot \delta _ { i } = \sigma _ { n } ^ { - 1 } p _ { n }.$$
Recall the notation m glyph[harpoonupright] A for the (non-rescaled) restriction of a measure to a subset A .
Proposition 5.2. Under hypothesis (H) , we have
$$( \sigma _ { n } R _ { k } ^ { n }, \mathcal { L } _ { n } \uparrow _ { R _ { k } ^ { n } } ) \overset { n \to \infty } { \longrightarrow } ( R _ { k }, \mathcal { L } \uparrow _ { R _ { k } } ), \quad \forall k \geq 1,$$
with respect to the Gromov-Hausdorff-Prokhorov topology.
The proof uses the techniques developed in [10, 21] and is postponed until Section 7. We prove in the following subsections that the convergence in Proposition 5.2 is sufficient to entail convergence of the cut trees. To be more precise, we denote by V n a p n -node independent of the p -tree T n , and recall that in the construction of H n := cut( T n , V n ) , the node V n ends up at the extremity of the path upon which we graft the discarded subtrees. Recall from the construction of H := cut( T , V ) in Section 3 that there is a point U , which is at distance L ∞ from the root. In Section 5.2, we prove Theorem 3.1, that is: if (H) holds, then
$$( \sigma _ { n } H ^ { n }, p _ { n }, V ^ { n } ) \underset { d, \text{GP} } { \underset { d, \text{GP} } { \longrightarrow } } ( \mathcal { H }, \hat { \mu }, U ),$$
jointly with the convergence in (5.5). From there, the proof of Theorem 3.2 is relatively short, and we provide it immediately (taking Theorem 3.1 or equivalently (5.6) for granted).
Proof of Theorem 3.2. For each n ≥ 1 , let ( ξ n i ) i ≥ 1 be a sequence of i.i.d. points of common law p n , and let ξ n 0 = V n . Let ( ξ i ) i ≥ 1 be a sequence of i.i.d. points of common law ˆ µ , and let ξ 0 = U . We let
$$\rho _ { n } = ( \sigma _ { n } d _ { H ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ) ) _ { i, j \geq 0 } \quad \text{and} \quad \rho _ { n } ^ { * } = ( \sigma _ { n } d _ { H ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ) ) _ { i, j \geq 1 }$$
the distance matrices in σ H n n = σ n cut( T n , V n ) induced by the sequences ( ξ n i ) i ≥ 0 and ( ξ n i ) i ≥ 1 , respectively. According to Lemma 4.1, the distribution of ξ n 0 = V n is p n , therefore ρ n is distributed as ρ ∗ n . Writing similarly
$$\rho = ( d _ { \mathcal { H } } ( \xi _ { i }, \xi _ { j } ) ) _ { i, j \geq 0 } \quad \text{and} \quad \rho ^ { * } = ( d _ { \mathcal { H } } ( \xi _ { i }, \xi _ { j } ) ) _ { i, j \geq 1 },$$
where d H denotes the distance of H = cut( T , V ) , (5.6) entails that ρ n → ρ in the sense of finitedimensional distributions. Combined with the previous argument, we deduce that ρ and ρ ∗ have the same distribution. However, ρ ∗ is the distance matrix of an i.i.d. sequence of law ˆ µ on H n . And the distribution of ρ determines that of V . As a consequence, the law of U is ˆ µ .
For the unconditional distribution of ( H , µ ˆ) , it suffices to apply the second part of Lemma 4.1, which says that ( H , n p n ) is distributed like ( T n , p n ) . Then comparing (5.6) with (5.1) shows that the unconditional distribution of ( H , µ ˆ) is that of ( T , µ ) .
In order to prove the similar statement for the sequence of complete cut trees G n = cut( T n ) that is Theorem 3.4, the construction of the limit metric space G = cut( T ) first needs to be justified by resorting to Aldous' theory of continuum random trees [5]. The first step consists in proving that the backbones of cut( T n ) converge. For each n ≥ 1 , let ( V n i , i ≥ 1) be a sequence of i.i.d. points of law p n . Recall that we defined cut( T ) using an increasing family ( S k ) k ≥ 1 , defined in (3.4). We show in Section 5.3 that
Lemma 5.3. Suppose that (H) holds. Then, for each k ≥ 1 , we have
$$\sigma _ { n } \text{ Span} ( \text{cut} ( T ^ { n } ) ; V _ { 1 } ^ { n }, \cdots, V _ { k } ^ { n } ) \xrightarrow { n \to \infty } S _ { k },$$
jointly with the convergence in (5.5) .
Combining this with the identities for the discrete trees in Section 4, we can now prove Theorems 3.4 and 3.5.
Proof of Theorem 3.4. By Theorem 4.10, (cut( T n ) , p n ) and ( T n , p n ) have the same distribution for each n ≥ 1 . Recall the notation R n k for the subtree of T n spanning k i.i.d. p n -points. Then for each k ≥ 1 we have
$$S _ { k } ^ { n } \coloneqq \text{Span} ( \text{cut} ( T ^ { n } ), V _ { 1 } ^ { n }, \dots, V _ { k } ^ { n } ) \stackrel { d } { = } R _ { k } ^ { n }.$$
Now comparing (5.7) with (5.2), we deduce immediately that, for each k ≥ 1 ,
$$S _ { k } \stackrel { d } { = } R _ { k }.$$
In particular the family ( S k ) k ≥ 1 is consistent and leaf-tight in the sense of Aldous [5]. This even holds true almost surely conditional on T . According to Theorem 3 and Lemma 9 of [5], this entails that conditionally on cut( T ) , the empirical measure 1 k ∑ k i =1 δ U i converges weakly to some probability measure ν on cut( T ) such that ( U , i i ≥ 1) has the distribution of a sequence of i.i.d. ν -points. This proves the existence of ν . Moreover,
$$S _ { k } \stackrel { d } { = } \text{Span} ( \text{cut} ( \mathcal { T } ), \xi _ { 1 }, \cdots, \xi _ { k } ),$$
where ( ξ , i i ≥ 1) is an i.i.d. µ -sequence. Therefore, (5.7) entails that ( σ n cut( T n ) , p n ) → (cut( T ) , ν ) in distribution with respect to the Gromov-Prokhorov topology.
Proof of Theorem 3.5. According to Theorem 3 of [5] the distribution of (cut( T ) , ν ) is characterized by the family ( S k ) k ≥ 1 . Since S k and R k have the same distribution for k ≥ 1 , it follows that (cut( T ) , ν ) is distributed like ( T , µ ) .
## 5.2 Convergence of the cut-trees cut( T n , V n ) : Proof of Theorem 3.1
In this part we prove Theorem 3.1 taking Proposition 5.2 for granted. Let us first reformulate (5.6) in the terms of the distance matrices, which is what we actually show in the following. For each n ∈ N , let ( ξ n i , i ≥ 2) be a sequence of random points of T n sampled independently according to the mass measure p n .
We set ξ n 1 = V n and let ξ n 0 be the root of H n = cut( T n , V n ) . Similarly, let ( ξ , i i ≥ 2) be a sequence of i.i.d. µ -points and let ξ 1 = V . Recall that the mass measure ˆ µ of H = cut( T , V ) is defined to be the push-forward of µ by the canonical injection φ . We set ̂ ξ i = φ ξ ( i ) for i ≥ 2 , ̂ ξ 1 = U and ̂ ξ 0 to be the root of H .
Then the convergence in (5.6) is equivalent to the following:
$$( \sigma _ { n } d _ { H ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ), 0 \leq i < j < \infty ) \overset { n \to \infty } { \underset { d } { \longrightarrow } } ( d _ { \mathcal { H } } ( \widehat { \xi } _ { i }, \widehat { \xi } _ { j } ), 0 \leq i < j < \infty ),$$
jointly with
$$\left ( \sigma _ { n } d _ { T ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ), 1 \leq i < j < \infty \right ) \overset { n \to \infty } { \underset { d } { \longrightarrow } } \left ( d _ { \mathcal { T } } ( \xi _ { i }, \xi _ { j } ), 1 \leq i < j < \infty \right ),$$
in the sense of finite-dimensional distributions. Notice that (5.9) is a direct consequence of (5.1). In order to express the terms in (5.8) with functionals of the cutting process, we introduce the following notations. For n ∈ N , let P n be a Poisson point process on R + × T n with intensity measure dt ⊗L n , where L n = p n /σ n . For u, v ∈ T n , recall that J u, v K denotes the path between u and v . For t ≥ 0 , we denote by T n t the set of nodes still connected to V n at time t :
$$& T _ { t } ^ { n } \coloneqq \{ x \in T ^ { n } \colon [ 0, t ] \times \left [ V ^ { n }, x \right ] \cap \mathcal { P } _ { n } = \varnothing \}. \\ \cdot \cdot \quad & \quad. \ e \, \tau \, \dots \quad \cdot \cdot \tau \quad \tau \quad \_ \tau \, \cdot \cdot \cdot \tau \, \sin \tau \, \frac { n } { n } \cap \infty$$
Recall that the remaining part of T at time t is T t = { x ∈ T : [0 , t ] × J V, x K ∩P = ∅ } . We then define
$$L _ { t } ^ { n } \coloneqq \text{Card} \left \{ s \leq t \colon p _ { n } ( T _ { s } ^ { n } ) < p _ { n } ( T _ { s - } ^ { n } ) \right \} \stackrel { a. s. } { = } \text{Card} \left \{ ( s, x ) \in \mathcal { P } _ { n } \colon s \leq t, x \in T _ { s - } ^ { n } \right \}. \quad \text{(5.10)}$$
This is the number of cuts that affect the connected component containing V n before time t . In particular, L n ∞ := lim t →∞ L n t has the same distribution as L T ( n ) in the notation of Section 4. Indeed, this follows from the coupling on page 17 and the fact that if P n = { ( t , x i i ) : i ≥ 1 } such that t 1 ≤ t 2 ≤ · · · then ( x i ) is an i.i.d. p n -sequence. Let us recall that L t , the continuous analogue of L n t , is defined by L t = ∫ t 0 µ ( T s ) ds in Section 3. For n ∈ N and x ∈ T n , we define the pair ( τ n ( x , ς ) n ( x )) to be the element of P n separating x from V n glyph[negationslash]
with the convention that inf ∅ = ∞ . In words, ς n ( x ) is the first cut that appeared on J V n , x K . For x ∈ T , ( τ ( x , ς ) ( x )) is defined similarly. We notice that almost surely τ ( ξ j ) < ∞ for each j ≥ 2 , since τ ( ξ j ) is exponential with rate L ( J V, ξ j K ) , which is positive almost surely. Furthermore, it follows from our construction of H n = cut( T n , V n ) that for n ∈ N and i, j ≥ 2 ,
$$\tau _ { n } ( x ) \coloneqq & \inf \{ t > 0 \, \colon [ 0, t ] \times \left [ \left [ V ^ { n }, x \right ] \right ] \cap \mathcal { P } _ { n } \neq \varnothing \}, \\ \cdots \cdots & \ e \sim & \quad \tau _ { n } \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
$$d _ { H ^ { n } } ( \xi _ { 0 } ^ { n }, \xi _ { 1 } ^ { n } ) & = L _ { \infty } ^ { n } - 1, \\ d _ { H ^ { n } } ( \xi _ { 0 } ^ { n }, \xi _ { j } ^ { n } ) & = L _ { \tau _ { n } ( \xi _ { j } ^ { n } ) } ^ { n } - 1 + d _ { T ^ { n } } ( \xi _ { j } ^ { n }, \varsigma _ { n } ( \xi _ { j } ^ { n } ) ) ; \\ d _ { H ^ { n } } ( \xi _ { 1 } ^ { n }, \xi _ { j } ^ { n } ) & = L _ { \infty } ^ { n } - L _ { \tau _ { n } ( \xi _ { j } ^ { n } ) } ^ { n } + d _ { T ^ { n } } ( \xi _ { j } ^ { n }, \varsigma _ { n } ( \xi _ { j } ^ { n } ) ),$$
$$d _ { H ^ { n } } ( \xi _ { 1 } ^ { n }, \xi _ { j } ^ { n } ) = L _ { \infty } ^ { n } - L _ { \tau _ { n } ( \xi _ { j } ^ { n } ) } ^ { n } + d _ { T ^ { n } } \left ( \xi _ { j } ^ { n }, \varsigma _ { n } ( \xi _ { j } ^ { n } ) \right ),$$
$$d _ { \mathcal { H } } ( \widehat { \xi } _ { 0 }, \widehat { \xi } _ { 1 } ) & = L _ { \infty }, \\ d _ { \mathcal { H } } ( \widehat { \xi } _ { 0 }, \widehat { \xi } _ { j } ) & = L _ { \tau ( \xi _ { j } ) } + d _ { \mathcal { T } } ( \xi _ { j }, \varsigma ( \xi _ { j } ) ) ; \\ d _ { \mathcal { H } } ( \widehat { \xi } _ { 1 }, \widehat { \xi } _ { j } ) & = L _ { \infty } - L _ { \tau ( \xi _ { j } ) } + d _ { \mathcal { T } } ( \xi _ { j }, \varsigma ( \xi _ { j } ) ).$$
while for i, j ≥ 2 ,
For n ∈ N and i, j ≥ 2 , if we define the event
$$\mathcal { A } _ { n } ( i, j ) & \coloneqq \{ \tau _ { n } ( \xi _ { i } ^ { n } ) = \tau _ { n } ( \xi _ { j } ^ { n } ) \} \stackrel { a. s. } { = } \{ \varsigma _ { n } ( \xi _ { i } ^ { n } ) = \varsigma _ { n } ( \xi _ { j } ^ { n } ) \},$$
and A c n ( i, j ) its complement, then on the event A n ( i, j ) , we have d H n ( ξ n i , ξ n j ) = d T n ( ξ n i , ξ n j ) . Similarly we define A ( i, j ) := { τ ( ξ i ) = τ ( ξ j ) } , and note that A ( i, j ) = { ς ( ξ i ) = ς ( ξ j ) } almost surely. Recall that (5.1) implies that σ d n T n ( ξ n i , ξ n j ) → d T ( ξ , ξ i j ) . Now, on the event A c n ( i, j ) , we have
$$d _ { H ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ) = \left | L _ { \tau _ { n } ( \xi _ { j } ^ { n } ) } ^ { n } - L _ { \tau _ { n } ( \xi _ { i } ^ { n } ) } ^ { n } \right | + d _ { T ^ { n } } \left ( \xi _ { j } ^ { n }, \varsigma _ { n } ( \xi _ { j } ^ { n } ) \right ) + d _ { T ^ { n } } \left ( \xi _ { i } ^ { n }, \varsigma _ { n } ( \xi _ { i } ^ { n } ) \right ),$$
if n ∈ N , and
$$d _ { \mathcal { H } } ( \widehat { \xi } _ { i }, \widehat { \xi } _ { j } ) = \left | L _ { \tau ( \xi _ { j } ) } - L _ { \tau ( \xi _ { i } ) } \right | + d _ { \mathcal { T } } ( \xi _ { j }, \varsigma ( \xi _ { j } ) ) + d _ { \mathcal { T } } ( \xi _ { i }, \varsigma ( \xi _ { i } ) ),$$
for the limit case. Therefore in order to prove (5.8), it suffices to show the joint convergence of the vector
$$\left ( \mathbf 1 _ { \mathcal { A } _ { n } ( i, j ) }, \tau _ { n } ( \xi _ { i } ^ { n } ), \sigma _ { n } d _ { T ^ { n } } \left ( \xi _ { j } ^ { n }, \varsigma _ { n } ( \xi _ { j } ^ { n } ) \right ), \left ( \sigma _ { n } L _ { t } ^ { n }, t \in \mathbb { R } _ { + } \cup \{ \infty \} \right ) \right )$$
to the corresponding quantities for T , for each i, j ≥ 2 . We begin with a lemma.
Lemma 5.4. Under (H) , we have the following joint convergences as n →∞ :
$$( \mathbf p _ { n } ( T _ { t } ^ { n } ) ) _ { t \geq 0 } \stackrel { d } { \rightarrow } ( \mu ( \mathcal { T } _ { t } ) ) _ { t \geq 0 },$$
in Skorokhod J 1 -topology, along with
$$( \mathbf 1 _ { \mathcal { A } _ { n } ( i, j ) }, 2 \leq i, j \leq k ) \stackrel { d } { \to } ( \mathbf 1 _ { \mathcal { A } ( i, j ) }, 2 \leq i, j \leq k ),$$
$$( \tau _ { n } ( \xi _ { j } ^ { n } ), 2 \leq j \leq k ) \stackrel { d } { \to } ( \tau ( \xi _ { j } ), 2 \leq j \leq k ), \quad a n d$$
$$\left ( \sigma _ { n } d _ { T ^ { n } } ( \xi _ { j } ^ { n }, \varsigma ( \xi _ { j } ^ { n } ) ), 2 \leq j \leq k \right ) \stackrel { d } { \rightarrow } ( d _ { \mathcal { T } } ( \xi _ { j }, \varsigma _ { n } ( \xi _ { j } ) ), 2 \leq j \leq k ),$$
for each k ≥ 2 , and jointly with the convergence in (5.5) .
Proof. Recall Proposition 5.2, which says that, for each k ≥ 2
$$( \sigma _ { n } R _ { k } ^ { n }, \mathcal { L } _ { n } \lceil _ { R _ { k } ^ { n } } ) \stackrel { n \to \infty } { \longrightarrow } ( R _ { k }, \mathcal { L } \lceil _ { R _ { k } } ),$$
in Gromov-Hausdorff-Prokhorov topology. By the properties of the Poisson point process, this entails that for t ≥ 0 ,
$$( \sigma _ { n } R _ { k } ^ { n }, \mathcal { P } _ { n } \lceil _ { [ 0, t ] \times R _ { k } ^ { n } } ) \stackrel { d } { \to } ( R _ { k }, \mathcal { P } \lceil _ { [ 0, t ] \times R _ { k } } ),$$
in Gromov-Hausdorff-Prokhorov topology, jointly with the convergence in (5.5). For each n ∈ N , the pair ( τ n ( ξ n i ) , ς n ( ξ n i )) corresponds to the first jump of the point process P n restricted to J V n 1 , ξ n i K . We notice that for each pair ( i, j ) such that 2 ≤ i, j ≤ k , the event A n ( i, j ) occurs if and only if τ n ( ξ n i ∧ ξ n j ) ≤ min { τ n ( ξ n i ) , τ n ( ξ n j ) } . Similarly, ( τ ( ξ i ) , ς ( ξ i )) is the first point of P on R × J V , ξ 1 1 K , and A ( i, j ) occurs if and only if τ ( ξ i ∧ ξ j ) ≤ min { τ ( ξ i ) , τ ( ξ j ) } . Therefore, the joint convergences in (5.13), (5.14) and (5.15) follow from (5.16). On the other hand, we have
$$\mathbf 1 _ { \{ \xi _ { i } ^ { n } \in T _ { t } ^ { n } \} } = \mathbf 1 _ { \{ t < \tau _ { n } ( \xi _ { i } ^ { n } ) \} }, \ \ t \geq 0, n \geq 1$$
For each fixed t ≥ 0 , this sequence of random variables converge to 1 { t<τ ξ ( i ) } = 1 { ξ i ∈T } t by (5.16). By the law of large numbers, k -1 ∑ 1 ≤ ≤ i k 1 { t<τ n ( ξ n j ) } → p n ( T n t ) almost surely. Then we can find a sequence k n →∞ slowly enough such that (see also [6, Section 2.3])
$$\frac { 1 } { k _ { n } } \sum _ { i = 1 } ^ { k } \mathbf 1 _ { \{ t < \tau _ { n } ( \xi _ { j } ^ { n } ) \} } \stackrel { d } { \to } \mu ( \mathcal { T } _ { t } ).$$
This entails that, as n →∞ ,
$$p _ { n } ( T _ { t } ^ { n } ) \stackrel { d } { \rightarrow } \mu ( \mathcal { T } _ { t } ).$$
↦
Using (5.17) for a sequence of times ( t m , m ≥ 1) dense in R + and combining with the fact that t → µ ( T t ) is decreasing, we obtain the convergence in (5.12), jointly with (5.13), (5.14), (5.15) and (5.5).
## Proposition 5.5. Under (H) , we have
$$( \sigma _ { n } L _ { t } ^ { n }, t \geq 0 ) \stackrel { n \to \infty } { \longrightarrow } ( L _ { t }, t \geq 0 )$$
with respect to the uniform topology, and jointly with the convergences in (5.13) , (5.14) and (5.15) . In particular, this entails that L ∞ < ∞ almost surely. Moreover we have
$$L _ { \infty } \stackrel { d } { = } d _ { \mathcal { T } } ( r ( \mathcal { T } ), V ),$$
where V is a random point of distribution µ . The distribution of d T ( r ( T ) , V ) is given in (2.5) .
The above proposition is a consequence of the following lemmas.
Lemma 5.6. Jointly with (5.13) , (5.14) and (5.15) , we have for any m ≥ 1 and ( t , i 1 ≤ i ≤ m ) ∈ R m + ,
$$\left ( \int _ { 0 } ^ { t _ { i } } \boldsymbol p _ { n } ( T _ { s } ^ { n } ) d s, \, 1 \leq i \leq m \right ) \overset { n \to \infty } { \longrightarrow } \left ( \int _ { 0 } ^ { t _ { i } } \mu ( \mathcal { T } _ { s } ) d s, \, 1 \leq i \leq m \right ).$$
Proof. This is a direct consequence of Lemma 5.4.
## Lemma 5.7. If we let
$$M _ { t } ^ { n } \coloneqq \sigma _ { n } L _ { t } ^ { n } - \int _ { 0 } ^ { t } \mathbf p _ { n } ( T _ { s } ^ { n } ) d s, \ \ n \geq 1 ;$$
then under the hypothesis that σ n → 0 as n →∞ , the sequence of variables ( σ M ,n n n t ≥ 1) converges to 0 in L 2 as n →∞ . Moreover, this convergence is uniform on compacts.
In particular, Lemma 5.6 and Lemma 5.7 combined entail that for any fixed t ≥ 0 , σ L n n t → L t in distribution. However, to obtain the convergence of σ L n n ∞ to L ∞ in distribution we need the following tightness condition.
Lemma 5.8. Under (H) , for every δ > 0 ,
$$\lim _ { t \to \infty } \lim \sup _ { n \to \infty } \mathbb { P } \left ( \sigma _ { n } ( L _ { \infty } ^ { n } - L _ { t } ^ { n } ) \geq \delta \right ) = 0,$$
↦
Proof of Lemma 5.7. Let N n t = Card ( { s, x ) ∈ P n : s ≤ t } be the counting process of P n . Then (N n t , t ≥ 0) is a Poisson process of rate 1 /σ n . We write d N n for the Stieltjes measure associated with t → N n t . For t ≥ 0 , let
$$\mathcal { M } _ { t } ^ { n } \coloneqq L _ { t } ^ { n } - \int _ { [ 0, t ] } \mathbf p _ { n } ( T _ { s - } ^ { n } ) d N _ { s } ^ { n }, \quad \text{and} \quad \mathcal { N } _ { t } ^ { n } \coloneqq \sigma _ { n } \int _ { [ 0, t ] } \mathbf p _ { n } ( T _ { s - } ^ { n } ) d N _ { s } ^ { n } - \int _ { 0 } ^ { t } \mathbf p _ { n } ( T _ { s } ^ { n } ) d s.$$
We notice that, by the definition of L n t ,
$$\mathcal { M } _ { t } ^ { n } = \sum _ { ( s, x ) \in \mathcal { P } _ { n } \colon s \leq t } \left ( \mathbf 1 _ { \{ x \in T _ { s - } ^ { n } \} } - \mathbf p _ { n } ( T _ { s - } ^ { n } ) \right ).$$
Since σ -1 n p n = L n , conditionally on T n s -, 1 { x ∈ T n s -} is a Bernoulli random variable of mean p n ( T n s -) . Therefore, we have
$$\mathbb { E } [ \mathcal { M } _ { t } ^ { n } \, | \, ( N _ { s } ^ { n } ) _ { s \leq t } ] = 0.$$
From this, we can readily show that M n is a martingale. On the other hand, classical results on the Poisson process entail that N n is also a martingale. Once combined, we see that M = n σ n M n + N n itself is a martingale. Therefore, by Doob's maximal inequality for the L 2 -norms of martingales, we obtain for any t ≥ 0 ,
$$\mathbb { E } \left [ \sup _ { s \leq t } ( M _ { s } ^ { n } ) ^ { 2 } \right ] \leq 4 \mathbb { E } \left [ ( M _ { t } ^ { n } ) ^ { 2 } \right ] = 4 \mathbb { E } \left [ ( \sigma _ { n } \mathcal { M } _ { t } ^ { n } ) ^ { 2 } \right ] + 4 \mathbb { E } \left [ ( \mathcal { N } _ { t } ^ { n } ) ^ { 2 } \right ],$$
as a result of (5.21). Direct computation shows that
$$\mathbb { E } [ ( \mathcal { M } _ { t } ^ { n } ) ^ { 2 } ] = \mathbb { E } \left [ \frac { 1 } { \sigma _ { n } } \int _ { 0 } ^ { t } \left ( p _ { n } ( T _ { s } ^ { n } ) - p _ { n } ^ { 2 } ( T _ { s } ^ { n } ) \right ) d s \right ], \quad \text{and} \quad \mathbb { E } [ ( \mathcal { M } _ { t } ^ { n } ) ^ { 2 } ] = \mathbb { E } \left [ \sigma _ { n } \int _ { 0 } ^ { t } p _ { n } ^ { 2 } ( T _ { s } ^ { n } ) d s \right ].$$
As a consequence, for any fixed t ,
$$\mathbb { E } \left [ \sup _ { s \leq t } ( M _ { s } ^ { n } ) ^ { 2 } \right ] \leq 4 \sigma _ { n } \mathbb { E } \left [ \int _ { 0 } ^ { t } p _ { n } ( T _ { s } ^ { n } ) d s \right ] \leq 4 \sigma _ { n } t \rightarrow 0,$$
as n →∞ .
We need an additional argument to prove Lemma 5.8. For each n ∈ N and s ≥ 0 , let ζ n ( s ) := inf { t > 0 : L n t ≥ glyph[floorleft] s glyph[floorright]} be the right-continuous inverse of L n t . Recall that from the construction of H n = cut( T n , V n ) , there is a correspondence between the vertex sets of the remaining tree at step glyph[lscript] -1 and the subtree in H at X glyph[lscript] . Then it follows Lemma 4.1 that
$$\left ( \mathfrak v ( T _ { \zeta ^ { n } ( s ) } ^ { n } ), 0 \leq s < L _ { \infty } ^ { n } \right ) \stackrel { d } { = } \left ( \mathfrak v ( \text{Sub} ( T ^ { n }, x _ { s } ^ { n } ) ), 0 \leq s < 1 + d _ { T ^ { n } } ( r ( T ^ { n } ), V ^ { n } ) \right ),$$
where x n s is the point on the path J r T ( n ) , V n K at distance glyph[floorleft] s glyph[floorright] from r T ( n ) . In particular, this entails
$$( p _ { n } ( T _ { \zeta ^ { n } ( s ) } ^ { n } ), 0 \leq s < L _ { \infty } ^ { n } ) \stackrel { d } { = } ( p _ { n } ( \text{ Sub} ( T ^ { n }, x _ { s } ^ { n } ) ), 0 \leq s < 1 + d _ { T ^ { n } } ( r ( T ^ { n } ), V ^ { n } ) ).$$
The limit of the right-hand side is easily identified using the convergence of p -trees in (5.1). Combined with (5.22), this will allow us to prove Lemma 5.8 by a time-change argument.
Let V be a random point of T of distribution µ . For 0 ≤ s ≤ d T ( r ( T ) , V ) , let x s be the point in J r ( T ) , V K at distance s from r ( T ) , or x s = V if glyph[lscript] > d r ( ( T ) , V ) . Similarly, we set x n s = V n if s ≥ 1 + d T n ( r T ( n ) , V n ) .
## Lemma 5.9. Under (H) , we have
$$\left ( \sigma _ { n } L _ { \infty } ^ { n }, \left ( \mathfrak { p } _ { n } \left ( T _ { \zeta ^ { n } ( s / \sigma _ { n } ) } ^ { n } \right ) \right ) _ { s \geq 0 } \right ) \overset { n \to \infty } { \longrightarrow } \left ( d _ { \mathcal { T } } ( r ( \mathcal { T } ), V ), \left ( \mu ( \text{Sub} ( \mathcal { T }, x _ { s } ) ) \right ) _ { s \geq 0 } \right ),$$
where the convergence of the second coordinates is with respect to the Skorokhod J 1 -topology.
Proof. Because of (5.22) and the fact σ n → 0 , it suffices to prove that
$$\left ( p _ { n } ( \text{ Sub} ( T ^ { n }, x _ { s / \sigma _ { n } } ^ { n } ), s \geq 0 \right ) \overset { n \to \infty } { \longrightarrow } \left ( \mu ( \text{ Sub} ( \mathcal { T }, x _ { s } ), s \geq 0 \right ),$$
with respect to the Skorokhod J 1 -topology, jointly with σ d n T n ( r T ( n ) , V n ) → d T ( r ( T ) , V ) in distribution. Recall that ( ξ n i , i ≥ 2) is a sequence of i.i.d. points of common law p n and set ξ n 0 = V n , ξ n 1 = ( r T n ) , for n ∈ N . Note that ( ξ n i , i ≥ 0) is still an i.i.d. sequence. Then it follows from (5.1) that
$$( \sigma _ { n } d _ { T ^ { n } } ( \xi _ { i } ^ { n }, \xi _ { j } ^ { n } ), i, j \geq 0 ) \stackrel { d } { \to } ( d _ { \mathcal { T } } ( \xi _ { i }, \xi _ { j } ), i, j \geq 0 )$$
in the sense of finite-dimensional distributions. Taking i = 0 and j = 1 , we get the convergence
$$\sigma _ { n } d _ { T ^ { n } } ( V ^ { n }, r ( T ^ { n } ) ) \stackrel { d } { \to } d _ { \mathcal { T } } ( V, r ( \mathcal { T } ) ).$$
On the other hand, for i ≥ 1 , ξ n i ∈ Sub( T n , x n s ) if and only if d T n ( ξ n i ∧ V n , r ( T n )) ≥ s . Since for any rooted tree ( T, d, r ) and u, v ∈ T we have 2 d r, u ( ∧ v ) = d r, u ( ) + d r, v ( ) -d u, v ( ) , we deduce that for any k, m ≥ 1 and ( s , j 1 ≤ j ≤ m ) ∈ R m + ,
$$\left ( 1 _ { \{ \xi _ { i } ^ { n } \in \text{Sub} ( T ^ { n }, x _ { s _ { j } / \sigma _ { n } } ^ { n } ) \} }, 1 \leq i \leq k, 1 \leq j \leq m \right ) \stackrel { d } { \to } \left ( 1 _ { \{ \xi _ { i } \in \text{Sub} ( \mathcal { T }, x _ { s _ { j } } ) \} }, 1 \leq i \leq k, 1 \leq j \leq m \right ),$$
↦
jointly with σ d n T n ( V n , r ( T n )) d → d T ( V, r ( T )) . Then the argument used to establish (5.17) shows the convergence of ( p n (Sub( T n , x n s/σ n ) , n ≥ 1) in the sense of finite-dimensional distributions. The convergence in the Skorokhod topology follows from the monotonicity of the function s → p n (Sub( T n , x n s )) .
Proof of Lemma 5.8. Let us begin with a simple observation on the Skorokhod J 1 -topology. Let D ↑ be the set of those functions x : R + → [0 , 1] which are nondecreasing and c` adl` ag. We endow D ↑ with the Skorokhod J 1 -topology. Taking glyph[epsilon1] > 0 and x ∈ D ↑ , we denote by κ glyph[epsilon1] ( x ) = inf { t > 0 : x t ( ) > glyph[epsilon1] } . The following is a well-known fact. A proof can be found in [35, Ch. VI, p. 304, Lemma 2.10]
↦
FACT If x n → x in D ↑ , n →∞ and t → x t ( ) is strictly increasing, then κ glyph[epsilon1] ( x n ) → κ glyph[epsilon1] ( x ) as n →∞ .
If x = ( x t , t ( ) ≥ 0) is a process with c` adl`g paths and a t 0 ∈ R + , we denote by R [ ] t 0 x the reversed process of x at t 0 :
$$\mathbf R _ { t _ { 0 } } [ x ] ( t ) = x \Big ( ( t _ { 0 } - t ) - \Big )$$
if t < t 0 and R [ ]( ) = t 0 x t x (0) otherwise. For each n ≥ 1 , let x n ( ) = t p n ( T n ζ n ( ) t ) , t ≥ 0 and denote by Λ n = R L n ∞ [ x n ] the reversed process at L n ∞ . Similarly, let y t ( ) = µ (Sub( T , x t )) , t ≥ 0 and denote by Λ = R D [ y ] for D = d T ( V, r ( T )) . Then almost surely Λ n ∈ D ↑ for n ∈ N and Λ ∈ D ↑ . Moreover,
Lemma 5.9 says that
$$\cdot \\ \left ( \Lambda _ { n } ( t / \sigma _ { n } ), t \geq 0 \right ) \underset { d } { \longrightarrow } \left ( \Lambda ( t ), t \geq 0 \right )$$
↦
in D ↑ . From the construction of the ICRT in Section 2.5 it is not difficult to show that t → Λ( ) t is strictly increasing. Then by the above FACT, we have σ κ n glyph[epsilon1] (Λ ) n → κ glyph[epsilon1] (Λ) in distribution, for each glyph[epsilon1] > 0 . In particular, we have for any fixed δ > 0 ,
$$\lim _ { \epsilon \to 0 } \lim \sup _ { n \to \infty } \mathbb { P } ( \sigma _ { n } \kappa _ { \epsilon } ( \Lambda _ { n } ) \geq \delta ) \leq \lim _ { \epsilon \to 0 } \mathbb { P } ( \kappa _ { \epsilon } ( \Lambda ) \geq \delta ) = 0,$$
since almost surely Λ( ) t > 0 for any t > 0 .
By Lemma 5.4, the sequence (( p n ( T n t )) t ≥ 0 , n ≥ 1) is tight in the Skorokhod topology. Combined with the fact that, for each fixed n , p n ( T n t ) ↘ 0 as t →∞ almost surely, this entails that for any fixed glyph[epsilon1] > 0
$$\lim _ { t _ { 0 } \to \infty } \lim \sup _ { n \to \infty } \mathbb { P } \left ( \sup _ { t \geq t _ { 0 } } p _ { n } ( T _ { t } ^ { n } ) \geq \epsilon \right ) = 0.$$
Now note that if L n t = k ∈ N , then T n t = T n ζ n ( k ) a.s. since no change occurs until the time of the next cut, in particular we have
$$p _ { n } ( T _ { t } ^ { n } ) = p _ { n } ( T _ { \zeta ^ { n } ( L _ { t } ^ { n } ) } ^ { n } ) \quad \text{a.s.},$$
from which we deduce that
$$\left \{ \boldsymbol p _ { n } ( T _ { t _ { 0 } } ^ { n } ) < \epsilon \right \} \subseteq \left \{ \kappa _ { \epsilon } ( \Lambda _ { n } ) \geq L _ { \infty } ^ { n } - L _ { t _ { 0 } } ^ { n } \right \} \text{ a.s.,}$$
Then we have
$$\left \{ \sigma _ { n } \left ( L _ { \infty } ^ { n } - L _ { t _ { 0 } } ^ { n } \right ) \geq \delta \right \} \cap \left \{ \sup _ { t \geq t _ { 0 } } \mathbf p _ { n } ( T _ { t } ^ { n } ) < \epsilon \right \} \subseteq \left \{ \sigma _ { n } \kappa _ { \epsilon } ( \Lambda _ { n } ) \geq \delta \right \}, \text{ a.s.}$$
## Therefore,
$$& \lim _ { n \to \infty } \mathbb { P } ( \sigma _ { n } ( L _ { \infty } ^ { n } - L _ { t _ { 0 } } ^ { n } ) \geq \delta ) \\ & \leq \lim _ { n \to \infty } \mathbb { P } \left ( \sup _ { t \geq t _ { 0 } } p _ { n } ( T _ { t } ^ { n } ) \geq \epsilon \right ) + \lim _ { n \to \infty } \mathbb { P } \left ( \sigma _ { n } ( L _ { \infty } ^ { n } - L _ { t _ { 0 } } ^ { n } ) \geq \delta \text{ and } \sup _ { t \geq t _ { 0 } } p _ { n } ( T _ { t } ^ { n } ) < \epsilon \right ) \\ & \leq \lim _ { n \to \infty } \mathbb { P } \left ( \sup _ { t \geq t _ { 0 } } p _ { n } ( T _ { t } ^ { n } ) \geq \epsilon \right ) + \lim _ { n \to \infty } \mathbb { P } \left ( \sigma _ { n } \kappa _ { \epsilon } ( \Lambda _ { n } ) \geq \delta \right ). \\ \vdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
In above, if we let first t 0 →∞ and then glyph[epsilon1] → 0 , we obtain (5.20) as a combined consequence of (5.24) and (5.25).
Proof of Proposition 5.5. We fix a sequence of ( t m , m ≥ 1) , which is dense in R + . Combining Lemmas 5.6 and 5.7, we obtain, for all k ≥ 1 ,
$$( \sigma _ { n } L _ { t _ { m } } ^ { n }, 1 \leq m \leq k ) \stackrel { n \to \infty } { \longrightarrow } ( L _ { t _ { m } }, 1 \leq m \leq k ),$$
jointly with the convergences in (5.13), (5.14), (5.15) and (5.5). We deduce from this and Lemma 5.8 that L ∞ < ∞ a.s. and
$$\sigma _ { n } L _ { \infty } ^ { n } \xrightarrow { n \to \infty } _ { d } L _ { \infty },$$
↦
jointly with (5.13), (5.14), (5.15) and (5.5), by Theorem 4.2 of [17, Chapter 1]. Combined with the fact that t → L t is continuous and increasing, this entails the uniform convergence in (5.18). Finally, the distributional identity (5.19) is a direct consequence of Lemma 5.9.
Proof of Theorem 3.1. We have seen that L ∞ < ∞ almost surely. Therefore the cut tree (cut( T , V ) , µ ˆ) is well defined almost surely. Comparing the expressions of d H n ( ξ n i , ξ n j ) given at the beginning of this subsection with those of d H ( ξ , ξ i j ) , we obtain from Lemma 5.4 and Proposition 5.5 the convergence in (5.8). This concludes the proof.
Remark. Before concluding this section, let us say a few more words on the proof of Proposition 5.5. The convergence of ( σ L ,t n n t ≥ 0) to ( L , t t ≥ 0) on any finite interval follows mainly from the convergence in Proposition 5.2. The proof here can be easily adapted to the other models of random trees, see [16, 39]. On the other hand, our proof of the tightness condition (5.20) depends on the specific cuttings on the birthday trees, which has allowed us to deduce the distributional identity (5.22). In general, the convergence of L n ∞ may indeed fail. An obvious example is the classical record problem (see Example 1.4 in [36]), where we have L n t → L t for any fixed t , while L n ∞ ∼ ln n and therefore is not tight in R .
## 5.3 Convergence of the cut-trees cut( T n ) : Proof of Lemma 5.3
Let us recall the settings of the complete cutting down procedure for T : ( V , i i ≥ 1) is an i.i.d. sequence of common law µ ; T V i ( ) t is the equivalence class of ∼ t containing V i , whose mass is denoted by µ i ( ) t ; and L i t = ∫ t 0 µ i ( s ds ) . The complete cut-tree cut( T ) is defined as the complete separable metric space ∪ k S k . We introduce some corresponding notations for the discrete cuttings on T n . For each n ≥ 1 , we
sample a sequence of i.i.d. points ( V n i , i ≥ 1) on T n of distribution p n . Recall P n the Poisson point process on R + × T n of intensity dt ⊗L n . We define
$$\tau$$
$$\mu _ { n, i } ( t ) & \coloneqq p _ { n } ( \{ u \in T ^ { n } \, \colon [ 0, t ] \times \left [ u, V _ { i } ^ { n } \right ] \cap \mathcal { P } _ { n } = \varnothing \} ), \\ L _ { t } ^ { n, i } & \coloneqq \text{Card} \{ s \leq t \, \colon \mu _ { n, i } ( s ) < \mu _ { n, i } ( s - ) \}, \quad \ t \geq 0, i \geq 1 ; \\ \tau _ { n } ( i, j ) & \coloneqq \inf \{ t \geq 0 \, \colon [ 0, t ] \times \left [ V _ { i } ^ { n }, V _ { j } ^ { n } \right ] \cap \mathcal { P } _ { n } \neq \varnothing \}, \quad 1 \leq i, j < \infty. \\ \text{the construction of } C ^ { n } - \text{out} ( T ^ { n } ) \, \text{ we have}$$
glyph[negationslash]
By the construction of G n = cut( T n ) , we have
$$d _ { G ^ { n } } ( V _ { i } ^ { n }, r ( G ^ { n } ) ) & = L _ { \infty } ^ { n, i } - 1, \\ d _ { G ^ { n } } ( V _ { i } ^ { n }, V _ { j } ^ { n } ) & = L _ { \infty } ^ { n, i } + L _ { \infty } ^ { n, j } - 2 L _ { \tau _ { n } ( i, j ) } ^ { n, i }, \quad 1 \leq i, j < \infty$$
where L n,i ∞ := lim t →∞ L n,i t is the number of cuts necessary to isolate V n i . The proof of Lemma 5.3 is quite similar to that of Theorem 3.1. We outline the main steps but leave out the details.
Sketch of proof of Lemma 5.3. First, we can show with essentially the same proof of Lemma 5.4 that we have the following joint convergences: for each k ≥ 1 ,
$$\left ( ( \mu _ { n, i } ( t ), 1 \leq i \leq k ), t \geq 0 \right ) \underset { d } { \overset { n \to \infty } { \longrightarrow } } \left ( ( \mu _ { i } ( t ), 1 \leq i \leq k ), t \geq 0 \right ),$$
with respect to Skorokhod J 1 -topology, jointly with
$$\left ( \tau _ { n } ( i, j ), 1 \leq i, j \leq k \right ) \overset { n \to \infty } { \longrightarrow } \left ( \tau ( i, j ), 1 \leq i, j \leq k \right ),$$
jointly with the convergence in (5.5). Then we can proceed, with the same argument as in the proof of Lemma 5.7, to showing that for any k, m ≥ 1 and ( t j , 1 ≤ j ≤ m ) ∈ R m + ,
$$\left ( \int _ { 0 } ^ { t _ { i } } \mu _ { n, i } ( s ) d s, \, 1 \leq j \leq m, 1 \leq i \leq k \right ) \underset { d } { \longrightarrow } \left ( \int _ { 0 } ^ { t _ { i } } \mu _ { i } ( s ) d s, \, 1 \leq j \leq m, 1 \leq i \leq k \right ).$$
Since the V n i , i ≥ 1 are i.i.d. p n -nodes on T n , each process ( L n,i t ) t ≥ 0 has the same distribution as ( L n t ) t ≥ 0 defined in (5.10). Then Lemmas 5.7 and 5.8 hold true for each L n,i , i ≥ 1 . We are able to show
$$\left ( \sigma _ { n } L _ { t } ^ { n, i }, 1 \leq i \leq k \right ) _ { t \geq 0 } \stackrel { n \to \infty } { \longrightarrow } \left ( L _ { t } ^ { i }, 1 \leq i \leq k \right ) _ { t \geq 0 },$$
with respect to the uniform topology, jointly with the convergences (5.30) and (5.5). Comparing (5.28) with (3.4), we can easily conclude.
In general, the convergence in (5.1) does not hold in the Gromov-Hausdorff topology. However, in the case where T is a.s. compact and the convergence (5.1) does hold in the Gromov-Hausdorff sense, then we are able to show that one indeed has GHP convergence as claimed in Theorem 3.6. In the following proof, we only deal with the case of convergence of cut( T n ) . The result for cut( T n , V n ) can be obtained using similar arguments and we omit the details.
Proof of Theorem 3.6. We have already shown in Lemma 5.3 the joint convergence of the spanning subtrees: for each k ≥ 1 ,
$$( \sigma _ { n } R _ { k } ^ { n }, \sigma _ { n } S _ { k } ^ { n } ) \stackrel { n \to \infty } { \underset { d, \text{GH} } { \longrightarrow } } ( R _ { k }, S _ { k } ).$$
We now show that for each glyph[epsilon1] > 0 ,
$$\lim _ { k \to \infty } \lim _ { n \to \infty } \mathbb { P } \left ( \max \left \{ d _ { \text{GH} } ( R _ { k } ^ { n }, T ^ { n } ), d _ { \text{GH} } ( S _ { k } ^ { n }, \text{cut} ( T ^ { n } ) ) \right \} \geq \epsilon / \sigma _ { n } \right ) = 0.$$
Since the couples ( S , n k cut( T n )) and ( R ,T n k n ) have the same distribution, it is enough to prove that for each glyph[epsilon1] > 0 ,
$$\lim _ { k \to \infty } \lim _ { n \to \infty } \mathbb { P } \left ( \sigma _ { n } \, d _ { \text{GH} } ( R _ { k } ^ { n }, T ^ { n } ) \geq \epsilon \right ) = 0.$$
Let us explain why this is true when ( σ T n n , p n ) → T ( , µ ) in distribution in the sense of GHP. Recall the space M k c of equivalence classes of k -pointed compact metric spaces, equipped with the k -pointed Gromov-Hausdorff metric. For each k ≥ 1 and glyph[epsilon1] > 0 , we set
$$A ( k, \epsilon ) \coloneqq \left \{ ( T, d, \mathbf x ) \in \mathbb { M } _ { c } ^ { k } \, \colon d _ { \text{GH} } \left ( T, \text{Span} ( T ; \mathbf x ) \right ) \geq \epsilon \right \}.$$
↦
It is not difficult to check that A k, glyph[epsilon1] ( ) is a closed set of M k c . Now according to the proof of Lemma 13 of [41], the mapping from M c to M k c : ( T, µ ) → m T,A k,glyph[epsilon1] k ( ( )) is upper-semicontinuous, where M c is the set of equivalence classes of compact measured metric spaces, equipped with the Gromov-HausdorffProkhorov metric and m k is defined by
$$m _ { k } ( T, A ( k, \epsilon ) ) \coloneqq \int _ { T ^ { k } } \mu ^ { \otimes k } ( d \mathbf x ) \mathbf 1 _ { \{ [ T, \mathbf x ] \in A ( k, \epsilon ) \} }.$$
Applying the Portmanteau Theorem for upper-semicontinuous mappings [17, p. 17, Problem 7], we obtain
$$\lim _ { n \to \infty } \sup _ { \mathbb { E } } \mathbb { E } \left [ m _ { k } \left ( ( \sigma _ { n } T ^ { n }, \mathbf p _ { n } ), A ( k, \epsilon ) \right ) \right ] \leq \mathbb { E } \left [ m _ { k } \left ( ( \mathcal { T }, \mu ), A ( k, \epsilon ) \right ) \right ],$$
or, in other words,
$$\lim _ { n \to \infty } \sup \mathbb { P } \left ( \sigma _ { n } \, \mathrm d _ { \text{GH} } \left ( T ^ { n }, R _ { k } ^ { n } \right ) \geq \epsilon \right ) \leq \mathbb { P } \left ( \mathrm d _ { \text{GH} } \left ( \mathcal { T }, R _ { k } \right ) \geq \epsilon \right ) \underset { k \to \infty } { \longrightarrow } 0,$$
since d GH ( R , k T ) → 0 almost surely for T is compact [5]. This proves (5.34) and thus (5.33). By [17, Ch. 1, Theorem 4.5], (5.32) combined with (5.33) entails the joint convergence in distribution of ( σ T n n , σ n cut( T n )) to ( T , cut( T )) in the Gromov-Hausdorff topology. To strengthen to the GromovHausdorff-Prokhorov convergence, one can adopt the arguments in Section 4.4 of [31] and we omit the details.
## 6 Reversing the one-cutting transformation
In this section, we justify the heuristic construction of shuff( H , U ) given in Section 3 for an ICRT H and a uniform leaf U . The objective is to define formally the shuffle operation in such a way that the identity (3.6) hold. In Section 6.1, we rely on weak convergence arguments to justify the construction of shuff( H , U ) by showing it is the limit of the discrete construction in Section 4.1. In Section 6.2, we then determine from this result the distribution of the cuts in the cut-tree cut( T , V ) and prove that with the right coupling, the shuffle can yield the initial tree back (or more precisely, a tree that is in the same GHP equivalence class, which is as good as it gets).
## 6.1 Construction of the one-path reversal shuff( H , U )
Let ( H , d H , µ H ) be an ICRT rooted at r ( H ) , and let U be a random point in H of distribution µ H . Then H is the disjoint union of the following subsets:
$$\mathcal { H } = \bigcup _ { x \in \left [ r ( \mathcal { H } ), U \right ] } F _ { x } \text{ where } \ F _ { x } \coloneqq \{ u \in T \colon \left [ r ( \mathcal { H } ), u \right ] \cap \left [ r ( \mathcal { H } ), U \right ] = \left [ r, x \right ] \}. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
It is easy to see that F x is a subtree of T . It is nonempty ( x ∈ F x ), but possibly trivial ( F x = { x } ). Let B := { x ∈ J r ( H ) , U K : µ H ( F x ) > 0 } ∪ { U } , and for x ∈ B , let S x := Sub( T, x ) \ F x , which is the
union of those F y such that y ∈ B and d H ( U, y ) < d H ( U, x ) . Then for each x ∈ B \ { U } , we associate an attaching point A x , which is independent and sampled according to µ H | S x , the restriction of µ H to S x . We also set A U = U .
Now let ( ξ , i i ≥ 1) be a sequence of i.i.d. points of common law µ H . The set F := ∪ x ∈ B F x has full mass with probability one. Thus almost surely ξ i ∈ F for each i ≥ 0 . We will use ( ξ i ) i ≥ 1 to span the tree shuff( H , U ) and the point ξ 1 is the future root of shuff( H , U ) . For each ξ i , we define inductively two sequences x i := ( x i (0) , x i (1) , · · · ) ∈ B and a i := ( a i (0) , a i (1) , · · · ) : we set a i (0) = ξ i , and, for j ≥ 0 ,
$$x _ { i } ( j ) = a _ { i } ( j ) \wedge U, \quad \text{and} \quad a _ { i } ( j + 1 ) = A _ { x _ { i } ( j ) }.$$
By definition of ( A , x x ∈ B ) , the distance d H ( r ( H ) , x i ( k )) is increasing in k ≥ 1 . For each i, j ≥ 1 , we define the merging time
$$\mathrm m g ( i, j ) \coloneqq \inf \{ k \geq 0 \, \colon \exists l \leq k \text{ and } x _ { i } ( l ) = x _ { j } ( k - l ) \},$$
with the convention inf ∅ = ∞ . Another way to present mg( i, j ) is to consider the graph on B with the edges { x, A x ∧ U } , x ∈ B , then mg( i, j ) is the graph distance between ξ i ∧ U and ξ j ∧ U . On the event { mg( i, j ) < ∞} , there is a path in this graph that has only finitely many edges, and the two walks x i and x j first meet at a point y i, j ( ) ∈ B (where by first, we mean with minimum distance to the root r ( H ) ). In particular, if we set I ( i, j ) , I ( j, i ) to be the respective indices of the element y i, j ( ) appearing in x i and x j , that is,
$$\mathcal { I } ( i, j ) = \inf \{ k \geq 0 \, \colon x _ { i } ( k ) = y ( i, j ) \} \quad \text{and} \quad \mathcal { I } ( j, i ) = \inf \{ k \geq 0 \, \colon x _ { j } ( k ) = y ( i, j ) \},$$
with the convention that I ( i, j ) = I ( j, i ) = ∞ if mg( i, j ) = ∞ , then mg( i, j ) = I ( i, j ) + I ( j, i ) . Write Ht( u ) = d u, u ( ∧ U ) for the height of u in the one of F x , x ∈ B ) , containing it. On the event { mg( i, j ) < ∞} we define γ i, j ( ) which is meant to be the new distance between ξ i and ξ j :
$$\gamma ( i, j ) \coloneqq \sum _ { k = 0 } ^ { \mathcal { I } ( i, j ) - 1 } \text{Ht} ( a _ { i } ( k ) ) + \sum _ { k = 0 } ^ { \mathcal { I } ( j, i ) - 1 } \text{Ht} ( a _ { j } ( k ) ) + d _ { \mathcal { H } } ( a _ { i } ( \mathcal { I } ( i, j ) ), a _ { j } ( \mathcal { I } ( j, i ) ) ),$$
with the convention if k ranges from 0 to -1 , the sum equals zero.
The justification of the definition relies on weak convergence arguments: Let p n , n ≥ 1 , be a sequence of probability measures such that (H) holds with θ the parameter of H . Let H n be a p n -tree and U n a p n -node. Let ( ξ n i ) i ≥ 1 be a sequence of i.i.d. p n -points. Then, the quantities S n x , B n , x n , a n , and
Figure 5: An example with I (1 2) = 3 , , I (2 1) = 1 , and mg(1 2) = 4 , . The dashed lines indicate the identifications where the root of the relevant subtrees are sent to. The blue lines represent the location of the path between ξ 1 and ξ 2 before the transformation.
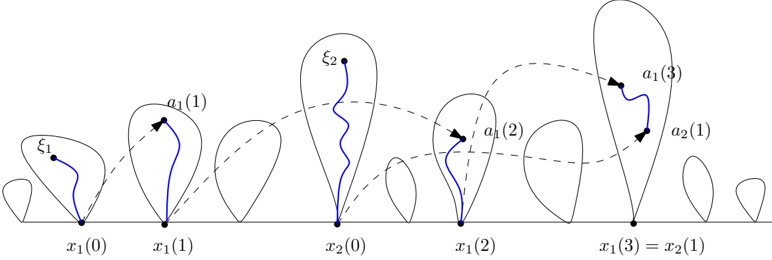
mg ( n i, j ) are defined for H n in the same way as S x , B x a , , , and mg( i, j ) have been defined for H . Let d H n denote the graph distance on H n . There is only a slight difference in the definition of the distances
$$\gamma ^ { n } ( i, j ) \coloneqq \sum _ { k = 0 } ^ { \mathcal { I } ^ { n } ( i, j ) - 1 } \left ( \text{Ht} ( a _ { i } ^ { n } ( k ) ) + 1 \right ) + \sum _ { k = 0 } ^ { \mathcal { I } ^ { n } ( j, i ) - 1 } \left ( \text{Ht} ( a _ { j } ^ { n } ( k ) ) + 1 \right ) + d _ { H ^ { n } } \left ( a _ { i } ( \mathcal { I } ^ { n } ( i, j ) ), a _ { j } ^ { n } ( \mathcal { I } ^ { n } ( j, i ) ) \right ),$$
to take into account the length of the edges { x, A n x } , for x ∈ B n . In that case, the sequence x n (resp. a n ) is eventually constant and equal to U n so that mg ( n i, j ) < ∞ with probability one. Furthermore, the unique tree defined by the distance matrix ( γ n ( i, j ) : i, j ≥ 1) is easily seen to have the same distribution as the one defined in Section 4.1, since the attaching points are sampled with the same distributions and ( γ n ( i, j ) : i, j ≥ 1) coincides with the tree distance after attaching. Recall that we have re-rooted shuff( H ,U n n ) at a random point of law p n . We may suppose this point is ξ n 1 . Therefore we have (Proposition 4.3)
$$( \text{shuff} ( H ^ { n }, U ^ { n } ), H ^ { n } ) & \stackrel { d } { = } ( H ^ { n }, \text{cut} ( H ^ { n }, U ^ { n } ) ),$$
by Lemma 4.1.
In the case of the ICRT H , it is a priori not clear that P (mg( i, j ) < ∞ ) = 1 . We prove that
Theorem 6.1. For any ICRT ( H , µ H ) and a µ H -point U , we have the following assertions:
- a) almost surely for each i, j ≥ 1 , we have mg( i, j ) < ∞ ;
- b) almost surely the distance matrix ( γ i, j ( ) , 1 ≤ i, j < ∞ ) defines a CRT, denoted by shuff( H , U ) ;
- c) (shuff( H , U ) , H ) and ( H , cut( H , V )) have the same distribution.
The main ingredient in the proof of Theorem 6.1 is the following lemma:
Lemma 6.2. Under (H) , for each k ≥ 1 , we have the following convergences
$$( \sigma _ { n } d _ { H ^ { n } } ( r ( H ^ { n } ), \mathbf x _ { i } ^ { n } ( j ) ), 1 \leq i \leq k, 0 \leq j \leq k ) \stackrel { n \to \infty } { \longrightarrow } ( d _ { \mathcal { H } } ( r ( \mathcal { H } ), \mathbf x _ { i } ( j ) ), 1 \leq i \leq k, 0 \leq j \leq k ), \quad ( 6. 2 ) \\ ( \mathbf p _ { n } ( S _ { x _ { i } ^ { n } ( j ) } ^ { n } ), 1 \leq i \leq k, 0 \leq j \leq k ) \stackrel { n \to \infty } { \longrightarrow } ( \mu _ { \mathcal { H } } ( S _ { x _ { i } ( j ) } ), 1 \leq i \leq k, 0 \leq j \leq k ),$$
and
$$\left ( \sigma _ { n } H ^ { n }, ( a _ { i } ^ { n } ( j ), 1 \leq i \leq k, 0 \leq j \leq k ) \right ) \underset { d } { \longrightarrow } \left ( \mathcal { H }, ( a _ { i } ( j ), 1 \leq i \leq k, 0 \leq j \leq k ) \right ),$$
in the weak convergence of the pointed Gromov-Prokhorov topology.
Proof. Fix some k ≥ 1 . We argue by induction on j . For j = 0 , we note that a n i (0) = ξ n i and x n i (0) = ξ n i ∧ U n . Then the convergences in (6.4) and (6.2) for j = 0 follows easily from (5.1). On the other hand, we can prove (6.3) with the same proof as in Lemma 5.9. Suppose now (6.2), (6.3) and (6.4) hold true for some j ≥ 0 . We Notice that a n i ( j +1) is independently sampled according to p n restricted to S x n i ( j ) , we deduce (6.4) for j + 1 from (5.1). Then the convergence in (6.2) also follows for j + 1 , since x n i ( j +1) = a n i ( j ) ∧ U n . Finally,the very same arguments used in the proof of Lemma 5.9 show that (6.3) holds for j +1 .
Proof of Theorem 6.1. Proof of a) By construction, shuff( H ,U n n ) is the reverse transformation of the one from H n to cut( H ,U n n ) in the sense that each attaching 'undoes' a cut. In consequence, since mg ( n i, j ) is the number of cuts to undo in order to get ξ n i and ξ n j in the same connected component, mg ( n i, j ) has the same distribution as the number of the cuts that fell on the path J ξ n i , ξ n j K . But the latter is stochastically bounded by a Poisson variable N n ( i, j ) of mean d H n ( ξ n i , ξ n j ) · E n ( i, j ) , where E n ( i, j ) is an independent exponential variable of rate d H n ( U ,ξ n n i ∧ ξ n j ) . Indeed, each cut is a point of the Poisson
point process P n and no more cuts fall on J ξ n i , ξ n j K after the time of the first cut on J U ,ξ n n i ∧ ξ n j K . But the time of the first cut on J U ,ξ n n i ∧ ξ n j K has the same distribution as E n ( i, j ) and is independent of P n restricted on J ξ n i , ξ n j K . The above argument shows that
$$\mathbb { m } ^ { n } ( i, j ) = \mathcal { I } ^ { n } ( i, j ) + \mathcal { I } ^ { n } ( j, i ) \leq _ { s t } N _ { n } ( i, j ), \quad i, j \geq 1, n \geq 1,$$
where ≤ st denotes the stochastic domination order. It follows from (5.1) that, jointly with the convergence in (5.1), we have N n ( i, j ) → N i, j ( ) in distribution, as n → ∞ , where N i, j ( ) is a Poisson variable with parameter d H ( ξ , ξ i j ) · E i, j ( ) with E i, j ( ) an independent exponential variable of rate d H ( U, ξ i ∧ ξ j ) , which is positive with probability one. Thus the sequence (mg ( n i, j ) , n ≥ 1) is tight in R + .
On the other hand, observe that for x ∈ B , P ( A x ∈ F y ) = µ H ( F y ) /µ H ( S x ) if y ∈ B and d H ( U, y ) < d H ( U, x ) . In particular, for two distinct points x, x ′ ∈ B ,
$$\mathbb { P } \left ( \exists \, y \in \mathbf B \text{ such that } A _ { x } \in F _ { y }, A _ { x ^ { \prime } } \in F _ { y } \right ) = \sum _ { y } \frac { \mu _ { \mathcal { H } } ^ { 2 } ( F _ { y } ) } { \mu _ { \mathcal { H } } ( S _ { x } ) \mu _ { \mathcal { H } } ( S _ { x ^ { \prime } } ) },$$
where the sum is over those y ∈ B such that d H ( U, y ) < min { d H ( U, x , d ) H ( U, x ′ ) } . Similarly, for n ≥ 1 ,
$$\mathbb { P } \left ( \exists \, y \in \mathbf B ^ { n } \text{ such that } A _ { x } ^ { n } \in F _ { y } ^ { n }, A _ { x ^ { \prime } } ^ { n } \in F _ { y } ^ { n } \right ) = \sum _ { y } \frac { p _ { n } ^ { 2 } ( F _ { y } ^ { n } ) } { p _ { n } ( S _ { x } ^ { n } ) p _ { n } ( S _ { x ^ { \prime } } ^ { n } ) }.$$
Then it follows from (6.2) and the convergence of the masses in Lemma 5.9 that
$$\mathbb { P } \left ( \mathcal { I } ^ { n } ( i, j ) = 1 ; \mathcal { I } ^ { n } ( j, i ) = 1 \right ) & = \mathbb { P } \left ( \exists \, y \in \mathbf B ^ { n } \text{ such that } A _ { x _ { i } ( 0 ) } ^ { n } \in F _ { y } ^ { n }, A _ { x _ { j } ( 0 ) } ^ { n } \in F _ { y } ^ { n } \right ) \\ & \stackrel { n \to \infty } { \longrightarrow } \mathbb { P } \left ( \mathcal { I } ( i, j ) = 1 ; \mathcal { I } ( j, i ) = 1 \right ).$$
By induction and Lemma 6.2, this can be extended to the following: for any natural numbers k , k 1 2 ≥ 0 , we have
$$\mathbb { P } \left ( \mathcal { I } ^ { n } ( i, j ) = k _ { 1 } ; \mathcal { I } ^ { n } ( j, i ) = k _ { 2 } \right ) \stackrel { n \to \infty } { \longrightarrow } \mathbb { P } \left ( \mathcal { I } ( i, j ) = k _ { 1 } ; \mathcal { I } ( j, i ) = k _ { 2 } \right ).$$
Combined with the tightness of (mg ( n i, j ) , n ≥ 1) = ( I n ( i, j ) + I n ( j, i ) , n ≥ 1) , this entails that
$$( \mathcal { I } ^ { n } ( i, j ), \mathcal { I } ^ { n } ( j, i ) ) \overset { n \to \otimes } { \longrightarrow } ( \mathcal { I } ( i, j ), \mathcal { I } ( j, i ) ), \ \ i, j \geq 1$$
jointly with (6.2) and (6.4), using the usual subsequence arguments. In particular, I ( i, j ) + I ( j, i ) ≤ st N i, j ( ) < ∞ almost surely, which entails that mg( i, j ) < ∞ almost surely, for each pair ( i, j ) ∈ N × N .
Proof of b) It follows from (6.4), (6.6) and the expression of γ i, j ( ) that
$$( \sigma _ { n } \gamma ^ { n } ( i, j ), i, j \geq 1 ) \overset { n \to \infty } { \longrightarrow } ( \gamma ( i, j ), i, j \geq 1 ),$$
in the sense of finite-dimensional distributions, jointly with the Gromov-Prokhorov convergence of σ H n n to H in (5.1). However by (6.1), the distribution of shuff( H ,U n n ) is identical to H n . Hence, the unconditional distribution of ( γ i, j ( ) , 1 ≤ i, j < ∞ ) is that of the distance matrix of the ICRT H . We can apply Aldous' CRT theory [5] to conclude that for a.e. H , the distance matrix ( γ i, j ( ) , i, j ≥ 1) defines a CRT, denoted by shuff( H , U ) . Moreover, there exists a mass measure ˜ µ , such that if ( ˜ ) ξ i i ≥ 1 is an i.i.d. sequence of law ˜ µ , then
$$( d _ { \text{shuff} } ( \mathcal { H }, U ) ( \tilde { \xi } _ { i }, \tilde { \xi } _ { j } ), 1 \leq i, j < \infty ) \stackrel { d } { = } ( \gamma ( i, j ), 1 \leq i, j < \infty ).$$
Therefore, we can rewrite (6.7) as
$$( \sigma _ { n } \text{ shuff} ( H ^ { n }, U ^ { n } ), \sigma _ { n } H ^ { n } ) \stackrel { n \to \infty } { \longrightarrow } ( \text{ shuff} ( \mathcal { H }, U ), \mathcal { H } ),$$
with respect to the Gromov-Prokhorov topology.
Proof of c) This is an easy consequence of (6.1) and (6.8). Let f, g be two arbitrary bounded functions continuous in the Gromov-Prokhorov topology. Then (6.8) and the continuity of f, g entail that
$$\mathbb { E } \left [ f ( \text{shuff} ( \mathcal { H }, U ) ) \cdot g ( \mathcal { H } ) \right ] & = \lim _ { n \to \infty } \mathbb { E } \left [ f ( \sigma _ { n } \text{ shuff} ( H ^ { n }, U ^ { n } ) ) \cdot g ( \sigma _ { n } H ^ { n } ) \right ] \\ & = \lim _ { n \to \infty } \mathbb { E } \left [ f ( \sigma _ { n } H ^ { n } ) \cdot g ( \sigma _ { n } \text{ cut} ( H ^ { n }, U ^ { n } ) \right ] \\ & = \mathbb { E } \left [ f ( \mathcal { H } ) \cdot g ( \text{cut} ( \mathcal { H }, U ) ) \right ],$$
where we have used (6.1) in the second equality. Thus we obtain the identity in distribution in c).
## 6.2 Distribution of the cuts
According to Proposition 4.3 and (6.1), the attaching points a n i ( j ) have the same distribution as the points where the cuts used to be connected to in the p n tree H n . Then Theorem 6.1 suggests that the weak limit a i ( j ) should play a similar role for the continuous tree. Indeed in this section, we show that a i ( j ) represent the 'holes' left by the cutting on ( T t ) t ≥ 0 .
Let ( T , d T , µ ) be the ICRT in Section 5. The µ -point V is isolated by successive cuts, which are elements of the Poisson point process P . Now let ξ , ξ ′ 1 ′ 2 be two independent points sampled according to µ . We plan to give a description of the image of the path J ξ , ξ ′ 1 ′ 2 K in the cut tree cut( T , V ) , which turns out to be dual to the construction of one path in shuff( H , U ) .
During the cutting procedure which isolates V , the path J ξ , ξ ′ 1 ′ 2 K is pruned from the two ends into segments. See Figure 6. Each segment is contained in a distinct portion ∆ T t := T t -\ T t , which is discarded at time t . Also recall that ∆ T t is grafted on the interval [0 , L ∞ ] to construct cut( T , V ) . The following is just a formal reformulation:
## Lemma 6.3. Let
$$( t _ { 1, 1 }, y _ { 1, 1 } ), ( t _ { 1, 2 }, y _ { 1, 2 } ), \cdots, ( t _ { 1, M _ { 1 } }, y _ { 1, M _ { 1 } } ) \quad \text{ and } \quad ( t _ { 2, 1 }, y _ { 2, 1 } ), ( t _ { 2, 2 }, y _ { 2, 2 } ), \cdots, ( t _ { 2, M _ { 2 } }, y _ { 2, M _ { 2 } } ),$$
be the respective (finite) sequences of cuts on J ξ , V ′ 1 K ∩ J ξ , ξ ′ 1 ′ 2 K and J ξ , V ′ 2 K ∩ J ξ , ξ ′ 1 ′ 2 K such that 0 < t i, 1 < t i, 2 < · · · < t i,M i < ∞ for i = 1 2 , . Then the points { y i,j : 1 ≤ j ≤ M,i i = 1 2 , } partition of the path J ξ , ξ ′ 1 ′ 2 K into segments and:
- · for i = 1 2 , , J ξ , y ′ i i, 1 K ⊂ ∆ T t i, 1 ;
- · for j = 1 2 , , · · · , M i -2 , K y i,j , y i,j +1 K ⊂ ∆ T t i,j +1 .
Finally, writing
$$t _ { m e } & \coloneqq \inf \{ t > 0 \, \colon \mathcal { P } _ { t } \cap \left [ \xi _ { 1 } ^ { \prime }, V \right ] \cap \left [ \xi _ { 2 } ^ { \prime }, V \right ] \neq \varnothing \} < \infty, \\ \vdots \, \dots \, \dots \, \vdots \, \lambda \, \tau$$
glyph[negationslash]
K y 1 ,M 1 , y 2 ,M 2 J is contained in ∆ T t me .
Proof. It suffices to prove that M ,M 1 2 are finite with probability 1 . The other statements are straightforward from the cutting procedure. But an argument similar to the one used in the proof of a) of Theorem 6.1 shows that M 1 + M 2 is stochastically bounded by a Poisson variable with mean d T ( ξ , ξ ′ 1 ′ 2 ) · t me , which entails that M ,M 1 2 are finite almost surely.
Recall that cut( T , V ) is defined so as to be a complete metric space. Denote by φ the canonical injection from ∪ t ∈C ∆ T t to cut( T , V ) . For 1 ≤ j ≤ M i -2 and i = 1 2 , , it is not difficult to see that there exists some point O t ( i,j ) of cut( T , V ) such that the closure of φ ( K y i,j , y i,j +1 K ) is J O t ( i,j ) , φ ( y i,j +1 ) K . Similarly, the closure of φ ( K y 1 ,M 1 , y 2 ,M 2 J ) is equal to J O t ( 1 ,M 1 ) , O ( t 2 ,M 2 ) K , with O t ( 1 ,M 1 ) , O ( t 2 ,M 2 )
Figure 6: An example with M 1 = 3 and M 2 = 1 . Above, the cuts partition the path between ξ ′ 1 and ξ ′ 2 into segments. The cross represents the first cut on J ξ , V ′ 1 K ∩ J ξ , V ′ 2 K . Below, the image of these segments in cut( T , V ) .
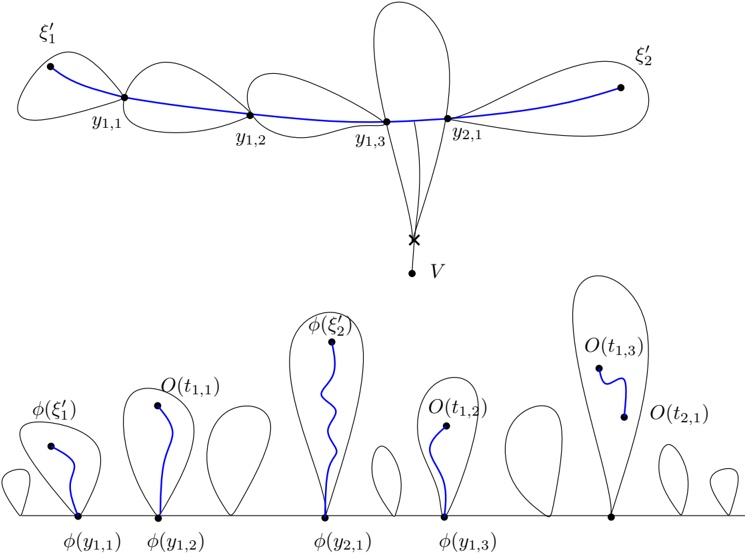
two leaves contained in the closure of φ (∆ T t me ) . Comparing this with Theorem 6.1, one may suspect that { O t ( 1 ,j ) : 1 ≤ j ≤ M , O t 1 } { ( 2 ,j ) : 1 ≤ j ≤ M 2 } should have the same distribution as { a 1 ( j ) : 1 ≤ j ≤ I (1 2) , } { , a 2 ( j ) : 1 ≤ j ≤ I (2 , 1) } . This is indeed true. In the following, we show a slightly more general result about all the points. For each t ∈ C = { t > 0 : µ (∆ T t ) > 0 } , let x t ( ) ∈ T be the point such that ( t, x ( )) t ∈ P . Then we can define O t ( ) to be the point of cut( T , V ) which marks the 'hole' left by the cutting at x t ( ) . More precisely, let ( t , x ′ ′ ) be the first element after time t of P on J r ( T ) , x ( ) t J . Then there exists some point O t ( ) such that the closure of φ ( K x t , x ( ) ′ K ) in cut( T , V ) is J O t , φ x ( ) ( ′ ) K .
Proposition 6.4. Conditionally on cut( T , V ) , the collection { O t , t ( ) ∈ C} is independent, and each O t ( ) has distribution ˆ µ restricted to ∪ s>t φ ( T s -\ T s ) .
Proof. It suffices to show that { O t , t ( ) ∈ C} has the same distribution as the collection of attaching points { A , x x ∈ B } introduced in the previous section. Observe that if we take ( H , U ) = (cut( T , V ) , L ∞ ) and replace { A , x x ∈ B } with { O t , t ( ) ∈ C} , then it follows that shuff( H , U ) is isometric to T , since the two trees are metric completions of the same distance matrix with probability one. In particular, we have
$$( \text{shuff} ( \mathcal { H }, U ), \mathcal { H } ) \stackrel { d } { = } ( \mathcal { T }, \text{cut} ( \mathcal { T }, V ) ).$$
Therefore, to determine the distribution of { O t , t ( ) ∈ C} , we only need to argue that the distribution of { A , x x ∈ B } is the unique distribution for which (6.9) holds. To see this, we notice that (6.9) implies that the distribution of ( γ i, j ( )) i,j ≥ 1 is unique. But from the distance matrix ( γ i, j ( )) i,j ≥ 1 (also given H and ( ξ , i i ≥ 1) ), we can recover ( a i (1) , i ≥ 1) , which is a size-biased resampling of ( A , x x ∈ B ) . Indeed, the sequence ( ξ k ) k ≥ 1 is everywhere dense in H . For x ∈ B , let ( ξ m k , k ≥ 1) be the subsequence consisting of the ξ i contained in F x . Then a i (1) ∈ F x if and only if lim inf k →∞ γ i, m ( k ) -Ht( ξ i ) = 0 , where
Ht( ξ i ) = d H ( ξ , ξ i i ∧ U ) . Moreover, if the latter holds, we also have d H ( a i (1) , ξ m k ) = γ i, m ( k ) -Ht( ξ i ) . By Gromov's reconstruction theorem [30, 3 1 2 ], we can determine a i (1) for each i ≥ 1 . By the previous arguments, this concludes the proof.
The above proof also shows that if we use ( O t , t ( ) ∈ C ) to define the points ( A , x x ∈ B ) then the shuffle operation yields a tree that is undistinguishable from the original ICRT T .
## 7 Convergence of the cutting measures: Proof of Proposition 5.2
Recall the setting at the beginning of Section 5.1. Then proving Proposition 5.2 amounts to show that for each k ≥ 1 , we have
$$\mu _ { 0 } \left ( \sigma _ { n } R _ { k } ^ { n }, \mathcal { L } _ { n } \lceil _ { R _ { k } ^ { n } } \right ) \overset { n \to \infty } { \longrightarrow } \left ( R _ { k } ( \mathcal { T } ), \mathcal { L } \lceil _ { R _ { k } } \right )$$
in Gromov-Hausdorff-Prokhorov topology. Observe that the Gromov-Hausdorff convergence is clear from (5.1), so that it only remains to prove the convergence of the measures.
Case 1 We first prove the claim assuming that θ i > 0 for every i ≥ 0 . In this case, define
$$m _ { n } \coloneqq \min \left \{ j \colon \sum _ { i = 1 } ^ { j } \left ( \frac { p _ { n i } } { \sigma _ { n } } \right ) ^ { 2 } \geq \sum _ { i \geq 1 } \theta _ { i } ^ { 2 } \right \},$$
and observe that m < n ∞ since ∑ i ≤ n ( p ni /σ n ) 2 = 1 ≥ ∑ i ≥ 1 θ 2 i . Note also that m n →∞ . Indeed, for every integer k ≥ 1 , since p ni /σ n → θ i , for i ≥ 1 , and θ k +1 > 0 , we have, for all n large enough,
$$\sum _ { i = 1 } ^ { k } \left ( \frac { p _ { n i } } { \sigma _ { n } } \right ) ^ { 2 } < \sum _ { i \geq 1 } \theta _ { i } ^ { 2 },$$
so that m > k n for all n large enough. Furthermore lim j →∞ θ j = 0 , and (H) implies that
$$\lim _ { n \to \infty } \frac { p _ { m _ { n } } } { \sigma _ { n } } = 0.$$
Combining this with the definition of m n , it follows that, as n →∞ ,
$$\sum _ { i \leq m _ { n } } \left ( \frac { p _ { n i } } { \sigma _ { n } } \right ) ^ { 2 } \rightarrow \sum _ { i \geq 1 } \theta _ { i } ^ { 2 }.$$
If n, k, M ≥ 1 , we set
$$\mathcal { L } _ { n } ^ { * } = \sum _ { m _ { n } < i \leq n } \frac { p _ { n i } } { \sigma _ { n } } \delta _ { i }, \quad \text{and} \quad \Sigma ( n, k, M ) = \sum _ { M < i \leq m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } \mathbf 1 _ { \{ i \in R _ { k } ^ { n } \} }.$$
Let glyph[lscript] n denote the (discrete) length measure on T n . Clearly, σ glyph[lscript] n n is the length measure of the rescaled tree σ T n n , seen as a real tree.
Lemma 7.1. Suppose that (H) holds. Then, for each k ≥ 1 , we have the following assertions:
a) as n →∞ , in probability
$$\hat { d } _ { P } \left ( \mathcal { L } _ { n } ^ { * } \lceil _ { R _ { k } ^ { n } }, \theta _ { 0 } ^ { 2 } \sigma _ { n } \ell _ { n } \rceil _ { R _ { k } ^ { n } } \right ) \to 0 ;$$
b) for each glyph[epsilon1] > 0 , there exists M = M k,glyph[epsilon1] ( ) ∈ N such that
$$\lim _ { n \to \infty } \mathbb { P } \left ( \Sigma ( n, k, M ) \geq \epsilon \right ) \leq \epsilon ;$$
Before proving Lemma 7.1, let us first explain why this entails Proposition 5.2.
Proof of Proposition 5.2 in the Case 1 . By Skorokhod representation theorem and a diagonal argument, we can assume that the convergence ( σ T n n , µ n , B n m ) → T ( , µ, B m ) , holds almost surely in the m -pointed Gromov-Prokhorov topology for all m ≥ 1 . Since the length measure glyph[lscript] n (resp. glyph[lscript] ) depends continuously on the metric of T n (resp. the metric of T ), according to Proposition 2.23 of [39] this implies that, for each k ≥ 1 ,
$$( \sigma _ { n } R _ { k } ^ { n }, \theta _ { 0 } ^ { 2 } \sigma _ { n } \ell _ { n } \uparrow _ { R _ { k } ^ { n } } ) \to ( R _ { k }, \theta _ { 0 } ^ { 2 } \ell \uparrow _ { R _ { k } } ),$$
almost surely in the Gromov-Hausdorff-Prokhorov topology. On the other hand, we easily deduce from the convergence of the vector B n m and (H) that, for each fixed m ≥ 1 ,
$$\left ( \sigma _ { n } R _ { k } ^ { n }, \sum _ { i = 1 } ^ { m } \frac { p _ { n i } } { \sigma _ { n } } \delta _ { i } \uparrow _ { R _ { k } ^ { n } } \right ) \rightarrow \left ( R _ { k }, \sum _ { i = 1 } ^ { m } \theta _ { i } \delta _ { \mathcal { B } _ { i } } \uparrow _ { R _ { k } } \right ),$$
almost surely in the Gromov-Hausdorff-Prokhorov topology. In the following, we write d n k , P (resp. d k P ) for the Prokhorov distance on the finite measures on the set R n k (resp. R k ). In particular, since the measures below are all restricted to either R n k or R k , we omit the notations glyph[harpoonupright] R n k , glyph[harpoonupright] R k when the meaning is clear from context. We write
$$\text{Kt} _ { m } ( \mathcal { L } ) \coloneqq \theta _ { 0 } ^ { 2 } \ell + \sum _ { i = 1 } ^ { m } \theta _ { i } \delta _ { \mathcal { B } _ { i } }$$
for the cut-off measure of L at level m . By Lemma 5.1, the restriction of L to R n k is a finite measure. Therefore, Kt m ( L → L ) almost surely in d k P as m →∞ .
Now fix some glyph[epsilon1] > 0 . By Lemma 7.1 we can choose some M = M k,glyph[epsilon1] ( ) such that (7.5) holds, as well as
$$\mathbb { P } ( \mathrm d _ { \mathrm P } ^ { k } ( \mathrm K t _ { M } ( \mathcal { L } ), \mathcal { L } ) \geq \epsilon ) \leq \epsilon.$$
Define now the approximation
$$\vartheta _ { n, M } \coloneqq \theta _ { 0 } ^ { 2 } \sigma _ { n } \ell _ { n } + \sum _ { i \leq M } \frac { p _ { n i } } { \sigma _ { n } } \delta _ { i }.$$
Then recalling the definition of L n in (5.4), and using (7.5) and (7.4), we obtain
$$\lim _ { n \to \infty } \sup _ { \mathbb { P } } \mathbb { P } ( \mathfrak d _ { \mathbb { P } } ^ { n, k } ( \vartheta _ { n, M }, \mathcal { L } _ { n } ) \geq \epsilon ) \leq \epsilon.$$
We notice that
$$\left ( \sigma _ { n } R _ { k } ^ { n }, \vartheta _ { n, M } \right ) \rightarrow \left ( R _ { k }, \text{Kt} _ { M } ( \mathcal { L } ) \right )$$
almost surely in the Gromov-Hausdorff-Prokhorov topology as a combined consequence of (7.6) and (7.7). Finally, by the triangular inequality, we deduce from (7.8), (7.9) and (7.10) that
$$\lim _ { n \to \infty } \sup _ { \substack { n \to \infty } } \mathbb { P } \left ( \mathrm d _ { \text{GHP} } \left ( ( \sigma _ { n } R _ { k } ^ { n }, \mathcal { L } _ { n } ), ( R _ { k }, \mathcal { L } ) \right ) \geq 2 \epsilon \right ) \leq 2 \epsilon,$$
for any glyph[epsilon1] > 0 , which concludes the proof.
Proof of Lemma 7.1. We first consider the case k = 1 . Define
$$D _ { n } \coloneqq d _ { T ^ { n } } ( r ( T ^ { n } ), V _ { 1 } ^ { n } ), \quad \text{ and } \quad F _ { n } ^ { \mathcal { L } } ( l ) \coloneqq \mathcal { L } _ { n } ^ { * } ( \mathbf B ( r ( T ^ { n } ), l ) \cap R _ { 1 } ^ { n } ),$$
where B ( x, l ) denotes the ball in T n centered at x and with radius l . Then the function F L n determines the measure L ∗ n glyph[harpoonupright] R n 1 in the same way a distributional function determines a finite measure of R + . Let
( X ,j n j ≥ 0) be a sequence of i.i.d. random variables of distribution p n . We define R n 0 = 0 , and for m ≥ 1 ,
$$\mathfrak { R } _ { m } ^ { n } = \inf \left \{ j > \mathfrak { R } _ { m - 1 } ^ { n } \colon X _ { j } ^ { n } \in \left \{ X _ { 1 } ^ { n }, X _ { 2 } ^ { n }, \cdots, X _ { j - 1 } ^ { n } \right \} \right \}$$
the m -th repeat time of the sequence. For l ≥ 0 , we set
$$F _ { n } ( l ) \coloneqq \sum _ { j = 0 } ^ { l \wedge ( \mathfrak { R } _ { 1 } ^ { n } - 1 ) } \sum _ { i > m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } \mathbf 1 _ { \{ X _ { j } ^ { n } = i \} }.$$
According to the construction of the birthday tree in [21] and Corollary 3 there, we have
$$( D _ { n }, F _ { n } ^ { \mathcal { L } } ( \cdot ) ) \stackrel { d } { = } ( \mathfrak { R } _ { 1 } ^ { n } - 1, F _ { n } ( \cdot ) ).$$
Let q n ≥ 0 be defined by q 2 n = ∑ i>m n p 2 ni . Then (7.3) entails lim n →∞ q n /σ n = θ 0 . For l ≥ 0 , we set
$$Z _ { n } ( l ) \coloneqq \left | F _ { n } ( l ) - \frac { q _ { n } ^ { 2 } } { \sigma _ { n } } \left ( ( l + 1 ) \wedge \mathfrak { R } _ { 1 } ^ { n } \right ) \right |.$$
We claim that sup l ≥ 0 Z n ( ) l → 0 in probability as n →∞ . To see this, observe first that
$$Z _ { n } ( l ) = \left | \sum _ { j = 0 } ^ { l \wedge ( \mathfrak { R } _ { 1 } ^ { n } - 1 ) } \left ( \sum _ { i > m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } \mathbf 1 _ { \{ X _ { j } ^ { n } = i \} } - \frac { q _ { n } ^ { 2 } } { \sigma _ { n } } \right ) \right |,$$
where the terms in the parenthesis are independent, centered, and of variance χ n := σ -2 n ∑ i>m n p 3 ni -σ -2 n q 4 n . Therefore, Doob's maximal inequality entails that for any fixed number N > 0 ,
$$\upsilon _ { n } \ \, \ q _ { n } \cdots \, \text{Inclusive,} \, \text{Low} \ > \upsilon, \\ \mathbb { E } \left [ \left ( \sup _ { l \geq 0 } Z _ { n } ( l ) 1 _ { \{ \upsilon _ { i } ^ { n } \leq N / \sigma _ { n } \} } \right ) ^ { 2 } \right ] & \leq \mathbb { E } \left [ \left ( \sup _ { l < \lfloor N / \sigma _ { n } } \sum _ { j = 0 } ^ { l } \left ( \sum _ { i > m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } 1 _ { \{ X _ { j } ^ { n } = i \} } - \frac { q _ { n } ^ { 2 } } { \sigma _ { n } } \right ) \right ) ^ { 2 } \right ] \\ & \leq 4 N \sigma _ { n } ^ { - 1 } \chi _ { n } \\ & \leq 4 N \frac { q _ { n } ^ { 2 } } { \sigma _ { n } ^ { 2 } } \frac { p _ { n m _ { n } } + q _ { n } ^ { 2 } } { \sigma _ { n } } \rightarrow 0 \\ \text{hv} \, ( 7 ) \, \text{and the fact that a.\ } / \sigma _ {. } \rightarrow \theta. \, \text{In natural,} \, it follows that}$$
by (7.2) and the fact that q n /σ n → θ 0 . In particular, it follows that
$$\sup _ { l \geq 0 } Z _ { n } ( l ) 1 _ { \{ \mathfrak { R } _ { 1 } ^ { n } \leq N / \sigma _ { n } \} } \to 0,$$
in probability as n → ∞ . On the other hand, the convergence of the p n -trees in (5.1) implies that the family of distributions of ( σ D ,n n n ≥ 1) is tight. By (7.12), this entails that
$$\lim _ { N \to \infty } \lim \sup _ { n \to \infty } \mathbb { P } \left ( \mathfrak { R } _ { 1 } ^ { n } > N / \sigma _ { n } \right ) = 0.$$
Combining this with (7.13) proves the claim.
↦
The generalized distribution function as in (7.11) for the discrete length measure glyph[lscript] n is l → ∧ l D n . Thus, since sup l Z n ( ) l → 0 in probability, the identity in (7.12) and q n /σ n → θ 0 imply that
$$d _ { \mathrm P } \left ( \mathcal { L } _ { n } ^ { * } \lceil _ { R _ { 1 } ^ { n } }, \theta _ { 0 } ^ { 2 } \sigma _ { n } \ell _ { n } \lceil _ { R _ { 1 } ^ { n } } \right ) \rightarrow 0$$
in probability as n →∞ . This is exactly (7.4) for k = 1 .
In the general case where k ≥ 1 , we set
$$D _ { n, 1 } \coloneqq D _ { n }, \quad D _ { n, m } \coloneqq d _ { T ^ { n } } \left ( b _ { n } ( m ), V _ { m } ^ { n } \right ), \ \ m \geq 2,$$
where b n ( m ) denotes the branch point of T n between V n m and R n m -1 , i.e, b n ( m ) ∈ R n m -1 such that J r T ( n ) , V n m K ∩ R n m -1 = J r T ( n ) , b n ( m ) K . We also define
$$F _ { n, 1 } ^ { \mathcal { L } } ( l ) \coloneqq F _ { n } ^ { \mathcal { L } }, \quad \text{and} \quad F _ { n, m } ^ { \mathcal { L } } ( l ) \coloneqq \mathcal { L } _ { n } ^ { * } ( \mathbf B ( b _ { n } ( m ), l ) \cap \mathbb { ] } b _ { n } ( m ), V _ { m } ^ { n } \mathbb { ] } ), \ \ m \geq 2.$$
Then conditional on R n k , the vector ( F L n, 1 ( ) · , · · · , F L n,k ( )) · determines the measure L ∗ n glyph[harpoonupright] R n k for the same reason as before. If we set
$$n$$
$$F _ { n, 1 } ( l ) \coloneqq F _ { n } ( l ), \quad \text{ and } \quad F _ { n, m } ( l ) \coloneqq \sum _ { j = \mathfrak { N } _ { m - 1 } ^ { n } + 1 } ^ { l \wedge ( \mathfrak { R } _ { m } ^ { n } - 1 ) } \sum _ { i > m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } \mathbf 1 _ { \{ X _ { j } ^ { n } = i \} }, \quad m \geq 2,$$
then Corollary 3 of [21] entails the equality in distribution
$$\left ( ( D _ { n, m }, F _ { n, m } ^ { \mathcal { L } } ( \cdot ) ), 1 \leq m \leq k \right ) \stackrel { d } { = } \left ( ( \Re _ { m } ^ { n } - \Re _ { m - 1 } ^ { n } - 1, F _ { n, m } ( \cdot ) ), 1 \leq m \leq k \right )$$
Then by the same arguments as before we can show that
$$\max _ { 1 \leq m \leq k } \sup _ { l \geq 0 } \left | F _ { n, m } ( l ) - \frac { q _ { n } ^ { 2 } } { \sigma _ { n } } \left ( l \wedge ( \mathfrak { R } _ { m } ^ { n } - \mathfrak { R } _ { m - 1 } ^ { n } - 1 ) \right ) \right | \rightarrow 0$$
in probability as n →∞ . This then implies (7.4) by the same type of argument as before.
Now let us consider (7.5). The idea is quite similar. For each M ≥ 1 , we set
$$\tilde { Z } _ { n, M } \coloneqq \sum _ { j = 0 } ^ { \mathfrak { R } _ { 1 } ^ { n } - 1 } \sum _ { M < i \leq m _ { n } } \frac { p _ { n i } } { \sigma _ { n } } \mathbf 1 _ { \{ X _ { j } ^ { n } = i \} }.$$
Then
$$\mathbb { E } \left [ \tilde { Z } _ { n, M } \mathbf 1 _ { \{ \mathfrak { R } _ { 1 } ^ { n } \leq N / \sigma _ { n } \} } \right ] \leq N \left ( \sum _ { M < i \leq m _ { n } } \frac { p _ { n i } ^ { 2 } } { \sigma _ { n } ^ { 2 } } \right ).$$
Using (7.2), (H) and the fact that ∑ i θ 2 i < ∞ , we can easily check that for any fixed N ,
$$\lim _ { M \to \infty } \lim \sup _ { n \to \infty } \mathbb { E } \left [ \tilde { Z } _ { n, M } \mathbf 1 _ { \{ \mathfrak { R } _ { 1 } ^ { n } \leq N / \sigma _ { n } \} } \right ] = 0.$$
By Markov's inequality, we have
$$\mathbb { P } ( \tilde { Z } _ { n, M } > \epsilon ) \leq \epsilon ^ { - 1 } \mathbb { E } [ \tilde { Z } _ { n, M } \mathbf 1 _ { \{ \Re _ { 1 } ^ { n } \leq N / \sigma _ { n } \} } ] + \mathbb { P } ( \Re _ { 1 } ^ { n } > N / \sigma _ { n } ).$$
According to (7.14) and (7.15), we can first choose some N = N glyph[epsilon1] ( ) then some M = M N glyph[epsilon1] ( ( ) , glyph[epsilon1] ) = M glyph[epsilon1] ( ) such that lim sup n P ( ˜ Z n,M > glyph[epsilon1] ) < glyph[epsilon1] . On the other hand, Corollary 3 of [21] says that Σ( n, 1 , M ) is distributed like ˜ Z n,M . Then we have shown (7.5) for k = 1 . The general case can be treated in the same way, and we omit the details.
So far we have completed the proof of Proposition 5.2 in the case where θ has all strictly positive entries. The other cases are even simpler:
Case 2 . Suppose that θ 0 = 0 , we take m n = n and the same argument follows.
Case 3 . Suppose that θ has a finite length I , then it suffices to take m n = I . We can proceed as before.
## References
- [1] R. Abraham and J.-F. Delmas. Record process on the continuum random tree. ALEA , 10:225-251, 2013.
| [2] | R. Abraham and J.-F. Delmas. The forest associated with the record process on a L´vy e tree. Stochastic Processes and their Applications , 123:3497-3517, 2013. |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [3] | L. Addario-Berry, N. Broutin, and C. Holmgren. Cutting down trees with a Markov chainsaw. The Annals of Applied Probability , 2013. to appear, arXiv:1110.6455 [math.PR]. |
| [4] | D. Aldous. The continuum random tree. I. Ann. Probab. , 19(1):1-28, 1991. |
| [5] | D. Aldous. The continuum random tree. III. Ann. Probab. , 21(1):248-289, 1993. |
| [6] | D. Aldous and J. Pitman. The standard additive coalescent. Ann. Probab. , 26(4):1703-1726, 1998. |
| [7] | D. Aldous and J. Pitman. Afamily of random trees with random edge lengths. Random Structures Algorithms 15(2):176-195, 1999. |
| [8] | D. Aldous and J. Pitman. Inhomogeneous continuum random trees and the entrance boundary of the additive coalescent. Probab. Theory Related Fields , 118(4):455-482, 2000. |
| [9] | D. Aldous and J. Pitman. Invariance principles for non-uniform random mappings and trees. In Asymptotic combinatorics with application to mathematical physics (St. Petersburg, 2001) , volume 77 of NATO Sci. Ser. II Math. Phys. Chem. , pages 113-147. Kluwer Acad. Publ., Dordrecht, 2002. |
| [10] | D. Aldous, G. Miermont, and J. Pitman. The exploration process of inhomogeneous continuum random trees, and an extension of Jeulin's local time identity. Probab. Theory Related Fields , 129(2):182-218, 2004. |
| [11] | D. Aldous, G. Miermont, and J. Pitman. Weak convergence of random p -mappings and the exploration process of inhomogeneous continuum random trees. Probab. Theory Related Fields , 133(1):1-17, 2005. |
| [12] | D. J. Aldous. The random walk construction of uniform spanning trees and uniform labelled trees. SIAM J. Discrete Math. , 3(4):450-465, 1990. |
| [13] | J. Bertoin. A fragmentation process connected to Brownian motion. Probability Theory and Related Fields 117:289-301, 2000. |
| [14] | J. Bertoin. Eternal additive coalescents and certain bridges with exchangeable increments. Annals of Proba- bility , 29:344-360, 2001. |
| [15] | J. Bertoin. Self-similar fragmentations. Annales de l'Institut Henri Poincar´: e Probabilit´s e et Statistiques , 38 (3):319-340, 2002. |
| [16] | J. Bertoin and G. Miermont. The cut-tree of large Galton-Watson trees and the Brownian CRT. The Annals of Applied Probability , 23:1469-1493, 2013. |
| [17] | P. Billingsley. Convergence of probability measures . John Wiley &Sons Inc., New York, 1968. |
| [18] | J.-M. Bismut. Last exit decompositions and regularity at the boundary of transition probabilities. Zeitschrift f¨r u Wahrscheinlichkeitstheorie und Verwandte Gebiete , 69:65-98, 1985. |
| [19] | A. Broder. Generating random spanning trees. In Proc. 30'th IEEE Symp. Found. Comp. Sci. , pages 442-447. 1989. |
| [20] | N. Broutin and M. Wang. Reversing the cut tree of the Brownian CRT. arXiv:1408.2924 [math.PR], 2014. |
| [21] | M. Camarri and J. Pitman. Limit distributions and random trees derived from the birthday problem with unequal probabilities. Electron. J. Probab. , 5:no. 2, 18 pp. (electronic), 2000. |
| [22] | A. Cayley. A theorem on trees. Quarterly Journal of Pure and Applied Mathematics , 23:376-378, 1889. |
| [23] | D. Dieuleveut. The vertex-cut-tree of Galton-Watson trees converging to a stable tree. arXiv:1312.5525 [math.PR], 2013. |
| [24] | M. Drmota, A. Iksanov, M. Moehle, and U. Roesler. A limiting distribution for the number of cuts needed to isolate the root of a random recursive tree. Random Structures and Algorithms , 34:319-336, 2009. |
| [25] | T. Duquesne and J.-F. Le Gall. Probabilistic and fractal aspects of L´vy e trees. Probab. Theory Related Fields 131(4):553-603, 2005. |
| [26] | S. N. Evans. Probability and real trees , volume 1920 of Lecture Notes in Mathematics . Springer, Berlin, 2008. Lectures from the 35th Summer School on Probability Theory held in Saint-Flour, July 6-23, 2005. |
| [27] | S. N. Evans and J. Pitman. Construction of Markovian coalescents. Ann. Inst. H. Poincar´ e Probab. Statist. , 34(3):339-383, 1998. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [28] | S. N. Evans, J. Pitman, and A. Winter. Rayleigh processes, real trees, and root growth with re-grafting. Probab. Theory Related Fields , 134(1):81-126, 2006. |
| [29] | J. Fill, N. Kapur, and A. Panholzer. Destruction of very simple trees. Algorithmica , 46:345-366, 2006. |
| [30] | M. Gromov. Metric structures for Riemannian and non-Riemannian spaces . Modern Birkh¨user a Classics. Birkh¨user a Boston Inc., Boston, MA, english edition, 2007. |
| [31] | B. Haas and G. Miermont. Scaling limits of Markov branching trees with applications to Galton-Watson and random unordered trees. Ann. Probab. , 40(6):2589-2666, 2012. |
| [32] | C. Holmgren. Random records and cuttings in binary search trees. Combinatorics, Probability and Comput- ing , 19:391-424, 2010. |
| [33] | C. Holmgren. A weakly 1-stable limiting distribution for the number of random records and cuttings in split trees. Advances in Applied Probability , 43:151-177, 2011. |
| [34] | A. Iksanov and M. M¨hle. o A probabilistic proof of a weak limit law for the number of cuts needed to isolate the root of a random recursive tree. Electronic Communications in Probability , 12:28-35, 2007. |
| [35] | J. Jacod and A. N. Shiryaev. Limit theorems for stochastic processes , volume 288 of Grundlehren der Math- ematischen Wissenschaften . Springer-Verlag, Berlin, 1987. ISBN 3-540-17882-1. |
| [36] | S. Janson. Random cutting and records in deterministic and random trees. Random Structures Algorithms , 29(2):139-179, 2006. ISSN 1042-9832. |
| [37] | J.-F. Le Gall and Y. Le Jan. Branching processes in L´vy e processes: the exploration process. Ann. Probab. , 26(1):213-252, 1998. |
| [38] | W. L¨hr. o Equivalence of Gromov-Prohorov- and Gromov's glyph[square] λ -metric on the space of metric measure spaces. Electron. Commun. Probab. , 18:no. 17, 10, 2013. |
| [39] | W. L¨hr, o G. Voisin, and A. Winter. Convergence of bi-measure R -Trees and the pruning process. arxiv:1304.6035 [math.PR], 2013. |
| [40] | A. Meir and J. Moon. Cutting down random trees. Journal of the Australian Mathematical Society , 11: 313-324, 1970. |
| [41] | G. Miermont. Tessellations of random maps of arbitrary genus. Ann. Sci. ´ Ec. Norm. Sup´r. e (4) , 42(5): 725-781, 2009. |
| [42] | A. Panholzer. Cutting down very simple trees. Quaestiones Mathematicae , 29:211-228, 2006. |
| [43] | A. R´nyi. e On the enumeration of trees. In Combinatorial Structures and their Applications (Proc. Calgary Internat. Conf., Calgary, Alta., 1969) , pages 355-360. Gordon and Breach, New York, 1970. | | null | [
"Nicolas Broutin",
"Minmin Wang"
] | 2014-08-01T12:05:38+00:00 | 2014-08-16T06:35:57+00:00 | [
"math.PR",
"cs.DM",
"math.CO"
] | Cutting down $\mathbf p$-trees and inhomogeneous continuum random trees | We study a fragmentation of the $\mathbf p$-trees of Camarri and Pitman
[Elect. J. Probab., vol. 5, pp. 1--18, 2000]. We give exact correspondences
between the $\mathbf p$-trees and trees which encode the fragmentation. We then
use these results to study the fragmentation of the ICRTs (scaling limits of
$\mathbf p$-trees) and give distributional correspondences between the ICRT and
the tree encoding the fragmentation. The theorems for the ICRT extend the ones
by Bertoin and Miermont [Ann. Appl. Probab., vol. 23(4), pp. 1469--1493, 2013]
about the cut tree of the Brownian continuum random tree. |
1408.0146v1 | ## Waiting times in queueing networks with a single shared server ∗
M.A.A. Boon † [email protected]
R.D. van der Mei ‡ [email protected]
E.M.M. Winands § [email protected]
R.D. van der Mei ‡ [email protected]
E.M.M. Winands § [email protected]
November, 2012
## Abstract
We study a queueing network with a single shared server that serves the queues in a cyclic order. External customers arrive at the queues according to independent Poisson processes. After completing service, a customer either leaves the system or is routed to another queue. This model is very generic and finds many applications in computer systems, communication networks, manufacturing systems, and robotics. Special cases of the introduced network include well-known polling models, tandem queues, systems with a waiting room, multi-stage models with parallel queues, and many others. A complicating factor of this model is that the internally rerouted customers do not arrive at the various queues according to a Poisson process, causing standard techniques to find waiting-time distributions to fail. In this paper we develop a new method to obtain exact expressions for the Laplace-Stieltjes transforms of the steady-state waiting-time distributions. This method can be applied to a wide variety of models which lacked an analysis of the waitingtime distribution until now.
Keywords: queueing network, waiting times, customer routing, shared server, polling
Mathematics Subject Classification: 60K25, 90B22
## 1 Introduction
In this paper we study a queueing network served by a single shared server that visits the queues in a cyclic order. Customers from the outside arrive at the queues according to independent Poisson processes, and the service time and switch-over time distributions are general. After receiving service at queue i , a customer is either routed to queue j with
∗ The research was done in the framework of the BSIK/BRICKS project, the European Network of Excellence Euro-NF, and of the project 'Service Optimization and Quality' (SeQual), funded by the Dutch agency SenterNovem.
† Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
‡ Department of Mathematics, Section Stochastics, VU University, De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands and Centre for Mathematics and Computer Science (CWI), 1098 SJ Amsterdam, The Netherlands
§ University of Amsterdam, Korteweg-de Vries Institute for Mathematics, Science Park 904, 1098 XH Amsterdam, The Netherlands
probability p i,j , or leaves the system with probability p i, 0 . We consider systems with mixtures of gated and exhaustive service. This model can be seen as an extension of the standard polling model (in which customers always leave the system upon completion of their service) by customer routing. Yet another view is provided by the notion that the system is a Jackson network with a dedicated server for each queue with the additional complexity that only one server can be active in the network simultaneously.
The possibility of re-routing of customers further enhances the already-extensive modelling capabilities of polling models, which find applications in diverse areas such as computer systems, communication networks, logistics, flexible manufacturing systems, robotics systems, production systems and maintenance systems (see, for example, [5, 18, 22, 32] for overviews). Applications of the introduced type of customer routing can be found in many of these areas. In this regard, we would like to mention a manufacturing system where products undergo service in a number of stages or in the context of rework [17], a Ferry based Wireless Local Area Network (FWLAN) in which nodes can communicate with each other or with the outer world via a message ferry [20], a dynamic order picking system where the order picker drops off the picked items at the depot where sorting of the items is performed [16], and an internal mail delivery system where a clerk continuously makes rounds within the offices to pick up, sort and deliver mail [27].
In the past many papers have been published on special cases of the current network. In some of these papers distributional results are derived as well; the techniques used do, however, not allow for extension to the general setting of the current paper. Some special case configurations are standard polling systems [32], tandem queues [23, 34], multi-stage queueing models with parallel queues [19], feedback vacation queues [9, 33], symmetric feedback polling systems [31, 33], systems with a waiting room [1, 30], and many others. In conclusion, one can say that the present research can be seen as a unifying analysis of the waiting-time distribution for a wide variety of queueing models.
The main contribution of this paper is the derivation of waiting-time distributions in queueing networks with a single roving server via the development of a new method. For this model we derive the Laplace-Stieltjes transform of the waiting-time distribution of an arbitrary (internally rerouted, or external) customer. Due to this intrinsic complexity of the model, studies in the past were restricted to queue lengths and mean delay figures (see [6, 27, 28, 29]). A complicating, yet interesting, factor is that the combined process of internal and external arrivals violates the classical assumption of Poisson (or even renewal) arrivals, implying that traditional methods are not applicable. The basic idea behind the new method is that we explicitly compute a priori all future service requirements upon arrival of a newly arriving customer. In doing so the prerequisites of the distributional form of Little's Law are overcome.
An important feature of the newly developed technique is that it can be applied to a myriad of models which lacked an analysis of the waiting-time distribution until now. One could apply the framework (possibly after some minor modifications) to obtain distributional results in all of the aforementioned special cases of the studied system [1, 9, 19, 23, 30, 31, 32, 33, 34] but also, for example, in a closed network [2], in an M/G/ 1 queue with permanent and transient customers [8], in a network with permanent and transient customers [3], or in a polling model with arrival rates that depend on the location of the server [4, 7]. Although we study a continuous-time cyclic system with gated or exhaustive service in each queue, we may extend all results - without complicating the analysis - to discrete time, to periodic polling, to batch
arrivals, or to systems with different branching-type service disciplines such as globally gated service.
The structure of the present paper is as follows. In Section 2, we introduce the model and notation. Section 3 analyses the waiting-time distribution of an arbitrary customer for gated service. In Section 4 we study the system with mixtures of gated and exhaustive service. In the penultimate section, we present some examples which show the wide range of applicability of the studied model. The final section of this paper contains a brief discussion.
## 2 Model description and notation
We consider a queueing network consisting of N ≥ 1 infinite buffer queues Q , . . . , Q 1 N . External customers arrive at Q i according to a Poisson arrival process with rate λ i , and have a generally distributed service requirement B i at Q i , with mean value b i := E [ B i ]. In general we denote the Laplace-Stieltjes Transform (LST) or Probability Generating Function (PGF) of a random variable X with ˜ X ( ). · The queues are served by a single server in cyclic order. Whenever the server switches from Q i to Q i +1 , a random switch-over time R i is incurred, with mean r i . The cycle time C i is the time between successive moments when the server arrives at Q i . The total switch-over time in a cycle is denoted by R = ∑ N i =1 R i , and its first two moments are r := E [ R ] and r (2) := E [ R 2 ]. Indices throughout the paper are modulo N , so Q 1 -N and Q N +1 both refer to Q 1 . All service times and switch-over times are mutually independent. This queueing network can be modelled as a polling system with the specific feature that it allows for routing of the customers: upon completion of service at Q i , a customer is either routed to Q j with probability p i,j , or leaves the system with probability p i, 0 . Note that p i, 0 should be greater than 0 for at least one queue, to make sure that customers can leave the system eventually. Moreover, note that ∑ N j =0 p i,j = 1 for all i , and that the transition of a customer from Q i to Q j takes no time. Since we consider the gated and exhaustive service disciplines, the model under consideration has a branching structure, which is discussed in more detail by Foss [15] in the context of queueing models, and by Resing [26] more specifically in the context of polling systems. The total arrival rate at Q i is denoted by γ i , which is the unique solution of the following set of linear equations:
$$\gamma _ { i } = \lambda _ { i } + \sum _ { j = 1 } ^ { N } \gamma _ { j } p _ { j, i }, \quad i = 1, \dots, N.$$
The offered load to Q i is ρ i := γ b i i and the total load is ρ := ∑ N i =1 ρ i . We assume that the system is stable, which means that ρ should be less than one (see [29]).
## 3 Gated service
In the present section we study the waiting-time distribution of an arbitrary customer for a system in which each queue receives gated service, which means that only those customers present at the server's arrival at Q i will be served before the server switches to the next queue. We define the waiting time W i of an arbitrary customer in Q i as the time between his arrival at this queue and the moment at which his service starts. As far as waiting times are
concerned, a customer that is routed to another queue, say Q j , upon his service completion is regarded as a new customer with waiting time W j . The waiting-time distribution is found by conditioning on the numbers of customers present in each queue at an arrival epoch. To this end, we study the joint queue-length distribution at several embedded epochs in Section 3.1. In Sections 3.2 and 3.3 we use these results to successively derive the cycle-time distribution and the waiting-time distributions of internally rerouted customers and external customers.
## 3.1 The joint queue-length distributions
Sidi et al. [29] derive the PGFs of the joint queue-length distributions in all N queues at visit beginnings, visit completions, and at arbitrary points in time. In order to keep this manuscript self-contained, we briefly recapitulate their approach, as it forms the starting point of our novel method to find the waiting time LSTs. There is one important adaptation that we have to make, which will prove essential for finding waiting time LSTs. We consider not only the customers in all N queues, but we distinguish between customers standing in front of the gate and customers standing behind the gate (meaning that they will be served in the next cycle). Hence, we introduce the N +1 dimensional vector z = ( z , . . . , z 1 N , z G ). The element z i , i = 1 , . . . , N , in this vector corresponds to customers in Q i standing in front of the gate. The element z G at position N +1 is only used during visit periods. During V j , the visit period of Q j , it corresponds to customers standing behind the gate in Q j . This makes the analysis of systems with gated service slightly more involved than systems with exhaustive service (discussed in the next section). Before studying the joint queue-length distributions, we briefly introduce some convenient notation:
glyph[negationslash]
glyph[negationslash]
$$\ m v c o m m o v e n m. \\ \Sigma ( \mathbf z ) & = \sum _ { j = 1 } ^ { N } \lambda _ { j } ( 1 - z _ { j } ), \\ \Sigma _ { i } ( \mathbf z ) & = \lambda _ { i } ( 1 - z _ { G } ) + \sum _ { j \neq i } \lambda _ { j } ( 1 - z _ { j } ), \\ P _ { i } ( \mathbf z ) & = p _ { i, 0 } + p _ { i, i } z _ { G } + \sum _ { j \neq i } p _ { i, j } z _ { j }.$$
Visit beginnings and completions. A cycle consists of N visit periods, V i , each of which is followed by a switch-over time R i , for i = 1 , . . . , N . A cycle C i starts with a visit to Q i and consists of the periods V , R , V i i i +1 , . . . , V i + N -1 , R i + N -1 . Let P denote any of these periods. We denote the joint queue length PGF at the beginning of P as ˜ LB ( P ) ( z ). The equivalent at the completion of period P is denoted by ˜ LC ( P ) ( z ). Since the gated service discipline is a so-called branching-type service discipline (see [26]), we can express each of these functions in terms of ˜ LB ( V i ) ( z ), for any i = 1 , . . . , N . These relations, which are sometimes called laws of
motion , are given below.
$$\widetilde { L C } ^ { ( V _ { i } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( V _ { i } ) } \Big ( z _ { 1 }, \dots, z _ { i - 1 }, \widetilde { B } _ { i } \Big ( \Sigma _ { i } ( \mathbf z ) \Big ) P _ { i } ( \mathbf z ), z _ { i + 1 }, \dots, z _ { N }, z _ { G } \Big ), \quad ( 3. 1 \text{a} )$$
$$\widetilde { L B } ^ { ( R _ { i } ) } ( \mathbf z ) = \widetilde { L C } ^ { ( V _ { i } ) } ( z _ { 1 }, \dots, z _ { N }, z _ { i } ),$$
$$\widetilde { L C } ^ { ( R _ { i } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( R _ { i } ) } ( \mathbf z ) \widetilde { R } _ { i } \left ( \Sigma ( \mathbf z ) \right ),$$
$$\widetilde { L } B ^ { ( V _ { i + 1 } ) } ( \mathbf z ) = \widetilde { L } C ^ { ( R _ { i } ) } ( \mathbf z ),$$
.
.
.
$$\widetilde { L } B ^ { ( V _ { i + N } ) } ( { \mathbf z } ) = \widetilde { L } C ^ { ( R _ { i + N - 1 } ) } ( { \mathbf z } ).$$
Note the subtle difference between ˜ LC ( V i ) ( z ) and ˜ LB ( R i ) ( z ), due to the fact that the gate in Q i is removed after the completion of V i , causing type G customers to become type i customers. In steady-state we have that ˜ LB ( V i + N ) ( z ) = ˜ LB ( V i ) ( z ), implying that we have obtained a recursive relation for ˜ LB ( V i ) ( z ). Resing [26] shows how a clever definition of immigration and offspring generating functions can be used to find an explicit expression for ˜ LB ( V i ) ( z ). For reasons of compactness we refrain from doing so in the present paper. Instead we want to point out that the recursive relation obtained from (3.1a)-(3.1e) can be differentiated with respect to the variables z , . . . , z 1 N , z G . The resulting set of equations, which are called the buffer occupancy equations in the polling literature, can be used to compute the moments of the queue-length distributions at all visit beginnings and completions.
Service beginnings and completions. We denote the joint queue length PGF at service beginnings and completions in Q j by respectively ˜ LB ( B j ) ( z ) and ˜ LC ( B j ) ( z ). Since a customer may be routed to another queue upon his service completion, we define ˜ LC ( B j ) ( z ) as the PGF of the joint queue-length distribution right after the tagged customer in Q j has received service (implying that he is no longer present in Q j ), but before the moment that he may join another queue (even though these two epochs take place in a time span of length zero). Eisenberg [14] observed the following relation, albeit in a slightly different model:
$$\widetilde { L B } ^ { ( V _ { i } ) } ( z ) + \gamma _ { i } \mathbb { E } [ C ] \widetilde { L C } ^ { ( B _ { i } ) } ( z ) P _ { i } ( z ) = \widetilde { L C } ^ { ( V _ { i } ) } ( z ) + \gamma _ { i } \mathbb { E } [ C ] \widetilde { L B } ^ { ( B _ { i } ) } ( z ).$$
Equation (3.2) is based on the observation that each visit beginning coincides with either a service beginning, or a visit completion (if no customer was present). Similarly, each visit completion coincides with either a visit beginning or a service completion. The long-run ratio between the number of visit beginnings/completions and service beginnings/completions in Q i is γ i E [ C ], with E [ C ] = E [ C i ] = r/ (1 -ρ ). The distribution of the cycle time is given in the next subsection.
Furthermore, Eisenberg observes the following simple relation between the joint queue-length distribution at service beginnings and completions:
$$\widetilde { L C } ^ { ( B _ { i } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( B _ { i } ) } ( \mathbf z ) \widetilde { B } _ { i } ( \Sigma _ { i } ( \mathbf z ) ) / z _ { i }.$$
Substitution of (3.3) in (3.2) gives an equation which can be solved to express ˜ LB ( B i ) ( z ) in ˜ LB ( V i ) ( z ) and ˜ LC ( V i ) ( z ).
Arbitrary moments. The PGF of the joint queue-length distribution at arbitrary moments, denoted by ˜ L ( z ), is found by conditioning on the period in the cycle during which the system is observed ( V , R , . . . , V 1 1 N , R N ).
$$\widetilde { L } ( { \mathbf z } ) = \frac { 1 } { \mathbb { E } [ C ] } \sum _ { j = 1 } ^ { N } \left ( \mathbb { E } [ V _ { j } ] \widetilde { L } ^ { ( V _ { j } ) } ( { \mathbf z } ) + r _ { j } \widetilde { L } ^ { ( R _ { j } ) } ( { \mathbf z } ) \right ),$$
with E [ V j ] = ρ j E [ C ]. In (3.4) the functions ˜ L ( V j ) ( z ) and ˜ L ( R j ) ( z ) denote the PGFs of the joint queue-length distributions at an arbitrary moment during V j and R j respectively:
$$\widetilde { L } ^ { ( V _ { j } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( B _ { j } ) } ( \mathbf z ) \frac { 1 - \widetilde { B } _ { j } ( \Sigma _ { j } ( \mathbf z ) ) } { b _ { j } \Sigma _ { j } ( \mathbf z ) },$$
$$\widetilde { L } ^ { ( R _ { j } ) } ( { \mathbf z } ) = \widetilde { L B } ^ { ( R _ { j } ) } ( { \mathbf z } ) \frac { 1 - \widetilde { R } _ { j } ( \Sigma ( { \mathbf z } ) ) } { r _ { j } \Sigma ( { \mathbf z } ) }.$$
The interpretation of (3.5) and (3.6) is that the queue length vector at an arbitrary time point in V j or R j is the sum of those customers that were present at the beginning of that service/switch-over time, plus vector of the customers that have arrived during the elapsed part of the service/switch-over time. For more details about the joint queue length and workload distributions for general branching-type service disciplines (in the context of polling systems, but also applicable to our model) we refer to Boxma et al. [11].
## 3.2 Cycle-time distributions
In the remainder of this paper we present new results for the model introduced in Section 2. We start by analysing the distributions of the cycle times C i , i = 1 , . . . , N . The idea behind the following analysis is to condition on the number of customers present in each queue at the beginning of C i (and, hence, of V i ). The cycle will consist of the service of all of these customers, plus all switch-over times R , . . . , R i i + N -1 , plus the services of all customers that enter during these services and switch-over times and will be served before the next visit beginning to Q i . The cycle time for polling systems without customer routing is discussed in Boxma et al. [10]. However, as it turns out, the analysis is severely complicated by the fact that customers may be routed to another queue and be served again (even multiple times) during the same cycle.
From branching theory we adopt the term descendants of a certain (tagged) customer to denote all customers that arrive (in all queues) during the service of this tagged customer, plus the customers arriving during their service times, and so on. If, upon his service completion, a customer is routed to another queue, we also consider him as his own descendant. We define B ∗ k,i , i = 1 , . . . , N ; k = 0 , . . . , N , as the service time of a type i -k (which is understood as N + i -k if i ≤ k ) customer at Q i -k , plus the service times of all of his descendants that will be served before or during the next visit of the server to Q i . The special case B ∗ 0 ,i is simply
the service time of a type i customer, i = 1 , . . . , N . A formal definition in terms of LSTs is given below:
$$\widetilde { B } _ { k, i } ^ { * } ( \omega ) = \widetilde { B } _ { i - k } \Big ( \omega + \sum _ { j = 0 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j, i } ^ { * } ( \omega ) ) \Big ) \widetilde { P } _ { k, i } ^ { * } ( \omega ), \quad k = 0, 1, \dots, N ; i = 1, \dots, N, \quad ( 3. 7 )$$
where
$$\widetilde { P } _ { k, i } ^ { * } ( \omega ) & = 1 - \sum _ { j = 0 } ^ { k - 1 } p _ { i - k, i - j } ( 1 - \widetilde { B } _ { j, i } ^ { * } ( \omega ) ), & k & = 0, 1, \dots, N ; i = 1, \dots, N. \quad ( 3. 8 )$$
For a type i -k customer, P ∗ k,i accounts for the service times of his descendants that are caused by the fact that he may be routed to another queue upon his service completion.
A similar function should be defined for the switch-over times:
$$\widetilde { R } _ { k, i } ^ { * } ( \omega ) = \widetilde { R } _ { i - k } \left ( \omega + \sum _ { j = 0 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j, i } ^ { * } ( \omega ) ) \right ), \quad \ \ k = 0, 1, \dots, N ; i = 1, \dots, N. \quad ( 3. 9 )$$
Note that, compared to (3.7), no term ˜ P ∗ k,i ( ω ) is required because no routing takes place at the end of a switch-over time.
Finally, we define the following N +1 dimensional vectors:
$$\mathbf B _ { k, i } = ( 1, \dots, 1, \widetilde { B } _ { k, i } ^ { * } ( \omega ), 1, \dots, 1 ), \quad \ \ k = 0, 1, \dots, N - 1 ; i = 1, \dots, N, \quad \ \ ( 3. 1 0 )$$
$$B _ { N, i } & = ( 1, \dots, 1, \widetilde { B } _ { 0, i } ^ { * } ( \omega ) ), & i = 1, \dots, N, & ( 3. 1 1 )$$
with ˜ B ∗ k,i ( ω ) at position i -k in (3.10) (or position N + i -k if k ≥ i ), and ˜ B ∗ 0 ,i ( ω ) at position N +1 in (3.11). We use ⊗ to denote the element-wise multiplication of vectors.
Proposition 3.1 The LST of the distribution of the cycle time C i is given by
$$\widetilde { C } _ { i } ( \omega ) = \widetilde { L B } ^ { ( V _ { i } ) } ( \bigotimes _ { k = 0 } ^ { N - 1 } \mathbf B _ { k, i - 1 } ) \prod _ { k = 0 } ^ { N - 1 } \widetilde { R } _ { k, i - 1 } ^ { * } ( \omega ), \quad i = 1, \dots, N.$$
The interpretation of (3.12) is that the length of a cycle starting with a visit to Q i is the sum of the extended service times of all customers present at the beginning of the cycle, and the sum of all extended switch-over times during the cycle. By extended service time (switch-over time) we refer to a service time (switch-over time) plus the service times of all customers that arrive during this service time (switch-over time) in one of the queues that are yet to be served during the remainder of the cycle, and all of their descendants that will be served before the end of the cycle.
Proof: To prove Proposition 3.1 we keep track of all the customers that will be served during one cycle. We condition on the numbers of customers present in each queue at the beginning of C i , denoted by n , . . . , n 1 N . Note that there are no gated customers present at this moment, because the gate has been removed at the beginning of the last switch-over time of the previous cycle. A cycle C i consists of:
- 1. the service of all customers present at the beginning of the cycle,
- 2. all of their descendants that will be served before the start of the next cycle (i.e., before the next visit to Q i ),
- 3. the switch-over times R , . . . , R 1 N ,
- 4. all customers arriving during these switch-over times that will be served before the start of the next cycle,
- 5. all of their descendants that will be served before the start of the next cycle.
We define S j for j = 1 , . . . , N , as the service time of a type j customer plus the service times of all of his descendants that will be served during (the remaining part of) C i . Since the service discipline is gated at all queues, we have:
$$S _ { j } = B _ { j } + \sum _ { k = j + 1 } ^ { i - 1 } \sum _ { l = 1 } ^ { N _ { k } ( B _ { j } ) } S _ { k _ { l } } + \begin{cases} S _ { m } \quad & \text{for $m=j+1,\dots,i-1,\,w.p.\,p_{j,m}$,} \\ 0 \quad & \text{w.p.\,1-\sum_{m=j+1}^{i-1}p_{j,m}$,} \end{cases} ( 3. 1 3 )$$
where N k ( T ) denotes the number of arrivals in Q k during a (possibly random) period of time T , and S k l is a sequence of (independent) extended service times S k . Note that S j depends on i , although we have chosen to hide this for presentational purposes. The gated service discipline is reflected in the fact that only customers arriving in (or rerouted to) Q j +1 , . . . , Q i -1 are being served during the residual part of C i . It can easily be shown that the LST of S i -k is ˜ B ∗ k -1 ,i -1 ( ω ) for k = 1 , . . . , N . Note that the first summation in (3.13) is cyclic, which may sometimes cause confusion (for example if j = i -1, when this is supposed to be a summation over zero terms). Avoiding this (possible) confusion is the main reason that we have chosen to define ˜ B ∗ k,i ( ω ), ˜ P ∗ k,i ( ω ) and ˜ R ∗ k,i ( ω ) relative to queue i ( k steps backward in time).
Using this branching way of looking at the cycle time, we can express C i in terms of R , . . . , R 1 N and S , . . . , S 1 N . First, however, we derive the following intermediate result.
$$\mathbb { E } \left [ e ^ { - \omega R _ { i - k } } \prod _ { j = i - k + 1 } ^ { i - 1 } \prod _ { l = 1 } ^ { N _ { j } ( R _ { j } ) } e ^ { - \omega S _ { j _ { l } } } \right ] & = \widetilde { R } _ { i - k } ( \omega + \sum _ { j = i - k + 1 } ^ { i - 1 } \lambda _ { j } ( 1 - \mathbb { E } [ e ^ { - \omega S _ { j } } ] ) ) \\ & = \widetilde { R } _ { k - 1, i - 1 } ^ { * } ( \omega ).$$
Now, introducing the shorthand notation n , . . . , n 1 N for the event that the numbers of customers at the beginning of C i in queues 1 , . . . , N are respectively n , . . . , n 1 N , we can find the cycle time LST conditional on this event.
$$\mathbb { E } \left [ e ^ { - \omega C _ { i } } \left | n _ { 1 }, \dots, n _ { N } \right ] & = \mathbb { E } \left [ \exp \left ( - \omega \sum _ { j = i - N } ^ { i - 1 } \left ( \sum _ { l = 1 } ^ { n _ { j } } S _ { j _ { l } } + R _ { j } + \sum _ { k = j + 1 } ^ { i - 1 } \sum _ { l = 1 } ^ { N _ { k } ( R _ { j } ) } S _ { k _ { l } } \right ) \right ) \right ] \\ & = \mathbb { E } \left [ \prod _ { j = i - N } ^ { i - 1 } \left ( \prod _ { l = 1 } ^ { n _ { j } } e ^ { - \omega S _ { j _ { l } } } \right ) e ^ { - \omega R _ { j } } \prod _ { k = j + 1 } ^ { i - 1 } \prod _ { l = 1 } ^ { N _ { k } ( R _ { j } ) } e ^ { - \omega S _ { k _ { l } } } \right ] \\ & = \prod _ { j = i - N } ^ { i - 1 } \left ( \prod _ { l = 1 } ^ { n _ { j } } \mathbb { E } \left [ e ^ { - \omega S _ { j _ { l } } } \right ] \right ) \prod _ { j = i - N } ^ { i - 1 } \mathbb { E } \left [ e ^ { - \omega R _ { j } } \prod _ { k = j + 1 } ^ { i - 1 } \prod _ { l = 1 } ^ { N _ { k } ( R _ { j } ) } \left ( e ^ { - \omega S _ { k _ { l } } } \right ) \right ] \\ & = \left ( \prod _ { k = 1 } ^ { N } \widetilde { B } _ { k - 1, i - 1 } ^ { * } ( \omega ) ^ { n _ { i - k } } \right ) \prod _ { k = 1 } ^ { N } \widetilde { R } _ { k - 1, i - 1 } ^ { * } ( \omega ).$$
Equation (3.12) follows after deconditioning.
glyph[square]
Remark 3.2 Because of our main interest in the waiting-time distributions, we have followed quite an elaborate path to find the LST of the cycle-time distribution. However, if one is merely interested in a quick way to find ˜ C ω i ( ), a more efficient approach can be used. One of the most efficient ways to find ˜ C ω i ( ) is to distinguish between customers that arrive from outside the network (external customers) and internally rerouted customers (internal customers). One can straightforwardly adapt the laws of motion (3.1a)-(3.1e) to find an expression for ˜ LB ( V i ) ′ ( z E 1 , z I 1 , . . . , z E N , z I N ). Just like ˜ LB ( V i ) ( z , . . . , z 1 N , z G ), ˜ LB ( V i ) ′ ( z E 1 , z I 1 , . . . , z E N , z I N ) stands for the PGF of the joint queue length at the beginning of V i , but now we distinguish between external and internal customers in each queue (indicated by z E j and z I j ). Since external customers arrive in Q i according to a Poisson process with intensity λ i , one can apply the distributional form of Little's Law (see, for example, Keilson and Servi [21]) to the external customers in Q i :
$$\widetilde { C } _ { i } ( \omega ) = \widetilde { L B } ^ { ( V _ { i } ) ^ { \prime } } ( 1, \dots, 1, 1 - \omega / \lambda _ { i }, 1, \dots, 1 ), \quad i = 1, \dots, N.$$
## 3.3 Waiting-time distributions
In this subsection we find the LSTs of W E i and W I i , the waiting-time distributions of arbitrary external and internal customers in Q i , and use them to obtain the LST of W i , the waiting time of an arbitrary customer. Recall that the waiting time W i of an arbitrary customer in Q i is the time between his arrival at this queue and the moment at which his service starts. Hence, even if a customer is routed to the same queue multiple times, each visit to this queue invokes a new waiting time. We stress that common methods used in the polling literature to find waiting time LSTs cannot be applied in our queueing network, because they rely heavily on the assumption that every customer in the system has arrived according to a Poisson process. Since this assumption is violated in our model, we have developed a novel approach to find the waiting time LST of an arbitrary customer in our network. The joint queue-length distributions at various epochs, as discussed in Subsection 3.1, play an essential role in the analysis. First we focus on the waiting times of internal customers, then we discuss the waiting times of external customers.
Internal customers. The arrival epoch of an internal customer always coincides with a service completion. Hence, we condition on the joint queue length and the arrival epoch of an internal customer to find his waiting time LST. The waiting time of an internal customer given that he arrives in Q i after a service completion at Q i -k is denoted by WC ( B i -k ) i ( i, k = 1 , . . . , N ). To find WC ( B i -k ) i , we only have to compute the probability that an arbitrary internal customer in Q i arrives after a service completion at Q i -k . The mean number of customers (internal plus external) present at the beginning of V i -k at Q i -k is γ i -k E [ C ]. Each of these customers joins Q i upon his service completion with probability p i -k,i . This observation combined with the fact that the mean number of internal customers arriving at Q i during the course of one cycle is ( γ i -λ i ) E [ C ], leads to the following result:
$$\widetilde { W } _ { i } ^ { I } ( \omega ) = \sum _ { k = 1 } ^ { N } \frac { \gamma _ { i - k } p _ { i - k, i } } { \gamma _ { i } - \lambda _ { i } } \widetilde { W C } _ { i } ^ { ( B _ { i - k } ) } ( \omega ), \quad i = 1, \dots, N.$$
As a consequence, the problem of finding ˜ W I i ( ) · is reduced to finding ˜ WC ( B i -k ) i ( ω ) for all i, k = 1 , . . . , N .
For notational reasons we first introduce the following N +1 dimensional vectors, which will appear several times in this section:
$$B _ { k, i } ^ { G } & = \begin{cases} B _ { 0, i } & \quad \text{ if } k < 0, \\ B _ { 0, i } \bigotimes B _ { j, i - 1 } & \quad \text{ if } k = 1, \dots, N, \\ B _ { N, i } \bigotimes B _ { j, i - 1 } & \quad \text{ if } k = N, \\ \intertext { a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a A. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. a. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. c. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. a. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. b. c. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. c. b. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. b. c. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. b. c. b. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. c. b. c. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. b. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. c. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. b.c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b.c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b.c. b.c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c. b. c$$
for i = 1 , . . . , N . Again, we use ⊗ to denote the element-wise multiplication of vectors.
## Proposition 3.3 We have
$$\widetilde { W C } _ { i } ^ { ( B _ { i - k } ) } ( \omega ) = \widetilde { L C } ^ { ( B _ { i - k } ) } ( \mathbf B _ { k, i } ^ { \mathbf G } ) \prod _ { j = 0 } ^ { k - 1 } \widetilde { R } _ { j, i - 1 } ^ { * } ( \omega ),$$
for i, k = 1 , . . . , N .
glyph[negationslash]
Proof: The key observation in the proof of Proposition 3.3 is that an arrival of an internally rerouted customer always coincides with some service completion. For this reason, we consider the system right after the service completion at, say, Q j ( j = 1 , . . . , N ). We compute the waiting time LST of a customer routed to Q i after being served in Q j , conditional on the numbers of customers of each type (now including gated customers) present at the arrival epoch ( not including the arriving customer himself). We denote by n , . . . , n 1 N , n G the event that the numbers of customers of all types are respectively n , . . . , n 1 N , n G . Let n iG := n i if i = , and j n iG := n G if i = . Note that the type j G customers are located behind the gate in Q j , and that the customer routed to Q i only has to wait for these customers in case i = j . The waiting time of the tagged customer consists of:
- 1. the service of all n j customers in front of the gate in Q j at the arrival epoch,
- 2. the service of all n j +1 , . . . , n i -1 customers present in Q j +1 , . . . , Q i -1 at the arrival epoch,
- 3. all of the descendants of the previously mentioned customers that will be served before the next visit to Q i ,
glyph[negationslash]
- 4. if i = , the service of all j n iG customers present in Q i at the arrival epoch; if i = , the j service of all n iG gated customers present in Q i at the arrival epoch,
- 5. the switch-over times R , . . . , R j i -1 ,
- 6. all customers arriving during these switch-over times that will be served before the next visit to Q i ,
- 7. all of their descendants that will be served before the next visit to Q i .
We denote the waiting time of an internal customer conditional on the event that he arrives in Q i after being served in Q j , and conditional on the event that the numbers of customers of all types at the arrival epoch are respectively n , . . . , n 1 N , n G , by WC ( B j ) ′ i . Just like in the proof of Proposition 3.1, we can express WC ( B j ) ′ i in terms of R , . . . , R 1 N and S , . . . , S 1 N :
$$W C _ { i } ^ { ( B _ { j } ) ^ { \prime } } = \sum _ { k = j } ^ { i - 1 } \left [ \sum _ { l = 1 } ^ { n _ { k } } S _ { k _ { l } } + R _ { k } + \sum _ { l = k + 1 } ^ { i - 1 } \sum _ { m = 1 } ^ { N _ { l } ( R _ { k } ) } S _ { l _ { m } } \right ] + \sum _ { l = 1 } ^ { n _ { i G } } B _ { i, l }.$$
Taking the LST of (3.16) leads to (3.15) after deconditioning. The derivation proceeds along the exact same lines as in the proof of Proposition 3.1, and is therefore omitted.
glyph[square]
External customers. External customers arrive in Q i according to a Poisson process with intensity λ i . We distinguish between customers arriving during a switch-over time and customers arriving during a visit time. The waiting time of an external customer in Q i given that he arrives during R i -k is denoted by W ( R i -k ) i ( i, k = 1 , . . . , N ). Similarly, we use W ( V i -k ) i to denote an external customer arriving in Q i during V i -k . The waiting time LST of an arbitrary external customer can be expressed in terms of ˜ W ( R i -k ) i ( ) and · ˜ W ( V i -k ) i ( ): ·
$$\widetilde { W } _ { i } ^ { E } ( \omega ) = \frac { 1 } { \mathbb { E } [ C ] } \sum _ { k = 1 } ^ { N } \left ( \mathbb { E } [ V _ { i - k } ] \widetilde { W } _ { i } ^ { ( V _ { i - k } ) } ( \omega ) + r _ { i - k } \widetilde { W } _ { i } ^ { ( R _ { i - k } ) } ( \omega ) \right ), \quad i = 1, \dots, N. \quad ( 3. 1 7 )$$
We first focus on the waiting time of customers arriving during a switch-over time. Consider a tagged customer arriving in Q i during R i -k , i, k = 1 , . . . , N . Since the remaining part of the switch-over time is part of the waiting time of the arriving customer, it will turn out that we need the joint distribution of all customers present at the arrival epoch and the residual part of R i -k , denoted by R R i -k . The PGF of the joint queue-length distribution at the arrival epoch is given by (3.6). Equation (3.6) is based on the observation that the number of customers in each queue at an arbitrary moment during R i -k is simply the sum of the number of customers present at the beginning of R i -k and the number of customers that have arrived during the elapsed (past) part of R i -k , denoted by R P i -k . These random variables are independent.
Hence, it is straightforward to adapt (3.6) to find the joint distribution of the queue lengths and residual part of R i -k , using the following result from elementary renewal theory:
$$\widetilde { R } _ { j } ^ { P R } ( \omega _ { P }, \omega _ { R } ) = \frac { \widetilde { R } _ { j } ( \omega _ { P } ) - \widetilde { R } _ { j } ( \omega _ { R } ) } { ( \omega _ { R } - \omega _ { P } ) r _ { j } }, \quad j = 1, \dots, N,$$
with ˜ R PR j ( ω P , ω R ) denoting the LST of the joint distribution of past and residual switch-over time R j . Hence,
$$\widetilde { L } ^ { ( R _ { j } ) } ( \mathbf z, \omega ) = \widetilde { L B } ^ { ( R _ { j } ) } ( \mathbf z ) \widetilde { R } _ { j } ^ { P R } ( \Sigma ( \mathbf z ), \omega ),$$
where ˜ L ( R j ) ( z , ω ) denotes the PGF-LST of the joint distribution of the number of customers of each type at an arbitrary moment during R j and the residual part of R j . Obviously, there are no gated customers present during a switch-over time.
Consequently, and also using PASTA, we can find the waiting-time distribution by conditioning on the number of customers present at an arbitrary moment during R i -k and on the residual switch-over time.
## Proposition 3.4 We have
$$\widetilde { W } _ { i } ^ { ( R _ { i - k } ) } ( \omega ) & = \widetilde { R } _ { i - k } ^ { P R } \left ( \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) + \lambda _ { i } ( 1 - \widetilde { B } _ { i } ( \omega ) ), \omega + \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) \right ) \\ & \times \widetilde { L B } ^ { ( R _ { i - k } ) } ( \mathbf B _ { k - t, i } ^ { G } ) \prod _ { j = 0 } ^ { k - 2 } \widetilde { R } _ { j, i - 1 } ^ { * } ( \omega ), \quad \ \ i, k = 1, \dots, N,$$
Proof: We consider an arbitrary customer arriving in Q i during R j . Similar to the proofs of the preceding propositions in this section, we condition on the number of customers present in all queues at the arrival epoch, denoted by n , . . . , n 1 N . As mentioned before, no gated customers are present during a switch-over time. However, we also condition on the residual length of R j , denoted by t R . The waiting time of the tagged customer consists of:
- 1. the service of all n j +1 , . . . , n i -1 customers present at the arrival epoch in Q j +1 , . . . , Q i -1 ,
- 2. the service of all their descendants that will be served before the start of the next visit to Q i ,
- 3. the service of all n i customers present at the arrival epoch in Q i ,
- 4. the residual switch-over time t R ,
- 5. the switch-over times R j +1 , . . . , R i -1 ,
- 6. the service of all customers arriving during t R , R j +1 , . . . , R i -1 that will be served before the start of the next visit to Q i ,
- 7. the service of all descendants of these customers that will be served before the start of the next visit to Q i .
If we denote the waiting time of a type i customer arriving during R j , conditional on n , . . . , n 1 N and t R , by W ( R j ) ′ i , we can summarise these items in the following formula:
$$W _ { i } ^ { ( R _ { j } ) ^ { \prime } } = \sum _ { k = j + 1 } ^ { i - 1 } \left [ \sum _ { l = 1 } ^ { n _ { k } } S _ { k _ { l } } + R _ { k } + \sum _ { l = k + 1 } ^ { i - 1 } \sum _ { m = 1 } ^ { N _ { l } ( R _ { k } ) } S _ { l _ { m } } \right ] + \sum _ { l = 1 } ^ { n _ { i } } B _ { i _ { l } } + t _ { R } + \sum _ { l = j + 1 } ^ { i - 1 } \sum _ { m = 1 } ^ { N _ { l } ( t _ { R } ) } S _ { l _ { m } }.$$
Taking the LST of (3.20) and using (3.18) leads to (3.19) after deconditioning. The derivation is not completely straightforward, but rather than providing it here, we refer to the proof of Proposition 3.5, which contains a similar derivation of a more complicated equation. glyph[square]
Now we only need to determine ˜ W ( V i -k ) i ( ). · Focussing on a tagged customer arriving in Q i during the service of a customer in Q i -k , for i, k = 1 , . . . , N , we can find ˜ W ( V i -k ) i ( ) · by conditioning on the number of customers in each queue at the arrival epoch and the residual service time. Similar to ˜ R PR j ( ), · we define the LST of the joint distribution of past and residual service time B j as
$$\widetilde { B } _ { j } ^ { P R } ( \omega _ { P }, \omega _ { R } ) = \frac { \widetilde { B } _ { j } ( \omega _ { P } ) - \widetilde { B } _ { j } ( \omega _ { R } ) } { ( \omega _ { R } - \omega _ { P } ) b _ { j } }, \quad j = 1, \dots, N.$$
We can now use Equations (3.5) and (3.21) to find the PGF-LST of the joint distribution of the number of customers of each type present at an arbitrary moment during V j and the residual service time of the customer that is being served at that moment:
$$\widetilde { L } ^ { ( V _ { j } ) } ( \mathbf z, \omega ) = \widetilde { L B } ^ { ( B _ { j } ) } ( \mathbf z ) \widetilde { B } _ { j } ^ { P R } ( \Sigma _ { j } ( \mathbf z ), \omega ).$$
Note that the customers arriving in Q j during the elapsed part of B j are gated customers.
## Proposition 3.5 We have
$$\widetilde { W } _ { i } ^ { ( V _ { i - k } ) } ( \omega ) & = \widetilde { B } _ { i - k } ^ { P R } \left ( \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) + \lambda _ { i } ( 1 - \widetilde { B } _ { i } ( \omega ) ), \omega + \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) \right ) \\ & \times \widetilde { L B } ^ { ( B _ { i - k } ) } ( \mathbf B _ { k, i } ^ { G } ) \prod _ { j = 0 } ^ { k - 1 } \widetilde { R } _ { j, i - 1 } ^ { * } ( \omega ) \times \frac { \widetilde { P } _ { k - 1, i - 1 } ^ { * } ( \omega ) } { \widetilde { B } _ { k - 1, i - 1 } ^ { * } ( \omega ) }, \\. &. &. &.$$
for i, k = 1 , . . . , N .
glyph[negationslash]
Proof: We denote by n , . . . , n 1 N , n G the numbers of customers of all types present at the arrival epoch of the tagged customer. The residual part of the service time of the customer being served at this arrival epoch is denoted by t R . Let n iG := n i if i = j , and n iG := n G if i = . The waiting time of a type j i customer arriving during V j , conditional on n , . . . , n 1 N , n G and the residual service time consists of the following components:
- 1. the service of n j -1 customers in front of the gate in Q j (We exclude the customer being served at the arrival epoch),
- 2. the service of all n j +1 , . . . , n i -1 customers present in Q j +1 , . . . , Q i -1 ,
- 3. all of the descendants of the previously mentioned customers that will be served before the next visit to Q i ,
glyph[negationslash]
- 4. if i = , the service of all j n iG customers present in Q i at the arrival epoch; if i = , the j service of all n iG gated customers present in Q i ,
- 5. the switch-over times R , . . . , R j i -1 ,
- 6. the residual service time t R ,
- 7. all customers arriving during t R and R , . . . , R j i -1 that will be served before the next visit to Q i ,
- 8. all of their descendants that will be served before the next visit to Q i ,
- 9. the (possible) future service of the customer being served at the arrival epoch, due to the fact that he may be routed to another queue that will be served before the next visit to Q i ,
- 10. the service of all descendants of this rerouted customer (Note that if he will be rerouted and served again, he will count as his own descendant).
## More formally:
$$\cdots \cdot \cdot \cdot \cdot \\ W ^ { ( V _ { j } ) ^ { \prime } } _ { i } & = \sum _ { l = 1 } ^ { n _ { j } - 1 } S _ { j, l } + \sum _ { k = j + 1 } ^ { i - 1 } \sum _ { l = 1 } ^ { n _ { k } } S _ { k _ { l } } + \sum _ { l = 1 } ^ { n _ { i _ { G } } } B _ { i _ { l } } + \sum _ { k = j } ^ { i - 1 } \sum _ { m = 1 } ^ { N _ { l } ( R _ { k } ) } S _ { l _ { m } } \Big ] \\ & + t _ { R } + \sum _ { l = j + 1 } ^ { i - 1 } \sum _ { m = 1 } ^ { N _ { l } ( t _ { R } ) } S _ { l _ { m } } + \begin{cases} S _ { l } & \text{for } l = j + 1, \dots, i - 1, \, w. p. \ p _ { j, l }, \\ 0 & \text{w.p. } 1 - \sum _ { l = j + 1 } ^ { i - 1 } p _ { j, l }, \end{cases}.$$
We now show that Equation (3.23) follows from taking the LST:
$$\begin{array} { l } \text{We now show that Equation (3.23) follows from taking the LST:} \\ \mathbb { E } [ e ^ { - \omega _ { i } } \int _ { l = 1 } ^ { n } \int _ { m = 1 } ^ { n } \int _ { \mathbb { A } } ] \\ = \mathbb { E } \left [ \prod _ { l = 1 } ^ { n j - 1 } e ^ { - \omega _ { i } } _ { \substack { i = 1 } } \int _ { m = j + 1 } ^ { n } \int _ { m = j + 1 } ^ { n } \int _ { \mathbb { A } } ^ { n \cdot \sum _ { \mathbb { A } } i } \mathbb { E } \left [ \prod _ { l = 1 } ^ { n i G } e ^ { - \omega _ { \mathbb { A } } _ { l } } \right ] \mathbb { E } \left [ \prod _ { l = 1 } ^ { n i G } e ^ { - \omega _ { \mathbb { A } } _ { l } } \right ] \mathbb { E } \left [ \prod _ { m = j } ^ { n i G } e ^ { - \omega _ { \mathbb { A } } _ { l } } \right ] \\ \end{array} \right ] \\ \times e ^ { - \omega _ { \mathbb { R } } } \mathbb { E } \left [ \prod _ { l = j + 1 } ^ { n } \int _ { m = 1 } ^ { n } \int _ { \mathbb { A } } ^ { n \cdot \sum _ { \mathbb { A } } i } \mathbb { E } [ e ^ { - \omega _ { \mathbb { A } } _ { l } } \right ] \left ( \sum _ { l = j + 1 } ^ { n } p _ { j, l } \mathbb { E } [ e ^ { - \omega _ { \mathbb { A } } _ { l } } ] + 1 - \sum _ { l = j + 1 } ^ { n } p _ { j, l } \right ) \\ \times e ^ { - \omega _ { \mathbb { R } } } \prod _ { l = j + 1 } ^ { n i - 1 } \sum _ { m = j + 1 } ^ { n i - 1 } \mathbb { E } [ e ^ { - \omega _ { \mathbb { A } } _ { l } } \right ] \right ) \\ \times e ^ { - \omega _ { \mathbb { R } } } \prod _ { l = j + 1 } ^ { n i - 1 } \sum _ { l = j + 1 } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } \int _ { \mathbb { A } } ^ { n i - 1 } ( \omega ) \\ = \mathbb { E } _ { k = 1, i = 1 } ^ { n } ( \omega ) ^ { n i - k } \int _ { l = 1 } ^ { k - 1 } \int _ { k = 1, i = 1 } ^ { n i - 1 } ( \omega ) ^ { n i - 1 } \int _ { k = 1 } ^ { k } \int _ { k = 1, i = 1 } ^ { k - 1, i = 1 } ( \omega ) \\ \times \exp \left [ - \left ( \omega + \sum _ { l = 1 } ^ { n i - 1 } ( 1 - \mathbb { E } [ e ^ { - \omega _ { \mathbb { A } } _ { l } } ) \right ) t _ { \mathbb { R } } \right ] \mathbb { E } _ { k = 1, i = 1 } ^ { n i - 1 } ( \omega ) \\ \end{array}, \\ \end{array}$$
where k = i -j (or k = N + i -j if j ≥ i ). Deconditioning of this expression leads to (3.23). glyph[square]
Arbitrary customers. Finally, we present the main result of this section: the LST of the waiting-time distribution of an arbitrary customer in Q i .
Theorem 3.6 The LST of the waiting-time distribution of an arbitrary customer in Q i , if this queue receives gated service, is given by:
$$\widetilde { W } _ { i } ( \omega ) = \frac { \gamma _ { i } - \lambda _ { i } } { \gamma _ { i } } \widetilde { W } _ { i } ^ { I } ( \omega ) + \frac { \lambda _ { i } } { \gamma _ { i } } \widetilde { W } _ { i } ^ { E } ( \omega ), \quad i = 1, \dots, N,$$
where ˜ W I i ( ω ) and ˜ W E i ( ω ) are given by (3.14) and (3.17), respectively.
Proof: The result follows immediately after conditioning on the event that an arbitrary customer is an internal or external customer. glyph[square]
## 4 Exhaustive service
In this section we study systems with mixtures of gated and exhaustive service, that is, some queues are served exhaustively whereas other queues receive gated service. We restrict ourselves to presenting the results, but for reasons of compactness we omit all proofs as they can be produced similar to the proofs in the previous section.
Throughout we use the index e ∈ { 1 , . . . , N } to refer to an arbitrary queue with exhaustive service, which means that customers are being served until the queue is empty. This means that, in contrast to gated service, customers arriving in Q e during V e will be served during that same visit period. This is true, even if the customer has just received service in Q e and was routed back to Q e again. To deal with this issue, we define an extended service time B exh e which is the total amount of service that a customer receives during a visit period V e before being routed to another queue (or leaving the system), cf. [29]. As stated in [29], B exh e is the geometric sum, with parameter p e,e , of independent random variables with the same distribution as B e . The LST of B exh e is given by
$$\widetilde { B } _ { e } ^ { \text{exh} } ( \omega ) = \frac { ( 1 - p _ { e, e } ) \widetilde { B } _ { e } ( \omega ) } { 1 - p _ { e, e } \widetilde { B } _ { e } ( \omega ) }.$$
We denote a busy period of type e customers by BP e . The PGF-LST of the joint distribution of a busy period and the number of customers served during this busy period satisfies the following equation:
$$\widetilde { B } P _ { e } ( z, \omega ) = z \widetilde { B } _ { e } ^ { \text{exh} } \left ( \omega + \lambda _ { e } ( 1 - \widetilde { B } P _ { e } ( z, \omega ) ) \right ).$$
## 4.1 The joint queue-length distributions
Visit beginnings and completions. The laws of motion (3.1a)-(3.1e) have to be adapted if a queue receives exhaustive service. First we need to redefine Σ ( i z ) and P i ( z ) if Q i is served exhaustively, and introduce P exh i ( z ):
$$\Sigma _ { e } ( \mathbf z ) = \sum _ { j \neq e } \lambda _ { j } ( 1 - z _ { j } ),$$
$$\dots$$
glyph[negationslash]
$$N$$
glyph[negationslash]
$$P _ { e } ( \mathbf z ) & = p _ { e, 0 } + \sum _ { j = 1 } ^ { N } p _ { e, j } z _ { j }, \\ P _ { e } ^ { \text{exh} } ( \mathbf z ) & = \frac { p _ { e, 0 } } { 1 - p _ { e, e } } + \sum _ { j \neq e } \frac { p _ { e, j } } { 1 - p _ { e, e } } z _ { j },$$
for all e ∈ { 1 , . . . , N } corresponding to queues with exhaustive service. The laws of motion now change accordingly:
$$\widetilde { L } C ^ { ( V _ { e } ) } ( \mathbf z ) & = \widetilde { L } B ^ { ( V _ { e } ) } \left ( z _ { 1 }, \dots, z _ { e - 1 }, \widetilde { B } P _ { e } \left ( P _ { e } ^ { \text{exh} } ( \mathbf z ), \Sigma _ { e } ( \mathbf z ) \right ), z _ { e + 1 }, \dots, z _ { N }, 1 \right ), \\ \widetilde { L } B ^ { ( R _ { e } ) } ( \mathbf z ) & = \widetilde { L } C ^ { ( V _ { e } ) } ( \mathbf z ),$$
for any exhaustively served Q e .
Service beginnings and completions. Eisenberg's relation (3.2) remains valid for queues with exhaustive service. Note that P e ( z ) should not be replaced by P exh e ( z ) for exhaustive queues in (3.2)! Relation (3.3) should be slightly changed for queues with exhaustive service, since customers are not placed behind a gate:
$$\widetilde { L C } ^ { ( B _ { e } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( B _ { e } ) } ( \mathbf z ) \widetilde { B } _ { e } ( \Sigma ( \mathbf z ) ) / z _ { e }.$$
Arbitrary moments. Equation (3.4) for the PGF of the joint queue-length distribution at arbitrary moments remains valid if some of the queues have exhaustive service. However, ˜ L ( V j ) ( z ) should be adapted for queues with exhaustive service by replacing gated customers with 'ordinary' type e customers:
$$\widetilde { L } ^ { ( V _ { e } ) } ( \mathbf z ) = \widetilde { L B } ^ { ( B _ { e } ) } ( \mathbf z ) \frac { 1 - \widetilde { B } _ { e } \left ( \Sigma ( \mathbf z ) \right ) } { b _ { e } \Sigma ( \mathbf z ) }.$$
## 4.2 Cycle-time distributions
The fact that customers arriving in an exhaustively served queue, say Q i -k , during V i -k are served before the end of this visit period, requires changes in the definition of ˜ B ∗ k,i ( ω ).
$$\widetilde { B } _ { k, i } ^ { * } ( \omega ) = \widetilde { B } P _ { i - k } \left ( \widetilde { P } _ { k, i } ^ { * } ( \omega ), \omega + \sum _ { j = 0 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j, i } ^ { * } ( \omega ) ) \right ), \ \ k = 0, 1, \dots, N ; i = 1, \dots, N, \ \ ( 4. 1 )$$
where
$$\widetilde { P } _ { k, i } ^ { * } ( \omega ) = 1 - \sum _ { j = 0 } ^ { k - 1 } \frac { p _ { i - k, i - j } } { 1 - p _ { i - k, i - k } } ( 1 - \widetilde { B } _ { j, i } ^ { * } ( \omega ) ), \quad \ \ k = 0, 1, \dots, N ; i = 1, \dots, N. \ \ ( 4. 2 )$$
Given this modified definition of ˜ B ∗ k,i ( ω ), the function ˜ R ∗ k,i ( ω ) remains unchanged. The expression for the LST of the cycle time C i , given by (3.12), also remains valid for systems containing exhaustively served queues.
## 4.3 Waiting-time distributions
Internal customers. The waiting time LST of internal customers (3.14) is determined by conditioning on the event that an arrival in Q i follows a service completion in some Q i -k . As stated before, for queues with exhaustive service we need to take into account that customers that are routed back to the same queue will be served during the same visit period. For an arbitrary exhaustively served queue Q e , this results in
$$\widetilde { W } _ { e } ^ { I } ( \omega ) = \sum _ { k = 0 } ^ { N - 1 } \frac { \gamma _ { e - k } p _ { e - k, e } } { \gamma _ { e } - \lambda _ { e } } \widetilde { W } _ { e } ^ { ( B _ { e - k } ) } ( \omega ).$$
Compared to (3.14), the summation starts at k = 0 and runs up to k = N -1. We now introduce
$$\mathbf B ^ { \prime } _ { o, i } = ( 1, \dots, 1, \widetilde { B } _ { i } ( \omega ), 1, \dots, 1 ), \quad i = 1, \dots, N,$$
with ˜ B ω i ( ) at the position corresponding to customers in Q i . If Q i has exhaustive service, there is a subtle difference with B 0 i , which has ˜ BP i (1 , ω ) at position i . We can now determine ˜ WC ( B e -k ) e ( ω ) for any Q e that receives exhaustive service:
$$\widetilde { \ W C } _ { e } ^ { ( B _ { e - k } ) } ( \omega ) & = \widetilde { L C } ^ { ( B _ { e - k } ) } ( \mathbf B _ { o, e } ^ { \prime } \bigotimes _ { j = 0 } ^ { k - 1 } \mathbf B _ { j, e - 1 } ) \prod _ { j = 0 } ^ { k - 1 } \widetilde { R } _ { j, e - 1 } ^ { * } ( \omega ), \quad k = 1, \dots, N - 1, \\ \widetilde { \ W C } _ { e } ^ { ( B _ { e } ) } ( \omega ) & = \widetilde { L C } ^ { ( B _ { e } ) } ( \mathbf B _ { o, e } ^ { \prime } ).$$
For each Q i that receives gated service, we can still use (3.14) with the modified definition of ˜ B ∗ k,i ( ω ) for each Q i -k which receives exhaustive service.
External customers. The waiting time LST of external customers (3.17) is determined by conditioning on the event that an arrival in Q i takes place during V i -1 , . . . , V i -N or during R i -1 , . . . , R i -N . Before discussing the waiting times of external customers arriving in an exhaustively served queue, it is important to realise that allowing some queues to have exhaustive service will now also require some changes to waiting times of customers arriving in a queue with gated service. This means that (3.23) should now become
$$& \text{in a queue with gated service. }'I \text{his means that } ( 3. 2 3 ) \text{ should now become} \\ \widetilde { W } _ { i } ^ { ( V _ { i - k } ) } ( \omega ) = \widetilde { B } _ { i - k } ^ { P R } \left ( \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) + \lambda _ { i } ( 1 - \widetilde { B } _ { i } ( \omega ) ) + \lambda _ { i - k } ( 1 - \widetilde { B } _ { k - 1, i - 1 } ^ { * } ( \omega ) ), \\ & \quad \omega + \sum _ { j = 1 } ^ { k - 1 } \lambda _ { i - j } ( 1 - \widetilde { B } _ { j - 1, i - 1 } ^ { * } ( \omega ) ) + \lambda _ { i - k } ( 1 - \widetilde { B } _ { k - 1, i - 1 } ^ { * } ( \omega ) ) \right ) \\ & \times \widetilde { L B } ^ { ( B _ { i - k } ) } ( B _ { 0, i } \bigotimes _ { j = 0 } ^ { k - 1 } B _ { j, i - 1 } ) \prod _ { j = 0 } ^ { k - 1 } \widetilde { R } _ { j, i - 1 } ^ { * } ( \omega ) \times \frac { 1 - \sum _ { j = 0 } p _ { i - k, i - j - 1 } ( 1 - \widetilde { B } _ { j, i - 1 } ^ { * } ( \omega ) ) } { \widetilde { B } _ { k - 1, i - 1 } ^ { * } ( \omega ) }, \\ & \quad \text{if } Q _ { i, - k } \text{ receives exhaustive service (and } Q _ { i } \text{ receives gated service). } \text{ Compared to } ( 3. 2 3 ) \text{ we}$$
if Q i -k receives exhaustive service (and Q i receives gated service). Compared to (3.23) we can see that there are two additional terms λ i -k ( 1 -˜ B ∗ k -1 ,i -1 ( ω ) ) which take into account that customers arriving in Q i -k during the elapsed and during the residual part of the present service time B i -k will be served during the present visit period. Furthermore, we can see that ˜ P ∗ k -1 ,i -1 ( ω ) has been replaced by 1 -∑ k -1 j =0 p i -k,i - -j 1 ( 1 -˜ B ∗ j,i -1 ( ω ) ) , which is required because the customer being served should be allowed to return to Q i -k upon his service completion.
If Q e receives exhaustive service we have to make some additional changes. We have
$$\widetilde { W } _ { e } ^ { E } ( \omega ) = \frac { 1 } { \mathbb { E } [ C ] } \sum _ { k = 1 } ^ { N } \left ( \mathbb { E } [ V _ { e - k + 1 } ] \widetilde { W } _ { e } ^ { ( V _ { e - k + 1 } ) } ( \omega ) + r _ { e - k } \widetilde { W } _ { e } ^ { ( R _ { e - k } ) } ( \omega ) \right ),$$
where we have chosen to denote the waiting time LST of customers arriving in Q e during V e as ˜ W ( V e ) e ( ω ) rather than ˜ W ( V e -N ) e ( ω ) to illustrate the fact that they will be served during the same visit period. The expression for ˜ W ( R e -k ) e ( ω ), given by (3.19), should be slightly modified if Q e receives exhaustive service. However, since the only required modification is that B 0 i , should be replaced by B ′ 0 i , , we refrain from giving the complete expression.
If k > 0, the expression for ˜ W ( V e -k ) e ( ω ) remains almost the same as (3.23) if Q e -k receives gated service, or (4.4) if Q e -k receives exhaustive service. The only change is, once again, that B 0 i , should be replaced by B ′ 0 i , . The case k = 0 results in a much simpler expression, since we only have to wait for the service times of the customers that were present at the beginning of the present service (excluding the customer in service) plus the service times of the customers that have arrived in Q e during the elapsed part of the present service, plus the residual service time:
$$\widetilde { W } _ { e } ^ { ( V _ { e } ) } ( \omega ) = \widetilde { B } _ { e } ^ { P R } \left ( \lambda _ { e } ( 1 - \widetilde { B } _ { e } ( \omega ) ), \omega \right ) \frac { \widetilde { L B } ^ { ( B _ { e } ) } ( \mathbf B _ { o, e } ^ { \prime } ) } { \widetilde { B } _ { e } ( \omega ) }.$$
Arbitrary customers. The LST of the waiting-time distribution of an arbitrary customer in an exhaustively served queue immediately follows after conditioning on the event that an arbitrary customer is either an internal or an external customer, similar to the derivation of (3.25). The result is presented in the theorem below.
Theorem 4.1 The LST of the waiting-time distribution of an arbitrary customer in Q i , if this queue receives exhaustive service, is given by:
$$\widetilde { W } _ { i } ( \omega ) = \frac { \gamma _ { i } - \lambda _ { i } } { \gamma _ { i } } \widetilde { W } _ { i } ^ { I } ( \omega ) + \frac { \lambda _ { i } } { \gamma _ { i } } \widetilde { W } _ { i } ^ { E } ( \omega ), \quad i = 1, \dots, N,$$
where ˜ W I i ( ω ) and ˜ W E i ( ω ) are defined in (4.3) and (4.5).
## 5 Applicability of the model
In this section we give some numerical examples that indicate the versatility of the model that we have discussed. To this end, we use some examples that can be found in the existing literature, and show how our model can be used to describe the various systems and find the relevant performance measures. Hence, most of the results presented in this section are not novel, but the way of deriving them is new.
Example 1: tandem queues with parallel queues in the first stage. We first use an example that was introduced by Katayama [19], who studies a network consisting of three queues. Customers arrive at Q 1 and Q 2 , and are routed to Q 3 after being served (see Figure 1). This model, which is referred to as a tandem queueing model with parallel queues in the first stage, is a special case of the model discussed in the present paper. We simply put p 1 3 , = p 2 3 , = p 3 0 , = 1 and all other p i,j are zero. We use the same values as in [19]: λ 1 = λ / 2 10, service times are deterministic with b 1 = b 2 = 1, and b 3 = 5. The server serves the queues exhaustively, in cyclic order: 1, 2, 3, 1, . . . . The only difference with the model discussed in [19] is that we introduce (deterministic) switch-over times R 2 = R 3 = 2. We assume that no time is required to switch between the two queues in the first stage, so r 1 = 0. In Figure 2 we show the means and standard deviations of the waiting times of customers at the three queues. These plots reveal that in the heavy-traffic regime, as ρ ↑ 1, the mean waiting times of customers in Q 3 are close to those in Q 1 , but the standard deviations of
Figure 1: Tandem queues with parallel queues in the first stage, as discussed in Example 1.
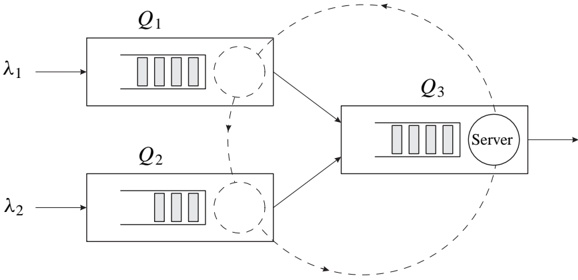
the waiting times in Q 3 are closer to those in Q 2 . Further inspection of the exact results, obtained by differentiating the LSTs, confirms that in both cases the limits are very close, but not exactly the same.
It is also interesting to study the light-traffic behaviour of the system, i.e., as ρ ↓ 0. From the plots in Figure 2 we can see that, as ρ ↓ 0, the mean waiting times are all equal, but the standard deviation of the waiting times in Q 1 and Q 2 is different than in Q 3 . From the LSTs of the waiting-time distributions we can obtain the exact expressions when ρ ↓ 0, by taking the Taylor expansion in ρ at ρ = 0 and subsequently ignoring all O ( ρ ) terms. This, combined with the fact that R 1 = 0 and all of the routing probabilities are either 0 or 1, considerably simplifies all expressions from the previous section:
$$\min \alpha \, \alpha \, \alpha \, \min \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \, \min \colon \\ & \widetilde { W } _ { 1 } ( \omega ) = \widetilde { W } _ { 1 } ^ { E } ( \omega ) \to \frac { r _ { 2 } } { r } \widetilde { W } _ { 1 } ^ { ( R _ { 2 } ) } ( \omega ) + \frac { r _ { 3 } } { r } \widetilde { W } _ { 1 } ^ { ( R _ { 3 } ) }, \\ & \widetilde { W } _ { 3 } ( \omega ) = \widetilde { W } _ { 3 } ^ { I } ( \omega ) \to \frac { \lambda _ { 1 } } { \lambda _ { 1 } + \lambda _ { 2 } } \widetilde { W } _ { 3 } ^ { ( B _ { 1 } ) } ( \omega ) + \frac { \lambda _ { 2 } } { \lambda _ { 1 } + \lambda _ { 2 } } \widetilde { W } _ { 3 } ^ { ( B _ { 2 } ) } ( \omega ). \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{matrix}$$
Since we are considering the case ρ ↓ 0, these expressions can be simplified even further to closed-form expressions, because ignoring all O ( ρ ) terms is equivalent to regarding the system as being empty all the time:
$$( \omega ).$$
$$\begin{array} { c } \text{$\pi$ was } \\ \widetilde { W } _ { 1 } ( \omega ) \rightarrow \frac { r _ { 2 } } { r } \widetilde { R } _ { 2 } ^ { P R } ( 0, \omega ) \widetilde { R } _ { 3 } ( \omega ) + \frac { r _ { 3 } } { r } \widetilde { R } _ { 3 } ^ { P R } ( 0, \omega ), \\ \widetilde { W } _ { 2 } ( \omega ) \rightarrow \frac { r _ { 2 } } { r } \widetilde { R } _ { 2 } ^ { P R } ( 0, \omega ) \widetilde { R } _ { 3 } ( \omega ) + \frac { r _ { 3 } } { r } \widetilde { R } _ { 3 } ^ { P R } ( 0, \omega ), \\ \widetilde { W } _ { 3 } ( \omega ) \rightarrow \frac { \lambda _ { 1 } } { \lambda _ { 1 } + \lambda _ { 2 } } \widetilde { R } _ { 1 } ( \omega ) \widetilde { R } _ { 2 } ( \omega ) + \frac { \lambda _ { 2 } } { \lambda _ { 1 } + \lambda _ { 2 } } \widetilde { R } _ { 2 } ( \omega ). \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{array}$$
These expressions reveal the true behaviour of the system in light traffic. The waiting times in Q 1 and Q 2 are simply the total residual switch-over time, with mean r (2) / r 2 = 2 and second moment r (3) / r 3 = 16 3. / For queue Q 3 the situation is different, because this queue only contains internally rerouted customers. Customers being rerouted from Q 1 have to wait for the switch-over times R 1 + R 2 , whereas customers arriving from Q 2 have to wait only for
R 2 . Since R 1 = 0, the waiting time only consists of R 2 = 2 in both cases. Substituting all parameter values results in the following LT limits of the waiting-time LSTs:
$$\widetilde { W } _ { 1 } ( \omega ) \rightarrow \frac { 1 - e ^ { - 4 \omega } } { 4 \omega }, \quad \widetilde { W } _ { 2 } ( \omega ) \rightarrow \frac { 1 - e ^ { - 4 \omega } } { 4 \omega }, \quad \widetilde { W } _ { 3 } ( \omega ) \rightarrow e ^ { - 2 \omega } \quad ( \rho \downarrow 0 ).$$
Differentiating the LSTs gives the following results as ρ ↓ 0:
$$\mathbb { E } [ W _ { 1 } ] & \to 2, & \mathbb { E } [ W _ { 2 } ] & \to 2, & \mathbb { E } [ W _ { 3 } ] & \to 2, \\ \text{sd} [ W _ { 1 } ] & \to \sqrt { 4 / 3 }, & \text{sd} [ W _ { 2 } ] & \to \sqrt { 4 / 3 }, & \text{sd} [ W _ { 3 } ] & \to 0.$$
Figure 2: Means and standard deviations of the waiting times in the first numerical example.
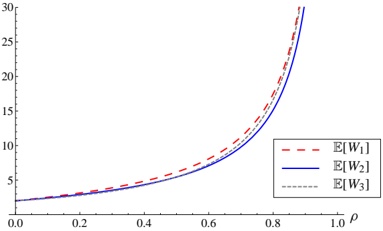
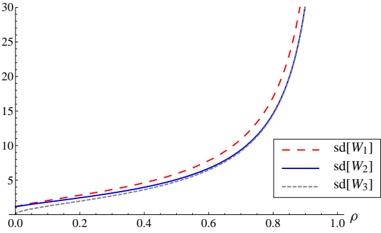
Example 2: a two-stage queueing model with customer feedback. This second example is introduced by Tak´cs [30], a and extended by Ali and Neuts [1]. The queueing system under consideration consists of a waiting room, in which customers arrive according to a Poisson process with intensity λ , and a service room. The customers are all transferred simultaneously to the service room where they receive service in order of arrival. However, at the moment of the transfer to this service room M additional 'overhead customers' are added to the front of this queue. (In [30] M is a constant, in [1] it is a random variable.) Upon service completion, each customer leaves the system with probability q , and returns to the waiting room with probability 1 -q . Overhead customers leave the system with probability one after being served. As soon as the last customer in the service room finishes service (and either leaves the system, or returns to the waiting room) all customers present in the waiting room are transferred to the service room, where they will receive service after a new batch of overhead customers has been served, and so on. A schematic representation of this model is depicted in Figure 3.
We use the same input parameters as Tak´cs [30]: a q = 2 3 and / λ/µ = 1 6, where 1 / /µ is the mean service time in the service room. This service time is exponentially distributed. The number of overhead customers that are added to the front of the queue is a constant with value M . We can model this system in terms of our network with a single, shared server by defining arrival intensities λ 1 = λ and λ 2 = 0. The service times in stations 1 and 2 are respectively 0 and exponentially distributed with mean b 2 = 1 /µ . The routing probabilities are p 1 2 , = 1 and p 2 1 , = 1 3, the other / p i,j are zero. The service times of the overhead
Figure 3: The two-stage queueing model with customer feedback, as discussed in Example 2.
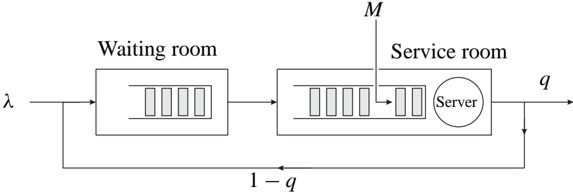
customers are also exponentially distributed with parameter µ . Hence, we can model the addition of M overhead customers as a switch-over time which is ErlangM distributed with parameter µ . The switch-over time between Q 2 and Q 1 is zero. Note that, since b 1 = 0, there is no difference between gated and exhaustive service. By differentiation of the waiting time LSTs (3.25), we can obtain explicit expressions for all moments of the waiting-time distributions for this example. The first three moments of the waiting times are given below.
$$\mathbb { E } [ W _ { 1 } ] & = \frac { 1 + M } { 2 \mu }, \quad \mathbb { E } [ W _ { 1 } ^ { 2 } ] & = \frac { ( M + 1 ) ( 1 1 M + 2 5 ) } { 2 7 \mu ^ { 2 } }, \quad \mathbb { E } [ W _ { 1 } ^ { 3 } ] & = \frac { ( M + 1 ) ( M ( 4 3 M + 2 2 3 ) + 3 1 0 ) } { 1 0 8 \mu ^ { 3 } }, \\ \mathbb { E } [ W _ { 2 } ] & = \frac { 1 + 7 M } { 6 \mu }, \quad \mathbb { E } [ W _ { 2 } ^ { 2 } ] & = \frac { ( M + 1 ) ( 3 7 M + 1 1 ) } { 2 7 \mu ^ { 2 } }, \quad \mathbb { E } [ W _ { 2 } ^ { 3 } ] & = \frac { ( M + 1 ) ( M + 2 ) ( 1 7 5 M + 8 1 ) } { 1 0 8 \mu ^ { 3 } }.$$
The results are slightly different from those presented in [30], because Tak´cs also considers a the overhead customers in the computations of the waiting times and allows them to return to the waiting room after their service is completed. Modelling this situation would require one minor adaptation in the laws of motion (adding the overhead customers at the beginning of V 2 ) and another adaptation in the waiting time LST (conditioning on the event that a new customer is an overhead customer). These changes are not too difficult but beyond the scope of this paper.
## 6 Discussion and further research
In this section, we not only elaborate on the developed method and its applicability, but we also discuss possible ways of extending the present study.
Method. As mentioned in the introduction, the main complicating factor of the model under consideration is caused by the rerouting of internal customers. This implies that the total arrival process at each queue is not Poisson, and not even renewal. Traditional methods to determine waiting-time distributions in each queue are based on the distributional form of Little's Law, which relies on the assumption of Poisson arrivals. Contrary to the distributional form of Little's Law, we explicitly make use of the branching structure to find waiting-time distributions. The main idea is that upon the arrival of a tagged customer Y at time t at Q i we compute a priori the total future service times at each of the queues, for all the other customers present in the system at time t that will be served before customer Y enters service
at Q i (see (3.7)). Additionally, we add the total future service requirements of all external arrivals (and their descendants) that will be served before customer Y enters service (see (3.9)). The advantage of this method is that a system no longer needs to satisfy all of the prerequisites required to apply the distributional form of Little's Law (see [21]).
Applicability. The novel approach of this paper to find the LST of the waiting-time distribution can also be applied to other types of models with a single server serving multiple queues. Obviously, one can apply it to standard polling models (without customer routing) by simply taking p i, 0 = 1 and p i,j = 0 for j > 0. However, the developed methodology carries almost directly over to tandem queues [23, 34], multi-stage queueing models with parallel queues [19], feedback vacation queues [9, 33], symmetric feedback polling systems [31, 33], systems with a waiting room [1, 30], closed networks [2], M/G/ 1 queues with permanent and transient customers [8], networks with permanent and transient customers [3], or polling models with arrival rates that depend on the location of the server [4, 7].
Further research. Since the model can be described as a multi-type branching process, explicit closed-form expressions can be obtained for the waiting-time distributions under heavytraffic (HT) assumptions. Such expressions are appealing because they give fundamental insight in how the system performance depends on the system parameters, and in particular on the routing probabilities p i,j . HT asymptotics can be obtained by combining insights from multi-type branching processes [35], fluid analyses [24, 25], and the heavy-traffic averaging principle by Coffman et al. [12, 13]. The HT analysis is relevant because in practice the proper operation of the system is particularly important when the system is heavily loaded. The HT asymptotics form an excellent basis for the development of approximations for the waiting-time distributions for arbitrary loads. For the mean waiting times, preliminary results are obtained in [6].
From a practical perspective, motivated by applications in production systems [5], an important extension of the model under consideration is a model where customers visit a predetermined, class-specific sequence of queues in a fixed order. In our model one would have to define multiple customer classes, each having their own fixed visit order through the system. The method presented in this paper forms a good basis for this extension.
## Acknowledgements
The authors are grateful to Ivo Adan and Onno Boxma for providing valuable comments on earlier drafts of the present paper.
## References
- [1] O. M. E. Ali and M. F. Neuts. A service system with two stages of waiting and feedback of customers. Journal of Applied Probability , 21:404-413, 1984.
- [2] E. Altman and U. Yechiali. Polling in a closed network. Probability in the Engineering and Informational Sciences , 8(3):327-343, 1994.
- [3] R. Armony and U. Yechiali. Polling systems with permanent and transient jobs. Communications in Statistics. Stochastic Models , 15(3):395-427, 1999.
- [4] M. A. A. Boon, A. C. C. van Wijk, I. J. B. F. Adan, and O. J. Boxma. A polling model with smart customers. Queueing Systems , 66(3):239-274, 2010.
- [5] M. A. A. Boon, R. D. van der Mei, and E. M. M. Winands. Applications of polling systems. Surveys in Operations Research and Management Science , 16:67-82, 2011.
- [6] M. A. A. Boon, R. D. van der Mei, and E. M. M. Winands. Queueing networks with a single shared server: light and heavy traffic. SIGMETRICS Performance Evaluation Review , 39(2):44-46, 2011.
- [7] O. J. Boxma. Polling systems. In K. Apt, L. Schrijver, and N. Temme, editors, From universal morphisms to megabytes: A Baayen space odyssey - Liber amicorum for P. C. Baayen , pages 215-230. CWI, Amsterdam, 1994.
- [8] O. J. Boxma and J. W. Cohen. The M/G/ 1 queue with permanent customers. IEEE Journal on Selected Areas in Communications , 9(2):179-184, 1991.
- [9] O. J. Boxma and U. Yechiali. An M/G/ 1 queue with multiple types of feedback and gated vacations. Journal of Applied Probability , 34:773-784, 1997.
- [10] O. J. Boxma, J. Bruin, and B. H. Fralix. Waiting times in polling systems with various service disciplines. Performance Evaluation , 66:621-639, 2009.
- [11] O. J. Boxma, O. Kella, and K. M. Kosi´ski. n Queue lengths and workloads in polling systems. Operations Research Letters , 39:401-405, 2011.
- [12] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems with zero switchover times: A heavy-traffic averaging principle. The Annals of Applied Probability , 5(3):681-719, 1995.
- [13] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems in heavy-traffic: A Bessel process limit. Mathematics of Operations Research , 23:257-304, 1998.
- [14] M. Eisenberg. Queues with periodic service and changeover time. Operations Research , 20(2):440-451, 1972.
- [15] S. Foss. Queues with customers of several types. In A. A. Borovkov, editor, Advances in Probability Theory: Limit Theorems and Related Problems , pages 348-377. Optimization Software, 1984.
- [16] Y. Gong and R. de Koster. A polling-based dynamic order picking system for online retailers. IIE Transactions , 40:1070-1082, 2008.
- [17] S. E. Grasman, T. L. Olsen, and J. R. Birge. Setting basestock levels in multiproduct systems with setups and random yield. IIE Transactions , 40(12):1158-1170, 2008.
- [18] D. Grillo. Polling mechanism models in communication systems - some application examples. In H. Takagi, editor, Stochastic Analysis of Computer and Communication Systems , pages 659-699. North-Holland, Amsterdam, 1990.
| [19] | T. Katayama. A cyclic service tandem queueing model with parallel queues in the first stage. Stochastic Models , 4:421-443, 1988. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [20] | V. Kavitha and E. Altman. Queueing in space: design of message ferry routes in static adhoc networks. In Proceedings ITC21 , 2009. |
| [21] | J. Keilson and L. D. Servi. The distributional form of Little's Law and the Fuhrmann- Cooper decomposition. Operations Research Letters , 9(4):239-247, 1990. |
| [22] | H. Levy and M. Sidi. Polling systems: applications, modeling, and optimization. IEEE Transactions on Communications , 38:1750-1760, 1990. |
| [23] | S. S. Nair. A single server tandem queue. Journal of Applied Probability , 8(1):95-109, 1971. |
| [24] | T. L. Olsen and R. D. van der Mei. Polling systems with periodic server routeing in heavy traffic: distribution of the delay. Journal of Applied Probability , 40:305-326, 2003. |
| [25] | T. L. Olsen and R. D. van der Mei. Periodic polling systems in heavy-traffic: renewal arrivals. Operations Research Letters , 33:17-25, 2005. |
| [26] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems 13:409-426, 1993. |
| [27] | D. Sarkar and W. I. Zangwill. File and work transfers in cyclic queue systems. Manage- ment Science , 38(10):1510-1523, 1992. |
| [28] | M. Sidi and H. Levy. Customer routing in polling systems. In P. King, I. Mitrani, and R. Pooley, editors, Proceedings Performance '90 , pages 319-331. North-Holland, Amsterdam, 1990. |
| [29] | M. Sidi, H. Levy, and S. W. Fuhrmann. A queueing network with a single cyclically roving server. Queueing Systems , 11:121-144, 1992. |
| [30] | L. Tak´cs. a A queuing model with feedback. Revue fran¸aise c d'automatique, d'informatique et de recherche op´rationnelle. e Recherche op´rationnelle e , 11(4):345-354, 1977. |
| [31] | H. Takagi. Analysis and applications of a multiqueue cyclic service system with feedback. IEEE Transactions on Communications - TCOM , 35(2):248-250, 1987. |
| [32] | H. Takagi. Analysis and application of polling models. In G. Haring, C. Lindemann, and M. Reiser, editors, Performance Evaluation: Origins and Directions , volume 1769 of Lecture Notes in Computer Science , pages 424-442. Springer Verlag, Berlin, 2000. |
| [33] | T. Takine, H. Takagi, and T. Hasegawa. Sojourn times in vacation and polling systems with Bernoulli feedback. Journal of Applied Probability , 28(2):422-432, 1991. |
| [34] | M. Taube-Netto. Two queues in tandem attended by a single server. Operations Research 25(1):140-147, 1977. |
| [35] | R. D. Van der Mei. Towards a unifying theory on branching-type polling models in heavy traffic. Queueing Systems , 57:29-46, 2007. | | 10.1007/s11134-012-9334-6 | [
"Marko Boon",
"Rob van der Mei",
"Erik Winands"
] | 2014-08-01T12:08:55+00:00 | 2014-08-01T12:08:55+00:00 | [
"math.PR",
"cs.PF"
] | Waiting times in queueing networks with a single shared server | We study a queueing network with a single shared server that serves the
queues in a cyclic order. External customers arrive at the queues according to
independent Poisson processes. After completing service, a customer either
leaves the system or is routed to another queue. This model is very generic and
finds many applications in computer systems, communication networks,
manufacturing systems, and robotics. Special cases of the introduced network
include well-known polling models, tandem queues, systems with a waiting room,
multi-stage models with parallel queues, and many others. A complicating factor
of this model is that the internally rerouted customers do not arrive at the
various queues according to a Poisson process, causing standard techniques to
find waiting-time distributions to fail. In this paper we develop a new method
to obtain exact expressions for the Laplace-Stieltjes transforms of the
steady-state waiting-time distributions. This method can be applied to a wide
variety of models which lacked an analysis of the waiting-time distribution
until now. |
1408.0147v1 | ## Networked control systems in the presence of scheduling protocols and communication delays ∗
Kun Liu , Emilia Fridman, Laurentiu Hetel † ‡ §
August 4, 2014
## Abstract
This paper develops the time-delay approach to Networked Control Systems (NCSs) in the presence of variable transmission delays, sampling intervals and communication constraints. The system sensor nodes are supposed to be distributed over a network. Due to communication constraints only one node output is transmitted through the communication channel at once. The scheduling of sensor information towards the controller is ruled by a weighted Try-Once-Discard (TOD) or by Round-Robin (RR) protocols. Differently from the existing results on NCSs in the presence of scheduling protocols (in the frameworks of hybrid and discrete-time systems), we allow the communication delays to be greater than the sampling intervals. A novel hybrid system model for the closed-loop system is presented that contains time-varying delays in the continuous dynamics and in the reset conditions . A new Lyapunov-Krasovskii method, which is based on discontinuous in time Lyapunov functionals is introduced for the stability analysis of the delayed hybrid systems. Polytopic type uncertainties in the system model can be easily included in the analysis. The efficiency of the time-delay approach is illustrated on the examples of uncertain cart-pendulum and of batch reactor.
Key words networked control systems, time-delay approach, scheduling protocols, hybrid systems, Lyapunov-Krasovskii method.
AMS subject classification. 93D15, 93D05.
## 1 Introduction
Networked Control Systems (NCSs) are systems with spatially distributed sensors, actuators and controller nodes which exchange data over a communication
∗ This work was partially supported by Israel Science Foundation (grant No 754/10), the Knut and Alice Wallenberg Foundation and the Swedish Research Council.
† ACCESS Linnaeus Centre and School of Electrical Engineering, KTH Royal Institute of Technology, SE-100 44 Stockholm, Sweden, [email protected]
‡ School of Electrical Engineering, Tel Aviv University, Tel Aviv, 69978 Israel, [email protected]
§ University Lille Nord de France, LAGIS, FRE CNRS 3303, Ecole Centrale de Lille, Cite Scientifique, BP 48, 59651 Villeneuve d'Ascq cedex, France, [email protected]
data channel [1]. In many NCSs, only one node is allowed to use the communication channel at once. The communication along the data channel is orchestrated by a scheduling rule called protocol. The introduction of communication network media offers several practical advantages: reduced costs, ease of installation and maintenance and increased flexibility.
Three main approaches have been used to model the sampled-data control and later to the NCSs: a discrete-time [6, 10], an impulsive/hybrid system [18, 20] and a time-delay [7, 9, 11, 12] approaches. The hybrid system approach, which was inspired by [23], has been applied to nonlinear NCSs under Try-OnceDiscard (TOD) and Round-Robin (RR) protocols in [15, 20]. In the framework of discrete-time approach, network-based stabilization of linear time-invariant systems with TOD/RR protocols and communication delays has been considered in [6]. Variable sampling intervals and/or small communication delays (that are smaller than the sampling intervals ) have been considered in the above works.
Note that in the absence of scheduling protocols, all the three approaches are applicable to non-small communication delays (see e.g., [3, 19]). The time-delay approach that was recently suggested in [16] allowed, for the first time, to treat NCSs under RR protocol in the presence of non-small communication delays. In [16] the closed-loop system was presented as a switched system with multiple ordered delays.
In the present paper, we consider linear (probably, uncertain) NCS with additive essentially bounded disturbances in the presence of scheduling protocols, variable sampling intervals and transmission delays. Our first goal is to extend the time-delay approach to NCSs under TOD protocol in the presence of communication delays that are allowed to be non-small. This leads to a novel hybrid system model for the closed-loop system, where time-varying delays appear in the dynamics and in the reset equations . Since a similar hybrid system model corresponds to RR protocol, we derive new conditions for Input-To-State (ISS) under RR protocol as well. These conditions are computationally simpler than the existing ones of [16] though may lead to more conservative results. A novel Lyapunov-Krasovskii method is introduced for hybrid delayed systems, which is based on discontinuous in time Lyapunov functionals.
Polytopic type uncertainties in the system model can be easily included in the analysis. The efficiency and advantages of the presented approach are illustrated by two examples. Some preliminary results were presented in [17].
Notation: Throughout the paper, the superscript ' T ' stands for matrix transposition, R n denotes the n dimensional Euclidean space with vector norm | · | , R n × m is the set of all n × m real matrices, and the notation P > 0 , for P ∈ R n × n means that P is symmetric and positive definite. The symmetric elements of the symmetric matrix will be denoted by ∗ , λ min ( P ) denotes the smallest eigenvalue of matrix P . The space of functions φ : [ -τ M , 0] → R n , which are absolutely continuous on [ -τ M , 0] , and have square integrable first order derivatives is denoted by W [ -τ M , 0] with the norm ‖ φ ‖ W = max θ ∈ -[ τ M , 0] | φ θ ( ) | +
[ ∫ 0 -τ M | ˙ ( φ s ) | 2 ds ] 1 2 . Z + denotes the set { 0, 1, 2, . . . }, whereas N denotes the natural numbers. The symbol x t denotes x t ( θ ) = x t ( + ) θ , θ ∈ -[ τ M , 0] , whereas
Figure 1: System architecture with N sensors
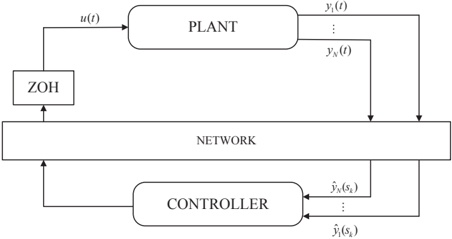
‖ w t , t [ 0 ] ‖ ∞ stands for the essential supremum of the Euclidean norm | w t [ 0 , t ] | , where w : [ t 0 , t ] → R n w . MATI and MAD denote Maximum Allowable Transmission Interval and Maximum Allowable Delay, respectively.
## 2 Problem formulation
## 2.1 The description of NCS and the hybrid model
Consider the system architecture in Figure 1 with plant
$$\dot { x } ( t ) = A x ( t ) + B u ( t ) + D \omega ( t ), \ \ t \geq 0,$$
where x t ( ) ∈ R n is the state vector, u t ( ) ∈ R m is the control input, ω t ( ) ∈ R q is the essentially bounded disturbance. Assume that there exists a real number ∆ > 0 such that ‖ ω [0 , t ] ‖ ∞ ≤ ∆ for all t ≥ 0 . The system matrices A, B and D can be uncertain with polytopic type uncertainties.
The system has several nodes ( N distributed sensors, a controller node and an actuator node) which are connected via the network. The measurements are given by y i ( ) = t C x t i ( ) ∈ R n i , i = 1 , . . . , N, ∑ N i =1 n i = n y and we denote C = [ C T 1 · · · C T N ] T , y t ( ) = [ y T 1 ( ) t · · · y T N ( ) t ] T ∈ R n y . Let s k denote the unbounded monotonously increasing sequence of sampling instants
$$0 = s _ { 0 } < s _ { 1 } < \dots < s _ { k } < \dots, \ k \in \mathbb { Z } _ { + }, \lim _ { k \to \infty } s _ { k } = \infty.$$
At each sampling instant s k , one of the outputs y i ( s k ) ∈ R n i is transmitted via the sensor network. We suppose that data loss is not possible and that the transmission of the information over the network is subject to a variable delay η k . Then t k = s k + η k is the updating time instant of the Zero-Order Hold (ZOH).
Differently from [6, 15], we do not restrict the network delays to be small with t k = s k + η k < s k +1 , i.e. η k < s k +1 -s k . As in [19] we allow the delay
to be non-small provided that the old sample cannot get to the destination (to the controller or to the actuator) after the most recent one. Assume that the network-induced delay η k and the time span between the updating and the most recent sampling instants are bounded:
$$( 2 ) \quad \ t _ { k + 1 } - t _ { k } + \eta _ { k } \leq \tau _ { M }, \ 0 \leq \eta _ { m } \leq \eta _ { k } \leq M \text{AD}, \ k \in \mathbb { Z } _ { + },$$
where τ M denotes the maximum time span between the time
$$s _ { k } = t _ { k } - \eta _ { k }$$
at which the state is sampled and the time t k +1 at which the next update arrives at the destination. Here η m and MAD are known bounds and τ M = MATI+MAD . Since MATI = τ M -MAD ≤ τ M -η m , η m > τ M 2 implies that the network delays are non-small due to η k ≥ η m > τ M -η m . In the examples of Section 6, we will show that our method is applicable for η m > τ M 2 .
Denote by ˆ( y s k ) = [ ˆ y T 1 ( s k ) · · · ˆ y T N ( s k ) ] T ∈ R n y the output information submitted to the scheduling protocol. At each sampling instant s k , one of the system nodes i ∈ { 1 , . . . , N } is active, that is only one of ˆ ( y i s k ) values is updated with the recent output y i ( s k ) . Let i ∗ k ∈ { 1 , . . . , N } denote the active output node at the sampling instant s k , which will be chosen due to scheduling protocols.
Consider the error between the system output y s ( k ) and the last available information ˆ( y s k -1 ) :
$$e ( t ) = \text{col} \{ e _ { 1 } ( t ), \cdots, e _ { N } ( t ) \} \equiv \hat { y } ( s _ { k - 1 } ) - y ( s _ { k } ), \\ t \in [ t _ { k }, t _ { k + 1 } ), \ k \in \mathbb { Z } _ { + }, \ \hat { y } ( s _ { - 1 } ) \stackrel { \Delta } { \equiv } 0, \ e ( t ) \in \mathbb { R } ^ { n _ { \nu } }. \\ \dashrightarrow \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots.$$
We suppose that the controller and the actuator are event-driven (in the sense that the controller and the ZOH update their outputs as soon as they receive a new sample). The most recent output information at the controller level is denoted by ˆ( y s k ) .
## Static output feedback control
Assume that there exists a matrix K = [ K 1 · · · K N ] , K i ∈ R m n × i such that A + BKC is Hurwitz. Then, the static output feedback controller has a form
/negationslash where i ∗ k is the index of the active node at s k and η k is communication delay. We obtain thus the impulsive closed-loop model with the following continuous dynamics:
$$( 5 ) \quad u ( t ) = K _ { i _ { k } ^ { * }$$
/negationslash
$$\begin{array} { c c } \dot { x } ( t ) = A x ( t$$
where A 1 = BKC, B i = BK , i i = 1 , . . . , N.
Taking into account (4), we obtain
$$\begin{array} { r c l } e _ { i } ( t _ { k + 1$$
and
/negationslash
$$\begin{array} { r c l } \text{nd} \\ e _ { i } ($$
Thus, the delayed reset system is given by
$$\begin{array} {$$
/negationslash
Therefore, (6)-(7) is the hybrid model of the NCS. Since x t ( k -η k ) = x t ( -τ ( )) t for t ∈ [ t k , t k +1 ) with τ ( ) t = t -t k + η k ∈ [ η m , τ M ] (cf. (2)), the hybrid system model (6)-(7) contains the piecewise-continuous delay τ ( ) t in the continuous-time dynamics (6). Even for η k = 0 we have the delayed state x t ( k ) = x t ( -τ ( )) t with τ ( ) = t t -t k .
Note that the first updating time t 0 corresponds to the time instant when the first data is received by the actuator. Assume that initial conditions for (6)-(7) are given by x t 0 ∈ W [ -τ M , 0] and e t ( 0 ) = -Cx t ( 0 -η 0 ) = -Cx 0 .
## Dynamic output feedback control
Assuming that the controller is directly connected to the actuator, consider a dynamic output feedback controller of the form
$$\dot { x } _ { c } ( t ) = A _ { c } x _ { c } ( t ) + B _ { c } \hat { y } ( s _ { k } ), \\ u ( t ) = C _ { c } x _ { c } ( t ) + D _ { c } \hat { y } ( s _ { k } ), \ t \in [ t _ { k }, t _ { k + 1 } ), \ k \in \mathbb { Z } _ { + },$$
where x c ( ) t ∈ R n c , A , B , C c c c and D c are the matrices with appropriate dimensions. Let e i ( )( t i = 1 , . . . , N ) be defined by (4). The closed-loop system can be presented in the form of (6)-(7), where x , e i and the matrices are changed by the ones with the bars as follows:
$$\begin{array} { l l l } \intertext { the ones with the bars as follows: } \bar { x } = \left [ \begin{array} { c c } x \\ x _ { c } \end{array} \right ], \, \bar { A } = \left [ \begin{array} { c c } A & B C _ { c } \\ 0 _ { n _ { c } \times n } & A _ { c } \end{array} \right ], \, \bar { B } _ { i } = \left [ \begin{array} { c c } B D _ { c } \\ B _ { c } \end{array} \right ], \, \bar { D } = \left [ \begin{array} { c c } D \\ 0 _ { n _ { c } \times q } \end{array} \right ], \\ \bar { A } _ { 1 } = \left [ \begin{array} { c c } B D _ { c } C & 0 _ { n _ { c } \times n _ { c } } \\ B _ { c } C & 0 _ { n _ { c } \times n _ { c } } \end{array} \right ], \, \bar { C } _ { 1 } = \left [ \begin{array} { c c } C _ { 1 } & 0 \\ 0 & 0 \end{array} \right ], \, \bar { C } _ { i } \in \mathbb { R } ^ { n _ { \nu } \times ( n + n _ { c } ) }, \\ \bar { C } _ { 2 } = \left [ \begin{array} { c c } 0 _ { n \times n _ { 1 } } & C _ { 2 } ^ { T } & 0 \\ 0 _ { n \times n _ { 1 } } & 0 & 0 \end{array} \right ], \, \dots, \, \bar { C } _ { N } = \left [ \begin{array} { c c } 0 & C _ { N } ^ { T } \\ 0 & 0 \end{array} \right ] ^ { T }, \\ \bar { e } _ { 1 } ( t ) = [ e _ { 1 } ^ { T } ( t ) \ 0 ] ^ { T }, \, \bar { e } _ { 2 } ( t ) = [ 0 _ { 1 \times n _ { 1 } } & e _ { 2 } ^ { T } ( t ) \ 0 ] ^ { T }, \cdots \, \bar { e } _ { N } ( t ) = [ 0 \, \ e _ { N } ^ { T } ( t ) ] ^ { T }, \, \bar { e } _ { i } ( t ) \in \mathbb { R } ^ { n _ { \nu } }. \\ \text{Remark $2.1 $ In $ [15]$, $ a $ piecewise-continuous $error $e(t)$ = $\hat{y}(t_{k}) - y(t), t \, \in$}$$
Remark 2.1 In [15], a piecewise-continuous error e t ( ) = ˆ( y t k ) -y t , t ( ) ∈ [ s k , s k +1 ] is defined, which leads to the non-delayed continuous dynamics. The
derivation of reset equations is based on the assumption of small communication delays, that is avoided in our approach. In our approach e t ( ) is different: it is given by (4) and is piecewise-constant. As a result, our hybrid model is different with the delayed continuous dynamics. Moreover, in the absence of scheduling protocols, the closed-loop system is given by non-hybrid system (6), where e t ( ) ≡ 0 . The latter is consistent with the time-delay model considered e.g. in [11, 12].
## 2.2 Scheduling protocols
## TOD protocol
In TOD protocol, the output node i ∈ { 1 , . . . , N } with the greatest (weighted) error will be granted the access to the network.
Definition 2.2 (Weighted TOD protocol) Let Q i > 0( i = 1 , . . . , N ) be some weighting matrices. At the sampling instant s k , the weighted TOD protocol is a protocol for which the active output node with the index i ∗ k is defined as any index that satisfies
$$( 8 ) \quad | \sqrt { Q } _ { i _ { k } ^ { * } } e _ { i _ { k } ^ { * } } ( t ) | ^ { 2 } \geq | \sqrt { Q } _ { i } e _ { i } ( t ) | ^ { 2 }, \ t \in [ t _ { k }, t _ { k + 1 } ), \ k \in \mathbb { Z } _ { + }, \ i = 1, \dots, N.$$
A possible choice of i ∗ k is given by
$$i _ { k } ^ { * } = \min \{ \arg \max _ { i \in \{ 1, \dots, N \} } | \sqrt { Q } _ { i } \left ( \hat { y } _ { i } ( s _ { k - 1 } ) - y _ { i } ( s _ { k } ) \right ) | ^ { 2 } \}. \\ \text{conditions for commutino the weiothino matrices } O. \quad O, \text{ will be } c$$
The conditions for computing the weighting matrices Q , . . . , Q 1 N will be given in Theorem 3.2 below.
Remark 2.3 For implementation of TOD protocol in wireless networks we refer to [4].
## RR protocol
The active output node is chosen periodically:
$$\begin{array} { c } i _ { k } ^ { * } = i _ { k + N } ^ { * }, \, f o r \ a l l \, k \in \mathbb { Z } _ { + }, \\ i _ { j } ^ { * } \neq i _ { l } ^ { * }, \, f o r \ 0 \leq j < l \leq N - 1. \end{array}$$
/negationslash
Remark 2.4 Note that another model for the closed-loop system under RR protocol was given in [16]. The model in [16] is a switched system with ordered delays τ 1 ( ) t < · · · < τ N ( ) t , where τ i ( ) t = t -t k -i +1 + η k -i +1 , i = 1 , . . . , N . A Lyapunov-Krasovskii analysis of the latter model is based on the standard time-independent Lyapunov functional for interval delay.
Definition 2.5 The hybrid system (6)-(7) with essentially bounded disturbance ω is said to be partially ISS with respect to x (or x -ISS) if there exist constants b > 0 , δ > 0 and c > 0 such that the following holds for t ≥ t 0
$$| x ( t ) | ^ { 2 } \leq b e ^ { - \delta ($$
for the solutions of the hybrid system initialized with x t 0 = φ ∈ W [ -τ M , 0] and e t ( 0 ) ∈ R n y . The hybrid system (6)-(7) is ISS if additionally the following bound is valid for t ≥ t 0
$$| e ( t ) | ^ { 2 } \leq & \, b e ^ { - \$$
Our objective is to derive Linear Matrix Inequality (LMI) conditions for the partial ISS of the hybrid system (6)-(7) with respect to the variable of interest x . In [5], the notion of partial stability was also used. In Section 3 below, ISS of (6)-(7) under TOD protocol with N sensor nodes will be studied. For N = 2 , less restrictive conditions will be derived in Section 4, and it will be shown that the same conditions guarantee x -ISS of (6)-(7) under RR protocol. In Section 5, the latter conditions will be extended to RR protocol with N ≥ 2 .
## 3 ISS under TOD protocol: general N
/negationslash
Note that the differential equation for x given by (6) depends on e i ( ) t = e i ( t k ) , t ∈ [ t k , t k +1 ) with i = i ∗ k only. Consider the following Lyapunov functional:
$$\begin{array} {$$
where x t ( θ ) ∆ = x t ( + θ , ) θ ∈ [ -τ M , 0] and where we define (for simplicity) x t ( ) = x , 0 t < 0 .
Here the terms
$$e _ { i } ^ { T } ( t ) Q _ { i } e _ { i }$$
are piecewise-constant, ˜ ( V t, x t , x ˙ t ) presents the standard Lyapunov functional for systems with interval delays τ ( ) t ∈ [ η m , τ M ] . The novel piecewise-continuous
in time term V G is inserted to cope with the delays in the reset conditions . It is continuous on [ t k , t k +1 ) and do not grow in the jumps (when t = t k +1 ), since
$$\text{comunous on } \lfloor \iota _ { k }, \i$$
where we applied Jensen's inequality (see e.g., [14]). The function V e ( ) t is thus continuous and differentiable over [ t k , t k +1 ) . The following lemma gives sufficient conditions for the x -ISS of (6)-(8):
Lemma 3.1 Let there exist positive constants α, b, 0 < Q i ∈ R n i × n i , 0 < U i ∈ R n i × n i , 0 < G i ∈ R n i × n i , i = 1 , . . . , N, and V e ( ) t of (10) such that along (6) the following inequality holds
/negationslash
$$& \text{are your own any one} \\ & ( 1 2 ) & \dot { V } _ { e } ( t ) + 2 \alpha V _ { e } ( t ) - \frac { 1 } { \tau _ { M } - \eta _ { m } } \sum _ { i = 1, i \neq i _ { k } ^ { * } } ^ { N } | \sqrt { U } _ { i } e _ { i } ( t ) | ^ { 2 } \\ & - 2 \alpha | \sqrt { Q _ { i _ { k } ^ { * } } } e _ { i _ { k } ^ { * } } ( t ) | ^ { 2 } - b | \omega ( t ) | ^ { 2 } \leq 0, \ t \in [ t _ { k }, t _ { k + 1 } ). \\ & \text{assume additionally that}$$
$$( 1 3 ) \quad \Omega _ { i } \stackrel { \Delta } { = } \left [ \begin{smallmatrix} - \frac { 1 - 2 \alpha ( \tau _ { M } - \eta _ { m } ) } { N - 1 } Q _ { i } + U _ { i } } & Q _ { i } \\ * & Q _ { i } - G _ { i } e ^ { - 2 \alpha \tau _ { M } } \end{smallmatrix} \right ] < 0, \ i = 1, \dots, N. \\ \Gamma _ { m } \quad.. \quad.. \quad.. \quad.. \quad.. \quad. \quad. \quad. \quad. \quad. \quad.$$
Then V e ( ) t does not grow in the jumps along (6)-(8):
/negationslash
Moreover, the following bounds hold for a solution of (6)-(8) initialized by x t 0 ∈ W [ -τ M , 0] , e ( t 0 ) ∈ R n y :
$$\begin{array} { l } \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ ( 1 4 ) & \Theta \stackrel { \Delta } { = } } V _ { e } ( t _ { k + 1 } ) - V _ { e } ( t _ { k + 1 } ^ { - } ) + \sum _ { i = 1, i \neq i _ { k } ^ { * } } ^ { N } | \sqrt { U _ { i } } e _ { i } ( t _ { k } ) | ^ { 2 } \\ & + 2 \alpha ( \tau _ { M } - \eta _ { m } ) | \sqrt { Q _ { i _ { k } ^ { * } } } e _ { i _ { k } ^ { * } } ( t _ { k } ) | ^ { 2 } \leq 0. \end{array} \\ \begin{array} { l } \Theta \equiv \Delta & V _ { e } ( t _ { k + 1 } ) - V _ { e } ( t _ { k + 1 } ^ { - } ) + \sum _ { i = 1, i \neq i _ { k } ^ { * } } ^ { N } | \sqrt { U _ { i } } e _ { i } ( t _ { k } ) | ^ { 2 } \\ & + 2 \alpha ( \tau _ { M } - \eta _ { m } ) | \sqrt { Q _ { i _ { k } ^ { * } } } e _ { i _ { k } ^ { * } } ( t _ { k } ) | ^ { 2 } \leq 0. \end{array} \\ \text{Moreover, the following bounds holds for a solution of } ( 6 ) - ( 8 ) \text{ initialized by } x _ { t } \\ W | _ { - \tau }.. \ \partial | _ { \ e } ( t _ { \wedge } \searrow \mathbb { P } ^ { n _ { u } }. \end{array}$$
$$& V ( t, x _ { t }, \dot { x } _ { t } ) \leq e ^ { - 2 \alpha ( t - t _ { 0 } ) } V _ { e } ( t _ { 0 } ) + \frac { b } { 2 \alpha } \Delta ^ { 2 }, \ t \geq t _ { 0 }, \\ & V _ { e } ( t _ { 0 } ) = V ( t _ { 0 }, x _ { t _ { 0 } }, \dot { x } _ { t _ { 0 } } ) + \sum _ { i = 1 } ^ { N } | \sqrt { Q _ { i } } e _ { i } ( t _ { 0 } ) | ^ { 2 }, \\ & \text{and}$$
$$& \dots \\ & ( 1 6 ) \quad \sum _ { i = 1 } ^ { N } | \sqrt { Q _ { i } } e _ { i } ( t ) | ^ { 2 } \leq \tilde { c } e ^ { - 2 \alpha ( t - t _ { 0 } ) } V _ { e } ( t _ { 0 } ) + \frac { b } { 2 \alpha } \Delta ^ { 2 }, \\ & \text{where } \tilde { c } = e ^ { 2 \alpha ( \tau _ { M } - \eta _ { m } ) }, \text{ simplify ISS of } ( 6 ) \text{-} ( 8 ).$$
where ˜ = c e 2 α τ ( M -η m ) , implying ISS of (6)-(8).
Proof. Since ∫ t t k e -2 α t ( -s ) ds ≤ τ M -η m , t ∈ [ t k , t k +1 ) and | ω t ( ) | ≤ ∆ , by the comparison principle, (12) implies (17)
/negationslash
$$V _ { e } ( t ) & \leq e ^ { - 2 \alpha ( t -$$
Note that (13) yields 0 < 2 α τ ( M -η m ) < 1 and U i ≤ 1 -2 α τ ( M -η m ) N -1 Q i ≤ Q , i i = 1 , . . . , N . Hence,
$$& ( 1 8 ) \quad V ( t, x _ { t }, \dot { x }$$
Since ˜ V | t = t k +1 = ˜ V | t = t -k +1 and e t ( -k +1 ) = e t ( k ) , we obtain
/negationslash
Then taking into account (11) we find
$$\begin{array} {$$
/negationslash
/negationslash
Note that under TOD protocol
$$\begin{array} { l } \text{em using no account} \, ( 1 1 )$$
/negationslash
Denote ζ i = col { e i ( t k ) , C i [ x s ( k ) -x s ( k +1 )] } . Then, employing (7) and (3) we arrive at
$$\dots \dots \dots - \dots - r \dots \dots$$
/negationslash that yields (14).
$$\Theta & \leq - | \sqrt { G _ { i _ { k } ^ { * } } e ^ { - 2 \alpha \tau _ { M } } - Q _ { i _ { k } ^ { * } } } C _ { i _ { k } ^ { * } } [ x ( s _ { k } ) - x ( s _ { k + 1 } ) ] | ^ { 2 } + \sum _ { i = 1, i \neq i _ { k } ^ { * } } ^ { N } \zeta _ { i } ^ { T } \Omega _ { i } \zeta _ { i } & \leq 0, \\ \text{that yields (14).}$$
The inequalities (14) and (17) with t = t -k +1 imply
Then
$$V _ { e } ( t _ { k + 1 } ) \leq e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { k } ) } V _ { e } ( t _ { k } ) + b \Delta ^ { 2 } \int _ { t _ { k } } ^ { t _ { k + 1 } } e ^ { - 2 \alpha ( t _ { k + 1 } - s ) } d s. \\ \text{Then}$$
$$V _ { e } ( t _ { k + 1 } ) & \leq e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { k - 1 } ) } V _ { e } ( t _ { k - 1 } ) + b \Delta ^ { 2 } \int _ { t _ { k - 1 } } ^ { t _ { k + 1 } } e ^ { - 2 \alpha ( t _ { k + 1 } - s ) } d s \\ & \leq e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { 0 } ) } V _ { e } ( t _ { 0 } ) + b \Delta ^ { 2 } \int _ { t _ { 0 } } ^ { t _ { k + 1 } } e ^ { - 2 \alpha ( t _ { k + 1 } - s ) } d s. \\ \underset { \sim \epsilon \, \neq \, \partial \, \left ( \partial \, \times \, \mathfrak { k } \, \underset { \sim \, \partial \, \dots \, \dots } { \dots } } { \dots } }$$
Replacing in (19) k +1 by k and using (18), we arrive at (15), which yields x -ISS of (6)-(8) because
$$\lambda _ { m i n } ( P ) | x ( t ) | ^ { 2 } \leq V ( t, x _ { t }, \dot { x } _ { t } ), \, V ( t _ { 0 }, x _ { t _ { 0 } }, \dot { x } _ { t _ { 0 } } ) \leq \delta \| x _ { t _ { 0 } } \| _ { W } ^ { 2 }$$
for some scalar δ > 0 . Moreover, (19) with k + 1 replaced by k implies (16) since for t ∈ [ t k , t k +1 )
$$e ^ { - 2 \alpha ( t _ { k } - t _ { 0 } ) } = e ^ { - 2 \alpha ( t - t _ { 0 } ) } e ^ { - 2 \alpha ( t _ { k } - t ) } \leq \tilde { c } e ^ { - 2 \alpha ( t - t _ { 0 } ) }.$$
By using Lemma 3.1 and the standard arguments for the delay-dependent analysis, we derive LMI conditions for ISS of (6)-(8) (see Appendix A for the proof):
Theorem 3.2 Given 0 ≤ η m < τ M , α > 0 , assume that there exist positive scalar b , n × n matrices P > 0 , S 0 > 0 , R 0 > 0 , S 1 > 0 , R 1 > 0 , S 12 , n i × n i matrices Q > i 0 , U > i 0 , G > i 0 , i = 1 , . . . , N, such that (13) and the following inequalities are feasible:
$$\Phi = \left [ \begin{array} { c c } R _ { 1 } & S _ { 1 2 } \\ * & R _ { 1 } \end{array} \right ] \geq 0,$$
$$\begin{pmatrix} \Sigma _ { i } - ( F ^ { i } ) ^ { T } \Phi F ^ { i } e ^ { - 2 \alpha \tau _ { M } } & \Xi _ { i } ^ { T } H \\ * & - H \end{pmatrix} < 0, \ i = 1, \dots, N,$$
where (22)
/negationslash
/negationslash
$$\text{where} ( 2 2 ) \\ H = \eta _ { m } ^ { 2 } R _ { 0 } + ( \tau _ { M } - \eta _ { m } ) ^ { 2 } R _ { 1 } + ( \tau _ { M } - \eta _ { m } ) \sum _ { l = 1 } ^ { N } C _ { l } ^ { T } G _ { l } C _ { l }, \\ \Sigma _ { i } = ( F _ { 1 } ^ { i } ) ^ { T } P \Xi _ { i } + ( \Xi ^ { i } ) ^ { T } P F _ { 1 } ^ { i } + \Upsilon _ { i } - ( F _ { 2 } ^ { i } ) ^ { T } R _ { 0 } F _ { 2 } ^ { i } e ^ { - 2 \alpha \eta _ { m } }, \\ F _ { 1 } ^ { i } = [ I _ { n } \ 0 _ { n \times ( 3 n + n _ { y } - n _ { i } + q ) } ], \\ F _ { 2 } ^ { i } = [ I _ { n } \ - I _ { n } \ 0 _ { n \times ( 2 n + n _ { y } - n _ { i } + q ) } ], \\ F _ { 3 } ^ { i } = [ I _ { n } \ - I _ { n } \ 0 _ { n \times n } \ - I _ { n } \ - I _ { n } \ 0 _ { n \times ( n _ { y } - n _ { i } + q ) } \ ], \\ \Xi _ { i } = [ A \ 0 _ { n \times n } \ A _ { 1 } \ 0 _ { n \times n } \ B _ { 2 } \ \cdots B _ { N } \ D ], \ i = 1, \\ \Xi _ { i } = [ A \ 0 _ { n \times n } \ A _ { 1 } \ 0 _ { n \times n } \ B _ { 1 } \ \cdots \ B _ { j _ { j } \neq i } \cdots B _ { N } \ D ], \ i = 2, \dots N, \\ \Upsilon _ { i } = \text{diag} \{ S _ { 0 } + 2 \alpha P, - ( S _ { 0 } - S _ { 1 } ) e ^ { - 2 \alpha \eta _ { m } }, 0 _ { n \times n }, - S _ { 1 } e ^ { - 2 \alpha \tau _ { M } }, \psi _ { 2 }, \cdots, \psi _ { N }, - b I _ { q } \}, \ i = 1, \\ \Upsilon _ { i } = \text{diag} \{ S _ { 0 } + 2 \alpha P, - ( S _ { 0 } - S _ { 1 } ) e ^ { - 2 \alpha \eta _ { m } }, 0 _ { n \times n }, - S _ { 1 } e ^ { - 2 \alpha \tau _ { M } }, \psi _ { 1 } ; \cdots \psi _ { j _ { j } \neq i } ; \cdots \psi _ { N }, - b I _ { q } \}, \\ i = 2, \dots N, \ \psi _ { j } = - \frac { \tau _ { M } - \eta _ { m } } { \tau _ { M } - \eta _ { m } } U _ { j } + 2 \alpha Q _ { j }, \ j = 1, \dots, N. \\ \text{Then solutions of the hybrid system} ( 6 ) - ( 8 ) \text{ satisfy the bound} ( 15 ), \text{where} V ( t, x _ { t }, \dot { x } _ { t } ) \\ \text{is} \ q i v e n b y \ ( 1 0 ), \ i m p l y i n q \ ISS \text{ of} ( 6 ) - ( 8 ). \ \text{ If the above LMIs are feasible with}$$
Then solutions of the hybrid system (6)-(8) satisfy the bound (15), where V ( t, x t , x ˙ t ) is given by (10), implying ISS of (6)-(8). If the above LMIs are feasible with α = 0 , then the bound (15) holds with a small enough α 0 > 0 .
## 4 ISS under TOD/RR protocol: N = 2
For N = 2 less restrictive conditions than those of Theorem 3.2 for the x -ISS of (6)-(7) will be derived via a different from (10) Lyapunov functional:
/negationslash
$$V _ { e } ( t ) & = V ( t, x _ { t }, \dot { x } _ { t } ) + \frac { t _ { k + 1 } - t } { \tau _ { M } - \eta _ { m } } \{ e _ { i } ^ { T } ( t ) Q _ { i } e _ { i } ( t ) \} _ { | i \neq i _ { k } ^ { * } }, \\ Q _ { 1 } & > 0, \ Q _ { 2 } > 0, \ \alpha > 0, \ t \in [ t _ { k }, t _ { k + 1 } ), \ k \in \mathbb { Z } _ { + }, \\. \quad. \quad. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
where i ∗ k ∈ { 1 2 , } and V ( t, x , x t ˙ t ) is given by (10) with G i = Q e i 2 ατ M . The term t k +1 -t τ M -η m { e T i ( t k ) Q e i i ( t k ) } is inspired by the similar construction of Lyapunov functionals for the sampled-data systems [8, 18, 22]. The following statement holds:
Lemma 4.1 Given N = 2 , if there exist positive constants α, b and V e ( ) t of (23) such that along (6)-(8) ((6), (7), (9)) the following inequality holds
$$\dot { V } _ { e } ( t ) + 2 \alpha V _ { e } ( t ) - b | \omega ( t ) | ^ { 2 } \leq 0, \ \ t \in [ t _ { k }, t _ { k + 1 } ).$$
Then V e ( ) t does not grow in the jumps along (6)-(8) ((6), (7), (9)), where
$$\Theta & \stackrel { \Delta } { = } V _ { e } ( t _ { k + 1 } ) - V _ { e } ( t _ { k + 1 } ^ { - } ) \leq 0.$$
The bound (15) is valid for a solution of (6)-(8) ((6), (7), (9)) with the initial condition x t 0 ∈ W [ -τ M , 0] , e t ( 0 ) ∈ R n y , implying the x -ISS of (6)-(8) ((6), (7), (9)).
Proof. Since | ω t ( ) | ≤ ∆ , (24) implies
$$& V _ { e } ( t ) \leq e ^ { - 2 \alpha ( t - t _ { k } ) } V _ { e } ( t _ { k } ) + b \Delta ^ { 2 } \int _ { t _ { k } } ^ { t } e ^ { - 2 \alpha ( t - s ) } d s, \ t \in [ t _ { k }, t _ { k + 1 } ). \\ & \text{Noting that}$$
Noting that
/negationslash we obtain employing (11)
$$V _ { e } ( t _ { k + 1 } ) & \leq \tilde { V } _ { | t = t _ { k + 1 } } + | \sqrt { Q } _ { i } e _ { i } ( t _ { k + 1 } ) | _ { | i \neq i _ { k + 1 } ^ { * } } \\ & \quad + \sum _ { i = 1 } ^ { 2 } ( \tau _ { M } - \eta _ { m } ) \int _ { t _ { k + 1 } - \eta _ { k + 1 } } ^ { t _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { G _ { i } } C _ { i } \dot { x } ( s ) | ^ { 2 } d s, \\ \text{we obtain employing (11)}$$
/negationslash
/negationslash
We will prove that Θ ≤ 0 under TOD and RR protocols, respectively. Under TOD protocol we have
$$\Theta & \leq e _ { i } ^ { T } ( t _ { k + 1 } ) Q _ { i } e _ { i } ( t _ { k + 1 } ) _ { | i \neq i _ { k + 1 } ^ { * } } + V _ { G | t = t _ { k + 1 } } - V _ { G | t = t _ { k + 1 } ^ { - } } \\ & \leq e _ { i } ^ { T } ( t _ { k + 1 } ) Q _ { i } e _ { i } ( t _ { k + 1 } ) _ { | i \neq i _ { k + 1 } ^ { * } } - \sum _ { i = 1 } ^ { 2 } | \sqrt { Q _ { i } } C _ { i } [ x ( t _ { k } - \eta _ { k } ) - x ( t _ { k + 1 } - \eta _ { k + 1 } ) ] | ^ { 2 }. \\ \text{We will prove that } \Theta \leq 0 \text{ under TOD and RR protocols, respectively. } \text{ Under}$$
/negationslash
$$e _ { i } ^ { T } ( t _ { k + 1 } ) Q _ { i } e _ { i } ( t _ { k + 1 } ) _ { | i \neq i _ { k + 1 } ^ { * } } \leq e _ { i _ { k } ^ { * } } ^ { T } ( t _ { k + 1 } ) Q _ { i _ { k } ^ { * } } e _ { i _ { k } ^ { * } } ( t _ { k + 1 } )$$
for i ∗ k +1 = i ∗ k , whereas
/negationslash
$$e _ { i } ^ { T } ( t _ { k + 1 } ) Q _ { i } e _ { i } ( t _ { k + 1 } ) _ { | i \neq i _ { k + 1 } ^ { * } } = e _ { i _ { k } ^ { * } } ^ { T } ( t _ { k + 1 } ) Q _ { i _ { k } ^ { * } } e _ { i _ { k } ^ { * } } ( t _ { k + 1 } )$$
for i ∗ k +1 = i ∗ k . Then, taking into account (7) we obtain
$$\L k + 1 / \L k \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \\ \Theta & \leq | \sqrt { Q _ { i } } C _ { i } [ x ( t _ { k } - \eta _ { k } ) - x ( t _ { k + 1 } - \eta _ { k + 1 } ) ] | _ { | i = i _ { k } ^ { * } } ^ { 2 } \\ & - \sum _ { i = 1 } ^ { 2 } | \sqrt { Q _ { i } } C _ { i } [ x ( t _ { k } - \eta _ { k } ) - x ( t _ { k + 1 } - \eta _ { k + 1 } ) ] | ^ { 2 } \leq 0. \\ \intertext {ler RR protocol we have } i _ { k + 1 } ^ { * } \neq i _ { k } ^ { * } \text{ meaning that } ( 2 7 ) \text{ holds and that } \Theta \leq \\ \text{$w$ to $real$ for $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $geq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neeq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $peq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq e $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ne$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $pe$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ge$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ neeq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq$peq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ne$geq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $ne$peq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $peq$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq$ne$neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq $neq$$
/negationslash
/negationslash
Under RR protocol we have i ∗ k +1 = i ∗ k meaning that (27) holds and that Θ ≤ 0 . Then the result follows by the arguments of Lemma 3.1.
Remark 4.2 Differently from Lemma 3.1, Lemma 4.1 guarantees (19) that does not give a bound on e i ∗ k ( t k ) since V e ( ) t for t ∈ [ t k , t k +1 ) does not depend on e i ∗ k ( t k ) . That is why Lemma 4.1 guarantees only x -ISS. However, as explained in Remark 5.3 below, under RR protocol x -ISS implies boundedness of e .
In the next section, we will extend the result of Lemma 4.1 under RR protocol to the case of N ≥ 2 . Theorem 5.2 below (in the particular case of N = 2 ) will provide LMIs for the x -ISS of (6)-(8) ((6), (7), (9)).
## 5 ISS under RR protocol: N ≥ 2
Under RR protocol (9), the reset system (7) can be rewritten as
$$\begin{array} { c } x ( t _ { k + 1 } ) = x ( t _ { k + 1 } ^ { - } ), \\ e _ { i _ { k - j } ^ { * } } ( t _ { k + 1 } ) = C _ { i _ { k - j } ^ { * } } [ x ( s _ { k - j } ) - x ( s _ { k + 1 } ) ], \\ j = 0, \dots, N - 1 \text{ if } k \geq N - 1, \end{array}$$
where the index k -j corresponds to the last updated measurement in the node i ∗ k -j .
Consider the following Lyapunov functional:
$$\begin{array} { c } V _ { e } ( t ) = V ( t, x _ { t }, \dot { x } _ { t } ) + V _ { Q }, \quad t \geq t _ { N - 1 }, \\ V ( t, x _ { t }, \dot { x } _ { t } ) = \tilde { V } ( t, x _ { t }, \dot { x } _ { t } ) + V _ { G }, \end{array}$$
where ˜ ( V t, x t , x ˙ t ) is given by (10). The discontinuous in time terms V Q and V G are defined as follows:
(30)
$$& ( 3 0 ) \\ & V _ { Q } = \sum _ { j = 1 } ^ { N - 1 } \frac { t _ { k + 1 } - t } { j ( \tau _ { M } - \eta _ { m } ) } | \sqrt { Q _ { i _ { k - j } ^ { * } } } e _ { i _ { k - j } ^ { * } } ( t ) | ^ { 2 }, \ k \geq N - 1, \ t \in [ t _ { k }, t _ { k + 1 } ), \\ & V _ { G } = \begin{cases} \sum _ { i = 1 } ^ { N } ( \tau _ { M } - \eta _ { m } ) \int _ { s _ { k } } ^ { t } e ^ { 2 \alpha ( s - t ) } | \sqrt { G _ { i } } C _ { i } \dot { x } ( s ) | ^ { 2 } d s, \ k \geq N, \ t \in [ t _ { k }, t _ { k + 1 } ), \\ \sum _ { i = 1 } ^ { N } ( \tau _ { M } - \eta _ { m } ) \int _ { s _ { 0 } } ^ { t } e ^ { 2 \alpha ( s - t ) } | \sqrt { G _ { i } } C _ { i } \dot { x } ( s ) | ^ { 2 } d s, \ t \in [ t _ { N - 1 }, t _ { N } ), \end{cases} \\ & \text{where for } i = 1, \dots, N$$
where for i = 1 , . . . , N
$$G _ { i } = ( N - 1 ) Q _ { i } e ^ { 2 \alpha$$
Here V e does not depend on e i ∗ k ( t k ) . Note that given i = 1 , . . . , N , e i -term appears N -1 times in V Q for every N intervals [ t k + j , t k + +1 j ) , j = 0 , . . . , N -1 (except of the interval with i ∗ k + j = i ). This motivates N -1 in (31) because V G is supposed to compensate V Q term.
As in the previous sections, the term V G is inserted to cope with the delays in the reset conditions. It is continuous on [ t k , t k +1 ) and does not grow in the jumps (when t = t k +1 ), since for k > N -1 (cf. (11)) (32)
and for k = N -1
$$V _ { G | t = t _ { k + 1 } } - V _ { G | t$$
$$\dots \dots \dots \dots \dots \dots \dots \$$
The term V Q grows in the jumps as follows:
$$\begin{array} { r c l } \kappa \, - & & \cdot &$$
where we have used Jensen's inequality and the bound
$$\begin{array} {$$
Since 1 ≤ e 2 α τ [ M +( N -2)( τ M -η m )] e 2 α s ( k -j -t k +1 ) for j = 0 , . . . , N -2 , we obtain
$$V _ { Q | _ { t = t _ { k + 1 } } } - V _ { Q | _ { t = t _ { k + 1 } } } & \leq \sum _ { j = 0 } ^ { N - 2 } ( \tau _ { M } - \eta _ { m } ) e ^ { 2 \alpha [ \tau _ { M } + ( N - 2 ) ( \tau _ { M } - \eta _ { m } ) ] } \\ & \quad \times \int _ { s _ { k - j } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i _ { k - j } ^ { * } } } C _ { i _ { k - j } ^ { * } } \dot { x } ( s ) | ^ { 2 } d s. \\ \text{The following lemma gives sufficient conditions for the $x$-ISS of $(6),(9),(28)$}.$$
The following lemma gives sufficient conditions for the x -ISS of (6), (9), (28) (see Appendix B for proof):
Lemma 5.1 If there exist positive constants α, b and V e ( ) t of (29) such that along (6), (9), (28) the inequality (24) is satisfied for k ≥ N -1 . Then the following bound holds along the solutions of (6), (9), (28):
$$V _ { e } ( t _ { k + 1 } ) & \leq e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { N - 1 } ) } V _ { e } ( t _ { N - 1 } ) + \Psi _ { k + 1 } \\ & \quad + b \Delta ^ { 2 } \int _ { t _ { N - 1 } } ^ { t _ { k + 1 } } e ^ { - 2 \alpha ( t _ { k + 1 } - s ) } d s, \ k \geq N - 1, \\ \text{where}$$
Moreover, for all t ≥ t N -1
$$\vdash \vdash \ J _ { t _ { N - 1 } } \lambda \lambda \lambda \nu, \nu \varepsilon - \lambda \nu, \\ \text{where} \\ ( 3 7 ) \\ \Psi _ { k + 1 } = - ( \tau _ { M } - \eta _ { m } ) e ^ { 2 \alpha [ \tau _ { M } + ( N - 2 ) ( \tau _ { M } - \eta _ { m } ) ] } \\ \times & \left [ \sum _ { j = 0 } ^ { N - 3 } ( N - 2 - j ) \int _ { s _ { k - j - 1 } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i _ { k - j } } } C _ { i _ { k - j } ^ { * } } \dot { x } ( s ) | ^ { 2 } d s \\ + ( N - 1 ) \int _ { s _ { k } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i _ { k + 1 } } } C _ { i _ { k + 1 } ^ { * } } \dot { x } ( s ) | ^ { 2 } d s \right ] \leq 0. \\ \text{Moreover}, \text{ for all } t \geq t _ { N - 1 } \\ \cdot \quad \cdot \quad \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \Lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \phi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \chi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \x \,.$$
$$\begin{array} { c } V ( t, x _ { t }, \dot { x } _ { t } ) \leq e ^ { - 2 \alpha ( t - t _ { N - 1 } ) } V _ { e } ( t _ { N - 1 } ) + \frac { b } { 2 } \Delta ^ { 2 }, \\ V _ { e } ( t _ { N - 1 } ) = V ( t _ { N - 1 }, x _ { t _ { N - 1 } }, \dot { x } _ { t _ { N - 1 } } ) + \sum _ { i = 1 } ^ { N } | \sqrt { Q _ { i } } e _ { i } ( t _ { N - 1 } ) | ^ { 2 }. \\ \intertext { The latter inequality guarantees the $x$-ISS of $(6), $(9)$, $(28)$ for $t\geq t_{N-1}$.} } \end{array}$$
The latter inequality guarantees the x -ISS of (6), (9), (28) for t ≥ t N -1 .
By using Lemma 5.1, arguments of Theorem 3.2 and the fact that for j = 1 , . . . N -1
$$\frac { d } { d t } \frac { t _ { k + 1 } - t } { j ( \tau _ { M } - \eta _ { m } ) } = - \frac { 1 } { j ( \tau _ { M } - \eta _ { m } ) } \leq - \frac { 1 } { ( N - 1 ) ( \tau _ { M } - \eta _ { m } ) }, \\ \omega = \omega \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ a \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ o n \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ u n \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e \ e e$$
we arrive at the the following result:
Theorem 5.2 Given 0 ≤ η m < τ M and α > 0 , assume that there exist positive scalar b , n × n matrices P > 0 , S 0 > 0 , R 0 > 0 , S 1 > 0 , R 1 > 0 , S 12 and n i × n i matrices Q > i 0 ( i = 1 , . . . , N ) such that (20) and (21) are feasible with U i = Q i N -1 , where G i is given by (31) . Then for N > 2 solutions of the hybrid system (6), (9), (28) satisfy the bound (38) with V ( t, x t , x ˙ t ) given by (29), meaning x -ISS for t ≥ t N -1 . For N = 2 solutions of the hybrid system (6)-(8) ((6), (7), (9)) satisfy the bound (15) meaning x -ISS (for t ≥ t 0 ). Moreover, if the above LMIs are feasible with α = 0 , then the solution bounds hold with a small enough α 0 > 0 .
Remark 5.3 For N = 2 and α = 0 , the LMIs of Theorem 3.2 are more restrictive than those of Theorem 5.2: (13) of Theorem 3.2 yields ( N -1) U < Q < G i i i , whereas in Theorem 5.2 we have ( N -1) 2 U i = ( N -1) Q i = G i that leads to larger U i for the same G i . The latter helps for the feasibility of (21) , where U i > 0 appears on the main diagonal only (with minus). However, Theorem 3.2 achieves ISS with respect to the full state col { x, e } and provides the solution bound for t ≥ t 0 , while Theorem 5.2 guarantees only x -ISS.
Note that Theorem 5.2 under RR protocol guarantees boundedness of e as well. Indeed, since e t ( N ) in (28) depends on x (0) , . . . , x ( t N -η N ) and t N ≤ Nτ M (this can be verified similar to (34)), relations (28) yield
$$| e _ { i } ( t ) | ^ { 2 } \leq c ^ { \prime } s u p _ { \theta \in [ - N \tau _ { M }, 0 ] } | x ( t + \theta ) | ^ { 2 }, \ t \geq t _ { N }$$
with some c ′ > 0 , which together with (38) imply
$$| e _ { i } ( t ) | ^ { 2 } \leq c ^ { \prime \prime } [ e ^ { - 2 \alpha ( t - t _ { N - 1 } ) } V _ { e } ( t _ { N - 1 } ) + \Delta ^ { 2 } ]$$
for some c ′′ > 0 and all t ≥ t N + Nτ M .
Remark 5.4 The LMIs of Theorems 3.2 and 5.2 are affine in the system matrices. Therefore, in the case of system matrices from an uncertain time-varying polytope
$$\begin{array} { c } \Omega = \sum _ { j = 1 } ^ { M } g _ { j } ( t ) \Omega _ { j }, \quad 0 \leq g _ { j } ( t ) \leq 1, \\ \sum _ { j = 1 } ^ { M } g _ { j } ( t ) = 1, \quad \Omega _ { j } = \left [ \ A ^ { ( j ) } \quad B ^ { ( j ) } \quad D ^ { ( j ) } \ \right ], \\ e \, \text{ to solve these LMIs simulataneously for all the $M$ vertices $\Omega_{j}$,} \\ e \, \text{ decision matrices.} \end{array}$$
one have to solve these LMIs simultaneously for all the M vertices Ω j , applying the same decision matrices.
## 6 Examples
## 6.1 Example 1: uncertain inverted pendulum
Consider an inverted pendulum mounted on a small car. We focus on the stability analysis in the absence of disturbance. Following [13], we assume that the friction coefficient between the air and the car, f c , and the air and the bar, f b , are not exactly known and time-varying: f c ( ) t ∈ [0 15 . , 0 25] . and f b ( ) t ∈ [0 15 . , 0 25] . . The linearized model can be written as (1), where the matrices A = E -1 A f and B = E -1 B 0 are determined from
$$A = E ^ { - \ell } A _ { f } \text{ and } B = E ^ { - \ell } B _ { 0 } \text{ are determined from} \\ E = \left [ \begin{array} { c c c c } 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 3 / 2 & - 1 / 4 \\ 0 & 0 & - 1 / 4 & 1 / 6 \end{array} \right ], \\ A _ { f } = \left [ \begin{array} { c c c c } 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & - ( f _ { c } + f _ { b } ) & f _ { b } / 2 \\ 0 & 5 / 2 & f _ { b } / 2 & - f _ { b } / 3 \end{array} \right ] \quad \text{and} \quad B _ { 0 } = \left [ \begin{array} { c c c c } 0 \\ 0 \\ 1 \\ 0 \end{array} \right ].$$
Here A belongs to uncertain polytope, defined by four vertices corresponding to f /f c b = 0 15 . and f /f c b = 0 25 . . The pendulum can be stabilized by a state feedback u t ( ) = Kx t ( ) , where x = [ x , x 1 2 , x 3 , x 4 ] T , with the gain
$$K = [ 1 1. 2 0 6 2 \ - 1 2 8. 8 5 9 7 \ 1 0. 7 8 2 3 \ - 2 2. 2 6 2 9 ].$$
In this model, x 1 and x 2 represent cart position and velocity, whereas x , x 3 4 represent pendulum angle from vertical and its angular velocity respectively. In practice x , x 1 2 and x 3 , x 4 (presenting spatially distributed components of the state of the pendulum-cart system) are not accessible simultaneously. Suppose that the state variables are not accessible simultaneously. Consider first N = 2 and
$$C _ { 1 } = \left [ \begin{array} { c c c } 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \end{array} \right ], \, C _ { 2 } = \left [ \begin{array} { c c c } 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \right ].$$
The applied controller gain K has the following blocks:
$$K _ { 1 } = \left [ \ 1 1. 2 0 6 2 \ - 1 2 8. 8 5 9 7 \ \right ], \ K _ { 2 } = \left [ \ 1 0. 7 8 2 3 \ - 2 2. 2 6 2 9 \ \right ]. \\ \text{For the values of } \eta _ { m } \text{ given in Table 1, we apply Theorems 3.2 and 5.2}$$
For the values of η m given in Table 1, we apply Theorems 3.2 and 5.2 with α = 0 , b = 0 via Remark 5.4 and find the maximum values of τ M = MATI+MAD that preserve the stability of the hybrid system (6)-(7) with ω t ( ) = 0 with respect to x . From Table 1, it is observed that under TOD or RR protocol the conditions of Theorem 5.2 possess less decision variables, and stabilize the system for larger τ M than the results in [16] under RR protocol. Moreover, when η m > τ M 2 ( η m = 0 02 0 04) . , . , our method is still feasible (communication delays are larger than the sampling intervals). The computational time for solving the LMIs (in seconds) under the TOD protocol is essentially less than that under RR protocol in [16] (till 36% decrease).
Table 1: Example 1 (N=2): max. value of τ M = MATI+MAD
| τ M \ η m | 0 | 0.005 | 0.01 | 0.02 | 0.04 | Decision variables |
|----------------------|-------|---------|--------|--------|--------|----------------------|
| [16] (RR) | 0.023 | 0.026 | 0.029 | 0.035 | 0.046 | 146 |
| Theorem 3.2 (TOD) | 0.014 | 0.018 | 0.021 | 0.029 | 0.044 | 84 |
| Theorem 5.2 (TOD/RR) | 0.025 | 0.028 | 0.031 | 0.036 | 0.047 | 72 |
Consider next N = 4 , where C , . . . , C 1 4 are the rows of I 4 and K ,. . . , K 1 4 are the entries of K given by (39). Here the maximum values of τ M that preserve the stability of (6)-(7) with ω t ( ) = 0 with respect to x are given in Table 2. Also here Theorem 5.2 leads to less conservative results than Theorem 3.2.
Table 2: Example 1 (N=4): max. value of τ M = MATI+MAD
| τ M \ η m | 0 | 0.01 |
|-------------------|-------|--------|
| Theorem 3.2 (TOD) | 0.003 | 0.012 |
| Theorem 5.2 (RR) | 0.006 | 0.015 |
## 6.2 Example 2: batch reactor
We illustrate the efficiency of the given conditions on the example of a batch reactor under the dynamic output feedback (see e.g., [15]), where N = 2 and
$$A = \left [ \begin{array} { c c c c } 1. 3 8 0 & - 0. 2 0 8 & 6. 7 1 5 & - 5. 6 7 6 \\ - 0. 5 8 1 & - 4. 2 9 0 2 & 0 & 0. 6 7 5 \\ 1. 0 6 7 & 4. 2 7 3 & - 6. 6 5 4 & 5. 8 9 3 \\ 0. 0 4 8 & 4. 2 7 3 & 1. 3 4 3 & - 2. 1 0 4 \end{array} \right ],$$
For the values of η m given in Table 3, we apply Theorems 3.2 and 5.2 with α = 0 , b = 0 and find the maximum values of τ M = MATI+MAD that preserve the stability of the hybrid system (6)-(7) with ω t ( ) = 0 with respect to x . From Table 3 it is seen that the results of our method essentially improve the results in [15], and are more conservative than those obtained via the discrete-time approach. Recently in [2] the same result τ M = 0 035 . as ours in Theorem 5.2 for η m = 0 , MAD = 0 01 . has been achieved. In [2] the sum of squares method is developed in the framework of hybrid system approach. We note that the sum of squares method has not been applied yet to ISS. Moreover, our conditions are simple LMIs with a fewer decision variables. When η m > τ M 2 ( η m = 0 03 0 04) . , . , our method is still feasible (communication delays are larger than the sampling intervals). The computational time under the TOD protocol is essentially less than that under RR protocol in [16] (till 32% decrease).
$$A = \left [ \begin{array} { c c c c } 1. 3 8 0 & - 0. 2 8 & 6. 7 1 5 & - 5. 6 7 6 \\ - 0. 5 8 1 & - 4. 2 9 0 2 & 0 & 0. 6 7 5 \\ 1. 0 6 7 & 4. 2 7 3 & - 6. 6 5 4 & 5. 8 9 3 \\ 0. 0 4 8 & 4. 2 7 3 & 1. 3 4 3 & - 2. 1 0 4 \end{array} \right ], \\ B = \left [ \begin{array} { c c c c } 0 & 0 \\ 5. 6 7 9 & 0 \\ 1. 1 3 6 & - 3. 1 4 6 \\ 1. 1 3 6 & 0 \end{array} \right ], \, C = \left [ \frac { C _ { 1 } } { C _ { 2 } } \right ] = \left [ \frac { 1 } { 0 } & 1 & - 1 \\ 0 & 1 & 0 & 0 \end{array} \right ], \\ \left [ \frac { A _ { c } } { C _ { c } } \left | \ B _ { c } \\ \frac { C _ { c } } { C _ { c } } \right | \ D _ { c } \right ] = \left [ \frac { 0 } { - 2 } & 0 & 1 & 0 \\ 0 & 8 & 5 & 0 \end{array} \right ].$$
## 7 Conclusions
In this paper, a time-delay approach has been developed for the ISS of NCS with scheduling protocols, variable transmission delays and variable sampling intervals. A novel hybrid system model with time-varying delays in the continuous dynamics and in the reset equations is introduced and a new Lyapunov-
Table 3: Example 2: max. value of τ M = MATI+MAD for different η m
| τ M \ η m | 0 | 0.004 | 0.01 | 0.02 | 0.03 | 0.04 |
|-----------------------|--------|---------|--------|--------|--------|--------|
| [15]( MAD = 0 . 004 ) | 0.0108 | 0.0133 | - | - | - | - |
| [6]( MAD = 0 . 03 ) | 0.069 | 0.069 | 0.069 | 0.069 | 0.069 | - |
| Theorem 3.2 (TOD) | 0.019 | 0.022 | 0.027 | 0.034 | 0.042 | 0.050 |
| Theorem 5.2 (TOD/RR) | 0.035 | 0.037 | 0.041 | 0.047 | 0.053 | 0.059 |
| [16] (RR) | 0.042 | 0.044 | 0.048 | 0.053 | 0.058 | 0.063 |
Krasovskii method is developed. The ISS conditions of the delayed hybrid system are derived in terms of LMIs. Differently from the existing (hybrid and discrete-time) methods on the stabilization of NCS with scheduling protocols, the time-delay approach allows non-small network-induced delay (which is not smaller than the sampling interval). Future work will involve consideration of more general NCS models, including packet dropouts, packet disordering, quantization and scheduling protocols for the actuator nodes.
## A Proof of Theorem 3.2
Proof. Consider t ∈ [ t k , t k +1 ) , k ∈ Z + and define ξ i ( ) t = col { x t , x t ( ) ( -η m ) , x ( t -τ ( )) t , x ( t -τ M ) , e 1 ( ) t , · · · , e j ( ) t , · · · , e N ( ) t , ω ( ) t } with i = i ∗ k ∈ N , j = i . Differentiating V e ( ) t along (6) and applying Jensen's inequality, we have
/negationslash
$$j \neq i. \ D i f e r e n t i a l i n g \, V _ { e } ( t ) \, \text{ along} \, ( 6 ) \, \text{ and applying Jensen's inequality, we have} \\ \eta _ { m } \int _ { t - \eta _ { m } } ^ { t } \dot { x } ^ { T } ( s ) R _ { 0 } \dot { x } ( s ) d s \geq \int _ { t - \eta _ { m } } ^ { t } \dot { x } ^ { T } ( s ) d s R _ { 0 } \int _ { t - \eta _ { m } } ^ { t } \dot { x } ( s ) d s \\ = \xi _ { i } ^ { T } ( t ) ( F _ { 2 } ^ { i } ) ^ { T } R _ { 0 } F _ { 2 } ^ { i } \xi _ { i } ( t ), \\ - ( \tau _ { M } - \eta _ { m } ) \int _ { t - \tau _ { M } } ^ { t - \eta _ { m } } \dot { x } ^ { T } ( s ) R _ { 1 } \dot { x } ( s ) d s \\ = - ( \tau _ { M } - \eta _ { m } ) \int _ { t - \tau ( t ) } ^ { t - \eta _ { m } } \dot { x } ^ { T } ( s ) R _ { 1 } \dot { x } ( s ) d s - ( \tau _ { M } - \eta _ { m } ) \int _ { t - \tau _ { M } } ^ { t - \tau ( t ) } \dot { x } ^ { T } ( s ) R _ { 1 } \dot { x } ( s ) d s \\ \leq - \frac { \tau _ { M } - \eta _ { m } } { \tau ( t ) - \eta _ { m } } \xi _ { i } ^ { T } ( t ) \left [ \left [ I _ { n } \, 0 _ { n \times n } \right ] F ^ { i } \right ] ^ { T } R _ { 1 } [ I _ { n } \, 0 _ { n \times n } ] F ^ { i } \xi _ { i } ( t ) \\ - \frac { \tau _ { M } - \eta _ { m } } { \tau _ { M } - \tau ( t ) } \xi _ { i } ^ { T } ( t ) \left [ [ 0 _ { n \times n } \, I _ { n } ] F ^ { i } \right ] ^ { T } R _ { 1 } [ 0 _ { n \times n } \, I _ { n } ] F ^ { i } \xi _ { i } ( t ) \\ \leq - \xi _ { i } ^ { T } ( t ) ( F ^ { i } ) ^ { T } \Phi F ^ { i } \xi _ { i } ( t ). \\ \text{The latter inequality holds if} \, ( 2 0 ) \, \text{ is feasible} \, [ 2 1 ]. \ \text{ Then}$$
The latter inequality holds if (20) is feasible [21]. Then
/negationslash
$$\begin{array} {$$
if Σ + Ξ i T i H Ξ i -( F i ) T Φ F e i -2 ατ M < 0 , i.e., by Schur complement, if (21) is feasible. Thus due to Lemma 3.1, inequalities (13), (20) and (21) imply (15).
## B Proof of Lemma 5.1
Proof. Since | ω t ( ) | ≤ ∆ , (24) implies
$$( 4 0 ) \quad & V ( t, x _ { t }, \dot { x }$$
Note that V e ( t k +1 ) = ˜ V | t = t k +1 + V Q | t = t k +1 + V G | t = t k +1 . Taking into account (28) and the relations ˜ V t = t k +1 = ˜ V t = t -k +1 , e t ( -k +1 ) = e t ( k ) , we obtain due to (31), (32) and (35) for k > N -1 (41)
$$( 4 1 ) \overset { \cdot } { \equiv } & V _ { e$$
whereas for k = N -1 due to (33) and (35)
$$\text{whereas for $k=1\nu-1$ use $\omega(\,\$$
We will prove (36) by induction. For k = N -1 we have
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \$$
which implies (36).
Assume that (36) holds for k -1 ( k ≥ N -1 ):
$$V _ { e } ( t _ { k } ) \leq e ^ { - 2 \alpha ( t _ { k } - t _ { N - 1 } ) } V _ { e } ( t _ { N - 1 } ) + \Psi _ { k } + b \Delta ^ { 2 } \int _ { t _ { N - 1 } } ^ { t _ { k } } e ^ { - 2 \alpha ( t _ { k } - s ) } d s. \\ \text{Then due to } ( 4 0 ) \text{ for } t = t _ { k + 1 } ^ { - } \text{ we obtain}$$
Then due to (40) for t = t -k +1 we obtain
$$V _ { e } ( t _ { k + 1 } ) & \leq \Theta _ { k + 1 } + e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { k } ) } \Psi _ { k } + e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { N - 1 } ) } V _ { e } ( t _ { N - 1 } ) \\ & \quad + b \Delta ^ { 2 } \int _ { t _ { N - 1 } } ^ { t _ { k + 1 } } e ^ { - 2 \alpha ( t _ { k + 1 } - s ) } d s.$$
We have
$$\text{We have} \\ e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { k } ) } \Psi _ { k } = - ( \tau _ { M } - \eta _ { m } ) e ^ { 2 \alpha [ \tau _ { M } + ( N - 2 ) ( \tau _ { M } - \eta _ { m } ) ] } \\ \times & \left [ \sum _ { l = 0 } ^ { N - 3 } ( N - 2 - l ) \int _ { s _ { k - l - 2 } } ^ { s _ { k } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } \times | \sqrt { Q _ { i _ { k - 1 } - l } } C _ { i _ { k - 1 } - l } ^ { * } \dot { x } ( s ) | ^ { 2 } d s \right ] \\ + & ( N - 1 ) \int _ { s _ { k - 1 } } ^ { s _ { k } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i _ { k } } ^ { * } } C _ { i _ { k } ^ { * } } \dot { x } ( s ) | ^ { 2 } d s \right ] \\ = & - ( \tau _ { M } - \eta _ { m } ) e ^ { 2 \alpha [ \tau _ { M } + ( N - 2 ) ( \tau _ { M } - \eta _ { m } ) ] } \left [ \sum _ { j = 0 } ^ { N - 2 } ( N - 1 - j ) \\ \times & \int _ { s _ { k - j - 1 } } ^ { s _ { k } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i _ { k - j } } ^ { * } } C _ { i _ { k - j } ^ { * } } \dot { x } ( s ) | ^ { 2 } d s \right ]. \\ \text{Then, taking into account } ( 4 1 ), we find$$
Then, taking into account (41), we find
$$& \text{Then, taking into account (41), we find} \\ & \Theta _ { k + 1 } + e ^ { - 2 \alpha ( t _ { k + 1 } - t _ { k } ) } \Psi _ { k } \leq ( \tau _ { M } - \eta _ { m } ) e ^ { 2 \alpha [ \tau _ { M } + ( N - 2 ) ( \tau _ { M } - \eta _ { m } ) ] } \\ & \quad \times \left [ \sum _ { j = 0 } ^ { N - 2 } \int _ { s _ { k } - j - 1 } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i ^ { * } _ { k - j } } } C _ { i ^ { * } _ { k - j } } \dot { x } ( s ) | ^ { 2 } d s \\ & \quad \ \ - \sum _ { i = 1 } ^ { N } ( N - 1 ) \int _ { s _ { k } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i ^ { * } _ { k - j } } } C _ { i ^ { * } _ { k - j } } \dot { x } ( s ) | ^ { 2 } d s \\ & \quad \ - \sum _ { j = 0 } ^ { N - 2 } ( N - 1 - j ) \int _ { s _ { k - j - 1 } } ^ { s _ { k } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } \times | \sqrt { Q _ { i ^ { * } _ { k - j } } } C _ { i ^ { * } _ { k - j } } \dot { x } ( s ) | ^ { 2 } d s \right ] \\ & \quad \times \left [ \sum _ { j = 0 } ^ { N - 2 } ( N - 2 - j ) \int _ { s _ { k - j - 1 } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } \times | \sqrt { Q _ { i ^ { * } _ { k - j } } } C _ { i ^ { * } _ { k - j } } \dot { x } ( s ) | ^ { 2 } d s \\ & \quad \ + ( N - 1 ) \int _ { s _ { k } } ^ { s _ { k + 1 } } e ^ { 2 \alpha ( s - t _ { k + 1 } ) } | \sqrt { Q _ { i ^ { * } _ { k + 1 } } } C _ { i ^ { * } _ { k + 1 } } \dot { x } ( s ) | ^ { 2 } d s \right ] \\ & = \Psi _ { k + 1 }, \\ & \text{which implies (36). Hence, (36) and (40) yield (38). } \ \text{m}$$
which implies (36). Hence, (36) and (40) yield (38).
## References
- [1] P. Antsaklis and J. Baillieul. Special issue on technology of networked control systems. Proceedings of the IEEE , 95(1), 5-8, 2007.
- [2] N.W. Bauer, P.J.H. Maas and W.P.M.H. Heemels. Stability analysis of networked control systems: A sum of squares approach. Automatica , 48, 1514-1524, 2012.
- [3] M.B.G. Cloosterman, L. Hetel, N. van de Wouw, W.P.M.H. Heemels, J. Daafouz and H. Nijmeijer. Controller synthesis for networked control systems. Automatica , 46(10), 1584-1594, 2010.
- [4] D. Christmann, R. Gotzhein, S. Siegmund and F. Wirth. Realization of Try-Once-Discard in Wireless Multi-hop Networks. In Proceedings of the 18th World IFAC Congress , Milano, Italy, 2011.
- [5] D. Dacic and D. Nesic. Quadratic stabilization of linear networked control systems via simultaneous protocol and controller design. Automatica , 43, 1145-1155, 2007.
| [6] | M.C.F. Donkers, W.P.M.H. Heemels, N. van de Wouw and L. Hetel. Sta- bility analysis of networked control systems using a switched linear sys- tems approach. IEEE Transactions on Automatic Control , 56(9), 2101- 2115, 2011. |
|-------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [7] | E. Fridman. Use of models with aftereffect in the problem of design of op- timal digital control. Automation and Remote Control , 53(10), 1523-1528, 1992. |
| [8] | E. Fridman. A refined input delay approach to sampled-data control. Au- tomatica , 46, 421-427, 2010. |
| [9] | E. Fridman, A. Seuret and J.P. Richard. Robust sampled-data stabilization of linear systems: an input delay approach. Automatica , 40, 1441-1446, 2004. |
| [10] | H. Fujioka. A discrete-time approach to stability analysis of systems with aperiodic sample-and-hold devices. IEEE Transactions on Automatic Con- trol , 54(10), 2440-2445, 2009. |
| [11] | H. Gao, T. Chen and T. Chai. Passivity and passification for networked control systems. SIAM Journal on Control and Optimization , 46(4): 1299- 1322, 2007. |
| [12] | H. Gao, X. Meng, T. Chen and J. Lam. Stabilization of networked control systems via dynamic output-feedback controllers. SIAM Journal on Control and Optimization , 48(5): 3643-3658, 2010. |
| [13] | J.C. Geromel, R.H. Korogui and J. Bernussou. H 2 and H ∞ robust out- put feedback control for continuous time polytopic systems. IET Control Theory & Applications , 1(5), 1541-1549, 2007. |
| [14] | K. Gu, V. Kharitonov and J. Chen. Stability of time-delay systems . Birkhauser: Boston, 2003. |
| [15] | W.P.M.H. Heemels, A.R. Teel, N. van de Wouw and D. Nesic. Networked control systems with communication constraints: tradeoffs between trans- mission intervals, delays and performance. IEEE Transactions on Auto- matic Control , 55(8), 1781-1796, 2010. |
| [16] | K. Liu, E. Fridman and L. Hetel. Stability and L 2 -gain analysis of net- worked control systems under Round-Robin scheduling: a time-delay ap- proach. Systems & Control Letters , 61(5): 666-675, 2012. |
| [17] | K. Liu, E. Fridman and L. Hetel. Network-based control via a novel analysis of hybrid systems with time-varying delays. In Proceedings of the 51th IEEE Conference on Decision and Control , Maui, Hawaii, 2012. |
| [18] | P. Naghshtabrizi, J. Hespanha and A.R. Teel. Exponential stability of im- pulsive systems with application to uncertain sampled-data systems. Sys- tems & Control Letters , 57, 378-385, 2008. |
- [19] P. Naghshtabrizi, J. Hespanha and A.R. Teel. Stability of delay impulsive systems with application to networked control systems. Trans. of the Inst. of Measurement and Control, Special Issue on Hybrid and Switched Systems , 32(5), 511-528, 2010.
- [20] D. Nesic and A.R. Teel. Input-output stability properties of networked control systems. IEEE Transactions on Automatic Control , 49(10), 16501667, 2004.
- [21] P. Park, J. Ko and C. Jeong. Reciprocally convex approach to stability of systems with time-varying delays. Automatica , 47, 235-238, 2011.
- [22] A. Seuret. A novel stability analysis of linear systems under asynchronous samplings. Automatica , 48, 177-182, 2012.
- [23] G.C. Walsh, H. Ye and L.G. Bushnell. Stability analysis of networked control systems. IEEE Control Systems Technology , 10, 438-446, 2002. | null | [
"Kun Liu",
"Emilia Fridman",
"Laurentiu Hetel"
] | 2014-08-01T12:09:47+00:00 | 2014-08-01T12:09:47+00:00 | [
"cs.SY",
"math.OC"
] | Networked control systems in the presence of scheduling protocols and communication delays | This paper develops the time-delay approach to Networked Control Systems
(NCSs) in the presence of variable transmission delays, sampling intervals and
communication constraints. The system sensor nodes are supposed to be
distributed over a network. Due to communication constraints only one node
output is transmitted through the communication channel at once. The scheduling
of sensor information towards the controller is ruled by a weighted
Try-Once-Discard (TOD) or by Round-Robin (RR) protocols. Differently from the
existing results on NCSs in the presence of scheduling protocols (in the
frameworks of hybrid and discrete-time systems), we allow the communication
delays to be greater than the sampling intervals. A novel hybrid system model
for the closed-loop system is presented that contains {\it time-varying delays
in the continuous dynamics and in the reset conditions}. A new
Lyapunov-Krasovskii method, which is based on discontinuous in time Lyapunov
functionals is introduced for the stability analysis of the delayed hybrid
systems. Polytopic type uncertainties in the system model can be easily
included in the analysis. The efficiency of the time-delay approach is
illustrated on the examples of uncertain cart-pendulum and of batch reactor. |
1408.0148v1 | ## High-efficiency waveguide couplers via impedance-tunable transformation optics
Jun Cao, 1,2 Lifa Zhang, 3 Weifeng Jiang, 1 Senlin Yan, 2 and Xiaohan Sun 1, a)
1) National Research Center for Optical Sensing/Communications Integrated Networking, Department of Electronics Engineering, Southeast University, Nanjing 210096, China
2) Department of Physics, Nanjing Xiaozhuang University, Nanjing 211171, China
3) Department of Physics, The University of Texas at Austin, Austin, Texas 78712, USA
(Dated: 28 July 2014)
We design compact waveguide couplers via impedance-tunable transformation optics. By tuning impedance coefficients in the original space, two-dimensional metallic and dielectric waveguide couplers are designed with a high efficiency. Through tuning refractive index simultaneously, we find that the transformation medium inside a designed metallic waveguide coupler can be a reduced-parameter material for coupling waves between waveguides with arbitrary different cross sections and embedded media. In the design of dielectric waveguide couplers, we apply two different schemes: one is that both core region and its cladding region are contained in a transformed space, the other is only core region contained in the transformed space. The former has a very high efficiency near 100% ; the latter is less efficient with a very small decline which can be a simplified candidate in the design of near-perfect dielectric waveguide couplers. The transformation medium for dielectric waveguide couplers can also be reduced-parameter material by selecting appropriate refractive index coefficients. Two-dimensional numerical simulations confirm our design with good performances.
Couplers are very essential electromagnetic (EM) devices, which act as intermediary components to reduce mode mismatch in order to transfer light efficiently between waveguides of different cross sections and embedded media. The conventional method to reduce the coupling loss is to introduce a connected taper with a gradient change of size 1-3 ; however, it is very space consuming. With the progress of integrated optical circuits, the fiber-to-chip coupling remains a critical problem. To solve it, various couplers via different mechanisms have been proposed, such as the grating coupler 4-7 , parabolic reflector 8 , and luneburg lens ; but the reported coupling effi9 ciency are still very low. Thus to efficiently couple EM waves in waveguides is still a challenging topic up to now.
transformation optics. By tuning the impedance coefficient of the coupler, the mode waves can be coupled efficiently between two waveguides with arbitrarily different cross sections and embedded media. Through tuning the refractive index in the original space, the transformation medium can be reduced-parameter materials (magnetic-response-onlymaterials for TE polarization or dielectric-response-only materials for TM polarization). Different schemes have been implemented and compared for the design of high-efficiency dielectric waveguide couplers.
Transformation optics, as a unconventional theory reported by Pendry 10 and Leonhardt 11 , provides a powerful tool to design various optical devices 12-19 . However, in the technique applied in some cases 20-22 to manipulate the intensity of the electromagnetic fields out of a transformation medium, there is a mismatch of impedance at boundaries and the resulted reflections limit its applications. Different taper structures placed with transformation medium have been applied to the design of waveguide couplers 23 , but the impedance mismatch has not been solved thus the coupler performance are not satisfied. In Ref. 24 , impedance has been matched by inserting another special impedance-matched media in one of waveguides, however it can not be easily generalized to arbitrary coupling waves. Very recently, we proposed a generalized theory of impedance-tunable transformation optics in the geometric optics limit 25 , which not only can manipulate impedance match but also can provide more flexibilities to select realizable transformation medium.
In this letter, we design two-dimensional (2D) metallic and dielectric waveguide couplers using the impedance-tunable
a) Electronic mail: [email protected]
In the theory of impedance-tunable transformation optics 25 , the relative permittivity ε i j ′ ′ and permeability µ i j ′ ′ of the transformation medium for a given coordinate transformation x ′ = x ′ ( x ) can be expressed as
$$\varepsilon ^ { i ^ { \prime } j ^ { \prime } } & =$$
Here A i ′ i = ∂ x ,y ,z ( ′ ′ ′ ) ∂ x,y,z ( ) denotes a Jacobian tensor between the transformed space ( x , y , z ′ ′ ′ ) and the original space ( x, y, z ) , and the impedance coefficient k is a spatial continuous function.
Based on the strategy of impedance-tunable transformation optics, a 2D compact waveguide coupler is designed as shown in Fig. 1, where waveguide WG1 and WG2 of different width h 1 and h 2 are connected by a linear taper structure ABCD of length d as a waveguide coupler. The relative permittivity and permeability of the media in WG1 and WG2 are ε 1 , µ 1 and ε 2 , µ 2 respectively. To couple waves efficiently from WG1 to WG2 in the + z direction, the region ABCD are embedded with transformation medium, which compresses the rectangular region ABC'D' in the original space to trapezoidal region ABCD in the transformed space. We apply the transformation defined in the 2D compressor/expander design 19,25 :
$$x ^ { \prime } = x [ 1 - \frac { z } { d } ( 1 -$$
FIG. 1. (Color online) Schematic diagram of the waveguide coupler using the impedance-tunable transformation optics. The width, relative permittivity, permeability of the waveguide WG1 and WG2 are h 1 , ε 1 , µ 1 and h 2 , ε 2 , µ 2 respectively; the length of the coupler is d , and embedded in a transformation medium.
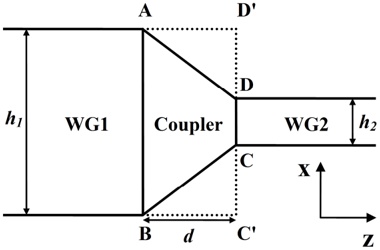
where γ = h 2 h 1 is the compression coefficient.
ε
Different from Ref. 25 where the background of transformation media is supposed to be air, arbitrary background media ε 1 , µ 1 and ε 2 , µ 2 are discussed here. Thus we reset the material parameters in the original space to calculate a new impedance function k . Without changing the refractive index, the permittivity and permeability of the original medium are set to be ε /k 1 and kµ 1 . No unique function of k can be selected, but there is no guarantee that the transformation medium can be a reduced-parameter material. A normal incident plane wave illuminating upon the coupler is discussed in the geometrical optics limit. Similar to the derivation in Ref. 25 , the function k can be set as k = d d -z ′ (1 -γ √ ε 2 µ 1 ) for
1
µ
2
TE polarization, and k = d -z ′ (1 -γ √ ε 1 µ 2 ε 2 µ 1 ) d for TM polarization. Note that only when the impedance of embedded media in WG1 and WG2 are equal, ε µ 1 2 = ε µ 2 1 , the function k are the same as that in Ref. 25 , which leads to a reduced-parameter transformation medium.
Reduced sets of material properties are generally favored in the two-dimensional transformation-optical design 12,26 due to its easier realization. In this paper, in order to obtain a reduced-parameter transformation medium for arbitrary conditions, we generalize the theory of impedance-tunable transformation optics to the design of waveguide coupler that the refractive index in the original space can also be tunable, and the relative permittivity and permeability in the original space are reset to be ε ij = ε z δ ( ) ij /k and µ ij = kµ z δ ( ) ij . The refractive index n = √ ε z µ z ( ) ( ) in the original space is a z -dependent continuous function, thus it will not change the light rays compared to the conventional transformation. For
µ
′
z
TE polarization we set
ε z
(
) =
p
,
µ z
(
) =
p
+
1
d
(
µ
2
-
µ
)
ε
′
1
+
z
(
ε
2
-
1
1
ε
)
′
and
d
$$\infty \frac { \varepsilon _ { 1 } + \frac { z ^ {$$
that coefficient p as refractive index coefficient, large p performance of the coupler at low frequencies.
for TM polarization µ z ( ) = p , ε z ( ) = p 1 d 2 1 µ 1 + z ′ d ( µ 2 -µ 1 ) . Note has not change the impedance but change its refractive index of the transformation medium, we define it will extend the application of the geometric optics approximation, and improve the
FIG. 2. (Color online) The normalized y direction electric field distribution of a waveguide coupler. (a) A traditional case without transformation; (b) An impedance-nontunable transformation case; (c) and (d) are impedance-tunable transformation cases for TE 01 mode with p = 1 and p = 3 , respectively; (e) and (f) are impedancetunable transformation cases for TE 02 mode with p = 1 and p = 3 , respectively.
Applying the continuity of the total tangential electric and magnetic fields, one can obtain k = d d -z ′ (1 -γ ) for TE polar- ization and k = d -z ′ (1 -γ ) d for TM polarization, which satisfy the impedance match condition at the boundaries AB and CD of the coupler. The parameters of the transformation medium associated with TE polarization can be written as:
$$\text{sovo w.m. } \colon & p \text{sovo w.$$
The material based on the above transformation is of magnetic response only. We also can obtain a dielectric-response-only transformation medium associated with TM polarization as:
$$\begin{array} {$$
To investigate the performance of the waveguide coupler embedded with impedance-tunable transformation medium, we do two-dimensional numerical simulations using COMSOL Multiphysics for TE-mode waves incidence (similar calculation for TM-mode waves can also be done). For a metallic waveguide, the calculation domain is bounded by a perfectly electric conductor. In our simulations, without loss of generality, the width of the waveguide WG1 and WG2 are set to be
FIG. 3. (Color online) Coupling efficiency of a metallic waveguide coupler for TE 01 mode as a function of frequency. The blue dotted and green dashed line correspond to couplers without transformation and with impedance-nontunable transformation, respectively; the black dash-dotted and red solid line correspond to couplers with impedance-tunable transformation for p = 1 and p = 3 , respectively.
h 1 = 0 4 . mand h 2 = 0 1 . mrespectively, and ε 1 = 4 , µ 1 = 1 , and ε 2 = 1 , µ 2 = 9 respectively. The length of the coupler is d = 0 2 . m. TE mode waves are excited at a port with an incident frequency f = 3 GHz. Fig. 2 shows electric field simulation results, in which the inset (a)-(d) are for TE 01 mode, and the inset (e)-(f) are for TE 02 mode. Figure 2(a) shows a traditional design case without transformation medium in the coupler, where the coupling efficiency η = W /W 2 1 is 51% due to the obvious reflections ( W 1 and W 2 are the coupler input and output power, respectively). For a conventional transformation medium embedded in the coupler (an impedance non-tunable case for k = 1 ), as shown in Fig. 2(b), although the wave profile are preserved well, even more serious reflections occur at the exit boundary of the coupler, resulting in an amplitude modulation of the incoming wave, and the simulated coupling efficiency is only 15% . While the impedancetunable transformation medium embedded in the coupler with p = 1 , Fig. 2(c) shows a good performance with the coupling efficiency near 98% , and improved to 99% in Fig. 2(d) with a larger refractive index coefficient p = 3 , which is almost reflectionless. The coupler using the impedance-tunable transformation optics can also be applied to couple high-order mode waves efficiently; Fig. 2(e) and Fig. 2(f) are simulated results of TE 02 mode with p = 1 and p = 3 respectively, with a similar coupling efficiency to that of TE 01 mode.
Figure 3 shows the coupling efficiency of TE 01 modes for an impedance-tunable coupler, an impedance-nontunable one and a traditional one without transformation simulated from 0 5 . GHz to 6 GHz. As can be clearly seen from Fig. 3, the traditional transformation optics does not exhibit enough competitive advantages compared to the conventional case without transformation, and thus limits its applications in many cases. However, by introducing a tunable impedance, we can obtain a coupler with extremely high efficiencies except in the vicinity of the cutoff frequency. In the whole range of frequency,
FIG. 4. (Color online) The normalized y direction electric field distribution of a dielectric waveguide coupler with total transformation (a), with only core transformation (refractive index nontunable) (b), with only core transformation (refractive index tunable with p = 1 ) (c) and with only core transformation (refractive index tunable with p = 6 ) (d).
the impedance-tunable coupler has a best performance compared to the impedance-nontunable one via traditional transformation optics and the traditional one without transformation. The inevitable unperfect coupling performance at low frequencies due to the geometric optics limit can be improved through setting large refractive index coefficient p , the cost is that the relative permittivity of the transformation medium is not 1 and extreme larger parameters will increase the difficulty of realization of designed transformation medium. Nevertheless we still can properly increase p to increase the performance at low frequencies while it is not difficult to be realized in designed medium.
Beside a metallic waveguide, an efficient dielectric waveguide coupler is also very important in optical design. Using the impedance-tunable transformation optics method, a 2D compact dielectric waveguide coupler can be designed with high efficiency and less space occupation.
For a dielectric waveguide, distribution of the EM field can be divided into two regions: a concentrated dielectric core and an evanescent air cladding. Therefore to couple waves with a high efficiency, the transformed space can also be divided into an inner space (major contribution) and an outer space (minor contribution). For the total transformation the embedded medium can be obtained through setting different original spaces and tuning different impedance coefficients for inner and outer parts. Note that in order to preserve the profile of the mode waves in the dielectric waveguide coupler the refractive index in the inner original space can not be tunable, resulted a non-reduced sets of material properties in the inner space of the coupler. However at high frequencies or in high-indexcontrast waveguide, a simple method is acceptable to omit evanescent energy and only focus on the core energy coupling. Thus only inner transformation medium (core transformation) can be considered with a slightly reduced coupling efficiency as we will see in the simulations latter; and the transformation medium also can be reduced-parameter material if we carefully set the refractive index coefficient p .
FIG. 5. (Color online) Coupling efficiency of a dielectric waveguide coupler as a function of frequency. The blue dotted, green dashed and red solid lines correspond to the couplers with total transformation, with only core transformation, and with only core transformation while the transformation medium is reduced-parameter material (refractive index tunable with p = 6 ) , respectively.
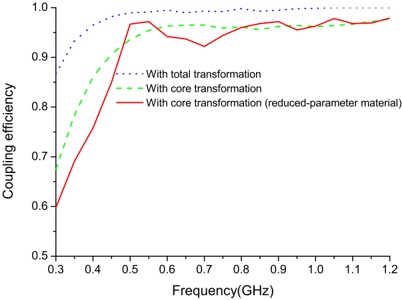
In total transformation, the relative permittivity and permeability in the inner and outer original space are set to be ε ij = ε δ 1 ij /k 1 , µ ij = k δ 1 ij and ε ij = δ ij /k 2 , µ ij = k δ 2 ij respectively. One can obtain k 1 = d d -z ′ (1 -γ √ ε 2 ε 1 ) , k 2 = d d -z ′ (1 -γ ) for TE polarization, and k 1 = d -z ′ (1 -γ √ ε 1 ε 2 ) d , k 2 = d -z ′ (1 -γ ) d for TM polarization.
In numerical simulations, the relative permittivity of cores in dielectric waveguide WG1 and WG2 are set as ε 1 = 2 and ε 2 = 20 , the width of the core in WG1 and WG2 are 0.4 m and 0.1 m, respectively, the coupler length is 0.2 m. The incident frequency is set to be 0.6 GHz, thus only TE 01 mode can exist in WG1 and WG2. Fig. 4(a) shows that TE 01 mode waves have been coupled from WG1 to WG2 with a high coupling efficiency over 99% . As a simplified method with only core transformation, Fig. 4(b) shows a little difference compared to Fig. 4(a), with a slightly reduced coupling efficiency but also near to 97% . Note that in simulations of Fig. 4(b), the refractive index in the original core space is fixed, resulting in no reduced-parameter transformation medium. If we let the refractive index tunable, reduced-parameter material can be obtained. But such reduced parameter may make refractive index of the core less than its of cladding thus cause large radiation loss if we select a small refractive index coefficient p ; as shown in Fig. 4(c) the coupling efficiency is only 61% with p = 1 . While if we set a large refractive index coefficient p = 6 in Fig. 4(d), the coupling efficiency near 95% can be obtained.
As a further step, the coupling efficiency with only core transformation and total transformation have been simulated at different incident frequencies from 0.3 GHz to 1.2 GHz in Fig. 5. The coupling efficiency of the dielectric waveguide coupler increases at high frequencies, where high-order mode waves may propagate in the waveguide, but the performance never be affected with the coupling efficiency near to 100% by total transformation design, and a very small decline of efficiency for only core transformation, which can be a proper candidate in the design of near-perfect dielectric waveguide coupler. The transformation medium also can be reducedparameter material by setting a appropriate tunable refractive index, but with a lower coupling efficiency.
In conclusion, to reduce the mode mismatch, the impedance-tunable transformation optics have been applied to the design of metallic and dielectric waveguide couplers with a high efficiency. It is found that reduced-parameter medium can be obtained by tuning the refractive index in the original space. The declined performance at low frequencies can be improved by setting a large refractive index. The method can be further applied to three-dimensional waveguide coupler design in the future, especially for fiber-to-chip coupling.
Acknowledgements -We acknowledge support from the Frontier Research and Development Projects of Jiangsu Province, China, under grants of BY2011147 and BY2013073.
- 1 V. R. Almeida, R. R. Panepucci, and M. Lipson, Opt. Lett 28 , 1302 (2003). 2 K. Shiraishi, H. Yoda, A. Ohshima, H. Ikedo, and C. S. Tsai, Appl. Phys. Lett. 91 , 141120 (2007).
- 3 P. Sun and R. M. Reano, Opt. Express 17 , 4565 (2009).
- 4 D. Taillaert, F. Van Laere, M. Ayre, W. Bogaerts, D. Van Thourhout, P. Bienstman, and R. Baets, Jpn. J. Appl. Phys. 45 , 6071 (2006).
- 5 G. Roelkens, D. Vermeulen, D. Van Thourhout, R. Baets, S. Brision, P. Lyan, P. Gautier, and J.-M. Fedeli, Appl. Phys. Lett. 92 , 231101 (2008). 6 B. Schmid, A. Petrov, and M. Eich, Opt. Express 17 , 11066 (2009).
- 7 L. Liu, M. Pu, K. Yvind, and J. M. Hvam, Appl. Phys. Lett. 96 , 051126 (2010).
- 8 T. Dillon, J. Murakowski, S. Shi and D. Prather, Opt. Lett 33 , 896 (2008).
9
B. Arigong, J. Ding, H. Ren, R. Zhou, H. Kim, Y. Lin, and H. Zhang, J.
Appl. Phys.
114
,
14431 (2013).
- 10 J. B. Pendry, D. Schurig, and D. R. Smith, Science 312 , 1780 (2006).
- 11 U. Leonhardt, Science 312 , 1777 (2006).
- 12 D. Schurig, J. J. Mock, B. J. Justice, S. A. Cummer, J. B. Pendry, A. F. Starr, and D. R. Smith, Science 314 , 977 (2006).
- 13 J. Huangfu, S. Xi, F. Kong, J. Zhang, H. Chen, D. Wang, B.-I. Wu, L. Ran, and J. A. Kong, J. Appl. Phys. 104 , 014502 (2008).
- 14 Y. Lai, H. Y. Chen, D. Z. Han, J. J. Xiao, Z.-Q. Zhang, and C. T. Chan, Phys. Rev. Lett. 102 , 253902 (2009).
- 15 H. Chen and C. T. Chan, Appl. Phys. Lett. 90 , 241105 (2007).
- 16 M. Rahm, D. Schurig, D. A. Roberts, S. A. Cummer, D. R. Smith, and J. B. Pendry, Photonics Nanostruct. Fundam. Appl. 6 , 87 (2008).
- 17 T. Yang, H. Y. Chen, X. D. Luo, and H. R. Ma, Opt. Express 16 , 18545 (2008).
- 18 W. X. Jiang, T. J. Cui, H. F. Ma, X. M. Yang, and Q. Cheng, Appl. Phys. Lett. 93 , 221906 (2008).
- 19 M. Rahm , S. A. Cummer, D. Schurig, J. B. Pendry, and D. R. Smith, Phys. Rev. Lett. 100 , 063903 (2008).
- 20 M. Rahm, D. A. Roberts, J. B. Pendry, and D. R. Smith, Opt. Express 16 , 11555 (2008).
- 21 W. X. Jiang, T. J. Cui, H. F. Ma, X. Y. Zhou, and Q. Cheng, Appl. Phys. Lett. 92 , 261903 (2008).
- 22 D.-H. Kwon and D. H. Werner, Opt. Express 17 , 7807 (2009).
- 23 P.-H. Tichit, S. N. Burokur, and A. Lustrac, Opt. Express 18 , 767 (2010).
- 24 H. Y. Xu, B. Zhang, G. Barbastathis and H. D. Sun, J. Opt. Soc. Am. B 28 , 2633 (2011).
- 25 J. Cao, L. F. zhang, S. L. Yan, and X. H. Sun, Appl. Phys. Lett. 104 , 191102 (2014).
- 26 W. Cai, U. K. Chettiar, A. V . Kildishev, and V . M. Shalaev, Nat. Photon. 1 , 224 (2007). | null | [
"Jun Cao",
"Lifa Zhang",
"Weifeng Jiang",
"Senlin Yan",
"Xiaohan Sun"
] | 2014-08-01T12:15:36+00:00 | 2014-08-01T12:15:36+00:00 | [
"physics.optics"
] | High-efficiency waveguide couplers via impedance-tunable transformation optics | We design compact waveguide couplers via impedance-tunable transformation
optics. By tuning impedance coefficients in the original space, two-dimensional
metallic and dielectric waveguide couplers are designed with a high efficiency.
Through tuning refractive index simultaneously, we find that the transformation
medium inside a designed metallic waveguide coupler can be a reduced-parameter
material for coupling waves between waveguides with arbitrary different cross
sections and embedded media. In the design of dielectric waveguide couplers, we
apply two different schemes: one is that both core region and its cladding
region are contained in a transformed space, the other is only core region
contained in the transformed space. The former has a very high efficiency near
100%; the latter is less efficient with a very small decline which can be a
simplified candidate in the design of near-perfect dielectric waveguide
couplers. The transformation medium for dielectric waveguide couplers can also
be reduced-parameter material by selecting appropriate refractive index
coefficients. Two-dimensional numerical simulations confirm our design with
good performances. |
1408.0150v3 | ## The Proton Radius from Bayesian Inference
Krzysztof M. Graczyk ∗ and Cezary Juszczak
Institute for Theoretical Physics, University of Wroc/suppress law, pl. M. Borna 9, 50-204, Wroc/suppress law, Poland
The methods of Bayesian statistics are used to extract the value of the proton radius from the elastic ep scattering data in a model independent way. To achieve that goal a large number of parametrizations (equivalent to neural network schemes) are considered and ranked by their conditional probability P (parametrization | data) instead of using the minimal error criterion. As a result the most probable proton radii values ( r p E = 0 899 . ± 0 003 fm, . r p M = 0 879 . ± 0 007 fm) are obtained . and systematic error due to freedom in the choice of parametrization is estimated. Correcting the data for the two photon exchange effect leads to smaller difference between the extracted values of r p E and r p M . The results disagree with recent muonic atom measurements.
PACS numbers: 13.40.Gp, 25.30.Bf, 14.20.Dh, 84.35.+i
Keywords: proton radius, proton form-factors, two-photon exchange correction
The problem of the proton radius is being discussed in the particle and atomic physics for many years but recently it has received even more attention due to the new results coming form the Lamb shift measurements of the muonic hydrogen atom ( µp ) [1]. It is a very accurate estimate of the proton radius but it is inconsistent with the CODATA value (compilation of the measurements in hydrogen atom and analysis of the electron-proton scattering data) [2]. This disagreement, called 'the proton radius puzzle', has not been explained yet. There are many proposals to resolve the problem including considering different types of interaction for ep and µp [3] or 'weakening the assumptions of perturbative formulation of quantum electrodynamics within the proton' [4]. In this paper we introduce a novel approach to the extraction of the proton radius from the ep scattering data, which allows one to control the model dependence of the result within a Bayesian objective algorithm.
The electromagnetic (E-M) structure of the proton is encoded in the electric G E and magnetic G M form factors, which are also the crucial input for the atomic (hydrogen-like) calculations [5]. In the low Q 2 limit in the Breit frame they are related with the distributions of the electric charge and magnetic momentum inside the nucleon [6]. In particular the nucleon radius is expressed by the slope of the form factors at vanishing Q 2 :
$$r _ { E, M } ^ { p } \equiv \left ( - \frac { 6 } { G _ { E, M } ( 0 ) } \, \frac { d G _ { E, M } ( Q ^ { 2 } ) } { d Q ^ { 2 } } \Big | _ { Q ^ { 2 } = 0 } ^ { \frac { 1 } { 2 } } \cdot \quad ( 1 ) \quad \text{direct} \\ \text{The value of $r_{E,M}^{p}$ can be obtained from the scattering} \\ \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{and} \, \text{or} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \,\text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is}\, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{is} \, \text{\ }$$
∣ The value of r p E,M can be obtained from the scattering data (mainly elastic ep ). Recent results include [7-11] and a more complete list can be found in Refs. [3, 12, 13]. These analyses have been performed in the spirit of the frequentistic statistics.
The values of the proton radius (related to the electric charge distribution) obtained by different authors during
∗ Electronic address: [email protected]
FIG. 1: (Color online) The scheme of the neural network (with H = 4 hidden units) used in the analysis, for reference see Eq. 6. Every line (connection) corresponds to one parameter w i . Gray circles denote the sigmoid functions, open circles are constants.
the last fifty years, range from about 0.8 fm to about 0.9 fm [14]. Indeed, as it was demonstrated in [8, 9] the results depend the choice of the form factor parametrization but it is obvious that the collection of datasets used in the analysis also matters. Even the right choice of the number of parameters in a given class of parametrizations can be a challenge. More parameters in the fit can always reduce the χ 2 error but at some point the fit tends to reproduce statical fluctuations of the experimental measurements. Such a model overfits the data i.e. describes existing points with unrealistic precision but has no predictive power - introducing new data points drastically increases the χ 2 error and spoils the quality of the fit. This is connected with the so called bias variance tradeoff. Some attempt to resolve this problem has been made in Ref. [9] where conformal mapping was used in order to exploit the analytic properties of the form factors.
Our philosophy is different. In contrast to the frequentistic statistics methods used in the above papers, we use the Bayesian statistics which is well suited to model comparison. Within this framework, adapted for neural networks, we select the most optimal model (according to the data) and extract the value of the proton radius.
The extraction of the nucleon form factors in [15] was our first use of the Bayesian neural network framework. In the next paper [16] the approach was significantly im-
FIG. 2: (Color online) Logarithm of evidence for the best neural networks in each scheme. Solid/dashed lines correspond to the analyses of the data corrected/not corrected by the TPE effect. Points mark the best models for each analysis.
proved to obtain the two-photon exchange (TPE) correction to unpolarized elastic ep cross section. However, because of some physical assumptions these analyses were not dedicated to the lowQ 2 region. In the present paper we overcome this difficulty because: (i) the TPE contribution (elastic and inelastic described by box diagrams with nucleon and ∆(1232) resonance as intermediate hadronic states) calculated in [17] is subtracted from the data and only E-M form factors are extracted from the cross section and polarization transfer data; (ii) the form factors are re-parameterized in order to automatically fulfil G E (0) = G M (0) /µ p = 1 ( µ p is the proton magnetic moment); (iii) our software has been significantly improved in terms of accuracy and efficiency.
Here we briefly outline the Bayesian framework, for more details see [15-17]. The main idea is to consider a large class of models. By a model we mean the function N used to fit the data D and two conditional probabilities: P ( { w i }|N ) - prior which accommodates the initial assumption about the { w i } , and the likelihood P ( D|{ w i } N , ); { w i } is the set of parameters of the function N . Then the models are ranked by the conditional probability P ( N|D ), which can be replaced by the evidence P ( D|N ) if the data is the same and no model is preferred at the beginning of the analysis.
For any given model we denote with { w i } MP the configuration of the parameters which maximizes the posterior
$$P ( \{ w _ { i } \} | \mathcal { D }, \mathcal { N } ) = \frac { P ( \mathcal { D } | \{ w _ { i } \}, \mathcal { N } ) P ( \{ w _ { i } \} | \mathcal { N } ) } { P ( \mathcal { D } | \mathcal { N } ) }. \quad ( 2 ) \quad \text{by o} \\ \sigma G _ { \varepsilon } ^ { 2 }.$$
Finding { w i } MP in one of the steps of the analysis.
Usually the evidence is peaked at { w i } MP and it simplifies to the likelihood at the maximum multiplied by the Occam factor which makes too complex models less
FIG. 3: (Color online) The form factor G /G E D ( G D = 1 (1 + / Q / . 2 0 71GeV ) ). 2 2 Red, blue and magenta lines correspond to the best models in the analysis with data limited by Q 2 cutoff = 1, 3 and 10 GeV 2 respectively. The areas colored with magenta, blue and red denote 1 σ uncertainty due to the change in the fit parameters (calculated within the Hessian approximation). The gray lines show models which are best for neural networks with definite number of hidden units, but are not globally best.
likely [18]
$$\begin{array} { c } \Phi _ { \text{$\mathcal{ } } } & \cdot & \cdot \\ \text{$P(\mathcal{ }D|\mathcal{N})$} \approx P(\mathcal{ }D|\{w_{i}\}_{M P},\mathcal{N})$} \underbrace { ( 2 \pi ) ^ { \frac { W } { 2 } } ( \det A ) ^ { - \frac { 1 } { 2 } } } _ { O c c a m \, f a c t o r }, \\ \intertext { \text{te} } & \text{where $W$ is the number of parameters $\{w_{i}$} \} \text{ and } A _ { i j } = \\ & - \nabla \dots \nabla \dots \, \ln P ( \i u u \, \downarrow | \mathcal{ }D \, \mathcal{ }M \, | } \end{array}$$
∣ For the function N we take the feed-forward neural networks with one hidden layer of units (Fig. 1), which correspond to linear combinations of sigmoid functions. This class of functions can be used to approximate any continuous function with arbitrary precision [19].
where W is the number of parameters { w i } and A ij = - ∇ w i ∇ w j ln P ( { w i }|D N , ) ∣ { w i } = { w i } MP .
The prior function for the neural network parameters { w i } has the standard form P { ( w i }| α, N ) ∼ e -αE w where E w = 1 2 ∑ W i =1 w 2 i . The parameter α is the regularizer which determines the width of the initial Gaussian distribution for the parameters. In principle it should be treated as another parameter of the model and its optimal value α MP is also obtained during the analysis. The likelihood is defined by the χ 2 distribution
$$\mathbb { N } _ { e _ { - } } \quad \mathcal { P } \left ( \mathcal { D } | \left \{ w _ { i } \right \}, \alpha, \mathcal { N } \right ) \sim e ^ { - \chi _ { c r. } ^ { 2 } \left ( \mathcal { D }, \{ w _ { i } \} \right ) - \chi _ { P T } ^ { 2 } \left ( \mathcal { D }, \{ w _ { i } \} \right ) }. \quad ( 4 )$$
The χ 2 cr. includes the unpolarized elastic ep scattering cross section data, which are assumed to be parametrized by one-photon exchange formula σ R = Q G 2 2 M / 4 M 2 p + εG 2 E ( M p is the proton mass, ε denotes photon polarizability). Each independent set of cross section measurements is characterized by its systematic normalization uncertainty so we introduce a separate normalization parameter for every data set. Values of these parameters are
obtained by an iterative algorithm described in [16]. The χ 2 PT includes the form factor ratio µ G p E /G M data from the polarization transfer measurements. We consider the same selection of data as in [16] with one additional data set from [20] and make the prior assumption that all data sets are equally relevant. The MAMI data [7] are not included in the analysis because of the difficulties described in [21].
The optimal configuration { α, w i } MP is found by an iterative procedure based on the fact that the maximum of the posterior corresponds to the minimum over { w i } of the error function S ( D { , w i } ) ≡ χ 2 cr. ( D { , w i } ) + χ 2 PT ( D { , w i } ) + α MP E w and also ∂ ∂α P D| ( α, N ) ∣ α = α MP = 0, where
$$\begin{array} { c } \chi _ { c r. } ( \mathcal { V }, \underline { \mathcal { W } } _ { i J } ) \rightarrow \chi _ { P T } ( \mathcal { V }, \underline { \mathcal { W } } _ { i J } ) \rightarrow \alpha _ { M P } \mathcal { L } _ { w } \quad \text{and} \quad \text{as} \quad \cdots \rightarrow \\ \frac { \partial } { \partial \alpha } \mathcal { P } \left ( \mathcal { D } \right | \alpha, \mathcal { N } \right ) \Big | _ { \alpha = \alpha _ { M P } } = 0, \text{ where} & & \text{$T$} \right | \\ & & \text{our} \\ \mathcal { P } \left ( \mathcal { D } \right | \alpha, \mathcal { N } \right ) = \int d w \mathcal { P } \left ( \mathcal { D } \right | \left \{ w _ { i } \right \}, \alpha, \mathcal { N } \right ) \mathcal { P } \left ( \left \{ w _ { i } \right \} \right | \alpha, \mathcal { N } \right ). \quad \text{num} \\ \text{for} \quad & \text{dep} \\ \text{Eventually the algorithm of evidence for the model } \mathcal { M } & \text{$\Delta$} \quad \cdots \right. \end{array}$$
Eventually the logarithm of evidence for the model N (in the Hessian approximation) reads:
$$\ln P ( \mathcal { D } | \mathcal { N } ) \ \approx \ - S ( \mathcal { D }, \{ w _ { i } \} _ { M P } ) + \frac { W } { 2 } \ln \alpha _ { M P } - \frac { 1 } { 2 } \ln \det A \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\mathcal { N } \right ) \ & \approx \ - S ( \mathcal { D }, \{ w _ { i } \} _ { M P } ) + \frac { W } { 2 } \ln \alpha _ { M P } - \frac { 1 } { 2 } \ln \det A \quad \text{cons} \\ & \quad - \frac { 1 } { 2 } \ln \sum _ { i = 1 } ^ { W } \frac { 1 } { 2 } \frac { \lambda _ { i } } { \lambda _ { i } + \alpha _ { M P } } \quad ( 5 ) \quad \text{izati} \\ A. \, \cdot \ = \ \nabla \quad \nabla \quad \mathcal { S } ( \mathcal { D } \ \mathcal { I } w. \, \mathfrak { U } \ \text{and} \ \lambda. \, \mathfrak { s } \ \text{ are the} \quad \text{This}$$
where A kj = ∇ w k ∇ w j S ( D { , w i } ) and λ k -s are the eigenvalues of the matrix ∇ w i ∇ w j ( χ cross ( D { , w i } ) + χ PT ( D { , w i } )).
As the form factors G E , G M describe the properties of the same object, they must be related, so we parametrize them with a single feed forward neural network with one input ( Q 2 ) and two outputs, o E and o M (see Fig. 1),
$$G _ { E } = ( 1 - Q ^ { 2 } o _ { E } ) G _ { D }, \ \ G _ { M } = \mu _ { p } ( 1 - Q ^ { 2 } o _ { M } ) G _ { D }, \ ( 6 ) \quad \ \ln ^ { \mu }$$
where G D ( Q 2 ) = ( 1 + Q /M 2 2 V ) -2 and M 2 V = 0 71 GeV . . 2 Then the value of the proton radius is given by
$$\left ( r _ { E, M } ^ { p } \right ) ^ { 2 } = \left ( r _ { d i p o l e } ^ { p } \right ) ^ { 2 } + 6 o _ { E, M } ( Q ^ { 2 } = 0 ), \quad ( 7 ) \quad \text{also} \\ \text{where} \, ( r ^ { p } \quad \rangle ^ { 2 } = 1 2 / M ^ { 2 } \colon \text{We see that the network out} \quad \text{$\tan$}$$
where ( r p dipole ) 2 = 12 /M 2 V . We see that the network outputs at Q 2 = 0 directly contribute to the deviation of the proton radius from the dipole form factor value.
In Refs. [14, 22] it was shown that modifying the cross section data by the Coulomb distortion (CD) is important in the extraction of the proton radius. On the other hand, the CD is a part of the TPE effect 1 , which has to be subtracted from the data to obtain the form factors which agree with the polarization transfer measurements
1 The relevance of the TPE effect and higher order Born corrections in the proton radius extraction is also discussed in Refs. [23] and [24, 25] respectively.
TABLE I: The values of the proton radii obtained with 1 σ uncertainty due to variation in the parameter space. H is the number of hidden units of the best model.
| Q 2 cutoff (GeV | r p M (fm) | r p E (fm) | H |
|-------------------|-------------------|-------------------|-----|
| 1 | 0 . 879 ± 0 . 007 | 0 . 899 ± 0 . 003 | 1 |
| 3 | 0 . 883 ± 0 . 007 | 0 . 899 ± 0 . 003 | 4 |
| 10 | 0 . 953 ± 0 . 065 | 0 . 897 ± 0 . 005 | 6 |
[26]. Similarly as in [27] we correct the cross section data by the TPE contribution (calculated in [17] in similar way as in [28, 29]).
The set of all possible parametrizations is infinite. In our approach the models are grouped according to the number of units in the hidden layer. For each group we found the { w , α i } which maximize the evidence. The dependence of the maximal evidence on the number of hidden units is plotted in Fig. 2. For every analysis the evidence reaches a peak (which defines the best model) and then starts to fall. Because of this fact we do not consider the networks with more then 40 hidden units. The total number of obtained neural network parameterizations exceeded half million.
It needs to be underlined that the models which maximize the evidence are not those which minimize the χ 2 . This is true in each class of models and also globally. The χ 2 min decreases with the number of parameters possibly saturating at some point. But the models with the lowest χ 2 tend to overfit the data, which is one of the reasons why the χ 2 min is not a suitable criterion for ranking the models. The other problems of χ 2 -based criteria are discussed in [3]. Objective mathematical methods for model comparison are provided by the Bayesian statistics.
In Fig. 3 it is shown how the form factor plots depend on the choice of the parametrization. The gray lines correspond to the best models in each group, while the globally best for each analysis are shown with color. Certainly the choice of the form factor parametrization has also strong impact on the obtained proton radius value (Fig. 4). Hence it is crucial to have criterion for finding the model which is the most favorable by the measurements. On the other hand each model can be true with the probability P ( N|D ) (proportional to the evidence) so it is possible to calculate the expected value of the proton radius and the systematic uncertainty due to the choice of the model. In practice the expected value is very close to the most probable value (see Tables I and II).
In Fig. 4 we show the proton radii values obtained from the analyses where data points with Q 2 above Q 2 cutoff = 1, 3 and 10 GeV 2 are rejected (for the data uncorrected by the TPE we considered only Q 2 cutoff = 1 , 3 GeV ). 2 The choice of the value for the cutoff has small impact on the extraction of the proton radii. For the result of our analysis we take those from the lowest cut, namely r p E = 0 899 . ± 0 003 fm and . r p M = 0 879 . ± 0 007 fm. .
TABLE II: The expected value (according to evidence probability distribution) of the proton radii with systematic uncertainty due to the choice of the parametrization (given by the variance).
| Q 2 cutoff (GeV | r p M (fm) | r p E (fm) |
|-------------------|---------------------|---------------------|
| 1 | 0 . 8792 ± 0 . 0006 | 0 . 8989 ± 0 . 0001 |
| 3 | 0 . 8828 ± 0 . 0063 | 0 . 8988 ± 0 . 0003 |
| 10 | 0 . 9205 ± 0 . 0606 | 0 . 8968 ± 0 . 0029 |
On the other hand the r p E 's obtained based on the minimal error criterion depend on the cutoff choice. These results are smaller than those indicated by the evidence and have larger uncertainties, see Fig. 4. We leave for future studies within the Bayesian framework the quantitative investigation of the dependence of the results on the data set selection and Q 2 cutoff value. Eventually it can be seen in Fig. 4 that using the data uncorrected by TPE effect leads to larger uncertainties of r p E and r p M and larger difference r p E -r p M (0 02 fm with TPE and 0 09 fm . . without).
We would like to emphasize that according to our knowledge the present work is the first extraction of the proton radius based on the Bayesian methods. The extracted value of the proton radius r p E agrees with previous results [9, 14, 27] but disagrees with the muonic atom measurements [1]. The subtracting of the TPE correction from the cross section data plays an important role in the analysis.
The calculations have been carried out in Wroclaw Centre for Networking and Supercomputing ( http://www.wcss.wroc.pl ), grant No. 268.
- [1] R. Pohl, A. Antognini, F. Nez, F. D. Amaro, F. Biraben, et al. , Nature 466 , 213 (2010).
- [2] P. J. Mohr, B. N. Taylor, and D. B. Newell, Rev.Mod.Phys. 84 , 1527 (2012), arXiv:1203.5425 [physics.atom-ph] .
- [3] E. Kraus, K. Mesick, A. White, R. Gilman, and S. Strauch, (2014), arXiv:1405.4735 [nucl-ex] .
- [4] K. Pachucki and K. A. Meissner, (2014), arXiv:1405.6582 [hep-ph] .
- [5] K. Pachucki, Phys.Rev. A53 , 2092 (1996).
- [6] F. Ernst, R. Sachs, and K. Wali, Phys.Rev. 119 , 1105 (1960).
- [7] J. Bernauer et al. (A1 Collaboration), Phys.Rev.Lett. 105 , 242001 (2010), arXiv:1007.5076 [nucl-ex] .
- [8] J. Bernauer et al. (A1 Collaboration), (2013), 10.1103/PhysRevC.90.015206, arXiv:1307.6227 [nucl-ex] .
- [9] R. J. Hill and G. Paz, Phys.Rev. D82 , 113005 (2010), arXiv:1008.4619 [hep-ph] .
- [10] I. Lorenz, H.-W. Hammer, and U.-G. Meissner, Eur.Phys.J. A48 , 151 (2012), arXiv:1205.6628 [hep-ph] .
- [11] I. Lorenz and U. G. Meissner, (2014), arXiv:1406.2962 [hep-ph] .
- [12] Z. Epstein, G. Paz, and J. Roy, (2014), arXiv:1407.5683 [hep-ph] .
- [13] S. G. Karshenboim, (2014), arXiv:1405.6515 [hep-ph] .
- [14] I. Sick, Phys.Lett. B576 , 62 (2003), arXiv:nucl-ex/0310008 [nucl-ex] .
- [15] K. M. Graczyk, P. Plonski, and R. Sulej, JHEP 1009 , 053 (2010), arXiv:1006.0342 [hep-ph]
FIG. 4: (Color online) The proton radii corresponding to the models which are the best within particular data selection and neural network scheme. The results for the data corrected by the TPE are marked with black /triangle , /square , and © for Q 2 cutoff = 1, 3 and 10 GeV 2 respectively. The results for the uncorrected data are marked with blue ∇ and ♦ for Q 2 cutoff = 1 and 3 GeV 2 respectively. The filled points mark the best result for each case. The three leftmost red points are the best results according to the minimum of the error function. For clarity their x-coordinate has been changed. Their ln(evidence) values are -718, -1070, and -1311. The picture is based on the analysis of 39 · 5 = 195 models.
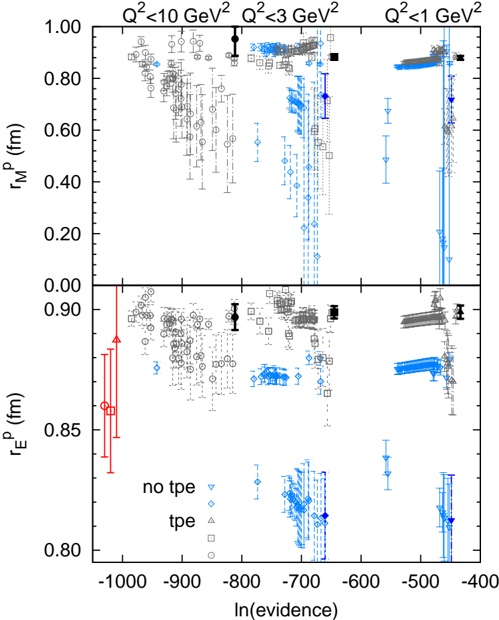
.
- [16] K. M. Graczyk, Phys.Rev. C84 , 034314 (2011), arXiv:1106.1204 [hep-ph] .
- [17] K. M. Graczyk, Phys.Rev. C88 , 065205 (2013), arXiv:1306.5991 [hep-ph] .
- [18] D. MacKay, Bayesian Methods for Adaptive Models , Ph.D. thesis, California Institute of Technology (1991).
- [19] G. Cybenko, Math Control, Signal 2 , 303 (1989).
- [20] X. Zhan, K. Allada, D. Armstrong, J. Arrington, W. Bertozzi, et al. , Phys.Lett. B705 , 59 (2011), arXiv:1102.0318 [nucl-ex] .
- [21] J. Arrington, Phys.Rev.Lett. 107 , 119101 (2011), arXiv:1108.3058 [nucl-ex] .
- [22] R. Rosenfelder, Phys.Lett. B479 , 381 (2000), arXiv:nucl-th/9912031 [nucl-th] .
- [23] M. Gorchtein, (2014), arXiv:1406.1612 [nucl-th] .
- [24] J. Arrington, J.Phys. G40 , 115003 (2013), arXiv:1210.2677 [nucl-ex] .
- [25] J. Arrington and I. Sick, Phys.Rev. C70 , 028203 (2004), arXiv:nucl-ex/0406014 [nucl-ex] .
- [26] J. Arrington, W. Melnitchouk, and
- J. Tjon, Phys.Rev. C76 , 035205 (2007), arXiv:0707.1861 [nucl-ex] . [27] P. G. Blunden and I. Sick, Phys.Rev. C72 , 057601 (2005), arXiv:nucl-th/0508037 [nucl-th] .
- [28] P. Blunden, W. Melnitchouk, and J. Tjon, Phys.Rev. C72 , 034612 (2005), arXiv:nucl-th/0506039 [nucl-th] .
- [29] S. Kondratyuk, P. Blunden, W. Melnitchouk, and J. Tjon, Phys.Rev.Lett. 95 , 172503 (2005), arXiv:nucl-th/0506026 [nucl-th] . | 10.1103/PhysRevC.90.054334 | [
"Krzysztof M. Graczyk",
"Cezary Juszczak"
] | 2014-08-01T12:23:44+00:00 | 2015-05-14T10:17:01+00:00 | [
"hep-ph",
"nucl-ex",
"nucl-th"
] | The Proton Radius from Bayesian Inference | The methods of Bayesian statistics are used to extract the value of the
proton radius from the elastic $ep$ scattering data in a model independent way.
To achieve that goal a large number of parametrizations (equivalent to neural
network schemes) are considered and ranked by their conditional probability
$P(\mathrm{parametrization}\,|\,\mathrm{data})$ instead of using the minimal
error criterion. As a result the most probable proton radii values
($r_E^p=0.899\pm 0.003$ fm, $r_M^p=0.879\pm 0.007$ fm) are obtained and
systematic error due to freedom in the choice of parametrization is estimated.
Correcting the data for the two photon exchange effect turns out to be
important to obtain the agreement between the $r_E^p$ and $r_M^p$ values. The
results disagree with recent muonic atom measurements. |
1408.0151v1 | ## Queueing networks with a single shared server: Light and heavy traffic
M.A.A. Boon Department of Mathematics and Computer Science Eindhoven University of Technology P.O. Box 513, 5600MB Eindhoven, The Netherlands [email protected]
R.D. van der Mei Centre for Mathematics and Computer Science (CWI) Department of Probability and Stochastic Networks 1098 SJ Amsterdam, The Netherlands [email protected]
## ABSTRACT
We study a queueing network with a single shared server, that serves the queues in a cyclic order according to the gated service discipline. External customers arrive at the queues according to independent Poisson processes. After completing service, a customer either leaves the system or is routed to another queue. This model is very generic and finds many applications in computer systems, communication networks, manufacturing systems and robotics. Special cases of the introduced network include well-known polling models and tandem queues. We derive exact limits of the mean delays under both heavy-traffic and light-traffic conditions. By interpolating between these asymptotic regimes, we develop simple closed-form approximations for the mean delays for arbitrary loads.
E.M.M. Winands Department of Mathematics, Section Stochastics VU University De Boelelaan 1081a, 1081HV Amsterdam, The Netherlands [email protected]
Applications of this type of customer routing can be found, for example, in manufacturing when products undergo service in a number of stages or in the context of rework. The present research can be seen as a unifying analysis for a variety of special cases (besides polling systems), such as tandem queues [5], multi-stage queueing models with parallel servers [4], feedback vacation queues [2] and many others.
## Categories and Subject Descriptors
G.3 [ Mathematics of Computing ]: Probability and StatisticsQueueing Theory
## General Terms
Theory, Performance
## Keywords
Queueing network, heavy traffic, light traffic, approximation
## 1. INTRODUCTION
In this paper we study a queueing network served by a single shared server, that visits the queues in a cyclic order. Each queue receives gated service. Customers from the outside arrive at the queues according to independent Poisson processes, and the service time and switch-over time distributions are general. After receiving service at queue i , a customer is either routed to queue j with probability p i,j , or leaves the system with probability p i, 0 . This model can be seen as an extension of the standard polling model by customer routing, introduced and analyzed by Sidi et al. [7, 8]. The possibility of re-routing of customers further enhances the already-extensive modeling capabilities of polling models, which find applications in diverse areas such as computer systems, communication networks, logistics, flexible manufacturing systems, robotics systems, production systems and maintenance systems (see, for example, [1] for overviews).
The main contribution of the present paper is twofold. Firstly, we study exact heavy-traffic (HT) asymptotics of the system under consideration. Under HT scalings we derive a closed-form expression for the joint queue-length vector at polling instants under HT scalings. This result, in turn, is shown to lead to a closed-form expression for the expected delay at a queue at an arbitrary moment. This expression is strikingly simple and shows explicitly how the expected delays depend on the system parameters, and in particular, on the routing probabilities p i,j . Secondly, we derive a closedform approximation for the mean delay for arbitrary loads, based on an interpolation between the light-traffic (LT) and HT limits. Numerical results are presented to assess the accuracy of this approximation. We would like to note that the analysis of the present paper can be extended in several directions, for example different server routing policies or service disciplines. For reasons of compactness, these results are however not discussed.
The remainder of this paper is organized as follows. In Section 2 we describe the model in further detail. This model is analyzed under HT scalings in Section 3. In Section 4 we develop an approximation based on the LT and HT limits for the mean waiting times and give a numerical example.
## 2. MODEL DESCRIPTION
In this paper we consider a queueing network consisting of N ≥ 2 infinite buffer queues Q ,. . . , Q 1 N . External customers arrive at Q i according to a Poisson arrival process with rate λ i , and have a generally distributed service requirement B i at Q i , with mean value b i := E B [ i ], and second moment b (2) i := E B [ 2 i ]. The queues are served by a single server in cyclic order. Whenever the server switches from Q i to Q i +1 , a switch-over time R i is incurred, with mean r i . The cycle time C i is the time between successive moments when the server arrives at Q i . The total switch-over time in a cycle is denoted by R = ∑ N i =1 R i and its first two mo- ments are r := E [ R ] and r (2) := E [ R 2 ]. Indices throughout the paper are modulo N , so Q N +1 actually refers to Q 1 . All service times and switch-over times are mutually independent. Each queue receives gated service, which means that only those customers present at the server's arrival at Q i will be served before the server switches to the next queue. This queueing network can be modeled as a polling system with the specific feature that it allows for routing of the customers: upon completion of service at Q i , a customer is either routed to Q j with probability p i,j , or leaves the system with probability p i, 0 . Note that ∑ N j =0 p i,j = 1 for all i , and that the transition of a customer from Q i to Q j takes no time. The model under consideration has a branching structure, which is discussed in more detail by Resing [6]. The total arrival rate at Q i is denoted by γ i , which is the unique solution of the following set of linear equations:
$$\gamma _ { i } = \lambda _ { i } + \sum _ { j = 1 } ^ { N } \gamma _ { j } p _ { j, i }, \quad i = 1, \dots, N.$$
The offered load to Q i is ρ i := γ b i i and the total utilisation is ρ := ∑ N i =1 ρ i . We assume that the system is stable, which means that ρ should be less than one (see [8]). The total service time of a customer is the total amount of service given during the presence of the customer in the network, denoted by ˜ B i , and its first two moments by ˜ b i := E B [ ˜ i ] and ˜ b (2) i := E B [ ˜ 2 i ]. The first two moments are uniquely determined by the following set of linear equations: For i = 1 , . . . , N ,
$$\tilde { b } _ { i } \ = \ b _ { i } + \sum _ { j = 1 } ^ { N } \tilde { b } _ { j } p _ { i, j }, \\ \tilde { b } _ { i } ^ { ( 2 ) } \ = \ b _ { i } ^ { ( 2 ) } + 2 b _ { i } \sum _ { j = 1 } ^ { N } \tilde { b } _ { j } p _ { i, j } + \sum _ { j = 1 } ^ { N } \tilde { b } _ { j } ^ { ( 2 ) } p _ { i, j }. \\ \tilde { n } \equiv \ e a c h m i k l a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d e n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b c a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d c a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n n e n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d b a n d$$
For each variable x (which may be a scalar, a vector or a matrix) that is a function of ρ , we denote its value evaluated at ρ = 1 by ˆ. x Also, we will be taking HT limits, letting ρ ↑ 1. To be precise, the limit is taken such that the arrival rates λ , . . . , λ 1 N are increased, while keeping the service and switch-over time distributions, the routing probabilities and the ratios between these arrival rates fixed. Also, an N -dimensional vector x has components ( x , . . . , x 1 N ).
## 3. HEAVY-TRAFFIC ANALYSIS
Let X := ( X ...,X 1 N ) be the N -dimensional vector that describes the joint queue length at a visit beginning at Q 1 . Sidi et al. [8] show that the joint queue-length process at successive visit beginnings to Q 1 constitutes an N -dimensional multi-type branching process (MTBP) with immigration in each state. In this section we focus on the limiting behavior of X as ρ goes to 1.
Theorem 1 The joint queue-length vector at polling instants at Q 1 has the following asymptotic behavior:
$$\text{at } Q _ { 1 } \text{ has the following assymmptotic behavior} \colon & \quad \text{$\quad \text{$\quad \\ ( 1 - \rho ) \left ( \begin{array} { c } X _ { 1 } \\ \vdots \\ X _ { N } \end{array} \right ) \stackrel { d } { \rightarrow } \frac { \tilde { b } ^ { ( 2 ) } } { 2 \tilde { b } ^ { ( 1 ) } \end{array} \frac { 1 } { \delta } \left ( \begin{array} { c } \hat { u } _ { 1 } \\ \vdots \\ \hat { u } _ { N } \end{array} \right ) \ \Gamma ( \alpha, 1 ) \quad ( \rho \uparrow 1 ),$$
with
$$\text{with} \\ u _ { i } \coloneqq \lambda _ { i } \sum _ { j = i } ^ { N } \rho _ { j } + \sum _ { j = i } ^ { N } \gamma _ { j } p _ { j, i } \quad ( i = 1, \dots, N ), \\ \delta \coloneqq \underline { \hat { u } } ^ { \top } \underline { \tilde { b } } = \sum _ { i = 1 } ^ { N } \underline { \lambda } _ { i } \underline { \tilde { b } } _ { i } \sum _ { j = i + 1 } ^ { N } \underline { \rho } _ { j } + \sum _ { i = 1 } ^ { N } \underline { \tilde { b } } _ { i } \sum _ { j = i } ^ { N } \underline { \gamma } _ { j } p _ { j, i }, \quad ( 1 ) \\ \alpha \coloneqq 2 r \delta \frac { \underline { \tilde { b } } ^ { ( 1 ) } } { \underline { b } ^ { ( 2 ) } }, \\ \tilde { b } ^ { ( k ) } \coloneqq \sum _ { i = 1 } ^ { N } \lambda _ { i } \mathbb { E } [ \tilde { B } _ { i } ^ { k } ] / \sum _ { j = 1 } ^ { N } \lambda _ { j }, \\ \text{and where } \Gamma ( \alpha, 1 ) \text{ is a gamma-distributed random variable} \\ \text{with shape parameter } \alpha \text{ and scale parameter } 1.$$
and where Γ( α, 1) is a gamma-distributed random variable with shape parameter α and scale parameter 1.
For reasons of compactness we omit the proof, noting that the basis for the proof is given by the general framework as proposed in [9].
/negationslash
Next, we focus on the workload in the individual queues. To this end, we note that simple balancing arguments can be used to show that E [ C i ] = r/ (1 -ρ ), which does not depend on i . To obtain HT-results for the amount of work in each queue, we use the Heavy Traffic Averaging Principle (HTAP) for polling systems [3]. When the system becomes saturated, two limiting processes take place. The scaled total workload tends to a Bessel-type diffusion whereas the work in each queue is changing at a much faster rate than the total workload. This implies that during the course of a cycle, the total workload can be considered as constant, while the workloads of the individual queues fluctuate according to a fluid model. The HTAP relates these two limiting processes. The fluid limit of the per-queue workload is obtained by dividing by r/ (1 -ρ ) and letting ρ ↑ 1. For our model, the fluid model for the workload at Q i is a piecewise linear function. More precisely, it is easy to show that the fluid limit of the mean amount of work at Q i at the beginning of a visit to Q j is ∑ j + N -1 k = i ˆ γ b k ˜ ( ˆ i λ b i k + p k,i ) for j = i and ˆ γ b i i for j = . i Moreover, in the fluid limit the probability that at an arbitrary moment the server is visiting Q j is ˆ ρ j ( j = 1 , . . . , N ). Combining these observations, one can obtain the following expression for δ i , defined as the fluid limit of the average amount of work at Q i .
$$\text{$Lemma $1$ for $i=1,\dots,N$,} \\ \text{that} \\ ; Q _ { 1 }. \quad & \delta _ { i } = \frac { 1 } { 2 } \hat { \rho } _ { i } \hat { \gamma } _ { i } \tilde { b } _ { i } ( 1 + \hat { \lambda } _ { i } b _ { i } + p _ { i, i } ) & ( 2 ) \\ \text{ss at} \\ \text{sinal} \\ \text{on in} \\ \text{avor} \quad & \quad \, _ { j = i + 1 } ^ { i + N - 1 } \hat { \rho } _ { j } ( \frac { 1 } { 2 } \hat { \gamma } _ { j } \tilde { b } _ { i } ( \hat { \lambda } _ { i } \tilde { b } _ { j } + p _ { j, i } ) + \sum _ { k = i } ^ { j - 1 } \hat { \gamma } _ { k } \tilde { b } _ { i } ( \hat { \lambda } _ { i } b _ { k } + p _ { k, i } ) ). \\ \text{$\text{$\text{$\text{$\text{$k$} } } } \quad \, _ { \quad \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots$$
Note that in the classical case where p i,j = 0 for all i, j we have δ i = ˆ (1 + ˆ ) ρ i ρ i / 2. Moreover, it is easily verified that ∑ N i =1 δ i = , where δ δ is defined in (1).
Subsequently, the diffusion limit of the total workload process and the workload in the individual queues can be related using the HTAP. To this end, we start with the cycle-time distribution under HT scalings.
Lemma 2 For i = 1 , . . . , N ,
$$( 1 - \rho ) C _ { i } \stackrel { d } { \rightarrow } \Gamma ( \alpha, \mu ), \quad ( \rho \uparrow 1 ),$$
with α = 2 rδb ˜ (1) /b ˜ (2) and µ = 2 ˜ δb (1) /b ˜ (2) .
Note that the distribution of C i no longer depends on i in the HT limit. The proof can be found along the same lines as in [9]. Lemma 2 implies that the HT limit of the mean (scaled) amount of work found by an arbitrary customer is δ i E [ C ], where C is the length-biased cycle time, with limiting distribution Γ( α +1 , µ ). Again, see [9] for more details.
The (HT limit of the) mean waiting time of an arbitrary customer in Q i can be found by application of Little's Law to the mean queue length at Q i , which is simply the mean amount of work in Q i divided by the mean total service time.
Theorem 2 For i = 1 , . . . , N ,
$$\tilde { \Phi } ( 1 - \rho ) \mathbb { E } [ W _ { i } ] & \to \left ( r + \frac { \tilde { b } ^ { ( 2 ) } } { 2 \delta \tilde { b } ^ { ( 1 ) } } \right ) \frac { \delta _ { i } } { \tilde { b } _ { i } \hat { \gamma } _ { i } }, \quad ( \rho \uparrow 1 ). \quad ( 3 ) \quad \text{$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$ \quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad\text{$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ \text{$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$$$
Remark 1 (Insensitivity) Equation (3) reveals a variety of properties about the dependence of the limiting mean delay with respect to the system parameters. The mean waiting times E [ W i ] are independent of the visit order of the server, depend on the switch-over time distributions only through r , and depend on the service-time distributions only through ˜ b (1) and ˜ b (2) .
## 4. APPROXIMATION
The LT limit of E [ W i ] can be found by conditioning on the customer type (external or internally routed).
Theorem 3 For i = 1 , . . . , N ,
$$\mathbb { E } [ W _ { i } ] \to \frac { \lambda _ { i } } { \gamma _ { i } } \frac { r ^ { ( 2 ) } } { 2 r } + \sum _ { j = i - N } ^ { i - 1 } \frac { \gamma _ { j } p _ { j, i } } { \gamma _ { i } } \sum _ { k = j } ^ { i - 1 } r _ { k }, \quad ( \rho \downarrow 0 ). \ \ ( 4 ) \quad [ 1 ] \ \, \overset { 5. } { 1 }$$
In light traffic we ignore all O ρ ( ) terms, which implies that we can consider a customer as being alone in the system. Equation (4) can be interpreted as follows. An arbitrary customer in Q i has arrived from outside the network with probability λ i γ i . In this case he has to wait for a residual total switchover time with mean r (2) / r 2 . If a customer in Q i arrives after being served in another queue, say Q j (with probability γ p j j,i /γ i ), he has to wait for the mean switchover times r , . . . , r j i -1 .
Subsequently, we construct an interpolation between the LT and HT limits that can be used as an approximation for the mean waiting times. For i = 1 , . . . , N ,
$$W _ { i } ^ { a p p r o x } = \frac { w _ { i } ^ { L T } + ( w _ { i } ^ { H T } - w _ { i } ^ { L T } ) \rho } { 1 - \rho }, \quad \quad ( 5 )$$
where w LT i and w HT i are the LT and HT limits respectively, as given in (4) and (3). Because of the way W approx i is constructed, it has the nice properties that it is exact as ρ ↓ 0 and ρ ↑ 1. Furthermore, it satisfies a so-called pseudoconservation law for the mean waiting times, which is derived in [8]. This implies that the W approx i yields exact results for symmetric (and, hence, single-queue) systems.
We do not aim at giving an extensive numerical study to assess the accuracy of the approximation. Instead, we give one numerical example that indicates the versatility of the model that we have discussed, and shows the practical usage of the approximation (5). To this end, we use an example that was introduced by Katayama [4], who studies a network consisting of three queues. Customers arrive at Q 1 and Q 2 , and are routed to Q 3 after being served. This model, which is referred to as a tandem queueing model with parallel queues in the first stage, is a special case of the model discussed in the present paper. We simply put p 1 3 , = p 2 3 , = p 3 0 , = 1 and all other p i,j are zero. We use the same values as in [4]: λ 1 = λ / 2 10, service times are deterministic with b 1 = b 2 = 1, and b 3 = 5. The server visits the queues in cyclic order: 1, 2, 3, 1, . . . . The only difference with the model discussed in [4] is that we introduce (deterministic) switch-over times r 2 = r 3 = 2. We assume that no time is required to switch between the two queues in the first stage, so r 1 = 0. In Table 1 we show the mean waiting times of customers at the three queues and their approximated values. From this table we can see that the accuracy is best for values of ρ close to 0 or 1, but the overall accuracy is very good in general.
Table 1: Results for the numerical example.
| ρ | 0 . 01 | 0 . 1 | 0 . 3 | 0 . 5 | 0 . 7 | 0 . 9 | 0 . 99 |
|----------------------|----------|---------|---------|---------|---------|---------|----------|
| E [ W 1 ] W approx | 2 . 05 | 2 . 53 | 3 . 87 | 6 . 07 | 10 . 95 | 34 . 87 | 356 . 60 |
| 1 | 2 . 04 | 2 . 40 | 3 . 53 | 5 . 57 | 10 . 34 | 34 . 17 | 355 . 86 |
| E [ W 2 ] W approx | 2 . 05 | 2 . 56 | 4 . 01 | 6 . 45 | 11 . 95 | 39 . 05 | 403 . 97 |
| 2 | 2 . 04 | 2 . 45 | 3 . 74 | 6 . 05 | 11 . 46 | 38 . 49 | 403 . 39 |
| E [ W 3 ] W approx 3 | 2 . 02 | 2 . 26 | 3 . 18 | 5 . 04 | 9 . 62 | 33 . 00 | 349 . 85 |
| E [ W 3 ] W approx 3 | 2 . 04 | 2 . 39 | 3 . 51 | 5 . 52 | 10 . 22 | 33 . 69 | 350 . 57 |
## 5. REFERENCES
- [1] M. A. A. Boon, R. D. van der Mei, and E. M. M. Winands. Applications of polling systems. Surveys in Operations Research and Management Science , 16:67-82, 2011.
- [2] O. J. Boxma and U. Yechiali. An M/G/ 1 queue with multiple types of feedback and gated vacations. Journal of Applied Probability , 34:773-784, 1997.
- [3] E. G. Coffman, Jr., A. A. Puhalskii, and M. I. Reiman. Polling systems in heavy-traffic: A Bessel process limit. Mathematics of Operations Research , 23:257-304, 1998.
- [4] T. Katayama. A cyclic service tandem queueing model with parallel queues in the first stage. Stochastic Models , 4:421-443, 1988.
- [5] S. S. Nair. A single server tandem queue. Journal of Applied Probability , 8(1):95-109, 1971.
- [6] J. A. C. Resing. Polling systems and multitype branching processes. Queueing Systems , 13:409-426, 1993.
- [7] M. Sidi and H. Levy. Customer routing in polling systems. In P. King, I. Mitrani, and R. Pooley, editors, Proceedings Performance '90 , pages 319-331. North-Holland, Amsterdam, 1990.
- [8] M. Sidi, H. Levy, and S. W. Fuhrmann. A queueing network with a single cyclically roving server. Queueing Systems , 11:121-144, 1992.
- [9] R. D. van der Mei. Towards a unifying theory on branching-type polling models in heavy traffic. Queueing Systems , 57:29-46, 2007. | 10.1145/2034832.2034843 | [
"Marko Boon",
"Rob van der Mei",
"Erik Winands"
] | 2014-08-01T12:29:30+00:00 | 2014-08-01T12:29:30+00:00 | [
"math.PR",
"cs.PF"
] | Queueing networks with a single shared server: light and heavy traffic | We study a queueing network with a single shared server, that serves the
queues in a cyclic order according to the gated service discipline. External
customers arrive at the queues according to independent Poisson processes.
After completing service, a customer either leaves the system or is routed to
another queue. This model is very generic and finds many applications in
computer systems, communication networks, manufacturing systems and robotics.
Special cases of the introduced network include well-known polling models and
tandem queues. We derive exact limits of the mean delays under both
heavy-traffic and light-traffic conditions. By interpolating between these
asymptotic regimes, we develop simple closed-form approximations for the mean
delays for arbitrary loads. |
1408.0153v1 | ## Flow problem in three-dimensional geometry
Maxim Zaytsev 1) , Vyacheslav Akkerman 2)
1) Nuclear Safety Institute of Russian Academy of Sciences
115191 Moscow, ul. Bolshaya Tulskaya, 52, Russia
2) West Virginia University Morgantown, WV 26506-6106, USA
## Abstract
It is shown how a complete set of hydrodynamic equations describing an unsteady threedimensional viscous flow nearby a solid body, can be reduced to a closed system of surface equations using the method of dimension reduction of over-determined systems of differential equations. These systems of equations allow determining the surface distribution of the resulting stresses on the surface of this body as well as all other quantities characterizing the hydrodynamic flow around it.
Keywords : flow problem, hydrodynamic flow, viscosity, solids, stress on the body surface, differential equation on the surface
## Introduction
In application, nonlinear equations of hydrodynamics are often one of the obstacles involved in the study of many phenomenas, such as turbulence, hydrodynamic discontinuities motion, movement of the fronts of chemical reactions, etc. [1-4]. (During their modeling in practical problems often one has to produce a very fine numerical grid in space and time, which requires large computing power and time-consuming) When modeling such equations in practical problem, one has to often produce a very fine numerical grid in space and time which is time consumming and requires large computing power hence rendering the methode as not practical [5]. In this regard, various ways of reducing the complete system of hydrodynamic equations in terms of a system of surface equations are of a large scientific interest. [6-11]. Such a procedure can reduce the dimension of the problem by one (3 2 D D , 2 1 D D ), which significantly reduces the required computational power. In particular, the corresponding computer program could directly calculate the hydrodynamic discontinuities with viscosity, sound formation and other changes in the density of gases and liquids (using the information only on the surface). For example, the problem of describing the potential flow in a plane can be reduced to an integral equation on the boundary for a vanishingly small viscosity (Dirichlet, Neumann) [1, 4]. This equation relates the tangential and normal components of the velocity. If one of the components is known on the boundary of the body, one can define all the external flow.
In this paper we reduce the equations of a viscous medium "in the volume" to surface equations and demonstrate how the proposed method can reduce the dimension of the problems in viscous flow, which makes the equations easier to simplify the calculations in a variety of applications. General methods proposed for overdetemination of the Navier-Stokes equations in three-dimensional and two-dimensional case, which theoretically allows reducing them to a closed system of equations on any surface [12, 13]. No significant simplifying assumptions, which would limit the generality of the consideration of these phenomena, are considered.
## 1. Formulation of problem
Movement of solids in viscous media is characterized by the conditions on the boundary of a solid, where the particles stick to it. In other words, the rate of viscous medium on the surface of the body u is determined by the kinematic characteristics of the surface, for example,
it can be expressed in terms of the speed of the body surface V . Force F acting on a unit surface area is [1]
$$F _ { i } = P n _ { i } - \sigma _ { i k } ^ { / } n _ { k }$$
where n is normal to the surface, and
$$\sigma _ { i k } ^ { \prime } = \eta \left ( \frac { \partial u _ { i } } { \partial x _ { k } } + \frac { \partial u _ { k } } { \partial x _ { i } } \right )$$
the viscous stress tensor and - coefficient of dynamic viscosity. Therefore, according to equation (1), in this case, for any point on the body surface in a Cartesian coordinate system 2 1 , , τ τ n one has
$$F _ { n } = P + 2 \eta \left ( \frac { \partial u _ { 1 } } { \partial \tau _ { 1 } } + \frac { \partial u _ { 2 } } { \partial \tau _ { 2 } } \right ),$$
$$F _ { 1 } = \eta \left ( \frac { \partial u _ { 1 } } { \partial n } + \frac { \partial u _ { n } } { \partial \tau _ { 1 } } \right ) = \eta \left ( \omega _ { 2 } + 2 \frac { \partial u _ { n } } { \partial \tau _ { 1 } } \right ),$$
$$F _ { _ { 2 } } = \eta \left ( \frac { \partial u _ { _ { 2 } } } { \partial n } + \frac { \partial u _ { _ { n } } } { \partial \tau _ { _ { 2 } } } \right ) = \eta \left ( - \omega _ { _ { 1 } } + 2 \frac { \partial u _ { _ { n } } } { \partial \tau _ { _ { 2 } } } \right )$$
(see Fig. 1). In addition, the force F relates to the velocity of the body V via the laws of rigid body motion dynamics. Unsteady flow around fixed solids in viscous medium is different from the above by cancelling velocity conditions at the boundary [1]:
$$V = 0 \, \mathbf u \, \mathbf u = 0 \,.$$
## 2. Overdetermination of Navier-Stokes equations
We confine ourselves here to an incompressible viscous flow in three-dimensional space in the gravity field g . To illustrate this, the Navier-Stokes equations take the form [1]
$$\frac { \partial \mathbf u } { \partial t } - \mathbf u \times \mathfrak { o } + \nabla \left ( P + \frac { 1 } { 2 } \mathbf u ^ { 2 } \right ) = - \nu \nabla \times \mathfrak { o } + g \,,$$
$$\omega = \nabla \times \mathfrak { u } \,,$$
div
0,
u
(9)
where - is the kinematic viscosity coefficient. These equations allow us to find the unknown velocity vector t , r u and the pressure profile t P , r at any given point and time in space, i.e. for any t , r . We introduce a "correction" α to the vector u and 'pseudo-density' t , r in order to generalize the system of equations (7) - (9) as follows
$$\frac { \partial ( \mathfrak { u } + \mathfrak { a } ) } { \partial t } - \left [ ( \mathfrak { u } + \mathfrak { a } ) \times ( \mathfrak { w } + \nabla \times \mathfrak { a } ) \right ] + \nabla \left ( P + \frac { 1 } { 2 } \mathfrak { u } ^ { 2 } \right ) = \mathfrak { g } \,,$$
$$\frac { \partial \rho } { \partial t } + ( \mathfrak { u } + \mathfrak { a } ) \cdot \nabla \rho + \rho \cdot \text{div} ( \mathfrak { u } + \mathfrak { a } ) = 0 \,,$$
$$\frac { \partial \alpha } { \partial t } = [ \alpha \times \omega + \mathfrak { u } \times ( \nabla \times \mathfrak { a } ) + \mathfrak { a } \times ( \nabla \times \mathfrak { a } ) ] + \nu \nabla \times \omega$$
$$\omega = \nabla \times \mathfrak { u } \,,$$
$$\text{div} \, = \, 0 \,.$$
Actually, the equations (11) and (12) respectively determine t , r and α but the equation (10) is resulting from Equations (7) and (12). Vector field α u can be formally considered as inviscid hydrodynamic flow with density t , r and pressure 2 2 1 1 2 2 P u u α .
We go one to one to the pseudo Lagrangian variables of initial position of the gas particles and time ( ) (i.e. marking) , 0 t r
d
r
dt
(
,
)
(
,
)
(
,
)
(
,
)
t
t
t
t
u
r
α
r
ω
r
α
r
,
$$\mathbf r = \mathbf r ( \mathbf r _ { 0 }, t ) \quad \mathbf r \quad \mathbf r _ { 0 } = \mathbf r _ { 0 } ( \mathbf r, t ), \ \mathbf r _ { 0 } \Big | _ { t = 0 } = \mathbf r \,.$$
We chose ( , ) so that t r
$$\lambda ( \mathfrak { w } + \nabla \times \mathfrak { a } ) \cdot \nabla \rho + \rho ( \mathfrak { w } + \nabla \times \mathfrak { a } ) \cdot \nabla \lambda = 0 \,.$$
Hence, it can be shown that
$$\frac { \partial \mathbf r _ { 0 } } { \partial t } + \left ( \mathbf u + \mathbf a + \mathcal { A } \left ( \mathfrak w + \nabla \times \mathbf a \right ) \right ) \cdot \nabla \mathbf r _ { 0 } = 0 \,.$$
Then, according to appendix A, from the equations (10) and (11) one yields the following expressions:
$$\frac { ( \omega + \nabla \times \mathfrak { a } ) \cdot \nabla r _ { 0 } } { \rho } = \frac { ( \omega _ { 0 } ( \mathbf r _ { 0 } ) + \nabla \times \mathfrak { a } _ { 0 } ( \mathbf r _ { 0 } ) ) } { \rho _ { 0 } ( \mathbf r _ { 0 } ) },$$
$$\frac { 1 } { \rho } \frac { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } { \partial ( x, y, z ) } = \frac { 1 } { \rho _ { 0 } ( \mathbf r _ { 0 } ) } \,,$$
where 0 α , 0 , 0 0 u ω - initial distribution of the variables α , , ω . Let 0 0 and α 0 1. Then (18) and (19) can be transformed to the form [14]:
$$\omega _ { x } + \nabla \times \alpha _ { x } - \left | \frac { \partial \mathbf r _ { 0 } } { \partial y } \left ( \frac { \partial \mathbf r _ { 0 } } { \partial z } \right ) \left ( \mathbf r _ { 0 } \right ) \right | = 0 \,,$$
$$\omega _ { y } + \nabla \times \alpha _ { y } - \left | \frac { \partial \mathbf r _ { 0 } } { \partial z } \left ( \frac { \partial \mathbf r _ { 0 } } { \partial x } \right ) \left ( \mathbf r _ { 0 } \right ) \right | = 0 \,,$$
$$\omega _ { z } + \nabla \times \alpha _ { z } - \left | \frac { \partial r _ { 0 } } { \partial x } \left ( \frac { \partial r _ { 0 } } { \partial y } \right ) = 0 \,.$$
Actually, from three equations (20) - (22) only two are independent [14]. Formula (19) takes the form
$$\frac { 1 } { \rho } \frac { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } { \partial ( x, y, z ) } = 1.$$
Thus, we have obtained an overdetermined system of 16 differential equations (7) - (9) (11) (12) (16) (20) (21) (23) plus any of the equations from (17) and of 15 unknowns α , u , ω , P , , и 0 r . Causation analysis shows that the system is consistent and valid [12-14]. It is possible to add to the equation (12) a nontrivial external force.
## 3. Viscous flow in a three-dimensional case
We derive a system of equations describing the unsteady flow around the fixed rigid body in three-dimensional incompressible viscous stream. Let us denote
$$& S _ { 1 } = \alpha _ { x } \,, \ S _ { 2 } = \alpha _ { y } \,, \ S _ { 3 } = \alpha _ { z } \,, \ S _ { 4 } = u _ { x } \,, \ S _ { 5 } = u _ { y } \,, \ S _ { 6 } = u _ { z } \,, \ S _ { 7 } = \omega _ { x } \,, \ S _ { 8 } = \omega _ { y } \,, \ S _ { 9 } = \omega _ { z } \,, \\ & S _ { 1 0 } = P \,, \ S _ { 1 1 } = \rho \,, \ S _ { 1 2 } = \lambda \,, \ S _ { 1 3 } = x _ { 0 } \,, \ S _ { 1 4 } = y _ { 0 } \,, \ S _ { 1 5 } = z _ { 0 } \,.$$
Then, a system of 16 equations (7) - (9), (11), (12), (16), (20), (21), (23) plus any of the equations (17) can be written in form
$$H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial r }, \frac { \partial S _ { v } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 1 5 \,, \, k = 1 \dots 1 6 \,.$$
We now turn to the coordinate system 1 2 , , τ τ n at point M (see Fig. 1). Then equations (25) can be written as
$$H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial \tau _ { 1 } }, \frac { \partial S _ { v } } { \partial \tau _ { 2 } }, \frac { \partial S _ { v } } { \partial n }, \frac { \partial S _ { v } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 1 5 \,, \, k = 1 \dots 1 6 \,.$$
We differentiate equations (26) in the direction n 14 times. Then we obtain the 240 equations of the form
$$\left [ H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial \tau _ { 1 } }, \frac { \partial S _ { v } } { \partial \tau _ { 2 } }, \frac { \partial S _ { v } } { \partial n } \frac { \partial S _ { v } } { \partial t } \dots \right ) \right ] ^ { ( i ) } _ { n } = 0 \,, \, v = 1 \dots 1 5 \,, \, k = 1 \dots 1 6 \,, \, i = 0 \dots 1 4 \,.$$
We denote
$$S _ { v } ^ { j } = \partial ^ { j } S _ { v } / \partial n ^ { j }$$
where 0...15 , j 0 v v S S . Then 240 equations (27) can be written as:
$$O _ { _ { h } } \left ( S _ { _ { v } } ^ { j }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial \tau _ { 1 } }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial \tau _ { 2 } }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 1 5 \,, \, h = 1 \dots 2 4 0 \,, \, j = 0 \dots 1 5 \,.$$
We extend the variable 0 12 12 S S along the boundary of the body as follow:
$$( \alpha \cdot \mathbf n ) + \lambda ( \omega + \nabla \times \alpha ) \cdot \mathbf n = 0 \,.$$
Let 0 be the equation of the solid surface in the coordinate system ( ) , ( 0 0 t g r ) (15). Then , 0 t r from (6) and (30) its speed is equal to
$$\cdot = \frac { \dot { g } _ { t } + \left ( \left ( \mathbf u + \mathbf \alpha + \lambda \left ( \mathbf \omega + \nabla \times \mathbf \alpha \right ) \right ) \cdot \nabla g \right ) } { } =$$
$$\dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ & V _ { 0 } = \frac { g _ { 0 t } } { | \nabla _ { 0 } g _ { 0 } | } = \frac { g _ { t } + \left ( \left ( u + \alpha + \lambda \left ( \omega + \nabla \times \alpha \right ) \right ) \cdot \nabla g \right ) } { | \nabla _ { 0 } g _ { 0 } | } = \\ & = \frac { | \nabla g | } { | \nabla _ { 0 } g _ { 0 } | } \left ( V + u _ { n } + \left ( \alpha \cdot \mathbf n \right ) + \lambda \left ( \omega + \nabla \times \alpha \right ) \cdot \mathbf n \right ) = 0. \\ - \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \collections$$
In the coordinate system ( ) , 0 t r the solid body is not moving.
Thus, the dependence of the derivative to n in the transformed system of differential equations (29) is missing, and we obtain a closed system of 240 surface differential equations strictly along the boundary of a solid and a corresponding number of variables. In fact, some of the variables are determined from (6) and (30). At the initial time, it is required to know nontrivial vorticity 0 0 r ω and some of its spatial derivatives on the surface (formula (20), (21)). It is always possible to find where the vorticity is non-trivial, because there is a viscous boundary layer on the surface.
The advantage is that the system actually describes the process of flow past the body surface in terms of the surface itself. Calculations show [15, 16] that the expressions (29) obtained in an analytical form are extremely cumbersome. Their writing out is beyond the scope of this paper. However, one provides a detailed algorithm of their obtaining.
## 4. Overdetermination of the complete system of hydrodynamic equations
Complete system of equations describing the hydrodynamic environment in a nonuniform unsteady 3D case is [1]
$$\frac { \partial \rho } { \partial t } + \text{div} ( \rho \mathbf u ) = 0 \,,$$
$$\frac { \partial \mathbf u } { \partial t } - \mathbf u \times \mathbf v = - \nabla \left ( \frac { \mathbf u ^ { 2 } } { 2 } \right ) - \frac { \nabla P } { \rho } + \frac { \nabla \sigma } { \rho } + \frac { \mathbf F } { \rho } \,,$$
$$\omega = \nabla \times \mathfrak { u } \,,$$
$$\psi = & \text{div} \,,$$
$$\rho T \left [ \frac { \partial s } { \partial t } + ( \mathbf u \nabla ) s \right ] = Q - \text{div} q + \Phi \,,$$
$$T = T ( \rho, s ), \ P = P ( \rho, s ),$$
$$\nabla w = T \cdot \nabla s + \frac { \nabla P } { \rho },$$
where , u , P , T , w и s - are density, velocity, pressure, temperature, specific heat function, and the entropy (per unit mass) of the medium, respectively. Here F и Q - are volumetric force and heat generation respectively, T q - is the heat flow equation ( - thermal conductivity), - the viscous stress tensor, for which we have
$$\nabla \sigma = \mu \left ( \Delta \mathfrak { u } + \frac { 1 } { 3 } \nabla ( \nabla \mathfrak { u } ) \right ) = \mu \left ( - \nabla \times \mathfrak { w } + \frac { 4 } { 3 } \nabla \psi \right ).$$
Here is - shear dynamic viscosity. The dissipation function in (36) is equal to
$$\Phi = \frac { \mu } { 2 } \left ( \frac { \partial u _ { i } } { \partial x _ { k } } + \frac { \partial u _ { k } } { \partial x _ { i } } \right ) ^ { 2 } - \frac { 2 } { 3 } \, \mu \left ( \frac { \partial u _ { i } } { \partial x _ { i } } \right ) ^ { 2 }.$$
Equations (37) and (38) -are thermodynamic relations that depend on the properties of the medium.
We introduce a "correction" t , r α to the vector ) and 'pseudo-density' , ( t r u t , r , which we determine from equations:
$$\frac { \hat { \partial } \rho ^ { \bullet } } { \hat { \partial } t } + ( \mathfrak { u } + \mathfrak { a } ) \cdot \nabla \rho ^ { \bullet } + \rho ^ { \bullet } \text{div} ( \mathfrak { u } + \mathfrak { a } ) = 0 \,,$$
$$\frac { \partial \alpha } { \partial t } = [ \alpha \times \omega + \mathfrak { u } \times ( \nabla \times \mathfrak { a } ) + \mathfrak { a } \times ( \nabla \times \mathfrak { a } ) ] - T \nabla s - \frac { \nabla \sigma } { \rho } - \frac { \mathrm F } { \rho } \,.$$
Termwise folded formula (42) and (33) and taking the operation « » on both sides, we find, using (38), that equation (33) is equivalent to the following expressions
$$\lambda & \lambda _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots \Delta _ { 0 } ^ { 2 } \cdots.$$
$$\frac { \partial ( \omega + \nabla \times \mathfrak { a } ) } { \partial t } = \nabla \times [ ( \mathfrak { u } + \mathfrak { a } ) \times ( \omega + \nabla \times \mathfrak { a } ) ].$$
We go one to one to the pseudo Lagrangian variables of initial position of the gas particles and time ( ) (i.e. marking) , t r
0
$$\frac { d { \mathbf r } } { d t } = { \mathbf u } \left ( { \mathbf r }, t \right ) + { \mathbf a } \left ( { \mathbf r }, t \right ) + \lambda \left ( { \mathbf v } \left ( { \mathbf r }, t \right ) + \nabla \times { \mathbf a } \left ( { \mathbf r }, t \right ) \right ),$$
$$= \mathbf r ( \mathbf r _ { 0 }, \mathbf l ) \ \mathbf r _ { 0 } = \mathbf r _ { 0 } ( \mathbf r, \mathbf l ), \ \mathbf r _ { 0 } | _ { \mathbf l = 0 } = \mathbf r _ { 0 }.$$
$$\frac { \dots } { d t } = \mathfrak { u } \left ( \mathbf r, t \right ) + \mathbf a \left ( \mathbf r, t \right ) + \lambda \left ( \mathfrak { o } \left ( \mathbf r, t \right ) + \nabla \times \mathbf a \left ( \mathbf r, t \right ) \right ), \\ \mathbf r = \mathbf r \left ( \mathbf r _ { 0 }, t \right ) \quad \mathfrak { u } \quad \mathbf r _ { 0 } = \mathbf r _ { 0 } \left ( \mathbf r, t \right ), \ \mathbf r _ { 0 } \Big | _ { t = 0 } = \mathbf r \,.$$
We chose ( , ) so that t r
$$\lambda ( \tilde { \omega } + \nabla \times \tilde { \alpha } \ ) \cdot \nabla \rho ^ { \bullet } + \rho ^ { \bullet } ( \tilde { \omega } + \nabla \times \tilde { \alpha } \ ) \cdot \nabla \lambda = 0.$$
Hence, it can be shown that
$$\frac { \partial r _ { 0 } } { \partial t } + \left ( \mathfrak { u } + \mathfrak { a } + \lambda \left ( \mathfrak { v } + \nabla \times \mathfrak { a } \ \right ) \right ) \cdot \nabla r _ { 0 } = 0 \,.$$
Equations (41) and (44) can be transformed to the form (see Appendix A)
$$\frac { ( \omega + \nabla \times \alpha ) \cdot \nabla r _ { 0 } } { \rho ^ { \bullet } } = \frac { ( \omega _ { 0 } ( r _ { 0 } ) + \nabla \times \alpha _ { 0 } ( r _ { 0 } ) ) } { \rho ^ { \bullet } _ { 0 } ( r _ { 0 } ) },$$
$$\frac { 1 } { \rho ^ { \bullet } } \frac { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } { \partial ( x, y, z ) } = \frac { 1 } { \rho ^ { \bullet } _ { 0 } ( \mathbf r _ { 0 } ) } \,,$$
where 0 α , 0 , 0 0 u ω - initial distribution of the variables α , , ω . Let 0 0 and α 0 0 . Then it can be shown [14], equations (48) - (49) can be transformed to
$$\omega _ { x } + \nabla \times \alpha _ { x } - \left | \frac { \partial \mathbf r _ { 0 } } { \partial y } \left ( \frac { \partial \mathbf r _ { 0 } } { \partial z } \right ) \left ( \mathbf r _ { 0 } \right ) \right | = 0 \,,$$
$$\omega _ { y } + \nabla \times \alpha _ { y } - \left | \frac { \left | \partial \mathbf r _ { 0 } } { \partial z } \left ( \frac { \partial \mathbf r _ { 0 } } { \partial x } \right ) \left | = 0 \,,$$
$$\omega _ { z } + \nabla \times \alpha _ { z } - \left | \frac { \partial r _ { 0 } } { \partial x } \left ( \frac { \partial r _ { 0 } } { \partial y } \right ) = 0 \,.$$
and the formula (49) takes the form
$$\frac { 1 } { \rho ^ { \bullet } } \frac { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } { \partial ( x, y, z ) } = \frac { 1 } { \rho _ { 0 } \left ( { \mathbf r } _ { 0 } \right ) }.$$
As a result, we get the following overdetermined system of 21 equations (32) - (38) (41) - (43), (46), (50), (51), (53), plus any of the equations from (47) and of 20 unknowns , * ,
$$\mathfrak { u } \,, \, \omega \,, \, \mathfrak { a } \,, \, P \,, \, T \,, \, s \,, \, w \,, \, \psi \,, \, \lambda \,, \, \mathfrak { r } _ { 0 }.$$
## 5. Three-dimensional general stream
We derive a system of equations describing the unsteady flow around the fixed rigid body in three-dimensional stream in the general case. Let
1 x S , 2 y S , 3 z S , 4 x S u , 5 y S u , 6 z S u , 7 x S , 8 y S , 9 z S , 10 S P , 11 S , 12 S , 13 0 S x , 14 0 S y , 15 0 S z , 16 S , 17 S T , 18 S s , 19 S , 20 S w , 21 x S q , 22 y S q , 23 z S q . (54)
Then the system of 24 partial differential equations of the first order (32) - (38) (41) (43), (46), (50), (51), (53), plus any of the equations from (47) can be written as
$$H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial r }, \frac { \partial S _ { v } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 2 3 \,, \, k = 1 \dots 2 4 \,.$$
We now turn to the coordinate system 1 2 , , τ τ n at point M (see Fig. 1). Then equations (55) can be written as
$$H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial \tau _ { 1 } }, \frac { \partial S _ { v } } { \partial \tau _ { 2 } }, \frac { \partial S _ { v } } { \partial n }, \frac { \partial S _ { v } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 2 3 \,, \, k = 1 \dots 2 4 \,.$$
Differentiating equations (56) in the direction n 22 times, we obtain 552 equations of the form
$$\left [ H _ { k } \left ( S _ { v }, \frac { \partial S _ { v } } { \partial \tau _ { 1 } }, \frac { \partial S _ { v } } { \partial \tau _ { 2 } }, \frac { \partial S _ { v } } { \partial n } \frac { \partial S _ { v } } { \partial t } \dots \right ) \right ] _ { n } ^ { ( i ) } = 0 \,, \, v = 1 \dots 2 3 \,, \, k = 1 \dots 2 4 \,, \, i = 0 \dots 2 2 \,.$$
Denote
$$S _ { v } ^ { j } = \partial ^ { j } S _ { v } / \partial n ^ { j }$$
where 0...23, j 0 v v S S . Then 552 equations (57) can be written as:
$$O _ { _ { h } } \left ( S _ { _ { v } } ^ { j }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial \tau _ { 1 } }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial \tau _ { 2 } }, \frac { \partial S _ { _ { v } } ^ { j } } { \partial t } \dots \right ) = 0 \,, \, v = 1 \dots 2 3 \,, \, h = 1 \dots 5 5 2 \,, \, j = 0 \dots 2 3 \,.$$
We extend the variable 0 12 12 S S along the boundary of the body as follows:
$$( \alpha \cdot \mathbf n ) + \lambda ( \omega + \nabla \times \alpha ) \cdot \mathbf n = 0 \,.$$
Let 0 ) , ( 0 0 t g r be the equation of the solid surface in the coordinate system ( ) (45). , 0 t r Similarly as in section 3, in the coordinate system ( ) , the solid is static. , 0 t r
Similarly, dependence on derivative to n in the transformed system of differential equations (59) is missing, and we obtain a closed system of 552 surface differential equations strictly along the boundary of a solid and the same number of variables (58). In fact, some
variables were already defined by (6) and (60), as well as by conditions of the heat transfer on surface of the body.
## Conclusion
In this paper, using a special transformation of variables we have reduced the full set of hydrodynamic equations describing the unsteady flow around a rigid body in terms of threedimensional flow to a system of equations on the surface. These equations can greatly simplify the numerical simulation and explore the deeper features of the flow process. First, they reduce the dimension of the task by a unit; there is no need to solve the hydrodynamic equations in the boundary layer. Second, besides the gas velocity at the surface they allow defining how all other parameters characterizing the flow (such as, u , P , ω etc.) change at the boundary.
It should be noted that not all of the obtained equations are with respect to time distinct systems. Therefore, in order to determine the stress distribution in addition to the initial data one should require examining boundary conditions. Through the previous, the information on the external flow is undoubtedly affecting the evolution of the whole effect of the flow on the body. They may need to be defined numerically using the additional code in space, the accuracy of which is important, but not in the entire volume, and only near the curves on the surface of the body along which the boundary conditions are determined.
The systems of equations obtained in this paper are essentially three-dimensional ones, ie, degenerate into the two-dimensional case. In the two-dimensional case (see Fig. 2) in order to override the hydrodynamic equations, it is necessary instead of transformations (15), (45) to use a different transformation similar to (A.12) (see Appendix A):
$$\frac { d \mathbf r } { d t } = \mathbf u + \mathbf \alpha + \frac { \left ( \omega + \nabla \times \mathbf \alpha \right ) } { \left | \omega + \nabla \times \mathbf \alpha \right | ^ { 2 } } \times \nabla \beta \,, \quad \mathbf r = \mathbf r ( \mathbf r _ { 0 }, t ) \,, \, \mathbf r _ { 0 } = \mathbf r _ { 0 } ( \mathbf r, t ) \,, \, \mathbf r _ { 0 } \right | _ { \mathbf r = 0 } = \mathbf r \,.$$
An additional condition should be implemented instead of (16)
$$\left ( \frac { \left ( \omega + \nabla \times \alpha \right ) } { \left | \omega + \nabla \times \alpha \right | ^ { 2 } } \times \nabla \beta \right ) \nabla \rho + \rho \nabla \beta \cdot \left ( \nabla \times \frac { \left ( \omega + \nabla \times \alpha \right ) } { \left | \omega + \nabla \times \alpha \right | ^ { 2 } } \right ) = 0 \,.$$
Parameter is determined so that the boundary of the body did not move in the coordinates 0 r (see (30) and (60)).
Despite the complexity , our description can successfully be used in applications, such as less expensive calculation of lift or drag coefficient in the external wing of impingement (including supersonic) flow, as well as the walls of the heat exchangers of nuclear reactors. The
Approach developed here is quite general and can be applied to other problems [14, 17]. If a more simple way is subsequently proposed to override the Navier-Stokes equations, the number of computations significantly reduced. This article may be of interest to researchers engaged in finding the analytical solutions of the equations of hydrodynamics. For example, according to the proposed method the hydrodynamic equations in the volume can be reduced to a system of equations on the surface and even get an overdetermined system of surface equations. Consequently, it can already be reduced to an overdetermined system of equations along a curve on the surface, etc. up to the analytical solution.
It should be noted that the override method itself is quite simple and already described by the authors [14] where a method of overriding the hydrodynamic equations described in Sec. 2 and Sec. 4 is provided. However, in this paper we apply it to a specific practical problem.
## Appendix A
Integrals of motion
Consider the Euler equations of an ideal incompressible fluid in the 3D case, in the form [1]
$$\frac { \partial \omega } { \partial t } = \nabla \times [ \mathfrak { u } \times \omega ],$$
$$\overline { \partial t }$$
$$\text{div} \, \iota = 0 \,.$$
We also consider the Lagrangian variables (i.e. markup) ) . Multiply both sides of , ( t r r r
0
0 0 (A.1) to x . Then
$$\nabla x _ { 0 } \cdot \frac { \partial \omega } { \partial t } = \nabla x _ { 0 } \cdot \nabla \times [ \mathfrak { u } \times \omega ] = - \text{div} ( \nabla x _ { 0 } \times [ \mathfrak { u } \times \omega ] ) = - \text{div} ( \mathfrak { u } ( \omega \cdot \nabla x _ { 0 } ) ) + \text{div} ( \omega ( \mathfrak { u } \cdot \nabla x _ { 0 } ) ) =$$
$$= - \mathfrak { u } \cdot \nabla ( \mathfrak { v } \cdot \nabla x _ { 0 } ) + \mathfrak { v } \cdot \nabla ( \mathfrak { u } \cdot \nabla x _ { 0 } ) = - \mathfrak { u } \cdot \nabla ( \mathfrak { v } \cdot \nabla x _ { 0 } ) - \mathfrak { v } \cdot \nabla \left ( \frac { \partial x _ { 0 } } { \partial t } \right ).$$
Here we have used the property of Lagrange variables:
$$\frac { \partial x _ { 0 } } { \partial t } + u _ { x } \, \frac { \partial x _ { 0 } } { \partial x } + u _ { y } \, \frac { \partial x _ { 0 } } { \partial y } + u _ { z } \, \frac { \partial x _ { 0 } } { \partial z } = 0 \,.$$
Consequently,
$$\frac { \partial } { \partial t } \left ( \mathfrak { w } \cdot \nabla x _ { 0 } \right ) + \mathfrak { u } \cdot \nabla ( \mathfrak { w } \cdot \nabla x _ { 0 } ) = \frac { d } { d t } \left ( \mathfrak { w } \cdot \nabla x _ { 0 } \right ) = 0 \Rightarrow \mathfrak { w } \cdot \nabla x _ { 0 } = \omega _ { 0 x } ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) \,,$$
where u t dt d / / - time derivative in the Lagrangian variables, , , ( z y x ω
vorticity distribution ω . Similarly 0 0 0 0 0 , , z y x y y ω 0 0 0 0 0 , , z y x z z ω .
) -0 0 0 0 initial and
From the continuity equation (A.2) one follows
$$& \text{from one community equation (A.z.) one follows} \\ & \text{div} \, = \, 0 \, \Rightarrow \, \left ( \frac { \partial ( u _ { x }, y, z ) } { \partial ( x, y, z ) } + \frac { \partial ( x, u _ { y }, z ) } { \partial ( x, y, z ) } + \frac { \partial ( x, y, u _ { z } ) } { \partial ( x, y, z ) } \right ) = 0 \,,$$
$$& \partial _ { \Delta } \cdot \frac { d \Delta } { d t } = 0 \,, \\ & \tau. e. \, \frac { \partial ( x, y, z ) } { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } = 1.$$
$$\ t. e. \, \frac { \partial ( x, y, z ) } { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } = 1.$$
Expressing ω using (A.3), we also have x t z y x x 0 0 0 0 0 , , , ω , y t z y x y 0 0 0 0 0 , , , ω , z t z y x z 0 0 0 0 0 , , , ω , где 0 0 0 0 , , x y z (see [1] page 31).
We also consider the general equation of continuity
$$\frac { \hat { \partial } \rho } { \hat { \partial } t } + \mathfrak { u } \cdot \nabla \rho + \rho \cdot \text{div} \mathfrak { u } = 0 \,.$$
Passing to the Lagrangian variables, we find [6]
$$& \text{assing to one Lagrangian variances, we in} \, \{ 0 \} \\ & \frac { d \rho } { d t } + \rho \cdot \left ( \frac { \partial ( u _ { x }, y, z ) } { \partial ( x, y, z ) } + \frac { \partial \left ( x, u _ { y }, z \right ) } { \partial ( x, y, z ) } + \frac { \partial ( x, y, u _ { z } ) } { \partial ( x, y, z ) } \right ) = 0 \,,$$
$$\frac { d \rho } { d t } + \frac { \rho } { \Delta } \cdot \frac { d \Delta } { d t } = 0 \,,$$
i.e.
$$\rho \cdot \Delta = \rho \cdot \frac { \partial ( x, y, z ) } { \partial ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) } = \rho _ { 0 } ( x _ { 0 }, y _ { 0 }, z _ { 0 } ) \text{ - integral of motion.}$$
In the case const , but const s , there is a clear connection between the pressure and density S P P the corresponding integrals are
$$\frac { \omega \cdot \nabla x _ { _ { 0 } } } { \rho } \,, \ \frac { \omega \cdot \nabla y _ { _ { 0 } } } { \rho } \, \bar { u } \ \frac { \omega \cdot \nabla z _ { _ { 0 } } } { \rho } \,.$$
Similarly, we obtain
$$\frac { \nu \left ( \mathbf r _ { 0 }, t \right ) } { \rho } = \frac { \omega _ { 0 } \cdot \nabla _ { 0 } \mathbf r } { \rho _ { 0 } },$$
The same results can be obtained if a more general transformation of the variables is used instead of Lagrangian variables
$$\frac { d \mathbf r } { d t } = \mathbf u ( \mathbf r, t ) + \lambda ( t ) \cdot \mathbf v ( \mathbf r, t ) \,,$$
where ) , ( 0 t r r r и ) , , ( 0 0 t r r r r r 0 0 t , а t - some function on t . Similar arguments can be established that in these variables, 0 x ω , 0 y ω , 0 z ω and the Jacobian of this transformation do not depend explicitly on time in an ideal fluid. Instead of t we can take t z y x , , , , including 0 , , , , , , t z y x t z y x ω to satisfy 0. div ω u Expressing also ω , we obtain 0 0 0 , x t x r ω , 0 0 0 , y t y r ω , 0 0 0 , z t z r ω
.
In the case const , but const s , there is a clear connection between the pressure and density S P P it is possible for the same reason in (A.5) to take t z y x , , , , including 0 . Then the corresponding integrals are ω ω
$$\frac { \omega \cdot \nabla x _ { 0 } } { \rho } = \frac { \omega _ { 0 _ { x } } ( { \mathbf r } _ { 0 } ) } { \rho _ { 0 } ( { \mathbf r } _ { 0 } ) } \,, \ \frac { \omega \cdot \nabla y _ { 0 } } { \rho } = \frac { \omega _ { 0 _ { y } } ( { \mathbf r } _ { 0 } ) } { \rho _ { 0 } ( { \mathbf r } _ { 0 } ) } \,, \ \frac { \omega \cdot \nabla z _ { 0 } } { \rho } = \frac { \omega _ { 0 _ { z } } ( { \mathbf r } _ { 0 } ) } { \rho _ { 0 } ( { \mathbf r } _ { 0 } ) } \, \mathfrak { u } \ \rho \Delta = \rho _ { 0 } ( { \mathbf r } _ { 0 } ) \,.$$
In fact, it requires only a negligible term 2 / P in equation (A.1), taking into account the compressibility of the fluid, which is performed at a characteristic velocity of its motion being much less than the speed of sound. [1].
$$\nabla \times [ \mathbf F \times \mathfrak { o } ] = 0 \,.$$
$$& \text{Going further. We solve the equation for the vector } F \\ & \nabla \times \left [ F \times \omega \right ] = 0 \,.$$
Consequently,
$$[ F \times \omega ] = \nabla \beta \,.$$
Then
$$\omega \nabla \beta = 0 \ u \ \omega \times [ F \times \omega ] = \omega \times \nabla \beta.$$
The solution of this equation has the form
$$F = \frac { \omega } { | \omega | ^ { 2 } } \times \nabla \beta + \lambda \omega \,.$$
We now change the variables
$$\frac { d \mathbf r } { d t } = \mathbf u + \frac { \omega } { \left | \omega \right | ^ { 2 } } \times \nabla \beta + \lambda \omega \,, \, \mathbf r = \mathbf r ( \mathbf r _ { 0 }, t ) \,, \, \mathbf r _ { 0 } = \mathbf r _ { 0 } \left ( \mathbf r, t \right ) \,, \, \mathbf r _ { 0 } \right | _ { t = 0 } = \mathbf r$$
and thus implement the conditions
$$\omega \nabla \beta = 0 \text{ and div} \left ( \frac { \omega } { | \omega | ^ { 2 } } \times \nabla \beta + \lambda \omega \right ) = \nabla \beta \cdot \left ( \nabla \times \frac { \omega } { | \omega | ^ { 2 } } \right ) + \left ( \omega \nabla \right ) \lambda = 0 \,.$$
Then these variables 0 x ω , 0 y ω , 0 z ω and the Jacobian of this transformation do not depend explicitly on time. Similarly, one can take into account compressibility.
In the two-dimensional case, the change of variables (A.10) has the form
$$\frac { d \mathbf r } { d t } = \mathbf u + \frac { \omega } { \left | \omega \right | ^ { 2 } } \times \nabla \beta \,, \, \mathbf r = \mathbf r ( \mathbf r _ { 0 }, t ) \,, \, \mathbf r _ { 0 } = \mathbf r _ { 0 } ( \mathbf r, t ) \,, \, \mathbf r _ { 0 } \right | _ { t = 0 } = \mathbf r \,,$$
where
$$\begin{array} { c } \psi \\ \frac { \mathfrak { v } } { \left | \mathfrak { v } \right | ^ { 2 } } \times \nabla \beta = \frac { 1 } { \omega } \begin{pmatrix} - \frac { \partial \beta } { \partial y } \\ \frac { \partial \beta } { \partial x } \end{pmatrix}. \\ \dots \quad \dots \dots. \end{array}$$
Condition (A.11) becomes
$$\frac { \partial \omega } { \partial x } \frac { \partial \beta } { \partial y } - \frac { \partial \omega } { \partial y } \frac { \partial \beta } { \partial x } = 0 \, \quad \text{ or } \quad \beta = G ( \omega, t ) \,.$$
As a result, the change of variables (A.12) can be written as
$$\frac { d \mathbf r } { d t } = \mathbf u + \mu \left ( \omega, t \right ) \nabla \times \omega \,, \, \mathbf r = \mathbf r \left ( \mathbf r _ { 0 }, t \right ) \,, \, \mathbf r _ { 0 } = \mathbf r _ { 0 } \left ( \mathbf r, t \right ) \,, \, \mathbf r _ { 0 } \Big | _ { t = 0 } = \mathbf r \,.$$
( А .14)
These variables allow
$$\omega = \omega _ { 0 } \left ( x _ { 0 }, y _ { 0 } \right ) \text{ and } \frac { \hat { \partial } ( x _ { 0 }, y _ { 0 } ) } { \hat { \partial } ( x, y ) } = 1 \,.$$
## REFERENCES
- 1. L. D. Landau and E. M. Lifshitz , Course of Theoretical Physics, Vol. 6: Fluid Mechanics (Nauka, Moscow,1986; Butterworth-Heinemann, Oxford, 1987).
- 2. Williams F.A. Combustion Theory. -Benjamin Cummings, Menlo Park, CA, 1985.
- 3. Ya. B. Zel'dovich, G. I. Barenblatt, V. B. Librovich, and G. M. Makhviladze , The Mathematical Theory of Combustion and Explosion (Nauka, Moscow, 1980; Consultants Bureau, New York, 1985).
- 4. A. N. Tikhonov and A. A. Samarskii, Equations of Mathematical Physics (Nauka, Moscow, 1966; Dover, New York, 1990).
- 5. A. A. Samarskii and Yu. P. Popov, Difference Methods for Solving Problems of Gas Dynamics (Nauka, Moscow, 1980) [in Russian].
- 6. M.L. Zaytsev, V.B. Akkerman, A Nonlinear Theory for the Motion of Hydrodynamic Discontinuity Surfaces, JETP, 108 , No 4, pp. 699-717 (2009)
- 7. M.L. Zaytsev and V.B. Akkerman, Method for Describing the Steady-State Reaction Front in a Two-Dimensional Flow, JETP Letters, 92 , No 11, pp. 731-734 (2010)
- 8. Bychkov V., Zaytsev M. and Akkerman V. Coordinate-free description of corrugated flames with realistic gas expansion // Phys. Rev. E. - 2003. - V. 68. -P. 026312.
- 9. Joulin G., El-Rabii H. and K. Kazakov K. On-shell description of unsteady flames // J. Fluid Mech. - 2008. - V. 608. - P. 217.
- 10. Ott E. Nonlinear evolution of the Rayleigh-Taylor instability of thin layor // Phys. Rev. Lett. -1972. - Vol. 29. - P. 1429-1432.
- 11. Book D.L, Ott E., Sulton A.L. Rayleigh-Taylor instability in the "shallow-water" approximation // Phys. Fluids. -1974. - Vol.17. N4. - P.676-678.
- 12. Зайцев M. Л ., Аккерман В . Б . Метод снижения размерности в задачах арогидродинамики // Труды 52ой научной конференции МФТИ " Современные проблемы фундаментальных и прикладных наук ". -2009. Часть VI. С . 10-13.
- 13. Зайцев M. Л ., Аккерман В . Б . Метод снижения размерности в переопределенных системах дифференциальных уравнений в частных производных // Труды 53ой научной конференции МФТИ " Современные проблемы фундаментальных и прикладных наук ". -2010. Часть VII, Т . 3. С . 41-42.
- 14. V.B. Akkerman and M.L. Zaytsev, Dimension Reduction in Fluid Dynamics Equations, Computational Mathematics and Mathematical Physics, Vol. 8 No. 51, pp. 1418-1430 (2011)
- 15. G. V. Korenev, Tensor Calculus (Moscow Institute of Physics and Technology, Moscow, 1996) [in Russian].
- 16. J. A. Schouten, Tensor Analysis for Physicists (Clarendon, Oxford, 1954; Nauka, Moscow, 1965).
- 17. M.L. Zaytsev, V.B. Akkerman, Free Surface and Flow Problem for a Viscous Liquid, JETP, 113 , No 4, pp. 709-713 (2011)
## FIGURES
Fig. 1. Rigid body in a viscous medium
Fig. 2. A solid in viscous fluid in the two-dimensional case
 | null | [
"Maxim Zaytsev",
"Vyacheslav Akkerman"
] | 2014-08-01T12:43:04+00:00 | 2014-08-01T12:43:04+00:00 | [
"physics.flu-dyn",
"math-ph",
"math.MP"
] | Flow problem in three-dimensional geometry | It is shown how a complete set of hydrodynamic equations describing an
unsteady three-dimensional viscous flow nearby a solid body, can be reduced to
a closed system of surface equations using the method of dimension reduction of
over-determined systems of differential equations. These systems of equations
allow determining the surface distribution of the resulting stresses on the
surface of this body as well as all other quantities characterizing the
hydrodynamic flow around it. |
1408.0154v1 | ## Deformed Carroll particle from 2+1 gravity
Jerzy Kowalski-Glikman ∗ and Tomasz Trze´ sniewski † Institute for Theoretical Physics, University of Wroc/suppressaw, l Pl. Maksa Borna 9, Pl-50-204 Wroc/suppressaw, l Poland
(Dated: August 4, 2014)
We consider a point particle coupled to 2+1 gravity, with de Sitter gauge group SO (3 , 1). We observe that there are two contraction limits of the gauge group: one resulting in the Poincar´ e group, and the second with the gauge group having the form AN (2) /multicloseleft an (2) ∗ . The former case was thoroughly discussed in the literature, while the latter leads to the deformed particle action with de Sitter momentum space, like in the case of κ -Poincar´ particle. e However, the construction forces the mass shell constraint to have the form p 2 0 = m 2 , so that the effective particle action describes the deformed Carroll particle.
Gravity in 2+1 dimensions seems to be, at first sight, an incredibly dull theory. It does not possess any local degrees of freedom and local Newtonian interactions between masses as well as gravitational waves are absent [1], [2], [3]. Therefore it can be described by a topological field theory as firmly established in the seminal paper of Witten [4] (and slightly earlier in [5].) Remarkably, the picture changes dramatically when one adds point particles to pure gravity. Then the gauge degrees of freedom of gravity at the particle's worldlines become dynamical. By solving for [6], [7] (or integrating out in the path integral formalism [8], [9]) the remaining (gauge) degrees of freedom of gravity we are left with a nontrivial particles dynamics, which includes not only the 'pure' particles' degrees of freedom, but also the back reaction resulting from the presence of the gravitational field created by the particles themselves. Since in 2+1 dimensions gravitational 'action at a distance' is absent, the only thing that this back reaction can do is to deform the original free particles' actions.
In this letter we show that one of the possible deformed actions, which can be obtained from 2+1 gravity is an action of the deformed Carroll particle with AN (2) momentum space [10], [11] and κ -Minkowski (noncommutative) spacetime [12], [13]. The Carroll particle [14] is a relativistic particle model in the limit in which the velocity of light becomes zero. Such a particle cannot move ( . . . it takes all the running you can do, to keep in the same place . . . [15]) and its relativistic symmetry group is a particular contraction of the Poincar´ group [16], [17]. e The Carroll group has attracted some attention recently, because it seems to become potentially relevant in several distinct fields of theoretical physics, see [18] for discussion and references. It also arises in loop quantum cosmology [19] in the context of so-called asymptotic silence, of which the Carrollian (or ultralocal) limit is a particular realization. More specifically, the Carrollian limit appears at the transition between the low-curvature (Lorentzian) regime and the high-curvature regime in
∗ [email protected]
† [email protected]
which the metric is Euclidean. It is supposed that at this transition the symmetry group should change from Poincar´ e to Carroll and eventually to Euclidean.
In all these cases a simple free dynamical relativistic particle model possessing Carroll symmetry is of great interest, because it exhibits physics of the Carrollian world, providing an insight into it. It is reasonable to expect that in this world some remnants of particles' interactions should still be present, and that the situation is similar to that of gravity coupling in 2+1 dimensions. Indeed, in the limit c → 0 the local interactions are frozen, and only the topological sector of gravity can be present. This is exactly the situation that we encounter in 2+1 dimensions, where local degrees of freedom of gravity are not possible. Therefore it could be claimed that the D + 1, D > 2 analogue of the 2+1 deformed particle action, derived below, might be the correct effective description of the Carrollian particle interacting with its own gravitational field.
Let us start with a short discussion of 2+1 gravity coupled to particles. According to [4] 2+1 gravity can be described by a Chern-Simons theory with an appropriate gauge group; here we will use the 2+1-dimensional de Sitter group, with three Lorentz generators J a and three translational generators P a , satisfying
$$[ J _ { a }, J _ { b } ] = \epsilon _ { a b } ^ { \, c } \, J _ { c } \,, \ \ [ J _ { a }, P _ { b } ] = \epsilon _ { a b } ^ { \, c } \, P _ { c } \,, \ \ [ P _ { a }, P _ { b } ] = - \epsilon _ { a b } ^ { \, c } \, J _ { c } \,,$$
where, since the cosmological constant is absorbed into the translational generators, all generators are dimensionless. It is convenient to make use of the time plus space decomposition of spacetime and to accordingly decompose the Chern-Simons connection one-form into
$$A = A _ { 0 } d t + A _ { S } \,.$$
The Lagrangian of the Chern-Simons theory of connection A coupled to a point particle takes the form
$$L = \frac { k } { 4 \pi } \int \left \langle \dot { \mathbf A } _ { S } \wedge \mathbf A _ { S } \right \rangle - \left \langle \mathcal { C } \, h ^ { - 1 } \dot { h } \right \rangle + \int \left \langle A _ { 0 }, \frac { k } { 2 \pi } F _ { S } - h \mathcal { C } h ^ { - 1 } \delta ^ { 2 } ( \vec { x } ) \, d x ^ { 1 } \wedge d x ^ { 2 } \right \rangle \,,$$
where the spatial curvature F S = d A S +[ A S , A S ]. Let us pause for a moment to explain the meaning of the terms in this Lagrangian. The bracket 〈∗〉 denotes an Ad-invariant inner product on the Lie algebra of the gauge group, which in our case is defined to be
$$\langle J _ { a } P _ { b } \rangle = \eta _ { a b } \,, \quad \langle J _ { a } J _ { b } \rangle = \langle P _ { a } P _ { b } \rangle = 0 \,.$$
The coupling constant k can be related to the physical parameters, the Planck mass κ (which in 2+1 dimensions is purely classical) and the cosmological constant as follows
$$\frac { k } { 2 \pi } = \frac { \kappa } { \sqrt { \Lambda } } \,.$$
Then, the first term in (3) describes the pure gravity while the second one is the particle term. More precisely, h includes the translation and Lorentz transformation acting on the particle and providing it with an arbitrary position, momentum, and angular momentum, while C is a gauge algebra element characterizing the particle at rest at the origin,
$$\mathcal { C } = \frac { m } { \sqrt { \Lambda } } \, J _ { 0 } + s \, P _ { 0 } \,,$$
where m is the mass and s the spin of the particle in the rest frame.
Last but not least, the integrand in the third term in (3) can be seen as a constraint relating the curvature with the mass/spin of the particle
$$\frac { k } { 2 \pi } F _ { S } = h \mathcal { C } h ^ { - 1 } \delta ^ { 2 } ( \vec { x } ) \, d x ^ { 1 } \wedge d x ^ { 2 } \,,$$
enforced by the Lagrange multiplier A 0 . It bounds together the gravitational and particle degrees of freedom, therefore we may use it to solve for the latter in terms of the former.
In order to proceed further we divide the space into two regions: the disc D with the particle at its center, on which we introduce the coordinates r ∈ [0 , 1], φ ∈ [0 , 2 π ], and the asymptotic empty region E (with r ≥ 1). They share the boundary Γ at r = 1. Then by virtue of (7) in the asymptotic region the connection is flat and has the form
$$A _ { S } ^ { ( \mathcal { D } ) } = \gamma d \gamma ^ { - 1 } \,,$$
where γ is an element of the gauge group. In the particle region D the general solution of (7) can also be found and it is given by
$$\mu - \mu \\ \mu \nu \\ A _ { S } ^ { ( \varepsilon ) } = \bar { \gamma } \, \frac { 1 } { k } \mathcal { C } d \phi \, \bar { \gamma } ^ { - 1 } + \bar { \gamma } d \bar { \gamma } ^ { - 1 } \,, \quad \bar { \gamma } ( 0 ) = h \,,$$
(note that ddφ = 2 π δ 2 ( /vector x dx ) 1 ∧ dx 2 ). Substitution of (8) into the Lagrangian yields the boundary term and the so-called WZW term. The same is the case for the second term in (9). Contribution from the first term in (9) can be rewritten as
$$2 \left \langle \partial _ { 0 } ( \bar { \gamma } \mathcal { C } \bar { \gamma } ^ { - 1 } d \phi ) \wedge \bar { \gamma } d \bar { \gamma } ^ { - 1 } \right \rangle = - 2 \partial _ { 0 } \left \langle \mathcal { C } d \phi \wedge \bar { \gamma } ^ { - 1 } d \bar { \gamma } \right \rangle - 2 d \left \langle \mathcal { C } d \phi \bar { \gamma } ^ { - 1 } \dot { \gamma } \right \rangle + 4 \pi \, \delta ( \bar { x } ) \, d x ^ { 1 } \wedge d x ^ { 2 } \left \langle \mathcal { C } \, \bar { \gamma } ^ { - 1 } \dot { \gamma } \right \rangle \,, \quad ( 1 0 ) \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where the first term can be neglected being a total time derivative and the last one cancels the particle term in (3). Summing all the contributions and adopting the opposite orientation of the boundary Γ for the terms coming from the disc D we obtain the total Lagrangian
$$\mu _ { - } & \mu _ { - } & \mu _ { - } \\ L & = \frac { k } { 4 \pi } \int _ { \Gamma } \left \langle \dot { \gamma } \gamma ^ { - 1 } d \gamma \gamma ^ { - 1 } - \dot { \bar { \gamma } } \bar { \gamma } ^ { - 1 } d \bar { \gamma } \bar { \gamma } ^ { - 1 } + \frac { 2 } { k } \mathcal { C } d \phi \dot { \bar { \gamma } } \gamma ^ { - 1 } \right \rangle \\ & + \frac { k } { 4 \pi } \int _ { \mathcal { E } } \left \langle \dot { \gamma } \gamma ^ { - 1 } d \gamma \gamma ^ { - 1 } \wedge d \gamma \gamma ^ { - 1 } \right \rangle + \frac { k } { 4 \pi } \int _ { \mathcal { D } } \left \langle \dot { \bar { \gamma } } \gamma ^ { - 1 } d \bar { \gamma } \bar { \gamma } ^ { - 1 } \wedge d \bar { \gamma } \gamma ^ { - 1 } \right \rangle. \\ \mu _ { - } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
In the next step we impose the continuity condition on the boundary Γ, A ( D ) S | Γ = A ( E ) S | Γ . Solving this equation we find the expression
$$\gamma ^ { - 1 } | _ { \Gamma } = N e ^ { \frac { 1 } { k } \mathcal { C } \phi _ { \bar { \gamma } } - 1 } | _ { \Gamma } \,, \ \ d N = 0 \,,$$
where N = N t ( ) is an arbitrary gauge group element.
The idea now is to use the continuity condition (12) to simplify the Lagrangian (11). Unfortunately, this condition is very difficult to disentangle in the case of the gauge group SO (3 , 1). Therefore in what follows we will consider only contractions of this gauge group, leading to the effective gauge group having the form of the semidirect product of some new group and the dual of its algebra G /multicloseleft g ∗ , see [20].
Before deriving the main result of this paper, let us pause for a moment to recall the well known construction in the case of the standard contraction of de Sitter group SO (3 , 1) to the Poincar` group, which e
can be presented as SO (2 , 1) /multicloseleft so (2 , 1) ∗ /similarequal SO (2 , 1) /multicloseleft /CA 3 . To this end we introduce the rescaled translation generators, ˜ P a ≡ √ Λ P a . Then (1) is replaced by
$$[ J _ { a }, J _ { b } ] = \epsilon _ { a b } ^ { \ c } J _ { c }, \ \ [ J _ { a }, \tilde { P } _ { b } ] = \epsilon _ { a b } ^ { \ c } \tilde { P } _ { c }, \ \ [ \tilde { P } _ { a }, \tilde { P } _ { b } ] = - \Lambda \epsilon _ { a b } ^ { \ c } J _ { c }$$
and 〈 J P a ˜ b 〉 = √ Λ η ab . If we now take the limit Λ → 0 then [ ˜ P , P a ˜ ] = 0, while the remaining commutators b are unchanged. Moreover, √ Λ in the scalar product cancels its inverse in the definition of k/ π 4 , cf. (5) and thus no divergencies appear in this limit. Furthermore, with the help of Cartan decomposition a gauge group element can be written as a product
$$g = j \mathfrak { p } = ( \iota _ { 3 } + \iota ^ { a } J _ { a } ) ( 1 + \xi ^ { a } \tilde { P } _ { a } ) \,, \quad j \in \mathrm S O ( 2, 1 ) \,, \quad \mathfrak { p } \in \mathrm s o ( 2, 1 ) ^ { * } \,,$$
where the coordinates ι on SO (2 , 1) group satisfy ι 2 3 + 1 4 ι a ι a = 1.
Applying (14) to group elements in the Lagrangian (11) we find that the WZW terms cancel out and only the boundary ones remain, giving
$$L = \frac { k } { 2 \pi } \int _ { \Gamma } \left \langle j ^ { - 1 } j \, d \xi - \bar { j } ^ { - 1 } \dot { \bar { j } } \, d \bar { \xi } + \frac { 1 } { k } \mathcal { C } _ { P } d \phi \bar { j } ^ { - 1 } \dot { \bar { j } } + \frac { 1 } { k } \mathcal { C } _ { J } d \phi \, \left [ \bar { j } ^ { - 1 } \dot { \bar { j } }, \bar { \xi } \right ] \right \rangle \,,$$
where we also neglected the total time derivative 1 k C dφξ ˙ ¯ . Meanwhile, the sewing condition (12) factorizes into j -1 = n e 1 k C J φ ¯ j -1 and -ξ = Ad( ) n h -Ad( n e 1 k C J φ ) ¯ , ξ where we write the decomposition (14) of N as N = n (1 + h ), n ∈ SO (2 , 1), h ∈ so (2 , 1) ∗ . C can be separated into C = C J + C P , C J = m/ √ Λ J 0 , C P = s/ √ Λ ˜ . P 0 Substituting the above expressions into (15) we get
$$L = \frac { k } { 2 \pi } \int _ { \Gamma } d \left \langle e ^ { - \frac { 1 } { k } \mathcal { C } _ { J } \phi } \dot { \mathfrak { n } } ^ { - 1 } \mathfrak { n } \, e ^ { \frac { 1 } { k } \mathcal { C } _ { J } \phi } \bar { \xi } - \mathfrak { n } ^ { - 1 } \dot { \mathfrak { n } } \, \frac { 1 } { k } \mathcal { C } _ { P } \phi \right \rangle \,,$$
where ¯ ξ ≡ ¯ ξ a ˜ . P a Integrating (16) over φ from 0 to 2 π and noticing that ¯ is a single-valued function on Γ, ξ hence ¯ (0) = ξ ¯ (2 ξ π ), we finally obtain [7]
$$L = \kappa x ^ { a } \left ( \dot { \Pi } \Pi ^ { - 1 } \right ) _ { a } - s \left ( \mathfrak { n } ^ { - 1 } \mathfrak { i } \right ) _ { 0 }, \\ e _ { \ } \cdots, \quad \ddots \quad a \, \tilde { \mathfrak { n } } \, - \,. \, \bar { \bar { \varepsilon } } \infty \,.. - 1 \quad, \, \mu \quad \cdots \quad, \quad \cdots \quad,$$
with the new variables of particle's position x = x a ˜ P a ≡ n ¯ (0) ξ n -1 and 'group valued momentum' Π, defined as
$$\Pi \equiv \mathfrak { n } \, e ^ { - \frac { 2 \pi } { k } \mathcal { C } _ { J } } \mathfrak { n } ^ { - 1 } = e ^ { - \frac { m } { k } \mathfrak { n } J _ { 0 } \mathfrak { n } ^ { - 1 } } \,.$$
Thus the Lagrangian (17) describes a deformed particle, whose momentum is now given by the group element Π defined above instead of the algebra element mJ 0 .
The group valued momentum Π is not arbitrary, but is given by the conjugation of e -2 π k C J by the Lorentz group element n . If we parametrize m J n 0 n -1 = q a J a then from (18) we find
$$\Pi = p _ { 3 } - \frac { 1 } { \kappa } \, p ^ { a } J _ { a } \,, \quad p _ { 3 } ^ { 2 } + \frac { 1 } { 4 \kappa ^ { 2 } } \, p _ { a } p ^ { a } = 1 \,, \quad p _ { 3 } = \cos \left ( \frac { | q | } { 2 \kappa } \right ) \,, \quad p ^ { a } = 2 \kappa \frac { q ^ { a } } { | q | } \, \sin \left ( \frac { | q | } { 2 \kappa } \right ) \,. \quad \ \ ( 1 9 ) \\ \intertext { t follow that } \, \text{the moment on } \, \text{a or coordinate on } \, \text{that} \, \text{that} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \,\text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \,\text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in}\, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \,\text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in } \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \,\text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \,\text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{in} \, \text{in} \, \text{and} \, \text{$$
It follows that the momenta p a are coordinates on the three dimensional Anti-de Sitter space constrained by the deformed mass shell condition. Introducing the Lagrange multiplier λ , the final action for the spinless case C P = 0 can be written in the components as
$$S = \int d t \left ( p _ { 3 } \dot { p } _ { a } x ^ { a } + \frac { 1 } { 2 \kappa } \epsilon _ { a b c } \dot { p } ^ { a } x ^ { b } p ^ { c } - \dot { p } _ { 3 } p _ { a } x ^ { a } \right ) + \lambda \left ( p _ { a } p ^ { a } - 4 \kappa ^ { 2 } \sin ^ { 2 } \frac { m } { 2 \kappa } \right ) \,,$$
where p 3 ≡ √ 1 -1 4 κ 2 p p a a . The detailed discussion of the properties of this action can be found in [6]. In the spinning case there is an additional term of the form -s ( n n 3 ˙ 0 -n n 0 ˙ 3 + 1 2 ( n n 1 ˙ 2 -n n 2 ˙ 1 )).
Let us now turn to the main result of this paper. The contraction of the de Sitter group SO (3 , 1) to Poincar´ e group is pretty well known and the resulting Lagrangian (17) has been derived and thoroughly analyzed e.g., in [6], [7]. It turns out, however, that there exist another contraction of the de Sitter group that to our knowledge has not been discussed in the literature. Contrary to the case considered above, where the translation sector of SO (3 , 1) was 'flattened', we consider 'flattening' of the Lorentz sector of SO (3 , 1).
To describe this new contraction let us return to the original algebra (1) and consider its Iwasawa decomposition into SO (2 , 1) and AN (2). The generators of the latter are defined as a linear combination of the original Lorentz and translation generators
$$S _ { a } & = P _ { a } + \epsilon _ { a 0 b } \, J ^ { b } \,,$$
so that we have
$$[ J _ { a }, J _ { b } ] = \epsilon _ { a b } ^ { \ c } \, J _ { c } \,, \quad [ J _ { a }, S _ { b } ] = \epsilon _ { a b } ^ { \ c } \, S _ { c } - \eta _ { a b } \, J _ { 0 } + \eta _ { b 0 } \, J _ { a } \,, \quad [ S _ { a }, S _ { b } ] = \eta _ { a 0 } \, S _ { b } - \eta _ { b 0 } \, S _ { a } \,.$$
The virtue of this decomposition is that the generators J a and S a form subalgebras of the algebra so (3 , 1); the price to pay, however, is that the cross commutators become quite complicated. Let us now rescale ˜ J a ≡ √ Λ J a to obtain
$$[ \tilde { J } _ { a }, \tilde { J } _ { b } ] = \sqrt { \Lambda } \, \epsilon _ { a b c } \, \tilde { J } ^ { c } \,, \ \ [ \tilde { J } _ { a }, S _ { b } ] = \sqrt { \Lambda } \, \epsilon _ { a b c } \, S ^ { c } + ( \eta _ { b 0 } \, \tilde { J } _ { a } - \eta _ { a b } \, \tilde { J } _ { 0 } ) \,, \ \ [ S _ { a }, S _ { b } ] = \eta _ { a 0 } \, S _ { b } - \eta _ { b 0 } \, S _ { a } \,,$$
which after contraction Λ → 0 takes the form
$$[ \tilde { J } _ { a }, \tilde { J } _ { b } ] = 0 \,, \ \ [ \tilde { J } _ { a }, S _ { b } ] = ( \eta _ { b 0 } \, \tilde { J } _ { a } - \eta _ { a b } \, \tilde { J } _ { 0 } ) \,, \ \ [ S _ { a }, S _ { b } ] = \eta _ { a 0 } \, S _ { b } - \eta _ { b 0 } \, S _ { a } \,.$$
It is worth mentioning that, as it was in the case of the Poicar´ algebra above, the algebra (24) is a Lie e algebra of the group G /multicloseleft g ∗ , where G is now the group AN (2) generated by the last commutator in (24).
In terms of the new generators the scalar products read
$$\left \langle \tilde { J } _ { a } S _ { b } \right \rangle = \sqrt { \Lambda } \, \eta _ { a b } \,, \quad \left \langle \tilde { J } _ { a } \tilde { J } _ { b } \right \rangle = \left \langle S _ { a } S _ { b } \right \rangle = 0 \,.$$
In spite of the fact that this scalar product becomes degenerate in the limit Λ → 0, in the effective particle action Λ is cancelled out and the contraction limit is not singular.
A gauge group element can now be decomposed into
$$\gamma = j \mathfrak { s } = ( 1 + \iota ^ { a } \tilde { J } _ { a } ) \, e ^ { \sigma ^ { i } \, S _ { i } } \, e ^ { \sigma ^ { 0 } \, S _ { 0 } } \,, \ \ i = 1, 2 \,,$$
where for s we use the parametrization that proved convenient in the context κ -Poincar´ theories [21] and e is related to the other parametrization s = ξ 3 + ξ a S a via σ 0 = 2 log( ξ 3 + 1 2 ξ 0 ), σ i = ( ξ 3 + 1 2 ξ 0 ) ξ i .
Since it is our goal to obtain a curved momentum space after the Λ → 0 limit is taken, we must change the form of C = C J + C S , describing the particle at rest, so as to have the mass in the S sector. Adjusting dimensions properly we get C J = s/ √ Λ ˜ , J 0 C S = m/ √ Λ S 0 .
After these preparations we can return to the formulae (11), (12). Writing N = (1+ n ) h , with h ∈ AN (2), n ∈ so (2 , 1) and using the factorization (26) one first finds that
$$\mathfrak { s } ^ { - 1 } = \mathfrak { h } \exp \left ( \frac { 1 } { k } \mathcal { C } _ { S } \phi \right ) \bar { \mathfrak { s } } ^ { - 1 } \,.$$
Next, from the commutation relations (24), for an arbitrary s we have
$$\mathfrak { s } \exp \left ( \frac { 1 } { k } \mathcal { C } _ { J } \phi \right ) \mathfrak { s } ^ { - 1 } = \exp \left ( \frac { 1 } { k } \mathcal { C } _ { J } \phi \right ) \,.$$
As a result one obtains the second condition
$$\mathfrak { u } = \exp \left ( \frac { 1 } { k } \mathcal { C } _ { J } \phi \right ) \mathfrak { s } \left ( 1 - n \right ) \mathfrak { s } ^ { - 1 } \,,$$
where we denote u ≡ ¯ j -1 j .
We now plug the factorization (26) into our starting Lagrangian (11), finding
$$L = \frac { k } { 2 \pi } \int _ { \Gamma } \left \langle \dot { \mathfrak { u } } \, \mathfrak { u } ^ { - 1 } \left ( d \bar { \mathfrak { s } } \, \bar { \mathfrak { s } } ^ { - 1 } - \bar { \mathfrak { s } } \, \frac { 1 } { k } \, \mathcal { C } d \phi \, \bar { \mathfrak { s } } ^ { - 1 } \right ) + \frac { 1 } { k } \, \mathcal { C } d \phi \, \bar { \mathfrak { s } } ^ { - 1 } \dot { \mathfrak { s } } \right \rangle \,.$$
Substituting the continuity conditions for u and s into (30) and keeping in mind the limit Λ → 0 we obtain
$$L = \frac { k } { 2 \pi } \int \left \langle \partial _ { 0 } \left ( \bar { s e } ^ { - \ddagger } C _ { S } \phi _ { \hbar { h } } ^ { - 1 } n \hbar { e } ^ { \ddagger } C _ { S } \phi _ { \hbar { s } } ^ { - 1 } \right ) \left ( - d \bar { s } \bar { s } ^ { - 1 } + \bar { s } \frac { 1 } { k } \, C _ { S } d \phi \bar { s } ^ { - 1 } \right ) + \frac { 1 } { k } \, C _ { J } d \phi \bar { s } ^ { - 1 } \dot { \bar { s } } \right \rangle \,. \quad ( 3 1 )$$
In the last step, neglecting the total time derivative and integrating over the angular variable we eventually obtain the expression very similar to (17)
$$L = \frac { k } { 2 \pi } \left \langle \Pi \dot { \Pi } ^ { - 1 } x \right \rangle + \left \langle \mathcal { C } _ { J } \bar { \mathfrak { s } } ^ { - 1 \dot { \mathfrak { s } } } \right \rangle, \\ - \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
but with the deformed momenta Π being now the elements of the AN (2) group, instead of the Lorentz group SO (2 , 1), to wit
$$\Pi \equiv \bar { s } \, e ^ { \frac { 2 \pi } { k } \mathcal { C } _ { S } } \bar { s } ^ { - 1 } \,, \quad x \equiv \bar { s } \, \mathfrak { h } ^ { - 1 } ( 0 ) n ( 0 ) \mathfrak { h } ( 0 ) \bar { s } ^ { - 1 } \,.$$
The Lagrangian (32) is the main result of our paper.
Since the Lorentz group SO (2 , 1) is, as a manifold, the three dimensional Anti-de Sitter space, while AN (2) is a submanifold of the three dimensional de Sitter space, we managed to obtain the momentum space of positive, instead of the negative, constant curvature. Moreover, contrary to (17), which is defined only in 2+1 dimension, the expression (32) can be readily generalized to any spacetime dimension.
Let us now turn to the detailed discussion of the properties of Lagrangian (32). The first thing to notice is that the first equation in (33) puts severe restrictions on the form of momentum Π. Indeed if we write
$$\Pi = e ^ { p ^ { i } / \kappa \, S _ { i } } \, e ^ { p ^ { 0 } / \kappa \, S _ { 0 } } \,,$$
and take ¯ to have the form s we immediately find that
$$\bar { \mathfrak { s } } = e ^ { \bar { \sigma } ^ { i } S _ { i } } \, e ^ { \bar { \sigma } ^ { 0 } S _ { 0 } } \,,$$
$$p ^ { 0 } = m \,, \quad p ^ { i } = \kappa \, ( 1 - e ^ { \frac { m } { \kappa } } ) \, \bar { \sigma } ^ { i } \,.$$
As it was in the case considered above these equations play a role of the mass shell relation, and force the energy to be constant, independently of the particle dynamics. In the undeformed case (which can be obtained in the limit κ → ∞ ) such mass shell condition makes the particle effectively frozen, it can not move, and for that reason, following [14] we call it the 'Carroll particle.'
In the following discussion we will consider only the spinless case. It turns out that this is in fact the general case, because the spin term does not contribute nontrivially to the equations of motion. Indeed an arbitrary variation δ ¯ = s /pi1 ¯, s δ ¯ s -1 = -¯ s -1 /pi1 of this term results in a total time derivative
$$\delta \left \langle \mathcal { C } _ { J } \bar { s } ^ { - 1 } \dot { \bar { s } } \right \rangle = \left \langle \bar { s } \mathcal { C } _ { J } \bar { s } ^ { - 1 } \dot { \omega } \right \rangle = \frac { d } { d t } \left \langle \mathcal { C } _ { J } \varpi \right \rangle \,, \\ \dots \, \dots \, \sim \, \left ( \cdots \, \right ) \, \right )$$
because ˜ J 0 commutes with all S generators (cf. (24).)
Let us discuss the deformed Lagrangian in more details. Expressed in components of momentum p a it reads
$$L = x ^ { 0 } \dot { p } _ { 0 } + x ^ { i } \dot { p } _ { i } - \kappa ^ { - 1 } x ^ { i } \, p _ { i } \dot { p } _ { 0 } + \lambda ( p _ { 0 } ^ { 2 } - m ^ { 2 } ) \,,$$
where, as before, we introduce the Lagrange multiplier λ to enforce the mass shell constraint. The equations of motion following from variations over x are momentum conservations ˙ p a = 0, while the ones resulting from the variation over momenta give
$$\dot { x } ^ { 0 } = 2 \lambda \, p _ { 0 } = 2 \lambda \, m \,, \quad \dot { x } ^ { i } = 0 \,,$$
so that indeed the Carroll particle is always at rest. Furthermore, from (33) we may also find the explicit expressions for the components x 0 = n 0 -( e ζ 0 -¯ σ 0 ¯ σ i -ζ i ) n i , x i = e ζ 0 -¯ σ 0 n i . Then (39) will give some conditions for coordinates of n , h = e ζ S i i e ζ 0 S 0 and ¯. s
The presence of the nonlinear, deformed term in the Lagrangian (38) results in the nontrivial Poisson bracket algebra of the κ -deformed phase space [22]
$$\left \{ x ^ { i }, p _ { j } \right \} = \delta _ { j } ^ { i } \,, \quad \left \{ x ^ { 0 }, p _ { 0 } \right \} = 1 \,, \quad \left \{ x ^ { 0 }, p _ { i } \right \} = - \frac { 1 } { \kappa } p _ { i } \,, \quad \left \{ x ^ { 0 }, x ^ { i } \right \} = \frac { 1 } { \kappa } \, x ^ { i } \,, \quad \left \{ 4 0 \right ) \\ \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \,.$$
Meanwhile, symmetries of the action obtained from the Lagrangian (38) form the algebra of infinitesimal deformed Carroll transformations, containing
- · rotations
$$\delta x ^ { i } = \rho \, \epsilon ^ { i } _ { \, j } \, x ^ { j } \,, \quad \delta p _ { i } = \rho \, \epsilon _ { i } ^ { \, j } \, p _ { j } \,, \quad \delta x ^ { 0 } = \delta p _ { 0 } = 0 \, ;$$
- · deformed boosts
$$\delta x ^ { 0 } = ( 1 + \kappa ^ { - 1 } p _ { 0 } ) \, \lambda _ { i } \, x ^ { i } \,, \quad \delta p _ { i } = - \lambda _ { i } \, p _ { 0 } \,, \quad \delta x ^ { i } = \delta p _ { 0 } = 0 \, ;$$
- · deformed translations
$$\delta x ^ { 0 } = a ^ { 0 } \,, \quad \delta x ^ { i } = e ^ { p _ { 0 } / \kappa } \, a ^ { i } \,, \quad \delta p _ { a } = 0 \, ;$$
- · the spatial conformal transformation
$$\delta x ^ { i } = \eta \, x ^ { i } \,, \quad \delta p _ { i } = - \eta \, p _ { i } \,, \quad \delta x ^ { 0 } = \delta p _ { 0 } = 0 \,,$$
where ρ , λ i , a a , η are parameters of the respective transformations.
Actually, as noted in [14] the undeformed Carroll particle has an infinite dimensional symmetry. This property holds in the deformed case as well, and the generator of the infinitesimal transformations δφ a = { φ , G a } , where φ is an arbitrary function on phase space, is given by
$$G = f ( p _ { 0 } / \kappa ) p _ { 0 } \, \xi ^ { 0 } ( x ^ { i } ) + p _ { i } \, \xi ^ { i } ( x ^ { i } ) \,, \quad f ( 0 ) = 1 \,,$$
where f ( p /κ 0 ) is an arbitrary function of energy, while ξ i ( x i ), ξ 0 ( x i ) are arbitrary functions of position.
Let us complete this paper with some comments.
First it should be stressed that the particle model we derived (32) can be extended to any number of spacetime dimensions D +1, simply by replacing the group AN (2) with AN ( D ). This makes it potentially much more relevant for real physical systems than the model based on Poincar´ group (17), whose application e is strictly restricted to 2+1 dimensions.
In our view, the most significant result of this paper is the derivation of a particle model with κ -deformed phase space (40) from the first principles as a deformation of the free particle model resulting from the interaction of the particle with its own gravitational field. However, it turns out that the model we obtained is not the κ -Poincar´ particle discussed in the context of Doubly Special Relativity [10] or Relative Locality e [23], [21], but the deformed Carroll particle, with completely frozen dynamics. It is therefore still an open problem if the κ -Poincar´ particle can be derived from the particle-gravity system as an effective deformed e particle theory. We will revisit this issue in the forthcoming paper.
There is a curious similarity between Carrollian relativity, being the relativistic theory obtained in the limit c → 0, in which no local interactions are possible and the very similar feature of the 2+1 gravity and the topological limit of gravity in 3+1 dimensions [24], [25], [26]. Especially in the 3+1 case it would be of interest to find out if gravity is described by a topological field theory in the Carrollian limit (for some discussion of this issue see [27].)
As already mentioned, the Carrollian limit appears in many distinct areas of theoretical physics, the common feature of whose is the presence of gravity in one form or another. The free and interacting particle models are extremely useful in that they help to grasp the underlying physics. It seems that the deformed model presented here, which already takes into account self-gravitational interactions might be of great interest, especially in the context of cosmological investigations [19].
## ACKNOWLEDGMENT
This work was supported by funds provided by the National Science Center under the agreement DEC2011/02/A/ST2/00294. TT acknowledges the support by the Foundation for Polish Science International PhD Projects Programme co-financed by the EU European Regional Development Fund and the additional
funds by the European Human Capital Program.
- [1] A. Staruszkiewicz, 'Gravitation Theory in Three-Dimensional Space,' Acta Phys. Polon. 24 , 735 (1963).
- [2] S. Deser, R. Jackiw and G. 't Hooft, 'Three-Dimensional Einstein Gravity: Dynamics of Flat Space,' Annals Phys. 152 , 220 (1984).
- [3] S. Deser and R. Jackiw, 'Three-Dimensional Cosmological Gravity: Dynamics of Constant Curvature,' Annals Phys. 153 , 405 (1984).
- [4] E. Witten, '(2+1)-Dimensional Gravity as an Exactly Soluble System,' Nucl. Phys. B 311 , 46 (1988).
- [5] A. Achucarro and P. K. Townsend, 'A Chern-Simons Action for Three-Dimensional anti-De Sitter Supergravity Theories,' Phys. Lett. B 180 , 89 (1986).
- [6] H.-J. Matschull and M. Welling, 'Quantum mechanics of a point particle in (2+1)-dimensional gravity,' Class. Quant. Grav. 15 , 2981 (1998) [gr-qc/9708054].
- [7] C. Meusburger and B. J. Schroers, 'Poisson structure and symmetry in the Chern-Simons formulation of (2+1)-dimensional gravity,' Class. Quant. Grav. 20 , 2193 (2003) [arXiv:gr-qc/0301108].
- [8] L. Freidel and E. R. Livine, 'Ponzano-Regge model revisited III: Feynman diagrams and effective field theory,' Class. Quant. Grav. 23 , 2021 (2006) [hep-th/0502106].
- [9] L. Freidel and E. R. Livine, 'Effective 3-D quantum gravity and non-commutative quantum field theory,' Phys. Rev. Lett. 96 , 221301 (2006) [hep-th/0512113].
- [10] J. Kowalski-Glikman and S. Nowak, 'Doubly special relativity and de Sitter space,' Class. Quant. Grav. 20 , 4799 (2003) [hep-th/0304101].
- [11] M. Arzano and J. Kowalski-Glikman, 'Kinematics of a relativistic particle with de Sitter momentum space,' Class. Quant. Grav. 28 , 105009 (2011) [arXiv:1008.2962 [hep-th]].
- [12] J. Lukierski, H. Ruegg and W. J. Zakrzewski, 'Classical quantum mechanics of free kappa relativistic systems,' Annals Phys. 243 , 90 (1995) [hep-th/9312153].
- [13] S. Majid and H. Ruegg, 'Bicrossproduct structure of kappa Poincare group and noncommutative geometry,' Phys. Lett. B 334 , 348 (1994) [hep-th/9405107].
- [14] E. Bergshoeff, J. Gomis and G. Longhi, 'Dynamics of Carroll Particles,' arXiv:1405.2264 [hep-th].
- [15] Lewis Carroll, Through the Looking Glass and what Alice Found There, London: MacMillan (1871).
- [16] H. Bacry and J. Levy-Leblond, 'Possible kinematics,' J. Math. Phys. 9 , 1605 (1968).
- [17] C. -G. Huang, Y. Tian, X. -N. Wu, Z. Xu and B. Zhou, 'Geometries for Possible Kinematics,' Sci. China G 55 (2012) 1978 [arXiv:1007.3618 [math-ph]].
- [18] C. Duval, G. W. Gibbons, P. A. Horvathy and P. M. Zhang, 'Carroll versus Newton and Galilei: two dual non-Einsteinian concepts of time,' Class. Quant. Grav. 31 , 085016 (2014) [arXiv:1402.0657 [gr-qc]].
- [19] J. Mielczarek, 'Asymptotic silence in loop quantum cosmology,' AIP Conf. Proc. 1514 , 81 (2012) [arXiv:1212.3527].
- [20] C. Meusburger and B. J. Schroers, 'The Quantization of Poisson structures arising in Chern-Simons theory with gauge group G x g*,' Adv. Theor. Math. Phys. 7 , 1003 (2004) [hep-th/0310218].
- [21] J. Kowalski-Glikman, 'Living in Curved Momentum Space,' Int. J. Mod. Phys. A 28 , 1330014 (2013) [arXiv:1303.0195 [hep-th]].
- [22] G. Amelino-Camelia, J. Lukierski and A. Nowicki, 'kappa-deformed Covariant Phase Space and Quantum-Gravity Uncertainty Relations,' Phys. Atom. Nucl. 61 , 1811 (1998) [Yad. Fiz. 61 (1998) 1925] [hep-th/9706031].
- [23] G. Amelino-Camelia, L. Freidel, J. Kowalski-Glikman and L. Smolin, 'The principle of relative locality,' Phys. Rev. D 84 , 084010 (2011) [arXiv:1101.0931 [hep-th]].
- [24] L. Freidel and A. Starodubtsev, 'Quantum gravity in terms of topological observables,' hep-th/0501191.
- [25] L. Freidel, J. Kowalski-Glikman and A. Starodubtsev, 'Particles as Wilson lines of gravitational field,' Phys. Rev. D 74 , 084002 (2006) [gr-qc/0607014].
- [26] J. Kowalski-Glikman and A. Starodubtsev, 'Effective particle kinematics from Quantum Gravity,' Phys. Rev. D 78 , 084039 (2008) [arXiv:0808.2613 [gr-qc]].
- [27] G. Dautcourt, 'On the ultrarelativistic limit of general relativity,' Acta Phys. Polon. B 29 , 1047 (1998) [gr-qc/9801093]. | 10.1016/j.physletb.2014.08.066 | [
"J. Kowalski-Glikman",
"T. Trzesniewski"
] | 2014-08-01T12:43:17+00:00 | 2014-08-01T12:43:17+00:00 | [
"hep-th",
"gr-qc"
] | Deformed Carroll particle from 2+1 gravity | We consider a point particle coupled to 2+1 gravity, with de Sitter gauge
group SO(3,1). We observe that there are two contraction limits of the gauge
group: one resulting in the Poincare group, and the second with the gauge group
having the form AN(2) \ltimes \an(2)^*. The former case was thoroughly
discussed in the literature, while the latter leads to the deformed particle
action with de Sitter momentum space, like in the case of kappa-Poincare
particle. However, the construction forces the mass shell constraint to have
the form p_0^2 = m^2, so that the effective particle action describes the
deformed Carroll particle. |
1408.0155v2 | ## Field-reversed bubble in deep plasma channels for high quality electron acceleration
A. Pukhov , O. Jansen , T.Tueckmantel , J. Thomas 1 1 1 1 and I. Yu. Kostyukov 2 3 , 1 Institut fuer Theoretische Physik I, Universitaet Duesseldorf, 40225 Germany 2 Lobachevsky National Research University of Nizhni Novgorod, 603950, Nizhny Novgorod, Russia and 3
Institute of Applied Physics RAS, Nizhny Novgorod 603950, Russia
We study hollow plasma channels with smooth boundaries for laser-driven electron acceleration in the bubble regime. Contrary to the uniform plasma case, the laser forms no optical shock and no etching at the front. This increases the effective bubble phase velocity and energy gain. The longitudinal field has a plateau that allows for mono-energetic acceleration. We observe as low as 10 -3 r.m.s. relative witness beam energy uncertainty in each cross-section and 0.3% total energy spread. By varying plasma density profile inside a deep channel, the bubble fields can be adjusted to balance the laser depletion and dephasing lengths. Bubble scaling laws for the deep channel are derived. Ultra-short pancake-like laser pulses lead to the highest energies of accelerated electrons per Joule of laser pulse energy.
PACS numbers: PACS1
The laser wake field acceleration (LWFA) [1] in underdense plasmas provides an option for high gradient particle acceleration [2]. Especially efficient is the bubble regime [3] when the laser expels background plasma electrons from the first half of the plasma wave. The advantage of the cavitated region is the transverse uniformity of its axial accelerating field [4] so that the energy gain of the accelerated electrons is not affected by their lateral motions in the bubble and the bunch can remain monoenergetic. The quasi-monoenergetic electron bunches are readily registered in experiments [5].
Despite various theoretical approaches: the phenomenological model of the bubble [4], the nonlinear theory of blowout regime [6, 7] and the similarity theory [8], -a self-consistent analytical description of the bubble regime is still absent.
The bubble theories exist for homogeneous plasmas only. Similarity theory together with energy conservation arguments resulted in the 'optimal' scaling laws for homogeneous plasma [9]. These were tested in 3d PIC simulations [10]. The scalings assume that the laser energy is converted into the bubble fields first and then harvested by the electron bunch. The leading similarity parameters for the bubble in homogeneous plasmas are the S -number S = n /an e c glyph[lessmuch] 1 and the pulse aspect ratio Π = cτ/R ≤ 1 . Here, n e is the plasma electron density and n c = π/r λ e 2 0 is the critical plasma density for a laser pulse with the wavelength λ 0 , a = eE /mcω 0 0 is the dimensionless laser amplitude, ω 0 = 2 πc/λ 0 , and r e = e /mc 2 2 is the classical electron radius, τ is the pulse duration and R is its radius.
In a uniform plasma, the bubble regime has some drawbacks. First, the laser energy depletion length is shorter than the electron dephasing length. This limits the maximum electron energy gain. Second, the transverse bubble fields acting on the accelerated electron bunch are strongly focusing. Thus, electrons running forward with the relativistic factor γ oscillate about the bub- ble axis at the betatron frequency ω β = ω / p √ 2 γ , where ω p = √ 4 πe n /m 2 e is the background plasma frequency. A relativistic electron can easily come into betatron resonance with the Doppler-shifted laser that may result in energy exchange [11]. This betatron resonance broadens the electron bunch energy distribution and deteriorates the beam quality [12, 13].
Here, we consider the bubble regime of electron acceleration, but in a deep plasma channel rather than in a uniform plasma. This allows for a significant improvement of the acceleration . We demonstrate that (i) the effective bubble phase velocity and energy gain increase in the channel; (ii) the longitudinal field has a plateau that allows for mono-energetic acceleration; (iii) the focusing force acting on the accelerated bunch is strongly reduced; (iv) the bubble scaling laws and the bubble field distribution for the deep channel are derived; (v) according to the new scaling laws, ultra-short pancake-like laser pulses match the dephasing and depletion length in the channel and thus lead to the highest energy gains of accelerated electrons per Joule of laser pulse energy . In simulations, we observe as low as 10 -3 r.m.s. relative witness beam energy uncertainty in each cross-section and 0.3% total energy spread. The lack of focusing in the channel eliminates the very possibility of a betatron resonance and leads to much sharper beam energy distributions.
Normally, plasma channels are used to guide weakly relativistic pulses over distances much larger than the Rayleigh length Z R = πR /λ 2 0 . These channels are shallow as a rule, i.e., the relative on-axis plasma density depletion is slight. Schroeder et al. [14] suggested recently the use of nearly hollow plasma channels to provide independent control over the focusing and accelerating forces. Chiou et al. [15] revealed that the transverse electric field of the wake is not monotonic in the hollow channel. However, these papers were limited only to a quasilinear regime of the plasma wake generation and a rectangular channel density profile.
Table I: Laser-plasma parameters used in the simulations and the observed electron energies. Expected energies from the scaling law are in brackets. All the lasers had a 0 = 10 ; the channel parameter δ = 0 3 . .
| W L , J | 2.2 | 17.6 | 141 |
|----------------|-----------|----------------|----------------|
| τ , fs | 4 | 8 | 16 |
| R , µ m | 8 | 16 | 32 |
| n 0 , 1/cm 3 | 5 · 10 18 | 1 . 25 · 10 18 | 0 . 31 · 10 18 |
| R ch , µ m | 6 | 12 | 24 |
| l i , µ m | 0.8 | 1.6 | 3.2 |
| N i , pC | 10 | 20 | 40 |
| E i , GeV | 0.1 | 0.4 | 1.6 |
| L A , cm | 1.6 | 12.8 | 100 |
| E dc max , GeV | 1.5 | 6 (6) | 23.5 (24) |
A plasma channel is not required for laser guiding in the bubble regime, since the laser pulse is self-guided by the cavitated region of the bubble. Thus, a preformed shallow plasma channel is not expected to change the bubble dynamics significantly. However, as will be seen, a deep plasma channel i.e., one that is (nearly) empty onaxis, can strongly modify the bubble fields, the nonlinear laser dynamics, and the trapping. We are looking for laser-plasma parameters that maximize energy of the accelerated electron bunch and improve its quality: mainly, reduce the energy spread.
The laser pulse energy W L is the technologically important characteristics of a laser pulse. It is limited, e.g. by size of the active crystal or by compression gratings, etc. We are comparing the energy scalings for the two cases: the uniform plasma case and the deep channel case.
In uniform plasma, the similarity scalings for electron bunch energy E max from a bubble [9] can be expressed in terms of the laser pulse power P L , duration τ and energy W L = P τ L :
$$\mathcal { E } _ { \max } ^ { \text{uniform} } \in \sqrt { P _ { L } e ^ { 2 } c \tau } \lambda _ { 0 } ^ { - 1 } = \lambda _ { 0 } ^ { - 1 } \sqrt { W _ { L } e ^ { 2 } c \tau } \quad ( 1 ) \quad \text{files} \quad$$
The scaling of Eq. (1) favors longer laser pulses. This reflects the mechanism of laser pulse depletion in the standard bubble. The laser pulse interacts with plasma electrons at the very front only. The major part of the pulse propagates freely in the cavitated region. Thus, the pulse tail slowly overtakes its head, where an 'optical shock' is formed and the pulse 'etches'. This 'etching' leads to the pulse shortening [16] and faster dephasing that in turn lowers the maximum energy gain. The highest electron energies are achieved with 'spherical' laser pulses, whose duration cτ equals their radius R [10]. Such pulses fill the cavitated region completely and interact with the accelerated bunch affecting its quality.
Also, in the uniform plasma case, the bubble may continuously trap electrons causing strong beam loading and thus large energy spread. Also, the accelerating field
Figure 1: Simulation results for the case R = 32 µ m. a) The cross-section of the plasma electron density and the longitudinal bubble field; b) on-axis accelerating field of the bubble, GV/m. Flattening of E z at the bubble rear part is visible. The broken lines in frame (a) mark the vacuum part of the plasma channel. The purple rippling of the E z at the bubble head is caused by the short laser pulse.
in the standard bubble is a linear function of the longitudinal coordinate [4, 6]. If one wants a truly monoenergetic acceleration of externally injected particles, the witness bunch to be accelerated must be extremely short. Demanding, e.g. 1% energy spread, the witness bunch should not occupy more than 1% of the bubble length.
The use of the deep plasma channel gives us several new control parameters to improve the acceleration. We consider channels with a zero plasma density on-axis and some smoothly growing density at the borders. We have chosen the following parameterization for the plasma radial profile: n e = n 0 [ δ exp( r/R ch ) -1] , for r ≥ r 0 and n e = 0 for r < r 0 , where r 0 = R ch ln(1 /δ ) . Such profiles can be produced by ablation from walls of an empty capillary [17]. The parameters n , δ, R 0 ch provide enough freedom to adjust fields in the channel while ensuring a smooth guiding of the relativistically intense laser pulse. In simulations, we reduced the maximum plasma density far from the channel axis for numerical stability.
The freedom on the bubble fields in the deep channel allows the achievement of much higher electron energies with a laser of a given pulse energy. Let us assume that the accelerating bubble field E is completely at our disposal and that the laser pulse energy is converted primarily into that field. The laser pulse energy scales as W L ∝ R Icτ 2 , where I is the laser intensity. We omit dimensionless numerical factors like π etc. as we are interested in parametric dependencies only. The numerical pre-factors can be obtained from gauging the scaling laws against PIC simulations.
We can find the pulse depletion length L d by com-
Figure 2: Transverse electric field of the bubble for the laser radius R = 40 λ 0 and a 0 = 10 . a) Homogeneous plasma: the field is focusing. b) Channel: the field reverses its sign in the channel walls; the smooth curve gives the analytic solution for the field E y .
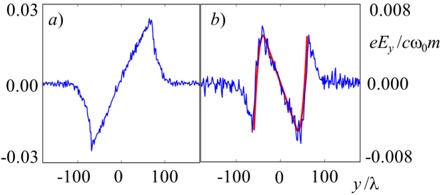
paring the energy deposited in the wake field W wake ∝ E R L 2 2 d and the initial pulse energy, W wake = W L :
$$L _ { \mathrm d } \in I c \tau E ^ { - 2 }. \quad \ \ ( 2 ) \quad \ \ w i$$
Here we assume a cylindrically symmetric bubble whose radius scales together with the laser radius R .
The particle acceleration is limited either by the laser pulse depletion (2), or by electron dephasing. In the uniform plasma case, it was the laser pulse depletion that limited acceleration in the bubble regime. In the deep channel case of interest here, however, the depletion length can be adjusted by properly choosing the accelerating field E , as can be seen from (2). The maximum particle energy is achieved when the depletion length L d equals the dephasing length L A . Otherwise, the maximum energy gain is limited by the shortest of the two lengths and is lower. The dephasing length scales as L A ∝ Rγ 2 L , where γ L is the relativistic γ -factor associated with the laser group velocity. In a deep plasma channel, γ L is not influenced by the plasma and is defined solely by the laser pulse radius so that we can write γ L ∝ k R 0 , where k 0 = 2 π/λ 0 . For the dephasing length we obtain
$$L _ { A } ^ { d c } \in k _ { 0 } ^ { 2 } R ^ { 3 } \quad \quad ( 3 ) \quad \text{en}$$
We reuire the depletion length of Eq. (2) to be equal the dephasing length (3) and obtain for the bubble field E ∝ √ Icτ/k R 2 0 3 in the deep plasma channel. This leads to the maximum energy gain scaling
$$\mathcal { E } _ { \max } ^ { \text{dc} } \in e L _ { \text{A} } E \in e \sqrt { I c \tau k _ { 0 } ^ { 2 } R ^ { 3 } } = k _ { 0 } \sqrt { m c ^ { 2 } W _ { L } r _ { e } R } \ \ ( 4 ) \quad \text{paran}.$$
The deep channel scaling (4) differs dramatically from the uniform plasma bubble scaling (1). While the uniform plasma case requires the maximum pulse duration τ , in the deep channel, pulses with radius R as large as possible have an advantage.
A deeper insight in the bubble field configuration provides the quasistatic theory, which implies that the bubble slowly evolves in time and the bubble fields depend on ξ = t -z [18-20]. The nonlinear theory of the bubble in homogeneous plasma [6] can be generalized to transversally inhomogeneous plasma (details be published elsewhere). It follows from the theory that the bubble field not too close to the edge of the bubble is defined by the source function s r ( b ) ≡ (1 / 2 r 2 b ) GLYPH<1> r b 0 ρ ion ( r ) rdr :
$$\Phi _ { \Phi } & \quad \mathbf E \approx \mathbf e _ { r } \left [ \frac { 2 r _ { b } ^ { 2 } s ( r ) } { r } - r s ( r _ { b } ) \right ] - \mathbf e _ { z } 2 \xi s ( r _ { b } ), \, \mathbf B \approx - r s ( r _ { b } ). \\ \kappa \, \infty \quad \Phi _ { \Phi } \quad, \quad \Phi _ { \Phi } \quad, \quad \Phi _ { \Phi } \quad,$$
For homogeneous plasma ρ ion ( r ) = 1 we recover known expression for the bubble field [4] E ≈ e r r/ 4 -e z ξ/ 2 and B ≈ -e ϕ r/ 4 . For the plasma channel with exponential profile discussed above the source function takes a form s r ( ) = | e n | 0 ( r 2 0 -r 2 +2 ηr ch δ ) / ( 4 r 2 b ) , for r ≥ r 0 and s r ( ) = 0 for r < r 0 , where η = exp( r/r ch ) ( r -r ch ) + exp( r /r 0 ch ) ( r ch -r 0 ) . The obtained solution says that inside the vacuum part of the plasma channel r < r 0 the bubble field is purely electromagnetic B ϕ = E r = 2( r/ξ E ) z . In the channel walls, the ion field is added and can reverse the sign of the transversal electric field (see Fig.2) . Another conclusion is that the plasma channel reduces the gradients of the accelerating and focusing forces in comparision with homogeneous plasma.
To check the quasi-static theory and the energy scalings, we perform a series of 3d PIC simulations using the code VLPL [21]. We run the code in laboratory frame for simulations with the smallest pulse radius. The laser pulse is circularly polarized and has the envelope a ( t, r ) = a 0 exp ( -r 2 /R 2 -t 2 /τ 2 ) . The envelope is cut to zero at t = 2 τ, r = 2 R . We assume laser wavelength λ 0 = 800 nm.
We observe very little or no self-injection in the bubble when an empty on-axis channel is used. Thus, we inject an external co-propagating witness electron bunch at the end of the bubble. It has the half-length l i , initial energy E i , and the total charge N i . The simulation parameters are collected in Table I.
We selected an extremely short laser pulse with τ 0 = 4 fs, R 0 = 8 µ m, and energy of W L = 2 2 . J as the first member for the sequence of three in our power of 2 scaling sequence for both pulse duration and radius, as given in Table I. Although such short and energetic pulses do not exist yet, projects are under way to achieve similar parameters. According to the similarity rule, we scale simultaneously the laser pulse radius and duration with the same factor α = 2 from stage n to stage n + 1 : R ( n +1) = αR ( n ) and τ ( n +1) = ατ ( n ) so that the aspect ratio Π = R/cτ ≈ 6 7 . remains fixed, i.e. the pulses are
Figure 3: Simulation results for the case R = 32 µ m ( R = 40 λ 0 ). a) Energy spectra of the witness beam at different acceleration stages. b) Evolution of relative r.m.s. spectral width σ E i . The homogenous acceleration lasts for the first 30 cm and minumum spectral width of 0.3% is reached. Later, the bunch gains positive energy chirp due to dephasing and the spectrum widens. c) Longitudinal phase space of the witness bunch at different propagation distances. d) The final phase space of the bunch zoomed. The local energy uncertainty is 10 -3 and is limited by numerical resolution.
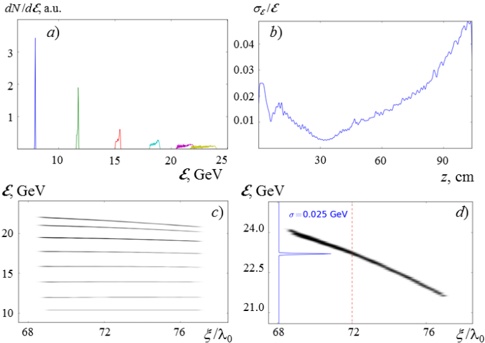
Figure 4: Nonlinear evolution of the laser pulse for the simulation case R = 32 µ m. No typical for bubble regime pulse shortening or 'optical shock' formation.
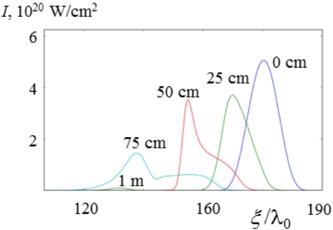
pancake-like. This allows us to reproduce the wake field (the bubble) exactly without additional search for the optimal plasma channel parameters. The other parameters scale as R ch(n+1) = αR ch(n) , n e n ( +1) = α -2 n e n ( ) , E ( n +1) = α -1 E ( n ) , L A(n+1) = α L 3 A( n ) , and the particle energy scales as E max( n +1) = α 2 E max( n ) . The three scaled cases are digested in Table I. The most energetic pulse with τ 2 = 16 fs, radius R 2 = 32 µ m and energy of W L = 141 J would correspond to the planned Apollon laser [22]. The acceleration lengths range from L A = 2 cm for the shortest laser, to L A = 1 m for the largest laser pulse. These distances can be simulated only using the Lorentz boost [23].
The bubble generated by the largest laser pulse radius R = 32 µ m is shown in Fig.1. The accelerating field,
Fig.1(a), is transversely uniform. It allows for monoenergetic acceleration of wide electron bunches. This transverse field uniformity is also observed in homogeneous plasmas. The on-axis profile of the accelerating field in the channel, Fig.1(b), however, differs from that in the uniform plasma case. There is a region of flat accelerating field at the very back of the bubble. This region can be used to accelerate reasonably long witness bunches mono-energetically.
Fig.2 shows the bubble transverse fields in the bubble corresponding to the case R = 40 λ 0 and a 0 = 10 . We compare predictions of the quasi-static model with the numerical simulations. In the bubble center, dE /dy y ≈ 0 08 . , dE /dξ z ≈ 0 15 . ≈ 2( dE /dy y ) in the simulation and dE /dy y ≈ 0 08 . , dE /dξ z ≈ 0 16 = 2( . dE /dy y ) in the models that is in a very good agreement. Fig.2(b) clearly shows the field reversal in the channel.
To check the acceleration, we inject a witness bunch that occupies about 10% of the bubble length. The energy spectra of the accelerated bunch are shown in Fig.3(a) at different times. The bunch stays very monoenergetic for the first 30 cm of acceleration, because it was injected in the flat accelerating field part of the bubble. The relative r.m.s. energy spread σ / E E , Fig.3(b), of the bunch is merely 0.3% when it gains 7.5 GeV energy. This is much better than the ratio of the bunch length to the bubble length that is 10%. Later, the bunch slowly leaves this flat E -field region and advances into the region with linearly growing E z -field. Finally, it gains a positive energy chirp as seen in the bunch longitudinal phase space, Fig.3(c).
However, the quality of acceleration is best understood when we zoom in at the longitudinal phase space of the witness bunch, Fig.3(d). The r.m.s relative width of the witness bunch energy uncertainty taken at a particular longitudinal position is merely 10 -3 and is probably defined by numerical resolution of our code. This very narrow energy spread is due to (i) the transverse uniformity of accelerating field in the bubble and (ii) the lack of a betatron resonance in the hollow channel.
Fig. 4 shows the nonlinear evolution of the laser pulse. Very different from the uniform plasma case, we observe no laser pulse shortening and no optical shock formation. The channel parameters were chosen to balance the dephasing length and the laser depletion length: L A = L D = 1 m.
In conclusion, we have shown that electron acceleration in deep plasma channels is scalable and the energy scalings favor ultra-short pancake-like laser pulses. The accelerating field has a nearly flat field region at the rear, where the accelerating field depends only slightly on the longitudinal coordinate. This allows for nearly monoenergetic acceleration of a witness bunch.
This work has been supported by the Deutsche Forschungsgemeinschaft via GRK 1203 and SFB TR 18, by EU FP7 project EUCARD-2 and by the Government
of the Russian Federation (Project No. 14.B25.31.0008) and by the Russian Foundation for Basic Research (Grants No. 13-02-00886, 13-02-97025).
- [1] E. Esarey, C. B. Schroeder, and W. P. Leemans, Rev. Mod. Phys. 81 , 1229 (2009)
- [2] C. Joshi and A. Caldwell, 'Plasma Accelerators,' Handbook for Elementary Particle Physics, Volume III, edited by S. Myers and H. Schopper, Heidelberg, Springer (2013), 12-1.
- [3] A. Pukhov, J. Meyer-ter-Vehn, Applied Physics B 74 , 355 (2002)
- [4] I. Kostyukov, A. Pukhov, S. Kiselev, Phys. Plasmas 11 , 5256 (2004)
- [5] V. Malka Laser Plasma Accelerators, in Laser-Plasma Interactions and Applications, Scottish Graduate Series, pp 281-301 (2013)
- [6] W. Lu et al. PRSTAB 10 , 061301 (2007)
- [7] W. Lu et al., Phys. Rev. Lett. 96 , 165002 (2006).
- [8] S. Gordienko, A. Pukhov Physics of Plasmas 12 , 043109
(2004).
- [9] A. Pukhov, S. Gordienko, Phil Tr. R. Soc. A, 364 , 623 (2006).
- [10] O. Jansen, T. Tückmantel, and A. Pukhov, Eur. Phys. J. Special Topics 223 , 1017-1030 (2014)
- [11] APukhov, ZM Sheng, J Meyer-ter-Vehn, Physics of Plasmas 6 , 2847 (1999)
- [12] S. Cipiccia et al Nature Physics 7, 867 (2011)
- [13] J L Shaw et al., arXiv:1404.4926 (2014)
- [14] C. B. Schroeder, E. Esarey, C. Benedetti, W. Leemans Phys.Plasmas 20 , 080701 (2013)
- [15] T. C. Chiou et. al., Physics of Plasmas 2 , 310 (1995)
- [16] J. Faure et al., Phys. Rev. Lett. 95 , 205003 (2005).
- [17] Y. Katzir et al. Appl. Phys. Lett. 95 , 031101 (2009).
- [18] P. Sprangle, E. Esarey, and A. Ting, Phys. Rev. Lett. 64 , 2011 (1990)
- [19] D. H. Whittum, Phys. Plasmas, 4 , 1154 (1997)
- [20] P. Mora and Th. M. Antonsen Jr., Phys. Plasmas 4 , (1997)
- [21] A. Pukhov Journal of Plasma Physics 61 , 425 (1999).
- [22] F. Giambruno et al., Appl. Opt. 17 , 2617 (2011).
- [23] J.-L. Vay, C. G. R. Geddes, E. Cormier-Michel, and D. P. Grote, Phys. Plasmas 18 , 030701 (2011) | 10.1103/PhysRevLett.113.245003 | [
"A. Pukhov",
"O. Jansen",
"T. Tueckmantel",
"J. Thomas",
"I. Yu. Kostyukov"
] | 2014-08-01T12:43:51+00:00 | 2014-11-20T13:18:27+00:00 | [
"physics.plasm-ph"
] | Field-reversed bubble in deep plasma channels for high quality electron acceleration | We study hollow plasma channels with smooth boundaries for laser-driven
electron acceleration in the bubble regime. Contrary to the uniform plasma
case, the laser forms no optical shock and no etching at the front. This
increases the effective bubble phase velocity and energy gain. The longitudinal
field has a plateau that allows for mono-energetic acceleration. We observe as
low as 10^{-3} r.m.s. relative witness beam energy uncertainty in each
cross-section and 0.3% total energy spread. By varying plasma density profile
inside a deep channel, the bubble fields can be adjusted to balance the laser
depletion and dephasing lengths. Bubble scaling laws for the deep channel are
derived. Ultra-short pancake-like laser pulses lead to the highest energies of
accelerated electrons per Joule of laser pulse energy. |
1408.0158v1 | ## Realizing PT -symmetric non-Hermiticity with ultra-cold atoms and Hermitian multi-well potentials
Manuel Kreibich, Jörg Main, Holger Cartarius, and Günter Wunner Institut für Theoretische Physik 1, Universität Stuttgart, 70550 Stuttgart, Germany
We discuss the possibility of realizing a non-Hermitian , i. e. an open two-well system of ultra-cold atoms by enclosing it with additional time-dependent wells that serve as particle reservoirs. With the appropriate design of the additional wells PT -symmetric currents can be induced to and from the inner wells, which support stable solutions. We show that interaction in the mean-field limit does not destroy this property. As a first method we use a simplified variational ansatz leading to a discrete nonlinear Schrödinger equation. A more accurate and more general variational ansatz is then used to confirm the results.
## I. INTRODUCTION
Since the first realization of PT -symmetric gain and loss in optical wave guides [1] much effort has been made to realize analogous systems in various fields of physics, e. g. lasers [2], electronics [3], microwave cavities [4], and to make use of new effects arising from nonlinearity, viz. the Kerr nonlinearity in optical wave guides [5]. PT symmetry originates from quantum mechanics and stands for a combined action of parity and time-reversal. Despite the non-Hermiticity of PT -symmetric Hamiltonians, in a certain range of parameters entirely real eigenvalue spectra exist [6]. Due to a formal analogy between quantum mechanics and electromagnetism, the formulation of PT symmetry has spread to those systems, leading to the above mentioned realizations. However, the experimental verification in a genuine quantum system has not been achieved so far.
In a PT -symmetric system there is a balanced gain and loss of probability density (or electromagnetic field in analogue systems). According to a proposal in [7] such a quantum mechanical system could be realized with a Bose-Einstein condensate (BEC) in a double-well potential where particles are injected into one well and removed from the other. Indeed, it could be shown that the system is ideally suited for a first-experimental observation of PT symmetry in a quantum system [8]. There is progress in coupling two BECs and at the same time eject particles [9], but an actual realization of PT symmetry using a BEC is still missing.
On the other hand much theoretical work has been done on PT -symmetric BECs, including the proof of existence of stable states of interacting systems [10], a microscopic treatment based on the Bose-Hubbard model [11], and a thorough investigation on dynamics of stable and unstable regimes [12]. In contrast to injecting and removing particles from a double-well potential, one could think of a double-well included in a tilted optical lattice, with an incoming and outgoing transport of particles, so called Wannier-Stark systems [13, 14]. These incoming and outgoing particle currents could in principle serve as the necessary currents for realizing a PT -symmetric system.
In a recent Rapid Communication [15] we followed the
Figure 1. (a) Two-mode model with an imaginary potential V , where - in this case - particles are removed from the left well and injected into the right. (b) Such a system could be realized by coupling two additional wells to the system, where the tunneling currents to and from the outer wells are used as an implementation of the imaginary potential. The outer wells act as (limited) particle reservoirs and have to be chosen time-dependent.
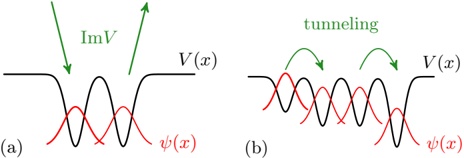
simplest approach to this idea, namely to couple two additional wells to the double well potential (see Fig. 1), and use the arising currents as a theoretical realization of PT symmetry in a quantum mechanical system. We showed that for a specific time-dependent choice of the well depths and coupling strengths of the additional wells, the inner wells behave exactly as the wells of a PT -symmetric two-well system, thus serving as a possible experimental realization.
It is the purpose of this paper investigate more deeply our approach, especially for the case of interacting atoms, and to formulate a more accurate method to confirm the results. In Sec. II we derive the few-mode model or discrete nonlinear Schrödinger equation (DNLSE) from the Gross-Pitaevskii equation (GPE) using a simple variational ansatz, where each well is populated by a single time-independent Gaussian function. The results are applied in Sec. III to show that a Hermitian fourmode model can be chosen such that the middle wells behave exactly as the wells of the PT -symmetric twomode model. This is exemplified for some parameters. In Sec. IV we use an extended variational ansatz for the realization of PT symmetry. Still one Gaussian function per well is used, but each Gaussian function is fully dynamical in its parameters, thus giving a more accurate description of the system. The method is compared with
the simply Gaussian ansatz. In Sec. V we conclude our work.
## II. FROM THE GROSS-PITAEVSKII EQUATION TO A FEW-MODE MODEL
In this section we apply the steps that lead from the GPE, which describes the dynamics of a BEC at absolute zero temperature, to a DNLSE or few-mode-model. At first we presents our ansatz and calculate the necessary integrals. To derive the equations of motion (EOM) in a Schrödinger form we use the method of symmetric orthogonalization. In Sec. III the results are used and applied to different scenarios.
## A. Simplified variational ansatz
We start with the well-known GPE,
$$i \hbar { \partial } _ { t } \psi ( { \boldsymbol r }, t ) = \left [ - \frac { \hbar { ^ { 2 } } } { 2 m } \Delta + V ( { \boldsymbol r } ) + g \left | \psi ( { \boldsymbol r }, t ) \right | ^ { 2 } \right ] \psi ( { \boldsymbol r }, t ). \quad \text{Our } \colon _ { \substack { ( 1 ) \ \text{Schröd} \\ \text{modif} } }$$
The interaction strength is given by g = 4 π glyph[planckover2pi1] 2 Na/m with the s-wave scattering length a and particle number N . For the external multi-well potential V ( r ) we use a Gaussian profile for each well,
$$V ( r ) = \sum _ { k = 1 } ^ { N _ { w } } V ^ { k } \exp \left [ - \frac { 2 x ^ { 2 } } { w _ { x } ^ { 2 } } - \frac { 2 y ^ { 2 } } { w _ { y } ^ { 2 } } - \frac { 2 ( z - s _ { z } ^ { k } ) ^ { 2 } } { w _ { z } ^ { 2 } } \right ], \ \ ( 2 )$$
with a total number of N w wells. Each well k has the potential depth V k < 0 and is displaced along the z -direction by s k z . Such a potential could, e. g., be created experimentally by the method presented in [16].
There is various work on how to transform the GPE (1) into a DNLSE [17, 18] by integrating out the spatial degrees of freedom. In general, an ansatz of the form
$$\psi ( r, t ) = \sum _ { k } d ^ { k } ( t ) g ^ { k } ( r ),$$
is used, where d k ( ) t is the (complex) amplitude and g k ( r ) the localized wave function in well k . Usually, a set of Wannier functions is applied [19]. In this work [Sec. III], we use a single Gaussian function for each well. With this ansatz we can derive analytical formulae for the matrix elements of the DNLSE or few-mode model, and thus open an easy way to actually compute the localized wave functions by a simple energy minimization process. In Sec. IV we extend the variational ansatz to obtain more accurate results.
The simplified variational ansatz is given by the superposition of N G Gaussian functions, one for each well, N w = N G , with
$$g ^ { k } ( r ) = e ^ { - A _ { x } ^ { k } x ^ { 2 } - A _ { y } ^ { k } y ^ { 2 } - A _ { z } ^ { k } ( z - q _ { z } ^ { k } ) ^ { 2 } }. \quad \ ( 4 )$$
The parameters A ,A ,A k x k y k z ∈ ❘ describe the width of each Gaussian function in each direction, and q k z ∈ ❘ the displacement along the z -direction. We treat these parameters in this section as time-independent. The timedependence of the wave function comes from the amplitude d k ( ) t in Eq. (3).
We insert ansatz (3) into the GPE i glyph[planckover2pi1] ∂ ψ t = ˆ Hψ , multiply from the left with ( g l ) ∗ , and integrate over ❘ 3 . Then, we are left with
$$\mathrm i \hbar { K } \dot { d } = \mathrm H d.$$
Here, the amplitudes d k are written as a vector d = ( d , . . . , d 1 N G ) T ∈ ❈ N G . The matrix K describes the overlap, and H the Hamiltonian matrix elements. They are given by the integrals (see Sec. II B for their explicit calculation)
$$K _ { l k } = \left \langle g ^ { l } | g ^ { k } \right \rangle,$$
$$H _ { l k } = \left \langle g ^ { l } \right | \hat { H } \left | g ^ { k } \right \rangle. \text{ \quad \ \ } ( 6 b )$$
Our aim is to derive EOM for the amplitudes in a Schrödinger form, i. e. i glyph[planckover2pi1] ˙ d eff = H eff d eff , with possibly modified amplitudes and matrix elements. Equation (5) would be of that form if K was proportional to the identity matrix. Since the Gaussian functions g k are nonorthogonal this is not the case. For that reason, we perform a symmetric orthogonalization in Sec. II C.
## B. Evaluation of the integrals
The occurring integrals in Eqs. (6) are solely based on the Gaussian integral
$$\intertext { a d } \int _ { \substack { \infty \\ \mathcal { d } = - \infty } } ^ { \infty } \int _ { \substack { \mathcal { d } x \, x ^ { n } \, e ^ { - A x ^ { 2 } + p x } } } & = \frac { \partial ^ { n } } { \partial p ^ { n } } \int _ { \substack { \mathcal { d } x \, e ^ { - A x ^ { 2 } + p x } } } \\ & = \frac { \partial ^ { n } } { \partial p ^ { n } } \sqrt { \frac { \pi } { A } } \, e ^ { p ^ { 2 } / 4 A }, \quad \text{Re } A > 0. \\ \intertext { a d } \int _ { \substack { \mathcal { d } x \, - \infty \\ \mathcal { d } = - \infty } } \cdots \cdots \cdots \cdots$$
For convenience we define the abbreviations
$$A _ { \alpha } ^ { k l } = A _ { \alpha } ^ { k } + ( A _ { \alpha } ^ { l } ) ^ { * }, \quad \alpha = x, y, z, \quad ( 8 \text{a} )$$
$$\kappa _ { \alpha } ^ { k l } = A _ { \alpha } ^ { k } ( A _ { \alpha } ^ { l } ) ^ { * } / A _ { \alpha } ^ { k l },$$
$$\beta _ { \alpha } ^ { k l } = \sqrt { \frac { A _ { \alpha } ^ { k l } w _ { \alpha } ^ { 2 } } { A _ { \alpha } ^ { k l } w _ { \alpha } ^ { 2 } + 2 } }, \quad \quad \quad ( 8 c )$$
$$c ^ { k l } = \, e ^ { - \kappa _ { z } ^ { k l } ( q _ { z } ^ { k } - q _ { z } ^ { l } ) ^ { 2 } },$$
The integrals of K can now easily be calculated with Eq. (7) for the case n = 0 , the result is
$$K _ { l k } = \sqrt { \frac { \pi } { A _ { x } ^ { k l } } } \sqrt { \frac { \pi } { A _ { y } ^ { k l } } } \sqrt { \frac { \pi } { A _ { z } ^ { k l } } } c ^ { k l }.$$
For the calculation of the Hamiltonian matrix H , we separate it into a kinetic term T , an external potential term V , and an interaction term W .
For the kinetic term we need integrals of the form shown in Eq. (7) with n = 2 and we obtain
$$T _ { l k } = K _ { l k } \left [ \kappa _ { x } ^ { k l } + \kappa _ { y } ^ { k l } + \kappa _ { z } ^ { k l } - 2 ( \kappa _ { z } ^ { k l } ) ^ { 2 } ( q _ { z } ^ { k } - q _ { z } ^ { l } ) ^ { 2 } \right ]. \ ( 1 0 ) \quad \text{with } i \,.$$
To calculate the integrals necessary for the external potential, the parameters A and p in Eq. (7) are shifted by the parameters of the external potential. The result is
$$& V _ { l k } = K _ { l k } \beta _ { x } ^ { k l } \beta _ { y } ^ { k l } \beta _ { z } ^ { k l } \sum _ { m } V ^ { m } \\ & \times \exp \left \{ - \frac { 2 \left [ A _ { z } ^ { k } ( s _ { z } ^ { m } - q _ { z } ^ { k } ) + ( A _ { z } ^ { l } ) ^ { * } ( s _ { z } ^ { m } - q _ { z } ^ { l } ) \right ] ^ { 2 } } { A _ { z } ^ { k l } ( A _ { z } ^ { k l } w _ { z } ^ { 2 } + 2 ) } \right \}. \quad ( 1 1 ) \quad \text{D.} \quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{
d _ { \quad } } \quad \quad \quad$$
Since the operator of the interaction potential W is nonlinear, its matrix elements depend on the amplitudes d k . With the standard Gaussian integral we obtain
$$W _ { l k } = \sum _ { i, j } \tilde { W } _ { l k j i } ( d ^ { j } ) ^ { * } d ^ { i }, \text{ \quad \ \ } ( 1 2 ) \text{ \ \ } \text{ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{$\text{$\text{no}$} } }$$
where we defined the four-rank tensor
$$& \text{where we defined the four-rank tensor} \\ & \bar { W } _ { l k j i } = \frac { 4 \pi \hslash ^ { 2 } N a } { m } \sqrt { \frac { \pi } { A _ { z } ^ { i j k l } } } \sqrt { \frac { \pi } { A _ { z } ^ { i j k l } } } \sqrt { \frac { \pi } { A _ { z } ^ { i j k l } } } \\ & \quad \times \exp \left [ - \frac { A _ { z } ^ { i } ( A _ { z } ^ { j } ) ^ { * } ( q _ { z } ^ { i } - q _ { z } ^ { j } ) ^ { 2 } + A _ { z } ^ { i } ( A _ { z } ^ { l } ) ^ { * } ( q _ { z } ^ { i } - q _ { z } ^ { l } ) ^ { 2 } } { A _ { z } ^ { i j k l } } \right ] \\ & \quad \times \exp \left [ - \frac { A _ { z } ^ { k } ( A _ { z } ^ { j } ) ^ { * } ( q _ { z } ^ { k } - q _ { z } ^ { j } ) ^ { 2 } + A _ { z } ^ { k } ( A _ { z } ^ { l } ) ^ { * } ( q _ { z } ^ { k } - q _ { z } ^ { l } ) ^ { 2 } } { A _ { z } ^ { i j k l } } \right ] \\ & \quad \times \exp \left [ - \frac { A _ { z } ^ { i } A _ { z } ^ { k } ( q _ { z } ^ { i } - q _ { z } ^ { k } ) ^ { 2 } + ( A _ { z } ^ { j } ) ^ { * } ( A _ { z } ^ { l } ) ^ { * } ( q _ { z } ^ { j } - q _ { z } ^ { l } ) ^ { 2 } } { A _ { z } ^ { i j k l } } \right ] \\ & \quad \text{and} \\ & \text{and the new abbreviations}$$
and the new abbreviations
$$A _ { \alpha } ^ { i j k l } = A _ { \alpha } ^ { i j } + A _ { \alpha } ^ { k l }, \quad \alpha = x, y, z. \quad \ ( 1 4 ) \quad \text{whe}$$
## C. Symmetric orthogonalization
We calculated all necessary integrals for setting up the EOMs (5), which are not of the form of a Schrödinger equation (cf. Sec. II A). To achieve this, we now transform the EOM into a Schrödinger form with the method of symmetric orthogonalization [20]: Since K is Hermitian there exists a unitary transformation U such that D = UKU † is diagonal with real entries. Then we can construct the Hermitian matrix
$$\mathbf x = \mathbf U ^ { \dagger } \mathbf D ^ { - 1 / 2 } \mathbf U. \quad \quad \ \ ( 1 5 )$$
This matrix has the properties that XKX = ✶ , and furthermore, if H is Hermitian, so is XHX . Now, we can use this matrix to transform Eq. (5) to
$$i \hbar { ( } X K X ) ( X ^ { - 1 } \dot { d } ) = ( X H X ) ( X ^ { - 1 } d ). \quad ( 1 6 )$$
With the definitions d eff = X -1 d and H eff = XHX , and the above property of X we arrive at the EOM for d eff in Schrödinger form
$$i \hbar { d } _ { \text{eff} } = \mathbf H _ { \text{eff} } d _ { \text{eff} }$$
with a Hermitian Hamiltonian matrix H eff (if H is Hermitian). We note, that the normalization condition for the wave function ψ transforms as
$$\text{by} \quad \ 1 & \stackrel {! } { = } \int \text{d} ^ { 3 } r \, \left | \psi \right | ^ { 2 } = d ^ { \dagger } \text{K} d = ( X ^ { - 1 } d ) ^ { \dagger } ( \text{XXKX} ) ( X ^ { - 1 } d ) \\ & \quad = d ^ { \dagger } _ { \text{eff} } d _ { \text{eff} }.$$
## D. Application of symmetric orthogonalization and nearest-neighbor approximation
By means of symmetric orthogonalization we can transform the EOM (5) into a Schrödinger form since we know K analytically. Without any further approximations the analytical expressions can become quite complicated. At this point, we introduce as usual the nearest neighbor approximation to obtain analytical and simple approximate expressions for X and H eff .
The structure of the matrix elements K lk [see Eq. (9)] allows for a natural approximation since the function c kl drops exponentially with increasing distance of wells | k - | l . We say a term is of order n when | k - | l = n . As an approximation we only consider terms up to order n = 1 . Hence, we have K = K (0) + K (1) with
$$K _ { l k } ^ { ( 0 ) } = \left ( \frac { \pi } { 2 } \right ) ^ { 3 / 2 } \frac { \delta _ { k l } } { \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } } } \quad \ \ ( 1 9 )$$
and
$$K _ { l k } ^ { ( 1 ) } = \sqrt { \frac { \pi } { A _ { x } ^ { k l } } } \sqrt { \frac { \pi } { A _ { y } ^ { k l } } } \sqrt { \frac { \pi } { A _ { z } ^ { k l } } } c ^ { k l } \left ( \delta _ { k, l + 1 } + \delta _ { k + 1, l } \right ), \ \ ( 2 0 )$$
where A k α,R = Re A k α , and - for later use A k α,I = Im A k α . Using this expansion, we calculate the zeroth order of X by the requirement X (0) K (0) X (0) = ✶ . We obtain
$$X _ { l k } ^ { ( 0 ) } = \left ( \frac { 2 } { \pi } \right ) ^ { 3 / 4 } \, \delta \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } \delta _ { k l }. \quad ( 2 1 )$$
To calculate the first order we start with
$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{#\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{s\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text'$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text<$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$$
ignore second order terms, insert the known quantities, and solve for X (1) , which yields
$$\text{---- ---- ---- ---- ---- ---- } \,, \, \cdot \, \dots \, \cdot \, \dots \, \cdot \, \cdot \, \dots \\ \text{fural} \,, & X ^ { ( 1 ) } _ { l k } = & - \left ( \frac { 8 } { \pi } \right ) ^ { 3 / 4 } \frac { c ^ { k l } } { \sqrt { A ^ { k l } _ { x } } \sqrt { A ^ { k l } _ { y } } \sqrt { A ^ { k l } _ { z } } } \left ( \delta _ { k, l + 1 } + \delta _ { k + 1, l } \right ) \\ \text{can} \, & \times \frac { \sqrt { A ^ { k } _ { x, R } A ^ { k } _ { y, R } A ^ { k } _ { z, R } } ^ { k } A ^ { l } _ { x, R } A ^ { l } _ { y, R } A ^ { l } _ { z, R } } { \sqrt { A ^ { k } _ { x, R } A ^ { k } _ { y, R } A ^ { k } _ { z, R } } + \sqrt { A ^ { l } _ { x, R } A ^ { l } _ { y, R } A ^ { l } _ { z, R } } }. \quad ( 2 3 )$$
Now we are able to calculate analytical approximations for the transformed Hamiltonian H eff . We observe that for the linear parts, i. e. the kinetic and external potential part, the matrix elements of H are proportional to K , so we can write H lin lk = K h lk lin lk [cf. Eqs. (10) and (11)]. Thus, the orders of H lin are given by the orders of K . Therefore, for the zeroth order transformed Hamiltonian we obtain
$$H _ { \text{eff}, l k } ^ { \text{lin}, ( 0 ) } = \sum _ { m, n } X _ { l m } ^ { ( 0 ) } K _ { m n } ^ { ( 0 ) } X _ { n k } ^ { ( 0 ) } h _ { m n } ^ { \text{lin} } = h _ { k k } ^ { \text{lin} } \delta _ { k l }. \quad ( 2 4 )$$
The zeroth order contributes to the linear diagonal elements of H lin eff , so they can be identified with the onsite energy E k = h lin kk . With Eqs. (10) and (11) we can write
$$& E _ { k } = \frac { \hslash ^ { 2 } } { 2 m } \left ( A _ { x, R } ^ { k } + A _ { y, R } ^ { k } + A _ { z, R } ^ { k } \right ) \\ & \quad + V ^ { k } \beta _ { x } ^ { k k } \beta _ { y } ^ { k k } \beta _ { z } ^ { k k } \exp \left [ - 2 ( \beta _ { z } ^ { k k } ) ^ { 2 } ( s _ { z } ^ { k } - q _ { z } ^ { k } ) ^ { 2 } / w _ { z } ^ { 2 } \right ], \ \ ( 2 5 ) \quad \text{These}$$
where we considered only the term with m = k in the sum in Eq. (11) to be consistent with zeroth order.
The first order terms of H lin eff are given by the first order terms of the expression
$$( X ^ { ( 0 ) } + X ^ { ( 1 ) } ) ( \mathbf H ^ { \mathrm i \mathrm n, ( 0 ) } + \mathbf H ^ { \mathrm i \mathrm n, ( 1 ) } ) ( X ^ { ( 0 ) } + X ^ { ( 1 ) } ), \ \ ( 2 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
which gives, after inserting all known quantities,
$$H _ { \text{eff}, l k } ^ { \text{lin}, ( 1 ) } = & - 2 \sqrt { 2 } \frac { \sqrt { A _ { x } ^ { k }, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { l } A _ { x, R } ^ { l } A _ { y, R } ^ { l } A _ { z, R } ^ { l } } { \sqrt { A _ { x, R } ^ { k } } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } + \sqrt { A _ { x, R } ^ { l } A _ { y, R } ^ { l } A _ { z, R } ^ { l } } } { \sqrt { A _ { x, R } ^ { k } } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } + \frac { \text{$_{l}$} } { \sqrt { A _ { x, R } ^ { k } } A _ { y, R } ^ { k } A _ { z, R } ^ { l } } \right ) } \quad \text{condit} \\ & \times \left ( \frac { E _ { k } - h _ { l k } } { \sqrt { A _ { x, R } ^ { k } } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } + \frac { E _ { l } - h _ { l k } } { \sqrt { A _ { x, R } ^ { l } } A _ { y, R } ^ { l } A _ { z, R } ^ { l } } \right ) } \right ) } { \sqrt { A _ { x } ^ { k l } } \sqrt { A _ { y } ^ { k l } } \sqrt { A _ { z } ^ { k l } } } \left ( \delta _ { k, l + 1 } + \delta _ { k + 1, l } \right ). \quad ( 2 7 ) \\ \text{These elements can be identified as the tunneling ele-}$$
These elements can be identified as the tunneling elements of the few-mode model, i. e. J lk = -H lin , (1) eff ,lk , since they are the super- and sub-diagonal entries. The quantity h lin lk is given by Eqs. (10) and (11), where in v lk we only consider nearest-neighbor contributions,
$$v _ { l k } & = \beta _ { x } ^ { k l } \beta _ { y } ^ { k l } \beta _ { z } ^ { k l } \\ & \times \left ( V ^ { k } \exp \left \{ - \frac { 2 \left [ A _ { z } ^ { k } ( s _ { z } ^ { k } - q _ { z } ^ { k } ) + ( A _ { z } ^ { l } ) ^ { * } ( s _ { z } ^ { k } - q _ { z } ^ { l } ) \right ] ^ { 2 } } { A _ { z } ^ { k l } ( A _ { z } ^ { k l } w _ { z } ^ { 2 } + 2 ) } \right \} \quad \text{sister} \quad \text{lowin} \quad \text{discre} \\ & + V ^ { l } \exp \left \{ - \frac { 2 \left [ A _ { z } ^ { k } ( s _ { z } ^ { l } - q _ { z } ^ { k } ) + ( A _ { z } ^ { l } ) ^ { * } ( s _ { z } ^ { l } - q _ { z } ^ { l } ) \right ] ^ { 2 } } { A _ { z } ^ { k l } ( A _ { z } ^ { k l } w _ { z } ^ { 2 } + 2 ) } \right \} \right ). \\ & \quad \infty \, \text{for two calculated the matrix alternate of the} \quad \text{A}.$$
So far we have calculated the matrix elements of the linear transformed Hamiltonian H lin eff . We now turn our attention to the interaction part. Since the operator W is nonlinear and depends on the amplitudes d k , they must be transformed, too. For the transformed operator, we obtain
$$\intertext { a }, \sigma _ { 1 } ^ { \infty } \intertext { tial } \ W _ { \text{eff}, l k } & = \sum _ { i, j, m, n, p, q } X _ { l m } \tilde { W } _ { m n j i } X _ { n k } ( X _ { j p } d _ { \text{eff} } ^ { p } ) ^ { * } ( X _ { i q } d _ { \text{eff} } ^ { q } ) \\ \intertext { K } _ { \text{ian} } & = \sum _ { p, q } \underbrace { \sum _ { i, j, m, n } X _ { l m } X _ { p j } \tilde { W } _ { m n j i } X _ { n k } X _ { i q } } _ { \equiv \tilde { W } _ { \text{eff}, l k p q } } ( d _ { \text{eff} } ^ { p } ) ^ { * } d _ { \text{eff} } ^ { q }. \\ & \intertext { r } _ { \text{ r } } \cdots \cdots \cdots \cdots \cdots \cdots.$$
For the interaction term, we only consider onsiteelements, i. e. elements with i = j = k = l in ˜ W lkji , since mainly these terms contribute to the interaction part. For the transformed four-rank tensor, we then obtain
$$\tilde { W } _ { \text{eff}, k k k k } = \frac { 4 \hbar { ^ { 2 } } N a } { \sqrt { \pi } m } \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } }. \quad ( 3 0 )$$
These elements are the nonlinear coupling constants, c k = ˜ W eff ,kkkk . The whole action of the transformed Hamiltonian then reads
$$W _ { \text{eff}, l k } = c _ { k } | d ^ { k } | ^ { 2 } \delta _ { k l }. \text{ \quad \ \ } ( 3 1 )$$
We have all necessary matrix-elements in nearestneighbor approximation. Using this knowledge we can calculate these elements from the Gaussian variational approach, or - vice verse - determine the parameters of the realistic potential (2) by knowing the matrix elements. As an application this is done in Sec. III. The parameters A k α and q k z can be computed by minimizing the mean-field energy of the system for a given initial condition with
$$\int _ { \substack { E _ { \text{mf} } = \sum _ { k, l } ( d ^ { l } ) ^ { * } \left ( T _ { l k } + V _ { l k } \right ) d ^ { k } \\ + \frac { 1 } { 2 } \sum _ { i, j, k, l } ( d ^ { l } ) ^ { * } d ^ { k } W _ { l k j i } ( d ^ { j } ) ^ { * } d ^ { i }. \quad ( 3 2 ) \\ \text{el} \text{-} }$$
For this minimization, all parameters A k α , q k z and d k have to be varied with the norm constraint (18), which is computationally much cheaper than a grid calculation. The results of this section could also be used to calculate the parameters of the Bose-Hubbard model.
Now that we have all matrix elements, we can begin our actual investigation of a realization of a non-Hermitian system, first by means of few-mode models. In the following we will adopt the usual notation and write for the discrete wave function ψ k instead of d k .
## III. FEW-MODE MODELS
## A. Equivalence of the two- and four-mode models
We now return to the idea mentioned in the introduction and sketched in Fig. 1, i. e. the embedding of a
non-Hermitian double-well with a closed four-well structure. Before analyzing the possibility of realizing a nonHermitian system with a Hermitian model, we discuss the basic properties of the non-Hermitian two-mode model, which is given by
$$\mathbf H _ { 2 } = \begin{pmatrix} E _ { 1 } + c _ { 1 } \left | \psi _ { 1 } \right | ^ { 2 } & - J _ { 1 2 } \\ - J _ { 1 2 } & E _ { 2 } + c _ { 2 } \left | \psi _ { 2 } \right | ^ { 2 } \end{pmatrix} \quad ( 3 3 ) \quad \ \ \ \ a _ { n } ^ { \prime }$$
with complex onsite energies E k ∈ ❈ , which make the Hamiltonian non-Hermitian. This system has intensively been investigated in [21]. The time derivatives of the observables, that is particle number n k = ψ ψ ∗ k k and particle current j kl = i J kl ( ψ ψ k ∗ l -ψ ψ ∗ k l ) , can be easily calculated, which gives
$$\partial _ { t } n _ { 1 } = - j _ { 1 2 } + 2 n _ { 1 } \, \text{Im} \, E _ { 1 }, & & ( 3 4 a ) & &.$$
$$\partial _ { t } n _ { 2 } = j _ { 1 2 } + 2 n _ { 2 } \, \text{Im} \, E _ { 2 }, & & ( 3 4 b ) \quad \text{Com} _ { \dots \, 1 \,. }$$
$$\partial _ { t } j _ { 1 2 } & = 2 J _ { 1 2 } ^ { 2 } ( n _ { 1 } - n _ { 2 } ) + ( \text{Im} \, E _ { 1 } + \text{Im} \, E _ { 2 } ) j _ { 1 2 } \\ & \quad + J _ { 1 2 } ( \text{Re} \, E _ { 1 } - \text{Re} \, E _ { 2 } + c _ { 1 } n _ { 1 } - c _ { 2 } n _ { 2 } ) C _ { 1 2 }, \ ( 3 4 c ) \\ \cdot \cdot \cdot \cdot \cdot \cdot$$
$$( 3 4 c )$$
$$\partial _ { t } C _ { 1 2 } & = ( \text{Im} \, E _ { 1 } + \text{Im} \, E _ { 2 } ) C _ { 1 2 } \\ & \quad - ( \text{Re} \, E _ { 1 } - \text{Re} \, E _ { 2 } + c _ { 1 } n _ { 1 } - c _ { 2 } n _ { 2 } ) \tilde { j } _ { 1 2 }, \quad ( 3 4 d ) \quad \text{This}$$
where we defined C kl = ψ ψ k l + ψ ψ ∗ k ∗ l and ˜ j kl = i( ψ ψ k ∗ l -ψ ψ ∗ k l ) = j 12 /J 12 . In Eqs. (34a) and (34b) we see that the imaginary parts of the onsite energies act as additional sources or sinks to the particle flow, the quantities j e 1 = 2 n 1 Im E 1 and j e 2 = -2 n 2 Im E 2 can be identified as currents to and from the environment, thus, this Hamiltonian describes an open quantum system.
The general solutions for the nonlinear model (33) are calculated in [21]. For convinience we only discuss the results of the linear, i. e. non-interacting case ( c 1 = c 2 = 0 ). Then, the eigenvalues are given by
$$E _ { \pm } = \frac { E _ { 1 } + E _ { 2 } } { 2 } \pm \sqrt { J _ { 1 2 } ^ { 2 } + \frac { ( E _ { 1 } - E _ { 2 } ) ^ { 2 } } { 2 } }. \quad ( 3 5 ) \quad \text{To s} \quad.$$
Requirement for PT symmetry leads to the condition E 1 = E ∗ 2 , which is for instance fulfilled by E 1 = iΓ and E 2 = -iΓ , a situation with balanced gain and loss. Then, the eigenvalues are E ± = √ J 2 12 -Γ 2 . For Γ < J 12 they are real, whereas for Γ > J 12 the PT symmetry is broken and the eigenvalues are purely imaginary.
It is now our main purpose to investigate whether the behavior of the non-Hermitian two-mode model (33) can be described by a Hermitian four-mode model, which is given by
$$\mathbf H _ { 4 } ( t ) = \begin{pmatrix} E _ { 0 } ( t ) & - J _ { 0 1 } ( t ) & 0 & 0 \\ - J _ { 0 1 } ( t ) & E _ { 1 } & - J _ { 1 2 } & 0 \\ 0 & - J _ { 1 2 } & E _ { 2 } & - J _ { 2 3 } ( t ) \\ 0 & 0 & - J _ { 2 3 } ( t ) & E _ { 3 } ( t ) \end{pmatrix} \quad \text{where} \\ + \text{diag} \left ( c _ { 0 } \left | \psi _ { 0 } \right | ^ { 2 }, c _ { 1 } \left | \psi _ { 1 } \right | ^ { 2 }, c _ { 2 } \left | \psi _ { 2 } \right | ^ { 2 }, c _ { 3 } \left | \psi _ { 3 } \right | ^ { 2 } \right ). \quad ( 3 6 ) \text{ fullfill}$$
Two additional wells are coupled to the system, they act as a particle reservoir for the inner wells. The onsite energies and tunneling elements of the outer wells may be time-dependent. Since this model shall be Hermitian, the onsite energies are real, E k ∈ ❘ .
To derive a relationship between the two- and fourmode model we calculate the time derivatives of the same observables as in the two-mode model, which yields
$$\partial _ { t } n _ { 1 } = j _ { 0 1 } - j _ { 1 2 },$$
$$\text{the} \quad \partial _ { t } n _ { 2 } = j _ { 1 2 } - j _ { 2 3 },$$
$$\text{ly} _ { \mathbb { b } _ { \mathbb { c } } } \quad \partial _ { t } j _ { 1 2 } & = 2 J _ { 1 2 } ^ { 2 } \left ( n _ { 1 } - n _ { 2 } \right ) - J _ { 1 2 } \left ( J _ { 0 1 } C _ { 0 2 } - J _ { 2 3 } C _ { 1 3 } \right ) \\ \text{cle} _ { \mathbb { c } } & \quad + J _ { 1 2 } \left ( E _ { 1 } - E _ { 2 } + c _ { 1 } n _ { 1 } - c _ { 2 } n _ { 2 } \right ) C _ { 1 2 }, \quad \left ( 3 7 c \right )$$
$$( 3 7 c )$$
$$\text{ated}, \quad \partial _ { t } C _ { 1 2 } = J _ { 0 1 } \tilde { j } _ { 0 2 } - J _ { 2 3 } \tilde { j } _ { 1 3 } - ( E _ { 1 } - E _ { 2 } + c _ { 1 } n _ { 1 } - c _ { 2 } n _ { 2 } ) \tilde { j } _ { 1 2 }.$$
Comparing with Eqs. (34) we find that for the two-mode model the following condition must hold,
$$\text{Im} \, E _ { 1 } = - \text{Im} \, E _ { 2 } \Rightarrow E _ { 1 } = E _ { 2 } ^ { * }. \text{ \quad \ \ } ( 3 8 )$$
This means that only the PT -symmetric two-mode model, as discussed above, may be simulated by the four-mode model. From now on we write E 1 = iΓ and E 2 = -iΓ with Γ ∈ ❘ . Furthermore, the real parts of the onsite energies E 1 and E 2 and the coupling element J 12 have to agree between the two models. We are then left with the following conditions,
$$j _ { 0 1 } = 2 \Gamma n _ { 1 },$$
$$j _ { 2 3 } = 2 \Gamma n _ { 2 },$$
$$0 = J _ { 0 1 } C _ { 0 2 } - J _ { 2 3 } C _ { 1 3 }, \text{ \quad \ \ } ( 3 9 c )$$
$$0 = J _ { 0 1 } \tilde { j } _ { 0 2 } - J _ { 2 3 } \tilde { j } _ { 1 3 }. \text{ \quad \ \ } ( 3 9 d )$$
To summarize at this point, if these conditions are fulfilled at every time, the two middle wells of the Hermitian four-mode model behave exactly as the wells of the PT -symmetric two-mode model. These four conditions seem to be independent, but we shall see in App. A that Eq. (39d) follows if Eqs. (39a)-(39c) are fulfilled.
We now have to make clear that these conditions can indeed be fulfilled by giving suitable time-dependencies to the elements of the four-mode Hamiltonian. Equation (39c) can simply be fulfilled by choosing
$$J _ { 0 1 } ( t ) = d C _ { 1 3 } ( t ), \quad J _ { 2 3 } ( t ) = d C _ { 0 2 } ( t ), \quad ( 4 0 )$$
glyph[negationslash]
where d = 0 is a real, time-independent quantity. The tunneling elements are then time-dependent. With J 01 and J 23 determined there are no free parameters left to fulfill Eqs. (39a) and (39b). Instead, we can set the timederivatives of these equations with the help of the remaining onsite energies E 0 and E 3 . We calculate the timederivatives of j 01 and j 23 using the Schrödinger equation,
which yields
$$\partial _ { t } j _ { 0 1 } & = ( \partial _ { t } J _ { 0 1 } ) \tilde { j } _ { 0 1 } + 2 J _ { 0 1 } ^ { 2 } \left ( n _ { 0 } - n _ { 1 } \right ) + J _ { 0 1 } J _ { 1 2 } C _ { 0 2 } \\ & \quad + J _ { 0 1 } \left ( E _ { 0 } - E _ { 1 } + c _ { 0 } n _ { 0 } - c _ { 1 } n _ { 1 } \right ) C _ { 0 1 } \\ & \stackrel {! } { = } \partial _ { t } j _ { 0 1 } ^ { \text{tar} }, \\ \wedge \cdot \quad \tau \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda } \cdot \tilde { \lambda }$$
$$\begin{array} { c } \bar { \ } _ { \L v _ { 0 1 } } \,, & \vee \cdots \,, \\ \partial _ { t } j _ { 2 3 } = & ( \partial _ { t } J _ { 2 3 } ) \, \tilde { j } _ { 2 3 } + 2 J _ { 2 3 } ^ { 2 } \, ( n _ { 2 } - n _ { 3 } ) - J _ { 2 3 } J _ { 1 2 } C _ { 1 3 } \\ & + J _ { 2 3 } \, ( E _ { 2 } - E _ { 3 } + c _ { 2 } n _ { 2 } - c _ { 3 } n _ { 3 } ) \, C _ { 2 3 } \\ \overset {! } { = } & \partial _ { t } j _ { 2 3 } ^ { \text{tar} }, & ( 4 1 b ) \end{array}$$
$$& \stackrel {. } { = } & \partial _ { t } j _ { 0 1 } ^ { \quad. } \quad ( 4 1 \tt a ) \quad ( 4 1 \tt a ) \quad \\ _ { 3 } & = ( \partial _ { t } J _ { 2 3 } ) \, \tilde { j } _ { 2 3 } + 2 J _ { 2 3 } ^ { 2 } \, ( n _ { 2 } - n _ { 3 } ) - J _ { 2 3 } J _ { 1 2 } C _ { 1 3 } \quad & 0. \\ & \quad + J _ { 2 3 } \, ( E _ { 2 } - E _ { 3 } + c _ { 2 } n _ { 2 } - c _ { 3 } n _ { 3 } ) \, C _ { 2 3 } \quad & 0. \\ & \stackrel {! } { = } & \partial _ { t } j _ { 2 3 } ^ { \quad \tt a r } \quad ( 4 1 b ) \quad & 0.$$
with the target currents determined by Eqs. (39a) and (39b). The time derivatives of the tunneling elements J 01 and J 23 are given by
$$\partial _ { t } J _ { 0 1 } & = d \partial _ { t } C _ { 1 3 } \\ & = d \left ( J _ { 0 1 } \tilde { j } _ { 0 3 } + J _ { 1 2 } \tilde { j } _ { 2 3 } - J _ { 2 3 } \tilde { j } _ { 1 2 } \right ) \\ & \quad + d \left ( E _ { 3 } - E _ { 1 } + c _ { 3 } n _ { 3 } - c _ { 1 } n _ { 1 } \right ) \tilde { j } _ { 1 3 }, \quad \left ( 4$$
$$\begin{array} { c } \kappa \, \langle \nu _ { 1 1 } \nu _ { 0 0 } \cdot \, \kappa _ { 1 2 } \nu _ { 2 0 } \cdot \, \kappa _ { 2 0 1 1 } \rangle \\ & + d \left ( E _ { 3 } - E _ { 1 } + c _ { 3 } n _ { 3 } - c _ { 1 } n _ { 1 } \right ) \tilde { j } _ { 1 3 }, \quad & ( 4 2 \tt a ) \quad & \text{Figur} \\ & + d \left ( E _ { 3 } - E _ { 0 } + c _ { 2 } \\ & = d \left ( J _ { 0 1 } \tilde { j } _ { 1 2 } - J _ { 1 2 } \tilde { j } _ { 0 1 } - J _ { 2 3 } \tilde { j } _ { 0 3 } \right ) \\ & + d \left ( E _ { 2 } - E _ { 0 } + c _ { 2 } n _ { 2 } - c _ { 0 } n _ { 0 } \right ) \tilde { j } _ { 0 2 }. \quad & ( 4 2 b ) \quad & \text{of } J _ { 1 1 }. \\ & \text{and } o \end{array}$$
Inserting this into Eqs. (41), the onsite energies E 0 and E 3 are determined by a linear set of equations,
$$\begin{pmatrix} C _ { 0 1 } C _ { 1 3 } & \tilde { j } _ { 0 1 } \tilde { j } _ { 1 3 } \\ - \tilde { j } _ { 0 2 } \tilde { j } _ { 2 3 } & - C _ { 0 2 } C _ { 2 3 } \end{pmatrix} \begin{pmatrix} E _ { 0 } \\ E _ { 3 } \end{pmatrix} = \begin{pmatrix} v _ { 0 } \\ v _ { 3 } \end{pmatrix}, \quad ( 4 3 ) \quad \text{cho} \\ \quad \text{ we c}$$
with the entries
$$v _ { 0 } & = \partial _ { t } j _ { 0 1 } ^ { \text{tar} } / d - J _ { 1 2 } \tilde { j } _ { 2 3 } - d \left ( C _ { 1 3 } \tilde { j } _ { 0 3 } - C _ { 0 2 } \tilde { j } _ { 1 2 } \right ) \tilde { j } _ { 0 1 } \\ & \quad - 2 d C _ { 1 3 } ^ { 2 } \left ( n _ { 0 } - n _ { 1 } \right ) - J _ { 1 2 } C _ { 0 2 } C _ { 1 3 } \\ & \quad - \left ( c _ { 3 } n _ { 3 } - c _ { 1 } n _ { 1 } \right ) \tilde { j } _ { 0 1 } \tilde { j } _ { 1 3 } - \left ( c _ { 0 } n _ { 0 } - c _ { 1 } n _ { 1 } \right ) C _ { 0 1 } C _ { 1 3 }, \\ & \quad \sim \text{tar} \, \cdots \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot } \text{ } \tilde { \cdot }$$
$$v _ { 3 } & = \partial _ { t } j _ { 2 3 } ^ { \text{tar} } / d + J _ { 1 2 } \tilde { j } _ { 0 1 } - d \left ( C _ { 1 3 } \tilde { j } _ { 1 2 } - C _ { 0 2 } \tilde { j } _ { 0 3 } \right ) \tilde { j } _ { 2 3 } \\ & \quad - 2 d C _ { 0 2 } ^ { 2 } \left ( n _ { 2 } - n _ { 3 } \right ) + J _ { 1 2 } C _ { 0 2 } C _ { 1 3 } & \quad \text{Now,} \\ & \quad - \left ( c _ { 2 } n _ { 2 } - c _ { 0 } n _ { 0 } \right ) \tilde { j } _ { 0 2 } \tilde { j } _ { 2 3 } - \left ( c _ { 2 } n _ { 2 } - c _ { 3 } n _ { 3 } \right ) C _ { 0 2 } C _ { 2 3 }, & \quad \text{ments} \\ & \quad - \text{(44b)} & \quad \text{two-n}$$
where we set E 1 = E 2 = 0 , since - as discussed above - the real parts of these elements have to agree between the two- and four-mode model.
We have to note that by means of the onsite energies E 0 and E 3 we do not fix the currents, but their timederivatives. For this reason the initial probabilities and currents have to be chosen such that they fulfill the conditions (39). In the following section we apply these results to obtain solutions for different starting conditions.
## B. Results
Before presenting our results we give the necessary initial conditions. We insert the definition of the particle current and the solutions for the tunneling elements (40)
0.6
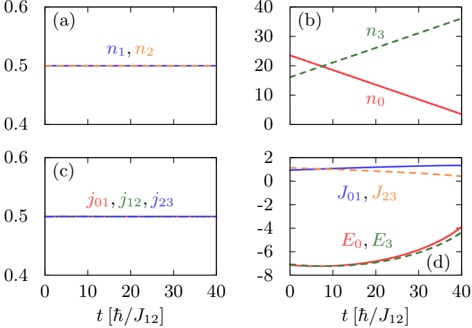
40
Figure 2. Realization of a stationary PT -symmetric solution within the four-mode model. (a) Particles numbers in well 1 (solid) and well 2 (dashed), both equal to 1 2 / . (b) Particle numbers in well 0 (solid) and well 3 (dashed). (c) Particle currents j 01 (solid), j 12 (dashed) and j 23 (dash-dotted) in units of J 12 / glyph[planckover2pi1] . (d) Tunneling elements J 01 (solid), J 23 (dashed), and onsite energies E 0 (solid), E 3 (dashed), in units of J 12 .
into the two Eqs. (39a) and (39b) and express everything in terms of the wave function ψ k . We are allowed to choose the global phase of the initial wave function, so we choose ψ I 2 = 0 . We assume the real parts ψ R 0 and ψ R 3 to be arbitrary but fixed. We are left with (after simple rearrangement)
$$\psi _ { 3 } ^ { I } & = \frac { \Gamma } { 2 d \psi _ { 0 } ^ { R } }, \\ & \quad \,.$$
$$\psi _ { 0 } ^ { I } = \frac { \psi _ { 0 } ^ { R } \psi _ { 1 } ^ { I } } { \psi _ { 1 } ^ { R } } - \frac { \Gamma n _ { 1 } } { 2 d \psi _ { 1 } ^ { R } \left ( \psi _ { 1 } ^ { R } \psi _ { 3 } ^ { R } + \psi _ { 1 } ^ { I } \psi _ { 3 } ^ { I } \right ) }. \quad ( 4 5 b )$$
Now, the wave function ψ k fulfills the necessary conditions and with the time-dependencies of the matrix elements from Sec. III A we can simulate the PT -symmetric two-mode model.
First we consider a stationary solution in the noninteracting case [cf. Eq. (35)] for Γ /J 12 = 0 5 . . Fig. 2 shows the results. As expected the particle numbers in the two middle wells are both equal and constant in time (with normalization n 1 + n 2 = 1 ), as well as the particle currents. For this reason, the number of particles decreases (left well) or increases linearly (right well), with the slope ˙ n 0 = -Γ / glyph[planckover2pi1] and ˙ n 3 = Γ / glyph[planckover2pi1] , respectively. The matrix elements of the four-mode model vary slightly in time. Thus, we have shown that the conditions (39) can be fulfilled for a finite time.
As a second example we prepare a non-stationary solution at t = 0 , with ψ 1 (0) = √ 0 6 . and ψ 2 (0) = √ 0 4 . (see Fig. 3). In this case the particle numbers in the two middle wells oscillate in time with a phase difference ∆ φ < π leading to a non-constant added number of particles, which is a typical feature of PT -symmetric
35
Figure 3. Same as Fig. 2, but for oscillatory dynamics. Additionally, the added number of particles n 1 + n 2 is plotted as crosses in (a). As the particle number in the reservoir well 0 decreases and gets close to zero, the conditions cannot be fulfilled anymore and the simulation breaks down.
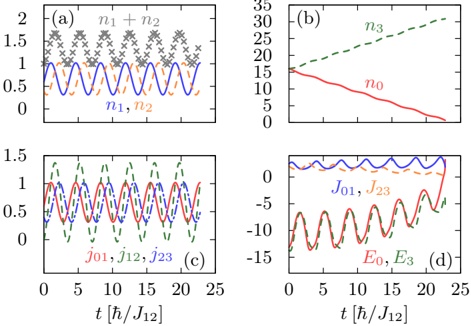
12
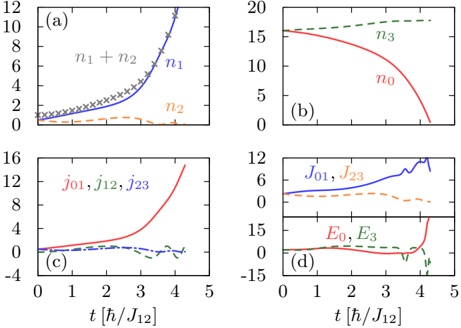
20
Figure 4. Same as Fig. 2, but for the interacting case ( c = -1 ), which leads to a collapsing dynamics, indicating a change of stability. The reservoir is emptying in a short time domain such that the time available for PT symmetry is quite short.
systems. Since well 0 acts as a particle reservoir the number of particles decreases and gets close to zero up to the point where the linear system of equations (43) cannot be fulfilled anymore (determinant of coefficient matrix equals zero). This shows that the time available for a simulation of PT symmetry with a reservoir is limited. The matrix elements in this case show a quasi-oscillatory behavior.
Next, we consider a system with attractive interaction c = -1 . In such a system it is known that the ground state changes its stability in an additional bifurcation (for repulsive interaction, the excited state changes its stability) [12]. This phenomenon is highly correlated to the
Figure 5. Same as Fig. 2, but for an adiabatic current ramp ( Γ f /J 12 = 0 5 . , t /t f 0 = 60 ) for realistic parameters of the external potential. Instead of the matrix elements, in (d) we show the parameters of the potential, δ k marks the displacement from equidistant potential wells. There is a total number of particles of N = 10 4 . See text for units.
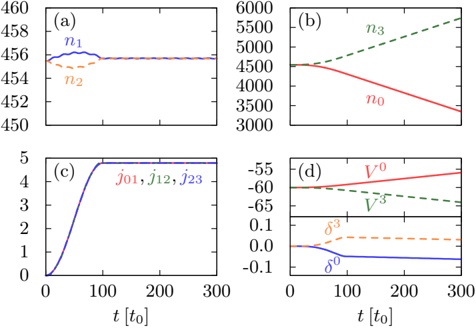
occurrence of self-trapping states. In our example 2 × 2 system [Eq. (33)] the ground state is already unstable for the given interaction strength, so that the ground state with a small perturbation is expected to collapse. The calculation is shown in Fig. 4. The particle number n 1 increases exponentially, which marks the beginning of collapse. To support the exponential increase, the particle number in the reservoir n 0 is decreasing exponentially, so that the simulation breaks down after a quite short time interval. The matrix elements now show a rather complex time-dependency.
As the last example we calculate an experimentally more realistic scenario. Up to now - as mentioned above - we had to start with appropriate wave functions in order to obtain PT symmetry. This is nearly impossible in an experiment. To overcome this, we use an adiabatic change of the PT parameter from zero to its target value. We start at the ground state of the Hermitian four-mode model (with Γ = 0 ) and increase Γ to its target value Γ f . If this change is slow enough, we arrive approximately at the PT -symmetric ground state. The specific time dependence we use is Γ( ) = Γ [1 t f -cos( πt/t f )] / 2 for t ∈ [0 , t f ] .
In the following we simulate a condensate of N = 10 5 atoms of 87 Rb. We use units based on the potential width in z -direction, w z , which we set w z = 1 µ m . The basic unity of energy is E 0 = glyph[planckover2pi1] 2 /mw 2 z , which yields E /h 0 = 116 Hz . The basic unit of time is t 0 = mw / 2 z glyph[planckover2pi1] = 1 37 ms . . The wells have widths of w x = w y = 4 w z = 4 µ m , and are initially positioned equidistantly with a distance of 1 8 . w z = 1 8 . µ m . The potential depths are given by V 0 = V 3 = -60 E 0 and V 1 = V 2 = -45 E 0 . We use a scattering length of a = 2 83 . a B with a B being the Bohr radius.
We calculate the adiabatic ramp for Γ f /J 12 = 0 5 . and t /t f 0 = 60 . The results are shown in Fig. 5. The total particle number and currents are scaled to a particle number of N = 10 5 , the currents are given in units of 1 /t 0 , the potential depths in units of E 0 . Instead of the positions of the potential wells we plot the difference of the position from its initial value, δ k = s k z -s k z ( t = 0) . By means of the relations derived in Sec. II we can transform from the calculated matrix elements to parameters of the external potential.
After time t f an approximate PT -symmetric state is obtained. This can be seen by the constant number of particles in the middle wells, despite an increasing and decreasing number in wells 3 and 0, respectively, which is a clear sign of PT symmetry, also in a possible experiment. The potential depths of the outer wells have to be adjusted in a simple way, the positions vary within a few percent of the distance of the wells. This shows that the simple four-mode model can be used to describe a realistic scenario and to obtain the necessary parameters of the external potential.
We have applied our results from Sec. III A to different initial conditions and system parameters and have shown that it is indeed possible to realize a PT -symmetric system with a Hermitian four-mode model. In the following Section we investigate this scenario in the framework of the GPE and a variational ansatz with Gaussian functions. In particular we verify that the results from this section agree.
## IV. VARIATIONAL ANSATZ WITH GAUSSIAN FUNCTIONS
## A. Variational ansatz and equations of motion
After the simple approach in the previous section we now investigate the possible realization in the framework of the GPE with an extended variational ansatz. We use a superposition of Gaussian functions, where - in contrast to the simpler approach of Sec. II A - all variational parameters are considered as time-dependent,
$$\psi = \sum _ { k } \, \mathrm e ^ { - ( r - q ^ { k } ) ^ { \mathrm T } \mathrm A ^ { k } ( r - q ^ { k } ) + \mathrm i p ^ { k } ( r - q ^ { k } ) - \gamma ^ { k } }. \quad ( 4 6 ) \quad \text{exter} \quad \text{space} \quad \text{$space} \quad \text{$total_s$}$$
The matrices A k = diag( A ,A ,A k x k y k z ) ∈ ❈ 3 × 3 describe the width of each Gaussian function in each direction, the vectors q k = (0 0 , , q k z ) T ∈ ❘ 3 and p k = (0 0 , , p k z ) T ∈ ❘ 3 the position and momentum, respectively, and the scalar quantities γ k ∈ ❈ the amplitude and phase. This variational ansatz can describe a much richer dynamics than ansatz (4) and thus we expect more accurate results.
The equations of motion follow from the timedependent variational principle in the formulation of McLachlan [22], which states that the quantity
$$I = | | \text{i} \hbar { \phi } - \hat { H } \psi | | ^ { 2 }$$
z
Figure 6. External potential V ext ; the darker, the deeper the potential. The wells are separated into regions by walls at positions right in the middle between two minima. The integral over | ψ | 2 in a region k is the particle number n k ; the current through a wall is denoted by j k,k +1 . See text for exact definitions. With this separation we obtain a formulation analogous to the four-mode model (Sec. III).
shall be minimized with respect to φ and φ = ˙ ψ is set afterwards. Details of the necessary calculation can be found in Ref. [23], where the ansatz (46) has been used to study the collision of anisotropic solitons in a BEC. The EOM are given by
$$\mathrm i \hbar { \sum } _ { k } \left \langle \frac { \partial \psi } { \partial z _ { l } } \left | \frac { \partial \psi } { \partial z _ { k } } \right \rangle \dot { z } _ { k } = \left \langle \frac { \partial \psi } { \partial z _ { l } } \right | \hat { H } \left | \psi \right \rangle, \quad ( 4 8 )$$
where z = ( A ,. . . , γ 1 x N G ) T is the vector of all variational parameters. Stationary solutions are given by fixed points of (48), whereas the dynamics can be calculated by integrating Eq. (48) with a numerical integrator.
In Sec. III we started our considerations by calculating the time-derivatives of the observables. In the case of the continuous GPE with a non-Hermitian potential this leads to the modified equation of continuity
$$\dot { \rho } + \text{div} \, j = 2 \rho \text{ Im } V,$$
with ρ = | ψ | 2 and j = glyph[planckover2pi1] ( ψ ∗ ∇ ψ -ψ ∇ ψ ∗ ) / 2 m i . The imaginary part of the potential acts as an additional source or sink to the probability flow. Instead of adjusting the matrix elements, we need to adjust the parameters of the external potential. Since Eq. (49) is given on the whole space ❘ 3 , one would need to change the external potential at every point in space, which is not manageable, neither in theory nor in an experiment.
To overcome this problem we use the results of Sec. III as a roadmap for this continuous system. For that, we separate the individual wells by walls between two minima of the potential at positions z k = ( s k z + s k +1 z ) / 2 for k = 1 2 3 , , , z 0 → -∞ and z 4 → ∞ (see Fig. 6). To obtain time derivatives of discrete observables as in the few-mode model, we integrate the continuity equation for the Hermitian four-well potential over a volume
$$V ^ { k } = \{ ( x, y, z ) ^ { \mathrm T } | - \infty < x, y < \infty, z _ { k - 1 } < z < z _ { k } \}.$$
This yields
$$\mu _ { \nu } \dots \quad & \partial _ { t } \iiint _ { V ^ { k } } d ^ { 3 } r \, \rho & = - \iiint _ { V ^ { k } } d ^ { 3 } r \, \text{div} \, j & \quad \begin{array} { c c c c } 5 0 \\ 4 8 \\ 4 4 \\ 4 2 \\ 4 0 \\ 4 0 \\ \cdot \, & - \iiint _ { \partial V ^ { k } } d A \cdot j. & \quad ( 5 1 ) & \quad \begin{array} { c c c c } 5 0 \\ 4 0 \\ 5 5 0 \\ 5 0 0 \\ 5 0 0 \\ \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \end{array}$$
The integral on the left-hand side can be interpreted as the number of particles in well k . On the right-hand side we used Gauss's theorem. The surface integrals goes over a box, where the areas in the x z -- and y z --plane go to infinity. We assume the current j to also vanish at infinity, so only the integral over the two surfaces in the x y --plane contribute. Thus, we can write
$$\partial _ { t } n _ { k } = - \underset { - \infty } { \overset { \infty } { \int } } \, \mathrm d x \underset { - \infty } { \overset { \infty } { \int } } \, \mathrm d y \left [ j _ { z } ( x, y, z _ { k } ) - j _ { z } ( x, y, z _ { k - 1 } ) \right ]. \, \underset { - \infty } { \overset { \infty } { \int } } \, \mathrm d x \underset { 3 } { \overset { \infty } { \int } } \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \cdots } { \overset { \infty } { \int } } \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm d x \, \mathrm \cdots }$$
The integral over the z -component of j evaluated at z k represents the current from well k to k +1 , which we write as j k,k +1 , for z k -1 this represents the current from well k -1 to k , j k -1 ,k . We finally obtain from the continuity equation
$$\partial _ { t } n _ { k } = j _ { k - 1, k } - j _ { k, k + 1 }, \quad \ \ ( 5 3 ) \quad ^ { \text{sy$} } _ { \infty \, \vee }$$
where j -1 0 , = j 3 4 , = 0 .
Therefore, with Eq. (53) we have an analogous equation as for the few-mode-model (37). We can use the same method to realize a PT -symmetric system. At every time step of the numerical integration of the equations of motion (48) we vary the parameters of the external potential such that the observables show the desired behavior. This is done via a nonlinear root search, in contrast to the analytical solutions of Sec. III A. In Sec. III B we showed that the positions of the outer wells barely needed to be adjusted. As a simplification we only vary the depths of the outer wells V 0 , V 3 and demand the outer currents j 01 , j 23 to reach the desired values. We are left with a two-dimensional root search. In the following section we determine the realization of PT symmetry within the GPE and compare the results with those of the few-mode-model.
## B. Results and comparison with few-mode models
We use the variational ansatz to simulate the adiabatic current ramp of Sec. III B (with same parameters) for a BEC in a four-well potential. For simplification, we do not give a specific value of the PT parameter Γ but a target particle current of j tar = 5 /t 0 . Fig. 7 shows the results. It is not a priori clear whether the quantity n k = ( d k eff ) ∗ d k eff - resulting from the transformed amplitudes of the simplified variational approach - can be compared with the integrated probability density n k of
Figure 7. Adiabatic current ramp calculated with variational ansatz (lines) and four-mode model (crosses) for the same system. Shown are (a) particle numbers in the middle wells, (b) particle numbers in outer wells, (c) potential depths of the outer wells in units of E 0 , and (d) particle current j 12 . There are small deviations, but overall the four-mode model is a valid approximation compared to the variational ansatz.
the extended variational approach. We show in App. B that this comparison is indeed possible and reasonable.
Overall, there is the same qualitative behavior between the two approaches. The particle number in the middle wells is slightly under estimated in the four-mode model due to its origin as an approximation. Because of the fixed positions of the outer wells for the variational approach, n 1 and n 2 are not exactly equal, but the difference is small compared to the absolute number. We can conclude that we can now also create an (approximate) PT -symmetric state within the variational approach and verify that the results from the four-mode model are a good approximation.
The variational approach gives us access to the wave function at each time step (see Fig. 8). As indicated by the particle numbers in Fig. 7, the amplitudes in the middle wells stay almost constant, whereas the amplitudes in the outer wells increase or decrease in time. This could also be measured in an experiment and could serve as a proof of realized PT symmetry.
0.20
Figure 8. Modulus squared of the wave function | ψ | 2 at x, y = 0 for different times t . The amplitudes of the outer parts increase or decrease, whereas the amplitudes in the middle wells stay constant, a clear sign of PT symmetry, also in an experiment.
## V. CONCLUSION
By means of a simple variational ansatz -with localized time-independent Gaussian functions - and the method of symmetric orthogonalization we could transform the GPE for a multi-well potential to a simple fewmode model. The parameters of the variational ansatz are obtained by an energy minimization process in a computationally cheap way. With the results one can, on the one hand, calculate the elements of the few-mode model for a specific system, and on the other determine the parameters of the external potential by knowing the timedependent matrix elements.
These results are applied to the PT -symmetric twomode model and to the Hermitian four-mode model. With this model we could show that the four-mode model can be designed in such a way such that the middle wells behave exactly as the two-wells of the PT -symmetric two-mode model. Thus, this Hermitian (closed) system can be used as a possible realization of a quantum mechanical PT -symmetric system. With an extended Gaussian variational ansatz - with full time-dependent Gaussian functions, which can describe a much richer dynamics - we confirmed the qualitative results of the few-mode model.
In this paper we applied the idea to embed a two-well system into a closed system for the simplest case. It is possible for future work to use a greater embedding which could result in a simpler time-dependence of the additional parameters. The ideas presented in this paper could also serve as a possible road map for an investigation of the Bose-Hubbard model and its many-particle effects.
## ACKNOWLEDGMENTS
This work was supported by DFG. M.K. is grateful for support from the Landesgraduiertenförderung of the Land Baden-Württemberg.
## Appendix A: Analytical considerations
In Sec. III A we derived four conditions [Eqs. (39)] such that the Hermitian four-mode model can simulate the PT -symmetric two-mode model. However, only three of them are independent, which will be shown in this appendix. For that, we need the relations
$$C _ { j j } \tilde { j } _ { i k } = C _ { i j } \tilde { j } _ { j k } + \tilde { j } _ { i j } C _ { j k }, \text{ \quad \ \ } ( \text{A1a} )$$
$$C _ { j j } C _ { i k } = C _ { i j } C _ { j k } - \tilde { j } _ { i j } \tilde { j } _ { j k }, \text{ \quad \ \ } ( \text{A1b} )$$
which can be proved by simply inserting the definitions of these quantities.
We start with Eqs. (39a) and (39b), insert the solutions (40), take the square and use Eqs. (A1). We get
$$\tilde { j } _ { 0 1 } ^ { 2 } \tilde { j } _ { 2 3 } ^ { 2 } + \frac { 2 \Gamma } { d } \tilde { j } _ { 1 2 } \tilde { j } _ { 0 1 } \tilde { j } _ { 2 3 } - C _ { 1 2 } ^ { 2 } \frac { n _ { 3 } } { n _ { 1 } } \tilde { j } _ { 0 1 } ^ { 2 } + \frac { 4 \Gamma ^ { 2 } } { d ^ { 2 } } n _ { 1 } n _ { 2 } = 0, \\ \intertext { e } _ { \omega }$$
$$\ e s ^ { \quad \tilde { j } _ { 0 1 } ^ { 2 } \tilde { j } _ { 2 3 } ^ { 2 } } + \frac { 2 \Gamma } { d } \tilde { j } _ { 1 2 } \tilde { j } _ { 0 1 } \tilde { j } _ { 2 3 } - C _ { 1 2 } ^ { 2 } \frac { n _ { 0 } } { n _ { 2 } } \tilde { j } _ { 2 3 } ^ { 2 } + \frac { 4 \Gamma ^ { 2 } } { d ^ { 2 } } n _ { 1 } n _ { 2 } = 0. \\ \ t z ^ { ( \text{A2b} ) }$$
Taking the difference yields
$$\tilde { j } _ { 2 3 } ^ { 2 } & = \frac { n _ { 2 } n _ { 3 } } { n _ { 0 } n _ { 1 } } \tilde { j } _ { 0 1 } ^ { 2 } \\ \Leftrightarrow \tilde { j } _ { 2 3 } & = s _ { 3 } \sqrt { \frac { n _ { 2 } n _ { 3 } } { n _ { 0 } n _ { 1 } } } \tilde { j } _ { 0 1 }, \quad \quad ( \Lambda 3 )$$
where s 3 = ± 1 gives the sign of ˜ j 23 compared to ˜ j 01 . Inserting this result into Eq. (A2a) gives a fourth-order polynomial equation for ˜ j 01 . The result is
$$\underset { \mathfrak { m } _ { 1 } } { \mathfrak { e } } _ { \mathfrak { m } _ { 2 } } \quad \tilde { j } _ { 0 1 } = s _ { 2 } \sqrt { 2 n _ { 0 } n _ { 1 } \left ( 1 - \alpha + s _ { 1 } \sqrt { ( 1 - \alpha ) ^ { 2 } - \beta ^ { 2 } } \right ) }, \ \ ( A 4 )$$
with the definitions
$$\alpha = \frac { \gamma } { 2 } \underset { \varepsilon \quad. } { \left ( \beta + \frac { \gamma } { 2 } \right ) } \,, \quad \quad \quad ( A 5 \tt a )$$
$$\beta = s _ { 3 } \frac { \Gamma } { d } \frac { 1 } { \sqrt { n _ { 0 } n _ { 3 } } }, \quad \quad ( A 5 b )$$
$$\gamma = \frac { \tilde { j } _ { 1 2 } ^ { \cdot } } { \sqrt { n _ { 1 } n _ { 2 } } }. \quad \quad \quad ( A 5 c )$$
Using Eqs. (A1) we can find all other quantities ˜ j kl and C kl , especially those needed for the investigation of the
fourth condition J 01 ˜ j 02 -J 23 ˜ j 13 = dC 13 ˜ j 02 -dC 02 ˜ j 23 ,
$$C _ { 0 2 } = s _ { 2 } \sin g \, d \sqrt { 2 n _ { 0 } n _ { 2 } \left ( 1 - \alpha - s _ { 1 } \sqrt { ( 1 - \alpha ) ^ { 2 } - \beta ^ { 2 } } \right ) }, \\ ( A 6 a )$$
$$C _ { 1 3 } = s _ { 2 } \, \text{sign} \, d \sqrt { 2 n _ { 1 } n _ { 3 } \left ( 1 - \alpha - s _ { 1 } \sqrt { ( 1 - \alpha ) ^ { 2 } - \beta ^ { 2 } } \right ) }, \quad \text{plus t} \\ \frac { ( A 6 b ) } { \sqrt { \ } \text{Th} }$$
$$\tilde { j } _ { 0 2 } = s _ { 6 } \sqrt { 2 n _ { 0 } n _ { 2 } \left ( 1 + \alpha + s _ { 1 } \sqrt { ( 1 - \alpha ) ^ { 2 } - \beta ^ { 2 } } \right ) }, \ ( A 6 c ) \quad \psi$$
$$\tilde { j } _ { 1 3 } = s _ { 6 } \sqrt { 2 n _ { 1 } n _ { 3 } \left ( 1 + \alpha + s _ { 1 } \sqrt { ( 1 - \alpha ) ^ { 2 } - \beta ^ { 2 } } \right ) }. \ ( A 6 d ) \quad \text{with $1$}$$
All signs s i are determined by the phases of the initial wave function. We can now calculate the fourth condition and find
$$J _ { 0 1 } \tilde { j } _ { 0 2 } - J _ { 2 3 } \tilde { j } _ { 1 3 } = 0. \quad \quad ( A 7 ) \quad \text{wii}$$
Thus, the first three conditions of Eqs. (39) imply the validity of the fourth one. With the results of the matrix elements of Sec. III A, namely J 01 , J 23 , E 0 and E 3 , we find an exact equivalence of the two- and four-mode models also for interacting atoms. Furthermore, with the results of this appendix, we can calculate these matrix elements, once the quantities n 1 , n 2 and ˜ j 12 are known.
## Appendix B: Comparison of probabilities for few-mode-model and Gaussian functions
As discussed in Sec. IVB it is not a priori clear whether we can compare the particle numbers obtained from the four-mode model and the extended variational approach. In this appendix we take a closer look at both quantities.
The transformation of the amplitudes from the fourmode model, resulting from symmetric orthogonalization, is given by the inverse of the matrix X (cf. Sec. II C),
$$d _ { \text{eff} } ^ { l } & = \sum _ { k } ( \mathbf X ^ { - 1 } ) _ { l k } d ^ { k } \\ & = \sum _ { k } \left [ ( \mathbf X ^ { - 1 } ) _ { l k } ^ { ( 0 ) } + ( \mathbf X ^ { - 1 } ) _ { l k } ^ { ( 1 ) } \right ] d ^ { k }. \quad ( B 1 ) \begin{pmatrix} \text{$\text{can}$} \\ \text{dist} \\ \text{mod} \\ \end{pmatrix}.$$
The individual orders of the inverse matrix can easily be calculated, we get
$$\text{calculated, we get} \\ ( X ^ { - 1 } ) _ { l k } ^ { ( 0 ) } & = \sqrt { \frac { \pi ^ { 3 } } { 8 } } \frac { 1 } { \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } } \delta _ { l k }, \\ ( X ^ { - 1 } ) _ { l k } ^ { ( 1 ) } & = \sqrt { 8 \pi ^ { 3 } } \frac { \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } A _ { x, R } ^ { l } A _ { y, R } ^ { l } A _ { z, R } ^ { l } } } { \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } } + \sqrt { A _ { x, R } ^ { l } A _ { y, R } ^ { l } A _ { z, R } ^ { l } } } + \sqrt { \text{unify.} } \text{bersc} \\ & \quad \times \frac { c ^ { k l } } { \sqrt { A _ { x } ^ { k l } } \sqrt { A _ { y } ^ { k l } } \sqrt { A _ { z } ^ { k l } } } ( \delta _ { k, l - 1 } + \delta _ { k, l + 1 } ). \ ( B 2 a ) \ \text{Since} \ \text{the} \ p \varepsilon$$
The main contribution to the particle number n k = ( d k eff ) ∗ d k eff is then given by
$$n _ { k } = \sqrt { \frac { \pi ^ { 3 } } { 8 } } \frac { 1 } { \sqrt { A _ { x, R } ^ { k } A _ { y, R } ^ { k } A _ { z, R } ^ { k } } } \left | d ^ { k } \right | ^ { 2 }, \quad \text{(B3)}$$
plus terms involving neighboring amplitudes.
The extended variational ansatz is given by
$$\psi = \sum _ { k } d ^ { k } e ^ { - A _ { x } ^ { k } x ^ { 2 } - A _ { y } ^ { k } y ^ { 2 } - A _ { z } ^ { k } ( z - q _ { z } ^ { k } ) ^ { 2 } + i ( z - q _ { z } ^ { k } ) p _ { z } ^ { k } }, \quad ( B 4 )$$
with the amplitude d k = exp( -γ k ) . The probability density can then be written as
$$\underset { \rho } { \pi } = \sum _ { k, l } d ^ { k } ( d ^ { l } ) ^ { * } \, e ^ { - A _ { x } ^ { k l } x ^ { 2 } - A _ { y } ^ { k l } y ^ { 2 } - A _ { z } ^ { k l } z ^ { 2 } + i \tilde { p } _ { z } ^ { k l } z - \tilde { \gamma } ^ { k l } }, \quad ( B 5 )$$
with the definitions
$$\text{he} \quad \tilde { p } _ { z } ^ { k l } = 2 [ A _ { z } ^ { k } q _ { z } ^ { k } + ( A _ { z } ^ { l } ) ^ { * } q _ { z } ^ { l } ] + \text{i} ( p _ { z } ^ { k } - p _ { z } ^ { l } ), \quad \text{(B6a)}$$
$$\frac { \iota \sigma } { 2 }, \quad \tilde { \gamma } ^ { k l } = A _ { z } ^ { k } ( q _ { z } ^ { k } ) ^ { 2 } + ( A _ { z } ^ { l } ) ^ { * } ( q _ { z } ^ { l } ) ^ { 2 } + i ( q _ { z } ^ { k } p _ { z } ^ { k } - q _ { z } ^ { l } p _ { z } ^ { l } ). \ \ ( B 6 b )$$
We integrate ρ over the region discussed in Sec. IVA. The integral over x and y yields
$$\rho _ { z } = \sum _ { k, l } d ^ { k } ( d ^ { l } ) ^ { * } \frac { \pi } { \sqrt { A _ { x } ^ { k l } } \sqrt { A _ { y } ^ { k l } } } \, e ^ { - A _ { z } ^ { k l } z ^ { 2 } + \tilde { p } _ { z } ^ { k l } z - \tilde { \gamma } ^ { k l } }. \quad ( B 7 )$$
The integral over z goes over a finite interval, say a ≤ z ≤ b , we can express the result in terms of the error function,
$$\text{clear} \quad \text{uncount}, \\ \text{ional} \quad \text{$n(a,b)=\frac{1}{2}\sum_{k,l}d^{k}(d^{l})^{*}\frac{\pi^{3}}{\sqrt{A_{x}^{k}}\sqrt{A_{y}^{k}}\sqrt{A_{z}^{k}}^{l}-\tilde{\gamma}^{k}l}$} \\ \text{four} \quad \text{$\times\left[\text{erf}\left(\frac{2A_{z}^{k}b-\tilde{p}_{z}^{k}l}{4\sqrt{A_{z}^{k}} \right) -\text{erf} \left(\frac{2A_{z}^{k}a-\tilde{p}_{z}^{k}l}{4\sqrt{A_{z}^{k}} \right) \right].} \\ \text{$\times\left[\text{erf}\left(\frac{2A_{z}^{k}b-\tilde{p}_{z}^{k}l}{4\sqrt{A_{z}^{k}} \right) \right].} \\ \text{$\times\left[\text{erf}\left(\frac{2A_{z}^{k}b-\tilde{p}_{z}^{k}l}{4\sqrt{A_{z}^{k}} \right) \right].}$$
To obtain the number of particles in well i , we evaluate this expression at points a and b between the wells, we can write a = q i z -glyph[lscript]/ 2 and b = q i z + glyph[lscript]/ 2 with glyph[lscript] the distance between two wells. As in the case for the fourmode model, the main contribution of the sum results for the summand with i = k = l . We get approximately
$$n _ { i } = \sqrt { \frac { \pi ^ { 3 } } { 8 } } \frac { \text{erf} \left ( \sqrt { A _ { z, R } ^ { i } \ell ^ { 2 } / 2 } \right ) } { \sqrt { A _ { x, R } ^ { i } A _ { y, R } ^ { i } A _ { z, R } ^ { i } } } \left | d ^ { i } \right | ^ { 2 }.$$
For typical values of A i z,R glyph[lscript] 2 the error function is close to unity. Thus, it is reasonable to compare the particle numbers obtained from the four-mode model [Eq. (B3)] with those from the extended variational ansatz [Eq. (B9)]. Since the particle currents are given by the derivatives of the particle numbers, this is also the case for the particle currents.
- [1] C. E. Rüter, K. G. Makris, R. El-Ganainy, D. N. Christodoulides, M. Segev, and D. Kip, Nat. Phys. 6 , 192 (2010).
- [3] J. Schindler, A. Li, M. C. Zheng, F. M. Ellis, and T. Kottos, Phys. Rev. A 84 , 040101 (2011).
- [2] Y. D. Chong, L. Ge, and A. D. Stone, Phys. Rev. Lett. 106 , 093902 (2011).
- [4] S. Bittner, B. Dietz, U. Günther, H. L. Harney, M. MiskiOglu, A. Richter, and F. Schäfer, Phys. Rev. Lett. 108 , 024101 (2012).
- [6] C. M. Bender and S. Boettcher, Phys. Rev. Lett. 80 , 5243 (1998).
- [5] H. Ramezani, T. Kottos, R. El-Ganainy, and D. N. Christodoulides, Phys. Rev. A 82 , 043803 (2010).
- [7] S. Klaiman, U. Günther, and N. Moiseyev, Phys. Rev. Lett. 101 , 080402 (2008).
- [9] Y. Shin, G. B. Jo, M. Saba, T. A. Pasquini, W. Ketterle, and D. E. Pritchard, Phys. Rev. Lett. 95 , 170402 (2005).
- [8] D. Dast, D. Haag, H. Cartarius, G. Wunner, R. Eichler, and J. Main, Fortschritte der Physik 61 , 124 (2013).
- [10] H. Cartarius and G. Wunner, Phys. Rev. A 86 , 013612 (2012).
- [11] E. M. Graefe, H. J. Korsch, and A. E. Niederle, Phys.
- Rev. Lett. 101 , 150408 (2008).
- [13] A. Zenesini, C. Sias, H. Lignier, Y. Singh, D. Ciampini, O. Morsch, R. Mannella, E. Arimondo, A. Tomadin, and S. Wimberger, New J. Phys. 10 , 053038 (2008).
- [12] D. Haag, D. Dast, A. Löhle, H. Cartarius, J. Main, and G. Wunner, Phys. Rev. A 89 , 023601 (2014).
- [14] C. Elsen, K. Rapedius, D. Witthaut, and H. J. Korsch, J. Phys. B 44 , 225301 (2011).
- [16] K. Henderson, C. Ryu, C. MacCormick, and M. G. Boshier, New J. Phys. 11 , 043030 (2009).
- [15] M. Kreibich, J. Main, H. Cartarius, and G. Wunner, Phys. Rev. A 87 , 051601(R) (2013).
- [17] A. Trombettoni and A. Smerzi, Phys. Rev. Lett. 86 , 2353 (2001).
- [19] I. Bloch, J. Dalibard, and W. Zwerger, Rev. Mod. Phys. 80 , 885 (2008).
- [18] A. Smerzi and A. Trombettoni, Phys. Rev. A 68 , 023613 (2003).
- [20] P. Löwdin, J. Chem. Phys. 18 , 365 (1950).
- [22] A. D. McLachlan, Mol. Phys. 8 , 39 (1964).
- [21] E.-M. Graefe, J. Phys. A 45 , 444015 (2012).
- [23] R. Eichler, D. Zajec, P. Köberle, J. Main, and G. Wunner, Phys. Rev. A 86 , 053611 (2012). | 10.1103/PhysRevA.90.033630 | [
"Manuel Kreibich",
"Jörg Main",
"Holger Cartarius",
"Günter Wunner"
] | 2014-08-01T12:52:11+00:00 | 2014-08-01T12:52:11+00:00 | [
"quant-ph",
"cond-mat.quant-gas",
"nlin.CD"
] | Realizing PT-symmetric non-Hermiticity with ultra-cold atoms and Hermitian multi-well potentials | We discuss the possibility of realizing a non-Hermitian, i.e. an open
two-well system of ultra-cold atoms by enclosing it with additional
time-dependent wells that serve as particle reservoirs. With the appropriate
design of the additional wells PT-symmetric currents can be induced to and from
the inner wells, which support stable solutions. We show that interaction in
the mean-field limit does not destroy this property. As a first method we use a
simplified variational ansatz leading to a discrete nonlinear Schr\"odinger
equation. A more accurate and more general variational ansatz is then used to
confirm the results. |
1408.0164v1 | The spatial scan statistic: A new method for spatial aggregation of categorical raster maps
- J.W. Coulston†, N. Zaccarelli‡, K.H. Riitters§, F.H. Koch† and G. Zurlini‡*
- † North Carolina State University, Department of Forestry and Environmental Resources Campus Box 8008, Raleigh, NC, 27695-8008, USA
- ‡ University of Salento, Department of Biological and Environmental Sciences and Technologies, 73100 Lecce, Italy
- § USDA Forest Service, Southern Research Station, Forestry Sciences Laboratory 3041 Cornwallis Road, Research Triangle Park, NC, 27709 USA
- * To whom correspondence should be addressed, [email protected]
## Abstract
Multiple-scale and broad-scale assessments often require rescaling the original data to a consistent grain size for analysis. Rescaling categorical raster data by spatial aggregation is common in large area ecological assessments. However, distortion and loss of information are associated with aggregation. Using a majority rule generally results in dominant classes becoming more pronounced and rare classes becoming less pronounced. Using nearest neighbor techniques generally maintains the global proportion of each category in the original map but can lead to disaggregation. In this paper we implement the spatial scan statistic for spatial aggregation of categorical raster maps and describe the behavior of the technique at the local level (aggregation unit) and global level (map). We also contrast the spatial scan statistic technique with the majority rule and nearest neighbor approaches. In general, the scan statistic technique behaved inverse the majority rule approach in that rare classes rather than abundant classes were preserved. We suggest the scan statistic techniques should be used for spatial aggregation of categorical maps when preserving heterogeneity and information from rare classes are important goals of the study or assessment.
Key words: scaling , spatial filtering, image enhancement, resampling, land cover maps, heterogeneity
## 1 Introduction
In order to quantify spatial heterogeneity satisfactorily and detect characteristic scales of landscapes, it is widely recognized that landscapes should be examined at multiple scales. The role played by scale in landscape analysis can be described by distinguishing between the scale of observation (the scale at which the natural world is translated into data) and the scale of analysis (the scale at which patterns are revealed from the data) (Li and Reynolds 1995). Often they are not identical. The scale of observation stems directly from the characteristics of the system studied, the questions asked, and the data collection protocols. The scale of observation is an inherent property of the data and is often changed into scale of analysis because of the difficulties in collecting data at multiple
scales of observation. The scale of analysis is determined by the interaction of the original scale of observation with the methods used for data transformation, including aggregation, magnification, and resampling.
Large-area (regional, national extent) ecological assessments rely on a variety of spatial information across a range of scales (grain sizes). For instance, land cover or land use data commonly serve as the basis for such assessments. Many of these spatial data sets are derived from satellite imagery collected by sensors with different grain sizes, such as the Landsat Thematic Mapper (30m), the Moderate Resolution Imaging Spectroradiometer (250m to 1000m), and the Advanced Very High Resolution Radiometer (1000m). Other frequently used raster data such as digital elevation models, interpolated climate data, and soil data are also available in varied grain sizes. Combining these data for national or regional ecological assessments often requires rescaling or aggregating to the same spatial resolution to enable efficient computation and simplify the interpretation of analytical outputs (.e.g., Coulston and Riitters 2005, Verburg and Veldkamp 2004). Unfortunately, distortion and the loss of potentially critical information are common side effects when changing grain size, particularly for categorical raster data sets (Gardner et al. 1982).
Two methods of spatial aggregation for categorical raster maps are standard with geographic information systems software packages: block majority filtering (MAJ) and nearest neighbor resampling (NN). Suppose an input map originally has a 30m x 30m grain size and the desired output map has a 90m x 90m grain size. MAJ aggregates by examining the category of the nine original pixels within each 90m x 90m aggregation unit and assigns the unit the category that occurs most often. NN is similar to a twodimensional systematic sample in that every k×k unit of the raster map is sampled based on the center pixel. Following the example from above, a sample is taken on a three pixel by three pixel spacing to aggregate to a 90m x 90m pixel size. In addition to these methods, He et al. (2002) developed a random rule approach to spatial aggregation. This method works similar to the NN method except that the sample pixel randomly drawn from the pixels within the aggregation unit. Theoretically the NN and random rule methods should yield similar results however, the NN method does have potential bias. Because the NN method is a systematic sample, it can be biased if the classes exhibit a repetitive pattern with periodicity similar to the sample spacing (Steel et al. 1997). Beyond these issues, attention has been given to the general influence of spatially aggregating categorical raster maps on measures of amount and pattern (e.g., He et al. 2002, Moody and Woodcock 1995, Turner et al. 1989). In general, the MAJ aggregation technique forces dominant classes to become more dominant and rare classes to become rarer. However, the degree to which classes become more or less dominant depends on the spatial pattern of the original map. The NN method generally preserves the relative proportions but at the same time can degrade spatial pattern by introducing disaggregation (He et al. 2002). This often gives NN-aggregated maps a 'salt and pepper' appearance.
Categorical maps, regardless of the number of categories, can be thought of as a series of binary maps. Suppose a three-class map has developed, forest, and cultivated categories. Then, the three-class map is a combination of a developed / non-developed map, a forest / non-forest map, and a cultivated / non-cultivated map. These maps can be summarized by counts, both globally and within each aggregation unit. There are specific statistical
models to deal with count data derived from a binary response; however, with few exceptions, these techniques have not been extended to the spatial domain. One technique developed for spatial and spatial-temporal count data is the spatial scan statistic (Kulldorff 1997). The spatial scan statistic was first developed for human epidemiology but has also been applied in ecology, brain imaging, psychology, toxicology, and veterinary medicine (Coulston and Riitters 2003, Yoshida 2003, Margai and Henry 2003, Sudakin et al. 2002, Hoar et al. 2003, respectively). The general objective of the scan statistic is to identify clusters of measurement units for which the occurrence of events is significantly more likely within the cluster than outside of the cluster. The scan statistic quantifies the importance of each potential cluster based on likelihood ratios and tests the significance of each potential cluster based on Monte Carlo simulation. Typically, the output clusters vary in size and shape. However, if the search for important potential clusters is omitted, and instead the map is divided into contiguous, non-overlapping squares of the same size then the resulting 'clusters' may serve as equal area aggregation units. In turn, the scan statistic likelihood ratio can be calculated for each class within a given aggregation unit and this information can be used to determine the final classification of the unit when changing grain size.
The objectives of this study were to (1) implement the spatial scan statistic model to aggregate a 30m categorical map of land cover (2) describe the differences between aggregated maps created using the spatial scan statistic and other methods typically used for spatial aggregation and (3) suggest when the spatial scan statistic an appropriate method for spatial aggregation.
## 2 Materials and Methods
We used National Land Cover Data (NLCD) as the basis for our analysis (Vogelmann et al. 2001). The NLCD project used Landsat Thematic Mapper (TM) imagery (circa 1992) to classify the land cover of the coterminous United States in 21 classes at a grain size of 0.09 ha (30m by 30m). For the purposes of this study we collapsed the 21 original classes to seven broader classes (Table 1).
We selected a study area in southeastern Wisconsin, USA (43°17' N, 88°42' W) that encompassed approximately 13934 km2 (Figure 1). Based on the reclassified NLCD map, our study area was mostly cultivated (~ 72 %). Forest comprised approximately 12 percent of the study area, and wetland and urban categories each comprised six percent. We used three methods of spatial aggregation-MAJ, NN, and the spatial scan statistic (SCAN)- to change the grain size of the original map from 0.09 ha pixels to 7.29 ha, 26.01 ha, and 98.01 ha pixels (representing 9×9, 17×17, and 33×33 blocks of the original pixels). SCAN can be applied using two different statistical models: the Bernoulli model and Poisson model. We used the Bernoulli model (Kulldorff 1997) for our analysis. To implement this procedure the likelihood ratio was calculated for each land cover category within each aggregation unit.
The likelihood ratio based on the Bernoulli model was
$$& \text{$mne unmovnauuauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauauau
& \Psi _ { a x } = ( c / n ) ^ { c } \left ( ( n - c ) / n \right ) ^ { n - c } \left ( ( C - c ) / ( N - n ) \right ) ^ { C - c } \left ( ( ( N - n ) - ( C - c ) ) / ( N - n ) \right ) ^ { ( N - n ) - ( C - c ) } I & & [ 1 ]$$
| Landcover (NLCD Classification) | Pixels | Percent | Connectivity |
|-------------------------------------------|----------|-----------|----------------|
| Water | 458528 | 2.96 | 0.89 |
| (11 Open Water) | | | |
| (12 Perennial Ice/Snow) | | | |
| Developed | 914122 | 5.90 | 0.80 |
| (21 Low Intensity Residential) | | | |
| (22 High Intensity Residential) | | | |
| (23 Commercial/Industrial/Transportation) | | | |
| Barren | 18711 | 0.12 | 0.81 |
| (31 Bare Rock/Sand/Clay) | | | |
| (32 Quarries/Strip Mines/Gravel Pits) | | | |
| (33 Transitional) | | | |
| Forested | 1853204 | 11.97 | 0.65 |
| (41 Deciduous Forest) | | | |
| (42 Evergreen Forest) | | | |
| (43 Mixed Forest) | | | |
| Grass/Shrubland | 152767 | 0.99 | 0.34 |
| (51 Shrubland) | | | |
| (71 Grasslands/Herbaceous) | | | |
| Cultivated | 11167042 | 72.13 | 0.94 |
| (61 Orchards/Vineyards/Other) | | | |
| (81 Pasture/Hay) | | | |
| (82 Row Crops) | | | |
| (83 Small Grains) | | | |
| (84 Fallow) | | | |
| (85 Urban/Recreational Grasses) | | | |
| Wetlands | 918001 | 5.93 | 0.70 |
| (91 Woody Wetlands) | | | |
| (92 Emergent Herbaceous Wetlands) | | | |
Total
15482375
Table 1. Classification and characteristics of the study area at the original 0.09 ha grain size. Connectivity represents the probability that an adjacent pixel (4-neighbor rule) is of the same class.
Figure 1. The study area in southeastern Wisconsin, USA (represented by the diagonal hatch bars).
- Ψaz = the likelihood ratio for aggregation unit a and land cover category z
- c = the number of pixels of category within aggregation unit z a
- n = the number of pixels in each aggregation unit
- C = the total number of pixels of category z within the study area
- N = the total number of pixels in the study area.
- I = indicator function where I = 1 if (c/n) ≥ (C/N) and zero otherwise.
The aggregation unit was then assigned the category with the greatest likelihood ratio value.
Figure 2. Example of a 7×7 aggregation unit composed of cultivated land, forest, and wetlands.
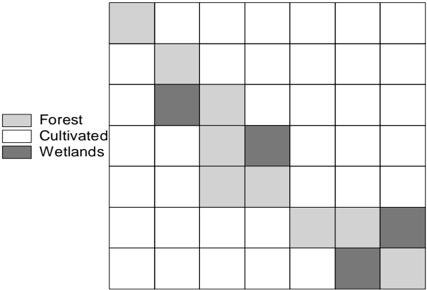
Use of the three aggregation techniques is best illustrated with a comparative example. Suppose Figure 2 represents a 7×7 pixel aggregation unit made up of forest, cultivated, and wetland cover types. Based on MAJ, this aggregation unit would be classified as cultivated because more pixels are classified as cultivated than either forest or wetlands. The NN method would instead classify this aggregation unit as wetlands because the center pixel (i.e., the location of the systematic sample point) is classified as wetlands. To apply the SCAN, we calculate the likelihood ratio for each category. The variables c and n are counts from the aggregation unit while the variables C and N are based on mapwide totals from Table 1. Notably, these variables allow the SCAN to incorporate both local and global (i.e., image-wide) information about each class during the aggregation process. For the forest category, c =9, n =49, C =1853204, and N =15482375. The likelihood ratio is generally computed in logarithmic form because of computer limitations on exponents, so log(Ψforest) = 0.836. For the cultivated class, c =36, n =49, C =11167042, N =15482375, and log(Ψcultivated)=0.022. For the wetlands class, c =4, n =49, C =918001, N =15482375, and log(Ψwetlands)=0.197. Because the forest class has the greatest log likelihood ratio, the aggregation unit would be classified as forest by SCAN. To compare the three aggregation approaches, we investigated measures of both their global and local behavior. To describe the global behavior of each technique, we recorded the relative proportions of the map occupied by each land cover class at the three aggregation grain sizes. We examined local behavior using cumulative distribution functions (CDF) and agreement matrices. The CDFs allowed us to visually compare the local-scale characteristics of each method across land cover classes. To calculate the CDF for each aggregation technique and grain size, we computed the proportion ( Pz ) of
original 0.9-ha pixels within each aggregation unit that were in the land cover category ultimately assigned to the unit by the aggregation method. Returning to the example aggregation unit in Figure 2, the Pz for the MAJ technique-which classified the unit as cultivated-was 0.73. In contrast, the Pz for the NN technique (where = wetlands) was z 0.08 and the Pz for the SCAN technique (where = forest) was 0.18. We then compiled z the Pz for each aggregation unit, aggregation method, and grain size was then used to create the CDFs.
We constructed agreement matrices to examine categorical overlap between maps of the same grain size on a pixel-by-pixel basis. Specifically, we examined overall agreement as well as Cohen's kappa ( K hat ) across land cover classes for each grain size (Jensen 1996). We also examined individual land cover class agreement among aggregation methods.
## 3 Results
The MAJ, NN, and SCAN methods exhibited different trends when aggregating the original map to the 7.29, 26.01, and 98.01 ha grain sizes (Figure 3).
SCAN

Original Map (0.09 ha)
MAJ


Figure 3. The original seven-class land cover map and maps aggregated at the 7.29, 26.01, and 98.01 ha grain sizes using each aggregation technique.





The MAJ method increased the proportion of the cultivated class (i.e., the most dominant class) by an average of 6.0 percent and decreased the proportions of rarer classes such as forest, water, and wetlands (Figure 4). The NN method tended to preserve the original proportions of each class across grain sizes, but the classes became less spatially cohesive. This was particularly evident at the 98.01 ha resolution, where a significant 'salt-and-pepper' effect was observable, in contrast to the cohesiveness exhibited by the MAJ and SCAN techniques (Figure 3). The SCAN technique behaved in a manner inverse to the MAJ technique, emphasizing rare classes such as forest and wetlands (Figures 3 and 4). The proportions of these rarer classes increased at the expense of the more abundant classes such as cultivated, which represented ~72% of the landscape at the 0.09 ha grain size, but only ~52% of the landscape at the 98.01 ha resolution.
Figure 4. Percent of the land cover map represented by (A) cultivated land and forest and (B) across grain sizes based on the MAJ method (open circle), the NN method (solid line), and the SCAN method (open triangle).
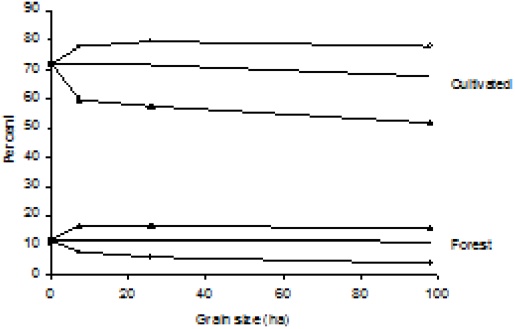
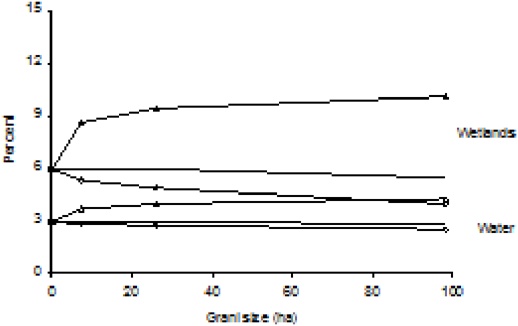
Looking at the local behavior of each aggregation technique as represented by the CDFs (Figure 5), the techniques performed similarly when Pz > 0.8, regardless of grain size. In short, when any category represented more than 80% of an aggregation unit, the z aggregation unit was classified as that category by all three techniques. The NN and SCAN techniques also performed similarly when Pz < 0.2. The largest difference between techniques occurred when Pz ~ 0.45: The disparity between the CDFs of the MAJ and the SCAN techniques grew as the grain size increased. Generally, when Pz > 0.2 and Pz < 0.8, the CDF for the SCAN technique was above the CDFs for the NN and MAJ techniques.
Figure 5. Cumulative distribution functions (CDFs) for each aggregation method for the 7.29 ha grain size (A), the 26.01 ha grain size (B), and the 98.01 ha grain size (C).
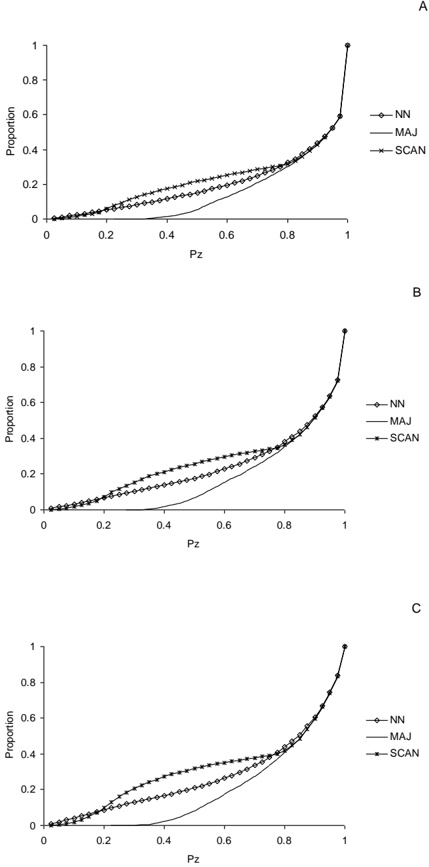
The SCAN method assigned a category to each aggregation unit (Equation 1) by comparing the proportion of category within each aggregation (i.e. z c z / n z ) to the overall proportion of category in the original map (i.e. z C N z / z ). Because of the indicator function I , an aggregation unit could only be classified as category z if c z / n z > C N z / z (the proportion of the category in the aggregation unit was greater than its overall proportion in the original map). When c z / n z > C N z / z the log likelihood ratio was a measure of the concentration of the category within the aggregation unit compared to the concentration of the category in the entire map. This preserved rarer classes, which could have a high log likelihood ratio at relatively low values of Pz (Figure 6). In contrast, for an aggregation unit to be classified as agriculture (the most abundant class) the proportion had to be greater than ~ 0.76 (Figure 6).
Figure 6. Log likelihood ratio versus the proportion (Pz) of each aggregation unit, across grain sizes. The curves for the urban and wetland classes overlap because of the similar proportions occupied by each of these categories in the original map.
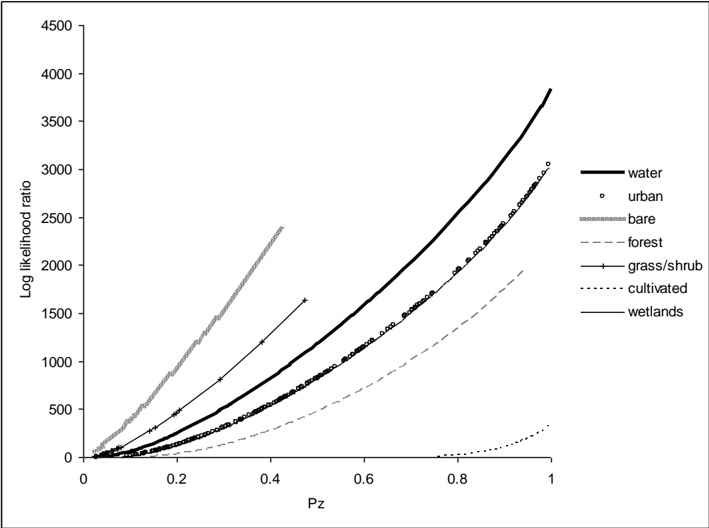
Percent agreement between maps created using each aggregation method ranged from 81% agreement between the MAJ and SCAN methods at the 7.29 ha grain size to 71.2% agreement between the NN and SCAN methods at the 98.01 ha grain size (Table 2). In general, the agreement between the SCAN method and the MAJ and NN methods decreased as the grain size increased. Among all grain sizes, the overall percent agreement between the SCAN and the MAJ methods was higher than the agreement between the SCAN and NN methods, although the Khat coefficients suggested slightly higher agreement between the SCAN and the NN methods at the 26.01 ha and 98.01 ha grain sizes.
SCAN
SCAN
Table 2. Overall percent agreement and Khat comparing maps produced using the SCAN method with maps produced using the MAJ and NN methods across grain size.
| | MAJ | MAJ | NN | NN |
|---------------|-------------|---------|-------------|---------|
| Grain size ha | Agreement % | K hat % | Agreement % | K hat % |
| 7.29 | 81.0 | 63.0 | 79.8 | 62.4 |
| 26.01 | 77.3 | 55.8 | 76.0 | 56.1 |
| 98.01 | 72.0 | 46.1 | 71.2 | 48.8 |
grass/shrub forest
wetlands developed
bare water
cultivated total MAJ
Table 3. Agreement matrix for the SCAN and MAJ aggregation techniques at the 7.29 ha grain size. Note that the land cover classes are in order of increasing connectivity (see Table 1).
| grass/shrub | forest | wetlands | MAJ developed | bare | water | cultivated | total SCAN | |
|---------------|----------|------------|-----------------|--------|---------|--------------|--------------|--------|
| 419 | 248 | 106 | 60 | 0 | 3 | 3667 | 4503 | 9.3% |
| 0 | 13510 | 0 | 0 | 0 | 0 | 18203 | 31713 | 42.6% |
| 0 | 613 | 9937 | 0 | 0 | 0 | 5906 | 16456 | 60.4% |
| 0 | 227 | 0 | 11302 | 0 | 0 | 5210 | 16739 | 67.5% |
| 6 | 20 | 13 | 17 | 231 | 5 | 233 | 525 | 44.0% |
| 0 | 174 | 111 | 39 | 0 | 5310 | 1360 | 6994 | 75.9% |
| 0 | 0 | 0 | 0 | 0 | 0 | 113618 | 113618 | 100.0% |
| 425 | 14792 | 10167 | 11418 | 231 | 5318 | 148197 | | |
| 98.6% | 91.3% | 97.7% | 99.0% | 100.0% | 99.8% | 76.7% | | 81.0% |
grass/shrub forest
wetlands developed
bare water
cultivated total NN
Table 4. Agreement matrix for the SCAN and NN aggregation techniques at the 7.29 ha grain size. Note that the land cover classes are in order of increasing connectivity (see Table 1).
| grass/shrub | forest | wetlands | NN developed | bare | water | cultivated | total SCAN | |
|---------------|----------|------------|----------------|--------|---------|--------------|--------------|-------|
| 816 | 616 | 202 | 122 | 1 | 10 | 2736 | 4503 | 18.1% |
| 442 | 15852 | 1140 | 228 | 0 | 91 | 13960 | 31713 | 50.0% |
| 171 | 2393 | 9115 | 38 | 1 | 303 | 4435 | 16456 | 55.4% |
| 110 | 1177 | 163 | 10451 | 2 | 86 | 4750 | 16739 | 62.4% |
| 14 | 54 | 13 | 19 | 224 | 7 | 194 | 525 | 42.7% |
| 28 | 433 | 399 | 146 | 0 | 5035 | 953 | 6994 | 72.0% |
| 246 | 2258 | 366 | 176 | 3 | 28 | 110541 | 113618 | 97.3% |
| 1827 | 22783 | 11398 | 11180 | 231 | 5560 | 137569 | | |
| 44.7% | 69.6% | 80.0% | 93.5% | 97.0% | 90.6% | 80.4% | | 79.8% |
On an individual class basis, the SCAN method was more likely to assign pixels to the same category as the MAJ or NN methods when the category in the original map was more connected (Tables 3 and 4). For example the grass/shrub category had low connectivity in the original map (Table 1). At the 7.29 ha grain size, the SCAN method only had 9.3% agreement with the MAJ method (Table 3) and 18.1% agreement with the NN method (Table 4) for this class. In contrast, the cultivated category had high connectivity in the original map. Subsequently, the SCAN method had 100% agreement with the MAJ method and 97.3% agreement with the NN method at the 7.29 ha grain size. The barren class, however, did not follow the general trend of increased agreement with increased connectivity: It had a relatively high connectivity value, but the agreement between the SCAN method and the NN and MAJ methods was 44% and 42.7%, respectively. This was because the overall proportion of the barren class was 0.12% in the original map and therefore could exhibit a high log likelihood ratio even at low values of P z (Figure 6).
While all of the pixels classified as cultivated by the SCAN method were also classified as cultivated by the MAJ method, the MAJ method assigned a further ~34,500 pixels to
the cultivated class at the 7.29 ha grain size (Table 3). Therefore, the MAJ method only agreed with the SCAN method 76.7% of the time for the cultivated class at the 7.29 ha scale. In general, agreement between the SCAN and MAJ methods decreased with increasing abundance of a given category in the original image.
## 4 Discussion
Changing scale by manipulating data can be a useful surrogate for observing the landscape directly with two or more sensors at different resolutions. However, the of 'rescaling data' like in aggregation procedures is still rudimentary although some remote sensing (e.g., Openshaw 1984; Justice et al. 1989; Jelinski and Wu 1996; Bian and Butler 1999; Wu 2004). More understanding can come out from the direct comparison of different aggregation techniques like those compared in this paper.
Regardless of how data are changed subsequently at the scale of analysis, one must be cautious in interpreting results from rescaled data, and be aware that patterns and scales to those embodied into the data set the rescaling is based on.
surrogate fundamentally differs from direct observation. Our understanding of the effects insight may be gained from a synthesis of numerous studies carried out in geography and revealed in such analyses may not correspond to those in the real landscapes, or not even
Selecting an appropriate aggregation technique should be based on the goals of the particular study. No one technique is optimal for all situations, and each aggregation technique distorts different aspects of the original image. For instance, the MAJ technique is often used to approximate land cover information derived from a sensor with a coarser grain size, because it is seen as a reasonable simulation of how the coarser sensor behaves (He et al. 2002). Nonetheless, in studies relating to landscape heterogeneity, the SCAN and NN techniques may be more appropriate because they tend to preserve the presence of each class in some fashion, while the MAJ technique tends to lose rare classes completely (Turner et al. 1989). Ecologists are often interested in relating the broad-scale patterns of sparsely or sporadically distributed habitat within a matrix of mostly non-habitat to bioclimatic, topographic, and edaphic factors derived from information of a different grain (e.g., Coulston and Riitters 2005). In such cases, the SCAN technique may be most appropriate because it maintains and enhances the presence of less abundant land cover classes during aggregation.
Commonly accepted methods of spatially aggregating categorical raster maps do not use both local and global information. The majority rule uses only local information and is biased towards more abundant and highly connected classes (Turner et al. 1989). Nearest neighbor approaches, as well as the random rule approach suggested by He et al. (2002), preserve relative proportions at a global scale because they behave similarly to a simple random sample. However, they tend to produce spatially disaggregated patterns (He et al. 2002). Turner et al. (1989) suggested that developing methods that preserve information across spatial scales is critical. The spatial scan statistic can be used to spatially aggregate classified satellite imagery and preserve information from less abundant classes by incorporating both global and local scale information.
There are several landscape metrics that describe the spatial pattern of categorical raster maps. Based on a multivariate factor analysis, Riitters et al. (1995) found that commonly used landscape metrics represent approximately six independent dimensions of pattern in
categorical raster maps.These six dimensions can be represented by the following univariate metrics: average perimeter-area ratio, contagion, standardized patch shape, patch perimeter-area scaling, number of attribute classes, and large-patch density-area scaling. With the exception of the number of attribute classes, comparing these metrics across grain size is problematic and may be invalid because the results reflect scalerelated errors rather than true differences in pattern (Turner et al. 2001). For example, aggregating maps, regardless of technique, creates larger patches of a more uniform shape unless the class ceases to exist, and patch-based metrics will be artificially changed as a result (Turner et al. 1989, Turner et al. 2001, He et al. 2002). Contagion is also difficult to interpret across grain sizes; in particular, the direction of change in contagion metrics due to spatial aggregation depends on whether area is taken into account. For example suppose an input map has a grain size of 0.09 ha and we change the grain size of the map to 7.29 ha. If we define contagion as the probability that a pixel of one class is next to a pixel of the same class, then contagion decreases with spatial as grain size increases. However, if contagion is considered the probability that a 0.09 ha square block of land of one class is next to a 0.09 ha square block of land of the same class then contagion increases with spatial aggregation because each 7.29 ha aggregation unit is comprised of 81 0.09 ha square blocks. Results not shown here demonstrated that the direction of change in patch-based and contagion-based metrics with increasing grain size was similar for the three aggregation techniques, although the magnitude was slightly different among aggregation techniques.
In this paper we introduced the spatial scan statistic as a technique to aggregate categorical raster maps to coarser resolutions using fixed windows. The spatial scan statistic can also be used in a sliding window capacity for digital image post-processing. It is a generally accepted practice to use a filter to reduce speckle in an image classified on a per-pixel basis (Davis and Peet 1997, Goodchild 1994, ERDAS 2003). In cases where these 'speckles' represent classes of particular interest, the spatial scan statistic can be used as a filter to enhance rare classes. For example, Koch (2005) created a decision tree classifier for mapping eastern hemlock ( Tsuga canadensis ) stands in the southern Appalachian Mountains based on Advanced Spaceborne Thermal Emission and Reflection Radiometer imagery and ancillary data. The resulting stand map was a key piece of information for identifying stands at risk of infestation by an insect pest, hemlock woolly adelgid ( Adelges tsugae ), and prioritizing them for control efforts. While hemlocks are scattered throughout the region, distinct stands are relatively rare features in the southern Appalachians, representing ~2% of the U.S. total (McWilliams and Schmidt 1999). Using the spatial scan statistic as a filter to enhance the pattern of hemlock would reduce omission errors as well as yield a map emphasizing the proximity and potential connectivity of hemlock stands for enabling adelgid spread. There are several techniques available to spatially aggregate categorical raster maps. The spatial scan statistic is a technique which can be used with count data derived from a binary response such as categorical raster maps. This technique uses information from both global and local scales and compares the relative importance among land cover classes to spatially aggregate raster maps. In situations where it is necessary to preserve information from less abundant classes the spatial scan statistic provides a viable alternative to nearest neighbor resampling and block majority filtering.
## Acknowledgments
The research described in this article was supported in part by a Cooperative Agreement between North Carolina State University and the U.S. Forest Service. Computing facilities were provided by the Center for Landscape Pattern Analysis.
## References
Bian L. and Butler R. 1999. Comparing effects of aggregation methods on statistical and spatial properties of simulated spatial data. Photogrammetric Engineering and Remote Sensing 65: 73-84.
Coulston, J.W., Riitters, K.H. 2005. Preserving biodiversity under current and future climates: a case study. Global Ecology and Biogeography 14: 31-38.
Coulston, J.W., Riitters, K.H. 2003. Geographic analysis of forest health indicators using spatial scan statistics. Environmental Management 31: 764-773.
Davis, W.A., Peet, F.G. 1977. A method of smoothing digital thematic maps. Remote Sensing of Environment 6: 45-49.
ERDAS. 2003. ERDAS Field Guide, seventh edition. Leica Geosystems GIS & Mapping, LLC, Atlanta GA. 672 pp.
Gardner, R.H., Cale, W.G., O'Neill, R.V. 1982. Robust analysis of aggregation error. Ecology 63: 1771-1779.
Goodchild, M.F. 1994. Integrating GIS and remote-sensing for vegetation and analysis and modeling- methodological issues. Journal of Vegetation Science 5: 615-626. He, H.S., Ventura, S.J., Mladenoff, D.J. 2002. Effects of spatial aggregation approaches on classified satellite imagery. International Journal of Geographic Information Science 16: 93-109.
Hoar, B.R., Chomel, B.B., Rolfe, D.L., Chang, C.C., Fritz, C.L., Sacks, B.N., Carpenter, T.E. 2003. Spatial analysis of Yersinia pesti s and Bartonella vinsonii subsp. berkhoffii seroprevalence in California coyotes ( Canis latrans ). Preventive Veterinary Medicine 56: 299-311.
Jelinski D.E. and Wu J. 1996. The modifiable areal unit problem and implications for landscape ecology. Landscape Ecology 11: 129-140.
Jensen, J.R. 1996. Introductory Digital Image Processing: A Remote Sensing Perspective. Prentice Hall, Upper Saddle River, NJ. 318 pp.
Justice C.O., Markham B.L., Townshend J.R.G. and Kennard R.L. 1989. Spatial degradation of satellite data. International Journal of Remote Sensing 10: 1539-1561. Koch, F.H. 2005. Spatial Tools for Managing Hemlock Woolly Adelgid in the Southern Appalachians. PhD Dissertation. North Carolina State University, Raleigh, NC. 225 pp. Kulldorff, M. 1997. A spatial scan statistic. Communications in Statistics: Theory and Methods 26:1481-1496.
Li, H., Reynolds, J.F. 1995. On definition and quantification of heterogeneity. Oikos 73: 280-284.
Margai, F., Henry, N. 2003. A community-based assessment of learning disabilities using environmental and contextual risk factors. Social Science and Medicine 56: 10731085.
McWilliams, W.H., Schmidt, T.L. 1999. Composition, structure, and sustainability of hemlock ecosystems in eastern North America. Pages 5-10 in: K. A. McManus, K.S. Shields, D. R. Souto, eds., Proceedings: Symposium on Sustainable Management of Hemlock Ecosystems in Eastern North America, June 22-24, 1999, Durham, NH. USDA Forest Service, Northeastern Research Station, General Technical Report NE-267.
Moody, A., Woodcock, C.E. 1995. The influence of scale and the spatial characteristics of landscapes on land-cover mapping using remote sensing. Landscape Ecology 6: 363379.
Openshaw S. 1984. The Modifiable Areal Unit Problem. GeoBooks, Norwich, UK. of Biology 70: 439-466.
Riitters, K.H., O'Neill, R.V., Hunsaker, C.T., Wickham, J.D., Yankee, D.H., Timmins, S.P., Jones, K.B., Jackson, B.L. 1995. A factor analysis of landscape pattern and structure metrics. Landscape Ecology 10: 23-39.
Steel, R.G.D, Torrie, J.J., Dickey, D.A. 1997. Principles and Procedures of Statistics: A Biometrical Approach, Third Edition. The McGraw-Hill Companies, Inc. New York. 666 pp.
Sudakin, D.L., Horowitz, Z., Giffin, S. 2002. Regional variation in the incidence of symptomatic pesticide exposures: Applications of geographic information systems. Journal of Toxicology - Clinical Toxicology 40: 767-773.
Turner, M.G., O'Neill, R.V., Gardner, R.H., Milne B.T. 1989. Effects of changing spatial scale on the analysis of landscape pattern. Landscape Ecology 3: 153-162. Turner, M.G., Gardner, R.H., O'Neill, R.V. 2001. Landscape Ecology In Theory and
- Practice - Pattern and Process. Springer-Verlag, New York. 401 pp.
Verburg, P.H., Veldkamp, A. 2004. Projecting land use transitions at forest fringes in the Philippines at two spatial scales. Landscape Ecology 19: 77-98.
Vogelmann, J. E., Howard, S.M., Yang, L., Larson, C.R., Wylie, B.K., Driel, N. 2001. Completion of the 1990s national land cover data set for the conterminous United States from Landsat Thematic Mapper data and ancillary data sources. Photogrammetric Engineering & Remote Sensing 67: 650-662.
Wu J. 2004. Effects of changing scale on landscape pattern analysis: Scaling relations. Landscape Ecology 19: 125-138.
Yoshida, M., Naya, Y., Miyashita, Y. 2003. Anatomical organization of forward fiber projections from area TE to perirhinal neurons representing visual long-term memory in monkeys. Proceedings of the National Academy of Sciences of the United States of America 100: 4257-4262. | null | [
"J. W. Coulston",
"N. Zaccarelli",
"K. H. Riitters",
"F. H. Koch",
"G. Zurlini"
] | 2014-08-01T13:10:32+00:00 | 2014-08-01T13:10:32+00:00 | [
"q-bio.QM"
] | The spatial scan statistic: A new method for spatial aggregation of categorical raster maps | Multiple-scale and broad-scale assessments often require rescaling the
original data to a consistent grain size for analysis. Rescaling categorical
raster data by spatial aggregation is common in large area ecological
assessments. However, distortion and loss of information are associated with
aggregation. Using a majority rule generally results in dominant classes
becoming more pronounced and rare classes becoming less pronounced. Using
nearest neighbor techniques generally maintains the global proportion of each
category in the original map but can lead to disaggregation. In this paper we
implement the spatial scan statistic for spatial aggregation of categorical
raster maps and describe the behavior of the technique at the local level
(aggregation unit) and global level (map). We also contrast the spatial scan
statistic technique with the majority rule and nearest neighbor approaches. In
general, the scan statistic technique behaved inverse the majority rule
approach in that rare classes rather than abundant classes were preserved. We
suggest the scan statistic techniques should be used for spatial aggregation of
categorical maps when preserving heterogeneity and information from rare
classes are important goals of the study or assessment. |
1408.0166v1 | ## Lie symmetries of fundamental solutions of one (2+1)-dimensional ultra-parabolic Fokker-Planck-Kolmogorov equation
Sergii Kovalenko, 1 Valeriy Stogniy 2 and Maksym Tertychnyi 3
- 1
- Department of Physics, Faculty of Oil, Gas and Nature Engineering, Poltava National Technical University, Poltava, Ukraine
(e-mail: [email protected])
2 Department of Mathematical Physics, Faculty of Physics and Mathematics, National Technical University of Ukraine 'Kyiv Polytechnic Institute', Kyiv, Ukraine (e-mail: valeriy [email protected])
- 3 Department of Mathematics and Statistics, Faculty of Science, University of Calgary, Calgary, Canada
(e-mail: [email protected])
## Abstract
A (2+1)-dimensional linear ultra-parabolic Fokker-Planck-Kolmogorov equation is investigated from the group-theoretical point of view. By using the Berest-Aksenov approach, an algebra of invariance of fundamental solutions of the equation is found. A fundamental solution of the equation under study is computed in an explicit form as a weak invariant solution.
Keywords: Fokker-Planck-Kolmogorov equation, fundamental solution, Lie symmetries. 2010 Mathematical Subject Classification: 22E70, 35K70, 35Q84.
## 1 Introduction
The idea that a solution of any well-posed boundary problem for a particular linear partial differential equation (PDE) can be reduced to the construction of some solution of a special type (known as a fundamental solution) is one of the most powerful approaches in a classical mathematical physics. The method of integral transformations is a powerful and well-developed tool for the construction of the solutions of such a type. Unfortunately, this method is efficient only for linear PDE's with constant(or, at least, analytic) coefficients. Moreover, in some cases it is very difficult to investigate qualitative properties of fundamental solutions, because they can not be presented in an explicit form, but only in the form of inverse integral transformations. As a result, the development of more direct methods for the construction of fundamental solutions is an important problem of a modern mathematical physics. Especially, it is urgent in the case of PDE's with alternating coefficients. One of such modern methods is a classical Lie method for investigation of symmetrical properties of PDE's.
Group analysis of differential equations is a mathematical theory with an area of interest in the symmetry properties of differential equations. Basics of group analysis are in fundamental works of S. Lie and his scholars (see, for instance, [1]). Namely, Lie developed and was the first to use the tools of symmetry reduction. The main idea of this method is to search for the solution of the equation under consideration in the form of a special substitution (ansatz), that reduces the given equation to the differential equation with less number of independent variables.
Further development of group-theoretical methods of differential equations is mainly connected with works of the following mathematicians: G. Bikhoff [2], L. I. Sedov [3], A. J. A. Morgan [4], L. V. Ovsiannikov [5], N. H. Ibragimov [6-8], P. J. Olver [9,10], W. I. Fushchich [11-13] and others. At present, symmetry properties of many well-known equations of mechanics, gas dynamics, quantum physics, etc were investigated. Detailed analysis of results of research of symmetry properties of a wide range of linear and non-linear differential equations can be found in the monographs [5,6,11-16].
It is well-known, that as a rule fundamental solutions of linear PDE's are invariant with respect to the transformations, admitted by the prescribed equation [7, 17-25]. In particular, fundamental solutions of classical equations of mathematical physics such as the Laplace equa-
tion, the Heat equation, the Wave equation, etc have this property (see, for example, [18]). It means, that if a linear PDE (especially in case of an equation with alternating coefficients) has non-trivial symmetry properties, then we can use group-theoretical methods to construct its fundamental solution.
The object of our investigation is the linear (2+1)-dimensional ultra-parabolic FokkerPlanck-Kolmogorov equation
$$u _ { t } - u _ { x x } + x u _ { y } = 0, \quad ( x, y, t ) \in \mathbb { R } ^ { 3 },$$
where u = u t, x, y ( ), u t = ∂u ∂t , u y = ∂u ∂y , u xx = ∂ 2 u ∂x 2 .
Eq. (1) is the simplest and lowest dimensional version of the following (2 n +1)-dimensional linear ultra-parabolic equation
$$u _ { t } - \sum _ { j, l = 1 } ^ { n } ( k _ { j l } ( t, x, y ) u ) _ { x _ { j } x _ { l } } + \sum _ { j = 1 } ^ { n } ( f _ { j } ( t, x, y ) u ) _ { x _ { j } } + \sum _ { j = 1 } ^ { n } x _ { j } u _ { y _ { j } } = 0, \quad ( x, y, t ) \in \mathbb { R } ^ { 2 n + 1 }. \quad ( 2 ) \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
A.N. Kolmogorov introduced (2) in 1934 to describe the probability density of a system with 2 n degrees of freedom [26]. Here, the 2 n -dimensional space is the phase space, x = ( x , . . . , x 1 n ) is the velocity and y = ( y , . . . , y 1 n ) is the position of the system. It should be also stressed that Eq. (1) arises in mathematical finance in some generalization of the Black-Scholes model (see, for instance, [27, 28]).
Research of symmetry properties of Eq. (1) was commenced in work [29], where several point transformations of symmetries were found. But complete group analysis for this equation was not performed.
Maximal invariance algebra of Eq. (1) in Lie sense was calculated in work [30]. In addition, in this article an optimal system of sub-algebras was found for the calculated invariance algebra. Using two-dimensional sub-algebras, it was also performed the symmetry reduction and constructed several explicit invariant solutions of Eq. (1).
In this article, we continue research of symmetry properties of Eq. (1). The goal of our work is to find an invariance algebra of fundamental solutions of this equation and to construct in an explicit form the fundamental solution of Eq. (1) using already found symmetry algebra.
## 2 Symmetries of fundamental solutions of linear PDE's
Consider linear homogeneous PDE of p -th order with m independent variables
$$L u \equiv \sum _ { | \alpha | = 0 } ^ { p } A _ { \alpha } ( x ) D ^ { \alpha } u = 0, \quad x \in \mathbb { R } ^ { m }. \\. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
In (3) we use standard notations: x = ( x , . . . , x 1 m ), α = ( α , . . . , α 1 m ) is a multi-index with integer non-negative components, | α | = α 1 + . . . + α m ;
$$D ^ { \alpha } \equiv \left ( \frac { \partial } { \partial x ^ { 1 } } \right ) ^ { \alpha _ { 1 } } \dots \left ( \frac { \partial } { \partial x ^ { m } } \right ) ^ { \alpha _ { m } } ;$$
A α ( x ) are some smooth functions of the variable x .
Fundamental solution of Eq. (3) is a function u x, x ( 0 ) (namely, generalized), that yields the following equation
$$L u = \delta ( x - x _ { 0 } ),$$
where δ x ( -x 0 ) is the Dirac delta function.
Standard methods to find fundamental solutions of linear PDE's are the method of integral transformations (especially, in case of the equations with constant coefficients), the Green's functions method, etc. [31,32]. Here we consider an algorithm to find fundamental solutions of linear homogeneous PDE's by using symmetry groups of this equation.
Remind, that a non-degenerate local substitution of the variables x, u
$$\bar { x } ^ { i } = f ^ { i } ( x, u, a ), \ \bar { u } = g ( x, u, a ), \quad i = 1, \dots, m,$$
depending on a continuous parameter a is called a symmetry transformation of Eq. (3), if this equation does not change its form with respect to the new variables ¯ and ¯. x u A set G of all such transformations forms a Lie group (local, more precisely), that is called a symmetry group (or an acceptable group) of Eq. (3).
According to the Lie theory, the construction of the symmetry group G of Eq. (3) is equivalent to finding its infinitesimal transformations:
$$\bar { x } ^ { i } \approx x ^ { i } + a \cdot \xi ^ { i } ( x, u ), \ \bar { u } \approx u + a \cdot \eta ( x, u ), \ \ i = 1, \dots, m,$$
where x i ( x, u ) and η x, u ( ) are some smooth functions.
Linear differential operator of the first order
$$X = \sum _ { i = 1 } ^ { m } \xi ^ { i } ( x, u ) \frac { \partial } { \partial x ^ { i } } + \eta ( x, u ) \frac { \partial } { \partial u } \\ \prod _ { \substack { \text{immatrix} \text{convert} } } \, \text{for the amount } \mathcal { T } \text{ to one of $Y$ is also called a minimum} }.$$
is called an infinitesimal operator of the group G . The operator X is also called a symmetry operator of Eq. (3).
The group transformations (5) corresponding to the infinitesimal transformations (6) with the operator (7) are found using so called Lie equations:
$$\frac { d \bar { x } ^ { i } } { d a } = \xi ^ { i } ( \bar { x }, \bar { u } ), \ \frac { d \bar { u } } { d a } = \eta ( \bar { x }, \bar { u } ), \ \ i = 1, \dots, m$$
with the initial conditions
$$\bar { x } ^ { i } | _ { a = 0 } = x ^ { i }, \ \bar { u } | _ { a = 0 } = u.$$
So called infinitesimal criterion of invariance plays a fundamental role in the symmetry analysis of differential equation, that is in case of Eq. (3) can be formulated in the following form.
Theorem 1. The infinitesimal operator (7) is a symmetry operator of Eq. (3) , if and only if there exists such a function λ = λ x ( ) , that yields the following identities:
$$X ( L u ) \equiv \lambda ( x ) \cdot L u$$
for any function u = u x ( ) from the domain of Eq. (3) .
In Eq. (8), X p is the prolongation of p -th order of the infinitesimal operator (7), that is calculated by the well-known formula [5,9,13,16]:
$$X = X + \sum _ { k = 1 } ^ { p } \sum _ { i _ { 1 }, \dots, i _ { k } = 1 } ^ { m } \varphi ^ { i _ { 1 } \cdots i _ { k } } \frac { \partial } { \partial u _ { i _ { 1 } \cdots i _ { k } } },$$
where
$$\varphi ^ { i _ { 1 } \cdots i _ { k } } = D _ { i _ { 1 } } \cdots D _ { i _ { k } } \left ( \eta - \sum _ { i = 1 } ^ { m } \xi ^ { i } u _ { i } \right ) + \sum _ { i = 1 } ^ { m } \xi ^ { i } u _ { i _ { 1 } \cdots i _ { k } i }, \\ i _ { 1 }, \dots, i _ { k } = 1, \dots, m, \ \ k = 1, \dots, p.$$
Here we denote by D i the operator of total differentiation with respect to the variable x i :
$$D _ { i } = \frac { \partial } { \partial x ^ { i } } + u _ { i } \frac { \partial } { \partial u } + \sum _ { j = 1 } ^ { \infty } \sum _ { i _ { 1 }, \dots, i _ { j } = 1 } ^ { m } u _ { i _ { 1 } \cdots i _ { j } i } \frac { \partial } { \partial u _ { i _ { 1 } \cdots i _ { j } } }, \quad i = 1, \dots, m.$$
It was shown in [33], that the linear homogeneous PDE (3) given additional conditions p ≥ 2 and m ≥ 2 admits symmetry operators only of such a form
$$X = \sum _ { i = 1 } ^ { m } \xi ^ { i } ( x ) \frac { \partial } { \partial x ^ { i } } + \left ( \alpha ( x ) u + \beta ( x ) \right ) \frac { \partial } { \partial u }. \\ \inf i n t i o & \text{internal operators of the form } \mathbb { m } ( \mathbb { m } \text{ }the maximal invariance also for } \mathbb { e }$$
In the class of infinitesimal operators of the form (9), the maximal invariance algebra of Eq.
- (3) as a vector space is a direct sum of two sub-algebras: the sub-algebra, that consists of the operators of the form
and the infinite-dimensional subalgebra, that is generated by the operators
$$X & = \sum _ { i = 1 } ^ { m } \xi ^ { i } ( x ) \frac { \partial } { \partial x ^ { i } } + \alpha ( x ) u \frac { \partial } { \partial u }, \\ \text{nsional subalgebra, that is generated by the operators}$$
$$X = \beta ( x ) \frac { \partial } { \partial u },$$
where β = β x ( ) is an arbitrary smooth solution of Eq. (3).
It is clear, that the infinitesimal operators (11) are symmetry operators of Eq. (4). Hence, in the sequel we will consider only operators of the form given by (10).
Constructive method to find symmetries of the form (10) of linear inhomogeneous PDE's with δ -function in a right-hand side was proposed in works [17,20]. In the same articles, it was introduced an algorithm for construction of invariant fundamental solutions of the equations of the form (3).
Main result of these works is in the following statement.
Theorem 2. The Lie algebra of symmetry operators of the form (10) of Eq. (4) is a subalgebra of the Lie algebra of symmetry operators of Eq. (3) , which is defined by the following conditions:
$$\xi ^ { i } ( x _ { 0 } ) = 0,$$
where i = 1 , . . . , m .
$$\lambda ( x _ { 0 } ) + \sum _ { i = 1 } ^ { m } \frac { \partial \xi ^ { i } ( x _ { 0 } ) } { \partial x ^ { i } } = 0,$$
Formulate the algorithm to find fundamental solutions of a linear PDE using properties of its invariance algebra:
- 1. find a general form of symmetry operator of Eq. (3) and a relevant function λ x ( ), that yields identities (8);
- 2. using conditions (12) and (13), find a Lie algebra of symmetry operators of Eq. (4);
- 3. construct invariant fundamental solutions of Eq. (3) using symmetry operators of Eq. (4).
Remark 1. Formulated algorithm for construction of fundamental solutions using symmetries of linear PDE's with δ -function in a right-hand side is especially efficient for multi-dimensional linear equations and for the equations with alternating coefficients in case, if they allow rather wide invariance algebras.
Remark 2. To find generalized invariant fundamental solutions, it is necessary to solve reduced equations (these equations are written in invariants of corresponding transformation groups) on the set of generalized functions (see, for example, [19,20,34]).
## 3 Symmetries of fundamental solutions of Eq. (1)
Apply the method described in the previous section to the object of our research, in other words to the linear Fokker-Planck-Kolmogorov equation (1).
We define fundamental solution of Eq. (1) as a generalized function u = u t, x, y, t ( 0 , x 0 , y 0 ), that depends on t 0 , x 0 , y 0 as parameters and yields the equation
$$u _ { t } - u _ { x x } + x u _ { y } = \delta ( t - t _ { 0 }, x - x _ { 0 }, y - y _ { 0 } ),$$
given the additional condition u | t<t 0 = 0.
In work [30], it was shown that the maximal invariance algebra of Eq. (1) is generated by the following infinitesimal operators:
$$X _ { 1 } = \partial _ { x } + t \partial _ { y }, \ X _ { 2 } = 2 t \partial _ { t } + x \partial _ { x } + 3 y \partial _ { y } - 2 u \partial _ { u },$$
$$X _ { 3 } = t ^ { 2 } \partial _ { t } + ( t x + 3 y ) \partial _ { x } + 3 t y \partial _ { y } - ( 2 t + x ^ { 2 } ) u \partial _ { u },$$
$$X _ { 4 } = 3 t ^ { 2 } \partial _ { x } + t ^ { 3 } \partial _ { y } + 3 ( y - t x ) u \partial _ { u }, \ X _ { 5 } = 2 t \partial _ { x } + t ^ { 2 } \partial _ { y } - x u \partial _ { u },$$
$$X _ { 6 } = \partial _ { t }, \ X _ { 7 } = \partial _ { y }, \ X _ { 8 } = u \partial _ { u }, \ X _ { \infty } = \beta ( t, x, y ) \partial _ { u }.$$
In the last operator, the function β = β t, x, y ( ) is an arbitrary smooth solution of the equation under study.
Theorem 3. Eq. (14) admits an infinite-dimensional Lie algebra of symmetry operators with the following basis of finite-dimensional part:
$$\begin{array} { c c c c c } \cdot & \cdot & \cdot & \cdot \\ & Y _ { 1 } = 2 ( t - t _ { 0 } ) \partial _ { t } + ( x - x _ { 0 } ) \partial _ { x } - ( x _ { 0 } ( t - t _ { 0 } ) - 3 ( y - y _ { 0 } ) ) \partial _ { y } - 4 u \partial _ { u }, \\ & Y _ { 2 } = ( t ^ { 2 } - t _ { 0 } ^ { 2 } ) \partial _ { t } + ( ( t x + 3 y ) - ( t _ { 0 } x _ { 0 } + 3 y _ { 0 } ) ) \partial _ { x } + ( 3 ( y - y _ { 0 } ) t - t _ { 0 } x _ { 0 } ( t - t _ { 0 } ) ) \partial _ { y } - \\ & & - ( 2 ( t - t _ { 0 } ) + x ^ { 2 } - x _ { 0 } ^ { 2 } ) u \partial _ { u }, \\ & Y _ { 3 } = 3 ( t ^ { 2 } - t _ { 0 } ^ { 2 } ) \partial _ { x } + ( t ^ { 3 } - 3 t _ { 0 } ^ { 2 } t + 2 t _ { 0 } ^ { 3 } ) \partial _ { y } - 3 ( t x - y - ( t _ { 0 } x _ { 0 } - y _ { 0 } ) ) u \partial _ { u }, \\ & Y _ { 4 } = 2 ( t - t _ { 0 } ) \partial _ { x } + ( t - t _ { 0 } ) ^ { 2 } \partial _ { y } - ( x - x _ { 0 } ) u \partial _ { u }. \\ \prod _ { \infty } \tilde { \ } W i t a \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l \ t h a \ a n o n a l$$
Proof. Write the general form of symmetry operator of the finite-dimensional part of invariance algebra of Eq. (1)
or in a more detailed form
$$X = \sum _ { i = 1 } ^ { 8 } a _ { i } X _ { i },$$
$$X = & ( 2 a _ { 2 } t + a _ { 3 } t ^ { 2 } + a _ { 6 } ) \partial _ { t } + ( a _ { 1 } + a _ { 2 } x + a _ { 3 } ( t x + 3 y ) + 3 a _ { 4 } t ^ { 2 } + 2 a _ { 5 } t ) \partial _ { x } + \\ & + ( a _ { 1 } t + 3 a _ { 2 } y + 3 a _ { 3 } t y + a _ { 4 } t ^ { 3 } + a _ { 5 } t ^ { 2 } + a _ { 7 } ) \partial _ { y } + \\ & + ( - 2 a _ { 2 } - a _ { 3 } ( 2 t + x ^ { 2 } ) + 3 a _ { 4 } ( y - t x ) - a _ { 5 } x + a _ { 8 } ) u \partial _ { u },$$
where a i ( i = 1 , . . . , 8) are any real constants.
Substituting the infinitesimal operator (15) into Eq. (8), where we put Lu ≡ u t -u xx + xu y , p = 2, we find the function λ = λ t, x, y ( ), that corresponds to this operator:
$$\lambda ( t, x, y ) = - 4 a _ { 2 } - a _ { 3 } ( 4 t + x ^ { 2 } ) + 3 a _ { 4 } ( y - t x ) - a _ { 5 } x + a _ { 8 }.$$
Substituting (15) and (16) into Eqs. (12) and (13) (see, Th. 1), we obtain the following equalities:
$$& 2 a _ { 2 } t _ { 0 } + a _ { 3 } t _ { 0 } ^ { 2 } + a _ { 6 } = 0 ; \\ & a _ { 1 } + a _ { 2 } x _ { 0 } + a _ { 3 } ( t _ { 0 } x _ { 0 } + 3 y _ { 0 } ) + 3 a _ { 4 } t _ { 0 } ^ { 2 } + 2 a _ { 5 } t _ { 0 } = 0 ; \\ & a _ { 1 } t _ { 0 } + 3 a _ { 2 } y _ { 0 } + 3 a _ { 3 } t _ { 0 } y _ { 0 } + a _ { 4 } t _ { 0 } ^ { 3 } + a _ { 5 } t _ { 0 } ^ { 2 } + a _ { 7 } = 0 ; \\ & 2 a _ { 2 } - a _ { 3 } ( 2 t _ { 0 } - x _ { 0 } ^ { 2 } ) + 3 a _ { 4 } ( y _ { 0 } - t _ { 0 } x _ { 0 } ) - a _ { 5 } x _ { 0 } + a _ { 8 } = 0,$$
from which we easily derive
$$a _ { 1 } = - a _ { 2 } x _ { 0 } - a _ { 3 } ( t _ { 0 } x _ { 0 } + 3 y _ { 0 } ) - 3 a _ { 4 } t _ { 0 } ^ { 2 } - 2 a _ { 5 } t _ { 0 } ;$$
$$a _ { 6 } = - 2 a _ { 2 } t _ { 0 } - a _ { 3 } t _ { 0 } ^ { 2 } ;$$
$$a _ { 7 } = a _ { 2 } ( t _ { 0 } x _ { 0 } - 3 y _ { 0 } ) + a _ { 3 } t _ { 0 } ^ { 2 } x _ { 0 } + 2 a _ { 4 } t _ { 0 } ^ { 3 } + a _ { 5 } t _ { 0 } ^ { 2 } ;$$
$$a _ { 8 } = - 2 a _ { 2 } + a _ { 3 } ( 2 t _ { 0 } - x _ { 0 } ^ { 2 } ) - 3 a _ { 4 } ( y _ { 0 } - t _ { 0 } x _ { 0 } ) + a _ { 5 } x _ { 0 }.$$
$$& - a _ { 3 } ( t _ { 0 } x _ { 0 } + 3 y _ { 0 } ) - 3 a _ { 4 } t _ { 0 } ^ { 2 } - 2 a _ { 5 } t _ { 0 } ; \\ & - a _ { 3 } t _ { 0 } ^ { 2 } ; \\ & - 3 y _ { 0 } ) + a _ { 3 } t _ { 0 } ^ { 2 } x _ { 0 } + 2 a _ { 4 } t _ { 0 } ^ { 3 } + a _ { 5 } t _ { 0 } ^ { 2 } ; \\ & \cdot a _ { 3 } ( 2 t _ { 0 } - x _ { 0 } ^ { 2 } ) - 3 a _ { 4 } ( y _ { 0 } - t _ { 0 } x _ { 0 } ) + a _ { 5 } x _ { 0 }. \\ & \ n t c \ a. \ a. \ a. \ \text{ and } a. \ \text{br the calculated over}.$$
Substituting in (15) the constants a , a 1 6 , a 7 , and a 8 by the calculated expressions and having split with respect to the independent constants a , a 2 3 , a 4 , a 5 , we obtain that the finitedimensional part of invariance algebra of Eq. (14) is four-dimensional and generated by the following operators:
$$\text{nowing operators} \colon \\ Y _ { 1 } & = 2 ( t - t _ { 0 } ) \partial _ { t } + ( x - x _ { 0 } ) \partial _ { x } - ( x _ { 0 } ( t - t _ { 0 } ) - 3 ( y - y _ { 0 } ) ) \partial _ { y } - 4 u \partial _ { u }, \\ Y _ { 2 } & = ( t ^ { 2 } - t _ { 0 } ^ { 2 } ) \partial _ { t } + ( ( t x + 3 y ) - ( t _ { 0 } x _ { 0 } + 3 y _ { 0 } ) ) \partial _ { x } + ( 3 ( y - y _ { 0 } ) t - t _ { 0 } x _ { 0 } ( t - t _ { 0 } ) ) \partial _ { y } - \\ & \quad - ( 2 ( t - t _ { 0 } ) + x ^ { 2 } - x _ { 0 } ^ { 2 } ) u \partial _ { u }, \\ Y _ { 3 } & = 3 ( t ^ { 2 } - t _ { 0 } ^ { 2 } ) \partial _ { x } + ( t ^ { 3 } - 3 t _ { 0 } ^ { 2 } t + 2 t _ { 0 } ^ { 3 } ) \partial _ { y } - 3 ( t x - y - ( t _ { 0 } x _ { 0 } - y _ { 0 } ) ) u \partial _ { u }, \\ Y _ { 4 } & = 2 ( t - t _ { 0 } ) \partial _ { x } + ( t - t _ { 0 } ) ^ { 2 } \partial _ { y } - ( x - x _ { 0 } ) u \partial _ { u }. \\ \text{Invariance property of Eq. } ( 14 ) \text{ with respect to the operators of the form } \beta ( t, x, y ) \partial _ { u }, \text{ where}$$
Invariance property of Eq. (14) with respect to the operators of the form β t, x, y ( ) ∂ u , where β t, x, y ( ) is an arbitrary smooth solution of Eq. (1) is straightforward.
$$\text{The proof is now completed.}$$
Show how the results of Th. 3 can be applied to the construction of invariant fundamental solutions of Eq. (1). Use for this, for example, the two-dimensional algebra of operators 〈 Y , Y 1 4 〉 . Classical invariants corresponding to these operators can be derived from the system of equations
$$Y _ { 1 } I = 0, \ Y _ { 4 } I = 0,$$
where I = I ( t, x, y, u ), and the equations are solved in a classical sense. We obtain after related calculations:
$$I _ { 1 } = ( t - t _ { 0 } ) ^ { 2 } \exp \left [ \frac { ( x - x _ { 0 } ) ^ { 2 } } { 4 ( t - t _ { 0 } ) } \right ] u, \ I _ { 2 } = \frac { ( t - t _ { 0 } ) ( x + x _ { 0 } ) - 2 ( y - y _ { 0 } ) } { ( t - t _ { 0 } ) ^ { 3 / 2 } }. \\ \intertext { a n d i n d } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \pm \, \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \. \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \end{cases}$$
Classical invariant solution is found from the equality I 1 = ϕ I ( 2 ), from which we obtain a substitution (ansatz)
$$u = \frac { 1 } { ( t - t _ { 0 } ) ^ { 2 } } \exp \left [ - \frac { ( x - x _ { 0 } ) ^ { 2 } } { 4 ( t - t _ { 0 } ) } \right ] \varphi ( \omega ), \ \omega = I _ { 2 },$$
that reduces the equation under study (1) to the following ordinary differential equation:
$$\frac { d ^ { 2 } \varphi } { d \omega ^ { 2 } } + \frac { 3 } { 2 } \, \omega \frac { d \varphi } { d \omega } + \frac { 3 } { 2 } \, \varphi = 0.$$
It is well-known, that a particular solution of this equation is the following function [35, P. 216]:
$$\varphi = C \exp \left [ - \frac { 3 } { 4 } \, \omega ^ { 2 } \right ]. \quad \quad \quad$$
Substituting (18) to (17), we derive a classical invariant solution of Eq. (1) corresponding to the operators Y 1 and Y 4 :
$$u = \frac { C } { ( t - t _ { 0 } ) ^ { 2 } } \, \exp \left [ - \frac { ( x - x _ { 0$$
Substituting (19) to Eq. (14), it is easy to show that Lu t, x, y ( ) = 0. As a result, the solution (19) is not a fundamental solution of the Fokker-Planck-Kolmogorov equation (1). To construct its weak invariant solution we use Statement 1 from work [36], in other words we search for weak invariant solutions in the form
$$u = \frac { h ( t, x, y ) } { ( t - t _ { 0 } ) ^ { 2 } } \, \exp \left [ - \frac {$$
where h = h t, x, y ( ) ∈ D ′ ( R 3 ) (denote by D ′ = D ′ ( R 3 ) the space of generalized functions). The equations Y u 1 = 0 and Y u 4 = 0 give us correspondingly:
$$2 ( t - t _ { 0 } ) h _ { t } + ( x - x _ { 0 } ) h _ { x } - ( x _ { 0 } ( t -$$
$$2 ( t - t _ { 0 } ) h _ { x } + ( t - t _ { 0 } ) ^ { 2 } h _ { y } = 0.$$
$$x - x _ { 0 } ) h _ { x } & - ( x _ { 0 } ( t - t _ { 0 } ) - 3 ( y - y _ { 0 } ) ) h _ { y } = 0, \\ t - t _ { 0 } ) ^ { 2 } h _ { y } & = 0.$$
It is easy to see that the generalized function h t, x, y ( ) = C θ t 1 ( -t 0 ) + C 0 is a solution of these equations (here, θ t ( -t 0 ) is the Heaviside step function). We obtain using this fact:
$$u = \frac { C _ { 1 } \theta ( t - t _ { 0 } ) + C _ { 0 } } { ( t - t _ { 0 } ) ^ { 2 } } \, \exp \left [ - \frac { ( x - x _ { 0 } ) ^ { 2 } } { 4 ( t - t _ { 0 } ) } - \frac { 3 } { ( t - t _ { 0 } ) ^ { 3 } } \left ( y - y _ { 0 } - ( t - t _ { 0 } ) \frac { x + x _ { 0 } } { 2 } \right ) ^ { 2 } \right ]. \quad \ \ ( 2 0 )$$
Substituting (20) to Eq. (14), we find the constant C 1 = √ 3 2 π .
Hence, the fundamental solution of the Fokker-Planck-Kolmogorov equation (1)
$$u & = \frac { \frac { 3 } { 2 \pi } \, \theta ( t - t _ { 0 } ) + C _ { 0 } } { ( t - t _ { 0 } ) ^ { 2 } } \, \exp \left [ - \frac { ( x - x _ { 0 } ) ^ { 2 } } { 4 ( t - t _ { 0 } ) } - \frac { 3 } { ( t - t _ { 0 } ) ^ { 3 } } \left ( y - y _ { 0 } - ( t - t _ { 0 } ) \frac { x + x _ { 0 } } { 2 } \right ) ^ { 2 } \right ] \quad \ \ ( 2 1 ) \\. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \.. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \. & \.$$
is found as a weak invariant solution with respect to a two-dimensional algebra 〈 Y , Y 1 4 〉 of point symmetries of Eq. (14). In formula (21) we can put C 0 = 0, because a fundamental solution is defined up to the addition of any solution of a homogeneous equation.
Remark 3. The fundamental solution (21) was found by A. N. Kolmogorov [37] without using the methods of symmetry analysis of differential equations. Our calculations give grouptheoretical background for this solution and justify once again an empiric observation, that fundamental solutions of linear PDE's should be searched among the invariant solutions.
Remark 4. Using a similar scheme, as it was performed for Eq. (1) , we can investigate the symmetry properties of fundamental solutions of other many-dimensional and more complicated Kolmogorov type equations (2) . In this article, we restricted our attention to Eq. (1) in order not to lose the main idea of Berest-Aksenov method of construction of fundamental solutions of linear homogeneous PDE's using its group properties under complicated technical calculations.
## 4 Conclusions
In this article, using the Berest-Aksenov method [17,20] we found an invariance algebra of fundamental solutions of linear Fokker-Planck-Kolmogorov equation (1). Its operators were used to construct invariant fundamental solutions of this equation. It was shown that the fundamental solution (21) of Eq. (1), found by A. N. Kolmogorov is a weak invariant fundamental solution.
## References
- [1] S. Lie: Theory of Transformation Groups , vol. 1-3, B. G. Teubner, Leipzig 1888-93 (in German).
- [2] G. Birkhoff: Hydrodynamics: A Study in Logic, Fact and similitude , 1st ed., Princeton University Press, Princeton, N.J. 1950.
- [3] L. I. Sedov: Similarity and Dimensional Methods, 4th ed., Academic Press, New York 1959.
- [4] A.J. A. Morgan: The reduction by one of the number of independent variables in some systems of partial differential equations, Quart. J. Math. Oxford 3 (12) (1952), 250-259.
- [5] L. V. Ovsiannikov: Group Analysis of Differential Equations , Academic Press, New York 1982.
- [6] N.H. Ibragimov: Transformation Groups Applied to Mathematical Physics , D. Reidel, Dordrecht 1985.
- [7] N.Kn. Ibragimov: Group analysis of ordinary differential equations and the invariance principle in mathematical physics (for the 150th anniversary of Sophus Lie), Russ. Math. Surv. 47 (4) (1992), 89-156.
- [8] Yu.N. Grigoriev, NH. Ibragimov, VF. Kovalev and S. V. Meleshko: Symmetries of Integro-Differential Equations: With Applicatons in Mechanics and Plasma Physics , Springer, Dordrecht 2010.
- [9] P. J. Olver: Applications of Lie Groups to Differential Equations , 1st ed., Springer-Verlag, New York 1986.
- [10] P. J. Olver: Equivalence, Invariants, and Symmetry , Cambridge University Press, Cambridge 1995.
- [11] W.I. Fushchich and A. G. Nikitin: Symmetries of Maxwell's Equations , D. Reidel, Dordrecht 1987.
- [12] W.I. Fushchich and A. G. Nikitin: Symmetries of Equations of Quantum Mechanics , Allerton Press Inc., New York 1994.
- [13] W.I. Fushchich, W. M. Shtelen and N. I. Serov: Symmetry analysis and Exact Solutions of Equations of Nonlinear Mathematical Physics , Kluwer, Dordrecht 1993.
- [14] V.K. Andreev, O.V. Kaptsov, V.V. Pukhnachov and A.A. Rodionov: Applications of Group-Theoretical Methods in Hydrodynamics , Kluwer, Dordrecht 1998.
- [15] W. Miller (Jr.): Symmetry and Separation of Variables , Addison-Wesley, Reading, Mass. 1977.
- [16] V.I. Lahno, S. V. Spichak and V. I. Stogniy: Symmetry Analysis of Evolution Type equations , RCD, Moskow-Izhevsk 2004.
- [17] A.V. Aksenov: Symmetries of linear partial differential equations and fundamental solutions, Dokl. Math. 51 (3) (1995), 329-331.
- [18] A.V. Aksenov: Symmetries of fundamental solutions of linear partial differential equations, in: Symmetries of Differential Equations (G. N. Yakovenko, ed.), pp. 6-35, MFTI, Moskow 2009.
- [19] Yu.Yu. Berest: Construction of fundamental solutions for Huygens' equations as invariant solutions, Sov. Math. Dokl. 43 (2) (1991), 496-499.
- [20] Yu.Yu. Berest: Group analysis of linear differential equations in distributions and the construction of fundamental solutions, Differ. Equations 29 (11) (1993), 1700-1711.
- [21] Yu. Berest and Yu. Molchanov: Fundamental solutions for partial differential equations with reflection group invariance, J. Math. Phys. 36 (8) (1995), 4324-4339.
- [22] R.K. Gazizov and N.H. Ibragimov: Lie symmetry analysis of differential equations in finance, Nonlinear Dynam. 17 (4) (1998), 387-407.
- [23] M. Craddock and E. Platen: Symmetry group methods for fundamental solutions, J. Differential Equations 207 (2) (2004), 285-302.
- [24] M. Craddock: Fundamental solutions, transition densities and the integration of Lie symmetries, J. Differential Equations 246 (6) (2009), 2538-2560.
- [25] M. Craddock: Lie symmetry methods for multi-dimensional parabolic PDEs and diffusions, J. Differential Equations 252 (1) (2012), 56-90.
- [26] A.N. Kolmogoroff: Zuf¨llige Bewegungen (Zur Theorie der Brownschen Bewegung), a Ann. Math. 35 (1) (1934) 116-117.
- [27] E. Barucci, S. Polidoro and V. Vespri: Some results on partial differential equations and Asian options, Math. Models Methods Appl. Sci. 11 (3) (2001), 475-497.
- [28] A. Pascussi: Kolmogorov equations in physics and in finance, Progres in Nonlinear Differential Equations and their Applications 63 (2005), 313-324.
- [29] E. Lanconelli and S. Polidoro: On a class of hypoelliptic evolution operators, Rend. Semin. Mat. Torino 52 (1) (1994), 29-63
- [30] S. V. Spichak, V. I. Stogniy and I. M. Kopas: Symmetry properties and exact solutions of the linear Kolmogorov equation, Research Bulletin of NTUU 'Kyiv Politechnic Institute' 2011 (4) (2011), 93-97 (in Ukrainian).
- [31] A. Friedman: Partial Differential Equations of Parabolic Type , Prentice-Hall, Englewood Cliffs, N.J. 1964.
- [32] L. C. Evans: Partial Differential Equations , 2sd ed., American Mathematical Society, Providence 2010.
- [33] G. Bluman: Simplifying the form of Lie groups admitted by a given differential equation, J. Math. Anal. Appl. 145 (1) (1990), 52-62.
- [34] N. Dapi´ c, M. Kunzinger and S. Pilipovi´ c: Symmetry group analysis of weak solutions, Proc. London Math. Soc. 84 (3) (2002), 686-710.
- [35] A.D. Polyanin and V. F. Zaitsev: Handbook of Exact Solutions for Ordinary Differential Equations , 2sd ed., Chapmam & Hall/CRC, Boca Raton 2002.
- [36] Yu.Yu. Berest: Weak invariants of local trasformation groups, Differ. Equations 29 (10) (1993), 1561-1567.
- [37] A.N. Kolmogoroff: Zur theorie der steigen Zuf¨lligen prozesse, a Math. Ann. 108 (1) (1933), 149-160. | null | [
"Sergii Kovalenko",
"Valeriy Stogniy",
"Maksym Tertychnyi"
] | 2014-08-01T13:11:54+00:00 | 2014-08-01T13:11:54+00:00 | [
"math-ph",
"math.AP",
"math.MP",
"22E70, 35K70, 35Q84"
] | Lie symmetries of fundamental solutions of one (2+1)-dimensional ultra-parabolic Fokker--Planck--Kolmogorov equation | A (2+1)-dimensional linear ultra-parabolic Fokker--Planck--Kolmogorov
equation is investigated from the group-theoretical point of view. By using the
Berest--Aksenov approach, an algebra of invariance of fundamental solutions of
the equation is found. A fundamental solution of the equation under study is
computed in an explicit form as a weak invariant solution. |
1408.0167v1 | ## Observation of vacancy-induced suppression of electronic cooling in defected graphene
Qi Han, ∗ Yi Chen, ∗ Gerui Liu, Dapeng Yu, and Xiaosong Wu † State Key Laboratory for Artificial Microstructure and Mesoscopic Physics, Peking University, Beijing 100871, China
Collaborative Innovation Center of Quantum Matter, Beijing 100871, China
## Abstract
Previous studies of electron-phonon interaction in impure graphene have found that static disorder can give rise to an enhancement of electronic cooling. We investigate the effect of dynamic disorder and observe over an order of magnitude suppression of electronic cooling compared with clean graphene. The effect is stronger in graphene with more vacancies, confirming its vacancyinduced nature. The dependence of the coupling constant on the phonon temperature implies its link to the dynamics of disorder. Our study highlights the effect of disorder on electron-phonon interaction in graphene. In addition, the suppression of electronic cooling holds great promise for improving the performance of graphene-based bolometer and photo-detector devices.
## INTRODUCTION
In recent years, there has been considerable interest in utilizing graphene as photodetectors[1-8]. Most of these detectors are based on a hot electron effect, i.e. the electronic temperature being substantially higher than the lattice temperature. Two properties of graphene strongly enhance the effect. First, low carrier density gives rise to a very small electron specific heat. Second, weak electron-phonon (e-p) interaction reduces the heat transfer from the electron gas to the lattice. Thus, it is of practical interest to understand the e-p interaction in graphene. Both theoretical and experimental efforts have been devoted to this topic. Earlier work was mainly focused on clean graphene and considered the Dirac spectrum of electrons[9-15]. As the important role of impurities in electronic transport has been revealed, its effects on the e-p interaction began to draw attention[16-18]. For instance, due to the chiral nature of electrons, long range and short range potentials scatter electrons differently in graphene[19-21]. Recently, a strong enhancement of electronic cooling via e-p interaction in presence of short range disorder has been predicted[18]. This is achieved via a so-called supercollision process. When the carrier density is low, the Bloch-Gr¨neisen u temperature T BG can be quite small. Since T BG sets the maximum wave vector of phonons that can exchange energy with electrons, when T BG < T , only a portion of phonons can contribute to the energy relaxation. Interestingly, in presence of short range potentials, the theory has found that a disorder-assisted scattering process can occur, in which all available phonons are able to participate. As a result, the energy relaxation is strongly enhanced. Shortly, two experiments confirmed the supercollision[22, 23], although long range potential scattering usually dominates in such samples[24, 25]. In the case of long range potentials, Chen and Clerk have also predicted an increase of electronic cooling at low temperature for weak screening[17]. Note that besides the different potential profiles, e.g. long range or short range, disorder can be static or dynamic. Despite these studies, in which only static disorder was considered, the dynamics of disorder has not been addressed.
Here, we present an experimental investigation of the effect of vacancy on electronic cooling in both monolayer and bilayer defected graphene. In contrast to typical scattering potentials previously treated in theories or encountered in experiments, which are static, vacancies in our defected graphene are dragged by phonons, hence highly dynamic. By studying the nonlinear electric transport of defected graphene, a strong suppression of e-
p energy relaxation, instead of an enhancement in the case of static potentials, has been observed. The more disordered the graphene film, the stronger the suppression is. Our work provides new experimental insight on the effect of scattering potential on e-p interaction. Moreover, the suppression suggests that the performance of graphene hot electron photodetectors can be further improved by introducing vacancies.
## EXPERIMENT
In this work, we have investigated four exfoliated graphene samples on Si/SiO 2 substrates. Thickness of all the monolayer (SM1 and SM2) and bilayer (SB1, SB2) samples were estimated by optical contrast and confirmed by Raman spectroscopy[26]. Graphene flakes were patterned into ribbons, using e-beam lithography. 5 nm Ti/80 nm Au were e-beam deposited, followed by lift-off to form electrodes. Typical sample geometry can be seen in the inset of Fig. 1a. In order to introduce vacancies, samples were then loaded into a Femto plasma system and subject to Argon plasma treatment for various periods (from 1 to 5 s)[27]. Four-probe electrical measurements were carried out in a cryostat using a standard lock-in technique. Room temperature π -filters were used to avoid heating of electrons by radio frequency noise. Information for four samples are summarized in Table I.
## RESULTS AND DISCUSSION
Previously, we have already demonstrated a hot electron bolometer based on disordered graphene[28]. It has been shown that the divergence of the resistance at low temperature can be utilized as a sensitive thermometer for electrons. By applying Joule heating, the energy transfer rate between the electron gas and the phonon gas can be obtained. The same method has been employed in this work. As showing in Fig. 1a, the resistance of defected graphene exhibits a sharp increase as the temperature decreases. The divergence becomes stronger as one approaches the CNP. The R -T behavior can be well fitted to variable range hopping transport, described as R ∝ exp[( T /T 0 ) 1 3 / ][29]. Here, the characteristic temperature T 0 = 12 [ / πk B ν E ( F ) ξ 2 ], with k B the Boltzmann constant, ν E ( F ) the density of states at the Fermi level E F , and ξ the localization length. By fitting to this formula, the localization length ξ is determined. It is employed as a measure of the degree of disorder. ξ
near the CNP for all samples are listed in Table I.
In the steady state of Joule heating, the electron cooling power equals to the heating power. The corresponding thermal model is sketched in Fig. 1c. Two thermal energy transfer pathways are indicated, i.e. via electron diffusion into electrodes or e-p interaction into the lattice. In our strongly disordered graphene, the former is significantly suppressed due to a very low carrier diffusivity. It has been found that e-p interaction dominates the energy dissipation in such devices[28]. Then, the electronic temperature can be directly inferred from the resistance. Furthermore, it is estimated that the thermal conductance between the graphene lattice and the substrate is much higher than that due to e-p interaction. Thus, the phonon temperature T ph is approximately equal to the substrate temperature T [5, 22, 30]. Under these conditions, the energy balance at the steady state of Joule heating can be written as
$$P = A ( T _ { \text{e} } ^ { \delta } - T _ { \text{ph} } ^ { \delta } )$$
where P is the Joule Heating power, A is the coupling constant and T e is the electronic temperature. δ ranges from 2 to 6, depending on the detail of the e-p scattering process[12].
Upon Joule heating, the electronic temperature is raised, leading to decrease of the resistance, depicted in Fig. 1b. Based on the resistance as a function of temperature, we obtain the P -T e relation at different carrier densities, plotted in the insets of Fig. 2. P is also plotted against T 3 e -T 3 ph . The linear behavior agrees well with Eq. (1) with δ = 3 for both monolayer and bilayer graphene at all carrier densities. It has been theoretically shown that both clean monolayer and bilayer graphene can be described by Eq. (1) with δ = 4 at low temperature [9, 12]. In presence of disorder, e-p interaction is enhanced and δ is reduced to 3[17, 18]. δ obtained in our result is consistent with these theories, indicating the effect of defects. T 3 dependence has also been reported in some other experiments. In the following, we will compare our results in detail with previous theoretical and experimental results.
The e-p interaction is usually considered in two distinct regimes, high temperature and low temperature. In normal metals, Debye temperature θ D demarcates two regimes. Below θ D , the phase space of available phonons increases with temperature, while it becomes constant above it(all modes are excited). In graphene, because of its low carrier density, the BlochGr¨ uneisen temperature T BG becomes the relevant characteristic temperature. It is defined as 2 k B T BG = 2 hck F . Here k B is the Boltzmann constant, h the Plank constant, c the sound velocity of graphene and k F the Fermi wave vector. T BG stems from the momentum
conservation in e-p scattering. Because of it, when T ph > T BG , only a portion of phonons can participate in the process[31]. Considering the band structure of graphene, we have T BG = 2( c/v F ) E /k F B in monolayer graphene and T BG = 2( c/v F ) √ γ E 1 F /k B in bilayer graphene[12]. Here v F ≈ 10 6 m/s is the Fermi velocity, c ≈ 2 × 10 4 m/s and γ 1 ≈ 0 4 eV is the interlayer . coupling coefficient. Taking into account a residual carrier density n 0 ≈ 4 × 10 11 cm 2 due to charge puddles[32, 33], it can be readily estimated that even at the CNP, T BG > 34 K. It is much higher than T e = 1 5 K in our experiment. . Consequently, we are well in the low temperature regime.
In the low temperature regime, the whole population of phonons can interact with electrons. Thus, the disorder-assisted supercollision is negligible[18], which rules out it as the origin of the observed T 3 dependence. It has been theoretically shown that in the case of weak screening, static charge impurities leads to enhanced e-p cooling power over clean graphene and δ = 3[17]. For comparison, we plot our data, the theoretical cooling power of clean graphene in Fig. 3. The theoretical prediction of the cooling power per unit area in clean monolayer graphene is [12]
$$P _ { \text{clean} } = \frac { \pi ^ { 2 } D ^ { 2 } E _ { \text{F} } k _ { B } ^ { 4 } } { 1 5 \rho \hbar { ^ { 5 } } v _ { \text{F} } ^ { 3 } c ^ { 3 } } ( T _ { e } ^ { 4 } - T _ { \text{ph} } ^ { 4 } )$$
where ρ ≈ 0 76 . × 10 -6 kg/m 2 is the mass density of graphene and D is the deformation potential chosen as a common value 18 eV [23, 34, 35] (this choice will be discussed later). The theoretical cooling power P clean as a function of the carrier density and electron temperature is depicted as a transparent surface (with T ph =1.5 K) in Fig. 3a. It can be clearly seen that the cooling power of our disordered samples SM1 and SM2 (green and blue lines) are well below the surface at all carrier densities. For comparison, we also plot the data from two other experiments in which T 3 -dependence were observed at low temperatures[35, 36]. These results (with similar T ph ) are either on or above the surface. The suppression of the cooling in Fig. 3a is considerable. For instance, at n = 4 × 10 11 cm 2 and T e = 20 K, the theory predicts P clean =4.7 nW/ µ m . In Ref. 36 the cooling power was found to be 27 nW/ 2 µ m . 2 In sharp contrast, our experiment gives a cooling power of 0.33 nW/ µ m for SM1, over an 2 order of magnitude lower than that in clean graphene. For the more disordered sample, SM2, it is even smaller.
Similar suppression occurs in bilayer graphene samples, too. The cooling power per unit
area in clean bilayer graphene is given by [12]
$$P _ { \text{clean} } = \frac { \pi ^ { 2 } D ^ { 2 } \gamma _ { 1 } k _ { B } ^ { 4 } } { 6 0 \rho \hbar { ^ { 5 } } v _ { \text{F} } ^ { 3 } c ^ { 3 } } \sqrt { \frac { \gamma _ { 1 } } { E _ { \text{F} } } } ( T _ { \text{e} } ^ { 4 } - T _ { \text{ph} } ^ { 4 } )$$
Fig. 3a shows the plot of Eq. (3), the cooling power of the bilayer samples SB1, SB2 and the data from Ref. 36. Although not as pronounced as monolayer graphene, our data still below the theoretical surface. The weaker suppression may result from the fact that the bottom layer of bilayer graphene has experienced less damage by our low energy plasma than the top one[27]. Therefore, this less disordered layer provides a channel of substantial cooling.
The e-p coupling strength depends on the deformation potential D , which characterizes the band shift upon lattice deformation[37-39]. For the theoretical cooling power surface in Fig. 3, we use D = 18 eV. Note that D for graphene ranges from 10 to 70 eV in various experiments, but 18 eV is the most common value for graphene[35]. If the suppression is due to an over-estimated D , to account for the small cooling power, one would require D to be only about 5 eV, one-half of the lowest value reported. Therefore, we believe that the suppression cannot be explained by a small D .
By linear fits of P versus T 3 e -T 3 ph , the coupling constant A can be obtained. In Fig. 4, A is plotted as a function of carrier density n . A for all samples decreases when approaching the CNP. This is because fewer carriers at Fermi level could contribute to total cooling power of the sample.
We now take a look at the dependence of the coupling constant on the degree of disorder. As listed in Table I, the samples have been subject to various periods of plasma treatment. Consequently, the degree of disorder is different, indicated by the localization length ξ . For instance, ξ for SM1 and SM2 is 156 nm and 21 nm, respectively. As plotted in Fig. 4a, the coupling constant A of the less disordered SM1 is only about one-third of the value for the more disordered SM2. The dependence of A on ξ is consistent with the suppression of the e-p scattering by disorder. For the two bilayer samples, SB1 and SB2, the localization lengths are close. The n dependence of A for both samples aligns reasonably well and is consistent with the monolayer samples, see Fig. 4b.
The Joule heating experiment has also been carried out at different phonon temperatures T ph . In Fig. 4c, the coupling constant A is plotted as a function of T ph . Usually, A is independent of T ph , which is actually seen at low temperature for SB1. However, as the temperature goes above 7 K, A is enhanced. Later, we will show that the unexpected
T -dependence is likely related to the dynamic nature of vacancies.
At first glance, the suppression of electronic cooling by vacancies seems surprising, in that previous theories have predicted that disorder would enhance the cooling[17, 18]. Most of earlier experimental results have confirmed the enhancement[22, 23, 35, 36]. However, there is a key difference between those earlier studies and ours. In the former, disorder is theoretically considered to be static. This is indeed true in other experimental work, in which the dominant disorder is due to charge impurities[24, 25]. However, in our samples, the dominant disorder is vacancies, which are completely dragged by phonons. The effect of disorder on the e-p interaction has been studied in disordered metals and found to depend on the character of disorder[40-43]. In the case of static disorder, diffusive motion of electrons increases the effective interacting time between an electron and a phonon, leading to an enhancement of interaction. However, dynamic disorder modifies the quantum interference of scattering processes[41]. As a result, the interaction is suppressed, in accordance with the famous Pippard's inefficient condition[44]. It is reasonable to believe that the observed suppression results from dynamic disorder, vacancies. Furthermore, since the dynamics of disorder apparently depends on T ph , the dependence of the coupling constant A on the phonon temperature T ph is then conceivable. As described in Schmid's theory[40, 41], the e-p scattering is suppressed due to strong disorder. The resultant energy relaxation rate τ -1 e-p is of the order of ( q T l ) τ -1 0 where τ -1 0 ∝ T 3 is the relaxation rate in pure material, q T is the wave vector of a thermal phonon and l is the mean free path. As q T ∝ T ph , the relaxation rate increases with T ph , in agreement with our result.
It is also worthy to note that charge impurities are long range potentials that preserve the sublattice symmetry. This is in contrast to vacancies, which are short range potentials and break the sublattice symmetry. The theory for supercollision models disorder as short range potential[18], while in Ref. 17, disorder potential is long-ranged. This character of disorder strongly affects scattering of chiral electrons in graphene. Our samples represent a graphene system that is quite different from what was commonly seen, in that dynamic and short-ranged potentials dominate. Therefore, the quantitative understanding of our experimental results, including the power index δ , relies on future theory that takes both the dynamics and the symmetry of disorder into account.
## CONCLUSION
In conclusion, we have observed significant suppression of electronic cooling in defected graphene. The cooling power of both monolayer and bilayer graphene samples show T 3 e dependence, consistent with disorder-modified electron-phonon coupling in graphene [17, 18]. However, the magnitude of the cooling power is over an order of magnitude smaller than that of clean graphene predicted by theory[9, 12] and also less than other experiments [35, 36]. The more disordered a graphene film is, the lower cooling power is observed, confirming the effect of disorder. The suppression of electronic cooling is attributed to the dynamic nature of vacancies, which has not been studied in graphene. This effect can be utilized to further improve the performance of graphene-based bolometer and photo-detector devices.
This work was supported by National Key Basic Research Program of China (No. 2012CB933404, 2013CBA01603) and NSFC (project No. 11074007, 11222436, 11234001).
∗ These two authors contributed equally.
† [email protected]
- [1] X. Xu, N. M. Gabor, J. S. Alden, A. M. van der Zande, and P. L. McEuen, Nano Lett. 10 , 562 (2009).
- [2] N. M. Gabor, J. C. W. Song, Q. Ma, N. L. Nair, T. Taychatanapat, K. Watanabe, T. Taniguchi, L. S. Levitov, and P. Jarillo-Herrero, Science 334 , 648 (2011).
- [3] N. G. Kalugin, L. Jing, W. Bao, L. Wickey, C. D. Barga, M. Ovezmyradov, E. A. Shaner, and C. N. Lau, Appl. Phys. Lett. 99 , 013504 (2011).
- [4] D. Sun, G. Aivazian, A. M. Jones, J. S. Ross, W. Yao, D. Cobden, and X. Xu, Nat Nano 7 , 114 (2012).
- [5] J. Yan, M.-H. Kim, J. A. Elle, A. B. Sushkov, G. S. Jenkins, M. H. M., M. S. Fuhrer, and H. D. Drew, Nat Nano 7 , 472 (2012).
- [6] H. Vora, P. Kumaravadivel, B. Nielsen, and X. Du, Appl. Phys. Lett. 100 , 153507 (2012).
- [7] K. Yan, D. Wu, H. Peng, L. Jin, Q. Fu, X. Bao, and Z. Liu, Nat Commun 3 , 1280 (2012).
- [8] X. Cai, A. B. Sushkov, R. J. Suess, G. S. Jenkins, J. Yan, T. E. Murphy, H. D. Drew, and M. S. Fuhrer (2013), arXiv: 1305.3297.
- [9] S. S. Kubakaddi, Phys. Rev. B 79 , 075417 (2009).
- [10] R. Bistritzer and A. H. MacDonald, Phys. Rev. Lett. 102 , 206410 (2009).
- [11] W.-K. Tse and S. Das Sarma, Phys. Rev. B 79 , 235406 (2009).
- [12] J. K. Viljas and T. T. Heikkil¨, Phys. Rev. B a 81 , 245404 (2010).
- [13] A. C. Betz, F. Vialla, D. Brunel, C. Voisin, M. Picher, A. Cavanna, A. Madouri, G. F`ve, e J.-M. Berroir, B. Pla¸ais, et al., Phys. Rev. Lett. c 109 , 056805 (2012).
- [14] A. M. R. Baker, J. A. Alexander-Webber, T. Altebaeumer, and R. J. Nicholas, Phys. Rev. B 85 , 115403 (2012).
- [15] A. M. R. Baker, J. A. Alexander-Webber, T. Altebaeumer, S. D. McMullan, T. J. B. M. Janssen, A. Tzalenchuk, S. Lara-Avila, S. Kubatkin, R. Yakimova, C.-T. Lin, et al., Phys. Rev. B 87 , 045414 (2013).
- [16] F. T. Vasko and V. V. Mitin, Phys. Rev. B 84 , 155445 (2011).
- [17] W. Chen and A. A. Clerk, Phys. Rev. B 86 , 125443 (2012).
- [18] J. C. W. Song, M. Y. Reizer, and L. S. Levitov, Phys. Rev. Lett. 109 , 106602 (2012).
- [19] E. McCann, K. Kechedzhi, V. I. Fal'ko, H. Suzuura, T. Ando, and B. L. Altshuler, Phys. Rev. Lett. 97 , 146805 (2006).
- [20] K. Nomura and A. H. MacDonald, Phys. Rev. Lett. 98 , 076602 (2007).
- [21] X. S. Wu, X. B. Li, Z. M. Song, C. Berger, and W. A. de Heer, Phys. Rev. Lett. 98 , 136801 (2007).
- [22] A. C. Betz, S. H. Jhang, E. Pallecchi, R. Ferreira, G. Feve, J.-M. Berroir, and B. Placais, Nat Phys 9 , 109 (2013).
- [23] M. W. Graham, S.-F. Shi, D. C. Ralph, J. Park, and P. L. McEuen, Nat Phys 9 , 103 (2013).
- [24] S. Adam, E. H. Hwang, V. M. Galitski, and S. Das Sarma, Proc. Natl. Acad. Sci. USA 104 , 18392 (2007).
- [25] J. H. Chen, C. Jang, S. Adam, M. S. Fuhrer, E. D. Williams, and M. Ishigami, Nat Phys 4 , 377 (2008).
- [26] A. C. Ferrari, J. C. Meyer, V. Scardaci, C. Casiraghi, M. Lazzeri, F. Mauri, S. Piscanec, D. Jiang, K. S. Novoselov, S. Roth, et al., Phys. Rev. Lett. 97 , 187401 (2006).
- [27] J. Chen, T. Shi, T. Cai, T. Xu, L. Sun, X. Wu, and D. Yu, Appl. Phys. Lett. 102 , 103107 (2013).
- [28] Q. Han, T. Gao, R. Zhang, Y. Chen, J. Chen, G. Liu, Y. Zhang, Z. Liu, X. Wu, and D. Yu, Sci. Rep. 3 , 3533 (2013).
- [29] N. Mott, J. Non-Cryst. Solids 1 , 1 (1968).
- [30] I. V. Borzenets, U. C. Coskun, H. T. Mebrahtu, Y. V. Bomze, A. I. Smirnov, and G. Finkelstein, Phys. Rev. Lett. 111 , 027001 (2013).
- [31] M. S. Fuhrer, Physics 3 , 106 (2010).
- [32] Q. Li, E. H. Hwang, and S. Das Sarma, Phys. Rev. B 84 , 115442 (2011).
- [33] Y. Zhang, V. W. Brar, C. Girit, A. Zettl, and M. F. Crommie, Nat Phys 5 , 722 (2009).
- [34] J.-H. Chen, C. Jang, S. Xiao, M. Ishigami, and M. S. Fuhrer, Nat Nano 3 , 206 (2008).
- [35] K. C. Fong, E. E. Wollman, H. Ravi, W. Chen, A. A. Clerk, M. D. Shaw, H. G. Leduc, and K. C. Schwab, Phys. Rev. X 3 , 041008 (2013).
- [36] R. Somphonsane, H. Ramamoorthy, G. Bohra, G. He, D. K. Ferry, Y. Ochiai, N. Aoki, and J. P. Bird, Nano Lett. 13 , 4305 (2013).
- [37] J. Bardeen and W. Shockley, Phys. Rev. 80 , 72 (1950).
- [38] C. Herring and E. Vogt, Phys. Rev. 101 , 944 (1956).
- [39] H. Suzuura and T. Ando, Phys. Rev. B 65 , 235412 (2002).
- [40] A. Schmid, Zeitschrift f¨r Physik u 259 , 421 (1973).
- [41] A. Sergeev and V. Mitin, Phys. Rev. B 61 , 6041 (2000).
- [42] J. J. Lin and J. P. Bird, J. Phys.: Condens. Matter 14 , R501 (2002).
- [43] Y. L. Zhong, J. J. Lin, and L. Y. Kao, Phys. Rev. B 66 , 132202 (2002).
- [44] A. Pippard, Philosophical Magazine Series 7 46 , 1104 (1955).
## FIGURES
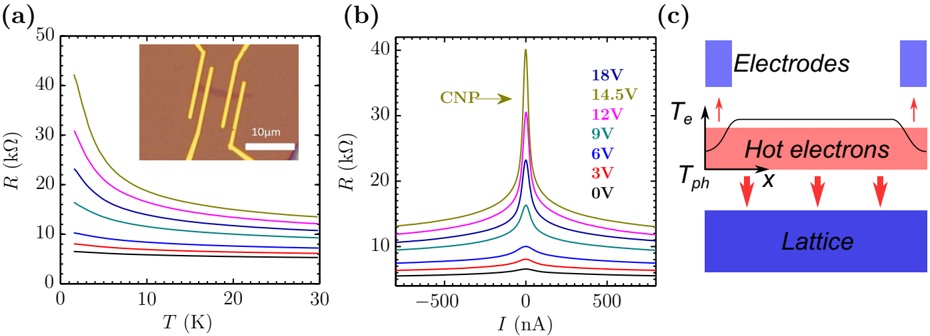
FIG. 1. Resistance of defected graphene. (a) Temperature dependence of resistance in sample SM1 at different gate voltages, showing divergence at low temperature. Inset: Optical micrograph of a typical device configuration. (b) Resistance of SM1 as a function of Joule heating current at different gate voltages at T = 1 5 K. The CNP is at 14.5 V. (c)Thermal model for the structure. . The pathways of heat dissipation are indicated by red arrows.
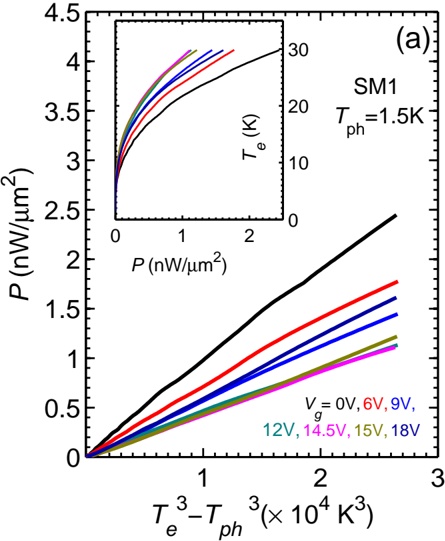
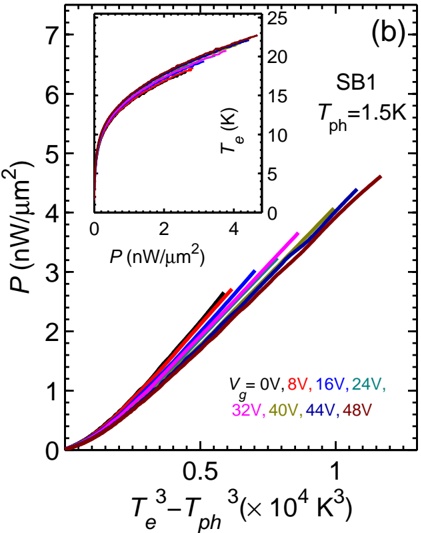
FIG. 2. Cooling power of monolayer and bilayer defected graphene. (a)(b) Cooling power P against T 3 e -T 3 ph shows a linear dependence for both monolayer and bilayer samples. Inset: P versus T e .
FIG. 3. Suppression of electronic cooling in defected graphene. (a) Cooling power of clean monolayer graphene is depicted as a transparent surface, with a logarithmic z-axis scale and as a function of T e and n . P for SM1 and SM2 are over an order of magnitude smaller than clean graphene at all carrier densities, while the data from others' work is either on or above the surface. n 0 is chosen as 4 × 10 11 cm 2 to account for charge puddles near CNP. T ph is 1.5 K in SM1 and the theoretical surface, 7K in SM2, 0.8 K in the data from Ref. 35 and 1.8 K in the data from Ref. 36. (b) Similar suppression is observed in bilayer defected graphene samples. n 0 is chosen as 4 × 10 11 cm . 2 T ph is 1.5K in SB1, SB2 and the theoretical surface, and 1.8 K in the data from Ref. 36.
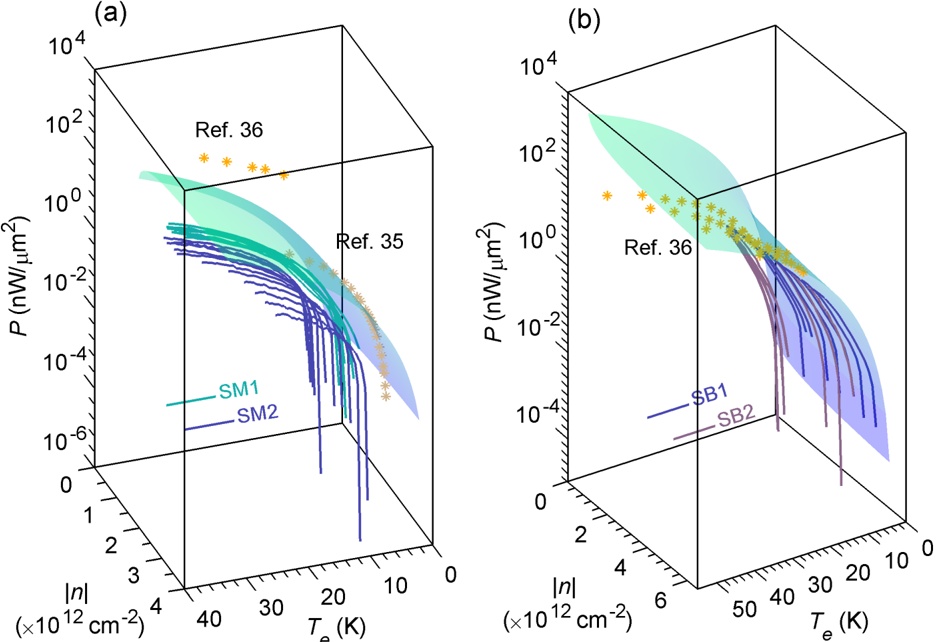
FIG. 4. Coupling constant A . (a) Extracted coupling constant A as a function of carrier density n in monolayer samples. The more defective sample, SM1, exhibits a smaller coupling constant. (b) Dependence of A on carrier density n in bilayer graphene samples. The curves for two samples with similar degree of disorder align reasonably well. (c) Dependence of A on phonon temperature T ph . The data of SM2 are plotted with respect to the right y-axis.
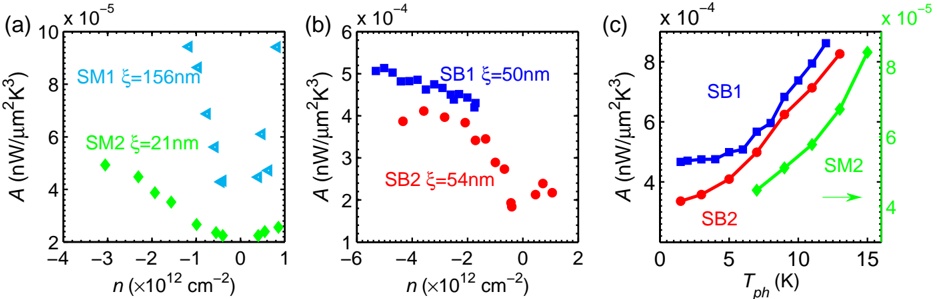
## TABLES
TABLE I. Sample information of four investigated devices. Different Ar gas flow rates and plasma treatment times have been applied to produce different amount of vacancies. V CNP is the charge neutrality point (CNP) of samples and ξ is the localization length near the CNP.
| Devices | Length( µ m) | Width( µ m) | Ar flow rate(sccm) | Plasma treatment period(s) | V CNP (V) | ξ (nm) |
|-----------|----------------|---------------|----------------------|------------------------------|-------------|----------|
| SM1 | 2 | 3 | 3 | 1 | 14.5 | 156 |
| SM2 | 6.7 | 2.7 | 4 | 3 | 30 | 21 |
| SB1 | 3 | 2.7 | 4 | 3.5 | 70 | 50 |
| SB2 | 6 | 2.7 | 4 | 5 | 57 | 54 | | 10.1103/PhysRevB.91.121404 | [
"Qi Han",
"Yi Chen",
"Gerui Liu",
"Dapeng Yu",
"Xiaosong Wu"
] | 2014-08-01T13:12:10+00:00 | 2014-08-01T13:12:10+00:00 | [
"cond-mat.mes-hall"
] | Observation of vacancy-induced suppression of electronic cooling in defected graphene | Previous studies of electron-phonon interaction in impure graphene have found
that static disorder can give rise to an enhancement of electronic cooling. We
investigate the effect of dynamic disorder and observe over an order of
magnitude suppression of electronic cooling compared with clean graphene. The
effect is stronger in graphene with more vacancies, confirming its
vacancy-induced nature. The dependence of the coupling constant on the phonon
temperature implies its link to the dynamics of disorder. Our study highlights
the effect of disorder on electron-phonon interaction in graphene. In addition,
the suppression of electronic cooling holds great promise for improving the
performance of graphene-based bolometer and photo-detector devices. |
1408.0168v1 | 1
## Numerical predictions of surface effects during the 2029 close
arXiv:1408.0168v1 [astro-ph.EP] 1 Aug 2014
## approach of asteroid 99942 Apophis
2
Yang Yu /star †
3
Derek C. Richardson †
4
Patrick Michel ‡
5
Stephen R. Schwartz ‡†
6
Ronald-Louis Ballouz †
7
/star School of Aerospace
8
Tsinghua University
9
Beijing 100084 China
10
† Department of Astronomy
11
University of Maryland
12
College Park MD 20740-2421 United States
13
‡ Lagrange Laboratory
14
University of Nice Sophia Antipolis, CNRS
15
Observatoire de la C o te dAzur, C.S. 34229, 06304 Nice Cedex 4, France
16
Printed August 4, 2014
17
Submitted to Icarus
18
61 manuscript pages
19
14 figures including 11 in color (online version only)
20
## Yang Yu et al.
- Proposed running page head: Surface effects on 99942 Apophis 21
- Please address all editorial correspondence and proofs to: Derek C. Richardson 22
- Derek C. Richardson 23
- Department of Astronomy 24
- Computer and Space Sciences Building 25
- Stadium Drive 26
- University of Maryland 27
- College Park MD 20742-2421 28
- Tel: 301-405-8786 29
- 30
Fax: 301-314-9067
- E-mail: [email protected] 31
## Abstract 32
- Asteroid (99942) Apophis' close approach in 2029 will be one of the most significant small33 body encounter events in the near future and offers a good opportunity for in situ exploration 34 to determine the asteroid's surface properties and measure any tidal effects that might al35 ter its regolith configuration. Resurfacing mechanics has become a new focus for asteroid 36 researchers due to its important implications for interpreting surface observations, including 37 space weathering effects. This paper provides a prediction for the tidal effects during the 38 2029 encounter, with an emphasis on whether surface refreshing due to regolith movement 39 will occur. The potential shape modification of the object due to the tidal encounter is first 40 confirmed to be negligibly small with systematic simulations, thus only the external pertur41 bations are taken into account for this work (despite this, seismic shaking induced by shifting 42 blocks might still play a weak role and we will look into this mechanism in future work). 43 A two-stage approach is developed to model the responses of asteroid surface particles (the 44 regolith) based on the soft-sphere implementation of the parallel N -body gravity tree code 45 pkdgrav . A full-body model of Apophis is sent past the Earth on the predicted trajectory 46 to generate the data of all forces acting at a target point on the surface. A sandpile con47 structed in the local frame is then used to approximate the regolith materials; all the forces 48 the sandpile feels during the encounter are imposed as external perturbations to mimic the 49 regolith's behavior in the full scenario. The local mechanical environment on the asteroid 50 surface is represented in detail, leading to an estimation of the change in global surface 51 environment due to the encounter. Typical patterns of perturbation are presented that de52
- pend on the asteroid orientation and sense of rotation at perigee. We find that catastrophic 53
## Yang Yu et al.
- avalanches of regolith materials may not occur during the 2029 encounter due to the small 54 level of tidal perturbation, although slight landslides might still be triggered in positions 55 where a sandpile's structure is weak. Simulations are performed at different locations on 56 Apophis' surface and with different body- and spin-axis orientations; the results show that 57 the small-scale avalanches are widely distributed and manifest independently of the asteroid 58 orientation and the sandpile location. We also include simulation results of much closer 59 encounters of the Apophis with Earth than what is predicted to occur in 2029, showing that 60 much more drastic resurfacing takes place in these cases. 61
- Keywords : Asteroids, dynamics; asteroids, surfaces; near-Earth objects; regoliths; tides, 62 solid body 63
## 1 INTRODUCTION 64
In this paper, we investigate numerically the behavior of granular material at the surface of 65 an asteroid during close approach to the Earth. We focus on the specific case of Asteroid 66 (99942) Apophis, which will come as close as 5 6 Earth radii on April 13th, 2029. We provide . 67 predictions about possible reshaping and spin-alteration of-and surface effects on-Apophis 68 during this passage, as a function of plausible properties of the constituent granular mate69 rial. Studies of possible future space missions to Apophis are underway, including one by 70 the French space agency CNES calling for international partners (e.g., Michel et al. 2012), 71 with the aim of observing this asteroid during the 2029 close encounter and characterizing 72 whether reshaping, spin-alteration, and/or surface motion occur. The numerical investiga73 tions presented here allow for estimation of the surface properties that could lead to any 74 observed motion (or absence of motion) during the actual encounter. 75
Apophis made a passage to the Earth at ∼ 2300 Earth radii in early 2013. At that time, 76 the Herschel space telescope was used to refine the determination of the asteroid's albedo 77 and size (M¨ uller et al. 2013). According to these observations, the albedo is estimated 78 to be about 0.23 and the longest dimension about 325 ± 15 m, which is somewhat larger 79 than previous estimates (270 ± 60 m, according to Delbo' et al. 2007). Concurrent radar 80 observations improved the astrometry of the asteroid, ruling out the possibility of a collision 81 with the Earth in 2036 to better than 1 part in 10 . 6 However, Wlodarczyk et al. (2013) 82 presented a possible path of risk for 2068. This finding has put off any crisis by ∼ 32 years 83 and makes exploring Apophis in 2029 to be more for scientific interest. To date, nothing is 84
- known about the asteroid's surface mechanical properties, and this is why its close passage in 85
Yang Yu et al.
- 2029 offers a great opportunity to visit it with a spacecraft, determine its surface properties, 86
- and, for the first time, observe potential modifications of the surface due to tidal effects. 87
88
And as Apophis approaches, it is likely that international interest in a possible mission will
- increase, since such close approaches of a large object are relatively rare. 89
The case for tidally induced resurfacing was made by Binzel et al. (2010; also see DeMeo 90 et al. 2013) and discussed by Nesvorn´ et al. (2010) to explain the spectral properties of y 91 near-Earth asteroids (NEAs) belonging to the Q taxonomic type, which appear to have fresh 92 (unweathered) surface colors. Dynamical studies of these objects found that those bodies 93 had a greater tendency to come close to the Earth, within the Earth-Moon distance, than 94 bodies of other classes in the past 500 kyr. The authors speculated that tidal effects during 95 these passages could be at the origin of surface material disturbance leading to the renewed 96 exposure of unweathered material. We leave a more general and detailed investigation of 97 this issue for future work, but if this result is true for those asteroids, it may also be true 98 for Apophis, which will approach Earth on Friday, April 13, 2029 no closer than about 99 29,500 km from the surface (i.e., 4 6 Earth radii, or 5 6 Earth radii from the center of the . . 100 planet; Giorgini et al. 2008). It is predicted to go over the mid-Atlantic, appearing to the 101 naked eye as a moderately bright point of light moving rapidly across the sky. Our aim 102 is to determine whether, depending on assumed mechanical properties, it could experience 103 surface particulate motions, reshaping, or spin-state alteration due to tidal forces caused by 104 Earth's gravity field. The classical Roche limit for a cohesionless fluid body of bulk density 105 2 4 g . / cm 3 to not be disrupted by tidal forces is ∼ 3 22 Earth radii, so we do not expect any . 106 violent events to occur during the rocky asteroid's 2029 encounter at 5 6 Earth radii. . 107
- The presence of granular material (or regolith) and boulders at the surface of small bodies 108
## Yang Yu et al.
has been demonstrated by space missions that visited or flew by asteroids in the last few 109 decades (e.g., Veverka et al. 2000; Fujiwara et al. 2006). It appears that all encountered 110 asteroids to date, from the largest one, the main belt Asteroid (4) Vesta by the Dawn 111 mission, to the smallest one, the NEA (25143) Itokawa, sampled by the Hayabusa mission, 112 are covered with some sort of regolith. In fact, thermal infrared observations support the 113 idea that most asteroids are covered with regolith, given their preferentially low thermal 114 inertia (Delbo' et al. 2007). There even seems to be a trend as a function of the asteroid's 115 size based on thermal inertia measurements: larger objects are expected to have a surface 116 covered by a layer of fine regolith, while smaller ones are expected to have a surface covered 117 by a layer of coarse regolith (Clark et al. 2002). This trend is consistent with observations 118 by the NEAR-Shoemaker spacecraft of the larger ( ∼ 17 km mean diameter) Eros, whose 119 surface is covered by a deep layer of very fine grains, and by the Hayabusa spacecraft of the 120 much smaller (320 m mean diameter) Itokawa, whose surface is covered by a thin layer of 121 coarse grains. However, interpretation of thermal inertia measurements must be made with 122 caution, as we do not yet have enough comparisons with actual asteroid surfaces to verify 123 that the suggested trend is systematically correct. 124
Thus, we are left with a large parameter space to investigate possible surface motion 125 during an Earth close approach of an asteroid with unknown surface mechanical properties. 126 Our approach is to consider a range of simple and well-controlled cases that certainly do 127 not cover all possibilities regarding Apophis' surface mechanical properties, but rather aim 128 at demonstrating whether, even in a simple and possibly favorable case for surface motion, 129 some resurfacing event can be expected to occur during the passage. For instance, instead 130 of considering a flat granular surface, we consider a sandpile consisting of a size distribution 131
## Yang Yu et al.
of spherical grains (Section 2.1) and vary the grain properties in order to include more or 132 less favorable cases for motion (from a fluid-like case to a case involving rough particles). 133 Slight disturbances may manifest as very-small-scale avalanches in which grain connections 134 readjust slightly, for example. The forces acting on the sandpile are obtained by measuring 135 all 'external' perturbations during the encounter, including body spin magnitude and orien136 tation changes, for cases in which the global shape remains nearly fixed, and again assuming 137 simple and favorable configurations of the asteroid. Indirectly, the encounter may also lead 138 to internal reconfigurations of the asteroid, which in turn produce seismic vibrations that 139 could propagate to the surface and affect the regolith material. These secondary modifica140 tions are not modeled here, although it may be possible in future work to account for this 141 by shaking the surface in a prescribed manner. In any case, for this particular encounter, we 142 demonstrate (Section 3.1) that any global reconfiguration will likely be small to negligible 143 in magnitude. 144
In the following, we first present, in Section 2, the numerical method used to perform our 145 investigation, including the initial conditions of the sandpile adopted to investigate surface 146 motion, the representation of the encounter, and the mechanical environment. Results are 147 described in Section 3, including potential reshaping of the asteroid, tidal disturbances for 148 Apophis' encounter in 2029, which is a function of the sandpile properties, spin orientation 149 changes, and the dependency of the location of the sandpile on the asteroid to the outcome 150 of the encounter. We also show the responses of the sandpiles for artificially close approaches 151 (4 0 and 2 0 Earth radii) to demonstrate that our method does predict significant alteration . . 152 of the sandpiles when this is certainly expected to happen. The investigation is discussed in 153 Section 4 and conclusions are presented in Section 5. 154
Yang Yu et al.
## 2 NUMERICAL METHOD 155
We use pkdgrav , a parallel N -body gravity tree code (Stadel 2001) adapted for particle 156 collisions (Richardson et al. 2000; 2009; 2011). Originally collisions in pkdgrav were treated 157 as idealized single-point-of-contact impacts between rigid spheres. A soft-sphere option was 158 added recently (Schwartz et al. 2012); with this new functionality, particle contacts last 159 many timesteps, with reaction forces dependent on the degree of overlap (a proxy for surface 160 deformation) and contact history-this is appropriate for dense and/or near-static granular 161 systems with multiple persistent contacts per particle. The code uses a 2nd-order leapfrog in162 tegrator, with accelerations due to gravity and contact forces recomputed each step. Various 163 types of user-definable confining walls are available that can be combined to provide complex 164 boundary conditions for the simulations. The code also includes an optional variable gravity 165 field based on a user-specified set of rules. 166
The spring/dash-pot model used in pkdgrav 's soft-sphere implementation is described 167 fully in Schwartz et al. (2012). Briefly, a (spherical) particle overlapping with a neighbor 168 or confining wall feels a reaction force in the normal and tangential directions determined 169 by spring constants ( k n , k t ), with optional damping and effects that impose static, rolling, 170 and/or twisting friction. The damping parameters ( C n , C t ) are related to the conventional 171 normal and tangential coefficients of restitution used in hard-sphere implementations, ε n 172 and ε t . The static, rolling, and twisting friction components are parameterized by dimen173 sionless coefficients µ s , µ r , and µ t , respectively. Plausible values for these parameters are 174 obtained through comparison with laboratory experiments (also see Section 2.1). Careful 175 consideration of the soft-sphere parameters is needed to ensure internal consistency, partic176
## Yang Yu et al.
ularly with the choice of k n , k t , and timestep-a separate code is provided to assist the user 177 with configuring these parameters correctly. The numerical approach has been validated 178 through comparison with laboratory experiments; e.g., Schwartz et al. (2012) demonstrated 179 that pkdgrav correctly reproduces experiments of granular flow through cylindrical hoppers, 180 specifically the flow rate as a function of aperture size, and found the material properties 181 of the grains also affect the flow rate. Also simulated successfully with the soft-sphere code 182 in pkdgrav were laboratory impact experiments into sintered glass beads (Schwartz et al. 183 184
2013), and regolith, in support of asteroid sampling mechanism design (Schwartz et al. 2014). We use a two-stage approach to model the effect of a tidal encounter on asteroid surface 185 particles (regolith). First, a rigid (non-deformable) object approximating the size, shape, 186 and rotation state of the asteroid is sent past the Earth on a fixed trajectory (in the present 187 study, the trajectory is that expected of (99942) Apophis-see Section 2.2; note that the 188 actual shape of Apophis is poorly known beyond an estimate of axis ratios, so we assume an 189 idealized ellipsoid for this study). All forces acting at a target point designated on the object 190 surface are recorded (Section 2.2). Then, a second simulation is performed in the local frame 191 of the target point, allowing the recorded external forces to affect the motion of particles 192 arranged on the surface (in the present study we consider equilibrated sandpiles). This two193 stage approach is necessary due to the large difference in scale between the asteroid as a 194 whole and the tiny regolith particles whose reactive motion we are attempting to observe. 195 We approximate the regolith, which in reality likely consists of a mixture of powders and 196 gravel (Clark et al. 2002), by a size distribution of solid spheres. We mimic the properties 197 of different materials by adjusting the soft-sphere parameters (Section 2.1). The soft-sphere 198 approach permits simulation of the behavior of granular materials in the near-static regime, 199
Yang Yu et al.
appropriate for the present case in which the regolith particles generally remain stationary 200 for hours and suffer a rapid disturbance only during the moments of closest approach to the 201 planet. In particular, the model permits a detailed look at the responses of local individual 202 particles even when the tidal effects are too weak to cause any macroscopic surface or shape 203 changes; this gives insight into the limit of tidal resurfacing effects. 204
## 2.1 Sandpile Initial Conditions 205
In order to assess the effect of tidal encounters on a small surface feature, we carried out 206 numerical simulations in a local frame consisting of a flat horizontal surface (i.e., the local 207 plane tangential to the asteroid surface at the target point) with a 'sandpile' resting on 208 top. The sandpile consists of N = 1683 simulated spherical particles with radii drawn from 209 a power-law distribution of mean 1 46 cm and . ± 0 29 cm width truncated (minimum and . 210 maximum particle radii 1 17 . and 1 75 . cm, respectively). Between the sandpile and the 211 floor is a rigid monolayer of particles drawn from the same distribution and laid down in 212 a close-packed configuration in the shape of a flat disk. This rigid particle layer provides 213 a rough surface for the sandpile to reduce spreading (Fig. 1). Three different sandpiles 214 were constructed using the material parameters described below. Particles were dropped 215 though a funnel from a low height onto the rough surface to build up the sandpile. These 216 sandpiles were allowed to settle until the system kinetic energy dropped to near zero. This 217 approach eliminates any bias that might arise from simply arranging the spheres by hand in 218 a geometrical way; the result should better represent a natural sandpile. 219
## Yang Yu et al.
For this study, we compared three different sets of soft-sphere parameters for the sandpile 221 particles (Table 1). Our goal was to define a set of parameters that spans a plausible range of 222 material properties given that the actual mechanical properties of asteroid surface material 223 are poorly constrained. In the specific case of Apophis, very little is known beyond the 224 spectral type, Sq (Binzel et al. 2009). There are no measurements of thermal properties that 225 might give an indication of the presence or absence of regolith on Apophis. Consequently, 226 we chose three sets of material parameters that span a broad range of material properties. 227 The first set, denoted 'smooth' in the table, consists of idealized frictionless spheres with a 228 small amount of dissipation (5%, chosen to match the glass beads case). This is about as 229 close to the fluid case that a sandpile can achieve while still exhibiting shear strength arising 230 from the discrete nature of the particles (and the confining pressure of surface gravity). It 231 is assumed this set will respond most readily to tidal effects due to the absence of friction 232 between the particles and the non-uniform size distribution. The second set, 'glass beads,' 233 is modeled after actual glass beads being used in a set of laboratory experiments to calibrate 234 numerical simulations of granular avalanches (Richardson et al. 2012). In this case ε t was 235 measured directly, which informed our choice for C t (Schwartz et al. 2012), and µ s and µ r 236 were inferred from matching the simulations to the experiments. The glass beads provide 237 an intermediate case between the near-fluid smooth spheres and the third parameter set, 238 denoted 'gravel.' 239
240
## Table 1.
The gravel parameters were arrived at by carrying out simple avalanche experiments 241 using roughly equal-size rocks collected from a streambed. In these experiments, the rocks 242
Yang Yu et al.
(without sharp edges) were released near the top of a wooden board held at a 45 ◦ incline. 243 The dispersal pattern on the stone floor was measured, including the distance from the 244 end of the board to approximately half of the material, the furthest distance traveled by 245 a rock along the direction of the board, and the maximum angle of the dispersal pattern 246 relative to the end of the board (Fig. 2a-c). A series of numerical simulations was then 247 performed to reproduce the typical behavior by varying the soft-sphere parameters (Fig. 248 2d-f). The values used in Table 1 for 'gravel' were found in this way. The µ s and µ r values 249 are quite large, reflecting the fact that the actual particles being modeled were not spheres. 250 A correspondingly smaller timestep is needed to adequately sample the resulting forces on 251 the particles in the simulations. The value of ε n was measured by calculating the average 252 first rebound height of sample gravel pieces that were released from a certain height; ε t was 253 not measured but since the rocks were rough it was decided to simply set ε t = ε n . This 254 exercise was not meant to be an exhaustive or precise study; rather, we sought simply to 255 find representative soft-sphere parameters that can account plausibly for the irregularities 256 in the particle shapes. In any case, we will find that such rough particles are difficult to 257 displace using tidal forces in the parameter range explored here, so they provide a suitable 258 upper limit to the effects. Similarly, we do not consider cohesion in this numerical study, 259 which would further resist particle displacement due to tidal forces. 260
261
Yang Yu et al.
## 2.2 Representation of Mechanical Environment 262
A new adaptation of pkdgrav developed in this work allows for the simulation of sandpiles 263 located on an asteroid surface, based on the motion equations of granular material in the 264 noninertial frame fixed to the chosen spot. Detailed mechanics involved in the local motion of 265 the sandpile during a tidal encounter were considered and represented in the code, including 266 the contact forces (reaction, damping, and friction between particles and/or walls) and the 267 inertial forces derived from an analysis of the transport motion of a flyby simulation. Here 268 we provide a thorough derivation of the relevant external force expressions. 269
270
## Figure 3.
Figure 3 illustrates four frames used in the derivation, the space inertial frame (SPC), 271 mass center translating frame (MCT), body fixed frame (BDY) and local frame (LOC). Eq. 272 (1) gives the connection between the spatial position and the local position of an arbitrary 273 particle in the sandpile, for which R is the vector from SPC's origin to the particle, R C is 274 the vector from SPC to MCT/BDY, l is the vector from MCT/BDY to LOC, and r is the 275 vector from LOC to the particle: 276
$$R = R _ { C } + 1 + r.$$
Equations (2)-(3) are derived by calculating the first- and second-order time derivatives 277 of Eq. (1), which denote the connections of velocity and acceleration between the spatial and 278 local representations, respectively. ω indicates the angular velocity vector of the asteroid 279 in SPC or MCT. The operator d d t denotes the time derivative with respect to the inertial 280
Yang Yu et al.
frame SPC, while ˜ d d t denotes the time derivative with respect to the body-fixed frame BDY 281 or LOC: 282
$$\frac { d } { d t } \mathbf R = \frac { d } { d t } \mathbf R _ { C } + \omega \times ( 1 + \mathbf r ) + \frac { \tilde { d } } { d t } \mathbf r,$$
$$\frac { d ^ { 2 } } { d t ^ { 2 } } \mathbf R = \frac { d ^ { 2 } } { d t ^ { 2 } } \mathbf R _ { C } + \omega \times [ \omega \times ( 1 + \mathbf r ) ] + \frac { \tilde { d } } { d t } \omega \times ( 1 + \mathbf r ) + 2 \omega \times \frac { \tilde { d } } { d t } \mathbf r + \frac { \tilde { d } ^ { 2 } } { d t ^ { 2 } } \mathbf r.$$
The dynamical equation for an arbitrary particle in the inertial frame SPC can be written 283 as Eq. (4), which shows that the forces a particle in the sandpile feels can be grouped into 284 three categories: F A denotes the local gravity from the asteroid; F P denotes the attraction 285 from the planet; and F C represents all the contact forces coming from other particles and 286 walls: 287
$$\frac { d ^ { 2 } } { d t ^ { 2 } } R = \mathbf F _ { A } + \mathbf F _ { P } + \mathbf F _ { C }.$$
We get the corresponding dynamical equation in the local frame LOC (Eq. (5)) by sub288 stituting Eq. (3) into Eq. (4), 289
$$\frac { \tilde { d } ^ { 2 } } { d t ^ { 2 } } \mathbf r = \mathbf F _ { C } + \mathbf F _ { A } + \mathbf F _ { P } - \frac { d ^ { 2 } } { d t ^ { 2 } } \mathbf R _ { C } - \omega \times [ \omega \times ( 1 + \mathbf r ) ] - \frac { \tilde { d } } { d t } \omega \times ( 1 + \mathbf r ) - 2 \omega \times \frac { \tilde { d } } { d t } \mathbf r. \quad ( 5 )$$
The terms on the right-hand side of Eq. (5) represent the mechanical environment of a 290 particle in the local sandpile during a tidal encounter, and can be interpreted as follows. 291 F C is the reaction force from the walls and surrounding particles, which is directly exported 292 by pkdgrav . F A is approximated by a constant value at the LOC's origin that acts as 293
## Yang Yu et al.
the uniform gravity felt throughout the whole sandpile, since the latter's size is negligible 294 compared with the asteroid dimensions. The difference between the planetary attraction 295 and the translational transport inertia force, F P -d 2 d t 2 R C , is the tidal force that plays the 296 primary role of moving the surface materials. The term -ω × [ ω × ( l + )] is the centrifugal r 297 force due to the rotation of the asteroid, -˜ d d t ω × ( l + ) is the librational transport inertia r 298 force (LTIF) that results when the rotational state changes abruptly during the encounter, 299 and -2 ω × ˜ d d t r is the Coriolis effect that only acts when particle movement occurs. 300
301
## Figure 4.
In the numerical scheme, we derived the component dynamical equations by projecting 302 Eq. (5) to LOC and treating each term separately. The local gravity F A and LOC origin l are 303 constant vectors, which were initialized in the simulations as parameters. The complications 304 arising from the asteroid motion (tidal force, angular velocity, and acceleration) were solved 305 within a simulation in advance, using a rigid rubble pile as the asteroid model and exporting 306 the physical quantities required in each step. To specify Apophis's encounter with Earth in 307 2029, we computed the planet trajectory by tracing back from the perigee conditions, 5 6 . 308 R E distance and 8 4 km/s encounter speed (Giorgini et al. 2008), where R . E indicates the 309 average Earth radius (6371 km). As Fig. 4 illustrates, a tri-axial ellipsoid model with axis 310 ratio 1.4:1.0:0.8 was employed to approximate the overall shape of Apophis (Scheeres et al. 311 2005), corresponding to an equivalent radius of 162 5 m (M¨ller et al. 2013). . u A rubble pile 312 bounded by the tri-axial model was constructed for the flyby simulation. The rubble pile 313 model consisted of N = 2855 equal-size spherical particles in a close-packed configuration. 314
The total mass was set to 4
×
10
10
3
315
.
kg (bulk density 2 4 g
/
cm ) with an initial rotation around
Yang Yu et al.
the maximum principle axis of inertia of period 30 4 h (Tholen et al. 2013). . Three markers 316 (non-coplanar with the origin) were chosen from the surface particles to track the variation 317 of the rubble pile's attitude in SPC. A complete list of its motion states during the encounter 318 was exported to a data file, which was accessed by the subsequent simulations with local 319 sandpiles. 320
## 3 RESULTS 321
## 3.1 Evaluation of Reshaping Effects 322
Richardson et al. (1998) showed the complicated behavior of a rotating rubble pile due to a 323 tidal encounter. Generally, a variation in rotational state is usually induced because of the 324 coupling effect between librational motion and orbital motion. Especially for elongated bod325 ies like Apophis, the terrestrial torques during its flyby may force a strong alteration of the 326 rotational state in a short period (Scheeres et al. 2005). The modifications in structure of the 327 rubble pile are also notable. The tidal encounter outcomes show a strong dependence on the 328 progenitor elongation, the perigee distance, and the time spent within the Roche sphere. The 329 outcomes also depend on the spin orientation of the progenitor to the extent that retrograde 330 rotators always suffer less catastrophic consequences than prograde ones (Richardson et al. 331 1998). However, the parameter space considered in that study (Richardson et al. 1998) did 332 not include the Apophis scenario in 2029, since the focus was on the conditions for full-scale 333 distortion or disruption. For this study, we first redid the flyby simulations (Section 2.2) 334 using a true (non-rigid) rubble pile model with the Apophis encounter parameters of 5 6 . 335
Yang Yu et al.
R E and 8 4 km/s. . We quantified the tidal reshaping effect by measuring the maximum net 336 change of a normalized shape factor defined by Eq. (6) (Hu et al. 2004), in which I 1 , I 2 , I 3 337 are the principal inertia moments, with I 1 /lessorequalslant I 2 /lessorequalslant I 3 : 338
$$\sigma \equiv \frac { I _ { 2 } - I _ { 1 } } { I _ { 3 } - I _ { 1 } }.$$
The shape factor σ ∈ [0 , 1] roughly describes the mass distribution of the body (0=oblate, 339 1=prolate). The initial rubble-pile model (equilibrated, prior to the encounter) had σ ∼ 0 73, . 340 and its relative change, defined by ∆ σ/σ , was measured for several simulations parameterized 341 by bulk density and constituent material type (Table 2). The corresponding Roche limits 342 are provided in the table, with the values estimated for the case of a circular orbit. The 343 reshaping effects show consistent results for all three types of materials, varying between a 344 noticeable change in shape (magnitude 10 -2 ) and a negligible change in shape (magnitude 345 10 ), 5 with the sharpest transition occurring for a critical bulk density ∼ 0 4 . g / cm 3 with 346 corresponding Roche limit of 5 6 R . E . This agrees with the analysis of Apophis' disruption 347 limit using a continuum theory for a body made up of solid constituents (Holsapple et al. 348 2006). Note we find that even a bulk density as low as 0 1 g . / cm 3 did not dislodge any 349 particles enough for them to end up in a new geometrical arrangement, due to the very short 350 duration of the tidal encounter. 351
352
Figure 5.
353
Table 2.
Since idealized equal-size spheres can arrange into crystal-like structures that may arti354 ficially enhance the shear strength of the body (Tanga et al. 2009; Walsh et al. 2012), we 355
## Yang Yu et al.
carried out a second suite of simulations with rubble piles made up of a bimodal distribution 356 of spheres (Fig. 5). The model consisted of 181 big particles of radius 19 3 m and 1569 small . 357 particles of radius 9 7 m, bounded by the same tri-axial ellipsoid as shown in Fig. 4, and . 358 arranged randomly. As before, the bulk density and material type were varied, with notable 359 differences in outcome compared to the equal-size-sphere cases (Table 2). Particles using the 360 'smooth' parameter set are not able to hold the overall shape of Apophis (the 1.4:1.0:0.8 361 tri-axial ellipsoid); instead the rubble pile collapses and approaches a near-spherical shape. 362 For the other two parameter sets, however, the overall shape of the rubble pile is main363 tained. Figure 6 shows the relative change of shape factor σ as a function of bulk density 364 for both types of simulations. As shown, the results from the unimodal and bimodal rubble 365 piles present similar trends: before reaching the Roche limit density, the reshaping remains 366 small (the magnitudes are 10 -5 -10 -4 with a certain amount of stochasticity); after that, 367 the reshaping effect sharply increases to around 10 -1 . The bimodal rubble piles show less 368 resistance to the tidal disturbance, since they have less-well-organized crystalline structures 369 compared to the unimodal cases; they therefore exhibit larger shape modifications (Walsh 370 et al. 2012). 371
372
## Figure 6.
Regardless, catastrophic events were not detected for either type of rubble pile until the 373 bulk density was as small as 0 1 . g / cm , 3 for all material parameter sets. Therefore, the 374 reshaping effects on Apophis in 2029 should be negligibly small for bulk densities in the 375 likely range (2-3 g / cm ). 3 Even so, minor internal reconfigurations resulting from the tidal 376 encounter may produce seismic waves that could propagate and affect the configuration of 377
## Yang Yu et al.
surface regolith. Since we are only looking at localized areas on the surface, isolated from 378 the rest of the body, vibrations emanating from other regions, in or on the asteroid, are not 379 evaluated in the current work, although again we expect these to be small or non-existent for 380 the specific case of the Apophis 2029 encounter. Only the 'external' forces acting directly 381 on the surface particles in the considered localized region are taken into account. We will 382 look into the effects of seismic activity, which may stem from other regions of the asteroid, 383 on an actual high-resolution rubble pile in future work. In this study, we focus on external 384 forces, outside of the rubble pile itself; the rigid rubble pile model is employed as a reasonable 385 simplification for the purpose of measuring the external forces on a surface sandpile. 386
## 3.2 Global Change of Mechanical Environment 387
The right-hand side of Eq. (5) provides a description of the constituents of the mechanical 388 environment experienced by a sandpile particle, including local gravity, tidal force, centrifugal 389 force, LTIF, and the Coriolis effect. Note the Coriolis force does not play a role before particle 390 motion begins, so it can be ignored when examining the causes of avalanches/collapses. The 391 centrifugal force and LTIF show weak dependence on local position r , so these terms can be 392 simplified by substituting l + r ≈ l , since the dimension of the sandpile is much smaller than 393 that of the asteroid. This leads to an approximation of the resultant environmental force 394 (Eq. (7)), which provides a uniform expression of the field force felt throughout the sandpile: 395
$$\mathbf F _ { E } = \mathbf F _ { A } + \mathbf F _ { P } - \frac { \mathbf d ^ { 2 } } { \mathbf d t ^ { 2 } } \mathbf R _ { C } - \omega \times ( \omega \times 1 ) - \frac { \tilde { \mathbf d } } { \mathbf d t } \omega \times 1.$$
The variation of F E shows a common pattern for different encounter trajectories and 396
Yang Yu et al.
different locations on the asteroid: it stays nearly invariable for hours as the planet is ap397 proaching/departing and shows a rapid single perturbation around the rendezvous. This 398 feature enables us to evaluate the mechanical environment by measuring the short-term 399 change of F E , and moreover, to make a connection between these external stimuli with the 400 responses of sandpiles in the simulations. Spherical coordinates ( F, θ, α ) are used to rep401 resent the resultant force (Fig. 7), in which F is the magnitude and θ and α denote the 402 effective gravity slope angle and deflection angle, respectively. 403
404
## Figure 7.
The effects of the environment force must be considered in the context of the sandpile 405 modeling. A rough approximation of the catastrophic slope angle (Eq. (8)) can be derived 406 from the conventional theory of the angle of repose for conical piles (Brown et al. 1966), 407 namely that avalanches will occur when the effective gravity slope angle θ exceeds θ C : 408
$$\theta _ { C } = \tan ^ { - 1 } ( \mu _ { S } ) - \theta _ { S }.$$
Here θ S denotes the resting angle of the (conical) sandpile, assumed to be less than the 409 repose angle tan -1 ( µ S ), and θ C denotes the critical slope angle, which, if exceeded by the 410 effective gravity slope angle, results in structural failure of the sandpile, i.e., an avalanche. 411 Essentially, the avalanches of the sandpile depend primarily on the instantaneous change of 412 the slope angle θ of the resultant force and should be only weakly related to the magnitude 413 F and deflection angle α . The global distribution of changes of θ were examined for the 414 duration of the encounter (see below). It would be difficult to make an exhaustive search 415 over all asteroid encounter orientations due to the coupling effects between the asteroid's 416
## Yang Yu et al.
rotation and the orbital motion. Instead, we chose 12 representative trajectories along the 417 symmetry axes of the Apophis model (at perigee) for study, which serves as a framework for 418 understanding the influence of encounter orientation and the strength of tidal disturbance at 419 different locations. (The technique used to match the orientation of the asteroid at perigee is 420 to first run a simulation in reverse starting at perigee with the required orientation, thereby 421 providing the correct asteroid state for a starting position far away.) Figure 8 shows the 422 12 trajectories along three mutually perpendicular planes, including both the prograde and 423 retrograde cases. This choice is based on the symmetry of the dynamical system, and all 12 424 trajectories have a speed of 8 4 km/s at a perigee distance of 5 6 R . . E . 425
426
## Figure 8.
Figure 8 presents these representative trajectories in order, each corresponding to a spe427 cial possible orientation of the encounter. The effective gravity slope angle changes through428 out the surface of the tri-axial ellipsoid model were recorded for each trajectory, with partic429 ular attention to the location and time of the maximum change. We found that these maxi430 mum changes concentrate at several minutes around perigee. Figure 9 shows the maximum 431 values of slope angle change along these trajectories, indicating that the largest perturbation 432 on slope angle is less than 2 . ◦ We verified that the achievable range of the effective gravity 433 slope angle during the encounter (Section 2.2) is within the safe limit predicted by Eq. (8) 434 for all three sandpiles (Section 2.1); that is, a slope change below 2 ◦ is not enough to trigger 435 any massive avalanches throughout the sandpiles. 436
## Yang Yu et al.
Figure 9 also shows a general dependence of the tidal perturbation on the orientation of 438 the encounter trajectory, namely that the three step levels seen in the figure correspond to 439 three directions of the relative planet motion at perigee. Trajectories 1-4 correspond to the 440 direction of the body long axis, which leads to relatively strong tidal effects; trajectories 5-8 441 correspond to the direction of the intermediate axis, which leads to moderate effects; while 442 trajectories 9-12 correspond to the direction of the short axis, which leads to relatively weak 443 tidal effects. Figure 10 illustrates the distribution of effective gravity slope angle change at 444 perigee for the three trajectory sets, with A denoting trajectories 1-4, B denoting trajectories 445 5-8, and C denoting trajectories 9-12. We confirm that the four trajectories in each set 446 present visually the same distribution around perigee, therefore we chose the patterns due 447 to trajectories 1, 5, and 9 for demonstration of sets A, B, and C, and generalize these three 448 patterns as representative. Several points can be inferred from Fig. 10. First, the direction 449 to the planet at perigee largely determines the global distribution of tidal perturbation, that 450 is, the strongest effects tend to occur along the long axis and the weakest effects along the 451 short axis. Second, at perigee, the largest slope change occurs near areas surrounding the 452 pole for the most favorable orientation (set A), while the largest slope change at the pole 453 occurs several minutes before or after perigee (see Fig. 11). These maximum slope changes 454 are about equal in magnitude (the change is only slightly smaller at the pole compared to 455 the area immediately surrounding it, but not enough to make a difference to the avalanches), 456 so for simplicity we just use the poles themselves as our testing points. Third, the duration 457 of strong tidal effects depends on the eccentricity of the encounter trajectory. We checked 458 the trajectories shown in Fig. 8 and found the duration of strong perturbation, defined for 459 illustration as the period when the force magnitude stays above 90% of the peak value, is tens 460
## Yang Yu et al.
of minutes long; correspondingly, the responses of the surface material are also transitory 461 and weak. 462
463
## Figure 10.
The three poles p , p x y and p z (see Figure 8) were chosen as the test locations for the 464 sample sandpiles since the effective gravity slope angle is near zero at these locations, which 465 enables the sandpiles to hold their initial shapes. Figure 11 illustrates the time variation of 466 slope angle at the poles during the encounter. The results derived from all 12 trajectories in 467 Fig. 8 are shown and to the same scale. The most perturbed pole is p y on the medium axis, 468 which gains the largest slope angle change for most cases, except in trajectories { 3,4,9,10 } . 469 It is notable that trajectories in the same plane always share similar variation at the three 470 poles, such as { 1,2,5,6 } , { 3,4,9,10 } , and { 7,8,11,12 } . The curves at p x and p y show similar 471 doublet shapes since those poles are both located in the rotational plane. The variation at 472 p z is more complicated due to the fact that the spin pole is not perpendicular to the orbit 473 plane. 474
475
## Figure 11.
Figure 11 can be used to estimate the changes in the mechanical environment at these 476 pole locations. Since the slope angle change is the primary mechanism to drive avalanches 477 on the sandpiles, the results derived from different trajectories serve as a framework to 478 determine the magnitude of tidal perturbation at the candidate locations and locations in 479 between, which turns out to be quite small for the Apophis encounter (less than about 1 ◦ in 480 slope for these cases). 481
Yang Yu et al.
## 3.3 Tidal Disturbances in 2029 482
As analyzed above, catastrophic avalanches solely due to external forces acting directly on 483 the surface particles may never occur on Apophis during the 2029 encounter since the tidal 484 perturbation will be very weak, however it might still have the potential to trigger some local 485 tiny landslides of the surface materials. Generally, the regolith experiences more activity 486 than the constituents deep in the asteroid due to the dynamical environment on the surface, 487 including the microgravity, maximum tidal and centrifugal acceleration, and smaller damping 488 forces from the surroundings due to the smaller confining pressure, therefore we conclude 489 that resurfacing due to external perturbations should occur before wholesale reshaping during 490 the encounter (discussed in Section 3.1). In the following sections we detail our numerical 491 examination of the local sandpiles for the predicted Apophis encounter scenario to estimate 492 the limit and magnitude of the material responses in 2029. 493
- One problem that must be confronted in the numerical simulations is that the soft-sphere 494 sandpiles exhibit slow outward spreading due to the accumulation of velocity noise, and this 495 slow spreading may eventually lead to a collapse of the whole sandpile. Unfortunately, our 496 integration time required is long (hours) for a granular system, thus the numerical noise has 497 to be well limited in our method. Two techniques are used in this study. First, as described 498 in Section 2.1, a rough pallet made up of closely packed spheres in a disk fixed to the ground 499 is used to reduce spreading of the bottom particles. Second, we introduce a critical speed 500 in the code, below which all motions are considered to be noise and are forced to zero. We 501 found a speed threshold ∼ 10 -10 m/s by launching hours-long simulations of a static sandpile 502 for different material properties and finding the corresponding minimum value of the critical 503
## Yang Yu et al.
speed that limits the numerical spreading. 504
Simulations of sandpiles without a flyby were carried out first, serving as a reference for 505 subsequent flyby simulations. Sandpiles in this situation were confirmed to stay equilibrated 506 for a long period, which suggests the avalanches in our numerical experiments (if any) would 507 be attributed entirely to the effects of the tidal encounter. We performed local simulations 508 with the sandpiles generated in Section 2.1 to consider the response of different materials 509 to the Apophis encounter. The local frames at the three poles p , x p y and p z (Fig. 8) 510 were used to position the sample sandpiles, and the flyby simulation data derived from the 511 12 fiducial trajectories were employed as the source of external perturbations for the local 512 simulations. There are 108 possible combinations in total for different materials, locations, 513 and trajectory orientations, covering a wide range of these undetermined parameters. In all 514 the simulations, the start distance of Apophis from the center of the planet was set to 18 515 R E to ensure the sandpiles were equilibrated fully before it approached the perigee. For our 516 study, we concentrated on the connections between the sandpile's responses and significant 517 variables, e.g., spin orientation and sandpile locations, by which we will get a better sense of 518 the surface processes due to a tidal encounter. The sandpiles located at pole p y for trajectory 519 2 (Fig. 8) were examined in detail, which is the case suffering the strongest tidal perturbation 520 (Fig. 11). Figure 12 illustrates the disturbances on sandpiles of three different materials for 521 this configuration. Each panel includes a snapshot of the sandpile after the tidal encounter 522 with the displaced particles highlighted and a diagram showing the time variations of the 523 total kinetic energy with planetary distance. Intensive events can be identified by noting 524 the peaks of the kinetic energy curves, and the particles involved in these events are marked 525 with different colors to show the correspondence between the disturbed site and occurrence 526
527
## Yang Yu et al.
time.
528
## Figure 12.
The scale of the disturbances proves to be tiny even for the 'strongest' case in Fig. 529 12. As illustrated, the displaced particles are few in number and mostly distributed on the 530 surface of the sandpile. We found that the maximum displacement of a given particle is 531 less than 0 8 times its radius; that is, these disturbances only resulted from the collapse of . 532 some local weak structures and the small chain reaction among the surrounding particles. 533 Moreover, the 'gravel' sandpile proves to be unaffected by the tidal encounter, because 534 the static friction is quite large (Table 1) and all particles are locked in a stable configu535 ration, in which case the total kinetic energy of the sandpile remains very small ( ∼ 10 -14 536 J). The 'glass beads' sandpile suffered small but concentrated disturbances that involved 537 very few particles. Accordingly, the displacements of these particles are relatively large. The 538 'smooth' sandpile presents near-fuild properties with many surface particles experiencing 539 small-amplitude sloshing. The motion eventually damps out and the displacements of the 540 involved particles are tiny (smaller than that of 'glass beads'). 541
Based on the detailed analysis of this representative scenario, we performed simulations 542 at other poles and at other orientations, constructing a database to reveal any connections 543 between disturbances and these parameters. However, the results show little association 544 between these two: for the 'gravel' sandpile, no disturbances were detected for any location 545 and any orientation due to the large µ S ; for the 'glass beads' sandpile, some small-scale 546 avalanches can always be triggered, while the occurrence (site and time) of these avalanches 547 seems to be widely distributed and independent of location and orientation; and for the 548
## Yang Yu et al.
'smooth' sandpile, surface particles can feel the tidal perturbation and show slight sloshing, 549 but no visible avalanches eventually resulted, because the initial low slope angle in this 550 case imposes a relatively stable structure that is always able to recover from the external 551 perturbations. 552
## 3.4 Tide-induced Avalanches at Closer Approaches 553
To illustrate the effect of stronger perturbations on our model sandpiles, we carried out a 554 few simulations of closer approaches, specifically at 4 0 and 2 0 R . . E , for the same encounter 555 speed of 8 4 . km/s. These scenarios, though unlikely to occur in 2029 based on current 556 understanding of Apophis' orbit, are presented here to illustrate the magnitudes of tidal 557 resurfacing effects over a wider range of perturbation strengths. 558
Flyby simulations of rubble piles were first carried out to quantify the reshaping effects, 559 using the monodisperse and bidisperse particle rubble-pile models (see Section 3.1). The 560 bulk densities for both models were set to ∼ 2 4 . g/cc. Table 3 presents the relative net 561 changes of shape factor ∆ σ/σ for these rubble piles of different materials at different perigee 562 distances. 563
564
## Table 3.
Table 3 shows results consistent with Section 3.1, namely that the bimodal rubble pile 565 shows greater fluidity and larger shape changes during the encounter. To be more specific, 566 the magnitude of reshaping effects at perigee distance 4 0 R . E (still larger than the Roche 567 limit of 3 22 R . E for a fluid body) remains small ( ∼ 10 -4 ), and that at perigee distance 2 0 . 568 R E (smaller than the Roche limit) achieves a significant level of 10 -3 -10 -1 . It is notable 569
## Yang Yu et al.
that the rubble piles did not experience any irreversible distortion even for an approach 570 distance as close as 2 0 R . E , because the duration of strong tidal effects is relatively short 571 (see Section 3.1). Anyway, in this section we still adopt the assumption of rigidity to measure 572 the quantities required by the local simulations, which is acceptable since these scenarios are 573 fictitious and only designed to exhibit some massive resurfacing effects. 574
For the same reason, in this section we do not present systematic local simulations for 575 different sandpile locations and orientations as done for the real encounter scenario; instead, 576 we simply place the sample sandpiles (see Fig. 1) at the pole of the body long axis p x , and 577 choose trajectory 1 (see Fig. 8) as the encounter trajectory to give rise to the maximum tidal 578 effects. Figures 13 and 14 illustrate the responses of the three sandpiles for perigee distance 579 4 0 R . E and 2 0 R . E , respectively. Each panel includes snapshots of the sandpile before and 580 after the tidal encounter, and the overall shape of the sandpile is traced with a white border 581 for emphasis. Diagrams showing the time variation of the total kinetic energy with planetary 582 distance are also included, in which the intensive avalanches can be identified by noting the 583 peaks of the kinetic energy curves (note the different vertical scales). 584
585
Figure 13.
586
Figure 14.
As illustrated in Fig. 13, the shape changes of the three sandpiles are still small (but 587 visible) for the encounter at 4 0 . R E perigee, and involve many more particles than the 588 encounter at 5 6 R . E (Fig. 12). And accordingly, the magnitudes of the total kinetic energy 589 increase consistently for the three sandpiles of different materials, except for the gravel case 590 at 4 0 R . E , where it appears the frictional 'lock' established when the pile was first created is 591
Yang Yu et al.
disturbed enough to cause a stronger distortion than might otherwise be expected, causing 592 a sharp spike in the kinetic energy plot. Essentially, the 'gravel' sandpile experienced a 593 more significant collapse than the 'glass bead' sandpile. As stated in Section 2.1, the three 594 sandpiles were constructed in a manner that allowed for some inherent randomness, thus 595 their energy state and strength may differ to some degree, and appearently the 'gravel' 596 sandpile was closer to its failure limit than the other two. This adds an extra element of 597 stochasticity to the results, an aspect to be explored in future work. 598
Figure 14 shows the results from the encounter at 2 0 R . E perigee, for which the encounter 599 trajectory partly entered the Roche sphere (3 22 R . E ). In this case, the shapes of the three 600 sandpiles are highly distorted during the encounter, with the involved particles slumped 601 towards the direction where the planet is receding. The corresponding changes in total 602 kinetic energy become extremely large when the massive avalanches occur, especially for the 603 'smooth' particles. 604
- The results of this section suggest that a 4 0 R . E encounter may alter the regolith on 605 Apophis' surface slightly, and a 2 0 R . E encounter may produce a strong resurfacing effect (of 606 course, we would expect considerable global distortion as well, if the asteroid is a rubble pile). 607 The shape changes of the sandpiles depend on the orientation of the encounter trajectory; 608 609
- i.e., particles can be dragged away along the direction in which the planet recedes.
## 4 DISCUSSION 610
- The argument about whether a terrestrial encounter can reset the regolith of NEAs has been 611 discussed for a while (e.g., Binzel et al. 2010, Nesvorn´ et al. 2010). y Important evidence is 612
Yang Yu et al.
provided by measurements of the spectral properties, which suggest that asteroids with orbits 613 conducive to tidal encounters with planets show the freshest surfaces, while quantitative 614 evaluation of this mechanism is still rare and rough. The two-stage approach presented in 615 this paper enables the most detailed simulations to date of regolith migration due to tidal 616 effects, which we have applied to make a numerical prediction for the surface effects during 617 the 2029 approach of (99942) Apophis. 618
We confirm that the shape modification of Apophis due to this encounter will likely 619 be negligibly small based on the results of systematic simulations parameterized by bulk 620 density, internal structure, and material properties. The analysis of the global mechanical 621 environment over the surface of Apophis during the 2029 encounter reveals that the tidal 622 perturbation is even too small to result in any large-scale avalanches of the regolith materials, 623 based on a plausible range of material parameters and provided that external forces acting 624 directly on the surface dominate any surface effects due to seismic activity emanating from 625 other regions of the body. Future work will explore these second-order surface effects and 626 their relevance to this encounter, and to cases of tidal resurfacing of small bodies in general. 627 It is notable that our approach is capable of capturing slight changes in the regolith (modeled 628 as sandpiles); thus, through numerical simulation, we find that this weak tidal encounter does 629 trigger some local disturbances for appropriate material properties. 630
These possible disturbances, though local and tiny, are essentially related to the nature 631 of the sandpile, which is actually a bunch of rocks and powders in a jammed state. The 632 sandpile is formed by a competition between the constituents to fall under gravity and 633 eventually reach an equilibrium with mutual support. It can hold a stable shape under a 634 constant environment force at low sandpile densities (compared with close packing), which 635
## Yang Yu et al.
is primarily due to interior collective structures, called bridges, that are formed at the same 636 time as the sandpile and are distributed non-uniformly throughout the sandpile (Mehta 637 2007). The soft-sphere method provides a detailed approximation to a real sandpile in terms 638 of the granular shape and contact mechanics, which can well reproduce the bridges that 639 dominate the structure of the sandpile. Accordingly, we can describe the nuanced responses 640 due to the changes in ( F, θ, α )-see Section 3.2 and Fig. 7. Changing the slope angle θ 641 is the most efficient way to break the equilibrium of substructures in the sandpile, while 642 changing the magnitude F and deflection angle α may also play a role in the causes of 643 avalanches. Changes in F can readjust the interparticle overlaps and cause collapse of some 644 bridges, which is a principal mechanism of compaction by filling the voids during small 645 structural modifications (Mehta et al. 2004). This dependence was recently demonstrated in 646 experiments of measuring the angle of repose under reduced gravity (Kleinhans et al. 2011). 647 Similarly, the weak links in bridges of the sandpile may also be disturbed and broken during 648 the sweeping of α in the plane. In addition, Mehta et al. (1991) pointed out that even slight 649 vibration caused by the environment force may result in collapse of long-lived bridges, which 650 is also responsible for the sandpile landslides during the encounter. 651
Although the magnitudes of the avalanches are different for the three materials we tested, 652 they are nonetheless all very small. We note the occurrence of these local avalanches shows 653 little dependence on the orientation/location of the sandpile, because all the perturbations 654 are small in magnitude and the sandpile behavior, these small-scale avalanches, actually 655 depends on the presence of weak bridges inside the sandpile, which in turn could be sensitive 656 to the changes of the environmental force's magnitude, deflection angle, and slope angle in 657 a somewhat random way. 658
Yang Yu et al.
In any case, this numerical study shows that tidal resurfacing may not be particularly 659 effective at moderate encounter distances. We predict that overall resurfacing of Apophis, 660 regolith will not occur if the only source of disturbance is external perturbations. Mini661 landslides on the surface may still be observed by a visiting spacecraft with sufficiently 662 sensitive monitoring equipment. This provides a great motivation for in situ exploration of 663 Apophis in 2029 (Michel et al. 2012). 664
## 5 CONCLUSIONS 665
This paper provides a numerically derived prediction for the surface effects on (99942) 666 Apophis during its 2029 approach, which is likely to be one of the most significant as667 teroid encounter events in the near future. A two-stage scheme was developed based on the 668 soft-sphere code implementation in pkdgrav to mimic both a rubble pile's (rigid and flexi669 ble) responses to a planetary flyby and a sandpile's responses to all forms of perturbations 670 induced by the encounter. The flyby simulations with the rubble pile indicate that reshaping 671 effects due to the tidal force on Apophis in 2029 will be negligibly small for bulk densities 672 in the expected range (2-3 g / cm ). 3 The resultant environmental force felt by the sandpile 673 on the asteroid surface was approximated with a uniform analytical expression, which led 674 to an estimate of the changes in the global mechanical environment. Three typical patterns 675 of perturbation were presented based on the asteroid body and spin orientation at perigee, 676 showing a general dependence of the magnitude of tidal perturbation on the orientation of 677 the trajectory. Twelve fiducial trajectories were used to calculate the magnitude of the tidal 678 perturbation at three poles of the tri-axial ellipsoid model, indicating that the strongest 679
## Yang Yu et al.
tidal perturbation appears where the local slope is originally steep and that the duration of 680 the strong perturbation is short compared with the whole process. The tidal perturbation 681 on surface materials is confirmed to be quite weak for the 2029 encounter, therefore large682 scale avalanches may never occur. However, we showed this weak perturbation does trigger 683 some local tiny landslides on the sample sandpiles, though the involved particles are few 684 in number and are distributed on the surface of the sandpile. These small-scale avalanches 685 result from the breaking of weak substructures by slight external perturbations, therefore 686 the occurrence of these local avalanches is widely distributed and presents little dependence 687 on the encounter parameters. The simulations of closer approaches show that an encounter 688 at 2 0 R . E is capable of triggering some massive avalanches of the sandpiles, i.e., to alter 689 the regolith on Apophis' surface significantly (although the entire body would also undergo 690 significant shape change in this case). 691
Further research will be performed to generalize our work over a wide range of possible 692 asteroid-planet encounter conditions. And as stated above, we will also investigate whether 693 even slight internal perturbations in the asteroid during tidal encounters may contribute to 694 noticeable surface motions. 695
Yang Yu et al.
## Acknowledgments 696
This material is based on work supported by the US National Aeronautics and Space Ad697 ministration under Grant Nos. NNX08AM39G, NNX10AQ01G, and NNX12AG29G issued 698 through the Office of Space Science and by the National Science Foundation under Grant 699 No. AST1009579. Some simulations in this work were performed on the 'yorp' cluster 700 administered by the Center for Theory and Computation in the Department of Astron701 omy at the University of Maryland. Patrick Michel acknowledges support from the French 702 space agency CNES. Ray tracing for Figs.1, 2, 4, 5 and 12 was performed using POV-Ray 703 (http://www.povray.org/). 704
Yang Yu et al.
## References 705
Benz, W., Asphaug, E., 1999. Catastrophic disruptions revisited. Icarus 142, 5-20. 706
707
708
709
Binzel, R.P., Rivkin, A.S., Thomas, C.A., Vernazza, P., Burbine, T.H., DeMeo, F.E., Bus, S.J., Tokunaga, A.T., Birlan, M., 2009. Spectral properties and composition of potentially hazardous Asteroid (99942) Apophis. Icarus 200, 480-485.
710
711
712
713
714
715
716
717
718
719
720
721
722
723
Binzel, R.P., Morbidelli, A., Merouane, S., DeMeo, F.E., Birlan, M., Vernazza, P., Thomas, C.A., Rivkin, A.S., Bus, S.J., Tokunaga, A.T., 2010. Earth encounters as the origin of fresh surfaces on near-Earth asteroids. Nature 463, 331-334.
Brown, R.L., Richards, J.C., 1966. Principles of Powder Mechanics. Oxford: Pergamon.
Clark, B.E., Hapke, B., Pieters, C., Britt, D., 2002. Asteroid space weathering and regolith evolution. In: Bottke Jr., W.F., Cellino, A., Paolicchi, P., Binzel, R.P. (Eds.), Asteroids III. Univ. of Arizona Press, Tucson, pp. 485-500.
Delbo', M., Cellino, A., Tedesco, E.F., 2007. Albedo and size determination of potentially hazardous asteroids: (99942) Apophis. Icarus 188, 266-269.
DeMeo, F.E., Binzel, R.P., Lockhart, M., 2013. Mars encounters cause fresh surfaces on some near-Earth asteroids. Icarus 227, 112-122.
Fujiwara, A. Kawaguchi, J., Yeomans, D.K., Abe, M., Mukai, T., Okada, T., Saito, J., Yano, H., Yoshikawa, M., Scheeres, D.J., Barnouin-Jha, O., Cheng, A.F., Demura, H., Gaskell, R.W., Hirata, N., Ikeda, H., Kominato, T., Miyamoto, H., Nakamura,
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
- 741
742
743
Yang Yu et al.
- A.M., Nakamura, R., Sasaki, S., Uesugi, K., 2006. The rubble-pile asteroid Itokawa as observed by Hayabusa. Science 312, 1330-1334.
Giorgini, J.D., Benner, L.A.M., Ostro, S.J., Nolan, M.C., Busch, M.W., 2008. Predicting the Earth encounters of (99942) Apophis. Icarus 193, 1-19.
Holsapple, A., Michel, P., 2006. Tidal disruptions: A continuum theory for solid bodies. Icarus 183, 331-348.
Hu, W., Scheeres, D.J., 2004. Numerical determination of stability regions for orbital motion in uniformly rotating second degree and order gravity fields. Planetary and Space Science 52, 685-692.
Jutzi, M., Michel, P., Benz, W., Richardson, D.C., 2010. Fragment properties at the catastrophic disruption threshold: The effect of the parent body's internal structure. Icarus 207, 54-65.
Kleinhans, M.G., Markies, H., de Vet, S.J., in 't Veld, A.C., Postema, F.N., 2011. Static and dynamic angles of repose in loose granular materials under reduced gravity. Journal of Geophysical Research 116, E11004.
Nesvorn´, D., Bottke Jr., W.F., Vokrouhlick´, D., Chapman, C.R., Rafkin, S., 2010. y y Do planetary encounters reset surfaces of near Earth asteroids? Icarus 209, 510-519.
Mehta, A., 2007. Granular Physics. Cambridge University Press.
Mehta, A., Barker, G.C., 1991. Vibrated powders: A microscopic approach. Physics Review Letter 67, 394-397.
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
Yang Yu et al.
Mehta, A., Barker, G.C., Luck, J.M., 2004. Cooperativity in sandpiles: Statistics of bridge geometries. Journal of Statistical Mechanics: Theory and Experiment. P10014.
Michel, P., Benz, W., Tanga, P., Richardson, D.C., 2001. Collisions and gravitational reaccumulation: Forming asteroid families and satellites. Science 294, 1696-1700.
Michel, P., Prado, J.Y., Barucci, M.A., Bousquet, P., Chiavassa, F., Groussin, O., Herique, A., Hestroffer, D., Hinglais, E., Lopes, L., Martin, T., Mimoun, D., R´me, H., Thuillot, e W., 2012. Probing the interior of asteroid Apophis: A unique opportunity in 2029. Special Session 7 of the XXVIII IAU General Assembly, 29-31 August, 2012, Beijing (China), Abstract Book.
Richardson, D.C., Bottke, Jr., W.F., Love, S.G., 1998. Tidal distortion and disruption of Earth-crossing asteroids. Icarus 134, 47-76.
Richardson, D.C., Quinn, T., Stadel, J., Lake, G., 2000. Direct large-scale N -body simulations of planetesimal dynamics. Icarus 143, 45-59.
Richardson, D.C., Leinhardt, Z.M., Melosh, H.J., Bottke Jr., W.F., Asphaug, E., 2002. Gravitational aggregates: Evidence and evolution. In: Bottke Jr., W.F., Cellino, A., Paolicchi, P., Binzel, R.P. (Eds.), Asteroids III. Univ. of Arizona Press, Tucson, pp. 501-515.
Richardson, D.C., Michel, P., Walsh, K.J., Flynn, K.W., 2009. Numerical simulations of asteroids modeled as gravitational aggregates. Planetary and Space Science 57, 183192.
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
Yang Yu et al.
Richardson, D.C., Walsh, K.J., Murdoch, N., Michel, P., 2011. Numerical simulations of granular dynamics: I. Hard-sphere discrete element method and tests. Icarus 212, 427-437.
Richardson, D.C., Blum, J., Weinhart, T., Schwartz, S.R., Michel, P., Walsh, K.J., 2012. Numerical simulations of landslides calibrated against laboratory experiments for application to asteroid surface processes. American Astronomical Society, DPS meeting 44, 105.06.
Scheeres, D.J., Benner, L.A.M., Ostro, S.J., Rossi, A., Marzari, F., Washabaugh, P., 2005. Abrupt alteration of Asteroid 2004 MN4's spin state during its 2029 Earth flyby. Icarus 178, 281-283.
Schwartz, S.R., Richardson, D.C., Michel, P., 2012. An implementation of the soft-sphere discrete element method in a high-performance parallel gravity tree-code. Granular Matter 14, 363-380.
Schwartz, S.R., Michel, P., Richardson, D.C., 2013. Numerically simulating impact disruptions of cohesive glass bead agglomerates using the soft-sphere discrete element method. Icarus 226, 67-76.
Schwartz, S.R., Michel, P., Richardson, D.C., Yano, H., 2014. Low-speed impact simulations into regolith in support of asteroid sampling mechanism design I.: Comparison with 1-g Experiments. Planet. Space Sci., in press.
Stadel, J., 2001. Cosmological N -body simulations and their analysis. Thesis, University of Washington. 141 pp.
785
786
787
788
789
790
791
792
793
794
795
Yang Yu et al.
Tanga, P., Comito, C., Paolicchi, P., Hestroffer, D., Cellino, A., DellOro, A., Richardson, D. C., Walsh, K. J., Delbo', M., 2009. Rubble-pile reshaping reproduces overall asteroid shapes. The Astrophysical Journal 706, 197-202.
Tholen, D.J., Micheli, M., Elliott, G.T., 2013. Improved astrometry of (99942) Apophis. Acta Astronautica 90, 56-71.
Veverka, J., and 32 co-authors, 2000. NEAR at Eros: Imaging and spectral results. Science 289, 2088-2097.
Walsh, K. J., Richardson, D.C., Michel, P., 2012. Spin-up of rubble-pile asteroids: Disruption, satellite formation, and equilibrium shapes. Icarus 220, 514-529.
Wlodarczyk, I., 2013. The potentially dangerous asteroid (99942) Apophis. Monthly Notices of the Royal Astronomical Society 434(4), 3055-3060.
Table 1: Soft-sphere parameter sets used to represent three different material properties of sandpiles in the simulations. Here µ s is the coefficient of static friction (= tan -1 φ , where φ is the material friction angle), µ r is the coefficient of rolling friction, ε n is the normal coefficient of restitution (1 = elastic, 0 = plastic), ε t is the tangential coefficient of restitution (1 = no sliding friction), k n is the normal spring constant (kg / s 2 ), and k t is the tangential spring constant (also kg / s 2 ).
| Parameter | Gravel | Glass Beads | Smooth |
|-------------|----------|---------------|----------|
| µ s | 1.31 | 0.43 | 0 |
| µ r | 3 | 0.1 | 0 |
| ε n | 0.55 | 0.95 | 0.95 |
| ε t | 0.55 | 1 | 1 |
| k n | 83.3 | 83.3 | 83.3 |
| k t | 23.8 | 23.8 | 23.8 |
Table 2: Relative net change of shape factor ∆ σ/σ for the flexible rubble-pile model of monodisperse and bidispersed particles, parameterized by the bulk density and material property. The results of bidisperse smooth particles are omitted since the rubble pile in this case cannot hold the overall shape of a 1.4:1.0:0.8 tri-axial ellipsoid at Apophis' spin rate. The estimates of Apophis' Roche limit (second column) corresponding to the indicated bulk density are calculated assuming a fluid body in a circular orbit around Earth. For reference, the Apophis encounter distance in 2029 will be about 5.6 R E .
| Density (g / cm 3 ) | Roche Limit (R E ) | Dispersion | Gravel | Glass Beads | Smooth |
|-----------------------|----------------------|------------------|---------------------------------|---------------------------------|-------------------|
| 2.4 | 3.22 | Unimodal Bimodal | 6 . 62 × 10 - 5 8 . 36 × 10 - 4 | 7 . 76 × 10 - 5 6 . 00 × 10 - 4 | 3 . 26 × 10 - 5 - |
| 2 | 3.42 | Unimodal Bimodal | 5 . 19 × 10 - 5 9 . 67 × 10 - 4 | 8 . 84 × 10 - 5 6 . 06 × 10 - 4 | 8 . 67 × 10 - 5 - |
| 1.5 | 3.77 | Unimodal Bimodal | 2 . 75 × 10 - 5 4 . 73 × 10 - 4 | 9 . 54 × 10 - 5 3 . 51 × 10 - 4 | 3 . 60 × 10 - 5 - |
| 1 | 4.31 | Unimodal Bimodal | 1 . 88 × 10 - 5 9 . 07 × 10 - 4 | 4 . 95 × 10 - 5 5 . 57 × 10 - 4 | 4 . 68 × 10 - 5 - |
| 0.5 | 5.43 | Unimodal Bimodal | 1 . 99 × 10 - 5 2 . 82 × 10 - 3 | 1 . 45 × 10 - 5 2 . 31 × 10 - 4 | 2 . 16 × 10 - 5 - |
| 0.1 | 9.29 | Unimodal Bimodal | 2 . 37 × 10 - 2 6 . 54 × 10 - 2 | 3 . 12 × 10 - 3 1 . 31 × 10 - 1 | 2 . 47 × 10 - 2 - |
Table 3: Relative net change of shape factor ∆ σ/σ for the rubble piles of monodisperse and bidisperse particles, parameterized by the perigee distance and material property. As before, the results of bidisperse smooth particles are omitted since they cannot maintain Apophis' tri-axial ellipsoidal shape.
| Perigee (R E ) | Dispersion | Gravel | Glass Beads | Smooth |
|------------------|------------------|---------------------------------|---------------------------------|-------------------|
| 2 | Unimodal Bimodal | 1 . 45 × 10 - 3 4 . 48 × 10 - 2 | 1 . 42 × 10 - 3 7 . 95 × 10 - 2 | 5 . 62 × 10 - 1 - |
| 4 | Unimodal Bimodal | 1 . 32 × 10 - 4 9 . 37 × 10 - 4 | 7 . 18 × 10 - 4 8 . 09 × 10 - 4 | 5 . 88 × 10 - 4 - |
## Figure Captions 796
797
798
799
800
801
Figure 1: Snapshots of sandpiles constructed using three different materials, which are (a) 'gravel,' (b) 'glass beads,' and (c) 'smooth,' with corresponding soft-sphere parameters listed in Table 1. The same constituent spheres are used in each sandpile both for the free particles (green) and the rigid particles (white). The values of average slope and pile height after equilibrium is achieved are indicated in the snapshots.
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
Figure 2: Snapshots of the avalanche experiment and corresponding simulations. In the experiments, ∼ 340 similar-size gravel pieces were piled up on the slope each time and released all at once by removing the supporting board. Snapshots from both the experiment and simulation include frames from the beginning (a, d), middle (b, e), and end (c, f) of the avalanche event, respectively.
Figure 3: Sketch of the frames used for deriving the motion equations of the local sandpile, indicated with different colors. SPC (black) is an inertial frame with the origin and axes set by pkdgrav . MCT (blue) is a noninertial translating frame with the origin at the mass center of the asteroid and x , y , z -axes parallel to SPC. BDY (green) is a noninertial frame that is fixed to the asteroid and initially coincides with MCT. LOC (red) is a frame fixed to the asteroid surface, taking the origin to be where the sandpile is located and choosing the z -axis to be normal to the surface at that point.
Figure 4: Diagram of Asteroid (99942) Apophis'. The tri-axial ellipsoid (light gray) denotes the overall shape model, while the arranged particles (khaki) denote the rubblepile model used for numerical simulations. The highlighted particles (red) are markers
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
## Yang Yu et al.
used for determining the attitude of the asteroid in SPC.
Figure 5: Snapshot of the rubble-pile model for Apophis with bimodal particles in irregular packing. The tri-axial ellipsoid (light gray) denotes the overall shape model, and the arranged particles (khaki) show the rubble-pile model used for numerical simulations.
Figure 6: The relative change of shape factor σ as a function of bulk density during the encounter. The solid line (with triangular points) shows the results for the original rubble pile with equal-sized particles. The dashed line (with square points) shows the results for the bimodal rubble pile with irregular packing.
Figure 7: Sketch of the environmental force that the sandpile feels in LOC. The plane (gray) indicates the local tangential plane. The red arrow indicates the environmental force given by Eq. (7). Label F indicates its magnitude, and θ and α indicate the slope angle (elevation) and deflection angle (azimuth) of the effective gravity, respectively.
Figure 8: Sketch of the fiducial trajectories in different orientations. These trajectories (blue numbered lines) are placed in the perpendicular planes (yellow) of the Apophis model (gray ellipsoid), matching the three axial directions at perigee. The blue arrows show the prograde and retrograde directions. The red arrow denotes the angular velocity. p , p , p x y z indicate the poles along the three axes x , y , z , respectively.
Figure 9: Maximum values of slope angle change for the fiducial trajectories. The stars denote the maximum values, and the dashed lines denote the levels of tidal perturbation (the average of the 4 values in each case), which divide the 12 trajectories into 3 basic catagories according to the spin orientation at perigee. See Fig. 8 for the trajectory
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
orientations.
Figure 10: Global distribution of slope angle change at perigee for the three trajectory sets A, B and C, each including 4 trajectories of the same spin orientation at perigee (see text for an explanation of each set). A uniform colormap ranging up to 1 8 . ◦ is used for the three plots.
Figure 11: Time variation of the effective gravity slope angle at the poles p x (dashed lines), p y (solid lines), and p z (dotted lines) during the encounter. Each subgraph corresponds to one fiducial trajectory marked with its number on the upper left (refer to Fig. 8).
Figure 12: Snapshots of sandpiles after the tide-induced avalanches in 2029, with corresponding time variations of their total kinetic energy. The three panels include the results of sandpiles constructed using the three materials (a) 'gravel,' (b) 'glass beads,' and (c) 'smooth,' respectively. Particles that moved more than 0 1 of a parti-. cle radius during the avalanches are highlighted. The peaks in the total kinetic energy curves indicate occurrence of avalanches; the peaks are labeled, and corresponding particles that moved appreciably are marked in different colors (red, blue, orange) in the snapshots. The dotted line in each graph shows the evolution of the planet-asteroid distance during the encounter.
Figure 13: Snapshots of the sample sandpiles before and after the avalanches induced 856 by the encounter at 4 0 R . E perigee, with corresponding time variations of their total 857 kinetic energy. The white lines in the snapshots indicate the original and final shapes 858
- of the sandpiles. The peaks in the total kinetic energy curves indicate occurrence of 859 avalanches, and the dotted line shows the variation of the planet-asteroid distance 860 during the encounter. 861
- Figure 14: Same as Fig. 13, but for the encounter at 2 0 R . E perigee. 862
(a) Sandpile with 'gravel' parameter set.
(b) Sandpile with 'glass beads' parameter set.
- (c) Sandpile with 'smooth' parameter set.
Figure 1:
## Yang Yu et al.

- (a) Experiment: Beginning
- (d) Simulation: Beginning
- (b) Experiment: Middle
- (e) Simulation: Middle
- (c) Experiment: End
- (f) Simulation: End



Figure 2:


Figure 3:
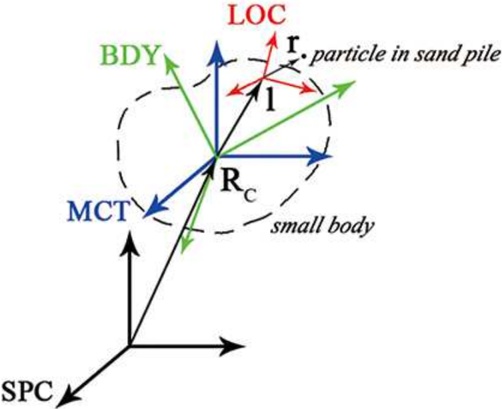
Figure 4:
Figure 5:
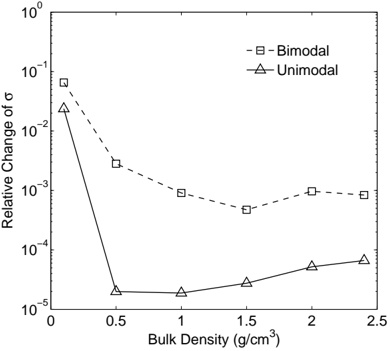
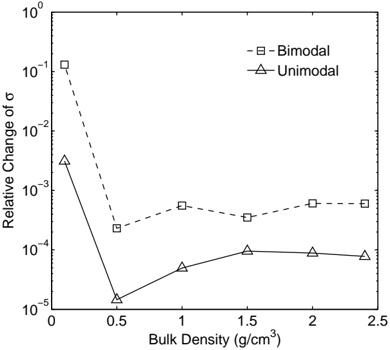
- (a) Rubble piles with 'gravel' parameter set.
- (b) Rubble piles with 'glass beads' parameter set.
- (c) Rubble piles with 'smooth' parameter set.
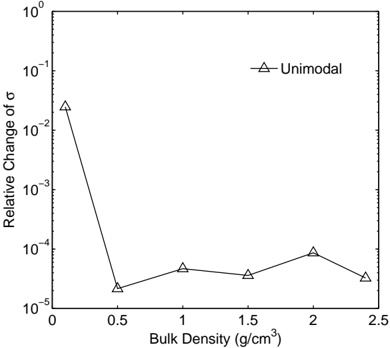
Figure 6:
Figure 7:
Figure 8:
Figure 9:
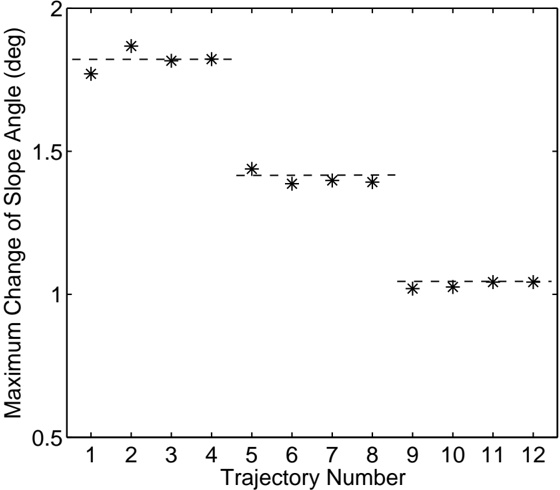
Figure 10:
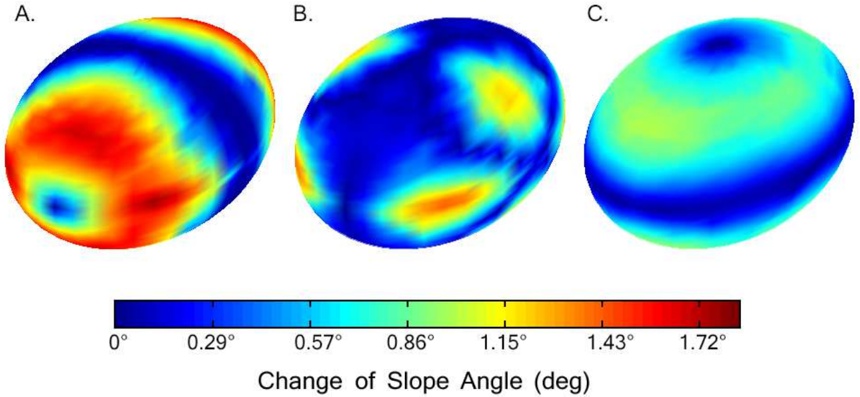
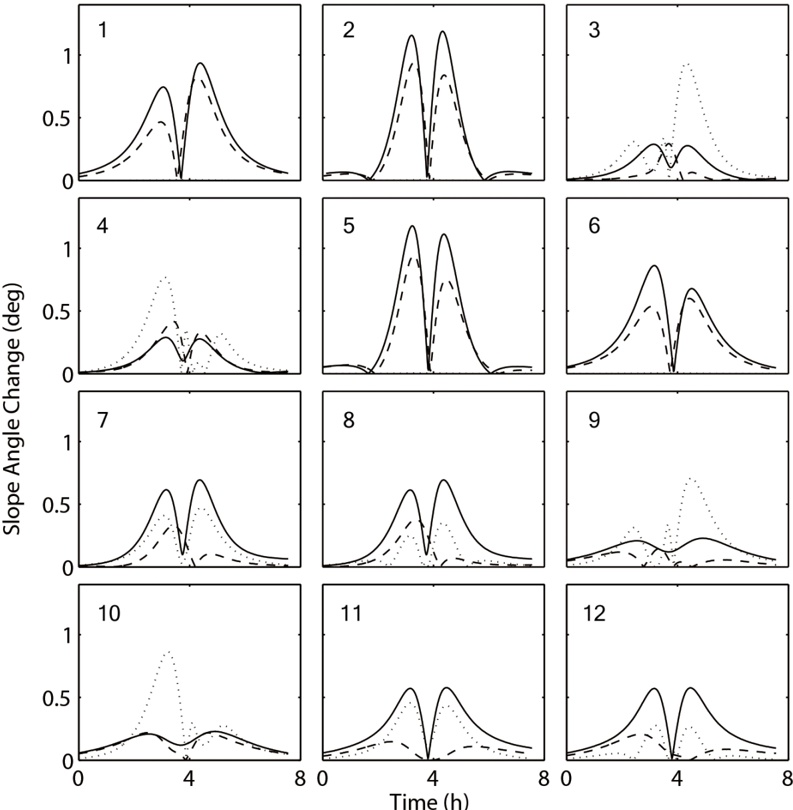
Time (h)
Figure 11:
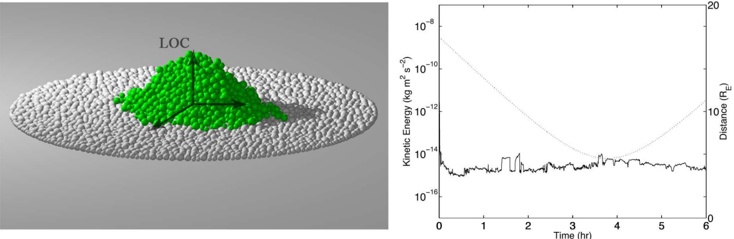
Time (hr)
- (a) Avalanches with 'gravel' parameter set.
- (b) Avalanches with 'glass beads' parameter set.
- (c) Avalanches with 'smooth' parameter set.
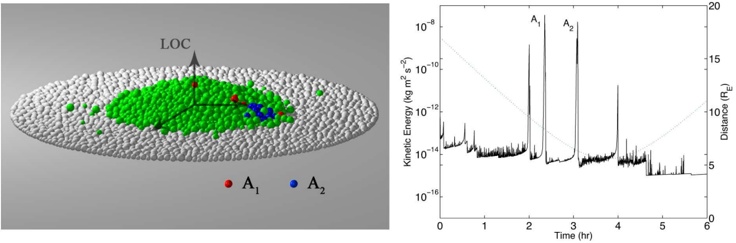
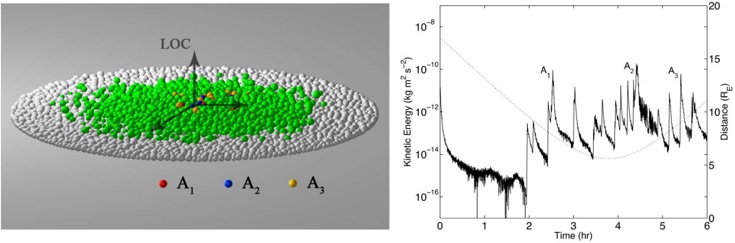
Figure 12:
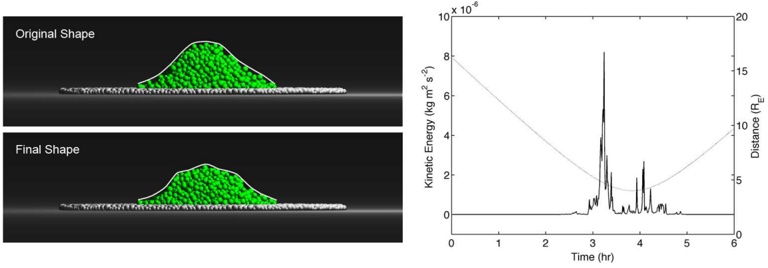
- (a) Shape changes with 'gravel' parameter set.
- (b) Shape changes with 'glass beads' parameter set.
- (c) Shape changes with 'smooth' parameter set.
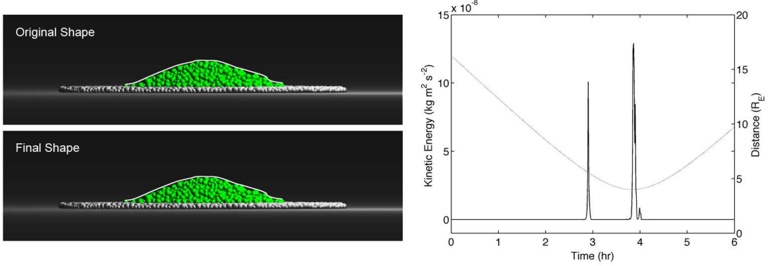
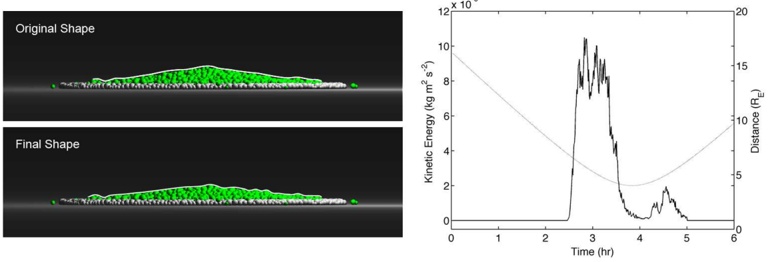
Figure 13:
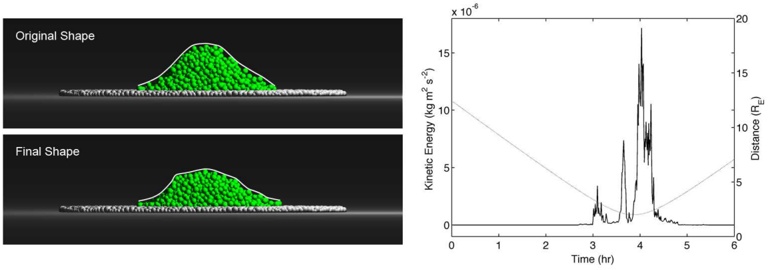
- (a) Shape changes with 'gravel' parameter set.
- (b) Shape changes with 'glass beads' parameter set.
- (c) Shape changes with 'smooth' parameter set.
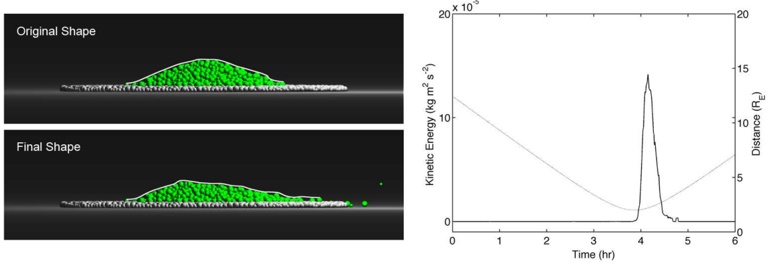
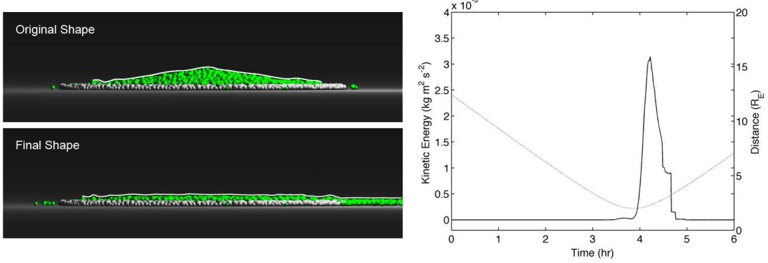
Figure 14: | 10.1016/j.icarus.2014.07.027 | [
"Yang Yu",
"Derek C. Richardson",
"Patrick Michel",
"Stephen R. Schwartz",
"Ronald-Louis Ballouz"
] | 2014-08-01T13:17:19+00:00 | 2014-08-01T13:17:19+00:00 | [
"astro-ph.EP"
] | Numerical predictions of surface effects during the 2029 close approach of asteroid 99942 Apophis | Asteroid (99942) Apophis' close approach in 2029 will be one of the most
significant small-body encounter events in the near future and offers a good
opportunity for in situ exploration to determine the asteroid's surface
properties and measure any tidal effects that might alter its regolith
configuration. Resurfacing mechanics has become a new focus for asteroid
researchers due to its important implications for interpreting surface
observations, including space weathering effects. This paper provides a
prediction for the tidal effects during the 2029 encounter, with an emphasis on
whether surface refreshing due to regolith movement will occur. The potential
shape modification of the object due to the tidal encounter is first confirmed
to be negligibly small with systematic simulations, thus only the external
perturbations are taken into account for this work (despite this, seismic
shaking induced by shifting blocks might still play a weak role and we will
look into this mechanism in future work). A two-stage approach is developed to
model the responses of asteroid surface particles (the regolith) based on the
soft-sphere implementation of the parallel N-body gravity tree code pkdgrav. A
full-body model of Apophis is sent past the Earth on the predicted trajectory
to generate the data of all forces acting at a target point on the surface. A
sandpile constructed in the local frame is then used to approximate the
regolith materials; all the forces the sandpile feels during the encounter are
imposed as external perturbations to mimic the regolith's behavior in the full
scenario. The local mechanical environment on the asteroid surface is
represented in detail, leading to an estimation of the change in global surface
environment due to the encounter. Typical patterns of perturbation are
presented that depend on the asteroid orientation and sense of rotation at
perigee. |
1408.0169v1 | ## Long-term Ks -band photometric monitoring of L dwarfs
B. López Martí 1 2 ; and M. R. Zapatero Osorio 3
- 1 Centro de Astrobiología (INTA-CSIC), P.O. Box 78, E-28261 Villanueva de la Cañada, Madrid, Spain e-mail: [email protected]
- 2 Saint Louis University - Madrid Campus, Division of Science, Engineering and Nursing, Avenida del Valle 34, E-28003 Madrid, Spain
- 3 Centro de Astrobiología (INTA-CSIC), Carretera de Ajalvir km. 4, E-28850 Torrejón de Ardoz, Spain
Received ; accepted
## ABSTRACT
Context. Ultracool dwarfs ( . 2500 K) are known to display photometric variability in short timescales (hours to days), which has usually been related to rotation-modulated dust cloud patterns, or to unresolved companions.
Aims. We perform photometric time-series analysis of a sample of ten early to mid-L dwarfs in the field over three years of Ks -band observations with the OMEGA 2000 infrared camera of the 3.5m telescope on Calar Alto Observatory between January 2010 and December 2012. This study represents the first systematic long-term photometric monitoring of this kind of object to date.
Methods. We perform Ks -band di GLYPH<11> erential photometry of our targets (with typical errors of GLYPH<6> 15-30 mmag at the 1 GLYPH<27> level) by subtracting a reference flux from each photometric measurement. This reference flux is computed using three nearby, probably constant stars in the target's field-of-view. We then construct and visually inspect the light curves to search for variability, and use four di GLYPH<11> erent periodogram algorithms to look for possible periods in our photometric data.
Results. Our targets do not display long-term variability over 1 GLYPH<27> compared to other nearby stars of similar brightness, nor do the periodograms unveil any possible periodicity for these objects, with two exceptions: 2MASS J02411151-0326587 and G196-3B. In the case of 2MASS J02411151-0326587 (L0), our data suggest a tentative period of 307 GLYPH<6> 21 days, at 40% confidence level, which seems to be associated with peak-to-peak variability of 44 GLYPH<6> 10 mmag. This object may also display variability in timescales of years, as suggested by the comparison of our Ks-band photometry with 2MASS. For G196-3B (L3), we find peak-to-peak variations of 42 GLYPH<6> 10 mmag, with a possible photometric period of 442 GLYPH<6> 7 days, at 95% confidence level. This is roughly the double of the astrometric period reported by Zapatero Osorio et al. (2014). Given the significance of these results, further photometric data are required to confirm the long-term variability.
Conclusions. Our results suggest that early- to mid-L dwarfs are fairly stable in the Ks -band within GLYPH<6> 90 mmag at the 3 GLYPH<27> level over months to years, which covers hundreds to tens of thousands of rotation cycles. Two out of ten targets show periodic photometric variability at 2.2 GLYPH<22> mwith peak-to-peak variations of about 40 mmag and tentative periods of GLYPH<24> 300 and GLYPH<24> 450 d.
Key words. stars: low-mass, brown dwarfs - stars: individual: 2MASS J00332386-1521309, 2MASS J00452143 + 1634446, 2MASS J02411151-0326587, 2MASS J03552337 + 1133437, 2MASS J05012406-0010452, G196-3B, 2MASS J10224821 + 5825453, 2MASS J15525906 + 2948485, 2MASS J17260007 + 1538190, 2MASS J22081363 + 2921215 - Techniques: photometric
## 1. Introduction
Brown dwarfs have similar physical properties to the coolest and lowest mass stars and to the giant planets; all these groups are termed generically as 'ultracool dwarfs' ( Tef f . 2500 K). Their most relevant characteristics are their fully convective interiors and the presence of molecules and dust in their atmospheres. For M dwarfs, the most prominent features are the broad TiO and VO absorption bands seen in the red part of their optical spectra. As we proceed towards lower temperature, the refractary elements aggregate into grains and their signature disappears from the spectra of L-dwarfs (Tsuji et al. 1996; Allard et al. 1997; Kirkpatrick et al. 1999; Martín et al. 1999). These objects are characterized by a dusty cloud deck in their atmospheres, which also include silicate and iron particles. In addition, their spectra display absorption of metal hydrides (FeH, CrH) and strong alkali lines (K, Na, Rb, Cs), as well as absorption bands of water and CO. For still lower temperatures, these clouds settle below the photosphere and disappear, and methane and water become the most important features in the spectra of T-dwarfs (Kirkpatrick 2005, and references therein).
Work by many groups over the past decades has shown that ultracool dwarfs display optical and or infrared photometric / variability in timescales of hours or days, usually attributed to rotationally driven cloud instabilities, pulsation, or the presence of unresolved companions (e.g. Bailer-Jones 2005; Goldman 2005; Heinze et al. 2013, and references therein). However, the hypothesis that some of the reported variability is caused by magnetic activity cannot be ruled out, at least for early-type ultracool dwarfs (e.g. Littlefair et al. 2008). On one hand, H GLYPH<11> emission, a proxy for chromospheric activity, has been reported even for Ttype objects (e.g. Burgasser et al. 2000); on the other hand, many ultracool dwarfs with spectral types as late as T6.5 are reported to be radio pulsators, a phenomenon usually related to magnetic activity. This radio pulsation has sometimes been related to optical periodic variability (e.g. Lane et al. 2007; Hallinan et al. 2008; Route & Wolszczan 2012; Harding et al. 2013). Some authors argue, however, that even if some magnetic activity is present, the coupling of the (supposedly weak) magnetic field with the atmosphere will not be very strong, ruling out magnetic cool spots as those detected in solar-type stars (e.g. Gelino et al. 2002; Mohanty et al. 2002).
Clouds, binarity, or magnetic activity may also yield photometric variability at longer timescales. In solar-type stars, periodic, low-amplitude (a few mmag) photometric variations have been reported, and are generally attributed to spot cycles similar to that of our Sun (e.g., Lockwood et al. 1997; Radick et al. 1998). In ultracool dwarfs, however, owing to their dusty atmospheres, it seems more likely that long-term variations are produced by weather phenomena, probably resembling those observed in the giant planets of our own Solar System. In the case of planets, long-term periodic photometric variations are expected to be associated with global changes in the planet's belts and zones, and with seasonal cycles modifying the largescale cloud structures (e.g. Sánchez-Lavega et al. 1991, 2011; Sánchez-Lavega & Gómez 1996). Although little work has been done so far in quantifying these e GLYPH<11> ects, these variations are expected to have low amplitudes (not more than a few percent; R. Hueso, private communication) and cover timescales of one to two years in longer cycles of ten to 30 years; such variability has been reported at least for Uranus and Neptune, with optical ( B -band) peak-to-peak variations of about 25 and 7 mmag, respectively, over several decades (Lockwood & Jerzykiewicz 2006). Irregular and brusque variations caused by storms or structural changes in the planet's belts have also been observed in giant planets (e.g. Tejfel et al. 1994; Sánchez-Lavega 1994; Rogers 2009; Fletcher et al. 2011; Pérez-Hoyos et al. 2012), and they are likely to happen in ultracool dwarfs as well.
Photometric data from di GLYPH<11> erent epochs, separated by months, are already available for a few ultracool dwarfs (e.g. Metchev et al. 2013), suggesting that these objects may indeed display variability at these timescales. However, to our knowledge no systematic long-term monitoring of these objects had been carried out so far. This paper presents a study of long-term (from three months to three years) variability of ten nearby ultracool dwarfs. Our work is thus the first prospect exploring variability in this time range at such low temperatures.
The structure of the paper is as follows: Section 2 presents a brief description of our targets. The procedures to obtain di GLYPH<11> erential and absolute photometry from our images are explained in Section 3. Section 4 describes the periodogram analysis carried out on our data. We discuss our results in Section 5. Finally, Section 6 summarizes our conclusions.
## 2. Target description
The targets studied in this work are the same objects presented in the parallax study by Zapatero Osorio et al. (2014): ten ultracool field dwarfs of spectral types L0 to L5 and spectroscopic evidence for low-gravity atmospheres (Cruz et al. 2009; Zapatero Osorio et al. 2014, and references therein). The trigonometric parallaxes measured by Zapatero Osorio et al. (2014) confirmed that they are located at nearby distances (9-47 pc). In the same work, seven of the objects were confirmed to be young (10-500 Myr) and substellar (4-25 MJ ) by their location in the Hertzprung-Russell diagram, while three of them ( J0241-0326, J1022 + 5825 and J1552 + 2948) were shown to be probably older than 500 Myr and to have masses closer to or above the lithium burning mass limit. Table 1 summarizes the relevant information about our objects.
The analysis of the multi-epoch astrometric data ( d GLYPH<11> ) revealed no companions with masses above 25 MJ in face-on, circular orbits with periods between 60-90 days and three years around any of the targets. The only possible exception was G196-3B, for which a tentative signal corresponding to a period of about 228.46 days was detected, hinting at a similar-mass
Fig. 1. Example of the kind of diagram used to select the reference and comparison stars. The plot shows the standard deviation of the di GLYPH<11> erential magnitudes of the stars in the J0241-0326 field, computed with respect to a large sample of these stars, versus the instrumental magnitude (see text for details). Variable stars stand out in this diagram because of their large standard deviations compared to other stars of similar brightness. Our target is indicated with a red circle, and the finally selected reference and comparison stars are plotted with green squares and blue diamonds, respectively.
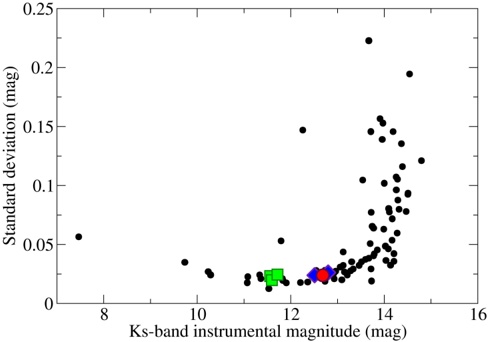
double system with a separation of 0.27 AU (for details, see Zapatero Osorio et al. 2014). However, the possible binary nature of G196-3B needs to be confirmed with additional observations.
## 3. Data processing
## 3.1. Instrumental photometry
For our photometric time-series analysis, we made use of the same multi-epoch Ks-band images used by Zapatero Osorio et al. (2014) in their astrometric study. We refer to that work for a complete description of the data, including the observing log, and of the data reduction. We only considered the images taken with the wide-field (15' GLYPH<2> 15') OMEGA2000 camera installed in the prime focus of the 3.5m telescope of Calar Alto Observatory (Almería, Spain). Our observations were carried out in the period between 2010 January to 2012 December, typically once per month; thus, our time baseline is 3 yr. However, owing to a technical failure of the telescope, the observations were interrupted for eight months between 2010 August and 2011 March. The number of images per target ranged between 12 and 27. The data were taken and processed in a standard way, as explained in Zapatero Osorio et al. (2014).
Automatic object search and aperture photometry on the OMEGA2000 Ks-band images were performed using SExtractor (Bertin & Arnouts 1996) in a two-step procedure: First, we ran SExtractor with default parameters to identify the brightest objects in each image, and to measure their full-width at halfmaximum (FWHM). The average FWHM for each image was then used as the aperture radius to perform the photometry of all the objects in the image in the second SExtractor run; values ranged between 1.7 and 4 00 , depending on night conditions. Both the detection and analysis threshold were set to 5 GLYPH<27> over back-
Table 1. Target properties a
| Object | SpT | d (pc) | Age range (Myr) | Mass ( M J ) | ¯ K s b (mag) | GLYPH<27> K c (mag) | 2MASS K s (mag) |
|----------------------------------|--------------|-------------------|-------------------|----------------|-----------------------|-----------------------|-----------------------|
| 2MASS J00332386 GLYPH<0> 1521309 | L4 GLYPH<12> | 40 GLYPH<6> 4 | GLYPH<20> 10 | 4 | 13.439 GLYPH<6> 0.011 | GLYPH<6> 0.04 | 13.410 GLYPH<6> 0.039 |
| 2MASS J00452143 + 1634446 | L2 GLYPH<12> | 17.5 GLYPH<6> 0.6 | 10-100 | 15 | 11.326 GLYPH<6> 0.005 | GLYPH<6> 0.02 | 11.366 GLYPH<6> 0.021 |
| 2MASS J02411151 GLYPH<0> 0326587 | L0 GLYPH<13> | 47 GLYPH<6> 6 | GLYPH<21> 500 | 80 | 14.175 GLYPH<6> 0.005 | GLYPH<6> 0.018 | 14.04 GLYPH<6> 0.05 |
| 2MASS J03552337 + 1133437 | L5 GLYPH<13> | 9.0 GLYPH<6> 0.4 | 50-500 | 23 | 11.531 GLYPH<6> 0.029 | GLYPH<6> 0.12 | 11.526 GLYPH<6> 0.021 |
| 2MASS J05012406 GLYPH<0> 0010452 | L4 GLYPH<13> | 19.6 GLYPH<6> 1.4 | 50-500 | 25 | 12.952 GLYPH<6> 0.012 | GLYPH<6> 0.05 | 12.963 GLYPH<6> 0.035 |
| G196 GLYPH<0> 3B | L3 GLYPH<12> | 24 GLYPH<6> 2 | 10-300 | 15 | 12.795 GLYPH<6> 0.004 | GLYPH<6> 0.02 | 12.778 GLYPH<6> 0.034 |
| 2MASS J10224821 + 5825453 | L1 GLYPH<12> | 21.6 GLYPH<6> 0.6 | 100-1000 | 50 | 12.112 GLYPH<6> 0.008 | GLYPH<6> 0.04 | 12.160 GLYPH<6> 0.025 |
| 2MASS J15525906 + 2948485 | L0 GLYPH<12> | 21.0 GLYPH<6> 0.4 | GLYPH<21> 500 | 75 | 12.028 GLYPH<6> 0.007 | GLYPH<6> 0.04 | 12.022 GLYPH<6> 0.028 |
| 2MASS J17260007 + 1538190 | L3 GLYPH<12> | 35 GLYPH<6> 4 | 10-300 | 20 | 13.748 GLYPH<6> 0.004 | GLYPH<6> 0.02 | 13.659 GLYPH<6> 0.050 |
| 2MASS J22081363 + 2921215 | L3 GLYPH<13> | 47.2 GLYPH<6> 1.6 | 10-300 | 15 | 14.092 GLYPH<6> 0.005 | GLYPH<6> 0.03 | 14.148 GLYPH<6> 0.073 |
## Notes.
- a References: Cruz et al. (2009); Zapatero Osorio et al. (2014); this work.
- b Mean Ks -band magnitude measured in this work. The error is the standard error of the mean, calculated using Eq. 2
- c Standard deviation of the Ks -band measurements from this work.
ground. In this second run, fluxes (in counts) as well as magnitudes were stored.
## 3.2. Differential photometry
Di GLYPH<11> erential photometry was performed with respect to three reference stars in each field, which were used to compute the reference flux to be subtracted from the target flux, as explained below. These stars were preferably chosen to be brighter than the target itself, but this was often di GLYPH<14> cult to accomplish, because our targets are among the brightest objects seen in the OMEGA2000 field-of-view. Therefore, we sometimes had to take stars of similar brightness ( GLYPH<6> 0 5 : mag) or even slightly fainter (up to 1 mag) than our target (e.g. for J0045 + 1634). In addition, for each target, two comparison stars of similar brightness were selected; these stars were used to check that any apparent variability was not caused by instrumental e GLYPH<11> ects. Most comparison and reference stars are seen within 5 0 from the corresponding target, in any case never further than 7 . 0
Wethen computed the standard deviations of the so-obtained di GLYPH<11> erential magnitudes over the whole observing period for all the stars detected in each field, and plotted them versus the instrumental magnitudes measured in the same observation. As discussed in Caballero et al. (2004), this diagram allows us to easily identify possible variable stars, which stand out immediately because of their high standard deviation values as compared with other stars of similar brightness. As an example, Fig. 1 shows the diagram for J0241-0326. By inspecting these diagrams, we ensured that the selected reference and comparison stars were likely to be non-variable, compared to the rest of stars of similar brightness in the same field. In the linearity range of the detector, typical standard deviations for constant stars had values . 5 mmag. However, a few stars stood out with standard deviations as high as two or three times the typical values for stars of similar brightness.
A very important requirement for both reference and comparison stars is that they are non-variable. To ensure that we selected appropriate objects, we proceeded as follows: First, a di GLYPH<11> erential magnitude was computed for every detected star and observation with respect to a large number of stars in the same field. The only condition imposed on these stars was that they should be relatively bright (in order to have enough signal-tonoise to ensure a good flux measurement) but still lie in the linearity range of the detector. For each star and observation, we used the relation:
$$d K & = - 2. 5 \cdot \log ( F - \frac { 1 } { N } \sum _ { i = 1 } ^ { N } F _ { i } ), & ( 1 ) & \text{As a} \\ & \text{and mag} \\ & \text{The resu}$$
where F is the flux of the star, N is the total number of stars considered in the field, and Fi is the flux of the i -th star in this sample of N stars. The average of all Fi fluxes provides a reference flux that is subtracted from the star's flux, and the resulting di GLYPH<11> erential flux is converted into a magnitude. The number N of stars used greatly varied depending on the field, from seven for J0045 + 1634 to 78 for J0241-0326.
The reference stars selected in this way were used to compute accurate di GLYPH<11> erential magnitudes for the targets and their comparison stars using Eq. 1. Note that the sum now included only the fluxes of the three selected, well-behaved reference stars ( N = 3). Table 2 lists the magnitude di GLYPH<11> erences GLYPH<1> KS between the targets and their respective comparison and reference stars ( GLYPH<1> KS = Kstar GLYPH<0> Ktarget ), and the GLYPH<27> ( dK ) values for all of them. In the rest of the paper, we will refer to the di GLYPH<11> erential photometry computed in this way. We will not use the di GLYPH<11> erential photometry computed using a large sample of stars, because it included objects that are likely to be variable. The purpose of the above exercise was only to discard obvious variable stars from the reference and comparison samples. The light curves of our targets are discussed in Section 5.1.
As a sanity check, we also computed the di GLYPH<11> erential fluxes and magnitudes using only two from the three reference stars. The resulting light curves for all possible combinations were visually inspected to confirm that the use of one particular star was not introducing some artificial variability in the data. The comparison concluded that all light curves for the same object (target or comparison star) showed very similar shapes, regardless of the stars used as reference to construct them. We also inspected the light curves lof the reference stars themselves (constructed using the other two stars as reference), and found no evident variability
Table 2. Magnitude di GLYPH<11> erences GLYPH<1> KS (defined as Kstar GLYPH<0> Ktarget ) with respect to the targets and standard deviations GLYPH<27> ( dK ) of the light curves for our targets and their comparison and reference stars.
| Field | Target | Comparison 1 | Comparison 1 | Comparison 2 | Comparison 2 | Reference 1 | Reference 1 | Reference 2 | Reference 2 | Reference 3 | Reference 3 |
|---------------------|-----------------------|--------------------|-------------------------|--------------------|-------------------------|--------------------|-------------------------|--------------------|-------------------------|--------------------|-------------------------|
| Field | GLYPH<27> ( dK (mmag) | GLYPH<1> K S (mag) | GLYPH<27> ( dK ) (mmag) | GLYPH<1> K S (mag) | GLYPH<27> ( dK ) (mmag) | GLYPH<1> K S (mag) | GLYPH<27> ( dK ) (mmag) | GLYPH<1> K S (mag) | GLYPH<27> ( dK ) (mmag) | GLYPH<1> K S (mag) | GLYPH<27> ( dK ) (mmag) |
| J0033 GLYPH<0> 1521 | GLYPH<6> 22 | 0.097 | GLYPH<6> 19 | GLYPH<0> 0.005 | GLYPH<6> 24 | GLYPH<0> 0.720 | GLYPH<6> 21 | GLYPH<0> 0.647 | GLYPH<6> 13 | GLYPH<0> 0.798 | GLYPH<6> 20 |
| J0045 + 1634 | GLYPH<6> 15 | 0.024 | GLYPH<6> 44 | 0.596 | GLYPH<6> 36 | GLYPH<0> 0.961 | GLYPH<6> 22 | GLYPH<0> 1.079 | GLYPH<6> 26 | GLYPH<0> 0.551 | GLYPH<6> 26 |
| J0241 GLYPH<0> 0326 | GLYPH<6> 19 | 0.290 | GLYPH<6> 13 | 0.352 | GLYPH<6> 23 | 0.841 | GLYPH<6> 16 | 0.826 | GLYPH<6> 11 | 0.736 | GLYPH<6> 14 |
| J0355 + 1133 | GLYPH<6> 18 | GLYPH<0> 1.369 | GLYPH<6> 11 | 0.152 | GLYPH<6> 16 | GLYPH<0> 0.984 | GLYPH<6> 22 | GLYPH<0> 0.920 | GLYPH<6> 23 | GLYPH<0> 0.848 | GLYPH<6> 15 |
| J0501 GLYPH<0> 0010 | GLYPH<6> 31 | GLYPH<0> 0.003 | GLYPH<6> 29 | 0.062 | GLYPH<6> 24 | 0.150 | GLYPH<6> 21 | GLYPH<0> 0.173 | GLYPH<6> 18 | 0.246 | GLYPH<6> 22 |
| G196 GLYPH<0> 3B | GLYPH<6> 23 | GLYPH<0> 0.112 | GLYPH<6> 17 | 0.232 | GLYPH<6> 19 | GLYPH<0> 0.320 | GLYPH<6> 21 | GLYPH<0> 0.315 | GLYPH<6> 20 | 0.196 | GLYPH<6> 33 |
| J1022 + 5825 | GLYPH<6> 21 | 0.607 | GLYPH<6> 11 | GLYPH<0> 0.352 | GLYPH<6> 27 | 0.712 | GLYPH<6> 21 | 0.770 | GLYPH<6> 22 | 0.801 | GLYPH<6> 23 |
| J1552 + 2948 | GLYPH<6> 18 | GLYPH<0> 0.004 | GLYPH<6> 20 | 0.007 | GLYPH<6> 22 | 0.055 | GLYPH<6> 30 | 0.414 | GLYPH<6> 20 | GLYPH<0> 0.533 | GLYPH<6> 27 |
| J1726 + 1538 | GLYPH<6> 16 | 0.045 | GLYPH<6> 16 | 0.052 | GLYPH<6> 19 | GLYPH<0> 0.486 | GLYPH<6> 17 | GLYPH<0> 0.467 | GLYPH<6> 11 | GLYPH<0> 0.406 | GLYPH<6> 14 |
| J2208 + 2921 | GLYPH<6> 40 | GLYPH<0> 0.066 | GLYPH<6> 32 | 0.031 | GLYPH<6> 43 | GLYPH<0> 3.731 | GLYPH<6> 29 | GLYPH<0> 4.070 | GLYPH<6> 19 | GLYPH<0> 3.703 | GLYPH<6> 15 |
in them: their GLYPH<27> ( dK ) values are similar to what is found for the light curves of the comparison stars.
## 3.3. Absolute photometry
The instrumental photometry was calibrated with respect to the 2 Micron All-Sky Survey (2MASS) system (Skrutskie et al. 2006) using all the 2MASS sources present in the field to derive a zero point for each image; this zero point was then subtracted from the instrumental magnitudes. The so-calibrated magnitudes were averaged to derive a mean Ks -band magnitude for each target, as listed in Table 1. In each case, the standard error of the mean, GLYPH<27> ¯ K , was computed from the standard deviation of the absolute magnitudes GLYPH<27> K (typically between 0.02 and 0.04 mag; see Table 1) and the number of observations Nobs as
$$\sigma _ { K } & = \frac { \sigma _ { K } } { \sqrt { N _ { o b s } } } & ( 2 ) & \text{$prearedir$} \\ & \text{confirm} \, \mathbb { 1 }$$
algorithms, each suitable for a particular type of variability. The Lomb-Scargle periodogram (LS; Scargle 1982) is an approximation of the Fourier transform for unevenly spaced time sampling; therefore, it is best suited to identify sinusoidal periodic signals. The Box Fitting Least Squares algorithm (BLS; Kovács et al. 2002) fits the time-series to a repeating box-shaped curve, and is thus optimized for the detection of transit events. We note, though, that such events are unlikely to be detectable with the time sampling of our observations, because a transit event in a timescale of months would only be possible with highly wideseparation binary systems, which are extremely rare among ultracool dwarfs (Allen et al. 2007). The third available algorithm is the Plavchan periodogram (Plavchan et al. 2008), a binless implementation of the phase dispersion minimization approach of Stellingwerf (1978). It identifies periods with coherent (i.e. smoothest) phased time-series curves, with no assumption about the shape of the underlying periodic signal. Hence, if a peak appeared in either the LS or the BLS periodogram, we expected to confirm it with the Plavchan algorithm.
For comparison, Table 1 also lists the published 2MASS Ks -band magnitudes for our objects. In general, our mean magnitudes agree well with the 2MASS values within the quoted errors and standard deviations. The magnitude di GLYPH<11> erences between 2MASS and our measurements are also in good agreement with the GLYPH<27> ( dK ) values for a constant star estimated from the di GLYPH<11> erential photometry of the comparison stars in every target field, meaning that the di GLYPH<11> erences are not significant. However, the di GLYPH<11> erences between our average magnitudes and the 2MASS values are certainly larger than the estimated errors and GLYPH<27> ( dK ) values for at least one object, namely J0241-0326 (0.135 mag, more than 2 GLYPH<27> di GLYPH<11> erence). This suggests that this object may be variable in timescales larger than considered in the present study, as the time span between the 2MASS observation and our OMEGA2000 photometry is 12 to 14 years. Interestingly, J0241-0326 is also one of our few targets displaying indications of possible variability (see Sect. 5).
## 4. Periodogram analysis
To test the periodicity of our targets, we made use of the online periodogram analysis tool from the NASA Exoplanet Archive 1 . The service provides periodicity analysis using three di GLYPH<11> erent
1 http: // exoplanetarchive.ipac.caltech.edu applications Periodogram / / /
The range of periods tested by the algorithms spanned from about 60 to about 1064 days (three to 35 months). We ran these algorithms not only on the light curves of our targets, but also on the light curves of the comparison and reference stars in exactly the same way as for the targets. This provided further evidence that none of these objects displayed significant variability (within our quoted errors) at the timescales we are probing, and are thus suitable for the purposes we are using them.
For those objects showing periodogram peaks, we used the CLEANalgorithm (Roberts et al. 1987) implemented in the Starlink PERIOD time-series analysis package to further test the reliability of those peaks. This algorithm is especially useful for unequally spaced data, providing a simple way to understand and remove the artifacts introduced by missing data. The algorithm was run with five iterations and a loop gain of 0.2 on a previous LS periodogram derived with the same package. The LS periodograms obtained with PERIOD are consistent with those of the NASA Exoplanet Archive tool for the same algorithm. The CLEANed periodograms, on the other hand, provide slightly different periods compared to the simple LS periodograms, and some peaks are not present as a result of the removal of artifacts. Neither the Plavchan nor the BLS algorithm are implemented in the PERIOD package.
The results from the periodogram analysis are discussed in Section 5.2.
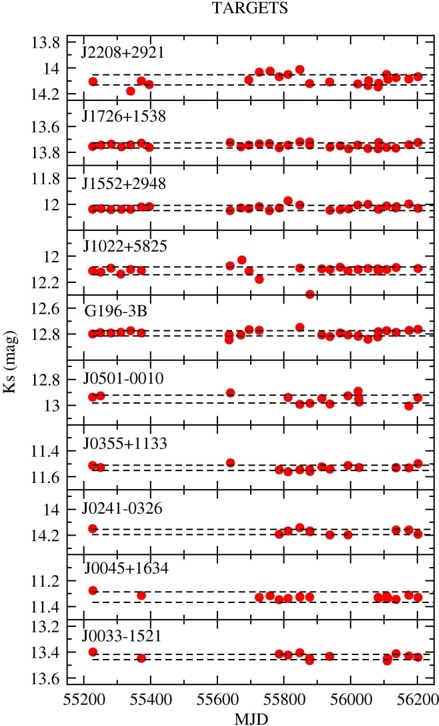
## REFERENCE STARS
Fig. 2. Photometric light curves for our ten targets (left panels), and for one of the reference stars used to compute the di GLYPH<11> erential photometry for each target (right panels). The di GLYPH<11> erential photometry (red circles and blue squares, respectively) has been shifted so that the average value corresponds to the mean Ks-magnitude of the objects. The horizontal dashed lines show the GLYPH<6> 1 GLYPH<27> variation with respect to the average values for two comparison stars in the field of view of each target and reference star.
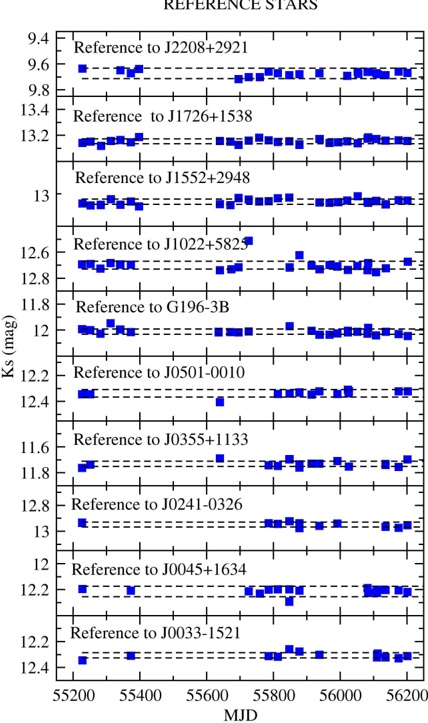
## 5. Results and discussion
## 5.1. Irregular variability
The light curves of our targets are shown in the left panels of Fig. 2. For better understanding, the di GLYPH<11> erential magnitudes are shifted, so that the mean value corresponds to the mean Ks -band magnitude listed in Table 1, computed as explained in Sect. 3.3. The horizontal dashed lines indicate the standard deviation of the di GLYPH<11> erential magnitudes, GLYPH<27> ( dK ), for a 'constant' star of similar brightness as our targets, which is estimated from the light curves of the corresponding comparison stars. These GLYPH<27> ( dK ) values, which represent the expected photometric error for our targets, are typically GLYPH<6> 15-30 mmag (see Table 2).
None of our targets display any photometric measurement deviating by more than 3 GLYPH<27> from their mean Ks magnitudes. Actually, as shown in Table 2, the standard deviations of the di GLYPH<11> erential photometry measurements for our targets GLYPH<27> ( dK ) coincide with those of the comparison stars in their fields of view. This suggests that no irregular variability of high photometric amplitude is seen in any of our targets during the time interval of the observations. The right panels of Fig. 2 show the light curves of one reference star per target, proving that the reference stars remain stable during the time interval of our study. We thus conclude that, at a confidence level of 99%, none of our early Ldwarfs show photometric variations with amplitudes higher than 90 mmag.
## 5.2. Periodic variability
Even at 1 GLYPH<27> , the periodogram analysis of the light curves may pinpoint the existence of periodic variability (e.g. Bartlett et al. 2009). However, for most of our targets, the algorithms unveiled no significant peaks, leading us to conclude that the majority of our objects are not periodically variable at the timescales that we can explore. A peak was considered significant if it had a pvalue < 0.1, where the p-value is defined as the probability that random noise will produce a peak with the same power value as the observed peak. With this criterion, we found a peak of possible significance in one or more of the periodograms in only four cases, namely J0241-0326, G196-3B, J1552 + 2948, and J2208 + 2921. For two of these objects, J0241-0326 and G1963B, there seems to be a rough agreement in at least three of
## 2MASS J02411151-0326587
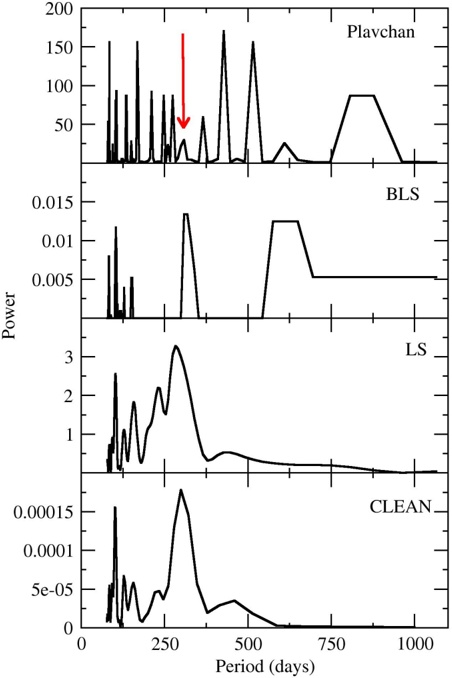
Fig. 3. Periodograms (left panels) and phased curves corresponding to their most significant peaks (right panels) for J0241-0326. In the phased curves, di GLYPH<11> erent symbol shapes indicate data points corresponding to the di GLYPH<11> erent cycles, while filled and open symbols of the same shape correspond to duplicated data points. The typical error bar is shown for the last data point. The red arrow in the upper left panel indicates the peak in best agreement with the highest peak in the rest of periodograms (see text for discussion).
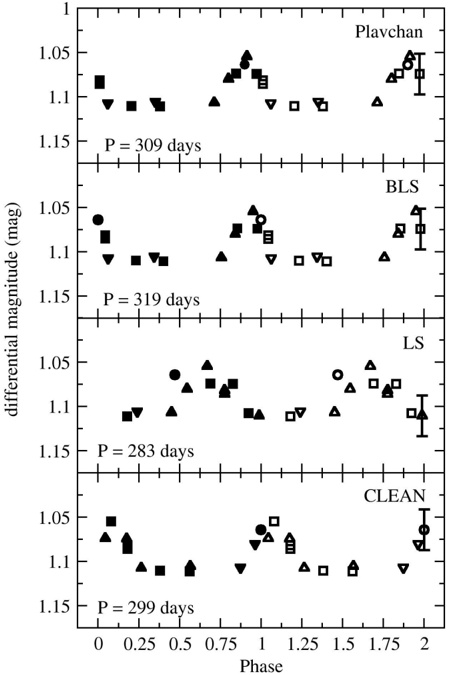
the four periodograms (see discussion below). For the other two objects (J1552 + 2948 and J2208 + 2921), however, there was no overall agreement among the peaks found by the di GLYPH<11> erent periodograms, and the folded light curves according to the periods suggested by the algorithms did not display any clear variability pattern. We thus conclude that the detected peaks for these two objects are probably artifacts caused by the time span and irregular sampling of our observations, and that no variability can be deduced for them from our data.
## 5.2.1. 2MASS J02411151-0326587 (J0241-0326)
The periodograms for the two objects displaying possible periodic variability are shown in the left panels of Figs. 3 and 4. The right panels show the phased light curves corresponding to the most significant period found with each algorithm. We will now discuss these objects in detail.
The object J0241-0326 displays a clear peak at 319 GLYPH<6> 33 days in the BLS periodogram (p-value = 0.048, computed for a sample of 120 periods and a Gaussian power distribution; second upper panel on the left in Fig. 3), where the error has been calculated as the FWHM of the peak. Also the LS periodogram (second lower panel on the left) displays a similar, though broad, peak, which would correspond to a possible period of 283 GLYPH<6> 55 days in this case. A similar value (299 GLYPH<6> 49 days) is found in the CLEANed periodogram (lowest left panel), fully consistent (at the 1 GLYPH<27> level) with the peaks found by the BLS and LS algorithms. The CLEAN and LS periodograms actually look very similar in shape.
The Plavchan periodogram (highest left panel of Fig. 3), on the other hand, displays a number of high peaks between 140 and 500 days that have no equivalent with the rest of the algorithms. This suggest that such peaks do not correspond to real periods,
## G196-3B
Fig. 4. Periodograms (left panels) and phased curves corresponding to their most significant peaks (right panels) for G196-3B. Symbols as in Fig. 3. The typical error bar is shown for the last data point.
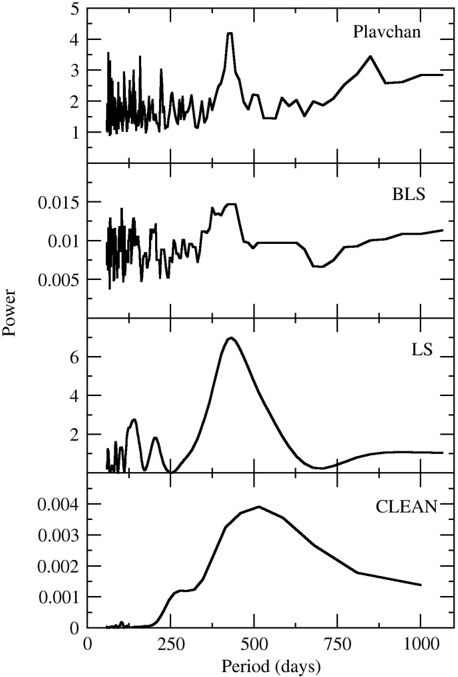
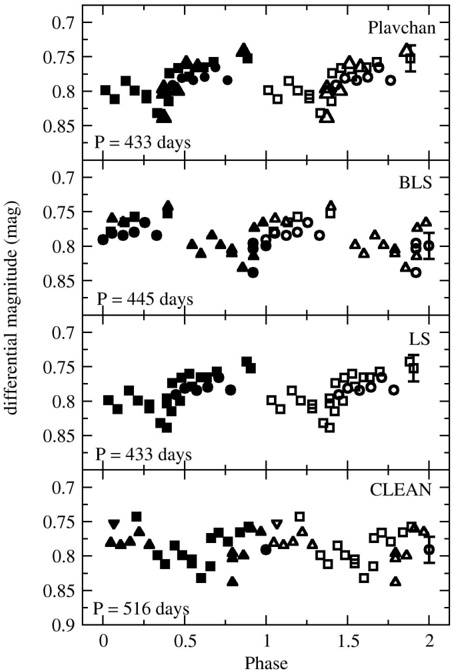
but are most probably artifacts. Interestingly, if such peaks are not considered, the most relevant feature beyond 200 days turns out to be a lower peak at 309 GLYPH<6> 8 days, fairly coincident with the peaks seen in the other periodograms. This peak is indicated with a red arrow in Fig. 3.
We computed the significance level of the resulting LS peak against the hypothesis of random noise and found it to be 40%. This value is low because of the many relatively high peaks at shortest periods, and because of the low number of data points. Even so, the fact that a prominent peak is found around very similar values in at least three of the four tested periodograms gives some credibility to the existence of periodicity in the data. Furthermore, no similar peaks are found in any of the comparison stars, which have p -values GLYPH<21> 0.2 for their most significant peaks (computed from the BLS algorithm as for the target), thus supporting the GLYPH<24> 300-days period of J0241 GLYPH<0> 0326.
Plavchan algorithm, where we show the curve folded according to the 309 days period. These curves indeed suggest periodic peak-to-peak luminosity variation of 44 GLYPH<6> 10 mmag. However, their exact shapes vary slightly depending on the period value used to fold the light curves (a result not at all unexpected), with the LS algorithm yielding a fairly sinusoidal curve and the rest of algorithms suggesting a longer quiescent phase between relatively fast increases and drops of luminosity. Clearly, our data are not su GLYPH<14> cient to constrain the shape of the light curve. Therefore, we refrain from providing any physical interpretation of the possible variability of this object until an improved dataset is available.
The phased curves corresponding to the possible period values associated with the highest peak from each periodogram are shown in the right panels of Fig. 3, except in the case of the
On the other hand, we recall that J0241-0326 is the only object in our sample showing relatively large disagreement between the 2MASS Ks magnitude and our OMEGA2000 Ks -band photometry: As shown in Table 1, the 2MASS measurement, which was taken in 1998, is about 0.1 mag brighter than our mean Ks magnitude, suggesting variability at even longer
timescales ( GLYPH<24> 10 yr) than the ones probed in this work. Follow-up observations may confirm this behaviour in the very long term.
We also note that Zapatero Osorio et al. (2011) reported linear polarization in the J-band for J0241-0326, which they related to the possible presence of dust, as this object is overluminous in the infrared ( & 2 GLYPH<22> m) compared to other L0 L1 dwarfs. Follow-/ up observations of this object suggest that the linear polarization in the J-band is variable (Miles-Páez et al. 2014). If confirmed, it would be interesting to study the possible link between the photometric variability and the variations in linear polarization for J0241-0326.
## 5.2.2. G196-3B
The object G196-3B presents a clear peak at 433 days in both the Plavchan periodogram (433 GLYPH<6> 19 days; highest left panel of Fig. 4) and the LS periodogram (433 GLYPH<6> 100 days; second lower panel on the left). In the latter case, the peak is quite broad and slightly assymmetric, being a bit broader towards longer times. A similar peak is also observed in the CLEANed periodogram (516 GLYPH<6> 276 days; lowest left panel); however, the found peak in this case is remarkably broader (thus less reliable) than in the LS and Plavchan periodograms. The BLS periodogram (second upper left panel) does not display clear peaks, although a much less significant maximum is found around a similar value, 445 GLYPH<6> 12 days. This may be caused by the fact that the BLS algorithm is not well suited to detect sinusoidal variations. Contrary to J0241 GLYPH<0> 0326, all LS, Plavchan, and BLS periodograms of G 196 GLYPH<0> 3B provide the lowest p-values (computed for a total of 270 periods and di GLYPH<11> erent power distributions) with the peak at 433-445 days. Particularly, we determine the statistical significance level of the LS peak at 433 days to be 95%.
Aperiod peak value of 445 days is also found with the LS algorithm comparison stars (with errors of around 70 days). However, the 445 days period of the comparison stars is not confirmed by any of the other three algorithms. Moreover, the pvalues obtained for the 445 days peak in the LS periodograms of these stars, which were also computed for a total of 270 periods and the same power distributions as for the target, are two orders of magnitude higher than that of G 196 GLYPH<0> B ( p = 0.0017) and have less statistical significance ( < 50%). No peak around 430-450 days is seen in the LS periodograms of two of the three reference stars.
For G196-3B, all the phased light curves shown in the right panels of Fig. 4, which correspond to the most significant peak in each periodogram, look fairly sinusoidal, with peak-to-peak variations of 42 GLYPH<6> 10 mmag. The periodic variation is least evident in the CLEANed phase curve (lowest right panel of Fig. 4) compared to the other three, a reflection of the much more uncertain period value. However, without further observations, the detection of variability in G196-3B remains tentative.
Interestingly, the astrometric analysis of these same data suggested a periodic variation of 228.46 days for G196-3B, a value nearly one-half of the maximum peak value we find with the periodogram analysis (Zapatero Osorio et al. 2014). This could indicate that both values are harmonics of the same physical period, which may be related to an unsolved companion. However, we cannot rule out the possibility that the astrometric period is actually induced by the photometric variation (if confirmed).
## 6. Conclusions and final remarks
In this paper, we investigated the long-term KS -band photometric variability of a sample of ten field L-dwarfs. Our data covered a range of three years with a typical rate of one observation per month. We performed aperture photometry and computed differential photometry for our targets using three bright reference stars near each object, with typical photometric errors of GLYPH<6> 1530 mmag. We then performed a periodogram analysis using four di GLYPH<11> erent algorithms (Plavchan, BLS, LS, and CLEAN) to search or periodicity in our photometric data.
The rotation periodicity of our targets is not available in the literature. However, L dwarfs are known to be fast rotators with spectroscopic rotational velocities ranging from GLYPH<24> 10 through GLYPH<24> 90 kms GLYPH<0> 1 at nearly one-third of the break-up velocity (Konopacky et al. 2012, and references therein). By adopting a radius of 0.1-0.3 R GLYPH<12> , which is the size predicted for L-type sources with ages between 50 Myr and a few Gyr by evolutionary models (Chabrier et al. 2000), the expected rotation periods of our targets lie in the interval 1-35 h. Our data do not sample these short periods of time, rather they cover hundreds ( > 750) to tens of thousands of rotation loops. Part of the photometric Ks dispersion seen in the derived light curves may be due to observing the targets at di GLYPH<11> erent phases of their rotation loops. From the notorious stability of our data, we conclude that any longterm cycle or irregular variability with amplitudes > 90 mmag and timescales of 60-90 days through three years can be discarded with a confidence level of 99%. This implies that any weather phenomena and or magnetic activity present in these / dwarfs do not modify the objects' brightness at 2.2 GLYPH<22> m significantly over thousands of rotation cycles.
At a lower confidence level and smaller light curve amplitude, the periodogram analysis suggested that at least two objects in our sample display long-term periodic variability that might be associated with weather or magnetic cycles: In the case of J0241-0326, our results suggest periodic, brief increases of luminosity with a weighted mean period of 307 GLYPH<6> 21 days, at a confidence level of 40%, and peak-to-peak variations of 44 GLYPH<6> 10 mmag. However, because of the low number of observations for this target, this should be confirmed with an improved dataset. Interestingly though, our absolute Ks -band photometry for this object is 0.1 mag fainter than its 2MASS magnitude, suggesting variability at even longer scales than studied in this work. The object G196-3B, on the other hand, displays a fairly sinusoidal phased curve corresponding to a weighted mean period of 442 GLYPH<6> 7 days at a confidence level of 95%, and peak-to-peak variations of GLYPH<6> 10 mmag. This period value is nearly a factor of two the astrometric period found by Zapatero Osorio et al. (2014). However, we are cautious about this result, because a similar period is also suggested by the periodograms for the comparison stars, albeit with p-values a factor of 100 higher. It is also unclear which physical e GLYPH<11> ect could produce the observed variation (if confirmed) at such a long scale, although the fact that the found possible period is nearly twice the astrometric period reported by Zapatero Osorio et al. (2014) suggests that the astrometric period could be driven by the photometric variability. Hence, for both J0241-0326 and G196-3B, follow-up observations are required to confirm the possible variability suggested by the present work, and to study its physical origin.
Acknowledgements. We thank J. A. Caballero and P. Miles-Páez for useful discussions, and R. Hueso for providing information on the photometric variability of the giant planets in our Solar System. This research was funded by the Spanish Plan Nacional de Astronomía y Astrofísica through project AYA 2011-30147C03-03.
This publication makes use of data products from the Two Micron All Sky Survey (2MASS), which is a joint project of the University of Massachusetts and the Infrared Processing and Analysis Center California Institute of Technology, / funded by the US National Aeronautics and Space Administration and National Science Foundation.
This work benefitted from the use of the SIMBAD database and the Vizier Catalogue Service, both operated at the CDS (Strasbourg, France); and of NASA's Astrophysics Data System (ADS). We used the following Virtual Observatory tools: STILTS (Taylor 2006) and TOPCAT (Taylor 2005), both developed by Mark Taylor at Bristol University; and Aladin, developed at the CDS. We also used Starlink's PERIOD package, as well as the periodogram services from the NASA Exoplanet Archive, operated by the California Institute of Technology.
## References
| Allard, F., Hauschildt, P. H., Alexander, D. R., & Starrfield, S. 1997, ARA&A, 35, 137 Allen, P. R., Koerner, D. W., McElwain, M. W., Cruz, K. L., &Reid, I. N. 2007, AJ, 133, 971 Bailer-Jones, C. A. L. 2005, in ESA Special Publication, Vol. 560, 13th Cam- bridge Workshop on Cool Stars, Stellar Systems and the Sun, ed. F. Favata, G. A. J. Hussain, &B. Battrick, 429 Bartlett, J. L., Ianna, P. A., &Begam, M. C. 2009, PASP, 121, 365 E. &Arnouts, S. 1996, A&AS, 117, 393 A. J., Kirkpatrick, J. D., Reid, I. N., et al. 2000, AJ, 120, 473 |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bertin, Burgasser, Caballero, J. A., Béjar, V. J. S., Rebolo, R., & Zapatero Osorio, M. R. |
| A&A, 424, 857 |
| 2004, |
| Cruz, K. L., Kirkpatrick, J. D., &Burgasser, A. J. 2009, AJ, 137, 3345 Fletcher, L. N., Orton, G. S., Rogers, J. H., et al. 2011, Icarus, 213, 564 |
| Gelino, C. R., Marley, M. S., Holtzman, J. A., Ackerman, A. S., & Lodders, K. 2002, ApJ, 577, 433 |
| Goldman, B. 2005, Astronomische Nachrichten, 326, 1059 |
| Hallinan, G., Antonova, A., Doyle, J. G., et al. 2008, ApJ, 684, 644 Harding, L. K., Hallinan, G., Boyle, R. P., et al. 2013, ApJ, 779, |
| Heinze, A. N., Metchev, S., Apai, D., et al. 2013, ApJ, 767, 173 |
| 101 |
| Kirkpatrick, J. D. 2005, ARA&A, 43, 195 |
| Kirkpatrick, J. D., Reid, I. N., Liebert, J., et al. 1999, ApJ, |
| 519, 802 |
| Konopacky, Q. M., Ghez, A. M., Fabrycky, D. C., et al. 2012, ApJ, 750, 79 |
| Kovács, G., Zucker, S., &Mazeh, T. 2002, A&A, 391, 369 Lane, C., Hallinan, G., Zavala, R. T., et al. 2007, ApJ, 668, L163 |
| Littlefair, S. P., Dhillon, V. S., Marsh, T. R., et al. 2008, MNRAS, L88 |
| 391, Lockwood, G. W. &Jerzykiewicz, M. 2006, Icarus, 180, 442 |
| Lockwood, G. W., Ski GLYPH<11> , B. A., &Radick, R. R. 1997, ApJ, 485, 789 Martín, E. L., Delfosse, X., Basri, G., Goldman, B.and Forveille, |
| tero Osorio, M. R. 1999, AJ, 118, 2466 |
| T., & Zapa- Metchev, S., Apai, D., Radigan, J., et al. 2013, Astronomische Nachrichten, |
| 334, 40 Miles-Páez et al. 2014, in preparation |
| Mohanty, S., Basri, G., Shu, F., Allard, F., &Chabrier, G. 2002, ApJ, 571, Pérez-Hoyos, S., Sanz-Requena, J. F., Barrado-Izagirre, N., et al. 2012, |
| 469 217, 256 Plavchan, P., Jura, M., Kirkpatrick, J. D., Cutri, R. M., &Gallagher, S. C. |
| Icarus, ApJS, 175, 191 Radick, R. R., Lockwood, G. W., Ski GLYPH<11> , B. A., & Baliunas, S. L. 1998, |
| 2008, ApJS, 118, 239 |
| Roberts, D. H., Lehar, J., &Dreher, J. W. 1987, AJ, 93, 968 |
| Rogers, J. H. 2009, The Giant Planet Jupiter Route, M. &Wolszczan, A. 2012, ApJ, 747, L22 |
| Sánchez-Lavega, A. 1994, Chaos, 4, 341 Sánchez-Lavega, A., Colas, F., Lecacheux, J., et al. 397 Sánchez-Lavega, A., del Río-Gaztelurrutia, T., |
| 1991, Hueso, R., |
| Nature, et al. 475, 71 |
| 353, 2011, Nature, |
| Sánchez-Lavega, A. &Gómez, J. M. 1996, Icarus, 121, 1 Scargle, J. D. 1982, ApJ, 263, 835 |
| Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, |
| 131, 1163 Stellingwerf, R. F. 1978, ApJ, 224, 953 |
| Taylor, M. B. 2005, in Astronomical Society of the Pacific Se- |
| Conference ries, Vol. 347, Astronomical Data Analysis Software and Systems XIV, ed. P. Shopbell, M. Britton, &R. Ebert, 29 Taylor, M. B. 2006, in Astronomical Society of the Pacific Conference |
| ries, Vol. 351, Astronomical Data Analysis Software and Systems XV, C. Gabriel, C. Arviset, D. Ponz, &E. Solano, 666 |
| Se- V. G., Vdovichenko, V. D., Sinyaeva, N. V., et al. 1994, J. Geophys. |
| Tejfel, 99, 8411 |
| ed. Tsuji, T., Ohnaka, K., Aoki, W., &Nakajima, T. 1996, A&A, 308, L29 |
| Zapatero Osorio, M. R., Béjar, V. J. S., Goldman, B., et al. 2011, ApJ, 740, 4 |
| Zapatero Osorio, M. R., Béjar, V. J. S., Miles-Páez, P. A., et al. 2014, A&A, |
| press |
| Res., |
| in | | 10.1051/0004-6361/201424141 | [
"Belén López Martí",
"María Rosa Zapatero Osorio"
] | 2014-08-01T13:18:08+00:00 | 2014-08-01T13:18:08+00:00 | [
"astro-ph.SR"
] | Long-term K$_S$-band photometric monitoring of L dwarfs | (abridged) We perform photometric time-series analysis of a sample of ten
early to mid-L dwarfs in the field over three years of $K_s$-band observations
with the OMEGA 2000 infrared camera of the 3.5m telescope on Calar Alto
Observatory between January 2010 and December 2012. We perform $K_s$-band
differential photometry of our targets (with typical errors of $\pm$15-30~mmag
at the 1$\sigma$ level) by subtracting a reference flux from each photometric
measurement. This reference flux is computed using three nearby, probably
constant stars in the target's field-of-view. We then construct and visually
inspect the light curves to search for variability, and use four different
periodogram algorithms to look for possible periods in our photometric data.
Our targets do not display long-term variability over 1$\sigma$ compared to
other nearby stars of similar brightness, nor do the periodograms unveil any
possible periodicity for these objects, with two exceptions:
2MASS~J02411151-0326587 and G196-3B. In the case of 2MASS~J02411151-0326587
(L0), our data suggest a tentative period of 307$\pm$21~days, at 40% confidence
level, which seems to be associated with peak-to-peak variability of
44$\pm$10~mmag. This object may also display variability in timescales of
years, as suggested by the comparison of our Ks-band photometry with 2MASS. For
G196-3B (L3), we find peak-to-peak variations of 42$\pm$10~mmag, with a
possible photometric period of 442$\pm$7~days, at 95% confidence level. This is
roughly the double of the astrometric period reported by Zapatero Osorio
(2014). Given the significance of these results, further photometric data are
required to confirm the long-term variability.These results suggest that early-
to mid-L dwarfs are fairly stable in the $K_s$-band within $\pm$90 mmag at the
3 $\sigma$ level over months to years, which covers hundreds to tens of
thousands of rotation cycles. |
1408.0172v1 | ## Radiative and Seesaw Threshold Corrections to the S 3 Symmetric Neutrino Mass Matrix
Shivani Gupta a and C. S. Kim b
Department of Physics and IPAP, Yonsei University, Seoul 120-749, Korea
Pankaj Sharma c
Korea Institute of Advanced Study, Seoul 130-722, Korea
## Abstract
We systematically analyze the radiative corrections to the S 3 symmetric neutrino mass matrix at high energy scale, say the GUT scale, in the charged lepton basis. There are significant corrections to the neutrino parameters both in the Standard Model (SM) and Minimal Supersymmetric Standard Model (MSSM) with large tan β , when the renormalization group evolution (RGE) and seesaw threshold effects are taken into consideration. We find that in the SM all three mixing angles and atmospheric mass squared difference are simultaneously obtained in their current 3 σ ranges at the electroweak scale. However, the solar mass squared difference is found to be larger than its allowed 3 σ range at the low scale in this case. There are significant contributions to neutrino masses and mixing angles in the MSSM with large tan β from the RGEs even in the absence of seesaw threshold corrections. However, we find that the mass squared differences and the mixing angles are obtained in their current 3 σ ranges at low energy when the seesaw threshold effects are also taken into account in the MSSM with large tan β .
PACS numbers: 14.60.Pq, 14.60.St
a [email protected]
b [email protected]
c [email protected]
## I. INTRODUCTION
The neutrino oscillation experiments have enriched our knowledge of masses and mixings of neutrinos and thus flavor structure of leptons. These developments aspire theorists to construct models for unraveling the symmetries of lepton mass matrices. For three neutrino flavors the solar and atmospheric mass squared differences are given as, ∆ m 2 12 ≈ 10 -5 eV 2 and | ∆ m 13 | 2 ≈ 10 -3 eV , where ∆ 2 m 2 ij = m 2 j -m 2 i and m i,j are the mass eigenvalues of neutrinos, respectively. With the evidence of nonzero value of reactor mixing angle θ 13 [1] we now have information of all three mixing angles contrary to earlier studies where only an upper bound on θ 13 existed. The lepton flavor mixing matrix comprising of three mixing angles and a CP violating phase is given as
$$\Lambda \, = \, \left ( \begin{array} { c c c c } c _ { 1 2 } c _ { 1 3 } & s _ { 1 2 } c _ { 1 3 } & s _ { 1 3 } e ^ { - i \delta _ { C P } } \\ - s _ { 1 2 } c _ { 2 3 } - c _ { 1 2 } s _ { 2 3 } s _ { 1 3 } e ^ { i \delta _ { C P } } & c _ { 1 2 } c _ { 2 3 } - s _ { 1 2 } s _ { 2 3 } s _ { 1 3 } e ^ { i \delta _ { C P } } & s _ { 2 3 } c _ { 1 3 } \\ s _ { 1 2 } s _ { 2 3 } - c _ { 1 2 } c _ { 2 3 } s _ { 1 3 } e ^ { i \delta _ { C P } } & - c _ { 1 2 } s _ { 2 3 } - s _ { 1 2 } c _ { 2 3 } s _ { 1 3 } e ^ { i \delta _ { C P } } & c _ { 2 3 } c _ { 1 3 } \end{array} \right ) \,.$$
Here c ij = cos θ ij , s ij = sin θ ij ; θ ij are the three mixing angles, δ CP is the Dirac CP phase. There are two additional CP phases if neutrinos are Majorana particles. The best fit values along with their 3 σ ranges of neutrino oscillation parameters [2] are shown in Table I. Dirac phase δ CP , which contributes to CP violation in the leptonic sector, is expected to be measured in the long baseline neutrino oscillation experiments. The strength of this leptonic CP violation is parameterized by Jarlskog rephasing invariant [3] J = c 12 s 12 c 23 s 23 c 2 13 s 13 sin δ CP . The two Majorana phases, however, contribute to the lepton number violating processes like neutrinoless double beta decay. The possible measurement of effective Majorana mass in the current and upcoming experiments like GERDA, EXO, CUORE, MAJORANA, SuperNEMO [4] will provide some additional constraints on the two Majorana phases and neutrino mass scale. The cosmological constraint on the sum of neutrino masses by the Planck Collaboration [5] is Σ m ν i < 0.23 eV at 95% C.L.. Depending on the values chosen for the priors this sum can be in the range (0 23 . -0 933) eV. An additional bound from the Solar . Pole Telescope Collaboration [6] gives Σ m ν i = 0.32 ± 0.11 eV. However, these bounds are expected to be tested in forthcoming observations. There are some challenges left namely to determine the absolute mass scale, mass hierarchy of neutrinos and the CP violation in leptonic sector amongst others.
Evidence for nonzero θ 13 has lead to many studies for the deviation from the assumed
TABLE I. The experimental constraints on neutrino parameters taken from [2].
| Parameter | Best fit | 3 σ |
|-----------------------------------|------------|------------------|
| ∆ m 2 12 / 10 - 5 eV 2 (NH or IH) | 7.54 | 6.99 - 8.18 |
| ∆ m 2 13 / 10 - 3 eV 2 (NH) | 2.43 | 2.19 - 2.62 |
| θ 12 | 33.64 ◦ | 30.59 ◦ - 36.8 ◦ |
| θ 13 | 8.93 ◦ | 7.47 ◦ -10.19 ◦ |
| θ 23 | 37.34 ◦ | 35.1 ◦ - 52.95 ◦ |
symmetries that predict the vanishing θ 13 value. Among many possible discrete flavor symmetries to produce the current data, S 3 has been extensively studied in literature [7]. It is the smallest discrete non-Abelian group which is the permutation of three objects. Perturbations to S 3 symmetric leptonic mass matrices have been used to study the mass spectra of the leptons and predict well known democratic [8] and tri-bimaximal neutrino mixing scenario [9]. The effective light neutrino mass matrix, M , invariant under ν S 3 is given as
$$M _ { \nu } = p I + q D,$$
where
$$I = \left ( \begin{array} { c c c } 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right ), \quad D = \left ( \begin{array} { c c c } 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array} \right ).$$
Here D is democratic matrix, p and q are in general complex parameters. There are quite a few studies about the breaking of S 3 symmetry in the leptonic sector [10-12] to produce the current observed neutrino oscillation data. It will be interesting to study order of breaking in the S 3 symmetric neutrino mass matrix that arise due to the RGE and the seesaw threshold corrections between the GUT scale Λ g and the electroweak scale Λ ew in the SM and MSSM. In the light of non zero θ 13 our main aim is to study the viability of producing the current neutrino oscillation data at Λ ew scale in an S 3 symmetric neutrino mass matrix M ν at Λ g when both radiative and seesaw threshold corrections are taken into account.
Earlier studies have shown that there are significant RGE corrections to neutrino masses and mixing angles particularly for quasi-degenerate neutrino spectrum in the MSSM with large tan β . The SM is extended by three heavy right handed neutrinos at high energy scale to generate neutrino masses in Type I seesaw mechanism [13]. The seesaw threshold corrections arise due to subsequent decoupling of these heavy right handed Majorana neutrinos at their respective masses. The structure of the Dirac mass matrix M D is proportional to the neutrino Yukawa coupling matrix Y ν . We take a general Y ν and scan the parameter space to obtain the desired mixing pattern. The right handed Majorana mass matrix M is found by inverting the Type I seesaw formula at Λ . The charged lepton mass matrix g M l at Λ g is taken to be diagonal. We study the running behavior of neutrino masses and mixings from Λ g down to Λ ew using the RGE for the Yukawa couplings in the S 3 symmetric M ν both in the SM and MSSM. Above the heaviest seesaw scale ( M 3 ) there is a full theory and thus RGEs for Yukawa couplings Y e , Y ν and mass matrix M are considered. However, since our right handed neutrino mass matrix M is hierarchical ( M < M 1 2 < M 3 ), we also consider the seesaw threshold effects and thus the respective set of effective theories in between these scales, arising from the subsequent decoupling of heavy right handed fields at their respective masses. In the SM we find that the atmospheric mass squared difference (∆ m 2 13 ) along with the neutrino mixing angles are generated in their present 3 σ ranges at the low energy scale. However, the solar mass squared difference (∆ m 2 12 ) is greater than its allowed value ( ≈ 10 -4 ) in the SM. We find that it is possible to radiatively generate the current neutrino masses and mixing angles from the S 3 invariant neutrino mass matrix M ν in the charged lepton basis, when the seesaw threshold effects are taken into account in the MSSM with large tan β . In the MSSM with large tan β the solar mass squared difference ∆ m 2 12 can be produced in its current range along with the other neutrino oscillation parameters at Λ ew in the presence of these threshold corrections.
In section II we give the form of lepton mass matrices considered at Λ . In the subsequent g section, we give the RGE equations governing from Λ g to Λ ew , in presence of the seesaw threshold effects both in the SM and MSSM. In section IV we study the order of corrections to the neutrino mass matrix in the presence of seesaw threshold effects. Section V gives our numerical results for both cases under consideration. We conclude in the last section.
## II. FORM OF LEPTON MASS MATRICES AT THE GUT SCALE
We consider the basis where charged lepton mass matrix ( M l ) is diagonal and the effective light neutrino mass matrix ( M ν ) is S 3 symmetric as given in Eq. (2). The Yukawa coupling matrix for charged leptons is given as
$$Y _ { e } = \frac { 1 } { v } \left ( \begin{array} { c c c } m _ { e } & 0 & 0 \\ 0 & m _ { \mu } & 0 \\ 0 & 0 & m _ { \tau } \end{array} \right ),$$
where the Higgs vacuum expectation value (VEV) v is taken to be 246 GeV in the SM and 246 cos · β GeV in the MSSM. The Yukawa coupling matrix Y ν for the light neutrinos is taken of the form Y ν = y U D ν ν as given in [14] where D is the diagonal matrix Diag( r , r 1 2 , 1). The three parameters y ν , r 1 and r 2 are real, positive dimensionless parameters that characterize eigenvalues of Y ν . The unitary matrix U ν is the product of the three rotation matrices R 23 ( ϑ 2 ) · R 13 ( ϑ e 3 -iδ ) · R 12 ( ϑ 1 ) having one CP violating phase δ . Thus, Y ν has seven unknown parameters viz. three eigenvalues, three mixing angles and one CP phase. We vary the three hierarchy ( y ν , r 1 , r 2 ) parameters and, though they are completely arbitrary, but assumed to be < O (1). Three angles ϑ 1 , ϑ 2 , ϑ 3 and δ are varied in the range of (0-2 π ).
The right handed mass matrix M is found by inverting the Type I seesaw formula as
$$M = - Y _ { \nu } M _ { \nu } ^ { - 1 } Y _ { \nu } ^ { T },$$
i.e. M in our study is found from Y ν and the S 3 symmetric neutrino mass matrix M ν at Λ g by inverting seesaw formula. The three right handed neutrino masses M 1 , M 2 and M 3 are obtained by diagonalizing the right handed Majorana mass matrix M . The light neutrino mass matrix M ν can be diagonalized by the unitary transformation R as R M R T ν . One of the possible form of R can be
$$R = U _ { T B M } = \left ( \begin{array} { c c c } \frac { 2 } { \sqrt { 6 } } & \frac { 1 } { \sqrt { 3 } } & 0 \\ - \frac { 1 } { \sqrt { 6 } } & \frac { 1 } { \sqrt { 3 } } & - \frac { 1 } { \sqrt { 2 } } \\ - \frac { 1 } { \sqrt { 6 } } & \frac { 1 } { \sqrt { 3 } } & \frac { 1 } { \sqrt { 2 } } \end{array} \right ).$$
The mass eigenvalues of M ν are p , p +3 q and p : corresponding to the light neutrino masses m 1 , m 2 and m 3 , respectively. Due to the degeneracy in the mass eigenvalues m 1 and m 3 , the diagonalizing matrix R is not unique. Degeneracy of masses implies that R is arbitrary up to
orthogonal transformation R 13 ( φ ), where φ is in 1-3 plane. Thus, most general diagonalizing matrix R is U TBM R 13 ( φ ), which implies the same physics as U TBM . In this work we set φ =0 without loss of generality [10, 12]. From the neutrino oscillation data we know ∆ m 2 12 ≈ 10 -5 and thus, there is small difference in the mass eigenvalues m 1 and m 2 which is a possible objection to this scenario of S 3 invariant approximation as here m 1 and m 3 are degenerate. The possible solution to this problem is given in [10, 12] where the complex numbers p and p +3 q are considered to have same magnitude but different directions. As shown in [10], q can be chosen completely imaginary and p is taken to be | p e | -i α 2 . The magnitudes of p and q can be written in terms of parameter x as
$$| p | = x \ s e c \frac { \alpha } { 2 }, \\ | q | = \frac { 2 } { 3 } x \ t a n \frac { \alpha } { 2 },$$
where x is a real free parameter and allowed range of α is 0 ≤ α < π . The magnitude of p and p +3 q can be made equal by adjusting the phase α . The parameter x vanishes when α =180 ◦ and thus this value is disallowed. Substituting the values of p and q given in Eq. (7), the magnitudes of the mass eigenvalues are given as
$$| m _ { 1 } | = | m _ { 2 } | = | m _ { 3 } | = x \ s e c \frac { \alpha } { 2 }.$$
This results in equal magnitude of all three mass eigenvalues and thus a degenerate spectrum of neutrinos to begin with at Λ . g As pointed out earlier in [10] that the phase α affects the rate of neutrinoless double beta decay but will not affect neutrino oscillation parameters. Thus, this phase is of Majorana type. When we run these masses from Λ g to highest seesaw scale M 3 , the degeneracy of the mass eigenvalues is lifted by RGE corrections. We consider the normal hierarchical spectrum of masses where m 1 is the lowest mass. The other two masses are given as m 2 = √ m 2 1 +∆ m 2 12 and m 3 = √ m 2 1 +∆ m 2 13 . Since the three mass eigenvalues at Λ g have equal magnitude the two mass squared differences are vanishing to begin with. Once the degeneracy of three mass eigenvalues is lifted, their non zero values are generated. In subsequent sections we will explore the generation of the solar and atmospheric mass squared differences, together with the three mixing angles in their current 3 σ limit at Λ ew through the radiative corrections from S 3 invariant neutrino mass matrix at Λ . g
## III. RGE EQUATIONS WITH SEESAW THRESHOLD EFFECTS
In Type I seesaw the SM is extended by introducing three heavy right handed neutrinos and keeping the Lagrangian of electroweak interactions invariant under SU (2) L × U (1) Y gauge transformation. In this case, the leptonic Yukawa terms of the Lagrangian are written as
$$- \, \mathcal { L } _ { \nu } = \bar { l } _ { e } \phi Y _ { e } e _ { R } + \bar { l } _ { e } \tilde { \phi } Y _ { \nu } \nu _ { R } + \frac { 1 } { 2 } \bar { \nu } _ { R } ^ { c } M \nu _ { R } + h. c..$$
Here φ is the SM Higgs doublet and ˜ = φ iσ φ 2 ∗ . e R and ν R are right handed charged lepton and neutrino singlets, Y e and Y ν are the Yukawa coupling matrices for charged leptons and Dirac neutrinos, respectively. The last term of Eq. (9) is the Majorana mass term for the right handed neutrinos.
Quite intensive studies have been done in literatures [15, 16] regarding the general features of RGE of neutrino parameters. At the energy scale below seesaw threshold i.e. when all the heavy particles are integrated out, the RGE of neutrino masses and mixing angles is described by the effective theory which is same for various seesaw models. But above the seesaw scale full theory has to be considered and thus, there can be significant RGE effects due to the interplay of heavy and light sector. The RGE equations and subsequent decoupling of heavy fields at their respective scales are elegantly given in Refs. [17-19]. The comprehensive study of the RGE and seesaw threshold corrections to various mixing scenarios is recently done in [20].
The effective neutrino mass matrix M ν above M 3 is given as
$$M _ { \nu } ( \mu ) = - \frac { v ^ { 2 } } { 2 } Y _ { \nu } ^ { T } ( \mu ) M ^ { - 1 } ( \mu ) Y _ { \nu } ( \mu ),$$
where v = 246 sin · β GeV in the MSSM and µ is the renormalization scale. Y ν and M are µ dependent. Since we study the evolution of leptonic mixing parameters from Λ g to Λ ew scale in a generic seesaw model we need to take care of the series of effective theories that arise by subsequent decoupling of the heavy right handed fields M i ( i =1,2,3) at their respective mass thresholds. The Yukawa couplings Y ν and M are dependent on the energy scale Λ. At the GUT scale we consider the full theory and the one loop RGEs for Y e , Y ν and M are given as
$$\dot { Y } _ { e } = \frac { 1 } { 1 6 \pi ^ { 2 } } Y _ { e } \left [ \alpha _ { e } + C _ { 1 } H _ { e } + C _ { 2 } H _ { \nu } \right ],$$
$$\dot { Y } _ { \nu } & = \frac { 1 } { 1 6 \pi ^ { 2 } } Y _ { \nu } \left [ \alpha _ { \nu } + C _ { 3 } H _ { e } + C _ { 4 } H _ { \nu } \right ], \\ \dot { M } & = \frac { 1 } { 1 6 \pi ^ { 2 } } C _ { 5 } \left [ ( Y _ { \nu } Y _ { \nu } ^ { \dagger } ) M + M ( Y _ { \nu } Y _ { \nu } ^ { \dagger } ) ^ { T } \right ],$$
where ˙ Y i = dY i dt ( = i e, ν ), t= ln µ/µ ( 0 ) with µ µ ( 0 ) being the running (fixed) scale, and H i = Y † i Y i ( i = e, ν ). The coefficients are C 1 = 3 2 , C 2 = -3 2 , C 3 = -3 2 , C 4 = 3 2 , C 5 = 1 in the SM and C 1 = 3 , C 2 = 1 , C 3 = 1 , C 4 = 3 , C 5 = 2 in the MSSM, respectively. The expressions for α e and α ν in the SM and MSSM are explicitly given as
$$\text{nd} \, \alpha _ { \nu } \text{ in the SM and MSSM are explicitly given as} \\ \alpha _ { e ( S M ) } & = T r ( 3 H _ { u } + 3 H _ { d } + H _ { e } + H _ { \nu } ) - ( \frac { 9 } { 4 } g _ { 1 } ^ { 2 } + \frac { 9 } { 4 } g _ { 2 } ^ { 2 } ), \\ \alpha _ { \nu ( S M ) } & = T r ( 3 H _ { u } + 3 H _ { d } + H _ { e } + H _ { \nu } ) - ( \frac { 9 } { 2 0 } g _ { 1 } ^ { 2 } + \frac { 9 } { 4 } g _ { 2 } ^ { 2 } ), \\ \alpha _ { e ( M S S M ) } & = T r ( 3 H _ { d } + H _ { e } ) - ( \frac { 9 } { 5 } g _ { 1 } ^ { 2 } + 3 g _ { 2 } ^ { 2 } ), \\ \alpha _ { \nu ( M S S M ) } & = T r ( 3 H _ { u } + H _ { \nu } ) - ( \frac { 3 } { 5 } g _ { 1 } ^ { 2 } + 3 g _ { 2 } ^ { 2 } ), \\ \text{re} \, q _ { 1 } \, \text{ are the } U ( 1 ) _ { V } \text{ and } S U ( 2 ) _ { I } \text{ gauge coupling constants.}$$
where g 1 2 , are the U (1) Y and SU (2) L gauge coupling constants.
The heavy right handed mass matrix M obtained from Eq. (5) is non diagonal and thus is diagonalized by the unitary transformation U R as
$$U _ { R } ^ { T } M U _ { R } = D i a g ( M _ { 1 }, M _ { 2 }, M _ { 3 } ).$$
The Yukawa coupling Y ν is accordingly transformed as Y U ν ∗ R . At the highest seesaw scale M 3 , the effective operator κ (3) is given by the matching condition as
$$\kappa _ { ( 3 ) } = 2 Y _ { \nu } ^ { T } M _ { 3 } ^ { - 1 } Y _ { \nu },$$
in the basis where M is diagonal. The Yukawa coupling Y ν above is a 3 × 3 matrix and all the variables are set to the scale M 3 . At the scale lower than M 3 ( µ < M 3 ) the effective neutrino mass matrix M ν is given as
$$M _ { \nu } = - \frac { v ^ { 2 } } { 4 } \{ \kappa _ { ( 3 ) } + 2 Y _ { \nu ( 3 ) } ^ { T } M _ { ( 3 ) } ^ { - 1 } Y _ { \nu ( 3 ) } \}.$$
As can be seen that M ν is the sum of κ (3) given in Eq. (14) and the seesaw factor which is obtained after decoupling M 3 . Thus, Y ν (3) is 2 × 3 and M (3) is 2 × 2 mass matrices. RGE between the scale M 3 and M 2 is governed by the running of κ (3) , Y ν (3) and M (3) . The running of κ (3) is given as
$$\dot { \kappa } _ { ( 3 ) ( S M ) } = \frac { 1 } { 1 6 \pi ^ { 2 } } \left [ ( C _ { 3 } H _ { e } + C _ { 6 } H _ { \nu ( 3 ) } ) ^ { T } \kappa _ { ( 3 ) } + \kappa _ { ( 3 ) } ( C _ { 3 } H _ { e } + C _ { 6 } H _ { \nu ( 3 ) } ) + \alpha _ { ( 3 ) } \kappa _ { ( 3 ) } \right ], \quad ( 1 6 )$$
$$\dot { \kappa } _ { ( 3 ) ( M S S M ) } = \frac { 1 } { 1 6 \pi ^ { 2 } } \left [ ( H _ { e } + C _ { 6 } H _ { \nu ( 3 ) } ) ^ { T } \kappa _ { ( 3 ) } + \kappa _ { ( 3 ) } ( H _ { e } + C _ { 6 } H _ { \nu ( 3 ) } ) + \alpha _ { ( 3 ) } \kappa _ { ( 3 ) } \right ],$$
where C 6 = 1 2 and H ν (3) = Y † ν (3) Y ν (3) . α (3) in the SM and MSSM is explicitily given as
$$\alpha _ { ( 3 ) ( S M ) } & = 2 \ T r ( 3 H _ { d } + 3 H _ { u } + H _ { e } + H _ { \nu ( 3 ) } ) - 3 g _ { 2 } ^ { 2 } + \lambda, \\ \alpha _ { ( 3 ) ( M S S M ) } & = 2 \ T r ( 3 H _ { u } + H _ { \nu ( 3 ) } ) - \frac { 6 } { 5 } g _ { 1 } ^ { 2 } - 6 g _ { 2 } ^ { 2 }.$$
The effective operator κ (2) at M 2 is given by the matching condition as
$$\kappa _ { ( 2 ) } = \kappa _ { ( 3 ) } + 2 Y _ { \nu ( 2 ) } ^ { T } M _ { ( 2 ) } ^ { - 1 } Y _ { \nu ( 2 ) }.$$
where all the parameters are set to seesaw scale M 2 . M ν at the scale below M 2 has the RGE equation given in Eq. (16). In their RGE expression we have Y ν (2) which is 1 × 3 and M (2) which is 1 × 1. The low energy effective theory operator κ (1) is obtained after integrating out all three heavy right handed fields. The one loop RGE for κ (1) from lowest seesaw scale M 1 down to Λ e scale is given as
$$\dot { \kappa } _ { ( 1 ) } = ( C _ { 3 } H _ { e } ^ { T } ) \kappa _ { ( 1 ) } + \kappa _ { ( 1 ) } ( C _ { 3 } H _ { e } ) + \alpha \kappa _ { ( 1 ) },$$
where
$$\begin{matrix} 3 g _ { 2 } ^ { z } + \lambda & \text{in the SM} \\ \\ 2 & \text{in the MSSM}. \end{matrix}$$
$$\alpha = 2 \ T r ( 3 H _ { u } + 3 H _ { d } + H _ { e } ) - 3 g _ { 2 } ^ { 2 } + \lambda \ \text{ in the SM},$$
$$\alpha = 2 \ T r ( 3 H _ { u } ) - \frac { 6 } { 5 } g _ { 1 } ^ { 2 } - 6 g _ { 2 } ^ { 2 } \text{ in } t$$
When the Higgs field gets VEV, the light neutrino mass matrix is obtained from κ (1) as M ν = κ (1) v 2 4 . We diagonalize M ν to obtain neutrino masses, mixing angles and CP phases.
## IV. NEUTRINO MASSES AND MIXINGS
The RGE above the highest seesaw scale M 3 depends on more parameters than below the lowest seesaw scale M 1 due to presence of the neutrino Yukawa couplings ( Y ν ). The RGE equations consist of H e , M and H ν out of which latter can be large. In the basis where charged lepton mass matrix is diagonal, M ν at two different energy scales Λ ew and Λ g are homogeneously related as [18, 21, 22]
$$M _ { \nu } ^ { \Lambda _ { e w } } = I _ { K } \cdot I ^ { T } \cdot M _ { \nu } ^ { \Lambda _ { g } } \cdot I.$$
Here I K is flavor independent factor arising from gauge interactions and fermion antifermion loops. It does not influence the mixing angles. The matrix I has the form
$$I & = D i a g ( e ^ { - \Delta _ { e } }, e ^ { - \Delta _ { \mu } }, e ^ { - \Delta _ { \tau } } ), \\ & \succeq D i a g ( 1 - \Delta _ { e }, 1 - \Delta _ { \mu }, 1 - \Delta _ { \tau } ) + \mathcal { O } ( \Delta _ { e, \mu, \tau } ^ { 2 } ),$$
where
$$\Delta _ { j } = \frac { 1 } { 1 6 \pi ^ { 2 } } \int [ 3 ( H _ { j } ) - ( H _ { \nu _ { j } } ) ] d t,$$
where j = e, µ, τ . Numerically, ∆ SM τ can be of the order of 10 -3 when Y τ ∼ . 01 and Y ν = 0 2 and the scale . µ and µ 0 are 10 12 and 10 , 2 respectively. In the MSSM, ∆ MSSM τ ∼ 10 -3 (1 + tan 2 β ) for the same values of Y ν and Y τ . In the absence of seesaw threshold effects, ∆ τ is small ≈ 10 -5 in the SM for the above mentioned values of Y τ .
At above seesaw scale appreciable deviations may occur only for large values of Y τ or Y ν . In the absence of seesaw threshold effects i.e. when there is no H ν term in Eq. (22) the radiative corrections are governed by ∆ τ term as ∆ e,µ is too small. On the other hand, due to the presence of large H ν , the seesaw threshold effects play a crucial role in the running of mixing angles. Below the seesaw scales, deviations are obtained from Y τ ∼ √ 2 m /v τ ≈ O (10 -2 ) in the SM, and ∼ √ 2 m τ v cos β in the MSSM. There can be significant deviations in the MSSM with large tan β which enhances Y τ . In the presence of seesaw threshold, appreciable deviations are possible as it is natural to have Y ν ∼ O (1). The analytic expressions for the running neutrino mixing angles, masses and CP phases are quite long and have been earlier derived in literatures [19, 21, 23]. As shown earlier in [16, 24], the mass squared differences in the denominator of the RGEs play a significant role in the evolution of neutrino mixing angles and phases, if the left-handed neutrinos are nearly degenerate.
## V. NUMERICAL RESULTS AND DISCUSSIONS
At the GUT scale Λ g we have seven free parameters in Y ν and two free parameters α and x in M ν . The three mixing angles in ϑ 1 , ϑ 2 and ϑ 3 and phase δ are allowed to take the values in the range (0-2 π ). The hierarchy parameters y ν , r 1 , r 2 and x are randomly varied and are expected to be < O (1). The physical range of phase α is from (0π ). The mass spectrum at the high scale is degenerate and thus we have vanishing solar and atmospheric mass squared difference to begin with. The parameter space at the Λ g with which the low energy neutrino
TABLE II. Numerical values of input and output parameters that are radiatively generated via the RGE and seesaw threshold effects both in the SM and MSSM. The input parameters are taken at Λ g = 2 × 10 16 GeV and tan β =55 in the MSSM.
| Parameters | SM | MSSM |
|-------------------|----------------|-------------------|
| Input | | |
| r 1 | 7 × 10 - 3 | 3 × 10 - 4 |
| r 2 | 0.33 | 0.34 |
| δ | 158.1 ◦ | 96.3 ◦ |
| y ν | 0.72 | 0.49 |
| θ 1 | 225.2 ◦ | 188.5 ◦ |
| θ 2 | 244.6 ◦ | 245.8 ◦ |
| θ 3 | 345.5 ◦ | 241.7 ◦ |
| x ( eV ) | 7.46 × 10 - 2 | 1 . 9 × 10 - 3 |
| α | 102.5 ◦ | 170.2 ◦ |
| Output | | |
| m 1 ( eV ) | 9 . 4 × 10 - 2 | 1 . 47 × 10 - 2 |
| θ 12 | 34.3 ◦ | 35.2 ◦ |
| θ 13 | 7.88 ◦ | 9.85 ◦ |
| θ 23 | 47.7 ◦ | 47.4 ◦ |
| ∆ m 2 12 ( eV 2 ) | 4.18 × 10 - 4 | 7 . 14 × 10 - 5 |
| ∆ m 2 13 ( eV 2 ) | 2.48 × 10 - 3 | 2 . 35 × 10 - 3 |
| M 1 (GeV) | 3.1 × 10 5 | 2 . 86 × 10 3 |
| M 2 (GeV) | 4.43 × 10 8 | 9 × 10 8 |
| M 3 (GeV) | 2.83 × 10 9 | 4 . 7 × 10 9 |
| J | -2.99 × 10 - 2 | - 3 . 87 × 10 - 2 |
| | m ee | ( eV ) | 9.2 × 10 - 2 | 1 . 03 × 10 - 2 |
data is obtained at the Λ ew is illustrated in Table II. The set of input parameters in that particular parameter space are also given in the table. We choose the set of parameters in parameter space at the high scale for which maximum value of θ 13 is obtained and the other mixing angles and mass squared differences are simultaneously obtained in current 3 σ range at Λ ew . However, the parameter space under consideration is only for illustration and not unique. Search for complete parameter space is an elaborate study and thus independent future work.
## A. Radiative Threshold corrections in the SM
Study of radiative corrections to S 3 symmetric neutrino mass matrix can be divided into three regions that are governed by different RGE equations. The first region is above the highest seesaw scale M 3 to Λ , g where there can be considerable contribution of Y ν . The second region is the region between the three seesaw scales and the third is below the lowest seesaw scale M 1 , where all heavy fields are decoupled. The solar mixing angle θ 12 can have large RGE corrections as the running is enhanced by the factor proportional to m 2 ∆ m 2 12 at the leading order, which can be large for degenerate spectrum. The RGE is comparatively small for other two mixing angles θ 23 and θ 13 , where the RGE is proportional to m 2 ∆ m 2 13 . However, for the degenerate neutrino mass spectrum there can be considerable corrections for these mixing angles, too. Below the seesaw scale the RGE corrections to the mixing angles in the SM are negligible as they get contributions only from Y τ . In Fig 1, we show the RGE corrections to the mixing angles and masses in the SM for the set of input parameters given in second column of Table II. Fig. 1 shows that below M 1 scale there is no significant corrections to the mixing angles. Below the lowest seesaw scale the running of the mass eigenvalues is significant even in the SM for degenerate as well as hierarchical neutrinos [16] due to the factor α given in Eq. (19), which is much larger than Y 2 τ . The running of masses is given by a common scaling of the mass eigenvalues [25]. Clearly, the RGE of each mass eigenvalue is proportional to the mass eigenvalue itself. The running of masses in Fig. 1 can be seen to start from the degenerate values of masses at Λ g and there are significant corrections to the masses below M 1 . Earlier analyses [24] studied the successful generation of mass squared differences and mixing angles for degenerate neutrinos in the SM. In their analysis it is shown that the generation of mass squared differences is very sensitive
to the value of sin 2 θ 12 , which should be greater than 0.99 to fit the mass squared differences simultaneously with the consistent angles. This limit is, however, completely ruled out by the current oscillation data. The degeneracy of three mass eigenvalues is lifted by the RGE running from Λ g to M 3 . Potentially significant breaking of neutrino mass degeneracy is provided by the RGE effects. The seesaw threshold effects in addition increase the mass splitting between the masses m 2 and m 3 required to fit the masses with the current data in
50
0.12
40
30
20
10
0
0.115
0.11
0.105
0.1
0.095
0.09
(deg)
ij
θ
0
2
4
6
8
10
θ
θ
θ
12
14
16
0
2
4
6
8
Log10(
µ
/GeV)
Log10(
µ
10
/GeV)
FIG. 1. The RGE of the mixing angles, masses and mass squared differences between the GUT scale Λ g and the electroweak scale Λ ew in the SM. The initial values of the parameters are given in the second column of Table II. The boundaries of three grey shaded areas, i.e. dark, medium and light denote the points when heavy right handed singlets M 3 , M 2 and M 1 are integrated out respectively.
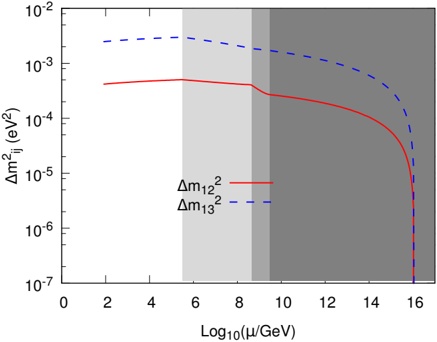
13
23
12
mi (eV)
12
m1
m3
m2
14
16
terms of mass squared differences.
Running between and above the seesaw scales is modified by the contribution of Yukawa couplings Y ν . The contribution of Y ν in the RGE can result all the three mixing angles in their current allowed ranges at the EW scale in the SM. Thus, there are significant corrections to mixing angles even in the SM in the presence of the seesaw threshold effects when there is exactly the degenerate mass spectrum to begin with. As can be seen from Fig. 1, the mixing angles at the GUT scale are θ 23 = 45 , ◦ θ 12 = 35 3 . ◦ and θ 13 = 0 . For the set of ◦ parameters given in the second column of Table II we get the mixing angles in the allowed range at the electroweak scale in the SM. θ 23 is found to have values below maximality. The presence of seesaw threshold corrections and thus Y ν in the RGE equations make this possible even in the SM, as can be seen in Fig. 1. The grey shaded area in Fig. 1 and Fig. 2 illustrates the ranges of effective theories that emerge when we integrate out heavy right handed singlets. At each seesaw scales, i.e. M 1 , M 2 and M 3 , one heavy singlet is integrated out and thus (n-1) × 3 sub-matrix of Y ν remains. Therefore, the running behavior between these scales can be different from running behavior below or above these scales. Between these scales the neutrino mass matrix comprises of two terms κ ( n ) and 2 Y T ν n ( ) M -1 R n ( ) Y ν n ( ) , as given in Eq. (15). It is shown in [16] that in the SM these two terms between the thresholds are quite different which can give dominant contribution to the running of mixing angles in this region. Both θ 12 and θ 13 in Fig. 1 get large corrections between three seesaw scales. θ 23 gets the deviation of ≈ 2.7 ◦ in the upper direction.
Three neutrino mixing angles can be generated in their current allowed ranges starting from S 3 symmetric neutrino mass matrix at the Λ g in the SM as there can be large corrections when we consider the seesaw threshold effects. In the SM, atmospheric mass squared difference ∆ m 2 13 is generated within the current oscillation data limit ( ≈ 2 48 . × 10 -3 ) starting from the vanishing value at the Λ g since all masses are degenerate, as seen from Fig. 1. The solar mass squared difference ∆ m 2 12 of the order of ≈ 10 -4 eV 2 is simultaneously generated at the Λ ew , as shown in Fig.1 which is larger than its present value. The byproduct of this analysis is the masses of right-handed neutrinos that are determined from Eqs. (5) and (13) and are not free parameters. The values of effective Majorana mass | M ee | and Jarlskog rephasing invariant ( J ) at the Λ ew are also calculated for particular set of parameters given in Table II. We conclude that in the SM the RGE in addition to seesaw threshold effects cannot simultaneously produce the solar mass squared difference in its allowed range at low
scale along with the other neutrino oscillation parameters.
## B. Radiative Threshold corrections in the MSSM
As stated earlier we divide the radiative corrections to S 3 symmetric neutrino mass matrix into three regions governed by different RGE equations in the MSSM. In the region below
FIG. 2. The RGE of the mixing angles, masses and mass squared differences between the GUT scale Λ g and the electroweak scale Λ ew in the MSSM with tan β =55. The initial values of the parameters are given in the third column of Table II. The boundaries of three grey shaded areas, i.e. dark, medium and light denote the points when heavy right handed singlets M 3 , M 2 and M 1 are integrated out respectively.
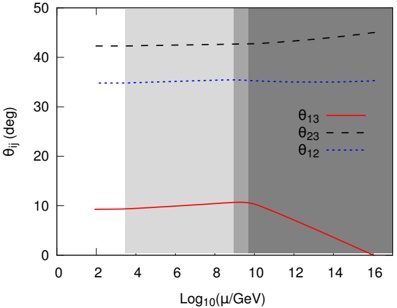
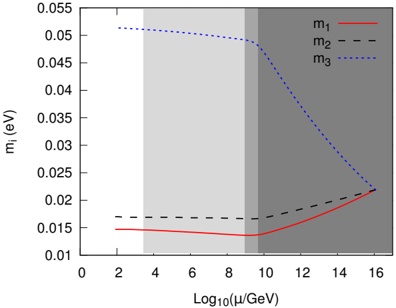
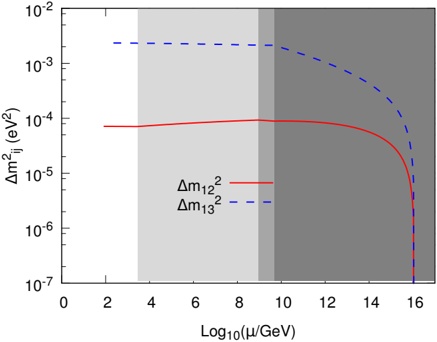
the lightest seesaw scale, for the SM and MSSM with small tan β , Yukawa coupling Y τ ∼ 0.01 is small, and thus there cannot be large RGE corrections in these cases. For large tan β these corrections can be larger due to the presence of factor Y 2 τ (1+tan 2 β ) in the MSSM. We show the RGE of mixing angles and masses in the MSSM with tan β =55 in Fig. 2 for the set of input parameters given in third column of Table II. In the region above the energy scale M 1 , we get contributions from another Yukawa coupling Y ν which brings in more free parameters in the analysis. In the region for the MSSM with large tan β the presence of seesaw threshold effects can enhance the RGE of the mixing angles significantly. As can be seen from Fig. 2, we can have all three mixing angles simultaneously in the current limit at the EW scale starting from S 3 symmetric neutrino mass matrix at the Λ . g Fig. 2 shows that there are large corrections to θ 13 ( ∼ 9.85 ) between the Λ ◦ g and M 3 scale due to the presence of Y ν . As mentioned earlier, the running of neutrino mass matrix between the seesaw thresholds gets contributions from two terms κ ( n ) and 2 Y T ν n ( ) M -1 R n ( ) Y ν n ( ) given in Eq. (15). As shown in the SM, these two terms are different and thus results in the enhanced running between the different energy regimes. On the other hand, in the MSSM, as can be seen from Fig. 2, there are not much deviations in the mixing angles between the energy scales. It is because in the MSSM the two contributions are almost identical and thus cancel each other resulting in minimum deviation in those regions. The only significant corrections occurs in the region above the highest seesaw scale M 3 due to relatively large Y ν .
The mixing angle θ 12 does not have much corrections and θ 23 receives the correction of 2.5 ◦ in the upper direction and is thus above maximal. The running of masses in the MSSM (Fig. 2) is much larger than the SM due to the presence of tan β which in our case is large. The dominant effect, however, is the corrections in the range M 3 ≤ µ ≤ Λ g where the flavor dependent terms ( Y l and Y ν ) can be large. The interesting dependence of α ν (MSSM) and tan β on the running contributions of flavor dependent terms is given in [16]. For large tan β the contribution of Y e and Y ν become important. We also show the radiative corrections to the solar and atmospheric mass squared difference from the Λ g to the Λ ew for degenerate masses at the GUT scale in the MSSM with tan β =55. To begin with both the mass squared differences are zero at the GUT scale. From the mass squared differences shown in Fig 2, we see that the RGE in combination with seesaw threshold corrections can result both mass squared differences in their current 3 σ ranges at the low scale. The hierarchy parameters y ν , r 1 and r 2 though arbitrary but are found to be < O (1). For given set of input parameters
in Table II, the value of effective Majorana mass | M ee | is ≈ 10 -2 eV and that of J is ≈ 3.87 × 10 -2 . Thus, we find that it is possible to simultaneously obtain the neutrino oscillation parameters at the electroweak scale for S 3 mass matrix at the Λ g in the MSSM with large tan β .
## VI. CONCLUSIONS
We studied the RGE corrections to the S 3 symmetric neutrino mass matrix in the presence of seesaw threshold corrections both in the SM and MSSM. In the absence of seesaw threshold effects there are negligible corrections to the mixing angles in the SM and MSSM with low tan β . However, large corrections are possible in neutrino parameters once the seesaw threshold effects are taken into consideration both in the SM and MSSM. Above all seesaw scales there is the contribution of the Yukawa coupling, Y ν in addition to Y l and thus the RGE depends on more parameters than below the seesaw scales. Thus, we can say the corrections depend on the form of Y ν which has free parameters. In the SM we found that the mixing angles can be obtained in their current 3 σ range at the electroweak scale when we begin with S 3 neutrino mass matrix at the GUT scale Λ . The significant running occurs g between and above the seesaw threshold scales. Below the lowest seesaw scale there are no significant corrections as the only contribution comes from Y τ which is small. However, in this case of exactly equal magnitude of mass eigenvalues, the two mass squared difference are not simultaneously generated in the current range at the electroweak scale. The solar mass squared difference is found to be large ( O (10 -4 )) in comparison to its allowed value at the electroweak scale.
There can be large radiative corrections in the MSSM with tan β =55 when threshold effects are taken into consideration. The large corrections to the mixing angles occur at the scale above the seesaw threshold where the Yukawa coupling, Y ν , is present and has large free parameters which can enhance running for large tan β . All the mixing angles and the mass squared differences are obtained in their current 3 σ range at the low scale in this case. The free input parameters y ν , r 1 and r 2 are expected to be small < O (1). Thus, for the SM it is not possible to radiatively generate the solar mass squared difference at the electroweak scale in its current range. In the MSSM with large tan β we can generate all the masses and mixing angles in the current allowed range at the electroweak scale, starting from exactly
degenerate mass spectrum at the GUT scale.
## VII. ACKNOWLEDGEMENTS
The work of C. S. K and S. G. is supported by the National Research Foundation of Korea (NRF) grant funded by Korea government of the Ministry of Education, Science and Technology (MEST) (Grant No. 2011-0017430) and (Grant No. 2011-0020333).
- [1] K. Abe et al. [T2K Collaboration], Phys. Rev. Lett. 107 , 041801 (2011) [arXiv:1106.2822 [hepex]]; Y. Abe et al. [DOUBLE-CHOOZ Collaboration], Phys. Rev. Lett. 108 , 131801 (2012) [arXiv:1112.6353 [hep-ex]]; F. P. An et al. [DAYA-BAY Collaboration], Phys. Rev. Lett. 108 , 171803 (2012) [arXiv:1203.1669 [hep-ex]]; J. K. Ahn et al. [RENO Collaboration], Phys. Rev. Lett. 108 , 191802 (2012) [arXiv:1204.0626 [hep-ex]].
- [2] G. L. Fogli, E. Lisi, A. Marrone, D. Montanino, A. Palazzo and A. M. Rotunno, Phys. Rev. D 86 (2012) 013012 [ arXiv:hep-ph/1205.5254 ].
- [3] C. Jarlskog, Phys. Rev. Lett. 55 , 1039 (1985).
- [4] A. A. Smolnikov [GERDA Collaboration], arXiv: 0812.4194 [nucl-ex]; M. Auger et al. [EXO Collaboration], Phys. Rev. Lett. 109 , 032505 (2012); http://www.mpi-hd.mpg.de/gerda/; P. Gorla et al. [CUORE Collaboration], J. Phys. Conf. Ser. 375 , 042013 (2012) ; Wilkerson J. F et al. [MAJORANA Collaboration], J. Phys. Conf. Ser. 375 , 042010 (2012); Barabash A. S et al. [SuperNEMO Collaboration], J. Phys. Conf. Ser. 375 , 04201 (2012).
- [5] P. A. R. Ade et al. [Planck Collaboration], Planck 2013 results. XVI. Cosmological parameters , [ arXiv:astro-ph.CO/1303.5076 ].
- [6] Z. Hou, C. L. Reichardt, K. T. Story, B. Follin, R. Keisler et al. , arXiv:1212.6267 [astroph.CO].
- [7] S. Pakwasa, H. Sugawara, Phys. Lett. B 73 , 61 (1978); E. Derman, Phys. Rev. D 19, 317 (1979); E. Ma, Phys. Rev. D 61 , 033012 (2000) [hep-ph/9909249]; M. Tanimoto, Phys. Lett. B 483 , 417 (2000) [hep-ph/0001306]; P. F. Harrison and W. G. Scott, Phys. Lett. B 557 , 76 (2003) [hep-ph/0302025]; S. -L. Chen, M. Frigerio and E. Ma, Phys. Rev. D 70 , 073008 (2004) [Erratum-ibid. D 70 , 079905 (2004)] [hep-ph/0404084]; F. Caravaglios and S. Morisi,
hep-ph/0503234; W. Grimus and L. Lavoura, JHEP 0508 , 013 (2005) [hep-ph/0504153]; R. N. Mohapatra, S. Nasri and H. -B. Yu, Phys. Lett. B 639 , 318 (2006) [hep-ph/0605020]; N. Haba and K. Yoshioka, Nucl. Phys. B 739 , 254 (2006) [hep-ph/0511108]; Y. Koide, Eur. Phys. J. C 50 , 809 (2007) [hep-ph/0612058]; C. -Y. Chen and L. Wolfenstein, Phys. Rev. D 77 , 093009 (2008) [arXiv:0709.3767 [hep-ph]]; F. Feruglio and Y. Lin, Nucl. Phys. B 800 , 77 (2008) [arXiv:0712.1528 [hep-ph]]; Y. H. Ahn, S. K. Kang, C. S. Kim and T. P. Nguyen, Phys. Rev. D 82 , 093005 (2010) [arXiv:1004.3469 [hep-ph]]; D. A. Dicus, S. -F. Ge and W. W. Repko, Phys. Rev. D 82 , 033005 (2010) [arXiv:1004.3266 [hep-ph]]; Z. -z. Xing, D. Yang and S. Zhou, Phys. Lett. B 690 , 304 (2010) [arXiv:1004.4234 [hep-ph]]; D. Meloni, S. Morisi and E. Peinado, J. Phys. G 38 , 015003 (2011) [arXiv:1005.3482 [hep-ph]]; R. Jora, J. Schechter and M. N. Shahid, Phys. Rev. D 82 , 053006 (2010) [arXiv:1006.3307 [hep-ph]].
- [8] H. Fritzsch and Z. -Z. Xing, Phys. Lett. B 372 , 265 (1996) [hep-ph/9509389]; M. Fukugita, M. Tanimoto and T. Yanagida, Phys. Rev. D 57 , 4429 (1998) [hep-ph/9709388]; H. Fritzsch and Z. -z. Xing, Phys. Rev. D 61 , 073016 (2000) [hep-ph/9909304].
- [9] P. F. Harrison and W. G. Scott, Phys. Lett. B 535 , 163 (2002) [hep-ph/0203209]; P. F. Harrison and W. G. Scott, Phys. Lett. B 557 , 76 (2003) [hep-ph/0302025]; X. -G. He and A. Zee, Phys. Rev. D 68 , 037302 (2003) [hep-ph/0302201]; Prog. Theor. Phys. 109 , 795 (2003) [Erratumibid. 114 , 287 (2005)] [hep-ph/0302196].
- [10] S. Dev, S. Gupta and R. R. Gautam, Phys. Lett. B 702 , 28 (2011) [arXiv:1106.3873 [hep-ph]]; S. Dev, R. R. Gautam and L. Singh, Phys. Lett. B 708 , 284 (2012) [arXiv:1201.3755 [hep-ph]]. [11] S. Zhou, Phys. Lett. B 704 , 291 (2011) [arXiv:1106.4808 [hep-ph]].
- [12] R. Jora, S. Nasri and J. Schechter, Int. J. Mod. Phys. A 21 , 5875 (2006) [hep-ph/0605069]; R. Jora, J. Schechter and M. Naeem Shahid, Phys. Rev. D 80 , 093007 (2009) [Erratum-ibid. D 82 , 079902 (2010)] [arXiv:0909.4414 [hep-ph]]; R. Jora, J. Schechter and M. N. Shahid, Int. J. Mod. Phys. A 28 , 1350028 (2013) [arXiv:1210.6755 [hep-ph]].
- [13] P. Minkowski, Phys. Lett. B 67 , 421 (1977); T. Yanagida, (O.Sawada and A. Sugamoto, eds.), KEK, Tsukuba, Japan, 1979, p. 95; M. Gell-Mann, P. Ramond, and R. Slansky, (P. Van Nieuwenhuizen and D. Z. Freedman, eds.), North Holland, Amsterdam, 1979, p.315; R. N. Mohapatra and G. Senjanovic Phys. Rev. Lett. 44 , 912 (1980).
- [14] J. -w. Mei and Z. -z. Xing, Phys. Rev. D 70 , 053002 (2004) [hep-ph/0404081].
- [15] K. S. Babu, C. N. Leung and J. T. Pantaleone, Phys. Lett. B 319 , 191 (1993) [arXiv:9309223 [hep-ph]]; S. Antusch, M. Drees, J. Kersten, M. Lindner and M. Ratz, Phys. Lett. B 519 , 238 (2001) [hep-ph/0108005]; S. Antusch, M. Drees, J. Kersten, M. Lindner and M. Ratz, Phys. Lett. B 525 , 130 (2002) [hep-ph/0110366]; S. Antusch, J. Kersten, M. Lindner and M. Ratz, Phys. Lett. B 538 , 87 (2002) [hep-ph/0203233]; A. S. Joshipura, S. D. Rindani and N. N. Singh, Nucl. Phys. B 660 , 362 (2003) [hep-ph/0211378]; T. Ohlsson, H. Zhang and S. Zhou, Phys. Rev. D 87 , 013012 (2013) [arXiv:1211.3153 [hep-ph]].
- [16] S. Antusch, J. Kersten, M. Lindner and M. Ratz, Nucl. Phys. B 674 , 401 (2003) [hepph/0305273].
- [17] P. H. Chankowski and Z. Pluciennik, Phys. Lett. B 316 , 312 (1993) [hep-ph/9306333]; S. Antusch, J. Kersten, M. Lindner, M. Ratz and M. A. Schmidt, JHEP 0503 , 024 (2005) [hepph/0501272]; T. Ohlsson and S. Zhou, arXiv:1311.3846 [hep-ph].
- [18] J. R. Ellis and S. Lola, Phys. Lett. B 458 , 310 (1999) [hep-ph/9904279].
- [19] J. -w. Mei, Phys. Rev. D 71 , 073012 (2005) [hep-ph/0502015].
- [20] S. Gupta, S. K. Kang and C. S. Kim, arXiv:1406.7476 [hep-ph].
- [21] S. Goswami, S. Khan and S. Mishra, arXiv:1310.1468 [hep-ph].
- [22] A. Dighe, S. Goswami and W. Rodejohann, Phys. Rev. D 75 , 073023 (2007) [hep-ph/0612328]; A. Dighe, S. Goswami and P. Roy, Phys. Rev. D 76 , 096005 (2007) [arXiv:0704.3735 [hep-ph]].
- [23] J. Bergstrom, M. Malinsky, T. Ohlsson and H. Zhang, Phys. Rev. D 81 , 116006 (2010) [arXiv:1004.4628 [hep-ph]]; J. Bergstrom, T. Ohlsson and H. Zhang, Phys. Lett. B 698 , 297 (2011) [arXiv:1009.2762 [hep-ph]].
- [24] J. A. Casas, J. R. Espinosa, A. Ibarra and I. Navarro, Nucl. Phys. B 556 , 3 (1999) [hepph/9904395]; J. A. Casas, J. R. Espinosa, A. Ibarra and I. Navarro, Nucl. Phys. B 569 , 82 (2000) [hep-ph/9905381].
- [25] P. H. Chankowski and S. Pokorski, Int. J. Mod. Phys. A 17 , 575 (2002) [hep-ph/0110249]. | 10.1016/j.physletb.2014.12.005 | [
"Shivani Gupta",
"C. S. Kim",
"Pankaj Sharma"
] | 2014-08-01T13:23:26+00:00 | 2014-08-01T13:23:26+00:00 | [
"hep-ph"
] | Radiative and Seesaw Threshold Corrections to the $S_3$ Symmetric Neutrino Mass Matrix | We systematically analyze the radiative corrections to the $S_3$ symmetric
neutrino mass matrix at high energy scale, say the GUT scale, in the charged
lepton basis. There are significant corrections to the neutrino parameters both
in the Standard Model (SM) and Minimal Supersymmetric Standard Model (MSSM)
with large tan$\beta$, when the renormalization group evolution (RGE) and
seesaw threshold effects are taken into consideration. We find that in the SM
all three mixing angles and atmospheric mass squared difference are
simultaneously obtained in their current 3$\sigma$ ranges at the electroweak
scale. However, the solar mass squared difference is found to be larger than
its allowed 3$\sigma$ range at the low scale in this case. There are
significant contributions to neutrino masses and mixing angles in the MSSM with
large tan$\beta$ from the RGEs even in the absence of seesaw threshold
corrections. However, we find that the mass squared differences and the mixing
angles are obtained in their current 3$\sigma$ ranges at low energy when the
seesaw threshold effects are also taken into account in the MSSM with large
tan$\beta$. |
1408.0173v2 | ## Variational Depth from Focus Reconstruction
Michael Moeller, Martin Benning, Carola Sch¨nlieb, Daniel Cremers o ∗
November 6, 2014
## Abstract
This paper deals with the problem of reconstructing a depth map from a sequence of differently focused images, also known as depth from focus or shape from focus . We propose to state the depth from focus problem as a variational problem including a smooth but nonconvex data fidelity term, and a convex nonsmooth regularization, which makes the method robust to noise and leads to more realistic depth maps. Additionally, we propose to solve the nonconvex minimization problem with a linearized alternating directions method of multipliers (ADMM), allowing to minimize the energy very efficiently. A numerical comparison to classical methods on simulated as well as on real data is presented.
## 1 Introduction
The basic idea for depth from focus (DFF) approaches is to assume that the distance of an object to the camera at a certain pixel corresponds to the focal setting at which the pixel is maximally sharp. Thus, for a given data set of differently focused images, one typically first finds a suitable contrast measure at each pixel. Subsequently, the depth at each pixel is determined by finding the focal distance at which the contrast measure is maximal. Figure 1 illustrates this approach. DFF differs from depth from defocus (cf. [1-3]) in the sense that many images are given and depth clues are obtained from the sharpness at each pixel. Depth from defocus on the other hand tries to estimate the variance of a spatially varying blur based on a physical model and uses only very few images. Generally, the measurements of differently focused images do not necessarily determine the depth of a scene uniquely, such that the estimation of a depth map is an ill-posed problem. The ambiguity of the depth map is particularly strong in textureless areas.
The literature dealing with the shape from focus problem has very different contributions. A lot of work has targeted the development of different measures for sharpness and focus (cf. [4] for an overview). Other works deal with different methods of filtering the contrast coefficients before determining the maximum, i.e. the depth. The ideas range from windowed averaging (e.g. [5]), over differently shaped kernels, to nonlinear filtering as proposed in [6]. In [7,8], the authors proposed to detect regions with a high variance in the depth map and suggested to smooth the depth in these parts by interpolation. Pertuz, Puig, and Garcia analyzed the behavior of the contrast curve in order to identify and remove low-reliability regions of the depth map in [9]. Ideas for using different focus measures and fusing the resulting depth estimates in a variational approach using the total variation (TV) regularization have been proposed in [10]. However, very little work has been done on finding a noisefree depth map in a single variational framework.
Formulating the shape from focus problem in a variational framework has the advantage that one clearly defines a cost function and tries to find a solution which is optimal with respect to the costs. More importantly, regularity can be imposed on the depth estimate itself, e.g. by favoring piecewise constant solutions. Additionally, our framework is robust to noise and controls the ill-posedness of the shape from focus problem.
∗ M.M. (corresponding author, email [email protected]) is with the Department of Mathematics, Technische Universit¨t M¨nchen, Boltzmannstrasse 3, 85748 Garching. M.B. is with the Institute of Mathematics and Image Computing (MIC), a u Universit¨t zu L¨beck, Maria-Goeppert-Str. 3, 23562 L¨beck, Germany. C.S. is with the Department of Applied Mathematics a u u and Theoretical Physics, Centre for Mathematical Sciences, Wilberforce Road, Cambridge, CB3 0WA, United Kingdom. D.C. are with the Department of Computer Science, Technische Universit¨t M¨nchen, Boltzmannstrasse 3, 85748 Garching. a u


- (a) Visualization of the data as a cube.
(b) Depth map reconstruction by finding the maximal contrast.
Figure 1: Example of a simple DFF reconstruction: The data set of images can be visualized as a data cube (a), where the z-direction corresponds to a change of focus from the front to the back. In order to determine the focal setting at which the contrast is maximal, one picks a contrast measure, applies a windowed filtering to the contrast coefficients and selects the focal setting for which the coefficients are maximal. By knowing the distance at which a region appears maximally sharp in a focal setting, one reconstructs the depth. Figure (b) shows an example of the depth map, where red values indicate being far away from the camera and blue values correspond to pixels close to the camera. The result was obtained by using the modified Laplacian contrast measure with 9 × 9 windowed filtering as used in the comparison in [4].
While variational methods belong to the most successful class of methods for general image reconstruction tasks and have successfully been used in several depth from defocus approaches (c.f. [3, 11-13]), very little work has been done on using them for the DFF problem. The only work the authors are aware of is the method proposed in [14], where the framework of Markov random fields was used to derive an energy minimization method consisting of two truncated quadratic functionals. However, using two nonconvex functionals in a setting where the dependency of the depth on the contrast is already nonconvex, results in a great risk of only finding poor local minima. For instance, any initialization with pixels belonging to both truncated parts is a critical point of such an approach.
This paper has two contributions: First, we propose a variational framework for the shape from focus problem using the total variation (TV) regularization [15]. Secondly, we discuss the problem of minimizing the resulting nonconvex energy efficiently. While schemes that can guarantee the convergence to critical points are computationally expensive, we propose to tackle the minimization problem by an alternating minimization method of multipliers (ADMM) with an additional linearization of the nonconvex part.
## 2 A Variational Approach
## 2.1 Proposed Energy
We propose to define a functional E : R n × m → R that maps a depth map d ∈ R n × m to an energy, where a low energy corresponds to a good depth estimate. The dimension of the depth map, n × m , coincides with the dimension of each image. The energy consists of two terms, E = D + αR . The data fidelity term D takes the dependence on the measured data into account and the regularization term R imposes the desired smoothness. The parameter α determines the trade-off between regularity and fidelity. We find the final depth estimate as the argument that minimizes our energy:
$$\hat { d } = \arg \min _ { d } D ( d ) + \alpha R ( d ).$$
Typical approaches from literature find the depth estimate by maximizing some contrast measure and we refer the reader to [4] for an overview of different contrast measures and their performance. Since we want to reconstruct the depth map by an energy minimization problem (rather than maximization) it seems natural to choose the negative contrast at each pixel as the data fidelity term,
$$D ( d ) = - \sum _ { i } \sum _ { j } c _ { i, j } ( d _ { i, j } ),$$
where c i,j denotes the (precomputed) function that maps a depth at pixel ( i, j ) to the corresponding contrast value. With this choice our method is a generalization of methods that maximize the contrast at each pixel separately, since they are recovered by choosing α = 0.
The regularization term R imposes some smoothness on the recovered depth map and should therefore depend on the prior knowledge we have about the expected depth maps. In this paper we use the discrete isotropic TV, R d ( ) = ‖ Kd ‖ 2 1 , , where K is the linear operator such that Kd is a matrix with an approximation to the x -derivative in the first column, to the y -derivative in the second column, and ‖ g ‖ 2 1 , := ∑ √ ∑ i j ( g i,j ) 2 .
## 2.2 Contrast Measure
In this work, we choose the well-known modified Laplacian (MLAP) function [16] as a measure of contrast. Note that under good imaging conditions the thorough study in [4] found that Laplacian based operators like the modified Laplacian consistently were among the contrast measures yielding the best performances. We determine
$$\text{MLAP} ( i, j, k ) = \sum _ { l } | ( \partial _ { x x } I ) ( i, j, l, k ) | + | ( \partial _ { y y } I ) ( i, j, l, k ) |$$
with ( ∂ xx I )( i, j, l, k ) denoting the approximate second derivative of the l -th color channel of the k -th image in the focus sequence in x -direction at pixel ( i, j ) using a filter kernel [1 , -2 , 1]. For each pixel ( i, j ) we determine the continuous contrast function c i,j ( x ) depending on a depth x by an eighth order polynomial approximation to the MLAP( i, j, k ) data. Polynomial approximations for determining the contrast curve have previously been proposed in [17] and offer a good and computationally inexpensive continuous representation of the contrast, which we need for the variational formulation (2). Different from [17] we use a higher order polynomial to approximate a noise free contrast curve using all data points, see Figure 2 for an example. Obviously, areas with lots of texture are well suited for determining the depth. In areas with no texture (Figure 2 (b)) the contrast measure consists of mostly noise. The magnitude of the contrast values is very low in this case, such that in a variational framework its influence will be small.
We can see that the contrast values can be well approximated by smooth curves such as splines or - for the sake of simplicity in the minimization method - by a higher order polynomial. However, we can also see that even the smoothed contrast curves will not be convex. Thus, our data fidelity does not couple the pixels, and is smooth, but nonconvex. The regularization term on the other hand is convex, but couples the pixels and is nonsmooth, i.e. not differentiable in the classical sense. In the next section we will propose an efficient algorithm that exploits the structure of the problem to quickly determine depth maps with low energies.
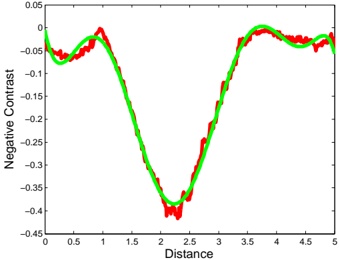
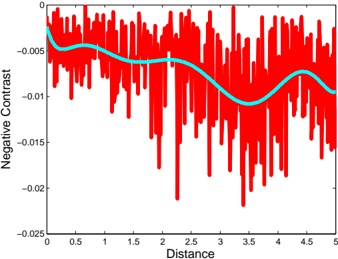
- (a) Contrast curve at green point
(b) Contrast curve at cyan point
(c) Example image to illustrate the positions of the example points.

Figure 2: Examples for how the contrast curves look at different pixels. While pixels with a lot of surrounding structure (green point) result in a strong and clear contrast curve with an easy to identify minimum, textureless areas (cyan point) cause problems (as expected).
## 3 Numerical Minimization
In the literature of nonconvex optimization, particularly the one related to image processing, there exist approaches for problems of the form smooth nonconvex plus nonsmooth convex that provably convergence to critical points under mild conditions. Such approaches include for instance forward-backward splittings (FBS), see [ ? , 18] and the references therein, and methods based on the difference of convex functions (DC), e.g. [19]. The drawback of these methods is that they require to solve a problem like TV denoising at each iteration which makes these schemes computationally expensive. A simple FBS approach that provably converges to a critical point would be
$$d ^ { k + 1 } = \arg \min _ { d } \frac { 1 } { 2 } \| d - d ^ { k } + \tau \nabla D ( d ^ { k } ) \| ^ { 2 } + \tau \alpha R ( d ).$$
While one avoids the difficulty of dealing with the nonconvex term by linearizing it, it can be seen that one still has to minimize the sum of a quadratic fidelity and a nonsmooth regularization term, which can be costly. Therefore, we propose to apply the alternating directions method of multipliers (ADMM) (cf. [20]) in the same way as if the energy was convex. We introduce a new variable g along with the constraint g = Kd , such that we can rewrite the energy minimization problem (1) as
$$( \hat { d }, \hat { g } ) = \arg \min _ { d, g } D ( d ) + \alpha \| g \| _ { 2, 1 } \text{ such that } g = K d.$$
The constraint g = Kd is enforced iteratively by using the augmented Lagrangian method. The minimization for g and d is done in an alternating fashion such that a straight forward application of the ADMM would yield
$$d ^ { k + 1 } = & \arg \min _ { d } \frac { \lambda } { 2 } \| K d - g ^ { k } + b ^ { k } \| _ { 2 } ^ { 2 } + D ( d ),$$
$$g ^ { k + 1 } = & \arg \min _ { g } \frac { \lambda } { 2 } \| g - K d ^ { k + 1 } + b ^ { k } \| _ { 2 } ^ { 2 } + \alpha \| g \| _ { 2, 1 }, & & ( 3 b )$$
$$b ^ { k + 1 } = & b ^ { k } + ( K d ^ { k + 1 } - d ^ { k + 1 } ).$$
Due to the nonconvexity of D d ( ) subproblem (3a) is still difficult to solve, which is the reason why we additionally incorporate the FBS idea of linearizing the nonconvex term. The final computational scheme becomes
$$\text{pravex} \, \text{$two$ as $or$ in amazing one nonvex $rem. $me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$,} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \, \text{$me$} \\ d ^ { k + 1 } = & \arg \min _ { d } \frac { \lambda } { 2 } \| d - d ^ { k } + \tau \nabla D ( d ^ { k } ) \| ^ { 2 }, \\ g ^ { k + 1 } = & \arg \min _ { g } \frac { \lambda } { 2 } \| g - K d ^ { k + 1 } + b ^ { k } \| _ { 2 } ^ { 2 } + \alpha \tau \| g \| _ { 2, 1 }, \\ b ^ { k + 1 } = & b ^ { k } + ( K d ^ { k + 1 } - d ^ { k + 1 } ). \\ \text{w each subproblem can be solved very efficiently.} \, The update for $d$ involves the inversion of $$$
Note that now each subproblem can be solved very efficiently. The update for d involves the inversion of the operator ( λK K T + ) (a discretization of I I -λ ∆) which can be done using a discrete cosine transform. The update for g has a closed form solution known as soft shrinkage of z = Kd k +1 -b k ,
$$g _ { i, j } = \frac { z _ { i, j } } { \| z _ { i, \colon } \| _ { 2 } } \cdot \max ( \| z _ { i, \colon } \| _ { 2 } - \alpha \tau / \lambda, 0 ).$$
In this sense, the proposed algorithm can also be interpreted as solving each FBS subproblem with a single ADMM iteration (and keeping the primal and dual variables). We simply omit converging to the minimum of the convex energy but compute a new linearization of the data fidelity term at each iteration. From a different point of view, the above could also be interpreted as a generalization of Bregmanized operator splitting [21]. In the context of the literature on inverse problems the linearization is related to the Levenberg-Marquardt method. Although the techniques contributing to the algorithm are all known, the authors are not aware of any literature using the method as stated above - even in the convex setting. Hence, let us briefly state a convergence result in the convex setting:
Theorem 3.1. If D and R are convex and the symmetric Bregman distance with respect to D S , D ( d, v ) = 〈 d -v, p d -p v 〉 with p d ∈ ∂D d ( ) , p v ∈ ∂D v ( ) , can be bounded by 1 2 τ ‖ d - ‖ v 2 , then the iterates d k produced by (4) converge to a solution ˆ d of (1) with
$$\tau \left ( S _ { D } ( p ^ { k }, \hat { p$$
and ‖ Kd k +1 -g k ‖ 2 ≤ C/k for some constant C .
The proof follows the arguments of Cai et al. in [22], and is given in the appendix.
While the idea of applying splitting methods to nonconvex problems as if they were convex is not new, a convergence theory is still an important open problem. Recently, progress has been made for particular types of nonconvexities, e.g. [23,24]. One result we became aware of after the preparation of this manuscript is the preprint [25] by Li and Pong. They investigate the behavior of ADMM algorithms for nonconvex problems and even include the linearization proposed in this manuscript. They prove the convergence of the algorithm to stationary points under the assumption that the nonconvex part is smooth with bounded Hessian and that the linear operator ( K in our notation) is surjective. Unfortunately, the latter is not the case for our problem. However, the proposed method numerically results in a stable optimization scheme that is more efficient than methods that solve a full convex minimization problem at each iteration.
Another class of methods related to our approach are quadratic penalty methods, cf. [26], which we would obtain by keeping b k fixed to zero and steadily increasing λ . Variations exist where the alternating minimizations are repeated several times before increasing the penalty parameter τ , see e.g. [27]. We refer the reader to [28] for a discussion on the convergence analysis for this class of methods. While we find a steadily increasing parameter λ to improve the convergence speed, we observe that including the update in b k , i.e. doing ADMM instead of a quadratic penalty, leads to a much faster algorithm.
## 4 Numerical Results
## 4.1 Experiments on Simulated Data
The numerical experiments are divided into three parts. In the first part, we test the proposed framework on simulated data with known ground truth and compare it to classical depth from focus methods. We use the Matlab code provided at http://www.sayonics.com/downloads.html by the authors of [9] and [4] for the simulation of the defocused data as well as for computing depth maps. The simulation can take an arbitrary input image (typically some texture) and creates a sequence of images (15 in our examples) that are focus blurred as if the textured had a certain shape. A mixture of intensity dependent and intensity independent Gaussian white noise is added to the images to simulate realistic camera noise. We refer to [4] as well as to the implementation and demonstration at http://www.sayonics.com/downloads.html for details. The classical depth from focus code allows to choose different contrast measures and different filter sizes, i.e. different mean filters applied to the contrast values before the actual depth is determined. The depth can have subpixel accuracy by using the default 3p Gaussian interpolation. The code additionally allows to apply a median filter to the final depth map to further average out errors. Since the objective of this paper is the introduction of variational methods to the depth from focus problem we limit our comparison to the modified Laplacian (MLAP) contrast measure for the variational as well as for the classical approach and just vary the filtering strategies.
We set up the variational model as proposed in Section 2, and minimize it computationally as described in Section 3. Figure 3 shows a comparison of our framework with differently filtered depth from focus methods along with the mean squared error (MSE) to the ground truth for a stack of differently focused images using the texture in the upper left of Figure 3 for the simulation.
As we can see the variational approach behaves superior to the classical ones. The image used to simulate the results shown in Figure 3 is textured almost everywhere such that parts with high contrast can often be identified accurately. However, the simulated depth map changes quickly, which is the reason why there exists a region which does not appear perfectly sharp in any of the 15 simulated images. As we can see in Figure 3 this region causes big problems and even a 41 × 41 contrast filtering followed by an 11 × 11 median filtering cannot remove the erroneous parts completely. Moreover, strong filtering can only be applied without visible loss of details if the underlying depth map is smooth. The latter holds for the simulated depth maps used for the comparison, but is unrealistic for real data. The problem of unreliable regions has been addressed in [9] before, however, by making a binary decision for or against the reliability of each pixel. Our variational approach handles unreliable regions automatically, in the sense that they do not show large contrast maxima such that their influence on the total energy is small. This allows the method to change the depth at these
Figure 3: Comparison of different depth from focus methods for simulated data. Top row from left to right: Texture image used for the simulation, true simulated depth map, 3d view of the simulated scene. Bottom row from left to right: MLAP depth estimate with 9 × 9 windowed filtering, MLAP depth estimate with 41 × 41 windowed filtering and an additional 11 × 11 median filter on the resulting depth image, our proposed variational scheme with regularization parameter α = 1 2. The mean squared error (MSE) is given for each / of the depth map reconstructions.
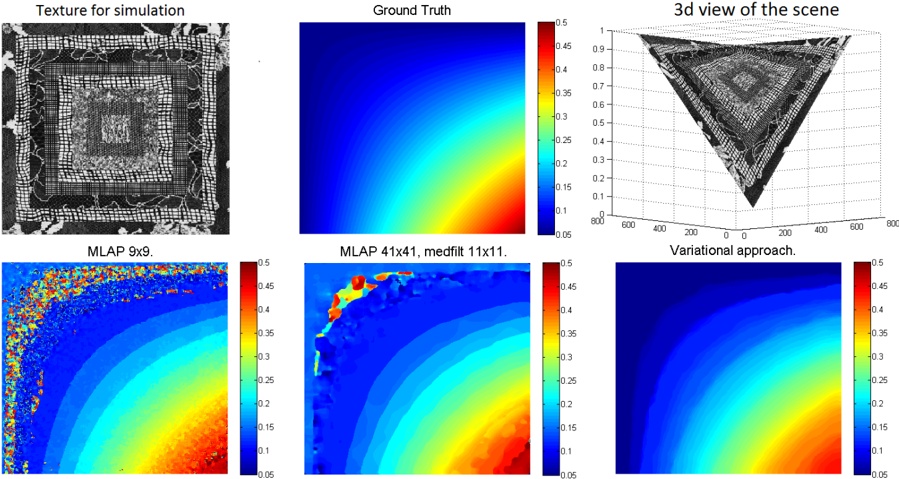
pixels at low costs and, in this sense, leads to a fuzzy instead of a binary decision for the reliability of pixels. Additional to the simulation in Figure 3, we chose three more types of depth maps for our simulated data. The root mean square error values (RMSE) in Table 4.1 show that the variational approach showed superior performance for all simulated shapes.
Table 1: RMSE values different methods obtained on the simulated depth maps. MLAP 1 denotes a 9 × 9 windowed filtering of the MLAP contrast coefficients. MLAP 2 denotes a 41 × 41 windowed filtering of the MLAP contrast coefficients followed by a 11 × 11 median filter on the depth map. TV denotes our variational approach using TV regularization for different parameters.
| Method / Shape | Cone | Plane | Cosine | Sphere |
|------------------|--------|---------|----------|----------|
| MLAP 1 | 2.51 | 9.87 | 4.07 | 8.64 |
| MLAP 2 | 1.41 | 5.14 | 1.83 | 5.06 |
| TV, α = 1 | 1.45 | 1.01 | 1.73 | 0.96 |
| TV, α = 1 / 4 | 1.23 | 1.15 | 1.24 | 0.89 |
| TV, α = 1 / 8 | 1.27 | 1.26 | 1.43 | 0.97 |
Smooth surfaces are not very realistic scenarios for depth maps in practice, because they do not contain jumps and discontinuities. Therefore, we compare the different methods on real data in the next section.
## 4.2 Experiments on Real Data
We test the proposed scheme on two data sets recorded with different cameras. One was downloaded from Said Pertuz' website, http://www.sayonics.com/downloads.html , and consists of 33 color images with 640 × 480 pixels resolution captured with a Sony SNC RZ50P camera, f = 91mm.
The results obtained by two differently filtered classical approaches as well as by using the variational method with three different regularization parameters is shown in Figure 4. As we can see, the variational approaches yield smoother and more realistic depth maps. Even with very large filterings the MLAP depth estimate still contains areas that are erroneously determined to be in the image foreground. Depending on the choice of regularization parameter the results of our variational approach show different levels of details and different amounts of errors. However, even for the smallest regularization parameter no parts of the image are estimated to be entirely in the fore- or background. Generally, due to the rather low quality of the data and large textureless parts the estimation of the depth is very difficult on these images.



(a) Example image

(d)
Variational approach,
(b) 9 × 9 windowed MLAP maximization.

(c) 41 × 41 windowed MLAP maximization with 11 × 11 median filter.
(e) Variational α = 1 7. /

approach, approach,
α
= 1 5.
/
(f) Variational α = 1 10. /
Figure 4: Comparison of depth from focus reconstruction on real data for differently filtered classical methods and our variational approach for different regularization parameters.
For our second test, we use high quality data taken with the ARRI Alexa camera . 1 The latter data set consists of 373 images of a tabletop scene with an original resolution of 1080 × 1920 pixels which we downscaled by a factor of two to reduce the amount of data. To record the image stack, the focus was continuously and evenly changed from the front to the back of the scene using a wireless compact unit (WCU-4) connected to a motor for focus adjustments. The images ran through the usual ARRI processing chain, which drastically influences the data characteristics as observed in [29].
As we can see in the results shown in Figure 5, the depth estimation on the second, high quality data set works much better. Both MLAP methods succeed in finding the general structure of a reasonable
1 Provided by the Arnold and Richter Cine Technik, www.arri.com

(a) Example for one image of the focus sequence.

(c) Depth map obtained after filtering MLAP coefficients with a 9 × 9 window.
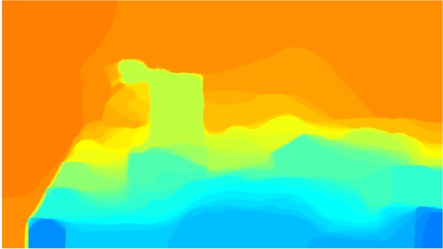
(e) Variational approach with α = 1 4. /
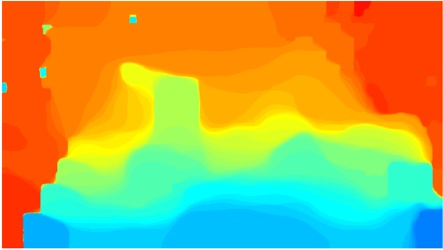
(b) Depth map obtained after filtering MLAP coefficients with a 21 × 21 window and applying a 5 × 5 median filter to the resulting depth map.

(d) Variational approach with α = 1 12. /
(f) Variational approach with α = 1 28. /

(g) Applying TV denoising to image (b) with a regularization parameter of 26.
(h) Applying TV denoising to image (b) with a regularization parameter of 6.
Figure 5: Comparison of depth from focus reconstruction on real data for differently filtered classical methods and our variational approach for different regularization parameters.
depth map. However, obvious errors can be seen at some parts of the wall, the checkerboard and some transitions between objects on the table. The variational approaches succeed in finding a much more realistic solution by eliminating all noise in the depth image. Particularly impressive is the fact that they even restore the wall in the background, the checkerboard and the plastic cups in the foreground. All these things are not reconstructed correctly in the windowed approaches. As expected, the regularization parameter allows the user to determine the trade-off between keeping little details and suppressing noise.
In addition to the results of two classical and three variational approaches, Figure 5 shows the results obtained by first reconstructing the depth map and then applying TV denoising to the resulting depth map. While this procedure has the advantage that the TV problem is convex, it treads the estimation of the depth independent of the denoising. As we can see, our proposed joint approach for denoising a depth map with small TV works much better. Large parts that have erroneously been mapped to the foreground are very difficult to remove when applying TV denoising to the depth map and large regularization parameters are required. For the joint variational approach, mapping parts from the fore- to the background and vice versa is rather cheap as long as the contrast values do not show strong preferences for one over the other. Thus, the joint reconstruction is better suited for recovering realistic, noise-free depth maps.
## 4.3 Convergence of the Proposed Algorithm
For the experiments shown in the previous subsection we used the minimization scheme described in Section 3 which we initialized with the 15 × 15 filtered MLAP depth estimate that have been additionally blurred with a 21 × 21 mean filter. The latter was done due to the observation that the minimization with false initializations that attains extreme values performs much worse than blurriness in a moderate range of depth values. As for the ADMM parameter we start with λ = 1 and increase the parameter at each iteration by 2%. Since we are using the scaled form of ADMM we consequently have to divide b k by 1 02 at each iteration . (see [20] for details).
Iteration
Figure 6: Convergence plots for linearized ADMM algorithm applied to the variational DFF problem. As we can see the total energy as well as the difference of successive iterates show a nice and monotonic decay. The squared glyph[lscript] 2 norm of the difference between successive iterates decays to an order of 10 -30 after the 1000 iterations. The decay of ‖ Kd k -g k ‖ shows some small oscillations which we, however, only see for ‖ Kd k -g k ‖ 2 ≤ 10 -9 . It is remarkable that all three plots are almost linear (in the logarithmic domain) indicating a linear convergence of the displayed quantities.
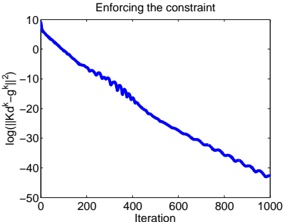
Starting with a small λ gives the two variables d and g the freedom to behave more independent of one another. Experimentally, this helps avoiding bad local minima. Increasing λ seems to lead to a stabilization as well as to an acceleration of the algorithm. Note that similar effects have previously been observed in the related primal-dual hybrid gradient algorithm in the nonconvex setting in [30]. Throughout our experiments the time step was fixed at τ = 8 and we ran our algorithm for 400 iterations.
To give some numerical evidence of the convergence, we ran the algorithm for 1000 iterations on the ARRI data with a regularization parameter of α = 1 12. / We plotted the decay of energy in a logarithmic fashion, i.e. log( E d ( k ) -E d ( 1000 )), in Figure 6 on the left hand side. As we can see the algorithm shows
nice decay properties. Also included in Figure 6 are the decays of ‖ g k +1 -g k ‖ 2 + ‖ d k +1 -d k ‖ 2 (middle) and ‖ Kd k -g k ‖ 2 (right), both plotted in a logarithmic fashion.
Although ‖ Kd k -g k ‖ 2 shows some oscillations in the logarithmic plot, it decayed nicely to less than 10 -40 . One can verify from the optimality conditions arising from the updates in (4) that both residual converging to zero provably leads to the convergence to a critical point of our nonconvex energy (along subsequences).
The total computational for determining the sharpness, determining the polynomial fitting, computing an initial depth estimate and performing 400 iterations of the minimization algorithm took less than three seconds on a sequence of 33 images with 640 × 480 pixels resolution (corresponding to the image used in figure 4) using a Cuda-GPU implemetation. The source code is freely available at https://github.com/ adrelino/variational-depth-from-focus . The authors would like to thank Adrian Haarbach, Dennis Mack, and Markus Schlaffer, who ported our Matlab code to the GPU. We'd like to point out that the main computational costs of the algorithm currently consists of determining the sharpness values (about 2.38 seconds in the aforementioned example) - a task which has to be done even for the classical DFF approaches which do not use regularization. The actual minimization using the ADMM algorithm takes less than 0.2 seconds.
## 5 Conclusions & Outlook
In this paper we proposed a variational approach to the shape from focus problem, which can be seen as a generalization of current common shape from focus approaches. It uses an efficient nonconvex minimization scheme to determine depth maps which are based on prior knowledge such as a realistic depth map often being piecewise constant. We showed in several numerical experiments that the proposed approach often yields results superior to classical depth from focus techniques. In future work we will incorporate more sophisticated regularizations in our studies. Additionally, we'll work on correcting the inherent loss of contrast caused by the total variation regularization by applying nonlinear Bregman iterations in the fashion of [31] to our nonconvex optimization problem.
## Acknowledgements
M.B. and C.S. were supported by EPSRC GrantEP/F047991/1, and the Microsoft Research Connections. C.S. additionally acknowledges the support of the KAUST Award No. KUK-I1-007-43. M.M. and D.C. were supported by the ERC Starting Grant 'ConvexVision'.
## References
- [1] P. Favaro and S. Soatto, 3-D Shape Estimation and Image Restoration: Exploiting Defocus and Motionblur . Secaucus, NJ, USA: Springer New York, Inc., 2006.
- [2] P. Favaro, S. Soatto, M. Burger, and S. Osher, 'Shape from defocus via diffusion,' IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 30, no. 3, pp. 518-531, 2008.
- [3] X. Lin, J. Suo, X. Cao, and Q. Dai, 'Iterative feedback estimation of depth and radiance from defocused images,' in Computer Vision ACCV 2012 , ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2013, vol. 7727, pp. 95-109.
- [4] S. Pertuz, D. Puig, M. Garcia, and M. Angel, 'Analysis of focus measure operators for shape-fromfocus,' Pattern Recogn. , vol. 46, no. 5, pp. 1415-1432, 2013.
- [5] A. Thelen, S. Frey, S. Hirsch, and P. Hering, 'Improvements in shape-from-focus for holographic reconstructions with regard to focus operators, neighborhood-size, and height value interpolation,' IEEE Trans. on I. Proc. , vol. 18, no. 1, pp. 151-157, 2009.
| [6] | M. Mahmood and T.-S. Choi, 'Nonlinear approach for enhancement of image focus volume in shape from focus,' IEEE Trans. on Image Proc. , vol. 21, no. 5, pp. 2866-2873, 2012. |
|-------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [7] | M. Muhammad, H. Mutahira, A. Majid, and T. Choi, 'Recovering 3d shape of weak textured surfaces,' in Proceedings of the 2009 International Conference on Computational Science and Its Applications , ser. ICCSA '09. Washington, DC, USA: IEEE Computer Society, 2009, pp. 191-197. |
| [8] | M. Muhammad and T. Choi, 'An unorthodox approach towards shape from focus,' in Image Processing (ICIP), 2011 18th IEEE International Conference on , 2011, pp. 2965-2968. |
| [9] | S. Pertuz, D. Puig, and M. Garcia, 'Reliability measure for shape-from-focus,' Image Vision Comput. vol. 31, no. 10, pp. 725-734, 2013. |
| [10] | M. Mahmood, 'Shape from focus by total variation,' in 2013 IEEE 11th IVMSP Workshop , 2013, pp. 1-4. |
| [11] | P. Favaro, 'Recovering thin structures via nonlocal-means regularization with application to depth from defocus,' in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on , 2010, pp. 1133-1140. |
| [12] | H. Liu, Y. Jia, H. Cheng, and S. Wei, 'Depth recovery from defocus images using total variation,' in Computer Modeling and Simulation, 2010. ICCMS '10. Second International Conference on , vol. 2, 2010, pp. 146-150. |
| [13] | V. Namboodiri, S. Chaudhuri, and S. Hadap, 'Regularized depth from defocus,' in Image Processing, 2008. ICIP 2008. 15th IEEE International Conference on , 2008, pp. 1520-1523. |
| [14] | V. Gaganov and A. Ignatenko, 'Robust shape from focus via markov random fields,' in GraphiCon'2009 2009, pp. 74-80. |
| [15] | L. Rudin, S. Osher, and E. Fatemi, 'Nonlinear total variation based noise removal algorithms,' Physica D , vol. 60, pp. 259-268, 1992. |
| [16] | S. Nayar and Y. Nakagawa, 'Shape from focus,' IEEE Trans. Pattern Anal. Mach. Intell. , vol. 16, no. 8, pp. 824-831, 1994. |
| [17] | M. Subbarao and T. Choi, 'Accurate recovery of three-dimensional shape from image focus,' IEEE Trans. Pattern Anal. Mach. Intell. , vol. 17, no. 3, pp. 266-274, 1995. |
| [18] | H. Attouch, J. Bolte, and B. Svaiter, 'Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods,' Math. Prog. , vol. 137, no. 1-2, pp. 91-129, 2013. |
| [19] | T. P. Dinh, H. Le, H. L. Thi, and F. Lauer, 'A Difference of Convex Functions Algorithm for Switched Linear Regression,' to appear in IEEE Transactions on Automatic Control. |
| [20] | S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, 'Distributed optimization and statistical learning via the alternating direction method of multipliers,' Found. Trends Mach. Learn. , vol. 3, no. 1, pp. 1-122, 2011. |
| [21] | X. Zhang, M. Burger, X. Bresson, and S. Osher, 'Bregmanized nonlocal regularization for deconvolution and sparse reconstruction,' SIAM J. Imaging Sci. , vol. 3, no. 3, pp. 253-276, 2010. [Online]. Available: http://dx.doi.org/10.1137/090746379 |
| [22] | J. Cai, S. Osher, and Z. Shen, 'Split bregman methods and frame based image restoration,' Multiscale Modeling & Simulation , vol. 8, no. 2, pp. 337-369, 2010. |
| [23] | T. Valkonen, 'A primal-dual hybrid gradient method for non-linear operators with applications to mri,' Inverse Problems , vol. 30, no. 5, p. 055012, 2014. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [24] | T. Moellenhoff, E. Strekalovskiy, M. Moeller, and D. Cremers, 'The primal-dual hybrid gradient method for semiconvex splittings,' 2014, preprint. Arxiv: http://arxiv.org/pdf/1407.1723.pdf. |
| [25] | G. Li and T. Pong, 'Splitting method for nonconvex composite optimization,' 2014, preprint. Arxiv: http://arxiv.org/pdf/1407.0753.pdf. |
| [26] | M. Nikolova, M. K. Ng, and C.-P. Tam, 'Fast Nonconvex Nonsmooth Minimization Methods for Image Restoration and Reconstruction,' IEEE Transactions on Image Processing , vol. 19, no. 12, pp. 3073- 3088, 2010. |
| [27] | D. Krishnan and R. Fergus, 'Fast Image Deconvolution using Hyper-Laplacian Priors.' , 2009, pp. 1033-1041. |
| [28] | H. Attouch, J. Bolte, P. Redont, and A. Soubeyran, 'Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the kurdyka-lojasiewicz inequality,' Math. Oper. Res. , vol. 35, no. 2, pp. 438-457, May 2010. |
| [29] | S. Andriani, H. Brendel, T. Seybold, and J. Goldstone, 'Beyond the kodak image set: A new reference set of color image sequences,' in 2013 20th IEEE International Conference on Image Processing (ICIP) , 2013, pp. 2289-2293. |
| [30] | E. Strekalovskiy and D. Cremers, 'Real-Time Minimization of the Piecewise Smooth Mumford-Shah Functional,' in Proceedings of the European Conference on Computer Vision (ECCV) , 2014, p. (To appear). |
| [31] | M. Bachmayr and M. Burger, 'Iterative total variation schemes for nonlinear inverse problems,' Inverse Problems , vol. 25, 2009. |
## Appendix: Proof of Theorem (3.1)
Proof. Let ˆ be a critical d point and denote ˆ = g Kd,b ˆ ˆ ∈ ατ λ ∂ ‖ ˆ g ‖ 2 1 , . Furthermore, denote d k e = d k -ˆ , d g k e = g k -ˆ, g b k e = b k -ˆ , b p k e = ∇ D d ( k ) -∇ D d ( ˆ ) and q k e ∈ ∂ ‖ g k ‖ 2 1 , - ‖ ‖ ∂ ˆ g 2 1 , . Then the optimality conditions arising from algorithm (4) yield
$$0 = & \lambda K ^ { T } ( K d _ { e } ^ { k + 1$$
The inner product of the first equation with d k +1 e yields
$$\begin{array} {$$
The inner product of the second equation with g k +1 e results in
$$0 = & - \lambda \langle K d _ { e } ^ { k + 1 } -$$
Adding the two estimates above leads to
$$0 = & \frac { \lambda } { 2 } ( \| K d _ { e } ^$$
where we used the fact that 〈 q k +1 e , g k +1 e 〉 = S R ( g k +1 , g ˆ). We use the update formula for b k +1 to obtain that
$$\langle b _ { e } ^ { k }, K d _ { e } ^ { k + 1 } - g _ { e } ^ { k + 1 } \rangle = \frac { 1 } { 2 } ( \| b _ { e } ^ { k + 1 } \| ^ { 2 } - \| b _ { e } ^ { k } \| ^ { 2 } - \| K d _ { e } ^ { k + 1 } - g _ { e } ^ { k + 1 } \| ^ { 2 } ).$$
Due to the linearization we have the term 〈 p , d k e k +1 e 〉 in our current estimate instead of the symmetric Bregman distance. Thus, we estimate
$$\langle p _ { e } ^ { k }, d _ { e } ^ { k + 1 } \rangle = & S _ { D } ( d ^ { k }, \hat { d } ) + \langle p _ { e } ^ { k }, d _ { e } ^ { k + 1 } - d _ { e } ^ { k } \rangle \\ = & S _ { D } ( d ^ { k }, \hat { d } ) - S _ { D } ( d ^ { k }, d ^ { k + 1 } ) + \langle p ^ { k + 1 }, d ^ { k + 1 } - d ^ { k } \rangle - \langle \hat { p }, d ^ { k + 1 } - d ^ { k } \rangle \\ \geq & S _ { D } ( d ^ { k }, \hat { d } ) - S _ { D } ( d ^ { k }, d ^ { k + 1 } ) + D ( d ^ { k + 1 } ) - D ( d ^ { k } ) - \langle \hat { p }, d ^ { k + 1 } - d ^ { k } \rangle,$$
where we used p k +1 ∈ ∂D d ( k +1 ) along with the convexity of D for the last inequality. Inserting (6) and (7) into (5) yields
$$\text{into} \ ( 5 ) \, \text{yields} \\ 0 \geq & \frac { \lambda } { 2 } \left ( \| K d _ { e } ^ { k + 1 } - g _ { e } ^ { k + 1 } \| ^ { 2 } + \| g _ { e } ^ { k + 1 } \| ^ { 2 } - \| g _ { e } ^ { k } \| ^ { 2 } + \| K d _ { e } ^ { k + 1 } - g _ { e } ^ { k } \| ^ { 2 } \right ) \\ & + \frac { \lambda } { 2 } \left ( \| b _ { e } ^ { k + 1 } \| ^ { 2 } - \| b _ { e } ^ { k } \| ^ { 2 } - \| K d _ { e } ^ { k + 1 } - g _ { e } ^ { k + 1 } \| ^ { 2 } \right ) + \frac { 1 } { 2 } \left ( \| d _ { e } ^ { k + 1 } \| ^ { 2 } - \| d _ { e } ^ { k } \| ^ { 2 } \right ) + \frac { 1 } { 2 } \| d _ { e } ^ { k } - d _ { e } ^ { k + 1 } \| ^ { 2 } \\ & - \tau S _ { D } ( d ^ { k }, d ^ { k + 1 } ) + \tau S _ { D } ( d ^ { k }, \hat { d } ) + \alpha \tau S _ { R } ( g ^ { k + 1 }, \hat { g } ) + \tau ( D ( d ^ { k + 1 } ) - D ( d ^ { k } ) - \langle \hat { p }, d ^ { k + 1 } - d ^ { k } \rangle \right ) \\ \geq & \frac { \lambda } { 2 } \left ( \| g _ { e } ^ { k + 1 } \| ^ { 2 } - \| g _ { e } ^ { k } \| ^ { 2 } + \| b _ { e } ^ { k + 1 } \| ^ { 2 } - \| b _ { e } ^ { k } \| ^ { 2 } \right ) + \frac { \lambda } { 2 } \| K d _ { e } ^ { k + 1 } - g _ { e } ^ { k } \| ^ { 2 } + \frac { 1 } { 2 } \left ( \| d _ { e } ^ { k + 1 } \| ^ { 2 } - \| d _ { e } ^ { k } \| ^ { 2 } \right ) \\ & + \tau S _ { D } ( d ^ { k }, \hat { d } ) + \alpha \tau S _ { R } ( g ^ { k + 1 }, \hat { g } ) + \tau \left ( D ( d ^ { k + 1 } ) - D ( d ^ { k } ) - \langle \hat { p }, d ^ { k + 1 } - d ^ { k } \rangle \right ),$$
where we used the assumption 1 2 ‖ d k +1 e -d k e ‖ 2 -τS D ( p , p k k +1 ) ≥ 0 for the second inequality. Now we can sum over this inequality from k = 0 to n to obtain
$$\sum \text{over} \, \text{uns} & \, \text{margin} \, \text{from} \, \kappa = 0 \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \text{u} \, \rightarrow \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \rightarrow \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{\array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{arr} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \, \text{array} \,
& \quad + \tau \sum _ { k = 0 } ^ { n } \left ( S _ { D } ( d ^ { k }, \hat { d } ) + \alpha S _ { R } ( g ^ { k + 1 }, \hat { g } ) \right ) + \underbrace { \tau \left ( D ( d ^ { n + 1 } ) - D ( \hat { d } ) - \langle \hat { p }, \hat { d } ^ { n + 1 } - D \hat { d } \rangle \right ) } _ { \geq 0 } \\ & \quad - \tau \left ( D ( d ^ { 0 } ) - D ( \hat { d } ) - \langle \hat { p }, \hat { d } ^ { 0 } - \hat { d } \rangle \right ) \,, \\. & \quad. & \quad. & \quad. & \quad.$$
such that we finally obtain
$$& \frac { \lambda } { 2 } ( \| g _ { e } ^ { 0 } \| ^ { 2 } + \| b _ { e } ^ { 0 } \| ^ { 2 } ) + \frac { 1 } { 2 } \| d _ { e } ^ { 0 } \| ^ { 2 } + \tau \left ( D ( d ^ { 0 } ) - D ( \hat { d } ) - \langle \hat { p }, d ^ { 0 } - \hat { d } \rangle \right ) \\ \geq & \frac { \lambda } { 2 } \sum _ { k = 0 } ^ { n } \| K d _ { e } ^ { k + 1 } - g ^ { k } \| ^ { 2 } + \sum _ { k = 0 } ^ { n } \left ( S _ { D } ( d ^ { k }, \hat { d } ) + \alpha S _ { R } ( g ^ { k + 1 }, \hat { g } ) \right ).$$
Since the sums are bounded for all n and the summands are nonnegative, we can conclude their convergence to zero with a rate as least as fast as 1 /k , which yields the assumption. | 10.1109/TIP.2015.2479469 | [
"Michael Moeller",
"Martin Benning",
"Carola Schönlieb",
"Daniel Cremers"
] | 2014-08-01T13:26:41+00:00 | 2014-11-05T11:03:55+00:00 | [
"cs.CV",
"math.OC"
] | Variational Depth from Focus Reconstruction | This paper deals with the problem of reconstructing a depth map from a
sequence of differently focused images, also known as depth from focus or shape
from focus. We propose to state the depth from focus problem as a variational
problem including a smooth but nonconvex data fidelity term, and a convex
nonsmooth regularization, which makes the method robust to noise and leads to
more realistic depth maps. Additionally, we propose to solve the nonconvex
minimization problem with a linearized alternating directions method of
multipliers (ADMM), allowing to minimize the energy very efficiently. A
numerical comparison to classical methods on simulated as well as on real data
is presented. |
1408.0174v1 | ## HIGH-ENERGY X-RAY IMAGING OF THE PULSAR WIND NEBULA MSH 15 -5 2 : CONSTRAINTS ON PARTICLE ACCELERATION AND TRANSPORT
Hongjun An 1 , Kristin K. Madsen 2 , Stephen P. Reynolds 3 , Victoria M. Kaspi 1 , Fiona A. Harrison 2 , Steven E. Boggs 4 , Finn E. Christensen 5 , William W. Craig 4,6 , Chris L. Fryer 7 , Brian W. Grefenstette 2 , Charles J. Hailey 8 , Kaya Mori 8 , Daniel Stern 9 , and William W. Zhang 10
1 Department of Physics, McGill University, Montreal, Quebec, H3A 2T8, Canada
2 Cahill Center for Astronomy and Astrophysics, California Institute of Technology, Pasadena, CA 91125, USA 3 Physics Department, NC State University, Raleigh, NC 27695, USA 4 Space Sciences Laboratory, University of California, Berkeley, CA 94720, USA 5 DTU Space, National Space Institute, Technical University of Denmark, Elektrovej 327, DK-2800 Lyngby, Denmark 6 Lawrence Livermore National Laboratory, Livermore, CA 94550, USA 7 CCS-2, Los Alamos National Laboratory, Los Alamos, NM 87545, USA 8 Jet Propulsion Laboratory, California Institute of Technology, Pasadena, CA 91109, USA
Goddard Space Flight Center, Greenbelt, MD 20771, USA
Columbia Astrophysics Laboratory, Columbia University, New York NY 10027, USA 9 10
Draft version August 4, 2014
## ABSTRACT
We present the first images of the pulsar wind nebula (PWN) MSH 15 -5 2 in the hard X-ray band ( > ∼ 8 keV), as measured with the Nuclear Spectroscopic Telescope Array (NuSTAR) . Overall, the morphology of the PWN as measured by NuSTAR in the 3-7 keV band is similar to that seen in Chandra high-resolution imaging. However, the spatial extent decreases with energy, which we attribute to synchrotron energy losses as the particles move away from the shock. The hard-band maps show a relative deficit of counts in the northern region towards the RCW 89 thermal remnant, with significant asymmetry. We find that the integrated PWN spectra measured with NuSTAR and Chandra suggest that there is a spectral break at 6 keV which may be explained by a break in the synchrotron-emitting electron distribution at ∼ 200 TeV and/or imperfect cross calibration. We also measure spatially resolved spectra, showing that the spectrum of the PWN softens away from the central pulsar B1509 -58, and that there exists a roughly sinusoidal variation of spectral hardness in the azimuthal direction. We discuss the results using particle flow models. We find non-monotonic structure in the variation with distance of spectral hardness within 50 ′′ of the pulsar moving in the jet direction, which may imply particle and magnetic-field compression by magnetic hoop stress as previously suggested for this source. We also present 2-D maps of spectral parameters and find an interesting shell-like structure in the N H map. We discuss possible origins of the shell-like structure and their implications.
Subject headings: ISM: supernova remnants - ISM: individual (G320.4 -1.2) - ISM: jets and outflows - X-rays: ISM - stars: neutron - pulsars: individual (PSR B1509 -58)
## 1. INTRODUCTION
A pulsar wind nebula (PWN) is a region of particles accelerated in a shock formed by the interaction between the pulsar's particle/magnetic flux and ambient matter such as a supernova remnant (SNR) or the interstellar medium (ISM). It has been theorized that the shock, called a termination shock, can accelerate particles to ∼ 10 15 eV, which are believed to contribute to the cosmic ray spectrum from low energies up to the 'knee' at ∼ 10 15 eV (e.g., de Jager et al. 1992; Atoyan et al. 1996). In a PWN, the shock-accelerated particles propagate downstream and emit synchrotron photons under the effects of the magnetic fields in that region (Wilson 1972a,b; Rees & Gunn 1974). The electrons in the hard tail of the energy distribution produce X-rays, and thus the detection of synchrotron X-rays indirectly proves the existence of high energy electrons. Therefore, X-ray emitting PWNe are particularly interesting for studying particle shock acceleration, and for studying the inter- action of high energy particles with their environments (see Gaensler & Slane 2006, for a review).
Since the accelerated particles in young PWNe lose their energy primarily via synchrotron radiation at a rate proportional to E 2 , the energy distribution of the particles softens with distance from the shock, an effect called 'synchrotron burn-off'. As the particle spectrum softens, the emitted photon spectrum is expected to soften as well. Details of the softening depend on the physical environment and the particle flow in the PWNe; these have been modeled using particle advection (e.g., Kennel & Coroniti 1984; Reynolds 2003, 2009) and/or diffusion (e.g., Gratton 1972; Tang & Chevalier 2012). In particular, the advection models predict the radial profile of the photon index to be flat out to the PWN edge and then to soften rapidly, while diffusion models predict a gradual spectral softening with radius. The particle spectrum can be inferred from the photon spectrum as they are directly related. Therefore, spatially resolved spectra or energy resolved images can be compared to
Table 1 Summary of observations
| Obs. No. | Observatory | Obs. ID | Exposure (ks) | Start Date (MJD) |
|------------|---------------|---------------|-----------------|--------------------|
| C1 | Chandra | 754 | 19 | 51770.6 |
| C2 | Chandra | 5534 | 49 | 53367.4 |
| C3 | Chandra | 5535 | 43 | 53408.6 |
| C4 | Chandra | 6116 | 47 | 53489.2 |
| C5 | Chandra | 6117 | 46 | 53661 |
| N1 | NuSTAR | 40024004002 | 42 | 56450.9 |
| N2 | NuSTAR | 40024002001 a | 43 | 56451.8 |
| N3 | NuSTAR | 40024003001 | 44 | 56452.6 |
| N4 | NuSTAR | 40024001002 | 34 | 56519.6 |
Notes. All Chandra observations were made with the timed exposure mode (TE) on ACIS-I chips.
a Only used for the spectral analysis along the jet and timing analysis.
model prediction to infer the particle flow properties and the physical environments in PWNe.
MSH 15 -5 2 (also known as 'Hand of God') is a large TeV-detected PWN which is powered by the central 150ms X-ray pulsar B1509 -58 at a distance of ∼ 5.2 kpc (Gaensler et al. 1999). The radius of the PWN is ∼ 5 ′ ( ∼ 7 6 pc) and it has a very asymmetric morphology with . complicated internal structures in the X-ray band (e.g., Gaensler et al. 2002; DeLaney et al. 2006; Yatsu et al. 2009). Notably, it has a hard jet directed south-east, similar to that seen in some PWNe such as the Crab nebula (Mori et al. 2004). North of the PWN, there is a large thermal shell structure (RCW 89) which is thought to be powered by the PWN through finger-like structures (Yatsu et al. 2005). The synchrotron burn-off effect in this PWN was previously measured with XMM-Newton in the 0.5-10 keV band by Sch¨ck et al. (2010). o They measured the burn-off effect in that band by integrating the spectrum azimuthally, however, given the highly asymmetric morphology, a more in-depth analysis is warranted.
In this paper, we report on the spatial and spectral properties of the PWN MSH 15 -5 2 in a broad X-ray band measured with NuSTAR and Chandra . We present a two-dimensional synchrotron burn-off map for the first time using energy-resolved images and spatially resolved spectra. We describe the observations and data reduction in Section 2, and show the data analysis and results in Section 3. We discuss the implications of the analysis results in Section 4 and present the summary in Section 5.
## 2. OBSERVATIONS
The NuSTAR instrument has two co-aligned hard Xray optics and focal plane modules (modules A and B with each module having four detectors), and is the most sensitive satellite to date in the 3-79 keV band. The energy resolution is 400 eV at 10 keV (FWHM), and the temporal resolution is 2 µ s (see Harrison et al. 2013, for more details), although the accuracy on orbital timescales is ∼ 2 ms due to long-term clock drift. NuSTAR has unparalleled angular resolution in the hard X-ray band (HPD=58 ). ′′ The fine broadband angular response enables us to study detailed morphological changes with energy for large PWNe such as MSH 15 -5 2 , and NuSTAR 's temporal resolution is sufficient to filter
Figure 1. Normalized pulse profile for PSR B1509 -58 in the 3-79 keV band measured with NuSTAR . Note that the off-pulse phases (0.7-1.0, dotted vertical lines) include DC emission of the pulsar as well as the nebula emission.
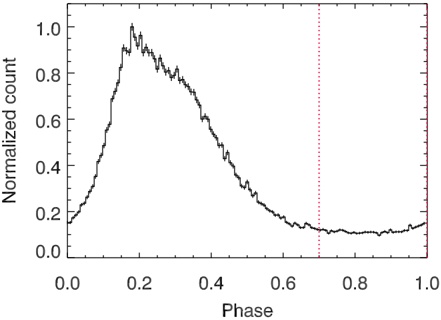
out contamination from the bright central pulsar (e.g., see Chevalier 2005; Kaspi, Roberts & Harding 2006, for pulsars in PWNe).
MSH 15 -5 2 was observed with NuSTAR in 2013 July with a total net exposure of ∼ 160 ks. Although the NuSTAR field of view (FoV) is large enough to observe the whole PWN with a single pointing, we used four different pointings in order to better sample different regions of the PWN. We also analyzed archival Chandra ACIS (Garmire et al. 2003) observations in order to verify our spatial analysis technique, and to broaden the energy range for spectroscopy (see also Gaensler et al. 2002; DeLaney et al. 2006; Yatsu et al. 2009). Table 1 summarizes the observations used in this paper. The NuSTAR observation N2 was pointed to the jet, and most of the PWN fell outside the FoV. Therefore we used this observation only for the timing analysis in Section 3.1 and the spectral analysis along the jet direction in Section 3.3.3.
The NuSTAR data were processed with nupipeline 1.3.0 along with CALDB version 20131007, and the Chandra data were reprocessed using the chandra repro tool of CIAO 4.5 along with CALDB 4.5.7. We further processed the cleaned event files for analyses as described below.
## 3. DATA ANALYSIS AND RESULTS
## 3.1. Timing Analysis
Since the pulsar B1509 -58 is very bright, we needed to minimize its contamination in the PWN imaging and spectral analysis. For the Chandra data, the pulsar contamination was removed by image filtering. However, we were not able to do the image filtering for NuSTAR because its point spread function (PSF) is broad. Therefore, we selected the off-pulse interval in the NuSTAR data for the image and spectral analyses below.
We extracted the pulsar events in the NuSTAR observations in a 30 ′′ radius circle in the 379 keV band, barycenter-corrected the events using R.A.=15 13 h m 55 s . 52, Decl.= -59 08 08 8 ◦ ′ . ′′ (J2000, Caraveo, Mereghetti & Bignami 1994) to produce event lists, and divided each observation into three subintervals, yielding twelve sub-intervals for the four observations. We performed H test (de Jager et al. 1989)
on the event lists to measure the period for the subintervals and fit the period to a linear function to find the spin period and the spin-down rate. The pulsations were measured with very high significance in each subinterval, and the measured period and the spin-down rate were 0 1517290191(14) s and 1 5281(4) . . × 10 -12 s s -1 for 56450 MJD, respectively. We folded the light curves using the measured period, and show the resulting pulse profile in Figure 1. We used phases 0.7-1.0 for the PWN to minimize the pulsar contamination in all the subsequent NuSTAR data analyses in this paper. The other phase interval was used for the pulsar analysis which will be presented elsewhere. We note that there is contamination from the DC emission of the pulsar even in the off-pulse interval. For example, ∼ 1.6% of the DC counts are expected in a circle of R = 30 ′′ at a distance of 60 ′′ from the pulsar, but much less at larger distances.
## 3.2. Image Analysis
In order to produce energy-resolved PWN images, we first produced a merged Chandra image of the five observations in Table 1 using the merge obs tool of CIAO 4.5 in the 0.5-2 keV, 2-4 keV and 4-7 keV bands with bin size 4 pixels (Fig. 2). Note that the central 4 ′′ × 4 ′′ corresponding to the pulsar emission was removed in these images.
For NuSTAR observations, we extracted events in the energy bands 3-7 keV, 7-12 keV, 12-25 keV, and 2540 keV for the off-pulse phase. After the phase selection, the pulsar component is expected to be reduced significantly. The NuSTAR absolute aspect reconstruction accuracy on long timescales is ∼ 8 ′′ (90% confidence), which can blur the resulting merged image obtained with the three observations and two modules. Therefore, we aligned the images by registering the pulsar to the known position before phase filtering. Since only one point source (the pulsar) was significantly detected in each observation, we were not able to fully correct the position (e.g., for translation, rotation and scale). We note that the rotational misalignments are measured and corrected with high accuracy (Harp et al. 2010), and a small residual change in scale is not a concern for the spatial scales of our analyses. Therefore, we assumed that the position offsets were caused by pure translations.
In order to produce deblurred images of the NuSTAR observations for comparison with the low-energy highresolution Chandra images, we corrected for the exposure and deconvolved the NuSTAR images with the PSF using the arestore tool of CIAO 4.5. We then merged the deconvolved images (see Fig. 2). The number of iterations in the deconvolution process was determined by comparing the deconvolved NuSTAR image to the Chandra image in a similar band. We chose the energy bands so that the average photon energy weighted by the response and the spectrum in a NuSTAR band is similar to that in a Chandra band, and used the 3-7 keV and 4-7 keV bands for NuSTAR and Chandra , respectively.
Using the 2-D images, we produced projected profiles along the jet axis (the south-east to north-west direction) in order to compare the deconvolved 3-7 keV NuSTAR profile with the 4-7 keV Chandra profile. Here, we filled the pulsar region in the Chandra data which were removed above with the average counts of the surrounding pixels. We rotated the images 60 ◦ clockwise with the origin being the pulsar position, so that the jet structure lies in the horizontal direction (x-axis). We projected the images in Figure 2 onto the axis along the jet, subtracted background, smoothed the profile over a 25 ′′ scale, and normalized the scale with respect to the brightest point at the center. The backgrounds were assumed to be flat over the detector chips. The background normalization factor was first determined by taking a box in a sourcefree region, and then further adjusted by matching the y-projected profiles of the source and the background at large distance from the center for each energy band. We found that the results presented below are not sensitive to the background subtraction since background accounts for only small fraction of the intensity. We find that NuSTAR -measured profile in the 3-7 keV band is similar to that measured with Chandra in the 4-7 keV band (see dashed and dot-dashed curves in fig. 3), and that the results of the deconvolution are not very sensitive to the number of iterations (e.g., 15-50), and we used 20 iterations.
While the deconvolved NuSTAR image (Fig. 2e) shows similar overall morphology to the high-resolution Chandra image in the similar band (Fig. 2d), there are differences. Most notably, the small arc-like structure and the elongation in the central region ( R < ∼ 30 ) are not ′′ resolved in the NuSTAR images. This is because the structures are smaller than the FWHM ( ∼ 18 ) of ′′ the NuSTAR PSF. Also note that RCW 89, ∼ 6-7 ′ north, is not clearly visible in the NuSTAR data. This is mainly because the NuSTAR observations did not have much exposure in that region; most of RCW 89 fell outside the FoV during the observations.
To measure the size of the narrow structures around the pulsar, we projected events between -50 ′′ and 50 ′′ in the y-axis direction onto the x-axis in several energy bands. The profile is very asymmetric and is not smooth on large scales ( R > ∼ 100 ). ′′ Furthermore, the deconvolution produces artificial structures in the outer regions due to the paucity of counts. Therefore, defining a size (e.g., full width 1% maximum) is impractical on a large scale. However, the source images are smooth on smaller scales ( R < ∼ 50 ), allowing us to measure the FWHM and ′′ HWHM in the northern and the southern directions of the projected profiles in several bands without smoothing the images. We measured the sizes by calculating the relative brightness with respect to the peak, and show them in Figures 4a-c. Although there are different structures in the northern and the southern directions, the HWHM's are similar to each other and to half the FWHM.
We calculated the spectrumand response-weighted average energy for each energy band, fit the widths to a power-law function R E ( ) = R E 0 m as suggested by Reynolds (2009), and measured the decay index m for various y-integration widths (e.g., ∼ 40-130 ). The mea-′′ sured decay index was stable over this range, as shown in Figure 4d. Note, however, that our measurement is based on deconvolved images, and our uncertainties are therefore approximate.
(a)
Figure 2. MSH 15 -5 2 images measured with NuSTAR and Chandra in a 10 ′ × 12 ′ rectangular region: ( a ) A NuSTAR and Chandra combined false-color image in the 0.5-40 keV band (see http://www.nustar.caltech.edu/image/nustar140109a), and intensity maps (b-h) of ( b ) Chandra 0.5-2 keV, ( c ) Chandra 2-4 keV, ( d ) Chandra 4-7 keV, ( e ) NuSTAR 3-7 keV, ( ) f NuSTAR 7-12 keV, ( g ) NuSTAR 12-25 keV, ( h ) NuSTAR 25-40 keV, and ( ) i NuSTAR exposure map and a box corresponding to the images. For the NuSTAR data, we used off-pulse time intervals only in order to minimize the effect of the central pulsar PSR B1509 -58. Exposure and vignetting corrections are applied to the images. A circle with radius 30 ′′ is shown in panels b-h in black for reference. Note that the images use a logarithmic scale, and each image has a different background level.

Figure 3. Projected profiles at several energy bands. The profiles are obtained by projecting the images in Fig. 2 onto the jet axis and smoothing over 25 ′′ .
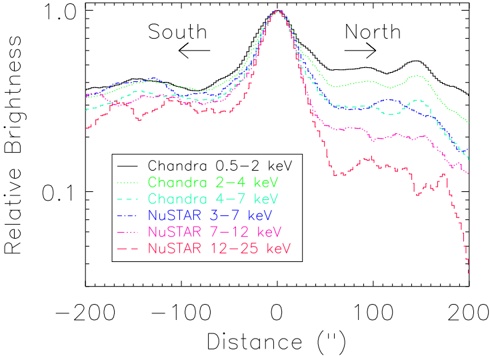
The image analysis shows a spectral change with radius in the PWN, and we therefore tried to see differences in spectra at different radii. We extracted spectra in various regions as described, and backgrounds from source-free regions, and fit them with an absorbed power-law model.
Since spatial blurring due to the PSF size is much more significant for NuSTAR than Chandra , we did not attempt to fit the spectrum jointly except for one case of using a large aperture (Section 3.3.1), where PSF 'blurring' is not a large effect. However, we jointly fit the spectra taken with single telescope at different epochs.
We used the χ 2 and the lstat statistics in XSPEC 12.8.1 to fit the spectra (Arnaud 1996). Results from the two methods were consistent, and we primarily report the results obtained with the χ 2 statistics. Since the NuSTAR data are not sensitive to the hydrogen column density ( N H ) and the results are not affected by small change of N H , we froze it at a previously reported value (0 95 . × 10 22 cm -2 ; Gaensler et al. 2002). We used a cross-normalization factor to account for a slight difference between NuSTAR module A and B, and between observations. For the Chandra data fitting, we let N H vary and introduced a cross-normalization factor between observations.
## 3.3.1. Spectrum of the Entire Nebula
We first measured the total spectrum of the PWN using a source extraction aperture of R =5 centered at the ′ pulsar position for a phase interval 0.7-1.0 in the NuSTAR data. Photons with energies up to ∼ 20-30 keV were detected above background for each observation. We extracted a spectrum for this aperture in each of the three NuSTAR observations, N1, N3 and N4 in Table 1, and jointly fit the spectra to a power law. The measured power-law index is 2.06 and the absorptioncorrected 3-10 keV flux is 5.9 × 10 -11 erg cm -2 s -1 (see Table 2). For the Chandra data, we extracted source spectra using the same 5 ′ aperture, ignoring the central 5 ′′ in order to minimize the pulsar contamination, and jointly fit the five Chandra spectra of each region to a power-law model in the 0.5-7 keV band because background dominates above 7 keV. We note that the
Chandra data fits were not acceptable with χ 2 /dof of 2632/2214 ( p = 1 × 10 -9 ), having large residuals in the low energy band below 2 keV. This is perhaps because the large regions are a mixture of subregions with different spectra (e.g., see Section 3.3.4). We therefore fit the data above 2 keV only with frozen N H . When removing photons below 2 keV, the remaining data were fit to a single power-law model with a slightly smaller photon index, having χ 2 /dof=1757/1704 ( p = 0 18). . The crossnormalization factors for the five Chandra observations are all within 1%. Note that letting N H vary also yields an acceptable fit ( χ 2 /dof=1756/1703) with N H =0.91(4) and Γ = 1 90(1). .
The Chandra -measured spectrum in the 2-7 keV band is significantly harder than that measured with NuSTAR in the 3-20 keV band. We note that our results are consistent with the previous measurements made with BeppoSAX and INTEGRAL (Mineo et al. 2001; Forot et al. 2006). Mineo et al. (2001) reported a photon index of 1.90(2) in the 1.6-10 keV band for a 4 ′ aperture, which is consistent with our Chandra measurement in the 2-7 keV band. In the hard band, the reported photon indices were 2.1(2) and 2.12(5) for BeppoSAX (20-200 keV) and INTEGRAL (15-100 keV), respectively. Note that the large apertures used for BeppoSAX and INTEGRAL include the RCW 89 region, but the effect of RCW 89 is negligible because the emission is very soft (Yatsu et al. 2005) and the telescopes operate only above 15 keV. The photon index we measure with NuSTAR in the 15-30 keV band is 2.1(1) for the 5 -aperture, which agrees with the previ-′ ous measurements. The results of our measurements are summarized in Table 2.
Since the large apertures include many subregions with different spectral properties as we show below (see Sections 3.3.1, 3.3.3, and 3.3.4), a single power law may not properly represent the combined spectrum. In particular, we find that the best-fit photon index for the Chandra data becomes smaller as we ignore lower energy spectral channels, that is, the spectrum appears to harden (is concave up) as we move to higher energies. However, this is the opposite to what we see with NuSTAR (Table 2). While this may imply a spectral break in the X-ray band, some other effects such as contamination from the pulsar and/or RCW 89, or cross-calibration systematics between the two instruments may have some impact. Therefore, we investigate some possibilities below in order to see if the discrepancy in the spectral index measurements of NuSTAR and Chandra is caused by a spectral break.
First, we note that the pulsar contamination was not completely removed in the Chandra data. Excising 5 ′′ leaves 2-5% pulsar emission in the R = 5 ′ aperture, which may bias the PWN spectrum. In order to see the effects quantitatively, we fit the pulsed spectrum of the pulsar in the NuSTAR data (total spectrum minus the DC level in Fig. 1) with a power-law model and find that the photon index is 1.36(1) and the 3-10 keV flux is 2 24(3) . × 10 -11 erg s -1 cm -2 which broadly agree with the previous measurements (Cusumano et al. 2001; Ge et al. 2012). We added this pulsar component to the Chandra fit assuming 5% of the pulsar emission is in the 5 ′ aperture after the 5 ′′ excision. Thus, the spectral model was a double power-law model, one for the
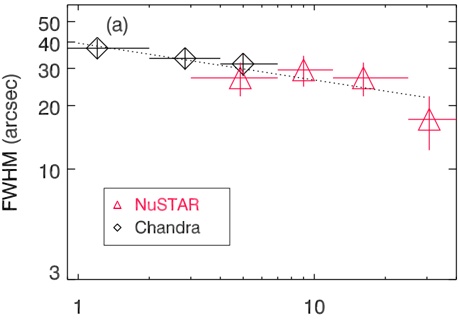
Figure 4. Widths of projected profiles in several energy bands and the best-fit power-law functions, R E ( ) = R E 0 m , for the FWHM (a), HWHM of the northern (b) and the southern (c) nebulae for a width of 100 ′′ , and the decay indices m vs integration widths (d).
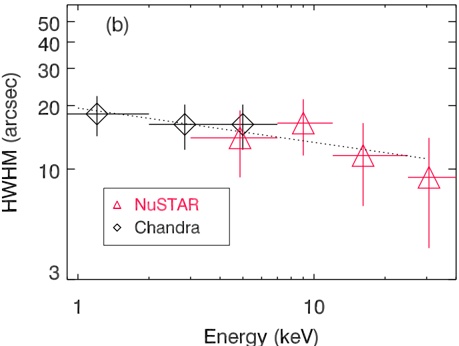
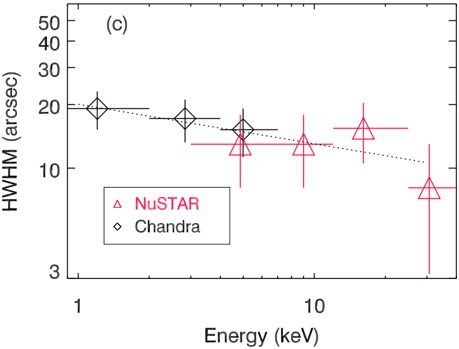
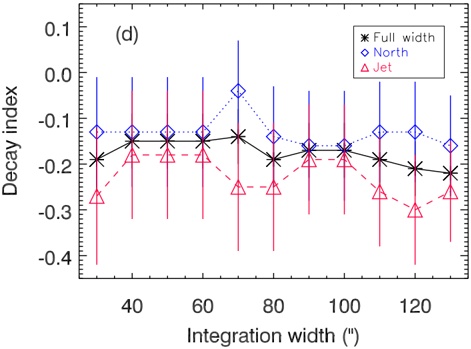
pulsar emission and the other for the PWN emission. We froze the pulsar component, fit the PWN spectrum, and find that the spectral index of the PWN does not change. Since the spectral index of the pulsed spectrum may be different in the soft band, we changed the spectral index of the pulsar component to 1.19 as reported by Cusumano et al. (2001) in the 1.6-10 keV band, and find that the photon index of the entire PWN softens only by ∆Γ = 0 01. We further increased the pulsar flux by 10% . and find no change in the spectral index of the PWN. We verified the results by increasing the excision region to 10 ′′ . Note that the DC component of the pulsar is not included in this study. However, the unmodeled DC component is much smaller than the pulsed component as seen in Figure 1, so the effect would be negligible in the Chandra data fit.
Second, we consider the effect of the pulsar DC component in the NuSTAR data. Although the DC component is negligible in the Chandra data due to the image filtering, the DC component presents in the NuSTAR data because time filtering does not remove the DC emission. Although it is not possible to measure the DC spectrum accurately, we estimated 3-10 keV DC flux using a 30 ′′ aperture as follows. With NuS-
TAR , we measure the total (pulsed+DC+nebula) and the pulsed flux to be 3 29 . × 10 -11 erg s -1 cm -2 and 2 24 . × 10 -11 erg s -1 cm -2 , respectively. The nebula flux is measured to be 7 5 . × 10 -12 erg s -1 cm -2 with Chandra (Section 3.3.3). By subtracting the pulsed and the nebula flux from the total flux, the 3-10 keV DC flux is estimated to be 3 1 . × 10 -12 erg s -1 cm -2 . We assumed that the photon index is 1.7, similar to the NuSTAR -measured value for the 30 ′′ aperture (Section 3.3.3). We included the DC emission in the NuSTAR fit of the 5 -aperture ′ spectrum, and followed the procedure described above for the pulsar contamination estimation in the Chandra data. This procedure effectively removes the DC component from the PWN spectrum. However, note that removing such a hard spectrum only softens the spectrum of the entire PWN, making the discrepancy larger. We therefore arbitrarily changed the photon index of the DC component to 2.5 to mitigate the possibility of having very soft DC emission and find that the photon index of the entire PWN hardens only by ∆Γ = 0 02. .
Third, we varied the background level by ± 30%, and found that spectral indices change only by 0.02 and 0.01 for Chandra and NuSTAR , respectively. We also used different background regions and found that the spectral
Table 2 Best-fit parameters for the total PWN emission spectrum
| Data a | Model b | Radius ′ | Energy (keV) | N H c (10 22 cm - 2 ) | Γ s | F PL d | E break (keV) | Γ h | χ 2 /dof |
|----------|-----------|------------|----------------|-------------------------|----------|----------|-----------------|---------|------------|
| C | PL | 5 | 2-7 | 0.95 | 1.912(5) | 5.98(2) | · · · | · · · | 1757/1704 |
| C | PL | 5 | 3-7 | 0.95 | 1.90(1) | 6.00(3) | · · · | · · · | 1408/1359 |
| N | PL | 5 | 3-7 | 0.95 | 2.03(2) | 5.93(7) | · · · | · · · | 543/587 |
| N | PL | 5 | 3-20 | 0.95 | 2.06(1) | 5.91(5) | · · · | · · · | 1895/1887 |
| N | PL | 5 | 15-30 | 0.95 | 2.1(1) | 6.6(1) | · · · | · · · | 576/579 |
| N + C | PL | 5 | 2-20 | 0.95 | 1.950(4) | 5.77(5) | · · · | · · · | 3878/3592 |
| N + C | BPL | 5 | 2-20 | 0.95 | 1.918(5) | 5.88(5) | 6.3(3) | 2.12(2) | 3691/3590 |
Notes. 1 σ uncertainties are given in parentheses at the same decimal place as the last digit. a
- N: NuSTAR , C: Chandra .
- b PL: powerlaw model, and BPL: bknpower model in XSPEC .
- d Absorption corrected 3-10 keV flux in units of 10 -11 erg s -1 cm -2 .
- c Frozen.
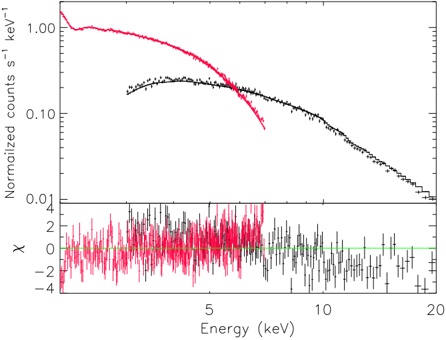
Figure 5. Joint fit results of the NuSTAR and the Chandra spectra for the single power-law (left) and the broken power-law (right) models. Spectra obtained with each telescope are merged for display purpose only.
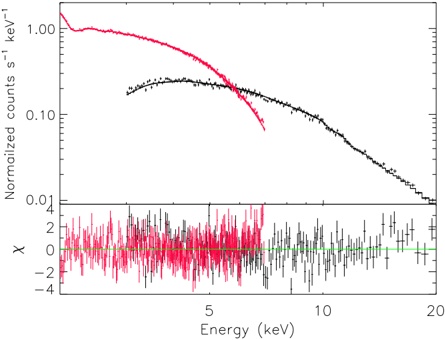
indices do not change significantly.
Finally, we estimate the contamination of the RCW 89 emission in the NuSTAR data. Using the NuSTAR PSF, we estimated the contamination of a structure at ∼ 6 ′ into the 5 ′ circle to be ∼ 14%. We extracted the RCW 89 spectrum from the NuSTAR observation N1 which sampled the RCW 89 best among the NuSTAR observations. We added the spectrum as additional background in the PWN spectral fit. Since the other observations N3 and N4 sampled only a small fraction of the RCW 89 region, we used the RCW 89 spectrum extracted from N1 for these observations as well. We varied the normalization of the RCW 89 background from 0.14 to 0.28 in order to account for the fact that the actual RCW 89 region may be larger than what we sampled with NuSTAR , and found that the photon index changes by < ∼ 0.02.
TEGRAL did. Since NuSTAR is calibrated so that the spectrum of the Crab nebula is a simple power law with a photon index of 2.1, larger than the Chandra -measured value of 1.95 (Kirsch et al. 2005), the spectral break we see for MSH 15 -5 2 could be explained by imperfect cross-calibration.
The large discrepancy in the spectral index measurements between NuSTAR and Chandra cannot be explained by a combination of the above effects. We therefore consider alternatives below. We note that there may be cross-calibration systematics between NuSTAR and Chandra . For example, Kirsch et al. (2005) showed that systematic uncertainties between X-ray observatories caused by cross calibration are significant using observations of the Crab nebula, for which the authors found that Chandra and BeppoSAX /LECS measured smaller spectral indices than BeppoSAX /MECS and IN-
However, the cross-calibration effects may be different from source to source depending on the spectral shape, and the measurements made for the Crab nebula may not be directly translated into the case of MSH 15 -5 2 . We therefore consider an alternative; the discrepancy of spectral indices between the Chandra and the NuSTAR measurements is caused by a spectral break. We jointly fit the 2-7 keV Chandra and the 3-20 keV NuSTAR data with a single power law and a broken power law. We find that a single power law does not describe the data well having χ 2 /dof=3878/3592 ( p = 5 × 10 -4 ), but a broken power law with a break energy of 6.3 keV does ( χ 2 /dof=3691/3590, p = 0 12). The results are pre-. sented in Table 2 and Figure 5.
We compared the NuSTAR and the Chandra spectra in the same energy range below the possible break at 6 keV in order to see if the break is a single sharp break. If so, we expect the NuSTAR and the Chandra spectra to be same regardless of the difference in the effective area shape. We fit the NuSTAR and the Chandra spectra in the common energy band, defined as 3E max , where
Figure 6. Azimuthal variation of spectral hardness and flux measured with NuSTAR (triangles) and Chandra (diamonds) at R = 60 ′′ (a), R = 120 ′′ (b), and R = 180 ′′ (c) from the pulsar. Sinusoidal trends for the photon index variation are shown in dotted lines, and solid lines connecting flux data points are shown for clarity. Flux is in units of 10 -12 erg s -1 cm -2 . N H values measured with Chandra for the same regions are shown in (d)-(f).
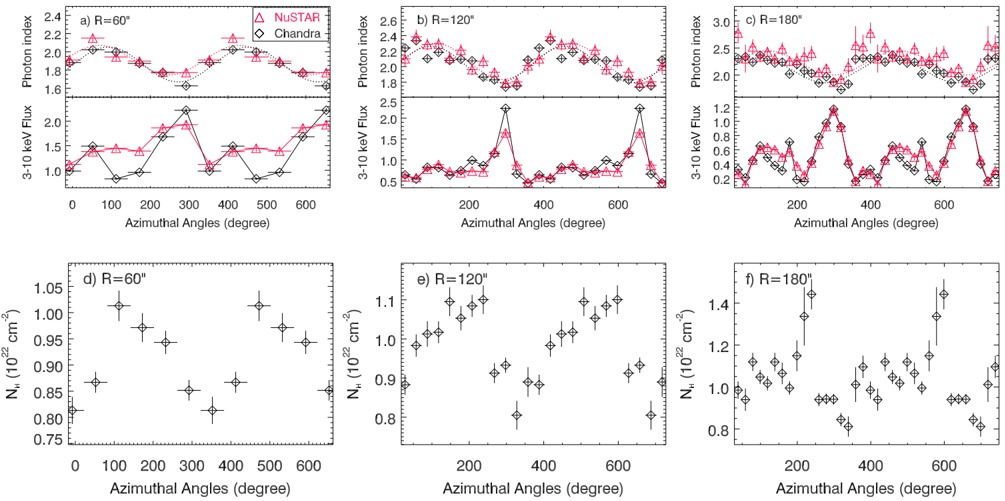
we vary E max from 4.5 keV to 7 keV. In the lowest energy band (3-4.5 keV), the NuSTAR and Chandra results agreed with photon indices of 1.99(7) and 1.98(2). However, as the upper energy range increased to 5 keV and above, the NuSTAR results were significantly softer than that of Chandra . For example, the photon indices are 2.03(2) and 1.90(1) in the 3-7 keV band, for NuSTAR and Chandra respectively, inconsistent with each other with 90% confidence. This suggests that the spectral break is likely to be caused by the cross-calibration effect. However, if the spectral break is real, the observational discrepancy in the common energy band may imply that the broadband spectrum is not sharply broken at 6.3 keV but slowly curves over a energy range (e.g., 4-7 keV) probably because different regions in the 300 ′′ aperture have different break energies. In this case, NuSTAR collects relatively more photons above the break than Chandra does since it has rising effective area in that band, yielding a softer spectrum.
## 3.3.2. Azimuthal Variation of the Spectrum
In order to see if the PWN spectrum varies azimuthally, we first extracted NuSTAR events in 30 ′′ radius circles for six, twelve, and eighteen azimuth angles for three radial distances, 60 ′′ , 120 , and 180 ′′ ′′ from the pulsar, respectively. The regions do not overlap. For each region, backgrounds were extracted from an aperture of R = 45 ′′ in a source-free region on the same detector chip. We jointly fit the NuSTAR spectra for the three observations N1, N2 and N4. The energy ranges for the fit were 3-20 keV, where the source events were detected above the background. We performed these analysis for the same regions with the Chandra data in the 0.5-7 keV band.
We show the results in Figure 6, where the azimuth angle φ is defined from east in a clockwise direction. A sinusoidal variation of the spectral hardness is clearly visible for each radial group, and the spectrum is hardest in the jet region ( φ ∼ 300 ). ◦ The flux values also peak in the jet regions but do not seem to vary sinusoidally. Note there is a small discrepancy between the NuSTAR and Chandra measurements in Figure 6; the NuSTAR -measured spectral indices are larger than those measured with Chandra in general. While this may suggest the spectral break we see in the spectrum of entire nebula (Section 3.3.1), it could be due to PSF mixing in the NuSTAR data; when there is a sharp spatial contrast such as the jet or image edge, it is convolved with the PSF in the NuSTAR data.
It appears that the photon index covaries with N H in Figure 6. We checked if there is a correlation between the two quantities using Pearson's product moments, and found no clear correlation in any radial group.
## 3.3.3. Spectral Variation in the Northern Nebula and in the Jet
Since we observe significant spectral variation in the azimuthal direction, we analyzed the northern nebula and the jet separately. For the northern nebula we used annular regions, ignoring the southern part. Hence, each region covers the upper > ∼ 180 ◦ in azimuth angle. The innermost region was a circle with radius 30 ′′ centered at the pulsar, and annuli with width 30 ′′ or 60 , ′′ and boxes were used for the outer regions (see Fig. 7a white). We used the off-pulse phase only for NuSTAR , and ignored the central pulsar using a circle with radius 5 ′′ for Chandra .
Figure 7. Selected regions for studying the spectral variation in the northern nebula (white annuli and boxes) and in the jet (yellow circles) (a), and spectral variation in the northern and the southern jet directions (b)-(e). Radial variation of the photon indices and surface brightness in the northern nebula (b) and in the jet (c) measured with NuSTAR (triangles) and Chandra (diamonds). Also shown are the best-fit broken line (blue solid line) and the power law (magenta dotted line). Legends are same for (b) and (c). Brightness is measured in the 3-10 keV band in units of 10 -15 erg s -1 cm -2 arcsec -2 . Radial profiles of N H measured with Chandra are shown in (d) for the northern nebula and in (e) for the jet. Note that the range for the x-axis of (d) is different from that of (b) because N H was not measured for the last two data points in (b).
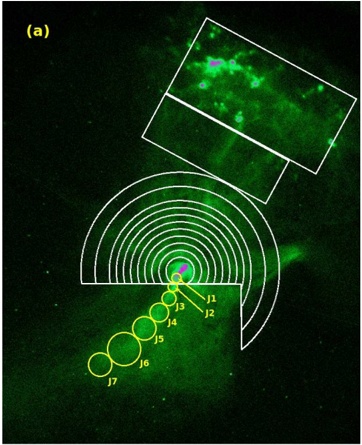
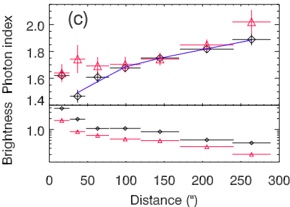
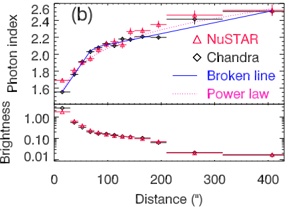
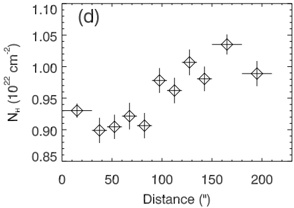
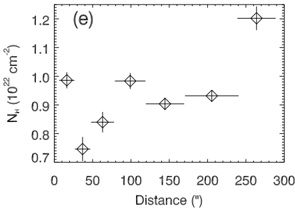
We separately fit the NuSTAR (N1, N2, and N4) and the Chandra (C1-C5) spectra of each region with an absorbed power-law model. Since there is significant thermal contamination from RCW 89 in the Chandra data at large distances (see the two upper white box regions in Fig. 7a), we ignore the low energy data below ∼ 3 keV for the two rectangular regions for the Chandra fits. We also tried to model the RCW 89 regions using the vnei plus a power law in XSPEC , and fit the Chandra data in the 0.5-7 keV band. The result for the photon index was sensitive to the remnant model but broadly agree with what we found by fitting data above 3 keV only (see also Yatsu et al. 2005). Our results for the Chandra data are consistent with, but more accurate than those obtained by DeLaney et al. (2006) who used ∼ 60 ks of observations taken from 2000 August to 2003 October. We present our measurements in Figure 7b and d.
There is a hint of a possible break in the linear slope of the radial profile of the photon index Γ( R ) (Fig. 7b). We measured the location of the break in the northern nebula using a broken line fit. We first fit the Chandra measured photon index profile, and found that the break occurs at R break = 71 ± 3 . We note that using a constant ′′ N H over the field changes Γ only slightly and gives a consistent result ( R break = 68 ± 2 ′′ ). The NuSTAR profile gives a larger R break = 150 ± 10 ′′ because of the large photon index at smaller radii which might be biased by mixing from outer regions. We also find that a single powerlaw model Γ( R ) = Γ 0 R η with η = 0 149 . ± 0 003 broadly . agrees with the data (see Fig. 7b).
While our results show that N H increases with radius, we note that it is possible to force the N H to be constant and allow only the photon index to vary. For example, an N H value of 0 957 . ± 0 005 . × 10 22 cm -2 constant over the field with photon indices of 1.58-2.16 fits the data out to R = 200 ′′ in Figure 7 ( χ 2 /dof=12289/12363), which implies no radial variation of N H and smaller variation of the photon index with radius. However, the N H profile given in Figure 7d provides better fit with χ 2 /dof=12223/12353 corresponding to F-test probability of 2 × 10 -10 . We also verified that the results do not change if we fit the spectra only in the 0.5-6 keV (below the spectral break, see section 3.3.1) in order to reduce the effect of the complex continuum. We note that better constraining Γ and N H by jointly fitting the NuSTAR data is not possible because of the PSF mixing in the NuSTAR data and the spectral break (Section 3.3.1).
Since spectral softening is expected in the jet direction as well, we measured the spectral variation along the southern jet. To do this, we extracted source spectra using non-overlapping circular apertures with radii 10 ′′ , 10 , 15 ′′ ′′ , 20 ′′ , 25 , 35 ′′ ′′ , and 25 ′′ along the jet (see yellow circles in Fig. 7a), which we refer to as regions J1-J7. Note that the center of J1 is R ∼ 15 ′′ from the pulsar, and all the NuSTAR observations (N1-N4) were used for this analysis. We fit the spectra in each region with an absorbed power law, and measured the photon index and flux. The results are presented in Figures 7c and e.
The spectral indices of the J2 region measured with Chandra and NuSTAR are very different, which may suggest that there is a strong spectral break. However, we note that measuring the spectral parameters with NuSTAR was difficult for regions with sharp spectral changes because the NuSTAR PSF changes from a circular shape to an elliptical shape with off-axis angle (An et al. 2014), and thus regions with different off-axis angles have different degrees of azimuthal mixing. The four NuSTAR observations had different pointings and thus different
Figure 8. The spectral indices in the central regions, corresponding to the innermost two data points of Fig 7 ( R < 50 ′′ ), with a higher spatial resolution.
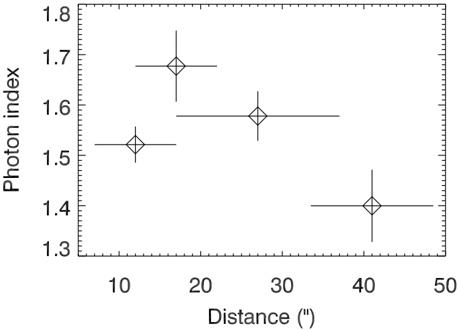
off-axis and azimuthal angles. In particular, in the regions J1-J2 where we use small apertures and the source spectrum strongly varies, spatial mixing has significant impact on the NuSTAR results. Therefore, the discrepancies in the spectral index between the NuSTAR and Chandra measurements, and even between the NuSTAR observations are expected. The mixing was not a concern in the analysis of the northern nebula in which spectral variation is not severe.
We also measured the location of the break in the radial profile of the photon index in the jet direction using the Chandra measurement in Figure 7c. Here we ignored the first data point for the reason described below. A fit to a broken line gave a break location of R break = 110 ± 30 . ′′ A single power-law model also fits the data with a power index η = 0 12 . ± 0 01 (Fig. 7c). .
We note that the first Chandra data point, corresponding to region J1, shows a very soft spectrum compared to the next one in J2, unexpected in synchrotron cooling models (e.g., Reynolds 2003; Tang & Chevalier 2012). The steady-state solutions may not be applicable to the inner region within ∼ 1 ′ of the pulsar for this source, as DeLaney et al. (2006) found strong variability in the brightness and morphology in that region.
We tried to see if the spectral hardness in J1 varied over time. We first jointly fit the Chandra spectra of the region taken from the five observations C1-C5 with a common N H , but separate photon index and cross normalization for each observation, and found that the photon indices are all within the 1 σ uncertainty of the value in Figure 7. We carried out the same analysis for the J2 region, and found that the spectrum of one observation (C1, Obs. ID 754) was slightly softer than the others (Γ = 1 62 . ± 0 12) but not significantly. . It is probably because the region in this observation fell on the detector chip gap. Therefore, we conclude that the spectral index did not change significantly over time in this region.
Since spectral hardness covaries with N H , the spectral difference between the J1 and J2 regions may be less significant if we consider the covariance. In order to investigate the effect of covariance, we ignored Obs. ID 754 because the J2 region in this observation was on the chip gap. We then jointly fit the spectra of each region, varied both N H and Γ using the steppar tool in
XSPEC and found that the 99% contours do not overlap, which suggests that the difference is significant with the covariance as well, and the spectrum of the J1 region is significantly softer than that of the J2 region. If we take the best-fit values, the N H variations of ∼ 3 × 10 21 cm -2 imply extremely high densities of n ∼ 2000 cm -3 for an assumed line-of-sight distance of 0.5 pc (similar to the transverse distance for the assumed distance to the source of 5.2 kpc) in the regions with high N H .
We further spatially resolved the J1-J2 regions using overlapping circular regions with radius 5 ′′ . We fit the spectrum of each region with a power-law model, and found spectral softening in the innermost regions ( R < ∼ 20 ). ′′ We show the photon indices in Figure 8.
Note that N H increases with radius in the northern nebula. In the jet direction, we used finer spatial resolution, and see a more complicated change; there is a dip at R =30-70 . At large distances, we find that ′′ N H is large. This structure is visible in the 2-D N H map as well (see Fig. 9). Note also that the power-law index ( η ) of the photon index profile is larger in the northern nebula than in the jet, that is, the spectral steepening is more rapid, which was also implied by the imaging analysis above (e.g., Fig. 3).
## 3.3.4. 2-D Maps of the Spectral Parameters
We produced 2-D maps of the spectral parameters for the ∼ 9 ′ × 11 ′ field containing the PWN. We used a 1 ′ × 1 ′ square region, sliding it over the field with a step of 0.5 . ′ Thus, two adjacent regions overlap by 50%. Backgrounds were extracted from far outer regions. In order to minimize the pulsar contamination, we excluded a circular region with radius 5 ′′ for the Chandra data, and used the pulse phase 0.7-1.0 only for the NuSTAR data.
After extracting 0.5-7 keV spectra in each region for the five Chandra observations, we jointly fit the spectra with a common absorbed power-law model having different cross normalization factors between observations and allowing all the parameters to vary throughout. The same procedure was applied to the NuSTAR data in the 3-20 keV band with N H frozen to the Chandra -measured value in each region. After producing the 2-D maps, we select regions with positive flux with 3 σ confidence and show the results in Figure 9. The average (median) of the 1 σ uncertainties for the parameters obtained with the Chandra data were 1 8 . × 10 -14 erg cm -2 s -1 (1 6 . × 10 -14 erg cm -2 s -1 ), 0.07 (0.05), and 5 6 . × 10 20 cm -2 (3 6 . × 10 20 cm -2 ), for flux, photon index, and N H , respectively. For NuSTAR , the uncertainties were 6 0 . × 10 -14 erg cm -2 s -1 (5 8 . × 10 -14 erg cm -2 s -1 ) and 0.15 (0.12) for flux and photon index, respectively. The flux map shows the structures seen in the count map (Fig. 2). We also note that the photon index map shows the same structure seen in the radial and the azimuthal profiles (Figs. 6 and 7); the photon index increases radially outwards.
We find an interesting shell-like structure in the N H map (top right panel of Fig. 9). Since it is possible that the structure is produced by a correlation between Γ and N H , we calculated the correlation coefficient between pairs of parameters using Pearson's product moments. The coefficients were transformed into Fisher coefficients to calculate the significance. In this study, we
Figure 9. Top: 2-D maps of 3-10 keV brightness in units of 10 -12 erg cm -2 s -1 arcmin -2 , power-law photon index, and N H (from left to right) measured with Chandra by fitting the spectra in the 0.5-7 keV band. Bottom left and middle: Brightness and photon index measured with NuSTAR by fitting the spectra in the 3-20 keV band. Bottom right: Chandra counts map and the field for the 2-D maps (white dashed box). The location of the pulsar, PSR B1509 -58, is noted with a star except for in the bottom right plot. We arbitrarily assigned zero values to the spectral parameters in regions where the parameters are unconstrained due to paucity of source counts (dark blue regions).
found that the correlation between flux and photon index is -0 58, and the significance is 12 . σ , implying the correlation is statistically significant. No correlation was found between N H and Γ or any other combination of parameters.
we note that quantitative comparison with the NuSTAR map is difficult unless we know the details of the broadband spectrum in each region.
We further tried to fit the Chandra data with a single N H value of 0 95 . × 10 22 cm -2 for the entire nebula, and found that the fits became worse, having average χ 2 per average dof of 555/547 compared to the value of 538/546 for the fit with variable N H . The single N H fit turned the large N H regions into spectrally hard regions which are not visible in the NuSTAR map. However,
## 4. DISCUSSION
We have presented the first hard X-ray images of MSH 15 -5 2 above ∼ 8 keV. The broadband images show the synchrotron burn-off effect which is asymmetric in space (see Figs. 2 and 3). We find a possible spectral break at E break = 6 keV in the spectrum of entire PWN. From the spatially resolved spectral analysis, we found that the spectral index varies sinusoidally in the azimuth
direction from ∼ 2 in the north to 1.6 in the south at a distance of 60 ′′ (1.5 pc) from the pulsar and monotonically increases with distance from 1.6 to 2.5 (Fig. 7). These trends were observed with both NuSTAR and Chandra . We found that spectral hardness turns over at R = 35 ′′ and decreases more slowly beyond R ∼ 60 ′′ along the jet (Fig. 7), and showed that there is a previously unrecognized shell-like structure of radius ∼ 3 ′ in the N H map (Fig. 9).
## 4.1. Image
The NuSTAR images in the hard band ( > ∼ 7 keV, Figs. 2e-h) show that the source shrinks with energy in the 2-D projection on the sky, which is attributed to the synchrotron burn-off effect. While the effect has been shown for this source in a previous study of azimuthally integrated spectra (Sch¨ck et al. 2010), o this is the first time it is shown with a 2-D imaging analysis over a broad X-ray band. In particular, we found that the burn-off effect is stronger in the northern direction than in the jet direction (Fig. 3). Although it is very difficult to build a full 2-D model that can reproduce the measured images, matching overall morphological changes in energy may give us important clues to understand particle outflow in the PWN.
The change of the size with energy can be used for inferring properties of the particle flow in the PWN using theoretical models (Kennel & Coroniti 1984; Reynolds 2009). For example, the results of Reynolds (2009) can be rewritten in a form appropriate for sources whose spectral break ∆ between radio and X-ray power laws, and size index m can both be measured:
$$\frac { \Delta } { ( - m ) } & = \left ( \frac { 1 } { \epsilon } \right ) \left ( 1 + 2 \epsilon + \left ( 3 + 2 \alpha _ { r } \right ) m _ { \rho } / 3 + \left ( 1 + \alpha _ { r } \right ) m _ { b } \right ), \quad \underset { \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$
$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$ \end{vmatrix} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array}} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{\array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end</array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c _ { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} { c } \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \\ \end{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{arr} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \begin{array} \, \$$
where m x is the index of an assumed power-law function for a quantity x ∝ R m x ( x = ρ or b for mass density and magnetic-field strength, respectively), α r is the energy index of the radio spectrum, and /epsilon1 is a confinement parameter (e.g., /epsilon1 = 1 for conical jets, Reynolds 2009). For the values we derive for MSH 15 -5 2 of α r = 0 2, . ∆ = 0 86 . , and m = -0 2 (Section 3.2), the formula gives .
$$1 + 1. 1 m _ { \rho } + 1. 2 m _ { b } = 2. 3 \epsilon.$$
This condition requires either that the mass in the flow is not constant (for instance, due to mass evaporated from thermal gas filaments joining the outflow; Lyutikov 2003), or that magnetic flux is not conserved (for instance, due to turbulent amplification or reconnection): either m b or m ρ , or both, must be positive. Various combinations of gradients can reproduce our results. For instance, a conical flow /epsilon1 = 1 requires 1 1 . m ρ +1 2 . m b = 1 3, . approximately met if density is constant and magnetic field rises as radius - or vice versa. A confined flow with /epsilon1 = 0 44 (roughly parabolic) would have . m ρ ∼ -= m b , which could be satisfied with both constant density and constant magnetic field, or with one dropping as fast as the other increases.
## 4.2. Spectra of the Entire PWN
We find that the integrated spectrum of the entire nebula measured with NuSTAR is a simple power law with photon index 2.06 (Table 2). This is similar to values previously reported based on BeppoSAX and INTEGRAL data (Γ = 2 08 . ± 0 01, . 2 12 . ± 0 05; . Mineo et al. 2001; Forot et al. 2006). The Chandra -measured parameters for a single power-law model above 2 keV imply a harder spectrum than that measured with NuSTAR (see Table 2), which is also seen in the spectra extracted for other inner regions (e.g., Figs. 6 and 7). We note that our Chandra spectral fit results are consistent with that measured previously with BeppoSAX (Γ = 1 90 . ± 0 02 . in the 1.6-10 keV band for a 4 ′ aperture, Mineo et al. 2001).
Since the large aperture include many subregions with different spectral parameters, we expect to see a harder spectrum at high energies if the spectra of the subregions are simple power laws in the 0.5-20 keV. However, the 3-20 keV NuSTAR spectra are much softer than the Chandra spectra, which is the opposite to what is expected from a sum of simple power-law spectra. We find that contamination of the pulsar and the backgrounds can explain only ∼ 0 01 . of the photon index discrepancy of the NuSTAR and Chandra measurements, while the measured difference is 0.15. The correction for the pulsar, the RCW 89 contamination and the background variation in the data seem not to explain the discrepancy between the NuSTAR and the Chandra results.
We find that the discrepancy between the NuSTAR and the Chandra measurements is likely to be caused, at least in part, by imperfect cross calibration of the instruments. However, if the break is real, it implies a break in the energy distribution of the shock accelerated electrons at ∼ 200 TeV (having the peak synchrotron power at 6 keV) for a magnetic field strength of 10 µ G, assuming synchrotron emission (e.g., Equation 5 in TC12).
We note that a spectral break in the X-ray band has recently been reported for G21.5 -0.9 (Nynka et al. 2014) and the Crab Nebula (Madsen et al. 2014) and may be common to other young PWNe as well. If true, this has important implications on the particle acceleration mechanism in PWNe. Sensitive broadband X-ray observations of other PWNe will be helpful.
## 4.3. Spectral Variation
Using the broadband X-ray data obtained with NuSTAR and Chandra , we find an azimuthal variation of the spectral index. For the PWN 3C 58, Slane et al. (2004) suggested a possible azimuthal variation of the spectral hardness based on a scenario where current flows out from the pulsar's pole and returns in the equator (Blandford 2002). However, Slane et al. (2004) did not find an obvious azimuthal variation in the PWN 3C 58 within R ∼ 2 pc for a distance 3.2 kpc we find for MSH 15 -5 2 at R =1.5-4.5 pc. Furthermore, we find the azimuthal spectral variation in MSH 15 -5 2 is likely sinusoidal and different from that of the flux. This azimuthal spectral variation of the emission may hint at a large scale current flow, however, it could also be due to azimuthal diffusion of jet particles in MSH 15 -5 2 .
A radial change of the spectral index of MSH 15 -5 2 was reported by Sch¨ck et al. (2010). o While they integrated the spectrum over the full azimuthal angle, we measured the profiles for the northern and the jet directions separately because the two regions are different.
We found that significant softening with radius is seen in both directions, more significantly in the northern region. Interestingly, the radial profile of the photon index (rate of spectral steepening) flattens with radius as is also seen in 3C 58 (Slane et al. 2004).
An outflow model considering both diffusion and advection was developed by Tang & Chevalier (2012) (TC12 hereafter), where they calculated the change of the spectral index with distance from the central pulsar with an assumed electron injection spectrum and diffusion coefficient, and were able to reproduce the radial variation of the spectral index for three compact PWNe, the Crab nebula, G21.5 -0.9, and 3C 58. The model has been applied to PWNe where the particle escape times (the times for particles to diffuse a distance R in the Bohm limit), are longer than their ages (Equation 2 in TC12):
$$t _ { e s c } & \approx 1 6, 0 0 0 \left ( \frac { R _ { P W N } } { 2 \ p c } \right ) ^ { 2 } \left ( \frac { E _ { e } } { 1 0 0 \, \text{TeV} } \right ) ^ { - 1 } \left ( \frac { B } { 1 0 0 \, \mu G } \right ) \, \text{yr}, \quad \text{SED} \\ \text{where $R_{\dots}$ is the problem of the DWN $E$ is the answer}, \quad 6 \, \text{ke} ^ { \quad r }$$
where R PWN is the radius of the PWN, E e is the energy of synchrotron emitting particles, and B is the magneticfield strength in the PWN. Using the size R ∼ 10 pc, E e = 100-600 TeV (Forot et al. 2006; Nakamori et al. 2008), and an estimation of the magnetic-field strength of 8-17 µ G(Gaensler et al. 2002; Aharonian et al. 2005), we find that t esc is 5000-7000 yr, greater than the spindown estimated age of τ c = 1700 yr. Since the photon spectrum we are using in this work corresponds to a smaller E e , t esc can be larger than the above estimation. However, we note that there have been suggestions that the true age of the PWN is > ∼ 6000 yr based on the association with RCW 89, larger than the spin-down estimation (e.g., Seward, Harnden, & Murdin et al. 1983). If so, there may be particles escaping the PWN and the particle spectrum in the outer parts of the PWN becomes steeper, which may be the case for old ( > ∼ 10 5 yr) PWNe. For young PWNe, TC12 uses a reflecting boundary condition at the outer edge of the PWN. We note that the TC12 model is for spherically symmetric PWNe and may not be optimal for MSH 15 -5 2 . However, the azimuthal variation in the northern nebula is not large (see Fig. 6), and thus the model may provide a reasonable description of the source in that region.
In this model, the angular size of the 'flat' region where the radial profile of the spectral index is flat can be used to estimate the diffusion coefficient (Equation 14 of TC12). This is calculated using the following equations:
and
$$\theta _ { \text{float} } \approx \theta \left ( \frac { 6 ^ { 1 / 2 } } { 2 } \left [ \frac { \nu _ { R } } { \nu } \right ] ^ { 1 / 4 } - 1 \right )$$
$$\nu _ { R } & = 1 \times 1 0 ^ { 1 7 } \left ( \frac { D } { 1 0 ^ { 2 7 } \, \text{cm} ^ { 2 } \, s ^ { - 1 } } \right ) ^ { 2 } \left ( \frac { 1 \, \text{pc} } { R _ { \text{PWN} } } \right ) ^ { 4 } \left ( \frac { 1 0 0 \mu G } { B } \right ) ^ { 3 } \, \text{Hz}, \quad \text{ind} \, \text{clear} \\ \text{when} \, \partial _ { \text{ } } \, \partial _ { \text{ } } \, \text{is to an union} \, \text{in of the union} \, \text{th} \, \text{on} \, \partial _ { \text{ } } \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \end{cases}$$
where θ flat is the angular size of the region that has a flat photon index profile, θ is the angular size of the PWN, ν is the photon frequency, and D is the diffusion coefficient.
We find that photon index profile steepens more slowly beyond R = 71 ′′ and R = 110 ′′ in the northern and the jet regions, respectively. Note that the radial profile of the spectral index in the northern nebula shows a flat region between R = 70 -200 ′′ ′′ although the profile seems not to show any flat region in the southern nebula. We use the value for the northern nebula for the size of the flat region of TC12. Assuming the size of the source is R PWN ∼ 300 ′′ and using the above formulae with ν = 2 4 . × 10 17 Hz (1 keV), we estimated the diffusion coefficient to be 4-13 × 10 27 cm 2 s -1 for B =8-17 µ G, which is slightly larger than that estimated for 3C 58 by numerical modeling (2 9 . × 10 27 cm 2 s -1 , TC12).
Using the diffusion coefficient we estimated above, we calculate the critical particle energy E R for which the diffusion distance is equal to the size of the PWN (see Table 3 of TC12) and where the electron distribution has a break (Gratton 1972), using formulae given by TC12: R = (4 D/QE R ) 1 2 and Q = 1 58 . × 10 -3 B 2 erg s -1 . For MSH 15 -5 2 , we find E R to be 130-190 TeV for B =817 µ G. It is interesting to note that this is similar to the maximum electron energies inferred from broadband SED modeling (130 or 250 TeV; Nakamori et al. 2008), and that inferred from the possible spectral break at 6 keV we measured in Section 3.3.1.
We note that the spectrum in the jet direction is significantly softer in the innermost J1 region compared to that in the farther J2 region. Such behavior is not expected in simple advection and/or diffusion models, since the synchrotron emitting particle spectrum only softens with distance. This simple picture may not be appropriate in the regions where the particle flow may be more complicated due to magnetic hoop stress as suggested for this source by Yatsu et al. (2009). The authors found a ringlike structure with R ∼ 10 ′′ using Chandra data and interpreted the structure as the termination shock for this PWN. Based on the morphology, the authors further suggested that the shock accelerated particles are diverted and squeezed towards the poloidal direction right below the ring due to magnetic hoop stress (e.g., Lyubarsky 2002). We also find that the jet structure becomes narrower to R ∼ 35 ′′ and then broader. Furthermore, the spectral hardness turn-over, non-monotonic variation of the spectral index (see Fig. 7), happens near the location where the jet is narrowest, which might be occurring because of the compression of the magnetic fields and particles.
## 4.4. The 2-D Spectral Maps
We presented 2-D maps of the spectral parameters. The maps visualize the properties of the source very well, and can be compared with 3-D PWN models.
We showed that the 2-D map of N H has a shell-like structure. The density is low near the central pulsar, increasing out to R ∼ 3 ′ (see also Figs. 6 and 7). We note that the fit value of N H could in principle be degenerate with other spectral parameters. However, we do not find clear evidence of correlation between N H and photon index or flux from our analysis (see Section 3.3.4), and using a constant N H degrades the fit significantly.
A higher column density is observed in the south and the east directions (see Fig. 9). If the material responsible for N H was produced by the supernova, one would expect the pulsar to have a kick in the opposite direction of the material, towards the north-east direction, which is consistent with the direction of the kick velocity for PSR B1509 -58 estimated by Rots (2004) based on 2800
days of timing. However, Livingstone & Kaspi (2011) found no evidence of proper motion using 28 years of timing data. Nevertheless, we do not see any enhanced emission in the shell-like structure, which makes the supernova ejecta scenario less plausible.
Alternatively, the structure may be an interstellar bubble produced by the stellar wind of the supernova progenitor (e.g., Castor, McCray & Weaver 1975). In the wind model, the size of the bubble is given by a simple formula:
$$R _ { s } ( t ) = 2 8 \left ( \frac { \dot { M } _ { 6 } V _ { 2 0 0 0 } ^ { 2 } } { n _ { 0 } } \right ) ^ { 1 / 5 } t _ { 6 } ^ { 3 / 5 } \, \text{pc},$$
where ˙ M 6 is the mass loss rate of the progenitor in units of 10 -6 M /circledot yr -1 , V 2000 is the speed of the wind in units of 2000 km s -1 , n 0 is the number density (cm -3 ) of the interstellar medium, and t 6 is the time in units of 10 6 yr. The radius of the ring structure we observe is ∼ 5 pc, much smaller than the calculated value for a typical O6 star. However, the value can vary significantly for different input parameters, and due to spatial nonuniformity of the interstellar medium or radiative loss (e.g., Weaver et al. 1977).
The asymmetric shell structure may be explained by outbursts of massive stars. The massive star progenitors of core-collapse supernovae undergo a variety of instabilities that drive episodic mass loss: e.g., pulsations driven by bumps in the continuum opacity (Lamers & Nugis 2002; Fryer, Rockefeller & Young 2006; Paxton et al. 2013) and explosive shell burning (Quataert & Shiode 2012; Arnett, Meakin & Viallet 2014). These outbursts occur up until the collapse of the star and are believed to have large asymmetries. An outburst a few thousand years prior to collapse could explain the features we observe at 5 pc in the remnant.
If, as suggested above, the shell-like structure at R ∼ 3 ′ was formed by the stellar wind, the structure would have to avoid being swept up or destroyed by the SN ejecta. If the supernova ejecta did not fill a full spherical shell, a part of the wind-produced shell can be left over. In this case, density of the shell is expected to be higher in the direction where the supernova ejecta were less dense. We see such a trend when comparing our N H map with the radio image of the SNR (Figs. 2 and 3 of Gaensler et al. 1999); there are more ejecta in the northern region than in the southern region.
We have estimated the mass of hydrogen contained in the observed shell-like structure. Using the measured radial profile of N H shown in Figure 7d, the excess mass compared to the central region is ∼ 460 M /circledot , large compared to the ∼ 12 M /circledot one would estimate for a sphere with R = 5 pc for typical interstellar density of 1 cm -3 . Furthermore, the large amount of material in the structure should produce H I emission, which we do not see in the 20 cm map (Fig. 4 of Gaensler et al. 1999). This may be because the radio continuum emission was not subtracted in the radio map and/or because the X-ray measurement is sensitive only to foreground material while the radio observations are sensitive to both foreground and background structures.
We note that we cannot unambiguously rule out the possibility of a constant N H over the field; the observed
N H being an artifact of a more complex underlying continuum. Thus, it is very difficult to clearly interpret the structure using X-ray observations only. Nevertheless, if the shell-like structure in the N H map is intrinsic to the source, it may support the idea of the existence of an underdense region around the supernova progenitor, which was suggested to explain the discrepancy between the pulsar's characteristic age of ∼ 1700 yr (Kaspi et al. 1994) and the SNR age of > 10000 yr based on the RCW 89 association (Seward, Harnden, & Murdin et al. 1983). This requires further confirmation by observations in other bands.
## 5. SUMMARY
We have presented energy-resolved images of the PWN MSH 15 -5 2 in the hard X-ray band ( E > 8 keV) for the first time. The images in different X-ray bands shrink with energy as a result of the synchrotron burn-off effect. On small scales ( R < ∼ 50 ′′ ), we show that the size shrinkage with energy can be explained with a particle advection model. Using this model, we discuss properties of the wind outflow in the jet direction. We find that the combined NuSTAR Chandra / spectrum of the entire PWN requires a break at 6 keV, which may be due to cross-calibration effects. However, if the spectral break is intrinsic to the source, it implies a break in the shock accelerated electron distribution. We measured the spectral index profiles on large scales ( R ∼ 5 ) ′ in the northern and jet directions. The spectrum softens with radius in both directions, an effect we interpret with a combined diffusion/advection model; further numerical simulations with the model are required for more accurate interpretation. We find an interesting sinusoidal variation of the spectral hardness in the azimuthal direction which may have implications for the particle diffusion in the PWN. Such a variation has not been seen in other PWNe, though it has been predicted in pulsar current flow models (Blandford 2002). We find a spectral hardness turn-over in the jet direction at a distance of ∼ 35 ′′ from the pulsar. Finally, we presented 2-D maps of spectral parameters of the source, and find that the N H map shows an interesting shell-like structure which implies high particle density. However, this feature could result from a complex underlying continuum, and so requires further confirmation.
This work was supported under NASA Contract No. NNG08FD60C, and made use of data from the NuSTAR mission, a project led by the California Institute of Technology, managed by the Jet Propulsion Laboratory, and funded by the National Aeronautics and Space Administration. We thank the NuSTAR Operations, Software and Calibration teams for support with the execution and analysis of these observations. This research has made use of the NuSTAR Data Analysis Software (NuSTARDAS) jointly developed by the ASI Science Data Center (ASDC, Italy) and the California Institute of Technology (USA). V.M.K. acknowledges support from an NSERC Discovery Grant and Accelerator Supplement, the FQRNT Centre de Recherche Astrophysique du Qu´ ebec, an R. Howard Webster Foundation Fellowship from the Canadian Institute for Advanced Research
(CIFAR), the Canada Research Chairs Program and the Lorne Trottier Chair in Astrophysics and Cosmology.
## REFERENCES
Aharonian, F., Akhperjanian, A. G., Aye, K. -M., Bazer-Bachi, A. R., Beilicke, M. & et al. 2005, A&A, 435, L17
- An, H., Madsen, K. K., Westergaard, N. J. & et al. 2014, Proc. SPIE, 9144, 91441Q
- Arnaud, K. A. 1996, in ASP Conf. Ser. 101, Astronomical Data Analysis Software and Systems V, ed. G. H. Jacoby & J. Barnes (San Francisco,CA: ASP), 17
- Arnett, W. D., Meakin, C. & Viallet, M. 2014, AIP Advances 4, 4, arXiv:1312.3279
- Atoyan, A. M., & Aharonian, F. A. 1996, MNRAS, 278, 525 Blandford, R. D. 2002, in Proc. MPA/ESO/MPE/USM Joint Astron. Conf., Lighthouses of the Universe: The Most Luminous Celestial Objects and Their Use for Cosmology (Berlin: Springer), 381, arXiv:0202265
- Castor, J., McCray, R. & Weaver, R. 1975, ApJ, 200, L107 Caraveo, P. A., Mereghetti, S. & Bignami, G. F. 1994, ApJ, 423, L125
- Chevalier, R. A. 2005, ApJ, 619, 839
- Cusumano, G., Mineo, T., Massaro, E., Nicastro, L., Trussoni, E., Massaglia, S., Hermsen, W., & Kuiper, L. 2001, A&A, 375, 397
- de Jager, O. C., & Harding, A. K., et al. 1992, ApJ, 396, 161
- de Jager, O. C., Swanepoel, J. W. H., & Raubenheimer, B. C., et al. 1989, A&A, 221, 180
- DeLaney, T., Gaensler, B. M., Arons, J. & Pivovaroff, M. J. 2006, ApJ, 640, 929
- Forot, M., Hermsen, W., Renaud, M., Laurent, P., Grenier, I., Goret, P., Khelifi, B., & Kuiper, L. 2006, ApJ, 651, L45
- Fryer, C. L., Rockefeller, G. & Young, P. A. 2006, ApJ, 647, 1269 Gaensler, B. M., Arons, J., Kaspi, V. M., Pivovaroff, M. J., Kawai, N., & Tamura, K. 2002, ApJ, 569, 878
- Gaensler, B. M., Brazier, K. T. S., Manchester, R. N., Johnston, S. & Green, A. J. 1999, MNRAS, 305, 736
- Gaensler, B. M., & Slane, P. O. 2006, ARA&A, 44, 17
- Garmire, G. P., Bautz, M. W., Ford, P. G., Nousek, J. A., & Ricker, G. R. 2003, Proc. SPIE, 4851, 28
- Gratton, L. 1972, Ap&SS, 16, 81
- Ge, M. Y., Lu, F. J., Qu, J. L., Zheng, S. J., Chen, Y., & Han, D. W. 2012, ApJS, 199, 32
- Harp, D. I., Liebe, C. C., Craig, W., Harrison, F., Kruse-Madsen, K., Zoglauer, A. 2010, Proc. SPIE, 7738, 77380Z
- Harrison, F. A., Craig, W. W., Christensen, F. E., et al. 2013, ApJ, 770, 103
- Kaspi, V. M., Manchester, R. N., Siegman, B., Johnston, S., & Lyne, A. G. 1994, ApJ, 422, L83
- Kaspi, V. M., Roberts, M. S. E., & Harding, A. K. 2006, in Compact Stellar X-Ray Sources, ed. W. Lewin & M. van der Klis (Cambridge: Cambridge Univ. Press), 279
- Kirsch, M. G. F., Briel, U. G., Burrows, D., & et al. 2005, Proc. SPIE, 5898, 589803
- Kennel, C. F., & Coroniti, F. V. 1984, ApJ, 283, 710
- Lamers, H. J. G. L. M. & Nugis, T. 2002 A&A, 395, L1
- Livingstone, M. A., & Kaspi, V. M. 2011, ApJ, 742, 31 Lyubarsky, Y. E., 2002, MNRAS, 329, 34L
- Lyutikov, M., 2003, MNRAS, 339, 623
- Madsen, K. K., Reynolds, S., Harrison, F. A., & et al. 2014, ApJ, submitted
- Mineo, T., Cusumano, G., Maccarone, M. C., Massaglia, S., Massaro, E., & Trussoni, E. 2001, A&A, 380, 695
- Mori, K., Burrows, D. N., Hester, J. J., Pavlov, G. G., Shibata, S., & Tsunemi, H. 2004, ApJ, 609, 186
- Nakamori, T., Kubo, H., Yoshida, T., Tanimori, T., Enomoto, R., & et al. 2007, ApJ, 677, 297
- Nynka, M., Hailey, C. J., Reynolds, S. P., & et al. 2014, ApJ, 789, 72
- Paxton, B., Cantiello, M., Arras, P., & et al. 2013, ApJS, 208, 4 Quataert, E. & Shiode, J. 2012, MNRAS, 423, L92
- Reynolds, S. P. 2003, in Proc. IAU Colloquium 192, 10 Years of SN1993J, Valencia, Spain, April 2003, arXiv:0308483 Reynolds, S. P. 2009, ApJ, 703, 662
- Rees, M. J. & Gunn, J. E. 1974, MNRAS, 167, 1
- Rots, A. H. 2004, in AIP Conf. Proc. 714, X-Ray Timing 2003: Rossi and Beyond, ed. P. Kaaret, F. K. Lamb & J. H. Swank (Melville: AIP), 309
- http://adsabs.harvard.edu/abs/2004AIPC..714..309R Sch¨ ock, F. M., B¨sching, I., de Jager, O. C., Eger, P., & Vorster, u M. J. 2010, A&A, 515, A109
- Seward, F. D., Harnden, Jr., F. R., Murdin, P., & Clark, D. H. 1983, ApJ, 267, 698
- Sironi, L., & Spitkovsky, A. 2009, ApJ, 698, 1523
- Slane, P., Helfand, D. J., van der Swaluw, E., & Murray, S. S. 2004, ApJ, 616, 403
- Tang, X., & Chevalier, R. 2012, ApJ, 752, 83
- Weaver, R., McCray, R., Castor, J., Shapiro, P., & Moore, R. 1977, ApJ, 218, 377
- Wilson, A. S. 1972a, MNRAS, 160, 355
- Wilson, A. S. 1972b, MNRAS, 160, 373
- Yatsu, Y., Kawai, N., Kataoka, J., Kotani, T., Tamura, K., & Brinkmann, W. 2005, ApJ, 631, 312
- Yatsu, Y., Kawai, N., Shibata, S., & Brinkmann, W. 2009, PASJ, 61, 129 | 10.1088/0004-637X/793/2/90 | [
"Hongjun An",
"Kristin K. Madsen",
"Stephen P. Reynolds",
"Victoria M. Kaspi",
"Fiona A. Harrison",
"Steven E. Boggs",
"Finn E. Christensen",
"William W. Craig",
"Chris L. Fryer",
"Brian W. Grefenstette",
"Charles J. Hailey",
"Kaya Mori",
"Daniel Stern",
"William W. Zhang"
] | 2014-08-01T13:34:35+00:00 | 2014-08-01T13:34:35+00:00 | [
"astro-ph.HE"
] | High-Energy X-ray Imaging of the Pulsar Wind Nebula MSH~15-52: Constraints on Particle Acceleration and Transport | We present the first images of the pulsar wind nebula (PWN) MSH 15-52 in the
hard X-ray band (>8 keV), as measured with the Nuclear Spectroscopic Telescope
Array (NuSTAR). Overall, the morphology of the PWN as measured by NuSTAR in the
3-7 keV band is similar to that seen in Chandra high-resolution imaging.
However, the spatial extent decreases with energy, which we attribute to
synchrotron energy losses as the particles move away from the shock. The
hard-band maps show a relative deficit of counts in the northern region towards
the RCW 89 thermal remnant, with significant asymmetry. We find that the
integrated PWN spectra measured with NuSTAR and Chandra suggest that there is a
spectral break at 6 keV which may be explained by a break in the
synchrotron-emitting electron distribution at ~200 TeV and/or imperfect cross
calibration. We also measure spatially resolved spectra, showing that the
spectrum of the PWN softens away from the central pulsar B1509-58, and that
there exists a roughly sinusoidal variation of spectral hardness in the
azimuthal direction. We discuss the results using particle flow models. We find
non-monotonic structure in the variation with distance of spectral hardness
within 50" of the pulsar moving in the jet direction, which may imply particle
and magnetic-field compression by magnetic hoop stress as previously suggested
for this source. We also present 2-D maps of spectral parameters and find an
interesting shell-like structure in the NH map. We discuss possible origins of
the shell-like structure and their implications. |
1408.0175v1 | ## Characterizing the Parents: Exoplanets Around Cool Stars
Kaspar von Braun , Tabetha S. Boyajian , Gerard T. van Belle , 1 2 3 Andrew Mann , Stephen R. Kane 4 5
1 Max-Planck-Institute for Astronomy (MPIA), K¨nigstuhl 17, 69117 o Heidelberg, Germany; [email protected]
- 2 Yale University, P.O. Box 208101, New Haven, CT 06520-8101, USA
3 Lowell Observatory, 1400 West Mars Hill Road, Flagstaff, AZ 86001, USA
4 University of Texas, 2515 Speedway, Stop C1400, Austin, TX 78712-1205, USA
5 San Francisco State University, 1600 Holloway Ave., San Francisco, CA 94132, USA
Abstract. The large majority of stars in the Milky Way are late-type dwarfs, and the frequency of low-mass exoplanets in orbits around these late-type dwarfs appears to be high. In order to characterize the radiation environments and habitable zones of the cool exoplanet host stars, stellar radius and effective temperature, and thus luminosity, are required. It is in the stellar low-mass regime, however, where the predictive power of stellar models is often limited by sparse data volume with which to calibrate the methods. We show results from our CHARA survey that provides directly determined stellar parameters based on interferometric diameter measurements, trigonometric parallax, and spectral energy distribution fitting.
## 1. 'Why?' and 'How?': Introduction and Methods
Essentially every astrophysical parameter of any exoplanet is a function of its equivalent host star parameters (radius, surface temperature, mass, etc.). You only understand any exoplanet as well as you understand its respective parent star. The main purpose of the presented research is to directly characterize exoplanets in orbits around their hosts and to produce empirical constraints to stellar models. We use infrared and optical interferometry, coupled with spectral energy distribution fitting and trigonometric parallax values, to get estimates of stellar radii and effective temperatures that are as modelindependent as possible. For more details, see, e. g., Boyajian et al. (2013) and von Braun et al. (2014). For transiting planets, using literature photometry and spectroscopy time-series data allows for the determination of model-independent planetary and stellar masses, radii, and bulk densities (e. g., von Braun et al., 2012).
Figure 1.: Habitable zones are calculated based on our empirical values of stellar radii and effective temperatures. This plot shows the system architecture of the GJ 876 system. The HZ is shown in grey. Planets b and c spend most or all of their orbital durations in the HZ. For scale: the size of the box is 0.8 AU × 0.8 AU. Adapted from von Braun et al. (2014).
## 2. 'So What?': Results
Our results provide empirically determined values for stellar radii, effective temperatures, and luminosities. They confirm the well-documented discrepancy between predicted and empirical radii and temperatures (e.g., Torres et al., 2010; Boyajian et al., 2012, 2013) and can thus provide constraints to improvements to stellar models. They can furthermore be used to establish relations to predict stellar sizes based on observable quantities, like stellar broad-band colors, for stars too faint and/or small to be studied interferometrically (Boyajian et al., 2014). In addition, any individual system's circumstellar habitable zone (HZ) is a function of stellar radius and effective temperature (Fig. 1).
## 3. 'And what have you done for me lately?': Status
Over the course of the last 5+ years, we have been using the CHARA interferometric arrray to directly determine the stellar parameters of over 100 mainsequence stars and of around 30 exoplanet host stars, with a particular emphasis on cool stars (Fig. 2).
Acknowledgements. We would like to sincerely thank the organizers for a phantastic conference. We furthermore express our gratitude to the poster judges for their thumbs up on our work. This research has made use of the Habitable Zone Gallery at hzgallery.org (Kane & Gelino, 2012).
Figure 2.: Empirical H-R Diagram for all stars with interferometrically determined stellar radii whose random uncertainties are smaller than 5%. The diameter of each data point is representative of the logarithm of the corresponding stellar radius. Error bars in effective temperature and luminosity are smaller than the size of the data points. Exoplanet host stars are shown in red; stars that are not currently known to host any exoplanets are shown in grey. Stellar radii data are taken from Baines et al. (2008, 2012, 2013); Bigot et al. (2006); Boyajian et al. (2008, 2012, 2013); di Folco et al. (2004, 2007); Henry et al. (2013); Kervella et al. (2003); Ligi et al. (2012); Richichi et al. (2005); van Belle et al. (1999); van Belle & von Braun (2009); von Braun et al. (2011a,b, 2012, 2014); White et al. (2013).
Figure 3.: Thank you, organizers and poster judges!

## References
```
<_VisualBasic_>
``` | null | [
"Kaspar von Braun",
"Tabetha S. Boyajian",
"Gerard T. van Belle",
"Andrew Mann",
"Stephen R. Kane"
] | 2014-08-01T13:37:11+00:00 | 2014-08-01T13:37:11+00:00 | [
"astro-ph.SR",
"astro-ph.EP"
] | Characterizing the Parents: Exoplanets Around Cool Stars | The large majority of stars in the Milky Way are late-type dwarfs, and the
frequency of low-mass exoplanets in orbits around these late-type dwarfs
appears to be high. In order to characterize the radiation environments and
habitable zones of the cool exoplanet host stars, stellar radius and effective
temperature, and thus luminosity, are required. It is in the stellar low-mass
regime, however, where the predictive power of stellar models is often limited
by sparse data volume with which to calibrate the methods. We show results from
our CHARA survey that provides directly determined stellar parameters based on
interferometric diameter measurements, trigonometric parallax, and spectral
energy distribution fitting. |
1408.0176v1 | ## Spin-polarized quasiparticle transport in exchange-split superconducting aluminum on europium sulfide
M. J. Wolf, 1 C. S¨rgers, u 2 G. Fischer, 2 and D. Beckmann 1, ∗
1 Institut f¨r Nanotechnologie, u Karlsruher Institut f¨r Technologie (KIT), Karlsruhe, u Germany 2 Physikalisches Institut, Karlsruher Institut f¨r Technologie u (KIT), Karlsruhe, Germany
(Dated: August 4, 2014)
We report on nonlocal spin transport in mesoscopic superconducting aluminum wires in contact with the ferromagnetic insulator europium sulfide. We find spin injection and long-range spin transport in the regime of the exchange splitting induced by europium sulfide. Our results demonstrate that spin transport in superconductors can be manipulated by ferromagnetic insulators, and opens a new path to control spin currents in superconductors.
## I. INTRODUCTION
In conventional superconductors, electrons are bound in singlet Cooper pairs with zero spin. In hybrid structures with magnetic elements, triplet Cooper pairs and spin-polarized supercurrents can be created. 1-6 In addition, spin-polarized quasiparticles can be injected into superconductors, 7 with very long spin relaxation times. 8-10 Both effects open the possibility to achieve spintronics functionality with superconductors. Recently, we have observed long-range spin-polarized quasiparticle transport in superconducting aluminum in the presence of a large Zeeman splitting of the density of states, 9 and demonstrated that the superconductor acts as a spin filter for quasiparticles injected from a paramagnetic metal. 11 These observations open the possibility to use superconducting aluminum as an active element for spintronics. The design of complex structures with switchable elements requires, however, a local control of the spin splitting, which cannot be achieved by a homogeneous applied magnetic field. In hybrid structures of ferromagnetic insulators and superconductors, an exchange splitting of the density of states of the superconductor can be induced due to spin-active scattering at the interface between the materials. 12,13 Such structures are candidates for new spintronics functionality in superconductors, 14-17 and in particular to control and manipulate the spin splitting. 18 A very promising material for this purpose is europium sulfide (EuS), which has been used in the past in superconducting hybrid structures as a means to induce an exchange splitting, 19,20 as a spin-filter material, 21,22 and for superconducting spin valves 16 and spin switches. 18 EuS is a II-VI semiconductor with a direct band gap of E g = 1 7 eV at . room temperature and exhibits isotropic Heisenberg ferromagnetism with a Curie temperature T C = 16 5 K. . 23 At low temperatures (few K) it can be considered as an insulator. In this paper, we extend our previous experiments 9,11 to spin transport in mesoscopic superconducting aluminum wires with an exchange splitting induced by the ferromagnetic insulator EuS.
FIG. 1. (color online) False-color scanning electron microscopy image of a section of one of our samples together with the measurement scheme with the injection (inj) and detection (det) circuits.
## II. SAMPLES AND EXPERIMENT
Our samples were fabricated in a two-step process. First, EuS films of thickness t EuS = 10 -25 nm were evaporated onto a Si (111) substrate heated to T S ≈ 800 ◦ C. The films have a strong 〈 111 〉 texture with a small fraction of 〈 100 -oriented 〉 grains. The Curie temperature T C ≈ 16 4 K and saturation magnetization . M s ≈ 7 µ B per formula unit agree well with bulk properties. The coercive field is typically a few mT, consistent with negligible magnetocrystalline anisotropy as expected for a Heisenberg ferromagnet. Details of the film preparation and characterization can be found in Ref. 24. In the second step, aluminum/iron structures were fabricated by e-beam lithography and shadow evaporation techniques on top of the EuS films. The EuS films were coated with PMMA resist, and after exposure and development they were mounted in the evaporation chamber. First, a short Ar ion etching step was used to clean the exposed surface
TABLE I. Overview of sample properties. Range of normal-state tunnel conductances G , EuS film thickness t EuS . Aluminum film properties: film thickness t Al , critical temperature T c , critical magnetic field µ H 0 c , diffusion constant D , maximum exchange field B ∗ sat .
| Sample | G ( µ S) | t EuS (nm) | t Al (nm) | T c (K) | µ 0 H c (T) | D (cm 2 / s) | B ∗ sat (T) |
|----------|------------|--------------|-------------|-----------|---------------|----------------|---------------|
| A | 690 - 750 | 22 | 10.5 | 1.55 | 0.95 | 20.4 | 1.75 |
| B | 380 - 450 | 10 | 9.5 | 1.6 | 1.45 | 13.6 | 1.2 |
of the EuS film to ensure good contact with the metal films. Next, a thin superconducting aluminum strip of thickness t Al ≈ 10 nm was evaporated and then oxidized in situ to form an insulating tunnel barrier. Then ferromagnetic iron ( t Fe ≈ 15 -25 nm) was evaporated under a different angle to form six tunnel junctions to the aluminum, with contact separations d spanning 0 5 to 5 . µ m. Additional copper layers were evaporated under different angles to reduce the resistance of the iron leads. Figure 1 shows a scanning electron microscopy image of a section of one of our samples, together with the experimental scheme.
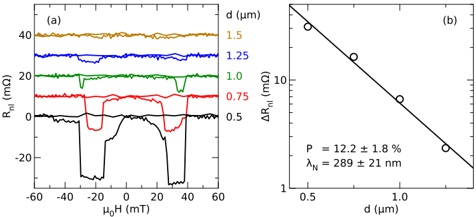
The samples were mounted into a shielded box thermally anchored to the mixing chamber of a dilution refrigerator. A magnetic field was applied in the plane of the substrate, along the direction of the iron wires. We will refer to the applied field by H throughout this paper, whereas B will be used to describe the effective spin splitting of the density of states (both fieldinduced and exchange-induced). Using a combination of dc bias and low-frequency ac excitation, we measured both the local differential conductance g loc = dI inj /dV inj of individual junctions as well as the nonlocal differential conductance g nl = dI det /dV inj for different injector/detector pairs in the superconducting state. For the nonlocal conductance, we plot the normalized signal ˆ g nl = g nl / ( G inj G det ) throughout the paper, where G inj and G det are the normal-state conductances of the injector and detector junction, respectively. Also, we mainly focus on data at T = 50 mK. In addition to the conductances in the superconducting state, we measured the nonlocal linear resistance R nl = dV det /dI inj in the normal state at T = 4 2 K. .
Similar results were obtained on two samples (A and B). An overview of sample parameters can be found in Table I. We will focus here mostly on results from sample A.
## III. RESULTS
Before we describe the results in the superconducting state, we first characterize spin transport in the normal state. Figure 2(a) shows the nonlocal resistance R nl as a function of applied magnetic field H for different pairs of contacts at T = 4 2 K. . Data are shown for major hysteresis loops in both sweep directions, and offset for
FIG. 2. (color online) (a) Nonlocal resistance R nl as a function of applied magnetic field H for different contact separation d in the normal state at T = 4 2 K. . The data are shifted vertically for clarity. (b) Spin-valve signal ∆ R nl as a function of contact distance d (symbols), and fit to an exponential decay (line).
clarity. In both sweep directions, two switches can be observed between parallel (P) and antiparallel (AP) configuration. From these, we extract the spin-valve signal ∆ R nl = R (P) nl -R (AP) nl . The spin-valve signal is plotted as a function of contact distance d in Fig. 2(b), together with a fit to the standard expression 25,26
$$\Delta R _ { \text{nl} } = P ^ { 2 } \frac { \rho \lambda _ { N } } { \mathcal { A } } \exp ( - d / \lambda _ { N } ), \quad \ \ ( 1 ) \\ D \text{ is to the main evaluation of the total random}$$
where P is the spin polarization of the tunnel conductance, ρ is the normal-state resistivity of the aluminum, A is the cross-section area of the aluminum, and λ N is the normal-state spin-diffusion length. From the fit, we obtain P = 12 2 . ± 1 8% and . λ N = 289 ± 21 nm. With the electron diffusion coefficient D determined from the normal-state resistivity we obtain the spin relaxation time τ sf = λ 2 N /D = 41 ps.
We now focus on results in the superconducting state. Figure 3(a) shows the local differential conductance of one contact as a function of the injection bias voltage V inj for different applied magnetic fields H at T = 50 mK. The data at zero field show negligible subgap conductance and a gap singularity at V inj ≈ 220 µ V, consistent with the expected gap ∆ 0 = 1 76 . k B T c = 230 µ eV. Upon increasing the field, a spin splitting of the density of states quickly develops, which is much larger than the Zeeman splitting due to the applied field. We fit our data with the standard model for high-field tunneling 27,28 to
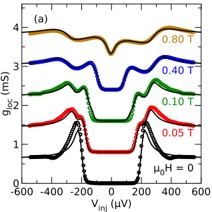
FIG. 3. (color online) (a) Local differential conductance g loc = dI inj /dV inj of one junction as a function of injector bias V inj for different applied magnetic fields H (symbols) and fits (lines). (b) Magnetization of the EuS film (solid line, left ordinate) and induced exchange field B ∗ for different contacts (symbols, right ordinate) as a function of the applied field. (c) Pair potential ∆ as a function of normalized field H/H c . (d) Normalized pair-breaking parameter Γ / ∆ 0 as a function of ( H/H c ) 2 .
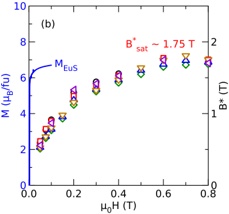
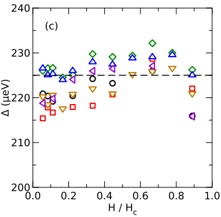
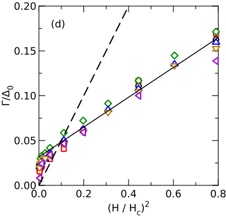
extract the normal-state junction conductance G inj , the spin-polarization P of the tunnel conductance, the pair potential ∆, the orbital pair-breaking parameter Γ, the spin-orbit scattering strength b so , and the spin splitting. The latter appears as an effective magnetic field in the fit, which we denote by B fit . The spin splitting consists of two parts, the Zeeman splitting due to the applied field µ H 0 , and the exchange splitting induced by the EuS, which we will denote by B ∗ = B fit -µ H 0 , following the literature. 19
In Fig. 3(b), we plot B ∗ obtained from fitting the spectra of all six junction as a function of the applied field. B ∗ increases almost linearly at small field, and then saturates for µ H > 0 0 5 T at . B ∗ sat = 1 75 T. Consequently, . most of the spin splitting of the density of states results from the exchange field. A similar behavior was found for all samples, with some variation of both the magnitude of B ∗ sat and the applied field where saturation sets in. For comparison, we show the magnetization M EuS of the EuS film obtained by SQUID magnetometry in the same plot. As can be seen, the magnetization is fully saturated at a field of a few 10 mT, much below the saturation of the exchange splitting. The reason for the discrepancy of the field dependence of M EuS and B ∗ is not known. In the past, averaging over multi-domain magnetization states of EuS has been assumed as a possible cause of the slow saturation of B ∗ . 19 However, this explanation is at variance with the fast saturation of M EuS , as well as the small junction size of the order of the dirty-limit coherence length of the aluminum film ( ξ S = 76 nm). Considering the fact that the induced exchange field is the result of spin-active scattering of quasiparticles at the interface between Al and EuS, we assume that a difference between bulk magnetism (as seen by magnetometry) and interface magnetism (as seen by the aluminum) is the cause of the different field scales. Magnetic moments at the interface may deviate from the magnetization direction due to the broken symmetry and different anisotropy at the interface. A further clue supporting this interpretation is the fact that B ∗ sat varies from sample to sample even for similar aluminum film thickness. In our two-step fabrication process, we expect that the interface properties depend sensitively on the Ar ion etching between fabrication steps.
The pair potential ∆, plotted in Fig. 3(c), remains almost constant at ∆ 0 ≈ 225 µ eV (dashed line) as a function of applied field up to the critical field. We find B ∗ sat + µ H 0 c = 2 7 T in good agreement with the estimate . of the Pauli limiting field µ H 0 p = ∆ 0 / √ 2 µ B = 2 75 T. . The normalized orbital pair breaking parameter Γ / ∆ 0 is plotted in Fig. 3(d) as a function of ( H/H c ) 2 . For a thin film in parallel magnetic field, the expectation is Γ ∆ / 0 = ( H/H c ) 2 / 2 if orbital pair breaking effects dominate. 29 This assumption is plotted as a dashed line. Indeed, Γ follows an H 2 dependence at high fields, but with a smaller slope and an additional offset (solid line). From these observations we conclude that the critical field is determined by spin splitting rather than by orbital pair breaking. Below 0 1 T, Γ increases faster than . expected, and the H 2 dependence at high fields extrapolates to an offset Γ( H = 0) / ∆ 0 ≈ 0 03. This may indicate . additional pair breaking due to magnetic inhomogeneity of the EuS film, or the fringing fields of the iron wires. For the spin-orbit parameter we obtain b so ≈ 0 14 at high . fields, much larger than expected for aluminum. 28
In Fig. 4, we focus on the nonlocal differential conductance. Figs. 4(a) and (b) show the normalized nonlocal conductance ˆ g nl as a function of injector bias V inj for different magnetic fields H . As in our previous work, 9,11 asymmetric peaks due to spin injection into the spinsplit density of states are observed upon increasing the magnetic field, as seen in Fig. 4(a). Due to the increased spin splitting by the exchange field of the EuS, the peaks are clearly visible even at a field as small as 10 mT. At larger fields, the peaks broaden due to the increased spin splitting. In contrast to the previous work, however, the peaks actually split into two sub-peaks at small and large bias, as seen in Fig. 4(b). The dashed lines indicate the pair potential. The two sub-peaks essentially follow the spin splitting of the density of states. In Figs. 4(c) and (d), we show the evolution of the spin signal as a function of contact distance for low and high fields, respectively. In the low-field regime, Fig. 4(c), where a single peak is observed for each bias polarity, the peak uniformly de-
FIG. 4. (color online) Normalized nonlocal differential conductance ˆ g nl = g nl / ( G inj G det ) as a function of injector bias V inj . (a) and (b): Data for different applied magnetic fields H for one pair of contacts. (c) and (d): Data for different contact distances at two different applied fields.
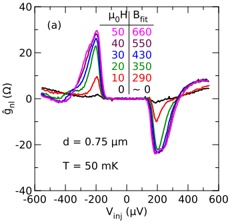
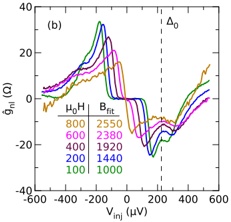
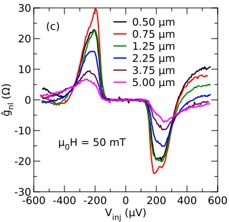
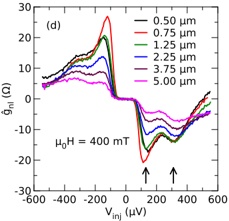
FIG. 5. (color online) (a) Normalized nonlocal differential conductance ˆ g nl as a function of bias voltage V inj for one contact pair and applied field (symbols) and theoretical prediction ˆ g nl ∝ g ↓ -g ↑ (line). (b) Relaxation length λ S of the spin signal as a function of bias voltage V inj for different magnetic fields H .
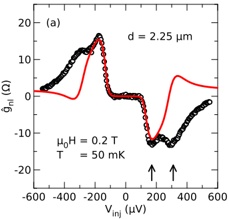
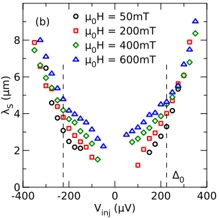
creases with increasing contact distance. At high fields, Fig. 4(d), the two sub-peaks (indicated by arrows for the positive bias side) decay on different length scales. This can be clearly seen by comparing the data at d = 0 5 . µ m and 5 µ m. At small contact distance, the low-bias peak (at about V inj = 140 µ V) is larger, whereas at large distance, the high-bias peak (at about V inj = 310 µ V) is larger.
Spin injection into the spin-split density of states is proportional to the difference of the conductances for spin up and down, g nl ∝ g ↓ -g ↑ . 9,11 We can therefore predict the bias dependence of g nl from the fits of the local conductance. Fits to this prediction have been successful in describing the data of our previous experiments. 9,11,30 In Fig. 5(a), we compare the bias dependence of the measured spin signal to the predicted signal for one set of parameters. The model predicts a single peak for each bias polarity, restricted to the bias window of the spin splitting. As soon as the bias reaches the upper spin band, the signal should be cancelled by injection of quasiparticles with opposite spin. The observed data are in qualitative contrast to this expectation. Instead of a cancellation, the spin signal actually further increases once the upper spin band is reached and shows a second sub-peak. This observation is systematic for the high-field data.
To analyze the relaxation length of the spin signal, we made exponential fits of ˆ g nl at a given bias as a function of contact distance. In Fig. 5(b), the relaxation length λ S obtained from these fits is plotted as a function of bias voltage V inj for different magnetic fields H . λ S is a few µ m, similar to samples without EuS film. In general, λ S increases with bias. At small bias, in the range of the spin splitting, λ S also increases with magnetic field, again similar to the previous experiments without EuS. At higher bias, where both spin bands contribute to conductance, λ S becomes nearly independent of the field.
## IV. DISCUSSION
The microscopic explanation of the induced exchange splitting is spin-active scattering at the interface between EuS and Al, which can be expressed in terms of spinmixing angles. 12,13 For diffusive systems, a broad distribution of spin-mixing angles is expected. Recently, appropriate boundary conditions for the Usadel equation have been derived. 31 For a thin superconducting layer on top of a ferromagnetic insulator, the spin-active scattering can be expressed in this model by dimensionless parameters γ φ,i . The γ φ,i depend on moments of increasing order of the distribution of spin-mixing angles. The first-order parameter, γ φ, 1 , acts like an effective Zeeman field, whereas the second-order parameter, γ φ, 2 , acts in the same way as pair breaking. The higher-order terms have no apparent analogy. With this analogy, we can express B ∗ sat as γ φ, 1 ≈ 0 062 (0 049) for sample A (B). If we . . further tentatively attribute the residual pair-breaking strength Γ( H = 0) to spin-active scattering, this yields γ φ, 2 ≈ 0 004 (0 002). . . As mentioned in the previous section, we obtain an anomalously large spin-orbit scattering strength b so ≈ 0 14 from the fits. . However, if we interpret the normal-state spin-diffusion time as the spin-orbit scattering time (Elliott-Yafet mechanism 32,33 ), we can estimate b so = ¯ h/ τ 3 so ∆ = 0 024. This appears much more 0 . realistic for aluminum, 28 and is also similar to literature data for aluminum on EuS. 19 An interesting question to theory is whether fits including higher-order γ φ terms might remove the discrepancy, and provide additional insight into the scattering mechanism at the interface.
For the nonlocal signal, we find that applied fields of 10 mT are sufficient to enable spin injection and transport. The relaxation length of a few microns is similar to what has been found in structures without EuS. At high fields, the spin signal is qualitatively different from the expectation, with increased spin injection instead of cancellation as the upper spin band starts to contribute. In our previous experiments, we have found a high-bias tail of the spin signal in some samples. 9,11 A possible explanation for this behavior are spin flips in combination with fast energy relaxation, as explained in Ref. 11. The same mechanism could be at play here, and might be more pronounced because the density-of-states features are sharper due to the relative weakness of orbital pairbreaking effects. On the other hand, spin-active scattering may lead to the generation of triplet Cooper pairs in the superconductor. This might lead to a qualitatively different spin injection and relaxation behavior. Lacking a quantitative model for either effect, we can only refer this question to theory.
- ∗ e-mail address: [email protected]
- 1 F. S. Bergeret, A. F. Volkov, and K. B. Efetov, Phys. Rev. Lett. 86 , 4096 (2001).
- 2 F. S. Bergeret, A. F. Volkov, and K. B. Efetov, Rev. Mod. Phys. 77 , 1321 (2005).
- 3 R. S. Keizer, S. T. B. Goennenwein, T. M. Klapwijk, G. Miao, G. Xiao, and A. Gupta, Nature 439 , 825 (2006).
- 4 T. S. Khaire, M. A. Khasawneh, W. P. Pratt, and N. O. Birge, Phys. Rev. Lett. 104 , 137002 (2010).
- 5 J. W. A. Robinson, J. D. S. Witt, and M. G. Blamire, Science 329 , 59 (2010).
- 6 M. Eschrig, Phys. Today 64 (1), 43 (2011).
- 7 M. Johnson, Appl. Phys. Lett. 65 , 1460 (1994).
- 8 H. Yang, S.-H. Yang, S. Takahashi, S. Maekawa, and S. S. P. Parkin, Nat. Mater. 9 , 586 (2010).
- 9 F. H¨bler, M. J. Wolf, D. Beckmann, u and H. v. L¨hneysen, o Phys. Rev. Lett. 109 , 207001 (2012).
- 10 C. H. L. Quay, D. Chevallier, C. Bena, and M. Aprili, Nat. Phys. 9 , 84 (2013).
- 11 M. J. Wolf, F. H¨bler, S. Kolenda, H. v. L¨hneysen, u o and D. Beckmann, Phys. Rev. B 87 , 024517 (2013).
- 12 T. Tokuyasu, J. A. Sauls, and D. Rainer, Phys. Rev. B 38 , 8823 (1988).
- 13 A. Millis, D. Rainer, and J. A. Sauls, Phys. Rev. B 38 , 4504 (1988).
- 14 D. Huertas-Hernando, Y. V. Nazarov, and W. Belzig, Phys. Rev. Lett. 88 , 047003 (2002).
- 15 F. Giazotto and F. Taddei, Phys. Rev. B 77 , 132501 (2008).
- 16 B. Li, G.-X. Miao, and J. S. Moodera, Phys. Rev. B 88 , 161105 (2013).
## V. CONCLUSION
In conclusion, we have shown spin injection and transport in mesoscopic superconducting aluminum wires with an exchange splitting induced by the ferromagnetic insulator europium sulfide. The salient features observed in the experiment are consistent with the previous literature on spectroscopy and spin transport in high-field superconductivity. Our results show that ferromagnetic insulators are promising materials to control spin transport in superconductors at mesoscopic length scales and to implement spintronics functionality.
## ACKNOWLEDGMENTS
We thank W. Belzig, M. Eschrig, and A. Cottet for useful discussions. This work was supported by the Research Network 'Functional Nanostructures' of the Baden-W¨ urttemberg-Stiftung.
- 17 A. Pal, Z. H. Barber, J. W. A. Robinson, and M. G. Blamire, Nat. Commun. 5 , 3340 (2014).
- 18 B. Li, N. Roschewsky, B. A. Assaf, M. Eich, M. EpsteinMartin, D. Heiman, M. M¨nzenberg, u and J. S. Moodera, Phys. Rev. Lett. 110 , 097001 (2013).
- 19 X. Hao, J. S. Moodera, and R. Meservey, Phys. Rev. Lett. 67 , 1342 (1991).
- 20 Y. M. Xiong, S. Stadler, P. W. Adams, and G. Catelani, Phys. Rev. Lett. 106 , 247001 (2011).
- 21 J. S. Moodera, X. Hao, G. A. Gibson, and R. Meservey, Phys. Rev. Lett. 61 , 637 (1988).
- 22 X. Hao, J. S. Moodera, and R. Meservey, Phys. Rev. B 42 , 8235 (1990).
- 23 W. Zinn, J. Magn. Magn. Mater. 3 , 23 (1976).
- 24 M. J. Wolf, C. S¨ urgers, G. Fischer, T. Scherer, and D. Beckmann, J. Magn. Magn. Mater. 368 , 49 (2014).
- 25 T. Valet and A. Fert, Phys. Rev. B 48 , 7099 (1993).
- 26 F. J. Jedema, H. B. Heersche, A. T. Filip, J. J. A. Baselmans, and B. J. van Wees, Nature 416 , 713 (2002).
- 27 K. Maki, Prog. Theor. Phys. 32 , 29 (1964).
- 28 R. Meservey, P. M. Tedrow, and R. C. Bruno, Phys. Rev. B 11 , 4224 (1975).
- 29 K. Maki, Prog. Theor. Phys. 31 , 731 (1964).
- 30 M. J. Wolf, F. H¨bler, u S. Kolenda, and D. Beckmann, Beilstein J. Nanotechnol. 5 , 180 (2014).
- 31 A. Cottet, D. Huertas-Hernando, W. Belzig, and Y. V. Nazarov, Phys. Rev. B 80 , 184511 (2009).
- 32 R. J. Elliott, Phys. Rev. 96 , 266 (1954).
- 33 Y. Yafet, in Solid State Physics , Vol. 14, edited by F. Seitz and D. Turnbull (Academic Press, New York, 1963) p. 1. | 10.1103/PhysRevB.90.144509 | [
"M. J. Wolf",
"C. Sürgers",
"G. Fischer",
"D. Beckmann"
] | 2014-08-01T13:38:11+00:00 | 2014-08-01T13:38:11+00:00 | [
"cond-mat.supr-con",
"cond-mat.mes-hall"
] | Spin-polarized quasiparticle transport in exchange-split superconducting aluminum on europium sulfide | We report on nonlocal spin transport in mesoscopic superconducting aluminum
wires in contact with the ferromagnetic insulator europium sulfide. We find
spin injection and long-range spin transport in the regime of the exchange
splitting induced by europium sulfide. Our results demonstrate that spin
transport in superconductors can be manipulated by ferromagnetic insulators,
and opens a new path to control spin currents in superconductors. |
1408.0177v2 | ## Parameter Estimation in SAR Imagery using Stochastic Distances and Asymmetric Kernels
Juliana Gambini, Julia Cassetti, Mar´ ıa Magdalena Lucini, and Alejandro C. Frery, Senior Member
Abstract -In this paper we analyze several strategies for the estimation of the roughness parameter of the G 0 I distribution. It has been shown that this distribution is able to characterize a large number of targets in monopolarized SAR imagery, deserving the denomination of 'Universal Model.' It is indexed by three parameters: the number of looks (which can be estimated in the whole image), a scale parameter, and the roughness or texture parameter. The latter is closely related to the number of elementary backscatters in each pixel, one of the reasons for receiving attention in the literature. Although there are efforts in providing improved and robust estimates for such quantity, its dependable estimation still poses numerical problems in practice. We discuss estimators based on the minimization of stochastic distances between empirical and theoretical densities, and argue in favor of using an estimator based on the Triangular distance and asymmetric kernels built with Inverse Gaussian densities. We also provide new results regarding the heavytailedness of this distribution.
with respect to bias and mean squared error. Also, Silva et al. [5] computed analytic improvements for that estimator. Such approaches reduce both the bias and the mean squared error of the estimation, at the expense of computing somewhat cumbersome correction terms, and yielding estimators whose robustness is largely unknown.
Index Terms -Feature extraction, image texture analysis, statistics, synthetic aperture radar, speckle
## I. INTRODUCTION
T HE statistical modeling of the data is essential in order to interpret SAR images. Speckled data have been described under the multiplicative model using the G family of distributions which is able to describe rough and extremely rough areas better than the K distribution [1], [2]. The survey article [3] discusses in detail several statistical models for this kind of data.
Under the G model different degrees of roughness are associated to different parameter values, therefore it is of paramount importance to have high quality estimators. Several works have been devoted to the subject of improving estimation with two main venues of research, namely, analytic and resampling procedures.
The analytic approach was taken by Vasconcellos et al. [4] who quantified the bias in the estimation of the roughness parameter of the G 0 A distribution by maximum likelihood (ML). They proposed an analytic change for improved performance
This work was supported by Conicet, CNPq, and Fapeal.
Juliana Gambini is with the Instituto Tecnol´ ogico de Buenos Aires, Av. Madero 399, C1106ACD Buenos Aires, Argentina and with Depto. de Ingenier´ ıa en Computaci´ on, Universidad Nacional de Tres de Febrero, Pcia. de Buenos Aires, Argentina, [email protected] .
Julia Cassetti is with the Instituto de Desarrollo Humano, Universidad Nacional de Gral. Sarmiento, Pcia. de Buenos Aires, Argentina.
Magdalena Lucini is with the Facultad de Ciencias Exactas, Naturales y Agrimensura, Universidad Nacional del Nordeste, Av. Libertad 5460, 3400 Corrientes, Argentina.
Alejandro C. Frery is with the LaCCAN, Universidade Federal de Alagoas, Av. Lourival Melo Mota, s/n, 57072-900 Macei´ o -AL, Brazil, [email protected]
Cribari-Neto et al. [6] compared several numerical improvements for that estimator using bootstrap. Again, the improvement comes at the expense of intensive computing and with no known properties under contamination. Allende et al. [7] and Bustos et al. [8] also sought for improved estimation, but seeking the robustness of the procedure. The new estimators are resistant to contamination, and in some cases they also improve the mean squared error, but they require dealing with influence functions and asymptotic properties not always immediately available to remote sensing practitioners.
A common issue in all the aforementioned estimation procedures, including ML, and to those based on fractional moments [1] and log-cumulants [9]-[11] is the need of iterative algorithms for which there is no granted convergence to global solutions. Such lack of convergence usually arises with small samples, precluding the use of such techniques in, e.g., statistical filters. Frery et al. [12] and Pianto and CribariNeto [13] proposed techniques which aim at alleviating such issue, at the cost of additional computational load.
The main idea of this work is to develop an estimation method for the G 0 I model with good properties (as measured by its bias, the mean squared error and its ability to resist contamination) even with samples of small and moderate size, and low computational cost. In order to achieve this task, we propose minimizing a stochastic distance between the fixed empirical evidence and the estimated model.
Shannon proposed a divergence between two density functions as a measure of the relative information between the two distributions. Divergences were studied by Kullback and Leibler and by R´ enyi [14], among others. These divergences have multiple applications in signal and image processing [15], medical image analysis diagnosis [16], and automatic region detection in SAR imagery [17]-[20]. Liese and Vajda [21] provide a detailed theoretical analysis of divergence measures.
Cassetti et al. [22] compared estimators based on the Hellinger, Bhattacharyya, R´ enyi and Triangular distance with the ML estimator. They presented evidence that the Triangular distance is the best choice for this application, but noticed that histograms led to many numerical instabilities. This work presents improvements with respect to those results in the following regards: we assess the impact of contamination in the estimation, we employ kernels rather than histograms and
we compare estimators based on the Triangular distance with the ML, Fractional Moments and Log-Cumulants estimators. Among the possibilities for such estimate, we opted for employing asymmetric kernels.
Kernels have been extensively applied with success to image processing problems as, for instance, object tracking [23]. Kernels with positive support, which are of particular interest for our work, were employed in [24], [25]. The general problem of using asymmetric kernels was studied in [26].
In [27], the authors demonstrate, through extensive modeling of real data, that SAR images are best described by families of heavy-tailed distributions. We provide new results regarding the heavytailedness of the G 0 I distribution; in particular, we show that it has heavy tails with tail index 1 -α .
The paper unfolds as follows. Section II recalls the main properties of the G 0 I model and the Maximum Likelihood, the 1 2 -moment and the log-cumulants methods for parameter estimation. Estimation with stochastic distances is presented in Section III, including different ways of calculating the estimate of the underlying density function and the contamination models employed to assess the robustness of the procedure. Section IV presents the main results. Section V discusses the conclusions.
## II. THE G 0 I MODEL
The return in monopolarized SAR images can be modeled as the product of two independent random variables, one corresponding to the backscatter X and the other to the speckle noise Y . In this manner Z = XY represents the return in each pixel under the multiplicative model.
For monopolarized data, speckle is modeled as a Γ distributed random variable, with unitary mean and shape parameter L ≥ 1 , the number of looks, while the backscatter is considered to obey a reciprocal of Gamma law. This gives rise to the G 0 I distribution for the return. Given the mathematical tractability and descriptive power of the G 0 I distribution for intensity data [2], [28] it represents an attractive choice for SAR data modeling.
The density function for intensity data is given by
$$f _ { \mathcal { G } _ { I } ^ { 0 } } ( z ) = \frac { L ^ { L } \Gamma ( L - \alpha ) } { \gamma ^ { \alpha } \Gamma ( - \alpha ) \Gamma ( L ) } \frac { z ^ { L - 1 } } { ( \gamma + z L ) ^ { L - \alpha } }, \quad ( 1 ) \quad \bullet \ \phi \\ \text{here } - \alpha. \, \gamma. \, z > 0 \text{ and } L > 1. \, The \, r \text{-order moments are}$$
$$\infty - \alpha, \, _ { 1 }, \, _ { 2 } \times \, \infty \, \text{and} \, \in \, \colon \, \text{me} \, \text{you} \, \text{in} \, \text{me} \, \text{and} \, \text{me} \, \text{me} \, \text{and} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \,\text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me}. \, \\ E ( Z ^ { r } ) = \left ( \frac { \gamma } { L } \right ) ^ { r } \frac { \Gamma ( - \alpha - r ) } { \Gamma ( - \alpha ) } \frac { \Gamma ( L + r ) } { \Gamma ( - \alpha ) }, \quad \ ( 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{vided} \, \alpha < - r. \text{ and infinite otherwise.}$$
where -α, γ, z > 0 and L ≥ 1 . The r -order moments are provided α < -r , and infinite otherwise.
One of the most important features of the G 0 I distribution is the interpretation of the α parameter, which is related to the roughness of the target. Values close to zero (typically above -3 ) suggest extreme textured targets, as urban zones. As the value decreases, it indicates regions with moderate texture (usually α ∈ [ -6 , -3] ), as forest zones. Textureless targets, e.g. pasture, usually produce α ∈ ( -∞ -, 6) . This
With the double purpose of simplifying the calculations and making the results comparable, in the following we choose the scale parameter such that E Z ( ) = 1 , which is given by γ ∗ = -α -1 .
is the reason why the accuracy in the estimation of α is so important.
Let z = ( z , . . . , z 1 n ) be a random sample of n independent draws from the G 0 I model.
$$\text{equation} \colon \\ \Psi ^ { 0 } ( \widehat { \alpha } _ { \text{ML} } ) - \Psi ^ { 0 } ( L - \widehat { \alpha } _ { \text{ML} } ) - \log ( 1 - \widehat { \alpha } _ { \text{ML} } ) + \\ \frac { \widehat { \alpha } _ { \text{ML} } } { 1 - \widehat { \alpha } _ { \text{ML} } } + \frac { 1 } { n } \sum _ { i = 1 } ^ { n } \log ( 1 - \widehat { \alpha } _ { \text{ML} } + L z _ { i } ) - \\ \frac { \widehat { \alpha } _ { \text{ML} } - L } { n } \sum _ { i = 1 } ^ { n } \frac { 1 } { 1 - \widehat { \alpha } _ { \text{ML} } + L z _ { i } } = 0, \\ \text{where } \Psi ^ { 0 } ( \cdot ) \text{ is the digamma function. Some of the issues} \\ \text{posed by the solution of this equation have been discussed,} \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
Assuming γ ∗ = - -α 1 , the ML estimator for the parameter α , namely ̂ α ML is the solution of the following nonlinear equation:
where Ψ ( ) 0 · is the digamma function. Some of the issues posed by the solution of this equation have been discussed, and partly solved, in [12].
Fractional moments estimators have been widely used with success [1], [29]. Using r = 1 2 / in (2) one has to solve
Estimation based on log-cumulants is gaining space in the literature due to its nice properties and good performance [9][11]. Following Tison et al. [30] the main second kind statistics can be defined as:
$$\text{sums} \quad \text{success} \quad \text{$1$], [29]. Using $r=1/2$ in (2) one has to solve} \\ \text{cedure.} \quad \text{$1$} \sum _ { i = 1 } ^ { n } \sqrt { z _ { i } } - \sqrt { \frac { - \widehat { \alpha } _ { M o m 1 2 } - 1 } { L } } \frac { \Gamma ( - \widehat { \alpha } _ { M o m 1 2 } - \frac { 1 } { 2 } ) } { \Gamma ( - \widehat { \alpha } _ { M o m 1 2 } ) } \frac { \Gamma ( L + \frac { 1 } { 2 } ) } { \Gamma ( L ) } = 0. \\ \text{Estimation based on log-cumulants is gaining space in the} \\ \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \text{$1$} \quad \end{cases}$$
- · First second kind characteristic function: φ x ( s ) = ∫ ∞ 0 u s -1 p x ( u du )
- · Second second kind characteristic function: ψ x ( s ) = log φ x ( s )
- · First order second kind characteristic moment:
- · First order second kind characteristic cumulant (logcumulant)
$$\text{cond kind characteristic moment: } \\ \tilde { m } _ { r } = \frac { d \phi _ { x } ( s ) } { d s } \Big | _ { s = 1 }. \quad \text{(4)} \\ \text{second kind characteristic cumulant (log-}$$
$$\tilde { k } _ { r } = \frac { d \psi _ { x } ( s ) } { d s } \Big | _ { s = 1 }. \quad \quad ( 5 ) \\ ( u ) \text{ then we have} \colon \\ \vdots ^ { 1 - s } \tau / \cdots \tau + \cdots \tau / \cdots \tau$$
˜ ∣ Using the developments presented in [30], we have that ˜ k 1 = ˜ m 1 and the empirical expression for the first logcumulant estimator for n samples z i is ̂ ˜ k 1 = n -1 ∑ n i =1 log z i . Therefore
$$\begin{array} { c c c } a s & | s = 1 \\ \text{If } p _ { x } ( u ) = f _ { \mathcal { G } _ { 1 } ^ { 0 } } ( u ) \text{ then we have} \colon \\ ( 1 ) & \bullet & \phi _ { x } ( s ) = \frac { \left ( \frac { L } { \gamma } \right ) ^ { 1 - s } \Gamma ( - 1 + L + s ) \Gamma ( 1 - s - \alpha ) } { \Gamma ( L ) \Gamma ( - \alpha ) } \\ & \bullet & \widetilde { m } _ { 1 } = \frac { d \phi _ { x } ( s ) } { d s } \Big | _ { s = 1 } = - \log ( \frac { L } { \gamma } ) + \Psi ^ { 0 } ( L ) - \Psi ^ { 0 } ( - \alpha ). \\ & \text{Using the developments presented in } [ 3 0 ], \text{ we have that} \\ \sim & k _ { 1 } \text{ } = \widetilde { m } _ { 1 } \text{ and the empirical expression for the first } \log - \end{array}$$
$$\widetilde { k } _ { 1 } & = - \log \frac { L } { \gamma } + \Psi ^ { 0 } ( L ) - \Psi ^ { 0 } ( - \alpha ). \quad \quad ( 6 ) \\ \text{suming } \gamma ^ { * } & = - \alpha - 1, \text{ the Log-Cumulant estimator of } \alpha,$$
$$\text{but} \quad \text{denoted by } \widehat { \alpha } _ { L C u m } \, \text{is then the solution of } k _ { 1 } = - \log \frac { L } { 1 - \widehat { \alpha } _ { L C u m } } + \\ \text{ited to} \quad \Psi ^ { 0 } ( L ) - \Psi ^ { 0 } ( - \widehat { \alpha } _ { L C u m } ), \, \text{that is, the solution of} \\ \text{typically} \quad \frac { 1 } { n } \sum _ { i = 1 } ^ { n } \log z _ { i } = - \log \frac { L } { 1 - \widehat { \alpha } _ { L C u m } } + \Psi ^ { 0 } ( L ) + \Psi ^ { 0 } ( - \widehat { \alpha } _ { L C u m } ). \, ( 7 ) \\ \text{reless} \quad \text{The ability of these estimators to resist outliers has not still} \\. \, \text{This} \quad \text{been assessed}.$$
Assuming γ ∗ = -α -1 , the Log-Cumulant estimator of α , denoted by ̂ α LCum is then the solution of ̂ ˜ k 1 = -log L 1 -̂ α LCum + Ψ ( 0 L ) -Ψ ( 0 -α LCum ) , that is, the solution of
The ability of these estimators to resist outliers has not still been assessed.
In the following we provide new results regarding the heavytailedness of the G 0 I distribution. This partly explains the numerical issues faced when seeking for estimators for its parameters: the distribution is prone to producing extreme values. The main concepts are from [31]-[33].
Definition 1: The function /lscript : R → R is slow-varying in the infinite if for every t > 0 holds that
$$\lim _ { x \rightarrow + \infty } \frac { \ell ( t x ) } { \ell ( x ) } = 1.$$
Definition 2: A probability density function f ( x ) has heavy tails if for any η > 0 holds that
$$f ( x ) = \ell ( x ) x ^ { - \eta },$$
where /lscript is a slow-varying function in the infinite, and η is the tail index.
The smaller the tail index is, the more prone to producing extreme observations the distribution is.
Proposition 1: The G 0 I distribution has heavy tails with tail index 1 -α .
$$P r o o f \colon \text{Defining $\ell(x)=f_{\mathcal{G}_{I}^{0}(x)x^{-\alpha+1}$ we have that } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\lim _ { x \to + \infty } \frac { \ell ( t x ) } { \ell ( x ) } & = \lim _ { x \to + \infty } \frac { ( t x ) ^ { L - 1 } \, ( L t x + \gamma ) ^ { \alpha - L } \, ( t x ) ^ { 1 - \alpha } } { x ^ { L - 1 } \, ( L x + \gamma ) ^ { \alpha - L } \, x ^ { 1 - \alpha } } \\ & = \lim _ { x \to + \infty } t ^ { L - \alpha } \left ( \frac { L x + \gamma } { L t x + \gamma } \right ) ^ { L - \alpha } = 1. \quad \text{ with } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text { } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text$$
This holds for every t > 0 , so /lscript is as in Def. 1
As expected, the tail index is a decreasing function on α , then the G 0 I distribution is more prone to producing extreme observations when the roughness parameter is bigger.
The remainder of this section is devoted to proving that the G 0 I model is outlier-prone. Consider the random variables z , . . . , z 1 n and the corresponding order statistics Z 1: n ≤ · · · ≤ Z n n : .
Definition 3: The distribution is absolutely outlier-prone if there are positive constants ε, δ and an integer n 0 such that
$$\Pr ( Z _ { n \colon n } - Z _ { n - 1 \colon n } > \varepsilon ) \geq \delta$$
holds for every integer n ≥ n 0 .
A sufficient condition for being absolutely outlier-prone is that there are positive constants ε, δ, x 0 such that the density of the distribution satisfies, for every x ≥ x 0 , that
$$\frac { f ( x + \varepsilon ) } { f ( x ) } \geq \delta. \quad \text{(8)} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
Since
$$\lim _ { x \to + \infty } \frac { f _ { \mathcal { G } _ { I } ^ { 0 } } ( x + \varepsilon ) } { f _ { \mathcal { G } _ { I } ^ { 0 } } ( x ) } & = \lim _ { x \to + \infty } \left ( \frac { x + \varepsilon } { x } \right ) ^ { L - 1 } \left ( \frac { L x + \gamma } { L ( x + \varepsilon ) + \gamma } \right ) ^ { L - \alpha } \\ & = 1, \quad \text{where $b$ i} \\ \text{Amono}$$
we are in the presence of an absolutely outlier-prone model.
## III. ESTIMATION BY THE MINIMIZATION OF STOCHASTIC DISTANCES
Information Theory provides divergences for comparing two distributions; in particular, we are interested in distances between densities. Our proposal consists of, given the sample z , computing ̂ α , estimator of α , as the point which minimizes the distance between the density f G 0 I and an estimate of the underlying density function.
Cassetti et al. [22] assessed the Hellinger, Bhattacharyya, R´ enyi and Triangular distances, and they concluded that the latter outperforms the other ones in a variety of situations. The Triangular distance between the densities f V and f W with common support S is given by
$$\dots \psi _ { P } \psi _ { S } \psi _ { S } \psi _ { S } \psi _ { S } \\ d _ { T } ( f _ { V }, f _ { W } ) = \int _ { S } \frac { ( f _ { V } - f _ { W } ) ^ { 2 } } { f _ { V } + f _ { W } }. \quad \quad ( 9 )$$
Let z = ( z , . . . , z 1 n ) be a random sample of n independent G 0 I ( α , γ 0 ∗ 0 , L 0 ) -distributed observations. An estimate of the underlying density function of z , denoted ̂ f , is used to define the objective function to be minimized as a function of α . The estimator for the α parameter based on the minimization of the Triangular distance between an estimate of the underlying density ̂ f and the model f G 0 I , denoted by α T , is given by where γ ∗ 0 and L 0 are known and d T is given in (9). Solving (10) requires two steps: the integration of (9) using the G 0 I density and the density estimate ̂ f , and optimizing with respect to α . To the best of the authors' knowledge, there are no explicit analytic results for either problem, so we rely on numerical procedures. The range of the search is established to avoid numerical instabilities.
$$& \text{the Triangular distance between an estimate of the underlying} \\ & \text{density } f \text{ and the model } f _ { \mathcal { G } _ { I } ^ { 0 } }, \text{ denoted by } \widehat { \alpha } _ { T }, \text{ is given by} \\ & \widehat { \alpha } _ { T } = \arg \min _ { - 2 0 \leq \alpha \leq - 1 } d _ { T } \left ( f _ { \mathcal { G } _ { I } ^ { 0 } } ( \alpha, \gamma _ { 0 } ^ { * }, L _ { 0 } ), \widehat { f } ( z ) \right ), \quad ( 1 0 ) \\ & \text{where } \gamma _ { 0 } ^ { * } \text{ and } L _ { 0 } \text{ are known and } d _ { T } \text{ is given in } ( 9 ). \text{ Solv-} \\ & \text{in } f \text{$1\partial$ radius to time} \text{ the integration of $0\times inc} \text{ the}$$
We also calculate numerically the ML, the 1 2 -moment and Log-Cumulants based estimators using the same established range of the search and compare all the methods through the bias and the mean squared error by simulation.
## A. Estimate of the Underlying Distribution
The choice of the way in which the underlying density function is computed is very important in our proposal. In this section we describe several possibilities for computing it, and we justify our choice.
Histograms are the simplest empirical densities, but they lack unicity and they are not smooth functions.
Given that the model we are interested is asymmetric, another possibility is to use asymmetric kernels [24], [26]. Let z = ( z , . . . , z 1 n ) be a random sample of size n , with an unknown density probability function f , an estimate of its density function using kernels is given by
$$\widehat { f _ { b } } ( t ; z ) = \frac { 1 } { n } \sum _ { i = 1 } ^ { n } K ( t ; z _ { i }, b ), \\ \text{he bandwidth of the kernel } K.$$
where b is the bandwith of the kernel K .
Among the many available asymmetric kernels, we worked with two: the densities of the Gamma and Inverse Gaussian
distributions. These kernels are given by
$$K _ { \Gamma } ( t ; z _ { i }, b ) & = \frac { t ^ { z _ { i } / b } \exp \{ - t / b \} } { b ^ { z _ { i } / b + 1 } \Gamma ( z _ { i } / b + 1 ) }, \text{and} \quad \begin{array} { c } \Phi \\ \text{have} \\ \text{pro} \end{array} \\ K _ { \text{IG} } ( t ; z _ { i }, b ) & = \frac { 1 } { \sqrt { 2 \pi b t ^ { 3 } } } \exp \left \{ - \frac { 1 } { 2 b z _ { i } } \left ( \frac { t } { z _ { i } } + \frac { z _ { i } } { t } - 2 \right ) \right \}, \quad \begin{array} { c } \Phi \\ \text{has} \end{array} \\ \text{connective} \nu \text{ for every } t \ > \ 0 \text{ } \text{Fmnitial studies led one to } \text{ can} \end{array}$$
respectively, for every t > 0 . Empirical studies led us to employ b = n -1 / 2 / 5 .
As an example, Figure 1 shows the G 0 I ( -3 2 1) , , density and three estimates of the underlying density function obtained with n = 30 samples: those produced by the Gamma and the Inverse Gaussian kernels, and the histogram computed with the Freedman-Diaconis method.
Fig. 1. Fitting the G 0 I density of thirty G 0 I ( -3 2 1) , , observations in different ways, along with the histogram.
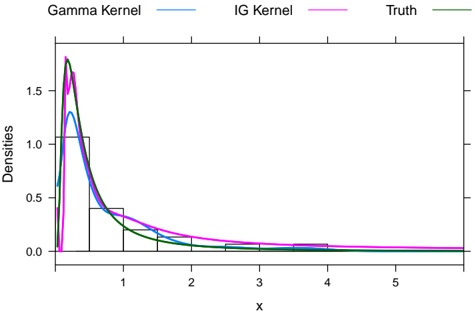
As it can be seen, fitting the underlying density function using kernels is better than using a histogram. After extensive numerical studies, we opted for the K IG kernel due to its low computational cost, its ability to describe observations with large variance, and its good numerical stability. In agreement with what Bouezmarni and Scaillet [26] reported, the Gamma kernel is also susceptible to numerical instabilities.
## B. Contamination
Estimators in signal and image processing are often used in a wide variety of situations, so their robustness is of highest importance. Robustness is the ability to perform well when the data obey the assumed model, and to not provide completely useless results when the observations do not follow it exactly. Robustness, in this sense, is essential when designing image processing and analysis applications. Filters, for instance, employ estimators based, typically, in small samples which, more often than not, receive samples from more than one class. Supervised classification relies on samples, and the effect of contamination (often referred to as 'training errors') on the results has been attested, among other works, in [34].
In order to assess the robustness of the estimators, we propose three contamination models able to describe realistic departures from the hypothetical 'independent identically distributed sample' assumption.
One of the sources of contamination in SAR imagery is the phenomenon of double bounce which results in some pixels having a high return value. The presence of such outliers may provoke big errors in the estimation.
In order to assess the robustness of the proposal, we generate contaminated random samples using three types (cases) of contamination, with 0 < /epsilon1 /lessmuch 1 the proportion of contamination. Let the Bernoulli random variable B with probability of success /epsilon1 model the occurrence of contamination. Let C ∈ R + be a large value.
- · Case 1: Let W and U be such that W ∼ G 0 I ( α , γ 1 ∗ 1 , L ) , and U ∼ G 0 I ( α , γ 2 ∗ 2 , L ) . Define Z = BU + (1 -B W ) , then we generate { z , . . . , z 1 n } identically distributed random variables with cumulative distribution function
$$\begin{array} {$$
where F G 0 I ( α,γ,L ) is the cumulative distribution function of a G 0 I ( α, γ, L ) random variable.
- · Case 3: Consider W ∼ G 0 I ( α, γ ∗ , L ) and U ∼ G 0 I ( α, 10 k γ , L ∗ ) with k ∈ N . Return Z = BU + (1 -B W ) , then { z , . . . , z 1 n } are identically distributed random variables with cumulative distribution function
- · Case 2: Consider W ∼ G 0 I ( α , γ 1 ∗ 1 , L ) ; return Z = BC + (1 -B W ) .
$$( 1 - \epsilon ) \mathcal { F } _ { \mathcal { G }$$
All these models consider departures from the hypothesized distribution G 0 I ( α, γ ∗ , L ) . The first type of contamination assumes that, with probability /epsilon1 , instead of observing outcomes from the 'right' model, a sample from a different one will be observed; notice that the outlier may be close to the other observations. The second type returns a fixed and typically large value, C , with probability /epsilon1 . The third type is a particular case of the first, where the contamination assumes the form of a distribution whose scale is k orders of magnitude larger than the hypothesized model. We use the three cases of contamination models in our assessment.
## IV. RESULTS
A Monte Carlo experiment was set to assess the performance of each estimation procedure. The parameter space consists of the grid formed by (i) three values of roughness: α = {-1 5 . , -3 , - } 5 , which are representative of areas with extreme and moderate texture; (ii) three usual levels of signalto-noise processing, through L = { 1 3 8 , , } ; (iii) sample sizes n = { 9 25 49 81 121 1000 , , , , , } , related to squared windows of side 3 , 5 , 7 , 9 and 11 , and to a large sample; (iv) each of the three cases of contamination, with /epsilon1 = { 0 001 0 005 0 01 . , . , . } , α 2 = {-4 , -15 } , C = 100 and k = 2 .
̂ In the following figures, 'ML', 'T','Mom12' and 'LCum' denote the estimator based on the Maximum likelihood, Triangular distance, 1 2 -moment and Log-Cumulant, respectively.
One thousand samples were drawn for each point of the parameter space, producing { ̂ α , . . . , α 1 ̂ 1000 } estimates of each kind. Estimates of the mean ̂ α = (1000) -1 ∑ 1000 i =1 ̂ α i , bias ̂ ̂ ∑ B α ( ) = ̂ α i -α and mean squared error ̂ mse = (1000) -1 1000 i =1 ( α i -α ) 2 were then computed and compared.
Sample sizes are in the abscissas, which are presented in logarithmic scale. The estimates of the mean are presented with error bars which show the Gaussian confidence interval at the 95% level of confidence. Only a few points of this parameter space are presented for brevity, but the remaining results are consistent with what is discussed here.
Figure 2 shows the mean of the estimators ̂ α in uncontaminated data ( /epsilon1 = 0 ) with different values of n and L . Only two of the four estimators lie, in mean, very close to the true value: ̂ α MV and ̂ α T; it is noticeable how far from the true value lie ̂ α LCum and ̂ α Mom12 when α = -5 . It is noticeable that ̂ α ML has a systematical tendency to underestimate the true value of α . Vasconcellos et al. [4] computed a first order approximation of such bias for a closely related model, and our results are in agreement with those. The estimator based on the Triangular distance α T compensates this bias.
̂ Figure 3 shows the sample mean squared error of the estimates under the same situation, i.e., uncontaminated data. In most cases, all estimators have very similar mse , not being possible to say that one is systematically the best one. This is encouraging, since it provides evidence that ̂ α T exhibits the first property of a good robust estimator, i.e., not being unacceptable under the true model.
The mean times of processing, measured in seconds, for each method and each case, were computed, as an example, the mean times of processing for L = 1 and n = 81 are presented in Table I. It can be seen that the new method has a higher computational cost. The other cases are consistent with this table. The details of the computer platform are presented in the appendix.
TABLE I MEAN TIMES FOR SIMULATED DATA WITHOUT CONTAMINATION, L = 1 , n = 81
| MV | DT | Moment 1 2 | Log Cumulant |
|---------|---------|--------------|----------------|
| 0 . 003 | 2 . 223 | 0 . 0001 | 0 . 003 |
Figures 4 and 5 show, respectively, the sample mean and mean squared error of the estimates under Case 1 contamination with α 2 = -15 , /epsilon1 = 0 01 . , and varying n and L . This type of contamination injects, with probability /epsilon1 = 0 01 . , observations with almost no texture in the sample under analysis. As expected, the influence of such perturbation is more noticeable in those situations where the underlying model is further away from the contamination, i.e., for larger values of α . This is particularly clear in Fig. 5, which shows that the mean squared errors of ̂ α ML, ̂ α Mom12 and ̂ α LCum are larger than that of ̂ α T for L = 3 8 , , with not a clear distinction for L = 1 except that ̂ α T is at least very competitive in the α = -3 , -5 cases.
Figures 6 and 7 present, respectively, the sample mean and sample mean squared error of the estimates under Case 2 contamination with /epsilon1 = 0 001 . and C = 100 . This type of contamination injects a constant value ( C = 100 ) with probability /epsilon1 = 0 001 . instead of each observation from the G 0 I distribution. Since we are considering samples with unitary mean, this is a large contamination. In this case, ̂ α T is, in
Fig. 2. Sample mean of estimates under uncontaminated data. The blue line is the true parameter.
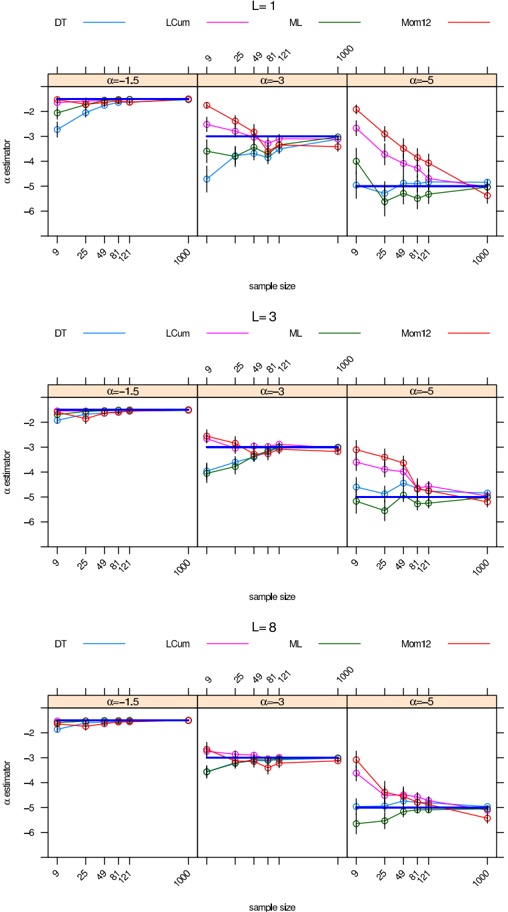
mean, closer to the true value than the other methods, and its mean square error the smallest.
Figures 8 and 9 show, respectively, the sample mean and mean squared error of the estimates under Case 3 with /epsilon1 = 0 005 . with k = 2 . This kind of contamination draws, with probability /epsilon1 = 0 005 . , an observation from a G 0 I distribution with a scale one hundred times larger than that of the 'correct' model. The behavior of the estimators follows the same pattern for L = 3 8 , : ̂ α T produces the closest estimates to the true value with reduced mean squared error. There is no good estimator for the single-look case with this case of contamination.
As previously mentioned, the iterative algorithms which implement the 1 2 -moment and Log-Cumulant estimators often fail to converge. In the Monte Carlo experiment, if 1 2 -moment or Log-Cumulant fail, we eliminate the estimators computed
with the other methods in the corresponding iteration, so the amount of elements for calculating the mean ̂ α , the bias and the mean squared error is lower than 1000 . As an example, Table II informs the number of such situations for Case 1 and α 2 = -15 , /epsilon1 = 0 01 . . These results are consistent with other situations under contamination, and they suggest that these methods are progressively more prone to fail in more heterogeneous areas.
Data from a single-look L-band HH polarization in intensity format E-SAR [35] image was used in the following. Figure 10 shows the regions used for estimating the texture parameter.
Fig. 3. Sample mean squared error of estimates under uncontaminated data.
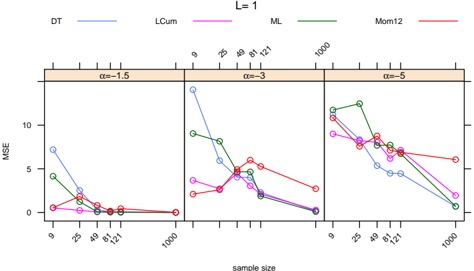
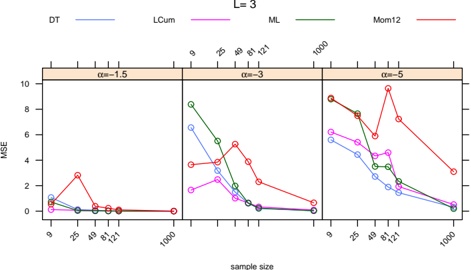
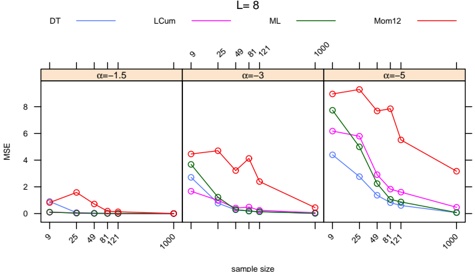
TABLE II PERCENTAGE OF SITUATIONS FOR WHICH NO CONVERGENCE WAS OBSERVED FOR THE MOMENTS AND LOG-CUMULANT METHODS IN CASE 1, α 2 = -15 , /epsilon1 = 0 01 .
| L | 1 2 -Moment | Log-Cumulant |
|-----|---------------|----------------|
| 1 | 22 . 87 | 21 . 56 |
| 3 | 11 . 71 | 11 . 87 |
| 8 | 5 . 81 | 6 . 04 |
Table III shows the results of estimating the α parameter for
each rectangular region, where NA means that the corresponding estimator is not available.
The Kolmogorov-Smirnov test (KS-test) is applied to two samples: x , from the image, and y , simulated. Babu and Feigelson [36] warn about the use of the same sample for parameter estimation and for performing a KS test between the data and the estimated cumulative distribution function. We then took the real sample x , used to estimate the parameters with the four methods under assessment, and then samples of the same size y were drawn from the G 0 I law with those parameters. The KS test was then performed between x and y for the null hypothesis H 0 'both samples come from the same distribution,' and the complementary alternative hypothesis.
Table IV shows the sample p -values. It is observed that the null hypothesis is not rejected with a significance level of 5 % in any of the cases. This result justifies the adequacy of the
Fig. 4. Sample mean of estimates, Case 1 with α 2 = -15 and /epsilon1 = 0 01 . .
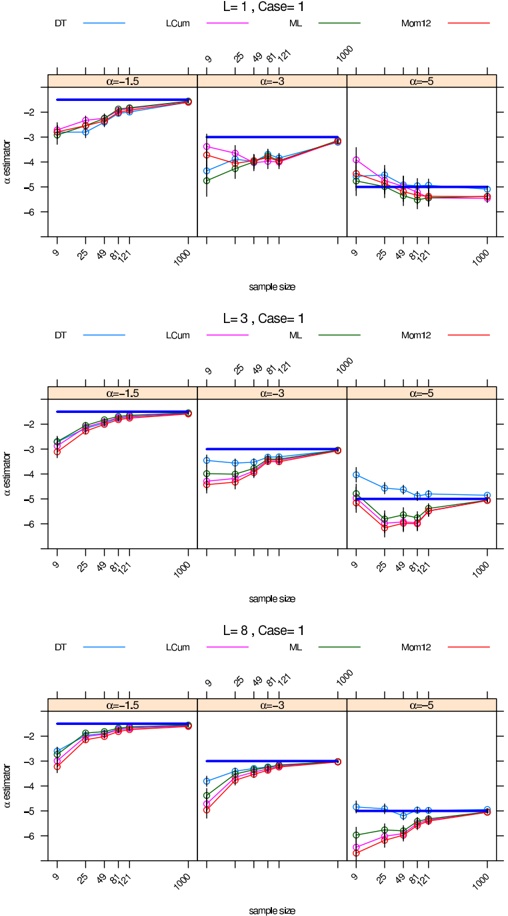
model for the data.
Fig. 11 shows the regions used for estimating the texture parameter under the influence of a corner reflector. Table V shows the estimates of α for each rectangular region in the image of Fig. 11(b). The Maximum Likelihood, 1 2 -moment and Log-Cumulant estimators are unable to produce any estimate in small samples. They only produce sensible values when the sample is of at least 90 observations, The Log-Cumulant method is the one which requires the largest sample size to produce an acceptable estimate. The estimator based on the Triangular distance yields plausible values under contamination even with very small samples.
Table VI presents the p -values of the KS test, applied as previously described to the samples of Fig. 11(b). Estimators based on the 1 2 -moments and on Log-Cumulants failed to produce estimates in two samples and, therefore, it was not
possible to apply the procedure. The other samples did not fail to pass the KS test, except for the Blue sample and the Maximum Likelihood estimator. These results leads us to conclude that the underlying model is a safe choice regardless the presence of contamination and the estimation procedure.
## V. CONCLUSIONS
We proposed a new estimator for the texture parameter of the G 0 I distribution based on the minimization of a stochastic distance between the model (which is indexed by the estimator) and an estimate of the probability density function
Fig. 5. Sample mean squared error of estimates, Case 1 with α 2 = -15 and /epsilon1 = 0 01 . .
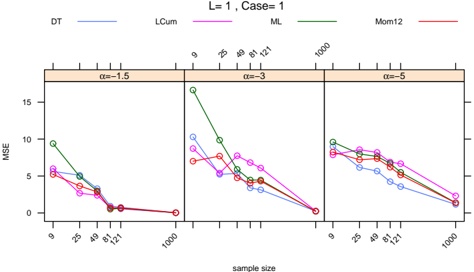
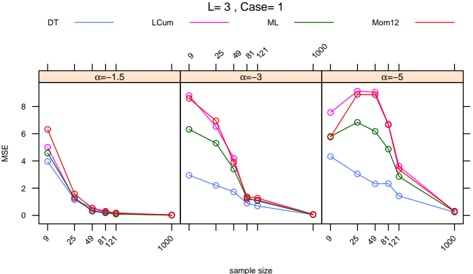
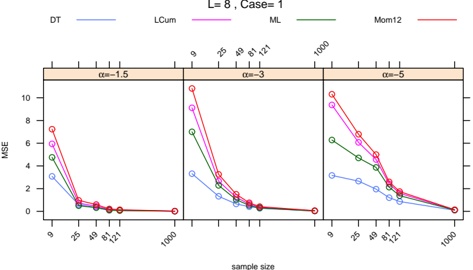
built with asymmetric kernels. We defined three models of contamination inspired in real situations in order to assess the impact of outliers in the performance of the estimators. The difficulties of estimating the textured parameter of the G 0 I distribution were further investigated and justified throughout new theoretical results regarding its heavytailedness.
Regarding the impact of the contamination on the performance of estimators, we observed the following. Only Fractional Moment and Log-Cumulant estimators fail to converge.
- · Case 1: Regardless the intensity of the contamination, the
bigger the number of looks, the smaller the percentage of situations for which no convergence if achieved.
- · Cases 2 and 3: the percentage of situations for which there is no convergence increases with the level of contamination, and reduces with α .
In the single-case look the proposed estimator does not present excellent results, but it never fails to converge whereas the others are prone to produce useless output.
The new estimator presents good properties as measured by its bias and mean squared error. It is competitive with the Maximum Likelihood, Fractional Moment and Log-Cumulant estimators in situations without contamination, and outperforms the other techniques even in the presence of small levels of contamination.
For this reason, it would be advisable to use ̂ α T in every situation, specially when small samples are used and/or when
Fig. 6. Sample mean of estimates, Case 2 with C = 100 , /epsilon1 = 0 001 . .
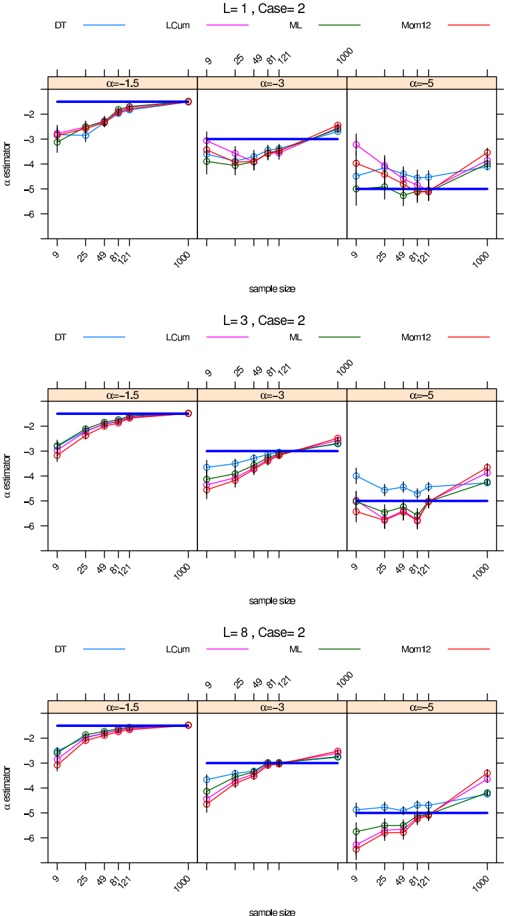
there is the possibility of having contaminated data. The extra computational cost incurred in using this estimator is, at most, the twenty times the required to compute ̂ α ML, but its advantages outnumber these extra computer cycles.
## APPENDIX
Simulations were performed using the R language and environment for statistical computing [37] version 3.0.2. The adaptIntegrate function from the cubature package was used to perform the numerical integration required to evaluate the Triangular distance, the algorithm utilized is an adaptive multidimensional integration over hypercubes.
In order to numerically find ̂ α LCum we used the function uniroot implemented in R to solve (7).
The computer platform is Intel(R) Core i7, with 8 GB of memory and 64 bits Windows 7. Codes and data are available upon request from the corresponding author.
## REFERENCES
- [1] A. C. Frery, H.-J. M¨ uller, C. C. F. Yanasse, and S. J. S. Sa nt'Anna, 'A model for extremely heterogeneous clutter,' IEEE Transactions on Geoscience and Remote Sensing , vol. 35, no. 3, pp. 648-659, 1997.
- [2] M. Mejail, J. C. Jacobo-Berlles, A. C. Frery, and O. H. Bustos, 'Classification of SAR images using a general and tractable multiplicative model,' International Journal of Remote Sensing , vol. 24, no. 18, pp. 3565-3582, 2003.
- [3] G. Gao, 'Statistical modeling of SAR images: A survey,' Sensors , vol. 10, no. 1, pp. 775-795, 2010.
- [4] K. L. P. Vasconcellos, A. C. Frery, and L. B. Silva, 'Improving estimation in speckled imagery,' Computational Statistics , vol. 20, no. 3, pp. 503-519, 2005.
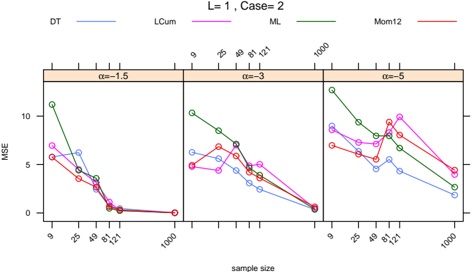
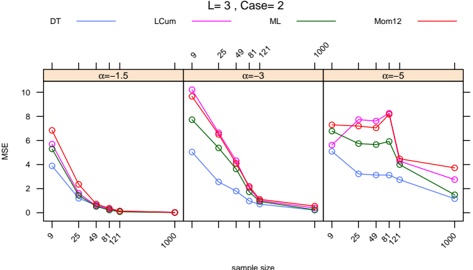
sample size
Fig. 7. Sample mean squared error of estimates, Case 2 with C = 100 , /epsilon1 = 0 001 . .
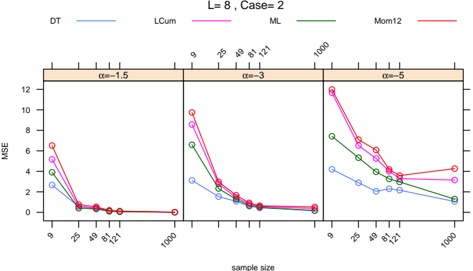
- [5] M. Silva, F. Cribari-Neto, and A. C. Frery, 'Improved likelihood inference for the roughness parameter of the GA0 distribution,' Environmetrics , vol. 19, no. 4, pp. 347-368, 2008.
- [6] F. Cribari-Neto, A. C. Frery, and M. F. Silva, 'Improved estimation of clutter properties in speckled imagery,' Computational Statistics and Data Analysis , vol. 40, no. 4, pp. 801-824, 2002.
- [7] H. Allende, A. C. Frery, J. Galbiati, and L. Pizarro, 'M-estimators with asymmetric influence functions: the GA0 distribution case,' Journal of Statistical Computation and Simulation , vol. 76, no. 11, pp. 941-956, 2006.
- [8] O. H. Bustos, M. M. Lucini, and A. C. Frery, 'M-estimators of roughness and scale for GA0-modelled SAR imagery,' EURASIP Journal on Advances in Signal Processing , vol. 2002, no. 1, pp. 105-114, 2002.
- [9] S. Anfinsen and T. Eltoft, 'Application of the matrix-variate Mellin
transform to analysis of polarimetric radar images,' IEEE Transactions on Geoscience and Remote Sensing , vol. 49, no. 6, pp. 2281-2295, 2011.
- [10] F. Bujor, E. Trouve, L. Valet, J.-M. Nicolas, and J.-P. Rudant, 'Application of log-cumulants to the detection of spatiotemporal discontinuities in multitemporal SAR images,' IEEE Transactions on Geoscience and Remote Sensing , vol. 42, no. 10, pp. 2073-2084, 2004.
- [11] S. Khan and R. Guida, 'Application of Mellin-kind statistics to polarimetric } distribution for SAR data,' IEEE Transactions on Geoscience and Remote Sensing , vol. 52, no. 6, pp. 3513-3528, June 2014.
- [12] A. C. Frery, F. Cribari-Neto, and M. O. Souza, 'Analysis of minute features in speckled imagery with maximum likelihood estimation,' EURASIP Journal on Advances in Signal Processing , vol. 2004, no. 16, pp. 2476-2491, 2004.
- [13] D. M. Pianto and F. Cribari-Neto, 'Dealing with monotone likelihood in a model for speckled data,' Computational Statistics and Data Analysis , vol. 55, pp. 1394-1409, 2011.
- [14] C. Arndt, Information Measures: Information and Its Description in Science and Engineering . Springer, 2004.
- [15] S. Aviyente, F. Ahmad, and M. G. Amin, 'Information theoretic measures for change detection in urban sensing applications,' in IEEE Workshop on Signal Processing Applications for Public Security and Forensics , 2007, pp. 1-6.
- [16] B. Vemuri, M. Liu, S.-I. Amari, and F. Nielsen, 'Total Bregman divergence and its applications to DTI analysis,' IEEE Transactions on
- Medical Imaging , vol. 30, no. 2, pp. 475-483, 2011.
- [17] A. Nascimento, R. Cintra, and A. Frery, 'Hypothesis testing in speckled data with stochastic distances,' IEEE Transactions on Geoscience and Remote Sensing , vol. 48, no. 1, pp. 373-385, 2010.
- [18] W. B. Silva, C. C. Freitas, S. J. S. Sant'Anna, and A. C. Frery, 'Classification of segments in PolSAR imagery by minimum stochastic distances between Wishart distributions,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 6, no. 3, pp. 1263-1273, 2013.
- [19] A. D. C. Nascimento, M. M. Horta, A. C. Frery, and R. J. Cintra, 'Comparing edge detection methods based on stochastic entropies and distances for PolSAR imagery,' IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 7, no. 2, pp. 648663, Feb. 2014.
- [20] R. C. P. Marques, F. N. Medeiros, and J. Santos Nobre, 'SAR image segmentation based on level set approach GA0 model,' IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 34, no. 10, pp. 2046-2057, 2012.
- [21] F. Liese and I. Vajda, 'On divergences and informations in statistics and information theory,' IEEE Transactions on Information Theory , vol. 52, no. 10, pp. 4394-4412, 2006.
- [22] J. Cassetti, J. Gambini, and A. C. Frery, 'Parameter estimation in SAR imagery using stochastic distances,' in Proceedings of The 4th AsiaPacific Conference on Synthetic Aperture Radar (APSAR) , Tsukuba,
Fig. 8. Sample mean of estimates, Case 3 with /epsilon1 = 0 005 . and k = 2 .
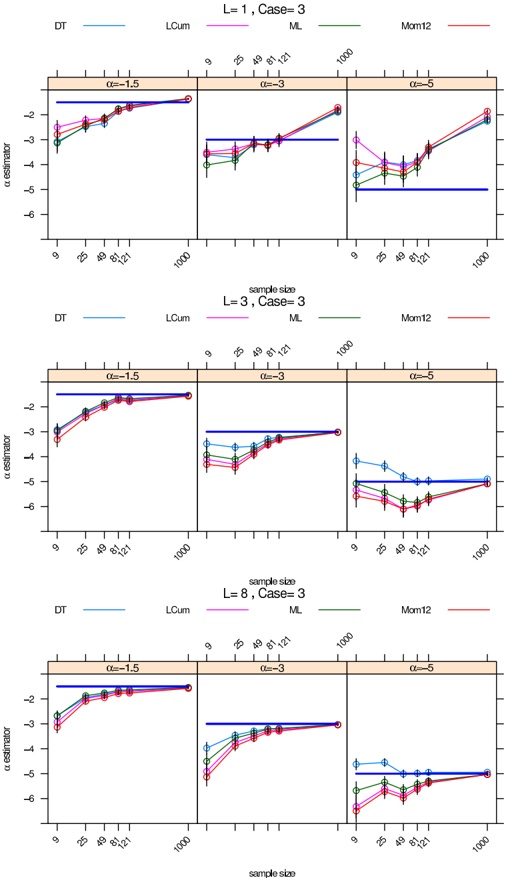
Japan, 2013, pp. 573-576.
- [23] B. Han, D. Comaniciu, Y. Zhu, and L. Davis, 'Sequential kernel density approximation and its application to real-time visual tracking,' IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 30, no. 7, pp. 1186-1197, 2008.
- [24] S. Chen, 'Probability density functions estimation using Gamma kernels,' Annals of Institute Statistical Mathematics , vol. 52, no. 3, pp. 471-480, 2000.
- [25] O. Scaillet, 'Density estimation using inverse and reciprocal inverse Gaussian kernels,' Journal of Nonparametric Statistics , vol. 16, no. 12, pp. 217-226, 2004.
- [26] T. Bouezmarni and O. Scaillet, 'Consistency of asymmetric kernel density estimators and smoothed histograms with application to income data,' Econometric Theory , pp. 390-412, 2005.
- [27] A. Achim, P. Tsakalides, and A. Bezerianos, 'SAR image denoising via Bayesian wavelet shrinkage based on heavy-tailed modeling,' IEEE Transactions on Geoscience and Remote Sensing , vol. 41, pp. 17731784, 2003.
- [28] M. E. Mejail, A. C. Frery, J. Jacobo-Berlles, and O. H. Bustos, 'Approximation of distributions for SAR images: Proposal, evaluation and practical consequences,' Latin American Applied Research , vol. 31, pp. 83-92, 2001.
- [29] J. Gambini, M. Mejail, J. J. Berlles, and A. Frery, 'Accuracy of local edge detection in speckled imagery,' Statistics & Computing , vol. 18, no. 1, pp. 15-26, 2008.
- [30] C. Tison, J.-M. Nicolas, F. Tupin, and H. Maitre, 'A new statistical model for Markovian classification of urban areas in high-resolution SAR images,' IEEE Transactions on Geoscience and Remote Sensing ,
Fig. 9. Sample mean squared error of estimates, Case 3 with /epsilon1 = 0 005 . and k = 2 .
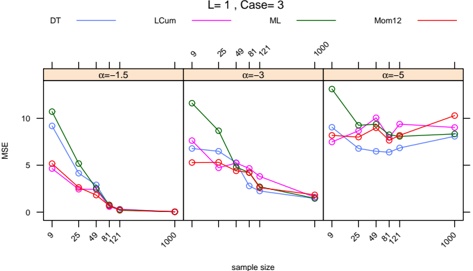
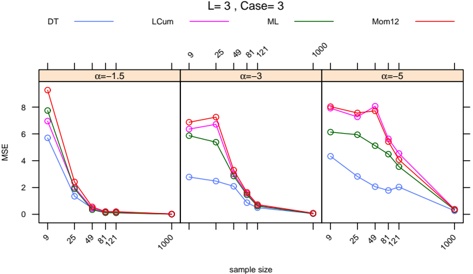
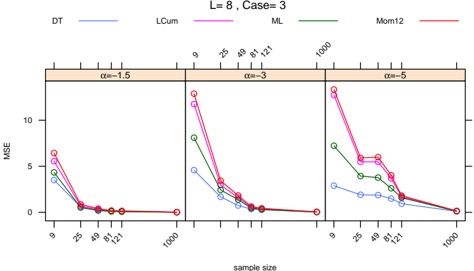
vol. 42, no. 10, pp. 2046-2057, 2004.
- [31] R. F. Green, 'Outlier-prone and outlier-resistant distributions,' American Statistical Association , vol. 71, no. 354, pp. 502-505, 1976.
- [32] J. Danielsson, B. N. Jorgensen, M. Sarma, and C. G. de Vries, 'Comparing downside risk measures for heavy tailed,' Economics Letters , vol. 92, no. 2, pp. 202-208, 2006.
- [33] J. Rojo, 'Heavy-tailed densities,' Wiley Interdisciplinary Reviews Computing Statistics , vol. 5, no. 10, pp. 30-40, 2013.
- [34] A. C. Frery, S. Ferrero, and O. H. Bustos, 'The influence of training errors, context and number of bands in the accuracy of image classification,' International Journal of Remote Sensing , vol. 30, no. 6, pp. 1425-1440, 2009.
- [35] R. Horn, 'The DLR airborne SAR project E-SAR,' in Proceedings IEEE International Geoscience and Remote Sensing Symposium , vol. 3. IEEE Press, 1996, pp. 1624-1628.
- [36] G. J. Babu and E. D. Feigelson, 'Astrostatistics: Goodness-of-fit and all that!' in Astronomical Data Analysis Software and Systems XV ASP Conference Series. , vol. 351, 2006, pp. 127-136.
- [37] R Core Team, R: A Language and Environment for Statistical

Fig. 10. Real SAR image and the regions used to estimate the α -parameter.
(a) Single-look E-SAR image with a corner reflector.

(b) Regions of interest.

Fig. 11. Samples of several sizes in a real SAR image with a corner reflector, used to estimate the α -parameter.
Computing , R Foundation for Statistical Computing, Vienna, Austria, 2013. [Online]. Available: http://www.R-project.org/

Juliana Gambini received the B.S. degree in Mathematics and the Ph.D. degree in Computer Science both from Universidad de Buenos Aires (UBA), Argentina. She is currently Professor at the Instituto Tecnol´ ogico de Buenos Aires (ITBA), Buenos Aires, and Professor at Universidad Nacional de Tres de Febrero, Pcia. de Buenos Aires. Her research interests include SAR image processing, video processing and image recognition.
TABLE III
ESTIMATIONS OF THE α -PARAMETER USING THE SAMPLES SHOWN IN FIG. 10
TABLE VI
| Color | size | ̂ α M V | ̂ α T | ̂ α Mom12 | ̂ α LCum | time MV | time DT | time 1 2 Mom | time LCum |
|---------|--------|----------|---------|------------|-----------|-----------|-----------|----------------|-------------|
| Magenta | 100 | - 1 . 9 | - 2 . 7 | - 1 . 9 | - 1 . 7 | 0 . 03 | 5 . 85 | 0 . 03 | 0 . 02 |
| Green | 48 | - 2 . 5 | - 2 . 5 | - 2 . 9 | - 3 . 1 | 0 . 00 | 3 . 31 | 0 . 00 | 0 . 00 |
| Blue | 25 | - 4 . 9 | - 3 . 0 | NA | NA | 0 . 00 | 2 . 08 | 0 . 00 | 0 . 00 |
| Yellow | 90 | - 6 . 2 | - 5 . 1 | - 6 . 6 | - 6 . 8 | 0 . 00 | 5 . 16 | 0 . 00 | 0 . 00 |
| Red | 64 | - 1 . 8 | - 1 . 9 | - 1 . 9 | - 1 . 8 | 0 . 00 | 4 . 17 | 0 . 00 | 0 . 00 |
SAMPLE p -VALUES OF THE KOLMOGOROV-SMIRNOV TEST USING THE SAMPLES SHOWN IN FIG. 11(B)
| | p -value | p -value | p -value | p -value |
|---------|------------|------------|------------|------------|
| Color | TestMV | TestDT | TestMom | TestLogCum |
| Magenta | 0 . 38 | 0 . 93 | NA | NA |
| Green | 0 . 11 | 0 . 93 | NA | NA |
| Blue | 0 . 01 | 0 . 11 | 0 . 400 | 0 . 11 |
| Yellow | 0 . 19 | 0 . 31 | 0 . 460 | 0 . 15 |
| Red | 0 . 23 | 0 . 12 | 0 . 008 | 0 . 02 |
Mar´ ıa Magdalena Lucini received her BS and PhD degrees in mathematics from the Universidad Nacional de C´ ordoba, Argentina, in 1996 and 2002, respectively. She currently is Professor at the Universidad Nacional del Nordeste, and a researcher of CONICET, both in Argentina. Her research interests include statistical image processing and modelling, hyperspectral data, SAR and PolSAR data.

Julia Cassetti received the B.Sc. degree in Mathematics and a postgraduate diploma in Mathematical Statistics, both from the Universidad de Buenos Aires (UBA), Argentina. She is currently an Assistant Professor at the Universidad Nacional de General Sarmiento, Argentina. Her research interests are SAR imaging and applied statistics.
TABLE IV
SAMPLE p -VALUES OF THE KOLMOGOROV-SMIRNOV TEST WITH SAMPLES FROM THE IMAGE IN FIG. 10
| | p -value | p -value | p -value | p -value |
|---------|------------|------------|------------|------------|
| Color | TestMV | TestDT | TestMom | TestLCum |
| Magenta | 0 . 46 | 0 . 58 | 0 . 28 | 0 . 69 |
| Green | 0 . 37 | 0 . 85 | 0 . 37 | 0 . 37 |
| Blue | 0 . 15 | 0 . 07 | NA | NA |
| Yellow | 0 . 63 | 0 . 98 | 0 . 76 | 0 . 22 |
| Red | 0 . 30 | 0 . 30 | 0 . 21 | 0 . 99 |
TABLE V ESTIMATIONS OF THE α -PARAMETER USING THE SAMPLES SHOWN IN FIG. 11(B)
| Color | size | ̂ α M V | ̂ α T | ̂ α M om 12 | ̂ α L Cum | timeMV | timeDT | timeMom12 | timeLogcum12 |
|---------|--------|----------|---------|--------------|------------|----------|----------|-------------|----------------|
| Magenta | 15 | - 20 . 0 | - 4 . 1 | NA | NA | 0 . 03 | 1 . 95 | 0 . 03 | 0 . 03 |
| Green | 42 | - 9 . 2 | - 5 . 0 | NA | NA | 0 . 00 | 4 . 04 | 0 . 00 | 0 . 00 |
| Blue | 90 | -3.5 | -2.7 | -4.7 | -14.2 | 0.02 | 4.85 | 0.00 | 0.00 |
| Yellow | 156 | - 2 . 2 | - 1 . 8 | - 2 . 6 | - 3 . 4 | 0 . 01 | 8 . 35 | 0 . 00 | 0 . 00 |
| Red | 225 | - 1 . 9 | - 1 . 7 | - 2 . 1 | - 2 . 5 | 0 . 02 | 10 . 97 | 0 . 00 | 0 . 00 |


Alejandro C. Frery (S'92-SM'03) received the B.Sc. degree in Electronic and Electrical Engineering from the Universidad de Mendoza, Argentina. His M.Sc. degree was in Applied Mathematics (Statistics) from the Instituto de Matem´ atica Pura e Aplicada (IMPA, Rio de Janeiro) and his Ph.D. degree was in Applied Computing from the Instituto Nacional de Pesquisas Espaciais (INPE, S˜ ao Jos´ e dos Campos, Brazil). He is currently the leader of LaCCAN Laborat´ orio de Computac ¸ ˜o Cient´ ıfica e a An´ alise Num´rica e , Universidade Federal de Alagoas,
Brazil. His research interests are statistical computing and stochastic modelling. | 10.1109/JSTARS.2014.2346017 | [
"Juliana Gambini",
"Julia Cassetti",
"María Magdalena Lucini",
"Alejandro C. Frery"
] | 2014-08-01T13:41:51+00:00 | 2014-08-04T08:12:12+00:00 | [
"cs.IT",
"math.IT",
"stat.AP"
] | Parameter Estimation in SAR Imagery using Stochastic Distances and Asymmetric Kernels | In this paper we analyze several strategies for the estimation of the
roughness parameter of the $\mathcal G_I^0$ distribution. It has been shown
that this distribution is able to characterize a large number of targets in
monopolarized SAR imagery, deserving the denomination of "Universal Model" It
is indexed by three parameters: the number of looks (which can be estimated in
the whole image), a scale parameter, and the roughness or texture parameter.
The latter is closely related to the number of elementary backscatters in each
pixel, one of the reasons for receiving attention in the literature. Although
there are efforts in providing improved and robust estimates for such quantity,
its dependable estimation still poses numerical problems in practice. We
discuss estimators based on the minimization of stochastic distances between
empirical and theoretical densities, and argue in favor of using an estimator
based on the Triangular distance and asymmetric kernels built with Inverse
Gaussian densities. We also provide new results regarding the heavytailedness
of this distribution. |
1408.0178v1 | and spectropolarimetry
Proceedings IAU Symposium No. 307, 2014
G. Meynet, C. Georgy, J.H. Groh & Ph. Stee, eds.
c © 2014 International Astronomical Union
DOI: 00.0000/X000000000000000X
## The magnetic field of ζ Ori A
## A. Blaz`re , C. Neiner , J-C. Bouret , A. Tkachenko e 1 1 2 3 † and the MiMeS collaboration
1 LESIA, Observatoire de Paris, UMR 8109 du CNRS, UPMC, Universit´ e Paris-Diderot, 5 place Jules Janssen, 92195 Meudon, France email: [email protected]
2
Aix-Marseille University, CNRS, LAM, UMR 7326, 13388 Marseille, France 3 Instituut voor Sterrenkunde, KU Leuven, Celestijnenlaan 200D, B-3001 Leuven, Belgium
Abstract. Magnetic fields play a significant role in the evolution of massive stars. About 7% of massive stars are found to be magnetic at a level detectable with current instrumentation (Wade et al. 2013) and only a few magnetic O stars are known. Detecting magnetic field in O stars is particularly challenging because they only have few, often broad, lines to measure the field, which leads to a deficit in the knowledge of the basic magnetic properties of O stars. We present new spectropolarimetric Narval observations of ζ Ori A. We also provide a new analysis of both the new and older data taking binarity into account. The aim of this study was to confirm the presence of a magnetic field in ζ Ori A. We identify that it belongs to ζ Ori Aa and characterize it.
Keywords. stars: magnetic fields, stars: early-type, stars: individual ( ζ Ori A)
## 1. Introduction
A magnetic field seems to have been detected in the supergiant O9.5I star ζ OriA (Bouret et al. 2008). This magnetic field is the weakest ever reported in a massive star. Thanks to this measurement of the magnetic field one can locate ζ OriA in the magnetic confinement-rotation diagram (Petit et al. 2013). ζ OriA is the only known magnetic massive star with a confinement parameter below 1, i.e. without a magnetosphere. However, Hummel et al. (2013) recently found that ζ OriA is a O9.5I+B1IV binary star with a period of 2687.3 ± 7.0 days, so the magnetic field of ζ OriA and its confinement parameter might have been wrongly estimated.
## 2. Spectropolarimetric analysis
Spectropolarimetric data were obtained with Narval at TBL between 2008 and 2012. To improve the signal-to-noise ratio, we have coadded spectra obtained on the same night, leading to 36 average spectra. We applied the well-known and commonly used LeastSquares Deconvolution (LSD) technique (Donati et al. 1997) on each average spectrum. The mask is created from a list of lines extracted from VALD (Piskunov et al. 1995; Kupka & Ryabchikova 1999) using the effective temperature T eff =30000K and the log g=3.25. We then extracted LSD Stokes I and V profiles for each night as well as null (N) polarization profiles to check for spurious signatures. We see clear Zeeman signatures some nights (see left panel of Fig. 1). ζ OriA is thus confirmed to be magnetic. However, ζ OriA is a binary and we ignore which component of the binary is magnetic, or if both components are magnetic. To provide an answer to this question we must disentangle the composite spectra.
† Postdoctoral Fellow of the Fund for Scientific Research (FWO), Flanders, Belgium
Figure 1: Left: Examples of I (bottom), null N (center) and Stokes V (top) profiles for two nights. Right: I (bottom), null N (center) and Stokes V (top) profiles for October 25, 2008, for ζ OriAa (left) and ζ OriAb (right). The red lines represent the averaged signal.
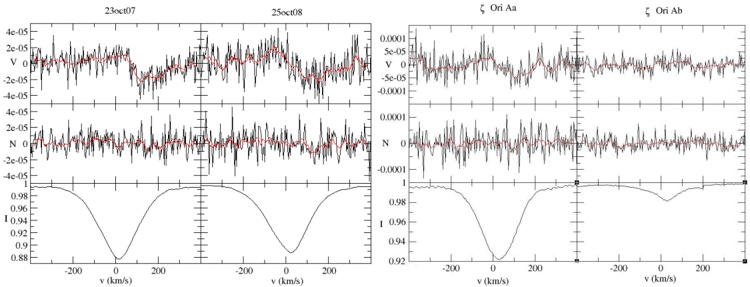
## 3. Disentangling the spectra
We used the Fourier-based formulation of the spectral disentangling method (Hadrava 1995) as implemented in the FDBinary code (Ilijic et al. 2004) to try to separate the individual spectra of both components of the ζ OriA binary system. This method failed due to a bad phase coverage of the binary period.
Therefore we used a second method to disentangle the spectra: for each component of ζ OriA we computed a synthetic spectrum with their respective temperature and log g. Based on these synthetic spectra, we checked which lines in the observations comes from only one of the component. We created two distinct masks with lines from only one of the component and we used LSD with these masks. We find that the magnetic field is present in ζ OriAa and not in ζ OriAb (see right panel of Fig. 1).
## 4. Conclusion
We confirm that ζ OriA is a magnetic star. The magnetic field is present in the supergiant ζ OriAa and no magnetic field is detected in its companion ζ OriAb.
## References
Bouret, J.-C., Donati, J.-F., Martins, F., et al. 2008, MNRAS 389, 75 Donati, J.-F., Semel, M., Carter, B. D., Rees, D. E., & Collier Cameron, A. 1997, MNRAS 291,
658
Hadrava, P. 1995, A&AS 114, 393
Hummel, C. A., Rivinius, T., Nieva, M.-F., et al. 2013, A&A 554, A52
Ilijic, S., Hensberge, H., Pavlovski, K., & Freyhammer, L. M. 2004, Vol. 318 of ASPCS , p. 111 Kupka, F. & Ryabchikova, T. A. 1999, Publications de l'Observatoire Astronomique de Beograd 65, 223
Petit, V., Owocki, S. P., Wade, G. A., et al. 2013, MNRAS 429, 398
Piskunov, N. E., Kupka, F., Ryabchikova, T. A., Weiss, W. W., & Jeffery, C. S. 1995, A&AS
112, 525
Wade, G. A., Grunhut, J., Alecian, E., et al. 2013, IAUS 302, ArXiv e-prints 1310.3965 | 10.1017/S1743921314007108 | [
"A. Blazère",
"C. Neiner",
"J-C. Bouret",
"A. Tkachenko",
"the MiMeS collaboration"
] | 2014-08-01T13:47:22+00:00 | 2014-08-01T13:47:22+00:00 | [
"astro-ph.SR"
] | The magnetic field of $ζ$ Ori A | Magnetic fields play a significant role in the evolution of massive stars.
About 7% of massive stars are found to be magnetic at a level detectable with
current instrumentation and only a few magnetic O stars are known. Detecting
magnetic field in O stars is particularly challenging because they only have
few, often broad, lines to measure the field, which leads to a deficit in the
knowledge of the basic magnetic properties of O stars. We present new
spectropolarimetric Narval observations of $\zeta$ Ori A. We also provide a new
analysis of both the new and older data taking binarity into account. The aim
of this study was to confirm the presence of a magnetic field in $\zeta$ Ori A.
We identify that it belongs to $\zeta$ Ori Aa and characterize it. |
1408.0179v2 | ## Constructive Interference Between Disordered Couplings Enhances Multiparty Entanglement in Quantum Heisenberg Spin Glass Models
Utkarsh Mishra, Debraj Rakshit, R. Prabhu, Aditi Sen(De) and Ujjwal Sen
Harish-Chandra Research Institute, Chhatnag Road, Jhunsi, Allahabad 211 019, India
Abstract. Disordered systems form one of the centrestages of research in many body sciences and lead to a plethora of interesting phenomena and applications. A paradigmatic disordered system consists of an one-dimensional array of quantum spin-1/2 particles, governed by the Heisenberg spin glass Hamiltonian with natural or engineered quenched disordered couplings in an external magnetic field. These systems allow disorder-induced enhancement for bipartite and multipartite observables. Here we show that simultaneous application of independent quenched disorders results in disorder-induced enhancement, while the same is absent with individual application of the same disorders. We term the phenomenon as constructive interference and the corresponding parameter stretches as the Venus regions. Interestingly, it has only been observed for multiparty entanglement and is absent for the single- and two-party physical quantities.
## 1. Introduction
Research in implementation of quantum devices has led to the identification of useful multiparty quantum information processing tasks, like quantum secret sharing [1], cluster state quantum computation [2-4], quantum state transmission [5], and distributed quantum dense coding [6-8]. These multisite tasks have already been implemented in several physical systems like ion-traps [9, 10], photons [11], optical lattices [12], and superconducting qubits [13-15]. It is widely believed that understanding the role of bipartite and multipartite entanglement [16] in these protocols in particular and quantum many-body systems in general, is crucial to gain the ability to build scalable decoherence-resistant efficient quantum devices. The wide interest in such activities is also due to the fact that several concepts developed in quantum information science turn out to be useful tools to detect co-operative phenomena [17-19], like quantum phase transitions and thermal transitions, and can help to develop approximate methods to obtain the ground states of non-integrable systems [20].
The importance of studying the effect of disorder in many-body systems can hardly be overestimated [21-30]. Realization of most physical systems inherently results in impurities or defects, which may suppress the physical properties of the systems [31-35]. However, disordered systems, both classical and quantum, display counterintuitive phenomena like disorder-induced enhancement in several physical quantities like magnetization, classical correlators, and entanglement (see [30, 36-41] and references therein). At the same time, disordered systems sustain rich phases like spin glass [42-45] and Bose glass [46,47], and phenomena like Anderson localization [48] and high T -superconductivity [49-51]. Recent experimental developments, especially c in ultra-cold gases, give rise to the possibility of introducing disorder in a controlled way and hence paves the way for novel recipes of observation of these properties in the laboratory.
In this paper, we concentrate on the behavior of different physical quantities for the ground state of one-dimensional quenched disordered quantum Heisenberg (or XYZ ) models or quantum Heisenberg spin glass models. Specifically, we consider three paradigmatic classes of disordered Heisenberg spin glass Hamiltonians: the quenched disorder is in (a) the 'planar' couplings, (b) the 'azimuthal' couplings, and in (c) both the planar and azimuthal couplings. The main results of the paper are as follows: (i) We find that both bipartite and multipartite entanglement can be enhanced, in some parameter space of the Hamiltonian, by the introduction of all the disorder combinations, mentioned in (a), (b) and (c). (ii) We find that in all these models, there are large surfaces in the parameter space in which the magnetization and classical correlators behave in a complementary way to bipartite and multipartite entanglement. (iii) More important, and rather engrossing is the uncovering of parameter ranges where the individual insertions of planar and azimuthal quenched disorder couplings do not result in disorder-induced enhancement of a multiparty entanglement measure, while the same appears in the simultaneous presence of the disorders. We term the phenomenon as constructive interference of the disordered couplings and call the coupling parameter ranges as the Venus regions. (iv) Importantly, such constructive interference is not observed in singleas well as two-site physical quantities like magnetization, classical correlators, and bipartite entanglement. Moreover, changing the Hamiltonian, for example, to the XY model also wipes out the phenomenon.
The counterintuitive nature of constructive interference for a physical quantity leads us to believe that it can have implications in fundamental and applicational regimes. Moreover, multiparty quantum information processing tasks typically have origins in the bipartite domain. Instances where the converse occurs are few and far between, and indicates important diversions from the usual track (see e.g. [2-4,53-62]). The fact that constructive interference is observed only for multipartite entanglement in the presence of impurities is also in the spirit of these latter instances.
## 2. The Heisenberg quantum spin glasses and enhancement score
We introduce the four different Heisenberg Hamiltonians which are studied in the paper.
Case 0: The one-dimensional disordered quantum Heisenberg (or XYZ ) model with nearest-neighbour interactions in an external magnetic field is described by the Hamiltonian
$$H _ { \langle J, \delta \rangle } = \kappa \left [ \sum _ { \langle i, j \rangle } \frac { J _ { i j } } { 4 } \left [ ( 1 + \gamma ) \sigma _ { i } ^ { x } \sigma _ { j } ^ { x } + ( 1 - \gamma ) \sigma _ { i } ^ { y } \sigma _ { j } ^ { y } \right ] + \sum _ { \langle i, j \rangle } \frac { \delta _ { i j } } { 4 } \sigma _ { i } ^ { z } \sigma _ { j } ^ { z } - \frac { h } { 2 } \sum _ { i } ^ { N } \sigma _ { i } ^ { z } \right ].$$
Here, J ij (1 -γ ) and J ij (1 + γ ) are proportional to the xx and yy interactions, while δ ij is that to the zz one. N is the number of spins. γ measures the anisotropy between the first two interactions, and is dimensionless. J ij , δ ij , and h are also dimensionless. κ is a constant, and has the units of energy. J ij are independently and identically distributed (i.i.d.) Gaussian random variables with mean 〈 J 〉 and unit standard deviation. Similarly, δ ij are i.i.d. Gaussian random variables with mean 〈 δ 〉 and unit standard deviation. We set 〈 λ 〉 = 〈 J /h 〉 and 〈 µ 〉 = 〈 δ /h 〉 , which are therefore again dimensionless. σ k i ( k = x, y, z ) are the Pauli spin matrices at the i th site and 〈 ij 〉 indicates that the corresponding summation is over nearest-neighbour spins. The applied field, h , is kept ordered throughout the paper. In this work, we consider periodic and open boundary conditions for systems with N < 10 and N > 10, respectively. For the relatively larger systems with open boundary condition, we calculate the local observables (the one- and two-site quantities) at the center of the chain. For example, we investigate magnetization of the ( N/ 2) th site, and the two-site observables, such as correlators and bipartite entanglement, corresponding to the ( N/ ,N/ 2 2 + 1) pair.
Case 1: Quantum Heisenberg model. In this case, the Hamiltonian, which we denote by H , has site-independent couplings, i.e., J ij = J and δ ij = δ . Since we will be in need of multisite state characteristics, the Bethe ansatz [63] is difficult to apply in an efficient way, especially in the disordered cases considered. We denote J/h and δ/h as λ and µ respectively.
Case 2: Quantum Heisenberg 'planar' spin glass. In this case, the planar couplings, J ij 's are disordered and chosen from i.i.d Gaussian distribution with mean 〈 λ 〉 = 〈 J /h 〉 and unit standard deviation, while the couplings δ ij are considered to be siteindependent, and fixed at δ . In analogy with Eq. (1), we denote the Hamiltonian by H 〈 J 〉 .
Case 3: Quantum Heisenberg 'azimuthal' spin glass. The system in this case is governed by the Hamiltonian, H 〈 δ 〉 , in which J ij = J , while the couplings, δ ij , are i.i.d. Gaussian random variables with mean 〈 δ 〉 and unit standard deviation.
In the models that we consider here, the disordered parameters are quenched (see Appendix A.2). In a disordered system, if a quenched averaged physical quantity, Q av , associated with a state of the system is larger than the same quantity, Q , of the corresponding ordered system in the analogous state, then the value of the physical quantity is said to exhibit a disorder-induced enhancement. To characterize such advantage, we introduce the enhancement score, ∆ Q , of a physical quantity Q . The enhancement scores for the different physical quantities indicate the usefulness of the disordered system in comparison with the corresponding ordered system with respect to that physical quantity. It is a quantification of the usefulness, and is exactly the amount of the physical quantity in the disordered system which exceeds that in the ordered system. More precisely, we set
$$\Delta _ { a, b, \dots } ^ { \mathcal { Q } } = | \mathcal { Q } _ { a v } ( \langle a \rangle, \langle b \rangle, \dots ) | - | \mathcal { Q } ( \langle a \rangle, \langle b \rangle, \dots ) |.$$
Here, Q av ( 〈 a , 〉 〈 b , . . . 〉 ) is the quenched averaged value of a physical quantity, Q , of the system where the averaging is performed over the system parameters, a, b, . . . , which follow Gaussian distributions with mean 〈 a 〉 , 〈 b , . . . 〉 and standard deviations σ a , σ , . . . b respectively. The definition can of course be generalized to the case of other probability distributions. Q 〈 〉 〈 〉 ( a , b , . . . ) is the corresponding physical quantity for the ordered case of the same system, where the values of the system parameters a, b, . . . are kept constant (i.e., they are not disordered) at 〈 a , 〉 〈 b , . . . 〉 respectively. Both Q av and Q usually depend also on other system parameters (that are not disordered) which are kept the same for both the systems (disordered and ordered) and which are kept silent in the notation. A positive enhancement score for a physical quantity, Q , in a certain range of the system parameters will imply that 'disorder-induced enhancement' or 'disorder-induced enhanement' is attained for Q in that region of the parameter space. Whereas, a negative value of the same will indicate that Q gets degraded.
We now investigate the behavior of different measurable quantities in all the three disordered models viz Cases 0, 2 and 3. We compute the ground state in each of these models and investigate the behavior of the enhancement score, ∆ , Q ξ corresponding to physical quantities like, magnetization, M z , which is a single-site observable, nearest-neighbor classical correlator, T zz , and concurence, C , which are two-site observables, and genuine geometric measure, E as a multipartite quantity (see Appendix B for the definitions of these quantities). Here, ξ denotes the aggregate of system parameters that are quenched disordered. There is a wide range of the anisotropy parameter, γ , and magnetic field strength, h , of these models for which disorder-induced enhancement phenomena is observed. Also for a range of values of these parameters the complementarity behavior between classical and quantum quantities are observed. In general, these features of all the observables remain qualitatively similar with the variation of γ and h . However, we observe that the phenomena of constructive interference is observed beyond a certain value of the critical magnetic field, h c , which depends on the system size. If the system size is five or more than five spins, h c is approximately 0.7. For the purpose of depiction of the effects, throughout this paper, we choose γ = 0 7 and . h = 0 8. . However, the effects are In the following, we begin our discussion by reporting disorder-induced enhancement for the quantities mentioned above, where disorder corresponds to the Cases 0, 2, and 3 respectively. We highlight the complementarity behavior exhibited by the classical and quantum observables in these cases. We then move to discuss the constructive interference phenomena.
While investigating the disordered cases, quenched averaging is performed over
Figure 1. Disorder-induced enhancement and complementarity when both planar and azimuthal couplings are quenched disordered. The enhancement scores (∆ Q λ,µ ) for (a) magnetization (∆ M µ z λ, ), (b) the zz -classical correlator (∆ T zz λ,µ ), (c) bipartite quantum correlation as quantified by concurrence (∆ C λ ), and (d) genuine multipartite quantum correlation measure quantified by generalized geometric measure (∆ E λ,µ ) for N = 6. In these panels, the quantities along ordinates are 〈 λ 〉 , while the abscissae represent the 〈 µ 〉 . Quenched average of the observable is performed over 5 × 10 3 random realizations. The regions represented in red are the ones for which ∆ Q is positive indicating that the corresponding physical quantity Q attains a higher value with the introduction of disorder in these regions. The areas represented in blue are the ones for which ∆ Q is negative and they point to parameter regions where the Q is higher in the corresponding clean system. In the white regions, Q remains unaltered by the introduction of disorder in the system. All the parameters plotted here are dimensionless.
5 × 10 3 realizations. For fixed values of 〈 λ , 〉 〈 δ 〉 , and h , we have performed the numerical simulations for higher number of realizations and have found that the corresponding quenched physical quantities have already converged for 5 × 10 3 realizations or before.
## 3. Disorder-induced enhancement and complementarity in classical and quantum quantities
We investigate here the behaviour of enhancement scores of different physical quantities for the case when the disorder is introduced in both planar and azimuthal couplings (see Eq. (1)). In Fig. 1, we show the behavior of the enhancement scores of magnetization, zz -correlator, concurrence, and generalized geometric measure (GGM), with the variation of 〈 λ 〉 and 〈 µ 〉 . In all the cases considered, we have observed
Figure 2. Disorder-induced enhancement and complementarity in planar spin glass. The plots in the different panels are for (a) ∆ M z λ , (b) ∆ T zz λ , (c) ∆ , C λ and (d) ∆ E λ . The disordered Hamiltonian for the enhancement scores is H 〈 λ 〉 , whose 6 i.i.d. Gaussian random variables, λ ij , have mean 〈 λ 〉 and unit standard deviation. In each of these panels, the ordinate is 〈 λ 〉 and the abscissa is µ . All other considerations are the same as in Fig. 1.
disorder-induced enhancement also for T xx and T yy . We do not exhibit them in the figures given. The investigation shows that for all observables, there exist regions in which the enhancement score is vanishing. These appear as white regions in the panels in the figure. Also, for large mean values of the disordered interactions, where the simultaneous presence of ferro- and anti-ferromagnetic couplings due to the disorder is absent, the enhancement scores vanish. In all the observables considered, viz. magnetization, classical correlators, and bipartite as well as multipartite entanglement, for a given 〈 µ 〉 , there typically appears oscillations in the surface of the enhancement score as we scan the 〈 λ 〉 axis and occasionally such oscillations have a positive enhancement score in their crests and negative one in their troughs. The parameter regions, which have a positive enhancement for a certain physical quantity, indicates an disorder-induced enhancement for that quantity. See Fig. 1 for a depiction. It can also be seen from Fig. 1 that there exists wide stretches of parameter regime, where the bi-, and multi-party quantum correlations enhance compared to the clean system even though the classical correlator and the magnetization diminish and vice-versa. Such complementary features are true for all types of disorder considered here including Case 2 and 3 (See Fig. 2 and 3 respectively). However, as it is expected, there is a change in parametric regime at which the disorder-induced enhancement appears for
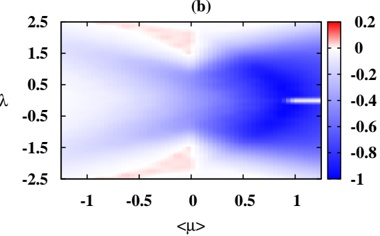
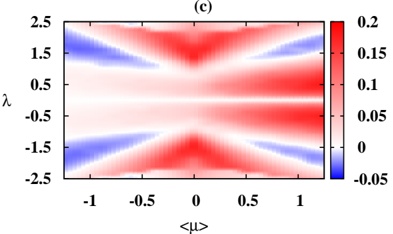
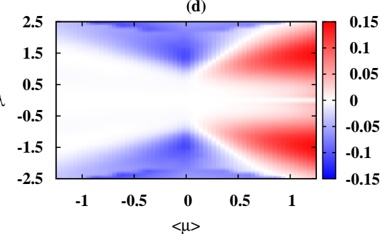
λ
Figure 3. Disorder-induced enhancement and complementarity in azimuthal spin glass. The plots in the different panels are for (a) ∆ M z µ , (b) ∆ T zz µ , (c) ∆ C µ , and (d) ∆ E µ . The disordered Hamiltonian for the enhancement scores is H 〈 δ 〉 , whose 6 i.i.d. Gaussian random variables, δ ij , have mean 〈 δ 〉 and unit standard deviation. In each of these panels, the ordinate is λ and the abscissa is 〈 µ 〉 . All other considerations are the same as in Fig. 1.
different cases of disorder. For example, the behavior of the enhancement scores for magnetization and classical correlators are quite similar for Cases 2 and 3 while this is not true for concurrence and GGM. Specifically, we observe that along the λ = 0 line, ∆ C µ ≈ 0 in Case 3, while ∆ C λ > 0 for Case 2 (See Fig. 2 and 3).
## 4. Constructive interference
The Heisenberg Hamiltonian that we study involve planar and azimuthal interaction strengths, which may both be Gaussian distributed quenched disordered variables. Our calculations show that irrespective of whether they are individually or jointly present, a spectrum of measurable quantities show disorder-induced enhancement, instead of getting diminished in the presence of defects. At this juncture, we ask a more radical question: Does there exist any observable which gets enhanced in the joint presence of the disorders while it deteriorates when the randomness is applied individually in either of the couplings, in the Heisenberg spin glass models? Mathematically, we are looking for the following conditions to be satisfied simultaneously by an observable Q :
Constructive interference between disorders for entanglement in spin models
8
Figure 4. Constructive interference. The panels exhibit plots with the enhancement score of GGM, denoted as ∆ E , as the ordinate, and the system parameter, α , as the abscissa for Heisenberg spin glasses with (a) N = 6, (b) N = 8, and the enhancement score of approximate GGM, denoted as ∆ E (2) with (c) N = 12, and (d) N = 16, where N is the number of quantum spin-1/2 particles in the system. In panels (a) and (b), red circles connected with dashed lines represent the cases when disorder is present in both the couplings (planar as well as azimuthal), and for these cases, α represents 〈 λ 〉 and ∆ E represents ∆ E λ,µ . We choose 〈 δ 〉 = -0 9. . The blue squares connected with dotted lines are for the cases when disorder is present only in the planar coupling. In these cases, α represents 〈 λ 〉 , ∆ E represents ∆ E λ , and δ is fixed at -0 9. . The green triangles connected with dash-dotted lines represent the cases when disorder is present only in the azimuthal coupling. In these cases, α represents λ , ∆ E represents ∆ E µ , and 〈 δ 〉 = -0 9. . The black solid lines, parallel to the horizontal axes are drawn to separate the positive and negative regions of the enhancement score of GGM. The insets show blow-ups of the regions with constructive interference. The depiction of the cases for ∆ E (2) in panels (c) and (d) are analogous to the cases for ∆ E shown in the panels (a) and (b). All other descriptions are the same as in Fig. 1. The insets show blow-ups of the regions with constructive interference. For all the plots, we have chosen γ = 0 7 and . h = 0 8. . All quantities plotted here are dimensionless.
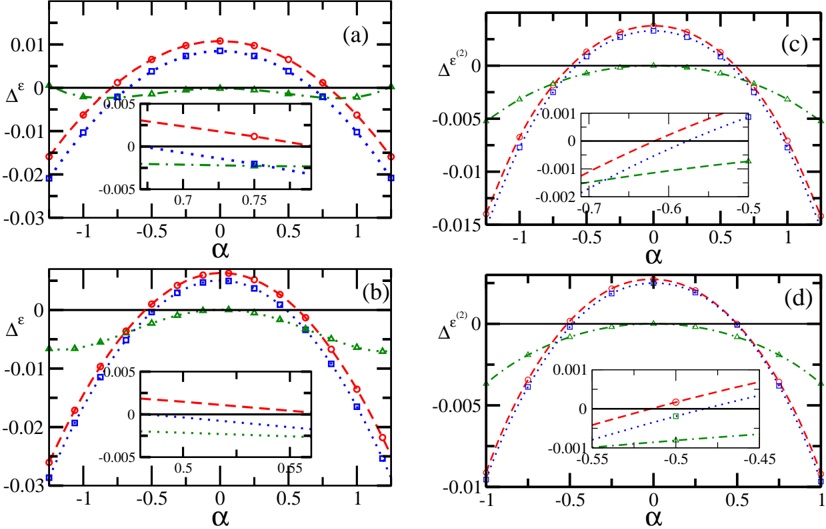
$$\Delta _ { \lambda, \mu } ^ { \mathcal { Q } } \quad = | \mathcal { Q } _ { a v } ( \langle \lambda \rangle, \langle \mu \rangle ) | - | \mathcal { Q } ( \langle \lambda \rangle, \langle \mu \rangle ) | > 0, \quad \quad ( 3 ) \\ \text{while} \quad \ \. \ \dots \dots \dots \dots \dots \dots$$
$$\Delta _ { \lambda } ^ { \mathcal { Q } } \quad = | \mathcal { Q } _ { a v } ( \langle \lambda \rangle ) | - | \mathcal { Q } ( \langle \lambda \rangle ) | < 0,$$
$$\Delta _ { \mu } ^ { \mathcal { Q } } \quad = | \mathcal { Q } _ { a v } ( \langle \mu \rangle ) | - | \mathcal { Q } ( \langle \mu \rangle ) | < 0.$$
Here, µ = 〈 µ 〉 in Eq. (4) and Q av ( 〈 λ 〉 ) corresponds to the planar spin glass. Similarly, λ = 〈 λ 〉 in Eq. (5) and Q av ( 〈 µ 〉 ) corresponds to the azimuthal spin glass. Any observable satisfying the above set of equations would imply that the competing random interactions can interfere constructively for the quantity Q . We refer to this phenomenon as the 'constructive interference of Q '. We have extensively investigated the above equations for various finite number of spins in the Heisenberg Hamiltonian ranging from N = 6 to N = 20, and scanned over significant ranges of the system parameters. While smaller system sizes are handled by exact diagonalization, the relatively larger ones are investigated by employing the density matrix renormalization group techniques [52]. The investigations help us to identify certain parameter ranges, where the system exhibits the phenomenon of the constructive interference in the genuine multipartite quantum correlation as quantified by the generalized geometric measre (GGM), denoted by E [68]. Interestingly, no other observable, considered here, shows such a behavior. This includes (single-site) magnetizations, two-site classical correlators, and two-site entanglement.
Let us first discuss the results corresponding to the Heisenberg spin glass models, consisting of a comparatively small number of spins. The behavior of quantum correlations, in this case can be examined in experimentally realizable systems like ion traps, photons, etc [9-15], and hence can be verified and observed in the laboratories. All the results presented in this case are obtained by performing exact diagonalization of the Hamiltonians. Fig. 4 shows the enhancement scores for the GGM for different system sizes, and for different blending of disordered couplings. The anisotropy and external magnetic field strength are again chosen as 0 7 and 0 8 respectively. . . The coupling strength, δ , in the azimuthal direction, is -0 9 for the case when it is ordered, . while in the cases when the azimuthal couplings, δ ij , are disordered, they are chosen with mean -0 9 and unit standard deviation. .
Whenever any of the curves, in the panels of Fig. 4, is positive, the corresponding disordered system has higher value of GGM as compared to that of the ordered system. It is clear from Figs. 4(a-b) that for GGM, ∆ , ∆ , as well as ∆ E λ E µ E λ,µ are positive, showing disorder-induced enhancement although in different parameters ranges with the system sizes N = 6 and N = 8 respectively. Note that there exists other parameter ranges than those exhibited in the panels of Fig. 4(a)-(b) where such phenomenon occurs. The choice of the parameters and parameter ranges in Figs. 4 are for the following specific purpose. Near the two values of α (= 〈 λ , 〉 here), where the curves of ∆ E λ,µ crosses the horizontal axes, one obtains regions where disorderinduced enhancement for GGM is exhibited with the introduction of both planar and azimuthal disorders, while the same is absent with the inclusion of just any one of these disorders. We call these as 'Venus regions'. For example, for N = 6 (see Fig. 4(a)), the two distinct ranges of α (which represents either 〈 λ 〉 or λ ), in which the constructive interference can be observed are [ -0 78 . , -0 67] and [0 68 . . , 0 78]. . In these regions, the enhancement score, ∆ E λ,µ (red circles connected by dashed line), is positive while the other two enhancement scores, viz., the ∆ E λ (blue squares connected by dotted
Constructive interference between disorders for entanglement in spin models
10
Figure 5. The enhancement scores for (a) magnetization, M z , (b) T zz -correlator, and (c) concurrence, C , against α for systems with N = 6. Same quantities are again shown in (d), (e), and (f) for N = 20 calculated using DMRG method discussed in Appendix A. All other descriptions are the same as given in Fig. 4.
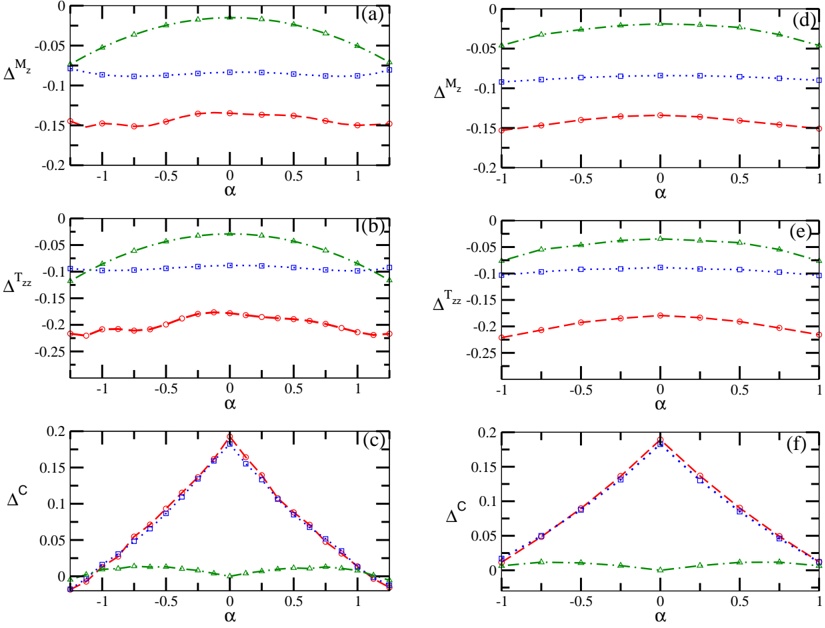
line) and ∆ E µ (green triangles connected by dot-dashed line), remain negative. Note that with increasing number of particles, the Venus regions, i.e., the windows of α demonstrating constructive interference moves towards α = 0. Interestingly, no such phenomenon is found in other quantities considered in this paper, viz., magnetization, two-point correlators, and bipartite entanglement (see Figs. 3(a) and 3(b)). It is worth mentioning here that the Venus regions do not surface without an external magnetic field. In fact, depending on N , there exists a critical magnetic field strength, h c , only beyond which the constructive interference can be observed. Below h c , the ∆ E λ lies above the ∆ E λ,µ and the ∆ E µ . As the external magnetic field is increased beyond h c , the curve corresponding to the ∆ E λ,µ goes above that of ∆ E λ and ∆ , resulting in the E µ emerging of the Venus regions. We find that the h c is approximately 0 75 for . N = 8.
It is natural to ask if the results presented above also holds for the disordered Heisenberg systems with larger number of spins. However, exact computation of the quenched averaged GGM, in systems with large number of parties, is hindered, due to the following three key reasons: ( ) i An exponential growth of the Hilbert space
with increasing number of parties essentially prohibits one from performing exact diagonalization of the Hamiltonian. in the systems with large number of spins. ( ii ) For obtaining the desired accuracy, as one tries to obtain convergence in the quenched averaging of physical quantities, it typically requires a large number (approximately 5 × 10 3 to 8 × 10 ) of random realizations, unless the quantities are self-averaging, 3 which is not the case for all genuine multipartite observables. ( iii ) Determination of multipartite entanglement, as quantified by the GGM, requires all possible bipartite splits, and the number of bipartitions in an N -party system is ∑ N/ 2 r =1 ( n r ) , which increases substantially with increasing N . For example, the number of bipartitions required to evaluate the GGM for the N = 8 system is 162, whereas it grows to over half a million for the system involving just 20 parties.
The difficulty in computing GGM can partly be curbed by choosing selective bipartitions instead of considering all possible bipartitions. We therefore introduce E (2) as a measure of multipartite entanglement, defined as E (2) = 1 -max { { η 2 i } { , η 2 i,i +1 } ∣ ∣ i =1 ,...,N } , where η i and η i,i +1 are the maximum Schmidt coefficients of the singleand nearest-neighbor two-body reduced density matrices respectively. We call it the 'approximate GGM'. Although E (2) may not be a genuine multiparty entanglement measure, it does quantify multiparty entanglement and it is certainly an entanglement monotone.
For the Heisenberg spin models with and without disorder, we evaluate the approximate GGM and plot the enhancement scores in Fig. 4(c-d). Here we consider the spin systems with sizes N = 12 (Fig. 4(c)), and N = 16 (Fig. 4(d)). The symbols are kept consistent with Figs. 4(a-b). It can clearly be noticed that the ∆ E (2) again identify two distinct ranges of the parameter α (on the negative and positive sides of α ), where the Venus regions materialize. We also find that the conclusions drawn from the E (2) are consistent with the physics discussed by studying the system with smaller sizes. For example, the windows of α exhibiting constructive interference shifts towards α = 0 with increasing number of spins. We have carried out analysis upto N = 20 and confirm the existance of a non-zero region, where constructive interference occurs. It is to be noted that the shrinking observed, of the Venus regions, could be due to the modification of the multiparty entanglement measure, since we have already observed that no two-party or single-site observables exhibit the constructive interference. It is plausible that in the presence of both the disorders, multipartite entanglement will exhibit a Venus region even in the thermodynamical limit.
At this point, it will be interesting to look for generalized features in the disordered system that may be specific to quantum phases of the corresponding ordered system. Particularly, it is interesting to identify the phase of the corresponding ordered system where the phenomenon of constructive interference appears due to the application of disorder. The homogeneous spin-1/2 quantum XYZ model exhibits a rich phase diagram, consisting of the antiferromagnetic (AFM) phase, magnetized or polarized phase (PP), spin-flop (SF) phase, and floating phase (FP) (see Ref. [69] and references therein). While we find that the phenomenon of disorder-induced enhancement is not phase-specific, that of constructive interference appears in the so-called SF phase, which is characterized by N´el ordering in the y-direction for small values of e µ/λ .
While we have used the GGM as a measure of multiparty entanglement, there do exist other measures. It would be interesting to learn if the phenomena of disorderinduced enhancement and constructive interference are observed in other measures of multiparty entanglement. For this purpose, in addition to GGM, we consider another
measure of multiparty entanglement, viz. the tangle (denoted as τ , and also known as the monogamy score for squared concurrence) [70]. We examine its behavior as a function of α for a selective set of parameters for which we have reported the occurrence of disorder-induced enhancement and constructive interference for GGM in this work. The results indicate that disorder-induced enhancement of multiparty entanglement is a potentially generic feature. On the other hand, constructive interference does not occur in the parameter region that supported the same for GGM.
We additionally investigate the magnetization, two-point correlations in the zz direction and the concurrence [67] in this regime. Figures 3(c) and 3(d) show their behavior for N = 12 and N = 16, respectively. As already mentioned, we find no constructive interference phenomena in any of these quantities. Note that the results for these larger systems are obtained by using DMRG technique, which consider the spin chains to be open (see Methods for details). For N -site systems, the bipartite classical and quantum correlations are calculated for the ( N/ ,N/ 2 2+1) pairs, so that boundary effects are minimized. The magnetization is calculated for the N/ 2 th site. As it can be readily understood, for systems with periodic boundary condition, which we have used for smaller systems, one is free to select any site or pair of neighboring sites for calculating a given singleor two-site observable, as then the quenched averaged quantities are site independent. However when we use DMRG, one cannot rule out the boundary effects on the physical quantities, particularly the local ones including one- and two-body quantities, even for large systems. Global observables, like genuine multisite entanglement, are not expected to change with the introduction of a single interaction (required for going from open to periodic boundary condition). Nevertheless, we find that a satisfactory description of the phenomena under study viz., disorder-induced enhancement and constructive interference, is possible, even for the local observables, with open DMRG, provided the system size is not too small and the measurement of the observables on either fringe is excluded. This has been confirmed by a simple test, where we examine the quantitative values of disorder-averaged magnetization at the adjacent sites located at the center of the chain (( N/ 2) th and ( N/ 2 + 1) th sites), and the bipartite quantities corresponding to the adjacent bipartite sub-systems at the center, constituted of the ( N/ 2 -1 , N/ 2) and ( N/ ,N/ 2 2 + 1) site pairs. A close quantitative agreement of the quantities corresponding to both the cases implies that the qualitative features of the local quantities remain unfazed by the end effects.
## 5. Conclusion
In summary, we have studied the quantum Heisenberg spin system in onedimension with random coupling interactions. We have examined the behavior of the magnetization, classical as well as the two-party quantum correlations, and multipartite entanglement for the ground states. The relevant results are presented for various system sizes ranging from five to twenty quantum spin-1/2 particles. While the small systems were dealt by exact numerical diagonalization, we adopt the density matrix renormalization technique to investigate comparatively larger spin systems. In the presence of impurities in the couplings, there exists different parameter regions for the different observables which show enhancement due to disorder - also known as the disorder-induced enhancement phenomenon. The physical quantities like magnetization, classical correlators, bipartite and multipartite entanglement always find a range of parameters in which they increase with the introduction of disorder.
Perhaps more radically, our studies uncover the novel phenomenon of constructive interference, where we observe that the parameters of the system can be tuned in such a way that disorder-induced order appears due to simultaneous presence of randomness in two different couplings, while it is absent when disorder is present individually in either of the couplings.
The constructive interference, which is caused due to the interplay between competing random coupling strengths in different directions, appears only in the multipartite entanglement, and is absent in bipartite as well as single-site physical quantities considered, exhibiting the significance of multiparty observables in cooperative physical phenomena. It would be interesting to understand the connection of these phenomena with localization-delocalization transition at finite temperature [72].
## Appendix A. Methods:
Appendix A.1. Exact diagonalization and DMRG technique.
The smaller spin systems can be simulated by directly diagonalizing the Hamiltonian matrix. However, the same is not true for larger spin systems due to the exponential growth of the Hilbert space, due to which the computations are either highly expensive or computationally hard. In order to perform numerical simulations for systems with a larger number of spins, we adopt the finite-size density matrix renormalization group method [52] with the open boundary condition, which is an iterative numerical approach for obtaining highly accurate low energy physics of quantum many-body systems. We choose to work with open boundary conditions as it is well known that the accuracy drops significantly for closed boundary conditions. For N -site systems, the bipartite classical and quantum correlations are calculated for the ( N/ ,N/ 2 2+1) pairs, so that boundary effects are minimized. In the DMRG approach, starting from a portion of the system, known as system block, the system size is enlarged step by step until the desired system size is reached. At each step, the Hilbert space is truncated by retaining only those Schmidt basis vectors which corresponds to the m highest Schmidt coefficients λ i , i = 1 2 , , · · · , m , of the block reduced density matrix. The value of the physical quantities for the disordered spin chain are achieved by performing several sweeps of the finite system DMRG [52].
## Appendix A.2. Quenched averaging
In the disordered models, that we have considered, the physical parameters of the system are 'quenched', i.e., the time scales in which the dynamics of the system takes place is much shorter in comparison to the time in which the disordered system parameters equilibrate. It implies that during the observation-time of the system, a particular realization of the random disorder parameters remains frozen. The physically relevant values determining the equilibrium statistical properties of the system observables (physical quantities) are, therefore, their quenched averaged values, where we first compute the value of the physical quantity of interest for a given disorder configuration of the system and subsequently perform the averaging over the probability distribution of the disorder.
The term 'quenched' in context of randomness can be seen as having been derived from the process of sudden cooling (i.e., quench) of a liquid to obtain a glass, which
Constructive interference between disorders for entanglement in spin models
Figure A1. (Color online.) Illustration of convergence during quenched averaging. ∆ E (2) as a function of the number of random realizations, N g , for the case when the Hamiltonian belongs to case 2, with 〈 λ 〉 = 0 for N = 12. All quantities plotted are dimensionless.
is devoid of any long-range structural order, with atoms trapped in random positions, resulting in 'quenched' disordered competing interactions in couplings. The glass is however heading towards its structural equilibration extremely slowly and will take a very large time to do so. Therefore, for the observation time for a given observable, the configuration is understood to be fixed.
In this work, the random parameters are chosen from independent and identically distributed Gaussian distributions with a given mean ( µ ) and standard deviation ( σ ). This, in principle, allows the random couplings to vary from -∞ to + ∞ . However, as the random parameters are chosen from a Gaussian distribution, the coupling coefficients, in reality, are roughly confined within µ -3 σ to µ +3 . The probability of σ a randomly chosen coupling appearing from extreme fringes is understandably small. The cases coming from extreme fringes have a rather negligible contribution. As a result, the quantities smoothly converge towards fixed values with increasing number of random realizations. We test convergence of the quenched averaged quantities with the increase in number of Gaussian distributed random configurations, N g . We find that it typically requires a few thousand of random numbers to reach the desired convergence. Fig. (A1) shows an example of convergence for ∆ E (2) , where the convergence is up to the third decimal point.
## Appendix B. Magnetization and classical correlators
The physical quantities that we have studied are single-site observables like magnetization, two-site observables like classical correlators, and bipartite as well as multipartite quantum correlation measures. For the Heisenberg Hamiltonian, that we consider, in both ordered as well as disordered cases, the x and y components of the magnetization of the ground state vanish, while the z component of the magnetization, M i z = Tr( σ ρ z i A i ), of the single-site reduced density matrix ( ρ A i ) at the i th site of the ground state is in general non-vanishing. In the disordered case, one has to further perform a quenched averaging over the relevant variables to obtain the physically meaningful quenched averaged magnetization. The classical correlators between the i th and j th sites are defined as T ij αβ = Tr( σ α i ⊗ σ β j ρ AB ij ) with α, β = x, y, z and with ρ AB ij being the bipartite density matrix obtained from the ground state. It can be
shown that the off-diagonal correlators of the ground state vanish in both ordered and disordered cases [64-66].
Concurrence. In case of bipartite entanglement, we first found the N -party ground state of a given Hamiltonian, and then we trace out all the ( N -2) parties except two nearest-neighbour sites and subsequently considered the entanglement of that two-party state. In this work, we have used the concurrence [67] as the bipartite entanglement measure. The concurrence, C AB , of the nearest-neighbour bipartite state, ρ AB , is defined as C AB = max 0 { , λ 1 -λ 2 -λ 3 -λ 4 } , where λ i ( i = 1 2 3 4) , , , are the square roots of the eigenvalues of the matrix ρ AB ˜ ρ AB , in decreasing order, and ˜ ρ AB = ( σ y A ⊗ σ y B ) ρ ∗ AB ( σ y A ⊗ σ y B ), where complex conjugation is with respect to the computational basis. Concurrence is a monotonically increasing function of the entanglement of formation, which in turn is defined as the average entanglement required to create the bipartite quantum state, modulo certain additivity problems [67].
Genuine multiparty measurement (GGM). As a measure of genuine multiparty entanglement, we have employed the GGM [68] (cf. [71]). In case of quantum systems composed of more than two subsystems, the quantification of entanglement is much more involved in comparison to the bipartite case. This is because in a multipartite scenario, there are qualitatively different kinds of entangled states like bi-separable, tri-separable, etc., and there are also genuine multipartite entangled states. For pure multiparty states, genuine multiparty entangled states are defined as those which are not product across any bipartition. In order to quantify genuine multiparty entanglement, we use the GGM which is based on the distance between the N -party pure state, and an N -party pure state which is not genuinely multiparty entangled. More specifically, the GGM for an N -party pure quantum state, | ψ N 〉 , is given by E | ( ψ N 〉 ) = 1 -max |〈 φ N | ψ N 〉| 2 , where the maximization is taken over all N -party pure quantum states, | φ N 〉 , that are not genuinely multiparty entangled. It is possible to evaluate the maximization analytically for an arbitrary state | ψ N 〉 and is given by E | ( ψ N 〉 ) = 1 -max { η 2 A B : |A∪B = 1 { , . . . , N } A∩B , = ∅} , where η A B : is the maximal Schmidt coefficient of | ψ N 〉 in the bipartite split A : B . The GGM gives us a 'distance' of the multiparty state under consideration from the set of states which are not genuinely multiparty entangled.
## Acknowledgments
We acknowledge the useful discussions with Luigi Amico during the meeting on Quantum Information Processing and Applications (QIPA-2013) held at the HarishChandra Research Institute (HRI), India. RP acknowledges support from the Department of Science and Technology, Government of India, in the form of an INSPIRE faculty scheme at HRI. We acknowledge computations performed at the cluster computing facility in HRI. This work has been developed by using the DMRG code released within the 'POWDER with Power' project (www.dmrg.it).
## References
- [1] M. ˙ ukowski, A. Zeilinger, M. A. Horne, and H. Weinfurter, Acta Phys. Pol. A Z 93 , 187 (1998); M. Hillery, V. Buˇek, and A. Berthiaume, Quantum secret sharing, Phys. Rev. A z 59 , 1829 (1999); A. Karlsson, M. Koashi, and N. Imoto, Phys. Rev. 59 , 162 (1999); R. Cleve, D. Gottesman, and H.-K. Lo, Phys. Rev. Lett. 83 , 648 (1999); D. Gottesman, Phys. Rev. A 61 , 042311 (2000); W. Tittel, H. Zbinden, and N. Gisin, Phys. Rev. 63 , 042301 (2001); S. K. Singh and R. Srikanth, Phys. Rev. 71 , 012328 (2005); Z.-j. Zhang, Y. Li, and Z.-x. Man, Phys. Rev. 71 , 044301 (2005); K. Chen and H.-K. Lo, Quantum Inf. Comput. 7 , 689 (2007);
- D. Markham and B. C. Sanders, Phys. Rev. A 78 , 042309 (2008); R. Demkowicz-Dobrza´ski, n A. Sen(De), U. Sen, and M. Lewenstein, Phys. Rev. 80 , 012311 (2009); A. Marin and D. Markham,Phys. Rev. 88 , 042332 (2013).
- [2] R. Raussendorf and H. J. Briegel, Phys. Rev. Lett. 86 , 5188 (2001).
- [3] F. Meier, J. Levy, and D. Loss, Phys. Rev. B 68 , 134417 (2003); R. Raussendorf, D. E. Browne, and H. J. Briegel, Phys. Rev. A 68 , 022312 (2003); M. A. Nielsen, Phys. Rev. Lett. 93 , 040503 (2004); H. J. Briegel, D. E. Browne, W. D¨r, R. Raussendorf, and M. V. den Nest, Nat. u Phys. 5 , 19 (2009).
- [4] P. Walther, K. J. Resch, T. Rudolph, E. Schenck1, H. Weinfurter, V. Vedral, M. Aspelmeyer and A. Zeilinger, Nature 434 , 169 (2005).
- [5] S. Bose, Contemporary Physics 48 , 13 (2008). G. M. Nikolopoulos and I. Jex, Quantum State Transfer and Network Engineering (Springer, Heidelberg, 2013).
- [6] C. H. Bennett and S. J. Wiesner, Phys. Rev. Lett. 69 , 2881 (1992).
- [7] K. Mattle, H. Weinfurter, P. G. Kwiat, and A. Zeilinger, Phys. Rev. Lett. 76 , 4656 (1996).
- [8] D. Bruß, G. M. D'Ariano, M. Lewenstein, C. Macchiavello, A. Sen De, U. Sen, Phys. Rev. Lett. 93 , 210501 (2004).
- [9] D. Leibfried, R. Blatt, C. Monroe, and D. Wineland, Rev. Mod. Phys. 75 , 281 (2003).
- [10] H. H¨ affner, C. Roos, and R. Blatt, Phys. Rep. 469 , 155 (2008).
- [11] T. E. Northup and R. Blatt, Nat. Photonics 8 , 356 (2014).
- [12] I. Bloch, Nat. Phys. 1 , 23 (2005). P. Treutlein, T. Steinmetz, Y. Colombe, B. Lev, P. Hommelhoff, J. Reichel, M. Greiner, O. Mandel, A. Widera, T. Rom, I. Bloch, and T. W. H¨ ansch, Fortschr. Phys. 54 , 702 (2006).
- [13] Y. Makhlin, G. Sch¨n, and A. Shnirman, Rev. Mod. Phys. o 73 , 357 (2001); D. Vion, A. Aassime, A. Cottet, P. Joyez, H. Pothier, C. Urbina, D. Esteve, and M. Devoret, Science 296 , 866 (2002); M. H. Devoret, A. Wallraff, and J. M. Martinis, arXiv:cond-mat/0411174 (2004).
- [14] J. Q. You and F. Nori, Phys. Today 58 , 42 (2005). G. Wendin and V. Shumeiko, Handbook of Theoretical and Computational Nanotechnology (American Scientific Publishers, 2006), chap. Superconducting Quantum Circuits, Qubits and Computing.
- [15] J. Clarke and F. Wilhelm, Nature (London) 453 , 1031 (2008).
- [16] R. Horodecki, P. Horodecki, M. Horodecki, and K. Horodecki, Rev. Mod. Phys. 81 , 865 (2009).
- [17] S. Sachdev, Quantum Phase Transitions (Cambridge University Press, Cambridge, 1999).
- [18] M. Lewenstein, A. Sanpera, V. Ahufinger, B. Damski, A. Sen De, U. Sen, Adv. Phys. 56 , 243 (2007).
- [19] L. Amico, R. Fazio, A. Osterloh, and V. Vedral, Rev. Mod. Phys. 80 , 517 (2008).
- [20] F. Verstraete, J. I. Cirac, and V. Murg, Adv. Phys. 57 , 143 (2008).
- [21] W. G. Brown, L. F. Santos, D. J. Starling, and L. Viola, Phys. Rev. E 77 , 021106 (2008); G. Refael and J. E. Moore, J. Phys. A: Math. Theor. 42 , 504010 (2009).
- [22] F. C. Nix and W. Shockley, Rev. Mod. Phys. 10 , 1 (1938).
- [23] P. Dean, Rev. Mod. Phys. 44 , 127 (1972).
- [24] R. J. Elliott, J.A. Krumhansl, and P. L. Leath, Rev. Mod. Phys. 46 , 465 (1974).
- [25] A. S. Barker, Jr. and A. J. Sievers, Rev. Mod. Phys. 47 , S1 (1975).
- [26] P. A. Lee and T. V. Ramakrishnan, Rev. Mod. Phys. 57 , 287 (1985).
- [27] A. G. Aronov and Yu.V. Sharvin, Rev. Mod. Phys. 59 , 755 (1987).
- [28] J. C. Dyre and T. B. Schrøder, Rev. Mod. Phys. 72 , 873 (2000).
- [29] F. Igl´i and C. Monthus, Phys. Rep. o 412 , 277 (2005).
- [30] G. Misguich and C. Lhuillier, Two-dimensional quantum antiferromagnets, Frustrated Spin Systems , edited by H. T. Diep (World-Scientific, Singapore, 2005).
- [31] J. T. Karvonen, L. J. Taskinen, and I. J. Maasilta, Phys. Rev. B 72 , 012302 (2005).
- [32] J. Salafranca and L. Brey, Phys. Rev. B 73 , 214404 (2006).
- [33] H. C. Hsu, W. L. Lee, J.-Y. Lin, H. L. Liu, and F. C. Chou, Phys. Rev. B 81 , 212407 (2010).
- [34] T. Berlijn, D. Volja, and W. Ku, Phys. Rev. Lett. 106 , 077005 (2011).
- [35] B. Jaworowski, P. Potasz, and A. W´ ojs, Disorder induced loss of magnetization in Lieb's graphene quantum dots, Superlattices and Microstructures 64 , 44 (2013).
- [36] A. Aharony, Phys. Rev. B 18 , 3328 (1978).
- [37] J. Villain, R. Bidaux, J.-P. Carton, and R. Conte, J. Physique 41 , 1263 (1980); B. J. Minchau and R. A. Pelcovits, Phys. Rev. B 32 , 3081 (1985); C. L. Henley, Phys. Rev. Lett. 62 , 2056 (1989); A. Moreo, E. Dagotto, T. Jolicoeur, and J. Riera, Phys. Rev. B 42 , 6283 (1990); D. E. Feldman, J. Phys. A 31 , L177 (1998); G. E. Volovik, JETP Lett. 84 , 455 (2006); D. A. Abanin, P. A. Lee, and L. S. Levitov, Phys. Rev. Lett. 98 , 156801 (2007); L. Adamska, M. B. Silva Neto, and C. Morais Smith, Phys. Rev. B 75 , 134507 (2007);
- [38] A. Niederberger, T. Schulte, J. Wehr, M. Lewenstein, L. Sanchez-Palencia, and K. Sacha,
Phys. Rev. Lett. 100 , 030403 (2008); A. Niederberger, T. Schulte, J. Wehr, M. Lewenstein, L. Sanchez-Palencia, and K. Sacha, Phys. Rev. Lett. 100 , 030403 (2008); A. Niederberger, J. Wehr, M. Lewenstein, and K. Sacha, Europhys. Letts. 86 , 26004 (2009); A. Niederberger, M. M. Rams, J. Dziarmaga, F. M. Cucchietti, J. Wehr, and M. Lewenstein, Phys. Rev. A 82 , 013630 (2010); D. I. Tsomokos, T. J. Osborne, and C. Castelnovo, Phys. Rev. B 83 , 075124 (2011); M. S. Foster, H.-Y. Xie, and Y.-Z. Chou, Phys. Rev. B 89 , 155140 (2014).
- [39] P. Villa Mart´ ın, J. A. Bonachela, and M. A. Mu˜oz, Phys. Rev. E n 89 , 012145 (2014).
- [40] L. F. Santos, G. Rigolin, and C. O. Escobar, Phys. Rev. A 69 , 042304 (2004).
- C. Mej´ ıa-Monasterio, G. Benenti, G. G. Carlo, and G. Casati, Phys. Rev. A 71 , 062324 (2005); A. Lakshminarayan and V. Subrahmanyam, Phys. Rev. A 71 , 062334 (2005); R. L´ opez-Sandoval and M. E. Garcia, Phys. Rev. B 74 , 174204 (2006); J. Karthik, A. Sharma, and A. Lakshminarayan, Phys. Rev. A 75 , 022304 (2007); W. G. Brown, L. F. Santos, D. J. Sterling, and L. Viola, Phys. Rev. E 77 , 021106 (2008); F. Dukesz, M. Zilbergerts, and L. F. Santos, New J. Phys. 11 , 043026 (2009); J. Hide, W. Son, and V. Vedral, Phys. Rev. Lett. 102 , 100503 (2009); K. Fujii and K. Yamamoto, Phys. Rev. A 82 , 042109 (2010);
- [41] R. Prabhu, S. Pradhan, A. Sen(De), and U. Sen, Phys. Rev. A 84 , 042334 (2011).
- [42] K. Binder and A. P. Young, Rev. Mod. Phys. 58 , 801 (1986).
- [43] D. Belitz, T. R. Kirkpatrick, and T. Vojta, Rev. Mod. Phys. 77 , 579 (2005).
- [44] A. Das and B. K. Chakrabarti, Rev. Mod. Phys. 80 , 1061 (2008).
- [45] H. Alloul, J. Bobroff, M. Gabay, and P. J. Hirschfeld, Rev. Mod. Phys. 81 , 45 (2009).
- [46] J. P. A. Z´˜iga and N. Laflorencie, Phys. Rev. Lett. ´ un 111 , 160403 (2013).
- [47] Z. Yao, K. P. C. da Costa, M. Kiselev, and N. Prokofev, Phys. Rev. Lett. 112 , 225301 (2014).
- [48] P. W. Anderson, Phys. Rev. 109 , 1492 (1958).
- [49] E. Dagotto, Rev. Mod. Phys. 66 , 763 (1994).
- [50] P. A. Lee, N. Nagaosa, and X.-G. Wen, Rev. Mod. Phys. 78 , 17 (2006).
- [51] X.-L. Qi and S.-C. Zhang, Rev. Mod. Phys. 83 , 1057 (2011) and references therein.
- [52] S. R. White, Phys. Rev. Lett. 69 , 2863 (1992); U. Schollw¨ck, Rev. Mod. Phys. o 77 , 259 (2005); G. De Chiara, M. Rizzi, D. Rossini, and S. Montangero, J. Comput. Theor. Nanosci. 5 , 1277 (2008).
- [53] A. R. Calderbank and P. W. Shor, Phys. Rev. A. 54 , 1098 (1996).
- [54] A. M. Steane, Proc. R. Soc. London A. 452 , 2551 (1996).
- [55] W. D¨ ur, G. Vidal, and J. I. Cirac, Phys. Rev. A 62 , 062314 (2000).
- [56] W. D¨ ur, Phys. Rev. Lett. 87 , 230402 (2001).
- [57] D. Kaszlikowski, L. C. Kwek, J. Chen, and C. h. Oh, Phys. Rev. A 66 , 052309 (2002).
- [58] A. Sen(De), U. Sen, and M. Zukowski, Phys. Rev. A ˙ 66 , 062318 (2002).
- [59] R. Augusiak and P. Horodecki, Phys. Rev. A 74 , 010305 (2006).
- [60] T. V´ ertesi and N. Brunner, Phys. Rev. Lett. 108 , 030403 (2012).
- [61] T. V´ ertesi and N. Brunner, arXiv:1405.4502 [quant-ph] (2014).
- [62] T. Moroder, O. Gittsovich, M. Huber, and O. G¨hne, arXiv:1405.0262 [quant-ph] (2014). u
- [63] H. Bethe Zur, Z. Phys. 71 , 205 (1931).
- [64] E. Lieb, T. Schultz, and D. Mattis, Ann. Phys. (N.Y.) 16 , 407 (1961).
- [65] E. Barouch, B. M. McCoy, and M. Dresden, Phys. Rev. A 2 , 1075 (1970).
- [66] E. Barouch and B. M. McCoy, Phys. Rev. A 3 , 786 (1971).
- [67] W. K. Wootters, Phys. Rev. Lett. 80 , 2245 (1998).
- [68] A. Sen(De) and U. Sen, Phys. Rev. A 81 , 012308 (2010).
- [69] F. Pinheiro, G. M. Bruun, J.-P. Martikainen, Jonas Larson, Phys. Rev. Lett. 111 , 205302 (2013).
- [70] V. Coffman, J. Kundu, and W. K. Wootters, Phys. Rev. A 61 , 052306 (2000); T. Osborne and F. Verstraete, Phys. Rev. Lett. 96 , 220503 (2006).
- [71] A. Shimony, Ann. N.Y. Acad. Sci. 755 , 675 (1995). H. Barnum and N. Linden, J. Phys. A 34 , 6787 (2001); T.-C. Wei and P.M. Goldbart, Phys. Rev. A 68 , 042307 (2003); T. -C. Wei, M. Ericsson, P. M. Goldbart, and W. J. Munro, Quantum Inform. Compu. 4 , 252 (2004); D. Cavalcanti, Phys. Rev. A 73 , 044302 (2006); J. Eisert and D. Gross, in Lectures on Quantum Information, edited by D. Bruss and G. Leuchs (Wiley-VCH, Weinheim, 2006); M. Balsone, F. Dell'Anno, S. De Siena, and F. Illuminatti, Phys. Rev. A 77 , 062304 (2008); L. E. Buchholz, T. Moroder and O. G¨hne, Ann. Phys. (Berlin), doi: u 10.1002/andp.201500293; T. Das, S. S. Roy, S. Bagchi, A. Misra, A. Sen De, U. Sen, arXiv:1509.02085 [quant-ph].
- [72] R. Nandkishore and D. A. Huse, Anl. Rev. Con. Mat. Phys., 6 , 15 (2015). | 10.1088/1367-2630/18/8/083044 | [
"Utkarsh Mishra",
"Debraj Rakshit",
"R. Prabhu",
"Aditi Sen De",
"Ujjwal Sen"
] | 2014-08-01T13:58:32+00:00 | 2016-09-08T03:28:36+00:00 | [
"quant-ph",
"cond-mat.dis-nn",
"cond-mat.str-el"
] | Constructive Interference Between Disordered Couplings Enhances Multiparty Entanglement in Quantum Heisenberg Spin Glass Models | Disordered systems form one of the centrestages of research in many body
sciences and lead to a plethora of interesting phenomena and applications. A
paradigmatic disordered system consists of an one-dimensional array of quantum
spin-1/2 particles, governed by the Heisenberg spin glass Hamiltonian with
natural or engineered quenched disordered couplings in an external magnetic
field. These systems allow disorder-induced enhancement for bipartite and
multipartite observables. Here we show that simultaneous application of
independent quenched disorders results in disorder-induced enhancement, while
the same is absent with individual application of the same disorders. We term
the phenomenon as constructive interference and the corresponding parameter
stretches as the Venus regions. Interestingly, it has only been observed for
multiparty entanglement and is absent for the single- and two-party physical
quantities. |
1408.0180v1 | ## Linear Locally Repairable Codes with Random Matrices
Toni Ernvall, Thomas Westerbäck and Camilla Hollanti
## Abstract
In this paper, locally repairable codes with all-symbol locality are studied. Methods to modify already existing codes are presented. Also, it is shown that with high probability, a random matrix with a few extra columns guaranteeing the locality property, is a generator matrix for a locally repairable code with a good minimum distance. The proof of this gives also a constructive method to find locally repairable codes.
## I. INTRODUCTION
## A. Locally Repairable Codes
In the literature, three kinds of repair cost metrics are studied: repair bandwidth [1], disk-I/O [2], and repair locality [3], [4], [5]. In this paper, the repair locality is the subject of interest.
Given a finite field F q with q elements and an injective function f : F k q → F n q , let C denote the image of f . We say that C is a locally repairable code (LRC) and has all-symbol ( r, δ ) -locality with parameters ( n, k, d ) , if the code C has minimum (Hamming) distance d and all the n symbols of the code have ( r, δ ) -locality. The concept was introduced in [6]. The j th symbol has ( r, δ ) -locality if there exists a subset S j ⊆ { 1 , . . . , n } such that j ∈ S j , | S j | ≤ r + δ -1 and the minimum distance of the code obtained by deleting code symbols corresponding the elements of { 1 , . . . , n } \ S j is at least δ . LRCs are defined when 1 ≤ r ≤ k . By a linear LRC we mean a linear code of length n and dimension k .
In [6] it is shown that we have the following bound for a locally repairable code C of length n , dimension k , minimum distance d and all-symbol ( r, δ ) -locality:
$$d \leq n - k - \left ( \left \lceil \frac { k } { r } \right \rceil - 1 \right ) \left ( \delta - 1 \right ) + 1$$
A locally repairable code that meets this bound is called optimal . For this reason we write d opt ( n, k, r, δ ) = n -k -(⌈ k r ⌉ -1 ) ( δ -1) + 1 .
Part of this work appeared at Global Wireless Summit 2014, Aalborg, Denmark.
T. Ernvall is with Turku Centre for Computer Science, Turku, Finland and with the Department of Mathematics and Statistics, University of Turku, Finland (e-mail:[email protected]).
- T. Westerbäck is with Department of Mathematics and Systems Analysis, Aalto University (e-mail:[email protected]).
- C. Hollanti is with Department of Mathematics and Systems Analysis, Aalto University (e-mail:[email protected]).
## B. Related Work
In the all-symbol locality case the information theoretic trade-off between locality and code distance for any (linear or nonlinear) code was derived in [7]. In [8], [9], [10] and [11] the existence of optimal LRCs was proved for several parameters ( n, k, r ) . Good codes with the weaker assumption of information symbol locality are designed in [12]. In [3] it was shown that there exist parameters ( n, k, r ) for linear LRCs for which the bound of Eq. (1) is not achievable. LRCs corresponding MSR and MBR points are studied in [13].
## C. Contributions and Organization
In this paper, we will study codes with all-symbol locality, when given parameters n , k , r , and δ . We will show methods to find smaller and larger codes when given a locally repairable code. At some occasions when the starting point is optimal, also the resulting code is optimal. We will also show that random matrices with a few non-random extra columns guaranteeing the repair property generate a linear LRCs with good minimum distance, with probability approaching to one as the field size approaches the infinity.
Section II gives two procedures to exploit already existing codes when building new ones. In that section we are restricted to the case δ = 2 . To be exact, it explains how we can build a new linear code of length n + 1 and dimension k + 1 with all-symbol repair locality r + 1 from an already existing linear code of length n and dimension k with all-symbol repair locality r such that the minimum distance remains the same. The same section also introduces a method to find a smaller code when given a code associated to parameters ( n, k, r ) . Namely the procedure gives a code of length n -1 , dimension k ′ ≥ k -1 , minimum distance d ′ ≥ d and all-symbol locality r .
In Section III we study random matrices with a few non-random extra columns guaranteeing the repair property. By using the ideas of Section IV it is shown that these random codes perform well with high probability. The proof of this is postponed to Section IV.
In Section IV we give a construction of almost optimal linear locally repairable codes with all-symbol locality. By almost optimal we mean that the minimum distance of a code is at least d opt ( n, k, r, δ ) -δ +1 .
## II. BUILDING CODES FROM OTHER CODES
## A. Definitions
In this section we will restrict us in the case δ = 2 and show how we can build a new linear code of length n +1 and dimension k +1 with all-symbol repair locality r +1 from an already existing linear code of length n and dimension k with all-symbol repair locality r such that the minimum distance remains the same. Also, we will show how to find a code for parameters ( n ′ = n -1 , k ′ ≥ k -1 , d ′ ≥ d, r ′ = r ) . That is, we will show how to enlarge codes and how to reduce codes.
First we need some definitions. Here q is a prime power and F q is a finite field with q elements. Let x y , ∈ F n q . Then d ( x y , ) is the Hamming distance of x and y . The weight of x is w ( x ) = d ( x 0 , ) . The sphere with radius s and center x is defined as
$$B _ { s } ( { \mathbf x } ) = \{ { \mathbf y } \in \mathbb { F } _ { q } ^ { n } \ | \ d ( { \mathbf x }, { \mathbf y } ) \leq s \}.$$
Define furthermore
$$V _ { q } ( n, s ) = | B _ { s } ( { \mathbf x } ) | = \sum _ { i = 0 } ^ { s } \binom { n } { i } ( q - 1 ) ^ { i }.$$
For V q ( n, s ) we have a trivial upper bound
$$V _ { q } ( n, s ) \leq ( 1 + s ) \binom { n } { \lfloor \frac { n } { 2 } \rfloor } q ^ { s }.$$
## B. Enlarging codes
If r = k then we always get an optimal linear LRC by an MDS code. Hence in this section we will assume that r < k .
Theorem 2.1: Suppose we have a linear LRC for parameters ( n, k, d, r ) over a field F q with q > d ( n glyph[floorleft] n 2 glyph[floorright] ) and r < k . Then there exists a linear LRC for parameters ( n ′ = n +1 , k ′ = k +1 , d ′ = d, r ′ = r +1) over the same field.
Proof: Let C be a linear LRC for parameters ( n, k, d, r ) over a field F q with q > d ( n glyph[floorleft] n 2 glyph[floorright] ) . Let G be its generator matrix, i.e. , G is k × n matrix such that its row vectors form a basis for C .
Suppose that k is maximal in the meaning that there does not exist a linear LRC for parameters ( n, k +1 , d, r ) over a field F q . This assumption can be made without loss of generality because we can remove extra base vectors from the resulting code if the dimension is too large. This does not reduce the minimum distance nor increase the repair locality.
Notice first that (1) gives
$$k + d \leq n - \left \lceil \frac { k } { r } \right \rceil + 2 \leq n - 2 + 2 = n$$
and hence
$$| C | V _ { q } ( n, d - 1 ) & \leq q ^ { k } \cdot ( 1 + d - 1 ) \binom { n } { \lfloor \frac { n } { 2 } \rfloor } q ^ { d - 1 } \\ & = d \binom { n } { \lfloor \frac { n } { 2 } \rfloor } q ^ { k + d - 1 } \\ & < q ^ { k + d } \\ & \leq q ^ { n }. \\ x i s a \text{ vector } x \in \mathbb { F } ^ { n } \text{ with distance at least } d \text{ to vectors of } C. \text{ Denote} h V G \text{ a new } ( k + 1 ) \times ( n + 1 )$$
Therefore there exists a vector x ∈ F n q with distance at least d to vectors of C . Denote by G 2 a new ( k +1) × ( n +1) matrix
$$\left ( \frac { \ G \, \left | \, \mathbf 0 ^ { t } } { \mathbf x \, \right | \, 1 } \right )$$
where 0 is an all-zero vector from F k q .
Denote by C 2 a code that G 2 generates. Clearly C 2 ⊆ F n +1 q and its dimension is k +1 . Its minimum distance is d : Let u = a y + z where a ∈ F q , y = ( x | 1) and z = ( z ′ | 0) with z ′ being a vector form C . Now if a = 0 we have
$$w ( \mathbf u ) = w ( \mathbf z ) = w ( \mathbf z ^ { \prime } ) \geq d$$
glyph[negationslash]
and if a = 0 we have
$$w ( \mathbf u ) = w ( a ^ { - 1 } \mathbf u ) = w ( \mathbf y + a ^ { - 1 } \mathbf z ) = d ( \mathbf y, - a ^ { - 1 } \mathbf z ) = d ( \mathbf x, - a ^ { - 1 } \mathbf z ^ { \prime } ) + d ( 1, 0 ) \geq d + 1.$$
The code C 2 has repair locality r +1 : In the matroid M 1 represented by G each i = 1 , . . . , n is contained in a circuit of size at most r +1 . Hence in the matroid M 2 represented by G 2 each i = 1 , . . . , n is contained in a circuit of size at most r +2 . And hence we chose k to be maximal we have that n +1 is contained in some circuit of size at most r +2 . This completes the proof.
The following example illustrates the strength of the above result in the case that r and k are close enough to each other.
Example 2.1: Suppose δ = 2 and let r ∈ [ k 2 , k ) and C be an optimal linear locally repairable code for parameters ( n, k, d, r ) over a field F q with q > d ( n glyph[floorleft] n 2 glyph[floorright] ) . Because of the optimality we have
$$d = n - k - \left \lceil \frac { k } { r } \right \rceil + 2 = n - k.$$
Theorem 2.1 results a locally repairable code for parameters ( n ′ = n +1 , k ′ = k +1 , d ′ = d, r ′ = r +1) . This code is also optimal:
$$n ^ { \prime } - k ^ { \prime } - \left \lceil \frac { k ^ { \prime } } { r ^ { \prime } } \right \rceil + 2 = n - k - \left \lceil \frac { k + 1 } { r + 1 } \right \rceil + 2 = n - k = d = d ^ { \prime }.$$
Hence the proof of the above theorem gives a procedure to build optimal codes using already known optimal codes in the case that the size of the repair locality is at least half of the code dimension.
## C. Puncturing codes
Puncturing is a traditional method in classical coding theory. The next theorem shows that this method is useful also in the context of locally repairable codes.
Theorem 2.2: Suppose we have a locally repairable code C ⊆ F n q with all-symbol locality associated to parameters ( n, k, d, r ) . There exists a code C ′ ⊆ F n -1 q associated to parameters ( n ′ = n -1 , k , d , r ′ ′ ′ = ) r with k ′ ≥ k -1 and d ′ ≥ d . Also, if C is linear then we may assume that C ′ is linear.
Proof: Write
$$C _ { x } = \{ y \in C \ | \ y = ( x, z ) \text{ where } z \in \mathbf F _ { q } ^ { n - 1 } \}$$
## for x ∈ F q .
Clearly each element of C is contained in precisely one of the subsets C x with x ∈ F q . Hence there exists a ∈ F q such that
$$| C _ { a } | \geq \frac { | C | } { q } = q ^ { k - 1 }.$$
Define C ′ to be a code we get by puncturing the first component of C a , i.e. ,
$$C ^ { \prime } = \{ z \in \mathbf F _ { q } ^ { n - 1 } \ | \ ( a, z ) \in C _ { a } \}.$$
Now, C ′ is of size at least k , its minimum distance d ′ is the same as the minimum distance of C a , that is, at least the minimum distance of C and hence d ′ ≥ d , and C ′ has repair locality r . Indeed, suppose we need to repair the j th node. If the first node from the original system is not in the repair locality, then the repair can be made as in the original code. If the first node is in the repair locality, then we know that there is a stored into that node and hence the repair can be made using the other nodes from the original locality.
′
If C is linear then it is easy to verify that we can choose a to be 0 and in this case also C is linear.
Example 2.2: Suppose that C is an optimal code. It is associated with parameters ( n, k, d, r ) with equality
$$d = n - k - \left \lceil \frac { k } { r } \right \rceil + 2.$$
Let C ′ be a code formed from C using method explained in Theorem 2.2. Hence it is associated with parameters ( n ′ = n -1 , k ′ ≥ k -1 , d ′ ≥ d, r ′ = ) r . This code is optimal if
$$d = n - k - \left \lceil \frac { k - 1 } { r } \right \rceil + 2.$$
This is true if and only if
$$\left \lceil \frac { k } { r } \right \rceil = \left \lceil \frac { k - 1 } { r } \right \rceil,$$
i.e. , r does not divide k -1 .
## III. RANDOM MATRICES AS GENERATOR MATRICES FOR LOCALLY REPAIRABLE CODES
## A. The structure of the codes
We will study such linear codes that nodes are divided into such non-overlapping sets S , S 1 2 , . . . , S A that any node x ∈ S j can be repaired by any | S j \ { x }| -( δ -2) = | S j | -δ +1 nodes from the set S j . We also require that | S j | ≤ r + δ -1 and to guarantee the all-symbol repairing property, that ∪ A j =1 S j = { 1 , . . . , n } . Suppose we have a k -dimensional linear code and nodes, say, 1 2 , , . . . , s ( δ ≤ s ≤ r + δ -1 ) corresponding columns in the generator matrix, form a repair set S 1 . Denote the k × s matrix these columns define by G and write t = s -δ +1 . Intuitively it is natural to require that G is of maximal rank, that is, the rank of G is t .
By the locality assumption, any t columns can repair any other column, i.e. , any t columns span the same subspace as all the s columns. So we have
$$G = ( { \mathbf x } _ { 1 } | \dots | { \mathbf x } _ { t } | { \mathbf y } _ { 1 } | \dots | { \mathbf y } _ { \delta - 1 } )$$
where each y j can be represented as a linear combination of x 1 , . . . , x t and x 1 , . . . , x t are linearly independent. This gives that
$$G = ( \mathbf x _ { 1 } | \dots | \mathbf x _ { t } ) ( I _ { t } | B )$$
where I t is an identity matrix of size t and B is t × ( δ -1) matrix.
Let G ′ consist of some t columns of G and C consist of the corresponding columns of ( I t | B ) . It is easy to verify that
$$G ^ { \prime } = ( { \mathbf x } _ { 1 } | \dots | { \mathbf x } _ { t } ) C$$
and hence
$$\text{rank} ( C ) = \text{rank} ( ( \mathbf x _ { 1 } | \dots | \mathbf x _ { t } ) C ) = \text{rank} ( G ^ { \prime } ) = t.$$
Consider a submatrix of B corresponding rows i 1 , . . . , i l and columns j 1 , . . . , j l . It is easy to check that this submatrix is invertible if and only if a submatrix corresponding the columns { 1 , . . . , t } \ { i 1 , . . . , i l } and { t + j 1 , . . . , t + j l } of ( I t | B ) is invertible. This is invertible since the rank of the submatrix of G corresponding the same columns is t . Hence any square submatrix of B is invertible
Suppose that matrices ( I t 1 | B 1 ) , . . . , ( I t A | B A ) are of this form. It is natural to study codes with generator matrix of form
$$( ( { \mathbf x } _ { 1, 1 } | \dots | { \mathbf x } _ { 1, t _ { 1 } } ) ( I _ { t _ { 1 } } | B _ { 1 } ) | \dots | ( { \mathbf x } _ { A, 1 } | \dots | { \mathbf x } _ { A, t _ { A } } ) ( I _ { t _ { A } } | B _ { A } ) )$$
and ask how we should choose the vectors x 1 1 , , . . . , x 1 ,t 1 , . . . , x A, 1 , . . . , x A,t A such that the given code has the biggest possible minimum distance.
Notice also that since the rank of a generator matrix is k , we have
$$k & \leq \text{rank} \left ( ( \mathbf x _ { 1, 1 } | \dots | \mathbf x _ { 1, t _ { 1 } } ) ( I _ { t _ { 1 } } | B _ { 1 } ) \right ) + \dots + \text{rank} \left ( ( \mathbf x _ { A, 1 } | \dots | \mathbf x _ { A, t _ { A } } ) ( I _ { t _ { A } } | B _ { A } ) \right ) \\ & \leq t _ { 1 } + \dots + t _ { A }$$
and hence
$$k \leq n - A ( \delta - 1 ) \leq n - \left \lceil \frac { n } { r + \delta - 1 } \right \rceil ( \delta - 1 ).$$
## B. Random codes
In this subsection we study locally repairable codes generated by random matrices with a few extra columns consisting of linear combinations of the previous columns guaranteing the repair property. It is shown that this kind of code has a good minimum distance with probability approaching to 1 as the field size q approaches infinity. The proof of this is postponed to the subsection IV-B.
Theorem 3.1: Given parameters ( n, k, r, δ ) and A > 0 with r < k , n -A δ ( -1) ≥ k , and positive integers s 1 ≤ s 2 ≤ · · · ≤ s A such that n = ∑ A j =1 s j and δ ≤ | s j | ≤ r + δ -1 for all j = 1 , . . . , A . Assume also we have matrices B , B , . . . , B 1 2 A such that B j is such a ( s j -δ +1) × ( δ -1) matrix that all its square submatrices are invertible ( j = 1 , . . . , A ). Let x i,j be uniformly independent and identically distributed random variables over F q .
Consider matrices E F , and G that are defined as follows:
$$\text{ mauces $E$, $F$ and $v$ unit are ueinemu as nouws.} \\ E = \begin{pmatrix} x _ { 1, 1 } & x _ { 1, 2 } & \cdots & x _ { 1, n - A ( \delta - 1 ) } \\ x _ { 2, 1 } & x _ { 2, 2 } & \cdots & x _ { 2, n - A ( \delta - 1 ) } \\ \vdots & \vdots & \ddots & \vdots \\ x _ { k, 1 } & x _ { k, 2 } & \cdots & x _ { k, n - A ( \delta - 1 ) } \end{pmatrix} = ( E _ { 1 } | E _ { 2 } | \dots | E _ { A } ), & ( 4 ) \\ \vdots \cdots \cdots \cdots$$
where E j is a k × ( s j -δ +1) matrix,
$$F = ( E _ { 1 } B _ { 1 } | E _ { 2 } B _ { 2 } | \dots | E _ { A } B _ { A } )$$
and
$$G = ( E | F ).$$
With probability approaching to one as q →∞ , G is a generator matrix for a k -dimensional locally repairable code of length n with all-symbol ( r, δ ) -locality and minimum distance
$$d \geq n - k - z ( \delta - 1 ) + 1$$
where z is an integer with properties
$$\sum _ { j = 1 } ^ { z } ( s _ { j } - \delta + 1 ) \leq k - 1 \text{ and } \sum _ { j = 1 } ^ { z + 1 } ( s _ { j } - \delta + 1 ) > k - 1.$$
## IV. CODE CONSTRUCTION
## A. Construction
glyph[negationslash]
In this subsection we will give a construction for linear locally repairable codes with all-symbol locality over a field F q with q > 2( rδ ) r 4 r +1 +4 r +1 ( n +2( rδ ) r 4 r +1 k -1 ) when given parameters ( n, k, r, δ ) such that n -⌈ n r + δ -1 ⌉ ( δ -1) ≥ k . We also assume that k < n and n ≡ 1 2 , , . . . , δ -1 mod r + δ -1 . Write n = a r ( + δ -1)+ b with 0 ≤ b < r + δ -1 .
We will construct a generator matrix for a linear code under above assumptions. The minimum distance of the constructed code is studied in Subsection IV-C.
Next we will build A = ⌈ n r + δ -1 ⌉ sets S , S 1 2 , . . . , S A such that each of them consists of r + δ -1 vectors from F k q except S A that consists of n -( A -1)( r + δ -1) vectors from F k q . Write
$$M = ( I _ { r } | B _ { r \times ( \delta - 1 ) } ) = \begin{pmatrix} a _ { 1, 1 } & \dots & a _ { 1, r + \delta - 1 } \\ \vdots & & \vdots \\ a _ { r, 1 } & \dots & a _ { r, r + \delta - 1 } \end{pmatrix}$$
where I r is an identity matrix of size r and B r × ( δ -1) is such r × ( δ -1) matrix that all its square submatrices are invertible. Define further
$$U _ { 0 } = \{ a _ { i _ { 1 }, i _ { 2 } } \ | \ 1 \leq i _ { 1 } \leq r \text{ and } 1 \leq i _ { 2 } \leq r + \delta - 1 \}$$
and glyph[negationslash]
$$U _ { m + 1 } = \left \{ a - \frac { b c } { d } \ | \ a, b, c, d \in U _ { m } \text{ and } d \neq 0 \right \} \cup U _ { m }$$
for m = 0 , . . . , r . We have U 0 ≤ rδ , | U m +1 | ≤ | U m | 4 and | U r +1 | ≤ ( rδ ) 4 r +1 .
First, choose any r linearly independent vectors g 1 1 , , . . . , g 1 ,r ∈ F k q . Let
$$\mathbf s _ { 1, r + j } = \sum _ { l = 1 } ^ { r } a _ { l, r + j } \mathbf g _ { 1, l }$$
for j = 1 , . . . , δ -1 . These r + δ -1 vectors form the set S 1 . Notice that these vectors correspond the columns of matrix
$$( g _ { 1, 1 } | \dots | g _ { 1, r } ) M.$$
This set has the property that any r vectors from this set are linearly independent.
Let 1 < i ≤ A . Assume that we have i -1 sets S , S 1 2 , . . . , S i -1 such that when taken at most k vectors from these sets, at most r vectors from each set, these vectors are linearly independent. Next we will show inductively that this is possible by constructing the set S i with the same property.
Let g i, 1 be any vector such that when taken at most k -1 vectors from the already built sets, with at most r vectors from each set, then g i, 1 and these k -1 other vectors are linearly independent. This is possible since ( n k -1 ) q k -1 < q k .
Write s ( h ) i,r + m = ∑ h l =1 a l,r + m i,l g for m = 1 , . . . , δ -1 and h = 1 , . . . , r and to shorten the notation, write s i,r + m = s ( r ) i,r + m for m = 1 , . . . , δ -1 .
Suppose we have j -1 vectors g i, 1 , . . . , g i,j -1 such that when taken at most k vectors from the sets S , S 1 2 , . . . , S i -1 or { g i, 1 , . . . , g i,j -1 , s ( j -1) i,r +1 , . . . , s ( j -1) i,r + δ -1 } , with at most r vectors from each set S , S 1 2 , . . . , S i -1 and at most j -1 vectors from the set { g i, 1 , . . . , g i,j -1 , s ( j -1) i,r +1 , . . . , s ( j -1) i,r + δ -1 } , then these vectors are linearly independent.
Let glyph[negationslash]
$$V _ { j } = \{ u _ { 1 } g _ { i, 1 } + \dots + u _ { j } g _ { i, j } \ | \ u _ { h } \in U _ { r + 1 } \text{ and } u _ { j } \neq 0 \} \bigcup \{ g _ { i, 1 }, \dots, g _ { i, j } \}.$$
Notice that V j is finite and to be precise, | V j | < 2 | U r +1 | j ≤ 2( rδ ) j 4 r +1 .
Choose g i,j to be any vector with the following properties: when taken at most k -1 vectors from the sets S , S 1 2 , . . . , S i -1 or V j -1 , with at most r vectors from each set S , S 1 2 , . . . , S i -1 and at most j -1 vectors from the set V j -1 , then none of the vectors in V j \ { g i, 1 , . . . , g i,j -1 } does not belong to a subspace that these k -1 other vectors span. This is possible because there are at most ( n +2( rδ ) j 4 r +1 k -1 ) different possibilities to choose, each of the options span a subspace with q k -1 vectors, and since q is large we have 2( rδ ) j 4 r +1 +4 r +1 ( n +2( rδ ) j 4 r +1 k -1 ) q k -1 < q k . Notice that u g i,j + v ∈ V (where V is some subspace) if and only if u g i,j ∈ -v + V .
To prove the induction step we have to prove the following thing: when taken at most k vectors from sets S , S 1 2 , . . . , S i -1 or { g i, 1 , . . . , g i,j , s ( j ) i,r +1 , . . . , s ( j ) i,r + δ -1 } , with at most r vectors from each set S , S 1 2 , . . . , S i -1 and at most j vectors from the set { g i, 1 , . . . , g i,j , s ( j ) i,r +1 , . . . , s ( j ) i,r + δ -1 } , then these vectors are linearly independent. Let 1 ≤ l ≤ j , v be a sum of at most k -l vectors from the sets S , S 1 2 , . . . , S i -1 with at most r vectors from each set. We will assume a contrary: We have coefficients s , . . . , s 1 l ∈ F q \ { 0 } such that:
$$\mathbf v + \sum _ { m = 1 } ^ { l } s _ { m } \sum _ { h = 1 } ^ { j } a _ { h, f _ { m } } \mathbf g _ { i, h } = 0$$
glyph[negationslash]
with f 1 ≤ · · · ≤ f l and f m ∈ { j +1 , j +2 , . . . , r } for m = 1 , . . . , l .
Write
$$\sum _ { m = 1 } ^ { l } s _ { m } \sum _ { h = 1 } ^ { j } a _ { h, f _ { m } } \mathbf g _ { i, h } = \sum _ { h = 1 } ^ { j } b _ { h } \mathbf g _ { i, h },$$
i.e. ,
$$\begin{pmatrix} b _ { 1 } \\ \vdots \\ b _ { j } \end{pmatrix} = \begin{pmatrix} a _ { 1, f _ { 1 } } & \dots & a _ { 1, f _ { l } } \\ \vdots & & \vdots \\ a _ { j, f _ { 1 } } & \dots & a _ { j, f _ { l } } \end{pmatrix} \begin{pmatrix} s _ { 1 } \\ \vdots \\ s _ { l } \end{pmatrix}.$$
glyph[negationslash]
Without loss of generality we may assume that a j,f l = 0 .
glyph[negationslash]
Let t be the smallest non-negative integer such that b j -t = 0 . Such t exists since the rank of ( a h,f i ) j × l is l and glyph[negationslash]
$$\begin{pmatrix} s _ { 1 } \\ \vdots \\ s _ { l } \end{pmatrix} \neq 0.$$
Hence we have
$$\begin{pmatrix} \mathbb { \langle } \nu \rangle \\ b _ { 1 } \\ \vdots \\ b _ { j - t } \\ 0 \\ \vdots \\ 0 \end{pmatrix} = \begin{pmatrix} b _ { 1 } \\ c _ { 1, f _ { 1 } } ^ { ( 1 ) } & \dots & c _ { 1, f _ { 1 - 1 } } ^ { ( 1 ) } & 0 \\ \vdots & & \vdots & \vdots \\ c _ { j - t, f _ { 1 } } ^ { ( 1 ) } & \dots & c _ { j - t, f _ { 1 - 1 } } ^ { ( 1 ) } & 0 \\ c _ { j - t + 1, f _ { 1 } } & \dots & c _ { j - t + 1, f _ { 1 - 1 } } ^ { ( 1 ) } & 0 \\ \vdots & & \vdots & \vdots \\ c _ { j - 1, f _ { 1 } } ^ { ( 1 ) } & \dots & c _ { j - 1, f _ { 1 - 1 } } ^ { ( 1 ) } & 0 \\ a _ { j, f _ { 1 } } & \dots & a _ { j, f _ { 1 - 1 } } & a _ { j, f _ { 1 } } \end{pmatrix} \begin{pmatrix} s _ { 1 } \\ \vdots \\ s _ { 1 } \end{pmatrix} \\ f _ { i } = \frac { a _ { h, f _ { 1 } } a _ { j, f _ { 1 } } } { a _ { i }, r } \in U _ { 1 }. \end{pmatrix} \begin{pmatrix} \mathbb { \langle } \nu \rangle \nu \\ \nu \rangle \nu \\ \nu \rangle \nu \\ s _ { l } \end{pmatrix} \begin{pmatrix} \mathbb { \langle } \nu \rangle \nu \\ \vdots \\ s _ { l } \end{pmatrix}$$
where c (1) h,f i = a h,f i -a h,f l a j,f i a j,f l ∈ U 1 .
This gives
$$& \text{This gives} \\ & \begin{pmatrix} b _ { 1 } \\ \vdots \\ b _ { j - t } \\ 0 \\ \vdots \\ 0 \end{pmatrix} = \begin{pmatrix} c _ { 1, f _ { 1 } } ^ { ( 1 ) } & \dots & c _ { 1, f _ { 1 - 1 } } ^ { ( 1 ) } \\ \vdots & & \vdots \\ c _ { j - t, f _ { 1 } } ^ { ( 1 ) } & \dots & c _ { j - t, f _ { 1 - 1 } } ^ { ( 1 ) } \\ c _ { j - t + 1, f _ { 1 } } & \dots & c _ { j - t + 1, f _ { 1 - 1 } } ^ { ( 2 ) } \\ \vdots & & \vdots \\ s _ { l - 1 } \end{pmatrix} \\ & \text{and by continuing the process} \end{pmatrix} \begin{pmatrix} s _ { 1 } \\ \vdots & & \vdots \\ s _ { j - t, f _ { 1 } } ^ { ( 2 ) } & \dots & c _ { 1, f _ { 1 - 1 } } ^ { ( 2 ) } & 0 \\ \vdots & & \vdots & \vdots \\ c _ { j - t, f _ { 1 } } ^ { ( 2 ) } & \dots & c _ { j - t, f _ { 1 - 1 } } ^ { ( 2 ) } & 0 \\ \vdots & & \vdots & \vdots \\ s _ { l - 1 } \end{pmatrix} \\ & \text{and by continuing the process}$$
and by continuing the process
$$\begin{array} { c c c c } & & \binom { b _ { 1 } } { \vdots } = \begin{pmatrix} c _ { 1, f _ { 1 } } ^ { ( t ) } & \dots & c _ { 1, f _ { l - t } } ^ { ( t ) } \\ \vdots & & \vdots \\ c _ { j - t, f _ { 1 } } ^ { ( t ) } & \dots & c _ { j - t, f _ { l - t } } ^ { ( t ) } \end{pmatrix} \begin{pmatrix} s _ { 1 } \\ \vdots \\ s _ { l - t } \end{pmatrix}$$
where c ( v ) h,f i = c ( v -1) h,f i -c ( v -1) h,f l -v +1 c ( v -1) j -v +1 ,f i c ( v -1) j -v +1 ,f l -v +1 ∈ U v for 2 ≤ v ≤ t .
glyph[negationslash]
We can continue the process ( i.e. , c ( v -1) j -v +1 ,f l -v +1 = 0 ) since the smallest non-invertible square matrix in the right lower corner of
$$\begin{pmatrix} a _ { 1, f _ { 1 } } & \dots & a _ { 1, f _ { l } } \\ \vdots & & \vdots \\ a _ { j, f _ { 1 } } & \dots & a _ { j, f _ { l } } \end{pmatrix} \\. \quad \cdot \cdot \cdot \cdot \end{pmatrix}$$
has the side length at least t +2 , if even exist. Indeed, suppose that matrices in the right lower corner with side length less than or equal to N are invertible and N is maximal. The value N is well-defined since the square matrix
with side length 1 is invertible. Assume contrary: N ≤ t and write
$$C = \begin{pmatrix} a _ { j - N + 1, f _ { 1 } } & \dots & a _ { j - N + 1, f _ { l - N } } \\ \vdots & & \vdots \\ a _ { j, f _ { 1 } } & \dots & a _ { j, f _ { l - N } } \end{pmatrix}.$$
Assume first that C is a zero matrix. Now
$$0 = \begin{pmatrix} a _ { j - N + 1, f _ { l - N + 1 } } & \dots & a _ { j - N + 1, f _ { l } } \\ \vdots & & \vdots \\ a _ { j, f _ { l - N + 1 } } & \dots & a _ { j, f _ { l } } \end{pmatrix} \begin{pmatrix} s _ { l - N + 1 } \\ \vdots \\ s _ { l } \end{pmatrix}$$
that is not possible.
Assume then that C is not a zero matrix. Clearly N is greater than or equal to the number of columns in
$$\begin{pmatrix} \cdot \dots & \cdot \dots & \cdot \dots & \cdot \dots & \cdot \\ \begin{pmatrix} a _ { 1, f _ { 1 } } & \dots & a _ { 1, f _ { l } } \\ \vdots & & \vdots \\ a _ { j, f _ { 1 } } & \dots & a _ { j, f _ { l } } \end{pmatrix} \\ \dots & \cdot \dots & \end{pmatrix}$$
corresponding the columns of B r × ( δ -1) . Hence
$$\begin{pmatrix} \dots \cdot \cdot _ { \prime } \\ a _ { j - N, f _ { l - N } } & \dots & a _ { j - N, f _ { l } } \\ \vdots & & \vdots \\ a _ { j, f _ { l - N } } & \dots & a _ { j, f _ { l } } \end{pmatrix} = ( \mathbf e _ { 1 } | \mathbf e _ { 2 } | \dots | \mathbf e _ { \epsilon } | B ^ { \prime } ) \\ \cdot \cdot \cdot \cdot \cdot \cdot _ { \cdot } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{pmatrix}$$
where each e i has one 1 and other elements are zeros, and these 1 s are in different rows, and all the square submatrices of B ′ are invertible. Hence it is also invertible, against assumption. This proves that N ≥ t +1 .
glyph[negationslash]
Hence also c ( ) t j -t,f l -t = 0 , and we have
$$\text{$n$values $0$} \, \text{ are inveu$} \, \text{ in a iso inveu$} \, \text{, against asumipuion. $1$} \, \text{$pvoves $uai$} \, \leq \, + \, 1. \\ \text{ Hence also} \, \hat { \Phi } _ { 1 } ^ { ( t ) } \neq 0, \text{ and we have} \\ \left ( \begin{array} { c } b _ { 1 } \\ \left ( \begin{array} { c } c _ { 1, f } - \frac { c _ { 1 } ^ { ( t ) } } { c _ { 1, f } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } \\ c _ { 1, f } ^ { ( t ) } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ c _ { 1, f } ^ { ( t ) } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ \vdots \\ b _ { j - t } \end{array} \right ) & = \left ( \begin{array} { c } b _ { 1 } \\ \left ( \begin{array} { c } c _ { 1, f } - \frac { c _ { 1 } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ c _ { 1, f } ^ { ( t ) } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ \vdots \\ b _ { j - t } \end{array} \right ) & = \left ( \begin{array} { c } c _ { 1, f } - \frac { c _ { 1 } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ c _ { 1, f } ^ { ( t ) } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ c _ { 1, f } ^ { ( t ) } - \frac { c _ { 1, f } ^ { ( t ) } } { c _ { 1, f } ^ { ( t ) } } & \dots \\ \vdots \\ \vdots \\ \end{array} \right ) \\ \text{ and hence} \\ \end{array} \right ) \\ \, \stackrel { l } { \sim } \, \frac { j } { \nmid } \, \stackrel { j } { \nmid } \, \end{array} \right )$$
and hence
$$& \text{and hence} \\ & 0 = \text{v} + \sum _ { m = 1 } ^ { t } s _ { m } \sum _ { h = 1 } ^ { j } a _ { h, f _ { m } } \mathfrak { g } _ { i, h } \\ & = \text{v} + \sum _ { m = 1 } ^ { t - t - 1 } s _ { m } \sum _ { h = 1 } ^ { j - t - 1 } \left ( c _ { h, f _ { m } } ^ { ( t ) } - \frac { c _ { j - t, f _ { m } } ^ { ( t ) } c _ { h, f _ { m - t } } ^ { ( t ) } } { c _ { j - t, f _ { 1 - t } } ^ { ( t ) } } \right ) \mathfrak { g } _ { i, h } + \frac { s _ { 1 } c _ { j - t, f _ { 1 } } ^ { ( t ) } + \cdots + s _ { l - t } c _ { j - t, f _ { 1 - t } } ^ { ( t ) } } { c _ { j - t, f _ { l - t } } ^ { ( t ) } } \sum _ { h = 1 } ^ { j - t } c _ { h, f _ { 1 - t } } ^ { ( t ) } \mathfrak { g } _ { i, h }$$
which cannot be true since ( l - -t 1) + 1 ≤ j -t and ∑ j -t h =1 c ( ) t h,f l -t g i,h is chosen such that it does not belong to the subspace that v , ∑ j - -t 1 h =1 ( c ( ) t h,f 1 -c ( t ) j -t,f 1 c ( t ) h,f l -t c ( t ) j -t,f l -t ) g i,h , . . . , ∑ j - -t 1 h =1 ( c ( ) t h,f l - -t 1 -c ( t ) j -t,f l - -t 1 c ( t ) h,f l -t c ( t ) j -t,f l -t ) g i,h span, and s 1 c ( t ) j -t,f 1 + ··· + s l -t c ( t ) j -t,f l -t ( t ) = 0 since b j -t = 0 .
glyph[negationslash]
glyph[negationslash]
$$\psi _ { j - t, f _ { l - t } }$$
glyph[negationslash]
t Now, the sets S i consist of vectors { g i, 1 , . . . , g i,r , s i,r +1 , . . . , s i,r + δ -1 } for i = 1 , . . . , a . If b = 0 the set S A consists of vectors { g A, 1 , . . . , g A,b -δ +1 , s ( b -δ +1) i,r +1 , . . . , s ( b -δ +1) i,r + δ -1 } . The matrix G is a matrix with vectors from the sets S , S 1 2 , . . . , S A as its column vectors, i.e. ,
$$G = ( G _ { 1 } | G _ { 2 } | \dots | G _ { A } )$$
where for i = 1 , . . . , a , and
$$c$$
$$G _ { \mathbf j } = ( g _ { j, 1 } | \dots | g _ { j, r } | s _ { i, r + 1 } | \dots | s _ { i, r + \delta - 1 } )$$
$$G _ { A } = \left ( g _ { A, 1 } | \dots | g _ { A, b - \delta + 1 } | s _ { i, r + 1 } ^ { ( b - \delta + 1 ) } | \dots | s _ { i, r + \delta - 1 } ^ { ( b - \delta + 1 ) } \right )$$
glyph[negationslash]
if b = 0 .
To be a generator matrix for a code of dimension k , the rank of G has to be k . By the construction the rank is k if and only if n -A δ ( -1) ≥ k , and this is what we assumed.
Remark 4.1: Notice that the estimations for q are very rough in the construction. This is because we are mainly interested in the randomized case in which q →∞ .
Remark 4.2: Notice that in the above construction we could have chosen different matrices M = ( I r | B r × ( δ -1) ) for each G j . Also, the sets S j do not have to be of the given size. We only need to assume that
$$\sum _ { j } | S _ { j } | = n$$
and δ ≤ | S j | ≤ r + δ -1 . Then the corresponding matrix is of type ( I | S j |-δ +1 | B ( | S j |-δ +1) × ( δ -1) ) .
## B. Construction with random vectors
If we choose randomly the vector g i,j in the above construction the probability that we get a nonsuitable choice is at most
$$2 ( r \delta ) ^ { r 4 ^ { r + 1 } + 4 ^ { r + 1 } } { n + 2 ( r \delta ) ^ { r 4 ^ { r + 1 } } } { k - 1 } q ^ { k - 1 }.$$
The size of the whole vector space is q k . Hence the probability that the whole code is as in our construction, is at least
$$\left ( \frac { q ^ { k } - 2 ( r \delta ) ^ { r 4 ^ { r + 1 } + 4 ^ { r + 1 } } ( \tilde { \ m a t { k - 1 } } ^ { r + 2 ( r \delta ) ^ { r + 1 } } ) q ^ { k - 1 } } { q ^ { k } } \right ) ^ { n } = \left ( 1 - \frac { 2 ( r \delta ) ^ { r 4 ^ { r + 1 } + 4 ^ { r + 1 } } \left ( \tilde { \ m a t { k - 1 } } ^ { r + 2 ( r \delta ) ^ { r + 1 } } ) } { q } \right ) ^ { n } \to ( 1 - 0 ) ^ { n } = 1,$$
as
q
→∞
.
## C. The minimum distance of the constructed code
Next we will calculate the minimum distance of the constructed code with the assumption that the sets S j are of size s j ( j = 1 , . . . , A ), respectively. Assume also that s 1 ≤ · · · ≤ s A . Write
$$\mathbf G = \left ( E _ { 1 } | F _ { 1 } | E _ { 2 } | F _ { 2 } | \dots | E _ { A } | F _ { A } \right ),$$
where E j = ( g j, 1 | . . . | g j,s j -δ +1 ) and F j = ( s j,r +1 , . . . , s j,r + δ -1 ) for j = 1 , . . . , A .
$$\text{Let } e _ { 1 }, \dots, e _ { k } \in \mathbb { F } _ { q } \text{ be such elements that}$$
$$( e _ { 1 }, \dots, e _ { k } ) G$$
is a vector of minimal weight. By changing columns between E j s and F j s we may assume that the weight of
$$\left ( e _ { 1 }, \dots, e _ { k } \right ) \left ( E _ { 1 } | E _ { 2 } | \dots | E _ { A } \right )$$
is minimal, that is, it has the biggest possible amount of zeros. So it has k -1 zeros.
Suppose that
$$( e _ { 1 }, \dots, e _ { k } ) F _ { j }$$
glyph[negationslash]
has a zero, i.e. , its weight is not δ -1 . If ( e , . . . , e 1 k ) E j = 0 , then by changing columns between E j and F j we would get one more zero into ( e , . . . , e 1 k ) ( E E 1 | 2 | . . . | E A ) and that is not possible. Hence the number of zeros in ( e , . . . , e 1 k ) ( F 1 | F 2 | . . . | F A ) is at most z δ ( -1) where z is an integer with properties
$$\sum _ { j = 1 } ^ { z } ( s _ { j } - \delta + 1 ) \leq k - 1 \text{ and } \sum _ { j = 1 } ^ { z + 1 } ( s _ { j } - \delta + 1 ) > k - 1.$$
Hence the minimum distance of the code is
$$n - ( k - 1 ) - z ( \delta - 1 ).$$
Example 4.1: Suppose that n = A r ( + δ -1) and choose that s j -δ + 1 = r for all j = 1 , . . . , A . Then, z = ⌊ k -1 ⌋ and hence the minimum distance is
r
$$n - ( k - 1 ) - \left \lfloor \frac { k - 1 } { r } \right \rfloor ( \delta - 1 ) = n - k - \left ( \left \lceil \frac { k } { r } \right \rceil - 1 \right ) ( \delta - 1 ) + 1 = d _ { \text{opt} } ( n, k, r, \delta )$$
and hence the construction is optimal.
Suppose then that n = a r ( + δ -1) + b with 0 ≤ b < r + δ -1 . If 0 < b < δ then using the above optimal code with extra b zero columns in the generator matrix we get a code with minimum distance d opt ( n -b, k, r, δ ) = d opt ( n, k, r, δ ) -b .
If b ≥ δ then choose s j = r + δ -1 for j = 1 , . . . , a and s a +1 = b . Now z = ⌈ k -b + δ -1 r ⌉ and hence the minimum distance is
$$n - k - \left \lceil \frac { k - b + \delta - 1 } { r } \right \rceil ( \delta - 1 ) + 1.$$
The distance d opt ( n, k, r, δ ) -( n -k -⌈ k -b + δ -1 ⌉ ( δ -1) + 1 )
r is
$$( \delta - 1 ) \left ( \left \lceil \frac { k - b + \delta - 1 } { r } \right \rceil - \left \lceil \frac { k } { r } \right \rceil + 1 \right ) \leq \delta - 1$$
and hence the code is again at least almost optimal.
## V. CONCLUSION
In this paper we have studied linear locally repairable codes with all-symbol locality. We have constructed codes with almost optimal minimum distance. Namely, the difference between largest achievable minimum distance of locally repairable codes and the minimum distance of our codes is maximally δ -1 . Instead of just giving a construction, it is shown that by using random matrices with a guaranteed locality property, such matrix generates an almost optimal LRC with probability approaching to one as the field size approaches to infinity.
Also, methods to build new codes for different parameters using already existing codes are presented. Namely, a method to find a bigger code and a method to find a smaller code are presented.
As a future work it is still left to find the exact expression of the largest achievable minimum distance of the linear locally repairable code with all-symbol locality when given the length n and the dimension k of the code and the locality ( r, δ ) .
## REFERENCES
- [1] A. G. Dimakis, P. B. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran, 'Network coding for distributed storage systems,' IEEE Transactions on Information Theory, vol. 56, no. 9, pp. 4539-4551, September 2010.
- [2] I. Tamo, Z. Wang, J. Bruck, 'MDS array codes with optimal rebuilding,' in 2011 IEEE International Symposium on Information Theory Proceedings (ISIT), pp. 1240-1244, 2011.
- [3] P. Gopalan, C. Huang, H. Simitci, S. Yekhanin, 'On the locality of codeword symbols,' IEEE Transactions on Information Theory, vol. 58, no. 11, pp. 6925-6934, 2011.
- [4] F. Oggier, A. Datta, 'Self-repairing homomorphic codes for distributed storage systems,' in INFOCOM, 2011 Proceedings IEEE, pp. 1215-1223.
- [5] D. S. Papailiopoulos, J. Luo, A. G. Dimakis, C. Huang, J. Li 'Simple regenerating codes: Network coding for cloud storage,' in INFOCOM, 2012 Proceedings IEEE, pp. 2801-2805.
- [6] N. Prakash, Govinda M. Kamath, V. Lalitha, P. Vijay Kumar, 'Optimal Linear Codes with a Local-Error-Correction Property,' 2012 IEEE International Symposium on Information Theory Proceedings (ISIT), pp. 2776-2780.
- [7] D. S. Papailiopoulos, A. G. Dimakis, 'Locally repairable codes,' 2012 IEEE International Symposium on Information Theory Proceedings (ISIT), pp. 2771-2775.
- [8] I. Tamo, D. S. Papailiopoulos, A. G. Dimakis, 'Optimal locally repairable codes and connections to matroid theory,' 2013 IEEE International Symposium on Information Theory Proceedings (ISIT), pp. 1814-1818.
- [9] W. Song, S. H. Dau, C. Yuen, T. J. Li, 'Optimal Locally Repairable Linear Codes,' arXiv:1307.1961 , 2013.
- [10] Ankit Singh Rawat, O. Ozan Koyluoglu, N. Silberstein, S. Vishwanath, 'Optimal Locally Repairable and Secure Codes for Distributed Storage Systems,' arXiv:1210.6954 [cs.IT] , 2012.
- [11] I. Tamo, A. Barg, 'A family of optimal locally recoverable codes,' arXiv:1311.3284 , 2013.
- [12] C. Huang, M. Chen, J. Lin, 'Pyramid codes: Flexible schemes to trade space for access efficiency in reliable data storage systems,' Sixth IEEE International Symposium on Network Computing and Applications, 2007, pp. 79-86.
- [13] Govinda M. Kamath, N. Prakash, V. Lalitha, P. Vijay Kumar, 'Codes with Local Regeneration,' arXiv:1211.1932 [cs.IT] , 2012. | null | [
"Toni Ernvall",
"Thomas Westerbäck",
"Camilla Hollanti"
] | 2014-08-01T13:59:16+00:00 | 2014-08-01T13:59:16+00:00 | [
"cs.IT",
"math.IT"
] | Linear Locally Repairable Codes with Random Matrices | In this paper, locally repairable codes with all-symbol locality are studied.
Methods to modify already existing codes are presented. Also, it is shown that
with high probability, a random matrix with a few extra columns guaranteeing
the locality property, is a generator matrix for a locally repairable code with
a good minimum distance. The proof of this gives also a constructive method to
find locally repairable codes. |
1408.0181v1 | ## Strongly nonlinear thermovoltage and heat dissipation in interacting quantum dots
Miguel A. Sierra 1 and David S´ anchez 1
1 Instituto de F´ ısica Interdisciplinar y Sistemas Complejos IFISC (UIB-CSIC), E-07122 Palma de Mallorca, Spain
We investigate the nonlinear regime of charge and energy transport through Coulomb-blockaded quantum dots. We discuss crossed effects that arise when electrons move in response to thermal gradients (Seebeck effect) or energy flows in reaction to voltage differences (Peltier effect). We find that the differential thermoconductance shows a characteristic Coulomb butterfly structure due to charging effects. Importantly, we show that experimentally observed thermovoltage zeros are caused by the activation of Coulomb resonances at large thermal shifts. Furthermore, the power dissipation asymmetry between the two attached electrodes can be manipulated with the applied voltage, which has implications for the efficient design of nanoscale coolers.
PACS numbers: 73.23.-b, 73.50.Lw, 73.63.Kv, 73.50.Fq
Introduction .-In 1993 Staring et al. [1] reported an intriguing behavior of the thermovoltage V th generated across a thermally-driven Coulomb-blockaded quantum dot. Their observations first indicated an increase of V th with the temperature bias, in agreement with the Seebeck effect. Strikingly enough, for larger heating V th decreased, then vanished for a nonzero thermal difference and finally changed its sign. Very recently, Fahlvik Svensson et al. [2] investigated the nonlinear thermovoltage properties of nanowires and made a similar observation. The effect was attributed to a temperature-induced level renormalization because the piled-up charge depends on the applied thermal gradient [3]. However, the potential response was treated as a fitting parameter and singleelectron tunneling processes were not properly taken into account.
The subject is interesting for several reasons. First, Coulomb-blockade effects are ubiquitous and govern the transport properties of a large variety of systems: quantum dots [4], molecular bridges [5], carbon nanotubes [6], optical lattices [7], etc. On the other hand, nanostructures are ideal candidates to test novel thermoelectric effects boosting heat-to-work conversion performances [8, 9]. Importantly, nonlinearities and rectification mechanisms that lead to the phenomena reported in Refs. 1 and 2 can be more easily tested in small conductors with strongly energy dependent densities of states [3, 1022]. We emphasize that there is a close relation between the thermopower of a junction and its heat dissipation properties, as demonstrated in Refs. 23-25 for the linear regime of transport. Therefore, ascertaining the conditions under which thermovoltages acquire a significant nonlinear contribution has broader implications for power generation and cooling applications [26].
We begin our discussion by noticing that vanishing thermovoltages imply the existence of zero thermocurrent states. Unlike voltage-driven currents, which have a definite sign for a bias voltage V > 0 and never cross the V axis for normal conductors (an exception is the Hall resistance of an illuminated two-dimensional electron gas [27]), electric transport subjected a thermal gradient θ displays regions of positive or negative thermocurrents depending on the thermopower sign (positive for electron-like carriers, negative for hole-like ones [28]). Nevertheless, this is not sufficient for the thermocurrent to cross the θ axis since the thermopower is constant in linear response. Therefore, a strongly negative differential thermoconductance L = dI / dθ is needed to drive the current I from positive to negative values. This results in an interesting effect-further contact heating may switch off the thermocurrent flowing across the dot. Notably, this is a purely nonlinear thermoelectric effect and has no counterpart with either the voltage-driven case or the linear thermoelectric regime.
Theoretical model .-Our results are based on the Anderson model with constant charging energy U ,
$$\mathcal { H } = \mathcal { H } _ { \text{leads} } + \mathcal { H } _ { \text{dot} } + \mathcal { H } _ { \text{tun} } \,, \quad \quad ( 1 )$$
where H leads = ∑ αkσ ε αkσ C † αkσ C αkσ is the Hamiltonian of left ( α = L ) and right ( α = R ) reservoirs coupled to the dot. These are described as an electronic band of states with continuous wavenumber k and spin index σ = {↑ ↓} , . H dot = ∑ σ ε d d † σ d σ + Ud d d d † ↑ ↑ † ↓ ↓ is the dot Hamiltonian with quasilocalized level ε d (we consider a single level for definiteness). H tun = ∑ αkσ ( V αkσ C † αkσ d σ + h c . . ) is the coupling term that hybridizes dot and leads' states with tunneling amplitudes V αkσ .
The electronic current is given by the time evolution of the expected occupation in one of the reservoirs, I α = -ed n ⟨ α ⟩/ dt , with n α = ∑ kσ C † αkσ C αkσ . Since the total density commutes with the Hamiltonian of Eq. (1), current conservation demands that I L + I R = 0 in the steady state. Hence, we can define the current flowing through the system as I ≡ I L = -I R . Within the Keldysh formalism [29], I is expressed as I = ( / e πh ̵ ) Re ∑ kσ ∫ ∞ -∞ dEV αkσ G < σ,αkσ ( E ) , where G < σ,αkσ ( E ) = ( 1 / ̵ ) ∫ h dEG < σ,αkσ ( t, t ′ ) e iE t ( -t ′ )/ ̵ h is the Fourier transform of the lesser Green function G < σ,αkσ ( t, t ′ ) = i ̵ h ⟨ C † αkσ ( t ′ ) d σ ( )⟩ t . Following Ref. [30], the current readily becomes
$$\underset { \underset { \underset { \underset { \underset { \underset { \pi } { \pi } } { \pi } } } { \text{mal} } } \quad I = - \frac { e } { \pi \hbar } \int d E \sum _ { \sigma } \frac { \Gamma _ { L } \Gamma _ { R } } { \Gamma } \text{Im} G _ { \sigma, \sigma } ^ { r } ( E ) [ f _ { L } ( E ) - f _ { R } ( E ) ] \,.$$
G r is the dot retarded Green function in the presence of both coupling to the continuum states and electronelectron interactions. Γ α ( E ) = 2 πρ α ( E V )∣ ασ ∣ 2 denotes the level broadening due to coupling to the leads (total linewidth Γ = Γ L + Γ R ), with ρ α = ∑ k δ ( E -ε αk ) the α lead density of states. We consider the wide band limit and take Γ α as constant. Finally, in Eq. (2) f α ( E ) = 1 /[ 1 + exp ( E -µ α )/( k B T α )] is the Fermi-Dirac function for lead α with electrochemical potential µ α = E F + eV α and temperature shift T α = T + θ α ( E F is the common Fermi energy and T is the background temperature).
The spectral function given by (- / 1 π ) Im G r in Eq. (2) can be determined from the equation-of-motion technique followed by a decoupling procedure [31]. We restrict ourselves to the Coulomb blockade regime ( k B T, Γ ≪ U ) and neglect cotunneling and Kondo correlations. This approach yields an excellent characterization of the transport properties of strongly interacting quantum dots for temperatures larger than the Kondo temperature, T > T K . The retarded Green function can be assessed by neglecting the correlators ⟪ d † ¯ σ C αkσ ¯ d σ , d † σ ⟫ ≃ 0 and ⟪ C † αkσ ¯ d ¯ σ d σ , d † σ ⟫ ≃ 0 (virtual charge excitations in the dot) and ⟪ C αkσ C † βqσ ¯ d ¯ σ , d † σ ⟫ ≃ 0 and ⟪ C αkσ d † ¯ σ C βqσ ¯ , d † σ ⟫ ≃ 0 (spin excitations in the leads). Thus, G r σ,σ ( E ) = ( 1 - ⟨ n ¯ σ ⟩)/( E -ε d + i Γ 2 / ) + ⟨ n ¯ σ ⟩/( E -ε d -U + i Γ 2 / ) depends on the dot occupation for reversed spin ¯, σ ⟨ n σ ⟩ = 1 2 πi ∫ dEG < σ,σ ( E ) . Thus, G r must be calculated in a self-consistent fashion. Using the Keldysh equation G < = i [ Γ L L f ( E ) + Γ R R f ( E )]∣ G r ∣ 2 , we close the system of equations. G r has two poles at E = ε d and E = ε d + U broadened by Γ and weighted by ( 1 -⟨ n ¯ σ ⟩) and ⟨ n ¯ σ ⟩ , respectively. Then, the generalized transmission ( Γ Γ L R / Γ Im ) G r σ,σ ( E, { V α } { , θ α }) depends, quite generally, on both voltage and temperature shifts, as the occupation does, which is a fundamental difference with noninteracting models [34].
We find the spin-dependent occupations
$$\langle n _ { \sigma } \rangle = A ( 1 - \langle n _ { \bar { \sigma } } \rangle ) + B \langle n _ { \bar { \sigma } } \rangle \,, \quad \quad ( 3 ) \quad \text{as $1$}$$
$$\langle n _ { \bar { \sigma } } \rangle = A ( 1 - \langle n _ { \sigma } \rangle ) + B \langle n _ { \sigma } \rangle \,, \quad \quad ( 4 ) \quad \text{ else}$$
where A and B are specified below. The Hamiltonian in Eq. (1) is invariant under spin rotations since no Zeeman splitting is present in the system. Hence, the mean occupation in the dot ⟨ n ⟩ = ⟨ n σ ⟩+⟨ n ¯ σ ⟩ is simply given by
$$\langle n \rangle = \frac { 2 A } { 1 + A - B } \,, \quad \quad \ \ ( 5 ) \quad \ \ f r c ^ { \nu \omega } _ { \text{op} }$$
with A = ( 1 2 / π ) ∫ dE [ Γ L L f ( E )+ Γ R R f ( E )]/[( E -ε d ) 2 + Γ 2 4 ] and B = ( 1 2 / π ) ∫ dE [ Γ L L f ( E )+ Γ R R f ( E )]/[( E ε -d -U ) 2 + Γ 2 4 ] . At equilibrium, ⟨ n σ ⟩ = ⟨ n ⟩/ 2 ranges between 0 and 1 depending on the value of ε d , which can be tuned with an external gate potential. As is well known, the dot occupation significantly changes when ε d crosses the spectral function peaks located at E = E F and E = E F + U (degeneracy points). In between, the charge is approximately quantized. We now investigate departures of this behavior when the dot is driven out of equilibrium due to either voltage or thermal gradients.
Voltage-driven case .-We consider a voltage bias V symmetrically applied to the leads and set E F = 0 as the reference energy point, µ L = -µ R = eV / 2. Inserting Eq. (5) and the G r expression in Eq. (2), we calculate the I -V characteristic curves for different values of the dot level, see Fig. 1(a). When the single-particle peaks are at resonance with the Fermi energy ( ε d = 0 or ε d = U ), the system behaves as an ohmic junction for voltages around V = 0. With increasing V the current reaches a plateau and then increases again when the leads' electrochemical potential realigns with the dot level, which causes an enhancement of the occupation as shown in the inset of Fig. 1(a). This result [32] agrees with phenomenological models of Coulomb blockade [33]. Clearly, the differential conductance G = dI / dV traces show a Coulomb diamond structure as in Fig. 1(b).
The occupation is voltage independent in the particlehole symmetry point ( ε d = -U / 2), in which case the conductance is minimal around V = 0. Only for that case the transformation d → d † leaves Eq. (1) invariant and the electron density in the dot follows a Fermi distribution. Away from ε d = -U / 2 the dot distribution is not Fermi-like since A and B become doubly stepped functions. Therefore, the occupation [e.g., for ε d = -3 U / 4 in the inset Fig. 1(a)] exhibits a nonmonotonic dependence with V and the conductance shows four peaks as seen in Fig. 1(b).
Temperature-driven case .-We present in the bottom panel of Fig. 1 the effect of a temperature shift ∆ T > 0 applied to one of the electrodes: θ L = ∆ T and θ R = 0 for positive temperature differences θ = T L -T R > 0, and θ L = 0 and θ R = ∆ T yielding θ < 0. Noticeably, the thermocurrent curves I ( θ ) in Fig. 1(c) lack the Coulomb staircases seen in Fig. 1(a). For ε d = -U / 2 the thermocurrent is identically zero since the dot spectral function of Eq. (2) is symmetric around E F . At resonance, I grows as the lead gets hotter because more thermally excited electrons are able to tunnel through the nanostructure. A similar response is obtained for level positions between 0 and U at small θ . Further increasing of θ , however, gives rise to dramatic changes. For ε d = -3 U / 4 the thermocurrent reaches a maximum and then decreases, crossing the θ axis. In other words, a strong heating of one of the contacts reverses the electronic flow, driving the electrons from the cold to the hot side . This striking behavior is opposite for gate potentials closer to the Fermi energy, see Fig. 1(c) for ε d = -0 15 . U . This is a purely nonlinear property of thermoelectric transport that is reflected in the nonmonotonic occupation, see the inset of Fig. 1(c).
The differential thermoelectric conductance L = dI / dθ is shown in Fig. 1(d). The Coulomb diamonds of Fig. 1(b) are transformed into a butterfly structure with strong changes of sign across the points ε d = 0 and ε = U for fixed θ , in agreement with the experiment [2]. The effect is more intense for moderate values of the temperature shift θ ≲ 10 T , a scale dominated by the charging energy.
FIG. 1. (Color online). (a) Current-voltage characteristics of a dc-biased single-level Coulomb-blockaded quantum dot (see the sketch) for the indicated gate voltages (level positions). Inset: dot occupation as a function of the voltage bias. (b) Differential conductance versus level position and bias voltage. (c) Thermocurrent of a single-level Coulomb-blockaded quantum dot as a function of the temperature difference shown in the sketch. (d) Differential thermoelectric conductance versus level position and bias voltage. Parameters: charging energy U = 10 and background temperature k B T = 0 1. . All energies are expressed in terms of Γ L = Γ R = Γ 2. /
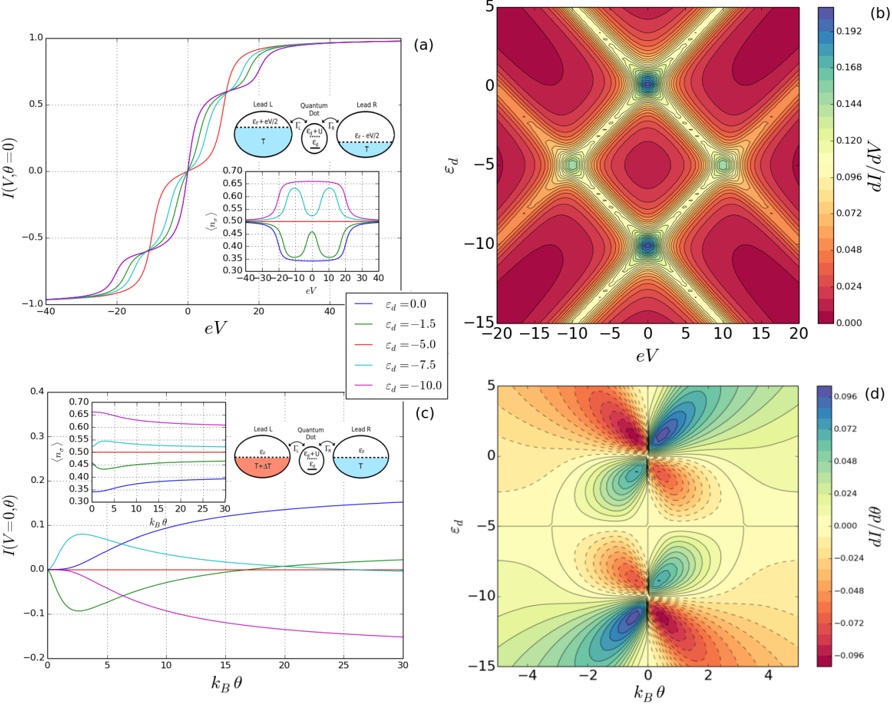
As expected, we obtain L = 0 for ε d = -U / 2 independently of θ . Above (below) this symmetry point, L is positive (negative) in the small θ regime, which is a manifestation of the Seebeck effect for electron-like (hole-like) carrier transport.
mocurrent at point B . Further increase of θ causes a dominant contribution of holes and I takes on negative values (point C ).
Thermocurrent and thermovoltage .-The strong nonlinearities in the I -θ curves can be easily understood with a level diagram as sketched in the left panel of Fig. (2). For ε d = -3 U / 4 the E = ε d ( E = ε d + U ) pole lies below (above) E F (dot-dashed line). If the left lead is heated, thermally excited electrons contribute significantly to the current through the E = ε d + U channel and the thermocurrent becomes maximal [point labeled as A in the right side of Fig. (2)]. As the left contact becomes hotter, the distribution function looses its step form unlike the cold contact. As a consequence, holes (electrons traveling from the right reservoir below E F ) counterbalance the flux from the left side, giving rise to a vanishing ther-
The thermovoltage or Seebeck voltage V th is determined from the open-circuit condition I ( V th , θ ) = 0, which we solve numerically to obtain V th = V th ( θ ) . Except for ε d = -U / 2, the thermovoltage is generally nonzero. For a small thermal bias, V th is a linear function of θ , yielding a constant thermopower, where the (differential) thermopower is defined as S θ ( ) = dV th / dθ . For ε d close to E F + U ( E F ), S is positive (negative) for θ → 0, which can distinguish transport due to electrons or holes. With increasing θ , the thermovoltage grows because larger biases are needed to compensate the thermoelectric flow. Hence, there exists a nice correlation between the V th ( θ ) and I th ( θ ) curves [cf. Fig. 1(c)]. For any value ε d ∈ ( E ,E F F + U ) (except the special point ε = -U / 2) we always find a θ value such that V th = 0.
FIG. 2. (Color online). Left panel: energy diagram corresponding to the current states of the right panel. E F ( ε d ) is indicated with dashed (dotted-dashed) lines. Right panel: thermocurrent as a function of the temperature difference for ε d = -3 U / 4 as taken from Fig. 1(c). Note that the electron flow from the left (right) electrode at point A C ( ) dominates but exactly cancels out for point B .
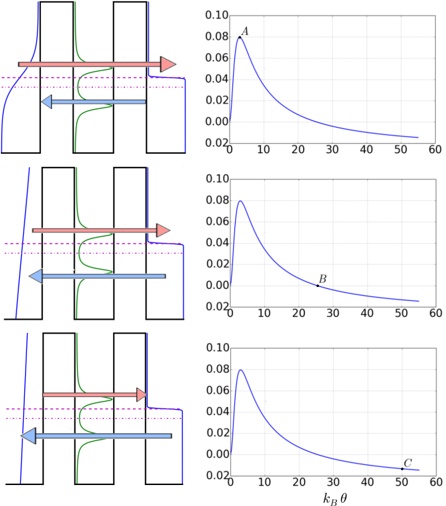
The reason is clear from the above discussion. For the point B marked in Fig. (2) it is unnecessary to apply a voltage bias to counteract the thermal gradient because the thermocurrent is already zero. This effect would also be observable in dot systems with two levels but we remark that the experiments of our interest [1, 2] are done in the Coulomb blockade regime.
Asymmetric dissipation and rectification .-The reciprocal effect to the Seebeck conversion is the Peltier effect [42-44], which describes a reversible heat that, unlike the Joule heating, can be used to cool a system by electric means. Recent experiments [24] suggest an asymmetric rectification of the generated heat in a voltage-driven atomic-scale junction. These results are interesting because whereas rectification effects are well understood in the electric case [35-41] much less is known about the way power is dissipated in a voltage-biased mesoscopic conductor. The linear part of the rectified heat follows from the linear-response Peltier coefficient. Therefore, the dissipated power can be larger or smaller for a given bias V as compared with its reversed value, depending on whether the atomic resonance lies above or below E F . However, nonlinear deviations were observed for larger V [24]. Here, we demonstrate that the heat rectification can be tuned with V for a fixed position of ε d .
The heat current is derived from J α =
FIG. 3. (Color online). (a) Thermovoltage as a function of the temperature difference for the indicated values of the gate voltages (level positions). (b) Differential thermopower S = dV th / dθ in units of k B / e . Parameters: U = 10, k B T = 0 1 and . energy is given in units of Γ L = Γ R = Γ 2. /
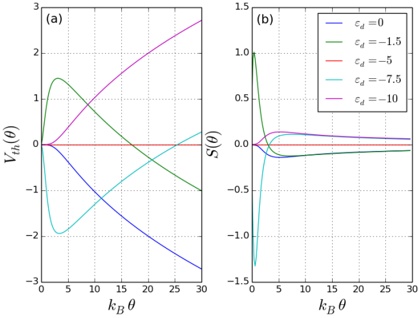
d ⟨∑ kσ ε αkσ C † αkσ C αkσ ⟩/ dt ,
$$\underset { \left ( \varepsilon _ { d } \right ) } { \text{orre} } \text{-} \\ \text{anel:} } \, J _ { \alpha } = \sum _ { \sigma } \frac { \Gamma _ { L } \Gamma _ { R } } { \pi \hbar { \Gamma } } \int d E \left ( \mu _ { \alpha } - E \right ) \text{Im} \, G _ { \sigma, \sigma } ^ { r } [ f _ { L } ( E ) - f _ { R } ( E ) ] \, 6 \right )$$
which satisfies the Joule law J L + J R = -IV . We consider the case where J ≡ J L is a function of voltage only ( θ = 0). Figure 4(a) shows the heat current as a function of V for several values of ε d . Only for ε d = -U / 2, J exhibits a symmetric behavior, as expected. We observe that the curves quickly depart from the linear regime [see the inset of Fig. 4(b)]. Thus, Joule and higher order effects start soon to dominate. Interestingly, for ε d = -3 U / 4 the heat current shows a nontrivial zero for finite V . The resulting asymmetry under V reversal is apparent for, e.g., ε d = U . Our results also show that the heat current is invariant under the joint transformation V →-V and ε d →-ε d -U (see, e.g., the ε d = 0 and ε d = -U cases).
In Fig. 4(b) we depict the rectification factor J V ( ) -J (-V ) for different dot level positions. At resonance ( ε d = 0), the rectification is always positive, i.e., the dissipation is larger for V > 0 than for V < 0 and increases with voltage. Clearly, for V > 0 heat can flow through either E = 0 or E = U peaks while for V < 0 energy can be transported through the E = 0 resonance only. The situation is reversed for ε d = -U . The dissipation is now larger for negative voltages than for positive polarities. More importantly, the rectification factor can change its sign for a given value of ε d , as indicated in Fig. 4(b) for ε d = -3 U / 4. Notice that this is a purely nonlinear effect. While in the linear case the rectification can be changed with tuning ε d and this effect heavily depends on the transmission energy dependence [24], here a voltage scan leads to a value where the transformation V → -V leaves J invariant. Furthermore, it is straightforward to show that the power difference between the left and right electrodes for a given bias, J L ( V ) -J R ( V ) , equals
FIG. 4. (Color online). Heat current as a function of applied voltage in the isothermal case θ = 0. Dot level positions are also indicated. Inset: Detail of the dissipated power around zero voltage. (b) Asymmetric dissipation versus voltage bias for the same gate voltages. Parameters: U = 10, k B T = 0 1 . and energy is given in units of Γ L = Γ R = Γ 2. /
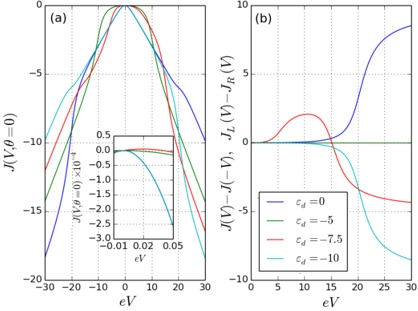
- [1] A. A. M. Staring, L. W. Molenkamp, B. W. Alphenaar, H. van Houten, O. J. A. Buyk, M. A. A. Mabesoone, C. W. J. Beenakker, and C. T. Foxon, Europhys. Lett. 22 , 57 (1993).
- [2] S. Fahlvik Svensson, E. A. Hoffmann, N. Nakpathomkun, P. M. Wu, H. Q. Xu, H. A. Nilsson, D. S´ anchez, V. Kashcheyevs and H. Linke, New J. Phys. 15 , 105011 (2013).
- [3] D. S´nchez and R. L´pez, Phys. Rev. Lett. a o 110 , 026804 (2013).
- [4] L. P. Kouwenhoven, C. M. Marcus, P. L. McEuen, S. Tarucha, R. M. Westervelt, and N. S. Wingreen, in Nato ASI conference proceedings, edited by L. P. Kouwenhoven, G. Sch¨ on, and L. L. Sohn (Kluwer, Dordrecht, 1997), pp. 105-214.
- [5] J. Park et al. , Nature (London) 417 , 722 (2002).
- [6] H. W. Postma, T. Teepen, Z. Yao, M. Grifoni, and C. Dekker, Science 293 , 76 (2001).
- [7] P. Cheinet, S. Trotzky, M. Feld, U. Schnorrberger, M. Moreno-Cardoner, S. F¨lling, and I. Bloch, Phys. Rev. o Lett. 101 , 090404 (2008).
- [8] Y. Dubi and M. Di Ventra, Rev. Mod. Phys. 83 , 131 (2011).
- [9] G. Benenti, G. Casati, T. Prosen, and K. Saito, arXiv:1311.4430 (preprint).
- [10] D. Boese and R. Fazio, Europhys. Lett. 56 , 576 (2001).
- [11] M. Krawiec and K. I. Wysoki´ nski, Phys. Rev. B 75 , 155330 (2007).
- [12] D. M.-T. Kuo and Y. Chang, Phys. Rev. B 81 , 205321 (2010).
- [13] R. S. Whitney, Phys. Rev. B 87 , 115404 (2013).
- [14] J. Meair and P. Jacquod, J. Phys.: Condens. Matter 25 ,
J V ( ) -J (-V ) if the dot spectral function is symmetric under V reversal. Our system indeed shows this property for symmetric couplings, Γ L = Γ R [see the inset of Fig. 1(a), where the occupation is an even function of V ]. Therefore, heat can be dissipated equally between the leads ( J L = J R ) for V ≠ 0 [see Fig. 4(b) for ε d = -3 U / 4], despite the fact that the transmission strongly depends on energy, unlike the linear case [24]. This is again an effect which can be observed in the nonlinear regime of transport only.
Conclusion .-We have examined a counterintuitive phenomenon seen in experiments-with increasingly thermal gradient applied to a quantum dot the created thermovoltage diminishes and even becomes zero for a nonzero temperature bias. We have shown that the effect is due to the combined influence of the two peaks arising from a Coulomb blockade level. Furthermore, we predict a reciprocal effect-the power rectification becomes zero for a finite voltage, which can be relevant for the design of nanodevices with controllable dissipation. Further work should clarify the role of (higher-order) cotunneling processes [45, 46] and Kondo interactions [47-49].
Acknowledgments .-We thank R. L´ opez for useful discussions. Work supported by MINECO under Grant No. FIS2011-23526 and MECD.
082201 (2013).
- [15] R. L´ opez and D. S´ anchez, Phys. Rev. B 88 , 045129 (2013).
- [16] S. Hershfield, K. A. Muttalib, and B. J. Nartowt, Phys. Rev. B 88 , 085426 (2013).
- [17] J. Matthews, F. Battista, D. S´nchez, P. Samuelsson, H. a Linke, arXiv:1306.3694 (preprint).
- [18] S.-Y. Hwang, D. S´nchez, M. Lee, and R. L´pez, New J. a o Phys. 15 , 105012 (2013).
- [19] P. Dutt and K. Le Hur, Phys. Rev. B 88 , 235133 (2013).
- [20] R. S. Whitney, Phys. Rev. Lett. 112 , 130601 (2014).
- [21] N. A. Zimbovskaya, arXiv:1405.6968 (preprint).
- [22] J. Azema, P. Lombardo, A.-M. Dar´ e, arXiv:1407.5065 (preprint).
- [23] M. Leijnse, M. R. Wegewijs, and K. Flensberg, Phys. Rev. B 82 , 045412 (2010).
- [24] W. Lee, K. Kim, W. Jeong, L. A. Zotti, F. Pauly, J. C. Cuevas, and P. Reddy, Nature 498 , 209 (2013); L. A. Zotti, M. B¨rkle, F. Pauly, W. Lee, K. Kim, W. Jeong, u Y. Asai, P. Reddy and J. C. Cuevas, New J. Phys. 16 , 015004 (2014).
- [25] O. Entin-Wohlman, J.-H. Jiang, and Y. Imry, Phys. Rev. E 89 , 012123 (2014).
- [26] F. Giazotto, T. T. Heikkil¨, A. Luukanen, A. M. Savin, a and J. P. Pekola, Rev. Mod. Phys. 78 , 217 (2006).
- [27] R.G. Mani, J.H. Smet, K. von Klitzing, V. Narayanamurty, W.B. Johnson, and V. Umansky, Nature (London) 420 , 646 (2002).
- [28] P. Reddy, S. Y. Jang, R. A. Segalman, and A. Majumdar, Science 315 , 1568 (2007).
- [29] See, e.g., H. Haug and A.-P. Jauho, Quantum Kinetics in Transport and Optics of Semiconductors (Springer,
Berlin, 2007).
- [30] Y. Meir and N. S. Wingreen, Phys. Rev. Lett. 68 , 2512 (1992).
- [31] A. C. Hewson, Phys. Rev. 144 , 420 (1966).
- [32] Y. Meir and N. S. Wingreen, and P. A. Lee, Phys. Rev. Lett. 66 , 3048 (1991).
- [33] C. W. J. Beenakker, Phys. Rev. Lett. 44 , 1646 (1991).
- [34] P. N. Butcher, J. Phys.: Condens. Matter 2 , 4869 (1990).
- [35] A. M. Song, A. Lorke, A. Kriele, J. P. Kotthaus, W. Wegscheider, and M. Bichler, Phys. Rev. Lett. 80 , 3831 (1998).
- [36] H. Linke, W. D. Sheng, A. Svensson, A. Lofgren, L. Christensson, H. Q. Xu, P. Omling, and P. E. Lindelof, Phys. Rev. B 61 , 15914 (2000).
- [37] I. Shorubalko, H. Q. Xu, I. Maximov, P. Omling, L. Samuelson, and W. Seifert, Appl. Phys. Lett. 79 , 1384 (2001).
- [38] R. Fleischmann and T. Geisel, Phys. Rev. Lett. 89 , 016804 (2002).
- [39] M. B¨ uttiker and D. S´nchez, Phys. Rev. Lett. a 90 , 119701 (2003).
- [40] T. Gonz´ alez, B. G. Vasallo, D. Pardo, and J. Mateos,
- Semicond. Sci. Technol. 19 , S125 (2004).
- [41] B. Hackens, L. Gence, C. Gustin, X. Wallart, S. Bollaert, A. Cappy, and V. Bayot, Appl. Phys. Lett. 85 , 4508 (2004).
- [42] I. O. Kulik, J. Phys.: Condens. Matter 6 , 9737 (1994).
- [43] E. N. Bogachek, A. G. Scherbakov, and U. Landman, Phys. Rev. B 60 , 11678 (1999).
- [44] M. Zebarjadi, K. Esfarjani, and A. Shakouri, Appl. Phys. Lett. 91 , 122104 (2007).
- [45] M. Turek and K. A. Matveev, Phys. Rev. B 65 , 115332 (2002).
- [46] K. Torfason, A. Manolescu, S. I. Erlingsson, and V. Gudmundsson, Physica E 53 , 178 (2013).
- [47] B. Dong and X. L. Lei, J. Phys.: Condens. Matter 14 , 11747 (2002).
- [48] R. Scheibner, H. Buhmann, D. Reuter, M. N. Kiselev, and L. W. Molenkamp, Phys. Rev. Lett. 95 , 176602 (2005).
- [49] T. A. Costi and V. Zlati´ c, Phys. Rev. B 81 , 235127 (2010). | 10.1103/PhysRevB.90.115313 | [
"Miguel A. Sierra",
"David Sanchez"
] | 2014-08-01T14:01:00+00:00 | 2014-08-01T14:01:00+00:00 | [
"cond-mat.mes-hall",
"cond-mat.stat-mech",
"cond-mat.str-el"
] | Strongly nonlinear thermovoltage and heat dissipation in interacting quantum dots | We investigate the nonlinear regime of charge and energy transport through
Coulomb-blockaded quantum dots. We discuss crossed effects that arise when
electrons move in response to thermal gradients (Seebeck effect) or energy
flows in reaction to voltage differences (Peltier effect). We find that the
differential thermoelectric conductance shows a characteristic Coulomb
butterfly structure due to charging effects. Importantly, we show that
experimentally observed thermovoltage zeros are caused by the activation of
Coulomb resonances at large thermal shifts. Furthermore, the power dissipation
asymmetry between the two attached electrodes can be manipulated with the
applied voltage, which has implications for the efficient design of nanoscale
coolers. |
1408.0183v1 | ## Two-dimensional interpolation using a cell-based searching procedure
## Roberto Cavoretto
Department of Mathematics 'G. Peano', University of Torino, Via Carlo Alberto 10, 10123 Torino, Italy [email protected]
## Abstract
In this paper we present an efficient algorithm for bivariate interpolation, which is based on the use of the partition of unity method for constructing a global interpolant. It is obtained by combining local radial basis function interpolants with locally supported weight functions. In particular, this interpolation scheme is characterized by the construction of a suitable partition of the domain in cells so that the cell structure strictly depends on the dimension of its subdomains. This fact allows us to construct an efficient cell-based searching procedure, which provides a significant reduction of CPU times. Complexity analysis and numerical results show such improvements on the algorithm performances.
Keywords : Partition of unity, Local methods, Searching techniques, Fast algorithms, Scattered data
## 1. Introduction
Let { ( x i , f i ) , i = 1 2 , , . . . , n } be a finite set of discrete data, with x i ∈ Ω ⊆ R 2 , and f i ∈ R . The x i are called the nodes , while the (corresponding) f i are the data values . The latter are obtained by sampling some (unknown) function f : Ω → R at the nodes, i.e. f i = f ( x i ), i = 1 2 , , . . . , n .
Therefore, the scattered data interpolation problem consists in finding a continuous function R : Ω → R such that
$$\mathcal { R } ( \mathbf x _ { i } ) = f _ { i }, \quad \ i = 1, 2, \dots, n.$$
Here, we consider the problem of constructing an efficient algorithm for bivariate interpolation of (large) scattered data sets. It is based on the partition of unity method for constructing a global interpolant by blending radial basis functions (RBFs) as local approximants and using locally supported weight functions.
Now, starting from the results of previous researches (see [1, 3, 4, 5, 6]) where efficient searching procedures based on the partition of the domain in strips or spherical zones are considered, we extend the previous ideas replacing the strip-based partition structure with a cell-based one. The latter leads to the creation of a cell-based searching procedure, whose origin comes from the repeated use of a quicksort routine with respect to different directions, enabling
us to pass from not ordered to ordered data structures. In particular, this process is strictly related to the construction of a partition of the domain Ω in square cells, which consists in generating two orthogonal families of parallel strips, where the original data set is suitably split up in ordered data subsets.
Then, exploiting the ordered data structure and the domain partition, the cell algorithm is efficiently implemented and optimized by connecting the method itself with the effective cell-based searching procedure. More precisely, the considered technique is characterized by the construction of a double structure of crossed strips, which partitions the domain in square cells and strictly depends on the dimension of its subdomains, providing a significant improvement in the searching procedures of the nearest neighbour points compared to the searching techniques in [1, 3, 4]. The final result is an efficient algorithm for bivariate interpolation of scattered data. Finally, complexity analysis and numerical tests show the high efficiency of the proposed algorithm.
The paper is organized as follows. In Section 2 we recall some theoretical results: firstly, we introduce the radial basis functions referring to existence and uniqueness of RBF interpolants, then we give a general description of the partition of unity method, which makes use of local RBF approximants. In Section 3, we present in detail the cell algorithm, which is efficiently implemented and optimized by using a cell-based searching procedure. Then, in Section 4 complexity of this algorithm is analyzed as well. Finally, Section 5 shows numerical results concerning efficiency and accuracy of the cell-based partition algorithm.
## 2. Local interpolation scheme
## 2.1. Radial basis functions
A suitable approach to solving the scattered data interpolation problem is to make the assumption that the interpolating function R is expressed as a linear combination of radial basis functions φ : [0 , ∞ → ) R , i.e.,
$$\mathcal { R } ( \mathbf x ) = \sum _ { j = 1 } ^ { n } c _ { j } \phi ( | | \mathbf x - \mathbf x _ { j } | | _ { 2 } ), \quad \mathbf x \in \mathbb { R } ^ { 2 },$$
where ||·|| 2 is the Euclidean distance, and R satisfies the interpolation conditions (1).
Thus, solving the interpolation problem under this assumption leads to a system of linear equations of the form
$$A c = f,$$
where the entries of the interpolation matrix A are given by
$$a _ { i j } = \phi ( | | \mathbf x _ { i } - \mathbf x _ { j } | | _ { 2 } ), \quad \ i, j = 1, 2, \dots, n,$$
c = [ c 1 , c 2 , . . . , c n ] T , and f = [ f , f 1 2 , . . . , f n ] T . Moreover, we know that the interpolation problem is well-posed , that is a solution to a problem exists and
is unique, if and only if the matrix A is non-singular. A sufficient condition to have non-singularity is that the corresponding matrix is positive definite (see, e.g., [7]).
Now, we remind that a real-valued continuous even function φ is called positive definite on R 2 if
$$\sum _ { i = 1 } ^ { n } \sum _ { j = 1 } ^ { n } c _ { i } c _ { j } \phi \left ( { \mathbf x } _ { i } - { \mathbf x } _ { j } \right ) \geq 0$$
for any n pairwise distinct nodes x 1 , x 2 , . . . , x n ∈ R 2 , and c = [ c 1 , c 2 , . . . , c n ] T ∈ R n . The function φ is called strictly positive definite on R 2 if the quadratic form (4) is zero only for c ≡ 0 .
Therefore, if φ is strictly positive definite, the interpolant (2) is unique, since the corresponding interpolation matrix (3) is positive definite and hence non-singular.
Some of the most popular strictly positive definite RBFs are
$$\begin{smallmatrix} \phi _ { G } ( r ) & = & e ^ { - \alpha ^ { 2 } r ^ { 2 } }, \\ \phi _ { W 2 } ( r ) & = & ( 1 - c r ) _ { + } ^ { 4 } ( 4 c r + 1 ), \end{smallmatrix} \quad ( \text{Wendand} ^ { \prime } s \ C ^ { 2 } \text{ function} )$$
where α, c ∈ R + are the shape parameters , r = || x -x i || 2 , and ( ) · + denotes the truncated power function. Note that Gaussian (G) is a globally supported function of infinite smoothness, whereas Wendland's function (W2) is compactly supported one with degree of smoothness 2. For further details, see [14].
## 2.2. Partition of unity interpolant
The partition of unity method was firstly suggested in [2, 9] in the context of meshfree Galerkin methods for the solution of partial differential equations (PDEs), but now it is also commonly used in the field of approximation theory (see [14]). In particular, this approach enables us to decompose a large problem into many small problems, and at the same time ensures that the accuracy obtained for the local fits is carried over to the global one. In fact, the partition of unity method we here consider can be thought as a modified Shepard's method with higher-order data, where local approximations R j are RBFs. Similar local approaches involving Shepard's type methods were considered in [1, 8, 10, 11, 12].
Thus, the partition of unity method consists in partitioning the open and bounded domain Ω ⊆ R 2 into d subdomains Ω j such that Ω ⊆ ⋃ d j =1 Ω j with some mild overlap among the subdomains. At first, we choose a partition of unity, i.e. a family of compactly supported, non-negative, continuous functions W j with supp( W j ) ⊆ Ω j such that
$$\sum _ { j = 1 } ^ { d } W _ { j } ( { \mathbf x } ) = 1, \quad \mathbf x \in \Omega.$$
Then, we can consider the global interpolant
$$\mathcal { I } ( \mathbf x ) = \sum _ { j = 1 } ^ { d } \mathcal { R } _ { j } ( \mathbf x ) W _ { j } ( \mathbf x ),$$
where the local radial basis function
$$\mathcal { R } _ { j } ( \mathbf x ) = \sum _ { k = 1 } ^ { m _ { j } } c _ { k } \phi ( | | \mathbf x - \mathbf x _ { k } | | _ { 2 } )$$
is obtained by solving a local interpolation problem, which is constructed using the m j nodes belonging to each subdomain Ω . j Note that if the local approximants satisfy the interpolation conditions at node x i , i.e. R j ( x i ) = f ( x i ), then the global approximant also interpolates at this node, i.e. I ( x i ) = f ( x i ), for i = 1 2 , , . . . , n .
In order to be able to formulate error bounds we need some technical conditions. Then, we require the partition of unity functions W j to be k-stable , i.e. each W j ∈ C k ( R 2 ), j = 1 2 , , . . . , d , and for every multi-index β ∈ N m 0 with | β | ≤ k there exists a constant C β > 0 such that
$$| | D ^ { \beta } W _ { j } | | _ { L _ { \infty } ( \Omega _ { j } ) } \leq C _ { \beta } / \delta _ { j } ^ { | \beta | },$$
where δ j = diam(Ω ). j
In accordance with the statements in [13] we require some additional regularity assumptions on the covering { Ω j } d j =1 . Therefore, setting X n = { x i , i = 1 2 , , . . . , n } ⊆ Ω, an open and bounded covering { Ω j } d j =1 is called regular for (Ω , X n ) if the following properties are satisfied:
- (a) for each x ∈ Ω, the number of subdomains Ω j with x ∈ Ω j is bounded by a global constant K ;
- (b) each subdomain Ω j satisfies an interior cone condition;
- (c) the local fill distances h X j , Ω j are uniformly bounded by the global fill distance h X n , Ω , where X j = X n ∩ Ω . j
Therefore, assuming that:
- · φ ∈ C k ν ( R 2 ) is a strictly positive definite function;
- · { Ω j } d j =1 is a regular covering for (Ω , X n );
- · { W j } d j =1 is k -stable for { Ω j } d j =1 ;
we have the following convergence result (see, e.g., [7, 14]), i.e., the error between f ∈ N φ (Ω), where N φ is the native space of φ , and its partition of unity interpolant (5) can be bounded by
$$| D ^ { \beta } f ( { \mathbf x } ) - D ^ { \beta } \mathcal { I } ( { \mathbf x } ) | \leq C h _ { \mathcal { X } _ { n }, \Omega } ^ { ( k + \nu ) / 2 - | \beta | } | f | _ { \mathcal { N } _ { \phi } ( \Omega ) },$$
for all x ∈ Ω and all | β | ≤ k/ 2.
## 3. Cell algorithm
In this section we present an efficient algorithm for bivariate interpolation of scattered data sets lying on the domain Ω = [0 1] , 2 ⊂ R 2 , which is based on the partition of unity method for constructing a global interpolant by blending RBFs as local approximants and using locally supported weight functions. It is efficiently implemented and optimized by connecting the interpolation method itself with an effective cell-based searching procedure. In particular, the implementation of this algorithm is based on the construction of a cell structure , which is obtained by partitioning the domain Ω in square cells, whose sizes strictly depend on the dimension of its subdomains. Such approach leads to important improvements in the searching processes of the nearest neighbour points compared to the searching techniques presented in [1, 3, 4].
## 3.1. Input and output
INPUT:
- · X n = ( { x , y i i ) , i = 1 2 , , . . . , n } , set of nodes;
- · F n = { f , i i = 1 2 , , . . . , n } , set of data values;
- · C d = (¯ { x , y i ¯ ) i , i = 1 2 , , . . . , d } , set of subdomain points (centres);
- · E s = (˜ { x , y i ˜ ) i , i = 1 2 , , . . . , s } , set of evaluation points.
## OUTPUT:
- · A s = {I (˜ x , y i ˜ ) i , i = 1 2 , , . . . , s } , set of approximated values.
## 3.2. Data partition phase
Stage 1. The set X n of nodes and the set E s of evaluation points are ordered with respect to a common direction (e.g. the y -axis), by applying a quicksort y procedure .
Stage 2. For each subdomain point (¯ x , y i ¯ ), i i = 1 2 , , . . . , d , a local circular subdomain is constructed, whose half-size (the radius) depends on the subdomain number d , that is
$$\delta _ { s u b d o m } = \sqrt { \frac { 2 } { d } }.$$
This value is suitably chosen, supposing to have a nearly uniform node distribution and assuming that the ratio n/d ≈ 4.
Stage 3. A double structure of crossed strips is constructed as follows:
i) a first family of q strips, parallel to the x -axis, is considered taking
$$q = \left \lceil \frac { 1 } { \delta _ { s u b d o m } } \right \rceil,$$
and a quicksort x procedure is applied to order the nodes belonging to each strip;
- ii) a second family of q strips, parallel to the y -axis, is considered.
Note that each of the two strip structures are ordered and numbered from 1 to q ; moreover, the choice in (7) follows directly from the side length of the domain Ω (unit square), that here is 1, and the subdomain radius δ subdom .
Stage 4. The domain (unit square) is partitioned by a cell-based structure consisted of q 2 square cells, whose length of the sides is given by δ cell ≡ δ subdom . Then, the following structure is considered:
- · the sets X n , C d and E s are partitioned by the cell structure into q 2 subsets X n k , C d k and E p k , k = 1 2 , , . . . , q 2 ,
where n k , d k and p k are the number of points in the k -th cell.
## 3.3. Localization phase
Stage 5. In order to identify the cells to be examined in the searching procedure, we consider two steps as follows:
- (A) since δ cell ≡ δ subdom , the ratio between these quantities is denoted by i ∗ = δ subdom /δ cell = 1. So the number j ∗ = (2 i ∗ + 1) 2 of cells to be examined for each node is 9.
- (B) for each cell k = [ v, w ], u, v = 1 2 , , . . . , q , a cell-based searching procedure is considered, examining the points from the cell [ v -i ∗ , w -i ∗ ] to the cell [ v + i ∗ , w + i ∗ ]. Note that if v -i ∗ < 1 and/or w -i ∗ < 1, or v + i ∗ > q and/or w + i ∗ > q , then we set v -i ∗ = 1 and/or w -i ∗ = 1, and v + i ∗ = q and/or w + i ∗ = . q
Then, after defining which and how many cells are to be examined, the cell-based searching procedure is applied:
- · for each subdomain point of C d k , k = 1 2 , , . . . , q 2 , to determine all nodes belonging to a subdomain. The number of nodes of the subdomain centred at (¯ x , y i ¯ ) is counted and stored in i m i , i = 1 2 , , . . . , d ;
- · for each evaluation point of E p k , k = 1 2 , , . . . , q 2 , in order to find all those belonging to a subdomain of centre (¯ x , y i ¯ ) and radius i δ subdom . The number of subdomains containing the i -th evaluation point is counted and stored in r i , i = 1 2 , , . . . , s .
## 3.4. Evaluation phase
Stage 7. A local approximant R j ( x, y ) and a weight function W x,y j ( ), j = 1 2 , , . . . , d , is found for each evaluation point.
Stage 8. Applying the global fit (5), the surface can be approximated at any evaluation point (˜ x, y ˜) ∈ E s .
## 4. Complexity
The partition of unity algorithm involves the use of the standard sorting routine quicksort, which requires on average a time complexity O ( M log M ), where M is the number of nodes to be sorted. Specifically, we have a data partition phase consisting of building the data structure, where the computational cost is:
- · O ( n log n ) for sorting all n nodes;
- · O ( s log s ) for sorting all s evaluation points.
Moreover, in order to compute the local RBF interpolants, we have to solve d linear systems and the cost is:
- · O ( m 3 i ), i = 1 2 , , . . . , d , where m i is the number of nodes in the i -th subdomain.
Then, for the k -th evaluation point of E s the cost is:
$$\bullet \ r _ { k } \cdot \mathcal { O } ( m _ { i } ), \, i = 1, 2, \dots, d, \, k = 1, 2, \dots, s.$$
Finally, the algorithm requires 3 n , 3 d and 3 s storage requirements for the data, and m i , i = 1 2 , , . . . , d , locations for the coefficients of each local RBF interpolant.
## 5. Numerical results
In this section we present some tests to verify performance and effectiveness of the cell-based partition algorithm on scattered data sets. The code is implemented in C/C++ language, while numerical results are carried out on a Intel Core 2 Duo Computer (2.1 GHz). In the experiments we consider a node distribution with n = 4225 16641 66049 uniformly random Halton nodes generated , , by using the program given in [15]. The partition of unity algorithm is run considering d = 1024 4096 16384 subdomain points and , , s = 33 × 33 evaluation (or grid) points, which are contained in the unit square Ω = [0 , 1] 2
The performance of the interpolation algorithm is verified taking the data values by Franke's test function
$$& f ( x, y ) = \frac { 3 } { 4 } \exp \left [ - \frac { ( 9 x - 2 ) ^ { 2 } + ( 9 y - 2 ) ^ { 2 } } { 4 } \right ] + \frac { 3 } { 4 } \exp \left [ - \frac { ( 9 x + 1 ) ^ { 2 } } { 4 9 } - \frac { 9 y + 1 } { 1 0 } \right ] \\ & \quad + \frac { 1 } { 2 } \exp \left [ - \frac { ( 9 x - 7 ) ^ { 2 } + ( 9 y - 3 ) ^ { 2 } } { 4 } \right ] - \frac { 1 } { 5 } \exp \left [ - ( 9 x - 4 ) ^ { 2 } - ( 9 y - 7 ) ^ { 2 } \right ]. \\ & \text{Moreover, since we are concerned to noint, out the effectiveness of the nro-}$$
Moreover, since we are concerned to point out the effectiveness of the proposed algorithm, in Table 1 we compare CPU times (in seconds) obtained by running the cell algorithm described in Section 3, and the strip algorithm proposed in [6]. This comparison highlights the high efficiency of the cell algorithm, which gives us a considerable saving of time.
Table 1: CPU times (in seconds) obtained by running the cell algorithm ( t cell ) and the strip algorithm ( t strip ).
| n | d | t cell | t strip |
|-------|-------|----------|-----------|
| 4225 | 1024 | 0.3 | 0 . 4 |
| 16641 | 4096 | 0.8 | 1 . 3 |
| 66049 | 16384 | 2.6 | 6 . 5 |
Then, in order to test accuracy of the local algorithm, in Table 2 we report the Root Mean Square Errors (RMSEs), i.e.
$$R M S E = \sqrt { \frac { 1 } { s } \sum _ { i = 1 } ^ { s } | f ( { \mathbf x } _ { i } ) - \mathcal { I } ( { \mathbf x } _ { i } ) | ^ { 2 } }. \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
The error computation is achieved by considering both globally and locally supported RBFs for suitable values of the shape parameters, i.e., α 2 = 50 for φ G , and c = 1 for φ W 2 . We observe that the local scheme turns out to be accurate, even if we do not consider the optimal values for the shape parameters, namely those values for which we get the best possible results. However, these choices give a good compromise among accuracy and stability.
Table 2: RMSEs with α 2 = 50 and c = 1 for Franke's function.
| n | 4225 | 16641 | 66049 |
|-------|---------------|---------------|---------------|
| φ G | 3 . 0045E - 4 | 2 . 8214E - 5 | 1 . 5200E - 6 |
| φ W 2 | 2 . 2145E - 4 | 5 . 3127E - 5 | 9 . 3027E - 6 |
Then, in Figure 1 we plot the behavior of the RMSEs by varying values of the shape parameters for Franke's function. These graphs (and other ones obtained considering different test functions we omit for brievity) point out that, if an optimal search of the shape parameters was performed, in some cases the results of accuracy reported in this section could be improved of one or even two orders of magnitude. Note that each evaluation is carried out by choosing equispaced values of the shape parameter with α 2 ∈ [1 , 100], and c ∈ [0 1 . , 2].
By analyzing numerical tests and the related pictures, we observe that Wendland's function φ W 2 has greater stability than Gaussian φ G and good accuracy. However, these graphs give an idea on stability and enable us to choose 'sure' values for the shape parameters. These tests confirm theoretical results and suggest to use basis functions with a moderate order of smoothness, thus avoiding the well-known ill-conditioning problems of infinitely smooth RBFs, in particular if we are dealing with a very large number of nodes.
Figure 1: RMSEs obtained by varying α 2 and c for Franke's function.
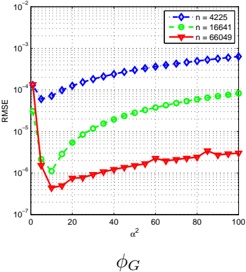
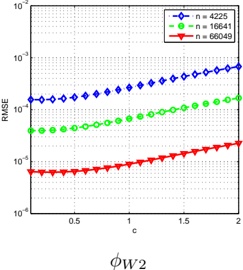
## References
- [1] G. Allasia, R. Besenghi, R. Cavoretto & A. De Rossi, Scattered and track data interpolation using an efficient strip searching procedure, Appl. Math. Comput. 217 (2011), 5949-5966.
- [2] I. Babuˇ ska & J. M. Melenk, The partition of unity method, Internat. J. Numer. Methods. Engrg. 40 (1997), 727-758.
- [3] R. Cavoretto & A. De Rossi, Fast and accurate interpolation of large scattered data sets on the sphere, J. Comput. Appl. Math. 234 (2010), 15051521.
- [4] R. Cavoretto & A. De Rossi, Spherical interpolation using the partition of unity method: an efficient and flexible algorithm, Appl. Math. Lett. 25 (2012), 1251-1256.
- [5] R. Cavoretto, A unified version of efficient partition of unity algorithms for meshless interpolation, in: T. E. Simos et al. (Eds.), Proceedings of the ICNAAM 2012 , AIP Conf. Proc., vol. 1479, Amer. Inst. Phys., Melville, New York, 2012, pp. 1054-1057.
- [6] R. Cavoretto, Partition of unity algorithm for two-dimensional interpolation using compactly supported radial basis functions, 2012, submitted for publication.
- [7] G. E. Fasshauer, Meshfree Approximation Methods with MATLAB , World Scientific Publishers, Singapore, 2007.
- [8] D. Lazzaro, L. B. Montefusco, Radial basis functions for the multivariate interpolation of large scattered data sets, J. Comput. Appl. Math. 140 (2002), 521-536.
- [9] J. M. Melenk & I. Babuˇ ska, The partition of unity finite element method: basic theory and applications, Comput. Methods. Appl. Mech. Engrg. 139 (1996) 289-314.
- [10] R. J. Renka, Multivariate interpolation of large sets of scattered data, ACM Trans. Math. Software 14 (1988), 139-148.
- [11] R. J. Renka, Algorithm 660: QSHEP2D: Quadratic Shepard method for bivariate interpolation of scattered data, ACM Trans. Math. Software 14 (1988), 149-150.
- [12] W. I. Thacker, J. Zhang, L. T. Watson, J. B. Birch, M. A. Iyer & M. W. Berry, Algorithm 905: SHEPPACK: Modified Shepard algorithm for interpolation of scattered multivariate data, ACM Trans. Math. Software 37 (2010), Art. 34, 1-20.
- [13] H. Wendland, Fast evaluation of radial basis functions: Methods based on partition of unity, in: C. K. Chui et al. (Eds.), Approximation Theory X: Wavelets, Splines, and Applications , Vanderbilt Univ. Press, Nashville, TN, 2002, pp. 473-483.
- [14] H. Wendland, Scattered Data Approximation , Cambridge Monogr. Appl. Comput. Math., vol. 17, Cambridge Univ. Press, Cambridge, 2005.
- [15] T.-T. Wong, W.-S. Luk & P.-A. Heng, Sampling with Hammersley and Halton points, J. Graphics Tools 2 (1997), 9-24. | null | [
"Roberto Cavoretto"
] | 2014-08-01T14:05:41+00:00 | 2014-08-01T14:05:41+00:00 | [
"math.NA"
] | Two-dimensional interpolation using a cell-based searching procedure | In this paper we present an efficient algorithm for bivariate interpolation,
which is based on the use of the partition of unity method for constructing a
global interpolant. It is obtained by combining local radial basis function
interpolants with locally supported weight functions. In particular, this
interpolation scheme is characterized by the construction of a suitable
partition of the domain in cells so that the cell structure strictly depends on
the dimension of its subdomains. This fact allows us to construct an efficient
cell-based searching procedure, which provides a significant reduction of CPU
times. Complexity analysis and numerical results show such improvements on the
algorithm performances. |
1408.0184v2 | ## Double Higgs production at LHC, see-saw type II and Georgi-Machacek model
S.I. Godunov, 1, 2, ∗ M.I. Vysotsky, 1, 3, 4, † and E.V. Zhemchugov 1, ‡
1 Institute for Theoretical and Experimental Physics, Moscow, 117218, Russia
2 Novosibirsk State University, Novosibirsk, 630090, Russia
3 Moscow Institute of Physics and Technology,
141700, Dolgoprudny, Moscow Region, Russia
4 Moscow Engineering Physics Institute, 115409, Moscow, Russia
## Abstract
The double Higgs production in the models with isospin-triplet scalars is studied. It is shown that in the see-saw type II model the mode with an intermediate heavy scalar, pp → H + X → 2 h + X , may have the cross section which is compatible with that in the Standard Model. In the GeorgiMachacek model this cross section could be much larger than in SM since the vacuum expectation value of the triplet can be large.
∗ [email protected]
† [email protected]
‡ [email protected]
This paper is our present to Valery Anatolievich Rubakov on his anniversary. Many students (and not only students) in the world are studying Physics reading his excellent books, papers and listening his brilliant lectures.
## I. INTRODUCTION
After the discovery of the Higgs-BE boson at LHC [1] the next steps to check the Standard Model (SM) are: the measurement of the coupling constants of the Higgs boson with other SM particles ( ¯ tt, WW, ZZ, bb, ττ, . . . ¯ ¯ ) with better accuracy and the measurement of the Higgs self-coupling which determines the shape of the Higgs potential. In the SM the triple and quartic Higgs couplings are predicted in terms of the known Higgs mass and vacuum expectation value. Deviations from these predictions would mean the existence of New Physics in the Higgs potential. The triple Higgs coupling can be measured at LHC in double Higgs production, in which the gluon fusion dominates: gg → hh . However, the 2 h production cross section is very small. According to [2] at √ s = 14 TeV the cross section σ NNLO ( gg → hh ) = 40 2 fb with (10 . -15) % accuracy. For the final states with the reasonable signal/background ratios (such as hh → bbγγ ¯ ) only at HL-LHC with integrated luminosity ∫ L dt = 3000 fb -1 double Higgs production will be found and triple Higgs coupling will be measured [3] . 1 We are looking for the extensions of the SM Higgs sector in which the double Higgs production is enhanced.
One of the well-motivated examples of non-minimal Higgs sector is provided by the seesaw type II mechanism of the neutrino mass generation [6]. In this mechanism a scalar isotriplet with hypercharge Y ∆ = 2 (∆ ++ , ∆ + , ∆ ) is added to the SM. The vacuum expec0 tation value (vev) of the neutral component v ∆ generates Majorana masses of the left-handed neutrinos. There are two neutral scalar bosons in the model: the light one in which the doublet Higgs component dominates and which should be identified with the particle discovered at LHC ( h M ; h = 125 GeV), and the heavy one in which the triplet Higgs component dominates ( H ). The neutrino masses equal f v i ∆ , where f i ( i = 1 2 3) originates from Yukawa , , couplings of Higgs triplet with the lepton doublets. If neutrinos are light due to a small value of v ∆ while f i are of the order of one, then H decays into the neutrino pairs. Three
1 The decays into bbττ ¯ ¯ and bbW ¯ + W -Higgs coupling [4, 5].
final states can be even more promising for the measurement of triple
states H ±± (or ∆ ±± ), H ± , and H are almost degenerate in the model considered in Sect. II and the absence of the same-sign dileptons at LHC from H ±± → l ± ± l decays provides the lower bound m H > 400 GeV [7]. We are interested in the opposite case: v ∆ reaches the maximum allowed value while neutrinos are light because of small values of f i . In this case H → hh can be the dominant decay mode of a heavy neutral Higgs. In this way we get an additional mechanism of the double h production at LHC.
The bound m H ++ > 400 GeV [7] cannot be applied now since H ±± mainly decays into the same-sign diboson [8]. We only need H to be heavy enough for H → hh decay to occur. This case is analyzed in Sect. II. The invariant mass of additionally produced hh state peak at ( p 1 + p 2 ) 2 = m 2 H which is a distinctive feature of the proposed mechanism, see also [9, 10].
H contains a small admixture of the isodoublet state which makes gluon fusion a dominant mechanism of H production at LHC. The admixture of the isodoublet component in H equals approximately 2 v ∆ /v , where v ≈ 250 GeV is the vacuum expectation value of the neutral component of isodoublet, and in Sect. II for √ s = 14 TeV and M H = 300 GeV we will get σ ( gg → H ) ≈ 25 fb. Taking into account that Br ( H → hh ) is about 80%, we obtain 50% enhancement of double Higgs production in comparison with SM.
Since the nonzero value of v ∆ violates the well checked equality of the strength of charged and neutral currents at tree level,
$$\frac { g ^ { 2 } / M _ { W } ^ { 2 } } { \bar { g } ^ { 2 } / M _ { Z } ^ { 2 } } = 1 + 2 \frac { v _ { \Delta } ^ { 2 } } { v ^ { 2 } },$$
v ∆ should be less than 5 GeV (see Sect. II). The numerical estimate of gg → H cross section was made for maximum allowed value v ∆ = 5 GeV when the isodoublet admixture is about 5%.
The bound v ∆ < 5 GeV is removed in the Georgi-Machacek model [11], in which in addition to ∆ a scalar isotriplet with glyph[vector] Y = 0 is introduced. If the vev of the neutral component of this additional field equals v ∆ then we get just one in the r.h.s. of (1): correction proportional to v 2 ∆ is cancelled. Thus v ∆ can be much larger than 5 GeV. The bounds on v ∆ come from the measurement of the 125 GeV Higgs boson couplings to vector bosons and fermions, which would deviate from their SM values: c i → c i [ 1 + a i ( v ∆ /v ) 2 ] .
The consideration of an enhancement of 2 h production in GM variant of see-saw type II model is presented in Sect. III. Since at the moment the accuracy of the measurement of c i values in h production and decay is poor, v ∆ as large as 50 GeV is allowed and
σ ( gg → H ) can reach 2 pb value which makes it accessible with the integrated luminosity ∫ L dt = 300 fb -1 prior to HL-LHC run. We summarize our results in Conclusions.
## II. DOUBLE h PRODUCTION IN H DECAYS AT LHC
## A. Scalar sector of the see-saw type II model
In this subsection we will present the necessary formulas; for a detailed description see [12]. In addition to the SM isodoublet field Φ,
$$\Phi \equiv \begin{bmatrix} \Phi ^ { + } \\ \Phi ^ { 0 } \end{bmatrix} \equiv \begin{bmatrix} \Phi ^ { + } \\ \frac { 1 } { \sqrt { 2 } } \left ( v + \varphi + i \chi \right ) \end{bmatrix},$$
in see-saw type II an isotriplet is introduced:
$$\begin{array} { l l } \text{in see-saw type 11 an isotriplet is introduce} \colon \\ \Delta \equiv \frac { \vec { \Delta } \vec { \sigma } } { \sqrt { 2 } } = \begin{bmatrix} \Delta ^ { 3 } / \sqrt { 2 } & ( \Delta ^ { 1 } - i \Delta ^ { 2 } ) / \sqrt { 2 } \\ ( \Delta ^ { 1 } + i \Delta ^ { 2 } ) / \sqrt { 2 } & - \Delta ^ { 3 } / \sqrt { 2 } \end{bmatrix} \equiv \begin{bmatrix} \delta ^ { + } / \sqrt { 2 } & \delta ^ { + + } \\ \delta ^ { 0 } & - \delta ^ { + } / \sqrt { 2 } \end{bmatrix}, \\ \delta ^ { 0 } = \frac { 1 } { \sqrt { 2 } } \left ( v _ { \Delta } + \delta + i \eta \right ). \end{bmatrix}$$
Here glyph[vector] σ are the Pauli matrices.
The scalar sector kinetic terms are
$$\mathcal { L } _ { \text{kinetic} } = \left | D _ { \mu } \Phi \right | ^ { 2 } + \text{Tr} \left [ \left ( D _ { \mu } \Delta \right ) ^ { \dagger } \left ( D _ { \mu } \Delta \right ) \right ],$$
where
$$D _ { \mu } \Phi = \partial _ { \mu } \Phi - i \frac { g } { 2 } A _ { \mu } ^ { a } \sigma ^ { a } \Phi - i \frac { g ^ { \prime } } { 2 } B _ { \mu } \Phi, \quad \quad \quad _ { - a }$$
a
D
σ
µ
∆ =
∂
µ
∆ +
gε
A
[
a
abc
b
c
′
a
]
µ
∆
-
ig B
µ
∆
√
2
=
$$= \partial _ { \mu } \Delta - i \frac { g } { 2 } \left [ A _ { \mu } ^ { a } \sigma ^ { a }, \Delta \right ] - i g ^ { \prime } B _ { \mu } \Delta.$$
Hypercharge Y Φ = 1 was substituted for isodoublet and Y ∆ = 2 for isotriplet. The terms quadratic in vector boson fields are the following:
$$\mathcal { L } _ { V ^ { 2 } } = g ^ { 2 } \left | \delta ^ { 0 } \right | ^ { 2 } W ^ { + } W ^ { - } + \frac { 1 } { 2 } g ^ { 2 } \left | \Phi ^ { 0 } \right | ^ { 2 } W ^ { + } W ^ { - } + \bar { g } ^ { 2 } \left | \delta ^ { 0 } \right | ^ { 2 } Z ^ { 2 } + \frac { 1 } { 4 } \bar { g } ^ { 2 } \left | \Phi ^ { 0 } \right | ^ { 2 } Z ^ { 2 }.$$
Vector boson masses are
$$\text{s are} \\ \begin{cases} \, M _ { W } ^ { 2 } & = & \frac { g ^ { 2 } } { 4 } \left ( v ^ { 2 } + 2 v _ { \Delta } ^ { 2 } \right ), \\ \, M _ { Z } ^ { 2 } & = & \frac { \bar { g } ^ { 2 } } { 4 } \left ( v ^ { 2 } + 4 v _ { \Delta } ^ { 2 } \right ). \end{cases}$$
For the ratio of vector boson masses neglecting the radiative corrections from isotriplet (not a bad approximation as far as the heavy triplet decouples) we get:
$$\frac { M _ { W } } { M _ { Z } } \approx \left ( \frac { M _ { W } } { M _ { Z } } \right ) _ { \text{SM} } \left ( 1 - \frac { v _ { \Delta } ^ { 2 } } { v ^ { 2 } } \right ).$$
Comparing the result of SM fit [14, p.145], M SM W = 80 381 GeV, with the experimental . value, M exp W = 80 385(15) GeV, at 3 . σ level we get the following upper bound:
$$v _ { \Delta } < 5 \text{ GeV},$$
and since the cross sections we are interested in are proportional to ( v ∆ ) 2 we will use an upper bound v ∆ = 5 GeV for numerical estimates in this section.
From the numerical value of Fermi coupling constant in muon decay we obtain:
$$v ^ { 2 } + 2 v _ { \Delta } ^ { 2 } = \left ( 2 4 6 \text{ GeV} \right ) ^ { 2 },$$
so for v ∆ glyph[lessorsimilar] 5 GeV the value v = 246 GeV can be safely used in deriving (10).
The scalar potential looks like:
$$V ( \Phi, \Delta ) & = - \frac { 1 } { 2 } m _ { \Phi } ^ { 2 } \left ( \Phi ^ { \dagger } \Phi \right ) + \frac { \lambda } { 2 } \left$$
which is a truncated version of the most general renormalizable potential (see for example [13], eq. (2.6)). We may simply suppose that the coupling constants which multiply the omitted terms in the potential ( λ , λ 1 2 , λ 4 , and λ 5 ) are small. In the case of SM only the first line in (12) remains; mass of the Higgs boson equals m Φ = 125 GeV while its expectation value v 2 ≈ m /λ 2 Φ ≈ (246 GeV) , 2 λ ≈ 0 25. .
Since at the minimum of (12) the following equations are valid:
$$\begin{cases} \begin{array} { c c } \frac { 1 } { 2 } m _ { \Phi } ^ { 2 } & = & \frac { 1 } { 2 } \lambda v ^ { 2 } - \mu v _ { \Delta },$$
for vev's of isodoublet and isotriplet we obtain:
$$v ^ { 2 } = \frac { m _ { \Phi } ^ { 2 } M _ { \Delta } ^ { 2 } } { \lambda M _ { \Delta } ^ { 2 } - \mu ^ { 2 } }, \quad \quad \quad$$
$$v _ { \Delta } = \frac { \stackrel { \mapsto } { \mu } m _ { \Phi } ^ { 2 } } { 2 \lambda M _ { \Delta } ^ { 2 } - 2 \mu ^ { 2 } } = \frac$$
Quadratic in ϕ, δ terms according to (12) are
$$V ( \varphi, \delta ) = \frac { 1 } { 2 } m _ { \Phi } ^ { 2 } \varphi ^ { 2 } + \frac { 1 } { 2 } M _ { \Delta } ^ { 2 } \delta ^ { 2 } - \mu v \varphi \delta.$$
Here and below the terms suppressed as ( v ∆ /v ) 2 are omitted.
Denoting the states with the definite masses as h and H we obtain:
$$\begin{bmatrix} \varphi \\ \delta \end{bmatrix} = \begin{bmatrix} \cos \alpha & - \sin \alpha \\ \sin \alpha & \cos \alpha \end{bmatrix} \begin{bmatrix} h \\ H \end{bmatrix}, \text{ } \tan 2 \alpha = \frac { 2 \mu v } { M _ { \Delta } ^ { 2 } - m _ { \Phi } ^ { 2 } },$$
$$M _ { h } ^ { 2 } = \frac { 1 } { 2 } \left ( m _ { \Phi } ^ { 2 } + M _ { \Delta } ^ { 2 } - \sqrt { \left ( M _ { \Delta } ^ { 2 } - m _ { \Phi } ^ { 2 } \right ) ^ { 2 } + 4 \mu ^ { 2 } v ^ { 2 } } \right ) \approx m _ { \Phi } ^ { 2 },$$
$$M _ { H } ^ { 2 } = \frac { 1 } { 2 } \, \dot { \left ( m _ { \Phi } ^ { 2 } + M _ { \Delta } ^ { 2 } + \sqrt { \left ( M _ { \Delta } ^ { 2 } - m _ { \Phi } ^ { 2 } \right ) ^ { 2 } + 4 \mu ^ { 2 } v ^ { 2 } } \right ) } \approx M _ { \Delta } ^ { 2 }.$$
Since tan 2 α ≈ 4 v ∆ /v glyph[lessmuch] 1, mass eigenstate h consists mostly of ϕ and H consists mostly of δ . We suppose that the particle observed by ATLAS and CMS is h , so M h is about 125 GeV.
The scalar sector of the model in addition to the massless goldstone bosons, which are eaten up by the vector gauge bosons, contains one double charged field H ++ , one single charged field H + , and three real neutral fields A, H , and h . H + is mostly δ + with small Φ + admixture, A is mostly η with small χ admixture. All these particles except h are heavy; their masses equal M ∆ with small corrections proportional to v 2 ∆ /M ∆ .
## B. H decays
The second and fourth terms in potential (12) contribute to H → 2 h decays:
$$\frac { \lambda } { 2 } \left ( \Phi ^ { \dagger } \Phi \right ) ^ { 2 } \rightarrow \frac { \lambda v } { 2 } \varphi ^ { 3 },$$
$$\frac { \mu } { \sqrt { 2 } } \left ( \Phi ^ { T } i \sigma ^ { 2 } \Delta ^ { \dagger } \Phi + h. c. \right ) \rightarrow - \frac { \mu } { 2 } \delta \left ( \varphi ^ { 2 } - \chi ^ { 2 } \right ),$$
where in the second line χ is dominantly a goldstone state which forms the longitudinal Z polarization.
With the help of (17) we obtain the expression for the effective lagrangian which describes H → 2 h decay:
$$\mathcal { L } _ { H h h } = \frac { \mu } { 2 } \left [ 1 + \frac { 3 } { \left ( \frac { M _ { H } } { M _ { h } } \right ) ^ { 2 } - 1 } \right ] H h ^ { 2 } = v _ { \Delta } \frac { M _ { H } ^ { 2 } } { v ^ { 2 } } \left [ 1 + \frac { 3 } { \left ( \frac { M _ { H } } { M _ { h } } \right ) ^ { 2 } - 1 } \right ] H h ^ { 2 }.$$
In the see-saw type II model neutrino masses are generated by the Yukawa couplings of isotriplet ∆ with lepton doublets. These couplings generate H → νν decays as well. As it was noted in [8] for v ∆ > 10 -3 GeV diboson decays dominate. It happens because the amplitude of diboson decay is proportional to v ∆ , while Yukawa couplings f i are inversely proportional to it, f ∼ m /v ν ∆ . That is why for v ∆ glyph[greaterorsimilar] 1 GeV leptonic decays are completely negligible.
The amplitudes of H → ZZ and H → W W + -decays are contained in (7):
$$\mathcal { L } _ { H V V } & = g ^ { 2 } \left ( v _ { \Delta } \cos \alpha - \frac { 1 } { 2 } v \sin \alpha \right ) W ^ { + } W ^ { - } H + \bar { g } ^ { 2 } \left ( v _ { \Delta } \cos \alpha - \frac { 1 } { 4 } v \sin \alpha \right ) Z ^ { 2 } H \\ & \approx - g ^ { 2 } \frac { M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } { 1 - M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } v _ { \Delta } W ^ { + } W ^ { - } H + \frac { \bar { g } ^ { 2 } } { 2 } \frac { 1 - 2 M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } { 1 - M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } v _ { \Delta } Z ^ { 2 } H, \\ \text{and use too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too too good \, \colon$$
and we see that H → W W + -decay is suppressed (see, for example, [15]).
H → tt ¯ decay occur through ϕ admixture:
$$\mathcal { L } _ { H t \bar { t } } = \sin \alpha \frac { m _ { t } } { v } t \bar { t } H = \frac { 2 v _ { \Delta } / v } { 1 - M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } \frac { m _ { t } } { v } t \bar { t } H,$$
as well as H decay into two gluons:
$$\mathcal { L } _ { H g g } = \frac { \alpha _ { s } } { 1 2 \pi } \sin \alpha G _ { \mu \nu } ^ { 2 }.$$
Let us note that all the amplitudes of H decays are proportional to triplet vev v ∆ .
For the decay probabilities we obtain:
$$\mathcal { \lambda } _ { H \to h h } = \frac { v _ { \Delta } ^ { 2 } } { v ^ { 4 } } \frac { M _ { H } ^ { 3 } } { 8 \pi } \left [ \frac { 1 + 2 \left ( \frac { M _ { h } } { M _ { H } } \right ) ^ { 2 } } { 1 - \left ( \frac { M _ { h } } { M _ { H } } \right ) ^ { 2 } } \right ] ^ { 2 } \sqrt { 1 - 4 \frac { M _ { h } ^ { 2 } } { M _ { H } ^ { 2 } } },$$
$$\Gamma _ { H \rightarrow Z Z } = \frac { v _ { \Delta } ^ { 2 } } { v ^ { 4 } } \frac { M _ { H } ^ { 3 } } { 8 \pi } \left [ \frac { 1 - 2 \left ( \frac { M _ { h } } { M _ { H } } \right ) ^ { 2 } } { 1 - \left ( \frac { M _ { h } } { M _ { H } } \right ) ^ { 2 } } \right ] ^ { 2 } \left ( 1 - 4 \frac { M _ { Z } ^ { 2 } } { M _ { H } ^ { 2 } } + 1 2 \frac { M _ { Z } ^ { 4 } } { M _ { H } ^ { 4 } } \right ) \sqrt { 1 - 4 \frac { M _ { Z } ^ { 2 } } { M _ { H } ^ { 2 } } }, \quad \ ( 2 7 )$$
$$\Gamma _ { H \rightarrow W W } = \frac { v _ { \Delta } ^ { 2 } } { v ^ { 4 } } \frac { M _ { H } ^ { 3 } } { 4 \pi } \left [ \frac { M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } { 1 - \left ( \frac { M _ { h } } { M _ { H } } \right ) ^ { 2 } } \right ] ^ { 2 } \left ( 1 - 4 \frac { M _ { W } ^ { 2 } } { M _ { H } ^ { 2 } } + 1 2 \frac { M _ { W } ^ { 4 } } { M _ { H } ^ { 4 } } \right ) \sqrt { 1 - 4 \frac { M _ { W } ^ { 2 } } { M _ { H } ^ { 2 } } }, \quad ( 2 8 )$$
$$\Gamma _ { H \to t \bar { t } } = \frac { v _ { \Delta } ^ { 2 } } { v ^ { 4 } } \frac { N _ { c } m _ { t } ^ { 2 } M _ { H } } { 2 \pi } \frac { \lambda ^ { 2 } _ { 1 } M _ { H } } { ( 1 - M _ { h } ^ { 2 } / M _ { H } ^ { 2 } ) ^ { 2 } } \left ( 1 - 4 \frac { m _ { t } ^ { 2 } } { M _ { H } ^ { 2 } } \right ) ^ { 3 / 2 },$$
where N c = 3 is the number of colors. Finally for the width of decay into two gluon jets we obtain:
$$\Gamma _ { H \rightarrow g g } = \frac { v _ { \Delta } ^ { 2 } } { v ^ { 4 } } \frac { M _ { H } ^ { 3 } } { 2 \pi } \left ( \frac { \alpha _ { s } } { 3 \pi } \right ) ^ { 2 } \left ( 1 - \frac { M _ { h } ^ { 2 } } { M _ { H } ^ { 2 } } \right ) ^ { - 2 },$$
TABLE I. The cross sections of Higgs production via gg fusion. Values for the SM Higgs are taken from Table 4 in [16]. All numbers in this and following tables correspond to 14 TeV LHC energy.
| M h (GeV) | 125 | 300 |
|---------------|---------------|---------------|
| σ gg → h (pb) | 49 . 97 ± 10% | 11 . 07 ± 10% |
| M H (GeV) | X | 300 |
| σ gg → H (fb) | X | 25 ± 10% |
and it is always negligible.
In what follows we suppose that M H < 350 GeV and the decay H → tt ¯ is forbidden kinematically. Let us note that even for M H > 350 GeV the branching ratio of H → 2 h decay is large, however H production cross section becomes small due to the large H mass.
The lighter H the larger its production cross section, however, for M H < 250 GeV the decay H → 2 h is kinematically forbidden. That is why for numerical estimates we took the value M H = 300 GeV for which H → 2 h and H → ZZ decays dominate 2 and Γ H → 2 h / Γ H → ZZ ≈ 4. Thus 300 GeV (or a little bit lighter) H mostly decays to two 125 GeV Higgs bosons.
A technical remark: the equality Γ H → hh = Γ H → ZZ in the limit M H glyph[greatermuch] M ,M h H glyph[greatermuch] M Z follows from the equality (up to the sign) of H → 2 h and H → 2 χ decay amplitudes, see (21).
## C. H production at LHC
The dominant mechanism of H production is the gluon fusion, cross section of which equals that of SM Higgs production multiplied by sin 2 α ≈ [(2 v ∆ /v ) / (1 -M /M 2 h 2 H )] 2 ≈ 2 4 . · 10 -3 . In Table I the relevant numbers are presented. All the numbers correspond to 14 TeV LHC energy.
The subdominant mechanisms of H production are ZZ fusion and associative ZH production. Comparing ZZh and ZZH vertices we will recalculate the cross sections of SM
2 The decay H → ZZ → ( l + l -) ( l + l -) provides great opportunity for the discovery of heavy Higgs H .
TABLE II. The cross sections (QCD NLO) of scalar bosons production in VBF calculated with the help of HAWK (see also Table 10 in [16]).
| M h (GeV) | 125 | 300 |
|--------------------|---------|----------|
| σ V V → h (fb) | 4342(5) | 1418(1) |
| σ W + W - → h (fb) | 3272(4) | 1053(1) |
| σ ZZ → h (fb) | 1087(1) | 365(1) |
| M H (GeV) | X | 300 |
| σ ZZ → H (fb) | X | 0.365(1) |
TABLE III. The cross sections of the associative SM Higgs production from Table 14 in [16] and of associative H production recalculated with the help of (32).
| M h (GeV) | 125 | 300 |
|-----------------|-----------|---------------|
| σ W ∗ → Wh (fb) | 1504 ± 4% | 67 . 6 ± 4% |
| σ Z ∗ → Zh (fb) | 883 ± 5% | 41 . 6 ± 5% |
| M H (GeV) | X | 300 |
| σ Z ∗ → ZH (fb) | X | 0 . 0416 ± 5% |
processes of h production into that of H production. In SM we have
$$\mathcal { L } _ { h Z Z } = \frac { 1 } { 4 } \bar { g } ^ { 2 } v Z ^ { 2 } h.$$
From (23) we get:
$$\sigma _ { Z Z \to H } = \left ( \frac { 2 v _ { \Delta } } { v } \frac { 1 - 2 M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } { 1 - M _ { h } ^ { 2 } / M _ { H } ^ { 2 } } \right ) ^ { 2 } \times \left ( \sigma _ { Z Z \to h } \right ) ^ { \text{SM} } \approx 1 0 ^ { - 3 } \times \left ( \sigma _ { Z Z \to h } \right ) ^ { \text{SM} },$$
the same relation holds for Z ∗ → ZH associative production cross section.
We separate VBF cross section of SM Higgs production into that in W W + -fusion (which dominates) and in ZZ fusion (which is the one that matters for H production) with the help of the computer code HAWK [17]. The obtained results are presented in Table II.
In Table III the results for the associative ZH production cross sections are presented.
We see that gluon fusion dominates H production at LHC. Using model parameters v ∆ = 5 GeV and M H = 300 GeV, we obtain that the branching ratio of H → 2 h decay
equals ≈ 80%. Thus, decays of H provide ≈ 20 fb of double h production cross section in addition to 40 fb coming from SM. However, unlike SM in which 2 h invariant mass is spread along rather large interval, in the case of H decays 2 h invariant mass equals M H .
## III. H PRODUCTION ENHANCEMENT IN GEORGI-MACHACEK VARIANT OF SEE-SAW TYPE II MODEL
The amplitudes of H production both via gg fusion and VBF are proportional to the triplet vev v ∆ and due to the upper bound v ∆ < 5 GeV these amplitudes and the corresponding cross sections are severely suppressed.
The triplet vev v ∆ should be small in order to avoid the noticeable violation of custodial symmetry which guarantees the degeneracy of W and Z bosons in the SM at tree level in the limit g ′ = 0 , cos θ W = 1. The vacuum expectation value of the complex isotriplet ∆ glyph[vector] with hypercharge Y ∆ = 2 violates the custodial symmetry, see (8). The custodial symmetry is preserved when two isotriplets (complex ∆ and real glyph[vector] glyph[vector] ξ with Y ξ = 0) are added to SM and when vev's of their neutral components are equal [11]. Thus in GM variant of see-saw type II model v ∆ is not bounded by (10) and can be considerably larger. Instead of (8) in GM model we have:
$$\begin{cases} \ M _ { W } ^ { 2 } \, = \, \frac { g ^ { 2 } } { 4 } \left ( v ^ { 2 } + 4 v _ { \Delta } ^ { 2 } \right ), \\ \ M _ { Z } ^ { 2 } \, = \, \frac { \bar { g } ^ { 2 } } { 4 } \left ( v ^ { 2 } + 4 v _ { \Delta } ^ { 2 } \right ), \end{cases}$$
and instead of (11):
$$v ^ { 2 } + 4 v _ { \Delta } ^ { 2 } = \left ( 2 4 6 \text{ GeV} \right ) ^ { 2 }.$$
Note that our v ∆ is by √ 2 bigger than what is usually used in the papers devoted to GM model; our v is also usually denoted by v Φ , while the value 246 GeV is denoted by v .
The scalar particles are conveniently classified in GM model by their transformation properties under the custodial SU (2). Two singlets which mix to form mass eigenstates h and H are:
$$\begin{cases} \, H _ { 1 } ^ { 0 } \, = \, \varphi, \\ \, H _ { 2 } ^ { 0 } \, = \, \sqrt { \frac { 2 } { 3 } } \delta + \sqrt { \frac { 1 } { 3 } } \xi ^ { 0 }, \end{cases}$$
see, for example, [18]. Due to considerable admixture of ξ 0 in H 0 2 the HW W + -coupling constant is not suppressed and three modes of H decays are essential: H → hh, H → W W , H + -→ ZZ .
The recently discovered Higgs boson should be identified with h . The deviations of h couplings to vector bosons and fermions from their values in SM lead to the upper bound on v ∆ . These deviations in the limit of heavy scalar triplets were studied in a recent paper [18] (see also [19]). From equations (59) and (61) of [18] we get the following estimates for the ratios of the hV V (here V = W, Z ) and hff ¯ coupling constants to that in SM:
$$\begin{cases} \ k _ { V } \, \approx \, 1 + 3 \, \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 }, \\ \ k _ { f } \, \approx \, 1 - \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 }. \end{cases}$$
Since at LHC the Higgs boson h is produced mainly in gluon fusion through t -quark triangle, for the ratio of the cross sections to that in SM we get:
$$\begin{cases} \quad \mu _ { \tau \bar { \tau } } \, \approx \, 1 - \left ( 2 \frac { v _ { \Delta } } { v } \right ) ^ { 2 }, \\ \quad \mu _ { V V } \, \approx \, 1 + \left ( 2 \frac { v _ { \Delta } } { v } \right ) ^ { 2 }. \end{cases}$$
Since h → bb ¯ decay is studied in associative production, V ∗ → V h → V bb ¯ , we get
$$\mu _ { b \bar { b } } \approx 1 + \left ( \frac { 2 v _ { \Delta } } { v } \right ) ^ { 2 }.$$
Finally in case of h → γγ decay SM factor 16 / 9 -7 in the amplitude is modified in the following way:
$$\frac { 1 6 } { 9 } - 7 & \rightarrow \left [ 1 - \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 } \right ] \left [ \frac { 1 6 } { 9 } \left ( 1 - \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 } \right ) - 7 \left ( 1 + 3 \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 } \right ) \right ] = \\ & = \frac { 1 6 } { 9 } \left ( 1 - 2 \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 } \right ) - 7 \left ( 1 + 2 \left ( \frac { v _ { \Delta } } { v } \right ) ^ { 2 } \right ),$$
where the first factor in the first line takes into account damping of h production in gluon fusion. 3
Let us suppose that v ∆ is ten times larger than the number used in Section II, v GM ∆ = 50 GeV. Then from (34) we get v GM ≈ 225 GeV, and µ ττ ¯ ≈ 0 8, while . µ WW = µ ZZ = µ bb ≈ 1 2. . From (39) we get: µ γγ ≈ 1 4. . With the up-to-date level of the experimental accuracy one can not exclude these deviations of the quantities µ i from their SM values ( µ i ) SM ≡ 1.
One order of magnitude growth of v ∆ leads to two orders of magnitude growth of H production cross section. Hence 300 GeV heavy Higgs boson H can be produced at 14 TeV LHC with 2 pb cross section which should be large enough for it to be discovered prior
3 We take into account only t -quark and W -boson loops omitting the loops with charged Higgses.
to HL-LHC. The search strategy should be the same as for the SM Higgs boson: gg → H → ZZ decay is a golden discovery mode, the cross section of which can be as large as (2 pb) × Br( H → ZZ ) GM , where Br ( H → ZZ ) GM depends on the model parameters, see [18].
## IV. CONCLUSIONS
The case of extra isotriplet(s) provides rich Higgs sector phenomenology with additional to SM Higgs boson charged and neutral scalar particles. With the growth of triplet vev, production cross section of new scalar grows and the dominant decays of new particles become decays to gauge and lighter scalar bosons. The charged scalars (Φ ++ , Φ ) are + produced through electroweak interactions. The bounds on the model parameters from nondiscovery of Φ ++ and Φ + with the 8 TeV LHC data and the prospects of their discovery at 14 TeV LHC are discussed in particular in [20]. In the present paper we have discussed the neutral heavy Higgs production at LHC in which the gluon fusion dominates. H → 2 h decay contributes significantly to the double Higgs production and even may dominate in the GM variant of the see-saw type II model. The best discovery mode for H is the 'golden mode' pp → HX → ZZX , and its cross section can be only few times smaller than for the heavy SM Higgs.
After this paper had been written, paper [21] appeared in arXiv in which the enhancement of double Higgs production due to heavy Higgs decay is considered in the framework of MSSM model with two isodoublets. H → 2 h resonant decay in MSSM at small tan β was previously analyzed in [9].
We are grateful to A. Denner for the clarifications concerning HAWK code and to C. Englert and J. Zurita for providing us with relevant references. The authors are partially supported under the grants No. 12-02-00193, 14-02-00995, and NSh-3830.2014.2. SG was also supported by Dynasty Foundation and by the Russian Federation Government under grant No. 11.G34.31.0047.
[1] G. Aad et al [ATLAS Collaboration], Phys.Lett. B716 , 1 (2012); S.Chatrchyan et al [CMS Collaboration], Phys.Lett. B716 ,30 (2012).
- [2] D. de Florian, J. Mazzitelli, DESY-14-080, LPN-14-073, arXiv:1405.4704.
- [3] J. Baglio, PoS DIS2014 120 (2014), arXiv:1407.1045.
- [4] M.J. Dolan, C. Englert, and M. Spannowsky, JHEP 1210 , 112 (2012).
- [5] A. Papaefstathiou, Li Lin Yang, and J. Zurita, Phys. Rev. D 87 , 011301 (2013).
- [6] J. Schechter, J.W.F. Valle, Phys.Rev. D22 , 2227 (1980); T.P. Cheng, L.F. Li, Phys.Rev. D22 , 2860 (1980); M. Magg, Ch. Wetterich, Phys.Lett. B94 , 61 (1980);
- R.N. Mohapatra, G. Senjanovic, Phys.Rev. D23 , 165 (1981).
- [7] G. Aad et al [ATLAS Collaboration], Phys.Rev. D85 , 032004 (2012); S.Chatrchyan et al [CMS Collaboration], Eur.Phys.J. C72 , 2189 (2012).
- [8]
- K. Yagyu, arXiv: 1405.5149; Sh. Kanemura, K. Yagyu, H. Yokoya, Phys.Lett. B726 , 316 (2013).
- [9] M.J. Dolan, C. Englert, and M. Spannowsky, Phys. Rev. D87 , 055002 (2013).
- [10] V. Barger, L.L. Everett, C.B. Jackson, A. Peterson, G. Shaughnessy, arXiv:1408.0003.
- [11] H. Georgi, M. Machacek, Nucl.Phys. B262 , 463 (1985).
- [12] S. Kraml, E. Accomando et al , CERN-2006-009, arXiv:hep-ph/0608079.
- [13] P.S. Bhupal Dev, D. K. Ghosh, N. Okada, I. Saha, JHEP 2013 , No. 03, 150 (2013).
- [14] J. Beringer et al , Phys.Rev. D86 010001 (2012).
- [15] P. F. Perez, T. Han, G.-Yu Huang, T. Li, K. Wang, Phys.Rev. D78 015018 (2008).
- [16] S. Dittmaier et al , CERN-2011-002, arXiv:1101.0593.
- [17] A. Denner, S. Dittmaier, S. Kallweit, A. M¨ck, HAWK, u http://omnibus.uni-freiburg.de/ ~ sd565/programs/hawk/hawk.html .
- [18] K. Hartling, K. Kumar, H. E. Logan, Phys.Rev. D90 , 015007 (2014).
- [19] C. Englert, E. Re, M. Spannowsky, Phys. Rev. D87 , 095014 (2013).
- [20] Ch.-W. Chiang, K. Yagyu, JHEP 2013 , No. 01, 026 (2013); Ch.-W. Chiang, Sh. Kanemura, K. Yagyu, UT-HET-096, arXiv:1407.5053; Sh. Kanemura, M. Kikuchi, K. Yagyu, H. Yokoya, UT-HET-091, arXiv:1407.6547.
- [21] B. Bhattacherjee, A. Choudhury, arXiv:1407.6866. | 10.1134/S1063776115030073 | [
"S. I. Godunov",
"M. I. Vysotsky",
"E. V. Zhemchugov"
] | 2014-08-01T14:09:40+00:00 | 2014-09-18T13:35:02+00:00 | [
"hep-ph",
"hep-ex"
] | Double Higgs production at LHC, see-saw type II and Georgi-Machacek model | The double Higgs production in the models with isospin-triplet scalars is
studied. It is shown that in the see-saw type II model the mode with an
intermediate heavy scalar, $pp\to H+X\to 2h+X$, may have the cross section
which is compatible with that in the Standard Model. In the Georgi-Machacek
model this cross section could be much larger than in SM since the vacuum
expectation value of the triplet can be large. |
1408.0185v1 | ## Landauer-Büttiker and Thouless conductance
L. Bruneau , V. Jakši´ c 1 2 , Y. Last 3 , C.-A. Pillet 4
1 Département de Mathématiques and UMR 8088 CNRS and Université de Cergy-Pontoise 95000 Cergy-Pontoise, France
2 Department of Mathematics and Statistics McGill University 805 Sherbrooke Street West Montreal, QC, H3A 2K6, Canada
3 Institute of Mathematics The Hebrew University 91904 Jerusalem, Israel
4 Université de Toulon, CNRS, CPT, UMR 7332, 83957 La Garde, France Aix-Marseille Université, CNRS, CPT, UMR 7332, 13288 Marseille, France
Dedicated to the memory of Markus Büttiker
Abstract. In the independent electron approximation, the average (energy/charge/entropy) current flowing through a finite sample S connected to two electronic reservoirs can be computed by scattering theoretic arguments which lead to the famous Landauer-Büttiker formula. Another well known formula has been proposed by Thouless on the basis of a scaling argument. The Thouless formula relates the conductance of the sample to the width of the spectral bands of the infinite crystal obtained by periodic juxtaposition of S . In this spirit, we define Landauer-Büttiker crystalline currents by extending the Landauer-Büttiker formula to a setup where the sample S is replaced by a periodic structure whose unit cell is S . We argue that these crystalline currents are closely related to the Thouless currents. For example, the crystalline heat current is bounded above by the Thouless heat current, and this bound saturates iff the coupling between the reservoirs and the sample is reflectionless. Our analysis leads to a rigorous derivation of the Thouless formula from the first principles of quantum statistical mechanics.
## 1 Introduction
Recent rigorous formulations of the Landauer-Büttiker formula [AJPP, BSP, CJM, N] in the framework of nonequilibrium quantum statistical mechanics have opened the way to the mathematical study of a variety of related transport phenomena in quantum mechanics [GJW, JLPa, JLPi]. This paper is a continuation of this line of research. Our main goal here is to provide a mathematically rigorous proof of the celebrated Thouless conductance formula.
This paper is organized as follows. In Section 1.1 we review the Electronic Black Box Model and the corresponding Landauer-Büttiker formula. These topics have been discussed from both technical and pedagogical point of view in [AJPP, BSP] and the reader may consult these works for additional information. The notions of Thouless energy and Thouless conductance are reviewed in Section 1.2. Our main results are stated in Section 2. The proofs are given in Section 3.
Acknowledgment. The research of V.J. was partly supported by NSERC. The research of Y.L. was partly supported by The Israel Science Foundation (Grant No. 1105/10) and by Grant No. 2010348 from the United States-Israel Binational Science Foundation (BSF), Jerusalem, Israel. A part of this work has been done during a visit of L.B. to McGill University supported by NSERC. Another part was done during the visit of V.J. to The Hebrew University supported by ISF.
## 1.1 The Electronic Black Box Model and the Landauer-Büttiker formula
The Electronic Black Box Model (abbreviated EBBM) describes a finite sample S connected to two infinitely extended electronic reservoirs R l/r (where l/r stands for left/right) in the independent electron approximation. The coupling between the sample and the reservoirs allows for a flow of energy/charge/entropy through the joint system R l + S + R r .
We shall restrict our attention to one-dimensional samples in the tight binding approximation. Thus, the sample S is a free Fermi gas with one-particle Hilbert space h S = glyph[lscript] 2 ( Z L ) , where Z L = [1 , L ] ∩ Z is a finite lattice. Its Hamiltonian h S is a Jacobi matrix with parameters { J x } 1 ≤ x<L , { λ x } 1 ≤ ≤ x L ,
$$( h _ { \mathcal { S } } u ) ( x ) = J _ { x } u ( x + 1 ) + J _ { x - 1 } u ( x - 1 ) + \lambda _ { x } u ( x ), \quad x \in Z _ { L }, \quad \ \ ( 1. 1 )$$
and Dirichlet boundary condition u (0) = u L ( +1) = 0 . The reservoir R l/r is a free Fermi gas with one-particle Hilbert space h l/r and one-particle Hamiltonian h l/r . The one-particle Hilbert space and Hamiltonian of the composite system R l + S + R r are
$$\mathfrak { h } = \mathfrak { h } _ { l } \oplus \mathfrak { h } _ { \mathcal { S } } \oplus \mathfrak { h } _ { r },$$
$$h _ { 0 } = h _ { l } \oplus h _ { \mathcal { S } } \oplus h _ { r }.$$
The coupling of the sample with the reservoir R l/r is realized by the hopping Hamiltonian
$$v _ { l / r } = | \chi _ { l / r } \rangle \langle \psi _ { l / r } | + | \psi _ { l / r } \rangle \langle \chi _ { l / r } |,$$
where χ l/r ∈ h l/r is a unit vector while ψ l = δ 1 and ψ r = δ L are Kronecker delta functions in h S . The one-particle Hamiltonian of the coupled system is
$$h = h _ { 0 } + \kappa v = h _ { 0 } + \kappa ( v _ { l } + v _ { r } ),$$
glyph[negationslash]
where κ = 0 is the coupling strength. As observed in [BJP], for the purposes of discussing transport properties of the coupled system R l + S + R r one may assume, without loss of generality, that χ l/r is a cyclic vector for h l/r . Hence, passing to the spectral representation we may assume that h l/r acts as multiplication by E on
$$\mathfrak { h } _ { l / r } = L ^ { 2 } ( \mathbb { R }, \mathrm d \nu _ { l / r } ( E ) ),$$
where ν l/r is the spectral measure of h l/r associated to χ l/r . Moreover, in this representation one has χ l/r ( E ) = 1 and ν l/r ( R ) = 1 .
Let Γ ( ) -h be the fermionic Fock space over h and denote by a f ( ) /a ∗ ( f ) the annihilation/creation operator on Γ ( ) -h associated to f ∈ h . The algebra of observables of the EBBM is the C ∗ -algebra O of all bounded operators on Γ ( ) -h generated by the identity I and { a ∗ ( f ) a g ( ) | f, g ∈ h } .
Let H = dΓ( h ) be the second quantized Hamiltonian. The map
$$\tau ^ { t } ( a ^ { * } ( f ) a ( g ) ) = e ^ { i t H } a ^ { * } ( f ) a ( g ) e ^ { - i t H } = a ^ { * } ( e ^ { i t h } f ) a ( e ^ { i t h } g ),$$
extends to a strongly continuous group of ∗ -automorphisms of O and the pair ( O , τ t ) is a C ∗ -dynamical system. The states of the EBBM are normalized positive linear functionals on O .
Since we are dealing with independent electrons, quasi-free states on O will be of particular relevance. Let ρ be a self-adjoint operator of h such that 0 ≤ ρ ≤ I . The gauge-invariant quasi-free state of density ρ is the unique state ω ρ on O satisfying
$$\omega _ { \rho } ( a ^ { * } ( f _ { 1 } ) \cdots a ^ { * } ( f _ { n } ) a ( g _ { m } ) \cdots a ( g _ { 1 } ) ) = \delta _ { n, m } \det \{ \langle g _ { i }, \rho f _ { j } \rangle \},$$
for any integers n, m and all f , . . . , f 1 n , g 1 , . . . , g m ∈ h .
The initial state ω 0 of the EBBM is the gauge-invariant quasi-free state of density
$$\rho _ { 0 } = \rho _ { l } \oplus \rho _ { \mathcal { S } } \oplus \rho _ { r },$$
where ρ l/r is the operator of multiplication by the Fermi-Dirac density
$$\rho _ { l / r } ( E ) = \frac { 1 } { 1 + \mathrm e ^ { \beta _ { l / r } ( E - \mu _ { l / r } ) } }.$$
In other words, the reservoir R l/r is initially in thermal equilibrium at inverse temperature β l/r > 0 and chemical potential µ l/r ∈ R . None of our results depends on the particular choice of the initial density ρ S of the sample.
The EBBM is the quantum dynamical system ( O , τ t , ω 0 ) .
The basic questions regarding this system concern its behavior in the large time limit t → ∞ . To deal with this limit we observe that the initial state ω 0 = ω ρ 0 evolves in time as
$$\omega _ { t } = \omega _ { 0 } \circ \tau ^ { t } = \omega _ { \rho _ { t } },$$
where the density at time t is given by
$$\rho _ { t } = e ^ { - i t h } \rho _ { 0 } e ^ { i t h }.$$
One expects that ω t → ω + as t → ∞ , where the non-equilibrium steady state ω + carries energy/charge/entropy current induced by the initial temperature/chemical potential differential. These currents can be expressed by Landauer-Büttiker formulas involving transmission properties of individual electrons evolving under the dynamics generated by the one-particle Hamiltonian h . These heuristics is mathematically formalized as follows.
The observables describing energy and charge current out of R l/r are
$$\Phi _ { l / r } = \mathrm d \Gamma ( - \mathrm i [ h, h _ { l / r } ] ) = \kappa \left ( a ^ { * } ( \mathrm i h _ { l / r } \chi _ { l / r } ) a ( \psi _ { l / r } ) + a ^ { * } ( \psi _ { l / r } ) a ( \mathrm i h _ { l / r } \chi _ { l / r } ) \right ),$$
$$\mathcal { I } _ { l / r } = \mathrm d \Gamma ( - \mathrm i [ h, 1 _ { l / r } ] ) = \kappa \left ( a ^ { * } ( \mathrm i \chi _ { l / r } ) a ( \psi _ { l / r } ) + a ^ { * } ( \psi _ { l / r } ) a ( \mathrm i \chi _ { l / r } ) \right ).$$
The entropy current associated to the heat flux dissipated into the reservoirs is
$$\mathcal { J } = - \beta _ { l } ( \Phi _ { l } - \mu _ { l } \mathcal { I } _ { l } ) - \beta _ { r } ( \Phi _ { r } - \mu _ { r } \mathcal { I } _ { r } ).$$
The transmittance of the sample is the function 1
$$\mathbb { R } \ni E \mapsto \mathcal { T } ( E ) = 4 \kappa ^ { 4 } | \langle \psi _ { l }, ( h - E - i 0 ) ^ { - 1 } \psi _ { r } \rangle | ^ { 2 } \, \text{Im} \, F _ { l } ( E ) \, \text{Im} \, F _ { r } ( E ), \quad \quad ( 1. 2 )$$
↦
where
$$F _ { l / r } ( E ) = \langle \chi _ { l / r }, ( h _ { l / r } - E - \mathrm i 0 ) ^ { - 1 } \chi _ { l / r } \rangle. & & ( 1. 3 ) \\ \omega _ { \cdot \cdot \cdot } / E \searrow \infty \ e n d \, ^ { 2 }$$
Note that Im F l/r ( E ) ≥ 0 and 2
$$\{ E \in \mathbb { R } \, | \, \mathcal { T } ( E ) > 0 \} = \Sigma _ { l } \cap \Sigma _ { r },$$
where
$$\Sigma _ { l / r } = \left \{ E \in \mathbb { R } \, | \, \text{Im} \, F _ { l / r } ( E ) > 0 \right \} \\ \text{not set to the absolute} \, \text{contain} \, \text{contain} \, \text{$\epsilon_{k}$} \,.$$
is the essential support of the absolutely continuous spectrum of h l/r .
For E ∈ R we set
$$\zeta _ { l / r } ( E ) = \beta _ { l / r } ( E - \mu _ { l / r } ), \quad \Delta _ { l / r } ( E ) = \rho _ { l / r } ( E ) - \rho _ { r / l } ( E ),$$
and
$$\varsigma ( E ) = ( \zeta _ { r } ( E ) - \zeta _ { l } ( E ) ) \Delta _ { l } ( E ) = ( \zeta _ { l } ( E ) - \zeta _ { r } ( E ) ) \Delta _ { r } ( E ). \\ \intertext { t i c r } \frac { \lambda } { R } = \frac { R } { R } \text{ and }.. \text{ } -.. \text{ } \text{ then } \text{$\sim E\uplus$ combination in both that it is attribute, no one}.$$
Our basic assumption in the following is:
Note that if β l = β r and µ l = µ r then ς ( E ) vanishes identically but that it is strictly positive for all E ∈ R otherwise.
Assumption A. The one-particle Hamiltonian h has no singular continuous spectrum.
The starting point of this paper is the following result [AJPP].
Theorem 1.1 Suppose that Assumption A holds. Then for all A ∈ O the limit
$$\omega _ { + } ( A ) = \lim _ { t \rightarrow \infty } \frac { 1 } { t } \int _ { 0 } ^ { t } \omega _ { s } ( A ) d s,$$
exists and defines a state ω + on O . Moreover, the following formulas for the average steady currents hold:
$$\langle \Phi _ { l / r } \rangle _ { + } = \omega _ { + } ( \Phi _ { l / r } ) = \frac { 1 } { 2 \pi } \int _ { \mathbb { R } } \mathcal { T } ( E ) E \Delta _ { l / r } ( E ) \mathrm d E,$$
$$\langle \mathcal { I } _ { l / r } \rangle _ { + } = \omega _ { + } ( \mathcal { I } _ { l / r } ) = \frac { 1 } { 2 \pi } \int _ { \mathbb { R } } \mathcal { T } ( E ) \Delta _ { l / r } ( E ) \mathrm d E,$$
$$\langle \mathcal { J } \rangle _ { + } = \omega _ { + } ( \mathcal { J } ) = \frac { 1 } { 2 \pi } \int _ { \mathbb { R } } \mathcal { T } ( E ) \varsigma ( E ) \text{d} E.$$
1 This function is defined for Lebesgue a.e. E ∈ R .
2 This identity is understood modulo sets of Lebesgue measure zero.
We finish this section with a number of remarks regarding this result.
Remark 1. Theorem 1.1 deals with the simplest non-trivial setting in the study of electronic transport in the independent electron approximation. Various generalizations of this setting and of Theorem 1.1 can be found in [AJPP, N, BSP].
Remark 2. We have chosen units in such a way that the electronic charge e , the reduced Planck constant glyph[planckover2pi1] , and the Boltzmann constant k B are unity. The energy, charge, and entropy currents in the above formulas are expressed in units of 1 / glyph[planckover2pi1] , e/ glyph[planckover2pi1] and k B / glyph[planckover2pi1] . Note also that these formulas do not include the spin degeneracy which should be accounted for by a factor 2 .
Remark 3. If Assumption A is replaced by the stronger assumption that h has no singular spectrum, then
$$\omega _ { + } ( A ) = \lim _ { t \rightarrow \infty } \omega _ { t } ( A ),$$
holds for all A ∈ O .
$$\rho _ { \beta, \mu } = \frac { 1 } { 1 + \mathrm e ^ { \beta ( h - \mu ) } }.$$
Remark 4. If β l = β r = β and µ l = µ r = µ , then ω + is the thermal equilibrium state of the coupled system R l + S + R r for the given intensive thermodynamic parameters, i.e., the quasi-free state of density glyph[negationslash]
In this case, all currents vanish in average. In the following we shall exclude this possibility and assume that β l = β r or/and µ l = µ r . The state ω + is then a non-equilibrium steady state of the EBBM and (1.6) are the Landauer-Büttiker formulas for the steady state currents.
glyph[negationslash]
Remark 5. Apart from the choice of the intensive thermodynamic parameters β l/r and µ l/r , the transmission coefficient T ( E ) completely determines the steady state currents. It follows from (1.4) that the steady state currents are non-vanishing iff the Lebesgue measure | Σ l ∩ Σ r | of the set Σ l ∩ Σ r is strictly positive, i.e., iff there exists an open scattering channel between the left and the right reservoir. Note the obvious conservation laws
$$\omega _ { + } ( \Phi _ { l } ) + \omega _ { + } ( \Phi _ { r } ) = 0, \quad \omega _ { + } ( \mathcal { I } _ { l } ) + \omega _ { + } ( \mathcal { I } _ { r } ) = 0.$$
Entropy balance in the steady state ω + implies that
$$\langle \mathcal { J } \rangle _ { + } = - \beta _ { l } ( \langle \Phi _ { l } \rangle _ { + } - \mu _ { l } \langle \mathcal { I } _ { l } \rangle _ { + } ) - \beta _ { r } ( \langle \Phi _ { r } \rangle _ { + } - \mu _ { r } \langle \mathcal { I } _ { r } \rangle _ { + } ), \\ \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
coincides with the rate of entropy production in S [AJPP]. It follows from the above observation that 〈J 〉 + ≥ 0 , and that the inequality is strict iff | Σ l ∩ Σ r | > 0 .
Remark 6. The proof of Theorem 1.1 is based on the scattering theory of the pair ( h, h 0 ) and elucidates the physical meaning of T ( E ) . It follows from the trace class scattering theory that the wave operators 3
$$w _ { \pm } = s - \lim _ { t \to \pm \infty } e ^ { i t h } e ^ { - i t h _ { 0 } } 1 _ { \text{ac} } ( h _ { 0 } ),$$
3 1 ac ( h 0 ) is the spectral projection on the absolutely continuous part of the spectrum of h 0 .
exist and are complete. The scattering matrix s = w w ∗ + -is a unitary operator on
$$\mathfrak { h } _ { \text{ac} } ( h _ { 0 } ) = \text{Ran} \, 1 _ { \text{ac} } ( h _ { 0 } ) = \text{Ran} \, 1 _ { \text{ac} } ( h _ { l } ) \oplus \text{Ran} \, 1 _ { \text{ac} } ( h _ { r } ),$$
and acts as the operator of multiplication by a unitary 2 × 2 matrix
$$s ( E ) = \begin{bmatrix} s _ { l l } ( E ) & s _ { l r } ( E ) \\ s _ { r l } ( E ) & s _ { r r } ( E ) \end{bmatrix}.$$
One then has
$$\mathcal { T } ( E ) = | s _ { l r } ( E ) | ^ { 2 } = | s _ { r l } ( E ) | ^ { 2 }, \\ \mathbb { u } \colon = \mathbb { m } \cdots \dots \dots \dots \dots \dots \dots \dots$$
i.e., the transmittance T ( E ) is the transmission probability between the left and right reservoir at energy E .
Remark 7. An additional insight into T ( E ) can be obtained by taking into account the spatial structure of the reservoirs. Suppose that the reservoirs are non-trivial in the sense that the measures ν l/r have non-vanishing absolutely continuous component. The standard orthogonal polynomial construction (see Theorem I.2.4 in [Si]) provides a unitary operator U : h → glyph[lscript] 2 ( Z ) such that the following holds:
$$( i ) \ U \mathfrak { h } _ { l } = \ell ^ { 2 } ( \left ] - \infty, 0 \right ] \cap \mathbb { Z } ), U \mathfrak { h } _ { \mathcal { S } } = \mathfrak { h } _ { \mathcal { S } } \text{ and } U \mathfrak { h } _ { r } = \ell ^ { 2 } ( [ L + 1, \infty [ \cap \mathbb { Z } ).$$
- (ii) There is a Jacobi matrix on glyph[lscript] 2 (] - ∞ , 0] ∩ Z ) , with parameters { J x } x< 0 , { λ x } x ≤ 0 and Dirichlet boundary condition such that for u ∈ glyph[lscript] 2 (] -∞ , 0] ∩ Z )
$$( U h _ { l } U ^ { * } u ) ( x ) = J _ { x } u ( x + 1 ) + J _ { x - 1 } u ( x - 1 ) + \lambda _ { x } u ( x ), \quad ( x \leq 0, u ( 1 ) = 0 ).$$
(iii) Uh U S ∗ = h S .
- (iv) There is a Jacobi matrix on glyph[lscript] 2 ([ L + 1 , ∞∩ [ Z ) , with parameters { J x } x>L , { λ x } x>L and Dirichlet boundary condition such that for u ∈ glyph[lscript] 2 ([ L +1 , ∞∩ [ Z )
$$( U h _ { r } U ^ { * } u ) ( x ) = J _ { x } u ( x + 1 ) + J _ { x - 1 } u ( x - 1 ) + \lambda _ { x } u ( x ), \quad ( x > L, u ( L ) = 0 ).$$
$$( \nu ) \ U \chi _ { l } = \delta _ { 0 } \text{ and } U \chi _ { r } = \delta _ { L + 1 }.$$
$$( v i ) \text{ if } J _ { 0 } = J _ { L } = \kappa, \text{ then for } u \in \ell ^ { 2 } ( \mathbb { Z } )$$
$$( U h U ^ { * } u ) ( x ) = J _ { x } u ( x + 1 ) + J _ { x - 1 } u ( x - 1 ) + \lambda _ { x } u ( x ).$$
It follows that our EBBM is unitarily equivalent to a Jacobi matrix EBBM on glyph[lscript] 2 ( Z ) .
For z ∈ C + let u l/r ( · , z ) be the unique solution of the equation
$$J _ { x } u _ { l / r } ( x + 1, z ) + J _ { x - 1 } u _ { l / r } ( x - 1, z ) + \lambda _ { x } u _ { l / r } ( x, z ) = z u _ { l / r } ( x, z ),$$
that is square summable at ±∞ and normalized by u l/r (0 , z ) = 1 . For all x ∈ Z and Lebesgue a.e. E ∈ R the limit
$$\lim _ { \epsilon \downarrow 0 } u _ { l / r } ( x, E + \text{i} \epsilon ) = u _ { l / r } ( x, E ),$$
exists, is finite, and solves (1.7) with z = E . For Lebesgue a.e. E ∈ Σ r the solution u r ( E ) is not a multiple of a real solution and so u r ( E ) is also a solution of (1.7) linearly independent of u r ( E ) . Hence, for Lebesgue a.e. E ∈ Σ r one has
$$u _ { l } ( E ) = \alpha ( E ) \overline { u _ { r } ( E ) } + \beta ( E ) u _ { r } ( E ).$$
The spectral reflection probability of [GNP, GS] is
$$R _ { r } ( E ) = \left | \frac { \beta ( E ) } { \alpha ( E ) } \right | ^ { 2 }.$$
glyph[negationslash]
One extends R r to R by setting R r ( E ) = 1 for E ∈ Σ r . R E l ( ) is defined analogously. A simple computation (see Section 5 in [JLPa]) gives
$$R _ { r } ( E ) = R _ { l } ( E ) = | s _ { l l } ( E ) | ^ { 2 } = | s _ { r r } ( E ) | ^ { 2 }.$$
Hence,
$$\mathcal { T } ( E ) = 1 - R _ { r } ( E ) = 1 - R _ { l } ( E ), \\ \colon \dots \dots \colon \colon \dots \colon \dots \colon \dots \colon \colon \dots \colon \colon \dots \colon \colon \colon \dots \colon \colon \colon \colon \dots \colon \colon \colon \colon \dots \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{matrix}$$
is the spectral transmission probability at the energy E .
## 1.2 The Thouless energy and the Thouless conductance formula
We start with a review of the notions of Thouless energy and conductance as discussed in the physics literature. We follow [La] and our main goal is to extract mathematically well-defined quantities that correspond to these heuristic notions.
## 1.2.1 Heuristics
Let δt be the typical time spent in S by an electron on its journey from one reservoir to the other. The Mandelstam-Tamm time-energy uncertainty relation δE δt glyph[greaterorsimilar] 1 ([MT], see also [FP, Bu]) imposes a lower bound on the energy spread δE of the electron wave function. This sets the Thouless energy scale E Th ∼ δE [Th]. Assuming a diffusive behavior, one has L 2 ∼ Dδt where L is the sample size and D the diffusion constant, and hence
$$E _ { \text{Th} } \gtrsim \frac { D } { L ^ { 2 } }.$$
Einstein's relation
$$\sigma = D \varrho \lesssim L ^ { 2 } E _ { \text{Th} } \varrho,$$
further links D to the conductivity σ of the sample and its density of states glyph[rho1] . Finally, glyph[rho1] relates to the typical energy level spacing ∆ E of the sample as
$$\varrho L \Delta E \sim 1.$$
It follows that
$$\sigma \lesssim L \frac { E _ { \text{Th} } } { \Delta E },$$
and hence that the conductance g = L -1 σ of the one-dimensional sample satisfies
$$g \lesssim g _ { \text{Th} } = \frac { E _ { \text{Th} } } { \Delta E }.$$
The quantity at the r.h.s. of this formula is known as the Thouless conductance. Although the above derivation is extremely heuristic in nature, the Thouless conductance g Th and the closely related Thouless energy E Th are widely accepted by both theoretical and experimental physicists and play an important role in the scaling theory of localization [AALR].
The above argument and the resulting inequality on the l.h.s. of (1.8) suggest that we should consider g Th as an upper bound on the conductance of the sample S . Indeed, for such a microscopic system the conductance is not an intrinsic property of the sample, but depends also on the reservoirs and the nature of the coupling, which determines the reservoir's ability to feed the available energy levels of the sample. Thus, one expects that saturation of the Thouless bound (1.8) occurs for optimal feeding of the sample by the reservoirs, a property of the joint system R l + S + R r which we shall try to elucidate in the remaining part of this paper (see Remarks 1 and 4 after Theorem 2.3).
## 1.2.2 The crystal model
There is a simple way to make the sample transparent to incoming electrons and hence to ensure its optimal feeding: it suffices to implement the reservoirs in such a way that the joint system R l + S + R r is periodic. We shall call crystalline EBBM the model obtained by repeating the sample so as to obtain a periodic crystal with unit cell S (a construction closely related to the scaling argument of [ET]).
Consider the periodic Jacobi matrix h crystal on glyph[lscript] 2 ( Z ) obtained by extending the Jacobi parameters { λ x } 1 ≤ ≤ x L and { J x } 1 ≤ x<L of the sample Hamiltonian h S to the entire lattice Z by setting J L = κ S and
$$J _ { x + n L } = J _ { x }, \quad \lambda _ { x + n L } = \lambda _ { x },$$
glyph[negationslash]
for any n ∈ Z and x ∈ Z L . The internal coupling constant κ S is a priori an arbitrary parameter, except for the obvious constraint κ S = 0 . In practice it will be determined by the physics of the problem. In a model where the sample parameters J x are independent copies of a random
variable, κ S will be another instance of this variable. If h S is a discrete Schrödinger operator with J x = J for all x ∈ Z L the choice of κ S = J appears natural.
In the crystaline EBBM model, the single particle Hilbert spaces of the reservoirs are h l = glyph[lscript] 2 (] -∞ , 0] ∩ Z ) and h r = glyph[lscript] 2 ([ L +1 , ∞∩ [ Z ) , the corresponding single particle Hamiltonians are Jacobi matrices with parameters {{ J x } x< 0 , { λ x } x< 0 } , {{ J x } x>L , { λ x } x>L } and Dirichlet boundary condition, χ l = δ 0 , χ r = δ L +1 , and the coupling constant is set to κ = κ S . The one particle Hamiltonian of the coupled system is h crystal .
We emphasize that the crystallization of the sample is specified by the pair ( S , κ S ) and not by S alone.
The Bloch-Floquet decomposition of h crystal reads
$$\ell ^ { 2 } ( \mathbb { Z } ) = \int _ { \mathfrak { B } _ { L } } ^ { \oplus } \mathfrak { h } _ { \mathcal { S } } \, \mathrm d k, \quad h _ { \text{crystal} } = \int _ { \mathfrak { B } _ { L } } ^ { \oplus } h ( k ) \, \mathrm d k,$$
where B L = [ -π/L, π/L ] is the first Brillouin zone of the crystal and h k ( ) is the self-adjoint operator on h S obtained from (1.1) by replacing Dirichlet by Bloch boundary conditions
$$u ( 0 ) = \mathrm e ^ { - \mathrm i k L } u ( L ), \quad u ( L + 1 ) = \mathrm e ^ { \mathrm i k L } u ( 1 ).$$
The spectrum of h k ( ) consists of L eigenvalues ε 1 ( k ) ≤ · · · ≤ ε L ( k ) which are even functions of k , real analytic and strictly monotone on ]0 , π/L [ . Moreover
$$\varepsilon _ { L } ( 0 ) > \varepsilon _ { L } ( \pi / L ) \geq \varepsilon _ { L - 1 } ( \pi / L ) > \varepsilon _ { L - 1 } ( 0 ) \geq \varepsilon _ { L - 2 } ( 0 ) > \cdots$$
Thus, the spectrum of h crystal is
$$\text{sp} ( h _ { \text{crystal} } ) = \bigcup _ { k \in \mathcal { B } _ { L } } \text{sp} ( h ( k ) ) = \bigcup _ { j = 1 } ^ { L } B _ { j },$$
where B j is a closed interval with boundary points ε j (0) and ε j ( π/L ) (see Theorem 5.3.4 in [Si] and Figure 1).
For simplicity, suppose that the reservoirs are at zero temperature, i.e., β l = β r = ∞ , and assume that µ l < µ r . In this case the function ∆ r is the characteristic function of the interval [ µ , µ l r ] and the Landauer-Büttiker formula for the steady charge current out of the right reservoir becomes
$$\omega _ { + } ( \mathcal { J } _ { r } ) = \frac { 1 } { 2 \pi } \int _ { \mu _ { l } } ^ { \mu _ { r } } \mathcal { T } ( E ) \mathrm d E.$$
Since the transmittance of a unit cell in a perfect crystal is the characteristic function of its spectrum, we get
$$\omega _ { + } ( \mathcal { J } _ { r } ) = \frac { 1 } { 2 \pi } | \text{sp} ( h _ { \text{crystal} } ) \cap [ \mu _ { l }, \mu _ { r } ] |,$$
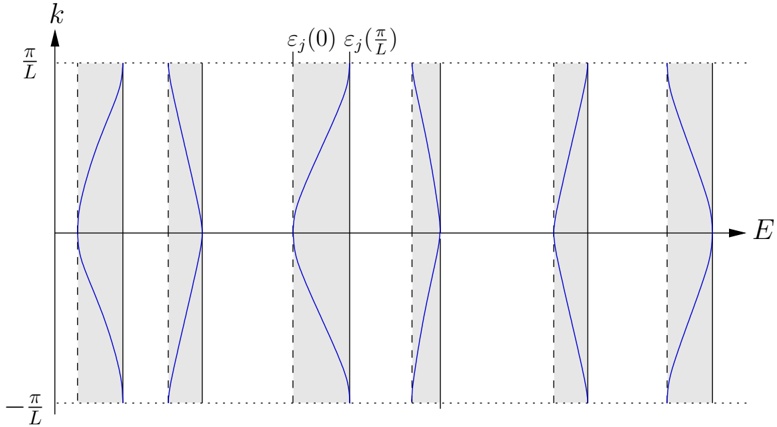
-
Figure 1: Eigenvalues of h k ( ) and the band spectrum of h crystal .
from which we infer that the mean conductance of the sample on the energy window I = [ µ , µ l r ] is given by
$$g ( I ) = \frac { 1 } { 2 \pi } \frac { | \text{sp} ( h _ { \text{crystal} } ) \cap I | } { | I | }. \\ \cdot \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
We shall now argue that this expression can be interpreted as the Thouless conductance associated to the energy window I . In order for the level spacing ∆ E to be well defined, the interval I should contain several bands B j of h crystal . The energy uncertainty within a single band B j ⊂ I is of the order of the band width | B j | = | ε j ( π/L ) -ε j (0) | which coincides with the variation of the eigenvalue ε j ( k ) as the Bloch boundary condition changes from periodic to anti-periodic (see Figure 2). A rough but convenient estimate of the energy uncertainty within the window I is given by the arithmetic mean
$$\delta E \sim \frac { \sum _ { B _ { j } \subset I } | B _ { j } | } { \sum _ { B _ { j } \subset I } 1 } \sim \frac { | \text{sp} ( h _ { \text{crystal} } ) \cap I | } { \sum _ { B _ { j } \subset I } 1 }.$$
On the other hand, the mean level spacing within I is given by
$$\Delta E \sim \frac { | I | } { \sum _ { B _ { j } \subset I } 1 },$$
and the Thouless conductance becomes
$$g _ { \text{Th} } \sim \frac { \delta E } { \Delta E } \sim \frac { | \text{sp} ( h _ { \text{crystal} } ) \cap I | } { | I | }.$$
Figure 2: Energy uncertainty δE j and level spacing ∆ E j for the j -th band in the window I .
According to the previous arguments, we shall define the Thouless conductance of the pair ( S , κ S ) for the energy window I ⊂ R by where h crystal is the periodization of h S with J L = κ S .
$$g _ { \text{Th} } ( I ) = \frac { 1 } { 2 \pi } \frac { | \text{sp} ( h _ { \text{crystal} } ) \cap I | } { | I | }, \\ \intertext { \text{periodization of $h_{\text{c} }$ with $J_{r} = \kappa_{\text{c} }$}.$$
Note that if κ S = 0 , then sp( h crystal ) = sp( h S ) and g Th ( I ) = 0 for all intervals I . More generally, the width of the L Bloch bands satisfies | B j | = O ( κ S ) as κ S → 0 , and
$$g _ { \text{Th} } ( I ) = \mathcal { O } ( \kappa _ { \mathcal { S } } )$$
in this limit.
## 2 The crystalline limit
To further elaborate on the connection between Thouless conductance and the Landauer-Büttiker formula, we shall now consider the approximation of h crystal by finite repetitions of the sample S connected to arbitrary reservoirs.
Let h crystal be as in the previous section. Given a positive integer N , let h ( N ) S be the restriction of h crystal to the finite lattice Z NL = [1 , NL ] ∩ Z with Dirichlet boundary condition. Hence h ( N ) S is a Jacobi matrix acting on h ( N ) S = glyph[lscript] 2 ( Z NL ) whose Jacobi parameters satisfy
$$J _ { x + n L } = J _ { x }, \quad \lambda _ { x + n L } = \lambda _ { x }, \quad ( x \in Z _ { L }, n = 0, 1, \dots, N - 1 ), \\ \cdot \quad \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \, \tau \}$$
where { J x } 1 ≤ x<L and { λ x } 1 ≤ ≤ x L are the Jacobi parameters of the original sample Hamiltonian h S and J L = κ S . The pairs ( h ( N ) S , h ( N ) S ) define a sequence of sample systems which are coupled to the reservoirs R l/r as in Section 1.1. The reservoirs' single particle Hilbert spaces and Hamiltonains ( h l/r , h l/r ) , the vectors χ l/r , and the coupling strength κ do not depend on N , and one takes ψ l = δ 1 , ψ r = δ NL . We assume that the one-particle Hamiltonian h ( N ) of the coupled systems satisfies Assumption A for all N 4 and we denote by ω ( N ) + , Φ ( N ) l/r , I ( N ) l/r , J ( N ) the respective NESS and flux observables. We are interested in the large N limit of the charge, energy and entropy steady currents (see Figure 3).
4 Besides the crystaline ones, see Section 1.2.2, a concrete example of reservoirs where this is the case is h l/r = glyph[lscript] 2 ( Z + ) , h l/r = -k ∆ , k > 0 . For other examples and general results regarding this point we refer the reader to [GJW].
Figure 3: The EBBM described by the Hamiltonian h ( N ) for N = 7 .

Let h ( ) l crystal and h ( r ) crystal be the restrictions of h crystal to glyph[lscript] 2 (( -∞ , 0] ∩ Z ) and glyph[lscript] 2 ([1 , ∞ ∩ ) Z ) with Dirichlet boundary conditions. Denote by
$$m _ { l } ( E ) & = \langle \delta _ { 0 }, ( h ^ { ( l ) } _ { \text{crystal} } - E - \text{i0} ) ^ { - 1 } \delta _ { 0 } \rangle, \\ m _ { r } ( E ) & = \langle \delta _ { 1 }, ( h ^ { ( r ) } _ { \text{crystal} } - E - \text{i0} ) ^ { - 1 } \delta _ { 1 } \rangle, \\.. \. \. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \ \hat { \ }. \.$$
the respective Weyl m -functions. One easily shows that Im m l/r ( E ) > 0 for Lebesgue a.e. E ∈ sp( h crystal ) . We set T ∞ ( E ) = 0 for E ∈ R \ (sp( h crystal ) ∩ Σ l ∩ Σ ) r and
$$\mathcal { T } _ { \infty } ( E ) = \left [ 1 + \frac { 1 } { 4 } \left ( \frac { | \kappa _ { S } ^ { 2 } m _ { r } ( E ) - \kappa ^ { 2 } F _ { r } ( E ) | ^ { 2 } } { \ln { ( \kappa _ { S } ^ { 2 } m _ { r } ( E ) ) } \ln { ( \kappa ^ { 2 } F _ { r } ( E ) ) } } + \frac { | \kappa _ { S } ^ { 2 } m _ { l } ( E ) - \kappa ^ { 2 } F _ { l } ( E ) | ^ { 2 } } { \ln { ( \kappa _ { S } ^ { 2 } m _ { l } ( E ) ) } \ln { ( \kappa ^ { 2 } F _ { l } ( E ) ) } } \right ) \right ] ^ { - 1 } \ ( 2. 2 )$$
for E ∈ sp( h crystal ) ∩ Σ l ∩ Σ r . Obviously, 0 ≤ T ∞ ( E ) ≤ 1 for Lebesgue a.e. E ∈ R .
Let
$$\mathcal { T } _ { N } ( E ) = 4 \kappa ^ { 4 } | \langle \psi _ { l }, ( h ^ { ( N ) } - E - \mathrm i 0 ) ^ { - 1 } \psi _ { r } \rangle | ^ { 2 } \, \text{Im} \, F _ { l } ( E ) \, \text{Im} \, F _ { r } ( E ), \\ \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \end{$$
be the transmittance of the N -fold repeated pair ( S , κ S ) . Our main technical result is:
Theorem 2.1 For any f ∈ L 1 ( R ) one has
$$\lim _ { N \to \infty } \int \mathcal { T } _ { N } ( E ) f ( E ) \, \mathrm d E = \int \mathcal { T } _ { \infty } ( E ) f ( E ) \, \mathrm d E.$$
The proof of this theorem is given in Section 3. As an immediate consequence, one has
## Theorem 2.2
$$\langle$$
$$\text{Theorem 2.2} \\ \langle \Phi _ { l / r } \rangle _ { \infty } & = \lim _ { N \to \infty } \omega _ { + } ^ { ( N ) } ( \Phi _ { l / r } ^ { ( N ) } ) = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \mathcal { T } _ { \infty } ( E ) E \Delta _ { l / r } ( E ) \, \text{d} E, \\ \langle \mathcal { I } _ { l / r } \rangle _ { \infty } & = \lim _ { N \to \infty } \omega _ { + } ^ { ( N ) } ( \mathcal { I } _ { l / r } ^ { ( N ) } ) = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \mathcal { T } _ { \infty } ( E ) \Delta _ { l / r } ( E ) \, \text{d} E, \\ \langle \mathcal { J } \rangle _ { \infty } & = \lim _ { N \to \infty } \omega _ { + } ^ { ( N ) } ( \mathcal { J } ^ { ( N ) } ) = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \mathcal { T } _ { \infty } ( E ) \varsigma ( E ) \, \text{d} E.$$
Obviously, the conservation laws
$$\langle \Phi _ { l } \rangle _ { \infty } + \langle \Phi _ { r } \rangle _ { \infty } & = 0, \\ \langle \mathcal { I } _ { l } \rangle _ { \infty } + \langle \mathcal { I } _ { r } \rangle _ { \infty } & = 0, \\ \cdot \.$$
hold, as well as the entropy balance relation
$$\langle \mathcal { J } \rangle _ { \infty } = - \beta _ { l } ( \langle \Phi _ { l } \rangle _ { \infty } - \mu _ { l } \langle \mathcal { I } _ { l } \rangle _ { \infty } ) - \beta _ { r } ( \langle \Phi _ { r } \rangle _ { \infty } - \mu _ { r } \langle \mathcal { I } _ { r } \rangle _ { \infty } ).$$
## 2.1 Thouless conductance revisited
Given a finite sample described by h S , h S , κ S and its periodization h crystal , the Thouless currents associated to chemical potentials µ l/r and inverse temperatures β l/r are defined by setting T ∞ ( E ) = 1 in the formulas (2.4), i.e., by assuming that the transport between the reservoirs is reflectionless. The Thouless current formulas are:
$$\langle \Phi _ { l / r } \rangle _ { \text{Th} } = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } E \Delta _ { l / r } ( E ) \text{d} E,$$
$$\langle \mathcal { I } _ { l / r } \rangle _ { \text{Th} } = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \Delta _ { l / r } ( E ) \text{d} E,$$
$$\langle \Phi _ { l / r } \rangle _ { \text{Th} } & = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } E \Delta _ { l / r } ( E ) \text{d} E, \\ \langle \mathcal { I } _ { l / r } \rangle _ { \text{Th} } & = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \Delta _ { l / r } ( E ) \text{d} E, \\ \langle \mathcal { J } \rangle _ { \text{Th} } & = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) } \varsigma ( E ) \text{d} E. \\ \text{intervation now}$$
One has again the conservation laws
$$\langle \Phi _ { l } \rangle _ { \text{Th} } + \langle \Phi _ { r } \rangle _ { \text{Th} } & = 0, \\ \langle \mathcal { I } _ { l } \rangle _ { \text{Th} } + \langle \mathcal { I } _ { r } \rangle _ { \text{Th} } & = 0,$$
and
$$\langle \mathcal { J } \rangle _ { \text{Th} } = - \beta _ { l } ( \langle \Phi _ { l } \rangle _ { \text{Th} } - \mu _ { l } \langle \mathcal { I } _ { l } \rangle _ { \text{Th} } ) - \beta _ { r } ( \langle \Phi _ { r } \rangle _ { \text{Th} } - \mu _ { r } \langle \mathcal { I } _ { r } \rangle _ { \text{Th} } ). \\ \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
Recall the definition of crystalline EBBM given in Section 1.2.2. The following theorem is a direct consequence of the definition of Thouless currents (2.5) and of Theorem 2.2.
## Theorem 2.3 (1)
$$\langle \mathcal { J } \rangle _ { \text{Th} } = \sup \, \langle \mathcal { J } \rangle _ { \infty }, \\ \dots \dots \dots \dots$$
where the supremum is taken over all realizations of the reservoirs. Moreover, this supremum is achieved if the EBBM is crystalline.
$$( 2 ) \ I f \mu _ { l } = \mu _ { r } = \mu, \, \mu \leq \inf \text{sp} ( h _ { \text{crystal} } ), \, a n d \, \beta _ { l } > \beta _ { r }, \, \text{then}$$
$$\langle \Phi _ { r } \rangle _ { T h } = \sup \, \langle \Phi _ { r } \rangle _ { \infty },$$
and the supremum is achieved if the EBBM is crystalline. If β l < β r , then this result holds for 〈 Φ l 〉 . If µ ≥ sup sp( h crystal ) , the same results hold with exchange of l and r .
$$( 3 ) \ I f \, \beta _ { l } = \beta _ { r } \, a n d \, \mu _ { l } < \mu _ { r }, \, t h e n$$
$$\langle \mathcal { I } _ { r } \rangle _ { \text{Th} } = \sup \, \langle \mathcal { I } _ { r } \rangle _ { \infty }, \\.. \,. \,. \,. \,. \,. \,......$$
and the supremum is achieved if the EBBM is crystalline. If µ > µ l r , then this result holds for 〈I 〉 l .
Remark 1. All suprema in the previous theorem are achieved iff the transport between the reservoirs is reflectionless, that is, iff T ∞ ( E ) = 1 for Lebesgue a.e. E ∈ sp( h crystal ) . The crystalline EBBM provide such reservoirs. To elucidate this point further, note that T ∞ ( E ) = 1 for Lebesgue a.e. E ∈ sp( h crystal ) iff σ h ( crystal ) ⊂ Σ l ∩ Σ r and
$$\kappa _ { \mathcal { S } } ^ { 2 } m _ { r / l } ( E ) = \kappa ^ { 2 } F _ { r / l } ( E ),$$
for Lebesgue a.e. E ∈ sp( h crystal ) . Since sp( h crystal ) has positive Lebesgue measure, the theory of boundary values of analytic functions (see [Ja] or any book on harmonic analysis) yields that for any z = E +i glyph[epsilon1] with glyph[epsilon1] > 0 ,
$$\kappa _ { \mathcal { S } } ^ { 2 } \langle \delta _ { 0 }, ( h _ { \text{crystal} } ^ { ( l ) } - z ) ^ { - 1 } \delta _ { 0 } \rangle = \kappa ^ { 2 } \langle \chi _ { l }, ( h _ { l } - z ) ^ { - 1 } \chi _ { l } \rangle,$$
$$\kappa _ { \mathcal { S } } ^ { 2 } \langle \delta _ { 1 }, ( h _ { \text{crystal} } ^ { ( r ) } - z ) ^ { - 1 } \delta _ { 1 } \rangle = \kappa ^ { 2 } \langle \chi _ { r }, ( h _ { r } - z ) ^ { - 1 } \chi _ { r } \rangle.$$
These relations imply
$$\kappa _ { \mathcal { S } } ^ { 2 } \nu _ { \text{crystal} } ^ { ( l / r ) } = \kappa ^ { 2 } \nu _ { l / r },$$
where ν ( l/r ) crystal is the spectral measure of h ( l/r ) crystal associated to δ /δ 0 1 . Since ν ( l/r ) crystal and ν l/r are probability measures, we conclude that κ 2 S = κ 2 and ν ( l/r ) crystal = ν l/r . Thus, the transport between the reservoirs is reflectionless iff κ 2 = κ 2 S and h r/l is unitarily equivalent to h ( r/l ) crystal . In other words, all suprema in the previous theorem are achieved iff the EBBM is unitarily equivalent to a crystalline EBMM up to (for the transport purposes) irrelevant choice of the sign of κ .
Remark 2. Part (2) holds whenever E ∆ l/r ( E ) has a definite sign on sp( h crystal ) and, similarly, Part (3) holds whenever ∆ l/r ( E ) has a definite sign on sp( h crystal ) . In the lack of a definite sign one cannot expect a variational characterization of Thouless currents in terms of the crystalline Landauer-Büttiker currents. Note that
$$\Delta _ { l / r } ( E ) = \frac { \sinh ( ( \zeta _ { r / l } ( E ) - \zeta _ { l / r } ( E ) ) / 2 ) } { 2 \cosh ( \zeta _ { l } ( E ) / 2 ) \cosh ( \zeta _ { r } ( E ) / 2 ) },$$
so that the sign of ∆ l/r ( E ) is the same as the sign of
$$\zeta _ { r / l } ( E ) - \zeta _ { l / r } ( E ) = ( \beta _ { r / l } - \beta _ { l / r } ) E - ( \beta _ { r / l } \mu _ { l / r } - \beta _ { l / r } \mu _ { l / r } ). \\ \dots \quad \cdots \quad \cdots \quad \cdots \quad \cdots.$$
In the non-trivial case β l = β r , ∆ l/r ( E ) changes the sign at precisely one point glyph[negationslash]
$$E _ { c } = \frac { \beta _ { r / l } \mu _ { l / r } - \beta _ { l / r } \mu _ { l / r } } { \beta _ { r / l } - \beta _ { l / r } }. \\ \twoheadrightarrow { \sim } \left ( h \right ) \quad \cdots \, \colon = \, \colon \, \text{sub-lab} \, \text{to-show} \,.$$
If additional information about sp( h crystal ) is available, the above fact can be used to obtain further relations between the crystalline Landauer-Büttiker currents (2.4) and Thouless currents (2.5).
Remark 3. If β l = β r = ∞ , µ < µ l r , and I = [ µ , µ l r ] , then
$$\langle \Phi _ { r } \rangle _ { \text{Th} } = \frac { 1 } { 2 \pi } \int _ { \text{sp} ( h _ { \text{crystal} } ) \cap I } E \text{d} E,$$
$$\langle \mathcal { I } _ { r } \rangle _ { \text{Th} } = \frac { 1 } { 2 \pi } | \text{sp} ( h _ { \text{crystal} } ) \cap I |.$$
Thus, the Thouless formula (1.9) indeed describes the maximal conductance at zero temperature for the given potential interval I :
$$g _ { \text{Th} } ( I ) = \frac { \langle \mathcal { I } _ { r } \rangle _ { \text{Th} } } { \mu _ { r } - \mu _ { l } } = \sup \frac { \langle \mathcal { I } _ { r } \rangle _ { \infty } } { \mu _ { r } - \mu _ { l } }. \\ \dots \dots \dots \dots \dots \dots \dots \dots$$
Remark 4. Since the crystalline Landauer-Büttiker formulas (2.4) are derived from the first principles of quantum statistical mechanics, Theorem 2.3 can be considered a rigorous quantum statistical derivation of the Thouless energy formula. This derivation also identifies the heuristic notion of "optimal feeding" of electrons with reflectionless transport between the reservoirs.
## 3 Proof of Theorem 2.1
## 3.1 Sample transmittance and Green matrix
We first connect the transmittance (1.2) to the sample's Green function. Recall that F l/r are defined in (1.3) and denote by F E ( ) the 2 × 2 diagonal matrix with entries F l ( E ) and F r ( E ) . We also introduce the 2 × 2 Green matrices G ( N ) S ( z ) and G ( N ) ( z ) with entries
$$G _ { S, a b } ^ { ( N ) } ( z ) = \langle \psi _ { a }, ( h _ { \mathcal { S } } ^ { ( N ) } - z ) ^ { - 1 } \psi _ { b } \rangle,$$
$$G _ { a b } ^ { ( N ) } ( z ) = \langle \psi _ { a }, ( h ^ { ( N ) } - z ) ^ { - 1 } \psi _ { b } \rangle,$$
where a, b ∈ { l, r } (recall that ψ l = δ 1 and ψ r = δ NL ). As usual, we write G ( N ) ab ( E ) = G ( N ) ab ( E +i0) .
The full Green matrix G ( N ) and the sample Green matrix G ( N ) S are related by (see Lemma 2.1 in [BJP])
$$G _ { \mathcal { S } } ^ { ( N ) } ( E ) = ( I - \kappa ^ { 2 } G _ { \mathcal { S } } ^ { ( N ) } ( E ) F ( E ) ) G ^ { ( N ) } ( E ),$$
from which we deduce
$$G _ { l r } ^ { ( N ) } ( E ) = \frac { G _ { \mathcal { S }, l r } ^ { ( N ) } ( E ) } { \det ( I - \kappa ^ { 2 } G _ { \mathcal { S } } ^ { ( N ) } ( E ) F ( E ) ) }. \quad \quad \ \ ( 3. 1 ) \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
Combined with (1.2) and (1.6) this allows us the expression of the transmittance of the sample and hence the steady currents in terms of the Green matrix G ( N ) S .
## 3.2 Green and transfer matrix
Our next step is to relate the sample's Green matrix to the transfer matrix of the periodic Jacobi matrix h crystal .
Following [Si] the transfer matrix at energy E is defined by
$$T _ { n } ( E ) = A _ { n } ( E ) \cdots A _ { 1 } ( E ),$$
where
$$A _ { x } ( E ) = J _ { x } ^ { - 1 } \left [ \begin{array} { c c } E - \lambda _ { x } & - 1 \\ J _ { x } ^ { 2 } & 0 \end{array} \right ].$$
Note that det A x ( E ) = 1 for any x and hence det T n ( E ) = 1 as well. A function u satisfies the finite difference equation h crystal u = Eu if and only if for any x one has
$$A _ { x } \left [ \begin{array} { c } u ( x ) \\ J _ { x - 1 } u ( x - 1 ) \end{array} \right ] = \left [ \begin{array} { c } u ( x + 1 ) \\ J _ { x } u ( x ) \end{array} \right ].$$
Lemma 3.1 For any x, y, u, v ∈ C one has
$$G _ { \mathcal { S } } ^ { ( N ) } ( E ) \left [ \begin{array} { c } x \\ y \end{array} \right ] = \left [ \begin{array} { c } u \\ v \end{array} \right ] \Longleftrightarrow T _ { N L } ( E ) \left [ \begin{array} { c } u \\ - x \end{array} \right ] = \left [ \begin{array} { c } - \kappa _ { \mathcal { S } } ^ { - 1 } y \\ \kappa _ { \mathcal { S } } v \end{array} \right ].$$
↦
In other words, the matrix P : ( x, y, u, v ) → ( u, -x, -κ -1 S y, κ S v ) maps the graph of G ( N ) S ( E ) to that of T NL ( E ) .
Remark. This lemma is a slight generalization of Lemma 2.2 in [BJP]. We include the proof for the reader convenience.
Proof. Fix N and E ∈ R \ sp( h ( N ) S ) . For f ∈ glyph[lscript] 2 ( Z NL ) , the function
$$u ( x ) = \langle \delta _ { x }, ( h _ { \mathcal { S } } ^ { ( N ) } - E ) ^ { - 1 } f \rangle$$
satisfies the finite difference equation
$$( h _ { \text{crystal} } - E ) u = f,$$
with boundary conditions u (0) = u NL ( +1) = 0 . Using the transfer matrix
$$T ( x, y ) = A _ { x } A _ { x - 1 } \cdots A _ { y + 1 },$$
the solution of the initial value problem for (3.2) can be written as
$$\left [ \begin{array} { c } u ( x + 1 ) \\ J _ { x } u ( x ) \end{array} \right ] = T ( x, 0 ) \left [ \begin{array} { c } u ( 1 ) \\ J _ { 0 } u ( 0 ) \end{array} \right ] - \sum _ { y = 1 } ^ { x } T ( x, y - 1 ) \left [ \begin{array} { c } 0 \\ f ( y ) \end{array} \right ].$$
Setting x = NL and taking the boundary conditions and J NL = J 0 = κ S into account yields
$$\left [ \begin{array} { c } 0 \\ \kappa _ { \mathcal { S } } u ( N L ) \end{array} \right ] = T _ { N L } ( E ) \left [ \begin{array} { c } u ( 1 ) \\ 0 \end{array} \right ] - \sum _ { y = 1 } ^ { N L } T ( N L, y - 1 ) \left [ \begin{array} { c } 0 \\ f ( y ) \end{array} \right ],$$
which is an equation for the unknown u (1) and u NL ( ) . Setting f = δ 1 and f = δ NL , we obtain the following equations for the entries of the matrix G ( N ) S ( E ) :
$$T _ { N L } ( E ) & \left [ \begin{array} { c } G _ { \mathcal { S }, l l } ^ { ( N ) } ( E ) \\ - 1 \end{array} \right ] = \left [ \begin{array} { c } 0 \\ \kappa _ { \mathcal { S } } G _ { \mathcal { S }, r l } ^ { ( N ) } ( E ) \end{array} \right ], \\ _ { - \quad \Phi \Phi } \Phi _ { - \quad \Phi \Phi } \Phi _ { - \quad \Phi \Phi }$$
$$T _ { N L } ( E ) \left [ \begin{array} { c } G _ { \mathcal { S }, l r } ^ { ( N ) } ( E ) \\ 0 \end{array} \right ] = \left [ \begin{array} { c } - \kappa _ { \mathcal { S } } ^ { - 1 } \\ \kappa _ { \mathcal { S } } G _ { \mathcal { S }, r r } ^ { ( N ) } ( E ) \end{array} \right ].$$
Thus, the two linearly independent vectors
$$\left \{ [ G _ { \mathcal { S }, l l } ^ { ( N ) } ( E ), - 1, 0, \kappa _ { \mathcal { S } } G _ { \mathcal { S }, r l } ^ { ( N ) } ( E ) ] ^ { T }, [ G _ { \mathcal { S }, l r } ^ { ( N ) } ( E ), 0, - \kappa _ { \mathcal { S } } ^ { - 1 }, \kappa _ { \mathcal { S } } G _ { \mathcal { S }, r r } ^ { ( N ) } ( E ) ] ^ { T } \right \},$$
span the graph of T NL ( E ) . One easily checks that they are the images by the matrix P of the two vectors [1 , 0 , G ( N ) S ,ll ( E , G ) ( N ) S ,rl ( E )] T and [0 , 1 , G ( N ) S ,lr ( E , G ) ( N ) S ,rr ( E )] T which span the graph of G ( N ) S ( E ) . ✷
## 3.3 Transfer matrix eigenvalues and eigenfunctions
Since the Jacobi matrix h crystal is periodic, one has T NL ( E ) = T L ( E ) N for any N . The eigenvalues and eigenvectors of the one-period transfer matrix T L ( E ) will thus play an important role. Since det T L ( E ) = 1 , we may write its eigenvalues as α E ( ) and α E ( ) -1 . It is a standard result (see, e.g., [RS4, Si]) that these eigenvalues are either complex conjugated (and hence of modulus 1) or real. The first case occurs iff | tr T L ( E ) | ≤ 2 which is in turn equivalent to E ∈ sp( h crystal ) . We denote by
$$\Psi _ { \pm } ( E ) = \left [ \begin{array} { c } \phi _ { \pm } ( E ) \\ \kappa _ { \mathcal { S } } \psi _ { \pm } ( E ) \end{array} \right ]$$
an eigenvector of T L ( E ) associated to its eigenvalue α E ( ) ± 1 with the following conventions:
(N1) When E ∈ sp( h crystal ) we chose | α E ( ) | -1 < 1 < α E | ( ) | and real eigenvectors.
glyph[negationslash]
(N2) When E ∈ sp( h crystal ) we chose Ψ ( -E ) = Ψ ( + E ) . Since the two eigenvectors are linearly independent, they can be normalized by φ ± ( E ) = 1 , which further implies Im ψ ± ( E ) = 0 . We then select α E ( ) such that Im ψ + ( E > ) 0 .
glyph[negationslash]
Using Lemma 3.1 and T NL ( E ) = T L ( E ) N , we get
$$G _ { S } ^ { ( N ) } ( E ) & = \frac { - \kappa _ { S } ^ { - 1 } } { D _ { N } ( E ) } \left [ \begin{array} { c c } \phi _ { + } ( E ) \phi _ { - } ( E ) ( \alpha ( E ) ^ { N } - \alpha ( E ) ^ { - N } ) & \phi _ { + } ( E ) \psi _ { - } ( E ) - \phi _ { - } ( E ) \psi _ { + } ( E ) \\ \phi _ { + } ( E ) \psi _ { - } ( E ) - \phi _ { - } ( E ) \psi _ { + } ( E ) & \psi _ { + } ( E ) \psi _ { - } ( E ) ( \alpha ( E ) ^ { N } - \alpha ( E ) ^ { - N } ) \end{array} \right ] \\ \dots \dots$$
where
$$D _ { N } ( E ) = \alpha ( E ) ^ { N } \phi _ { + } ( E ) \psi _ { - } ( E ) - \alpha ( E ) ^ { - N } \phi _ { - } ( E ) \psi _ { + } ( E ).$$
An elementary calculation yields
$$\det ( I - \kappa ^ { 2 } G _ { S } ^ { ( N ) } ( E ) F ( E ) ) = \frac { \alpha ( E ) ^ { N } \widetilde { \phi } _ { + } ( E ) \widetilde { \psi } _ { - } ( E ) - \alpha ( E ) ^ { - N } \widetilde { \phi } _ { - } ( E ) \widetilde { \psi } _ { + } ( E ) } { \alpha ( E ) ^ { N } \phi _ { + } ( E ) \psi _ { - } ( E ) - \alpha ( E ) ^ { - N } \phi _ { - } ( E ) \psi _ { + } ( E ) }, \\ \intertext { a n o }$$
where
$$\widetilde { \psi } _ { \pm } ( E ) = \psi _ { \pm } ( E ) + \eta ^ { 2 } \kappa _ { \mathcal { S } } \phi _ { \pm } ( E ) F _ { l } ( E ), \quad \widetilde { \phi } _ { \pm } ( E ) = \phi _ { \pm } ( E ) + \eta ^ { 2 } \kappa _ { \mathcal { S } } \psi _ { \pm } ( E ) F _ { r } ( E ), \quad ( 3. 3 )$$
and we have set
$$\eta = \frac { \kappa } { \kappa _ { \mathcal { S } } }.$$
Inserting the last relations into (3.1) leads to the following expression for the off-diagonal element of the full Green matrix
$$G _ { l r } ^ { ( N ) } ( E ) = - \kappa _ { \mathcal { S } } ^ { - 1 } \frac { \phi _ { + } ( E ) \psi _ { - } ( E ) - \phi _ { - } ( E ) \psi _ { + } ( E ) } { \alpha ( E ) ^ { N } \widetilde { \phi } _ { + } ( E ) \widetilde { \psi } _ { - } ( E ) - \alpha ( E ) ^ { - N } \widetilde { \phi } _ { - } ( E ) \widetilde { \psi } _ { + } ( E ) }.$$
## 3.4 The large N limit
We proceed to evaluate the large N limit of T N ( E ) in distributional sense.
We write the left hand side of (2.3) as T N, 1 ( f ) + T N, 2 ( f ) with
$$\mathcal { T } _ { N, 1 } ( f ) = \int _ { \text{sp} ( h _ { \text{crystal} } ) \cap \Sigma _ { l } \cap \Sigma _ { r } } \mathcal { T } _ { N } ( E ) f ( E ) \, \mathrm d E,$$
$$\mathcal { T } _ { N, 2 } ( f ) = \int _ { \mathbb { R } \langle \text{sp} ( h _ { \text{crystal} } ) \cap \Sigma _ { l } \cap \Sigma _ { r } ) } \mathcal { T } _ { N } ( E ) f ( E ) \, \mathrm d E.$$
To deal with T N, 2 ( f ) we prove
Lemma 3.2 For almost all E ∈ R \ (sp( h crystal ) ∩ Σ l ∩ Σ ) r one has
$$\lim _ { N \to \infty } \mathcal { T } _ { N } ( E ) = 0.$$
Proof. Combining (1.2) and (3.4), we get
$$\mathcal { T } _ { N } ( E ) = 4 \kappa ^ { 2 } \eta ^ { 2 } \left | \frac { \phi _ { + } ( E ) \psi _ { - } ( E ) - \phi _ { - } ( E ) \psi _ { + } ( E ) } { \alpha ( E ) ^ { N } \widetilde { \phi } _ { + } ( E ) \widetilde { \psi } _ { - } ( E ) - \alpha ( E ) ^ { - N } \widetilde { \phi } _ { - } ( E ) \widetilde { \psi } _ { + } ( E ) } \right | ^ { 2 } \, \text{Im} \, F _ { l } ( E ) \, \text{Im} \, F _ { r } ( E ). \\ \intertext { a n d } \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \end{array}$$
It follows from (1.4) that T N ( E ) = 0 for almost all E ∈ R \ (Σ l ∩ Σ ) r and all N . Thus, it suffices to consider E ∈ (Σ l ∩ Σ ) r \ sp( h crystal ) .
glyph[negationslash]
For such E , the eigenvectors Ψ ( ± E ) are real and | α E ( ) | > 1 by Condition (N1). Moreover, Im F l/r ( E ) > 0 by (1.5). We claim that this implies ˜ φ + ( E ψ ) ˜ -( E ) = 0 from which the result clearly follows. To prove this claim, we argue by contradiction. Assume that ˜ φ + ( E ) = 0 (the case ˜ ψ -( E ) = 0 is similar). It follows from (3.3) that
$$\text{Im} \, \widetilde { \phi } _ { + } ( E ) = \eta ^ { 2 } \kappa _ { \mathcal { S } } \psi _ { + } ( E ) \text{Im} \, F _ { r } ( E ) = 0,$$
and hence ψ + ( E ) = 0 . Using (3.3) again we get φ + ( E ) = ˜ φ + ( E ) = 0 . We conclude that Ψ ( + E ) = 0 , a contradiction. ✷
Since 0 ≤ T N ( E ) ≤ 1 and f ∈ L 1 ( R ) , Lemma 3.2 and the dominated convergence theorem yield that T N, 2 ( f ) → 0 as N →∞ . It thus remains to analyze T N, 1 ( f ) . To this end, we relate the eigenvectors of T L to the Weyl m -functions (2.1).
Lemma 3.3 For any E ∈ sp( h crystal ) , we have
$$\psi _ { + } ( E ) = - \frac { 1 } { \kappa _ { \mathcal { S } } m _ { r } ( E ) }, \quad \psi _ { - } ( E ) = - \kappa _ { \mathcal { S } } m _ { l } ( E ).$$
Proof. Let us write the one-period transfer matrix as
$$T _ { L } ( E ) = \left [ \begin{array} { c c } a ( E ) & b ( E ) \\ c ( E ) & d ( E ) \end{array} \right ].$$
Since det T L ( E ) = 1 , we can write the discriminant of the quadratic equation
$$c ( E ) z ^ { 2 } + ( a ( E ) - d ( E ) ) z - b ( E ) = 0,$$
as (tr T L ( E )) 2 -4 , which is negative for E ∈ sp( h crystal ) . Thus, (3.6) has two complex conjugate solutions. The solution with positive imaginary part is m E r ( ) and the other one is 1 /κ m 2 S l ( E ) . We refer the reader to Section 5.2 in [Si] for a proof of these facts.
Using the representation (3.5) and taking Condition (N2) into account, one easily shows that the eigenvalues and eigenvectors of T L ( E ) are determined by α E ( ) = e i θ E ( ) and
$$\kappa _ { \mathcal { S } } \psi _ { \pm } ( E ) = \frac { 1 } { b ( E ) } \left ( \mathrm e ^ { \pm i \theta ( E ) } - a ( E ) \right ) = \frac { 1 } { b ( E ) } \left ( \frac { d ( E ) - a ( E ) } { 2 } \pm \mathrm i \sin \theta ( E ) \right ),$$
where θ E ( ) ∈ -] π, π [ is defined by
$$\cos \theta ( E ) = \frac { 1 } { 2 } \text{tr} T _ { L } ( E ), \quad \text{sign} ( \theta ( E ) ) = \text{sign} ( b ( E ) ).$$
Note that the product of the two solutions of (3.6) is
$$- \, \frac { b ( E ) } { c ( E ) } = \frac { m _ { r } ( E ) } { \kappa _ { \mathcal { S } } ^ { 2 } m _ { l } ( E ) } = | m _ { r } ( E ) | ^ { 2 } > 0,$$
so that b E ( ) and c E ( ) have opposite signs. It follows that the solutions of (3.6) are
$$m _ { r } ( E ) = \frac { 1 } { c ( E ) } \left ( \frac { d ( E ) - a ( E ) } { 2 } - \text{i} \sin \theta ( E ) \right ),$$
$$\frac { 1 } { \kappa _ { \mathcal { S } } ^ { 2 } m _ { l } ( E ) } = \frac { 1 } { c ( E ) } \left ( \frac { d ( E ) - a ( E ) } { 2 } + \text{i} \sin \theta ( E ) \right ).$$
Comparing these relations with (3.7) and using (3.9) yield the result.
✷
To formulate our next result, let the real functions r E ( ) ≥ 0 and ϑ E ( ) be defined by the following polar decomposition
$$\frac { m _ { l } ( E ) - \eta ^ { 2 } F _ { l } ( E ) } { \overline { m } _ { l } ( E ) - \eta ^ { 2 } F _ { l } ( E ) } \, \frac { m _ { r } ( E ) - \eta ^ { 2 } F _ { r } ( E ) } { \overline { m } _ { r } ( E ) - \eta ^ { 2 } F _ { r } ( E ) } \, \frac { \overline { m } _ { r } ( E ) } { m _ { r } ( E ) } = r ( E ) \mathrm e ^ { i \vartheta ( E ) }.$$
Lemma 3.4 Let I ⊂ sp( h crystal ) ∩ Σ l ∩ Σ r . If there exists δ < 1 such that r E ( ) ≤ δ for almost all E ∈ I , then
$$\lim _ { N \to \infty } \int _ { I } \mathcal { T } _ { N } ( E ) f ( E ) \, \mathrm d E = \int _ { I } \mathcal { T } _ { \infty } ( E ) f ( E ) \, \mathrm d E,$$
for any f ∈ L 1 ( R ) .
Proof. Combining Lemma 3.3 with (1.2) and (3.4) we can write the transmittance of the N -fold repeated sample as
$$\mathcal { T } _ { N } ( E ) & = \frac { 1 6 \eta ^ { 4 } \text{Im} \, m _ { r } ( E ) \text{Im} \, m _ { l } ( E ) } { | \overline { m } _ { r } ( E ) - \eta ^ { 2 } F _ { r } ( E ) | ^ { 2 } | \overline { m } _ { l } ( E ) - \eta ^ { 2 } F _ { l } ( E ) | ^ { 2 } } \frac { \text{Im} \, F _ { l } ( E ) \text{Im} \, F _ { r } ( E ) } { | 1 - r ( E ) \text{e} ^ { i ( 2 N \theta ( E ) + \vartheta ( E ) ) | ^ { 2 } } }, \quad ( 3. 1 1 ) \\ \cdot \quad \lambda \equiv \cdot \cdot \cdot \cdot \cdot \cdot \cdot \lambda \equiv \cdot \cdot \cdot \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot \cdot \cdot \cdot \lambda \cdot$$
where θ E ( ) is defined by (3.8). Expanding the right hand side of (3.11) in powers of r E ( ) , one obtains
$$\mathcal { T } _ { N } ( E ) = \mathcal { T } _ { \infty } ( E ) \sum _ { k \in \mathbb { Z } } r ( E ) ^ { | k | } \text{e} ^ { \text{i} k ( 2 N \theta ( E ) + \vartheta ( E ) ) },$$
where T ∞ ( E ) is given by (2.2). Since r E ( ) ≤ δ < 1 on I , this expansion is uniformly convergent for E ∈ I , and we have
$$\lim _ { N \to \infty } \int _ { I } \mathcal { T } _ { N } ( E ) f ( E ) \, \mathrm d E = \lim _ { N \to \infty } \sum _ { k \in \mathbb { Z } } \int _ { I } \mathcal { T } _ { \infty } ( E ) r ( E ) ^ { | k | } \mathrm e ^ { i k ( 2 N \theta ( E ) + \vartheta ( E ) ) } f ( E ) \, \mathrm d E.$$
Since the function θ E ( ) is strictly monotone in each band of h crystal (see, e.g., Sections 5.3-5.4 in [Si]), the Riemann-Lebesgue lemma yields the result. ✷
For k > 0 , set
$$I _ { k } = \{ E \in \text{sp} ( h _ { \text{crystal} } ) \cap \Sigma _ { l } \cap \Sigma _ { r } \, | \, \text{Im} \, F _ { l / r } ( E ) \geq 1 / k \text{ and } \, | \text{tr} \, T _ { L } ( E ) | < 2 - 1 / k \},$$
and I ′ k = (sp( h crystal ) ∩ Σ l ∩ Σ ) r \ I k . Obviously,
$$\lim _ { k \to \infty } | I _ { k } ^ { \prime } | = 0.$$
It follows from the proof of Lemma 3.3 that there is glyph[epsilon1] k > 0 such that Im m l/r ( E ) ≥ glyph[epsilon1] k for almost every E ∈ I k . One easily concludes that there exists δ k < 1 such that
$$& \left | \frac { m _ { l / r } ( E ) - \eta ^ { 2 } F _ { l / r } ( E ) } { \overline { m } _ { l / r } ( E ) - \eta ^ { 2 } F _ { l / r } ( E ) } \right | \leq \delta _ { k }, \\ \ast \quad \left | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right | \right |$$
holds for almost every E ∈ I k . Thus, for such E ,
$$r ( E ) = \left | \frac { m _ { l } ( E ) - \eta ^ { 2 } F _ { l } ( E ) } { \overline { m } _ { l } ( E ) - \eta ^ { 2 } F _ { l } ( E ) } \right | \left | \frac { m _ { r } ( E ) - \eta ^ { 2 } F _ { r } ( E ) } { \overline { m } _ { r } ( E ) - \eta ^ { 2 } F _ { r } ( E ) } \right | \leq \delta _ { k } ^ { 2 } < 1.$$
## Writing
$$\lambda \left | \mathcal { T } _ { N, 1 } ( f ) - \int \mathcal { T } _ { \infty } ( E ) f ( E ) \, \mathrm d E \right | & \leq \left | \int _ { I _ { k } } ( \mathcal { T } _ { N } ( E ) - \mathcal { T } _ { \infty } ( E ) ) f ( E ) \, \mathrm d E \right | \\ & \quad + \int _ { I _ { k } ^ { \prime } } | ( \mathcal { T } _ { N } ( E ) - \mathcal { T } _ { \infty } ( E ) ) f ( E ) | \, \mathrm d E, \\ \mu \dots \dots \dots \nu \dots \nu \dots \nu \dots \nu$$
and applying Lemma 3.4 to I k , we get
$$\lim _ { N \to \infty } \sup \left | \mathcal { T } _ { N, 1 } ( f ) - \int \mathcal { T } _ { \infty } ( E ) f ( E ) \, \mathrm d E \right | \leq 2 \int _ { I ^ { \prime } _ { k } } | f ( E ) | \, \mathrm d E.$$
This estimate and (3.12) yield
$$\lim _ { N \to \infty } \mathcal { T } _ { N, 1 } ( f ) = \int \mathcal { T } _ { \infty } ( E ) f ( E ) \, \mathrm d E$$
and Theorem 2.1 follows.
## References
[AALR] Abrahams, E., Anderson, P.W., Licciardello, D.C., and Ramakrishnan, T.V.: Scaling theory of localization: Absence of quantum diffusion in two dimensions. Phys. Rev. Lett. 42 , 673-676 (1979).
- [AJPP] Aschbacher, W., Jakši´ c, V., Pautrat, Y., and Pillet, C.-A.: Transport properties of quasi-free fermions. J. Math. Phys. 48 , 032101 (2007).
[BSP] Ben Sâad, R., and Pillet, C-A.: A geometric approach to the Landauer-Büttiker formula. J. Math. Phys. 55 , 075202 (2014).
- [Bu] Busch, P.: The time-energy uncertainty relation. In Time in Quantum Mechanics, second edition. J.G. Muga, R. Sala Mayato and Í.L. Egusquiza editors. Springer, Berlin, 2008.
- [BJP] Bruneau, L., Jakši´ c, V ., and Pillet, C.A.: Landauer-Büttiker formula and Schrödinger conjecture. Commun. Math. Phys., 319 , 501-513 (2013).
[CJM] Cornean, H.D., Jensen, A., and Moldoveanu, V.: A rigorous proof of the LandauerBüttiker formula. J. Math. Phys. 46 , 042106 (2005).
- [ET] Edwards, J.T., and Thouless, D.J.: Numerical studies of localization in disordered systems. J. Phys. C: Solid State Phys. 5 , 807-820 (1972).
| [FP] | Fröhlich, J., and Pfeifer, P.: Generalized time-energy uncertainty relations and bounds on lifetimes of resonances. Rev. Mod. Phys. 67 , 759-779 (1995). |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [GJW] | Grech, P., Jakši´, c V., and Westrich, M.: The spectral structure of the electronic black box Hamiltonian. Lett. Math. Phys. 103 , 1135-1147 (2013). |
| [GNP] | Gesztesy, F., Nowell, R., and Potz, W.: One-dimensional scattering theory for quan- tum systems with nontrivial spatial asymptotics. Diff. Integral Eqs. 10 , 521-546 (1997). |
| [GS] | Gesztesy, F., and Simon, B.: Inverse spectral analysis with partial information on the potential I. The case of an a.c. component in the spectrum. Helv. Phys. Acta 70 , 66-71 (1997). |
| [Ja] | Jakši´, c V.: Topics in spectral theory. Open Quantum Systems I. The Hamiltonian Approach. Lecture Notes in Mathematics 1880 , 235-312, Springer, 2006. |
| [JLPa] | Jakši´, c V., Landon, B., and Panati, A.: A note on reflectionless Jacobi matrices. To appear in Commun. Math. Phys. |
| [JLPi] | Jakši´, c V., Landon, B., and Pillet, C.-A.: Entropic fluctuations in XY chains and reflectionless Jacobi matrices. Ann. Henri Poincaré, 14 , 1775-1800 (2013). |
| [La] | Last, Y.: Conductance and spectral properties. Ph.D. Thesis, Technion (1994). |
| [N] | Nenciu, G.: Independent electrons model for open quantum systems: Landauer- Büttiker formula and strict positivity of the entropy production. J. Math. Phys. 48 , 033302 (2007). |
| [MT] | Mandelstam, L., and Tamm, I.: The uncertainty relation between energy and time in non-relativistic quantum mechanics. J. Phys. (Moscow) 9 , 249-254 (1945). |
| [RS4] | Reed, M., and Simon, B.: Methods of Modern Mathematical Physics IV. Analysis of Operators. Academic Press, New York, 1978. |
| [Si] | Simon, B.: Szegö's Theorem and Its Descendants. Spectral theory for L 2 Perturba- tions of Orthogonal Polynomials. M.B. Porter Lectures. Princeton University Press, Princeton, NJ, 2011. |
| [Th] | Thouless, D.J.: Maximum metallic resistance in thin wires. Phys. Rev. Lett. 39 , 1167-1169 (1977). | | 10.1007/s00220-015-2321-0 | [
"Laurent Bruneau",
"Vojkan Jaksic",
"Yoram Last",
"Claude-Alain Pillet"
] | 2014-08-01T14:13:41+00:00 | 2014-08-01T14:13:41+00:00 | [
"math.SP",
"math-ph",
"math.MP",
"quant-ph"
] | Landauer-Büttiker and Thouless conductance | In the independent electron approximation, the average
(energy/charge/entropy) current flowing through a finite sample S connected to
two electronic reservoirs can be computed by scattering theoretic arguments
which lead to the famous Landauer-B\"uttiker formula. Another well known
formula has been proposed by Thouless on the basis of a scaling argument. The
Thouless formula relates the conductance of the sample to the width of the
spectral bands of the infinite crystal obtained by periodic juxtaposition of S.
In this spirit, we define Landauer-B\"uttiker crystalline currents by extending
the Landauer-B\"uttiker formula to a setup where the sample S is replaced by a
periodic structure whose unit cell is S. We argue that these crystalline
currents are closely related to the Thouless currents. For example, the
crystalline heat current is bounded above by the Thouless heat current, and
this bound saturates iff the coupling between the reservoirs and the sample is
reflectionless. Our analysis leads to a rigorous derivation of the Thouless
formula from the first principles of quantum statistical mechanics. |
1408.0186v2 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Heavy Ion Collision evolution modeling with ECHO-QGP
V. Rolando a,b , G. Inghirami c,d , A. Beraudo , L. Del Zanna e c,d,f , F. Becattini c,d , V. Chandra , d A. De Pace e , M. Nardi e a Dipartimento di Fisica e Scienze della Terra, Universit` di Ferrara, Via Saragat 1, I-44100 Ferrara, Italy a b INFN - Sezione di Ferrara, Via Saragat 1, I-44100 Ferrara, Italy c Dipartimento di Fisica e Astronomia, Universit` di Firenze, Via G. Sansone 1, I-50019 Sesto F .no (Firenze), Italy a d INFN - Sezione di Firenze, Via G. Sansone 1, I-50019 Sesto F.no (Firenze), Italy e INFN - Sezione di Torino, Via P. Giuria 1, I-10125 Torino, Italy f INAF - Osservatorio Astrofisico di Arcetri, L.go E. Fermi 5, I-50125 Firenze, Italy
## Abstract
We present a numerical code modeling the evolution of the medium formed in relativistic heavy ion collisions, ECHO-QGP. The code solves relativistic hydrodynamics in (3 + 1) GLYPH<0> D, with dissipative terms included within the framework of Israel-Stewart theory; it can work both in Minkowskian and in Bjorken coordinates. Initial conditions are provided through an implementation of the Glauber model (both Optical and Monte Carlo), while freezeout and particle generation are based on the Cooper-Frye prescription. The code is validated against several test problems and shows remarkable stability and accuracy with the combination of a conservative (shock-capturing) approach and the high-order methods employed. In particular it beautifully agrees with the semi-analytic solution known as Gubser flow, both in the ideal and in the viscous Israel-Stewart case, up to very large times and without any ad hoc tuning of the algorithm.
Keywords: QGP, Hydrodynamics, Heavy-ion, Heavy-ion collision
## 1. Introduction
During the past years hydrodynamics has been aknowledeged as the most powerful tool to study the evolution of the medium formed in high-energy nuclear collisions. For this reason a variety of calculations and numerical codes have been developed, starting from the simple longitudinal boost-invariant Bjorken (1 + 1) GLYPH<0> D calculation [1], passing through (2 + 1) GLYPH<0> D and (3 + 1) GLYPH<0> D codes solving ideal hydrodynamics [2-4], up to more complex and structured codes simulating a full (3 + 1) GLYPH<0> D viscous evolution for the QGP fluid[5-10].
In order to solve dissipative hydrodynamics, one needs to deal with a set of non-linear partial di GLYPH<11> erential equations, which includes the conservation of the energy momentum tensor ( @GLYPH<22> T GLYPH<22>GLYPH<23> = 0) and of conserved charges like the baryon number ( @GLYPH<22> N GLYPH<22> = 0), together with the time evolution of the bulk viscosity ( GLYPH<5> ) and the shear stress tensor ( GLYPH<25> GLYPH<22>GLYPH<23> ). The system is closed by the choice of a suitable Equation of State (EoS). While the naive relativistic extension of the Navier-Stokes equations is a GLYPH<11> ected by a well known causality problem, a consistent theoretical setup to include dissipative e GLYPH<11> ects is the one formulated by Israel and Stewart [11] .
In this context ECHO-QGP was presented last year [12], equipped with second-order treatment of causal relativistic viscosity e GLYPH<11> ects and unique features such as the possibility of choosing between two di GLYPH<11> erent metric tensors and of solving either purely ideal or viscous hydrodynamics equations. As the other analogous tools, ECHO-QGP is characterized by a modular structure, allowing one to address the modeling of the initial conditions, the solution of the hydrodynamic evolution of the medium - representing the core of the code - and, eventually, the simulation of
the final particle decoupling. ECHO-QGP is highly customizable, allowing the user to choose among a variety of initial conditions (including both optical and Monte Carlo Glauber model) as well as the possibility of defining an energy density (or entropy density) profile from scratch. The same principle applies to the equation of state: ECHOQGP can handle both analytical and tabulated equations of state. The decoupling stage exploits the Cooper-Frye prescription[13], allowing the calculation of a mean spectrum of or the Monte Carlo generation of a discrete set of particles. The hypersurface detection has been recently upgraded with the embedding of a refined algorithm which creates a smooth mesh[14].
In order to ensure the reliability of the solving algorithm for the evolution stage, in our original publication [12] we showed how ECHO-QGP is able to overcome several numerical tests, displaying a beautiful agreement with some special analytic solutions. In the present contribution the above e GLYPH<11> orts in validationg the code will be briefly reminded and extended to the case of the so called Gubser-flow (both ideal and viscous), meanwhile appeared in the literature [15-17]. The latter represents a very important test, since the code has to reproduce a very non-trivial flow in (2 + 1)D in the presence of non-vanishing viscosity and relaxation time. ECHO-QGP turns out to be able to overcome such a test.
Finally, having at our disposal such a validated tool, we will outline our future programs.
## 2. Testing ECHO-QGP
ECHO-QGP has been widely tested, displaying agreement with analytic and semi-analytic solutions and other publicly available numerical codes.
Among the various test performed, an important role is played by the (2 + 1)-D shock-tube problem. Shock-capturing numerical schemes are designed to handle and evolve discontinuous quantities invariably arising due to the nonlinear nature of the fluid equations. In order to validate these codes, typical tests are the so-called shock-tube problems, performed in the heavy-ion field also by [18]. The test gives a good esteem of the behavior of the fluid in presence of non-vanishing GLYPH<17>= s . In figure 1, we compare the energy density profile for the viscid and unviscid case, where the high accuracy of the results and the absence of numerical spurious oscillations near the shock front in the ideal case can be appreciated.
(a) Shock tube test: velocity profile
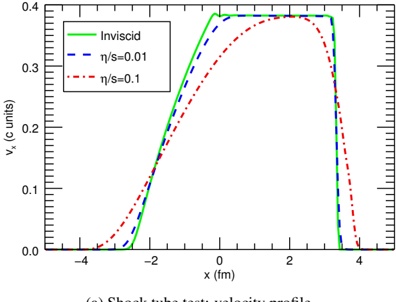
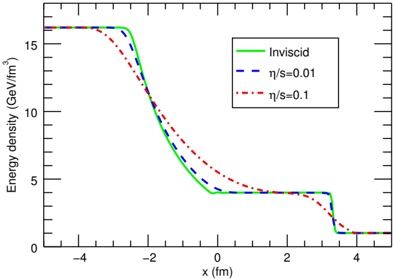
(b) Shock tube test: energy density profile
Figure 1: Shock tube test for ECHO-QGP. The test is performed placing an initial diaphragm along the diagonal of a square box (201 points and size 10 fm along x and y) adopting Minkowskian Cartesian coordinates, and letting ECHO-QGP evolve from t = 1 up to t = 4 fm c. = The temperatures in the sides of the diaphragm are chosen to be T L = 0 4 GeV and : T R = 0 2 GeV. It can be appreciated how the viscosity a : GLYPH<11> ects the evolution, and how ECHO-QGP handles shocks in the ideal case without the introduction of dumps.
Another fundamental qualifying test which numerical hydrodynamic codes have recently started addressing is the so called Gubser-flow. The latter is a (2 + 1)D solution for a conformal fluid (with an EoS P = e = 3) characterized by
longitudinal boost invariance and non-trivial azymuthally symmetric radial expansion. It was derived first by Gubser et al. [15, 16] for an ideal fluid and extended only last year to the viscous case, within the Israel-Stewart setup, by Marrochio et al. [17]. The derivation of the solution is based on a rescaling of the metric (Weyl rescaling) and on a change of coordinates, which allows one to exploit at best the symmetries of the system arising from conformal invariance. In particular, one applies to the metric ds 2 = GLYPH<0> d GLYPH<28> 2 + dr 2 + r 2 d GLYPH<30> 2 + GLYPH<28> 2 d GLYPH<17> 2 the rescaling ds 2 ! ds ˆ 2 GLYPH<17> ds 2 =GLYPH<28> 2 .
In addition, one has to perform the coordinate transformation ds ˆ 2 = GLYPH<0> d GLYPH<26> 2 + cosh 2 GLYPH<26> ( d GLYPH<18> 2 + sin 2 GLYPH<18> d GLYPH<30> 2 ) + d GLYPH<17> 2 ; where the new coordinates are given by sinh GLYPH<26> GLYPH<17> GLYPH<0> 1 GLYPH<0> q 2 ( GLYPH<28> 2 GLYPH<0> r 2 ) 2 q GLYPH<28> and tan GLYPH<18> GLYPH<17> 2 qr 1 + q 2 ( GLYPH<28> 2 GLYPH<0> r 2 ) , where q is an arbitrary energy scale. In the new space (with quantities labeled by a hat) the fluid is at rest, ˆ u GLYPH<22> = ( GLYPH<0> 1 0 0 0), and the only equations to solve are: ; ; ;
$$\frac { 1 } { \hat { T } } \frac { d \hat { T } } { d \rho } + \frac { 2 } { 3 } \tanh \rho = \frac { 1 } { 3 } \tanh \rho \bar { \pi } _ { \eta } ^ { \eta }, & \hat { \tau } _ { R } \left [ \frac { d \bar { \pi } _ { \eta } ^ { \eta } } { d \rho } + \frac { 4 } { 3 } \left ( \bar { \pi } _ { \eta } ^ { \eta } \right ) ^ { 2 } \tanh \rho \right ] + \bar { \pi } _ { \eta } ^ { \eta } = \frac { 4 } { 3 } \frac { \hat { \eta } } { \hat { S } \hat { T } } \tanh \rho, & ( 1 )$$
where ¯ GLYPH<25> GLYPH<17> ˆ GLYPH<25>= ˆ ˆ. Ts Physical quantities in Minkowski space can be obtained from the above equations through the mapping
$$T = \hat { T } / \tau, \quad u _ { \mu } = \tau \frac { \partial \hat { x } ^ { \alpha } } { \partial x ^ { \mu } } \hat { u } _ { \alpha }, \quad \pi _ { \mu \nu } = \frac { 1 } { \tau ^ { 2 } } \frac { \partial \hat { x } ^ { \alpha } } { \partial x ^ { \mu } } \frac { \partial \hat { x } ^ { \beta } } { \partial x ^ { \nu } } \hat { \pi } _ { \alpha \beta }$$
and compared to the numerical solution provided by ECHO-QGP, as displayed in Fig. 2.
The results have been obtained without any fine tuning of the parameters or modifications of the reconstruction algorithm. Nonetheless, ECHO-QGP reproduces with very high accuracy (the discrepancy is on average of the order of 0.1%) and up to late times (we verified the agreement up to 10 fm c) the temperature (see Fig. / 2d), all the shearstress tensor components (see Figs. 2a,2b,2c) and obviously the flow (not shown).
## 3. Conclusions
ECHO-QGP guarantees stability and precision, as well as completeness in documentation and ease in the usage. We presented all those ECHO-QGP features in [12] and we remark its suitablity to model heavy-ion collisions showing how well it reproduces the flow and shear stress tensor in the viscous relativistic frame proposed in ref. [15-17]. Moreover, ECHO-QGP has been positively used for the investigation fluctuation propagations[19, 20], and it is currently used to study vorticity e GLYPH<11> ects on the directed flow (in preparation).
## 4. Aknowledgements
We would like to thank G. Denicol and the authors of the reference [17] for interesting discussions and advices about the semi-analytic solution. V.R. would like to thank prof. R. Tripiccione, G. Pagliara and A. Drago for their help in many interesting discussions about the decoupling stage.
This work has been supported by the Italian Ministry of Education and Research, grant n. 2009WA4R8W.
## References
- [1] J. Bjorken, Phys.Rev. D27 (1983) 140-151. doi:10.1103/PhysRevD.27.140 .
- [2] P. F. Kolb, J. Sollfrank, U. W. Heinz, Phys.Rev. C62 (2000) 054909. arXiv:hep-ph/0006129 doi:10.1103/PhysRevC.62.054909 , .
- [3] P. F. Kolb, R. Rapp, Phys.Rev. C67 (2003) 044903. arXiv:hep-ph/0210222 doi:10.1103/PhysRevC.67.044903 , .
- [4] P. F. Kolb, U. W. Heinz, arXiv:nucl-th/0305084 .
.
- [5] M. Luzum, P. Romatschke, Physical Review Letters 103 (26) (2009) 1-4. doi:10.1103/PhysRevLett.103.262302
- [6] R. Baier, P. Romatschke, U. A. Wiedemann, Physical Review C 73 (6) (2006) 18. arXiv:0602249 doi:10.1103/PhysRevC.73.064903 , .
- [7] P. Romatschke, Int.J.Mod.Phys. E19 (2010) 1-53. arXiv:0902.3663 doi:10.1142/S0218301310014613 , .
- [8] S. Ryu, S. Jeon, C. Gale, B. Schenke, C. Young, Nucl.Phys. A904-905 (2013) 389c-392c. doi:10.1016/j.nuclphysa.2013.02.031 .
- [9] C. Gale, S. Jeon, B. Schenke, P. Tribedy, R. Venugopalan, Phys.Rev.Lett. 110 (2013) 012302. doi:10.1103/PhysRevLett.110.012302 .
- [10] B. Schenke, S. Jeon, C. Gale, Phys.Rev. C82 (2010) 014903. arXiv:1004.1408 doi:10.1103/PhysRevC.82.014903 , .
- [11] W. Israel, J. Stewart, Annals Phys. 118 (1979) 341-372. doi:10.1016/0003-4916(79)90130-1 .
- [12] L. Del Zanna, V. Chandra, G. Inghirami, V. Rolando, A. Beraudo, A. De Pace, G. Pagliara, G. Drago, F. Becattini, EPJ C73 (2013) 2524. doi:10.1140/epjc/s10052-013-2524-5 .
- [13] Cooper, Fred and Frye, Graham, Physical Review D 10 (1) (1974) 186-189. doi:{10.1103/PhysRevD.10.186} .
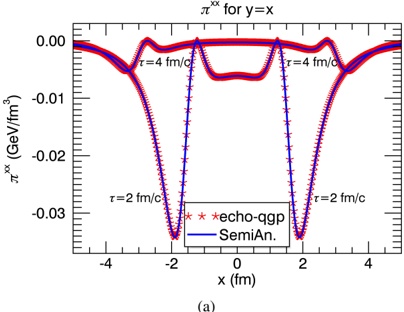
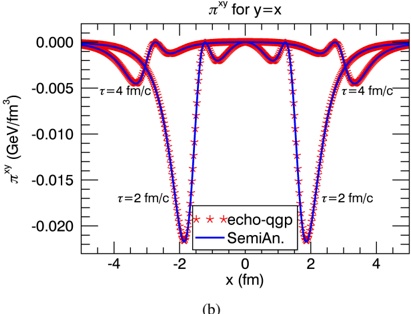
(b)
Figure 2: Comparison between the semi-analytic solution, eq. 1 and an ECHO-QGP (2 + 1) GLYPH<0> D simulation within the Bjorken coordinate metrics. The test is performed letting the fluid evolution be initialized with a symmetric energy density profile together, created ad hoc. The simulation has been performed with a grid of 0.025 fm in space and 0.001 fm in time. The shear viscosity to entropy density ratio is set to GLYPH<17>= s = 0 2, while the shear relaxation time is : GLYPH<28> R = 5 GLYPH<17>= ( e + P ). The energy scale is fixed at q = 1 fm GLYPH<0> 1 while the equation of state must be the one of a conformal fluid, we choose e = 3 P .
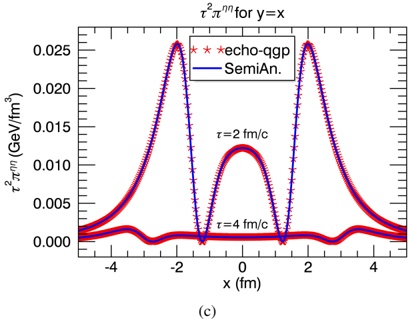
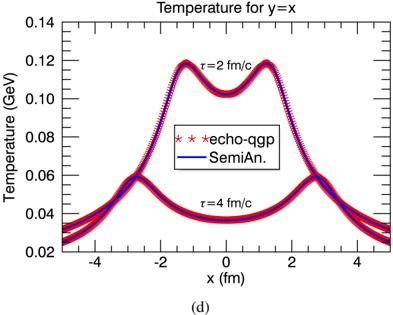
The excellent agreement between the two can be appreciated for every component of the shear stress tensor (we show here just GLYPH<25> xx , GLYPH<25> xy and GLYPH<25> GLYPH<17>GLYPH<17> , but all the components present the same agreement), and for the thermodynamic variables (again we just show the temperature). For the sake of clearness, we show here just two close time steps ( GLYPH<28> = 2 and GLYPH<28> = 4), but the quality of the result is maintained up to much higher times. We remark then ECHO-QGP reproduces the semi-analytic solution without any need of fine-tuning.
- [14] P. Huovinen, H. Petersen, EPJ A48 (2012) 171. arXiv:1206.3371 doi:10.1140/epja/i2012-12171-9 , .
- [15] S. S. Gubser, A. Yarom, Nucl.Phys. B846 (2011) 469-511. arXiv:1012.1314 doi:10.1016/j.nuclphysb.2011.01.012 , .
- [16] S. S. Gubser, Phys.Rev. D82 (2010) 085027. arXiv:1006.0006 doi:10.1103/PhysRevD.82.085027 , .
- [17] H. Marrochio, J. Noronha, G. S. Denicol, M. Luzum, S. Jeon, et al., arXiv:1307.6130 .
- [18] E. Molnar, H. Niemi, D. Rischke, EPJ C65 (2010) 615-635. arXiv:0907.2583 doi:10.1140/epjc/s10052-009-1194-9 , .
- [19] S. Floerchinger, U. A. Wiedemann, A. Beraudo, L. Del Zanna, G. Inghirami, V. Rolando, arXiv:1312.5482 .
- [20] S. Floerchinger, U. A. Wiedemann, arXiv:1405.4393 . | 10.1016/j.nuclphysa.2014.08.011 | [
"Valentina Rolando",
"Gabriele Inghirami",
"Andrea Beraudo",
"Luca Del Zanna",
"Francesco Becattini",
"Vinod Chandra",
"Arturo De Pace",
"Marzia Nardi"
] | 2014-08-01T14:15:49+00:00 | 2014-08-05T07:21:53+00:00 | [
"hep-ph",
"nucl-th"
] | Heavy Ion Collision evolution modeling with ECHO-QGP | We present a numerical code modeling the evolution of the medium formed in
relativistic heavy ion collisions, ECHO-QGP. The code solves relativistic
hydrodynamics in $(3+1)-$D, with dissipative terms included within the
framework of Israel-Stewart theory; it can work both in Minkowskian and in
Bjorken coordinates. Initial conditions are provided through an implementation
of the Glauber model (both Optical and Monte Carlo), while freezeout and
particle generation are based on the Cooper-Frye prescription. The code is
validated against several test problems and shows remarkable stability and
accuracy with the combination of a conservative (shock-capturing) approach and
the high-order methods employed.
In particular it beautifully agrees with the semi-analytic solution known as
Gubser flow, both in the ideal and in the viscous Israel-Stewart case, up to
very large times and without any ad hoc tuning of the algorithm. |
1408.0187v2 | ## Relevance of the eigenstate thermalization hypothesis for thermal relaxation
Abdellah Khodja, 1, ∗ Robin Steinigeweg, 2, † and Jochen Gemmer 1, ‡
1 Department of Physics, University of Osnabr¨ck, u D-49069 Osnabr¨ck, Germany u 2 Institute for Theoretical Physics, Technical University Braunschweig, D-38106 Braunschweig, Germany
(Dated: June 19, 2015)
We study the validity of the eigenstate thermalization hypothesis (ETH) and its role for the occurrence of initial-state independent (ISI) equilibration in closed quantum many-body systems. Using the concept of dynamical typicality, we present an extensive numerical analysis of energy exchange in integrable and nonintegrable spin-1 / 2 systems of large size outside the range of exact diagonalization. In case of nonintegrable systems, our finite-size scaling shows that the ETH becomes valid in the thermodynamic limit and can serve as the underlying mechanism for ISI equilibration. In case of integrable systems, however, indication of ISI equilibration has been observed despite the violation of the ETH. We establish a connection between this observation and the need of choosing a proper parameter within the ETH.
PACS numbers: 05.30.-d, 75.10.Jm, 03.65.Yz, 05.45.Pq
## I. INTRODUCTION
Due to experiments in ultracold atomic gases [1-5], the question of thermalization in closed quantum systems has experienced an upsurge of interest in recent years. It is, however, a paradigm of standard thermodynamical processes that the final equilibrium state is generally independent of the details of the initial state. But this general initial-state independence (ISI) is challenging to proof from an underlying theory such as quantum mechanics. While for local density matrices of subsystems the issue of necessary and sufficient conditions for ISI is subtle [6, 7], for expectation values of observables a widely accepted sufficient condition for ISI is the validity of the eigenstate thermalization hypothesis (ETH) [8-10]. It claims that the expectation values of a given observable A should be similar for energy eigenstates | n 〉 if the energy eigenvalues E n are close to each other, i.e., 〈 n A n | | 〉 ≈ 〈 n A n ′ | | ′ 〉 if E n ≈ E n ′ . The relation to ISI equilibration can be seen from considering the dynamics
$$\underset { \Lambda } { \geq } \quad a ( t ) \coloneqq \text{Tr} \{ \rho ( t ) \, A \} = \sum \nolimits _ { n m } \rho _ { n m } \, A _ { m n } \, e ^ { \imath ( E _ { m } - E _ { n } ) t } \ \ ( 1 ) \quad \text{witho} \quad \text{if one}$$
with A mn = 〈 mAn | | 〉 and averaging over sufficiently long times. Given that there are no degeneracies [11], this averaging yields
$$\bar { a } \approx \sum \nolimits _ { n } \rho _ { n n } \, A _ { n n } \,. \quad \quad ( 2 ) \quad \text{th} \quad.$$
If, as the ETH claims, all A nn from an energy region around E are similar, i.e., A nn ≈ A E ( ), then obviously ¯ a ≈ A E ( ) regardless of the initial state ρ (0), as long as it is also restricted to the same energy region. Hence, if various a t ( ) from an energy shell equilibrate at all (for
∗ Electronic address: [email protected]
† Electronic address: [email protected]
‡ Electronic address: [email protected]
FIG. 1: (color online) Schematic representation of the systems for the study of energy exchange between a 'left' (L) and 'right' (R) part.
conditions on that see Refs. [7, 11]), they must do so at the same value A E ( ), i.e., ISI applies.
Much less clear is whether or not the validity of the ETH is also a physically necessary condition for ISI in the sense that no relevant set of states can exhibit ISI without the ETH being fulfilled. (It is surely necessary if one requires that all states exhibit ISI.) Equation (2) allows for mathematically constructing different initial states with the same ¯ even in cases a where the ETH does not apply (see, e.g., Refs. [12, 13]). Thus, the ETH may not be a physically necessary condition. However, the ETH has numerically been found to be fulfilled for a variety of systems and observables, and it is commonly expected that the ETH applies to few-body observables in nonintegrable quantum systems [8, 9, 16, 17]. But this expectation is still lacking a rigorous proof. Therefore, the crucial question is: Is the ETH the 'force that drives' physical equilibration?
In the present paper, we consider this question by two different numerical approaches: i) We study the ETH concerning energy exchange for a variety of coupled subsystems. From the second law, ISI equilibration is strongly expected for each setting. ii) We investigate equilibration dynamics in systems for which the ETH is
/negationslash clearly violated. In both approaches, we apply the concept of dynamical typicality [18-22] and provide a careful finite-size scaling since, for any finite system, the ETH is never strictly fulfilled (i.e., A nn = A E ( ) except for trivial cases) [21, 23-25]. Our study in i) unveils that the ETH is fulfilled for energy exchange in nonintegrable systems and particularly approaches the thermodynamic limit according to a power-law dependence on the effective Hilbert-space dimension. Our investigations in ii) are different from other approaches based on quantum quenches [16, 26-30] or a period of time-dependent driving [31]. Still, we use pure initial states. But we prepare initial states with the property that the observable of interest deviates largely from its equilibrated value, while these states are still restricted to an energy shell. We consider this subclass of all possible initial states to be generic for equilibration experiments. As a main result, we observe ISI relaxation of energy exchange in an integrable system where the ETH clearly breaks down. In this way, we unveil the need of choosing a proper ETHviolation parameter.
This paper is structured as follows: In the next Sec. II we introduce the numerical method used as well as the models and observable studied. Then we summarize and discuss in Sec. III our results on the ETH and ISI equilibration in nonintegrable systems. The following Sec. III is devoted to the relationship between the ETH and ISI equilibration for the specific case of integrable systems and the above mentioned 'observable-displaced' initial states. In the last Sec. V we summarize and draw conclusions.
## II. METHOD, MODELS, AND OBSERVABLE
Convenient parameters to quantify the ETH w.r.t. a given Hamiltonian H and observable A are
$$\bar { A } = \sum _ { n = 1 } ^ { d } p _ { n } \, A _ { n n } \,, \ \Sigma ^ { 2 } = \sum _ { n = 1 } ^ { d } p _ { n } \, A _ { n n } ^ { 2 } - \bar { A } ^ { 2 } \,, \quad ( 3 ) \quad \text{$\text{$\text{$copy$}$} } \\ \text{are s} \\ \text{are $cc}$$
where A nn are diagonal matrix elements w.r.t. the Hamiltonian eigenstates | n 〉 with eigenvalues E n , p n ∝ e -( E n -¯ ) E 2 / σ 2 2 is a probability distribution centered at ¯ , E and d is the Hilbert-space dimension. The quantities ¯ ( A E,σ ¯ ) and Σ( ¯ E,σ ) are obviously functions of ¯ and an E energy width σ . Routinely, the ETH is said to be fulfilled if Σ is small. However, whenever σ is finite, Σ can only be zero for vanishing slopes of ¯ , A i.e., ∂A/∂E ¯ ¯ = 0. Therefore, for finite σ , the ETH is fulfilled if Σ → ∂A/∂E σ ¯ ¯ in the limit of large system sizes [21].
A crucial point in this paper is of course finite-size scaling. To render this scaling as convincing as possible, one needs data on systems as large as possible. Usually, checking the ETH requires exact diagonalization [24, 25] that is limited to rather small system sizes. Thus, we employ a recently suggested method [21] that is based on dynamical typicality and allows for the extraction of
FIG. 2: (color online) Mean energy difference ¯ D of energy eigenstates in an energy shell of width σ = 0 6 around . ¯ , E calculated for the model in Fig. 1 (a) with anisotropy ∆ = 0 3 . and system size N L = 8. For the 'average eigenstate', the distribution of energy onto the subsystems is proportional to their sizes.
information on the ETH from the temporal propagation of pure states. This propagation can be performed by iterative algorithms such as Runge-Kutta [20-22], Chebyshev [32, 33], etc. and is feasible for larger system sizes. We use a fourth-order Runge-Kutta iterator with a sufficiently small time step. Due to typicality-related reasons, the so-computed quantities ¯ and Σ are subject to statisA tical errors. These errors, however, turn out to be smaller than the symbol sizes used in this paper [22].
We study systems consisting of two weakly coupled XXZ spin-1 / 2 chains (except for one example discussed below). The Hamiltonian of the chains has open boundary conditions and is given by
$$\ e m s _ { \text{ital} } \quad \cdot \quad \cdot \quad \cdot \quad \cdot \\ \text{on} \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd. \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd. \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdor \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd. \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd. \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \ \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \ ::� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \d� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \cd� \quad \cd� \cd� \quad \cd� \cd� \cd� \quad \cd� \quad \cd� \cd� \quad \cd� \cd� \cd� \cd� \cd� \quad \cd� \cd� \cd� \cd� \quad \cd� \cd� \cd� \cd� \quad \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \quad \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \quad \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd. \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \d� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd� \cd$$
where j = L, R labels the 'left' and 'right' chain. N L , N R are the respective numbers of spins in the chains, see Figs. 1 (a)-(c). J = 1 is the antiferromagnetic exchange coupling constant and ∆ is the exchange anisotropy. h i,j are spatially random magnetic fields in z direction that are drawn at random according to a uniform distribution between -W/ 2 and W/ 2. This way of introducing disorder is similar to the random on-site potential of the Anderson model, widely investigated in the context of many-body localization [34].
To allow for energy exchange, we add a coupling term H C between the two chains: H = H L + H R + H C . This term has a very similar form and reads
$$\underset { \text{size} } { \text{ere} } ^ { N _ { L } } \underset { i = 1 } { \text{$N_{L}$} } c _ { i } \left ( S _ { i, L } ^ { x } S _ { i, R } ^ { x } + S _ { i, L } ^ { x } S _ { i, R } ^ { x } + \Delta S _ { i, L } ^ { z } S _ { i, R } ^ { z } \right ), \ \ ( 5 )$$
where J C is the coupling strength. For c i = 1, the total Hamiltonian H represents a nonintegrable structure of ladder type while, for c i = δ i, ( 1), H reduces to a single chain. This chain is integrable for J = J C and W = 0 only. We also consider the intermediate case with c i = δ i, ( 1) + δ i, N ( L ) and a two-dimensional situation with
c i = 1: In this situation the chains in Eq. (4) are replaced by N j × N j lattices with interactions between all nearest neighbors and the coupling in Eq. (5) is replaced by an interaction at the contact of the lattices, as illustrated in Fig. 1 (d).
The observable A we are going to investigate for accord with the ETH is the energy difference. A is represented by the operator D = H L -H R . For any left-right symmetric model and observable, the ETH is necessarily fulfilled. Thus, to avoid this trivial case, we choose right chains to consist of twice as much spins as the left chains throughout this paper, see Figs. 1 (a)-(c). In the twodimensional situation we choose the right-lattice side to have one spin more than the left-lattice side.
## III. RESULTS ON NONINTEGRABLE SYSTEMS
First, we consider ¯ ( ¯ ), D E i.e., the mean energy difference for the energy eigenstates in a small energy interval centered at ¯ . E We control the smallness of this energy interval by choosing σ = 0 6. (This choice is kept for the . remainder of this paper.) Results on the model in Fig. 1 (a) are displayed in Fig. 2 for various coupling strengths J C at fixed anisotropy ∆ = 0 3 and system size . N L = 8.
To gain insight into the results in Fig. 2, let us consider the following analog to the standard equipartition theorem: Assume that every term in the Hamiltonian ('bond') contains for energy eigenstates an amount of energy proportional to its strength. For weak coupling, the energies corresponding to terms of H C can be neglected. Then one expects a left/right-chain partition of energy as ( N L -1) / N ( R -1) = 7 / 15, yielding an energy difference ¯ = ( D N L -N R ) / N ( R + N L -2) ¯ = E -4 ¯ E/ 11. This expectation is indicated by the solid line in Fig. 2. Clearly, the equipartition assumption is well justified for a wide range of interactions strengths J C ≤ 0 6. . We find this principle to hold for each model addressed in this paper, even though not shown explicitly here. This finding is a first main result, although not at the center of the investigation in this paper.
Next we turn to the ETH. To limit computational effort, we focus on the energy regime around ¯ = 0, howE ever, we have found similar results for other points in energy space. For the E = 0 regime we compute both, d eff = Tr { e -( H -¯ ) E 2 / σ 2 2 } and Σ ′ = Σ -∂D/∂Eσ ¯ ¯ . d eff has the meaning of the number of eigenstates that constitute the 'relevant' energy shell. Σ is the quantity that is ex-′ pected to approach zero if the ETH is fulfilled. (We get ∂D/∂Eσ ¯ ¯ = 0 21 throughout this paper.) . For all models studied, we show in Fig. 3 a double logarithmic plot of Σ as a function of ′ d eff that increases with system size.
In Figs. 3 (a)-(c) we summarize our results on Σ ′ for the model in Fig. 1 (a): In Fig. 3 (a) we vary the coupling strength J C at fixed anisotropy ∆ = 0 3; In Fig. 3 . (b) we vary the anisotropy ∆ at fixed coupling strength J C = 0 3; and in Fig. 3 (c) we study cases of weak and in-.
FIG. 3: (color online) The parameter Σ , quantifying the de-′ gree of ETH violation, as a function of the effective dimension d eff that increases with system sizes. The violation appears to vanish according to a power law in the limit of large system sizes, regardless of the properties of the specific models studied in (a)-(d). For model parameters, see text.
termediate amount of disorder for ∆ = 0 6 and . J C = 0 3. . In Fig. 3 (d) we show results for the same values ∆ = 0 6 . and J C = 0 3 but for . W = 0 and the different coupling structure in Fig. 1 (b) and the two-dimensional case in Fig. 1 (d).
In all cases, Σ ′ apparently scales with d eff as a power law Σ ′ ∝ d -γ eff , which is in accord with the findings in Ref. [25]. Consequently, the ETH is fulfilled in the limit of large system sizes. This is our second main result. It indeed indicates that the relaxation of the energy difference between weakly coupled quantum objects may be generically expected for all sorts of initial states. For a random-matrix model, one would expect a power-law scaling with the exponent γ = 0 5. For all nonintegrable . cases we studied we find a slightly different exponent. If we call closeness to γ = 0 5 the 'amount' of noninte-. grability, then the two-dimensional case in Fig. 1 (d) is the most nonintegrable one studied here. For the onedimensional cases, the amount of nonintegrability does not depend crucially on the coupling constant J C in the small J C regime, while the dependence on the anisotropy ∆ is nonmonotonic.
## IV. MICROCANONICAL OBSERVABLE, DISPLACED STATES AND RESULTS ON INTEGRABLE SYSTEMS
The above findings certainly raise immediately the question of ISI equilibration in integrable models: Is it reasonable to expect the violation of ISI equilibration for two subsystems which are connected to form an integrable system? Comparable investigations found answers in both directions [27, 28, 35], even for nonintegrable systems [14, 15, 36]. To analyze this question, we study a
FIG. 4: (color online) The ETH parameter Σ ′ (circles), the scaled ETH parameter v (squares), and the long-time value r for the integrable Heisenberg chain in an energy window of width σ = 0 6 around energy . ¯ = 0. All quantities are shown E as a function of the inverse number of spins 1 /N L .
pure Heisenberg chain, from the point of view depicted in Fig. 1 (c). As already mentioned, this Heisenberg chain is integrable for J C = 1, ∆ = 0 6 and . W = 0. For this model, we show in Fig. 4 (circles) results on Σ ′ as a function of 1 /N L .
Unlike all previous examples, Σ ′ does not decrease as system size increases, which is in accord with the system being integrable. To clarify the impact on relaxation, we analyze the dynamics of 'microcanonical' and 'observable-displaced' initial states ρ MOD ,
$$\rho _ { \text{MOD} } \colon \in e ^ { - ( H ^ { 2 } + \beta ^ { 2 } [ D - d ( 0 ) ] ^ { 2 } ) / 2 \sigma ^ { 2 } } \,. \quad \quad ( 6 ) \quad \text{for} \, \cdot$$
Obviously, the parameter d (0) controls the degree of observable displacement. The energy is concentrated within a width σ around zero. Since H and D do not commute, we need to find a compromise between energy concentration and observable displacement, done by tuning β . We choose σ = 0 6, . β = 0 5, . and d (0) = ± N L . This state may be viewed as being based on Jayne's principle: It represents the maximum-entropy state under given means and variances for energy and observable.
A comment on the usage of this type of initial states as opposed to initial states generated by quantum quenches may be instructive. While quantum-quench approaches produce a complex, non-stationary state, it may or may not make the considered observable deviating from its long-time average. The MOD state, on the other hand, is deliberately designed to obtain a specific initial value of the considered observable while keeping the energy reasonably well-defined. Thus, the MOD approach facilitates the generation of initial values of the observable that are 'substantially off-equilibrium', to put it in a catchy phrase. Using the above parameters, we indeed get Tr { ρ MOD D (0) } ≈ d (0) = ± N L . The largest eigenvalue of D is upper-bounded by D ≤ 9 / 4( N L -1). Hence, the initial expectation value of D reaches at least 50% of the difference between its highest possible value and its long-time average. Corresponding values for standard quench dynamics are usually much lower [15, 16].
Note also that such a MOD state does not necessarily feature a smooth probability distribution w.r.t. energy, as suggested in Ref. [37] to explain ISI.
Numerically, ρ MOD is challenging to compute for sys- tems beyond the reach of exact diagonalization. Thus, we prepare the partially random state
$$| \phi _ { \text{MOD} } \rangle = \langle \varphi | \rho _ { \text{MOD} } | \varphi \rangle ^ { - 1 / 2 } \, \rho _ { \text{MOD} } ^ { 1 / 2 } \, | \varphi \rangle \,, \quad ( 7 )$$
where | ϕ 〉 is a random state drawn according to the unitary invariant (Haar-) measure. In the context of typicality, e.g, from Ref. [19, 22], it may be inferred that the dynamics of | φ MOD 〉 are similar to those of ρ MOD w.r.t. to the observable, i.e.,
$$\underset { \dots } { w } \text{ of } \quad d ( t ) = \langle \phi _ { M O D } | D ( t ) | \phi _ { M O D } \rangle = \text{Tr} \{ \rho _ { M O D } \, D ( t ) \} + \epsilon \,, \ ( 8 )$$
where /epsilon1 is a random variable with zero mean. The standard deviation of /epsilon1 is upper bounded by (Tr { ρ MOD D 4 } /d eff ) 1 / 2 . Thus, since the density of states is large at ¯ = 0, we get E /epsilon1 ≈ 0.
Using Runge-Kutta we can prepare these initial states and compute the time evolution of energy-difference expectations d t ( ) divided by their initial values d (0), i.e., r t ( ) = d t /d ( ) (0). In Fig. 5 we depict our results for three system sizes N L = 4, 6 and 8. Remarkably, the scaled differences r t ( ) are practically independent of the sign of the initial value d (0). While the energy difference r t ( ) decays, it does not decay all the way to zero. In fact, the fluctuations around the corresponding nonzero equilibrium value decrease for increasing system size N L . Thus, for finite systems, there is indeed no clean ISI equilibration. Since we find the same behavior for the overwhelming majority of all states prepared according to Eq. (7), it is reasonable to claim that the validity of the ETH is imperative for ISI equilibration. However, comparing Figs. 5 (a), (b), and (c) indicates that r t ( ) decreases at large times as system size increases. (Considering r t ( ) at large times as a central quantity is also suggested in Ref. [38].) This finding implies that ISI equilibration may be expected for this specific system and observable in the limit of large system sizes, regardless of the ETH being fulfilled. While it is well-known that also integrable systems may exhibit ISI (see the corresponding statement at the beginning of this section), these examples either refer to situations where the ETH may apply w.r.t. the considered observable regardless of integrability [14] and/or initial states generated from quenches that are not tailored to make the considered observable initially deviating largely from its long-time average [15]. In contrast to that, our finding addresses the occurrence of ISI for a situation where the violation of the ETH is numerically evident and the initial state is specifically chosen to initially deviate largely from its long-time average. This is a third main result of our paper.
The above results naturally lead to the question why larger systems exhibit equilibration that is closer to ISI even though Σ ′ is essentially the same for large and small systems. To clarify this question, let us consider a quantity that takes the 'natural' scale of the operator into account, rather than just the bare Σ . ′ Therefore, we define a scaled ETH parameter v as v := (Σ ) ′ 2 /δ 2 , where δ is the variance of the operator spectrum within the respective energy regime, i.e., δ 2 = D 2 -¯ D 2 . The bar in D 2 and
FIG. 5: Real-time decay of energy-difference expectation values d t ( ), divided by their initial values d (0), for initial states in Eq. (7) and three system sizes: (a) N L = 4, (b) N L = 6, and (c) N L = 8. While r t ( ) = d t /d ( ) (0) does not vanish for long times and finite systems, comparing (a), (b), and (c) indicates a vanishing r t ( ) for long times in the limit of large system sizes. For more details on finite-size scaling, see Fig. 4 (triangles).
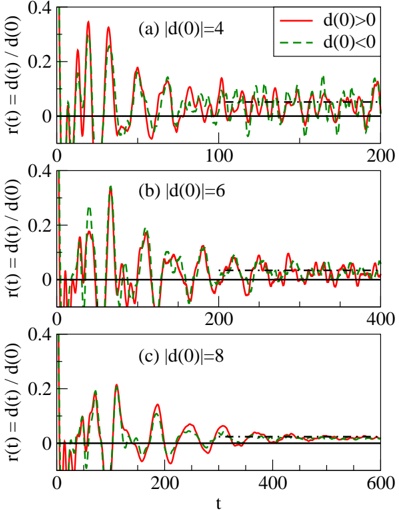
- [1] S. Trotzky, P. Cheinet, S. Folling, M. Feld, U. Schnorrberger, A. M. Rey, A. Polkovnikov, E. A. Demler, M. D. Lukin, and I. Bloch, Science 319 , 295 (2008).
- [2] S. Hofferberth, I. Lesanovsky, B. Fischer, T. Schumm, and J. Schmiedmayer, Nature 449 , 324 (2007).
- [3] I. Bloch, J. Dalibard, and W. Zwerger, Rev. Mod. Phys. 80 , 885 (2008).
- [4] M. Cheneau, B. Barmettler, D. Poletti, M. Endres, P. Schauß, T. Fukuhara, C. Gross, I. Bloch, C. Kollath, and S. Kuhr, Nature 481 , 484 (2012).
- [5] T. Langen, R. Geiger, M. Kuhnert, B. Rauer, and J. Schmiedmayer, Nature Phys. 9 , 640 (2013).
- [6] O. Lychkovskiy, Phys. Rev. E 82 , 011123 (2010).
- [7] N. Linden, S. Popescu, A. J. Short, and A. Winter, Phys. Rev. E 79 , 061103 (2009).
- [8] J. M. Deutsch, Phys. Rev. A 43 , 2046 (1991).
- [9] M. Srednicki, Phys. Rev. E 50 , 888 (1994).
- [10] M. Rigol, V. Dunjko, and M. Olshanii, Nature 452 , 854 (2008).
- [11] P. Reimann, Phys. Rev. Lett. 101 , 190403 (2008).
- [12] A. del Campo, Phys. Rev. A 84 , 012113 (2011).
- [13] A. Riera, C. Gogolin, and J. Eisert, Phys. Rev. Lett. 108 , 080402 (2012).
- [14] D. Rossini, A. Silva, G. Mussardo, and G. E. Santoro,
D is still defined according to Eq. (3). Obviously, even if Σ does not decrease as system size increases, ′ v may still do so. To find out whether or not it actually does, one has to compute the two quantities D 2 and D . This computation can be done by the same typicality-based method used so far in this paper. In Fig. 4 (squares) we show the corresponding result. Apparently, v vanishes in the limit of large system sizes even though Σ ′ does not. This observation suggests that v is a reliable predictor of ISI equilibration that can vanish even if systems are integrable or close to integrability.
## V. SUMMARY AND CONCLUSION
In this paper we studied the validity of the ETH and its role for the occurrence of ISI equilibration in closed quantum many-body systems. Using the concept of dynamical typicality, we presented an extensive numerical analysis of energy exchange in integrable and nonintegrable spin-1 / 2 systems of large size outside the range of exact diagonalization. In case of nonintegrable systems, our finite-size scaling showed that the ETH becomes valid in the thermodynamic limit and can serve as the underlying mechanism for ISI equilibration. In case of integrable systems, however, indication of ISI equilibration has been observed despite the violation of the ETH and initial states that specifically facilitate the deviation of the observable from its equilibrium value. We established a connection between this observation and the need of choosing a proper parameter within the ETH.
Phys. Rev. Lett. 102 , 127204 (2009).
- [15] M. Rigol, M. Srednicki, Phys. Rev. Lett. 108 , 110601 (2012).
- [16] M. Rigol, Phys. Rev. Lett. 103 , 100403 (2009).
- [17] G. Biroli, C. Kollath, and A. M. L¨uchli, Phys. Rev. Lett. a 105 , 250401 (2010).
- [18] S. Goldstein, J. L. Lebowitz, R. Tumulka, and N. Zanghi, Phys. Rev. Lett. 96 , 050403 (2006).
- [19] C. Bartsch and J. Gemmer, Phys. Rev. Lett. 102 , 110403 (2009).
- [20] T. A. Elsayed and B. V. Fine, Phys. Rev. Lett. 110 , 070404 (2013).
- [21] R. Steinigeweg, A. Khodja, H. Niemeyer, C. Gogolin, and J. Gemmer, Phys. Rev. Lett. 112 , 130403 (2014).
- [22] R. Steinigeweg, J. Gemmer, and W. Brenig, Phys. Rev. Lett. 112 , 120601 (2014).
- [23] T. N. Ikeda, Y. Watanabe, and M. Ueda, Phys. Rev. E 87 , 012125 (2013).
- [24] R. Steinigeweg, J. Herbrych, and P. Prelovˇ sek, Phys. Rev. E 87 , 012118 (2013).
- [25] W. Beugeling, R. Moessner, and M. Haque, Phys. Rev. E 89 , 042112 (2014).
- [26] M. Rigol, A. Muramatsu, and M. Olshanii, Phys. Rev. A 74 , 053616 (2006).
- [27] M. Rigol, V. Dunjko, V. Yurovsky, and M. Olshanii, Phys. Rev. Lett. 98 , 050405 (2007).
- [28] L. F. Santos, F. Borgonovi, and F. M. Izrailev, Phys. Rev. Lett. 108 , 094102 (2012).
- [29] K. He and M. Rigol, Phys. Rev. A 87 , 043615 (2013).
- [30] I. Gudyma, A. Maksymov, and M. Dimian, Phys. Rev. E 88 , 042111 (2013).
- [31] T. Monnai, Phys. Rev. E 84 , 011126 (2011).
- [32] H. De Raedt and K. Michielsen, Computational Methods for Simulating Quantum Computers in Handbook of Theoretical and Computational Nanotechnology (American Scientific Publishers, Los Angeles, 2006).
- [33] K. De Raedt, K. Michielsen, H. De Raedt, B. Trieu, G.
- Arnold, M. Richter, T. Lippert, H. Watanabe, and N. Ito, Comput. Phys. Commun. 176 , 121 (2007).
- [34] A. Pal and D. A. Huse, Phys. Rev. B 82 , 174411 (2010).
- [35] T. Kinoshita, T. Wenger, and D. S. Weiss, Nature 440 , 900 (2006).
- [36] C. Gogolin, M. P. M¨ller, and J. Eisert, Phys. Rev. Lett. u 106 , 040401 (2011).
- [37] T. N. Ikeda, Y. Watanabe, and M. Ueda, Phys. Rev. E 84 , 021130 (2011).
- [38] V. A. Yurovsky and M. Olshanii, Phys. Rev. Lett. 106 , 025303 (2011). | 10.1103/PhysRevE.91.012120 | [
"Abdellah Khodja",
"Robin Steinigeweg",
"Jochen Gemmer"
] | 2014-08-01T14:22:33+00:00 | 2015-06-18T11:55:32+00:00 | [
"quant-ph",
"cond-mat.stat-mech"
] | Relevance of the eigenstate thermalization hypothesis for thermal relaxation | We study the validity of the eigenstate thermalization hypothesis (ETH) and
its role for the occurrence of initial-state independent (ISI) equilibration in
closed quantum many-body systems. Using the concept of dynamical typicality, we
present an extensive numerical analysis of energy exchange in integrable and
nonintegrable spin-1/2 systems of large size outside the range of exact
diagonalization. In case of nonintegrable systems, our finite-size scaling
shows that the ETH becomes valid in the thermodynamic limit and can serve as
the underlying mechanism for ISI equilibration. In case of integrable systems,
however, indication of ISI equilibration has been observed despite the
violation of the ETH. We establish a connection between this observation and
the need of choosing a proper parameter within the ETH. |
1408.0188v1 | ## A conjugate gradient minimisation approach to generating holographic traps for ultracold atoms
Tiffany Harte, 1 2 , Graham D. Bruce, 1 3 , Jonathan Keeling 1 and Donatella Cassettari 1 , ∗
1 School of Physics and Astronomy, University of St Andrews, St Andrews, Fife KY16 9SS, UK 2 Clarendon Laboratory, University of Oxford, Parks Road, Oxford, OX1 3PU, UK 3 SUPA Dept. of Physics, University of Strathclyde, 107 Rottenrow, Glasgow, G4 0NG, UK ∗
[email protected]
Abstract: Direct minimisation of a cost function can in principle provide a versatile and highly controllable route to computational hologram generation. However, to date iterative Fourier transform algorithms have been predominantly used. Here we show that the careful design of cost functions, combined with numerically efficient conjugate gradient minimisation, establishes a practical method for the generation of holograms for a wide range of target light distributions. This results in a guided optimisation process, with a crucial advantage illustrated by the ability to circumvent optical vortex formation during hologram calculation. We demonstrate the implementation of the conjugate gradient method for both discrete and continuous intensity distributions and discuss its applicability to optical trapping of ultracold atoms.
© 2014 Optical Society of America
OCIS codes: (020.0020) Atomic and molecular physics; (020.1475) Bose-Einstein condensates; (020.7010) Laser trapping; (090.1760) Computer holography; (090.1995) Digital holography; (230.6120) Spatial light modulators.
## References and links
- 1. I. Bloch, J. Dalibard, and S. Nascimbene, 'Quantum simulations with ultracold quantum gases,' Nat Phys 8 , 267-276 (2012).
- 2. A. D. Cronin, J. Schmiedmayer, and D. E. Pritchard, 'Optics and interferometry with atoms and molecules,' Rev. Mod. Phys. 81 , 1051-1129 (2009).
- 3. K. Henderson, C. Ryu, C. MacCormick, and M. G. Boshier, 'Experimental demonstration of painting arbitrary and dynamic potentials for Bose-Einstein condensates,' New J. Phys. 11 , 043030 (2009).
- 4. C. Muldoon, L. Brandt, J. Dong, D. Stuart, E. Brainis, M. Himsworth, and A. Kuhn, 'Control and manipulation of cold atoms in optical tweezers,' New Journal of Physics 14 , 073051 (2012).
- 5. S. Bergamini, B. Darqui´ e, M. Jones, L. Jacubowiez, A. Browaeys, and P. Grangier, 'Holographic generation of microtrap arrays for single atoms by use of a programmable phase modulator,' J. Opt. Soc. Am. B 21 , 1889-1894 (2004).
- 6. V. Boyer, R. M. Godun, G. Smirne, D. Cassettari, C. M. Chandrashekar, A. B. Deb, Z. J. Laczik, and C. J. Foot, 'Dynamic manipulation of Bose-Einstein condensates with a spatial light modulator,' Phys. Rev. A 73 , 031402 (2006).
- 7. B. Zimmermann, T. M¨ uller, J. Meineke, T. Esslinger, and H. Moritz, 'High-resolution imaging of ultracold fermions in microscopically tailored optical potentials,' New Journal of Physics 13 , 043007 (2011).
- 8. D. Trypogeorgos, T. Harte, A. Bonnin, and C. Foot, 'Precise shaping of laser light by an acousto-optic deflector,' Opt. Express 21 , 24837-24846 (2013).
- 9. G. D. Bruce, S. L. Bromley, G. Smirne, L. Torralbo-Campo, and D. Cassettari, 'Holographic power-law traps for the efficient production of Bose-Einstein condensates,' Phys. Rev. A 84 , 053410 (2011).
- 10. G. D. Bruce, J. Mayoh, G. Smirne, L. Torralbo-Campo, and D. Cassettari, 'A smooth, holographically generated ring trap for the investigation of superfluidity in ultracold atoms,' Phys. Scr. T143 , 014008 (2011).
- 11. N. Houston, E. Riis, and A. S. Arnold, 'Reproducible dynamic dark ring lattices for ultracold atoms,' J. Phys. B 41 , 211001 (2008).
- 12. D. McGloin, G. Spalding, H. Melville, W. Sibbett, and K. Dholakia, 'Applications of spatial light modulators in atom optics,' Opt. Express 11 , 158-166 (2003).
- 13. M. Pasienski and B. DeMarco, 'A high-accuracy algorithm for designing arbitrary holographic atom traps,' Opt. Express 16 , 2176-2190 (2008).
- 14. A. L. Gaunt and Z. Hadzibabic, 'Robust digital holography for ultracold atom trapping,' Sci. Rep. 2 , 721 (2012).
- 15. J. G. Lee and W. T. Hill III, 'Spatial shaping for generating arbitrary optical dipoles traps for ultracold degenerate gases,' (2014). http://arxiv.org/abs/1406.4084 .
- 16. J. R. Hui, X. Wu, and C. Warde, 'Addressing large arrays of electrostatic actuators for adaptive optics applications,' Proc. SPIE 5553 , 17-27 (2004).
- 17. J. Fort´gh, H. Ott, S. Kraft, A. G¨nther, and C. Zimmermann, 'Surface effects in magnetic microtraps,' Phys. a u Rev. A 66 , 041604 (2002).
- 18. M. Mitchell, An Introduction to Genetic Algorithms (MIT Press, Cambridge, MA, 1998).
- 19. M. Clark and R. Smith, 'A direct-search method for the computer design of holograms,' Opt. Commun. 124 , 150-164 (1996).
- 20. V. Boyer, C. M. Chandrashekar, C. J. Foot, and Z. J. Laczik, 'Dynamic optical trap generation using FLC SLMs for the manipulation of cold atoms,' J. Mod. Opt. 51 , 2235-2240 (2004).
- 21. M. C. Payne, M. P. Teter, D. C. Allan, T. A. Arias, and J. D. Joannopoulos, 'Iterative minimization techniques for ab initio total-energy calculations: molecular dynamics and conjugate gradients,' Rev. Mod. Phys. 64 , 1045-1097 (1992).
- 22. R. Liu, B.-Z. Dong, G.-Z. Yang, and B.-Y. Gu, 'Generation of pseudo-nondiffracting beams with use of diffractive phase elements designed by the conjugate-gradient method,' J. Opt. Soc. Am. A 15 , 144 (1998).
- 23. R. Liu, B.-Y. Gu, B.-Z. Dong, and G.-Z. Yang, 'Design of diffractive phase elements that realize axial-intensity modulation based on the conjugate-gradient method,' J. Opt. Soc. Am. A 15 , 689 (1998).
- 24. R. Liu, B.-Y. Gu, B.-Z. Dong, and G.-Z. Yang, 'Diffractive phase elements that synthesize color pseudonondiffracting beams,' Opt. Lett. 23 , 633 (1998).
- 25. G. Zhou, X. Yuan, P. Dowd, Y.-L. Lam, and Y.-C. Chan, 'Efficient method for evaluation of the diffraction efficiency upper bound of diffractive phase elements,' Opt. Lett. 25 , 1288 (2000).
- 26. G. Zhou, X. Yuan, P. Dowd, Y.-L. Lam, and Y.-C. Chan, 'Design of diffractive phase elements for beam shaping: hybrid approach,' Opt. Soc. Am. A 18 , 791 (2001).
- 27. W. H. Press, B. P. Flannery, S. A. Teukolsky, and W. T. Vetterling, Numerical Recipes: The Art of Scientific Computing (Cambridge University Press, Cambridge, 1987).
- 28. J. R. Shewchuk, 'An introduction to the conjugate gradient method without the agonizing pain,' (1994). http://www.cs.cmu.edu/˜ quake-papers/painless-conjugate-gradient.pdf .
- 29. M. Johansson and J. Bengtsson, 'Robust design method for highly efficient beam-shaping diffractive optical elements using an iterative-fourier-transform algorithm with soft operations,' Journal of Modern Optics 47 , 13851398 (2000).
- 30. A. Bartok-Partay, S. Cereda, G. Csanyi, J. Kermode, I. Solt, W. Szlachta, C. Varnai, and S. Winfield. http://www.libatoms.org .
- 31. P. Senthilkumaran, F. Wyrowski, and H. Schimmel, 'Vortex stagnation problem in iterative Fourier transform algorithms,' Opt. Laser Eng. 43 , 43-56 (2005).
## 1. Introduction
In recent years there has been extraordinary progress in cold atom physics and its applications in fields such as quantum computation and simulation of condensed-matter systems, precision measurements, and matter-wave interferometry [1,2]. In this context, arbitrary time-dependent optical trapping potentials are particularly appealing, with a variety of geometries including toroids and ring lattices already realised by acousto-optic or holographic means [3, 4]. Experiments have been performed with discrete arrays of optical dipole traps, loaded with either thermal atoms [4, 5] or quantum degenerate atomic gases [3, 6, 7], in which individual trapping sites can be moved, addressed and manipulated. Important too are continuous trapping geometries: the primary subject of the present work are extended (as opposed to diffractionlimited) power-law potentials, proposed both as a static supplement to a trapping potential to cancel unwanted external potentials [8], and in a dynamic sequence as a tool for the efficient production of Bose-Einstein condensates [9]. Other interesting continuous potentials include engineered waveguides with dynamic bright regions, shown to be suitable for studies of BEC superfluidity [10].
Technologies employed so far in the realisation of these arbitrary optical trapping patterns include acousto-optic deflection of a laser beam to produce either a composite static intensity distribution [8] or a rapidly-scanned profile [3, 7, 11], digital micro-mirror devices (DMDs) [4], and computer-generated holograms implemented with phase-only spatial light modulators (SLMs) [5,6,9,10,12-15]. The high phase-resolution available in phase-only SLMs offers significant advantages for versatility of the accessible trapping patterns, though at the cost of lower switching speed between frames if compared to acousto-optic modulators and digital mirror devices. However, with new technologies currently being developed for grey-scale phase-only SLMs with kHz refresh rates [16], this versatility may become accessible at sufficiently high update rates for high-speed dynamic manipulation of trapped atoms. The primary challenge of phase-only SLMs is the computational complexity inherent in reproducing the target intensity distribution on the trapping plane. This paper demonstrates an alternative reliable and efficient method to address this problem.
Our investigation concerns an SLM consisting of 256 × 256 programmable pixels; each pixel is able to impose a phase retardation between 0 and 2 π in steps of 2 π / 256 on an incident laser beam. The resulting digital hologram is calculated to reconstruct a given target intensity pattern in the far field, or equivalently in the focal plane of a lens, in which atoms will be trapped. The calculated phase mask φ pq and the incident laser field A Spq 0 , with indices p and q denoting pixel position, determine the SLM-plane electric field:
$$E _ { i n } = A _ { 0 } S _ { p q } \exp \left ( i \phi _ { p q } \right ).$$
We express this electric field as an array of N pixels; propagation through focussing optics can be calculated by a fast Fourier transform. The electric field in the output plane is therefore given by
$$E _ { o u t } = \frac { A _ { 0 } } { N } \sum _ { p q } S _ { p q } \exp ( i \phi _ { p q } ) \exp \left ( - \frac { 2 \pi i } { N } \left ( p n + q m \right ) \right ),$$
with output-plane coordinates denoted by n and m . As only the modulus of Eout is relevant for optical trapping, we have output-plane phase freedom: consequently the phase φ pq required to recreate a given target intensity is not unique, and solutions are found numerically. The general problem of phase retrieval, which includes both the above case of laser beam shaping where the modulus of the field is known in both planes, and the related problem of image reconstruction where the field modulus is known only in the output plane, can be solved using a variety of methods. These fall broadly into two categories: iterative Fourier transform algorithms (IFTAs), and algorithms based on the minimisation of a cost function. The IFTA calculation encourages convergence from an initial phase guess to one yielding the target intensity using successive Fourier transforms between SLM and output planes, imposing the known or desired electric field amplitude at each step. For the purpose of atom trapping in arbitrary geometries, where smoothness is a primary consideration (as corrugations of the trapping potential cause fragmentation of cold atom clouds [17]), the best results so far have been achieved by the mixed-region amplitude freedom (MRAF) variant of the IFTA [9, 10, 13, 14]. In MRAF, the output plane is divided into two regions: a signal region in which the intensity is restricted to match the target intensity pattern, and a noise region in which the intensity is unconstrained. This separation allows for increased accuracy and smoothness in the signal region, leading to computed intensity patterns with residual root-mean-square (RMS) errors of less than a few percent. A secondary consideration in designing optical traps is the light-usage efficiency of the computer-generated hologram. One motivation for the use of phase-only spatial light modulators rather than amplitude modulators is that the former do not deliberately remove light from the incident beam.
However, the MRAF algorithm gains accuracy by deliberately lowering this efficiency. Furthermore, lacking a minimisation principle, IFTA approaches provide no guarantee of converging, and their final state can be highly dependent on the initial phase pattern used.
In contrast, cost function minimisation algorithms are inherently more directional than IFTAs: the cost function encodes all constraints and desired properties of the intensity pattern, and can be designed with terms accounting for specific output plane features (such as high lightusage efficiency) in addition to adherence to the target intensity profile. Within this category, established beam shaping methods include genetic algorithms and direct search algorithms, both of which are less computationally efficient than IFTAs [13]. Genetic algorithms [18] seek the global minimum of the cost function, and as such are computationally demanding but accurate. Direct search algorithms [19, 20], in which SLM pixel values are sequentially altered with only changes reducing the cost function being retained, are limited to just a few phase levels due to computational intensity, and as such work well for simple targets but struggle to reproduce more intricate patterns.
In this paper, we consider an alternative approach to the beam shaping problem, in which the cost function is minimised by a conjugate gradient local search algorithm. Conjugate gradient minimisation, a well-established method for minimising high-dimensional smooth functions, is widely used in contexts such as electronic structure [21]. Here we find that this approach successfully combines computational efficiency and algorithm versatility, allowing the accurate reproduction of a variety of target intensity profiles relevant for optical trapping of atoms. The simplest cost function we study, a least-squares difference from the desired pattern, leaves localised defects which have low cost but present significant problems for atom trapping. However, these defects can be removed by systematically modifying the cost function, and we discuss the forms of cost functions required to eliminate them. This flexibility in cost function definition, a useful feature common to all minimisation algorithms, also allows us to go beyond the simple definitions of signal and noise regions, and to fine-tune our algorithm for different experimental requirements simply by adding cost function terms and applying different weightings across the output plane.
Laser beam shaping via an algorithm that relies entirely on gradient-based local search has been relatively unexplored so far. Examples of this are found in [22-24], where conjugate gradient minimisation is used to generate pseudo-non diffractive beams in which the target is a given axial intensity distribution. Gradient-based local search techniques are also used as part of more complex algorithms, such as hybrid algorithms for beam shaping in which they are combined with genetic algorithms to increase the reliability in locating the global minimum for the generation of flat top laser beams [25, 26]. The present work shows that gradient-based local search can be applied to a much wider range of beam shaping problems, and that it can be applied on its own: finding a local minimum is sufficient for a good reproduction of a variety of targets.
## 2. The conjugate gradient calculation method
At the heart of this method is quantifying the error between target and predicted intensity by defining a cost function C . Minimisation of C is performed over all SLM pixel phase values, while computational efficiency is ensured by incorporating gradient information. Figure 1 illustrates the application of conjugate gradient minimisation to hologram calculation.
The process is initialised by defining a target intensity distribution, an incident laser field amplitude, and an initial phase guess. This may be the summation of analytically-expressed phase patterns to form an educated guess, e.g. quadratic and linear phase gradients giving expansion and position-offset of the intensity in the output plane [13], or it may be a random array taking values between 0 and 2 π , with each element corresponding to an SLM pixel.
Fig. 1. Block diagram illustrating the conjugate gradient minimisation approach to hologram solution.
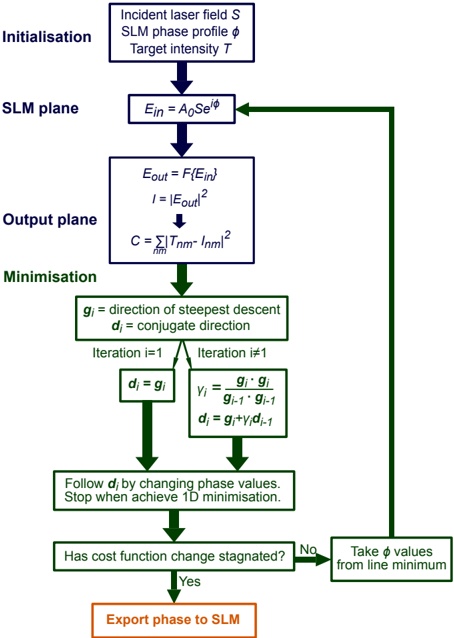
Weighting arrays are also defined during this initialisation stage. This weighting process is significantly more flexible than the simple definition of signal and noise regions characteristic of the MRAF IFTA. Output plane regions can be arbitrarily weighted according to their importance: we can allocate a pixel-dependent prefactor to individual cost function terms according to their relative importance in different output plane regions. For the remainder of this paper, the high-intensity output region forming the trapping pattern is referred to as the trapping region, with the signal and noise regions retaining the same meanings as in MRAF: the signal region is the trapping region plus some border which will remain devoid of light, while the noise region is the remainder of the plane where light may be deposited without adversely affecting the trapping potential. For example, the cost function can be allocated a larger weighting, so greater importance, in the trapping region than the remainder of the output plane, while the highest intensity parts of this region preferentially seen by the atoms can be given yet more prominence than those of lower intensity. With our cost function approach, we can provide a smooth transition between signal and noise region weightings which reduces noise accumulation at the signal region border. By comparison, a typical light pattern calculated using MRAF places much of the noise region light at the boundary of the signal and noise regions.
Upon each iteration, the output electric field corresponding to the current phase profile is calculated, with phase array components generated by the minimisation routine. This multidimensional minimisation is composed of one-dimensional steps, each seeking to minimise the cost function by changing phase values. The initial step minimises the cost function in the local gradient direction; subsequent consecutive minimisation directions are conjugate and independent, to avoid repetition of minimisation directions [27, 28]. Conjugate directions d are those satisfying [21, 28]:
$$\mathfrak { d } _ { i } \cdot H _ { C } \cdot \mathfrak { d } _ { j } = 0,$$
where HC is the Hessian matrix of the cost function. However, the power of the conjugate gradient descent approach is that the Hessian does not need to be calculated explicitly, but is rather built up by application of the following procedure. The i th direction is calculated using [21]:
$$\mathfrak { d } _ { i } = \mathfrak { g } _ { i } + \gamma _ { i } \mathfrak { d } _ { i - 1 }$$
where g i is the direction of steepest descent at the termination point of step i -1 and γ i is the scalar
$$\gamma _ { i } = \frac { g _ { i } \cdot g _ { i } } { g _ { i - 1 } \cdot g _ { i - 1 } }.$$
The fast Fourier transforms used in the calculations map a N × N array in the SLM plane onto a N × N array in the output plane. If N is chosen to be the number of pixels in the SLM, then the size of each output plane pixel is exactly the diffraction limit of the system. Aliasing in the output plane is avoided by selecting a value for N , in accordance with the Nyquist criterion, of twice the number of pixels in the SLM [29]. Therefore the phase array is surrounded by zeroes to double its size and optimise output plane sampling at each iteration. Correspondingly enlarging the target array, the resolution of the cost calculation is optimised. Iteration continues until the difference between consecutive cost values stagnates: a minimum of the chosen cost function has been located. Our calculations make use of the libatoms library [30].
## 3. Versatility via cost function definition
The cost function should be such that its minimum corresponds to the desired pattern. There are however a number of other features required for the algorithm to operate efficiently: it should be efficient to evaluate derivatives of the cost function; the function should not have local minima which give poor trapping profiles. Indeed, as we will see below, a naive choice of cost function leads to local minima containing optical vortices. Furthermore, the conjugate gradient approach assumes an approximately quadratic function [27]. A simple cost function may purely concern target reproduction accuracy, expressed as a sum over output plane pixels ( n m , ) of differences between target Tnm and calculated output intensity:
$$C = \sum _ { n m } \left ( T _ { n m } - | E _ { o u t, n m } | ^ { 2 } \right ) ^ { 2 } = \sum _ { n m } \left ( T _ { n m } - | A _ { 0 } \tilde { \psi } _ { n m } | ^ { 2 } \right ) ^ { 2 }$$
using
$$\tilde { \psi } _ { n m } = \frac { 1 } { N } \sum _ { p q } \psi _ { p q } \exp \left ( - \frac { 2 \pi i } { N } ( p n + q m ) \right )$$
with ψ pq = Spq exp ( i φ pq ) , where indices p and q indicate general input plane pixels. A 0 is a free scale parameter allowing for the fact that the overall scale of the target potential is not necessarily matched to the laser power and Spq allows for the possibility of an input field with a slowly varying intensity, e.g. a Gaussian input beam. The cost function gradient required by the minimisation algorithm must be calculated with respect to φ rs , the phase value at a specific SLM pixel. For this cost function, the corresponding gradient is
$$\frac { \partial C } { \partial \phi _ { r s } } = 4 A _ { 0 } ^ { 2 } \text{Re} \left ( i \psi _ { r s } ^ { * } X _ { r s } \right )$$
where
$$\text{re} \\ \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
Additional terms in the cost function can incorporate experimentally relevant output plane features. Such features could, for instance, include noise suppression at the signal region boundary to aid trap loading, or in a dynamic sequence for real-time manipulation of trapped atoms, a cost function term could be introduced to reduce intensity fluctuations between consecutive frames in the sequence. The application of additional cost function terms is illustrated here by the suppression of optical vortex formation. We find that the cost function in Eq. (6) is effective for lattice distributions, but inadequate for large continuous patterns due to the emergence of optical vortices within the trapping region during calculation. These vortices are characterised by a sudden drop in intensity coinciding with a local phase winding by a multiple of 2 π , and they arise because they can be initially beneficial to cost function reduction. However, their prevention is imperative to all hologram calculation schemes. From following the evolution of our conjugate gradient minimisation, it appears the local vorticity cannot change, and so these vortices can only be removed by annihilation of oppositely charged vortex pairs, or by moving vortices to regions of low intensity.
Figure 2 illustrates the vortices formed within the output plane of a second-order powerlaw intensity distribution calculated using the cost function defined in Eq. (6) with no regional weightings applied, starting from an educated guess. Since the algorithm has identified a local minimum of the cost function, the observation of these vortices suggest that the cost function does not sufficiently penalise them. Indeed, since the vortex cores are small, they only introduce a very localised deviation from the pattern. Moreover, there is only a small change in cost function as vortices move through the pattern, and hence minimisation of this cost function does not effectively eliminate vortices once formed. In minimising this cost function, vortex removal is principally achieved by gradually shifting them towards lower-intensity regions where their cost is reduced, but this is obstructed in regions of high vortex density where phase contours can become tangled [31]. Vortex elimination is therefore only realistically achievable if their early formation is suppressed such that their numbers remain manageable. Given that the cost function can be chosen at will (within the constraints given above), our approach to eliminating vortices becomes a question of choosing a better cost function such that vortices do not remain frozen in the final pattern.
A cost function that penalises large localised deviations more than the simple cost function in Eq. (6) is
$$C _ { t } = \sum _ { n m } \left ( T _ { n m } - | A _ { 0 } \tilde { \psi } _ { n m } | ^ { 2 } \right ) ^ { t }.$$
The higher the value of t , the higher the cost of large discrepancies relative to small, increasing the cost contribution of trapping-region vortices. Fewer vortices persist, but at the expense of trap smoothness. In practice we find that powers higher than four produce too rough an intensity distribution with insufficient vortex improvements to justify this sacrifice. The Ct gradient is
$$\frac { \partial C _ { t } } { \partial \phi _ { r s } } = 2 t A _ { 0 } ^ { 2 } \text{Re} \left ( i \psi _ { r s } ^ { * } X _ { r s } \right ).$$
Alternatively, we can also specify cost functions that perform active smoothing by associating a cost with intensity variations between neighbouring pixels. For example, to apply active smoothing over the four nearest-neighbour pixels, we use the cost function
Fig. 2. Second-order power-law trapping potential calculated using the cost function in Eq. 6. (left) Two-dimensional profiles and vertical line profiles taken through the centre of the pattern for target (upper inset and cyan line) and calculated output (lower inset and red points). The colorbar applies to the insets and to all subsequent figures. The predicted output is distorted by deep optical vortices. These vortices inhibit further improvements in accuracy, resulting in a poor fit to the target intensity. The root-mean square (RMS) fractional error between target and predicted output is 26%. (right) Vortex locations on the output plane, with red pixels indicating 2 π phase windings and blue pixels -2 π . The black circle indicates the trapping region. While the vortex density is reduced within this region in comparison to the remainder of the output plane, 232 are established within the trapping region with an insignificant fraction removed with further iterations due to the tangled phase contours.
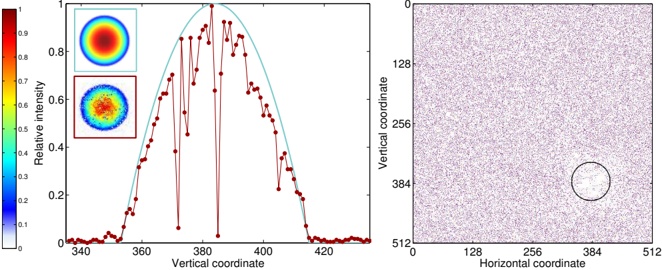
$$C _ { s } = & \sum _ { n m } \left [ \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { n ( m - 1 ) } | ^ { 2 } \right ) ^ { 2 } + \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { n ( m + 1 ) } | ^ { 2 } \right ) ^ { 2 } \\ & + \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { ( n - 1 ) m } | ^ { 2 } \right ) ^ { 2 } + \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { ( n + 1 ) m } | ^ { 2 } \right ) ^ { 2 } \right ]. \\ \text{The gradient is calculated in the same way for all four terms in $C_{s}$. For instance, the gradient}$$
$$\frac { \partial C _ { s } ^ { ( 1 ) } } { \partial \phi _ { r s } } = \frac { 4 } { N } \text{Re} \left ( i \psi _ { r s } \left ( X _ { 1 r s } ^ { * } - X _ { 2 r s } ^ { * } \right ) \right )$$
The gradient is calculated in the same way for all four terms in Cs . For instance, the gradient for the first term, Cs ( 1 ) = ∑ nm ( | ˜ ψ nm | 2 -| ˜ ψ n m ( -1 ) | 2 ) 2 , is where
$$X _ { 2 r s } = \frac { 1 } { N } \sum _ { n m } ^ { n m } \left [ \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { n ( m - 1 ) } | ^ { 2 } \right ) \tilde { \psi } _ { n ( m - 1 ) } \exp \left ( \frac { 2 \pi i } { N } ( r n + s m ) \right ) \right ]. \quad \quad ( 1 5 ) \\ \text{Sequential combination of $C_{t=4}$ and $C_{t=2}$ establishes a vortex-free trap region with subse-}$$
$$v \text{here} & \quad X _ { 1 r s } = \frac { 1 } { N } \sum _ { n m } \left [ \left ( | \tilde { \psi } _ { n m } | ^ { 2 } - | \tilde { \psi } _ { n ( m - 1 ) } | ^ { 2 } \right ) \tilde { \psi } _ { n m } \exp \left ( \frac { 2 \pi i } { N } ( r n + s m ) \right ) \right ] & & ( 1 4 ) \\ v _ { \cdot } \quad - \, 1 \, \subsetneq \, \left [ \int _ { 1 \tilde { \sigma } _ { n } + 1 } \int _ { 2 \tilde { \sigma } _ { n } + 1 } \int _ { 3 \tilde { \sigma } _ { n } + 1 } \int _ { 4 \tilde { \sigma } _ { n } + 1 } \int _ { 5 \tilde { \sigma } _ { n } + 1 } & & ( 1 1 )$$
Sequential combination of Ct = 4 and Ct = 2 establishes a vortex-free trap region with subsequent smoothing; as an alternative approach, simultaneous combination of Ct = 2 and Cs terms is also successfully implemented to demand both accuracy and smoothness. Calculated outputs corresponding to these examples are illustrated in Fig. 3 for the same second-order power-law pattern shown in Fig. 2.
For the sequential Ct application shown in Fig. 3(a), we initially use Ct = 4 to apply coarse corrections to the calculated intensity pattern, then follow this with more refined corrections
Fig. 3. Second-order power-law trapping potentials calculated with more sophisticated cost functions, starting with an educated guess phase. (left) Line profiles through pattern centre and two-dimensional profiles as insets. Calculated intensity patterns are denoted by points while the target profile is indicated with a cyan line. (right) output plane vortex map with the trapping region indicated by the black circle. (a) Ct = 4 (purple, upper inset) and subsequent Ct = 2 application (red, lower inset). Applying Ct = 4 generates an approximate fit to the target while suppressing the initial vortex number. Subsequent smoothing using Ct = 2 improves the accuracy and smoothness, and clears residual vortices from the trapping region. (b) A combination of Ct = 2 and Cs achieves both direct smoothing and high reproduction accuracy.

using Ct = 2. The cost function on signal region pixels is given a weighting of 10 times that of noise region pixels during the Ct = 4 stage; for Ct = 2 application the signal region is weighted by a factor of 10 12 ( 1 + T ) relative to the noise region with T the target value of a given pixel, while a linear slope over 8 pixels smooths the weightings between these two regions and discourages noise accumulation near the target intensity distribution. The calculated fractional RMS error is 1.4% after 3000 iterations of Ct = 4 application and 0.07% following an additional 10000 iterations of Ct = 2 smoothing, with 70 vortices remaining in the signal region. However, as they are confined to low-intensity regions these vortices do not degrade the trapping pattern. The efficiency of the algorithm in placing light within the trapping region is 47% prior to smoothing and 45% afterwards. However, efficiency varies widely according to weighting choice: one method of improving efficiency is to demand an accuracy across the entire output plane comparable to that of the signal region, requiring more iterations to achieve the desired trapping region accuracy.
In the combined Ct = 2 and Cs approach, the signal and noise regions are not given relative weightings for the Ct = 2 term, but the Cs term is weighted according to the target value for each pixel within the signal region and set to zero in the noise region. Competition between the accuracy and smoothing terms reduce accuracy as compared to the pure discrepancy power method, with a fractional RMS error of 0.43% after 30000 iterations in the example shown in Fig. 3(b). However, appropriate balancing of terms results in effective vortex suppression and sufficient prediction accuracy. 130 vortices remain in the low-intensity region of the trapping pattern, which again is less relevant for atom trapping. Furthermore, regional weightings increase the efficiency to 64%. We also find that this active smoothing method is particularly resilient to initialisation conditions, increasing the chance of success of a given iteration run.
Fig. 4. Target (i) and calculated output intensity (ii) for the square lattice (a) and stirring ring pattern (b). Both are generated from a random initial phase and have RMS errors of 0.58% and 3.0% respectively.
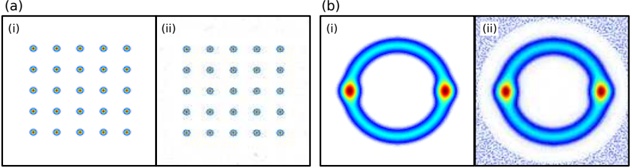
With MRAF, the output quality depends critically on the initial phase guess and on the initialisation parameters, which have to be carefully chosen to suppress the formation of optical vortices during the calculation process [13]. In contrast, with conjugate gradient minimisation, optical vortex suppression is achieved by a judicious cost function choice. Having determined these cost functions, the output quality is then largely insensitive to the initial phase guess, to the point that high accuracy can be achieved even with a random phase guess. For this reason, while conjugate gradient minimisation converges in more iterations than are required in MRAF, the two methods end up with a comparable computational efficiency, because with conjugate gradient minimisation it is not necessary to run the code for many different choices of initial phase patterns. Initialisation resilience would be of further benefit in dynamical sequences as it increases the chance of success of all frames from a single initialisation step.
Displayed in Fig. 4 are examples illustrating the general applicability of the method to both continuous distributions and discrete arrays, showcasing the successful elimination of highintensity borders next to the signal region. Both patterns are generated from a random initial guess; remarkably, for the ring pattern, we find that an initially random phase pattern results in quicker convergence to the final form than an apparently educated guess. The lattice pattern is calculated using solely a Ct = 2 term: smoothing is found to cause blurring of the pattern edges, and the Ct = 2 term is sufficient to remove vortices from these smaller intensity features before they become established. The small size of the spots allows the vortices to escape more easily and they are therefore not frozen into the final pattern. The signal region is weighted by a factor of 10 4 relative to the noise region, with a linearly sloped border of 4 pixels connecting these two regions sufficient to discourage noise accumulation near the signal region boundary. After 4000 iterations, the RMS signal region error is 0.58%. The stirring ring pattern, so called because it can be used to induce superfluid rotation [10], has an RMS signal region error of 3.0% after 2500 iterations. This example is calculated using a combination of Ct = 2 and Cs terms, with the signal region given an overall weighting of 10 relative to the noise region with a border of 8 pixels connecting these to prevent disruptive noise accumulation, and the smoothing term given a weighting of ½ ( Tmax -Tnm ) , with Tmax the maximum target value and Tnm the target values on individual pixels, in the signal region only.
## 4. Conclusion
Conjugate gradient minimisation of an appropriate cost function has been verified as a viable alternative to the established methods of hologram generation. By applying well-developed conjugate gradient approaches and optimised numerical libraries, the cost function minimisation approach allows careful guiding of the calculation process by choice of a sensible cost function with an analytical gradient. In particular, we show that tailoring the cost function beyond its simplest form is important and that the flexibility inherent in the cost function definition should be exploited to guide output plane features of interest. We illustrate this by directly suppressing optical vortices in the calculated intensity profiles by associating a cost either with large deviations from the target intensity or with intensity fluctuations between neighbouring pixels. Both methods successfully suppress vortices to optimise trapping potential accuracy, though active smoothing is more appropriate in potentials without sharp features. This precision guiding and the ability to tailor the weightings assigned to each pixel has also allowed us to avoid the formation of the high-intensity signal region border characteristic of the MRAF approach, while retaining the flexibility characteristic of regional definitions and the ability to accurately reproduce a wide range of intensity patterns suitable for trapping ultracold atoms. The method has also proven to be resilient to initialisation conditions, which may be of benefit in designing dynamic sequences of intensity patterns from a single initialisation step.
Further improvements could be achieved by incorporating a measured laser beam profile into the calculation process to correct for beam imperfections, and considering Helmholtz propagation of light within the model [14]. | 10.1364/OE.22.026548 | [
"Tiffany Harte",
"Graham D. Bruce",
"Jonathan Keeling",
"Donatella Cassettari"
] | 2014-08-01T14:29:09+00:00 | 2014-08-01T14:29:09+00:00 | [
"cond-mat.quant-gas",
"physics.atom-ph",
"physics.optics"
] | A conjugate gradient minimisation approach to generating holographic traps for ultracold atoms | Direct minimisation of a cost function can in principle provide a versatile
and highly controllable route to computational hologram generation. However, to
date iterative Fourier transform algorithms have been predominantly used. Here
we show that the careful design of cost functions, combined with numerically
efficient conjugate gradient minimisation, establishes a practical method for
the generation of holograms for a wide range of target light distributions.
This results in a guided optimisation process, with a crucial advantage
illustrated by the ability to circumvent optical vortex formation during
hologram calculation. We demonstrate the implementation of the conjugate
gradient method for both discrete and continuous intensity distributions and
discuss its applicability to optical trapping of ultracold atoms. |
1408.0189v1 | ## Local times for multifractional Brownian motion in higher dimensions: A white noise approach
## Wolfgang Bock ,
CMAF, Universidade de Lisboa, 1649-003 Lisbon, Portugal. Email: [email protected]
## José Luís da Silva ,
CCM, University of Madeira, Campus da Penteada, 9020-105 Funchal, Portugal. Email: [email protected]
## Herry P. Suryawan
Department of Mathematics Sanata Dharma University Yogyakarta, Indonesia Email: [email protected]
August 4, 2014
## Abstract
We present the expansion of the multifractional Brownian (mBm) local time in higher dimensions, in terms of Wick powers of white noises (or multiple Wiener integrals). If a suitable number of kernels is subtracted, they exist in the sense of generalized white noise functionals. Moreover we show the convergence of the regularized truncated local times for mBm in the sense of Hida distributions.
Keywords : Local time, multifractional Brownian motion, white noise analysis.
## 1 Introduction
Over the last decades fractional Brownian motion (fBm) with Hurst parameter H has become an intensively studied object. This centered Gaussian process B H with covariance function
$$\mathbb { E } ( B _ { H } ( t ) B _ { H } ( s ) ) = \frac { 1 } { 2 } \left ( | t | ^ { 2 H } + | s | ^ { 2 H } - | t - s | ^ { 2 H } \right ), \ \ t, s > 0, \\ \hat { \ }. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \. \ \.$$
was first introduced by Mandelbrot and Van-Ness [MvN68]. Instead of giving an exhaustive overview about fBm we refer to the articles [AN03, Ben03b, Ben03a, DHPD00, EvdH03, HØ03, Nua06, DOS08] and monographs [BHØZ07, Mis08] and the references therein.
To overcome this Lévy Véhel and Peltier [PLV95] and Benassi et.al. [BJR97] independently introduced multifractional Brownian motion (mBm) B h , where the regularity of the paths is a function of time. The covariance of the centered Gaussian process B h is given by
Due to its properties such as Hölder continuity of any order less than H , long-range dependence and stationary increments, the process is used for modeling problems from telecommunications, finance and engineering. Although there are various problems accessible, the use of fBm involves a restriction to a certain Hölder continuity H of the paths for all times of the process. For many applications this is too restrictive and variable timedependent Hölder continuities of the paths are needed.
$$\mathbb { E } ( B _ { h } ( t ) B _ { h } ( s ) ) = \frac { C \left ( \frac { h ( t ) + h ( s ) } { 2 } \right ) ^ { 2 } } { C ( h ( t ) ) C ( h ( s ) ) } \left [ \frac { 1 } { 2 } ( t ^ { h ( t ) + h ( s ) } + s ^ { h ( t ) + h ( s ) } - | t - s | ^ { h ( t ) + h ( s ) } ) \right ],$$
where h : [0 , T ] -→ (1 / , 2 1) is a continuous function and
$$C ( x ) \coloneqq \left ( \frac { 2 \pi } { \Gamma ( 2 x + 1 ) \sin ( \pi x ) } \right ) ^ { 1 / 2 },$$
where Γ is the Gamma function. Different properties of this process are recently studied, such as Hölder continuity of the paths and Hausdorff dimension [BJR97, BDG08], as well as local times of mBm [ASX11, BDG07,
MWX08] and estimates for the local Hurst parameters [BFG13]. In white noise analysis mBm was treated recently in [LLV14] together with its respective stochastic calculus.
In this article we use a white noise approach to determine the kernels in the Wiener-Itô-Segal chaos decomposition of the (truncated) local time of a d -dimensional mBm for h : [0 , T ] -→ (1 / 2 1) , . As in [DOS08] for fBm, we show the convergence of the regularized local time for mBm to the truncated local time via the convergence of Hida distributions.
## 2 Gaussian white noise analysis
In this section we review some of the standard concepts and theorems of white noise analysis used throughout this work, and refer to [HKPS93, KLP + 96, Kuo96] and references therein for a detailed presentation.
We start with the basic Gel'fand triple
$$S _ { d } \subset L _ { d } ^ { 2 } \subset S _ { d } ^ { \prime },$$
where S d := S ( R R , d ) , d ∈ N , is the space of vector valued Schwartz test functions, S ′ d its topological dual and the central Hilbert space L 2 d := L 2 ( R R , d ) of square integrable vector valued functions, i.e.,
$$| f | _ { 0 } ^ { 2 } = \sum _ { i = 1 } ^ { d } \int _ { \mathbb { R } } f _ { i } ^ { 2 } ( x ) \, d x, \ \ f \in L _ { d } ^ { 2 }.$$
Since S d is a nuclear space, represented as projective limit of a decreasing chain of Hilbert spaces ( H p ) p ∈ N , see e.g.[RS75] and [GV68], i.e.
$$S _ { d } = \bigcap _ { p \in \mathbb { N } } H _ { p },$$
we have that S d is a countably Hilbert space in the sense of Gel'fand and Vilenkin [GV68]. We denote the corresponding norm on H p by | · | p , with the convention H 0 = L 2 d . Let H -p be the dual space of H p and let 〈· , ·〉 denote the dual pairing on H -p × H p . H p is continuously embedded into L 2 d . By identifying L 2 d with its dual via the Riesz isomorphism, we obtain the chain H p ⊂ L 2 d ⊂ H -p . Note that S ′ d = ⋃ p ∈ N H -p , i.e. S ′ d is the inductive limit of the increasing chain of Hilbert spaces ( H -p ) p ∈ N , see e.g. [GV68]. We denote the dual pairing of S ′ d and S d also by 〈· , ·〉 .
Let B be the σ -algebra generated by cylinder sets on S ′ d . By Minlos' theorem there is a unique probability measure µ d on ( S , ′ d B ) with characteristic function given by
$$\int _ { S _ { d } ^ { \prime } } e ^ { i \langle w, \varphi \rangle } d \mu _ { d } ( w ) = \exp \left ( - \frac { 1 } { 2 } | \varphi | _ { 0 } ^ { 2 } \right ), \quad \varphi \in S _ { d }.$$
Hence, we have defined the white noise measure space ( S , ′ d B , µ d ) . The complex Hilbert space L 2 ( µ d ) := L 2 ( S , ′ d B , µ d ) is canonically isomorphic to the Fock space of symmetric square integrable functions
$$L ^ { 2 } ( \mu _ { d } ) \simeq \left ( \bigoplus _ { k = 0 } ^ { \infty } \text{Sym} L ^ { 2 } ( \mathbb { R } ^ { k }, k! d ^ { k } x ) \right ) ^ { \otimes d }$$
which implies the Wiener-Itô-Segal chaos decomposition for any element F in L 2 ( µ d )
$$F ( w ) = \sum _ { n \in \mathbb { N } ^ { d } } \langle \colon w ^ { \otimes n } \, \colon, F _ { n } \rangle$$
with the kernel function F n in the Fock space. We introduce the following notation for simplicity
$$\mathbf n = ( n _ { 1 }, \dots, n _ { d } ) \in \mathbb { N } _ { 0 } ^ { d }, \ \ n = n _ { 1 } + \dots + n _ { d }, \ \ n! = n _ { 1 }! \dots n _ { d }!$$
and for any w = ( w , . . . , w 1 d ) ∈ S ′ d
$$\colon w ^ { \otimes n } \coloneqq \colon w _ { 1 } ^ { \otimes n _ { 1 } } \colon \otimes \dots \otimes \colon w _ { d } ^ { \otimes n _ { d } } \colon,$$
where : w ⊗ n : denotes the n -th Wick tensor power of the element w ∈ S ′ 1 , for its definition see e.g. [HKPS93]. For any F ∈ L 2 ( µ d ) , the isomorphism (1) yields
$$\| F \| _ { L ^ { 2 } ( \mu _ { d } ) } ^ { 2 } \coloneqq \sum _ { n \in \mathbb { N } ^ { d } } n! | F _ { n } | _ { 0 } ^ { 2 },$$
where the symbol | · | 0 is also preserved for the norms on L 2 ( R R , d ) ˆ ⊗ n C , for simplicity. By the standard construction with the space of square-integrable functions w.r.t. µ d as central space, we obtain the Gel'fand triple of Hida test functions and Hida distributions.
$$( S _ { d } ) \subset L ^ { 2 } ( \mu _ { d } ) \subset ( S _ { d } ) ^ { \prime }.$$
In the following we denote the dual pairing between elements of ( S d ) ′ and ( S d ) by 〈 〈· , ·〉 〉 . For F ∈ L 2 ( µ d ) and ϕ ∈ ( S d ) , with kernel functions f n and ϕ n , resp. the dual pairing yields
$$\left \langle \left \langle F, \varphi \right \rangle \right \rangle = \sum _ { n } n! \left \langle f _ { n }, \varphi _ { n } \right \rangle$$
This relation extends the chaos expansion to Φ ∈ ( S d ) ′ with distribution valued kernels Φ n such that
$$\left \langle \left \langle \Phi, \varphi \right \rangle \right \rangle = \sum _ { n } n! \left \langle \Phi _ { n }, \varphi _ { n } \right \rangle,$$
for every generalized test function ϕ ∈ ( S d ) with kernels ϕ n .
Instead of reviewing the detailed construction of these spaces we give a characterization in terms of the S -transform.
Definition 1. Let ξ ∈ S d , then : exp( 〈 ., ξ 〉 ) : := ∞ ∑ k =0 1 k ! 〈 : . ⊗ n : , ξ ⊗ n 〉 ∈ ( S d ) and we define the S -transform of Φ ∈ ( S d ) ′ by
$$( S \Phi ) ( \xi ) = \left \langle \left \langle \Phi, \colon \exp ( \left \langle., \xi \right \rangle ) \, \colon \right \rangle.$$
Definition 2 ( U -functional) . A function F : S d -→ C is called a U -functional whenever
↦
- 1. for every ϕ 1 , ϕ 2 ∈ S d the mapping R glyph[owner] λ → F λ ( ϕ 1 + ϕ 2 ) has an entire extension to z ∈ C ,
- 2. there are constants K , K 1 2 > 0 such that
$$\left | F ( z \varphi ) \right | \leq K _ { 1 } \exp \left ( K _ { 2 } \left | z \right | ^ { 2 } \left \| \varphi \right \| ^ { 2 } \right ), \quad \forall z \in \mathbb { C }, \varphi \in S _ { d }$$
for some continuous norm ‖ · ‖ on S d .
We are now ready to state the aforementioned characterization result.
Theorem 3 (cf. [KLP + 96], [PS91]) . The S -transform defines a bijection between the space ( S d ) ′ and the space of U -functionals. In other words, Φ ∈ ( S d ) ′ if and only if S Φ : S d → C is a U -functional.
Based on Theorem 3 a deeper analysis of the space ( S d ) ′ can be done. The following Corollaries concern the convergence of sequences and the Bochner integration of families of generalized functions in ( S d ) ′ (for more details and proofs see e.g. [HKPS93], [KLP + 96], [PS91]).
Corollary 4. Let (Φ ) n n ∈ N be a sequence in ( S d ) ′ such that
- 1. for all ϕ ∈ S d , (( S Φ )( n ϕ )) n ∈ N is a Cauchy sequence in C ,
- 2. there are K , K 1 2 > 0 such that for some continuous norm ‖ · ‖ on S d one has
$$| ( S \Phi _ { n } ) ( z \varphi ) | \leq K _ { 1 } \exp \left ( K _ { 2 } | z | ^ { 2 } \| \varphi \| ^ { 2 } \right ), \ \ \varphi \in S _ { d }, \ n \in \mathbb { N }, \ z \in \mathbb { C }.$$
Then (Φ ) n n ∈ N converges strongly in ( S d ) ′ to a unique Hida distribution.
↦
Corollary 5. Let (Ω , B , m ) be a measure space and λ → Φ λ be a mapping from Ω to ( S d ) ′ . We assume that the S -transform of Φ λ fulfills the following two properties:
↦
- 1. The mapping λ → ( S Φ )( λ ϕ ) is measurable for every ϕ ∈ S d ,
- 2. The S Φ λ obeys the estimate
$$| ( S \Phi _ { \lambda } ) ( z \varphi ) | \leq C _ { 1 } ( \lambda ) \exp \left ( C _ { 2 } ( \lambda ) | z | ^ { 2 } \| \varphi \| ^ { 2 } \right ), \ \ z \in \mathbb { C }, \varphi \in S _ { d },$$
for some continuous norm ‖ · ‖ on S d and for C 1 ∈ L 1 (Ω , m ) , C 2 ∈ L ∞ (Ω , m ) .
Then
$$\int _ { \Omega } \Phi _ { \lambda } \, d m ( \lambda ) \in ( S _ { d } ) ^ { \prime }$$
and
$$S \left ( \int _ { \Omega } \Phi _ { \lambda } \, d m ( \lambda ) \right ) ( \varphi ) = \int _ { \Omega } ( S \Phi _ { \lambda } ) ( \varphi ) \, d m ( \lambda ), \quad \varphi \in S _ { d }.$$
At the end of this section we introduce the notion of truncated kernels, defined via their Wiener-Itô-Segal chaos decomposition.
Definition 6. For Φ ∈ ( S d ) ′ with kernels F , n n ∈ N d 0 and k ∈ N 0 we define truncated Hida distribution by
$$\Phi ^ { ( k ) } = \sum _ { n \in \mathbb { N } _ { 0 } ^ { d } \colon n \geq k } \langle \colon. ^ { \otimes n } \colon, F _ { n } \rangle.$$
Obviously one has Φ ( k ) ∈ ( S d ) ′ .
## 3 Multifractional Brownian motion
Multifractional Brownian motion (mBm) in dimension 1 , was introduced by Peltier and Lévy Véhel [PLV95], Benassi et al. [BJR97] as zero mean Gaussian process with covariance given by
$$R _ { h } ( t, s ) = \frac { C \left ( \frac { h ( t ) + h ( s ) } { 2 } \right ) ^ { 2 } } { C ( h ( t ) ) C ( h ( s ) ) } \left [ \frac { 1 } { 2 } ( t ^ { h ( t ) + h ( s ) } + s ^ { h ( t ) + h ( s ) } - | t - s | ^ { h ( t ) + h ( s ) } ) \right ],$$
where the normalizing constant is defined by
$$C ( x ) \coloneqq \left ( \frac { 2 \pi } { \Gamma ( 2 x + 1 ) \sin ( \pi x ) } \right ) ^ { 1 / 2 },$$
where Γ is the Gamma function. Let us fix some notations. By ˆ u we denote the Fourier transform of u and let L 1 loc ( R ) be the set of measurable functions which are locally integrable in R . Each f ∈ L 1 loc ( R ) gives rise to an element in S ′ 1 , denoted by T f namely, for any ϕ ∈ S 1 , 〈 T , ϕ f 〉 = GLYPH<1> R f ( x ϕ x ) ( ) dx .
In order to obtain a realization of mBm in the framework of white noise analysis we introduce the following operator, see [LLV14]. For any H ∈ (1 / 2 1) , we define the operator
$$( \widehat { M _ { H } u } ) ( y ) = \frac { \sqrt { 2 \pi } } { C ( H ) } | y | ^ { 1 / 2 - H } \hat { u } ( y ),$$
where ˆ u denotes the Fourier transform of the function u . The operator M H is well defined in the space
$$L _ { H } ^ { 2 } ( \mathbb { R } ) \coloneqq \{ u \in S _ { 1 } ^ { \prime } \, \colon \, \hat { u } = T _ { f } ; \, f \in L _ { \text{loc} } ^ { 1 } ( \mathbb { R } ) \text{ and } \| u \| _ { H } < \infty \},$$
where the norm
$$\| u \| _ { H } ^ { 2 } \coloneqq \frac { 1 } { C ( H ) ^ { 2 } } \int _ { \mathbb { R } } | x | ^ { 1 - 2 H } | \hat { u } ( x ) | ^ { 2 } \, d x$$
is the inner product norm on the Hilbert space L 2 H ( R ) given by
$$( u, v ) _ { H } = \frac { 1 } { C ( H ) ^ { 2 } } \int _ { \mathbb { R } } | x | ^ { 1 - 2 H } \hat { u } ( x ) \overline { \hat { v } } ( x ) \, d x.$$
Another possible representation for the operator M H is as follows [LLV14, Eq. 2.4]
$$( M _ { H } \varphi ) ( x ) = \gamma ( H ) \langle | \cdot | ^ { H - 3 / 2 }, \varphi ( x + \cdot ) \rangle = \colon \gamma ( H ) \langle \Theta _ { H }, \varphi ( x + \cdot ) \rangle, \quad \varphi \in S _ { 1 } ( \mathbb { R } ), \\, \dots$$
$$\gamma ( H ) \coloneqq \frac { \sqrt { \Gamma ( 2 H + 1 ) \sin ( \pi H ) } } { 2 \Gamma ( H - 1 / 2 ) \cos ( \pi ( H - 1 / 2 ) / 2 ) }.$$
where
Note that Θ H is a generalized function from S ′ 1 , i.e. for any ψ ∈ S 1 we have 〈 Θ H , ψ 〉 = 〈| y | H -3 2 / , ψ ( y ) 〉 .
The operator M H establishes an isometry between the Hilbert spaces L 2 H ( R ) and L 2 ( R ) [LLV14, Prop. 2.10]. Below we review some useful properties of the operator M H .
Proposition 7. Let M H be the operator defined above and H ∈ (1 / 2 1) , .
- 1. Then M H is an isometric isomorphism between the Hilbert spaces L 2 H ( R ) and L 2 ( R ) .
- 2. For any f, g ∈ L 2 ( R ) ∩ L 2 H ( R ) we have
$$\int _ { \mathbb { R } } f ( x ) ( M _ { H } g ) ( x ) \, d x = \int _ { \mathbb { R } } ( M _ { H } f ) ( x ) g ( x ) \, d x.$$
Moreover, for any f ∈ L 1 loc ( R ) ∩ L 2 H ( R ) and g ∈ S 1 , we have
$$\langle f, M _ { H } g \rangle = ( M _ { H } f, g ) _ { L ^ { 2 } ( \mathbb { R } ) }.$$
- 3. There exists a constant D such that for every k ∈ N 0 := N ∪ { 0 } we have
$$\max _ { x \in \mathbb { R } } | ( M _ { H } e _ { k } ) ( x ) | \leq \frac { D } { C ( H ) } ( k + 1 ) ^ { 2 / 3 },$$
where e k := M -1 H h k and h k is the k-th Hermite function.
- 4. There exists p ∈ N such that for all t ∈ [0 , T ] and ϕ ∈ S 1 we have
$$\left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { H } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | \leq | \gamma ( H ) | \, | \Theta _ { H } | _ { - p } \, t \, \sup _ { x \in \mathbb { R } } | \varphi ( x + \cdot ) | _ { p },$$
with Θ H as in (2).
Proof. The items 1., 2. and 3. are proved in [LLV14, Thm 2.14, 2.15]. Assertion 4 . is a direct consequence of 2. under the use of the Cauchy-Schwarz inequality and the representation (2) for the operator M H .
Next we define the operator M H for a measurable functional parameter h : [0 , T ] -→ (1 / , 2 1) . For two indicator functions we define
$$R _ { h } ( t, s ) \coloneqq ( \mathbb { I } _ { [ 0, t ) }, \mathbb { I } _ { [ 0, s ) } ) _ { h } \coloneqq \frac { 1 } { C ( h ( t ) ) C ( h ( s ) ) } \int _ { \mathbb { R } } | x | ^ { 1 - 2 h ( x ) } \hat { \mathbb { I } } _ { [ 0, t ) } ( x ) \overline { \hat { \mathbb { I } } } _ { [ 0, s ) } ( x ) \, d x,$$
which can be extended by linearity to the pre-Hilbert space of simple functions ( E ( R ) , ( · , · ) h ) .
- (A1) From now on we assume that h : [0 , T ] -→ (1 / 2 1) , is a continuous function.
↦
Remark 8 . For all h : [0 , T ] -→ (1 / , 2 1) satisfying (A1), the bilinear form ( · , · ) h is an inner product. See [LLV14, Prop. 3.1]. Moreover we define the linear map M h : E ( R ) -→ L 2 ( R ) , 1 1 [0 ,t ) → M h 1 1 [0 ,t ) := M h t ( ) 1 1 [0 ,t ) := M H 1 1 [0 ,t ) | H = ( ) h t .
Definition 9. For h satisfying (A1) we define the L 2 ( µ 1 ) random variable B h ( ) t by
$$B _ { h } ( t ) = \langle \cdot, M _ { h } \mathbb { I } _ { [ 0, t ) } \rangle.$$
↦
- 1. One can show that the process ( ω, t ) → B h ( ω, t ) is a one-dimensional mBm, see [LLV14].
- 2. There is a continuous version of the process B h ( ) t by Kolmogorov's theorem and we use the same notation for this continuous version.
Remark 10 . The completion of E ( R ) with respect to ( · , · ) h is a Hilbert space denoted by L 2 h ( R ) . Moreover the operator M h is an isometry between ( E ( R ) , ( · , · ) h ) and ( L 2 ( R ) , ( · , · )) , which can be extended to an isometry between L 2 h ( R ) and L 2 ( R ) .
The next proposition shows certain properties of 1-dimensional mBm.
Proposition 11. The process B h ( ) t , t ≥ 0 has the following properties.
- 1. The characteristic function of B h ( ) t is given by
$$\mathbb { E } ( e ^ { i \lambda B _ { h } ( t ) } ) \ & = \ \int _ { S _ { 1 } ^ { \prime } ( \mathbb { R } ) } e ^ { i \lambda \langle w, M _ { h } \mathbb { 1 } _ { [ 0, t ) } \rangle } \, d \mu _ { 1 } ( w ) = \exp \left ( - \frac { \lambda ^ { 2 } } { 2 } | M \mathbb { 1 } _ { [ 0, t ) } | _ { 0 } ^ { 2 } \right ) \\ & = \ \exp \left ( - \frac { \lambda ^ { 2 } } { 2 } t ^ { 2 h ( t ) } \right ).$$
- 2. The expectation of B h ( ) t is zero.
- 3. The variance of B h ( ) t is given by
$$\mathbb { E } ( B _ { h } ^ { 2 } ( t ) ) = t ^ { 2 h ( t ) }.$$
- 4. The covariance of B h ( ) t is
$$R _ { h } ( t, s ) \ \colon = \ \mathbb { E } ( B _ { h } ( t ) B _ { h } ( s ) ) \\ = \ \frac { C \left ( \frac { h ( t ) + h ( s ) } { 2 } \right ) ^ { 2 } } { C ( h ( t ) ) C ( h ( s ) ) } \left [ \frac { 1 } { 2 } ( t ^ { h ( t ) + h ( s ) } + s ^ { h ( t ) + h ( s ) } - | t - s | ^ { h ( t ) + h ( s ) } ) \right ].$$
In Figures 1 and 2 the method of Wood and Chan [CW98] was used to motion.
simulate mBm on the interval [0 , 1] for different Hurst parameter functionals. Now we are ready to define the d -dimensional multifractional Brownian
Definition 12 ( d -dimensional mBm) . Let h satisfy (A1). A d -dimensional mBm with functional parameter h is defined by
$$B _ { h } ( t ) = \left ( B _ { h, 1 } ( t ), \dots, B _ { h, d } ( t ) \right ), \ \ t \geq 0,$$
where B h,i ( ) t , i = 1 , . . . , d , are d independent 1 -dimensional mBms.
Properties of B h ( ) t :
- 1. The expectation is zero
$$\mathbb { E } ( B _ { h } ( t ) ) = 0.$$
Figure 1: Multifractional Brownian motion for parameter functional h. Simulated with the method of Wood and Chan with s = 10000 discretization points. Here the Hölder continuity of the path is linearly increasing in time.
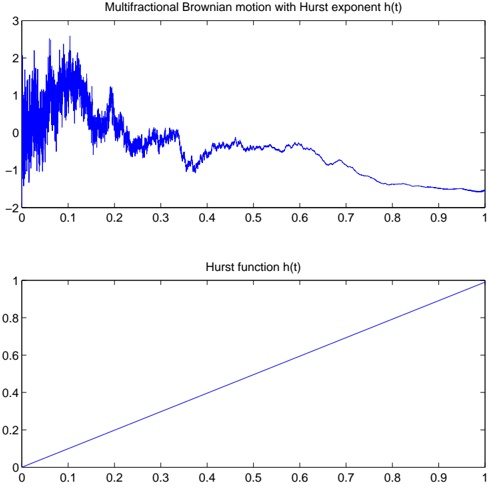
Figure 2: Multifractional Brownian motion for parameter functional h . Simulated with the method of Wood and Chan with s = 10000 discretization points. Here the Hölder continuity of the path is the function h t ( ) = 0 4 + 0 5 sin(5 . . πt . )
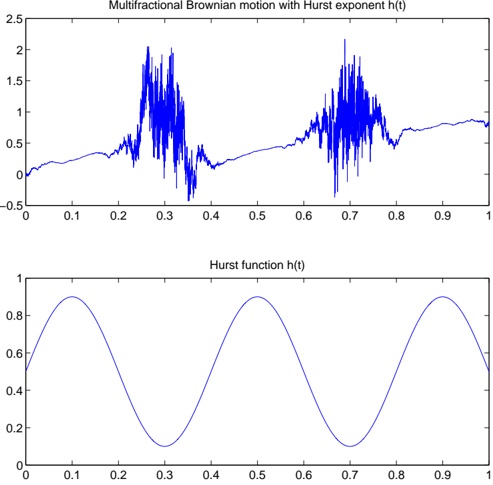
- 2. The characteristic function of B h ( ) t is given, for any x ∈ R d , by
$$\int _ { S _ { d } ^ { \prime } } e ^ { i ( \lambda, B _ { h } ( w, t ) ) _ { \mathbb { R } ^ { d } } } \, d \mu _ { d } ( w ) \ & = \ \exp \left ( - \frac { 1 } { 2 } \sum _ { k = 1 } ^ { d } x _ { k } ^ { 2 } | M _ { h } \mathbb { 1 } _ { [ 0, t ) } | _ { 0 } ^ { 2 } \right ) \\ & = \ \exp \left ( - \frac { 1 } { 2 } t ^ { 2 h ( t ) } | x | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ).$$
- 3. Covariance matrix of B h ( ) t :
$$\text{cov} ( B _ { h } ( t ) ) = ( \delta _ { i j } t ^ { 2 h ( t ) } ) _ { i, j = 1 } ^ { d }.$$
## 4 Local time
The time a process spends in a certain point y ∈ R d is called the local time of the process. Formally the local time is given by the time integral over a Dirac delta function of the process. This Donsker's delta function is a well-defined and studied object in white noise analysis, see e.g. [LLSW93, HKPS93, Oba94, Kuo96]. For mBm recently the concept of local times was introduced and studied, see e.g. [BDG07, MWX08, ASX11] and references therein.
In this section we determine the kernel functions for the local time and the regularized local time of mBm. Moreover we show that for a suitable number of truncated kernel functions the local time of mBm is a Hida distribution and can be obtained as a limit of the regularized local time.
Proposition 13. For t > 0 the Bochner integral
$$\delta ( B _ { h } ( t ) ) \coloneqq \left ( \frac { 1 } { 2 \pi } \right ) ^ { d } \int _ { \mathbb { R } ^ { d } } e ^ { i ( \lambda, B _ { h } ( t ) ) _ { \mathbb { R } ^ { d } } } \, d \lambda$$
is a Hida distribution and for any ϕ ∈ S d its S -transform given by
$$S \delta ( B _ { h } ( t ) ) ( \varphi ) = \left ( \frac { 1 } { \sqrt { 2 \pi } \, t ^ { h ( t ) } } \right ) ^ { d } \exp \left ( - \frac { 1 } { 2 t ^ { 2 h ( t ) } } \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \, \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ).$$
Proof. First we compute the S -transform of the integrand in (3) for any ϕ ∈ S d :
$$S e ^ { i ( \lambda, B _ { h } ( t ) ) _ { \mathbb { R } ^ { d } } } ( \varphi ) & = \exp \left ( - \frac { 1 } { 2 } | \lambda | _ { \mathbb { R } ^ { d } } ^ { 2 } t ^ { 2 h ( t ) } + i \left ( \lambda, \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right ) _ { \mathbb { R } ^ { d } } \right ). \\ \intertext { I t i c a l o r t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o n t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t i t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t s t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o th o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o te h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t ho t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t k o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o u t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t g o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o t h o { \Phi } \Phi ( \Phi ), \quad \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \alpha \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \beta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \da \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \dep \Delta \Delta \Delta$$
It is clear that the S -transform is λ -measurable for any ϕ ∈ S d . On the other hand, for any z ∈ C and all ϕ ∈ S d we obtain
$$\begin{array} { l l } \text{It is clear that the $S$-transform is $\lambda$-measurable for any $\varphi \in S_{d}$. On the} \\ \text{other hand, for any $z \in \mathbb{C}$ and all $\varphi \in S_{d}$ we obtain} \\ & | S e ^ { i ( \lambda, B _ { h } ( t ) ) _ { R d } ( z \varphi ) | } \\ = & \left | \exp \left ( - \frac { 1 } { 2 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } + i z \left ( \lambda, \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right ) _ { \mathbb { R } d } \right ) \right | \\ \leq & \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } \right ) \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } + | z | \left ( \lambda, \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | \right ) ^ { 2 } \right ) \\ \leq & \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } \right ) \exp \left ( - \left ( \frac { 1 } { 2 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { h ( t ) } - \frac { 1 } { t ^ { h ( t ) } } | z | \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | \right ) ^ { 2 } \right ) \\ & \times \exp \left ( \frac { 1 } { t ^ { 2 h ( t ) } } | z | ^ { 2 } \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | ^ { 2 } _ { \mathbb { R } d } \right ) \\ \leq & \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } \right ) \exp \left ( \frac { 1 } { t ^ { 2 h ( t ) } } | z | ^ { 2 } \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | ^ { 2 } _ { \mathbb { R } d } \right ) \\ \leq & \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } d } ^ { 2 } t ^ { 2 h ( t ) } \right ) \exp \left ( | z | ^ { 2 } | \varphi | _ { \mathbb { R } d } ^ { 2 } \right ). \\ \text{Thus we have the following bound} \\ & | S e ^ { i ( \lambda, B _ { h } ( t ) ) _ { R d } ( \tau, \tau \lambda ) | < \exp \tbinom { - 1 } { \lambda | ^ { 2 } \cdot t ^ { 2 h ( t ) } } \right ) \exp \tbinom { | \tau | ^ { 2 } | _ { \lambda | ^ { 2 } \cdot | \tau ^ { 2 } } \lambda }$$
Thus we have the following bound
$$| S e ^ { i ( \lambda, B _ { h } ( t ) ) _ { \mathbb { R } ^ { d } } } ( z \varphi ) | \leq \exp \left ( - \frac { 1 } { 4 } | \lambda | _ { \mathbb { R } ^ { d } } ^ { 2 } t ^ { 2 h ( t ) } \right ) \exp \left ( | z | ^ { 2 } | \varphi | _ { 0 } ^ { 2 } \right ),$$
where, as a function of λ , the first factor is integrable on R d and the second factor is constant. The result (4) follows from (5) and integration with respect to λ .
In the following theorem we characterize the truncated local time of mBm as a Hida distribution. Therefore we use the notation δ ( N ) for the truncated Donsker's delta function as in 6, i.e. for any ϕ ∈ S d
$$S \delta ^ { ( N ) } ( B _ { h } ( t ) ) ( \varphi ) = \left ( \frac { 1 } { \sqrt { 2 \pi } \, t ^ { h ( t ) } } \right ) ^ { d } \exp _ { N } \left ( - \frac { 1 } { 2 t ^ { 2 h ( t ) } } \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ),$$
with exp N ( x ) := ∑ ∞ n = N n 1 ! x n for x ∈ C .
(A2) Let h satisfy (A1) and sup t ∈ [0 ,T ) h t ( ) < 1+2 N 2 N + d , for a fixed N ∈ N 0 and d ∈ N .
Theorem 14. For h satisfying (A2) with dimension d ∈ N and N ∈ N 0 , the Bochner integral
$$L _ { h } ^ { ( N ) } ( T ) \coloneqq \int _ { 0 } ^ { T } \delta ^ { ( N ) } ( \mathbf B _ { h } ( t ) ) \, d t$$
is a Hida distribution.
Proof. The proof uses again Corollary 5 with respect to the Lebesgue measure in [0 , T ] . It follows from (4) that
$$S \delta ^ { ( N ) } ( B _ { h } ( t ) ) ( \varphi ) = \left ( \frac { 1 } { \sqrt { 2 \pi } \, t ^ { h ( t ) } } \right ) ^ { d } \exp _ { N } \left ( - \frac { 1 } { 2 t ^ { 2 h ( t ) } } \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \, \mathbb { I } _ { [ 0, t ) } ) ( x ) \, d x \right | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ), \\ \text{which is measurable in $t$ for every $\tau\in S$, $I$} \text{in$\emph{Proposition}(7\rangle-4$ we obtain}$$
which is measurable in t for every ϕ ∈ S d . Using Proposition (7)-4. we obtain the following bound for any z ∈ C and all ϕ ∈ S d
$$& \text{and working your $v$} \times \aleph \, \text{and} \, \tilde { \varphi } \, \infty \, \text{and} \, \tilde { \varphi } \, \infty \, \text{and} \\ & \quad | S \delta ^ { ( N ) } ( B _ { h } ( t ) ) ( z \varphi ) | \\ & \leq \quad & \left ( \frac { 1 } { \sqrt { 2 \pi } \, t ^ { h } ( t ) } \right ) ^ { d } \exp _ { N } \left ( \frac { 1 } { 2 t ^ { 2 h ( t ) } } | \gamma ( h ( t ) ) | ^ { 2 } \, | \Theta _ { h ( t ) } | _ { - p } ^ { 2 } t ^ { 2 } | z | ^ { 2 } \left ( \sup _ { x \in \mathbb { R } } \varphi ( x + \cdot ) | _ { p } \right ) ^ { 2 } \right ). \\ & \leq \quad & \left ( \frac { 1 } { \sqrt { 2 \pi } \, t ^ { h ( t ) } } \right ) ^ { d } \exp _ { N } \left ( \frac { 1 } { 2 } K ( h ) t ^ { 2 - 2 h ( t ) } | z | ^ { 2 } \| \varphi \| ^ { 2 } \right ), \\ & \text{where $K(h\,\is\information\text{and} \, of $t$ that sum $.\ - | h(t\| - \mathcal { B } \times 1\, \text{and} \, new}$$
where K h ( ) is independent of t (note that sup t ∈ [0 ,T ] | h t ( ) | = β < 1 ) and we defined the continuous norm on S d by
$$\| \varphi \| \coloneqq \sup _ { x \in \mathbb { R } } | \varphi ( x + \cdot ) | _ { p }.$$
The estimation
$$\exp _ { N } \left ( \frac { 1 } { 2 } K ( h ) t ^ { 2 - 2 h ( t ) } | z | ^ { 2 } \| \varphi \| ^ { 2 } \right ) \leq t ^ { 2 N ( 1 - h ( t ) ) } \exp \left ( \frac { K ( h ) } { 2 } | z | ^ { 2 } \| \varphi \| ^ { 2 } \right )$$
allows us to obtain the bound
$$| S \delta ^ { ( N ) } ( B _ { h } ( t ) ) ( z \varphi ) | \ \leq \ \left ( \frac { 1 } { \sqrt { 2 \pi } } \right ) ^ { d } t ^ { 2 N ( 1 - h ( t ) ) - d h ( t ) } \exp \left ( \frac { K ( h ) } { 2 } | z | ^ { 2 } \| \varphi \| ^ { 2 } \right ),$$
which is integrable in t ∈ [0 , T ) due to (A2). The proof follows from the application of Corollary 5.
Theorem 15. For h satisfying (A2) for dimension d and N ∈ N 0 , the kernels functions of L ( N ) h ( T ) are given by
$$& F _ { h, 2 n } ( u _ { 1 }, \dots, u _ { 2 n } ) = \frac { 1 } { n! } \left ( \frac { 1 } { \sqrt { 2 \pi } } \right ) ^ { d } \left ( - \frac { 1 } { 2 } \right ) ^ { n } \int _ { 0 } ^ { T } \frac { 1 } { t ^ { 2 h ( t ) N + d h ( t ) } } \prod _ { j = 1 } ^ { 2 n } ( M _ { h ( t ) } \mathbb { I } _ { [ 0, t ] } ) ( u _ { j } ) \, d t \\ & \text{for each $n \in \mathbb{N}^{d}$ such that $n > N$ } \ A l l \text{ the other kernels } F _ { i \,. } \text{ are zero}$$
for each n ∈ N d such that n ≥ N . All the other kernels F h, n are zero.
Proof. The kernels of L ( N ) h ( T ) are obtained by its S -transform. Therefore we use Corollary 5 and integrate (6) over [0 , T ] . For any ϕ ∈ S d , we have
$$\text{$\nu$} \varphi \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \col{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{ $\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\mu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$ } \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \rowel$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$}\colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \col: \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \tilde { \nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu`} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \colon \text{$\nu$} \\ \text{Comparing it with the general form of the chaos expansion$$
Comparing it with the general form of the chaos expansion
$$L _ { h } ^ { ( N ) } ( T ) = \sum _ { n \in \mathbb { N } ^ { d } } \langle \colon w ^ { \otimes n } \, \colon, F _ { h, n } \rangle$$
we obtain F h, n as in (7). This completes the proof.
Remark 16 . The result of Theorem 14 shows that for d = 1 all local times are well-defined, but for d ≥ 2 they are well-defined after truncation of divergent terms. This motivates the study of a regularized version, namely we discuss
$$L _ { h, \varepsilon } ( T ) \coloneqq \int _ { 0 } ^ { T } \delta _ { \varepsilon } ( \mathbf B _ { h } ( t ) ) \, d t, \quad \varepsilon > 0,$$
where
$$\delta _ { \varepsilon } ( B _ { h } ( t ) ) \coloneqq \left ( \frac { 1 } { \sqrt { 2 \pi \varepsilon } } \right ) ^ { d } \exp \left ( - \frac { 1 } { 2 \varepsilon } | B _ { h } ( t ) | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ).$$
Theorem 17. Let ε > 0 be given and h satisfy (A2).
- 1. The functional L h,ε ( T ) is a Hida distribution with kernels functions given by
$$F _ { h, \varepsilon, 2 n } ( u _ { 1 }, \dots, u _ { 2 n } ) \ = \ \frac { 1 } { n! } \left ( \frac { 1 } { \sqrt { 2 \pi } } \right ) ^ { d } \left ( - \frac { 1 } { 2 } \right ) ^ { n } \int _ { 0 } ^ { T } \frac { 1 } { ( \varepsilon + 2 h ( t ) ) ^ { n + d / 2 } } ( 8 ) \\ \times \prod _ { j = 1 } ^ { 2 n } ( M _ { h } \mathbb { I } _ { [ 0, t ) } ) ( u _ { j } ) \, d t$$
for each n = ( n , . . . , n 1 d ) ∈ N d and F h,ε, n = 0 if at least one of the n j is an odd number.
- 2. For ε tends to zero the truncated functional L ( N ) h,ε ( T ) converges strongly in ( S d ) ′ to the truncated local time L ( N ) h ( T ) .
Proof. 1. First we compute the S -transform of the integrand of L h,ε ( T ) . For any ϕ ∈ S , d we obtain
$$S \delta _ { \varepsilon } ( B _ { h } ( t ) ) ( \varphi ) \ = \ & \ \left ( \frac { 1 } { \sqrt { 2 \pi ( \varepsilon + t ^ { 2 h } ( t ) ) } } \right ) ^ { d } \exp \left ( \ - \ \frac { 1 } { 2 ( \varepsilon + t ^ { 2 h } ( t ) ) } \\ & \quad \times \left | \int _ { \mathbb { R } } \varphi ( x ) ( M _ { h } \, \mathbb { I } _ { [ 0, t } ) ( x ) \, d x \right | _ { \mathbb { R } ^ { d } } ^ { 2 } \right ), \\. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
which is measurable in t . Thus, for any z ∈ C and ϕ ∈ S d , by Proposition 7-4. we arrive at the following bound
$$| S \delta _ { \varepsilon } ( B _ { h } ( t ) ) ( z \varphi ) | \leq \left ( \frac { 1 } { \sqrt { 2 \pi ( \varepsilon + t ^ { 2 h ( t ) } ) } } \right ) ^ { d } \exp \left ( K ( h ) | z | ^ { 2 } \frac { t ^ { 2 } } { 2 ( \varepsilon + t ^ { 2 h ( t ) } ) } \| \varphi \| ^ { 2 } \right ).$$
On the other hand, t 2 2( ε + t 2 h t ( ) ) is bounded in [0 , T ] and ( ε + t 2 h t ( ) ) -d/ 2 is integrable on [0 , T ] , therefore we may conclude, by Corollary 5, that L h,ε ( T ) ∈
( S d ) ′ . In addition, for any ϕ ∈ S d , we have
$$( S _ { d } ) ^ { \prime }. \, In \, \text{addition, for any } \varphi \in S _ { d }, \, \text{ we have} \\ ( S L _ { h, e } ( T ) ) ( \varphi ) \ = \ \int _ { 0 } ^ { T } \left ( S \delta _ { \varepsilon } ( B _ { h } ( t ) ) \right ) ( \varphi ) \, d t \\ = \ \left ( \frac { 1 } { \sqrt { 2 } \pi } \right ) ^ { d } \int _ { 0 } ^ { T } \frac { 1 } { ( \varepsilon + t ^ { 2 h ( t ) } ) d / 2 } \sum _ { n = 0 } ^ { \infty } \frac { ( - 1 ) ^ { n } } { 2 ^ { n } ( \varepsilon + t ^ { 2 h ( t ) } ) ^ { n } } \\ & \times \sum _ { \substack { n _ { 1 } \dots, n _ { d } \in \mathbb { N } \\ n _ { 1 } + \dots + n _ { d } = n } } } \frac { 1 } { n _ { 1 }! \dots n _ { d }! } \prod _ { j = 1 } ^ { d } \left ( \int _ { \mathbb { R } } \varphi _ { j } ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t } ) ( x ) \, d x \right ) ^ { 2 n _ { j } } d t. \\ = \ \left ( \frac { 1 } { \sqrt { 2 } \pi } \right ) ^ { d } \int _ { 0 } ^ { T } \sum _ { n = 0 } ^ { \infty } \left ( - \frac { 1 } { 2 } \right ) ^ { n } \frac { 1 } { ( \varepsilon + t ^ { 2 h ( t ) } ) ^ { n + d / 2 } } \\ & \times \sum _ { \substack { n _ { 1 } \dots, n _ { d } \in \mathbb { N } \\ n _ { 1 } + \dots + n _ { d } = n } } \frac { 1 } { n! } \prod _ { j = 1 } ^ { d } \left ( \int _ { \mathbb { R } } \varphi _ { j } ( x ) ( M _ { h } \mathbb { I } _ { [ 0, t } ) ( x ) \, d x \right ) ^ { 2 n _ { j } } d t. \\ \text{Comparing the latter expression with the kernels } F _ { h, e, n } \, \text{from the chaos ex-} \\ \text{pansion of } L _ { h, e } ( T )$$
Comparing the latter expression with the kernels F h,ε, n from the chaos expansion of L h,ε ( T )
$$L _ { h, \varepsilon } ( T ) = \sum _ { n \in \mathbb { N } ^ { d } } \langle \colon w ^ { \otimes n } \, \colon, F _ { h, \varepsilon, n } \rangle,$$
we conclude that whenever one of the n j in n = ( n , . . . , n 1 d ) is odd we have F h,ε, n = 0 , otherwise they are given by the expression (8). 2. To check the convergence we shall use Corollary 4 and fact that
$$\left ( S L _ { h, \varepsilon } ^ { ( N ) } ($$
Thus, for all z ∈ C and all ϕ ∈ S d we estimate ( SL ( N ) h,ε ( T ) ) ( z ϕ ) by
$$\begin{array} {$$
for a certain constant C h, T ( ) > 0 , which shows the uniform boundedness condition. Moreover, using similar calculations as in Theorem 14, for any t ∈ [0 , T ] , yields
$$\left | ( S L _ { h, \varepsilon } ^ { ( N ) }$$
This upper bound together with the fact that 1 / 2 < h t ( ) < 1 , for any t ∈ [0 , T ] , gives an integrable function on [0 , T ] . Finally, an application of Lebesgue's dominated convergence theorem implies the other condition in order to apply Corollary 4. This completes the proof.
## Acknowledgments
H.P.S. and W.B. would like to thank the financial support of FCT - Fundação para a Ciência e a Tecnologia through the project Refª PEst-OE/MAT/UI0219/2014. W.B. thanks for the fellowship in the FCT-project PTDC/MAT-STA/1284/2012.
## References
[AN03] E. Alòs and D. Nualart. Stochastic integration with respect to the fractional Brownian motion. Stoch. Stoch. Rep. , 75(3):129-152, 2003. 2
[ASX11] A. Ayache, N.-R. Shieh, and Y. Xiao. Multiparameter multifrac- tional Brownian motion: Local nondeterminism and joint conti- nuity of the local times. Annales de l'Institut Henri Poincaré, Probabilités et Statistiques , 47(4):1029-1054, 11 2011. 3, 13
[BDG07]
B. Boufoussi, M. Dozzi, and R. Guerbaz. Sample path properties of the local time of multifractional Brownian motion. Bernoulli , 13(3):849-867, 08 2007. 3, 13
[BDG08]
B. Boufoussi, M. Dozzi, and R. Guerbaz. Path properties of a class of locally asymptotically self similar processes. Electronic Journal of Probability , 13(29):898-921, 2008. 2
| [Ben03a] | C. Bender. An Itô formula for generalized functionals of a frac- tional Brownian motion with arbitrary Hurst parameter. Stochas- tic Process. Appl. , 104(1):81-106, 2003. 2 |
|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Ben03b] | C. Bender. An S -transform approach to integration with respect to a fractional Brownian motion. Bernoulli , 9(6):955-983, 2003. 2 |
| [BFG13] | P. Bertrand, M. Fhima, and A. Guillin. Local estimation of the Hurst index of multifractional Brownian motion by increment ratio statistic method. ESAIM: Probability and Statistics , 17:307- 327, 1 2013. 3 |
| [BHØZ07] | F. Biagini, Y. Hu, B. Øksendal, and T. Zhang. Stochastic Calcu- lus for Fractional Brownian Motion and Applications . Probability and Its Applications. Springer, 2007. 2 |
| [BJR97] | A. Benassi, S. Jaffard, and D. Roux. Elliptic Gaussian ran- dom processes. Revista Matematica Iberoamericana , 13(1):19-90, 1997. 2, 7 |
| [CW98] | G. Chan and A. Wood. Simulation of multifractional Brownian motion. In Roger Payne and Peter Green, editors, COMPSTAT , pages 233-238. Physica-Verlag HD, 1998. 10 |
| [DHPD00] | T. E. Duncan, Y. Hu, and B. Pasik-Duncan. Stochastic calcu- lus for fractional Brownian motion. I. Theory. SIAM J. Control Optim. , 38(2):582-612 (electronic), 2000. 2 |
| [DOS08] | C. Drumond, M. J. Oliveira, and J. L. Silva. Intersection lo- cal times of fractional Brownian motions as generalized white noise functionals. In C. C. Bernido and V. C. Bernido, editors, Stochastic and Quantum Dynamics of Biomolecular Systems , vol- ume 1021 of AIP Conference Proceedings , pages 34-45, Melville, NY: American Institute of Physics (AIP), 2008. AIP Conference Proceedings 1021. 2, 3 |
| [EvdH03] | R. J. Elliott and J van der Hoek. A general fractional white noise theory and applications to finance. Math. Finance , 13(2):301- 330, 2003. 2 |
| [GV68] | I. M. Gel'fand and N. Ya. Vilenkin. Generalized Functions , vol- ume 4. Academic Press, Inc., New York and London, 1968. 3 |
|------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [HKPS93] | T. Hida, H. H. Kuo, J. Potthoff, and L. Streit. White Noise. An Infinite Dimensional Calculus . Kluwer Academic Publishers, Dordrecht, 1993. 3, 4, 6, 13 |
| [HØ03] | Y. Hu and B. Øksendal. Fractional white noise calculus and applications to finance. Infin. Dimens. Anal. Quantum Probab. Relat. Top. , 6(1):1-32, 2003. 2 |
| [KLP + 96] | Yu. G. Kondratiev, P. Leukert, J. Potthoff, L. Streit, and W. Westerkamp. Generalized functionals in Gaussian spaces: The characterization theorem revisited. J. Funct. Anal. , 141(2):301- 318, 1996. 3, 5, 6 |
| [Kuo96] | H. H. Kuo. White Noise Distribution Theory . CRC Press, Boca Raton, New York, London and Tokyo, 1996. 3, 13 |
| [LLSW93] | A. Lascheck, P. Leukert, L. Streit, and W. Westerkamp. Quan- tum mechanical propagators in terms of Hida distributions. Rep. Math. Phys. , 33:221-232, 1993. 13 |
| [LLV14] | J. Lebovits and J. Lévy Véhel. White noise-based stochastic cal- culus with respect to multifractional Brownian motion. Stochas- tics , 86(1):87-124, 2014. 3, 7, 8, 9 |
| [Mis08] | Y. S. Mishura. Stochastic Calculus for Fractional Brownian Motion and Related Processes . Lecture Notes in Mathematics. Springer-Verlag Berlin Heidelberg, Berlin, Heidelberg, 2008. 2 |
| [MvN68] | B. B. Mandelbrot and J. W. van Ness. Fractional Brownian mo- tions, fractional noises and applications. SIAM Review , 10:422- 437, 1968. 2 |
| [MWX08] | M. Meerschaert, D. Wu, and Y. Xiao. Local times of multifrac- tional brownian sheets. Bernoulli , 14(3):865-898, 08 2008. 3, 13 |
| [Nua06] | David Nualart. Stochastic calculus with respect to fractional Brownian motion. Annales de la faculté des sciences de Toulouse Mathématiques , 15(1):63-78, 2006. 2 |
```
[Oba94] N. Obata. White Noise Cal
``` | 10.1142/S0219025716500260 | [
"Wolfgang Bock",
"Jose Luis da Silva",
"Herry Pribawanto Suryawan"
] | 2014-08-01T14:29:40+00:00 | 2014-08-01T14:29:40+00:00 | [
"math.PR"
] | Local times for multifractional Brownian motion in higher dimensions: A white noise approach | We present the expansion of the multifractional Brownian (mBm) local time in
higher dimensions, in terms of Wick powers of white noises (or multiple Wiener
integrals). If a suitable number of kernels is subtracted, they exist in the
sense of generalized white noise functionals. Moreover we show the convergence
of the regularized truncated local times for mBm in the sense of Hida
distributions. |
1408.0190v1 | ## On the self-intersection number of the nonsingular models of rational cuspidal plane curves
Keita Tono
## Abstract
In this paper, we consider rational cuspidal plane curves having at least three cusps. We give an upper bound of the self-intersection number of the proper transforms of such curves via the minimal embedded resolution of the cusps. For a curve having exactly three cusps, we show that the self-intersection number is equal to the bound if and only if the curve coincides with the quartic curve having three cusps.
## 1 Introduction
Let C be an algebraic curve on P 2 = P 2 ( C ). A singular point of C is said to be a cusp if it is a locally irreducible singular point. We say that C is cuspidal if C has only cusps as its singular points. Suppose that C is rational and cuspidal. Let C ′ be the proper transform of C via the minimal embedded resolution of the cusps. Let ( C ′ ) 2 denote its self-intersection number. For instance, ( C ′ ) 2 = d if C is the rational cuspidal plane curve defined by the equation x d = y d -1 z , where d > 2 and ( x, y, z ) are homogeneous coordinates of P 2 . We estimate ( C ′ ) 2 in the following way.
Theorem 1. Let C be a rational cuspidal plane curve with n cusps. If n ≥ 3 , then ( C ′ ) 2 ≤ 7 -3 n .
/negationslash
Remark 1.1. It was proved in [H1, Theorem 3.5] that if Γ is a smooth curve of genus g ≥ 1 on a smooth rational projective surface S ( S = P 2 if g = 1), then Γ 2 ≤ 4 g + 4. From this fact we infer that if C is a cuspidal plane curve of genus g ≥ 1 with n cusps then ( C ′ ) 2 ≤ 4 g +4 -2 n . It was shown in [SST] that for given integers g, n with g ≥ 0, 1 ≤ n ≤ 2 g +2 there exist sequences of cuspidal plane curves C of genus g with n cusps such that ( C ′ ) 2 = 4 g +4 -2 n .
2010 Mathematics Subject Classification. 14H50
Key words and phrases. plane curve, cusp, self-intersection number.
Supported by JSPS Grant-in-Aid for Scientific Research (22540040) and the Fuujukai Foundation.
Let C be a rational cuspidal plane curve with n cusps. It was proved in [T1] that n ≤ 8. We denote by κ = κ ( P 2 \ C ) the logarithmic Kodaira dimension of the complement of C . By [W], we see κ = 2 if n ≥ 3. Moreover, if n = 2, then κ ≥ 0. If n = 1, then it was proved in [Y] that κ = -∞ if and only if ( C ′ ) 2 > -2. If n = 2, then ( C ′ ) 2 ≤ 0 by [T3]. From these facts and Theorem 1, ( C ′ ) 2 is bounded from above if κ = -∞ .
/negationslash
There are no known examples of rational cuspidal plane curves having more than 4 cusps. There is only one known rational cuspidal plane curve C with 4 cusps. The curve C is a quintic curve with ( C ′ ) 2 = -7 ([N, Theorem 2.3.10]). In [FZ1] (resp. [FZ2], [Fe]), a sequence of rational cuspidal plane curves C of degree d with three cusps was constructed, where d ≥ 4 (resp. d = 2 k + 3, d = 3 k + 4, k ≥ 1). They satisfy ( C ′ ) 2 = 2 -d (resp. ( C ′ ) 2 = -k -2, ( C ′ ) 2 = -k -3). The bound given by Theorem 1 is the best possible one for the case in which n = 3 as the quartic curve C with three cusps satisfies ( C ′ ) 2 = -2. Moreover, we prove the following:
Theorem 2. Let C be a rational cuspidal plane curve with three cusps. Then ( C ′ ) 2 = -2 if and only if C coincides with the quartic curve having three cusps.
In [T2], it was proved that the rational cuspidal plane curves C with n = 1, κ = 2 and ( C ′ ) 2 = -2 coincide with those constructed by Orevkov in [O]. In [T3], the rational cuspidal plane curves C with n = 2, κ = 2 and ( C ′ ) 2 = -1 were classified. Theorem 2 is a similar result for the case in which n = 3.
## 2 Preliminaries
In this section we prepare the proof of our theorems.
## 2.1 Linear chains
Let D be a divisor on a smooth projective surface V . Let D ,.. . , D 1 r be the irreducible components of D . We call D an SNC-divisor if D is a reduced effective divisor, each D i is smooth, D D i j ≤ 1 for distinct D , D i j , and D i ∩ D j ∩ D k = ∅ for distinct D , D , D i j k . Assume that D is an SNCdivisor. We use the following notation and terminology (cf. [Fu, Section 3] and [MT1, Chapter 1]). A blow-up at a point P ∈ D is said to be sprouting (resp. subdivisional ) with respect to D if P is a smooth point (resp. node) of D . We also use this terminology for the case in which D is a point. By definition, the blow-up is subdivisional in this case.
Assume that each D i is rational. Let Γ = Γ( D ) denote the dual graph of D . We give the vertex corresponding to a component D i the weight D 2 i . We sometimes do not distinguish between D and its weighted dual
/negationslash graph Γ. Assume that Γ is connected and linear. In case where r > 1, the weighted linear graph Γ together with a direction from an endpoint to the other is called a linear chain . By definition, the empty graph ∅ and a weighted graph consisting of a single vertex without edges are linear chains. If necessary, renumber D ,.. . , D 1 r so that the direction of the linear chain Γ is from D 1 to D r and D D i i +1 = 1 for i = 1 , . . . , r -1. We denote Γ by [ -D ,.. . , 2 1 -D 2 r ]. We sometimes write Γ as [ D ,.. . , D 1 r ]. The linear chain Γ is called admissible if Γ = ∅ and D 2 i ≤ -2 for each i . We define the discriminant d (Γ) of Γ as the determinant of the r × r matrix ( -D D i j ). We set d ( ∅ ) = 1.
/negationslash
Let A = [ a , . . . , a 1 r ] be a linear chain. We use the following notation if A = ∅ :
$$^ { t } A \coloneqq [ a _ { r }, \dots, a _ { 1 } ], \ \overline { A } \coloneqq [ a _ { 2 }, \dots, a _ { r } ], \ \underline { A } \coloneqq [ a _ { 1 }, \dots, a _ { r - 1 } ].$$
The discriminant d A ( ) has the following properties ([Fu, Lemma 3.6]).
Lemma 2.1. Let A = [ a , . . . , a 1 r ] be a linear chain, where a , . . . , a 1 r are integers.
- (i) If r > 1 , then d A ( ) = a d A 1 ( ) -d A ( ) = d ( t A ) = a d A r ( ) -d A ( ) .
- (ii) If r > 1 , then d A d A ( ) ( ) -d A d A ( ) ( ) = 1 .
- (iii) If A is admissible, then gcd( d A , d A ( ) ( )) = 1 and d A ( ) > d A ( ) > 0 .
Let A be an admissible linear chain. The rational number e A ( ) := d A /d A ( ) ( ) is called the inductance of A . By [Fu, Corollary 3.8], the function e defines a one-to-one correspondence between the set of all the admissible linear chains and the set of rational numbers in the interval (0 , 1). For a given admissible linear chain A , the admissible linear chain A ∗ := e -1 (1 -e ( t A )) is called the adjoint of A ([Fu, 3.9]). Admissible linear chains and their adjoints have the following properties ([Fu, Corollary 3.7, Proposition 4.7]).
Lemma 2.2. Let A and B be admissible linear chains.
- (i) If e A ( ) + e B ( ) = 1 , then d A ( ) = d B ( ) and e ( t A ) + e ( t B ) = 1 .
- (ii) We have A ∗∗ = A , t ( A ∗ ) = ( t A ) ∗ and d A ( ) = d A ( ∗ ) = d A ( ∗ ) + d A ( ) .
For integers m n , with n ≥ 0, we define [ m n ] = [ n ︷ ︸︸ ︷ m,... , m ], t n = [2 n ]. For non-empty linear chains A = [ a , . . . , a 1 r ], B = [ b 1 , . . . , b s ], we write A ∗ B = n
[ A,a r + b 1 -1 , B ], A ∗ n = ︷ ︸︸ ︷ A ∗ · · · ∗ A , where n ≥ 1 and a , . . . , a 1 r , b 1 , . . . , b s are integers. We remark that ( A ∗ B ) ∗ C = A ∗ ( B ∗ C ) for non-empty linear chains A B , and C . By using Lemma 2.1 and Lemma 2.2, we can show the following lemma.
Lemma 2.3. Let A = [ a 1 + 1 , . . . , a r + 1] be an admissible linear chain, where a , . . . , a 1 r are positive integers.
- (i) For a positive integer n , we have [ A,n +1] ∗ = t n ∗ A ∗ .
- (ii) We have A ∗ = t a r ∗ · · · ∗ t a 1 .
## 2.2 Vanishing theorem and Zariski decomposition
/negationslash
Let V be a smooth projective surface, K a canonical divisor and D = 0 a Q -divisor on V . Write D as D = ∑ r i =1 q D i i , where q i ∈ Q \{ } 0 and all D i 's are distinct irreducible curves. The divisor D is said to be numerically effective ( nef , for short) if DC ≥ 0 for all curves C on V . We define /floorleft D /floorright = ∑ i /floorleft q i /floorright D i and /ceilingleft D /ceilingright = -/floorleftD /floorright , where /floorleft q i /floorright is the greatest integer less than or equal to q i . We will use the following vanishing theorem ([Mi], [S2, Theorem 5.1]).
Theorem 3. Let D be a nef Q -divisor on a smooth projective surface V and K a canonical divisor on V . If D > 2 0 , then h i ( V, K + /ceilingleft D /ceilingright ) = 0 for i > 0 .
We denote by Q ( D ) the Q -vector space generated by D ,.. . , D 1 r . The divisor D is said to be contractible if the intersection form defined on Q ( D ) is negative definite ([Fu, Section 6]). The divisor D is said to be pseudoeffective if DH ≥ 0 for all nef divisors H on V . By [Fu, Theorem 6.3], if D is pseudo-effective, then there exists an effective Q -divisor N satisfying the following conditions.
- (i) N is contractible if N = 0.
/negationslash
- (ii) H = D -N is nef.
- (iii) HE = 0 for all irreducible components E of N .
The divisor N is determined by the numerical equivalence class of D by [Fu, Lemma 6.4]. The decomposition D = H + N is called the Zariski decomposition of D . The divisor N (resp. H ) is called the negative part (resp. nef part ) of D .
From now on, we assume that V and D satisfy the following conditions.
- (Z1) D = 0 is an SNC-divisor such that K + D is pseudo-effective.
/negationslash
- (Z2) Each ( -1)-curve E ≤ D satisfies ( D -E E > ) 2 or, ( D -E E ) = 2 and E intersects only a single irreducible component of D .
Following [Fu, MT1], we use the following terminology. The divisor D is said to be rational if each D i is rational. Let 0 < T = ∑ t j =1 T j ≤ D be a divisor, where T j 's are irreducible. The divisor T is called a twig of D if ( D -T 1 ) T 1 = 1, ( D -T j ) T j = 2 and T j -1 T j = 1 for j ≥ 2. Suppose that T is
a rational twig of D . The twig T is said to be admissible if T 2 j < -1 for all j . We infer under the assumption (Z2) that a rational twig is contractible if and only if it is admissible. There exists an irreducible component D i of D such that T D t i = 1 and D i /notlessequal T . The rational twig T is said to be maximal if D i is not rational or ( D -D D > i ) i 2. Suppose that the twig T is rational and contractible. The element Bk( T ) ∈ Q ( T ) satisfying Bk( T T ) j = ( K + D T ) j for all j is called the bark of T .
Let B be a connected component of D . The divisor B is called a rod if the dual graph Γ( B ) of B is linear. The divisor B is called a rational fork if it satisfies the following conditions.
- (i) B = C + T (1) + T (2) + T (3) is rational, where T (1) , T (2) , T (3) are contractible maximal rational twigs of D and C is an irreducible curve such that ( B -C C ) = 3.
- (ii) ( K + B -Σ Bk( i T ( ) i )) C < 0.
Suppose that B is a rational rod or a rational fork. Suppose also that B is contractible. The element Bk( B ) ∈ Q ( B ) satisfying Bk( B E ) = ( K + B E ) for all irreducible components E of B is called the bark of B . Let B , B , . . . 1 2 be the all rational rods and rational forks which are contractible. Let T , T 1 2 , . . . denote the all rational maximal twigs which are contractible and not contained in any B i . The divisor Bk( D ) = ∑ i Bk( B i ) + ∑ j Bk( T j ) is called the bark of D .
Let N denote the negative part of K + D . We will use the following facts. See [Fu, Section 6] and [MT1, Chapter 1]. Note that rods (resp. rational forks) are called clubs (resp. abnormal rational clubs ) in [Fu, Section 6]. The divisor Bk( D ) is denoted by Bk ( ∗ D ) and called the thicker bark of D .
Lemma 2.4. The following assertions hold under the assumptions (Z1), (Z2).
- (i) All rational rods, rational forks and rational twigs of D belong to Q ( N ) . In particular, they are contractible.
/negationslash
- (ii) If N = Bk( D ) and any connected component of D is not a rational rod, then there exists a ( -1 )-curve E ⊂ Supp( N ) such that DE ≤ 1 and E /notlessequal D . Moreover, E meets with Supp(Bk( D )) if DE = 1 .
Proof. (i) By [Fu, Lemma 6.13], all rational rods and rational twigs of D belong to Q ( N ). Let B be a rational fork. Write B as B = C + T (1) + T (2) + T (3) as in the definition of rational forks. Since ( N -Σ Bk( i T ( ) i )) C ≤ ( K + D -Σ Bk( i T ( ) i )) C < 0, we have C ∈ Q ( N ) by [Fu, Lemma 6.15]. Hence B ∈ Q ( N ).
- (ii) We note that all rational twigs are admissible by (i) and (Z2). Thus the assertion follows from [Fu, Lemma 6.20]. See also Section 1.6, 1.7, 1.8 of [MT1].
Lemma 2.5. In addition to the assumptions (Z1), (Z2), suppose that N = Bk( D ) , κ V ( \ D ) = 2 and that every rational rod and rational fork of D contains an irreducible component E with E 2 < -2 . Then the following assertions hold.
- (i) /floorleft N /floorright = 0 .
- (ii) h 1 ( V, 2 K + D ) = h 2 ( V, 2 K + D ) = 0 .
- (iii) h 0 ( V, 2 K + D ) = K K ( + D ) + D K ( + D / ) 2 + χ ( O V ) .
Proof. We have /floorleft N /floorright = Bk( /floorleft D ) /floorright = 0 by [MT1, Section 1.4 and Lemma 1.5] and the assumption. Since κ V ( \ D ) = 2, we see H > 2 0 by [K]. We apply Theorem 3 to H . We have 0 = h i ( V, K + /ceilingleft H /ceilingright ) = h i ( V, 2 K + D + /ceilingleftN /ceilingright ) = h i ( V, 2 K + D ) for i = 1 2. The last equality follows from the Riemann-Roch , formula.
## 2.3 The bigenus of Q-homology planes
/negationslash
Let V be a smooth projective surface, K a canonical divisor and D = 0 an SNC-divisor on V . Suppose that X := V \ D is a Q -homology plane. That is, H X, i ( Q ) = { } 0 for i > 0. In this section, we compute the bigenus h 0 ( V, 2 K + D ) of X ([S1]). We will use the following facts ([Fu, Corollary 2.5, Theorem 2.8], [H2, Theorem II.4.2] and [MT2, Main Theorem]).
Lemma 2.6. The following assertions hold,
- (i) X is affine.
- (ii) h 1 ( V, O V ) = h 2 ( V, O V ) = 0 .
- (iii) Γ( D ) is a connected rational tree.
- (iv) D is not contractible.
- (v) If κ X ( ) = 2 , then X does not contain topologically contractible algebraic curves.
From now on, we assume that V and D satisfy the following conditions.
- (H1) κ X ( ) = 2.
- (H2) All ( -1)-curves E ≤ D satisfy ( D -E E > ) 2.
Note that V, D satisfy the conditions (Z1), (Z2) in Section 2.2. Let K + D = H + N be the Zariski decomposition, where N is the negative part of K + D .
Proposition 2.7. Let V , D be as above satisfying the assumptions (H1), (H2). Then the following assertions hold.
- (i) D is neither a rational rod nor a rational fork.
- (ii) We have N = Bk( D ) , /floorleft N /floorright = 0 .
- (iii) We have h 1 ( V, 2 K + D ) = h 2 ( V, 2 K + D ) = 0 , h 0 ( V, 2 K + D ) = K K ( + D ) .
/negationslash
Proof. The divisor D is neither a rational rod nor a rational fork by Lemma 2.4 (i) and Lemma 2.6 (iv). Suppose N = Bk( D ). By the assertion (i) and Lemma 2.4 (ii), there exists a ( -1)-curve E /notlessequal D such that DE ≤ 1, which contradicts Lemma 2.6 (i), (v). We have χ ( O V ) = 1, D K ( + D ) = -2 by Lemma 2.6 (ii), (iii). Thus the remaining assertions follow from Lemma 2.5.
We will use the following lemma to show Theorem 2.
/negationslash
Lemma 2.8. Let ϕ : V → W be the composition of successive blow-ups over a smooth projective surface W and D = 0 an SNC-divisor on V . Let P ∈ W be the center of the first blow-up of ϕ and E the exceptional curve of the last blow-up over P . Assume that the following conditions are satisfied.
- (1) V \ D is a Q -homology plane with κ V ( \ D ) = 2 .
- (2) E /notlessequal D .
Then the following assertions hold.
- (i) At least two locally irreducible branches of ϕ D ( ) pass through P .
- (ii) Suppose that exactly two locally irreducible branches D ,D 1 2 of ϕ D ( ) pass through P . Suppose also that D ,D 1 2 intersect each other at P transversally. Let D ,D ′ 1 ′ 2 denote the proper transforms of D ,D 1 2 via ϕ , respectively. Then the dual graph of D ′ 1 + ϕ -1 ( P ) + D ′ 2 has the following shape, where 0 ≤ T , T 1 2 ≤ D may be empty.
$$D _ { 1 } ^ { \prime } \circ \underset { T _ { 1 } } { \longleftarrow } \underset { E } { \longleftarrow } \underset { T _ { 2 } } { \longleftarrow } \underset { T _ { 2 } } { \longleftarrow } \underset { T _ { 2 } } { \longleftarrow } \circ D _ { 2 } ^ { \prime }$$
Proof. It is enough to show the assertions for the case in which all blow-ups of ϕ are done over P .
/negationslash
- (i) By Lemma 2.6 (iv), ϕ D ( ) is not a point (cf. [Mu]). Let D ′ denote the proper transform of ϕ D ( ) via ϕ . The divisor T := ϕ -1 ( P ) is an SNC-divisor. The dual graph of T is a connected tree. If P ∈ ϕ D ( ), then T ⊂ V \ D , which contradicts the fact that V \ D is affine. Thus P ∈ ϕ D ( ). Suppose that there is only one locally irreducible branch of ϕ D ( ) which passes through P . Then T ∩ D ′ consists of a single point Q .
/negationslash
We see T = E since E D \ is not topologically contractible by Lemma 2.6. Suppose that T 0 := T -E does not intersect D ′ . Then D ′ intersects only
E /notlessequal D among the irreducible components of T . Since D is connected, we have T 0 ⊂ V \ D , which is absurd. Hence T 0 ∩ D ′ = { Q } . We note that E may pass through Q . If T E 0 = 1, then E ∩ D = ∅ or E ∩ D = one point , { } which contradicts Lemma 2.6. Thus T E 0 ≥ 2 and T 0 is not connected. Let T 1 be a connected component of T 0 which does not passes through Q . Then T 1 intersects only E /notlessequal D among the irreducible components of T -T 1 . This means that T 1 ⊂ V \ D , which is impossible.
/negationslash
(ii) It follows from (i) that the dual graph of D ′ 1 + ϕ -1 ( P ) + D ′ 2 is linear. Suppose that there exists an irreducible component E ′ of ϕ -1 ( P ) -E such that E ′ /notlessequal D . If E ∩ E ′ = ∅ , then DE = 1, which contradicts Lemma 2.6. Thus E ∩ E ′ = ∅ . Then D ′ 1 + ϕ -1 ( P ) + D ′ 2 -E -E ′ is not connected. Since D is connected, V \ D contains a connected component of D ′ 1 + ϕ -1 ( P ) + D ′ 2 -E -E ′ , which is impossible.
## 3 Proof of Theorem 1 and Theorem 2
Let C be a rational cuspidal plane curve and P , . . . , P 1 n the cusps of C . We will use the fact that P 2 \ C is a Q -homology plane. Let σ : V → P 2 be the composition of a shortest sequence of blow-ups such that the reduced total transform D := σ -1 ( C ) is an SNC-divisor. Let C ′ be the proper transform of C . For each k , the dual graph of σ -1 ( P k ) + C ′ has the following shape.
Here D ( k ) 0 is the exceptional curve of the last blow-up over P k and h k ≥ 1. By definition, A ( k ) 1 contains the exceptional curve of the first blow-up over P k . The morphism σ contracts A ( k ) h k + D ( k ) 0 + B ( k ) h k to a ( -1)-curve E , A ( k ) h k -1 + E + B ( k ) h k -1 to a ( -1)-curve, and so on. The self-intersection number of every irreducible component of A ( k ) i and B ( k ) i is less than -1 for each i . See [BK, MaSa] for detail.
We give the graphs A ( k ) 1 , . . . , A ( k ) h k (resp. B ( k ) 1 , . . . , B ( k ) h k ) the direction from the left-hand side to the right (resp. from the bottom to the top) in the above figure. We assign each vertex the self-intersection number of the corresponding curve as its weight. With these directions and weights, we regard A ( k ) i and B ( k ) i as linear chains. See Section 2.1.
We may assume σ = σ ( n ) ◦· · · ◦ σ (1) , where σ ( k ) is the composition of the blow-ups over P k of σ . There exists a decomposition σ ( k ) = σ ( k ) 0 ◦ σ ( k ) 1 ◦· · · ◦ σ ( k ) h k such that σ ( k ) i contracts [ A ( k ) i , 1 , B ( k ) i ] to a ( -1)-curve for each i ≥ 1.
Let η ( k ) i denote the number of the sprouting blow-ups of σ ( k ) i with respect to the ( -1)-curve. We will use the following lemma ([T2, Propositon 12]).
Lemma 3.1. We have A ( k ) i = t η ( k ) i ∗ B ( k ) ∗ i , A ( k ) ∗ i = [ B ( k ) i , η ( k ) i + 1] for each i, k . In particular, A ( k ) i contains an irreducible component E such that E 2 < -2 .
## 3.1 Proof of Theorem 1
Let K be a canonical divisor on V . Let ω k (resp. η k ) denote the number of the subdivisional (resp. sprouting) blow-ups of σ over P k , where the blowup at P k is regarded as a subdivisional one. We have η k = ∑ h k i =1 η ( k ) i and ω k + η k = the number of the blow-ups of σ ( k ) . We complete the proof of Theorem 1 by showing the following proposition. We note that κ = 2 if n ≥ 3 by [W].
$$& \text{Proposition } 3. 2. \ I f \overline { \kappa } = 2, \text{ then } 0 \leq K ( K + D ) = 7 - 2 n - ( C ^ { \prime } ) ^ { 2 } - \sum _ { k = 1 } ^ { n } \eta _ { k }. \\ & M _ { \text{commission} } \quad \text{and} \, k \in \mathcal { C } ^ { \prime } \times 2 \times 7 \quad 2 \infty.$$
Moreover, we have ( C ′ ) 2 ≤ 7 -3 n .
Proof. We have K K ( + D ) = 7 -D 2 -∑ n k =1 ( ω k + η k ). It was proved in [MaSa, Lemma 4] that D 2 = ( C ′ ) 2 -∑ n k =1 ( ω k -2). Thus we get K K ( + D ) = 7 -2 n -( C ′ ) 2 -∑ n k =1 η k . The surface V \ D is a Q -homology plane satisfying the conditions (H1), (H2) in Section 2.3. By Proposition 2.7, we have 0 ≤ K K ( + D ). The second blow-up of σ over P k is a sprouting one for each k . This fact shows the last inequality.
## 3.2 Proof of Theorem 2
Assume that n = 3 and ( C ′ ) 2 = -2. By [W], we have κ = 2. By Lemma 3.1 and Proposition 3.2, we get the following:
Lemma 3.3. The following assertions hold for each k .
$$( i ) \ h _ { k } = 1 \ a n d \ \eta _ { 1 } ^ { ( k ) } = 1.$$
$$( i i ) \ A _ { 1 } ^ { ( k ) } = t _ { 1 } * B _ { 1 } ^ { ( k ) * } \ a n d \ A _ { 1 } ^ { ( k ) * } = [ B _ { 1 } ^ { ( k ) }, 2 ].$$
Let σ ′ : V → V ′ be the contraction of D (2) 0 and D (3) 0 . Since σ ′ ( C ′ ) 2 = 0, there exists a P 1 -fibration p ′ : V ′ → P 1 such that σ ′ ( C ′ ) is a nonsingular fiber. Put p = p ′ ◦ σ ′ : V → P 1 . On V , there are two irreducible components of A ( k ) 1 + B ( k ) 1 meeting with D ( k ) 0 for each k . One of them must be a ( -2)curve and the other must not. Let D ( k ) 1 be the ( -2)-curve and let D ( k ) 2 be the remaining one. Put S 1 = D (1) 0 , S 2 = D (2) 2 , S 3 = D (3) 2 , S 4 = D (2) 1 and S 5 = D (3) 1 . The curves S , . . . , S 1 5 are 1-sections of p . Namely, the
intersection number of them and a fiber is equal to one. The divisor D contains no other sections of p . The divisor F ′ 0 := C ′ + D (2) 0 + D (3) 0 is a singular fiber of p .
The surface X = V \ D is a Q -homology plane. A general fiber of p | X is isomorphic to a curve C (4 ∗ ) = P 1 \ { 5 points } . Cf. [MiSu]. There exists a birational morphism ϕ : V → Σ d from V onto the Hirzebruch surface Σ d for some d ≥ 0. The morphism ϕ is the composition of the successive contractions of the ( -1)-curves in the singular fibers of p , and p ◦ ϕ -1 : Σ d → P 1 is a P 1 -bundle.
Lemma 3.4. We may assume that ϕ S ( 1 + S 2 + S 3 ) is smooth. The following assertions hold.
- (i) ϕ S ( 1 ) ∼ ϕ S ( 2 ) ∼ ϕ S ( 3 ) (linearly equivalent), d = ϕ S ( 1 ) 2 = 0 .
- (ii) We have ϕ F ( ′ 0 ) = ϕ C ( ′ ) . The fiber ϕ F ( ′ 0 ) passes through ϕ S ( 2 ) ∩ ϕ S ( 4 ) and ϕ S ( 3 ) ∩ ϕ S ( 5 ) .
- (iii) ϕ contains exactly one blow-up over ϕ S ( 1 ) . The set ϕ S ( 1 ) ∩ ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of a single point, which coincides with the center of the blow-up.
- (iv) ϕ S ( 4 ) 2 = ϕ S ( 5 ) 2 = ϕ S ( 4 ) ϕ S ( 5 ) = 2 , ϕ S ( 4 ) ϕ S ( 1 ) = ϕ S ( 5 ) ϕ S ( 1 ) = 1 .
Proof. By [T3, Lemma 17], we may assume that ϕ S ( 1 + S 2 + S 3 ) is smooth. We have ϕ S ( 1 ) ∼ ϕ S ( 2 ) ∼ ϕ S ( 3 ) and ϕ S ( 1 ) 2 = 0. If ϕ contracts C ′ , then ϕ S ( 1 + S 2 + S 3 ) must be singular. Thus ϕ F ( ′ 0 ) = ϕ C ( ′ ) and ϕ contracts D (2) + D (3) . Hence ϕ F ( ′ ) passes through ϕ S ( ) ∩ ϕ S ( ) and ϕ S ( ) ∩ ϕ S ( ).
/negationslash
0 0 0 2 4 3 5 For i = 4 5, , put ε i = ϕ S ( i ) ϕ S ( 1 ). We have ϕ S ( i ) 2 = 2 ε i because ϕ S ( i ) ∼ ϕ S ( 1 ) + (a fiber of p ◦ ϕ -1 ) ε i . Since ϕ S ( i ) intersects ϕ S ( i -2 ), we see ε i > 0. Because S 2 1 = -1, ϕ contains exactly one blow-up over ϕ S ( 1 ). This means that ε 4 = ε 5 = 1 and that ϕ S ( 1 ) ∩ ϕ S ( 4 ) ∩ ϕ S ( 5 ) = ∅ . We have ϕ S ( 4 ) ϕ S ( 5 ) = ε 4 + ε 5 = 2. The remaining assertions are clear.
We use Lemma 3.4 to show the following:
Lemma 3.5. The following assertions hold.
/negationslash
- (i) For i = 4 5 , , ϕ contains exactly four blow-ups over ϕ S ( i ) . The centers of the blow-ups must be the points of intersection of ϕ S ( i ) and the other sections ϕ S ( j ) ( j = i ).
- (ii) If a fiber F of p ◦ ϕ -1 intersects ϕ S ( 1 + · · · + S 5 ) in five points, then the proper transform F ′ of F via ϕ is not a component of D and intersects D (1) 0 , D (2) 1 and D (3) 1 .
Proof. The first assertion of (i) follows from the fact that S 2 i = -2 and ϕ S ( i ) 2 = 2. The second follows from Lemma 3.4 and the fact that S i does not intersect the other sections on V . By (i) and Lemma 3.4 (iii), ϕ does not perform blow-ups over F ∩ ϕ S ( 1 + S 4 + S 5 ). This means that F ′ intersects D (1) 0 , D (2) 1 and D (3) 1 . Since the dual graph of D contains no loops, F ′ is not a component of D .
By Lemma 3.4, ϕ S ( 2 ) ∩ ϕ S ( 5 ) and ϕ S ( 3 ) ∩ ϕ S ( 4 ) consist of a single point, respectively.
Lemma 3.6. The two points ϕ S ( 2 ) ∩ ϕ S ( 5 ) , ϕ S ( 3 ) ∩ ϕ S ( 4 ) are on a single fiber of p ◦ ϕ -1 .
Proof. Suppose the contrary. Let F 2 (resp. F 3 ) denote the fiber of p ◦ ϕ -1 passing through ϕ S ( 2 ) ∩ ϕ S ( 5 ) (resp. ϕ S ( 3 ) ∩ ϕ S ( 4 )). Let F ′ i denote the proper transform of F i via ϕ for i = 2 3. , By Lemma 3.4 (iii), F ′ i intersects S 1 . It follows from Lemma 3.4 and Lemma 3.5 (i) that F ′ i intersects D ( ) i 1 . Since the dual graph of D does not contain loops, F ′ i is not a component of D .
Suppose that ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of one point. Let F be the fiber of p ◦ ϕ -1 passing through ϕ S ( 4 ) ∩ ϕ S ( 5 ). By Lemma 3.5 (ii), the proper transform via ϕ of every fiber of p ◦ ϕ -1 other than F and ϕ F ( ′ 0 ) is not a component of D . This contradicts the fact that there are three irreducible components of D -D (1) 0 meeting with D (1) 0 , each of which is contained in a fiber of p . Hence ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of two points.
Let E be the exceptional curve of the blow-up of ϕ at ϕ S ( 1 ) ∩ ϕ S ( 4 ) ∩ ϕ S ( 5 ). By Lemma 3.4 (iii) and Lemma 3.5 (i), the proper transform E ′ of E by ϕ intersects S 1 , S 4 and S 5 . Thus E ′ is not a component of D . By the same argument as above, there are at most two components of D -D (1) 0 meeting with D (1) 0 , which is absurd.
By Lemma 3.4 (iv), the set ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of one or two points.
Lemma 3.7. If ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of two points, then deg C = 4 .
Proof. We show σ -1 ( P k ) = D ( k ) 0 + D ( k ) 1 + D ( k ) 2 for each k . Put { Q 1 } = ϕ S ( 1 ) ∩ ϕ S ( 5 ), { Q 2 } = ϕ S ( 2 ) ∩ ϕ S ( 5 ) and { Q 3 } = ϕ S ( 4 ) ∩ ϕ S ( 5 ) \{ Q 1 } . For each i , let F i be the fiber of p ◦ ϕ -1 passing through Q i . Put { Q 4 } = ϕ S ( 3 ) ∩ ϕ S ( 4 ). The fiber F 2 passes through Q 4 by Lemma 3.6. Since S , . . . , S 1 5 do not intersect each other, ϕ performs blow-ups at all Q i 's. Let E i be the exceptional curve of the blow-up at Q i . We sometimes use the same symbols to denote the proper transforms of E i , ϕ S ( i ), etc. via blow-ups. Let F ′ i denote the proper transform of F i via ϕ .
By Lemma 3.4 (iii) and Lemma 3.5 (i), ϕ does not perform blow-ups at E 1 ∩ ϕ S ( 1 ), E 1 ∩ ϕ S ( 4 ) and E 1 ∩ ϕ S ( 5 ) after the blow-up at Q 1 . This
means that E 1 intersects S 1 , S 4 and S 5 on V . Thus E 1 is not a component of D . It follows from Lemma 2.8 (i) that ϕ does not perform blow-ups over E 1 . By Lemma 3.5 (ii), the proper transforms via ϕ of the fibers of p ◦ ϕ -1 other than ϕ F ( ′ 0 ), F 1 , F 2 and F 3 are not contained in D . By Lemma 3.4 (iii), ϕ does not perform blow-ups over ϕ S ( 1 ) \ { Q 1 } . Thus F ′ 2 and F ′ 3 are contained in D and intersect S 1 = D (1) 0 . It follows that F 2 + F 3 coincides with the image of D (1) 1 + D (1) 2 under ϕ . We have ( F ′ 3 ) 2 < -2 since ϕ performs blow-ups at Q 3 , ϕ S ( 2 ) ∩ F 3 and ϕ S ( 3 ) ∩ F 3 . Hence F ′ 2 = D (1) 1 and F ′ 3 = D (1) 2 .
Since ( F ′ 2 ) 2 = -2, ϕ only performs two blow-ups over F 2 . The centers coincide with Q 2 and Q 4 . The curve E 4 is not a component of D because it intersects S 4 = D (2) 1 and F ′ 2 = D (1) 1 on V . By Lemma 2.8 (i), ϕ does not perform blow-ups over E 4 . Similarly, E 2 is not a component of D and ϕ does not perform blow-ups over E 2 . It follows that D (1) 1 intersects only D (1) 0 among the components of D -D (1) 1 . Hence ( F ′ 3 ) 2 = ( D (1) 2 ) 2 = -3.
We see that ϕ does not perform blow-ups over F 3 \ ( ϕ S ( 2 + S 3 ) ∪{ Q 3 } ). By Lemma 3.5 (i), ϕ does not perform blow-ups at E 3 ∩ ϕ S ( 4 ) and E 3 ∩ ϕ S ( 5 ) after the blow-up at Q 3 . Thus E 3 intersects F ′ 3 , S 4 and S 5 on V . Hence E 3 is not a component of D . It follows that S i +2 = D ( ) i 1 intersects only D ( ) i 0 among the components of D -D ( ) i 1 for i = 2 3. Hence , S 2 i = ( D ( ) i 2 ) 2 = -3.
For i = 2 3, let , E 3 ,i be the exceptional curve of the blow-up at F 3 ∩ ϕ S ( i ). Since S 2 i = ( F ′ 3 ) 2 = -3, ϕ does not perform blow-ups at E 3 ,i ∩ ϕ S ( i ) and E 3 ,i ∩ F 3 after the blow-up at F 3 ∩ ϕ S ( i ). This means that E 3 ,i intersects F ′ 3 = D (1) 2 and S i = D ( ) i 2 on V . Thus E 3 ,i is not a component of D . Hence D (1) 2 intersects only D (1) 0 among the components of D -D (1) 2 . Since S 2 i = -3, ϕ does not perform blow-ups at F 1 ∩ ϕ S ( 2 ) and F 1 ∩ ϕ S ( 3 ). Thus F ′ 1 is not a component of D . Hence D ( ) i 2 intersects only D ( ) i 0 among the components of D -D ( ) i 2 .
From now on, we assume that ϕ S ( 4 ) ∩ ϕ S ( 5 ) consists of one point. We prove that the assumption causes a contradiction. Let F 1 (resp. F 2 ) be the fiber of p ◦ ϕ -1 passing through ϕ S ( 4 ) ∩ ϕ S ( 5 ) (resp. ϕ S ( 4 ) ∩ ϕ S ( 3 )). For each i , put T i = ϕ -1 ( F i ). Let b i be the number of the irreducible components of T i which are not contained in D .
Lemma 3.8. The fibration p has exactly three singular fibers F , T ′ 0 1 , T 2 . We have b 1 + b 2 = 6 .

Proof. It follows from Lemma 3.5, Lemma 3.6 and Lemma 2.8 that p has exactly three singular fibers F , T ′ 0 1 , T 2 . Let ρ V ( ) denote the Picard number of V and r D ( ) the number of the irreducible components of D . We have ρ V ( ) = r D ( ). The number of the blow-ups of ϕ is equal to r D ( ) + b 1 + b 2 -(the number of the sections in D ) -(the number of the singular fibers). Thus r D ( ) = ρ V ( ) = ρ (Σ ) + d r D ( ) + b 1 + b 2 -8.
Figure 1: The weighted dual graph of T 1 + S 1 + · · · + S 5
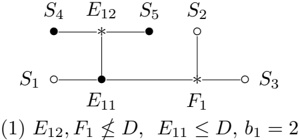
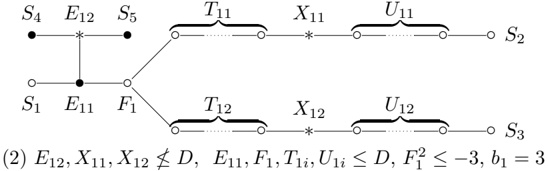
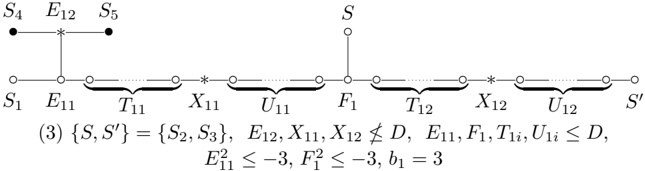
The next lemma describes the structure of the fibration p .
Lemma 3.9. We may assume that the weighted dual graph of T 1 + S 1 + · · · + S 5 (resp. T 2 + S 1 + · · · + S 5 ) coincides with that in Figure 1 (2) (resp. Figure 2 (2)). The weighted dual graph of σ -1 ( P 2 ) coincides with that in Figure 3. In the figures, ∗ (resp. · ) denotes a ( -1 )-curve (resp. ( -2 )-curve).
Proof. We first show that the weighted dual graph of T 1 + S 1 + · · · + S 5 coincides with one of those in Figure 1. Let E ij be the exceptional curve of the j -th blow-up ϕ ij of ϕ over F i for i = 1 2. , We use the same symbols to denote the proper transforms of E ij , ϕ S ( j ), etc. via blow-ups. Since S 4 = D (2) 1 and S 5 = D (3) 1 do not intersect each other, we may assume that the centers of ϕ 11 and ϕ 12 are ϕ S ( 4 ) ∩ ϕ S ( 5 ).
/negationslash
By Lemma 3.5 (i), ϕ does not perform blow-ups at E 12 ∩ ϕ S ( 4 ) and E 12 ∩ ϕ S ( 5 ). This means that E 12 intersects S 4 = D (2) 1 and S 5 = D (3) 1 on V . Thus E 12 /notlessequal D . By Lemma 2.8 (i), ϕ does not perform blow-ups over E 12 . By Lemma 3.4 (iii), E 11 and F 2 intersect S 1 on V . Let E be an irreducible components of a fiber of p which meets with D (1) 0 . It follows from Lemma 3.5 (ii) that E is not a component of D if E = C , E ′ 11 , F 2 . Since three irreducible components of D -D (1) 0 meet with D (1) 0 , the curves
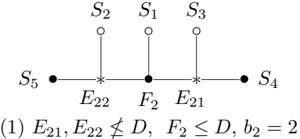
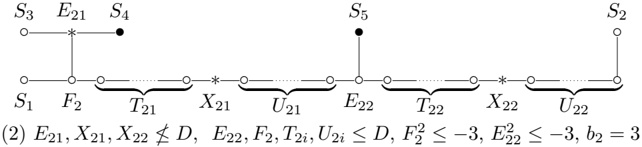
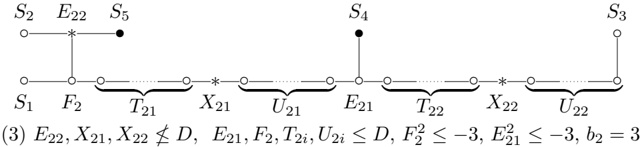
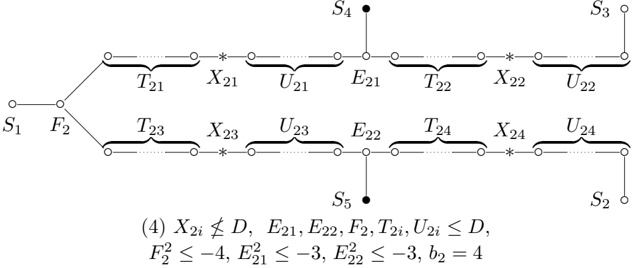
Figure 2: The weighted dual graph of T 2 + S 1 + · · · + S 5
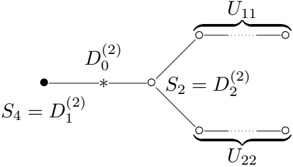
︸
︷︷
︸
Figure 3: The weighted dual graph of σ -1 ( P 2 )
E 11 , F 2 must be components of D . By Lemma 2.8 (i), ϕ does not perform blow-ups over E 11 \ F 1 .
Suppose F 1 /notlessequal D . By Lemma 2.8 (i), ϕ does not perform further blowups over F 1 . We have E 11 = D (1) 1 . The weighted dual graph of T 1 + S 1 + · · · + S 5 coincides with (1) in this case. Suppose F 1 ≤ D . Since D does not contain loops, ϕ performs blow-ups at two or three points of the three points F 1 ∩ ( E 11 + ϕ S ( 2 + S 3 )). If the latter case occurs, then it follows from Lemma 2.8 (ii) that D is not connected, which is absurd. Thus the former case must occur. It follows from Lemma 2.8 (ii) that the weighted dual graph of T 1 + S 1 + · · · + S 5 coincides with (2) (resp. (3)) if ϕ does not perform (resp. performs) a blow-up at F 1 ∩ E 11 .
We next show that the weighted dual graph of T 2 + S 1 + · · · + S 5 coincides with one of those in Figure 2. By Lemma 3.5 (i), we may assume that the center of ϕ 21 (resp. ϕ 22 ) is ϕ S ( 4 ) ∩ F 2 (resp. ϕ S ( 5 ) ∩ F 2 ). Furthermore, ϕ does not perform blow-ups at ϕ S ( 4 ) ∩ E 21 and ϕ S ( 5 ) ∩ E 22 . If ϕ does not perform blow-ups over F 2 further, then the weighted dual graph of T 2 + S 1 + · · · + S 5 coincides with (1). We have E 21 , E 22 /notlessequal D in this case.
Suppose that ϕ performs blow-ups over F 2 further. If ϕ does not perform blow-ups over E 21 , then E 21 intersects S 3 = D (3) 2 and S 4 = D (2) 1 on V . Thus E 21 /notlessequal D . If ϕ performs a blow-up over E 21 , then it must be done over E 21 ∩ ϕ S ( 3 ) or E 21 ∩ F 2 by Lemma 2.8 (i). Moreover, we have E 21 ≤ D . Since D contains no loops, it must be done over both of E 21 ∩ ϕ S ( 3 ) and E 21 ∩ F 2 . Similar arguments are valid for E 22 . If ϕ performs blow-ups over both of E 21 and E 22 , then the weighted dual graph of T 2 + S 1 + · · · + S 5 coincides with (4). Otherwise it coincides with (2) or (3).
Now we show that the weighted dual graph of σ -1 ( P 2 ) coincides with that in Figure 3. We say that p is of type ( i j ) if T 1 (resp. T 2 ) coincides with ( ) i in Figure 1 (resp. ( j ) in Figure 2). We prove that p is of type (2-2) or (2-3). By Lemma 3.8, p must be of type (1-4), (2-2), (2-3), (32) or (3-3). Suppose p is of type (1-4). We have A (1) 1 = [ F , . . . 2 ] and B (1) 1 = [2]. By Lemma 3.3, A (1) 1 = [ B (1) 1 , 2] ∗ = [3]. This contradicts the fact that F 2 2 ≤ -4 on V . Suppose p is of type (3-2) or (3-3). In this case, we have { D (1) 1 , D (1) 2 } = { E 11 , F 2 } . But E 2 11 ≤ -3 and F 2 2 ≤ -3, which contradicts ( D (1) 1 ) 2 = -2. By changing the roles of P 2 and P 3 , if necessary, we may assume that p is of type (2-2). It follows that the weighted dual graph of σ -1 ( P 2 ) coincides with that in Figure 3.
We can arrange the order of the blow-ups of ϕ such that ϕ = ϕ 0 ◦ ϕ 11 ◦ ϕ 12 ◦ ϕ 22 ◦ ϕ 21 . Here ϕ ij contracts T ij + X ij + U ij to a point in Figure 1 (2) and Figure 2 (2). The morphism ϕ 0 contracts E 11 + E 12 + E 21 + E 22 + D (2) 0 + D (3) 0 to points. We use the same symbols to denote the proper transforms of ϕ C ( ′ ), ϕ S ( j ), etc. via blow-ups. The morphism ϕ 0 performs the blow-ups at ϕ C ( ′ ) ∩ ϕ S ( 2 ) and F 2 ∩ ϕ S ( 2 ). The morphism ϕ 11 performs the blow-up at
F 1 ∩ ϕ S ( 2 ) and ϕ 22 performs the blow-up at E 22 ∩ ϕ S ( 2 ). Thus S 2 2 ≤ -4. By Lemma 3.9, we have A (2) 1 = [ . . . , -S 2 2 ] and B (2) 1 = [2]. By Lemma 3.3, we see A (2) 1 = t 1 ∗ B (2) ∗ 1 = [3]. Hence S 2 2 = -3, which is a contradiction. Thus ϕ S ( 4 ) ∩ ϕ S ( 5 ) must consist of two points. We have completed the proof of Theorem 2.
## References
| [BK] | Brieskorn, E., Kn¨rrer, o H.: Plane algebraic curves. Basel, Boston, Stuttgart: Birkh¨user a 1986. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Fe] | Fenske, T.: Rational cuspidal plane curves of type ( d, d - 4) with χ (Θ V 〈 D 〉 ) ≤ 0, Manuscripta Math. 98 (1999), 511-527. |
| [Fu] | Fujita, T.: On the topology of non-complete algebraic surfaces, J. Fac. Sci. Univ. Tokyo Sect. IA Math. 29 (1982), 503-566. |
| [FZ1] | Flenner, H., Zaidenberg, M.: On a class of rational cuspidal plane curves, Manuscripta Math. 89 (1996), 439-459. |
| [FZ2] | Flenner, H., Zaidenberg, M.: Rational cuspidal plane curves of type ( d, d - 3), Math. Nachr. 210 (2000), 93-110. |
| [H1] | Hartshorne, R.: Curves with high self-intersection on algebraic sur- faces, Publ. Math. I.H.E.S. 36 (1969), 111-125. |
| [H2] | Hartshorne, R.: Ample subvarieties of algebraic varieties, Lecture Notes in Mathematics 156. Berlin, Heidelberg: Springer 1970. |
| [K] | Kawamata, Y.: On the classification of non-complete algebraic surfaces, Lecture Notes in Mathematics 732. Berlin, Heidelberg: Springer 1979, 215-232. |
| [MaSa] | Matsuoka, T., Sakai, F.: The degree of rational cuspidal curves, Math. Ann. 285 (1989), 233-247. |
| [MiSu] | Miyanishi, M., Sugie, T.: Q -homology planes with C ∗∗ -fibrations, Osaka J. Math. 28 (1991), 1-26. |
| [MT1] | Miyanishi, M., Tsunoda, S.: Non-complete algebraic surfaces with logarithmic Kodaira dimension -∞ and with non-connected bound- aries at infinity, Japan. J. Math. 10 (1984), 195-242. |
| [MT2] | Miyanishi, M., Tsunoda, S.: Absence of the affine lines on the ho- mology planes of general type, J. Math. Kyoto Univ. 32 (1992), |
443-450.
| [Mi] | Miyaoka, Y.: On the Mumford-Ramanujam vanishing theorem on a surface, Journ´es e de g´om´trie e e alg´brique e d'Angres, (1979), 239- 247, Alphen aan den Rijn: Sijthoff and Nordroff 1980. |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Mu] | Mumford, D.: The topology of normal singularities of an algebraic surface and a criterion for simplicity, Publ. Math. I.H.E.S. 9 (1961), 5-22. |
| [N] | Namba, M.: Geometry of projective algebraic curves, New York, Basel: Dekker 1984. |
| [O] | Orevkov, S. Yu.: On rational cuspidal curves I. Sharp estimate for degree via multiplicities, Math. Ann. 324 (2002), 657-673. |
| [S1] | Sakai, F.: Kodaira dimensions of complements of divisors, Complex Analysis and Algebraic Geometry, Iwanami and Cambridge Univ. Press, (1977), 239-257. |
| [S2] | Sakai, F.: Weil divisors on normal surfaces, Duke Math. J. 51 (1984), 877-887. |
| [SST] | Sakai, F. and Saleem, M. and Tono, K.: Hyperelliptic plane curves of type ( d, d - 2), Beitr¨ge a zur Algebra und Geometrie 51 (2010), 31-44. |
| [T1] | Tono, K.: On the number of cusps of cuspidal plane curves, Math. Nachr. 278 (2005), 216-221. |
| [T2] | Tono, K.: On Orevkov's rational cuspidal plane curves, J. Math. Soc. Japan 64 (2012), 365-385. |
| [T3] | Tono, K.: On a new class of rational cuspidal plane curves with two cusps, Preprint. arXiv:1205.1248 |
| [W] | Wakabayashi, I.: On the logarithmic Kodaira dimension of the com- plement of a curve in P 2 , Proc. Japan Acad. 54 , Ser. A (1978), 157-162. |
| [Y] | Yoshihara, H.: Rational curves with one cusp (in Japanese), Sugaku 40 (1988), 269-271. |
E-mail address : [email protected]
Department of Mathematics, Graduate School of Science and Engineering, Saitama University, Saitama-City, Saitama 338-8570, Japan. | null | [
"Keita Tono"
] | 2014-08-01T14:35:38+00:00 | 2014-08-01T14:35:38+00:00 | [
"math.AG",
"14H50"
] | On the self-intersection number of the nonsingular models of rational cuspidal plane curves | In this paper, we consider rational cuspidal plane curves having at least
three cusps. We give an upper bound of the self-intersection number of the
proper transforms of such curves via the minimal embedded resolution of the
cusps. For a curve having exactly three cusps, we show that the
self-intersection number is equal to the bound if and only if the curve
coincides with the quartic curve having three cusps. |
1408.0193v1 | ## A RobustICA-Based Algorithm for Blind Separation of Convolutive Mixtures
Zaid Albataineh and Fathi M. Salem
Circuits, Systems, And Neural Networks (CSANN) Laboratory Department of Electrical and Computer Engineering, Michigan State University, East Lansing, Michigan 48824-1226, U.S.A. Email: [email protected], [email protected]
Abstract -We propose a frequency-domain method based on robust independent component analysis (RICA) to address the multichannel Blind Source Separation (BSS) problem of convolutive speech mixtures in highly reverberant environments. We impose regularization processes to tackle the ill-conditioning problem of the covariance matrix and to mitigate the performance degradation in the frequency domain. We apply an algorithm to separate the source signals in adverse conditions, i.e. high reverberation conditions when short observation signals are available. Furthermore, we study the impact of several parameters on the performance of separation, e.g. overlapping ratio and window type of the frequency domain method. We also compare different techniques to solve the frequency-domain permutation ambiguity. Through simulations and real-world experiments, we verify the superiority of the presented convolutive algorithm among other BSS algorithms, including recursive regularized ICA (RRICA), independent vector analysis (IVA).
Index Terms -Blind Source Separation (BSS), Independent Component Analysis (ICA), Robust Independent Component Analysis (RobustICA), highly reverberant environments, gradient descent algorithms, Recursive Regularized ICA (RR-ICA), Independent Vector Analysis (IVA).
## I. INTRODUCTION
Blind Source Separation (BSS) [1] has a solid theoretical foundation and many potential applications. In fact, BSS has remained a very important topic of research and development for a long time in many areas, such as biomedical engineering, image processing, communication systems, speech enhancement, remote sensing, etc. BSS techniques do not require any prior knowledge about a mixing matrix or source signals and do not require any training data.
Independent Component Analysis (ICA) is a powerful tool in BSS and Multichannel Blind Deconvolution (MBD) [1], [2]. ICA is a key factor of BSS and unsupervised learning algorithms. ICA techniques do not assume full a priori knowledge about the mixing environment, source signals, etc. Also, ICA is related to Principle Component Analysis (PCA) and Factor Analysis (FA) in multivariate analysis and data mining. This is especially the case when corresponding to second order methods in which the components or factors are in the form of a Gaussian distribution [1], [2], [6].
Nevertheless, ICA is a statistical technique that includes higher order statistics (HOS), where the goal is to represent a set of random variables as a linear transformation of statistically independent components [1].
ICA methods usually assume certain properties of the sources or mixing system in order to exploit a separation criterion which imposes the same properties on their estimates. In ICA of speech signals, several approaches have been proposed in a simple case of instantaneous linear mixtures [615]. However, convolutive linear mixtures are considered more suitable in real-world applications [1-3]. Several convolutive ICA approaches have been proposed for time domain [3], [4], [42-43] and frequency domain [32-40] methods. Refer to [3], [22] for more details of existing convolutive ICA methods.
One can exploit the inherent non-stationary attribute of natural speech signals by using the second order statistics (SOS) method [2]. Mixing environments are considered to be stationary environments and, even in a short period, one can exploit the higher order statistics e.g. Joint Approximation Diagonalization (JAD) problem as in [9], [10]. According to [42], [46], online BSS algorithms can be adapted in the time domain under non-stationary conditions. However, the time domain approach suffers from slow convergence, lack of stability and high computational complexity [22].
Alternatively, a block online frequency domain BSS algorithm is proposed in [22], [28]. In this case, one can apply the separation processes on individual blocks of the input data over time. Furthermore, one can assume that the mixing environment is stationary in short time windows. This means that the source signals don't change their location during this interval of time. This requires choosing the right time frame to guarantee that the separation algorithms are accurate enough with this given observed data within this window. For more details, refer to [43], in which there is a recent ICA algorithm based on the time domain framework for the short mixtures.
The proposed recursive regularized ICA [40] algorithms allow estimating a large number of demixing matrices even with a short amount of data. Despite the good performance of the aforementioned algorithms, it is considered to be semiblind since it is based on prior knowledge about the acoustic source signals, i.e.: the acoustic propagation and the spectral
characteristic of the source signals. In [22], [31], Authors studied the relationship between the number of frames of the STFT analysis and the BSS algorithms based on frequency framework. They argued the BSS algorithms in frequency domain are significantly affected by the number of the mixing matrices. Also in [22], [31], Authors proposed a method of applying the ICA adaptation to a group of frequencies in order to leave the size of the STFT large enough to achieve accurate separation processes. This method assumed that the acoustic propagation approximated is based on an anechoic model, i.e. as the DRR decreases.
There are several drawbacks for separating the acoustic sources based on frequency domain methods [22], [40]. First of all, when we have a high reverberation environment, this requires us to increase the number of demixing matrices to ensure an efficient estimation for the source signals. However, this requirement is not easy to satisfy, especially if we have short observation signals of the source signals. Therefore, inspired by the works of V. Zarzoso,P. Comon [5], [6], this paper considers several challenges for the convolutive mixtures in the frequency domain in order to carry out the RobustICA-based algorithm in the frequency domain. We can summarize these challenges as follows.
- Increasing the immunity of the BSS algorithm towards the outlets, e.g. signals' length, additive noise, reverberation time and source moving etc.
- Implementing should be optimized to be suitable for the real-time operation [42] in order to make the real-time DSP processor handle the computational cost without interruptions or distortions.
- Effectively treating the scaling and permutation problems in the frequency domain.
- Reducing the computational complexity of the ICA algorithms based on the frequency framework.
- Controlling the accuracy of the ICA algorithm especially when short mixtures are available and the demixing matrices are not constrained by any anechoic model.
Regarding the paper's notation of matrix computation, a matrix is denoted as a bold capital letter such as , is the matrix transpose of , its Frobenius norm is marked by , an identity matrix of size n is denoted as , a vector is denoted as bold small letter such as , and scalars are denoted as a small letter such as .
The remainder of the paper is organized as follows. Section II provides a brief description of convolutive mixtures and the problem statement. Section III presents the RobustICA-based method in the frequency domain. In Section IV, we perform solving the ambiguities in the ICA algorithm based on the frequency domain. The comparative experiments' results and conclusions are given in Section V and Section VI, respectively.
## II. CONVOLUTIVE MIXTURES
A convolutive mixture can be considered a natural extension of the instantaneous BSS problem. Assume an -dimensional vector of received discrete time signals is to be produced at time from an -dimensional vector of source signals , where , by using a stable mixture model [2]:
1.0
$$\mathbf x ( k ) = \Sigma _ { p = - } ^ { \infty }$$
2.0
$$\text{with } \Sigma _ { - \infty } ^ { \infty } \left \| \mathbf H _ { p } \right \| \leq \infty \text{ \quad \ } ( 1 )$$
where represents the linear convolution operator and is an ( ) matrix of mixing coefficients at time-lag .
## A. Problem Definition
Assume that elements denote the coefficients of the Finite Impulse Response (FIR) filter and is the maximum unknown channel length. Then, the noise-free convolutive model is written as follows:
$$\mathbf x ( k ) = \Sigma _ { p = 0 } ^ { L - 1 } \mathbf H _ { p } \mathbf s ( k - p ) \text{ \quad \ \ } ( 2 )$$
Thus, one can find an approximate inverse channel matrix in order to recover the source signals such that
$$\mathcal { H } _ { q } * \mathbf x ( \mathbf k ) = \sum _ { q = - 0 } ^ { Q - 1 } \mathbf W _ { q } \mathbf x ( \mathbf k - q ) = \hat { \mathbf s } ( \mathbf k ) \quad ( 3 )$$
where is the length of the inverse of the channel impulse response. There are two approaches to solve this problem and recover the source signals.
Time domain approaches have several general drawbacks; for example, should be selected at least equal to the unknown true channel . Therefore, for a long mixing filter, which means long transfer functions, the computation will be too expensive [2], [14], [22]. Using the IIR filter instead of the long FIR filter to overcome this problem causes increased instability and might require inversion of the non-minimum phase filters [2], [3], [22]. Moreover, time approaches are sensitive to channel order mismatch [3]. That said, time domain methods are suitable and very efficient for small mixing filters such as in a communication channel [2], [12].
Because of all these limitations to time domain approaches, we focus our study on frequency domain approaches to solve the BSS problem. The main advantage of a frequency domain BSS approach is the ability to apply the set of any instantaneous ICA algorithms to solve the convolutive BSS problem. On the other hand, the main challenges of BSS in the frequency domain are permutation and scaling ambiguities. Refer to [1], [3], [22] for a recent survey. However, one can re-map the aforementioned BSS models into the frequency domain by applying the Discrete Fourier Transform (DFT) on the observed signals in order to transform it to the instantaneous mixtures problem as follows:
$$( 4 )$$
where is a frequency index, is a frame index, and . The previous equation is considered to be valid only for periodic signals . However, it is approximately valid if the time-convolution is circular. Therefore, ensuring that the time convolution is circular [1] requires making the Fourier Transform length significantly larger than the maximum length of the mixing channels [6]. In [28], [40], researchers imposed the spectral smoothing approach in order to mitigate the circularity effect in frequency domain BSS methods. In practice, to avoid the convergence into local minima during the separation processes, one can separate the observed signal at each frequency bin. Thus, the sampled observed signals are sampled at the discrete time instant using the sampling frequency . Then one can transform the sampled signals into time-frequency domain using the short time Fourier transform (STFT) applied to overlapped samples of the observed signals. However, one can express the time-frequency of the mth sensor at frame as follows
$$\mathbf x ( q, w ) = & \sum _ { n _ { s } } \mathbf x _ { s } ( n _ { s } ) \mathbf w \sin \left ( \frac { n _ { s } - q. \text{shift} } { f _ { s } } \right ) e ^ { - j 2 \pi w \frac { n _ { s } } { f _ { s } } } \quad \text{detect} \\ & \forall \, w = \frac { t } { T } f _ { s } \,, q \in \, [ 0, \dots, T - 1 ] \quad \text{(5)} \quad N \, x \, N \, \mathbf c \quad \text{can be}$$
Where denotes the windowing function, here, we usually use the Hanning window since it is typically for acoustic signals. The Hanning window [17] is given by
$$\mathbb { m } = \frac { 1 } { 2 } \left ( 1 + \cos \left ( \frac { z \pi n _ { s } } { T } \right ) \right ) \quad \quad ( 6 )$$
In a real-world scenario, we use the reverberation time to approximately define the length of the impulse response, since the impulse response functions are theoretically infinite. The reverberation time is the required time that reduces the energy of sounds into where the sound signal becomes no longer active or 'dies away'. Therefore, the convolutive ICA model can be approximated into a series of the instantaneous ICA model as follows:
$$( 7 )$$
Where represents the frequency bin, denotes the time domain frame, e.g. in a short time frequency transform, is a column vector of the observed signals in frequency domain, is a column vector of the original source signals and is an mixing matrix in frequency domain.
For the sake of simplicity, let us assume that the number of source signals is equal to the number of the observed signals , i.e., . Thus, by applying the ICA algorithm to the at each frequency bin, one can recover the estimated source signals as follows:
$$( 8 )$$
where is the demixing matrix at frequency bin. Also, due to the well-known symmetry property of the Fourier Transform, one can simply find demixing matrices ( ) as a half of the frequency bins , and then use the symmetry property to find the others.
## III. THE PRESENTED METHOD BASED ON THE ROBUSTICA FRAMEWORK
In this section, a new strategy is proposed, based on the RobustICA method of the kurtosis framework. Here, one needs to first recall the time-frequency representation of the observed vector equation (2),
$$( 1 6 )$$
The aim of this study is to estimate the demixing matrix from the observed vector under the assumption that the impulse response of all mixing filters is assumed constant during the recording. The estimated source vector is given as the following at each frequency bin:
$$( 1 7 )$$
## A. Step1: Preprocessing (Data Whitening)
In the preprocessing step, the demixing matrices are detected up to a unitary matrix using the second order statistic (SOS). This step was used to reduce the noise and to eliminate redundancy in the data at each frequency bin. The covariance matrix ( ) of the noise-free observed signals can be expressed by
$$\frac { \iota } { \xi } - ( 1 8 )$$
By substituting in (16), one gets as follows
$$( 1 9 )$$
By imposing Tikhonov regularization techniques [47] to avoid the ill-posed problem, where it is well-known that regularization is an effective way to avoid the ill-conditioned matrix, the equation (19) becomes as follows:
$$( 2 0 )$$
Where is an identity matrix, and ( ( )) it is regularization parameter with is a positive constant and is a trace operator of the estimation covariance matrix . Note that the regularization method here just adds energy constraint in order to boost the covariance matrix to be a well-conditioned matrix. Therefore, the can be decomposed as
$$( w ) \quad \quad ( 2 1 )$$
where is a matrix satisfying
$$\colon \mathbf I _ { \mathbf N } \, \quad \ \ ( 2 2 )$$
and is an diagonal matrix. So, from (22), the matrix will be
$$( 2 3 )$$
where is a full rank unitary matrix and . However, the whitening step obtained matrix so that
the whitened data vector has covariance of identity matrix , which can be obtained as follows:
$$\mathfrak { l }, w ) \quad \quad \ \ ( 2 4 ) \quad \mathfrak { k } _ { \mu }$$
$$( 2 5 ) = \frac { 1 } { 2 }$$
The estimated source signals can be recovered with a linear Zero-Forcing (ZF) equalizer. Then the estimated source vector is
$$\mathfrak { l }, w )$$
After the preprocessing step, the estimation of the source signals reduces to determining the unitary matrix (rotation matrix).
## B. Step 2: Determining the rotation matrix (unitary matrix) .
One way of finding the rotational matrix is by maximizing the normalized fourth-order marginal cumulant (Kurtosis contrast) of the whitened data in (25). To estimate in (26), this paper exploits the statistical independence of the equalized source vector. More precisely, the unitary matrix will be estimated by utilizing the independent property of the estimated source vector at each frequency bin in the normalized fourth-order marginal cumulant of whitened data as follows:
$$\underset { \mu \nu } { \alpha }, w ) = \frac { E [ | y ( q, w ) | ^ { 4 } ] - 2 E ^ { 2 } [ | y ( q, w ) | ^ { 2 } ] - | E [ y ( q, w ) ^ { 2 } ] | ^ { 2 } } { E ^ { 2 } [ | y ( q, w ) | ^ { 2 } ] } \underset { \mu \nu } { \alpha } \quad ( 2 7 )$$
where represents the expectation operator. Based on the deflation approach to ICA [30], one can estimate the nth source signal as follows
$$( 2 8 )$$
where represents the conjugate-transpose operator, is the nth column vector of the demixing matrix and is nth source signal at each th frequency bin and qth frame time. According to [1], [2], the column vector of the demixing matrix can be estimated for all users due to the batch adaptation by a gradient decent method as follows
$$( 2 9 )$$
where denotes the iteration index, is the nth column vector of the demixing matrix at iteration and is the gradient of the contrast measure that updates the demixing vector in the demixing matrix . Gradient function depends on the cost function that ICA would maximize /minimize in order to extract the source signal [5]. Herein, this paper refers to the use of the ICA techniques based on the kurtosis criterion, which is given in (27), as follows:
$$\eta, w \Big | _ { \begin{array} { c } \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots\\ \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd.. \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd: \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd. \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd> \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd>: \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd< \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd>. \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd>< \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd: \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd>] \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd; \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd... \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd=== \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd} \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cdjs \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd> \\ \cd>$$
Having the RobustICA's search-method of the kurtosis criterion in (30) in order to choose the optimal step size [6] as follows:
$$\ r g _ { \ \mu } ^ { \max } | K ( y ( q, w ) + \mu g ( q, w ) ) | \quad ( 3 1 )$$
where is the gradient of Kurtosis contrast . One can easily choose the optimal step size based on one of the algebraic methods instead of using the exact line search as in [13], [14] to avoid the intensive computation and other limitations as in [6]. Therefore, it is easy to find the global optimum step size for the criteria that can be expressed as a polynomial function of due to its roots, e.g. the criteria kurtosis [6], the constant modulus [13] and the constant power [2]. Therefore, the RobustICA performs an optimal step-size of estimating the nth source signal, based on optimization, for lth iteration, th frequency bin, and th frame as follows:
- o Step1) initialize value for the weight vector
- o Step2) Compute the optimal step size polynomial coefficients. For Kurtosis contrast, the optimal step size polynomial is given by
$$\mu _ { \mu } \mu _ { \mu } ^ { n } \mu _ { \mu } ^ { n }$$
where the coefficients can be obtained at each iteration by the observed signal block and the current values of and . Details can be found in [6].
- o Step 3) Extract the optimal step size polynomial root . The root can be obtained by using the Ferrari's formula as in [48].
- o Step 4) Select the optimal step size polynomial root as follows
$$\stackrel {. } { g } \stackrel { m a x } { \mu } | K \left ( y _ { n } ^ { l } ( q, w ) + \mu g _ { n } ^ { l } ( q, w ) \right ) | \ ( 3 3 )$$
- o Step 5) Find the updated weighed vector
$$( 3 4 )$$
where is the nth gradient of Kurtosis contrast at lth iteration.
- o Step 6) Normalize and update the weight vector
$$\underset { \ell \,. } { \overset { l + 1 } { n } } = \frac { u _ { n } \nu } { \| u _ { n } ^ { l + 1 } \| } \underset { \ell } { \overset { l + 1 } { n } }$$
where is a norm of .
- o Step 7) Go back to step 2 until the convergence.
To prevent locking onto a previously extracted source, or when the old and new vectors are in the same direction, the learning converges and their absolute dotproduct value reaches close to 1. Thus, owning the deflation method proposed in [30] avoids different vectors from converging at the same maxima. However, each vector of { } needs to be orthogonalized before each iteration. Based on the Gram-Schmidt orthogonalization, the deflation scheme estimates each independent component at each iteration step. Gram-Schmidt orthogonalization of component can be expressed as follows
$$\coloneqq u _ { n + 1 } ^ { l } - \sum _ { n = 1 } ^ { N } \left ( { \boldsymbol u } _ { n + 1 } ^ { l } { \boldsymbol u } _ { n } ^ { l } \right ) { \boldsymbol u } _ { n } ^ { l } \text{ \quad \ \ } ( 3 6 )$$
$$\stackrel { + 1 } { i + 1 } = \frac { u _ { n + 1 } ; \stackrel { \cdot } { i } } { \| u _ { n + 1 } ^ { 1 + 1 } \| }$$
where a new weight vector is obtained by subtracting the vector projected from the old weight vector.
The following steps summarize the presented algorithm procedure:
- o Start
- o Perform the time-frequency representation as in (4).
- o For each frequency bin
- o Pre-processing of the observed data and imposing the Tikhonov regularization parameter to avoid the ill-conditioning problem of the covariance matrix and to mitigate the performance degradation.
(38) where is a positive constant and represents the trace of the estimation covariance matrix of the observation signals.
- o Initialize matrix (equals identify matrix ), where N is the number of sources.
- o For each user
- o Initialize column vector of the demixing matrix
- o While loop
- o Evaluate in (13)
- o Select the optimal step size polynomial root in (33)
- o Update weighed vector in (34)
- o Do the orthogonalization and normalization in (36) and (37), respectively
- o Find nth users:
$$( 3 9 )$$
- o Do deflation by subtracting the estimated nth source contribution to the as follows [30]:
(40)
Where is the symbol direction estimated via least squares, and it is given by
$$( 4 1 )$$
- o Check the convergence point. if so, End while loop , otherwise, go back until the convergence.
- o Save in the .
- o End for loop
.
- o Save the demixing matrix
- o End loop .
## IV. SCALING AND PERMUTATION AMBIGUITIES
Assume is the rotational matrix that is computed at each bin. The least square estimation of the mixing matrix is given by
$$( 4 2 )$$
where
$$( 4 3 )$$
However, one can express the estimated mixing matrix in terms of the perfect mixing matrix as follows:
$$( 4 4 )$$
where is an unknown diagonal matrix and is an unknown permutation matrix. Therefore, we have to estimate and matrices to solve the scaling and permutation ambiguities.
## A. Estimation of the diagonal matrix
Several methods to compensate the scale ambiguity have been proposed in the literature. Thus, we choose to estimate the diagonal matrix using the minimal distortion principle [3], [22]. The is given in [3] as
$$( 4 5 )$$
(46) where is a matrix in which all its entries are / , and where is the number of observations whereas is the number of sources, and returns a matrix that contains the diagonal elements of matrix and sets the other nondiagonal elements of matrix zeros.
The interpretation of (46), in a sense of perfect separation, is that each estimated source averages along the sensors in the sense of all other sources have turned off. In other words, the Minimal Distortion Principle assumes that the nth source is scaled with respect to the image at the nth microphone [40]. Therefore, the rescaled source signals can be expressed as follows:
$$( 4 7 )$$
$$( 4 8 )$$
## B. Estimation of the permutation matrix
Despite the fact that this section estimates the permutation matrix proposed in several current works in the literature, estimating the permutation matrix is still considered a very challenging problem that needs to be addressed. Assume that we have source signals which are presented in the BSS problem; then there are factorial times the possible permutations at each bin, which yields a complex combinational problem.
There are several previously mentioned techniques used to solve the permutation problem in the literature [3], [22]. In this paper, we will review and evaluate them in terms of computational complexity and performance.
One can divide these methods into two main solution groups, which solve the permutation ambiguity in the frequency domain as follows:
- Group based on geometric information, such as Time Direction of Arrivals (TDOA) and Direction of Arrivals (DOA) [3], [21], [22], [40].
- Group based on clustering-based techniques [22], [31], [32], [35].
Many of these techniques are based on geometric information, such as estimation of the direction of arrival (DOA) and Time difference of Arrival (TDOA) as in [22], [27]. Other techniques depend on the coherence of the unmixing filter coefficients. In other words, these techniques take advantage of some prior knowledge about mixing filters and restrict the mixing matrix to be continuous in frequency domain. Furthermore, in [34], Parra imposes smoothness to the de-mixing filter values in the frequency domain. Also, a restriction is made with the frequency domain update rule so that it is associated with the limited length filter in the time domain. Such a restriction may not be considered sophisticated, especially in a case of reverberant environment, since it is necessary to have a long length filter to cover all reverberations. Although it can be avoided by choosing a large frame size, it still causes more overall complexity, especially, when the short mixtures are available. In terms of the properties of speech, there are other categories, which have been proposed in literature, to estimate the permutation matrix and make the spectral alignment.
The most common is based on the inter-frequency correlation of speech envelopes [33], [36]. The inter-frequency correlation technique exploits the nature of speech production, where it's known that all spectral components of speech signals increase as the talker speaks louder. In that sense, several weighted techniques and criteria have been proposed to impose the frequency-coupling between the adjacent frequency bins. For more details, see [3], [22]. Although these techniques perform well in the simulations, they are not sophisticated when they are applied to a real recording room. They suffer from propagation error or delays. For example, if an error occurs at a certain frequency bin, it may increase the possibility that it will occur again at the following frequency bins. Therefore, in the literature [3], [22], [32], researchers avoid propagation error by estimating a frequencyindependent reference profile, which is called a centroid, due to using a clustering-based method for each separated source. They then structure the frequency-dependent profiles such that they are all matched with a different frequencyindependent reference profile at each frequency bin.
The main steps of the clustering-based techniques are as follows:
- Define the quantities that are used in the clustering, such as the signal envelopes of the source profiles, the log-power of the source profiles, etc.
- Choose the measure that is used to determine the matching level between the centroids and the profiles, such as correlation, distance, etc.
- Choose the cluster technique.
In [21], [28], the profile of a separated signal is chosen as the envelope of the separated source where | | . In [22], Authors are chosen for the profile of a separated signal to be a certain dominance measure. Whereas, in [38], the profile of a separated signal is defined to be its centered log-power spectral density where the log-power profile is given as follows:
$$\Psi _ { n } ( q, w ) = \log \left [ U _ { n, \colon } ( w ) \mathbf R _ { x x } ( q, w ) U _ { n, \colon } ^ { H } ( w ) \right ] \quad ( 4 9 ) \quad f o l l o w \cdot$$
In clustering-based approaches, the length of the profiles is also an important parameter in terms of accuracy, especially for short signals. This work is essentially going to set up the profiles for the overlapping frames over the whole signal. Once we construct the profiles of the separated signals, then we compute the centroids in order to perform the clustering. The clustering-based technique is essentially based on the assumption that profiles coming from the same source at different frequency bins still have more match level than those coming from other sources. Actually, the most common methods to associate each source profile to a centroid at each frequency bin are based on 1) maximizing correlation measures [69], [70] and 2) minimizing distance measures across the factorial times of the possible permutations at each frequency bin [38]. However, authors employ the iterative techniques to update the centroids and the permutation matrices. In other words, they update the centroids first, and then they permute the source profiles to each desired centroid and match them together using one of the two previous measures, i.e. distance [38] or correlation in [21], [28] and [31].
In spite of the fact that the aforementioned iterative methods perform well, they tend to be significantly more expensive in terms of cost and computational complexity since they have the factorial times of the possible permutations at each frequency bin. To avoid this drawback in the aforementioned iterative methods in [32], Nion et al. propose a more efficient modification of the clustering strategy, which is updating the whole permutation matrices and centroids simultaneously. In other words, the update of the centroids and permutation matrices are not interleaved. Thus, their modification has improved these iterative methods in terms of computational complexity.
Their methods can be summarized as follows:
Step 1. Determine the centroids and compute them.
Consider the matrix that is structured from the profiles . One can extend the matrix to the matrix by concatenating the matrices . In order to enforce the profile points in matrix varying smoothly with time, we have to encounter the computation of the profiles for overlapping frames. Hereafter, we just need to classify these profile points into clusters due to applying the k-mean algorithm on the matrix to carry out a frequency-independent centroid matrix [ ] . The centroid matrix is structured by summing all the points within a cluster, which have attained a minimum distance regarding the centroid cluster.
## Step 2. Estimate the permutation matrices.
In the previous step, we reduced the computational processes to find that the permutation matrix , subject to , matches the frequency-independent centroid matrix at each frequency bin. Therefore, one can choose to minimize the distance that is given in [38] as follows
$$( 5 0 )$$
Or one can chose the correlation criteria that is given by [21],
[22] [31] as follows
∑ 〈 〉 (51) where 〈 〉 is the correlation coefficient.
In terms of performance, the first group generally does better than the second group, especially at the small data sample available. But it is not optimal in a practical sense, since we don't usually have geometric information about the real environmental conditions. In that sense, the second group performed better than first group, especially if we have a large sample set of data, because they are based on the clusteringbased techniques (i.e.: correlation, distance, etc.) and they are more robust to real-world scenarios. For more details, refer to [3] [22].
## V. EXPERIMENTS' RESULTS
In this section, Monte Carlo Simulations are carried out. It
is assumed that the number of sources is equal to the number of observation 'sensors'. The experiments have been carried out using the MATLAB software on an Intel Core i5 CPU 2.4GHz processor and 4G MB RAM. We examine the performance of the RobustICA-based algorithm developed in this paper. The time-frequency representation of the observed data is computed as explained in section II due to the ShortTime-Fourier-Transform. Then, for each frequency bin, we find the demixing matrix.We will solve the scale and permutation ambiguities based on the aforementioned techniques.
To help explain this process, we divided this section into two subsections. First, we illustrate the performance of the RobustICA-based algorithm with different permutation methods in the literature [3], [22]. We study the effect of the type of the windows on the performance of the presented algorithm as well as the effect of overlapping parameter. Second, we provide the performance of the presented algorithm in two real-world scenarios that are generated in adverse conditions by F. Nesta, in [40], and compare it with other state-of-the-arts in [40], [20], and [34] and [38], labeled as 'RR-ICA', 'IVA', 'Parra', and 'Pham', respectively. In this paper, we evaluate the performance of the presented algorithm due to the BSS\_EVAL toolbox, which is proposed in [49]. We use time-invariant filters of 1024 taps to represent the signal-to-interference ratio (SIR) and source-to-distortion ratio (SDR).
## A. Section 1
In this subsection, we study the computational complexity and the performance of the presented algorithm based on several criteria to solve the scale and permutation ambiguities in the frequency domain BSS problem.
Let's define these criteria as follows:
- Method 1 is the RobustICA-based algorithm with clustering of envelope profiles with a distance measure iterative procedure [22], [31].
- Method 2 is the RobustICA-based algorithm with clustering of log-power profiles with a correlation measure iterative procedure [22], [50].
- Method 3 is the RobustICA-based algorithm with clustering of envelope profiles with a distance measure kmeans procedure [35], [32].
- Method 4 is the RobustICA-based algorithm with clustering of log-power profiles with a correlation measure kmeans procedure [22], [32].
- Method 5 is the RobustICA-based algorithm with clustering of dominance-profiles with a correlation measure iterative procedure [22].
- Method6 is the RobustICA-based algorithm with clustering of dominance-profiles with a correlation measure iterative kmeans procedure [22], [32].
Fig. 1. Configuration of the two experimental setups that were conducted by Francesco Nesta1 in [40]:, a) room is characterized for Test1, b) classroom is characterized for Test2
In this section, we have used real world recordings, drawn from the experiments which were conducted in [40] named Test1. We would like to thank the authors who provided these recordings on their website 'http://bssnesta.webatu.com/testhscma.html'. The two sources were recorded at with two microphones spaced apart to avoid spatial aliasing. The chosen room was characterized by a moderate reverberant time of . The room had dimensions of as shown in Fig. 1. The signal duration was fixed at 9 sec.
Fig. 2. Results obtained in Test1 experiments. The SIR performance of the presented algorithm with various permutation solvers
In fig. 2 and fig.3, we show the performance of the RobustICA-based algorithm with various aforementioned techniques of permutation solvers in terms of the SIR and SDR, respectively. In comparison, we notice that the dominance-profiles provide more robustness in terms of the signal's length, although the envelope profiles are more sensitive to the signal's length than the log-power profiles. Moreover, the dominance-profiles' approach with the iterative procedure has the same performance as with the kmean procedure. Also, Fig.4 shows the corresponding CPU time of each permutation method that need to solve the permutation ambiguity.
Fig. 3. Results obtained in Test1 experiments. The SDR performance of the presented algorithm with various permutation solvers
Based on these observations, we use the dominance-profiles approach with the iterative procedure after the RobustICAbased algorithm in the rest of these experiments. In Fig. 5, we illustrate the impact of the window's types on the performance of the proposed algorithm in terms of SIR and SDR respectively. And, we test the performance of the presented algorithm versus the overlapping parameter as shown in Fig 6.
The best performance of the presented algorithm was achieved during the certain range of the overlapping percentage. Therefore, based on these results, we use the 0.65 overlapping parameters with Hamming window type .
Fig. 4. Corresponding CPU time for each method.
Fig. 5. Results obtained in Test2 experiments. The SIR performance of the presented algorithm with various window types
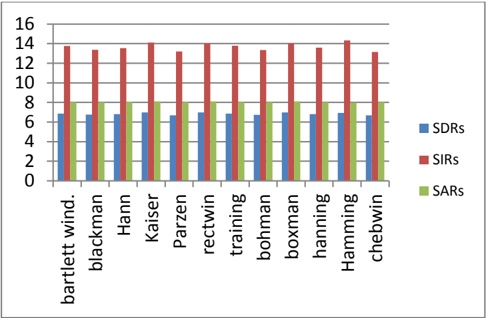
## B. Section 2
In this section, we perform the separation of the two mixture observations that consist of two sources. We have used the two tests 'Test1 and Test2' of the real world recordings, drawn from the experiments that were conducted in [40] (see Fig. 1). Test2 uses the real world recordings of adverse reverberant conditions, as in Fig 1. The room is a reverberant class-room with dimensions 4.75 m Length x 5.92 m Width x 4.5 m Height . The reverberation time is around 700 milliseconds . The signal duration was fixed to be 9 sec. After we got the demixing matrix for each frequency bin, we used the Inverse Fourier Transform to obtain the mixing matrix in the time domain.
- The independent vector analysis IVA [14] used with step size 0.1 and number of iterations is 1000.
- Parra's method [34], used with number of iterations is 1000.
- Pham's algorithm [35] and [38], used with FFT overlapping, equals and a window size equal to 5.
- RR-ICA algorithm reported in [40].
Fig. 6. Results obtained in Test2 experiments. The SIR performance of the presented algorithm with various overlap ratios
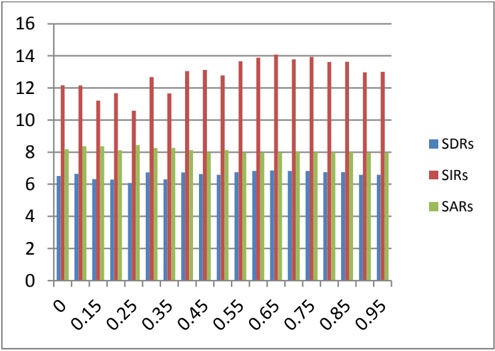
Fig. 7. Results obtained in the Test1 experiments. Best performance is reported in terms of SIR, by applying the given algorithms with different signal lengths
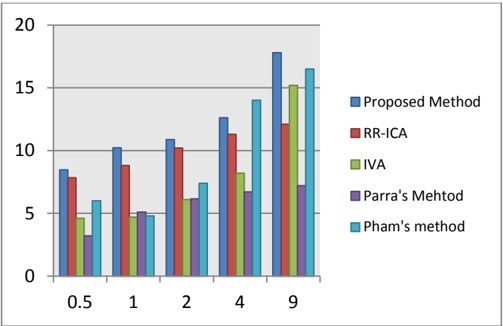
Fig 7 & 8 and 9 & 10, show the summary analysis of the presented algorithm versus other algorithms for the Test1 and Test2 configurations, respectively. These graphs report the best performance of each algorithm over the FFT size. Obviously, the RobustICA-based algorithm outperforms the other algorithms for any signal length in terms of SIR and SDR.
Moreover, in Fig. 11, we illustrate the impact of the FFT length on the performance of the proposed algorithm in terms of SIR. Clearly, the presented algorithm performs well, especially during reasonable FFT length in regard to other corresponding algorithms as shown in Fig.11.
Based on these results, one can show that the presented algorithm is stable in terms of the high reverberation environment and variations of the observations' parameters. Furthermore, the presented algorithm performs well in terms of stability and speed convergence. Owning the optimal step size, deflation and regularization techniques makes the presented algorithm more robust and allows it to perform well even in adverse conditions.
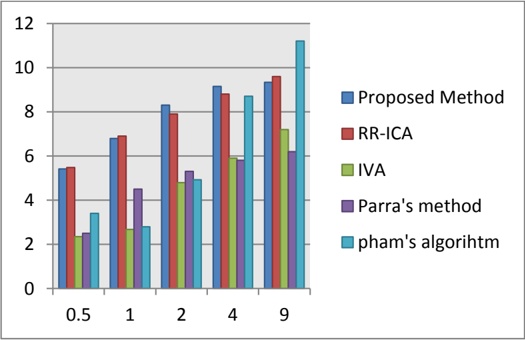
Fig. 8. Results obtained in the Test1 experiments. Best performance is reported in terms of SDR, by applying the given algorithms with different signal lengths
Fig. 9. Results obtained in the Test2 experiments. Best performance is reported in terms of SIR, by applying the given algorithms with different signal lengths
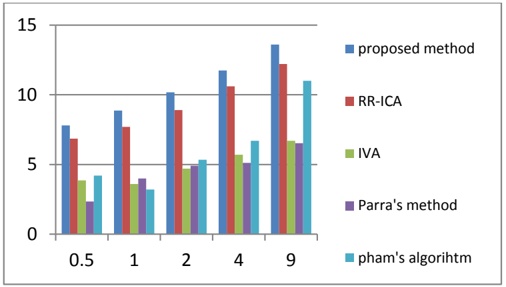
Fig. 10. Results obtained in the Test2 experiments. Best performance is reported in terms of SDR, by applying the given algorithms with different signal lengths
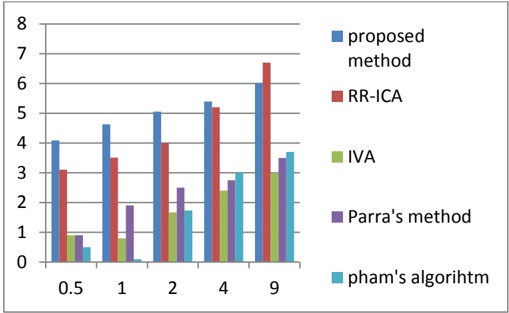
## VI. CONCLUSION
This paper presented the RobustICA-based algorithm to solve the frequency-domain BSS problem for convolutive acoustic mixtures in several adverse conditions. Through the real-world experiments, we show the superiority of the presented algorithm among other popular algorithms in the literature in terms of the performance and complexity computation. Moreover, we compared several permutation solvers in terms of computation complexity and performance to provide the RobustICA-based algorithm with an efficient frequency-dependent permutation scheme. Finally, we studied the effect of several parameters on the separation performance of the presented algorithm. We also presented the effect of the type of the window on the separation performance and we also showed that the performance improves at a certain range of overlapping between the signals. Lastly, in this paper, we showed the performance of a system that can work efficiently with around 0.5-10 seconds of input data, which is close to the real-time implementation. Accordingly, the presented algorithm is optimized to be suitable for the real-time operation. As a result, it is suitable for a large number of applications to ensure the real-time implementation.
Fig. 11. Impact of FFT length, 2-by-2 case, Results obtained in the Test2 experiments.
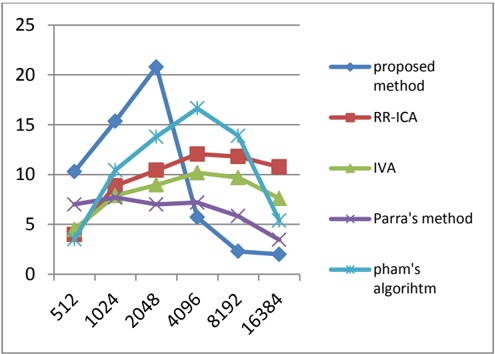
## REFERENCES
- [1] P. Comon, C. Jutten (eds.), 'Handbook of Blind Source Separation Independent Component Analysis and Applications.' (Academic Press, Oxford, 2010).
- [2] A. Cichocki, S.-I. Amari, Adaptive Blind Signal and Image Processing : Learning Algorithms and Applications, John Wiley & Sons, Inc., 2002.
- [3] M. S. Pedersen, J. Larsen, U. Kjems, and L. C. Parra, 'A survey of convolutive blind source separation methods,' in Springer Handbook of Speech Processing. New York: Springer, 2007.
- [4] A. Cichocki, R. Zdunek, S.-I. Amari, Nonnegative matrix and tensor factorizations: applications to exploratory multi-way analysis and Blind Source Separation, John Wiley & Sons, Inc., 2009.
- [5] P. COMON, ``Independent Component Analysis, a new concept,'' Signal Processing, Elsevier, 36(3):287--314, April 1994PDF Special issue on Higher-Order Statistics.
- [6] V. Zarzoso and P. Comon, 'Robust Independent Component Analysis by Iterative Maximization of the Kurtosis Contrast with Algebraic Optimal Step Size,' IEEE Transactions on Neural Networks, vol. 21, no. 2, pp. 248-261, 2010.
- [7] Hyvarinen. A, "Fast and robust fixed-point algorithm for independent component analysis". IEEE Transactions on Neural Network, vol. 10, no. 3, pp. 626-634, May 1999.
- [8] Hyvarinen. A. E.Oja, "A fast fixed-point algorithm for independent component analysis,' Neural Computation, vol. 9, no. 7, pp. 1483-1492, 1997.
- [9] F. Cardoso. On the performance of orthogonal source separation algorithms. In Proc. EUSIPCO, pages 776-779, 1994a.
- [10] Jean-François Cardoso, 'High-order contrasts for independent component analysis,' Neural Computation, vol. 11, no 1, pp. 157-192, Jan. 1999.
- [11] A. Bell, T. J. Sejnowski, 'An information-maximization approach to blind separation and blind deconvolution', Neural Computation, 7:11291159, 1995.
- [12] K. Waheed and F. Salem, 'Blind information-theoretic multiuser detection algorithms for DS-CDMA and WCDMA downlink systems,' IEEE Trans. Neural Netw., vol. 16, no. 4, pp. 937-948, Jul. 2005.
- [13] A.-J. van der Veen and A. Paulraj, 'An analytical constant modulus algorithm,' IEEE Trans. Signal Process., vol. 44, pp. 1136- 1155, 1996.
- [14] D. T. Pham and P. Garat, 'Blind separation of mixture of independent sources through a quasi-maximum likelihood approach,' IEEE Trans. Signal Process, vol. 45, no. 7, pp. 1712-1725, Jul. 1997.
- [15] B. A. Pearlmutter and L. C. Parra, 'Maximum likelihood blind source separation: A context-sensitive generalization of ICA,' Adv. Neural Inf. Process. Syst., pp. 613-619, Dec. 1996.
- [16] Fujisawa, H. and Eguchi, S. (2008). Robust parameter estimation with a small bias against heavy contamination. J. Multivariate Anal. 99 20532081.
- [17] S.C.Douglas, X.Sun, "Convolutive blind separation of speech mixtures using the natural gradient," Speech commun, vol. 39. pp. 65-78, (2002).
- [18] Yoshioka, Takuya Nakatani, Tomohiro Miyoshi, Masato Okuno, Hiroshi G. "Blind Separation and Dereverberation of Speech Mixtures by Joint Optimization,' IEEE Transactions on Audio Speech and Language Processing, Volume. 19, Issue. 1, pp. 69, 2011.
- [19] A. Cichocki, R. Zdunek, S. Amari, G. Hori and K. Umeno, 'Blind Signal Separation Method and System Using Modular and HierarchicalMultilayer Processing for Blind Multidimensional Decomposition, Identification, Separation or Extraction,' Patent pending, No. 2006124167, RIKEN, Japan, March 2006.
- [20] Intae Lee, Taesu Kim, and Te-Won Lee. Independent vector analysis for convolutive blind speech separation. In Blind Speech Separation. Springer, September 2007.
- [21] Solvang, Hiroko Kato Nagahara, Yuichi Araki, Shoko Sawada, Hiroshi Makino, Shoji "Frequency-Domain Pearson Distribution Approach for Independent Component Analysis (FD-Pearson-ICA) in Blind Source Separation,' IEEE Transactions on Audio Speech and Language Processing, Volume 17, Issue. 4, pp. 639, 2009.
- [22] H. Sawada, S. Araki, and S. Makino. Frequency-domain blind source separation. In Blind Speech Separation. Springer, September 2007.
- [23] Saruwatari, H. Kawamura, T. Nishikawa, T. Lee, A. Shikano, K. "Blind source separation based on a fast-convergence algorithm combining ICA and beamforming,' IEEE Transactions on Audio Speech and Language Processing, Volume 14, Issue 2, pp. 666, 2006.
- [24] Low, S.Y. Nordholm, S. Togneri, R. "Convolutive Blind Signal Separation With Post-Processing,' IEEE Transactions on Speech and Audio Processing, Volume 12, Issue 5, pp. 539, 2004.
- [25] F. Nest, P. Svaizer and M. Omologo 'Convolutive BSS of short mixturesby ICA recursively regularized across frequencies", IEEETrans. Audio, Speech, Lang. Process., vol. 19, no. 3, pp.624 -639 2011
- [26] S. C. Douglas and M. Gupta "Scaled natural gradient algorithms for instantaneous and convolutive blind source separation", Proc. ICASSP, vol. II, pp.637 -640 2007
- [27] T. S. Wada and B.-H. Juang "Acoustic echo cancellation based on independent component analysis and integrated residual echo enhancement", Proc. WASPAA, pp.205 -208 2009
- [28] H. Sawada , S. Araki , R. Mukai and S. Makino "Blind extraction of dominant target sources using ICA and time-frequency masking", IEEE Trans. Audio, Speech, Lang. Process., vol. 14, no. 6, pp.2165 -2173 2006
- [29] S. Araki , S. Makino , T. Nishikawa and H. Saruwatari "Fundamental limitation of frequency domain blind source separation for convolutive mixture of speech", Proc. ICASSP, pp.2737 -2740 2001
- [30] E. Ollila "The deflation-based fastICA estimator: Statistical analysis revisited", IEEE Trans. Signal Process., vol. 58, no. 3, pp.1527 -1541 2010
- [31] H. Sawada, R. Mukai, S. Araki, and S. Makino, 'A robust and precise method for solving the permutation problem of frequency-domainblind source separation,' IEEE Trans. Speech Audio Process., vol. 12, no. 5, pp. 530-538, Sep. 2004.
- [32] D. Nion , K. N. Mokios , N. D. Sidiropoulos and A. Potamianos "Batch and adaptive PARAFAC-based blind separation of convolutive speech mixtures", IEEE Trans. Audio, Speech Lang. Process., vol. 18, no. 6, pp.1193 -1207 2010
- [33] K. Rahbar and J.-P. Reilly "A frequency domain method for blind source separation of convolutive audio mixtures", IEEE Trans. Speech Audio Process., vol. 13, no. 5, pp.832 -844 2005 [online] Available: http://www.ece.mcmaster.ca/~reilly/kamran/id18.htm
- [34] L. Parra and C. Spence "Convolutive blind separation of non-stationary sources", IEEE Trans. Speech Audio Process., vol. 8, no. 3, pp.320 327 2000 [online] Available: http://ida.first.fhg.de/~harmeli/download/download\_convbss.html
- [35] C. Serviegrave;re and D.-T. Pham 'Permutation correction in the frequency domain in blind separation of speech mixtures", EURASIP J. Appl. Signal Process., no. 1, pp.1 -16 2006
- [36] N. Mitianoudis and M. Davies'Audio source separation of convolutive mixtures", IEEE Trans. Speech Audio Process., vol. 11, no. 5, pp.489 497 2003
- [37] A. Westner and J. V. M. Bove 'Blind separation of real world audio signals using overdetermined mixtures", Proc. ICA\'99, 1999 [online] Available: http://sound.media.mit.edu/ica-bench
- [38] D.-T. Pham, C. Servi&egrave;re and H. Boumaraf "Blind separation of convolutive audio mixtures using nonstationarity", Proc. Int. Workshop Indep. Compon. Anal. Blind Signal Separation (ICA\'03), pp.981 -986 2003
- [39] F. Nesta, 'Techniques for robust source separation and localization in adverse environment', PhD thesis, University of Trento, April, 2010.
- [40] F. Nesta , P. Svaizer and M. Omologo "Convolutive BSS of short mixturesby ICA recursively regularized across frequencies", IEEETrans. Audio, Speech, Lang. Process., vol. 19, no. 3, pp.624 -639 2011 http://bssnesta.webatu.com/testhscma.html
- [41] Herbert Buchner, Robert Aichner, and Walter Kellermann. TRINICON: A versatile framework for multichannel blind signal processing. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing, volume 3, pages 889-892, Montreal, Canada, May 17-21 2004.
- [42] Robert Aichner, Herbert Buchner, Fei Yan, and Walter Kellermann. A real-time blind source separation scheme and its application to reverberant and noisy acoustic environments. Signal Process. 86(6):1260-1277, 2006.
- [43] Z. Koldovsky and P. Tichavsky. Time-domain blind audio source separation using advanced component clustering and reconstruction. In Proceedings of HSCMA, Trento, Italy, May 2008.
- [44] J.-T. Chien and H.-L. Hsieh 'Nonstationary source separation using sequential and variational Bayesian learning", IEEE Trans. Neural Netw. Learn, Syst., vol. 24, no. 5, pp.681 -694 2013
- [45] E. Vincent, S. Araki, and P. Bofill. The 2008 signal separation evaluation campaign: A community-based approach to large-scale evaluation. In ICA '09: Proceedings of the 8th International Conference on Independent Component Analysis and Signal Separation, pages 734741, Berlin, Heidelberg, 2009. Springer-Verlag.
- [46] Takahashi, Yu. Saruwatari, H., Shikano, K., "Real-time implementation of blind spatial subtraction array for hands-free robot spoken dialogue system,' Intelligent Robots and Systems, 2008. IROS 2008. IEEE/RSJ International Conference on, On page(s): 1687-1692.
- [47] V. V. Vasin, 'Some tendencies in the Tikhonov regularization of illposed problems,' J. Inverse and Ill-Posed Problems, vol. 14, no. 8, pp. 813-840, Dec. 2006.
- [48] W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, Numerical Recipes in C. The Art of Scientific Computing, 2nd. Cambridge, UK: Cambridge University Press, 1992.
- [49] E. Vincent, C. Fevotte, and R. Gribonval. Performance measurement in blind audio source separation. IEEE Trans. Audio, Speech and Language Processing, 14(4):1462-1469, 2006.
- [50] M. Zibulevsky, 'Blind source separation with relative Newton method,' in Proc. ICA 2003, 2003, pp. 897-902. | null | [
"Zaid Albataineh",
"Fathi M. Salem"
] | 2014-08-01T14:47:33+00:00 | 2014-08-01T14:47:33+00:00 | [
"cs.LG",
"cs.SD"
] | A RobustICA Based Algorithm for Blind Separation of Convolutive Mixtures | We propose a frequency domain method based on robust independent component
analysis (RICA) to address the multichannel Blind Source Separation (BSS)
problem of convolutive speech mixtures in highly reverberant environments. We
impose regularization processes to tackle the ill-conditioning problem of the
covariance matrix and to mitigate the performance degradation in the frequency
domain. We apply an algorithm to separate the source signals in adverse
conditions, i.e. high reverberation conditions when short observation signals
are available. Furthermore, we study the impact of several parameters on the
performance of separation, e.g. overlapping ratio and window type of the
frequency domain method. We also compare different techniques to solve the
frequency-domain permutation ambiguity. Through simulations and real world
experiments, we verify the superiority of the presented convolutive algorithm
among other BSS algorithms, including recursive regularized ICA (RR ICA),
independent vector analysis (IVA). |
1408.0194v1 | ## Critical current oscillation by magnetic field in semiconductor nanowire Josephson junction
## Tomohiro Yokoyama ∗
Kavli Institute of Nanoscience, Delft University of Technology, Delft, The Netherlands and Center for Emergent Matter Science, RIKEN Institute, Wako, Japan
## Mikio Eto
Faculty of Science and Technology, Keio University, Yokohama, Japan
## Yuli V. Nazarov
Kavli Institute of Nanoscience, Delft University of Technology, Delft, The Netherlands (Dated: August 4, 2014)
We study theoretically the critical current in semiconductor nanowire Josephson junction with strong spinorbit interaction. The critical current oscillates by an external magnetic field. We reveal that the oscillation of critical current depends on the orientation of magnetic field in the presence of spin-orbit interaction. We perform a numerical simulation for the nanowire by using a tight-binding model. The Andreev levels are calculated as a function of phase di ff erence ϕ between two superconductors. The DC Josephson current is evaluated from the Andreev levels in the case of short junctions. The spin-orbit interaction induces the e ff ective magnetic field. When the external field is parallel with the e ff ective one, the critical current oscillates accompanying the 0π like transition. The period of oscillation is longer as the angle between the external and e ff ective fields is larger.
PACS numbers:
## I. INTRODUCTION
The spin-orbit (SO) interaction has attracted a lot of interest. In narrow-gap semiconductors, such as InAs and InSb, the strong SO interaction has been reported and many phenomena based on the SO interaction are investigated intensively, e.g., spin Hall e ff ect . 1 The SO interaction has a great advantage also for the application to the spintronic devices and to quantum information processing. InAs and InSb nanowires are interesting platform for the application and studied in recent experiments, e.g., the electrical manipulation of single electron spins in quantum dots fabricated on the nanowires . 2 Nanowire-superconductor hybrid systems have been also examined for the search of Majorana fermions induced by the SO interaction and the Zeeman e ff ect . 3
In Josephson junctions, the supercurrent flows when the phase di ff erence ϕ between two superconductors is present. In this paper, we investigate theoretically the Josephson junction of semiconductor nanowires with strong SO interaction. The supercurrent in semiconductor nanowires has been reported by experiment groups 4,5 . The Josephson e ff ect with SO interaction has been studied theoretically for some materials, e.g., magnetic normal metals 6 , where the combination of SO interaction and exchange interaction results in an unconventional current-phase relation, I ( ϕ ) = I 0 sin( ϕ -ϕ 0 ). The phase shift ϕ 0 deviates the ground state of junction from ϕ = 0 or π , which is so-called ϕ 0 -state. The anomalous supercurrent is obtained at ϕ = 0. In previous studies, we have pointed out that the anomalous e ff ect is attributed to the spin-dependent channel mixing due to the SO interaction 7,8 . In the present study, we focus on the critical current oscillation when an external magnetic field is applied. The DC Josephson current is evaluated from the Andreev levels in the case of short junction. We examine a numerical calculation using a tight-binding model for the nanowire. In this model, a particular form of SO interac-
FIG. 1: Model for a semiconductor nanowire Josephson junction. A tight-binding model is applied for the normal region with hard-wall potentials for the nanowire. The nanowire is represented by a quasi-one dimensional system along the x direction. The normal region is 0 < x < L and the superconducting region induced by the proximity e ff ect is x < 0, x > L .
tion can be considered. When the angle between the external field and an e ff ective magnetic field due to the SO interaction is smaller, the oscillation period of critical current is shorter.
## II. MODEL
The nanowire along the x direction is connected to two superconductors (Fig. 1). At x < 0 and x > L , the superconducting pair potential is induced into the nanowire by the proximity e ff ect. We assume that the pair potential is ∆ ( x ) = ∆ 0 e i ϕ/ 2 at x < 0 and ∆ ( x ) = ∆ 0 e -i ϕ/ 2 at x > L , where ϕ is the phase di ff erence between the two superconductors. In the normal region at 0 < x < L , ∆ ( x ) = 0. When a magnetic field is applied to the junction, the Zeeman e ff ect is taken into account in the nanowire. The magnetic field is not too large to break the superconductivity and screened in the superconducting regions. The Hamiltonian is given by H = H 0 + H SO + H Z with H 0 = p 2 / 2 m + V conf + V imp, the
Rashba interaction H SO = ( α/ /planckover2pi1 )( py σ x -px σ y ), and the Zeeman term H Z = g µ B B · ˆ σ / 2, using e ff ective mass m g , -factor g ( < 0 for InSb), Bohr magneton µ B, and Pauli matrices ˆ . σ We neglect the orbital magnetization e ff ect in the nanowire. V conf describes the confining potential for the nanowire. V imp represents the impurity potentials. We consider short junction, where the spacing between two superconductors is much smaller than the coherent length in the normal region, L /lessmuch ξ . There is no potential barrier at x = 0 , L . The Zeeman energy E Z = | g µ BB | and the pair potential ∆ 0 are much smaller than the Fermi energy E F.
The Bogoliubov-de Gennes (BdG) equation is written as
$$\left ( \begin{array} { c } H - E _ { \text{F} } & \hat { \Delta } \\ \hat { \Delta } ^ { \dagger } & - ( H ^ { * } - E _ { \text{F} } ) \end{array} \right ) \left ( \begin{array} { c } \psi _ { \text{e} } \\ \psi _ { \text{h} } \end{array} \right ) = E \left ( \begin{array} { c } \psi _ { \text{e} } \\ \psi _ { \text{h} } \end{array} \right ) \quad ( 1 )$$
with ˆ ∆ = ∆ ( x g )ˆ. ψ e = ( ψ e + , ψ e -) T and ψ h = ( ψ h + , ψ h -) T are the spinors for electron and hole, respectively. ˆ g = -i ˆ σ y . The energy E is measured from the Fermi level E F. The BdG equation determines the Andreev levels En ( | En | < ∆ 0 ) as a function of ϕ .
The ground state energy of junction is given by E gs ( ϕ ) = -(1 / 2) ∑ n ′ En ( ϕ ), where the summation is taken over all the positive Andreev levels, En ( ϕ ) > 0. The contribution from continuous levels ( | E | > ∆ 0 ) can be disregarded for the short junctions . At zero temperature, the supercurrent is calculated 9 as I ( ϕ ) = (2 e / /planckover2pi1 )( dE gs / d ϕ ). The current is a periodic function for -π ≤ ϕ < π . The maximum (or absolute value of minimum) of I ( ϕ ) yields the critical current I c .
The BdG equation in eq. (1) is expressed in terms of the scattering matrix . 9 The scattering matrix of electrons (holes) transport in the normal region is given by ˆ S e ( ˆ S h ). ˆ S e and ˆ S h are related to each other by ˆ S e = ˆ S ∗ h for the short junctions. We denote ˆ S e = ˆ S and ˆ S h = ˆ S ∗ . The Andreev reflection at x = 0 and L is described by the scattering matrix ˆhe r for the conversion from electron to hole and ˆeh r for that from hole to electron. The normal reflection can be neglected. The matrix coe ffi cients of ˆ r he and ˆeh, e.g., exp r {-i arccos( E / ∆ 0 ) -i ϕ/ 2 } for ˆhe r at x = 0, are calculated from the boundary condition at x = 0 and L . The SO interaction does not a ff ect the Andreev reflection coe ffi cients. The Andreev levels, En ( ϕ ), are obtained from the product of ˆ , S ˆ r he , and ˆeh, r
$$\det \left ( \hat { 1 } - \hat { r } _ { \text{eh} } \hat { S } ^ { * } \hat { r } _ { \text{he} } \hat { S } \right ) = 0. \quad \quad ( 2 ) \quad E _ { \text{gs} } ^ { \text{i} } \\ \theta \cdot \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{cases}$$
Equation (2) is equivalent to the BdG equation (1).
To calculate the scattering matrix ˆ , S we adopt the tightbinding model which discretizes a two-dimensional space ( xy plane). The edges of nanowire are represented by a hard-wall potential. The width of nanowire is W = 12 a with the lattice constant a = 10nm. The Fermi wavelength is fixed at λ F = 18 a , where the number of conduction channels is unity. The length of normal region is L = 50 a . The on-site random potential by impurities is taken into account, the distribution of which potential is uniform. We set that the mean free path due to the impurity scattering is l mfp / L = 1. The SO length is l SO / L = 0 2 with . l SO = k -1 α = /planckover2pi1 2 / ( m α ). The magnetic field is B = B ˆ e θ with the angle θ from the x axis in the xy plane.
FIG. 2: Numerical results of phase di ff erence ϕ 0 at the minimum of ground-state energy when the number of conduction channel is unity and l mfp / L = 1. The SO interaction is l SO / L = 0 2. . The results are for a sample. (a) Grayscale plot of ϕ 0 in the plane of magnetic field θ B = E L Z / ( /planckover2pi1 v F ) and its direction θ . (b) Cross section of panel (a) at θ = 0 5 . π (solid), 0 3 . π (broken), 0 15 . π (dotted), and 0 (dotted broken lines).
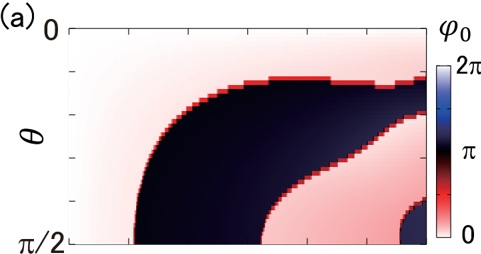
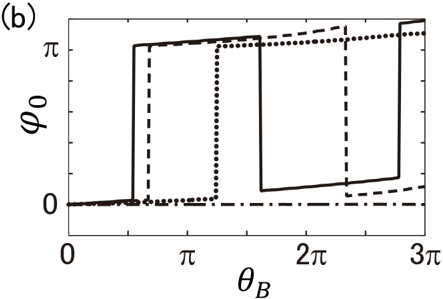
## III. RESULTS
We consider a sample for the nanowire. For the magnetic field, we introduce a parameter, θ B = E L Z / ( /planckover2pi1 v F), which means an additional phase due to the Zeeman e ff ect in the propagation of electron and hole. Here, v F is the Fermi velocity in the absence of SO interaction.
Figure 2 shows the phase di ff erence ϕ 0 at the minimum of E gs when the magnetic field is increased and rotated. In the absence of SO interaction, ϕ 0 takes only 0 or π exactly and clear 0π transition happens (see Ref. 8 ). In the presence of SO interaction, ϕ 0 is deviated from 0 and π , where the anomalous Josephson current is obtained. When the magnetic field is in the y direction ( θ = π/ 2), the transition between ϕ 0 ≈ 0 and ϕ 0 ≈ π takes place around θ B = π/ 2 3 , π/ 2 , · · · . The transition points are shifted gradually to large θ B with decreasing of angle θ . At θ ≈ 0, the transition is not observed in Fig. 2.
The transition points in ϕ 0 corresponds to the position of cusps of critical current. Figure 3(a) exhibits the critical current when the magnetic field increases. The critical current I c oscillates as a function of θ B . The distance of cusps is longer when the direction of magnetic field is tilted from the y axis. For the parallel magnetic field to the nanowire ( θ = 0), I c has
FIG. 3: Numerical results of critical current I c when N = 1 and l mfp / L = 1. The SO interaction is l SO / L = 0 2. . I 0 ≡ e ∆ 0 / /planckover2pi1 . The sample is the same as that in Fig. 2. (a) I c as a function of magnetic field θ B = E L Z / ( /planckover2pi1 v F ) when θ = 0 5 . π (solid), 0 3 . π (broken), 0 15 . π (dotted), and 0 (dotted broken lines). (b) I c as a function of magnetic field orientation θ when θ B = π/ 2 (solid), π (broken), and 2 π (dotted lines).
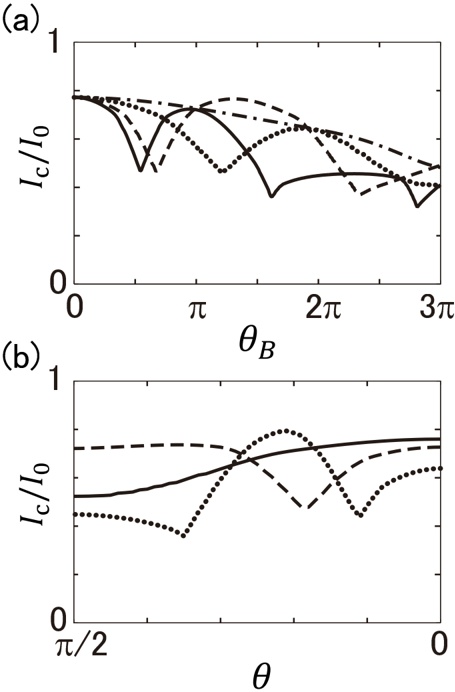
no cusp in accordance with no transition. The critical current decreases with increase of θ B although ϕ 0 is almost fixed at zero in Fig. 2(b). Figure 3(b) shows I c when the magnetic field is rotated in the xy plane. The strength of magnetic field is fixed for each line. We find the transition by the angle θ in Fig. 2(a). The critical current also oscillates as a function of θ . For small magnetic field ( θ B < π/ 2), I c changes monotonically. The oscillation by θ is obtained for large magnetic field. If the state of junction at θ = π/ 2 is ϕ 0 ≈ π (0), the critical current shows one cusp (two cusps) in Fig. 3(b). Therefore we can estimate the state at θ = π/ 2 from the number of cusps.
∗ E-mail me at: [email protected]
1 Kato Y K, Myers R C, Gossard A C, and Awschalom D D 2004 Science 306 1910
## IV. CONCLUSIONS AND DISCUSSION
We have studied the DC Josephson e ff ect in the semiconductor nanowire with strong SO interaction. We have examined a numerical simulation using the tight-binding model in the case of short junction. The combination of SO interaction and Zeeman e ff ect in the nanowire results in the anomalous Josephson e ff ect. The critical current oscillates as a function of magnetic field. In the presence of SO interaction, the oscillation of critical current depends on the magnetic field orientation. The oscillation period is shorter when the magnetic field is perpendicular to the nanowire. For a parallel magnetic field to the nanowire, the transition and the cusp of critical current are not found.
In this numerical model, we have considered the Rashba interaction. In the quasi-one-dimensional nanowire, the e ff ective magnetic field induced by the Rashba interaction is in the y direction. The anisotropy of critical current oscillation is understood intuitively by the spin precession in the propagation of electron and hole. When the external magnetic field is parallel to the e ff ective field (the y direction), the spin quantization axis is fixed in that direction. The electron and hole receive the additional phase in the propagation. On the other hand, when the external field is in the x direction, the spin quantization axes for electron and hole are not parallel with each other since the e ff ective fields for electron and hole are antiparallel. The spin of electron and hole forming the Andreev bound state is rotated, which rotation cancels out the phase θ B due to the Zeeman splitting. As a result, the critical current oscillation disappears. In the case of general SO interaction, the e ff ective field would be deviated from the y axis. By measuring the anisotropy of critical current oscillation, we can evaluate the direction of e ff ective field due to the SO interaction.
## Acknowledgments
We acknowledge financial support by the Motizuki Fund of Yukawa Memorial Foundation. We acknowledge fruitful discussions about experiments with Professor L. P. Kouwenhoven, A. Geresdi, V. Mourik, K. Zuo of Delft University of Technology. T.Y. is a JSPS Postdoctoral Fellow for Research Abroad.
## References
2 Nadj-Perge S, Pribiag V S, van den Berg J W G, Zuo K, Plissard S R, Bakkers E P A M, Frolov S M, and Kouwenhoven L P 2012 Phys. Rev. Lett. 108 166801
- 3 Mourik V, Zuo K, Frolov S M, Plissard S R, Bakkers E P A M, and Kouwenhoven L P 2012 Science 336 1003
- 4 Doh Y-J, van Dam J A, Roest A L, Bakkers E P A M, Kouwenhoven L P, and Franceschi S De 2005 Science 309 272
- 5 Kouwenhoven L P, Geresdi A, Mourik V, and Zuo K (private communications)
- 6 Buzdin A 2008 Phys. Rev. Lett. 101 107005
- 7 Yokoyama T, Eto M, and Nazarov Yu V 2013 J. Phys. Soc. Jpn. 82 054703
- 8 Yokoyama T, Eto M, and Nazarov Yu V 2014 Phys. Rev. B 89 195407
- 9 Beenakker C W J 1991 Phys. Rev. Lett 67 3836; 1992 Phys. Rev. Lett 68 1442(E) | null | [
"Tomohiro Yokoyama",
"Mikio Eto",
"Yuli V. Nazarov"
] | 2014-08-01T14:50:10+00:00 | 2014-08-01T14:50:10+00:00 | [
"cond-mat.mes-hall",
"cond-mat.supr-con"
] | Critical current oscillation by magnetic field in semiconductor nanowire Josephson junction | We study theoretically the critical current in semiconductor nanowire
Josephson junction with strong spin-orbit interaction. The critical current
oscillates by an external magnetic field. We reveal that the oscillation of
critical current depends on the orientation of magnetic field in the presence
of spin-orbit interaction. We perform a numerical simulation for the nanowire
by using a tight-binding model. The Andreev levels are calculated as a function
of phase difference $\varphi$ between two superconductors. The DC Josephson
current is evaluated from the Andreev levels in the case of short junctions.
The spin-orbit interaction induces the effective magnetic field. When the
external field is parallel with the effective one, the critical current
oscillates accompanying the $0$-$\pi$ like transition. The period of
oscillation is longer as the angle between the external and effective fields is
larger. |
1408.0195v3 | /negationslash
## SURVEY ARTICLE: SEVENTY YEARS OF SALEM NUMBERS
## CHRIS SMYTH
Abstract. I survey results about, and recent applications of, Salem numbers.
## 1. Introduction
In this article I state and prove some basic results about Salem numbers, and then survey some of the literature about them. My intention is to complement other general treatises on these numbers, rather than to repeat their coverage. This applies particularly to the work of Bertin and her coauthors [9, 12, 14] and to the application-rich Salem number survey of Ghate and Hironaka [45]. I have, however, quoted some fundamental results from Salem's classical monograph [101].
Recall that a complex number is an algebraic integer if it is the zero of a polynomial with integer coefficients and leading coefficient 1. Then its (Galois) conjugates are the zeros of its minimal polynomial , which is the lowest degree polynomial of that type that it satisfies. This degree is the degree of the algebraic integer.
A Salem number is a real algebraic integer τ > 1 of degree at least 4, conjugate to τ -1 , all of whose conjugates, excluding τ and τ -1 , have modulus 1. Then τ + τ -1 is a real algebraic integer > 2, all of whose conjugates = τ + τ -1 lie in the real interval ( -2 2). Such numbers are easy to find: an , example is τ + τ -1 = 1 2 (3+ √ 5), giving ( τ + τ -1 -3 2 ) 2 = 5 4 , so that τ 4 -3 τ 3 + 3 τ 2 -3 τ +1 = 0 and τ = 2 1537 . . . . . We note that this polynomial is a socalled (self)-reciprocal polynomial: it satisfies the equation z deg P P z ( -1 ) = P z ( ). This means that its coefficients form a palindromic sequence: they read the same backwards as forwards. This holds for the minimal polynomial of every Salem number. It is simply a consequence of τ and τ -1 having the same minimal polynomial. Salem numbers are named after Rapha¨ el Salem, who, in 1945, first defined and studied them [100, Section 6].
2010 Mathematics Subject Classification. Primary 11R06.
Key words and phrases. Salem number.
Salem numbers are usually defined in an apparently more general way, as in the following lemma. It shows that this apparent greater generality is illusory.
/negationslash
Lemma 1 (Salem [101, p.26]) . Suppose that τ > 1 is a real algebraic integer, all of whose conjugates = τ lie in the closed unit disc | z | ≤ 1 , with at least one on its boundary | z | = 1 . Then τ is a Salem number (as defined above).
↦
Proof. Taking τ ′ to be a conjugate of τ on | z | = 1, we have that τ ′ = τ ′-1 is also a conjugate τ ′′ say, so that τ ′-1 = τ ′′ . For any other conjugate τ 1 of τ we can apply a Galois automorphism mapping τ ′′ → τ 1 to deduce that τ 1 = τ -1 2 for some conjugate τ 2 of τ . Hence the conjugates of τ occur in pairs τ , τ ′ ′-1 . Since τ itself is the only conjugate in | z | > 1, it follows that τ -1 is the only conjugate in | z | < 1, and so all conjugates of τ apart from τ and τ -1 in fact lie on | z | = 1. /square
It is known that an algebraic integer lying with all its conjugates on the unit circle must be a root of unity (Kronecker [62]). So in some sense Salem numbers are the algebraic integers that are 'the nearest things to roots of unity'. And, like roots of unity, the set of all Salem numbers is closed under taking powers.
Lemma 2 (Salem [100, p.169]) . If τ is a Salem number of degree d , then so is τ n for all n ∈ N .
/negationslash
Proof. If τ is conjugate to τ ′ then τ n is conjugate to τ ′ n . So τ n will be a Salem number of degree d unless some of its conjugates coincide: say τ n 1 = τ n 2 with τ 1 = τ 2 . But then, by applying a Galois automorphism mapping τ 1 → τ , we would have τ n = τ n 3 say, where τ 3 = τ is a conjugate of τ , giving | τ n | > 1 while | τ n 3 | ≤ 1, a contradiction. /square
↦
/negationslash
Which number fields contain Salem numbers? Of course one can simply choose a list of Salem numbers τ, τ ′ , τ ′′ , . . . say, and then the number field Q ( τ, τ ′ , τ ′′ , . . . ) certainly contains τ, τ ′ , τ ′′ , . . . . However, if one is interested only in finding all Salem numbers in a field Q ( τ ) for τ a given Salem number, we can be much more specific.
/negationslash
Proposition 3 (Salem [100, p.169]) . (i) A number field K is of the form Q ( τ ) for some Salem number τ if and only if K has a totally real subfield Q ( α ) of index 2 , and K = Q ( τ ) with τ + τ -1 = α , where α > 2 is an irrational algebraic integer, all of whose conjugates = α lie in ( -2 2) , .
- (ii) Suppose that τ and τ ′ are Salem numbers with τ ′ ∈ Q ( τ ) . Then Q ( τ ′ ) = Q ( τ ) and, if τ ′ > τ , then τ /τ ′ is also a Salem number in Q ( τ ) .
- (iii) If K = Q ( τ ) for some Salem number τ , then there is a Salem number τ 1 ∈ K such that the set of Salem numbers in K consists of the powers of τ 1 .
- Proof. (i) Suppose that K = Q ( τ ) for some Salem number τ . Then, defining α = τ + τ -1 , every conjugate α ′ of α is of the form α 1 = τ 1 + τ -1 1 , where τ 1 , a conjugaste of τ , either is one of τ ± 1 or has modulus 1. Hence α 1 is real, and so α is totally real with α > 2 and all other conjugates of α in ( -2 2). Also, because , Q ( α ) is a proper subfield of Q ( τ ) and τ 2 -ατ +1 = 0 we have [ Q ( τ ) : Q ( α )] = 2.
/negationslash
Conversely, suppose that K has a totally real subfield Q ( α ) of index 2, and K = Q ( τ ), where α > 2 is an irrational algebraic integer, all of whose conjugates = α lie in ( -2 2), and , τ + τ -1 = α . Then for every conjugate τ 1 of τ we have τ 1 + τ -1 1 = α 1 for some conjugate α 1 of α , and for every conjugate α 1 of α we have τ 1 + τ -1 1 = α 1 for some conjugate τ 1 of τ . If α 1 = α then τ 1 = τ ± 1 . Otherwise, α 1 ∈ ( -2 2) and so , | τ 1 | = 1. Furthermore, as α is irrational it does indeed have a conjugate α 1 ∈ -( 2 2) for which the corresponding , τ 1 has modulus 1. Hence τ is a Salem number.
- (ii) By (i) we can write τ ′ as τ ′ = p α ( ) + τq α ( ), where p z , q ( ) ( z ) ∈ Q [ z ] and α = τ + τ -1 . If τ ′ had lower degree than τ , say [ Q ( τ ) : Q ( τ ′ )] = k > 1 then, for the d = [ Q ( τ ) : Q ] conjugates τ i of τ , k of the values p τ ( i + τ -1 i ) + τ q i ( τ i + τ -1 i ) would equal τ ′ and another k of them would equal τ ′ -1 . In particular, p τ ( i + τ -1 i ) + τ q i ( τ i + τ -1 i ) would be real for some nonreal τ i , giving q τ ( i + τ -1 i ) = 0 and hence, on applying a suitable automorphism, that q α ( ) = 0. Thus we would have τ ′ = p α ( ), a contradiction, since p α ( ) is totally real. So k = 1 and Q ( τ ′ ) = Q ( τ ).
↦
Since τ ′ ∈ Q ( τ ), it is a polynomial in τ . Therefore any Galois automorphism taking τ → τ -1 will map τ ′ to a real conjugate of τ ′ , namely τ ′± 1 . But it cannot map τ ′ to itself for then, as τ is also a polynomial in τ ′ , τ would be mapped to itself, a contradiction. So τ ′ is mapped to τ ′-1 by this automorphism. Hence τ τ ′ -1 is conjugate to its reciprocal. So the conjugates of τ τ ′ -1 occur in pairs x, x -1 . Again, because τ ′ is a polynomial in τ , any automorphism fixing τ
will also fix τ ′ , and so fix τ τ ′ -1 . Likewise, any automorphism fixing τ ′ will also fix τ .
Next consider any conjugate of τ τ ′ -1 in | z | > 1. It will be of the form τ τ ′ 1 -1 1 , where τ ′ 1 is a conjugate of τ ′ and τ 1 is a conjugate of τ . For this to lie in | z | > 1, we must either have | τ ′ 1 | > 1 or | τ 1 | < 1, i.e., τ ′ 1 = τ ′ or τ 1 = τ -1 . But in the first case, as we have seen, τ 1 = τ , so that τ τ ′ 1 -1 1 = τ τ ′ -1 , while in the second case τ ′ 1 = τ ′-1 , giving τ τ ′ 1 -1 1 = ττ ′-1 < 1. Hence τ τ ′ -1 itself is the only conjugate of τ τ ′ -1 in | z | > 1. It follows that all conjugates of τ τ ′ -1 apart from ( τ τ ′ -1 ) ± 1 must lie on | z | = 1, making τ τ ′ -1 a Salem number.
- (iii) Consider the set of all Salem numbers in K = Q ( τ ). Now the number of Salem numbers < τ in K is clearly finite, as there are only finitely many possibilities for the minimal polynomials of such numbers. Hence there is a smallest such number, τ 1 say. For any Salem number, τ ′ say, in K we can choose a positive integer r such that τ r 1 ≤ τ ′ < τ r +1 1 . But if τ r 1 < τ ′ then, by (ii) and Lemma 2, τ τ ′ -r 1 would be another Salem number in K which, moreover, would be less than τ 1 , a contradiction. Hence τ ′ = τ r 1 .
/square
The statements (ii) and (iii) above in fact represent a slight strengthening of Salem's results, as they do not assume that all Salem numbers in K have degree [ K : Q ].
We now show that the powers of Salem numbers have an unusual property.
Proposition 4 (Essentially Salem [100], reproduced in [101]) . For every Salem number τ and every ε > 0 there is a real number λ > 0 such that the distance ‖ λτ n ‖ of λτ n to the nearest integer is less than ε for all n ∈ N .
The result's first explicit appearance seems to be in Boyd [17], who credits Salem. A proof comes from an easy modification the proof in [100, pp 164-166].
Proof. We consider the standard embedding of the algebraic integers Z ( τ ) as a lattice in R d defined for k = 0 1 , , . . . , d -1 by the map
$$\tau ^ { k } & \mapsto ( \tau ^ { k }, \tau ^ { - k }, \text{Re} \, \tau ^ { k } _ { 2 }, \text{Im} \, \tau ^ { k } _ { 2 }, \text{Re} \, \tau ^ { k } _ { 3 }, \text{Im} \, \tau ^ { k } _ { 3 }, \dots, \text{Re} \, \tau ^ { k } _ { d / 2 }, \text{Im} \, \tau ^ { k } _ { d / 2 } ), \\ \cdot \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots$$
↦
where τ ± 1 , τ ± 1 j ( j = 2 , . . . , d/ 2) are the conjugates of τ . As this is a lattice of full dimension d , we know that for every ε ′ > 0 there are lattice points in the 'slice' { ( x , . . . , x 1 n ) ∈ R n : | x i | < ε ′ ( i = 2 , . . . , d ) } . Such a lattice
point corresponds to an element λ τ ( ) of Z ( τ ) with conjugates λ i satisfying | λ i | < √ 2 ε ′ ( i = 2 , . . . , d ).
Next, consider the sums
$$\sigma _ { n } = \lambda ( \tau ) \tau ^ { n } + \lambda ( \tau ^ { - 1 } ) \tau ^ { - n } + \lambda ( \tau _ { 2 } ) \tau _ { 2 } ^ { n } + \lambda ( \tau _ { 2 } ^ { - 1 } ) \tau _ { 2 } ^ { - n } + \dots \lambda ( \tau _ { d / 2 } ) \tau _ { d / 2 } ^ { n } + \lambda ( \tau _ { d / 2 } ^ { - 1 } ) \tau _ { d / 2 } ^ { - n },$$
where λ x ( ) ∈ Z [ x ]. Since σ n is a symmetric function of the conjugates of τ it is rational. As it is an algebraic integer, it is in fact Since all terms λ τ ( -1 ) τ -n , λ τ ( 2 ) τ n 2 , λ τ ( -1 2 ) τ -n 2 , . . . , λ τ ( d/ 2 ) τ n d/ 2 , λ τ ( -1 d/ 2 ) τ -n d/ 2 are < √ 2 ε ′ in modulus, we see that d/ 2 d/ 2 , , a rational integer.
$$\ e u u \sigma, \ w \prec \sigma \infty \ e u u \sigma \\ | \sigma _ { n } - \lambda ( \tau ) \tau ^ { n } | & < ( d - 1 ) \sqrt { 2 } \varepsilon ^ { \prime }. \\ \ e u u \sigma \infty \sqrt { \varepsilon } \infty \quad \ e u u \sigma \infty \ e u u \sigma \end{pmatrix}$$
Hence, choosing ε ′ = ε/ (( d -1) √ 2), we have ‖ λτ n ‖ ≤ | σ n -λ τ ( ) τ n | < ε . /square
In fact, this property essentially characterises Salem (and Pisot) numbers among all real numbers. Recall that a Pisot number is an algebraic integer greater than 1 all of whose conjugates, excluding itself, all lie in the open unit disc | z | < 1. Pisot [95] proved that if λ and τ are real numbers such that
$$\left ( \begin{array} { c } 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1
\\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\
1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1\\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 | \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 2 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 0 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 3 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 6 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 4 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 5 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 9 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 8 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 7 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ & 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1</ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1'); 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1 \\ 1$$
for all integers n ≥ 0 then τ is either a Salem number or a Pisot number and λ ∈ Q ( τ ). The denominator in this result was later improved by Cantor [31] to 2 eτ ( τ +1)(2+ √ log λ ), and then by Decomps-Guilloux and GrandetHugot [33] to e τ ( +1) (2 + 2 √ log λ ). However, Vijayaraghavan [117] proved that for each ε > 0 there are uncountably many real numbers α > 1 such that ‖ α n ‖ < ε for all n ≥ 0. To be compatible with (1), it is clear that such α that are not Pisot or Salem numbers must be large (depending on ε ). Specifically, if α > (2 eε ) -1 2 / then there is no contradiction to (1). Furthermore, Boyd [17] proved that if the bound B in (1) is replaced by 10 B then τ can be transcendental.
For more results concerning the distribution of the fractional parts of λτ n for τ a Salem number, see Dubickas [36], Za¨ ımi [118, 119, 120], and Bugeaud's monograph [29, Section 2.4].
## 2. A smallest Salem number?
Define the polynomial L z ( ) by
$$L ( z ) & = z ^ { 1 0 } + z ^ { 9 } - z ^ { 7 } - z ^ { 6 } - z ^ { 5 } - z ^ { 4 } - z ^ { 3 } + z + 1. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
This is the minimal polynomial of the Salem number τ 10 = 1 176 . . . . , discovered by D. H. Lehmer [63] in 1933 (i.e., before Salem numbers had been defined!). Curiously, the polynomial L ( -z ) had appeared a year earlier in
Reidemeister's book [96] as the Alexander polynomial of the ( -2 3 7) pret-, , zel knot. Lehmer's paper seems to be the first where what is now called the Mahler measure of a polynomial appears: the Mahler measure M P ( ) of a monic one-variable polynomial P is the product ∏ i max(1 , | α i | ) over the roots α i of the polynomial. For a survey of Mahler measure see [112]; for its multivariable generalisation, see Boyd [21] and Bertin and Lal´ ın [13].
Lehmer also asked whether the Mahler measure of any nonzero noncyclotomic irreducible polynomial with integer coefficients is bounded below by some constant c > 1. This is now commonly referred to as 'Lehmer's problem' or (inaccurately) as 'Lehmer's conjecture' - see [112]. If indeed there were such a bound, then certainly Salem numbers would be bounded away from 1, but this would not immediately imply that there is a smallest Salem number (but see the end of Section 3.1). However, the 'strong version' of 'Lehmer's conjecture' states that one can take c = τ 10 , implying that there is indeed a smallest Salem number, namely τ 10 . A consequence of this strong version is the following.
Conjecture 5. Suppose that d ∈ N and α , α , . . . , α 1 2 d are real numbers with α 1 ∈ (2 , τ 10 + τ -1 10 ) and α , α , . . . , α 2 3 d ∈ -( 2 2) , . Then ∏ d i =1 ( x + α i ) ∈ Z [ x ] .
/negationslash
(Note that τ 10 + τ -1 10 = 2 026 . . . . .) For if there were α , α , . . . , α 1 2 d in the intervals stated with ∏ d i =1 ( x + α i ) ∈ Z [ x ], then the algebraic integer τ > 1 defined by τ + τ -1 = α 1 would be a Salem number less than τ 10 .
## 3. Construction of Salem numbers
3.1. Salem's method. Salem [101, Theorem IV, p.30] found a simple way to construct infinite sequences of Salem numbers from Pisot numbers. Now if P z ( ) is the minimal polynomial of a Pisot number, then, except possibly for some small values of n , the polynomials S n,P, ± 1 ( z ) = z n P z ( ) ± z deg P P z ( -1 ) factor as the minimal polynomial of a Salem number, possibly multiplied by some cyclotomic polynomials. In particular, for P z ( ) = z 3 -z -1, the minimal polynomial of the smallest Pisot number, S 8 ,P, -1 = ( z -1) L z ( ). Salem's construction shows that every Pisot number is the limit on both sides of a sequence of Salem numbers. (The construction has to be modified slightly when P is reciprocal; this occurs only for certain P of degree 2.)
Boyd [18] proved that all Salem numbers could be produced by Salem's construction, in fact with n = 1. It turns out that many different Pisot numbers can be used to produce the same Salem number. These Pisot numbers can be much larger than the Salem number they produce. In particular, on taking P z ( ) = z 3 -z -1 and ε = -1, the minimal polynomial of the
smallest Pisot number θ 0 = 1 3247 . . . . , Salem's method shows that there are infinitely many Salem numbers less than θ 0 . This fact motivates the next definition, due to Boyd.
Salem numbers less than 1 3 are called . small . A list of 39 such numbers was compiled by Boyd [18], with later additions of four each by Boyd [20] and Mossinghoff [86], making 47 in all - see [87]. (The starred entries in this list are the four Salem numbers found by Mossinghoff. They include one of degree 46.) Further, it was determined by Flammang, Grandcolas and Rhin [43] that the table was complete up to degree 40. This was extended up to degree 44 by Mossinghoff, Rhin and Wu [88] as part of a larger project to find small Mahler measures. Their result shows that if Conjecture 5 is false then any counterexample to that conjecture must have degree d ≥ 23.
In [22] Boyd showed how to find, for a given n ≥ 2, ε = ± 1 and real interval [ a, b ], all Salem numbers in that interval that are roots of S n,P,ε ( z ) = 0 for some Pisot number having minimal polynomial P z ( ). In particular, of the four new small Salem numbers that he found, two were discovered by this method. The other two he found in [22] are not of this form: they are roots only of some S 1 ,P,ε ( z ) = 0.
Boyd and Bertin [10, 11] investigated the properties of the polynomials S 1 ,P, ± 1 ( z ) in detail. For a related, but interestingly different, way of constructing Salem numbers, see Boyd and Parry [26].
Let T denote the set of all Salem numbers (Salem's notation). (It couldn't be called S , because that is used for the set of all Pisot numbers. The notation S here is in honour of Salem, however: Salem [98] had proved the magnificent result that the Pisot numbers form a closed subset of the real line.) Salem's construction shows that the derived set (set of limit points) of T contains S . Salem [101, p.31] wrote 'We do not know whether numbers of T have limit points other than S '. Boyd [18, p. 327] conjectured that there were no other such limit points, i.e., that the derived set of S ∪ T is S . (Not long before, he had conjectured [19] that S ∪ T is closed - a conjecture that left open the possibility that some numbers in T could be limit points of T .)
Salem's construction shows that every Pisot number is a limit from below of Salem numbers. So if the derived set of S ∪ T is indeed S , then any limit point of Salem numbers from above is also a limit point of Salem numbers from below. Hence Boyd's conjecture implies that there must be a smallest Salem number.
3.2. Salem numbers and matrices. One strategy that has been used to try to solve Lehmer's Problem is to attach some combinatorial object (knot, graph, matrix,. . . ) to an algebraic number (for example, to a Salem number). But it is not clear whether the object could throw light on the (e.g.) Salem number, or, on the contrary, that the Salem number could throw light on the object.
Typically, however, such attachment constructions seem to work only for a restricted class of algebraic numbers, and not in full generality. For example, McKee, Rowlinson, and Smyth considered star-like trees as the objects for attachment. this was extended by McKee and Smyth to more general graphs [73] and then to integer symmetric matrices [74, 75]. (These can be considered as generalisations of graphs: one can identify a graph with its adjacency matrix - an integer symmetric matrix having all entries 0 or 1, with only zeros on the diagonal.) The main tool for their work was the following classical result, which deserves to be better known.
Theorem 6 (Cauchy's Interlacing Theorem - for a proof see for instance [41]) . Let M be a real n × n symmetric matrix, and M ′ be the matrix obtained from M by removing the i th row and column. Then the eigenvalues λ , . . . , λ 1 n of M and the eigenvalues µ , . . . , µ 1 n -1 of M ′ interlace, i.e.,
$$\lambda _ { 1 } \leq \mu _ { 1 } \leq \lambda _ { 2 } \leq \mu _ { 2 } \leq \dots \leq \mu _ { n - 1 } \leq \lambda _ { n }.$$
We say that an n × n integer symmetric matrix M is cyclotomic if all its eigenvalues lie in the interval [ -2 2]. , It is so-called because then its associated reciprocal polynomial
$$P _ { M } ( z ) & = z ^ { n } \det \left ( ( z + z ^ { - 1 } ) I - M \right ) \\ \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \ \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \ & \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \omega \quad \ome }$$
has all its roots on | z | = 1 and so (Kronecker again) is a product of cyclotomic polynomials. Here I is the n × n identity matrix.
The cyclotomic graphs are very familiar.
Theorem 7 ( J.H. Smith [109]) . The connected cyclotomic graphs consist of the (not necessarily proper) induced subgraphs of the Coxeter graphs ˜ A n ( n ≥ 2) , ˜ D n ( n ≥ 4) , ˜ E 6 , ˜ E 7 , ˜ E 8 , as in Figure 1.
(These graphs also occur in the theory of Lie algebras, reflection groups, Lie groups, Tits geometries, surface singularities, subgroups of SU ( 2 C ) (McKay correspondence),. . . ).
McKee and Smyth [74] describe all the cyclotomic matrices, of which the cyclotomic graphs form a small subset. They prove in [75] that the strong version of Lehmer's conjecture is true for the set of polynomials P M :
Figure 1. The Coxeter graphs ˜ E , E , E , A 6 ˜ 7 ˜ 8 ˜ n ( n /greaterorequalslant 2) and ˜ D n ( n /greaterorequalslant 4). (The number of vertices is 1 more than the index.)
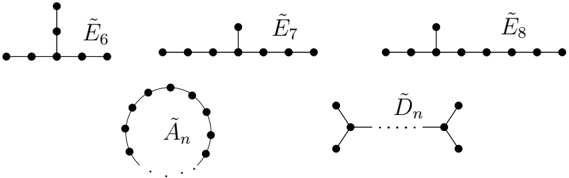
namely, if M is not a cyclotomic matrix, then P M has Mahler measure at least τ 10 = 1 176 . . . . , the smallest known Salem number. In fact they show that the smallest three known Salem numbers are all Mahler measures of P M for some integer symmetric matrix M , while the fourth-smallest known Salem number is not.
Most constructions of families of Salem numbers produce a monic reciprocal integer polynomials having roots τ > 1, 1 /τ < 1 and all other roots on the unit circle. The final stage of the construction requires that each polynomial be expressed as a product of irreducible factors. Then, by Kronecker's Theorem [62], the irreducible factor having 1 /τ as a root must also have τ as a root, and any other factors must be cyclotomic polynomials. For τ to be a Salem number, the first-mentioned factor must also have a root of modulus 1. To determine its degree, it is usually necessary to determine the degrees of the cyclotomic factors. One method, used by Smyth [111] and McKee and Yatsyna [78] (see also Beukers and Smyth [15]), is to make use of the fact [111, Lemma 2.1] that every root of unity ω is conjugate to one of ω 2 , -ω 2 or -ω . A second method is to use results of Mann [70] on sums of roots of unity. This method was used by Gross, Hironaka and McMullen [46] for polynomials coming from modified Coxeter diagrams, and by Brunotte and Thuswaldner [27] for polynomials coming from star-like trees.
For other construction methods for Salem numbers see Lakatos [63, 64, 65] and also [71, 72, 73, 76, 77, 110, 111]. In particular, in [63, 65] Lakatos shows that Salem numbers arise as the spectral radius of Coxeter transformations of certain oriented graphs containing no oriented cycles.
3.3. Traces of Salem numbers. McMullen [80, p.230] asked whether there are any Salem numbers of trace less than -1. McKee and Smyth [71, 72] found examples of Salem numbers of trace -2, and indeed showed that there are Salem numbers of every trace. It is known [111] that the smallest degree of a Salem number of trace -1 is 8, and there are Salem
numbers of trace -1 for every even degree at least 8. Recently McKee and Yatsyna [78] have shown that there are Salem numbers of trace -2 for every even degree at least 38.
If τ has degree d ≥ 10 then its trace is known to be at least at least /floorleft 1 -d/ 9 /floorright - see [72]. Conversely, Salem numbers having trace -T ≤ -2 must have degree d ≥ /floorleft 2 1 + 9 2 T /floorright (corrected from [72, p. 35]). For -T = -2 this bound is attained, it having been shown in [71] that there are two Salem numbers of trace -2 and degree 20. For a summary of the status of even degrees 20 < d < 38 for which there are known to be or not to be Salem numbers of degree d and trace -2, see [78, Section 3].
All of these lower bounds for the degree of a Salem number of given negative trace make use of the fact that, for a Salem number τ , the number τ +1 /τ +2 is a totally positive algebraic integer. Thus known lower bounds of the type trace( α ) > λd ′ for totally positive algebraic integers α of degree d ′ ≥ 5 can be used. Specifically, one readily deduces that, from such an inequality, a Salem number of degree d ≥ 10 has trace at least /floorleft 1 -(1 -λ/ 2) d /floorright , and a Salem number of trace -T ≤ -2 has degree at least 2 /floorleft T 2 -λ /floorright + 2. (The results quoted above are for λ = 16 9.) /
For -T = -3 the above bound gives d ≥ 28, later improved by Flammang [42] to d ≥ 30. In the other direction El Omani, Rhin and Sac- ´ p´e E e [90] have recently found Salem number examples of trace -3 and degree 34. Their computations strongly suggest that 34 is in fact the smallest degree for Salem numbers of trace -3. Recently Liang and Wu [68] have shown that a Salem number of trace -4 must have degree at least 40, and a Salem number of trace -5 must have degree at least 50.
For an interesting survey of the trace problem for totally positive algebraic integers see Aguirre and Peral [1].
## 3.4. Distribution modulo 1 of the powers of a Salem number. Let
τ > 1 be a Salem number of degree d . Salem [101, Theorem V, p.33] proved that although the powers τ n mod 1 of τ are everywhere dense on (0 1), , they are not uniformly distributed on this interval. In fact, the asymptotic distribution function of τ n mod 1 is that of a sum 2 ∑ d/ 2 -1 j =1 cos θ j , where the θ j are independent random variables uniformly distributed on [0 , π ]. In the simplest case, d = 4, a routine calculation shows that for x ∈ [0 , 1]
$$& \text{Prob} ( \tau ^ { n } \bmod 1 \leq x ) = \\ & \frac { 1 } { 2 } + \frac { \arcsin ( \frac { x + 1 } { 2 } ) + \arcsin ( \frac { x } { 2 } ) + \arcsin ( \frac { x - 1 } { 2 } ) + \arcsin ( \frac { x - 2 } { 2 } ) } { \pi }.$$
In particular, Prob(1 / 4 ≤ τ n mod 1 ≤ 3 / 4) = 0 4134038362, significantly . less than 1 / 2.
More generally, Akiyama and Tanigawa [3] gave a quantitative description of how far the sequence τ n mod 1 is from being uniformly distributed. They show, for τ a Salem number of degree 2 d ′ ≥ 8 and A N ( { τ n } , I ) being the number of n ≤ N for which the fractional part { τ N } lies in a subinterval I of [0 , 1], that lim N →∞ 1 N A N ( { τ n } , I ) exists and satisfies
$$\left | \lim _ { N \to \infty } \frac { 1 } { N } A _ { N } ( \{ \tau ^ { n } \}, I ) - | I | \right | \leq 2 \zeta \left ( \frac { 1 } { 2 } ( d ^ { \prime } - 1 ) \right ) ( 2 \pi ) ^ { 1 - d ^ { \prime } } | I |. \\ \intertext { t \dots } \left | \tau \right | \colon \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \cdots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau \right | \dots \right | \tau
}$$
Here | I | is the length of I . Note that this difference tends to 0 as d ′ →∞ , so that { τ n } is more nearly uniformly distributed mod 1 for τ of large degree. See also [34].
- 3.5. Sumsets of Salem numbers. Dubickas [35] shows that a sum of m ≥ 2 Salem numbers cannot be a Salem number, but that for every m ≥ 2 there are m Salem numbers whose sum is a Pisot number and also m Pisot numbers whose sum is a Salem number.
- 3.6. Galois group of Salem number fields. Lalande [66] and Christopoulos and McKee [32] studied the Galois group of a number field defined by a Salem number. Let τ be a Salem number of degree 2 n , K = Q ( τ ) and L be its Galois closure. Then it is known that G := Gal( L/ Q ) ≤ C n 2 /multicloseright S n . Conversely, if K is a real number field of degree 2 n > 2 with exactly 2 real embeddings, and, for its Galois closure L , that G ≤ C n 2 /multicloseright S n , then Lalande proved that K is generated by a Salem number.
Now, for a Salem number τ , let K ′ = Q ( τ + τ -1 ), L ′ be its Galois closure and N ⊂ G be the fixing group of L ′ . Then Christopoulos and McKee showed that G is isomorphic to N /multicloseright Gal( L / ′ Q ), where N is isomorphic to either C n 2 or C n -1 2 . The latter case is possible only when n is odd.
Amoroso [4] found a lower bound, conditional on the Generalised Riemann Hypothesis, for the exponent of the class group of such number fields L .
- 3.7. The range of polynomials Z [ τ ] . P. Borwein and Hare [16] studied the 'spectrum' of values a 0 + a τ 1 + · · · + a τ n n when the a i ∈ {-1 1 , } , n ∈ N and τ is a Salem number. They showed that if τ was a Salem number defined by being the zero of a polynomial of the form z m -z m -1 -z m -2 -·· ·-z 2 -z +1 for some m ≥ 4 , then this spectrum is discrete. They also asked [16, Section 7]
- · Are these the only Salem numbers with this spectrum discrete?
- · Are the only τ where this spectrum is discrete and M τ ( ) < 2 necessarily Salem numbers or Pisot numbers?
Feng [40] remarked that it follows from Garsia [44, Lemma 1.51] that, given a Salem number τ and m ∈ N there exists c > 0 and k ∈ N (depending on τ and m ) such that for each n ∈ N there are no nonzero numbers ξ = ∑ n -1 i =0 a τ i i with a i ∈ Z , | a i | ≤ m and | ξ | < c n k . He asks whether, conversely, if τ is any non-Pisot number in (1 , m + 1) with this property, then must τ necessarily be a Salem number?
Hare and Mossinghoff [49] show, given a Salem number τ < 1 2 (1+ √ 5) of degree at most 20, that some sum of distinct powers of -τ is zero, so that -τ satisfies some Newman polynomial.
- 3.8. Other Salem number studies. Salem [100], [101, p. 35] proved that every Salem number is the quotient of two Pisot numbers.
For connections between small Salem numbers and exceptional units, see Silverman [108].
Dubickas and Smyth [37] showed that any line in C containing two nonreal conjugates of a Salem number cannot contain the Salem number itself.
Akiyama and Kwon [2] constructed Salem numbers satisfying polynomials whose coefficients are nearly constant.
For generalisations of Salem numbers, see Bertin [7, 8], Cantor [30], Kerada [59], Meyer [85], Samet [102], Schreiber [105] and Smyth [110]. Note the correction made to [102] in [110]. See also Section 4.1 below for 2-Salem numbers.
## 4. Salem numbers outside Number Theory
The survey of Ghate and Hironaka [45] contains many applications of Salem numbers, for the period up to 1999. Only a few of the applications they describe are briefly recalled here, in subsections 4.1, 4.2 and 4.3. Otherwise, I concentrate on developments since their paper appeared.
For some of these applications, the restriction that Salem numbers should have degree at least 4 can be dropped: the results also hold for reciprocal Pisot numbers, whose minimal polynomials are x 2 -ax +1 for a ∈ N , n ≥ 3. Some authors include these numbers in the definition of Salem numbers. Accordingly, I will allow these numbers to be (honorary!) Salem numbers in this section.
(Note, however, that for τ such a 'quadratic Salem number', the fractional parts of the sequence { τ n } n ∈ N tend to 1 as n →∞ , whereas for true Salem numbers this sequence is dense in (0 1), as stated , in Section 3.4.
Furthermore, neither Proposition 3(ii) nor (iii) would hold, since the proof of Lemma 3(ii) depends on a Salem number having a nonreal conjugate. Indeed, for the example Salem number τ = 2 1537 . . . . in the introduction, the field Q ( τ ) contains the Salem numbers τ n ( n = 1 2 , , . . . ), with τ the smallest Salem number in this field. However, Q ( τ ) also contains the 'quadratic Salem number' τ + τ -1 = 1 2 (3 + √ 5), which is not a power of τ .)
4.1. Growth of groups. For a group G with finite generating set S = S -1 , we define its growth series F G,S ( x ) = ∑ ∞ n =0 a x n n , where a n is the number of elements of G that can be represented as the product of n elements of S , but not by fewer. For certain such groups, F G,S ( x ) is known to be a rational function. Then expanding F G,S ( x ) out in partial fractions leads to a closed formula for the a n . See [45, Section 4] for a detailed description, including references. See also [5].
In particular, let G be a Coxeter group generated by reflections in d ≥ 3 geodesics in the upper half plane, forming a polygon with angles π/p i ( i = 1 2 , , . . . , d ), where ∑ i π/p i < π . Taking S to be the set of these reflections, it is known (Cannon and Wagreich, Floyd and Plotnick, Parry) that then the denominator of F G,S ( x ) - call it ∆ p 1 ,p 2 ,...,p d ( x ) - is the minimal polynomial of a Salem number, τ say, possibly multiplied by some cyclotomic polynomials. Then the a n grow exponentially with growth rate lim n →∞ a n +1 /a n = τ . Hironaka [53] proved that among all such ∆ p 1 ,p 2 ,...,p d ( x ), the lowest growth rate was achieved for ∆ p 1 ,p 2 ,p 3 ( x ), which is Lehmer's polynomial L x ( ), with growth rate τ 10 = 1 176 . . . . .
/negationslash
To generalise a bit, define a real 2-Salem number to be an algebraic integer α > 1 which has exactly one conjugate α ′ = α outside the closed unit disc, and at least one conjugate on the unit circle. Then all conjugates of α apart from α ± 1 and α ′ ± 1 have modulus 1. Zerht and Zerht-Liebensd¨rfer o [121] give examples of infinitely many cocompact Coxeter groups ('Coxeter Garlands') in H 4 with the property that their growth function has denominator
$$D _ { n } ( z ) & = p _ { n } ( z ) + n q _ { n } ( z ) \\ & = z ^ { 1 6 } - 2 z ^ { 1 5 } + z ^ { 1 4 } - z ^ { 1 3 } + z ^ { 1 2 } - z ^ { 1 0 } + 2 z ^ { 9 } - 2 z ^ { 8 } + 2 z ^ { 7 } - z ^ { 6 } + z ^ { 4 } - z ^ { 3 } + z ^ { 2 } - 2 z + 1 \\ & \quad + n z ( - 2 z ^ { 1 4 } + z ^ { 1 2 } + z ^ { 1 0 } + z ^ { 9 } + 2 z ^ { 7 } + z ^ { 5 } + z ^ { 4 } + z ^ { 2 } - 2 ),$$
which, if irreducible, would be the minimal polynomial of a 2-Salem number.
Umemoto [115] showed that D t 1 ( ) is irreducible , 1 and also produced infinitely many cocompact Coxeter groups whose growth rate is a 2-Salem number of degree 18. The growth rate in these examples is the larger of the two 2-Salem conjugates that are outside the unit circle. This is compatible with a conjecture of Kellerhals and Perren [58] that the growth rate of a Coxeter group acting on hyperbolic n -space should be a Perron number (an algebraic integer α whose conjugates different from α are all of modulus less than | α | .) This has been verified for n = 3 for so-called generalised simplex groups by Komori and Umemoto [61].
For some other recent papers on non-Salem growth rates see [56], [57], [60].
- 4.2. Alexander Polynomials. A result of Seifert tells us that a polynomial P ∈ Z [ x ] is the Alexander polynomial of some knot iff it is monic and reciprocal, and P (1) = ± 1. In particular, Hironaka [53] showed that ∆ p ,p 1 2 ,...,p d ( -x ) is the Alexander polynomial of the ( p , p 1 2 , . . . , p d , -1) pretzel knot. Hence, from the result of the previous section, we see that Alexander polynomials are sometimes Salem polynomials (albeit in -x ).
Indeed, Silver and Williams [107], in their study of Mahler measures of Alexander polynomials, found families of links whose Alexander polynomials had Mahler measure equal to a Salem number. The first family l ( q ) was obtained [107, Example 5.1] from the link 7 2 1 by giving q full righthanded twists to one of the components as it passed through the other component (the trivial knot). The Mahler measure of the Alexander polynomials of these links produced a decreasing sequence of Salem numbers for q = 1 2 , , . . . , 11. For q = 10 the Salem number 1.18836. . . (the secondsmallest known) was produced, with minimal polynomial
$$x ^ { 1 8 } - x ^ { 1 7 } + x ^ { 1 6 } - x ^ { 1 5 } - x ^ { 1 2 } + x ^ { 1 1 } - x ^ { 1 0 } + x ^ { 9 } - x ^ { 8 } + x ^ { 7 } - x ^ { 6 } - x ^ { 3 } + x ^ { 2 } - x + 1,$$
while q = 11 gave the Salem number M L x ( ( )) = 1 17628 . . . . . For q > 11 Salem numbers were not produced. The second example was obtained in a similar way [107, Example 5.8], using the link formed from the knot 5 1 by an adding the trivial knot encircling two strands of the knot, and then giving these strands q full right-hand twists. For increasing q ≥ 3 this gave a monotonically increasing sequence of Salem numbers tending to the
1 In fact, one can show that D n ( z ) is irreducible for all n ≥ 1. A sketch is as follows: comparison with the table [87] shows that neither root of D n ( z ) in | z | > 1 can be a Salem number. Then putting z = e it , the fact that e -8 it p n ( e it ) /q n ( e it ) is real and > 0 for small t > 0 shows that D n ( z ) has no cyclotomic factors. (Selberg [106, p. 705] remarks that he has always found a sketch of a proof much more informative than a complete proof.)
smallest Pisot number θ 0 = 1 3247 . . . . . These Salem numbers are equal to the Mahler measure M x ( 2( q +1) ( x 3 -x -1) + x 3 + x 2 -1). Furthermore, M x ( n ( x 3 -x -1) + x 3 + x 2 -1) is also a Salem number for n ≥ 9 and odd. Silver (private communication) has shown that these Salem numbers are also Mahler measures of Alexander polynomials: 'Putting an odd number of half-twists in the rightmost arm of the pretzel knot produces 2-component links rather than knots. Their Alexander polynomials have two variables. However, setting the two variables equal to each other produces the so-called 1-variable Alexander polynomials, and indeed the 'odd' sequence of Salem polynomials . . . results.'
- 4.3. Lengths of closed geodesics. It is known that there is a bijection between the set of Salem numbers and the set of closed geodesics on certain arithmetic hyperbolic surfaces. Specifically, the length of the geodesic is 2 log τ , where τ is the Salem number corresponding to the geodesic. Thus there is a smallest Salem number iff there is a geodesic of minimal length among all closed geodesics on all arithmetic hyperbolic surfaces. See Ghate and Hironaka [45, Section 3.4] and also Maclachlan and Reid [79, Section 12.3] for details.
- 4.4. Arithmetic Fuchsian groups. Neumann and Reid [89, Lemmas 4.9, 4.10] have shown that Salem numbers are precisely the spectral radii of hyperbolic elements of arithmetic Fuchsian groups. See also [45], [79, pp. 378-380] and [67, Theorem 9.7].
The following result is related.
Theorem 8 ( Sury [114] ) . The set of Salem numbers is bounded away from 1 iff there is some neighbourhood U of the identity in SL ( 2 R ) such that, for each arithmetic cocompact Fuchsian group Γ , the set Γ ∩ U consists only of elements of finite order.
A Fuchsian group is a subgroup Γ of PSL ( 2 R ) that acts discontinuously on the upper half-plane H (i.e., for z ∈ H no orbit Γ z has an accumulation point).
## 4.5. Dynamical systems.
- 4.5.1. For given β > 1, define the map T β : [0 , 1] → [0 , 1) by T x β = { βx } , the fractional part of βx . Then from x = /floorleft βx /floorright β + T β x β we obtain the identity x = ∑ ∞ n =1 /floorleft βT n -1 β x /floorright β n , the (greedy) β -expansion of x [93].
Klaus Schmidt [103] showed that if the orbit of 1 is eventually periodic for all x ∈ Q ∩ [0 , 1) then β is a Salem or Pisot number. He also conjectured
that, conversely, for β a Salem number, the orbit of 1 is eventually periodic. This conjecture was proved by Boyd [23] to hold for Salem numbers of degree 4. However, using a heuristic model in [25], his results indicated that while Schmidt's conjecture was likely to also hold for Salem numbers of degree 6, it may be false for a positive proportion of Salem numbers of degree 8. As Boyd points out, the basic reason seems to be that, for β a Salem number of degree d , this orbit corresponds to a pseudorandom walk on a d -dimensional lattice. Under this model, but assuming true randomness, the probability of the walk intersecting itself is 1 for d ≤ 6, but is less than 1 for d > 6. Recently, computational degree-8 evidence relating to Boyd's model was compiled by Hichri [51], [52].
Hare and Tweddle [50, Theorem 8] give examples of Pisot numbers for which the sequences of Salem numbers from Salem's construction that tend to the Pisot number from above have eventually periodic orbits. See also [24].
For a survey of β -expansions when β is a Pisot or Salem number, see [48]. See also Vaz, Martins Rodrigues, and Sousa Ramos [116].
- 4.5.2. Lindenstrauss and Schmidt [69, Theorem 6.3] showed that there exists 'a connection between two-sided beta-shifts of Salem numbers and the nonhyperbolic ergodic toral automorphisms defined by the companion matrices of their minimal polynomials. However, this connection is much more complicated and tenuous than in the Pisot case' - see [104] and [69, Theorem 6.1].
- 4.6. Surface automorphisms. A K3 surface is a simply-connected compact complex surface X with trivial canonical bundle. The intersection form on H 2 ( X, Z ) makes it into an even unimodular 22-dimensional lattice of signature (3 , 19); see [84, p.17]. Now let F : X → X be an automorphism of positive entropy of a K3 surface X . Then McMullen [80, Theorem 3.2] has proved that the spectral radius λ F ( ) (modulus of the largest eigenvalue) of F acting by pullback on this lattice is a Salem number. More specifically, the characteristic polynomial χ F ( ) of the induced map F ∗ | H 2 ( X, R ) → H 2 ( X, R ) is the minimal polynomial of a Salem number multiplied by k ≥ 0 cyclotomic polynomials. Since χ F ( ) has degree 22, the degree of λ F ( ) is at most 22. (If X is projective, X has Picard group of rank at most 20, and so λ F ( ) has degree at most 20.)
It is an interesting problem to describe which Salem numbers arise in this way. McMullen [80] found 10 Salem numbers of degree 22 and trace -1, also having some other properties, from which he was able to construct
from each of these Salem numbers a K3 surface automorphism having a Siegel disc. (These were the first known examples having Siegel discs.) Gross and McMullen [47] have shown that if the minimal polynomial S x ( ) of a Salem number of degree 22 has | S ( -1) | = | S (1) | = 1 (which they call the unramified case) then it is the characteristic polynomial of an automorphism of some (non-projective) K3 surface X . (If the entropy of F is 0 then this characteristic polynomial is simply a product of cyclotomic polynomials.) It is known (see [80, p.211] and references given there) that the topological entropy h F ( ) of F is equal to log λ F ( ), so is either 0 or the logarithm of a Salem number.
For each even d ≥ 2 let τ d be the smallest Salem number of degree d . McMullen [82, Theorem 1.2] has proved that if F : X → X is an automorphism of any compact complex surface X with positive entropy, then h F ( ) ≥ log τ 10 = log(1 176 . . . . ) = 0 162 . . . . . Bedford and Kim [6] have shown that this lower bound is realised by a particular rational surface automorphism. McMullen [83] showed that it was realised for a non-projective K3 surface automorphism, and later [84] that it was realised for a projective K3 surface automorphism. He showed that the value log τ d was realised for a projective K3 surface automorphism for d = 2 4 6 8 10 or 18, but not for , , , , d = 14, 16, or 20. (The case d = 12 is currently undecided.)
Oguiso [92] remarked that, as for K3 surfaces (see above), the characteristic polynomial of an automorphism of arbitrary compact K¨hler surface is a also the minimal polynomial of a Salem number multiplied by k ≥ 0 cyclotomic polynomials. This is because McMullen's proof for K3 surfaces in [80] is readily generalised. In another paper [91] he proved that this result also held for automorphisms of hyper-K¨hler manifolds. Oguiso [92] also cona structed an automorphism F of a (projective) K3 surface with λ F ( ) = τ 14 . Here the K3 surface was projective, contained an E 8 configuration of rational curves, and the automorphism also had a Siegel disc.
Reschke [97] studied the automorphisms of two-dimensional complex tori. He showed that the entropy of such an automorphism, if positive, must be a Salem number of degree at most 6, and gave necessary and sufficient conditions for such a Salem number to arise in this way.
/negationslash
- 4.7. Salem numbers and Coxeter systems. Consider a Coxeter system ( W,S ), consisting of a multiplicative group W generated by a finite set S = { s , . . . , s 1 n } , with relations ( s s i j ) m ij = 1 for each i, j, where m ii = 1 and m ij ≥ 2 for i = . The j s i act as reflections on R n . For any w ∈ W let λ w ( ) denote its spectral radius. This is the modulus of the largest eigenvalue of its
action on R n . Then McMullen [81, Theorem 1.1] shows that when λ w ( ) > 1 then λ w ( ) ≥ τ 10 = 1 176 . . . . . This could be interpreted as circumstantial evidence for τ 10 indeed being the smallest Salem number.
The Coxeter diagram of ( W,S ) is the weighted graph whose vertices are the set S , and whose edges of weight m ij join s i to s j when m ij ≥ 3. Denoting by Y a,b,c the Coxeter system whose diagram is a tree with 3 branches of lengths a , b and c , joined at a single node, McMullen also showed that the smallest Salem numbers of degrees 6, 8 and 10 coincide with λ w ( ) for the Coxeter elements of Y 3 3 4 , , , Y 2 4 5 , , and Y 2 3 7 , , respectively. In particular, λ w ( ) = τ 10 for the Coxeter elements of Y 2 3 7 , , .
4.8. Dilatation of pseudo-Anosov automorphisms. For a closed connected oriented surface S having a pseudo-Anosov automorphism that is a product of two positive multi-twists, Leininger [67, Theorem 6.2] showed that its dilatation is at least τ 10 . This follows from McMullen's work on Coxeter systems quoted above. The case of equality is explicitly described (in particular, S has genus 5). (However, on surfaces of genus g there are examples of pseudo-Anosov automorphisms having dilatations equal to 1+ O (1 /g ) as g →∞ . These are not Salem numbers when g is sufficiently large.)
4.9. Bernoulli convolutions. Following Solomyak [113], let λ ∈ (0 , 1), and Y λ = ∑ ∞ n =0 ± λ n , with the ± chosen independently '+' or ' -' each with probability 1 2 . Let ν λ ( E ) be the probability that Y λ ∈ E , for any Borel set E . So it is the infinite convolution product of the means 1 2 ( δ -λ n + δ λ n ) for n = 0 1 2 , , , . . . , ∞ , and so is called a Bernoulli convolution . Then ν λ ( E ) satisfies the self-similarity property
$$\nu _ { \lambda } ( E ) = \frac { 1 } { 2 } \left ( \nu _ { \lambda } ( S _ { 1 } ^ { - 1 } E ) + \nu _ { \lambda } ( S _ { 2 } ^ { - 1 } E ) \right ),$$
/negationslash where S x 1 = 1 + λx and S x 2 = 1 -λx . It is known that the support of ν λ is a Cantor set of zero length when λ ∈ (0 , 1 2 ), and the interval [ -(1 -λ ) -1 , (1 -λ ) -1 ] when λ ∈ ( 1 2 , 1). When λ = 1 2 , ν λ is the uniform measure on [ -2 2]. Now the Fourier transform ˆ ( , ν λ ξ ) of ν λ is equal to ∏ ∞ n =0 cos( λ ξ n ). Salem [102, p. 40] proved that if λ ∈ (0 , 1) and 1 /λ is not a Pisot number, then lim ξ →∞ ˆ ( ν λ ξ ) = 0. This contrasts with an earlier result of Erd˝s that if o λ = 1 2 and 1 /λ is a Pisot number, then ˆ ( ν λ ξ ) does not tend to 0 as ξ →∞ . Furthermore Kahane [54] (as corrected in [94, p. 10]) proved that if 1 /λ is a Salem number then for each ε > 0
$$\lim _ { \xi \to \infty } \sup _ { \xi \to \infty } | \hat { \nu } _ { \lambda } ( \xi ) | \, | \xi | ^ { \varepsilon } = \infty.$$
The only property of Salem numbers used in the proof of (2) is Proposition 4. Now consider the set S a,γ of all λ ∈ ( a, 1) such that ∫ ∞ -∞ | ˆ ( ν λ ξ ) | 2 | ξ | 2 γ dξ < ∞ . Then Peres, Schlag and Solomyak [94, Proposition 5.1] use this set, Lemma 2 and (2), to give a sufficient condition for the set T of Salem numbers to be bounded away from 1. Specifically, they prove that if there exist some γ > 0 and a < 1 such that S a,γ is a so-called residual set (i.e., it is the intersection of countably many sets with dense interiors), then 1 is not a limit point of T .
/negationslash
Concerning the behaviour of ˆ ( ν λ ξ ) as ξ →∞ , where 1 /λ = θ > 1 is an algebraic integer: if θ has another conjugate θ ′ = θ outside the unit circle, then Bufetov and Solomyak [28, Corollary A.3] recently proved that ˆ ( ν λ ξ ) is bounded by a negative power of log ξ as ξ →∞ . On the other hand, it is a result of Erd˝s [38] that when o θ is a Pisot number then lim sup ξ →∞ ˆ ( ν λ ξ ) is positive, showing that such a bound is not possible for Pisot numbers. Bufetov and Solomyak ask, however, whether a bound of that kind might hold for Salem numbers (the only remaining undecided case for an algebraic integer θ > 1).
Recently Feng [39] has also studied ν λ when 1 /λ is a Salem number, proving that then the corresponding measure ν λ is a multifractal measure satisfying the multifractal formalism in all of the increasing part of its multifractal spectrum.
For two very readable surveys of Bernoulli convolutions, including connections with Salem numbers, see Kahane's 'Reflections on Paul Erd˝s . . . ' o article [55] and the much longer survey by Peres, Schlag and Solomyak [94] referred to above.
Acknowledgements. This paper is an expanded version of a talk that I gave at the meeting 'Growth and Mahler measures in geometry and topology' at the Mittag-Leffler Institute, Djursholm, Sweden, in July 2013. I would like to thank the organisers Eriko Hironaka and Ruth Kellerhals for the invitation to attend the meeting, and to thank them, the Institute staff and fellow participants for making it such a stimulating and pleasant week.
I also thank David Boyd, Yann Bugeaud, Nigel Byott, Eriko Hironaka, Aleksander Kolpakov, James McKee, Curtis McMullen, Andrew Ranicki, Georges Rhin, Dan Silver, Joe Silverman, Boris Solomyak, Timothy Trudgian and especially the referee for their very helpful comments and corrections on earlier drafts of this survey.
## References
- [1] Aguirre, Juli´n ; Peral, Juan Carlos. The trace problem for totally positive algea braic integers. With an appendix by Jean-Pierre Serre. London Math. Soc. Lecture Note Ser., 352 , Number theory and polynomials, 1-19, Cambridge Univ. Press, Cambridge, 2008.
- [2] Akiyama, Shigeki ; Kwon, Do Yong, Constructions of Pisot and Salem numbers with flat palindromes. Monatsh. Math. 155 (2008), no. 3-4, 265-275.
- [3] Akiyama, Shigeki ; Tanigawa, Yoshio, Salem numbers and uniform distribution modulo 1. Publ. Math. Debrecen 64 (2004), no. 3-4, 329-341.
- [4] Amoroso, Francesco, Une minoration pour l'exposant du groupe des classes d'un corps engendr´ e par un nombre de Salem. Int. J. Number Theory 3 (2007), no. 2, 217-229.
- [5] Bartholdi, Laurent; Ceccherini-Silberstein, Tullio G., Salem numbers and growth series of some hyperbolic graphs. Geom. Dedicata 90 (2002), 107-114.
- [6] Bedford, Eric; Kim, Kyounghee, Periodicities in linear fractional recurrences: degree growth of birational surface maps. Michigan Math. J. 54 (2006), no. 3, 647-670.
- [7] Bertin, M. J., K-nombres de Pisot et de Salem. Advances in number theory (Kingston, ON, 1991), 391-397, Oxford Sci. Publ., Oxford Univ. Press, New York, 1993.
- [8] , K-nombres de Pisot et de Salem. Acta Arith. 68 (1994), no. 2, 113-131.
- [9] , Quelques nouveaux r´sultats sur les nombres de Pisot et de Salem. Number e theory in progress, Vol. 1 (Zakopane-Ko´ scielisko, 1997), 1-9, de Gruyter, Berlin, 1999.
- [10] Bertin, M.-J.; Boyd, David W., Une caract´risation de certaines classes de nombres e de Salem. C. R. Acad. Sci. Paris S´r. I Math. e 303 (1986), no. 17, 837-839.
- [11] ; , A characterization of two related classes of Salem numbers. J. Number Theory 50 (1995), no. 2, 309-317.
- [12] Bertin, M.-J.; Decomps-Guilloux, A.; Grandet-Hugot, M.; Pathiaux-Delefosse, M.; Schreiber, J.-P., Pisot and Salem numbers. Birkh¨user Verlag, Basel, 1992. a
- [13] Bertin, Marie-Jos´; Lal´ ın, Matilde , Mahler measure of multivariable polynomials. e Women in numbers 2: research directions in number theory, 125-147, Contemp. Math., 606 , Amer. Math. Soc., Providence, RI, 2013.
- [14] Bertin, Marie-Jos´; Pathiaux-Delefosse, Martine, Conjecture de Lehmer et petits e nombres de Salem. Queen's Papers in Pure and Applied Mathematics, 81 . Queen's University, Kingston, ON, 1989.
- [15] Beukers, F. ; Smyth, C. J. Cyclotomic points on curves. Number theory for the millennium, I (Urbana, IL, 2000), 67-85, A K Peters, Natick, MA, 2002.
- [16] Borwein, Peter; Hare, Kevin G., Some computations on the spectra of Pisot and Salem numbers. Math. Comp. 71 (2002), no. 238, 767-780.
- [17] Boyd, David W., Transcendental numbers with badly distributed powers. Proc. Amer. Math. Soc. 23 (1969), 424-427.
- [18] , Small Salem numbers. Duke Math. J. 44 (1977), no. 2, 315-328.
- [19] , Pisot sequences which satisfy no linear recurrence. Acta Arith. 32 (1977), no. 1, 89-98.
- [20] , Pisot and Salem numbers in intervals of the real line. Math. Comp. 32 (1978), no. 144, 1244-1260.
- [21] , Speculations concerning the range of Mahler's measure. Canad. Math. Bull. 24 (1981), no. 4, 453-469.
- [22] , Families of Pisot and Salem numbers. Seminar on Number Theory, Paris 1980-81 (Paris, 1980/1981), 19-33, Progr. Math., 22 , Birkh¨user, Boston, Mass., a 1982.
- [23] , Salem numbers of degree four have periodic expansions. Th´orie des nome bres (Quebec, PQ, 1987), 57-64, de Gruyter, Berlin, 1989.
- [24] , The beta expansion for Salem numbers. Organic mathematics (Burnaby, BC, 1995), 117-131, CMS Conf. Proc., 20, Amer. Math. Soc., Providence, RI, 1997.
- [25] , On the beta expansion for Salem numbers of degree 6. Math. Comp. 65 (1996), no. 214, 861-875, S29-S31.
- [26] Boyd, David W.; Parry, Walter, Limit points of the Salem numbers. Number Theory (Banff, AB, 1988), 27-35, de Gruyter, Berlin, 1990.
- [27] Brunotte, Horst; Thuswaldner, J¨ rg M., Salem numbers from a class of star-like o trees. arXiv:1501.05557v1 [Math.NT] 22 Jan 2015.
- [28] Bufetov, Alexander I.; Solomyak, Boris, On the modulus of continuity for spectral measures in substitution dynamics. Adv. Math. 260 (2014), 84129.
- [29] Bugeaud, Yann . Distribution modulo one and Diophantine approximation. Cambridge Tracts in Mathematics, 193. Cambridge University Press, Cambridge, 2012.
- [30] Cantor, David G. On sets of algebraic integers whose remaining conjugates lie in the unit circle. Trans. Amer. Math. Soc. 105 (1962), 391-406.
- [31] , On power series with only finitely many coefficients (mod 1): solution of a problem of Pisot and Salem. Acta Arith. 34 (1977/78), no. 1, 43-55.
- [32] Christopoulos, Christos; McKee, James, Galois theory of Salem polynomials. Math. Proc. Cambridge Philos. Soc. 148 (2010), no. 1, 47-54.
- [33] Decomps-Guilloux, Annette; Grandet-Hugot, Marthe, Nouvelles caractrisations des nombres de Pisot et de Salem. Acta Arith. 50 (1988), no. 2, 155-170.
- [34] Doche, Christophe; Mend` es France, Michel; Ruch, Jean-Jacques, Equidistribution modulo 1 and Salem numbers. Funct. Approx. Comment. Math. 39 (2008), part 2, 261-271.
- [35] Dubickas, Art¯ras, Arithmetical properties of powers of algebraic numbers. Bull. u London Math. Soc. 38 (2006), no. 1, 70-80.
- [36] , Sumsets of Pisot and Salem numbers. Expo. Math. 26 (2008), no. 1, 85-91.
- [37] Dubickas, Art¯ras; Smyth, Chris, On the lines passing through two conjugates of u a Salem number. Math. Proc. Cambridge Philos. Soc. 144 (2008), no. 1, 29-37.
- [38] Erd˝ os, Paul, On a family of symmetric Bernoulli convolutions. Amer. J. Math. 61 (1939), 974976.
- [39] Feng, De-Jun, Multifractal analysis of Bernoulli convolutions associated with Salem numbers. Adv. Math. 229 (2012), no. 5, 3052-3077.
- [40] , On the topology of polynomials with bounded integer coefficients. Preprint.
- [41] Fisk, Steve, A very short proof of Cauchy's interlace theorem for eigenvalues of Hermitian matrices, Amer. Math. Monthly, 112 (2005), No. 2, p. 118. Also arXiv:math/0502408 http://arxiv.org/abs/math/0502408 .
- [42] Flammang, V. Trace of totally positive algebraic integers and integer transfinite diameter. Math. Comp. 78 (2009), no. 266, 1119-1125.
- [43] Flammang, V.; Grandcolas, M.; Rhin, G., Small Salem numbers. Number theory in progress, Vol. 1 (Zakopane-Ko´ scielisko, 1997), 165-168, de Gruyter, Berlin, 1999.
- Garsia, A.M., Arithmetic properties of Bernoulli convolutions, Trans. Amer. Math.
- [44] Soc. 102 (1962), 409-432.
- [45] Ghate, Eknath; Hironaka, Eriko, The arithmetic and geometry of Salem numbers. Bull. Amer. Math. Soc. (N.S.) 38 (2001), no. 3, 293-314.
- [46] Gross, Benedict H.; Hironaka, Eriko; McMullen, Curtis T. Cyclotomic factors of Coxeter polynomials. J. Number Theory 129 (2009), no. 5, 1034-1043.
- [47] Gross, Benedict H.; McMullen, Curtis T., Automorphisms of even unimodular lattices and unramified Salem numbers. J. Algebra 257 (2002), no. 2, 265-290.
- [48] Hare, Kevin G., Beta-expansions of Pisot and Salem numbers. Computer algebra 2006, 67-84, World Sci. Publ., Hackensack, NJ, 2007.
- [49] Hare, Kevin G. ; Mossinghoff, Michael J., Negative Pisot and Salem numbers as roots of Newman polynomials. Rocky Mountain J. Math. 44 (2014), no. 1, 113-138.
- [50] Hare, Kevin G. ; Tweedle, David, Beta-expansions for infinite families of Pisot and Salem numbers. J. Number Theory 128 (2008), no. 9, 2756-2765.
- [51] Hichri, Hachem, On the beta expansion of Salem numbers of degree 8. LMS J. Comput. Math. 17 (2014), no. 1, 289-301.
- [52] , Beta expansion for some particular sequences of Salem numbers. Int. J. Number Theory 10 (2014), no. 8, 2135-2149.
- [53] Hironaka, Eriko, The Lehmer polynomial and pretzel links. Canad. Math. Bull. 44 (2001), no. 4, 440-451. Erratum: ibid. 45 (2002), no. 2, 231.
- [54] Kahane, J.-P. Sur la distribution de certaines s´ries al´atoires. Colloque de Th´orie e e e des Nombres (Univ. Bordeaux, Bordeaux, 1969), 119-122. Bull. Soc. Math. France, M´ em. No. 25, Soc. Math. France Paris, 1971.
- [55] , Bernoulli convolutions and self-similar measures after Erd˝s, in 'Reflections o on Paul Erd˝s on his birth century', (K. Alladi, S. Krantz, eds.), Notices Amer. o Math. Soc. 62 (2015), no. 2, 136-140.
- [56] Kellerhals, Ruth, Cofinite hyperbolic Coxeter groups, minimal growth rate and Pisot numbers. Algebr. Geom. Topol. 13 (2013), no. 2, 1001-1025.
- [57] Kellerhals, Ruth ; Kolpakov, Alexander, The minimal growth rate of cocompact Coxeter groups in hyperbolic 3-space. Canad. J. Math. 66 (2014), no. 2, 354-372.
- [58] Kellerhals R.; Perren G., On the growth of cocompact hyperbolic Coxeter groups, European J. Combin. 32 (2011), no. 8, 1299-1316.
- [59] Kerada, Mohamed, Une caract´ erisation de certaines classes d'entiers alg´briques e g´ en´ralisant les nombres de Salem. Acta Arith. e 72 (1995), no. 1, 55-65.
- [60] Kolpakov, Alexander, Deformation of finite-volume hyperbolic Coxeter polyhedra, limiting growth rates and Pisot numbers. European J. Combin. 33 (2012), no. 8, 1709-1724.
- [61] Komori, Yohei; Umemoto, Yuriko, On the growth of hyperbolic 3-dimensional generalized simplex reflection groups. Proc. Japan Acad. Ser. A Math. Sci. 88 (2012), no. 4, 62-65.
- [62] Kronecker, Leopold, Zwei S¨tse ¨ber Gleichungen mit ganzzahligen Coefficienten, a u J. Reine Angew. Math. 53 (1857), 173-175. See also Werke. Vol. 1, 103-108, Chelsea Publishing Co., New York, 1968.
- [63] Lakatos, Piroska, Salem numbers, PV numbers and spectral radii of Coxeter transformations. C. R. Math. Acad. Sci. Soc. R. Can. 23 (2001), no. 3, 71-77.
- [64] , A new construction of Salem polynomials. C. R. Math. Acad. Sci. Soc. R. Can. 25 (2003), no. 2, 47-54.
- [65] , Salem numbers defined by Coxeter transformation. Linear Algebra Appl. 432 (2010), no. 1, 144-154.
- [66] Lalande, Franck, Corps de nombres engendr´s par un nombre de Salem. Acta Arith. e 88 (1999), no. 2, 191-200.
- [67] Leininger, Christopher J., On groups generated by two positive multi-twists: Teichm¨ller curves and Lehmer's number. Geom. Topol. u 8 (2004), 1301-1359.
- [68] Liang, Yanhua ; Wu, Qiang. The trace problem for totally positive algebraic integers. J. Aust. Math. Soc. 90 (2011), no. 3, 341-354.
- [69] Lindenstrauss, Elon; Schmidt, Klaus, Symbolic representations of nonexpansive group automorphisms. Probability in mathematics. Israel J. Math. 149 (2005), 227-266.
- [70] Mann, Henry B. On linear relations between roots of unity. Mathematika 12 (1965), 107-117.
- [71] McKee, James; Smyth, Chris, Salem numbers of trace -2 and traces of totally positive algebraic integers. Algorithmic number theory, 327-337, Lecture Notes in Comput. Sci., 3076 , Springer, Berlin, 2004.
- [72] ; , There are Salem numbers of every trace. Bull. London Math. Soc. 37 (2005), no. 1, 25-36.
- [73] ; , Salem numbers, Pisot numbers, Mahler measure, and graphs. Experiment. Math. 14 (2005), no. 2, 211-229.
- [74] ; , Integer symmetric matrices having all their eigenvalues in the interval [2 , 2]. J. Algebra 317 (2007), no. 1, 260-290.
- [75] ; , Integer symmetric matrices of small spectral radius and small Mahler measure. Int. Math. Res. Not. IMRN 2012, no. 1, 102-136.
- [76] ; , Salem numbers and Pisot numbers via interlacing. Canad. J. Math. 64 (2012), no. 2, 345-367.
- [77] McKee, J. F.; Rowlinson, P.; Smyth, C. J., Salem numbers and Pisot numbers from stars. Number theory in progress, Vol. 1 (Zakopane-Ko´ scielisko, 1997), 309-319, de Gruyter, Berlin, 1999.
- [78] McKee, J. F.; Yatsyna, P., Salem numbers of trace -2 and a conjecture of Estes and Guralnick. Preprint 2015.
- [79] Maclachlan, Colin; Reid, Alan W., The arithmetic of hyperbolic 3-manifolds. Graduate Texts in Mathematics, 219 . Springer-Verlag, New York, 2003.
- [80] McMullen, Curtis T., Dynamics on K3 surfaces: Salem numbers and Siegel disks. J. Reine Angew. Math. 545 (2002), 201-233.
- [81] , Coxeter groups, Salem numbers and the Hilbert metric. Publ. Math. Inst. Hautes ´ tudes Sci. No. E 95 (2002), 151-183.
- [82] , Dynamics on blowups of the projective plane. Publ. Math. Inst. Hautes ´ tudes Sci. No. E 105 (2007), 49-89.
- [83] , K3 surfaces, entropy and glue. J. Reine Angew. Math. 658 (2011), 1-25.
- [84] , Automorphisms of projective K3 surfaces with minimum entropy. Preprint.
- [85] Meyer, Yves, Algebraic numbers and harmonic analysis. North-Holland Mathematical Library, Vol. 2 . North-Holland Publishing Co., Amsterdam-London; American Elsevier Publishing Co., Inc., New York, 1972.
- [86] Mossinghoff, Michael J., Polynomials with small Mahler measure. Math. Comp. 67 (1998), no. 224, 1697-1705, S11-S14.
- [87] , List of small Salem numbers.
- http://www.cecm.sfu.ca/ ∼ mjm/Lehmer/lists/SalemList.html
- [88] Mossinghoff, Michael J.; Rhin, Georges; Wu, Qiang, Minimal Mahler measures. Experiment. Math. 17 (2008), no. 4, 451-458.
- [89] Neumann, Walter D.; Reid, Alan W., Arithmetic of hyperbolic manifolds. Topology '90 (Columbus, OH, 1990), 273-310, Ohio State Univ. Math. Res. Inst. Publ., 1 , de Gruyter, Berlin, 1992.
- [90] S. El Otmani; G. Rhin; J.-M. Sac- ´ p´e, A Salem number with degree 34 and trace E e 3. J. Number Th. (to appear 2015).
- [91] Oguiso, Keiji, Salem polynomials and birational transformation groups for hyperK¨ ahler manifolds. (Japanese) S¯gaku u 59 (2007), no. 1, 1-23. English translation: Salem polynomials and the bimeromorphic automorphism group of a hyper-K¨hler a manifold. Selected papers on analysis and differential equations, Amer. Math. Soc. Transl. Ser. 2, 230 (2010), 201-227.
- [92] , The third smallest Salem number in automorphisms of K3 surfaces. Algebraic geometry in East Asia-Seoul 2008, 331-360, Adv. Stud. Pure Math., 60 , Math. Soc. Japan, Tokyo, 2010.
- [93] Parry, W., On the β -expansions of real numbers. Acta Math. Acad. Sci. Hungar. 11 (1960), 401-416.
- [94] Peres, Yuval; Schlag, Wilhelm ; Solomyak, Boris. Sixty years of Bernoulli convolutions. Fractal geometry and stochastics, II (Greifswald/Koserow, 1998), 39-65, Progr. Probab., 46 , Birkhuser, Basel, 2000.
- [95] Pisot, Charles, R´partition (mod 1) des puissances successives des nombres r´els. e e Comment. Math. Helv. 19 (1946), 153-160.
- [96] Reidemeister, K., Knot theory. Translated from the German by Leo F. Boron, Charles O. Christenson and Bryan A. Smith. BCS Associates, Moscow, Idaho, 1983.
- [97] Reschke, Paul, Salem numbers and automorphisms of complex surfaces. Math. Res. Lett. 19 (2012), no. 2, 475-482.
- [98] Salem, R., A remarkable class of algebraic integers. Proof of a conjecture of Vijayaraghavan. Duke Math. J. 11 (1944), 103-108.
- [99] , Sets of uniqueness and sets of multiplicity. II. Trans. Amer. Math. Soc. 56 (1944), 32-49.
- [100] , Power series with integral coefficients. Duke Math. J. 12 (1945), 153-172.
- [101] , Algebraic numbers and Fourier analysis. D. C. Heath and Co., Boston, Mass., 1963.
- [102] Samet, P. A., Algebraic integers with two conjugates outside the unit circle. I: Proc. Cambridge Philos. Soc. 49 (1953), 421-436; II: ibid 50 (1954), 346.
- [103] Schmidt, Klaus, On periodic expansions of Pisot numbers and Salem numbers. Bull. London Math. Soc. 12 (1980), no. 4, 269-278.
- [104] , Algebraic coding of expansive group automorphisms and two-sided betashifts. Monatsh. Math. 129 (2000), no. 1, 37-61.
- [105] Schreiber, Jean-Pierre, Sur les nombres de Chabauty-Pisot-Salem des extensions alg´briques de e Q p . C. R. Acad. Sci. Paris S´r. A-B e 269 (1969), A71-A73.
- [106] Selberg, Atle, Collected papers. Vol. I. Springer-Verlag, Berlin, 1989.
- [107] Silver, Daniel S.; Williams, Susan G., Mahler measure of Alexander polynomials. J. London Math. Soc. (2) 69 (2004), no. 3, 767-782.
- [108] Silverman, Joseph H., Small Salem numbers, exceptional units, and Lehmer's conjecture. Symposium on Diophantine Problems (Boulder, CO, 1994). Rocky Mountain J. Math. 26 (1996), no. 3, 1099-1114.
- [109] Smith, John H., Some properties of the spectrum of a graph. Combinatorial Structures and their Applications (Proc. Calgary Internat. Conf., Calgary, Alta., 1969) pp. 403-406 Gordon and Breach, New York, 1970.
- [110] Smyth, C. J., Generalised Salem numbers. Groupe de travail en th´orie analytique e et ´l´mentaire des nombres, 1986-1987, 130-135, Publ. Math. Orsay, e e 88-01 , Univ. Paris XI, Orsay, 1988.
- [111] , Salem numbers of negative trace. Math. Comp. 69 (2000), no. 230, 827-838.
- [112] , The Mahler measure of algebraic numbers: a survey. Number theory and polynomials, 322-349, London Math. Soc. Lecture Note Ser., 352 , Cambridge Univ. Press, Cambridge, 2008.
- [113] Solomyak, Boris, On the random series ∑ ± λ n (an Erd˝s problem). Ann. of Math. o (2) 142 (1995), no. 3, 611-625.
- [114] Sury, B., Arithmetic groups and Salem numbers. Manuscripta Math. 75 (1992), no. 1, 97-102.
- [115] Umemoto, Yuriko, The growth function of Coxeter dominoes and 2-Salem numbers. Algebr. Geom. Topol. 14 (2014), no. 5, 2721-2746.
- [116] Vaz, Sandra; Martins Rodrigues, Pedro; Sousa Ramos, Jos´, Pisot and Salem nume bers in the β -transformation. Iteration theory (ECIT '06), 168-179, Grazer Math. Ber., 351 , Institut f¨r Mathematik, Karl-Franzens-Universit¨t Graz, Graz, 2007. u u
- [117] Vijayaraghavan, T., On the fractional parts of powers of a number. IV. J. Indian Math. Soc. (N.S.) 12, (1948). 33-39.
- [118] Za¨ ımi, Toufik, On integer and fractional parts of powers of Salem numbers. Arch. Math. (Basel) 87 (2006), no. 2, 124-128.
- [119] , An arithmetical property of powers of Salem numbers. J. Number Theory 120 (2006), no. 1, 179-191.
- [120] , Comments on the distribution modulo one of powers of Pisot and Salem numbers. Publ. Math. Debrecen 80 (2012), no. 3-4, 417-426.
- [121] Zehrt, Thomas; Zehrt-Liebend¨rfer, Christine, The growth function of Coxeter garo lands in H 4 . Beitr. Algebra Geom. 53 (2012), no. 2, 451-460.
School of Mathematics and Maxwell Institute for Mathematical Sciences, University of Edinburgh, Edinburgh, EH9 3JZ, Scotland
E-mail address : [email protected] | 10.1112/blms/bdv027 | [
"Chris Smyth"
] | 2014-08-01T14:50:31+00:00 | 2015-04-01T14:14:29+00:00 | [
"math.NT",
"11R06"
] | Survey article: Seventy years of Salem numbers | I survey results about, and recent applications of, Salem numbers. |
1408.0196v2 | ## Noname manuscript No.
(will be inserted by the editor)
## Adaptive Blind CDMA Receivers Based on ICA Filtered Structures
Zaid Albataineh · Fathi M. Sale
the date of receipt and acceptance should be inserted later
Abstract Code Division Multiple Access (CDMA) is a channel access method adopted by various radio technologies world-wide. In particular, CDMA is used as an access method in many mobile standards such as CDMA2000 and WCDMA. We address the problem of blind multiuser equalization in the wideband CDMA systems in the noisy multipath propagation environment. Herein, we propose three new blind receiver schemes based on variations of Independent Component Analysis (ICA) within several filtering structures. These adaptive blind CDMA (ABC) receivers do not require knowledge of the propagation parameters or spreading code sequences of the users-they primarily exploit the natural assumption of statistical independence among the symbol signals. We also develop three semi-blind adaptive detectors by incorporating new adaptive methods into the standard Rake receiver structure. Extensive comparative case-studies, based on Bit error rate (BER) performance are carried out for as a function of (i) the number of users, (ii) the number of symbols per user, and (iii) the signal to noise ratio (SNR).The conventional detectors include the baseline Linear Minimum mean squared error (LMMSE) detector. The results show that the proposed methods outperform other detectors in estimating the symbol signals from the received mixed CDMA signals. Moreover, the new blind detectors mitigate the multi access interference (MAI) in CDMA.
Keywords Direct Sequence Code Division Multiple Access (DS-CDMA) systems · Wide-band CDMA (W-CDMA) · Independent Component Analysis (ICA) · Robust ICA · Linear Minimum mean squared error (LMMSE) · Multi Access Interference (MAI) · Rake detector · Principle Component Anaylisis (PCA) · FAST ICA · Bit error rate (BER) · signal to noise ratio (SNR).
Address(es) of author(s) should be given
## 1 Introduction
Code Division Multiple Access (CDMA) is a channel access method ubiquitously used in various modalities and platforms worldwide. It is based on spread-spectrum technology as is found, e.g., in third-generation (3G) cellular telephony, terrestrial and satellite communications systems, and indoor wireless networks [1-2], [9]. Although, LTE (4G) is utilized by several cellular companies inside and outside the U.S., their networks are still not fully built, and LTE coverage is still not universal. Thus, most of the older 2G and 3G systems are ubiquitous and exist in parallel with the newer 4G systems worldwide. In the U.S., companies like AT&T and T-Mobile use GSM/WCDMA/HSPA while Verizon, Sprint, and MetroPCS use CDMA2000/EV-DO [3-5]. Moreover, the newer LTE wireless interface is incompatible with the 2G and 3G networks, so that it must be operated on a separate wireless spectrum. While 4G technology is intended to eventually replace the 3G technologies, it is now evident that it will take some time before LTE coverage is fully developed and widely adopted even in the developed countries [26-27].
As with any radio communication system, CDMA-based systems also suffer from various types of interferences. Specifically, they suffer from (i) an internal multiple access interference (MAI) due to the non-ideal cross-correlations among the users spreading sequences, (ii) narrow-band inter-symbol interference (ISI), and (iii) background noise at the receiver. These drawbacks affect the performance of a CDMA system. The conventional detectors most frequently utilized to counteract CDMA interference is based on second order statistics. In highly loaded systems, conventional detectors are not considered a suitable choice. Most of the conventional detectors suffer from external interference sources and treat all interferences as a lumped background noise. In CDMA-based systems, however, the primary source of interference is MAI. This has motivated the development of numerous interference rejection techniques to overcome the MAI and the near-far problem in conventional receivers [1, 7]. Several state-of-the-art approaches have been proposed in the literature to overcome this challenge, e.g., using pilot signals and training [40].
In CDMA-based systems, multiuser detection is desirable in order to enhance channel capacity and mitigate MAI [10, 21]. Multiuser detection has been introduced to obtain an optimum multiuser detector for multi-Gaussian channels in [1]. Several suboptimal detectors have also been proposed in [6-8], to overcome the computational complexity in realizing optimal detectors. In [1] and [32-36], training pilot sequence techniques have been used to present suboptimal detectors, namely an adaptive linear detector and a zero-forcing detector.
In [20, 21], Wang and Poor proposed the blind minimum mean square error (MMSE) and the blind de-correlating detectors. The suboptimal detector based on the linear minimum mean square error (LMMSE) method has been described in [32].In [31-36], adaptive blind detectors were proposed based on incorporating the minimum output energy with constrained optimization methods. Several subspace approaches were proposed in the literature, e.g., in [20],
[23], [36]. In [10], several types of group-blind linear detectors were proposed in order to enhance the performance for the uplink and downlink channels. The key idea of these detectors is to take advantage of the cross-correlation matrix which was constructed by exploiting the correlation between successive samples of received signals. These detectors, however, are too complex to be practically implemented, especially at the mobile unit. Also, they require information regarding signal timing and the spreading codes of the desired user.
The aforementioned techniques periodically require the base station to send a training sequence that must be known by the mobile receiver in order to enable the latter in estimating the parameters of the channel propagation model. These parameters also attempt to capture the multiple reflections of the radio waves on encountered obstacles, i.e. buildings, cars, trees, etc. Furthermore, according to [42], it has been reported that 20% of the bandwidth in GSM, and up to 40% in UMTS CDMA, is devoted to the training sequence. In spite of the good performance of the training sequence techniques, the cost tends to be significantly large in terms of bandwidth. Adaptive signal processing techniques, on the other hand, provide more efficient methods for CDMA systems in the presence of high dynamic conditions as a result of the receiver mobility, the short channel codes and the fortuitous channel access. In particular, the desire to ensure a high communication rate has made blind adaptive techniques a hot topic, driven by their potential to eliminate/reduce training sessions. Moreover, blind techniques help recover symbol signals in other situations e.g., i) eavesdropping, where using the training sequence is not available, and ii) tracking, when the receiver fails to keep the desired user locked in track. It is also noted that the underlying user symbol sequences are reasonably assumed to be statistically independent. Therefore, statistical independence, or near independence, is a key assumption that makes a CDMA system suitable for the blind techniques, e.g., using information maximization [1] or minimum mutual information [6]. In [6-8], typical CDMA based systems are represented by wide stationary slowly fading multipath environment and are expressed by a linear multi-channel convolution model. Thus, the received signals in a CDMA mobile can be considered as signals generated by the linear convolutive model of statistically independent components of independent users as shown in [6], [10], [31-36]. The adaptive LMMSE detector has been originally proposed to overcome the necessary complex matrix inversion operation [38]; however, it still requires the spreading codes of all users. While the LMMSE detector maybe suitable for the uplink to the base station, as computational resources are usually abundant, it is less practical in the downlink to the receiver as computational resources are scarcer.
This paper aims at recovering the source symbol sequences from the linear convolutive received mixture without any knowledge of the user short channelizing codes and in the absence of explicit channel identification. In essence, the paper proposes improved blind adaptive detections, based on the state space approach[37, 6],using the natural gradient method for multipath channels of CDMA-based systems. Three update-laws are derived for various
filtering structures [6] and then three adaptive blind CDMA detectors are introduced for more effective MAI, ISI suppression and symbol estimation. The second contribution of the paper is three semi-blind adaptive stochastic gradient algorithms fused into the conventional Rake receiver. Specifically, we fuse algorithms based on, respectively, FastICA, RobustICA, and principle component analysis (PCA). Furthermore, higher order statistics (HOS) are exploited in order to make the proposed methods robust and secure against incomplete cross-correlation and the near-far problem in conventional detectors [42]. Extensive Monte Carlo simulations have been carried out to verify and evaluate the effectiveness of the proposed methods in estimating the users symbols. In summary, we provide metric comparisons in the bit error-rate (BER) as a function of (i) the number of users, and (ii) the number of symbols per user, and (iii) the signal-to-noise (SNR). The comparisons include the proposed methods with existing and conventional ones in terms of BER performance and computational complexity.
We now set the notation used throughout the paper. Lower case letters denote scalars, bold lower case letters denote vectors, and bold upper case letters denote matrices. Moreover, the following symbols are used:
- * ( ) . T refers to the transpose operator;
- * ( ) . H refers to the Hermitian transpose operator;
- * trace ( ) refers to the trace operator; .
- * j = √ -1 refers to the imaginary symbol;
- * diag ( ) refers to the standard diagonal of a matrix; .
- * Diag ( ) . refers to the diagonal of a block matrix, where elements may be block matrices themselves;
- * sgn ( ) refers to the sign operator; .
- * E . [ ] refers to the statistical expectation operator.
The remainder of the paper is organized as follows. In Section II, brief descriptions and derivations of synchronous CDMA signal models in multipath fading are presented. The conventional Rake receiver model is described in Section III. Section IV is dedicated to the derivation of adaptive update laws and to the proposed new detection schemes. The comparative simulations with summary results and conclusions are given in Section V and Section VI, respectively.
## 2 CDMA SIGNAL MODEL
We now briefly present two signal models for a CDMA based system using one layer of channel spreading codes. Specifically, we describe the DS-CDMA signal and WCDMA signal models in a typical synchronous CDMA system usually employed, e.g., for cellphones, indoor ATM, and certain ad hoc wireless networks [1], [3].
## 2.1 A DS-CDMA Receiver Signal Model
In a DS-CDMA system, several users share the medium simultaneously by using unique individualized code signatures. We refer to Fig. 1 below for a typical system schematic block diagram. In this paper, we assume the data transmission to be quaternary phase shift keying (QPSK). At the mobile unit receiver, assume a total of K active users in an L multipath environment and M transmitted symbols during the observation frame time. The simplest downlink received signal model r t ( ), at the time sample t over a single symbol interval is given by [21]
$$r \left ( t \right ) = \sum _ { m = 1 } ^ { M } \sum _ { k = 1 } ^ { K } \sum _ { l = 0 } ^ { L - 1 } \alpha _ { l m } b _ { k, m } s _ { k } \left ( t - m T _ { b } - d _ { l } T _ { c } \right ) + n \left ( t \right ) \text{ \quad \ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text$$
where
- -l,k,m are path, user and symbol indices, respectively.
- -α lm is the path gain - in the downlink model the path gain is assumed to be the same among users because all users' signals are transmitted together. Thus, the path gain α lm and propagation delay factor d l do not depend on the user k.
- -b k,m is the kth user m symbol.
- -s k ( ) is the kth user spreading code (chip sequence). .
- -d l is the propagation delay factor.
- -t, T b , T c are time, symbol, and chip duration, respectively.
- -n t ( ) is the channel additive white Gaussian noise (AWGN) with zero mean and covariance equals q.
The system is assumed to be time-invariant, over a small duration, which means that the channel parameters are much slower than the frequency of transmitted symbol data. Let us assume that G is the number of chips per symbol, K is the number of users, and L is the number of paths. Thus, the scalar form of Equation (1) can be transformed to a vector form [6, 21] as:
$$r = H S b + n$$
where r is a received (G1) dimensional vector signal; H is a (G1) x G matrix with G1 ≥ G+L -1, which represents the multipath propagation coefficients; S is a G x K block-diagonal matrix; b is a K dimensional vector, which represents the users data symbols; and n is the ( G 1) dimensional channel noise vector with covariance matrix, say, Q . This standardized model of received signals has been used in deriving the conventional detectors, e.g., Match filter, Rake filter, blind LMMSE and other blind detectors [21]. We shall use it in our development as well. In addition, an alternative two-tap symbol signal model is given by [10]:
$$r _ { n } = H _ { 0 } b _ { n } + H _ { 1 } b _ { n - 1 } + n _ { n } = \bar { H } \bar { b } _ { n } + n _ { n }$$
where
Fig. 1 Signal generation model for a typical QPSK DS-CDMA system
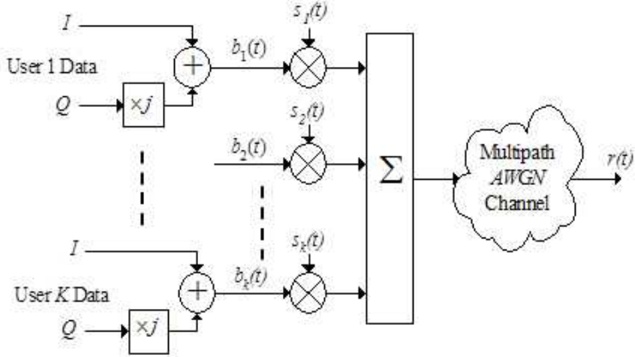
- * r n is the total received user's signal vector;
- * H 0 = [ h 1 , . . . , h k ] is the signature matrix of the current symbol vectors of all users including MAI, specifically,
$$\max \pi, \, \text{perm} ( \Omega ), \\ h _ { k } = \begin{bmatrix} 0 \\ h _ { k } ( 0 ) \\ \cdot \\ \cdot \\ h _ { k } ( G - D _ { l } - 1 ) \end{bmatrix} \quad \begin{bmatrix} 4 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 1 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ \cdot \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 3 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 2 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 6 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 5 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 9 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ } 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 } \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 4 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } _ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } { } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } & } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } $ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }; } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }} } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } \\ } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }$$
- * H 1 = [ ¯ h 1 , . . . , ¯ h k ] is the signature matrix of the previous symbol vectors of all users including ISI, where,
$$\mathbb { m } _ { 5 } \omega, \, \text{max}, \\ \mathring { h } _ { k } = \begin{bmatrix} \ h _ { k } \left ( G - D _ { l } \right ) \\. \\. \\ \hbar { \, } \left ( G + L - 1 \right ) \\ 0 \end{bmatrix} \quad & \quad ( 5 ) \\ \bullet \, \cdot \, \cdot \,. \,. \,. \,. \,. \,. \,.$$
D l ∈ { 0 1 , , . . . , G - } 1 is the delay in chip periods.
- * ¯ H = [ H H 0 1 ] is the signature matrix of all users;
- * b n = [ b 1 ( n , . . . , ) b K ( n )] T are the current symbols of all users;
- * b n -1 = [ b 1 ( n -1) , . . . , b K ( n -1)] T are the previous symbols of all users;
- * ¯ b n = [ b T n , b T n -1 ] T are the augmented two-tap symbols of all users;
- * n n = [ n ( nG ,..., ) n ( nG + G -1)] T is the independent white composite Gaussian Noise vector. We defer further details to [6, 10].
In the asynchronous uplink CDMA systems, one can assume that the columns of H 0 and H 1 are mutually independent. Therefore, ¯ H is a full rank matrix. Whereas for the synchronous downlink CDMA communication, ¯ H is full-rank with some restrictions. The main focus in this paper is on the synchronous downlink CDMA communication system, although our proposed algorithms work well in the uplink asynchronous CDMA systems [10], [30].
## 2.2 WCDMA Receiver Signal Model
One difference between a WCDMA system and a DS-CDMA system is the presence of scrambling codes. The main cause of the MAI in WCDMA systems is the intra-cell multiple user signals sharing the same multipath channels. Fig. 2 depicts a block diagram that shows the additional code scrambling before transmission through the air interface. In Fig. 2, DPDCH stands for Dedicated Physical Data CHannel which is a term adopted in UMTS (Universal Mobile Telecommunications Systems) and a S/P block stands for serial to parallel Converter. Consequently, the basic received signal model r(t) is given by [6]:
$$r \left ( t \right ) = \sum _ { m = 1 } ^ { M } \sum _ { k = 1 } ^ { K } \sum _ { l = 0 } ^ { L } \alpha _ { l m } b _ { k, m } c _ { k } \left ( t - \ d _ { l } T _ { c } \right ) s _ { k } \left ( t - m T _ { b } - d _ { l } T _ { c } \right ) + n \left ( t \right ) \quad ( 6 )$$
where, in addition to the previous parameters, one adds c k (t) ∈ {± 1 ± } j , the complex cell-specific scrambling sequences. The remaining variables are defined in model (1). The received signal at the mobile unit is passed through a chip-matched filter and sampled at the chip rate. The received discrete vector r in this case can be expressed as [6, 10, 21].
$$r = \text{HCSb} + n$$
where C is the GxG complex diagonal scrambling matrix with CC H = I GxG and the remaining variables are defined similarly as in (2). The form of C is given by:
$$C \, = \, \text{diag} ( \mathbf c _ { 1 } \, \ \mathbf c _ { 2 } \dots \ \ \mathbf c _ { G } \, ) \quad \quad \quad ( 8 ) \\ \text{where} \, \mathbf c _ { i } \in \{ \pm 1 \, \pm j \} \quad \forall \ 1 \leq i \, \leq G$$
## 3 CONVENTIONAL BLIND LINEAR MULTIUSER DETECTORS
We briefly describe the baseline conventional linear multiuser detectors such as the Match Filter (MF), the Rake receiver and the LMMSE detector in multipath environments. For further details, see [1, 9]. '
Fig. 2 Signal generation based on the proposed 3GPP UMTS FDD standard
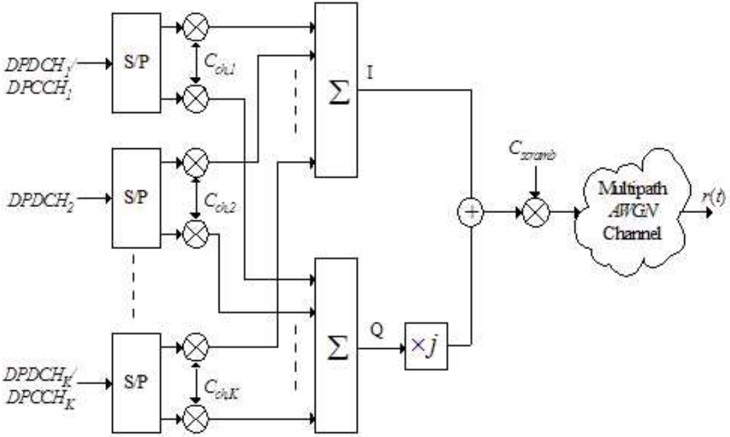
## 3.1 Single user detector (SUD)
The SUD is a standard MF detector which exploits the users code signature to provide an estimate of the users symbol sequence from the received data. This detector completely ignores the presence of MAI due to other users. One can express the MF detector for the ith user in the DS-CDMA system as follows:
$$b _ { i, M F } ^ { D } = S _ { i } ^ { H } r$$
where S i = Diag ( ¯ s i , ¯ s i , . . . , ¯ s i ) , ¯ s i = [0 0 . . . s i . . . 0]. s i is the ith users signature code, r is the received discrete signal vector, and b D i , MF is the estimated DS-CDMA ith symbol vector.
## 3.2 Rake Detector
Perhaps, the most popular linear user detection is the Rake detector, which consists of multiple parallel chip-delayed SUD fingers. In this paper, we implement the Rake detector with the estimated known channel gain coefficients, but not the channel delays. One can express the Rake detector for the DSCDMA system mathematically as follows:
$$b _ { i, \text{Rake} } ^ { D } = S _ { i } ^ { H } H ^ { H } r$$
where H represents the estimated channel matrix, and b D Rake i , is the estimated ith users symbol vector.
## 3.3 LMMSE Detector
Conventional linear detectors based on the Least Square (LS), Zero-Force (ZF) and BLUE algorithms [9] perform poorly especially in the presence of colored noise. The LMMSE detector, however, is considered to be one of the best linear detectors for DS-CDMA systems. Mathematically, one can express the LMMSE as follows:
$$b _ { i, L M M S E } ^ { D } = S _ { i } ^ { H } \mathbf H ^ { H } \left ( \sigma ^ { 2 } \mathbf H \mathbf H ^ { H } + Q \right ) ^ { - 1 } r$$
where ( σ 2 HH H + Q ) = R = E [ rr H ] is the auto-correlation of the received data at the mobile unit, and σ 2 is the average power of the received signal. There are several drawbacks in the implementation of the LMMSE receiver. The main drawback is that the computation of the auto-correlation R is very expensive. If possible, one may use eigen-structure decomposition instead of inverting the auto-correlation matrix R directly to obtain
$$b _ { i, L M M S E } ^ { W } = S _ { i } ^ { H } H ^ { H } \left ( V _ { s } D _ { s } ^ { - 1 } V _ { s } ^ { H } \right ) r$$
where V s is the estimated eigen-vector matrix of the auto-correlation matrix R , and D s is the corresponding diagonal eigenvalue matrix. Additionally, one can use adaptive algorithms to estimate the LMMSE users symbols as in [32].
## 4 THE PROPOSED ADAPTIVE BLIND DETECTION SCHEMES
In this section, we introduce new blind detection strategies for the filtering structures. We propose three blind multiuser detectors based on (i) a feedforward structure, (ii) a feedback structure I, and (iii) a feedback structure II, as in [6]. These filtering structures are depicted in figures 3, 4 and 5, respectively.
To that end, one recalls the discrete received signal model (3), namely,
$$r _ { n } = H _ { 0 } b _ { n } + H _ { 1 } b _ { n - 1 } + n _ { n }$$
The aim here is to detect the symbol vector b n from the received data vector r n , over the discrete index n, under the following assumptions:
- * AS1) the G1xK matrices H 0 and H 1 are of full column rank.
- * AS2) the symbol signal vector series, b n , have statistically independent components and are identically distributed (i.i.d).
- * AS3) the Additive Noise vector n n is white, Gaussian, and independent of the symbol source signals.
- * AS4) the power of the transmitted symbol signals are normalized to be unity.
- * AS5) the maximum lag in the entire multipath channels is smaller than the spreading gain G of the CDMA codes.
- * AS6) the CDMA system is not over-saturated, which means the number of users (K) is less than the number of the spreading gain (G).
- * AS7) the channel is assumed to be a slowly fading wide sense stationary.
For methodical convenience, each detector algorithm involves two steps: first, a preprocessing stage; second, the (matrix) rotation stage based on the filtering structures. In the next subsection, we will present the common preprocessing stage (i.e., whitening processes), and then we will derive each of the three algorithms based on each filtering structure in individual subsections.
## 4.1 Step1: Preprocessing (i.e. Data Whitening)
The outcome of this step is that the symbol signals are detected up to a unitary rotational matrix. This step uses second order statistics (SOS) in order to normalize the variance (or power) of the received discrete signal vector. It may also be used to eliminate redundancy in the data based on PCA. Under Assumptions AS1-AS4, the G1xG1 covariance matrix, say ( Cov ), of the noiseless received discrete signal vector can be expressed as
$$C o v = E \left [ r _ { n } r _ { n } ^ { H } \right ] - q I _ { G 1 }$$
We will now consider the two-tap signal model. Then we may generalize it using induction techniques. Under Assumptions AS1-AS7, substituting r n from eqn (3) into (13) results in the following covariance matrix:
$$\begin{smallmatrix} \text{Cov} = \text{H} _ { 0 } E \left [ b _ { n } b _ { n } ^ { H } \right ] \text{H} _ { 0 } ^ { H } + \text{H} _ { 1 } E \left [ b _ { n - 1 } b _ { n - 1 } ^ { H } \right ] \text{H} _ { 1 } ^ { H } \\ \text{Cov} = \text{H} _ { 0 } \text{H} _ { 0 } ^ { H } + \text{H} _ { 1 } \text{H} _ { 1 } ^ { H } = \left [ \text{H} _ { 0 } \text{ } \text{H} _ { 1 } \right ] \text{[H} _ { 0 } \text{ } \text{H} _ { 1 } \right ] ^ { H } \end{smallmatrix}$$
Observe that under AS2, E [ b b n H n ] = I K and [ b n -1 b H n -1 ] = I K . Without loss of generality, we shall briefly proceed with the basic algebraic procedure by adopting the eigen-structure decomposition for the symmetric square matrix Cov and use it to obtain a singular value decomposition for the combined matrix [ H 0 H 1 ] Thus, let
$$C o v = V D V ^ { H }$$
where V is a G1xG1 matrix of orthogonal eigenvectors satisfying
$$V V ^ { H } = V ^ { H } V = I _ { G 1 }$$
and D is the corresponding G1xG1 diagonal eigen-matrix containing its eigenvalue entries along the diagonal. Thus, from (14), the GxG H 0 and H 1 matrices can be represented respectively as
$$\begin{smallmatrix} { \mathbf H } _ { 0 } = { \mathbf V } _ { 0 } { \Lambda } _ { 0 } { \mathbf U } _ { 0 } ^ { \mathbf H } \\ { \mathbf H } _ { 1 } = { \mathbf V } _ { 1 } { \Lambda } _ { 1 } { \mathbf U } _ { 1 } ^ { \mathbf H } \end{smallmatrix}$$
where V 0 and V 1 are composed of orderly non-overlapping columns of the G1xG1 unitary matrix V U . 0 and U 1 are constant but unknown KxK right
singular-value unitary matrices with U U 0 0 H = U U 1 1 H = I K , and Λ 0 and Λ 1 are the appropriate GxK singular value matrices. We note that the whitening or algebraic PCA procedure can (i) estimate the noise power in eqn(13) and (ii) reduce the whitened signal dimension to the signal subspace, in this case K. Now, we process the received data to obtain the (whitened) data, specifically, we define:
$$r _ { n } ^ { w } = \Lambda ^ { + } \mathbf V ^ { H } r _ { n }$$
where the KxG1 matrix Λ + denotes the pseudo-inverse of the singular value matrices. One simplifies (18) to eventually obtain:
$$r _ { n } ^ { w } = U _ { 0 } ^ { \, H } b _ { n } + U _ { 1 } ^ { \, H } b _ { n - 1 } + \left ( \Lambda ^ { + } V ^ { H } \right ) n _ { n }$$
Thus, the whitening step renders the whitened data expressed in (18) or (19) as having a reduced dimension to the symbol space and a covariance matrix equal to the identity. That is E [ r w wH n r n ] = I K .
Note that, after the preprocessing step, the detection of the symbol signal ˆ b n reduces to determining or compensating for the unknown K x K (rotation) unitary matrices U 0 and U 1 . Next, we proceed with the development and derivations of the three proposed adaptive filtering structures, based on (i) feed-forward structure (FF), (ii) feedback structure I (FB-I) and (iii) feedback structure II (FB-II) [6].
Remark: For the purposes of the adaptive filtering to be discussed next, we shall re-label these unknown (but fixed) unitary matrices as the starred values for the environment. Specifically, in eqn(19), we set
∗
$$U _ { 0 } = U _ { 0 } ^ { * } \\ U _ { 1 } = U _ { 1 } ^ { * }$$
The developed adaptive filtering will have parameter matrices that, when adaptation is successful, will converge to (approximately) these fixed starred environment parameters.
4.2 Step 2a: Determining the rotation unitary matrix U for the feedforward structure
The output from the FF structure, as depicted in Fig. 3, is expressed as
$$y _ { n } = U _ { 0 } r _ { n } ^ { w } + \sum _ { k = 1 } ^ { K } U _ { k } r _ { n - k } ^ { w }$$
For simplicity of presentation, we begin with a two-tap model; thus the two-tap FF structure becomes
$$y _ { n } = U _ { 0 } r _ { n } ^ { w } + U _ { 1 } r _ { n - 1 } ^ { w }$$
$$\Phi _ { 0 } r _ { n } ^ { w } + U _ { 1 } r _ { n - 1 } ^ { w }$$
Fig. 3 Feed-Forward (FF) Demixing Structure
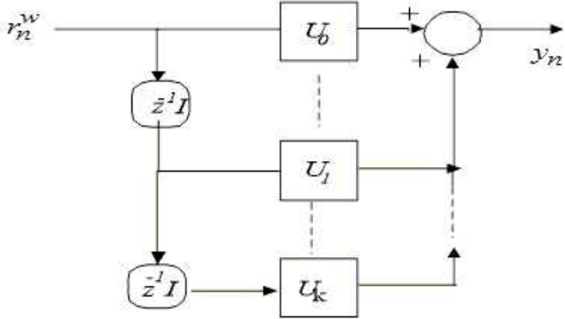
The goal for a successful adaptive algorithm is to bring about the convergence of the parameter matrices to the (starred) environment parameters. Specially, the adaptive algorithm succeeds when its parameter matrices converge to U ∗ 0 , and U ∗ 1 respectively.
We now proceed with the development. One can re-write this convolutive filter (21) as the following (static) map
$$\left [ \begin{smallmatrix} y _ { n } \\ r _ { n - 1 } ^ { w } \end{smallmatrix} \right ] = \left [ \begin{smallmatrix} U _ { 0 } & & U _ { 1 } \\ 0 & & I \end{smallmatrix} \right ] \left [ \begin{smallmatrix} r _ { n } ^ { w } \\ r _ { n - 1 } ^ { w } \end{smallmatrix} \right ]$$
Then, one defines, respectively, the new augmented output, the static map, and the augmented input as
$$\tilde { Y } & = \begin{bmatrix} y _ { n } \\ r _ { n - 1 } ^ { w } \end{bmatrix} \\ \tilde { U } & = \begin{bmatrix} U _ { 0 } & 0 \\ U _ { 1 } & 1 \end{bmatrix} \\ \tilde { R } & = \begin{bmatrix} r _ { n } ^ { w } \\ r _ { n - 1 } ^ { w } \end{bmatrix} \\ \? 2 \end{bmatrix} \text{becomes the static ma}$$
Thus, the expression in (22) becomes the static map
$$\tilde { \mathbf Y } = \tilde { U } ^ { H } \tilde { \mathbf R }$$
Based on the natural gradient approach [43, 44], the update law for the columns of the augmented de-mixing matrix ˜ U can be expressed as
$$u ^ { + } = u - \mu E \left [ \tilde { R } \left ( g \left ( u ^ { H } \tilde { R } \right ) \right ) \right ]$$
where u , respectively u + , is the current, respectively next, value of one column vector of ˜ , U µ is the step size and g is the chosen score function. Noting the structure of the de-mixing matrix in (23), one decomposes the column vector as
$$u = \begin{bmatrix} u _ { 0 } \\ u _ { 1 } \end{bmatrix}$$
Hence, the update law is correspondingly decomposed as (Note, we have suppressed the E . [ ] operator):
$$\begin{bmatrix} u _ { 0 } ^ { + } \\ u _ { 1 } ^ { + } \end{bmatrix} = \begin{bmatrix} u _ { 0 } \\ u _ { 1 } \end{bmatrix} - \mu \, \begin{bmatrix} r _ { n } ^ { w } \\ r _ { n - 1 } ^ { w } \end{bmatrix} g \left ( y _ { n } \right )$$
where u 0 , u 1 are the column vectors of U 0 and U 1 in (22), respectively. Therefore, the update laws for the individual (sub-) columns are
$$u _ { 0 } ^ { + } = u _ { 0 } - \mu r _ { n } ^ { w } g \left ( y _ { n } \right )$$
$$u _ { 1 } ^ { + } = u _ { 1 } - \mu r _ { n - 1 } ^ { w } g \left ( y _ { n } \right )$$
Now, by induction, the update law for the kth lag element u k is
$$u _ { k } ^ { + } = u _ { k } - \mu r _ { n - k } ^ { w } g \left ( y _ { n } \right )$$
4.3 Step 2b: Determining the rotation unitary matrix U based on feedback structure I (FB-I)
The output of FB-I, as depicted in Fig. 4, results in the filtering expression
$$y _ { n } = U _ { 0 } ^ { - 1 } \left ( r _ { n } ^ { w } - \sum _ { k = 1 } ^ { K } U _ { k } y _ { n - k } \right )$$
Consider now just two taps of FB-I , i.e.,
$$y _ { n } = U _ { 0 } ^ { - 1 } \left ( r _ { n } ^ { w } - U _ { 1 } y _ { n - 1 } \right )$$
One can re-write this convolutive filter into the following augmented static form
$$\begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix} = \begin{bmatrix} U _ { 0 } & & U _ { 1 } \\ 0 & & I \end{bmatrix} \begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix}$$
Or
$$\begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix} = \begin{bmatrix} U _ { 0 } & & U _ { 1 } \\ 0 & & I \end{bmatrix} ^ { - 1 } \begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix}$$
Fig. 4 Feedback Demixing Structure I FB-I
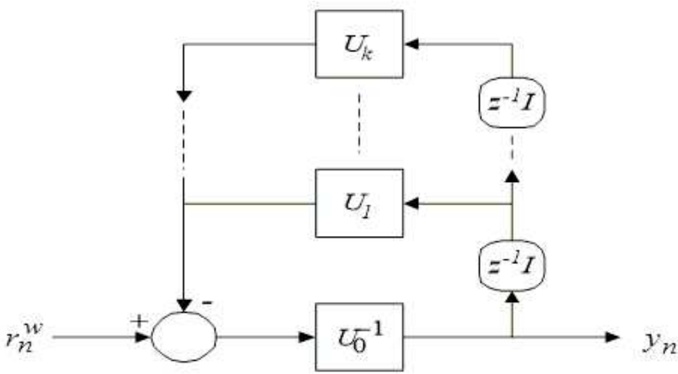
$$\begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix} = \begin{bmatrix} U _ { 0 } ^ { - 1 } & - U _ { 0 } ^ { - 1 } U _ { 1 } \\ 0 & I \end{bmatrix} \begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix}$$
Thus, in this case, one defines the augmented output, de-mixing matrix, and input as follows:
$$\tilde { Y } & = \begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix} \\ \tilde { U } & = \begin{bmatrix} U _ { 0 } & 0 \\ U _ { 1 } & I \end{bmatrix} \\ \tilde { R } & = \begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix} \\ \} ) \, \text{into the compact equatic}$$
One then re-expresses (32) into the compact equation
$$\tilde { \mathbf R } = \tilde { U } ^ { H } \tilde { \mathbf Y }$$
Again, using the natural gradient approach, the update law for a column of the de-mixing matrix˜ U is
$$u ^ { + } = u - \mu E \left [ \tilde { Y } \left ( g \left ( u ^ { H } \tilde { Y } \right ) \right ) \right ]$$
As before, u , respectively u + , is the current, respectively next, value of one column vectors of ˜ , U µ is the step size and g is the chosen score function.
One can exploit the block matrix structure of the de-mixing matrix and simplify the update law. To that end, consider the block matrix
$$u ^ { 0 } = \begin{bmatrix} u _ { 0 } ^ { 0 } \\ u _ { 1 } ^ { 0 } \end{bmatrix}$$
Thus, the update laws can be calculated to produce
$$\begin{bmatrix} u _ { 0 } ^ { + } \\ u _ { 1 } ^ { + } \end{bmatrix} = \begin{bmatrix} u _ { 0 } \\ u _ { 1 } \end{bmatrix} - \ \mu \begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix} \, g \left ( u _ { 0 } y _ { n } + u _ { 1 } y _ { n - 1 } \right ) \quad \quad ( 3 7 )$$
Similarly, the next block matrices can be defined as
$$u ^ { 1 } = \left [ \begin{smallmatrix} 0 \\ i ^ { 1 } \end{smallmatrix} \right ]$$
This leads to the specialized form
$$\left [ \begin{matrix} 0 ^ { + } \\ i ^ { + } \end{matrix} \right ] = \left [ \begin{matrix} 0 \\ i \end{matrix} \right ] - \mu \, \left [ \begin{matrix} y _ { n } \\ y _ { n - 1 } \end{matrix} \right ] g \left ( y _ { n - 1 } \right )$$
Thus, the update laws for the individual columns are
$$u _ { 0 } ^ { + } = u _ { 0 } - \mu y _ { n } g \left ( r _ { n } ^ { w } \right )$$
and
$$u _ { 1 } ^ { + } = u _ { 1 } - \mu y _ { n - 1 } g \left ( r _ { n } ^ { w } \right )$$
Analogously, by induction, the update law for the kth lag element, say u k is
$$u _ { k } ^ { + } = u _ { k } - \mu y _ { n - k } g \left ( r _ { n } ^ { w } \right )$$
4.4 Step 2c: Determining the rotation unitary matrix U based on Feedback Structure II
The output of FB-II, as depicted in Fig. 5, is expressed as:
$$y _ { n } = U _ { 0 } r _ { n } ^ { w } + \sum _ { k = 1 } ^ { K } U _ { k } y _ { n - k }$$
Again, consider two taps of FB-II, i.e.,
$$y _ { n } = U _ { 0 } r _ { n } ^ { w } - U _ { 1 } y _ { n - 1 } & & ( 4 4 )$$
Hence, one re-writes this convolutive filter in the following augmented static form
$$\begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix} = \begin{bmatrix} U _ { 0 } & & - U _ { 1 } \\ 0 & & I \end{bmatrix} \begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix}$$
Similarly, define the augmented entities as
$$\tilde { Y } = \begin{bmatrix} y _ { n } \\ y _ { n - 1 } \end{bmatrix}$$
Fig. 5 Feedback Demixing Structure II (FB-II)
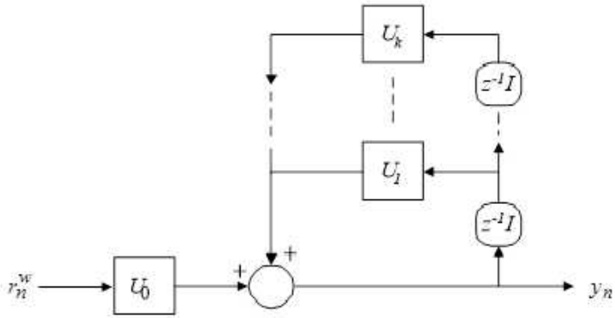
$$\tilde { U } & = \begin{bmatrix} U _ { 0 } & 0 \\ - U _ { 1 } & I \end{bmatrix} \\ \tilde { R } & = \begin{bmatrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{bmatrix} \\. &. &.$$
Thus one re-writes (45) into the compact mapping
$$\tilde { \mathbf Y } = \tilde { U } ^ { H } \tilde { \mathbf R }$$
Using the natural gradient approach, the update laws for a weight column of the de-mixing matrix ˜ U is expressed as
$$\mathfrak { u } ^ { + } = \mathfrak { u } - \mu \mathbb { E } \left [ \tilde { R } \left ( g \left ( \mathfrak { u } ^ { H } \tilde { R } \right ) \right ) \right ]$$
where, as before, u , respectively u + , is the current, respectively next, value of one column vectors of ˜ , U µ is the step size and g ( ) is the chosen score function. . One can appropriately decompose a column vector in order to simplify the update expressions as:
$$u = \begin{bmatrix} u _ { 0 } \\ u _ { 1 } \end{bmatrix}$$
Then the update law becomes decomposed as follows:
$$\left [ \begin{matrix} u _ { 0 } ^ { + } \\ u _ { 1 } ^ { + } \end{matrix} \right ] = \left [ \begin{matrix} u _ { 0 } \\ u _ { 1 } \end{matrix} \right ] - \mu \, \left [ \begin{matrix} r _ { n } ^ { w } \\ y _ { n - 1 } \end{matrix} \right ] g \left ( y _ { n } \right )$$
Thus, the update laws for the individual sub-columns are
$$u _ { 0 } ^ { + } = u _ { 0 } - \mu r _ { n } ^ { w } g ( y _ { n } )$$
and
$$u _ { 1 } ^ { + } = u _ { 1 } - \mu y _ { n - 1 } g \left ( y _ { n } \right )$$
Finally, by induction, the update law for the kth lag element u k is
$$u _ { k } ^ { + } = u _ { k } - \mu y _ { n - k } g \left ( y _ { n } \right )$$
4.5 The proposed adaptive Rake-based detectors
While the previous filtering structures constitute new adaptive filters, one can augment the existing conventional Rake detectors to improve its performance adaptively. We now develop three adaptive modifications of the conventional Rake detector based on, respectively, Independent Component Analysis (ICA), Robust ICA and Principle Component Analysis (PCA). Recalling the Rake detector's structure as given in (10), one can mathematically express the adaptive modified Rake detector for DS-CDMA systems as follows:
$$b _ { i, \text{Rake} } ^ { D } = S _ { i } ^ { H } W H ^ { H } r$$
where, as before, H is the crudely estimated (inverse) channel matrix usually based only on time-delays of the finger Rake filter, S i is a vector associated with the ith user's signature code, and b D Rake i , is the estimated ith user's symbol. A GxG matrix W is inserted which will adaptively augment and improve the estimate of the channel inverse. In the following, we summarize the process in Algorithms 1, 2, and 3 to adaptively estimate the matrix W using the FastICA, Robust ICA and PCA algorithms, respectively.
## Algorithm 1 Adaptive Rake based FastICA method
1: procedure Initialization
2:
r ← M × N matrix of realization
3:
W = I G ← Initial demixing matrix
4: Itr ← number of iterations
5: γ ← Step Size
6: H ← the estimated channel matrix
7: g ( y ) = y 3 ← the nonlinear fcn
8:
Pre-Whitening
:
9:
r
←
V
∗
r
=
Λ
((
-
1
)
/
2
)
E
T
r
10:
For Loop
:
11:
i
←
1
. . . N
12:
r
←
WH r
H
(:
,
i
)
13:
W
+
←
E g
[[
(
Wr
)]
T
]
-
E g
[
′
(
Wr W
)]
14: Normalization :
15: W + ← W norm W / ( )
16: b D ICA i , (: , i ) ← S H i W¯ H H r
17: goto For Loop .
18:
close
;
19: Output :
20: b D ICA i , ← the estimated Symbols
## Algorithm 2 Adaptive Rake based RICA method
- 1: procedure Initialization 2: r ← M × N matrix of realization 3: W = I G ← Initial demixing matrix 4: Itr ← number of iterations 5: µ ← Step Size 6: H ← the estimated channel matrix 7: g ( y ) ← the gradient of the Kurtosis 8: Pre-Whitening : 9: r ← V ∗ r = Λ (( -1 ) / 2 ) E T r 10: For Loop : 11: i ← 1 . . . N 12: r ← WH r H (: , i ) 13: W + ← W + µ ( I G -g r ( ) ∗ g r ( ) H ) W 14: Normalization : 15: W + ← W norm W / ( ) 16: b D RICA i , (: , i ) ← S H i W¯ H H r 17: goto For Loop . 18: close ; 19: Output : 20: b D RICA i , ← the estimated Symbols
## Algorithm 3 Adaptive Rake based PCA method
```
Algorithm 3 Adaptive Rake based PCA n
==============================================================================
1: procedure INITIALIZATION
2: r <- M x N matrix of realization
3: W = I _ { G } <- Initial demixing matrix
4: Itr <- number of iterations
5: \gamma <- Step Size
6: H <- the estimated channel matrix
7: Pre-Whitening:
8: r <- V * r = A((-1)/2) E T r
9: For Loop:
10: i <- 1 \dots N
11: r <- WHH ^ r (:, i)
12: W + <- W + \gamma (I _ { G } - r * r ^ H ) W
13: Normalization:
14: W + <- W /norm (W)
15: b _ { I _ { PCA } (:, i) <- S _ { WHH ^ r } }
16: goto For Loop.
17: close;
18: Output:
19: b _ { I _ { PCA } <- the estimated Symbols
}
```
## 5 SIMULATION RESULTS
A series of extensive simulations are carried out in order to verify and evaluate the performance of the proposed adaptive filters and algorithms in the multipath downlink DS-CDMA system in the presence of AWGN. We summarize the case study results as follows. We assume a constant spreading gain, which is G = 63 for Gold Codes and G = 64 for Orthogonal Variable Spreading Factor (OVSF) codes. The received CDMA signal experiences five multipath
channels L=5 with delays of 0,1,2,3 ,4 chips, respectively. Also, we set the complex attenuation coefficients to represent the multipath channels, specifically, h 0 = 0 3684 + 0 5364 , . . i h 1 = 0 1982 + 0 0187 , . . i h 2 = 0 0237 + 0 5683, . . h 3 = 0 1112 + 0 0835 , and . . i h 4 = 0 2203 + 0 2756 , respectively. We use the . . i following model function for sub-Gaussian sources for which the source signals have a negative kurtosis sign:
$$g ^ { \text{SUB} } \left ( \hat { \mathbf b } \right ) = \hat { \mathbf b } - \left ( \tanh \left ( \text{Re} \left \{ \hat { \mathbf b } \right \} \right ) + j \tanh \left ( \text{Im} \left \{ \hat { \mathbf b } \right \} \right ) \right ) \quad \ \ ( 5 4 )$$
Monte Carlo Simulations have been run to verify the validity of the algorithms. We also use the signal-to-noise ratio (SNR) as a figure of merit which represents the ratio of the energy per symbol and the power spectral density (PSD) of the noise. Moreover, all the user symbols are assumed to be transmitted with the same power. Fig. 6 (a) and (b) show the simulation results of BER vs. SNR for the proposed detectors in contrast to the existing and conventional ones for the number of users K=30 and K=50, respectively. The other parameters were set as (i) number of symbols M=1000 and (ii) number of paths L=5, with the values of SNR in the range of -10 dB to 30dB.
Fig. 6 shows that the proposed algorithms improve the performance of the CDMA system. One observes that the blind multiuser detection based on FBII has resulted in the lowest BER, and thus it outperforms all other detectors. One also observes that the proposed algorithms work even in cases which cause difficulties for the LMMSE receiver, as in the high SNR ratio, and when the sample set is fairly small. Moreover, the performance of the blind multiuser detection degrades as the number of users increases as comparatively seen in Fig. 6 (b).
Furthermore, we have also evaluated the effect of the OVSF codes as depicted in Fig. 7. As in Fig. 7, it is generally the case that using the OVSF codes enhances the performance of the proposed methods.
In the WCDMA System case, we assume that the channel coefficients are h 0 = 0 3684 + 0 5364 , . . i h 1 = 0 1982 + 0 0187 , . . i h 2 = 0 0237 + 0 5683, . . h 3 = 0 1112+0 0835 , and . . i h 4 = 0 2203+0 2756 , respectively. Also, all user-specific . . i codes use two types of spreading codes, namely, Gold codes with spreading gain G=63 and OVSF (or Walsh-Hadamard) codes with spreading gain G=64.
In Fig. 8 and 9, we document and demonstrate the performance of the various methods in terms of BER for the WCDMA downlink scenario. We observe that the LMMSE is slightly better than some presented detectors under good SNR conditions. However, the proposed algorithm based on FB-II outperforms all detectors over all SNR depicted ranges and has again produced the lowest BER when compared to all other methods.
It is also worthwhile to compare the presented algorithms with a relatively large data sample set. Thus, Fig. 10 and Fig. 11 present the performance of the various detectors with fairly long sample set, namely, M=30 000 in each of the DS-CDMA and WCDMA systems. It is noted that the benchmark LMMSE detector performs much better for high SNR. It is plausible to assume that the LMMSE detector becomes better than other detectors under good SNR
Fig. 6 Average BER as a function of SNR for DS-CDMA downlink. Using Gold codes G=63. (a) Using 30 users (b) Using 50 users
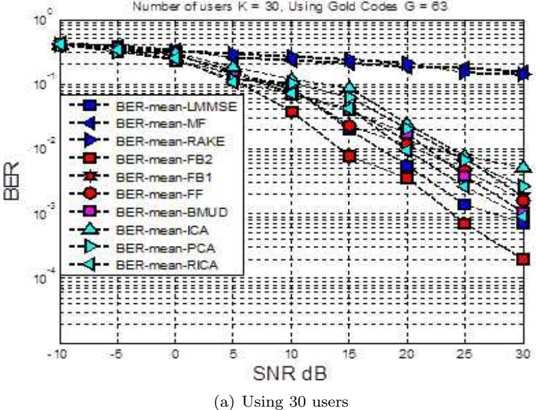
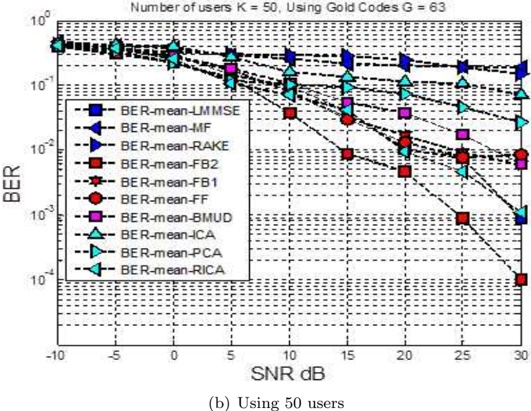
conditions. However, the proposed algorithm based on FB-II has exceeded the LMMSE detector at all SNRs less than 22 dB.
Finally, we evaluate the effect of the number of users and the size of the sample set on the performance of the proposed FB-II method in Figs. 12 and 13, respectively. In Fig. 12, the simulation results show the BER vs. SNR
Fig. 7 Average BER as a function of SNR for DS-CDMA downlink. Using OVSF codes G=64. (a) Using 30 users (b) Using 50 users
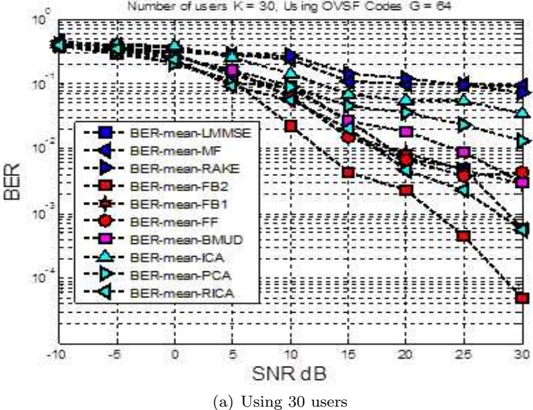
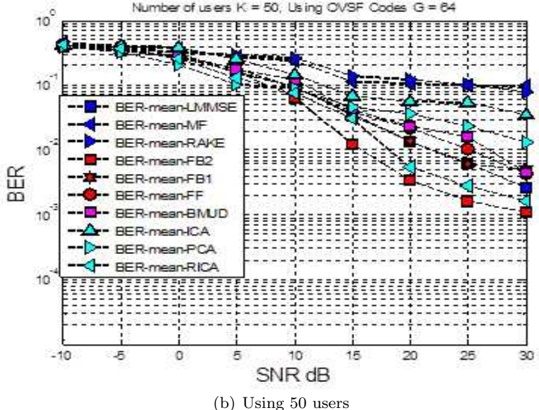
with various K users at 500 symbols for each user for blind multiuser detection based on the FB II detector. As expected, Fig. 12 shows that the FB-II detector decreases in performance as K, the number of users, is increased. Moreover, Fig. 13 shows the simulation results of BER vs. SNR with 30 users (K=30) for various data samples (M). The proposed FB-II algorithm appears robust
Fig. 8 Average BER as a function of SNR for WCDMA downlink. Using Gold codes G=63. (a) Using 30 users (b) Using 50 users
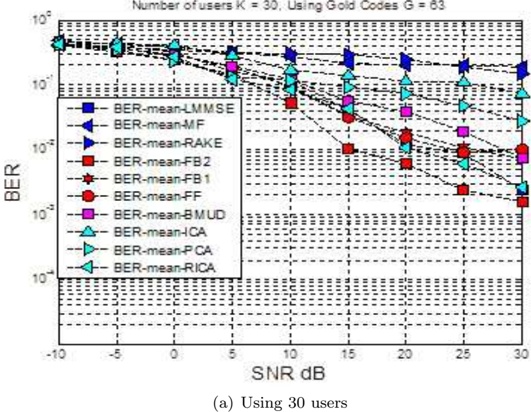
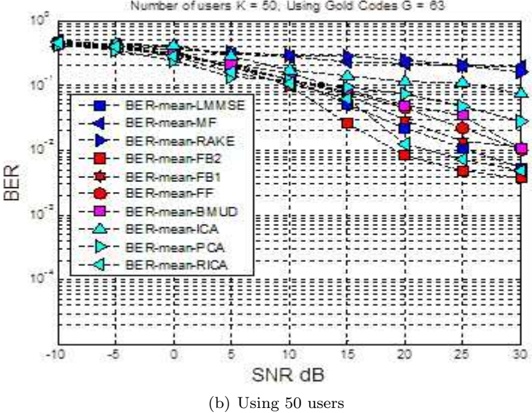
and performs resonably well, and it is obvious that its performance improves more consistently as M increases by mitigating the MIA.
Overall, the proposed variant detectors and algorithms perform well in solving the symbol estimation problem in the DS/WCDMA downlink system, especially when the size of the sample set is reasonably small.
Fig. 9 Average BER as a function of SNR for WCDMA downlink. Using OVSF codes G=64. (a) Using 30 users (b) Using 50 users
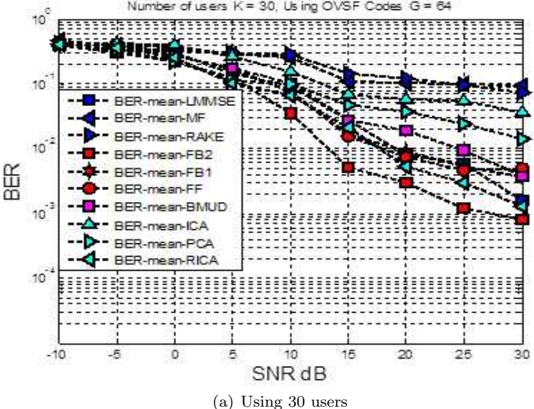
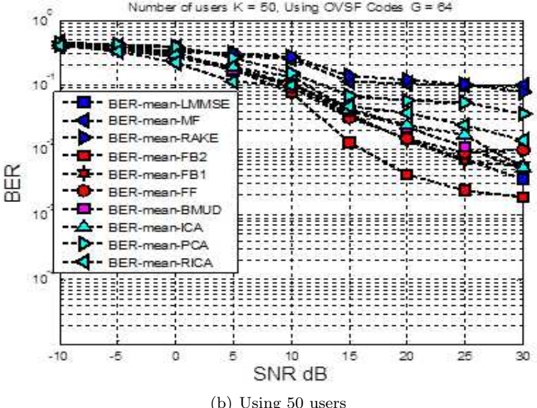
## 6 CONCLUSION
We have presented formulations, derivations, and subsequent extensive simulations of various filtering algorithms within various structures for multi-user detection in CDMA based systems. We have developed three blind multiuser
Fig. 10 Average BER as a function of SNR for DS-CDMA downlink. For 30 users (a) Using Gold codes G=63. (b) Using OVSF codes G=64.
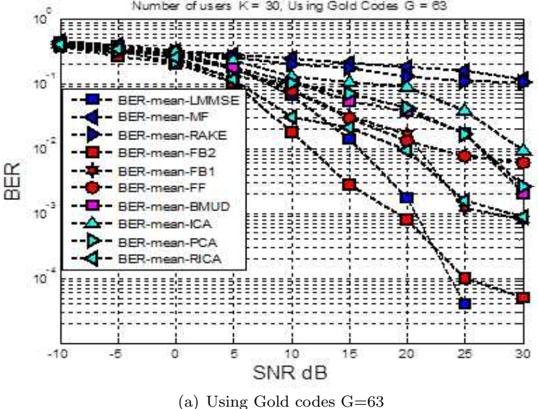
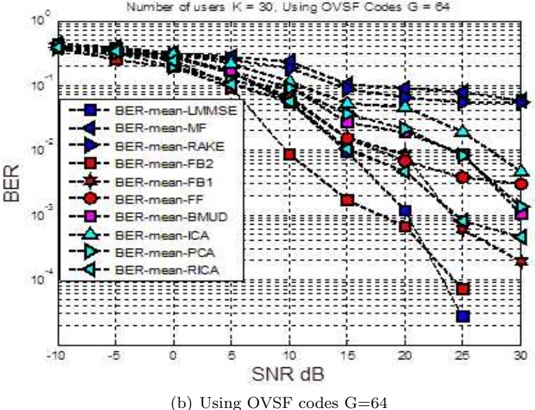
detectors based on different filtering structures and three algorithms, namely, ICA, RICA and PCA. The results appear to show that the proposed structures perform well in the symbol estimation problem in DS/CDMA systems and more generally outperform all other detectors, including the LMMSE detector. Our results also show that MAI can be mitigated by the proposed
Fig. 11 Average BER as a function of SNR for WCDMA downlink. For 30 users (a) Using Gold codes G=63. (b) Using OVSF codes G=64.
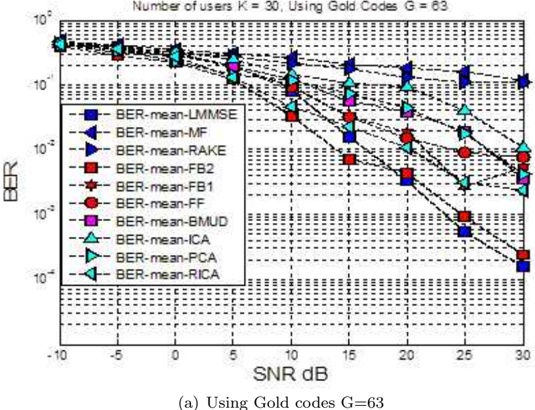
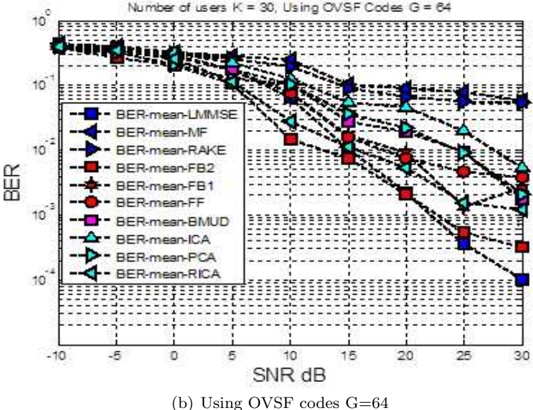
algorithms, particularly the proposed FB-II detector. Although the FB-II detector further improves as the size of the sample set increases, the results show that it performs well even when the sample sets are small- unlike the LMMSE detector. Finally, the proposed algorithms, unlike the adaptive LMMSE detector, do not require the spreading codes of the interfering users. While these
Fig. 12 Average BER as a function of SNR for various number of users K
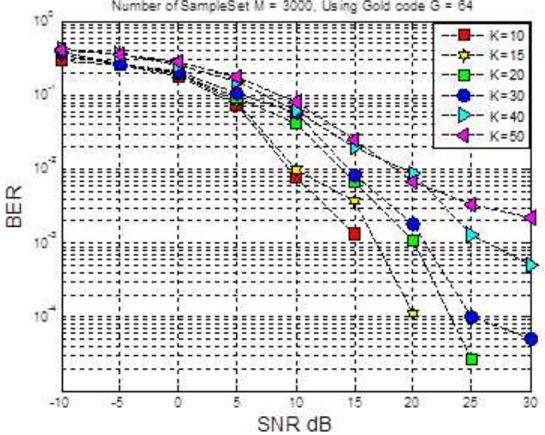
Fig. 13 Average BER as a function of SNR for various sample sets M
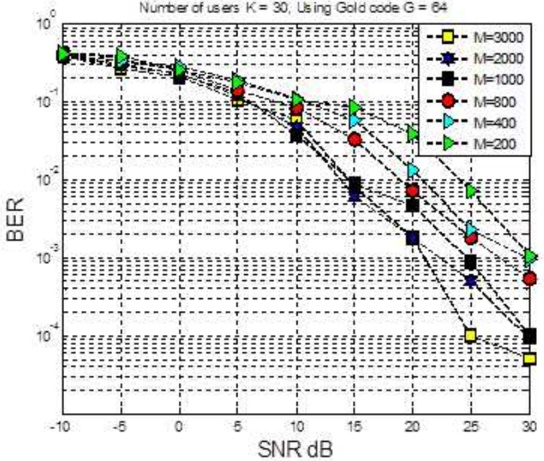
detectors are more suitable for the downlink case, they can also be used in the uplink case as well.
## Acknowledgement
This research was supported in part by the NSF Grant ECCS-1549517.
## References
- 1. X. D. Wang and H. V. Poor, Wireless Communication Systems: Advanced Techniques for Signal Reception. Prentice Hall, 2004.
- 2. P. Comon, C. Jutten (eds.), Handbook of Blind Source Separation Independent Component Analysis and Applications (Academic Press, Oxford, 2010).
- 3. 'An Introduction to LTE'. 3GPP LTE Encyclopedia. Retrieved December 3, 2010.
- 4. LTE An End-to-End Description of Network Architecture and Elements. 3GPP LTE Encyclopedia. 2009.
- 5. 'Verizon launches its first LTE handset'. Telegeography.com. 2011-03-16. Retrieved 201203-15.
- 6. K. Waheed, F. Salem, Blind information-theoretic multiuser detection algorithms for DSCDMA and WCDMA downlink systems, IEEE Trans. Neural Netw., vol. 16, no. 4, pp. 937948, Jul. 2005.
- 7. R.C. de Lamare, Diniz, P.S.R., Blind Adaptive Interference Suppression Based on SetMembership Constrained Constant-Modulus Algorithms With Dynamic Bounds ', IEEE Trans. Signal Process., vol. 56, no. 5, pp. 1288 1301 2013
- 8. L. Hu, X. Zhou, L. Zhang, 'Blind Multiuser Detection Based on Tikhonov Regularization', IEEE Communications Letters, vol. 15, no. 5, May 2011.
- 9. S. Verdu, Multiuser Detection. Cambridge U.K.: Cambridge Univ. Press, 1998.
- 10. G. B. G. Zhang and L. Zhang 'Group-blind intersymbol multiuser detection for downlink cdma with multipath', IEEE transaction on Wireless Communications, vol. 4, no. 2, pp.434 -443 2005
- 11. R. C. de Lamare , M. Haardt and R. Sampaio-Neto 'Blind adaptive constrained reducedrank parameter estimation based on constant modulus design for CDMA interference suppression', IEEE Trans. Signal Process., vol. 56, no. 6, pp.2470 -2482 2008
- 12. Z. Albataineh, F. Salem, New blind multiuser detection DS-CDMA algorithm based on Extension of Efficient FAST Independent Component Analysis (EF-ICA). 4th International Conference on Intelligent Systems Modelling and Simulation (ISMS), pp. 543-548, 2013.
- 13. Z. Albataineh, F. Salem, New blind multiuser detection DS-CDMA algorithm using simplified fourth order cumulant matrices IEEE International Symposium on Circuit and System (ISCAS), pp. 1946-1949, 2013.
- 14. Jean-Franois Cardoso, High-order contrasts for independent component analysis, Neural Computation, vol. 11, no 1, pp. 157-192, Jan. 1999.
- 15. X. Liu, R. B. Randall, A New Efficient Independent Component Algorithm: Joint Approximate Diagonalization of Simplified Cumulant Matrices. The 16th National Congress of Australian Institute of Physics, Canberra, Australia, 2005.
- 16. V. Zarzoso and P. Comon, Robust Independent Component Analysis by Iterative Maximization of the Kurtosis Contrast With Algebraic Optimal Step Size, IEEE Transactions on Neural Networks, vol. 21, no. 2, pp. 248-261, 2010.
- 17. Hyvarinen. A, 'Fast and robust fixed-point algorithm for independent component analysis'. IEEE Transactions on Neural Network, Vol. lo, no. 3, pp. 626-634, May 1999.
- 18. E. Oja and Z. Yuan 'The fastICA algorithm revisited: Convergence-analysis', IEEE Trans. Neural Netw., vol. 17, no. 6, pp.1370 -1381 2006
- 19. X. G. Doukopoulos and G. V. Moustakides 'Adaptive power techniques for blind channel estimation in CDMA systems', IEEE Trans. Signal Process., vol. 53, no. 3, pp.1110 -1120 2005
- 20. X. Wand and H. V. Poor, Blind multiuser detection: A subspace approach', IEEE Trans. Inform. Theory, vol. 44, pp.677 -690 1998
- 21. X. Wang and A. Host-Madsen, 'Group-blind multiuser detection for uplink CDMA', IEEE J. Sel. Areas Commun., vol. 17, no. 11, pp.1971 -1984 1999
- 22. S. Cui, M. Kisialiou , Z.-Q. Luo and Z. Ding 'Robust blind multiuser detection against signature waveform mismatch based on second-order cone programming', IEEE Trans. Commun., vol. 4, no. 4, pp.1285 -1291 2005
- 23. A. Kachenoura , L. Albera , L. Senhadji and P. Comon 'ICA: A potential tool for BCI systems', IEEE Signal Process. Mag., vol. 25, no. 1, pp.57 -68 2008
- 24. P. Loubation and E. Moulines, On blind multiuser forward link channel estimation by the subspace method: Identifiability results, IEEE Trans. Signal Process., vol. 48, no. 8, pp. 23662376, Aug. 2000.
- 25. E. Oja and Z. Yuan 'The fastICA algorithm revisited: Convergence-analysis', IEEE Trans. Neural Netw., vol. 17, no. 6, pp.1370 -1381 2006
- 26. http://www.bloomberg.com/slideshow/2013-09-19/countries-with-the-most-4g-mobileusers.html,slide1
- 27. http://gigaom.com/2013/09/20/mapping-out-the-worlds-lte-coverage-its-in-fewerplaces-than-you-think/
- 28. J. W. H. Kao, S. M. Berber, and V. Kecman, Blind multiuser detection of a chaosbased CDMA system using support vector machine, in Proc. IEEE 10th Int. Symp. Spread Spectrum Tech. Applicat., Aug. 2008, pp. 5862.
- 29. T. Yang and B. Hu 'Blind multiuser detection based on kernel approximation', Advances in Neural Networks, vol. 3973, pp.94 -101 2006
- 30. J. Kao, S. Berber, and V. Kecman, 'Blind Multi-User Detector for Chaos-Based CDMA Using Support Vector Machine,' IEEE Neural Networks, vol. 21, pp. 1221 1231, 2010.
- 31. Jiang Zhang, Hang Zhang ; Zhifu Cui, Dual-antenna-based blind joint hostile jamming cancellation and multi-user detection for uplink of asynchronous direct-sequence codedivision multiple access systems, IEEE Communications IET, vol. 7, 2013
- 32. X. Liu, K. C. Teh and E. Gunawan, 'A blind adaptive MMSE multiuser detector over multipath CDMA channels and its analysis,' IEEE Trans. Commun., vol. 7, no. 1, pp. 90-97, Jan 2008.
- 33. M. Hubert, P. J. Rousseeuw, and K. Branden, ROBPCA: A new approach to robust principal component analysis, Technometr., vol. 47, no. 1, pp. 6479, 2005.
- 34. X. X. Zhang and T. S. Qiu, 'Blind multiuser detection based on improved Infomax and Fast ICA,' 2010, 2nd International Conference on Advanced Computer Control, Shenyang, 2010, pp. 476-479.
- 35. Y. Washizawa , Y. Yamashita , T. Tanaka and A. Cichocki 'Blind extraction of global signal from multi-channel noisy observations', IEEE Trans. Neural Netw., vol. 21, no. 9, pp.1472 -1481 2010
- 36. A. Bayati, S. Prakriya and S. Prasad, Semi-blind space-time receiver for multiuser detection of DS/CDMA signals in multipath channels, The Institution of Engineering and Technology, vol. 153, no. 3, 2006.
- 37. K. Waheed and F. M. Salem, Blind Source Recovery: A Framework in the State Space, Journal of Machine Learnin Research, 4 (2003) pp. 1114-1146.
- 38. Koivisto T, Koivunen V. Blind Dispreading of Short-Code DS-CDMA Signals in Asynchronous Multi-user Systems. Signal Processing, 2007, 11(87): 2560-2568.
- 39. L. De Lathauwer and A. de Baynast 'Blind deconvolution of DS-CDMA signals by means of decomposition in rank-(1,L,L) terms', IEEE Trans. Signal Process., vol. 56, no. 4, pp.1562 -1571 2008
- 40. W. N. Yuan , Y. F. Tu and P. Z. Fan 'Optimal training sequences for cyclic-prefix-based single-carrier multi-antenna systems with space-time block-coding', IEEE Trans. Wireless Commun., vol. 7, no. 11, pp.4047 -4050 2008
- 41. L. Hu, X. Zhou, L. Zhang, 'Blind Multiuser Detection Based on Tikhonov Regularization', IEEE Communications Letters, vol. 15, no. 5, May 2011.
- 42. D. Nion and L. De Lathauwer, A Block-Component Model Based Blind DS-CDMA Receiver, IEEE Trans. on Signal Processing, Vol. 56, No. 11, pp. 5567-5579, Nov. 2008.
- 43. S. C. Douglas and M. Gupta 'Scaled natural gradient algorithms for instantaneous and convolutive blind source separation', Proc. ICASSP, vol. II, pp.637 -640 2007
- 44. Shun-Ichi Amari, Natural gradient works efficiently in learning, Neural Computation, v.10 n.2, p.251-276, Feb. 15, 1998 | null | [
"Zaid Albataineh",
"Fathi M. Salem"
] | 2014-08-01T14:52:47+00:00 | 2016-01-14T22:26:25+00:00 | [
"cs.IT",
"cs.LG",
"math.IT"
] | A Blind Adaptive CDMA Receiver Based on State Space Structures | Code Division Multiple Access (CDMA) is a channel access method, based on
spread-spectrum technology, used by various radio technologies world-wide. In
general, CDMA is used as an access method in many mobile standards such as
CDMA2000 and WCDMA. We address the problem of blind multiuser equalization in
the wideband CDMA system, in the noisy multipath propagation environment.
Herein, we propose three new blind receiver schemes, which are based on state
space structures and Independent Component Analysis (ICA). These blind
state-space receivers (BSSR) do not require knowledge of the propagation
parameters or spreading code sequences of the users they primarily exploit the
natural assumption of statistical independence among the source signals. We
also develop three semi blind adaptive detectors by incorporating the new
adaptive methods into the standard RAKE receiver structure. Extensive
comparative case study, based on Bit error rate (BER) performance of these
methods, is carried out for different number of users, symbols per user, and
signal to noise ratio (SNR) in comparison with conventional detectors,
including the Blind Multiuser Detectors (BMUD) and Linear Minimum mean squared
error (LMMSE). The results show that the proposed methods outperform the other
detectors in estimating the symbol signals from the received mixed CDMA
signals. Moreover, the new blind detectors mitigate the multi access
interference (MAI) in CDMA. |
1408.0198v1 | ## 3D Printing the Big Letters in the JDRF Logo
Edward Aboufadel Grand Valley State University
Version 1.0, August 2014
## 1 Introduction
The purpose of this short paper is to describe a project to manufacture a 3D-print of the big letters in the logo for JDRF (formerly known as the Juvenile Diabetes Research Foundation). The methods described in this paper involve processing the image of the logo through a Mathematica script, and the methods can be applied to most logos and other images that are sparse in the sense of not having many edges within the image. With the Mathematica script, a STereoLithography (.stl) file is created that can be used by a 3D printer. Finally, the object is created on a 3D printer. We assume that the reader is familiar with the basics of 3D printing.
## 2 The JDRF Logo
JDRF (formerly known as the Juvenile Diabetes Research Foundation) is a major charity devoted to preventing, treating, and curing type-1 diabetes. Type-1 diabetes (also called T1D) occurs when the immune system is triggered to start destroying insulin-producing beta cells in the pancreas. The cause of this trigger is uncertain, and a cure is not in sight at this time. People with T1D introduce artificial insulin into their bodies through injections or an insulin pump, and continuous glucose monitors are now available in order to track glucose levels in the blood at five-minute intervals. Type-1 diabetes should not be confused with the more common type-2 diabetes that afflicts a considerable number of Americans. About 1% of Americans have T1D. (There is a member of the author's family afflicted with T1D.)

Figure 1: Logo of JDRF in grayscale.
A grayscale version of the logo for JDRF can be found in Figure 1. (The logo of JDRF is often seen in a specific shade of blue.) The method described below will not work very well on the
'Improving Lives. Curing Type 1 Diabetes' part of the logo, at least for a 3D print the size of a hand, because of the relatively small size of the letters, and the number of letters. However, the big 'JDRF' is a good candidate for our method because of the relative simplicity of the four letters. There is a also a way to address the lines which have a gradient of greyscale, located above and below the four letters. We will describe our method in the next section.
## 3 Mathematica Code
The code in this section is modified from code created in 2013 by Melissa Sherman-Bennett and Sylvanna Krawczyk, who were my research students at our REU program. See the URL below for more 3D printing results.
The first four lines of code loads the logo into a matrix image of grayscale values (on a 0 to 1 scale). Specifically, the first line clears the memory in Mathematica, and the next lines load and process the image file from the directory C: data 3d \ \ . We have the ColorConvert command because when the Import command creates three matrices (for colors red, blue, and green), even if the jpeg file is greyscale.
## ClearAll["Global'*"]
input = Import["C:\\data\\3d\\JDRF.jpg"];
size = Import["C:\\data\\3d\\JDRF.jpg", "ImageSize"];
image = ColorConvert[Image[input, "Real"], "Grayscale"];
Next, we define a function that we are going to apply to every entry in image . The basic idea is that the interior of the four letters will built up to a height of 5.2 millimeters from the build plate of the 3D printer. The background of the logo will be at a height of 1.2 millimeters. For the gradient lines, we define a gradient height, starting at 5.2 millimeters and decreasing in a reasonable way. The way to read the following function is first there is a test that we are in a background area of the logo ( x > 0 9 - nearly white). . If that test fails, then we go to another test to see if we are in the area of one of the four letters ( x < 0 25 - very dark). . If that test also fails, we must be on one of the gradient lines, and we use the function x -> -0 5 . ∗ x +1 3. Later, we will multiply the . heights by 4. Here is the function:
## bound[x\_] := If[x > 0.9, 0.3, If[x < 0.25, 1.3, -0.5*x + 1.3]];
The next command in Mathematica is to apply this function to the image and convert to a matrix (or table). The defined variation of i and j in this command takes into account that the image is stored in memory backwards from what we want to print. There is a multiplication by 4 in this command, but that could also be implemented in the function above.
data = ArrayPad[Table[4*bound[ImageData[image][[i, j]]], {i, 1, size[[2]], 1}, {j, size[[1]], 1, -1}], {1, 1}, 0];
Finally, we generate an image in Mathematica, and then export that image as an STL file. Some key options here are the DataRange which indicates that the print will be 80 millimeters by 28 millimeters (and as we have seen previously, 5.2 millimeters tall), and Axes -> True, BoxRatios -> Automatic which instructs Mathematica to create an image that is true to the dimensions defined. The image is then exported as an STL file which can be then used on a 3D printer.
Figure 2: Plot of height function for our print.
object = ListPlot3D[data, DataRange -> {{0, 80}, {0,
Axes -> True, BoxRatios -> Automatic, ColorFunction -> Function[{x, y, Export["C:\\data\\3d\\JDRF.stl", object]
28}}, z}, Hue[z]]]
The image created by the ListPlot3D can be found in Figure 2. The 3D print of the letters and the gradient lines can be found in Figure 3. Another example of a logo printed using this method (and some additional tweaks) is the logo celebrating the 100th anniversary of Pi Mu Epsilon, the national honor society in mathematics. A photo of that 3D print can be found in Figure 4.
Figure 3: 3D Print of the Big Letters in the Logo.

## 4 Appendix: URLs
- · JDRF home page http://www.jdrf.org/
- · Prof. Aboufadel's 3D printing page http://sites.google.com/site/aboufadelreu/Profile/ 3d-printing
Figure 4: 3D Print of the logo for the PME 100th anniversary.
 | null | [
"Edward F. Aboufadel"
] | 2014-08-01T14:58:10+00:00 | 2014-08-01T14:58:10+00:00 | [
"math.HO"
] | 3D Printing the Big Letters in the JDRF Logo | The purpose of this short paper is to describe a project to manufacture a
3D-print of the big letters in the logo for JDRF (formerly known as the
Juvenile Diabetes Research Foundation). The methods described in this paper
involve processing the image of the logo through a Mathematica script, and the
methods can be applied to most logos and other images that are sparse in the
sense of not having many edges within the image. With the Mathematica script, a
STereoLithography (.stl) file is created that can be used by a 3D printer.
Finally, the object is created on a 3D printer. We assume that the reader is
familiar with the basics of 3D printing. |
1408.0200v1 | ## Towards a Domain Specific Language for a Scene Graph based Robotic World Model
Sebastian Blumenthal and Herman Bruyninckx
Abstract -Robot world model representations are a vital part of robotic applications. However, there is no support for such representations in model-driven engineering tool chains. This work proposes a novel Domain Specific Language (DSL) for robotic world models that are based on the Robot Scene Graph (RSG) approach. The RSG-DSL can express (a) application specific scene configurations, (b) semantic scene structures and (c) inputs and outputs for the computational entities that are loaded into an instance of a world model.
## I. INTRODUCTION
Robots interact with the real world by safe navigation and manipulation of the objects of interest. A digital representation of the environment is crucial to fulfill a given task. Although a world model is a central component of most robotic applications a Domain Specific Language (DSL) has not been developed yet. One reason for this is the lack of a common world model approach. The scene graph based world model approach Robot Scene Graph (RSG) [1] tries to overcome this hurdle. It acts as a shared resource for a full 3D environment representation in a robotic system. It accounts for dynamic scenes by providing a short-term memory, allows to hierarchically organize scenes, supports uncertainty for object poses, has semantic annotations for scene elements and can host computational entities. While other approaches have a stronger focus on certain world modeling aspects like probabilistic tracking of semantic entities [2] or hierarchical representations for geometric data [3], the RSG emphasizes a holistic view on the world modeling domain. This work extends the RSG approach by a RSG-DSL to model the structural and computational aspects of the scene graph. It is accompanied by a model to text transformation to generate code for an implementation of the RSG which is a part of the BRICS\_3D C++ open source library [4].
ADSLis a formal language that allows to express a certain aspect of a problem domain. It creates an abstraction in order to quickly create new applications and it imposes constraints on a programmer to prevent from programming errors. A structured development of a new DSL is organized in four levels of abstractions M0 to M3 [5]:
- · M0 : The M0 level is an instantiation of a DSL model. Typically this results in generated code for a (generic) programming language that can be compiled and executed.
All authors are with the Department of Mechanical Engineering, Katholieke Universiteit Leuven, Belgium. Corresponding author: [email protected]
- · M1 : The M1 level comprises models that conform to a certain DSL that is defined on the M2 level.
- · M2 : A meta model on the M2 level specifies the DSL in a formal way. This definition has to conform to the meta meta model of M3.
- · M3 : The M3 level defines the meta meta model which is a generic model to describe DSLs.
The goal of the RSG-DSL for a robotic world model is manifold. This DSL can describe the structural and behavioral parts of a scene that are part of a specific robotic application. It allows to combine the required world model elements at design time. The a priori known structure of a system can include the involved robots with their kinematic structures and their geometries, previously known parts in the environment or the places in the structure where to store online sensor data. Results of the behavioral function blocks , which can contain any kind of computation, are stored in the scene graph as well. The selection and the configuration of the function blocks has an important influence on how the world model will appear at runtime. For example, the presence of an object recognition function block can enrich the scene graph with task-relevant objects. The above items can be specified on the code level. However, the RSG-DSL reduces the required number of lines of code to encode the scene graph. The C++ API assumes a correct order of creation of scene primitives, while the RSG-DSL does not have this restriction.
The proposed DSL allows to express input and output data for the function blocks. This data consists of scene structures to represent parts of the scene graph. For instance, a segmentation algorithm module consumes a point cloud as input structure and generates a set of new point clouds with associated spatial relations pointing to the center of the segments.
In addition, the RSG-DSL is able to express prior semantic knowledge about a scene. It is possible e.g. to encode a generic version of a table that consists of a table plate and four legs. This can serve as input for a function block that analyzes the perceived scene to recognize that particular structure.
The remainder of the paper is organized as follows: Section II summaries related work and Section III gives a brief introduction to the world model concept. Details of the RSG-DSL are explained in Section IV and its capabilities are illustrated with examples in Section V. The paper is closed with a conclusion in Section VI.
## II. RELATED WORK
Recently interest has been risen in robotics to create DSLs for various sub-aspects of robotic systems. The Task Frame Formalism DSL [6] has been proposed to describe the control and coordination aspects of robotic software systems. A DSL to express geometric relations between rigid bodies [7] helps to correctly set up spatial relations as constraints will be automatically evaluated on the M1 level. Two DSL variants are discussed: one version is embedded into the Prolog programming language and the second one uses the Eclipse Modeling Framework (EMF) [8]. The Prolog approach results in a directly executable code while the EMF variant benefits from the Eclipse tool chain including an editor that supports syntax highlighting and auto-completion. The Grasp Domain Definition Language [9] is developed in the EMF framework as well. It demonstrates that multiple dedicated robotic languages can be further composed into more complex ones.
DSL approaches in the 3D computer animation domain have been recently developed for 3D scenes. The streaming approach for 3D data [10] uses a meta model for scene elements to cope with various 3D scene formants. In a similar way the SSIML [11] approach tries to abstract from the existing 3D formats and APIs method calls. It is meant as a DSL for development of 3D applications. However, in contrast to a robotic world model the complete access to the world state is given. To the best of the authors knowledge a DSL for a robotic world model does not exist yet.
## III. WORLD MODEL PRIMITIVES
The goal of the world model is to act as a shared resource among multiple involved processes in an application. Such processes could be related to the various robotic domains like planning, perception, control or coordination. To be able to satisfy the needs of the different domains the world model has to offer at least the following set of properties: It appears as shared and possibly distributed resource. It takes the dynamic nature and imprecision of sensing of real-world scenes into account, allows for multi-resolution queries and supports annotations with semantic tags.
The scene graph based world model RSG consists of objects and relations among them [1]. These relations are organized in a Directed Acyclic Graph (DAG) similar as for approaches used in the computer animation domain. The directed graph allows one to structure a scene in a hierarchical top-down manner. For instance, a table has multiple cups, whereas multiple tables are contained in a room, multiple rooms in a building and so on. Traversals on such a hierarchical structure can stop browsing the graph at a certain granularity to support multi-resolution queries. The graph itself supports four different types of nodes. All node types have in common that each instance has a unique ID, a list of attached attributes for semantic tags and one or more parent nodes. Details of the four node types are given below:
- · Node : The Node is a generic leaf in the graph. It can be seen as a base class for the other node types.
- · GeometricNode : A GeometricNode is a leaf in the graph that has geometric data like a box, a cylinder, a point cloud or a triangle mesh. The data is time stamped and immutable i.e. once inserted the data connote be altered until deletion to prevent inconsistencies in case multiple processes consume the same geometric data at the same time.
- · Group : The Group can have child nodes. These parent child relations form the DAG structure.
- · Transform : The Transform is a special Group node that expresses a rigid transform relation between its parents and its children. Each transform node in the scene graph stores the data in a cache with associated time stamps to form a short-term memory.
The Transforms are essential to capture the dynamic nature of a scene as changes over time can be tracked by inserting new data into the caches. Moreover, such a short-term memory enables to make predictions on the near future. This requires dedicated algorithms to be executed by the word model as described later. In contrast to the Transforms , geometric data is defined to be immutable. Hence, changes on the geometric data structures do not have to be tracked. In case a geometry of a part of a scene does change over time a new GeometricNode would have to be added. The accompanying time stamps still allow to deduce the geometric appearance of a scene at a certain point of time. All temporal changes in the world model are explicitly represented.
The RSG approach uses a graph structure. Thus, it is possible to store multiple paths formed by the preceding parents to a part of a scene. This case expresses that multiple information to the same entity is available. For example, an object could be detected by two sensors at the same time. Different policies for resolving such situations are possible. Selection of the most promising path like the latest path denoted by the latest time stamps associated with the transforms is one possibility, while choosing a path with the help of the semantic tags is another one. Probabilistic fusion strategies [12] are an alternative, given covariance information on the transform data is available. This kind of uncertainty data can be stored in the temporal caches as well. The details of representing uncertainty and fusion strategies are planned as future work.
Besides the structural and temporal aspects, the world model contains function blocks to define any kind of computation. A function block consumes and produces scene graph elements. Algorithms for estimating near future states are one example of such a computation. A function block can be loaded as a plugin to the world model and is executed on demand. This allows to move the computation near to the data to improve efficiency of the executed computations. Conceptually the scene graph is a shared resource among all function blocks. Concurrent access to the scene is possible since geometric data is defined to be immutable. Transforms provide a temporal cache such that inserting new data will not affect retrieval of transform data by another function block as long as queries are within the cache limits.
Fig. 1. Excerpt from Ecore model of the structural part of the world model. For the sake of readability some elements are not shown: the quantities for the geometries and transformation matrix are omitted and the Mesh definition is skipped because it is defined analogous to the PointCloud type.
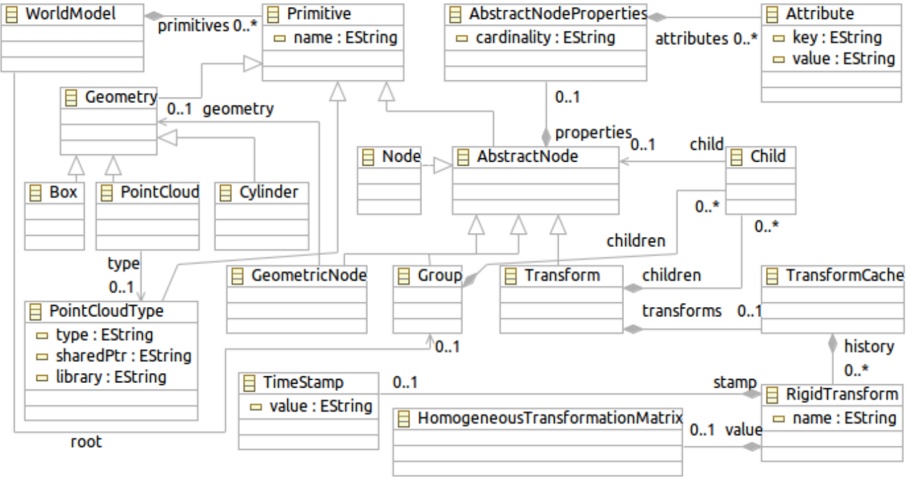
The RSG can be used as a shared resource in a multithreaded application. However crossing the system boundaries of a process or a computer requires additional communication mechanisms. Many component-based frameworks in robotics including ROS [13], OROCOS [14] and YARP [15] provide a communication layer for distributed components. These frameworks are mostly message-oriented and do not support a shared data structure like a world model well. Thus, we allow the RSG to create and maintain local copies of the scene graph [16]. Subsequent graph updates need to be encapsulated in the framework specific messages. Further details on the RSG world model and its primitives can be found in [1].
For a robotic application a set of design decisions has to be made to deploy the shared world model approach. Thus, a DSL for such a world model facilitates the development efforts for a specific application.
## IV. A DSL FOR A SCENE GRAPH BASED WORLD MODEL
## A. Choice of modeling framework
This work uses the Eclipse Modeling Framework (EMF) [8] as DSL framework. For two reasons: first, it allows one to make use of the Eclipse tool chain to generate an editor with syntax highlighting. Second, other robotic DSLs that already exist in this framework could be potentially reused. A candidate is the geometric relations DSL [7]. The integration into the world model DSL is left as future work.
In addition to the proposed DSL, a model to text transformation is provided that generates code to be used in conjunction with the C++ implementation of the RSG which is part of the BRICS\_3D library. Hence, this work mainly contributes to the M2 and M0 levels.
## B. M2: DSL definition
The RSG-DSL for the scene graph based world model is defined with the Xtext grammar language [17]. The corresponding Ecore meta model representation as part of the EMF is completely generated from that Xtext definition. The RSG-DSL re-uses an existing DSL for units of measurements that is defined with Xtext as well. This is achieved via grammar mixins .
The overall design approach is to find a minimal set of DSL primitives and their relations that are sufficient to represent the domain of an environment representation that is based on the RSG approach. The core primitives are the different node types and the function blocks. The graph structure allows to relate nodes to each other. The function blocks relate to the graph in the sense that graph structures serves as input and output data structure.
One central element of the RSG-DSL are the node types as shown in Section III. As depicted in Fig. 1 the Ecore model represents the common properties for all node types within the AbstractNodeProperties that can have a list of Attributes . An attribute is a key value pair. The Group and the Transform are the only node types that have children by referencing to the AbstractNode . The other two node types Node and GeometricNode are thus leaves in the scene graph.
The RSG-DSL identifies and references all node types by their names. This seems to be in conflict with the requirement that nodes have unique IDs but the description of a world model on M1 level can be seen as a generic template for a
Fig. 2. Ecore model of function blocks for data processing. Input and output data is specified via hooks and structure definitions. Hooks describe where the data is located at run time, while structure definition describes how the data looks like.
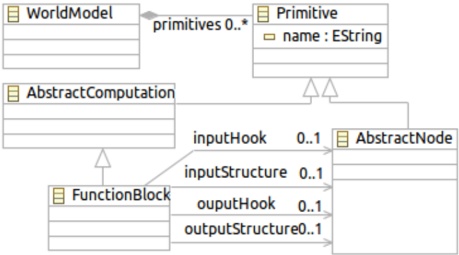
scene of an application [11]. The constraint of unique IDs has to hold on the M0 instance level and can be considered as an implementation detail. The world model implementation has facilities to provide and maintain unique IDs.
Each geometric data that can be contained in a GeometricNode has its dedicated representation within the RSG-DSL. Special attention has to be paid to the PointCloud and Mesh types as legacy data types shall be supported on M0 level. The PointCloudType collects all necessary information to be able to generate code for any point cloud representation used in an application. The Mesh representation follows analogously. On the M0 level this variability is mapped to a template based class.
The temporal cache for the Transform node is modeled by the TransformCache . It consists of a list of RigidTransform s while a single entry is formed by a HomogeneousTransformationMatrix and an associated TimeStamp . The values for the geometric data, the transformation matrix and the time stamps are accompanied with units of measurements.
The FunctionBlock model (cf. Fig. 2) to represent the behavioral aspect of the world model consists of four references to AbstractNode s: An inputHook , an inputStructure , an outputHook and an outputStructure . The hooks reefer to a subgraph at run-time that is to be consumed for further processing or it defines where to add the results of a computation to the scene graph. The structure property represents at design time the expected structure of a scene that is required for an encapsulated algorithm. For example, a function block that implements an algorithm for segmentation of point cloud data can have a PointCloud node as structural input. As output structure it provides any number of Transform nodes pointing to the centroids of the segmented point clouds. Each Transform has a PointCloud as child node to represent a single segment. To be able to express such multiplicities in the input and output structures the DSL foresees a cardinality attribute that is available in the
Function blocks can be used to create processing chains. All intermediate results of such a chain are stored in the scene graph. The input and output structures allows to check on the M1 level if the output of one function block matches as input for a successor function block. A trigger mechanism that can execute function blocks based on changes in the scene or based on signaling by other function blocks is planned as future work.
## C. M0: Code generation
Xtend is used to realize the model to text transformation from the M1 to the M0 level. As the world model primitives are available in the RSG implementation the code generation for them is a straight forward mapping to the respective API calls. The RSG-DSL has no assumptions on the order of primitives. On the implementation level, children can not be added to parents that will be created afterwards. To overcome this hurdle the transformation uses a depth-first search based graph traversal for the model primitives to ensure correct order of creation.
Adding a new primitive with the help of the API will return a unique ID which will be kept in a variable that is labeled with the same name as in the model. These corresponding variables improve readability of the generated code on the one hand and keep the unique ID property on the other hand.
The primitives that are in the subgraph of the root node of the WorldModel will be stored in a SceneSetup.h file to represent the application specific scene. This file can be included and used within the application.
All FunctionBlock s result in dedicated header files for each generated interface. An implementation for a function block has to inherit from such an interface. This strategy is inspired by the Implementation Gap Pattern [18] and it separates generated code from hand-written code via inheritance.
## V. EXAMPLES
To illustrate the capabilities of the RSG-DSL a set of examples on the M1 and the M0 level is given below.
## A. A robot application scene
Listing 1 demonstrates an application scene that consists of a subgraph for a sensor and a kitchen table attached to the group1 Group . The table could be a part of the environment that is expected to be there but its exact position has to be further deduced by some function block. The root keyword defines the application scene subgraph. For the sake of readability the structure for the robot carrying the sensor is omitted and subsumed by a single worldToCamera Transform . Note that the transform data is accompanied by units of measurements (cf. lines 20 to 22 ). In case of a moving sensor with respect to the world frame further transform data has to be inserted into the cache. Here the provided information given by the RSG-DSL can be seen as an initial value. The sensor Group is supposed to be the
place where online sensor data will be hooked in that might serve as input for a function block.
An excerpt of the resulting model to text transformation is presented in Listing 2. The respective API method invocations for group1 Group and worldToCamera Transform are shown. Lines 2 to 4 indicate the mapping of M1 level node names to IDs on the M0 level.
```
<_Go_>
```
Listing 1. Application scene setup represented with the RSG-DSL.
## B. Scene structure for a semantic entity
As an example for a semantic entity a table is defined in Listing 3. It relates the geometric parts into a scene structure. All legs have a spatial relation from the center of the tablePlate defined by the Transform node that is a child of the kitchenTable Group node. The example shows only one table leg but the other definitions follow analogously. The results are depicted in the Fig. 3 and Fig. 4. The used visualization functionality for the graph structure and the 3D visualization are part of the RSG implementation and demonstrate that the model to text transform of the example works as expected.
```
Listing 3. Kitchen table represented with the RSG-DSL.
Group kitchenTable {
Attribute ("name", "kitchen_table")
Attribute ("affordance", "pushable")
child tablePlate
child leg1tf
child leg2tf
child leg3tf
child leg4tf
}
```
Listing 3. Kitchen table represented with the RSG-DSL.
```
<_Go_>
```
Fig. 3. 3D visualization of the kitchen table.
## C. Interface definition for a function block
A FunctionBlock definition for a point cloud based segmentation algorithms is depicted in Listing 4. The input structure reefers to a point cloud node that contains an internal representation based on the Point Cloud Library (PCL) [19]. Input and output point clouds are of the same type as shown in lines 7 and 8 . As output structure a planes Group node is specified that can have zero or more
```
Listing 2. Except from generated code for M0 level. Some comments and additional line breaks have been added after generation.
std::vector<rsg::Attribute> attributes; // Instantiation of list of attributes.
unsigned int rootNodeId; // IDs correspond to names in model on M1 level.
unsigned int groupId;
unsigned int worldToCameraId;
// [...]
/* Add group1 as a new node to the scene graph */
attributes.clear();
attributes.push_back(Attribute ("name", "scene_objects"));
wm->scene.addGroup(rootNodeId, groupId, attributes); // groupId is an output parameter
// [...] // and returns a unique ID.
/* Add worldToCamera as a new node to the scene graph */
attributes.clear();
attributes.push_back(Attribute ("name", "wm_to_sensor_tf"));
brics_3d::HHomogeneousMatrix44::HHomogeneousMatrix44Ptr worldToCameraInitialTf(
new brics_3d::HomogeneousMatrix44( // Instantiation of HomogeneousTransformationMatrix primitive.
1.0, 0.0, 0.0,
0.0, 1.0, 0.0,
0.0, 0.0, 1.0,
0.0 * 1.0, 0.0 * 1.0, 1.0 * 1.0 // Values are scaled to SI unit [m].
));
wm->scene.addTransformNode(rootNodeId, worldToCameraId, attributes, worldToCameraInitialTf,
brics_3d::rsg::TimeStamp(0.0, Units::Second) // Value is scaled to SI unit [s].
);
```
Listing 2. Excerpt from generated code for M0 level. Some comments and additional line breaks have been added after generation.
Fig. 4. Scene graph structure for the application scene including the kitchen table. Yellow nodes show Transform s while green nodes indicate GeometricNode s. The on M0 level generated IDs are shown in square brackets. Attached attributes are given in brackets. In addition the Transform nodes indicate the translational values T = ( x , y , z ) and the size of the temporal cache via the Updates field.
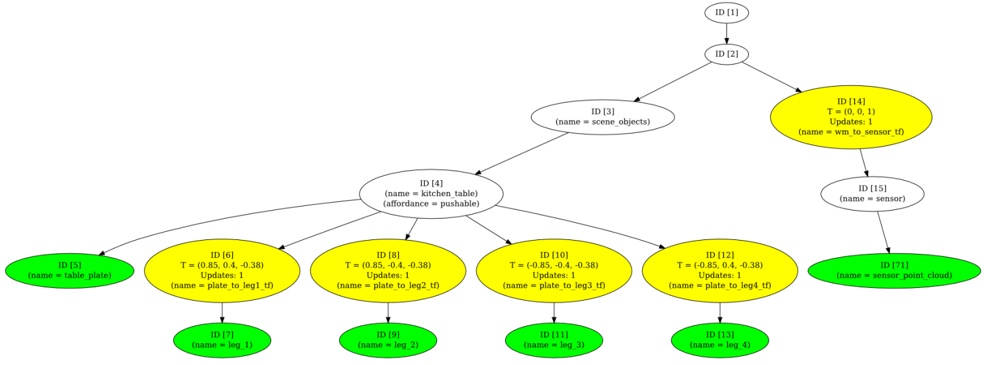
Transform s that are supposed to point to the centroids of the calculated point cloud segments. Line 21 reflects this variability by using the optional cardinality keyword. In this case the "*" terminal symbol has the semantics of any number .. According to the outputHook in line 44 all results will be inserted to the scene graph as child node of the sensor node (cf. Section V-A). An implementation of the function block can be achieved with functionality offered by PCL for instance. Algorithmic details are beyond the scope of this paper. Other point cloud processing libraries could have been chosen as well. Whatever choice the application programmer has been made, it is explicitly represented in the model on the M1 level.
Listing 4.
A function block represented with the RSG-DSL.
```
centroids:
Listing 4. A function block represented with the RSG-DSL.
!flects this | PointCloudType PointCloudPCL {
keyword:
type "pcl::PointCloud<PointType>"
sharedPtr "pcl::PointCloud<PointType>::Ptr"
nantics of
library "pcl"
line 44 all
}
d node of
function of the PointCloud inputCloud type PointCloudPCL
offered by PointCloud planeCloud type PointCloudPCL
the scope
GeometricNode pointCloud {
ries could
Attribute ("name", "point_cloud")
pplication
geometry inputCloud
sented in
Group planes {
Attribute ("name", "planes")
```
```
child tfToPlaneCentroid
Transform tfToPlaneCentroid { Systems, (FP7/20C } */
}
*/
*
*
* /*
} +
/*
*/
```
## VI. CONCLUSION
This work has presented the RSG-DSL: a DSL for a robotic world model based on the Robot Scene Graph (RSG). It is grounded in executable behavior as code can be generated to be used with an API for an existing implementation of the RSG approach. The RSG-DSL allows to express (a) application specific scene setups, (b) semantic scene structures and (c) inputs and outputs for the function blocks which are a part of the world model approach.
The RSG-DSL makes a contribution to improve the robot development work flow as world model aspects can be explicitly represented in a model-driven tool chain. Thus, a developer can create a robotic application quicker and less error prone.
Future work will include extension of the RSG-DSL approach by multiple levels of detail representations for geometries, uncertainty representations and trigger entities for function blocks. Currently the scene setup definition is centered around a single robot system. Language support for distributed and multi-robot applications are important improvements for the proposed DSL. The inclusion of other existing DSLs like the geometric relations DSL is a promising research direction with the goal of contributing to a robotic DSL that can be composed of a set of languages representing various robotic subfields like world modeling, planning, perception, reasoning or coordination.
## ACKNOWLEDGEMENTS
The authors acknowledge the fruitful discussions at the 4th International Workshop on Domain-Specific Languages and models for ROBotic systems (DSLRob-13) co-located with IEEE/RSJ IROS 2013, Tokyo, Japan. Insights from the discussions have lead to a clarified version of this paper.
The authors acknowledge the support from the KULeuven Geconcerteerde Onderzoeks-Acties Model based intelligent robot systems and Global real-time optimal control of autonomous robots and mechatronic systems , and from the European Union's 7th Framework Programme (FP7/2007-2013) projects BRICS (FP7-231940), ROSETTA (FP7-230902), RoboHow.Cog (FP7-288533), and SHERPA (FP7-600958).
## REFERENCES
- [1] S. Blumenthal, H. Bruyninckx, W. Nowak, and E. Prassler, 'A Scene Graph Based Shared 3D World Model for Robotic Applications,' in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany , 2013.
- [2] J. Elfring, S. van den Dries, M. van de Molengraft, and M. Steinbuch, 'Semantic world modeling using probabilistic multiple hypothesis anchoring,' Robotics and Autonomous Systems , vol. 61, no. 2, pp. 95 - 105, 2013.
- [3] K. Wurm, D. Hennes, D. Holz, R. Rusu, C. Stachniss, K. Konolige, and W. Burgard, 'Hierarchies of octrees for efficient 3D mapping,' in Intelligent Robots and Systems (IROS), 2011 IEEE/RSJ International Conference on . IEEE, 2011, pp. 4249-4255.
- [4] S. Blumenthal, 'BRICS\_3D Documentation pages,' 2013. [Online]. Available: http://www.best-of-robotics.org/brics\_3d/
- [5] International Organization for Standardization, 'ISO/IEC 19502: International Standard: Information technology - Meta Object Facility (MOF),' 2005.
- [6] M. Klotzbücher, R. Smits, H. Bruyninckx, and J. De Schutter, 'Reusable hybrid force-velocity controlled motion specifications with executable Domain Specific Languages,' in Intelligent Robots and Systems (IROS), 2011 IEEE/RSJ International Conference on , 2011, pp. 4684-4689.
- [7] T. De Laet, W. Schaekers, J. de Greef, and H. Bruyninckx, 'Domain Specific Language for Geometric Relations between Rigid Bodies targeted to robotic applications,' CoRR , vol. abs/1304.1346, 2013.
- [8] Eclipse Modeling Framework Project, 'Eclipse Modeling Framework Project (EMF),' 2013. [Online]. Available: http://www.eclipse.org/ modeling/emf/
- [9] S. Schneider and N. Hochgeschwender, 'Towards a Declarative Grasp Specification Language,' in Workshop on Combining Task and Motion Planning of the IEEE International Conferenceon Robotics and Automation , 2013.
- [10] J. Haist and P. Korte, 'Adaptive streaming of 3D-GIS geometries and textures for interactive visualisation of 3D city models,' 2006.
- [11] M. Lenk, A. Vitzthum, and B. Jung, 'Model-driven iterative development of 3D web-applications using SSIML, X3D and JavaScript,' in Proceedings of the 17th International Conference on 3D Web Technology . ACM, 2012, pp. 161-169.
- [12] R. Smith, M. Self, and P. Cheeseman, 'Estimating uncertain spatial relationships in robotics,' Autonomous robot vehicles , vol. 1, pp. 167193, 1990.
- [13] M. Quigley, B. Gerkey, K. Conley, J. Faust, T. Foote, J. Leibs, E. Berger, R. Wheeler, and A. Ng, 'Ros: an open-source robot operating system,' in ICRA workshop on open source software , vol. 3, no. 3.2, 2009.
- [14] H. Bruyninckx, 'Open robot control software: the orocos project,' in IEEE International Conference on Robotics and Automation , vol. 3, 2001, pp. 2523 - 2528.
- [15] G. Metta, P. Fitzpatrick, and L. Natale, 'Yarp: Yet another robot platform,' International Journal on Advanced Robotics Systems , vol. 3, no. 1, pp. 43-48, 2006.
- [16] M. Naef, E. Lamboray, O. Staadt, and M. Gross, 'The blue-c distributed scene graph,' in Proceedings of the workshop on Virtual environments 2003 . ACM, 2003, pp. 125-133.
- [17] Xtext project, 'Xtext -Language Development Made Easy! -Eclipse,' 2013. [Online]. Available: http://www.eclipse.org/Xtext/ documentation.html
- [18] M. Fowler, Domain-specific languages . Pearson Education, 2010.
- [19] R. B. Rusu and S. Cousins, '3D is here: Point Cloud Library (PCL),' in IEEE International Conference on Robotics and Automation (ICRA) , Shanghai, China, May 9-13 2011. | null | [
"Sebastian Blumenthal",
"Herman Bruyninckx"
] | 2014-08-01T15:07:42+00:00 | 2014-08-01T15:07:42+00:00 | [
"cs.RO"
] | Towards a Domain Specific Language for a Scene Graph based Robotic World Model | Robot world model representations are a vital part of robotic applications.
However, there is no support for such representations in model-driven
engineering tool chains. This work proposes a novel Domain Specific Language
(DSL) for robotic world models that are based on the Robot Scene Graph (RSG)
approach. The RSG-DSL can express (a) application specific scene
configurations, (b) semantic scene structures and (c) inputs and outputs for
the computational entities that are loaded into an instance of a world model. |
1408.0202v2 | ## Analysis of Recurrent Linear Networks for Enabling Compressed Sensing of Time-Varying Signals
MohammadMehdi Kafashan, Anirban Nandi, and ShiNung Ching
## Abstract
Recent interest has developed around the problem of dynamic compressed sensing, or the recovery of timevarying, sparse signals from limited observations. In this paper, we study how the dynamics of recurrent networks, formulated as general dynamical systems, mediate the recoverability of such signals. We specifically consider the problem of recovering a high-dimensional network input, over time, from observation of only a subset of the network states (i.e., the network output). Our goal is to ascertain how the network dynamics lead to performance advantages, particularly in scenarios where both the input and output are corrupted by disturbance and noise, respectively. For this scenario, we develop bounds on the recovery performance in terms of the dynamics. Conditions for exact recovery in the absence of noise are also formulated. Through several examples, we use the results to highlight how different network characteristics may trade off toward enabling dynamic compressed sensing and how such tradeoffs may manifest naturally in certain classes of neuronal networks.
## Index Terms
Recurrent networks, linear dynamic systems, over-actuated systems, sparse input, l 1 minimization
## I. INTRODUCTION
W E consider the analysis of recurrent networks for facilitating recovery of a high-dimensional, time-varying, sparse input in the presence of both corrupting disturbance and confounding noise. The network receives an input u t and generates the observations (network outputs), y t via its recurrent dynamics, i.e.,
$$x _ { t + 1 } & = f ( x _ { t }, u _ { t }, d _ { t } ) \\ y _ { t } &$$
where, here, x t are the network states, d t is the corrupting disturbance and e t is the confounding noise. Our focus is on how the network dynamics, embedded in f ( ) · , g ( ) · , impact the extent to which u t can be inferred from y t in the case where the dimensionality of the latter is substantially less than that of the former. We will focus exclusively on the case where these dynamics are linear.
Such a problem, naturally, falls into the category of sparse signal recovery or compressed sensing (CS), for under-determined linear systems [1]-[3]. It is well known that for such problems, exact and stable recovery can be achieved under certain assumptions related to the statistical properties of the observed signal [4]-[7]. Classical CS, however, does not typically consider temporal dynamics associated with the recovery problem.
## A. Motivation
Given the natural sparsity of electrical signals in the brain, CS has been linked to important questions in neural decoding [8], [9], i.e., how the brain represents and transforms information. Understanding the dynamics of brain networks in the context of CS is a crucial aspect of this overall problem [8], [10]-[12]. Such networks are, of course, not static. Thus, recent interest has grown around so-called dynamic CS and, specifically, on the recovery of signals subjected to transformation via a dynamical system (or, network). In this context, sparsity has been formulated in three ways: 1) In the network states (state sparsity) [13]-[15]; 2) In the structure/parameters of the
- M. Kafashan and A. Nandi are with the Department of Electrical and Systems Engineering, Washington University in St. Louis, One Brookings Drive, Campus Box 1042, MO 63130, USA e-mail: [email protected], [email protected].
- S. Ching is with Faculty of Electrical Engineering & the Division of Biology and Biomedical Sciences, Washington University in St. Louis, One Brookings Drive, Campus Box 1042, MO 63130, USA e-mail: [email protected].
Fig. 1. Schematic of the considered network architecture. We study how the afferent, recurrent and output stages of this architecture interplay in order to enable accurate estimation of the input u t ( ) from y t ( ) in the presence of both disturbance and noise.
network model (model sparsity) [16], [17]; and 3) In the inputs to the network (input sparsity) [18]-[28]. Here, we consider this latter category of recovery problems.
Our motivation is to understand how three stages of a generic network architecture - an afferent stage, a recurrent stage, and an output stage (see Fig. 1) - interplay in order to enable an observer, sampling the output, to recover the (sparse) input. Such an architecture is pervasive in sensory networks in the brain wherein a large number of sensory neurons, receiving excitation from the periphery, impinge on an early recurrent network layer that transforms the afferent excitation en route to higher brain regions [29], [30]. Moreover, beyond neural contexts, understanding network characteristics for dynamic CS may aid in the analysis of systems for efficient processing of naturally sparse time-varying signals [20]; and in the design of resilient cyber-physical systems [18], [19], [21], wherein extrinsic perturbations are sparse and time-varying. Toward these potential instantiations, our specific aim in this paper is to elucidate fundamental dynamical characteristics of linear networks for exact and stable recovery of the (sparse) input signal, corrupted by an input disturbance.
## B. Paper Contributions
To achieve our specific aim, we develop and present the following contributions:
- 1) We develop analytical conditions on the network dynamics, related to the classical notion of observability for a linear system, such that the network admits exact and stable (in the presence of output noise) input recovery.
- 2) We derive an upper bound in terms of the network dynamics, for the l 2 -norm of the reconstruction error over a finite time horizon. This error can be defined in terms of both the disturbance and the noise.
- 3) Based on the error analysis, we characterize a basic tradeoff between the ability of a network to simultaneously reject input disturbances while still admitting stable recovery.
- 4) We highlight network characteristics that optimally balance this tradeoff, and demonstrate via several examples their ability to reconstruct corrupted time-varying input from noisy observations. In particular, we highlight an example of a rate-based neuronal network, and how specific features of the network architecture mediate these tradeoffs.
## C. Prior Results in Sparse Input Recovery
The sparse input recovery problem for linear systems can be formulated in both the spatial and temporal dimension. Our contributions are related to the former. As mentioned above, in this context, previous work has considered recovery of spatially sparse inputs for network resilience [18], [19] and encoding of inputs with sparse increments [20]. In [21], conditions for exact sparse recovery are formulated in terms of a coherence-based observability criterion for intended applications in cyber-physical systems. Our contributions herein provide a general set of analytical results, including performance bounds, pertaining to exact and stable sparse input recovery of linear systems in the presence of both noise and disturbance.
A second significant line of research in sparse input recovery problems pertains to the temporal dimension. There, the goal is to understand how a temporally sparse signal (i.e., one that takes the value of zero over a nontrivial portion of its history) can be recovered from the state of the network at a particular instant in time. This problem forms the underpinning of a characterization of 'memory' in dynamical models of brain networks [22]-[27]. In particular, in [28] the problem of ascertaining memory is related to CS performed on the network states, over a receding horizon of a scalar-valued input signal. In contrast to these works, we consider spatial sparsity of vectorvalued inputs with explicit regard for both disturbance and an overt observation equation, i.e., states are not be directly sampled, but are transformed to an (in general lower-dimensional) output.
## D. Paper Outline
The remainder of the paper is organized as follows. In Section II we provide motivation of the current work and formulate the problem in detail. In Section III we develop theoretical results on the performance of the proposed recovery method. Simulation results for several different scenarios are provided in Section IV. Finally, conclusions are formulated in Section V.
## II. PROBLEM FORMULATION
We consider a discrete-time model for a linear network, formulated in the typical form a linear dynamical system, i.e.,:
$$r _ { k + 1 } & = \text{Ar} _ { k } + \text{Bu} _ { k } + \text{d} _$$
where k is an integer time index, r k ∈ R n is the activity of the network nodes (e.g., in the case of a rate-based neuronal network [31]-[37], the firing rate of each neuron), u k ∈ R m is the extrinsic input, d k ∈ R n is the input disturbance, e k ∈ R p is the measurement noise independent from d k , and y k ∈ R p is the observation at time k . The matrix A ∈ R n × n describes connections between nodes in the network, B ∈ R n × m contains weights between input and output and C ∈ R p × n is the measurement matrix. Such a model is, of course, quite general and can be used to describe recurrent dynamics in neuronal networks [38]-[42], machine learning applications such as pattern recognition and data mining [43]-[46], etc.
We consider the case of bounded disturbance and noise, i.e., ‖ e k ‖ /lscript 2 ≤ /epsilon1 , ‖ d k ‖ /lscript 2 ≤ /epsilon1 ′ . Since m , the number of input nodes, is larger than n , the number of output nodes, B takes the form of a 'wide' matrix. We assume that at each time at most s input nodes are active ( s -sparse input), leading to an /lscript 0 constraint to (1) at each time point:
$$\| \mathbf u _ { k } \| _ { \ell _ { 0 } } & \leq s. & \quad \quad \quad$$
In the absence of disturbance and noise, recovering the input of (1) with the /lscript 0 constraint (2) amounts to the optimization problem:
$$( P 0 ) \underset { ( r _ { k } ) ^ { K } _ { k = 0 } ( u _ { k } ) ^ { K -$$
It is clear that Problem ( P 0 ) is a non-convex discontinuous problem, which is not numerically feasible and is NP-Hard in general [47]. For static cases, such /lscript 0 optimization problems fall into the category of combinatorial optimization which require exhaustive search to find the solution [48].
Thus, throughout this paper, we follow the typical relaxation methodology used for such problems wherein the /lscript 0 norm is relaxed to the l 1 norm, resulting in the problem:
$$\text{u-1 month, rounding} & \text{$m$ and previous} \\ ( P 1 ) \quad & \minimize _ { ( r _$$
In the case that either input disturbance, or measurement noise, or both exist, we solve the following convex optimization Problem ( P 2 ):
$$( P 2 ) & \underset { ( r _ { k } ) ^ { K } _ { k = 0 } ( \mathbf u _ { k } ) ^ { K - 1 } _ { k = 0 } } { \minimize } \underset { k = 0 } { \sum _ { k = 0 } ^ { K - 1 } \| \mathbf u _ { k } \| _ { \ell _$$
where /epsilon1 ′′ is 2-norm of a surrogate parameter that aggregates the effects of disturbance and noise. In the case of noisy measurement with no disturbance /epsilon1 ′′ = /epsilon1 . In the next section, we show conditions for the network (1) under which Problems ( P 1 ) and ( P 2 ) result in exact and stable solutions.
## III. RESULTS
We will develop our results in several steps. First, we consider two cases for the observation matrix C in the absence of input disturbance, and proceed to establish existence and performance guarantees for solutions to the convex problems ( P 1 ) and ( P 2 ) for each case. After that, we continue the analysis to characterize the ability of a network to reject input disturbances while still admitting stable recovery in the presence of disturbance and noise, simultaneously.
## A. Preliminaries
We begin by recalling some basic matrix notation and matrix norm properties that will be used throughout this paper. Given normed spaces ( R n 1 , ‖ ‖ . /lscript 2 ) and ( R n 2 , ‖ ‖ . /lscript 2 ) , the corresponding induced norm or operator norm denoted by ‖ ‖ . i, 2 over linear maps D : R n 1 → R n 2 , D ∈ R n 2 × n 1 is defined by where σ ( M ) is the set of eigenvalues of M (or the spectrum of M ).
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \$$
Definition 1 : A vector is said to be s -sparse if ‖ c ‖ /lscript 0 ≤ s , in other words it has at most s nonzero entries.
It is well known that in the static case (standard CS), exact and stable recovery of sparse inputs can be obtained under the restricted isometry property (RIP) [4]-[7], [49], defined as:
Definition 2 : The restricted isometry constant δ s of a matrix Φ ∈ R n × m is defined as the smallest number such that for all s -sparse vectors c ∈ R m the following equation holds
$$( 1 - \delta _ { s } ) \| c \| _ { \ell _ { 2 } } ^ { 2 } \leq \| \Phi c \| _ { \ell _ { 2 } } ^ { 2 } \leq ( 1 + \delta _ { s } ) \| c \| _ { \ell _ { 2 } } ^ { 2 }. \quad \quad \quad$$
It is known that many types of random matrices with independent and identically distributed entries or subGaussian matrices satisfy the RIP condition (7) with overwhelming probability [50]-[52].
## B. Case 1: Full-rank Square Observation Matrix C without Input Disturbance
In the first case, we consider (1) in the absence of input disturbance ( d k = 0 ) and we assume that the linear map C : R n → R n , p = n , has no nullspace, N ( C ) = { } 0 , which means that the network states can be exactly recovered by inverting the observation equation (1) (the trivial case being C equal to the identity). Our first result establishes a one to one correspondence between sparse input and observed output for the system (1).
Lemma 3 : Suppose that the sequence ( y k ) K k =0 from noiseless measurements is given, and A B C , , , N ( C ) = { } 0 are known. Assume the matrix B satisfies the RIP condition (7) with isometry constant δ 2 s < 1 . Then, there is a unique s -sparse sequence of ( u k ) K -1 k =0 and a unique sequence of ( r k ) K k =0 that generate ( y k ) K k =0 .
Proof. See Appendix A.

Having established the existence of a unique solution, we now proceed to study convex Problems ( P 1 ) and ( P 2 ) that recover these solutions. First, we provide theoretical results for the stable recovery of the input where measurements are noisy i.e., ( P 2 ).
Theorem 4 : (Noisy recovery) Assume that the matrix B satisfies the RIP condition (7) with δ 2 s < √ 2 -1 . Suppose that the sequence ( y k ) K k =0 is given and generated from sequences ( ¯ r k ) K k =0 and s -sparse ( ¯ u k ) K -1 k =0 based on
$$\bar { r } _ { k + 1 } & = A \bar { r } _ { k } + \mathbf B \bar { u } _ { k }, \ k = 0, \cdots, K - 1 \\ y _ { k } & = C \bar { r } _ { k } + e _ { k }, \ k = 0, \dots, K,$$
where ( ‖ e k ‖ /lscript 2 ≤ /epsilon1 ) K k =0 and A B C , , , N ( C ) = { } 0 are known. Then, the solution to Problem ( P 2 ) obeys where
$$\sum _ { k = 0 } ^ { K - 1 } \| \mathfrak { u } _ { k } ^ { * } - \bar { \mathfrak { u } } _ { k } \| _ { \ell _ { 2 } } \leq C _ { s } \epsilon,$$
$$C _ { s } = 2 \alpha C _ { 0 } K ( 1 - \rho ) ^ { - 1 }.$$
C , 0 ρ, α are given explicitly below:
$$n & \text{explicitly below} \colon \\ & C _ { 0 } = \frac { 1 } { \sqrt { \sigma } } \left ( 1 + \sqrt { \frac { \sigma _ { \max } \left ( C ^ { T } C \right ) \sigma _ { \max } \left ( A ^ { T } A \right ) } { \sigma _ { \min } \left ( C ^ { T } C \right ) } } \right ), \\ & \alpha = \frac { 2 \sqrt { 1 + \delta _ { 2 s } } } { 1 - \delta _ { 2 s } }, \\ & \rho = \frac { \sqrt { 2 } \delta _ { 2 s } } { 1 - \delta _ { 2 s } }, \\ & \sigma _ { \min } \left ( C ^ { T } C \right ) < \sigma < \sigma _ { \max } \left ( C ^ { T } C \right ). \\ & \text{at the the sequences} \left ( \mathfrak { r } _ { k } ^ { * } \right ) _ { k = 0 } ^ { K } \text{ and sparse} \left ( \mathfrak { u } _ { k } ^ { * } \right ) _ { k = 0 } ^ { K - 1 } \text{ are the solutions of Problem} \left ( P ^ { 2 } \right ). \text{ First we} \right ) \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{
} \text{
& \text{or the $\|\mathfrak{r}_{k}_{k}_{\mathfrak{e2}$ in the following Lemma.} } \text{ \text{ } \text : . - " ' < + |$$
Lemma 5 : Suppose that the sequence ( y k ) K k =0 is given and generated from sequences ( ¯ r k ) K k =0 and s -sparse ( ¯ u k ) K -1 k =0 based on (8), where ( ‖ e k ‖ /lscript 2 ≤ /epsilon1 ) K k =0 and A B C , , , N ( C ) = { } 0 are known. Then, any solution r ∗ k to Problem ( P 2 ) obeys
Proof. Assume that the the sequences ( r ∗ k ) K k =0 and sparse ( u ∗ k ) K -1 k =0 are the solutions of Problem ( P 2 ). First we derive the bound for the ‖ r ∗ k -¯ r k ‖ /lscript 2 in the following Lemma.
$$\| \mathbf r _ { k } ^ { * } - \bar { \mathbf r } _ { k } \| _ { \ell _ { 2 } } & \leq \frac { 2 \epsilon } { \sqrt { \sigma _ { \min } \left ( \mathbb { C } ^ { T } \mathbb { C } \right ) } }$$
## Proof. See Appendix B
From Lemma 5, non-singularity of C and the equation y k = CA¯ r k -1 + CB¯ u k -1 + e k we can derive a bound for ‖ B u ( ∗ k -¯ u k ) ‖ /lscript 2 as
$$\text{a 5, non-singularity of $C$ and the equation $y_{k}=CA\bar{r}_{k-1}+CB\bar{u}_{k-1}+e_{k}$ we can derive a bound} \\ \text{i} _ { k } \left \| _ { \ell _ { 2 } } \text{ as} \\ \sqrt { \sigma } \right \| B \left ( \text{u} _ { k } ^ { * } - \bar { \mathbf u } _ { k } \right ) \left \| _ { \ell _ { 2 } } = \left \| C B \left ( \text{u} _ { k } ^ { * } - \bar { \mathbf u } _ { k } \right ) \right \| _ { \ell _ { 2 } } \\ & = \left \| ( \text{e} _ { k + 1 } ^ { * } + \text{e} _ { k + 1 } ) + C \text{A} ( \bar { r } _ { k } - \text{r} _ { k } ^ { * } ) \right \| _ { \ell _ { 2 } } \\ & \leq \left \| \text{e} _ { k + 1 } + \text{e} _ { k + 1 } ^ { * } \right \| _ { \ell _ { 2 } } + \left \| C \text{A} ( \bar { r } _ { k } - \text{r} _ { k } ^ { * } ) \right \| _ { \ell _ { 2 } } \\ & \leq 2 \epsilon \left ( 1 + \sqrt { \frac { \sigma _ { m a x } \left ( C ^ { T } C \right ) \sigma _ { m a x } \left ( A ^ { T } A \right ) } { \sigma _ { m i n } \left ( C ^ { T } C \right ) } } \right ),$$
which results in
$$\| \mathbf B \left ( \mathbf u _ { k } ^ { * } - \bar { \mathbf u } _ { k } \right ) \| _ { \ell _ { 2 } } \leq 2 C _ { 0 } \epsilon. \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ ( 1 4 ) \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
Now, denote u ∗ k = ¯ u k + h k where h k can be decomposed into a sum of vectors h k,T 0 ( k ) , h k,T 1 ( k ) , h k,T 2 ( k ) , · · · for each k , each of sparsity at most s . Here, T 0 ( k ) corresponds to the location of non-zero elements of ¯ u k , T 1 ( k ) to the location of s largest coefficients of h k,T c 0 ( k ) , T 2 ( k ) to the location of the next s largest coefficients of h k,T c 0 ( k ) ,
and so on. Also, let T 01 ( k ) ≡ T 0 ( k ) ∪ T 1 ( k ) . Extending the technique in [7], [49], it is possible to obtain a cone constraint for the input in the linear dynamical systems.
Lemma 6 : (Cone constraint) The optimal solution for the input in Problem ( P 2 ) satisfies
$$\sum _ { k = 0 } ^ { K - 1 } \| \mathbf h _ {$$
Proof. See Appendix C.
We can further establish a bound for the right hand side of (15):
Lemma 7 : The optimal solution for the input in Problem ( P 2 ) satisfies the following constraint
$$\sum _ { k = 0 } ^ { K - 1 } \| \mathbf h _ {$$
Proof. See Appendix D.
Finally, based on Lemma 6 and Lemma 7, it is easy to see that
$$\ n L e m a { 6 } & \text{ and Lemma 7, it is easy to$$
We now state a Theorem that characterizes the solution for the noiseless case (P1), which follows as a special case of (P2) as the noise variance approaches zero.
Theorem 8 : (Noiseless recovery) Assume that the matrix B satisfies the RIP condition (7) with δ 2 s < √ 2 -1 . Suppose that the sequence ( y k ) K k =0 is given and generated from sequences ( ¯ r k ) K k =0 and s -sparse input ( ¯ u k ) K -1 k =0 based on dynamical equation (1), and A B C , , , N ( C ) = { } 0 are known. Then the sequences ( ¯ r k ) K k =0 and ( ¯ u k ) K -1 k =0 are the unique minimizer to Problem ( P 1 ).
Proof. It is sufficient to consider /epsilon1 = 0 in equation (49) which results in ‖ h 0 ,T 01 (1) ‖ /lscript 2 = · · · = ‖ h K -1 ,T 01 ( K -1) ‖ /lscript 2 = 0 from equation (54), which implies that all elements of vectors h 0 , · · · , h K -1 are zero and ( u ∗ k = ¯ u k ) K -1 k =0 .
## C. Case 2: Observation Matrix C Satisfying Observability Condition without Input Disturbance
In this case, we consider (1) in the absence of input disturbance ( d k = 0 ) with the linear map C : R n → R p , p < n . Thus, direct inversion of C is not possible in this case. For any positive K , we define the standard linear observability matrix as
$$\mathcal { O } _ { K } \equiv \begin{pmatrix} C$$
If rank ( O K ) = n , then the system (1) is observable in the classical sense 1 . However, we do not assume any knowledge of the input other than the fact that it is s -sparse at each time. Note that if we simply iterate the output
1 The system is said to be observable if, for any initial state and for any known sequence of input there is a positive integer K such that the initial state can be recovered from the outputs y 0 , y 1 ,..., y K .
s
s
Fig. 2. The matrix B s k is the n × s matrix corresponding the active columns of the full matrix B at time step k .
equation in (1) for K +1 time steps and exploit the fact that the input vector is s -sparse as shown in Fig. 2, we obtain:
where J s K is as follows:
$$\begin{array} {$$
$$\mathcal { J } _ { K } ^ { s } = \begin{pmatrix} 0 & 0 & \cdots & 0 \\ \mathcal { C } B _ { 0 } ^ { s } & 0 & \cdots & 0 \\ \mathcal { C } A B _ { 0 } ^ { s } & \mathcal { C } B _ { 1 } ^ { s } & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ \mathcal { C } A ^ { K - 1 } B _ { 0 } ^ { s } & \mathcal { C } A ^ { K - 2 } B _ { 1 } ^ { s } & \cdots & \mathcal { C } B _ { K - 1 } ^ { s } \end{pmatrix}, \quad ( 2 0 )$$
( ) In the next Theorem, we establish conditions under which a one to one correspondence exists between sparse input and observed output for the system (1).
where B s i is the n × s matrix corresponding the active columns of B (corresponding to nonzero input entries) at time step i (see Fig. 2). In general, we do not know where active columns of B are located at each time a priori . We define J s K as the set of all possible matrices satisfying the structure in (20), where the cardinality of this set is m K s .
Lemma 9 : Suppose that the sequence ( y k ) K k =0 from noiseless measurements is given, and A B , and C are known. Assume rank ( O K ) = n and the matrix CB satisfies the RIP condition (7) with isometry constant δ 2 s < 1 . Further, assume
$$\ r a n k ( [ \mathcal { O } _ { K } & \mathcal { J } _ { K } ^ { 2 s } ] ) = n + r a n k ( \mathcal { J } _ { K } ^ { 2 s } ), \ \forall \mathcal { J } _ { K } ^ { 2 s } \in \mathbf J _ { K } ^ { 2 s }. \\. & \quad. \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cd� \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cd: \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cd.. \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cd> \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdents \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdocks \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cdots \ \cd><> \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ } \end{cases}$$
Then, there is a unique s -sparse sequence of ( u k ) K -1 k =0 and a unique sequence of ( r k ) K k =0 that generate ( y k ) K k =0 .
Proof. See Appendix E.
Remark 10 : The rank condition implies that all columns of the observability matrix must be linearly independent of each other (i.e., the network is observable in the classical sense) and of all columns of J s K . Since the exact location of the nonzero elements of the input vector are not known a priori , this condition is specified over all J 2 s K . Thus, (21) is a combinatorial condition. From our simulation studies, we observe that this condition holds for random Gaussian matrices almost always and, moreover, can be numerically verified for certain salient random networks (see also Example 3 in Section IV).
Having established the existence of a unique solution, we now proceed to study the convex problems ( P 1 ) and ( P 2 ) that recover these solutions for this case. First, we provide theoretical results for the stable recovery of the input where measurements are noisy i.e., (P2).
Theorem 11 : (Noisy recovery) Assume rank ( O K ) = n and the matrix CB satisfies the RIP condition (7) with δ 2 s < √ 2 -1 . assume (21) holds. Suppose that the sequence ( y k ) K k =0 is given and generated from sequences ( ¯ r k ) K k =0 and s -sparse ( ¯ u k ) K -1 k =0 based on (8), where ( ‖ e k ‖ /lscript 2 ≤ /epsilon1 ) K k =0 and A B , and C are known. Then, any s -sparse solution of Problem ( P 2 ) obeys
$$\exists \, C _ { s } \ s u c h \ t h a t \, \sum _ { k = 0 } ^ { K - 1 } \| \mathfrak { u } _ { k } ^ { * } - \bar { \mathfrak { u } } _ { k } \| _ { \ell _ { 2 } } \leq C _ { s } \epsilon.$$
Proof. See Appendix F.
Theorem 12 : (Noiseless recovery) Assume rank ( O K ) = n and the matrix CB satisfies the RIP condition (7) with δ 2 s < √ 2 -1 . Further, assume (21) holds. Suppose that the sequence ( y k ) K k =0 is given and generated from sequences ( ¯ r k ) K k =0 and s -sparse inputs ( ¯ u k ) K -1 k =0 based on dynamical equation (8), where /epsilon1 = 0 and A B , and C are known. Then the sequences ( ¯ r k ) K k =0 and ( ¯ u k ) K -1 k =0 are the unique minimizer to Problem ( P 1 ).
Proof. It can be concluded from Lemma 9 and Theorem 11 that with the assumption stated in the theorem and /epsilon1 = 0 the sequences ( ¯ r k ) K k =0 and ( ¯ u k ) K -1 k =0 are the unique minimizer to Problem ( P 1 ).
Remark 13 : Imposing an RIP condition on the combined matrix CB bears some conceptual similarity to the formulation of an overcomplete dictionary in the classical compressed sensing literature [53], [54]. In this sense, the B matrix (i.e., the afferent stage) can be interpreted as a dictionary that transforms the sparse input u onto the recurrent network states.
## D. Case 3: Optimal Network Design to Enable Recovery in the Presence of Disturbance and Noise
Finally, we show how eigenstructure of the network implies a fundamental tradeoff between stable recovery and rejection of disturbance (i.e., corruption).
It is easy to see from (9) that the upper-bound of the recovery error is reduced by decreasing the maximum singular value of A . Thus, from now on we use the upper-bound of the input recovery error as a comparative measure of performance. In the absence of both disturbance and noise, the best error performance is achieved when A = 0 , i.e., the network is static, which in intuitive since in this scenario any temporal effects would smear the salient parts of the signal.
On the other hand, having dynamics in the network should improve the error performance in the presence of the disturbance. To demonstrate this, consider (1) with d k nonzero. When A = 0 , i.e., a static network, the disturbance can be exactly transformed to the measurement equation resulting in Cd k + e k as a surrogate measurement noise with
In this case, the error upper-bound can be obtained by exploiting the result of Theorem 4 as
$$\text{$a$ to the measurement equation resulting in $\mathcal{Co}_{k}+e_{k}$ as a surrogate measurement noise} \\ & \| \text{Cd}_{k}+e_{k} \| _ { \ell _ { 2 } } \leq \sqrt { \sigma ^ { \prime } \epsilon ^ { \prime } + \epsilon, } \\ & \sigma _ { \min } \left ( \text{C} ^ { T } \text{C} \right ) < \sigma ^ { \prime } < \sigma _ { \max } \left ( \text{C} ^ { T } \text{C} \right ). } \\ \text{er-bound can be obtained by exploiting the result of Theorem $4$ as} \\ & K = 1$$
$$\sum _ { k = 0 } ^ { K - 1 } & \| u _ { k } ^ { * } - \bar { u } _ { k } \| _ { \ell _ { 2 } } \leq C _ { s } ^ { \prime } ( \sqrt { \sigma ^ { \prime } } \epsilon ^ { \prime } + \epsilon ), \\ C _ { s } ^ { \prime } & = \frac { 2 } { \sqrt { \sigma } } \alpha K ( 1 - \rho ) ^ { - 1 }. \\ \text{is not accessible to another man that determine to the output as shown. }$$
When A is nonzero, it is not possible to exactly map the disturbance to the output as above. Nevertheless, it is straightforward to approximate the relative improvement in performance. For instance, consider a system with A symmetric and where the disturbance and input are in displaced frequency bands. Then it is a direct consequence of linear filtering that the power spectral density of the disturbance can be attenuated according to
$$\mathcal { S } _ { \text{d} } \text{fin} ( e ^$$
Fig. 3. The recovered input for (A) p = n (B) p = 35 for both static (middle images) and dynamic (left images) CS where n = 45 and m = 68 . Original input is in the right hand side denoted as true digit.
where ω is the frequency of the disturbance. So, for instance, if ω = π ,
$$\text{s.s.s.s.s.s.s.s.s.s$$
where λ i ( A ) is the i th eigenvalue of matrix A . Assuming the input is sufficiently displaced in frequency from the disturbance, the error upper-bound can be then readily approximated using the results of Theorem 4 as follows
$$\text{e error upper-bound can be then readily approximated using the results of Theorem 4 as$$
By comparing (24) and (27), it is easy to verify that A and C can be designed in a way to reduce error upper-bound at least by a factor of two, assuming σ ′ and σ ′′ are close to each other. In the examples below, we will show that, in fact, performance in many cases can exceed this bound considerably.
## IV. EXAMPLES
In this section, we present several examples that demonstrate the developed results. For solving our convex optimization problems, we used CVX with MATLAB interface [55], [56]. To create example networks, we generated the matrices A B C , , using a Gaussian random number generator in MATLAB.
## A. Example 1: One-step and Sequential Recovery
In this experiment, we consider a dynamical system with sparse input which satisfies conditions in Theorem 11. Here, we consider random Gaussian matrices for A B , and C , with n = 45 , m = 68 . The input is defined as the image of a digit, shown in Fig. 3 with values between 0 and 1, where the horizontal axis is treated as time, i.e., column k of the image is the input to the system at time k .
We proceed to perform input recovery in two ways: (i) by solving ( P 1 ) in one step over the entire horizon K , i.e., one-step recovery; and (ii) by solving ( P 1 ) K times, sequentially, i.e., recovery at each time step. We compare the outcomes for two cases:
a) Full Rank C : Fig. 3A shows the recovered input for the case that p = n for both one-step and sequential recovery, and it can be seen that sparse input can be recovered in two cases perfectly. This is expected, since in this case, C can be inverted at each time step.
Fig. 4. (A) MSE versus the maximum singular value of A , for several random realization of A with noise and in the absence of disturbance. (B) MSE versus the maximum singular value of A , for several random diagonal A with noise and disturbance.
Fig. 5. MSE as a function of (A) log (1 //epsilon1 ) and (B) log (1 //epsilon1 ′ ) for the reconstructed input with n = 50 , m = 100 over 100 random trials (different random matrices A B C , , in each trial).
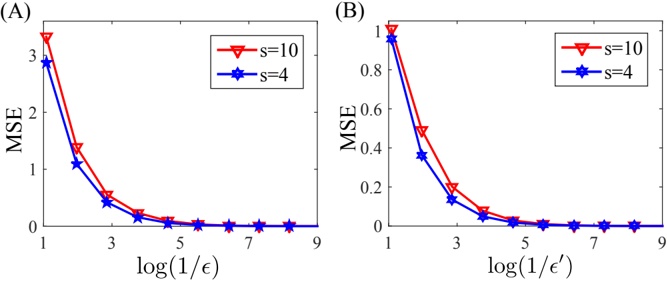
b) C Satisfying Observability Condition: Fig. 3B of the figure illustrates the results for the case that p = 35 , but where C satisfies the observability condition. It is clear that sequential dynamic CS can not recover the input exactly. However, from our results (Theorem 12) we expect that one-step recovery (over the entire horizon) is possible, as is evidenced in the figure.
## B. Example 2: Recovery in the Presence of Disturbance and Noise
Fig. 4A shows the mean square error ( MSE ) versus the maximum singular value of A , for several random realization of A , in the case of full rank C . In this study, e k is assumed to follow an uniform distribution U -( 0 5 . , 0 5) . while d k = 0 . It can be seen from this figure that by increasing √ σ max ( A A T ) , the recovery performance is degraded, as we expect based on the derived bound for the error in (9).
We conducted simulation experiments to examine the effect of the noise and disturbance strength on the reconstruction error. Fig. 5 shows the average MSE for the reconstructed input versus log (1 //epsilon1 ) and log (1 //epsilon1 ′ ) , respectively with n = 50 , m = 100 for 100 random trials (different random matrices A, B, C in each trial). This figure shows that the reconstruction error decreases as a function of noise energy.
To contrast Fig. 4A, we consider the case when disturbance is added to the input. In Fig. 4B, we show the MSE versus √ σ max ( A A T ) for several random diagonal matrices A when e k ∼ U -( 0 5 . , 0 5) . and d k ∼ N (0 1) , . As expected from our results, √ σ max ( A A T ) can not be arbitrary small, since in this case the disturbance would entirely corrupt the input.
The next study illustrates recovery in the presence of both disturbance and noise for a smoothly changing sequence of 64 images (frames). Each frame, is corrupted with disturbance and at each time, and the difference between two consecutive frames is considered as the sparse input to the network. The disturbance d k is assumed to be a random variable drown from a Gaussian distribution, N (0 0 2) , . , passed through a fifth-order Chebyshev high pass
Fig. 6. (A) Four noiseless frames of a movie. Recovery via (B) static CS and (C) dynamic CS in the presence of disturbance.
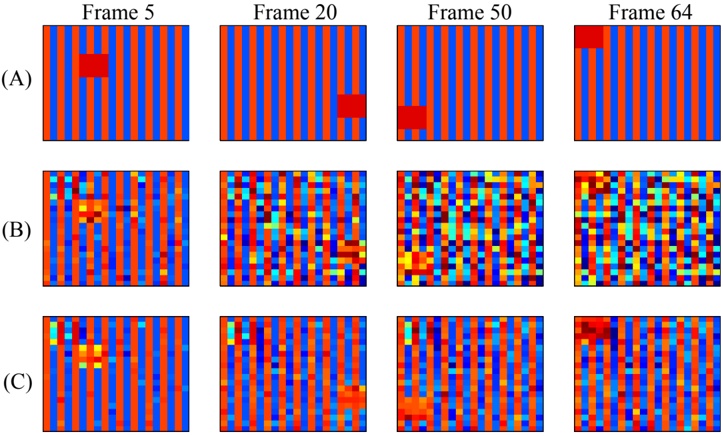
Fig. 7. PSNR of the recovered frame versus frame number for both CS with and without dynamics.
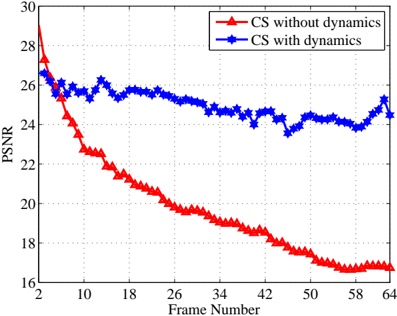
filter. Each frame has m = 400 pixels and K = 64 . Furthermore, we consider random Gaussian matrices for B and C with n = p = 200 .
We proceeded to design the matrix A to balance the performance bound (9) and the ability to reject the disturbance as per Section III-D. Fig. 6A shows the original frames at different times. We assumed the first frame is known exactly. Frames recovered from the output of a static network , i.e., A = 0 are depicted in Fig. 6B. In contrast, frames recovered from the output of the designed dynamic network are shown in Fig. 6C. It is clear from the figure that quality of recovery is better in the latter case. Fig. 7 illustrates the PSNR, defined as 10log( 1 MSE ) as a function of frame number with and without dynamics. It can be concluded from this figure that having a designed matrix A results in recovery that is more robust to disturbance, while without dynamics, error propagates over time, and the reconstruction quality is degraded.
## C. Example 3: Input Recovery in an Overactuated Rate-Based Neuronal Network
A fundamental question in theoretical neuroscience centers on how the architecture of brain networks enables the encoding/decoding of sensory information [10], [57]. In our final example, we use the results of Theorems 4 and 12 to highlight how certain structural and dynamical features of neuronal networks may provide the substrate for sparse input decoding.
Fig. 8. (A) The maximum singular value of A versus the inhibition percentage. MSE of input recovery in the presence of (B) Noise and (C) Disturbance as a function of the percent of inhibitory neurons.
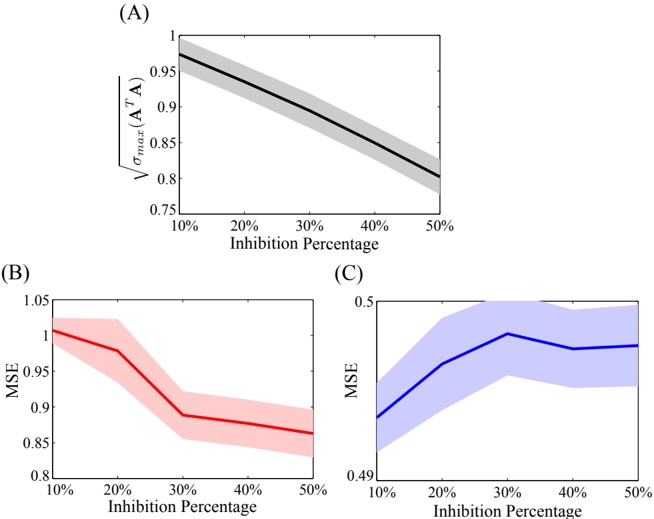
Specifically, we consider a firing rate-based neuronal network [34] of the form
$$\mathbf T _ { r } \frac { d r } { d t } = - r +$$
with input rates u ∈ R m , output rates r ∈ R n , a feed-forward synaptic weight matrix W ∈ R n × m , and a recurrent synaptic weight matrix M ∈ R n × n . We consider n = 50 neurons which receive synaptic inputs from m = 100 afferent neurons, i.e., neurons that impinge on the network in question. Here, T r ∈ S n + is a diagonal matrix whose diagonal elements are the time constants of the neurons. A discrete version of (28), alongside a linear measurement equation can be written in the standard form (1) where A = I n -∆ t T r -1 +∆ t T r -1 M is related to connections between nodes in the network, and B = ∆ t T r -1 W contains weights between input and output nodes. For this example, we assume that the network connectivity has a Watts-Strogatz small-world topology [58] with connection probability p M and rewiring probability q M .
The recurrent synaptic matrix M is defined as
$$\begin{array} {$$
For the purposes of illustration, we select the diagonal elements of matrix T r , from a uniform distribution U (0 1 . , 0 2) . . We study the recovery performance associated with the network over 100 time steps, assuming a timescale of milliseconds and an discretization step of 0 1 . ms . At each time step, the nonzero elements of the input vector u , i.e., firing rate of the afferent neurons, are drawn from an uniform distribution U (0 5 . , 1 5) . . Moreover, we assume that elements of the observation matrix C are drawn from a Gaussian distribution N (0 1) , . Finally, we assume m E ij and m I ij are drawn from lognormal distributions ln N (0 1) , and ln N (0 0 1) , . , respectively. The latter assumption is chosen for illustration only and is not related to known physiology.
1) Recovery Performance from Error Bounds: We proceed to conduct a Monte Carlo simulation of 100 different realizations of W M , and C . Fig. 8A illustrates that the maximum singular value of the matrix A decreases as a function of the percent of inhibitory neurons. Thus, we anticipate from our derived performance bounds that performance in terms of mean square error (MSE) should be best for networks with high inhibition in the presence of noise. This prediction bears out in Fig. 8B, where we indeed observe a monotone relationship between MSE
Fig. 9. (A) Examining the rank condition (21) in the networks of Example 3, with p = 30 , for different values of s . (B) The probability of exact recovery of dynamic sparse input to the network over s .
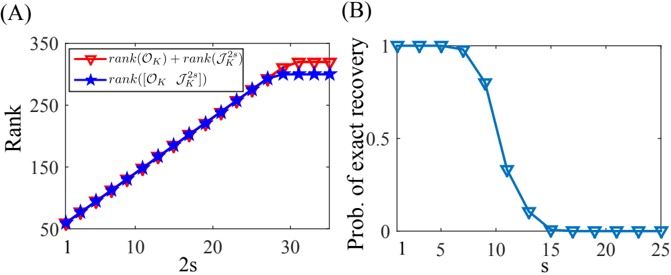
and inhibition. On the one hand, low-inhibition is favorable for facilitating recovery in the presence of disturbance depicted in Fig. 8C. Such tradeoffs are interesting to contemplate when considering the functional advantages of network architectures observed in biology, such as the pervasive 80-20 ratio of excitatory to inhibitory neurons [34], [59]. Together, Figs. 8B and 8C illustrate how the excitatory-inhibitory ratio mediate a basic tradeoff in the capabilities of a rate-based neuronal network.
2) Recoverable Sparsity based on Theorem 12: Having ascertained the performance tradeoff curves, we sought to characterize in more detail the level of recoverable sparsity with specific connection to Theorem 12 and (21). We considered networks as above, but with p = 30 and 20/80 for the ratio of inhibitory/excitatory over 10 time steps for 100 random trials. Thus, the output of the network is of lower dimension than the network state space and the observability matrix is of nontrivial construction. Fig. 9A shows that for this setup, the rank condition (21) holds up to 2 s = 27 . Thus, Theorem 12 predicts that recover will be possible (to within the RIP condition on CB ) for signals with 13 nonzero elements. Fig. 9B validates this theoretical prediction by illustrating recovery performance in the absence of disturbance and noise for different values s . It is observed that when the rank condition holds, reconstruction is perfect and that the probability of exact recovery is decreased by increasing s , as expected.
## V. CONCLUSION
## A. Summary
In this paper, we present several results pertaining to the effect of temporal dynamics on compressed sensing of time-varying signals. Specifically, we considered the recovery of sparse inputs to a linear dynamical system (network) from limited observation of the network states. We provide basic conditions on the system that ensure solution existence and, further, derive several bounds in terms of the system dynamics for recovery performance in the presence of both input disturbance and observation noise. We show that dynamics can play opposing roles in mediating accurate recovery with respect to these two different sources of corruption. Thus, our results indicate tradeoffs that may inform the design of dynamical systems for time-varying compressed sensing. These tradeoffs are illustrated through a series of examples, including one that highlights how the developed theory could be used to interrogate the functional role of inhibition in a neuronal network.
## B. Implications and Future Work
The results can have both engineering and scientific impacts. In the former case, the goal may be to design networks to process time-varying signals that are naturally sparse, such as high-dimensional neural data, or to be resilient to time-varying sparse perturbations. In the latter case, the goal is to understand how the naturally occurring architectures of networks, such as those in the brain, confer advantages for processing of afferent signals. In both cases, a precursor to further study are a set of verifiable conditions that overtly link network characteristics/dynamics to sparse input processing. Our paper provides such conditions for networks with linear dynamics and develops illustrative examples that highlight these potential applications. Treatment of systems with nonlinear dynamics, as well as a more detailed examination of random networks using the theory, are left as subjects for future work.
## APPENDIX A
## PROOF OF LEMMA 3
Based on the assumption on the null space of the linear map C : R n → R n , given ( y k ) K k =0 , there is a unique sequence of ( r k ) K k =0 . We now prove the uniqueness of ( u k ) K -1 k =0 . First, consider the following equations:
$$\begin{array} {$$
$$y _ { K } = C \text{Ar} _ { K - 1 } + \text{$$
The remainder of the proof is by contradiction. Let us assume that the sequence ( u k ) K -1 k =0 is not unique and there is another sequence of s -sparse ( ˆ u k ) K -1 k =0 which satisfies (30), leading to
$$\begin{array} { c } y _ { 0 } = C r _ { 0 } \\ y$$
$$\begin{smallmatrix} \\ \vdots \\ \end{smallmatrix}$$
$$y _ { K } = \text{CAr} _ { K - 1 } + \text{$$
Therefore, based on (30) and (31) we can conclude that
$$\begin{array} {$$
Matrix C is non-singular, hence equation (33) can be simplified as follows:
$$B ( u _ { 0 } - \hat { u } _ { 0 } ) = \dots$$
Based on the assumption that the matrix B satisfies the RIP condition (7) with isometry constant δ 2 s < 1 and the fact that the support of the vectors ( u 0 -ˆ u 0 ) , · · · , ( u K -1 -ˆ u K -1 ) are at most 2 s , the lower bound of the RIP condition for B results in
$$\ n \, \text{for $B$ results in} \\ ( 1 - \delta _$$
which means that u 0 = ˆ u 0 , · · · , u K -1 = ˆ u K -1 and the sequence of s -sparse vectors ( u k ) K -1 k =0 is unique.
## APPENDIX B PROOF OF LEMMA 5
If r ∗ k is the solution to Problem ( P 2 ), then y ∗ k = Cr ∗ k satisfies the inequality in ( P 2 ) which means that ‖ y k -y ∗ k ‖ /lscript 2 ≤ /epsilon1 which can be reformulated as
$$y _ { k } ^ { * } = y _ { k } + e _ { k } ^$$
By replacing y k from (8) in (35) we have which results in
$$C r _ { k } ^ { * } & = C \bar { r } _ { k }$$
$$\| \mathbf r _ { k } ^ { * } - \bar { \mathbf r } _ { k } \| _ { \ell _ { 2 } } = \| \mathbf C ^ { - 1 } \left ( \mathbf e _ { k } + \mathbf e _ { k } ^ { * } \right ) \| _ { \ell _ { 2 } }. \\ \intertext { a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a n d a } \| \left ( \mathbf r _ { k } ^ { * } - \bar { \mathbf r } _ { k } \right ) \| \right )$$
Finally, we can derive the error bound for the state error at each time by substituting (6) into (37) as
$$\text{an derive the error bound for the state error at each time by substituting (6) into (37) as } \| \mathfrak { r } _ { k } ^ { * } - \bar { \mathfrak { r } } _ { k } \| _ { \ell _ { 2 } } & \leq \sqrt { \sigma _ { m a x } \left ( C ^ { - T } C ^ { - 1 } \right ) } \ \| e _ { k } + e _ { k } ^ { * } \| _ { \ell _ { 2 } } \\ & \leq \sqrt { \sigma _ { m a x } \left ( C ^ { - T } C ^ { - 1 } \right ) } \ \left ( \| e _ { k } \| _ { \ell _ { 2 } } + \| e _ { k } ^ { * } \| _ { \ell _ { 2 } } \right ) & & & ( 3 8 ) \\ & = \frac { 2 \epsilon } { \sqrt { \sigma _ { m i n } \left ( C ^ { T } C \right ) } }$$
## APPENDIX C
## PROOF OF LEMMA 6
For each j ≥ 2 and k = 0 , · · · , K -1 we have
$$\| \mathbf h _ { k, T _ { j } ( k ) } \| _ { \ell _ { 2 } } & \leq s ^ { 1 / 2 } \| \mathbf h _ { k, T _ { j } ( k ) } \| _ { l _ { \infty } } \leq s ^ { - 1 / 2 } \| \mathbf h _ { k, T _ { j - 1 } ( k ) } \| _ { \ell _ { 1 } },$$
and thus
$$\sum _ { j \geq 2 } \| \mathfrak { h } _ { k, T _ { j } ( k ) } \| _ { \ell _ { 2 } } & \leq s ^ { - 1 / 2 } ( \| \mathfrak { h } _ { k, T _ { 1 } ( k ) } \| _ { \ell _ { 1 } } + \| \mathfrak { h } _ { k, T _ { 2 } ( k ) } \| _ { \ell _ { 1 } } + \cdots ) \\ & \leq s ^ { - 1 / 2 } \| \mathfrak { h } _ { k, T _ { 2 } ^ { \zeta } ( k ) } \| _ { \ell _ { 1 } }. \\ \intertext { e have the following equation}$$
Therefore, we have the following equation
$$\lambda \ \cdot \ \cdot \\ \| \mathbf h _ { k, T _ { 0 } ^ { \sigma } ( k ) } \| _ { \ell _ { 2 } } & = \| \sum _ { j \geq 2 } \mathbf h _ { k, T _ { j } ( k ) } \| _ { \ell _ { 2 } } \leq \sum _ { j \geq 2 } \| \mathbf h _ { k, T _ { j } ( k ) } \| _ { \ell _ { 2 } } \\ & \leq s ^ { - 1 / 2 } \| \mathbf h _ { k, T _ { 0 } ^ { \sigma } ( k ) } \| _ { \ell _ { 1 } }. \\ \minimize \text{$thecostfunction in Problam $LDP$} \/$$
Since ( u ∗ k ) K -1 k =0 minimizes the cost function in Problem ( P 2 ),
$$\sum _ { k = 0 } ^ { K - 1 } \| \bar { u } _ { k } \| _ { \ell _ { 1 } } & \geq \sum _ { k = 0 } ^ { K - 1 } \| \bar { u } _ { k } ^ { * } \| _ { \ell _ { 1 } } = \sum _ { k = 0 } ^ { K - 1 } \| \bar { u } _ { k } + \bar { h } _ { k } \| _ { \ell _ { 1 } } \\ & = \sum _ { k = 0 } ^ { K - 1 } \left ( \sum _ { i \in T _ { 0 } ( k ) } | \bar { u } _ { k, i } + \sum _ { i \in T _ { 0 } ^ { * } ( k ) } | \bar { u } _ { k, i } + \bar { h } _ { k, i } | \right ) \\ & \geq \sum _ { k = 0 } ^ { K - 1 } ( \| \bar { u } _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 1 } } - \| \bar { h } _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 1 } } + \| \bar { h } _ { k, T _ { 0 } ^ { * } ( k ) } \| _ { \ell _ { 1 } } \\ & \quad + \| \bar { u } _ { k, T ^ { * } _ { 0 } ( k ) } \| _ { \ell _ { 1 } } ) \\ \dots \dots \dots \dots \epsilon \dots \epsilon \cap \tau \cap \tau \cap \tau \dots \dots \dots \epsilon \dots$$
k,T
+
‖
¯
u
c
0
(
k
)
‖
/lscript
1
)
¯ u 0 , · · · , ¯ u K -1 are non-zero for T 0 (0) , · · · , T 0 ( K -1) , respectively. Therefore,
$$\| \bar { \mathbf u } _ { 0, T _ { 0 } ^ { c } ( 0 ) } \| _ { \ell _ { 1 } } = \dots = \| \bar { \mathbf u } _ { K - 1, T _ { 0 } ^ { c } ( K - 1 ) } \| _ { \ell _ { 1 } } = 0$$
which gives
Considering
$$\sum _ { k = 0 } ^ { K - 1 } \| h _ { k, T _ { 0 } ^ { c } ( k ) } \| _ { \ell _ { 1 } } \leq \sum _ { k = 0 } ^ { K - 1 } \| h _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 1 } }.$$
$$\| \mathbf h _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 1 } } & \leq s ^ { 1 / 2 } \| \mathbf h _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 2 } }, & & ( 4 5 ) \\. \dots &.$$
and substituting it into (41) and (44) we have
$$\sum _ { k = 0 } ^ { K - 1 } \| h _ { k, T _ { 0 } ^ { 2 } ( k ) } \| _ { \ell _ { 2 } } \leq \sum _ { k = 0 } ^ { K - 1 } \| h _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 2 } },$$
## APPENDIX D
PROOF OF LEMMA 7
To find the bound for ∑ K -1 k =0 ‖ h k,T 01 ( k ) ‖ /lscript 2 , we start with
$$\text{Bh} _ { k } & = \text{Bh} _ { k, T _ { 0 1 } ( k ) } + \sum _ { j \geq 2 } \text{Bh} _ { k, T _ { j } ( k ) },$$
which gives
$$\| \text{Bh} _ { k, T _ { 0 1 } ( k ) } \| _ { \ell _ { 2 } } ^ { 2 } & = \langle \text{Bh} _ { k, T _ { 0 1 } ( k ) }, \text{Bh} _ { k } \rangle \\ & \quad - \langle \text{Bh} _ { k, T _ { 0 1 } ( k ) }, \sum _ { j \geq 2 } \text{Bh} _ { k, T _ { j } ( k ) } \rangle.$$
From (14) and the RIP condition for B ,
$$| \langle \text{Bh} _ { k, T _ { 0 1 } ( k ) }, \text{Bh} _ { k } \rangle | & \leq \| \text{Bh} _ { k, T _ { 0 1 } ( k ) } \| _ { \ell _ { 2 } } \| \text{Bh} _ { k } \| _ { \ell _ { 2 } } \\ & \leq 2 \epsilon C _ { 0 } \sqrt { 1 + \delta _ { 2 s } } \| \text{h} _ { k, T _ { 0 1 } ( k ) } \| _ { \ell _ { 2 } }, \\ \text{plication of the parallelogram identity for disjoint subsets } T _ { 0 } ( k ) \text{ and } T _ { j } ( k ), j \geq 2 \text{ results in}$$
and, moreover, application of the parallelogram identity for disjoint subsets T 0 ( k ) and T j ( k , j ) ≥ 2 results in
$$| \langle \text{Bh} _ { k, T _ { 0 } ( k ) }, \text{Bh} _ { k, T _ { j } ( k ) } \rangle | \leq \delta _ { 2 s } \| \text{h} _ { k, T _ { 0 } ( k ) } \| _ { \ell _ { 2 } } \| \text{h} _ { k, T _ { j } ( k ) } \| _ { \ell _ { 2 } }. \\ \cdots \cdots \cdots \cdots \cdots$$
Inequality (50) holds for T 1 in place of T 0 . Since T 0 and T 1 are disjoint
$$\sin \pi _ { 1 } \Pi \cos \pi _ { 0 } \cdot \Pi \cos \pi _ { 0 } \sum \pi _ { 1 } \sum \max \pi _ { 0 } \\ \left \| \mathbf h _ { k, T _ { 0 } ( k ) } \right \| _ { \ell _ { 2 } } + \left \| \mathbf h _ { k, T _ { 1 } ( k ) } \right \| _ { \ell _ { 2 } } \leq \sqrt { 2 } \| \mathbf h _ { k, T _ { 0 1 } ( k ) } \| _ { \ell _ { 2 } },$$
which results in
$$\text{ts in} & ( 1 - \delta _ { 2 s } ) \| \$$
It follows from (40) and (52) that
$$\| \mathbf h _ { k, T _ { 0 1 } ( k ) } \|$$
Now, using (44) and (53) we can conclude that which means
$$\Lambda \, \text{and} \, ( 5 3 ) \, \text{$$
$$\sum _ { k = 0 } ^ { K - 1 } \| \mathbf h _ {$$
## APPENDIX E
## PROOF OF LEMMA 9
We start the proof using contradiction. Let us assume that the sequence of ( u k ) K -1 k =0 and ( r k ) K k =0 is not unique and there is another sequence of s -sparse ( ˆ u k ) K -1 k =0 and ( ˆ r k ) K k =0 which satisfies the system (1) with noiseless measurements. Note that u k -ˆ u k has at most 2 s nonzero elements. Similar to the depiction in Fig. 2, we can rewrite (19) based on 2 s columns of B corresponding to 2 s active non-zero elements of u k -ˆ u k as
$$\begin{array} {$$
$$\bigvee ^ { J \, N } / \bigvee _ { K - 1 } / \\ \binom { y _ { 0 } } { y _ { 1 } } & = \mathcal { O } _ { K } \hat { r } _ { 0 } + \mathcal { J } _ { K } ^ { 2 s } \begin{pmatrix} \hat { u } _ { 0 } ^ { 2 s } \\ \hat { u } _ { 1 } ^ { 2 s } \\ \vdots \\ \hat { u } _ { K - 1 } ^ { 2 s } \end{pmatrix}.$$
By subtracting the above equations from each other we have
$$\text{ove equations nom eam one} \, \text{me} \, \text{me} \, \text{have} \\ \mathcal { O } _ { K } ( r _ { 0 } - \hat { r } _ { 0 } ) + \mathcal { J } _ { K } ^ { 2 s } \begin{pmatrix} u _ { 0 } ^ { 2 s } - \hat { u } _ { 0 } ^ { 2 s } \\ u _ { 1 } ^ { 2 s } - \hat { u } _ { 1 } ^ { 2 s } \\ \vdots \\ u _ { K - 1 } ^ { 2 s } - \hat { u } _ { K - 1 } ^ { 2 s } \end{pmatrix} = 0. \quad & ( 5 8 ) \\ \text{is that rank} ( \mathcal { O } _ { K } ) = n \, \text{ and rank} ( [ \mathcal { O } _ { K } - \mathcal { J } _ { K } ^ { 2 s } ] ) = n + \text{rank} ( \mathcal { J } _ { K } ^ { 2 s } ), \, \forall \mathcal { J } _ { K } ^ { 2 s } \in \mathcal { J } _ { K } ^ { 2 s }, \, \text{all columns of} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{ne} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \, \text{me} \,$$
Based on assumptions that rank ( O K ) = n and rank ([ O K J 2 s K ]) = n + rank ( J 2 s K ) , ∀J 2 s K ∈ J 2 s K s , all columns of the observability matrix must be linearly independent of each other, and of all columns of the J 2 K matrix. Hence, the vector r 0 -ˆ r 0 = 0 . Having r 0 = ˆ r 0 and the matrix CB satisfying the RIP condition (7) with isometry constant δ 2 s < 1 , it is easy to see that u k = ˆ u k and therefore there exists unique state and s -sparse input sequences.
## APPENDIX F
## PROOF OF THEOREM 11
Lets assume that the the sequences ( r ∗ k ) K k =0 and s -sparse ( u ∗ k ) K -1 k =0 are the solutions of Problem ( P 2 ). In this case (58) can be rewritten as
$$\mathcal { O } _ { K } ( r _ { 0 } ^ { * } - \bar { r } _ { 0 } ) + \mathcal { J } _ { K } ^ { 2 s } \begin{pmatrix} u _ { 0 } ^ { * 2 s } - \bar { u } _ { 0 } ^ { 2 s } \\ u _ { 1 } ^ { * 2 s } - \bar { u } _ { 1 } ^ { 2 s } \\ \vdots \\ u _ { K - 1 } ^ { * 2 s } - \bar { u } _ { K - 1 } ^ { 2 s } \end{pmatrix} = \begin{pmatrix} e _ { 0 } \\ e _ { 1 } \\ \vdots \\ e _ { K } \end{pmatrix} + \begin{pmatrix} e _ { 0 } ^ { * } \\ e _ { 1 } ^ { * } \\ \vdots \\ e _ { K } ^ { * } \end{pmatrix}, \\ \| _ { \mathcal { L } _ { 2 } } \leq \epsilon. \ B a s e d o n a s u m p t i o n s t a r a n k ( \mathcal { O } _ { K } ) = n \, \text{and} \, \text{rank} ( [ \mathcal { O } _ { K } \, \mathcal { J } _ { K } ^ { 2 s } ] ) = n + \text{rank} ( \mathcal { J } _ { K } ^ { 2 s } ), \, \forall \mathcal { J } _ { K } ^ { 2 s } \in J _ { K } ^ { 2 s } \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \end{pmatrix},$$
$$\text{we have} \quad & y _ { 1 } ^ { * } = C A _ { 0 } ^ { * } + C B u _ { 0 } ^ { * } \\ & y _ { 1 } = C A _ { 0 } + C B \bar { u } _ { 0 } + e _ { 0 }, \ \| e _ { 0 } \| _ { \ell _ { 2 } } \leq \epsilon. & ( 6 0 ) \\ & y _ { 1 } ^ { * } = y _ { 1 } + e _ { 0 } ^ { * }, \ \| e _ { 0 } ^ { * } \| _ { \ell _ { 2 } } \leq \epsilon \\ \text{satisfies the RIP condition} \, ( 7 ) \, \text{with isometr constant} \, \delta _ { \lambda _ { \lambda } } < \sqrt { 2 } - 1. \, \text{with the same annroach}$$
where ‖ e ∗ k ‖ /lscript 2 ≤ /epsilon1 . Based on assumptions that rank ( O K ) = n and rank ([ O K J 2 s K ]) = n + rank ( J 2 s K ) , ∀J 2 s K ∈ J 2 s K we can project the above equation using the projection ( I -P J 2 s K ) where P J 2 s K = J 2 s K ( J 2 s T K J 2 s K ) -1 J 2 s T K . It is straightforward to verify that ( I -P J 2 s K ) J 2 s K = 0 and therefore there exists a C J such that ‖ r ∗ 0 -¯ r 0 ‖ /lscript 2 ≤ C /epsilon1 J . After finding the error bound for r ∗ 0 , sequentially we can find the error bound for the input vectors at each time. For instance at k = 1 , we have
Because the matrix CB satisfies the RIP condition (7) with isometry constant δ 2 s < √ 2 -1 , with the same approach used in Appendices B and D, it is straightforward to verify that there exists a C k such that ‖ u ∗ k -¯ u k ‖ /lscript 2 ≤ C /epsilon1 k , which means that always the recovered sparse input is upper bounded by a constant, C s multiple of the observation error.
## ACKNOWLEDGMENTS
We would like to thank Professor Humberto Gonzalez (WUSTL) for helpful input and discussions. ShiNung Ching holds a Career Award at the Scientific Interface from the Burroughs-Wellcome Fund. This work was partially supported by AFOSR 15RT0189, NSF ECCS 1509342 and NSF CMMI 1537015, from the US Air Force Office of Scientific Research and the US National Science Foundation, respectively.
## REFERENCES
- [1] E. J. Cand` es and M. B. Wakin, 'An introduction to compressive sampling,' IEEE Signal Process. Mag. , vol. 25, no. 2, pp. 21-30, 2008.
- [2] Y. C. Eldar and G. Kutyniok, Compressed sensing: theory and applications . Cambridge University Press, 2012.
- [3] J. Haupt, W. U. Bajwa, M. Rabbat, and R. Nowak, 'Compressed sensing for networked data,' IEEE Signal Process. Mag. , vol. 25, no. 2, pp. 92-101, 2008.
- [4] D. L. Donoho, 'For most large underdetermined systems of linear equations the minimal l 1 norm solution is also the sparsest solution,' Comm. Pure Appl. Math. , vol. 59, no. 6, pp. 797-829, 2006.
- [5] E. J. Cand` es, J. Romberg, and T. Tao, 'Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information,' IEEE Trans. Inf. Theory , vol. 52, no. 2, pp. 489-509, 2006.
- [6] E. J. Candes and T. Tao, 'Decoding by linear programming,' IEEE Trans. Inf. Theory , vol. 51, no. 12, pp. 4203-4215, 2005.
- [7] E. J. Candes, J. K. Romberg, and T. Tao, 'Stable signal recovery from incomplete and inaccurate measurements,' Comm. Pure Appl. Math. , vol. 59, no. 8, pp. 1207-1223, 2006.
- [8] P. C. Petrantonakis and P. Poirazi, 'A compressed sensing perspective of hippocampal function,' Frontiers in Systems Neuroscience , vol. 8, 2014.
- [9] X. X. Wei and A. A. Stocker, 'A bayesian observer model constrained by efficient coding can explain'anti-bayesian'percepts,' Nat. Neurosci. , vol. 18, no. 10, pp. 1509-1517, 2015.
- [10] B. A. Olshausen et al. , 'Emergence of simple-cell receptive field properties by learning a sparse code for natural images,' Nature , vol. 381, no. 6583, pp. 607-609, 1996.
- [11] V. J. Barranca, G. Kovaˇ ciˇ c, D. Zhou, and D. Cai, 'Network dynamics for optimal compressive-sensing input-signal recovery,' Phys. Rev. E , vol. 90, no. 4, p. 042908, 2014.
- [12] --, 'Sparsity and compressed coding in sensory systems.' PLoS Computational Biology , vol. 10, no. 8, 2014.
- [13] N. Vaswani, 'Kalman filtered compressed sensing,' in Proc. 15th IEEE International Conference on Image Processing , 2008, pp. 893-896.
- [14] A. Charles, M. S. Asif, J. Romberg, and C. Rozell, 'Sparsity penalties in dynamical system estimation,' in Proc. 45th IEEE Annual Conference on Information Sciences and Systems (CISS), , 2011, pp. 1-6.
- [15] M. B. Wakin, B. M. Sanandaji, and T. L. Vincent, 'On the observability of linear systems from random, compressive measurements,' in Proc. 49th IEEE Conference on Decision and Control (CDC) , 2010, pp. 4447-4454.
- [16] B. M. Sanandaji, T. L. Vincent, M. B. Wakin, R. T´ oth, and K. Poolla, 'Compressive system identification of lti and ltv arx models,' in Proc. 50th IEEE Conf. on Decision and Control and European Control Conference (CDC-ECC) , 2011, pp. 791-798.
- [17] D. Napoletani and T. D. Sauer, 'Reconstructing the topology of sparsely connected dynamical networks,' Phys. Rev. E , vol. 77, no. 2, p. 026103, 2008.
[18]
Y. Shoukry, P. Nuzzo, A. Puggelli, A. L. Sangiovanni-Vincentelli, S. A. Seshia, and P. Tabuada, 'Secure state estimation under sensor attacks: A satisfiability modulo theory approach,'
arXiv preprint arXiv:1412.4324
,
2014.
- [19] H. Fawzi, P. Tabuada, and S. Diggavi, 'Secure estimation and control for cyber-physical systems under adversarial attacks,' IEEE Trans. Automatic Control , vol. 59, no. 6, pp. 1454-1467, 2014.
- [20] D. E. Ba, B. Babadi, P. L. Purdon, and E. N. Brown, 'Exact and stable recovery of sequences of signals with sparse increments via differential l 1 minimization,' in Proc. Advances in Neural Information Processing Systems (NIPS) , 2012, pp. 2636-2644.
- [21] S. Sefati, N. J. Cowan, and R. Vidal, 'Linear systems with sparse inputs: Observability and input recovery,' in Proc. IEEE American Control Conference (ACC) , 2015, pp. 5251-5257.
- [22] H. Jaeger, 'Short term memory in echo state networks,' GMD report, German National Research Center for Information Technology , 2001.
- [23] O. L. White, D. D. Lee, and H. Sompolinsky, 'Short-term memory in orthogonal neural networks,' Phys. Rev. Lett. , vol. 92, no. 14, p. 148102, 2004.
- [24] S. Ganguli, D. Huh, and H. Sompolinsky, 'Memory traces in dynamical systems,' Proceedings of the National Academy of Sciences , vol. 105, no. 48, pp. 18 970-18 975, 2008.
- [25] M. Hermans and B. Schrauwen, 'Memory in linear recurrent neural networks in continuous time,' Neural Networks , vol. 23, no. 3,
- pp. 341-355, 2010.
- [26] E. Wallace, H. R. Maei, and P. E. Latham, 'Randomly connected networks have short temporal memory,' Neural Comput. , vol. 25, no. 6, pp. 1408-1439, 2013.
[27]
S. Ganguli and H. Sompolinsky, 'Short-term memory in neuronal networks through dynamical compressed sensing,' in
Proc. Advances in neural information processing systems
,
2010, pp. 667-675.
- [28] A. S. Charles, H. L. Yap, and C. J. Rozell, 'Short-term memory capacity in networks via the restricted isometry property,' Neural Comput. , vol. 26, no. 6, pp. 1198-1235, 2014.
- [29] I. Ito, R. C.-Y. Ong, B. Raman, and M. Stopfer, 'Sparse odor representation and olfactory learning.' Nat. Neurosci. , vol. 11, no. 10, pp. 1177-1184, Oct 2008.
- [30] B. Raman, J. Joseph, J. Tang, and M. Stopfer, 'Temporally diverse firing patterns in olfactory receptor neurons underlie spatiotemporal neural codes for odors.' J. Neurosci. , vol. 30, no. 6, pp. 1994-2006, Feb 2010.
[31]
S.
Ostojic,
N. Brunel, and V.
Hakim, 'How connectivity, background
activity, and synaptic
properties shape
the cross-correlation
between spike trains,'
J.
Neurosci.
,
vol. 29, no. 33, pp. 10 234-10 253, 2009.
- [32] M. Kafashan, B. J. Palanca, and S. Ching, 'Bounded-observation kalman filtering of correlation in multivariate neural recordings,' in Proc. 36th Annu. Int. Conf. Eng. Med. Biol. , 2014.
- [33] L. F. Abbott, 'Lapicques introduction of the integrate-and-fire model neuron (1907),' Brain Res. Bull. , vol. 50, no. 5, pp. 303-304, 1999.
- [34] P. Dayan and L. Abbott, Theoretical neuroscience: computational and mathematical modeling of neural systems , ser. Comput. Neurosci.
- Cambridge, MA, USA: Massachusetts Institute of Technology Press, 2005.
- [35] E. M. Izhikevich et al. , 'Simple model of spiking neurons,' IEEE Trans. Neural Netw. , vol. 14, no. 6, pp. 1569-1572, 2003.
- [36] M. Kafashan, K. Q. Lepage, and S. Ching, 'Node selection for probing connections in evoked dynamic networks,' in Proc. 53nd IEEE Annu. Conf. Decision and Control (CDC) , 2014.
- [37] M. Kafashan and S. Ching, 'Optimal stimulus scheduling for active estimation of evoked brain networks,' J. Neural Eng. , vol. 12, no. 6, p. 066011, 2015.
- [38] R. J. Douglas and K. A. Martin, 'Recurrent neuronal circuits in the neocortex,' Curr. Biol. , vol. 17, no. 13, pp. R496-R500, 2007.
- [39] T. Kohonen and E. Oja, 'Fast adaptive formation of orthogonalizing filters and associative memory in recurrent networks of neuron-like elements,' Biol. Cybern. , vol. 21, no. 2, pp. 85-95, 1976.
- [40] H. S. Seung, D. D. Lee, B. Y. Reis, and D. W. Tank, 'Stability of the memory of eye position in a recurrent network of conductance-based model neurons,' Neuron , vol. 26, no. 1, pp. 259-271, 2000.
- [41] N. F. G¨ uler, E. D. Ubeyli, and I. G¨ uler, ¨ ˙ 'Recurrent neural networks employing lyapunov e xponents for EEG signals classification,' Expert Syst. Appl. , vol. 29, no. 3, pp. 506-514, 2005.
- [42] C. W. Omlin and C. L. Giles, 'Extraction of rules from discrete-time recurrent neural networks,' Neural Netw. , vol. 9, no. 1, pp. 41-52, 1996.
- [43] B. Ghanem and N. Ahuja, 'Sparse coding of linear dynamical systems with an application to dynamic texture recognition,' in Proc. 20th IEEE Int. Conf. Pattern Recog. (ICPR) , 2010, pp. 987-990.
- [44] X. Wei, H. Shen, and M. Kleinsteuber, 'An adaptive dictionary learning approach for modeling dynamical textures,' in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP) . IEEE, 2014, pp. 3567-3571.
- [45] L. Li, 'Fast algorithms for mining co-evolving time series,' Carnegie Inst. Tech., Dept. Computer Science, Tech. Rep. CMU-CS-11-127., 2011.
- [46] Y. Tao, C. Faloutsos, D. Papadias, and B. Liu, 'Prediction and indexing of moving objects with unknown motion patterns,' in Proc. ACM SIGMOD Int. Conf. Management of data , 2004, pp. 611-622.
- [47] S. Muthukrishnan, Data streams: Algorithms and applications . New Brunswick, NJ, USA: Now Publishers Inc, 2005.
- [48] R. G. Parker and R. L. Rardin, Discrete optimization . San Diego, CA, USA: Academic Press Professional, Inc., 1988.
- [49] E. J. Candes, 'The restricted isometry property and its implications for compressed sensing,' Comptes Rendus Mathematique , vol. 346, no. 9, pp. 589-592, 2008.
- [50] E. J. Candes and T. Tao, 'Near-optimal signal recovery from random projections: Universal encoding strategies?' IEEE Trans. Inf. Theory , vol. 52, no. 12, pp. 5406-5425, 2006.
- [51] R. Baraniuk, M. Davenport, R. DeVore, and M. Wakin, 'A simple proof of the restricted isometry property for random matrices,' Constr. Approx. , vol. 28, no. 3, pp. 253-263, 2008.
- [52] S. Mendelson, A. Pajor, and N. Tomczak-Jaegermann, 'Uniform uncertainty principle for bernoulli and subgaussian ensembles,' Constr. Approx. , vol. 28, no. 3, pp. 277-289, 2008.
- [53] E. Candes, L. Demanet, D. Donoho, and L. Ying, 'Fast discrete curvelet transforms,' Multiscale Modeling & Simulation , vol. 5, no. 3, pp. 861-899, 2006.
- [54] E. J. Cand` es and D. L. Donoho, 'New tight frames of curvelets and optimal representations of objects with piecewise c2 singularities,' Commun. Pure Appl. Math. , vol. 57, no. 2, pp. 219-266, 2004.
- [55] I. CVX Research, 'CVX: Matlab software for disciplined convex programming, version 2.0,' Aug. 2012.
- [56] M. C. Grant and S. P. Boyd, 'Graph implementations for nonsmooth convex programs,' in Recent Advances in Learning and Control . Springer, 2008, pp. 95-110.
- [57] A. L. Barth and J. F. Poulet, 'Experimental evidence for sparse firing in the neocortex,' Trends in Neurosci. , vol. 35, no. 6, pp. 345-355, 2012.
- [58] D. J. Watts and S. H. Strogatz, 'Collective dynamics of small-worldnetworks,' Nature , vol. 393, no. 6684, pp. 440-442, 1998.
- [59] P. D. King, J. Zylberberg, and M. R. DeWeese, 'Inhibitory interneurons decorrelate excitatory cells to drive sparse code formation in a spiking model of v1,' J. Neurosci. , vol. 33, no. 13, pp. 5475-5485, 2013.
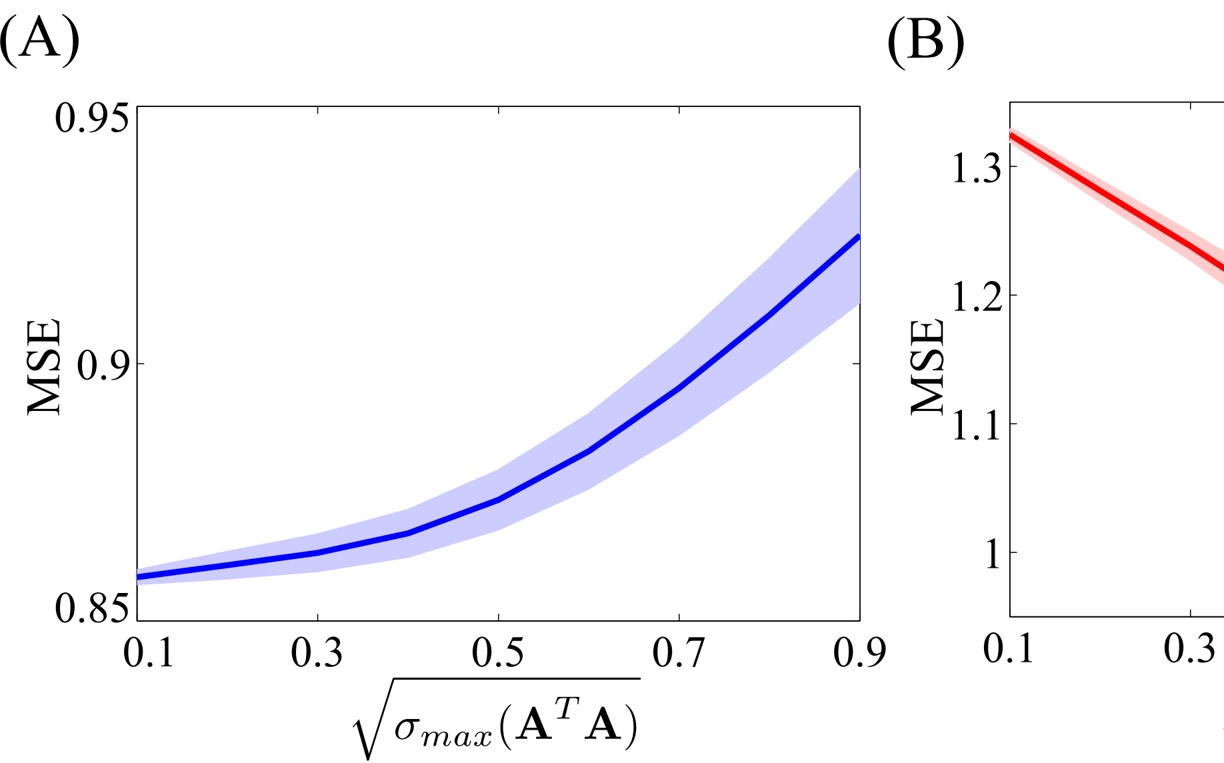 | null | [
"MohammadMehdi Kafashan",
"Anirban Nandi",
"ShiNung Ching"
] | 2014-08-01T15:13:58+00:00 | 2015-11-06T20:48:37+00:00 | [
"math.OC"
] | Analysis of Recurrent Linear Networks for Enabling Compressed Sensing of Time-Varying Signals | Recent interest has developed around the problem of dynamic compressed
sensing, or the recovery of time-varying, sparse signals from limited
observations. In this paper, we study how the dynamics of recurrent networks,
formulated as general dynamical systems, mediate the recoverability of such
signals. We specifically consider the problem of recovering a high-dimensional
network input, over time, from observation of only a subset of the network
states (i.e., the network output). Our goal is to ascertain how the network
dynamics lead to performance advantages, particularly in scenarios where both
the input and output are corrupted by disturbance and noise, respectively. For
this scenario, we develop bounds on the recovery performance in terms of the
dynamics. Conditions for exact recovery in the absence of noise are also
formulated. Through several examples, we use the results to highlight how
different network characteristics may trade off toward enabling dynamic
compressed sensing and how such tradeoffs may manifest naturally in certain
classes of neuronal networks. |
1408.0203v1 | ## Dynamics of Generalized Tachyon Field in Teleparallel Gravity
Behnaz Fazlpour a 1 and Ali Banijamali b 2
- a Department of Physics, Babol Branch, Islamic Azad University, Babol, Iran
- b Department of Basic Sciences, Babol University of Technology, Babol, Iran
## Abstract
We study dynamics of generalized tachyon scalar field in the framework of teleparallel gravity. This model is an extension of tachyonic teleparallel dark energy model which has been proposed in [26]. In contrast with tachyonic teleparallel dark energy model that has no scaling attractors, here we find some scaling attractors which means that the cosmological coincidence problem can be alleviated. Scaling attractors present for both interacting and non-interacting dark energy, dark matter cases.
PACS numbers: 95.36.+x, 98.80.-k, 04.50.kd
Keywords: Generalized Tachyon Field; Teleparallel gravity; Phase-space analysis.
1 [email protected]
2 [email protected]
## 1 Introduction
The usual proposal to explain the late-time accelerated expansion of our universe is an unknown energy component, dubbed as dark energy. The natural choice and most attractive candidate for dark energy is the cosmological constant but it is not well accepted because of the cosmological constant problem [1] as well as the age problem [2]. Thus, many dynamical dark energy models as alternative possibilities have been proposed. Quintessence, phantom, k-essence, quintom and tachyon field are the most familiar dark energy models in the literature (for reviews on dark energy models, see [3]). The tachyon field arising in the context of string theory [4] and its application in cosmology both as a source of early inflation and late-time cosmic acceleration has been extensively studied [5-8].
The so-called 'Teleparallel Equivalent of General Relativity' or Teleparallel Gravity was first constructed by Einstein [9-12]. In this formulation one uses the curvature-less weitzenbock connection instead of the torsion-less Levi-Civita connection. The relevant lagrangian in teleparallel gravity is the torsion scalar T which is constructed by contraction of the torsion tensor. We recall that the Einstein-Hilbert Lagrangian R is constructed by contraction of the curvature tensor. Since teleparallel gravity with torsion scalar as lagrangian density is completely equivalent to a matter-dominated universe in the framework of general relativity, it can not be accelerated. Thus one should generalize teleparallel gravity either by replacing T with an arbitrary function -the so-called f ( T ) gravity [13-15] or by adding dark energy into teleparallel gravity allowing also a non-minimal coupling between dark energy and gravity. Note that both approaches are inspired by the similar modifications of general relativity i.e. f ( R ) gravity [16, 17] and non-minimally coupled dark energy models in the framework of general relativity [18-20].
Recently Geng et al. [21, 22] have included a non-minimal coupling between quintessence and gravity in the context of teleparallel gravity. This theory has been called 'teleparallel dark energy' and its dynamics was studied in [23-25]. Tachyonic teleparallel dark energy is a generalization of teleparallel dark energy by inserting a non-canonical scalar field instead of quintessence in the action [26]. Phase-space analysis of this model has been investigated in [27]. On the other hand, there is no physical argument to exclude the interaction between dark energy and dark matter. The interaction between these completely different component of our universe has same important consequences such as addressing the coincidence problem [28]. In this paper we consider generalized tachyon field as responsible for dark energy in the framework of teleparallel gravity. We will be interested in performing a dynamical analysis of such a model in FRW space time. In such a study we investigate our model for both interacting and non-interacting cases. The basic equations are presented in section 2. In section 3 the evolution equations are translated in the language of the autonomous dynamical system by suitable transformation of the basic variables. Subsection 3.1 deals with phase-space analysis as well as the cosmological implications of the equilibrium points of the model in non-interacting dark energy dark matter case. In subsection 3.2 an interaction between dark energy and dark matter has been considered an critical points and their behavior extracted. Section 5 is devoted to a short summary of our results.
## 2 Basic Equations
Our model is described by the following action as a generalization of tachyon teleparallel dark energy model [26],
$$S = \int d ^ { 4 } x e \left [ \mathcal { L } _ { T } + \mathcal { L } _ { \varphi } + \mathcal { L } _ { m } \right ], \\ \mathcal { L } _ { T } = \frac { T } { 2 \kappa ^ { 2 } }, \\ \mathcal { L } _ { \varphi } = \xi f ( \varphi ) T - V ( \varphi ) ( 1 - 2 X ) ^ { \beta }, \\ \mathrm e \, \text{the orthonormal components of the tet} \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ }$$
$$\mathcal { L } _ { \varphi } = \xi f ( \varphi ) T - V ( \varphi ) ( 1 - 2 X ) ^ { \beta }, \\ = \mathcal { \L i } \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \cdots \quad T \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \collections \quad.$$
where e = det e ( i µ ) = √ -g ( e i µ are the orthonormal components of the tetrad) while T 2 κ 2 is the Lagrangian of teleparallelism with T as the torsion scalar (for an introductory review of teleparallelism see [11]). L ϕ
shows a non-minimal coupling of generalized tachyon field ϕ with gravity in the framework of teleparallel gravity and X = 1 2 ∂ µ ϕ∂ µ ϕ . The second part in L ϕ is the Lagrangian density of the generalized tachyon field which has been studied in Ref [29]. f ( ϕ ) is the non-minimal coupling function, ξ is a dimensionless constant measuring the non-minimal coupling and L m is the matter Lagrangian. For β = 1 2 our model reduced to tachyonic teleparallel dark energy discussed in [26]. Here we consider the case β = 2 for two reasons. The first is that for arbitrary β our equations will be very complicated and one can not solve them analytically and the second is that for β = 2 we will obtain interesting physical results as we will see below.
Furthermore, due to complexity of tachyon dynamics Ref [30] has proposed an approach based on a redefinition of the tachyon field as follows,
$$\varphi \to \phi = \int d \varphi \sqrt { V ( \varphi ) } \Leftrightarrow \partial \varphi = \frac { \partial \phi } { \sqrt { V ( \phi ) } }. \\ \text{closed autonomous system and perform the phase-space analysis of the model we apply}$$
In order to obtain a closed autonomous system and perform the phase-space analysis of the model we apply (2) in (1) for β = 2 that leads to the following action:
$$S = \int d ^ { 4 } x e \left [ \frac { T } { 2 \kappa ^ { 2 } } + \xi f ( \phi ) T - V ( \phi ) ( 1 - \frac { 2 X } { V ( \phi ) } ) ^ { 2 } + \mathcal { L } _ { m } \right ].$$
In a spatially-flat FRW space-time,
$$d s ^ { 2 } = d t ^ { 2 } - a ^ { 2 } ( t ) ( d r ^ { 2 } + r ^ { 2 } d \Omega ^ { 2 } ), \\. \quad \.$$
and a vierbein choice of the form e i µ = diag (1 , a, a, a ), the corresponding Friedmann equations are given by,
$$H ^ { 2 } & = \frac { 1 } { 3 } ( \rho _ { \phi } + \rho _ { m } ), & & ( 5 )$$
$$\dot { H } = - \frac { 1 } { 2 } \left ( \rho _ { \phi } + P _ { \phi } + \rho _ { m } + P _ { m } \right ), \\ \intertext { \text{lo normal and a dot stand for the derivative with respect to the cosmic time} }$$
where H = ˙ a a is the Hubble parameter and a dot stands for the derivative with respect to the cosmic time t . In these equations, ρ m and P m are the matter energy density and pressure respectively.
The effective energy density and pressure of generalized tachyon dark energy read,
$$\rho _ { \phi } = V ( \phi ) + 2 \dot { \phi } ^ { 2 } - 3 \frac { \dot { \phi } ^ { 4 } } { V ( \phi ) } - 6 \xi H ^ { 2 } f ( \phi ),$$
and
$$P _ { \phi } = - V ( \phi ) + 2 \xi ( 3 H ^ { 2 } + 2 \dot { H } ) f ( \phi ) + 1 0 \xi H f _ {, \phi } \dot { \phi } + \dot { \phi } ^ { 2 } ( 2 - \frac { \dot { \phi } ^ { 2 } } { V ( \phi ) } ),$$
where f ,φ = df dφ .
The equation of motion of the scalar field can be obtained by variation of the action (3) with respect to φ ,
$$\ddot { \phi } + 3 \mu ^ { - 2 } \nu ^ { 2 } H \dot { \phi } + \frac { 1 } { 4 } \nu ^ { 2 } ( 1 + \frac { 3 \dot { \phi } ^ { 4 } } { V ^ { 2 } ( \phi ) } ) V _ {, \phi } + 6 \xi \nu ^ { 2 } H ^ { 2 } f _ {, \phi } = - \frac { Q } { \dot { \phi } },$$
with Q a general interaction coupling term between dark energy and dark matter, µ = 1 √ 1 -2 X V and ν = 1 √ 1 -6 X V . In (7), (8) and (9) we have used the useful relation,
$$T & = - 6 H ^ { 2 }, & ( 1 0 )$$
which simply arises from the calculation of torsion scalar for the FRW metric (4). The scalar field evolution (9) expresses the continuity equation for the field and matter as follows
$$\dot { \rho } _ { \phi } + 3 H ( 1 + \omega _ { \phi } ) \rho _ { \phi } = - Q,$$
$$\dot { \rho } _ { m } + 3 H ( 1 + \omega _ { m } ) \rho _ { m } = Q,$$
where ω φ = P φ ρ φ is the equation of state parameter of dark energy which is attributed to the scalar field φ . The barotropic index is defined by γ ≡ 1 + ω m with 0 < γ < 2.
Although, dynamics of tachyonic teleparallel dark energy has been studied in [27], no scaling attractors found. Here we are going to perform a phase-space analysis of generalized tachyonic teleparallel dark energy and as we will see below some interesting scaling attractors appear in such theory.
## 3 Cosmological Dynamics
In order to perform phase-space and stability analysis of the model, we introduce the following auxiliary variables:
$$x \equiv \frac { \dot { \phi } } { \sqrt { V } }, \ y \equiv \frac { \sqrt { V } } { \sqrt { 3 } H }, \ u \equiv \sqrt { f }. \quad \quad ( 1 3 )$$
The auxiliary variables allow us to straightforwardly obtain the density parameter of dark energy and dark matter
$$\Delta _ { m } \equiv \frac { \rho _ { m } } { 3 H ^ { 2 } } = 1 - \Omega _ { \phi },$$
$$\Omega _ { \phi } \equiv \frac { \rho _ { \phi } } { 3 H ^ { 2 } } & = \mu ^ { - 2 } y ^ { 2 } ( 1 + 3 x ^ { 2 } ) - 2 \xi u ^ { 2 }, \\ & \wedge \rho _ { m } \quad. \quad \wedge \quad \ w.$$
while the equation of state of the field reads
ω
φ
φ
≡
P
φ
ρ
where α ≡ f ,φ √ f and
$$r _ { \varphi } ^ { r _ { \varphi } } = \frac { - \mu ^ { - 4 } y ^ { 2 } + 2 \xi u [ \frac { 5 \sqrt { 3 } } { 3 } \alpha x y + u ( 1 - \frac { 2 } { 3 } s ) ] } { \mu ^ { - 2 } y ^ { 2 } ( 1 + 3 x ^ { 2 } ) - 2 \xi u ^ { 2 } },$$
$$s = - \frac { \dot { H } } { H ^ { 2 } } = ( 2 \xi u ^ { 2 } + 1 ) ^ { - 1 } \left [ 5 \sqrt { 3 } \alpha \xi u x y + 6 \mu ^ { - 2 } x ^ { 2 } y ^ { 2 } - \frac { 3 } { 2 } \gamma \mu ^ { - 2 } y ^ { 2 } ( 1 + 3 x ^ { 2 } ) \right ] + \frac { 3 \gamma } { 2 }. \quad \quad ( 1 7 ) \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
Another quantities with great physical significance namely the total equation of state parameter and the deceleration parameter are given by
$$\check { \omega } _ { t o t } & \equiv \frac { P _ { \phi } + P _ { m } } { \rho _ { \phi } + \rho _ { m } } = \mu ^ { - 2 } y ^ { 2 } ( 4 x ^ { 2 } - \gamma ( 1 + 3 x ^ { 2 } ) ) + 2 \xi u [ \frac { 5 \sqrt { 3 } } { 3 } \alpha x y + u ( \gamma - \frac { 2 } { 3 } s ) ] + \gamma - 1, \quad \quad ( 1 8 )$$
and
˙
H
1
H
q
≡ -
1
-
2
=
2
+ 3
2
ω
tot
$$\cdots \quad - \quad - \quad - \\ = \frac { 3 } { 2 } \mu ^ { - 2 } y ^ { 2 } ( 4 x ^ { 2 } - \gamma ( 1 + 3 x ^ { 2 } ) ) + \xi u [ 5 \sqrt { 3 } \alpha x y + u ( 3 \gamma - 2 s ) ] + \frac { 3 \gamma } { 2 } - 1. \quad \ ( 1 9 ) \\ \alpha \text{ auxiliary variables} ( 1 \cdots \, \text{$1\cup$ the solution amounts} ( 5 \cdots \, \text{$6\cup$ and} \, ( 0 \cup \, \text{can be exact as mathematical event} }$$
Using auxiliary variables (13) the evolution equations (5), (6) and (9) can be recast as a dynamical system of ordinary differential equations
$$\mu _ { \nu } ^ { - } \mu _ { \nu } ^ { - } \mu _ { \nu } ^ { - } \mu _ { \nu } ^ { 2 } ( 1 + 3 x ^ { 4 } ) y - 4 \alpha \xi \nu ^ { 2 } u y ^ { - 1 } - 2 \sqrt { 3 } \mu ^ { - 2 } \nu ^ { 2 } x ] - \hat { Q },$$
$$y ^ { \prime } & = \left ( \, - \, \frac { \sqrt { 3 } } { 2 } \lambda x y + s \right ) y,$$
$$u ^ { \prime } & = \frac { \sqrt { 3 } \alpha x y } { 2 },$$
where ˆ = Q Q ˙ φH √ V ( φ ) , λ ≡ -V ,φ κV and prime in equations (20)-(22) denotes differentiation with respect to the so-called e-folding time N = ln a .
From now we concentrate on exponential scalar field potential of the form V = V e 0 -kλφ and the non-minimal coupling function of the form f ( φ ) ∝ φ 2 . These choices lead to constant λ and α respectively.
The next step is the introduction of interaction term Q to obtain an autonomous system out of equations (20)-(22). The fixed points ( x , y c c , u c ) for which x ′ = y ′ = u ′ = 0 depend on the choice of the interaction term Q and two general possibilities will be treated in the sequel. The stability of the system at a fixed point can be obtained from the analysis of the determinant and trace of the perturbation matrix M . Such a matrix can be constructed by substituting linear perturbations x → x c + δx, y → y c + δy and u → u c + δu about the critical point ( x , y c c , u c ) into the autonomous system (20)-(22). The 3 × 3 matrix M of the linearized perturbation equations of the autonomous system is shown in appendix A. Therefor, for each critical point we examine the sign of the real part of the eigenvalues of M . According to the usual dynamical system analysis, if the eigenvalues are real and have opposite signs, the corresponding critical point is a saddle point. A fixed point is unstable if the eigenvalues are positive and it is stable for negative real part of the eigenvalues.
In the following subsections we will study the dynamics of generalized tachyon field with different interaction term Q . Without lose of generality we assume γ = 1 for simplicity.
## 3.1 The case for Q = 0
The first case Q = 0 clearly means there is no interaction between dark energy and background matter. In this case, there are two critical points presented in Table 1. From equations (14) and (16) one can obtain the corresponding values of density parameter Ω φ and equation of state of dark energy ω φ at each point. Also, using equation (19) we can find the condition required for acceleration ( q < 0) at each point. These parameters and conditions have been shown in Table 1. The stability and existence conditions of critical points A 10 and A 2 are presented in Table 2. We mention that the corresponding eigenvalues of perturbation matrix M at critical points A 10 and A 2 are considerably involved and here we do not present their explicit expressions but we can find sign of them numerically.
Critical point A 1 : This critical point is a scaling attractor if ξ > 0, α < 0 and λ < 0. Thus, it can give the hope alleviate the cosmological coincidence problem. A 1 is a saddle point for α > 0 and ξ λ > 0.
Critical point A 2 : A 2 can also be a scaling attractor of the model or a saddle point under the same conditions as for A 1 .
In figure 1 we have chosen the values of the parameters ξ , λ and α , such that A 1 become a stable attractor of the model. Plots in figure 1 show the phase-space trajectories on x -y , x -u and u -y planes from left to right respectively. The same plots are shown in figure 2 for critical point A 2 . Note that the values of the parameter have chosen in the way that A 2 become a stable point of the model. In figure 3, the corresponding 3 dimensional phase-space trajectories of the model have been presented. One can see that A 1 and A 2 are stable attractor of the model in the left and right plots respectively.
| label | ( x c , y c , u c ) | Ω φ | ω φ | acceleration |
|---------|-------------------------|------------------------------|-------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------|
| A 1 | 0 , 2 √ λ 1 , λλ 1 2 αξ | 4 λ 1 ( 1 - λ 2 8 ξα 2 λ 1 ) | 16 ξ 2 α 4 ( λ 2 λ 2 1 +2 ξα 2 ) ( λ 2 λ 1 - 8 ξα 2 ) | λ 2 > ξα 2 (4 λ 1 - 1) λ 2 1 ( 1 + √ 1 - 32 λ 1 (1 - 4 λ 1 ) 2 ) or λ 2 < ξα 2 (4 λ 1 - 1) λ 2 1 ( 1 - √ 1 - 32 λ 1 (1 - 4 λ 1 ) 2 ) |
| A 2 | 0 , 2 √ λ 2 , λλ 2 2 αξ | 4 λ 2 ( 1 - λ 2 8 ξα 2 λ 2 ) | 16 ξ 2 α 4 ( λ 2 λ 2 2 +2 ξα 2 ) ( λ 2 λ 2 - 8 ξα 2 ) | λ 2 > ξα 2 (4 λ 2 - 1) λ 2 2 ( 1 + √ 1 - 32 λ 2 (1 - 4 λ 2 ) 2 ) or λ 2 < ξα 2 (4 λ 2 - 1) λ 2 2 1 - √ 1 - 32 λ 2 (1 - 4 λ 2 ) 2 |
(
)
Table 1: Location of the critical points and the corresponding values of the dark energy density parameter Ω φ and equation of state ω φ and the condition required for an accelerating universe for Q = 0. Here λ 1 = α ( 4 αξ + √ 16 α ξ 2 2 -2 λ ξ 2 ) λ 2 and λ 2 = α ( 4 αξ -√ 16 α ξ 2 2 -2 λ ξ 2 ) λ 2 .
Table 2: Stability and existence conditions of the critical points of the model for Q = 0.
| label | stability | existence |
|---------|---------------------------------------------------------------------------|--------------------------------|
| A 1 | saddle point if α > 0 and ξ λ > 0 stable point if ξ > 0 , α < 0 and λ < 0 | for all ξ < 0 or ξ ≥ λ 2 8 α 2 |
| A 2 | saddle point if α < 0 and ξ λ < 0 stable point if ξ > 0 , α > 0 and λ > 0 | for all ξ < 0 or ξ ≥ λ 2 8 α 2 |
| label | ( x c , y c , u c ) | Ω φ | ω φ | acceleration |
|---------|----------------------------|------------------------|----------------------------------------------------|-----------------------------------------|
| B 1 | 0 , 2 √ 2 λαξθ 1 λ , θ 1 | 2 ξθ 1 ( 4 α λ - θ 1 ) | 2 ( ξθ 3 1 + 2 α λ ) ( θ 1 - 4 α λ ) (1+2 ξθ 2 1 ) | λ > 8 α ( ξθ 2 1 - 1) θ 1 (8 ξθ 2 1 +1) |
| B 2 | 0 , 2 √ 2 λαξθ 2 λ , θ 2 | 2 ξθ 2 ( 4 α λ - θ 2 ) | 2 ( ξθ 3 2 + 2 α λ ) ( θ 2 - 4 α λ ) (1+2 ξθ 2 2 ) | λ > 8 α ( ξθ 2 2 - 1) θ 2 (8 ξθ 2 2 +1) |
| B 3 | 0 , - 2 √ 2 λαξθ 1 λ , θ 1 | 2 ξθ 1 ( 4 α λ - θ 1 ) | 2 ( ξθ 3 1 + 2 α λ ) ( θ 1 - 4 α λ ) (1+2 ξθ 2 1 ) | λ > 8 α ( ξθ 2 1 - 1) θ 1 (8 ξθ 2 1 +1) |
| B 4 | 0 , - 2 √ 2 λαξθ 2 λ , θ 2 | 2 ξθ 2 ( 4 α λ - θ 2 ) | 2 ( ξθ 3 2 + 2 α λ ) θ 2 - 4 α λ (1+2 ξθ 2 2 ) | λ > 8 α ( ξθ 2 2 - 1) θ 2 (8 ξθ 2 2 +1) |
(
)
Table 3: Location of the critical points and the corresponding values of the dark energy density parameter Ω φ and equation of state ω φ and the condition required for an accelerating universe for Q = βκρ m ˙ . φ Here θ 1 = ( 4 αξ + √ 16 α ξ 2 2 -2 λ ξ 2 ) 2 λξ and θ 2 = ( 4 αξ -√ 16 α ξ 2 2 -2 λ ξ 2 ) 2 λξ .
## 3.2 The case for Q = βκρ m ˙ φ
This deals with the most familiar interaction term extensively considered in the literature (see e.g. [25, 31-34]). Here ˆ Q in terms of auxiliary variables is ˆ Q = √ 3 βy -1 Ω m . Inserting such an interaction term in equations (20)-(22) and setting the left hand sides of the equations to zero lead to the critical points B 1 , B 2 , B 3 and B 4 presented in Table 3. In the same table we have provided the corresponding values of Ω φ and ω φ as well as the condition needed for accelerating universe at each fixed points.
The stability and existence conditions for each point presented in Table 4. Since the corresponding eigenvalues of the fixed points are complicated we do not give them here but one can obtain their signs numerically and so concludes about the stability properties of the critical points.
Critical point B 1 : This point exists for λ > 0 and ξ ≥ λ 2 8 α 2 . However it is an unstable saddle point.
Critical point B 2 : The critical point B 2 exists for λ > 0 and ξ < 0 or ξ ≥ λ 2 8 α 2 . This point is a scaling attractor of the model if α > 0 and ξ > 0. Figure 4 shows clearly such a behavior of the model for suitable choices of ξ , λ and α .
Critical point B 3 : This point exists for negative values of λ and ξ or when ξ ≥ λ 2 8 α 2 . Also, it is a stable point if α < 0 and ξ > 0 and a saddle point if α > 0 and ξ < 0. The values of parameters have been chosen in figure 5 such that B 3 become a attractor of the model as it is clear from phase-space trajectories.
Critical point B 4 : The point B 4 exists for λ < 0 and ξ ≥ λ 2 8 α 2 . It is a stable point if α < 0 and ξ > 0. In figure 6 values of the parameter ξ and α are those satisfy these constraints and so B 4 becomes a attractor point for phase-plane trajectories. The corresponding 3-dimensional phase-space trajectories of the model for attractor points B 2 (left), B 3 (middle) and B 4 (right) are plotted in figure 7.
## 4 Conclusion
A model of dark energy with non-minimal coupling of quintessence scalar field with gravity in the framework of teleparallel gravity was called teleparallel dark energy [21]. If one replaces quintessence by tachyon field in such a model then tachyonic teleparallel dark energy will be constructed [26].
Moreover, although dark energy and dark matter scale differently with the expansion of our universe, ac-
Table 4: Stability and existence conditions of the critical points of the model for Q = βκρ m ˙ . φ
| label | stability | existence |
|---------|-----------------------------------------------------------------|----------------------------------------------|
| B 1 | saddle point if α > 0 and ξ > 0 | λ > 0 and ξ ≥ λ 2 8 α 2 |
| B 2 | saddle point if α < 0 and ξ < 0 stable point if α > 0 and ξ > 0 | λ > 0 and for all ξ < 0 or ξ λ 2 2 |
| B 3 | saddle point if α > 0 and ξ < 0 stable point if α < 0 and ξ > 0 | ≥ 8 α λ < 0 and for all ξ < 0 or ξ λ 2 8 α 2 |
| B 4 | stable point if α < 0 and ξ > 0 | ≥ λ < 0 and ξ ≥ λ 2 8 α 2 |
cording to the observations [35] we are living in an epoch in which dark energy and dark matter densities are comparable and this is the well-known cosmological coincidence problem [24]. This problem can be alleviated in most dark energy models via the method of scaling solutions in which the density parameters of dark energy and dark matter are both non-vanishing over there.
In this paper we investigated the phase-space analysis of generalized tachyon cosmology in the framework of teleparallel gravity. Our model described by action (1) which generalizes tachyonic teleparallel dark energy model proposed in [26]. We found some scaling attractors in our model for the case β = 2. These scaling attractors are A 1 and A 2 when there is no interaction between dark energy and dark matter. B 2 , B 3 and B 4 are scaling attractors in the case that dark energy interacts with dark matter through the interacting term Q = βκρ m ˙ . φ Our results show that generalized tachyon field represents interesting cosmological behavior in compare with ordinary tachyon fields in the framework of teleparallel gravity because there is no scaling attractor in the latter model. So, generalized tachyon field gives us the hope that cosmological coincidence problem can be alleviated without fine-tunings. One can study our model for different kinds of potential and other famous interaction term between dark energy and dark matter.
Figure 1: From left to right, the projections of the phase-space trajectories on the x -y , x -u and u -y planes with ξ = 0 5, . λ = -0 6 and . α = -2 for Q = 0. For these values of the parameters, point A 1 is a stable attractor of the model.
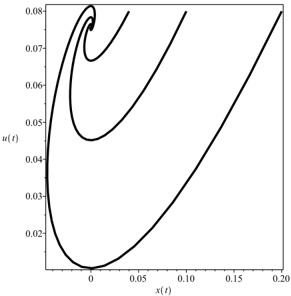
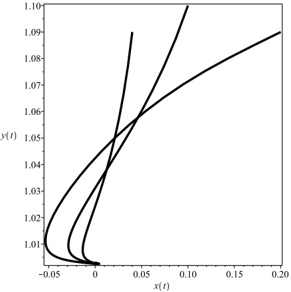
Figure 2: From left to right, the projections of the phase-space trajectories on the x -y , x -u and u -y planes with ξ = 0 5, . λ = 0 6 and . α = 2 for Q = 0. For these values of the parameters, point A 2 is a stable attractor of the model.
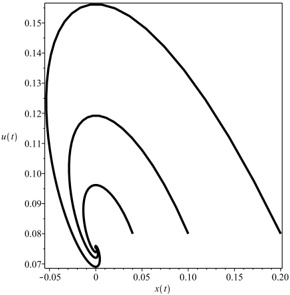
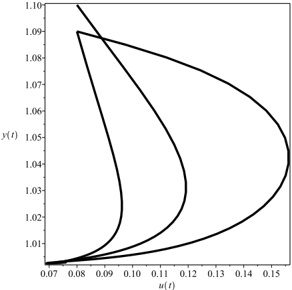
Figure 3: 3-dimensional phase-space trajectories of the model for Q = 0 with stable attractors A 1 (left) and A 2 (right) . The values of the parameters are those mentioned in figure 1 and 2 respectively.
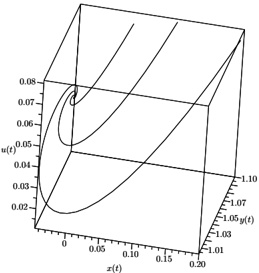
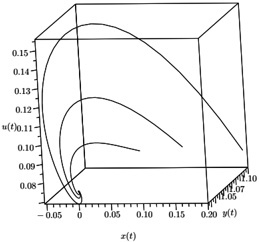
Figure 4: From left to right, the projections of the phase-space trajectories on the x -y , x -u and u -y planes with ξ = 0 5, . λ = 0 6, . α = 2 and β = 1 5 for . Q = βκρ m ˙ . φ For these values of the parameters, point B 2 is a stable attractor of the model.
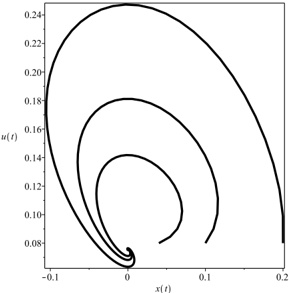
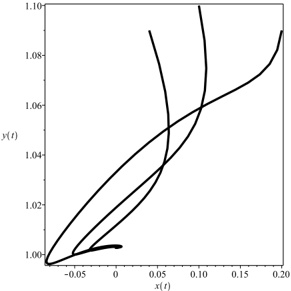
Figure 5: From left to right, the projections of the phase space trajectories on the x -y , x -u and u -y planes with ξ = 0 5, . λ = -0 6, . α = -2 and β = 1 5 for . Q = βκρ m ˙ . φ For these values of the parameters, point B 3 is a stable attractor of the model.
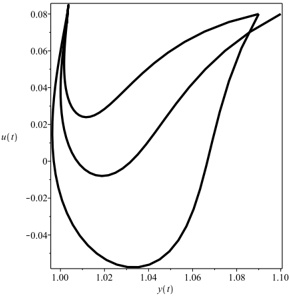
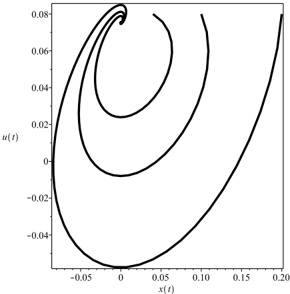
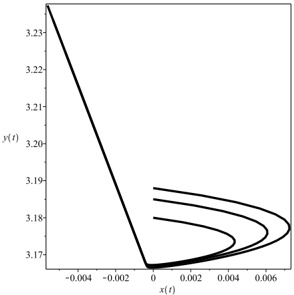
Figure 6: From left to right, the projections of the phase space trajectories on the x -y , x -u and u -y planes with ξ = 0 5, . λ = -0 6, . α = -2 and β = 1 5 for . Q = βκρ m ˙ . φ For these values of the parameters, point B 4 is a stable attractor of the model.
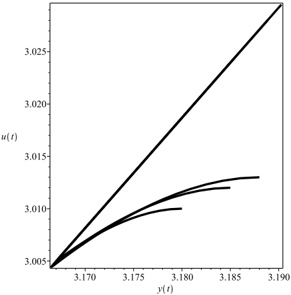
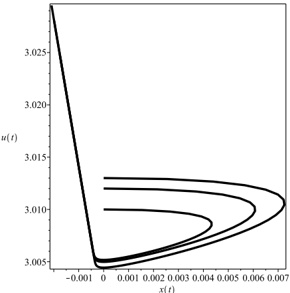
Figure 7: 3-dimensional phase-space trajectories of the model for Q = βκρ m ˙ φ with stable attractors B 2 (left), B 3 (middle) and B 4 (right). The values of the parameters are those mentioned in figure 4, 5 and 6 respectively.
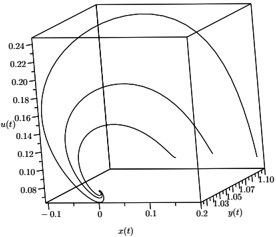
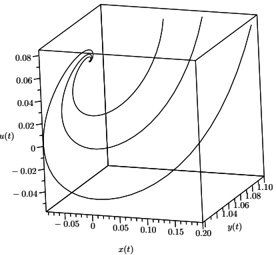
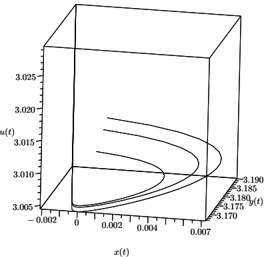
## 5 Appendix: Perturbation Matrix Elements
The elements of 3 × 3 matrix M of the linearized perturbation equations for the real and physically meaningful critical points ( x , y c c , u c ) of the autonomous system (20)- (22) read,
$$& \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \\ M _ { 1 1 } = 3 \nu _ { c } ^ { 2 } \left ( \frac { \sqrt { 3 } } { 2 } \lambda x _ { c } y _ { c } ( 2 x _ { c } ^ { 2 } + \nu _ { c } ^ { 2 } ( 1 + 3 x _ { c } ^ { 4 } ) ) - 6 \mu _ { c } ^ { - 2 } \nu _ { c } ^ { 2 } x _ { c } ^ { 2 } - 4 \sqrt { 3 } \alpha \xi u _ { c } x _ { c } \nu _ { c } ^ { 2 } y _ { c } ^ { - 1 } \right ) + \sqrt { 3 } \lambda x _ { c } y _ { c } - 3 + M _ { 1 1 }, \ \ ( 2 3 )$$
$$M _ { 1 2 } = \frac { \sqrt { 3 } } { 4 } \left ( \lambda ( 2 x _ { c } ^ { 2 } + \nu _ { c } ^ { 2 } ( 1 + 3 x _ { c } ^ { 4 } ) ) + 8 \alpha \xi u _ { c } \nu _ { c } ^ { 2 } y _ { c } ^ { - 2 } \right ) + \mathcal { M } _ { 1 2 },$$
$$M _ { 1 3 } = - 2 \sqrt { 3 } \alpha \xi \nu _ { c } ^ { 2 } y _ { c } ^ { - 1 } + \mathcal { M } _ { 1 3 },$$
$$M _ { 2 1 } = \frac { 2 y _ { c } ^ { 2 } \left ( \sqrt { 3 } \alpha \xi u _ { c } + 3 x _ { c } y _ { c } \nu _ { c } ^ { - 2 } \right ) } { \left ( 2 \xi u _ {$$
$$M _ { 2 2 } = \frac { 2 y _ { c } ( - \frac { 9 } { 4 } \mu _ { c } ^ { - 4 } y _ { c } + 5 \sqrt { 3 } \alpha \xi x _ { c } u _ { c } ) } { ( 2 \xi u _ { c$$
$$M _ { 2 3 } = \frac { 6 \xi u _ { c } y _ { c } ^ { 2 } ( - \frac { 1 0 \sqrt { 3 } } { 3 } \alpha \xi u _ { c } x _ { c } + \mu _ { c } ^ { - 4 } y _ { c }$$
$$M _ { 3 1 } = \frac { \sqrt { 3 } \alpha y _ { c } } { 2 }, \ M _ { 3 2 } = \frac { \sqrt { 3 } \alpha x _ { c } } { 2 }, \ M _ { 3 3 } = 0, \quad \quad \quad$$
where in the case of Q = 0 we have M 11 = M 12 = M 13 = 0 and in the case of Q = βκρ m ˙ φ we have
$$\mathcal { M } _ { 1 1 } = 4 \sqrt { 3 } \beta \nu _ { c } ^ { - 2 } x _ { c } y _ { c },$$
$$\mathcal { M } _ { 1 2 } = 2 \sqrt { 3 } \beta \mu _ { c } ^ { - 2 } ( 1 + 3 x _ { c } ^ { 2 } ), \\ \mathcal { M } _ { 1 3 } = - 4 \sqrt { 3 } \beta \xi u _ { c } y _ { c } ^ { - 1 }. \\ \text{es of the matrix } M \text{ for each critical noint. one determines its stability conditions.}$$
Examining the eigenvalues of the matrix M for each critical point, one determines its stability conditions.
## References
- [1] S. Weinberg, Rev. Mod. Phys. 61 , 1 (1989); S. M. Carroll, Living Rev. Rel. 4 , 1 (2001).
- [2] R.-J. Yang and S. N. Zhang, Mon. Not. R. Astron. Soc. 407 , 1835 (2010).
- [3] Y. -F. Cai, E. N. Saridakis, M. R. Setare and J. -Q. Xia, Phys. Rept. 493 , 1 (2010); K. Bamba, S. Capozziello, S. Nojiri and S. D. Odintsov, Astrophys. Space Sci. 342 , 155 (2012).
- [4] Y. -F. Cai, E. N. Saridakis, M. R. Setare and J. -Q. Xia, Phys. Rept. 493 , 1 (2010); K. Bamba, S. Capozziello, S. Nojiri and S. D. Odintsov, Astrophys. Space Sci. 342 , 155 (2012).
- [5] A. Sen, Phys. Scripta 117 , 70-75 (2005).
- [6] G. W. Gibbons, Phys. Lett. B 537 , 1 (2002).
- [7] M. R. Garousi, Nucl. Phys. B 584 , 284 (2000).
- [8] A. Sen, Mod. Phys. Lett. A 17 , 1797 (2002).
- [9] A. Unzicker and T. Case, [arXiv:physics/0503046].
- [10] K. Hayashi and T. Shirafuji, Phys. Rev. D 19 , 3524 (1979) [ Addendum-ibid. D 24 , 3312 (1982)].
- [11] R. Aldrovandi and J. G. Pereira, Teleparallel Gravity: An Introduction , Springer, Dordrecht (2013).
- [12] J. W. Maluf, Annalen Phys. 525 , 339 (2013).
- [13] R. Ferraro and F. Fiorini, Phys. Rev. D 75 , 084031 (2007).
- [14] G. R. Bengochea and R. Ferraro, Phys. Rev. D 79 , 124019 (2009).
- [15] E. V. Linder, Phys. Rev. D 81 , 127301 (2010).
- [16] A. De Felice and S. Tsujikawa, Living Rev. Rel. 13 , 3 (2010).
- [17] S. i. Nojiri and S. D. Odintsov, Phys. Rept. 505 , 59 (2011).
- [18] B. L. Spokoiny, Phys. Lett. B 147 , 39 (1984); F. Perrotta, C. Baccigalupi and S. Matarrese, Phys. Rev. D 61 , 023507 (1999).
- [19] V. Faraoni, Phys. Rev. D 62 , 023504 (2000); E. Elizalde, S. Nojiri and S. D. Odintsov, Phys. Rev. D 70 , 043539 (2004).
- [20] O. Hrycyna and M. Szydlowski, JCAP 0904 , 026 (2009); O. Hrycyna and M. Szydlowski, Phys. Rev. D 76 , 123510 (2007); R. C. de Souza and G. M. Kremer, Class. Quant. Grav. 26 , 135008 (2009); A. A. Sen and N. Chandrachani Devi, Gen. Rel. Grav. 42 , 821 (2010).
- [21] C. -Q. Geng, C. -C. Lee, E. N. Saridakis, Y. -P. Wu, Phys. Lett. B 704 , 384-387 (2011).
- [22] C. -Q. Geng, C. -C. Lee and E. N. Saridakis, JCAP 1201 , 002 (2012).
- [23] C. Xu, E. N. Saridakis and G. Leon, [arXiv:1202.3781 [gr-qc]].
- [24] H. Wei, Phys. Lett. B 712 , 430 (2012).
- [25] G. Otalora, JCAP 1307 , 044 (2013).
- [26] A. Banijamali and B. Fazlpour, Astrophys. Space Scie. 342 , 229 (2012).
- [27] G. Otalora, Phys. Rev. D 88 , 063505 (2013).
- [28] S. H. Pereira, A. Pinho S. S. and J. M. Hoff da Silva, [arXiv:1402.6723 [gr-qc]].
- [29] S. Unnikrishnan, Phys. Rev. D 78 , 063007 (2008); R. Yang and J. Qi, Eur. Phys. J. C 72 , 2095 (2012).
- [30] I. Quiros, T. Gonzalez, D. Gonzalez, Y. Napoles, R. Garcia-Salcedo and C. Moreno, Class. Quant. Grav. 27 , 215021 (2010).
- [31] E. J. Copeland, A. R. Liddle and D. Wands, Phys. Rev. D 57 , 4686 (1998).
- [32] L. Amendola, Phys. Rev. D 60 , 043501 (1999); Z. K. Guo, R. G. Cai and Y. Z. Zhang, JCAP 0505 , 002 (2005).
- [33] H. Wei, Nucl. Phys. B 845 , 381 (2011).
- [34] L. P. Chimento, A. S. Jakubi, D. Pavon and W. Zimdahl, Phys. Rev. D 67 , 083513 (2003).
- [35] E. J. Copeland, M. Sami and S. Tsujikawa, Int. J. Mod. Phys. D 15 , 1753 (2006); J. Frieman, M. Turner and D. Huterer, Ann. Rev. Astron. Astrophys. 46 , 385 (2008); S. Tsujikawa, arXiv:1004.1493 [astro-ph.CO]. | null | [
"Behnaz Fazlpour",
"Ali Banijamali"
] | 2014-08-01T15:14:38+00:00 | 2014-08-01T15:14:38+00:00 | [
"gr-qc",
"hep-th"
] | Dynamics of Generalized Tachyon Field in Teleparallel Gravity | We study dynamics of generalized tachyon scalar field in the framework of
teleparallel gravity. This model is an extension of tachyonic teleparallel dark
energy model which has been proposed in [26]. In contrast with tachyonic
teleparallel dark energy model that has no scaling attractors, here we find
some scaling attractors which means that the cosmological coincidence problem
can be alleviated. Scaling attractors present for both interacting and
non-interacting dark energy, dark matter cases. |
1408.0204v1 | ## Functional Principal Component Analysis and Randomized Sparse Clustering Algorithm for Medical Image Analysis
Nan Lin 1 , Junhai Jiang , Shicheng Guo 1 1,2 and Momiao Xiong 1,*
1 Human Genetics Center, Division of Biostatistics, School of Public Health, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA
2 State Key Laboratory of Genetic Engineering and Ministry of Education Key Laboratory of Contemporary Anthropology, Collaborative Innovation Center for Genetics and Development, School of Life Sciences and Institutes of Biomedical Sciences, Fudan University, Shanghai 200433, China
Running Title : Randomized Image Cluster Analysis
Key words : Randomized dimension reduction, sparse cluster analysis, two dimensional functional principal component analysis, medical image analysis
Table counts: 6
Figures counts: 2
Abstract counts: 250
Main body words counts: 4780
* Address for correspondence and reprints: Dr. Momiao Xiong, Division of Biostatistics, Human Genetics Center, The University of Texas Health Science Center at Houston, 1200 Pressler st, Houston, Texas 77030, (Phone): 713-500-9894, (Fax): 713-500-0900, E-mail:
[email protected]
## ABSTRACT
Due to advances in sensors, growing large and complex medical image data have the ability to visualize the pathological change in the cellular or even the molecular level or anatomical changes in tissues and organs. As a consequence, the medical images have the potential to enhance diagnosis of disease, prediction of clinical outcomes, characterization of disease progression, management of health care and development of treatments, but also pose great methodological and computational challenges for representation and selection of features in image cluster analysis. To address these challenges, we first extend one dimensional functional principal component analysis to the two dimensional functional principle component analyses (2DFPCA) to fully capture space variation of image signals. Image signals contain a large number of redundant and irrelevant features which provide no additional or no useful information for cluster analysis. Widely used methods for removing redundant and irrelevant features are sparse clustering algorithms using a lasso-type penalty to select the features. However, the accuracy of clustering using a lasso-type penalty depends on how to select penalty parameters and a threshold for selecting features. In practice, they are difficult to determine. Recently, randomized algorithms have received a great deal of attention in big data analysis. This paper presents a randomized algorithm for accurate feature selection in image cluster analysis. The proposed method is applied to ovarian and kidney cancer histology image data from the TCGA database. The results demonstrate that the randomized feature selection method coupled with functional principal component analysis substantially outperforms the current sparse clustering algorithms in image cluster analysis.
## Highlights:
We develop a novel two dimensional FPCA method for image data reduction.
Using feature selection we develop sparse clustering algorithms.
We use provable randomized algorithm to select features for cluster analysis.
We develop a novel randomized sparse clustering algorithm for imaging data analysis.
## 1. Introduction
Image clustering is to cluster the objects into groups such that the objects within the same group are similar, while the objects in different groups are dissimilar (Yang et al. 2010; Bong and Rajeswari, 2012). Image clustering is a powerful tool to better organize and represent images in image annotation, image indexing, and segmentation and subtype disease identification. Data dimension reduction is essential to the success of image clustering analysis.
Feature extraction and feature selection are two popular types of methods for dimensionality reduction. A widely used method for feature extraction is principal component analysis (PCA). However, PCA does not explore spatial information. It takes the set of spectral images as an unordered set of high dimensional pixels (Gupta and Jacobson, 2006). Spatial information is very important for image cluster and classification analysis. To overcome limitations of PCA and to utilize spatial information of the image signal, the functional expansion of images based on Fourier and wavelet transform are proposed as a useful tool for image feature extraction and data denoising (Strela et al. 1999). Recently, wavelet PCA in which we compute principal components for a set of wavelet coefficients is proposed (Gupta and Jacobson, 2006) to explore both spatial and spectral information. The wavelet PCA improves efficiency to extract image features, but not explicitly considers smoothing image signals over space. To overcome this limitation and fully utilize both spatial and spectral information, we extend one dimensional functional principal component analysis (FPCA) to two dimensional FPCA.
Traditional statistical methods for image cluster and classification analysis often fail to obtain accurate results because of the high dimensional nature of image data (Samiappan et al. 2013). Noisy and irrelevant features result in overfitting. The high dimensionality makes the clustering algorithms very slow (Boutsidis and Magdon-Ismail, 2013). The high dimensionality of image provides a considerable challenge for designing efficient clustering algorithms (Boutsidis et al.
2013). Removing noise, redundant and irrelevant features and retaining a minimal feature subset will dramatically improve the accuracy of image cluster analysis (Aroquiaraj and Thangavel, 2013). The sparse method is a widely used method for feature selection in which a lasso-type penalty provides a general framework to simultaneously find the clusters and the important clustering features in image cluster analysis (Witten and Tibshirani, 2010; Kondo et al. 2012). Although the sparse clustering methods can improve accuracy, it may fail to generate reasonable clusters when the data include a few outliers. In practice, the performance of sparse clustering depends on the selection of penalty parameters and threshold for cutting off features. However, the selection of penalty parameters and threshold proves difficult. Despite the success of feature selection in image clustering, very few provable accurate feature selection methods for clustering exist (Boutsidis et al. 2013).
Alternatively, a randomized method is proving useful when the number of features is prohibitively large (Stracuzzi 2008). An efficient randomized feature selection method for k -means clustering randomly selects the features with probabilities that are calculated via singular value decomposition of the data matrix (Boutsidis and Magdon-Ismail, 2013; Boutsidis et al. 2013). This algorithm has a very useful property that can theoretically guarantee the quality of the clusters. To the best of our knowledge, this efficient and provable accurate randomized feature selection algorithm has not been applied to the image cluster analysis.
Although feature selection and feature extraction are widely used to reduce the dimensionality of the image, we have observed very few practices to combine feature selection and feature extraction together for dimension reduction. We can expect that applying feature selection algorithm to select extracted features from a set of artificial features that are computed via feature extraction will improve the accuracy of image clustering.
The purpose of this paper is to develop a comprehensive sparse clustering algorithm with four components for image cluster analysis. The first component is to use high dimensional FPCA as a feature extraction technique. The second component includes a theoretically provable accurate randomized feature selection algorithm. The third component is to combine feature selection and feature extraction together for dimensionality reduction. The fourth component is spectral clustering with low rank matrix decomposition that can effectively remove noises and ensure the robustness of the algorithms. To evaluate its performance for image cluster analysis, the proposed method is applied to 176 ovarian cancer histology images with the drug response status (106 images with positive drug response and 70 images with drug resistance) and 188 kidney histology images (121 images from tumor samples and 67 images from normal samples) from the TCGA database. Our results strongly demonstrate that the proposed method for feature selection substantially outperform other existing feature selection methods. Software for implementing the proposed methods can be downloaded from our website http://www.sph.uth.tmc.edu/hgc/faculty/xiong/index.htm and http://www.bioconductor.org/.
## 2. Material and methods
## 2.1. Two dimensional functional principal component analysis
One dimensional functional principal component analysis (FPCA) has been well developed (Ramsay and Silverman, 2005). Now we extend one dimensional FPCA to two dimensional FPCA. Consider a two dimensional region. Let s and t denote coordinates in the s axis and t axis, respectively. Let ) be a centered image signal located at , ( t s x s and t of the region. The signal ) is a function of locations , ( t s x s and t .
Consider a linear combination of functional values:
$$f = \underset { S T } { \underset { T } { \int } } \beta ( s, t ) x ( s, t ) d s d t \,,$$
where ) is a weight function. To capture the variations in the random functions, we chose , ( t s weight function ) to maximize the variance of , ( t s f . By the formula for the variance of stochastic integral (Henderson and Plaschko, 2006), we have
$$\text{var} ( f ) = \iint _ { S T S T } \iint _ { S T } \beta ( s _ { 1 }, t _ { 1 } ) R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 1 } d t _ { 1 } d s _ { 2 } t _ { 2 }$$
where )) is the covariance function of the image signal , ( ), , ( cov( ) , , , ( 2 2 1 1 2 2 1 1 t s x t s x t s t s R function ) . Since multiplying , ( t s x ) by a constant will not change the maximizer of the ( t variance ) , we impose a constraint to make the solution unique: ( f Var
$$\underset { r \, r } { \iint } \beta ^ { 2 } ( s, t ) d s d t = 1.$$
Therefore, to find the weight function, we seek to solve the following optimization problem:
$$\max \quad & \iint _ { S \ T } \iint _ { S \ T } \beta ( s _ { 1 }, t _ { 1 } ) R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 1 } d t _ { 1 } d s _ { 2 } t _ { 2 } \\ s. t. \quad & \iint _ { S \ T } \beta ^ { 2 } ( s, t ) d s d t = 1.$$
Using the Lagrange multiplier, we reformulate the constrained optimization problem (3) into the following non-constrained optimization problem:
$$\max _ { \beta } \left ( \frac { 1 } { 2 } \int \int \int \beta ( s _ { 1 }, t _ { 1 } ) R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 1 } d t _ { 1 } d s _ { 2 } t _ { 2 } + \frac { 1 } { 2 } \lambda ( 1 - \int \int \beta ^ { 2 } ( s _ { 1 }, t _ { 1 } ) d s _ { 1 } d t _ { 1 } ) \,, \ \ ( 4 )$$
where is a penalty parameter.
By variation calculus (Sagan, 1969), we define the functional
$$J [ \beta ] = \frac { 1 } { 2 } \int \int \int _ { S \ T \ S \ T } \beta ( s _ { 1 }, t _ { 1 } ) R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 1 } d t _ { 1 } d s _ { 2 } t _ { 2 } + \frac { 1 } { 2 } \lambda ( 1 - \int \int \beta ^ { 2 } ( s _ { 1 }, t _ { 1 } ) d s _ { 1 } d t _ { 1 } ) \. \text{ Its first}$$
variation is given by
$$\S J [ h ] & = \frac { d } { d \varepsilon } J [ \beta ( s, t ) + \varepsilon h ( s, t ) ] \\ & = \iint [ \iint [ R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 2 } t _ { 2 } - \lambda \beta ( s _ { 1 }, t _ { 1 } ) ] h ( s _ { 1 }, t _ { 1 } ) d s _ { 1 } d t _ { 1 } \\ & = \iint [ \iint [ \iint R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 2 } t _ { 2 } - \lambda \beta ( s _ { 1 }, t _ { 1 } ) ] ^ { 2 } d s _ { 1 } d t _ { 1 } = 0,$$
which implies the following integral equation
$$\underset { S \, \uparrow } { \iint } R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) \beta ( s _ { 2 }, t _ { 2 } ) d s _ { 2 } d t _ { 2 } = \lambda \beta ( s _ { 1 }, t _ { 1 } )$$
for an appropriate eigenvalue . The left side of the integral equation (5) defines a two dimensional integral transform R of the weight function . Therefore, the integral transform of the covariance function )is referred to as the covariance operator , , , ( 2 2 1 1 t s t s R R . The integral equation (5) can be rewritten as
$$R \beta = \lambda \beta \,,$$
where ) is an eigenfunction and referred to as a principal component function. Equation (6) , ( t s is also referred to as a two dimensional eigenequation. Clearly, the eigenequation (6) looks the same as the eigenequation for the multivariate PCA if the covariance operator and eigenfunction are replaced by the covariance matrix and eigenvector.
Since the number of function values is theoretically infinite, we may have an infinite number of eigenvalues. Provided the functions i X and i Y are not linearly dependent, there will be only 1 nonzero eigenvalues, where N N is the total number of is sampled individuals ( G A n n N , A n is the number of individuals sampled from cases and G n is the number of individuals sampled from controls). Eigenfunctions satisfying the eigenequation are orthonormal (Ramsay and Silverman, 2005). In other words, equation (6) generates a set of principal component functions:
$$R \beta _ { k } = \lambda _ { k } \beta _ { k }, \quad \text{ with } \lambda _ { 1 } \geq \lambda _ { 2 } \geq \cdots.$$
These principal component functions satisfy
$$( 1 ) \, \underset { S \, T } { \iint } \beta _ { k } ^ { 2 } ( s, t ) d s d t = 1 \text{ and }$$
$$( 2 ) \, \iint _ { S \, T } \beta _ { k } ( s, t ) \beta _ { m } ( s, t ) d s d t = 0, \, \text{for all } \, m < k.$$
The principal component function 1 with the largest eigenvalue is referred to as the first principal component function and the principal component function 2 with the second largest eigenvalue is referred to as the second principal component function, and continuing.
## 2.2. Computations for the principal component function and the principal component score
The eigenfunction is an integral function and difficult to solve in closed form. A general strategy for solving the eigenfunction problem in (5) is to convert the continuous eigen-analysis problem to an appropriate discrete eigen-analysis task (Ramsay and Silverman 2005). In this paper, we use basis function expansion methods to achieve this conversion.
Let { . We expand 2 define j, each For functions. Fourier of series the be )} ( 2 1 -2j j t j j each image signal function ) as a linear combination of the basis function , ( t s x i j :
$$x _ { i } ( s, t ) = \sum _ { k = 1 } ^ { K } \sum _ { l = 1 } ^ { K } c _ { k j } ^ { ( i ) } \phi _ { k } ( s ) \phi _ { l } ( t ) \,.$$
Let t T i i i i i i c c c c c c C ] ,..., ,..., ,..., , ,..., [ ) ( ) ( ) ( ) ( ) ( ) ( and T t t t )] ( , ), ( [ ) ( . Then, equation (7)
KK K K K i 1 2 21 1 11 K 1 can be rewritten as
$$x _ { i } ( s, t ) = C _ { i } ^ { T } \left ( \phi ( s ) \otimes \phi ( t ) \right ),$$
where denotes the Kronecker product of two matrices.
Define the vector-valued function T N t s x t s x t s X )] , ( , ), , ( [ ) , ( 1 . The joint expansion of all N random functions can be expressed as
$$X ( s, t ) = C ( \phi ( s ) \otimes \phi ( t ) )$$
where the matrix C is given by
$$C = \begin{bmatrix} C _ { 1 } ^ { T } \\ \vdots \\ C _ { N } ^ { T } \end{bmatrix}.$$
In matrix form the variance-covariance function of the image signal function can be expressed as
$$R ( s _ { 1 }, t _ { 1 }, s _ { 2 }, t _ { 2 } ) & = \frac { 1 } { N } X ^ { T } ( s _ { 1 }, t _ { 1 } ) X ( s _ { 2 }, t _ { 2 } ) \\ & = \frac { 1 } { N } [ \phi ^ { T } ( s _ { 1 } ) \otimes \phi ^ { T } ( t _ { 1 } ) C ^ { T } C [ \phi ( s _ { 2 } ) \otimes \phi ( t _ { 2 } ) ].$$
Similarly, the eigenfunction ) can be expanded as , ( t s
$$\beta ( s, t ) = \sum _ { j = 1 } ^ { K } \sum _ { k = 1 } ^ { K } b _ { j k } \phi _ { j } ( s ) \phi _ { k } ( t ) \text{ \ or }$$
$$\beta ( s, t ) = [ \phi ^ { T } ( s ) \otimes \phi ^ { T } ( t ) ] b$$
where T KK K K b b b b b ] ,..., ,..., ,..., [ 1 1 11 . Substituting expansions (9) and (10) of the variancecovariance ) and eigenfunction , , , ( 2 2 1 1 t s t s R ) into the functional eigenequation (5), we , ( t s
obtain
$$[ \phi ^ { T } ( s _ { 1 } ) \otimes \phi ^ { T } ( t _ { 1 } ) ] \frac { 1 } { N } C ^ { T } C b = \lambda [ \phi ^ { T } ( s _ { 1 } ) \otimes \phi ^ { T } ( t _ { 1 } ) ] b \,.$$
Since equation (11) must hold for all s and , we obtain the following eigenequation: t
$$\frac { 1 } { N } C ^ { T } C b = \lambda b \,.$$
Solving eigenequation (12), we obtain a set of orthonormal eigenvectors j b . A set of orthonormal eigenfunctions is given by
$$\beta _ { j } ( s, t ) = [ \phi ^ { T } ( s ) \otimes \phi ^ { T } ( t ) ] b _ { j }, j = 1, \dots, J \,.$$
The random functions ) can be expanded in terms of eigenfunctions as , ( t s x i
$$x _ { i } ( t, s ) = \sum _ { j = 1 } ^ { J } \xi _ { i j } \beta _ { j } ( s, t ), i = 1, \dots, N,$$
where S T j i ij dsdt t s s t x . , ) , ( ) , ( J j N i ,..., 1 , ,..., 1 are FPC scores.
## 2.3. Randomized feature selection for k - means clustering
The most widely used clustering method in practice is k -means algorithm. However, using k means to cluster millions or billions of features is not simple and straightforward (Boutsidis and Mardon-Ismail, 2013). An attractive strategy is to select a subset of features and optimize the k -means of objective on the low dimensional representation of the original high dimensional data. A natural question is whether feature selection will lose valuable information by throwing away potentially useful features which could lead to a significantly higher clustering error. Here, we introduce a randomized feature selection algorithm with provable guarantees (Boutsidis et al. 2013).
-means algorithm.
For the self-contain, we begin with a linear algebraic formulation of k Many materials are from Boutsidis et al. 2013. Consider a set of m points:
$$A ^ { T } = [ P _ { 1 }, \dots, P _ { m } ] \in R ^ { n \times m } \,.$$
A k partition of m points is a collection
$$S = \{ S _ { 1 }, S _ { 2 }, \dots, S _ { k } \},$$
of k non-empty pairwise disjoint sets covering the entire dataset. K -means clustering minimizes the within-cluster sum of squares . Let |, be the size of | j j S s j S . For each set j S , define its centroid (the mean of data points within the set j S ):
$$\mu _ { j } = \frac { 1 } { s _ { j } } \sum _ { p _ { i } \in S _ { j } } P _ { i } \,.$$
The k -means objective function is defined as
$$\underline { m }$$
$$F ( P, S ) = \sum _ { i = 1 } ^ { m } \| P _ { i } - \mu ( P _ { i } ) \| _ { 2 } ^ { 2 } \,,$$
where ) is the centroid of the cluster to which ( i P i P belongs.
The k -means objective function can be transformed to a more convenient linear algebraic formulation. A k clustering S of A can be represented by its clustering indicator matrix m n R X . Specifically, its element ij X is defined as
$$X _ { i j } = \begin{cases} \frac { 1 } { \sqrt { s _ { j } } } & P _ { i } \in S _ { j } \\ 0 & \text{otherwise}. \end{cases}$$
Each row of X has one non-zero element, corresponding to the cluster to which the data point belongs. Each column has j s non-zero elements, which denotes the data points belonging to cluster j S . The linear algebraic formulation of the k -means objective function can be expressed as
$$F ( A, X ) = & \| A - X X ^ { T } A \| _ { F } ^ { 2 } \\ = & \sum _ { i = 1 } ^ { m } \| P _ { i } ^ { T } - X _ { i } X ^ { T } A \| _ { 2 } ^ { 2 } \\ = & \sum _ { i = 1 } ^ { m } \| P _ { i } ^ { T } - \mu ( P _ { i } ) ^ { T } \ | _ { 2 } ^ { 2 },$$
where || ) is the Frobenius norm of a matrix ( || W W T Tr W , X is the i th row of X ,
$$\text{where } \| W \| _ { F } = \sqrt { T r ( W ^ { T } W ) } \text{ is the Frobenius norm of a matrix } W \, \ X _ { i } \text{ is the } i \, \text{th} \, \text{r} \\ X ^ { T } A = [ \mu _ { 1 } ^ { T }, \dots, \mu _ { k } ^ { T } ] ^ { T } \text{ and } X _ { i } X ^ { T } X = \mu ( P _ { i } ) ^ { T } \,.$$
Our goal is to find an indicator matrix opt X which minimizes|| 2 || F T A XX A :
$$X _ { o p t } = \underset { X \in R ^ { m \in \real k } } { \arg \min } \, \left \| \, A - X X ^ { T } A \, \right \| _ { F } ^ { 2 }.$$
## Define
$$F _ { o p t } = & \| A - X _ { o p t } X _ { o p t } ^ { T } A \, | | _ { F } ^ { 2 } \,.$$
It is noted that A X T Xopt opt has rank at most k . Singular value decomposition of the matrix A is given by
$$A = U _ { k } \Sigma _ { k } V _ { k } ^ { T } + U _ { \rho - k } \Sigma _ { \rho - k } V _ { \rho - k } ^ { T } \,,$$
where ) is rank of the matrix , min( n m A , k m k R U and ) ( k m k R U contain the left singular vectors of A , k n k R V and ) ( k n k R V contain the right singular vectors. Singular values 0are contained in the matrices ... 2 1 k k k R and ) )( ( k k k R . Let
A
T
T
T
k
k
k
k
k
k
V
AV
V
U
and
k
k
k
k
A
A
V
U
A
. Since
A
is the best rank
k
approximation to A and A X T Xopt opt has rank at most k , we obtain
$$\| \, A - A _ { k } \, \| _ { F } ^ { 2 } \leq \| \, A - X _ { o p t } X _ { o p t } ^ { T } A \, \| _ { F } ^ { 2 } \leq F _ { o p t }.$$
The feature selection for k -means clustering algorithm is to select a subset of r columns r m R C from A , which is a representation of the m data points in the low r -dimensional selected feature space. Then, the goal of k -means clustering algorithm in the selected feature space is to find partition of m which minimizes|| 2 || F T C XX C :
$$\tilde { X } _ { o p t } = \underset { X \in R ^ { m \prec k } } { \arg \min } \ \left \| C - X X ^ { T } C \right \| _ { F } ^ { 2 }.$$
k
k
Therefore, feature selection is to seek selection of features such that
$$\| A - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A \| _ { F } ^ { 2 } \leq \gamma \| A - X _ { o p t } X _ { o p t } ^ { T } A \| _ { F } ^ { 2 } \,.$$
The basic idea of randomized feature selection is that any matrix C which can be used to approximate matrix A can also be used for dimensionality reduction in k -means cluster analysis (Boutsidis et al. 2013; Drineas et al. 1999). We seek matrix C that minimizes
$$\| \, A - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A \, \| _ { F } ^ { 2 } = & \| \, A _ { k } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A _ { k } \, \| _ { F } ^ { 2 } + \| \, A _ { p - k } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A _ { p - k } \, \| _ { F } ^ { 2 } \\ = & \| \, A V _ { k } V _ { k } ^ { T } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A V _ { k } V _ { k } ^ { T } \, \| _ { F } ^ { 2 } + \| \, A _ { p - k } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A _ { p - k } \, \| _ { F } ^ { 2 } \\ = & \| \, A V _ { k } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A V _ { k } \, \| _ { F } ^ { 2 } + \| \, A _ { p - k } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A _ { p - k } \, \| _ { F } ^ { 2 }$$
Let k AV C . Then, T k k CV A . The minimization problem (18) can be reduced to minimizing 2 || || F T C XX C .
Using formula k AV C to calculate the matrix C requires the entire dataset . Next, our goal is A to select columns of the matrix A to approximate C . We denote the sampling matrix r n i i R e e r ] ,..., [ 1 , where i e are the standard basis vectors with its i th element being one and all other elements being zeroes. Let r r R S be a diagonal rescaling matrix. Define S A C . The matrices and S can be generated by randomized sampling. Since singular value decomposition of a large matrix A may be difficult, we will also use a sampling algorithm to generalize a matrix Z which approximates k V . Thus, the matrix A can be decomposed to E AZZ T A , where the matrix n m R E . We still use opt X ~ to denote the output cluster indicator matrix of some -approximation matrix on ( ) . Then, we can estimate the upper bound of the clustering error , k C 2 || ~ ~ || F T opt opt A X X A as follows (Boutsidis and Magdon-Ismail 2013).
$$\| A - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A \| _ { F } ^ { 2 } = & \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } + ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) E \, \| _ { F } ^ { 2 } \,.$$
Because m k T T E Z 0 we have
$$( ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } ) ( ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) E ) ^ { T } = 0 _ { m \times m } \,.$$
Consequently, equation (19) can be reduced to
$$\| A - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A \| _ { F } ^ { 2 } = & \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } \| _ { F } ^ { 2 } + \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) E \, \| _ { F } ^ { 2 } \\ \leq & \, \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } \, \| _ { F } ^ { 2 } + \| E \, \| _ { F } ^ { 2 }$$
Given and S , we have (Boulsidis and Margdon-Ismail, 2013)
$$A \mathbb { Z Z } ^ { T } = A \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } + Y \,,$$
where n m R Y is a residual matrix and (.) denotes the pseudo-inverse of a matrix. It is noted that
$$\| A B \| _ { F } \leqslant \| A \, \| _ { F } \| B \, \| _ { F } \,, \, \| W Z ^ { T } \, \| _ { F } = \sqrt { \ } T r ( W Z ^ { T } Z W ) = \| W \, \| _ { F } \text{ and for any two matrices},$$
$$\left \| Y _ { 1 } + Y _ { 2 } \left \| _ { F } ^ { 2 } \leq 2 \left \| Y _ { 1 } \left \| _ { F } ^ { 2 } + 2 \left \| Y _ { 2 } \left \| _ { F } ^ { 2 }.$$
Then, the first term in equation (20) can be further bounded by
$$\| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } & \| _ { F } ^ { 2 } \leq 2 \, \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } \, \| _ { F } ^ { 2 } \, + 2 \, \| Y \, \| _ { F } ^ { 2 } \\ & \leq 2 \, \| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } \| ( Z ^ { T } \Omega S ) ^ { + } \, \| _ { F } \, + 2 \, \| Y \, \| _ { F }$$
Using equation (17), we obtain
$$\| ( I _ { m } - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } & \| _ { F } \leq 2 \gamma \, \| ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } \| ( Z ^ { T } \Omega S ) ^ { + } \, \| _ { F } ^ { 2 } + 2 \| Y \, \| _ { F } ^ { 2 } \\ & \leq 2 \gamma \frac { | ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) } + 2 \, \| Y \, \| _ { F } ^ { 2 }$$
Since rank ( k S Z T ) , we have
$$Z ^ { T } \Omega S ( Z ^ { T } \Omega S ) ^ { + } = I _ { k }$$
and
$$A Z Z ^ { T } - A Z Z ^ { T } \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } = 0 _ { m x n } \,, \, \text{which implies that}$$
$$Y & = A \mathbb { Z Z } ^ { T } - A \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } \\ & = A \mathbb { Z Z } ^ { T } - A \mathbb { Z Z } ^ { T } \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } - ( A - A \mathbb { Z Z } ^ { T } ) \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } \\ & = - ( A - A \mathbb { Z Z } ^ { T } ) \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T }.$$
Therefore, we have
$$\| Y \, & | | _ { F } ^ { 2 } = & \| ( A - A Z Z ^ { T } ) \Omega S ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } \, | | _ { F } ^ { 2 } \\ \leq & \| ( A - A Z Z ^ { T } ) \Omega S \, | | _ { F } ^ { 2 } \| ( Z ^ { T } \Omega S ) ^ { + } Z ^ { T } \, | | _ { F } ^ { 2 } \\ \leq & \| ( A - A Z Z ^ { T } ) \Omega S \, | | _ { F } ^ { 2 } \| ( Z ^ { T } \Omega S ) ^ { + } \, | | _ { F } ^ { 2 } \\ = & \frac { \| ( A - A Z Z ^ { T } ) \Omega S \, | | _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) }.$$
Combining equations (23) and (24), we obtain:
$$\| ( I _ { m } - \tilde { X } _ { o p t } \tilde { X } _ { o p t } ^ { T } ) A Z Z ^ { T } & \| _ { F } ^ { 2 } \leq 2 \gamma \frac { | ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) } + 2 \, \| Y \, \| _ { F } ^ { 2 } \\ & \leq 2 \frac { \gamma \, | ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } + 2 \, \| ( A - A Z Z ^ { T } ) \Omega S \, \| _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) } \quad ( 2 5 ) \\ & \leq 2 \frac { \gamma \, \| ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } + \| E \Omega S \, \| _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) }$$
Combining equations (20) and (25) we obtain the following upper bound:
$$\| A - \widetilde { X } _ { o p t } \widetilde { X } _ { o p t } ^ { T } A \| _ { F } ^ { 2 } \leq 2 \frac { \gamma \, | \, ( I _ { m } - X _ { o p t } X _ { o p t } ^ { T } ) A \Omega S \, \| _ { F } ^ { 2 } + \| E \Omega S \, \| _ { F } ^ { 2 } } { \sigma _ { k } ^ { 2 } ( Z ^ { T } \Omega S ) } + \| E \, \| _ { F } ^ { 2 } \,.$$
The upper bound provides information about how to choose , Z and S . We chose Z to make the residual E small. Several terms in the upper bound can be used to guide the selection of the sampling and rescaling matrices and S .The first term in the numerator of the upper bound is the clustering error of the input partition in the reduced dimension space. We chose and S to make this clustering error small. The residual E is involved in the second term of the numerator and final term in the inequality (26). We chose and S such that they will not substantially increase the size of the residual E . The term in the denominator involves , Z and S . Therefore, the selected and S do not significantly change the singular structure of the projection matrix Z and ensure that ) is large. Under these guidance, the following randomized feature ( 2 S Z T k selection algorithm can be developed.
## 2.4 Randomized feature selection algorithms
Let k be the number of clusters and be the errors that are allowed.
$$\text{Set } r = k + \left [ \frac { k } { \varepsilon } \right ] + 1 \text{ as the number of features being selected. Consider data matrix}$$
$$A = \begin{bmatrix} a _ { 1 1 } & \cdots & a _ { 1 n } \\ \vdots & \cdots & \vdots \\ a _ { m 1 } & \cdots & a _ { m n } \end{bmatrix}.$$
Let i denote the index of the individual sample and j be the index of feature. We intend to select r features.
Procedures of algorithms are given as follows.
- 1. Generate an r n standard Gaussian matrix R, with ) . 1 , 0 ( ~ N Rij
- 2. Let r m R AR Y .
- 3. Orthonormalize the columns of the matrix Y , which leads to the matrix r m R Q .
- 4. Singular value decomposition of the matrix A Q T : T T V U A Q .
Let k n R Z be the top k right singular vectors of A Q T , i.e., ] . ,..., [ 1 k V V Z
- 5. Calculate the sampling probability:
$$P _ { i } = \frac { \| Z _ { ( i ) } \| _ { 2 } ^ { 2 } } { \| Z \| _ { F } ^ { 2 } }, i = 1, \dots, n, \sum _ { i = 1 } ^ { n } P _ { i } = 1, \text{ where } Z _ { ( i ) } \text{ is the $i$-th row of the matrix } Z \text{ and}$$
$$\left \| \, Z \, \right \| _ { F } ^ { 2 } = t r ( Z Z ^ { T } ) \,.$$
- 6. Initiate r n 0 and r r S 0 .
For r t ,..., 1 , pick an integer t i from the set { ,2,..., }with probability 1 n t i P and replacement, set
$$\Omega ( i _ { t }, t ) = 1 \text{ and } S ( t, t ) = \frac { 1 } { \sqrt { r P _ { i _ { t } } } } \,.$$
End
- 7. Return r m R S A C .
## 3. Results
We tested our algorithm on two cancer histology image datasets downloaded from the TCGA database. The first dataset is an ovarian cancer dataset, which includes 176 histology images taken from 106 drug sensitive and 76 drug resistant tissue samples. The second dataset is Kidney Renal Clear Cell Carcinoma (KIRC) dataset which includes 188 histology images taken from 121 KIRC tumor and 67 normal tissue samples.
We compared the performance of our algorithm with the standard K - means and regularization-based sparse K - means clustering algorithms (Witten and Tibshirani 2010). We also compared the performance of the two FPCA with the Fourier expansion and SIFT descriptor (Chen and Tian 2006 ). We use cluster accuracy (ACC) which is defined as the proportion of correctly clustered images, cluster sensitivity which is defined as the proportion of correctly clustered drug sensitive or tumor samples, and cluster specificity which is defined as the proportion of correctly clustered drug resistant or normal samples, for performance evaluation in this study..
## 3.1. Comparison of two dimensional FPCA with Fourier expansion and SIFT descriptor
To intuitively illustrate the power of FPCA to reduce the dimension of image data, we first presented Figure 1 which showed the original and reconstructed lena face and KIRC tumor cell images. We observed that the reconstructed lena and images of KIRC tumor cell using only 6 functional principal components (FPCs) and 188 FPCs, respectively, are very close to the original images. However, even when we used the16, 129 terms in the Fourier expansion to reconstruct the lena face and KIRC cell images, the reconstructed images were still unclear. Then, we compared the accuracies of the standard k-means algorithms for clustering ovarian cancer and KIRC tissue samples using FPC scores, Fourier expansion coefficients and SIFT descriptors as image features. The results were summarized in Table 1. We observed from Table
1 that the cluster analysis using FPC scores as features has a higher accuracy than using Fourier expansion coefficients and SIFT descriptors for both ovarian cancer and KIRC datasets.
## 3.2. Performance of standard k-means clustering algorithm, sparse k-means clustering algorithm and randomized sparse k-means clustering algorithm
We compared the performance of the standard k -means clustering algorithm and sparse kmeans clustering algorithm and randomized sparse k -means clustering algorithm in the ovarian and KIRC cancer studies. The SPARCL package was used for implementing the sparse K -means clustering algorithm (Witten and Tibshirani 2010). The SIFT descriptor (Lowe 2004) was used as features. The images in the ovarian cancer study were taken before treatment. Therefore, the images were used to predict drug response. The results were summarized in Table 2. Table 2 showed that the randomized k-means clustering algorithms used significantly smaller features, but achieved higher accuracy than both the standard K-means and sparse k-means algorithms.
## 3.3. Performance of standard k-means, sparse k-means and randomized sparse kmeans clustering algorithms using FPC scores
We studied the performance of standard k-means, sparse k-means and randomized sparse k-means clustering algorithm using the FPC scores as image features. The results of this application of three clustering algorithms to two cancer imaging datasets were summarized in Table 3. Again, the randomized sparse k-means algorithms used the smallest number of FPC scores, but had the highest clustering accuracy, followed by sparse k-means clustering algorithms. The standard k-means clustering algorithms used the largest number of FPC scores, but achieved the lowest clustering accuracy. Comparing Table 3 with Table 2, we found that FPCA substantially improved clustering accuracy. Specifically, for the KIRC dataset we observed that replacing the SIFT descriptor with FPC scores increased the clustering accuracies of the
stand k-means, sparse k-means and randomized sparse k-means from 68.09% to 80.85%, 58.51% to 81.91%, and 72.87% to 83.51%, respectively.
## 3.4. Performance of standard spectral, sparse K-means, and randomized sparse spectral clustering algorithms using Fourier expansion coefficients
To further evaluate the performance of randomized sparse clustering algorithm, we considered spectral clustering algorithm, another type of clustering algorithms (Liu et al., 2013). We used three algorithms: standard spectral, sparse k-means and randomized spectral clustering algorithms with Fourier expansion coefficients to conduct clustering analysis for the ovarian cancer and KIRC datasets. Table 4 was presented to summarize the results. The performance patterns of the three clustering algorithms using Fourier expansion coefficients as imaging features were the same as that using other features. Table 4 showed that sparse principle for spectral clustering algorithms still improved cluster accuracy and randomized sparse clustering algorithms had the highest accuracy among the three clustering algorithms. We also observed that in general, using Fourier expansion coefficients as imaging features had less accuracy than using FPC scores as features (See Tables 4 and 5).
## 3.5. Performance of standard spectral, sparse K-means, and randomized sparse spectral clustering algorithms using FPC score
FPCA can improve clustering accuracy. This does not depended on which clustering algorithms are used. Table 5 showed the performance of standard spectral, sparse k-means and randomized spectral clustering algorithms with FPC scores in cluster analysis of two TCGA cancer datasets. We can clearly see that standard spectral, sparse k-means and randomized spectral clustering algorithms with FPC scores took much less features, but can reach as high as or even better
clustering accuracy than these methods using Fourier expansion coefficients as features. Table 5 again demonstrated that in most cases FPCA can substantially improve the performance of the clustering algorithms.
## 3.6. Multiple cluster analysis
Although a population can be divided into two groups: normal and patient groups, in general, patients' subpopulation is highly heterogeneous and has complex str uctures. Patients need to be further divided into several more homogeneous groups. Table 6 presented results of three clustering algorithms for multiple cluster analysis in the KIRC studies where tumor cells were partitioned into three groups. Neoplasm histologic grade which is based on the microscopic morphology of a neoplasm with hematoxylin and eosin (H&E) staining (G1, G2, G3 and G4) was selected as prognostic factors of survival (Erdogan et al., 2004). In the present analysis, patients of G1 and G2 were regrouped as group 1 patients. Patients of G3 were regrouped as group 2 patients and patients of G4 were regrouped as group 3 patients. Table 6 suggested that the randomized sparse k-means had the highest accuracy for clustering KIRC tumor cell grades, followed by sparse k-means and standard k-means clustering algorithms, where accuracy was defined as the proportion of individuals who were correctly assigned to groups. As shown in Figure 2, clustering tumor cells has a close relationship with cell pathology which characterizes progressing and development of tumors. In Figure 2a, morphology of nucleus that was represented by black circles changed slowly. When disease proceeded nucleus became large and expanded (Figure 2b). When tumors proceeded to the final stage, the nucleus was metastated and became blur (Figure 2c).
## 4. Discussion
In this paper, we proposed to combine feature extraction and feature selection for cluster analysis of imaging data and developed FPCA-based randomized sparse clustering algorithms.
The data in image applications are high-dimensional. Dimension reduction is a key to the success of imaging cluster analysis. To successfully perform image cluster analysis, we addressed several issues for dimensional reduction in the sparse image cluster analysis.
First issue is how to use feature extraction to reduce the data dimension. In other words, we construct a small set of new artificial features that are often linear combinations of the original features and then the k-means method is used to cluster on the constructed features. A variety of methods for feature extraction has been developed. PCA or FPCA are popular methods for feature extraction. However, FPCA is developed for one dimensional data and cannot be simply applied to two or three dimensional imaging data. Here we extended FPCA from one dimension to two or three dimensions and applied it to extraction of imaging features. Real histology imaging cluster analysis showed that the FPCA for imaging dimension reduction substantially outperformed the SIFT descriptor and Fourier expansion and is the one of choice for imaging feature extraction.
A second issue is to develop sparse clustering algorithms that attempts to identify features underlying clusters and remove noise and irrelevant variables. There are two types of sparse clustering algorithms. One type of algorithms is to optimize weighted within-cluster sum of squares and use a lasso type penalty to select weights and features. The difficulty with this type of constrained based sparse clustering algorithms is how to determine a threshold that is used to remove features. In theory, the features corresponding to non-zero weights will be selected for clustering. In practice, all weights vary continuously. Determining an appropriate threshold
to cut of irrelevant features is a difficult challenge. An alternative approach is to randomly and directly select a small subset of the actual features that can ensure to approximately reach the optimal k-means objective value. Both mathematic formulations of the k-means objective function and sampling algorithms to optimize objective function have well be developed. We can expect that the developed randomized sparse k-means clustering algorithms can work very well. Using real cancer imaging data, we showed that (1) both randomized k-means clustering and lasso-type k-means clustering algorithms substantially outperformed the standard k-means algorithm, and (2) performance of the randomized k-means sparse clustering algorithm was much better than that of the lasso type sparse k-means clustering algorithms.
A third issue is to combine feature extraction and feature selection. Feature extraction and feature selection are two major tools for dimension reduction. In imaging cluster analysis, feature extraction and feature selection are often used separately for data reduction. The main strength of our approach is to integrate feature extraction and feature selection into a dimension reduction tool before clustering images. We first performed two dimensional FPCA of images to extract group structure information of images. The resulting vector of FPC scores containing image group information were used to represent the features of the images. Then, we designed a random matrix column selection algorithm to select some components of the vector of FPC scores for further cluster analysis. Finally, k-means method was used to cluster the selected FPC scores. We showed that k-means method with combined feature extraction and feature selection as dimension reduction had the highest cluster accuracy in two real cancer clustering studies.
The fourth issue is the independence of dimension reduction benefits for clustering from the used clustering methods. Appropriate use of feature extraction and feature reduction may substantially improve the performance of clustering algorithms. This conclusion will not depend on which clustering algorithms are used. We demonstrated that cluster accuracies of both sparse k-means and sparse spectral clustering were higher than standard k-means and spectral clustering without dimension reduction.
While the proposed method provides a powerful approach to image cluster analysis, some challenges still remain. The randomized feature selection algorithms have deep connections with the objective function of k -means clustering and low-rank approximations to the data or feature matrix. However, the solutions to optimize the objective function of k -means clustering may not correspond to the true group structure of the image data well, which in turn, will compromise the performance of the randomized feature selection methods. Selection of the number of features also depends on the accuracy of low-rank approximation. Although we can provide theoretic calculation of the number of selected features, in practice we need to automatically calculate it by iterating the feature selection algorithm from the data, which requires heavy computation for large datasets. The randomized feature selection for multiple groups clustering still has serious limitation. Clustering images into multiple groups is an important, but a challenge problem. The main purpose of this paper is to stimulate discussion about what are the optimal strategies for high dimensional image cluster analysis. We hope that our results will greatly increase confidence in applying the dimension reduction to image cluster analysis.
## 5. Conclusions
We extended one dimensional FPCA to the two dimensional FPCA and develop novel sparse cluster analysis methods which combine two dimensional FPCA with randomized feature selection to reduce the high dimension of imaging data. We used stochastic calculus to derive the formula for calculation of the variance of integral of weighted linear combination of two dimensional signals of images. We formulated two dimensional FPCA as a maximization of this variance with respect to weight function (functional components) of two variants and used variation of theory to find solutions that are solutions to integral equations with two variants. We used functional expansion to develop computational methods for solving integral equations with respect to functional components and finding FPC scores which are taken as features for cluster analysis.
Followed the approach of Boutsidis et al. (2013), we explored matrix approximation theory and a technique of Rudelson and Vershynin (2007) to design a randomized method to select FPC scores as features for cluster analysis with probability that are correlated with the right singular vectors of the FPC score matrix. In theory, we can prove that the randomized feature selection algorithm guarantees the quality of the resulting clusters. The developed randomized algorithms integrating FPC scores as features for dimension reduction can be applied to kmeans and spectral clustering algorithms. Results on clustering histology images in the ovarian cancer and KIRC cancer studies showed that the randomized k -means and spectral clustering algorithms integrating FPCA substantially outperform other existing clustering algorithms with and without feature selection. The randomized sparse clustering algorithms integrating FPCA is a choice of methods for image clustering.
## Acknowledgments
The project described was supported by grants 1R01AR057120-01 and 1R01HL106034-01 from the National Institutes of Health and NHLBI, respectively. The authors wish to acknowledge the contributions of the research institutions, study investigators, field staff and study participants in creating the TCGA datasets for biomedical research.
## Conflict of interest
The authors declare that they have no competing interests.
## Vitae
Nan Lin received four year undergraduate education at the Jilin University in China and got the bachelor degree in biomedical engineering. Then he continued his graduate study in the field of biomedical engineering and got the master degree in biomedical engineering at Purdue University. After that, he moved to the University of Illinois, Urbana-Champaign and received two years' graduate training in statistics and got the master degree in statistics. Currently, I am pursuing my Ph.D degree in biostatistics at the University of Texas, Health Science Center at Houston.
Junhai Jiang is a Ph.D. student at the University of Texas Health Science Center at Houston. He got his Bachelor's degree at the Fudan University in 2011 and his major was statistics.
Afterwards, he got the degree of Master of Science in the Department of Mathematics and Statistics in Texas Tech University in 2013, and right now, he is a biostatistic Ph. D student under Dr. Momiao Xiong's supervision.
Shicheng Guo is a Ph.D. candidate student in medical genetics program, supervised by Dr. Li Jin, at the Fudan University, Shanghai, China. He obtained his bachelor degree from the school of life sciences, Northeast Agricutural University, Harbin, China in 2009. Currently, he is a visiting student and research assistant at Dr. Momiao Xiong's lab in the School of public health, University of Texas Health Science Center at Houston. He is focusing on cancer related susceptibility variants identification, diagnostic and prognostic biomarker discovery and risk prediction based on genetic and epigenetic variations as well as cancer early diagnosis based on the joint analysis of high-dimensional image, RNA-seq, methylation-seq datasets.
Momiao Xiong, Ph. D, Professor, Division of Biostatistics and Human Genetics Center, School of Public Health, the University of Texas Health Science Center at Houston . He obtained his PhD degree from the Department of Statistics at the University of Georgia in 1993 and finished his postdoctoral training in computational biology from the University of Southern California in 1995. His research is in the area of statistical genetics, bioinformatics, machine learning and image analysis.
## Figure Legend
Figure 1. (a) . Original image of the Lena face image. (b) Six lena face images are downloaded from the USC SIPI Image Database (Web: http://sipi.usc.edu/database/). All six lena face images were used to perform FPCA. Reconstruction of the images of one of the six lena face images using its 6 FPC scores. (c) All six lena face images were used to perform the Fourier expansion. Reconstruction of the same lena face image as that in (b) using its first 16129 Fourier coefficients (d) Original image of one of the 121 histology images of the kidney cancer cells. (e) A total of 188 kidney histology images (121 kidney cancer cells and 67 kidney normal cells) were downloaded from the TCGA database. All images were used to perform FPCA. Reconstruction of histology images of kidney cancer cells by using its 188 FPCA scores. (f) All 188 kidney histology images were used to perform the Fourier expansion. Reconstruction of the same kidney histology image as that in (e) by using its first 16,129 Fourier expansion coefficients Figure 2 . Historic pathology images. (a) Pathology grades 1 and 2, (b) pathology grade 3 and (c) pathology grade 4.
Tables -means clustering algorithm for FPCA, descriptor
Table 1. Performance of standard k and Fourier expansion
| | Ovarian Cancer | Ovarian Cancer | Ovarian Cancer | KIRC | KIRC | KIRC |
|------------|------------------|------------------|------------------|----------|-------------|-------------|
| | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| FPCA | 0.570 | 0.660 | 0.400 | 0.835 | 0.926 | 0.672 |
| Descriptor | 0.557 | 0.547 | 0.547 | 0.681 | 0.587 | 0.701 |
| Fourier | 0.557 | 0.557 | 0.557 | 0.803 | 0.917 | 0.597 |
Table 2. Performance of standard K-means, sparse K-means and randomized K-means clustering algorithm using the SIFT descriptor
| | Ovarian Cancer | Ovarian Cancer | Ovarian Cancer | Ovarian Cancer | KIRC | KIRC | KIRC | KIRC |
|---------------------|------------------|------------------|------------------|------------------|----------|----------|-------------|-------------|
| | Features | Accuracy | Sensitivity | Specificity | Features | Accuracy | Sensitivity | Specificity |
| k -means | 2,560 | 0.557 | 0.547 | 0.547 | 2,560 | 0.681 | 0.587 | 0.701 |
| Sparse k- means | 574 | 0.545 | 0.472 | 0.657 | 597 | 0.585 | 0.62 | 0.522 |
| Randomized k -means | 70 | 0.608 | 0.708 | 0.457 | 100 | 0.729 | 0.818 | 0.567 |
Table 3. Performance of standard k -means, sparse kmeans and randomized sparse k -means clustering algorithms using FPC scores.
| | Ovarian Cancer | Ovarian Cancer | Ovarian Cancer | Ovarian Cancer | KIRC | KIRC | KIRC | KIRC |
|----------------------------|------------------|------------------|------------------|------------------|----------|----------|-------------|-------------|
| | Features | Accuracy | Sensitivity | Specificity | Features | Accuracy | Sensitivity | Specificity |
| k -means | 176 | 0.574 | 0.660 | 0.400 | 188 | 0.809 | 0.917 | 0.612 |
| Sparse k -means | 81 | 0.585 | 0.670 | 0.457 | 92 | 0.819 | 0.819 | 0.642 |
| Randomized sparse k -means | 23 | 0.653 | 0.793 | 0.486 | 5 | 0.835 | 0.926 | 0.672 |
Table 4. Performance of standard spectral, sparse k -means clustering and sparse spectral with randomized feature selection clustering algorithms with Fourier expansion.
| | ovarian cancer | ovarian cancer | ovarian cancer | ovarian cancer | KIRC | KIRC | KIRC | KIRC |
|--------------------------------|------------------|------------------|------------------|------------------|----------|----------|-------------|-------------|
| | Features | Accuracy | Sensitivity | Specificity | Features | Accuracy | Sensitivity | Specificity |
| Spectral clustering | 65025 | 0.5568 | 0.5566 | 0.5571 | 65025 | 0.8032 | 0.9174 | 0.5970 |
| Sparse k -means | 959 | 0.5455 | 0.5000 | 0.6143 | 161 | 0.8191 | 0.9174 | 0.6418 |
| Randomized Spectral clustering | 100 | 0.6420 | 0.5755 | 0.7429 | 10 | 0.8351 | 0.9256 | 0.6716 |
Table 5. Performance of standard spectral, sparse k -means, and sparse spectral with randomized feature selection clustering algorithms using FPC scores as features
| | ovarian cancer | ovarian cancer | ovarian cancer | ovarian cancer | KIRC | KIRC | KIRC | KIRC |
|--------------------------------|------------------|------------------|------------------|------------------|----------|----------|-------------|-------------|
| | Features | Accuracy | Sensitivity | Specificity | Features | Accuracy | Sensitivity | Specificity |
| Spectral clustering | 176 | 0.585 | 0.670 | 0.460 | 188 | 0.819 | 0.917 | 0.642 |
| Sparse k -means | 176 | 0.545 | 0.500 | 0.614 | 188 | 0.819 | 0.860 | 0.746 |
| Randomized Spectral clustering | 23 | 0.688 | 0.858 | 0.429 | 13 | 0.835 | 0.909 | 0.702 |
Table 6. Performance of standard k -means, sparse k -means and randomized -means algorithms for clustering k KIRC tumor cell grades
| | TRUE | TRUE | TRUE | TRUE |
|----------------------------|-----------------|-----------------------|--------------------------------|-----------------------|
| Method | Assigned | Group1 | Group 2 | Group 3 |
| k -means | Group 1 Group 2 | 17 (58.6%) 12 (41.4%) | 15 (53.6%) 12 (42.9%) 1 (3.4%) | 7 (50.0%) 7 (50.0%) 0 |
| | Group 1 Group 2 | 10 13 | 6 (21.4%) 17 | |
| | Group 3 | 0 | | |
| | Accuracy | 40.80% | | |
| Sparse k- means | | (34.5%) | | 3 (21.4%) |
| Sparse k- means | | (44.8%) | (60.7%) | 7(50.0%) |
| Sparse k- means | Group 3 | 6 (20.7%) | 5 (17.9%) | 4 (28.6%) |
| Sparse k- means | Accuracy | 43.70% | | |
| Randomized sparse k -means | Group 1 | 14 (48.3%) | 4 (14.3%) | 2 (14.3%) |
| Randomized sparse k -means | Group 2 | 8 (27.6%) | 20 (71.4%) | 8 (57.1%) |
| Randomized sparse k -means | Group 3 | 7 (24.1%) | 4 (14.3%) | 4 (28.6%) |
| Randomized sparse k -means | Accuracy | 53.50% | | |
## References
Aroquiaraj, I.L., Thangavel, K., 2013. Mammogram image feature selection using unsupervised tolerance rough set relative reduct algorithm. 2013 International Conference on Pattern Recognition, Informatics and Mobile Engineering (PRIME), Feb. 21-22, 479-484.
Bong, C.W., Rajeswari, M., 2012. Multiobjective clustering with metaheuristic: current trends and methods in image segmentation. IET Image Processing. 6, 1-10.
Boutsidis, C., Magdon-Ismail, M., 2013. Deterministic feature selection for K-means clustering. IEEE Transactions on Information Theory. 59(9), 6099-6110.
Boutsidis, C., Zouzias, A., Mahoney, M. W., Drineas, P., 2013. Randomized dimensionality reduction for K-means clustering. arXiv preprint arXiv:1110.2897.
Chen, J., Tian, J., 2006. Rapid multi-modality preregistration based on SIFT descriptor. Conf Proc IEEE Eng Med Biol Soc. 1, 1437-1440.
Drineas, P., Frieze, A., Kannan, R., Vempala, S., Vinay, V., 1999. Clustering in large graphs and matrices. Proceedings of the tenth annual ACM-SIAM symposium on Discrete algorithms. 99, 291-299.
Erdogan, F., Demirel, A., Polat, O., 2004. Prognostic significance of morphologic parameters in renal cell carcinoma. International Journal of Clinical Practice. 58(4), 333-336.
Gupta, M. R., Jacobson, N. N. P., 2006. Wavelet principal component analysis and its application to hyperspectral images. IEEE Int. Conf. Image Processing. 1585-1588.
Henderson, D., Plaschko, P., 2006. Stochastic Differential Equations in Science and Engineering. World Scientific, New Jersey.
Kondo, Y., Salibian-Barrera, M., Zamar, R., 2012. A robust and sparse K-means clustering algorithm. arXiv:1201.6082.
Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., Ma, Y., 2013. Robust recovery of subspace structures by low-rank representation. IEEE Trans. On Pattern Analysis and Machine Learning. 35(1), 171-184.
Ramsay, J.O., Silverman, B.W., 2005. Functional Data Analysis. Springer, New York.
Sagan, H., 1969. Introduction to the Calculus of Variations. Dover Publications, Inc., New York. Samiappan, S., Prasad, S., Bruce, L. M., 2013. Non-uniform random feature selection and kernel density scoring with SVM based ensemble classification for hyperspectral image analysis. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. 6(2), 792-780.
Stracuzzi, D. J., 2008. Randomized feature selection. Computational Methods of Feature Selection. Liu, H. and Motoda, H. (Eds.), Chapman & Hall/CRC Data Mining and Knowledge Discovery Series. New York, pp. 41-59.
Strela, V.,Heller, P.N., Strang, G., Topiwala, P., Heil, C., 1999. The application of multiwavelet filterbanks to image processing. IEEE Trans. Image Processing. 8(4), 548 - 563.
Witten, D. M.,Tibshirani, R., 2010. A framework for feature selection in clustering. J. Am. Stat. Assoc. 105(490), 713-726.
Yang, Y., Xu, D., Nie, F., Yan, S., Zhuang, Y., 2010. Image clustering using local discriminant models and global integration. IEEE Trans. Image Processing. 19(10), 2761-2773.
Figure 1.

Figure 2.
 | 10.1371/journal.pone.0132945 | [
"Nan Lin",
"Junhai Jiang",
"Shicheng Guo",
"Momiao Xiong"
] | 2014-08-01T15:15:48+00:00 | 2014-08-01T15:15:48+00:00 | [
"stat.ML",
"cs.AI",
"cs.CV",
"cs.LG"
] | Functional Principal Component Analysis and Randomized Sparse Clustering Algorithm for Medical Image Analysis | Due to advances in sensors, growing large and complex medical image data have
the ability to visualize the pathological change in the cellular or even the
molecular level or anatomical changes in tissues and organs. As a consequence,
the medical images have the potential to enhance diagnosis of disease,
prediction of clinical outcomes, characterization of disease progression,
management of health care and development of treatments, but also pose great
methodological and computational challenges for representation and selection of
features in image cluster analysis. To address these challenges, we first
extend one dimensional functional principal component analysis to the two
dimensional functional principle component analyses (2DFPCA) to fully capture
space variation of image signals. Image signals contain a large number of
redundant and irrelevant features which provide no additional or no useful
information for cluster analysis. Widely used methods for removing redundant
and irrelevant features are sparse clustering algorithms using a lasso-type
penalty to select the features. However, the accuracy of clustering using a
lasso-type penalty depends on how to select penalty parameters and a threshold
for selecting features. In practice, they are difficult to determine. Recently,
randomized algorithms have received a great deal of attention in big data
analysis. This paper presents a randomized algorithm for accurate feature
selection in image cluster analysis. The proposed method is applied to ovarian
and kidney cancer histology image data from the TCGA database. The results
demonstrate that the randomized feature selection method coupled with
functional principal component analysis substantially outperforms the current
sparse clustering algorithms in image cluster analysis. |
1408.0205v1 | ## Origin of the 6.4-keV line of the Galactic Ridge X-ray Emission
## - First Report -
T.G.Tsuru , H.Uchiyama , K.K.Nobukawa , M.Nobukawa , 1 2 1 1 S.Nakashima , K.Koyama , K.Torii , Y.Fukui , 3 1 4 4
1 Department of Physics, Kyoto University, Kitashirakawa, Sakyo, Kyoto, JAPAN 606-8502 2 Faculty of Education, Shizuoka University, 836 Ohya, Shizuoka, JAPAN 422-8529 3 ISAS, JAXA, 3-1-1 Yoshinodai, Chuo-ku, Sagamihara, Kanagawa, JAPAN 252-5210 4 Department of Astrophysics, Nagoya University, Furo-cho, Chikusa-ku, Nagoya, JAPAN 464-8602 E-mail(TGT): [email protected]
## Abstract
We report the first results from high-statistics observation of the 6.4-keV line in the region of l = +1 5 . ◦ to +3 5 . ◦ (hereafter referred to as GC East), with the goal to uncover the origin of the Galactic ridge X-ray emission (GRXE). By comparing this data with that from the previous observations in the region l = -1 5 . ◦ to -3 5 . ◦ (hereafter referred to as GC West), we discovered that the 6.4-keV line is asymmetrically distributed with respect to the Galactic center, whereas the 6.7-keV line is symmetrically distributed. The distribution of the 6.4-keV line follows that of 13 CO and its flux is proportional to the column density of the molecular gas. This correlation agrees with that seen between the 6.4-keV line and the cold interstellar medium (ISM) (H I + H ) in the region 2 | l | > 4 . ◦ This result suggests that the 6.4-keV emission is diffuse fluorescence from the cold ISM not only in GC East and West but also in the entire Galactic plane. This observational result suggests that the surface brightness of the 6.4-keV line is proportional to the column density of the cold ISM in the entire Galactic plane. For the ionizing particles, we consider X-rays and low energy cosmic-ray protons and electrons .
Key words:
Galaxy: center - Interstellar medium - X-ray spectra
## 1. Introduction: Neutral iron K line in the Galactic ridge
Suzaku successfully resolved the structure of the highly ionized iron K emission lines from the Galactic center region and determined the plasma temperature, not from the shape of the continuum spectrum, but from the ratio of the fluxes of the 6.7-keV line (He-like ions) to 6.9keV line (H-like ions), thanks to its large collecting area and precise spectroscopic performance. Koyama et al. (2007) and Yamauchi et al. (2009) found that the plasma temperature ( kT ∼ 5 5keV) of the Galactic ridge X-ray . emission (GRXE, | l | > 1 5 . ◦ ) is significantly lower than the plasma temperature ( kT ∼ 7keV) of the Galactic center diffuse X-ray emission (GCDX, | l | < 1 5 . ◦ ). Thus, these thermal emissions should have different origins.
Figure 1 shows the equivalent width map of the 6.4keV line (neutral iron) in and near the Galactic center region, in which the prominent features of Sagittarius (Sgr) A, B, C, D, and E are seen. Sgr D and E are new discoveries by Suzaku (Ryu 2013). The idea of Xray reflection nebula irradiated by Sgr A* is now widely accepted. No region with such high equivalent width has been discovered except the Galactic center region.
However, Suzaku observed uniform 6.4-keV line emission with nearly equal equivalent width that extends toward the Galactic ridge, where it also discovered the 6.4-keV line from GRXE (Ebisawa et al. 2008; Yamauchi et al. 2009). In addition, we found a hint that the 6.4-keV line emission from the GRXE to the east-side of the Galactic center region is stronger than that to the west-side (Maeda 1998; Uchiyama et al. 2011). Here, we present the first report of the high-statistics observation of the 6.4-keV line in the region of l = +1 5 . ◦ ∼ +3 5 . ◦ (hereafter referred to as GC East), which was done in the Suzaku AO-7 key project.
## 2. Observation
Our AO-7 project observation consists of 10 pointings of 100 ksec exposure each at the Galactic longitude from l = +1 5 . ◦ to +4 0 . . ◦ We had finished 7 pointings by February 2014 and were planned to do remaining three pointings during the spring 2014. Figure 2 shows mosaic images including the previous observation in the eight Xray energy bands from 0.5 to 8 keV. Artificial structures are apparent in the energy bands from 1 to 7 keV. These
Fig. 1. Equivalent width map of the 6.4-keV line in and near the Galactic center region obtained with Suzaku.
507075010 XIS3 (l b)=(3.25006212440054 0.403986429722952)
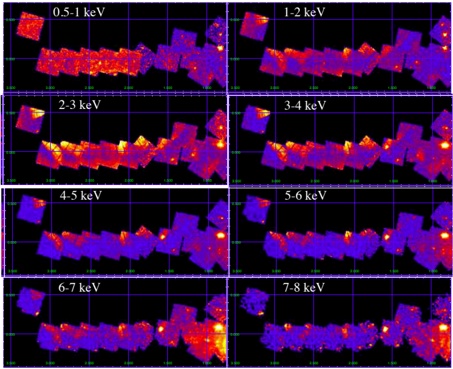
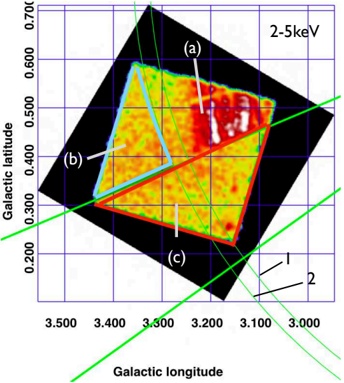
0.500
0.000
3.500
0.500
0.000
0.500
0.000
3.500
Fig. 2. X-ray mosaic mages in the eight energy bands from 0 5 . to 8 keV at the Galactic longitude of l = 1 ◦ to 3 5 . ◦ .
structures are due to stray X-ray light from GX 3 + 1, which is a very bright low-mass X-ray binary located at ( l, b ) = (+2 294 . ◦ , +0 7937 ) (Mori et al. . ◦ 2005). Thus, careful analyses are necessary.
## 2.1. Stray Light from GX 3 + 1
Figure 3 shows an typical image. The image is divided into three regions according to the type of stray light (Mori et al. 2005; Suzaku TD). Region (a) is called the 'secondary-reflection region', where the X-rays from the stray source are reflected only once by the secondary reflector. This region is the brightest of the three and a comb-like structure is clearly seen. Region (b) is the 'backside-reflection region', where the X-rays from the stray source are scattered at the backside of the primary reflector and are followed by the normal double reflection. The iron K line band is free from stray light because stray light is only bright below 1.5 keV. Region (c) is referred to as the 'quadrant-boundary region' and is the shadow of the structure of a quadrant of the XRT of the Suzaku satellite. This region is free from stray light.
3.000
2.500
3.000
2.500
Fig. 3. Example of X-ray images obtained in the Suzaku key project observation is reported here. The regions marked with (a), (b), and (c) are the secondary-reflection, backside-reflection, and quadrant-boundary regions, respectively (Mori 2005; Suzaku TD). The region between the two green lines is the shadow of the structure of the quadrant of the XRT of the Suzaku satellite. The both arcs of 1 and 2 share a common center at GX 3+1. Arc 1 passes the field of view center of this observation and arc 2 has a radius 2 arcmin larger than arc 1. Stray light comes only from the backside-reflection outside of arc 2.
## 2.2. The fluxes of the 6.4- and 6.7-keV lines
The stray light in the secondary-reflection region is too bright to obtain the continuum component of the GRXE. However, observation by XMM-Newton revealed no narrow iron K line in the spectrum of GX 3+1 (Piraino et al. 2012). Thus, we were able to use the entire field of view (FOV) to obtain the flux of iron K lines. For confirmation, we compare the iron flux obtained from the entire FOV with the iron flux in the quadrant-boundary region plus in the backside-reflection region, where the iron K line band is free from stray light. Figure 4 shows the flux of 6.7- and 6.4-keV lines as a function of the Galactic longitude. No significant difference between the two regions is observed. For good statistics, we adopt the iron K line flux from the entire FOV in the following analyses.
!
Fe XXV K
Profile
Fig. 4. The surface brightness of the 6.7-keV (upper panel) and 6.4-keV (lower panel) lines as a function of the Galactic longitude. Blue and red points represent the data obtained in the entire FOV region and the region of quadrant-boundary region plus the backside-reflection region, respectively.
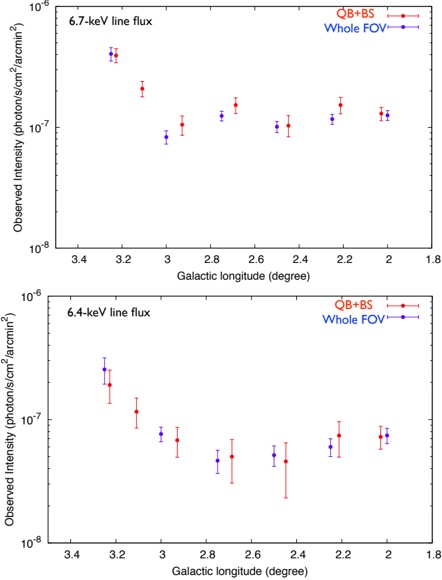
## 3. Results and Discussion
## 3.1. Asymmetrical distribution of the 6.4-keV line
Figure 5 shows the flux of the iron K emission lines as a function of Galactic longitude. This figure includes the data collected during the previous observation. Although the 6.7-keV line is symmetrically distributed with respect to the Galactic center, the 6.4-keV line is asymmetrically distributed. The flux of the 6.4-keV line in GC East is twice that in the region l = -1 5 . ◦ to 3 5 . ◦ (hereafter referred to as GC West). If the 6.4-keV line has the same origin as the 6.7-keV line, the two lines should have same symmetrical distribution. Thus, the observational results suggest that the origin of the 6.4keV line is different from that of the 6.7-keV line. Thus, GRXE consists comprises at least two components; one emitting the 6.4 keV line and the other emitting the 6.7 keV line.
## 3.2. Distribution of 6.4-keV line and molecular clouds
The 6.4-keV line is due to fluorescence from molecular clouds in the Galactic center region. Thus, using the data obtained with the NANTEN telescope (Takeuchi et al. 2010), we compare the distribution of the 6.4-keV line in GC East and West with that of the molecular clouds. Figure 6 shows the surface brightnesses of 13 CO and the 6.4-keV line as a function of the Galactic longitude. The surface brightness of 13 CO is the average from b = -0 126 . ◦ to+0 034 , whereas the surface brightness . ◦ of the 6.4-keV line is the average over the FOV. The 6.4-keV line follows the 13 CO surface brightness very well, which suggests that the 6.4-keV line is related to the molecular clouds. The structure at l = 3 2 . ◦ is the molecular cloud complex called 'Clump 2', which extends from ( l, b ) = (+3 2 . ◦ , 0 0 . ◦ ) to (+3 2 . ◦ , +0 5 ) (Bania . ◦ et al. 1977). In this region, the 6.4-keV line also follows the 13 CO surface brightness.
## 3.3. Correlation between the 6.4-keV line and cold ISM in Galactic plane
Figure 7 shows the surface brightness of the 6.4-keV line as a function of cold ISM column density in GC East and West. For this figure, we applied the conversion factor of N /W H ( 13 CO) = 1 × 10 23 cm -2 / 57 1 K km sec . -1 . Note that the cold ISM is dominated by molecular clouds in GC East and West. The figure shows that the flux of the 6.4-keV line is proportional to the cold ISM column density. This result suggests that the origin of the 6.4keV line is diffuse and could be fluorescence from the cold ISM.
We now discuss the entire Galactic plane beyond GC East and West. Uchiyama et al. (2014) recently found good correlation between the surface brightness of the 6.4-keV line and the cold ISM column density consisting of H I (Kalberla et al. 2005) and H 2 calculated from the CO map by Dame et al. (2001) in the region | l | > 4 ◦ in the Galactic longitude, where the contribution from H I gas to the cold ISM is significant, and molecular gas (H 2 ) as well. We find that the correlations are very consistent with each other (Figure 7), which suggests that the 6.4keV emission from the entire Galactic plane has the same diffuse origin as in GC East and West.
## 3.4. Ionizing Particles
Assuming that the origin of the 6.4-keV line fluorescence from the cold ISM, we now discuss ionizing particles. First, we consider the idea of an X-ray reflection nebula, which has already been observed in the Galactic center region. For Sgr A*, observation of the 6.4-keV line and 13 CO in GC East and West regions require a luminosity of ∼ 10 41 ergs sec -1 . The studies of the Galactic center region ( | l | < 1 5 . ◦ ) imply that Sgr A* was bright for about 700 yrs at the luminosity of ∼ 10 39 ergs sec -1 (Ryu 2013). Thus, the scenario would be possible for the 6.4-keV line also in GC East and West. However, maintaining a linear relationship through the entire Galactic plane shown in Figure 7 requires a monotonic increase in the luminosity of Sgr A* from 10 41 to 10 43 ergs sec -1 for the last 10 4 yrs, which is not impossible but seems rather artificial. The radiation sources would have to be bright binary sources
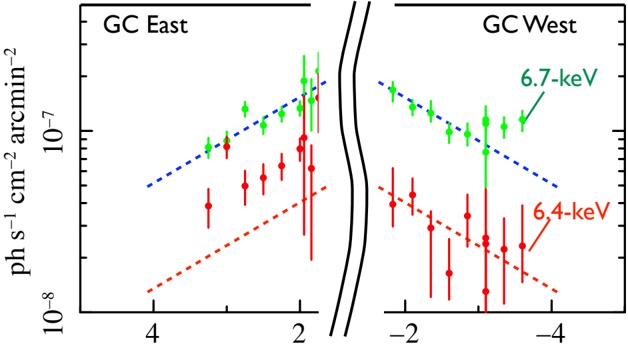
'()(*+,*-./01+,+234-53416447
'()(*+,*-./01+,+234-53416447
(ph s rcmin arcmin
Fig. 5. Surface brightness of 6.4-keV line (red) and 6.7-keV line (green) as a function of the Galactic longitude. Red and blue dashed lines are to guide the eye and show the symmetry with the respect to the Galactic center.
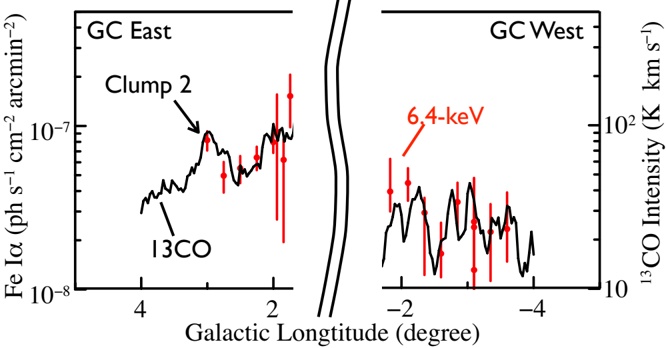
CO Intensity (K km s )
Fig. 6. The surface brightness of the 6.4-keV line (red) and intensity of 13 CO (black) as a function of galactic longitude.
and/or unresolved sources related to the diffuse 6.7-keV line of GRXE. We plan to investigate this possibility by comparing the distribution of the 6.4-keV line with the cold ISM and the X-ray sources.
Dogiel et al. (2011) and Tatischeff et al. (1999) attribute the continuum X-rays and the 6.4-keV line to the impact of low energy cosmic-ray protons (hereafter LECRp) on the cold ISM in the Galactic center region and Galactic plane. Assuming the spectrum of the galactic low energy cosmic-ray ( ∼ 10 MeV) is equal to that given by Ip et al. (1985), we find that a LECRp energy density of ∼ 1 × 10 eV cm 3 -3 is required. Thus, LECRp could be ionizing particles near the Galactic center region such as GC East and West. However, their energy density would be too high to explain the 6.4-keV line for the entire Galactic plane.
Valinia et al. (2000) propose the interaction of low
energy cosmic-ray electrons (hereafter LECRe) with the cold ISM as the mechanism for the GRXE origin including the 6.4-keV line, and they estimate an energy density of ∼ 1eV cm -3 . We find that the relationship shown in Figure 7 is consistent with this idea.
In this paper, we present the first results from the Suzaku key project 'Origin of the 6.4-keV line of the Galactic Ridge X-ray Emission'. Observation and data analysis of this key project is still ongoing. Our next step is to analyze spectra where features such as equivalent widths and absorption edges are crucial to uncover the origin of the 6.4-keV line and its ionizing particles.
## References
Bania et al. 1977, ApJ, 216, 381
Dame, T. M. et al. 2001, ApJ, 547, 792
Dogiel V. et al. 2011, PASJ, 63, 535
Fig. 7. Correlation between surface brightness of the 6.4-keV line and the cold ISM column density. Magenta and blue points are the data from GC East and West, respectively. Black points are the data from | l | > 4 ◦ that is adopted from Uchiyama et al. (2014).
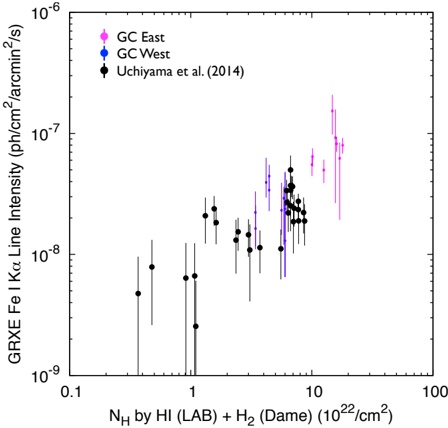
Ebisawa K. et al. 2008, 60, S223 Ip W.-H. et al. 1985, A&A, 149, 7 Kalberla, P. et al. 2005, A&A, 440, 775 Koyama K. et al. 2007, PASJ, 59, S245 Maeda Y. 1998, Doctor Thesis, Kyoto Univ. Mori H. et al. 2005, 57, 245 Piraino S. et al. 2012, A&A, 542, L27 Ryu S.G. 2013, Doctor Thesis, Kyoto University. Takeuchi T. et al. 2010, PASJ, 62, 557 Tatischeff V. et al. 1999, ASPC, 171, 226 The Suzaku Technical Description Uchiyama H. et al. 2011, 63, S903 Uchiyama H. et al. 2014, in prep. Valinia A. et al. 2000, ApJ, 543, 733
Yamauchi S. et al. 2009, PASJ, 61, S225 | null | [
"T. G. Tsuru",
"H. Uchiyama",
"K. K. Nobukawa",
"M. Nobukawa",
"S. Nakashima",
"K. Koyama",
"K. Torii",
"Y. Fukui"
] | 2014-08-01T15:22:34+00:00 | 2014-08-01T15:22:34+00:00 | [
"astro-ph.HE"
] | Origin of the 6.4-keV line of the Galactic Ridge X-ray Emission | We report the first results from high-statistics observation of the 6.4-keV
line in the region of $l= +1.5^\circ$ to $+3.5^\circ$ (hereafter referred to as
GC East), with the goal to uncover the origin of the Galactic ridge X-ray
emission (GRXE). By comparing this data with that from the previous
observations in the region $l=-1.5^\circ$ to $-3.5^\circ$ (hereafter referred
to as GC West), we discovered that the 6.4-keV line is asymmetrically
distributed with respect to the Galactic center, whereas the 6.7-keV line is
symmetrically distributed. The distribution of the 6.4-keV line follows that of
$^{13}$CO and its flux is proportional to the column density of the molecular
gas. This correlation agrees with that seen between the 6.4-keV line and the
cold interstellar medium (ISM) (H$_{\rm I}$ $+$ H$_2$) in the region
$|l|>4^\circ$. This result suggests that the 6.4-keV emission is diffuse
fluorescence from the cold ISM not only in GC East and West but also in the
entire Galactic plane. This observational result suggests that the surface
brightness of the 6.4-keV line is proportional to the column density of the
cold ISM in the entire Galactic plane. For the ionizing particles, we consider
X-rays and low energy cosmic-ray protons and electrons . |
1408.0206v1 | ## Feshbach modulation spectroscopy
∗
Andreas Dirks, Karlis Mikelsons, and J. K. Freericks Department of Physics, Georgetown University, Washington, DC 20057, USA
## H. R. Krishnamurthy
Centre for Condensed Matter Theory, Department of Physics, Indian Institute of Science, Bangalore 560012, India, and Jawaharlal Nehru Centre for Advanced Scientific Research, Bangalore 560064, India (Dated: August 4, 2014)
In the vicinity of a Feshbach resonance, a system of ultracold atoms on an optical lattice undergoes rich physical transformations which involve molecule formation and hopping of molecules on the lattice and thus goes beyond a single-band Hubbard model description. We propose to probe the behavior of this system with a harmonic modulation of the magnetic field, and thus of the scattering length, across the Feshbach resonance, as an alternative to lattice-depth modulation spectroscopy. In the regime in which the single-band Hubbard model is still valid, we provide simulation data for this type of spectroscopy. The method may uncover a route towards the efficient creation of ultracold molecules and provides an alternate means for lattice modulation spectroscopy.
PACS numbers: 03.75.-b, 03.75.Ss, 71.10.Fd
The field of ultracold atoms in optical lattices has been opening up new possibilities which include a controlled experimental realization of the fermionic Hubbard model [1, 2]. Further challenges and opportunities arise with the idea of manipulating and controlling molecules on an optical lattice. Molecules allow a much wider range of physical phenomena to be modelled and studied than is possible with atoms. However, it is more difficult to cool molecules down to the ground state via laser cooling, due to their more complex level structure which includes rotational and vibrational degrees of freedom. The cooling of individual atoms to a very low temperature followed by the formation of so-called preformed molecules on the optical lattice is thus a promising alternative [3]. Near a Feshbach resonance, bound states of these preformed molecules occur. Depending on the value of the magnetic field, molecules form and hop from one lattice site to the other; these processes are governed by the complex Fermi Resonance Hamiltonian (FRH) [4].
It is crucial to understand the FRH physics in order to control and optimize the formation process. Experimentally, the understanding may be facilitated by a spectroscopic method which we propose in the following. In case of the single-band Hubbard model, the so-called lattice modulation spectroscopy has been proven useful to study non-equilibrium dynamics. In lattice modulation spectroscopy, the intensity of the laser defining the optical lattice is varied harmonically. As a result, the hopping amplitude and the interaction strength both change as a function of time and the Mott gap can be measured directly in the experiment.
Working with a modulated magnetic field near a Feshbach resonance in order to examine a modulation of
∗ Electronic address: [email protected]
the scattering length has been investigated in a number of different contexts. It originally was used to describe Feshbach resonance management [5, 6] which controlled 'breathers' and solitons in trapped bosonic systems. Next, it was used to show how many-body effects and the periodic driving could push the tunneling to vanish [7] also in bosonic systems. More recently, it has been used to illustrate how one can obtain correlated hopping in bosonic systems when the amplitude of the magnetic field oscillation is small [8-10]. Experiments have also been carried out for bosonic systems [11] to examine driven collective excitations. Here, we focus on the Fermi version of the Hubbard model, and examine situations where the driving is pushed much closer to the Feshbach resonance, and even passing through it, where nonlinear effects become important.
While it is a powerful method to probe the atomic Hubbard physics, lattice modulation spectroscopy does not modify the sign of the interaction strength and is thus fundamentally limited when more general physics issues such as the molecule formation are to be studied.
We thus propose to probe the system with a harmonic modulation of the magnetic field
$$B ( t ) = \bar { B } + \chi _ { [ 0, t _ { \text{mod} } ] } ( t ) \cdot \Delta B \sin \omega t, \quad \ \ ( 1 )$$
near the Feshbach resonance, where
$$\chi _ { I } ( t ) = \begin{cases} 1 & \text{if $t\in I$} \\ 0 & \text{otherwise} \end{cases} \quad \quad ( 2 )$$
is the characteristic function of the modulation interval. In order to provide some numerical data for this spectroscopy method, we consider a system of fermionic 40 K atoms subject to the ab -Feshbach resonance [12] in an optical lattice with a laser wavelength of 1064 nm.
While at present, providing numerical results for the full FRH is beyond reach, we present numerical data for
the atomic Hubbard limit which are valid in the early stages of the preformed molecule formation process: [13]
$$H ( t ) & = \, - \, J ( t ) \sum _ { \langle i, j \rangle, \sigma } \left ( c _ { i \sigma } ^ { \dagger } c _ { j \sigma } + \text{h.c.} \right ) \quad \begin{array} { c } \cdot \cdot \cdot \\ \Xi ^ { c } \end{array} \cdot \\ & \quad + U ( t ) \sum _ { i } n _ { i \uparrow } n _ { i \downarrow } + \sum _ { i \sigma } \epsilon _ { i } n _ { i \sigma }. \end{array} \quad \begin{array} { c } \cdot \cdot \cdot \\ \Xi ^ { c } \end{array} \cdot \\ \dots \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
The time dependence of the lattice parameters reads J t ( ) = J 0 = const and U t ( ) = g t ( ) ∫ | w glyph[vector] ( r ) | 4 d r 3 , where w glyph[vector] ( r ) is the maximally localized Wannier function [14]. The time-dependent coupling constant g t ( ) = 4 π glyph[planckover2pi1] 2 a t /m ( ) is determined by the mass m of the 40 K atoms and the s -wave scattering length
$$a ( t ) = a _ { b g } \left ( 1 - \frac { \Delta } { B ( t ) - B _ { 0 } } \right ), \quad \quad ( 4 )$$
where a bg = 174 a 0 is the background scattering, B 0 = 202 1 . G is the position of the Feshbach resonance and ∆ = 8 0 . G is its width.
For simplicity, we consider a translationally invariant lattice in three dimensions at half filling in the Mottinsulating phase and study the behavior of the double occupancy. With a higher double occupancy, molecule formation is more likely to occur in the later stages of the driving of the full FRH system. Computationally, we employ a strong-coupling approach which works well at finite temperatures larger than the hopping and has already successfully modelled the conventional modulation spectroscopy [15-17]. In order to ensure the accuracy of the approach, we constrain the studied parameter range to a maximum value j max := max { J /U t 0 ( ) } t ∈ R ≈ 1 / 24.
For each lattice depth, the Feshbach resonance has a different effect on the hopping relative to the interaction, i.e. on j ( ) t := J /U t 0 ( ). Also, the magnetic field dependence of the hopping strength in units of the interaction j ( B ) := J /U B 0 ( ) plays a key role in the Feshbach spectroscopy of the Hubbard model. In Fig. 1, panel (b) shows this map for several lattice depths. Panel (a) shows the corresponding interaction strength. We limit our consideration to the interval [0 , j max ] indicated by the dashed line in panel (b). In addition, we assume that the amplitude of the magnetic field is realistically smaller than 5 G for the necessary modulation frequency of a couple of kHz. We also require the interaction to be significantly lower than the non-interacting bandgap which is also displayed in panel (a) at lattice depth V = 10 E R . This, together with the requirement that the renormalized hopping j , while small, should be large enough for the effects due to changes in it arising from changes in B to be measurable, constrains the considered parameter range to the right branches displayed in panel (b). Thus we consider magnetic field values within the interval ( B 0 +∆ 220 , G ] and lattice depths equal to or larger than 10 E R (for smaller V , the bandgap to the second band would be too small).
In experiments, the upper bound for the hopping does not apply. However, in the vicinity of the resonance,
FIG. 1: (Color online) ab -Feshbach resonances of the system 40 K for different lattice depths. The upper panel (a) shows the dependence of the interaction on the magnetic field and the lower panel (b) shows the resulting renormalized hopping j = J /U B 0 ( ).
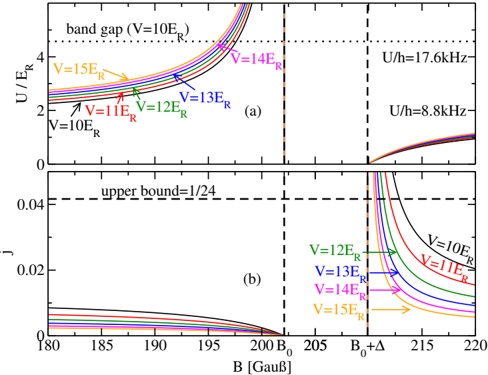
the strong dependence of the effective hopping on the field also results in a stronger dependence on the inhomgeneities of the magnetic field. It is thus also reasonable to keep the value of j below a certain threshold in experiments to reduce the effects of inhomogeneity.
In addition to the mean value of the magnetic field, other important parameters to be considered are the amplitude and the frequency of the field modulation. If the physical response of the system is sensitive to these values, this may help to determine unknown model properties (such as the lattice depth in the experiments) more precisely than possible in lattice depth modulation spectroscopy. In order to study such effects, we investigate the frequency dependence of the doublon production rate for fixed windows of magnetic field modulation.
The field modulation in Eq. (1) is parametrized by the magnetic field amplitude ∆ B , the average field value ¯ , B the length of the modulation time interval t mod , and the modulation frequency ω . ∆ B and ¯ B can alteratively be expressed in terms of the minimum and maximum values of the field strength, B min = ¯ B -∆ B and B max = ¯ + ∆ B B . These values also determine the minimum and maximum values of the renormalized hopping j ( B ) = J /U B 0 ( ). In order to translate B min/max into j min/max one uses Fig. 1(b).
We consider three field modulation intervals [ B min , B max ] first and compare the behavior for two lattice depths. Depending on the frequency, the field is modulated over a time interval [0 , t max ], with
$$t _ { \max } ( \omega ) = \left \lfloor \tilde { t } _ { \max } \cdot \left ( \frac { 2 \pi } { \omega } \right ) ^ { - 1 } \right \rfloor \times \frac { 2 \pi } { \omega }, \quad \ \ ( 5 )$$
and ˜ t max × U / 0 glyph[planckover2pi1] = 29, resulting in 2 to 6 field modulation cycles for glyph[planckover2pi1] ω/U 0 = 0 5 . . . . 1 5, . where U 0 := U B ( ¯ ). As
FIG. 2: (Color online) Doublon production at different values of B max . Each panel represents different values of V and B min . In panels (a), (c),(d), and (e), B min is chosen such that j max = 1 24. The initial temperature is / k B T = 0 1 . U 0 .
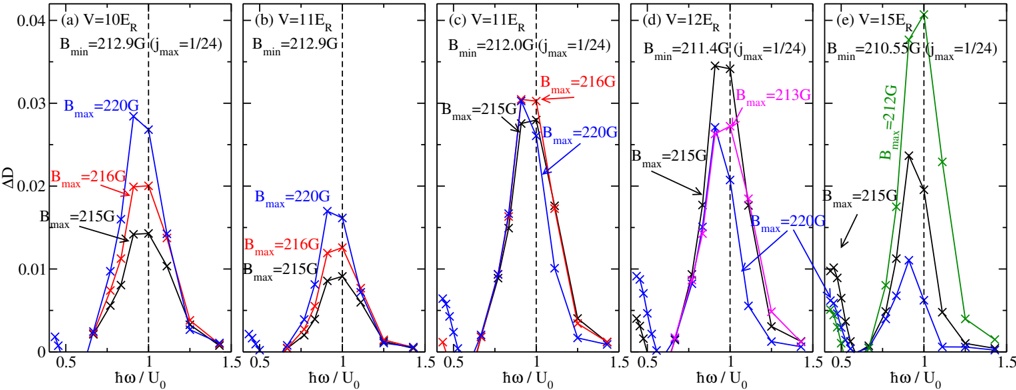
a physical observable, we study the excitation from the lower to the upper Hubbard band which is measured by the double occupancy per site
$$D ( t ) = \langle n _ { \uparrow } n _ { \downarrow } \rangle ( t ) \quad \ \ ( 6 ) \quad \stackrel { \dots } { \text{ac} ^ { 1 } }$$
and study the increase in this quantity, which we measure as
$$\Delta D \coloneqq \frac { U _ { 0 } } { h } \int _ { \tilde { t } _ { \max } + 2 - h / U _ { 0 } } ^ { \tilde { t } _ { \max } + 2 } \, d t \, D ( t ) - D ( t _ { 0 } ). \quad ( 7 ) \quad \overset { \text{or} \, \text{tn} } { \text{tav} } \\ \text{tion} \\ h = t$$
That is, the end value has been averaged over one oscillation period of a resonantly excited Hubbard system and compared to the initial value.
the cases (b) and (c) have in common is that the maximum in doublon production is shifted towards smaller frequencies for larger values of B max . The reason for this may be the lower time-averaged value of the interaction strength for larger values of B max in units of the respective values for U 0 = U B ( ¯ ). For example, in the simplified case B min = B 0 +∆, the time-averaged value of the interaction U tavg can be approximately written as U tavg /U 0 = 1 -( U bg / 2 U 0 ) × b 2 , where U bg is the interaction associated with the background scattering a bg and b = ( B max -B min ) / 2∆. A similar relation can be derived for the more realistic B min > B 0 +∆. However, since the width of the resonance is almost constant in both panels (b) and (c), this reasoning cannot be the whole story.
Figure 2 shows the resulting frequency dependence of ∆ D for three different values of B max , while we keep the minimum field value constant at B min = 212 9 . G . Panels (a) and (b) show the results for the lattice depths V = 10 E R and V = 11 E R , respectively. Since the hopping j max is smaller for a deeper lattice, less doublons are produced for V = 11 E R than for V = 10 E R . However, the behavior of the curves as a function of B max is qualitatively the same for the two lattice depths.
Hence we discuss the dependence of the resonance curves on B min in more detail. Figure 2 shows several resonance curves for two slightly different values of B min in panels (b) and (c), respectively. It shows that even the qualitative behavior of the Feshbach modulation can be quite sensitive to the details of the model. In panel (c), the shape and the strength of the resonances are approximately the same. For the slightly larger value of B min shown in panel (b), the resonance curves change drastically as a function of B max . The reason for this qualitatively different behavior is that in case (c) a larger fraction of the steep portion of the renormalized hopping j as a function of B (see Fig. 1) is sampled in the modulation procedure than in case (b). An effect which both
Furthermore, we can also compare the resonance curves for several lattice depths at a fixed maximum value j max of the renormalized hopping. This corresponds to identifying the value of B min for which the value j max is obtained, for each lattice depth. In this case, we choose j max = 1 24, which is also the upper theoretical bound / we introduced previously in order to assure the convergence of the strong-coupling method. Panels (a), (c),(d), and (e) of Fig. 2 show data for different lattice depths at a constant maximum value of j . We again find that the dependence on B max may depend very much on the lattice depth. While for the shallow lattice, V = 10 E R , increasing the modulation amplitude yields a stronger signal, we observe the opposite effect in a deeper lattice, V = 15 E R . This striking difference is due to the increasing nonlinearity of j ( B ) as V increases. For a shallow lattice, j ( B ) still exhibits a nearly linear behaviour, so the peak strength is proportional to the amplitude. In a deep lattice, j ( B ) is strongly nonlinear and the system is rather kicked than driven. An increased amplitude decreases the kick strength in a deep lattice, because j is close to j max for shorter time spans during the modula-
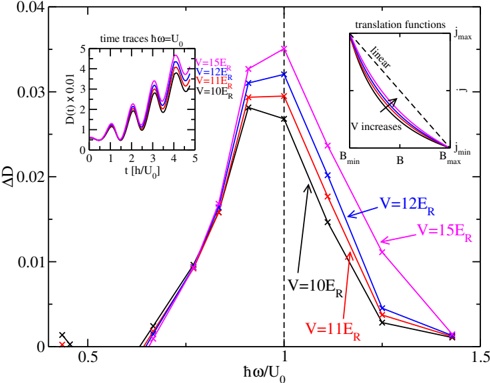
0
FIG. 3: (Color online) Magnetic modulation with the renormalized hopping j oscillating within the interval [ j min , j max ], with j max = 1 24 / and j min = j max / 2 for different lattice depths. The corresponding magnetic field intervals I B = [ B min , B max ] are I B ( V = 10 E R ) = [212 9 . G, 219 56 . G ], I B ( V = 11 E R ) = [212 0 . G, 215 52 . G ], I B ( V = 12 E R ) = [211 4 . G, 213 59 . G ], I B ( V = 15 E R ) = [210 55 . G, 211 32 . G ].
tion. As the lattice gets deeper, a second order peak appears at glyph[planckover2pi1] ω = U / 0 2, which is approximately as strong as the first-order peak for the strong modulation amplitude. The lattice depths between V = 10 E R and V = 15 E R interpolate between these two behaviors. In the very deep lattice, for V = 15 E R , the strongest doublon production can be achieved with a rather small amplitude corresponding to B max = 212 G , or ∆ B ≈ 0 73 . G .
Finally, in order to compare different lattice depths, we fix the values of B min and B max in such a way that the renormalized hopping oscillates between the values j min = 1 48 and / j max = 1 24. / The resulting resonance curves at different lattice depths are shown in Fig. 3. In contrast to the scenarios discussed in Fig. 2, the curves are now essentially identical. This underlines the central role of the renormalized hopping in interpreting both Feshbach and lattice depth modulation spectroscopy. However, we also observe a tendency towards a strong doublon production for deeper lattices. As can be seen in the left inset of Fig. 3, this is not related to the initial number of doubly occupied sites which is essentially identical for each lattice depth. Rather, the tendency is due to the shape of the translation function between magnetic field and effective hopping, as shown in the right inset of
[1] I. Bloch, J. Dalibard, and W. Zwerger, Rev. Mod. Phys. 80 , 885 (2008).
[2] T. Esslinger, Annual Review of Condensed Matter Physics 1 , 129 (2010).
Fig. 3. As the lattice depth is increased, the convexity of the translation function is decreased and approaches a linear behavior. This gives rise to an increase in the doublon production.
Conclusion. In this work we have proposed an experimental technique that is an alternative to conventional lattice modulation spectroscopy, where tuning and modulating a magnetic field near a Feshbach resonance allows for the system to have a time dependent interaction, with a constant hopping (the renormalized hopping, of course is time dependent). This changes the behavior of the driving of the system from a more kicked drive in the conventional approach to a smoother evolution in this case. We find that in some cases, the signal can have strong resonant effects that require fine tuning of the magnetic field, and hence have the potential to produce higher precision measurements. In addition, we find that the 'two-photon' peak at a frequency equal to half the average interaction strength, is often enhanced in these systems making it easier to study nonlinear excitation effects. Finally, we conjecture that even more interesting behavior will occur when the Feshbach modulation spectroscopy is pushed through the Feshbach resonance itself and allows for molecule formation. The many mutually coupled degrees of freedom in the FRH [4] promise a rich variety of physical effects which will be interesting to investigate both experimentally and theoretically. In particular, it will be interesting to explore the channels that lead to molecule formation spectroscopically. We do not yet have the ability to model and calculate the behavior of such spectroscopy, but experiments could potentially investigate such effects in the near future.
## I. ACKNOWLEDGMENTS
This work was supported by a MURI grant from the Air Force Office of Scientific Research numbered FA955909-1-0617. Supercomputing resources came from a challenge grant of the DoD at the Engineering Research and Development Center and the Air Force Research and Development Center. The collaboration was supported by the Indo-US Science and Technology Forum under the joint center numbered JC-18-2009 (Ultracold atoms). JKF also acknowledges the McDevitt bequest at Georgetown. HRK acknowledges support of the Department of Science and Technology in India. AD was in part supported by the Collaborative Research Center 1073 of the German Research Council.
[3] J.K. Freericks, M.M. Ma´ ska, Anzi Hu, Thomas M. Hanna, C.J. Williams, P.S. Julienne, R. Lema´ski, Phys. n Rev. A 81, 011605(R) (2010)
[4] M.L. Wall and L.D. Carr, Phys. Rev. Lett. 109 , 055302
(2012).
- [5] P.G. Kevrekidis, G. Theocharis, D. J. Frantzeskakis, and Boris A. Malomed, Phys. Rev. Lett. 90 , 230401 (2003).
- [6] F. Kh. Abdullaev, E. N. Tsoy, B. A. Malomed, and R. A. Kraenkel, Phys. Rev. A 68 , 053606 (2003).
- [7] Jiangbin Gong, Luis Morales-Molina, and Peter H¨nggi, a Phys. Rev. Lett. 103 , 133002 (2009).
- [8] ´ kos Rapp, Xiaolong Deng, and Luis Santos, Phys. Rev. A Lett. 109 , 203005 (2012).
- [9] M. Di Liberto, C. E. Creffield, G. I. Japaridze, and C. Morais Smith, Phys. Rev. A 89 , 013624 (2014).
- [10] Sebastian Greschner, Luis Santos, and Dario Poletti, preprint , arXiv:1407.6096 (2014), unpublished.
- [11] S. E. Pollack, D. Dries, and R. G. Hulet, K. M. F. Maga-
- lhaes, E. A. L. Henn, E. R. F. Ramos, M. A. Caraca˜has, n and V. S. Bagnato, Phys. Rev. A 81 , 053627 (2010).
- [12] Ch. Chin, R. Grimm, P. Julienne, E. Tiesinga, Rev. Mod. Phys. 82 , 1225 (2010).
- [13] J. Hubbard, Proceedings of the Royal Society of London 276 (1365), 238257 (1963).
- [14] W. Kohn, Phys. Rev. 115 , 809 (1959).
- [15] K. Mikelsons, J.K. Freericks, H. R. Krishnamurthy, Phys. Rev. Lett. 109 , 260402 (2012).
- [16] A. Dirks, K. Mikelsons, H.R. Krishnamurthy, J.K. Freericks, Phys. Rev. A 89 , 021602(R) (2014).
- [17] A. Dirks, K. Mikelsons, H.R. Krishnamurthy, J.K. Freericks, Phys. Rev. E 89 , 023306 (2014). | 10.1103/PhysRevA.92.053612 | [
"A. Dirks",
"K. Mikelsons",
"H. R. Krishnamurthy",
"J. K. Freericks"
] | 2014-08-01T15:27:56+00:00 | 2014-08-01T15:27:56+00:00 | [
"cond-mat.quant-gas",
"cond-mat.str-el",
"physics.atom-ph"
] | Feshbach modulation spectroscopy | In the vicinity of a Feshbach resonance, a system of ultracold atoms on an
optical lattice undergoes rich physical transformations which involve molecule
formation and hopping of molecules on the lattice and thus goes beyond a
single-band Hubbard model description. We propose to probe the behavior of this
system with a harmonic modulation of the magnetic field, and thus of the
scattering length, across the Feshbach resonance, as an alternative to
lattice-depth modulation spectroscopy. In the regime in which the single-band
Hubbard model is still valid, we provide simulation data for this type of
spectroscopy. The method may uncover a route towards the efficient creation of
ultracold molecules and provides an alternate means for lattice modulation
spectroscopy. |
1408.0208v1 | ## Error estimates for the Skyrme-Hartree-Fock model
## J. Erler 1 and P.-G. Reinhard 2
1 Division Biophysics of Macromolecules, German Cancer Research Center, INF 580, D-69120 Heidelberg, Germany
2 Institut f¨r Theoretische Physik II, Universit¨t Erlangen-N¨rnberg, Staudtstrasse 7, u a u D-91058 Erlangen, Germany
Abstract. There are many complementing strategies to estimate the extrapolation errors of a model which was calibrated in least-squares fits. We consider the SkyrmeHartree-Fock model for nuclear structure and dynamics and exemplify the following five strategies: uncertainties from statistical analysis, covariances between observables, trends of residuals, variation of fit data, dedicated variation of model parameters. This gives useful insight into the impact of the key fit data as they are: binding energies, charge r.m.s. radii, and charge formfactor. Amongst others, we check in particular the predictive value for observables in the stable nucleus 208 Pb, the super-heavy element 266 Hs, r -process nuclei, and neutron stars.
## 1. Introduction
This special volume is devoted to error analysis in connection with nuclear models, particularly those which are calibrated by fits to empirical data. This paper considers in particular the Skyrme-Hartree-Fock (SHF) approximation. This is a microscopic model for nuclear structure and dynamics whose structure can be deduced from general arguments of low-momentum expansion [1, 2] while the remaining model parameters are determined by adjustment to empirical data. In early stages, the calibration was more like an educated search [3]. Later developments became increasingly systematic searches [4, 5]. A first straightforward least-squares ( χ 2 ) fit with estimates of extrapolation errors was used in [6]. In the meantime, parametrizations have been steadily developed further including more and more data and exploiting the benefits of the χ 2 techniques, for recent examples see, e.g., [7, 8]. The availability of these thoroughly fitted parametrizations allowed a series of extensive studies of correlations within the models using covariance analysis which revealed interesting inter-relations between symmetry energy, neutron radius, and dipole spectra [9, 10, 11, 12]. In this paper, we want to discuss error analysis from a more general perspective. The basic principles have been detailed in [13]. We will exemplify a couple of the strategies outlined there for the case of SHF. We will chose as test observables partly standard observables from stable nuclei, e.g. giant resonances in 208 Pb, and partly far reaching extrapolations to r -process nuclei, super-heavy elements and neutron stars. The combination of strategies provides interesting insights into the predictive value of SHF for these observables. A particular and new aspect in this analysis, not much considered so far, is the variation of input data which allows to explore the impact of fit data on the parametrizations and with it on extrapolations.
The paper is outlined as follows: In section 2, we briefly summarize the needed formula of statistical analysis and the various strategies for estimating extrapolation errors. In section 3, we exemplify the chosen strategies step by step.
## 2. Fit of model parameter and error estimates
## 2.1. Quality measure and optimization
The paper [13] contains a very detailed explanation of least-squares ( χ 2 ) fits and related error analysis. We repeat here briefly the basic formula. It is typical for nuclear selfconsistent mean-field models that one can motivate their formal structure by microscopic considerations as, e.g., low-momentum expansion [2, 14]. But the model parameters p = ( p ...p 1 N p ) remain undetermined. They are calibrated to experimental data. To that end, one selects a representative set of observables {O ˆ i , i = 1 ...N d } , typically gross properties of the nuclear ground state as binding energies and radii. Then one proceeds along the standard scheme of statistical χ 2 analysis. We define the quality function as [15, 16, 17]
$$\cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cd� \chi ^ { 2 } ( \mathbf p ) = \sum _ { i = 1 } ^ { N _ { d } } \frac { ( \mathcal { O } _ { i } ( \mathbf p ) - \mathcal { O } _ { i } ^ { \exp } ) ^ { 2 } } { \Delta \mathcal { O } _ { i } ^ { 2 } }$$
where O i ( p ) stands for the calculated values, O exp i for experimental data, and ∆ O i for adopted errors. The best-fit model parameters p 0 are those for which χ 2 becomes the minimum, i.e. χ 2 0 = χ 2 ( p 0 ) = χ 2 min . The adopted parameters should be chosen such that χ 2 0 = N d -N p which is the number of degrees of freedom in the fit, see [13].
Not only the minimum alone, but also some vicinity represents a reasonable reproduction of data. Assuming a statistical distribution of errors, one can deduce a probability distribution W ( p ) ∝ exp( -χ 2 ( p )) of reasonable model parameters. Their domain is characterized by χ 2 ( p ) ≤ χ 2 0 +1 (see Sec. 9.8 of Ref. [15]). Its range is usually small and we can expand
$$\chi ^ { 2 } ( p ) \quad & \approx \chi _ { 0 } ^ { 2 } + \sum _ { \alpha, \beta = 1 } ^ { N _ { p } } ( p _ { \alpha } - p _ { 0, \alpha } ) ( \mathcal { C } ^ { - 1 } ) _ { \alpha \beta } ( p _ { \beta } - p _ { 0, \beta } ),$$
$$( \mathcal { C } ^ { - 1 } ) _ { \alpha \beta } = \frac { 1 } { 2 } \partial _ { p _ { \alpha } } \partial _ { p _ { \beta } } \chi ^ { 2 } \Big | _ { p _ { 0 } } \simeq \sum _ { i } J _ { i \alpha } J _ { i \beta } \,,$$
$$J _ { i \alpha } \quad = \frac { \partial _ { p _ { \alpha } } \mathcal { O } _ { i } | _ { p _ { 0 } } } { \Delta \mathcal { O } _ { i } }$$
where ˆ is the rescaled Jacobian matrix and J C the covariance matrix. The latter plays the key role in covariance analysis. The domain of reasonable parameters is thus given by p · C ˆ -1 · p ≤ 1 which defines a confidence ellipsoid in the space of model parameters. It is related to the probability distribution [15, 17]
$$W ( p ) \varpropto \exp ( - \frac { 1 } { 2 } p \cdot \hat { \mathcal { C } } ^ { - 1 } \cdot p ) \quad.$$
Any observable A is a function of model parameters A = A ( p ). The value of A thus varies within the confidence ellipsoid, and this results in some uncertainty ∆ A . Usually, one can assume that A varies weakly such that one can linearize it
$$A ( p ) \simeq A _ { 0 } + G ^ { A } \cdot ( p - p _ { 0 } ) \quad \text{for} \quad A _ { 0 } = A ( p _ { 0 } ) \quad \text{and} \quad G ^ { A } = \partial _ { p } A | _ { p _ { 0 } } \quad. ( 6 )$$
This assumption will be used throughout the paper, with exception of section 3.5 where we check non-linear effects.
The covariance matrix ˆ and the slopes C G A are the basic constituents of error estimates and correlations within statistical analysis addressed in the following.
## 2.2. Strategies for estimating errors
A χ 2 fit is a black box. One plugs in a model, chooses a couple of relevant fit data, and grinds the mill until one is convinced to have found the absolute minimum χ 2 0 together with the optimal parameters p 0 . What remains is to understand the model thus achieved, in particular its reliability in extrapolations to other observables. This is the quest for error estimates which does not have a simple and unique answer. One can only approach the problem from different perspective and so piece-wise put together an idea of the various sources of uncertainty. This has been discussed extensively from a general perspective in [13]. We will exemplify that here on some of the proposed strategies for the particular case of the Skyrme-Hartree-Fock (SHF) approach. We
assume that SHF is sufficiently well known to the reader and refer for details to the reviews [14, 18, 19].
The strategies for evaluating properties of the model and its uncertainties are here summarized in brief:
## (i) Extrapolation uncertainties from statistical analysis.
Using the probability distribution (5), one can deduce the uncertainty on the predicted value A 0 as
$$\Delta A = \sqrt { \overline { \Delta A ^ { 2 } } } \,, \, \overline { \Delta A ^ { 2 } } = \sum _ { \alpha \beta } G ^ { A } _ { \alpha } \mathcal { C } _ { \alpha \beta } G ^ { A } _ { \beta } \ \.$$
This is the statistical extrapolation error serving as useful indicator for safe and unsafe regions of the model. It will be exemplified in section 3.2.
## (ii) Correlations between observables from statistical analysis.
Again using W ( p ) from Eq. (5), one can deduce also the correlation, or covariance, between two observables A and B as
$$c _ { A B } = \frac { | \overline { \Delta A \, \Delta B } | } { \Delta A _ { 0 } \, \Delta B _ { 0 } } \ \.$$
A value c AB = 1 means fully correlated where knowledge of A ( p ) determines B ( p ). A value c AB = 0 means uncorrelated, i.e. A ( p ) and B ( p ) are statistically independent. We will exemplify covariance analysis in section 3.4.
## (iii) Sensitivity analysis for the model parameters p .
The Jacobian matrix ˆ together with the covariance matrix J ˆ allows to explore the C impact of each single model parameter p α on a given fit observable ˆ . O i Examples for this kind of analysis are found in [8, 20, 13].
## (iv) Dedicated variations of parameters.
It can be instructive to watch the trend of an observable A ( p ) when varying one parameter p α . This becomes particularly useful when expressing the SHF model parameters in terms of bulk properties of nuclear matter. This strategy will be exemplified in section 3.3.
## (v) Trends of residual errors.
A perfect model should produce a purely statistical (Gaussian) distribution of residuals O i ( p ) - O exp i . Unresolved trends indicate deficiencies of the model. All nuclear mean-field models produce still strong unresolved trends, see, e.g., [7, 8, 19]. We will discuss a compact version of this analysis in section 3.1.2.
- (vi) Variations of fit data. The fit observables ˆ O i stem from different groups of observables as, e.g., energy or radius. One can omit this or that group from the pool of fit data. Comparison with the full fit allows to explore the impact of the omitted group. This strategy will be initiated in section 3.1 and carried forth throughout the paper in combination with the other strategies.
## (vii) Comparison with predicted data.
A natural test is to compare a prediction (extrapolation) with experimental data.
The model is probably sufficient if the deviation remains within the extrapolation error (7). It is a strong indicator for a systematic error if this is not the case. An example is the energy of super-heavy nuclei where deviations (and residuals) point to a systematic problem of the SHF model [21].
- (viii) Variations of the model. The hardest part in modeling is to estimate the systematic error. All above strategies explore a model from within. This gives at best some indications for a systematic error. For more, one has to step beyond the given model. One way is to extend the model by further terms. Another way is to compare and/or accumulate the results from different models. Examples for the latter strategy can be found in [9, 12].
As discussed in [13], there is a basic distinction between statistical error and systematic error. Quantities related to the statistical error can be evaluated within the given model, here SHF, and quality measure χ 2 . This concerns points i-iv in the above list, to some extend also point vi. It is a valuable tool to estimate a lower limit for extrapolation errors. The systematic error, on the other hand, covers all insufficienties of the given model. There is no systematic way to estimate as we usually do not dispose of the exact solution to compare with. It can only be explored piece-wise from different perspectives. These are the methods in points vi-viii. Each one of the methods v-viii amounts to a large survey of the validity of SHF on its own. Thus we refer in this respect to the papers already mentioned in the list above.
## 3. Results and discussion
## 3.1. Choices for the variation of input data
First, we take up point vi of section 2.2, the variation of fit data. We explain in this section the strategy for variations and choice of input data. The parametrization thus obtained under the varied conditions will then be used throughout all the following sections. The variation of input data unfolds only in connection with the subsequent strategies.
Basis is the pool of fit data as developed and used in [7]. It contains binding energies, form parameters from the charge formfactor (r.m.s. radius r rms C , , diffraction radius R diffr C , , surface thickness σ C [22]), and pairing gaps ∆ pair in a selection of semimagic nuclei which had been checked to be well reproduced by mean-field models [23]. Furthermore, it includes some spin-orbit splittings ε ls in doubly magic nuclei. An unconstrained fit to the full set yields the parametrization SV-min. Now we have performed a series of fits with deliberate omission of groups of fit data. This yields the parametrizations as listed in table 1. We have also studied omission of ε ls or ∆ pair . This showed only minor effects and so we do not report on these variants. The effects of the various omissions on the average deviations in the first four blocks of data will be shown later in figure 2 and discussed at that place.
Table 1. Included data sets from the standard pool of fit data from finite nuclei [7]. A 'x' means included and '-' stands for excluded. The observables are explained in the text.
| | E B | r rms , C | R diff , C | σ C | ε ls | ∆ pair |
|------------|-------|-------------|--------------|-------|--------|----------|
| SV-min | x | x | x | x | x | x |
| 'no surf' | x | x | x | - | x | x |
| 'no rms' | x | - | x | x | x | x |
| 'no Formf' | x | x | - | - | x | x |
| 'E only' | x | - | - | - | x | x |
3.1.1. Effect on predicted observables In this section, we look at the effect of varied fit data on predicted/extrapolated observables, nuclear matter properties (NMP) and key observables of the two nuclei 208 Pb and 266 Hs. In 266 Hs, we consider the binding energy E b [24] and the fission barrier B f [25]. The experimental value for B f is augmented with an error bar as there remains a large uncertainty from experimental analysis. The binding energy include the rotational zero-point energy which is obligatory for deformed nuclei [23]. The fission barriers are taken relative to the collective ground state and include rotational correction [26, 27]. Note that we thus include for this observable some correlation effects beyond SHF which means that B f is not a pure mean-field observable. In 208 Pb, we consider the isoscalar giant monopole (GMR) and quadrupole (GQR) resonance, the isovector giant dipole resonance (GDR), and the dipole polarizability α D . These four observables are computed with the techniques of [28]. The NMP considered are: binding energy E/A , density ρ nm , incompressibility K , isoscalar effective mass m /m ∗ , symmetry energy a sym , and Thomas-Reiche-Kuhn (TRK) sum rule enhancement factor κ TRK , all taken at the equilibrium point of symmetric matter. Note that NMP can be viewed as observables ˆ and equally well as model A parameters ˆ A ≡ p α . This is no principle difference. All formula for uncertainty and correlations can be employed when identifying G p β α = δ αβ . Figure 1 shows the effect of the omissions of data on the observables and their uncertainties. Changes in uncertainty indicate the impact of the omitted data group an the observable. A shift of the average shows what data are pulling in which direction.
The effects on NMP (lower six panels) are large throughout. A most pronounced shift is produced by omitting R diffr C , (in 'no Formf' and 'E only') which leads to a large jump in bulk equilibrium density ρ nm and incompressibility K . There is also a jump in the isovector response a sym in addition to the generally strong changes. It is also interesting to note that radius information keeps the effective mass m /m ∗ down to values below 1 while fits without radii let m /m ∗ grow visibly above one. The reason is probably that m /m ∗ has an impact on the surface profile, thus on r rms C , and σ C , and, in turn, also on R diffr C , . The variances, of course, grow generally when omitting data. A particularly
-3
Figure 1. Lower 6 panels: Predicted nuclear-matter properties (NMP) with their extrapolation uncertainties for the parametrizations in table 1. Upper 6 panels: Predicted properties in finite nuclei, giant resonance energies and dipole polarizability α D in 208 Pb and binding energy E B as well as fission barrier B f in 266 Hs. The faint dotted horizontal lines indicate the experimental data.
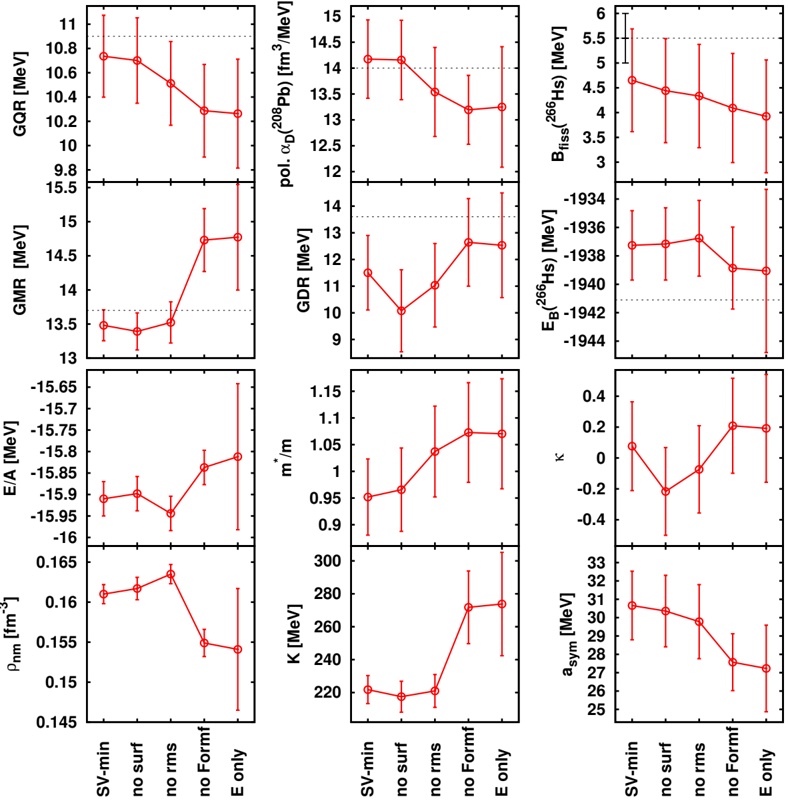
large increase emerges for the set 'E only'. This indicates that any information from the charge formfactor is extremely helpful to confine the parametrization. On the other hand, although the error bars for 'E only' are generally larger than for the other parametrizations, they are still in acceptable ranges. This shows that energy data alone can already provide a reasonable parametrization.
The upper block in figure 1 shows the effect of omission of fit data on observables in finite nuclei. The three giant resonances and the polarizability α D are known to have a one-to-one correspondence with each one NMP [7]: the GMR with K , the GQR with m /m ∗ , the GDR with κ TRK , and α D with a sym . These pairs of highly correlated observables shows the same trends. Note that this one-to-one correspondence is obtained
Figure 2. Average deviation (green) and r.m.s. deviation (red errorbars) for groups of observables in the pool of fit data.
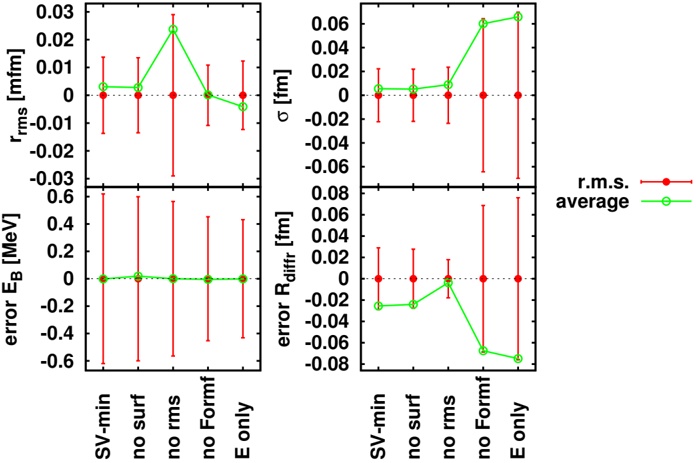
in the dedicated variation of one NMP when re-optimizing all other NMP (as explained in section 3.3); isolated variation can show more dependences as, e.g., a dependence of the GDR on a sym [29]. Note, furthermore, that the correspondence of α D with a sym is equivalent to a correspondence of α D with ∂ a ρ sym , because a sym is strongly correlated with ∂ a ρ sym [30]. The large effects from omission of R diffr C , in 'no Formf' which were seen in some NMP come up again here. Unlike NMP, observables in finite nuclei allow a comparison with experimental data. The giant resonances (with exception of GDR) and α D indicate that inclusion of radius information drives into the right direction which is a gratifying feature. Inclusion of radii is also beneficial for B f ( 266 Hs) but disadvantageous for E B ( 266 Hs). It is noteworthy that the trend of E B ( 266 Hs) is similar to the trend of ρ nm . This indicates some correlation between these two observables which is seen in figure 8.
Besides the strong impact of R diffr C , , there remain only few minor effects. The set 'E only' produces again a large growth of the variance for the energy observable E B ( 266 Hs) which correlates well with a similar huge growth for the bulk E/A .
3.1.2. Reproduction of fit observables In this subsection, we look at the effect of varied fit data on the average and r.m.s. residuals taken over a group of data. This is a compact, although already informative, version of the study of residuals mentioned under point v in section 2.2. Mean values deviating significantly from zero within the scale set by the uncertainties indicate a non-statistical distribution and thus some incompatibility of the observable with the model. Changes on the r.m.s. error indicate the sensitivity to a group of observables. Figure 2 shows the effects of the omissions on the average
residuals of fit observables. The average error of energy E B is always near zero which is not surprising because all fits include E B with large weight. Note that the zero average error does not exclude missing trends which are seen when plotting the systematics of energy deviations, see e.g. [21, 7, 8].
The diffraction radius R diffr C , is special in that it shows large average residuals for practically every case. In fact, the r.m.s. error is almost exhausted by the average error. Zero average error appears only for the set 'no rms' which omits r rms C , . This indicates that there is some incompatibility between r rms C , and R diffr C , in the present model. Negative average error means that the R diffr C , tend to be larger than the experimental values. The opposite trend is seen for r rms C , (upper left panel, case 'no rms') showing that r rms C , wants to be smaller than the data if R diffr C , is matching perfectly. The sets 'no Formf' and 'E only' show where R diffr C , ends up if it is not constrained by fit. The change of its average deviation (green lines) (and with it the average values) is significant. It grows to values of about 0 07 fm . -3 which is far larger than the allowed uncertainty from SV-min of about 0 02 fm . -3 (red error bars). Thus the reproduction of the charge formfactor is much degraded for these two sets. The question is whether this is an insufficiency of the SHF model or whether we see here a defect of the model for the intrinsic nucleon formfactor [6]. Note that the deviations are of the order of the adopted errors (0.04 fm -3 ). This indicates that a better simultaneous adjustment of E B and R diffr C , is not possible within the given SHF model. The trend of the average deviations of R diffr C , is very similar to the trend of ρ nm in figure 1. The correlation goes up to quantitative detail: From SV-min to 'E only', R diffr C , grows by 0.05 fm, i.e. by about 1%. The density ρ nm shrinks by about 0.005 fm -3 which corresponds perfectly to the radius effect.
The surface thickness σ C has generally a small average error. Omitting only σ C does not change much. The correct σ C emerges already if R diffr C , is properly constrained. We see, however, a drive to smaller surfaces if all formfactor observables are omitted in the fit.
## 3.2. Extrapolation uncertainties
According to point i in section 2.2, the most obvious result of statistical analysis are the uncertainties on extrapolated observables. It is natural that extrapolations become the more risky the farther away a nucleus is from the fit pool. This is demonstrated in figure 3 for the chain of Sn isotopes reaching out to very neutron rich r -process nuclei. The uncertainties of the fit observables E B and r rms,C are smallest for the fit nuclei and grow with distance to the fit region. The growth is large, by a factor of 6-10, for the extrapolation of E B and of two-neutron separation energy S 2 n into the neutron-rich region. This is a direction where isovector terms become important, but isovector NMP are not so well fixed in fits to nuclear ground states. Extrapolations to superheavy elements are probing more the isoscalar channel and are thus more robust showing only factor 2-3 growth in uncertainty, see E B ( 266 Hs) in figure 1. The fit 'E
Figure 3. Extrapolation uncertainties for binding energy E B (lower left panel), charge r.m.s. radius r rms C , (lower right panel), and two-neutron separation energy S 2 n (upper left panel) along the chain of even Sn isotopes. The few Sn nuclei which were included in the fits lie in between the two vertical dotted lines. Results are shown for two forces, SV-min and 'E only'.
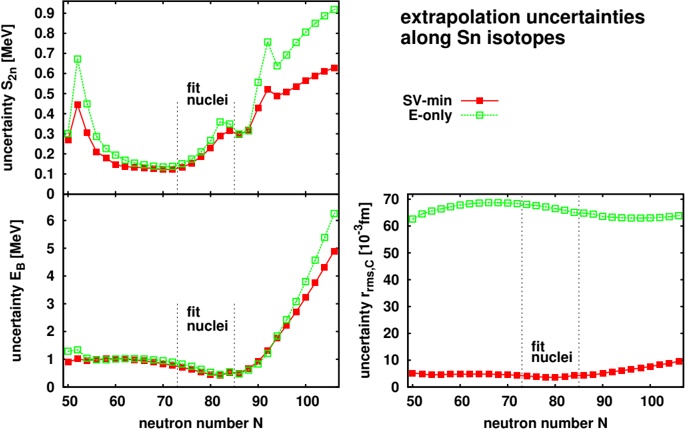
Figure 4. Left: E/A versus density for pure neutron matter for the parametrization developed with the fit protocol of SV-min while omitting certain blocks of observables. Right: The extrapolation uncertainties for the data shown in the left panel.
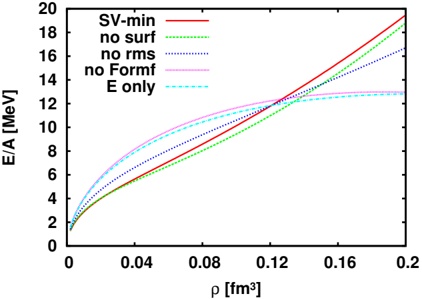
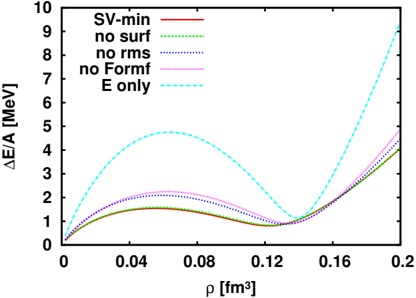
only' has comparable uncertainties on E B and S 2 n for the fit nuclei, but shows slightly faster growth outside this region. The effect is not dramatic which indicates that fits to energy suffice to predict energy observables. Different is the observable r rms,C . The fit 'E only' has an order of magnitude larger uncertainties than SV-min. However, both forces agree in the trend which is very flat over the whole chain. Predictions for radii thus are robust once radii are well fitted.
A very far extrapolation is involved in studying pure neutron matter as it is often done in nuclear astrophysics (see [31, 18, 32] and citations therein). The left panel of
figure 4 shows the equation of state (EoS) E/A neut ( ρ ) for pure neutron matter. There arise huge differences in its slope at ρ < 0 12 fm . -3 and ρ > 0 15 fm . -3 . In spite of these very different slopes, all EoS share about the same values around neutron density ρ ≈ 0 13 fm . -3 . It looks like a 'fixpoint' in the neutron EoS.
The right panel shows the corresponding extrapolation uncertainties. The errors follow the same trends as the deviations between the parametrizations in the left panel. In regions of large deviations, these are larger than the estimated uncertainties. The discrepancy indicates that systematic errors will play a role here. What the ρ -dependence of the uncertainties is concerned, it is astonishing that there arises a pronounced minimum just near this 'magic' density ρ ≈ 0 13 fm . -3 where all predictions approximately agree. Although, the actual position of the minimum varies a bit with the force the coincidence looks impressive. The reasons for this particularly robust point has yet to be found out.
The difference in neutron EoS, and particularly the difference in slope for ρ < 0 12 fm . -3 , has dramatic consequences for the stability of neutron stars. The two forces with small slope 'no Formf' and 'E only' do not yield a maximal radius at all because the neutron EoS becomes unbound for very large densities.
## 3.3. Variation of nuclear matter properties (NMP)
We now come to point iv of section 2.2, the dedicated variation of model parameters. We do that in terms of the NMP which are a form of model parameters with an intuitive physical content. We consider here a variation of only one NMP at a time (this differs from the variation in [7] where four NMP were kept fixed). Thus we keep only the one varied NMP at a dedicated value and fit all remaining, now 13, model parameters. This is so to say a correlated variation because it allows the other model parameters to find their new optimum value for the one given constrained NMP.
Figure 5 shows the maximal neutron star mass obtained by solving the TolmanOppenheimer-Volkoff equation (see [32] for details) as well as fission barriers and fission lifetimes of the super-heavy nucleus 266 Hs. Fission barriers were determined with respect to the collective ground state energy. The collective ground state and the lifetime were calculated using the procedure as described in [27]. The incompressibility K has little effect on all three observables while the effective mass m /m ∗ shows always strong trends. The effect on 266 Hs is understandable because m /m ∗ determines the spectral density and with it the shell-corrections which are known to have a strong influence on the fission path. Different behaviors are seen for a sym and κ TRK . Neutron matter depends sensitively on these isovector parameters while fission in 266 Hs reacts less dramatic, although there remains a non-negligible trend also here. However strong or weak the trends, all three observables gather influences from several NMP. Unlike the case of giant resonances [7], there is here no one-to-one correspondence between an observable and one NMP.
Figure 5. Results from systematic variation of NMP. The maximal mass of neutron stars (upper), fission lifetime (middle) and fission barrier (lower) in 266 Hs as function of the four varied NMP ( K m /m a , ∗ , sym , or κ TRK ). One NMP was fixed while performing free fit of all other parameters. In cases where data is missing for the neutron star mass, the equation of state is not stable for high densities (see figure 4). Dashed lines show experimental data for the maximal neutron star mass [33], the lifetime [34] and the barrier [25] of 266 Hs. Up-arrows indicate that these data are just lower limits.
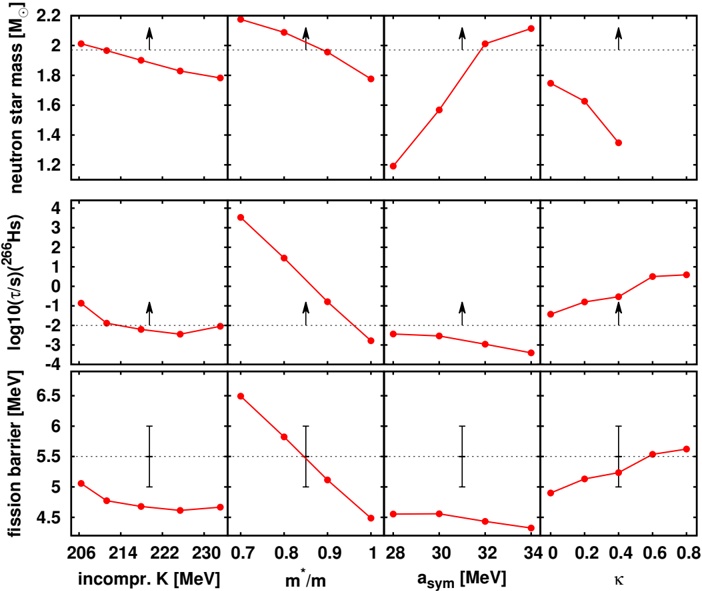
## 3.4. Covariances
Statistical correlations, also called covariances c AB between two observables A and B , see point ii of section 2.2, are a powerful tool to explore the hidden connections within a model. This quantity helps, e.g., to determine the information content of a new observable added to an existing pool of measurements. Examples and detailed discussions are found in previous papers [35, 11, 13]. We add here two new cases related to the observables and parametrizations addressed in this paper. Figure 6 shows the covariances for four observables, three of them being far extrapolations and one rather at the safe side. The latter case is the weak-charge formfactor F W in 208 Pb (right panel), taken at momentum q =0 475 fm, which is known to be closely related to the neutron . / radius [12]. It is fully correlated with all the static isovector observables a sym , d E/A ρ neut , and α D , but uncorrelated with the isoscalar NMP and the dynamic isovector response κ TRK . As an example for an exotic nucleus deep in the astro-physical r -process region, we have included 148 Sn in the considerations. The strong isovector correlations provide also a sizable correlation with this extremely neutron rich 148 Sn.
Figure 6. Correlations of the maximal mass of a neutron star, of the binding energy and of the fission barrier of the isotope 266 Hs, and of the weak-charge formfactor F W ( q = 0 475 . / fm) in 208 Pb with NMP and a couple of observables in finite nuclei, for the force SV-min. The E/A neut stands for the neutron EoS at ρ = 0 1 fm . -3 and d E/A ρ neut for its slope at this density. α D is the dipole polarizability, and r n the neutron r.m.s. radius. For the pairing strength, we show only the proton case. The correlations for neutron pairing strength are equivalent.
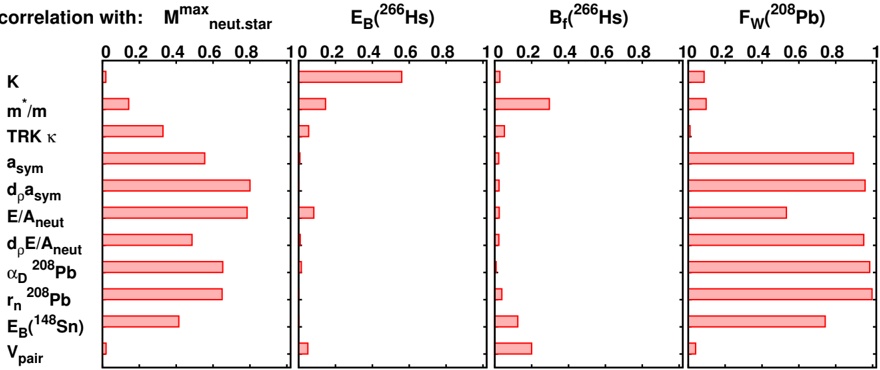
The maximal mass of a neutron star (left panel) shows a somewhat more mixed picture. It is, not surprisingly, most strongly correlated with the neutron EoS. There are also sizable correlations with all the static isovector observables (block from a sym to r n ) and to some extend with the extrapolation to the extremely neutron rich 148 Sn as well as κ TRK . Very little correlation exists with the isoscalar NMP K and m /m ∗ .
A much different picture emerges for the binding energy of the super-heavy 266 Hs: There is no really large correlation with any observable shown here. Negligible are correlations with static isovector observables. Some correlations exit for the parameters K m /m , ∗ , κ TRK , and V pair which indicates that all these four parameters have some impact on E B ( 266 Hs). The fission barrier B f ( 266 Hs) shows similarly a collection of many small correlations. The most pronounced here is the correlation with the effective mass m /m ∗ . This agrees with results in figure 5, where only m /m ∗ shows a significant trend for B f . Next to m /m ∗ comes the influence from pairing strength which is not surprising as pairing has a large effect near the barrier where the density of states is high.
We have seen in figure 4 that the neutron EoS has a pronounced variation of extrapolation uncertainties as function of ρ . In particular, there is a marked minimum at ρ ≈ 0.13 fm -3 . As complementing information, we show in the left panel of figure 7 the correlation of E/A neut ( ρ ) for neutron matter with the basic NMP. Not surprisingly, the symmetry energy a sym dominates, at least in the regions of low and high density. We see a minimum of correlations for all NMP, except κ TRK , just in the region where uncertainties are lowest and where all predictions for E/A neut agree, see figure 4. This is a remarkable coincidence for which we have not yet an explanation.
Figure 7. Correlations of E/A at various densities with the basic nuclear matter parameters (NMP). Left: for the neutron E/A neut . Right: for E/A sym of symmetric nuclear matter.
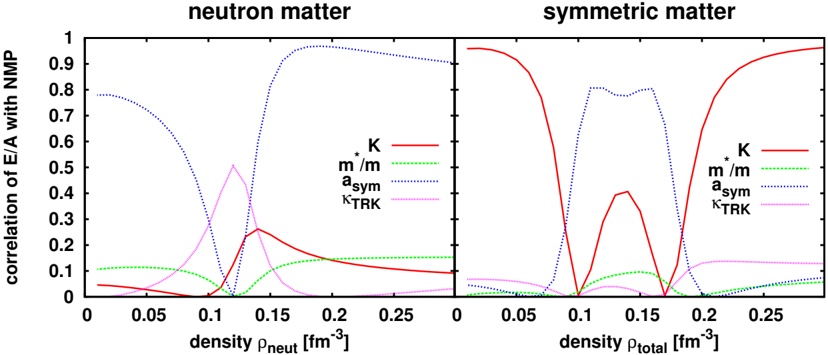
The right panel of figure 7 shows the correlations for E/A of symmetric matter (right panel), K is strongly correlated and dominates at low and high densities. It is interesting to see that a sym dominates with sizable correlations in the region ρ =0.100.16 fm -3 . This is plausible because these are the typical density values in the inner surface of a nucleus and this is the region where the dipole response is predominantly explored. The dynamic NMP, m /m ∗ and κ TRK , are almost uncorrelated everywhere.
Figure 8 shows the matrix of pairwise covariances for a selection of NMP and observables in finite nuclei. A matrix for SV-min (right panel) was already discussed in [20]. It segregates nicely into four groups of observables: static isoscalar around K , dynamic isoscalar around m /m ∗ , static isovector around a sym , and dynamic isovector around κ TRK . The basic bulk NMP E/A and ρ nm are weakly correlated with the static isovector block. The same block is also weakly correlated with the extremely neutron rich extrapolation 148 Sn. The far superheavy nucleus Z=120/N=182 has a bit of low correlations to all other observables, similar to 266 Hs in figure 6.
The left panel of figure 8 shows the result for the set 'E only'. The four blocks of mutually correlated observables remain almost the same, however, sometimes with somewhat reduced correlation. A marked change appears for ρ nm which was strongly linked to the static isoscalar K block for SV-min and now moves totally to the basic NMP E/A . This case demonstrates that changing the fit data can have an impact on the covariances, and in general does. It is rather surprising that the two fits show so widely similar trends in covariances.
The set 'E only' does not include any radius information in the data. This allows to compute also the covariances with charge radii. The left panel thus includes also R diffr C , and r rms C , amongst the observables. Both, R diffr C , and r rms C , , have about the same correlations. These are strong with the block of basic NMP E/A and ρ nm plus the isoscalar surface energy a surf . This confirms the findings from figure 1 where we see
Figure 8. Correlation matrix for a couple of observables computed from the fit to all data SV-min (right panel) and 'E only' where all information from radii and surface thickness is omitted (left panel). High correlation is indicated by light yellow, no correlation by deep black.
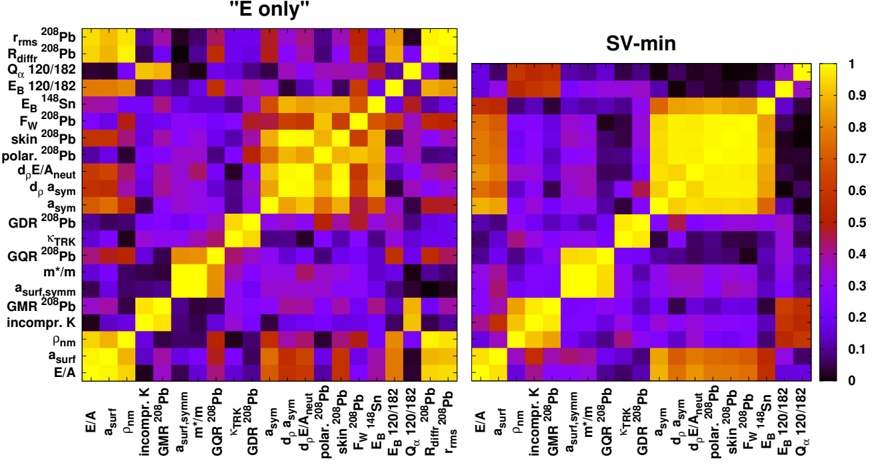
that radius information has a large impact on the basic bulk binding. There are some correlations with the binding energy of the superheavy element Z=120/N=182 which is not a surprise as this nucleus also correlates with the block E/A and ρ nm . All other correlations are not significant.
## 3.5. Beyond linear analysis
Standard χ 2 -analysis assumes that an observable A ( p ) depends linearly on the model parameters p within the range of reasonable p . We have checked that assumption by carrying the expansion (6) for the observables up to quadratic terms still assuming a quadratic form for χ 2 as function of the parameters. The simple rules of integrating polynomials with Gaussians allow to compute uncertainties and correlations also for this non-liner case in straightforward manner. Figure 9 shows the ratio of extrapolation uncertainties computed from the quadratic expansion to those from the linear model for a broad selection of observables. We had also checked the weight of the quadratic terms explicitly and this delivers the same picture. Thus we take this ratio as a simple measure of (non-)linearity. The faint black horizontal line indicates the limit up to which the assumption of linearity is acceptable. Most observables are thus in the linear regime, a few of them reach into the non-linear regime, and some of them (superheavy elements and neutron stars) are dramatically non-linear with ratios going up to 100. However, this example has to be taken as an order of magnitude estimate. Such a highly nonlinear requires a more careful evaluation of correlation according to Spearman's analysis
Figure 9. Ratio of extrapolation uncertainties with curvature correction and without computed with SV-min. The horizontal line indicates a critical ratio of 3 above which curvature effects become important.
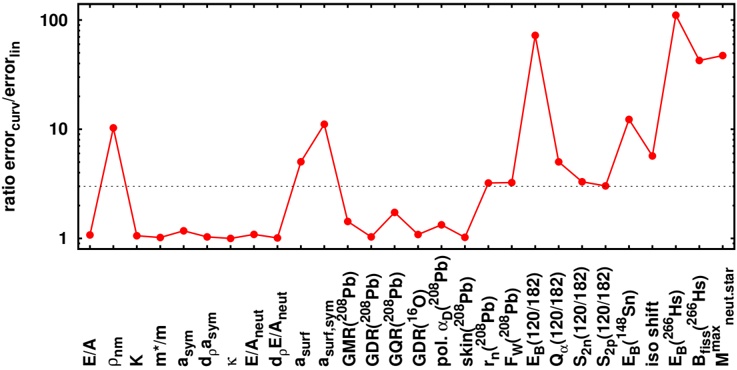
[36] which goes beyond the scope of this paper.
We have also checked the effect of non-linearity on covariances c AB for SV-min. The basic sorting into strongly correlated combinations and weakly correlated ones is maintained. It is only at closer inspection that one can spot some changes of correlations if a non-linear observable is involved. In most cases, non-linearity's reduce correlations slightly.
## 4. Conclusions and outlook
We have explored the uncertainties inherent in the Skyrme-Hartree-Fock (SHF) approach by employing, out of many, five different strategies for error estimates: extrapolation error from χ 2 analysis, covariances between pairs of observables from χ 2 analysis, trends with systematically varied model parameters (practically nuclear matter parameters), trends of residual errors, and block-wise variation of fit data. For the latter strategy, we have fitted a couple of new parametrizations where differing groups of fit observables had been omitted, once the r.m.s. radii, once the surface thickness, once both formfactor observables (surface, diffraction radius), and finally all form information (surface, diffraction radius, r.m.s. radius). This makes, together with the full fit, five parametrizations which are then used in combination with all further analysis. Some of the strategies yield similar information (e.g. trend with parameters and covariances), however from different perspectives which makes it useful to consider both. In any case, the combination of strategies is more informative than any single strategy alone. Out of the many interesting aspects worked out in the above studies, we emphasize here a few prominent findings and indicate the directions for further development:
- (i) Fits only to binding energy (omitting any radius information) yield already a
very acceptable description of nuclear properties. The error on diffraction radius and surface thickness grows by factor 3-4, but remains with about 0.08 fm in an acceptable range. However, the uncertainties in extrapolations can grow large which proves the usefulness of having radius information in the fit. Radius information is strongly correlated with bulk binding (equilibrium energy and density) as well as surface energy and it helps to fix theses quantities.
- (ii) We have found a conflict between the description of r.m.s. radius and diffraction radius. Fitting only one of the both spoils the other one. Fitting both yields a compromise. The precision which can be achieved is small (0.02-0.04 fm), but limited to that in the present model. Further development work on SHF and the computation of radii is required to harmonize the data.
- (iii) Extrapolations to exotic nuclei show, of course, increasing uncertainties with increasing distance to the set of fit nuclei. The growth of errors is large for energies of r -process nuclei (factor 6-10) and moderate for energies of super-heavy elements (factor 2-3). Errors on radii, on the other hand, remain even nearly constant. This is related to the tight connection of radii to bulk binding (see point i above).
- (iv) The more dramatic extrapolation to neutron stars is plagued by much larger uncertainty. Neutron matter is highly correlated to isovector forces which are less well fixed by fits to existing nuclei. The variation of fit data shows that there are probably large systematic errors beyond the statistical uncertainties. In spite of the generally large uncertainties, there is a 'magic' region around density 0.13 fm -3 where all parametrizations yield surprisingly small uncertainties and very similar predictions. This effect deserves further investigation.
- (v) We have checked the assumption of linear parameter dependence, employed in standard statistical analysis, for many observables. Most of them show sufficient linearity, but some deviate dramatically. These are typically the observables in far extrapolations, exotic nuclei and neutron stars. The impact of non-linearity on extrapolation uncertainties and covariances has yet to be investigated.
Acknowledgments: This work was supported by the Bundesministerium f¨r Bildung u und Forschung (BMBF) under contract number 05P09RFFTB.
## References
- [1] Negele J W and Vautherin D 1972 Phys. Rev. C 5 1472
- [2] Reinhard P G and Toepffer C 1994 Int. J. Mod. Phys. E 3 435
- [3] Beiner M, Flocard H, Nguyen Van Giai and Quentin P 1975 Nucl. Phys. A238 29-69
- [4] Bartel J, Quentin P, Brack M, Guet C and H˚kansson H B 1982 Nucl. Phys. a A386 79-100
- [5] Tondeur F, Brack M, Farine M and Pearson J 1984 Nucl. Phys. A 420 297
- [6] Friedrich J and Reinhard P G 1986 Phys. Rev. C 33 335-351
- [7] Kl¨ upfel P, Reinhard P G, B¨rvenich T J and Maruhn J A 2009 Phys. Rev. C u 79 034310
- [8] Kortelainen M, Lesinski T, Mor´ e J, Nazarewicz W, Sarich J, Schunck N, Stoitsov M V and Wild S 2010 Phys. Rev. C 82 024313
- [9] Piekarewicz J, Agrawal B K, Col` G, Nazarewicz W, Paar N, Reinhard P G, Roca-Maza X and o Vretenar D 2012 Phys. Rev. C 85 041302
- [10] Nazarewicz W, Reinhard P G, Satu/suppress la W and Vretenar D 2013 Eur. Phys. J. A; arXiv:1307.5782
- [11] Reinhard P G and Nazarewicz W 2013 Phys. Rev. C 87 014324
- [12] Reinhard P G, Piekarewicz J, Nazarewicz W, Agrawal B K, Paar N and Roca-Maza X 2013 Phys. Rev. C 88 034325
- [13] Dobaczewski J, Nazarewicz W and Reinhard P G 2014 J. Phys. G 41
- [14] Bender M, Heenen P H and Reinhard P G 2003 Rev. Mod. Phys. 75 121
- [15] Brandt S 1997 Statistical and computational methods in data analysis (Springer, New York)
- [16] Bevington P R and Robinson D K 2003 Data Reduction and Error Analysis for the Physical Sciences (McGraw-Hill)
- [17] Tarantola A 2005 Inverse problem theory and methods for model parameter estimation (SIAM, Philadelphia)
- [18] Stone J and Reinhard P G 2007 Prog. Part. Nucl. Phys. 58 587
- [19] Erler J, Kl¨pfel P and Reinhard P G 2011 J. Phys. G u 38 033101
- [20] Kortelainen M, McDonnell J, Nazarewicz W, Reinhard P G, Sarich J, Schunck N, Stoitsov M V and Wild S M 2012 Phys. Rev. C 85 024304
- [21] Erler J, Kl¨pfel P and Reinhard P G 2010 J. Phys. G u 37 064001
- [22] Friedrich J and V¨gler N 1982 Nucl. Phys. A o 373 192
- [23] Kl¨ upfel P, Erler J, Reinhard P G and Maruhn J A 2008 Eur. Phys. J A 37 343
- [24] Wang M, Audi G, Wapstra A, Kondev F, MacCormick M, Xu X and Pfeiffer B 2012 Chinese Physics C 36 1603
- [25] P´ eter J 2004 Eur. Phys. J. A 22 271
- [26] Schindzielorz N, Erler J, Kl¨pfel P, Reinhard P G and Hager G 2009 Int. J. Mod. Phys. E u 18 773
- [27] Erler J, Langanke K, Loens H P, Martinez-Pinedo G and Reinhard P G 2012 Phys. Rev. C 85 025802
- [28] Reinhard P G 1992 Ann. Phys. (Leipzig) 504 632
- [29] Trippa L, Col` G and Vigezzi E 2008 Phys. Rev. C o 77 061304
- [30] Roca-Maza X, Brenna M, Col'o G, Centelles M, nas X V, Agrawal B K, Paar N, Vretenar D and Piekarewicz J 2013 Phys. Rev. C 88 024316
- [31] Lattimer J M 2012 Ann. Rev. Nucl. Part. Sci. 62 485
- [32] Erler J, Horowitz C J, Nazarewicz W, Rafalski M and Reinhard P G 2013 Phys. Rev. C 87 044320
- [33] Demorest P B, Pennucci T, Ransom S M, Roberts M S E and Hessels J W T 2010 Nature 467 209
- [34] Hofmann S, Heßberger F, Ackermann D, Antalic S, Cagarda P, Fwiok S, Kindler B, Kojouharova J, Lommel B, Mann R, M¨nzenberg G, Popeko A, Saro S, Sch¨tt H and Yeremin A 2001 Eur. u o Phys. J. A 10 (1) 5-10
- [35] Reinhard P G and Nazarewicz W 2010 Phys. Rev. C 81 051303
- [36] Schmid F and Schmidt R 2007 Statistics and probability letters 77 407 | 10.1088/0954-3899/42/3/034026 | [
"J. Erler",
"P. -G. Reinhard"
] | 2014-08-01T15:43:33+00:00 | 2014-08-01T15:43:33+00:00 | [
"nucl-th"
] | Error estimates for the Skyrme-Hartree-Fock model | There are many complementing strategies to estimate the extrapolation errors
of a model which was calibrated in least-squares fits. We consider the
Skyrme-Hartree-Fock model for nuclear structure and dynamics and exemplify the
following five strategies: uncertainties from statistical analysis, covariances
between observables, trends of residuals, variation of fit data, dedicated
variation of model parameters. This gives useful insight into the impact of the
key fit data as they are: binding energies, charge r.m.s. radii, and charge
formfactor. Amongst others, we check in particular the predictive value for
observables in the stable nucleus $^{208}$Pb, the super-heavy element
$^{266}$Hs, $r$-process nuclei, and neutron stars. |
1408.0209v1 | ## Magnetic structure of Yb Pt Pb: Ising moments on the Shastry-Sutherland Lattice 2 2
1 1 1 1 1 2
W. Miiller , L.S. Wu , M. S. Kim , T. Orvis , J. W. Simonson , M. Gam˙ za , D. E. McNally , C. S. Nelson , G. Ehlers , A. Podlesnyak , J.S. Helton , Y. Zhao 1 3 4 4 5 5 6 , , Y. Qiu 5 6 , , J. R. D. Copley , J. W. Lynn , I. Zaliznyak , and M. C. Aronson 5 5 2 1 2 , ∗ 1 Department of Physics and Astronomy, Stony Brook University, Stony Brook, NY 11794 2 Condensed Matter Physics and Materials Science Department, Brookhaven National Laboratory, Upton, NY 11973 3 National Synchrotron Light Source, Brookhaven National Laboratory, Upton, NY 11973 4 Quantum Condensed Matter Division, Oak Ridge National Laboratory, Oak Ridge, Tennessee 37831 5 NIST Center for Neutron Research, Gaithersburg, MD 20899 and 6 Department of Materials Science and Engineering, University of Maryland, College Park, MD 20742
(Dated: August 4, 2014)
Neutron diffraction measurements were carried out on single crystals and powders of Yb Pt Pb, 2 2 where Yb moments form planes of orthogonal dimers in the frustrated Shastry-Sutherland Lattice (SSL). Yb Pt Pb 2 2 orders antiferromagnetically at T N =2.07 K, and the magnetic structure determined from these measurements features the interleaving of two orthogonal sublattices into a 5 × × 5 1 magnetic supercell that is based on stripes with moments perpendicular to the dimer bonds, which are along (110) and (-110). Magnetic fields applied along (110) or (-110) suppress the antiferromagnetic peaks from an individual sublattice, but leave the orthogonal sublattice unaffected, evidence for the Ising character of the Yb moments in Yb Pt Pb. Specific heat, magnetic suscep2 2 tibility, and electrical resistivity measurements concur with neutron elastic scattering results that the longitudinal critical fluctuations are gapped with ∆E glyph[similarequal] 0.07 meV.
Much attention has focussed on coupled spin-dimer systems, where frustrated magnetic order can lead to spin liquid states [1, 2]. The Shastry-Sutherland Lattice (SSL), consisting of planes of orthogonal dimers with intradimer exchange J and interdimer exchange J ′ , is of particular interest as it has been solved [3] to show that the ground state is ordered antiferromagnetically (AF) for J/J ′ ≤ ( J/J ′ ) C and otherwise has a singlet ground state with gapped magnetic excitations. Insulating SrCu (BO ) 2 3 2 has such a SSL dimer liquid ground state [4-6], where frustrated exchange interactions create complex ordered superstructures at high fields [7-9], resulting in quantized plateaux in the magnetic field H dependence of the magnetization M(H)[10-12].
Most SSL systems are magnetically ordered, where the closure of the singlet dimer gap yields a nonzero M(H) that makes AF order possible even for H=0 [13-17]. In metallic Yb Pt Pb, Yb moments form the SSL (Fig. 1a) 2 2 and AF order appears below T N =2.07 K [17]. Magnetic susceptibility χ (T) measurements [18] find that J glyph[similarequal] 5 K and J/J ′ glyph[similarequal] 1, and a field of only 1.23 T, applied along the (110) or (-110) dimer bonds, suppresses the H=0 AF order, accompanied by quantized M(H) steps [1820] that culminate in the saturation of M(H) at glyph[similarequal] 3 T. The magnetic structures of SSL systems reflect the nearfrustration of short-ranged magnetic interactions, and in Yb Pt Pb, where strong Ising anisotropy confines large 2 2 and classical Yb moments to the SSL planes, the H=0 AF structure is analogous to but distinct from those found in SrCu (BO ) 2 3 2 at high fields, where quantum Heisenberg spins S=1/2 are perpendicular to the SSL layers.
here demonstrate that the Ising Yb moments in Yb Pt Pb 2 2 have a remarkably complex AF structure, with a commensurate superlattice of ordered stripes consisting of moment-bearing and magneticallycompensated Yb-pairs with moments perpendicular to the (110) and (-110) dimer bonds. The magnetic cell contains 200 Yb atoms, arranged in two orthogonal sublattices (SLs) that can be separately polarized by magnetic fields. The persistence of AF order in the surviving SL shows that the two orthogonal bonds of the H=0 SSL are decoupled by field, leading to a unique high field ground state. The AF order parameter in Yb Pt Pb 2 2 is mirrored in the temperature dependencies of the specific heat C/T and the temperature derivatives of χ (T) and the electrical resistivity ρ (T), suggesting that the stripe-ordered ground state is preceded by the dynamical freezing of longitudinal critical fluctuations that are gapped.
Neutron diffraction measurements presented
Crystals of Yb Pt Pb 2 2 were grown from Pb flux [17]. Neutron scattering experiments were performed using an incident neutron wavelength of 2.359 ˚ on the A BT-7 triple axis spectrometer at the NIST Center for Neutron Research (NCNR) [21] on 5 g of powder prepared by triturating single crystals, and on a 60 mg single crystal. x-ray diffraction measurements were carried out on this same crystal on beamline X21 at the National Synchrotron Light Source (NSLS), with an incident x-ray energy of 10 keV. Neutron scattering experiments were conducted on a 6 g collection of ∼ 300 oriented single crystals of Yb 2 Pt Pbwith an angular mosaic perpendic2 ular to the c-axis od glyph[similarequal] 2 degrees, using an incident energy E =3.27 meV at the Disk Chopper Spectrometer (DCS) i
at NCNR [22], while E =3.32 meV was used at the Cold i Neutron Chopper Spectrometer (CNCS) at the Spallation Neutron Source. Measurements of χ (T) were carried out using a Quantum Design Magnetic Phenomena Measurement System, while ρ (T) and C were measured using a Quantum Design Physical Phenomena Measurement System.
Neutron diffraction measurements show clear evidence for AF order below T N =2.07 K [17]. Fig. 1a shows the elastic intensity in the (HHL) scattering plane at 1.5 K, obtained at CNCS on the collection of aligned Yb Pt Pb 2 2 crystals. The (002) and (112) nuclear peaks are present at all temperatures, however satellite peaks emerge around (000) and (111) for T ≤ T N . The AF wave vector q 1 = ( δ, δ, 0 ) with δ = 0 2 . ± 0 02 . in reciprocal lattice units (rlu) is deduced from Gaussian fits to the (1δ ,1δ ,1) satellites(Fig. 1b), indicating that AF order involves a 5 × 5 × 1 superstructure. The temperature dependencies of the integrated intensities of the ( δ δ , ,1) and (1δ ,1δ ,1) AF peaks have the appearance of order parameters that are substantially broadened near T N (Fig. 1b,inset).
Our scattering geometry accesses a strip of the (HK1) plane (Fig. 1c), where a quartet of AF satellites forms around both (001) and (111), signalling the SSL plane retains fourfold symmetry in AF Yb Pt Pb. 2 2 Thus, there are two AF wave vectors, q 1 =(0.2,0.2,0) and q 2 =(-0.2,0.2,0) that define two orthogonal SLs, each containing half of the Yb moments. The fourth (1+ δ ,1+ ,1) satellite δ around (111) is much weaker than can be explained by either the Yb magnetic form factor or self-absorption corrections, and we will show below that this is captured by our magnetic structure model. A 3 T field H ‖ (-110) saturates all antiparallel moments [17, 23], and Fig. 1d shows that only the AF peaks with q 1 ⊥ H survive. Their Ising character restricts the Yb moments to be along or perpendicular to the (110) and (-110) dimer bonds. Both configurations are allowed by symmetry, but our magnetic structure produces no AF peaks for moments oriented along the dimer bonds. We conclude that the Yb moments are perpendicular to their own dimer bonds, so the q 1 =(0.2,0.2,0) SL is formed by dimers oriented along (110) with moments along (-110) and for the orthogonal q 2 =(-0.2,0.2,0) SL the dimers are along (-110) with moments along (110). The Ising character of the Yb moments is accommodated in Yb Pt Pb 2 2 by the formation of two orthogonal SLs, as the magnetization anisotropy suggests [23].
The magnetic structure of Yb Pt Pb is obtained from 2 2 the refinement of neutron diffraction data obtained on a 5g powder using BT-7. The 10 K neutron powder pattern (Fig. 2a) is well refined using the reported U 2 Pt Sn 2 -type tetragonal structure [24]. The 0.5 K neutron powder diffraction pattern has additional peaks corresponding to AF order (Fig. 2a), also evident in the (HH0) scan obtained at CNCS on the aligned crystal array (Fig. 2b).
FIG. 1. a) Elastic scattering in HHL plane at 1.5 K. Inset: orthogonal Yb dimers along (110) and (-110) form the SSL. b) Intensity of the (0.8,0.8,1) AF peak at different temperatures. Solid lines are Gaussian fits. Inset: temperature dependencies of the intensities of the (0.2,0.2,1) (black points) and (0.8,0.8,1) (red points) AF peaks. Solid lines are guides for the eye. Elastic scattering at 1.5 K in the (HK1) planes for magnetic fields H=0 (c) and at 1.6 K for H=3 T (d).
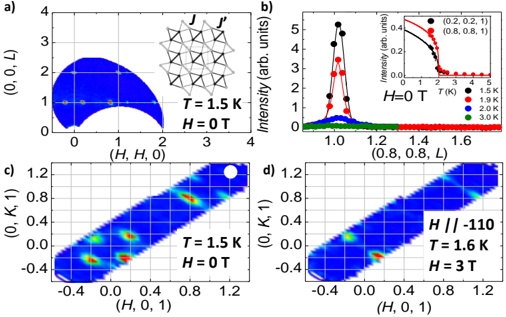
These (1 ± δ ,1 ± δ ,0) AF satellites arise from Yb moments that are perpendicular to (HH0) and to q 1 . No scans were performed along directions parallel to (-HH0), however we have added to Fig. 2b the second set of AF satellites from the moments perpendicular to q 2 . The 1.5 K (HH0) neutron scan (Fig. 2c) carried out on BT-7 using a 60 mg single crystal shows two satellites flanking each of the (110), (220), and (330) nuclear Bragg peaks, while their absence in x-ray scans carried out on the same crystal (Fig. 2c) indicates no structural distortion occurs at T N .
Since the magnetic structure of Yb Pt Pb 2 2 is quite complex, involving two different AF wave vectors and the formation of a 5 × × 5 1 supercell with 200 Yb moments, it cannot be determined solely from conventional representation analysis. However, the Ising character of the Yb moments greatly constrains our magnetic model. The anisotropy of M(H) indicates that the Yb moments lie in the SSL planes, and have no components perpendicular to either (110) or (-110). No canting and no modulation of the Yb moment amplitude is possible. The crystal structure consists of Yb dimers in the SSL planes with long bonds (3.889 ˚ ) and short bonds(3.545 ˚ ), potenA A tially having different Yb moments M1 and M2. The unit cell contains z = 0 and z = 1 2 planes with both types of / dimers, but they are staggered so that along the c-axis a long dimer with Yb moment M 1 ( z = 0) is always below a short dimer with Yb moment M 2 ( z = 1 2). /
Yb dimers are the building blocks of the magnetic structure. Since the Yb moments of the crystal-field doublet ground state are large and classical, we consider here the four configurations of two distinguishable moments
FIG. 2. a) Neutron powder diffraction patterns at 10 K (top) and 0.5 K (bottom), with indexed AF and nuclear peaks. Red lines are Rietveld fits (see text). b) HK0 plane for T ≤ T N =2.07 K, indicating nuclear · and main AF satellites q 1 ( · ) and q 2 ( ◦ ), as well as AF harmonics 3 q 1 ( glyph[squaresolid] ) and 3 q 2 ( glyph[square] ). 1.5 K CNCS data are overplotted. c) Neutron (BT-7, 1.5 K, top) and x-ray (X21, 1.8 K, bottom) HH0 scans of 0.06 g single crystal, with sample holder peaks(stars), nuclear peaks (Filled blue points), and first order (first harmonic) AF peaks (full and open red points)from our magnetic model. d) residual χ 2 for 1024 stripe configurations. Red circle encloses the 10 solutions with lowest χ 2 =0.064.
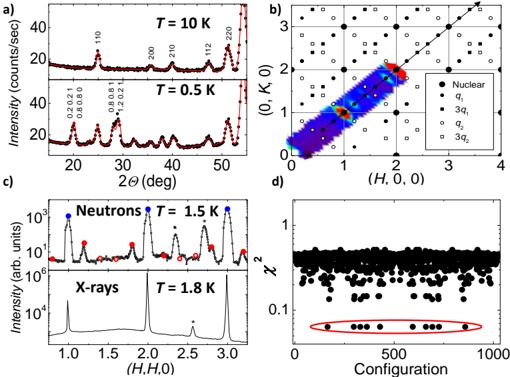
(Fig. 3), i.e. ↑↓ , ↓↑ , ↑↑ , and ↓↓ , and not the singlettriplet states of two indistinguishable quantum spins as in SrCu (BO ) . 2 3 2 The fourfold symmetry of the SSL plane requires two interleaving and orthogonal magnetic SLs in each SSL plane (Figs. 3a,b). Inspired by the stripelike structures of high field SrCu (BO ) 2 3 2 [7, 8, 25], we construct the 5 × × 5 1 AF superlattice of Yb Pt Pb 2 2 from stripes, each with single configurations of Yb pairs having dimer bonds along (110) and moments parallel to (-110) for the SL with q 1 = (0.2,0.2.0) and with dimer bonds along (-110) and moments parallel to (110) for the perpendicular SL with q 2 =(-0.2,0.2.0) (Fig. 3). Each SSL plane consists of two perpendicular arrangements of dimer stripes, and both orthogonal SLs are present in the z = 0 and z = 1 2 planes (Figs. / 3a,b). The AF wave vectors q 1 2 , =( ± 0.2,0.2,0) indicate there must be a net AF alignment of the neighboring z = 0 and z = 1 2 / planes, where a moment bearing ↑↑ dimer stripe in the z = 0 plane (Fig. 3a), requires an antiparallel moment bearing ↓↓ dimer stripe in the neighboring z = 1 2 plane / (Fig. 3b). Similarly, stripes of ↑↓ dimers in the z = 0 plane must be stacked beneath stripes of ↓↑ dimers in the z = 1 2 plane. / For both SLs and in both z = 0 and z = 1 2 planes, stripes based on each of the four dimer / configurations can be arranged in a total of 1024 different ways within the 5 × 5 × 1 AF supercell of Yb Pt Pb. 2 2
q
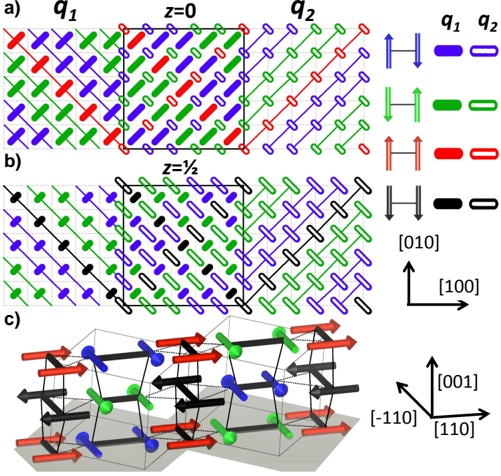
q2
FIG. 3. Key: the four configurations of classical Yb dimers, on the q 1 (filled symbols) and q 2 (open symbols) sublattices. Symbols are elongated in the direction of the dimer bond, larger (smaller) symbol sizes indicate long (short) dimers. The z=0 (a) and z=1/2 (b) planes are formed by interleaving orthogonal q 1 (left) and q 2 (right) sublattices, to form the 5 × × 5 1 AF supercell (solid lines, center panels). Each sublattice consists of ordered sequences of stripes consisting of single dimer types (different colors). c) A fragment of the complete magnetic structure, showing AF stacking of short and long dimers along the c-axis.
These 1024 stripe configurations were refined against the form factor corrected 0.5 K neutron powder data(Fig. 2a) using Fullprof [26]. The computed diffraction patterns were subtracted from the 0.5 K diffraction pattern to generate a residual χ 2 for each configuration. Fig. 2d shows that there are 10 configurations that have markedly smaller values of χ 2 =0.064, consisting of the five permutations of the stripe sequence ( ↑↓ ↑↓ ↓↑ ↓↑ ↑↑ , , , , ) and its mirror reflection ( ↓↑ ↓↑ ↑↓ ↑↓ ↓↓ , , , , )(Figs. 3a,b). The fit gives the same Yb moment on every site, M 1 = M 2 = 3.8 ± 0.2 µ B /Yb, in good agreement with the 4 µ B /Yb of the Yb 3+ |± 7/2 > Kramers doublet ground state [27], and with the measured saturation moment M 110 [17, 23]. The simulated powder pattern that corresponds to the configuration with the lowest χ 2 agrees very well with the 0.5 K powder pattern (Fig. 2a). Computed nuclear and AF peak intensities are also in excellent agreement with the peak heights found in the 0.5 K (HH0) single crystal scan (Fig. 2c).
The refined AF structure for Yb Pt Pb is remarkably 2 2 intricate (Fig. 3). Both SLs in each SSL layer are netmoment bearing, containing individual ↑↑ or ↓↓ stripes, spatially separated by two pairs of magnetically compen-
sated ↓↑ or ↑↓ stripes for a total of five stripes per magnetic unit cell. The moment-bearing stripes in neighboring SSL layers are arranged AF along the c-axis, and a fragment of the 5 × × 5 1 magnetic unit cell is depicted in Fig. 3c, emphasizing the three-dimensionality of the magnetic structure of Yb Pt Pb. 2 2 The Ising character of the Yb moments requires two orthogonal SLs in each SSL layer, where half of the moments are parallel to (110) and the other half to (-110). Consequently, only the q 1 SL, which has dimer bonds along (110) and moments perpendicular to (110), will be saturated by fields in the (-110) direction. The AF peaks associated with the q 2 SL are unaffected by field (Fig. 1d), as is its phase line T N (B)=2.07 K [23], demonstrating that the two SLs are independent.
The directions but not the magnitudes of the Yb dimer moments are modulated by a square wave with a periodicity of 5 chemical unit cells. We observed 3 δ harmonics in the (HH1) scans of the 6 g array of aligned crystals at 1.5 K (CNCS) and at 0.1 K (DCS) (Fig. 4a). The ratio of the ( δ δ , ,1) AF peak to the (3 δ ,3 δ ,1) harmonic is 0.122 in our model, agreeing with the experimental data at 0.1 K. The model correctly estimates the intensities of the nuclear and main AF peaks at 1.5 K, although the 3 δ harmonics are much weaker than predicted, implying the presence of longitudinal critical fluctuations that are quenched between 1.5 K and 0.1 K. C/T and the temperature derivatives of ρ (T) and χ (T) (Fig. 4b) all show peaks at T N =2.07 K, as well as an additional broad feature at glyph[similarequal] 0.8 K. ρ (T) was measured with the current along the c-axis and with a magnetic field oriented along (110), and it is plotted with its temperature derivative ∂ρ ∂ / T in Fig. 4c for H=0, 1T, and 5 T. The ordering anomaly remains fixed at T N =2.07 K, indicating that the q 1 SL continues to affect ρ (T), even when the q 2 SL has been fully polarized by the 5 T field. While the general appearance of the broad maximum in ∂ρ ∂ / T changes slightly in field, it remains centered at 0.8 K in all fields.
The picture that emerges from the data in Fig. 4 is that individual Yb dimers form above T N , consistent with the intradimer exchange J glyph[similarequal] 0.6 meV deduced from fits to χ (T) [18]. As T → T N , these dimers assemble into a striped magnetic structure, accompanied by the gradual suppression of critical fluctuations in favor of static order. These longitudinal fluctuations freeze between 1.5 K and 0.1 K and the much stronger temperature dependencies in C/T and the temperature derivatives of χ (T) and ρ (T) above 0.8 K are together indications that these critical modes are gapped by ∆E/k B glyph[similarequal] 0 8 K, where k . B is Boltzmann's constant.
The magnetic structure of Yb Pt Pb 2 2 is based on stripes of moment-bearing and non-moment bearing configurations of two classical Yb moments. It is reminiscent of the striped order found by nuclear magnetic resonance experiments in SrCu (BO ) 2 3 2 [8, 9], where in-
FIG. 4. a) (HH1) scans at 1.5 K (top, CNCS) and 0.1 K (bottom, DCS). Blue circles are nuclear intensities, filled (open) red points are fundamental (first harmonic) AF peaks from our magnetic model, glyph[star] marks Al peaks. b) Temperature dependencies of the specific heat C/T, and the temperature derivatives of ρ and χ , the latter measured in a dc field of 0.1 T along (110). All data are normalized at T N =2.07 K to emphasize similar temperature dependencies. c) ρ (T) and ∂ρ ∂ / T at different fields H ‖ (110). Vertical dashed lines in b) and c) are at T N =2.07 K and 0.8 K.
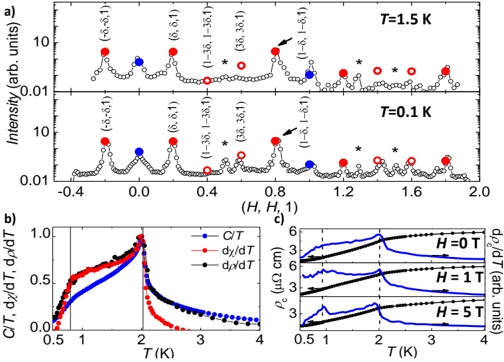
creasing fields drive the SSL dimers based on Cu-based S=1/2 quantum spins through a sequence of discrete patterns of singlet and triplet states, reflecting the frustration of short-ranged exchange interactions inherent to the SSL [7, 25]. We find a much larger separation between the moment-bearing stripes in metallic Yb Pt Pb, sug2 2 gesting that here the frustration may involve long-ranged interactions, perhaps mediated by the conduction electrons. The low fields required for the suppression of AF order, for the cascade of magnetization steps that suggest intermediate structures [19, 20], and for SL saturation in Yb Pt Pb may permit future investigations of the in2 2 termediate field states using neutron scattering, currently impossible in SrCu (BO ) 2 3 2 where fields approaching 30 T are required to drive analogous modulated phases [1012].
The strong Ising anisotropy that restricts the Yb moments to the (110) and (-110) directions has far-reaching implications for the AF order in Yb Pt Pb. 2 2 Unlike SrCu (BO ) 2 3 2 and also TmB 4 [14], where the moments are perpendicular to the SSL planes with a single AF wave vector, two perpendicular SLs are required in Yb Pt Pb 2 2 to accommodate the Ising moments [23], which can be independently polarized by field. Once one SL is fully polarized, the SSL motif of orthogonal dimers is destroyed in favour of a square lattice of the remaining Yb dimers with spacing that approaches 8 ˚ , although A the same T N =2.07 K that was found at H=0 when both SLs order is maintained. This is a very different AF state
than has been envisaged for SSL systems with Heisenberg spins [3], and it is possible that SSL physics does not act alone in determining the underlying magnetism of Yb Pt Pb. 2 2
We acknowledge valuable discussions with T. Sakakibara. Work at Stony Brook University was supported by NSF-DMR-1310008. Use of the NSLS was supported by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences, under Contract No. DE-AC0298CH10886. This work utilized facilities at NCNR that were supported in part by the National Science Foundation under Agreement No. DMR-0944772. Research conducted at SNS was sponsored by the Scientific User Facilities Division, Office of Basic Energy Sciences, US Department of Energy.
- ∗ [email protected]
- [1] T. M. Rice, Science 298 , 760 (2002).
- [2] L. Balents, Nature 464 , 199 (2010).
- [3] B. Sutherland and B. S. Shastry, Physica 1088 , 1069 (1981).
- [4] S. Miyahara and K. Ueda, J. Phys.: Cond. Matter 15 , R327 (2003).
- [5] B. D. Gaulin, et al., Phys. Rev. Lett. 93 , 267202 (2004).
- [6] K. Kakurai, et al, Prog. Theor. Phys. Suppl. 159 , 22
(2005).
- [7] T. Momoi and K. Totsuka, Phys. Rev. B 62 , 15607 (2000).
- [8] K. Kodama, et al, Science 298 , 395 (2002).
- [9] M. Takigawa, et al, Phys. Rev. Lett. 110 , 067201 (2013).
- [10] S. E. Sebastian, et al, Proc. Nat. Acad. Sci 105 , 20157 (2008).
- [11] M. Jaime, et al, Proc. Nat. Acad. Sci 109 , 12404 (2012).
- [12] Y. H. Matsuda, et al, Phys. Rev. Lett. 111 , 137204 (2013).
- [13] S. Michimura, et al,Physica B 378 -380 , 596 (2006).
- [14] K. Siemensmeyer, et al, E. Wulf, Phys. Rev. Lett. 101 , 177201 (2008).
- [15] S. Yoshii, et al, Phys. Rev. Lett. 101 , 087202 (2008).
- [16] S. Matas, et al, J. Phys.: Conf. Series 200 , 032041 (2010).
- [17] M. S. Kim, M. C. Bennett, and M. C. Aronson, Phys. Rev. B 77 , 174401 (2008).
- [18] M. S. Kim and M. C. Aronson, Phys. Rev. Lett. 110 , 017201 (2013).
- [19] Y. Shimura, et al,J. Phys. Soc. Japan 81 , 103601 (2012).
- [20] K. Iwakawa, et al, J. Phys. Soc. Japan 81 . SB058-1 (2012).
- [21] J. W. Lynn, et al, J. Research NIST 117 , 61 (2012).
- [22] J.R.D. Copley and J.C. Cook, Chem. Phys. 292 , 477 (2003)
- [23] A. Ochiai, et al, J. Phys. Soc. Japan 80 , 123705 (2011).
- [24] R. Pottgen, et al, J. Solid State Chem. 145 , 668 (1999).
- [25] S. Miyahara and K. Ueda, Phys. Rev. B 61 , 3417 (2000).
- [26] J. Rodriguez-Carvajal, Commission on powder diffraction (IUCr) Newsletter 26 , 12 (2001).
- [27] M. C. Aronson, et al, J. Low Temp. Phys. 161 , 98 (2010). | 10.1103/PhysRevB.93.104419 | [
"W. Miiller",
"L. S. Wu",
"M. S. Kim",
"T. Orvis",
"J. W. Simonson",
"M. Gamaza",
"D. E. McNally",
"C. S. Nelson",
"G. Ehlers",
"A. Podlesnyak",
"J. S. Helton",
"Y. Zhao",
"Y. Qiu",
"J. R. D. Copley",
"J. W. Lynn",
"I. Zaliznyak",
"M. C. Aronson"
] | 2014-08-01T15:44:24+00:00 | 2014-08-01T15:44:24+00:00 | [
"cond-mat.str-el"
] | Magnetic structure of Yb2Pt2Pb: Ising moments on the Shastry-Sutherland Lattice | Neutron diffraction measurements were carried out on single crystals and
powders of Yb2Pt2Pb, where Yb moments form planes of orthogonal dimers in the
frustrated Shastry-Sutherland Lattice (SSL). Yb2Pt2Pb orders
antiferromagnetically at TN=2.07 K, and the magnetic structure determined from
these measurements features the interleaving of two orthogonal sublattices into
a 5*5*1 magnetic supercell that is based on stripes with moments perpendicular
to the dimer bonds, which are along (110) and (-110). Magnetic fields applied
along (110) or (-110) suppress the antiferromagnetic peaks from an individual
sublattice, but leave the orthogonal sublattice unaffected, evidence for the
Ising character of the Yb moments in Yb2Pt2Pb. Specific heat, magnetic
susceptibility, and electrical resistivity measurements concur with neutron
elastic scattering results that the longitudinal critical fluctuations are
gapped with E about 0.07 meV. |
1408.0210v3 | ## A Fast Summation Method for translation invariant kernels
Fabien Casenave ∗
August 25, 2015
## Abstract
We derive a Fast Multipole Method (FMM) where a low-rank approximation of the kernel is obtained using the Empirical Interpolation Method (EIM). Contrary to classical interpolationbased FMM, where the interpolation points and basis are fixed beforehand, the EIM is a nonlinear approximation method which constructs interpolation points and basis which are adapted to the kernel under consideration. The basis functions are obtained using evaluations of the kernel itself. We restrict ourselves to translation-invariant kernels, for which a modified version of the EIM approximation can be used in a multilevel FMM context; we call the obtained algorithm Empirical Interpolation Fast Multipole Method (EIFMM). An important feature of the EIFMM is a built-in error estimation of the interpolation error made by the low-rank approximation of the far-field behavior of the kernel: the algorithm selects the optimal number of interpolation points required to ensure a given accuracy for the result, leading to important gains for inhomogeneous kernels.
## 1 Introduction
We consider the following problem: compute approximations of many sums of the form
$$f ( \bar { x } _ { i } ) = \sum _ { j = 1 } ^ { N } \sigma _ { j } K ( \bar { x } _ { i }, \bar { y } _ { j } ), 1 \leq i \leq N,$$
for a set of potentials σ j , and target points ¯ x i ∈ Ω and source points ¯ y j ∈ Ω, where Ω ⊂ R 3 , with a controllable error glyph[epsilon1] . The domain Ω and N are fixed for all computations, but the potentials σ j and the points ¯ x i and ¯ y j can vary from one computation to another. The many-query situation can come from a temporal N-body problem (in which case the set of source points equals the set of observation points), or the iterative resolution of a dense linear system.
Various algorithms have been proposed to tackle such problems. Some methods only using numerical evaluations of K have been proposed, see [1, 8, 15]. Many methods, e.g. the mosaic skeleton method [27], hierarchical matrices [20], the Fast Multipole Method (FMM) [17] (and its algebraic generalization H2-matrices [18, 19]), the panel clustering method [21], rely on local low-rank approximations of K :
$$K ( x, y ) & \approx \sum _ { l, m = 1 } ^ { d } \Delta _ { l, m } g _ { l } ( x ) h _ { m } ( y ), x \in I, y \in J,$$
where I and J are subsets of Ω. Such approximations can be analytic, like interpolation (for instance the Chebyshev interpolation as in [14, 20]), or multipole expansions. FMM for general kernels have been developed leading to kernel-independent procedures, see [24, 28]. In [13], another kernelindependent FMM algorithm, based on the Chebyshev interpolation to obtain the low-rank approximation (2) of K , is developed and called Black-Box FMM. Since the algorithm we present here is in the same family as the one developed in [13], our numerical experiments contain comparisons with this method. For other kernel-independent interpolation based procedures, see [10, 11]. Adaptive Cross Approximation (ACA) [3, 4] directly constructs approximations from the evaluations of the kernel on the target and source points K x , y (¯ i ¯ ), by selecting some columns and rows of the matrix ( j K x , y (¯ i ¯ )) j i,j .
∗ IGN LAREG, Univ Paris Diderot, Sorbonne Paris Cit´ e, 5 rue Thomas Mann, 75205 Paris Cedex 13, France.
Approximating a matrix by extracting some of its rows and columns has been investigated in [16]. With ACA methods, (2) is such that g l depends on J and h m depends on I , which leads to a storage complexity of dN log( N ). With FMM and H2-matrices, g l and h m are independent of respectively J and I , which allows additional factorization and the use of nested basis to lower the storage complexity to dN . An improved ACA exploiting the nested basis property has been proposed in [5].
In this work, a low-rank approximation of K is obtained with the Empirical Interpolation Method (EIM), a procedure that represents a two-variable function in a so-called affine dependent formula and that is used in the Reduced Basis community, [2]. The EIM provides a non-linear and functiondependent interpolation: the basis functions and interpolation points are not fixed a priori but are computed during a greedy procedure, which differs from the Chebyshev interpolations. The procedure should capture any irregularity of the kernel better than a fixed basis interpolation procedure, since the basis functions of the EIM are based on evaluations of the kernel itself. Theoretical results on the convergence of EIM interpolation error in the general case are limited, to the author knowledge, to an upper bound of 2 d -1 of the Lebesgue constant, where d is the number of interpolation points, see [2, Proposition 3.2]. Various numerical studies illustrate the efficiency of the EIM [12, 22, 23, 26], even though a theoretical analysis validating this efficiency is not available yet. Depending on the kernel (and on the level in the tree for inhomogeneous kernels), the EIM selects an optimal number of terms that ensures a given accuracy of the approximation. Such a variable-order interpolation procedure have been used in [6] in the H2-matrix context with Lagrange polynomials.
A direct application of the EIM algorithm to the kernel K to obtain a local low-rank approximation (2) is such that g l depends on J and h m depends on I , and therefore is not compatible with a multilevel FMM: a nested basis procedure cannot be derived. To correct this, we make use of the translation-invariant hypothesis of K and derive a local-global low-rank EIM approximation of K , in the sense that one variable is restricted to a local small subdomain while the other variable is taken in almost all the domain. Then, we derive recursive formulae to produce a multilevel FMM for this modified approximation: this is detailed in Section 3.3. The modified approximation uses four summations, instead of two summations for the Black-Box FMM. However, we will see that the M2L step, the most expensive one, has the same complexity as the Black-Box FMM one with respect to the number on interpolation points. Our algorithm requires a precomputation step, during which the greedy step of the EIM at each level is carried-out, at well as compression of some operators. In our simulations, we did not notice any speedup on homogeneous kernels compared to Black-Box FMM. For inhomogeneous kernels, the approximation problem gets easier as we get higher in the tree: corresponding EIM require much less interpolation points and speedups are measured. In 10 6 points test-cases, depending on the kernel, the EIFMM gets more interesting if one has to compute more than 2 to 18 queries of the summation. In a 10 8 points test-case, for the kernel e -r 2 , the precomputation step becomes negligible, and a single query is computed twice as fast for a nearly one order of magnitude better accuracy.
In Section 2, the EIM is recalled. In Section 3 is presented the new FMM algorithm, called the Empirical Interpolation Fast Multipole Method (EIFMM): first, a four-summation formula based on the EIM is derived in Section 3.1, that can be used in a multilevel FMM procedure, then a monolevel version of the EIFMM is proposed in Section 3.2, and a multilevel one in Section 3.3. In Section 4, the overall execution time is reduced using some precomputation and classical compression of the M2L step. Finally, numerical experiments are presented in Section 5, and conclusions are drawn in Section 6.
## 2 The Empirical Interpolation Method
Consider a function K x,y ( ) defined over D x × D y assumed to be real-valued for simplicity, where D x , D y ⊂ Ω. Fix an integer d . The Empirical Interpolation Method provides a way to approximate this function in the following form:
$$K ( x, y ) \approx ( I _ { d } K ) ( x, y ) \coloneqq \sum _ { m = 1 } ^ { d } \lambda _ { m } ( x ) q _ { m } ( y ),$$
where λ m ( x ) is such that
$$\sum _ { m = 1 } ^ { d } B _ { l, m } \lambda _ { m } ( x ) = K ( x, y _ { l } ), \quad \forall 1 \leq l \leq d.$$
The functions q m ( ) · and the matrix B ∈ R d × d , which is lower triangular with unity diagonal, are constructed in Algorithm 1, where δ d = Id -I d and ‖· ‖ D y is a norm on D y , for instance the L ∞ ( D y )-or the L 2 ( D y )-norm. In practice, the argmax appearing in Algorithm 1 is searched over finite subsets of D x and D y , denoted respectively by D x, trial and D y, trial and called training sets. Notice that Algorithm 1 also constructs the set of points { y l } 1 ≤ ≤ l d in D y used in (4), and a set of points { x l } 1 ≤ ≤ l d in D x . These points are interpolations points for the approximation of K (see Property 2.1) and are different from the target and source points ¯ x , y i ¯ . j
## Algorithm 1 Greedy algorithm of the EIM
- 1. Choose d > 1
- 2. Set k := 1
- 3. Compute x 1 := argmax x ∈D x ‖ K x, ( · ) ‖ D y
- 4. Compute y 1 := argmax y ∈D y | K x ,y ( 1 ) |
$$\begin{array} { c } 5. \text{ Set } q _ { 1 } ( \cdot ) \coloneqq \frac { K ( \lambda _ { 1 }, \cdot ) ^ { \nu } } { K ( x _ { 1 }, y _ { 1 } ) } \\. \text{ c} \sim D \quad. = 1 \end{array}$$
- 6. Set B 1 1 , := 1
- 7. while k < d do
- 8. Compute x k +1 := argmax ( x ∈D x ‖ δ k K )( x, · ) ‖ D y
- 9. Compute y k +1 := argmax ( y ∈D y | δ k K x )( k +1 , y ) |
$$\begin{array} { c c c } 1 0. & \text{Set $q_{k+1}(\cdot) \coloneqq \frac{(\tilde{d}_{k} \tilde{K})\tilde{(x_{k+1},\cdot)}$} } { ( \delta _ { k } K ) ( x _ { k + 1 }, y _ { k + 1 } ) } \\ \text{C++ $r$} \end{array}. \begin{array} { c } \text{Set $q_{k+1}(\tilde{d}_{k} \tilde{K})\tilde{(x_{k+1},\cdot)}$} } { ( \delta _ { k } K ) ( x _ { k + 1 }, y _ { k + 1 } ) } \\ \text{C++ $r$} \end{array}. \begin{array} { c } \text{Set $q_{k+1}(\tilde{d}_{k} \tilde{K})\tilde{(x_{k+1},\cdot)}$} } \\ \text{C++ $r$} \end{array}.$$
- 11. Set B k +1 ,m := q m ( y k +1 ), for all 1 ≤ m ≤ k +1
- 12. k ← k +1
- 13. end while
The following assumption is made:
(H) The dimension of Span ( x ∈D x K x, ( · ) , ) is larger than d .
From [ (H) ], the functions { K x , ( l · ) } 1 ≤ ≤ l d are linearly independent (otherwise, ( δ k K )( µ k +1 , x k +1 ) = 0 for some k in Algorithm 1).
It is shown in [7] that the approximation (3) can be written in the form
$$\left ( I _ { d } K \right ) ( x, y ) = \sum _ { l, m = 1 } ^ { d } \Delta _ { l, m } K ( x, y _ { l } ) K ( x _ { m }, y ),$$
where ∆ = B -t Γ -1 , and where the matrix Γ is is upper triangular and constructed recursively in the loop in k of Algorithm 1 in the following way:
- · k = 1:
$$\Gamma _ { 1, 1 } = K ( x _ { 1 }, y _ { 1 } ),$$
- · k → k +1:
$$\Gamma _ { k + 1, k + 1 } & = ( \delta _ { k } K ) ( x _ { k + 1 }, y _ { k + 1 } ), \\ \Gamma _ { m, k + 1 } & = 0, & \forall 1 \leq m \leq k, \\ \Gamma _ { k + 1, m } & = \alpha _ { m }, & \forall 1 \leq m \leq k,$$
where the vector α is such that ∑ k m =1 B l,m α m = K x ( k +1 , y l ), for all 1 ≤ l ≤ k .
[First interpolation point]
[First basis function]
[Initialize matrix B ]
[( k +1)-th interpolation point]
[( k +1)-th basis function]
[Increment matrix B ]
[Increment the size of the decomposition]
The particular form (5) is the key to the use of the EIM approximation in a fast multipole context. We recall the interpolation property of I d K ; see [23, Lemma 1]:
Property 2.1 (Interpolation property) . For all 1 ≤ m ≤ d ,
$$\begin{cases} \, ( I _ { d } K ) ( x, y _ { m } ) = K ( x, y _ { m } ), & \text{for all } x \in \mathcal { D } _ { x }, \\ \, ( I _ { d } K ) ( x _ { m }, y ) = K ( x _ { m }, y ), & \text{for all } y \in \mathcal { D } _ { y }. \end{cases}$$
An important aspect is that the error made by the EIM approximation over the training set D x, trial ×D y, trial , denoted glyph[epsilon1] k and defined as glyph[epsilon1] k := max ( y ∈D y | δ k K )( x k +1 , y ) , is monitored during the greedy | procedure. In practice, a stopping criterion is used on glyph[epsilon1] k instead of on the number of interpolation points d , which was used to simplify the presentation of the EIM. Hence, depending on the regularity of the function K , the EIM will automatically select the number of interpolation points to certify the error over D x, trial ×D y, trial .
## 3 The Empirical Interpolation Fast Multipole Method
The FMM algorithm is based on a low-rank approximation of the far-field behavior of the kernel of the form (2). Such approximations enable some factorizations in the computation of key-quantities and the propagation of information through a tree structure, resulting in lowering the complexity of the computation of (1). For a general presentation of the FMM algorithm, see the original article [17, Section 3].
## 3.1 A suitable approximation
For the simplicity of the presentation, the algorithm is described in 1D. It can be readily extended in 2D and 3D. Consider a kernel K x,y ( ), ( x, y ) ∈ Ω × Ω, where Ω = ( -L 2 , L 2 ) is the complete domain on which the FMM computation is carried out. The kernel is supposed translation invariant, i.e. such that K x,y ( ) = K x ( -a, y -a ), ∀ a ∈ R . The domain Ω is partitioned in 2 κ intervals, κ ∈ N ∗ , of length 2 l κ , with l κ := 2 - -κ 1 L . Consider two intervals I and J , well-separated in the sense that min ( x,y ) ∈ × I J | x -y | ≥ 2 l κ . To anticipate the generalization to higher dimensions, I and J are called 'boxes' in what follows. We denote c I and c J the center of the boxes I and J . Consider an EIM approximation constructed over I × J :
$$K ( x, y ) \approx \sum _ { l, m = 1 } ^ { d } \Delta _ { l, m } ^ { I, J } K ( x, y _ { l } ^ { J } ) K ( x _ { m } ^ { I }, y ), \quad x \in I, \ \ y \in J,$$
where I and J superscripts have been added to underline the box-dependent quantities (as deduced from Algorithm 1). In (6), K x,y ( J l ) depends on J , the box containing y and K x ( I m , y ) depends on I , the box containing x : as stated in the introduction, this approximation is then not suitable for a multilevel FMM procedure.
Define now I 0 := { x -c ˆ J , x ∈ ˆ I } for all box ˆ in the partitioning of Ω and all box J ˆ well separated I from ˆ , J and define J 0 the box of length 2 l κ located at the center of Ω (notice that J 0 is not a box from the partitioning of Ω). In our setting, J 0 = ( -l κ , l κ ) and I 0 = ( -L + l κ , -3 l κ ) ∪ (3 l κ , L -l κ ), see Figure 1. In other words, J 0 is a source box translated to the center of the domain, I 0 is the union of possible target boxes, translated in the same fashion.
Since K x,y ( ) = K x ( -c J , y -c J ), with x -c J ∈ I 0 and y -c J ∈ J 0 , it is inferred that
$$K ( x, y ) \approx \sum _ { l, m = 1 } ^ { d } \Delta _ { l, m } ^ { I _ { 0 }, J _ { 0 } } K ( x - c _ { J }, y _ { l } ^ { J _ { 0 } } ) K ( x _ { m } ^ { I _ { 0 } }, y - c _ { J } ),$$
where the EIM is carried out on D x = I 0 and D y = J 0 . An important aspect is that I 0 and J 0 are fixed domains, independent from the boxes I and J containing respectively x and y . Consider the
Figure 1: Representation of the partitioning of Ω in 1D for κ = 3 and of the corresponding boxes I 0 and J 0 .
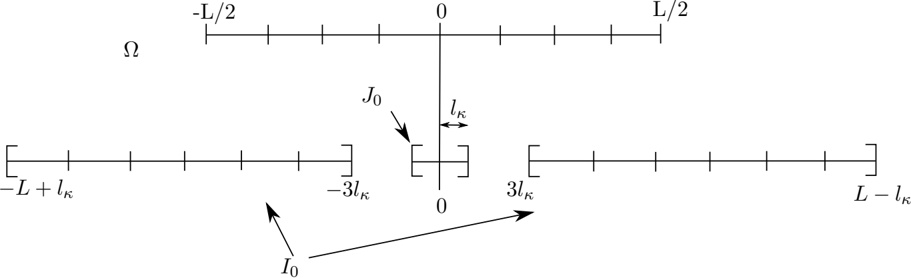
first evaluation of the kernel in (7). There holds K x ( -c J , y J 0 l ) = K x ( -c I , y J 0 l + c J -c I ), where x -c I ∈ J 0 and y J 0 l + c J -c I ∈ I 0 . It is then inferred that
$$K ( x - c _ { J }, y _ { l } ^ { J _ { 0 } } ) \approx \sum _ { l ^ { \prime }, m ^ { \prime } = 1 } ^ { d } \Delta _ { l ^ { \prime }, m ^ { \prime } } ^ { J _ { 0 }, I _ { 0 } } K ( x - c _ { I }, y _ { l ^ { \prime } } ^ { I _ { 0 } } ) K ( x _ { m ^ { \prime } } ^ { J _ { 0 } }, y _ { l } ^ { J _ { 0 } } + c _ { J } - c _ { I } ), \quad \ 1 \leq l \leq m,$$
where a second EIM has been carried out on D x = J 0 and D y = I 0 (with the same number of terms d for simplicity). Notice that if the kernel is symmetric, ∆ I 0 ,J 0 = (∆ J ,I 0 0 ) , t x I 0 m = y I 0 m for all 1 ≤ m ≤ d , and y J 0 m = x J 0 m for all 1 ≤ m ≤ d . Injecting (8) into (7):
$$K ( x, y ) & \approx \sum _ { l ^ { \prime } = 1 } ^ { d } K ( x - c _ { I }, y _ { l ^ { \prime } } ^ { J _ { 0 } } ) \sum _ { m ^ { \prime } = 1 } ^ { d } \Delta _ { l ^ { \prime }, m ^ { \prime } } ^ { J _ { 0 }, J _ { 0 } } \sum _ { l = 1 } ^ { d } K ( x _ { m ^ { \prime } } ^ { J _ { 0 } }, y _ { l } ^ { J _ { 0 } } + c _ { J } - c _ { I } ) \sum _ { m = 1 } ^ { d } \Delta _ { l, m } ^ { I _ { 0 }, J _ { 0 } } K ( x _ { m } ^ { I _ { 0 } }, y - c _ { J } ), x \in I, y \in J. \\ \tau _ { n } ( \in \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ( \tau _ { n } ) \tau _ { n } ).$$
In (9), the only term depending on the boxes I and J (besides x and y themselves) are c I and c J , the center of the boxes I and J . Hence, in the low-rank approximation, the x -dependent function K x ( -c I , y I 0 l ′ ) no longer depends on J and the y -dependent function K x ( I 0 m , y -c J ) no longer depends on I . As a consequence, the non-trivial manipulation leading to (9) are required for the use of EIM interpolation in a multilevel FMM context.
Notice that in all the kernel evaluations in (9), the first and second variables are always separated by a distance of at least 2 l κ .
## 3.2 A monolevel multipole method
Consider a set of N target points { ¯ x i } 1 ≤ ≤ i N , N source points { ¯ y j } 1 ≤ ≤ j N in Ω, and N potentials { σ j } 1 ≤ ≤ j N , with N glyph[greatermuch] 1. We look for a low complexity approximation of
$$f ( \bar { x } _ { i } ) = \sum _ { j = 1 } ^ { N } \sigma _ { j } K ( \bar { x } _ { i }, \bar { y } _ { j } ), \quad 1 \leq i \leq N.$$
We say that two boxes I and J are well-separated if min x,y ∈ × I J | x - | ≥ y 2 l κ . The set of boxes wellseparated from I is denoted F ( I ), its complement in Ω is the neighborhood of I and is denoted N ( I ). The FMM aims at compressing the 'far' interactions in the following fashion:
$$f _ { \mathcal { F } } ( \bar { x } _ { i } ) = \sum _ { J \in \mathcal { F } ( I ) } \sum _ { \bar { y } _ { j } \in J } \sigma _ { j } K ( \bar { x } _ { i }, \bar { y } _ { j } ), \quad \text{ for all box } I \text{ and all } \bar { x } _ { i } \in I.$$
A monolevel multipole method can be directly derived from (9) to approximate f F (¯ ), see Algox i rithm 2. The obtained approximation of f F (¯ ) is denoted x i f F , FMM (¯ ). x i An approximation of f (¯ ) is x i then given by
$$f ( \bar { x } _ { i } ) \approx f _ { \mathcal { F }, \text{FRM} } ( \bar { x } _ { i } ) + f _ { \mathcal { N } } ( \bar { x } _ { i } ),$$
Table 1: Complexity of each step of Algorithm 2 and of the near interactions term.
| Step number | Complexity |
|---------------|----------------|
| 1 | dN |
| 2 | d 2 (2 D ) κ |
| 3 | d 2 (2 D ) 2 κ |
| 4 | d 2 (2 D ) κ |
| 5 | dN |
| f N | N 2 (2 D ) - κ |
where the 'near' interactions are defined by
$$f _ { \mathcal { N } } ( \bar { x } _ { i } ) = \sum _ { \bar { y } _ { j } \in \mathcal { N } ( I ) } \sigma _ { j } K ( \bar { x } _ { i }, \bar { y } _ { j } ).$$
## Algorithm 2 Monolevel EIFMM
- 1. Compute W I m := ∑ ¯ y j ∈ I σ K x j ( I 0 m , y ¯ j -c I ), for all box I and all 1 ≤ m ≤ d
- 2. Compute ˆ W I l := ∑ d m =1 ∆ I 0 ,J 0 l,m W I m , for all box I and all 1 ≤ l ≤ d
- 3. Compute l I m ′ := ∑ J ∈F ( I ) ∑ d l =1 K x ( J 0 m ′ , y J 0 l + c J -c I ) ˆ W J l , for all box I and all 1 ≤ m ′ ≤ d
- 4. Compute ˆ l I l ′ := ∑ d m ′ =1 ∆ J ,I 0 0 l ′ ,m ′ l I l ′ , for all box I and all 1 ≤ m ′ ≤ d
- 5. Compute f F , FMM (¯ ) := x i ∑ d l ′ =1 K x (¯ i -c I , y I 0 l ′ ) ˆ l I l ′ , for all box I and all x i ∈ I
In Table 1 is given the complexity of each step of Algorithm 2. For step 3 and the computation of the near interactions to be in the same order in N , one must impose (2 D ) 2 κ ∝ N 2 (2 D ) -κ , leading to a overall complexity of the sum of order N 4 3 . As classically done in the literature, the derivation of a multilevel multipole method allows to lower the complexity in N of the algorithm to linear.
## 3.3 A multilevel multipole method
The domain of computation Ω = ( -L 2 , L 2 ) is now organized as a binary tree with κ +1 levels. Level 0 is the root of the tree: there is one box equal to Ω, level 1 contains the partitioning of Ω into two boxes of length L 2 , and the following levels are obtained by partitioning each box of the previous level in the same fashion, up to level κ .
A superscript k is now added to the quantities previously defined, to indicate that they depend on the level k . Two EIM's are to be considered at each level, in the same fashion as in Section 3.1, where now the domains depend on the level k in the tree: I k 0 = ( -L + l k , -3 l k ) ∪ (3 l k , L -l k ), and J k 0 = ( -l k , l k ).
For symmetric kernels, this amount of precomputation can be lowered to one EIM by level. The key to a multilevel method stands in the ability to derive recursion formulae to propagate information from the level κ to the level 0 in the upward pass, and from the level 0 to the level κ in the downward pass.
Black-Box FMM, at least in its original version, is proposed with a constant-order of interpolation, which enables to propagate the information through the levels of the tree without introducing additional errors. Considering a variable-order Chebyshev interpolation is possible, but one must carefully analyse the introduced error, as done in [6] in the context of H2-matrices. In our method, the domains of approximation depicted in Figure 1 naturally enable a variable-order interpolation depending on the level of the tree, for which the introduced error is the same as the EIM approximation error in (9). As a consequence, the variable-order aspect of the approximation is directly obtained at the required accuracy, and the length of the approximation is automatically optimized at each level of the tree, which leads to important gains for inhomogeneous kernels.
## 3.3.1 Recursion for the upward pass: multipole to multipole (M2M)
The goal is to compute
$$W _ { m } ^ { I ^ { k } } \coloneqq \sum _ { \bar { y } _ { j } \in I ^ { k } } \sigma _ { j } K ( x _ { m } ^ { I ^ { k } _ { 0 } }, \bar { y } _ { j } - c _ { I ^ { k } } ),$$
for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ m ≤ d k by recursion. The initialization of the recursion consists in computing W I κ m at level κ using (14). Then, suppose W I k m is available at level k , there holds
$$W _ { m } ^ { I ^ { k - 1 } } = \sum _ { \vec { y } _ { j } \in I ^ { k - 1 } } \sigma _ { j } K ( x _ { m } ^ { I _ { 0 } ^ { k - 1 } }, \vec { y } _ { j } - c _ { I ^ { k - 1 } } ) = \sum _ { J ^ { k } \in \mathcal { C } ( I ^ { k - 1 } ) } \sum _ { \vec { y } _ { j } \in J ^ { k } } \sigma _ { j } K ( x _ { m } ^ { I _ { 0 } ^ { k - 1 } } + c _ { J ^ { k - 1 } - c _ { J ^ { k } }, \vec { y } _ { j } - c _ { J ^ { k } } ), \quad ( 1 5 )$$
where C ( I k -1 ) denotes the children boxes of I k -1 . To obtain a recursion on W I k -1 m , i.e. to compute W I k -1 m using some values of W J k m , for J k being boxes at the level k , we will use the EIM approximations already computed at level k to derive (9). One must check that the corresponding EIM approximations are evaluated on the right domains, namely I k 0 and J k 0 .
For all ¯ y j ∈ J k , -l k ≤ ¯ y j -c J k ≤ l k , i.e. ¯ y j -c J k ∈ J k 0 . Then, for all J k ∈ C ( I k -1 ), -l k ≤ c I k -1 -c J k ≤ l k (see for instance Figure 3). Moreover, since x I k -1 0 m ∈ I k -1 0 = ( -L + l k -1 , -3 l k -1 ) ∪ (3 l k -1 , L -l k -1 ), it is inferred that
$$- L + l _ { k } \leq x _ { m } ^ { J _ { 0 } ^ { k - 1 } } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } } \leq - 5 l _ { k } \leq - 3 l _ { k } \text{ or } 3 l _ { k } \leq 5 l _ { k } \leq x _ { m } ^ { J _ { 0 } ^ { k - 1 } } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } } \leq L - l _ { k },$$
i.e. x I k -1 0 m + c I k -1 -c J k ∈ I k 0 . Therefore, the EIM from level k can then be used to write the following approximation:
$$K ( x _ { m } ^ { J ^ { k - 1 } _ { 0 } } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } }, \bar { y } _ { j } - c _ { J ^ { k } } ) \approx \sum _ { p, q = 1 } ^ { d ^ { k } } \Delta _ { p, q } ^ { I ^ { k } _ { 0 }, J ^ { k } _ { 0 } } K ( x _ { m } ^ { J ^ { k - 1 } _ { 0 } } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } }, y _ { p } ^ { J ^ { k } _ { 0 } } ) K ( x _ { q } ^ { J ^ { k } _ { 0 } }, \bar { y } _ { j } - c _ { J ^ { k } } ), \quad ( 1 6 )$$
where the approximation error is of the same order as in the (9).
Then, injecting (16) into (15), it is inferred that
$$\int n, \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \text{in} \, \end{cases} \\ W ^ { I ^ { k - 1 } _ { m } } _ { m } & \approx \sum _ { p, q = 1 } ^ { d ^ { k } } \Delta ^ { I ^ { k } _ { 0 }, J ^ { k } _ { 0 } } _ { p, q } \sum _ { J ^ { k } \in \mathcal { C } ( I ^ { k - 1 } ) } K ( x ^ { I ^ { k - 1 } _ { 0 } } _ { m } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } }, y ^ { J ^ { k } _ { p } } _ { p } ) \sum _ { \tilde { \nu } _ { j } \in J ^ { k } } \sigma _ { j } K ( x ^ { I ^ { k - 1 } _ { 0 } } _ { m } + c _ { I ^ { k - 1 } } - c _ { J ^ { k } }, y ^ { J ^ { k } _ { p } } _ { p } ) W ^ { J ^ { k } } _ { q }, \\ \text{which would be an exception for the normal use in the same fashion as for the normal}$$
which provides a recursive formula for the upward pass. In the same fashion as for the monolevel version, we then compute
$$\hat { W } _ { l } ^ { I ^ { k } } \coloneqq \sum _ { m = 1 } ^ { d ^ { k } } \Delta _ { l, m } ^ { I ^ { k } _ { 0 }, J ^ { k } _ { 0 } } W _ { m } ^ { I ^ { k } }, \\.$$
for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ l ≤ d k .
## 3.3.2 Transfer pass: multipole to local (M2L)
We denote I ( I k ), the set of boxes that are the children of the boxes in the neighborhood of the parent of I k but are well-separated from I k at level k , and call it the interaction list of I k , see Figure 2.
The M2L step consists in computing
$$g _ { m ^ { \prime } } ^ { I ^ { k } } \coloneqq \sum _ { J ^ { k } \in \mathcal { I } ( I ^ { k } ) } \sum _ { l = 1 } ^ { d ^ { k } } K ( x _ { m ^ { \prime } } ^ { J ^ { k } _ { 0 } }, y _ { l } ^ { J ^ { k } _ { 0 } } + c _ { J ^ { k } } - c _ { I ^ { k } } ) \hat { W } _ { l } ^ { J ^ { k } },$$
for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ m ′ ≤ d k .
Figure 2: Representation of the neighborhood and the interaction list of a box I k and level k .
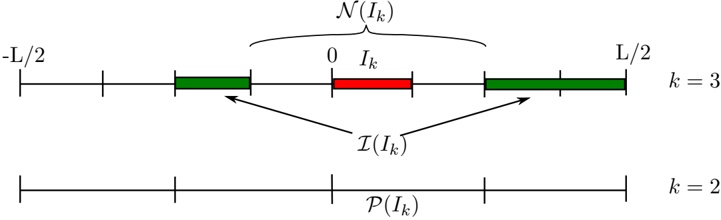
## 3.3.3 Recursion for the downward pass: local to local (L2L)
The goal is to compute
$$l _ { m ^ { \prime } } ^ { I ^ { k } } \coloneqq \sum _ { J ^ { k } \in \mathcal { F } ( I ^ { k } ) } \sum _ { l = 1 } ^ { d ^ { k } } K ( x _ { m ^ { \prime } } ^ { J _ { 0 } ^ { k } }, y _ { l } ^ { J _ { 0 } ^ { k } } + c _ { J ^ { k } } - c _ { I ^ { k } } ) \hat { W } _ { l } ^ { J ^ { k } },$$
for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ m ′ ≤ d k by recursion. The initialization of the recursion consists in computing l I 2 m ′ at level 2 using (20). Then, suppose l I k m ′ is available, there holds
$$l ^ { I ^ { k + 1 } } _ { m ^ { \prime } } = g ^ { I ^ { k + 1 } } _ { m ^ { \prime } } + \sum _ { J ^ { k } \in \mathcal { F } ( \mathcal { P } ( I ^ { k + 1 } ) ) \ J ^ { k + 1 } \in \mathcal { C } ( J ^ { k } ) } \sum _ { l = 1 } ^ { d ^ { k + 1 } } K ( x ^ { J ^ { k + 1 } } _ { m ^ { \prime } }, y ^ { J ^ { k + 1 } } _ { l } + c _ { J ^ { k + 1 } } - c _ { I ^ { k + 1 } } ) \hat { W } ^ { J ^ { k + 1 } } _ { l }$$
$$l _ { m ^ { \prime } } ^ { I ^ { k + 1 } } & = g _ { m ^ { \prime } } ^ { I ^ { k + 1 } } + \sum _ { J ^ { k } \in \mathcal { F } ( \mathcal { P } ( I ^ { k + 1 } ) ) } \sum _ { J ^ { k + 1 } \in \mathcal { C } ( J ^ { k } ) } \sum _ { l = 1 } ^ { d ^ { k + 1 } } K ( x _ { m ^ { \prime } } ^ { J ^ { k + 1 } _ { 0 } }, y _ { l } ^ { J ^ { k + 1 } _ { 0 } } + c _ { J ^ { k + 1 } } - c _ { J ^ { k + 1 } } ) \hat { W } _ { l } ^ { J ^ { k + 1 } _ { 0 } } \\ & = g _ { m ^ { \prime } } ^ { I ^ { k + 1 } _ { 0 } } + \sum _ { J ^ { k } \in \mathcal { F } ( \mathcal { P } ( I ^ { k + 1 } ) ) } \sum _ { J ^ { k + 1 } \in \mathcal { C } ( J ^ { k } ) } \sum _ { l = 1 } ^ { d ^ { k + 1 } _ { 0 } } K ( x _ { m ^ { \prime } } ^ { J ^ { k + 1 } _ { 0 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) }, y _ { l } ^ { J ^ { k + 1 } _ { 0 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } ) \hat { W } _ { l } ^ { J ^ { k + 1 } _ { 0 } }, \\ \text{where $\mathcal{P} ( I ^ { k + 1 } ) \text{ denotes the parent of $I^{k+1}$}.$$
where P ( I k +1 ) denotes the parent of I k +1 .
It is seen on Figures 3 and 4 that
$$- l _ { k + 1 } \leq c _ { I ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } \leq l _ { k + 1 },$$
and that
$$- L + 3 l _ { k + 1 } \leq c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } \leq - 7 l _ { k + 1 } \text{ or } 7 l _ { k + 1 } \leq c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } \leq L - 3 l _ { k + 1 }.$$
Figure 3: Possible values for c I k +1 -c P ( I k +1 ) and c J k +1 -c J k , and smallest possible values for c J k +1 -c P ( I k +1 ) and c P ( I k +1 ) -c J k , with J k well-separated from P ( I k +1 ) at level k , and J k +1 child of J k .
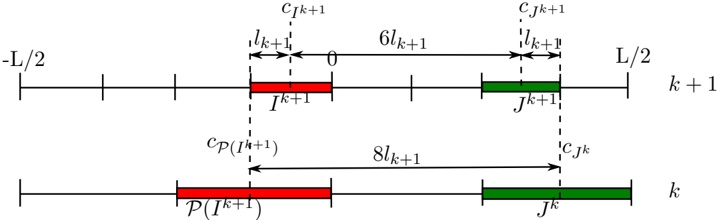
$$\text{Since $x_{m^{\prime}}_{0}^{k+1},y_{f}^{k+1}^{k+1} \in J_{0}^{k+1}$, it is then readily verified that $x_{m^{\prime}}_{0}^{k+1}+c_{f}_{f}+1}-c_{\mathcal{P}(f^{k+1}) \in J_{0}^{k}$ and}$$
$$- L + 2 l _ { k + 1 } = - L + l _ { k } \leq y _ { l } ^ { j ^ { k + 1 } _ { 0 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( l ^ { k + 1 } ) } \leq - 6 l _ { k + 1 } = - 3 l _ { k } \text{ or } 3 l _ { k } \leq y _ { l } ^ { j ^ { k + 1 } _ { 0 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( l ^ { k + 1 } ) } \leq L - l _ { k },$$
Figure 4: Largest possible value for c J k +1 -c P ( I k +1 ) and c P ( I k +1 ) -c J k , with J k well-separated from P ( I k +1 ) at level k , and J k +1 child of J k .
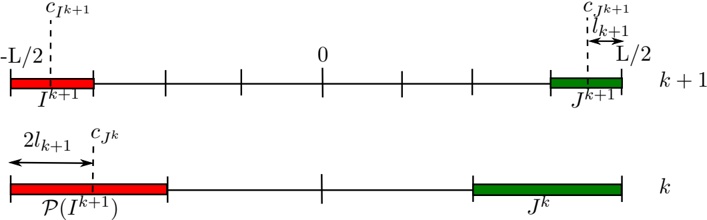
i.e. y J k +1 0 l + c J k +1 -c P ( I k +1 ) ∈ I k 0 . Therefore, the EIM from level k can then be used to write the following approximation
$$K ( x _ { m ^ { \prime } } ^ { J _ { 0 } ^ { k + 1 } } + c _ { I ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) }, y _ { l } ^ { J _ { 0 } ^ { k + 1 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } ) \approx \\ \sum _ { p ^ { \prime }, q ^ { \prime } = 1 } ^ { d ^ { k } } \Delta _ { p ^ { \prime }, q ^ { \prime } } ^ { J _ { 0 } ^ { k }, J _ { 0 } ^ { k } } K ( x _ { m ^ { \prime } } ^ { J _ { 0 } ^ { k + 1 } } + c _ { I ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) }, y _ { p ^ { \prime } } ^ { I _ { 0 } ^ { k } } ) K ( x _ { q ^ { \prime } } ^ { J _ { 0 } ^ { k } }, y _ { l } ^ { J _ { 0 } ^ { k + 1 } } + c _ { J ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) } ). \\ \sum _ { p ^ { \prime }, q ^ { \prime } = 1 } ^ { d ^ { k } } \cdots \cdots \cdots \cdots \cdots \cdots.$$
Then, injecting (22) into (21), it is inferred that
$$& \L ^ { \cdot } _ { m ^ { \prime } } \approx g ^ { l k + 1 } _ { m ^ { \prime } } + \sum _ { J ^ { k } \in \mathcal { F } ( \mathcal { P } ( I ^ { k + 1 } ) ) } \sum _ { J ^ { k + 1 } \in \mathcal { C } ( J ^ { k } ) } \sum _ { p ^ { \prime }, q ^ { \prime } = 1 } ^ { d ^ { k } } \Delta ^ { J ^ { k } _ { 0 }, I ^ { k } _ { 0 } } _ { p ^ { \prime }, q ^ { \prime } } \sum _ { l = 1 } ^ { d ^ { k + 1 } } K ( x ^ { J ^ { k + 1 } _ { 0 } } _ { m ^ { \prime } } + c _ { I ^ { k + 1 } } - c _ { P ( I ^ { k + 1 } ) }, y ^ { J ^ { k + 1 } _ { 0 } } _ { p ^ { \prime } } ) \\ & \quad K ( x ^ { J ^ { k } _ { 0 } } _ { q ^ { \prime } }, y ^ { J ^ { k + 1 } _ { 0 } } _ { l } + c _ { J ^ { k + 1 } } - c _ { P ( I ^ { k + 1 } ) } ) \hat { W } ^ { J ^ { k + 1 } _ { l } } _ { l }. \\ & \quad \nu ^ { k + 1 } _ { \nu ^ { k + 1 } }$$
Consider K x ( J k 0 q ′ , y J k +1 0 l + c J k +1 -c P ( I k +1 ) ) = K x ( J k 0 q ′ + c P ( I k +1 ) -c J k , y J k +1 0 l + c J k +1 -c J k ). Since J k ∈ F P ( ( I k +1 )) and J k is the parent of J k +1 , it is seen on Figures 3 and 4 that
$$- l _ { k + 1 } \leq c _ { J ^ { k + 1 } } - c _ { J ^ { k } } \leq l _ { k + 1 },$$
and that
$$- L + 4 l _ { k + 1 } \leq c _ { \mathcal { P } ( I ^ { k + 1 } ) } - c _ { J ^ { k } } \leq - 8 l _ { k + 1 } \text{ or } 8 l _ { k + 1 } \leq c _ { \mathcal { P } ( I ^ { k + 1 } ) } - c _ { J ^ { k } } \leq L - 4 l _ { k + 1 }.$$
Since x J k 0 q ′ , y J k +1 0 l ∈ J k +1 0 , J k ∈ F P ( ( I k +1 )), and J k is the parent of J k +1 , it is readily verified that y J k +1 0 l + c J k +1 -c J k ∈ J k 0 and
$$- L + l _ { k } \leq - L + 3 l _ { k + 1 } \leq x _ { q ^ { \prime } } ^ { J ^ { k } _ { 0 } } + c _ { P ( l ^ { k + 1 } ) } - c _ { J ^ { k } } \leq - 7 l _ { k + 1 } \leq - 3 l _ { k } \text{ or } 3 l _ { k } \leq x _ { q ^ { \prime } } ^ { J ^ { k } _ { 0 } } + c _ { P ( l ^ { k + 1 } ) } - c _ { J ^ { k } } \leq L - l _ { k },$$
i.e. x J k 0 q ′ + c P ( I k +1 ) -c J k ∈ I k 0 . Therefore, the EIM from level k can then be used again to write the following approximation
$$\dots \dots \circ \lambda r r \dots \dots \dots \\ K ( x _ { q ^ { \prime } } ^ { J _ { 0 } ^ { k } } + c _ { \mathcal { P } ( I ^ { k + 1 } ) } - c _ { J ^ { k } }, y _ { l } ^ { J _ { 0 } ^ { k + 1 } } + c _ { J ^ { k + 1 } } - c _ { J ^ { k } } ) & \approx \\ \sum _ { u, v = 1 } ^ { d ^ { k } } \Delta _ { u, v } ^ { I _ { 0 } ^ { k }, J _ { 0 } ^ { k } } K ( x _ { q ^ { \prime } } ^ { J _ { 0 } ^ { k } } + c _ { \mathcal { P } ( I ^ { k + 1 } ) } - c _ { J ^ { k } }, y _ { u ^ { \prime } } ^ { J _ { 0 } ^ { k } } ) K ( x _ { v ^ { \prime } } ^ { J _ { 0 } ^ { k } }, y _ { l } ^ { J _ { 0 } ^ { k + 1 } } + c _ { J ^ { k + 1 } } - c _ { J ^ { k } } ). \\ \lambda \dots,$$
Injection (24) into (23), making use of the formula (18) to express ˆ W J k +1 l , it is inferred that
$$l _ { m ^ { \prime } } ^ { l ^ { k + 1 } } & \approx g _ { m ^ { \prime } } ^ { l ^ { k + 1 } } + \sum _ { J ^ { k } \in \mathcal { F } ( \mathcal { P } ( l ^ { k + 1 } ) ) } \sum _ { J ^ { k + 1 } \in \mathcal { C } ( J ^ { k } ) } \sum _ { p ^ { \prime }, q ^ { \prime } = 1 } ^ { d ^ { k } } \Delta _ { p ^ { \prime }, q ^ { \prime } } ^ { J ^ { k } _ { 0 }, l ^ { k } _ { 0 } } \sum _ { l = 1 } ^ { d ^ { k + 1 } } K ( x _ { m ^ { \prime } } ^ { J ^ { k + 1 } _ { 0 } } + c _ { l ^ { k + 1 } } - c _ { \mathcal { P } ( l ^ { k + 1 } ) }, y _ { p ^ { \prime } } ^ { l ^ { k } _ { 0 } } ) \\ & \stackrel { d ^ { k } } { \stackrel { d ^ { k } } { \longrightarrow } } \cdots I ^ { k } \cdots \cdots I ^ { k } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \dots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots i ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k +1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \dots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ {k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \ddots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ {k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k - 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdets \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ {k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cdots I ^ { k + 1 } \cd$$
d
d
∑
I
k
k
k
k
k
k
+1
k
+1
k
+1
∆
0
,J
J
J
I
J
I
,J
k
+1
u,v
0
∑
J
q
′
P
(
I
)
J
0
l
J
J
0
l,m
m
k
+1
k
k
+1
k
u
v
0
K x
(
+
c
-
c
, y
0
)
K x
(
0
, y
+
c
-
c
)
∆
0
W
.
u,v
=1
m
=1
Making use of K x ( I k 0 v , y J k +1 0 l + c J k +1 -c J k ) = K x ( I k 0 v + c J k -c J k +1 , y J k +1 0 l ) and K x ( J k 0 q ′ + c P ( I k +1 ) c J k , y J k 0 u ) = K x ( J k 0 q ′ , y J k 0 u + c J k -c P ( I k +1 ) ), and reorganizing some terms, there holds
$$-$$
$$l _ { m ^ { \prime } } ^ { I ^ { k + 1 } } \approx g _ { m ^ { \prime } } ^ { I ^ { k + 1 } } + \sum _ { p ^ { \prime }, q ^ { \prime } = 1 } ^ { d ^ { k } } \Delta _ { p ^ { \prime }, q ^ { \prime } } ^ { J _ { 0 } ^ { k }, I _ { 0 } ^ { k } } K ( x _ { m ^ { \prime } } ^ { J _ { 0 } ^ { k + 1 } } + c _ { I ^ { k + 1 } } - c _ { \mathcal { P } ( I ^ { k + 1 } ) }, y _ { p ^ { \prime } } ^ { I _ { 0 } ^ { k } } )$$
$$\sum _ { j ^ { k } \in F ( P ( l ^ { k + 1 } ) ) \, u = 1 } ^ { d ^ { k } } K ( x _ { q ^ { \prime } } ^ { j ^ { k } }, y _ { u ^ { \prime } } ^ { k ^ { \prime } } + c _ { j ^ { k } } - c _ { P ( l ^ { k + 1 } ) } ) \sum _ { v = 1 } ^ { d ^ { k } } \Delta _ { u, v ^ { \prime } } ^ { t ^ { k } _ { 0 }, j ^ { k } _ { 0 } } ^ { d ^ { k } _ { 0 } } \sum _ { l, m = 1 } ^ { d ^ { k + 1 } } \Delta _ { l, m } ^ { t ^ { k + 1 } _ { 0 }, j ^ { k + 1 } _ { 0 } } \sum _ { j ^ { k + 1 } \in C ( j ^ { k } ) } K ( x _ { v ^ { \prime } } ^ { j ^ { k } _ { 0 } } + c _ { j ^ { k } } - c _ { j ^ { k + 1 }, j ^ { k } _ { 1 } } ) W _ { m } ^ { t ^ { k + 1 } },$$
︸
︷︷
︸
=
W
J k
︸
= ˆ
J k
v
using (17)
︷︷
using (18)
︸
︸
︸
=
l
P
(
q
′
︷︷
using (20)
(26)
which provides a recursive formula for the upward pass. In the same fashion as for the monolevel version, we then compute
$$\hat { l } ^ { I ^ { \kappa } } _ { l ^ { \prime } } \coloneqq \sum _ { m ^ { \prime } = 1 } ^ { d ^ { \kappa } } \Delta ^ { J ^ { \kappa } _ { 0 }, I ^ { \kappa } _ { 0 } } _ { l ^ { \prime }, m ^ { \prime } } l ^ { I ^ { \kappa } } _ { l ^ { \prime } },$$
for all box I κ at level κ and all 1 ≤ l ′ ≤ d κ .
## 3.3.4 Algorithm and complexity
Using the recursion formulae derived above, the multilevel procedure is detailed in Algorithm 3.
## Algorithm 3 Multilevel EIFMM
- 1. Compute W I κ m = ∑ ¯ y j ∈ I κ σ K x j ( I κ 0 m , y ¯ j -c I κ ), for all box I κ at level κ and all 1 ≤ m ≤ d κ
- 2. Compute W I k m = ∑ d k +1 p,q =1 ∆ I k +1 0 ,J k +1 0 p,q ∑ J k +1 ∈C ( I k ) K x ( I k 0 m + c I k -c J k +1 , y J k +1 0 p ) W J k +1 q , for all box I k at all levels κ -1 ≥ k ≥ 0 and all 1 ≤ m ≤ d k +1
- 3. Compute ˆ W I k l = ∑ d k m =1 ∆ I k 0 ,J k 0 l,m W I k m , for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ l ≤ d k
- 4. Compute g I k m ′ = ∑ J k ∈I ( I k ) ∑ d k l =1 K x ( J k 0 m ′ , y J k 0 l + c J k -c I k ) ˆ W J k l , for all box I k at all level k with 0 ≤ k ≤ κ and all 1 ≤ m ′ ≤ d k .
- 5. Let l I 0 m ′ = g I 0 m ′ and compute l I k m ′ = g I k m ′ + ∑ d k -1 p ,q ′ ′ =1 ∆ J k -1 0 ,I k -1 0 p ,q ′ ′ K x ( J k 0 m ′ + c I k -c P ( I k ) , y I k -1 0 p ′ ) l P ( I k ) q ′ for all box I k at all levels 1 ≤ k ≤ κ and all 1 ≤ m ′ ≤ d k -1 κ κ
- 7. Compute f F , FMM (¯ ) = x i ∑ d κ l ′ =1 K x (¯ i -c I κ , y I κ 0 l ′ ) ˆ l I κ l ′ , for all box I κ and all x i ∈ I κ at level κ
- 6. Compute ˆ l I κ l ′ := ∑ d κ m ′ =1 ∆ J 0 ,I 0 l ′ ,m ′ l I κ l ′ for all box I κ at level κ and all 1 ≤ l ′ ≤ d κ
The complexity of the multilevel procedure is given in Table 2. For step 4 and the computation of the near interactions to be in the same order in N , one must impose (2 D κ ) ∝ N 2 (2 D ) -κ , leading to a overall complexity of the sum of order N . The choice that minimizes the overall cost is κ ∝ log( N ) and a constant number of points per box at the level κ . As for any multilevel FMM algorithm, the complexity of step 3 in Algorithm 2 has been reduced by replacing the sum over J ∈ L ( I ) (which is of complexity linear in N ) by a sum over J ∈ I ( I ) (which is of complexity independent in N ), making use of the fact that the set of boxes well-separated from I k at level k contains the set of boxes well-separated from the parent of I k at level k -1. By precomputing some terms, independent to the location of the particles, the complexity of the steps 2, 4 and 5 can be reduced.
## 4 Optimizing the overall complexity
## 4.1 Precomputations for the M2M and L2L steps
Recall that when using an EIM approximation, there holds ∆ = B -t Γ -1 , where the matrices B and Γ are triangular and constructed in a precomputation step. In practice, the condition number of the
I k
+1 )
W
u
Table 2: Complexity of each step of Algorithm 3 (for the most expensive level) and of the near interactions term ; n I denotes the maximum number of elements in the interaction list of a box (4 in 1D, 40 in 2D and 316 in 3D).
| Step number | Complexity |
|---------------|------------------|
| 1 | dN |
| 2 | d 3 (2 D ) κ |
| 3 | d 2 (2 D ) κ |
| 4 | d 2 n I (2 D ) κ |
| 5 | d 3 (2 D ) κ |
| 6 | d 2 (2 D ) κ |
| 7 | dN |
| f N | N 2 (2 D ) - κ |
matrix Γ worsens as the EIM approximation gets more accurate. It is well known in linear algebra that when a matrix Γ is ill-conditioned, a direct resolution of the linear system Γ x = b for some b ∈ R d provides a result much less polluted by numerical errors than first inverting the matrix Γ and then computing the matrix vector product Γ -1 b . Since the matrices Γ and B are triangular, computing ∆ = b y by first solving Γ x = b and then solving B y t = x is of the same complexity d 2 as the direct matrix-vector product.
Consider step 2 in Algorithm 3 at level k :
$$W _ { m } ^ { I ^ { k } } = \sum _ { p, q = 1 } ^ { d ^ { k + 1 } } \Delta _ { p, q } ^ { I _ { 0 } ^ { k + 1 }, J _ { 0 } ^ { k + 1 } } \sum _ { J ^ { k + 1 } \in \mathcal { C } ( I ^ { k } ) } K ( x _ { m } ^ { I _ { 0 } ^ { k } } + c _ { I ^ { k } } - c _ { J ^ { k + 1 } }, y _ { p } ^ { J _ { 0 } ^ { k + 1 } } ) W _ { q } ^ { J ^ { k + 1 } }.$$
Wesee that W I k m = ∑ J k +1 ∈C ( I k ) K I k ,J k +1 ∆ I k +1 0 ,J k +1 0 W J k +1 , where K I k ,J k +1 m,p = K x ( I k 0 m + c I k -c J k +1 , y J k +1 0 p ), 1 ≤ m ≤ d k , 1 ≤ p ≤ d k +1 . The matrix K I k ,J k +1 M M 2 := K I k ,J k +1 ∆ I k +1 0 ,J k +1 0 can be precomputed as ( (∆ I k +1 0 ,J k +1 0 ) ( t K I k ,J k +1 ) t ) t , where each matrix-vector product for each column of ( K I k ,J k +1 ) t is computed solving linear systems involving B and Γ matrices to preserve numerical accuracy, as explained in the previous paragraph. Notice that K I k ,J k +1 M M 2 only depends on the relative position of I k and J k +1 . Since J k +1 is a child of I k , there are actually only 2 D different operators K I k ,J k +1 M M 2 , where D denotes the dimension of the space containing the particles. We denote them K i M M 2 , 1 ≤ i ≤ 2 D , and step 2 in Algorithm 3 at level k is reduced to
$$W _ { m } ^ { I ^ { k } } = \sum _ { i = 1 } ^ { 2 ^ { D } } K _ { M 2 M } ^ { i } W _ { q } ^ { J ^ { k + 1 } _ { i } },$$
where J k +1 i denotes the i th child of I k . This step is now of complexity d 2 2 D (2 D k ) at level k , and the leading order of step 2 in Algorithm 3 is d 2 2 D (2 D κ ) -1 = d 2 (2 D κ ) .
The same optimization is done for step 5 in Algorithm 3, reducing the complexity of this step to the order d 2 (2 D κ ) .
## 4.2 Optimization of the M2L step
It is well known that the M2L step is the most expensive one. Numerous efforts have been made to reduce the execution time of this step without degrading the accuracy of the overall result, see in particular [25]. We use the optimization denoted SArcmp in [25]. It consists of a bivariate ACA applied to the collection of all the M2L operators at each level, followed by a truncated SVD. The bivariate ACA and truncated SVD is then applied for each M2L operator at each level to increase further the compression. The procedure is detailed for symmetric kernels for completeness of the presentation.
Consider a level k and the collection of all the M2L operators at this level. Consider a level k , a box I k of the tree at this level k , and a box J k in the interaction list of I k . The vector δ := c J k -c I k only depends on the relative position of the boxes I k and J k . Therefore, there are only n I = 7 D -3 D different M2L matrices K δ i,j := K x ( J k 0 i , y J k 0 j + ) per level (we recall that δ D denotes the dimension of the space containing the particles), see (19). We suppose that EIM algorithms have been carriedout for a certain error bound glyph[epsilon1] , leading to the choice of d k interpolation points. The M2L matrices are organized in one large matrix as follows K fat := [ K K ...K δ 1 δ 2 δ n I ], where K fat ∈ R d k × n d I k . Two rectangular matrices U, V are computed by a bivariate ACA such that | UV | F ≤ | glyph[epsilon1] K fat | F , where | · | F denotes the Frobenius norm. Then, two QR decompositions are computed, such that U = Q R U U and ( V ) t = Q R V V , and a SVD is computed on R U ( R V ) . t Denote s i , 1 ≤ i ≤ d k , the singular values of R U ( R V ) t in decreasing order, and ˆ , U ˆ V the unitary matrices such that R U ( R V ) t = ˆ diag( U s V ) ˆ . The two following filters are applied: (i) keep the first j singular values such that s j s 0 ≤ glyph[epsilon1] ≤ s j -1 s 0 , (ii) keep the first j singular values such that ∑ j i =1 s i ∑ d k i =1 s i ≥ 1 -glyph[epsilon1] ≥ ∑ j -1 i =1 s i ∑ d k i =1 s i . We denote r k the number of kept singular values. Denote ˆ U r k and ˆ V r k the first r k columns of respectively ˆ U and ˆ . V Following [13], we can show that the M2L step can be reduced to size r k × r k (instead of size d k × d k ) matrix-vector products involving the matrices C δ := ˆ U T r k K U δ ˆ r k , plus low complexity pre- and post-processing steps. Then, the same compression is applied locally for each compressed M2L operator C δ . This time, the bivariate ACA is applied on each C δ , producing the rectangular matrices U and V . The QR decompositions, SVD and filters are applied in the same fashion, selecting the singular values s k . The rectangular matrices ˆ U s k and ˆ V s k are constructed, and a diagonal matrix S s k , whose diagonal entries are the square roots of the selected singular values, is constructed. Then, we construct ˜ U s k = Q U U ˆ s k S s k ∈ R r k × s k and ˜ V s k = SV ˆ s k Q t V ∈ R s k × r k , so that C δ is approximated by ˜ U s k ˜ V s k . Thus, size r k × r k matrix-vector products involving the matrices C δ are replaced by two r k × s k matrix-vector products involving the matrices ˜ U s k and ˜ V s k .
## 5 Numerical experiments in 3D
## 5.1 Some elements on the implementation
The EIFMM has been implemented in C++, using the open source library scalfmm, see [9]. From [29], scalfmm is one of the fastest opensource library for FMM computations. We will mainly compare our implementation of the EIFMM to the Chebyshev interpolation-based implementation in scalfmm, which follows the Black-Box FMM [13]. In our code, the EIM precomputation and the SArcmp precomputation steps are performed in C++ using BLAS and LAPACK, and stored in binary files. These precomputations are then read by the modified scalfmm library, using also BLAS for the basic linear algebra operations.
## 5.2 Test-cases
We consider sets of points included in Ω = ( -0 5 . , 0 5) . 3 , randomly taken following (i) a uniform law in Ω, (ii) a uniform law on the sphere of radius 0 5 and (iii) a modification of the set (ii) in an ellipsoid, . see Figure 5.
When comparing runtimes, we have to make sure that the Black-Box FMM is used in a optimal way. There are two parameters to choose: the number of interpolation points per dimension and the accuracy glyph[epsilon1] c of the compression. First, we chose 3 interpolation points per dimension and compute the relative error with glyph[epsilon1] c = 10 -15 . Then, if this relative error is smaller than the desired one, we search by dichotomy the largest value of the glyph[epsilon1] c so that the relative error is smaller or equal to the desired one. Otherwise, we increase the number of interpolation points per dimension by one and repeat the process. That way, the runtimes comparison is fair in the sense that Block-Box FMM is not artificially slowed down by a too large number of interpolation points together with a too large value for glyph[epsilon1] c . Notice that this trick is necessary since we do not know in advance how the Chebyshev interpolation will perform in practice for a new kernel, while for the EIFMM, the error estimate automatically selects the right number of interpolation points.
Figure 5: Sets of points considered in the numerical applications, from left to right: random (5000 points), sphere (10100 points), and ellipsoid (1944 points). The values for the number of points have been chosen for representation reasons, higher values will be considered in the numerical experiments.
## 5.3 Performance for the Laplace kernel
In this section, we compare runtimes of the FMM summation using the Black-Box FMM and the EIFMM. The computations are carried out in sequential, on a laptop with 4 GB of RAM and a Intel(R) Core(TM) i5 CPU M 560 @ 2.67GHz. For the Black-Box FMM, we use the so-called symmetric M2L compression, based on local SVD for each M2L operator. The symmetric M2L compression exploit the symmetry of the Chebyshev nodes to express the M2L step as matrix-matrix products, and even if the complexity of this step is not improved, runtimes are drastically improved due to better reuse of memory cache by the processor. Proposed in [25], the symmetric compression is currently, to the author's knowledge, the most efficient compression strategy for the Black-Box FMM. Since the approximation (9) used in EIFMM has four summations instead of two for Black-Box FMM, the steps 3 and 6 in Algorithm 3 for EIFMM are not present in Black-Box FMM.
In Figure 6 are represented execution time with respect to the relative error on the FMM summation for the Laplace kernel, for the symmetric Black-Box FMM, the EIFMM and the fastest algorithm available in scalfmm. This latter is dedicated to the Laplace kernel, explaining why it performs better than the other two. The test-case corresponds to 10 6 random points taken in the unit cube, organized in a 6-level tree, see Figure 5, left picture. The execution times are better for Black-Box FMM at low accuracy, and equivalent between EIFMM and Black-Box FMM at high accuracy. Notice that since the Laplace kernel is homogeneous, the difficulty of the approximation problem does not change from one level to another in the tree. As a consequence, the variable-order capability of our algorithm is not exploited for this kernel. In what follows, inhomogeneous kernels are considered and gains on runtimes are observed. Precomputation times will be investigated in the following section as well.
## 5.4 Performance for some inhomogeneous kernels
The advantages of the EIFMM mainly apply to inhomogeneous kernels, for which the error estimation allows the selection of an optimal number of interpolation points at each level of the tree by the EIM.
## 5.4.1 1-million-point test-cases
The three test-cases presented in Figure 5 are considered: 10 6 random points in the unit cube with a 6level tree (denoted 'cube'), 992 046 points at the surface of a sphere and an ellipsoid, with respectively , 8-level and 9-level trees (denoted respectively 'sphere' and 'ellipsoid').
Figures 7, 8 and 9 present execution times of the long-range FMM accelerated terms with respect to the relative error on the FMM summation, respectively for the kernels cos 20 r r , e -r 2 and √ r 2 +1, for the three test-cases (cube, sphere and ellipsoid). The reported runtimes do not contain the times required to build the tree, nor the EIM, M2L compression, M2M and L2L precomputations. For the EIFMM, we use the SArcmp compression for the M2L operators, as described in Section 4.2. Due to smaller interpolation formulae, EIFMM enables memory savings with respect to Black-Box FMM. In the figures, missing data correspond to cases requiring more memory than available with our computer,
Figure 6: Execution time with respect to the relative error on the FMM summation for the Laplace kernel; black: symmetric Black-Box FMM, blue: EIFMM, red: fastest spherical algorithm available in scalfmm.
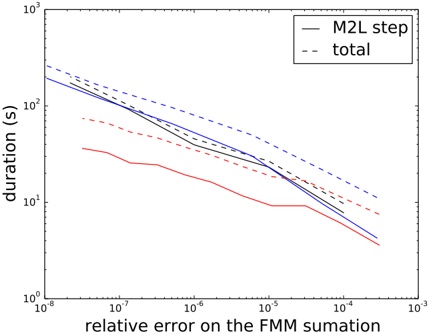
for which EIFMM can be used, but not Blakc-Box FMM. For the three kernels, and especially the last two, the EIFMM is much faster than the Black-Box FMM, because the error estimation and the greedy procedure in EIFMM allows the selection of an optimal number of interpolation points at each level of the tree. For instance, for the kernel e -r 2 on the ellipsoid and a relative error of 10 -6 , the Black-Box FMM needs 6 interpolation points per dimension (i.e. 216 interpolation points), whereas the EIFMM needs respectively 167, 74, 36, 21, 13, 10, 9, and 4 points at levels 2 to 9 of the tree. As we go deeper in the tree, the interpolation problems become easier, and the EIM selects fewer points to produce an interpolation of the same quality. √
Table 3 provides precomputations and executions times for the kernels cos(20 r ) r , e -r 2 and r 2 +1 on the cube test-case. Notice that in order not to artificially disadvantage Black-Box FMM, we report values with EIFMM set to a better relative accuracy and we neglect the precomputation times of BlackBox FMM (which are short anyway). In the reported cases, EIFMM becomes advantageous (i.e. the EIFMM precomputations times are compensated by faster long-range FMM terms computation time) if one has to compute more than 2 to 18 FMM summations.
√
| kernel | cos(20 r ) r | cos(20 r ) r | e - r 2 | e - r 2 | r 2 +1 | r 2 +1 |
|------------------------------------|----------------|----------------|------------|------------|------------|------------|
| algorithm | EIFMM | BBFMM | EIFMM | BBFMM | EIFMM | BBFMM |
| relative accuracy | 2 × 10 - 4 | 4 × 10 - 4 | 2 × 10 - 6 | 3 × 10 - 6 | 1 × 10 - 5 | 2 × 10 - 5 |
| EIM precomp time (s) | 73 | - | 30 | - | 10 | - |
| compression time (s) | 177 | - | 33 | - | 1.1 | - |
| tree construction time (s) | 3 | 3 | 3 | 3 | 3 | 3 |
| long-range FMM terms comp time (s) | 52 | 69 | 5.4 | 37 | 3.5 | 4.3 |
| short-range terms comp time(s) | 32 | 32 | 30 | 30 | 16 | 16 |
| minimum EIFMM calls | 18 | 18 | 2 | 2 | 14 | 14 |
Table 3: Precomputations and executions times for the kernels cos(20 r ) r , e -r 2 and √ r 2 +1 on the cube test-case. The last line indicates the minimum FMM summations to compute for EIFMM to be faster than Black-Box FMM (BBFMM), taking all precomputations times into account.
## 5.4.2 100-million-point test-case
We consider 10 8 random points in the unit cube (Figure 5, left) in a 9-level tree, with the e -r 2 kernel. The computations are carried-out in sequential on a Intel(R) Xeon(R) CPU E5-4620 v2 @ 2.60GHz
Figure 7: Execution time of the long-range FMM accelerated terms with respect to the relative error on the FMM summation for the kernel cos 20 r r , black: symmetric Black-Box FMM, blue: EIFMM. From top to bottom and left to right: cube, sphere and ellipsoid test-cases.
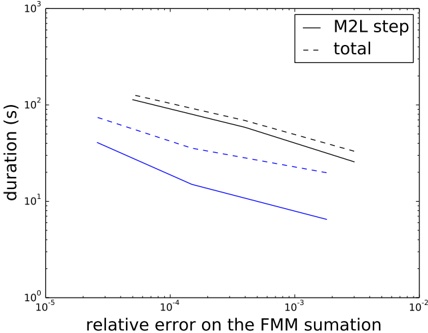
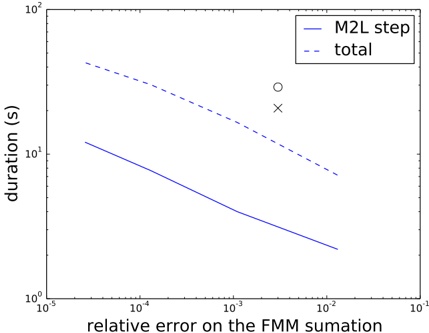
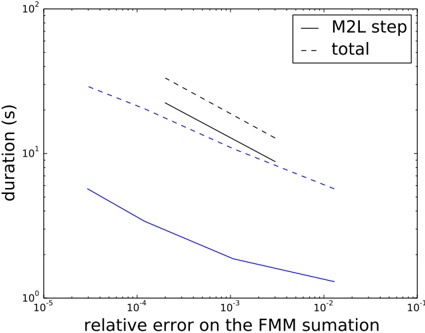
## and 128 GB of RAM.
Table 4 presents the relative accuracy and the execution times of all the steps for two simulations using EIFMM and Black-Box FMM. For a better accuracy, the EIFMM is faster than the BlackBox FMM, including the precomputation times (increasing the accuracy with Black-Box FMM would require more than 128 GB of RAM). In this case, EIFMM is interesting even for a single FMM computation. Notice that the precomputations for EIFMM are negligible for such large cases: the precomputation complexity is linear with respect to the number of levels in the tree (therefore logarithmic with respect to N ). Moreover, for inhomogeneous kernels, the approximation problem for an additional level is easier than the previous approximation problems, leading to even faster additional EIM and M2L compression precomputation times.
## 6 Conclusion and outlook
This work introduces a new Fast Multipole Method (FMM) using a low-rank approximation of the kernel based on the Empirical Interpolation Method (EIM), called the Empirical Interpolation Fast Multipole Method (EIFMM). The proposed multilevel algorithm is implemented in scalfmm, a FMM library written in C++. The important feature of the EIFMM is a built-in error estimation of the interpolation error made by the low-rank approximation of the far-field behavior of the kernel. As a consequence, the algorithm automatically selects the optimal number of interpolation points required to ensure a given accuracy for the result, leading to important execution time reduction for
Figure 8: Execution time of the long-range FMM accelerated terms with respect to the relative error on the FMM summation for the kernel e -r 2 , black: symmetric Black-Box FMM, blue: EIFMM. From top to bottom and left to right: cube, sphere and ellipsoid test-cases.
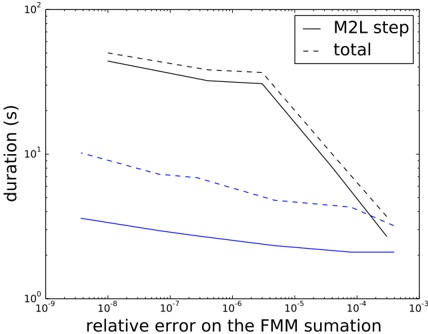
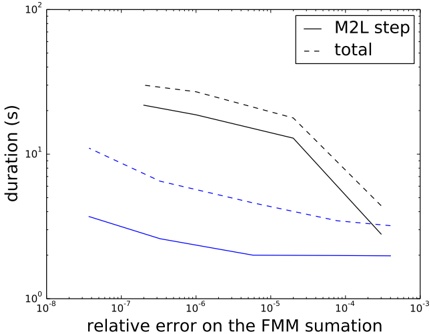
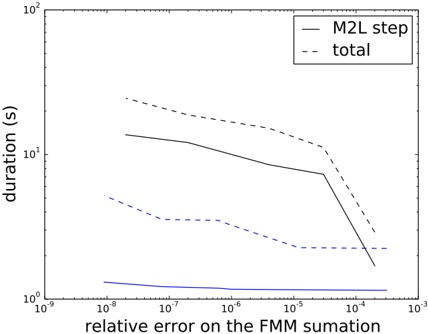
inhomogeneous kernels, for which the difficulty of the approximation varies from one level of the tree to another.
## Acknowledgement
The author wish to thank Centre National d'Etudes Spatiales for financial support through the TOSCA committee, Guillaume Sylvand (Airbus Group Innovations, INRIA) for drawing his attention to fast multipole methods, thoroughly reading the manuscript and for many fruitfull discussions, Tony Leli` evre (CERMICS) and Alexandre Ern (CERMICS) for fruitful discussions, and Mathieu Ruffat (Diginext) for his C++ expertise.
## References
- [1] B. Alpert, G. Beylkin, R. Coifman, and V. Rokhlin. Wavelet-like bases for the fast solutions of second-kind integral equations. SIAM J. Sci. Comput. , 14(1):159-184, 1993.
- [2] M. Barrault, Y. Maday, N. C. Nguyen, and A. T. Patera. An 'empirical interpolation' method: application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Mathematique , 339(9):667 - 672, 2004.
Figure 9: Execution time of the long-range FMM accelerated terms with respect to the relative error on the FMM summation for the kernel √ r 2 +1, black: symmetric Black-Box FMM, blue: EIFMM. From top to bottom and left to right: cube, sphere and ellipsoid test-cases.
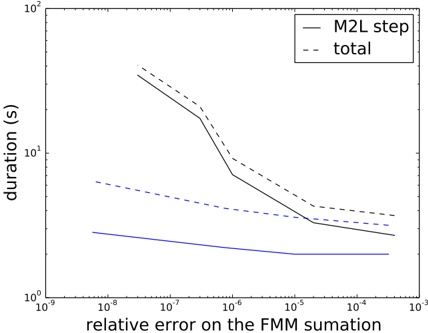
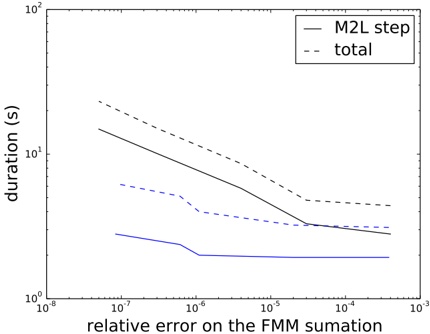
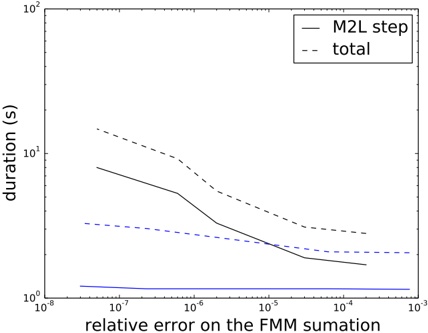
- [3] M. Bebendorf. Approximation of boundary element matrices. Numerische Mathematik , 86(4):565589, 2000.
- [4] M. Bebendorf and S. Rjasanow. Adaptive low-rank approximation of collocation matrices. Computing , 70(1):1-24, 2003.
- [5] M. Bebendorf and R. Venn. Constructing nested bases approximations from the entries of nonlocal operators. Numerische Mathematik , 121(4):609-635, 2012.
- [6] S. B¨rm, M. L¨hndorf, and J.M. Melenk. Approximation of integral operators by variable-order o o interpolation. Numerische Mathematik , 99(4):605-643, 2005.
- [7] F. Casenave, A. Ern, and T. Leli`vre. A nonintrusive reduced basis method applied to aeroacoustic e simulations. Advances in Computational Mathematics , pages 1-26, 2014.
- [8] H. Cheng, Z. Gimbutas, P.G. Martinsson, and V. Rokhlin. On the compression of low-rank matrices. SIAM J. Sci. Comput. , 26(4):1389-1404, 2005.
- [9] O. Coulaud, B. Bramas, and C. Piacibello. Scalfmm, C++ Fast Multipole Method Library for HPC. http://scalfmm-public.gforge.inria.fr/doc/ .
- [10] A. Dutt, M. Gu, and V. Rokhlin. Fast algorithms for polynomial interpolation, integration, and differentiation. SIAM Journal on Numerical Analysis , 33(5):1689-1711, 1996.
Table 4: Accuracy and execution times for the 100 million points test-case. P2M, M2M, M2L, L2L and L2P corresponds respectively to the steps (1), (2-3), (4), (5-6) and (7) in Algorithm 3.
| algorithm | EIFMM | Black-Box FMM |
|----------------------------|-------------|-----------------|
| relative accuracy | 7 × 10 - 5 | 6 × 10 - 4 |
| EIM precomp time | 22.8 s | - |
| compression time | 1.3 s | - |
| tree construction time (s) | 9 min 10 s | 9 min 10 s |
| P2M (1) | 1 min 13 s | 2 min 17 s |
| M2M (2-3) | 31 s | 49 s |
| M2L (4) | 10 min 39 s | 53 min 01 s |
| L2L (5-6) | 41 s | 59 s |
| L2P (7) | 1 min 42 s | 3 min 55 s |
| total long-range FMM terms | 14 min 46 s | 1 h 01 min 01 s |
| short-range terms | 19 min 36 s | 19 min 36 s |
| total | 43 min 56 s | 1 h 29 min 47 s |
- [11] A. Dutt and V. Rokhlin. Fast fourier transforms for nonequispaced data. SIAM Journal on Scientific Computing , 14(6):1368-1393, 1993.
- [12] J. L. Eftang and B. Stamm. Parameter multi-domain 'hp' empirical interpolation. International Journal for Numerical Methods in Engineering , 90:412-428, 2012.
- [13] W. Fong and E. Darve. The black-box fast multipole method. Journal of Computational Physics , 228(23):8712 - 8725, 2009.
- [14] K. Giebermann. Multilevel approximation of boundary integral operators. Computing , 67(3):183207, 2001.
- [15] Z. Gimbutas, L. Greengard, and M. Minion. Coulomb interactions on planar structures: Inverting the square root of the laplacian. SIAM Journal on Scientific Computing , 22(6):2093-2108, 2001.
- [16] S.A. Goreinov, E.E. Tyrtyshnikov, and N.L. Zamarashkin. A theory of pseudoskeleton approximations. Linear Algebra and its Applications , 261(1-3):1 - 21, 1997.
- [17] L. Greengard and V. Rokhlin. A fast algorithm for particle simulations. Journal of Computational Physics , 135(2):280-292, 1997.
- [18] W. Hackbusch. A sparse matrix arithmetic based on H-matrices. part I: Introduction to Hmatrices. Computing , 62(2):89-108, 1999.
- [19] W. Hackbusch and S. B¨ orm. Data-sparse approximation by adaptive H2-matrices. Computing , 69(1):1-35, 2002.
- [20] W. Hackbusch and S. B¨ orm. H2-matrix approximation of integral operators by interpolation. Applied Numerical Mathematics , 43(1-2):129 - 143, 2002. 19th Dundee Biennial Conference on Numerical Analysis.
- [21] W. Hackbusch and Z.P. Nowak. On the fast matrix multiplication in the boundary element method by panel clustering. Numerische Mathematik , 54(4):463-491, 1989.
- [22] Y. Maday and O. Mula. A generalized empirical interpolation method: Application of reduced basis techniques to data assimilation. 4:221-235, 2013.
- [23] Y. Maday, N. C. Nguyen, A. T. Patera, and S. Pau. A general multipurpose interpolation procedure: the magic points. Communications On Pure And Applied Analysis , 8(1):383-404, 2008.
| [24] | P.G. Martinsson and V. Rokhlin. An accelerated kernel-independent fast multipole method in one dimension. SIAM J. Sci. Comput , 26:1389-1404, 2005. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [25] | M. Messner, B. Bramas, D. Coulaud, and E. Darve. Optimized M2L Kernels for the Chebyshev Interpolation based Fast Multipole Method. CoRR , abs/1210.7292, 2012. |
| [26] | B. Peherstorfer, D. Butnaru, K. Willcox, and H.-J. Bungartz. Localized discrete empirical inter- polation method. SIAM Journal on Scientific Computing , 36(1):A168-A192, 2014. |
| [27] | E. Tyrtyshnikov. Mosaic-skeleton approximations. CALCOLO , 33(1-2):47-57, 1996. |
| [28] | L. Ying, G. Biros, and D. Zorin. A kernel-independent adaptive fast multipole algorithm in two and three dimensions. J. Comput. Phys. , 196(2):591-626, 2004. |
| [29] | R. Yokota. Fast multipole methods benchmark. https://sites.google.com/site/rioyokota/research/fmm | | null | [
"Fabien Casenave"
] | 2014-08-01T15:49:16+00:00 | 2015-08-22T13:05:44+00:00 | [
"math.NA",
"cs.NA"
] | A Fast Summation Method for translation invariant kernels | We derive a Fast Multipole Method (FMM) where a low-rank approximation of the
kernel is obtained using the Empirical Interpolation Method (EIM). Contrary to
classical interpolation-based FMM, where the interpolation points and basis are
fixed beforehand, the EIM is a nonlinear approximation method which constructs
interpolation points and basis which are adapted to the kernel under
consideration. The basis functions are obtained using evaluations of the kernel
itself. We restrict ourselves to translation-invariant kernels, for which a
modified version of the EIM approximation can be used in a multilevel FMM
context; we call the obtained algorithm Empirical Interpolation Fast Multipole
Method (EIFMM). An important feature of the EIFMM is a built-in error
estimation of the interpolation error made by the low-rank approximation of the
far-field behavior of the kernel: the algorithm selects the optimal number of
interpolation points required to ensure a given accuracy for the result,
leading to important gains for inhomogeneous kernels. |
1408.0211v1 | ## LOW DISTORTION EMBEDDINGS BETWEEN C K ( ) SPACES
## ANTON ´ IN PROCH ´ ZKA A † AND LUIS S ´ NCHEZ-GONZ ´ LEZ A A ‡
Abstract. We show that, for each ordinal α < ω 1 , the space C ([0 , ω α ]) does not embed into C K ( ) with distortion strictly less than 2 unless K ( α ) = . ∅
/negationslash
## 1. Introduction
A mapping f : M → N between metric spaces ( M,d ) and ( N,ρ ) is called Lipschitz embedding if there are constants C , C 1 2 > 0 such that C d x, y 1 ( ) ≤ ρ f ( ( x , f ) ( y )) ≤ C d x, y 2 ( ) for all x, y ∈ M . The distortion dist( f ) of f is defined as inf C 2 C 1 where the infimum is taken over all constants C , C 1 2 which satisfy the above inequality. We say that M embeds into N with distortion D (in short M↪ → D N ) if there exists a Lipschitz embedding f : M → N with dist( f ) ≤ D (in short f : M↪ → N ). In this case, if the target space N is a Banach space, we may always assume (by
D changing f ) that C 1 = 1. The N -distortion of M is defined as c N ( M ) := inf { D : M↪ → D N } . The main result of this article (Theorem 1) implies in particular that, for every countable ordinal α and every β < ω α , the space C ([0 , ω α ]) does not embed into the space C ([0 , β ]) with distortion strictly less than 2. On the other hand, it has been shown by Kalton and Lancien [15] that every separable metric space embeds into c 0 with distortion 2. Since every C K ( ) contains c 0 as a closed subspace, our result gives c C ([0 ,β ]) ( C ([0 , ω α ])) = 2 if β < ω α .
It is a well known theorem of Mazurkiewicz and Sierpi´ski (see [13, Theorem 2.56]) that every n countable ordinal interval [0 , β ] (every countable Hausdorff compact in fact) is homeomorphic to the interval [0 , ω α · n ] where for some α < ω 1 and 1 ≤ n < ω . Thus the corresponding spaces of continuous functions are isometrically isomorphic. We do not know, whether one has c C ([0 ,ω α · m ]) ( C ([0 , ω α · n ])) = 2 for 1 ≤ m<n<ω but we get as a byproduct of the proof of our main result that, for every 1 ≤ D < 2 and every 1 ≤ m < ω , there is 1 ≤ n < ω such that for all α < ω 1 the space C ([0 , ω α · n ]) does not embed into the space C ([0 , ω α · m ]) with distortion D (Proposition 13).
Metric spaces M and N are called Lipschitz homeomorphic if there is a surjective Lipschitz embedding from M onto N . Such embedding is then called Lipschitz homeomorphism . The theorem of Amir [3] and Cambern [8] is the following generalization of Banach-Stone theorem: Let K and L be two compact spaces. If there exists a linear isomorphism f : C K ( ) → C L ( ) such that dist( f ) < 2, then K and L are homeomorphic. A result of Cohen [9] shows that the constant 2 above is optimal but at the present it is not clear whether one could draw the same conclusion under the weaker hypothesis of f : C K ( ) → C L ( ) being a Lipschitz homeomorphism
The second named author was partially supported by MICINN Project MTM2012-34341 (Spain) and FONDECYT project 11130354 (Chile). This work started while L. S´nchez-Gonz´lez held a post-doc posia a tion at Universit´ Franche-Comt´. e e
such that dist( f ) < 2. The results of Jarosz [14], resp. Dutrieux and Kalton [11], resp. G´ orak [12], show that K and L are homeomorphic if there is a Lipschitz homeomorphism f : C K ( ) → C L ( ) such that dist( f ) < 1+ ε ( ε > 0 universal but small), resp. dist( f ) < 17 / 16, resp. dist( f ) < 6 / 5. The main result of this article also implies that if K and L are two countable compacts, then assuming the existence of a Lipschitz homeomorphism f : C K ( ) → C L ( ) with dist( f ) < 2 implies that K and L have the same height (Corollary 14).
The proof of the main result consists in identifying a uniformly discrete subset of C ([0 , ω α ]) which does not embed into C ([0 , β ]) with distortion strictly less than 2 if β < ω α . The uniform discreteness allows to translate the above results into the language of uniform and net homeomorphisms (Corollary 14). Also, using Zippin's lemma, it permits to prove that if the Szlenk index of a Banach space X satisfies Sz( X ) ≤ ω α , then C ([0 , ω ω α ]) does not embed into X with distortion strictly less than 2 (Theorem 15). This can be understood as a refinement of our result in [18] that C ([0 , 1]) does not embed into any Asplund space with distortion strictly less than 2. The underlying idea of the proof there is basically the same as here (and originates in fact in [1] and in [4]) but the proof is not obscured by the technicalities that are necessary in the present article.
Finally, let us recall the following result of Bessaga and Pe/suppress lczy´ski n [7, 13]: Let ω ≤ α ≤ β < ω 1 . Then C ([0 , α ]) is linearly isomorphic to C ([0 , β ]) iff β < α ω . It is a longstanding open problem whether C ([0 , β ]) can be Lipschitz homeomorphic to a subspace of C ([0 , α ]) if β > α ω . Our results described above imply that the distortion of any such Lipschitz homeomorphism onto a subspace must be at least 2.
Besides this Introduction, the paper features two more sections. In Section 2 the main theorem is stated and proved. In Section 3 we state and prove its various consequences.
## 2. Main theorem
Theorem 1. For every ordinal α < ω 1 there exists a countable uniformly discrete metric space M α ⊂ C ([0 , ω α ]) such that M α does not embed with distortion strictly less than 2 into C K ( ) if K ( α ) = ∅ .
We start by defining finite metric graphs that do not embed well into /lscript n ∞ if n is small. We then 'glue' them together infinitely many times, via a relatively natural procedure that we call sup-amalgamation. The sup-amalgamation is done in a precise order which will be encoded by certain trees on N .
## 2.1. Construction of 3-level metric graphs.
Definition 2. Let C , . . . , C 1 h be pairwise disjoint sets. We put
$$M ( C _ { 1 }, \dots, C _ { h } ) = \{ 0 \} \text{ first level}$$
$$\begin{smallmatrix} \cdot & \cdot \cdot \cdot \\ & \cdot \cup \bigcup _ { i = 1 } ^ { h } C _ { i } \text{ second level} \\ & \cup F ( C _ { 1 }, \dots, C _ { h } ) \text{ third level} \\ & \cdot \sim \cdot \quad \cdot \cdot \cdot & \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \end{smallmatrix}$$
where F C , . . . , C ( 1 h ) = {{ c , . . . , c 1 h } : c i ∈ C i } . We turn M C ,..., C ( 1 h ) into a graph by putting an edge between x, y ∈ M C ,..., C ( 1 h ) iff x = 0 and y ∈ ⋃ C i or x ∈ ⋃ C i , y ∈ F C , . . . , C ( 1 h ) and x ∈ y . We consider the shortest path distance d on M C ,..., C ( 1 h ).
Lemma 3. Let C , . . . , C 1 h be pairwise disjoint sets and let us assume that C 1 = { 1 2 , } . We denote F = F C , . . . , C ( 1 h ) . Then there is an isometric embedding f : M C ,..., C ( 1 h ) → /lscript ∞ ( F ) which satisfies
- · f ( 0 ) = 0 ,
- · f ( x )( β ) ∈ {± } 1 for all x ∈ ⋃ h i =1 C i and all β ∈ F , · f (1)( β ) = 1 and f (2)( β ) = -1 for all β ∈ F .
Proof. We define first a mapping g : M C ,..., C ( 1 h ) → /lscript ∞ ( F ) as g x ( )( β ) = d x, β ( ) -d ( 0 , β ). It is clearly 1-Lipschitz. Given x, y ∈ M C ,..., C ( 1 h ), we can always find A, B ∈ F such that d A, B ( ) = d A, x ( ) + d x, y ( ) + d y, B ( ). We have g x ( )( B ) -g y ( )( B ) = d x, B ( ) -d y, B ( ) = d x, B ( ) + d x, A ( ) -d A, B ( ) + d x, y ( ) ≥ g x, y ( ). So g is an isometry. Observe that g ( 0 ) = 0 and also g satisfies the second additional property. Now since 1 ∈ β iff 2 / β ∈ for any β ∈ F , we have that g (1)( β ) = +1 iff g (2)( β ) = -1 for all β ∈ F . We thus define
$$\cdot \, + \, \Pi \, \mathcal { Y } \, \Sigma _ { J } \, & = \, \mathcal { Y } \, \sigma _ { J } \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Smega \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Salpha \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sphi \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sbeta \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \S alpha \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sig \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigs \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigm \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sg \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sappa \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Ssigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Lambda \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \SIG \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Siga \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sgo \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sega \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Spsc \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Svg \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \Sigma \, \$$
for all x ∈ M C ,..., C ( 1 h
$$A ( C _ { 1 }, \dots, C _ { h } ). & & \Box$$
## 2.2. Sup-amalgam of metric spaces.
/negationslash
Definition 4. Let (( M,d i i )) i ∈ I be a collection of metric spaces of uniformly bounded diameter. Let us assume that there is a set A and a distinguished point 0 ∈ A such that A ⊂ M i for every i ∈ I . A product ( P, d ) is the set P = ∏ i ∈ I M i equipped with the metric d x, y ( ) = sup i ∈ I d i ( x i , y ( ) ( )). i The set M A ⊂ P defined by x ∈ M A iff either x i ( ) = x j ( ) ∈ A for all i, j ∈ I or there exists exactly one i ∈ I such that x i ( ) / A ∈ and for all j = i we have x j ( ) = 0 , equipped with the metric d , is called the sup-amalgam of ( M i ) with respect to A . We denote it ( M i ) i ∈ I /A .
/negationslash
Standing assumption SA1: Even though the definition admits the possibility that d i and d j for i = j are different on A , in what follows we will always assume that d i /harpoonupright A × A = d j /harpoonupright A × A . In that case there is a canonical isometric copy of A in M A which we will denote by A again. Standing assumption SA2: We will also assume from now on that for each i ∈ I we have that d i ( x, y ) ≥ 1 for all x, y ∈ M i and d i ( x, 0 ) ≤ 1 for each x ∈ A . Then, for each i ∈ I , the canonical copy of M i in M A is isometric to M i .
Proof: We only need to show that for x ∈ A and y ∈ M i \ A we have d i ( x, y ) = d x, y ( ). This is equivalent to saying that d j ( x, 0 ) ≤ d i ( x, y ) for all j ∈ I . /square
Lemma 5. a) Let A be a finite set. Let ( M n n ) ∈ N be a sequence of metric spaces of uniformly bounded diameter such that 0 ∈ A ⊂ M n for every n ∈ N . We assume SA1 and SA2. If for each n ∈ N there is an ordinal α n < ω 1 and an isometric embedding f n : M n → C ([0 , α n ]) so that for each n ∈ N we have
- · f n ( 0 ) = 0 ,
- · f n ( x )( β ) ∈ {± } 1 for each x ∈ A \ { 0 } =: A ∗ and β ∈ [0 , α n ] ,
then there are N ≤ 2 | A ∗ | and an isometric embedding f : M A → C ([0 , ( ∞ ∑ n =1 α n ) · N ]) such that b) Let us assume moreover that 1 2 , ∈ A and that for every n ∈ N we have f n (1)( β ) = 1 and f n (2)( β ) = -1 for all β ∈ [0 , α n ] . Then we have f (1)( β ) = 1 and f (2)( β ) = -1 for all ∞ .
$$f ( 0 ) & = 0 \text{ and } f ( x ) ( \beta ) \in \{ \pm 1 \} \text{ for each } x \in A _ { * } \text{ and } \beta \in [ 0, ( \sum _ { n = 1 } ^ { \infty } \alpha _ { n } ) \cdot N ]. \\ b ) & \text{ Let us assume moreover theta } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
}$$
$$\ a n a _ { \ } J _ { n } ( 2 ) ( \rho ) = - 1 \ J o r \\ \beta & \in [ 0, ( \sum _ { n = 1 } ^ { n } \alpha _ { n } ) \cdot N ]. \\ c ) \ F i n a l l y, \ a s s u m e \ \eta$$
c) Finally, assume moreover that A = { 0 , 1 2 , } . Then N = 1 .
Proof. Let us consider the restriction g of the product mapping
↦
$$\text{Cluster the resource in} \, y \, o l \, o r \, p o u c t \, m a p p i n g \\ \prod _ { n = 1 } ^ { \infty } M _ { n } \ni x \mapsto \left ( f _ { n } ( x ( n ) ) \right ) _ { n = 1 } ^ { \infty } \in \left ( \bigoplus _ { n = 1 } ^ { \infty } C ( [ 0, \alpha _ { n } ] ) \right ) _ { \infty } \\ \text{The manner in} \, a \, \text{is also both on} \, \text{atom} \, a / \mathfrak { m } = 0 \, \text{and for each} \, \mathcal { m } \, \mathcal { m }$$
to the set M A . The mapping g is clearly an isometry, g ( 0 ) = 0 and for each x ∈ M A \ A we have g x ( ) ∈ C ([0 , ∞ ∑ n =1 α n ]) as it has exactly one non-zero entry. Notice that g a ( ) ∈ C ([0 , ∞ ∑ n =1 α n )) for
$$& y ( \psi ) \searrow \times \{ \psi, \sum _ { n = 1 } ^ { \infty } \omega _ { n } \} \circ \imath \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.c.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coc-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{www.coco-go.co.uk}, \quad \text{\ } \int _ { n = 1 } ^ { \infty } \Delta _ { n } \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \quad. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,.. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,.$$
/negationslash
The set T ε ∩ [0 , η ] is clopen for each η < ∑ α n and each ε ∈ I . Let ( J ε ) ε ∈ I be mutually disjoint copies of [0 , ∞ ∑ n =1 α n ], say J ε = [0 , ∑ ∞ n =1 α n ] ×{ } ε . If x ∈ A ∗ , we define f ( x ) as the continuous function on ⋃ ε ∈ I J ε such that f ( x )( β ) = ε x ( ) when β ∈ J ε . If x ∈ M A \ A ∗ we choose η < ∑ α n such that g x ( )( γ ) = 0 for γ > η and we define f ( x ) as the continuous function on ⋃ ε ∈ I J ε such that for each ε ∈ I we have
Let us consider I = { ε ∈ {± } 1 A ∗ : T ε = ∅ } . The sets ( T ε ) ε ∈ I are a disjoint cover of [ 0 , ∞ ∑ n =1 α n ) .
$$\in \i \, \text{we have} \\ f ( x ) ( ( \beta, \varepsilon ) ) & = \begin{cases} g ( x ) ( \beta ) & \text{when $\beta \in T_{\varepsilon} \cap [0,\eta]$} \\ 0 & \text{otherwise.} \end{cases}$$
Notice that we have f ( 0 ) = 0 and f ( x )( β ) ∈ {± } 1 for x ∈ A ∗ and β ∈ ⋃ ε ∈ I J ε . Let us check that f is an isometry. Using that g is an isometry and the definition of f and T ε , it is obvious that
$$\text{that} \\ d ( x, y ) = \| g ( x ) - g ( y ) \| = \sup \left \{ | f ( x ) ( \beta ) - f ( y ) ( \beta ) | \, \colon \beta \in \bigcup _ { \varepsilon \in I } \overline { T _ { \varepsilon } \times \{ \varepsilon \} } \right \}. \\ \text{On the other hand checkin} \sigma \text{ the four.} \text{subsibilities} \, ( r \in \ A. \ or \ r \not \in \ A. \, \lambda \, \lambda \, \text{and} \, ( n \in \ A. \ or \ n \not \in \ A. \, \text{or} \, n$$
On the other hand, checking the four possibilities ( x ∈ A ∗ or x / A ∈ ∗ ) and ( y ∈ A ∗ or y / ∈ A ∗ ), and remembering SA2, we see that | f ( x )( β ) -f ( y )( β ) | ≤ d x, y ( ) if β / ∈ ⋃ ε ∈ I T ε ×{ } ε .
Thus, f is an isometry from M A into C ( ⋃ ε ∈ I J ε ) . It is clear that ⋃ ε ∈ I J ε is homeomorphic to
The hypothesis in b) means that ε (1) = 1 and ε (2) = -1 for every ε ∈ I . Now the definition of f on A ∗ gives the conclusion of b).
$$\sum _ { n = 1 } ^ { \infty } \alpha _ { n } \right ) \cdot N ] \text{ where } N \coloneqq | I |. \text{ Hence } f \, maps \, \text{isometrically } M _ { A } \, \text{into } C ( [ 0, ( \sum _ { n = 1 } ^ { \infty } \alpha _ { n } ) \cdot N ] ). \\ \text{The hypothesis in } b ) \, \text{means that } \varepsilon ( 1 ) = 1 \, \text{and } \varepsilon ( 2 ) = - 1 \, \text{for every } \varepsilon \in I. \text{ Now the definition}$$
The hypothesis in b) and c) mean that I = { } ε where ε (1) = 1, ε (2) = -1. So N = 1. /square
Given a metric space M , a mapping f : M → C K ( ), points a, b ∈ M and a constant 1 ≤ D < 2 we denote
$$X _ { a, b } ^ { f } \coloneqq \{ x ^ { * } \in K \, \colon | \langle x ^ { * }, f ( a ) - f ( b ) \rangle | \geq 4 - 2 D \} \,.$$
The duality above means the evaluation at the point x ∗ ∈ K . Wedo not indicate the dependence on D since it will always be clear from the context, which D we have in mind.
$$& \text{Lemma} \, 6. \, \text{Let} \, C _ { 1 }, \dots, C _ { h } \, \text{be pairwise disjoint finite sets, we denote} \, A = \{ 0 \} \cup \bigcup _ { i = 1 } ^ { h } C _ { i }. \, \text{Let} \\ & ( M _ { n } ) _ { n \in \mathbb { N } } \, \text{be a sequence of metric spaces of uniformly bounded diameter such that} \, A \subset M _ { n } \, \text{for} \,.$$
( M n ) n ∈ N be a sequence of metric spaces of uniformly bounded diameter such that A ⊂ M n for every n ∈ N (and they satisfy SA1 and SA2). Let 1 ≤ D < 2 and let K be a Hausdorff compact. We assume that for each n ∈ N there is an ordinal α n < ω 1 and an integer β n ∈ N such that every f n : M ↪ n → D C K ( ) satisfies
/negationslash
$$\begin{array} { c } \left | \bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f _ { n } } \cap K ^ { ( \alpha _ { n } ) } \right | \geq \beta _ { n } \\ \text{Then the sup-amalgam $M_{A}$ } = \end{array}$$
∣ ∣ for all a i = b i ∈ C i ⊂ M n . Then the sup-amalgam M A = ( M n ) ∞ n =1 /A satisfies for every f : M ↪ A → D C K ( ) ,
- a) if α m < lim n α n = α for all m ∈ N , then
/negationslash
/negationslash
$$\bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f } \cap K ^ { ( \alpha ) } \neq \emptyset$$
for all a i = b i ∈ C i ⊂ M A . b) if α n = α for all n ∈ N , then
/negationslash for all a i = b i ∈ C i ⊂ M A .
Proof. Let f : M ↪ A → D C K ( ). Then f n := f /harpoonupright M n is an embedding of M n into C K ( ) with dist( f n ) ≤ D , and the conclusion follows. /square
$$\aleph, \, & t h e n \\ \left | \bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f } \cap K ^ { ( \alpha ) } \right | \geq \sup \beta _ { n } \\ M _ { A }. \\ \text{Then } \, & f _ { n } \ \coloneqq \ f \ \restriction _ { M _ { n } } \ \text{is an embed}$$
Clearly, we do not cover all the possibilities in the above lemma, but these two are the interesting for us.
2.3. Iterative construction of M α . We use trees here in a very basic fashion as index sets. For the notation, check [13]. For two finite sequences m = ( m , . . . , m 1 h ) and n = ( n , . . . , n 1 l ), we write m n /frown = ( m , . . . , m 1 h , n 1 , . . . , n l ) for their concatenation. We omit the parentheses for the sequences of length one, thus ( n ) is written as n . Let us construct for every ordinal α < ω 1 the tree T α +1 on N as follows:
- · T 1 = N
- · if α is limit, we choose some α n ↗ α and put T α +1 = N ∪ ∞ ⋃ n =1 n T /frown α n +1
- · if α is non-limit, we put T α +1 = N ∪ ∞ ⋃ n =1 n T /frown α
where n T /frown α = { n m /frown : m ∈ T α } . Clearly, for each α , the tree T α +1 is well founded. Further, let us define a derivation on trees as follows:
$$T ^ { \prime } = \{ ( n _ { 1 }, \dots, n _ { h } ) \in T \, \colon ( n _ { 1 }, \dots, n _ { h - 1 }, k ) \text{ is not maximal in } T \text{ for some } k \in \mathbb { N } \}$$
There is an index o naturally tied to this derivation. We put T (0) = T , T ( α +1) = ( T ( α ) ) ′ and T ( α ) = ⋂ β<α T ( β ) whenever α is a limit ordinal. We put o T ( ) = inf { α : T ( α ) = ∅ } if the set is nonempty, otherwise o T ( ) = ∞ . We do not intend to characterize the trees for which o T ( ) < ∞ . Instead, we will compute the index of the trees T α +1 above. It is worth noting that for every α, β and n ∈ T ( β ) α +1 the set of successors of n in T ( β ) α +1 is either empty or equal to { n k /frown : k ∈ N } . Lemma 7. For each α < ω 1 we have o T ( α +1 ) = α +1 .
Proof. We have clearly o T ( 1 ) = 1 since all the nodes are maximal, and are mutual siblings. Assume the claim to be true for all β < α , we try to prove it for α . If α = β +1 is non-limit, ∞
α + 1. Finally assume that α is limit, we have T α +1 = N ∪ ∞ ⋃ n =1 n T /frown α n +1 . It is thus clear that
$$& \text{assume the claim to be true for all } \beta < \alpha, \, \text{we try to prove it for } \alpha. \, \text{if } \alpha = \beta + 1 \, \text{is non-limit}, \\ & \text{we have } T _ { \alpha + 1 } = \mathbb { N } \cup \bigcup _ { n = 1 } ^ { \infty } n ^ { \wedge } T _ { \beta + 1 }. \, \text{It is thus clear that } T _ { \alpha + 1 } ^ { ( \beta + 1 ) } = T _ { 1 } \, \text{and so } o ( T _ { \alpha + 1 } ) = \beta + 1 + 1 = \\ & \wedge + 1 \, \mathbb { m } \colon \, \underset { \alpha + 1 } { \mathbb { m } + \wedge \colon \, \colon + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha +\alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha - \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \beta + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha + \alpha +
\end{cases}$$
$$T _ { \alpha + 1 } ^ { ( \alpha _ { m } + 1 ) } = & \, \, \mathbb { N } \cup \bigcup _ { n = m + 1 } ^ { \infty } \ n \, \overset { \sim } { T } _ { \alpha _ { n } + 1 } ^ { ( \alpha _ { m } + 1 ) } \text{ for all } m \in \mathbb { N }. \, \text{ Hence } T _ { \alpha + 1 } ^ { ( \alpha ) } = T _ { 1 }, \text{ and so } o ( T _ { \alpha + 1 } ) = \alpha + 1. \quad \square \\ & \text{For each node of a tree } T _ { \lambda + 1 } \text{ it will be important to know how many derivations it takes till}$$
Lemma 8. For each α < ω 1 and each n ∈ T α +1 the ordinal r α +1 ( n ) := inf { β : n ∈ max T ( β ) α +1 } is isolated ( 0 or successor).
For each node of a tree T α +1 it will be important to know how many derivations it takes till the node becomes maximal.
Proof. Induction on α . Clearly true for α = 0 (we have r 1 ( n ) = 0 for each n ∈ T 1 ). Assume the claim to be true for α . Then r α +1+1 ( n ) = o T ( α +1 ) = α +1 for all n ∈ N by the construction of the tree T α +2 and by Lemma 7. Further, for each n ∈ N and each n ∈ T α +1 , the ordinal r α +1+1 ( n n /frown ) = r α +1 ( n ) is isolated by the inductive hypothesis. In the case when α is limit and the claim has been proved for all β < α , we have r α +1 ( n ) = o T ( α n +1 ) = α n +1 for all n ∈ N by the construction of the tree T α +1 and by Lemma 7. Further, for each n ∈ N and each n ∈ T α n +1 , the ordinal r α +1 ( n n /frown ) = r α n +1 ( n ) is isolated by the inductive hypothesis. /square
Definition 9. Let ( A i ) ∞ i =0 be a sequence of countably infinite pairwise disjoint sets which will be fixed from now on. Suppose that A i = { a , a i 1 i 2 , . . . } and denote A k i = { a , . . . , a i 1 i k } for all i ≥ 0 and k ≥ 1. We assume that A 2 0 = { 1 2 , } . To shorten the notation we put
$$M _ { \overline { n } } ^ { 0 } = M ( A _ { 0 } ^ { 2 }, A _ { 1 } ^ { n _ { 1 } }, \dots, A _ { h } ^ { n _ { h } } )$$
for each n = ( n , . . . , n 1 h ) ∈ N h .
Let us fix µ < ω 1 from now on. The tree T = T µ +1 encodes a construction of a metric space. First we consider all the maximal elements max T of T . We thus have a collection M 0 = { M 0 n : n ∈ max T } . Each space in this collection is finite. Once M α = { M α n : n ∈ max T ( α ) } has been defined, we pass to the collection M α +1 = { M α +1 n : n ∈ max T ( α +1) } as follows. For every n = ( n , . . . , n 1 h ) ∈ max T ( α +1) we put
When α < µ is a limit ordinal, we define the elements of M α = { M α n : n ∈ max T ( α ) } as M α n = lim β<α M β n . This definition makes sense since for every n ∈ max T ( α ) there is β 0 < α such that n ∈ max T ( β ) for all β 0 ≤ β < α . Indeed, by Lemma 8, we may take β 0 = r µ +1 ( n ). It is isolated, so β 0 < α .
$$& \text{every } n = ( n _ { 1 }, \dots, n _ { h } ) \in \max { 1 } \stackrel { \lambda \cdots \nu } { \lambda \nu } \text{ we put } \\ & M _ { \pi } ^ { \alpha + 1 } = \begin{cases} ( M _ { \pi ^ { \alpha } } ^ { \alpha } ) _ { k = 1 } ^ { \infty } / ( \{ 0 \} \cup A _ { 0 } ^ { 2 } \cup A _ { 1 } ^ { n _ { 1 } } \cup \dots \cup A _ { h } ^ { n _ { h } } ) & \text{if } \overline { n } \in \max { T } ^ { ( \alpha + 1 ) } \sum { \lambda } { T } ^ { ( \alpha ) } \\ M _ { \pi } ^ { \alpha } & \text{if } \overline { n } \in \max { T } ^ { ( \alpha + 1 ) } \cap \max { T } ^ { ( \alpha ) }. \\ \cdots & \cdots \end{cases}$$
At the end of the day we have M µ = { M µ n : n ∈ N } which we glue into a single space M µ +1 ∅ = ( M µ n ) ∞ n =1 / ( { 0 } ∪ A 2 0 ).
Lemma 10. For every 1 ≤ α ≤ µ +1 for every n = ( n , . . . , n 1 h ) ∈ max T ( α ) (or rather n = ∅ in the case α = µ + 1 ) there are N ≤ 2 2+ n 1 + ... + n h and an isometric embedding f : M α n → C ([0 , ω α · N ]) such that f ( 0 ) = 0 , f (1) ≡ 1 and f (2) ≡ -1 . When α = µ +1 , we have N = 1 .
Proof. By the definition of the spaces in M 0 , we get the claim for α = 1 using Lemma 3 and Lemma 5 a)-b) (here the ordinals α n are finite so the spaces C ([0 , α n ]) and /lscript ∞ ( α n ) are isometric). For α > 1, the proof is a standard transfinite induction argument exploiting Lemma 5 a)-b). Finally, when α = µ + 1, the definition of M µ +1 ∅ shows that also the part c) of Lemma 5 applies. /square
Lemma 11. (i) For each 1 ≤ D < 2 there exists a constant C D = ( log ( /floorleft D 2 -D /floorright +1 )) -1 > 0 such that for every α ≤ µ and every n = ( n , . . . , n 1 h ) ∈ max T ( α ) and every f : M ↪ α n → D C K ( ) we have
/negationslash
$$& \varkappa \quad - \,, \quad \varkappa \quad - \,, \quad \varkappa \quad - \,, \\ & \quad \left | X _ { 1, 2 } ^ { f } \cap \bigcap _ { i = 1 } ^ { h - 1 } X _ { a _ { i }, b _ { i } } ^ { f } \cap K ^ { ( r _ { \mu + 1 } ( \pi ) ) } \right | \geq C _ { D } \log ( n _ { h } ) \\ & \quad _ { i } ^ { n _ { i } }, \, 1 \leq i \leq h - 1 \, \left ( \text{with the obvious meaning when } h = 1 ). \\ & \leq D < 2 \ a n d \ e v e r y \ f \, \colon M _ { \emptyset } ^ { \mu + 1 } \underset { \sim } { \hookrightarrow } C ( K ) \ w e \ h a v e$$
∣ ∣ for all a i = b i ∈ A n i i , 1 ≤ i ≤ h -1 (with the obvious meaning when h = 1 ). (ii) For each 1 ≤ D < 2 and every f : M µ +1 ∅ ↪ → D C K ( ) we have
/negationslash
$$X _ { 1, 2 } ^ { f } \cap K ^ { ( \mu + 1 ) } \neq \emptyset.$$
Proof. We will proceed by a transfinite induction on α . We assume the result to be true for every β < α and we want to prove it for α . Clearly it is enough to prove the claim for
α = r µ +1 ( n ). Indeed, if α > r µ +1 ( n ) then M α n and M r µ +1 ( n ) n are the same, and the result follows by the inductive hypothesis.
In the case 0 < α = r µ +1 ( n ), the node n just became maximal, i.e. n ∈ max T ( α ) \ max T ( β ) where α = β + 1 (remember Lemma 8). This means that the immediate successors { n k /frown : k ∈ N } of n in T ( β ) are all maximal in T ( β ) and M α n = ( M β n /frown k ) ∞ k =1 / ( { 0 } ∪ A 2 0 ∪ A n 1 1 ∪ . . . ∪ A n h h ) .
By the inductive hypothesis we have for every k ∈ N and every f k : M β n /frown k ↪ → D C K ( ) that
/negationslash
By the construction of T µ +1 it is clear that we have two types of non-maximal nodes n ∈ T µ +1 : a ) those for which ( r µ +1 ( n k /frown )) k ∈ N is a strictly increasing sequence of ordinals and
$$\text{By one unique.} \text{nypometesis we have for every } \kappa \in \mathbb { v } \text{ and every } J _ { k } \colon \mathbb { N } _ { \ n \sim k } \overset { \sim } { \to } \cup \mathbb { N } \\ ( 1 ) & \left | X _ { 1, 2 } ^ { f _ { k } } \cap \bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f _ { k } } \cap K ^ { ( r _ { \mu + 1 } ( \overline { n } \sim k ) ) } \right | \geq C _ { D } \log ( k ) \\ \text{for every choice} \, a _ { i } \neq b _ { i } \in A _ { i } ^ { n _ { i } }, \, 1 \leq i \leq h. \\ \text{By the construction of} \, T _ { \mu + 1 } \text{ it is clear that we have two types of non-maximal} \, \mathbb { n } \\ \lambda \, \text{thooc for which} \, \text{$(\mp\sim\lambda$} \, \cdots$} \, \text{$\sim$} \, \text{atrix$b$} \, \text{inocoincase} \, \text{on each of and in} \, \mathbb { n }.$$
- b ) those for which it is a constant sequence.
The case a) means that β is a limit ordinal and sup { r µ +1 ( n k /frown ) : k ∈ N } + 1 = r µ +1 ( n ) by the definition of r µ +1 ( n ). The case b) means that β is a successor and for all k ∈ N we have r µ +1 ( n k /frown ) + 1 = r µ +1 ( n ).
Let f be an embedding such that d x, y ( ) ≤ ‖ f ( x ) -f ( y ) ‖ ≤ Dd x, y ( ). Remembering (1), we apply Lemma 6 to get
/negationslash
/negationslash
$$X _ { 1, 2 } ^ { f } \cap \bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f } \cap K ^ { ( r _ { \mu + 1 } ( \overline { n } ) ) } \neq \emptyset \\ A _ { i } ^ { n _ { i } }, \, 1 \leq i \leq h. \text{ Notice that since sup} \, \{ r _ { \mu + }$$
for every choice a i = b i ∈ A n i i , 1 ≤ i ≤ h . Notice that since sup { r µ +1 ( n ) : n ∈ N } = µ , we can put formally r µ +1 ( ∅ ) = µ +1, and so the above also proves (ii).
/negationslash
Now we need to pass from 'non-empty' to 'larger than C D log( n h )'. We may assume that f ( 0 ) = 0. Let a i = b i ∈ A n i i be fixed for 1 ≤ i ≤ h -1. By the above there exists
/negationslash
$$x _ { a, b } ^ { * } & \in X _ { 1, 2 } ^ { f } \cap \bigcap _ { i = 1 } ^ { h - 1 } X _ { a _ { i }, b _ { i } } ^ { f } \cap X _ { a, b } ^ { f } \cap K ^ { ( r _ { \mu + 1 } ( \overline { n } ) ) } \\ \intertext {. We set. } \Gamma & = \left \{ x ^ { * }, \colon a. b \in A ^ { n _ { h } } a \neq h \right \}. \text{ Now}$$
for each a = b ∈ A n h h . We set Γ = { x ∗ a,b : a, b ∈ A n h h , a = b } . Now { 〈 ( f ( a , γ ) 〉 ) γ ∈ Γ : a ∈ A n h h } ⊂ B /lscript ∞ (Γ) (0 , D )
/negationslash is (4 -2 D )-separated set of cardinality n h . We thus get that | Γ | ≥ C D log( n h ).
/negationslash
It remains to prove what happens if α = 0. So let f : M ↪ 0 n → D C K ( ) and let a i = b i ∈ A n i i ,
1 ≤ i ≤ h , be given. We put A = { } ∪ { 1 a i : 1 ≤ i ≤ h } and B = { } ∪ { 2 b i : 1 ≤ i ≤ h } . We get by the triangle inequality that each x ∗ ∈ K such that |〈 x , f ∗ ( A ) -f ( B ) 〉| = ‖ f ( A ) -f ( B ) ‖ satisfies
$$x ^ { * } \in X _ { 1, 2 } ^ { f } \cap \bigcap _ { i = 1 } ^ { h } X _ { a _ { i }, b _ { i } } ^ { f }. \\ \text{ove we get the desired ineq}$$
Now by the same argument as above we get the desired inequality.

1 2 ,
Proof of Theorem 1. Let α < ω 1 be given. If it is isolated, say α = µ +1, we put M α := M µ +1 ∅ . This space embeds isometrically into C ([0 , ω α ]) by Lemma 10. By Lemma 11 (ii) we see that if M µ +1 ∅ ↪ → D C K ( ), D < 2, then K ( α ) = ∅ .
/negationslash
Finally, if α is a limit ordinal we choose µ n ↗ α and we put
$$M _ { \alpha } = ( M _ { \emptyset } ^ { \mu _ { n } + 1 } ) _ { n = 1 } ^ { \infty } / ( \{ 0 \} \cup A _ { 0 } ^ { 2 } ).$$
/negationslash
Since ∑ µ n = α and since M µ n +1 ∅ embeds isometrically into C ([0 , ω µ n +1 ]) for every n ∈ N , Lemma 5 shows that M α embeds isometrically into C ([0 , ω α ]). If f : M ↪ α → D C K ( ), D < 2, then X f 1 2 , ∩ K ( µ n +1) = ∅ for each n ∈ N . This is a decreasing set of compact sets. Hence X f ∩ K ( α ) = ∅ . /square
/negationslash
## 3. Concluding remarks
/negationslash
Remark 12. Let α < ω 1 and let K be a Hausdorff compact space such that K ( α ) = ∅ . We denote by C 0 ( K ) the closed subspace of C K ( ) of the functions whose restrictions on K ( α ) are identically zero. An inspection of above proof shows that C ([0 , ω α ]) does not embed with distortion strictly less than 2 into C 0 ( K ). In particular, C ([0 , ω α ]) does not embed with distortion strictly less than 2 into C 0 ([0 , ω α ]). For α = 1 the last statement means that c does not embed with distortion strictly less than 2 into c 0 . This also follows from [15, Proposition 3.1] as an easy but entertaining exercise.
Proposition 13. Let 1 ≤ D < 2 be given. Then for every 1 ≤ m<ω there is 1 ≤ n < ω such that for all α < ω 1 the space C ([0 , ω α · n ]) does not embed into the space C ([0 , ω α · m ]) with distortion D .
Proof. We find k ∈ N such that C D log( k ) > m and we put n = 2 2+ k . Suppose first that α is a successor ordinal. Notice that if we consider k as an element of max T ( α ) α +1 , we have r α +1 ( k ) = α . By Lemma 11, the space M α k as defined in Definition 9 does not embed with distortion D into C ([0 , ω α · m ]). On the other hand, it embeds isometrically into C ([0 , ω α · n ]) by Lemma 10. If α is a limit ordinal, we replace A 2 0 by A k 0 in Definition 9 and we consider the space
˜ M α := ( M α l +1 ∅ ) ∞ l =1 / ( { 0 } ∪ A k 0 ) . As above, we see that ˜ M α embeds isometrically into C ([0 , ω α · n ]). By repeating the proof of Lemma 11 we get that ˜ M α does not embed with distortion D into C ([0 , ω α · m ]). We leave the details to the reader. /square
We recall that if X and Y are Banach spaces and u : X → Y is uniformly continuous, the following Lipschitz constant of u at infinity
$$l _ { \infty } ( u ) = \inf _ { \eta > 0 } \sup _ { \| x - x ^ { \prime } \| \geq \eta } \frac { \| u ( x ) - u ( x ^ { \prime } ) \| } { \| x - x ^ { \prime } \| }$$
is finite (sometimes called Corson-Klee lemma, see [5, Proposition 1.11]). The uniform distance between X and Y is d U ( X,Y ) = inf l ∞ ( u ) · l ∞ ( u -1 ), where the infimum is taken over all uniform homeomorphisms between X and Y .
A net in a Banach space X is a subset N of X such that there exist a, b > 0 which satisfy
/negationslash
- · for any x, x ′ ∈ N with x = x ′ , we have ‖ x -x ′ ‖ ≥ a and,
- · for any x ∈ X , there exists y ∈ N with ‖ x - ‖ ≤ y b .
We say that two Banach spaces are net-equivalent when they have Lipschitz homeomorphic nets. The net distance between X and Y is the number d N ( X,Y ) = inf dist( f ) where the infimum is taken over all mappings f : N → M with N ⊂ X and M ⊂ Y being nets. Finally d L ( X,Y ) = inf dist( f ) where the infimum is taken over all Lipschitz homeomorphisms f : X → Y . It is well known and easy to see that for any couple of Banach spaces X and Y we have
$$d _ { N } ( X, Y ) \leq d _ { U } ( X, Y ) \leq d _ { L } ( X, Y ).$$
/negationslash
Corollary 14. Let γ = α < ω 1 and n, m ∈ N . Then d N ( C ([0 , ω γ · n ]) , C ([0 , ω α · m ])) ≥ 2 .
This corollary answers partially Problem 2 in [12].
Proof. In fact, we are going to prove the stronger claim that for β < ω α and for every net N in C ([0 , ω α ]) there is no Lipschitz embedding f : N → C ([0 , β ]) such that dist( f ) < 2.
/negationslash
Let us suppose that such f and N exist. Assume that N is an ( a, b )-net and consider a mapping π : C ([0 , ω α ]) → N such that ‖ x -π x ( ) ‖ ≤ b . Let us consider M α as a subset of C ([0 , ω α ]) which we can by Theorem 1. Since d x, y ( ) ≥ 1 for all x = y ∈ M α , we have, for λ > 2 , that dist( b π /harpoonupright λM α ) ≤ ( 1 + 2 b λ ) ( 1 + 2 b λ -2 b ) . Thus it is clear that for λ large enough we have dist( g ) < 2 for the embedding g : M α → C ([0 , β ]) defined as g x ( ) = 1 λ f ( π λx ( )) for x ∈ M α . According to Theorem 1, such embedding cannot exist. Contradiction. /square
Finally, we will give a lower bound on the Szlenk index of a Banach space X that admits a certain M α with distortion strictly less than 2 (for the definition and properties of the Szlenk index, the reader can consult [13, 16]).
Theorem 15. Let X be an Asplund space and assume that M ω α embeds into X with distortion strictly less than 2 for an ordinal α < ω 1 . Then Sz( X ) ≥ ω α +1 .
For the proof we will need the following version of Zippin's lemma as presented in [6, page 27], see also [19, Lemma 5.11].
Zippin's lemma. Let X be a separable Banach space with separable dual and let 1 2 > ε > 0 . Then there exist a compact K , an ordinal β < ω Sz X, ( ε 8 )+1 , a subspace Y of C K ( ) , isometric to C ([0 , β ]) and an embedding i : X → C K ( ) with ‖ ‖ ‖ i i -1 ‖ < 1 + ε such that for any x ∈ X we have
$$\text{dist} ( i ( x ), Y ) \leq 2 \varepsilon \left \| i ( x ) \right \|.$$
Proof. Let us assume that M ω α ↪ → D X with D < 2. Let ε > 0 be small enough so that D ′ = D (1 + ε ) < 2 and also that for η := 2 εD ′ we have 1 + 4 ε 1 -2 η D < ′ 2. Let K and β < ω Sz( X, ε 8 )+1 be as in Zippin's lemma. Then M ω α embeds into C K ( ) with distortion D < ′ 2 via some embedding g such that d x, y ( ) ≤ ‖ g x ( ) -g y ( ) ‖ ≤ Dd x,y ′ ( ) and, without loss of generality, that g ( 0 ) = 0. Thus for every x ∈ M ω α we have ‖ g x ( ) ‖ ≤ 2 D ′ . We know that for each x ∈ M ω α there is f ( x ) ∈ C ([0 , β ]) such that ‖ g x ( ) -f ( x ) ‖ ≤ η . This implies that ‖ g x ( ) -g y ( ) ‖ -2 η ≤ ‖ f ( x ) -f ( y ) ‖ ≤ ‖ g x ( ) -g y ( ) ‖ +2 . Now since 1 η ≤ d x, y ( ) we have d x, y ( )(1 -2 η ) ≤ ‖ f ( x ) -f ( y ) ‖ ≤ d x, y ( ) D ′ (1 + 4 ε . )
This proves that f is a Lipschitz embedding of M ω α into C ([0 , β ]) with distortion strictly less than 2 and so, according to Theorem 1, we have β ≥ ω ω α . This implies that Sz( X > ω ) α and so Sz( X ) ≥ ω α +1 by [13, Theorem 2.43]. /square
An interesting immediate consequence of the above theorem is the fact that, for every γ < α < ω 1 and for every equivalent norm |·| on C ([0 , ω ω γ ]), the space M ω α does not embed with distortion strictly less than 2 into ( C ([0 , ω ω γ ]) , |·| ).
## References
- [1] I. Aharoni, Every separable metric space is Lipschitz equivalent to a subset of c + 0 , Israel J. Math. 19 (1974), 284-291.
- [2] F. Albiac and N. Kalton, Topics in Banach space theory , Graduate Texts in Mathematics, vol. 233, Springer, New York, 2006.
- [3] D. Amir, On isomorphisms of continuous function spaces , Israel J. Math. 3 1965 205-210.
- [4] F. Baudier, A topological obstruction for small-distortion embeddability into spaces of continuous functions on countable compact metric spaces , arXiv:1305.4025 [math.FA]
- [5] Y. Benyamini and J. Lindenstrauss, Geometric nonlinear functional analysis , AMSColloquium publications, Volume 48.
- [6] Y. Benyamini, An extension theorem for separable Banach spaces , Israel J. Math. 29 (1978), no. 1, 24-30.
- [7] C. Bessaga and A. Pe/suppress lczy´ski, n Spaces of continuous functions. IV. On isomorphical classification of spaces of continuous functions , Studia Math. 19 (1960), 53-62.
- [8] M. Cambern, On isomorphisms with small bound , Proc. Amer. Math. Soc. 18 1967 1062-1066.
- [9] H.B. Cohen, A bound-two isomorphism between C X ( ) Banach spaces , Proc. Amer. Math. Soc. 50, 1975, 215-217.
- [10] R. Deville, G. Godefroy and V. Zizler, Smoothness and renormings in Banach spaces, Pitman Monographs and Surveys in Pure and Applied Mathematics 64 (Longman Scientific & Technical, Harlow, 1993).
- [11] Y. Dutrieux and N. Kalton, Perturbations of isometries between C K ( ) -spaces , Studia Math. 166 (2005), no. 2, 181-197.
- [12] R. G´ orak, Coarse version of the Banach-Stone theorem , J. Math. Anal. Appl. 377 (2011), no. 1, 406-413.
- [13] P. H´jek, V. Montesinos-Santaluc´ ıa, J. Vanderwerff and V. Zizler. a Biorthogonal systems in Banach spaces . CMS Books in Mathematics/Ouvrages de Math´ ematiques de la SMC, 26. Springer, New York, 2008.
- [14] K. Jarosz, Nonlinear generalizations of the Banach-Stone theorem , Studia Math. 93 (1989), 97-107.
- [15] N. Kalton and G. Lancien, Best constants for Lipschitz embeddings of metric spaces into c 0 , Fund. Math. 199 (2008), no. 3, 249-272.
- [16] G. Lancien, A survey on the Szlenk index and some of its applications , Rev. R. Acad. Cien. Serie A Mat., 100(1-2), 2006, 209-235.
- [17] A. Pe/suppressczy´ski l n and Z. Semadeni, Spaces of continuous functions. III. Spaces C (Ω) for Ω without perfect subsets , Studia Math. 18 (1959), 211-222.
- [18] A. Proch´zka and L. S´nchez, a a Low distortion embeddings into Asplund Banach spaces , arXiv:1311.4584.
- [19] H. Rosenthal, The Banach Spaces C K ( ), in Handbook of the geometry of Banach spaces, Vol. 2, 1823, North-Holland, Amsterdam, 2003.
- [20] M. Zippin, The separable extension problem , Israel J. Math. 26 (1977), no. 3-4, 372-387.
- † Universit´ Franche-Comt´ e, Laboratoire de Math´matiques UMR 6623, 16 route de Gray, e e 25030 Besanc ¸on Cedex, France
E-mail address : [email protected]
- ‡ Departamento de Ingenier´ ıa Matem´tica, Facultad de CC. F´ ısicas y Matem´ticas, Univera a sidad de Concepci´n, Casilla 160-C, Concepci´n, Chile o o
E-mail address : [email protected] | null | [
"Antonín Procházka",
"Luis Sánchez-González"
] | 2014-08-01T15:54:28+00:00 | 2014-08-01T15:54:28+00:00 | [
"math.FA",
"46B20, 46B85"
] | Low distortion embeddings between $C(K)$ spaces | We show that, for each ordinal $\alpha<\omega_1$, the space
$C([0,\omega^\alpha])$ does not embed into $C(K)$ with distortion strictly less
than $2$ unless $K^{(\alpha)}\neq \emptyset$. |
1408.0212v2 | ## Quantization of β -Fermi-Pasta-Ulam Lattice with Nearest and Next-nearest Neighbour Interactions
Aniruddha Kibey , Rupali Sonone , Bishwajyoti Dey a a 1a , J. Chris Eilbeck b a Department of Physics, University of Pune, Pune - 411007, India b Department of Mathematics and Maxwell Institute, Heriot-Watt University, Riccarton, Edinburgh, EH14 4AS, UK
## Abstract
We quantize the β -Fermi-Pasta-Ulam (FPU) model with nearest and next-nearest neighbor interactions using a number conserving approximation and a numerically exact diagonalization method. Our numerical mean field bi-phonon spectrum shows excellent agreement with the analytic mean field results of Ivi´ and Tsironis ((2006) Physica D 216 200), except for the wave c vector at the midpoint of the Brillouin zone. We then relax the mean field approximation and calculate the eigenvalue spectrum of the full Hamiltonian. We show the existence of multi-phonon bound states and analyze the properties of these states by varying the system parameters. From the calculation of the spatial correlation function we then show that these multi-phonon bound states are particle like states with finite spatial correlation. Accordingly we identify these multi-phonon bound states as the quantum equivalent of the breather solutions of the corresponding classical FPU model. The four-phonon spectrum of the system is then obtained and its properties are studied. We then generalize the study to an extended range interaction and consider the quantization of the β -FPU model with next-nearest-neighbor interactions. We analyze the effect of the next-nearest-neighbor interactions on the eigenvalue spectrum and the correlation functions of the system.
1 [email protected] Accepted in Physica D
## 1. Introduction
The Fermi-Pasta-Ulam (FPU) model marked the beginning of the field of nonlinear dynamics. It was initially introduced to examine the possibility of equipartition of energy in a chain of coupled nonlinear oscillators in the thermodynamic limit [1]. Since then this model has been used to study many important problems in non-equilibrium statistical mechanics, in particular heat conduction in a 1D chain [2]. Other interesting aspects of the dynamics of FPU lattice are the occurrence of intrinsic localized modes (ILMs) or discrete breathers (DBs). ILMs or DBs are time periodic and spatially localized solutions of the nonlinear lattice and occur due to the balance between nonlinearity and discreteness. ILMs have been experimentally observed in various physical systems ranging from lattice vibrations in crystals and magnetic solids, Josephson junction, photonic crystals etc. ILMs have been used for modeling observed physical processes in polymers and bio-polymers such as, folding in the polypeptide chain, targeted breaking of chemical bonds, charge and energy transport in conducting polymers etc., see [3] for a review. MacKay and Aubry rigorously established the existence of breather excitations in lattices under a wide range of conditions [4]. Exact compact breather-like solutions of the two-dimensional FPU lattice were also obtained [5]. The effect of long-range interactions, the geometry of the chain and nonlinear dispersion on the dynamics of breathers in two-dimensional FPU lattices, and the usefulness of these solutions for energy localization and transport in various physical systems are reported in [6].
It is well known that the integrable classical field equations, such as the sine-Gordon equation [7], nonlinear Schrodinger equation [8] and modified and extended KdV equations [9], support classical breather solutions which are a bound state of soliton and antisoliton pair with continuum classical spectrum. On the other hand the Bohr-Sommerfeld semi-classical quantization for classical breathers shows discrete excitations which are bound states of small-amplitude wave excitations [10]. Faddeev and Korepin, while studying the quantum theory of solitons for integrable systems, showed that the breathers of classical integrable field equations are indeed multi-phonon bound states [11]. These studies led to the question of the nature of quantum breathers in nonlinear lattices. Even though there has been some studies along this line for the nonlinear Klein-Gordon lattice and discrete nonlinear Schrodinger equation [12], not much is known about the nature of quantum breathers in FPU lattice model. The problem of quantization of classical
discrete breathers in FPU model is difficult to solve exactly due to the nonlocal and anharmonic nature of interactions in the model, which give rise to number non conserving terms in the Hamiltonian. Various truncation methods have been used to obtain the approximate eigenspectra of the system. Ivi´ and Tsironis [13] studied analytically the discrete breather quantization c problem in a β -FPU lattice by truncating the Hamiltonian to include only number conserving terms, and analyzed the bi-phonon sector of the model under the mean field approximation. The number conserving approximation is equivalent to rotating wave approximation used for studying the classical discrete breathers. Ivi´ and Tsironis showed the occurrence of bi-phonons c of two types, the on-site and nearest neighbor site and interpreted these biphonons as the quantum counterparts of the classical FPU discrete breathers. Xin-Guang and Yi [14] showed the occurrence of a third type, a mixed biphonon state, in a β -FPU model from their numerical exact diagonalization study. However they did not study the four-phonon eigenspectra, the correlation functions, or the effect of the long range interactions on the eigenspectra of the system. Riseborough studied analytically the quantized breather problem on FPU lattice in the two-phonon sector by truncating the equation of motion of the two-phonon propagator, using the ladder approximation in which the single-phonon self-energies are neglected [15]. From the poles of the two-phonon propagator he obtained isolated frequencies which represent the discrete dispersion relations for the collective breather excitations. Recently the bound states of four bosons in the quantum β -FPU lattice have been reported in [16]. However, they did not study the effect of the long range interactions and the spatial correlation functions of the system.
In this paper we study this problem by numerically exact diagonalization using the number state basis and including only number conserving terms. The numerically exact diagonalization method has been successfully applied to the Bose-Hubbard and modified Bose-Hubbard Hamiltonians ([17]-[19]). The purposes of our studies are manifold: (i) to check how the analytical results of Ivi´ c and Tsironis [13], which are obtained under the mean field approximation and in the large eigenvalue limit, compare with the numerically exact diagonalization mean field results; (ii) to go beyond the mean field approximation and obtain numerical eigenspectra of the system; (iii) to study the problem for the higher quanta sector; (iv) to calculate the spatial correlation functions to identify and establish the main characteristics of the spatial localization of the discrete breathers in the quantum excitation spectrum and (v) to generalize the problem to examine the effect of
increasing range of interactions, for which we study the β -FPU model with next-nearest-neighbor (NNN) interactions. Interestingly, we find that the analytical mean field results in the large eigenvalue limit of Ivi´ and Tsironis c [13] agree very well with our numerically exact diagonalization results. We also find that the eigenspectra for the complete Hamiltonian (beyond the mean field case) is quite different as compared to that of the mean field case. Contrary to the mean field case, the nearest neighbor site bi-phonon mode do not get distinctly separated from the quasi-continuum band. This is in agreement with [14]. The four-phonon spectrum shows that the states which belong to the free phonon band now split into several bands due to the effect of nonlinearity. The isolated band corresponds to discrete breathers. A similar splitting of bands for the higher quanta sector of the Klein Gordon type nonlinear lattice has been reported by Wang et al. [20] from their numerically exact diagonalization calculations using an Einstein phonon basis. The spatial correlation functions for the on-site bi-phonon, as well as the four-phonon states, show strong localization at particular sites. This shows the particle like nature of the states which identifies these states with corresponding classical on-site discrete breathers. Similarly, the inclusion of the NNN interaction in the β -FPU model changes the lattice periodicity and its effect on the eigenspectra is clearly seen.
It may be noted that the number conserving approximation cannot be used for α -Fermi-Pasta-Ulam lattice. This is because the cubic interaction terms in the α -Fermi-Pasta-Ulam Hamiltonian are all number nonconserving.
It is appropriate to mention here that quantum breather excitations have been seen in experiments as sharp discrete peaks in the excitation spectrum of the ionic crystal NaI [21], as bound states of up to seven phonons in PtCl [22], as two-phonon bound states in the infrared absorption spectra of CO 2 crystals [23], as a carrier of vibrational energy without dispersing for over more than 10 7 unit cells of layered crystal muscovite [24] etc. See [12] for more details.
The plan of the paper is as follows: In Sec. 2 we describe the Hamiltonian of the β -Fermi-Pasta-Ulam lattice and the quantization scheme. We write the Hamiltonian in terms of the phonon creation and annihilation operators within the number conserving approximation. In section 3 we describe the computational method. In section 4 we write the Hamiltonian under the mean field approximation. In section 5 we write the complete and mean field Hamiltonians for NNN interaction in terms of the phonon creation and
annihilation operators and in section 6 we present the results and discussion. Finally we conclude in section 7.
## 2. The β -Fermi-Pasta-Ulam model and its quantization
The Hamiltonian for the classical one dimensional β -FPU model for N identical oscillators in a periodic lattice is given by [13]
$$H = \sum _ { j } \left [ \frac { p _ { j } ^ { 2 } } { 2 m } + \frac { \alpha } { 2 } \left ( x _ { j } - x _ { j - 1 } \right ) ^ { 2 } + \frac { \beta } { 4 } \left ( x _ { j } - x _ { j - 1 } \right ) ^ { 4 } \right ]$$
where α is the nearest-neighbor harmonic force constant and β is the anharmonic force constant. The position and momentum operators of the j -th particle can be written in terms of the phonon creation and annihilation operators as
$$\begin{matrix} \\ \end{matrix}$$
$$x _ { j } \ & = \ \sqrt { \frac { \hbar } { 2 m \omega } } \left ( a _ { j } ^ { \dagger } + a _ { j } \right ) \\ p _ { j } \ & = \ i \sqrt { \frac { \hbar } { 2 m \omega } } \left ( a _ { j } ^ { \dagger } - a _ { j } \right )$$
The creation and annihilation operators follow the commutation relations given by [ a , a j † k ] = δ jk , and [ a , a j k ] = [ a , a † j † k ] = 0. Retaining only the number conserving terms, by virtue of the lattice periodicity and assuming N → ∞ ,where N is the number of lattice sites, the Hamiltonian can be written as [13]
$$H \ = \ & \ \epsilon _ { o } + \hbar { \bar { \omega } } \sum _ { j } a _ { j } ^ { \dagger } a _ { j } - J ^ { \prime } \sum _ { j } a _ { j } ^ { \dagger } \left ( a _ { j + 1 } + a _ { j - 1 } \right ) \\ & + B \sum _ { j } \left [ a _ { j } ^ { \dagger 2 } a _ { j } ^ { 2 } + \frac { 1 } { 2 } a _ { j } ^ { \dagger 2 } \left ( a _ { j + 1 } ^ { 2 } + a _ { j - 1 } ^ { 2 } \right ) \right ] \\ & + B \sum _ { j } \sum _ { s = \pm 1 } \left [ a _ { j } ^ { \dagger } a _ { j } a _ { j + s } ^ { \dagger } a _ { j + s } - \left ( a _ { j } ^ { \dagger 2 } a _ { j } a _ { j + s } + \text{h.c.} \right ) \right ] \\ \text{where}$$
where
$$\epsilon _ { 0 } \ = \ \frac { \hbar { \omega } N } { 2 } \left ( 1 + \frac { 3 \beta } { 2 \alpha } \left ( \frac { \hbar } { 2 M \omega } \right ) \right ),$$
$$\bar { \omega } \ = \ \omega \left ( 1 + \frac { 3 \beta } { \alpha } \left ( \frac { \hbar } { 2 M \omega } \right ) \right ),$$
$$J ^ { \prime } \ = \ \alpha \left ( \frac { \hbar } { 2 M \omega } \right ) \left ( 1 + \frac { 3 \beta } { \alpha } \frac { \hbar } { M \omega } \right ),$$
$$B \ = \ 3 \beta \left ( \frac { \hbar } { 2 M \omega } \right ) ^ { 2 }$$
## 3. The Computational Method
In Eqs. (1) and (2) we assume that the number of lattice sites is infinite, but in practice we can work with a finite number of sites. To simulate the infinite lattice, with finite number of sites, we incorporate the periodic boundary conditions (ring geometry). We consider a system with f lattice sites. Since we use the number conserving approximation, the Hamiltonian operator commutes with the number operator ˆ N = ∑ f j =1 a a † j j , where j = 1 2 3 , , , . . . , f are lattice points. This implies that the operators H and ˆ have N simultaneous eigenstates. Hence we can block-diagonalize the Hamiltonian matrix using simultaneous eigenstates of H and ˆ N as
$$H = \left ( \begin{array} { c c c c } H _ { 0 } & 0 & 0 & \cdots \\ 0 & H _ { 1 } & 0 & \cdots \\ 0 & 0 & H _ { 2 } & \cdots \\ \vdots & \vdots & \vdots & \ddots \end{array} \right )$$
where each block H m describes states with m bosons. This greatly simplifies the calculations. Because of this block diagonal structure, it is possible to deal with each block independently [17, 18]. For example in the paper we have calculated the energy spectrum for two quanta sector and four quanta sector. This corresponds to the blocks H 2 (Section 6.1) and H 4 (Section 6.2) respectively.
In the number state representation, the basis state is denoted by | ψ n 〉 = [ n , n , ....n 1 2 f ], where n j denotes the number of quanta (bosons) at lattice site j . For example [1 1 0 0], represents a two quanta state with four lattice sites, with one boson each at the first and the other at the second lattice sites and no bosons at the other two lattice sites, N = ∑ j n j . For m quanta and f sites there are ( m f + -1)! m f !( -1)! possible states [17, 18]. For example for a 1D periodic lattice of f = 3 sites and m = 2 bosons, there are 6 possible states [2 0 0 ], [0 2 0 ], [0 0 2 ], [1 1 0 ], [0 1 1 ], and [1 0 1 ] and therefore H 2 for this particular case is 6 × 6 matrix.
To generate the Hamiltonian matrix, we make use of a hash table [25]. To generate the label for each state, we assign a weight to each lattice point as w j = √ p j where p j is the j th prime. The label for a state is given by, σ ([ state ]) = ∑ j = f j =1 w n j j , where n j is the number of quanta at the j th lattice point. Use of the hash table considerably reduces the number of operations needed to generate the Hamiltonian matrix.
Further, under the periodic boundary conditions, the Hamiltonian is invariant under the action of the translation operator ˆ . T Hence we can use the translation invariant states to further block-diagonalize each block of the Hamiltonian matrix [17, 18]. The number of translation invariant states ( N ) for the system is given by [17, 18]
$$\mathcal { N } = \frac { ( m + f - 1 )! } { m! f! }$$
Hence for 2 quanta and 3 sites, the number of translation invariant states is 2 for each value of k . The two translation invariant states of a system with two quanta and three lattice sites are given by
$$\left | \psi _ { 1 } \right \rangle \ = \ \left [ 2 \ 0 \ 0 \right ] + t \left [ 0 \ 2 \ 0 \right ] + t ^ { 2 } \left [ 0 \ 0 \ 2 \right ]$$
$$\left | \psi _ { 2 } \right \rangle \ = \ \left [ 1 \ 1 \ 0 \right ] + t \left [ 0 \ 1 \ 1 \right ] + t ^ { 2 } \left [ 1 \ 0 \ 1 \right ]$$
where t= e ik , with corresponding k values 0 , ± 2 π/ 3, so that t 3 = 1. Thus we can further block-diagonalize H 2 into three 2 × 2 blocks H 2 ,k using the translationally invariant states. The eigenvalues and eigenvectors of each of the 2 × 2 blocks can be calculated separately. This greatly reduces the memory requirement of each calculation. The allowed values of k for a lattice with f sites are k = 2 π f ν , where ν = 0 , ± 1 , ± 2 , ... ± ( f 2 -1) , ± f 2 for f even and ν = 0 , ± 1 , ± 2 , ... ± f -1 2 for f odd [17].
The number of invariant states increase rapidly with increase in the number of quanta and also with the number of lattice points. An arbitrary state vector of the system is given by
$$\left | \Psi \right \rangle = \sum _ { j } C _ { j } \left | \psi _ { j } \right \rangle$$
The normalization condition 〈 Ψ Ψ | 〉 = 1 gives ∑ j | C j | 2 = 1.
Exact numerical diagonalization, using the LAPACK package [26], is then used to calculate the eigenvalues and eigenvectors of the Hamiltonian matrix for the m -quanta sector on a lattice with f sites. To plot
the energy spectrum we have considered glyph[epsilon1] ( k ) = ( E j ( k ) -2¯ hω / J ) 2 ′ , where E j ( k ) are the eigenvalues of the Hamiltonian matrix. The k dependence of the energy E j ( k ) = 〈 Ψ | H | Ψ 〉 comes from the t = e ik dependence of the general state vector | Ψ 〉 of the system (Eq.(10)), , with k = 2 πν f , where ν = 0 , ± 1 , ± 2 , . . . , ± ( f -1) / 2, through the translation invariant states | ψ 1 〉 and | ψ 2 〉 (Eqs.(8 and 9)).
Spatial correlation function : To identify breathers in the eigenspectra so obtained, we calculate the spatial correlation function to establish the main characteristic of spatial localization. The spatial correlation of the displacements at sites separated by n -lattice spacings is given by the expression [20]
$$f _ { \alpha } \left ( j - j ^ { \prime } \right ) = \left \langle \alpha \right | \hat { x _ { j ^ { \prime } } } \, \hat { x _ { j } } \left | \alpha \right \rangle$$
where | α 〉 denotes the eigenvector of the Hamiltonian and x j is the displacement at the j th site. Using the phonon creation and annihilation operators and the number conserving approximation, we can write the above correlation function as
$$f _ { \alpha } \left ( j - j ^ { \prime } \right ) = \frac { \hbar } { 2 m \omega } \left \langle \alpha \right | \left ( a _ { j ^ { \prime } } ^ { \dagger } a _ { j } + a _ { j ^ { \prime } } a _ { j } ^ { \dagger } \right ) \left | \alpha \right \rangle$$
## 4. Mean field approximation :
The last two terms in Eq. (2) describes bivibron tunneling [13]. These terms may be treated within the mean field approximation as an effective single vibron intersite tunneling and written as 2 〈 a a † 〉 ∑ j a † j ( a j +1 + a j -1 ), where 〈 a a † 〉 denote the expectation value of the number operator a a † in an arbitrary state of the system. The details are given in the Appendix. These two bivibron tunneling terms can now be added to the single vibron tunneling terms (3rd term in Eq. (2)) to get the mean field Hamiltonian with effective parameter J = J ′ +2 B a a 〈 † 〉 [13]. The effective Hamiltonian takes the form
$$\vec { \Phi } _ { \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Phi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi\Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psigma \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi \Psi
H _ { \text{MF} } = \begin{array} { c } \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma \\ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \varsigma & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad &\quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad \\ H _ { \text{MF} } } & = & \begin{array} { c } \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \ varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \varsigma & \ varsigma & \varsigma \\ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad \\ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & & & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad \\ \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad &
& \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad &
& \quad & \quad \ & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \ \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \ \quad & \quad & \ \ & \quad &$$
Thus mean field approach approximates the direct bivibron tunneling process by effective single vibron tunneling. This allows approximate analytic solution of the problem as shown in [13].
## 5. The Fermi-Pasta-Ulam lattice with nearest and next-nearestneighbor interaction
Here we generalize the problem by including next-nearest neighbor interactions to examine the effect of the long-range interaction on the energy spectrum and correlation function of the system. Physical systems such as polymers and biopolymers contain various charged groups which interact with a long-range Coulomb force. Similarly, the excitation transfer in molecular crystals and energy transport in biopolymers are due to the transition dipole-dipole interactions. Several studies of the classical discrete breathers in presence of long-range interactions in one-dimensional chain have been reported in the literature, for details see [6]. Here we consider the onedimensional β -FPU chain with nearest and next-nearest neighbor interactions. The classical Hamiltonian can be written as
$$H \ = \ \sum _ { j } \left [ \frac { p _ { j } ^ { 2 } } { 2 m } + \frac { \alpha } { 2 } \left ( x _ { j } - x _ { j - 1 } \right ) ^ { 2 } + \frac { \alpha _ { 1 } } { 2 } \left ( x _ { j } - x _ { j - 2 } \right ) ^ { 2 } \\ + \frac { \beta } { 4 } \left ( x _ { j } - x _ { j - 1 } \right ) ^ { 4 } + \frac { \beta _ { 1 } } { 4 } \left ( x _ { j } - x _ { j - 2 } \right ) ^ { 4 } \right ]$$
Retaining only the number conserving terms and by virtue of the lattice periodicity, the Hamiltonian can be written as
$$\text{remaining only one number conserving terms and by virtue of the nature} \\ H \ = \ \varepsilon _ { o } + 2 \hbar { \varpi } \sum _ { j } a _ { j } ^ { \dagger } a _ { j } - J ^ { \prime } \sum _ { j } a _ { j } ^ { \dagger } ( a _ { j + 1 } + a _ { j - 1 } ) \\ + B \sum _ { j } \left [ a _ { j } ^ { \dagger } a _ { j } ^ { 2 } + \frac { 1 } { 2 } a _ { j } ^ { \dagger 2 } \left ( a _ { j + 1 } ^ { 2 } + a _ { j - 1 } ^ { 2 } \right ) \right ] \\ + B \sum _ { j } \sum _ { s = \pm 1 } \left [ a _ { j } ^ { \dagger } a _ { j } a _ { j + s } ^ { \dagger } a _ { j + s } - ( a _ { j } ^ { \dagger 2 } a _ { j } a _ { j + s } + h. c ) \right ] \\ - J _ { 1 } ^ { \prime } \sum _ { j } a _ { j } ^ { \dagger } ( a _ { j + 2 } + a _ { j - 2 } ) \\ + B _ { 1 } \sum _ { j } \left [ a _ { j } ^ { \dagger 2 } a _ { j } ^ { 2 } + \frac { 1 } { 2 } a _ { j } ^ { \dagger 2 } \left ( a _ { j + 2 } ^ { 2 } + a _ { j - 2 } ^ { 2 } \right ) \right ] \\ + B _ { 1 } \sum _ { j } \sum _ { s = \pm 2 } \left [ a _ { j } ^ { \dagger } a _ { j } a _ { j + s } ^ { \dagger } a _ { j + s } - ( a _ { j } ^ { \dagger 2 } a _ { j } a _ { j + s } + h. c ) \right ] \quad ( 1 4 ) \\ \text{where the $J^{\prime}$ and $B$ are given by Eqs. (5) and (6) respectively and the $J_{1}^{2}$ and $R$. are given by Eqs. (5) and (6) respectively and the $J_{1}^{2}$ and $R$. are given by Eqs. (5)$$
where the J ′ and B are given by Eqs. (5) and (6) respectively and the J ′ 1 and B 1 are given by
$$J _ { 1 } ^ { \prime } \ & = \ \alpha _ { 1 } \left ( \frac { \hbar } { 2 M \omega } \right ) \left ( 1 + \frac { 3 \beta _ { 1 } } { \alpha _ { 1 } } \frac { \hbar } { M \omega } \right ), \\ B _ { 1 } \ & = \ 3 \beta _ { 1 } \left ( \frac { \hbar } { 2 M \omega } \right ) ^ { 2 }$$
Using the mean field approximation as mentioned above, the mean field Hamiltonian for the β -FPU lattice with NN and NNN interactions in a given quanta sector can be written as
$$\left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{any} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} } { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { {array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array } { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } { \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \right ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( {array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{ array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \text ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \\ \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \end{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{ array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{ array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } { \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } { \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } { \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \\ \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \top ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array} { c } \left ( \begin{array}$$
$$+ B \sum _ { j } \sum _ { s = \pm 1 } a _ { j } ^ { \dagger } a _ { j + s } ^ { \dagger } a _ { j + s } \\ - ( J _ { 1 } ^ { \prime } + 2 B _ { 1 } \left < a ^ { \dagger } a \right > ) \sum _ { j } a _ { j } ^ { \dagger } \left ( a _ { j + 2 } + a _ { j - 2 } \right ) \\ + B _ { 1 } \sum _ { j } \left [ a _ { j } ^ { \dagger 2 } a _ { j } ^ { 2 } + \frac { 1 } { 2 } a _ { j } ^ { \dagger 2 } \left ( a _ { j + 2 } ^ { 2 } + a _ { j - 2 } ^ { 2 } \right ) \right ] \\ + B _ { 1 } \sum _ { j } \sum _ { s = \pm 2 } a _ { j } ^ { \dagger } a _ { j } a _ { j + s } ^ { \dagger } a _ { j + s } \\ \\ - \dots \colon \infty \colon \dots.$$
## 6. Results and Discussions
## 6.1. Two quanta sector
We first consider the discrete breather bands at the second quantum level ( m = 2) or in the two-quanta sector. This corresponds to the block H 2 of the Hamiltonian matrix (Eq.(7)). The m = 2 state is obtained by operating two phonon creation operators on the ground state of the system. For example, for a lattice with three sites the m = 2 state is given by the (Eq.(10)) along with (Eqns.(8 and 9)). For details see (Eq.(13)) of [13]. We have considered a lattice of 101 lattice sites. As mentioned above, for odd number of sites the allowed maximum value of k = ± 2 π f ( f -1) 2 ∼ ± π for large f . Therefore we plot the eigenspectrum for - ≤ 1 k π ≤ +1.
To begin with, we compare our numerical exact diagonalization mean field result with the approximate analytical mean field result of Ivi´ and Tsiroc nis [13] for the two-quanta sector. For easy reference, we have reproduced the mean field results of [13] as Fig. 1(e). Fig. 1(a) shows our numerical results obtained for the choice of parameter value 2 B/J = -2 which is same as the parameter value considered in [13] (shown in Fig. 1.(e) by red lines). Fig. 1.(e) shows that the two bands corresponding to the on-site and nearest-neighbor (off-site) biphonon states (continuous and dotted red curves respectively) cross each other at k/π = ± 1 2 . Ivi´ and Tsironis attributed this c behavior to the approximate nature of their analytical calculations and suggested to verify this fact through numerically exact diagonalization method. As mentioned in the introduction, one of the motivations of our present work is to compare the analytic mean field results of Ivi´ and Tsironis with our exc act diagonalization results. From our study we find that that the crossings of the two bound biphonon bands at k/π = ± 1 2 as obtained by Ivi´ and Tsironis c is indeed an artifact of the approximate nature of their analytic calculations,
as our numerically exact diagonalization results (Fig. 1(a)) shows no such band crossings. Fig. 1(b) shows the energy spectrum for the complete Hamiltonian where the parameter J ′ is related to mean field parameters J in Fig. 1(a) by the relation J = J ′ + 2 B a a 〈 † 〉 . Fig. 1.(c) is the numerical mean field result for another set of parameter value 2 B/J = -20. This large value of the parameter (2 B/J ) shows the separation of the two bound states very clearly (shown by the red lines). Again, our numerical mean field results do not show any band crossing at k/π = ± 1 2 . Fig. 1.(d) shows the eigenspectra for the complete Hamiltonian where the parameter J ′ is related to mean field parameters J in Fig. 1(c) by the relation J = J ′ +2 B a a 〈 † 〉 . Fig. 1.(f) shows the results only for the complete Hamiltonian. This figure is plotted for large value of the parameter | B | = 1 2857 to show larger band separation between . the lowest two bands. The biphonon spectrum for repulsive interaction B > 0 is exactly symmetric to the one for attractive interaction B < 0, but above the free two-phonon band (not shown in the figure). However, contrary to the mean field case, the off-site biphonon mode is not distinctly separated from the quasi-continuum band even for large values of 2 B/J ′ . This is in agreement with the results of Xin-Guang and Yi [14]. To see why the off-site biphonon mode is not distinctly separated from the quasi-continuum band, we consider the matrix obtained for the two quanta mean-field Hamiltonian (Eq. (13)) given by

where D k ( ) = 2¯ hω +2 B (1+cos( k )), E ± ( k ) = -√ 2(1+exp( ± ik )) J , F ± ( k ) = J (1 + exp( ± ik )), G k ( ) = -2 J cos( 1 2 ( f +1) ) and k H = 2(1 + B ). Similarly,
the matrix obtained for the complete Hamiltonian (Eq. (2)) is

where D k ′ ( ) = 2¯ hω +2 B (1 + cos( k )), E ′ ± ( k ) = -√ 2(1 + exp( ± ik ))( J ′ + B ), F ′ ± ( k ) = J ′ (1+exp( ± ik )), G k ′ ( ) = -2 J ′ cos( 1 2 ( f +1) ) and k H ′ = 2(1+ B ). If we consider the two matrices, we notice that the change in the nonlinearity parameter B affects all the off-diagonal elements in H MF ( k ), whereas, it affects only the first two off-diagonal elements of H comp ( k ). Hence the two matrices are similar only for very small values of B . The presence of the extra B term in H MF ( k ) causes the lowering of the eigenvalues corresponding to the off-site breather. Thus the off-site breather appears separate from the continuum band in the mean field case.
To show that the lowest isolated bands in Fig. 1 actually corresponds to the quantum equivalent of the on-site classical discrete breather, we establish their main characteristics, the spatial localization, by calculating the spatial correlation function.
To calculate the spatial correlation function for the on-site discrete breather, we consider the eigenvector | α 〉 (Eq. (12)) that corresponds to the lowest eigenvalue of the Hamiltonian matrix (for complete Hamiltonian, Eq. (2)). Fig. 2(a) and Fig. 2(b) show the spatial correlation function for the on-site discrete breather for the centre and edge of the Brillouin zone respectively. The parameters B and J ′ are the same as in Fig. 1.(f). From the figure we can see that the spatial correlation function has a large peak at n -n ′ = 0 and is almost zero for other values of n -n ′ . This means that the breather is spatially localized at a single site n , which is a key characteristic of onsite discrete breathers. Fig. 2(c) and 2(d) shows the correlation functions for the mean field Hamiltonian (Eq. (13)). The values of the parameters B and J are same as the values in Fig. 1.(a).
The localization property can also be seen from the plot of the probability
| C i | 2 of the translational invariant states | ψ i 〉 corresponding to the ground state of the system [18]. Fig. 3(a) and Fig. 3(b) show the plots corresponding to the wavevector k at the center and near the edge of the Brillouin zone respectively. From the figures we notice that at the centre of the Brillouin zone (Fig. 3(a)), the value of | C 1 | 2 is much greater than elsewhere. This implies that the ground state system prefers to be in the on-site bound states. This corresponds to the 2-on-site breather band [2 , 0 , ... ] plus its cyclic permutations (Eq. (8)). On the other hand, near the edge of the Brillouin zone (Fig. 3(b)), the value of | C 2 | 2 is much greater than the rest. Hence the system prefers to be in the off-site bound state [1 , 1 0 , , ... ] plus cyclic permutations (Eq. (9)). These results are in agreement with Xin-Guang and Yi [14]. Fig. 3(c) and Fig. 3(d) show the corresponding figures for the mean field Hamiltonian (Eq. (13)) and it shows behavior similar to that for the full Hamiltonian case (Eq. (2)).
## 6.2. Four quanta sector
]
So far we have restricted our study to the two-quanta sector. Proceeding in the same way we have generalized the studies to the case of the four-quanta sector, corresponding to the block H 4 of the Hamiltonian matrix. In this case we expect five bands as there are five possibilities of distributing four quantas on f lattice sites. These are [4 , 0 0 0 , , , .... ] , [3 , 1 0 0 , , , .... ] , [2 , 2 0 0 , , , .... ] , [2 , 1 1 0 , , , .... and [1 1 1 1 0 0 , , , , , .... ] and their cyclic permutations. Fig. 4 shows the eigenspectra for the complete Hamiltonian (Eq. (2)) for four quanta sector for the attractive interaction B < 0 case. Here we have considered 51 lattice sites. From the figure we see that the energy spectrum has the same qualitative behavior as the two-quanta case (Fig. 1(d)) as discussed above. However, here the continuum band splits into other bands. As expected, we can observe 5 bands clearly. The overlap of the 3rd and 4th band as seen in the figure reduces with increase in the strength of nonlinearity parameter B and these two bands gets separated. We have not shown the separated bands here, since for larger value of B , the lowest band splits further away from the other bands and it is difficult to show all the bands in the same figure. The lowest band which is separated by a large magnitude corresponds to the single 4-on-site breather band, [4 , 0 , ... ] plus cyclic permutations (similar to Eq. (8) for the two-quanta case). The next lowest band corresponds to the 3-on-site breather band plus single boson band [3 , 1 0 , , ... ] plus cyclic permutations. The third band is the double 2-on-site breather band [2 , 2 0 , , ... ] plus cyclic permutations, the 4-th band is the 2-on-site breather band plus two
single bosons [2 , 1 1 0 , , , ... ] plus cyclic permutations and 5-th band (top band) consists of only single bosons [1 , 1 1 1 0 , , , , ... ]. It is interesting to mention here that these five bands for the 4-quanta sector as mentioned above also occur in the discrete nonlinear Schrodinger (DNLS) model [27].
Fig. 5(a) shows the correlation function for the lowest band (Fig. 4) of the four-quanta sector for 11 lattice sites. From the figure we can see that, as expected for the lowest band at the center of the Brillouin zone ( k/π = 0), the correlation function have a large peak at n -n ′ = 0 and is almost zero for other values of n -n ′ . The large peak corresponds to 4-on-site discrete breather state. Small finite values of the correlation function for non-zero values of n -n ′ as seen in the figure are due to finite size effect of the lattice. This can be seen from Fig. 5(b) where we have plotted the same correlation function for 51 lattice sites and we can see that most of these peaks at nonzero value of n -n ′ disappear. Fig. 5(c) shows the correlation function for the next lowest band (Fig. 4) of the four-quanta sector for 11 lattice sites. As mentioned above, this band corresponds to the 3-on-site breather band plus single boson band [3 , 1 0 , , ... ] plus cyclic permutations. From the figure we can see that there is a large peak at n -n ′ = 0 and oscillations of the correlation function which have significant weight even at large values of n -n ′ . The large peak corresponds to 3-on-site discrete breather state and the oscillation corresponds to the one free-phonon state. To show that the oscillation is not a finite size effect, we have calculated the same correlation function for 51 lattice sites as shown in Fig. 5(d). From the figure we can see that the oscillations have significant weight even at n -n ′ = 6.
## 6.3. Two quanta sector with next-nearest neighbour interaction
We now present the results for the one-dimensional β -FPU lattice with nearest and next nearest neighbor interactions (Eq. (14)). This is topologically equivalent to a zig-zag chain. If the lattice periodicity for the straight chain is a , then for the zig-zag chain it is doubled to 2 a . Accordingly the Brillouin zone boundary for the zig-zag chain is at half its value ( π/ a 2 ) as compared to that of the straight chain. Thus the energy spectrum for the one-dimensional β -FPU lattice with NN and NNN interactions is expected to be qualitatively similar to that of the same lattice system with only nearest neighbor interactions (Eq. (2)), except that the Brillouin zone boundary of the NNN will be at half of the value as that of the NN. This is exactly shown in Fig. 6 for the mean field Hamiltonian (Eq. (15)) and in Fig. 7 for the full Hamiltonian (Eq. (14)) for the two-quanta sector. Comparison of Fig. 6
with Fig 1(c) for the mean field case, we see that the nature of the energy spectrum is similar in both cases, and the Brillouin zone boundary in Fig. 6 occurs at exactly half the value of the zone boundary in Fig. 1(c). Comparison of Fig. 7 and Fig. 1(d) also shows similar behavior for the respective full Hamiltonian cases. Fig. 8 (a) and (b) show the plots for the correlation functions calculated for the lowest mode of the eigenvalue spectrum (Fig. 7) at the centre and the edge of the Brillouin zone respectively. This mode corresponds to on-site discrete breather or the on-site bound biphonon state. The peak of the correlation function at a particular site n -n ′ = 0 shows the localization property of the discrete breather. Fig. 8(c) and Fig. 8(d) are the plots of the probability amplitudes at the center and edge of the Brillouin zone respectively. From Fig. 8(c) we can see that there is a large amplitude of | C 1 | 2 , which corresponds to the on-site discrete breather or the on-site bound biphonon mode for k = 0. On the other hand at the edge of the Brillouin zone | C 2 | 2 shows that the 2-off-site bound biphonon state is more probable. Similar behavior is observed for the mean field Hamiltonian (Eq. (15)).
## 7. Conclusion
In conclusion, we have studied the quantization of the β -FPU lattice with nearest and next-nearest neighbor interactions using boson quantization rules and number conserving approximations. The eigenvalue spectra in the twoand four-quanta sector are obtained using an numerically exact diagonalization technique. From the calculation of the energy spectrum and correlation function of the system, we have shown that the quantum breathers exist as bound states of onsite and nearest sites multi-phonons. We have shown that the probability amplitude of the translational invariant states corresponding to a quantum discrete breather state depends on the wave vector. For the wavevector at the centre of the Brillouin zone, quantum breathers with bound states of onsite multi-phonons are preferred. On the contrary, for the wavevector at the edge of the Brillouin zone, the quantum breathers with bound states of nearest sites multi-phonons are preferred. The inclusion of next-nearest neighbour interactions do not change the nature of the eigenspectra and the correlation functions of the system except that the Brillouin zone is reduced to half.
## 8. Appendix A:
The bivibron tunneling term ∑ j ( a † j ) 2 a a j j ± 1 can be written as: ∑ j ( a † j ) 2 a a j j ± 1 = ∑ j a a a a † j † j j j ± 1 = ∑ j a a a † j † j j ± 1 a j = ∑ j a a † j j ± 1 a a † j j In the mean field approximation we take out the expectation value of the last two terms. This gives the bivibron tunneling term as ∑ j ( a † j ) 2 a a j j ± 1 ≈ 〈 a a † 〉 ( ∑ j a a † j j ± 1 ).
Similarly, the corresponding h.c. term can be written as: ∑ j a † j ± 1 a a a † j j j = ∑ j a a † j † j ± 1 a a j j = ∑ j a a a † j j † j ± 1 a j . Under mean field approximation this term can be written as ≈ 〈 a a † 〉 ∑ j a † j ± 1 a j which for an infinite lattice ( N → ∞ ) can be written as 〈 a a † 〉 ∑ j a a † j j ∓ 1 .
We now show that 〈 a a † j j 〉 = 〈 a a † 〉 = m , independent of lattice site j and depends only on the number of quanta m in the state. For this we consider a system with three lattice sites and a state | Ψ with two quanta ( 〉 m = 2). The state is given by Eq. (10) along with Eq. (8) and Eq. (9).
$$a _ { 1 } ^ { \dagger } a _ { 1 } | \Psi \rangle \ & = \ C _ { 1 } a _ { 1 } ^ { \dagger } a _ { 1 } | \psi _ { 1 } \rangle + C _ { 2 } a _ { 1 } ^ { \dagger } a _ { 1 } | \psi _ { 2 } \rangle \\ & = \ C _ { 1 } \left ( 2 [ 2 \ 0 \ 0 ] + 0 + 0 \right ) + C _ { 2 } \left ( [ 1 \ 1 \ 0 ] + 0 + t ^ { 2 } [ 1 \ 0 \ 1 ] \right )$$
Taking the scalar product with 〈 Ψ and using orthonormality condition for | the number states [2 0 0] , [0 2 0] , .. [1 1 0] .. , we get
$$\langle \Psi | a _ { 1 } ^ { \dagger } a _ { 1 } | \Psi \rangle = 2 | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } = 2 ( | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } ) = 2$$
Similarly,
$$a _ { 2 } ^ { \dagger } a _ { 2 } | \Psi \rangle = C _ { 1 } \left ( 0 + 2 t [ 0 \ \ 2 \ \ 0 ] + 0 \right ) + C _ { 2 } \left ( [ 1 \ \ 1 \ \ 0 ] + t [ 0 \ \ 1 \ \ 0 ] + 0 \right )$$
and
$$a _ { 3 } ^ { \dagger } a _ { 3 } | \Psi \rangle = C _ { 1 } \left ( 0 + 0 + 2 t ^ { 2 } [ 0 \ \ 0 \ \ 2 ] \right ) + C _ { 2 } \left ( 0 + t [ 0 \ \ 1 \ \ 1 ] + t ^ { 2 } [ 1 \ \ 0 \ \ 1 ] \right )$$
Taking the scalar product with 〈 Ψ , we get |
$$\langle \Psi | a _ { 2 } ^ { \dagger } a _ { 2 } | \Psi \rangle = 2 | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } = 2 ( | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } ) = 2$$
and,
$$\langle \Psi | a _ { 3 } ^ { \dagger } a _ { 3 } | \Psi \rangle = 2 | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } = 2 ( | C _ { 1 } | ^ { 2 } + | C _ { 2 } | ^ { 2 } ) = 2$$
This shows that 〈 a a † j j 〉 = 〈 a a † 〉 is independent of j . To show that 〈 a a † 〉 is independent of f , we consider a system with 5 lattice sites. For the two quanta sector ( m = 2) and five lattice sites ( f = 5) we get,
$$a _ { 1 } ^ { \dagger } a _ { 1 } | \Psi \rangle \ & = \ C _ { 1 } ( 2 [ 2 \ 0 \ 0 \ 0 \ 0 ] + 0 + 0 + 0 + 0 ) + C _ { 2 } ( [ 1 \ 1 \ 0 \ 0 \ 0 ] + 0 \\ & + \ 0 + 0 + t ^ { 4 } [ 1 \ 0 \ 0 \ 0 \ 1 ] ) + C _ { 3 } ( [ 1 \ 0 \ 1 \ 0 \ 0 ] + 0 + 0 \\ & + \ t ^ { 3 } [ 1 \ 0 \ 0 \ 1 \ 0 ] + 0 )$$
Hence,
〈 Ψ | a a † 1 1 | Ψ = 2 〉 | C 1 | 2 + | C 2 | 2 + | C 2 | 2 + | C 3 | 2 + | C 3 | 2 = 2( | C 1 | 2 + | C 2 | 2 + | C 3 | 2 ) = 2 Similarly 〈 Ψ | a a † 2 2 | Ψ = Ψ 〉 〈 | a a † 3 3 | Ψ = Ψ 〉 〈 | a a † 4 4 | Ψ = Ψ 〉 〈 | a a † 5 5 | Ψ = 2( 〉 | C 1 | 2 + | C 2 | 2 + | C 3 | 2 ) = 2. In general, for an arbitrary state | Ψ with 〉 m quanta and f lattice sites 〈 Ψ | a a † n n | Ψ = 〉 m for all lattice sites i.e. n = 1 2 , , . . . , f .
Acknowledgement: BD would like to thank DST and BCUD-PU for financial assistance through research projects and INSA-RSE for a visiting fellowship. BD would also like to thank Heriot-Watt University, Edinburgh, UK and ICTP, Trieste, Italy for hospitality, where part of the work was done.
## References
- [1] Focus issue on the occasion of the fifty years of Fermi-Pasta-Ulam problem (2005) Chaos 15.
- [2] S. Lepri, R. Livi and A. Poloti (2005) Chaos 15 015118; A. Fillipov, B. Hu, B. Li and A. Zeltser (1998) J. Phys. A: Math. Gen. 31 7719; G. Benettin, R. Livi and A. Ponno (2009) J. Stat. Phys. 135 873.
- [3] S. Flach and A.V. Gorbach (2008) Phys. Rep. 467 1.
- [4] R. S. MacKay and S. Aubry (1994) Nonlinearity 7 1623.
- [5] R. Sarkar and B. Dey (2006) J. Phys. A: Math. Gen. 39 L99.
- [6] R. Sarkar and B. Dey (2007) Phys. Rev. E 76 016605; R. Sarkar and B. Dey (2007) Eur. Phys. J. Special Topics 147 73 and references therein.
- [7] M. J. Ablowitz, D. J. Kaup, A. C. Newell and H. Segur (1973) Phys. Rev. Lett. 30 1262.
- [8] N. N. Akhmediev, V. M. Eleonskii, N. E. Kulagin (1987) Theoretical and Mathematical Physics 72 Issue 2 809.
- [9] R. Grimshaw, A. Slunyaev and E. Pelinovsky (2010) Chaos 20 013102.
- [10] R. F. Dashen, B. Hasslacher and A. Neveu (1974) Phys. Rev. D 10 4114; (1975) ibid. 11 3424.
- [11] L. D. Faddeev and V. E. Korepin (1978) Phys. Rep. 42 Issue 1 1.
- [12] For a review see, R. A. Pinto and S. Flach in Dynamical Tunneling: Theory and Experiment (2011) CRC Press, Eds. S. Keshavamurthy and P. Schlagheck, pp 339-382.
- [13] Z. Ivi´ and G. P. Tsironis (2006) Physica D 216 200. c
- [14] H. Xin-Guang and T. Yi (2008) Chin. Phys. B 17 4268.
- [15] P. S. Riseborough (2012) Phys. Rev. E 85 011129.
- [16] H. Xin-Guang et al. (2013) Pramana - J. Phys. 81 839.
- [17] A. C. Scott, J. C. Eilbeck and H. Gilhøj (1994) Physica D 78 194.
- [18] J. C. Eilbeck and F. Palmero (2004) Phys. Letts. A 331 Issue 3-4 201 ; J. Chris Eilbeck, Proceedings of the Third Conference 'Localization and Energy Transfer in Nonlinear Systems', June 17-21, San Lorenzo de El Escorial Madrid, eds L. Vzquez, R. S. MacKay, M. P. Zorzano, World Scientific, Singapore, 177-186, 2003
- [19] Z. I. Djoufack, A. Kenfack-Jiotsa, J. P. Nguenang and S. Domngang (2010) J. Phys.: Condens. Matter 22 205502.
- [20] W. Z. Wang, J. Tinka Gammel, A. R. Bishop and M. I. Salkola (1996) Phys. Rev. Lett. 76 3598.
- [21] M. E. Manley et al. (2009) Phys. Rev. B 79 134304.
- [22] B. I. Swanson et al. (1999) Phys. Rev. Lett. 82 3288.
- [23] D. A. Dows and V. Schettino (1973) J. Chem. Phys. 58 5009.
- [24] F. M. Russell and J. C. Eilbeck (2007) Euro. Phys. Lett. 78 10004.
- [25] J. M. Zhang and R. X. Dong (2010) Eur. J. Phys. 31 591.
- [26] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney and D. Sorensen (1999) Lapack User's Guide.
- [27] J. Dorignac, J.C. Eilbeck, M. Salerno, and A. C. Scott (2004), Phys. Rev. Letts. 93 025504.
Figure 1: Energy spectrum for(a) Mean field Hamiltonian for B = -0 2 . and J = 0 2 . (b) Complete Hamiltonian for B = -0 2 . and J ′ = 1 (c) Mean field Hamiltonian for B = -0 2439 and . J = 0 02439, (d) Complete Hamiltonian for . B = -0 2439 and . J ′ = 1, (e) Mean Field Results of Ivi´ and c Tsironis, (figure obtained from [13]) (f) Complete Hamiltonian for B = -1 2857 and . J ′ = 1
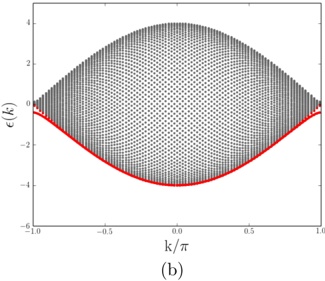
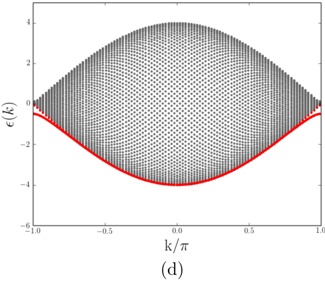
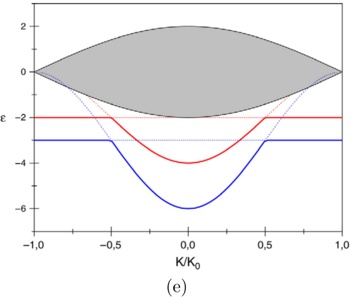
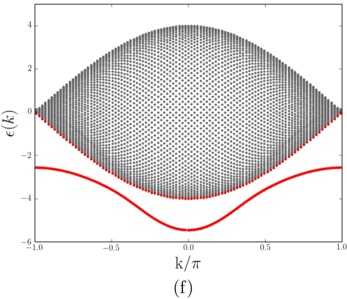
Figure 2: (a)Spatial correlation Function for k/π = 0 , B = -1 2857 . , J ′ = 1 for the complete Hamiltonian, (b)Spatial correlation Function for k/π = 50 51 / , B = -1 2857 . , J ′ = 1 for the complete Hamiltonian, (d) Correlation Function for k/π = 50 51 / , B = -0 2 . , J = 0 2 for the mean field Hamiltonian, (c) Correlation Function for . k/π = 0 , B = -0 2 . , J = 0 2 for the mean field Hamiltonian .
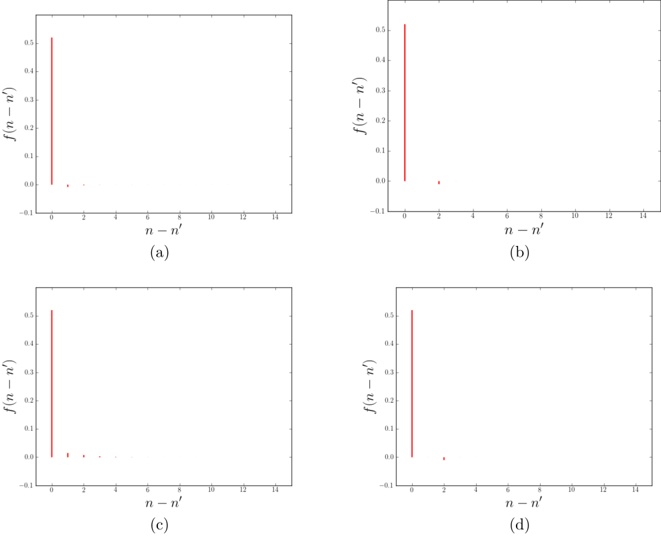
Figure 3: (a) | C i | 2 for k/π = 0 , B = -1 2857 . , J ′ = 0 07 for the complete Hamiltonian, (b) . | C i | 2 for k/π = 50 51 / , B = -1 2857 . , J ′ = 0 07 for the complete Hamiltonian, (c) . | C i | 2 for k/π = 0 , B = -0 2 . , J = 0 2, for mean field Hamiltonian, (d) . | C i | 2 for k/π = 50 51 / , B = -0 2 . , J = 0 2, for mean field Hamiltonian .
Figure 4: Energy spectrum of the complete Hamiltonian for four quanta, m = 4, and 51 sites, B = -20 0 and . J ′ = 1 0 .
Figure 5: Spatial correlation function for the complete Hamiltonian, for four quanta, m = 4, with k/π = 0 , B = -20 0 and . J = 1 0, (a) for lowest energy mode with 11 sites, . (b) for lowest energy mode with 51 sites, (c) for second lowest energy mode with 11 sites, (d) for the second lowest energy mode with 51 sites.
Figure 6: Energy spectrum of the mean field Hamiltonian with nearest and next nearest neighbor interactions for, m=2, B = -5 0 . , J = 1 , B 1 = -2 5 . , J 1 = 0 5, 101 sites .
Figure 7: Energy spectrum of the complete Hamiltonian with nearest and next nearest neighbor interactions for, m=2, B = -5 0 . , J ′ = 1 , B 1 = -2 5, . J ′ 1 = 0 5, 101 sites .
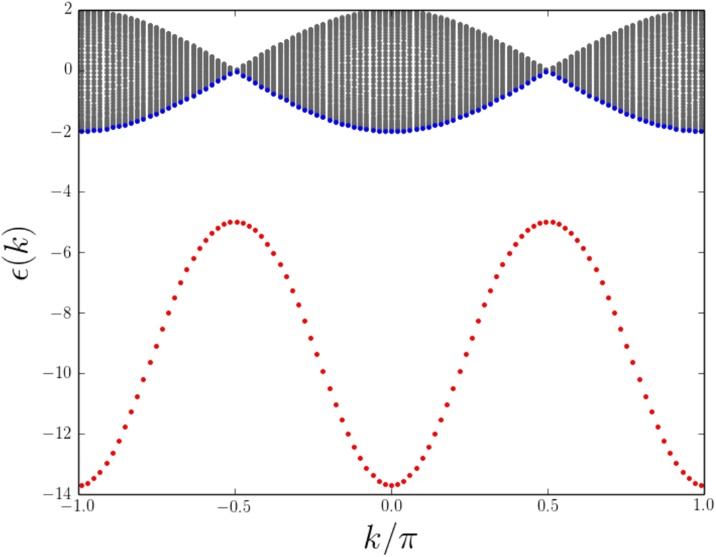
Figure 8: (a) Spatial correlation function for k/π = 0 , B = -5 0 . , J = 1 , B 1 = -2 5 and . J 1 = 0 5, (b) Spatial correlation function for . k/π = 50 51 / , B = -5 0 . , J = 1 , B 1 = -2 5 . and J 1 = 0 5, (c) . | C i | 2 for k/π = 0 , B = -5 0 . , J = 1 , B 1 = -2 5 and . J 1 = 0 5, (d) . | C i | 2 for k/π = 50 51 / , B = -5 0 . , J = 1 , B 1 = -2 5 . , J 1 = 0 5 of the complete Hamiltonian with . nearest and next nearest neighbor interactions
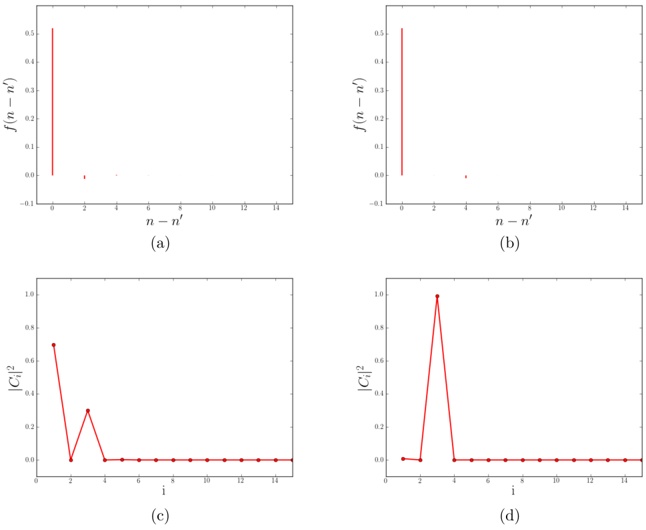 | null | [
"Aniruddha Kibey",
"Rupali Sonone",
"Bishwajyoti Dey",
"J. Chris Eilbeck"
] | 2014-08-01T15:58:01+00:00 | 2014-12-08T11:28:11+00:00 | [
"nlin.PS",
"cond-mat.other",
"quant-ph"
] | Quantization of β-Fermi-Pasta-Ulam Lattice with Nearest and Next-nearest Neighbour Interactions | We quantize the \beta-Fermi-Pasta-Ulam (FPU) model with nearest and
next-nearest neighbour interactions using a number conserving approximation and
a numerical exact diagonalization method. Our numerical mean field bi-phonon
spectrum shows excellent agreement with the analytic mean field results of
Ivi\'{c} and Tsironis ((2006) Physica D 216 200), except for the wave vector at
the midpoint of the Brillouin zone. We then relax the mean field approximation
and calculate the eigenvalue spectrum of the full Hamiltonian. We show the
existence of multi-phonon bound states and analyze the properties of these
states as the system parameters vary. From the calculation of the spatial
correlation function we then show that these multi-phonon bound states are
particle like states with finite spatial correlation. Accordingly we identify
these multi-phonon bound states as the quantum equivalent of the breather
solutions of the corresponding classical FPU model. The four-phonon spectrum of
the system is then obtained and its properties are studied. We then generalize
the study to an extended range interaction and consider the quantization of the
\beta-FPU model with next-nearest-neighbour interactions. We analyze the effect
of the next-nearest-neighbour interactions on the eigenvalue spectrum and the
correlation functions of the system. |
1408.0213v1 | ## Smart Meter Privacy for Multiple Users in the Presence of an Alternative Energy Source
Jesus Gomez-Vilardebo ∗ and Deniz G¨ und¨ uz † ∗ Centre Tecnol` ogic de Telecomunicacions de Catalunya (CTTC), Castelldefels, Spain † Imperial College London, London, UK [email protected], [email protected]
Abstract -Smart meters (SMs) measure and report users' energy consumption to the utility provider (UP) in almost realtime, providing a much more detailed depiction of the consumer's energy consumption compared to their analog counterparts. This increased rate of information flow to the UP, together with its many potential benefits, raise important concerns regarding user privacy. This work investigates, from an information theoretic perspective, the privacy that can be achieved in a multi-user SM system in the presence of an alternative energy source (AES). To measure privacy, we use the mutual information rate between the users' real energy consumption profile and the SM readings that are available to the UP. The objective is to characterize the privacy-power function , defined as the minimal information leakage rate that can be obtained with an average power limited AES. We characterize the privacy-power function in a singleletter form when the users' energy demands are assumed to be independent and identically distributed over time. Moreover, for binary and exponentially distributed energy demands, we provide an explicit characterization of the privacy-power function. For any discrete energy demands, we demonstrate that the privacypower function can always be efficiently evaluated numerically. Finally, for continuous energy demands, we derive an explicit lower-bound on the privacy-power function, which is tight for exponentially distributed loads.
2022. However, the massive deployment of SMs at homes have also raised serious concerns regarding user privacy [3]. High resolution SM readings can allow anyone who has access to this data to infer valuable private information regarding user behaviour, including the type of electrical equipments used, the time, frequency and duration of usage [4], and even the TV channel that is being watched, as reported in [5]. The privacy of smart meter data is more critical for businesses, such as data centers, factories, etc., whose energy consumption behaviour can reveal important information about their business to competitors. As pointed out in [6], depending on the monitoring granularity different consumption patterns can be identified. With a granularity of hours or minutes, one can identify the user's presence, with a granularity of minutes or seconds one can infer the activities of appliances such as TV or refrigerator, and with a granularity of seconds one could detect bursts of power and identify the activity of appliances such as microwaves, coffee machines or toasters.
## I. INTRODUCTION
With the adoption of smart meters (SMs) in energy distribution networks the utility providers (UPs) are able to monitor the grid more closely, and predict the changes in the demand more accurately. This, in turn, allows the UPs to increase the efficiency and the reliability of the grid by dynamically adjusting the energy generation and distribution, as well as the prices, thereby, also influencing the user demand. SMs also benefit the users by allowing them to monitor their own energy consumption profile in almost real time. Consumers can use this information to cut unnecessary consumption, or to reduce the cost by dynamically shifting consumption based on the prices dynamically set by the UPs.
SM deployment is spreading rapidly worldwide [1]. In Europe, the adoption of SMs has been mandated by a directive of the European Parliament [2], which requires 80% SM adoption in all European households by 2020 and 100% by
This work was partially supported by the Catalan Government under SGR2009SGR1046 and by the Spanish Government under projects TEC201017816 and TSI-020400-2011-18.
Several methods have been proposed in the literature to provide privacy to SM users while keeping the benefits of SMs for control and monitoring of the grid. In [7] user anonymization is proposed by the participation of a trusted third party. Bohli et al. [8] propose sending the aggregated energy consumption of a group of users and in [9] users protect their privacy by adding random noise to their SM readings before being forwarded to the UP. Similarly, [10] proposes quantization of SM readings.
In all of the above work, privacy is obtained by distorting/transforming the SM readings before being forwarded to the UP. However, energy is provided to the user by the UP, and in principle, the UP can easily track user's energy consumption by installing its own smart measurement devices at points where the user connects to the grid. It seems that no level of privacy can be achieved under such a strong assumption; however, users can conceal the patterns corresponding to individual devices and usage patterns by manipulating their energy consumption. This can be achieved either by filtering the energy consumption over time by means of a storage device such as an electric car battery [11], [12], [13] and [14], or by considering the availability of an alternative energy source (AES) [14], [15]. An AES can model a connection to a second energy grid, such as a microgrid, or a renewable energy source, such as a solar panel.
In our model, we assume that the users can satisfy part of their energy demand from the AES. While the UP can track the energy it provides to the users perfectly, it does not have access to the instantaneous values of the amount of energy the user receives from the AES. Hence, a certain level of privacy will be achieved depending on the amount of power available from the AES. For instance, if the power that the AES can provide is sufficient enough to satisfy, at any time, all the energy demand of the appliances, the privacy problem can be resolved in a straightforward manner, as no power is requested from the power grid. However, in general, the AES will be limited in terms of the average power it can support, and as we show in this paper, how the user utilizes the energy provided by the AES is critical from the privacy perspective. We measure the privacy through the mutual information rate between the user's real energy consumption and the energy provided by the UP (the SM readings). Mutual information has previously been proposed as a measure of privacy in several works [16]-[18], and in particular, for SM systems in [10], [12] and [14].
In our previous work [15], [19] we have characterized the minimum information leakage rate in the case of a single user with an average and peak power constrained AES. We have shown that there is a very close connection with this problem and the rate-distortion problem in lossy source compression [20] albeit with significant differences. Here we generalize our results to multiple users. In this scenario (see Fig. 1), multiple users, each with its own independent energy demand, share a single AES. The reason for users to share an AES can be economical. AESs, such as solar panels, and efficient energy storage units are expensive facilities, and may be shared by multiple parties to reduce cost. There could be also energy efficiency reasons: consider a scenario in which multiple smart meters belong to the same user; for example, different buildings of the same company. In such a case, the most energy efficient solution requires the centralized management of the AES for all the components of the system.
We assume that there is one separate SM for each user, and the privacy is measured by the total information leaked to the UP about the users' energy consumption. A single energy management unit (EMU) receives users' instantaneous energy demands and decides how much energy to provide to each user from the AES, while satisfying the average power constraint. We first introduce the privacy-power function which characterizes the minimal information leakage rate to the UP for a given AES average power constraint. We then provide a single-letter information theoretic characterization of the privacy-power function for the multi-user scenario when the input loads are independent and identically distributed (i.i.d.) random variables. While the EMU can employ energy management policies with memory, our result shows that a memoryless energy management policy that randomly requests energy from the AES is optimal, significantly simplifying the implementation.
We consider both discrete and continuous input loads. For discrete input load distributions, we first show that the optimal output alphabet can be limited to the input alphabet without loss of optimality, which allows us to write the privacypower function as the solution of a convex optimization problem with linear constraints. As a result, the privacypower function with discrete input loads can be evaluated numerically in polynomial time. We also provide a closedform expression for the privacy-power function when the input loads are independent and binary distributed. Using numerical optimization, we compare the optimal privacy-power function with two heuristic power allocation schemes. We consider a time-division heuristic scheme which, at each time instant, obtains the requested energy either from the grid or from the AES, but not from both simultaneously. We also consider an output load limiting heuristic scheme which limits the output load to a fixed maximum value in order to cover up any variation in the energy demand beyond this value. We numerically show that our optimal scheme provides significant privacy gains compared to these heuristic energy management policies.
While the numerical evaluation of the privacy-power function for general continuous input load distributions is elusive, we derive the Shannon lower bound (SLB) on the privacypower function, and show that this lower bound is tight when users have independent exponentially distributed input loads. For the latter case, we also show that the optimal allocation of the energy generated by the AES among the users can be obtained by the reverse waterfilling algorithm [20]. The users with low average input load satisfy all their demand from the AES, while the users with higher average load receive the same amount of energy from the grid.
The rest of the paper is organized as follows. In Section II, we introduce the system model, and provide a single-letter information theoretic characterization of the privacy-power function when users have i.i.d. energy demands over time. Then we show that the privacy-power function for independent users can be solved by simply minimizing the sum of the individual privacy-power functions with a sum average power constraint. The derivation of the privacy-power function for discrete input loads and its particularization to binary input loads is addressed in Section III. Then in Section IV the privacy-power function for continuous input loads is studied and particularized to the exponential distribution. Numerical results are provided in Section V. Finally, conclusions are drawn in Section VI.
## II. SYSTEM MODEL
We consider the discrete time SM model depicted in Fig. 1. We have N users connected to the energy grid. The energy requested by user i at time instant t is denoted by X t i ( ) ∈ X i , where X i is the support set of the energy demand of user i . We consider the availability of an AES in the system. The AES can provide energy to the users at a maximum average power of P . The AES reduces the energy requested from the grid; but the primary use of the AES here is to create privacy against the UP and other third parties.
The energy flow in the system is managed by the EMU. The EMU receives, at time t , the energy demands of all the users, i.e., the vector X ( ) t = [ X 1 ( ) t , ..., X N ( )] t . Part of the energy demand of the users can be supported by the AES, while the remainder is provided directly from the energy grid.
Fig. 1. Smart meter model studied in this paper. The EMU receives the energy demand from multiple users, U , . . . , U 1 N , and decides how much of the energy demand of each user should be provided from the AES. The remainder of the energy demands are satisfied from the grid, which are measured and reported by the SMs to the UP. The privacy is measured through the information leakage rate, which measures how much information the UP receives about the input load [ X (1) , . . . , X ( n )] by observing the SM readings [ Y (1) , . . . , Y ( n )] .
We denote by Y i ( ) t ∈ Y i , the amount of energy user i gets from the grid at time t , or equivalently, the reading of SM i at time t . We define Y ( ) = [ t Y 1 (1) , ..., Y N ( )] t as the aggregated SM readings available to the UP at time t . The energy demand of each user has to be satisfied fully at any time, that is, we do not allow outages or delaying/shifting the user demand. Moreover, we do not allow increasing privacy at the expense of wasting energy, i.e., we have 0 ≤ Y i ( ) t ≤ X t i ( ) for all t .
At the EMU, we consider energy management policies which, at each time instant t , decide on the amount of power that will be provided from the AES to each of the users based on the input loads up to time t , X t = [ X (1) , ..., X ( )] t , and the output loads up to the previous time instant, Y t -1 = [ Y (1) , ..., Y ( t -1)] . We allow stochastic energy management policies, that is, the output load at time t , Y ( ) t , can be a random function of X t and Y t -1 . We assume that, while the UP knows P , the average power generated by the AES, it does not have access to the instantaneous values of the energy users receive from the AES.
Definition 1: Denote the vector of input and output load alphabets for all the users as X N = [ X 1 , ..., X N ] and Y N = [ Y 1 , ..., Y N ] , respectively. A lengthn energy management policy is composed of, possibly stochastic, power allocation functions
$$f _ { t } \colon \mathcal { X } ^ { N \times t } \times \mathcal { Y } ^ { N \times ( t - 1 ) } \to \mathcal { Y } ^ { N }, \quad \ \ ( 1 ) \quad _ { \ } D e j$$
for t = 1 , ..., n, such that
$$\text{Y} ( t ) & = f _ { t } ( \text{X} ( 1 ), \dots, \text{X} ( t ), \text{Y} ( 1 ), \dots, \text{Y} ( t - 1 ) ), \quad ( 2 ) \quad \text{The $F$} \\ \text{with $X_{i}(t) \geq Y_{i}(t) \geq 0$ for all $1 \leq i \leq N$ and $1 \leq t \leq n$.} \quad \text{vacy tha} \\ \text{The goa}$$
We measure the privacy achieved by an n -length energy management policy with the information leakage rate . Assuming that the statistical behavior of the energy demand is known by the UP, its initial uncertainty about the real energy consumption can be measured by the entropy rate 1 n H ( X n ) .
This uncertainty is reduced to 1 n H ( X Y n | n ) once the UP observes the output load. Hence, the information leaked to the UP can be measured by the reduction in the uncertainty, or equivalently, by the mutual information rate between the input and the output loads,
$$I _ { n } \stackrel { \triangle } { = } \frac { 1 } { n } I \left ( { \mathbf X } ^ { n } ; { \mathbf Y } ^ { n } \right ).$$
Notice that if we could provide all the energy required by the users from the AES, we could achieve perfect privacy, i.e., we would have I n = 0 for all n , by letting Y i ( ) t = 0 for all i and t . However, in general the AES will be limited in terms of the average power it can provide.
We are thus interested in characterizing the achievable level of privacy as a function of the average power P that is provided by the AES, given by
$$P _ { n } = \mathbb { E } \left [ \sum _ { i = 1 } ^ { N } \frac { 1 } { n } \sum _ { t = 1 } ^ { n } ( X _ { i } ( t ) - Y _ { i } ( t ) ) \right ], \quad ( 4 ) \\ \text{re the expectation is take over the joint probability distri-}$$
where the expectation is take over the joint probability distribution of the input and output loads.
Definition 2: An information leakage rate - average power pair ( I, P ) is said to be achievable if there exists a sequence of energy management policies of duration n with lim n →∞ I n ≤ I , and lim n →∞ P n ≤ P .
Definition 3: The privacy-power function , I ( P ) , is the infimum of the information leakage rates I such that ( I, P ) is achievable.
The privacy-power function characterizes the level of privacy that can be achieved by an average power limited AES. The goal of the EMU is to achieve the minimum information leakage rate by optimally allocating the limited energy from the AES over the users and time.
This model of an AES is appropriate for energy sources with their own large energy storage unit, which can provide energy reliably at a certain rate for a sufficiently long duration
of time. A peak power constraint on the AES, in addition to the average power constraint, is also considered in [19]. On the other hand, in [14] we have explicitly considered the energy generation process at the AES, in which case the EMU is limited not only by the average power it can pull from the AES, but also the generated energy plus the energy available in the battery at each time instant. Such instantaneous constraints that vary over time depending on the energy management policy and the energy arrival process at the AES, render the analysis significantly harder as they prevent us from invoking information theoretic arguments that will be instrumental in obtaining the single-letter results in this work.
Our goal here is to give a mathematically tractable expression for the privacy-power function, and identify the optimal energy management policy that achieves it. In the rest of the paper, we consider i.i.d. input loads for simplicity, as this will allow us to obtain a single-letter expression for the privacypower function. Note that in most real-life applications there is a significant correlation among energy demands over time. The i.i.d. assumption allows us to characterize the optimal privacy-preserving solutions, which will be instrumental in identifying solutions for more realistic energy consumption models. Moreover, the i.i.d input load model might be valid in scenarios where the energy consumption either does not have memory at any time scale, or can be modelled as i.i.d. over the time scale of interest. This could be the case, for example, when there is a huge number of applications in use at any time, e.g., in a data center, where the input load can be modelled as i.i.d. over time for different traffic/ load states.
In the next theorem, we show that if the input load vectors X ( ) t are i.i.d. over time with f X ( x ) , we can characterize the function I ( P ) in a single-letter format. Note that the instantaneous energy demands of the users can be correlated with each other.
Theorem 1: The privacy-power function I ( P ) for an i.i.d. input load vector X = [ X ,. . . , X 1 N ] with distribution f X ( x ) is given by
$$\mathcal { I } ( P ) = \inf _ { \substack { f _ { \mathbf Y } | \mathbf X ( y | \mathbf x ) \colon \mathbb { E } [ \sum _ { i = 1 } ^ { N } ( X _ { i } - Y _ { i } ) ] \leq P, \\ 0 \leq Y _ { i } \leq X _ { i }, \, i = 1,.. N } } I ( \mathbf X ; \mathbf Y ), \quad ( 5 ) \quad \lambda \quad \text{We} \\ \text{can all} \quad \text{mano}.$$
where Y = [ Y , . . . , Y 1 N ] is the corresponding vector of SM readings.
Some basic properties of the privacy-power function I ( P ) are characterized in the following lemma. The proof follows from standard techniques based on time-sharing arguments [20].
Lemma 1: The privacy-power function I ( P ) , given above, is a non-increasing convex function of P .
## Next we prove Theorem 1.
Proof: We first prove the achievability. Given a conditional probability distribution f Y X | ( y x | ) that satisfies (5), we generate each Y ( ) t independently using f Y X | ( y ( ) t | x ( )) t . The mutual information leakage rate is then given by I ( X Y ; ) whereas the average power constraint in (5) is trivially satisfied.
For the converse, assume that there is an n -length energy management policy that satisfies the instantaneous and average constraints in (5). Let H ( X ) denote the entropy of the random variable X . The information leakage rate of the resulting output load vector will satisfy the following chain of inequalities:
$$\text{he} \quad \frac { 1 } { n } I ( X ^ { n } ; \boldsymbol Y ^ { n } ) = \frac { 1 } { n } \left [ H ( \boldsymbol X ^ { n } ) - H ( \boldsymbol X ^ { n } | \boldsymbol Y ^ { n } ) \right ],$$
$$& \cdot \quad \text{$\quad$ put load vector will satisfy the following chain of inequalities:$} \\ & \mathcal { M } \quad \text{$n$} \quad \ell \in \quad \frac { 1 } { n } \left [ H ( X ^ { n } ; Y ^ { n } ) = \frac { 1 } { n } \left [ H ( X ^ { n } ) - H ( X ^ { n } | Y ^ { n } ) \right ], \quad \text{$(6a)$} \\ & \quad = \frac { 1 } { n } \sum _ { t = 1 } ^ { n } \left [ H ( X ( t ) ) - H ( X ( t ) | X ^ { t - 1 } Y ^ { n } ) \right ], \quad \text{$(6b)$} \\ & \quad \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad\end{cases} \\ & \quad \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$
& \quad \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{ $\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad` \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{$\quad` \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad` \ \text{$\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad` \quad$ \quad` \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \text{$\quad\quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \ $ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$
& \quad \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \quad$ \$$
where (6b) follows from the assumption that the input loads are i.i.d. over time, (6c) follows as conditioning reduces entropy; (6e) follows from the definition of the privacy-power function I · ( ) ; (6f) follows from the convexity of function I · ( ) stated in Lemma 1 and Jensen's inequality; and finally (6g) follows since the energy management policy has to satisfy the average power constraint and I · ( ) is a non-increasing function of its argument.
Remark 1.1: The achievability part of the proof reveals that the optimal energy management policy is memoryless; that is, it can be achieved by simply looking at the instantaneous input load, and generating the output load randomly using the optimal conditional probability, which simplifies the operation of the EMU significantly. This results in a stochastic energy management policy rather than a deterministic one.
We note here that the same performance in Theorem 1 can also be achieved by a deterministic block-based energy management policy if the user knew all the future energy demands over a block of n time instants.
We also note the similarity between the privacy-power function in (5) and the classical rate-distortion function [20]. The characterization of the privacy-power function for a multiuser SM system is equivalent to the rate-distortion function for a vector source with a difference distortion measure
$$d ( \mathbf x, \mathbf y ) = \begin{cases} \sum _ { i = 1 } ^ { N } x _ { i } - y _ { i }, & \text{if $y_{i}\leq x_{i}$, $\forall i$} \\ \infty, & \text{otherwise.} \end{cases} \quad ( 7 )$$
However, despite the similarity between the expressions of the rate-distortion and the privacy-power functions, their operational definitions are quite different. In the case of lossy source compression, there is an encoder and a decoder and the ratedistortion function characterizes the minimum number of bits per sample that the encoder should send to the decoder, such that the decoder can reconstruct the source sequence within the specified average distortion level. In lossy source compression,
the encoder observes the whole block of n source samples, and maps them to an index from the compression codebook, which is agreed upon in advance.
There are major differences between the two problems. In the SM privacy problem, there is neither an agreed codebook nor a digital interface. Here Y n is the direct output of the 'encoder', rather than the reconstruction of the decoder based on the transmitted index. The EMU does not operate over blocks of input load realizations; instead, the output load is decided instantaneously based on the previous input and output loads. Similarly, in the SM privacy problem, there is no encoder or decoder either, although the EMU can be considered as an encoder and Y n as the reconstruction of the input load X n . However, the 'distortion' constraint between the input and output loads in the SM privacy problem stems from the constraint on the available power that the AES can generate, rather than the limited rate of encoding as in the rate -distortion problem.
Having clarified the distinctions between the privacy-power and rate-distortion functions, we also remark the differences between our formulation of the SM privacy problem and the privacy-utility framework studied in [10]. In our privacy model the SM readings are not tempered, and thus, the SMs report the exact amount of energy received from the grid. On the other hand, in [10], the SM readings are considered as the samples of an information source, which are compressed before being forwarded to the UP in order to hide their real values; and hence, privacy is achieved at the expense of distorting the SM measurements. The distortion constraint in [10] is explicit and measures the utility of the compressed SM samples.
If the users' input loads are independent from each other, but not necessarily identically distributed, the multi-user privacypower function in (5) simplifies further. The following chain of inequalities lower bound the privacy-power function under this assumption:
$$o \text{ measures lower you use privacy-power function under } \colon \text{ is only } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ In } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ IN } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ out } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{ in } \text{
where we have defined P _ { i } = \mathbb { E } [ X _ { i } - Y _ { i } ], \text{ and } \mathbb { I } _ { X _ { i } } ( \cdot ) \text{ denotes } \text{ the privacy power function for a system with an input load } \text{..........................................................................................................................................................................................................$$
∑ Following the above arguments, the problem of characterizing the optimal privacy-power function for a multi-user SM
where we have defined P i = E [ X i -Y i ] , and I X i ( ) · denotes the privacy power function for a system with an input load distribution f X i ( x i ) . We can achieve equality in (8b) with independent EMU policies for individual users, f Y X | ( y x | ) = ∏ N i f Y i | X i ( y i | x i ) . Consequently, we can achieve equality in (8d) by using the single user optimal energy management policy for each of the input loads separately, while satisfying the total average power constraint, N i =1 P i ≤ P .
system is reduced to the following optimization problem
$$\mathcal { I } ( P ) = \inf _ { \sum _ { i = 1 } ^ { N } P _ { i } \leq P } \sum _ { i = 1 } ^ { N } \mathcal { I } _ { \chi _ { i } } \left ( P _ { i } \right ). \quad ( 9 ) \\ \text{he following sections, we use the information theoretic}$$
In the following sections, we use the information theoretic single-letter characterization of the privacy-power function in order to obtain either closed-form solutions or numerical algorithms that give us the optimal energy management policies in multi-user SM systems with certain input load distributions and an average power constraint on the AES.
## III. DISCRETE INPUT LOADS
In the previous section we have characterized the privacypower function for i.i.d. input loads as an optimization problem in a single-letter format in (5). Now we will show that this problem can always be efficiently solved for any discrete input load distribution. In addition, for the particular case where all the users have binary input loads, we give a closed-form expression for the privacy-power function.
For discrete input and output alphabets, the characterization of the privacy-power function I P ( ) in (5) is a convex optimization problem since the mutual information is a convex function of the conditional probabilities, f Y X | ( y x | ) , for y ∈ Y N , x ∈ X N , and the constraints are linear. Then, (5) can be solved numerically, e.g., by the efficient Blahut-Arimoto (BA) algorithm [20]. However, while the input load alphabet, defined by the system based on the energy demand profiles of the users, can be discrete, the output load alphabet is not necessarily discrete, and the output load, in general ,can take any real value. The next theorem shows that for discrete input load alphabets, the output load alphabet can be constrained to the input alphabet without loss of optimally, i.e., Y = X , and consequently, for any given discrete input alphabet the privacypower function can always be computed efficiently. This result is only valid for i.i.d. input loads, but does not require users' input loads to be independent from each other.
Theorem 2: Without loss of optimality, for discrete input load alphabets, the output load alphabet Y N can be constrained to the input load alphabet, i.e., Y N = X N .
Proof: Let the discrete input load alphabets for each user be defined as a possibly infinite set
$$\mathcal { X } _ { i } = \{ x _ { i, 1 }, \dots, x _ { i, m _ { i } } \colon x _ { i, j } < x _ { i, j + 1 } \},$$
where m i = + ∞ if the input alphabet is countably infinite. Define X C i as the set of non-negative real numbers that are not in the input load alphabet for each user i . For any vector x = [ x , ...., x 1 N ] ∈ X N define the set
$$\Omega \left ( { \mathbf x } \right ) \stackrel { \triangle } { = } \left ( x _ { 1 } ^ { - }, x _ { 1 } \right ] \times \dots \times \left ( x _ { N } ^ { - }, x _ { N } \right ]$$
where × denotes the Cartesian product and x -i = max { x ∈ { 0 , X } i : x < x i } . Now assume that the optimal privacy-power function in (5) is achieved by the conditional probability distribution f Y X | ( y x | ) , which might take positive values for some y i ∈ X C i . We define the following new conditional probability distribution:
$$\mathfrak { z c t e r - 1 } f _ { \hat { Y } | X } ( \hat { y } | x ) = \begin{cases} 0, & \text{if $\existsi\colon\hat{y}_{i}\in\mathcal{X}_{i}^{C}$,} \\ \int _ { \Omega ( \hat { y } ) } f _ { Y | X } ( y | x ) d y, & \text{if $\hat{y}_{i}\in\mathcal{X}_{i}$, $\, \forall i$.} \end{cases}$$
The new conditional probability function does not allow any output value in X C i for any i , i.e., the output alphabet is limited to the input alphabet. Instead, any output vector y = [ y , . . . , y 1 N ] , which has a non-zero probability according to f Y X | ( y x | ) , is assigned to a new output vector [ˆ y , . . . , y 1 ˆ N ] such that
$$\hat { y } _ { i } = \min \{ x \in \mathcal { X } _ { i } \, \colon x \geq y _ { i } \}. \quad \quad ( 1 0 ) ^ { \text{ ando} }$$
Notice that the energy management policy, f ˆ X Y | ( ˆ x y | ) , is still feasible since the output load, at any time instant, is still less than what is requested by the appliances, i.e., ˆ y i ≤ x , i ∀ i . Moreover, with this new conditional distribution the power load demanded from the AES can only have a smaller average value compared to the original energy management policy, since the output load is not reduced for any input load value. Thus, it only remains to show that the new conditional distribution leaks at most the same amount of information to the UP. Notice that the new output load ˆ Y is a deterministic function of Y define in (10). Hence, from the information processing inequality, we have that X -Y -ˆ Y form a Markov chain, and consequently, I ( X Y , ) ≥ I ( X ˆ , Y ) , which completes the proof.
## A. Binary Input Loads
The simplest discrete input load model we can consider is a binary input alphabet with independent Bernoulli input load distributions for all the users, i.e., X i ∼ Ber ( p i ) , where p i = p X i ( L i ) and X i = { L , H i i } for i = 1 , ..., N . Observe that the average power required by the i -th user is given by P X i = L i + ∆ (1 i -p i ) , where ∆ = i H i -L i . This power consumption model corresponds to a scenario in which the users, at each time instant, require either a constant high power load level H i , or a constant low power load level L i , i.e., the standby power consumption level. When there is a power demand, the EMU fulfills this demand either obtaining the energy from the UP, or from the AES according to p Y X | .
From Theorem 2, the optimal output distribution Y i is also binary for all i . Hence, the power allocated from the AES to each user is a binary random variable over the set { 0 ∆ , i } . Note that, since we require Y i ≤ X i , we can only provide energy from the AES to user i if X t i ( ) = H i and Y i ( ) = t L i , and consequently, p X Y i i ( L , H i i ) = 0 and p X Y i i ( L , L i i ) = p X i ( L i ) = p i . The energy obtained from the AES is then directly related to p X Y i i ( H , L i i ) by P i = ∆ i p X Y i i ( H , L i i ) , and we can express the mutual information I ( X Y i ; i ) for the bivariate binary distribution
$$p _ { X _ { i } Y _ { i } } & = \left [ \begin{array} { c c } p _ { i } & 0 \\ \frac { P _ { i } } { \Delta _ { i } } & 1 - p _ { i } - \frac { P _ { i } } { \Delta _ { i } } \end{array} \right ], \\ \intertext { s t o n o f $ D $, e e f o i n o n e. }$$
as a function of P i as follows:
$$I _ { \mathrm B _ { i } } \left ( P _ { i } \right ) = \frac { P _ { i } } { \Delta _ { i } } \log _ { 2 } \left ( \frac { P _ { i } } { \Delta _ { i } } \right ) - \left ( p _ { i } + \frac { P _ { i } } { \Delta _ { i } } \right ) \log _ { 2 } \left ( p _ { i } + \frac { P _ { i } } { \Delta _ { i } } \right ) \\ - \left ( 1 - p _ { i } \right ) \log _ { 2 } \left ( 1 - p _ { i } \right ). \quad \text{where} \, \, \text{variable}$$
Observe that I B i ( P i ) is a monotonically decreasing function of P i , and I B i (∆ (1 i -p i )) = 0 . Consequently, the privacypower function for the binary model for a single user is given by
$$\mathcal { I } _ { \mathrm B _ { i } } ( P _ { i } ) = \left ( I _ { \mathrm B _ { i } } \left ( P _ { i } \right ) \right ) ^ { + }, \text{ \quad \ \ } \text{(11)}$$
where ( x ) + = max( x, 0) .
By particularizing (9) with I X i ( P i ) = I B i ( P i ) for all i , and solving the resultant problem, we find the optimal power allocation P ∗ i as
$$P _ { i } ^ { * } = \begin{cases} \ \Delta _ { i } p _ { i } \frac { 1 - p _ { \Delta _ { i } } } { p _ { \Delta _ { i } } } & \text{if $p_{i}<p_{\Delta_{i}}$,} \\ \Delta _ { i } ( 1 - p _ { i } ) & \text{otherwise,} \end{cases}$$
where p ∆ i ( λ ) = 1 -e -λ ∆ i , and λ is chosen such that ∑ N i =1 P ∗ i = P . Note that p ∆ i satisfies 0 ≤ p ∆ i ≤ 1 . Then, the privacy-power function for the multiple users with independent binary input load distributions is given by
$$\text{may]} & \text{may]} \text{put toau usuouoons is given } \text{$\mathcal{Y}$} \\ \mathcal { I } _ { \mathrm B } ( P ) & = \sum _ { i = 1 } ^ { N } \mathcal { I } _ { \mathrm B _ { i } } ( P _ { i } ^ { * } ), & ( 1 3 ) \\ & = \sum _ { i = 1 } ^ { N } \left ( H _ { \mathrm B } ( p _ { i } ) - \frac { p _ { i } } { p _ { \Delta _ { i } } } H _ { \mathrm B } ( p _ { \Delta _ { i } } ) \right ) ^ { + }, & ( 1 4 ) \\ \text{where} \, H _ { \mathrm B } ( p ) & \text{ denotes the entropy of a Ber} ( p ) & \text{ distribution.} \\ - \,. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &. &.$$
where H B ( p ) denotes the entropy of a Ber ( p ) distribution. Each user can achieve full privacy I B i ( P ∗ i ) = 0 by obtaining an average power of P X i -L i = ∆ (1 i -p i ) from the AES, the remaining power L i is obtained from the grid without incurring any lost of privacy. However, if the average power obtained from the AES is below P X i -L i then the energy obtained from the grid comes at the expense of a loss in privacy. Note that P ∗ i and I B ( P ) depend on the input load parameters P X i , L i , ∆ i , and p i in a non-straightforward manner. We postpone the detailed analysis of this privacypower function to Section V.
## IV. CONTINUOUS INPUT LOADS
For continuous input loads, the optimal output alphabet is also continuous. Consequently, efficient algorithms, such as the BA algorithm, do not yield the optimal solution to (5). In this case, we provide a lower bound on the privacypower function by using the Shannon lower bound. We then show that this lower bound is achievable when the users have independent exponentially distributed input loads.
Using the SLB [20], for any input load distribution, we have
$$\mathcal { I } _ { X _ { i } } ( P _ { i } ) \geq \left ( \mathbf h ( X _ { i } ) - \ln \left ( P _ { i } \right ) \right ) ^ { + } \, \mathbf n a t s, \quad \ \ ( 1 5 )$$
where h ( X ) denotes the differential entropy of the continuous random variable X . Observe that,
$$I ( X _ { i }, Y _ { i } ) = \mathfrak { h } ( X _ { i } ) - \mathfrak { h } ( X _ { i } | Y _ { i } ),$$
$$= h ( X _ { i } ) - h ( X _ { i } - Y _ { i } | Y _ { i } ), \text{ \quad \ \ } ( 1 6 b )$$
$$\geq h ( X _ { i } ) - h ( X _ { i } - Y _ { i } ), \text{ \quad \ \ } ( 1 6 c )$$
$$\geq h ( X _ { i } ) - h ( \text{Exp} ( \mathbb { E } \left [ X _ { i } - Y _ { i } \right ] ) ), \quad ( 1 6 d )$$
$$= h ( X _ { i } ) - \ln \left ( P _ { i } \right ), \quad \text{(16e)}$$
where we have used Exp ( λ ) to denote an exponential random variable with mean λ . In the above chain of inequalities, (16c) follows as conditioning reduces entropy, and (16d) follows since exponential distribution maximizes the entropy among all nonnegative distributions with a given mean value [20].
Next, we present the necessary and sufficient conditions for any piecewise continuous input load distribution f X ( x ) to achieve the SLB, together with the conditional probability distribution f Y X | ( y x | ) achieving it. We denote by u x ( ) , the unit step function which assigns 0 for x < 0 , and 1 for x ≥ 0 . The Dirac delta function is denoted by δ x ( ) . We use f ′ ( x ) to denote the first order derivative of f ( x ) and f ( x + i ) = lim x → x +
$$f ( x ) \text{ and } f ( x _ { i } ^ { - } ) \, = \, \lim _ { x \to x _ { i } ^ { - } } f ( x ) \text{ and } x \to x _ { i } ^ { + } \text{ and } x \to x _ { i } ^ { - } \\ \text{man that } x \, \cdots \, \infty \, \text{ from the left and right and right and right and right and right}$$
i
mean that x → x i from the left and right, respectively. Finally, we define ∆ ( f x i ) = f ( x + i ) -f ( x -i ) .
Theorem 3: Suppose that the input load distribution f X ( x ) is continuous on R + except for a countable number of jump discontinuities or non-differentiable points X D = { x , ..., x 1 D } . Then, the SLB (15) is achieved for all P satisfying g Y ( y ) ≥ 0 , ∀ y ∈ R + , where
$$g _ { Y } ( y ) = g _ { Y _ { C } } ( y ) + g _ { Y _ { D } } ( y ) \quad \quad ( 1 7 ) \quad \text{powe}$$
is a mixture of a continuous and a discrete function specified as follows:
$$g _ { Y _ { C } } ( y ) = f _ { X } ( y ) + \mathbb { E } [ V ] f _ { X } ^ { \prime } ( y ), \ y \in \mathcal { R } _ { + } / \mathcal { X } _ { D },$$
$$g _ { Y _ { D } } ( y ) = \mathbb { E } [ V ] \sum _ { \ } ^ { D } \Delta _ { X } ( x _ { i } ) \delta ( y - x _ { i } ), \ y \in \mathcal { X } _ { D }.$$
For all P , at which the SLB is achieved, the output distribution is given by f Y ( y ) = g Y ( y ) and the optimal conditional output load distribution reads f Y X | ( y x | ) = f V ( x -y ) f Y ( y ) f X ( x ) where f V ( v ) = 1 E [ V ] e -v E [ V ] u v ( ) .
$$\sum _ { i = 0 } ^ { \nu } \\ \text{SI.B}$$
Proof: To show this results, we need to find the conditional distribution f Y X | ( y x | ) that satisfies the SLB with equality [20]. We require the random variables V = X -Y and Y to be independent, and V to be distributed according to an exponential distribution V ∼ Exp ( P ) with mean P . We first obtain the output distribution f Y ( y ) from its Laplace transform L f Y ( s ) = L ( f Y ( y ))( s ) as
$$\mathcal { L } f _ { Y } ( s ) & = \frac { \mathcal { L } f _ { X } ( s ) } { \mathcal { L } f _ { V } ( s ) }, \\ & = \mathcal { L } f _ { X } ( s ) \left ( 1 + \mathbb { E } [ V ] s \right ).$$
Then, it follows that f Y ( y ) is given by (17). The conditional distribution f Y X | ( y x | ) is obtained using the fact that f X Y | ( x y | ) = f V ( x -y ) . Finally, it can be shown that ∫ ∞ 0 f Y ( y dy ) = 1 ; and thus, the achievability is guaranteed by requiring f Y ( y ) ≥ 0 , ∀ y ∈ R + .
Remark 3.1: If the achievability condition in Theorem 3 is satisfied for a given P max , it is satisfied at any P ≤ P max . Then it follows that, there is a unique critical average power level, P 0 , such that I X ( P ) = h ( X ) -ln ( P ) for all P ≤ P 0 and I X ( P ) > h ( X ) -ln ( P ) for all P > P 0 .
To find a lowerbound on the privacy-power function in the case of multiple users with continuous input load distributions, we replace I X i ( P i ) with ( h ( X i ) -ln ( P i )) + in (9), and find the corresponding optimal power allocation P ∗ i as
$$P _ { i } ^ { * } = \begin{cases} \lambda, & \text{if $e^{h(X_{i})}>\lambda$}, \\ e ^ { h(X_{i}) }, & \text{otherwise}, \end{cases} \quad ( 1 8 ) \quad \text{all the} \quad$$
Fig. 2. The reverse waterfilling solution for the optimal power provided to each user from the AES.
where λ is chosen such that ∑ N i =1 P ∗ i = P . Then the privacypower function for multiple users can be lower-bounded by
$$\mathcal { I } _ { \mathbf X } ( P ) \geq \sum _ { i = 1 } ^ { N } \left ( \mathbf h ( X _ { i } ) - \ln \left ( \lambda \right ) \right ) ^ { + } \ n a t s. \quad \ \ ( 1 9 )$$
## A. Exponential Input Loads
For an exponential input load distribution with mean λ i , i.e., X i ∼ Exp ( λ i ) , the SLB in (15) is achievable by using the conditional distribution [19]
$$f _ { Y _ { i } | X _ { i } } \left ( y | x \right ) = \frac { \lambda _ { i } } { P _ { i } } e ^ { - \frac { ( x - y ) } { P _ { i } } } e ^ { \frac { x } { \lambda _ { i } } } f _ { Y _ { i } } ( y ),$$
where f Y i is a mixture of a continuous and a discrete distribution specified by
$$f _ { Y _ { i } } ( y ) = \left ( 1 - \frac { P _ { i } } { \lambda _ { i } } \right ) \frac { 1 } { \lambda _ { i } } e ^ { - \frac { y } { \lambda _ { i } } } + \frac { P _ { i } } { \lambda _ { i } } \delta ( y ). \\ \intertext { n t h i v a v o w n o u r f i n o t i o n f o r s o c i n a l e n c a r i n t }$$
Then the privacy-power function for a single user with an exponential input load with mean λ i can be explicitly characterized as follows:
$$\mathcal { I } _ { \mathcal { E } _ { i } } ( P _ { i } ) = \begin{cases} \ \ln \left ( \frac { \lambda _ { i } } { P _ { i } } \right ), & \text{if $P_{i}\leq \lambda_{i}$,} \\ 0, & \text{otherwise.} \end{cases}$$
By particularizing (9) with I X i ( P i ) = I E i ( P i ) for all i , and solving the resultant problem, we find the optimal AES power allocation among users, P ∗ i , as the well-known reverse waterfilling solution
$$P _ { i } ^ { * } & = \begin{cases} \ \lambda, \quad \text{if } \lambda < \lambda _ { i }, \\ \ \lambda _ { i }, \quad \text{if } \lambda \geq \lambda _ { i }, \end{cases} \\ & \ \cdot \dots \ \neg N \ \neg \quad \neg$$
where λ is chosen such that ∑ N i =1 P ∗ i = P . The reverse waterfilling power allocation is illustrated in Fig. 2 for three users with independent exponentially distributed energy demands with means λ , λ 1 2 , and λ 3 , respectively. The optimal reverse water level is given by λ , where the heights of the shaded areas in the figure correspond to the average AES powers allocated to the different users. We observe that the optimal energy management policy satisfies all the energy demands of the users whose average input load is below λ , directly from the AES. Hence, no information
Fig. 3. Privacy-power function for a binary input-output system with different p values.
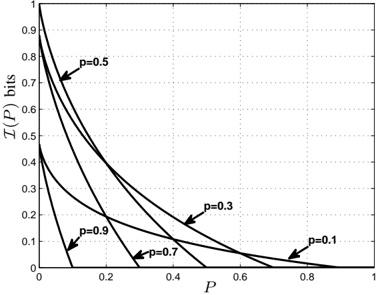
Fig. 4. Privacy-power function for a uniform input load, and different EMU policies.
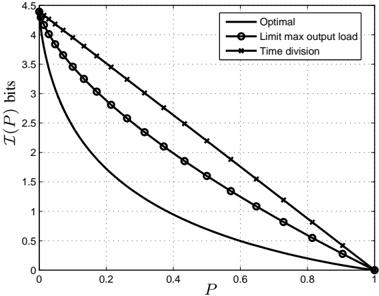
is leaked to the UP about the energy consumption of these users; user 1 and user 3 in the figure. The rest of the users receive exactly the same amount of power λ from the AES, and the remainder of their energy demand is satisfied from the grid. Finally, the privacy-power function for multiple users with exponential input loads can be expressed as
$$\mathcal { I } _ { \text{E} } ( P ) = \sum _ { i = 1 } ^ { N } \left ( \ln \left ( \frac { \lambda _ { i } } { \lambda } \right ) \right ) ^ { + }. \quad \quad ( 2 1 ) \quad \text{from} \\ \quad \text{inters} \\ \quad \text{a lig}$$
## V. NUMERICAL RESULTS
In this section we numerically analyze the privacy-power function in a SM system with various input load distributions and number of users, by explicitly evaluating the information theoretic optimal leakage rate expressions.
## A. Single User Scenario
In order to illustrate the behaviour of the privacy-power function for a simple binary input load system, we first consider a single user with an input load alphabet X = Y = { 0 1 , } , and p X (0) = p . We plot the I ( P ) function for the binary input load in Fig. 3 for different p values. As expected,
Fig. 5. Individual privacy achieved by three users I X i ( P ) , i = { 1 2 3 , , } , all with the same input load alphabet δ i = 1 i = 1 2 3 { , , } , but with different input load distributions as a function of the average AES power P .
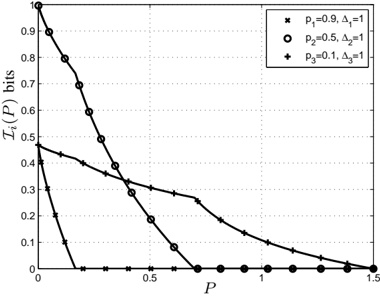
Fig. 6. Individual privacy achieved by three users I X i ( P ) , i = { 1 2 3 , , } , each with a different input load alphabet and input load distribution, as a function of the average AES power P .
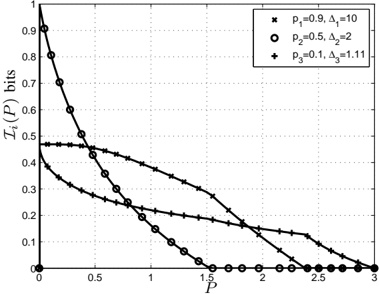
the required average power from the AES is maximum when the user wants perfect privacy, and it is zero when no privacy is required. We also observe that the privacy-power function is decreasing in P and convex. Another interesting observation from the figure is the fact that the I ( P ) curves for two different input load distributions, i.e., different p values, might intersect. This means that, to achieve the same level of privacy a lighter input load might require lower or higher average power than a heavier input load. Also note that the two different input load distributions, say p = 0 1 . and p = 0 9 . , have the same level of privacy when there is no AES in the system; however, the input load with lower average energy demand, i.e., the one with p = 0 9 . , achieves perfect privacy with a much lower P value.
Next, we use the discrete uniform distribution to compare the privacy protection achieved by the information theoretical optimal policy derived here, with different heuristic policies. In this case, the input load has a uniform distribution U x ( ) with input load alphabet X = { 0 , c, 2 c, ..., ( N -1) c } , where c = 2 N -1 is a constant used to impose a mean value of E [ X ] = 1 . Based on Theorem 2, the output load alphabet can be limited
to X without loss of optimality. We set N = 21 and in Fig. 4 we plot the privacy-power function for the optimal strategy obtained by the BA algorithm together with the privacy-power functions of the following two heuristic strategies:
Time Division: In this policy, at each time instant, the EMU gets all the energy needed by the user, either from the AES or from the grid, but not from both simultaneously. Then, to satisfy the average power constraint at the AES, the EMU obtains energy from the AES with probability P E [ X ] . The information leaked to the UP, is thus given by
$$I ( X ; Y ) & = H ( X ) - H ( X | Y = 0 ) \frac { P } { \mathbb { E } [ X ] } \\ & \quad - H ( X | Y = x ) \left ( 1 - \frac { P } { \mathbb { E } [ X ] } \right ), \\ & = \left ( 1 - \frac { P } { \mathbb { E } [ X ] } \right ) \log _ { 2 } N. \\ \text{Limit Maximum Output Load: In this policy, we use th} \\ \text{$\dots$} \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
Limit Maximum Output Load: In this policy, we use the AES to limit the maximum energy received from the grid. At each time instant, we get all the energy from the grid X t ( ) = Y ( ) t if X t ( ) < kc , whereas if X t ( ) ≥ kc we get Y ( ) = t kc from the grid and the remaining energy is taken from the AES. In this case, for each k = 0 , ..., N -1 , the average power requested from the AES is given by
$$P = ( N - 1 - k ) \, ( \stackrel { \cdot } { N } - k ) \frac { c } { 2 N },$$
and the information leaked to the UP is
$$I ( X ; Y ) & = H ( X ) - \Pr ( Y = k c ) H ( X | Y = k c ), \\ & = \log _ { 2 } N - \frac { N - k } { 2 N } \log _ { 2 } ( N - k ). \\.. \colon = \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
In Fig. 4, we can observe that given an average power limited AES, the privacy achieved by both of these heuristics is significantly lower than that of the optimal EMU policy.
## B. Multi-user Scenario
Next we consider a multi-user scenario with N = 3 users. We assume equal binary load levels H i = 1 and L i = 0 , but different average energy demands with p 1 = 0 9 . , p 2 = 0 5 . , and p 3 = 0 1 . ; thus we have P X 1 = 0 1 . , P X 2 = 0 5 . , P X 3 = 0 9 . . Fig. 5 illustrates the privacy for each user I B i ( P ∗ i ) as a function of the average power P available at the AES. Notice that, although users 1 and 3, in the absence of an AES, leak the same amount of information to the UP, since H B (0 1) = . H B (0 9) . , user 1 achieves perfect privacy much more rapidly since it has a lower average energy demand. Also note that, user 3 achieves perfect privacy for a much higher value of P , even compared to user 2, which leaks the highest amount of information when there is no AES, as it has the highest entropy.
Remember that, as opposed to the exponential input load scenario, in the binary case, the privacy-power function I B i ( P ∗ i ) for each user does not depend solely on the average power demand of the user, but on both of the parameters ∆ i and p i . To illustrate this dependence, we consider a scenario
Fig. 7. I ( P ) with respect to the average AES power P for binary input loads with different number of users.
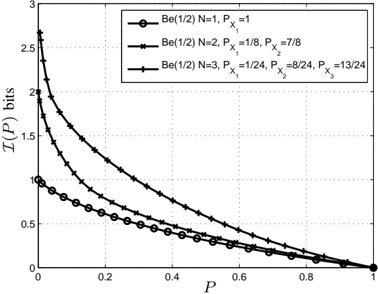
again with N = 3 users, but with equal average power demands P X i = ∆ (1 i -p i ) , while L i = 0 for all i . We choose different parameters ∆ i and p i for each user. Fig. 6 again shows the privacy of each user as a function of the average power P . Observe that the optimal power allocation quickly reduces the information leaked by user 2, and achieves perfect privacy for this user much before the other two, although this is the user leaking the most amount of information in the absence of an AES. The input power loads for users 1 and 3 have equal entropy, but with different behaviours; user 1 demands large amounts of energy but very rarely, while user 3 demands low amounts of energy very frequently. The optimal EMU policy seen by these users also differs significantly. While for user 1 the privacy-power function is a concave monotonically decreasing function, for user 3 the privacy-power function is monotonically decreasing but piecewise convex.
Next, we study the effect of the number of users on the privacy-power function. In Fig. 7, we depict the optimal information leakage rate with respect to the available average AES power for binary input loads with different number of users N = 1 2 3 { , , } . We can observe that with more than one user, we have different regimes of operation corresponding to the number of users that receive energy from the grid. Similarly, in Fig. 8 we consider the scenario with exponential input loads. In both models, regardless of the number of users in the system the total average power consumed by the users is fixed to P X . In the figures we set P X = 1 . As expected, if the average power provided by the AES is equal to the total average power demanded by the users, perfect privacy can be achieved. Instead, as the average power of the AES goes to zero, all the information is revealed to the UP, and thus, the information leakage rate is equal to the sum of the entropies of all the input loads. In between these two extremes the privacy-power function exhibits a monotone decreasing convex behaviour, and the information leakage rate increases with the number of users in the system.
## VI. CONCLUSIONS
We have introduced and studied the privacy-power function, I ( P ) , which characterizes the achievable information theoretic
Fig. 8. I ( P ) with respect to the average AES power P for exponential input loads with different number of users.
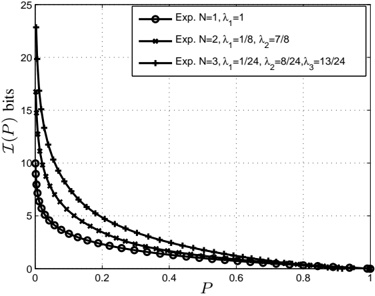
privacy in a multi-user SM system in the presence of an AES. We have provided a single-letter information theoretic characterization for I ( P ) , and showed that it can be evaluated numerically when the input loads are discrete. We have also provided explicit characterization of the privacy-power function for binary and exponential input load distributions. We have shown that the optimal allocation of the energy provided by the AES in the exponentially distributed input load scenario can be derived using the reverse waterfilling algorithm, which resembles the rate-distortion function for multiple Gaussian sources.
We believe that the proposed information theoretic framework for privacy in SM systems provides valuable tools to identify the fundamental challenges and limits for this critical problem, whose importance will only increase as SM adoption becomes more widespread. Many interesting research problems implore further studies, including time correlated input loads, systems with multiple EMUs, as well as cost and pricing issues considering dynamic pricing over time.
## REFERENCES
- [1] P. Wunderlich, D. Veit, and S. Sarker, 'Adoption of information systems in the electricity sector: The issue of smart metering,' in Proc. Americas Conference on Information Systems , Seattle, WA, Aug 2012.
- [2] 'Directive 2009/72/ec of the european parliament and of the council of 13 july 2009 concerning common rules for the internal market in electricity and repealing directive 2003/54/ec,' Official Journal of the Eureopean Union , vol. 46, no. L 211, pp. 55-93, 14 Aug. 2009.
- [3] P. McDaniel and S. McLaughlin, 'Security and privacy challenges in the smart grid,' IEEE Security Privacy , vol. 7, no. 3, pp. 75-77, May-Jun. 2009.
- [4] A. Predunzi, 'A neuron nets based procedure for identifying domestic appliances pattern-of-use from energy recordings at meter panel,' in Proc. IEEE Power Eng. Society Winter Meeting , New York, Jan. 2002.
- [5] U. Greveler, B. Justus, and D. Loehr, 'Multimedia content identification through smart meter power usage profiles,' in Computers, Privacy and Data Protection (CPDP) , Brussels, Belgium, Jan. 2012.
- [6] A. Molina-Markham, P. Shenoy, K. Fu, E. Cecchet, and D. Irwin, 'Private memoirs of a smart meter,' in Proceedings of the 2Nd ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Building , ser. BuildSys '10. New York, NY, USA: ACM, 2010, pp. 6166. [Online]. Available: http://doi.acm.org/10.1145/1878431.1878446
- [7] C. Efthymiou and G. Kalogridis, 'Smart grid privacy via anonymization of smart metering data,' in Proc. IEEE Int'l Conf. Smart Grid Comm. , Gaithersburg, MD, Oct. 2010.
- [8] J.-M. Bohli, C. Sorge, and O. Ugus, 'A privacy model for smart metering,' in IEEE ICC , Capetown, South Africa, May 2010.
- [9] S. Wang, L. Cui, J. Que, D. Choi, X. Jiang, S. Cheng, and L. Xie, 'A randomized response model for privacy preserving smart metering,' IEEE Trans. Smart Grid , vol. 3, no. 3, pp. 1317-1324, Mar. 2012.
- [10] L. Sankar, S. Rajagopalan, S. Mohajer, and H. Poor, 'Smart meter privacy: A theoretical framework,' Smart Grid, IEEE Transactions on , vol. 4, no. 2, pp. 837-846, 2013.
- [11] G. Kalogridis, C. Efthymiou, S. Denic, T. Lewis, and R. Cepeda, 'Privacy for smart meters: Towards undetectable appliance load signatures,' in IEEE Int'l Conf. Smart Grid Com. , Gaithersburg, MD, Oct. 2010.
- [12] D. Varodayan and A. Khisti, 'Smart meter privacy using a rechargeable battery: Minimizing the rate of information leakage,' in Proc. IEEE Int. Conf. Acoust. Speech Sig. Proc. , Prague, Czech Republic, May 2011.
- [13] W. Yang, N. Li, Y. Qi, W. Qardaji, S. McLaughlin, and P. McDaniel, 'Minimizing private data disclosures in the smart grid,' in Proc. ACM Conference on Computer and Communications Security , Raleigh, NC, Oct. 2012.
- [14] O. Tan, D. G¨ und¨ uz, and H. V. Poor, 'Increasing smart me ter privacy through energy harvesting and storage devices,' IEEE Journal on Selected Areas in Communications: Smart Grid Communications , vol. 7, no. 31, pp. 1331-1341, Jul. 2013.
- [15] D. Gunduz and J. Gomez-Vilardebo, 'Smart meter privacy in the presence of an alternative energy source,' in Proc. IEEE Int'l Conf. on Comm. , Budapest, Hungary, June 2013.
- [16] D. Agrawal and C. C. Aggarwal, 'On the design and quantification of privacy preserving data mining algorithms,' in Proc. Symposium on Principles of Database Systems , Santa Barbara, CA, May 2001.
- [17] D. Rebollo-Monedero and J. D.-F. J. Forn´ e, 'From t-closeness-like privacy to postrandomization via information theory,' IEEE Trans. Knowl., Data Eng. , vol. 22, no. 11, pp. 1623-1636, Nov. 2010.
- [18] L. Sankar, S. Rajagopalan, and H. Poor, 'Utility-privacy tradeoffs in databases: An information-theoretic approach,' Information Forensics and Security, IEEE Transactions on , vol. 8, no. 6, pp. 838-852, June 2013.
- [19] J. Gomez-Vilardebo and D. Gunduz, 'Privacy of smart meter systems with an alternative energy source,' in IEEE Int'l Sym. Inform. Theory , Istanbul, Turkey, Jul. 2013.
- [20] T. M. Cover and J. A. Thomas, Elements of Information Theory . WileyInterscience, 1991. | null | [
"Jesus Gomez-Vilardebo",
"Deniz Gündüz"
] | 2014-08-01T15:59:50+00:00 | 2014-08-01T15:59:50+00:00 | [
"cs.IT",
"math.IT"
] | Smart Meter Privacy for Multiple Users in the Presence of an Alternative Energy Source | Smart meters (SMs) measure and report users' energy consumption to the
utility provider (UP) in almost real-time, providing a much more detailed
depiction of the consumer's energy consumption compared to their analog
counterparts. This increased rate of information flow to the UP, together with
its many potential benefits, raise important concerns regarding user privacy.
This work investigates, from an information theoretic perspective, the privacy
that can be achieved in a multi-user SM system in the presence of an
alternative energy source (AES). To measure privacy, we use the mutual
information rate between the users' real energy consumption profile and the SM
readings that are available to the UP. The objective is to characterize the
\textit{privacy-power function}, defined as the minimal information leakage
rate that can be obtained with an average power limited AES. We characterize
the privacy-power function in a single-letter form when the users' energy
demands are assumed to be independent and identically distributed over time.
Moreover, for binary and exponentially distributed energy demands, we provide
an explicit characterization of the privacy-power function. For any discrete
energy demands, we demonstrate that the privacy-power function can always be
efficiently evaluated numerically. Finally, for continuous energy demands, we
derive an explicit lower-bound on the privacy-power function, which is tight
for exponentially distributed loads. |
1408.0215v1 | ## A study of decays to strange final states with GlueX in Hall D using components of the BaBar DIRC
(A proposal to the 42 nd Jefferson Lab Program Advisory Committee)
M. Dugger, 1 B. Ritchie, 1 I. Senderovich, 1 E. Anassontzis, 2 P. Ioannou, 2 C. Kourkoumeli, 2 G. Vasileiadis, 2 G. Voulgaris, 2 N. Jarvis, 3 W. Levine, 3 P. Mattione, 3 W. McGinley, 3 C. A. Meyer, 3 R. Schumacher, 3 M. Staib, 3 F. Klein, 4 D. Sober, 4 N. Sparks, 4 N. Walford, 4 D. Doughty, 5 A. Barnes, 6 R. Jones, 6 J. McIntyre, 6 F. Mokaya, 6 B. Pratt, 6 W. Boeglin, 7 L. Guo, 7 E. Pooser, 7 J. Reinhold, 7 H. Al Ghoul, 8 V. Crede, 8 P. Eugenio, 8 A. Ostrovidov, 8 A. Tsaris, 8 D. Ireland, 9 K. Livingston, 9 D. Bennett, 10 J. Bennett, 10 J. Frye, 10 M. Lara, 10 J. Leckey, 10 R. Mitchell, 10 K. Moriya, 10 M. R. Shepherd, 10 O. Chernyshov, 11 A. Dolgolenko, 11 A. Gerasimov, 11 V. Goryachev, 11 I. Larin, 11 V. Matveev, 11 V. Tarasov, 11 F. Barbosa, 12 E. Chudakov, 12 M. Dalton, 12 A. Deur, 12 J. Dudek, 12 H. Egiyan, 12 S. Furletov, 12 M. Ito, 12 D. Mack, 12 D. Lawrence, 12 M. McCaughan, 12 M. Pennington, 12 L. Pentchev, 12 Y. Qiang, 12 E. Smith, 12 A. Somov, 12 S. Taylor, 12 T. Whitlatch, 12 B. Zihlmann, 12 R. Miskimen, 13 B. Guegan, 14 J. Hardin, 14 J. Stevens, 14 M. Williams, 14 V. Berdnikov, 15 G. Nigmatkulov, 15 A. Ponosov, 15 D. Romanov, 15 S. Somov, 15 I. Tolstukhin, 15 C. Salgado, 16 P. Ambrozewicz, 17 A. Gasparian, 17 R. Pedroni, 17 T. Black, 18 L. Gan, 18 S. Dobbs, 19 K. Seth, 19 X. Ting, 19 A. Tomaradze, 19 T. Beattie, 20 G. Huber, 20 G. Lolos, 20 Z. Papandreou, 20 A. Semenov, 20 I. Semenova, 20 W. Brooks, 21 H. Hakobyan, 21 S. Kuleshov, 21 O. Soto, 21 A. Toro, 21 I. Vega, 21 N. Gevorgyan, 22 H. Hakobyan, 22 and V. Kakoyan 22
(The GlueX Collaboration)
1
Northwestern University
Arizona State University 2 University of Athens 3 Carnegie Mellon University 4 Catholic University of America 5 Christopher Newport University 6 University of Connecticut 7 Florida International University 8 Florida State University 9 University of Glasgow 10 Indiana University 11 ITEP Moscow 12 Jefferson Lab 13 University of Massachusetts Amherst 14 Massachusetts Institute of Technology 15 MEPhI 16 Norfolk State University 17 North Carolina A&T State 18 University of North Carolina Wilmington 19
20 University of Regina
21 Santa Maria University
22 Yerevan Physics Institute
(Dated: June 1, 2014)
We propose to enhance the kaon identification capabilities of the GlueX detector by constructing an FDIRC (Focusing Detection of Internally Reflected Cherenkov) detector utilizing the decommissioned BaBar DIRC components. The GlueX FDIRC would significantly enhance the GlueX physics program by allowing one to search for and study hybrid mesons decaying into kaon final states. Such systematic studies of kaon final states are essential for inferring the quark flavor content of hybrid and conventional mesons. The GlueX FDIRC would reuse one-third of the synthetic fused silica bars that were utilized in the BaBar DIRC. A new focussing photon camera, read out with large area photodetectors, would be developed. We propose operating the enhanced GlueX detector in Hall D for a total of 220 days at an average intensity of 5 × 10 7 γ /s, a program that was conditionally approved by PAC39.
## I. PREAMBLE
cays to strange final states with GlueX in Hall D' [1]. The proposal requested 220 days of data taking with the
In 2012, the GlueX Collaboration submitted a proposal to PAC39 titled 'A study of meson and baryon de-
GlueX detector operating at an intensity of 5 × 10 7 γ /s on target. A necessary component of the broad physics program put forth in this proposal was an upgrade to the GlueX particle identification (PID) capability. At the time of the proposal, a design for an upgraded PID system had not been finalized. The PAC granted conditional approval stating in its summary document:
GlueX is the flagship experiment in Hall D; the theoretical motivation for the proposed extension of running is very sound. However, the success of the experiment depends crucially on the final design of the kaon identification system. The PAC39 therefore recommends C2 conditional approval, contingent upon the final design of the particle ID system.
In 2013, the GlueX Collaboration returned to PAC40 with a proposal [2] demonstrating that some states with hidden and open strangeness were accessible with the baseline GlueX design, provided that the statistical precision of the data sample was sufficient. PAC40 approved an additional 200 days of running at 5 × 10 7 γ /s on target with an 'A' scientific rating for this program. The PAC40 report noted:
The PAC was impressed by the level of sophistication of the GlueX software and analysis which is essential for the achievement of a significant kaon and hyperon program even in the absence of dedicated hardware. Still the complete mapping of the spectrum of conventional and exotic hadrons will ultimately require the implementation of dedicated particle ID in the forward direction, extending the kaon identification capability to 10 GeV/ . c The PAC therefore encourages the collaboration to move forward with the design of such system and aim at an early installation, if at all possible.
The 10 GeV/ c momentum cutoff cited by the PAC was motivated by preliminary designs for a dual-radiator RICH discussed in our previous proposals rather than any specific physics requirement. Concurrently with our preparation for PAC40, it became apparent that there was an opportunity to utilize components of the BaBar DIRC detector . In fall of 2013, a team of five members 1 of the GlueX Collaboration visited SLAC to understand the condition of the DIRC components and details about their utilization. The conclusion of this visit was that there are no insurmountable technical challenges in utilizing the BaBar DIRC; the opportunity presents a unique
1 At the time of our original proposal the BaBar DIRC was to be used in Super B , a next-generation B -factory experiment. The cancellation of Super B in late 2012 made the DIRC components available for reuse.
and cost-effective solution to upgrade the PID capability of GlueX , providing a significant enhancement in our kaon identification capability.
In December 2013, members of the collaboration submitted a detailed conceptual design for utilizing the DIRC to SLAC for consideration. As this was precisely the request of PAC39, a final design of the particle ID system, we present this design in the document that follows. The physics case remains largely the same from that presented in our PAC39 proposal [1] and is repeated in part here for completeness.
## II. INTRODUCTION AND MOTIVATION
The GlueX experiment, currently under construction and scheduled to start operating in Hall D at Jefferson Lab in fall 2014, will provide the data necessary to construct quantitative tests of non-perturbative QCD by studying the spectrum of light-quark mesons and baryons. The primary goal of the GlueX experiment is to search for and study the spectrum of so-called hybrid mesons that are formed by exciting the gluonic field that couples the quarks. QCD-based calculations predict the existence of hybrid meson states, including several that have exotic quantum numbers that cannot be formed from a simple quark/anti-quark pair. To achieve its goal, GlueX must systematically study all possible decay modes of conventional and hybrid mesons, including those with kaons. The addition of a Cherenkov-based particle identification system utilizing the BaBar DIRC (Detection of Internally Reflected Cherenkov) components will dramatically increase the number of potential hybrid decay modes that GlueX can access and will reduce the experimental backgrounds from misidentified particles in each mode. This enhanced capability will be crucial in order for the GlueX experiment to realize its full discovery potential.
In this section we motivate the GlueX experiment and discuss the importance of kaon identification in the context of the GlueX physics program. The subsequent section discusses the baseline GlueX design and run plan. Both of these sections are largely reproduced from Refs. [1, 2], documents that were developed jointly by the GlueX Collaboration.
## A. The GlueX experiment
A long-standing goal of hadron physics has been to understand how the quark and gluonic degrees of freedom that are present in the fundamental QCD Lagrangian manifest themselves in the spectrum of hadrons. Of particular interest is how the gluon-gluon interactions might give rise to physical states with gluonic excitations. One class of such states is the hybrid meson, which can be naively thought of as a quark anti-quark pair coupled to a valence gluon ( qqg ¯ ). Recent lattice QCD calculations [3]
predict a rich spectrum of hybrid mesons. A subset of these hybrids has an exotic experimental signature: angular momentum ( J ), parity ( P ), and charge conjugation ( C ) that cannot be created from just a quark-antiquark pair. The primary goal of the GlueX experiment in Hall D is to search for and study these mesons.
Our understanding of how gluonic excitations manifest themselves within QCD is maturing thanks to recent results from lattice QCD. This numerical approach to QCD considers the theory on a finite, discrete grid of points in a manner that would become exact if the lattice spacing were taken to zero and the spatial extent of the calculation, i.e., the 'box size,' was made large. In practice, rather fine spacings and large boxes are used so that the systematic effect of this approximation should be small. The main limitation of these calculations at present is the poor scaling of the numerical algorithms with decreasing quark mass. In practice most contemporary calculations use a range of artificially heavy light quarks and attempt to observe a trend as the light quark mass is reduced toward the physical value. Trial calculations at the physical quark mass have begun, and regular usage is anticipated within a few years.
The spectrum of eigenstates of QCD can be extracted from correlation functions of the type 〈 0 |O f ( ) t O † i (0) 0 , | 〉 where the O † are composite QCD operators capable of interpolating a meson or baryon state from the vacuum. The time-evolution of the Euclidean correlator indicates the mass spectrum ( e -m t n ), and information about quark-gluon substructure can be inferred from matrix-elements 〈 n |O | † 0 . 〉 In a series of recent papers [47], the Hadron Spectrum Collaboration has explored the spectrum of mesons and baryons using a large basis of composite QCD interpolating fields, extracting a spectrum of states of determined J P C ( ) , including states of high internal excitation.
As shown in Fig. 1, these calculations show a clear and detailed spectrum of exotic J PC mesons, with a lightest 1 -+ state lying a few hundred MeV below a 0 + -and two 2 + -states. Through analysis of the matrix elements 〈 n |O | † 0 〉 for a range of different quark-gluon constructions, O , we can infer [3] that although the bulk of the non-exotic J PC spectrum has the expected systematics of a qq ¯ bound state system, some states are only interpolated strongly by operators featuring non-trivial gluonic constructions. One may interpret these states as nonexotic hybrid mesons, and by combining them with the spectrum of exotics, it is possible to isolate the lightest hybrid supermultiplet of (0 1 2) , , -+ and 1 --states at a mass roughly 1.3 GeV heavier than the ρ meson. The form of the operator that has the strongest overlap onto these states has an S -wave qq ¯ pair in a color octet configuration and an exotic gluonic field in a color octet with J P C g g g = 1 + -, a chromomagnetic configuration. The heavier (0 2) , + -states, along with some positive parity non-exotic states, appear to correspond to a P -wave coupling of the qq ¯ pair to the same chromomagnetic gluonic excitation.
A similar calculation for isoscalar states uses both uu ¯ + dd ¯ and ss ¯ constructions and is able to extract both the spectrum of states and also their hidden flavor mixing. (See Fig. 1.) The basic experimental pattern of significant mixing in the 0 -+ and 1 ++ channels and small mixing elsewhere is reproduced, and for the first time, we are able to say something about the degree of mixing for exoticJ PC states. In order to probe this mixing experimentally, it is essential to be able to reconstruct decays to both strange and non-strange final state hadrons.
## B. The importance of kaon identification
The primary goal of the GlueX experiment is to conduct a definitive mapping of states in the light meson sector, with an emphasis on searching for exotic mesons. Ideally, we would like to produce the experimental analogue of the lattice QCD spectrum pictured in Fig. 1, enabling a direct test of our understanding of gluonic excitations in QCD. In order to achieve this, one must be able to reconstruct strange final states, as observing decay patterns of mesons has been one of the primary mechanisms of inferring quark flavor content. An example of this can be seen by examining the two lightest isoscalar 2 ++ mesons in the lattice QCD calculation in Fig. 1. The two states have nearly pure flavors, with only a small (11 ) mixing in the ◦ glyph[lscript]glyph[lscript] ¯ and ss ¯ basis. A natural experimental assignment for these two states are the f 2 (1270) and the f ′ 2 (1525). An experimental study of the branching ratios shows that B ( f 2 (1270) → KK / ) B ( f 2 (1270) → ππ ) ≈ 0 05 . and B ( f ′ 2 (1525) → ππ / ) B ( f ′ 2 (1525) → KK ) ≈ 0 009 [8], which support the . prediction of an f 2 (1270) ( f ′ 2 (1525)) with a dominant glyph[lscript]glyph[lscript] ¯ ( ss ¯) component. By studying both strange and nonstrange decay modes of mesons, GlueX hopes to provide similarly valuable experimental data to aid in the interpretation of the hybrid spectrum.
## 1. Exotic ss ¯ states
While most experimental efforts to date have focused on the lightest isovector exotic meson, the J PC = 1 -+ π 1 (1600), lattice QCD clearly predicts a rich spectrum of both isovector and isoscalar exotics, the latter of which may have mixed glyph[lscript]glyph[lscript] ¯ and ss ¯ flavor content. A compilation of the 'ground state' exotic hybrids is listed in Table I, along with theoretical estimates for masses, widths, and key decay modes. It is expected that initial searches with the baseline GlueX hardware will target primarily the π 1 state. Searches for the η 1 , h 0 , and b 2 may be statistically challenging, depending on the masses of these states and the production cross sections. With increased statistics and kaon identification, the search scope can be broadened to include these heavier exotic states in addition to the ss ¯ states: η ′ 1 , h ′ 0 , and h ′ 2 . The η ′ 1 and h ′ 2 are particularly interesting because some models predict
FIG. 1. A compilation of recent lattice QCD computations for both the isoscalar and isovector light mesons from Ref. [3], including glyph[lscript]glyph[lscript] ¯ ( | glyph[lscript]glyph[lscript] ¯ 〉 ≡ ( | uu ¯ 〉 + | dd ¯ ) 〉 / √ 2 ) and ss ¯ mixing angles (indicated in degrees). The dynamical computation is carried out with two flavors of quarks, light ( ) and strange ( glyph[lscript] s ). The s quark mass parameter is tuned to match physical ss ¯ masses, while the light quark mass parameters are heavier, giving a pion mass of 396 MeV. The black brackets with upward ellipses represent regions of the spectrum where present techniques make it difficult to extract additional states. The dotted boxes indicate states that are interpreted as the lightest hybrid multiplet - the extraction of clear 0 -+ states in this region is difficult in practice.
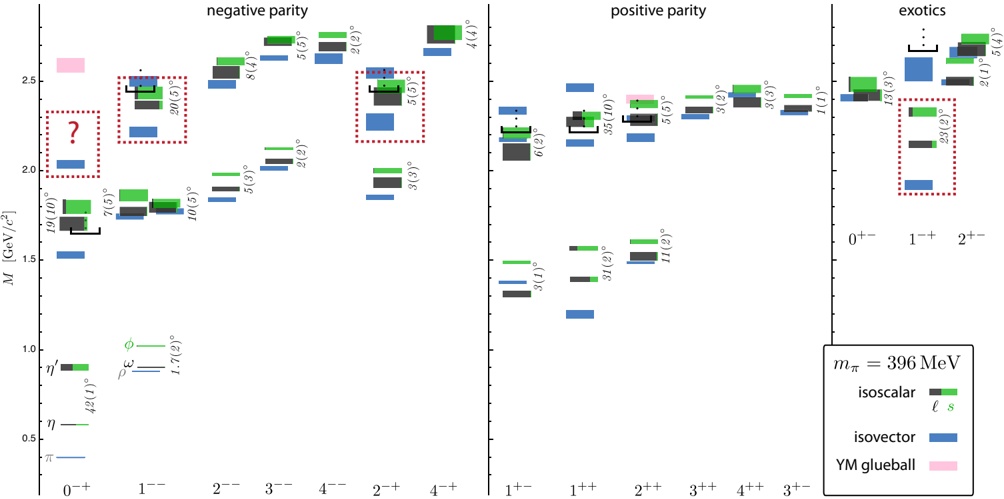
these states to be relatively narrow, and that they should decay through well-established kaon resonances.
Observations of various π 1 states have been reported in the literature for over fifteen years, with some analyses based on millions of events [9]. However, it is safe to say that there exists a fair amount of skepticism regarding the assertion that unambiguous experimental evidence exists for exotic hybrid mesons. If the scope of exotic searches with GlueX is narrowed to only include the lightest isovector π 1 state, the ability for GlueX to comprehensively address the question of the existence of gluonic excitations in QCD is greatly diminished. On the other hand, clear identification of all exotic members of the lightest hybrid multiplet, the three exotic π ± , 0 1 states and the exotic η 1 and η ′ 1 , which can only be done by systematically studying a large number of strange and non-strange decay modes, would provide unambiguous experimental confirmation of exotic mesons. A study of decays to kaon final states could demonstrate that the η 1 candidate is dominantly glyph[lscript]glyph[lscript] ¯ while the η ′ 1 candidate is ss ¯, as predicted by initial lattice QCD calculations. Such a discovery would represent a substantial improvement in the experimental understanding of exotics. In addition, further identification of members of the 0 + -and 2 + -nonets as well as measuring the mass splittings with the 1 + -states will validate the lattice QCD inspired phenomenological picture of these states as P -wave couplings of a gluonic field with a color-octet qq ¯ system.
## 2. Non-exotic ss ¯ mesons
As discussed above, one expects the lowest-mass hybrid multiplet to contain (0 , 1 2) , -+ states and a 1 --state that all have about the same mass and correspond to an S -wave qq ¯ pair coupling to the gluonic field in a P -wave. For each J PC we expect an isovector triplet and a pair of isoscalar states in the spectrum. Of the four sets of J PC values for the lightest hybrids, only the 1 -+ is exotic. The other hybrid states will appear as supernumerary states in the spectrum of conventional mesons. The ability to clearly identify these states depends on having a thorough and complete understanding of the meson spectrum. Like searching for exotics, a complete mapping of the spectrum of non-exotic mesons requires the ability to systematically study many strange and non-strange final states. Other experiments, such as BESIII or COMPASS, are carefully studying this with very high statistics data samples and have outstanding capability to cleanly study any possible final state. While
TABLE I. A compilation of exotic quantum number hybrid approximate masses, widths, and decay predictions. Masses are estimated from dynamical LQCD calculations with M π = 396 MeV /c 2 [3]. The PSS (Page, Swanson and Szczepaniak) and IKP (Isgur, Kokoski and Paton) model widths are from Ref. [22], with the IKP calculation based on the model in Ref. [23]. The total widths have a mass dependence, and Ref. [22] uses somewhat different mass values than suggested by the most recent lattice calculations [3]. Those final states marked with a dagger ( ) are ideal for experimental exploration because there are † relatively few stable particles in the final state or moderately narrow intermediate resonances that may reduce combinatoric background. (We consider η , η ′ , and ω to be stable final state particles.)
| Approximate J PC | Approximate J PC | Approximate J PC | Total Width (MeV) | Total Width (MeV) | Relevant Decays | Final States |
|--------------------|--------------------|--------------------|---------------------|---------------------|---------------------------------------------|-----------------------------------------|
| Mass (MeV) | Mass (MeV) | Mass (MeV) | PSS | IKP | Relevant Decays | Final States |
| π 1 | 1900 | 1 - + | 80 - 170 | 120 | b 1 π † , ρπ † , f 1 π † , a 1 η , η ′ π † | ωππ † , 3 π † , 5 π , η 3 π † , η ′ π † |
| η 1 | 2100 | 1 - + | 60 - 160 | 110 | a 1 π , f 1 η † , π (1300) π | 4 π , η 4 π , ηηππ † |
| η ′ 1 | 2300 | 1 - + | 100 - 220 | 170 | K 1 (1400) K † , K 1 (1270) K † , K ∗ K † | KKππ † , KKπ † , KKω † |
| b 0 | 2400 | 0 + - | 250 - 430 | 670 | π (1300) π , h 1 π | 4 π |
| h 0 | 2400 | 0 + - | 60 - 260 | 90 | b 1 π † , h 1 η , K (1460) K | ωππ † , η 3 π , KKππ |
| h ′ 0 | 2500 | 0 + - | 260 - 490 | 430 | K (1460) K , K 1 (1270) K † , h 1 η | KKππ † , η 3 π |
| b 2 | 2500 | 2 + - | 10 | 250 | a 2 π † , a 1 π , h 1 π | 4 π , ηππ † |
| h 2 | 2500 | 2 + - | 10 | 170 | b 1 π † , ρπ † | ωππ † , 3 π † |
| h ′ 2 | 2600 | 2 + - | 10 - 20 | 80 | K 1 (1400) K † , K 1 (1270) K † , K ∗ 2 K † | KKππ † , KKπ † |
the production mechanism of GlueX is complementary to that of charmonium decay or pion beam production and is thought to enhance hybrid production, it is essential that the detector capability and statistical precision of the data set be competitive with other contemporary experiments in order to maximize the collective experimental knowledge of the meson spectrum.
Given the numerous discoveries of unexpected, apparently nonqq ¯ states in the charmonium spectrum, a state that has attracted a lot of attention in the ss ¯ spectrum is the Y (2175), which is assumed to be an ss ¯ vector meson (1 --). The Y (2175) (also denoted as φ (2170)) has been observed to decay to ππφ and has been produced in both J/ψ decays [10] and e + e -collisions [11, 12]. The state is a proposed analogue of the Y (4260) in charmonium, a state that is also about 1.2 GeV heavier than the ground state triplet ( J/ψ ) and has a similar decay mode: Y (4260) → ππJ/ψ [13-16]. The Y (4260) has no obvious interpretation in the charmonium spectrum and has been speculated to be a hybrid meson [17-20], which, by loose analogy, leads to the implication that the Y (2175) might also be a hybrid candidate. It should be noted that the spectrum of 1 --ss ¯ mesons is not as well-defined experimentally as the cc ¯ system; therefore, it is not clear that the Y (2175) is a supernumerary state. However, GlueX is ideally suited to study this system. We know that vector mesons are copiously produced in photoproduction; therefore, with the ability to identify kaons, a precision study of the 1 --ss ¯ spectrum can be conducted with GlueX . Some have predicted [21] that the potential hybrid nature of the Y (2175) can be explored by studying ratios of branching fractions into various kaonic final states. In addition, should GlueX be able to conclude that the Y (2175) is in fact a supernumerary vector meson, then a search can be made for the exotic 1 -+ ss ¯ member of the multiplet ( η ′ 1 ), evidence of which would provide a definitive interpretation of the Y (2175) and likely have implications on how one interprets charmonium data.
## III. THE BASELINE GLUEX PROGRAM
## A. Detector design and construction
A schematic view of the GlueX detector is shown in Fig. 2. The civil construction of Hall D is complete and the collaboration gained control of both Hall D and the Hall D tagger hall in 2012. All major detector subsystems have been installed in Hall D, and commissioning with beam is expected to begin in the Fall of 2014. The collaboration consists of over a hundred members, including representation from the theory community.
The GlueX photon beam originates from coherent bremsstrahlung radiation produced by the 12 GeV electron beam impinging on a 20 µ m diamond wafer. Orientation of the diamond and downstream collimation produce a photon beam peaked in energy around 9 GeV with about 40% linear polarization. A coarse tagger tags a broad range of electron energy, while precision tagging in the coherent peak is performed by a tagger microscope. A downstream pair spectrometer is utilized to measure photon conversions and determine the beam flux. Polarization will be measured independently by measuring the angular distribution of pair production in the field of an atomic electron (triplet photoproduction).
At the heart of the GlueX detector is the 2 2 T super-. conducting solenoid, which provides the essential magnetic field for tracking. The solenoidal geometry also has the benefit of reducing electromagnetic backgrounds in the detectors since low energy e + e -pairs spiral within a small radius of the beamline. Charged particle tracking
FIG. 2. A schematic of the GlueX detector and beam.
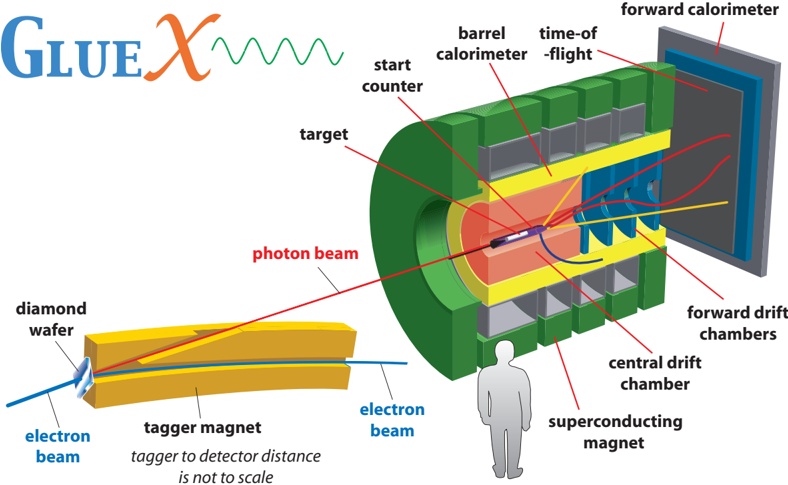
is performed by two systems: a central straw-tube drift chamber (CDC) and four six-plane forward drift chamber (FDC) packages. The CDC is composed of 28 layers of 1.5-m-long straw tubes. The chamber provides r -φ measurements for charged tracks. Sixteen of the 28 layers have a 6 ◦ stereo angle to supply z measurements. Each FDC package is composed of six planes of anode wires. The cathode strips on either side of the anode cross at ± 75 ◦ angles, providing a two-dimensional intersection point on each plane.
cm-thick scintillator bars, provides about 70 ps timing resolution on forward-going tracks within about 10 ◦ of the beam axis. This information is complemented by time-of-flight data from the BCAL and specific ionization ( dE/dx ) measured with the CDC, both of which are particularly important for identifying the recoil proton in γp → Xp reactions. Finally, identification of the beam bunch, which is critical for timing measurements, is performed by a thin start counter that surrounds the target.
Like tracking, the GlueX calorimetry system consists of two detectors: a barrel calorimeter with a cylindrical geometry (BCAL) and a forward lead-glass calorimeter with a planar geometry (FCAL). The primary goal of these systems is to detect photons that can be used to reconstruct π 0 's and η 's, which are produced in the decays of heavier states. The BCAL is a relatively highresolution sampling calorimeter, based on 1 mm doubleclad Kuraray scintillating fibers embedded in a lead matrix. It is composed of 48 four-meter-long modules; each module having a radial thickness of 14.7 radiation lengths. Modules are read out on each end by silicon SiPMs, which are not adversely affected by the high magnetic field in the proximity of the GlueX solenoid flux return. The forward calorimeter is composed of 2800 lead glass modules, stacked in a circular array. Each bar is coupled to a conventional phototube. The fractional energy resolution of the combined calorimetry system δ E /E ( ) is approximately 5%-6% / √ E [GeV].
The particle ID capabilities of GlueX are derived from several subsystems. A dedicated forward time-of-flight wall (TOF), which is constructed from two planes of 2.5-
As of June 2014, the CDC, FDC, BCAL, FCAL, and TOF have all be assembled in the hall. The beam-line instrumentation and the target and start counter package remain to be installed. Both calorimeters are fully cabled and have successfully recorded cosmic ray tracks. Studies using the tracking chambers in conjunction with the BCAL to observe cosmic ray events are planned. Commissioning with beam is expected to take place in Fall 2014.
## B. Proposed run plan
The GlueX physics program was presented initially to the Jefferson Lab Program Advisory Committee (PAC) in 2006 [24]. The first beam time allocations were made for the commissioning phases of GlueX after the presentation to the PAC in 2010 [25]. This allocation covered phases I-III of the run plan highlighted in Table II. In 2012, the collaboration presented a proposal to the PAC [1] for running at design intensity with enhanced particle identification capability (noted as Phase IV+ in
Table II). The PAC conditionally approved this proposal pending a final design of the particle identification hardware. In 2013 the collaboration returned to the PAC to present a proposal for running at design intensity with limited PID capability [2], this was approved by the PAC and 200 days of beam for Phase IV was granted.
In this document, we present our conceptual design for developing a FDIRC for GlueX using the BaBar components and are therefore seeking approval of Phase IV+, first proposed in 2012 [1]. Our goal is to pursue construction of this design on a time scale that allows us to merge both Phase IV and Phase IV+ into a single run.
## IV. AN FDIRC FOR GLUEX: CONCEPTUAL DESIGN
In the following section we discuss the conceptual design of a DIRC particle identification detector that is built from the BaBar DIRC components.
## A. Mechanical design and optics
The world's first DIRC detector was developed and utilized by the BaBar experiment. It provided excellent particle identification performance up to about 4 GeV/c [26]. The radiator of the BaBar DIRC consisted of a barrel made up of twelve boxes each containing twelve synthetic fused silica (henceforth referred to as quartz 2 ) bars. Quartz was chosen because of the following properties of the material: it has a large index of refraction ( n ) and a small chromatic dispersion; it has a long attenuation length; it is highly resistant to ionizing radiation; and it is possible to polish its surface. Each box is hermetically sealed and nitrogen gas constantly flows through the box to prevent any contamination which would compromise the preservation of the Cherenkov angle by total internal reflection.
Figure 3 shows the assembly of one DIRC box. Each bar is 17.25 mm thick, 35 mm wide and 4.9 m long and was produced by glueing four smaller bars end-to-end. One end of each box is coupled to a volume instrumented with photodetectors (the photon camera), while the other end has a mirror that reflects light back to the readout side. The readout side also has a quartz wedge glued to it. Neighboring bars are optically isolated by a 0.15 mm gap created using aluminum shims.
The quartz bars are used both as radiators and as light guides for the Cherenkov light trapped in the bars by total internal reflection. The number of photons produced per unit path length ( x ) of a particle with charge q per
2 In this document, we will refer to synthetic fused silica as quartz for the sake of brevity; however, it is worth noting that quartz is birefringent and, thus, not suitable for use in the DIRC.
FIG. 3. Schematic diagram of one BaBar box showing the 12 quartz bars (4.9m long), mirror ends, wedges and window ends [26].
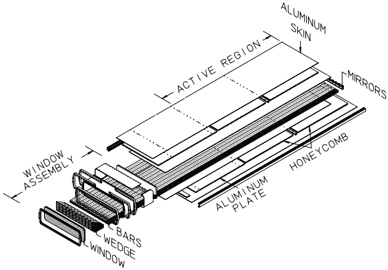
unit photon wavelength ( λ ) can be estimated using the following expression:
$$\frac { d ^ { 2 } N } { d x d \lambda } = \frac { 2 \pi \alpha q ^ { 2 } } { \lambda ^ { 2 } } \left [ 1 - \frac { 1 } { \beta ^ { 2 } n ^ { 2 } ( \lambda ) } \right ], \quad \quad ( 1 )$$
where α is the electromagnetic coupling constant and β is the velocity of the incoming particle divided by the speed of light. The index of refraction of the material n is a function of the wavelength of the emitted photon. The large index of refraction of the quartz material leads to a large number of Cherenkov photons produced within the wavelength acceptance of the DIRC (300-600 nm) (see Fig. 4).
The Cherenkov light produced by a particle of velocity β is emitted at an angle with respect to the direction of the particle's velocity, referred to as the Cherenkov angle ( θ C ), given by
$$\cos \theta _ { C } = \frac { 1 } { \beta n ( \lambda ) }.$$
Figure 4 shows the Cherenkov angle for different particle types. One can see that for an average quartz index of refraction 〈 n 〉 = 1 473, the maximal Cherenkov angle is . about 47 . The critical angle for trapping light via total ◦ internal reflection at the quartz-nitrogen boundary, given by the ratio of the indices of refraction, is θ critical ≈ 42 7 . ◦ ; thus, θ C > θ critical over most of the momentum range of interest for all particle types. An example of the path followed by a single photon trapped within a bar is shown in Fig. 5. The Cherenkov angle is preserved as the photon travels through the bar to the photodetectors.
## B. Focusing DIRC design
The initial photon camera of the BaBar DIRC detector was very large and filled with 6000 liters of purified water. Recently, a new design with focusing mirrors has been
TABLE II. A table of relevant parameters for the various phases of GlueX running.
| | Approved | Approved | Approved | Conditionally Approved | Conditionally Approved |
|-----------------------------------------|------------|------------|------------|--------------------------|--------------------------|
| | Phase I | Phase II | Phase III | Phase IV | Phase IV+ |
| Duration (PAC days) | 30 | 30 | 60 | 200 | 220 a |
| Minimum electron energy (GeV) | 10 | 11 | 12 | 12 | 12 |
| Average photon flux ( γ /s) | 10 6 | 10 7 | 10 7 | 5 × 10 7 | 5 × 10 7 |
| Level-one (hardware) trigger rate (kHz) | 2 | 20 | 20 | 200 | 200 |
| Raw Data Volume (TB) b | 60 | 600 | 1200 | 2300 | 2300 |
- a Twenty days are allocated for FDIRC commissioning.
- b Phase IV(+) assume a level-three software trigger is implemented.
developed that permits detection of the Cherenkov light produced in the quartz radiator using a much more compact design [27-31]. The focusing DIRC (FDIRC) was designed at SLAC with the constraint that the BaBar boxes cannot be altered [32]. The new photon camera system is about 25 times smaller than the camera used at BaBar yet has approximately the same Cherenkov angle resolution. The focusing design has the following advantages: the background rate is lower; the chromatic effect can be corrected for; the thickness of the bars can be corrected for; and the total number of photo-multipliers required is greatly reduced.
Figure 6 shows the focusing scheme of the FDIRC prototype developed at SLAC [32], adapted for use in the GlueX detector. The photon camera consists of two new quartz wedges and a Focusing Oil Box (FOB). The bars, window and wedges are glued end-to-end and are all made of quartz. The FOB consists of cylindrical and flat mirrors to focus the light onto the PMT plane immersed in an oil bath. The geometry of the FOB has not yet been optimized; it is shown here as a simplified rectangular volume.
The cylindrical mirror removes the effect of the bar thickness on the Cherenkov angle resolution since parallel rays are focused on the same point on the detector plane. The flat mirror then reflects the light almost perpendicularly to the detector plane. The total PMT surface to be covered is 2668 mm x 312 mm.
The addition of the new wedges ensures that the photons are reflected by the cylindrical mirrors. The first wedge (458 mm × 20 mm) is required to account for the flange geometry and support structure. The second wedge (1051 mm × 58 mm) covers the full length of two neighboring boxes and eliminates side reflections that lead to ambiguities in the reconstruction and reduction in the FDIRC performance. The expansion volume of the FOB is filled with a specific oil (CARGILLE 50350 or BICRON BC-599-14) whose index of refraction closely matches that of quartz; thus, large refraction between the different media is avoided.
## C. GlueX FDIRC
Figure 7 shows a schematic diagram of the proposed GlueX FDIRC detector. The acceptance in the forward region of GlueX is limited by the solenoid at ≈ 11 ; ◦ thus, to fully cover the acceptance requires four BaBar boxes, each containing 12 quartz bars. The bar boxes will be oriented vertically in the GlueX hall and placed symmetrically around the beam line. A single FOB will be used for all of the bars and placed below the bar boxes. The FDIRC detector will fit into the reserved space between the downstream end of the GlueX detector solenoid and the time-of-flight wall.
GEANT4 simulations of the GlueX FDIRC are under development. An example of Cherenkov light propagation in the GlueX FDIRC is shown in Fig. 8. Figure 9 shows the occupancy in the PMT plane for many identical charged particles thrown perpendicularly to a bar for both the GlueX and SLAC designs. In the SLAC design, photons entering the focusing block at large angles reflect from the sides giving rise to the crossed pattern. The alignment of the boxes in GlueX permits using one common FOB with a single readout system and avoids the side reflections seen with the focusing block design. Removing side reflections is highly desirable in the reconstruction as it avoids introducing ambiguities in the pattern recognition. A more detailed comparison of the patterns observed in the two designs is shown in the Appendix Fig. 29.
Figure 10 shows the photon position in the photodetector plane as a function of the arrival time of the photon, while Fig. 11 shows the photon arrival time and path length as a function of the number of bounces that the photon makes before being detected. The two bunches separated in time correspond to forward and backward emitted photons. The forward photons go directly from the creation point to the readout side while the backward photons are reflected by the mirrors and then traverse the entire length of the bar. In the current configuration, the forward photons begin to arrive about 27 ns after production corresponding to a path length of about 5 m making 200 bounces. The backward photons travel about twice the distance making about 400 bounces. The large num-
FIG. 4. (top) Cherenkov angle computed for four different charged particles (e, pion, kaon and proton), as a function of the momentum, for a fixed < n > = 1 473 quartz index of re-. fraction. (bottom) Number of Cherenkov photons produced in 17.25 mm of quartz material and within the photon wavelength range 300-600 nm, for different particles, as a function of their momentum.
FIG. 5. A single photon bouncing within a bar. If the photon angle is bigger than the critical angle, the light is internally reflected and the Cherenkov angle is preserved as the photon travels through the bar.
FIG. 6. Side and rear views of the FDIRC. The bars, old wedges and windows are part of the original BaBar boxes. The new focusing camera consists of the new wedges ( A and B ) and the FOB containing the cylindrical and flat mirrors.
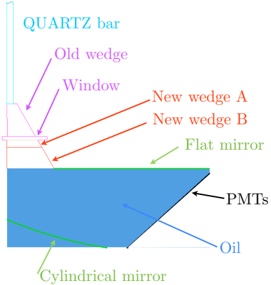
FIG. 7. Schematic diagrams of the GlueX FDIRC detector. Four BaBar boxes are required to cover the full acceptance. The bars are oriented vertically and placed symmetrically around the beam line. One FOB covers the full length of the four boxes.
FIG. 8. View of the GlueX FDIRC detector from the rear (top panel) and side (bottom panel). The propagation of the Cherenkov light through the different elements of the detector is visible. The rear view shows the collection of the light within a bar, while the side view shows the focusing scheme of the light on the PMTs surface.
ber of bounces made by the photons requires that the bars have excellent surface quality in order to preserve the Cherenkov angle. The position of the bars in the vertical direction has not yet been optimized. There is some freedom in their placing along this axis; thus, we are studying how the placement of the bars along the vertical axis affects the chromatic correction and other aspects of the FDIRC performance.
The GlueX application has two key differences from the focussing block design developed at SLAC for SuperB. First the variation in entry angle of charged par-
FIG. 9. Occupancy on the photodetector plane for a charged particle hitting a bar perpendicularly (efficiency not accounted for in this image) for the GlueX (top panel) and SLAC (bottom panel) designs.
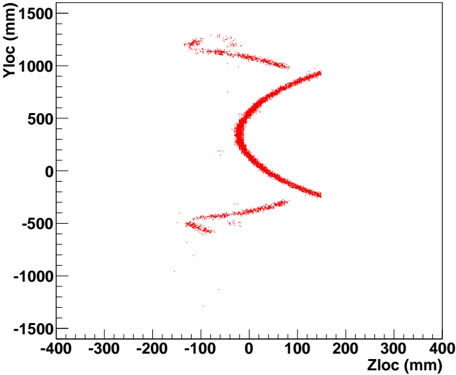
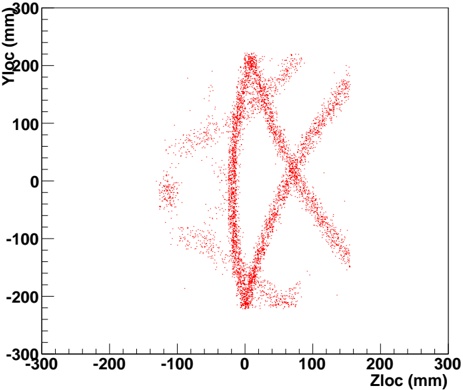
ticles into the FDIRC is relatively small given its downstream location. Second, all bar boxes can be arranged in a common plane, as opposed to the barrel shape of both BaBar and SuperB. It is these two properties that motivated us to explore the focussing oil box design in an attempt to find a simpler, more cost effective solution, that reduces ambiguities in the reconstruction. We recognize that our design, as sketched above, presents some mechanical challenges in construction. For example, coupling two A wedges from two different bar boxes to a common B wedge will be very challenging. Our goal at present is to develop the optical properties of the system that are optimal for GlueX . We may achieve similar
optical performance by using a mirror submerged in the oil box instead of a B wedge in air. As we work towards a final technical design we plan to examine and optimize these details considering cost, performance, and technical risk. If we cannot achieve our goals with a focussing oil box solution, we may always implement the focussing block design developed and tested at SLAC for SuperB.
FIG. 10. (top) Y position in the local photodetector coordinates vs the local arrival time of the photon. (bottom) onedimensional projection of the local time (using 50 identical pions). The local arrival time is defined as the time between the photon production to its detection.
## D. Readout
For satisfactory Cherenkov ring reconstruction, the DIRC detector needs a 2-dimensional photoreadout with a resolution on the order of a few millimeters. Although the yield of Cherenkov photons is proportional to 1 /λ 2 , due to the materials used in the BaBar DIRC bars espe-
FIG. 11. (top) local arrival time of the photons vs the number of bounces required to reach the detector. (bottom) path length of the photons vs the number of bounces required to reach the detector. The photon timing is defined as in Fig. 10.
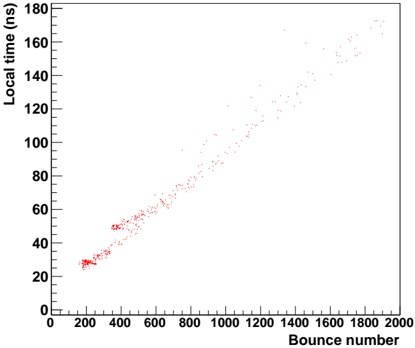
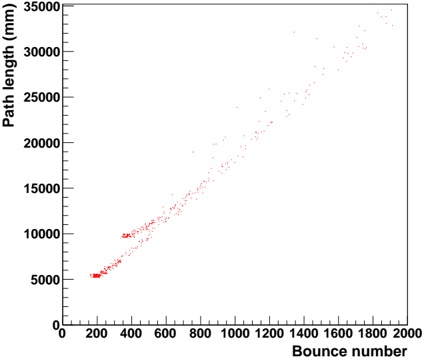
cially the EPOTEK 301-2 glue [27], only photons with wavelength longer than 300 nm can exit the DIRC bar boxes. Therefore the readout only needs to cover the range above 300 nm. In addition, due to the fringe field from the open solenoid used by the GlueX spectrometer, the readout has to be able to tolerate a magnetic field of about 100 Gauss.
Several readout options have been evaluated including multianode photomultiplier (MaPMT), Silicon photomultiplier (SiPM) and a newly developed large area pico-second photodetector (LAPPD) using the renovated micro-channel plate (MCP) technology [33]. At the end, we chose to focus on two types of photodetectors: the MaPMT and the LAPPD, with the LAPPD as our primary readout choice.
FIG. 12. The H8500 multianode photomultiplier manufactured by Hamamatsu.

## 1. Multianode Photomultiplier
Multianode photomultipliers have been recently tested for various Cherenkov detectors, including SuperB's focusing DIRC detector [34], Jefferson Lab CLAS12's RICH detector [36] and Jefferson Lab SoLID's light gas Cherenkov counter [35]. Most of these works focus on the H8500 MaPMT assembly [37] manufactured by Hamamatsu Corp. and it appears to be a solid solution for the DIRC readout.
The H8500 flat panel MaPMT assembly has an active area of 49 × 49 mm . 2 It has an 8 × 8 anode readout array, and each anode covers an area of 5.8 × 5.8 mm . 2 The packing factor of H8500 is a very tight 89% and this makes it very suitable for large area photon detection. The H8500 uses bialkali photocathode and borosilicate glass window, and is sensitive to photons of wavelength between 300 ∼ 650 nm and the maximum quantumefficiency in this range is close to 30%. The H8500 does have a variation using UV glass which extends the sensitive range down to 180 nm. But this won't be necessary for our DIRC design due to the wavelength cut-off that was mentioned.
If finer resolution is desired for more accurate Cherenkov angle measurement, the H9500 MaPMT [38] from Hamamatsu can be used instead. H9500 has the same dynode structure and geometry as H8500 and it has a 16 × 16 anode readout array with 256 3 × 3 mm 2 pixels.
The photodetection uniformity and the crosstalk between adjacent anode pixels of H8500 and H9500 were reported in literature and some results can be found in Ref [34, 36]. A relative variation up to 25% has been observed in the uniformity test as shown in Figure 13. The crosstalk pattern in Figure 14 shows a clear dependency upon the dynode mesh construction of the MaPMT. Although it is postulated that these behaviours will not be problematic for single photon detection of a RICH detector, further investigation will be needed to optimize the
FIG. 13. The relative uniformity of one H9500 pixel using laser scan [36].
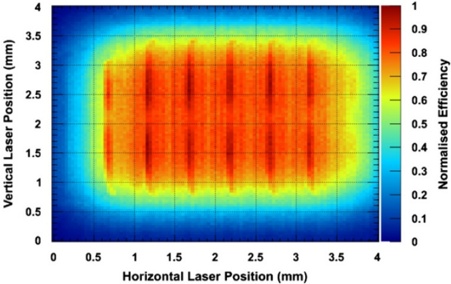
FIG. 14. The normalized crosstalk map of one H9500 pixel using single photoelectron laser scan [36].
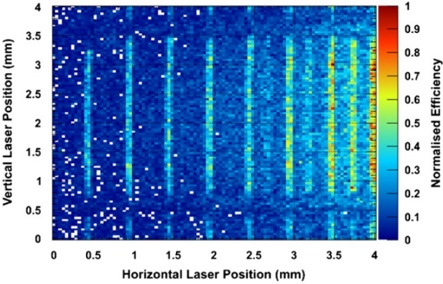
readout design and reconstruction algorithm.
In addition, the performance of H8500 in magnetic field was also studied at Jefferson Lab [35]. The test demonstrated that the H8500 MaPMT can operate without much degradation in a longitudinal field up to 300 Gauss. Although the drop of performance in transverse magnetic field is significantly more pronounced, up to 100 Gauss, such transverse field is also the easiest to shield in practice. Therefore, we conclude that MaPMTs will be able to operate in Hall-D's fringe field without shielding.
Recently, an upgraded version of the H8500 MaPMT has been revealed by Hamamatsu. The new H12700 MaPMT has the same geometry and output pin layout as the H8500. With a newly optimized dynode structure and voltage scheme, the collection efficiency has been greatly improved [39] and it now has a better separation of single photon signals from background, as shown in Figure 15.
As for the readout electronics, we will use the design of Jefferson Lab CLAS12's RICH detector [40] as a reference. The core of the design is to use the MAROC3 chip [41] specifically designed for the readout of 64channel MaPMTs. As shown in Figure 16, the MAROC3 chips digitize the analog signals from MaPMTs and pass
FIG. 15. Improvement of H12700's single photon detection capability [39].
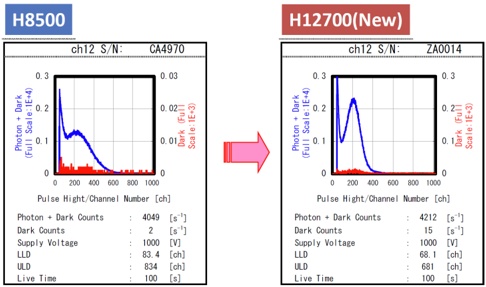
FIG. 16. Readout scheme of Jefferson Lab CLAS12's RICH detector.
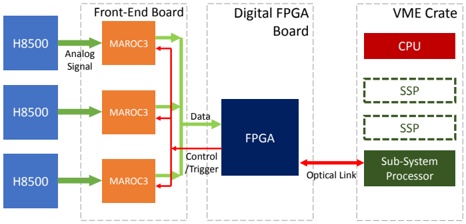
the resulting binary data stream to a digital FPGA board. The FPGA on board not only processes the data but also controls and provides triggers to the MAROC3 chips. The processed data from the FPGA will then be transmitted to a Jefferson Lab developed Sub-System Processor (SSP) [42] hosted in a VME crate through high speed optical links. The frontend board is currently under development by a group at INFN, and the digital FPGA board will be developed by Jefferson Lab's electronics group. These two groups together have demonstrated the feasibility of using MAROC3 chips for the RICH readout in a recent DOE project review. It's also worth mentioning that by using the Jefferson Lab SSP, such a readout system can be seamlessly integrated into the Hall D DAQ system.
## 2. Large Area Picosecond Photodetector
Since 2009, a new development of a large-area fast photo-detector using micro-channel plate (MCPPMT) [43] is being carried out by the large-area picoseconds photo-detector (LAPPD) collaboration [33] and they provide a very attractive, low cost, high performance readout solution for RICH detectors. The goal of this R&D program is to develop a family of largearea robust photo-detectors that can be tailored for a
FIG. 17. Schematic of LAPPD's MCP-PMT.
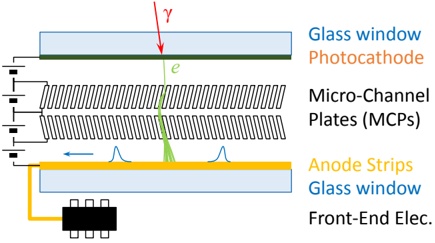
wide variety of applications where large-area economical photon detection is needed. The approach is to apply microchannel plate (MCP) technology to produce large-area photo-detectors with excellent space and time resolution. The schematic of such a detector is shown in Figure 17. In addition to having excellent resolution, the new devices should be relatively economical to produce in quantity. Such a detector can be used in many applications, such as precision time-of-flight measurements, readout of Cherenkov counters, and positron-emission tomography (PET) for medical imaging.
As the project is in its fourth year, excellent progress has been made. In particular, chemical vapor deposition (CVD) technique is being studied to form a photocathode on a large area glass window, and the resulting quantum efficiency is now over 25% for 350 nm wavelength. The collaboration applied atomic layer deposition (ALD) on capillary glass channel substrates (see Fig. 18) to produce MCPs [44] and has achieved better performance at much lower cost than standard commercial MCPs. The anode readout will use strip transmission lines [45] sampled by front-end waveform sampling chips. The LAPPD collaboration has assembled several prototypes using ceramic bodies (see Fig. 19) and small samples are expected to be available to early adopters in 2014.
When produced in large quantities, the manufacturing cost of LAPPD MCP-PMTs is expected to be less expensive than existing pixelated photo detectors such as Silicon Photomultipliers and Multi-anode Photomultiplier Tubes while still being able to provide comparable spatial resolution ( < 5 mm). Since LAPPD uses stripeline readout, this design significantly reduces the total channel count particularly for applications that need to cover a very large area such as a RICH detector. Under a low rate condition, the readout can be chained as shown in Figure 20 to further reduce the number of channels.
For the readout electronics, we can adopt the PSEC4 [46] ACIS developed by the LAPPD collaboration. It is a waveform sampling chip with a rate up to 15 GSample/s. A PSEC4 evaluation board in shown in Figure 21. Alternatively, as the total number of channels is expected to be a few hundred, we are also considering

FIG. 18. Photograph of a 20 × 20 cm 2 MCP made using ALD treatment of a borosilicate glass micro-capillary array. 20 mmpores, L/D ∼ 60:1, pore bias 8 ◦ . The multifiber hexagonal boundaries are visible in this backlit image.

FIG. 19. A 20 × 20 cm 2 ceramic body MCP-PMT prototype.

FIG. 20. The 3-tile anode. The connections between anode strips on neighboring tiles have been made by soldering small strips of copper to the silver silk-screened strips on the glass.
FIG. 21. The PSEC4 evaluation board [46]. The board uses a Cyclone III Altera FPGA (EP3C25Q240) and a USB 2.0 PC interface.

FIG. 22. The measured time distribution of signals from a focused fs laser source [48]. The signal was read from one side of a single strip line, fitted with a Gaussian.
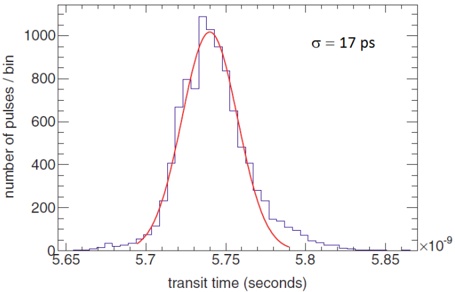
using Jefferson Lab's F1TDC [47] modules to readout signals from both sides of individual strips for a more versatile and sharable setup. Each F1TDC module has 16 TDCs with a resolution of 60 ps. In this scenario, flash ADCs will be connected to some of the channels for monitoring.
Another huge advantage that the LAPPD's MCPPMT can bring is the exceptional time resolution. The observed timing resolution for single photon hits has been measured to be better than 20 ps from a demountable prototype using metal photocathode [48], as shown in Figure 22. With such an excellent time resolution, the time-of-flight measured by the MCP-PMTs can be used for complementary particle identification.
The LAPPD's MCP-PMTs are a very attractive readout solution and therefore we make them our primary choice. A lot of properties of these detectors, including the radiation hardness and magnetic tolerance, have yet to be thoroughly tested. We will work together with the LAPPD collaboration to perform corresponding tests as early as possible.
## E. Integration and installation into the GlueX detector
As noted earlier, the existing GlueX design has space reserved for a particle identification device between the downstream end of the solenoid and the forward carriage that supports the time-of-flight and the forward calorimeter. Given the fixed length of the DIRC bar boxes, the height of the GlueX beamline off of the floor, and considerations about accessibility and hydrostatic pressure in the FOB, the most desirable orientation of the boxes is with the long axis oriented vertically with the existing window down. A sketch of the proposed installation is shown in Figure 23. Since such an orientation was never envisioned in the design of the boxes, potential mechanical problems must be carefully evaluated to ensure no
FIG. 23. A preliminary mechanical design showing the integration of the FOB and single bar box into the GlueX forward carriage.
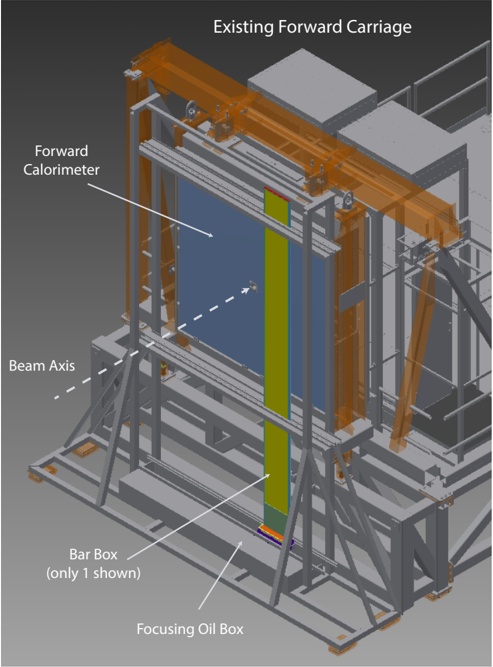
damage will result. It should be noted that nothing prohibits arranging the boxes horizontally if, at a later point, it is determined that a vertical orientation presents an unacceptable risk of damage. A horizontal arrangement would only complicate the support structure needed for the detector and consume large amounts of space in the existing Hall. The performance characteristics of the detector would remain unchanged.
In the vertical orientation the boxes themselves would remain rigid and dimensionally stable because the gravitational torques about the support points are less than they are in the horizontal orientation. One concern is that the vertical orientation causes the existing window to be loaded with the weight of the bars plus the spring load of the mirror. Because of the geometry of the existing wedge, the bulk of the load would be dispersed on the window near the supporting flange. A simple analysis of the worst case scenario, the load concentrated at a single point in the center of the window, shows a deflection of the window at center of about 0.0006', which is unlikely to result in breakage. The actual deflection is certain to be less. A second, finite element analysis using the exact geometry and a 45 psi load, which accounts for the
FIG. 24. A conceptual design for the installation jig that will allow the box to be oriented vertically and installed into the support fixture.
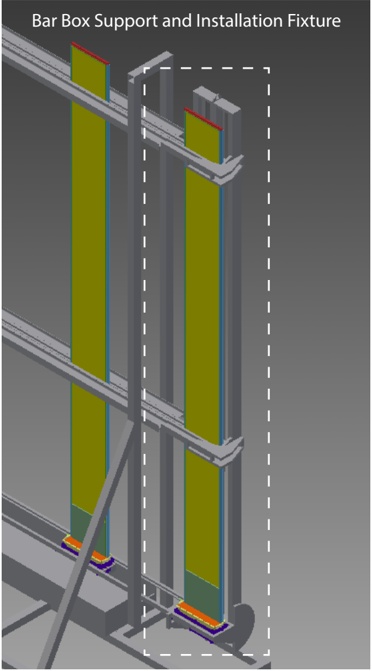
weight of the bars and the spring pressure, indicated a maximum bending stress around the edges of the window of 250 psi, much lower than the 7600 psi rupture strength of fused silica. This leads us to conclude that breakage or stress caused by deformation of the window is not a concern. If deemed necessary, we may procure a sample of the window material and conduct a destructive test to evaluate the deformation and breakage threshold.
An additional concern is maintaining the rigidity of the bar box in the transition from the horizontal to vertical orientation. In order to do this, the box will first be fixed to a rigid installation jig in the horizontal orientation. The jig will then be oriented vertically and fixed to the support structure on the forward carriage (see Fig. 24). The box will then be rolled, using the integrated rollers, off the jig and into the support structure, where it will be locked in place. We propose to test this installation technique utilizing the existing prototype bar box that was constructed using ordinary glass.
## V. EXPECTED FDIRC PERFORMANCE
In this section we detail the expected performance of the proposed GlueX FDIRC design. We begin by examining the discrimination power for single tracks. We conclude by folding this information into a simulation of inclusive photoproduction to estimate the background rejection power that the FDIRC provides.
## A. Single track particle identification
## 1. GlueX tracking resolution
Charged particle reconstruction in the GlueX detector is provided by the forward and central drift chambers (CDC and FDC) as described in Sec. III A. In this section we study the reconstructed track resolutions in the forward angle region of GlueX ( θ < 11 ) which is rel0 evant for the FDIRC detector. The reconstructed track variables which impact the particle identification performance of the FDIRC detector are the angle of incidence and position of the track crossing point, as well as the magnitude of the momentum as the particle enters the quartz bar.
To determine the resolution with which we can expect to measure these variables, we simulate single charged pions originating in the target of the GlueX detector, produced uniformly in azimuth for a range of polar angles and momenta. A complete GEANT model is used to simulate the GlueX detector response, and a Kalman Filter tracking algorithm is used to reconstruct the tracks in the drift chambers. The reconstructed track helix is then extrapolated through the magnetic field to the plane of the FDIRC detector.
The position and momentum resolution of the track as it enters the FDIRC detector are shown in Fig. 25. The incident angle resolution is shown in Fig. 26 for two variables, ψ X and ψ Y , which denote the angles with respect to the planes perpendicular and parallel to the bar's long axis, respectively. The resolution is momentum dependent. The GlueX detector has adequate particle identification for particles with momenta below about 2 GeV/ c using time-of-flight information; thus, for the FDIRC we are primarily concerned with particles above 2 GeV/ . c In this regime, the resolution on the input quantities to the FDIRC shown in Figs. 25 and 26 are better than is required (as we will show in the following section).
## 2. Cherenkov resolution and separation
The resolution on the Cherenkov angle of a single photon ( σ θ γ ) has many different contributions; these are listed in Table III. The Cherenkov angle resolution for a track ( σ θ C ) is given by
$$\sigma _ { \theta _ { C } } = \sqrt { \frac { \sigma _ { \theta _ { \gamma } } ^ { 2 } } { N _ { \gamma } } + \sigma _ { \theta _ { t r a c k } } ^ { 2 } },$$
where N γ is the number of Cherenkov photons detected. Based on the SLAC FDIRC prototype results, we expect the mean number of detected photons to be 25. The GlueX tracking system provides an angular resolution better than 1.5 mrad in the momentum range of interest; thus, the total Cherenkov angle resolution is expected to be better than 2.5 mrad (2.7 mrad) using a 5mm (6mm) detector pixel resolution.
TABLE III. Cherenkov angle error contributions for the FDIRC detector for a single Cherenkov photon. Table extracted from[32].
| Source of uncertainty | Contribution [mrad] |
|--------------------------------------|-----------------------|
| Chromatic error | 5.5 |
| Pixel contribution 5mm (6mm) | 5.8 (7) |
| Optical aberration | 4.5 |
| Transport along the bar | 2-3 |
| Bar thickness (after focusing) | ≈ 1 |
| Old wedge bottom inclined surface | 3.5 |
| Final error w/o chromatic correction | 10 (11) |
For a particle with β ≈ 1 and momentum ( ) well p above threshold entering the quartz bar, the number of σ separation ( N σ ) between pions and kaons can be approximated as
$$N _ { \sigma } \approx \frac { | m _ { \pi } ^ { 2 } - m _ { k } ^ { 2 } | } { 2 p ^ { 2 } \sigma \left [ \theta _ { C } \right ] \sqrt { n ^ { 2 } - 1 } }, \quad \quad ( 4 )$$
where m π ( m k ) is the pion (kaon) mass. A 2.5 mrad Cherenkov angle resolution provides K/π separation of at least 3 σ up to around 4 GeV/ . c
## 3. EM background
Interactions of the photon beam inside the GlueX detector produce background in the FDIRC from secondary electrons, positrons and photons. This EM background rate is important for two reasons: it will result in noise making determination of Cherenkov angles more difficult and it will cause more electronic channels to be read out increasing the event data size. The EM background from the beam was simulated using GEANT and the full GlueX MC. The rate at which particles produced by EM interactions enter the FDIRC is highly position dependent. As can be seen in Fig. 27, the rate falls off exponentially with distance from the beam line. The closest FDIRC bar will be placed 15 cm from the beam. Integrating over the region covered by the FDIRC, we expect roughly 8 photoelectrons per time segment readout by the data acquisition; thus, the EM background
FIG. 25. Track (left) position and (right) momentum resolution at the FDIRC.
FIG. 26. Track incident angle resolution at the FDIRC.
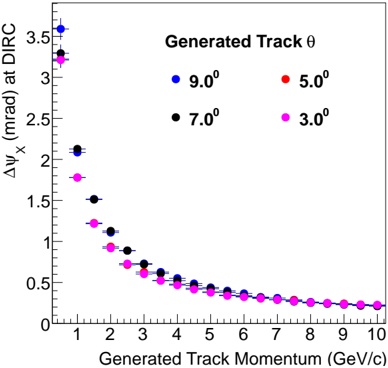
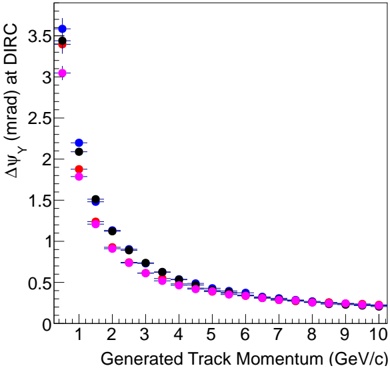
rate will not cause any significant increase in event size or reduction in performance.
which leads to a secondary vertex and the K π π + -+ π -final state:
## B. Strangeness reactions of interest
As described in section II B, to fully explore the spectrum of hybrid mesons, a systematic study of many hadronic final states is necessary, including those with kaons. The hybrid mesons with exotic quantum-number states that decay to kaons include the η ′ 1 , h ′ 0 , the h ′ 2 , which are all expected to couple to the KKππ final state, while both the η ′ 1 and the h ′ 2 are expected to couple to the KKπ final state. To study the GlueX sensitivity to these two final states, we have modeled two decay chains. For the KKπ state, we assume one of the kaons is a K S ,
$$\eta _ { 1 } ^ { \prime } ( 2 3 0 0 ) & \to K ^ { * } K _ { S } \\ & \to ( K ^ { + } \pi ^ { - } ) ( \pi ^ { + } \pi ^ { - } ) \\ & \to K ^ { + } \pi ^ { - } \pi ^ { + } \pi ^ { - }.$$
For the KKππ state we assume no secondary vertex:
$$h _ { 2 } ^ { \prime } ( 2 6 0 0 ) & \to K _ { 1 } ^ { + } K ^ { - } \\ & \to ( K ^ { * } ( 8 9 2 ) \pi ^ { + } ) K ^ { - } \\ & \to K ^ { + } K ^ { - } \pi ^ { - } \pi ^ { + }.$$
In addition to the exotic hybrid channels, there is an interest in non-exotic ss ¯ mesons. In order to study the sensitivity to conventional ss ¯ states, we consider an excitation of the normal φ meson, the known φ 3 (1850), which
FIG. 27. EM background expected in a plane near the FDIRC (arbitrary normalization). Each bin has a size of 4 cm × 4 cm. The dashed lines show location of the inner edge of the first FDIRC bar.
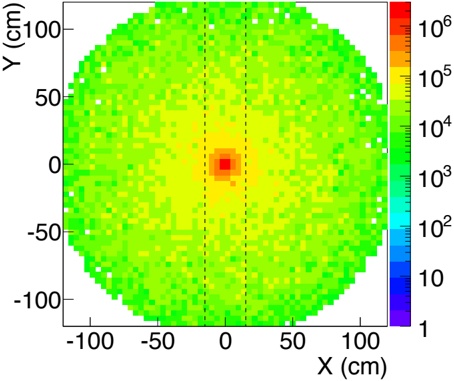
decays to KK ¯
$$\phi _ { 3 } ( 1 8 5 0 ) \to K ^ { + } K ^ { - } \,. \quad \quad \ ( 7 ) \quad t i t i$$
The detection efficiency of this state will be typical of φ -like states decaying to the same final state. Finally, as noted in Section II B, the Y (2175) state is viewed as a potential candidate for a non-exotic hybrid and has been reported in the decay mode
$$Y ( 2 1 7 5 ) & \to \phi f _ { 0 } ( 9 8 0 ) \\ & \to ( K ^ { + } K ^ { - } ) ( \pi ^ { + } \pi ^ { - } ) \,. \quad \quad ( 8 )$$
While this is the same KKππ state noted in reaction 6 above, the intermediate resonances make the kinematics of the final state particles different from the exotic decay channel noted above. Therefore, we simulate it explicitly. The final-state kaons from the reactions 5 - 8 will populate the GlueX detector differently, with different overlap of the region where the time-of-flight system can provide good K π / separation.
The remainder of this section describes a study of the sensitivity of the baseline GlueX detector to these reactions of interest involving kaons (Sec. V B 1), and the expected increase in sensitivity with the proposed FDIRC detector in GlueX (Sec. V B 3). The studies were performed using a larger scale pythia simulation of γp collisions processed through a complete geant model of the baseline GlueX detector and fully reconstructed with the GlueX analysis software. Signal samples were obtained from pythia events with the generated reaction topology, and the remainder of the inclusive photoproduction reactions were used as the background sample. Since many of the cross sections of interest are unknown we use pythia to predict the size of signal topologies of interest. The reactions listed above are several typical meson photoproduction reactions chosen to demonstrate FDIRC capability. The benefits of the FDIRC will certainly extend beyond these to other meson and baryon channels, some of which were discussed in our earlier proposals [1, 2].
## 1. Performance of the baseline GlueX detector
The baseline GlueX detector does not contain any single detector element that is capable of providing discrimination of kaons from pions over the full-momentum range of interest for many key reactions. However, the hermetic GlueX detector is capable of exclusively reconstructing all particles in the final state. In the case where the recoil nucleon is a proton that is detectable by the tracking chamber, this exclusive reconstruction becomes a particularly powerful tool for particle identification because conservation of four-momentum can be checked, via a kinematic fit, for various mass hypotheses for the final state particles. Many other detector quantities also give an indication of the particle mass, as assumptions about particle mass (pion or kaon) affect interpretation of raw detector information.
An incomplete list of potentially discriminating quantities include:
- · The confidence level (CL) from kinematic fitting that the event is consistent with the desired final state.
- · The CL(s) from kinematic fitting that the event is consistent with some other final states.
- · The goodness of fit ( χ 2 ) of the primary vertex fit.
- · The goodness of fit ( χ 2 ) of each individual track fit.
- · The CL from the time-of-flight detector that a track is consistent with the particle mass.
- · The CL from the energy loss ( dE/dx ) that a track is consistent with the particle type.
- · The change in the goodness of fit (∆ χ 2 ) when a track is removed from the primary vertex fit.
- · Isolation tests for tracks and the detected showers in the calorimeter system.
- · The goodness of fit ( χ 2 ) of possible secondary vertex fits.
- · Flight-distance significance for particles such as K S and Λ that lead to secondary vertices.
- · The change in goodness of fit (∆ χ 2 ) when the decay products of a particle that produces a secondary vertex are removed from the primary vertex fit.
The exact way that these are utilized depends on the particular analysis, but it is generally better to try to utilize as many of these as possible in a collective manner, rather than simply placing strict criteria on any one of them. This means that we take advantage of correlations between variables in addition to the variables themselves. One method of assembling multiple correlated measurements into a single discrimination variable, which has been used in this study, is a boosted decision tree (BDT) [49]. Traditionally, analyses have classified candidates using a set of variables, such as a kinematic fit confidence level, charged-particle time of flight, energy loss ( dE/dx ), etc. , where cuts are placed on each of the input variables to enhance the signal. In a BDT analysis, however, cuts on individual variables are not used; instead, a single classifier is formed by combining the information from all of the input variables.
A BDT is a multivariate classifier which is trained on a sample of known signal and background events to select signal events while maximizing a given figure of merit. The event selection performance is validated using an independent data sample, called a validation sample, that was not used in the training. If the performance is found to be similar when using the training (where it is maximally biased) and validation (where it is unbiased) samples, then the BDT performance is predictable. Practically, the output of the BDT is a single number for each event that tends towards one for signal-like events but tends towards negative one for background-like events. Placing a requirement on the minimum value of this classifier, which incorporates all independent information input to the BDT, allows one to enhance the signal purity of a sample. For a pedagogical description of BDTs, see Ref. [50]. The BDT algorithms used are contained within ROOT in the TMVA package [51].
Here we only consider the case where the recoil proton is reconstructed. A missing recoil nucleon reduces the number of constraints in the kinematic fit, and, consequently, dramatically diminishes the capability of the fit to discriminate pions from kaons. One can build a BDT for the reaction of interest, and look at the efficiency of selecting true signal events as a function of the sample purity. These studies do not include the efficiency of reconstructing the tracks in the detector, but start at the point where a candidate event containing five charged tracks has been found. In all cases we set the requirement on the BDT classifier in order to obtain a fixed final sample purity. For example, a purity of 90% implies a background at the 10% level. Any exotic signal in the spectrum would likely need to be larger than this background to be robust. Therefore, with increased purity we have increased sensitivity to smaller signals, but also lower efficiency. In Table IV we present the signal selection efficiencies (post reconstruction) for our four reactions of interest for the baseline GlueX detector and including a FDIRC detector in GlueX (more in Section V B 3). As noted earlier, these assume that the tracks have been reconstructed and do not include that efficiency. With the baseline GlueX detector, higher signal purities of 95% to 99%, which may be necessary to search for more rare final states, result in the signal efficiency dropping dramatically. This exposes the limit of what can be done with the baseline GlueX hardware.
## 2. Limitations of existing kaon identification algorithms
It is important to point out that the use of kinematic constraints to achieve kaon identification, without dedicated hardware, has limitations. By requiring that the recoil proton be reconstructed, we are unable to study charge exchange processes that have a recoil neutron. In addition, this requirement results in a loss of efficiency of 30%-50% for proton recoil topologies and biases the event selection to those that have high momentum transfer, which may make it challenging to conduct studies of the production mechanism. Our studies indicate that it will be difficult to attain very high purity samples with a multivariate analysis alone. In channels with large cross sections, the GlueX sensitivity will not be limited by acceptance or efficiency, but by the ability to suppress and parameterize backgrounds in the amplitude analysis; thus, we need high statistics and high purity. This latter statement is not only true for reactions that contain kaons but also applies to to reactions in which the dominant backgrounds arise from kaons. Supplemental kaon identification hardware will help suppress these background thereby enhancing the sensitivity. Finally, it is worth noting that our estimates of the kaon selection efficiency using kinematic constraints depends strongly on our ability to model the performance of the detector. Although we have constructed a complete simulation, the experience of the collaboration with comparable detector systems indicates that the simulated performance is often better than the actual performance in unforeseen ways.
## 3. Performance with FDIRC detector in GlueX
As described in Sec. V A, the single track particle identification of the FDIRC in GlueX is expected to provide 3 σ K/π separation up to momentum of ≈ 4 GeV/ . This c provides vital, independent information to the multivariate analysis that has a very high discrimination power. The FDIRC information is included in the BDT by converting the measured Cherenkov angle into a probability for each particle mass hypothesis ( π, K, and p ). We define a χ 2 for each particle mass hypothesis as
$$\chi _ { i } ^ { 2 } = \frac { \left ( \theta _ { C, i } ^ { e x p } - \theta _ { C } ^ { r e c o } \right ) ^ { 2 } } { \sigma _ { \theta _ { C } } ^ { 2 } },$$
where θ exp C,i is the expected Cherenkov angle for mass hypothesis i using the measured track momentum from the
TABLE IV. Efficiencies for identifying several final states in GlueX excluding reconstruction of the final state tracks.
| | η ′ 1 (2300) → K ∗ K S | η ′ 1 (2300) → K ∗ K S | h ′ 2 (2600) → K + 1 K - | h ′ 2 (2600) → K + 1 K - | φ 3 (1850) → K + K - | φ 3 (1850) → K + K - | Y (2175) → φf 0 (980) | Y (2175) → φf 0 (980) |
|--------|--------------------------|--------------------------|----------------------------|----------------------------|------------------------|------------------------|-------------------------|-------------------------|
| Purity | Baseline | FDIRC | Baseline | FDIRC | Baseline | FDIRC | Baseline | FDIRC |
| 0.90 | 0.36 | 0.48 | 0.33 | 0.49 | 0.67 | 0.74 | 0.46 | 0.65 |
| 0.95 | 0.18 | 0.33 | 0.16 | 0.34 | 0.61 | 0.68 | 0.20 | 0.55 |
| 0.99 | 0.00 | 0.05 | 0.00 | 0.08 | 0.18 | 0.38 | 0.03 | 0.28 |
drift chambers, θ reco C is the 'reconstructed' Cherenkov angle, and σ θ C is the Cherenkov angle resolution.
As we do not yet have a full FDIRC reconstruction algorithm, we use Eq. 9 as a proxy for the FDIRC performance. We use σ θ C = 2 5 mrad for all tracks (this is an . upper bound on the expected resolution; see Sec. V A). The track momentum resolution (see Fig. 25) is included in θ exp C,i . The 'reconstructed' Cherenkov angle is obtained by generating a random number from a Gaussian distribution whose mean is the expected Cherenkov and width is σ θ C . Aconfidence level for each particle mass hypothesis ( π , K p , ) is computed from Eqn. 9. These three values for each track are included in the BDT training, and the performance is evaluated in the same way as the baseline GlueX detector and shown in Table IV. We note that, depending on the choice of readout, the FDIRC may provide an improvement in time-of-flight measurements for charged particles over our baseline design. Further study is needed to quantify this improvement; therefore, we neglect it in the studies presented below.
At 95% purity, the signal efficiencies are typically about twice as high including the FDIRC into GlueX . Reaching 99% purity is not possible for several of these channels without the FDIRC. It is important to stress here that the purity levels are defined as correctly identified final state candidates divided by all candidates. In the case that exotic contributions to some channel are at the percent level, extracting such signals will require reaching 99% purity, which helps ensure that the backgrounds are smaller than the small signal of interest. Without the FDIRC, this will not be possible for many channels of interest. Finally, as noted above, the baseline numbers are dependent on the reliability of the simulation. For example, the discrimination power of the kinematic fit confidence level will decrease drastically if the GlueX detector resolution is worse than expected. The simulation of the FDIRC performance is based only on the Cherenkov-angle resolution. The value of 2.5 mrad is expected to be achievable; thus, the real-world performance enhancement obtained by adding the FDIRC is likely to be even greater than what is shown in Table IV.
## C. Effects of the FDIRC on other GlueX Systems
Installing the FDIRC results in a significant increase in material upstream of the FCAL. We have studied the effects of the FDIRC on the FCAL performance using
FIG. 28. Effects of the FDIRC material on FCAL photon reconstruction.
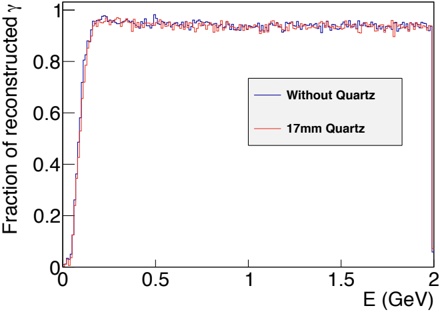
GEANT and found them to be minimal (see Fig. 28). The photon energy detection threshold increases from 160 MeV to 180 MeV. Above 500 MeV the photon reconstruction efficiency is unaffected. The small electronpositron opening angle from converted photons, along with the small distance between the FDIRC and FCAL, results in a single EM shower; thus, the effect of the FDIRC on photon reconstruction is minimal.
## VI. GLUEX FDIRC CONSTRUCTION PLAN
In this section we describe our preliminary construction schedule, budget, and provide a discussion of logistical details concerning construction, specifically transportation of the fragile DIRC components from SLAC to Jefferson Lab.
## A. Preliminary schedule
As noted earlier, our ultimate goal is to have the GlueX FDIRC operational for the Phase IV running that is currently estimated to take place in around 20172018. During 2014 we plan to develop a technical design for the detector, including a complete cost estimate and detailed construction schedule. We expect Jefferson Lab to appoint an external committee to review this technical design and construction plan during the summer of
2015. During 2014 we will continue to work with the LAPPD collaboration to be certain that large area photodetectors will provide a feasible solution for the FDIRC photon camera. Additional design efforts in 2014-2015 include optimizing the optics, exploring cost effective alternatives for the fluid in the FOB, and conducting materials testing to verify that the vertical orientation of the bar box is structurally sound. Construction of the support structure and FOB could begin in fiscal year 2016, after a technical design review. Integration and installation into the hall could then be complete in time for operation around 2017-2018.
## B. Transportation of DIRC components to Jefferson Lab
We have had preliminary discussions with Rock-It Cargo, a world-wide shipper of delicate art and industrial equipment. We plan to transport the bars from SLAC to Jefferson Lab over road via air ride trailer. The trailer will be temperature controlled and equipped with a liquid nitrogen dewar to maintain constant flow of nitrogen through the bar boxes. There is concern that optical joints between bars may be brittle, therefore physical shock should be avoided during transport. Based on discussions with Rock-It Cargo, a crew would construct a custom shipping crate under our supervision, which would then be transported to SLAC for loading. The crate would incorporate metal substructure to prohibit flexing of the boxes. The boxes themselves are relatively lightweight, which means that foam materials may be used to attenuate transport vibration. A group from Livermore Lab studied accelerations of a 12 ton load being transported by air ride trailer [52] and found that accelerations never exceeded 1.5 g 's in all three dimensions when the trailer was driven at 40 mph on typical Oakland, CA roads. Careful container design will attenuate these shock loads. If necessary, the mass of the trailer can be increased with an additional dummy load, which should further reduce acceleration. As a conservative limit, we evaluate internal stresses assuming a 3 g acceleration will be experienced during transit.
Assuming the bar box and internal bar support buttons remain rigid, acceleration of the box would cause bending of the bars in between the support buttons. Any elastic compression of the buttons would mitigate this bending. We evaluated the bending stress of a quartz bar when subjected to a 3 g load applied at a point in the center between two supports and parallel to the narrow dimension of the bar, which is a worse case scenario. We found the bending stress for a bar supported by buttons with 600 mm spacing, typical near the center of the bar, to be about 300 psi, which is over an order of magnitude less than typical tensile or rupture strengths for fused silica. In the vicinity of a bar-to-bar epoxy joint the button spacing is assumed to be 25 mm and the corresponding bending stress is about 1 psi. Reference [26] states a tensile strength of epoxy used in the DIRC that exceeds 1000 psi. The most sensitive area to such bending appears to be the region between the window and the first bar, a distance of about 100 mm that is occupied by the wedge and not supported by buttons. Here a conservative estimate of the bending stress, assuming the wedge has the same profile as the bar, yields an estimate of 9 psi. Even with the consideration that the strength of the epoxy may be degraded due to aging, it seems feasible to transport the components over road, provided that appropriate packaging and other considerations are made.
Prior to shipping the actual DIRC bars, we plan to instrument and ship a prototype bar box at SLAC that is filled with ordinary glass in an appropriate shipping crate. This will give us an opportunity to measure g -loads that may be experienced in transit. In addition small pieces of unpolished fused silica with a cross sectional profile the same as the actual bars can be procured, glued with the same epoxy as used in construction, and tested for strength.
## C. SLAC resources
A significant amount of infrastructure for DIRC construction and testing still remains at SLAC. The clean room used for assembling the bar boxes, with its large granite surface table that is capable of accommodating a full bar box, is still in usable condition. Assuming that our final optical design requires us to glue wedges to the existing bar boxes, it may be optimal to perform these operations in the SLAC clean room prior to transporting the bar boxes to Jefferson Lab. Also at SLAC is a cosmic ray test facility that is equipped with a bar box and muon hodoscope. This facility provides a unique opportunity to test readout and electronics with actual Cherenkov signals produced by cosmic ray muons. Due to the size of the bar box and the precision required of the timing and tracking system for cosmic rays, such a test setup cannot be easily replicated elsewhere. Finally, the personnel at SLAC who have experience with the BaBar DIRC have already provided an enormous amount of beneficial information in the development of our conceptual design; we hope to draw on this expertise, if possible, as we continue with the design and construction of a GlueX FDIRC.
## D. Preliminary budget
A preliminary material cost estimate for the FDIRC detector at GlueX is shown in Table V. This budget does not include technical or engineering manpower, indirect costs, or project management costs. Costs for wedge material and assembly are estimated from vendor quotes for the wedges as described in this document. A detailed optimization that balances performance, cost, and construction feasibility (technical risk) has not yet been performed. Costs for mechanical structures are estimated
based on experience with building similar structures. We base our current cost estimate for the photosensors and readout on our desire to use the LAPPD collaboration sensors, but recognize this technology is not yet available. Alternate sensors and readout options using existing technology are listed in the table for reference. All readout quotes include low voltage, crates, cables, and other necessary infrastructure to integrate with the Jefferson Lab data acquisition system.
## VII. CONCLUSION AND ACKNOWLEDGEMENTS
The ability to reconstruct kaon final states is absolutely critical in the context of attempting to study mesons and baryons with both explicit and hidden strangeness. Following the request of PAC39, we have developed and presented a conceptual design for an FDIRC detector to enhance the particle identification capabilities of the GlueX experiment. The FDIRC utilizes one-third of the quartz bars from the BaBar DIRC along with the bar boxes that house the bars. A focussing optical system consisting of mirrors submerged in oil is proposed. Our plan is to construct an optical system and readout around the large area micro-channel plate PMTs under development by the LAPPD Collaboration. However, alternate options based on multi-anode PMTs, which are more expensive but less technically risky exist.
The FDIRC provides enhanced PID capability for the
- [1] GlueX Collaboration, 'A study of meson and baryon decays to strange final states with GlueX in Hall D,' Presentation to PAC 39 , (2012). Available at: http://www.gluex.org/docs/pac39 proposal.pdf
- [2] GlueX Collaboration, 'An initial study of meson and baryon decays to strange final states with GlueX in Hall D,' Presentation to PAC 40 , (2013). Available at: http://www.gluex.org/docs/pac40 proposal.pdf
- [3] J. J. Dudek, Phys. Rev. D 84 , 074023 (2011).
- [4] J. J. Dudek, R. G. Edwards, M. J. Peardon, D. G. Richards and C. E. Thomas, Phys. Rev. Lett. 103 , 262001 (2009).
- [5] J. J. Dudek, R. G. Edwards, M. J. Peardon, D. G. Richards and C. E. Thomas, Phys. Rev. D 82 , 034508 (2010).
- [6] J. J. Dudek, R. G. Edwards, B. Joo, M. J. Peardon, D. G. Richards and C. E. Thomas, Phys. Rev. D 83 , 111502 (2011).
- [7] R. G. Edwards, J. J. Dudek, D. G. Richards and S. J. Wallace, Phys. Rev. D 84 , 074508 (2011).
- [8] J. Beringer et al. [Particle Data Group Collaboration], Phys. Rev. D 86 , 010001 (2012).
- [9] C. A. Meyer and Y. Van Haarlem, Phys. Rev. C 82 , 025208 (2010).
- [10] M. Ablikim et al. [BES Collaboration], Phys. Rev. Lett. 100 , 102003 (2008).
GlueX experiment that will increases the sensitivity and reduce backgrounds for final state topologies that are necessary to search for ss ¯ hybrid mesons and infer their quark flavor content. We propose a program consisting of 20 PAC days of beam for commissioning the FDIRC followed by 200 days of beam at an average intensity of 5 × 10 7 γ /s in order to conduct a program of studying the spectrum of hadrons that contain valence strange quarks. The proposed running is complementary to and could, in principle, be conducted concurrently with that approved by PAC40.
We would like to thank J. Va'vra, B. Ratcliff, and B. Wisniewski for their useful discussions and technical information they provided about the BaBar DIRC. We thank M. Benettoni and INFN of Padova for computer models of the BaBar DIRC box.
## VIII. APPENDIX
Figure 29 shows the expected distribution of photons on the PMT plane for charged pions intersecting the DIRC at various locations. The GlueX design greatly reduces the overlap in the patterns. There are still side reflections for hits in the bars that are farthest from the beam line. These reflections could be removed by instrumenting an additional 300 mm along the length of the FOB with PMTs; however, the cost of this extra instrumentation outweighs the benefits as it is unlikely to get particles near the limits of π/K separation in this region.
- [11] B. Aubert et al. [BABAR Collaboration], Phys. Rev. D 74 , 091103 (2006).
- [12] C. P. Shen et al. [Belle Collaboration], Phys. Rev. D 80 , 031101 (2009).
- [13] B. Aubert et al. [BABAR Collaboration], Phys. Rev. Lett. 95 , 142001 (2005).
- [14] T. E. Coan et al. [CLEO Collaboration], Phys. Rev. Lett. 96 , 162003 (2006).
- [15] Q. He et al. [CLEO Collaboration], Phys. Rev. D 74 , 091104 (2006).
- [16] C. Z. Yuan et al. [Belle Collaboration], Phys. Rev. Lett. 99 , 182004 (2007).
- [17] F. E. Close and P. R. Page, Phys. Lett. B 628 , 215 (2005).
- [18] S. -L. Zhu, Phys. Lett. B 625 , 212 (2005).
- [19] E. Kou and O. Pene, Phys. Lett. B 631 , 164 (2005).
- [20] X. -Q. Luo and Y. Liu, Phys. Rev. D 74 , 034502 (2006) [Erratum-ibid. D 74 , 039902 (2006)].
- [21] G. -J. Ding and M. -L. Yan, Phys. Lett. B 657 , 49 (2007).
- [22] P. R. Page, E. S. Swanson and A. P. Szczepaniak, Phys. Rev. D 59 , 034016 (1999).
- [23] N. Isgur, R. Kokoski and J. E. Paton, Phys. Rev. Lett. 54 , 869 (1985).
- [24] GlueX Collaboration, 'Mapping the Spectrum of Light Quark Mesons and Gluonic Excitations with Linearly Polarized Protons,' Presentation to PAC 30 , (2006). Available at: http://www.gluex.org/docs/pac30 proposal.pdf
- [25] GlueX Collaboration, 'The GlueX Experiment in Hall D,' Presentation to PAC 36 , (2010). Available at: http://www.gluex.org/docs/pac36 update.pdf
- [26] I. Adam et al. , Nucl. Instr. and Meth. A538 , 281 (2005).
- [27] C. Field et al. , Nucl. Instr. and Meth. A553 , 96 (2005).
- [28] C. Field et al. , Nucl. Instr. and Meth. A518 , 565 (2004).
- [29] J.F. Benitez et al. , Development of a focusing DIRC, IEEE Nuclear Science Conference Record, October 29, SLAC-PUB-12236 (2006).
- [30] J. Va'vra et al. , The Focusing DIRC- the First RICH Detector to Correct the Chromatic Error by Timing, Presented at Vienna Conference on Instrumentation, February, SLAC-PUB-12803 (2007).
- [31] J.F. Benitez et al. , Nucl. Instr. and Meth. A595 , 104 (2008).
- [32] J. Va'vra et al. , Nucl. Instr. and Meth. A718 , 541(2013).
- [33] LAPPD Collaboration, 'The Development of Large-Area Fast photo-detectors', Proposal to the Department of Energy's Office of High Energy Physics (2009).
- [34] F. Gargano et al. , Nucl. Instr. and Meth. A718 , 563 (2013).
- [35] S.P. Malace, B.D. Sawatzky, H. Gao, JINST 8 , P09004 (2013).
- [36] R.A. Montgomery et al. , Nucl. Instr. and Meth. A695 , 326 (2012).
- [37] Hamamatsu Photonics K. K., 'Mutlanode PMT Assembly H8500/H10966 Series', http://www.hamamatsu.com/resources/pdf/etd/ H8500 H10966 TPMH1327E02.pdf
- [38] Hamamatsu Photonics K. K., 'Mutlanode PMT Assembly H9500, H9500-03', http://www.hamamatsu.com/resources/pdf/etd/ H9500 H9500-03 TPMH1309E01.pdf
- [39] Ardavan Ghassemi, Technical Sales Rep for Scientific Projects, Hamamatsu Photonics K. K., Private Commu-
nication
- [40] M. Contalbrigo, E. cisbani, P. Rossi, Nucl. Instr. and Meth. A639 , 302 (2011).
- [41] S. Blin et al. , 'A generic photomultiplier readout chip', JINST 5 , C12007 (2010).
- [42] B. Raydo, 'Sub-System Processor Manual', https://coda.jlab.org/wiki/Downloads/HardwareManual/ SSP/SSP Module HallD.pdf , (2009).
- [43] M. Wetstein et al. [LAPPD Collaboration], Nucl. Instr. and Meth. A639 , 148 (2011).
- [44] O.W. Siegmund et al. , Nucl. Instr. and Meth. A695 , 168 (2012).
- [45] H. Grabas et al. , Nucl. instr. and Meth. A711 , 124 (2013).
- [46] E. Oberia et al. , submitted to Nucl. instr. and Meth., [arXiv:1309.4397] (2013).
- [47] Jefferson Lab Data Acquisition Group, 'F1TDC a High-Resolution, Multi-Hit, VME64x Time-to-Digital Converter', https://coda.jlab.org/wiki/Downloads/docs/manuals/ f1tdc v1 2.pdf , (2005).
- [48] B. Adams et al. , Rev. of Sci. Instr. 84 , 061301 (2013).
- [49] L. Brieman el al. , Classification and regression trees , Wadsworth International Group, Belmont, California (1984).
- [50] B.P. Roe et al. , Nucl. Instr. and Meth. A543 , 577 (2005).
- [51] A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E. von Toerne, and H. Voss, TMVA: Toolkit for Multivariate Data Analysis , PoS A CAT 040 (2007).
- [52] B. Thomas et al. , arXiv:1105.5409 [physics.ins-det] (2011).
TABLE V. Estimated material cost for the GlueX FDIRC in thousands of dollars. Costs for alternate photosensor and readout options are shown in brackets but not included in total estimated cost. These costs do not include manpower, overhead, or project management costs.
| Item | Estimated Cost [k$] |
|----------------------------------------------|-----------------------|
| Focussing oil box: | |
| New wedge material, machining, and polishing | $190 |
| Wedge assembly infrastructure | $15 |
| Oil (CARGILLE) | $120 |
| Focusing oil box | $10 |
| Mirrors | $40 |
| Photosensors and readout: | |
| LAPPD: 26 tiles × $6 | $156 |
| LAPPD PSEC4 readout: 900 channels × $0.20 | $180 |
| ( LAPPD TDC readout: 900 channels × $0.30 | ( $270 ) |
| ( MaPMT: 318 H8500 MaPMTs × $2.5 ) | ( $795 ) |
| ( MaPMT MAROC3 readout: 318 × $0.83 ) | ( $262 ) |
| Detector support structure | $50 |
| Bar box transport to Jefferson Lab | $30 |
| Calibration, monitoring, and control systems | $40 |
| Total estimated material cost | $831 |
FIG. 29. Comparison of the (right) original SLAC design to the (left) adapted version of the camera for GlueX . The figures correspond to the following: (top) a hit in the bar the far from the beam line; (middle) a hit in the central part of a box; and (bottom) a hit in the bar closest to the beam line.
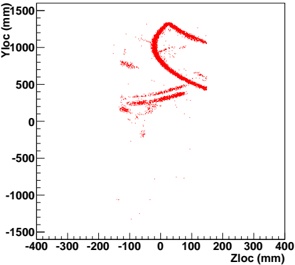
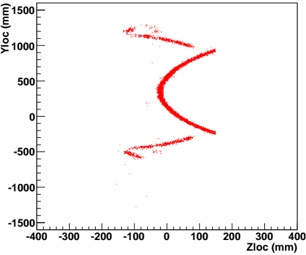
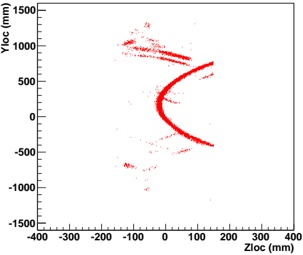
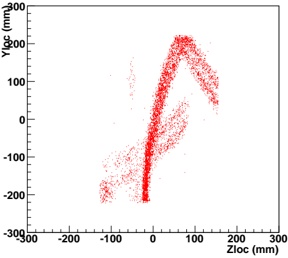 | null | [
"The GlueX Collaboration",
"M. Dugger",
"B. Ritchie",
"I. Senderovich",
"E. Anassontzis",
"P. Ioannou",
"C. Kourkoumeli",
"G. Vasileiadis",
"G. Voulgaris",
"N. Jarvis",
"W. Levine",
"P. Mattione",
"W. McGinley",
"C. A. Meyer",
"R. Schumacher",
"M. Staib",
"F. Klein",
"D. Sober",
"N. Sparks",
"N. Walford",
"D. Doughty",
"A. Barnes",
"R. Jones",
"J. McIntyre",
"F. Mokaya",
"B. Pratt",
"W. Boeglin",
"L. Guo",
"E. Pooser",
"J. Reinhold",
"H. Al Ghoul",
"V. Crede",
"P. Eugenio",
"A. Ostrovidov",
"A. Tsaris",
"D. Ireland",
"K. Livingston",
"D. Bennett",
"J. Bennett",
"J. Frye",
"M. Lara",
"J. Leckey",
"R. Mitchell",
"K. Moriya",
"M. R. Shepherd",
"O. Chernyshov",
"A. Dolgolenko",
"A. Gerasimov",
"V. Goryachev",
"I. Larin",
"V. Matveev",
"V. Tarasov",
"F. Barbosa",
"E. Chudakov",
"M. Dalton",
"A. Deur",
"J. Dudek",
"H. Egiyan",
"S. Furletov",
"M. Ito",
"D. Mack",
"D. Lawrence",
"M. McCaughan",
"M. Pennington",
"L. Pentchev",
"Y. Qiang",
"E. Smith",
"A. Somov",
"S. Taylor",
"T. Whitlatch",
"B. Zihlmann",
"R. Miskimen",
"B. Guegan",
"J. Hardin",
"J. Stevens",
"M. Williams",
"V. Berdnikov",
"G. Nigmatkulov",
"A. Ponosov",
"D. Romanov",
"S. Somov",
"I. Tolstukhin",
"C. Salgado",
"P. Ambrozewicz",
"A. Gasparian",
"R. Pedroni",
"T. Black",
"L. Gan",
"S. Dobbs",
"K. Seth",
"X. Ting",
"A. Tomaradze",
"T. Beattie",
"G. Huber",
"G. Lolos",
"Z. Papandreou",
"A. Semenov",
"I. Semenova",
"W. Brooks",
"H. Hakobyan",
"S. Kuleshov",
"O. Soto",
"A. Toro",
"I. Vega",
"N. Gevorgyan",
"H. Hakobyan",
"V. Kakoyan"
] | 2014-08-01T16:10:05+00:00 | 2014-08-01T16:10:05+00:00 | [
"physics.ins-det",
"hep-ex"
] | A study of decays to strange final states with GlueX in Hall D using components of the BaBar DIRC | We propose to enhance the kaon identification capabilities of the GlueX
detector by constructing an FDIRC (Focusing Detection of Internally Reflected
Cherenkov) detector utilizing the decommissioned BaBar DIRC components. The
GlueX FDIRC would significantly enhance the GlueX physics program by allowing
one to search for and study hybrid mesons decaying into kaon final states. Such
systematic studies of kaon final states are essential for inferring the quark
flavor content of hybrid and conventional mesons. The GlueX FDIRC would reuse
one-third of the synthetic fused silica bars that were utilized in the BaBar
DIRC. A new focussing photon camera, read out with large area photodetectors,
would be developed. We propose operating the enhanced GlueX detector in Hall D
for a total of 220 days at an average intensity of 5x10^7 {\gamma}/s, a program
that was conditionally approved by PAC39 |
1408.0216v1 | ## Production of light flavour hadrons at intermediate and high p T in pp, p-Pb and Pb-Pb collisions measured with ALICE
Michael Linus Knichel (for the ALICE Collaboration)
Physikalisches Institut, Ruprecht-Karls-Universit¨t Heidelberg, Im Neuenheimer a Feld 226, 69120 Heidelberg, Germany
## Abstract
Light flavour transverse momentum spectra at intermediate and high p T provide an important baseline for the measurement of perturbative QCD processes in pp, for the evaluation of initial state effects in p-Pb, and for investigating the suppression from parton energy loss in Pb-Pb collisions. The measurement of the nuclear modification factor R pPb for inclusive charged particles is extended up to 50 GeV/ c in p T compared to our previous measurement and remains consistent with unity up the largest momenta. Results on R pPb of charged pions, kaons and protons that cover up to 14 GeV/ c in p T are presented and compared to R pPb of inclusive charged particles. On the production of charged pions, kaons, and protons up to p T = 20 GeV/ c in Pb-Pb collisions final results for R AA are presented.
Key words: transverse momentum spectra, charged particles, light hadrons, proton-lead collisions, proton-proton collisions, heavy-ion collisions, LHC
## 1 Introduction
In proton-proton collisions particles at intermediate and high p T are produced in hard scattering processes with large virtuality. The cross section for these processes can be calculated with perturbative QCD (pQCD) approaches. Measurements of transverse momentum spectra provide a test of pQCD calculations which include non-perturbative effects in the parton distribution functions and fragmentation functions. Phenomenological approaches
Email address: [email protected] (Michael Linus Knichel (for the ALICE Collaboration)).
used in Monte Carlo event generators need to be tuned bases on measured data. Moreover, pp collisions provide a reference (QCD vacuum) to study the effects induced by the QCD medium formed in nucleus-nucleus collisions and by the nuclear initial-state in proton-nucleus collisions.
Initial and final state nuclear effects in p-Pb and Pb-Pb collisions result in particle production that differs from an incoherent superposition of nucleonnucleon collisions. The difference is quantified by the nuclear modification factor
$$R _ { A A, p P b } ( p _ { \text{T} } ) = \frac { \text{d} ^ { 2 } N ^ { A A, p P b } / \text{d} y \text{d} p _ { \text{T} } } { \langle N _ { \text{coll} } \rangle \text{ d} ^ { 2 } N ^ { p p } / \text{d} y \text{d} p _ { \text{T} } } = \frac { \text{d} ^ { 2 } N ^ { A A, p P b } / \text{d} y \text{d} p _ { \text{T} } } { \langle T _ { A A, p P b } \rangle \text{ d} ^ { 2 } \sigma ^ { p p p } / \text{d} y \text{d} p _ { \text{T} } }, \quad ( 1 )$$
where 〈 N coll 〉 is the average number of binary nucleon-nucleon collisions in one Pb-Pb or p-Pb collision and 〈 T 〉 is the average nuclear overlap function. For unidentified charged particles the rapidity y is approximated by the pseudorapidity η .
Proton-lead collisions allow the study of so-called cold nuclear matter (CNM) effects, for instance nuclear shadowing (nuclear modification of the parton distribution functions) and k T broadening (due to multiple scattering of the partons prior to the hard scattering). Collective effects might also be present in p-Pb collisions and are a possible explanation for the double-ridge recently observed in di-hadron correlations [1,2,3]. Preliminary results from CMS [4] and ATLAS [5] show an enhancement of particle production above 30 GeV/ c in p T compared to expectations from binary collision scaling. Since CNM effects are present also in nucleus-nucleus collisions they have to be taken into account in the interpretation of Pb-Pb results.
In collisions of heavy nuclei a hot QCD medium, the Quark-Gluon Plasma (QGP), is created leading to strong collective effects at low and intermediate p T (most prominently radial flow). In addition, parton energy loss in the QGP induces a suppression of the high p T particle yields.
For charged π , K, p we present preliminary results on R pPb ( p T < 14 GeV/ ) c and final results on R AA ( p T < 20 GeV/ ). The analysis of charged particles in c p-Pb is extended up to p T = 50 GeV/ c (the first analysis [6] was statistically limited to p T < 20 GeV/ ). c
## 2 Analysis
The ALICE experiment [7] is focused on the study of the hot and dense QCD medium created in heavy-ion collisions. Among the LHC experiments ALICE has unique particle identification (PID) capabilities at mid-rapidity
T
T
Fig. 1. Nuclear modification factor R pPb of primary charged particles at mid-rapidity | η cms | < 0 3 . measured in non-single-diffractive (NSD) p-Pb collisions at √ s NN = 5 02 TeV [16] . compared to model calculations using NLO pQCD with EPS09s nuclear PDFs [17], LO pQCD with additional implementation of cold nuclear matter effects [18] and HIJING 2.1 [19].
Fig. 2. Nuclear modification factor R pPb of primary charged π , K, p and Ξ at mid-rapidity measured in NSD p-Pb collisions at √ s NN = 5 02 TeV. .
( | η | < 0 9). The data presented here were collected with minimum bias triggers . from the Silicon Pixel Detector (SPD) and the VZERO scintillators. Charged tracks and the interaction vertex are reconstructed using the Inner Tracking System (ITS), a six-layer silicon detector, and the Time Projection Chamber (TPC). Pions with transverse momenta up to 2 GeV/ c (kaons up to 2.8 GeV/ c and protons up to 3 GeV/c) are identified on a track-by-track basis with different detectors providing PID over different momentum ranges (see e.g. [8] for details). The differential energy loss d E/ x d is measured in the ITS and the TPC and combined with time-of-flight measurements in the TOF detector and the Cherenkov angle from the High Momentum Particle Identification Detector (HMPID). For transverse momenta above 2-3 GeV/ c (currently up to p T = 20 GeV/ ) identified particle spectra are obtained from a statistical c analysis of the energy loss in the TPC in the relativistic rise region. The inclusive d E/ x d distribution is fitted - in intervals of p T and η - by the sum of four Gaussians ( π , K, p, e) with their mean and width fixed from clean samples of identified particles. The p T distributions are finally obtained as the product of the charged particle spectra and the fractions of π , K, p from the dE / dx analysis and corrected for the variations in acceptance and efficiency.
For the 2013 p-Pb data, with recent improvements in the reconstruction procedure, the transverse momentum resolution achieved by combined ITS-TPC tracking ranges from σ p ( T ) /p T ≈ 1% at p T = 1 GeV/ c to σ p ( T ) /p T ≈ 3% at p T = 50 GeV/ . In the previously reconstructed pp and Pb-Pb data the resoc
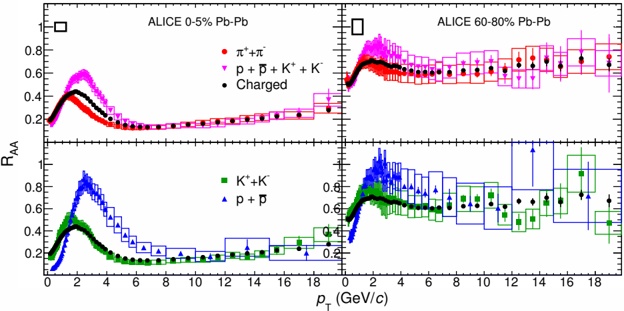
T
Fig. 3. The nuclear modification factor R AA of π , K, p in central (0-5%) and peripheral (60-80%) Pb-Pb collisions [8] compared to the R AA of inclusive charged particles [21].
lution is σ p ( T ) /p T ≈ 10% at p T = 50 GeV/ . Tracking and PID performance c of the ALICE detector are described in detail in [9].
## 3 Results
Transverse momentum spectra of primary charged particles have been measured in pp collisions at √ s = 0 9, 2.76 and 7 TeV [10]. Next-to-leading order . (NLO) pQCD calculations [11] over-predict the measured cross-sections by about a factor 2. A similar discrepancy has been observed for neutral pions [12] and by CMS [13,14]. Measured jet spectra [15] are in much better agreement with NLO calculations pointing to the fragmentation functions as main source of the discrepancy. However, NLO calculations give a reasonable description of the √ s dependence of p T distributions and are therefore used to scale the measured charged particle p T spectrum from √ s = 7 TeV to √ s = 5 02 TeV, the centre-of-mass energy of p-Pb collisions. At low trans-. verse momenta ( p T < 5 GeV/ ) the reference spectrum is constructed as a c bin-by-bin interpolation between the measurements at √ s = 2 76 TeV and . √ s = 7 TeV, assuming a power law behavior of the cross section with √ s for fixed p T . For identified hadrons ( π , K, p) the power law interpolation method is used for the full p T range (up to 14 GeV/ ). c
In p-Pb collisions at √ s NN = 5 02 TeV the nucleon-nucleon (NN) centre-of-. mass (CM) system is moving with ∆ y cm = 0 465 in the direction of the proton; . y and η cms are in the CM frame. As a sign convention we take y and η cms to be positive along the direction of the proton 1 . The average nuclear overlap
1 This is opposite to the convention used in [6].
of 〈 T pPb 〉 = 〈 N coll 〉 /σ INEL pp = 0 0983 . ± 0 0035 mb . -1 is obtained from a Monte Carlo Glauber simulation with σ INEL pp = (70 ± 5) mb.
Figure 1 shows R pPb for charged particles at mid-rapidity | η cms | < 0 3 in p-. Pb collisions [16], compared to three model calculations. The next-to-leading order (NLO) pQCD calculation with EPS09s nuclear PDFs [17] describes the charged particle data for p T > 6 GeV/ . The calculation is for c π 0 and describes well the R pPb of charged π over the full range ( p T < 1 3 . GeV/ ). c The leading order (LO) pQCD calculation with isospin effect, Cronin effect, cold nuclear matter energy loss and dynamical shadowing separately implemented [18] shows a decrease of R pPb with p T not seen in the data. In HIJING 2.1 [19] (shown with different factorization schemes) this decreasing trend is even more pronounced.
At low p T an approximate scaling with the number of participants is observed, corresponding to R pPb ≈ 0 57. A hint of an enhancement in the Cronin region . around p T = 2-4 GeV/ c is visible. Note that systematic uncertainties are correlated between neighbouring p T bins. Up to the largest p T of 50 GeV/ c no deviation from binary collision scaling is observed for charged particles, with an average 〈 R pPb 〉 = 0 969 . ± 0 056(stat ) . . ± 0 090(syst ) . . ± 0 06(norm ) . . for 28 < p T < 50 GeV/ . For charged jets c R pPb is consistent with unity up to 90 GeV/ c in p T [20]. Data presented by CMS [4] and ATLAS [5] show a rising trend in R pPb at large p T > 30 GeV/ c but given the current systematic uncertainties the difference is barely significant. As part of the difference comes from the reference spectrum, pp data √ s = 5 TeV would be very useful.
Figure 2 shows the R pPb for charged π , K, p up to p T = 14 GeV/ c and for Ξ up to 6 GeV/ . Ξ baryons are measured in their decay Ξ c -→ Λ π -, with the subsequent decay Λ → pπ -. The nuclear modification factor of π and K does not differ from the charged particle result within the systematic uncertainties. At intermediate momenta of 2 < p T < 6 GeV/ c a mass ordering with R π pPb ≈ R K pPb < R p pPb < R Ξ pPb is observed. In Pb-Pb collisions a similar mass ordering is observed and attributed to radial flow. A notable Cronin peak is only observed for p and Ξ implying that the small enhancement of R pPb for charged particles is driven by the protons. At larger transverse momenta of p T > 8 GeV/ c the nuclear modification factors of π , K, p are all consistent with unity.
The nuclear modification factor R AA for π , K, p up to 20 GeV/c [8] is shown in Figure 3 for central (0-5%) and peripheral (60-80%) Pb-Pb collisions at √ s NN = 2 76 TeV with comparison to the charged particle . R AA [21]. For large transverse momenta ( p T > 10 GeV/ ) the strong suppression observed for c inclusive charged particles does not depend on the particle type.
## 4 Conclusions
In p-Pb collisions soft particle production at low p T scales approximately with the number of participating nucleons and hard particle production at large p T scales with the number of binary nucleon-nucleon collisions, with a smooth transition in between. This indicates that there are no strong initial or final state nuclear effects at large p T . At intermediate p T the small enhancement (Cronin peak) is caused by protons. Identified light hadrons exhibit a mass ordering of R pPb at intermediate p T which is qualitatively similar to that in Pb-Pb collisions. At p T > 8 GeV/ c π , K and p R pPb is consistent with unity. In Pb-Pb collisions large suppression is observed for all particle species, with differences from radial flow visible in the R AA at low and intermediate p T , while above 10 GeV/ c the suppression is common for all species with the p/ π and K/ π ratios not differing from those in pp collisions.
## References
- [1] S. Chatrchyan, et al. [CMS Collaboration], Phys.Lett. B718 (2013) 795-814.
- [2] B. Abelev, et al. [ALICE Collaboration], Phys.Lett. B719 (2013) 29-41.
- [3] G. Aad, et al.[ATLAS Collaboration], Phys.Rev.Lett. 110 (2013) 182302.
- [4] CMS Collaboration, CERN Report No. CMS-PAS-HIN-12-017, 2013.
- [5] ATLAS Collaboration, CERN Report No. ATLAS-CONF-2014-029, 2014.
- [6] B. Abelev, et al. [ALICE Collaboration], Phys.Rev.Lett. 110 (2013) 082302.
- [7] K. Aamodt, et al. [ALICE Collaboration], JINST 3 (2008) S08002.
- [8] B. B. Abelev, et al. [ALICE Collaboration], arXiv:1401.1250 .
- [9] B. B. Abelev, et al. [ALICE Collaboration], arXiv:1402.4476 .
- [10] B. B. Abelev, et al. [ALICE Collaboration], Eur.Phys.J. C73 (2013) 2662.
- [11] R. Sassot, P. Zurita, M. Stratmann, Phys.Rev. D82 (2010) 074011.
- [12] B. Abelev, et al. [ALICE Collaboration], Phys.Lett. B717 (2012) 162-172.
- [13] S. Chatrchyan, et al. [CMS Collaboration], JHEP 1108 (2011) 086.
- [14] S. Chatrchyan, et al. [CMS Collaboration], Eur.Phys.J. C72 (2012) 1945.
- [15] B. Abelev, et al. [ALICE Collaboration], Phys.Lett. B722 (2013) 262-272.
- [16] B. B. Abelev, et al. [ALICE Collaboration], arXiv:1405.2737 .
- [17] I. Helenius, K. J. Eskola, H. Honkanen, C. A. Salgado, JHEP 1207 (2012) 073.
- [18] Z.-B. Kang, I. Vitev, H. Xing, Phys.Lett. B718 (2012) 482-487.
- [19] R. Xu, W.-T. Deng, X.-N. Wang, Phys.Rev. C86 (2012) 051901.
- [20] R. Haake (for the ALICE Collaboration), PoS EPS-HEP2013 (2013) 176.
- [21] B. Abelev, et al. [ALICE Collaboration], Phys.Lett. B720 (2013) 52-62. | null | [
"Michael Linus Knichel"
] | 2014-08-01T16:16:56+00:00 | 2014-08-01T16:16:56+00:00 | [
"nucl-ex",
"hep-ex"
] | Production of light flavour hadrons at intermediate and high pT in pp, p-Pb and Pb-Pb collisions measured with ALICE | Light flavour transverse momentum spectra at intermediate and high pT provide
an important baseline for the measurement of perturbative QCD processes in pp,
for the evaluation of initial state effects in p-Pb, and for investigating the
suppression from parton energy loss in Pb-Pb collisions. The measurement of the
nuclear modification factor RpPb for inclusive charged particles is extended up
to 50 GeV/c in pT compared to our previous measurement and remains consistent
with unity up the largest momenta. Results on RpPb of charged pions, kaons and
protons that cover up to 14 GeV/c in pT are presented and compared to RpPb of
inclusive charged particles. On the production of charged pions, kaons, and
protons up to pT = 20 GeV/c in Pb-Pb collisions final results for RAA are
presented. |
1408.0217v2 | ## Charge transfer across transition metal oxide interfaces: emergent conductance and new electronic structure
Hanghui Chen 1 2 , , Hyowon Park 1 2 , , Andrew J. Millis 1 and Chris A. Marianetti 2 1
Department of Physics,
Columbia University,
New York, NY, 10027, USA
2 Department of Applied Physics and Applied Mathematics,
Columbia University,
New York, NY, 10027, USA
(Dated: January 6, 2015)
## Abstract
We perform density functional theory plus dynamical mean field theory calculations to investigate internal charge transfer in an artificial superlattice composed of alternating layers of vanadate and manganite perovskite and Ruddlesden-Popper structure materials. We show that the electronegativity difference between vanadium and manganese causes moderate charge transfer from VO 2 to MnO 2 layers in both perovskite and Ruddlesden-Popper based superlattices, leading to hole doping of the VO 2 layer and electron doping of the MnO 2 layer. Comparison of the perovskite and Ruddlesden-Popper based heterostructures provides insights into the role of the apical oxygen. Our first principles simulations demonstrate that the combination of internal charge transfer and quantum confinement provided by heterostructuring is a powerful approach to engineering electronic structure and tailoring correlation effects in transition metal oxides.
## I. INTRODUCTION
Advances in thin film epitaxy growth techniques have made it possible to induce emergent electronic [1-10], magnetic [11-13] and orbital [14, 15] states, which are not naturally occurring in bulk constituents, at atomically sharp transition metal oxide interfaces [1619]. For example, the interface between the two nonmagnetic band insulators LaAlO 3 and SrTiO 3 [4] has been reported to exhibit both conductance [20] and magnetism [21] (see reviews [22-25] and references therein). At the interface of Mott insulators SrMnO 3 and LaMnO , hole doping on the Mn sites leads to rich phenomena, including metal-insulator 3 transition, charge/spin/orbital ordering and magnetoresistance [26-28].
In LaAlO /SrTiO 3 3 and related heterostructures, the interface electron gas is believed to be produced by the polar catastrophe mechanism, which leads to the transfer of charge from the sample surface to the interface. Here, we consider a different mechanism for controlling the electronic properties of an interface: namely, electronegativity-driven charge transfer. Recently, we have shown that internal charge transfer in a LaTiO /LaNiO 3 3 superlattice transforms metallic LaNiO 3 into a S = 1 Mott insulator and Mott insulating LaTiO 3 into a S = 0 band insulator [29]. A natural question arises: can we reverse the process and utilize internal charge transfer to induce conductance via oxide interfaces? In this regard, it is very tempting to explore Mott interfaces (one or both constituents are Mott insulators) due to the unusual phenomena (colossal magnetoresistance and high temperature superconductivity) exhibited in certain doped Mott insulators.
In this paper we use density functional theory + dynamical mean field theory (DFT+DMFT) to theoretically design a superlattice with emergent metallic behavior. We explore two different types of structure: the perovskite structure (referred to as 113-type) and the n = 1 Ruddlesden-Popper structure (referred to as 214-type). Among the four bulk constituents (SrVO , SrMnO , Sr VO 3 3 2 4 and Sr MnO ), all are correlation-driven insulators 2 4 except SrVO , which is a moderately correlated metal [30-32]. We show that the difference 3 of electronegativity between the elements V and Mn drives internal charge transfer from V to Mn sites, leading to a 'self-doping' at the interface and possibly inducing conductance as Mn sites become weakly electron doped and V sites hole doped.
The rest of the paper is organized as follows: Section II presents the theoretical methods. A schematic of band alignment is presented in Section III to illustrate the underlying
FIG. 1: Simulation cells of A ) bulk SrVO , 3 B ) bulk SrMnO 3 and C ) SrVO /SrMnO 3 3 superlattice; D ) bulk Sr VO , 2 4 E ) bulk Sr MnO 2 4 and F ) Sr 2 VO /Sr MnO 4 2 4 superlattice. The green atoms are Sr. The blue and purple cages are VO 6 and MnO 6 octahedra, respectively. The stacking direction of the superlattice is the [001] axis.
mechanism of charge transfer. All the bulk results from ab initio calculations are in Section IV and the results of vanadate-manganite superlattices are in Section V, both of which provide qualitative support and quantitative corrections to the schematic. The conclusions are in Section VI. Five Appendices present technical details relating to the insulating gaps of Sr VO 2 4 and Sr MnO , alternative forms of the double counting correction, LDA spectra of 2 4 the superlattices and the possibility of two consecutive repeating layers (i.e. 2/2 superlattices instead of 1/1 superlattices).
## II. COMPUTATIONAL DETAILS
The DFT [33, 34] component of our DFT+DMFT [35, 36] calculations is performed using a plane-wave basis [37], as implemented in the Vienna Ab-initio Simulation Package
(VASP) [38-41] using the Projector Augmented Wave (PAW) approach [42, 43]. Both local density approximation (LDA) [44] and Perdew-Burke-Ernzerhof generalied gradient approximation (GGA-PBE) [45] are employed. The correlated subspace and the orbitals with which it mixes are constructed using maximally localized Wannier functions [46] defined over the full 10 eV range spanned by the p d -band complex, resulting in an well localized set of d -like orbitals [47]. To find the stationary solution for our DFT+DMFT functional, we first find the self-consistent charge density within DFT. Subsequently we fix the charge density and converge the DMFT equations. A full charge self-consistency is not implemented in the present work. However, this approximation procedure is found to yield reasonable results in calculations of bulk systems [32, 48, 49].
For the bulk materials, we consider two structures: the experimental one and the theoretical relaxed structure obtained by the use of DFT. For the superlattice, we use DFT to obtain the relaxed structure. We compare LDA and GGA calculations and both exchange correlation functions yield consistent results. The simulation cell is illustrated in Fig. 1. The stacking direction of the superlattice is along [001]. We use an energy cutoff 600 eV. A 12 × 12 × 12 [ L x L z ] ( L x and L z are the lattice constants along the x and z directions, and [ x ] is the integer part of x ) Monkhorst-Pack grid is used to sample the Brillouin zone. Both cell and internal coordinates are fully relaxed until each force component is smaller than 10 meV/˚ and the stress tensor is smaller than 10 kBar. A Convergence of the key results are tested with a higher energy cutoff (800 eV) and a denser k -point sampling 20 × 20 × 20 [ L x L z ] and no significant changes are found.
For the vanadates, we treat the empty e g orbitals with a static Hartree-Fock approximation (recent work shows this approximation is adequate to describe the electronic structure of vanadates [32]), while correlations in the V t 2 g manifold are treated within single-site DMFT including the Slater-Kanamori interactions using intra-orbital Hubbard U V = 5 eV and J V = 0.65 eV [50-52]. For manganites, we treat the correlations on all the five Mn d orbitals within single-site DMFT using the Slater-Kanamori interactions with intra-orbital Hubbard U Mn = 5 eV and J Mn = 1 eV [53]. The DMFT impurity problem is solved using the continuous time quantum Monte Carlo method [54-56]. In order to use the 'segment' algorithm [57], we neglect the exchange and pairing terms in the Slater-Kanamori Hamiltonian. All the calculations are paramagnetic and the temperature is set to 232 K. Long-range magnetic ordering (in particular antiferromagnetism) might be induced at low temperature
on Mn sites in manganites and in superlattices. A thorough study of magnetic properties will be presented elsewhere [58]. For the superlattice, we solve the problem in the single-site DMFT approximation, meaning that the self energy is site local and is one function on the V site and a different one on the Mn site. The self energies are determined from two quantum impurity models, which are solved independently but coupled at the level of the self consistency condition.
An important outstanding issue in the DFT+DMFT procedure is the 'double counting correction' which accounts for the part of the Slater-Kanamori interactions already included in the underlying DFT calculation and plays an important role by setting the mean energy difference between the d and p bands. The p d -separation plays a crucial role in determining the band alignment, which affects the charge transfer. However, currently there is no exact procedure for the double counting correction. We use the U ′ double counting method recently introduced [49], where the parameter U ′ is the prefactor in the double-counting which determines the p d -separation and equivalently the number of electrons in the d -manifold. In this study, U ′ is chosen to produce an energy separation between the O p and transition metal d bands which is consistent with photoemission experiments. Our main qualitative conclusions do not depend on the details of the double counting scheme; in particular we show here they hold also for the conventional fully localized limit (FLL) double counting [59] which is the U ′ = U limit of the method of Ref. [49]. The reason behind that is because in the superlattice, it is the relative V d -Mn d energy separation that controls the charge transfer. The FLL double counting formula underestimates the p d -separation in both SrVO 3 and SrMnO 3 by about 1 eV. However, such an error is cancelled in the calculation of V d -Mn d energy separation. Therefore the FLL double counting does not change the charge transfer picture.
The spectral function presented throughout this work is defined as follows:
$$A _ { i } ( \omega ) = - \frac { 1 } { \pi N _ { k } } \sum _ { \mathbf k } \text{Im} \left ( [ ( \omega + \mu ) \mathbf I - H _ { 0 } ( \mathbf k ) - \Sigma _ { \mathrm t o t } ( \omega ) + V _ { d c } ) ] ^ { - 1 } \right ) _ { i i } \quad \quad ( 1 ) \\. \quad \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
where i is the label of a Wannier function, N k is the number of k -points, I is an identity matrix, H 0 ( k ) is the DFT-LDA band Hamiltonian in the matrix form using the Wannier basis. Σ tot ( ω ) is the total self-energy and is understood as a diagonal matrix only with nonzero entries on the correlated orbitals. Local tetragonal point symmetry of the V and
FIG. 2: Schematic band structure of A ) vanadates and B ) manganites. C ) is the band alignment of the superlattice before the charge transfer occurs, i.e. two independent Fermi levels. D ) is the band structure of the superlattice after the charge transfer occurs, i.e. with one common Fermi level. The dashed red line denotes the Fermi level.
Mn sites ensures that Σ( ω ) is diagonal within the correlated orbital subspace. µ is the chemical potential. V dc is the double counting potential, which is defined as [49]:
$$V _ { d c } = ( U ^ { \prime } - 2 J ) \left ( N _ { d } - \frac { 1 } { 2 } \right ) - \frac { 1 } { 2 } J ( N _ { d } - 3 )$$
Note that if U ′ = U , then we restore the standard FLL double counting formula [60]. For clarity, all the spectra functions presented in this paper are obtained from LDA+DMFT calculations. GGA+DMFT calculations yield qualitatively consistent results.
## III. SCHEMATIC OF BAND STRUCTURE AND BAND ALIGNMENT
We consider the following materials as components of the superlattice: SrVO , a moder3 ately correlated metal with nominal d -valence d 1 ; Sr VO , a correlation-driven insulator also 2 4 with nominal valence d 1 ; and SrMnO 3 and Sr MnO , both of which are 2 4 d 3 correlation-driven (Mott) insulators. Fig. 1 shows the atomic structure of the bulk phases of the constituent materials and the corresponding superlattices. Fig. 1 A B , , and C are bulk SrVO , bulk 3 SrMnO , and SrVO /SrMnO 3 3 3 superlattice, respectively. Fig. 1 D E , , and F are bulk Sr VO , 2 4 bulk Sr MnO , and Sr VO /Sr MnO 2 4 2 4 2 4 superlattice, respectively. In both superlattices, the
stacking direction is along the [001] axis. In the 214-type, the V atoms are shifted by a ( 1 2 , 1 2 ) lattice constant in the xy plane relative to the Mn atoms.
Fig. 2 is a schematic of the band structure of bulk vanadates, bulk manganites, and the band alignments in the superlattice (the small insulating gap of Sr VO 2 4 is not relevant here. There is a large energy separation (around 2 eV) between V d and O p states (see Fig. 2 A ). In the Mn-based materials (see Fig. 2 B ), the highest occupied states are Mn t 2 g -derived and the lowest unoccupied states are Mn e g -derived. Due to the electronegativity difference between V and Mn, visible as the difference in the energy separation of the transition metal d levels from the oxygen p levels, if we align the O p states between vanadates and manganites (see Fig. 2 C ), the occupied V t 2 g states overlap in energy with the unoccupied Mn e g states. The overlap drives electrons from V sites to Mn sites. As the superlattice is formed, a common Fermi level appears across the interface and thus we expect that Mn e g states become electron doped and V t 2 g states hole doped.
We make two additional points: i) though SrVO 3 is a metal and Sr VO 2 4 is an insulator with a small energy gap (around 0.2 eV) [30], the near Fermi level electronic structure does not affect the band alignment and therefore the internal charge transfer is expected to occur no matter whether there is a small energy gap in V t 2 g states at the Fermi level or not; ii) in our schematic, we assume that the main peak of O p states are exactly aligned between the vanadates and manganites in the superlattices. Of course, real material effects will spoil any exact alignment. We will use ab initio calculations to provide quantitative information on how O p states are aligned between the two materials.
## IV. BULK PROPERTIES
This section is devoted to properties of vanadates and manganites in their bulk single crystalline form. We perform DFT+DMFT calculations on both experimental structures and relaxed atomic structures obtained from DFT-LDA. The DFT-LDA relaxed V-O and Mn-O bond lengths, as well as the volume of VO 6 and MnO 6 octahedra, are summarized in Table I, along with the experimental bond lengths and octahedral volumes (in parentheses) for comparison. However, in order to directly compare to the photoemission data, we only present the spectral functions that are calculated using the experimental structures.
TABLE I: The in-plane and out-of-plane V-O and Mn-O bond lengths l of SrVO , SrMnO , Sr VO 3 3 2 4 and Sr MnO . The corresponding VO 2 4 6 and MnO 6 octahedral volumes Ω are also calculated. The relaxed structures are obtained from DFT-LDA and DFT-GGA non-spin-polarized calculations.
The experimental values which are referenced in the main text are also provided for comparison.
| | SrVO 3 | SrVO 3 | SrVO 3 | SrMnO 3 | SrMnO 3 | SrMnO 3 | SrVO 3 /SrMnO 3 | SrVO 3 /SrMnO 3 |
|--------------|-----------------|------------|------------|------------|------------|------------|-----------------------|-----------------------|
| | LDA | GGA | exp | LDA | GGA | exp | LDA | GGA |
| l in (V-O) | 1.89 ˚ A | 1.93 ˚ A | 1.92 ˚ A | - | - | - | 1.88 ˚ A | 1.92 ˚ A |
| l out (V-O) | 1.89 ˚ A | 1.93 ˚ A | 1.92 ˚ A | - | - | - | 1.85 ˚ A | 1.88 ˚ A |
| Ω VO 6 | 9.00 ˚ A 3 9.59 | ˚ A 3 | 9.44 ˚ A 3 | - | - | - | 8.72 ˚ A 3 | 9.24 ˚ A 3 |
| l in (Mn-O) | - | - | - | 1.86 ˚ A | 1.90 ˚ A | 1.90 ˚ A | 1.88 ˚ A | 1.92 ˚ A |
| l out (Mn-O) | - | - | - | 1.86 ˚ A | 1.90 ˚ A | 1.90 ˚ A | 1.89 ˚ A | 1.94 ˚ A |
| Ω MnO 6 | - | - | - | 8.58 ˚ A 3 | 9.15 ˚ A 3 | 9.15 ˚ A 3 | 8.91 ˚ A 3 | 9.54 ˚ A 3 |
| | Sr 2 VO 4 | Sr 2 VO 4 | Sr 2 VO 4 | Sr 2 MnO 4 | Sr 2 MnO 4 | Sr 2 MnO 4 | Sr 2 VO 4 /Sr 2 MnO 4 | Sr 2 VO 4 /Sr 2 MnO 4 |
| | LDA | GGA | exp | LDA | GGA | exp | LDA | GGA |
| l in (V-O) | 1.88 ˚ A | 1.92 ˚ A | 1.91 ˚ A | - | - | - | 1.85 ˚ A | 1.90 ˚ A |
| l out (V-O) | 1.96 ˚ A | 2.00 ˚ A | 1.95 ˚ A | - | - | - | 1.93 ˚ A | 1.95 ˚ A |
| Ω VO 6 | 9.24 ˚ A 3 | 9.83 ˚ A 3 | 9.49 ˚ A 3 | - | - | - | 8.81 ˚ A 3 | 9.39 ˚ A 3 |
| l in (Mn-O) | - | - | - | 1.82 ˚ A | 1.86 ˚ A | 1.90 ˚ A | 1.85 ˚ A | 1.90 ˚ A |
| l out (Mn-O) | - | - | - | 1.99 ˚ A | 2.04 ˚ A | 1.95 ˚ A | 1.99 ˚ A | 2.06 ˚ A |
| Ω MnO 6 | - | - | - | 8.79 ˚ A 3 | 9.41 ˚ A 3 | 9.39 ˚ A 3 | 9.08 ˚ A 3 | 9.92 ˚ A 3 |
## A. Bulk vanadates
We begin with bulk vanadates: SrVO 3 and Sr VO . SrVO 2 4 3 has a cubic structure with a lattice constant a =3.841 ˚ [62]. Sr VO A 2 4 forms n = 1 Ruddlesden-Popper structure with the in-plane lattice constant a = 3.826 ˚ and the out-of-plane lattice constant A c = 12.531 ˚ [63]. A We use a Hubbard U V = 5 eV on both vanadate materials to include correlation effects on V d orbitals, which is in the vicinity of previous studies [50-52].
Fig. 3 shows the orbitally-resolved spectral function A ω ( ) of bulk SrVO 3 (Fig. 3 A ) and bulk Sr VO 2 4 (Fig. 3 B ), along with the experimental photoemission data for bulk SrVO 3 [61].
FIG. 3: Orbitally resolved spectral function of A ) SrVO 3 and B ) Sr VO ; 2 4 C ) SrMnO 3 and D ) Sr MnO , obtained from LDA+DMFT calculations. 2 4 The pink dots are the experimental spectra for either SrVO 3 or SrMnO 3 (identical data are plotted alongside the theoretical spectra for the Ruddlesden-Popper structures) [61]. For vanadates, U ′ double counting is employed with U V = 5 eV and U ′ V = 3.5 eV. The red (very thick), blue (thin) and green (thick) curves are V t 2 g , V e g and O p projected spectral functions, respectively. For manganites, U ′ double counting is employed with U Mn = 5 eV and U ′ Mn = 4.5 eV. The red (thin), blue (very thick) and green (thick) curves are Mn t 2 g , Mn e g and O p projected spectral functions, respectively. The Fermi level is set at zero energy.
The threshold of O p states is around 2 eV below the Fermi level. We find that U ′ V = 3.5 eV yields a reasonable agreement between the calculated O p states and experimental photoemission data. At U V = 5 eV, with the p d -separation fixed by the experimental photoemission data, our DFT+DMFT calculations find SrVO 3 to be metallic, consistent with the experiment. However, they do not reproduce a Mott insulating state in Sr VO , 2 4 as observed in experiment. We show in the Appendix A that a metal-insulator transition
does occur in Sr VO 2 4 with an increasing Hubbard U V and a fixed p d -separation (via U ′ V ). However, the critical U V is larger than typical values employed previously in literature for the vanadates [51, 52]. It is possible that the experimentally observed narrow-gap insulating behavior (experimentally observed to persist above the N´ eel temperature [30, 64]) arises from long-range magnetic correlations and spatial correlations that are not captured in our single-site paramagnetic DMFT calculation. These correlations relate to low energy scale physics [65] and are not expected to affect the charge transfer energetics of interest here.
## B. Bulk manganites
Next we discuss the bulk manganites: SrMnO 3 and Sr MnO . 2 4 For ease of comparison with the superlattice results to be shown in the next section, we study here the cubic phase of SrMnO 3 (isostructural to SrVO ) with the lattice constant of 3 a = 3.801 ˚ (though other A structures of SrMnO 3 also co-exist) [66]. Sr MnO 2 4 forms the n = 1 Ruddlesden-Popper structure with in-plane and out-of-plane lattice constants a = 3.802 ˚ and A c = 12.519 ˚ [67]. A Consistent with the experimental estimation of Hubbard U from photoemission data [53], we use a Hubbard U Mn = 5 eV on both materials to include correlation effects on Mn d orbitals.
Fig. 3 shows the orbitally-resolved spectral function A ω ( ) of bulk SrMnO 3 (Fig. 3 C ) and Sr MnO 2 4 (Fig. 3 D ) [68]. The threshold of O p states is around 1 eV below the Fermi level. We find that U ′ Mn = 4.5 eV provides a good agreement between the calculated O p states and experimental photoemission data. We observe that for these parameters the occupied Mn t 2 g states are visible as a peak slightly above the leading edge of the oxygen band. We will show in Appendix B that modest changes of parameters will move this peak slightly down in energy so that it merges with the leading edge of the oxygen p states. The experimental situation is not completely clear. Published x-ray photoelectron spectroscopy work [69, 70] indicates a resolvable t 2 g peak at or slightly above the leading edge of the oxygen bands; other studies including recent photoemission measurements [61, 71] do not find a separately resolved t 2 g peak. The issue is not important for the results of this paper but further investigation of the location of the t 2 g states would be of interest as a way to refine our knowledge of the electronic structure of the manganites. With this value of U ′ Mn , the theory produces a small energy gap around 0.5 eV in both SrMnO 3 and Sr MnO . 2 4
However, the gap value is U Mn -dependent. We show in Appendix B that with the p d -separation fixed, via the adjustment of U ′ Mn , a larger U Mn increases the Mott gap by further separating the Mn lower and upper Hubbard bands. However, for the value of U Mn (around 5 eV) that is extracted from photoemission experiments [53], the size of the Mott gap of Sr MnO 2 4 is substantially underestimated, compared to the optical gap (around 2 eV) in experiment [30]. This discrepancy may arise because this calculation does not take into account spatial correlation [72]. However, the Mott gap is separated by Mn t 2 g and e g states, while the energy difference between O p states and Mn e g states (i.e. p d -separation) is fixed by the experimental photoemission data (via U ′ Mn ). We will show in the next section as well as in the Appendix B that it is the p d -separation that controls the charge transfer and therefore the underestimation of the Mott gap does not significantly affect our main results.
## V. VANADATE-MANGANITE SUPERLATTICES
In this section we discuss vanadate-manganite superlattices. There are two types: we refer to SrVO /SrMnO 3 3 superlattice as 113-type and refer to Sr VO /Sr MnO 2 4 2 4 superlattice as 214-type. The two types of superlattices have similarities and differences. In both types, the charge transfer from V sites to Mn sites occurs, in which electron dopes the Mn e g states and drains the V t 2 g states at the Fermi level. However, in the 214 type, the VO 6 and MnO 6 octahedra are decoupled and the charge transfer arises mainly from the electronegativity difference between V and Mn elements. In the 113 type, in addition to the electronegativity difference between V and Mn, the movement of the shared apical oxygen changes the hybridization and thus also affects the charge transfer. We will show below that due to the movement of the shared apical oxygen atom, the 113-type superlattice generically has a more enhanced charge transfer than the 214-type superlattice.
We discuss the phenomena of charge transfer in terms of: 1) structural properties, 2) electronic properties and 3) direct electron counting.
## A. Structural properties
Table I shows the DFT-LDA relaxed structure of SrVO /SrMnO 3 3 and Sr VO /Sr MnO 2 4 2 4 superlattices as well as the bulk materials. We see that the VO 6 octahedron is smaller in
FIG. 4: Orbitally resolved spectral function of vanadate-manganite superlattices, obtained from LDA+DMFT calculations. Left panels: SrVO /SrMnO 3 3 superlattice. Right panels: Sr VO /Sr MnO 2 4 2 4 superlattice. A ) and B ): Mn t 2 g (red thin) and Mn e g (blue thick) states; C ) and D ): V t 2 g (green thick) and V e g (violet thin) states; E ) and F ): O p states of the MnO 2 layer (turquoise thick) and O p states of the VO 2 layer (maroon thin). U ′ double counting is employed with U V = U Mn = 5 eV and U ′ V = 3.5 eV, U ′ Mn = 4.5 eV. The Fermi level is set at zero point.
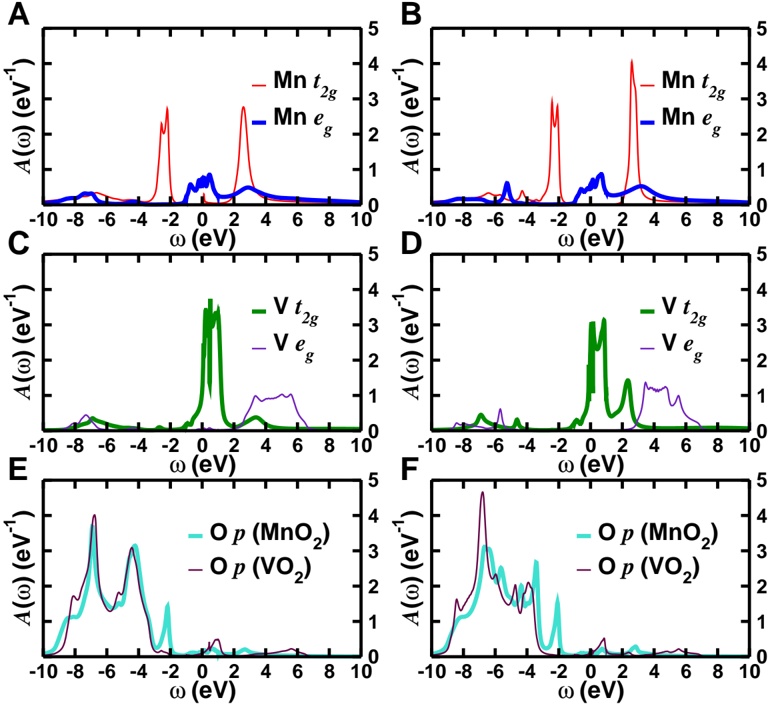
the superlattice than in the bulk, while the MnO 6 octahedron is larger. This is suggestive that the VO 6 octahedron loses electrons and the MnO 6 octahedron gains electrons (i.e that internal charge transfer from V to Mn sites occurs), and this will be quantified below.
## B. Electronic properties
Fig. 4 shows the orbitally resolved spectral function of the SrVO /SrMnO 3 3 superlattice (left panels) and the Sr VO /Sr MnO 2 4 2 4 superlattice (right panels). In both superlattices, the Mn e g states emerge at the Fermi level, while in bulk manganites, there is a small gap in the Mn d states (separated by Mn e g and t 2 g ) in both materials. In the VO 2 layer, V t 2 g states dominate at the Fermi level. Another feature worth noting is the O p states of the MnO 2 and of the VO 2 layers. Though the very first peak of O p states in the MnO 2 layer below the Fermi level is lined up with Mn t 2 g states due to strong covalency, the main peak almost exactly overlaps with that of O p states in the VO 2 layer. This supports our hypothesis in the schematic that the main peaks of O p states of the VO 2 and MnO 2 layers are aligned in the superlattices. We need to mention that the general features in electronic structure of the superlattices are robust for different double counting schemes. We show in Appendix C that the standard FLL double counting yields a very similar electronic structure of the superlattices. We also present LDA spectra in Appendix D for comparison to LDA+DMFT spectra.
Next, we compare the V t 2 g and Mn e g states between the superlattices and bulk materials to show how the Fermi level shifts in the two constituents. Fig. 5 A and B show the comparison of Mn e g and O p states of the MnO 2 layer between the superlattices and bulk manganites ( A : 113-type and B : 214-type). The Fermi levels of bulk manganites and of the superlattices are lined up in the same figure.
According to the schematic (Fig. 2), with respect to bulk manganites, both the Mn d and O p states in the MnO 2 layer are shifted towards the low energy-lying region due to the electron doping. Fig. 5 A and B clearly reproduce this rigid shift in i) Mn e g states from the bulk (blue or thin dark curves) to the superlattice (red or thick light) and ii) in O p states of the MnO 2 layer from the bulk (turquoise or thin light) to the superlattice (maroon or thick dark).
Similarly, Fig. 5 C and D show the comparison of V t 2 g and O p states (of the VO 2 layer) between the superlattices and bulk vanadates ( C : 113-type and D : 214-type). The Fermi levels of bulk vanadates and of the superlattices are lined up in the same figure. According to the schematic (Fig. 2), since electrons are drained out of V t 2 g state, both the V t 2 g states and O p states of the VO 2 layer are shifted towards the high energy-lying region, compared to
FIG. 5: A ) Comparison of Mn e g and O p states of the MnO 2 layer between the SrVO /SrMnO 3 3 superlattice and bulk SrMnO . 3 B ) Comparison of Mn e g and O p states of the MnO 2 layer between the Sr VO /Sr MnO 2 4 2 4 superlattice and bulk Sr MnO . 2 4 C ) Comparison of V t 2 g and O p states of the VO 2 layer between the SrVO /SrMnO 3 3 superlattice and bulk SrVO . 3 D ) Comparison of V t 2 g and O p states of the VO 2 layer between the Sr VO /Sr MnO 2 4 2 4 superlattice and bulk Sr VO . 2 4 The Fermi level is set at zero energy. 'SL' refers to the superlattices. All the spectra are obtained from LDA+DMFT calculations.
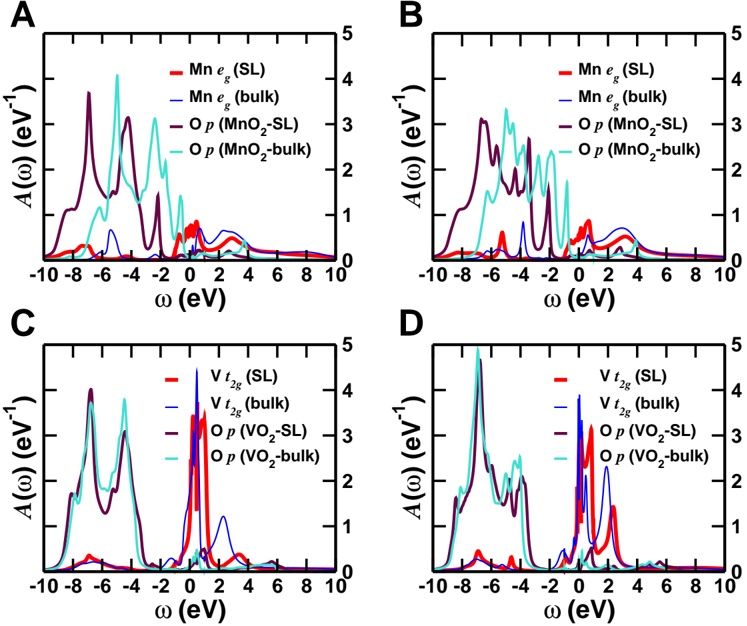
their counterparts in bulk vanadates. This shift can be seen (Fig. 5 C and D ) i) in the V t 2 g states from the bulk (blue or thin dark curves) to the superlattice (red or thick light) and ii) in the O p states of the VO 2 layer from the bulk (turquoise or thin light) to the superlattice (maroon or thick dark). However, since the peak of V t 2 g states at the Fermi level is much higher than that of Mn e g states, the shift in the V t 2 g states is much smaller than that in the Mn e g states. Fig. 5 reproduces our schematic of how V t 2 g and Mn e g states are shifted and re-arranged to reach one common Fermi level in a vanadate-manganite superlattice. A possible consequence is electron (hole) conductance in the MnO 2 (VO ) layer. 2
FIG. 6: Movement of the apical oxygen, corresonding changes in the energy of V d and Mn d states and enhancement of the charge transfer. A ) SrVO /SrMnO 3 3 superlattice and B ) Sr 2 VO /Sr MnO 4 2 4 superlattice. The green atoms are Sr. The blue and purple cages are VO 6 and MnO 6 octahedra, respectively. The arrows on the oxygen atoms indicate the atom movement. The arrows on the metal d states indicate the trend of energy shift. The length of the arrows is schematically proportional to the magnitude. C ) Table of the changes of out-of-plane V-O and Mn-O bonds ( δl V-O and δl Mn-O ) from bulk materials to the superlattices.
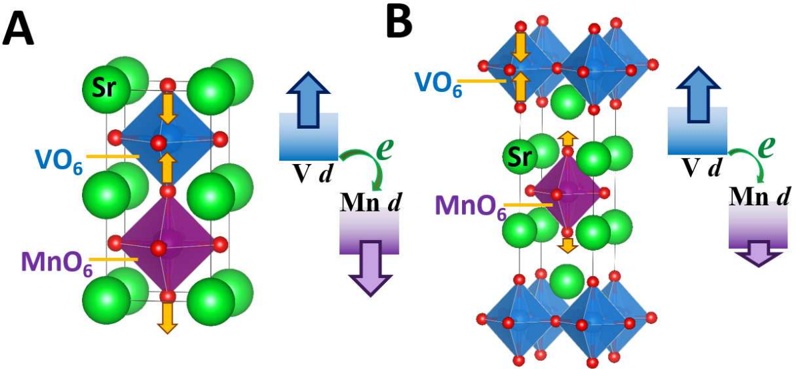
## C. Direct electron counting
Now we calculate the occupancy on each orbital by performing the following integral:
$$N _ { i } = \int _ { - \infty } ^ { \infty } A _ { i } ( \omega ) n _ { F } ( \omega ) d \omega$$
where A ω i ( ) is the spectral function for the i th orbital (defined from the Wannier construction), which is defined in Eq. (1). n F ( ω ) is the fermion occupancy factor. In order to explicitly display the charge transfer phenomenon, we calculate the V d and Mn d occupancy in both bulk materials and the superlattices. We summarize the results in Table II.
We can see that N d (V) decreases and N d (Mn) increases from bulk to the superlattices and an average charge transfer from V to Mn is 0.40 e for the 113-type superlattice and 0.25 e for the 214-type superlattice. Moreover, due to the strong covalency between transition metal d states and oxygen p states, the occupancy of oxygen p states also changes between bulk materials and the superlattices. For this reason, the change in d occupancy may not be an accurate representation of charge transfer.
We also calculate the total occupancy of VO 2 and MnO 2 layers and find that the total charge transfer between the two layers amounts to 0.53 for the 113-type superlattice and 0.38 for the 214-type superlattice. Unlike the 113-type superlattice in which the apical oxygen is shared by two octahedra, the 214-type superlattice has a unique property that each octahedron is decoupled between layers. Therefore in the superlattice, we can count the charge transfer from the VO 6 octahedron to the MnO 6 octahedron. Note that since we only take into account the p d -band manifold, the V and Mn octahedra include all the Wannier states and therefore in bulk Sr VO , the number of electrons per VO 2 4 4 unit is exactly 25 e and in bulk Sr MnO , the number of electrons per MnO 2 4 4 unit is exactly 27 e . We find that relative to the bulk materials, the V octahedron of the 214-type superlattice loses 0.48 e and Mn octahedron of the 214-type superlattice gains exactly 0.48 e . Comparison of this 0.48 e charge transfer to the 0.25 e found by only considering d orbitals further confirms that not only the transition metal d states but also oxygen p states participate in the charge transfer. From Table II, we can see that the internal charge transfer is stronger in the 113-type superlattice, compared to the 214-type. We show below that the difference arises because in the 113-type superlattice, the apical oxygen is shared by the VO 6 and MnO 6 octahedra, whereas the octahedra are decoupled in the 214-type.
We see from Table I) that due to the internal charge transfer, the VO 6 octahedron loses electrons and shrinks; on the other hand, the MnO 6 octahedron gains electrons and expands. Therefore the shared apical oxygen atom moves away from Mn sites and towards V sites (see Fig. 6 A ). A direct consequence is that the out-of-plane Mn-O hopping decreases and the out-of-plane V-O hopping increases. Since the V d and Mn d states are anti-bonding in nature, the changes in the metal-ligand hopping push the V d states higher in energy and lower the energy of Mn d states and thus enhance the internal charge transfer. In the 214-type superlattice, we have a different situation because the two oxygen octahedra have their own apical oxygen atoms, whose movements are decoupled. From the Table I and
Fig. 6 C , the VO 6 shrinks and the apical oxygen atom of VO 6 moves towards the V atom, just like the 113-type superlattice. However, the MnO 6 expands but the moveoment of apical oxygen is much smaller (the in-plane Mn-O bond does increase, so does the overall volume of MnO ). Therefore, the energy of V 6 d states is increased due to the enhanced out-of-plane V-O hopping, but the energy of Mn d states does not decrease much because the movement of apical oxygen atom is reduced (Fig. 6 B ). As a result, the charge transfer between V and Mn sites is weaker in the 214-type superlattice, compared to the 113-type superlattice.
Our discussions in this paper have focussed mainly on the (SrVO ) /(SrMnO ) 3 1 3 1 superlattice. Though m = 1 superlattices (in the notation of (SrVO ) 3 m /(SrMnO ) 3 m ) are easy for theoretical studies, experimentally it is more practical to grow m = 2 or larger m superlattices. We show in the Appendix E that comparing (SrVO ) /(SrMnO ) 3 1 3 1 and (SrVO ) /(SrMnO ) 3 2 3 2 superlattices, the charge transfer is very similar. However, for a large m , we will have inquivalent V sites and eventually the charge transfer will be confined to the interfacial region. Investigating the length scales associated with charge transfer is an important open question.
## VI. CONCLUSIONS
We use DFT+DMFT calculations to show that due to the difference in electronegativity, internal charge transfer could occur between isostructural vanadates and manganites in both 113-type and 214-type superlattices. The charge transfer is enhanced by associated lattice distortions. The moderate electronegativity difference between Mn and V leads to moderate charge transfer, in contrast to the LaTiO /LaNiO 3 3 superlattice, in which a complete charge transfer fills up the holes on the oxygen atoms in the NiO 2 layer [74]. The partially filled bands imply metallic conductance that could possibly be observed in transport, if the thin film quality is high enough that disorder is suppressed and Anderson localization does not occur [75]. Our study of a superlattice consisting of two different species of transition metal oxides establishes that internal charge transfer is a powerful tool to engineer electronic structure and tailor correlation effects in transition metal oxides [29, 76]. In particular, for vanadate-manganite superlattices, internal charge transfer may serve as an alternative approach to dope Mott insulators without introducing chemical disorder. Furthermore, as previous works have shown [77, 78], in addition to perovskite structure, Ruddlesden-Popper structures can also be an important ingredient in the design of oxide superlattices with
TABLE II: The occupancy of V d and Mn d states, as well as VO 2 and MnO 2 layers in vanadates, manganites and the superlattices. All the occupancies are calculated from Wannier basis using the DFT-LDA or DFT-GGA relaxed structures. ∆ N d (∆ N ) [73] is the average charge transfer between V d and Mn d states (VO 2 and MnO 2 layers, or VO 4 and MnO 4 octahedra), using the DFT-LDA relaxed structures.
| SrVO 3 | SrMnO 3 | SrVO 3 /SrMnO 3 | SrVO 3 /SrMnO 3 | |
|-------------|-------------|-----------------------|-----------------------|-----------|
| LDA/GGA | LDA/GGA | LDA/GGA | LDA/GGA | LDA/GGA |
| N d (V) | N d (Mn) | N d (V) | N d (Mn) | ∆ N d |
| 2.09/2.01 | 4.08/4.05 | 1.73/1.59 | 4.51/4.57 | 0.40/0.47 |
| N (VO 2 ) | N (MnO 2 ) | N (VO 2 ) | N (MnO 2 ) | ∆ N |
| 13.36/13.34 | 15.36/15.35 | 12.86/12.73 | 15.92/16.03 | 0.53/0.65 |
| Sr 2 VO 4 | Sr 2 MnO 4 | Sr 2 VO 4 /Sr 2 MnO 4 | Sr 2 VO 4 /Sr 2 MnO 4 | |
| LDA/GGA | LDA/GGA | LDA/GGA | LDA/GGA | LDA/GGA |
| N d (V) | N d (Mn) | N d (V) | N d (Mn) | ∆ N d |
| 2.07/2.00 | 4.12/4.11 | 1.86/1.71 | 4.41/4.44 | 0.25/0.31 |
| N (VO 2 ) | N (MnO 2 ) | N (VO 2 ) | N (MnO 2 ) | ∆ N |
| 13.35/13.34 | 15.42/15.44 | 13.01/12.90 | 15.83/15.91 | 0.38/0.46 |
| N (VO 4 ) | N (MnO 4 ) | N (VO 4 ) | N (MnO 4 ) | ∆ N |
| 25.00/25.00 | 27.00/27.00 | 24.52/24.42 | 27.48/27.58 | 0.48/0.58 |
tailored properties [79]. Finally, our examination of different materials raises the issue of the value of the double counting coefficient U ′ , determined here by fitting photoemission data. Understanding the variation of U ′ across the transition metal oxide family of materials is an important open problem.
## Acknowledgments
We are grateful to Darrell Schlom, Kyle Shen, Eric Monkman and Masaki Uchida for stimulating discussion and sharing the unpublished data with us. H. Chen is supported by National Science Foundation under Grant No. DMR-1120296. A. J. Millis is supported by
the Department of Energy under Grant No. DOE-ER-046169. H. Park and C. A. Marianetti are supported by FAME, one of six centers of STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA. Computational facilities are provided via XSEDE resources through Grant No. TG-PHY130003.
## Appendix A: Metal-insulator transition of Sr VO 2 4
In this appendix, we show that within single-site DMFT and with the p d -separation fixed by the experimental photoemission data, there is a metal-insulator transition in Sr VO 2 4 with an increasing Hubbard U V ( U ′ V is determined by the p d -separation for each given U V ). Fig. 7 A shows that for U V = 5 eV and U ′ V = 3.5 eV, Sr VO 2 4 is metallic with mainly V t 2 g states at the Fermi level, which is a reproduction of Fig 3 B . Fig. 7 B shows that with U V increased to 8 eV and U ′ V to 6.8 eV which approximately fixes the p d -separation, a metalinsulator transition occurs and Sr VO 2 4 is rendered a Mott insulator. However, the critical U V depends on the approximation scheme we employ. A more elaborate cluster-DMFT calculation and/or the inclusion of long range order may find a smaller critical U V [72].
FIG. 7: Orbitally resolved spectral function of Sr VO 2 4 , obtained from LDA+DMFT calculations. U ′ double counting is employed with A ) U V = 5 eV, U ′ V = 3.5 eV and B ) with U V = 8 eV, U ′ V = 6.8 eV. The red (very thick), blue (thick) and green (thin) curves are V t 2 g , V e g and O p projected spectral functions, respectively. The pink dots are experimental photoemission data for SrVO 3 [61]. The Fermi level is set at zero energy.
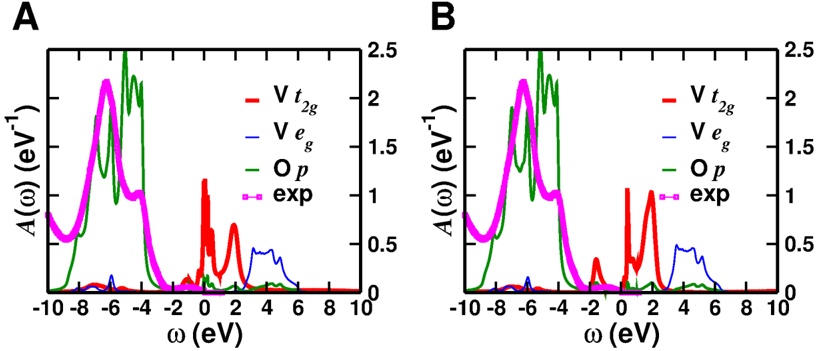
## Appendix B: Mott gap of Sr MnO 2 4 and its effects on Sr MnO /Sr VO 2 4 2 4 superlattices
In this appendix, we show how the Hubbard U Mn changes the Mott gap of Sr MnO 2 4 with the p d -separation approximately fixed. Fig. 8 A shows the orbitally resolved spectral function of Sr MnO 2 4 with U Mn = 8 eV and U ′ Mn = 7.5 eV. Note that since Sr MnO 2 4 is a Mott insulator, the Fermi level in the calculation is shifted at the conduction band edge, i.e. the edge of Mn e g states. In Fig. 3 D of the main text, the Mott gap of Sr MnO 2 4 is around 0.5 eV with U Mn = 5 eV and U ′ Mn = 4.5 eV. If we increase U Mn to 8 eV and U ′ Mn to 7.5 eV, the Mott gap is correspondingly increased to around 1 eV with the p d -separation fixed by the photoemission data [61]. The Mn t 2 g peak and the main peak of O p states now merge together. However, even with U Mn = 8 eV, the Mott gap is still smaller than the optical gap (around 2 eV) from experiment [30]. The difference could be due to spatial correlations not included in our single-site DMFT approximation [72].
Using the parameters U Mn = 8 eV and U ′ Mn = 7.5 eV, we redo the calculations on Sr VO /Sr MnO 2 4 2 4 superlattices (with U V = 5 eV and U ′ V = 3.5 eV) to test the effects of Mott gap size on charge transfer. As Fig. 8 B shows, the key features in electronic structure remain the same as Fig. 4 in the main text: i) Mn e g and V t 2 g states emerge at the Fermi level and ii) the main peaks of O p states associated with the MnO 2 and VO 2 layers are approximately aligned. This shows that it is the p d -separation that controls the charge transfer across the interface while the size of Mott gap plays a secondary role.
FIG. 8: A ) Orbitally resolved spectral function of Sr 2 MnO , obtained from LDA+DMFT calcu4 lations. U ′ double counting is employed with U Mn = 8 eV, U ′ Mn = 7.5 eV. The red (thin), blue (very thick) and green curves (thick) are Mn t 2 g , Mn e g and O p projected spectral functions, respectively. The pink dots are experimental photoemission data of SrMnO 3 [61]. The Fermi level is set at zero energy. B ) Orbitally resolved spectral function of Sr 2 VO /Sr MnO 4 2 4 superlattices, obtaine from LDA+DMFT calculations. U ′ double counting is employed with U Mn = 8 eV, U ′ Mn = 7.5 eV and U V = 5 eV, U ′ V = 3.5 eV. B1 ): Mn t 2 g (red thin) and Mn e g (blue thick) states; B2 ): V t 2 g (green thick) and V e g (violet thin) states; B3 ): O p states of the MnO 2 layer (turquoise thick) and O p states of the VO 2 layer (maroon thin).
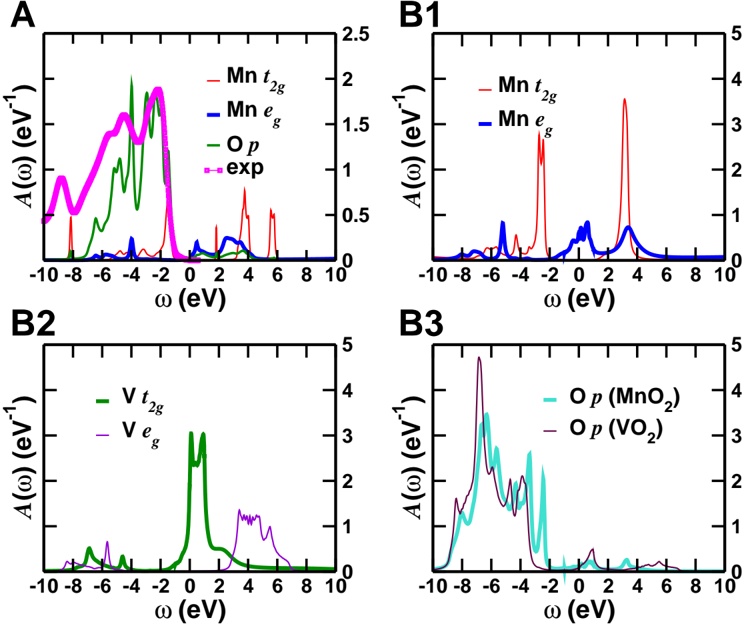
## Appendix C: Electronic structure calculated using the fully localized limit double counting
In this appendix, we show the electronic structure of both SrVO /SrMnO 3 3 and Sr VO /Sr MnO 2 4 2 4 superlattices, calculated using the standard fully localized limit (FLL) double counting. The orbitally resolved spectral function is shown in Fig. 9, which is compared to Fig. 4 in the main text. We employ U V = U Mn = 5 eV. We find the FLL double counting does not change the key features of electronic structure, such as the emergence of Mn e g and V t 2 g states at the Fermi level.
FIG. 9: Orbitally resolved spectral function of vanadate-manganite superlattices, obtained from LDA+DMFT calculations. Left panels: SrVO /SrMnO 3 3 superlattice. Right panels: Sr VO /Sr MnO 2 4 2 4 superlattice. A ) and B ): Mn t 2 g (red thin) and Mn e g (blue thick) states; C ) and D ): V t 2 g (green thick) and V e g (violet thin) states; E ) and F ): O p states of the MnO 2 layer (turquoise thick) and O p states of the VO 2 layer (maroon thin). Fully localized limit double counting is employed with U V = U Mn = 5 eV. The Fermi level is set at zero energy.
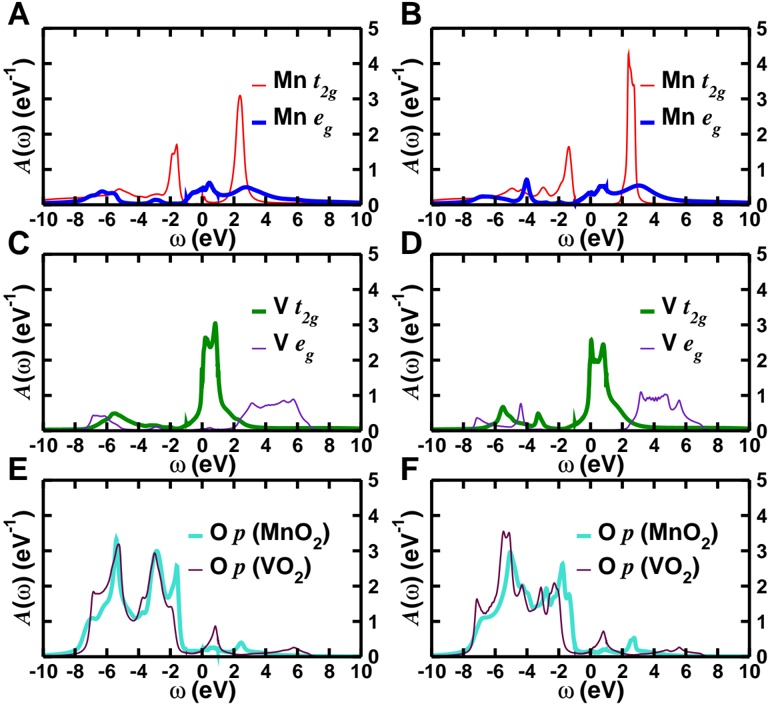
## Appendix D: Electronic structure calculated using the local density approximation
In this appendix, we show the electronic structure of both SrVO /SrMnO 3 3 and Sr VO /Sr MnO 2 4 2 4 superlattices, calculated using the local density approximation alone. The orbitally resolved spectral function is shown in Fig. 10, which is compared to Fig. 4 in the main text. We illustrate that without including strong correlation effect via Hubbard U , Mn t 2 g states lie around the Fermi level and do not split into lower and upper Hubbard bands.
FIG. 10: Orbitally resolved spectral function of vanadate-manganite superlattices, obtained from LDA calculations. Left panels: SrVO /SrMnO 3 3 superlattice. Right panels: Sr VO /Sr MnO 2 4 2 4 superlattice. A ) and B ): Mn t 2 g (red thin) and Mn e g (blue thick) states; C ) and D ): V t 2 g (green thick) and V e g (violet thin) states; E ) and F ): O p states of the MnO 2 layer (turquoise thick) and O p states of the VO 2 layer (maroon thin).
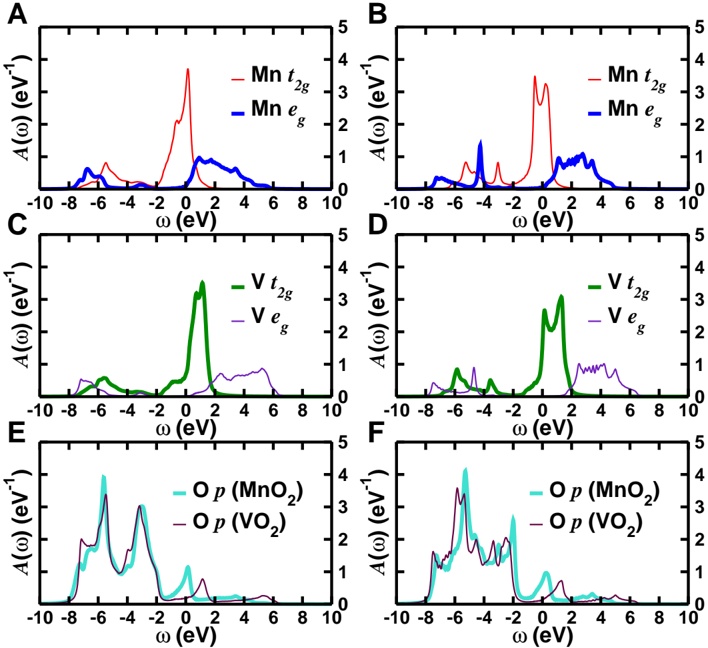
## Appendix E: (SrVO ) /(SrMnO ) 3 1 3 1 versus (SrVO ) /(SrMnO ) 3 2 3 2 superlattices
In this appendix, we compare the (SrVO ) /(SrMnO ) 3 1 3 1 superlattice to the (SrVO ) /(SrMnO ) 3 2 3 2 superlattice. We focus on the d occupancy and the charge transfer from V to Mn sites. Table III shows that N d of V sites and Mn sites are very similar between (SrVO ) /(SrMnO ) 3 1 3 1 and (SrVO ) /(SrMnO ) 3 2 3 2 superlattices.
TABLE III: The occupancy of V d and Mn d states, as well as VO 2 and MnO 2 layers in vanadates, manganites and the superlattices. All the occupancies without the parentheses are calculated from Wannier basis using the DFT-LDA relaxed structures. The occupancies in the parentheses are calculated from Wannier basis using the experimental structures.
| SrVO 3 | SrMnO 3 | (SrVO 3 ) 1 /(SrMnO 3 ) 1 | (SrVO 3 ) 1 /(SrMnO 3 ) 1 | (SrVO 3 ) 2 /(SrMnO 3 ) 2 | (SrVO 3 ) 2 /(SrMnO 3 ) 2 |
|---------------|---------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|
| N d (V) | N d (Mn) | N d (V) | N d (Mn) | N d (V) | N d (Mn) |
| 2.09 (2.03) | 4.08 (4.06) | 1.73 | 4.51 | 1.69 | 4.54 |
| N (VO 2 ) | N (MnO 2 ) | N (VO 2 ) | N (MnO 2 ) | N (VO 2 ) | N (MnO 2 ) |
| 13.36 (13.34) | 15.36 (15.35) | 12.86 | 15.92 | 12.82 | 15.95 |
- [1] A. Ohtomo, D. A. Muller, J. L. Grazul, and H. Y. Hwang, Nature 419 , 378 (2002).
- [2] S. Okamoto and A. J. Millis, Nature 428 , 630 (2004).
- [3] P. Moetakef, J. Y. Zhang, A. Kozhanov, B. Jalan, R. Seshadri, S. J. Allen, and S. Stemmer, Appl. Phys. Lett. 98 (2011).
- [4] A. Ohtomo and H. Y. Hwang, Nature 427 , 423 (2004).
- [5] S. Thiel, G. Hammerl, A. Schmehl, C. W. Schneider, and J. Mannhart, Science 313 , 1942 (2006).
- [6] N. Reyren, S. Thiel, A. D. Caviglia, L. F. Kourkoutis, G. Hammerl, C. Ricther, C. W. Schneider, T. Kopp, A. S. R¨etschi, D. Jaccard, et al., Science u 317 , 1196 (2007).
- [7] A. D. Caviglia, S. Gariglio, N. Reyren, D. Jaccard, T. Schneider, M. Gabay, S. Thiel, G. Hammerl, J. Mannhart, and J. M. Triscone, Nature 456 , 624 (2008).
- [8] T. Koida, M. Lippmaa, T. Fukumura, K. Itaka, Y. Matsumoto, M. Kawasaki, and H. Koinuma, Phys. Rev. B 66 , 144418 (2002).
- [9] S. Smadici, P. Abbamonte, A. Bhattacharya, X. Zhai, B. Jiang, A. Rusydi, J. N. Eckstein, S. D. Bader, and J.-M. Zuo, Phys. Rev. Lett. 99 , 196404 (2007).
- [10] B. R. K. Nanda and S. Satpathy, Phys. Rev. Lett. 101 , 127201 (2008).
- [11] A. Brinkman, M. Huijben, M. V. Zalk, J. Huijben, U. Zeitler, J. C. Maan, W. G. V. der Wiel, G. Rijnders, D. H. A. Blank, and H. Hilgenkamp, Nature Mater. 6 , 493 (2007).
- [12] J. A. Bert, B. Kalisky, C. Bell, M. Kim, Y. Hikita, H. Y. Hwang, and K. A. Moler, Nature Phys. 7 , 767 (2011).
- [13] L. Li, C. Richter, J. Mannhart, and R. C. Ashoori, Nature Phys. 7 , 762 (2011).
- [14] J. Chakhalian, J. W. Freeland, H.-U. Habermeier, G. Cristiani, G. Khaliullin, M. van Veenendaal, and B. Keimer, Science 318 , 1115 (2007).
- [15] E. Benckiser, M. W. Haverkort, S. Brck, E. Goering, S. Macke, A. Fra, X. Yang, O. K. Andersen, G. Cristiani, H.-U. Habermeier, et al., Nat. Mater. 10 , 189 (2011).
- [16] H. Y. Hwang, Science 313 , 1895 (2006).
- [17] Y. Tokura and H. Hwang, Nat. Mat. 7 , 694 (2008).
- [18] J. Mannhart and D. G. Schlom, Science 327 , 1607 (2010).
- [19] J. Chakhalian, A. J. Millis, and J. Rondinelli, Nat. Mater. 11 , 92 (2012).
- [20] N. Nakagawa, H. Y. Hwang, and D. A. Muller, Nature Mater. 5 , 204 (2006).
- [21] J. S. Lee, Y. W. Xie, H. K. Sato, C. Bell, Y. Hikita, H. Y. Hwang, and C. C. Kao, Nat. Mater. 12 , 703 (2013).
- [22] J. Mannhart, D. H. A. Blank, H. Y. Hwang, A. J. Millis, and J. M. Triscone, MRS Bull. 33 , 1027 (2008).
- [23] M. Huijben, A. Brinkman, G. Koster, G. Rijnders, H. Hilgenkamp, and D. H. A. Blank, Adv. Mat. 21 , 1665 (2009).
- [24] H. Chen, A. M. Kolpak, and S. Ismail-Beigi, Advanced Materials 22 , 2881 (2010).
- [25] P. Zubko, S. Gariglio, M. Gabay, P. Ghosez, and J.-M. Triscone, Annual Review of Condensed Matter Physics 2 , 141 (2011).
- [26] M. B. Salamon and M. Jaime, Rev. Mod. Phys. 73 , 583 (2001).
- [27] A. Moreo, M. Mayr, A. Feiguin, S. Yunoki, and E. Dagotto, Phys. Rev. Lett. 84 , 5568 (2000).
- [28] A. Bhattacharya, S. J. May, S. G. E. te Velthuis, M. Warusawithana, X. Zhai, B. Jiang, J.-M. Zuo, M. R. Fitzsimmons, S. D. Bader, and J. N. Eckstein, Phys. Rev. Lett. 100 , 257203 (2008).
- [29] H. Chen, A. J. Millis, and C. A. Marianetti, Phys. Rev. Lett. 111 , 116403 (2013).
- [30] J. Matsuno, Y. Okimoto, M. Kawasaki, and Y. Tokura, Phys. Rev. Lett. 95 , 176404 (2005).
- [31] R. Sønden˚, P. Ravindran, S. Stølen, T. Grande, and M. Hanfland, Phys. Rev. B a 74 , 144102 (2006).
- [32] H. T. Dang, A. J. Millis, and C. A. Marianetti, Phys. Rev. B 89 , 161113 (2014).
- [33] P. Hohenberg and W. Kohn, Phys. Rev. 136 , B864 (1964).
- [34] W. Kohn and L. J. Sham, Phys. Rev. 140 , A1133 (1965).
- [35] A. Georges, G. Kotliar, W. Krauth, and M. J. Rozenberg, Rev. Mod. Phys. 68 , 13 (1996).
- [36] G. Kotliar, S. Y. Savrasov, K. Haule, V. S. Oudovenko, O. Parcollet, and C. A. Marianetti, Rev. Mod. Phys. 78 , 865 (2006).
- [37] M. C. Payne, M. P. Teter, D. C. Allan, T. A. Arias, and J. D. Joannopoulos, Rev. Mod. Phys. 64 , 1045 (1992).
- [38] G. Kresse and J. Hafner, Phys. Rev. B 47 , 558 (1993).
- [39] G. Kresse and J. Hafner, Journal Of Physics-condensed Matter 6 , 8245 (1994).
- [40] G. Kresse and J. Furthmuller, Computational Materials Science 6 , 15 (1996).
- [41] G. Kresse and J. Furthm¨ller, Phys. Rev. B u 54 , 11169 (1996).
- [42] P. E. Bl¨chl, Phys. Rev. B o 50 , 17953 (1994).
- [43] G. Kresse and D. Joubert, Phys. Rev. B 59 , 1758 (1999).
- [44] J. P. Perdew and A. Zunger, Phys. Rev. B 23 , 5048 (1981).
- [45] J. P. Perdew, K. Burke, and M. Ernzerhof, Phys. Rev. Lett. 77 , 3865 (1996).
- [46] N. Marzari, A. A. Mostofi, J. R. Yates, I. Souza, and D. Vanderbilt, Rev. Mod. Phys. 84 , 1419 (2012).
- [47] The average spread per Wannier function for each constituent is: LDA-0.75 ˚ A 2 for SrVO , 3 0.80 ˚ A for SrMnO , 0.96 ˚ 2 3 A for Sr VO 2 2 4 and 0.83 ˚ A for Sr MnO ; GGA-0.73 ˚ 2 2 4 A for SrVO , 2 3 0.78 ˚ A 2 for SrMnO , 0.93 ˚ 3 A 2 for Sr 2 VO 4 and 0.90 ˚ A 2 for Sr 2 MnO . 4
- [48] X. Wang, M. J. Han, L. de' Medici, H. Park, C. A. Marianetti, and A. J. Millis, Phys. Rev. B 86 , 195136 (2012).
- [49] H. Park, A. J. Millis, and C. A. Marianetti, Phys. Rev. B 89 , 245133 (2014).
- [50] E. Pavarini, S. Biermann, A. Poteryaev, A. I. Lichtenstein, A. Georges, and O. K. Andersen, Phys. Rev. Lett. 92 , 176403 (2004).
- [51] I. A. Nekrasov, G. Keller, D. E. Kondakov, A. V. Kozhevnikov, T. Pruschke, K. Held, D. Vollhardt, and V. I. Anisimov, Phys. Rev. B 72 , 155106 (2005).
- [52] M. Aichhorn, L. Pourovskii, V. Vildosola, M. Ferrero, O. Parcollet, T. Miyake, A. Georges, and S. Biermann, Phys. Rev. B 80 , 085101 (2009).
- [53] J.-H. Park, C. T. Chen, S.-W. Cheong, W. Bao, G. Meigs, V. Chakarian, and Y. U. Idzerda, Phys. Rev. Lett. 76 , 4215 (1996).
- [54] P. Werner, A. Comanac, L. de' Medici, M. Troyer, and A. J. Millis, Phys. Rev. Lett. 97 , 076405 (2006).
- [55] P. Werner and A. J. Millis, Phys. Rev. B 74 , 155107 (2006).
- [56] K. Haule, Phys. Rev. B 75 , 155113 (2007).
- [57] E. Gull, A. J. Millis, A. I. Lichtenstein, A. N. Rubtsov, M. Troyer, and P. Werner, Rev. Mod. Phys. 83 , 349 (2011).
- [58] H. Chen, A. J. Millis and C. A. Marianetti, unpublished.
- [59] M. T. Czy˙ zyk and G. A. Sawatzky, Phys. Rev. B 49 , 14211 (1994).
- [60] In addition to the FLL and U ' double counting formulae, other double counting schemes also exist, such as the around mean field (AMF) limit: V dc = 9 10 ( U -2 J N ) d -1 5 JN d [59].
- [61] Eric Monkman, Masaki Uchida, Kyle Shen and Darrell Schlom, private communication.
- [62] T. Maekawa, K. Kurosaki, and Y. S., J. Alloys Compd. 426 , 46 (2006).
- [63] H. D. Zhou, B. S. Conner, L. Balicas, and C. R. Wiebe, Phys. Rev. Lett. 99 , 136403 (2007).
- [64] J. Teyssier, R. Viennois, E. Giannini, R. M. Eremina, A. G¨nther, J. Deisenhofer, u M. V. Eremin, and D. van der Marel, Phys. Rev. B 84 , 205130 (2011).
- [65] E. Gull, M. Ferrero, O. Parcollet, A. Georges, and A. J. Millis, Phys. Rev. B 82 , 155101 (2010).
- [66] R. Sønden˚, S. Stølen, P. Ravindran, and T. Grande, Phys. Rev. B a 75 , 214307 (2007).
- [67] K. Tezuka, M. Inamura, Y. Hinatsu, Y. Shimojo, and Y. Morii, J. Solid State Chem. 145 , 705 (1999).
- [68] Due to the insulating nature, the theoretical Fermi level of both SrMnO 3 and Sr MnO 2 4 is shifted to the Mn conduction band edge, and is aligned with the experimental Fermi level when the spectral function and the photoemission data are compared.
- [69] T. Saitoh, A. E. Bocquet, T. Mizokawa, H. Namatame, A. Fujimori, M. Abbate, Y. Takeda, and M. Takano, Phys. Rev. B 51 , 13942 (1995).
- [70] G. Zampieri, F. Prado, A. Caneiro, J. Bri´tico, M. T. Causa, M. Tovar, B. Alascio, M. Abbate, a and E. Morikawa, Phys. Rev. B 58 , 3755 (1998).
- [71] T. Saitoh, A. E. Bocquet, T. Mizokawa, H. Namatame, A. Fujimori, M. Abbate, Y. Takeda, and M. Takano, Jpn. J. Appl. Phys. 32 , Suppl. 32 (1993).
- [72] A. Go and A. J. Millis, arXiv:1311.6819 (2013).
- [73] The explicit definition of ∆ N d is ∆ N d = 1 2 ( | N d (V bulk ) -N d (V superlattice ) | + | N d (Mn bulk ) -N d (Mn superlattice ) | ) . ∆ N uses a similar definition.
- [74] The electronegativity χ of V in SrVO 3 and Mn in SrMnO 3 can be estimated by employing the Wannier functions to calculate the p d -separation. Among the three O p states, using the one with the highest onsite energy, and the relevant transition metal d states, we find that in SrVO , 3 χ (Vt 2 g ) = -3.13 eV and in SrMnO 3 χ (Mne g ) = -2.99 eV. Therefore χ (Mne g ) -χ (Vt 2 g ) = 0.14 eV > 0, leading to a moderate charge transfer from V to Mn. Applying the same methods to LaNiO 3 and LaTiO , we find that 3 χ (Nie g ) -χ (Tit 2 g ) = 2.93 eV, leading a complete charge transfer from Ti to Ni.
- [75] P. A. Lee and T. V. Ramakrishnan, Rev. Mod. Phys. 57 , 287 (1985).
- [76] J. E. Kleibeuker, Z. Zhong, H. Nishikawa, J. Gabel, A. M¨ller, F. Pfaff, M. Sing, K. Held, u R. Claessen, G. Koster, et al., Phys. Rev. Lett. 113 , 237402 (2014).
- [77] H. Akamatsu, K. Fujita, T. Kuge, A. Sen Gupta, A. Togo, S. Lei, F. Xue, G. Stone, J. M. Rondinelli, L.-Q. Chen, et al., Phys. Rev. Lett. 112 , 187602 (2014).
- [78] A. T. Mulder, N. A. Benedek, J. M. Rondinelli, and C. J. Fennie, Advanced Functional Materials 23 , 4810 (2013).
- [79] C.-H. Lee, N. D. Orloff, T. Birol, Y. Zhu, V. Goian, E. Rocas, R. Haislmaier, E. Vlahos, J. A. Mundy, L. F. Kourkoutis, et al., Nature 502 , 532 (2013). | 10.1103/PhysRevB.90.245138 | [
"Hanghui Chen",
"Hyowon Park",
"Andrew J. Millis",
"Chris A. Marianetti"
] | 2014-08-01T16:17:20+00:00 | 2015-01-02T22:13:03+00:00 | [
"cond-mat.mtrl-sci",
"cond-mat.str-el"
] | Charge transfer across transition metal oxide interfaces: emergent conductance and new electronic structure | We perform density functional theory plus dynamical mean field theory
calculations to investi- gate internal charge transfer in an artificial
superlattice composed of alternating layers of vanadate and manganite
perovskite and Ruddlesden-Popper structure materials. We show that the elec-
tronegativity difference between vanadium and manganese causes moderate charge
transfer from VO2 to MnO2 layers in both perovskite and Ruddlesden-Popper based
superlattices, leading to hole doping of the VO2 layer and electron doping of
the MnO2 layer. Comparison of the perovskite and Ruddlesden-Popper based
heterostructures provides insights into the role of the apical oxy- gen. Our
first principles simulations demonstrate that the combination of internal
charge transfer and quantum confinement provided by heterostructuring is a
powerful approach to engineering electronic structure and tailoring correlation
effects in transition metal oxides. |
1408.0218v1 | Resolved Stellar Populations in the Bulge and the Magellanic Clouds ASP Conference Series, Vol. eds. S. Points, A. Kunder c © Astronomical Society of the Pacific
## Formation Models of the Galactic Bulge
Ortwin Gerhard 1
1 Max Planck Institute for extraterrestrial Physics, PO Box 1312, Giessenbachstr., 85741 Garching, Germany
Abstract. The Galactic bulge is now considered to be the inner three-dimensional part of the Milky Way's bar. It has a peanut shape and is characterized by cylindrical rotation. In N-body simulations, box peanut bulges arise from disks through bar and / buckling instabilities. Models of this kind explain much of the structure and kinematics of the Galactic bulge and, in principle, also its vertical metallicity gradient. Cosmological disk galaxy formation models with high resolution and improved feedback models are now able to generate late-type disk galaxies with disk-like or barred bulges. These bulges often contain an early collapse stellar population and a population driven by later disk instabilities. Due to the inside-out disk formation, these bulges can be predominantly old, similar to the Milky Way bulge.
## 1. Introduction: the barred Galactic bulge
The Galactic bulge, subject of many studies here at CTIO observatory, is now considered to be the inner three-dimensional part of the Milky Way's bar. Its triaxial shape was first established by the COBE NIR photometry (Blitz & Spergel 1991; Dwek et al. 1995; Binney et al. 1997; Bissantz & Gerhard 2002). Star counts confirmed this but also pointed to a larger, in-plane bar, the so-called 'long bar' (Stanek et al. 1994; L´pezo Corredoira et al. 2005; Skrutskie et al. 2006; Benjamin et al. 2005; Cabrera-Lavers et al. 2007). Comparing the observed HI and CO lv-diagrams with hydrodynamic models showed that many of the observed features could be naturally, sometimes even quantitatively interpreted with gas flow models in barred potentials, modeled on the COBE data (Englmaier & Gerhard 1999; Fux 1999; Bissantz et al. 2003; Rodriguez-Fernandez &Combes 2008).
In recent years, Galactic bulge studies have been revitalized by new large photometric and spectroscopic surveys. With these new data, the density and metallicity structure of the Milky Way's bulge and its kinematics and dynamics have been mapped in much greater detail than possible before. Comparison of this information with models of bulge formation is promising to give us a better understanding of the origin of the Galactic bulge.
## 2. Box peanut bulge models from disk instability /
N-body simulations following the evolution of isolated disk galaxies have shown that stellar disks are often unstable to bar formation (Sellwood 1981; Athanassoula 2002; Debattista et al. 2006). Subsequently, the bar may quickly go through a second, so-
called buckling instability, resulting in the formation of an inner boxy bulge (Combes & Sanders 1981; Combes et al. 1990; Raha et al. 1991). The bar may then evolve by losing angular momentum to the dark matter halo, grow in size, and eventually go through a second buckling instability. This results in a a strongly peanut-shaped bulge (MartinezValpuesta et al. 2006) much like those seen in barred galaxies (Athanassoula 2005), which is supported by three-dimensional 2:1:2 resonant orbit families that support a characteristic X-shape (Pfenniger & Friedli 1991).
Recent star count and stellar kinematics data have shown that the predictions of these idealized models characterize the properties of the Milky Way bulge surprisingly well. The apparent magnitude plot for red clump stars in high-latitude pencil beams shows a clearly bimodal distance distribution, termed the 'split red clump'. This was first seen in 2MASS data (McWilliam & Zoccali 2010; Saito et al. 2011) but has also been confirmed with OGLE data (Nataf et al. 2010) and the ARGOS spectroscopic bulge sample (Ness et al. 2012). The split red clump is a signature of the X-shaped stellar orbits in the bulge. Recent deconvolution of the VVV DR1 star count data has shown that the Galactic bulge has the shape of a highly elongated bar with a strong peanut shape (Wegg & Gerhard 2013). The measured angle of the barred bulge to the line of sight is (27 ± 2) ◦ . Along the bar axes the density falls o ff roughly exponentially, with axis ratios (10 : 6.3 : 2.6) and exponential scale-lengths (0.70 : 0.44 : 0.18) kpc, but along the major axis the profile becomes shallower beyond 1.5 kpc.
N-body models with box peanut bulges grown from unstable disks have been used / to interpret not only the structure, but also the stellar kinematics and metallicity distribution of the Milky Way bulge. Gerhard & Martinez-Valpuesta (2012) showed that the flattening in the longitude profiles seen for | l | < 4 ◦ in low-latitude star counts (Nishiyama et al. 2005; Gonzalez et al. 2011) is naturally reproduced by the density distribution in a simulated box peanut bulge. / Li & Shen (2012) showed that their Nbody model shows a similar split red clump as the Galactic bulge when viewed at an appropriate orientation. N-body bulges also explain the near-cylindrical rotation and the velocity dispersion profiles seen in the BRAVA (Kunder et al. 2012) and Argos (Ness et al. 2013a) spectroscopic surveys (Shen et al. 2010; Ness et al. 2013b).
The match of the models to the kinematic data is very good and Shen et al. (2010) concluded that it would be worsened even by a fairly small additional classical bulge. Such a classical bulge could have arisen from an early merger episode that preceded the growth and subsequent instability of the early disk. Saha et al. (2012); Saha & Gerhard (2013) showed that angular momentum transfer from the bar and boxy bulge can spin up the preexisting bulge, so that it too develops cylindrical rotation. The radial dependence of the rotation is di ff erent between the two bulges though; thus some more work is needed on this issue.
The strongest argument for a classical bulge in the Milky Way has been the observation of a strong vertical metallicity gradient (Zoccali et al. 2008; Johnson et al. 2011; Gonzalez et al. 2013). However, a recent analysis of an N-body bulge showed that this argument is not compelling. If the Milky Way's bar and bulge formed rapidly from the disk at early times, then any preexisting metallicity gradients are preserved as vertical gradients in the final bulge, because of the incomplete violent relaxation during the instabilities (Martinez-Valpuesta & Gerhard 2013). Therefore, at present there is no strong evidence for a classical bulge in the Milky Way. Further chemodynamical analysis of the metallicity distribution and kinematics will be needed to clarify whether the Milky Way has a small classical bulge underneath its dominant peanut-shaped bulge,
and if so how this is related to the bulge metallicity components identified by Ness et al. (2013a) in the ARGOS sample.
The connection between the Milky Way's peanut bulge and planar bar is much less explored, primarily because this region is observationally less accessible. Hammersley et al. (2000); Benjamin et al. (2005); Cabrera-Lavers et al. (2007) found evidence from starcounts for a 'long bar' at an angle of ∼ 45 , apparently tilted relative to and ◦ therefore distinct from the barred bulge. Martinez-Valpuesta & Gerhard (2011) used an N-body model to argue that the long bar may nonetheless be the planar part of the same Galactic bar that contains the peanut bulge (see also Romero-G´mez et al. 2011). o In their model, the outer parts of the bar oscillate from trailing to leading, coupling with nearby spiral arms which rotate at lower pattern speed (Tagger et al. 1987). Future APOGEE kinematic observations in this region (e.g. Nidever et al. 2012) will test the model predictions and shed more light on the dynamical transition between bulge, two-dimensional bar, and inner disk.
## 3. Bulges in cosmological disk galaxy simulations
Galaxies in the hierarchical universe grow continuously by accretion of matter, and they are subjected to a variety of external perturbations, for example, from merging satellites. Therefore, eventually the idealized disk simulations will need to be superceded by more realistic disk galaxy formation simulations embedded in a cosmological setting. It has only become possible recently to follow realistic high-resolution, fully cosmological simulations from high redshift to now. These models are already stimulating our understanding of bulge formation, but they still have considerable uncertainties in how the star formation and feedback processes are modelled.
As a reference point, I start with a brief discussion of the dissipative collapse model by Samland & Gerhard (2003). This may be viewed as a modern version of the dissipative collapse envisaged by Eggen et al. (1962). The model considered the formation of a large disk galaxy in a 2 × 10 12 M , spinning ( /circledot λ = 0 05) halo, with accre-. tion history taken from cosmological simulations. Star formation and feedback were modelled by a 2-phase fluid cloud fluid model calibrated on observed star formation / rates, and the enrichment of Fe and α -elements was tracked separately. Axisymmetric collapse was followed excluding all minor mergers.
In this dissipative collapse, the galaxy formed from inside out. The star formation history closely followed the gas accretion history. The disk grew from initially small, thick and dynamically hot to a large, thin and cold disk at redshift z = 0. The final bulge consisted of at least two stellar populations. One was formed in the early rapid collapse phase, the second was formed later in the disk which grew bar unstable. They di ff ered by their [ α / Fe]-ratios; the final bulge contained [ α / Fe]-enhanced stars for a range of [Fe H], and also some super-solar stars made from gas channeled inwards by the bar. / This illustrates the chemodynamical signatures which can be used to understand the origin of the Milky Way bulge from the new data.
Obreja et al. (2013) compared the properties of bulges made in some of the recent cosmological simulations, from Brook et al. (2012); Dom´ enech-Moral et al. (2012). Generally, these simulations employ strong feedback to prevent overproduction of stars at early times. As in the dissipative collapse model, the star formation rate (SFR) in these simulations closely follows the mass accretion rate, and the formation history can be divided into an early starburst-collapse phase and a later phase with lower SFR
driven by disk instabilities and minor mergers. The stellar populations show corresponding age and metallicity distributions, with the old population being more metal poor and α -enhanced. Most of the old population found in the final bulge formed in disjoint places along filaments at high redshift (as opposed to in the early collapsing halo in the dissipative collapse model).
One can associate the rapid phase with a classical bulge, and the late phase with a box peanut or disky bulge. / Such a classical bulge is clearly di ff erent from a bulge formed by a late major merger. In all of the five simulations analyzed by Obreja et al. (2013), both components were present, with di ff erent mass ratio. Guedes et al. (2013) and Okamoto (2013) followed the evolution of such 'pseudo-bulges' in very high resolution simulations. The structure of these bulges is characterized by a Sersic index around n = 1 ± 0 5, . possibly depending on the feedback model. One important result from these simulations is that, because of the inside-out formation, the inner bulge region can form early and consist of predominantly very old stars, whereas the disk further out has a much more uniform star formation history. In the Eris simulation of Guedes et al, the bulge is built from the early, low-angular momentum part of the disk. This model does not have a final box peanut bulge like in the Milky Way, but it illus-/ trates how the bulge stars could be very old as is observed in Baade's window in the Galactic bulge.
## References
Athanassoula, E. 2002, ApJ, 569, L83. arXiv:astro-ph/0203368
-2005, MNRAS, 358, 1477. arXiv:astro-ph/0502316
Benjamin, R. A., Churchwell, E., Babler, B. L., Indebetouw, R., & et al. 2005, ApJ, 630, L149. arXiv:astro-ph/0508325
Binney, J., Gerhard, O., & Spergel, D. 1997, MNRAS, 288, 365. arXiv:astro-ph/9609066
Bissantz, N., Englmaier, P., & Gerhard, O. 2003, MNRAS, 340, 949. arXiv:astro-ph/ 0212516
Bissantz, N., & Gerhard, O. 2002, MNRAS, 330, 591. arXiv:astro-ph/0110368
Blitz, L., & Spergel, D. N. 1991, ApJ, 379, 631
Brook, C. B., Stinson, G., Gibson, B. K., Roˇ skar, R., Wadsley, J., & Quinn, T. 2012, MNRAS, 419, 771. 1105.2562
Cabrera-Lavers, A., Hammersley, P. L., Gonz´ alez-Fern´ an dez, C., L´pez-Corredoira, M., & et o al. 2007, A&A, 465, 825. arXiv:astro-ph/0702109
Combes, F., Debbasch, F., Friedli, D., & Pfenniger, D. 1990, A&A, 233, 82
Combes, F., & Sanders, R. H. 1981, A&A, 96, 164
Debattista, V. P., Mayer, L., Carollo, C. M., Moore, B., Wadsley, J., & Quinn, T. 2006, ApJ, 645, 209. arXiv:astro-ph/0509310
Dom´ enech-Moral, M., Mart´ ınez-Serrano, F. J., Dom´ ıngue z-Tenreiro, R., & Serna, A. 2012,
MNRAS, 421, 2510. 1201.2641
Dwek, E., Arendt, R. G., Hauser, M. G., Kelsall, T., & et al. 1995, ApJ, 445, 716
Eggen, O. J., Lynden-Bell, D., & Sandage, A. R. 1962, ApJ, 136, 748
Englmaier, P., & Gerhard, O. 1999, MNRAS, 304, 512. arXiv:astro-ph/9810208
Fux, R. 1999, A&A, 345, 787. arXiv:astro-ph/9903154
Gerhard, O., & Martinez-Valpuesta, I. 2012, ApJ, 744, L8. 1112.0179
Gonzalez, O. A., Rejkuba, M., Minniti, D., Zoccali, M., Valenti, E., & Saito, R. K. 2011, A&A, 534, L14. 1110.0925
Gonzalez, O. A., Rejkuba, M., Zoccali, M., Valent, E., Minniti, D., & Tobar, R. 2013, A&A, 552, A110. 1302.0243
Guedes, J., Mayer, L., Carollo, M., & Madau, P. 2013, ApJ, 772, 36. 1211.1713
Hammersley, P. L., Garz´ on, F., Mahoney, T. J., L´pez-Corr edoira, M., & Torres, M. A. P. 2000, o MNRAS, 317, L45. arXiv:astro-ph/0007232
Johnson, C. I., Rich, R. M., Fulbright, J. P., Valenti, E., & McWilliam, A. 2011, ApJ, 732, 108. 1103.2143
Kunder, A., Koch, A., Rich, R. M., de Propris, R., Howard, C. D., Stubbs, S. A., Johnson, C. I., Shen, J., Wang, Y., Robin, A. C., Kormendy, J., Soto, M., Frinchaboy, P., Reitzel, D. B., Zhao, H., & Origlia, L. 2012, AJ, 143, 57. 1112.1955
Li, Z.-Y., & Shen, J. 2012, ApJ, 757, L7. 1206.3779
L´ opez-Corredoira, M., Cabrera-Lavers, A., & Gerhard, O. E. 2005, A&A, 439, 107. arXiv: astro-ph/0504608
Martinez-Valpuesta, I., & Gerhard, O. 2011, ApJ, 734, L20 + . 1105.0928
-2013, ApJ, 766, L3. 1302.1613
Martinez-Valpuesta, I., Shlosman, I., & Heller, C. 2006, ApJ, 637, 214. arXiv:astro-ph/ 0507219
McWilliam, A., & Zoccali, M. 2010, ApJ, 724, 1491. 1008.0519
Nataf, D. M., Udalski, A., Gould, A., Fouqu´ e, P., & Stanek, K. Z. 2010, ApJ, 721, L28. 1007. 5065
Ness, M., Freeman, K., Athanassoula, E., Wylie-de-Boer, E., Bland-Hawthorn, J., Asplund, M., Lewis, G. F., Yong, D., Lane, R. R., & Kiss, L. L. 2013a, MNRAS, 430, 836. 1212.1540
Ness, M., Freeman, K., Athanassoula, E., Wylie-de-Boer, E., Bland-Hawthorn, J., Asplund, M., Lewis, G. F., Yong, D., Lane, R. R., Kiss, L. L., & Ibata, R. 2013b, MNRAS, 432, 2092. 1303.6656
Ness, M., Freeman, K., Athanassoula, E., Wylie-De-Boer, E., Bland-Hawthorn, J., Lewis, G. F., Yong, D., Asplund, M., Lane, R. R., Kiss, L. L., & Ibata, R. 2012, ApJ, 756, 22. 1207. 0888
Nidever, D. L., Zasowski, G., Majewski, S. R., Bird, J., & et al. 2012, ApJ, 755, L25. 1207. 3797
Nishiyama, S., Nagata, T., Baba, D., Haba, Y., & et al. 2005, ApJ, 621, L105. arXiv: astro-ph/0502058
Obreja, A., Dom´ ınguez-Tenreiro, R., Brook, C., Mart´ ınez -Serrano, F. J., Dom´nech-Moral, M., e
Serna, A., Moll´ a, M., & Stinson, G. 2013, ApJ, 763, 26. 1211.3906
Okamoto, T. 2013, MNRAS, 428, 718. 1203.5372
Pfenniger, D., & Friedli, D. 1991, A&A, 252, 75
Raha, N., Sellwood, J. A., James, R. A., & Kahn, F. D. 1991, Nat, 352, 411
Rodriguez-Fernandez, N. J., & Combes, F. 2008, A&A, 489, 115. 0806.4252
Romero-G´ omez, M., Athanassoula, E., Antoja, T., & Figueras, F. 2011, MNRAS, 418, 1176. 1108.0660
Saha, K., & Gerhard, O. 2013, MNRAS, 430, 2039. 1212.2317
Saha, K., Martinez-Valpuesta, I., & Gerhard, O. 2012, MNRAS, 421, 333. 1105.5797
Saito, R. K., Zoccali, M., McWilliam, A., Minniti, D., Gonzalez, O. A., & Hill, V. 2011, AJ, 142, 76. 1107.5360
Samland, M., & Gerhard, O. E. 2003, A&A, 399, 961. arXiv:astro-ph/0301499 Sellwood, J. A. 1981, A&A, 99, 362
Shen, J., Rich, R. M., Kormendy, J., Howard, C. D., De Propris, R., & Kunder, A. 2010, ApJ, 720, L72. 1005.0385
Skrutskie, M. F., Cutri, R. M., Stiening, R., Weinberg, M. D., & et al. 2006, AJ, 131, 1163 Stanek, K. Z., Mateo, M., Udalski, A., Szymanski, M., Kaluzny, J., & Kubiak, M. 1994, ApJ,
429, L73. arXiv:astro-ph/9404026
Tagger, M., Sygnet, J. F., Athanassoula, E., & Pellat, R. 1987, ApJ, 318, L43
Wegg, C., & Gerhard, O. 2013, ArXiv e-prints. 1308.0593
Zoccali, M., Hill, V ., Lecureur, A., Barbuy, B., Renzini, A., Minniti, D., G´mez, A., & Ortolani, o S. 2008, A&A, 486, 177. 0805.1218 | null | [
"Ortwin Gerhard"
] | 2014-08-01T16:17:57+00:00 | 2014-08-01T16:17:57+00:00 | [
"astro-ph.GA"
] | Formation Models of the Galactic Bulge | The Galactic bulge is now considered to be the inner three-dimensional part
of the Milky Way's bar. It has a peanut shape and is characterized by
cylindrical rotation. In N-body simulations, box/peanut bulges arise from disks
through bar and buckling instabilities. Models of this kind explain much of the
structure and kinematics of the Galactic bulge and, in principle, also its
vertical metallicity gradient. Cosmological disk galaxy formation models with
high resolution and improved feedback models are now able to generate late-type
disk galaxies with disk-like or barred bulges. These bulges often contain an
early collapse stellar population and a population driven by later disk
instabilities. Due to the inside-out disk formation, these bulges can be
predominantly old, similar to the Milky Way bulge. |
1408.0219v1 | ## The Galactic Bar
Ortwin Gerhard and Christopher Wegg
Abstract The Milky Way's bar dominates the orbits of stars and the flow of cold gas in the inner Galaxy, and is therefore of major importance for Milky Way dynamical studies in the Gaia era. Here we discuss the pronounced peanut shape of the Galactic bulge that has resulted from recent star count analysis, in particular from the VVV survey. We also discuss the question whether the Milky Way has an inner disky pseudo-bulge, and show preliminary evidence for a continuous transition in vertical scale-height from the peanut bulge-bar to the planar long bar.
## 1 Introduction
The Gaia satellite will soon provide us with exquisite data for the motions of stars in our Galaxy. The Milky Way's stellar bar has a strong influence on the orbits of stars inside the solar circle, and dominates the gas flow in the inner Galaxy. To understand the structure and dynamics of the Galactic bar better is therefore of prime importance in the Gaia era.
Renewed interest in the Galactic bar and bulge has also been triggered recently by unprecedented new near-infrared (NIR) photometric and spectroscopic surveys of the inner Galaxy. In this contribution, we summarize recent work on the structural properties of the Galactic bar and bulge based on such survey data.
About two thirds of all large disk galaxies are barred (Eskridge et al., 2000), including our Milky Way. Historically, several perceptive papers already suggested in the 1970s that the non-circular motions seen in HI observations towards the inner Galaxy could naturally be interpreted in terms of elliptical gas streamlines (Shane, 1972; Peters, 1975). But it was not until the 1990s that the barred nature of the Milky Way bulge was considered established. This revised view of our Galaxy was
Max Planck Institute for extraterrestrial Physics, PO Box 1312, Giessenbachstr., 85741 Garching, Germany, e-mail: [email protected],[email protected]
based on new data and ideas at that time: the NIR photometry by the COBE satellite (Weiland et al., 1994; Binney et al., 1997), enabling a global view of the bulge through the dust layer; new analysis of the inner Milky Way gas flows traced in longitude-velocity diagrams (Englmaier & Gerhard, 1999; Fux, 1999), in the context of triaxiality and bars in external galaxies; asymmetries in bulge star counts (Stanek et al., 1994; Lopez-Corredoira et al., 1997), and the newly measured optical depth for microlensing towards bulge fields (Paczynski et al., 1994; Bissantz et al., 1997). These data, as well as the kinematics of bulge stars available at the time (Zhao et al., 1994; Fux, 1997), could all be consistently explained in terms of a barred bulge model with its major axis in the first quadrant. 2MASS NIR star counts (L´ opez-Corredoira et al., 2005; Skrutskie et al., 2006), the cylindrical rotation in the bulge (Kunder et al., 2012; Ness et al., 2013; Shen et al., 2010), and other data have since confirmed and refined our understanding of the Galactic bar.
In external disk galaxies seen at low inclination, bars are easy to see but their vertical structure is not well-constrained. However, we now know from gas- and stellar-kinematic data that box or peanut-shaped (b/p) bulges in edge-on systems are related to bars (Merrifield & Kuijken, 1999; Chung & Bureau, 2004). Photometric data (L¨ utticke et al., 2000; Bureau et al., 2006) are consis tent with predictions from N-body models that bars in galaxies generally consist of an inner three-dimensional (3D) part, the b/p bulge, and a more extended 2D part of the bar (Athanassoula, 2005). In these simulations, a bar first grows from an unstable disk and then becomes unstable to a buckling instability which leads to an inner boxy bulge (Combes et al., 1990; Raha et al., 1991; Athanassoula & Misiriotis, 2002). The bar can then grow further through angular momentum loss to the dark matter halo, and eventually go through a second buckling instability which leads to the formation of a strongly peanut-shaped bulge (Martinez-Valpuesta et al., 2006). Similar secular evolution has been observed also in cosmologically more realistic simulations of disk galaxies, such as dissipative collapse models (Samland & Gerhard, 2003; Ness et al., 2014), or hierarchical disk galaxy models in which strong feedback and the absence of significant mergers ensure a relatively quiescent star formation history (Martig et al., 2012; Guedes et al., 2013).
## 2 Bulge distances from K-band magnitudes of red clump giants
Red clump giants are immensely useful for star count studies of the Galaxy. They are He core burning stars with a narrow range of luminosities and colours, hence can be employed to map out the distant-dependent structure of the Galactic bulge. Using the α -enhanced BASTI isochrones for various metallicities at age 10 Gyr from Pietrinferni et al. (2004), a metallicity-averaged luminosity function of bulge red clump (RC) stars has Gaussian σ ( K ) = 0 18 . mag, σ ( J -K ) = 0 05, . and MK RC , = -1 72 in the . KS -band (Wegg & Gerhard, 2013a). The KS -band magnitude is slightly brighter than the value from solar-neighbourhood RC stars (Alves, 2000). In the colour-magnitude diagram, RC stars are spread because of varia-
tions in distance, reddening, age, and metallicity. The variations in absolute KS -magnitude with age and metallicity are ∆ age MK RC , ∼ 0 03/Gyr at age 10 Gyr and . ∆ ZMK RC , ∼-0 28/dex (Salaris & Girardi, 2002). From the same study, for old stel-. lar populations the number of RC stars per unit initial mass varies by ∼ 10% for metallicities ∼ > . 0 02 solar. Therefore the distribution of RC stars is a good tracer of the stellar mass distribution in the bulge. Distances to individual RC giants in the upper bulge can be estimated with σ D ∼ 10%. At low latitudes, residual dust extinction broadens the clump magnitude distribution, leading to σ D ∼ 15% at | b | = 1deg (Gerhard & Martinez-Valpuesta, 2012).
## 3 The Galactic box/peanut bulge
The COBE data firmly established the boxy shape and the presence of longitudinal asymmetries in the Galactic bulge, which appears brighter and vertically more extended on the l > 0 side, but symmetric in latitude b (Weiland et al., 1994). These asymmetries are a signature of a triaxial bulge whose major axis is tilted in the Galactic plane relative to the line-of-sight (LOS) from the Sun to the Galactic centre (Blitz & Spergel, 1991). From these asymmetries, parametric and non-parametric bulge luminosity models were reconstructed (Dwek et al., 1995; Bissantz & Gerhard, 2002) and then used to study the influence of the Galactic bar on the gas dynamics and microlensing observations. However, uncertainties remained due to the lack of distance information in the COBE data and to the uncertainties in the extinction maps.
Red clump star counts in several fields across the bulge first illustrated the different distances to the near and far sides of the triaxial bulge (Stanek et al., 1994, 1997). With the 2MASS all sky data a first star count reconstruction of the bulge shape became possible, even if somewhat affected by the limit in the survey depth (L´ opez-Corredoira et al., 2005). More recent analysis of OGLE-III and 2MASS RC counts in upper bulge fields near the minor axis showed the presence of two density peaks along the LOS (Nataf et al., 2010; McWilliam & Zoccali, 2010). These results were interpreted as an X-shape in the bulge density distribution such as seen in N-body models of peanut bulges. Abundances and velocities derived from spectra of large numbers of bulge stars showed that only the more metal-rich stellar populations participate in this 'split red clump' (Ness et al., 2012).
The recent VVV survey is ∼ 3 -4 mag deeper than 2MASS and RC stars are visible all through the bulge even quite close to the Galactic plane. These data have brought a quantum leap for constraining the bulge density distribution. First results at b = ± 1deg showed clearly the in-plane tilt of the barred bulge, and also a structural change in the central | l | < 4deg (Gonzalez et al., 2011), indicating a less elongated distribution of stars in this region (Gerhard & Martinez-Valpuesta, 2012). In our recent work (Wegg & Gerhard, 2013a), we used the VVV DR1 data (Saito et al., 2012) for some 300 sightlines across | l | < 10deg and -10deg < b < 5deg, to measure the 3D density distribution of the Galactic bulge. For all these LOS, we con-
structed extinction- and completeness-corrected KS-band magnitude distributions, and deconvolved these with the K-band luminosity function of RC giants and red giant branch bump (RGBB) stars. The extinction model was determined from the RC stars themselves, with a method very similar to Gonzalez et al. (2011). Completeness effects were corrected based on artificial stars inserted in the VVV images. For the deconvolution we used a Lucy-Richardson scheme including a 'background component' of stars not in the RC+RGBB. This is a good approximation because the magnitudes of these stars vary over a wide range. The deconvolved LOS density distributions clearly show the split red clump at latitudes | b | ≥ 4deg.
For constructing the entire 3D bulge density distribution, we then assumed that the bulge is eightfold triaxially symmetric. This assumption can be checked at the end: the rms deviations between the mirror-symmetric points in the final model are indeed small. Finding the best eightfold symmetric distribution determines the tilt angle of the bar-bulge to the LOS to be ( 27 ± 2 deg, where the dominant error is sys-) tematic, arising from the details of the deconvolution process. Our final density map covers the inner (2 2 . × 1 4 . × 1 1) kpc of the bulge/bar. It is illustrated in Figures 1 . and 2. The density is typically accurate to ∼ 10% except at y > 1 kpc along the intermediate axis of the bar. In the projected density maps shown in Figs. 1, the region | b | < 1deg was extrapolated from b ≥ 1deg with a simple sech 2 -model (Portail et al., in preparation), because at these low latitudes the extinction and completeness corrections are too large for a reliable density deconvolution.
Fig. 1 shows a highly elongated bar, with projected axis ratios ≈ ( 1 : 2 1 . ) for isophotes reaching major axis radii ∼ 2 kpc. Above about 400 pc above the Galactic plane, a prominent X-structure is visible which explains the earlier measurements of the split red clump. This X-structure is characteristic for a class of b/p bulges (Bureau et al., 2006). In fact, the b/p bulge of the Milky Way is very strong, about as strong as in the proto-typical b/p bulge in NGC 128 (Wegg & Gerhard, 2013b). Beyond about 1 kpc along the major axis, the iso-surface density contours in the edge-on projection bend down and outwards to the Galactic plane.
## 4 Does the Milky Way have a disky pseudo-bulge?
Along the principal bar axes the density falls of approximately exponentially, as shown in Fig. 2. Exponential scale-lengths are (0.70:0.44:0.18) kpc, corresponding to axis ratios (10:6.3:2.6). The flattening of the major axis profile beyond ∼ 1 kpc signifies the transition to the longer, planar bar.
Particularly noteworthy is the very short vertical scale height in the centre, perhaps indicative of a central disk-like, high-density pseudo-bulge structure as is seen in many early and late type b/p bulge galaxies (Bureau et al., 2006), including the edge-on Milky Way analogue NGC 4565 (Kormendy & Barentine, 2010).
Additional support for this interpretation comes from the change-of-slope at | l | /similarequal 4deg seen in the VVV RC star count maxima longitude profiles for b = ± 1deg (Gonzalez et al., 2011; Wegg & Gerhard, 2013a). The simplest interpretation of this
Fig. 1 (a), top: The Galactic bulge as viewed from the north Galactic pole. (b), bottom: The bulge 3D density projected along the intermediate axis. Numbers give the surface density of RC stars in pc -2 , contours are spaced by 1/3 mag. The 3D density map extends to 1.15 kpc along the minor axis and to 1.4 kpc along the intermediate axis, and the projections are within these limits.
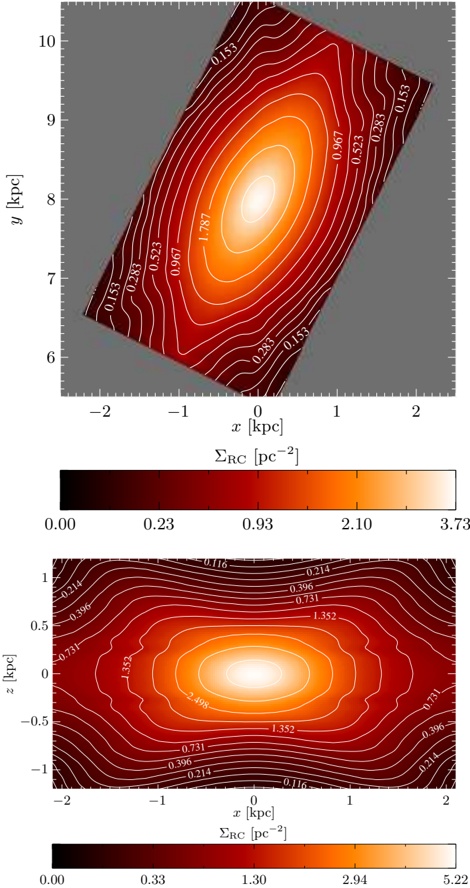
result is the presence of a rounder, more nearly axisymmetric central part of the bar, as illustrated by Gerhard & Martinez-Valpuesta (2012) with an N-body model with this property (see Figure 3). In fact, if the central parts of the Milky Way bar were completely axisymmetric, the inner slope of the longitude profile would be nearly zero. This model also predicted that the transition to a rounder inner parts was confined to a few degrees from the Galactic plane. This was later confirmed with VVV data by Gonzalez et al. (2012). However, more work is required particularly at low latitudes to confirm a disky pseudo-bulge in the Milky Way.
Fig. 2 Density of RC stars along the major axis (green), intermediate (blue), and minor axis (red) for the bulge. The major and intermediate axis profiles are offset from the Galactic plane by 187.5 pc. The error bars are the rms deviations between the eightfold symmetric points of the final bulge density distribution. The shaded regions show estimated systematic errors based on varying the details of the deconvolution procedure. From Wegg & Gerhard (2013a).
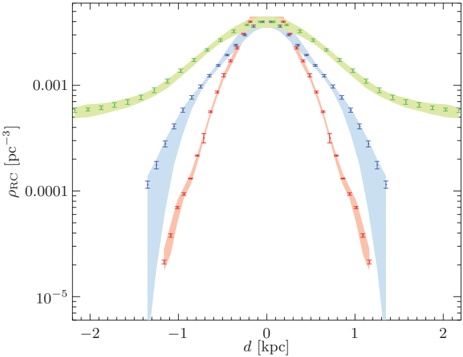
## 5 The long bar
Hammersley et al. (2000) first drew attention to an overdensity of stars in the Milky Way disk plane reaching outwards from the bulge region to l /similarequal 28deg. This structure was confirmed in several subsequent NIR star count investigations, e.g. with UKIDSS (Cabrera-Lavers et al., 2008). Due to its longitude extent and the narrow extent along the LOS it was termed the 'long bar'. In Spitzer Glimpse mid-infrared star counts (Benjamin et al., 2005), which are even less affected by dust, a corresponding long bar was inferred from a similar overdensity of sources observed on the l > 0 side. The long bar has a vertical scale-length of less than 100 pc, so is
Fig. 3 Maxima of RC magnitude distributions in the strips b = ± 1deg across longitude. In the top panel for VVV K-band counts from Gonzalez et al. (2011, open squares) and for an N-body model from Martinez-Valpuesta & Gerhard (2011, dots). The model reproduces the data well because its central parts near the symmetry plane are more axisymmetric than the main bar. In the bottom panel for slices through the model with different latitude as seen from the Sun. The change of slope seen in the simulated RC magnitude distributions for | b | < 2deg is absent at | b | = 5deg. From Gerhard & Martinez-Valpuesta (2012).
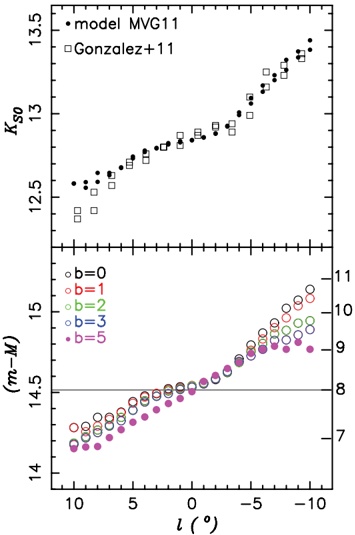
clearly a disk feature. Curiously, the orientation of the long bar inferred by all these investigations was at ∼ 45deg with respect to the LOS to the Galactic centre.
Such a misalignment of the long bar with the b/p bulge is difficult to understand dynamically. Two independent, misaligned barred structures with sizes differing by only a factor of ∼ 2 would be expected to align quickly, due to the mutual gravitational interaction. Note that secondary nuclear bars are generally ∼ 8 times smaller than the primary bars in their host galaxies (Erwin, 2011). Thus Martinez-Valpuesta & Gerhard (2011); Romero-G´ omez et al. (2011) both argued that the long bar would more likely be the 2D part of the Milky Way bar continuing outwards from the 3D barred bulge, such as generally seen in secularly evolved N-body models. Martinez-Valpuesta & Gerhard (2011) predicted star counts from an N-body model with a bar and inner boxy bulge formed in a buckling instability. They argued that approximate agreement with the star count data could be achieved if the ends of the planar part of the bar have developed leading ends through interaction with the adjacent spiral arm heads. They found that such a configuration was present in their model for ∼ 40% of the time in an evolutionary sequence from leading to straight to trailing, and also that some barred galaxies have bars with leading ends.
However, the star count maxima signifying the long bar (Cabrera-Lavers et al., 2008) show some discontinuities near l = 10deg and l = 20deg, and the LOS distance dispersion of these RC stars shows a large scatter when plotted versus longi-
tude. Therefore, in order to understand the Milky Way's planar bar better, we are currently reanalyzing the combined 2MASS, UKIDSS, and VVV surveys of the inner Galaxy (Wegg et al., in preparation). All data were extinction corrected and brought to a common photometric system. Fig. 4 shows the total star counts across the Galactic bulge and inner disk in a magnitude interval common to all surveys. From this map it is apparent that the vertical scale-height of the star counts decreases continuously from the maximum in the X-region of the b/p bulge into the planar bar and disk. This is confirmed more quantitatively by measuring the vertical gradients of the RC stars on the l > 0 side. There is no indication for two separate components in these plots. Investigation into the LOS distribution of RC stars versus longitude in the combined data is on-going. This will give us a better understanding of the long bar and the transition region between the bar and the adjacent disk in the Milky Way.
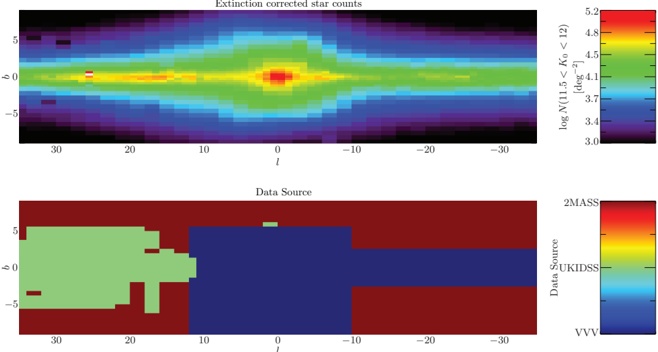
l
Fig. 4 The Galactic bulge and bar as seen from the Sun in K-band star counts combined from the cross-matched 2MASS, UKIDSS, and VVV surveys as shown in the lower panel. The magnitude range shown (11 5 . < MK < 12) is chosen such that the VVV data in the Galactic plane are not yet saturated and at the same time the 2MASS data are still complete in the region where they are used. This projection shows the continuous transition in the vertical scale-height from the inner 3D b/p bulge to the outer 2D bar.
## References
| Alves D. R., 2000, ApJ, 539, 732 Athanassoula E., 2005, MNRAS, 358, |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1477 |
| Athanassoula E., Misiriotis A., 2002, MNRAS, 330, 35 |
| Benjamin R. A., Churchwell E., Babler B. L., Indebetouw R., et al. 2005, ApJL, 630, L149 |
| Binney J., Gerhard O., Spergel D., 1997, MNRAS, 288, 365 |
| Bissantz N., Englmaier P., Binney J., Gerhard O., 1997, MNRAS, 289, 651 |
| Bissantz N., Gerhard O., 2002, MNRAS, 330, 591 |
| Blitz L., Spergel D. N., 1991, ApJ, 379, 631 |
| Bureau M., Aronica G., Athanassoula E., Dettmar R.-J., Bosma A., Freeman K. C., 2006, MNRAS, 370, 753 |
| Cabrera-Lavers A., Gonz´lez-Fern´ndez a a C., Garz´n o F., H ammersley P. L., L´pez- o Corredoira M., 2008, A&A, 491, 781 |
| Chung A., Bureau M., 2004, AJ, 127, 3192 |
| Combes F., Debbasch F., Friedli D., Pfenniger D., 1990, A&A, 233, 82 |
| Dwek E., Arendt R. G., Hauser M. G., Kelsall T., et al. 1995, ApJ, 445, 716 |
| Englmaier P., Gerhard O., 1999, MNRAS, 304, 512 |
| Erwin P., 2011, Memorie della Societa Astronomica Italiana Supplementi, 18, 145 P. B., Frogel J. A., Pogge R. W., Quillen A. C., Davies R. L., DePoy D. |
| Eskridge L., |
| Houdashelt M. L., Kuchinski L. E., Ram´rez ı S. V., Sellgren K., Terndrup D. M., Tiede G. P., 2000, AJ, 119, 536 |
| Fux R., 1997, A&A, 327, 983 |
| Fux R., 1999, A&A, 345, 787 |
| Gerhard O., Martinez-Valpuesta I., 2012, ApJL, 744, L8 |
| Gonzalez O. A., Rejkuba M., Minniti D., Zoccali M., Valenti E., Saito R. K., 2011, A&A, 534, L14 |
| Gonzalez O. A., Rejkuba M., Zoccali M., Valenti E., Minniti D., Schultheis M., Tobar R., Chen B., 2012, A&A, 543, A13 |
| Guedes J., Mayer L., Carollo M., Madau P., 2013, ApJ, 772, 36 P. L., Garz´n o F., Mahoney T. J., L´pez-Corredo o ira M., Torres M. A. P., 2000, MNRAS, 317, L45 |
| Hammersley |
| Kunder A., Koch A., Rich R. M., de Propris R., Howard C. D., Stubbs S. A., et al. 2012, AJ, 143, 57 |
| Lopez-Corredoira M., Garzon F., Hammersley P., Mahoney T., Calbet X., 1997, MNRAS, 292, L15 |
| L¨tticke u R., Dettmar R.-J., Pohlen M., 2000, A&A, 362, 435 |
| Martig M., Bournaud F., Croton D. J., Dekel A., Teyssier R., 2012, ApJ, 756, 26 Martinez-Valpuesta I., Gerhard O., 2011, ApJL, 734, L20+ |
| Martinez-Valpuesta I., Shlosman I., Heller C., 2006, ApJ, 637, 214 |
| McWilliam A., Zoccali M., 2010, ApJ, 724, 1491 |
| Merrifield M. R., Kuijken K., 1999, A&A, 345, L47 |
- Nataf D. M., Udalski A., Gould A., Fouqu´ e P., Stanek K. Z., 2010, ApJL, 721, L28 Ness M., Debattista V. P., Bensby T., Feltzing S., Roˇ skar R., Cole D. R., Johnson J. A., Freeman K., 2014, ApJL, 787, L19
- Ness M., Freeman K., Athanassoula E., Wylie-de-Boer E., Bland-Hawthorn J., Asplund M., et al. 2013, MNRAS, 432, 2092
- Ness M., Freeman K., Athanassoula E., Wylie-De-Boer E., Bland-Hawthorn J., Lewis G. F., et al. 2012, ApJ, 756, 22
- Paczynski B., Stanek K. Z., Udalski A., Szymanski M., Kaluzny J., Kubiak M., Mateo M., Krzeminski W., 1994, ApJL, 435, L113
Peters III W. L., 1975, ApJ, 195, 617
Pietrinferni A., Cassisi S., Salaris M., Castelli F., 2004, ApJ, 612, 168
Raha N., Sellwood J. A., James R. A., Kahn F. D., 1991, Nature, 352, 411
- Romero-G´ omez M., Athanassoula E., Antoja T., Figueras F., 2011, MNRAS, 418, 1176
- Saito R. K., Hempel M., Minniti D., Lucas P. W., et al. 2012, A&A, 537, A107 Salaris M., Girardi L., 2002, MNRAS, 337, 332
- Samland M., Gerhard O. E., 2003, A&A, 399, 961
- Shane W. W., 1972, A&A, 16, 118
- Shen J., Rich R. M., Kormendy J., Howard C. D., De Propris R., Kunder A., 2010, ApJL, 720, L72
- Skrutskie M. F., Cutri R. M., Stiening R., Weinberg M. D., et al. 2006, AJ, 131, 1163
- Stanek K. Z., Mateo M., Udalski A., Szymanski M., Kaluzny J., Kubiak M., 1994, ApJL, 429, L73
- Stanek K. Z., Udalski A., Szymanski M., Kaluzny J., Kubiak M., Mateo M., Krzeminski W., 1997, ApJ, 477, 163
- Wegg C., Gerhard O., 2013a, MNRAS, 435, 1874
- Wegg C., Gerhard O., 2013b, The Messenger, 154, 54
- Weiland J. L., Arendt R. G., Berriman G. B., Dwek E., Freudenreich H. T., Hauser
- M. G., et al., 1994, ApJL, 425, L81
Zhao H., Spergel D. N., Rich R. M., 1994, AJ, 108, 2154 | 10.1007/978-3-319-10614-4_4 | [
"Ortwin Gerhard",
"Christopher Wegg"
] | 2014-08-01T16:18:14+00:00 | 2014-08-01T16:18:14+00:00 | [
"astro-ph.GA"
] | The Galactic Bar | The Milky Way's bar dominates the orbits of stars and the flow of cold gas in
the inner Galaxy, and is therefore of major importance for Milky Way dynamical
studies in the Gaia era. Here we discuss the pronounced peanut shape of the
Galactic bulge that has resulted from recent star count analysis, in particular
from the VVV survey. We also discuss the question whether the Milky Way has an
inner disky pseudo-bulge, and show preliminary evidence for a continuous
transition in vertical scale-height from the peanut bulge-bar to the planar
long bar. |
1408.0220v2 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-8
## Experimental Results on p(d) + A Collisions at RHIC and the LHC
## Anne M. Sickles
Department of Physics, University of Illinois at Urbana-Champaign, Urbana, Illinois Physics Department, Brookhaven National Laboratory, Upton, New York
## Abstract
Recent experimental results at both the LHC and RHIC show evidence for hydrodynamic behavior in proton-nucleus and deuteronnucleus collisions ( p + A). This unexpected finding has prompted new measurements in p + A collisions in order to understand whether matter with similar properties is created in A + A and p + A collisions or whether another explanation is needed. In this proceedings, we will discuss the new experimental data and its interpretation within the context of heavy-ion collisions.
Keywords:
## 1. Introduction
Collisions of protons or deuterons with large nuclei (hereafter collectively refered to as p + A collisions) were studied as control measurements for heavy-ion collisions. Results since Quark Matter 2012 have cast doubt on this paradigm. The possible creation of hot nuclear matter has been suggested by measurements of long range azimuthal correlations in p + Pb collisions at the LHC and d + Au collisions at RHIC. These observations have motivated an abundance of vN and spectra measurements in small collision systems to determine to what extent a hydrodynamic description is applicable in p + A . Additionally, significant modifications to jets and highpT hadrons have been observed at the LHC which remain unexplained. In this proceedings we discuss a selection of the interesting experimental results related to p + A physics and highlight some of the open questions and new measurements that are needed.
The results discussed here are divided into three sections: highpT jets and hadrons, identified particles, and correlations.
## 2. HighpT Jets and Hadrons
One of the original motivations for p + A physics at RHIC and the LHC is to quantify nuclear modifications to the production of hard observables as a baseline for heavy-ion measurements. First results measurements of highpT single hadron production in both d + Au [1, 2] and p + Pb [3] were consistent with binary scaled p + p to pT GLYPH<25> 10 GeV / c at RHIC and to GLYPH<25> 20 GeV / c at the LHC. New results presented at this conference show that reconstructed jet spectra are approximately consistent with binary scaling to very high pT [4, 5, 6]. There is evidence for a slight excess of the nuclear modification factor, RpPb , ( < 20% at midrapidity) which is consistent with expectations from nuclear modifications to the parton distribution functions [7].
Surprisingly, single charged hadrons with pT > 30 GeV / c show a large and significant excess compared to binary scaling of p + p data (up to approximately a 40% increase) in recent measurements from the CMS [5] and ATLAS [8]
pQCD at
s
5 02 and 7 TeV [10].
In the lower panel of Fig. 1 the ratios of the spectra for backward (
0 8
.
<
η
cms
<
0 3 and
.
1 3
.
<
η
-
cms
<
0 8) pseudorapidity ranges to that at
.
η
cms
< .
0 3 are shown. The indication of a slight softening of the
-
|
|
p
T
spectrum when going from central to backward (Pb-side) pseudorapidity,
-
-
observed already in the pilot-run data of 2012 [4] (note opposite
η
cms sign convention in [4]) is confirmed with better
Transverse momentum dependence of inclusive primary charged-particle production . . .
5
significance and extended in
p
T
down to 0.15 GeV
/
c
.
A good description of our earlier measurement of spectra in p-Pb collisions [4] was achieved in the
EPOS3 model [14] including a hydrodynamical description of the collision, while the PHSD model [15]
significantly underestimated the spectra for
p
pQCD at
√
s
=
5 02 and 7 TeV [10].
.
T
values of several
GeV
/
c
.
In the lower panel of Fig. 1 the ratios of the spectra for backward (
0 8
.
<
η
cms
<
0 3 and
.
1 3
.
<
η
-
cms
<
0 8) pseudorapidity ranges to that at
.
η
cms
< .
0 3 are shown. The indication of a slight softening of the
-
|
|
pPb
=5.02 TeV, NSD
s
ALICE p-Pb
R
p
T
spectrum when going from central to backward (Pb-side) pseudorapidity,
1.3
NN
in the pilot-run data of 2012 [4] (note opposite
η
cms sign convention in [4]) is confirmed with better
1.2
charged particles significance and extended in
p
T
down to 0.15 GeV
/
c
.
1.1
1
0.9
A good description of our earlier measurement of spectra in p-Pb collisions [4] was achieved in the
EPOS3 model [14] including a hydrodynamical description of the collision, while the PHSD model [15]
significantly underestimated the spectra for
p
0.8
0.7
T
values of several
GeV
/
c
.
0.6
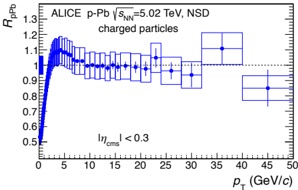
T
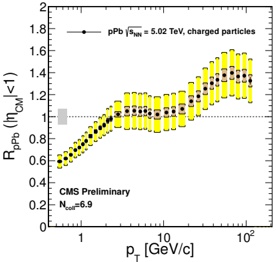
2 - comparison with CMS and ALIC
pPb glyph<c=1,font=/ERBPWC+font00000000192b5d8d>glyph<c=2,font=/ERBPWC+font00000000192b5d8d>glyph<c=3,font=/ERBPWC+font00000000192b5d8d>
glyph<c=1,font=/ERBPWC+font00000000192b5d8d>glyph<c=4,font=/ERBPWC+font00000000192b5d8d>glyph<c=5,font=/ERBPWC+font00000000192b5d8d>glyph<c=5,font=/ERBPWC+font00000000192b5d8d>glyph<c=6,font=/ERBPWC+font00000000192b5d8d>glyph<c=7,font=/ERBPWC+font00000000192b5d8d>glyph<c=4,font=/ERBPWC+font00000000192b5d8d>glyph<c=8,font=/ERBPWC+font00000000192b5d8d>
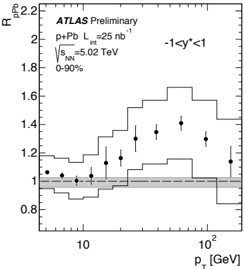
T
1.1
T
1
0.8 0.9 The nuclear modification factor of charged particles as a function of transverse momentum, measured minimum-bias (NSD) p-Pb collisions at √ s NN = 5 02 TeV in two pseudorapidity ranges, . η cms < . 0 3 and compatible with Figure 1. Charged hadron RpPb at p sNN = 5.02 TeV from ALICE [4], CMS [5] and ATLAS [8] (from left to right).
Fig. 2:
in
-
0.7
1 3
.
<
η
|
|
cms
< .
0 3.
The statistical errors are represented by vertical bars, the systematic errors by boxes around data points.
0.6
The relative systematic uncertainties on the normalization are shown as boxes around unity near
p
0.5
T
=
0.
50
In order to quantify nuclear effects in p-Pb collisions, the the nuclear modification factor, is calculated as:
Fig. 2:
The nuclear modification factor of charged particles as a function of transverse momentum, measured in
minimum-bias (NSD) p-Pb collisions at
-
5 02 TeV in two pseudorapidity ranges,
1 3
.
<
η
cms
< .
0 3.
The statistical errors are represented by vertical bars, the systematic errors by boxes around pPb
data points.
The relative systematic uncertainties on the normalization are shown as boxes around unity near where
N
is the charged particle yield in p-Pb collisions.
p
T e measurement of the nuclear modification factor
=
0.
Th for charged particle production in
and
1 3
.
<
η
cms
< .
0 3 is shown in Fig. 2.
in quadrature, of the p-Pb and pp spectra are added
T-differential yield relative to the pp reference,
In order to quantify nuclear effects in p-Pb collisions, the tic
-
separately for the statistical
The systematic uncertainties the nuclear modification factor, is calculated as: s.
are largely correlated
between adjacent
The total systematic uncertainty tion, the quadratic sum of the uncertainty on
CMS measurement
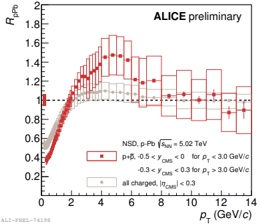
different trend
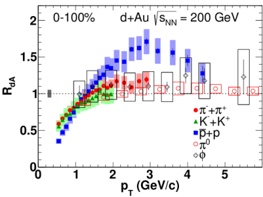
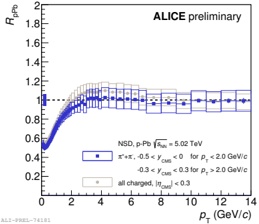
T
T
R
d 2 the normalization of the pp reference spectrum and
N
/
d
η
d
p
T
pPb
,
pPb
(
p
T
) =
,
〈
-
〈 T pPb 〉 d 2 σ pp / d η d p T where N pPb is the charged particle yield in p-Pb collisions. The measurement of the nuclear modification factor R pPb for charged particle production in | η cms | < . 0 3 and 1 3 . < η < . 0 3 is shown in Fig. 2. The uncertainties of the p-Pb and pp spectra are added Figure 2. RpPb for charged pions (left) and (anti-)protons (middle) for minimum bias p + Pb collisions [12]. Pions are consistent with unity for pT > 4 GeV / c and the (anti-)protons are enhanced by approximately 20-40% for 3 < pT < 6 GeV / c . Similar measurements in d + Au collisions at p sNN = 200 GeV are shown in the right panel [13]. Pions are consistent with unity and (anti-)protons are enhanced by approximately 60%.
cms in quadrature,
separately for the statistical
〉
and systematic uncertainties.
The systematic uncertainties are largely
correlated between adjacent
p
bins.
The total systematic uncertainty on the normaliza-
tion, the quadratic sum of the uncertainty on 〈 T pPb 〉 , the normalization of the pp reference spectrum and collaborations. Results from the ALICE experiment [4] do not show this excess however the pT reach is smaller and the statistical and systematic uncertainties are large in the region where the excess is observed in CMS and ATLAS. Results from all three collaborations are shown in Fig. 1. The excess is larger than is expected from the jet data and larger and with a di GLYPH<11> erent pT dependence than expected from the EPS09 [7] nuclear parton distribution functions [5]
T
It is notable that there is no p + p data at 5.02 TeV, so there are substantial uncertainties in the p + p reference, which has to be interpolated from higher and lower energy p + p collisions. An analysis by CMS has found that much of the di GLYPH<11> erence between the ALICE and CMS results is in the p + p reference, not the p + Pb measurement [5]. p + p running at 5 TeV is of interest to establishing the excess observed by CMS and ATLAS and is central to reducing the uncertainties which will enable more precise characterization of the charged hadron scaling. In the short term, understanding the origin of the reference di GLYPH<11> erences and direct comparison of the p + Pb spectra are of interest. The results from ATLAS and CMS could suggest some modification to jet fragmentation in p + Pb . It could also suggest that there is a larger fraction of quark jets than would be expected based on p + p collisions. That might create an excess because of the softer fragmentation of gluon jets than quark jets, but it has not been demonstrated that this would be able to account for the size and pT dependence of the charged hadron excess.
Centrality in p + A collisions has been measured by the forward energy in the nucleus going direction [9, 6, 10]. The centrality dependence of very highpT jet production in p + Pb has been measured by ATLAS [6] and they find an excess of jets in peripheral collisions and a suppression of jets in central collisions relative to binary scaling. These e GLYPH<11> ects cancel to produce the RpPb for minimum bias collisions that is nearly unity. This is similar to what was previously seen by PHENIX [11]. ATLAS has measured over a wide range in jet pseudorapidity and finds that for a large span in GLYPH<17> the binary collision scaled central to periphal jet ratio, RCP follows a constant trend as a function of the total jet momentum (not pT ).
(1)
)
T-differential yield relative to the pp reference,
2
1.8
1.6
1.4
1.2
1
0.8
0.6
0.4
0.2
0
1.3
0
1.2
1.1
1
0.9
0.8
0.7
0.6
0.5
0
-
-
|<1)
η
CM
(|
pPb
R
pPb
R
10
pPb
CMS Preliminar
N
=6.9
coll
1
glyph<c=1,font=/MZVGTI+font00000000192b5d8d>glyph<c=2,font=/MZVGTI+font00000000192b5d8d>glyph<c=3,font=/MZVGTI+font00000000192b5d8d>glyph<c=4,font=/MZVGTI+font00000000192b5d8d>glyph<c=5,font=/MZVGTI+font00000000192b5d8d>
glyph<c=4,font=/MZVGTI+font00000000192b5d8d>glyph<c=6,font=/MZVGTI+font00000000192b5d8d>glyph<c=7,font=/MZVGTI+font00000000192b5d8d>glyph<c=7,font=/MZVGTI+font00000000192b5d8d>glyph<c=8,font=/MZVGTI+font00000000192b5d8d>glyph<c=9,font=/MZVGTI+font00000000192b5d8d>glyph<c=6,font=/MZVGTI+font00000000192b5d8d>
ALICE p-Pb
N
s
char
10
15 g
|
|
cms
η
15
5
5
ons ns
3
3
4
4
5
Blast Wave
Blast Wave
FONLL
FONLL
6
7
8
p
9
10
(GeV/c)
T
3 (GeV/c) T p 7 8 9 10 (GeV/c) T p 0 1 2 3 4 5 6 7 8 9 10 0 Figure 3. (left) Blast-wave expectations for D and B meson nuclear modification factors at RHIC. (center) The resulting nuclear modification factor for electrons from the decay of D and B mesons (curves) and heavy meson decay electron measurement in central d + Au collisions (points) [20]. (right) The same quantity for D mesons and decay electrons at the LHC. Figures are from Ref. [21].
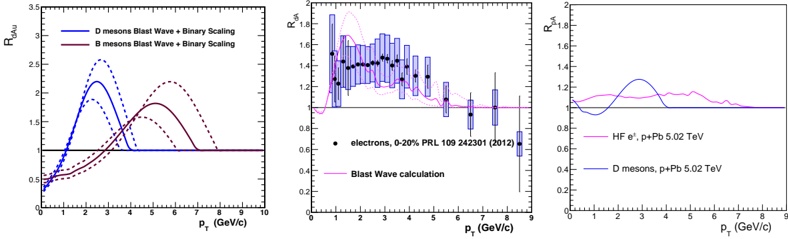
## 3. Identified Particle Measurements in p + A
The particle spectra at lower pT in d + Au collisions have shown an increased yield of protons and anti-protons compared to pions for 1.5 < pT < 3 GeV / c [14, 15]. New data from PHENIX [13] and ALICE [12] extend those measurements. The nuclear modification factors for pions and protons at both PHENIX and ALICE are shown in Fig. 2. In order to further understand the origin of the modified particle ratios, ALICE measured the ( GLYPH<3> + GLYPH<3> ¯ ) = 2 K S 0 ratio of both inclusive particles and those associated with reconstructed jets in p + Pb collisions [16]. The inclusive ( GLYPH<3> +GLYPH<3> ¯ ) = 2 K S 0 ratio is three times larger than that which is measured in reconstructed jets. This suggests that the species dependence of RpA is not associated with jets.
In light of the description of light hadrons at the LHC, it is natural to ask whether this descriptions extends to p s NN = 200 GeV d + Au collisions 1 and heavy mesons. Results from RHIC have shown a significant enhancement of electrons from the decay of heavy mesons in 0-20% central d + Au collisions [20]. If the enhancement observed in p + A collisions is from a radial flow boost, then D and B mesons will be more enhanced because of their larger mass. Blast-wave fits were done to the d + Auspectra in Ref. [13] and was found to give a good description of the spectra [21]. The blast-wave fit parameters from the light hadron spectra were used to determine a blast-wave prediction for the D and B meson spectra. These spectra were compared to theoretical calculations from Fixed-Order-Next-to-LeadingLog (FONLL) calculations [23, 24, 25] of D and B spectra. The resulting nuclear modification factors for D and B mesons are shown in Fig. 3 (left). In order to compare with the RHIC data which are for electrons from charm and bottom hadron decays, information about the decay kinematics from PYTHIA [26] is used. The resulting electron RdAu for 0-20% central d + Au collisions is shown in Fig. 3 (center) compared with the measurement from Ref. [20]. Given the uncertainties both on the data and the blast-wave parameters, the data and the calculation are in reasonable agreement. The calculations can also be done using the ALICE blast-wave parameters and the FONLL calculation at 5.02 TeV. At p s NN = 5.02 TeV the harder initial mesons spectra will lead to a smaller enhancement. The resulting RpA based on high multiplicity p + Pb blast-wave parameters from ALICE[19] is shown in Fig. 3 (right). The data from ALICE are thus far only for minimum bias p + Pb collisions so a direct comparison of the calculation to the data is not possible at this time.
Since the particle species dependent modifications seem to be associated with non-jet particle production it is interesting to determine if hydrodynamics can account for the patterns in the data. The ALICE collaboration has preformed blast-wave [17, 18] fits to the p + Pb spectra and find the di GLYPH<11> erent particle species are well described by a single set of blast-wave parameters and that the extracted velocities increase as function of the multiplicity of produced particles in the collision [19].
In asymmetric nuclear collisions, the particle production is also asymmetric around mid-rapidity. In d + Au collisions at p s NN = 200 GeV the maximum in dNch = d GLYPH<17> is near GLYPH<17> GLYPH<25> 2-3 in the Au-going direction [27]. Therefore,
1 It would also be interesting to determine if the original Cronin data [22] can be described with a blast-wave fit to see whether hydrodynamics might account for the Cronin e GLYPH<11> ect.
5
6
3.5
Heavy-flavour decay muons:
p
T
-differential
R
pPb
1.5
1
0.5
2.5
0
2.5
dA
R
2
2
1.5
1.5
1
Pb
p
μ
3 GeV4
5 0 < y < -1.4
6
∝
→
PYTHIA + EPS09s LO, D
-2.
1.4 < y < 2.0
∝
→
PYTHIA + EPS09s LO, D
(a) 60-88%
(b) 0-20%
away from midrapidity
0.5
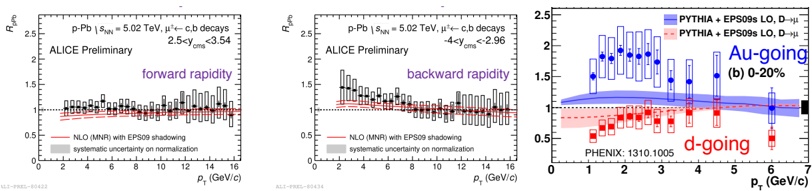
μ
μ
: 1.4 <|
η
| < 2.0
2
R
pPb at forward rapidity
:
consistent with unity within uncertainties over the whole measured
T
z
z R pPb at backward rapidity : slightly larger than unity in 2< p T <4 GeV/ and close to unity at higher c p T z Within uncertainties, data can be described by perturbative QCD calculations with EPS09 parameterization of shadowing 0.5 1 1.5 (c) 0-100% Figure 4. Nuclear modification factors for GLYPH<22> GLYPH<6> from heavy meson decays. Left and middle panels show RpPb for forward (left) and backward (middle) in minimum bias p + Pb collisions [28] and the right panel shows forward (squares) and backward (circles) RdAu in central d + Au collisions [29]. Curves on all panels show expectations from EPS09 [7]. directions in p + Pb collisions. and Ref. [29].
pQCD NLO (MNR): Nucl. Phys. B 373 (1992) 295; EPS09: K. J. Eskola et al., JHEP 04 (2009) 065
p
T
range
17
broadening, CNM E-loss)
T
I. Vitev (shadowing, k
Lim
0
1
2
3
4
5
6
7
(GeV/c) T p e GLYPH<11> ects which are sensitive to the bulk particle production would be expected to also be strong in this region as well. Correspondingly, in the in the d -going direction where there is less particle production, these e GLYPH<11> ects would be expected to be reduced. ALICE [28] and PHENIX [29] have measured muons from the decay of heavy mesons on both sides of midrapidity, in addition to the midrapidity electron measurements discussed above. The results are shown in Fig. 4. Both experiments observe an enhancement in the nucleus-going direction (denoted as 'backward'), which is perhaps somewhat larger in PHENIX than in ALICE though the systematic uncertainties are large on both measurements. In the proton-going direction (denoted as 'forward') ALICE observes an RpPb consistent with unity while PHENIX observes a small suppression in the d -going direction. The curves in Fig. 4 show the expectations from nuclear PDFs [7, 30]. The enhancement in the Au-going direction at RHIC is larger than is expected from EPS09s and the d -going RdAu is consistent with EPS09s expectations. In ALICE, the enhancement in the Pb-going direction is perhaps slightly larger than the expectation from EPS09, though the uncertainties on the data are large. p p + Au running at s NN = 200 GeV is expected in 2015. Since the d + Au data taking in 2008 silicon vertex detectors have been installed in both STAR and PHENIX. This will enable the separation of decay electrons from charm and bottom which will be sensitive to whether there is the mass dependence characteristic of radial flow as well as better comparisons to nuclear parton distribution functions and LHC data. Direct reconstruction of D mesons has been done at ALICE [28]. D mesons have been measured at RHIC with the 2003 d + Au data [31] and higher statistics measurements would be of great interest at RHIC both in p + Au and d + Au .
## 4. Azimuthal Correlations in p + A
The interest in azimuthal correlations in p + A collisions began with the observation of a long range correlation in pseudorapidity of particles close together in azimuth, the ridge , in p + Pb collisions [32]. The ridge has been understood in heavy-ion collisions as being due to azimuthal correlations from the initial geometry of the collision followed by hydrodynamic evolution. The discovery of a ridge in p + A collisions was immediately suggestive of collective behavior. The discovery that there was also an away-side ridge under the recoiling jet peak [33, 34] and that the correlations were larger in d + Au collisions than in p + Pb collisions [35] strongly suggested that the correlations were caused by hydrodynamic flow as is the case in nucleus-nucleus collisions. Another possible explanation is that the back-to-back correlations are due to Glasma diagrams in the Color-Glass Condensate [36]. Over the last year much experimental activity has gone into trying to understand the origin of these correlations. Here we highlight some new results and discuss future opportunities.
The most straightforward method removing dijet correlations is the peripheral subtraction method . In order to remove dijet correlations from high multiplicity, or central events, the correlations are measured in peripheral events (low multiplicity events). The peripheral subtraction technique relies on the assumption that modifications to jet correlations are small compared to the correlations attributed to vN . On the near side, sensitivity to this e GLYPH<11> ect can be reduced by increasing the GLYPH<17> separation between the particles. On the away side the jets are not well correlated in GLYPH<17> ,
The first results of v 2 in p + A systems were based on two particle azimuthal correlations. This method has several limitations. The main limitation is the influence of dijet correlations on the v 2 measurement. Additionally, this method is insensitive to the number of particles which are correlated. Here we discuss how more sophisticated techniques are being used to make qualitative improvements in the vN measurements in p + A collisions.
New d+Au
=200
1 @ s 2 NN
7
TPC-TPC
∆φ
TPC-TPC
∆φ
d+Au@200 GeV
d+Au@200 GeV
Correlations High- vs Low-m p : [1,3]x[1,3] GeV
Correlations High- vs Low-mult.
T
p : [1,3]x[1,3] GeV/
T
c
A ridge is observed with|
'K
|>6.0
FTPC Multiplicity
0<|
|<0.3
∆η
0.5<|
|<0.7
∆η
STAR Preliminary
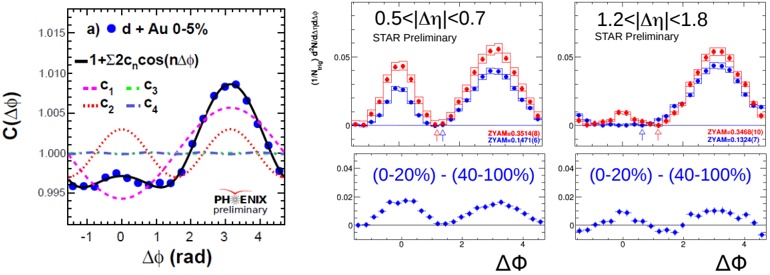
FTPC Multiplicity
1.2<|
∆η
|<1.8
STAR Preliminary
∆φ
(0-20%) - (40-100%)
high-mult. (cent.) > low-mult. (peri.) on both near-side and
Correlation between Au-going and d-going MPC towers
●
high-mult. (cent.) > low-mult. (peri.) on both near-side and away-side.
12 2014 May Li Yi, Purdue University 7 away-side. ● central - peripheral = 'double ridge' 2014 May Li Yi, Purdue University ● central - peripheral = 'double ridge' Figure 5. (left panel) Correlations of the ET measured by the d-going and Au-going MPC detectors 0-20% central d + Au collisions. A ridge correlation is seen for j GLYPH<1> GLYPH<17> j > 6. (top row, right two panels) Azimuthal correlation for 0-20% central events (light points) and 40-100% central events (dark points) for two di GLYPH<11> erent GLYPH<1> GLYPH<17> selections: 0.5-0.7 (middle) and 1.2-1.8 (right). The background has been subtracted using the zero yield at minimum technique [39]. (bottom row, right two panels) Results of a perpherial subtraction of the corresponding upper panels. Excess at GLYPH<1> GLYPH<30> GLYPH<25> 0 and GLYPH<1> GLYPH<30> GLYPH<25> GLYPH<25> are seen in all GLYPH<1> GLYPH<17> ranges (there is a downward shift in the right panel). Plot is from Ref. [40]. It should be noted that the centrality selections used here are not the same was used in Ref. [35].
so regardless of the GLYPH<17> separation between the particles the away side jet contribution to two-particle correlations is approximately constant. The measurement is then sensitive to di GLYPH<11> erences in the dijet correlations between central and peripheral events.
While at midrapidity PHENIX has a limited accessible GLYPH<1> GLYPH<17> range for charged particles, long range correlations have been shown between midrapidity charged hadrons and the energy in the Au-going muon piston calorimeter (MPC) [37, 38]. A ridge has also been observed in energy correlations between the Au-going and d-going MPCs with j GLYPH<1> GLYPH<17> j > 6 [38], as seen in Fig 5. PHENIX has used the Au-going energy to determine an event plane in d + Au collisions and measure the v 2 of charged hadrons near midrapidity with respect to this plane [37]. The event plane v 2 results are slightly lower than the two-particle correlation results in Ref. [35].
This limitation is particularly applicable to the first measurements of v 2 in d + Aucollisions [35]. There the required GLYPH<17> separation was between 0.5-0.7, limited by the size of the PHENIX charged particle acceptance. This separation is not enough to completely exclude the near side jet. In contrast, the LHC experiments and STAR have a wider midrapidity charged particle acceptance in GLYPH<17> allowing more complete suppression of the near side jet correlations.
The STAR detector has the ability to measure over a wider range in pseudorapidity separation. Results for central and peripheral correlations for a single pT selection and two GLYPH<1> GLYPH<17> selections are shown in Fig. 5. Following a peripheral subtraction near and away side correlations are observed in correlations with j GLYPH<1> GLYPH<17> j up to 1.8. In this GLYPH<1> GLYPH<17> range the near side jet is completely removed in 40-100% peripheral collisions and a small near side correlation is observed in 0-20% central collisions. In order to explore the possible e GLYPH<11> ects of dijet modifications between the jets in central and peripheral collisions, STAR introducted a scaling factor to match the near side jets in the small GLYPH<1> GLYPH<17> region. Applying this scaling factor to di GLYPH<11> erent GLYPH<1> GLYPH<17> selection causes the away side correlation to be reduced. There was discussion that this finding was inconsistent with the observation of collective e GLYPH<11> ects in d + Au collisions. This conclusion is premature. A study of the sensibility of this rescaling procedure in more pT bins is called for. Additionally, the validity of the peripheral subtraction method with a wide central bin (0-20%) and a rather central 'peripheral' bin (40-100%) is not clear and has not been demonstrated. Given the focus of the community on the topic of angular correlations in very small collisions, these and related studies should be given a high priority. The ATLAS collaboration has employed a similar technique [41], but both ridges remain. A fuller understanding of this procedure requires a systematic study as a function of pT , centrality, and GLYPH<17> acceptance (the ATLAS GLYPH<17> acceptance is much wider than that of the STAR detector).
Two-particle correlations alone are not sensitive to whether many or a few particles (for example as is the case with jets) are correlated. In the Color-Glass Condensate model only a few particles in the event should be correlated by the Glasma diagrams, whereas if hydrodynamics is the source of observed correlations all of the particles should be correlated. The event plane results discussed above suggest that many particles are correlated rather than just a
5
7
0.3
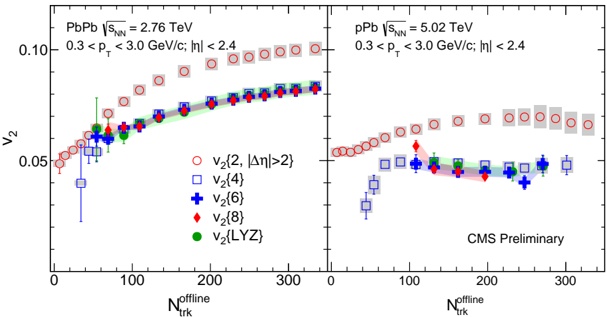
d+Au@200 GeV
v
collisions [2, 3, 5], with much improved uncertainti
(EP) 0-5%
extended
p
range.
It is about 20% higher than
2
T
Figure 6. v 2 in Pb + Pb (left) and p + Pb (right) collisions as measured with 2, 4, 6 and 8 particle cumulants as well as the Lee-Yang Zeros method [42]. The v 2 ngular correlations of values are plotted as a function of the number of o GLYPH<15> ine tracks as measured by CMS. A π , K and p in p-Pb collisions ALICE Collaboration 0.2 (2p) 0-5% 2 v Polynominal Fit CMS 0-2% ALICE 0-20% p +Pb at p T = 1 GeV/ , and the difference decre c few percent at p T > 2.0 GeV/ . c
ATLAS 0-2%
2
v
/ Fit
2
v
1.0
0.3
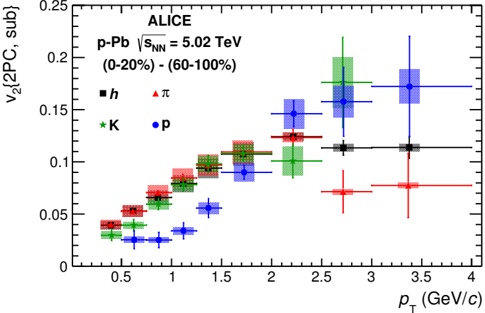
0-20% p+Pb @ 5.02 T
pion proton
collisions [2, 3, 5], with much improved uncertainties extended
about 20% higher than th
p
0.5
1.0
1.5
2.0
2.5
3
= 1 GeV/ , and the difference decreas
0.2
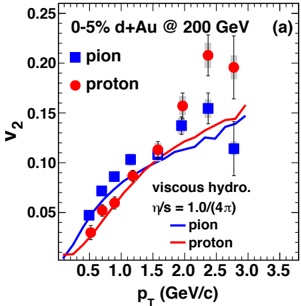
T
T
p
T
>
2.0 GeV/ .
c
2
v
T
few percent at
Fig. 4:
The Fourier coefficient
v
2
{
2PC sub
,
}
for hadrons (black squares), pions (red triangles), kaons plane method in Panel (a).
(green stars) and protons (blue circles) as a function of p p T from the correlation in the 0-20% multiplicity class after subtraction of the correlation from the 60-100% multiplicity class. The data is plotted at the averagep T for each considered p T interval and particle species under study. Error bars show statistical FIG. 3: Measured v 2 ( EP ) for midrapidity charged tracks in 0%-5% central d +Au at √ s NN = 200 GeV using the event FIG. 4: Measured v 2 ( p T ) for identified pio (anti)protons, each charged combined, in 0%-5% 0.1 0.25 0-5% d+Au @ 200 GeV (a) 0-20% p+Pb @ 5.02 TeV Figure 7. vN for GLYPH<25> GLYPH<6> and p p ; ¯ for high multiplicity + Pb collisions from ALICE [44] (left) and central d + Au collisions from PHENIX [37] (right). Shown on the PHENIX data is a hydrodynamic calculation from Ref. [45].
Also shown are
v
2
measured in central
uncertainties while shaded areas denote systematic uncertainties.
p
+Pb collisions at
s
= 5.02 TeV [2, 3, 5], and our
+Au collisions at RHIC. In panel (a) the data are co
0.20
pion pion
/ Fit
v
6 Summary Two-particle angular correlations of charged particles with pions, kaons and protons have been he event plane method) [37] and are shown in measured in p-Pb collisions at √ s NN = imize 5.02 TeV and expressed as associated yields per trigger particle. The Fourier coefficient v 2 was extracted from these correlations and studied as a function of p T and event multiplicity. In low-multiplicity collisions the p T and species dependence of v 2 resembles that observed in pp collisions at similar energy where correlations from jets dominate the measurement. In high-multiplicity p-Pb collisions a different picture emerges, where v p < v π is found up to about 2 GeV/ c . At 3-4 GeV/ , c v p is slightly larger than v π , albeit three subevents method [23, 24], with the other two event planes being (i) the second order event plane determined from central-arm tracks, restricted to low p T (0.2 GeV/ c < p T < 2.0 GeV/ ) to min c contribution from jet fragments; and (ii) the first order event plane measured with spectator neutrons in the shower-maximum detector on the Au-going side ( η < -6.5) [24, 25]. The systematic bined for each species, up to p T = 3 GeV/ c usi event plane method; the systematic uncertainties same as for inclusive charged hadrons. A dist mass-splitting can be seen. The meson v 2 is highe the baryon for p T < 1 5 GeV/ , as has been seen . c sally in heavy-ion collisions at RHIC [29-34]. Figu also shows calculations with Glauber initial con (GeV/c) T p FIG. 3: Measured v 2 ( EP ) for midrapidity charged tracks in 0%-5% central d +Au at √ s NN = 200 GeV using the event plane method in Panel (a). Also shown are v 2 measured in central p +Pb collisions at √ s NN = 5.02 TeV [2, 3, 5], and our prior measurements with two particle correlations ( v (2 p )) for (GeV/c) T p 0.5 1.0 1.5 2.0 2.5 3.0 3.5 (GeV/c) T p 0.5 1.0 1.5 2.0 2.5 3.0 FIG. 4: Measured v 2 ( p T ) for identified pions (anti)protons, each charged combined, in 0%-5% ce d +Au collisions at RHIC. In panel (a) the data are com with the calculation from a viscous hydrodynamic model Radial flow, in addition to modifications of the particle spectra discussed in Section 3, should also a GLYPH<11> ect the vN of hadrons in a mass dependent manner. Measurements of v 2 for pions and (anti-)protons are now available in both p + Pb (using the subtraction method) [44] and d + Au collisions (using t Fig. 7. In both collision systems, the mass ordering of v 2 characteristic of radial flow is observed. The splitting is larger in p + Pb collisions, consistent with larger radial flow in p + Pb collisions. A hydrodynamic calculation [45] is able to qualitatively describe both the p + Pb and d + Au results. However, the magnitude of the observed splitting in p + Pb collisions is larger than that expected within the calculation.
class and subtracting the 60-100% event class, results in qualitatively similar observations. On lants. average the v 2 values are 15-25% lower and the statistical uncertainties are about a factor 2 larger than in the 0-20% case. For the 40-60% event class, the statistical uncertainties are too large to draw a conclusion. The analysis was repeated using the energy deposited in the ZNA instead of the VZERO-A to define the event classes. The extracted v 2 values are consistently lower by about 12% due to the e different event sample selected in this way. However, the presented conclusions, in particular the observed difference of v p 2 and v π 2 compared between jet-dominated correlations (60-100% event class) and double-ridge dominated correlations (0-20% event class after subtraction), are unchanged. NN prior measurements with two particle correlations ( v 2 (2 p )) for d +Au collisions [6]. A polynomial fit to the current measurement and the ratios of experimental values to the fit are shown in the panel (b). resolution Res(Ψ Obs 2 ) is calculated through the standard with the calculation from a viscous hydrodynamic mo 28], and in panel (b) the v 2 data for pions and pro 0%-20% central p +Pb collisions at LHC are shown f parison [15]. Figure 4 shows the midrapidity v 2 ( p T ) for ide charged pions and (anti)protons, with charge sign 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 2 1.0 1.5 (b) 2 v 0.05 0.10 0.15 proton pion proton viscous hydro. ) π /s = 1.0/(4 η proton few. At the LHC, CMS has investigated this by measuring v 2 with cumu Results for Pb + Pb and p + Pb are shown in Fig. 6 [42]. The v 2 from two particle correlations with a rapidity separation between the two particles is found to be larger than the v 2 f 4 g ( v 2 as measured via four particle cumulants). However increasing the order of the cumulants from 4 to 8 does not change the observed v 2 in either Pb + Pb or p + Pb . Additionally, CMS has extracted v 2 from the Lee-Yang Zeros method [43] which involves correlations among all th particles in the event. The v 2 extracted via that method is also found to be consistent with the cumulant v 2 for four or more particles. These results are consistent with the origin of the correlations in hydrodynamic phenomena and is not the behavior that is expected from the Color-Glass Condensate where only a few particles would be expected to be correlated.
d
2 2 2 2 with low significance. ns uncertainties on the v 2 of charged hadrons are mainly for viscous hydrodynamics starting at 2 +Au collisions [6]. A polynomial fit to the current measure28], and in panel (b) the v 2 data for If the correlatio observed in p + A systems are a response to the initial collision geometry, then changing the
τ
= 0 5 fm/
.
pions and proto ment and the ratios of experimental values to the fit are shown
0%-20% central
p
+Pb collisions at LHC are shown for in the panel (b).
from the tracking background and pile-up effects, as de-
η/s
= 1 0
.
/
(4
π
), followed by a hadronic cascade [
scribed above,
and also from the difference in
v
12
parison [15].
2
from different
event plane
determinations.
To estimate the
systematic uncertainty of the latter we compare the
v
2
2
resolution Res(Ψ
Obs
) is calculated through the standard three subevents method [23, 24], with the other two event
extracted with the MPC-S event plane with that using the south (Au-going) beam-beam counter, and the two
measurements of
v
2
are consistent to within 5%.
planes being (i) the second order event plane determined from cen
The tral-arm tracks, restricted to low
v
2
of
p
T
(0.2 GeV/
charged hadrons for 0%-5% central
d
c
+Au
T
The splitting at lower
p
is also seen in the calcu
Because there are no known CGC calculations av
2
Figure 4 shows the midrapidity
v
(
p
T
)
for ident
charged pions and (anti)protons, with charge signs that would indicate a mass-splitting, it may be ch
ing - even in principle - to establish the observe
T
bined for each species, up to
p
= 3 GeV/
c
usin event plane method; the systematic uncertainties ar
dependence in the initial stages of the collision.
Th g tified
particle
v
2
in 0%-20%
p
+Pb collisions are in Fig. 4(b) for comparison [15].
The magnitude same as
for inclusive
charged hadrons.
A distin
d
√
p
(GeV/c)
0.1
1.5
0.0
projectile nucleus should be able to change the measured vN . This was seen in d + Au collisions where the v 2 in central d + Au collisions was found to be larger than in in p + Pb collisions [35] possibly due to the initial elongated shape of the deuteron. Pursuing that idea further, it might be possible to observe a large v 3 by colliding a triangluar nucleus with a large nucleus. In the time since this conference, RHIC has successfully delivered 3 He + Au collisions at p s NN = 200 GeV. Hydrodynamic calculations show some increase in the expected v 3 of these collisions compared to d + Au (in d + Au no significant v 3 has been observed [35, 37]), especially in very high multiplicity events where the 3 He nucleus could preferentally be oriented to maximize the triangularity of the collision region [45]. As a further comparison, p + Au running at RHIC is expected in 2015. The full collection of these three small nuclei collided with Au will provide the most constraining tests as to the correlations between the geometry of the initial state and the final state correlations.
## 5. Conclusions
There has been great interest in determining the role that hot nuclear matter e GLYPH<11> ects play in p + A collisions. A wealth of new measurements were presented at this conference aimed at precisely this question. The available data strongly suggests that the angular correlations observed in these small collision systems involve many (or all) of the particles in the event, persist to large pseudorapidity separations and are related to the collision geometry. The results from single identified particle measurements support this interpretation. Mass dependent enhancement in the RpA measurements has been observed and there are hints that this may extend to the heavy mesons. The modifications to the particle composition does not seem to originate in jets, but rather in non-jet particles.
While much of the interest in p + A has focussed on lowpT physics, high pT physics of hadrons, jets, other hard probes and the centrality dependence of their production has also been of great interest. E ects are seen which are GLYPH<11> larger than expected from nuclear modifications to the parton distribution functions, the origin of which is not understood. Some of these e GLYPH<11> ects are seen in the centrality dependent results and further investigation of the centrality determination in p + A and the correlations between that determination and the measured hard probes are under investigation. The comparison between p + Pb collisions at the LHC and the upcoming p + Au collsions at RHIC will be of great interest. In contrast to heavy-ion collisions, no evidence for jet quenching in p + A has been observed.
The similarity of all these measurements to what has been seen in heavy-ion collisions is striking and suggests a common origin of phenomena in both systems. There was much discussion at the conference on whether hydrodynamic models could explain the totality of the data small and large system data. First attempts at more comprehensive calculations are being made [46] and more work is clearly necessary. The ability to quantitatively extract GLYPH<17>= s from the central heavy-ion data will be unconvincing without a clear understanding of the applicability of hydrodynamics in small collision systems. Since smaller collision systems can create less matter and will live for a shorter period of time they potentially provide a good place to descriminate between models of the collision at very early times. Upcoming 3 He + Au and p + Au data to be taken at RHIC will be key to experimentally constraining the physics of small collision systems.
p + A systems have proven to be much more interesting and surprising than originally envisioned and might be providing the most discriminating opportunity to push our understanding of collective behavior in heavy-ion physics to its limits. Other surprising e GLYPH<11> ects remain unexplained. Upcoming p + A and 3 He + Au running at RHIC as well as more p + Pb measurements will provide more insight into the physics of asymmetric nuclear collisions.
## 6. Acknowledgements
I thank the organizers for providing such an enjoyable and stimulating conference. I would also like to thank all those who discussed their work with me in preparation for this talk. I would like to thank the ALICE, ATLAS, CMS, PHENIX and STAR collaborations for providing me with the material necessary to put this talk together in a timely manner. This work was supported by the DOE under contract number: DE-AC02-98CH10886.
## References
[1] J. Adams, et al., Phys.Rev.Lett. 91 (2003) 072304. arXiv:nucl-ex/0306024 .
- [2] S. Adler, et al., Phys.Rev.Lett. 91 (2003) 072303. arXiv:nucl-ex/0306021 .
- [4] S. Aiola, these proceedings.
- [3] B. Abelev, et al., Transverse Momentum Distribution and Nuclear Modification Factor of Charged Particles in p -Pb Collisions at p sNN = 5 02 : TeV, Phys.Rev.Lett. 110 (2013) 082302. arXiv:1210.4520 doi:10.1103/PhysRevLett.110.082302 , .
- [5] E. Appelt, these proceedings.
- [7] K. Eskola, H. Paukkunen, C. Salgado, EPS09: A New Generation of NLO and LO Nuclear Parton Distribution Functions, JHEP 0904 (2009) 065. arXiv:0902.4154 doi:10.1088/1126-6708/2009/04/065 , .
- [6] D. Perepelitsa, these proceedings.
- [8] P. Balek, these proceedings.
- [10] A. Toia, these proceedings.
- [9] A. Adare, et al., Centrality categorization for Rp d ( ) + A in high-energy collisions arXiv:1310.4793 .
- [11] D. V. Perepelitsa, Exploring cold nuclear matter e GLYPH<11> ects in d + Au with highpT reconstructed jets at PHENIX, Nucl.Phys. A904-905 (2013) 1003c-1006c. doi:10.1016/j.nuclphysa.2013.02.184 .
- [13] A. Adare, et al., Spectra and ratios of identified particles in Au + Au and d + Au collisions at p sNN = 200 GeV, Phys.Rev. C88 (2) (2013) 024906. arXiv:1304.3410 doi:10.1103/PhysRevC.88.024906 , . p
- [12] M. L. Knichel, these proceedings.
- [14] J. Adams, et al., Pion, kaon, proton and anti-proton transverse momentum distributions from p + p and d + Au collisions at sNN = 200GeV, Phys.Lett. B616 (2005) 8-16. arXiv:nucl-ex/0309012 doi:10.1016/j.physletb.2005.04.041 , .
- [16] X. Zhang, these proceedings.
- [15] S. Adler, et al., Nuclear e GLYPH<11> ects on hadron production in d = Au and p + p collisions at s(NN)**(1 2) / = 200-GeV, Phys.Rev. C74 (2006) 024904. arXiv:nucl-ex/0603010 doi:10.1103/PhysRevC.74.024904 , .
- [17] P. Kolb, P. Huovinen, U. W. Heinz, H. Heiselberg, Phys.Lett. B500 (2001) 232-240. arXiv:hep-ph/0012137 , doi:10.1016/ S0370-2693(01)00079-X .
- [19] B. B. Abelev, et al., Multiplicity Dependence of Pion, Kaon, Proton and Lambda Production in p-Pb Collisions at sNN = 5.02 TeV, Phys.Lett. B728 (2014) 25-38. arXiv:1307.6796 doi:10.1016/j.physletb.2013.11.020 , . p
- [18] E. Schnedermann, J. Sollfrank, U. W. Heinz, Thermal phenomenology of hadrons from 200-A GeV S / + S collisions, Phys.Rev. C48 (1993) 2462-2475. arXiv:nucl-th/9307020 doi:10.1103/PhysRevC.48.2462 , . p
- [20] A. Adare, et al., Cold-nuclear-matter e GLYPH<11> ects on heavy-quark production in d + Au collisions at sNN = 200 GeV, Phys.Rev.Lett. 109 (24) (2012) 242301. arXiv:1208.1293 doi:10.1103/PhysRevLett.109.242301 , .
- [22] J. Cronin, H. J. Frisch, M. Shochet, J. Boymond, R. Mermod, et al., Production of Hadrons with Large Transverse Momentum at 200-GeV, 300-GeV, and 400-GeV, Phys.Rev. D11 (1975) 3105. doi:10.1103/PhysRevD.11.3105 .
- [21] A. M. Sickles, Possible Evidence for Radial Flow of Heavy Mesons in d + Au Collisions, Phys.Lett. B731 (2014) 51-56. arXiv:1309.6924 , doi:10.1016/j.physletb.2014.02.013 .
- [23] M. Cacciari, S. Frixione, P. Nason, The p(T) spectrum in heavy flavor photoproduction, JHEP 0103 (2001) 006. arXiv:hep-ph/0102134 .
- [25] M. Cacciari, http://www.lpthe.jussieu.fr/ ~ cacciari/fonll/fonllform.html .
- [24] M. Cacciari, S. Frixione, N. Houdeau, M. L. Mangano, P. Nason, et al., Theoretical predictions for charm and bottom production at the LHC, JHEP 1210 (2012) 137. arXiv:1205.6344 doi:10.1007/JHEP10(2012)137 , .
- [26] T. Sjostrand, S. Mrenna, P. Z. Skands, A Brief Introduction to PYTHIA 8.1, Comput.Phys.Commun. 178 (2008) 852-867. arXiv:0710. 3820 doi:10.1016/j.cpc.2008.01.036 , .
- [28] S. Li, these proceedings.
- [27] B. Back, et al., Phys.Rev. C72 (2005) 031901. arXiv:nucl-ex/0409021 doi:10.1103/PhysRevC.72.031901 , .
- [29] A. Adare, et al., Cold-nuclear-matter e GLYPH<11> ects on heavy-quark production at forward and backward rapidity in d + Au collisions at p sNN = 200 GeV arXiv:1310.1005 .
- [31] J. Adams, et al., Phys.Rev.Lett. 94 (2005) 062301. arXiv:nucl-ex/0407006 doi:10.1103/PhysRevLett.94.062301 , .
- [30] I. Helenius, K. J. Eskola, H. Honkanen, C. A. Salgado, Impact-Parameter Dependent Nuclear Parton Distribution Functions: EPS09s and EKS98s and Their Applications in Nuclear Hard Processes, JHEP 1207 (2012) 073. arXiv:1205.5359 doi:10.1007/JHEP07(2012)073 , .
- [32] S. Chatrchyan, et al., Observation of long-range near-side angular correlations in proton-lead collisions at the LHC, Phys.Lett. B718 (2013) 795-814. arXiv:1210.5482 doi:10.1016/j.physletb.2012.11.025 , .
- [34] G. Aad, et al., Phys.Rev.Lett. 110 (2013) 182302. arXiv:1212.5198 .
- [33] B. Abelev, et al., Phys.Lett. B719 (2013) 29-41. arXiv:1212.2001 .
- [35] A. Adare, et al., Phys.Rev.Lett. arXiv:1303.1794 doi:10.1103/PhysRevLett.111.212301 , .
- [37] A. Adare, et al., Measurement of long-range angular correlation and quadrupole anisotropy of pions and (anti)protons in central d + Au collisions at p s NN = 200 GeV arXiv:1404.7461 .
- [36] K. Dusling, R. Venugopalan, Phys.Rev. D87 (2013) 094034. arXiv:1302.7018 .
- [38] S. Huang, these proceedings.
- [40] L. Yi, these proceedings.
- [39] N. Ajitanand, J. Alexander, P. Chung, W. Holzmann, M. Issah, et al., Phys.Rev. C72 (2005) 011902. arXiv:nucl-ex/0501025 .
- [41] S. Radhakrishnan, these proceedings.
- [43] R. Bhalerao, N. Borghini, J. Ollitrault, Analysis of anisotropic flow with Lee-Yang zeroes, Nucl.Phys. A727 (2003) 373-426. arXiv: nucl-th/0310016 doi:10.1016/j.nuclphysa.2003.08.007 , .
- [42] Q. Wang, these proceedings.
- [44] B. B. Abelev, et al., Phys.Lett. B726 (2013) 164-177. arXiv:1307.3237 doi:10.1016/j.physletb.2013.08.024 , .
- [46] B. Schenke, R. Venugopalan, Eccentric protons? Sensitivity of flow to system size and shape in p + p, p + Pb and Pb + Pb collisions arXiv: 1405.3605 .
- [45] J. Nagle, A. Adare, S. Beckman, T. Koblesky, J. O. Koop, et al. arXiv:1312.4565 . | 10.1016/j.nuclphysa.2014.09.084 | [
"Anne M. Sickles"
] | 2014-08-01T16:19:17+00:00 | 2014-08-21T14:24:07+00:00 | [
"nucl-ex"
] | Experimental Results on p(d)+A Collisions at RHIC and the LHC | Recent experimental results at both the LHC and RHIC show evidence for
hydrodynamic behavior in proton-nucleus and deuteron- nucleus collisions (p+A).
This unexpected finding has prompted new measurements in p+A collisions in
order to understand whether similar matter is created in A+A and p+A collisions
or whether some another explanation is needed. In this proceedings, we will
discuss the new experimental data and its interpretation within the context of
heavy ion collisions. |
1408.0221v1 | ## Las representaciones del cielo entre los Tomárâho
Guillermo Sequera 1 y Alejandro Gangui 2
## Abstract
The small community of the Tomárãho, an ethnic group culturally descendant from the Zamucos, became known on the South American and international scene only recently. Hidden from organized modern societies until the late 1980s, the Tomárãho maintained close contact with nature and developed original ways of explaining and understanding it. This article presents the first results of an interdisciplinary project seeking to provide a detailed analysis of different astronomical elements in the imagined sky of the Tomárãho. After a brief history of the community and their present day lifestyle, we introduce some of the protagonist figures of their ethnoastronomy. The main body of the article focuses on the stratification of the sky after the collapse of the châro tree which served as the world's axis in the Tomárãho cosmology. The study reveals the richness of the Tomárãho culture and highlights the need for more detailed research into the names and stories of the visible astronomical bodies and phenomena which have been observed by the inhabitants of this part of the Paraguayan Chaco.
1 Secretaría Nacional de Cultura de Paraguay
2 Instituto de Astronomía y Física del Espacio, Conicet/Universidad de Buenos Aires, Argentina
## Resumen
La pequeña comunidad de los Tomárãho, un grupo étnico cultural descendiente de los Zamucos, llegó a ser conocido en la América del Sur y en la escena internacional sólo recientemente. Oculto en las sociedades modernas organizadas hasta finales de 1980, los Tomárãho han mantenido un estrecho contacto con la naturaleza y desarrollado formas originales de la explicación y la comprensión de la misma. Este artículo presenta los primeros resultados de un proyecto interdisciplinario para proporcionar un detallado análisis de los diferentes elementos astronómicos en el imaginario cielo de los Tomárãho. Después de una breve historia de la comunidad y su estilo de vida actual se presentan algunas de las figuras protagonistas de su etnoastronomía. El cuerpo principal del artículo se centra en la estratificación del cielo, después de la caída de la châro, árbol que sirvió como eje del mundo en la cosmología Tomárãho. El estudio pone de manifiesto la riqueza de la cultura Tomárãho y pone de relieve la necesidad de una investigación más detallada sobre los nombres y las historias de los cuerpos visibles y fenómenos astronómicos que han sido observados por los habitantes de esta parte del Chaco paraguayo.
## Palabra clave
Etnoastronomía, antropología, chamacoco, Alto Paraguay
## Keywords
Ethnoastronomy, anthropology, chamacoco, Alto Paraguay
La pequeña comunidad de los Tomárâho, etnia del tronco cultural de los Zamucos, irrumpió en el escenario de la antropología sudamericana y mundial hace relativamente poco tiempo. Siempre alejados de las riberas del río Paraguay, este pueblo permaneció
por muchos años oculto a la mirada de las sociedades organizadas modernas. Como todo pueblo en estrecho contacto con la naturaleza, los Tomárâho mostraron una profunda y rica cosmovisión, que guarda paralelos con otras culturas aborígenes quizás más estudiadas, como así también detalles que le son propios. Esto también se da en su imaginario del cielo y de los personajes que guardan una estrecha relación con la bóveda celeste. Este trabajo se basa en los prolongados estudios antropológicos de G.Sequera quien, recientemente y en colaboración con el astrofísico A.Gangui, ha dado inicio al proyecto de llevar a cabo un análisis pormenorizado de los diversos elementos astronómicos presentes en el cielo imaginado por los Tomárâho y por otras etnias Chamacoco. Se hará una breve reseña sobre esta cultura aborigen: lugares donde viven y regiones de influencia en el pasado, su familia lingüistica, su modo de vida y cómo el avance de 'la civilización' afectó su cultura (y su supervivencia). Mencionaremos luego los trabajos de campo ya realizados durante décadas y algunos estudios y publicaciones existentes. Haremos también una descripción de la metodología de este trabajo de campo con sus prácticas antropológicas particulares (singularidades y dificultades). Por último, nos concentraremos en la forma en que conciben el cielo los Tomárâho, y describiremos el análisis que hemos venido haciendo en los últimos meses de trabajo conjunto.
## La cultura Tomárâho
El acto de vivir de una cultura se muestra de muchas maneras diferentes. Una posible es esa creatividad puesta en juego por el grupo humano en observar los fenómenos cambiantes de la naturaleza en su entorno, ponerles nombres a las cosas, nominar a las personas, a los animales y a las plantas, en fin, construir conocimientos y símbolos propios que le permitan adquirir una identidad y sobrevivir como sociedad. A esto aspiran los pueblos actuales y, en completo
paralelo, fue una motivación fuerte de las culturas del pasado; de aquellas más desarrolladas tecnológicamente, como así también de los pueblos que no siguieron el paso frenético de la 'civilización' y permanecieron en un contacto más estrecho con la naturaleza. La pequeña comunidad indígena de los Tomárâho es un ejemplo cercano de estos últimos.
Un primer contacto con representantes de este pueblo se dio en febrero de 1986, ocasión en la que uno de los autores (Sequera) pudo comprobar la situación de semi-exclavitud y fuerte dependencia que debían soportar los integrantes de este pueblo en su relación con la Empresa Carlos Casado. En complicidad con el Estado Paraguayo y desde finales del siglo XIX (pocos años después de terminada la guerra de la Triple Alianza que debilitó sobremanera esa nación), esa empresa de capitales anglo-argentinos se había apropiado indebidamente de las tierras de los Tomárâho y explotaba los quebrachales en forma intensiva con el fin de extraer madera para durmientes de vías férreas y para abastecer a sus industrias tanineras. Sin ningún tipo de derecho reconocido, los nativos se veían obligados a trabajar como hacheros bajo duras condiciones laborales y a ser testigos de la expoliación de los bosques chaqueños, convirtiéndose en víctimas indefensas del avasallamiento de su espacio vital (Sequera, 2006).
Reconocida la importancia de llevar adelante un estudio antropológico en el caso de esta minoría étnica, se realizaron estudios comparativos de fuentes etnográficas en diversas bibliotecas y centros de investigación, que ayudaron a clarificar el panorama sobre el posible origen y mención de los Tomárâho en cartas anuas jesuíticas y crónicas antiguas. Sequera, además, convivió con los nativos durante varios períodos entre 1987 y 1992, lo que le permitió llevar adelante un trabajo metódico de reconocimiento y transcripción de
la lengua Tomárâho, el inventariado en detalle de la representación social de su flora y su fauna, así como también la colecta y registro de un inmenso corpus mítico que trasluce la rica cosmovisión de esa parcialidad étnica. El trabajo etnográfico llevado adelante empleó las más adecuadas técnicas cualitativas de la antropología, con rigor científico en las observaciones y otorgándole suma importancia al trabajo de campo, basado en la actitud metodológica de la observación participante, de acuerdo con los trabajos del antropólogo polaco Bronislaw Malinowski (Malinowski, 1922).
Los Tomárâho (o Tomaráxo) son un pequeño grupo étnico que, junto con los Ybytóso (o Ebidóso), forman el grupo más grande de los Ishir (este último grupo es conocido en el Paraguay como los Chamacoco). Tradicionalmente cazadores-recolectores, los Chamacoco son ubicados en la clasificación lingüística como emparentados a la familia Zamuco. Otros grupos indígenas, los Ayoreo, también pertenecen a la familia lingüística Zamuco [ver Fig.1]. No es nuestra intención entrar aquí en las discusiones sobre la etimología de estas palabras y denominaciones, donde abundan propuestas dispares basadas principalmente en los escritos de cronistas europeos, comenzando quizás con el Viaje al Río de la Plata, 1534-1554 del arcabucero Ulrico Schmidl (1510-1580). En diversos catálogos de lenguas y dialectos, en recopilaciones de crónicas y otros textos europeos, surgen términos como Timinabas, luego Timinaha y otros similares, siempre en la categoría de los Zamuco. Se menciona que los pueblos que hablaban estas lenguas se hallaban en los bosques del Chaco, lejos del río Paraguay, hacia el interior de la región. Se menciona, además, que estos indígenas aun no habían sido 'reducidos a la misión jesuítica'. Todo da a pensar, pues, que se están refiriendo a los Tomárâho, aquellos habitantes cuyos descendientes Sequera visitó en proximidades de la zona
de San Carlos en 1986 y que, por sus costumbres ancestrales e idiosincrasia propias, permanecieron por muchos años al margen de la sociedad paraguaya [Fig.2].
## Los primeros contactos
Los Tomárâho fueron reconocidos y observados por diversos estudiosos ya a partir de fines del siglo XIX. Guido Boggiani, artista plástico italiano que se instala en Paraguay para la explotación del quebracho colorado, dedicó su tiempo libre en aprender sobre las costumbres de los Chamacoco. Instalado en Puerto Pacheco en el alto Chaco, Boggiani distingue dos categorías de indígenas, los 'mansos' (que hoy conocemos como los Ybytóso) y los 'bravos' (los Tomárâho). Estudió las costumbres y la lengua de los primeros, pero no alcanzó a tomar contacto con la comunidad de los últimos. El sueño de llegar a ellos y colectar de primera mano los datos etnográficos que aspiraba se vio truncado con la muerte del explorador, en plena misión, y envuelta en un halo de misterio que duraría hasta el día de hoy. A Boggiani siguió el alemán Herbert Baldus en 1923, quien retomó y extendió los estudios del italiano sobre las divisiones de los Chamacoco en tribus y sus ubicaciones geográficas y demás datos demográficos (Baldus, 1932). En sus escritos el autor señala que, en ese entonces, la población de los Tomárâho estaba compuesta por unas 300 familias.
Luego de los trabajos de Baldus habrá que esperar tres décadas para que los Chamacoco vuelvan a ser el foco de interés de antropólogos y lingüistas, esta vez en los trabajos de la investigadora eslovena Branislava Susnik. Es a partir de 1957 que Susnik inicia sus trabajos de campo y de colecta de datos entre los Ybytóso que viven y trabajan en empresas forestales ubicadas a lo largo del río Paraguay. Comparando con estudios previos y de mano de sus propias
observaciones, Susnik percibe el avasallador impacto de los nuevos modos de vida de la región sobre la cultura Ybytóso. La modificación de su habitat modifica sus costumbres, sus condiciones de vida, su régimen alimenticio y su antigua división del trabajo comunitario (de la 'caza al trabajo'). También surge un nuevo criterio de posesión y propiedad en el pasaje de la 'búsqueda a la apropiación de bienes y cosas', y se modifican asimismo otros valores tradicionales, por ejemplo el de la caza, cuando la introducción de la escopeta desplaza la ancestral relevancia que tenía la destreza en el empleo de las armas indígenas. Por otra parte surgen conflictos entre jóvenes y ancianos que ponen en peligro la antigua transmisión de la sabiduría Chamacoco entre generaciones, lo que erosiona fuertemente los cimientos de la etnia y da pie a una transculturación acelerada (Susnik, 1995 [1969]).
## Las prácticas chamánicas
El chamanismo entre los Chamacoco tiene una gran relevancia, en todo similar a la que encontramos en otras culturas indígenas. La música vocal está muy relacionada con los rituales de los chamanes, ya se trate de hombres o de mujeres. Estos integrantes prominentes de la tribu, conocidos como konsaha o ahanak, construyen sus propios repertorios basándose en sus sueños, llamados chykêra, los que estimulan la creación de los textos poéticos, las melodías y los ritmos. Los chamanes Chamacoco buscan dominar los sueños para proyectarlos en un canto, al que se denomina teichu. La producción de estos cantos es eminentemente personal, y puede ser transmitida a otros miembros de la comunidad, pero su ejecución es en general grupal, donde se mezclan varios cantos y se crea una atmósfera sonora muy atípica, con acompañamiento de instrumentos como sonajas y silbatos.
Las sonajas, llamadas por los Chamacoco osecha o paîkâra, son construidas a partir de las calabazas de algunas plantas trepadoras (de la especie Lagenaria siceraria) o con caparazones de tortugas terrestres, llamadas enermitak (Geochelone carbonaria), donde se introducen semillas secas o piedritas que les dan sonoridad. Estas sonajas vienen a representar el cielo y los chamanes identifican su parte superior con el centro de la bóveda celeste, porn hosýpyte [Fig.3]. El cuerpo del instrumento está pintado con 'relatos visuales' en forma de rombos y en el interior de estas figuras geométricas se representan las estrellas porrebija (Sequera, 2006). Los estudios sugieren una estrecha relación entre las técnicas vocales e instrumentales de los Chamacoco -especialmente de los Tomárâho, donde el chamanismo ha perdurado más intensamente- y su visión del mundo, un lazo entre la expresión sonora y la cosmovisión indígena que aun queda por investigar en profundidad (Cordeu, 1994).
Las prácticas chamánicas de los Chamacoco guardan muchas similitudes con las de otras culturas indígenas sudamericanas, e incluso de otros continentes: los sueños visionarios, el desdoblamiento de la personalidad, el trance alcanzado a través del canto, etc, son situaciones que se repiten en espacio y en tiempo. Es a través de estos sueños que los konsaha descubren para el resto de los integrantes de la tribu la verdadera 'topografía' del universo indígena y su interrelación con los relatos míticos heredados de sus ancestros. (Una exploración antropológica muy detallada, pero para el caso de los Qom, o tobas del Chaco argentino, puede verse en (Wright, 2005).)
## La imagen del mundo
Aunque los detalles topográficos del cosmos imaginado por los chamanes puede diferir entre comunidades indígenas vecinas, e incluso más entre culturas separadas por grandes distancias y
períodos históricos, muchas veces su estructura fundamental es muy similar. En general, existe una región superior que interpretamos como el cielo. Los hombres habitan el mundo del medio, que casi siempre es imaginado como una superficie plana rodeada por grandes extensiones de agua. Por último, el tercer reino, un mundo sumergido y oscuro, se ubica por debajo de la tierra y en él se penetra por ciertos lugares singulares, como grutas y grietas del terreno. En general, cada uno de estos reinos está habitado por espíritus que se relacionan con los hombres de muy diversas maneras. Las almas de hombres poderosos de las tribus, por lo general la de los chamanes, son capaces de viajar por estas regiones durante los sueños o los trances a los que llegan en ocasión de las ceremonias (Krupp, 1996). Durante los trances, estos representantes y defensores de las tribus se encuentran con espíritus benévolos, con los que deben interactuar, y también deben hacerles frente a los demoníacos, que pretenden llevar el mal a toda la tribu. Por ello, son frecuentes las luchas contra estos últimos, en las que solo aquellos chamanes con grandes poderes pueden resultar victoriosos.
El radio de influencia de una dada cultura primitiva puede denominarse su microcosmos. Este es necesariamente un espacio cerrado y limitado por regiones desconocidas. Hacia el interior de las 'murallas' (reales o imaginadas) se ubica ese espacio familiar, organizado y habitado, con todos los elementos que caracterizan un cosmos (Eliade, 1998 [1957]). Por el contrario, hacia el exterior de esos bordes se extienden las regiones oscuras, relacionadas con 'los otros', quizás con los extranjeros temibles, incluso con los peligros y la muerte. En todo espacio vital limitado existe algún lugar singular, especial por las características que la población le ha conferido. Uno de los sitios particulares que más relevancia ha tenido para muchas culturas es lo que se conoce como el 'centro'. Culturas avanzadas y
otras más primitivas han coincidido en este lugar común, que excede las lenguas y las costumbres. Así por ejemplo, entre los habitantes de la antigua ciudad-estado de Babilonia, el zigurat (como el dedicado al dios Marduk) ocupaba dicho centro mientras que, para los antiguos hebreos, hacía lo propio el Monte del Templo en la ciudad vieja de Jerusalén; por su parte, la Kaaba o 'casa de Dios' en La Meca, ciudad natal de Mahoma, es el equivalente del centro del mundo para los musulmanes. Muchos otros ejemplos han sido estudiados en la literatura (Krupp, 1996).
En el imaginario de los pueblos antiguos, estos sitios no solo representaban el centro del cosmos; también allí había ocurrido la Creación y de esos lugares había surgido la vida. Eran estos los puentes naturales, los enlaces verticales privilegiados, entre el cielo y la tierra y los únicos lugares desde donde la comunicación entre ambos reinos era posible. Podemos decir que el poder de los cielos y el efecto renovador de la potencia celestial descendía por los laterales de estos ejes simbólicos.
## Elementos astronómicos del cielo Ybytóso y Tomárâho
Los Chamacoco imaginan el mundo como una superficie plana en forma de disco, al que llaman hñymich. Sobre este inmenso disco de tierra se ubican los paisajes familiares para ellos, sus pueblos, ríos y bosques, y también las comarcas vecinas de otros pueblos con los que tuvieron contacto. El hñymich se apoya sobre las aguas de un mundo acuático al que llaman niogorot urr. Como sucede con otros pueblos antiguos, la presencia de un mundo acuoso subterráneo entra dentro de la cosmovisión Chamacoco por la importancia que ellos asignan a las fuentes de agua, en pozos y ríos (además, los seres míticos ahnapsûro son seres acuáticos, como veremos). El niogorot urr está
subdividido en varios estratos, ubicados a diferentes profundidades. Por encima del disco de la tierra se ubican varios cielos transparentes, llamados genéricamente porrioho. Son semiesferas inmensas que rodean a los hombres y que ellos imaginan apoyadas en los bordes del disco hñymich.
Aparte de estas descripciones relacionadas con la tierra, el inframundo y los cielos característicos, la concepción Chamacoco de lo celeste incluye muchas representaciones relacionadas con las estrellas, tanto individuales como en grandes grupos. Encontramos la Vía Láctea, llamada iomyny, y su significación, quizás como camino de las almas (Giménez Benítez et al., 2002), y otras 'nebulosas' del cielo bien visibles desde las regiones del gran Chaco Paraguayo, como las Nubes Grande (kajywysta) y Pequeña (kajywyhyrtâ) de Magallanes. También el Sol, al que llaman Deich, y la Luna, Xekulku, son protagonistas de varios relatos caros a su cultura (Cordeu, 19901991). Existen también ciertas narraciones que involucran al astro Venus, que ellos llaman Iohdle, o también madre de las estrellas, porrebe bahlohta, y que guardan relación con los demás astros y con los gentiles.
Muchos elementos del cosmos Chamacoco tienen seres protectores asignados, ya de trate de insectos (protegidos por el ser Ñîogogo, la rana Bufo granulosus) o de otros individuos de la avifauna local (protegidos por Wohôra, para los Tomárâho, o por Pêeta yrâhata, para los Ybytóso). Por su parte, las estrellas son protegidas por Abich, el astro hijo de Venus, mientras que el ñandú o avestruz local (Rhea americana), llamado Pemme-Kamytêrehe por los Chamacoco, se encarga del cuidado de Deich, el Sol [Fig.4]. En sus relatos y dibujos se ha podido representar también el kululte o châro, que es el 'árbol cósmico' o sostén del mundo y que, como en muchas otras culturas, funciona como nexo entre el porrioho y el niogorot urr. Como
veremos, el châro tiene un lugar privilegiado en las narraciones de los viajes chamánicos.
## El axis mundi
El simbolismo del centro está presente en muchas culturas y fue profundamente estudiado por los historiadores de las religiones. De acuerdo a Eliade la existencia de un centro cósmico es una consecuencia natural de la división de la realidad en lo sagrado (donde se concentra todo el valor) y lo profano (cuyo espacio no da ninguna orientación al hombre) (Eliade, 1998 [1957]). El mundo adquiere así un significado solo a través de hierofanías (del Griego, hieros, que indica sagrado, y phainein, revelarse, esto es, hierofanía podría traducirse como 'donde se revela lo sagrado'). Estas intrusiones de lo sagrado en lo profano establecen un sitio singular, un 'centro', que rompe con lo homogéneo de un espacio no relacionado con ninguna herencia mítica. Se interpreta también como un elemento que hace de nexo entre diversos planos existenciales; entre estos, uno es por supuesto el de la vida ordinaria, mientras que los otros niveles no son accesibles para los hombres, o al menos no para todos.
La disposición espacial de estos diferentes niveles se orienta en forma ortogonal al espacio plano terrestre, si bien es cierto que los límites de la tierra habitable también tienen connotaciones especiales. El traspaso entre estos niveles se da en la dirección vertical, ya sea hacia lo alto o, por el contrario, adentrándose en las entrañas de la tierra. La imagen típica que surge en el imaginario de los pueblos de diversas culturas es la de una montaña prominente, que se destaca en el paisaje, o la de un 'árbol cósmico', notable por su envergadura o ancianidad, u otro 'pilar' que cumple la función de unir el cielo con la tierra y con las regiones inferiores.
A este objeto se lo denomina en forma genérica un axis mundi, y la historia es pródiga en ejemplos; el zigurat mencionado previamente entre los babilonios, o el Monte Meru, la montaña sagrada de la tradición mitológica Hindú, por solo mencionar un par de casos. El zigurat representaba una montaña cósmica y el sacerdote que ascendía por sus terrazas accedía a la cima del universo; sus siete divisiones verticales emulaban los siete cielos astronómicos. También los templos eran construidos a imagen del axis mundi y unían diferentes niveles cósmicos, como es el caso del enorme monumento budista Borobudur ubicado en la isla de Java, en Indonesia. Llegar a su terraza superior equivalía a abandonar el espacio profano y a elevarse por la región pura de un nuevo nivel existencial (Eliade, 1974 [1955]). Veremos a continuación que existe un fuerte paralelo entre estas creencias y la figuración del cosmos de los Ybytóso y los Tomárâho del alto Chaco Paraguayo.
La montaña o pilar cósmico no solo se hallaba localizada en el centro del espacio organizado de las comunidades arcaicas; también muchas veces su cima representaba el sitio más elevado del mundo, una zona que ni los mayores diluvios de la humanidad habían podido alcanzar. Estos sitios fueron imaginados, a su vez, como una suerte de ombligo de la Tierra: lugares donde todo había sido creado, como si se tratase de un embrión. La Creación del mundo allí tomaba su lugar, para luego ir expandiéndose hacia la periferia, en todas las direcciones. Y por supuesto, también el hombre había tenido su génesis en ese centro del mundo; un centro de la Creación que un futuro trabajo etnográfico deberá también precisar para la comunidad de los Chamacoco, y para los Tomárâho en particular.
## El axis mundi Ybytóso y Tomárâho
La visión del universo aceptada por los Chamacoco imagina un árbol-sostén del mundo al que llaman kululte o châro. Este árbol pertenece a la especie Chorisia insignis, endémica del Paraguay y de países limítrofes; especie conocida en Castellano, entre otras denominaciones, como palo borracho. Como en muchas otras culturas, este árbol cósmico representa el nexo entre el cielo y la tierra. Se dice que es en la base de dicho árbol mitológico donde convergen todas las sepulturas [Fig.5].
El universo superior de los Chamacoco es imaginado como una superposición de cielos transparentes, que algunos párrafos más arriba llamamos porrioho, opuesto a la morada de los muertos en la tierra, donde hunde sus raíces el châro. El mito de origen narra que, en los tiempos de los antiguos, el cielo y la tierra estaban unidos por el árbol cósmico. Ambos reinos se encontraban, por así decirlo, fusionados, y los gentiles podían recorrer todo el ancho de estos lugares sin barreras ni impedimentos. Los primeros habitantes de la tierra, llamados yxyro poruwuhle, se alimentaban sin esfuerzo alguno, capturando animales y recogiendo los frutos de la tierra con facilidad.
Esta situación recuerda épocas mitológicas similares en otras culturas y bien puede nominarse una suerte de paraíso o jardín de la abundancia de los Chamacoco. Sin embargo, como los informantes que colaboraron con la investigación etnográfica coinciden en relatar, la historia cambió su rumbo un día en el que una viuda y sus hijos pidieron asistencia para proveerse de comida, ayuda que les fue denegada. Al ver esa falta de altruismo para con su familia y la pereza que mostraban sus vecinos, la viuda, llamada Dagylta, tomó la forma de un escarabajo y lentamente comenzó a roer la
madera del poderoso châro. En ese momento aparece en la historia un pájaro, el dichikîor, de la especie Polyborus plancus o Caracara plancus, conocido en Castellano como carancho, que intentó impedir a Dagylta llevar a cabo su cometido. Pero no lo logró, y finalmente el árbol cósmico terminó desplomándose sobre la tierra. (Entre los mocovíes de la zona chaqueña argentina existe una historia muy similar, donde la mujer se habría transformado en carpincho. Véase la crónica del padre jesuita Guevara, 1969 [1764]).
Dos imágenes que presentamos aquí representan la concepción del árbol cósmico en dos registros gráficos del integrante de la comunidad ybytóso Ogwa Flores Balbuena (Sequera, 2005). La primera (Fig.5) muestra una representación del mito de origen de la comunidad ybytóso y el lugar central que en éste ocupa el châro. En el dibujo puede distinguirse un extenso número de representantes de la avifauna local, así como también la acción de los gentiles que se desplazan por el tronco principal del árbol que conecta el cielo y la tierra. El segundo registro gráfico (Fig.6) muestra el árbol Ebyta (otro nombre del châro) como el pilar y sostén del mundo, en épocas previas a su caída por la accion de Dagylta. Este dibujo muestra los dos reinos unidos por el poderoso árbol y nuevamente algunos personajes que transitan por él.
Mientras Dagylta, bajo la forma de un escarabajo, desgastaba y debilitaba el tronco del árbol cósmico, muchos gentiles, que hasta entonces circulaban libremente entre cielo y tierra, previendo lo que podría suceder, decidieron descender. Otros, en cambio, más perezosos, quedaron rezagados y, una vez vencido el árbol, permanecieron por siempre en el reino de arriba, aferrados al firmamento, y se convirtieron en porrebija, las estrellas que pueblan el cielo de los Chamacoco. (Notemos que los Bosquimanos del desierto de Kalahari, en el sur del África, cuentan que las estrellas
son los primeros pueblos del mundo y que son como ellos, nómades, cazadores y recolectores; ver (Krupp, 1996). Por su parte, para los Qom del Chaco argentino, luego de un cataclismo que alteró la estructura del cielo y de la tierra, ciertos personajes también se convirtieron en las estrellas (Wright, 2005).)
Los Chamacoco cuentan que al cortarse el puente que unía ambos reinos se ensanchó el universo y ya nunca más cielo y tierra volvieron a juntarse. En las representaciones de Ogwa Flores mostradas en las Figuras anteriores el cielo se halla poblado de seres que se desplazan, interactúan y conviven con animales y plantas de la región superior. Y esta región se ubica tan solo pocos metros por encima de la copa de los árboles más altos de los bosques de la tierra. De las narraciones se desprende, además, que el mismo cielo refleja su color sobre el manto de hojas de la extremidad del follaje de dichos bosques. Al derrumbarse el châro, la zona de unión (de inserción) de esta suerte de pilar cósmico se cerró, transformando al cielo, que era visto como una capa espesa, dura y gris, en una región estratificada y dividida en múltiples niveles. El imaginario Chamacoco, a partir de ese evento fundacional de derrumbe, desarticula la ecúmene en dos mundos que se oponen: el reino de arriba, figurado ahora como un cielo semiesférico; el mundo inferior, apoyado sobre aguas primigenias, imaginado como un mundo náufrago (Sequera, 2006).
Esta separación Cielo-Tierra-Inframundo ya fue documentada ampliamente, tanto en trabajos antropológicos como en otros relacionados con la historia de las religiones. Nuevamente Eliade, en su libro Imágenes y símbolos, menciona el caso de los pigmeos Semang de la península de Malaca (península malaya). En el centro del mundo Semang se ubica una roca enorme (o quizás una colina de piedra caliza; ver Evans, 1968 [1937]), llamada Batu Ribn o Batu 'Rem, que cubre las regiones inferiores y, en tiempos antiguos,
constituía la base sobre la que se elevaba un tronco de árbol que llegaba al cielo. Inframundo, centro de la Tierra y la puerta del cielo quedaban entonces unidas por un mismo eje. Este eje, a su vez, era el camino a tomar para transitar entre una y otra región. Este pueblo narraba que en otro tiempo la comunicación con la divinidad y el cielo eran naturales y simples, pero que luego de una falta ritual esta relación se interrumpió. Quedó entonces como privilegio de chamanes lo que antes era natural para todos los integrantes del mundo Semang.
## El espacio-mundo Chamacoco
A partir del derrumbe del châro mitológico, evento de quiebre sucedido en épocas primigenias de la historia de los Ybytóso y los Tomárâho, el universo adquiere una arquitectura particular, donde se separan el mundo de arriba del subterráneo. El primero está ubicado por encima de la superficie terrestre e incluye seis estratos, comenzando con la zona de hábitat usual de las especies vegetales y animales. Esta capa, sólida y seca, es también morada de los hombres, y alcanza una altura equivalente a la de la palma más alta. A esta región se la llama pôrr iut, que en lengua Chamacoco significa cielo más bajo. A continuación se ubica una capa situada por encima de la terrestre y caracterizada por su humedad. Es llamada pôrr pehét o también pôrr erîch que, en lengua indígena, significa a mitad de los cielos (pehét significa espacio). Esta capa corresponde a la región donde se ubican las nubes y donde se originan las lluvias. También las tormentas, originadas por los seres osâsero (espíritus de las tormentas), encuentran en esta zona el lugar para desarrollarse [Fig.7]. Esta es la morada de los pajaritos junqueros petîis chyperme (Phleocryptes melanops) que acostumbran volar bajo en zonas pantanosas, y también la de los chamanes guía. Por su parte, los miembros de la comunidad Tomárâho afirman que esta
región está poblada de espíritus extraños, llamados osîoro kynaha, seres malignos que transmiten enfermedades, de origen microbiano o infeccioso, endémicas de muchas de esas zonas del Chaco Boreal. El ser mítico Nehmurt también se halla en el pôrr pehét.
El estrato siguiente del mundo de arriba es llamado pôrr pîxt (cielo verdadero) y los Chamacoco lo representan como una capa de neblina espesa, dominio del personaje conocido como Lapyxe, el hacedor de las lluvias. Muchos personajes actúan como guardianes de ciertas cosas, fenómenos y objetos animados o inanimados. Lapyxe, por su parte, es el guardián de las aguas. En esta región de encuentran tanto la Luna como el Sol pero con el segundo ubicado por debajo de la primera. De hecho, el contorno de la Luna marca el límite superior del pôrr pîxt. Este límite constituye el pórtico del cielo, barrera de difícil traspaso, pues es allí donde montan guardia los espíritus extraños osîoro kynaha. Estos son los principales obstáculos que deben sortear los chamanes ahanak cuando intentar viajar por los cielos del mundo de arriba durante sus vuelos chamánicos.
El cuarto cielo se llama pôrr yhyr (cielo alto) y es una ancha zona donde se encuentran las estrellas porrebija, así como también los grupos de estrellas que forman asterismos y constelaciones. Recordemos que en la visión Chamacoco, las estrellas habían surgido a partir de los seres que quedaron rezagados en la región superior al momento de la caída del châro, el árbol cósmico que en época inmemorial unía el cielo y la tierra. La luminaria mayor del cielo nocturno después de la Luna, el planeta Venus, que los indígenas llaman Iohdle, también se halla en este cielo límpido, junto con toda otra especie de objetos celestes. La Vía Láctea, que como vimos es llamada iomyny, se muestra en los cielos diáfanos del Chaco Paraguayo como una notoria franja blanquecina que atraviesa el firmamento, y también se ubica en el pôrr yhyr. Con la excepción de
algunos chamanes particularmente visionarios, nadie tiene el poder de incursionar en este cielo lejano y profundo.
Finalmente, los dos últimos estratos del mundo de arriba se llaman pôrr uhur (cielo del horizonte), el primero, y pôrr nahnyk (cielo frío) el más alto. El primero es el umbral del fin del firmamento, y la región en donde surge lo incógnito. El último es visto como el espacio indefinido que va más allá de los cielos interiores, y la región donde se ensancha el universo y predomina lo desconocido. Se trata de un cielo profundo donde el aire no llega. (Cordeu, 1994, ha sugerido una diferente estratificación del mundo superior, más relacionado con las propiedades cromáticas y atmosféricas del cielo.)
Viajemos ahora en la dirección vertical opuesta, esto es, hacia el reino de las profundidades. El mundo subterráneo, surgido en el imaginario Chamacoco luego de la caída del châro mitológico, se divide en tres estratos principales. Se trata de un mundo oculto y profundo, que se prolonga hacia las entrañas de la tierra y que tiene una constitución viscosa. Se piensa que es una zona donde reina la destrucción. La primera región, nîogoro urr, es una zona de humedales y cursos de agua superficiales. En este medio fluído se desplaza la mítica anguila dyhylygyta y también el uriche, similar al actual lobito de río (de la especie Lontra longicaudis). Estos animales coexisten también con espíritus que toman la apariencia de peces. Serían estos últimos quienes otorgarían poderes para luchar contra los espíritus extraños osîoro kynaha a los chamanes.
A la segunda capa subterránea se la imagina como una zona de aguas profundas, mezclada con lodo espeso y viscoso. Se la conoce como hñymich yhyrt, literalmente tierra de monte alto, y es la morada de monstruos similares a anguilas, entre los cuales el más fabuloso tanto por su dimensión como por su cabeza gigante y rojiza,
es el que los nativos llaman pêeta. Esta anguila-monstruo concede a ciertos chamanes el poder para desplazarse ágilmente por esta capa subterránea, para luego emerger del mundo náufrago a gran velocidad por cualquier parte de la tierra. Por último, la tercera capa subterránea se llama hñymich urruo y significa bajo tierra. En esta región se localiza el mundo oscuro y putrefacto de los cadáveres y la morada del ser llamado amyrmy lata, de aspecto similar a un armadillo gigante (Priodontes maximus) y al que se vincula con los chamanes iniciados.
Si bien estos diferentes estratos del mundo náufrago invocan destrucción, muerte y finalmente putrefacción de todo lo vivo, pueden sin embargo liberar ciertas fuerzas de ascensión como las que impulsan a los chamanes en la segunda capa (Sequera, 2006) y también las que caracterizan a los ahnapsûro (o axnábsero), los seres míticos originarios del mundo Chamacoco [Fig.8]. Descritos por primera vez por Boggiani en el año 1900 (Baldus, 1932; Susnik 1995 [1969]), los ahnapsûro son mencionados por todos los Chamacoco, aunque sólo los Tomárâho mantienen aún hoy en día la práctica ritual de la representación mítica (los mitos de origen emuhno). Estos seres acuáticos, de inmenso poderío y cuyo cuerpo está completamente recubierto de escamas y plumas, son los fundadores de la cultura Chamacoco, y en los orígenes convivieron con los primeros habitantes yxyro en armonía y les enseñaron a buscar el alimento para alimentar a la tribu. Su aparición hoy en el campamento Tomárâho es fuente de estremecimiento y alteración de la calma de la comunidad; regularmente se organizan representaciones rituales que conjuran ese temor [Fig.9].
## Perspectiva y proyectos futuros
Se mostraron algunas pinceladas de la inmensa riqueza de los Chamacoco en lo que hace a su relación con la naturaleza y con el cielo. Un largo y paciente trabajo etnográfico ha logrado revelar las características más salientes de este grupo aborigen en su conjunto y de las parcialidades Tomárâho e Ybytóso en particular. La familiarización con su cultura, la transcripción de su lengua, el lento mejoramiento de su situación social, y la educación respetando sus tradiciones e identidad cultural, son todos elementos en los que se ha ido progresando significativamente.
En este importante trabajo etnográfico, sin embargo, los aspectos astronómicos no fueron abordados con igual intensidad que los demás. Por ello, resta la tarea de hacer un trabajo detallado de reconocimiento e identificación de aspectos salientes del cielo Chamacoco, como así también de la verdadera significación del châro, el árbol cósmico que unía el cielo con la tierra y que aún hoy es central en los rituales del origen del mundo [Fig.10].
Estrellas prominentes visibles en diferentes momentos del año (como Sirio, o incluso asterismos notorios como el hoy conocido de las Tres Marías en el cinturón de Orión), sus nombres y las historias que seguramente se narraban sobre ellas; su imaginario sobre la presencia y características de la Vía Láctea; sus interpretaciones sobre fenómenos asombrosos y sorpresivos como los eclipses totales de Sol, sobre apariciones prolongadas en el cielo como las de los cometas o incluso esporádicas, como las estrellas fugaces, son algunos aspectos que, creemos, requieren una mayor atención.
La historia de Iohdle (Venus) que muchos años atrás vivió una relación matrimonial con un joven gentil Tomárâho, es tan solo una de las muchas narraciones con elementos astronómicos que
acostumbraban contar los ancianos. Muchas de estas historias aún perduran en la mente de los representantes de mayor edad de este grupo y un proyecto necesario es poder incorporarlas al patrimonio inmaterial de la humanidad antes de que se extravíen en las insondables nubes del tiempo. Otro estudio que vemos en el horizonte es tratar de interpretar la relación que existe entre las técnicas vocales e instrumentales de los Chamacoco y su visión del mundo, en especial en el empleo que ellos hacen de las sonajas (paîkâra) que, como vimos, vienen a representar el cielo estrellado.
Asimismo, nuestro proyecto pretende llevar a cabo, junto a integrantes de la comunidad Tomárâho actual, un trabajo de colecta de datos y reconocimiento de distribuciones de estrellas y constelaciones, zonas oscuras del cielo, nebulosas, etc. Serían mapas interpretados, con una carga simbólica muy importante, del cielo Tomárâho para la región del alto Chaco en diferentes épocas del año, que quizás nos digan mucho sobre el imaginario aborigen y sobre los elementos de la vida cotidiana que ellos proyectaban en el fondo oscuro del cielo. En resumen, pensamos que la representación Tomárâho del cielo no fue aun suficientemente explorada como un objeto de estudio en sí mismo y que se requiere más trabajo de campo en el área de la etnoastronomía como una actividad interdisciplinaria que incluya las competencias de antropólogos y de astrónomos.
## Bibliografía
Baldus, H. 1932, La 'mère commune' dans la mythologie de deux tribus sud-américains (Kagaba et Tumerehá). Revista del Instituto de Etnología de la Universidad Nacional de Tucumán, 2, 471-479.
Cordeu, E.J. 1990-1991, Lo cerrado y lo abierto. Arquitectura cosmovisional y patrón cognitivo de los tomaráxo del Chaco Boreal. Scripta Ethnologica. Suppl. 11, 9-31.
Cordeu, E.J. 1994, La Mujer-Estrella y la Maraca. Algunas correlaciones funcionales mitológicas y simbólicas de la sonaja shamánica de los indios tomaráxo. Cuadernos del Instituto Nacional de Antropología (Buenos Aires), 15, 23-36.
Eliade, M. 1974 [1955], Imágenes y símbolos, Taurus, Madrid.
Eliade, M. 1998 [1957], Lo sagrado y lo profano, Paidos, Barcelona.
Evans, I.H.N. 1968 [1937], The Negritos of Malaya, Routledge, London.
Giménez Benítez, S., López, A.M. y Granada, A. 2002, Astronomía aborigen del Chaco: Mocovíes I. La noción de nayic (camino) como eje estructurador. Scripta Etnológica 23, 39-48.
Guevara, J., S.J., 1969, Historia del Paraguay, Río de la Plata y Tucumán [1764], en Pedro de Ángelis (ed.), Colección de obras y documentos relativos a la Historia antigua y moderna de las Provincias del Río de la Plata, Tomo I, Plus Ultra, Buenos Aires.
Krupp, E.C. 1996, Skywatchers, Shamans and Kings: Astronomy and the Archaeology of Power, Wiley, New York.
Malinowski, B. 1922, Argonauts of the Western Pacific: an account of native enterprise and adventure in the archipelagoes of melanesian New Guinea, George Routledge & sons, London.
Schmidl U. 1903 [1567], Viaje al Río de la Plata, 1534-1554, notas bibliográficas y biográficas por Bartolomé Mitre, prólogo, traducciones y anotaciones por Samuel Alejandro Lafone
Quevedo, Biblioteca Virtual Miguel de Cervantes, http://www. cervantesvirtual.com/FichaObra.html?Ref=4911&portal=0
Sequera, G. 2005, Chamacoco cosmografía. Boras konsmuseum, Sweden.
Sequera, G. 2006, Tomárâho, la resistencia anticipada. Tomo I, Ceaduc, Asunción.
Susnik, B. 1995 [1969], Chamacocos I: Cambio cultural, 2da edición, Museo Etnográfico Andrés Barbero, Asunción.
Wright, P.G. 2005, Cosmografías. Etnografías Contemporáneas 1, 173-210.
## Figuras referenciadas en el texto (leyendas de las figuras):
- Fig.1 : Indígenas del Paraguay actual. Fuente: M. Chase-Sardi (infografía proveniente del Museo del Barro, Asunción del Paraguay).
- Fig.2 : Mapa de la región del Alto Chaco paraguayo, con algunas ciudades y pueblos destacados. Fuente: The curse of Nemur, de Ticio Escobar.
- Fig.3 : Sonajas empleadas por los chamanes Chamacoco, cuya parte superior es identificada con el centro de la bóveda celeste.
- Fig.4 : El ñandú, llamado Pemme-Kamytêrehe por los Chamacoco, se encarga del cuidado de Deich, el Sol.
- Fig.5 : El châro o kululte, árbol-sostén del mundo en la visión Chamacoco, nexo entre la tierra y el cielo.
- Fig.6 : El châro como pilar y sostén del mundo, en épocas previas a su caída por la acción de Dagylta.
- Fig.7 : Los espíritus de las tormentas, osâsero, en los dibujos de Ogwa Flores Balbuena.
- Fig.8 : Los seres míticos originarios del mundo Chamacoco, llamados ahnapsûro.
- Fig.9 : Representaciones rituales representando a los seres míticos originarios ahnapsûro.
- Fig.10 : Lugar prominente del châro durante la representación del origen del mundo Tomárâho.
## Figura 1.
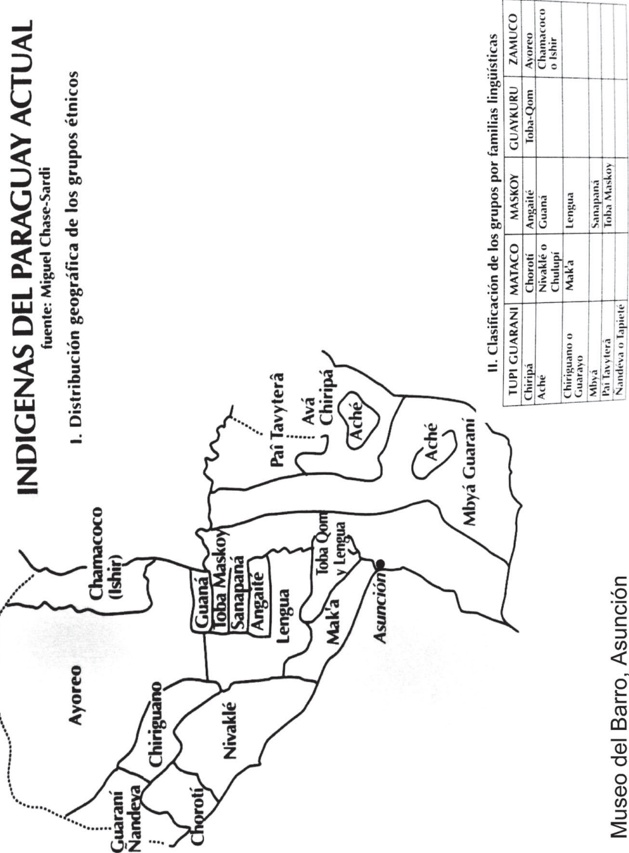
Figura 2.
## Figura 3.
8 88 1 8 1 1 @ 8 4
0
## Figura 4.
1
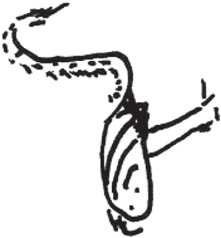

## 8 0 8 8 8 1 8
## Figura 5.
## Figura 6.
2
1 @ 8 1 1 8 8
Figura 7.

## Figura 8.

## 8
## Figura 9.

1 0 8 0 9;
## Figura 10.

## 1 1 | null | [
"Guillermo Sequera",
"Alejandro Gangui"
] | 2014-08-01T16:20:51+00:00 | 2014-08-01T16:20:51+00:00 | [
"physics.hist-ph",
"astro-ph.IM"
] | The representations of the sky among the Tomaraho | The Tom\'ar\~aho is an ethnic group of the Paraguayan Chaco who maintained
close contact with nature and developed original ways of explaining and
understanding it. This article presents the first results of an
interdisciplinary project seeking to provide a detailed analysis of different
astronomical elements in the imagined sky of the Tom\'ar\~aho. |
1408.0222v2 | ## Investigating bounds on decoherence in quantum mechanics via B and D-mixing
Alexander Lenz, , David Hodges, , Daniel Hulme, , Sandra Kvedaraite, , a a a a Jack Richings, , Jian Shen Woo , and Philip Waite a a a a Institute for Particle Physics Phenomenology, Durham University, DH1 3LE Durham, United Kingdom [email protected]
## Abstract
We investigate bounds on decoherence in quantum mechanics by studying B and D -mixing observables, making use of many precise new measurements, particularly from the LHC and B factories. In that respect we show that the stringent bounds obtained by a different group in 2013 rely on unjustified assumptions. Finally, we point out which experimental measurements could improve the decoherence bounds considerably.
Keywords: Quantum Mechanics, Decoherence, Mixing, B-Physics, CP violation
## 1. Introduction
The interpretation of quantum mechanics is still an open problem, see for example the very recent discussion of the quantum pigeonhole in [1]. Many of the related questions go back to the effect of entanglement that was studied in 1935 by Einstein, Podolsky and Rosen [2]. Numerous different systems have been investigated in that respect. It is also interesting to test the validity of the foundations of quantum mechanics in systems that are usually used to search for physics beyond the standard model. Therefore we discuss here the mixing of neutral mesons, which is a well-known and well-studied quantum mechanical effect, see e.g. [3] for an early discussion of B -mesons in that respect. It leads to the fact that the neutral mesons that are propagating in space-time are described by the mass eigenstates, e.g. B H and B L , which are linear combinations of the flavour eigenstates defined by the quark content,
October 2, 2014
e.g. B d = ( ¯ bd ) and ¯ B d = ( bd ¯ ):
$$B _ { H } \ & = \ p B _ { d } - q \bar { B }$$
$$B _ { L } \ = \ p B _ { d } + q \bar { B } _$$
In these systems we have the following observables: the mass difference ∆ M = M B ( H ) -M B ( L ), the decay rate difference ∆Γ = Γ( B L ) -Γ( B H ) and semi-leptonic CP asymmetries, which can be expressed as a sl = 2(1 -| q/p | ). For the two neutral B -meson systems, we now have quite precise experimental numbers for the mixing observables. The HFAG 2014 [4] values read:
| | B s | B d |
|------|-----------------------------|----------------------------|
| ∆ M | (17 . 761 ± 0 . 022) ps - 1 | (0 . 510 ± 0 . 003) ps - 1 |
| ∆Γ | (0 . 091 ± 0 . 008) ps - 1 | (0 . 001 ± 0 . 010) Γ |
| Γ | 1 1 . 512 ± 0 . 007 ps - 1 | 1 1 . 519 ± 0 . 005 ps - 1 |
| a sl | 0 . 0077 0 . 0042 | 0 . 0009 0 . 0021 |
-
±
-
±
where Γ denotes the total decay rate of the neutral B -mesons. The experimental numbers for ∆ M d , ∆ M s and ∆Γ s are now dominated by LHC measurements. The most precise values were obtained for ∆ M d by LHCb [5], for ∆ M s by LHCb [6] and for ∆Γ s by ATLAS [7], CMS [8] and LHCb [9]. Here no entanglement effects are expected to occur, hence we use these values as independent inputs for our investigations of decoherence. For the semileptonic asymmetries and ∆Γ d we do not yet have clear experimental evidence for a non-zero value; only some bounds are available. Thus we give for completeness the corresponding standard model predictions [10, 11, 12, 13, 14] of these quantities:
| | B s | B d |
|------|----------------------------|------------------------------|
| ∆Γ | (0 . 087 ± 0 . 021) ps - 1 | (0 . 0029 ± 0 . 0007) ps - 1 |
| a sl | (1 . 9 0 . 3) 10 - 5 | ( 4 . 1 0 . 6) 10 - 4 |
±
·
-
±
·
In the neutral D -meson system, typically the mixing parameters x , y and | p/q | are determined directly [4]:
$$x \coloneqq \frac { \Delta M } { \Gamma } \ = \ 0.$$
$$y \coloneqq \frac { \Delta \Gamma } { \underset { \text{$$
$$\begin{array} {$$
## 2. Decoherence in B-mixing
At the B-factories B-mesons were typically produced via the decay of the Υ(4 ) resonance, thus also producing entangled s ¯ B B d d pairs. To describe decoherence in B d -mixing, semileptonic decays of the neutral B-mesons were investigated, e.g. ¯ B d → l -¯ ν X l and B d → l + ν X l . If no mixing occurs, one gets from semi-leptonic decays events with one positively charged and one negatively charged lepton - so-called opposite-sign leptons. If mixing is taken into account one can also get events with two positively or two negatively charged leptons, so-called same-sign leptons. Following [15] we define the ratio of like-sign dilepton decays of a neutral B -meson to oppositesign dilepton events, R , (based on the investigations in [16, 17]), as
$$R \ = \ \frac { N ^ { + + } + N ^ { - - } } { N ^ { + - } + N ^ { - + } } \,.$$
N ++ denotes the events with two positively charged leptons in the final states and so on. In [15] Bertlmann and Grimus used the parameter ζ to describe decoherence effects in quantum mechanics in a phenomenological manner. ζ = 0 corresponds to the familiar case of quantum mechanics, while ζ = 1 describes a case where no quantum mechanical interference effects are occurring at all - corresponding to Furry's hypothesis [18]. The general expression for R in terms of the mixing parameters x , y and | p/q | then reads [15]
$$R \ = \ \frac { 1 } { 2 } \left ( \left | \frac { p } { q } \right | ^ { 2 } + \left | \frac { q } { p } \right | ^ { 2 } \right ) \frac { x ^ { 2 } + y ^ { 2 } + \zeta \left [ y ^ { 2 } \frac { 1 + x ^ { 2 } } { 1 - y ^ { 2 } } + x ^ { 2 } \frac { 1 - y ^ { 2 } } { 1 + x ^ { 2 } } \right ] } { 2 + x ^ { 2 } - y ^ { 2 } + \zeta \left [ y ^ { 2 } \frac { 1 + x ^ { 2 } } { 1 - y ^ { 2 } } - x ^ { 2 } \frac { 1 - y ^ { 2 } } { 1 + x ^ { 2 } } \right ] } \,. \quad \, \\ \text{This formula can be written more in the more compact form}$$
This formula can be written more in the more compact form
$$R \ = \ R _ { 0 } \frac { 1 } { \sqrt { 1 - a _ { s l } ^ { 2 } } } \frac { 1 + \alpha \zeta } { 1 + \beta \zeta }$$
with
$$R _ { 0 } \ = \ \frac { x ^ { 2 } + y ^ { 2 } } { 2 + x ^ { 2 } - y ^ { 2 } } \, \\ y ^ { 2 } ( 1 + x ^ { 2 } ) ^ { 2 } + x ^ { 2 } ( 1 - y ^ { 2 } ) ^ { 2 } \quad & \cdot \infty$$
$$\beta \ = \ \frac { \stackrel { \langle \cdot \cdot \cdot \cdot \cdot } { \stackrel { \sigma } { \stackrel { \sigma } { \stackrel { \prime } { \stackrel { \prime } { \stackrel { \prime } { \stackrel { \prime } { \sigma } } } } } } } { ( 2 + x ^ { 2 } - y ^ { 2 } ) ^ { 2 } } \stackrel { \langle \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot } { \stackrel { \sigma } { \stackrel { \prime } { \stackrel { \prime } { \stackrel { \prime } { \stackrel { \prime } { \sigma } } } } } } { ( 2 + x ^ { 2 } - y ^ { 2 } ) ( 1 + x ^ { 2 } ) ( 1 - y ^ { 2 } ) } \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad | \, p | ^ { 2 } \quad | \, q | ^ { 2 } \quad | \, a | ^ { 2 } \quad \end{array} \,,$$
$$\begin{array} { c c c } \alpha & = & \frac { \mu - \lambda \lambda ^ { \nu } } { ( x ^ { 2 } + y ^ { 2 } ) ( 1 + x ^ { 2 } ) ^ { 2 } + x ^ { 2 } ( 1 - y ^ { 2 } ) ^ { 2 } } \\ \alpha & & y ^ { 2 } ( 1 + x ^ { 2 } ) ^ { 2 } - x ^ { 2 } ( 1 - y ^ { 2 } ) ^ { 2 } & \nu \infty \end{array}, \quad & ( 1 2 ) \\ \nu \infty & \quad & y ^ { 2 } ( 1 + x ^ { 2 } ) ^ { 2 } - x ^ { 2 } ( 1 - y ^ { 2 } ) ^ { 2 } & \nu \infty \end{array}$$
$$a _ { s l } \ = \ \frac { N ^ { + + } - N ^ { - - } } { N ^ { + + } + N ^ { - - } } = \frac { \left | \frac { p } { q } \right | ^ { 2 } - \left | \frac { q } { p } \right | ^ { 2 } } { \left | \frac { p } { q } \right | ^ { 2 } + \left | \frac { q } { p } \right | ^ { 2 } } \,. \\ \text{also be expressed in terms of the mixing probability} \\ \partial _ { 0 } \,. \quad \, \text{$\mathfrak{ }$}$$
∣ ∣ ∣ ∣ R 0 can also be expressed in terms of the mixing probability
$$\chi = \frac { x ^ { 2 } + y ^ { 2 } } { 2 ( 1 + x ^ { 2 } ) }$$
as
The current values of χ from PDG [19] or HFAG [4] are not measured directly but derived via Eq.(15) from the direct measurements of ∆ M , ∆Γ and Γ. Historically R was approximated by R 0 and used to extract the mixing probability, see e.g. [20, 21].
$$R _ { 0 } & = \frac { \chi } { 1 - \chi } \,. & ( 1 6 ) \\ ^ { \prime } & \text{ from PDG } [ 1 9 ] \text{ or HFAG } [ 4 ] \text{ are not measured di-}$$
Eq.(10) represents our master equation. The numerical values of the coefficients in this equation can be calculated quite precisely by using the most recent experimental numbers from HFAG [4]. For the heavy neutral mesons we get:
| | B s = ¯ bs | B d = ¯ bd | D 0 = ( cu ¯) | |
|----------------|--------------------------------------|------------------------------------|------------------------------|------|
| R 0 | ( ) 0 . 997247 (1 ± 2 . 7 · 10 - 5 ) | ( ) 0 . 2308(1 ± 0 . 010) | 0 . 319 1 +0 . 27 - 0 . 25 ) | |
| α | 6 . 14 +0 . 88 - 0 . 80 · 10 - 3 | 0 . 6249 +0 . 0032 - 0 . 0032 | ( 1 . 51 +0 . 31 - 0 . 24 | . |
| β | 3 . 37 +0 . 88 - 0 . 80 · 10 - 3 | - 0 . 14424 +0 . 00077 - 0 . 00076 | 0 . 39 +0 . 24 - 0 . 17 | |
| 1 √ 1 - a 2 sl | 1 +3 . 0 +4 . 1 - 2 . 4 · 10 - 5 | 1 +4 . 1 +41 . 0 - 4 . 1 · 10 - 7 | 1 . 011 +0 . 043 - 0 . 010 | |
| | | | | (17) |
The above coefficients are known quite precisely for the neutral B -system, while there are still sizable uncertainties in the D -meson systems. If quantum
mechanics holds, i.e. ζ = 0, we predict (by using the measured values of ∆Γ, ∆ M , Γ and a sl ) the following values for the ratio R :
| | B s | B d | D 0 | . (18) |
|------|-------------------------------------|---------------------|----------------------------|----------|
| R QM | 0 . 997277 +0 . 000049 - 0 . 000036 | 0 . 2308 ± 0 . 0024 | 0 . 322 +0 . 089 - 0 . 079 | |
These numbers can be compared to the measured values of R stemming from ARGUS (1993) [20] and CLEO (1993) [21] for the B d -system. To our knowledge there are no measurements available for the B s or the D -meson system:
$$\begin{array} { c c c c } \boxed { \begin{array} { c c c } B _ { s } & B _ { d } & D ^ { 0 } \\ \end{array} } \\ \boxed { \begin{array} { c } R \end{array} } - \begin{array} { c } 0. 1 9 4 \left ( 1 \pm 0. 4 2 4 \right ) - \\ 0. 1 8 7 \left ( 1 ^ { + 0. 2 7 8 } _ { - 0. 2 3 9 } \end{array} \end{array} \right ) }. \quad & ( 1 9 ) \\ \text{ry in the table is from ARGUS [20], while the second is from} \\ \right ) [ 2 1 ]. \ A \text{ significant deviation of } R ^ { Q M } \text{ from the measured value} \end{array}$$
The first entry in the table is from ARGUS [20], while the second is from CLEO (1993) [21]. A significant deviation of R QM from the measured value R would point towards a violation of quantum mechanics, that could be described by a non-vanishing value of ζ . This can be expressed as
$$\zeta & = \frac { \frac { R } { R _ { 0 } } \sqrt { 1 - a _ { s l } ^ { 2 } } - 1 } { \alpha - \beta \frac { R } { R _ { 0 } } \sqrt { 1 - a _ { s l } ^ { 2 } } } \. \\ \text{unics holds, then } E q. ( 1 0 ) \text{ states } R = R _ { 0 } / \sqrt { 1 - a _ { s l } ^ { 2 } } \text{ and thus } \\.$$
If quantum mechanics holds, then Eq.(10) states R = R / 0 √ 1 -a 2 sl and thus Eq.(20) gives ζ = 0, as expected. Using the experimental values for R from [20] or [21] we get from Eq.(20) the following bounds on ζ :
$$\zeta \ & = \ - 0. 2 6 ^ { + 0. 3 0 } _ { - 0. 2 8 } \,, \\ \zeta \ & = \ - 0 \, 2 1 ^ { + 0. 4 6 } _ { - - }$$
$$\zeta \ = \ - 0. 2 1 ^ { + 0. 4 6 } _ { - 0. 5 3 } \,.$$
Eq.(21) has been calculated using the value of R measured by ARGUS [20], whereas Eq.(22) is derived from the CLEO value [21]. The central value for ζ is slightly negative, but the value ζ = 0 is within the one standard deviation region of the measured value of R , thus no decoherence effects can be seen yet in the neutral B d -system. Total decoherence, i.e. ζ = 1, is thus excluded by about four standard deviations. The uncertainty of the extracted value for ζ is completely dominated by the uncertainty in R . At this point, however, some caution is necessary. It was shown in [22, 23] that bounds on ζ depend
on the basis (flavour or mass basis) used for describing the neutral B-mesons. Thus quantitative statements describing the deviation from decoherence have to be taken with some care.
Using the old experimental inputs from Bertlmann and Grimus [15] we get
$$\zeta = - 0. 1 6 _ { - 0. 3 1 } ^ { + 0. 3 0 } \,.$$
The shift in the central value stems from the fact that at that time all the mixing parameters were known much less precisely. The uncertainty, which is dominated by R , stayed more or less the same, because we use the same value for R . Unfortunately there are no new measurements of the ratio R in the B d -system available and there exists no measurement at all in the B s or D -system. Thus we are limited by the experimental accuracy stemming from 1993. Here any new experimental investigation of R would be very helpful, using for example the huge data set collected by the B-factories. In that respect it is of course interesting to ask, what experimental precision in R would result in what bound on ζ ? We find:
| δR | ± 25% | ± 10% | ± 5% | ± 2% | ± 1% | ± 0 . 5% | . (24) |
|------|------------------|------------------|------------------|--------|--------|------------|----------|
| δζ | +1 . 15 - 1 . 07 | +0 . 45 - 0 . 44 | +0 . 23 - 0 . 22 | 0 . 10 | 0 . 06 | 0 . 05 | . (24) |
±
±
±
With a precision of 1% in R , the current uncertainties in x , y and | p/q | dominate the uncertainty in ζ .
The Belle Collaboration performed in [24] a time-dependent analysis of semileptonic B-decays and obtained a very strong bound on decoherence:
$$\zeta ^ { \text{Belle} } = 0. 0 2 9 \pm 0. 0 5 7 \,.$$
It is, however, not completely clear how to relate ζ Belle to our time-integrated analysis. Moreover, Belle neglected ∆Γ d and a sl , whose experimental values can still be in the percentage range, which is comparable to the uncertainty in ζ Belle .
## 3. The analysis of Alok and Banerjee from 2013
In [25] it was tried to avoid the experimental short-comings related to the almost unknown value of R by a trick: because Eq.(10) seems to indicate
R ≈ R 0 , it was assumed in Eq.(20) that R = R 0 . This is equivalent to starting from with χ defined in Eq.(15), in order to investigate bounds on decoherence. With that approximation we get
$$R = \frac { \chi } { 1 - \chi } \, \\ 5 \}. \text{ in order to investigate bounds on decomference.}$$
$$\zeta & = \frac { \sqrt { 1 - a _ { s l } ^ { 2 } } - 1 } { \alpha - \beta \sqrt { 1 - a _ { s l } ^ { 2 } } } \,, \\ \intertext { \text{loc} \text{ not depend at all on $R$ and has all coefficients quite} } \lambda _ { 1 } \colon \sim \alpha _ { 2 } \colon \sim \alpha _ { 3 } \colon \sim \alpha _ { 4 } \colon \sim \alpha _ { 5 } \colon \sim \alpha _ { 6 } \colon \sim \alpha _ { 7 } \colon \sim \alpha _ { 8 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 } \colon \sim \alpha _ { 9 }$$
an equation that does not depend at all on R and has all coefficients quite precisely known. Taking Eq.(27) as a starting point we obtain the following strong bounds on ζ :
$$\zeta ( B _ { d } ) \ & = \ - 0. 5 3 ^ { + 0. 5 3 } _ { - 5. 3 2 } \cdot 1 0 ^ { - 6 } \, \quad \ \ ( 2 8 ) \\ \zeta ( R \ \L ) \ & = \ - \infty \, \theta 1 0 7 ^ { + 0. 0 0 8 5 } \quad \ \ ( 2 8 )$$
$$\zeta ( B _ { s } ) \ = \ - 0. 0 1 0 7 ^ { + 0. 0 0 8 5 } _ { - 0. 0 1 4 9 } \,.$$
Thus Eq.(27) leads to very stringent constraints on decoherence in quantum mechanics, which are orders of magnitude better than the ones obtained in Eq.(21). Alok and Banerjee found that total decoherence is excluded by 34 standard deviations in the B d -system and by 24 - 31 standard deviations in the B s -system.
However, the first thing to notice when studying Eq.(27) is that now the value of ζ depends purely on the experimental value of a sl - a result which is in contradiction with the definition of a sl , which is independent of ζ .
Secondly, one now obtains also a non-vanishing ζ -value if one takes the standard model values for a s,d sl , which of course assume the validity of quantum mechanics:
$$\zeta \left ( a _ { s l } ^ { d, \text{SM} } \right ) & \ = \ - 1. 0 9 ^ { + 0. 3 0 } _ { - 0. 3 4 } \cdot 1 0 ^ { - 7 } \, & ( 3 0 ) \\ \zeta \left ( a _ { s l } ^ { s, \text{SM} } \right ) & \ = \ - 6. 5 3 ^ { + 2. 8 7 } _ { - 4. 6 2 } \cdot 1 0 ^ { - 8 } \. & ( 3 1 )$$
So we get a violation of quantum mechanics - albeit a tiny one - even if we take standard model predictions for the semi-leptonic asymmetries. This is clearly a contradiction and points to this method being invalid.
$$\zeta \overset { \lambda } { \left ( a _ { s l } ^ { s, \text{SM} } } \right ) \ = \ - 6. 5 3 _ { - 4. 6 2 } ^ { + 2. 8 7 } \cdot 1 0 ^ { - 8 } \,. \quad & ( 3 1 ) \\ \text{violation of quantum mechanics - albeit a tiny one - even if we}$$
Thirdly, Alok and Banerjee also found a bound in the B s -system, even though there was no measurement at all of R available in this system and R is the only quantity sensitive to decoherence effects.
Finally, it is clear that one cannot simply equate R and R 0 without taking into account the accuracy of this approximation as well as the independent uncertainties of R and R 0 . These uncertainties can be written as
$$R _ { 0 } \ & = \ \bar { R } _ { 0 } ( 1 \pm \delta _ { R _ { 0 } } ) \, \quad & ( 3 2 ) \\ R \ & = \ \bar { R } ( 1 + \delta _ { \cap } )$$
$$\stackrel { \mu } { R } \ = \ \stackrel { \mu } { \bar { R } } ( 1 \pm \delta _ { R } ) \.$$
The central value ¯ R 0 and the relative error δ R 0 are given in Eq.(17), R and δ R are given by the experimental value from 1993, see Eq. (19). Concerning the equality of R and R 0 : Eq.(10) shows that the relation between R and R 0 reads with 1 + /epsilon1 = 1 / √ 1 -a 2 sl . The tiny value of /epsilon1 can thus be read off from Eq.(17), while δ + and δ -can be estimated by varying ζ in the range of -1 to +1. One finds sizable values, that clearly cannot be neglected, because they present by far the dominant uncertainties:
$$R = R _ { 0 } \left ( 1 + \epsilon \right ) \left ( 1 _ { - \delta _ { - } } ^ { + \delta _ { + } } \right ) \, & & ( 3 4 ) \\ \sqrt { 1 - a _ { \ell } ^ { 2 } }. \ \text{ The tiny value of $\epsilon$ can thus be read off from}$$
$$\begin{matrix} \boxed { \ B _ { d } \ \ B _ { s } } \\ \boxed { \delta _ { + } \ \ 0. 9 0 \ \ 0. 0 0 2 7 } \\ \delta _ { - } \ \ 0. 6 7 \ \ 0. 0 0 2 8 \end{matrix} }.$$
Hence the correctly modified version of Eq.(20) reads
$$\zeta = \frac { \left ( 1 + \epsilon \right ) \left ( 1 _ { - \delta _ { - } } ^ { + \delta _ { + } } \right ) \sqrt { 1 - a _ { s l } ^ { 2 } } - 1 } { \alpha - \beta \left ( 1 + \epsilon \right ) \left ( 1 _ { - \delta _ { - } } ^ { + \delta _ { + } } \right ) \sqrt { 1 - a _ { s l } ^ { 2 } } } \,. \\ \intertext { n t that Alok and Banerjee have simply set } \epsilon, \delta _ { + } \text{ and } \delta _ { - } \text{ to zero in} \,.$$
It is evident that Alok and Banerjee have simply set /epsilon1 , δ + and δ -to zero in order to obtain Eq.(27). Taking the finite values of /epsilon1 , δ + and δ -into account one gets instead
$$\zeta & = \frac { 0 _ { - \delta _ { - } } ^ { + \delta _ { + } } } { \alpha - \beta \left ( 1 _ { - \delta _ { - } } ^ { + \delta _ { + } } \right ) } \,. & ( 3 7 ) \\ \intertext { ; the dependence on } \, \begin{matrix} a _ { s l } & \text{has disappeared, as it should.} \\ \end{matrix} \,.$$
Firstly, we see that the dependence on a sl has disappeared, as it should. Next, taking the the finite values of δ + , -from Eq.(35) into account we find using Eq.(37) simply that ζ lies in between -1 and +1, which was what we
initially assumed in order to obtain the values in Eq.(35). Therefore by rewriting Eq.(20), in order to avoid using the experimental value of R , one learns nothing new.
To summarise: by neglecting the dominant effect of δ + , -the authors of [25] artificially created a very precise relation, given in Eq.(27), which does not depend at all on R . We have shown that this approximation is unjustified and leads to a false conclusion.
## 4. Conclusion
In this paper we have investigated decoherence in B-mixing using the most recent values for the mixing observables. Within current experimental uncertainties we find no hint for any decoherence effect and total decoherence is excluded by about four standard deviations in the B d -system. The current precision is, however, strongly limited by the very imprecise value of the ratio of like-sign dilepton events to opposite-sign dilepton events, R . The most recent experimental number for R stems from 1993. Here any updated measurements, using, for example, the large data set of the B factories, would be very desirable. Moreover, first measurements of R for the B s -system (e.g. from the Υ(5 ) data set of Belle) and the s D -system, e.g. from BES would be very interesting.
Finally, we have also shown that the analysis in [25], which yields very precise bounds on possible decoherence is incorrect, as unjustified assumptions were made and the dominant uncertainty was simply neglected.
## Acknowledgements
We would like to thank Guennadi Borissov and Tim Gershon for their helpful discussion concerning the experimental status and Ashutosh K. Alok for comments on the manuscript.
## References
- [1] Y. Aharonov, F. Colombo, S. Popescu, I. Sabadini, D.C. Struppa and J. Tollaksen arXiv:1407.3194 [quant-ph].
- [2] A. Einstein, B. Podolsky and N. Rosen, Phys. Rev. 47 (1935) 777.
- [3] A. Datta and D. Home, Phys. Lett. A 119 (1986) 3.
- [4] Y. Amhis et al. [Heavy Flavor Averaging Group Collaboration], arXiv:1207.1158 [hep-ex]. and online update at http://www.slac.stanford.edu/xorg/hfag
- [5] RAaij et al. [LHCb Collaboration], Phys. Lett. B 719 (2013) 318 [arXiv:1210.6750 [hep-ex]].
- [6] RAaij et al. [LHCb Collaboration], New J. Phys. 15 (2013) 053021 [arXiv:1304.4741 [hep-ex]].
- [7] G. Aad et al. [ATLAS Collaboration], arXiv:1407.1796 [hep-ex].
- [8] CMS Collaboration [CMS Collaboration], CMS-PAS-BPH-13-012.
- [9] RAaij et al. [LHCb Collaboration], Phys. Rev. D 87 (2013) 11, 112010 [arXiv:1304.2600 [hep-ex]].
- [10] A. Lenz and U. Nierste, arXiv:1102.4274 [hep-ph].
- [11] A. Lenz and U. Nierste, JHEP 0706 (2007) 072 [hep-ph/0612167].
- [12] M. Ciuchini, E. Franco, V. Lubicz, F. Mescia and C. Tarantino, JHEP 0308 (2003) 031 [hep-ph/0308029].
- [13] M. Beneke, G. Buchalla, A. Lenz and U. Nierste, Phys. Lett. B 576 (2003) 173 [hep-ph/0307344].
- [14] M. Beneke, G. Buchalla, C. Greub, A. Lenz and U. Nierste, Phys. Lett. B 459 (1999) 631 [hep-ph/9808385].
- [15] R. A. Bertlmann and W. Grimus, Phys. Lett. B 392 (1997) 426 [hep-ph/9610301].
- [16] A. B. Carter and A. I. Sanda, Phys. Rev. D 23 (1981) 1567.
- [17] I. I. Y. Bigi and A. I. Sanda, Nucl. Phys. B 193 (1981) 85.
- [18] W. H. Furry Phys. Rev. 49 (1936) 393.
- [19] online update http://pdg.lbl.gov of J. Beringer et al. [Particle Data Group Collaboration], Phys. Rev. D 86 (2012) 010001.
- [20] H. Albrecht et al. [ARGUS Collaboration], Phys. Lett. B 324 (1994) 249.
- [21] J. E. Bartelt et al. [CLEO Collaboration], Phys. Rev. Lett. 71 (1993) 1680.
- [22] G. V. Dass and K. V. L. Sarma, Eur. Phys. J. C 5 (1998) 283 [hep-ph/9709249].
- [23] R. A. Bertlmann and W. Grimus, Phys. Rev. D 58 (1998) 034014 [hep-ph/9710236].
- [24] A. Go et al. [Belle Collaboration], Phys. Rev. Lett. 99 (2007) 131802 [quant-ph/0702267 [QUANT-PH]].
- [25] A. K. Alok and S. Banerjee, Phys. Rev. D 88 (2013) 9, 094013 [arXiv:1304.4063 [hep-ph]]. | 10.1016/j.nuclphysb.2014.09.007 | [
"Alexander Lenz",
"David Hodges",
"Daniel Hulme",
"Sandra Kvedaraite",
"Jack Richings",
"Jian Shen Woo",
"Philip Waite"
] | 2014-08-01T16:21:57+00:00 | 2014-10-01T12:47:23+00:00 | [
"hep-ph",
"hep-ex"
] | Investigating bounds on decoherence in quantum mechanics via B and D-mixing | We investigate bounds on decoherence in quantum mechanics by studying $B$ and
$D$-mixing observables, making use of many precise new measurements,
particularly from the LHC and B factories. In that respect we show that the
stringent bounds obtained by a different group in 2013 rely on unjustified
assumptions. Finally, we point out which experimental measurements could
improve the decoherence bounds considerably. |
1408.0223v2 | ## CENTRAL STRIPS OF SIBLING LEAVES IN LAMINATIONS OF THE UNIT DISK
DAVID J. COSPER, JEFFREY K. HOUGHTON, JOHN C. MAYER, LUKA MERNIK, AND JOSEPH W. OLSON
Abstract. Quadratic laminations of the unit disk were introduced by Thurston as a vehicle for understanding the (connected) Julia sets of quadratic polynomials and the parameter space of quadratic polynomials. The 'Central Strip Lemma' plays a key role in Thurston's classification of gaps in quadratic laminations, and in describing the corresponding parameter space. We generalize the notion of Central Strip to laminations of all degrees d ≥ 2 and prove a Central Strip Lemma for degree d ≥ 2 . We conclude with applications of the Central Strip Lemma to identity return polygons that show for higher degree laminations it may play a role similar to Thurston's lemma.
## 1. Introduction
Quadratic laminations of the unit disk were introduced by Thurston as a vehicle for understanding the (connected) Julia sets of quadratic polynomials and the parameter space of quadratic polynomials. The 'Central Strip Lemma' plays a key role in Thurston's classification of gaps in quadratic laminations [T09]. It is used to show that there are no wandering polygons for the angle-doubling map σ 2 on the unit circle. Moreover, when a polygon returns to itself, the iteration of σ 2 is transitive on the vertices. For σ 2 it is sufficient to prove these facts for triangles: there are no wandering triangles , and no identity return triangles . From these facts, the classification of types of gaps of a quadratic lamination, and a parameter space for quadratic laminations, follows. Thurston posed a question in his notes on laminations that he deemed important to further
Date : January 27, 2015.
2010 Mathematics Subject Classification. Primary: 37F20; Secondary: 54F15.
Key words and phrases. Julia set, holomorphic dynamics, lamination , identity return.
The authors thank the UAB Laminations seminar, and in particular Drs. Lex Oversteegen and Alexander Blokh and graduate student Ross Ptacek for useful conversations. The authors also thank the referee for useful comments that improved the presentation.
progress in the field: 'Can there be wandering triangles for σ 3 (and higher degree)?' When Blokh and Oversteegen [BO04, BO09] showed that the answer was 'yes,' the need to define and understand central strips for higher degree and their role in 'controlling' wandering and identity return polygons of a lamination became imperative. Contributions to this understanding were made by Goldberg [GM93], Milnor [Mil06, Mil00], Kiwi [K02], Blokh and Levin [BL02], Childers [C07], and others.
New results in this paper include Definition 1.9 of a sibling portrait , Definition 2.2 of a central strip , the statement and proof of the Central Strip Structure Theorem 2.3, the statement and proof of Theorem 2.9 (the generalized Central Strip Lemma), and Theorem 3.1 counting the number of different sibling portraits that could correspond to the preimage of a given non-degenerate leaf. The Central Strip Lemma can be used to provide new proofs of known results that the authors believe to be more transparent, yield more onformation about the laminations, and yield new results for laminations of degree d ≥ 3 . Initial applications to identity return triangles under σ 3 appear in this paper (see Section 4), and other applications, particularly to higher degree, will appear in subsequent papers.
1.1. Preliminaries. Let C denote the complex plane, D ⊂ C the open unit disk, D the closed unit disk, and S the boundary of the unit disk (i.e., the unit circle), parameterized as R Z / . For d ≥ 2 , define a map σ d : S → S by σ d ( ) = t dt (mod 1) .
Definition 1.1. A lamination L is a collections of chords of D , which we call leaves , with the property that any two leaves meet, if at all, in a point of S , and such that L has the property that
$$\mathcal { L } ^ { * } \coloneqq \mathbb { S } \cup \{ \cup \mathcal { L } \}$$
is a closed subset of D .
It follows that L ∗ is a continuum (compact, connected metric space). We allow degenerate leaves - all points of S are degenerate leaves. If glyph[lscript] ∈ L is a leaf, we write glyph[lscript] = ab , where a and b are the endpoints of glyph[lscript] in S . We let σ d ( glyph[lscript] ) be the chord σ d ( a σ ) d ( b ) . If it happens that σ d ( a ) = σ d ( b ) , then σ d ( glyph[lscript] ) is a point, called a critical value of L and we say glyph[lscript] is a critical leaf.
Proposition 1.2. Let σ ∗ d denote the linear extension of σ d to leaves of L , so that σ ∗ d is defined on L ∗ . Then σ ∗ d is continuous on L ∗ .
The proof is left to the reader.
- 1.2. Leaf Length Function. Fix the counterclockwise order < on S as the preferred (circular) order. Let | ( a, b ) | denote the length in the parameterization of S of the arc in S from a to b counterclockwise. Given a chord ab , there are two arcs of S subtended by ab . Define the length of ab , denoted | ab | , to be the shorter of | ( a, b ) | or | ( b, a ) | . The maximum length of a leaf is thus 1 2 . Note that the length of a critical leaf is i d for some i ∈ { 1 2 , , . . . j | j = glyph[floorleft] d 2 glyph[floorright]} .
Figure 1. Graph of the leaf length function.
Lemma 1.3. Let x = | glyph[lscript] | where glyph[lscript] ∈ L . Then the length τ d ( x ) of σ d ( glyph[lscript] ) is given by the function
$$\tau _ { d } ( x ) = \begin{cases} d x \text{ if } 0 \leq x \leq \frac { 1 } { 2 d } \\ 1 - d x \text{ if } \frac { 1 } { 2 d } \leq x \leq \frac { 1 } { 3 d } \\ d x - 1 \text{ if } \frac { 1 } { 2 d } \leq x \leq \frac { 1 } { 2 d } \\ 2 - d x \text{ if } \frac { 3 } { 2 d } \leq x \leq \frac { 2 d } { d } \\ \vdots \\ ( - 1 ) ^ { d } d x + ( - 1 ) ^ { d + 1 } \lfloor \frac { d - 1 } { 2 } \rfloor \text{ if } \frac { d - 2 } { 2 d } \leq x \leq \frac { d - 1 } { 2 d } \\ ( - 1 ) ^ { d + 1 } d x + ( - 1 ) ^ { d + 2 } \lfloor \frac { d } { 2 } \rfloor \text{ if } \frac { d - 1 } { 2 d } \leq x \leq \frac { 1 } { 2 } \end{cases} \\ \text{defined on the interval } [ 0, 1 / 2 ].$$
defined on the interval [0 , 1 / 2] .
The proof is left to the reader.
Proposition 1.4. The fixed points of τ d are of the form
$$\{ 0, \frac { 1 } { d + 1 }, \frac { 1 } { d - 1 }, \frac { 2 } { d + 1 }, \frac { 2 } { d - 1 }, \dots, \frac { j } { d + 1 }, \frac { j } { d - 1 }, \frac { j + 1 } { d + 1 } \dots, \leq \frac { 1 } { 2 } \}.$$
Thus, if j d +1 < glyph[lscript] | | < j d -1 for some j , then | σ d ( glyph[lscript] ) | < glyph[lscript] | | , and if j d -1 < | glyph[lscript] | < j +1 d +1 for some j , then | σ d ( glyph[lscript] ) | > glyph[lscript] | | .
The proof is left to the reader.
Lemma 1.5. A leaf glyph[lscript] of length | glyph[lscript] | < 1 d +1 will keep increasing in length under iteration of σ d until the length of some iterate | σ i d ( glyph[lscript] ) | ≥ 1 d +1 .
Proof. Consider τ d and the identity function. Each monotone interval of the map τ d and the identity function are linear. The first interval of τ d , defined on [0 , 1 / 2 d ] , has the equation τ d ( x ) = dx , therefore (0 , 0) is the only intersection on the first interval. On the second interval, [1 / 2 d, 1 /d ] , τ d ( x ) = 1 -dx . Therefore the intersection is 1 -dx = x or x = 1 d +1 . Since the graph of τ d is above the identity function on interval (0 , 1 d +1 ) , the length will keep increasing under iteration until it is at least 1 d +1 . glyph[square]
- 1.3. Sibling Invariant Laminations. Thurston's definition [T09] of invariant laminations did not involve sibling leaves. Blokh, Mimbs, Oversteegen, and Valkenburg showed in [BMOV] that each sibling invariant lamination (defined below) is a Thurston lamination, and each lamination induced by a locally connected Julia set is a sibling invariant lamination. They showed that to understand Julia sets via laminations, it is sufficient to consider sibling laminations. (More precisely, they showed that the closure of the space of quadratic sibling laminations in the Hausdorff metric contains all laminations induced by locally connected Julia sets.)
glyph[negationslash]
Definition 1.6. (Sibling Leaves) Let glyph[lscript] 1 ∈ L be a leaf and suppose σ d ( glyph[lscript] 1 ) = glyph[lscript] ′ , for some non-degenerate leaf glyph[lscript] ′ ∈ L . A leaf glyph[lscript] 2 ∈ L , disjoint from glyph[lscript] 1 , is called a sibling of glyph[lscript] 1 provided σ d ( glyph[lscript] 2 ) = glyph[lscript] ′ = σ d ( glyph[lscript] 1 ) . A collection S = { glyph[lscript] 1 , glyph[lscript] 2 , . . . , glyph[lscript] d } ⊂ L is called a full sibling collection provided that for each i , σ d ( glyph[lscript] i ) = glyph[lscript] ′ and for all i = j , glyph[lscript] i ∩ glyph[lscript] j = ∅ .
Definition 1.7. A lamination L is said to be sibling d -invariant (or simply invariant if no confusion will result) provided that
- (1) (Forward Invariant) For every glyph[lscript] ∈ L , σ d ( glyph[lscript] ) ∈ L .
- (2) (Backward Invariant) For every non-degenerate glyph[lscript] ′ ∈ L , there is a leaf glyph[lscript] ∈ L such that σ d ( glyph[lscript] ) = glyph[lscript] ′ .
- (3) (Sibling Invariant) For every glyph[lscript] 1 ∈ L with σ d ( glyph[lscript] 1 ) = glyph[lscript] ′ , a nondegenerate leaf, there is a full sibling collection { glyph[lscript] 1 , glyph[lscript] 2 , . . . , glyph[lscript] d } ⊂ L such that σ d ( glyph[lscript] i ) = glyph[lscript] ′ .
Definition 1.8. A gap in a lamination L is the closure of a component of D \L ∗ . A gap is critical iff two points in its boundary map to the same point. A finite gap is usually called a polygon . The leaves bounding a finite
gap are called the sides of the polygon. A polygon is called all-critical if every side is a critical leaf.
Definition 1.9 (Sibling Portrait) . The sibling portrait S of a full collection of sibling leaves is the collection of regions complementary to the sibling leaves. We call a complementary region a C-region provided all of the arcs in which the closure of the region meets the circle are short (length < 1 2 d ), and call it an R-region if all of the arcs are long (length > 1 2 d ). The degree of a complementary region T , denoted deg ( T ) is number of leaves in the boundary of T or, equivalently, the number of circular arcs in the boundary of T .
C -regions which meet the circle in more than one short arc will constitute the components of the central strip , Definition 2.2. We show in Theorem 2.3, subject to the condition that no sibling maps to a diameter, that each region is either a C -region or an R -region.
Topologically, a graph is a finite union of arcs (homeomorphic images of the interval [0 , 1] ) meeting only at endpoints. Endpoints of these arcs are called vertices and the arcs themselves are called edges . The degree of a vertex v is the number of edges that share v as an endpoint. A tree is a graph with no closed loops of edges in it.
Definition 1.10. The dual graph T S of the sibling portrait S of a full collection S of sibling leaves is defined as follows: let each complementary region correspond to a vertex of T S and each sibling leaf on the boundary of two regions correspond to an edge of T S between the vertices corresponding to the two regions.
Proposition 1.11. The dual graph of a sibling portrait under σ d is a connected tree consisting of d +1 vertices (components of the portrait), and d edges (sibling leaves between components that meet on their boundaries).
The proof is left to the reader. See Figure 5 for an example.
Proposition 1.12. Let S be the sibling portrait of a full collection S of sibling leaves under σ d . Let T denote a complementary region of S and T ′ the corresponding vertex of the dual graph T S . Then deg T ( ) = deg T ( ′ ) .
The proof is left to the reader.
In Theorem 2.3 below, we show that if the image leaf of a full sibling collection is not a diameter, then each of the complementary regions of the sibling portrait is either a C-region or an R-region of degree d ≥ 2 , or a terminal C- or R-region of degree 1 . (By 'terminal' region we mean a region corresponding to an endpoint of the dual graph.) Examples of sibling portraits for degrees d = 2 and d = 3 are in Figures 2 and 3. Figure 4 shows one of many possibilities for a sibling portrait for σ 6 .
Figure 2. Example of a sibling portrait with a central strip for σ 2 .
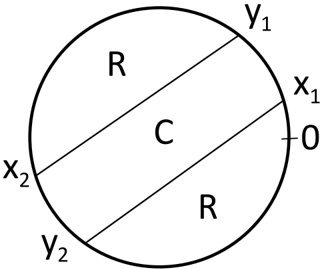
Remark 1.13 . Note that up to labeling of vertices and rotation, there are only two sibling portraits for d = 3 . Moreover, the sibling leaves, glyph[lscript] 1 , glyph[lscript] 2 , and glyph[lscript] 3 in the non-symmetric case are of three different lengths: 1 3 < glyph[lscript] | 1 | < 1 2 , 1 6 < glyph[lscript] | 2 | < 1 3 , and | glyph[lscript] 3 | < 1 6 . See Theorem 3.1 for the count for d > 3 .
Figure 3. Examples of all sibling portraits with a central strip for σ 3 with the same spacing of x i and y i points, up to rotational symmetry.
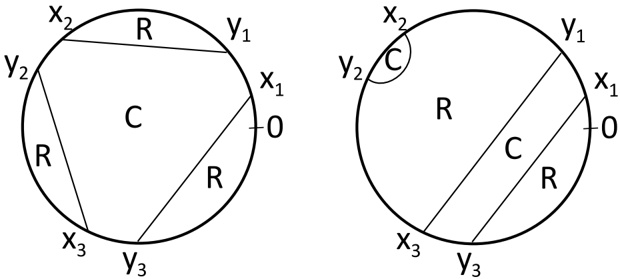
Proposition 1.14. Suppose S is a sibling portrait. Then the following
formula holds:
$$\sum _ { T \in S } ( d e g ( T ) - 1 ) = d - 1$$
Figure 4. Example of a sibling portrait for σ 6 . (Not to scale; though chords are straight, we sometimes draw them curved to stand out.)
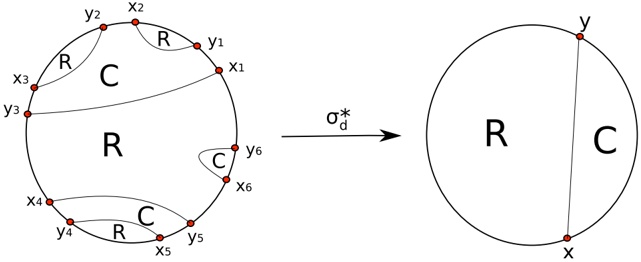
The proof is a direct consequence of the Euler characteristic of a tree.
Remark 1.15 . Note that the degree of a C-region T is the number of times the boundary of T wraps, under σ d , around the analog of the sector of the disk labeled C on the right side of Figure 4. A similar statement holds for R-regions.
## 2. Central Strips
Let L be a sibling d -invariant lamination.
Remark 2.1 . If S is a full sibling collection mapping to leaf glyph[lscript] = xy , then endpoints x , y i i of the preimage leaves alternate counterclockwise around S : x 1 < y 1 < x 2 < y 2 < · · · < x d < y d < x 1 . (Here we do not suppose that glyph[lscript] i = x y i i .) If a leaf is a multiple of 1 2 d long, then it maps to a leaf of length 1 2 , a diameter. A diameter leaf is either of fixed length or is critical (depending upon whether d is odd or even). As these can be handled as special cases, we consider only full sibling collections not having any leaf mapping to a diameter.
Definition 2.2. (Central Strip) Consider the sibling portrait of a full collection S of sibling leaves. Then the central strip C corresponding to S is the closure of the union of all C-regions C i with degree at least 2 . The degree of the central strip is deg C ( ) = min { deg C ( i ) } .
A tree with vertices labeled with two colors, and such that no edge connects vertices of the same color, is said to be bicolored .
Figure 5. Mapping of a sibling portrait to a bicolored tree.
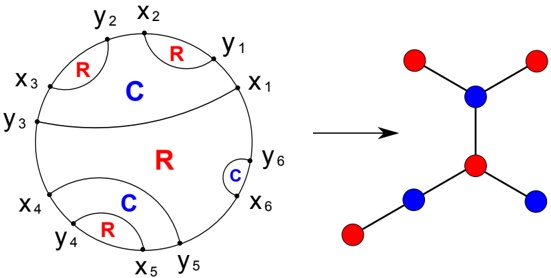
Theorem 2.3 (Central Strip Structure) . Let S be a full sibling collection of leaf glyph[lscript] 1 and its siblings such that σ d ( glyph[lscript] 1 ) is not a diameter. Then the following hold.
- (1) If some leaf in S is of length > 1 2 d , then there is a nonempty central strip C .
- (2) The dual graph of the sibling portrait corresponding to S is a planar bicolored tree where C-regions are colored one color and Rregions the other.
Proof. Suppose S = { glyph[lscript] 1 , glyph[lscript] 2 , . . . , glyph[lscript] d } . As in Remark 2.1, we label the endpoints of the sibling leaves x 1 < y 1 < · · · < x d < y d < x 1 in counterclockwise order so that x i is an endpoint of glyph[lscript] i . Note that the lengths of circular arcs between successive x and y points alternate between short (length < 1 2 d ) and long (length > 1 2 d , provided the full sibling collection does not map to a diameter. Without loss of generality assume ( x , y i i ) is short.
glyph[negationslash]
To prove (1), assume that some leaf is more than 1 2 d long. Let glyph[lscript] i be a long leaf. We know by assumption that glyph[lscript] i = x y i j , for some j = i . We claim that the region T with arc ( x , y i i ) in its boundary is a C-region and the region on the other side of glyph[lscript] i is an R-region. To see this we traverse the region T with arc ( x , y i i ) in its boundary counterclockwise. Refer to Figure 4. All sibling leaves map to a single image leaf xy . All short arcs map to the shorter (counterclockwise) arc ( x, y ) , and all long arcs map to the longer (counterclockwise) arc ( y, x ) . Thus, as we move from x i to y i in the domain, we traverse the (shorter) arc ( x, y ) in the range; then as we move from y i along a leaf emanating from it, we traverse the leaf xy from y to x in the range. Since short and long arcs alternate, we are now again
at some x k in the domain; we cannot be at x i again, else glyph[lscript] i with endpoint x i is a short leaf; we thus traverse the arc ( x , y k k ) in the domain while we again traverse the arc ( x, y ) in the range. Proceeding counterclockwise around the region T , we see that we encounter only short arcs in the domain each mapping to the counterclockwise arc ( x, y ) in the range. Note that we traversed at least two short arcs in the domain: ( x , y i i ) and ( x , y k k ) . Moreover, we encounter only long leaves in the boundary of T . Thus, T is a C-region with only long leaves and short arcs in its boundary, and deg T ( ) ≥ 2 .
On the other side of leaf glyph[lscript] i , by a similar argument, the region T ′ is an R-region bounded only by long arcs, though it may have both long and short leaves in its boundary. However, the short leaves in the boundary of T ′ can bound only degree 1 C-regions. Thus, T ′ , sharing long boundary leaf glyph[lscript] i with T , is an R-region.
In the above argument, we have shown both that when some leaf has length > 1 2 d , the central strip is nonempty, establishing conclusion (1) of the theorem, for we found at least one C-region of degree ≥ 2 , and that any leaf bounds a C-region on one side and an R-region on the other. So, if a pair of complementary regions share a boundary leaf, then one is a C-region and the other is an R-region.
To prove (2), we form the dual graph T S of the complementary regions of the sibling collection S as follows: let each complementary region correspond to a vertex of T S and each sibling leaf on the common boundary of two regions correspond to an edge of T S . Since D is connected and each sibling leaf disconnects D , T S is a connected tree. Refer to Figure 5. The proof of part (1) shows that the tree is bicolored, with C-regions being one color and R-regions the other. If no leaves are of length > 1 2 d , then all leaves are short and the regions bounded by them are degree 1 C-regions. The central region bounded by all of them and long arcs of the circle is a degree d R-region. In this case, there is no central strip. This completes part (2) of the proof. glyph[square]
Proposition 2.4. Let C i enumerate the complementary components of the full sibling collection S meeting the circle in short arcs and R i enumerate the complementary components of the full sibling collection meeting the circle in long arcs. Let T S be the corresponding bicolored tree, where C ′ i and R ′ i denote vertices corresponding to regions C i and R i , respectively. Then the number of edges of T S =
$$\sum _ { i } d e g ( C _ { i } ) = \sum _ { i } d e g ( C _ { i } ^ { \prime } ) = d = \sum _ { i } d e g ( R _ { i } ^ { \prime } ) = \sum _ { i } d e g ( R _ { i } ).$$
The proof is left to the reader.
Proposition 2.5. The maximum number of disjoint critical chords that can be contained in a component T of a sibling portrait is deg T ( ) -1 .
Proof. Let T be a component of a sibling portrait under σ d of degree k ≤ d . Without loss of generality, let the (closed) arcs of T ∩ S be
$$\mathcal { V } = \{ [ x _ { 1 }, y _ { 1 } ], [ x _ { 2 }, y _ { 2 } ], \dots, [ x _ { k }, y _ { k } ] \}.$$
glyph[negationslash]
Note that a critical chord must join one component of T ∩ S to another going from a point x i + glyph[epsilon1] i ∈ [ x , y i i ] , 0 ≤ glyph[epsilon1] i ≤ | ( x , y i i ) | , to a point x j + glyph[epsilon1] i ∈ [ x , y j j ] , j = i . Let E be a maximal collection of disjoint critical chords in T . It is not hard to see that the cardinality of E is at least k -1 ; just draw critical chords from k -1 different points of ( x , y 1 1 ) in succession to points, one in each of V - { [ x , y 1 1 ] } , in succession in counterclockwise order.
Let G T ( ) be a graph whose vertices are the elements of V and whose edges are elements of E joining elements of V . The proposition follows from the following claims about G T ( ) :
- (1) There are no cycles in G T ( ) .
- (2) G T ( ) is connected.
Given the claims, it follows that G T ( ) is a tree with k vertices, and thus k -1 edges. Hence, T contains at most k -1 disjoint critical chords.
To prove (1), suppose, by way of contradiction, that there is a cycle in G T ( ) of length m ≤ k . Without loss of generality, assume the cycle includes exactly the first m elements of V . Then in T there is a critical chord from a point x 1 + glyph[epsilon1] 1 ∈ ( x , y 1 1 ) , glyph[epsilon1] 1 ≥ 0 , to the point x 2 + glyph[epsilon1] 1 ∈ ( x , y 2 2 ) . Then there is a critical chord from a point x 2 + glyph[epsilon1] 2 ∈ ( x , y 2 2 ) , glyph[epsilon1] 2 > glyph[epsilon1] 1 since the critical chords are disjoint, to the point x 3 + glyph[epsilon1] 2 ∈ ( x , y 3 3 ) . Proceeding in this fashion around the cycle, we finally have a critical chord from a point x m + glyph[epsilon1] m ∈ ( x m , y m ) , glyph[epsilon1] m > glyph[epsilon1] m -1 > · · · > glyph[epsilon1] 1 , to a point x 1 + glyph[epsilon1] m ∈ ( x , y 1 1 ) . But then the first and last critical chords meet in T since glyph[epsilon1] m > glyph[epsilon1] 1 , a contradiction.
To prove (2), suppose, by way of contradiction, that G 0 and G 1 are two components of G T ( ) that are adjacent in counterclockwise order of vertices on S . Suppose that ( x , y r r ) is the last vertex in G 0 and ( x , y s s ) is the last vertex of G 1 in counterclockwise order. Then we can add the critical chord from y r to y s , connecting G 0 to G 1 , contradicting maximality of E . It may be necessary to move the endpoints in S of up to two elements of E slightly if they happened to have an y r or y s as an endpoint. glyph[square]
- 2.1. Central Strip Lemma. The Central Strip Lemma for σ 2 , stated below, was used by Thurston [T09] to show that there could be no wandering triangle for a lamination invariant under σ 2 . A triangle in a lamination is a union of three leaves meeting only at endpoints pairwise and forming
a triangle inscribed in S . A triangle wanders if its forward orbit consists only of triangles (i.e., no side is ever critical), and no two images of the triangle ever meet. This was the first step in Thurston's classification of, and description of a parameter space for, quadratic laminations. The Central Strip Lemma for σ 2 is also used to show that any polygon that returns to itself must return transitive on its vertices; hence, an invariant quadratic lamination cannot have an identity return triangle (see Definition 4.1). In a subsequent paper, we will recover and strengthen Kiwi's theorems that a d -invariant lamination cannot have a wandering ( d + 1) -gon, nor an identity return ( d +1) -gon.
Theorem 2.6 (Thurston) . Let C be the central strip in a quadratic lamination of leaf glyph[lscript] with | glyph[lscript] | > 1 3 . Then the following hold:
- (1) The first image glyph[lscript] 1 = σ 2 ( glyph[lscript] ) cannot reenter C .
- (2) If an iterate glyph[lscript] j = σ j 2 ( glyph[lscript] ) of glyph[lscript] reenters C , for least j > 1 , then it must connect the two components of C ∩ S .
Remark 2.7 . | glyph[lscript] | = 1 3 is a special case: (2) holds with j = 1 and glyph[lscript] = 1 2 3 3 maps to itself in reverse order.
In order to state and prove a Central Strip Lemma for d > 2 we will need to consider the fact that higher degree laminations can have more than one critical leaf or gap. To discuss the distance between chords we use a metric on chords defined by Childers [C07] which we call the endpoint metric .
Figure 6. Endpoint distance between two disjoint chords: d E ( x y , x 1 1 2 y 2 ) = | ( x , x 1 2 ) | + ( | y , y 2 1 ) | .
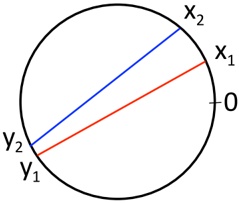
Definition 2.8. Suppose glyph[lscript] 1 = x y 1 1 and glyph[lscript] 2 = x y 2 2 are chords in D meeting at most in one pair of endpoints. We may suppose the circular order of the endpoints is x 1 < x 2 < y 2 ≤ y 1 . Define the endpoint distance between glyph[lscript] 1 and glyph[lscript] 2 to be
$$d _ { E } ( \ell _ { 1 }, \ell _ { 2 } ) = | ( x _ { 1 }, x _ { 2 } ) | + | ( y _ { 2 }, y _ { 1 } ) |.$$
If glyph[lscript] 1 = glyph[lscript] 2 we define the distance to be 0 .
See Figure 6 for an example. We define the endpoint metric only between non-crossing chords. The reader can check that on such chords it is a metric. See the proof of Theorem 2.3 for the definition of long and short arc length in the following theorem and its proof.
Theorem 2.9 (Central Strip Lemma) . Let C be a central strip of leaf glyph[lscript] and its siblings with long arc length > 1 d +1 . Let η be the short arc length. Then the following hold.
- (1) The first image glyph[lscript] 1 = σ d ( glyph[lscript] ) cannot reenter C .
- (2) The second image glyph[lscript] 2 = σ 2 d ( glyph[lscript] ) cannot reenter C with both endpoints in a single component of C ∩ S .
- (3) If an iterate glyph[lscript] j = σ j d ( glyph[lscript] ) of glyph[lscript] reenters C , for least j > 1 , and has endpoints lying in one component of C ∩ S , then iterate glyph[lscript] k , for some k ≤ j -1 , gets at least as close in the endpoint metric as η d j -k to a critical chord in D \ C .
Figure 7. An iterate of glyph[lscript] approaches a critical chord D .
Proof. Suppose C is a central strip with long arc length > 1 d +1 , so there is leaf glyph[lscript] = xy in its boundary such that | glyph[lscript] | > 1 d +1 and no leaf is a multiple of 1 2 d long. Let the short arc length be η . Then
$$\eta < \frac { 1 } { d } - \frac { 1 } { d + 1 } = \frac { 1 } { d ( d + 1 ) }.$$
Let { glyph[lscript] = glyph[lscript] 0 , glyph[lscript] 1 , glyph[lscript] 2 , . . . } be the orbit of glyph[lscript] . Note that the length of glyph[lscript] 1 is
$$| \ell _ { 1 } | = | \sigma _ { d } ( \ell _ { 0 } ) | = | ( \sigma _ { d } ( x ), \sigma _ { d } ( y ) | = d \eta < d ( \frac { 1 } { d ( d + 1 ) } ) = \frac { 1 } { d + 1 }.$$
Since the length of a component of C ∩ S is η , the endpoints of glyph[lscript] 1 cannot lie in one component of C ∩ S . On the other hand, since the length of glyph[lscript] 1 is less than 1 d +1 , it cannot connect two components, because the long arc length is > 1 d +1 . This establishes conclusion (1) of the theorem.
By Lemma 1.5, the length of glyph[lscript] i , for i > 1 , will grow until it is at least 1 d +1 long, so will continue not to fit into one component of C ∩ S . It may be that the orbit of glyph[lscript] never reenters C , or it may be that it reenters connecting two components of C ∩ S .
Suppose now that glyph[lscript] j = x y j j is the first iterate of glyph[lscript] that reenters C , and suppose that the endpoints of glyph[lscript] j lie in one component of C ∩ S . Then | glyph[lscript] j | ≤ η . The only way glyph[lscript] j can get to η or less in length is by approaching a critical chord D = ab not contained in C sufficiently close in the endpoint metric. (See Definition 2.8 and Figure 7. In Figure 7 the endpoints of glyph[lscript] j -1 are denoted e and f .) Suppose
$$d _ { E } ( \ell _ { j - 1 }, D ) = | ( x _ { j - 1 }, a ) | + | ( b, y _ { j - 1 } ) | \leq \frac { \eta } { d }.$$
Then, since σ d ( a ) = σ d ( b ) , we have | glyph[lscript] j | = ( | x , y j j ) | =
$$= | ( \sigma _ { d } ( x _ { j - 1 } ), \sigma _ { d } ( a ) ) | + | ( \sigma _ { d } ( b ), \sigma _ { d } ( y _ { j - 1 } ) |$$
$$= | ( \sigma _ { d } ( x _ { j - 1 } ), \sigma _ { d } ( y _ { j - 1 } ) | \leq d ( \frac { \eta } { d } ) = \eta. \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \varsigma \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
If the last close approach to a critical chord D before entering C were at an iterate k < j -1 , it would have to be even closer (by additional factors of 1 d ). This establishes part (3) of the theorem.
To see that the first iterate glyph[lscript] j of glyph[lscript] that might enter C with both endpoints in one component of C ∩ S must have j > 2 , suppose by way of contradiction that glyph[lscript] 2 has both endpoints in one component. By the proof of part (3), we have:
$$d \eta = | \overline { x y } | < \frac { 1 } { d + 1 } < \frac { 1 } { d }.$$
Now glyph[lscript] 1 must be sufficiently close to a critical chord D = ab outside central strip C to shrink glyph[lscript] 2 , so that
$$d _ { \text{E} } ( \overline { x y }, D ) = | ( a, x ) | + | ( y, b ) | \leq \frac { \eta } { d }.$$
But since | xy | < 1 d , glyph[lscript] 1 must be under D . Hence,
$$d _ { \text{E} } ( \overline { x y }, D ) + \overline { x y } = \frac { 1 } { d }.$$
By the above, we can compute that
$$d _ { \text{E} } ( \overline { x y }, D ) = \frac { 1 - d ^ { 2 } \eta } { d }.$$
Our supposition that glyph[lscript] 2 has both endpoints in one component implies that
$$\frac { 1 - d ^ { 2 } \eta } { d } \leq \frac { \eta } { d }.$$
From this and our definition of η it follows that
$$\frac { 1 } { d ^ { 2 } + 1 } \leq \eta < \frac { 1 } { d ( d + 1 ) },$$
a contradiction for all d ≥ 2 . This completes the proof of part (2). glyph[square]
Corollary 2.10 (Unicritical Central Strip Lemma) . Let C be a central strip of degree d of leaf glyph[lscript] and its siblings for the map σ d . Then no image of glyph[lscript] can re-enter C with both endpoints in a single component of C ∩ S .
Proof. Since C is a central strip of degree d for σ d , there must be a full sibling collection ( d leaves) in its boundary. Since it is a central strip, by definition | glyph[lscript] | > 1 2 d as is the length of all its siblings. But to have room for an all-critical d -gon inside the strip, | glyph[lscript] | < 1 d . If | glyph[lscript] | < 1 d +1 , it will grow in length under future iterates. So we lose no generality in assuming | glyph[lscript] | ≥ 1 d +1 . The case where | glyph[lscript] | is fixed at 1 d +1 is trivial. Since there is no critical chord outside C , it follows from the Central Strip Lemma 2.9, part (3), that no future image of glyph[lscript] can re-enter C with both endpoints in a single component of C ∩ S . glyph[square]
## 3. Counting Sibling Portraits and Central Strips
In the proof of Theorem 2.3, we showed that each sibling portrait corresponds to a bicolored tree. Now we show that the correspondence is one-to-one up to rotational symmetry.
Theorem 3.1. If glyph[lscript] is a non-degenerate leaf, not a diameter, then there are N d ( ) different full sibling collections which map onto glyph[lscript] , distinct up to rotational symmetry, where
$$N ( d ) = \frac { 1 } { d } \left ( \frac { 1 } { d + 1 } \left ( \begin{array} { c } 2 d \\ d \end{array} \right ) + \sum _ { n | d, n < d } \phi \left ( \frac { d } { n } \right ) \left ( \begin{array} { c } 2 n \\ n \end{array} \right ) \right )$$
and φ x ( ) is Euler's totient function , the number of positive integers less than, and relatively prime to, x .
The proof refers to Figure 8.
x1
Figure 8. Mapping a bicolored tree to a sibling portrait.
Proof. The goal is to show that there are just as many different full sibling families (equivalently sibling portraits) which map to the same leaf under σ d as there are different bicolored trees with d edges, up to rotation in the plane. The number of bicolored trees with d edges is known to be N d ( ) [BBLL09, Th. 21]. Thus we will use this correspondence to show there are N d ( ) different sibling portraits mapping to the same leaf. Refer to Fig. 8 during this proof.
The proof of Theorem 2.3 illustrates how to map a sibling portrait to a bicolored tree. It is easy to check that if two sibling portraits map to the same bicolored tree (up to rotation) then those two sibling portraits are the same (up to rotation in the plane). Therefore, since for every sibling portrait we can find a unique bicolored tree, there must be at least as many bicolored trees as sibling portraits.
Now assume we are given a bicolored tree with d edges like the one in Fig. 8. Since each edge corresponds to a leaf in the full sibling family and each leaf has two endpoints, we may correlate each side of an edge with an endpoint of the leaf. Label the sides of the edges in the tree in a counterclockwise order x , y 1 1 , x 2 , y 2 , . . . , x d , y d . Since we consider sibling portraits to be the same if one is a rotation of the other, then it does not matter which edge you choose to label x 1 with. However, since we generally assume ( x , y i i ) to be a short arc, the vertex of the tree between x i and y i must correspond to a C -region. Then in the unit circle, connect a leaf between x i and y j if they are two sides of the same edge in the tree. This will construct a full sibling family. Similarly, it is easy to check that if two bicolored trees map to the same sibling portrait then they are the same bicolored tree. Therefore for every bicolored tree there is a unique
sibling portrait. It then follows that there are exactly as many sibling portraits as bicolored trees. glyph[square]
The corollary below follows immediately since the only time a sibling portrait does not have a central strip is when all the boundary leaves are short.
Corollary 3.2. If glyph[lscript] is a non-degenerate leaf, not a diameter, then the number of different central strips, distinct up to rotational symmetry, whose boundary leaves map onto glyph[lscript] is N d ( ) -1 .
## 4. Applications to Identity Return Polygons for σ d , d ≥ 3
It will be convenient to be able to refer to points on the circle by their d -nary expansions. The pre-images under σ d of 0 partition the circle into d half-open intervals [ k -1 d , k d ) , for 1 ≤ k ≤ d , labeled successively from 0 with symbol { 0 1 , , . . . , d - } 1 . A point x of the circle is then labeled with its itinerary , an infinite sequence t 0 t 1 t 2 . . . t n . . . of symbols selected from { 0 1 , , . . . , d - } 1 , based upon which labeled interval σ n d ( x ) lies in. If a sequence of symbols repeats infinitely a finite sequence of length n , we write t 0 t 1 t 2 . . . t n to indicate the infinite sequence. For example, the point 1 3 is of period 2 under σ 2 . Thus, its σ 2 -itinerary, or binary expansion, is 01 . However, the σ 3 -itinerary, or ternary expansion, of 1 3 is 10 since σ 3 ( 1 3 ) = 0 . Using the d -nary expansion of a point x , the map σ d is the forgetful shift since the map sends
↦
$$t _ { 0 } t _ { 1 } t _ { 2 } \dots t _ { n } \dots \mapsto t _ { 1 } t _ { 2 } t _ { 3 } \dots t _ { n } \dots \,.$$
Definition 4.1. A (leaf or) polygon P in a d -invariant lamination is called an identity return polygon iff P is periodic under iteration of σ d , the polygons in the orbit of P are pairwise disjoint, and on its first return, each vertex (and thus each side) of P is carried to itself by the identity.
Note that we require the identity return polygon P be in a sibling d -invariant lamination. This is because without this restriction, one can produce examples of identity return polygons that satisfy the other conditions of Definition 4.1, but could not correspond to a Julia set. (See Figure 15 in connection with the proof of Lemma 4.7 for an example.) A periodic polygon in a sibling d -invariant lamination corresponds to a periodic branch point in a Julia set. Locally, the circular order of the branches is preserved by the polynomial. It is a non-obvious consequence of the definitions that in a sibling d -invariant lamination, a polygon maps under σ d preserving the circular order of its vertices [BMOV, Theorem 3.2]. An identity return polygon as we have defined it corresponds to a
Figure 9. A period 4 identity return triangle for σ 3 and a corresponding polynomial Julia set with the orbit of the branch point indicated (after Kiwi).
periodic branch point in a connected Julia set of a polynomial that returns to itself with no rotation around the branch point. See Figure 9 for an example of Kiwi [K02].
Figure 10. Examples of identity return d -gons for d = 3 and d = 4 under σ 3 and σ 4 , respectively; the vertices are labeled by their (periodic) expansions.
Example 4.2. There are identity return d -gons of period 3 for all d ≥ 3 . The vertices of an example of such a d -gon for σ d in d -nary expansion are
$$\{ \overline { 0 0 1 }, \overline { 0 0 2 }, \overline { 0 0 3 }, \dots, 0 0 ( d - 1 ), ( d - 1 ) ( d - 1 ) 0 \}.$$
In Figure 10 we illustrate an example of an identity return triangle of period 3 for σ 3 and identity return quadrilateral of period 3 for σ 4 . As shown by Thurston, invariant quadratic laminations cannot have an identity return triangle [T09], though they can have multiple identity return leaves. Generalizing Thurston's result for quadratic laminations, Kiwi [K02, Theorem 3.1] proved
Theorem 4.3 (Kiwi) . A d -invariant lamination cannot have an identity return k -gon for any k > d .
- 4.1. Properties of Identity Return Polygons. In what follows, we extract some facts about identity return polygons in general. Examples 4.2 and 4.5 show that the following theorem is sharp.
Theorem 4.4. There can be no period 2 identity return k -gon for σ d for k ≥ d .
Proof. It suffices to show that there does not exist an identity return d -gon of period 2 for σ d , since an identity return k -gon for k > d would contain an identity return d -gon. We argue by induction on d . It can be easily checked that there does not exist a period 2 identity return triangle for the map σ 3 ; all possible examples result in circular order reversing (see Figure 15). Now assume as the induction hypothesis that there does not exist an identity return ( d -1) -gon of period 2 under σ d -1 . By way of contradiction assume that there does exist an identity return d -gon of period 2 under σ d . Let a b , a 1 1 2 b 2 , ..., a d b d denote the itineraries of vertices of the identity return d -gon, with a , b i i ∈ B = { 0 1 , , ..., d -1 } for all i = 1 , ..., d . Consider the list of symbols A = ( a , ..., a 1 d , b 1 , ..., b d ) . Each element of B must appear in at least one entry of A , else we could define a identity return d -gon of period 2 for σ d -1 , which would contain an identity ( d -1) -gon, contradicting the induction hypothesis. This leads to two cases.
Case 1. Suppose that for some symbol 0 ≤ k ≤ d -1 , the symbol k appears more than twice in list A .
glyph[negationslash]
By the pigeon-hole principle, this means that some other symbol m = k will only appear once in A . Note that any such identity return polygon will be of the form shown in Figure 11 (illustrated for d = 4 and m = 3 , up to some rotational symmetry). By removing the vertex with that symbol from the polygon, one obtains a ( d -1) -gon which uses d -1 symbols. This contradicts the induction hypothesis.
Figure 11. Case 1 for σ 4 where m = 3 .
Figure 12. Case 2 for σ 5 with two vertices of a polygon in the ' 0 ' section.
## Case 2. Suppose that each symbol 0 ≤ k ≤ d -1 appears exactly twice in list A .
Then there are two vertices of the polygons in each 1 /d section of the circle corresponding to the symbols in B . Thus, one of the two polygons in the orbit must have two vertices in a 1 /d section of the circle corresponding to the symbol 0 in B or to the symbol d -1 in B ; otherwise the polygons would cross. First, let us assume two vertices of a polygon are in the ' 0 ' section (see Figure 12). The vertex in this section closest to the point 0 ∈ S , denote it 0 j , represents the first vertex (in counterclockwise circular
order from 0 ∈ S ) of the identity return polygon on the circle. The next vertex in order will be 0 k for some k > j ∈ B . Since the first coordinates of these vertices are 0 , then mapping them forward under σ d will yield vertices j 0 and k 0 . Since j < k , these vertices cannot map to the same 1 /d section.
Since circular order must be preserved, and all symbols are used, the two vertices must map either to vertices in adjacent 1 d sections (see Figure 12 on right), or j 0 must be the largest (in circular order) vertex in the image polygon (see Figure 12 on left). Since both vertices have 0 as their second coordinate, they must each be the first vertex of the polygons in the sections in which they appear. If the vertices map to adjacent 1 d sections, this is impossible because j 0 (preceeding k 0 in circular order in the image polygon) would not be the smallest in its section. If j 0 is the largest vertex in the image polygon, then preserving circular order requires k 0 to be the smallest vertex in the image polygon, contradicting j < k . All options lead to a contradiction, so no such polygon orbit is possible.
The argument is similar if an identity return polygon has two vertices in the ( d -1) section. glyph[square]
Figure 13. Period 2 identity return triangle for σ 4 .
Example 4.5. Period 2 identity return ( d -1) -gons exist under σ d for all d > 3 . See Figure 13 for d = 4 . The vertices of an example of such a ( d -1) -gon for σ d in d -nary expansion are
$$\{ \overline { 0 1 }, \overline { 0 2 }, \overline { 0 3 }, \dots, 0 ( d - 1 ).$$
4.2. Some Properties of Identity Return Triangles for σ 3 . The following propositions present a series of elementary facts about identity return triangles for σ 3 .
Figure 14. Spider web diagrams for leaf length function τ 3 .
Proposition 4.6. Let glyph[lscript] be a leaf in a 3 -invariant lamination which is not eventually of fixed length. Then glyph[lscript] must eventually get within 1 12 of a critical length.
Proof. Let glyph[lscript] be a leaf in an invariant lamination under σ 3 whose length is not eventually fixed. By Proposition 1.4, the fixed lengths under the leaf length function τ 3 are 1 4 and 1 2 . By Lemma 1.5, each leaf of length < 1 4 must eventually iterate to a leaf glyph[lscript] i = σ i 3 ( glyph[lscript] ) of length ≥ 1 4 (see 'spider web diagrams' in Figure 14). So assume | glyph[lscript] | > 1 4 . If 1 4 < glyph[lscript] | | < 5 12 , then we can place a critical chord so that in the endpoint metric (Definition 2.8) glyph[lscript] is within 1 12 of the critical chord. So we may assume 5 12 < glyph[lscript] | | < 1 2 . We apply the leaf length function τ 3 iteratively, observing that τ 3 ( | glyph[lscript] | ) is repelled from 1 2 because the graph of τ 3 is below the identity on the interval ( 1 3 , 1 2 ) . Thus, we see that there is a first k ≥ 1 such that 1 4 < τ k 3 ( | glyph[lscript] | ) < 5 12 (see Figure 14 on right). Hence, σ k 3 ( glyph[lscript] ) is within 1 12 of a critical chord. glyph[square]
Proposition 4.7. An identity return triangle in a 3 -invariant lamination cannot have a side of fixed length.
Proof. By Proposition 1.4, the fixed lengths under the leaf length function τ 3 are 1 4 and 1 2 . Let glyph[lscript] be a side of fixed length of an identity return triangle T . If | glyph[lscript] | = 1 2 , then glyph[lscript] is a diameter, and if glyph[lscript] is not fixed, σ 3 ( glyph[lscript] ) will cross glyph[lscript] , a contradiction of glyph[lscript] being a leaf of an invariant lamination. On the
Figure 15. Example of an 'almost' identity return triangle for σ 3 of period 2; it fails because the triangle maps forward reversing circular order.
other hand, if glyph[lscript] is fixed, then σ 3 ( T ) meets T , contradicting T being an identity return triangle. If | glyph[lscript] | = 1 4 , then the period of glyph[lscript] cannot be greater than 3 or it will meet its iterated image. If the period of glyph[lscript] were 3, then both endpoints of glyph[lscript] would have period 3 repeating ternary expansions (see Figure 10 for an example). But if we add 1 4 = 01 to a repeating ternary expansion for one endpoint of glyph[lscript] , the other endpoint of glyph[lscript] will not be period 3 repeating in ternary. It is possible to construct a period 2 triangle which appears to satisfy the definition (see Figure 15) and has a side of fixed length. However, there is no room for critical chords disjoint from the triangles in the orbit, and the triangle maps forward reversing circular order, thus it cannot be in a sibling d -invariant lamination. glyph[square]
Remark 4.8 . By way of notation, if T is an identity return triangle of least period n in a 3-invariant lamination, we denote the sides of the triangle by T = ABC , and the orbit of the triangle by
↦
T = T 0 = A B C 0 0 0 → σ 3 ( T 0 ) = T 1 = A B C 1 1 1 → . . . → T n = A B C n n n = T . 0
↦
↦
This notation can be extended to any identity return polygon.
Proposition 4.9. Let ABC be an identity return triangle of period k . If two sides A and B are of the same length, then there exists a unique i ∈ [0 , k ) such that A i and B i are within 1 12 of critical. Further, there
Figure 16. On left, a triangle with two equal sides of length between 1 4 and 1 3 ; on right, the length is between 1 3 and 5 12 .
is no critical chord c such that A i and B i are both within 1 12 of c in the endpoint metric.
Proof. Suppose that T 0 = A B C 0 0 0 is an identity return triangle and that | A 0 | = | B 0 | . Then for all i , we have | A i | = | B i | . By Propositions 4.6 and 4.7, there is an i such that 1 4 < A | i | = | B i | < 5 12 . If | A i | < 1 3 , as illustrated on the left in Figure 16, then, similar to the proof of Proposition 4.7, there is no room for two critical chords disjoint from T i , since A i and B i together occupy more than half the circle's arc. Hence, there is no room for siblings of T i , so no such sibling invariant lamination.
If | A i | > 1 3 , then there are two regions in D \ T i where one can place critical chords sufficiently close to A i and B i , the region with only A i on its boundary, and the region with only B i on its boundary. See Figure 16 on right where we include the siblings T ′ i and T ′′ i of triangle T i . Since | A i | < 5 12 , each of A i and B i is within 1 12 of a critical chord. That the i th iterate is unique with this property is clear, since any other such iterate would cross T i . glyph[square]
Proposition 4.10. Let T be an identity return n -gon ( n ≥ 3 ) in a 3 -invariant lamination. Then in the orbit of T two sides will simultaneously approach within 1 12 of a critical length. In fact, one of the following happens:
- (1) Two sides of T approach within 1 12 of two different critical chords at the same iterate.
- (2) Two sides of T approach within 1 12 of one side of the same critical chord at the same iterate.
Figure 17. On left, an identity return polygon approaches three different critical chords; in middle, an identity return polygon approaches just one critical chord; on right, an identity return polygon approaches exactly two critical chords (only one shown).
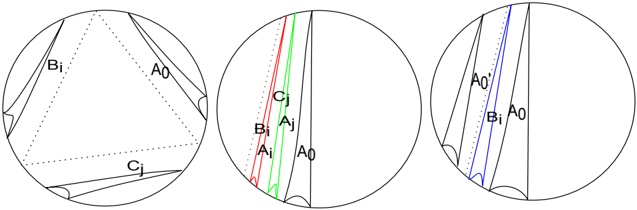
Furthermore, at that iterate these two sides are longer than any other side.
Remark 4.11 . Example 9 shows that the first case can occur. The cubic example in Figure 10 shows that the second case can occur.
Proof. Let T 0 = A B C ... 0 0 0 be an identity return n -gon in a 3 -invariant lamination. By Lemma 4.6 all the sides will eventually get within 1 12 of a critical chord. In case (1), the polygon must lie between the two critical chords. Hence, those two sides are longer than 1 3 , so all other sides are shorter than 1 3 . Now assume case (1) does not occur.
glyph[negationslash]
glyph[negationslash]
Without loss of generality, suppose that side A 0 is within 1 12 of a critical chord glyph[lscript] . So there exists an iterate i = 0 such that side B i is within 1 12 of a critical chord, not necessarily glyph[lscript] , and there exists an iterate 0 = j = i such that C j is within 1 12 of a critical chord, not necessarily glyph[lscript] , else we are done.
glyph[negationslash]
Suppose that the three sides A 0 , B i , and C j are close to the same critical chord glyph[lscript] , and approach no other critical chord closely. Without loss of generality let A 0 be the side furthest away from glyph[lscript] , while still being within 1 12 of glyph[lscript] . See Figure 17 in middle. Then T i is closer to glyph[lscript] and by the Central Strip Lemma (Theorem 2.9) sides A i and B i are long, since side A has not closely approached a different critical chord before iterate i . Triangle T j cannot be closer to glyph[lscript] since then, by the Central Strip Lemma,
the three sides are simultaneously close to 1 3 in length. Therefore, T j is between T i and T 0 (or siblings). Let T be of period k , so T 0 = T k . Then, the iterate T k + i is the first time the central strip of C j is re-entered, and since side C is never close to a different critical chord, C k + i needs to connect two components of the central strip by the Central Strip Lemma. But T k + i = T i has C i inside one component, a contradiction.
Suppose that all three sides are close to three different critical chords at iterates 0 , i , and j . Then the three critical chords must form an allcritical triangle. See Figure 17 on left. One of the polygons, say T 0 , must be outermost with respect to the all-critical triangle. As argued in the previous paragraph, T i and T j are then within the central strip of A 0 , contradicting in a similar fashion the Central Strip Lemma.
Therefore, the three sides A 0 , B i , and C j must approach exactly two different critical chords. By the pigeon hole principle, two sides must approach the same critical chord glyph[lscript] . Without loss of generality let those sides be A 0 and B i . Let A 0 be the one further away from the critical chord glyph[lscript] , but still within 1 12 of glyph[lscript] . Suppose that B i is within 1 12 of critical chord at iterate i . Then T i is inside the central strip of A 0 and its sibling A ′ 0 . Hence, two sides of the polygon T i are within 1 12 of a critical chord glyph[lscript] at the same iterate, and all other sides are within a central strip, so shorter. glyph[square]
Proposition 4.12. Let T be an identity return n -gon in a 3 -invariant lamination. Let A and B be two sides that are within 1 12 of a critical chord and C be the longest remaining side. If A and B are simultaneously within 1 12 of
- (1) two different critical chords at the same iterate, or
- (2) the same critical chord at the same iterate,
then the following occur, respectively:
- (a) σ 3 ( C ) becomes the longest side, or
- (b) σ 3 ( A ) or σ 3 ( B ) becomes the longest side.
## Proof. Let T = ABCD ...D 4 n .
Suppose (1) holds. Then T lies between two critical chords. Since there is a critical chord between A and its sibling A ′ , there must be a critical value underneath σ 3 ( A ) . Similarly, there is a critical value underneath σ 3 ( B ) . Furthermore, those two critical values are different since A and B approach two different critical chords. See Figure 18 on left.
Now, since T lies between two critical chords , σ 3 ( T ) lies in one half of the circle (else it crosses T ). Since σ 3 ( T ) is an n -gon, there must be a side C ′ with σ 3 ( A ) and σ 3 ( B ) underneath C ′ . Since σ 3 ( T ) lies in one half of the circle C ′ is longer than both σ 3 ( A ) and σ 3 ( B ) .
Figure 18. Image of a polygon with critical values marked.
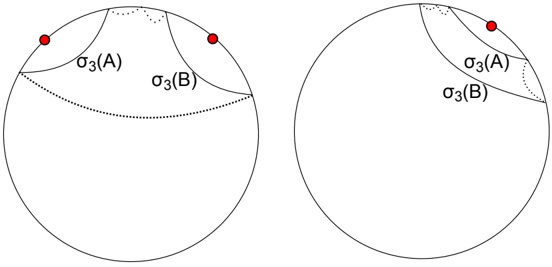
To see that C ′ = σ C ( ) , consider two cases:
Case 1 : | C | ≥ 1 6 . Let | A | = 1 3 + α , | B | = 1 3 + β and γ = ∑ n k =4 | D k | Clearly γ < 1 6 and | D i | < 1 6 for all i = 4 , ...n . Then | C | = 1 3 -α -β -γ . Then | σ 3 ( A ) | = 3 | A | -1 = 3 α , | σ 3 ( B ) | = 3 | B | -1 = 3 β , | σ 3 ( D i ) = 3 | D i | for all i = 4 , ...n , and | σ 3 ( C ) | = 1 - | 3 C | = 3 α + 3 β + 3 γ = | σ 3 ( A ) | + | σ 3 ( B ) | + ∑ n k =4 | σ 3 ( D k ) | . Therefore σ 3 ( C ) is the longest side.
Case 2 : | C < | 1 6 . Then all sides except A and B are shorter than 1 6 . Thus under the application of σ 3 the side lengths of σ 3 ( C , σ ) 3 ( D 4 ) , ..., σ 3 ( D n ) triple. Since C was the longest among C, D , ..., D 4 n , σ 3 ( C ) must be the longest among σ 3 ( C , σ ) 3 ( D 4 ) , ..., σ 3 ( D n ) . However, we have shown above that there exists at least one side that is longer than σ 3 ( A ) and σ 3 ( B ) . Thus σ 3 ( C ) must be the longest.
Cases 1 and 2 establish that (1) implies (a).
Now suppose (2) occurs. See Figure 18 on right. By the hypothesis, both A and B are within 1 12 of a critical chord glyph[lscript] . Then there is the same critical value underneath σ 3 ( A ) and σ 3 ( B ) . Since all remaining sides are between σ 3 ( A ) and σ 3 ( B ) , and since | σ 3 ( A , σ ) | | 3 ( B ) | < 1 4 , one of those (the outermost from the critical value) will be the longest. Thus, we have that (2) implies (b). glyph[square]
We conclude this section by proving the special case of Kiwi's Theorem (4.3) for σ 3 .
Theorem 4.13. There are no identity return quadrilaterals under σ 3 .
Proof. Suppose that such a quadrilateral T , of period n exists. Let A,B,C,D be the sides of T , not necessarily in circular order.
Figure 19. Impossible quadrilaterals under σ 3 : Case 1 of Theorem 4.13 on the left and Case 2 on the right.
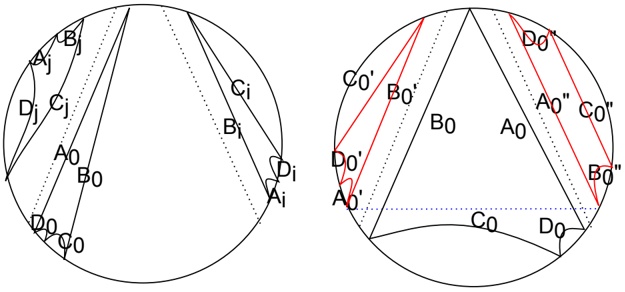
Case 1 : Suppose that for no iterate i are two sides within 1 12 of two different critical chords.
Then by 4.10 there exists an iterate T 0 where two sides of T 0 are within 1 12 of the same critical chord glyph[lscript] . Let A 0 and B 0 be those sides. The remaining sides must also eventually approach critical chords within 1 12 (Proposition 4.6).
Claim. We may assume without loss of generality that every approach to a given critical chord is closer than the previous approach to that critical chord.
To see this, suppose that at some iterate we have a quadrilateral T j further away from a given critical chord than quadrilateral T i , i < j , while at least one of the sides of T j is different from the sides of T i that are within 1 12 of a critical chord. Then, the different 'long' side of T i must approach a different critical chord at some iterate before returning to itself. Otherwise, the Central Strip Lemma is contradicted upon the return to T i . In that case, we could take T j as a starting point instead of T i , establishing the claim.
By Proposition 4.12 let B 1 be the longest side. Since | B 1 | < 1 4 , so will grow by Lemma 1.5, let B i be the next approach of side B to a critical chord. If A i is the second longest side, then we can take this as a starting point. So, without loss of generality, we can suppose that C i is the second longest. Then by the Claim and the Central Strip Lemma, the two sides must be close to a different critical chord glyph[lscript] ′ . Now we have a central strip of sides A , B 0 0 around glyph[lscript] and a central strip of B , C i i around glyph[lscript] ′ . Denote this state of affairs by [ glyph[lscript] : A , B 0 0 ] and [ glyph[lscript] ′ : B , C i i ] . See Figure 19 on left.
By Proposition 4.12 and without loss of generality, we may assume that C i +1 is the longest side. Let j be the iterate when C j next approaches a critical chord.
If A j is second longest then T j , by the Claim and the Central Strip Lemma, must be close to glyph[lscript] . But this gives us [ glyph[lscript] : A , C j j ] , [ glyph[lscript] ′ : B , C i i ] , which is up to renaming what we had before. If B j is second longest then by the Claim and the Central Strip Lemma T j must be close to glyph[lscript] ′ . This gives us [ glyph[lscript] : A , B 0 0 ] , [ glyph[lscript] ′ : C , B j j ] , which is what we had before but at a later iterate. If D j is the second longest, then T j cannot be within 1 12 of either critical chord, without, by the Claim, violating the Central Strip Lemma. Therefore, no such quadrilateral exists.
Case 2 : Now suppose that there is an iterate i where two sides, A i and B i approach two different critical chords.
Since this iterate is unique, if we find a subsequent iterate where both sides are within 1 12 of the same critical chord, then we can follow the argument in Case 1 to see that no such quadrilateral exists.
Refer to Figure 19 on the right. Let | A 0 | = 1 3 + α , | B 0 | = 1 3 + β , and note that α, β < 1 12 . Then | C 0 | + | D 0 | = 1 3 -α -β > 1 6 . First suppose that neither C 0 nor D 0 is longer than 1 6 . Then by the Leaf Length Function (1.3), | A 1 | = 3 α , | B 1 | = 3 β , | C 1 | = 3 | C 0 | and | D 1 | = 3 | D 0 | , and so | A 1 | + | B 1 | + | C 1 | + | D 1 | = 1 . This means that T 1 is on both sides of the diameter, so it will intersect T 0 . Therefore, we may suppose that | C 0 | > 1 6 . Then | A 1 | = 3 α , | B 1 | = 3 β , | C 1 | = 1 - | 3 C 0 | , and | D 1 | = 3 | D 0 | . Hence | C 1 | = | A 1 | + | B 1 | + | D 1 | .
If C 0 is not within 1 12 of a critical chord then C grows, so C i must be within a central strip formed by A 0 or B 0 on its first approach to critical length; let it be B 0 . Then by the Central Strip Lemma, C i and B i must be the two longest sides. Now we can follow the argument in Case 1, to see that no such quadrilateral exists.
Therefore, we may assume that C 0 is within 1 12 of a critical chord. Since | C 1 | < 1 4 , C 1 will continue to grow. So it must approach a critical length at some iterate i . If it approaches a critical chord within the central strip of A 0 or B 0 , we can follow the argument in Case I. So we may suppose that it approaches the same critical chord as at iterate 0 . Then it must go underneath C 0 , as otherwise side D never gets within 1 12 of a critical chord. There exists an iterate i when side D i is within 1 12 of a critical length. If quadrilateral T i is inside either of the central strips we can follow the Case I argument. So we may suppose that D i is within 1 12 of the same critical chord as C 0 . Then by the Central Strip Lemma, sides C i and D i , must be the two longest sides, so one of them remains the longest. Eventually, one of the sides A or B will become the second
longest, otherwise T cannot return to T 0 . Without loss of generality, let C and A be the two longest sides. Then as they approach critical length at iterate j , by the Central Strip Lemma the quadrilateral T j must be inside the central strip of A 0 . Again we can follow the argument in Case I. Therefore there is no such identity return quadrilateral. glyph[square]
4.3. Questions. We conclude with a series of questions and remarks.
Question 1. What is the appropriate generalization of Proposition 4.6 to σ d for d > 3 ?
In order to be able to use the full power of the Central Strip Lemma, we want leaves of an identity return polygon for σ d to get within 1 d d ( +1) of a critical chord. This need not happen even for a d -gon for σ d , in general. For example, the period 3 quadrilateral with vertices { 132 032 022 200 , , , } under σ 4 has a side, namely 022 200 , which never gets within 1 20 of a critical chord.
Question 2. With reference to Proposition 4.7, can an identity return polygon have a side of fixed length?
Question 3. With reference to Proposition 4.9, if an identity return polygon has two sides of the same length, must they simultaneously approach two different critical chords?
Question 4. What are the appropriate generalizations of Propositions 4.10 and 4.12 to σ d for d > 3 ?
We can show that if the two longest sides of an identity return polygon P in a d -invariant lamination are simultaneously within 1 2 d of the same critical chord, then one of the two longest sides of σ d ( P ) remains longest.
One can define 'identity return polygon' without assuming it is in a d -invariant lamination.
Definition 4.14 (Alternate Definition of Identity Return Polygon) . A polygon P in the closed unit disk is called an identity return polygon iff P is periodic under iteration of σ d , the polygons in the orbit of P are pairwise disjoint, circular order of vertices of P is preserved by the action of σ d on P , and on its first return, each vertex (and thus each side) of P is carried to itself by the identity.
Question 5. Does the existence of an identity return polygon P defined as in Definition 4.14 imply the existence of a d -invariant lamination containing P ?
Question 6. What polynomials have Julia sets with a vertex that returns to itself in the pattern of the identity return polygons of Figure 10? Of Example 4.2, in general?
Question 7. What is the 'simplest' 3 -invariant lamination that contains a given identity return triangle?
Here 'simplest' might mean, an invariant lamination with no leaves other than preimages of the triangle or their limit leaves, and with each of two sides of the triangle bordering a (different) infinite gap of the lamination.
Question 8. Is there any bound on the number of identity return triangle orbits that a 3 -invariant lamination can contain?
It is clear from proofs above that a 3 -invariant lamination can contain only one identity return triangle orbit where two sides of the triangle approach within 1 12 of two different critical chords on the same iterate.
Question 9. Given d > 2 and a period p > 2 (necessarily), how many distinct identity return d -gon orbits of period p can be formed under σ d ?
Question 10. Given d > 2 orbits of period p > 2 under σ d , is it the case that they form at most one identity return d -gon orbit?
That for d = 2 , the answer is 'yes' appears to be intimately connected to the detailed structure of parameter space [T09].
## References
| [BL02] | Blokh, A.; Levin, G. An inequality for laminations, Julia sets and 'growing trees'. Ergodic Theory Dynam. Systems 22 (2002), no. 1, 63-97. |
|----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [BO04] | Blokh, Alexander; Oversteegen, Lex. Wandering triangles exist. C. R. Math. Acad. Sci. Paris 339 (2004), no. 5, 365-370. |
| [BO09] | Blokh, Alexander; Oversteegen, Lex. Wandering gaps for weakly hyperbolic polynomials. Complex dynamics 139-168, AKPeters, Wellesley, MA, 2009. |
| [BMOV] | A. Blokh, D. Mimbs, L. Oversteegen, K. Valkenburg. Laminations in the language of leaves. Trans. Amer. Math. Soc. 365 (2013), no. 10, 5367âĂŞ5391. |
| [BBLL09] | M. Bóna, M. Bousquet, G. Labelle, P. Leroux. Enumeration of m -ary cacti. Advances in Applied Mathematics , 24, 2009, pp. 22-56. |
| [C07] | Childers, Douglas K. Wandering polygons and recurrent critical leaves. Ergodic Theory Dynam. Systems 27 (2007), no. 1, 87-107. |
| [GM93] | Goldberg, Lisa R. and Milnor, John. Fixed points of polynomial maps. II. Fixed point portraits. Ann. Sci. École Norm. Sup. (4) 26 (1993), no. 1, 51-98. |
| [K02] | Kiwi, J. Wandering orbit portraits. Trans. Amer. Math. Soc. 354 (2002), no. 4, 1473-1485 |
| [Mil06] | J.W. Milnor. Dynamics in one complex variable , volume no. 160. Princeton University Press, Princeton, 3rd edition, 2006. |
| [Mil00] | Milnor, John. Periodic orbits, externals rays and the Mandelbrot set: an expository account. Astérisque 261 (2000), xiii, 277-333. |
| [Nad92] | S. B. Nadler, Jr. Continuum theory. An introduction. Volume 158 of Mono- graphs and Textbooks in Pure and Applied Mathematics . Marcel Dekker Inc., New York, 1992. |
[T09] William P. Thurston. On the geometry and dynamics of iterated rational maps. Edited by Dierk Schleicher and Nikita Selinger and with an appendix by Schleicher in Complex dynamics. Families and friends. Edited by Dierk Schleicher. A K Peters, Ltd., Wellesley, MA, 2009.
E-mail address , David J. Cosper: [email protected]
E-mail address , Jeffrey K. Houghton: [email protected]
E-mail address , John C. Mayer: [email protected]
E-mail address , Luka Mernik: [email protected]
E-mail address , Joseph W. Olson: [email protected] | null | [
"David J. Cosper",
"Jeffrey K. Houghton",
"John C. Mayer",
"Luka Mernik",
"Joseph W. Olson"
] | 2014-08-01T16:23:58+00:00 | 2015-01-26T20:35:18+00:00 | [
"math.DS",
"37F20 (Primary), 54F15 (Secondary)"
] | Central Strips of Sibling Leaves in Laminations of the Unit Disk | Quadratic laminations of the unit disk were introduced by Thurston as a
vehicle for understanding the (connected) Julia sets of quadratic polynomials
and the parameter space of quadratic polynomials. The "Central Strip Lemma"
plays a key role in Thurston's classification of gaps in quadratic laminations,
and in describing the corresponding parameter space. We generalize the notion
of {\em Central Strip} to laminations of all degrees $d\ge2$ and prove a
Central Strip Lemma for degree $d\ge2$. We conclude with applications of the
Central Strip Lemma to {\em identity return polygons} that show it may play a
role similar to Thurston's lemma for higher degree laminations. |
1408.0224v2 | ## IMAGES OF GRAVITATIONAL AND MAGNETIC PHENOMENA DERIVED FROM 2D BACK-PROJECTION DOPPLER TOMOGRAPHY OF INTERACTING BINARY STARS
Mercedes T. Richards 1,2 , Alexander S. Cocking 1 , John G. Fisher 1 & Marshall J. Conover 1
1 Department of Astronomy & Astrophysics, Pennsylvania State University, University Park, PA 16802, U.S.A. [email protected], [email protected]
2 Institut f¨r Angewandte Mathematik, Ruprecht-Karls-Universit¨t Heidelberg, 69120 Heidelberg, Germany u a
Draft version September 10, 2014
## ABSTRACT
We have used 2D back-projection Doppler tomography as a tool to examine the influence of gravitational and magnetic phenomena in interacting binaries which undergo mass transfer from a magnetically-active star onto a non-magnetic main sequence star. This multi-tiered study of over 1300 time-resolved spectra of 13 Algol binaries involved calculations of the predicted dynamical behavior of the gravitational flow and the dynamics at the impact site, analysis of the velocity images constructed from tomography, and the influence on the tomograms of orbital inclination, systemic velocity, orbital coverage, and shadowing. The H α tomograms revealed eight sources: chromospheric emission, a gas stream along the gravitational trajectory, a star-stream impact region, a bulge of absorption or emission around the mass-gaining star, a Keplerian accretion disk, an absorption zone associated with hotter gas, a disk-stream impact region, and a hot spot where the stream strikes the edge of a disk. We described several methods used to extract the physical properties of the emission sources directly from the velocity images, including S-wave analysis, the creation of simulated velocity tomograms from hydrodynamic simulations, and the use of synthetic spectra with tomography to sequentially extract the separate sources of emission from the velocity image. In summary, the tomography images have revealed results that cannot be explained solely by gravitational effects: chromospheric emission moving with the mass-losing star, a gas stream deflected from the gravitational trajectory, and alternating behavior between stream state and disk state. Our results demonstrate that magnetic effects cannot be ignored in these interacting binaries.
Subject headings: accretion, accretion disks - catalogs - (stars:) binaries: eclipsing - stars: imaging - stars: magnetic field - techniques: image processing
## 1. INTRODUCTION
The effects of gravitational forces and magnetic fields have been recognized as playing an important role in the mass accretion process in a variety of astrophysical systems, including protostars, binaries containing compact objects, and massive galaxies with supermassive black holes. However, the consequences for accretion onto normal stars in close binary star systems are not as well understood. In this paper, we focus on binaries containing normal stars, specifically the Algol-type binaries with prototype β Per (Algol), which are progenitors of the cataclysmic variables (Iben & Tutukov 1985; Wheeler 2007). In these systems, the cool star displays enhanced magnetic activity associated with rapid rotation induced by tidal synchronization of the binary system, and the resulting dynamic phenomena are many times more powerful than those found on the Sun. Since the cool star is the source of the mass transfer stream, then this enhanced activity will influence the mass transfer process in a direct way.
however such evidence is typically sparse because these cool stars contribute only ∼ 5-15% to the total luminosity of the binary, depending on wavelength, with the highest contribution in the infrared. Moreover, any magnetic components in the H α line are masked by contributions from circumstellar gas flowing between and around the stars (Richards & Albright 1993). These magnetic phenomena observed in Algol binaries are similar to those detected in the double-cool star detached RS CVn binaries (Guinan & Gim´ enez 1994).
In the Algols, no magnetic activity is linked to the hot B-A-type mass-gaining star (Richards & Albright 1993; Peterson et al. 2010). However, both gyrosynchrotron radio emission and thermal X-ray emission are expected from the cool F-K-type mass-losing companion, mostly due to coronal activity (Richards & Albright 1993). Additional evidence of magnetic activity can be derived from the spectra (e.g., CaII H & K or H α emission),
The presence of an active magnetic field on the masslosing star can lead to magnetic threading of the gas flow from the L1 point towards the mass-gaining star when the ram pressure of the accretion flow exceeds the magnetic stress at the L1 point (Retter et al. 2005). As a consequence, the magnetic field will be dragged along with the fluid flow and eventually surround the mass gainer. This process is associated with the superhump phenomenon, which typically arises from the prograde apsidal precession of an eccentric accretion disk and is usually identified in cataclysmic variables (Vogt 1982; Patterson 1998, 1999). Superhumps were first detected in Algol binaries by Retter et al. (2005) using 2.3 GHz and 8.3 GHz observations of β Per derived from the 5.6-year continuous radio flare survey of Richards et al. (2003). This prediction of the superhump phenomenon in β Per was confirmed by Peterson et al. (2010) using 15 GHz VLBI observations. Astrometric methods have
also been used to confirm the association between the source of the radio emission and the physical location of the K-type mass-losing star, with a precision of ± 0.5 mas (Zavala et al. 2010; Peterson et al. 2011).
Indirect images of interacting binaries created with the aid of Doppler tomography have led to a better understanding of the role played by gravitational forces and magnetic fields. This image reconstruction technique was introduced by Marsh & Horne (1988) and then applied to cataclysmic variables and X-ray binaries (Kaitchuck et al. 1994; Morales-Rueda 2004; Schwope et al. 2004; Steeghs 2004; Vrtilek et al. 2004) and also to direct-impact and long-period Algol binaries (Richards et al. 1995; Richards & Albright 1996; Richards 2004). The images illustrate the movement of gas from the inner Lagrangian point towards and around normal or compact mass-gaining stars, and show that a well-defined accretion disk is formed around the massgaining star in the compact binaries. However, in the direct-impact systems the mass gainer is a normal main sequence star, and the stars are very close to each other relative to the orbital separation. The first 2D tomography images of these latter systems have shown that the path of the flow is usually governed by gravitational and Coriolis forces, and there is additional evidence that the active cool mass-losing star can have substantial influence on the mass transfer process (Richards & Albright 1996; Richards, Jones & Swain 1996).
In this paper, we assess the progress that has been made in 2D tomography of the direct-impact and longperiod Algols to identify patterns and similarities between systems with orbital periods from 1.2 days to 11.1 days; some preliminary results have appeared in conference proceedings (e.g., Richards 2004). In § 2, we describe the predicted dynamical behavior of the gravitational flow along the gas stream and beyond; in § 3, we describe the technique of Doppler tomography, and § 4 provides the application to the direct-impact systems. We also examine the influence of various system properties on the 2D images in § 5, specifically the effects of orbital inclination, systemic velocity, orbital phase coverage, inadequate velocity resolution, and the effect of the gas opacity known as shadowing. In § 6, we describe the techniques that can be used to extract physical properties of the gas flows directly from the images via four methods: an S-wave analysis; using hydrodynamic simulations to create simulated tomograms; using synthetic spectra to model the contributions of the accretion disk, gas stream, and other sources of emission; and using synthetic spectra with tomography to confirm visually that the separate accretion structures have been modeled accurately. The Results and Conclusions are given in § 7 and § 8, respectively.
## 2. UNDERSTANDING THE DIRECT-IMPACT SYSTEMS
The semidetached interacting Algol binaries contain a cool F-K III-IV secondary star which has expanded to fill its Roche lobe and is transferring material through a gas stream onto a hot B-A V primary star (the mass gainer); in this context, the primary is the brighter and more massive star. A radius vs. mass ratio or r -q diagram, as illustrated in Figure 1, can be used to predict the systems that should undergo direct impact of the gas stream onto the stellar photosphere. This figure
Table 1 Orbital Parameters
| System | P (days) | i ( ◦ ) | q | R 1 /a | K 1 (kms -1 ) | V o (kms -1 ) |
|----------|------------|-----------|------|----------|-----------------|-----------------|
| RZ Cas | 1.195 | 83 | 0.33 | 0.232 | 70.9 | - 45.5 |
| δ Lib | 2.327 | 78.6 | 0.35 | 0.3 | 76.6 | + 4.0 |
| RW Tau | 2.769 | 90 | 0.23 | 0.179 | 53 | - 20.2 |
| β Per | 2.867 | 81.4 | 0.22 | 0.206 | 44 | + 3.8 |
| TX UMa | 3.063 | 81 | 0.3 | 0.154 | 54.8 | - 13.0 |
| U Sge | 3.381 | 89 | 0.33 | 0.225 | 70 | - 10.0 |
| S Equ | 3.436 | 87.4 | 0.12 | 0.192 | 23 | - 48.0 |
| U CrB | 3.452 | 79.1 | 0.29 | 0.17 | 59.7 | - 6.7 |
| RS Vul | 4.478 | 78.7 | 0.31 | 0.267 | 54 | - 20.1 |
| SW Cyg | 4.573 | 87.1 | 0.21 | 0.155 | 32.3 | - 7.5 |
| CX Dra | 6.696 | 53 | 0.23 | 0.128 | 34.1 | + 3.54 |
| TT Hya | 6.953 | 84.4 | 0.27 | 0.089 | 23.9 | + 0.0 |
| AU Mon | 11.113 | 82 | 0.2 | 0.114 | 32.2 | +11.8 |
| V711 Tau | 2.838 | 33 | 1.25 | 0.113 | 61.7 | - 14.01 |
also shows the Roche geometries for the direct-impact systems and some wider binaries based on the properties listed in Table 1, derived from Richards & Albright (1999). Here, P is the orbital period of the binary; i is the orbital inclination; q = M /M 2 1 is the mass ratio of the binary; r = R /a 1 is the radius of the mass gainer, R 1 , relative to the binary separation a ; K 1 and K 2 (= K /q 1 ) are the velocity semi-amplitudes of the primary and secondary, respectively; and V o is the systemic velocity of the binary. Until these systems are resolved by an instrument with absolute phase angle calibration or direct imaging, the values of inclination will have an i vs. (180 -i ) ambiguity, corresponding to prograde vs. retrograde orbits. For the close binary in β Per, Zavala et al. (2010) found that the orbit of the binary is retrograde, so the inclination should be (180 -81 4) = 98 6 . . ◦ . However, we retain the usual convention here with angles up to 90 ◦ corresponding to prograde orbits.
In Figure 1, the direct-impact binaries will be found above the solid curve labeled ω d , corresponding to the radius of a stable accretion disk (e.g., δ Lib, RZ Cas, U Sge) since the mass gainer is larger in size than the predicted disk radius. However, the wider binaries that always form a stable accretion disk (e.g., S Cnc) will be found below the dashed curve labeled ω min , corresponding to the distance of closest approach of the gas stream, hence no impact is predicted since the size of the star is smaller than ω min ; these curves are based on the semianalytical ballistic calculations of Lubow & Shu (1975). It is noticeable that systems between the two curves may have a grazing impact between the gas stream and the mass gainer (e.g., S Equ, SW Cyg, CX Dra) while no impact is expected in other cases (e.g., TT Hya). In this scenario, the direct-impact systems typically have P < 5 -6 days (Struve 1949) while the grazing-impact systems have 6 < P < 12 days.
The dynamics of the direct impact can be understood in terms of the parameters given in Table 2, which lists the thermal or Kelvin-Helmholtz timescale, t kh = GM /RL 2 , where L = 4 πR σT 2 4 ; the dynamical or free fall timescale, t dyn /similarequal ( R /GM 3 ) 0 5 . ; the circularization timescale or the time for the gas to circle the mass gainer at a distance d from the center of the star, t cir = 2 πd/v cir , where v cir = ( GM/d ) 0 5 . and the values in the table correspond to d = R ; the synchronous veloc-
Figure 1. The r-q diagram, where r is the radius of the primary star in units of the separation of the binary and q is the mass ratio. The two curves plotted ω d and ω min represent the smallest radius of a stable accretion disk and the distance of closest approach of the gas stream, respectively.
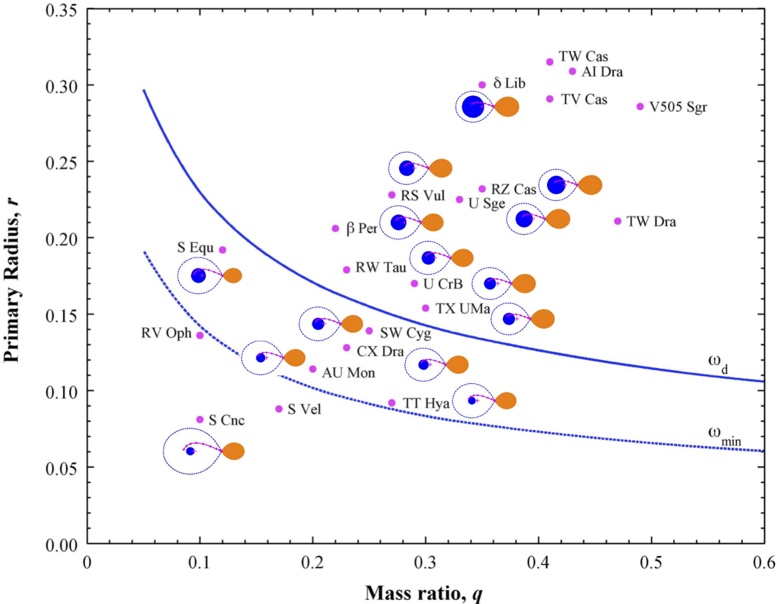
ity of each binary, v syn = 2 πR/P ; the escape velocity for the mass gainer, v esc = (2 GM/R ) 0 5 . ; and the velocity of the gas stream at the impact site or shock region, v imp , derived from the calculation of the gas stream trajectory. For these calculations, the mass, radius, luminosity, and temperature all refer to the mass-gaining star, and P is the orbital period.
Table 2 Dynamical Parameters
The values of t kh in Table 2 suggest that the mass gainer in a typical direct-impact system would radiate its reserves of thermal energy within ∼ 0 5 . -1 8 . × 10 6 yr. However, the star would take only ∼ 0.8 -3.9 hr to respond to the inflow of gas from the companion star ( t dyn in Table 2). Moreover, the gas beyond the impact site would circle the star in only ∼ 4 -17 hr at the stellar surface, d = R (see t cir in Table 2) or ∼ 7 -32 hr at a distance d = 1 5 . R from the center of the star. Moreover, the impact of the gas should spin up the star since the stream impact velocities of 430 -740 kms -1 are much higher than the ∼ 15 -90 kms -1 synchronous velocities of the mass gainer. The stream impact velocity is lower than the predicted escape velocity ( ∼ 550 -830 kms -1 ) except in the cases of RW Tau, RS Vul, and AU Mon.
To illustrate the expected behavior of the gas flow in the velocity domain, we compared plots of the Cartesian representation of the binary with the corresponding velocity frame (see Figure 2). Since the direct-impact systems have eccentricities that are very close to zero, then the binaries can be assumed to be tidally locked. The assumption of synchronous rotation ( P orb = P rot ) provides a relationship between the length and velocity scales that permits the locations of the stars to be plot-
| System | t kh (10 6 yr) | t dyn (hr) | t cir (hr) | v syn (kms -1 ) | v esc (kms -1 ) | v imp (kms -1 ) |
|----------|------------------|--------------|--------------|-------------------|-------------------|-------------------|
| RZ Cas | 1.62 | 0.84 | 3.75 | 62.3 | 673.8 | 514 ± 9 |
| δ Lib | 0.53 | 2.42 | 10.73 | 89.6 | 659.6 | 434 ± 3 |
| RW Tau | 1.07 | 1.27 | 5.63 | 40.2 | 671.3 | 739 ± 11 |
| β Per | 0.943 | 1.61 | 7.14 | 51.2 | 697.5 | 557 ± 7 |
| TX UMa | 1.79 | 1.15 | 5.11 | 38 | 772.6 | 644 ± 11 |
| U Sge | 0.736 | 2.26 | 10.03 | 62.9 | 719.4 | 558 ± 13 |
| S Equ | 0.735 | 1.67 | 7.4 | 41.2 | 649.8 | 566 ± 11 |
| U CrB | 1.43 | 1.49 | 6.6 | 44 | 781.1 | 719 ± 22 |
| RS Vul | 0.195 | 3.85 | 17.11 | 62.2 | 552.3 | 581 ± 8 |
| SW Cyg | 0.597 | 1.66 | 7.38 | 28.8 | 605.5 | 534 ± 8 |
| CX Dra | 1.4 | 1.85 | 8.24 | 30.2 | 834.2 | 576 ± 17 |
| TT Hya | 1.34 | 1.13 | 5.03 | 14.8 | 697.2 | - |
| AU Mon | 0.621 | 2.52 | 11.2 | 21 | 705.3 | 691 ± 65 |
ted in the velocity frame. Figure 2 also displays two large circles around the binary corresponding to the locus of a Keplerian accretion disk in the velocity frame if that disk fills the space between the photosphere and the Roche surface of the mass gainer; the largest solid circle and the smaller dashed circle mark the inner and outer edge of the accretion disk, respectively; and the plus sign marks the center of mass of the binary.
In both the Cartesian and velocity frames, the solid trajectory is the gravitational free-fall path of the gas stream from the L1 point under the influence of the Coriolis force, in the frame of reference of the binary. The trajectory has been divided into ten parts marked by small solid circles to permit a visual comparison of the
Figure 2. Predicted location of the impact site or shock region for direct-impact and grazing-impact systems, for decreasing values of r = R /a 1 . Each subsection shows the Cartesian frame (left image) and velocity frame (right image).
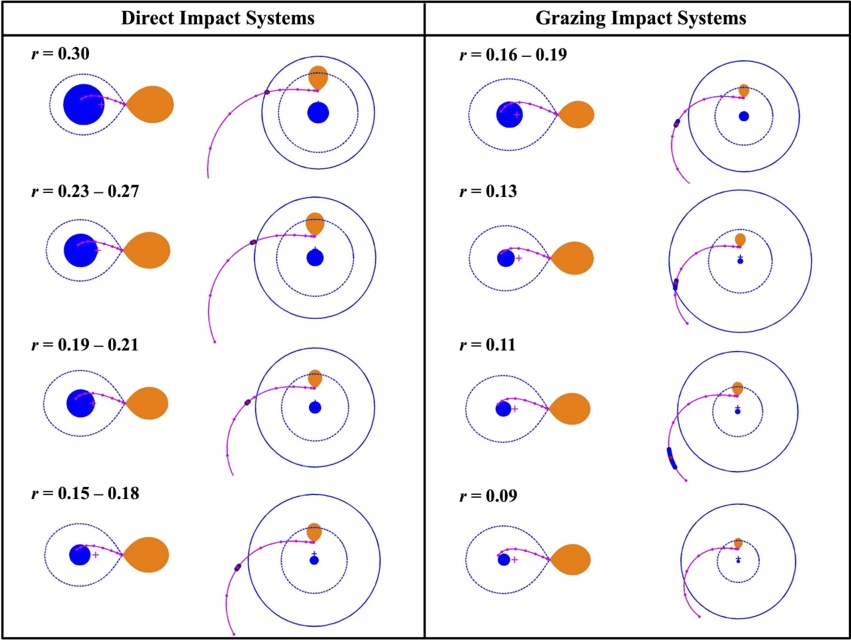
simultaneous position and velocity of a specific location along the gas stream trajectories. In addition, the large solid red circle and the extended blue region along the trajectory represent the median and range, respectively, of the predicted location of the stream-photosphere impact site. The values of the stream velocity at the impact site are listed under v imp in the last column of Table 2.
The impact site was examined in greater detail by Richards (1992) by calculating the ram pressure in the gas stream and the depth of the shock region relative to the stellar photosphere. The depth at which the shock forms is sensitive to the assumed valid of the mass transfer rate. Over a range of mass transfer rates, the stream reached a depth of 2 × 10 -5 R 1 below the photosphere to 4 × 10 -6 R 1 above the photoshere in the case of β Per, suggesting that most of the flow is reflected away from the shock region in this binary. The tangential component of the impact velocities listed in Table 2 can produce substantial differential rotation and redistribution of the gas flow around the mass gainer; and observational evidence of such high rotational velocity regions was found in ultraviolet spectra by Cugier & Molaro (1984) and at H α by Richards (1993). The impact also produces heating of the gas to temperatures of ∼ 10 5 -6 K, and evidence of the shock region was detected as a high temperature accretion region in ultraviolet spectra (Peters & Polidan 1984). Similar behavior is expected for the other directimpact systems.
So, purely in terms of gravitational and Coriolis forces, the gas flow from the L1 point will make direct impact with the surface of the mass gainer in most of the systems under study. Since the flow velocities are much higher than the synchronous velocity of the star, the impact should create an equatorial bulge on the surface of the star, and in a few cases, the gas may be expelled from the system. The conditions at the impact site will be turbulent, and the tangential component of the flow will propel the gas around the star well beyond the impact site on timescales of hours to days, until it reaches the location of the incoming gas stream.
## 3. IMPACT OF DOPPLER TOMOGRAPHY
The image reconstruction technique of tomography can be implemented in two steps: (1) the acquisition of a set of views of the object at directions around the object over the 360 ◦ range of angles; these views are called slices or projections that can be represented mathematically by the Radon transform (Radon 1917; Shepp 1983). (2) The recovery of an image of the original object may be obtained through a summation process called back projection, accomplished by taking each image projection and returning it along the path from which it was acquired. The quality of the reconstruction depends on the number of views acquired and the angular distribution of these views. In general, back-projection tomography uses ( n -1)-dimensional projections to calculate an n -dimensional image of an object (e.g., construct a 3D image using 2D projections, like CAT scans in medicine). Moreover, the technique is robust in that it can be applied to different types of measurements, for example: X-rays (medicine or archaeology), radar (satellite aper-
ture radar - SAR), sonar (oceanography), seismic waves (geophysics), and spectra (astronomy).
Tomography can be applied only if there exist different angular views of a system. For example, since the surface of Venus is obscured by thick clouds and is opaque at optical wavelengths, the reconstruction of its surface was achieved at radio frequencies using radar data collected by the NASA Magellan satellite which orbited the planet for four years from 1990-1994. Eclipsing binaries and rotating stars also provide us with changing views of the system and the reconstruction requires the use of spectra. In these latter cases, the gas motions detected through Doppler shifts of spectral lines are used to provide an image of the gas flows in velocity coordinates, so the technique is termed Doppler tomography .
In two-dimensional back-projection Doppler tomography, the Radon transform of the function, I ( v x , v y ), is a set of projections, p v, φ ( ) representing the line profile , with Doppler shift, v r , at each orbital phase, φ .
$$p ( v, \phi ) = & \int _ { - \infty } ^ { \infty } \int _ { - \infty } ^ { \infty } I ( v _ { x }, v _ { y } ) \delta ( v - v _ { r } ) \ d v _ { x } \ d v _ { y }$$
The reconstruction creates the 2D image I ( v x , v y ) directly from the 1D Doppler shifts of the line profile by inverting the equation for the Radon transform (Marsh & Horne 1988; Kaitchuck et al. 1994).
$$I ( v _ { x }, v _ { y } ) = & \int _ { 0 } ^ { 2 \pi } \int _ { - \infty } ^ { \infty } \int _ { - \infty } ^ { \infty } p ( v, \phi ) \ | \omega | \ e ^ { 2 \pi i \omega ( v - v _ { r } ) } \ d v \ d \omega \ d \phi \quad \begin{pmatrix} \begin{matrix} \begin{matrix} \end{matrix} \end{matrix} \end{pmatrix}$$
where v = ( -v x cos φ + v y sin φ ).
This filtered back-projection formulation can be extended to the next dimension to calculate I ( v x , v y , v z ) by changing p v, φ ( ) to p v, φ, ψ ( ), where ψ is the orbital inclination, setting v = ( -v x cos φ sin ψ + v y sin φ sin ψ + v z sin φ cos ψ ), and integrating over dv dω dφ dψ . The 3D case reverts to the 2D case for ψ = 90 , corresponding to ◦ total eclipses, compared to partial eclipses for lower inclinations. Moreover, while orbital inclinations close to 90 ◦ are preferred for 2D reconstructions, inclinations close to 45 ◦ are optimal for 3D reconstructions (Richards et al. 2010).
The application of Doppler tomography requires one main assumption, namely that the line profiles are broadened only by Doppler motions; which is a good first order approximation, although turbulent motions may contribute (see Kaitchuck et al. 1994 and the extensive discussion in Richards et al. 2010). In addition, we need numerous spectra distributed around the orbit of the binary, with high wavelength resolution and adequate coverage in orbital phase. The technique has been applied to spectra that are dominated by emission, but the generality of the equations suggests that the method may also be applied with prudence to absorption spectra.
In practice, tomography is a summation process and the velocity images are calculated by summing the normalized intensities of the spectra for all velocity pixels after they have been converted to the separate v x and v y components, and then sweeping through all phases around the orbit. In the calculation, the Doppler shifts typically range from -800 to +800 kms -1 relative to the rest wavelength of the line (e.g. H ). α The images are constructed in the velocity domain and can only be converted to the Cartesian domain if the separate velocity
Figure 3. Full-orbit data collection over several epochs for U CrB (left frame), and a representative set of these spectra stacked for epoch 1994 in order of orbital phase from 0.0 to 1.0 (right frame). The arrow in the left frame shows the direction of orbital motion. The spectra are summed in the tomography process relative to the rest wavelength of the H α line in the frame of reference of the mass-gaining star (vertical line).
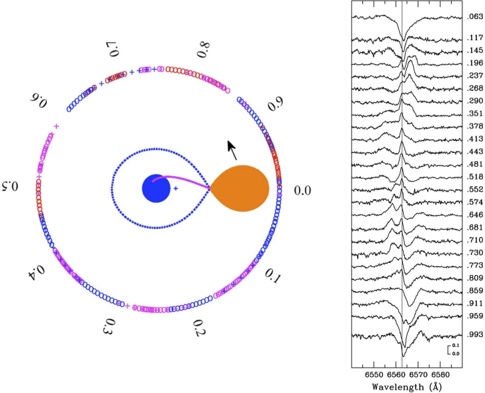
fields of all accretion structures (e.g., gas stream, accretion disk, etc.) are known.
Figure 3 illustrates the full orbit data collection procedure in the case of U CrB, with 294 phases over several epochs. A representative set of these spectra for epoch 1994 were stacked in order of orbital phase from 0.0 to 1.0 in preparation for the summation calculation. Since the spectra of the direct-impact systems are usually dominated by absorption near primary eclipse ( φ ∼ 0 9 . -0 1), . these eclipse spectra were typically excluded from the analysis for these systems. The tomography calculations were implemented using both Fortran and C++ codes with MATLAB as the platform for creating the plots of the images. The speed of the code depends sensitively on the number of orbital phases multiplied by the velocity resolution of the spectrum in pixels.
## 4. APPLICATION TO DIRECT IMPACT BINARIES
Doppler tomography has been applied to eclipsing systems which contain white dwarfs and neutron stars (e.g., cataclysmic variables or CVs, nova-like systems, and soft X-ray binaries), as well as non-compact main sequence stars (e.g., Algol binaries). The main differences between these systems are: (1) the accretion structures in the compact systems are bright relative to the stars, while the structures in the Algols are faint relative to the luminous main sequence mass-gaining star; and (2) the large size of the mass gainer in the Algols leads to the direct impact of the gas stream onto the stellar surface in the short-period Algols, while this type of impact does not occur in the long-period Algols or in compact systems. Hence, composite accretion structures should form in the short-period Algols compared to the classical accretion disks that have been detected in other systems. In all cases, the cool magnetically-active mass-losing star is expected to influence the resulting accretion structures.
Numerous time-resolved spectra of the target systems are required for the tomography calculation in order to
recover a well-resolved image of the gas flows (see Figure 3). Images are usually created from spectral lines in the optical regime since the expected gas temperatures are ∼ 10 K. However, 4 since the H α line is saturated in the spectra of CVs and X-ray binaries, relatively weaker lines have been used, e.g., He I λ 5015, He II λ 4686, H β . Many Doppler tomograms have been created for CVs (e.g., Marsh 2001; Morales-Rueda 2004; Steeghs 2004; Schwope et al. 2004), X-ray binaries (e.g., Vrtilek et al. 2004 for SMC X-1 and Her X-1), and the nova-like binary V3885 Sgr (Prinja et al. 2011). The first tomogram of a black-hole candidate, Cyg X-1, was made by Sharova et al. (2012).
Most of the direct-impact Algol binaries have weak emission-line spectra, so the emission from nonphotospheric gas can be enhanced by subtracting the composite spectrum of the stars from the observed spectrum to create a difference spectrum (e.g., Richards 1993). This subtraction process assumes that the circumstellar gas is optically thin, which is a good first order approximation. However, this assumption can be examined by comparing the tomography images derived separately from the observed and difference spectra (see Section 6). For the direct-impact systems, tomograms have been made predominantly from the H α line, and other images have been constructed from the H β , He I λ 6678, and Si II λ 6371 lines (e.g., CX Dra; Richards et al. 2000), and also from the Si IV λ 1063,1073 doublet and Si IV λ 1394 line in the ultraviolet (Kempner & Richards 1999).
## 4.1. Evidence of Gravitational and Magnetic Activity
Table 3 provides a summary of spectra of Algol binaries (epochs 1976 to 2003) that were processed into images, and it lists the number of orbits, N(orbits), the number of phases, N(phi), and the velocity resolution of the spectra, N(vel). These data were derived primarily from the extensive database of direct-impact systems described by Richards & Albright (1999) for which the spectra have high signal-to-noise (typically S/N > 100), high wavelength resolution (see Table 3), and coverage of the entire orbit of each binary (see Figure 3). Other spectra were included for three systems: β Per (epochs 1976-1977; Richards 1992), TT Hya (epochs 1985-2001; Miller et al. 2007), and AU Mon (epochs 1984 - 2003; Atwood-Stone et al. 2012). The best images are obtained from data with the highest number of phases distributed around the orbit (i.e., high N(phi)), and from spectra with the highest resolutions (i.e., high N(vel)). Moreover, datasets collected over the smallest number of orbits are preferred since they show the state of the gas over fewer dynamical timescales (see Table 2).
The 2D velocity images derived from back-projection Doppler tomography of the H α line are shown in four parts in Figure 4: 4(a-f), 4(g-l), 4(m-r), and 4(s-t), for thirteen systems listed in order of orbital period from P = 1 195 days (RZ Cas) to . P = 11 113 days (AU Mon). . In addition, the images of four systems are shown at multiple (2-3) epochs ( β Per, TX UMa, U Sge, U CrB). These figures show the Cartesian representation of each binary, the trailed spectrogram, color and contour tomograms and the corresponding color bar for the images. A reference template is overlaid on all images to show the expected locations of the stars, the gas stream gravitational trajectory, and the locus of a Keplerian accretion
Table 3 Data on a Variety of Algol Binaries and an RS CVn Binary
| System | Epoch | N(nights) | N(orbits) | N(phi) | N(vel) |
|----------|-----------|-------------|-------------|----------|----------|
| RZ Cas | 1994 | 7 | 5.9 | 28 | 262 |
| δ Lib | 1993 | 7 | 3 | 51 | 275 |
| RW Tau | 1994 | 7 | 2.5 | 30 | 275 |
| β Per | 1976-1977 | 23 | 156.9 | 59 | 728 |
| β Per | 1992 | 7 | 5.6 | 135 | 503 |
| β Per | 1994 | 7 | 2.4 | 36 | 275 |
| TX UMa | 1992 | 15 | 4.9 | 81 | 468 |
| TX UMa | 1993 | 29 | 27.4 | 114 | 468 |
| TX UMa | 1994 | 14 | 62 | 27 | 275 |
| U Sge | 1993 | 12 | 9.5 | 106 | 256 |
| U Sge | 1994 | 7 | 2.1 | 48 | 275 |
| S Equ | 1993 | 12 | 9.3 | 57 | 275 |
| U CrB | 1993 | 41 | 24.3 | 161 | 459 |
| U CrB | 1994 | 14 | 55 | 47 | 275 |
| RS Vul | 1993 | 12 | 7.1 | 81 | 275 |
| SW Cyg | 1994 | 7 | 1.5 | 36 | 275 |
| CX Dra | 1994 | 7 | 1 | 54 | 275 |
| TT Hya | 1994-1997 | 22 | 158.3 | 45 | 446 |
| AU Mon | 1988-2003 | 64 | 458.2 | 83 | 217 |
| V711 Tau | 1994 | 7 | 2.5 | 27 | 209 |
disk; these were illustrated in Figure 2 and described in Section 2.
In addition, since the mass-losing star in many interacting binaries is a cool magnetically-active star, we used the tomogram of the detached RS CVn binary V711 Tau (HR 1099) to illustrate the location of H α emission from a magnetically active star (see Table 3). V711 Tau consists of a G star with a K star that nearly fills its Roche lobe; and the tomogram shown in Figure 4 (t) illustrates that most of the emission arises from the K-star component, which is similar to the mass loser in the directimpact systems.
The tomograms of Algol binaries in Figure 4 reveal several distinct sources of H α emission which result from a combination of gravitational forces and magnetic activity. The main sources in the image are in accordance with the expected behavior of the gas flow from the L1 point under the influence of gravity and Coriolis forces, as described in Section 2. In addition, nearly all systems display evidence of magnetic activity associated with the mass-losing star. This latter result is surprising given that the mass-losing star contributes a small fraction of the total luminosity of the binary (only 5-15%, depending on wavelength), and it was considered to be relatively unimportant in the mass transfer process, besides being the source of the gas flow through the L1 point.
The sources of H α emission seen in the 2D images are described below:
(1) a source of magnetic activity associated with the cool mass-losing star , including emission from the chromosphere, prominences, flares, and coronal mass ejections. The tomogram of V711 Tau illustrated that the emission from the cool star has the same velocity as that star. This type of emission was detected in almost all systems, including RZ Cas, δ Lib, β Per, TX UMa, U Sge, S Equ, U CrB, RS Vul, CX Dra, and AU Mon; the exceptions were RW Tau, SW Cyg, and TT Hya. The byproducts of magnetic activity revealed in the velocity images of so many systems should not be surprising since the mass-losing stars have spectral types from F0 to K2
Figure 4(a-f). Two-dimensional H α Doppler tomograms of direct-impact and wider binaries in order of increasing orbital period: RZ Cas (epoch 1994), δ Lib (epoch 1993), RW Tau (epoch 1994), β Per (epochs 1976-77, 1992, 1994). For each system, we show the Cartesian representation of the binary (left frame), with the trailed spectrogram (middle frame), and the color and contour tomograms (right frames), with color bar intensities in normalized units relative to the continuum. The images were derived from difference spectra.
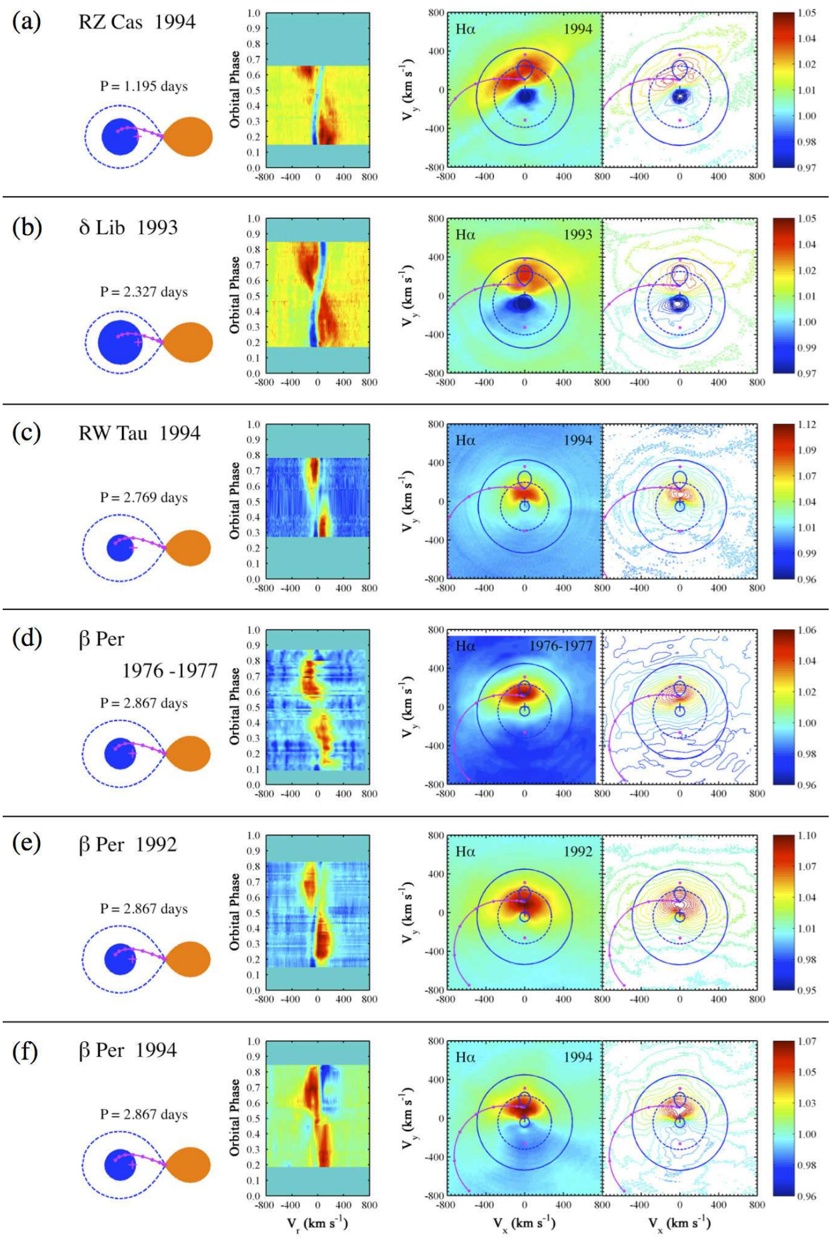
Figure 4(g-l). Same as Figure 4a for TX UMa (epochs 1992, 1993, 1994), U Sge (epochs 1993, 1994), S Equ (epoch 1993).
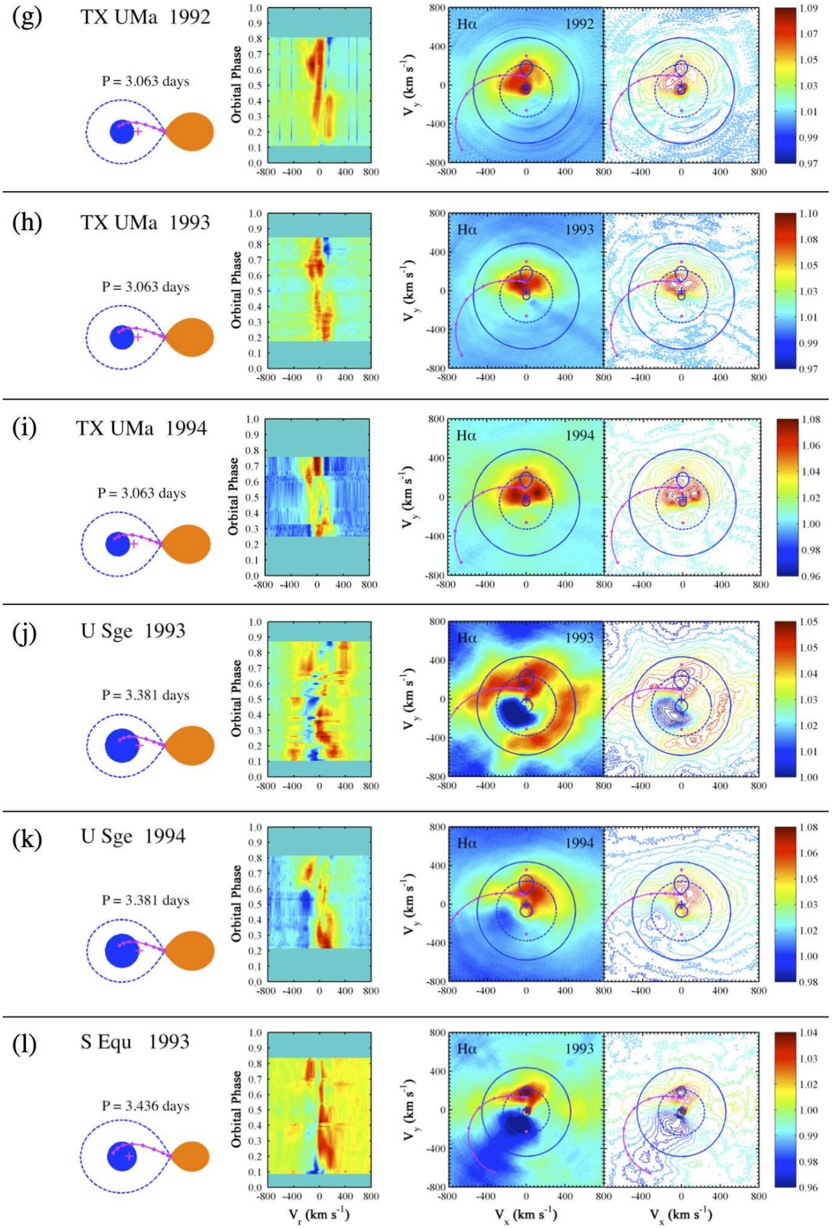
Figure 4(m-r). Same as Figure 4a for U CrB (epochs 1993, 1994), RS Vul (epoch 1993), SW Cyg (epoch 1994), TT Hya (epochs 1994-1997).
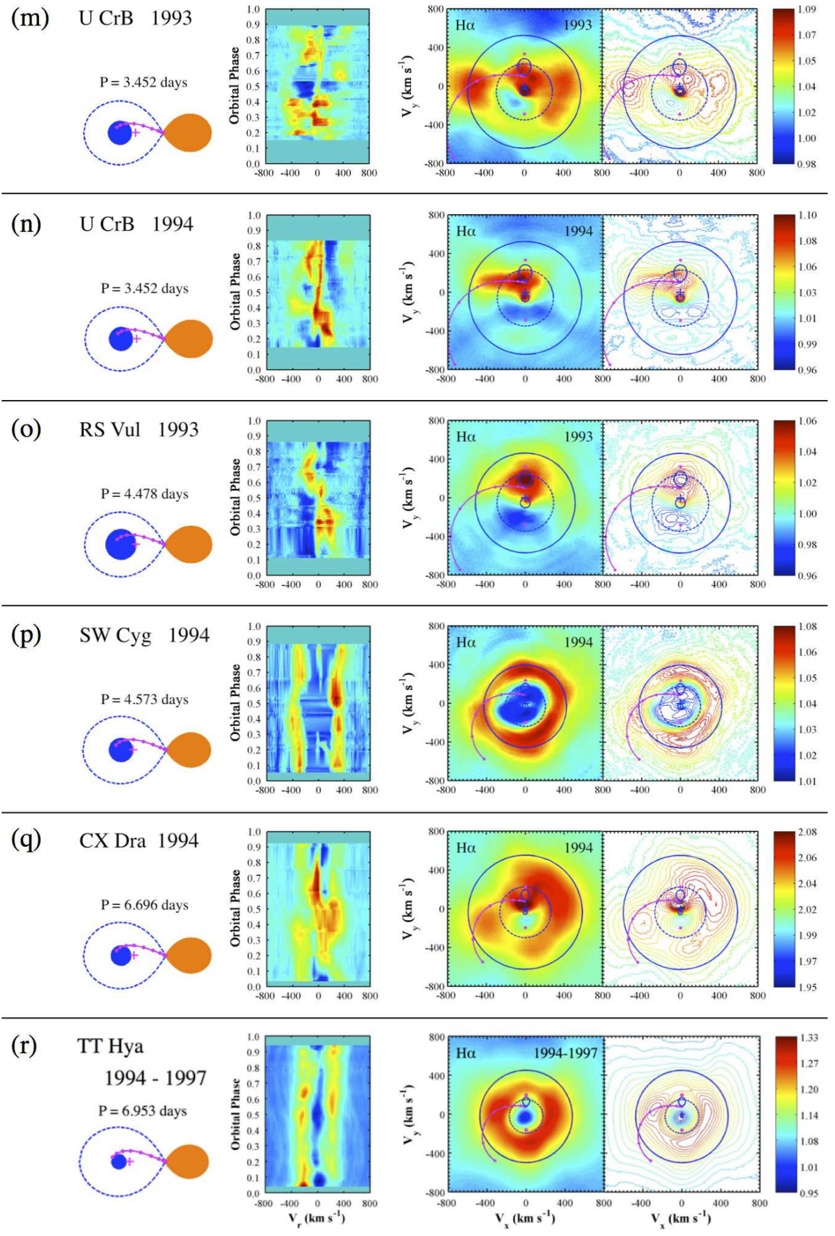
Figure 4(s-t). Same as Figure 4a for AU Mon (epochs 1988-2003) and the detached binary V711 Tau (epoch 1994), where the tomogram of the latter system was derived from observed spectra. V711 Tau consists of a G star with a K star that nearly fills its Roche lobe, and the tomogram shows that most of the H α emission arises from the more active K star, which is similar to the mass loser in the direct-impact systems.
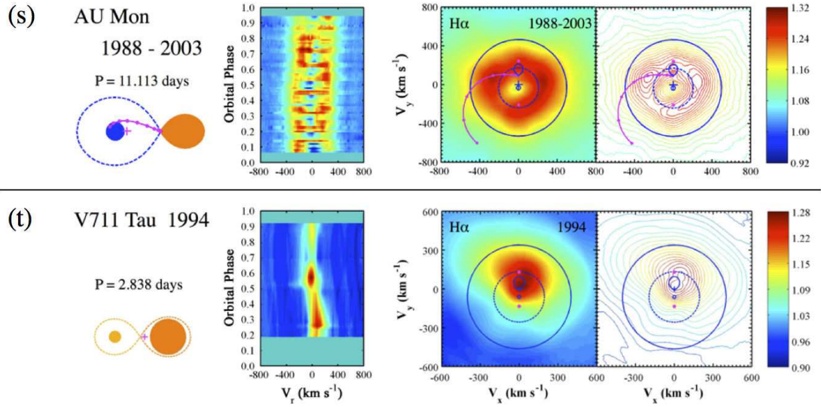
and there is independent evidence of magnetic activity in these systems (Richards & Albright 1993; Sarna et al. 1997).
(2) a gas stream along the predicted gravitational trajectory (e.g., RZ Cas, δ Lib, RW Tau, β Per, TX UMa, U Sge, S Equ, U CrB, RS Vul, CX Dra, AU Mon). In most of these systems, the gas stream flows along or close to the predicted gravitational trajectory. The exception is TX UMa in which the stream path appears to be deflected during epochs 1992 and 1994 but not during epoch 1993. It is interesting also that the emission associated with the cool star is weaker during epoch 1993 relative to the other epochs. TX UMa is known to be magnetically active (Richards & Albright 1993; Sarna et al. 1998), and therefore, it should not be surprising that enhanced magnetic activity in the form of prominences or coronal mass ejections could deflect the gas stream flow away from the expected gravitational trajectory.
primary bulge detected via photometry as a hot band around the equator of the mass gainer (e.g.,RZ Cas Olson 1982; U Sge Olson 1987). The impact increases the rotational velocity of the star beyond the synchronous value (Etzel & Olson 1993). Spectroscopic studies of TX UMa by Komzik et al. (2008) and Glazunova et al. (2011) also found that the mass-gainer in this binary rotates ∼ 1 5 . -2 times the synchronous velocity as a result of the impact. So, the images have confirmed the photometric and spectroscopic evidence of the circumprimary bulge.
With increased room between the stars, the gas stream can make its way around the mass-gaining star to form a transient or stable accretion disk (e.g., TT Hya and AU Mon).
(3) a star-stream impact region where the gas stream strikes the surface of the mass-gaining star. The expected location of this shock region was discussed in Section 2 and shown in Figure 2 for different values of the size of the mass gainer. In most cases, the shock should occur close to the intersection of the gas stream path and the circle representing the Keplerian velocity of the mass gainer. Extended emission at this location is visible in the velocity images for U Sge (epoch 1993), U CrB (epoch 1993), and S Equ.
(4) a bulge of extended absorption or emission around the mass-gaining star produced by the impact of the high velocity stream onto the slowly rotating photosphere (e.g., RZ Cas, δ Lib, TX UMa (epochs 1992 and 1994), U Sge (both epochs), S Equ, U CrB (both epochs), and RS Vul). This is the same region as the circum-
- (5) a transient or permanent accretion disk around the mass-gaining star. Accretion disks were found in all systems with P orb > . 4 6 d (e.g., SW Cyg, CX Dra, TT Hya, AU Mon). Disks were also found in U Sge (epoch 1994) and U CrB (epoch 1994), however the gas distribution in these two systems can be transformed from a disk-like state to a stream-like state within a few orbital cycles. The evidence of this variability can be seen in the trailed spectrograms and in the individual spectra through the change from a double-peaked profile to a single-peaked profile.
(6) an absorption zone where the gas flows are seen in absorption (e.g., U Sge, S Equ, U CrB, RS Vul, SW Cyg, CX Dra). A tomogram created from the SiIV λ 1394 line of U Sge is seen in Figure 7 and shows that the main source of emission in the ultraviolet overlaps with the absorption zone, which in turn represents the locus of hotter gas ( T ∼ 10 K). 5
(7) a disk-stream impact region where the circling gas strikes the incoming stream and is slowed by the impact (e.g., RW Tau, β Per, TX UMa, U Sge, S Equ, U CrB, RS Vul, CX Dra). The result is a region of emission nearly along the line of centers with velocities lower than that of a Keplerian disk, i.e., within the locus of the disk in the velocity image. Therefore, in the systems with 2 8 . d ≤ P orb < 6 7 . d , except for SW Cyg, after the gas stream strikes the star it has enough angular momentum to flow around the star until it comes in contact with
Figure 5. Types of emission structures identified in the tomograms, listed in order of increasing orbital period (top to bottom).
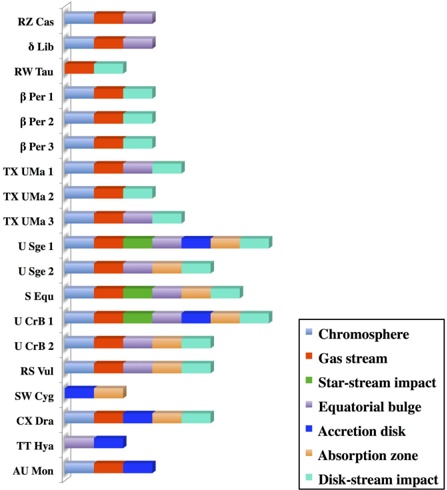
the incoming stream. In these systems, the density of the gas stream must be higher than the density of the gas that has circled the mass gainer. This region has been called the Localized Region (e.g., β Per, Richards 1992; RW Tau, Vesper & Honeycutt 2001; other systems, Vesper et al. 2001). In wider binaries, the gas stream makes a more grazing impact and forms a more extensive flow in an accretion disk, so it is more difficult to determine where the disk intersects with the incoming stream in the velocity image.
A pictorial representation of the variety of emission sources is shown in Figure 5. This figure illustrates that the gas stream emission was sufficiently bright to be detected in the images of most systems.
## 4.2. Transition from Stream-state to Disk-state
Figure 6 summarizes the transition in the line profile at quadrature, the emission sources in the velocity image, and the trailed spectrogram, with increasing binary separation (semi-major axis, a ). The progression from the upper to lower parts of this figure illustrate the transformation from the stream state to the disk state . In essence, the closest binaries (e.g., δ Lib) typically display only emission associated with the mass-losing star, and hence evidence of magnetic activity, because there is insufficient room for the gas stream to make its way around the mass gainer. If there is some extra room between the stars, the gas stream can progress farther along, and we find evidence of extended gas streams along the projected gravitational path in several systems (e.g., S Equ, RS Vul, U Sge, U CrB). In the widest systems (e.g., TT Hya, AU Mon), there is sufficient room to form a Keplerian accretion disk. Over the range of systems, the line profile at quadrature shows a progression from nearly singlepeaked profiles indicative of gas streams in the closest systems (smaller a ), to distinct double-peaked profiles
Figure 6. Summary of the transition in the line profile at quadrature, velocity image, and trailed spectrogram for a representative set of Algol binaries in our survey, from smaller binary separation (upper frames) to larger separation (lower frames). The progression illustrates the change from the stream state to the disk state. indicative of accretion disks in the wider systems (larger
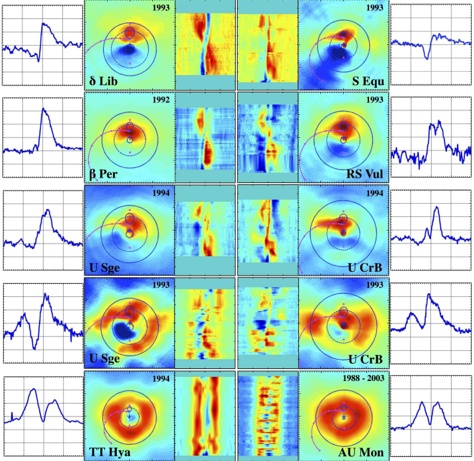
a ).
Potential variability in the images was examined in four systems for which data were collected at multiple epochs (i.e., β Per, TX UMa, U CrB, U Sge), although data were also collected over an extensive range of epochs for CX Dra, TT Hya, and AU Mon. The images of β Per suggest that this system was relatively stable over many orbital cycles (epochs 1976 to 1994), however there was a slight change in the direction of the gas stream in TX UMa between epochs 1992 and 1994, suggesting the influence of magnetic activity on the cool star in that system (see earlier discussion in Section 4.1). In addition,U CrB and U Sge are unusual because they display both stream-like and disk-like states at different epochs (see Figure 6 and Section 4.1), and a closer examination of their spectra suggest that these binaries may alternate regularly between the two states. Consequently, U CrB and U Sge have been designated as Alternating Systems , and the source of the variability may be linked to magnetic activity on the mass-losing star (see Richards et al. 2003 and the discussion in Section 6).
The images of accretion disks in the wide grazingimpact systems are similar to those of the cataclysmic variables (e.g., Kaitchuck et al. 1994; Szkody et al. 2000, 2001; Prinja et al. 2011). Hence, stable accretion disks are found in binaries containing both compact and main sequence mass gainers.
## 4.3. Multiwavelength Observations
Multiwavelength spectra of Algol binaries have been collected at wavelengths 4800 ˚ A -6700 ˚ , including the A Hβ Hα , , He I λ 6678, and Si II λ 6371 lines. In addition, ultraviolet spectra of 17 Algol binaries can be found in the IUE archives from epochs 1978 to 1996. The first ultraviolet image of U Sge was derived from the Si IV λ 1394 doublet (epoch 1983-1994) after the contribution
Figure 7. Multiwavelength tomograms of (a) U Sge and (b) CX Dra showing the emission structures detected at different wavelengths. The images of U Sge were obtained at H α (epochs 1993, 1994) and Si IV λ 1394 (epoch 1983 - 1994; Kempner & Richards 1999), and for CX Dra at H α , H , He I β λ 6678, and Si II λ 6371 (epochs 1975-1998; Richards et al. 2000).
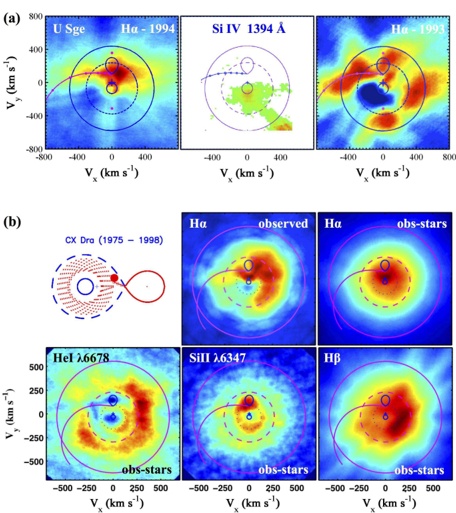
of the stars was extracted from the spectra. Figure 7(a) shows that the Si IV emission overlaps with the absorption zone identified in the H α image for epoch 1993, and can be interpreted as the locus of gas that was heated beyond the 10 K regime associated with H 4 α to temperatures of 10 5 K in the UV region (Kempner & Richards 1999). Figure 7(b) displays the multiwavelength images of CX Dra, and demonstrates that the He I λ 6678 and Si II λ 6371 emission arise from an extended accretion disk, while the H α and H β emission arise primarily from a compact region where the gas stream strikes the outer edge of the disk (Richards et al. 2000). These results suggest that a more comprehensive understanding of the gas flows can be obtained when images are constructed for different temperature regimes.
## 5. INFLUENCE OF THE SYSTEM PROPERTIES
The attractiveness of tomography is that it is a robust technique; however it is useful to discover how various criteria influence the resulting 2D image constructed from the back-projection technique. It should be noted that the tomograms shown in Figure 4 were computed without any filtering, smoothing, denoising or other regularization of the images. The only additional processing was to interpolate the images in orbital phase to reduce the radial spoke-like streaks produced by the back-projection procedure when there are gaps in orbital phase. In spite of the minimal processing, the amount of detail manifested in the images is truly remarkable.
In this section, we examine the effects of (1) orbital inclination, (2) systemic velocity, (3) orbital phase coverage, (4) velocity resolution, and (5) shadowing on the tomography results.
## 5.1. Orbital Inclination
The effects of adopting different values of orbital inclination are shown in Figure 8 for a direct-impact binary (e.g., U CrB) and a wider binary (e.g., TT Hya). The main result is that the image size decreases as the inclination increases from 50 ◦ to 90 . ◦ Moreover, the measured inclinations of U CrB ( i = 79 1 ) and TT Hya ( . ◦ i = 84 4 ) . ◦ lead to images that are consistent with the template of predicted locations for the gas stream and disk in the velocity frame.
## 5.2. Systemic Velocity
Figure 8 illustrates the effect of adopting a systemic velocity for the binary, V o , that is inconsistent with the measured value; the result is a distortion of the image. The example cases of U CrB and TT Hya have systemic velocities of -6 7 . kms -1 and 0 0 kms . -1 , respectively, and the corresponding 2D images are therefore similar to the image for V o = 0 kms -1 .
## 5.3. Orbital Phase Coverage and Velocity Resolution
Figure 8 illustrates the effect of phase coverage on the resulting 2D image using two subsets the U CrB and TT Hya data. The images were made from three sets of data: a subset of the full dataset (left frame), after this subset was interpolated to create a grid of 100 evenlyspaced phases (middle frame), and the full dataset (right frame). Insufficient orbital phase coverage creates radial spoke-like streaks across the diagram. However, an interpolation in orbital phase adequately represents the outcome when the full dataset is used to construct the image.
The resolution of the H α line was typically 0.17 ˚ /pixel A (N(vel) = 275) and was as fine as 0.09 ˚ /pixel (N(vel) = A 503). Since the wavelength or velocity resolution of the spectra is already very high, an increase in the resolution does not result in any significant improvement in the resulting 2D image. However, poor wavelength resolution in the spectrum would lead to a coarser image.
## 5.4. Shadowing and the Transparency of the Medium
The effect of shadowing results when the passage of light through a medium is obstructed because of the opacity of the medium. Hence, the view from one direction may not be identical to that from the opposite direction 180 ◦ away. A similar effect called an acoustic shadow in radar tomography occurs when radio waves fail to propagate due to some topological obstruction, or in medical tomography because of the attenuation of light by denser parts of the medium (Girard et al. 2011).
Figure 8 shows images produced from data at phases φ = 0 0 . -0 5 (left), . φ = 0 5 . -1 0 (middle), and the com-. plete data set (right) to check for the effect of shadowing in the example cases of U CrB and TT Hya. The rough resemblance between the images derived from half the orbit and that from the full orbit suggest that shadowing, if it exists, does not play a significant factor in the resulting tomograms. Instead, the uneven sampling of the data for each half orbit and the number of spectra in each dataset have larger effects on the resulting image.
An alternative way to examine the opacity of the medium is to compare the tomograms derived from the observed and difference spectra, since the subtraction of
Figure 8. Effects of the parameters on the 2D image: (a) orbital inclination: i = 50 ◦ -90 ◦ ; (b) systemic velocity: V o = -100 0 +100 km , , s -1 ; (c) phase coverage around the orbit for a subset of the data, an interpolation of the subset using 100 evenly-spaced phases, and the full dataset; and (d) shadowing study using data at phases φ = 0 0 . -0 5, . φ = 0 5 . -1 0, and the complete data set. . The results are shown for the cases of U CrB (epoch 1994; left frames) and TT Hya (epoch 1994-1997; right frames). The measured inclinations and systemic velocities of U CrB and TT Hya are (79 1 . ◦ , -6 7 kms . -1 ) and (84 4 . ◦ , 0 0 kms . -1 ), respectively.
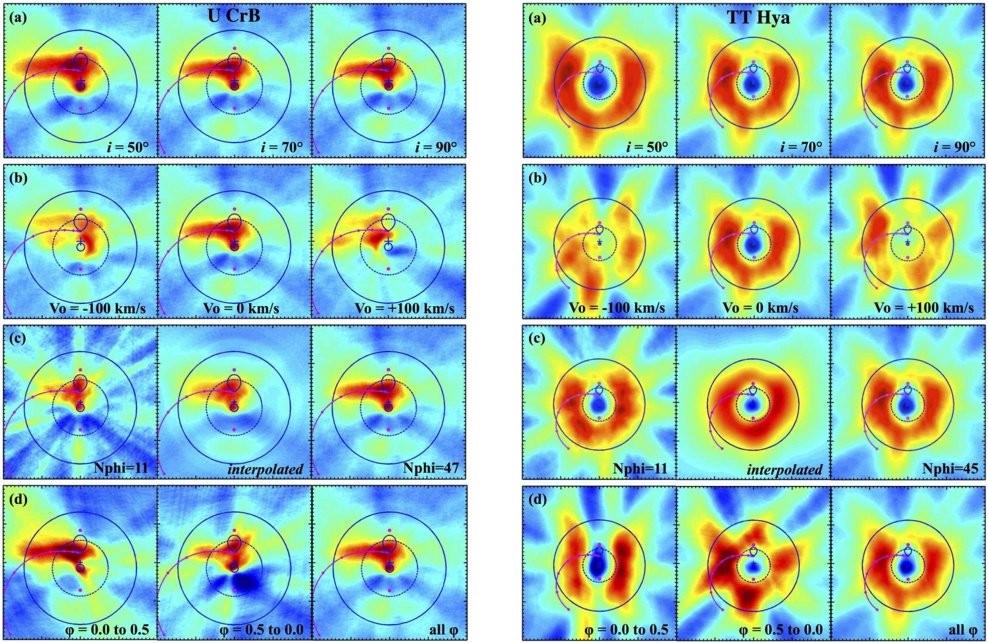
the stellar spectra from the observed spectrum assumes that the circumstellar gas is optically thin. In the case of CX Dra, the observed and difference H α images shown in Figure 7(b) are not similar in appearance, which suggests that the circumstellar gas in CX Dra was not optically thin. However, there is evidence from similar comparisons that the circumstellar gas is optically thin in TT Hya and AU Mon (see Section 6.3), in agreement with the results of the shadowing test for TT Hya (Figure 8).
## 6.1. S-wave Analysis
## 6. PHYSICAL PROPERTIES DERIVED FROM THE IMAGES
The 2D velocity images have provided visual confirmation of the existence of both gravitational and magnetic structures in the direct-impact and grazing-impact Algol binaries. In addition, the physical properties of the gas flows can be derived from the data and images using (1) an analysis of the S-wave patterns in the trailed spectrograms, (2) the creation of simulated tomograms derived from hydrodynamic simulations, (3) the computation of synthetic spectra of the accretion structures, and (4) a systematic extraction of the separate accretion structures using synthetic spectra with tomography. These procedures require substantial effort and we present here some examples of the results that have been achieved so far. These results have enhanced our interpretation and understanding of the gas flows in both the velocity and Cartesian frames.
The trailed spectra of the direct-impact binaries display one or two sinusoidal patterns called S-waves which represent the orbital radial velocity variations of the emission peaks (see Figures 4 and 6). These patterns can be used to identify the locations of the most intense sources of emission in the velocity image. Figure 9 shows that the H α emission peaks roughly follow the velocity curves of the stars, sometimes with a smaller amplitude, in direct-impact systems when they are in the stream state (e.g., δ Lib, RW Tau, β Per, U Sge, S Equ, U CrB, RS Vul). However, the emission peaks appear to be independent of the velocity curves when the gas is in a disk state (e.g., TT Hya).
In the direct-impact binaries, the larger variation is associated with the mass-losing star so the ratio of velocity semi-amplitudes of the mass loser and the S-wave source should be the same as the ratio of their distances from the center of mass. As a result, this S-wave source is located at a distance a s = a 2 × ( K /K s 2 ) from the c.m. of the binary, where K 2 is the velocity semi-amplitude of the mass loser, a 2 = a/ (1 + q ) is the distance of the mass loser from the c.m. of the binary, and K s is the velocity semi-amplitude of the S-wave. A similar argument follows for the other S-wave associated with the mass-gaining star.
S-wave analyses for β Per (epochs 1976-1977) and CX
Figure 9. Velocity curves of the stars superimposed on the trailed spectra. The first seven frames show that the H α emission peaks roughly follow the velocity curves of the stars in direct-impact systems when they are in the stream state (e.g., δ Lib, RW Tau, β Per, U Sge, S Equ, U CrB, RS Vul). However, the emission peaks appear to be independent of the velocity curves in last frame (bottom right) when the gas is in a disk state (e.g., TT Hya).
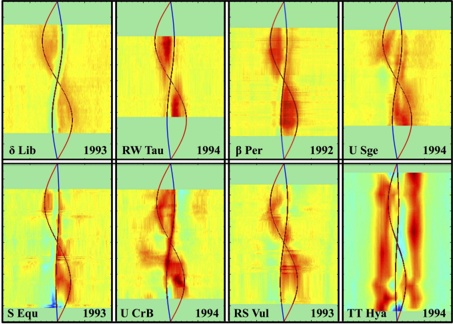
Dra (epochs 1975 - 1998) have identified the location of the most intense sources of H α emission in these binaries. Figure 10 illustrates the dominant S-wave solution in the velocity frame (large red dot; left frame), the S-wave superimposed on the trailed spectrum (middle frame), and the predicted source of the dominant S-wave in the Cartesian frame (large red dot; right frame) for these binaries.
For the case of β Per (epoch 1976-1977), the source of the dominant S-wave was located nearly along the line of centers between the stars, with coordinates ( V , V x y ) = ( -7 5 . , 77 3) . kms -1 relative to the center of mass of the binary (Richards, Jones & Swain 1996). The corresponding source in Cartesian coordinates was found at a distance a s = 0 53 . a compared to the location of the L 1 point at 0 650 . a from the c.m. of the binary, for K 2 = 201 kms -1 and q = 0 22. . This source is consistent with the location of the Localized Region in the Cartesian map predicted by Richards (1993).
The analysis of CX Dra (epochs 1975-1998) identified the dominant S-wave source at ( V , V x y ) = ( -21 0 . , 46 0) . kms -1 relative to the c.m. of the binary (Richards et al. 2000). The derived value of K s = 52 ± 3 kms -1 led to a s = 0 30 . a from the c.m. of the binary compared to a L 1 = 0 645 . a , for K 2 = 146 kms -1 and q = 0 23. . Figure 10 shows the position of the S-wave source relative to the predicted locus of the accretion disk derived from the HeI λ 6678 line (shown in Figure 7). This S-wave solution is consistent with the H α velocity image and suggests that the H α emission along the gas stream path was interrupted by the presence of a slightly hotter accretion disk. Hence, this source represents the location of the stream-disk impact site or 'hot spot' and should be added to the list of seven emission sources described in Section 4.1. Similar analyses can be performed for other systems.
## 6.2. Simulated Velocity Tomograms Derived from Hydrodynamic Calculations
Hydrodynamic simulations are useful in the study of accretion flows because they illustrate the evolution of
Figure 10. Illustration of the S-wave results for β Per (19761977; upper frames) and CX Dra (1975-1998; lower frames). The dominant S-wave solution in the velocity frame (large red dot; left frame), the S-wave superimposed on the trailed spectrum (middle frame), and the predicted source of the dominant S-wave in the Cartesian frame (large red dot; right frame) are shown along with the predicted locus of the accretion disk in CX Dra.
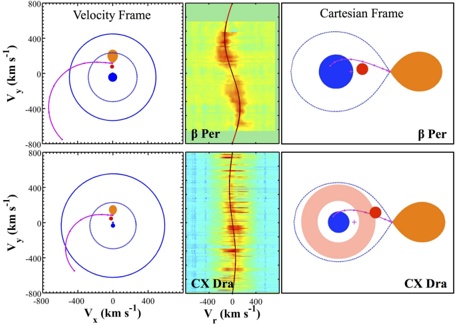
the flow under a variety of initial conditions, and can be used to constrain the properties of the gas flows derived from spectroscopic analysis. These simulations can be used to model the H α emissivity and to study the evolution of the flow simultaneously in spatial and velocity dimensions. This was achieved by Richards & Ratliff (1998) for two Algol binaries: β Per and TT Hya, which span the range from direct-impact to disk-state systems. They used the VH1 (Virginia Hydrodynamics-1) 2D hydrodynamics code, which incorporates the effects of gravity and Coriolis forces, and assumes optically-thin radiative cooling of the gas; no magnetic effects were included in these simulations.
For each binary, a simulated velocity tomogram can be constructed by summing the velocity images derived from the simulations over a range of epochs, t = (2 -4) P , where P is the orbital period, for comparison with the Doppler tomograms computed from observed spectra. Figure 11 shows the simulated velocity tomograms of β Per and TT Hya for two values of the initial density of the gas stream at the L1 point: 10 8 cm -3 and 10 9 cm -3 . In the case of β Per, only the gas stream would be observed at the lower density because the remaining gas is nearly a factor of 10 3 fainter than the gas stream, while both the gas stream and the disk would be observed at the higher density because they have comparable intensities. Similarly, the gas stream and disk are substantially brighter in TT Hya at the higher density.
The similarity between the H α Doppler tomograms of the alternating systems at different epochs (specifically U CrB and U Sge) and the simulated tomograms of β Per at the two densities suggest that the variable and alternating behavior of the gas flows may be associated with changes in the density of the gas stream, and hence with changes in the mass transfer rate (Richards & Ratliff 1998). Moreover, since the change between stream state and disk state in U CrB and U Sge can occur within days, which is much shorter than the Kelvin-Helmholtz timescales listed in Table 2, Richards et al. (2003) proposed that the alternating behavior may be triggered by flaring activity on the mass-losing star and could be associated with magnetic activity on the cool star.
Figure 11. Simulated velocity tomograms of β Per (top frames) and TT Hya (bottom frames) based on hydrodynamic simulations for two values of the initial density of the gas stream at the L1 point: 10 8 cm -3 (left frames) and 10 9 cm -3 (right frames). The H α emissivity, I, is given in powers of 10 on the color bar.
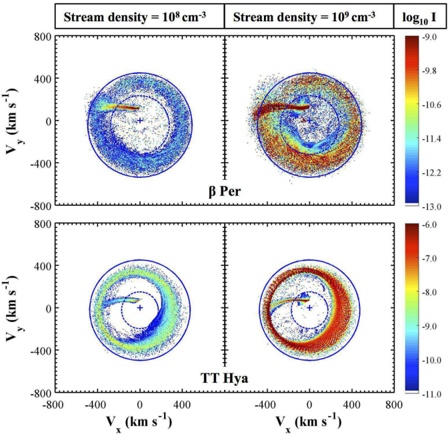
The significant flaring cycles for β Per (a direct-impact system) and for V711 Tau and UX Ari (two RS CVn binaries) at radio frequencies of 2.3 GHz and 8.3 GHz are given in Table 4 based on a 5.6-year nearly-continuous survey of radio flares (Richards et al. 2003). These results suggest that flares could influence the mass transfer process regularly, as often as every 8 - 42 orbital cycles. This survey demonstrated that radio flares from β Per occurred with a predictable cycle of 49 days, which could result in sporadic mass ejections through the L1 point on that timescale.
An alternative explanation is that the change in the image could result from the interaction between the incoming gas stream and the gas that has circled the star since the variability timescale of days is comparable to the circularization timescale t circ (see Table 2).
In the case of TT Hya, the hydrodynamic simulations produced an accretion disk that was asymmetric in both Cartesian space and velocity coordinates (Figure 11). This important result went unnoticed for nearly 10 years until a synthetic spectrum of a symmetric accretion disk was modeled, extracted from the observed spectrum, and used to construct a difference Doppler tomogram of TT Hya (Miller et al. 2007). This procedure revealed a small arc of emission within the locus of the accretion disk in the Doppler tomogram exactly at the location of the disk asymmetry seen in the simulated tomogram (see Figure 12 and Section 6.3). In summary, the construction of simulated tomograms from hydrodynamic calculations under controlled conditions have improved our understanding of the geometry and dynamics of the accretion flows in both velocity and Cartesian dimensions.
## 6.3. Extraction of Emission Sources using Synthetic Spectra
The computation of synthetic spectra provides us with a tool that can be used to extract the separate sources of emission from the composite tomograms of the direct-
Table 4 Periodicities of Radio Flares at 2.3 GHz and 8.3 GHz
| System | P orb (d) | Flaring cycles, P | P/P orb |
|----------|-------------|-------------------------|------------|
| β Per | 2.87 | 48.9 ± 1.7 | 17.1 |
| V711 Tau | 2.84 | 120.7 ± 3.4, 80.8 ± 2.5 | 42.5, 28.5 |
| UX Ari | 2.33 | 141.4 ± 4.5, 52.6 ± 0.7 | 22.0, 8.2 |
impact and disk-state Algol systems. The shellspec code can create composite spectra and light curves of interacting binaries which contain moving transparent or non-transparent 3D structures such as a disk, stream, spot, jet, or shell, in addition to the stars. This code solves the simple radiative transfer along the line of sight in LTE, in an optional optically thin 3D moving medium (see Budaj & Richards 2004 for details). In addition, Budaj, Richards & Miller (2005) used the code to examine the effects of various free parameters and how doublepeaked emission from an accretion disk is formed. They found that the overall strength of the emission is influenced mainly by the density and temperature of the disk, while the position and separation of the emission peaks are influenced by the outer disk radius, the inclination, and the radial density profile. Furthermore, the depth of the central absorption in the profile is very sensitive to the temperature, inclination, geometry, and dynamics of the disk.
The shellspec code was used to sequentially model the composite synthetic spectra of the (i) stars, (ii) stars and disk, (iii) stars, disk, and gas stream, or (iv) stars, disk, gas stream, and spot (e.g., Localized Region). These calculations require the availability of optimal values for the orbital elements and stellar properties, and well as initial estimates of the temperature, mass density and electron number density of the disk. The estimated density of the stream at the L1 point was chosen to improve the fit between the observed and synthetic emission at the quadratures of the orbit and during the eclipses. The density was allowed to vary along the stream to satisfy the continuity equation, and the electron number densities in the disk and stream were calculated from the temperature, density, and chemical composition using the Newton-Raphson linearization method. The resulting composite synthetic spectrum provides a good comparison with the observed H α spectra for TT Hya (Miller et al. 2007) and AU Mon (Atwood-Stone et al. 2012).
The comparison between the observed and synthetic spectra can provide us with the physical properties of the accretion structures. For TT Hya, Miller et al. (2007) adopted an initial disk temperature of 7000 K and found that the disk extends up to about 10 solar radii and has a vertical thickness comparable to the diameter of the primary star, with mass density of ∼ 10 -14 g cm -3 and electron number density of ∼ 10 10 cm -3 . The initial gas stream temperature was set to 8000 K, corresponding to the peak in H α emissivity, and the density of the gas stream at the L 1 point was estimated to be 2 × 10 -14 gcm -3 . Finally, a mass transfer rate of ∼ 2 × 10 -10 M yr /circledot -1 was derived from the velocity, density, and cross-section of the gas stream above and below the disk. A similar analysis for AU Mon revealed a mass transfer rate of ∼ 2 4 . × 10 -9 M yr /circledot -1 (Atwood-Stone et al. 2012).
Figure 12. Two-dimensional tomograms of the disk-state systems TT Hya (upper frames) and AU Mon (lower frames) illustrating the use of shellspec modeling to isolate the separate accretion structures (disk, gas stream, Localized Region). The images are derived from the (a) observed spectra, and when various accretion structures are subtracted from the observed spectra: (b) stellar spectra removed, (c) stars and disk removed, (d) stars, disk and stream removed, and (e) stars, disk, stream and Localized Region removed (AU Mon only).
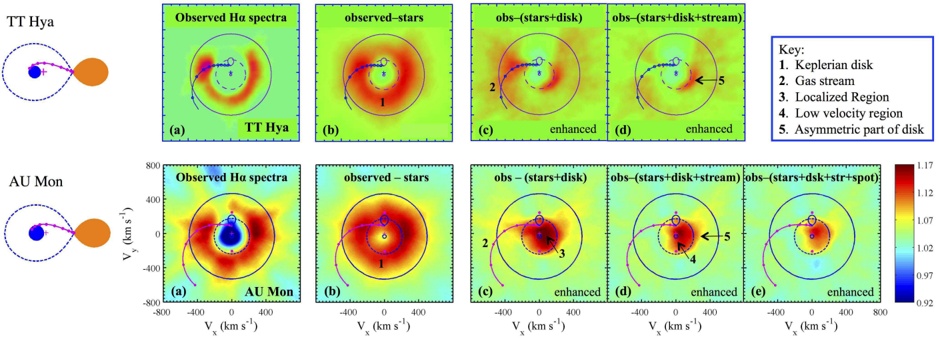
The synthetic spectra can also be used in combination with tomography to demonstrate visually that the separate sources of emission have been adequately modeled. This procedure has been accomplished for two disk-state systems, TT Hya and AU Mon, and the results are displayed in Figure 12. The refined properties derived from the comparison between the observed and synthetic spectra were used to generate composite synthetic spectra of the disk, stream, and other features for input to the tomography code.
state Algol binaries with orbital periods from 1.2 to 11.1 days. These systems undergo mass transfer from a magnetically-active star onto a normal, non-magnetic main sequence star. We have applied the technique of tomography and a variety of other procedures, both observational and theoretical, to derive a better understanding of the gravitational and magnetic phenomena associated with the mass transfer process in interacting binary stars.
The sequential modeling and extraction of the spectral contributions of the stars and various accretion structures resulted in the identification of an asymmetric accretion disk in both TT Hya and AU Mon (Miller et al. 2007; Atwood-Stone et al. 2012). The residual emission in the TT Hya image (Figure 12d; upper frames) is located within the locus of the accretion disk and it represents the asymmetric portion of the disk that was not included in the synthetic spectrum based on a symmetric disk; hence the accretion disk in TT Hya is asymmetric. An asymmetric disk and gas moving at sub-Keplerian velocities were also discovered in AU Mon from the tomograms (see Figure 12d; lower frames). A Localized Region was also detected in the AU Mon image; this emission was modeled as a 'spot' and removed from the image (see Figure 12e; lower frames); the density of this region was 8 × 10 -14 gcm -3 , which is comparable to that of the gas stream.
In summary, the shellspec code has proven to be an effective tool in the modeling of various accretion structures and for the calculation of critical parameters, such as the mass transfer rate, needed to compute accurate stellar evolution models. Moreover, the use of the synthetic spectra with tomography has led to the isolation and discovery of asymmetric accretion disks in two diskstate systems which have stable accretion disks. Moreover, this analysis has led to the successful modeling and extraction of the Localized Region from a composite spectrum, in the case of AU Mon.
## 7. RESULTS
In this paper, we have derived the behavior of the accretion flows in a range of direct-impact and disk-
(1) The r -q diagram was used as a predictive tool to determine which systems will undergo direct-impact accretion and which will form an accretion disk (Figure 1). In order to understand the predicted dynamical behavior of the gravitational flow along the gas stream, several key dynamical parameters were calculated, namely the thermal, dynamical, and circularization timescales which were then compared with the synchronous velocity, escape velocity for the mass gainer, and the velocity of the gas stream at the impact site. If only gravitational and Coriolis forces are considered, the gas flow from the L1 point will make direct impact with the surface of the mass gainer in the short-period systems, and the impact can create an equatorial bulge on the surface of this star because the velocity of the flow is typically much higher than the synchronous velocity of the star. The gas at the impact site will be turbulent, and the tangential component of the flow will propel the gas around the star well beyond the impact site on timescales of hours to days. The predicted behavior of the gas at the shock site was calculated for both the Cartesian and velocity frames for comparison with the Doppler tomograms (Figure 2).
(2) The image reconstruction technique of backprojection Doppler tomography was described mathematically, along with its advantages and constraints. In essence, this technique creates velocity images by summing the normalized intensities of the spectra at all velocities across the spectrum and for all viewing positions around the orbit. This procedure requires the availability of numerous spectra with high spectral resolution and high resolution in orbital phase (Figure 3). The 2D images shown in Figure 4 were computed without any filtering, smoothing, denoising or other regularization procedures, except for interpolation in orbital phase.
- (3) For the application of tomography, we analyzed
over 1300 time-resolved spectra of 13 Algol binaries collected at multiple wavelengths and multiple epochs (Figure 4). Most of the tomograms were constructed from H α spectra, and we included images derived from the H β , He I λ 6678, and Si II λ 6371 lines in the optical region, as well as the Si IV λ 1394 line in the ultraviolet region. The velocity images produced via tomography display seven distinct sources of emission that provide evidence of both gravitational and magnetic effects (Figure 5): (i) a source of magnetic activity associated with the cool mass-losing star, including emission from the chromosphere, prominences, flares, and coronal mass ejections; (ii) a gas stream along the predicted gravitational trajectory, which was identified in the images of nearly all of the systems in our survey; (iii) a star-stream impact region where the gas stream strikes the surface of the mass-gaining star; (iv) a bulge of extended absorption or emission around the mass-gaining star produced by the impact of the high velocity stream onto the slowly rotating photosphere; (v) a transient or permanent accretion disk around the mass-gaining star; (vi) an absorption zone which may be the locus of hotter gas beyond the 10 4 K regime associated with H α emission; and (vii) a disk-stream impact region where the circling gas strikes the incoming stream and is slowed by the impact to subKeplerian velocities. In addition, (viii) a hot spot where the gas stream strikes an already well-formed disk was found in one system by means of S-wave analysis.
The images, trailed spectrograms, and representative spectra at quadrature provide us with a consistent progression from the stream state to the disk state when the binaries are displayed in order of increasing orbital separation (Figure 6). This progression reveals the existence of the Alternating Systems which have been found in both the stream state and the disk state at different epochs. In addition, the multiwavelength spectra provide us with views of the gas flows at different temperatures (e.g., H α vs. He I spectra; Figure 7).
(4) We examined the influence of various system properties on the resulting 2D velocity images (see Figure 8). Orbital inclination causes the image size to decrease as the inclination increases from 50 ◦ to 90 ◦ . The adoption of an inaccurate systemic velocity results in the distortion of the image. Insufficient orbital phase coverage creates radial spoke-like streaks across the diagram which can be rectified if the data are interpolated in orbital phase. Inadequate velocity resolution across the spectrum can also be addressed by interpolation, but the observed spectra used in the analysis already have high resolution and do not require any interpolation. Finally, shadowing, or the presence of partially opaque gas, will influence the passage of light through a medium and this effect can be noticed if we view the binary from opposite directions. This latter effect was not detected in U CrB or TT Hya (see Figure 8). However, non-transparent gas was detected through a comparison between the observed and difference spectra of CX Dra.
(5) Finally, we summarized four methods that have been used to extract the physical properties and other characteristics of the gas flows directly from the velocity images: (a) S-wave analysis; (b) creation of simulated velocity tomograms from hydrodynamic simulations; c) sequential extraction of the separate emission sources using synthetic spectra of the disk, gas stream, and other sources of emission such as the Localized Region; and (d) using synthetic spectra with tomography to confirm that the separate accretion structures have been modeled accurately.
(a) A comparison of the trailed spectrograms with the velocity curves of the stars showed that there are compact structures within the gas flow that nearly follow the velocity curve of one of the stars; the orbital variation of these S-waves can be used to derive the location of the source in both the velocity and Cartesian frames. Hence, the S-wave analysis provides a means by which the information in the velocity map can be translated onto the Cartesian frame without knowledge of the composite velocity fields in the tomogram (Figures 9, 10).
(b) The construction of simulated tomograms from hydrodynamic calculations under controlled conditions provide a tool for comparison with the Doppler tomograms derived from the observations, and provide a direct connection between the geometry and dynamics of the accretion flows in both velocity and Cartesian dimensions under these controlled conditions (Figure 11). The simulated tomograms permitted an interpretation of the alternating behavior of U CrB and U Sge as due to periodic changes in the density of the gas stream, and hence in the mass transfer rate. Results from a radio flare survey suggest that the timescale of variability in radio flares from magnetically-active Algol binaries is comparable to that of the alternating systems, and hence the alternating behavior may be triggered by magnetic activity on the cool mass-losing star.
(c) The shellspec code has been used effectively to compute synthetic spectra in moving transparent or nontransparent 3D structures such as a disk, stream, spot, jet, or shell, in addition to the stars. It can be used to sequentially model the composite synthetic spectra of combinations of these structures (e.g., stars, disk, and gas stream) for comparison with the observed spectra. As a result, critical physical parameters, including the mass transfer rate, of these structures have been obtained for TT Hya and AU Mon with this code. These parameters are needed to compute accurate stellar evolution models.
(d) In combination with tomography, the synthetic spectra have been used to visually confirm the quality of the computed model. This procedure has led to the discovery of asymmetric accretion disks in TT Hya and AU Mon, as well as the isolation of a sub-Keplerian velocity region and a Localized Region in AU Mon.
## 8. CONCLUSIONS
The multi-tiered analysis performed in this work involved both theoretical tools and spectroscopic observations of Algol binaries from the stream state to the disk state. This analysis has provided observational evidence of the effects of gravitational forces on the accretion flows in these interacting binaries. Moreover, we have used images derived from 2D Doppler tomography to identify associations with magnetic activity of the cool star, which is the source of the accretion flow. These associations are distinct from the effects of gravitational effects on the gas flows and demonstrate that magnetic effects cannot be ignored in any of these interacting binary star systems.
The evidence is in the form of (i) chromospheric emission with the same velocity as that of the mass-losing
star arising from prominences, flares, and coronal mass ejections, and this emission was detected in 11 of the 13 systems studied; (ii) detection of a gas stream deflected from the predicted gravitational trajectory (e.g., TT Hya); and (iii) alternating behavior between stream state and disk state possibly caused by flaring activity (e.g., U Sge, U CrB).
The extension to 3D Doppler tomography is beginning to provide additional evidence of the influence of magnetic activity on the gas flows beyond the central orbital plane of the binary. The spectra employed in this study were used to calculate 3D tomograms of three systems: U CrB, RS Vul, and β Per (Agafonov et al. 2006, 2009; Richards et al. 2010, 2012). These 3D images suggest that magnetic threading of the gas, the superhump phenomenon, may alter the direction and intensity of the gas flow in the cases of RS Vul and β Per, and may be responsible for deflecting the gas stream away from the central plane to produce a tilted accretion disk in U CrB (Richards et al. 2012). These magnetic effects were mimicked using 3D hydrodynamic simulations by boosting the magnitude of the gas stream velocity to Mach 30 and by deflecting the initial gas stream at the L1 point by 45 ◦ from the orbital plane in U CrB and RS Vul (Raymer 2012). These simulations concluded that a deflected stream is a viable mechanism for producing the strong out-of-plane flows seen in the 3D tomographic images.
So, we have more to discover from the application of tomography to the rich set of spectra described in this study.
We thank the referee for helpful comments on the manuscript. This research involved undergraduate students (JF, MC) and a graduate student (AC), and it was partially supported by National Science Foundation grants AST-0908440 and DMS-1309808, and by the Institut f¨r u Angewandte Mathematik, Ruprecht-KarlsUniversit¨t Heidelberg, Germany. a
## REFERENCES
- Agafonov, M. I., Richards, M. T., & Sharova, O. I. 2006, ApJ, 652, 1547
- Agafonov, M. I., Sharova, O. I., & Richards, M. T. 2009, ApJ, 690, 1730
- Atwood-Stone, C., Miller, B. P., Richards, M. T., Budaj, J., & Peters, G. J. 2012, ApJ, 760, 134
- Budaj, J., & Richards, M. T., 2004, Contrib. Astron. Obs. Skalnat´ Pleso, 34, 167 e
- Budaj, J., Richards, M.T., & Miller, B. 2005, ApJ, 623, 411 Cugier, H., and Molaro, P. 1984, A&A, 140, 105.
- Etzel, P. B. & Olson, E. C. 1993, AJ, 106, 1200
- Girard, M. J. A., Strouthidis, N. G., Ethier, C. R., & Mari, J. M. 2011, Invest. Ophthalmol. Vis. Sci., 52 (No. 10), 7738
- Glazunova, L. V., Mkrtichian, D. E., & Rostopchin, S. I. 2011, MNRAS, 415, 2238
- Guinan, E. F., & Gim´ enez, A. 1994, in The Realm of Interacting Binary Stars, ed. J. Sahade, G. E. McCluskey, Jr. & Y. Kondo, (Dordrecht: Kluwer), p. 51
- Iben, I., & Tutukov, A. V. 1985, ApJS, 58, 661
- Kaitchuck, R. H., Schlegel, E. M., Honeycutt, R. K., Horne, K., Marsh, T. R., White, J. C., & Mansperger, C. S. 1994, ApJS, 93, 519
- Kempner, J. C. & Richards, M. T. 1999, ApJ, 512, 345
- Komzik, R., Chochol, D. & Grygar, J. 2008, Contrib. Astron. Obs. Skalnat´ Pleso, 38, 538 e
- Lubow, S. H., & Shu, F. H. 1975, ApJ, 198, 383
Marsh, T. R. 2001, Lecture Notes in Physics 573, 1 Marsh, T. R. & Horne, K. 1988, MNRAS, 235, 269
- Miller, B. P., Budaj, J., Richards, M. T., Koubsk´, P. & Peters, y
- G. J. 2007, ApJ, 656, 1075
- Morales-Rueda, L. 2004, AN, 325, 193
- Olson, E. C. 1982, PASP, 94, 700
- Olson, E. C. 1987, AJ, 94,1043
- Patterson, J. 1998, PASP, 110, 1132
- Patterson, J. 1999, in Disk Instabilities in Close Binary Systems, ed. S. Mineshige & J. C. Wheeler ( Tokyo: Universal Academy Press), p. 61
- Peters, G. J., & Polidan, R. S. 1984, ApJ, 283, 745
- Peterson, W. M., Mutel, R. L., Gudel, M. & Goss, W. M. 2010, Nature, 463, 207
- Peterson, W. M., Mutel, R. L., Lestrade, J.-F., G¨del, M., & u Goss, W. M. 2011, ApJ, 737, 104
- Prinja, R. K., Long, K. S. Long, Richards, M. T., Witherick, D.K., & Peck, L.W. 2012, MNRAS, 419, 3537
- Radon, J. 1917, Berichte S¨chsische Akademie der Wissenschaften a Leipzig Math. Phys. Kl. 69, 262 (reprinted in 1983: Proceedings of Symposia in Applied Math 27, 71)
- Raymer, E. 2012, MNRAS, 427, 1702
- Retter, A., Richards, M. T., & Wu, K. 2005, ApJ, 621, 417
- Richards, M. T. 1992, ApJ, 387, 329
- Richards, M. T. 1993, ApJS, 86, 255
- Richards, M. T. 2004, AN, 325, 229
- Richards, M. T., Agafonov, M. I., & Sharova, O. I. 2012, ApJ, 760, 8
- Richards, M. T., & Albright, G. E. 1993, ApJS, 88, 199
- Richards, M. T., & Albright, G. E. 1996, in Stellar Surface
- Structure, eds. K. Strassmeier and J. Linsky (Dordrecht: Kluwer), 493
- Richards, M. T., & Albright, G. E. 1999, ApJS, 123, 537 Richards, M. T., Albright, G. E., & Bowles, L. M. 1995, ApJ, 438, L103
- Richards, M. T., Jones, R. D., & Swain, M. A. 1996, ApJ, 459, 249
- Richards, M. T., Koubsk´, P., ˇ imon, V., Peters, G. J., Hirata, y S R., ˇ koda, P., & Masuda, S. 2000, ApJ, 531, 1003 S
Richards, M. T., & Ratliff, M. A. 1998, ApJ, 493, 326
- Richards, M. T., Sharova, O., & Agafonov, M. 2010, ApJ, 720, 996
- Richards, M. T., Waltman, E. B., Ghigo, F., & Richards, D. St. P. 2003, ApJS, 147, 337
- Sarna, M. J., Muslimov, A. G., & Yerli, S. K. 1997, MNRAS, 286, 209
- Sarna, M. J.,Yerli, S. K., & Muslimov, A. G. 1998, MNRAS, 297, 760
- Schwope, A. D., Staude, A., Vogel, J., & Schwarz, R. 2004, AN, 325, 197
- Sharova, O. I. et al. 2012, in IAU Symposium 282, From Interacting Binaries to Exoplanets: Essential Modeling Tools, eds. M. T. Richards & I. Hubeny (Cambridge: Cambridge U. Press), p. 201
- Shepp, L. A. 1983, Computed Tomography, Proc. of Symposia in Applied Math., Vol. 27, ed. L. A. Shepp (Providence: American Mathematical Society)
- Steeghs, D. 2004, AN, 325, 185
- Struve,O. 1949, MNRAS, 109, 487
- Szkody, P., Desai, V., & Hoard, D. W. 2000, AJ, 119, 365 Szkody, P., Nishikida, K., Long, K. S. & Fried, R. 2001, AJ, 121,
- 2761
- Vesper, D. N., & Honeycutt, R. K. 1993, PASP, 105, 731
- Vesper, D., Honeycutt, K., & Hunt, T. 2001, AJ, 121, 2723
- Vrtilek, S. D., Quaintrell, H., Boroson, B., & Shields, M. 2004, AN, 325, 209
- Vogt, N. 1982, ApJ, 252, 653
Wheeler, J. C. 2007, Cosmic Catastrophes (Cambridge:
Cambridge Univ. Press)
- Zavala, R. T., Hummel, C. A., Boboltz, D. A., Ojha, R. Shaffer, D. B., Tycner, C., Richards, M. T. & Hutter, D. J. 2010, ApJ, 715, L44 | 10.1088/0004-637X/795/2/160 | [
"Mercedes T. Richards",
"Alexander S. Cocking",
"John G. Fisher",
"Marshall J. Conover"
] | 2014-08-01T16:26:54+00:00 | 2014-09-09T15:34:26+00:00 | [
"astro-ph.SR"
] | Images of Gravitational and Magnetic Phenomena Derived from 2D Back-Projection Doppler Tomography of Interacting Binary Stars | We have used 2D back-projection Doppler tomography as a tool to examine the
influence of gravitational and magnetic phenomena in interacting binaries which
undergo mass transfer from a magnetically-active star onto a non-magnetic main
sequence star. This multi-tiered study of over 1300 time-resolved spectra of 13
Algol binaries involved calculations of the predicted dynamical behavior of the
gravitational flow and the dynamics at the impact site, analysis of the
velocity images constructed from tomography, and the influence on the tomograms
of orbital inclination, systemic velocity, orbital coverage, and shadowing. The
H$\alpha$ tomograms revealed eight sources: chromospheric emission, a gas
stream along the gravitational trajectory, a star-stream impact region, a bulge
of absorption or emission around the mass-gaining star, a Keplerian accretion
disk, an absorption zone associated with hotter gas, a disk-stream impact
region, and a hot spot where the stream strikes the edge of a disk. We
described several methods used to extract the physical properties of the
emission sources directly from the velocity images, including S-wave analysis,
the creation of simulated velocity tomograms from hydrodynamic simulations, and
the use of synthetic spectra with tomography to sequentially extract the
separate sources of emission from the velocity image. In summary, the
tomography images have revealed results that cannot be explained solely by
gravitational effects: chromospheric emission moving with the mass-losing star,
a gas stream deflected from the gravitational trajectory, and alternating
behavior between stream state and disk state. Our results demonstrate that
magnetic effects cannot be ignored in these interacting binaries. |
1408.0225v2 | ## A spectroscopic census in young stellar regions: the σ Orionis cluster
Jesús Hernández , Nuria Calvet 1 2 , Alice Perez 1 3 , , Cesar Briceño , Lorenzo Olguin , Maria E. 4 5 Contreras , Lee Hartmann 6 2 , Lori Allen , Catherine Espaillat , Ramírez Hernan 7 8 1
[email protected]
## ABSTRACT
We present a spectroscopic survey of the stellar population of the σ Orionis cluster. We have obtained spectral types for 340 stars. Spectroscopic data for spectral typing come from several spectrographs with similar spectroscopic coverage and resolution. More than a half of stars of our sample are members confirmed by the presence of lithium in absorption, strong H α in emission or weak gravity-sensitive features. In addition, we have obtained high resolution (R ∼ 34000) spectra in the H α region for 169 stars in the region. Radial velocities were calculated from this data set. The radial velocity distribution for members of the cluster is in agreement with previous work. Analysis of the profile of the H α line and infrared observations reveals two binary systems or fast rotators that mimic the H α width expected in stars with accretion disks. On the other hand there are stars with optically thick disks and narrow H α profile not expected in stars with accretion disks. This contribution constitutes the largest homogeneous spectroscopic data set of the σ Orionis cluster to date.
Subject headings: infrared: stars: formation - stars: pre-main sequence - open cluster and associations: individual ( σ Orionis cluster) protoplanetary systems: protoplanetary disk
1 Centro de Investigaciones de Astronomía, Apdo. Postal 264,Mérida 5101-A, Venezuela.
2 Department of Astronomy, University of Michigan, 500 Church Street, Ann Arbor, MI 48109, US
3 Departamento de Física, Universidad de Oriente, Venezuela
4 Cerro Tololo Interamerican Observatory, Casilla 603, La Serena, Chile
5 Depto. de Investigación en Física, Universidad de Sonora, S onora, México
6 Instituto de Astronomía, Universidad Nacional Autónoma deMéxico, Ensenada, BC, México
7 National Optical Astronomy Observatory, 950 North Cherry Avenue, Tucson, AZ 85719, USA
8 Department of Astronomy, Boston University, 725 Commonwealth Avenua, Boston, MA 02215, USA
## 1. Introduction
The σ Orionis cluster located in the Orion OB1 association was first recognized by Garrison (1967) as a group of 15 B-type stars around the massive and multiple system σ Ori AB. Low-mass members of the σ Orionis cluster were reported by Wolk (1996) and Walter et al. (1997), who found over 80 X-ray sources and spectroscopically identified more than 100 low mass, pre-main sequence (PMS) stars. A copious amount of work on this cluster have revealed several hundred low mass stars and brown dwarfs that could belong to the σ Orionis cluster (see Walter et al. 2008). In the Mayrit catalog, Caballero (2008a) presents a compilation of 241 stars and brown dwarfs which have known features of youth (Li I λ 6708 in absorption, strong emission of H α , infrared excess, X-ray emission or weak gravity-sensitive features). More than one third of these stars have disks identified using Spitzer photometry (Hernández et al. 2007aLuhman et al. 2008). Recently, deep ; and wide near infrared surveys have increased substantially the number of substellar candidates of the cluster (e.g., Lodieu et al. 2009; Béjar et al. 2011; Peña Ramírez et al. 2012). The σ Orionis cluster has a dense core extended from the center to a radius of 20 , in which most members are ′ located, and a rarefied halo extended up to 30 ′ (Caballero 2008b). Other general properties of the σ Orionis cluster are described by Walter et al. (2008).
The σ Orionis cluster is an excellent natural laboratory to study the formation and early evolution of stars and protoplanetary disks in the entire range of stellar masses, from their massive members to the lowest mass objects, such as brown dwarfs and free-floating planets. It has a evolutionary stage at which the beginnings of disk evolution become evident and thus a large diversity of protoplanetary disks is observed (Hernández et a . 2007a, l hereafter H07a). The age normally used for the cluster is 2-4 Myr (e.g., Zapatero Osorio et al. 2002; Oliveira & van Loon 2004; Franciosini et al. 2006; Sherry et al. 2008; Béjar et al. 2011 ; Caballero et al. 2012; Rigliaco et al. 2012; Peña Ramírez et al. 2012). Recently, Bell et al. (2013)have derived ages for 13 young stellar groups (including the σ Orionis cluster) that are a factor of two higher than the ages typically adopted in the literature. Regardless of the actual value of the age, a comparison of empirical isochrones reveals that the σ Orionis cluster must be younger than the λ Orionis cluster, the Orion OB1b association, the γ Velorum cluster and the 25 Ori cluster (Hernández et al. 2008; the age of ) these groups typically adopted in the literature covers the range from 5 to 10 Myr, and consistently, they have smaller protoplanetary disk frequencies than σ Ori.
The σ Orionis cluster is relatively near and the reddening toward the center of the cluster is low (E(B-V) /lessorsimilar 0.1 mag; Brown et al. 1994; Béjar et al. 1999, 2004; Sherry et a l. 2008). The distance of 352 + 166 -85 pc calculated by Hipparcos for the central system ( σ Ori AB) agrees, within the uncertainties, with the Hipparcos distance calculated for the overall population of the stellar subassociation OB1b (439 ± 33; Brown et al. 1998), which is statistically more reliable. This value agrees to the distance of 420 ± 30 estimated by Sherry et al. (2008) from main sequence fitting
corrected for the sub-solar metallicity expected in the Orion OB1 association (Cunha et al. 1998; Walter et al. 2008). On the other hand, assuming that σ Ori AB is a double system, Caballero (2008c) estimated a distance of 334 + 25 -22 for this object; however, he also estimated a distance of ∼ 385 pc in the case that σ Ori AB was a triple system. Few years later, Simón-Díaz et al.(2011) report a third massive star component confirming the σ Ori AB as a triple system (with masses of 19M , 15M /circledot /circledot and 9M /circledot ). Finally, recent interferometric observations of the σ Ori system during periastron in the Center for High Angular Resolution Astronomy (CHARA) with the Michigan Infra-Red Combiner (MIRC) yield a distance of 380.7 ± 7.1 pc for σ Ori AB (Gail Schaefer and John Monnier, private communication). This value is in agreement with the distance estimated by (Caballero 2008c) and within 2 σ from the distance reported by Sherry et al. (2008). In this paper, we assume a distance of 385 pc reported by Caballero (2008c).
Regardless of the numerous studies in the σ Orionis cluster, dozens of candidates remain without spectroscopic confirmation of membership (Caballero 2008), and spectroscopically determined stellar characterization exists for only a small fraction of the σ Orionis objects (Rigliaco et al. 2011, 2012; Cody & Hillenbrand 2010). Moreover, spectral types or effective temperatures published for members or candidates of the σ Orionis cluster are obtained from spectroscopic data with different spectral coverage and resolution and applying different methods, which could introduce systematic differences between several samples (e.g., Wolk 1996; Walter et al. 1997; Béjar et al. 1999; Zapatero Osorio et al. 2002; Barrado y Navascués et al. 2003;Scholz & Eislöffel 2004; González Hernández et 2008; Caballero 2006, 2008; Cody & Hillenbrand 2011; Caballero et al. 2012; Rigliaco et al. 2012). The spectral type is key for deriving fundamental quantities such as visual extinction, temperature and luminosity, which in turn allow the determination of stellar radii, masses and ages. In this contribution, we analyze several sets of spectroscopic data in order to obtain homogeneously spectral types and spectroscopic membership for stars in the σ Orionis cluster. This paper is organized as follows. In Section 2, we describe the observational data and the target selection in the cluster. In Section 3, we discuss results from the low resolution spectroscopic analysis (§3.1), the high resolution spectroscopic analysis (§3.2), memberships based on photometric data and proper motions analysis (§3.3), and an overall membership analysis of stars studied in this work (§3.4). In Section 4.1, we revisit the disk population of the σ Orionis cluster and we compare our results with the disk census from H07a. In Section 4.2, we discuss the relation between the infrared excesses of disk bearing stars and the accretion properties obtained from high resolution analysis of the H α
line. Finally, we present our conclusions in Section 5.
## 2. Observations and Target Selection
## 2.1. Optical Photometry
## 2.1.1. OSMOS Photometry
Weobtained optical photometry (UBVRCIC) of the center of the cluster on December 24, 2011 using the Ohio State Multi-Object Spectrograph (OSMOS) on the MDM 2.4 m Hiltner telescope (Stoll et al. 2010; Martini et al. 2011). We obtained two sets of images, one short exposure set (20, 15, 10, 5 and 5 seconds for U, B, V, RC and IC, respectively) and one long exposures set (3x200, 3x200, 3x150, 3x100 and 3x100 seconds for U, B, V, RC and IC, respectively). OSMOS has an all-refractive design that re-images a 20 diameter field-of-view onto the 4064x4064 MDM4K CCD ′ with a plate scale of 0.273 ′′ pixel -1 . The effective non-vignetted field of view is 18. 5 x 18. 5. ′ ′ We used 2 x 2 binning, which gives a final plate scale of 0.55 ′′ pixel -1 . The MDM4K CCD is read out using four amplifiers and has a known issue of crosstalk between the four CCD segments of each amplifier. When a CCD pixel is saturated, it creates spurious point sources in corresponding pixels on the other three segments.
Each OSMOS frame was first corrected by overscan using the IDL program proc4k written by Jason Eastman for the Ohio State 4k CCD imager and modified to process OSMOS data. We then performed the basic reduction following the standard procedure using IRAF. We performed aperture photometry for the initial sample (§2.2) with the IRAF package APPHOT. The IRAF routine mkapfile was used to determine aperture corrections for each filter. We used Landolt standard fields for photometric calibration in the Johnson-Cousin system (Landolt 2009, 1992). If a star was saturated in the long exposures images, then the short-exposure measurements were used. Non-detections in the combined long exposure images, saturated stars in short exposure images, and photometry affected by bleeding or crosstalk from saturated stars were removed. The saturation limit for the short exposure image is V ∼ 12 and the limit magnitude for the combined long exposure image is V ∼ 23.
## 2.1.2. Additional photometry
Since OSMOS photometry only covers the central region of the cluster (the dense core), we completed the optical data set used in this paper using Johnson-Cousin photometry from different catalogs.
- a) The CIDA Variability Survey of Orion (CVSO; Briceño et al.2005; Mateu et al. 2012), which is being carried out since 1999 using the Jurgen Stock 1 m Telescope with the QUEST I camera
(an array of 4x4 CCD detectors; Baltay et al. 2002) in the Venezuelan National Observatory at Llano del Hato. The region studied in this work is covered almost completely in this multi-epoch survey. Only a small region in the range of declination from -2.52 to -2.44 , corresponding to the ◦ ◦ gap between CCDs in the QUEST I camera (Vivas et al. 2004; Hernández et al. 2007a), lacks data. The saturation limit for this survey is V ∼ 13.5 and the limit magnitude is V ∼ 19.5.
- b) Sherry et al. (2004) presented a BVRCIC survey of 0.89 square degrees around the σ Orionis cluster. Observations were made with the 0.9 and 1.5 m telescopes at the Cerro Tololo InterAmerican Observatory (CTIO). The reported completeness limit is V=18 within 0.3 ◦ of the σ Ori ABstar and V=20 for regions more than 0.3 ◦ from the σ Ori AB star. This catalog includes optical photometry for 234 likely members of the cluster.
- c) The Cluster Collaboration's Photometric Catalogs collects photometric data for several young stellar associations and clusters. The catalogs were created using the optimal photometry algorithm described in Naylor (1998) and Naylor et al. (2002). For the σ Orionis cluster, Kenyon et al. (2005) and Mayne et al. (2007) presented RCICand BVICphotometry, respectively. These data sets were obtained using the Wide Field Camera on the 2.5 meters Issac Newton Telescope with the Harris BVR filters and the Sloan i filter. The magnitudes were calibrated using Landolt fields, thus the final photometry is reported in the Johson-Cousin systems. Sources of the initial sample with optical photometry from these catalogs cover a brightness range from V ∼ 11.5 to V ∼ 23.5
- d) The All-sky Compiled Catalogue of 2.5 million stars (ASCC-2.5 V3; Kharchenko & Roeser 2009). This catalog collects B and V Johnson photometry mainly from Hipparcos-Tycho family catalogs. The limiting magnitude is V ∼ 12-14, although the completeness limit (to 90%) is V ∼ 10.5 mag. We augmented the V, B optical data set toward the brightest objects using the ASCC-2.5 V3 catalog.
Using stars in common between the different catalogs and OSMOS photometry, we find (after 3 σ clipping) that the V-band measurements are comparable within 0.5%, 1.6% and 1.7% for the CVSO, Sherry et al. (2008) and the Cluster Collaboration Photometric Catalog, respectively. We do not have enough common stars between OSMOS data and Kharchenko & Roeser (2009) catalog to do this comparison.
## 2.2. Initial sample
The initial sample in this study includes all 2MASS sources (4659 sources; Cutri et al. 2003) in a region of 48 x48 centered at RA=84.7 and DEC=-2.6 . ′ ′ ◦ ◦ This region covers the field studied in H07a using the four channels of the InfraRed Array Camera (IRAC; Fazio et al. 2004). The 2MASS catalog is complete down to J < 15.8, which includes stars beyond the substellar limit
expected for the σ Orionis cluster (e.g., J ∼ 14.6; H07a). We compared sources from the 2MASS catalog and from the United Kingdom Infrared Telescope (UKIRT) Infrared Deep Sky Survey (UKIDSS; Lawrence et al. 2007, 2013). When 2MASS sources have poor photometric quality flag ("U", "F" or "E") for the J magnitude, we use photometric measurements reported in UKIDSS catalog.
Out of 31 UKIDSS sources with J < 15.8 and without 2MASS counterparts, 10 sources are galaxies based on the profile classification of UKIDSS and 16 sources are close visual binaries not resolved in 2MASS images (2MASS reports photometry only for the brightest companion). From the remaining 5 sources, 4 stars are background candidates and only one star is a photometric member based on its location in the Z versus Z-J color magnitude diagram (Lodieu et al. 2009). This star has an optically thick disk (SO 566; H07a) and the non-detection in 2MASS images suggests large variability (variability amplitude in J-band /greaterorsimilar 2.7). The star SO 566 was added to the initial sample of 4659 2MASS sources. Finally, there are 4 additional sources studied in H07a without 2MASS counterpart (SO 406, SO 336, SO 361 and SO 950). Since all these sources are fainter (J > 17.9 in UKIDSS) than the 2MASS completeness limit, they were not included in this study.
## 2.2.1. 2MASS sources without optical photometry
Out of 4660 sources in the initial sample, 4444 sources (95.4%) have optical counterparts (at least in filter V). Out of 216 sources without optical photometry, 160 stars are fainter than the completeness limit of 2MASS catalog and were not included in this study. Out of 56 stars brighter than the completeness limit of 2MASS catalog, 52 stars have photometric memberships reported by Lodieu et al. (2009) and 4 stars are brighter than the Z-band limit used by Lodieu et al. (2009) for their membership criteria. They found 14 photometric candidates, 35 background candidates, and 3 Galaxies based on the stellar profile classification and color magnitude diagrams. Three of these photometric candidates are studied in §3.1, the remaining 11 sources are detailed in the Appendix A.
## 2.3. Compilation of Known Members
We compiled lists of spectroscopically confirmed members of the σ Orionis cluster on the basis that they exhibit Li I λ 6708 in absorption or they have radial velocities expected for the kinematic properties of the cluster (hereafter "spectroscopic known members").
Using radial velocity measurements, Jeffries et al. (2006) showed that young stars located in
the general region of the cluster consist of two stellar groups kinematically separated by 7 km s -1 in radial velocity and with different mean ages and distances. One group has radial velocities from 27 km s -1 to 35 km s -1 , which is consistent with the radial velocity of the central star σ Ori AB (29.5 km s -1 ; Kharchenko et al. 2007). The other group has radial velocities from 20 km s -1 to 27 km s -1 , and could be in front of the first group and could have a median age and distance similar to older stellar groups associated with the sparser Orion OB1a subassociation (age ∼ 10 Myr; distance ∼ 326; Briceño et al. 2007). This older and kinematically dist inct stellar population (hereafter "the sparser stellar population") is located to the north-west of the central system and more difficult to detect in radial velocity distributions of stars located near the center of the cluster (Sacco et al. 2008). Using the limit defined by Jeffries et al. (2006), we included in our study 162 kinematic members of the σ Orionis cluster, with radial velocity between 27 and 35 km s -1 , from Zapatero Osorio et al. (2002), Kenyon et al. (2005), Caballero (2006), Burningham et al. (2005), Maxted et al. (2008), Sacco et al. (2008) and González Hernán ez et al. (2008). d
We also included as spectroscopic known members, 181 stars with Li I λ 6708 in absorption from Wolk (1996), Alcalá et al. (1996), Zapatero Osorio et al. (2002), Muzerolle et al. (2003), Barrado y Navascués et al. (2003), Andrews et al. (2004), Ken yon et al. (2005), Caballero (2006); Caballero et al. (2006), González Hernández et al. (2008), Sco et al. (2008), and Caballero et al. ac (2012). Since the presence of lithium is an indicator of youth in late type stars, our selection includes stars with reported spectral types K or M. Our list includes all late type stars with Li I λ 6708 in absorption compiled in the Mayrit Catalog (Caballero 2008a).
Additionally, we have compiled 168 X ray sources reported by Caballero (2008a), Skinner et al. (2008), López-Santiago & Caballero (2008), Caballero et al. (2009), Caballero et al. (2010a) or X ray sources in the XMM-Newton Serendipitous Source Catalogue 2XMMi-DR3 (XMM-SSC, 2010) with source detection likelihood (srcML) larger than 8 (sources with scrML < 8 may be spurious). Since young stars are strong X-ray emitters, likely members of the σ Orionis clusters are X ray stellar sources located above the ZAMS.
Finally, another indicator of youth is the infrared excess present when stars are surrounded by circumstellar disks. Using Spitzer Space Telescope observations, we reported 114 photometric candidates with infrared excesses (H07a).
Youth indicators based on the presence of Li I λ 6708 in absorption, X ray observations and infrared excesses do not discriminate interlopers from the sparser stellar population. Regardless of this expected contamination, we define the sample of known likely members (hereafter "known members") compiling kinematic members based on radial velocities, stars with Li I λ 6708 in absorption, X ray sources above the ZAMS and stars with infrared excesses. Table 1 shows information about the known member sample.
## 2.4. Target Selection
Using the photometric data compiled in §2.1.1 and §2.1.2 we selected photometric candidates of the σ Orionis cluster. Although we have V, RC, IC, and J magnitudes for most stars in the initial sample, we use the V-J color because is the most complete for our sample and it has the greatest color leverage for constraining PMS populations.
Figure 1 shows the color-magnitude diagram V vs V-J for sources in the initial sample with optical counterparts. We have estimated an empirical isochrone as the location of known members compiled in §2.3; stars with infrared excesses, young stars confirmed using the presence of Li I λ 6708 in absorption, kinematic members confirmed using radial velocities, and X ray sources above the ZAMS (Siess et al. 2000) located at 385 pc (Caballero 2008c). The empirical isochrone in Figure 1 was estimated using the median V-J color of the known members for 1 mag bins in the V band. Standard deviations ( σ ) were calculated using the differences between the observed colors and the expected colors from the empirical isochrone. We fitted two straight lines to the points representing by the empirical isochrone color + 3 σ and by the empirical isochrones color 3 σ . Photometric candidates are stars that fall between these lines (Hernández et al. 2008, 2010).
Our photometric sample includes the photometric candidates reported in H07a using a more limited optical photometric data set. The present sample is larger because we have included an updated version of the CVSO catalog (Mateu et al. 2012), photometry from the cluster collaboration and the new OSMOS photometry described in §2.1.1.
Out of 255 spectroscopic known members and disk bearing candidates, 249 stars are located in the photometric candidates region. Based on this, we lose about 2.4% of known members of the σ Orionis cluster with our photometric selection. Since targets for spectroscopic follow up generally are selected using photometric cuts, the exclusion percentage of know members could be a lower limit of the percentage of actual members excluded from our photometric selection. On the other hand, Burningham et al. (2005) found that photometric selection cuts do not miss significant numbers of bona-fide members of the σ Orionis cluster and thus the percentage of actual member excluded by our photometric selection can not be much higher than ∼ 2.4%. Since our photometric criteria to select candidates is conservative, contamination by background stars is present in the entire color range. At a color V-J ∼ 1 5, where a branch of old field stars crosses the PMS of the . σ Orionis cluster, the expected contamination level by non-members of the cluster is quite high (e.g., Hernández et al. 2008). Table 2 includes optical magnitudesfor the photometric candidates and for the known members not located in the photometric candidates region.
## 2.5. Low-Resolution Spectroscopy
Optical low-resolution spectra is a fundamental tool to identify and characterize young stars by using indicators as the presence of lithium in absorption, strong H α in emission or weak gravitysensitive features. We have obtained low-resolution spectra for 340 stars located in the the σ Orionis cluster. This spectroscopic data comes from several spectrographs with similar spectral coverage and resolution (see Table 3). Targets for spectroscopic follow-up were selected mainly from the sample of photometric members with infrared excesses or the sample of photometric members with X-ray counterparts. Except for observations obtained using the Hectospec multifibers spectrograph, target selection includes stars with V magnitude brighter than 16.5. Using the 3 Myr isochrone from Siess et al. (2000) and assuming a distance of 385 pc (Caballero 2008c) without reddening, this limit corresponds to stars of spectral type M3 or earlier (M ∗ > 0.35M /circledot ).
## 2.5.1. Hectospec
Weobtained low resolution spectra with the fiber-fed multiobject Hectospec instrument mounted on the 6.5m Telescope of the MMT Observatory (MMTO). Hectospec has 300 fibers that can be placed within a 1 ◦ diameter field. Each fiber subtends 1.5 ′′ on the sky (Fabricant et al. 2005). The observations were taken with 270 line mm -1 grating, providing ∼ 6 Å resolution and spectral coverage of 3650 - 9200 Å. The Hectospec data were reduced throug h the standard Hectospec data reduction pipeline (Mink et al. 2007). This pipeline assumes that the sky background does not vary significantly with position on the sky and uses combined sky fibers (fibers that point to empty portions of the sky) to correct for the sky background. In general, the σ Orionis cluster has a smooth background. However, there are some targets located in regions with variable sky background and therefore their spectra could have bad estimates of nebular lines. We have identified 16 stars with bad sky subtraction and for these stars we did not report measurements of the H α line. One observation was obtained on the night of 2006 October 11, which provided spectra for 160 photometric candidates and 56 additional stars in the field.
## 2.5.2. FAST
We obtained low-resolution spectra for 46 photometric candidates using the 1.5 m telescope of the Fred Lawrence Whipple Observatory (FWLO) with the FAST spectrograph (Fabricant et al. 1998), equipped with the Loral 512x2688 CCD. The spectrograph was set up in the standard configuration used for FAST COMBO projects, a 300 groove mm -1 grating and a 3 ′′ wide slit. This combination offers 3400Å of spectral coverage centered at 5 500 Å, with a resolution of 6 Å. This
data were observed as part of the program "Orion PMS Candidates" (#112; Briceño et al. 2005, 2007). The spectra were reduced at the Harvard-Smithsonian Center for Astrophysics using software developed specifically for FAST COMBO observations. Additionally, we have five stars collected as part of the FAST program "Ae/Be stars in OB associations" (#89; Hernández et al. 2005). Finally, using the FAST Public Archive 9 , we have collected spectra for 19 additional stars observed as part of different programs.
## 2.5.3. OSU-CCDS
Low resolution, long slit-spectra were obtained for 36 photometric candidates using the 1.3 mMcGraw-Hill Telescope of the MDM Observatory (MDMO) with the OSU (Ohio State University) Boller & Chivens CCD spectrograph (OSU-CCDS) equipped with the Loral 1200x800 CCD. We used the 158 grooves per mm grating centered at 5300 Å along with a 1' slit width . This configuration provides an effective resolution of 6.5 Å with 3400Å of spectral coverage (the nominal resolution of 4.1Å provides spectra under sampled at th e 1.3-m telescope). Observation were obtained on the nights of 2011 December 16 and 17. Processing of the raw frames and calibration of the spectra were carried out following standard procedures using the IRAF packages twodspec and onedspec.
## 2.5.4. Boller & Chivens - SPM
Lowresolution, long slit-spectra were obtained with the Boller & Chivens spectrograph mounted on the 2.1m telescope at the San Pedro Martir Observatory (OAN-SPM) 10 during three observing runs: 2011 Oct 28 to 30, 2012 Oct 18 to 21 and 2013 Jan 12 to 14. A Marconi CCD (13.5 µ mpix 1 ) with 2k x 2k pixel array was used as detector. We have used a 400 lines mm --1 dispersion grating along with a 2 ′′ slit width, giving a spectral resolution of ∼ 6 Å. Spectra reduction was carried out following standard procedures in XVISTA 11 . In order to eliminate cosmic rays from our spectra, we have obtained three spectra for each star and combined them to get a median individual spectrum. A total of 34 photometric candidates were observed with this instrument.
9 http://tdc-www.harvard.edu/cgi-bin/arc/fsearch
10 The Observatorio Astronómico Nacional at San Pedro Martir (OAN-SPM) is operated by the Instituto de Astronomía of the Universidad Nacional Autónoma de México.
11 XVISTA was originally developed as Lick Observatory Vista. It is currently maintained by Jon Holtzman at New Mexico State University and is available at http://ganymede.nmsu.edu/holtz/xvista.
## 2.5.5. Boller & Chivens - Cananea
Aset of low resolution, long-slit spectra was obtained with the Boller & Chivens spectrograph mounted on the 2.1m telescope at the Observatorio Astrofisico Guillermo Haro (Cananea, Mexico) 12 , during the nights 1-4 December 2012. A SITe CCD with 1k x 1k pixels of 24 microns was used as a detector. We have used a 150 lines mm -1 dispersion grating and a slit width of 2 ′′ , giving a spectral resolution of ∼ 10 Å. Observing strategy and spectra reduction were the same as described in §2.5.4. A total of 27 photometric candidates were observed with this instrument.
## 2.6. High resolution spectroscopy
We obtained high resolution spectra of a subset of candidates of the σ Orionis cluster using the Hectochelle fiber-fed multiobject echelle spectrograph mounted on the 6.5 m Telescope of the MMT Observatory (MMTO). Hectochelle can record up to 240 high resolution spectra simultaneously in a 1 ◦ circular field. Each fiber subtends 1.5 ′′ on the sky (Szentgyorgyi et al. 2011). We use the order-sorting filter OB26 which provides a resolution of R ∼ 34000 with 180Å of spectral coverage centered at 6625Å. In spite of the fact that the orde r-sorting filter OB26 is not optimal for radial velocity measurements (F˝ urész et al. 2008), the spe ctral coverage of this filter allows us to analyze the H α profile and the Li I λ 6708 line to identify young stars, accretors and non-accretors.
One Hectochelle field was obtained on the night of 2007 February 27 which provides high resolution spectra for 134 photometric candidates and 8 additional stars in the region studied in this work. The data were reduced using an automated IRAF pipeline developed by G. Furesz which utilizes the standard spectral reduction procedures, using IRAF and the tasks available under the packages mscred and specred. A more detailed description of Hectochelle data reduction can be found in Sicilia-Aguilar et al. (2006).
## 3. Spectral types and membership
## 3.1. Spectral analysis, youth features and Reddening Estimates
Spectral types were derived applying the SPTCLASS code on the sample of stars with low resolution spectra (§2.5). SPTCLASS is a semi-automatic spectral analyzing program that uses
12 The Observatorio Astrofísico Guillermo Haro (OAGH) is oper ated by Instituto Nacional de Astrofísica Optica y Electronica (INAOE).
empirical relations between spectral type and equivalent widths to classify and characterize stars based on selected features 13 . For spectral typing, it has three schemes optimized for different mass ranges (K5 or later, from late F to early K and F5 or earlier), which use different sets of spectroscopic features (Hernández et al. 2004; Sicilia-Aguilar et al. 2005; Downes et al. 2008). The user has to manually choose the best scheme for each star based on the prominent features in the spectrum and the consistency of several spectral indices. The equivalent width (hereafter EW) for each spectral feature is obtained by measuring the decrease in flux due to photospheric absorption line from the continuum that is expected when interpolating between two adjacent bands. The spectral features measured by this procedure are largely insensitive to reddening and the signal to noise ratio (S/N) of the spectra (as long as we have enough S/N to detect the spectral feature). Moreover, spectral types obtained by SPTCLASS are largely independent of luminosity because most of the indices selected are not sensitive to the surface gravity of the star (Hernández et al. 2004). However, SPTCLASS does not take into account the effect on the lines of the hot continuum emission produced by the accretion shocks. This continuum emission makes the photospheric absorption lines appear weaker and for K-type and M-type highly veiled stars the SPTCLASS outputs should be considered as the earliest spectral-type limits (Hsu et al. 2012). SPTCLASS is unable to give spectral types for highly veiled stars earlier than K-type (e.g. Continuum Stars in Hernández et al. 2004). In Table 4 we report spectral types for the sample observed in §2.5.
In Figure 2 we compare spectral types derived in this work with those published previously from selected works (Wolk 1996; Houk & Swift 1999; Zapatero Osorio et al. 2002; Caballero 2006; Caballero et al. 2012; Rigliaco et al. 2012). Additionally, our spectral types were compared with spectral types compiled in SIMBAD 14 database from different authors (Cohen & Kuhi 1979; Nesterov et al. 1995; Houk & Swift 1999; Zapatero Osorio et al. 2002; Barrado y Navascués et al. 2003; Muzerolle et al. 2003; Hernández et al. 2005; Briceño eal. 2005; Oliveira et al. 2006; Caballero et al. t 2006, 2010a, 2012; Gatti et al. 2008; Sherry et al. 2008; Skinner et al. 2008; Renson & Manfroid 2009; Nazé 2009; Cody & Hillenbrand 2010; Townsend et al. 201 0; Rigliaco et al. 2011, 2012). Most spectroscopic studies of the σ Orionis cluster have derived spectral types for low mass stars and very low mass stars (spectral types K5 or later). Thus, in Figure 2 we have few points of comparison in the solar type range (from F to early K). In general, and with the exception of Wolk (1996), spectral types reported previously by other authors, agree within the uncertainties, with spectral types calculated using SPTCLASS. Wolk (1996) used absorption line ratios of Ca I lines ( λ 6122, λ 6162 and λ 6494) and Fe I lines ( λ 6103, λ 6200 and λ 6574) as indicators of spectral types. The spectral types dependencies of these indicators are weak for stars with spectral types K-early or earlier. Additionally, the spectroscopic data set of Wolk (1996) have poor signal-to-noise ratios,
13 http://www.cida.gob.ve/ ∼ hernandj/SPTclass/sptclass.html
14 SIMBAD, Centre de Donneés astronomiques de Strasbourg, at h ttp://simbad.u-strasbg.fr/simbad/
which severely affects the measurements (Zapatero Osorio et al. 2002). A subset of the stars studied by Wolk (1996) were observed by Zapatero Osorio et al. (2002). Their spectral types, based on the measurements of molecular bands like TiO and CaH, match our determinations. On the other hand, Caballero (2006) used indices based on the EW of some lines (Fe I λ 6400, Ca I λ 6439, Ca I λ 6450, Ca I λ 6462 and Ca I λ 6717) to estimate spectral types. The spectral types dependencies of these indices are very weak in the spectral type range from G0 to K0, where we observe larger discrepancies between our spectral types and the spectral types reported by Caballero (2006).
EWs of Li I λ 6708 and H α lines were measured using the interactive mode of SPTCLASS in which two adjacent continuum points must be manually selected on the spectra to fit a Gaussian line to the feature 15 . We find that the typical uncertainties of EWs measured in this way are ∼ 10%. In Table 4 we assign a flag to each star based on the presence of Li I λ 6708 in absorption: "2" means that the star has Li I λ 6708 in absorption; "1" means that there are doubts about the measurement of Li I, generally, due to low S/N of the spectra; "0" means that Li I λ 6708 is not present in the spectra.
Based on the EW of H α and the criterion defined by Barrado y Navascués et al. (2003)to distinguish between accretors and non-accretors for stars with spectral type G5 or later, in Table 4 we classify stars into different groups: accretors (Acr), non-accretors (nAcr), and stars in which uncertainties for EWs of H α and spectral types fall on the limit between accretors and non-accretors (Acr?). We also have identified stars with spectral types earlier than G5 with H α in emission (ET em ) and with H α in absorption (E abs ). Figure 3 shows the relation between the EW of H α and the spectral type. In order to plot our data in a logarithmic scale, EWs of H α have been shifted by ten units (the dotted line is the limit between absorption and emission of H α ). Solid line delimits the area for accretors and non-accretor stars based on the EWs of H α emission line (Barrado y Navascués et al. 2003). Using different symbols we plot results obtained using different spectrographs (see Table 3). We also plot stars bearing protoplanetary disks (H07a). In general, stars above the Barrado's accretion cutoff were classified as stars bearing full disks (II) or Transitional Disks (TD) in H07a. There are some stars with optically thick disks below the H α EW criterion (SO 435, SO 467, SO 566, SO 598, SO 682, SO 823 and SO 967). These stars would be similar to CVSO 224 that was classified as a weak-line T Tauri star based on the EW of H α . However, using high resolution spectra, Espaillat et al. (2008) show that is a slowly accreting T Tauri star with accretion rate of 7x10 -11 M yr 1 estimated using the magnetospheric accretion models (Muzerolle et al. 2001). On /circledot -the other hand, there are diskless star that were classified as accretor (SO 229, SO 1123 and SO 1368). These diskless objects with H α in emission could have substantial contribution produced by strong chromospheric activity which is related to fast rotation. In section §4.2, we study in
15 In general, the spectroscopic features in which we obtain EW show Gaussian profiles
more detail slowly accreting stars and diskless stars that mimic the H α width expected in stars with accretion disks.
For very low mass stars (VLMS) observed with HECTOSPEC, we can use the line Na I λ 8195 as an additional indicator of youth (Downes et al. 2008). Since VLMS in the σ Orionis cluster are still contracting, their surface gravities are lower than that expected for a main sequence star with similar spectral type. The line Na I λ 8195 is the strongest one of the sodium doublet (Na I λλ 8183 8195) which is sensitive to surface gravity and varies significantly between M-type , field dwarf and PMS objects (Schlieder et al. 2012). The EW of the line Na I λ 8195 was estimated fitting a Gaussian function to the feature on the normalized spectrum. We use the continuum bands suggested by Schlieder et al. (2012) to normalize each spectrum. The uncertainties in EWs were calculated as in Kenyon et al. (2005) using the scale of HECTOSPEC ( ∼ 1.2Å/pixel) and the S/N of the continuum bands. Figure 4 shows normalized spectra of three stars with spectral type M5 illustrating the procedure to measure the line Na I λ 8195. The sources 05400029+0142097 and 05373723+0140149 are CVSO's stars spectroscopically confirmed as a dwarf field star and as a ∼ 10 Myr old star, respectively (Briceno et al in prep). The star SO 460 has Li I λ 6708 in absorption and has been confirmed previously as member of the σ Orionis cluster using radial velocity (Zapatero Osorio et al. 2002; Sacco et al. 2008; Maxted et al. 2008). It is apparent that the M type field star exhibits stronger absorption in the sodium doublet in comparison to the PMS stars.
Figure 5 shows the EW of Na I λ 8195 versus spectral type for stars in the σ Orionis sample, illustrating the procedure of using the sodium line as an additional criteria supporting membership in the VLMS of σ Ori. We display the median and the second and third quartiles of Na I λ 8195 measured for a sample of PMS stars (lower solid line) and for a sample of M-type field dwarfs (upper solid line) in the Orion OB1a and OB1b associations (Briceno in prep.). These PMS stars, with ages ranging from ∼ 5 to ∼ 10 Myr, were confirmed by the presence of Li I λ 6708 in absorption. In general, stars confirmed as members by the presence of Li I λ 6708 in the σ Orionis cluster (open squares) are below the median population of PMS stars in the OB1a and OB1b associations. On the other hand, stars selected as non members of the σ Orionis cluster (open circles) follow the median line of M-type field dwarfs in the OB1a and OB1b associations. Figure 5 shows that the separation between M-type field stars and PMS stars is more clear for later spectral types, so that for stars with spectral type M3 or later we use the EW of Na I λ 8195 as an additional criteria of youth; those stars located below the median line of the PMS stars in the OB1a and OB1b associations were identified as young stars (labeled with "Y" in column 10 of Table 4). Most of the σ Ori VLMS with uncertain membership based on Li I λ 6708 (crosses) have smaller values of EW of Na I λ 8195 and thus are likely members of the cluster. The stars SO 576 and SO 795 exhibit strong Na I λ 8195 line and thus are classified as M-type field stars (labeled with "N" in Table 4)
In order to estimate reddening for our sample, we calculate the root mean square of the dif-
ferences between the observed colors and the standard colors
$$R M S ( A _ { V } ) = \sqrt { \frac { \sum \left ( [ V - M _ { \lambda } ] _ { o b s } - [ 1 - \frac { A _ { \lambda } } { A _ { V } } ] \ast A _ { V } - [ V - M _ { \lambda } ] _ { s t d } \right ) ^ { 2 } } { n } }$$
where [ V -M λ ] obs are the observed colors V-Rc, V-Ic and V-J (when they are available), n is the number of colors used to calculate RMS( AV ) and [ V -M λ ] std are the corresponding standard colors for a given spectral type. The values of A λ AV were obtained from Cardelli et al. (1989) assuming the extinction law normally used for interstellar dust ( A λ AV = 0.832, 0.616 and 0.288 for Rc, Ic and J, respectively). We vary the visual extinction ( AV ) from 0 to 10 magnitudes in steps of 0.01 magnitudes and estimate visual extinction as the AV value with the lowest RMS( AV ). We use the intrinsic colors for main sequence stars from Kenyon & Hartmann (1995) and the intrinsic colors of 5-30 Myr old PMS stars from Pecaut & Mamajek (2013). Since these PMS intrinsic colors are given for stars F0 or later, we complete the standard colors for stars earlier than F0 using the intrinsic color of 09-M9 dwarf stars compiled by Pecaut & Mamajek (2013). Intrinsic colors of PMS stars earlier than G5 appear to be consistent with the dwarf sequence (Pecaut & Mamajek 2013).
Since PMS stars are in a different evolutionary stage than dwarf field stars, there may be systematic errors in the calculation of interstellar reddening when using main sequence calibrators. Figure 6 shows a comparison between the reddening calculated using the intrinsic colors for main sequence stars from Kenyon & Hartmann (1995) and the intrinsic colors for PMS stars from Pecaut & Mamajek (2013). In general, for stars in the spectral type range from G2 to M3 the visual extinctions estimated from Kenyon & Hartmann (1995) are larger than those estimated using PMS colors (Pecaut & Mamajek 2013). On the other hand, for stars later than M3 (open squares), visual extinctions estimated from Kenyon & Hartmann (1995) are slightly smaller than those estimated using PMS colors (Pecaut & Mamajek 2013).
Sorted by spectral types, Table 4 summarizes the results obtained from the low resolution dataset. Column (3) indicates the spectrograph used for each star (see Table 3). Column (4) shows spectral types. Columns (5), (7) and (9) show the EWs of Li I λ 6708, H α and Na I λ 8195, respectively. Flags based on these lines are shown in columns (6), (8) and (10). Columns (11) and (12) show visual extinctions calculated using standard colors for main sequence stars (Kenyon & Hartmann 1995) and using standard colors for PMS stars (Pecaut & Mamajek 2013).
## 3.2. Radial Velocity, H α and Li I λ 6708 measurements
We measured heliocentric radial velocities (RVs) in the high resolution spectra of the sample observed with Hectochelle. RVs were derived using the IRAF package "rvsao" which crosscorrelate each observed spectrum with a set of templates of known radial velocities (Tonry & Davis 1979; Mink & Kurtz 1998). We used the synthetic stellar templates from Coelho et al. (2005) with solar metallicity, surface gravity of log(g) = 3.5 and effective temperature ranging from 3500 to 7000 K in steps of 250 K. The use of synthetic templates enables us to explore a wider range of stellar parameters than a few observed templates (Tobin et al. 2009). We estimated the radial velocity and the template as those that gave the highest value of the parameter R, defined as the S/N of the cross correlation between the observed spectrum and the template. The RV error is calculated from the parameter R as (Tobin et al. 2009):
$$R V _ { e r r } = \frac { 1 4 ( k m s ^ { - 1 } ) } { 1 + R }$$
In Table 5 we report radial velocities for 95 stars in which R is larger than 4 (Rverr /lessorsimilar 2.8 km s -1 ). This sample includes 36 stars with known radial velocities compiled in §2.3. In general, the differences between our measurements and known radial velocities were less than 2 km s -1 (rms=1.9 km s -1 ). There are 5 stars (SO 616, SO 662, SO 791, SO 929 and SO 1094) with differences larger than 2 km s -1 . Since during its orbit around the center of mass radial velocities of the components of binaries could change, these 5 stars are labeled as binary candidates by radial velocity variability (RVvar). The cross correlation function also can be used to identify double lined spectroscopic binaries (SB2). We have identified 4 SB2 stars that show double peaks in the cross correlation function.
EWs of the Li I λ 6708 line reported in Table 5 were calculated fitting a Gaussian function to the line in the high resolution spectra. The errors of EWs were calculated as in Kenyon et al. (2005) using the scale of HECTOCHELLE (0.0786"/pixel) and the S/N of the continuum used to obtain the EW. Figure 7 shows a diagram of EWs of Li I λ 6708 versus radial velocities. The distribution of radial velocities can be described by a Gaussian function centered at 30.8 km s -1 with a standard deviation ( σ RV ) of 1.7 km s -1 . Applying a 3 σ RV criteria, we can define a radial velocity range for kinematic members of the cluster from 25.7 km s -1 to 35.9 km s -1 . These values are similar to those reported by Jeffries et al. (2006) for the stellar group associated with the star σ OriAB (27 - 35 km s -1 ). In Table 5 we label as kinematic members of the σ Orionis cluster stars with radial velocity in the membership range (flag "2") and as kinematic candidates of the sparser stellar population (see §2.3) stars with radial velocities from 20 km s -1 to 25.7km s -1 (flag "1"). Stars with radial velocity smaller than 20 km s -1 and larger than 35.9 km s -1 were flagged as kinematic non-member (flag "0"). Three stars with Li I λ 6708 in absorption fall in the last group.
The stars SO 362 and SO 1251 have RV>35.9 km s -1 and the star SO 243 has RV<20 km s -1 . The star SO 362 has a protoplanetary disk and its discrepant RV value could be caused by binarity. The Li I λ 6708 measured in the star SO 1251 is lower than those expected for the σ Orionis stellar population and thus its membership is uncertain. Since the spectral type of the star SO 243 is relatively early ( G5; see §3.1), the youth of this object is also uncertain. The shallow depth of the convective zone in stars earlier than K0 can allow them to reach the main sequence with a non-negligible amount of their primordial lithium content and thus Li I λ 6708 in absorption is not a reliable indicator of the PMS nature of these stars. Therefore, the presence of lithium in absorption in F type and G type stars is only evidence that these objects are not old disk, post main sequence stars (Briceno et al. 1997). Finally, we were unable to calculate radial velocities for 17 stars with Li I λ 6708 in absorption. These stars were included as spectroscopic members of the cluster.
The full width of H α at 10% of the line peak (WH α \_10%) is an indicator that allows to distinguish between accreting and non accreting young stellar objects. White & Basri (2003) suggested that WH α \_10% > 270 km s -1 indicates accretion independent of the spectral type. Jayawardhana et al. (2003) adopted a less conservative accretion cutoff of 200 km s -1 studying young very low mass stars and brown dwarfs. A newly born star is surrounded by a primordial optically thick disk which evolves due to viscous processes by which the disk is accreting material onto the star while expanding to conserve angular momentum (Hartmann et al. 1998). As a consequence of this and other evolutionary processes, the frequency of accretors and the accretion rate in the inner disks steadily decreases from 1 to 10 Myr (e.g. Calvet et al. 2005; Williams & Cieza 2011). Thus signatures of accretion can be used as indicators of membership in a young stellar region. In the case in which H α has a symmetric or quasi-symmetric profile in emission, we measured automatically the peak of the profile fitting a Gaussian function to the H α line. When the fitting of a single Gaussian function does not work (e.g. non-symmetric profiles), the peak of the H α line was selected manually. The WH α \_10% was measured as the width of the H α velocity profiles at 10% of the emission peak level (column 6 in Table 5). Following the criterion from White & Basri (2003), stars with WH \_10% α > 270 km s -1 were identified as accretors. Stars without measurements of WH α \_10% have comments in Table 5 about the H α profile.
## 3.3. Additional criteria for membership
Since the criteria used in §3.1 as indicators of youth are useful mainly for stars with spectral types K and M, we need to use additional criteria to confirm or reject candidates as member of the σ Orionis cluster. In general, the memberships described in this section are less reliable than those obtained from low resolution spectroscopic analysis (§3.1) and those obtained from high resolution spectroscopic analysis (§3.2) .
## 3.3.1. Photometric membership probabilities and variability
Pre-main sequence (PMS) stars are characterized by having a high degree of photometric variability of diverse nature (Herbst et al. 1994; Cody & Hillenbrand 2010, 2011). The variability is due to chromospheric and magnetic activity in the stellar surface (e.g., cool spots, flares and coronal mass ejections) and to protoplanetary disks around the stars (e.g., hot spots produced by accretion shocks, variable accretion rates and variable extinction produced by inhomogeneities in the dusty disk). Since the expected photometric variability in PMS stars are so diverse, it is difficult to apply variability criteria such as range of periods or light curves types to refine the selection of possible members of a young stellar group. However, we can use the location of variable stars in color magnitude diagrams to select them as PMS candidates. Briceño et al. (2001, 2005) indicate that selecting variable stars above the ZAMS located at the typical distance of a young stellar group clearly picks a significant fraction of members of that stellar group. Moreover, using the differences between the observed colors and the expected colors defined by empirical or theoretical isochrones, we can calculate photometric membership probabilities for the sample.
Figure 8 shows the procedure to estimate photometric membership probabilities. Based on [VJ] colors and V magnitudes, we tailored new indices (C rot and M rot ) using the following equations to rotate the color magnitude diagram of Figure 1:
$$C _ { r o t } = [ V - J ] * c o s ( \theta ) - ( V - V _ { 0 } ) * s i n ( \theta )$$
$$M _ { r o t } = V _ { 0 } + [ V - J ] * s i n ( \theta ) + ( V - V _ { 0 } ) * c o s ( \theta )$$
where V0 is the V value where the empirical isochrone has [V-J]=0 and θ is the angle where the root mean square of C rot for the known member sample is minimal ( ∼ 25.5 ). ◦ The distribution of C rot for known members (open circles) describes a Gaussian function with standard deviation of σ =0.32. Assuming a standard normal distribution we can transform C rot values to probabilities for our sample. The 3 σ criterion applied in §2.5.5 to select photometric candidates means that stars that fall outside of this criteria have membership probabilities lower than ∼ 0.3% (dotted lines in Figure 8). Notice that the photometric probability obtained here does not take into account the distribution of non-members in Figure 8. The contamination by non-members is much higher at negative values of C rot than at positive values of C rot . Also, the expected contamination is higher at M rot ∼ 13 where a branch of old field stars crosses the stellar population of the σ Orionis cluster.
Weplot in Figure 8 variable stars reported in the CVSO catalog (Briceño et al. 2005; Mateu et al. 2012), stars flagged as variable in the cluster collaboration's photometric catalogs (Kenyon et al. 2005; Mayne et al. 2007), variable low-mass stars and brown dwarfs of the σ Orionis cluster
(Cody & Hillenbrand 2010), and stars listed as known or suspected variables in The AAVSO International Variable Star Index (Watson 2006). In spite of the fact that this compilation of variable stars in the σ Orionis cluster is not complete, 60% of the stars within the one σ criteria (dotted lines; photometric probability higher than ∼ 32%) are reported as variable objects.
## 3.3.2. Proper motion and spatial distribution
In general, the motion of young stellar groups of the Orion OB1 association are mostly directed radially away from the Sun. Thus, the expected intrinsic proper motions in right ascension ( cos ( δ ) ∗ µ α ) and declination ( µ δ ) are small and comparable to measurement errors (Brown et al. 1998; Hernández et al. 2005). Particularly, Brown et al. (198) reported an average proper motion 9 for this stellar association of 0.44 mas/yr and -0.65 mas/yr for cos ( δ ) ∗ µ α and µ δ , respectively. Although we cannot use proper motion to separate potential cluster members from field star nonmembers, we can use criteria based on proper motions to identify and reject high proper motion sources as potential members of the σ Orionis cluster (e.g., Lodieu et al. 2009; Caballero 2010).
Wefollow a similar method used in Hernández et al. (2009) to ientify potential non-members d of the cluster. Figure 9 shows the vector point diagram for the photometric candidates with proper motions reported in The fourth US Naval Observatory CCD Astrograph Catalog (UCAC4; Zacharias et al. 2013). The distributions of proper motions for the known members (green X's) can be represented by Gaussians centered at cos ( δ ) ∗ µ α ∼ 2.2 mas/yr and µ δ ∼ 0.7 mas/yr, with standard deviations of 5.3 mas/yr and 4.1 mas/yr, respectively. These values agree within the errors with previous estimations for the entire OB association (e.g., Brown et al. 1998) and for the cluster (e.g., Kharchenko et al. 2005; Caballero 2007, 2010). Most known members ( ∼ 86%) are located in a well defined region represented for the 3 σ criteria (dotted ellipse) in the vector point plot. We also use a less conservative criteria of 5 σ (solid line ellipse) similar to the criteria used in previous works (Caballero 2007, 2010; Lodieu et al. 2009). With the exception of the stars SO 592, SO 936 and SO 1368, the 5 σ criteria includes all the known member sample. The star SO 592 is a radial velocity member with Li I λ 6708 in absorption (see §2.6). The star SO 1368, reported as diskless accretor in §3.1, has large error in cos ( δ ) ∗ µ α ∼ and thus the proper motion criteria for this object is uncertain. The star SO936 lies outside the vector point diagram. Its infrared excess at 8 µ m (H07a) is the only youth feature reported for this photometric candidate. Astrometric follow-up could help to find out if those stars are members of binary systems, they were ejected from the cluster early on during the formation process, or they belong to a moving group associated with Orion (Lodieu et al. 2009).
Based on the distribution of stars in the vector point diagram, we have classified our photometric candidates into three groups, stars inside of the 3 σ limit (proper motion flag "2"), stars between
the 3 σ and the 5 σ limit (proper motion flag "1") and stars with proper motions larger than the 5 σ criteria (proper motion flag "0"). In general, the proper motion flags agree with previous proper motion studies to identify high proper motion interlopers (Lodieu et al. 2009; Caballero 2010). Out of 29 stars studied by Caballero (2010) and located in the region studied in this work, 14 stars have proper motion in UCAC4. All the 13 photometric candidates identified by Caballero (2010) as high proper motion interlopers have proper motion flag "0". The other star is a background star (§2.4) rejected using optical colors (star #38 in Caballero 2010) . Only one star (054019750229558) reported by Lodieu et al. (2009) as proper motion non-member have proper motion flag "1". Additional studies are necessary to obtain youth features of this object.
Finally, Caballero (2008b) suggests that the σ Orionis cluster has two components: a dense core that extends from the center to a radius of 20 and a rarefied halo at larger separations. Mem-′ bers of the σ Orionis cluster have higher probability to be located in the dense core than in the rarefied halo. Thus, we also include a flag for the distance from the center of the cluster. Stars located closer than 20 have flag "1", otherwise have flag "0". ′
## 3.4. Membership analysis of the cluster
Depending on the spectral type range, obtaining memberships of stars that belong to a young stellar group can be a difficult process and some times we need to combine different membership indicators. Based on the spectroscopic and photometric analysis developed in §2.4, §4.1, §3.2, §3.1 and §3.3, and the information compiled in §2.3 about several membership criteria, we compile in Table 6 membership indicators for stars with spectral types obtained in §3.1. Columns (1) and (2) show source designations from H07a and Cutri et al. (2003), respectively. Column (3) shows the spectral type. Column (4) indicates the membership flag based on the presence of Li I λ 6708 in absorption from low resolution spectra (§3.1) and from high resolution spectra (§3.2). Columns (5) shows the references of known members based on Li I λ 6708. Columns (6) and (7) show the radial velocity information from our analysis (§3.2) and from previous works, respectively. Column (8) shows the classification based on the H α line and the accretion criteria from Barrado y Navascués et al. (2003, §3.1) and from White & Basri(2003, §3.2). Column (9) indicates the membership flag based on the line Na I λ 8195 (§3.1). Additional membership information based on the presence of protoplanetary disks, X ray emission, proper motion, distance from the center of the cluster and variability are in columns (10), (11), (12), (13) and (14), respectively. Column (15) gives the photometric membership probability calculated in §3.3 and column (16) indicates the visual extinction estimated using the PMS standard colors of Pecaut & Mamajek (2013, §3.1). Finally, our membership flags and comments are given in the last column. Similar to the membership study by Kenyon et al. (2005), some of our membership flags are arguable, but the
reader can reach their own conclusions based on the information in Table 6.
In general, stars with spectral types B or A in Table 6 were included as young stars by Caballero (2007) and Sherry et al. (2008) using proper motion, radial velocity, X ray and infrared observations and main sequence fitting analysis. The star SO 602 was not included in those studies. This star has discrepant radial velocity and very high visual extinction to be considered member of the σ Orionis cluster. The star SO 147 was not included in Sherry et al. (2008) and was rejected by Caballero (2007) based on the proper motions reported by Perryman et al. (1997). SO 147 is a X ray source and our RV measurements indicate that could be a young star member of the sparser population (Maxted et al. 2008) or a binary of the σ Orionis cluster. However, the visual extinction of SO 147 is higher than that expected for the cluster, thus its membership is uncertain. Sherry et al. (2008) suggested that SO 956 is too bright to be member of the cluster and SO 521 is too faint to be a member of the cluster. The star SO 956 has youth features like infrared excess and Xray emission and the star SO 521 is located above the ZAMS but with relatively low photometric membership probability. Thus is not clear the membership status of these two objects. Finally, the star SO 139 is relatively bright to be a member of the cluster and Sherry et al. (2008) suggested that it could be a member of the cluster if this star is an equal mass binary. In summary, the memberships of the stars SO 139, SO 956, SO 521 and SO 147 reported in Table 6 are uncertain.
It is more difficult to estimate membership for solar type stars (F and G). In this spectral type range, old stars cross the sequence defined by the σ Orionis cluster and thus the contamination level by non-members of the cluster is quite high. For some stars Li I λ 6708 appear in absorption. However, for solar type stars this is not a robust criteria of youth and it is only evidence that these objects are not old disk, post main sequence stars (Briceno et al. 1997; Hernández et al. 2004). Thus, we need to evaluate other membership indicators like presence of disks, X ray emission, variability, radial velocity proper motions, reddening and photometric membership probabilities to confirm or reject stars as members of the cluster. In Table 6, solar type stars with Li I λ 6708 in absorption have additional youth features that support their membership of the cluster (mainly X ray source, infrared excesses and variability). Four stars with Li I λ 6708 in absorption (SO 1123, SO 243, SO 92 and SO 379) have discrepant radial velocity that makes us to suspect that they are not a member of the cluster. Another possibility is that these stars are binaries with variable radial velocities. Since, the frequency of binaries increases with the stellar mass (Duchêne & Kraus 2013, e.g.,), the probability to find a binary member with discrepant radial velocity in solar type stars is higher in comparison with low mass stars. We labeled these stars as probable members. We rejected as members of the cluster stars with very low ( < 0.3%) photometric membership probability and stars with discrepant radial velocity that do not have additional features of youth. Finally, some stars do not have enough information to define their membership and were labeled as uncertain members.
For low mass stars (from K0 to M2.5) and for very low mass stars (M3 or later) the presence of
Li I λ 6708 in absorption is a reliable indicator of youth. For very low mass stars when the presence of Li I λ 6708 in absorption is uncertain (flag "1"), we used the measurements of NaI I λ 8195 to support the membership status. Moreover, stars with uncertain flag of Li I λ 6708 that exhibit other indicators to be member of the cluster (including previous Li I λ 6708 reported for the star) are also classified as members of the σ Orionis cluster. We also considered member of the cluster stars with protoplanetary disks classified as accretors using the H α line. Finally, radial velocity can be used as a strong membership criteria for stars in the entire spectral type range and could be use to separate the σ Ori stellar population and the sparser stellar population (see §2.3).
Optical spectra and SEDs for the entire sample with spectral types obtained in §3.1, plus additional information compiled from Tables 2, 4 and 6 for each star, is available on-line 16 . This online tool is a work in progress and we expect to add new objects and to extend the information about the population of the σ Orionis cluster.
Finally, Table 7 compiles membership information for a set of stars studied in high resolution (§3.2) but without low resolution analysis or spectral types (§3.1). Our memberships are based on radial velocity criteria, presence of Li I λ 6708 in absorption and the accretion criteria from White & Basri (2003).
## 4. Disk population and accretion
## 4.1. Revisiting the disk census in the cluster
In H07a, we studied the disk population in the region covered by the four channels of IRAC. Since mosaics of channels 4.5 µ mand 8.0 µ mhave a 6 .5 displacement to the north from the mosaics ′ of channels 3.6 µ mand 5.8 µ m, the region with the complete IRAC data set is smaller than the field of view of individual IRAC mosaics. MIPS observations in the σ Orionis cluster also cover more area in the north-south direction in comparison to the region covered by the complete IRAC data set. A more detailed description of MIPS and IRAC data can be found in H07a.
We searched for infrared excesses at 24 µ min the newly identified candidates within the photometric sample (Table 2) reanalyzing the MIPS observation of the σ Orionis cluster. We followed the procedure described in Hernández et al. (2007a,b, 2008, 2009, 2010) to identify stars with excess at 24 µ m. Figure 10 shows the color-color diagram used to select new disk bearing candidates of the cluster. Photospheric limits (dotted lines) were defined by H07a using the typical K-[24] color of disk less stars detected in the MIPS observation. An arbitrary limit between optically
16 http://sigmaori.cida.gob.ve/
thick disks (II) and debris disks (dashed line) was defined using the K-[24] color of a sample of known debris disks located in several young stellar groups (Hernandez et al. 2011). Open squares represent stars not included in the previous MIPS analysis (H07a). Out of 14 new disk bearing candidates, 12 have 24 µ minfrared excess expected in stars with optically thick disks. The remaining two stars show 24 µ m expected in stars with debris or evolved disks (K-24 /lessorsimilar 3.0; Hernandez et al. 2011). Two disk bearing candidates are potential galaxies based on the profile classification of UKIDSS (red X's). Spitzer photometry and disk type for each source are provided in Table 8.
## 4.2. Disk emission and Accretion Indicators
Independently of the spectral type, WH α \_10% is an indicator of accretion (White & Basri 2003; Jayawardhana et al. 2003). Studying very low mass young objects, Natta et al. (2004) found that WH \_10% can be used to roughly estimate accretion rates ( ˙ α M acc ). The relation of M ˙ acc as a function of WH α \_10% from Natta et al. (2004) indicates that stars accreting below the detectable level have log ( ˙ M acc ) /lessorsimilar -10.3 M /circledot yr -1 and log ( ˙ M acc ) /lessorsimilar -11 M /circledot yr -1 for the accretion cutoff of 270 km s -1 (White & Basri 2003) and 200 km s -1 (Jayawardhana et al. 2003), respectively, although a large chromospheric contamination is expected if the mass accretion rates have such low levels (Ingleby et al. 2011).
Figure 11 shows the relation between the WH α \_10% versus the IRAC SED slope determined from the [3.6]-[8.0] color. The horizontal solid line indicates the limit between optically thick disks and evolved disk objects based on their infrared excess at 8 µ m(Lada et al. 2006; Hernández et al. 2007a). We plotted stars with optically thick disks (open circles), evolved disks (open squares) and transitional disks (open triangles) from H07a. In general, diskless stars have WH α \_10% < 270 km s -1 which is the accretion cutoff proposed by White & Basri (2003). We found 8 objects with infrared excess at 8 µ m consistent with optically thick disks but that are not accreting or are accreting below the detectable level (hereafter very slow accretor). These stars are SO 467, SO 738, SO 435, SO 674, SO 451, SO 247, SO 697 and SO 662. The star SO 823 was also included as a very slow accretor candidate. This star has a strong absorption component at H α , we were unable to measure WH α \_10% and thus it was not included in Figure 11. On the other hand, low resolution spectra of SO 823 shows a single emission H α profile which suggests variability in the profile of H . Additionally, photometric measurements from CVSO indicate that SO 823 is a variable star α with amplitude of ∆ V ∼ 2.5 magnitudes. Objects such as UX Ori type and AA Tau type show photometric and spectroscopic variability, in which, H α could change from single emission line profile to a profile with a strong central absorption component.
Figure 12 shows the distribution on the IRAC color-color diagram ([5.8]-[8.0] vs. [3.6]-[4.5]) for stars studied in Figure11 . The very slow accretor candidates (including the star SO 823) were
plotted with solid circles. Stars with optically thick disks classified as accretor and very slow accretor candidates fall in similar region in this plot. Thus, very slow accretors candidates have similar infrared excesses in the IRAC bands in comparison with stars with optically thick disks classified as accretors using the accretion cutoff proposed by White & Basri (2003).
Lowresolution spectroscopic analysis (§3.1) supports the low accretion level for stars SO 823, SO 467, SO 435 and SO 451. Moreover, in Figure 3 we can identify four additional very low accretor candidates (SO 566, SO 598, SO 682 and SO 967) bearing optically thick disks which were classified as non-accretor following the criteria from Barrado y Navascués et al. (2003). High resolution studies are necessary to determine whether these stars are accreting or not (e.g. Espaillat et al. 2008; Ingleby et al. 2011).
Figure 13 shows normalized SEDs and H α profiles of the very slow accretor candidates detected in our high resolution spectra. For comparison, we show SEDs and profiles of a diskless star (SO 669) and two stars classified as accretor in Figure 11 (SO 397, SO 462). Particularly, the star SO 462 has WH α \_10% on the accretion cutoff defined by White & Basri (2003). The star SO 397 exhibit infrared excesses below the median SED for class II stars in the σ Orionis cluster. High inclination of the disk (edge-on) or dust settling could be responsible for the relatively small infrared excesses observed in this star. The star SO 823 has a jump in the SED between the 2MASS and the IRAC measurements which could be caused by variability or an unresolved binary. Some stars like SO 467, SO 435, SO 451 and SO 462 exhibit asymmetries in the H α profile that are characteristic of accreting disks. The emission of H α could have a contribution from the stellar chromosphere or the stars could have variable accretion rate, so the WH α \_10% could vary and would not be a robust quantitative indicator of accretion (e.g., Nguyen et al. 2009a,b). Thus, we need additional studies to understand whether these stars have stopped accreting, or if they are in a passive phase in which accretion is temporally stopped or if accretion is below the measurable levels in WH α \_10%. Previous studies have found very low accretors stars in other young stellar populations. Studying the accretion properties in Chamaleon I and ρ Oph, Natta et al. (2004) found a population of very low mass objects with evidence of disks but no detectable accretion activity estimated using several indicators of accretion. Nguyen et al. (2009a) also found a group of stars in Chamaeleon I ( ∼ 2Myr old) with excess at 8 µ m and accretion rates below the measurable levels in WH α \_10%. They also found that non-accreting objects with disks do not seem to exist in the Taurus-Auriga star forming region.
On the other hand, Figure 11 shows two diskless stars (SO 616 and SO 229) exhibiting WH \_10% larger than the accretors limits. One of these stars, SO 229, was identified as a double α lined spectroscopic binary from the cross correlation function while the star SO 616 was recognized as possible binary based on radial velocity variability. These two stars have Li I λ 6708 in absorption and spectral types of G2.5 and K7, respectively (see §3.1). In Figure 14, we compare
the Hectochelle spectra of SO 229 and SO 616 to stars with similar spectral types (G3 for SO 229 and K7 for SO 616). It is apparent that SO 299 and SO 616 have wider photospheric features. It is possible that wider spectral features are combined features from component in binary stars with similar spectral types. Another possibility is that the broadening of spectral lines in these objects can be caused by fast rotation. Non-accreting objects with projected rotational velocity larger than ∼ 50 km s -1 can generate WH α \_10% > 270 km s -1 (see Figure 5 of Jayawardhana et al. 2006). A multi-epoch spectroscopic analysis will help to reveal the nature of these objects.
Low resolution spectroscopic analysis(§3.1) shows three diskless stars (SO 229, SO 1123 and SO 1368) that mimic the H α width expected in stars with accretion disks (see Figure 3). The star SO 299 shows broad photospheric features that could be produced by binarity or fast rotation (Figure 14). The star SO1123 has been classified as spectroscopic binary (Caballero 2007) and fast rotator with a very high projected rotational velocity (Alcalá et al. 2000). The star SO 1368 is a variable star (Mayne et al. 2007) with spectral type K6.5 and still does not have information about multiplicity or rotation. These diskless objects with H α in emission could have substantial contribution produced by strong chromospheric activity related to fast rotation.
## 5. Summary and Conclusions
Combining 2MASS data (Cutri et al. 2003), new optical photometry obtained with the OSMOS instrument, an updated optical photometry from the CIDA Variability Survey of Orion and photometric information from previous work (Sherry et al. 2004; Kenyon et al. 2005; Mayne et al. 2007; Kharchenko & Roeser 2009), we defined a list of photometric candidates of the σ Orionis cluster. Substantial contamination is expected for solar type stars (V-J ∼ 1.5) because a branch of field stars cross the PMS population of the cluster in the color magnitude diagram used to select photometric candidates. A subset of these candidates were characterized using spectroscopic data.
We have applied a consistent spectral classification scheme aimed at PMS stars. Low resolution spectroscopic data set for spectral typing come from several instruments with similar spectral coverage and resolution. We were able to determine spectral types for 340 objects located in the general region of the σ Orionis cluster. Analysis of this data set enables us to define membership indicators based on the accretion status obtained from H α line (Barrado y Navascués et al. 2003), the presence of Li I λ 6708 in absorption (for LMS and for VLMS) and for a subset of VLMS observed with the Hectospec instrument the intensity of the line NaI I λ 8195. So far, this analysis constitutes the largest homogeneous spectroscopic characterization of members in the σ Orionis
- . Additionally, we were able to determine radial velocities for 95 stars out of a total sample of 142 objects observed at high resolution in the general region of the cluster. For this high resolution spectroscopic data set we also determined membership indicators based on the presence of
Li I λ 6708 in absorption and the width of the H α line (White & Basri 2003). The radial velocity distribution for members of the cluster is in agreement with previous works (e.g. Sacco et al. 2008; Maxted et al. 2008; González Hernández et al. 2008).
We have identified and assigned spectral types to 178 bona fide members of the σ Orionis cluster, combining results from our spectroscopic analysis, previous membership (based on radial velocity distribution and the presence of Li I λ 6708) and other membership indicators like detection of protoplanetary disks, X ray emission, proper motion criteria, distance from the central star, variability and photometric membership probability. We also have identified 14 bona fide members of the cluster using high resolution analysis and reported membership indicators. Additionally, we have identified and assigned spectral types to 25 probable members of the cluster. Finally 36 stars do not have enough information to assign membership (uncertain members).
Of particular interest are stars bearing an optically thick disks and narrow H α profile not expected in stars with accretion disks. Also objects with no infrared excess and H α line that mimic the H α width expected in stars with accretion disks (maybe because binarity or fast rotation). Additional multi-epoch observations are necessary to reveal the nature of these objects.
Additional information, the optical spectra, UBVRI magnitudes, membership indicators, and spectral energy distribution for each object analyzed in this work are reported on the World Wide Web 17 . Information in this website is a work in progress and we expect to increase the spectroscopic data base and the membership analysis for additional stars in the σ Orionis cluster.
We thank John Tobin for his advice during the reduction and analysis of the Hectochelle data. Thanks to Gail Schaefer and Jonh Monnier for insightful communications about the distance of the σ Orionis cluster. An anonymous referee provided many insightful comments. We thank Cecilia Mateu for providing the updated version of the CVSO catalog. We also thank Nelson Caldwell, Andy Szentgyorgyi, Perry Berlind, Michael Calkins and Susan Tokarz for their help in obtaining and processing the Hectospec and FAST spectra. I would like to thank the institutions and personnel that support data acquisition at the Observatorio Astronómico Nacional de Llano del Hato (CIDA), the Observatorio Astronómico Nacional at San Pedro Martir (UNAM), the Observatorio Astrofísico Guillermo Haro (INAOE), and the MDM Observator y (University of Michigan). This publication makes use of data products from the CIDA Equatorial Variability Survey, obtained with the J. Stock telescope at the Venezuela National Astronomical Observatory, which is operated by CIDA for the Ministerio del Poder Popular para Ciencia, Tecnología e Innovación of Venezuela. We also make use data products from UKIDSS (obtained as part of the UKIRT Infrared Deep Sky Survey) and from the Two Micron All Sky Survey, which is a joint project of the University of
17 http://sigmaori.cida.gob.ve/
Massachusetts and the Infrared Processing and Analysis Center/ California Institute of Technology. This work makes use of observations made with the Spitzer Space Telescope (GO-1 0037 and GO-1 0058), which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under a contract with NASA. Support for this work was provided by CIDA, the University of Michigan and by the grant UNAM-DGAPA IN109311.
## A. Known members, new disk bearing candidates and photometric candidates not listed in Table 6 and Table 7
Table 9 includes known members compiled in §2.3 and new disk bearing candidates identified in §4.1 which were not studied in §3.1 and §3.2. Except for stars observed using the Hectospec and Hectochelle multifibers spectrographs, our target selection includes stars with V < 16.5 (M ∗ > 0.35M /circledot ; see §2.5). Out of 125 stars included in Table 9, 107 stars (85.6%) are fainter than our target selection limit. Out of 18 stars with V<16.5, 3 stars are new disk bearing candidates. Sorted by optical brightness, Table 9 shows in columns (1) and (2) source designations from Hernández et al. (2007a) and Cutri et al. (2003), respective y. l Column (3) shows visual magnitudes (§2.1). Membership information based on the presence of protoplanetary disks, the presence of Li I λ 6708, radial velocity measurements, X ray emission, proper motion, distance from the center of the cluster and variability are in columns (4), (5), (6), (7), (8), (9) and (10), respectively. Column (11) gives the photometric membership probability calculated in §3.3.1. Spectral types and references are in columns (11) and (12), respectively.
Sorted by optical brightness, Table 10 includes additional photometric candidates with photometric membership probability higher than ∼ 32% (within the dashed lines in Figure 8). In this Tables we also include photometric candidates selected by Lodieu et al. (2009, ;UKIDSS'candidates) which are brighter than the completeness limit of 2MASS catalog (J ∼ 15.8). Out of 11 UKIDSS'candidates not included in Table 6, 4 UKIDSS'candidates were included in Table 9. The remaining 7 stars are listed in Table 10.
## REFERENCES
Alcalá, J. M., Terranegra, L., Wichmann, R., et al. 1996, A&A, 119, 7 S
Alcalá, J. M., Covino, E., Torres, G., et al. 2000, A&A, 353, 16 8
Andrews, S. M., Reipurth, B., Bally, J., & Heathcote, S. R. 2004, ApJ, 606, 353
Baltay, C., Snyder, J. A., Andrews, P., et al. 2002, PASP, 114, 780
| Barrado y Navascués, D., Béjar, V. J. S., Mundt, R., et al. 200, 3 A&A, 404, 171 |
|------------------------------------------------------------------------------------------------------------------------|
| Béjar, V. J. S., Zapatero Osorio, M. R. &Rebolo, R. 1999, ApJ,521, 671 |
| Béjar, V. J. S., Zapatero Osorio, M. R., &Rebolo, R. 2004, Astonomische r Nachrichten, 325, 705 |
| Béjar, V. J. S., Zapatero Osorio, M. R., Rebolo, R., et al. 201 1, ApJ, 743, 64 |
| Bell, C. P. M., Naylor, T., Mayne, N. J., Jeffries, R. D., &Littlefair, S. P. 2013, MNRAS, 434, 806 |
| Briceno, C., Hartmann, L. W., Stauffer, J. R., et al. 1997, AJ, 113, 740 |
| Briceño, C., Vivas, A. K., Calvet, N., et al. 2001, Science, 2 91, 93 |
| Briceño, C., Calvet, N., Hernández, J., Vivas, A. K., Hartman, n L., Downes, J. J., & Berlind, P. 2005, AJ, 129, 907. |
| Briceño, C., Hartmann, L., Hernández, J., Calvet, N., VivasA. , K., Furesz, G., &Szentgyorgyi, A. 2007, ApJ, 661, 1119 |
| Brown, A. G. A., de Geus, E. J., &de Zeeuw, P. T. 1994, A&A, 289, 101 |
| Brown, A. G. A., Walter, F. M., &Blaauw, A. 1998, arXiv:astro-ph/9802054 |
| Burningham, B., Naylor, T., Littlefair, S. P., &Jeffries, R. D. 2005, MNRAS, 356, 1583 |
| Caballero, J. A. 2006, Ph.D. Thesis, Universidad de La Laguna |
| Caballero, J. A., Martín, E. L., Dobbie, P. D., &Barrado Y Nav ascués, D. 2006, A&A, 460, 635 |
| Caballero, J. A. 2007, A&A, 466, 917 |
| Caballero, J. A. 2008a, A&A, 478, 667 |
| Caballero, J. A. 2008b, MNRAS, 383, 375 |
| Caballero, J. A. 2008c,MNRAS, 383, 750 |
| Caballero, J. A., Valdivielso, L., Martín, E. L., et al. 2008 , A&A, 491, 515 |
| Caballero, J. A., López-Santiago, J., de Castro, E., &Cornide, M. 2009, AJ, 137, 5012 |
| Caballero, J. A. 2010, A&A, 514, A18 |
| Caballero, J. A., Albacete-Colombo, J. F., &López-Santiago, J. 2010a, A&A, 521, A45 |
| Caballero, J. A., Cornide, M., &de Castro, E. 2010b, Astronomische Nachrichten, 331, 257 |
| Caballero, J. A., Cabrera-Lavers, A., García-Álvarez, D., &Pascual, S. 2012, A&A, 546, A59 |
|---------------------------------------------------------------------------------------------------------|
| Calvet, N., Briceño, C., Hernández, J., et al. 2005, AJ, 129,35 9 |
| Cardellim J. A., Clayton, G. C., &Mathis, J. S. 1989, ApJ, 345, 245 |
| Cody, A. M., &Hillenbrand, L. A. 2010, ApJS, 191, 389 |
| Cody, A. M., &Hillenbrand, L. A. 2011, ApJ, 741, 9 |
| Coelho, P., Barbuy, B., Meléndez, J., Schiavon, R. P., &Castlho, i B. V. 2005, A&A, 443, 735 |
| Cohen, M., &Kuhi, L. V. 1979, ApJS, 41, 743 |
| Cunha, K., Smith, V. V., &Lambert, D. L. 1998, ApJ, 493, 195 |
| Cutri, R. M., et al. 2003, VizieR Online Data Catalog, 2246, 0. |
| D'Alessio, P., Calvet, N., Hartmann, L., Franco-HernándezR., , &Servín, H. 2006, ApJ, 638, 314 |
| Downes, J. J., Briceño, C., Hernández, J., et al. 2008, AJ, 13, 6 51 |
| Duchêne, G., &Kraus, A. 2013, ARA&A, 51, 269 |
| Espaillat, C., Muzerolle, J., Hernández, J., et al. 2008, Ap, J 689, L145 |
| Fabricant, D., Cheimets, P., Caldwell, N., &Geary, J. 1998, PASP, 110, 79 |
| Fabricant, D., et al. 2005, PASP, 117, 1411 |
| Fazio, G. G., et al. 2004, ApJS, 154, 39 |
| Franciosini, E., Pallavicini, R., &Sanz-Forcada, J. 2006, A&A, 446, 501 |
| F˝rész, u G., Hartmann, L. W., Megeath, S. T., Szentgyorgyi,A. H., & Hamden, E. T. 2008, ApJ, 676, 1109 |
| Furlan, E., Hartmann, L., Calvet, N., et al. 2006, ApJS, 165, 568 |
| Garrison, R. F. 1967, PASP, 79, 433 |
| Gatti, T., Natta, A., Randich, S., Testi, L., &Sacco, G. 2008, A&A, 481, 423 |
| González Hernández, J. I., Caballero, J. A., Rebolo, R., et.a2008, l A&A, 490, 1135 |
| Hartmann, L. et al 1998, ApJ, 495, 385 |
Herbst, W., Herbst, D. K., Grossman, E. J., & Weinstein, D. 1994, AJ, 108, 1906
Hernández, J., Calvet, N., Briceño, C., Hartmann, L., & Berl nd, P. 2004, AJ, 127, 1682 i
Hernández, J., Calvet, N., Hartmann, L., Briceño, C., Sicil a-Aguilar, A., & Berlind, P. 2005, AJ, i 129, 856.
Hernández, J., et al. 2007, ApJ, 662, 1067
Hernández, J., et al. 2007, ApJ, 671, 1784
Hernández, J., Hartmann, L., Calvet, N., Jeffries, R. D., Gu ermuth, R., Muzerolle, J., & Stauffer, t J. 2008, ApJ, 686, 1195
Hernández, J., Calvet, N., Hartmann, L., et al. 2009, ApJ, 70, 705 7
Hernández, J., Morales-Calderon, M., Calvet, N., et al. 201, ApJ, 722, 1226 0
Hernandez, J., Calvet, N., Hartmann, L., et al. 2011, Revista Mexicana de Astronomia y Astrofisica Conference Series, 40, 243
Houk, N., & Swift, C. 1999, Michigan catalogue of two-dimensional spectral types for the HD Stars; vol. 5. By Nancy Houk and Carrie Swift. Ann Arbor, Michigan : Department of Astronomy, University of Michigan, 1999.
Hsu, W.-H., Hartmann, L., Allen, L., et al. 2012, ApJ, 752, 59
Ingleby, L., Calvet, N., Bergin, E., et al. 2011, ApJ, 743, 105
Jayawardhana, R., Mohanty, S., & Basri, G. 2003, ApJ, 592, 282
Jayawardhana, R., Coffey, J., Scholz, A., Brandeker, A., & van Kerkwijk, M. H. 2006, ApJ, 648, 1206
Jeffries, R. D., Maxted, P. F. L., Oliveira, J. M., & Naylor, T. 2006, MNRAS, 371, L6
Kenyon, S. J. & Hartmann, L. 1995, ApJS, 101, 117
Kenyon, M. J., Jeffries, R. D., Naylor, T., Oliveira, J. M., & Maxted, P. F. L. 2005, MNRAS, 356, 89
Kharchenko, N. V., Piskunov, A. E., Röser, S., Schilbach, E., & Scholz, R.-D. 2005, A&A, 438, 1163
Kharchenko, N. V., Scholz, R.-D., Piskunov, A. E., Röser, S., & Schilbach, E. 2007, Astronomische Nachrichten, 328, 889 Kharchenko, N. V., & Roeser, S. 2009, VizieR Online Data Catalog, 1280, 0 Lada, C. J., et al. 2006, AJ, 131, 1574 Landolt, A. U. 2009, AJ, 137, 4186 Landolt, A. U. 1992, AJ, 104, 340 Lawrence, A., et al. 2007, MNRAS, 379, 1599 Lawrence, A., Warren, S. J., Almaini, O., et al. 2013, VizieR Online Data Catalog, 2319, 0 Lodieu, N., Zapatero Osorio, M. R., Rebolo, R., Martín, E. L. , & Hambly, N. C. 2009, A&A, 505, 1115 López-Santiago, J., & Caballero, J. A. 2008, A&A, 491, 961 Luhman, K. L., Hernández, J., Downes, J. J., Hartmann, L., & Biceño, C. 2008, ApJ, 688, 362 r Mateu, C., Vivas, A. K., Downes, J. J., et al. 2012, MNRAS, 427, 3374 Mayne, N. J., Naylor, T., Littlefair, S. P., Saunders, E. S., & Jeffries, R. D. 2007, MNRAS, 375, 1220 Martini, P., Stoll, R., Derwent, M. A., et al. 2011, PASP, 123, 187 Maxted, P. F. L., Jeffries, R. D., Oliveira, J. M., Naylor, T., & Jackson, R. J. 2008, MNRAS, 385, 2210 Mink, D. J., Wyatt, W. F., Caldwell, N., et al. 2007, Astronomical Data Analysis Software and Systems XVI, 376, 249 Mink, D. J., & Kurtz, M. J. 1998, Astronomical Data Analysis Software and Systems VII, 145, 93 Murdin, P., & Penston, M. V. 1977, MNRAS, 181, 657 Muzerolle, J., Calvet, N., & Hartmann, L. 2001, ApJ, 550, 944 Muzerolle, J., Hillenbrand, L., Calvet, N., Briceño, C., & H artmann, L. 2003, ApJ, 592, 266 Natta, A., Testi, L., Muzerolle, J., et al. 2004, A&A, 424, 603
Naylor, T. 1998, MNRAS, 296, 339
| Naylor, T., Totten, E. J., Jeffries, R. D., et al. 2002, MNRAS, 335, 291 |
|---------------------------------------------------------------------------------------------------------------------|
| Nazé, Y. 2009, A&A, 506, 1055 |
| Nesterov, V. V., Kuzmin, A. V., Ashimbaeva, N. T., Volchkov, A. A., Röser, S., &Bastian, U. 1995, A&AS, 110, 367 |
| Nguyen, D. C., Jayawardhana, R., van Kerkwijk, M. H., et al. 2009, ApJ, 695, 1648 |
| Nguyen, D. C., Scholz, A., van Kerkwijk, M. H., Jayawardhana, R., & Brandeker, A. 2009, ApJ, 694, L153 |
| Oliveira, J. M., &van Loon, J. T. 2004, A&A, 418, 663 |
| Oliveira, J. M., Jeffries, R. D., van Loon, J. T., &Rushton, M. T. 2006, MNRAS, 369, 272 |
| Pecaut, M. J., &Mamajek, E. E. 2013, ApJS, 208, 9 |
| Peña Ramírez, K., Béjar, V. J. S., Zapatero Osorio, M. R., PetGotzens, r- M. G., & Martín, E. L. 2012, ApJ, 754, 30 |
| Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49 |
| Renson, P., &Manfroid, J. 2009, A&A, 498, 961 |
| Rigliaco, E., Natta, A., Testi, L., et al. 2012, A&A, 548, A56 |
| Rigliaco, E., Natta, A., Randich, S., Testi, L., &Biazzo, K. 2011, A&A, 525, A47 |
| Sacco, G. G., Franciosini, E., Randich, S., &Pallavicini, R. 2008, A&A, 488, 167 |
| Sherry, W. H., Walter, F. M., &Wolk, S. J. 2004, AJ, 128, 2316 |
| Sherry, W. H., Walter, F. M., Wolk, S. J., &Adams, N. R. 2008, AJ, 135, 1616 |
| Schlieder, J. E., Lépine, S., Rice, E., et al. 2012, AJ, 143, 1 14 |
| Scholz, A., &Eislöffel, J. 2004, A&A, 419, 249 |
| Scholz, A., Xu, X., Jayawardhana, R., et al. 2009, MNRAS, 398, 873 |
| Sicilia-Aguilar, A., Hartmann, L. W., Hernández, J., Brice ño, C., &Calvet, N. 2005, AJ, 130, 188 |
| Sicilia-Aguilar, A., et al. 2006, ApJ, 638, 897 |
| Siess, L., Dufour, E., &Forestini, M. 2000, A&A, 358, 593 |
Simón-Díaz, S., Caballero, J. A., & Lorenzo, J. 2011, ApJ, 74 2, 55
Skinner, S. L., Sokal, K. R., Cohen, D. H., et al. 2008, ApJ, 683, 796
Stoll, R., Martini, P., Derwent, M. A., et al. 2010, Proc. SPIE, 7735, 77354L.
Szentgyorgyi, A., Furesz, G., Cheimets, P., et al. 2011, PASP, 123, 1188
Tobin, J. J., Hartmann, L., Furesz, G., Mateo, M., & Megeath, S. T. 2009, ApJ, 697, 1103
Tonry, J., & Davis, M. 1979, AJ, 84, 1511
Townsend, R. H. D., Oksala, M. E., Cohen, D. H., Owocki, S. P., & ud-Doula, A. 2010, ApJ, 714, L318
Vivas, A. K., Zinn, R., Abad, C., et al. 2004, AJ, 127, 1158
Walter, F. M., Sherry, W. H., Wolk, S. J., & Adams, N. R. 2008, Handbook of Star Forming Regions, Volume I, 732
Walter, F. M., Wolk, S. J., Freyberg, M., & Schmitt, J. H. M. M. 1997, Mem. Soc. Astron. Italiana, 68, 1081
Watson, C. L. 2006, Journal of the American Association of Variable Star Observers (JAAVSO), 35, 318
White, R. J., & Basri, G. 2003, ApJ, 582, 1109
Williams, J. P., & Cieza, L. A. 2011, ARA&A, 49, 67
Wolk, S. J. 1996, Ph.D. Thesis, State Univ. New York at Stony Brook
Zapatero Osorio, M. R., Béjar, V. J. S., Pavlenko, Y., et al. 2 002, A&A, 384, 937
Zacharias, N., Finch, C. T., Girard, T. M., et al. 2013, AJ, 145, 44
This preprint was prepared with the AAS L A T E X macros v5.0.
Table 1. Compiled membership information of the σ Orionis cluster
| Name H07 | 2massID | RA degree | DEC degree | Disk type | Li I Ref | RV Ref | X Ray Ref |
|------------|------------------|-------------|--------------|-------------|------------|----------|-------------|
| SO27 | 05372306-0232465 | 84.3461 | -2.54628 | III | · · · | · · · | 19 |
| SO59 | 05372806-0236065 | 84.367 | -2.60182 | III | · · · | · · · | 16,19 |
| SO60 | 05372831-0224182 | 84.368 | -2.40506 | III | · · · | · · · | 16,19 |
| SO73 | 05373094-0223427 | 84.3789 | -2.39521 | II | · · · | · · · | 19 |
| SO77 | 05373153-0224269 | 84.3814 | -2.40749 | III | 6 | · · · | 16,19 |
| SO107 | 05373514-0226577 | 84.3964 | -2.44937 | III | · · · | · · · | 19 |
| SO116 | 05373648-0241567 | 84.402 | -2.69909 | III | 3,5,12 | · · · | · · · |
| SO762 | 05385060-0242429 | 84.7109 | -2.71192 | II | 5 | 5,13 | · · · |
| SO765 | 05385077-0236267 | 84.7116 | -2.60743 | III | 5,8 | 5,8 | 18 |
| SO976 | 05391699-0241171 | 84.8208 | -2.68809 | III | · · · | · · · | 14,18,19 |
| SO1185 | 05394340-0253230 | 84.9308 | -2.88974 | III | · · · | 5 | · · · |
| · · · | 05381741-0240242 | 84.5726 | -2.67341 | · · · | 2,3,5 | 13 | · · · |
| · · · | 05382557-0248370 | 84.6066 | -2.81028 | · · · | 2,3 | · · · | · · · |
| · · · 1 | 05390756-0212145 | 84.7815 | -2.20403 | · · · | · · · | · · · | · · · |
| · · · | 05390893-0257049 | 84.7872 | -2.95139 | · · · | 6 | · · · | · · · |
| · · · | 05402018-0226082 | 85.0841 | -2.43563 | · · · | · · · | · · · | 14 |
| · · · | 05402076-0230299 | 85.0865 | -2.50831 | · · · | · · · | · · · | 14 |
| · · · | 05402256-0233469 | 85.094 | -2.56303 | · · · | 6 | 7 | 14 |
| · · · | 05402301-0236100 | 85.0959 | -2.6028 | · · · | 6 | 13 | · · · |
Note. - Table 1 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
References: (1) Wolk (1996); (2) Zapatero Osorio et al. (2002); (3) Barrado y Navascués et al. (2003); (4) Andrews et al. (2004); (5) Kenyon et al. (2005); (6) Caballero (2006); (7) González Hernández et al. (2008); (8) Sacco et al. (2008); (9 Caballero et al. (2012); (10) Alcalá et al. ) (1996); (11) Caballero et al. (2006); (12) Muzerolle et al. (2003); (13) (Maxted et al. 2008); (14) Caballero (2008a); (15) Skinner et al. (2008); (16) López-Santiago & Caballero (2008); (17) Caballero et al. (2009); (18) Caballero (2010); (19) XMMN-SSC,2010); (20) Burningham et al. (2005)
Disk type: III=diskless, II=thick disk, I=class I, EV= evolved disk, TD=transition disk, DD=Debris disk
1 Strong H α line and Accretion disk (Scholz & Eislöffel 2004; Scholz et al. 2009)
2 Strong H α line and Accretion disk (Caballero 2008)
Table 2. Photometric candidates
| Name H07 | 2massID | RAJ2000 deg | DECJ2000 deg | U mag | B mag | V mag | R mag | I mag | J mag | Ref |
|------------|--------------------|---------------|----------------|--------------|--------------|--------------|--------------|--------------|----------------|-------|
| · · · | 05371360-0229293 | 84.3067 | -2.49147 | · · · | 16.48 ± 0.02 | 15.19 ± 0.00 | · · · | 13.52 ± 0.01 | 12.25 ± 0.04 | CLC |
| · · · | 05371373-0258190 3 | 84.3072 | -2.97196 | · · · | 21.53 ± 0.64 | 21.08 ± 0.02 | 19.74 ± 0.02 | 17.98 ± 0.05 | 16.11 ± 0.11 | CLC |
| · · · | 05371407-0221089 | 84.3086 | -2.35249 | · · · | · · · | 13.39 ± 0.02 | · · · | · · · | 11.18 ± 0.02 | CVSO |
| · · · | 05372254-0259363 | 84.344 | -2.99343 | · · · | · · · | 15.06 ± 0.01 | 14.13 ± 0.01 | 13.15 ± 0.01 | 11.73 ± 0.02 | S04 |
| SO77 | 05373153-0224269 | 84.3814 | -2.40749 | · · · | 17.32 ± 0.02 | 15.85 ± 0.01 | 14.72 ± 0.01 | 13.45 ± 0.01 | 12.11 ± 0.03 | S04 |
| SO189 | 05374924-0253118 | 84.4552 | -2.88662 | · · · | · · · | 18.04 ± 0.07 | 16.94 ± 0.02 | · · · | 14.44 ± 0.04 | CVSO |
| SO199 | 05374981-0246032 | 84.4576 | -2.76756 | · · · | · · · | 13.74 ± 0.02 | · · · | · · · | 11.69 ± 0.03 | CVSO |
| SO247 | 05375486-0241092 | 84.4786 | -2.6859 | · · · | 19.68 ± 0.18 | 18.34 ± 0.09 | 17.14 ± 0.06 | 15.43 ± 0.03 | 13.50 ± 0.03 | S04 |
| SO389 | 05381223-0218124 | 84.551 | -2.30345 | · · · | 16.79 ± 0.02 | 15.39 ± 0.01 | 14.51 ± 0.01 | 13.71 ± 0.01 | 12.66 ± 0.00 1 | CLC |
| SO411 | 05381412-0215597 | 84.5588 | -2.2666 | · · · | 10.93 ± 0.06 | 10.45 ± 0.06 | · · · | · · · | 9.39 ± 0.02 | K09 |
| SO563 | 05383157-0235148 | 84.6316 | -2.58746 | 18.19 ± 0.18 | 17.17 ± 0.02 | 15.85 ± 0.01 | 14.88 ± 0.01 | 13.77 ± 0.01 | 11.52 ± 0.03 | OS |
| SO567 | 05383243-0251215 | 84.6351 | -2.85597 | · · · | 14.20 ± 0.01 | 13.34 ± 0.01 | · · · | 12.24 ± 0.01 | 11.60 ± 0.03 | CLC |
| SO706 | 05384480-0233576 | 84.6867 | -2.56601 | 14.82 ± 0.02 | 13.73 ± 0.00 | 12.49 ± 0.00 | 11.77 ± 0.00 | 11.11 ± 0.00 | 10.01 ± 0.03 | OS |
| · · · | 05384503-0258340 | 84.6877 | -2.97612 | · · · | 21.78 ± 0.84 | 19.61 ± 0.01 | 18.24 ± 0.01 | 16.75 ± 0.01 | 15.20 ± 0.04 | CLC |
| SO739 | 05384818-0244007 | 84.7008 | -2.73355 | 21.27 ± 0.49 | 21.43 ± 0.09 | 19.76 ± 0.02 | 18.11 ± 0.01 | 16.13 ± 0.01 | 14.07 ± 0.03 | OS |
| SO927 | 05391151-0231065 | 84.798 | -2.51849 | 16.75 ± 0.07 | 16.98 ± 0.02 | 15.66 ± 0.01 | 14.64 ± 0.01 | 13.56 ± 0.01 | 11.99 ± 0.03 | OS |
| SO929 | 05391163-0236028 | 84.7985 | -2.6008 | 17.04 ± 0.07 | 15.82 ± 0.01 | 14.47 ± 0.00 | 13.61 ± 0.00 | 12.75 ± 0.00 | 11.62 ± 0.03 | OS |
| SO947 | 05391453-0219367 | 84.8106 | -2.32687 | · · · | 17.33 ± 0.02 | 15.90 ± 0.02 | 14.83 ± 0.02 | 13.60 ± 0.02 | 12.16 ± 0.03 | S04 |
| SO1081 | 05393056-0238270 3 | 84.8773 | -2.64084 | · · · | 19.36 ± 0.13 | 17.82 ± 0.05 | 16.61 ± 0.03 | 15.21 ± 0.02 | 13.81 ± 0.03 | S04 |
| SO1224 | 05394891-0229110 3 | 84.9538 | -2.48641 | · · · | 19.02 ± 0.10 | 17.34 ± 0.03 | 16.24 ± 0.02 | 14.70 ± 0.01 | 13.28 ± 0.03 | S04 |
| · · · | 05400405-0255375 | 85.0169 | -2.92711 | · · · | · · · | 17.46 ± 0.05 | 16.40 ± 0.02 | 15.18 ± 0.02 | 14.07 ± 0.03 | CVSO |
| · · · | 05402378-0228261 | 85.0991 | -2.47394 | · · · | · · · | 17.78 ± 0.05 | 16.74 ± 0.02 | · · · | 13.86 ± 0.04 | CVSO |
Note. - Table 2 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content. References: OS OSMOS (§2.1.1); CVSO CIDA Variability Survey of Orion (Briceño et al. 2005); S04 Sherry et al. (2004); CLCCluster Collaboration (Kenyon et al. 2005; Mayne et al. 2007); K09 Kharchenko & Roeser (2009)
1 J magnitude from UKIDSS
2 Known members not selected as photometric candidates
3 Sources labeled as galaxies by Lawrence et al. (2013)
- 35 -
Table 3. Low Resolution Spectrographs
| Observatory | Telescope meters | Spectrograph | Resolution at H α Å | REF | Spectral Coverage Å |
|----------------|--------------------|---------------------|-----------------------|-------------------------|-----------------------|
| MMTO | 6.5 | Hectospec (H) | 6 | Fabricant et al. (2005) | 3650-9200 |
| FLWO | 1.5 | FAST (F) | 6 | Fabricant et al. (1998) | 3800-7200 |
| MDMO | 1.3 | OSU-CCDS (O) | 6.5 | Measured with arc lines | 3900-7300 |
| OAN-SPM | 2.1 | Boller & Chiven (S) | 5.5 | Measured with arc lines | 3900-7200 |
| Guillermo-Haro | 2.1 | Boller &Chiven (C) | 10 | Measured with arc lines | 4100-7300 |
Table 4. Low resolution analysis
| Name H07 | 2massID | INST | Spectral Types | Li I Å | Li I flag | H α Å | H α flag | Na I Å | Na I flag | Av KH 95 mag | Av PM 13 mag |
|------------|------------------|--------|------------------|----------|-------------|---------|------------|-------------|-------------|----------------|----------------|
| · · · | 05384476-0236001 | F | B0.0 ± 1.5 | 0 | 0 | 3.1 | E abs | · · · | · · · | 0.00 | 0.00 |
| · · · | 05384561-0235588 | F | B2.0 ± 1.5 | 0 | 0 | 4.3 | E abs | · · · | · · · | 0.10 | 0.00 |
| · · · | 05402018-0226082 | F | B4.0 ± 1.5 | 0 | 0 | 5 | E abs | · · · | · · · | 0.17 | 0.00 |
| SO139 | 05374047-0226367 | F | A3.5 ± 2.5 | 0 | 0 | 11 | E abs | · · · | · · · | 0.00 | 0.14 |
| SO521 | 05382752-0243325 | F | A8.0 ± 2.5 | 0 | 0 | 8.3 | E abs | · · · | · · · | 0.18 | 0.84 |
| SO338 | 05380649-0228494 | S | F3.5 ± 2.0 | 0.1 | 1 | 3.5 | E abs | · · · | · · · | 0.72 | 0.72 |
| SO1352 | 05400696-0228300 | F | F7.5 ± 2.0 | 0 | 0 | 3.6 | E abs | · · · | · · · | 1.36 | 1.44 |
| SO1246 | 05395118-0222461 | H | G1.0 ± 2.5 | 0 | 0 | 1.5 | E abs | · · · | · · · | 2.41 | 2.49 |
| SO550 | 05383008-0221198 | H | G1.5 ± 2.5 | 0 | 0 | 1.8 | E abs | · · · | · · · | 2.05 | 2.12 |
| SO1286 | 05395658-0246236 | H | G5.0 ± 2.5 | 0 | 0 | 2.1 | nAcr | · · · | · · · | 1.83 | 1.70 |
| SO29 | 05372330-0229133 | H | G9.5 ± 2.0 | 0 | 0 | 1.8 | nAcr | · · · | · · · | 0.51 | 0.27 |
| SO449 | 05381879-0217138 | H | K0.0 ± 3.0 | 0 | 0 | 0 | nAcr | · · · | · · · | 1.00 | 0.83 |
| SO903 | 05390828-0249462 | F | K5.5 ± 1.5 | 0 | 0 | 0.4 | nAcr | · · · | · · · | 0.00 | 0.00 |
| SO1113 | 05393511-0247299 | F | K5.5 ± 1.5 | 0.5 | 2 | -1.1 | nAcr | · · · | · · · | 0.41 | 0.00 |
| SO1274 | 05395465-0246341 | S | K6.0 ± 1.0 | 0.3 | 2 | -36.5 | Acr | · · · | · · · | 1.40 | 0.92 |
| SO611 | 05383546-0231516 | H | K7.0 ± 1.0 | 0.6 | 2 | -2.7 | Acr? | · · · | · · · | 0.48 | 0.11 |
| SO35 | 05372384-0248532 | H 1 | M0.0 ± 1.5 | 0 | 1 | 2.4 | nAcr | · · · | · · · | 0.77 | 0.46 |
| SO726 | 05384746-0235252 | H | M0.5 ± 1.0 | 0.4 | 2 | -23 | Acr | 0.94 ± 0.08 | · · · | 0.03 | 0.00 |
| SO682 2 | 05384227-0237147 | C | M0.5 ± 1.0 | 0.2 | 1 | -2.7 | nAcr | · · · | · · · | 0.67 | 0.34 |
| SO600 | 05383479-0239300 | F | M1.0 ± 0.5 | 0 | 0 | 0.9 | nAcr | · · · | · · · | 0.71 | 0.34 |
| SO1282 | 05395594-0220366 | H | M2.0 ± 0.5 | 0.4 | 2 | -8.2 | nAcr | 1.37 ± 0.10 | · · · | 0.62 | 0.23 |
| SO444 | 05381824-0248143 | H | M3.0 ± 0.5 | 0.5 | 2 | -3.8 | nAcr | 0.83 ± 0.08 | Y | 0.12 | 0.08 |
| SO562 | 05383141-0236338 | H | M3.5 ± 1.5 | 0.1 | 2 | -77.7 | Acr | 0.52 ± 0.10 | Y | 0.07 | 0.14 |
| SO1053 | 05392650-0252152 | H | M4.0 ± 0.5 | 0.4 | 2 | -3.6 | nAcr | 1.02 ± 0.09 | Y | 0.00 | 0.00 |
| SO300 | 05380107-0245379 | H | M4.5 ± 0.5 | 0.4 | 2 | -92.6 | Acr | 0.65 ± 0.10 | Y | 0.14 | 0.26 |
| SO460 | 05382021-0238016 | H | M5.0 ± 0.5 | 0.4 | 2 | -10.6 | nAcr | 1.44 ± 0.14 | Y | 0.00 | 0.00 |
| SO283 | 05375840-0241262 | H | M5.5 ± 0.5 | 0.6 | 1 | -14.3 | Acr? | 0.99 ± 0.13 | Y | 0.00 | 0.00 |
| SO457 | 05381975-0236391 | F | M6.0 ± 0.5 | 0 | 0 | 0.2 | nAcr | · · · | · · · | 0.00 | 0.32 |
| SO209 | 05375110-0226074 | H 1 | M6.5 ± 2.5 | 0 | 1 | -13.3 | nAcr | · · · | · · · | · · · | · · · |
Note. -Table 4 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
INST: See Table 3
Li I flag: (2) Li I is present in absoprtion; (1) Li I uncertain; (0) Li I is not present on the spectrum
H α flag: (Acr) accretor; (nAcr) non-accretor; (Acr?) uncertain; (E abs ) star ealier than G5 with H α in absorption; (ET em ) star ealier than G5 with H α in emission
NaI I flag: (Y) member; (N) non-member
1 Low signal to noise (SN /lessorsimilar 15)
2 Slow accretor candidate
3 Diskless stars that mimic the H α width expected in stars with accretion disks
Table 5. High resolution analysis
| Name H07 | 2massID | RV km/s | RV flag | Li I Å | W10_H α km/s | Acretor | Disk type | Comments |
|------------|------------------|-------------|-----------|-------------|----------------|-----------|-------------|-----------------------------------------|
| SO52 | 05372692-0221541 | 9.6 ± 0.3 | 0 | · · · | · · · | · · · | III | H α in absorption, SB2 |
| SO59 | 05372806-0236065 | 29.8 ± 0.9 | 2 | · · · | 115.203 | N | III | H α in absorption, SB2 |
| SO74 | 05373105-0231436 | · · · | · · · | · · · | · · · | · · · | III | H α in absorption with central emission |
| SO247 | 05375486-0241092 | · · · | · · · | 0.25 ± 0.12 | 192.322 | N | II | H α in absorption with central emission |
| SO300 | 05380107-0245379 | · · · | · · · | · · · | 413.678 | Y | II | H α in absorption with central emission |
| SO341 | 05380674-0230227 | 33.7 ± 0.6 | 2 | 0.59 ± 0.07 | 427.684 | Y | II | H α in absorption with central emission |
| SO374 | 05380994-0251377 | 30.0 ± 0.6 | 2 | 0.44 ± 0.06 | 411.430 | Y | II | H α in absorption with central emission |
| SO411 | 05381412-0215597 | 22.2 ± 1.1 | 1 | 0.16 ± 0.01 | 294.276 | Y | TD | H α in absorption with central emission |
| SO489 | 05382354-0241317 | · · · | · · · | 0.41 ± 0.17 | 143.305 | N | III | H α in absorption with central emission |
| SO514 | 05382684-0238460 | · · · | · · · | · · · | · · · | · · · | II | inverse P Cygni profile |
| SO518 | 05382725-0245096 | 28.8 ± 0.6 | 2 | 0.43 ± 0.02 | 575.190 | Y | II | inverse P Cygni profile |
| SO539 | 05382911-0236026 | 33.2 ± 0.7 | 2 | 0.77 ± 0.10 | 152.280 | N | III | inverse P Cygni profile |
| SO548 | 05382995-0215405 | · · · | · · · | · · · | 133.636 | N | III | inverse P Cygni profile |
| SO616 | 05383587-0230433 | 23.8 ± 5.6 | 1 | 0.82 ± 0.03 | 465.422 | Y | III | RV VAR |
| SO697 | 05384423-0240197 | 29.4 ± 0.2 | 2 | 0.56 ± 0.02 | 198.812 | N | II | RV VAR |
| SO752 | 05384945-0249568 | -49.2 ± 0.6 | 0 | · · · | · · · | · · · | III | Double central absorption |
| SO1097 | 05393291-0247492 | 27.8 ± 1.3 | 2 | 0.59 ± 0.03 | 168.462 | N | III | Double central absorption |
| SO1251 | 05395253-0243223 | 46.0 ± 0.2 | 0 | 0.08 ± 0.04 | · · · | · · · | III | H α in absorption, EW[Li I ] < 0.1 |
| SO1352 | 05400696-0228300 | 34.9 ± 0.2 | 2 | · · · | · · · | · · · | III | H α in absorption |
| SO1361 | 05400889-0233336 | 30.1 ± 0.6 | 2 | 0.48 ± 0.02 | 362.225 | Y | II | H α in absorption |
| SO1370 | 05401304-0228314 | · · · | · · · | · · · | · · · | · · · | III | H α in absorption |
Note. - Table 5 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
RV flag: (2) kinematic member; (1) sparser stellar population candidate; (0) kinematic non-member
Accretor flag: (Y) accretor (W10\_H α > 270 km/s); (N) non-accretor (W10\_H α < 270 km/s)
Disk type: III=diskless, II=thick disk, I=class I, EV= evolved disk, TD=transition disk, DD=Debris disk
RV var : binary candidate by radial velocity variability
SB2: binary candidate identified in the cross correlation function
Table 6. Membership for stars with spectral types
| Name H07 | 2massID | Spectral types | Li I flag Low High | Li I Ref | RV flag | RV Ref | H α Low | flag High | NaI flag | Disk type | Xray Ref | PM flag | Dist flag | Var Ref | % pho | A V | Member flag |
|------------|------------------|------------------|----------------------|------------|-----------|----------|-----------|-------------|------------|-------------|----------------|-----------|-------------|-----------|---------|-------|---------------|
| · · · | 05384476-0236001 | B0.0 ± 1.5 | 0 · · · | · · · | · · · | · · · | E abs | · · · | · · · | · · · | 14,15,17,18,19 | 2 | 1 | · · · | 0.1 | 0.00 | M: 1 |
| SO139 | 05374047-0226367 | A3.5 ± 2.5 | 0 · · · | · · · | · · · | · · · | E abs | · · · | · · · | · · · | · · · | 2 | 1 | · · · | 86.1 | 0.14 | U: 3 |
| SO411 | 05381412-0215597 | F7.5 ± 2.5 | 2 2 | · · · | 1 | · · · | E | em Y | · · · | TD | 14 | 2 | 0 | · · · | 95.1 | 0.07 | M: |
| SO37 | 05372414-0225520 | G0.5 ± 2.0 | 0 · · · | · · · | · · · | · · · | E abs | · · · | · · · | · · · | · · · | 2 | 0 | · · · | · · · | · · · | U: |
| SO1307 | 05395930-0222543 | G2.0 ± 2.5 | 2 · · · | · · · | · · · | · · · | E abs | · · · | · · · | III | 14 | 2 | 0 | · · · | 44.9 | 0.63 | P: |
| SO981 | 05391807-0229284 | G7.5 ± 2.5 | 1 · · · | · · · | · · · | · · · | nAcr | · · · | · · · | DD | 14,17,18,19 | 2 | 1 | · · · | 52.4 | 0.56 | M: |
| · · · | 05392639-0215034 | K4.5 ± 2.0 | 2 · · · | 6 | · · · | · · · | Acr | · · · | · · · | II | · · · | 2 | 0 | 21,22,24 | 32.7 | 0.36 | M: 19 |
| SO670 | 05384135-0236444 | M2.0 ± 1.0 | 1 · · · | 8 | · · · | 8,13 | · · · | · · · | · · · | III | 15,18,19 | · · · | 1 | · · · | 42.3 | 0.30 | M: |
| SO27 | 05372306-0232465 | M3.0 ± 1.0 | 1 · · · | · · · | · · · | · · · | nAcr | · · · | Y | III | 19 | · · · | 0 | · · · | 7.4 | 0.57 | P: |
| SO545 | 05382961-0225141 | M4.0 ± 1.5 | 1 · · · | 5,12 | · · · | · · · ,5 | · · · | · · · | · · · | III | · · · | · · · | 1 | 24 | 79.3 | 2.21 | M: |
| SO466 | 05382089-0251280 | M5.5 ± 2.0 | 1 · · · | · · · | · · · | 13 | Acr? | · · · | · · · | III | · · · | · · · | 1 | · · · | 87.1 | 0.61 | M: |
| SO457 | 05381975-0236391 | M6.0 ± 0.5 | 0 0 | · · · | · · · | · · · | nAcr | Y | · · · | I | · · · | 2 | 1 | 22 | 0.0 | 0.32 | - N: 22 |
| SO209 | 05375110-0226074 | M6.5 ± 2.5 | 1 · · · | · · · | · · · | · · · | nAcr | · · · | · · · | III | · · · | · · · | 1 | · · · | · · · | · · · | 39 U: |
Note. - Table 6 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
References: (1) Wolk (1996); (2) Zapatero Osorio et al. (2002); (3) Barrado y Navascués et al. (2003); (4) Andrews et al. ( 2004); (5) Kenyon et al. (2005); (6) Caballero (2006); (7) González Hernández et al. (2008); (8) Sacco et al. (2008); (9 Caballero et al. (2012); (10) Alcalá et al. (1996); (11) Cabllero et al. (2006); (12) Muzerolle et al. (2003); (13) (Maxted et al. 2008); ) a (14) Caballero (2008a); (15) Skinner et al. (2008); (16) López-Santiago & Caballero (2008); (17) Caballero et al. (2009); (18) (Caballero 2010); (19) XMMN-SSC,2010); (20) Burningham et al. (2005); (21) CVSO (Briceño et al. 2005); (22) Cluster Collaboration (Kenyon et al. 2005; Mayne et al. 2007); (23) Cody & Hillenbrand (2010); (24) AAVSO
Disk type: III=diskless, II=thick disk, I=class I, EV= evolved disk, TD=transition disk, DD=Debris disk
Member-flag: M: member, N: non-member, U: uncertain, P: probable member, U: uncertain member
1 σ Orionis AB:Multiple system
2 HD37699: probable disk detected using IRAS (Caballero 2007)
3 HD37333: It is a member if is a equal mass binary (Sherry et al. 2008)
4 HD37564: It is too bright to be a cluster member (Sherry et al. 2008)
5 HD294273: It is too faint to be a cluster member (field star; Sherry et al. 2008)
Table 7. Membership for stars without spectral types studied in §3.2
| Name H07 | 2massID | Li flag | Li Ref | RV flag | RV Ref | H α flag | disk | Xray Ref | PM flag | Dist flag | Var flag | % pho | Member flag |
|------------|------------------|-----------|----------|-----------|----------|------------|--------|-------------|-----------|-------------|-------------|---------|---------------|
| SO1154 | 05393982-0233159 | 0 | 4 | · · · | · · · | Y | II | 14,19 | 2 | 1 | 21,22,23,24 | 22.7 | M: |
| SO82 | 05373187-0245184 | 0 | · · · | · · · | · · · | · · · | III | · · · | 2 | 0 | · · · | 22.9 | U: |
| SO164 | 05374491-0229573 | 0 | · · · | 0 | · · · | · · · | III | 14 | 2 | 1 | · · · | 10.6 | N: |
| SO251 | 05375512-0227362 | 2 | · · · | · · · | · · · | N | III | 19 | · · · | 1 | · · · | 95.3 | M: |
| SO302 | 05380167-0225527 | 0 | · · · | · · · | · · · | N | III | 16,18,19 | · · · | 1 | 22 | 74.7 | P: |
| SO304 | 05380221-0229556 | 0 | · · · | 1 | · · · | · · · | III | · · · | 1 | 1 | · · · | 33.6 | U: |
| SO329 | 05380561-0218571 | 0 | · · · | 0 | · · · | · · · | III | · · · | · · · | 1 | · · · | 0 | N: |
| SO371 | 05380966-0228569 | 0 | · · · | · · · | · · · | · · · | III | · · · | · · · | 1 | · · · | 0 | N: |
| SO424 | 05381589-0234412 | 0 | · · · | 0 | · · · | · · · | III | · · · | 2 | 1 | · · · | 3.1 | N: |
| SO482 | 05382307-0236493 | 0 | · · · | · · · | 20 | Y | II | · · · | · · · | 1 | 21,22,23 | 50.5 | M: |
| SO548 | 05382995-0215405 | 0 | · · · | · · · | · · · | N | III | · · · | · · · | 0 | 24 | 32 | U: |
| SO561 | 05383138-0255032 | 0 | · · · | 0 | · · · | · · · | III | · · · | 2 | 1 | · · · | 23.3 | N: |
| SO620 | 05383654-0233127 | 0 | · · · | · · · | · · · | · · · | III | · · · | 2 | 1 | · · · | 82.3 | U: |
| SO674 | 05384159-0230289 | 2 | 8 | 2 | 8 | N | II | · · · | 2 | 1 | 21,22 | 98.2 | M: |
| SO692 | 05384375-0252427 | 0 | 5 | · · · | 13,5 | N | III | · · · | · · · | 1 | 22 | 32.4 | M: |
| SO738 | 05384809-0228536 | 0 | 5 | · · · | 5 | N | II | · · · | · · · | 1 | · · · | 66.6 | M: |
| SO773 | 05385173-0236033 | 2 | 8 | · · · | 8 | N | III | 14,15,18,19 | · · · | 1 | 21 | 31.1 | M: |
| SO797 | 05385492-0228583 | 0 | 5 | · · · | 5 | N | III | 14,19 | · · · | 1 | · · · | 55.7 | M: |
| SO877 | 05390524-0233005 | 0 | 5,6 | · · · | 5 | N | III | 14,18,19 | 1 | 1 | 22,23 | 72.2 | M: |
| SO917 | 05391001-0228116 | 0 | · · · | · · · | 5 | · · · | EV | · · · | · · · | 1 | · · · | 3.6 | M: |
| SO946 | 05391447-0228333 | 0 | 3 | 2 | 8,2 | N | III | 14,18,19 | 1 | 1 | 22,23 | 44.5 | M: |
| SO1005 | 05392097-0230334 | 0 | 5 | · · · | 5 | N | III | 14,19 | · · · | 1 | 21,22,23 | 4.9 | M: |
| SO1043 | 05392561-0234042 | 2 | · · · | · · · | · · · | N | III | · · · | · · · | 1 | 21,23 | 49 | M: |
| SO1057 | 05392677-0242583 | 0 | 6 | · · · | · · · | · · · | EV | 19 | · · · | 1 | 22,23 | 8.1 | M: |
| SO1370 | 05401304-0228314 | 0 | · · · | · · · | · · · | · · · | III | · · · | · · · | 0 | · · · | 0 | N: |
References: (2) Zapatero Osorio et al. (2002); (3) Barrado y Navascués et al. (2003); (4) Andrews et al. (2004); (5) Kenyo n et al. (2005); (6) Caballero (2006); (8) Sacco et al. (2008); (13) (Maxted et al. 2008); (14) Caballero (2008a); (15) Skinner et al. (2008); (16) López-Santiago & Caballero (2008); (18) (Caballero 2010); (19) XMMN-SSC,2010); (20) Burningham et al. (2005); (21) CVS; (22) Cluster Collaboration (Kenyon et al. 2005; Mayne et al. 2007); (23) Cody & Hillenbrand (2010); (24) AAVSO
Disk type: III=diskless, II=thick disk, I=class I, EV= evolved disk, TD=transition disk, DD=Debris disk
Member-flag: M: member, N: non-member, U: uncertain, P: probable member, U: uncertain member
- 40 -
Table 8. New photometric candidates with infrared excess at 24 µ m
| Name | 2massID | V mag | [3.6] mag | [4.5] mag | [5.8] mag | [8.0] mag | [24] mag | Disk type |
|--------|------------------|---------|--------------|--------------|--------------|--------------|-------------|-------------|
| · · · | 05373456-0255588 | 22.7 | · · · | 13.45 ± 0.03 | · · · | 12.36 ± 0.04 | 8.73 ± 0.04 | II |
| SO238 | 05375398-0249545 | 18.47 | 11.11 ± 0.03 | 10.72 ± 0.03 | 10.39 ± 0.03 | 9.79 ± 0.03 | 7.24 ± 0.03 | II |
| · · · | 05381279-0212266 | 20.28 | 12.93 ± 0.03 | · · · | 12.30 ± 0.04 | · · · | 8.27 ± 0.03 | II |
| · · · | 05382503-0213162 | 17.44 | 11.83 ± 0.03 | · · · | 11.34 ± 0.03 | · · · | 8.39 ± 0.03 | II |
| · · · | 05382656-0212174 | 15.12 | 10.18 ± 0.03 | · · · | 9.31 ± 0.03 | · · · | 6.77 ± 0.03 | II |
| SO595 | 05383444-0228476 | 11.3 | 10.42 ± 0.03 | 10.29 ± 0.03 | 10.15 ± 0.03 | 9.95 ± 0.03 | 8.27 ± 0.03 | DD/EV |
| · · · | 05383981-0256462 | 14.62 | · · · | 9.31 ± 0.03 | · · · | 7.90 ± 0.03 | 5.05 ± 0.03 | II |
| · · · | 05384714-0257557 | 21.15 | · · · | 12.82 ± 0.03 | · · · | 11.55 ± 0.03 | 8.94 ± 0.04 | II |
| · · · | 05392639-0215034 | 14.51 | 9.33 ± 0.03 | · · · | 8.38 ± 0.03 | · · · | 4.18 ± 0.03 | II |
| SO1084 | 05393136-0252522 | 12.5 | 10.70 ± 0.03 | 10.77 ± 0.03 | 10.74 ± 0.03 | 10.68 ± 0.03 | 9.88 ± 0.06 | DD/EV |
| · · · | 05394097-0216243 | 18.01 | 11.05 ± 0.03 | · · · | 10.32 ± 0.03 | · · · | 7.57 ± 0.03 | II |
| · · · | 05394278-0258539 | 14.25 | · · · | 8.97 ± 0.03 | · · · | 7.75 ± 0.03 | 4.43 ± 0.03 | II |
| SO1340 | 05400477-0245245 | 18.87 | 12.87 ± 0.04 | 12.83 ± 0.04 | 12.63 ± 0.05 | 11.51 ± 0.04 | 9.13 ± 0.04 | II 1 |
| · · · | 05400676-0257389 | 18.67 | · · · | · · · | · · · | · · · | 9.58 ± 0.05 | II 1 |
Disk type: II=thick disk, DD/EV= debris disks or evolved disk
1 Potential galaxies based on the profile classification of UKIDSS
Table 9. Known members compiled in §2.3 and new disk bearing candidates not listed in Table 6 and Table 7
| Name H07 | 2massID | V mag | Disk Type | Li Ref | RV Ref | Xray ref | PM flag | Dist flag | Var Ref | % pho | Spectral Type | SpT Ref | Notes |
|------------|------------------|---------|-------------|----------|----------|------------|-----------|-------------|-----------|---------|-----------------|-----------|---------|
| · · · | 05401308-0230531 | 9.213 | · · · | · · · | · · · | · · · | 2 | 0 | · · · | 17.1 | B9.5,B9.5 | 32,33 | 2 |
| SO164 | 05374491-0229573 | 10.946 | III | · · · | · · · | 14 | 2 | 1 | · · · | 10.6 | G9.0 | 14 | |
| SO1084 | 05393136-0252522 | 12.500 | EV/DD | · · · | · · · | · · · | 1 | 0 | · · · | 0 | · · · | · · · | 4 |
| · · · | 05400365-0216461 | 14.946 | · · · | 6 | · · · | · · · | 2 | 0 | 22 | 74.7 | · · · | · · · | |
| SO663 | 05384053-0233275 | 17.649 | II | 8 | 8,13 | · · · | · · · | 1 | 21 | 32.8 | M4.0 | 8 | |
| SO1238 | 05395056-0234137 | 18.394 | III | 5 | 5,13 | · · · | · · · | 1 | 22,23 | 68.2 | M3.5 | 29 | |
| · · · | 05394299-0213333 | 18.580 | · · · | 5 | · · · | · · · | · · · | 0 | · · · | 44.4 | M4.0 | 29 | |
| SO976 | 05391699-0241171 | 18.862 | III | · · · | · · · | 14,18,19 | · · · | 1 | 22,23 | 15 | · · · | · · · | |
| SO1005 | 05392097-0230334 | 19.255 | III | 5 | · · · | 14,19 | · · · | 1 | 21,22,23 | 4.9 | M5.0 | 29 | |
| SO762 | 05385060-0242429 | 19.418 | II | 5 | 5,13 | · · · | · · · | 1 | 22 | 52.4 | M4,M5 | 29,30 | |
| SO767 | 05385100-0249140 | 20.040 | III | 5 | 5 | · · · | · · · | 1 | · · · | 6.9 | M4.5 | 29 | |
| SO1019 | 05392319-0246557 | 21.060 | III | 5 | · · · | · · · | · · · | 1 | · · · | 25.3 | M5.5 | 9 | |
| · · · | 05374557-0229585 | · · · | · · · | 6 | · · · | · · · | 2 | 1 | · · · | 0 | · · · | · · · | 3 |
| SO1215 | 05394741-0226162 | · · · | III | · · · | · · · | 18 | 2 | 1 | · · · | 0 | · · · | · · · | 3 |
Note. - Table 9 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
References: (1) Wolk (1996); (2) Zapatero Osorio et al. (2002); (3) Barrado y Navascués et al. (2003); (4) Andrews et al. ( 2004); (5) Kenyon et al. (2005); (6) Caballero (2006); (7) González Hernández et al. (2008); 8) Sacco et al. (2008); (9) Caballero et al. (2012); (12) Muzerolle et al. (2003); (13) (Maxted et al. ( 2008); (14) Caballero (2008a); (15) Skinner et al. (2008); (16) López-Santiago & Caballero (2008); (17) Caballero et al. (2009); (18) Caballero (2010); (19) XMMN-SSC,2010); (20) Burningham et al. (2005); (21) CVSO (Briceño et al. 2005); (22) Cluster Collaboration (Kenyon et a l. 2005; Mayne et al. 2007); (23) Cody & Hillenbrand (2010); (24) AAVSO; (25) Béjar et al.(1999); (26) (Scholz & Eislöffel 2004); (27) Cody & Hillenbrand (2011);(28) Rigliaco et al. (2012); (29) Oliveira et al. (2006); (30) Gatti et al. (2008); (31) Oliveira & van Loon (2004); (32) Sherry et al. (2008); (33) Houk & Swift (1999)
Disk type: III=diskless, II=thick disk, I=class I, EV= evolved disk, TD=transition disk, DD=Debris disk
1 Source labeled as galaxy by Lawrence et al. (2013)
2 Bright member of the cluster (Sherry et al. 2008; Caballero 2007)
3 Photometric candidate (Lodieu et al. 2009)
4 New disk bearing candidate (§4.1)
- 42 -
Table 10. Additional photometric candidates not listed in Table 6, Table 7 and Table 9
| Name H07 | 2massID | V mag | PM flag | Dist flag | Var Ref | % pho | Spectral Type | SpT Ref |
|------------|------------------|---------|-----------|-------------|-----------|---------|-----------------|-----------|
| · · · | 05372067-0249330 | 10.338 | 0 | 0 | · · · | 71.8 | G0 | 34 |
| · · · | 05401245-0252576 | 10.494 | 1 | 0 | · · · | 89.6 | F8 | 34 |
| SO168 | 05374536-0244124 | 10.659 | 0 | 1 | · · · | 88.6 | G0 | 34 |
| · · · | 05375781-0226335 | 10.744 | 0 | 1 | · · · | 33.0 | G0 | 34 |
| · · · | 05371881-0231364 | 10.847 | 0 | 0 | · · · | 56.8 | G0 | 34 |
| SO1224 | 05394891-0229110 | 17.34 | · · · | 1 | 21,23 | 39.1 | · · · | · · · 1 |
| · · · | 05402081-0224003 | 24.77 | · · · | 0 | · · · | 50.9 | · · · | · · · |
| SO1163 | 05394057-0225468 | · · · | 1 | 1 | · · · | · · · | F2 | 6,34 |
| · · · | 05385382-0244588 | · · · | · · · | 1 | · · · | · · · | · · · | · · · 2 |
| SO1141 | 05393816-0245524 | · · · | · · · | 1 | · · · | · · · | · · · | · · · 2 |
Note. -Table 10 is published in its entirety in the electronic edition of the Astrophysical Journal . A portion is shown here for guidance regarding its form and content.
References: (3) Barrado y Navascués et al. (2003); (6) Cabalero (2006);(21) CVSO (Briceño et al. 2005); (22) Cluster Collaboration (Kenyon et al. 2005; Mayne et al. 2007); (23) Cody & Hillenbrand (2010); (24) AAVSO; (29) Oliveira et al. (2006); (34) Nesterov et al. (1995)
1 Source labeled as galaxy by Lawrence et al. (2013)
2 Photometric candidate (Lodieu et al. 2009)
Fig. 1.V versus V-J color magnitude diagram, illustrating the selection of photometric members of the σ Orionis cluster. Open red circles represent stars with infrared excesses (H07a). Open squares represent young stars confirmed using the presence of Li I λ 6708 in absorption. Plus signs represent kinematic members confirmed using radial velocities. Symbols "x" represent X ray sources. Likely members are X ray sources above the zero age main sequence (ZAMS). The dashed line represents the empirical isochrone estimated from the median colors of the known members sample. Dotted lines limit the region where members are expected to fall (photometric member region). By comparison, the ZAMS from Siess et al. (2000) was plotted assuming a distance of 420 pc (Sherry et al. 2008) and 385 pc (Caballero 2008c). [See the electronic edition of the Journal for a color version of this figure.]
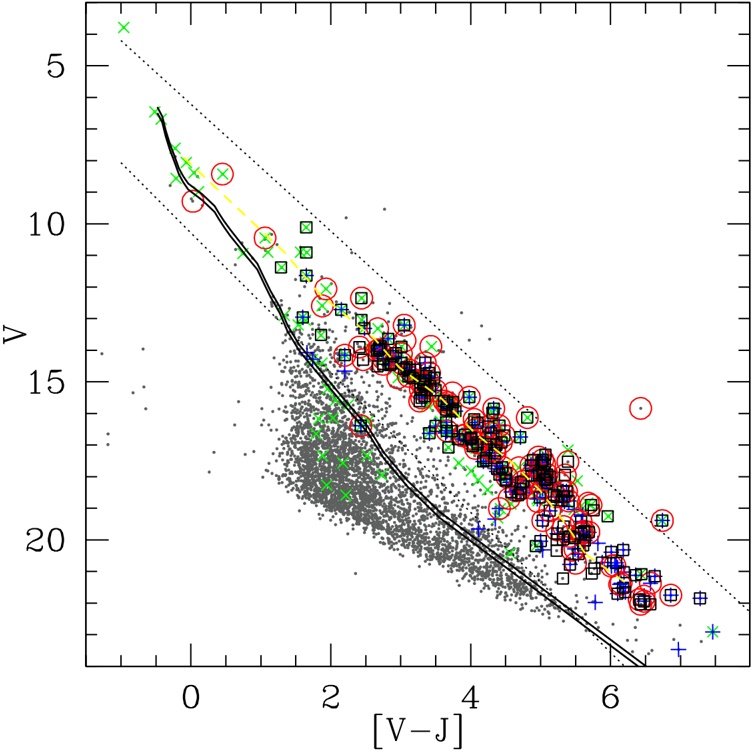
Fig. 2.- Comparison of spectral types determined in this work with previously published values: Wolk (1996), Caballero (2006), Zapatero Osorio et al. (2002), Caballero et al. (2012), Rigliaco et al. (2012), Houk & Swift (1999) and SIMBAD database (see reference in the text). Vertical error bars are the uncertainties derived from our spectral-type classification. For comparison, we show the line with slope 1. For most stars, the spectral types derived in this work agree, within the uncertainties, with previous determinations of spectral types. [See the electronic edition of the Journal for a color version of this figure.]
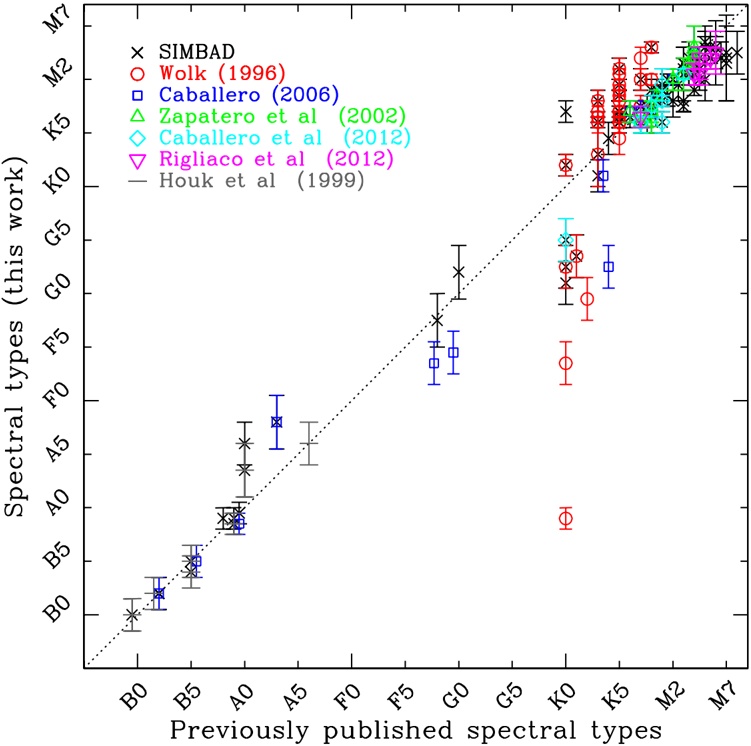
Fig. 3.- Relation between the EW of H α and the spectral type. In order to plot our data in a logarithmic scale, EWs have been shifted by ten units. Solid line indicates the limit for Classical and Weak-line T Tauri stars based on the H α in emission (Barrado y Navascués et al. 2003). Dotted line indicates the limit between emission and absorption of H α . We plot with different symbols spectra obtained from different spectrographs (see Table 3). We also indicate the disk type for the sample using Spitzer photometry (H07a). [See the electronic edition of the Journal for a color version of this figure.]
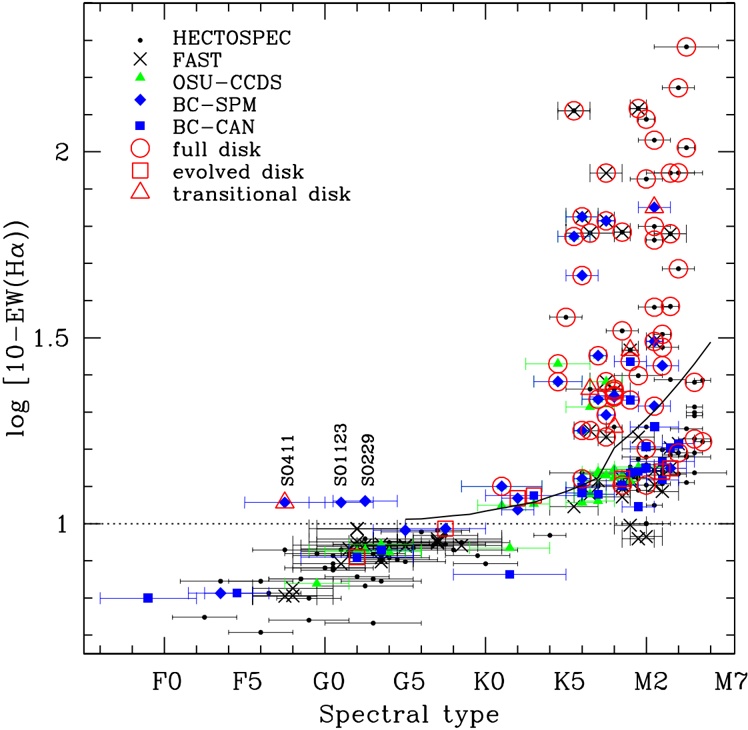
Fig. 4.- Normalized spectra of the sodium doublet (Na I λλ 8183 8195) for three M5 type stars , at different evolutionary stages. Vertical dotted lines represent the limits of the continuum bands used to normalize the spectra (Schlieder et al. 2012). A Gaussian function (blue line) was used to calculate the EW of the line Na I λ 8195. The M-type field dwarf (upper spectrum) exhibits the strongest absorption of this feature. The PMS star (middle spectrum) located in the 25 Ori stellar cluster (age ∼ 10 Myr; Briceño et al. 2007) exhibits fainter NaI λ 8195 than the M type field dwarf, but stronger absorption than the stars in the σ Orionis cluster (lower spectrum).
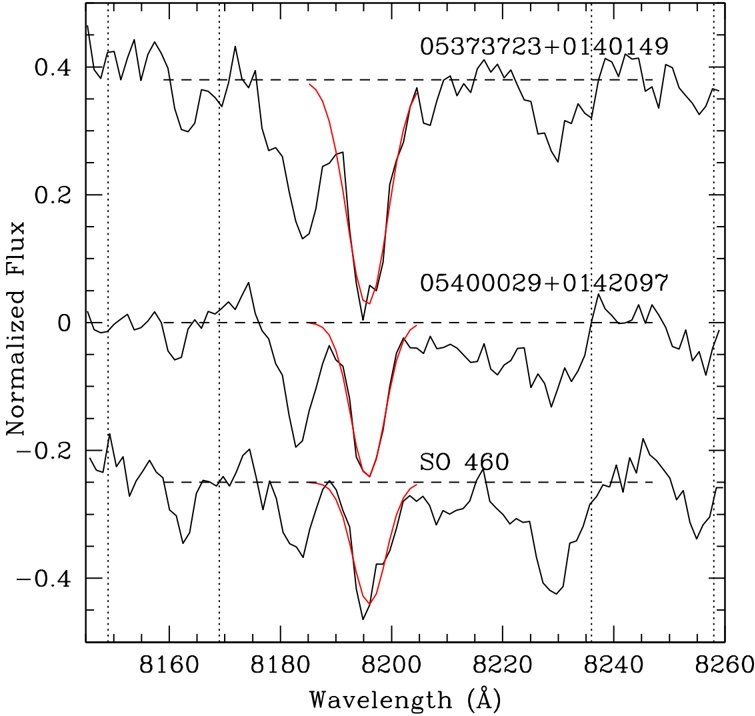
Fig. 5.- Relation between the EW of Na I λ 8195 and the spectral type for the sample of stars observed with Hectospec. We display the median and the second and third quartiles of Na I λ 8195 measured for a sample of PMS stars (age range ∼ 5-10 Myr; dots and lower solid line) and for a sample of M-type field dwarfs (plus symbol and upper solid line) in the Orion OB1 association (Briceno in prep). Open squares and open circles indicate stars in the σ Orionis cluster with and without Li I λ 6708, respectively. In general, stars with uncertain membership based on Li I λ 6708 (crosses) have smaller values of EW of Na I λ 8195. Using the sodium criteria, we identify as member of the σ Orionis cluster stars with spectral type M3 or later and located below the median values of the PMS population in the Orion OB1 association. The stars SO 576 and SO 795 were identified as M type field stars. [See the electronic edition of the Journal for a color version of this figure.]
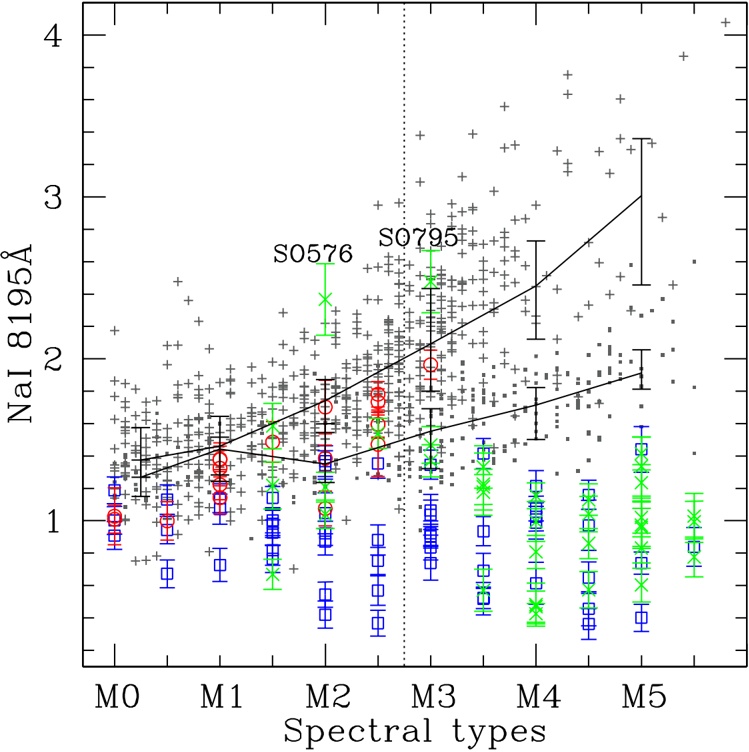
Fig. 6.- Comparison between interstellar reddening calculated using the intrinsic colors for main sequence stars (Kenyon & Hartmann 1995) and the intrinsic colors for PMS stars (Pecaut & Mamajek 2013). Open squares indicate stars with spectral type later than M3 and open circles indicate stars with spectral type range from G2 to M3. [See the electronic edition of the Journal for a color version of this figure.]
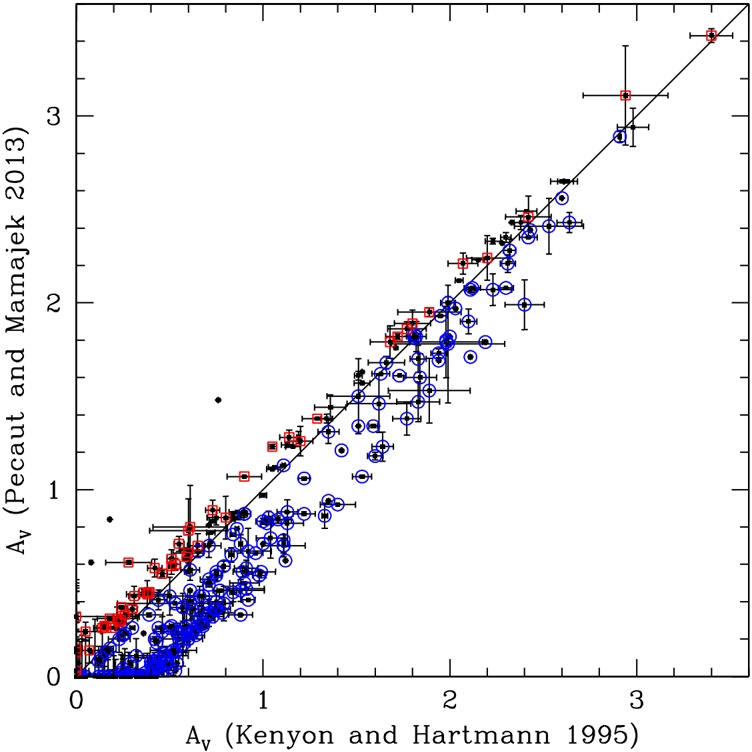
Fig. 7.- Equivalent width of Li I λ 6708 versus Radial Velocity obtained from Hectochelle data. Our RV distribution (third panel) is in agreement with the RV distribution obtained by Sacco et al. (2008, first panel) and with the RV distribution of the group 1 from Maxted et al. (2008, second panel). A Gaussian function was fitted to our RV distribution. The dotted vertical lines represent the center of the Gaussian and the 3 σ criteria used to identify kinematic members of the cluster. The dashed line represents the lower limit for the sparser stellar population (see 2.3). Disk types from H07a are plotted. We show binaries exhibiting double peaks in the correlation function (SB2) or binaries identified by radial velocity variability (RV var). Stars with Li I λ 6708 in absorption located to the left of the kinematic regions can be candidates of a more sparser and older group (group 2 in Maxted et al. 2008) or binary candidates of the cluster. The stars SO 243, SO 362, SO 1251 are located in the kinematic non-members region. [See the electronic edition of the Journal for a color version of this figure.]
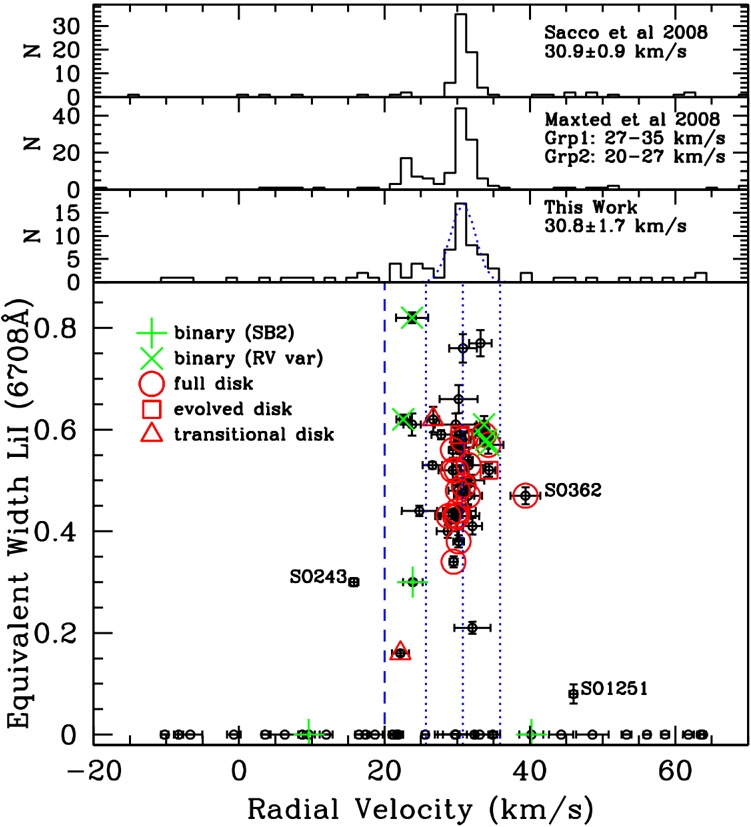
Fig. 8.- Diagram used to calculate photometric probabilities. The color magnitude diagram of Figure 1 was rotated in order to get the new variable C rot near zero for the known member sample (open circles and solid histogram in the upper panel). The red solid line represents the empirical isochrone. A Gaussian function (dotted histogram) was fitted to the C rot distribution of the known members. Stars identified as variables are plotted with symbol "X". Stars within the dotted vertical lines have photometric probabilities larger than 0.3% (|C rot |<3 σ ). Stars within the dashed vertical lines have photometric probabilities larger than 31.7% (|C rot |<1 σ ). The Dotted-dashed histogram and the long dashed histogram represent the distribution of variable stars and the distribution of the entire sample, respectively. [See the electronic edition of the Journal for a color version of this figure.]
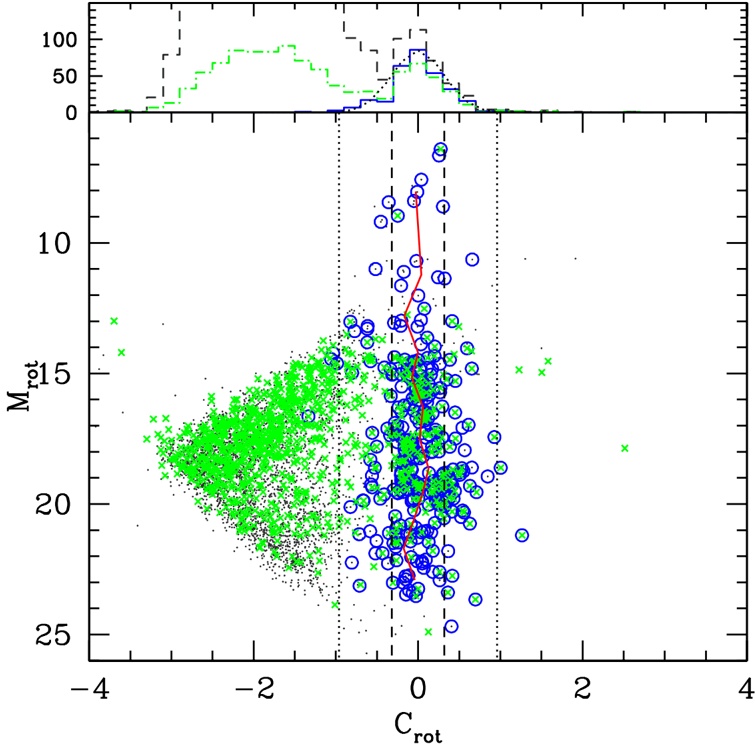
Fig. 9.- Vector point diagram for photometric candidates. Green crosses indicate the position of the known member sample, and the upper panel and right panel show its proper motion distribution in right ascension and declination, respectively. Gaussian function curve fitting indicates that those distributions are centered at cos ( δ ) ∗ µ α ∼ 2.2 ± 5.3 mas/yr and µ δ ∼ 0.7 ± 4.1 mas/yr. About 86% of the known members are located within the 3 σ limit (dotted ellipse). Almost all known members are located within 5 σ (solid ellipse) from the center of the distributions. Only the known members SO592, SO936 and SO1368 are located beyond the 5 σ criteria. [See the electronic edition of the Journal for a color version of this figure.]
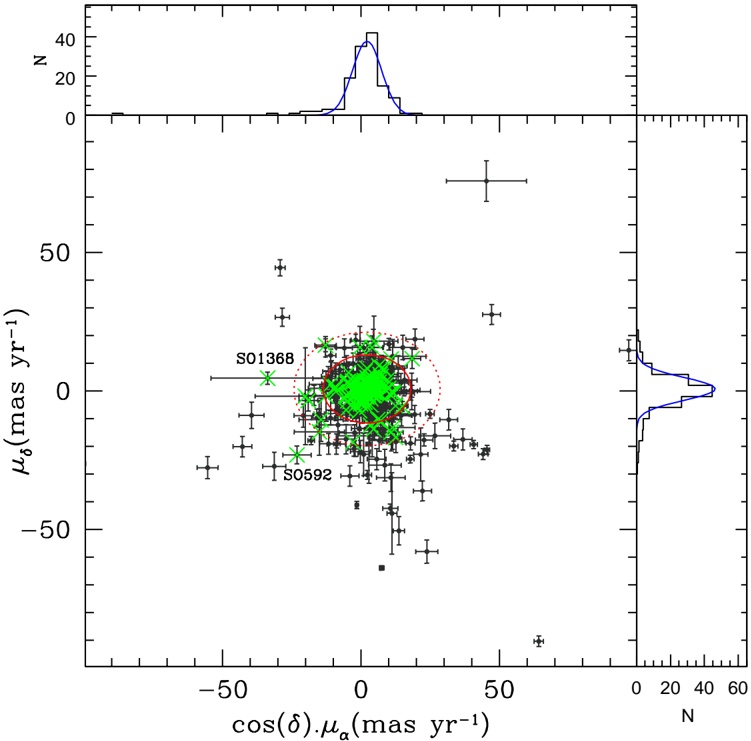
Fig. 10.- Color magnitude diagram K-24 versus V-J illustrating the detection of disks at 24 µ m. Circles and squares represent sources included and not included in the previous disk census (H07a), respectively. Dotted lines represent the photospheric K-24 colors estimated by H07a. The dashed line indicates an arbitrary limit between optically thick disks and debris disks estimated using a sample of debris disks located in several young stellar groups (Hernandez et al. 2011). Red X's are sources labeled as galaxies by Lawrence et al. (2013). [See the electronic edition of the Journal for a color version of this figure.]
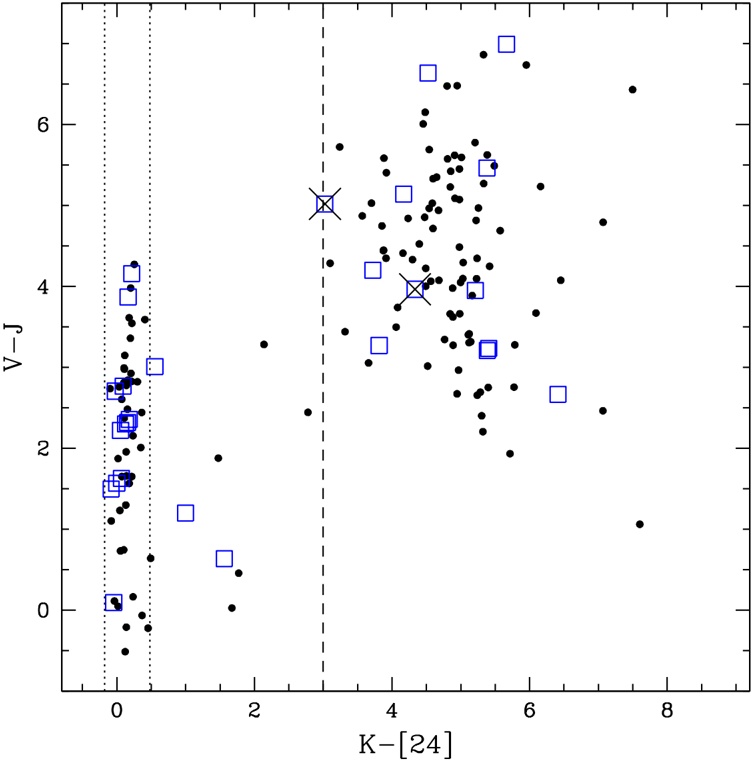
Fig. 11.- IRAC SED slope versus the full width of H α at 10% of the line peak. Dotted line and dashed line represent the limit between accretor and non accretor from White & Basri (2003) and Jayawardhana et al. (2003), respectively. Solid line indicates the limit between optically thick disks and evolved disks (Lada et al. 2006). Other symbols are similar to Figure 7. The disk less stars SO 299 and SO 616 can be binaries or fast rotators (see Figure 14). We identify 8 very slow accretors with optically thick disks. We also identify one transitional disk (SO 818) and one evolved disk (SO 905) with accretion below the measurable levels. [See the electronic edition of the Journal for a color version of this figure.]
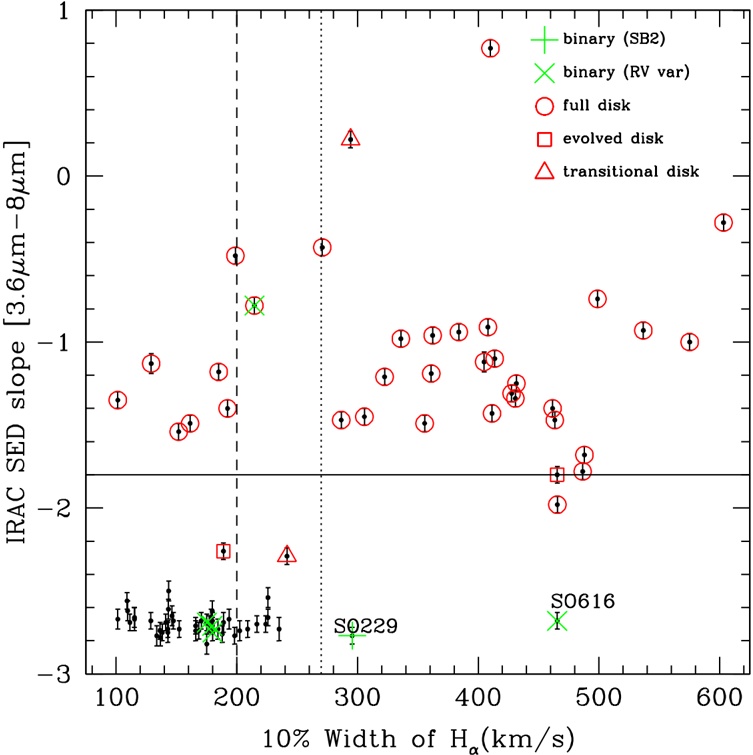
Fig. 12.- IRAC color-color diagram [5.8]-[8.0] vs. [3.6]-[4.5] for stars included in Figure 11. Solid circles represent the very slow accretors candidates. We also included in this plot the slow accretors candidate SO 823. The large dotted box represents the loci of classical T Tauri stars (CTTSs) with different accretion rates (D'Alessio et al. 2006). Very slow accretors candidates and stars with optically thick disks (Class II) which are above the accretion cutoff (White & Basri 2003) share the same region in this plot. Symbols are similar to Figure 11. [See the electronic edition of the Journal for a color version of this figure.]
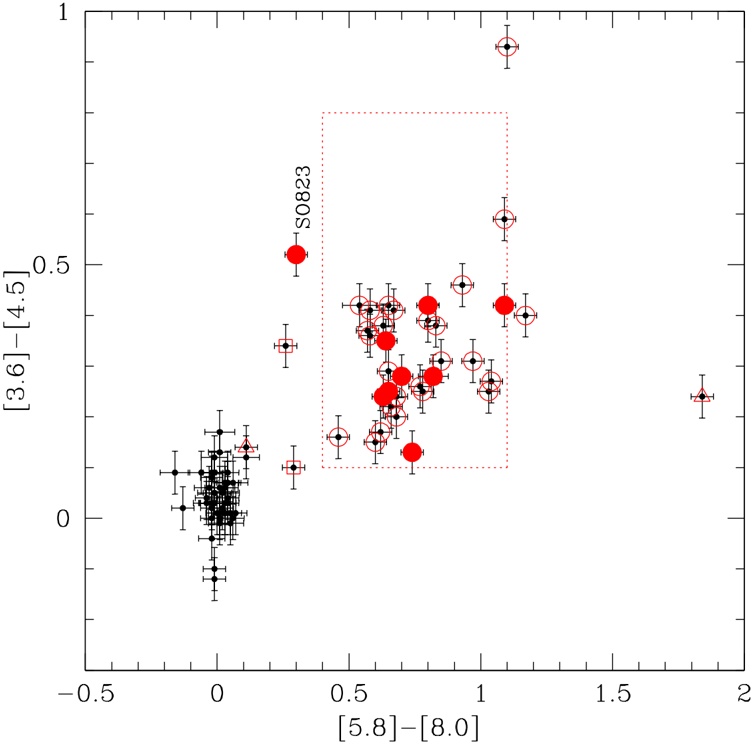
Fig. 13.- Spectral energy distributions (SEDs) and H α profiles for stars identified as very slow accretor candidates. For comparison we include a diskless star (SO 669) and two stars with accretion disks (SO 397 and SO 462). All SEDs are normalized at the J band. Values of the WH α \_10% in km s -1 are included in the panels that show the profile of H α . We do not measure the WH α \_10% of the star SO 823 which exhibit a strong absorption component in the H α line. In the panels that show the SEDs, we plot the median SED for Class II stars in Taurus (Furlan et al. 2006, solid lines), the median SED for Class II (dotted lines) and the median SED for Class III (dashed lines) in the σ Orionis cluster (H07a). [See the electronic edition of the Journal for a color version of this figure.]
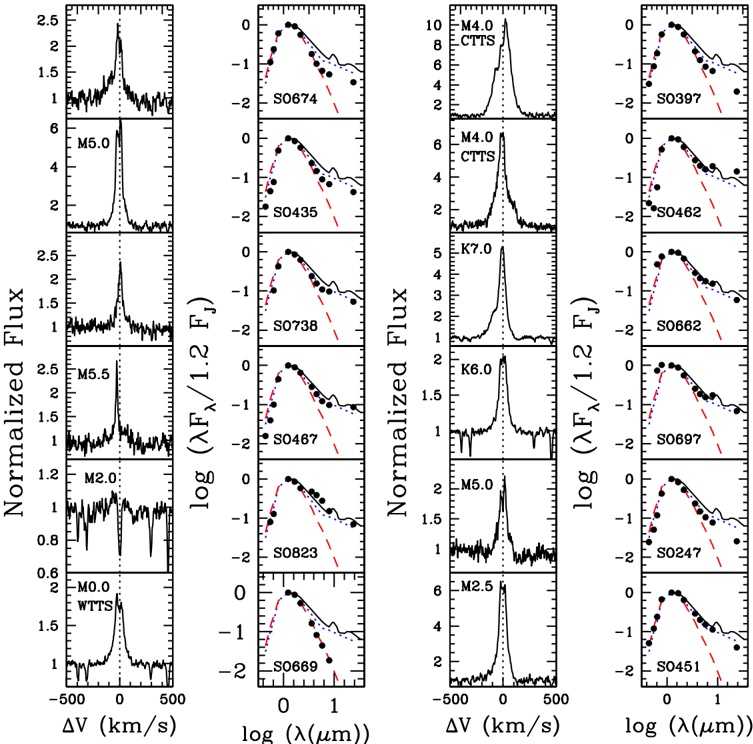
Fig. 14.- Hectochelle spectra of the diskless stars SO 229 and SO 616 which mimic stars with accretion disks. For comparison we show hectochelle spectra of disk less stars with similar spectral types. Clearly, SO 229 and SO 616 have wider photospheric features in comparison to those stars. The broader spectral features could be produced by combined spectral lines of stellar components with similar effective temperature or by fast rotation.
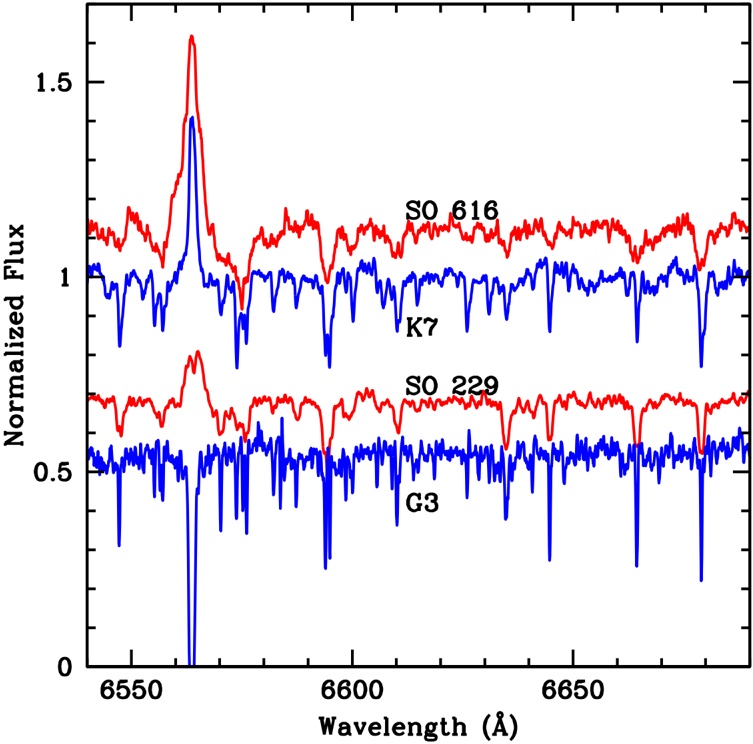 | 10.1088/0004-637X/794/1/36 | [
"Jesús Hernández",
"Nuria Calvet",
"Alice Perez",
"Cesar Briceño",
"Lorenzo Olguin",
"Maria E. Contreras",
"Lee Hartmann",
"Lori Allen",
"Catherine Espaillat",
"Ramírez Hernan"
] | 2014-08-01T16:34:56+00:00 | 2014-08-06T15:59:07+00:00 | [
"astro-ph.SR"
] | A spectroscopic census in young stellar regions: the Sigma Orionis cluster | We present a spectroscopic survey of the stellar population of the Sigma
Orionis cluster. We have obtained spectral types for 340 stars. Spectroscopic
data for spectral typing come from several spectrographs with similar
spectroscopic coverage and resolution. More than a half of stars of our sample
are members confirmed by the presence of lithium in absorption, strong
H$\alpha$ in emission or weak gravity-sensitive features. In addition, we have
obtained high resolution (R~34000) spectra in the H$\alpha$ region for 169
stars in the region. Radial velocities were calculated from this data set. The
radial velocity distribution for members of the cluster is in agreement with
previous work. Analysis of the profile of the H$\alpha$ line and infrared
observations reveals two binary systems or fast rotators that mimic the
H$\alpha$ width expected in stars with accretion disks. On the other hand there
are stars with optically thick disks and narrow H$\alpha$ profile not expected
in stars with accretion disks. This contribution constitutes the largest
homogeneous spectroscopic data set of the Sigma Orionis cluster to date. |
1408.0226v2 | ## Large gain quantum-limited qubit measurement using a two-mode nonlinear cavity
S. Khan , R. Vijay 1 2 , I. Siddiqi 3 , and A. A. Clerk 1 1 Department of Physics, McGill University, Montreal, Quebec, Canada H3A 2T8 2 Tata Institute of Fundamental Research, Mumbai 400005, India 3 Department of Physics, University of California, Berkeley, CA 94720
(Dated: December 9, 2014)
We provide a thorough theoretical analysis of qubit state measurement in a setup where a driven, parametrically-coupled cavity system is directly coupled to the qubit, with one of the cavities having a weak Kerr nonlinearity. Such a system could be readily realized using circuit QED architectures. We demonstrate that this setup is capable in the standard linear-response regime of both producing a highly amplified output signal while at the same time achieving near quantum-limited performance: the measurement backaction on the qubit is near the minimal amount required by the uncertainty principle. This setup thus represents a promising route for performing efficient large-gain qubit measurement that is completely on-chip, and that does not rely on the use of circulators or complex non-reciprocal amplifiers.
## I. INTRODUCTION
Among the many attractive aspects of circuit QED approaches to quantum information processing is the ability to use driven microwave cavities for high-fidelity qubit measurements [1-3]. The standard approach is to couple the qubit dispersively to the cavity, such that the resonant frequency of the cavity depends on the state of the qubit. By driving the cavity, the state of the qubit becomes encoded in the phase of the reflected drive tone. For an ideal realization, this initial measurement is quantum limited: the backaction disturbance to the qubit is as small as is permitted by quantum mechanics [1, 4]. In practice though, the qubit signal in the cavity output is too small to be sent directly to a room-temperature amplifier. One thus often first uses a low temperature amplification stage, based on a Josephson parametric amplifier (JPA) [5-13]. This amplifier is yet another driven microwave cavity, one that is made nonlinear by the addition of Josephson junctions. While such setups can yield extremely fast measurement rates, they unfortunately require the use of lossy magnetic circulators. This both adds to experimental complexity and bulkiness, and makes one susceptible to insertion losses.
A promising alternate approach is to combine the measurement and amplification cavities in the standard setup into a single system. One thus has an intrinsically nonlinear cavity which is directly coupled to a qubit, eliminating the need for circulators. Such approaches have been studied in regimes where the nonlinear cavity is driven past a bifurcation point in its dynamics, yielding the Josephson bifurcation amplifier [14-17], and a strong latching-style measurement of the qubit state. To obtain a continuous measurement, one could drive the nonlinear cavity close to (but not past) a point of bifurcation, similar to the driving conditions used to realize a paramp. Setups of this kind have been studied both theoretically [1822] and in experiment [18, 23, 24]. While the nonlinearity in these systems allows for large gain, this comes at the expense of an unavoidable large excess backaction on the qubit [19]. While this problem can be mitigated in more complex regimes having a stronger qubit-cavity coupling [21], for a single nonlinear cavity weakly coupled to a qubit, this excess backaction prevents quantum-limited performance.
FIG. 1. (a) Schematic diagram of the PARI setup. The linear cavity is used to provide tunable coupling between the qubit ˆ σ z and the nonlinear cavity; it can be adjusted to suppress excess backaction, while still allowing the output homodyne current ˆ I to see the amplified quadrature ˆ X e (cf. Eq. (30a)) and therefore the large gain G (cf. Eq. (32)). (b) Possible experimental realisation of the PARI setup in (a) in a superconducting circuit architecture. Both cavities are driven, at frequencies ω dj for j = (1 2) , , and λ 12 is the intercavity coupling strength. All components shown above can be cofabricated on-chip as an integrated qubit-amplifier system.
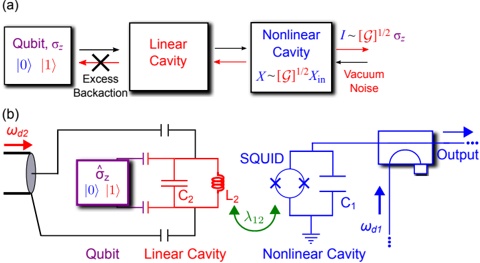
In this paper, we consider theoretically a new approach to making continuous qubit measurements. The goal is again to combine the measurement cavity and paramp cavities in a traditional setup into a single, circulator-free device. Unlike the work described above, we now consider directly coupling a qubit to a simple multi-mode structure with intrinsic nonlinearity. Our basic setup is shown in Fig. 1. Similar to a standard dispersive-measurement setup, we have a driven linear cavity dispersively coupled to a qubit, as well as a second driven nonlinear cavity. However, unlike the standard setup, we do not take the output field of the linear cavity and use it to drive (via a circulator) the nonlinear cavity. We instead directly couple these systems, such that the intracavity field of the linear cavity directly modulates the inductance of the nonlinear cavity. We refer to this setup as a 'parametric amplifier with resonant input' (PARI). Note that the amplification properties of a very different kind of two-mode nonlinear cavity were recently studied by Eichler et al. in Ref. 25; unlike our
work, they did not consider a direct coupling to a qubit.
It would appear that the PARI will suffer the same fate encountered when directly coupling a qubit to a single nonlinear cavity: there is nothing to protect the qubit from the large fluctuations associated with the nonlinear cavity, hence there will be backaction on the qubit far in excess of the quantum limit. Protecting the qubit from such fluctuations is precisely the role of the circulator in a standard cavity-circulator-paramp setup; the directional nature of the circulator prevents amplified noisy signals emanating from the amplifier input port from reaching the qubit. Similar protection could be achieved without a circulator, if one had a truly directional amplifier, one that did not produce amplified noise at its input port [26].
In the PARI design, there is no explicitly directional element preventing the qubit from seeing the nonlinear cavity and its large, amplified noise. The only element mitigating this coupling is the linear cavity. As we will see, this is already enough to effectively protect the qubit from excess backaction . There is an emergent directionality here as a result of having a driven system, and having the freedom to control the relative phase between the drive tones applied to each of the two cavities. We stress that the linear cavity does not act as a simple filter, suppressing noise at high/low frequencies. Rather, the driven linear cavity acts to control the phase-sensitive coupling of the qubit to the nonlinear cavity, in a manner that would be impossible if the qubit was coupled directly to the nonlinear cavity (as in, e.g., Ref. [19]).
Of course, simply protecting the qubit from backaction is not enough. We also want the system to truly act as an amplifier, producing a sufficiently large qubit signal as well as a sufficiently short measurement time τ meas = 1 Γ / meas (i.e. how long one must run the measurement before being able to distinguish the qubit ground state from the excited state). Our analysis shows that for experimentally feasible parameters, the PARI system has enough flexibility to allow both these goals to be achieved while at the same time having near-ideal backaction properties. We stress that as it contains no circulators, all components of our detector can be cofabricated on-chip. Hence the PARI setup realizes an integrated qubitamplifier system with a large output signal, fast measurement rate and near-quantum-limited backaction.
The remainder of this paper is organized as follows. In Sec. II, we introduce the model for the PARI system, and outline our basic analysis of the corresponding HeisenbergLangevin equations; of particular note is Sec. II E, where we develop an extremely useful mapping of this two-mode system to a single effective nonlinear cavity. In Sec III, we turn to analyzing and optimizing the properties of the PARI detector, viewed as a qubit state detector. We use linear-response theory to calculate the detector gain and noise properties. Our analysis reveals that optimal performance is possible using realistically weak cavity-cavity couplings, if one designs the system so that the damping rate of the nonlinear cavity is greater than that of the linear cavity, and weak nonlinearities are used. Using realistic experimental parameters, we predict that near quantum-limited performance should be possible with photon number gains ∼ 20 dB (cf. Fig. 3), and with fast measurement times ∼ 100 ns (cf. Fig. 4). The backaction is within a factor of 2 of its quantum limited value:
$$1 / \eta _ { \text{meas} } = \Gamma _ { \varphi } / \Gamma _ { \text{meas} } \simeq 1. 7 5 \text{ \quad \ \ } ( 1 )$$
where Γ ϕ is the rate of backaction-induced qubit dephasing (directly proportional to the backaction noise driving the qubit, cf. Eq. (35)), and Γ meas is the measurement rate (inversely proportional to the detector imprecision noise, cf. Eq. (51)). As discussed explicitly in section IV C, this performance (achieved completely on-chip) is on par with or better than modern circulator-based setups [27-30]. In contrast, if one directly (and weakly) coupled a qubit to a single nonlinear cavity, a gain of 20 dB would imply missing the quantum limit by a large factor of ∼ 50 .
## II. BASIC TWO-CAVITY SYSTEM AND ANALYSIS
## A. Hamiltonian and coupling
The two-cavity detector system we consider consists of a single nonlinear cavity with a Kerr type nonlinearity, coherently coupled to an ordinary linear cavity. Throughout this paper, we label the nonlinear cavity with the index 1 , and the linear cavity with index 2 . The two cavity Hamiltonians are given in terms of the cavity annihilation operators ˆ a j ( j = 1 2 , ) by
$$\underset { \text{pli-} } { n \text{ is} } \quad \hat { H } _ { 1 } = \hat { H } _ { 1 } ^ { s y s } + \hat { H } _ { 1 } ^ { \text{envt} } = \omega _ { c 1 } \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 1 } - \Lambda \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { 1 } \hat { a } _ { 1 } + \hat { H } _ { 1 } ^ { \text{envt} } \underset { \text{(2a)} } { ( 2 a ) }$$
$$\iowarpoonright _ { \alpha _ { i c } } \quad \hat { H } _ { 2 } = \hat { H } _ { 2 } ^ { s y s } + \hat { H } _ { 2 } ^ { \text{env} t } = \omega _ { c 2 } \hat { a } _ { 2 } ^ { \dagger } \hat { a } _ { 2 } + \hat { H } _ { 2 } ^ { \text{env} t } \quad \quad ( 2 b )$$
( glyph[planckover2pi1] = 1 ) where ω cj are the cavity resonance frequencies. For the nonlinear cavity Hamiltonian [cf. Eq. (2a)], the Kerr type nonlinearity has strength Λ glyph[lessmuch] κ 1 , where κ 1 is the nonlinear cavity damping rate; this system could be realised as a SQUID shunted with a capacitor in superconducting circuit architecture [31]. We assume a regime where the phase fluctuations of the SQUID are small enough for only the leading order Kerr nonlinearity to be important; the conditions under which higher order terms in an expansion of the SQUID cosine potential can be dropped are discussed in Sec. IV B. Both cavities are also driven externally, via coupling to external microwave transmission lines. The ˆ H envt j terms describe this driving, and the damping (at rate κ j ) of both cavities in a standard input-output theory approach [4, 32]; we neglect internal cavity losses.
The qubit to be measured is connected to the two-cavity system via a dispersive coupling to the linear cavity [1]; this coupling is described by the Hamiltonian,
$$\hat { H } _ { \sigma _ { z } } = A \hat { \sigma } _ { z } \hat { a } _ { 2 } ^ { \dagger } \hat { a } _ { 2 } \equiv \hat { \sigma } _ { z } \hat { F },$$
where ˆ σ z commutes with the qubit Hamiltonian. The cavity2 resonance frequency is modulated by the qubit state by an amount A , the dispersive coupling strength. We have introduced ˆ F , the effective backaction noise operator. Throughout this paper we will consider values of A small enough that a
linear response analysis of the detector is valid; when considering real experimental parameters, we will explicitly check the validity of this assumption. As is standard with dispersive qubit measurements, we measure the qubit in the energy eigenstate ( ˆ σ z ) basis. Measurements along other axes can be achieved by first performing a qubit rotation, as has been done in countless circuit QED experiments.
Finally, we describe the crucial element of the setup: how the two cavities are coupled to each other to allow the nonlinear cavity to learn about the qubit state. For the twocavity system within superconducting circuit architecture, the qubit state-dependent current in cavity2 generates a flux that threads the SQUID loop in cavity1 , therefore modulating its Josephson energy. This inductive coupling between the cavities takes the nonlinear form [see Appendix A],
$$\hat { H } _ { 1 2 } = \frac { 1 } { 2 } \left [ \lambda _ { 1 2 } ( \hat { a } _ { 2 } + \hat { a } _ { 2 } ^ { \dagger } ) \right ] ( \hat { a } _ { 1 } + \hat { a } _ { 1 } ^ { \dagger } ) ^ { 2 } \quad \quad ( 4 )$$
where λ 12 is the strength of the intercavity coupling. Note that the cavity2 'sum' quadrature effectively modulates the 'spring constant' of cavity1 .
We now make an important choice for the two cavity drive frequencies, ω dj ( j = 1 2) , , taking the linear cavity to be driven at twice the driving frequency of the nonlinear cavity:
$$\omega _ { d 2 } = 2 \omega _ { d 1 } \quad \ \ ( 5 ) \quad \text{an}$$
This choice of frequencies is unusual, in that the nonlinear cavity is effectively being coupled to a higher frequency signal, the field of the linear cavity. In particular, as we will show in Eq. (20), this choice (along with a rotating-wave approximation) leads to an emergence of effective parametric driving and photon hopping terms in the coupling Hamiltonian, as opposed to the usual dispersive ( ˆ ˆ a a † ) terms (which are nonresonant in this case).
The full system Hamiltonian is then given by ˆ H = ˆ H 1 + ˆ H 2 + ˆ H 12 + ˆ H σ z . We emphasise that the results of our analysis hold for a generic Hamiltonian of the form of ˆ H , involving a dispersive coupling between two independent modes. As mentioned earlier, our emphasis will be on weak qubit-detector couplings, allowing the use of quantum linearresponse theory [4]. In what follows, we will thus start by developing a description of the PARI in the absence of any coupling to a qubit (i.e. A → 0 ), and will then use this description combined with linear-response theory to determine its properties as a detector.
## B. Heisenberg-Langevin equations
Treating the cavity driving and dissipation as in standard input-output theory [4, 32], the Heisenberg-Langevin equations for the two cavity modes are ( j = 1 2 , )
$$\frac { d } { d t } \hat { a } _ { j } = - i [ \hat { a } _ { j }, \hat { H } _ { j } ^ { s y s } ] - i [ \hat { a } _ { j }, \hat { H } _ { 1 2 } ] - \frac { \kappa _ { j } } { 2 } \hat { a } _ { j } - \sqrt { \kappa _ { j } } \, \hat { a } _ { j } ^ { \text{in} } ( t ), \, ( 6 )$$
where the driving fields describe both coherent drive tones (amplitudes ¯ a in j ) as well as noise:
$$\hat { a } _ { 1 } ^ { \text{in} } ( t ) & = \bar { a } _ { 1 } ^ { \text{in} } e ^ { - i \omega _ { d 1 } t } + \hat { \xi } _ { 1 } ( t ), \\ \hat { a } _ { 2 } ^ { \text{in} } ( t ) & = \bar { a } _ { 2 } ^ { \text{in} } e ^ { i \delta } e ^ { - i \omega _ { d 2 } t } + \hat { \xi } _ { 2 } ( t ).$$
Here, ω dj = ω cj + ∆ j , with ∆ j denoting the detuning from cavity resonance. As we will see, the relative phase between the cavity drive tones will play an important role in allowing one to tune the system properties. We denote this phase difference δ , and without loss of generality take the ¯ a in j in Eqs. (7) to be real and positive. The operators ˆ ( ) ξ j t describe the classical and quantum vacuum noises that enter each cavity via the drive port; the noise is taken to be delta-correlated vacuum noise in the standard input-output theory approach [4, 32].
## C. Classical Cavity Amplitudes
As a result of the strong coherent drives on both cavities, the average cavity field amplitudes will be non-zero, 〈 ˆ a j 〉 glyph[negationslash] = 0 . Our first task will be to find these amplitudes by solving the classical equations of motion for our system. Consistent with our focus on weak qubit-detector couplings and use of linear response, we will solve for these amplitudes in the absence of any coupling to the qubit, and then use them to transform to a displaced interaction picture (with respect to the cavity drive frequencies):
$$\text{$\mathfrak { a }$} _ { j } \quad \hat { a } _ { j } ( t ) & = e ^ { - i \omega _ { d j } t } \left \{ \alpha _ { j } + e ^ { i \mu _ { j } } \left [ e ^ { i \beta } \hat { d } _ { j } ( t ) \right ] \right \} \quad ( j = 1, 2 ), \\ \text{$\mathfrak { a }$} _ { j } \quad \alpha _ { j } \equiv \langle \hat { a } _ { j } \rangle \equiv e ^ { i \mu _ { j } } \sqrt { \bar { n } _ { j } }.$$
Here ¯ n j are the respective cavity photon numbers due to the classical drives, µ j are the average cavity mode phases, and β is an overall phase that will be chosen later for convenience.
The values of the classical cavity mode amplitudes α j are determined by solving the classical equations of motion for both cavities (in the absence of any qubit coupling). The two coupled nonlinear equations obtained can be reduced to a single equation for the nonlinear cavity mode amplitude [see Appendix B],
$$\inf _ { \mathrm d e _ { \mathrm k } } \alpha _ { 1 } [ - i ( \Delta _ { 1 } + 2 \widetilde { \Lambda } | \alpha _ { 1 } | ^ { 2 } ) + \kappa _ { 1 } / 2 ] - i \eta \alpha _ { 1 } ^ { * } = - \sqrt { \kappa _ { 1 } } \, \bar { a } _ { 1 } ^ { \mathrm i n }. \ ( 9 )$$
We see that the cavity-cavity coupling modifies the classical amplitude equation for α 1 from that of a standard Kerr cavity in two ways. The first is a modification of the bare Kerr constant Λ in Eq. (2a) to the complex valued ˜ Λ ,
$$\widetilde { \Lambda } = \Lambda + \lambda _ { 1 2 } ^ { 2 } \left ( \frac { i \chi _ { 2 } } { 4 } \right ), \text{ \quad \ \ } \text{(10)}$$
where χ 2 ≡ χ 2 [ ω = 0] is the (complex) zero-frequency bare linear cavity susceptibility; for non-zero frequency,
$$\chi _ { 2 } [ \omega ] = \left [ - i ( \omega + \Delta _ { 2 } ) + \kappa _ { 2 } / 2 \right ] ^ { - 1 }. \quad \ \ ( 1 1 )$$
Also new, and more complicated, is the last term on the left hand side in Eq. (9), which involves α ∗ 1 ; this describes an effective parametric driving of cavity1 due to the coupling to cavity2 . The effective parametric drive strength η is given by
$$\eta = \lambda _ { 1 2 } \left ( \sqrt { \kappa _ { 2 } } \, \bar { a } _ { 2 } ^ { \text{in} } \, \chi _ { 2 } \, e ^ { i \delta } \right ). \quad \quad \quad ( 1 2 ) \quad \quad \quad$$
It can be shown [see Appendix B] that Eq. (9) can be written as a quintic polynomial in the nonlinear cavity photon number | α 1 | 2 = ¯ n 1 [33]:
$$\bar { n } _ { 1 } = \left [ \frac { \kappa _ { 1 } ( \bar { a } _ { 1 } ^ { \text{in} } ) ^ { 2 } } { D ^ { 2 } } \right ] & \left \{ \kappa _ { 1 } / 2 + i \eta + i ( \Delta _ { 1 }$$
where
$$D = \left | \kappa _ { 1 } / 2 - i \left ( \Delta _ { 1 } + 2 \widetilde { \Lambda } \bar { n } _ { 1 } \right ) \right | ^ { 2 } - | \eta | ^ { 2 } \quad ( 1 4 ) \quad \text{quadquad } \text{quad }$$
We see that in comparison to a single driven Kerr cavity (where the average photon number is determined from a cubic polynomial), the two-mode structure of the PARI system yields more complex nonlinear physics at even the classical level. In what follows, we will attempt to work in regimes where the cavity-cavity coupling λ 12 is weak enough that classical bifurcation physics described by Eq. (13) is not too different from that of a single driven Kerr cavity. At a point of bifurcation, the driven nonlinear cavity becomes multistable when the cavity photon number ¯ n 1 as a function of drive detuning acquires more than one stable solution. Just before this turning-over point is reached, the slope of ¯ n 1 versus ∆ 1 is nearly vertical, and thus the cavity becomes very sensitive to even small changes in detuning; it is near (but not past) this point of bifurcation that we wish to operate.
## D. Linearization procedure
Once the α j are found, the displacement and interaction picture transformation in Eq. (8) allows obtaining the transformed Heisenberg-Langevin equations of motion from Eqs. (6):
$$\frac { d } { d t } \hat { d } _ { j } = - i [ \hat { d } _ { j }, \hat { H } _ { j } ^ { d } ] - i [ \hat { d } _ { j }, \hat { H } _ { 1 2 } ^ { d } ] - \frac { \kappa _ { j } } { 2 } \hat { d } _ { j } - \sqrt { \kappa _ { j } } \, \hat { \xi } _ { j } ( t ), \, ( 1 5 ) \quad.$$
where ˆ H d j are the respective cavity Hamiltonians in the new frame. We focus on the standard regime of strong driving and weak intrinsic nonlinearity ( Λ glyph[lessmuch] κ 1 ), which allows us to drop terms that are cubic and quartic in ˆ d , d 1 ˆ † 1 ; formally, we are neglecting terms that are suppressed by factors of 1 /n ¯ 1 . The nonlinear cavity Hamiltonian in the displaced interaction picture thus takes the form of a detuned degenerate parametric amplifier:
$$\hat { H } _ { 1 } ^ { d } = - \widetilde { \Delta } _ { 1 } \hat { d } _ { 1 } ^ { \dagger } \hat { d } _ { 1 } - \frac { g _ { 1 } } { 2 } ( e ^ { - i 2 \beta } \hat { d } _ { 1 } ^ { \dagger } \hat { d } _ { 1 } ^ { \dagger } + h. c. ), \quad ( 1 6 ) \quad \text{ term} \quad \text{phase}$$
where the effective detuning ˜ ∆ 1 and parametric interaction strengths g 1 are given by
$$\Delta _ { 1 } = \Delta _ { 1 } + 4 \Lambda \bar { n } _ { 1 } \text{ \quad \ \ } ( 1 7 a )$$
$$g _ { 1 } = 2 \Lambda \bar { n } _ { 1 } \text{ \quad \ \ } ( 1 7 b )$$
The linear cavity Hamiltonian following the displacement transformation takes the form:
$$\hat { H } _ { 2 } ^ { d } = - \Delta _ { 2 } \hat { d } _ { 2 } ^ { \dagger } \hat { d } _ { 2 } + \widetilde { A } \hat { \sigma } _ { z } ( e ^ { i \beta } \hat { d } _ { 2 } + e ^ { - i \beta } \hat { d } _ { 2 } ^ { \dagger } + \frac { 1 } { \sqrt { n } _ { 2 } } \hat { d } _ { 2 } ^ { \dagger } \hat { d } _ { 2 } ) \ ( 1 8 )$$
where
$$\widetilde { A } = \sqrt { \bar { n } _ { 2 } } A \, \quad \, \quad \, \quad \, ( 1 9 )$$
is the dressed dispersive qubit-cavity coupling. The linear term in Eq. (18) is a qubit state-dependent drive on the linear cavity that encodes qubit state information in the linear cavity quadratures. In contrast, the nonlinear term provides a qubitstate dependent shift of the linear cavity drive detuning; this term would be of no consequence without the linear driving terms. Furthermore, we show later that for a strongly detuned linear cavity and a weak dispersive coupling, this shift in linear cavity drive detuning is a relatively small effect. Therefore, in calculating how the linear cavity quadratures learn about the qubit state, the final nonlinear term can be ignored.
However, the backaction due to this nonlinear term can be significant, since we anticipate the linear cavity quadratures to experience some amplification by virtue of the coupling to the nonlinear cavity. Large fluctuations in linear cavity photon number can contribute to a 'quadratic' backaction force noise; we characterize this important effect in detail and show that it can be suppressed using appropriate parameter choices, another key advantage of the PARI.
Finally, consider the form of the cavity-cavity coupling Hamiltonian, ˆ H d 12 in the displaced interaction picture. As already mentioned, we take the drive frequencies to satisfy ω d 2 = 2 ω d 1 , allowing us to make a further rotating wave approximation on this coupling (see discussion after Eq. (5)). Retaining only the leading (quadratic) terms in the displaced, rotating frame as before, we obtain:
$$\hat { H } _ { 1 2 } ^ { d } & = \left [ \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } ( e ^ { i \mu _ { 1 2 } } \hat { d } _ { 1 } ^ { \dagger } \hat { d } _ { 2 } + h. c. ) \\ & \quad + \frac { \widetilde { \lambda } _ { 1 2 } ^ { ( 2 ) } } { 2 } ( e ^ { i \mu _ { 1 2 } } e ^ { - i 2 \beta } ( \hat { d } _ { 1 } ^ { \dagger } ) ^ { 2 } + h. c. ) \right ], \quad ( 2 0 )$$
where the dressed intercavity couplings are defined as:
$$\widetilde { \lambda } _ { 1 2 } ^ { ( j ) } = \sqrt { \bar { n } _ { j } } \lambda _ { 1 2 } \quad ( j = 1, 2 ) \quad \quad ( 2 1 )$$
and
$$\mu _ { 1 2 } = \mu _ { 2 } - 2 \mu _ { 1 }, \text{ \quad \ \ } ( 2 2 )$$
where µ j = arg ( α j ) is the phase of the cavityj classical amplitude (cf. Eq. (8)). Note that this coupling is the only term in our Hamiltonian with an explicit dependence on these phases. Also note that this phase difference µ 12 is sensitive to
the relative phase δ between the two drives, and hence can be controlled in an experiment.
The transformed cavity-cavity coupling Hamiltonian in Eq. (20) has two types of terms. The first describes simple photon hopping between the two cavities; this term will allow the nonlinear cavity to know about the qubit. The second term is not a coupling, but effectively renormalizes the cavity1 Hamiltonian. It describes an effective parametric driving, and thus modifies the strength of the parametric drive term arising from the Kerr nonlinearity in cavity1 . We thus define an effective parametric drive strength g eff as:
$$- \, i g _ { \text{eff} } = ( g _ { 1 } - \widetilde { \lambda } _ { 1 2 } ^ { ( 2 ) } e ^ { i \mu _ { 1 2 } } ) e ^ { - i 2 \beta } \equiv | g _ { \text{eff} } | e ^ { i ( \phi _ { \varepsilon } - 2 \beta ) } \quad ( 2 3 )$$
For simplicity, we now make a choice for the reference phase β , defining β = φ / g 2 + π/ 4 , such that g eff is purely real, g eff = | g eff | [34].
## E. Mapping to a single effective nonlinear cavity
## 1. Eliminating the linear cavity
Our driven two-cavity system has been reduced to a linear system of equations, Eqs. (15). For further analysis, it is useful to exactly eliminate cavity2 from the problem, resulting in a description only involving the nonlinear cavity (albeit with modified properties and driving noises). This will be useful for calculating the gain and output noise of our detector; it also directly mirrors our intuition that the linear cavity acts as a tunable coupler between the qubit and the nonlinear cavity. The elimination procedure is described in Appendix C. Introducing canonical quadratures for the displaced cavity fields via ˆ d j = (ˆ x j + ˆ ) ip j / √ 2 , the Fourier-transformed equations for for the nonlinear cavity take the form:
$$\begin{pmatrix} \hat { x } _ { 1 } [ \omega ] \\ \hat { p } _ { 1 } [ \omega ] \end{pmatrix} = \mathbf M _ { \text{eff} } ^ { - 1 } [ \omega ] \begin{pmatrix} \hat { x } _ { e } ^ { \text{in} } [ \omega ] \\ \hat { p } _ { e } ^ { \text{in} } [ \omega ] \end{pmatrix} \quad \quad ( 2 4 ) \quad \text{and}$$
where the operators ˆ x in e , ˆ p in e describe both the incident noise on the system as well as the signal associated with the qubit (see Eq. (C12) in Appendix C). The matrix M eff [ ω ] is the dressed inverse susceptibility (i.e. inverse Green function) of the nonlinear cavity. It has the form
$$\mathbf M _ { \text{eff} } [ \omega ] \equiv \mathbf M _ { 1 } [ \omega ] - i \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } \mathbf \Sigma [ \omega ]. \quad \ \ ( 2 5 )$$
Here, M 1 is the nonlinear cavity inverse susceptibility in the absence of the photon-hopping term in Eq. (20); it simply corresponds to a detuned degenerate parametric amplifier with parametric interaction strength g eff [cf. Eq. (23)]. In contrast, Σ [ ω ] is an effective self-energy matrix, describing the dynamical modification of the nonlinear cavity's properties due to the photon-hopping coupling in Eq. (20). The full form of these matrices is given in Eqs. (C4), (C8) in Appendix C.
In the analysis to follow, we will focus on the lowfrequency properties of the PARI system. Focusing on ω = 0 in our interaction picture, we find that the dressed cavity1
susceptibility has the general form expected of a parametric amplifier driven by a detuned pump:
$$\mathbf M _ { \text{eff} } [ 0 ] = \begin{bmatrix} g _ { \text{eff} } - \frac { \kappa _ { \text{eff} } [ 0 ] } { 2 } & - \widetilde { \Delta } _ { \text{eff} } [ 0 ] \\ \widetilde { \Delta } _ { \text{eff} } [ 0 ] & - g _ { \text{eff} } - \frac { \kappa _ { \text{eff} } [ 0 ] } { 2 } \end{bmatrix} \quad ( 2 6 )$$
where the effective nonlinear cavity detuning ˜ ∆ eff and damping rate κ eff are given by
$$\widetilde { \Delta } _ { \text{eff} } [ 0 ] & \equiv \widetilde { \Delta } _ { \text{eff} } = \widetilde { \Delta } _ { 1 } - \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } \Delta _ { 2 } | \chi _ { 2 } | ^ { 2 } \\ \kappa _ { \text{eff} } [ 0 ] & \equiv \kappa _ { \text{eff} } = \kappa _ { 1 } + \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } \kappa _ { 2 } | \chi _ { 2 } | ^ { 2 } \quad \quad ( 2 7 )$$
Note that the general structure of M eff remains even if λ 12 = 0 : a single driven Kerr cavity also has linearized dynamics equivalent to a detuned, degenerate parametric amplifier [19]. We have thus mapped our system onto an effective singlecavity system.
It is worth noting that the contributions to M eff from the self-energy (i.e. photon hopping) are ∝ λ 2 12 , whereas the direct parametric driving due to cavity2 yields terms that are first order in λ 12 [cf. Eq. (23)]. As a result, it is this second effect that describes the dominant perturbation of the nonlinear cavity due to the cavity-cavity coupling.
## 2. Amplified and Squeezed Quadratures
We thus see that similar to a single driven Kerr cavity, the PARI system can be mapped onto an effective detuned degenerate parametric amplifier model. To make the amplification generated by such a system clearer, it is useful to introduce two new canonical cavity quadratures [19]. We first introduce the angle θ e to parametrize the relative size of the effective pump detuning to the parametric driving strength [Eqs. (27) and (23) respectively],
$$\sin \theta _ { e } = \Delta _ { \text{eff} } / g _ { \text{eff} }. \text{ \quad \ \ } ( 2 8 )$$
We will see that having amplification necessarily requires | ˜ ∆ eff | < g eff , hence we can take -π/ 2 ≤ θ e ≤ π/ 2 for all regimes of interest. In terms of the displaced nonlinear cavity operators ˆ d , d 1 ˆ † 1 , the rotated quadratures ˆ X ,P e ˆ e are then defined as
$$\hat { X } _ { e } & = \frac { 1 } { \sqrt { 2 } } \left ( e ^ { - i \theta _ { e } / 2 } \hat { d } _ { 1 } + e ^ { i \theta _ { e } / 2 } \hat { d } _ { 1 } ^ { \dagger } \right ) \\ \hat { P } _ { e } & = \frac { - i } { \sqrt { 2 } } \left ( e ^ { - i \theta _ { e } / 2 } \hat { d } _ { 1 } - e ^ { i \theta _ { e } / 2 } \hat { d } _ { 1 } ^ { \dagger } \right )$$
By expressing ( M eff ) -1 in this basis, the solutions of the nonlinear cavity equations of motion (at ω = 0 ) take the form
$$\nu _ { \lambda } ^ { - } \quad \hat { X } _ { e } = - \left [ ( \chi _ { e - } ) \hat { X } _ { e } ^ { \text{in} } - \tan \theta _ { e } ( \chi _ { e - } - \chi _ { e + } ) \hat { P } _ { e } ^ { \text{in} } \right ] \quad ( 3 0 a )$$
$$\hat { P } _ { e } = - ( \chi _ { e + } ) \hat { P } _ { e } ^ { \text{in} }$$
where ˆ X ,P in e ˆ in e are the corresponding quadratures of the effective input fields incident on cavity1 , and where the effective susceptibilities χ e ± are given simply by:
$$\chi _ { e + } [ 0 ] \equiv \chi _ { e + } = \left [ \kappa _ { \text{eff} } / 2 + \sqrt { g _ { \text{eff} } ^ { 2 } - \widetilde { \Delta } _ { \text{eff} } ^ { 2 } } \right ] ^ { - 1 } \quad ( 3 1 a ) \quad \ni \,,$$
$$\chi _ { e - } [ 0 ] \equiv \chi _ { e - } = \left [ \kappa _ { \text{eff} } / 2 - \sqrt { g _ { \text{eff} } ^ { 2 } - \widetilde { \Delta } _ { \text{eff} } ^ { 2 } } \right ] ^ { - 1 } \quad ( 3 1 b ) \quad \stackrel { \times } { | \Xi | } ^ { 2 }$$
Amplification in a detuned DPA model emerges when one tunes parameters so that the susceptibility χ e -diverges. This results both in extremely large fluctuations of the quadrature ˆ X e , and in amplification of signals driving this quadrature. The standard parametric photon number gain G is derived from the system scattering matrix (see e.g. [19]):
$$\mathcal { G } [ \omega ] = \left | 1 - \kappa _ { 1 } \chi _ { e - } [ \omega ] \right | ^ { 2 } \underset { \chi _ { e - } \rightarrow \infty } { \longrightarrow } \kappa _ { 1 } ^ { 2 } \chi _ { e - } ^ { 2 } \quad ( 3 2 ) \underset { \lambda _ { 1 2 } \nu } { \lambda _ { 1 2 } \nu } }$$
We thus see that ˆ X e represents the amplified quadrature of the cavity. In contrast, the orthogonal quadrature ˆ P e is not the squeezed quadrature of the cavity: signals incident in this quadrature can also emerge in ˆ X out e with amplification. As discussed in Ref. 19, the finite effective detuning ˜ ∆ eff leads to the fact that standard amplified and squeezed quadratures are not orthogonal.
For a single driven Kerr cavity, one can achieve a diverging χ e -by driving the system close to a point of bifurcation. In the PARI system, we have seen that the basic classical equations determining the classical amplitudes are modified; we thus first need to understand whether a similar bifurcation (and diverging χ e -) can still be attained, at cavity-cavity coupling strengths λ 12 sufficient to allow efficient qubit measurements.
## F. Bifurcation for weak cavity-cavity couplings
To ensure the PARI also exhibits a simple bifurcation in its classical dynamics (and hence amplification), we will focus on regimes of weak cavity-cavity coupling λ 12 , such that this only weakly perturbs the bifurcation that would occur in the uncoupled nonlinear cavity. Using equation Eq. (9) for the classical cavity1 amplitude, and the modification of the parametric driving strength in Eq. (23), we see that this requires:
$$\lambda _ { 1 2 } \sqrt { \bar { n } _ { 2 } } \ll 2 \Lambda \bar { n } _ { 1 } & & ( 3 3 a ) & & \text{$\text{$this$}$}$$
$$\lambda _ { 1 2 } \ll 2 \sqrt { \Lambda / | \chi _ { 2 } | } \, \text{ \quad \ \ } ( 3 3 b ) \text{ \ \ } t e$$
where ¯ n 2 is the linear cavity photon number. The first condition ensures that the coupling-induced parametric driving term in Eq. (9) ( ∝ η ) is much smaller than the main Kerr term ( ∝ Λ ). Note that this condition needs to be satisfied self-consistently, as ¯ n 1 follows from solutions to the classical equations of motion, and thus depends weakly on λ 12 . The second equation, and the requirement of a strongly detuned linear cavity ∆ 2 glyph[greatermuch] κ 2 , ensures that the imaginary Kerr constant induced by the cavity-cavity coupling (cf. Eq. (10)) is
FIG. 2. Plot of the nonlinear cavity photon number ¯ n 1 , against nonlinear cavity drive detuning ∆ 1 . We take a cavity-cavity coupling λ 12 weak enough (as per Eqs. (33)), to ensure a small perturbation of bifurcation physics; parameter values are listed on the plot. The detuning at which the bifurcation occurs when λ 12 = 0 is indicated by the dashed vertical line. The nonlinear cavity drive is adjusted so that the parametric gain G , is large, thereby pushing the nonlinear cavity close to, but not beyond the bifurcation,. The inset plot indicates G versus ∆ 1 ; the large maximum value indicates the preservation of amplification behaviour of the nonlinear cavity.
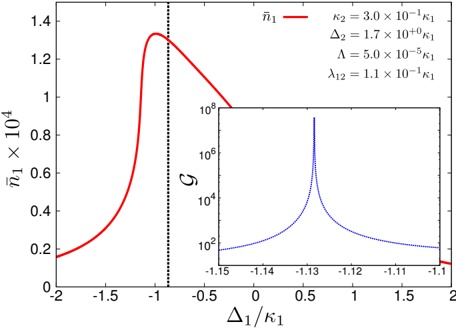
also much weaker than the main Kerr term Λ . These conditions together define the weak coupling regime in terms of the strength of the cavity-cavity coupling λ 12 , where we expect simple bifurcation physics to be retained.
To demonstrate that these conditions are sufficient, we solve Eq. (9) using an appropriately weak λ 12 , and using realistic values for κ 1 , κ 2 ; for reasons that will become clear in section IV A, we require ∆ 2 ∼ κ 1 glyph[greatermuch] κ 2 . Shown in Fig. 2 are resulting plots of the classical cavity1 intensity ¯ n 1 versus the cavity1 drive detuning ∆ 1 . The steepness of the plotted response curves indicates proximity to a bifurcation, and the possibility of large parametric gain. This is confirmed in the inset, where we plot the corresponding parametric photon number gain G [ ω = 0] for the modified nonlinear cavity.
The upshot of the analysis here is that as long as λ 12 is weak enough to satisfy Eqs. (33), one can still have simple bifurcation in the classical dynamics, and hence large parametric gain. We do see modifications in the position of the bifurcation point and the cavity1 drive strength needed to reach this point; further details of these modifications are given in Appendix B, including a perturbation theory approach to determining how the bifurcation shifts.
While a weak λ 12 ensures simple bifurcation physics, the coupling also needs to be sufficiently strong that the qubit signal in the nonlinear cavity output is suitably large. In Appendix G, we calculate a corresponding minimum useful value of λ 12 . Below this value, the coupling to the nonlinear cavity is so weak that it would be more efficient to use the linear cavity output field to read out the qubit state. We find
$$\lambda _ { 1 2 } ^ { \min } \sim \sqrt { \frac { \kappa _ { 1 } \kappa _ { 2 } } { \bar { n } _ { 1 } \mathcal { G } } }$$
## Conditions to ensure a simple bifurcation
Weak coupling regime
Strongly detuned cavity2
$$\frac { \lim e \sqrt { \frac { \kappa _ { 1 } \kappa _ { 2 } } { n _ { 1 } \mathcal { G } } } \ll \lambda _ { 1 2 } \ll \frac { 2 \Lambda \bar { n } _ { 1 } } { \sqrt { n _ { 2 } } } < 2 \sqrt { \frac { \Lambda } { | x _ { 2 } | } } } } { \Delta _ { 2 } \gg \kappa _ { 2 } }$$
Parameter list
Cavity j : damping rate κ j , drive strength ¯ a in j , drive detuning ∆ j
Nonlinear cavity Kerr constant, Λ
Intercavity coupling, λ 12
Relative drive phase, δ
Dispersive coupling, A
TABLE I. Conditions defining the parameter regimes that must be adhered to for the nonlinear cavity to be modified only weakly by its coupling to the linear cavity - the 'weak coupling' regime. The lower table lists the large number of tunable parameters in the PARI scheme that help optimize performance.
For sufficiently large parametric G , this minimum value is very far from the upper limits established by Eqs. (33). Thus, there is a large range of cavity-cavity coupling strengths where one can retain the simple bifurcation physics of a single nonlinear cavity, while still having enough qubit information transferred to the nonlinear cavity.
## III. ANALYSIS AND OPTIMIZATION OF DETECTOR NOISE AND RESPONSE
In the previous section, we demonstrated that the PARI system exhibits a bifurcation similar to a single, driven Kerr cavity, and that near such a point, it can be mapped on to a degenerate parametric amplifier (driven by a detuned pump). We now reintroduce the coupling to the qubit, and analyze the properties of the system as a continuous qubit detector. The PARI system has a large number of parameters, which we summarize in Table I. Thus, a key issue to address is how to pick these parameters to ensure optimal system performance.
We will start our analysis by addressing what seems to be the largest flaw in the design: the qubit is not sufficiently protected from the large noise associated with the driven nonlinear cavity, and hence will experience backaction noise well in excess of the quantum limit. We will show that this expectation is false: with appropriate parameter tuning, the qubit can be made immune to the large fluctuations in the nonlinear cavity. We will then turn to analyzing the output characteristics of the detector: both the gain (i.e. the size of the qubit signal) and the measurement rate (i.e. the size of this signal relative to the amount of noise in the detector output).
## A. Backaction noise
The basic dispersive coupling between the qubit and cavity2 was given in Eq. (3), where we introduced the backaction force operator ˆ F = Aa a ˆ ˆ † 2 2 . For a weak qubit-detector coupling A , the low frequency fluctuations ˆ F will dephase an ini- tial superposition in the qubit. This dephasing is described by the rate (see, e.g., [1, 4])
$$\Gamma _ { \varphi } = 2 S _ { F F } [ 0 ],$$
where S FF [ ω ] is the noise spectral density of ˆ F , evaluated at zero qubit coupling:
$$S _ { F F } [ \omega ] \equiv \int _ { - \infty } ^ { \infty } d t \, e ^ { i \omega t } \langle \hat { F } ( t ) \hat { F } ( 0 ) \rangle _ { 0 }. \quad \ ( 3 6 )$$
Working in the displaced interaction picture [cf. Eq. (8)], the backaction force operator takes the form:
$$\hat { F } = A \sqrt { \bar { n } _ { 2 } } ( e ^ { i \beta } \hat { d } _ { 2 } + h. c. ) + A \hat { d } _ { 2 } ^ { \dagger } \hat { d } _ { 2 } \equiv \hat { F } _ { \text{L} } + \hat { F } _ { \text{Q} } \ ( 3 7 )$$
We have split the backaction force operator into parts that are linear and quadratic in the ˆ d 2 operators. For a suitably strong cavity2 drive, ¯ n 2 glyph[greatermuch] 1 , the dominant noise contribution will come from ˆ F L ; we thus first study this quantity.
## 1. Linearized backaction and backaction avoidance
Using the linearized Heisenberg-Langevin equations for our system, we can decompose the Fourier-transformed Heisenberg-picture operator ˆ [ F L ω ] as
$$\hat { F } _ { \text{L} } [ \omega ] = \hat { F } _ { \text{L} } ^ { \text{int} } [ \omega ] + \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \left ( f _ { X } [ \omega ] \hat { X } _ { e } [ \omega ] + f _ { P } [ \omega ] \hat { P } _ { e } [ \omega ] \right ) ; \, ( 3 8 )$$
see Eq. (D1) in Appendix D for details. Here, ˆ F int L is the λ 12 -independent contribution to ˆ F L . It describes vacuum noise incident from the cavity2 input port which has not entered cavity1 , and hence has not been amplified by the nonlinear cavity. The remaining terms describe noise contributions emanating from the nonlinear cavity. We have written them in terms of the quadratures of the nonlinear cavity ˆ X e and ˆ P e , as introduced in Sec. II E (cf. Eq. (30a) and (30b)). f X [ ω , f ] P [ ω ] are real coefficients which are independent of the cavity1 susceptibility (cf. Eq. (D1)).
As discussed in Sec. II E, it is only the ˆ X e quadrature which experiences amplification due to the effective parametric interaction; thus, this is the only term in Eq. (38) which describes a diverging, amplified noise contribution near the bifurcation. Eliminating this large noise contribution thus involves tuning parameters such that the coefficient f X [ ω ] = 0 over frequencies of interest. We have in general:
$$\text{lative} \quad f _ { X } [ \omega ] = - \frac { \widetilde { A } } { \sqrt { 2 } } \left [ \chi _ { 2 } ^ { * } [ - \omega ] e ^ { i ( \mu _ { 1 2 } - \nu [ \omega ] ) } + \chi _ { 2 } [ \omega ] e ^ { - i ( \mu _ { 1 2 } - \nu [ \omega ] ) } \right ]$$
Here, the phase µ 12 is the relative phase between the classical cavity amplitudes (cf. Eq. (22)); it determines the effective phase of the linearized cavity-cavity coupling (cf. Eq. (20)). The remaining phase angle ν ω [ ] is
$$\nu [ \omega ] = \phi _ { g } / 2 + \theta _ { e } [ \omega ] / 2 + 3 \pi / 4, \text{ \quad \ \ } ( 4 0 )$$
where φ g is the phase of the effective parametric interaction in Eq. (23), and θ e [ ω ] characterises the rotation which defines the amplified ˆ X e quadrature at each frequency (cf. Eq. (28)). For reasons that will become clear shortly, we focus on the ω = 0 regime. Writing the bare cavity2 susceptibility defined in Eq. (11) as χ 2 [ ω ] = | χ 2 [ ω ] | exp( iφ 2 [ ω ]) , f X [ ω = 0] takes the form
$$f _ { X } [ 0 ] = - \sqrt { 2 } \widetilde { A } \left | \chi _ { 2 } [ 0 ] \right | \, \cos ( \mu _ { 1 2 } - \phi _ { 2 } [ 0 ] - \nu [ 0 ] ). \quad ( 4 1 ) \quad \widetilde { d _ { 2 } ^ { \dagger } } \hat { d _ { 2 } } \right )$$
Therefore, at zero frequency, one can make f X [0] (and hence the largest noise contribution to ˆ F L [ ω ] ) vanish by an appropriate choice of the phase µ 12 ; this phase can in turn be varied by tuning the relative phase δ between the two cavity drives. One needs:
$$\mu _ { 1 2 } - \phi _ { 2 } [ 0 ] - \nu [ 0 ] = ( 2 M + 1 ) \frac { \pi } { 2 }, \ \ M \in \mathbb { Z } \quad ( 4 2 ) \quad \frac { \mu _ { 1 2 } \infty } { 2 }.$$
In this zero-frequency case, when this reduced backaction condition is satisfied, the backaction noise in ˆ F L is
$$S _ { F _ { L } F _ { L } } [ 0 ] \simeq S _ { F _ { L } F _ { L } } ^ { \text{int} } [ 0 ] + S _ { F _ { L } F _ { L } } ^ { N L } [ 0 ], \quad \ \ ( 4 3 ) \quad \text{spec} i \text{v re}$$
$$S _ { F _ { L } F _ { L } } ^ { \text{int} } [ 0 ] = \widetilde { A } ^ { 2 } \kappa _ { 2 } | \chi _ { 2 } | ^ { 2 } & & ( 4 4 ) \quad \text{tribu}$$
$$S _ { F _ { L } F _ { L } } ^ { N L } [ 0 ] = \widetilde { A } ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } | \chi _ { 2 } | ^ { 2 } \kappa _ { 1 } \chi _ { e + } ^ { 2 } + \dots, \quad ( 4 5 ) \quad \text{ woul}$$
see Appendix D for an outline of the full calculation. S int F F L L [0] describes the unamplified contribution of vacuum noise incident on cavity2 , while S NL F F L L [0] describes the contribution of all noise processes involving the nonlinear cavity (including correlations between the two terms in Eq. (38)). This latter contribution is solely due to the non-amplified cavity quadrature (it is just a function of non-diverging susceptibility χ e + , which scales as 1 /κ 1 near the bifurcation), and thus the backaction noise and dephasing is independent of the amplified vacuum noise fluctuations in the nonlinear cavity . We see that careful tuning of the drive phases gives the system a kind of directionality: the nonlinear cavity will amplify the qubit signal, but the qubit will not see amplified vacuum noise emanating from the nonlinear cavity. This protection against backaction is impossible in systems where a qubit is directly, dispersively coupled to a nonlinear cavity, as there is no way to tune the cavity quadrature seen by the qubit; this is why these systems have a backaction far in excess of the quantum limit [19].
We stress that with appropriate parameter choices, enforcing Eq. (42) at ω = 0 will be enough to guarantee a noise suppression over a wide bandwidth. To see this, note that all the frequency dependence in this equation is ultimately related to the frequency dependence of χ 2 [ ω ] , the bare cavity2 susceptibility (cf. Eq. (11)). By choosing a cavity2 drive tone that is far detuned from resonance (i.e. ∆ 2 glyph[greatermuch] κ 2 ), χ 2 [ ω ] will effectively become frequency independent over the amplification bandwidth. As such, ensuring Eq. 42 holds at zero frequency ensures that it holds over this entire bandwidth. Fig. 6 in Appendix E indicates this frequency dependent behaviour and confirms that the zero frequency approximation is valid.
## 2. Quadratic backaction
We now turn to the fluctuations of ˆ F Q , the second term in Eq. (37) which is proportional to the photon number ˆ ˆ d d † 2 2 . While this term is smaller by a factor of ¯ n 2 than the leading contribution, the fact that it is quadratic in field operators implies that it can still contribute significant noise near bifurcation. Furthermore, calculating the autocorrelation of ˆ ˆ d d † 2 2 involves a convolution of ˆ d , d 2 ˆ † 2 correlators, which incorporates noise at all frequencies. The calculation of the various noise components of this term is outlined in section D; in the relevant large gain limit, the dominant contributions to the quadratic backaction can be approximately written as:
$$S _ { F _ { Q } F _ { Q } } [ 0 ] \simeq A ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) _ { \omega = 0, \ \Delta _ { 2 } } ^ { 4 } \frac { \mathcal { G } [ \omega ] ^ { 2 } } { \kappa _ { 1 } ^ { 2 } } \cdot | \chi _ { 2 } [ \omega ] | ^ { 4 } \cdot \Omega [ \omega ], \ ( 4 6 )$$
where G [ ω ] (parametric photon number gain) and | χ 2 [ ω ] | (cavity2 susceptibility) parametrize the nonlinear and linear cavity responses respectively, and Ω[ ω ] is an effective bandwidth. Near ω = 0 and ω = ∆ 2 , and over a frequency range specified by the bandwidth Ω[ ω ] , the nonlinear and linear cavity responses respectively are strongest, indicating a large contribution to the backaction noise. The G 2 dependence here would also occur in a single nonlinear cavity directly coupled to a qubit. While there is no simple tuning possible in the PARI that lets one completely suppress the amplified noise contribution to ˆ F Q , one can strongly reduce the relative importance of ˆ F Q compared to other terms by increasing the cavity2 photon number: S F Q F Q depends on the bare dispersive coupling A and not the dressed ˜ A (cf. Eq. (19)). In the limit where ¯ n 2 →∞ while the dressed dispersive coupling ˜ A is kept fixed, the quadratic backaction formally goes to zero. The PARI system also has additional tunability compared to a single-cavity system which allows a further suppression of this term; for a full discussion, see Appendix D.
## B. Detector response and amplifier forward gain
Having characterized the backaction noise of the PARI detector, we now examine how information on the qubit state appears at the detector output. Referring back to Fig. 1, recall that information about the qubit signal is obtained by measuring the field leaving the nonlinear cavity; this signal will thus benefit from amplification in this cavity. We consider a homodyne measurement, where one measures the quadrature of this output field containing the maximal amount of information on the qubit state. Details on the basics of homodyne measurement and their description can be found in, e.g., Refs. [4, 35]
We first want to understand the signal produced by the qubit, i.e. the average homodyne current associated with the two qubit σ z eigenstates. Note from Eq. (18) that in our displaced frame, the qubit both acts as an effective linear driving force on cavity2 , as well as shifts its frequency. We focus initially on the first effect, which is enhanced by the average
cavity2 photon number ¯ n 2 . Using the effective nonlinear cavity picture developed in Sec. II E, this qubit-induced drive will act as a driving force on both the ˆ X e and ˆ P e nonlinear cavity quadratures; it thus yields new terms in the driving fields in Eqs. (30a), (30b):
$$\hat { X } _ { e } ^ { \text{in} } & \to \hat { X } _ { e } ^ { \text{in} } - \left ( \sqrt { \frac { 2 } { \kappa _ { \text{eff} } } } \, \widetilde { A } \, \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \, | \chi _ { 2 } | \text{Im} \left [ e ^ { i ( \mu _ { 1 2 } + \phi _ { 2 } - \nu ) } \right ] \right ) \hat { \sigma } _ { z } } \quad \text{details} \quad \text{interres} \\ \hat { P } _ { e } ^ { \text{in} } & \to \hat { P } _ { e } ^ { \text{in} } + \left ( \sqrt { \frac { 2 } { \kappa _ { \text{eff} } } } \, \widetilde { A } \, \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \, | \chi _ { 2 } | \text{Re} \left [ e ^ { i ( \mu _ { 1 2 } + \phi _ { 2 } - \nu ) } \right ] \right ) \hat { \sigma } _ { z } } \quad \text{where} \quad \hat { \lambda } \, \cdot \,.$$
The measured homodyne current ˆ I 1 is just proportional to a quadrature of the output field leaving cavity1 , i.e. ˆ I 1 ∝ ( e iφ h ˆ d 1 out , + h.c. ) . For simplicity, we assume in what follows an optimal choice of quadrature, by appropriate choice of the homodyne angle φ h . Using standard input-output theory, we can easily calculate its stationary, average value. Considering the case where we are near bifurcation (and hence have a large parametric photon number gain G , cf. Eq. (32)), we find to leading order
$$\langle \hat { I } _ { 1 } \rangle & \equiv \chi _ { I F } [ 0 ] \langle \hat { \sigma } _ { z } \rangle, \\ \chi _ { I F } [ 0 ] & \simeq \sqrt { 2 } \, \widetilde { A } \, \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \, | \chi _ { 2 } | \, \sqrt { \mathcal { G } } \, \rho _ { e }, \quad \quad ( 4 8 ) \quad \text{ where }$$
where χ IF [0] is the zero-frequency detector response coefficient or 'forward gain' [4], and the angle-dependent prefactor ρ e is given by
$$\rho _ { e } = \sec \theta _ { e } \sin ( \mu _ { 1 2 } + \phi _ { 2 } - \nu + \theta _ { e } ). \quad ( 4 9 ) \quad \frac { \min } { \text{$fmd} }$$
All quantities are at zero frequency. For details of the full calculation, see Appendix E.
As expected, the response of the detector is enhanced by the large parametric gain G glyph[greatermuch] 1 generated when the PARI system is operated near bifurcation. Further, note that tuning the system to satisfy the reduced backaction condition [cf. Eq. (42)] does not make the forward gain vanish . The reduced backaction condition ensures that the qubit is coupled to the nonamplified quadrature ˆ P e of the nonlinear cavity; it thus efficiently drives the orthogonal amplified quadrature ˆ X e , leading to the large, amplified signal.
We have thus far ignored the second effect of the qubit on the linear cavity, namely a dispersive shift of the linear cavity drive detuning ∆ 2 [cf. Eq. (20)]. It turns out that for the case of a strongly detuned linear cavity and weak dispersive coupling so that A glyph[lessmuch] ∆ 2 (parameters indicated in Table II), ∆ 2 ± A produces less than a 1 % change in ∆ 2 . The resulting effect on the gain is small, and so the effect of the nonlinear term in the qubit-detector coupling can be neglected.
## C. Measurement imprecision noise and measurement rate
We now turn to analyzing the intrinsic noise in the output homodyne current, ¯ S II [ ω ] , in the PARI setup; along with the forward gain, this will determine the imprecision of our measurement and the measurement rate (the rate at which information on the qubit state is acquired). The calculation of this intrinsic zero-frequency noise S II [0] (i.e. calculated in the absence of any qubit coupling) follows straightforwardly from the linearized Heisenberg-Langevin equations for our system; details are presented in Appendix E. In the large gain limit of interest, we find to leading order
$$S _ { I I } [ 0 ] \simeq \frac { 1 } { 2 } \kappa _ { \text{eff} } \sec ^ { 2 } \theta _ { e } \, \mathcal { G },$$
where κ eff is the effective nonlinear cavity damping rate defined in Eq. (27). Apart from this renormalized value of κ 1 (which is due to the cavity-cavity interaction), this result has the same general form and dependence on G as for a single Kerr cavity driven near bifurcation [19].
We can now calculate the measurement time τ meas associated with our setup: how long will it take to resolve the qubit signal above the noise in the detector output. For the weak qubit-coupling, linear-response regime we consider, τ meas has the standard definition [4]
$$\frac { 1 } { \tau _ { \text{meas} } } = \Gamma _ { \text{meas} } = \frac { | \chi _ { I F } [ 0 ] | ^ { 2 } } { 2 S _ { I I } [ 0 ] } \equiv \frac { 1 } { 2 } S _ { z z } ^ { - 1 } \quad ( 5 1 )$$
where S II [0] is the intrinsic zero-frequency noise in the measured homodyne current (i.e. in the absence of any coupling to the qubit). In the last inequality, we have introduced the imprecision noise spectral density S zz [0] , which is just the output noise referred back to the qubit.
In the large gain limit, making use of Eqs. (48) and (50), we find
$$\colon \text{full} \quad \Gamma _ { \text{meas} } \simeq \left [ \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } | \chi _ { 2 } | ^ { 2 } \right ] \times \frac { 2 \widetilde { A } ^ { 2 } } { \kappa _ { \text{eff} } } \sin ^ { 2 } ( \mu _ { 1 2 } + \phi _ { 2 } - \nu + \theta _ { e } ) \ ( 5 2 )$$
The nonlinear cavity amplifies both the signal and the noise in the cavity output; as a result, the rate of information gain, Γ meas , is independent of G . This is identical to the case where one directly couples a qubit to a nonlinear cavity [19]. However, unlike this direct coupling case, there is additional tunability in the PARI setup. In particular, the coupling prefactors in Eq. (52) (i.e factor in square brackets) can be tuned to be larger than unity, even if λ 12 is so weak that it does not perturb the bifurcation physics of the nonlinear cavity.
In addition to having a large measurement rate, we also want the sheer magnitude of the output signal to be large enough that the noise of any following amplification stages is irrelevant. It is useful to quantify the size of the output noise via an effective number of thermal quanta ¯ n II : if the cavity were linear and in thermal equilibrium, how hot would it have to be to produce the same amount of output noise? This leads to the definition S II [0] = κ 1 2 (1 + 2¯ n II ) . As both the forward gain | χ IF [0] | 2 and output noise S II [0] scale as G , we are in good shape: ¯ n II ∝ G , and hence, in principle the magnitude of the output noise and signal can be made large enough to make the noise added in following amplification stages insignificant.
## IV. PARAMETER OPTIMIZATION FOR LARGE GAIN, QUANTUM-LIMITED PERFORMANCE
The previous section suggested that the PARI design should allow one to both produce a large-magnitude qubit signal, as well as a small backaction disturbance of the qubit (one that is immune to the amplified fluctuations of the nonlinear cavity). In this section, we show this indeed possible with realistic parameter choices, and also explain the rationale governing these choices.
We start by recalling that the fundamental Heisenberg constraint on the noise of any linear detector implies that there is a minimum possible value for the detector backaction: the backaction dephasing cannot be any smaller than the measurement rate [4]. We thus define the efficiency ratio η meas which characterizes the size of the actual detector backaction compared to this ideal minimum:
$$\frac { 1 } { \eta _ { \text{meas} } } = \Gamma _ { \varphi } / \Gamma _ { \text{meas} } = 4 S _ { z z } S _ { F F } \geq 1 \quad \ \ ( 5 3 ) \quad \ \ T A \, \mathfrak { m }$$
The quantum limit corresponds to achieving η meas = 1 .
## A. Procedure for selecting optimal parameters
In choosing parameters, the first step is to take the relative phase of the cavity drives to fulfill the reduced backaction condition of Eq. (42), which eliminates the contribution of amplified noise to the linear backaction operator ˆ F L . Once this is done, the remaining contributions to the backaction noise come from Eq. (43) (the remaining fluctuations in ˆ F L ) and Eq.(46) (fluctuations in the quadratic backaction operator ˆ F Q ); we begin by analysing the former.
The non-amplified fluctuations in ˆ F L arise from the intrinsic linear cavity backaction and the residual nonlinear cavity backaction. For signal extraction from the nonlinear cavity, the linear cavity backaction represents excess noise not directly tied to any information gain. Ideally, we require the residual nonlinear cavity backaction to be larger than this intrinsic linear cavity noise, so that more information is being extracted from the nonlinear cavity than is leaking out the linear cavity drive port; from Eq. (45), this occurs when the dressed coupling ˜ λ (1) 12 satisfies the constraint:
$$\left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } > \kappa _ { 1 } \kappa _ { 2 } \, \quad \ \ \ ( 5 4 ) \quad \ e a$$
As ¯ n 1 is itself dependent on λ 12 , this is a self-consistent equation for λ 12 . As we work near bifurcation, ¯ n 1 will be large and scaling roughly as κ / 1 (2 √ 3 Λ) [19]. For given values of κ , κ 1 2 and Λ , Eq. (54) constrains the minimum value of λ 12 . This then seems to imply that we should couple the cavities as strongly as possible, thus making ˜ λ (1) 12 large. However, an analysis of the quadratic backaction (cf. Eq. (46)) immediately reveals a problem: the dominant contributions to S F Q F Q depend quartically on the same dressed coupling, and therefore are enhanced more strongly than S NL F F L L when ˜ λ (1) 12 is increased.
TABLE II. Table indicating realistic parameter choices used in Figs. 3, 4, which satisfy the constraints in Eqs. (56a), (56b) as indicated by the lower tables. The cavity drive strengths ¯ a in j , relative drive phase δ , and the nonlinear cavity detuning ∆ 1 form a parameter space where optimal operating points are found via a numerical optimization routine.
| Parameter | Value (MHz) |
|-------------------------------------------------------|-------------------------------------------------------|
| Nonlinear cavity damping, κ 1 | 100 |
| Linear cavity damping, κ 2 , | 30 |
| Linear cavity detuning, ∆ 2 | 170 |
| Intercavity coupling, λ 12 | 1 . 10 |
| Dispersive coupling, A | 1 |
| Kerr constant, Λ | 0 . 005 |
| Nonlinear cavity detuning, ∆ 1 | (see caption) |
| Cavity drive strengths, ¯ a in j | (see caption) |
| Relative drive phase, δ | (see caption) |
| Quantum limited performance constraint | Quantum limited performance constraint |
| κ 2 1 √ G < ( ˜ λ (1) 12 ) 2 < ¯ n 2 (∆ 2 ) 2 G 3 / 2 | κ 2 1 √ G < ( ˜ λ (1) 12 ) 2 < ¯ n 2 (∆ 2 ) 2 G 3 / 2 |
| 0 . 10 < 1 . 14 < 4 . 93 | 0 . 10 < 1 . 14 < 4 . 93 |
| Weak coupling constraints | Weak coupling constraints |
| ˜ λ (2) 12 < 2Λ¯ n 1 , 2 √ Λ¯ n 2 | χ 2 | | ˜ λ (2) 12 < 2Λ¯ n 1 , 2 √ Λ¯ n 2 | χ 2 | |
| 0 . 45 < 0 . 80 , 0 . 74 | 0 . 45 < 0 . 80 , 0 . 74 |
Fortunately, the PARI system provides enough flexibility of parameter choices to overcome this problem. We enforce selfconsistently that both large terms in the quadratic backaction S F Q F Q , near ω = 0 , ∆ 2 , are smaller than the contribution to S F F L L from the nonlinear cavity. The form of each term is characterised in Appendix D; we find that to suppress the quadratic backaction, the following conditions must hold:
$$\begin{array} { c c c c c c c } \quad \cdot & & \quad \\ \quad \text{ity,} & & \quad S ^ { N L } _ { F _ { L } F _ { L } } > S ^ { ( 1 ) } _ { F _ { Q } F _ { Q } } & \Longrightarrow & \left ( \widetilde { \lambda } ^ { ( 1 ) } _ { 1 2 } \right ) ^ { 2 } < \frac { \bar { n } _ { 2 } ( \Delta _ { 2 } ) ^ { 2 } } { \mathcal { G } ^ { 3 / 2 } } \\ \quad \text{the} \\ \quad \text{ing} & & \quad S ^ { N L } _ { F _ { L } F _ { L } } > S ^ { ( 2 ) } _ { F _ { Q } F _ { Q } } & \Longrightarrow & \left ( \widetilde { \lambda } ^ { ( 1 ) } _ { 1 2 } \right ) ^ { 2 } < \bar { n } _ { 2 } ( \Delta _ { 2 } ) ^ { 2 } \left ( \frac { \kappa _ { 2 } } { \kappa _ { 1 } } \right ) ^ { 3 } & ( 5 5 ) \\ \quad \dots & & \end{array}$$
where S (1 2) , F Q F Q are the contributions to quadratic backaction near ω = 0 , ∆ 2 respectively (cf. Eq. (46)). These constraints are intuitively clear; large ¯ n 2 reduces the effect of the ˆ ˆ d d † 2 2 operator in the qubit-cavity coupling relative to the linearised backaction operator, and strong linear cavity detuning ensures the two cavity resonances are well-separated in frequency space. Both these conditions reduce the effect of the quadratic backaction, thereby enabling a stronger dressed intercavity coupling ˜ λ (1) 12 . This of course is beneficial for having the nonlinear cavity backaction be the dominant noise source, as described in the discussion following Eq. (54).
The final challenge then is to satisfy the above constraints with experimentally feasible parameter values, allowing close to quantum-limited performance while still being within the weak coupling regime and hence having large gain G . Focusing on realistic parameter choices and requiring weak κ 2 to suppress the imaginary modification of the Kerr constant (cf.
Sec. II F), we enforce κ 2 glyph[similarequal] κ / 1 √ G . This choice makes both conditions in Eq. (55) equivalent; combining the conditions for quantum limited performance in Eqs. (54), (55), and for the weak coupling regime in Eqs. (33a), (33b), we have:
$$\frac { \kappa _ { 1 } ^ { 2 } } { \sqrt { \mathcal { G } } } < \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } < \frac { \bar { n } _ { 2 } ( \Delta _ { 2 } ) ^ { 2 } } { \mathcal { G } ^ { 3 / 2 } } \, \begin{array} { c } \quad & \text{where} \\ \text{$56a$} \\ \text{$\text{$the\colon$} \end{array}.$$
$$\widetilde { \lambda } _ { 1 2 } ^ { ( 2 ) } < 2 \Lambda \bar { n } _ { 1 } \,, \, 2 \sqrt { \frac { \Lambda \bar { n } _ { 2 } } { | \chi _ { 2 } | } } \quad \ ( 5 6 b ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
We reiterate that these conditions are to be satisfied selfconsistently. The lower and upper boundaries of inequality (56a) are where S NL F F L L is comparable to the S int F F L L and S F Q F Q respectively; for ideal performance, we require ˜ λ (1) 12 to be not too close to either boundary, so that S NL F F L L is the dominant noise contribution. We will present an example parameter set that satisfies these constraints in the next section.
To summarize, near quantum-limited PARI performance requires (i) tuning the relative drive phase δ to satisfy the reduced backaction condition of Eq. (42), and (ii) choosing a cavity-cavity coupling λ 12 large enough to ensure that the residual nonlinear cavity backaction S F F L L overcomes the intrinsic linear cavity noise, but also not too large , so that the quadratic backaction remains small in comparison, while ensuring the nonlinear cavity is not too strongly modified. The balance required forces ˜ λ (1 2) , 12 , ˜ λ (2) 12 to satisfy Eqs. (56a), (56b) respectively.
These constraints allow us to see the advantage of weak nonlinearities in this setup. As mentioned earlier, large ¯ n 2 values are beneficial for quantum-limited performance, as they suppress the quadratic backaction operator. However, ¯ n 2 appears in the dominant modification of the nonlinear cavity bifurcation (cf. Eq. (56b)), and cannot be increased indefinitely, unless λ 12 is simultaneously decreased so that ˜ λ (2) 12 is held fixed. This, however, raises another potential problem: weakening λ 12 suppresses the gain and the measurement rate, and reduces S NL F F L L relative to S int F F L L . The way out is to ensure the dressed coupling ˜ λ (1) 12 is held fixed while λ 12 is decreased; reducing the Kerr nonlinearity Λ to increase ¯ n 1 achieves precisely this effect.
## B. Optimal performance with realistic parameter values
We now implement the above guidelines for choosing parameters, focusing on experimentally accessible values that yield near quantum-limited performance with parametric photon number gains G (defined in Eq. (32)) of O (100) , or O (20 dB) ; corresponding results for the gain, measurement rate and noise are shown in Figs. 3 and 4.
As discussed, one ideally needs a large cavity1 photon number ¯ n 1 , which requires a relatively weak cavity1 Kerr constant. We thus take a value Λ = 5 × 10 -5 κ 1 . Note that for standard lumped element resonators based on a shunted
SQUID, the strength of the Kerr nonlinearity is given by
$$\Lambda / \kappa _ { 1 } = \frac { \pi } { 2 } \frac { R } { R _ { K } },$$
where R is the effective shunt resistance , and R K = h/e 2 is the quantum of resistance. For typical setups with R ∼ 50 Ω , Kerr nonlinearities on the order of Λ ∼ 10 -2 κ 1 are standard [31]. Our chosen value of Λ /κ thus requires this nonlinearity to be weakened, or 'diluted'. The utility of such weakened nonlinearities, and methods for achieving this, have recently garnered attention [36]. One could for example introduce an additional linear inductance L 0 in series with the SQUID (Josephson inductance L J ). This effectively reduces Λ /κ by a factor of p 3 , where the participation ratio p = L / L J ( 0 + L J ) can be made small by choosing an appropriately large L 0 (see, e.g. Ref. [36]). Our chosen Λ /κ thus requires p glyph[similarequal] 0 1 . . One must also be careful that the weakened nonlinearity (and consequent larger photon numbers) do not cause higher nonlinearities in the SQUID potential to become relevant. This condition results in the constraint Qp glyph[greaterorsimilar] 5 , where Q is the nonlinear cavity quality factor [3740]. Using the parameters in Table II and taking a cavity1 resonance frequency ω c 1 = 6 GHz yields Q = 60 and p glyph[similarequal] 0 1 . . One thus satisfies the requirement on Qp , while at the same time having a not too-large cavity2 resonance frequency ω c 2 ∼ 2 ω c 1 ∼ 12 GHz. Finally, we note that weak nonlinearities can also be achieved by replacing the single SQUID with an array of SQUIDs, or by using transmissionline resonators (see Ref. [36, 41]).
Moving on to the remaining parameters, recall that optimal performance occurs when κ 2 ∼ κ / 1 √ G ; we take κ 2 = 0 3 . κ 1 . We then implement the optimization conditions. The resulting parameter choices are all shown in Table II. We take values that are experimentally realistic; more experimentallychallenging choices of parameters would lead to even more optimal performance. The nonlinear cavity drive strength ¯ a in 1 and detuning ∆ 1 are chosen to be close enough to the bifurcation to achieve the required parametric gain. A first order perturbation approach narrows the region in phase space where this bifurcation exists; a numerical optimization routine in ¯ a in 1 -∆ 1 -δ space is then implemented to tune these parameters to obtain closest-to-desired detector performance.
In Fig. 3, we plot both the parametric gain G (dashed blue), as well as the inverse efficiency ratio, 1 /η meas (solid red), both as a function of the nonlinear cavity detuning ∆ 1 . Wefind that as predicted, one can both achieve a large effective parametric gain of ∼ 20 dB (implying a large output signal), and have a backaction noise which is approximately a factor of 1 75 . more than the minimal quantum limited value. The corresponding efficiency is η meas glyph[similarequal] 0 57 . . Had one directly coupled the qubit to the nonlinear cavity, the backaction would exceed the quantum limit by a large factor ∼ 100 .
In Fig. 4 we plot the measurement rate Γ meas versus ∆ 1 for the same parameter set. We focus on the weak dispersive coupling regime, and take A = 0 01 . κ 1 . It is possible to obtain measurement rates on the order of 10 MHz with a nearly quantum-limited detector.
We note that the ability to reach the quantum limit on mea-
FIG. 3. Plot of the zero frequency parametric gain G [cf. Eq. (32)] (dashed blue, left-hand axis) and the inverse efficiency ratio 1 /η meas (cf. Eq. (53)) (solid red, right hand log axis), as a function of the nonlinear cavity detuning ∆ 1 . For optimal ∆ 1 glyph[similarequal] -0 83 . κ 1 , we obtain 1 /η meas glyph[similarequal] 1 75 . , with G glyph[similarequal] 100 . The drive parameters are all fixed for this plot: (¯ a in 1 ) 2 /κ 1 = (62 2) . 2 , (¯ a in 2 ) 2 /κ 1 = (45 5) . 2 , δ = 0 40 . , ¯ n 1 ∼ 8000 , ¯ n 2 ∼ 1200 . The dashed green curve with intermediate minimal backaction-imprecision product corresponds to the limit where ¯ n 2 → ∞ while ˜ A and ˜ λ (2) 12 are kept fixed; in this limit, the quadratic backaction S F Q F Q (cf. Eq. (46)) does not contribute. The dot-dashed black curve is the inverse efficiency where we also take κ 2 → 0 , thus suppressing the intrinsic linear cavity backaction S int FF (cf. Eq. (45)). In this limit, one can exactly reach the quantum limit.
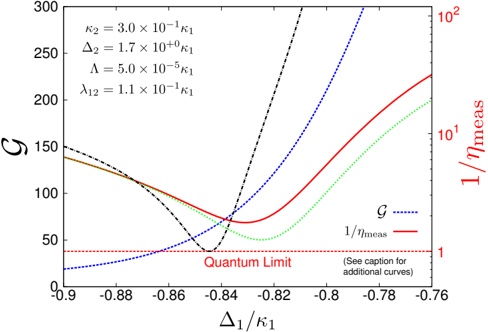
surement is restricted by the non-zero intrinsic linear cavity backaction S int F F L L and the second order backaction S F Q F Q . To see this, we include in Fig. 3 the dashed green curve showing the inverse efficiency ratio 1 /η meas with S F Q F Q taken to zero ( ¯ n 2 → ∞ , ˜ A held finite). Also included is the dot-dashed black curve showing this product with S int F F L L also excluded ( κ 2 → 0 ), indicating precisely quantum-limited measurement if both noise terms can be suppressed. The relative contributions of each term depends on which boundary of Eq. (56a) the dressed coupling ˜ λ (1) 12 is closer to.
As mentioned earlier, weak Kerr nonlinearities are advantageous for optimal PARI performance. Using a stronger value of Λ limits the cavity intensities ¯ n j , hence making the quadratic backaction more important. However, the multiple parameters in the PARI provide a way out; adjusting the linear cavity detuning ∆ 2 allows us to suppress S F Q F Q , albeit at the cost of a reduced measurement rate. In Fig. 8 in Appendix F, we include an analogous plot to Fig. 3, with a stronger nonlinearity, Λ = 10 -4 κ 1 ; we obtain η meas glyph[similarequal] 0 5 . with Γ meas ∼ 1 MHz .
We conclude this section by mentioning the freedom of parameter choices in the PARI scheme, even under the constraints of Eqs. (56a), (56b). The ability to tune the relative drive phase δ means that there exist multiple parameter sets allowing optimal PARI performance. This is explicitly shown in Figs. 7 (a), (b) in Appendix F, where 1 /η meas and G are analyzed in ∆ 1 -δ space; a manifold of optimal operating parameters can clearly be seen to exist.
FIG. 4. Plot of the zero frequency measurement rate Γ meas (dashed blue, left-hand axis) and the inverse efficiency ratio 1 /η meas (solid red, right hand log axis), as a function of the nonlinear cavity detuning ∆ 1 . For optimal ∆ = 1 -0 831 . , we have 1 /η meas glyph[similarequal] 1 75 . and Γ meas glyph[similarequal] 10 MHz . The drive parameters are the same as for Fig. 3: (¯ a in 1 ) 2 /κ 1 = (62 2) . 2 , (¯ a in 2 ) 2 /κ 1 = (45 5) . 2 , δ = 0 40 . , ¯ n 1 ∼ 8000 , ¯ n 2 ∼ 1200 . We take κ 1 = 100 MHz to compute the measurement rate, with the dispersive coupling strength A = 1 MHz; the choice for A is justified in the next section.
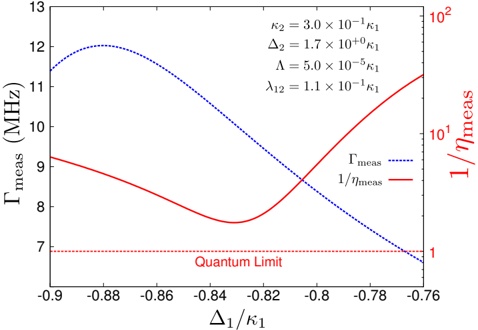
## C. Comparison to conventional circulator-based setup
The parametric photon number gain G (cf. Eq. (32)) allows a comparison of the amplification performance of the PARI scheme to that of conventional qubit-detector-amplifier setups. It is also useful to develop a meaningful way to compare the noise performance of both schemes in a common framework.
For the conventional setup, the linear cavity output signal is quantum-limited, but the necessary following amplification stage adds imprecision noise that causes deviations from ideal performance. Fortunately, the qubit is protected from additional backaction due to the use of circulators, and so the backaction noise after amplification, S FF , is unchanged from its quantum-limited value. The amplifier boosts the output signal but also makes it noisier; this added noise then modifies the output signal imprecision noise S zz to κ 1 2 (1 + 2¯ n add ) (for no noise added by the following amplifier, ¯ n add = 0 and S zz is unchanged). If, following amplification, the backactionimprecision product deviates from its quantum-limited value by a factor of x , then attributing this deviation solely to an increase in the imprecision noise, we can write S zz = x κ 1 2 ≡ κ 1 2 (1 + 2¯ n add ) , so that ¯ n add = ( x -1) / 2 . For the parameters used in Figs. 3, 4, we find x glyph[similarequal] 1 75 . , and the PARI noise performance is therefore equivalent to that of a standard qubit-cavity-amplifier setup where the paramp stage adds ¯ n add glyph[similarequal] 0 375 . quanta of noise.
FIG. 5. Plot of 〈 ∆ I 1 〉 (cf. Eq. (59)) against the dispersive coupling strength A . We see that for A ≤ 0 01 . κ 1 , the system response is approximately linear in A and the results of our analysis hold. We choose a value of A = 0 01 . κ 1 = 1 MHzfor Fig. 4 to operate within this linear regime while having a fast measurement rate.
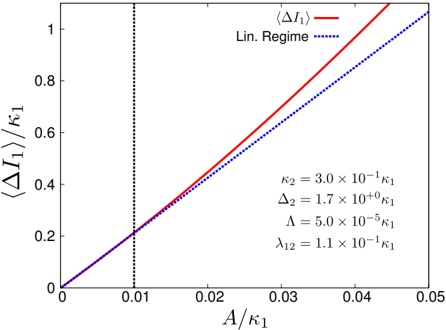
## D. Validity of linear response theory
Our analysis assumes operation of the PARI in the limit of weak dispersive coupling, so that the detector can be treated in the linear response regime. It is important to determine whether the parameter choices used in Figs. 3, 4 in fact allow the detector response to remain linear in the dispersive coupling strength A . A standard approach is to include the exact qubit-cavity dispersive coupling at the level of the classical equations; this coupling leads to a qubit state dependent shift of the linear cavity frequency by ± A , for ˆ σ z = {↑ ↓} , = { 1 , - } 1 respectively. We can then compute a classical cavity 1 output homodyne current that knows about A :
$$\langle \hat { I } _ { 1 \sigma _ { z } } \rangle ( A ) = \frac { \kappa _ { 1 } } { 2 } \left ( e ^ { i \phi _ { h } } \alpha _ { 1 \sigma _ { z } } ( A ) + h. c. \right ) \quad ( 5 8 ) \quad \text{systo}$$
The difference between the currents for the two possible states,
$$\langle \Delta I _ { 1 } \rangle = \langle \hat { I } _ { 1 \uparrow } \rangle - \langle \hat { I } _ { 1 \downarrow } \rangle \quad \quad ( 5 9 ) \quad \text{wh}$$
measures how well the detector output discriminates between these states; it is thus a measure of the detector response as a function of A . We plot 〈 ∆ I 1 〉 against A in Fig. 5 for the same parameters as Figs. 3, 4. For this optimal parameter set, choosing dispersive coupling strengths A glyph[lessorsimilar] 1 MHz (for κ 1 = 100 MHz) allows a linear detector response, and our analysis can be safely applied.
## V. CONCLUSIONS
In this paper, we have detailed the theory of a two-cavity amplifier for qubit state measurement in the linear response regime. The setup, where the linear cavity housing the qubit is coupled directly to the nonlinear cavity used for measurement, can be mapped to a single modified nonlinear cavity coupled to the qubit via a tunable coupling. Adhering to a weak intercavity coupling regime ensures retention of the nonlinear cavity's bifurcation, and hence a large amplifier gain. We find further that the linear cavity's response modifies the amplifier's properties. Crucially, the modified qubit-cavity coupling can be tuned to shield the qubit from linear measurement backaction, while the multiple parameter choices allow suppressing the quadratic backaction, all while preserving the large gain. Therefore, quantum-limited qubit state measurement that escapes a single nonlinear cavity detector within weak coupling is possible with the PARI device.
## VI. ACKNOWLEDGEMENTS
We thank Andrew Eddins, David Toyli, and Eli-Levenson Falk for many useful discussions. This work was supported by NSERC and the Army Research Office under Grant #: W911NF-14-1-0078.
## Appendix A: Derivation of intercavity coupling Hamiltonian
For the setup shown in Fig. 1 (b), the Josephson energy of the nonlinear circuit's SQUID can be written in terms of the flux threading the SQUID loop,
$$\hat { \Phi } _ { \text{ext} } = \Phi _ { B } + M \hat { I } _ { 2 } \text{ \quad \ \ } ( A 1 )$$
where Φ B is a static flux bias. The second term contains the contribution to the flux due to the coupling with the linear cavity, and is proportional to the current I 2 flowing in the linear resonator. M is the mutual inductance of the coupled cavity system. The physical Hamiltonian of the nonlinear cavity in Fig. 1 (b) is therefore:
$$\hat { H } _ { 1 } ^ { s y s } = \frac { \hat { Q } _ { 1 } ^ { 2 } } { 2 C _ { 1 } } - E _ { J } [ \hat { \Phi } _ { \text{ext} } ] \, \cos \left ( 2 \pi \frac { \hat { \Phi } _ { 1 } } { \Phi _ { 0 } } \right ) \quad ( A 2 )$$
where ˆ Φ ˆ , Q are the canonical coordinates describing the nonlinear cavity with shunt capacitance C 1 , and Φ 0 = h/ e 2 is the magnetic flux quantum. The first term includes the capacitive energy of the circuit, while the second is the Josephson energy term providing the nonlinearity and the intercavity coupling. This expression can be simplified via Taylor expansion, keeping terms up to and including ˆ Φ 4 1 , ignoring constant terms and the term proportional only to ˆ I 2 (these are accounted for in the total drive on the linear cavity). As a result, we obtain the quadratic- and quartic-inˆ Φ 1 terms that form the nonlinear cavity Hamiltonian with a Kerr type nonlinearity, as is standard, together with a term depending on both Φ 1 and ˆ I 2 ; we focus on this intercavity coupling term:
$$\hat { H } _ { 1 2 } = \left \{ \frac { M } { 2 } \left ( \frac { 2 \pi } { \Phi _ { 0 } } \right ) ^ { 2 } \frac { d E _ { J } } { d \Phi _ { e x t } } \Big | _ { \Phi _ { B } } \right \} \hat { I } _ { 2 } \hat { \Phi } _ { 1 } ^ { 2 } \quad ( A 3 )$$
To generalize and simplify the analysis, we now introduce the usual creation and annihilation operators for both cavities,
$$\hat { a } _ { j } = & \frac { 1 } { \sqrt { 2 \hbar { L } _ { j } \omega _ { c j } } } \hat { \Phi } _ { j } + i \frac { 1 } { \sqrt { 2 \hbar { C } _ { j } \omega _ { c j } } } \hat { Q } _ { j } \\ \hat { a } _ { j } ^ { \dagger } = & \frac { 1 } { \sqrt { 2 \hbar { L } _ { j } \omega _ { c j } } } \hat { \Phi } _ { j } - i \frac { 1 } { \sqrt { 2 \hbar { C } _ { j } \omega _ { c j } } } \hat { Q } _ { j } \quad \ ( A 4 ) \quad \text{The}$$
where ω cj = 1 / √ L C j j is the natural frequency of cavity j ( j = 1 2 , ). Using the fact that ˆ I 2 = ˆ Φ 2 /L 2 , we can rewrite the intercavity coupling term in Eq. (A3) in terms of creation and annihilation operators to get the form written in Eq. (4). From there, the intercavity coupling strength λ 12 can be extracted in terms of physical quantities,
$$\lambda _ { 1 2 } = 2 \omega _ { c 1 } \sqrt { \$$
To obtain a numerical estimate, we use the explicit form for the Josephson energy E J [Φ] = E 0 ∣ ∣ ∣ cos ( π Φ Φ 0 )∣ ∣ ∣ , and rewrite L 2 in terms of the characteristic impedance Z 2 = √ L /C 2 2 and ω c 2 , hence simplifying the expression for λ 12 ,
$$\lambda _ { 1 2 } & = \left [ M \cdot ( \omega _ {$$
i where R K = h/e 2 = 2Φ 0 /e is the quantum of resistance. Taking ω c 1 = (2 π )6 GHz, ω c 2 = (2 π )12 GHz, choosing Z 2 glyph[similarequal] Z 0 , where Z 0 is the impedance of free space, and noting that the angular factor will be O (1) for the static bias fluxes used in such setups, we obtain,
$$\lambda _ { 1 2 } \sim \left ( \frac { M } { p H } \$$
From the considered parameter choices (cf. Table II), we have a value of λ 12 glyph[similarequal] 1 1 . MHz, which would correspond to a mutual inductance M glyph[similarequal] 11 pH .
## Appendix B: Classical equations of motion
We consider the full Heisenberg equations for the two cavities, Eq. (6), and compute the classical equations of motion assuming a steady state coherent solution of the form indicated in Eq. (8), without the quantum operators. Imposing the driving frequency condition [cf. Eq. (5)] followed by a rotating wave approximation allows one to easily obtain the following classical equations of motion for the nonlinear and linear cavities respectively:
$$\begin{array} {$$
The second equation can be used to eliminate α 2 to obtain a complex nonlinear equation for α 1 ,
$$&, \quad \text{comp.} \lambda \text{numeric equation} \, \in$$
The first line in the equation above is just the classical equation of motion for an individual nonlinear cavity, while the second line represents the modifications due to the coupling to the linear cavity. We can rewrite the modifications proportional to λ 2 12 as changing the Kerr constant,
$$\underset { \text{in} } { \text{m} } \quad \alpha _ { 1 } \left [ - i ( \Delta _ { 1 } + 2 \widetilde { \Lambda } | \alpha _ { 1 } | ^ { 2 } ) + \kappa _ { 1 } / 2 \right ] - i \eta \alpha _ { 1 } ^ { * } = - \sqrt { \kappa _ { 1 } } \, \bar { a } _ { 1 } ^ { \text{in} }$$
where the modified Kerr constant ˜ Λ is as defined in Eq. (10), and the emergent parametric driving strength η is as defined in Eq. (12). Eq. (B2) mixes α 1 and α ∗ 1 , so that the phase of α 1 plays an important role. However, we now note that it is possible to write down the above equation and its complex conjugate as a matrix system:
$$\overline { \mathcal { C } _ { 2 } } \quad \begin{bmatrix} \kappa _ { 1 } / 2 - i \zeta & - i \eta \\ i \eta ^ { * } & \kappa _ { 1 } / 2 + i \zeta ^ { * } \end{bmatrix} \begin{pmatrix} \alpha _ { 1 } \\ \alpha _ { 1 } ^ { * } \end{pmatrix} = - \sqrt { \kappa _ { 1 } } \begin{pmatrix} \bar { a } _ { 1 } ^ { \text{in} } \\ \bar { a } _ { 1 } ^ { \text{in} } \end{pmatrix} \quad \text{(B4)}$$
where ζ is given by
$$\zeta = \Delta _ { 1 } + 2 \widetilde { \Lambda } | \alpha _ { 1 } | ^ { 2 }$$
Inverting the 2-by-2 matrix above allows an expression for α 1 that does not include explicit reference to its phase; squaring this expression allows one to obtain Eq. (13). The equation can be solved numerically for the nonlinear cavity photon number profiles indicated in Fig. 2.
The purely real equation is also more tractable for a perturbative expansion in the weak intercavity coupling strength. We expand the detuning, drive strength, and nonlinear cavity occupation around the unmodified nonlinear cavity bifurcation (∆ 1 0 , , a ¯ in 1 0 , ) (where dn /d ¯ 1 ∆ 1 →∞ ) [19],
$$\lambda _ { 1, 0 / } \, \stackrel { \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \\ \Delta _ { 1 } & = \Delta _ { 1, 0 } + \frac { \lambda _ { 1 2 } } { \kappa _ { 1 } } \cdot \Delta _ { 1, 1 } \\ \bar { a } _ { 1 } ^ { \text{in} } & = \bar { a } _ { 1, 0 } ^ { \text{in} } + \frac { \lambda _ { 1 2 } } { \kappa _ { 1 } } \cdot \bar { a } _ { 1, 1 } ^ { \text{in} } \\ \bar { n } _ { 1 } & = \bar { n } _ { 1, 0 } + \frac { \lambda _ { 1 2 } } { \kappa _ { 1 } } \cdot \bar { n } _ { 1, 1 } \quad \quad ( B 6 ) \\ \ n \, & \text{the influence use income that } \Lambda \,. \, \bar { a } ^ { \text{in} } \quad \bar { n } \,.$$
To retain the bifurcation, we impose that ∆ 1 1 , , ¯ a in 1 1 , , ¯ n 1 1 , be chosen such that the O λ ( 12 ) modifications to both the classical nonlinear equation and the diverging derivative at bifurcation dn /d ¯ 1 ∆ 1 , vanish. This yields a modified set of detuning and driving strengths describing the new position of the bifurcation:
$$& \text{bifurcation} \colon \\ \alpha _ { 2 } \alpha _ { 1 } ^ { * } & \Delta _ { 1 } = \Delta _ { 1, 0 } + \lambda _ { 1 2 } \sqrt { \kappa _ { 2 } } \, \bar { a } _ { 2 } ^ { \text{in} } | \chi _ { 2 } | \left [ \cos ( \delta + \phi _ { 2 } ) + \sqrt { 3 } \sin ( \delta + \phi _ { 2 } ) \right ] \\ \frac { \lambda _ { 1 2 } } { 2 } \alpha _ { 1 } ^ { 2 } & \bar { a } _ { 1 } ^ { \text{in} } = \bar { a } _ { 1, 0 } ^ { \text{in} } + \lambda _ { 1 2 } \sqrt { \kappa _ { 2 } } \, \bar { a } _ { 2 } ^ { \text{in} } \, | \chi _ { 2 } | \left [ \sin ( \delta + \phi _ { 2 } ) \left ( \sqrt { 3 } / 2 \Lambda \right ) ^ { 1 / 2 } \right ] \\ ( B 1 ) &$$
where φ 2 is defined via χ 2 = | χ 2 | exp( iφ 2 ) as before. An important observation - borne out by the numerics - is that the critical detuning and driving strength values are affected by the relative drive phase δ in particular, indicating that tuning δ nontrivially modifies the bifurcation physics.
## Appendix C: Effective nonlinear cavity
The set of four coupled Heisenberg equations of motion in the displaced frame, Eqs. (15), form a four-dimensional system. It is clearest to solve this system by expressing it in the canonical quadrature basis; this transform is carried out using
Eq. (C1) is also used to transform the input noise operators ˆ ξ j to the canonical basis, with the replacements ( ˆ d , d j ˆ ) † j → ( ˆ ξ , ξ j ˆ ) † j , (ˆ x , p j ˆ ) j → (ˆ x in j , p ˆ in j ) . Following this, the full fourdimensional system in the canonical basis can be written in Fourier space as,
$$( i \omega 1 + \mathbf M _ { c } ) \begin{pmatrix} \hat { x } _ { 1 } [ \omega ] \\ \hat { p } _ { 1 } [ \omega ] \\ \hat { x } _ { 2 } [ \omega ] \\ \hat { p } _ { 2 } [ \omega ] \end{pmatrix} = \begin{pmatrix} \sqrt { \kappa _ { 1 } } \, \hat { x } _ { 1 } ^ { \text{in} } [ \omega ] \\ \sqrt { \kappa _ { 1 } } \, \hat { p } _ { 1 } ^ { \text{in} } [ \omega ] \\ \sqrt { \kappa _ { 2 } } \, \hat { x } _ { 2 } ^ { \text{in} } [ \omega ] \\ \sqrt { \kappa _ { 2 } } \, \hat { p } _ { 2 } ^ { \text{in} } [ \omega ] \end{pmatrix} + \sqrt { 2 } \begin{pmatrix} 0 \\ - \cos \left ( \frac { \phi _ { x } } { 2 } + \frac { 3 \pi } { 4 } \right ) \\ \sin \left ( \frac { \phi _ { x } } { 2 } + \frac { 3 \pi } { 4 } \right ) \end{pmatrix} \hat { B } [ \omega ]$$
Here ˆ [ B ω ] = ˜ Aσ ˆ [ z ω ] describes the qubit's frequencydependent driving force on the linear cavity via the linearised dispersive coupling, and the susceptibility matrix M c is:
The off-diagonal matrices - the cross-terms - describe the intercavity coupling; in particular, these appear in the form of an effective rotation defined by the matrix R ( θ ) :
$$\mathbf M _ { c } = \begin{bmatrix} \mathbf M _ { 1 } & - \lambda _ { 1 2 } \sqrt { \bar { n } _ { 1 } } \, \mathbf R ( - \mu _ { 1 2 } - \pi / 2 ) \\ \lambda _ { 1 2 } \sqrt { \bar { n } _ { 1 } } \, \mathbf R ( \mu _ { 1 2 } + \pi / 2 ) & \mathbf M _ { 2 } \\ \quad & ( C 3 ) \\ \text{where the nonlinear cavitv response matrix } \mathbf M. \text{ and linear} \end{bmatrix} \quad \mathbf R ( \theta$$
where the nonlinear cavity response matrix M 1 and linear cavity response matrix M 2 take the forms:
$$M _ { 1 } = \begin{bmatrix} g _ { \text{eff} } - \frac { \kappa _ { 1 } } { 2 } & - \widetilde { \Delta } _ { 1 } \\ \widetilde { \Delta } _ { 1 } & - g _ { \text{eff} } - \frac { \kappa _ { 1 } } { 2 } \end{bmatrix}, \, M _ { 2 } = \begin{bmatrix} - \frac { \kappa _ { 2 } } { 2 } & - \Delta _ { 2 } \\ \Delta _ { 2 } & - \frac { \kappa _ { 2 } } { 2 } \end{bmatrix} \quad \begin{array} { c } \text{The $r$} \\ \text{Eq. (2)} \\ \text{total} \\ \text{to exp} \\ \text{aratel} \vdots \end{array}$$
The rotation is characterised by the angle µ 12 defined in Eq. (22). It is convenient to use the block matrix structure to expand Eq. (C2) into equations for both cavity modes separately:
$$( i \omega 1 + \mathbf M _ { 1 } ) \begin{pmatrix} \hat { x } _ { 1 } [ \omega ] \\ \hat { p } _ { 1 } [ \omega ] \end{pmatrix} - \lambda _ { 1 2 } \sqrt { \bar { n } _ { 1 } } \, \mathbf R \, ( - \mu _ { 1 2 } - \pi / 2 ) \begin{pmatrix} \hat { x } _ { 2 } [ \omega ] \\ \hat { p } _ { 2 } [ \omega ] \end{pmatrix} = \sqrt { \kappa _ { 1 } } \begin{pmatrix} \hat { x } _ { 1 } ^ { \infty } [ \omega ] \\ \hat { p } _ { 1 } ^ { \infty } [ \omega ] \end{pmatrix}$$
$$( i \omega 1 + \mathbf M _ { 2 } ) \begin{pmatrix} \hat { x } _ { 2 } [ \omega ] \\ \hat { p } _ { 2 } [ \omega ] \end{pmatrix} + \lambda _ { 1 2 } \sqrt { \frac { \cdot } { n } } _ { 1 } \mathbf R \left ( \mu _ { 1 2 } + \pi / 2 \right ) \begin{pmatrix} \dot { x } _ { 1 } [ \omega ] \\ \hat { p } _ { 1 } [ \omega ] \end{pmatrix} = \sqrt { \kappa _ { 2 } } \begin{pmatrix} \dot { x } _ { 2 } ^ { \infty } [ \omega ] \\ \hat { p } _ { 2 } ^ { \infty } [ \omega ] \end{pmatrix}$$
Note that we ignore the coupling to the qubit for the moment for clarity. A crucial part of our analysis involves solving Eq. (C6b) for the linear cavity quadratures and substituting the results into Eq. (C6a), to obtain a set of equations for the cavity-1 quadratures only. We thus obtain Eq. (24), an effec- tive two-dimensional system with the linear cavity eliminated:
$$\begin{pmatrix} \hat { x } _ { 1 } [ \omega ] \\ \hat { p } _ { 1 } [ \omega ] \end{pmatrix} = \mathbf M _ { \text{eff} } ^ { - 1 } [ \omega ] \begin{pmatrix} \hat { x } _ { e } ^ { \text{in} } [ \omega ] \\ \hat { p } _ { e } ^ { \text{in} } [ \omega ] \end{pmatrix} \quad \quad ( C 7 )$$
The effective response matrix M eff [ ω ] can be written in terms of the original nonlinear cavity response matrix M 1 together
$$\stackrel { \bullet } { 3 } \right ] _ { \text{or} } \quad \mathbf R ( \theta ) = \begin{bmatrix} \cos \theta & \sin \theta \\ - \sin \theta & \cos \theta \end{bmatrix} ; \quad \mathbf R ^ { - 1 } ( \theta ) = \mathbf R ( - \theta ) \quad ( \mathbf C 5 )$$
the matrix T c ,
$$\begin{smallmatrix} \text{the} \\ \text{by} \\ \hat { g } \, \delta \\ \hat { \hat { p } } _ { 1 } \\ \hat { \hat { x } } _ { 2 } \\ \hat { \hat { p } } _ { 2 } \end{smallmatrix} = \text{T} _ { c } \begin{pmatrix} \hat { d } _ { 1 } \\ \hat { d } _ { 1 } ^ { \dagger } \\ \hat { d } _ { 2 } ^ { \dagger } \end{pmatrix} = \frac { 1 } { \sqrt { 2 } } \begin{bmatrix} 1 & 1 & 0 & 0 \\ - i & i & 0 & 0 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & - i & i \end{bmatrix} \begin{pmatrix} \hat { d } _ { 1 } \\ \hat { d } _ { 1 } ^ { \dagger } \\ \hat { d } _ { 2 } ^ { \dagger } \end{bmatrix} \quad ( C 1 )$$
with the self-energy matrix introduced in Eq. (25),
$$\begin{array} { c c c c c } \quad \,.. &. \cdot \cdot \cdot \cdot \\ M _ { \text{eff} } [ \omega ] \equiv \mathbf M _ { 1 } [ \omega ] - i \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } \Sigma [ \omega ] \\ \Sigma [ \omega ] = \frac { i } { 2 } \begin{bmatrix} ( \chi _ { 2 } [ \omega ] + \chi _ { 2 } ^ { * } [ - \omega ] ) & i ( \chi _ { 2 } [ \omega ] - \chi _ { 2 } ^ { * } [ - \omega ] ) \\ - i ( \chi _ { 2 } [ \omega ] - \chi _ { 2 } ^ { * } [ - \omega ] ) & ( \chi _ { 2 } [ \omega ] + \chi _ { 2 } ^ { * } [ - \omega ] ) \end{bmatrix}$$
where the full linear cavity susceptibility takes the form
$$\chi _ { 2 } [ \omega ] = \left ( - i \omega + \kappa _ { 2 } / 2 \pm i \Delta _ { 2 } \right ) ^ { - 1 } \quad \text{(C9)}$$
and M 2 [ ω ] = iω 1 + M M 2 . eff [ ω ] is given explicitly by,
$$\underbrace { \mathbf M _ { \text{eff} } [ \omega ] = \begin{bmatrix} g _ { \text{eff} } - \frac { \kappa _ { \text{eff} } } { 2 } [ \omega ] & - \widetilde { \Delta } _ { \text{eff} } [ \omega ] \\ \widetilde { \Delta } _ { \text{eff} } [ \omega ] & - g _ { \text{eff} } - \frac { \kappa _ { \text{eff} } } { 2 } [ \omega ] \end{bmatrix} \quad ( C 1 0 ) \quad \text{Final} \quad \text{filed,} \quad \text{$\varepsilon$}$$
Finally, the drive vector on the nonlinear cavity is also modified, as describe in Eqs. (24); this can then be expressed as:
$$\binom { \hat { x } _ { e } ^ { \text{in} } [ \omega ] } { \hat { p } _ { e } ^ { \text{in} } [ \omega ] } = \sqrt { \kappa _ { 1 } } \binom { \hat { x } _ { 1 } ^ { \text{in} } [ \omega ] } { \hat { p } _ { 1 } ^ { \text{in} } [ \omega ] } - \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \left \{ \mathbf R \left ( \mu _ { 1 2 } + \pi / 2 \right ] \mathbf M _ { 2 } [ \omega ] \right \} ^ { - 1 } \sqrt { \kappa _ { 2 } } \binom { \hat { x } _ { 2 } ^ { \text{in} } [ \omega ] } { \hat { p } _ { 2 } ^ { \text{in} } [ \omega ] } \right )$$
We now reintroduce the coupling to the qubit in Eqs. (C2); the only change is to the modified drive on the effective system. It can be obtained from Eq. (C12) using the replacement:
where all quadratures are understood to be frequency dependent, the effective two-dimensional system of Eq. (24) can be written in this rotated basis as:
$$\sqrt { \kappa _ { 2 } } \begin{pmatrix} \hat { x } _ { 2 } ^ { \text{in} } \\ \hat { p } _ { 2 } ^ { \text{in} } \end{pmatrix} & \rightarrow \sqrt { \kappa _ { 2 } } \begin{pmatrix} \hat { x } _ { 2 } ^ { \text{in} } \\ \hat { p } _ { 2 } ^ { \text{in} } \end{pmatrix} + \sqrt { 2 } \begin{pmatrix} - \cos \left ( \frac { \phi _ { q } } { 2 } + \frac { 3 \pi } { 4 } \right ) \\ \sin \left ( \frac { \phi _ { q } } { 2 } + \frac { 3 \pi } { 4 } \right ) \end{pmatrix} \hat { B } [ \omega ] \\ \text{(where the frequency labels of the quadratures are $\sin$-\quad where} }$$
(where the frequency labels of the quadratures are suppressed).
The matrix M eff [ ω ] (cf. Eq. (C10)) bears similarity to the susceptibility matrix for a driven, damped nonlinear cavity with no coupling to a linear cavity. The full system is solved easily by first diagonalizing M eff [ ω ] ,
$$M _ { \text{eff} } [ \omega ] = - V _ { e } \begin{bmatrix} ( \chi _ { e - } [ \omega ] ) ^ { - 1 } & 0 \\ 0 & ( \chi _ { e + } [ \omega ] ) ^ { - 1 } \end{bmatrix} V _ { e } ^ { - 1 } \ \ ( C 1 4 ) \quad \text{freque} \quad \text{by ad}$$
where V e , the matrix of eigenvectors of M eff [ ω ] , is:
$$\mathbf V _ { e } = \begin{bmatrix} \cos ( \theta _ { e } / 2 ) & \sin ( \theta _ { e } / 2 ) \\ \sin ( \theta _ { e } / 2 ) & \cos ( \theta _ { e } / 2 ) \end{bmatrix} \quad \text{(C15)}$$
θ e is defined in Eq. (28), and the frequency-dependent effective nonlinear cavity susceptibilities are simply χ e ± [ ω ] -1 = ( -iω + χ -1 e ± ) , with χ e ± defined in Eq. (31a), (31b).
The analysis is most transparent in the rotated basis of amplified and squeezed quadratures, ˆ X ,P e ˆ e respectively, as discussed earlier. Using the transformation:
$$\begin{pmatrix} \hat { X } _ { e } \\ \hat { P } _ { e } \end{pmatrix} = \mathbf R ( \theta _ { e } / 2 ) \begin{pmatrix} \hat { x } _ { 1 } \\ \hat { p } _ { 1 } \end{pmatrix} \ ; \ \begin{pmatrix} \hat { X } _ { e } ^ { \text{in} } \\ \hat { P } _ { e } ^ { \text{in} } \end{pmatrix} = \mathbf R ( \theta _ { e } / 2 ) \begin{pmatrix} \hat { x } _ { e } ^ { \text{in} } \\ \hat { p } _ { e } ^ { \text{in} } \end{pmatrix} \quad \begin{pmatrix} \text{terms} \\ \hat { P } _ { L } ^ { \text{int} } [ \mu \\ ( C 1 6 ) \quad & \text{noise} \, \, \,$$
$$\begin{pmatrix} \hat { X } _ { e } [ \omega ] \\ \hat { P } _ { e } [ \omega ] \end{pmatrix} = \mathbf M _ { \text{eff} } ^ { - 1 } [ \omega ] \begin{pmatrix} \hat { X } _ { e } ^ { \text{in} } [ \omega ] \\ \hat { P } _ { e } ^ { \text{in} } [ \omega ] \end{pmatrix} \quad \text{(C17)}$$
where M -1 eff [ ω ] is given in terms of χ e ± [ ω ] by:
$$\text{the} _ { \text{iv} } \quad M _ { \text{eff} } ^ { - 1 } [ \omega ] = \begin{bmatrix} - \chi _ { e - } [ \omega ] & ( \chi _ { e - } [ \omega ] - \chi _ { e + } [ \omega ] ) \tan \theta _ { e } \\ 0 & - \chi _ { e + } [ \omega ] \end{bmatrix} \ ( C 1 8 )$$
The effective cavity output quadratures are then simply obtained by multiplying out Eqs. (C17), leading to the frequency-dependent versions of Eqs. (30a), (30b) (acquired by adding frequency labels to all quantities).
## Appendix D: Backaction force noise calculations
## a. Linearised backaction calculation
We begin by elaborating on the calculation of the linearised backaction, and start again by express the linearised backaction force operator ˆ F L (cf. Eq. (37)) in the rotated quadrature basis described in Appendix C. This is achieved by eliminating the linear cavity modes from ˆ F L , thereby expressing it in terms of the nonlinear cavity modes only. Upon transforming to the ˆ X , P e ˆ e basis, ˆ F L takes the form given in Eq. (38). The ˆ F int L [ ω ] operator is given in terms of the linear cavity input noise operators ˆ [ ξ 2 ω ] only , and is in particular independent of where the effective nonlinear cavity detuning, damping, and parametric interaction strength are:
$$\widetilde { \Delta } _ { \text{eff} } [ \omega ] & = \widetilde { \Delta } _ { 1 } + \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } \frac { i } { 2 } \left ( \chi _ { 2 } [ \omega ] - \chi _ { 2 } ^ { * } [ - \omega ] \right ) \\ \kappa _ { \text{eff} } [ \omega ] & = \kappa _ { 1 } + \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 2 } ( \chi _ { 2 } [ \omega ] + \chi _ { 2 } ^ { * } [ - \omega ] ) \\ g _ { \text{eff} } & = \left | g _ { 1 } - \widetilde { \lambda } _ { 1 2 } ^ { ( 2 ) } e ^ { i \mu _ { 1 2 } } \right | & ( C 1 1 )$$
λ 12 :
$$\hat { F } _ { L } ^ { \text{int} } [ \omega ] = \sqrt { \kappa _ { 2 } } \, \widetilde { A } & \left ( \chi _ { 2 } [ \omega ] e ^ { i ( \phi _ { g } / 2 - 3 \pi / 4 ) } \hat { \xi } _ { 2 } [ \omega ] & S _ { F _ { i } } \\ & + \chi _ { 2 } ^ { * } [ - \omega ] e ^ { - i ( \phi _ { g } / 2 - 3 \pi / 4 ) } \hat { \xi } _ { 2 } ^ { \dagger } [ \omega ] \right ) \quad ( D 1 )$$
The λ 12 dependent backaction terms involve f X [ ω ] , defined in Eq. (39), and f P [ ω ] , which is defined as:
$$f _ { P } [ \omega ] = i \frac { \widetilde { A } } { \sqrt { 2 } } \, \left [ \chi _ { 2 } ^ { * } [ - \omega ] e ^ { i ( \mu _ { 1 2 } - \nu [ \omega ] ) } - \chi _ { 2 } [ \omega ] e ^ { - i ( \mu _ { 1 2 } - \nu [ \omega ] ) } \right ] _ { \quad \text{Fuctu} \\ ( D 2 ) \quad \text{types} }.$$
We now move on to characterising the noise spectral density of the linearised backaction force. For calculations at nonzero frequencies, we compute the symmetrized noise spectral density, ¯ S FF [ ω ] , where:
$$\bar { S } _ { F F } [ \omega ] = \frac { 1 } { 2 } \left ( S _ { F F } [ \omega ] + S _ { F F } [ - \omega ] \right ) \quad \text{(D3)} \quad \text{if} \quad.$$
The unsymmetrized spectral density S FF [ ω ] , given by Eq. (36), can be computed using an application of the WienerKhinchin theorem, and the form of ˆ [ F L ω ] . It is simple to relate ˆ F L to the vacuum drives on both cavities, ˆ X ,P in j ˆ in j in the rotated basis using the solutions to Eqs. (C17). S FF [ ω ] , and hence ¯ S FF [ ω ] , can then be calculated using the usual correlation functions for these vacuum noise drives at zero temperature,
$$\langle \hat { X } _ { j } ^ { \text{in} } [ \omega ] \hat { X } _ { j } ^ { \text{in} } [ \omega ^ { \prime } ] \rangle & = \pi \delta ( \omega + \omega ^ { \prime } ) & S _ { F _ { c } } ^ { ( 1 } \\ \langle \hat { P } _ { j } ^ { \text{in} } [ \omega ] \hat { P } _ { j } ^ { \text{in} } [ \omega ^ { \prime } ] \rangle & = \pi \delta ( \omega + \omega ^ { \prime } ) & \\ \langle \hat { X } _ { j } ^ { \text{in} } [ \omega ] \hat { P } _ { j } ^ { \text{in} } [ \omega ^ { \prime } ] \rangle & = i \pi \delta ( \omega + \omega ^ { \prime } ) & & \text{(D4)} & & \text{On}$$
## b. Quadratic backaction calculation
The second backaction source is the quadratic backaction operator ˆ F Q (cf. Eq. (37)). The effect of this quadratic backaction can be computed from the relevant autocorrelation function G F Q F Q ( ) t ,
$$& G _ { F _ { Q } F _ { Q } } ( t ) = \langle \langle \hat { F } _ { Q } ( t ) \hat { F } _ { Q } ( 0 ) \rangle \rangle = A ^ { 2 } \langle \langle \hat { d } _ { 2 } ^ { \dagger } ( t ) \hat { d } _ { 2 } ( t ) \hat { d } _ { 2 } ^ { \dagger } ( 0 ) \hat { d } _ { 2 } ( 0 ) \rangle \rangle \quad \text{The
} \end{ 0 1 2 3 4 6 7 8 9 10 5 20 19 - ($$
We retain only connected terms, as indicated by the double angled brackets, and calculate the correlation function in the weak dispersive coupling regime so that the qubit-cavity coupling can be ignored; the remaining system Hamiltonian in terms of the ˆ d j operators - given by the sum ˆ H d 1 + ˆ H d 2 + ˆ H d 12 -is quadratic [cf. Eqs. (16), (18), (20)]. We therefore use Wick's theorem in going from the first line to the second to simplify the average. Fourier transforming the autocorrelation function G F Q F Q ( ) t allows computing the noise spectral density of the quadratic backaction, S F Q F Q [ ω ] , following ap- plication of the Wiener-Khinchin theorem [4],
$$\text{pawait on any number} \text{mm} \text{mm} \text{unused} \{ \tau _ { 1 }, \\ S _ { F _ { \text{Q} } F _ { \text{Q} } } [ \omega ] = A ^ { 2 } \int _ { - \infty } ^ { \infty } \frac { d \omega ^ { \prime } } { 2 \pi } & \left \{ S _ { d _ { 2 } ^ { \dagger } d _ { 2 } } [ \omega ^ { \prime } ] S _ { d _ { 2 } d _ { 2 } ^ { \dagger } } [ - \omega ^ { \prime } - \omega ] \\ + & S _ { d _ { 2 } ^ { \dagger } d _ { 2 } ^ { \dagger } } [ \omega ^ { \prime } ] S _ { d _ { 2 } d _ { 2 } } [ - \omega ^ { \prime } - \omega ] \right \} \\ \text{need} & \quad \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat{ \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat { \ } \hat$$
where the spectral density of two operators ˆ X, Y ˆ is simply:
$$S _ { X Y } [ \omega ] = \langle \hat { X } [ \omega ] \hat { Y } [ - \omega ] \rangle \text{ \quad \ \ } \text{(D7)}$$
Fluctuations in the linear cavity mode ˆ d 2 arise from three types of noise terms; in addition to noise incident directly on the linear cavity (a contribution independent of λ 12 ), ˆ d 2 is driven by noise incident on the nonlinear cavity that enters the linear cavity by virtue of the cavity-cavity coupling, and is hence ∝ λ 12 . Lastly, terms ∝ λ 2 12 involve noise incident on the linear cavity passing to the nonlinear cavity, being amplified, and then returning to drive ˆ d 2 .
For some analytic insight into the quadratic backaction, we focus on the zero frequency noise S F Q F Q [0] . The integrals over frequency space mean that S F Q F Q [0] sees noise at all frequencies (cf. Eq. (D6)), and as a result we expect large contributions near two frequencies, as indicated in Eq. (46). Near ω = 0 , the nonlinear cavity response G [0] is the dominant contribution, which also sets the bandwidth Ω[ ω = 0] = κ / 1 √ G . The linear cavity response here is set by the detuning ∆ 2 since the linear cavity is strongly detuned. The contribution to the quadratic backaction near ω = 0 is then:
$$S _ { F _ { \mathbb { Q } } F _ { \mathbb { Q } } } ^ { ( 1 ) } \simeq A ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 4 } \cdot \frac { 1 } { \Delta _ { 2 } ^ { 4 } } \cdot \frac { \mathcal { G } ^ { 2 } } { \kappa _ { 1 } ^ { 2 } } \cdot \frac { \kappa _ { 1 } } { \sqrt { \mathcal { G } } } = A ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 4 } \cdot \frac { \mathcal { G } ^ { 3 / 2 } } { \kappa _ { 1 } \Delta _ { 2 } ^ { 4 } } \\ \intertext { a n d }$$
On the other hand, near ω = ∆ 2 , the resonant linear cavity susceptibility dominates the backaction as | χ 2 | glyph[similarequal] 1 /κ 2 , and the bandwidth is therefore Ω[ ω = ∆ ] = 2 κ 2 . The nonlinear cavity response here is suppressed by a factor of the large linear cavity detuning, so that G [ ω = ∆ ] 2 glyph[similarequal] ( κ / 1 ∆ ) 2 2 . The quadratic backaction near ω = ∆ 2 is then
$$\text{lract} \quad S _ { F _ { Q } F _ { Q } } ^ { ( 2 ) } \simeq A ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 4 } \cdot \frac { 1 } { \kappa _ { 2 } ^ { 4 } } \cdot \frac { \kappa _ { 1 } ^ { 2 } } { \Delta _ { 2 } ^ { 4 } } \cdot \kappa _ { 2 } = A ^ { 2 } \left ( \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \right ) ^ { 4 } \cdot \frac { \kappa _ { 1 } ^ { 2 } } { \kappa _ { 2 } ^ { 3 } \Delta _ { 2 } ^ { 4 } }$$
The above estimates for the main contributions to the quadratic backaction integrals (cf. Eq. (D6)) are found to approximate the full integrals well. In the optimization procedure detailed in Section (IV A), these terms are required to be small relative to the intrinsic nonlinear cavity backaction, leading to the constraints in Eq. (55).
## Appendix E: Output homodyne current calculations
The full output homodyne current from the nonlinear cavity is the result of interference of the classical homodyne reference beam and the cavity output field; it can be written as [42]:
$$\cdot \quad \hat { I } _ { 1 } [ \omega ] = \sqrt { \kappa _ { 1 } } ( \cos \phi _ { h } \, \hat { x } _ { 1 } ^ { \text{out} } [ \omega ] + \sin \phi _ { h } \, \hat { p } _ { 1 } ^ { \text{out} } [ \omega ] ) \quad ( \text{E1} )$$
FIG. 6. Plot of the amplifier forward gain scaled by the dispersive qubit-cavity coupling, | χ IF [ ω /A ] | (dashed blue, left-hand axis) and the inverse efficiency ratio 1 /η meas (solid red, right-hand axis), both as a function of frequency ω , for the same parameter set as Fig. 3. As frequency increases, 1 /η meas first increases slowly as the reduced backaction condition is no longer satisfied. However, the concurrent reduction in gain G [ ω ] leads eventually to a reduced value of 1 /η meas , as expected. The vertical dashed line indicates the measurement rate ∼ 0 1 . κ 1 for our parameter choices. We see that over this frequency range, | χ IF [ ω ] | decreases somewhat; this is due to Γ meas becoming comparable to the amplification bandwidth, a feature that is controlled by the experimental value of κ 1 . Importantly, 1 /η meas increases relative to the zero frequency value by only a small amount, while the forward gain decreases by less than a factor of 2 ; our interest in the zero frequency performance of the PARI is therefore justified.
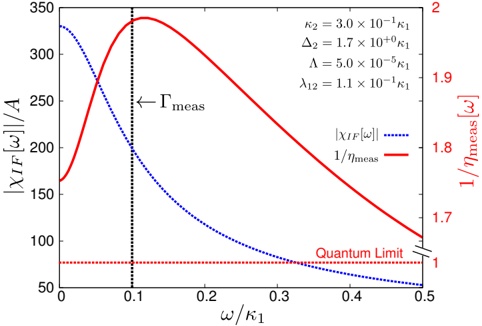
In standard input-output theory, these cavity output quadratures can be written in terms of the reflected input drives, and the intracavity field leaking out of the cavity [4]. Using the solutions to Eqs. (C17) in the rotated basis, the output homodyne current can be written in terms of the amplified and squeezed quadratures. In the particular case of the average homodyne current, the vacuum noise drive vanishes, leaving:
$$\langle \hat { I } _ { 1 } [ \omega ] \rangle = \kappa _ { 1 } \left [ \cos \phi _ { h } \langle \hat { X } _ { e } [ \omega ] \rangle + \sin \phi _ { h } \langle \hat { P } _ { e } [ \omega ] \rangle \right ] \quad ( \text{E2} ) \quad \underset { \dots \dots } { \overset { \cdots \dots } { \text{ invers} } }$$
where we take φ h → φ h + θ / e 2 to absorb angles associated with the transformation. The cavity drives can be related to the qubit states using the frequency-dependent version of Eq. (47):
$$\hat { \zeta } _ { e } ^ { \text{in} } [ \omega ] & \to \hat { \zeta } _ { e } ^ { \text{in} } [ \omega ] - \\ & \left ( \frac { \widetilde { A } \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } } { \sqrt { 2 } } \left [ i \chi _ { 2 } [ \omega ] e ^ { i ( \mu _ { 1 2 } - \nu ) } - i \chi _ { 2 } ^ { * } [ - \omega ] e ^ { i ( \mu _ { 1 2 } - \nu ) } \right ] \right ) \hat { \sigma } _ { z } } { \quad \text{indica} } \\ \hat { P } _ { e } ^ { \text{in} } [ \omega ] & \to \hat { P } _ { e } ^ { \text{in} } [ \omega ] + \\ & \left ( \frac { \widetilde { A } \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } } { \sqrt { 2 } } \left [ \chi _ { 2 } [ \omega ] e ^ { i ( \mu _ { 1 2 } - \nu ) } + \chi _ { 2 } ^ { * } [ - \omega ] e ^ { i ( \mu _ { 1 2 } - \nu ) } \right ] \right ) \hat { \sigma } _ { z } \quad ( \text{E3} ) \quad \text{drive} \\ & \quad 1 / \eta _ { \text{me} } \\ \text{where} \, we cunnree the frequency label on \, \hat { \zeta } \quad \text{Following this} \quad \text{close}$$
where we suppress the frequency label on ˆ σ z . Following this substitution into Eq. (C17) and taking the ensemble average, the averaged quadratures 〈 ˆ X ω , P e [ ] 〉 〈 ˆ [ e ω ] 〉 can be substituted in Eq. (E2). The amplifier forward gain for arbitrary frequency is given simply by the frequency-dependence version of the linear response relation in Eq. (48),
$$\overline { \frac { 3 } { 2 } } \quad \chi _ { I F } [ \omega ] = \frac { \widetilde { A } \, \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } } { \sqrt { 2 } } \kappa _ { 1 } \sec \theta _ { e } \left ( S _ { 1 } \chi _ { e - } [ \omega ] + S _ { 2 } \chi _ { e + } [ \omega ] \right ) \text{ (E4)}$$
where the coefficients S 1 [ ω , S ] 2 [ ω ] are given by
$$S _ { 1 } & = \cos \phi _ { h } \times \\ & \quad - \left ( i \chi _ { 2 } [ \omega ] e ^ { i ( \mu _ { 1 2 } - \nu + \theta _ { e } ) } - i \chi _ { 2 } ^ { * } [ - \omega ] e ^ { - i ( \mu _ { 1 2 } - \nu + \theta _ { e } ) } \right ) \\ S _ { 2 } & = - \sin \phi _ { h } \left ( \chi _ { 2 } [ \omega ] e ^ { i ( \mu _ { 1 2 } - \nu ) } + \chi _ { 2 } ^ { * } [ - \omega ] e ^ { - i ( \mu _ { 1 2 } - \nu ) } \right ) \text{ (E5)}$$
Near bifurcation, where the S 1 term dominates, the magnitude of the gain reduces to the result in Eq. (48). Furthermore, in the strongly detuned regime where φ 2 → π/ 2 , and once the reduced backaction condition (cf. Eq. (42)) is satisfied, the angular term ρ e in Eq. (48) takes the form:
$$\rho _ { e } & = \sec \theta _ { e } \, \sin \left [ ( 2 M + 1 ) \frac { \pi } { 2 } + \pi + \theta _ { e } \right ] \cos \phi _ { h } \\ & \Longrightarrow \, \sec \theta _ { e } \, \cos \theta _ { e } \, \cos \phi _ { h } = \cos \phi _ { h }$$
Clearly, choosing φ h = 0 sets ρ e → 1 , allowing us to drop this angular factor.
The imprecision noise spectral density of the output signal is defined in terms of the full output homodyne current for zero qubit coupling, analogously to S FF [ ω ] (cf. Eq. (36)),
$$S _ { I I } [ \omega ] \equiv \int _ { - \infty } ^ { \infty } d t \, e ^ { i \omega t } \langle \hat { I } ( t ) \hat { I } ( 0 ) \rangle _ { 0 }. \quad \text{(E7)}$$
S II [ ω ] is straightforward to compute by expressing the full output homodyne current in terms of ˆ X ,P e ˆ e , and making use of the usual correlation functions for the input drives [cf. Eqs (D4)].
While the complete ω -dependent expressions are unwieldy, we can observe the frequency dependence by computing the inverse efficiency ratio 1 /η meas as a function of frequency for parameter choices indicated in Table II; this is plotted in solid red in Fig. 6. We also include the forward gain | χ IF | (dashed blue).
## Appendix F: Freedom of parameter choice
In this section we include supplementary graphs that indicate the freedom of parameter choices afforded by the PARI scheme.
Figs. 7 (a), (b) are 3-D plots, against ∆ 1 and the cavity drive phase difference δ , of the inverse efficiency ratio 1 /η meas and the parametric gain G respectively, for fixed nonlinear cavity drive ¯ a in 1 ; all other parameters are fixed at the values indicated in Table II. The 'valley' (colored magenta) in Fig. 7 (a) indicates a region where the deviation from the quantum limit is at most a factor of 2 ( η meas ≥ 0 5 . ); clearly, a
FIG. 7. 3D plot against nonlinear cavity detuning ∆ 1 and relative phase difference δ between cavity drives, of (a) the inverse efficiency ratio 1 /η meas . The valley (magenta) indicates a region where η meas ≥ 0 5 . ; (b) the parametric gain G , for the same region as in (a). Clearly, in regions where the PARI performance is nearly quantumlimited [the valley in Fig. 7 (a)], G can be large, of O (20 dB) .
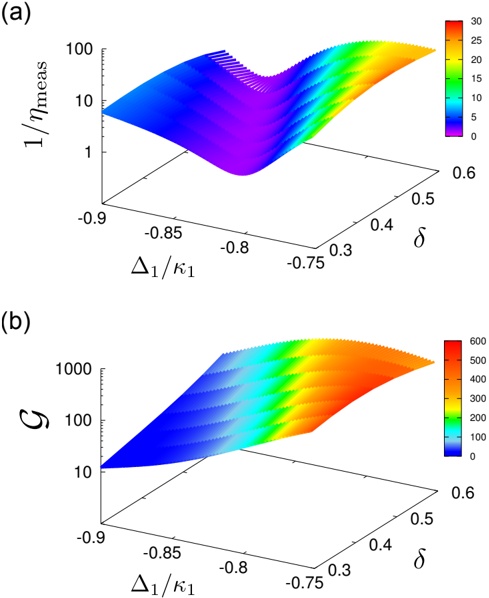
nontrivial set of parameters exists where this is true. Fig. 7 (b) indicates large gain over parameters corresponding to this valley; therefore, there are multiple parameter sets that are good choices for operation of the PARI detector.
Fig. 8 is a plot of the gain G and inverse efficiency ratio 1 /η meas as a function of nonlinear cavity detuning ∆ 1 with a Kerr constant Λ = 10 -4 κ 1 . This is twice as strong as the nonlinearity used for Figs. 3, 4. We find at the optimal detuning an inverse efficiency of glyph[similarequal] 2 01 . , with G still being large, G ∼ 80 . Strengthening Λ reduces the allowed values
- [1] A. Blais, R.-S. Huang, A. Wallraff, S. M. Girvin, and R. J. Schoelkopf, Phys. Rev. A 69 , 062320 (2004).
- [2] D. I. Schuster, A. Wallraff, A. Blais, L. Frunzio, R.-S. Huang, J. Majer, S. M. Girvin, and R. J. Schoelkopf, Phys. Rev. Lett. 94 , 123602 (2005).
- [3] J. Majer, J. M. Chow, J. M. Gambetta, J. Koch, B. R. Johnson, J. A. Schreier, L. Frunzio, D. I. Schuster, A. A. Houck, A. Wallraff, A. Blais, M. Devoret, S. Girvin, and R. J. Schoelkopf,
of ¯ n j , and hence we pay a cost in terms of the measurement rate; Γ meas now is ∼ 1 MHz , a factor of 10 slower than that in Fig. 4. Here, the drive parameters are given by: (¯ a in 1 ) 2 /κ 1 = (43 8) . 2 , (¯ a in 2 ) 2 /κ 1 = (57 0) . 2 , ¯ n 1 ∼ 3000 , ¯ n 2 ∼ 700 , and δ glyph[similarequal] 0 06 . . Again, an optimization procedure in ¯ a in 1 -∆ 1 -δ space has been performed.
FIG. 8. Plot of the parametric gain G (dashed blue, left-hand axis) and the inverse efficiency ratio 1 /η meas (solid red, right-hand log axis) as a function of nonlinear cavity detuning ∆ 1 , for a stronger Λ than in Figs. 3, 4. For optimal detuning, we find 1 /η meas glyph[similarequal] 2 01 . , with G glyph[similarequal] 80 , and Γ meas glyph[similarequal] 1 MHz .
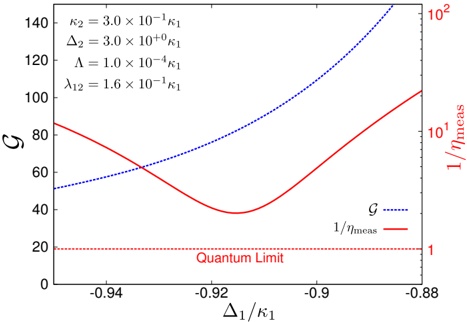
## Appendix G: Minimum useful value of λ 12
From a description of the output homodyne currents, it is possible to derive the minimum useful value of the intercavity coupling in the PARI scheme. We consider two types of qubit-cavity detector systems: the PARI detector, with output homodyne current ˆ I 1 , and a linear readout cavity capable of quantum limited qubit state measurement with unit gain, having corresponding output current ˆ I 2 . The forms of both currents are as follows:
$$\hat { I } _ { 1 } & \simeq \widetilde { A } \, \hat { \sigma } _ { z } \cdot \sqrt { \kappa _ { 1 } } \cdot | \chi _ { 2 } | \cdot \widetilde { \lambda } _ { 1 2 } ^ { ( 1 ) } \cdot \chi _ { e - } \\ \hat { I } _ { 2 } & \simeq \widetilde { A } \, \hat { \sigma } _ { z } \cdot \sqrt { \kappa _ { 2 } } \cdot | \chi _ { 2 } |$$
If ˆ I 1 and ˆ I 2 are equal, then using the nonlinear cavity serves no advantage over the single cavity system; this condition therefore leads to the minimum useful intercavity coupling strength, given in Eq. (34).
Nature 449 , 443 (2007).
- [4] A. A. Clerk, M. H. Devoret, S. M. Girvin, F. Marquardt, and R. J. Schoelkopf, Rev. Mod. Phys. 82 , 1155 (2010).
- [5] B. Yurke, J. Opt. Soc. Am. B 4 , 1551 (1987).
- [6] B. Yurke, L. R. Corruccini, P. G. Kaminsky, L. W. Rupp, A. D. Smith, A. H. Silver, R. W. Simon, and E. A. Whittaker, Phys. Rev. A 39 , 2519 (1989).
- [7] M. A. Castellanos-Beltran and K. W. Lehnert, Appl. Phys. Lett. 91 , 083509 (2007).
- [8] M. A. Castellanos-Beltran, K. D. Irwin, G. C. Hilton, L. R. Vale, and K. W. Lehnert, Nature Phys. 4 , 929 (2008).
- [9] T. Yamamoto, K. Inomata, M. Watanabe, K. Matsuba, T. Miyazaki, W. D. Oliver, Y. Nakamura, and J. S. Tsai, Appl. Phys. Lett. 93 , 042510 (2008).
- [10] N. Bergeal, F. Schackert, M. Metcalfe, R. Vijay, V. E. Manucharyan, L. Frunzio, D. E. Prober, R. J. Schoelkopf, S. M. Girvin, and M. H. Devoret, Nature 465 , 64 (2010).
- [11] B. Abdo, F. Schackert, M. Hatridge, C. Rigetti, and M. H. Devoret, Appl. Phys. Lett. 99 , 162506 (2011).
- [12] N. Roch, E. Flurin, F. Nguyen, P. Morfin, P. Campagne-Ibarcq, M. H. Devoret, and B. Huard, Phys. Rev. Lett. 108 , 147701 (2012).
- [13] J. Y. Mutus, T. C. White, E. Jeffrey, D. Sank, R. Barends, J. Bochmann, Y. Chen, Z. Chen, B. Chiaro, A. Dunsworth, J. Kelly, A. Megrant, C. Neill, P. J. J. O'Malley, P. Roushan, A. Vainsencher, J. Wenner, I. Siddiqi, R. Vijay, A. N. Cleland, and J. M. Martinis, Appl. Phys. Lett. 103 , 122602 (2013).
- [14] I. Siddiqi, R. Vijay, F. Pierre, C. M. Wilson, M. Metcalfe, C. Rigetti, L. Frunzio, and M. H. Devoret, Phys. Rev. Lett. 93 , 207002 (2004).
- [15] I. Siddiqi, R. Vijay, M. Metcalfe, E. Boaknin, L. Frunzio, R. J. Schoelkopf, and M. H. Devoret, Phys. Rev. B 73 , 054510 (2006).
- [16] A. Lupas ¸cu, E. F. C. Driessen, L. Roschier, C. J. P. M. Harmans, and J. E. Mooij, Phys. Rev. Lett. 96 , 127003 (2006).
- [17] R. Vijay, M. H. Devoret, and I. Siddiqi, Review of Scientific Instruments 80 , 111101 (2009).
- [18] F. R. Ong, M. Boissonneault, F. Mallet, A. Palacios-Laloy, A. Dewes, A. C. Doherty, A. Blais, P. Bertet, D. Vion, and D. Esteve, Phys. Rev. Lett. 106 , 167002 (2011).
- [19] C. Laflamme and A. A. Clerk, Phys. Rev. A 83 , 1155 (2011).
- [20] M. Boissonneault, A. Doherty, F. Ong, P. Bertet, D. Vion, D. Esteve, and A. Blais, Phys. Rev. A 85 , 022305 (2012).
- [21] C. Laflamme and A. A. Clerk, Phys. Rev. Lett. 109 , 123602 (2012).
- [22] M. Boissonneault, A. C. Doherty, F. R. Ong, P. Bertet, D. Vion, D. Esteve, and A. Blais, Phys. Rev. A 89 , 022324 (2014).
- [23] R. Vijay, D. H. Slichter, and I. Siddiqi, Phys. Rev. Lett. 106 , 110502 (2011).
- [24] J. E. Johnson, E. M. Hoskinson, C. Macklin, D. H. Slichter, I. Siddiqi, and J. Clarke, Phys. Rev. B 84 , 220503 (2011).
- [25] C. Eichler, Y. Salathe, J. Mlynek, S. Schmidt, and A. Wallraff, Phys. Rev. Lett. 113 , 110502 (2014).
- [26] B. Abdo, K. Sliwa, S. Shankar, M. Hatridge, L. Frunzio, R. Schoelkopf, and M. Devoret, Phys. Rev. Lett. 112 , 167701 (2014).
- [27] R. Vijay, C. Macklin, D. H. Slichter, S. J. Weber, K. W. Murch, R. Naik, A. N. Korotkov, and I. Siddiqi, Nature 490 , 77 (2012).
- [28] K. W. Murch, S. J. Weber, K. M. Beck, E. Ginossar, and I. Siddiqi, Nature 499 , 62 (2013).
- [29] K. W. Murch, S. J. Weber, C. Macklin, and I. Siddiqi, Nature 502 , 211 (2013).
- [30] G. de Lange, D. Rist` e, M. J. Tiggelman, C. Eichler, L. Tornberg, G. Johansson, A. Wallraff, R. N. Schouten, and L. DiCarlo, Phys. Rev. Lett. 112 , 080501 (2014).
- [31] M. Hatridge, R. Vijay, D. H. Slichter, J. Clarke, and I. Siddiqi, Phys. Rev. B 83 , 134501 (2011).
- [32] C. W. Gardiner and P. Zoller, Quantum Noise (Springer, Berlin, 2000).
- [33] W. Wustmann and V. Shumeiko, Phys. Rev. B 87 , 184501 (2013).
- [34] The input noise operators defined in Eq. (7) also depend on β , but the noise correlators are independent of this overall phase and hence it is not necessary to keep track of this.
- [35] H. Wiseman and G. Milburn, Quantum Measurement and Control (Cambridge University Press, 2010).
- [36] C. Eichler and A. Wallraff, EPJ Quantum Technology 1 , 2 (2014), 10.1140/epjqt2.
- [37] V. E. Manucharyan, E. Boaknin, M. Metcalfe, R. Vijay, I. Siddiqi, and M. Devoret, Phys. Rev. B 76 , 014524 (2007).
- [38] F. D. O. Schackert, A Practical Quantum-Limited Parametric Amplifier Based on the Josephson Ring Modulator , Ph.D. thesis, Yale University (2013).
- [39] B. Abdo, A. Kamal, and M. Devoret, Phys. Rev. B 87 , 014508 (2013).
- [40] A. Narla, K. M. Sliwa, M. Hatridge, S. Shankar, L. Frunzio, R. J. Schoelkopf, and M. H. Devoret, Appl. Phys. Lett. 104 , 232605 (2014).
- [41] X. Zhou, V. Schmitt, P. Bertet, D. Vion, W. Wustmann, V. Shumeiko, and D. Esteve, Phys. Rev. B 89 , 214517 (2014).
- [42] C. W. Gardiner and M. J. Collett, Phys. Rev. A 31 , 3761 (1985). | 10.1088/1367-2630/16/11/113032 | [
"Saeed Khan",
"R. Vijay",
"I. Siddiqi",
"Aashish A. Clerk"
] | 2014-08-01T16:37:16+00:00 | 2014-12-05T21:00:33+00:00 | [
"cond-mat.mes-hall",
"cond-mat.supr-con",
"quant-ph"
] | Large gain quantum-limited qubit measurement using a two-mode nonlinear cavity | We provide a thorough theoretical analysis of qubit state measurement in a
setup where a driven, parametrically-coupled cavity system is directly coupled
to the qubit, with one of the cavities having a weak Kerr nonlinearity. Such a
system could be readily realized using circuit QED architectures. We
demonstrate that this setup is capable in the standard linear-response regime
of both producing a highly amplified output signal while at the same time
achieving near quantum-limited performance: the measurement backaction on the
qubit is near the minimal amount required by the uncertainty principle. This
setup thus represents a promising route for performing efficient large-gain
qubit measurement that is completely on-chip, and that does not rely on the use
of circulators or complex non-reciprocal amplifiers. |
1408.0227v1 | Frascati Physics Series Vol. 58 (2014) Frontier Objects in Astrophysics and Particle Physics May 18-24, 2014
## UHECR AND GRB NEUTRINOS: AN INCOMPLETE REVOLUTION?
Daniele Fargion, Phys.Depart. Rome Univ.1 and INFN Rome1, Sapienza, Ple. A. Moro 2, Rome, 00185, Italy
## Abstract
At highest energy edges Ultra High Energy Cosmic Ray, (UHECR) and PeVs neutrino (UHE ), should soon offer new exciting astronomy. ν The fast and somehow contradictory growth of hundred of antagonist models shows the explosive vitality of those new astronomy frontiers. No conclusive understanding on the UHECR and UHE neutrino source are at hand. The earliest expectation of GRBs (as a one shoot Fireball model) as the main (UHE ν ) sources has been rejected. The source of UHECR as the expected GZK ones within our Super-Galactic Plane (within few tens Mpc) it has been quite disproved. However alternative models on GRB (as the long life precessing Jets) and the new updated records by AUGER, TA, ICECUBE are offering nevertheless partial understanding and early hint for point source correlations along our galaxy and toward Cen A, the nearest extragalactic AGN.
## 1 The Cosmic Ray Century
A century ago radioactivity was used to probe atomic nature. The same radioactivity was discovered around us made by electrons (beta), alfa (Helium nuclei) and gamma (photons). Radioactivity was apparently mainly made by terrestrial matter; indeed as one rise far from the soil radioactivity start to decline. However Victor Hess, a century ago, discovered that at highest altitude while in balloons the radioactivity first decrease , but soon, (a few km above the sea level), it grows to tens or even hundred times more than sea level: a cosmic radioactivity rules at highest sky, consequently the cosmic rays (CR) nature was born. To day we do know that CR are mixed up but they are mostly charged particles as proton, Helium and other nuclei; CR are well representative of our solar system element composition; electron and positron are also present in CR. Photons and Neutrinos are shining too. Photons (gamma from X to TeVs energy) are well observed. Neutrinos not, mainly because CR atmospheric neutrino secondary pollution and because extreme neutrino weak interaction. Cosmic Ray energies ranges in an almost steady power law for nearly eleven order of magnitude from GeV to ZeV energy. Cosmic rays are mostly stop at twenty km. altitude (ten meter water equivalent) by our safe protective terrestrial atmosphere. Moreover Charged CR are smeared by terrestrial, solar and galactic magnetic fields leading to confused homogeneous rain with no apparent source imprint. We are blind within such a smooth CR rain. No source, no astronomy at sight. In some sense the existence of large scale galactic magnetic fields (smearing CR) are testimony of the (mysterious) cosmic magnetic monopole absence (the celebrated Parker monopole bound). To be more accurate here on sea level we feel only a part of such smooth CR secondaries, traces made by scattering fragments of nucleons-nuclei that are raining in high altitude atmosphere, fragments known as muons or gamma and electron pairs, as well as secondary neutrino, called because of it, atmospheric neutrinos. These are the neutrino noises hiding a more rare underline neutrino astronomy. Most power-full CR (TeVs-PeVs-EeVs-ZeVs) are observed on sea level by their catastrophic pair-production chain, leading to a tree-like air-shower whose top vertex is the primary CR event and whose late ramification are the million or thousand of billion secondaries pairs leptons (and few hadrons). To observe such UHECR there are both water Cherenkov array detector (surface detectors in km 2 array) or Fluorescence Telescope array tracking air-shower lightening in the dark nights (in AUGER,HIRES,TA) experiments. At TeVs-PeVs energies CR air showering might blaze by Cherenkov flash, large optical telescope arrays (as Hess, Veritas, Magic) or large scintillator and water arrays as ARGO and Milagro as well as ice (ICECUBE). These telescope experiments found in last decade a large number of TeVs point sources (partially coincident with γ GeVs Fermi satellite signals); the array ones,ARGO and Milagro and ICECUBE CR, found a remarkable (tens degree size) anisotropy in the TeVs sky whose source is puzzling; we suggested an UHECR radioactive beamed imprint (mostly galactic) and its decay in flight as a possible source 21) . We also try to find here UHECR and UHE neutrino correlation as discussed and summarized in Fig 1. Charged particles in CR at higher and higher energies maybe accelerated on star flare, Supernova explosion shells, jets either in micro (as GRBs, SGRs) and-or in macro sites (as AGN nuclei, Quasars), in brightest Radio Galaxies or even along more candidate places 29) . We are all hunting for the CR sources nature since a century with no definitive success (yet). UHECR and UHE neutrino might point to them. Two main UHE neutrino models rise in last a few years: a Galactic and an Extragalactic origination, each of the two defending the UHECR and UHE neutrino traces within different arguments. Indeed in last decade we all hoped to reveal soon their origination by their extreme UHECR (possibly un-deflected) component, hundred billions times more energetic than lower GeV-TeV CR. UHECR if nucleon while crossing in random walk in our µ Gauss magnetic fields, have to fly within narrow angle δ rm -p /similarequal 2 5 . o . No such a clustering multiplet, out of a remarkable a triplet to be discussed, has been found see Fig1. UHECR, following AUGER composition data might be nuclei, light ones (He-like); in that case the incoherent random angle bending along the galactic plane and arms, crossing along the whole Galactic disk of 20 kpc arriving in different (alternating) spiral arm fields and within a characteristic coherent length of 2kpc for He nuclei becomes δ rm -He /similarequal 16 o 21) , well consistent with observed UHECR Cen A clustering, see Fig1. On the contrary UHECR might be heavy (Fe,Ni..) ones, explaining the extreme spread of UHECR events along Vela that is the nearest and brightest Gamma pulsar in the sky, see Fig1.
## 2 The one shoot Fireball failure versus GRB precessing jet
The UHE ν signature was expected to be associated in time with several GRB (Gamma Ray Burst) sources or with BL Lac flaring sources ; other source candidate are the Star-Burst galaxy and the Radio Galaxies. The most popular Fire-ball model of GRB (one huge shoot event, within or without a fountain jet) has been disproved. It should be noted that if GRB are not one shoot event but a long (decaying in hours-day scale time( t 10 4 s ) -1 life) jet 9) than its precessing blazing time (for neutrinos) should not be longer correlated with the short gamma-X blazing time (a constraint assumed of second-minute in Fireball times). Indeed in precessing GRBs Jet model it has been assumed since long ago a wider time scale to embrace also (otherwise mysterious) GRBs (as well as SGRs) precursors and statistical Jet solid angle 9) 11) . These observed precursor may be both gamma and neutrino events; such precursor neutrinos are indeed observed in a few GRB events: a 109 TeV neutrino, within 0 2 . o of GRB091230A, with a localization uncertainty of 0 2 , . o and detected time some 14 hours before the gamma GRB091230A trigger; a 1 3 TeV neutrino . 1 9 . o off GRB090417B, with localization uncertainty of 1 6 , and detection time . o 2249 seconds before the trigger of GRB090417B; a 3 3 TeV neutrino 6 1 . . o off GRB090219, with a localization uncertainty of 6 1 , and detection time 3594 . o seconds before the GRB090219 trigger. These three observed GRB-neutrino precursor neutrino event (unexplained in fireball one-shoot model) may be, at a few percent of all the UHE neutrino events in ICECUBE. Additional GRBs might be at higher redshift and they may be part of the ICECUBE UHE neutrino sources if one enlarge the GRB-neutrino time windows; however also AGN jet and local galactic UHE ν may play a role. As we shall show a few correlated UHE neutrino and UHECR may be present inside galactic plane as well as few smeared clustering in tens TeV γ CR anisotropy and spread multiplet in tens EeV UHECR around Cen-A may trace the UHECR astronomy, see details in Fig.1. It should be noted that if UHE neutrino will cluster in a spread tail group of events one might advocate either UHECR scattering along galactic gas (as for the Fermi bubble traced by its observed γ fountain), or one may suggest the radioactive (light and heavy) UHECR decay in flight, offering a possible correlation to UHECR 10 18 -10 20 eV clustering and the large scale Milagro-Argo-ICECUBE TeVs-PeVs γ anisotropy 20) , 21) .
## 3 The UHE neutrino flavor metamorphosis
Let us remind that neutrino are neutral and always un-deflected; (to be more precise in cosmology and for neutrino with mass in expanding universe once they became non relativistic neutrino might be bent by gravity too; this may play a minor role in largest scale dark matter density growth and large scale formation). Therefore the UHE neutrino may offer a new Astronomy. However, as we mentioned, at low (less than tens TeV) energies, neutrinos are polluted by abundant (CRs fragments), a smeared atmospheric neutrino noise that are hiding any underlying astrophysical neutrino point-source. Let us remind that atmospheric GeV neutrinos while being mostly born at a ratio ( ν e : ν µ : ν τ = 1 : 2 : 0) by proton-proton scattering interactions chain in atmosphere, once at hundred GeV-TeVs, they become ruled, at sea level, by muons neutrinos ( ν e : ν µ : ν τ /similarequal 0 1 : 1 : 0); this occurs because the relativistic pion (and Kaon) . still decay, feeding muons and anti-muons neutrinos while their muon decay, the main road to electron flavor birth, is inhibited by a longer muon lifetime. Therefore electron (and rarest charmed born tau flavor) presence at hundred GeV-TeVs are rare (less than 10%); most signals (at hundred GeV-TeVs) are muon neutrino tracks as observed by inner ICECUBE experiment, the Deep Core, in the last years. Here we don't discuss the atmospheric muon neutrino conversion and partial suppression by flavor mixing that is tuned at GeV energies and led to the PontecorvoMakiNakagawaSakata in last two decades. To consider the flavor mixing and possible experiment along the Earth see 23) However at higher energies (above tens TeV-PeV) the extraterrestrial signals might (and indeed do) overcome the softer atmospheric neutrino noise (mainly because the astrophysical hardest spectra). Indeed those extraterrestrial signals, while being expected to be born, in general, by p + p or p + γ in flux ratio,( ν e : ν µ : ν τ /similarequal 1 : 2 : 0), because of the mixing and because of the large galactic distances, may oscillate and converted into electron and tau neutrino flavor component. The outcome in a first approximation lead to a final equipartition flavor flux: ( ν e : ν µ : ν τ = 1 : 1 : 1), because of the complete flavor de-coherence mixing in flight. These ruling shower signals have been observed by last 3 years ICECUBE event data. The dominant ν e and ν τ interaction are mainly electromagnetic leading to Cherenkov spherical shower in ice. These majority of spherical shower events (28) are four times more abundant than muon tracks (7). This may sound contradictory keeping in mind that a third of these 35 events should be atmospheric muon or neutrino noise 18) (in principle all of them noise signals should mainly show up as muons, too many respect 7 observed ones); however because a very different detector flavor acceptance it maybe still consistent with ( ν e : ν µ : ν τ = 1 : 1 : 1) 26) , 6) , once considering also the Neutral Current contribute. Therefore the best hope and probe of a new UHE ν astronomy is the recent neutrino sudden flavor change at tens TeV-PeV energy 6) . But all showering cascades are smeared in their arrival direction ( ± 15 ) and they are making inconclusive any map correlation. Thereo fore a more directional astronomy is needed, as the one made by muon tracks. Additional such signals are able to open an UHE neutrino astronomy : they are in-written into few tens TeV energy ( crossing in ICECUBE) muons at horizons 24) ; the first estimate of nearly 40 of such events offer hope for soon novel astronomy. Unfortunately the recent published (TeV-PeVs) (not only those above tens-TeV-PeV) muon crossing inside the ICECUBE were painting a puzzling random map, not favoring any known or expected γ X source, 18) . A more restrictive filtering of those events (muon crossing above few Tens TeV) may be more telling for extraterrestrial nature, but such a selection has not been done yet 24) . We must remind that an anti-neutrino electron ¯ ν e + e peak resonance may tag and reveal a different neutrino sky volume. Indeed a Glashow resonance peak may rise by ¯ + ν e e → W -at E ¯ ν e = 6 3 PeV . 27) , but it has not been observed (yet), while observing 2 PeV cascade shower. This is suggesting either a sudden softening in the PeV neutrino spectra 6) or a smooth interchange (around ten TeV energy) between a soft power law in atmospheric neutrino with a harder extraterrestrial neutrino power law within a fine-tuned parameters (apt to avoid the expected Glashow signal as well as its ideal τ double bang signature) 28) . The powerful ν τ discover via its first bang inside a rock (mountain, or Earth) and its consequent τ escape outside in air, decaying in an amplified τ airshower, is a very promising adjoint neutrino astronomy at highest energy range PeVs-EeV, first foreseen more than 15 years ago 12) and to day widely searched in different large experimental array today 4) , 3) , 1) ,(the so called Earth skimming neutrinos, 13) ).
## 4 The UHECR fly undeflected: an UHECR Astronomy?
We expected that UHECR might flight straight because of their energetic rigidity, at best for UHECR proton. They survive the Lorentz bending and smoothing occuring for lower (up to EeV) CR. Such UHECR, well above EeV, are extremely rare, but their interaction at high altitude in atmosphere makes their explosive pair-production tree air-shower along their fall, proliferous and amplified into extended wide area (tens km square size). Their detection may be tested by wide spread km distance array, each detector even of minor volume (few square meter swimming-pool for Cherenkov detection) on the ground. Such experiments like Flys' Eye, AGASA, Hires, Auger, TA, were located in last two decades over hundreds or several thousands km square area. These UHECR (if nucleon or even nuclei) might exhibit a cut off (within nearly 2% of cosmic radius) because of the 'Cosmic Back Ground Radiation' opacity, mostly by p + γ → ∆ → π + nucleon interaction, the so-called photon-pion GZK cut off 30) . Their consequent GZK neutrinos (at EeV energies) are not observed yet and cannot feed the mentioned ICECUBE events. A more severe distance cut occur to UHECR nuclei propagation because of their fragility by photon-nuclei dissociation; moreover light and heavy nuclei are partially or totally bent while crossing the galaxy. Therefore their maps might trace only nearby local Universe well within 1 -2% percent of cosmic size. To escape the near Universe size (GZK size bounded, in case of UHECR clustering at far extragalactic edges) one may consider the UHE neutrinos at ZeV hitting the relic cosmic ones via Z-resonance (in analogy to Glashow W resonance) 10) : the Z UHE decay into nucleons or antinucleons might be the final trace explaining UHECR correlation well above GZK bounded universe; this proposal found much interest and it will be actual if UHECR are correlated with guaranteed AGN above GZK distances. UHECR neutron are also expected but well confined within one Mpc ( E n /similarequal 10 20 eV) size while UHE photons ( E γ /similarequal 10 18 -10 20 eV) are bounded within a few tens Mpc. No such UHECR neutron or photon source or clustering has been found (yet). UHE neutrino might test most of the far and secret Universe edges, but they may observe also nearby galactic sources. The simplest solution of UHECR (nearby Local Super-galactic plane) and of UHE neutrino (expected to be traces of GRBs) have been in a very recent years fallen away. New galactic and extragalactic candidate source have been considered, somehow with much dispute and disagreement in the scientific arena. Therefore UHECR either nucleon or nuclei must arise in a small (tens Mpc) or even narrow (few Mpc) Universe, possibly in sharp astronomy (for proton) or in a smeared clustering map (for light nuclei
or nearest galactic heavy nuclei). The last AUGER maps showed only marginal smeared clustering and a rarest remarkable triplet 31) . see Fig.1.
## 5 Conclusions
The difficult puzzle of UHECR astronomy and the UHE neutrino maps may soon be matched by cooperative test and overlapping. There are often unexplainable delay in UHECR (AUGER) data release. Nevertheless the sources as nearest AGN Cen A, rise as a remarkable smeared clustering of UHECR events in AUGER ( E UHECR > 6 · 10 19 eV as well in rare overlapping tens EeV long chain events foreseen 20) , and observed, 2) 21) , may be well understood if they are mostly made by He nuclei and its fragments. The nearest brightest γ pulsar Vela is also suspected to correlate a train of UHECR events (if heavy Fe,Ni,Co nuclei), and a doublet of ICECUBE neutrinos ( see Fig.1, event n. 3 (a muon) and 6 (a shower) in ICECUBE 17) )as well as a remarkable TeVs ICECUBE CR anisotropy 21) , Cen-X3 and Cygnus region is also rising in ARGO TeVs anisotropy 21) and in a very rich (7) recent UHECR multiplet clustering containing also new TA and old Hires events. The most surprising narrow triplet is the newest rarest highest energy doublet 31) , by an additional third event (by last TA UHECR data); other triplet and quadruplet point to unknown sources not far from galactic plane; they are possibly showing a cooperative galactic and extragalactic source role; we offered here first attempts in this difficult map understanding (see Fig.1). We believe that with care and with needed time we are going to disentangle ( within the fog of such noisy high energy sky) the first sources shining from our near and far Universe; we believe that most are related to precessing jet beaming, galactic and extragalactic in tuned and equiparable ratio (see also 25) ), and UHECR as well as UHE neutrino are not found along contemporaneous explosive or flaring event, because of a different timing of the jet blazing beam. UHE neutrinos are by most distant GRB and AGN blazing whose timing maybe often delayed or precursor respect gamma flaring or burst. On the contrary UHECR are mostly galactic or in nearest Universe. Few sources (UHECR-UHE ν ) overlap within nearest galaxy and AGN sky.
## 6 In memory
This article is devoted to Daniele Habib greatest linguist and translator, who disappeared in these days half a century ago.
## References
- 1. Y. Aita et al. ApJ 736 L12,(2011);
- 2. Auger Coll., 32ND INT.COSMIC RAY CONF., BEIJING,p-9-13. 2011
- 3. Auger Coll. Advances in High Energy Physics, vol. 2013, Article ID 708680
- 4. X. Bertou et.all Astropart. Phys., 17,183,(2002);
- 5. Courier, 31 May 2012, (http://cerncourier.com/cws/article/cern/49675)
- 6. D.Fargion,P.Paggi; Nuclear Inst. and Methods in Physics Research, A 753C (2014), pp. 9-13.
- 7. ICECUBE Collab. arXiv:1311.6519, Science, v.342, Nov. 2013.
- 8. Enberg R., Reno M.H., Sarcevic I.Phys. Rev. D 78, 043005 (2008);
- 9. D.Fargion, Astron.Astrophys.Suppl.Ser.138:507-508,1999;
- 10. D.Fargion, B. Mele, A. Salis, ApJ, 517:725 733, 1999;
- 11. D.Fargion, Memorie della Societa Astronomica Italiana Vol. 83 n. 1, 2012, 312-318. D.Fargion, M.Grossi,Nuovo Cim.C28:809-812,2005; Chin.J.Astron.Astrophys. 6S1 (2006) 342-348;
- 12. D.Fargion,et al.26th ICRC,He 6.1.09,p.396-398(1999). D.Fargion , ApJ, 570, 909,(2002); D. Fargion , et all. ApJ, 613, 1285, (2004);
- 13. J. L. Feng1,et al.Phys. Rev. Lett. 88, 161102 (2002);
- 14. Gaisser T.K.,Honda M. Ann.Rev.Nucl.Part.Sci.52:153-199,(2002)
- 15. Gora14)Gora D. et all., 10.1016/j.astropartphys.2014.06.005, (2014); D. Fargion et al. Journal of Physics: Conf. Series,110,6, (2008); NIMA, p. 146-150.10.1016/j.nima.2008.01.028 (2008)
- 16. Hill G., ICECUBE Coll., Neutrino 2014,Boston, June 2nd, (2014)
- 17. ICECUBE Collaboration, arXiv:1405.5303
- 18. ICECUBE Collaboration, arXiv:1406.6757
- 19. C.Kopper, ICECUBE coll;Rencontres de Moriond EW (2014);
- 20. D.Fargion, Progress in Particle and Nuclear Physics 64,363-365,(2010):
- 21. D.Fargion, Nuclear Inst. and Methods in Physics Research, A (2012), pp. 174-179
- 22. D.Fargion, D.D'Armiento,J. Phys. G: Nucl. Part. Phys. 39 (2012)
- 23. D.Fargion et al.ApJ. Volume 758 Number 1, 758, 3 (2012);
- 24. D.Fargion, arXiv:1404.5914;
- 25. P. Padovani,, E. Resconi,arXiv:1406.0376
- 26. F. Vissani, G. Pagliaroli, F. L. Villante, arXiv:1306.0211 , (2013)
- 27. S.L. Glashow, Phys. Rev. 118 , 316 (1960).
- 28. J. Learned, S. Pakvasa, ApJ 32671995.
- 29. P. Mszros;(2014) arXiv:1407.5671.
- 30. Greisen, K. Physical Review Letters 16 (17): 748,750, (1966); Zatsepin, G.T, Kuz'min, V.A. Zh. Eks. Teor. Fiz., Pis'ma Red. 4 (1966)144
- 31. S.V. Troizky, Pis'ma v ZhETF, vol. 96, iss. 1, pp. 14,17; (2012)
- 32. Ke Fang et all. arXiv:1404.6237
Figure 1: The UHECR map in equatorial coordinate following AUGER detector (South) and TA (in North) 32 ) . There are few clustering tagged by five arrows: the most left and north one point toward a TA-Hires multiplet along Cen-3X, one of the location of gamma anisotropy at TeV by Milagro-Argo detectors; the next arrow point toward the remarkable UHECR made by highest doublet (TA-AUGER) UHECR found recently 31 ) where a new third UHECR has been just found this year by TA; the probability to occur such an event is well below 10 -4 ; a third arrow on the center-right side point on to a clustering along a nearest AGN, Cen-a not far from the largest energetic 2 PeV event number n. 35 in ICECUBE over a doublet around the Cen A cluster, where an additional twin overlapping multi-plet occurs at 20 EeV energy see 2 ) ; the fourth arrow point to the nearest and brightest Gamma Pulsar, Vela, related to an aligned AUGER triplet event; the fifth arrow point to a doublet by TA and a singlet by AUGER, an additional single by Hires UHECR events nearby a well collimated UHE neutrino muon found by ICECUBE event n. ; all these five region are 5 candidate of UHECR and possibly UHE neutrino sources, mostly galactic.
 | null | [
"Daniele Fargion"
] | 2014-08-01T16:38:12+00:00 | 2014-08-01T16:38:12+00:00 | [
"astro-ph.HE",
"astro-ph.GA",
"hep-ph"
] | UHECR and GRB neutrinos: an incomplete revolution? | At highest energy edges Ultra High Energy Cosmic Ray, (UHECR) and PeVs
neutrino (UHE neutrino), should soon offer new exciting astronomy. The fast and
somehow contradictory growth of hundred of antagonist models shows the
explosive vitality of those new astronomy frontiers. No conclusive
understanding on the UHECR and UHE neutrino source are at hand. The earliest
expectation of GRBs (as a one shoot Fireball model) as the main (UHE neutrino)
sources has been rejected. The source of UHECR as the expected GZK ones within
our Super-Galactic Plane (within few tens Mpc) it has been quite disproved.
However alternative models on GRB (as the long life precessing Jets) and the
new updated records by AUGER, TA, ICECUBE are offering nevertheless partial
understanding and early hint for point source correlations along our galaxy and
toward Cen A, the nearest extragalactic AGN. |
1408.0228v1 | ## Real-time phase-reference monitoring of a quasi-optimal coherent-state receiver
Matteo Bina, 1,2 Alessia Allevi, 3, 4 Maria Bondani, 5,4 and Stefano Olivares 1,2, ∗
1 Dipartimento di Fisica, Universit` a degli Studi di Milano, 20133 Milano, Italy 2 CNISM UdR Milano Statale, via Celoria 16, 20133 Milano, Italy
3 Dipartimento di Scienza e Alta Tecnologia, Universit` degli Studi dell'Insubria, Via Valleggio 11, 22100 Como, Italy a
4 CNISM UdR Como, via Valleggio 11, 22100 Como, Italy
5 Istituto di Fotonica e Nanotecnologie, CNR, Via Valleggio 11, 22100 Como, Italy
(Dated: August 4, 2014)
The Kennedy-like receiver is a quasi-optimal receiver employed in binary phase-shift-keyed communication schemes with coherent states. It is based on the interference of the two signals encoding the message with a reference local oscillator and on/off photodetection. We show both theoretically and experimentally that it is possible to extract useful information about the phase reference by Bayesian processing of the very same data sample used to discriminate the signals shot by shot. We demonstrate that the minimum uncertainty in phase estimation, given by the inverse of the Fisher information associated with the statistics of the collected data, can be achieved. We also numerically and experimentally investigate the performances of our phase-estimation method in the presence of phase noise, when either on/off or photon-number resolving detectors are employed.
PACS numbers: 42.50.Ex; 03.67.Hk; 42.25.Hz; 42.50.Ar; 85.60.Gz
In a phase-estimation protocol, the probe signal is prepared in an optimized pure state that undergoes an unknown phase shift. The phase-shifted signal is then sent to a receiver that retrieves the information about the phase by implementing a suitable detection scheme [1]. The main goal is to reach the minimum uncertainty allowed by the setup, that is related to the Fisher information (FI) or, in the best case, the minimum uncertainty allowed by the very laws of quantum mechanics, which is given by the inverse of the quantum Fisher information [2].
to monitor the relative phase in this transmission scheme, the communication protocol must be interrupted and a (known) probe state must be sent to estimate the phase minimizing its uncertainty.
On the other hand, in a binary phase-shift-keyed communication (BPSK) channel based on coherent states, a π phase shift is imposed or not to an input coherent state | β 〉 , thus encoding the logical bit '1' or '0' into the state | β 〉 or | -β 〉 , respectively. In such a case, the problem is turned from the estimation of the phase to the discrimination between the two nonorthogonal phase-shifted coherent states | β 〉 and | -β 〉 and the goal becomes to reach the minimum error probability in the discrimination process, that is the Helstrom bound [1]. During the last decade, many solutions, based either on homodyne detection, photon-number resolving (PNR) detectors or hybrid receivers have been theoretically [3-5] and experimentally proposed [6-11].
The typical scheme used to discriminate among two or more optical coherent states involves an apparatus in which the signal interferes at a beam splitter (BS) with a reference coherent state, the local oscillator (LO), whose phase should be known and well defined. Therefore, the crucial point is the control of the phase of the LO [12] and one of the main limitations in the realization of this kind of receivers comes from phase-noise sources, which can affect the generation and propagation of the signals [13, 14]. It is worth noting that the discrimination must be carried out shot by shot, without any a-priori knowledge about the transmitted signal state. Such a situation requires the assumption that the relative phase between signal and LO always remains fixed. Moreover, in order
Motivated by the interest on coherent state setups as a resource for deep-space communication [15], in this Letter we investigate whether and at which extent it is possible to retrieve some information about the relative phase between signal and LO without interrupting the communication, but performing a suitable real-time processing of the same data used for the state discrimination. To this aim, we focus on a simple Kennedy-like receiver [16]. Since in its original scheme this kind of receiver employs on/off photodetectors, in the following we will refer to it as on/off receiver. In the present work, we also consider an enhanced version of the receiver, equipped with photon-number resolving detectors (PNR). We show that a suitable analysis of the detector output allows monitoring the phase of the LO down to the minimum uncertainty allowed by the detection scheme.
Detection scheme - Without loss of generality, we assume that the two coherent signals | ± β 〉 considered in the BPSK communication scheme are sent with the same prior probability, z 0 = z 1 = 1 2 / . The overall state reaching the receiver can be then described by the following density operator:
$$\hat { \varrho } ( \beta ) = \frac { 1 } { 2 } \left ( | \beta \rangle \langle \beta | + | - \beta \rangle \langle - \beta | \right ). \quad \quad ( 1 )$$
The state in Eq. (1) represents a phase-sensitive statistical mixture of two coherent states. To achieve shot-by-shot quasioptimal discrimination [3] with a Kennedy-like receiver, the state ˆ( glyph[rho1] β ) is mixed at a BS of transmittance τ with a LO excited in the coherent state | α 〉 .
By setting α = β √ τ/ (1 - √ τ ) , the overall output state can be written as ˆ glyph[rho1] out ( β ) = ˆ ( D β τ )ˆ( glyph[rho1] β √ τ ) ˆ D † ( β √ τ ) , where ˆ ( D z ) = exp( ˆ za † -z ∗ ˆ) a is the displacement operator and ˆ a is the annihilation operator, [ˆ a, a ˆ ] † = 1 . If we consider
only one output port of the BS, we have the following evolution for the input signals: | β 〉 → | 2 √ τ β 〉 = | ψ 1 〉 and | -β 〉 → | 〉 0 = | ψ 0 〉 , respectively. Under these conditions, the optimal strategy turns out to be the discrimination between the presence and the absence of light, which corresponds to the positive operator-valued measure { Π 1 = ∑ n> 0 | n 〉〈 n , | Π 0 = | 0 〉〈 0 |} . It is worth noting that in this case the use of on/off photodetectors, without any photonnumber discrimination power, is sufficient. In the limit τ → 1 , the error probability P e = 1 2 ( 〈 ψ 1 | Π 0 | ψ 1 〉 + 〈 ψ 0 | Π 1 | ψ 0 〉 ) in the discrimination is given by P e = 1 2 exp( - | 4 β | 2 ) , which is twice the minimum error probability given by the Helstrom bound when | β | glyph[greatermuch] 1 [1].
The previous treatment is based on the assumption that the relative phase φ between the input signal and the LO is constant and precisely known (in the present case φ = 0 ). On the other hand, by setting α = | β | e i φ τ/ (1 -τ ) and still in the limit τ → 1 , the error probability reads P e ( φ ) = [ 1 -e - | 4 β | 2 sin 2 ( φ/ 2) + e - | 4 β | 2 cos 2 ( φ/ 2) ] / 2 . Note that P e ( φ ) ≥ P e (0) ≡ P e . Furthermore, for small values of φ and high signal energy | β | 2 we have P e ( φ ) ≈ P e (0) + [ 1 2 + P e (0) ] | β | 2 φ 2 : in this regime, the larger the energy, the larger the error probability.
In our scheme, we assume that the input signal ˆ( glyph[rho1] β ) in Eq. (1) and the LO | α e i φ 〉 ( α, β ∈ ❘ and α, β > 0 ) are mixed at a BS with transmittance τ [17]. By defining a = α √ 1 -τ and b = β √ τ , the overall output state can be cast in the form ˆ glyph[rho1] out ( a, b, φ ) = ˆ ( D a e i φ )ˆ( ) ˆ glyph[rho1] b D † ( a e i φ ) and the photonnumber distribution Tr [ ˆ glyph[rho1] out ( a, b, φ ) | n 〉〈 n | ] of the transmitted beam reads
$$p _ { n } ( a, b, \phi ) = \frac { 1 } { 2 } \left ( \mathrm e ^ { - \nu _ { + } } \frac { \nu _ { + } ^ { n } } { n! } + \mathrm e ^ { - \nu _ { - } } \frac { \nu _ { - } ^ { n } } { n! } \right ), \quad ( 2 ) \quad \frac { \text{parti} } { \mathrm a \mathrm m \mathrm s }$$
which is the sum of two Poisson distributions depending on φ through the mean values ν ± = a 2 + b 2 ± 2 ab cos φ . Therefore, the real-time monitoring of the phase is attainable directly from Eq. (2) by using the same acquired data and a suitable estimation strategy, as described in the following.
Bayesian estimation -Let us assume that M signals are received by means of a PNR detector and { n k } = { n , n 1 2 , . . . , n M } , n k ∈ N , ∀ k , is the data sample corresponding to the detected number of photons. As { n k } implicitly depends on φ , we can build the sample probability P ( { n k }| φ ) = ∏ ∞ n =0 p n ( a, b, φ ) m n , being m n the number of occurrences of n detected photons, so that ∑ n m n = M . P ( { n k }| φ ) is thus the probability of obtaining the actual sample given φ . Thanks to Bayes theorem, we can write the posterior probability of φ given the sample, namely, P PNR ( φ |{ n k } ) = N PNR P ( { n k }| φ ) , where N PNR is a normalization factor and φ is assumed to be described by a uniform prior distribution. The Bayes estimator of φ is ¯ φ = ∫ dφφP PNR ( φ |{ n k } ) and its variance is Var φ = ∫ dφ φ ( -¯ ) φ 2 P PNR ( φ |{ n k } ) . It is well known [18, 19] that the Bayes estimator is asymptotically optimal if M glyph[greatermuch] 1 , that is Var φ → [ MF PNR φ ] -1 , where F PNR φ =
FIG. 1: (Color online) FI for on/off (left) and PNR (right) detection as a function of φ for a = b = 0 5 . , 0 6 . . 0 7 . , 0 8 . , 0 9 . , 1 0 . (blue lines, from bottom to top). In the two panels, the same encoding has been used in order to emphasize the higher values of F PNR φ with respect to F on/off φ . The red dashed lines are the FIs as expected in our experimental configuration ( a = 1 12 . and b = 0 79 . ).
∑ n p n ( a, b, φ )[ ∂ φ ln p n ( a, b, φ )] 2 is the FI associated with p n ( a, b, φ ) .
Since on/off detection can be seen as a particular case of PNR detection, the Bayes estimator can now be obtained straightforwardly. We identify the probabilities P off ≡ p 0 ( a, b, φ ) and P on ≡ ∑ n> 0 p n ( a, b, φ ) = 1 -P off . Therefore, given the same sample { n k } considered above, the sample probability reduces to P ( { n k }| φ ) = P m off off P m on on , where m off and m on = M -m off are the number of 'off' ( n k = 0 ) and 'on' ( n k > 0 ) events, respectively. The posterior probability is thus given by P on/off ( φ |{ n k } ) = N on/off P ( { n k }| φ ) . Also in this case the Bayes estimator asymptotically reaches the optimal value, where the corresponding FI reduces to F on/off φ = ( ∂ P φ off ) 2 ( P off P on ) -1 . In Fig. 1 we report the behavior of the FI in the case of on/off e PNR detection for a particular choice of the involved parameters. The FI displays a maximum in the interval (0 , π/ 2) , whereas it vanishes at φ = 0 , π/ 2 [20].
Numerical simulations - In order to test the proposed approach for retrieving the relative phase, we firstly performed Monte Carlo simulated experiments. The data samples were generated according to the photon-number probability distribution in Eq. (2), corresponding to the expected output state ˆ glyph[rho1] out ( a, b, φ ∗ ) , where φ ∗ is the actual value of the phase. In our simulations we chose to set φ ∗ = 0 3 . . We applied the Bayesian method to both the cases of on/off and PNR detection of the output signal and compared the two corresponding estimators ¯ φ and their standard deviations [see Fig. 2 (a) and (b)]. As it is apparent from the figure, the employment of PNR detectors brings the estimator ¯ φ to converge more rapidly, just after M ∼ 10 3 , to the expected value φ ∗ = 0 3 . than using the on/off scheme.
The Bayesian method is very powerful as it converges fast and, as we will see later, it provides a result robust against phase noise. Nonetheless, information about the phase parameter can also be retrieved in other ways, such as by inverting some measurable quantities depending on the parameter. Regarding our scheme, the measurement of the Fano factor F ( φ ) = Var [ ˆ ] N / N 〈 ˆ 〉 of the output state at the BS can be easily implemented by reconstructing the photon statistics
FIG. 2: (Color online) Phase estimation with simulated data using different methods: Bayesian strategies with on/off detectors (a) and PNR detectors (b), and the inversion of the Fano factor (c). The plots show the ratio ¯ φ/φ ∗ (solid curve) and the corresponding standard deviation (dashed curves) as a function of the number M of data sample. We set a = b = √ 2 and φ ∗ = 0 3 . .
FIG. 3: (Color online) Logarithmic plot of the variance Var φ , in numerical simulations, given by the Bayesian method for on/off detectors (red, dotted) and PNR detectors (blue, solid), and by the method of inversion of the Fano factor (green, dashed). We set φ ∗ = 0 3 . and a = b = √ 2 .
of the output by means of PNR detectors. The Fano factor of the displaced state ˆ glyph[rho1] out ( a, b, φ ) considered beforehand displays an explicit dependence on the phase parameter [21] that can be inverted to obtain φ . By analyzing the same Monte Carlo simulated data used before, according to the photon statistics p n ( a, b, φ ) , we can compare this inversion method with the Bayesian one. In particular, in Fig. 2 (c) we show the estimation of φ and the corresponding standard deviation as functions of the number of data M , with the same parameters employed for the Bayesian estimation. The plot clearly shows a slower convergence to the expected value φ ∗ , with very large fluctuations due to error propagation in the inversion method.
In Fig. 3 we compare the variances, plotted against the number of data samples M , provided by the three methods used
FIG. 4: (Color online) Logarithmic plot of the variance Var φ , in numerical simulations with input bracket states ˆ( glyph[rho1] b, γ ) , given by the Bayesian method for on/off detectors (red, dashed) and PNR detectors (blue, dashed), compared to the ideal case γ → 0 (solid lines). Simulated setup parameters: φ ∗ = 0 3 . , a = b = √ 2 and γ = π/ 4 .
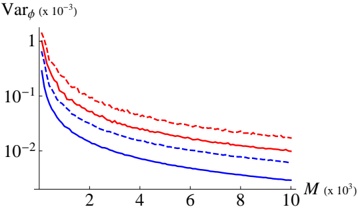
for retrieving the phase parameter φ : the Bayesian strategy for on/off and PNR detectors and the method of inversion of the Fano factor. The convergence to the expected value φ ∗ is clearly faster for Bayesian strategies than for the inversion of the Fano factor. In particular, the employment of PNR detectors results the best strategy since more information can be extracted from the reconstruction of the photon statistics.
In a more realistic scenario the input coherent states can be affected by noise during propagation. In this Letter we model the noise by introducing a uniform phase noise [22]. The resulting state is the so-called bracket state ˆ( glyph[rho1] b, γ ) ≡ γ -1 ∫ γ/ 2 -γ/ 2 dψ glyph[rho1] ˆ( b e i ψ ) [21], where γ is the noise parameter. Our aim is now to apply the same Bayesian approach by considering the photon-number probability distribution p n ( a, b, φ, γ ) ≡ γ -1 ∫ γ/ 2 -γ/ 2 dψ p n ( a, b, φ -ψ ) corresponding to the output state ˆ glyph[rho1] out ( a, b, φ, γ ) = ˆ ( D a e i φ )ˆ( glyph[rho1] b, γ ) ˆ D † ( a e i φ ) . The Bayesian strategies prove to be very robust in the phase estimation with this kind of noise, only showing small differences in the convergence (see Fig. 4) compared to the ideal case in the limit of vanishing noise ( γ → 0 ). As expected, the effect of the uniform phase noise described by the bracket states is a slight increase of the variance of the estimation procedure.
Experimental results - In our experimental setup, linearlypolarized pulses at 523 nm (5-ps-pulse duration, 500-Hzrepetition rate) were sent to a Mach-Zehnder interferometer, in which the relative phase between the two arms was changed by means of a piezoelectric movement operated step by step. The output state was delivered to a hybrid photodetector (HPD, R10467U-40, Hamamatsu; maximum quantum efficiency ∼ 0.5 at 500 nm, 1.4-ns response time), amplified and synchronously integrated [23, 24]. By exploiting the linearity of our device, the value of the relative phase can be determined at each piezo position, independent of the regularity and reproducibility of the movement [25]. Bracket states can be obtained in post-selection according to φ ∗ and the noise parameter γ . More in detail, the bracket states have been produced by selecting data samples corresponding to two different choices of the relative phase, namely φ ∗ glyph[similarequal] 0 25 . and
FIG. 5: (Color online) Left: experimental photon-number distributions p (exp) n obtained by PNR detection (green histograms) and theoretical expectations p n ( a, b, φ ¯ PNR , γ ) (blue lines) . Right: Bayesian probability distributions for the parameter φ , corresponding to a set of M = 4000 experimental data acquired with both on/off (red curve) and PNR (blue curve) detectors. The experimental parameters are a = 1 12 . , b = 0 79 . , φ ∗ glyph[similarequal] 0 25 . , γ = 0 (top row) and γ = π/ 4 (bottom row).
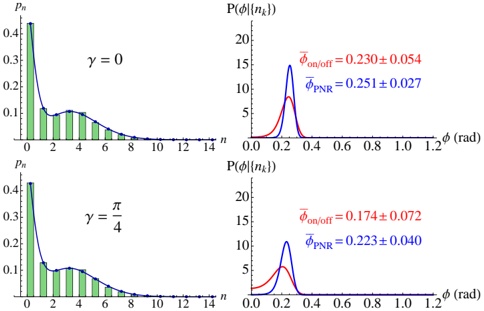
φ ∗ glyph[similarequal] π/ 4 with γ = π/ 4 and γ = π/ 2 , respectively.
The results are presented in Figs. 5 and 6, where we plot the measured photon statistics p (exp) n , the posterior Bayesian distributions P on/off ( φ |{ n k } ) and P PNR ( φ |{ n k } ) and the corresponding estimated phases ¯ φ on/off and ¯ φ PNR with their variances. Furthermore, in order to assess the quality of our reconstructions, we also plot the photon distributions p n ( a, b, φ ¯ PNR , γ ) , which have fidelities F =
∑ √ n p n ( a, b, φ, γ ¯ ) p (exp) n higher than 99 9% . to the experimental data [26]. In both Figures it is evident that the employment of a PNR detector allowed us to reconstruct with accuracy the photon number distribution p n ( a, b, φ, γ ¯ ) for the two bracket states (see left panels of Figs. 5 and 6) and to apply the Bayesian method to both the cases of on/off and PNR detection. If we focus on the first experimental test concerning φ ∗ glyph[similarequal] 0 25 . (Fig. 5), we can see that the Bayesian probability distributions, affected by a bias, show an asymmetric shape which is more marked in the case of on/off detection (see right panels in Fig. 5) [27]. Strikingly, PNR detection enhances the estimation as the Bayesian distribution is more peaked, has a smaller variance and a reduced asymmetry. The second experimental test for φ ∗ glyph[similarequal] π/ 4 displays better performances (see right panels in Fig. 6), in agreement with the behavior of FI in the plots of Fig. 1 (red dashed lines). PNR detection, again, provides an enhancement in the phase estimation describable in terms of a smaller variance and a more peaked Bayesian posterior distribution. In both situations, we note that the effect of the phase noise is to broaden the Bayesian distributions by increasing the variance, in agreement with the simulated data and the plot in Fig. 4. Nonetheless, the Bayesian strategy turns out to be very robust in the presence of phase noise, even if it is modeled, as in the present analysis, by a uniform
FIG. 6: (Color online) Left: experimental photon-number distributions p (exp) n obtained by PNR detection (green histograms) and theoretical expectations p n ( a, b, φ ¯ PNR , γ ) (blue lines). Right: Bayesian probability distributions for the parameter φ , corresponding to a set of M = 4000 experimental data acquired with both on/off (red curve) and PNR (blue curve) detectors. The experimental parameters are a = 1 12 . , b = 0 79 . , φ ∗ glyph[similarequal] π/ 4 , γ = 0 (top row) and γ = π/ 2 (bottom row).
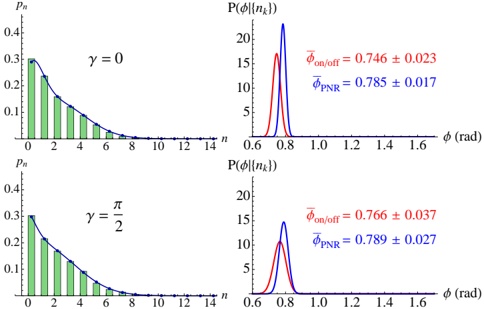
'white-noise' with a wide range such as γ = π/ 4 (second row of Fig. 5) and γ = π/ 2 (second row of Fig. 6).
Conclusions - We have proposed and demonstrated a realtime method to monitor the phase reference of a Kennedylike receiver without stopping the communication. We have provided the experimental realization of the protocol, which strengthen our theoretical model and numerical simulations. Phase estimation is usually implemented with a pure, optimized input probe state. Nevertheless, here we have shown that it is possible to perform a useful phase estimation also with a mixed, not optimized, probe state, that is the overall mixture of the two coherent states encoding the signal. Our strategy is based on Bayesian analysis and thus allows us to asymptotically reach the minimum uncertainty in the estimation collecting just few thousands of data. Furthermore, we have demonstrated the advantages of using PNR detectors with respect to on/off detectors and we have tested the performance of our strategy also in the presence of uniform phase noise. Our results pave the way to the real-time monitoring of the phase reference in more complicated communication systems or quantum optics setups, which require a precise control of the phase, e.g. in the generation of nonclassical states, such as squeezed states.
Acknowledgments -This work has been supported by MIUR (FIRB 'LiCHIS' RBFR10YQ3H).
∗ Electronic address: [email protected]
[1] C. W. Helstrom, Quantum Detection and Estimation Theory (Academic, New York, 1976).
[2] M. G. A. Paris, Int. J. Quant. Inf. 7 , 125 (2009).
[3] S. Olivares and M. G. A. Paris, J. Opt. B: Quantum Semiclass.
Opt. 6 , 69 (2004).
- [4] G. Cariolaro and G. Pierobon, IEEE Trans. Comput. 58 , 623 (2010).
- [5] A. Assalini, N. Dalla Pozza, and G. Pierobon, Phys. Rev. A 84 , 022342 (2011).
- [6] R. L. Cook, P. J. Martin, and J. M. Geremia, Nature 466 , 774 (2007).
- [7] C. Wittmann, U. L. Andersen, M. Takeoka, D. Sych, and G. Leuchs, Phys. Rev. Lett. 104 , 100505 (2010).
- [8] C. Wittmann, U. L. Andersen, M. Takeoka, D. Sych, and G. Leuchs, Phys. Rev. A 81 , 062338 (2010).
- [9] C. R. Muller, M. A. Usuga, C. Wittmann, M. Takeoka, Ch. Marquardt, U. L. Andersen, and G. Leuchs, New J. Phys. 14 , 083009 (2012).
- [10] S. Izumi, M. Takeoka, M. Fujiwara, N. Dalla Pozza, A. Assalini, K. Ema, and M. Sasaki, Phys. Rev. A 86 , 042328 (2012).
- [11] F. E. Becerra, J. Fan, G. Baumgartner, J. Goldhar, J. T. Kosloski, and A. Migdall, Nat. Photon. 7 , 147 (2013).
- [12] C. R. Muller, C. Wittmann, P. Marek, R. Filip, Ch. Marquardt, G. Leuchs, and U. L. Andersen, Phys. Rev. A 86 , 010305(R) (2012).
- [13] M. G. Genoni, S. Olivares, and M. G. A. Paris, Phys. Rev. Lett. 106 , 153603 (2011).
- [14] S. Olivares, S. Cialdi, F. Castelli, and M. G. A. Paris, Phys. Rev. A 87 , 050303(R) (2013).
- [15] C.-W. Lau, V. A. Vilnrotter, S. Dolinar, J. M. Geremia, and H. Mabuchi, IPN Progress Report 42-165 , 1 (2006).
- [16] R. S. Kennedy, MIT RLE Quarterly Progress Report, N. 108 (1973) unpublished.
- [17] Actually, if α = β , the configuration with τ = 1 2 / corresponds
- to the quasi optimal discrimination between the coherent states | ± β/ √ 2 〉 .
- [18] B. Teklu, S. Olivares, and M. G. A. Paris, J. Phys. B: At. Mol. Opt. Phys. 42 , 0335502 (2009).
- [19] S. Olivares, and M. G. A. Paris J. Phys. B: At. Mol. Opt. Phys. 42 , 055506 (2009).
- [20] It is worth noting that in both on/off and PNR detection, the FI goes to zero as φ → 0 : this is a consequence of the probe mixed state ˆ( glyph[rho1] β ) of Eq. (1), which is a balanced mixture of the state | β 〉 , that maximizes the FI for φ = 0 , and | -β 〉 , that leads to a null FI for φ = 0 .
- [21] A. Allevi, S. Olivares, and M. Bondani, Int. J. Quant. Inf. 12 , 1461018 (2014).
- [22] We do not consider losses since they only affect the amplitude of the coherent states but leave unchanged the other physical properties, such as the photon statistics, that is simply rescaled, and the phase.
- [23] M. Bondani, A. Allevi, A. Agliati, and A. Andreoni, J. Mod. Opt. 56 , 226 (2009).
- [24] A. Andreoni, and M. Bondani, Phys. Rev. A 80 , 013819 (2009).
- [25] M. Bondani, A. Allevi, and A. Andreoni, J. Opt. Soc. Am. B 27 , 333 (2010).
- [26] M. Bina, A. Mandarino, S. Olivares, and M. G. A. Paris, Phys. Rev. A 89 , 012305 (2014).
- [27] In the case of small phase parameter, φ glyph[similarequal] 0 25 . , the optimal estimator turns out to be the mode ˜ φ ≡ Max { P φ ( |{ n k } } ) , as the Bayes posterior probabilities are biased, resulting in ˜ φ on/off = 0 24 . and ˜ φ PNR = 0 25 . (for γ = 0 ) and ˜ φ on/off = 0 20 . and ˜ φ PNR = 0 23 . (for γ = π/ 4 ). | 10.1038/srep26025 | [
"Matteo Bina",
"Alessia Allevi",
"Maria Bondani",
"Stefano Olivares"
] | 2014-08-01T16:41:25+00:00 | 2014-08-01T16:41:25+00:00 | [
"quant-ph"
] | Real-time phase-reference monitoring of a quasi-optimal coherent-state receiver | The Kennedy-like receiver is a quasi-optimal receiver employed in binary
phase-shift-keyed communication schemes with coherent states. It is based on
the interference of the two signals encoding the message with a reference local
oscillator and on/off photodetection. We show both theoretically and
experimentally that it is possible to extract useful information about the
phase reference by Bayesian processing of the very same data sample used to
discriminate the signals shot by shot. We demonstrate that the minimum
uncertainty in phase estimation, given by the inverse of the Fisher information
associated with the statistics of the collected data, can be achieved. We also
numerically and experimentally investigate the performances of our
phase-estimation method in the presence of phase noise, when either on/off or
photon-number resolving detectors are employed. |
1408.0229v2 | ## Signs of a faint disc population at polluted white dwarfs
C. Bergfors 1 /star , J. Farihi 1 † , P. Dufour 2 and M. Rocchetto 1
D´ epartement de Physique, Universit´ e de Montr´al, Montr ´al, QC H3C 3J7, Canada e e
1 University College London, Department of Physics and Astronomy, Gower Street, London WC1E 6BT, UK 2
Accepted 2014 July 31. Received 2014 July 29; in original form 2014 June 5
## ABSTRACT
Observations of atmospheric metals and dust discs around white dwarfs provide important clues to the fate of terrestrial planetary systems around intermediate mass stars. We present Spitzer Infrared Array Camera observations of 15 metal polluted white dwarfs to investigate the occurrence and physical properties of circumstellar dust created by the disruption of planetary bodies. We find subtle infrared excess emission consistent with warm dust around KUV15519+1730 and HS2132+0941, and weaker excess around the DZ white dwarf G24558, which, if real, makes it the coolest white dwarf known to exhibit a 3 6 . µ m excess and the first DZ star with a bright disc. All together our data corroborate a picture where (1) discs at metal-enriched white dwarfs are commonplace and most escape detection in the infrared (possibly as narrow rings), (2) the discs are long lived, having lifetimes on the order of 10 6 yr or longer, and (3) the frequency of bright, infrared detectable discs decreases with age, on a timescale of roughly 500 Myr, suggesting large planetesimal disruptions decline on this same timescale.
Key words: circumstellar matter - planetary systems - white dwarfs
## 1 INTRODUCTION
Planetary systems around evolved stars and white dwarfs provide keys to understanding the history of planet formation in our Galaxy, and their fate - including that of our Solar System. Although no planetary mass objects have yet been discovered around single white dwarfs, several planets are known to orbit evolved stars and stellar remnants, e.g. pulsars (Wolszczan & Frail 1992), binary white dwarf + neutron star systems (e.g. Sigurdsson et al. 2003), giants and subgiants (e.g. Frink et al. 2002; Johnson et al. 2007; Sato et al. 2008; Bowler et al. 2010). These discoveries, together with the fact that more than 95% of all stars are destined to become white dwarfs, imply that at least some planetary systems survive post-main sequence evolution. Based on the prevalence of white dwarfs that have metal polluted atmospheres deriving from the accretion of planetary material, at least ≈ 30 per cent still have rocky minor (or major) planets (Sion et al. 2009; Zuckerman et al. 2010; Koester, G¨ ansicke & Farihi 2014).
mospheres consisting of pure hydrogen (DA type) or helium (nonDA) . Owing to their high surface gravity, the time-scale for any 1 metals to sink out of the atmosphere is short compared to the evolutionary time-scale for white dwarfs cooler than T eff /lessorsimilar 25 000 K, for which radiative forces are negligible (Koester 2009). The metal diffusion time-scale varies from only a few days for hot and young DAwhite dwarfs to a few 10 6 yr for helium and old hydrogen white dwarfs. Any heavy element enrichment in the atmospheres of cool white dwarfs therefore implies relatively recent accretion.
The presence and abundance pattern of metals in the atmospheres of white dwarfs, combined with often-observed infrared excesses, imply accretion of circumstellar material created by the disruption of minor planets within the stellar Roche limit. Since the first observation of infrared excess from a circumstellar disc around a (single) white dwarf (G29-38; Zuckerman & Becklin 1987), clues to the origin of the circumstellar dust have accumulated, primarily from spectroscopic observations. Most white dwarfs have thin at-
- /star E-mail: [email protected]
† Ernest Rutherford Fellow
The composition of the accreted material provides vital clues to its source. While early discoveries of polluted white dwarfs (e.g. Lacombe et al. 1983; Zuckerman et al. 2003) could not exclusively determine the origin of the accreted material - interstellar clouds, comets or asteroids have been suggested - the evidence has since become compelling that the accretion of planetary debris is the cause of the photospheric pollution and the only source that can adequately explain different observational properties. For instance, if accretion from the interstellar medium were responsible for the pollution it must have occurred relatively recently for DA stars. This theory is strongly disfavoured due to the lack of nearby dense interstellar clouds, and the relative absence of hydrogen in helium white dwarfs (see e.g. Farihi et al. 2010a).
The strongest support for accretion of disrupted planetesimals
1 White dwarfs are classified as D (degenerate) followed by identified optical or ultraviolet spectral features; in our sample we have types A (hydrogen) and B (helium), with Z denoting metal lines. DZ stars have helium-rich atmospheres but are too cool for He I absorption to be visible in their spectra (McCook& Sion 1999).
comes from the inferred composition of the circumstellar material, which has been shown to be silicate rich and carbon poor - in contrast to the interstellar medium which is rich in volatiles such as carbon. The first infrared spectra with Spitzer of the dusty white dwarfs G29-38 and GD 362 (Reach et al. 2005a; Jura et al. 2007a) showed strong silicate emission at 9 -11 µ m consistent in shape with zodiacal dust emission, and no signs of polycyclic aromatic hydrocarbon (PAH) emission which is abundant in the interstellar medium at mid-infrared wavelengths. These features in the infrared spectra have since been confirmed for all white dwarfs with circumstellar discs that have been observed with the Spitzer Infrared Spectrograph (Jura, Farihi & Zuckerman 2009), and additional silicate emission features were also found at 18 -20 µ m for G29-38 (Reach et al. 2009).
The metal abundances of the stars mirror the circumstellar material. Analysis of the heavily polluted atmosphere of GD 362 revealed 15 heavy elements, the relative abundances of which indicated that the debris had a composition that was similar to that of the Earth-Moon system (Zuckerman et al. 2007). In total 19 distinct metals have been detected in the atmospheres among several polluted white dwarfs from high resolution spectroscopic observations (e.g. Zuckerman et al. 2007; Melis et al. 2011; Dufour et al. 2012; Kawka & Vennes 2012; Xu et al. 2014).
To date, 30 previously published metal polluted white dwarfs show excess infrared emission, and in some cases metallic gas emission (G¨ ansicke et al. 2006, 2008; G¨ ansicke, Marsh & Southworth 2007; Farihi et al. 2012a; Melis et al. 2012), indicative of circumstellar debris. These discs are in general similar -the observed infrared excesses imply emission from hot circumstellar dust and a lack of cool dust outside of the stellar Roche limit ( r ≈ 1 R /circledot ). The now standard model for formation of these circumstellar discs involves a (as of yet undetected) planet perturbing a minor planetary body into a highly eccentric orbit (Debes & Sigurdsson 2002; Bonsor, Mustill & Wyatt 2011; Debes, Walsh & Stark 2012) which is tidally disrupted when it comes within the Roche limit. The planetary material is viscously spread into a vertically thin, optically thick flat disc of temperature T ∼ 1000 K with an inner edge near a radius where silicate grains would rapidly sublimate (Jura 2003; Rafikov & Garmilla 2012), from where it is accreted on to the white dwarf, causing the observed metal pollution. The composition of the accreted material therefore provides a way of measuring the bulk compositions of the disrupted minor or even major planets .
## 2 SCIENTIFIC MOTIVATION
To date, more than 200 white dwarfs have been searched for infrared excess, however dust emission from circumstellar discs has only been detected in those that have metal polluted atmospheres (von Hippel et al. 2007; Mullally et al. 2007; Farihi et al. 2012a). Previous studies have shown that while a significant fraction of polluted white dwarfs show infrared excess emission from circumstellar dust, the majority have no observable discs (Debes, Sigurdsson & Hansen 2007; Farihi, Jura & Zuckerman 2009). One possibility for the lack of observed disc emission around metal polluted white dwarfs is that the material is mainly gaseous from high speed collisions in discs with low particle densities (Jura, Farihi & Zuckerman 2007b). Alternatively, for helium white dwarfs which have long diffusion time, it is possible that the metals detected in the photosphere have been accreted from discs that have since dissipated.
Jura (2008) proposed a model in which massive dust discs, and hence those with observable infrared emission, originate from the disruption of large asteroids, while for the majority of metal polluted white dwarfs continuous accretion of small asteroids creates a mainly gaseous disc with low surface dust density and hence modest infrared excess. In fact, previous studies have detected relatively subtle excesses around white dwarfs, which can be modelled as narrow dust rings (Farihi, Zuckerman & Becklin 2008; Farihi et al. 2010b).
Observationally, the infrared bright disc frequency appears to be correlated with both the accretion rate (averaged over time for helium white dwarfs) and the white dwarf cooling age such that younger white dwarfs with high mass accretion rate are more prone to show infrared excess (Farihi et al. 2009; Xu & Jura 2012). This correlation is however somewhat biased since it is observationally more challenging to detect metal pollution in the warmest white dwarfs compared to cooler ones, resulting in a smaller number of relatively young metal polluted stars observed with Spitzer . Discriminating between these two groups of polluted white dwarfs those with infrared detectable dust and those without - could possibly indicate whether the pollutant is one single large asteroid or a collection of several smaller ones (Jura 2008), with implications for the interpretation of the heavy element abundance patters in a spectral analysis.
We observed 15 metal polluted white dwarfs with Spitzer IRACin search for infrared excess indicative of warm circumstellar dust. The aim of this study is to extend previous surveys by observing additional metal polluted white dwarfs, and especially investigate bright disc frequency among cooler stars. In Section 3 we present the Spitzer IRAC and complementary ground based observations and data reduction. The results and analysis are presented in Section 4, including the detection of infrared excess consistent with warm circumstellar dust for two, possibly three, of our targets: KUV 15519+1730, G245-58 and HS 2132+0941. We discuss the properties of the newly discovered infrared excesses in the context of disc frequency and lifetime in Section 5, and summarise the results of the survey in Section 6.
## 3 OBSERVATIONS AND DATA REDUCTION
## 3.1 Target selection and Spitzer IRAC observations
Our 15 targets were selected in 2010 as the bulk of metal enhanced nearby and relatively bright white dwarfs that had not been observed with the Spitzer Infrared Array Camera (IRAC). The majority of the targets are moderately polluted with [Ca/H(e)] /lessorsimilar -7 5 . and mainly with effective temperatures T eff /lessorequalslant 10 000 K. These targets belong to a region of temperature and Ca abundance phase space that had not been well explored in previous studies. Three targets, KUV 15519+1730, HS 2132+0941 and HE 2230-1230, are warm ( T eff /greaterorsimilar 13 000 K) and highly metal polluted ([Ca/H(e)] /greaterorsimilar -7 5 . ) white dwarfs, thus likely to have observable excess infrared emission from circumstellar dust.
Warm Spitzer (Werner et al. 2004) infrared observations were carried out with IRAC (Fazio et al. 2004a) in Cycle 7 within programs 70037 and 70116. 30 medium size dithers of 30 s integrations were obtained in the cycling pattern for each target in IRAC channels 1 ( 3 6 . µ m) and 2 ( 4 5 . µ m). When combined to a 900 s integration mosaic the many dithers efficiently reduce artefacts such as
Table 1. List of IRAC imaging targets. Coordinates are measured from the Cycle 7 IRAC images (equinox J2000.0).
| WD | Name | R. A. (h ms) | Dec ( ◦ ′ ′′ ) | SpT | T eff ( K ) | [Ca/H(e)] | Ref. |
|----------|----------------|----------------|------------------|-------|---------------|-------------|--------|
| 0122-227 | KUV01223-2245 | 01 24 44.8 | - 22 29 07 | DZ | 10 000 | - 9 . 4 | 1 |
| 0246+734 | G245-58 | 02 51 51.8 | +73 41 34 | DZ | 7500 | - 9 . 7 | 2 |
| 0543+579 | GD 290 | 05 47 56.5 | +57 59 22 | DAZ | 8140 | - 10 . 3 | 3 |
| 0625+100 | G105-B2B | 06 27 37.6 | +10 02 13 | DZ | 8800 | - 9 . 5 | 4 |
| 0816-310 | SCR0818 - 3110 | 08 18 40.5 | +31 10 29 | DZ | 6460 | - 9 . 2 | 5 |
| 0840-136 | LP786-1 | 08 42 48.3 | - 13 47 13 | DZ | 4870 | - 10 . 9 | 5 |
| 1009-184 | WT1759 | 10 12 01.5 | - 18 43 33 | DZ | 6040 | - 10 . 6 | 5 |
| 1055-039 | G163-28 | 10 57 47.8 | - 04 13 32 | DZ | 6500 | - 10 . 7 | 4 |
| 1338-311 | CE354 | 13 41 25.7 | - 31 24 50 | DZ | 8210 | - 10 . 0 | 6 |
| 1425+540 | G200-40 | 14 27 35.8 | +53 48 30 | DBAZ | 14 490 | - 9 . 3 | 7, 8 |
| 1551+175 | KUV15519+1730 | 15 54 09.1 | +17 21 24 | DBAZ | 15 550 | - 6 . 5 | 8 |
| 1821-131 | GJ2135 | 18 24 04.4 | - 13 08 49 | DAZ | 7030 | - 10 . 7 | 3 |
| 2132+096 | HS2132+0941 | 21 34 50.8 | +09 55 20 | DAZ | 13 200 | - 7 . 7 | 9 |
| 2157-574 | WT853 | 22 00 45.1 | - 57 11 24 | DAZ | 7220 | - 8 . 0 | 2, 10 |
| 2230-125 | HE2230 - 1230 | 22 33 38.8 | - 12 15 28 | DAZ | 20 300 | - 6 . 3 | 9 |
References: (1) Friedrich et al. (2000); (2) this paper; (3) Zuckerman et al. (2003); (4) Dupuis, Fontaine & Wesemael (1993); (5) Giammichele, Bergeron & Dufour (2012); (6) Dufour et al. (2007); (7) Kenyon et al. (1988); (8) Bergeron et al. (2011); (9) Koester et al. (2005); (10) Subasavage et al. (2007)
cosmic rays and bad pixels. Table 1 lists the observed targets, their coordinates at the epoch of observation, spectral types, published temperatures and calcium abundances.
Table 2. IRAC Ch1 and Ch2 photometry.
## 3.2 Spitzer IRAC photometry
The IRAC basic calibrated data (BCD) reduction pipeline produces flux-calibrated data frames from which photometry with a few per cent accuracy can be performed either directly on the individual images or after mosaic combination. We combined the additional artefact mitigated, corrected BCD (CBCD) images to a create a coadded mosaic image using the MOPEX post-BCD software 2 with a pixel size 0.6 arcsec pixel -1 .
We perform photometry following Farihi et al. (2008). The main effects that contribute to increase photometric uncertainties arise from the array location of the target, and the pixel phase effect where the position of the point-spread function (PSF) centroid on the peak pixel affects the photometric result (Reach et al. 2005b; Hora et al. 2008). Both the array-location and pixel-phase effects are expected to average out for well dithered data such as ours. Colour corrections are assumed to be negligible.
Aperture and PSF-fitting photometry was performed on the mosaic combined images for each target and filter using the IRAF APPHOT and DAOPHOT packages. To avoid photometric confusion, we perform photometry either using a small aperture of radius r = 4 pixel and 24-40 pixel sky annulus, with the corrections recommended in the IRAC Instrument Handbook, or PSF-fitting on the mosaic combined images. We calculate 1 σ errors of the aperture photometry by measuring the standard deviation in the sky, and adopt the errors reported by DAOPHOT for the PSF-fitting photometry, adding in quadrature a 5 per cent absolute calibration er-
2 Details on the reduction pipeline and additional software can be found in the IRAC Instrument Handbook and related documentation at the Spitzer Science Center (SSC) website at http://irsa.ipac.caltech.edu/data/SPITZER/docs/irac/
| WD | F 3 . 6 µm ( µ Jy) | F 4 . 5 µm ( µ Jy) | IR excess |
|------------|----------------------|----------------------|-------------|
| 0122-227 | 52 ± 3 | 38 ± 2 | N |
| 0246+734 a | 65 ± 5 | 47 ± 5 | Y |
| 0543+579 | 172 ± 9 | 106 ± 6 | N |
| 0625+100 | 82 ± 8 | 56 ± 7 | N |
| 0816-310 | 382 ± 19 | 248 ± 13 | N |
| 0840-136 | 550 ± 28 | 366 ± 18 | N |
| 1009-184 | 474 ± 24 | 291 ± 15 | N |
| 1055-039 | 129 ± 7 | 88 ± 5 | N |
| 1338-311 | 48 ± 5 | 32 ± 4 | N |
| 1425+540 | 163 ± 8 | 102 ± 5 | N |
| 1551+175 | 29 ± 2 | 26 ± 2 | Y |
| 1821-131 b | - | - | - |
| 2132+096 a | 98 ± 5 | 79 ± 5 | Y |
| 2157-574 | 252 ± 13 | 152 ± 8 | N |
| 2230-125 | 53 ± 3 | 34 ± 2 | N |
a Weighted average of fluxes extracted with DAOPHOT and APEX (see Section 3.4).
b Accurate fluxes could not be extracted for this target due to severe confusion.
ror to each measurement (see Farihi et al. 2008). Additional photometry was performed for a few targets using the Astronomical Point-source Extractor (APEX) in MOPEX to deblend some targets or confirm an infrared excess (see Section 3.4). The Spitzer IRAC photometry is listed in Table 2.
## 3.3 Ground based near-infrared photometry
Additional ground-based observations were obtained for some Spitzer IRAC targets in the near-infrared JHK s bands with the Long-slit Intermediate Resolution Infrared Spectrograph (LIRIS;
Figure 1. Spitzer IRAC 0 . ′′ 6 pixel -1 images in 3 6 . µ m(Ch 1) and 4 5 . µ m(Ch 2) of G245-58. The images are shown on identical square root scales. The target star appears slightly elongated at 4 5 . µ m, most likely due to a background object.


Manchado et al. 1998) at the 4.2 m William Herschel Telescope (WHT)in 2011 March and October, and with Son of ISAAC (SOFI; Moorwood, Cuby & Lidman 1998) at the 3.6 m New Technology Telescope (NTT) in 2011 August and 2012 January. The science targets were observed in a continuous dither pattern with individual exposure times of 30, 15, and 10 s at J , H , and K s respectively for a total integration time of 270 s in each filter. Each night three standard star fields from the ARNICA catalogue (Hunt et al. 1998) were observed for flux calibration.
is thus likely associated with circumstellar dust around the white dwarf.
Standard data reduction was performed. The median sky subtracted frames were shifted and average combined into a single image on which aperture photometry with IRAF APPHOT or, for targets with nearby sources, DAOPHOT, was performed using standard aperture radii between 3 8 . and 4 3 . arcsec and sky annuli in the range 5 0 . -8 6 . arcsec. Smaller apertures were used for the faintest sources ( m> 15 5 . mag), with corrections derived from bright stars in the same image. The flux calibration was good to 5 per cent or better on each night.
## 3.4 Photometric extraction of blended sources
G245-58 appears slightly elongated at 4 5 . µ m and therefore blending with a background object was suspected (Fig. 1). The additional source is brighter at 4 5 . µ m, where it appears relatively extended and diffuse, and hence it is likely a background galaxy.
In order to avoid contamination from the neighbouring source we performed PSF-fitting photometry on the science target using both DAOPHOT and APEX, in addition to aperture photometry, with the results listed in Table 3. A comparison between the aperture and PSF-fitting photometry showed that while the aperture photometry gives slightly higher flux densities, the values are consistent with those from the PSF-fitting photometry within errors. We also performed aperture photometry on the residual images generated by DAOPHOT after subtraction of the white dwarf, and found a residual flux density of 2 -4 per cent of the extracted target flux in both channels. This is well within the error bars and identical to that found for isolated targets analysed in the same manner. The potential contamination by the background source is therefore much smaller than the total flux excess measured compared to a white dwarf atmospheric model (see Section 4.3) and the infrared excess
As an additional test we compared the position relative to other stars in the field in the LIRIS JHK s and the 3 6 . and 4 5 . µ m IRAC images, since a shift of the PSF peak could indicate contamination of the photometry by the background source. We find no significant shift and conclude that the flux we extracted and measured in the IRAC images is that of the target. The PRF-fitting photometry with APEX gives marginally different values, and we adopt a weighted average from the two methods.
Based on our previous experience, approximately 1 out of 20 white dwarfs observed with IRAC needs some photometric deblending, but are typically recoverable (e.g. Farihi et al. 2010b). Our adopted flux measurement for G245-58 at 4 5 . µ m is 47 µ Jy, corresponding to 16.5 magnitudes (Vega). In order to assess the probability that the flux we measure is that of a background source and not the science target, we use IRAC 4 5 . µ m source counts from Fazio et al. (2004b). For the worst case scenario in which the galaxy contributes most of the flux measured at this wavelength, there are less than 2 × 10 4 galaxies deg -2 within a 1 mag interval centred at 17.0 mag. With a photometric aperture radius of 2 4 . arcsec, we find a probability of less than 1 per cent that the measured flux is due to a sufficiently bright background galaxy.
Two of our targets, WD 0625+100 and WD 1338-311, suffer from some blending with nearby stars. In both cases PSF-fitting photometry successfully de-convolved both point sources. No infrared excess is observed for these targets in IRAC, but flux contamination is the likely cause of excess seen in the Wide-field Infrared Survey Explorer ( WISE ; Wright et al. 2010) 3 4 . µ m flux of WD0625+100 (see Fig. 2). We also perform photometry with APEX and DAOPHOT for HS2132+0941 to confirm the infrared excess which is only seen at 4 5 . µ m. The photometry using both methods and the adopted values are listed in Table 3.
## 4 RESULTS AND ANALYSIS
## 4.1 Spectral Energy Distribution
Models of pure hydrogen and helium atmosphere white dwarfs (Koester 2010) for log g = 8 0 . were scaled to fit available photometric data in the optical from the Sloan Digital Sky Survey (SDSS;
Figure 2. Spectral energy distributions for target stars. Photometric data are from GALEX , SDSS, Subasavage et al. (2007, 2008), 2MASS, Table 4, WISE and IRAC (see Tables 2 and 4). The WISE 4 6 . µ mphotometry (light grey) have been slightly offset from the central wavelength in the plot for clarity.
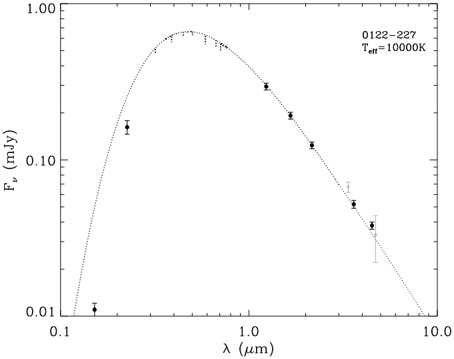
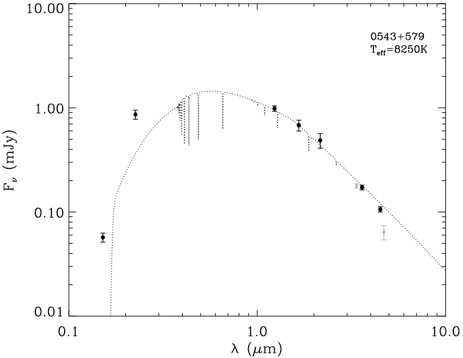
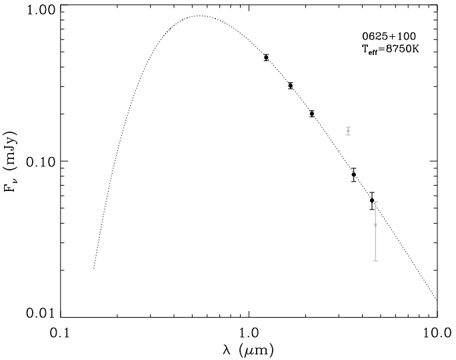
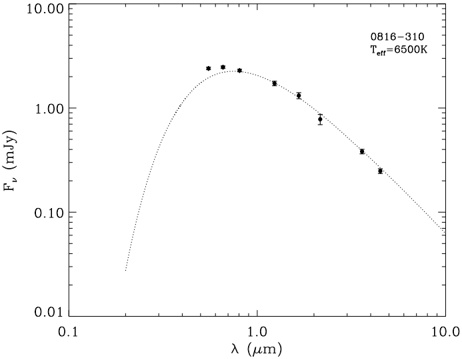
Table 3. IRAF and APEX photometry of G245-58 and HS 2132+0941.
Table 4. Ground-based JHK s photometry. All errors are 5 per cent
| Wavelength ( µ m ) | APEX ( µ Jy ) | DAOPHOT ( µ Jy ) | Adopted flux ( µ Jy ) |
|----------------------|-----------------|--------------------|-------------------------|
| G245-58 | G245-58 | G245-58 | G245-58 |
| 3 . 6 | 65 ± 4 | 64 ± 5 | 65 ± 5 |
| 4 . 5 | 45 ± 3 | 50 ± 5 | 47 ± 5 |
| HS2132+0941 | HS2132+0941 | HS2132+0941 | HS2132+0941 |
| 3 . 6 | 99 ± 5 | 96 ± 6 | 98 ± 5 |
| 4 . 5 | 81 ± 4 | 77 ± 5 | 79 ± 5 |
Stoughton et al. 2002), Subasavage et al. (2007, 2008), and in the near-infrared from Table 4 or the Two Micron All Sky Survey (2MASS; Skrutskie et al. 2006). We also plot in Fig. 2-4 ultraviolet photometry from the Galaxy Evolution Explorer ( GALEX ; Martin et al. 2005) if available, with 10 per cent error bars. The farultraviolet (FUV) and near-ultraviolet (NUV) data are however not
| WD | J (mag) | H (mag]) | K s (mag) | Instrument /Telescope |
|----------|-----------|------------|-------------|-------------------------|
| 0122-227 | 16.83 | 16.82 | 16.83 | SOFI/NTT |
| 0246+734 | 16.93 | 16.85 | 16.84 | LIRIS/WHT |
| 0625+100 | 16.35 | 16.32 | 16.3 | LIRIS/WHT |
| 1055-039 | 15.98 | 15.92 | 15.84 | SOFI/NTT |
| 1338-311 | 17.03 | 16.99 | 17.06 | SOFI/NTT |
| 1551+175 | 17.52 | 17.64 | 17.56 | SOFI/NTT |
| 1821-131 | 14.51 | 14.28 | 14.21 | SOFI/NTT |
| 2132+096 | 16.15 | 16.17 | 16.17 | SOFI/NTT |
considered for the model fitting as the fluxes may be affected by metal blanketing and extinction (Koester et al. 2011). When fitting the models we assumed error bars of 5 per cent for the SDSS photometry, errors as listed in catalogue for 2MASS data (minimum 5 per cent), and 3 per cent error bars for Johnson V and Cousins R and I photometric data from Subasavage et al. (2007, 2008). Figs 2
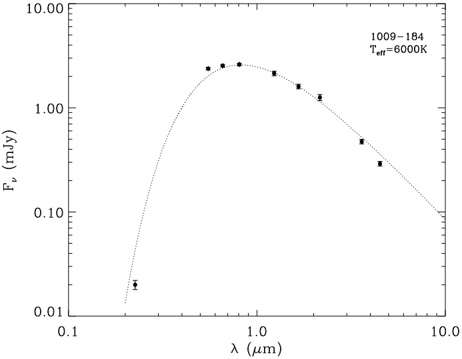
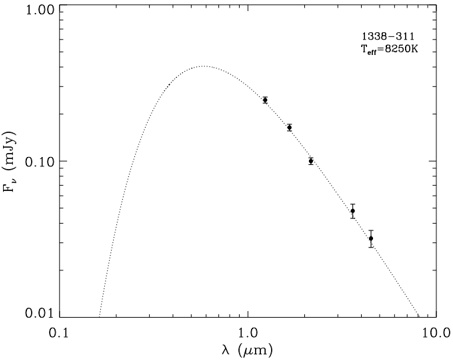
Figure 2. - continued
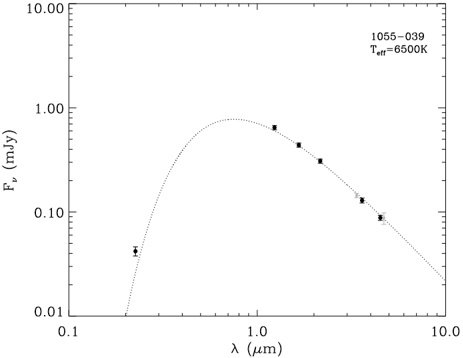
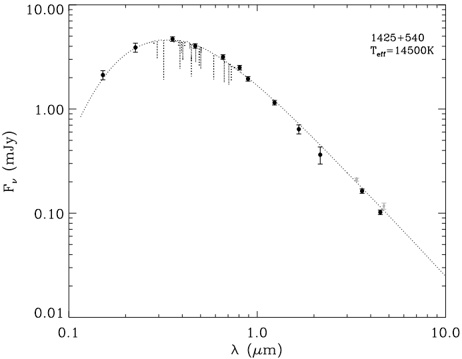
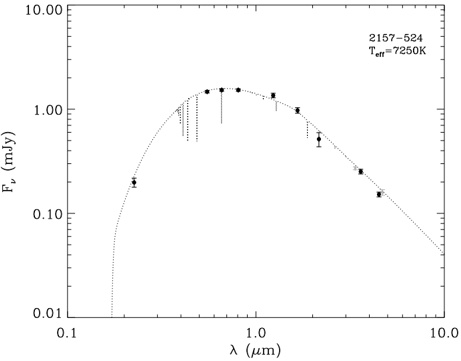
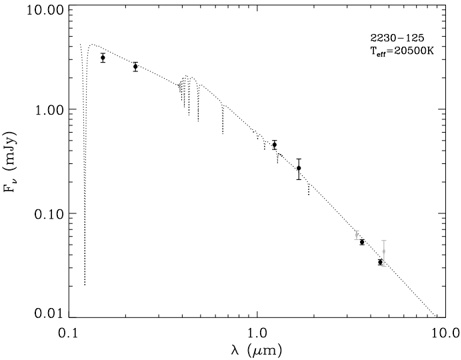
and 3 show the spectral energy distributions of the targets without infrared excess. Photometry from WISE at 3 4 . and 4 6 . µ m is plotted for comparison in these figures if available; it is not however considered for model fitting. WISE data are insufficient in spatial resolution and sensitivity for these observational goals (Melis et al. 2011; Rocchetto et al., in preparation).
Two of the 15 targets show clear infrared excess compared to the white dwarf atmospheric model at 3 6 . and 4 5 . µ m: KUV15519+1730 shows a 4 σ excess at both 3 6 . and 4 5 . µ m, and a 3 σ excess at 2 2 . µ m, compared to the best model fit to the optical and near-infrared data. We detect a less significant ( 2 5 . σ ≈ 20 -25 per cent) excess in both wavelength bands for G245-58 in what is likely the most subtle disc emission detected at at white dwarf. HS2132+0941 exhibits a 4 σ excess at 4 5 . µ m compared to the expected photospheric flux, but no significant excess at shorter wavelengths. The spectral energy distributions of these targets are shown in Fig. 4.
We model the infrared emission of these three stars using opaque and geometrically flat dust rings (Jura 2003), which well describe the thermal dust emission observed at metal-rich white dwarfs. For each star the stellar radius to distance ratio R /d ∗ is calculated using the cooling models of the Montr´ eal group 3 for the adopted stellar atmospheric model temperature and assuming log g = 8 0 . (Holberg & Bergeron 2006; Kowalski & Saumon 2006; Bergeron et al. 2011; Tremblay, Bergeron & Gianninas 2011), and three free parameters are varied to achieve a best fit to the near-infrared and IRAC data: the inner and outer disc temperature, T in and T out , and the inclination i of the disc. Corresponding disc radii are calculated following Chiang & Goldreich (1997).
While the inner edge temperature can be relatively well constrained by the emission at shorter wavelengths ( 2 2 . and 3 6 . µ m), there is significant degeneracy in these models and they should be considered descriptive rather than definitive. For subtle excesses as found for these three targets, the thermal dust emission can be equally well fitted with relatively wide rings at high inclination, or as narrow rings at modest inclination (Girven et al. 2012). We therefore present two sets of models for each target with excess emission in Table 5 and Fig. 4. These model disc parameters do not represent the actual disc properties, but give representative, physically realistic disc temperatures consistent with the data. Importantly, all realistic models place these discs completely within the Roche limit, and thus consistent with disrupted planetesimals. The targets and their infrared excesses are discussed more in detail in the following subsections.
## 4.2 KUV15519+1730
This helium white dwarf shows traces of hydrogen in its spectrum together with Ca H & K lines and is therefore classified as spectral type DBAZ (Wegner & Swanson 1990; Bergeron et al. 2011). The excess in each of the 3 6 . and 4 5 . µ m wavelength bands is derived compared to a pure helium atmosphere white dwarf model of T eff = 15500 K. The star also shows a ≈ 3 σ excess in the K s band data obtained with SOFI at the NTT. The white dwarf is isolated and there is no indication of photometric contamination. Fig. 4 shows the disc spectral energy distribution for the two sets of models using the model input parameters listed in Table 5.
3 http://www.astro.umontreal.ca/ ∼ bergeron/CoolingModels/
Figure 3. (See Fig. 2 caption). The photometry for WD 0840-136 is best fitted with a T = 5750 K black body (Section 4.5).
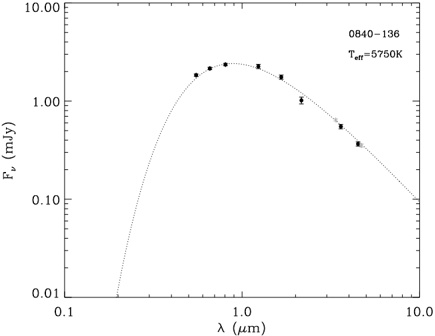
## 4.3 G245-58
Using a pure helium atmosphere model, the optical and nearinfrared photometry of this source is best fitted with T eff = 8250 K, and is shown in Fig. 4. Compared to this model, there is a 2 5 . σ infrared excess in both IRAC channels. We adopt the weighted average flux obtained with DAOPHOT and APEX for the 3 6 . and 4 5 . µ m IRAC photometry (see Section 3.4 and Table 3). The 2 5 . σ excess is derived using conservative absolute calibration errors of 5 per cent. The likelihood that this is a real excess is strengthened in two ways. First, Reach et al. (2005b) report an absolute IRAC calibration error of less than 3 per cent, which, if adopted here, would increase the infrared excess to > σ 3 . Second, the excess is observed in both IRAC channels while the background source is more prominent at 4 5 . µ m.
Taken at face value, the best fitting disc model to the weak excess at G245-58 confines the circumstellar dust into a markedly narrow ring - even for the high inclination model, the ring is smaller than four white dwarf radii. If the excess proves to be real, this is the first DZ star discovered with infrared excess, and the coolest with excess 3 6 . µ m emission.
We also fit metal-rich models of Dufour et al. (2007) to the short wavelength photometry of this source and derive a slightly cooler effective temperature of T eff = 7500 K and [Ca/He]= -9 7 . (see Table 1). These values are used in the following discussion and in Fig. 5 and 6.
## 4.4 HS2132+0941
We fit a T eff = 13000 K atmospheric model to optical and near infrared JHK s photometry for this hydrogen white dwarf. The star shows a 4 σ infrared excess at 4 5 . µ m but no significant excess at shorter wavelengths (see Fig. 4). This is uncommon - thermal disc emission is in general notable at white dwarfs at least in the 3 6 . µ m wavelength band and sometimes also in K s . It is however not unique. Observations of the cool white dwarf G166-58 with Spitzer IRAC revealed excess emission at 5 8 . and 7 9 . µ m only (Farihi et al. 2008), corresponding to dust no warmer than 400 K. For PG1225-079, excess emission was observed only at 7.9 µ m (Farihi et al. 2010b). Since we only see excess flux in one wavelength band for HS 2132+0941, the outer radius of the disc can not
Figure 4. (See Fig. 2 caption.) Disc model fits to the stars with infrared excess. The dashed red and blue lines show the disc emission model for highly inclined and narrow rings respectively (see Section 4.1 and Table 5), while the dash-dotted lines give the total emission from stellar atmosphere and disc combined.
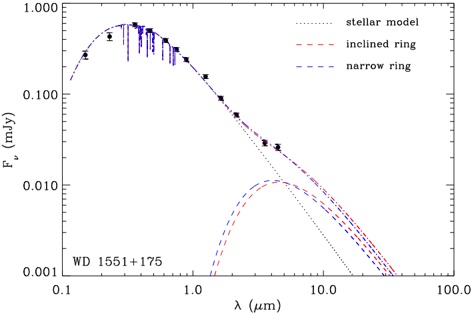
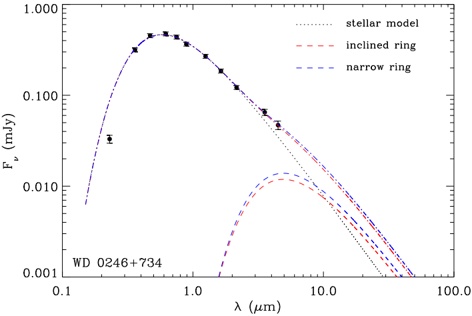
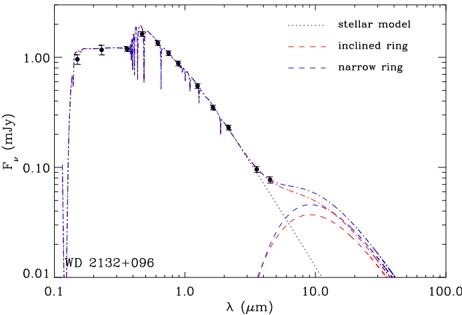
be well constrained. Until further observations are able to better constrain the nature of the excess, the best fitting disc model parameters are listed in Table 5.
## 4.5 WD0840-136
This cool DZ star has an estimated temperature of T eff ≈ 4900 K (Giammichele et al. 2012), while our coolest He atmosphere model has a temperature of T eff = 6000 K. We therefore fit a blackbody function to the photometric measurements in JHK s from 2MASS and in VRI from Subasavage et al. (2007), finding decent agreement for T = 5750 K which is shown in Fig 3. This illustrates the well known behaviour of He atmospheric models with metals (and thus free electrons), which generally yield colours similar to a metal-free (or blackbody) model of higher temperature.
## 5 DISCUSSION
## 5.1 Disc fraction as a function of cooling age
Metal polluted white dwarfs are common, yet only a fraction have observable disc emission. While the presence of metals in the atmospheres of helium white dwarfs may be explained as remnants of accretion from depleted discs due to the long diffusion times, the lack of discs around polluted hydrogen white dwarfs provides more of a puzzle.
Previous studies have shown that the fraction of polluted white dwarfs with discs observable as infrared excess is related to both metal accretion rate and effective temperature (i.e. cooling age) of the stars (e.g. von Hippel et al. 2007; Farihi et al. 2009; Xu & Jura 2012). Fig. 5 depicts the time averaged mass accretion (Farihi et al. 2012b; Girven et al. 2012) as a function of effective temperature for all polluted white dwarfs observed by Spitzer IRAC. Adding our observations to already published data yield 104 stars, and corroborates trends noted in previous studies: infrared excess appears to be positively correlated with higher temperatures and younger ages, while there is a lack of detected excesses around cooler and older white dwarfs. However, because warmer white dwarfs have more opaque atmospheres than cooler ones, only the strongest metal absorption is detectable in their atmospheres from the ground, introducing a bias in the trend of accretion rate with temperature (von Hippel et al. 2007; Zuckerman et al. 2010). Koester et al. (2014) obtained spectra of 85 DA white dwarfs with the Cosmic Origins Spectrograph on the Hubble Space Telescope and, when combined with ground-based observations, found no trend in accretion rate over cooling ages ≈ 40 Myr to ≈ 2 Gyr, or T eff = 5000 -23 000 K.
Fig. 6 depicts the fraction of polluted white dwarfs that have been observed with Spitzer IRAC for which disc emission was detected to those without. This distribution is somewhat biased since only the strongest pollution is detected for the warmest white dwarfs. High metal pollution is likely correlated with the most massive and therefore easily detected discs, thereby increasing the disc fraction for warm, young white dwarfs. Even so, from Fig. 5 it is clear that there is a trend of decreasing disc detections with decreasing temperature, even if considering only the most heavily polluted white dwarfs with [Ca/H(e)] > -7 5 . , consistent with previous findings (Farihi et al. 2009; Xu & Jura 2012). The fraction of metal enhanced white dwarfs with observable discs drops sharply around T eff ≈ 10 000 K, or around 500 Myr, suggesting the disruption of large asteroids subsides on this timescale.
## 5.2 A few discs around old white dwarfs
Jura (2008) provided a model in which the lack of infrared excess emission among metal polluted white dwarfs is plausibly explained
Table 5. Representative disc parameters obtained by fitting a model with high inclination or narrow radial extent.
| WD | T eff ( K ) | R ∗ /d ( 10 - 12 ) | T in ( K ) | T out ( K ) | r in ( R WD ) | r out ( R WD ) | i (deg) |
|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|
| Model 1: High inclination | Model 1: High inclination | Model 1: High inclination | Model 1: High inclination | Model 1: High inclination | Model 1: High inclination | Model 1: High inclination | Model 1: High inclination |
| 0246+734 | 8250 | 3.73 | 1200 | 900 | 7.8 | 11.4 | 80 |
| 1551+175 | 15500 | 1.80 | 1400 | 900 | 14.7 | 26.5 | 85 |
| 2132+096 | 13000 | 3.84 | 800 | 400 | 24.6 | 61.9 | 85 |
| Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings | Model 2: Narrow rings |
| 0246+734 | 8250 | 3.73 | 1000 | 970 | 9.9 | 10.4 | 60 |
| 1551+175 | 15500 | 1.80 | 1300 | 1200 | 16.2 | 18.1 | 60 |
| 2132+096 | 13000 | 3.84 | 600 | 520 | 36.0 | 43.6 | 60 |
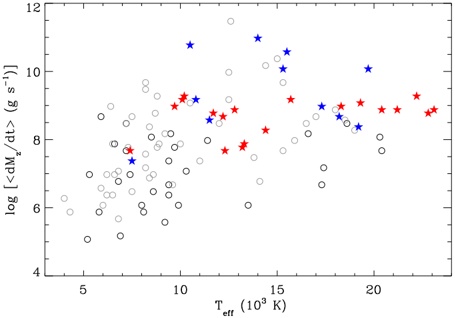
Figure 5. Mass accretion rate as a function of effective temperature for white dwarfs with known Ca abundance that have been observed with Spitzer IRAC. Hydrogen white dwarfs with infrared excesses are plotted as red stars, and as black circles otherwise. Similarly, helium white dwarfs with infrared excess are plotted as blue stars, and as grey circles otherwise.
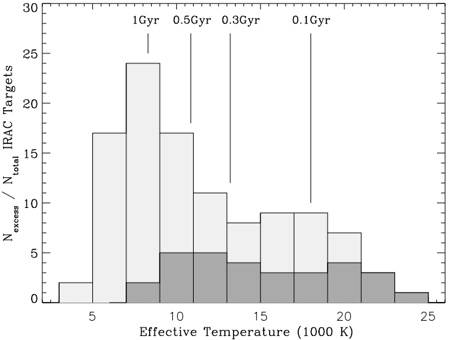
by accretion from tenuous or gaseous discs created as small asteroids enter a pre-existing disc at a non-zero inclination. In this model, erosion of the debris solids by sputtering creates a gaseous disc of vaporised asteroidal material, providing metals to be accreted by the host star but no observable infrared excess. Assuming a power-law mass distribution proportional to M -2 , similar to that of the solar system asteroid belt, implies that the majority of asteroids perturbed and destroyed within the tidal radius of the star are small, and massive discs may be expected to appear primarily for young systems in which larger asteroids (more massive than the pre-existing disc) are still relatively prevalent. In this picture, the observed trend of low detectable disc fraction for white dwarfs cooler than T eff /lessorsimilar 10 000 K, supports a scenario where large planetesimal disruptions become rare.
Before this study, only one white dwarf significantly cooler than 10 000 K was known to have an infrared excess: the hydrogen white dwarf G166-58 (Farihi et al. 2008). The excess emission of this star is unusual in being detectable beginning at 6 µ m. The possible discovery in this study of a weak infrared excess from a narrow dust ring around the cool DZ white dwarf G245-58, together with the subtle excess of G166-58, strengthens the idea that detectable discs become rare with age, but that there is a population of white
Figure 6. Fraction of polluted white dwarfs observed to have infrared excess with Spitzer IRAC. Light grey bins represent the total number of observed white dwarfs, dark grey those with observed disc emission. While the fraction of polluted white dwarfs with discs is higher for warmer and younger white dwarfs, the discoveries in this study add to the number of cooler white dwarfs with faint excesses, suggesting there is a population of white dwarfs which still retain dust at old age.
dwarfs that still retain bright dust discs at ages of ≈ 1 Gyr. The long metal diffusion time-scales for helium white dwarfs at this age imply that discs can prevail over time-scales of the order 10 6 years or longer, consistent with the findings of Girven et al. (2012) and the model described in Bochkarev & Rafikov (2011).
The fractional luminosity of discs around polluted white dwarfs has the potential to evolve with cooling age. Farihi (2011) first noted that the highest L IR /L ∗ occur only for relatively cool, dusty white dwarfs. This trend is consistent with an increasing area available to emitting solids interior to the fixed stellar Roche radius with decreasing stellar luminosity and temperature; the radius at which grains will rapidly sublimate moves inwards as a white dwarf ages (Rocchetto et al., in preparation). The relatively faint excesses around both G166-58 and G245-58 are remarkable in two ways. First, two detections among the coolest 42 stars (the three lowest T eff bins in Fig. 6) clearly indicate a low frequency of infrared excess, especially considering these stars have nearly maximal areas available to emitting dust. Second, these two excesses are among
the most subtle L IR /L ∗ detected, and indicate that typically only tenuous rings exist at these ages.
## 5.3 Subtle discs/narrow rings are common
Prior studies suggested that narrow rings may be present around metal polluted stars without observed infrared excess (Farihi et al. 2010b), and the three new discs discovered here corroborate this view. In fact, only Spitzer observations were capable of confirming dust in these particular systems; strong infrared excesses would have been previously detected in the K -band from the ground (Kilic et al. 2006), or with WISE (Hoard et al. 2013). Owing to the degeneracy between the spatial extent and inclination for faint discs such as these, we provided two representative disc models: one narrow at moderate inclination and the other more extended but at high inclination. However, it is geometrically unlikely that all three of these discs have high inclinations, and therefore the subtle excesses imply that the disc material is confined to narrow rings around each star. This is also likely for previously published infrared excesses with low L IR /L ∗ .
The disc model for G245-58 essentially represents the limit of what is confidently detectable using Spitzer IRAC. While 0.5 stellar radii ( 1 R WD ≈ 8800 km) is the most narrow ring inferred for any polluted white dwarf, it is still comparable to many planetary rings (Esposito 1993); e.g. the main ring of Jupiter is 6500 km wide. Dust rings as narrow as a few tenths of an Earth radius are suggested by the collective infrared properties of polluted white dwarfs, but are undetectable with current instrumentation. Our data support the existence of a population of white dwarfs with very faint dust discs, most of which are currently beyond detection limits and implying that dust discs are more common than what is observed. Future missions like the James Webb Space Telescope ( JWST ) and the Space Infrared telescope for Cosmology and Astrophysics ( SPICA ) with infrared spectroscopic capabilities should detect many more faint discs.
## 6 SUMMARYAND CONCLUSIONS
We observed 15 metal polluted white dwarfs with Spitzer IRAC to search for infrared excess emission indicative of circumstellar dust. Such excesses were found for two or possibly three white dwarfs in our target sample: KUV 15519+1730, HS 2132+0941 and G24558. Notably, all the dust emissions are subtle in L IR /L ∗ ; such subtle excesses not only imply narrow rings around these three stars, but also for faint discs discovered in previous studies. All together these data suggest an undetected population of weakly emitting discs at polluted white dwarfs, possibly resembling the planetary rings of the outer solar system.
The detection of discs at 1 Gyr white dwarfs supports previous findings that discs can persist for timescales of Myr or longer. For the infrared bright discs so far detected, the frequency is highest for warm and young white dwarfs, and clearly declines on a timescale of 500 Myr, possibly implying that the reservoir of large asteroids further out in the system is depleted on this timescale.
## ACKNOWLEDGMENTS
JF gratefully acknowledges the support of the STFC via an Ernest Rutherford Fellowship. CB and MR acknowledge support from the STFC. We are grateful to D. Koester for providing the white dwarf atmospheric models used. Balmer/Lyman lines in the models were calculated with the modified Stark broadening profiles of Tremblay & Bergeron (2009), kindly made available by the authors. The authors thank the anonymous reviewer for suggestions that improved the manuscript. This work is based on observations made with the Spitzer Space Telescope, which is operated by JPL/Caltech under a contract with NASA. This work has made use of data products from the SDSS, which is managed by the Astrophysical Research Consortium for the Participating Institutions, and from 2MASS, which is a joint project of the University of Massachusetts and IPAC/Caltech funded by NASA and NSF. This research has made use of the VizieR catalogue access tool and the SIMBAD database operated at CDS, Strasbourg, France, and the SAO/NASA Astrophysics Data System.
## REFERENCES
| Bergeron, P. et al., 2011, ApJ, 737, 28 Bochkarev, K. V., Rafikov, R. R., 2011, ApJ, 741, |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 36 Bonsor, A., Mustill, A. J., Wyatt, M. C., 2011, MNRAS, 414, 930 Bowler, B. P. et al., 2010, ApJ, 709, 396 Chiang, E. I., Goldreich, P., 1997, ApJ, 490, 368 |
| Debes, J. H., Sigurdsson, S., 2002, ApJ, 572, 556 |
| Debes, J. H., Sigurdsson, S., Hansen, B., 2007, AJ, 134, 1662 |
| Debes, J. H., Walsh, K. J., Stark, C., 2012, ApJ, 747, 148 |
| Dufour, P. et al., 2007, ApJ, 663, 1291 |
| Dufour, P., Kilic, M., Fontaine, G., Bergeron, P., Melis, C., Bochanski, J., 2012, ApJ, 749, 6 |
| Dupuis, J., Fontaine, G., Wesemael, F., 1993, ApJS, 87, 345 |
| Esposito, L. W., 1993, AREPS, 21, 487 |
| Farihi, J., Zuckerman, B., Becklin, E. E., 2008, ApJ, 674, 431 |
| Farihi, J., Jura, M., Zuckerman, B., 2009, ApJ, 694, 805 Farihi, J., Barstow, M. A., Redfield, S., Dufour, P., Hambly, |
| N. C., 2010a, MNRAS, 404, 2123 |
| Farihi, J., Jura, M., Lee, J.-E., Zuckerman, B., 2010b, ApJ, 714, 1386 |
| Farihi, J., 2011, in White Dwarf Atmospheres and Circumstellar Environments, ed. D. W. Hoard (Berlin: Wiley-VHC), pp 117- 171 |
| Farihi, J., G¨nsicke, a B. T., Steele, P. R., Girven, J., Burl eigh, M. R., Breedt, E., Koester, D., 2012a, MNRAS, 421, 1635 |
| Farihi, J., G¨nsicke, a B. T., Wyatt, M. C., Girven, J., Pringe, l J. E., King, A. R., 2012b, MNRAS, 424, 464 Fazio, G. G. et al., 2004a, ApJS, 154, 10 |
| Friedrich, S., Koester, D., Christlieb, N., Reimers, D., L., 2000, A&A, 363, 1040 |
| Fazio, G. G. et al., 2004b, ApJS, 154, 39 |
| Wisotzki, |
| Frink, S., Mitchell, D. S., Quirrenbach, A., Fischer, D. A., Marcy, G. W., Butler, R. P., 2002, ApJ, 576, 478 |
| G¨nsicke, a B. T., Marsh, T. R., Southworth, J., Rebassa- Mansergas, A., 2006, Science, 314, 1908 G¨nsicke, a B. T., Marsh, T. R., Southworth, J., 2007, MNRAS, |
| 380, L35 a B. T., Koester, D., Marsh, T. R., Rebassa-Manser gas, A., Southworth, J., 2008, MNRAS, 391, L103 |
| G¨nsicke, |
| Giammichele, N., Bergeron, P., Dufour, P., 2012, ApJS, 199, 29 Girven, J., Brinkworth, C. S., Farihi, J., G¨nsicke, a B. T., Hoard, D. W., Marsh, T. R., Koester, D., 2012, ApJ, 749, 154 |
| Hoard, D. W., Debes, J. H., Wachter, S., Leisawitz, D. T., |
| M., 2013, ApJ, 770, 21 |
| Cohen, Holberg, J. B., Bergeron, P., 2006, AJ, 132, 1221 |
| Hora, J. L., et al., 2008, PASP, 120, 1233 Hunt, L. K., Mannucci, F., Testi, L., Migliorini, S., Stanga, R. M., Baffa, C., Lisi, F., Vanzi, L., 1998, AJ, 115, 2594 J. A., et al., 2007, ApJ, 665, 785 M., 2003, ApJL, 584, L91 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Johnson, Jura, Jura, M., 2008, AJ, 135, 1785 |
| Jura, M., Farihi, J., Zuckerman, B., 2007b, ApJ, 663, 1285 Jura, M., Farihi, J., Zuckerman, B., Becklin, E. E., 2007a, AJ, 1927 |
| 133, Jura, M., Farihi, J., Zuckerman, B., 2009, AJ, 137, 3191 |
| Kawka, A., Vennes, S., 2012, A&A, 538, 13 Kenyon, S. J., Shipman, H. L., Sion, E. M., Aannestad, P. A., 1988, ApJL, 328, L65 |
| Kilic, M., von Hippel, T., Leggett, S. K., Winget, D. E., 2006, ApJ, |
| 646, 474 Koester, D., 2009, A&A, 498, 517 Koester, D., 2010, in Prada Moroni, P. G., Bono, G., School of As- trophysics 'F. Lucchin' X Cycle, First Course 2008, Vol. 81 of |
| A., et al., in Fowler A. M. ed., Infrared Astronomical Instrumentation, Vol. 3354 of SPIE Conference Series, LIRIS: a long-slit intermediate-resolution infrared spectrograph for the WHT. pp 448-455 Martin, D. C., et al., 2005, ApJL, 619, L1 McCook, G. P., Sion, E. M., 1999, ApJS, 121,1 |
| 272, 660 |
| Manchado, |
| Melis, C., Farihi, J., Dufour, P., Zuckerman, B., Burgasser, A. J., |
| 91, 9 Mullally, F., Kilic, M., Reach, W. T., Kuchner, M. J., von Hippel, T., Burrows, A., Winget, D. E., 2007, ApJS, 171, 206 R. R., Garmilla, J. A., 2012, ApJ, 760, 123 W. T., Kuchner, M. J., von Hippel, T., Burrows, A., lally, F., Kilic, M., Winget, D. E., 2005a, ApJL, 635, L161 W. T., et al., 2005b, PASP, 117, 978 |
| Rafikov, Reach, W. T., Lisse, C., von Hippel, T., Mullally, F., 2009, |
| Reach, Reach, 693, 697 B., et al., 2008, PASJ, 60, 1317 S., Richer, H. B., Hansen, B. M., Stairs, I. |
| Sato, Sigurdsson, Thorsett, S. E., 2003, Science, 301, 193 Sion, E. M., Holberg, J. B., Oswalt, T. D., McCook, G. |
| Wasatonic, R., 2009, AJ, 138, 1681 |
| Skrutskie, M. F., et al., 2006, AJ, 131, 1163 Stoughton, C., et al., 2002, AJ, 123, 485 Subasavage, J. P., Henry, T. J., Bergeron, P., Dufour, P., N. C., Beaulieu, T. D., 2007, AJ, 134, 252 |
| Subasavage, J. P., Henry, T. J., Bergeron, P., Dufour, P., |
| N. C., 2008, AJ, 136, 899 Tremblay, P.-E., Bergeron, P., 2009, ApJ, 696, 1755 Tremblay, P.-E., Bergeron, P., Gianninas, A., 2011, ApJ, 730, |
| 128 |
| Mul- |
| ApJ, H., P., |
| Hambly, Hambly, |
| Wegner, G., Swanson, S. R., 1990, AJ, 100, 1274 |
|-------------------------------------------------------------------------------------|
| Werner, M. W., et al., 2004, ApJS, 154, 1 |
| Wolszczan, A., Frail, D. A., 1992, Nature, 355, 145 |
| Wright, E. L., et al., 2010, AJ, 140, 1868 |
| Xu, S., Jura, M., 2012, ApJ, 745, 88 |
| Xu, S., Jura, M., Koester, D., Klein, B., Zuckerman, B., 2014, ApJ, 783, 79 |
| Zuckerman, B., Becklin, E. E., 1987, Nature, 330, 138 |
| Zuckerman, B., Koester, D., Reid, I. N., H¨nsch, u M., 2003, ApJ, 596, 477 |
| Zuckerman, B., Koester, D., Melis, C., Hansen, B. M., Jura, M., 2007, ApJ, 671, 872 |
| Zuckerman, B., Melis, C., Klein, B., Koester, D., Jura, M., 2010, ApJ, 722, 725 | | 10.1093/mnras/stu1565 | [
"Carolina Bergfors",
"Jay Farihi",
"Patrick Dufour",
"Marco Rocchetto"
] | 2014-08-01T16:42:58+00:00 | 2014-10-02T12:56:03+00:00 | [
"astro-ph.EP",
"astro-ph.SR"
] | Signs of a faint disc population at polluted white dwarfs | Observations of atmospheric metals and dust discs around white dwarfs provide
important clues to the fate of terrestrial planetary systems around
intermediate mass stars. We present Spitzer IRAC observations of 15 metal
polluted white dwarfs to investigate the occurrence and physical properties of
circumstellar dust created by the disruption of planetary bodies. We find
subtle infrared excess emission consistent with warm dust around KUV 15519+1730
and HS 2132+0941, and weaker excess around the DZ white dwarf G245-58, which,
if real, makes it the coolest white dwarf known to exhibit a 3.6 micron excess
and the first DZ star with a bright disc. All together our data corroborate a
picture where 1) discs at metal-enriched white dwarfs are commonplace and most
escape detection in the infrared (possibly as narrow rings), 2) the discs are
long lived, having lifetimes on the order of 10^6 yr or longer, and 3) the
frequency of bright, infrared detectable discs decreases with age, on a
timescale of roughly 500 Myr, suggesting large planetesimal disruptions decline
on this same timescale. |
1408.0230v2 | ## Asymptotic Behavior of Manakov Solitons: Effects of Potential Wells and Humps
V. S. Gerdjikov, A. V. Kyuldjiev ∗ †
Institute for Nuclear Research and Nuclear Energy, Bulgarian Academy of Sciences, 72 Tzarigradsko Chaussee, Blvd., 1784 Sofia, Bulgaria
## M. D. Todorov ‡
Department of Applied Mathematics and Computer Science, Technical University of Sofia, 8 Kliment Ohridski, Blvd., 1000 Sofia, Bulgaria
## Abstract
We consider the asymptotic behavior of the soliton solutions of Manakov's system perturbed by external potentials. It has already been established that its multisoliton interactions in the adiabatic approximation can be modeled by the Complex Toda chain (CTC). The fact that the CTC is a completely integrable system, enables us to determine the asymptotic behavior of the multisoliton trains. In the present study we accent on the 3-soliton initial configurations perturbed by sech-like external potentials and compare the numerical predictions of the Manakov system and the perturbed CTC in different regimes. The results of conducted analysis show that the perturbed CTC can reliably predict the long-time evolution of the Manakov system.
## 1 Introduction
The Gross-Pitaevski (GP) equation and its multicomponent generalizations are important tools for analyzing and studying the dynamics of the Bose-Einstein condensates (BEC), see the monographs [34, 21, 25] and the numerous references therein among which we mention [36, 4, 3, 23, 35, 44, 15, 30, 22, 7, 26, 28]. In the 3-dimensional case these equations can be analyzed solely by numerical methods. If we assume that BEC is quasi-one-dimensional then the GP equations mentioned above may be reduced to the nonlinear Schr¨dinger equation o (NLSE) perturbed by the external potential V ( x )
$$i u _ { t } + \frac { 1 } { 2 } u _ { x x } + | u | ^ { 2 } u ( x, t ) = V ( x ) u ( x, t ),$$
or to its vector generalizations (VNLSE)
$$i \vec { u } _ { t } + \frac { 1 } { 2 } \vec { u } _ { x x } + ( \vec { u } ^ { \dagger }, \vec { u } ) \vec { u } ( x, t ) = V ( x ) \vec { u } ( x, t ).$$
The Manakov model (MM) [31] is a two-component VNLSE with V ( x ) = 0 (for more details see [1, 20]).
∗ E-mail: [email protected]
† E-mail: [email protected]
‡ E-mail: [email protected]
The analytical approach to the N -soliton interactions was proposed by Zakharov and Shabat [46, 33] for the scalar NLSE, for a vector NLSE see [27]. They treated the case of the exact N -soliton solution where all solitons had different velocities. They calculated the asymptotics of the N -soliton solution for t → ±∞ and proved that both asymptotics are sums of N one-soliton solutions with the same sets of amplitudes and velocities. The effects of the interaction were shifts in the relative center of masses and phases of the solitons. The same approach, however, is not applicable to the MM, because the asymptotics of the soliton solution for t →±∞ do not commute.
The present paper is an extension of [10, 16, 17] where the main result is that the N -soliton interactions in the adiabatic approximation for the Manakov model can also be modeled by the CTC [13, 18, 12, 19]. More specifically, here we continue our analysis of the effects of external potentials on the soliton interactions. While in [10, 16, 7] we studied the effects of periodic, harmonic and anharmonic potentials, here we consider potential wells and humps of the form:
$$V ( x ) = \sum _ { s } c _ { s } V _ { s } ( x, y _ { s } ), \quad V _ { s } ( x, y _ { s } ) = \frac { 1 } { \cosh ^ { 2 } ( 2 \nu _ { 0 } x - y _ { s } ) }.$$
If c s is negative (resp. positive) V s ( x ) is a well (resp. hump) with width 1.7 at halfheight/depth. Adjusting one or more terms in (3) with different c s and y s we can describe wells and/or humps with different widths/depths and positions.
In the present paper we in fact prove the hypothesis in [6] and extend the results in [6, 7, 9, 29, 38, 45, 10, 8, 14] concerning the model of soliton interactions of vector NLSE (2) in adiabatic approximation.
The corresponding vector N -soliton train is a solution of (2) determined by the initial condition:
$$\vec { u } ( x, t = 0 ) = \sum _ { k = 1 } ^ { N } \vec { u } _ { k } ( x, t = 0 ), \quad \vec { u } _ { k } ( x, t ) = u _ { k } ( x, t ) \vec { n } _ { k }, \quad u _ { k } ( x, t ) = \frac { 2 \nu _ { k } e ^ { i \phi _ { k } } } { \cosh ( z _ { k } ) } \quad ( 4 )$$
with
$$z _ { k } & = 2 \nu _ { k } ( x - \xi _ { k } ( t ) ), \quad \quad \xi _ { k } ( t ) = 2 \mu _ { k } t + \xi _ { k, 0 }, \\ \phi _ { k } & = \frac { \mu _ { k } } { \nu _ { k } } z _ { k } + \delta _ { k } ( t ), \quad \quad \delta _ { k } ( t ) = 2 ( \mu _ { k } ^ { 2 } + \nu _ { k } ^ { 2 } ) t + \delta _ { k, 0 }, \quad \quad \quad$$
where the s -component polarization vector /vector n k = ( n k, 1 e iβ k, 1 , n k, 2 e iβ k, 2 , . . . , n k,s e iβ k,s ) T is normalized by the conditions
$$\langle \vec { n } _ { k } ^ { \dagger }, \vec { n } _ { k } \rangle \equiv \sum _ { p = 1 } ^ { s } n _ { k, p } ^ { 2 } = 1, \quad \sum _ { p = 1 } ^ { s } \beta _ { k ; s } = 0.$$
The adiabatic approximation holds true if the soliton parameters satisfy [24]:
$$| \nu _ { k } - \nu _ { 0 } | \ll \nu _ { 0 }, \quad | \mu _ { k } - \mu _ { 0 } | \ll \mu _ { 0 }, \quad | \nu _ { k } - \nu _ { 0 } | | \xi _ { k + 1, 0 } - \xi _ { k, 0 } | \gg 1, \quad \quad ( 7 )$$
for all k , where ν 0 = 1 N ∑ N k =1 ν k , and µ 0 = 1 N ∑ N k =1 µ k are the average amplitude and velocity, respectively. In fact we have two different scales:
$$| \nu _ { k } - \nu _ { 0 } | \simeq \varepsilon _ { 0 } ^ { 1 / 2 }, \quad | \mu _ { k } - \mu _ { 0 } | \simeq \varepsilon _ { 0 } ^ { 1 / 2 }, \quad | \xi _ { k + 1, 0 } - \xi _ { k, 0 } | \simeq \varepsilon _ { 0 } ^ { - 1 }.$$
We remind that the basic idea of the adiabatic approximation is to derive a dynamical system for the soliton parameters which would describe their interaction. This idea was
initiated by Karpman and Solov'ev [24] and modified by Anderson and Lisak [2]. Later this idea was generalized to N -soliton interactions [18, 13, 12, 19] and the corresponding dynamical system for the 4 N -soliton parameters was identified as a N -site complex Toda chain (CTC). The fact that the CTC, (just like its real counterpart - the Toda chain) is completely integrable gives additional possibilities. A detailed comparative analysis between the solutions of the RTC and CTC [11] shows that the CTC allows for a variety of asymptotic regimes, see Section 3 below. More precisely, knowing the initial soliton parameters one can effectively predict the asymptotic regime of the soliton train. Another possible use of the same fact is, that one can describe the sets of soliton parameters responsible for each of the asymptotic regimes. Another important advantage of the adiabatic approach consists in the fact, that one may consider the effects of various perturbations on the soliton interactions [24, 18].
The next step was to extend this approach to treat the soliton interactions of the Manakov solitons. More precisely, using the method of Anderson and Lisak [2] we derive a generalized version of the Complex Toda Chain (CTC) (see Eqs. (16), (17) below) as a model describing the behavior of the N -soliton trains of of the VNLSE (2) [6, 7, 8, 10, 17, 14]. This generalized CTC includes dependence on the polarization vectors /vector n k . It allows us to analyze how the changes of the polarization vectors influence the soliton interactions. Besides, the generalized CTC is also integrable with the consequence that one can predict the asymptotic regimes of the Manakov solitons and can describe the sets of soliton parameters that are responsible for each of the asymptotic regimes. Of course, just like for the scalar case, one can also analyze the effects of the various perturbations on the soliton interactions.
In Section 2 we outline how the variational approach developed in [2] can be used to derive the perturbed CTC (PCTC) model [10, 8] for sech -type external potentials. We also remind the reader about the asymptotic regimes of the soliton trains predicted by the CTC [13, 12]. In Section 3 we briefly treat the N -soliton interactions of the MM without external potential. Obviously in order to determine the N -soliton train for the MM, along with the usual sets of solitons parameters ν , µ k k , ξ k and δ k we need also the set of polarization vectors /vector n s . In Section 4 we derive the effects of the external potentials on the soliton interactions. This is a perturbed form of the CTC (PCTC) for generic potentials of the form (3). Section 5 is dedicated to the comparison between the numeric solutions of the perturbed VNLSE (2) with the predictions of the PCTC model. To this end we solve the VNLSE numerically by using an implicit scheme of Crank-Nicolson type in complex arithmetic. The concept of the internal iterations is applied (see [5]) in order to ensure the implementation of the conservation laws on difference level within the round-off error of the calculations [40, 41, 42]. The solutions of the relevant PCTC have been obtained using Maple. Knowing the numeric solution /vector u of the perturbed VNLSE we calculate he maxima of ( /vector u ,/vector † u ), compare them with the (numeric solutions) for ξ k ( ) of the PCTC and plot the presdicted by both models trajectories for each t of the solitons. Thus we are able to analyze the effects of the external potentials on the soliton interactions. Finally, Sections 6 and 7 contain discussion and conclusions.
## 2 Preliminaries
Here we briefly remind the derivation of the CTC as a model describing the N -soliton interactions VNLS systems using the variational approach [2].
## 2.1 Derivation of the CTC as a model for the soliton interaction of perturbed VNLS systems
The perturbed vector NLSE (2) allows Hamiltonian formulations with the Poisson brackets
$$\{ \vec { u } _ { j } ( x, t ), \vec { u } _ { k } ^ { * } ( y, t ) \} = \delta _ { j k } \delta ( x - y )$$
and the Hamiltonian
$$\lhd \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \ Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi
\rho \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phie \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Clone \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Lone \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis
\rho \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi\Phi \Psi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phis \Phi\Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Psi \Phis \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Phi \Ph$$
It also admits a Lagrangian of the form:
$$\lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow \lambda \rightarrow$$
In what follows we will analyze the large time behavior of the N -soliton train determined as the solution of the VNLSE by the initial condition (4), (5).
The idea of the variational approach of [2] is to insert the anzatz (4) into the Lagrangian, perform the integration over x and retain only terms of the orders of ε 1 2 / 0 and ε 0 . The first obvious observation is that only the nearest neighbors solitons will contribute such terms and
$$\mathcal { L } & = \sum _ { k = 1 } ^ { N } \mathcal { L } _ { k } + \sum _ { k = 1 } ^ { N } \sum _ { n = k \pm 1 } \widetilde { \mathcal { L } } _ { k n }. \\ \mathcal { H } \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots$$
Here L k correspond to the terms involving only the k -th soliton (see [10]):
$$\dots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,\quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,\, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad\, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \. \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \vdots \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
\quad \quad \quad$$
Finally the terms describing soliton-soliton interactions are given by:
$$\mathcal { L } _ { k n } & = 1 6 \nu _ { 0 } ^ { 3 } e ^ { - \Delta _ { k n } } ( R _ { k n } + R _ { k n } ^ { * } ) + \mathcal { O } ( \epsilon ^ { 3 / 2 } ), \\ R _ { k n } & = e ^ { i ( \widetilde { \delta } _ { n } - \widetilde { \delta } _ { k } ) } \langle \widetilde { n } _ { k }, \widetilde { n } _ { n } \rangle, \quad \widetilde { \delta } _ { k } = \delta _ { k } - 2 \mu _ { 0 } \xi _ { k }, \ \Delta _ { k n } = 2 s _ { k n } \nu _ { 0 } ( \xi _ { k } - \xi _ { n } ), \\ \intertext { w e s } _ { k, k + 1 } & = 1 \text{ and } s _ { k, k - 1 } = - 1. \sum _ { \substack { \mathcal { L } _ { k } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{matrix} }$$
where s k,k +1 = 1 and s k,k -1 = -1.
The next step is to consider L (11) as a Lagrangian of the dynamical system, describing the motion of the N -soliton train and providing the equations of motion for the (2 s + 2) N (6 N for the Manakov case) soliton parameters.
Let us first consider the unperturbed case, i.e. , V ( x ) = 0. Deriving the dynamical system we get terms of three different orders of magnitude: (i) terms of order ∆ 2 kn exp( -∆ kn ); (ii) terms of order ∆ kn exp( -∆ kn ) and (iii) terms of order exp( -∆ kn ). However the terms of types (i) and (ii) are multiplied by factors that are of the order of exp( -∆ kn ) due to the evolution equations for the soliton parameters. Finally, we arrive at the following set of dynamical equations for the soliton parameters:
$$\frac { d \xi _ { k } } { d t } & = 2 \mu _ { k }, & \frac { d \delta _ { k } } { d t } & = 2 \mu _ { k } ^ { 2 } + 2 \nu _ { k } ^ { 2 }, \\ \frac { d \nu _ { k } } { d t } & = 8 \nu _ { 0 } ^ { 3 } \sum _ { n } e ^ { - \Delta _ { k n } } i ( R _ { k n } - R _ { k n } ^ { * } ), & \frac { d \mu _ { k } } { d t } & = - 8 \nu _ { 0 } ^ { 3 } \sum _ { n } e ^ { - \Delta _ { k n } } ( R _ { k n } + R _ { k n } ^ { * } ).$$
In addition we obtain also a system of equations for the evolution of the polarization vectors:
$$\frac { d \vec { n } _ { k } } { d t } = 4 \nu _ { 0 } ^ { 2 } i \sum _ { n = k \pm 1 } ^ { \mu } e ^ { - \Delta _ { k n } } \left [ e ^ { i \widetilde { \theta } _ { n } - \widetilde { \theta } _ { k } ) } \vec { n } _ { n } - R _ { k n } \vec { n } _ { k } + e ^ { i \widetilde { \theta } _ { n } - \widetilde { \theta } _ { k } ) } \vec { n } _ { n } + R _ { k n } ^ { * } \vec { n } _ { k } \right ] + C _ { k } \vec { n } _ { k }.$$
where the constants C k are fixed up by the constraints on the polarization vectors. Indeed, from 〈 /vector n k † , /vector n k 〉 = 1 for all t one finds that C k + C ∗ k = 0, i.e. , the constants C k are purely imaginary. Let us now assume that C k = iθ k . Then from eqs. (6) and (15) we find that β k,s become time-dependent and up to terms of the order of /epsilon1 evolve linearly with time: β k,s ( ) t = β k,s (0) + θ t k . But such evolution is compatible with the second normalization condition in (6) only if θ k = 0; therefore C k = 0. Thus, from Eqs. (14) we get:
$$\frac { d ( \mu _ { k } + i \nu _ { k } ) } { d t } = 4 \nu _ { 0 } \left [ \langle \vec { n } _ { k }, \vec { n } _ { k - 1 } \rangle e ^ { q _ { k } - q _ { k - 1 } } - \langle \vec { n } _ { k + 1 }, \vec { n } _ { k } \rangle e ^ { q _ { k + 1 } - q _ { k } } \right ], \\ \text{-one}$$
where
q
k
=
-
2
ν ξ
0
k
+
k
ln 4
ν
2
0
-
i
(
δ
k
+
δ
0
+
kπ
-
2
µ ξ
0
k
)
,
$$\nu _ { 0 } = \frac { 1 } { N } \sum _ { s = 1 } ^ { N } \nu _ { s }, \quad \mu _ { 0 } = \frac { 1 } { N } \sum _ { s = 1 } ^ { N } \mu _ { s }, \quad \delta _ { 0 } = \frac { 1 } { N } \sum _ { s = 1 } ^ { N } \delta _ { s }.$$
Besides, from (14) and (17) there follows (see [18]):
$$\frac { d q _ { k } } { d t } = - 4 \nu _ { 0 } ( \mu _ { k } + i \nu _ { k } ).$$
and which proves the statement in [6]. Eq. (19), combined with the system of equations for the polarization vectors (15) provides the proper generalization of the CTC model for the MNLS.
$$\frac { d ^ { 2 } q _ { k } } { d t ^ { 2 } } = 1 6 \nu _ { 0 } ^ { 2 } \left [ \langle \vec { n } _ { k + 1 }, \vec { n } _ { k } \rangle e ^ { q _ { k + 1 } - q _ { k } } - \langle \vec { n } _ { k }, \vec { n } _ { k - 1 } \rangle e ^ { q _ { k } - q _ { k - 1 } } \right ], \\ \text{proves the statement in } [ 6 ]. \text{ E. } ( 1 9 ). \text{ combined with the system of equations for the}$$
The equations for the polarization vectors are nonlinear. So the whole system of equations for q k and /vector n k seems to be rather complicated and nonintegrable even for the unperturbed MNLS. However, all terms in the right hand sides of the evolution equations for /vector n k are of the order of /epsilon1 . This allows us to neglect the evolution of /vector n k and to approximate them with their initial values. As a result we obtain that the N -soliton interactions for the VNLSE in the adiabatic approximation are modeled by the CTC, see Section 3.
/negationslash
It is easy to see, that if all 〈 /vector n k +1 † , /vector n k 〉 = const = 0 then the CTC (19) is a completely integrable dynamical system, just like the real Toda chain.
Note also that the CTC models the soliton interactions for the VNLSE with any number of components . The effect of the polarization vectors on the interaction comes into CTC only through the scalar products m 0 s = 〈 /vector n k +1 , /vector n k 〉 . It is well known, that a gauge transformation /vector u → g /vector 0 u with any constant unitary matrix g 0 leaves the VNLSE, Eq. (2) invariant. Such transformation will change all polarization vectors simultaneously /vector n k → g /vector 0 n k but preserves their scalar products, and so will not influence the soliton interaction. Obviously, our CTC model is invariant under such transformations. Due to the above arguments our choice of the initial values of /vector n k 0 can be changed into g /vector 0 n k 0 with no effect on the interaction. That is why we specify only the scalar products m k 0 for our runs, which we have chosen to be real.
## 2.2 The effects of the sech -like potentials on CTC
Now we consider the effects of the external potentials of the form (3). To this end we have to calculate the integrals in the right hand side of eq. (12) and see how they would change the right hand sides of eqs. (14).
As it is clear from above, we have to replace L k in Eq. (12) by
$$\i m a \omega \nu, \, w \, \max \, \cos \, \infty \, \psi \omega \sim \widetilde { \ } k \, \Pi \, \infty. \, \infty y \\ \mathcal { L } _ { k, \text{pert} } & = \mathcal { L } _ { k } - 2 \nu _ { k } \int _ { - \infty } ^ { \infty } \frac { d x \, V ( x ) } { \cosh ^ { 2 } ( z _ { k } ) }.$$
while L kn remains unchanged. Thus we obtain the following PCTC system:
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ \frac { d \lambda _ { k } } { d t } = - 4 \nu _ { 0 } \left ( e ^ { q _ { k + 1 } - q _ { k } } ( \vec { n } _ { k + 1 } ^ { \dagger }, \vec { n } _ { k } ) - e ^ { q _ { k } - q _ { k - 1 } } ( \vec { n } _ { k } ^ { \dagger }, \vec { n } _ { k - 1 } ) \right ) + M _ { k } + i N _ { k }, \\ \frac { d q _ { k } } { d t } = - 4 \nu _ { 0 } \lambda _ { k } + 2 i ( \mu _ { 0 } + i \nu _ { 0 } ) \Xi _ { k } - i X _ { k }, \quad \frac { d \vec { n } _ { k } } { d t } = \mathcal { O } ( \epsilon ), \\ \text{where $\lambda_{\lambda} = u_{\lambda} + i \nu_{\lambda}. \ X_{\lambda} = 2 u_{\lambda} \Xi_{\lambda} + D_{\lambda}$ and}$$
where λ k = µ k + iν k , X k = 2 µ k Ξ k + D k and
$$& \text{where} \ \lambda _ { k } = \mu _ { k } + \imath \nu _ { k }, \, \mathcal { A } _ { k } = 2 \mu _ { k } \varsubseteq _ { k } + \mathcal { L } _ { k } \text{ and} \\ & N _ { k } = - \frac { 1 } { 2 } \int _ { \substack { \frac { d z _ { k } } { c o s h \, z _ { k } } } } \ln \, \left ( V ( y _ { k } ) u _ { k } \varepsilon ^ { - i \phi _ { k } } \right ), \quad M _ { k } = \frac { 1 } { 2 } \int _ { \substack { \frac { d z _ { k } \, \sinh \, z _ { k } } { c o s h ^ { 2 } \, z _ { k } } } } \, \text{Re} \, \left ( V ( y _ { k } ) u _ { k } \varepsilon ^ { - i \phi _ { k } } \right ), \\ & \Xi _ { k } = - \frac { 1 } { 4 \nu _ { k } ^ { 2 } } \int _ { \substack { \frac { d z _ { k } \, z _ { k } } { c o s h \, z _ { k } } } } \ln \, \left ( V ( y _ { k } ) u _ { k } \varepsilon ^ { - i \phi _ { k } } \right ), \quad D _ { k } = \frac { 1 } { 2 \nu _ { k } } \int _ { \substack { \frac { d z _ { k } \, ( 1 - \, z _ { k } \, \tanh \, z _ { k } ) } { c o s h \, z _ { k } } } \text{Re} \, \left ( V ( y _ { k } ) u _ { k } \varepsilon ^ { - i \phi _ { k } } \right ), \\ & \text{where} \ \mathfrak { a n } \ = \ \varepsilon, \, \, \,$$
where y k = z k / (2 ν 0 ) + ξ k .
As a result for our specific choice of V ( x ) we get:
$$M _ { k } = \sum _ { s } 2 c _ { s } \nu _ { k } P ( \Delta _ { k, s } ), \quad N _ { k } = 0, \quad \Xi _ { k } = 0, \quad D _ { k } = \sum _ { s } c _ { s } R ( \Delta _ { k, s } ), \quad ( 2 2 )$$
where ∆ k,s = 2 ν ξ 0 k -y s and the integrals describing the interaction of the solitons with the potential (see Figure 1(left panel))
$$\dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ P ( \Delta ) & = \frac { \Delta + 2 \Delta \cosh ^ { 2 } ( \Delta ) - 3 \sinh ( \Delta ) \cosh ( \Delta ) } { \sinh ^ { 4 } ( \Delta ) }, \\ R ( \Delta ) & = \frac { 6 \Delta \sinh ( \Delta ) \cosh ( \Delta ) - ( 2 \Delta ^ { 2 } + 3 ) \sinh ^ { 2 } ( \Delta ) - 3 \Delta ^ { 2 } } { 2 \sinh ^ { 4 } ( \Delta ) }. \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
The details of deriving the integrals are given in the Appendix.
The corrections to N k and P k , coming from the terms linear in u depend only on the parameters of the k -th soliton; i.e. , they are 'local' in k .
## 3 CTC and the Asymptotic Regimes of N -soliton Trains
The fact that the N -soliton trains for the scalar NLSE are modeled by an integrable model - CTC allowed one to to predict their asymptotic behavior. The method to do so was based on the exact integrability of the CTC [13] and on its Lax representation.
Here we shall show, that similar results hold true also for the CTC (14) modeling the soliton trains of the MM. Indeed, following Moser [32] we introduce the Lax pair
$$\dot { L } = [ B, L ],$$
where
$$L & = \sum _ { k = 1 } ^ { N } \left ( b _ { k } E _ { k k } + a _ { k } ( E _ { k, k + 1 } + E _ { k - 1, k } ) \right ), \\ B & = \sum _ { k = 1 } ^ { N } a _ { k } \left ( ( E _ { k, k + 1 } - E _ { k - 1, k } ) \,.$$
Here the matrices ( E kn pq ) = δ kp δ nq , and E kn = 0 whenever one of the indices becomes 0 or N +1; the other notations in (24) are as follows:
$$a _ { k } = \frac { 1 } { 2 } \sqrt { \langle \vec { n } _ { k + 1 }, \vec { n } _ { k } \rangle } e ^ { ( q _ { k + 1 } - q _ { k } ) / 2 }, \quad b _ { k } = \frac { 1 } { 2 } \left ( \mu _ { k } + i \nu _ { k } \right ). \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
One can check that the compatibility condition eq. (24) with L and B as in (25) is equivalent to the unperturbed CTC (14).
The first consequence of the Lax representation is that the CTC has N complex-valued integrals of motion provided by the eigenvalues of L which we denote by ζ k = κ k + iη k , k = 1 , . . . , N . Indeed the Lax equation means that the evolution of L is isospectral, i.e. , dζ /dt k = 0.
Another important consequence from the results of Moser [32] is that for the real Toda chain one can write down explicitly its solutions in terms of the scattering data, which consist of { ζ k , r k } N k =1 where r k are the first components of the properly normalized eigenvectors of L 0 [32, 39]. For the real Toda chain both ζ k = κ k and r k are real; besides all ζ k are different. Next Moser calculated the asymptotics of these solutions for t → ±∞ and showed that κ k determine the asymptotic velocities of the particles.
The formulae derived by Moser can easily be extended to the complex case [11]. The important difference is that all important ingredients such as eigenvalues ζ k and first components of the eigenvectors of L normalized to 1 now become complex valued. In addition, the important asset of L for the RTC, namely that all eigenvalues are real and different, is also lost. However the asymptotics of the solutions for t →±∞ can be calculated with the result:
$$q _ { k } ( t ) = - 2 \nu _ { 0 } \zeta _ { k } t - B _ { k } + \mathcal { O } ( e ^ { - D t } ),$$
where D in (27) is some real positive constant which is estimated by the minimal difference between the asymptotic velocities. Equating the real parts in eq. (27) we obtain:
$$\lim _ { t \to \infty } ( \xi _ { k } + 2 \kappa _ { k } t ) = \text{const}$$
which means that the real parts κ k of the eigenvalues of L determine the asymptotic velocities for the CTC. This fact will be used to classify the regimes of asymptotic behavior.
Let us also point out the important differences between RTC and CTC, namely:
D1) While for RTC q k , r k and ζ k are all real, for CTC they generically take complex values, e.g. ζ k = κ k + iη k ;
/negationslash
D2) While for RTC ζ k = ζ j for k = , for CTC no such restriction holds. j
/negationslash
/negationslash
As a consequence we find that the only possible asymptotic behavior in the RTC is the asymptotically free motion of the solitons. For CTC it is κ k that determines the asymptotic velocity of the k -th soliton. For simplicity and without loss of generality we assume that: tr L 0 = 0; ζ k = ζ j for k = ; and j κ 1 ≤ κ 2 ≤ · · · ≤ κ N . Then we have:
/negationslash
/negationslash
AFR The asymptotically free regime takes place if κ k = κ j for k = j , i.e. , the asymptotic velocities are all different. Then we have asymptotically separating, free solitons, see also [18, 12];
/negationslash
BSR The bound state regime takes place for κ 1 = κ 2 = · · · = κ N = 0, i.e. , all N solitons move with the same mean asymptotic velocity, and form a 'bound state'. The key question now will be the nature of the internal motions in such a bound state: is it quasi-equidistant or not?
MAR a variety of intermediate situations, or mixed asymptotic regimes happen when one group (or several groups) of particles move with the same mean asymptotic velocity; then they would form one (or several) bound state(s) and the rest of the particles will have free asymptotic motion.
Obviously the regimes (ii) and (iii), as well as the degenerate and singular cases, which we do not consider here have no analogies in the RTC and physically are qualitatively different from i).
The perturbed CTC taking into account the effects of the sech -like potentials to the best of our knowledge is not integrable and does not allow Lax representation. Therefore we are applying numeric methods to solve it.
## 4 Comparison Between the PCTC Model and Manakov Soliton Interactions
In this Section we will compare how well the PCTC model derived above predicts the soliton interactions as solutions of the MM with the external potentials of kind (3). Before that let us remind the well known result (see [13, 18, 12]) that the 3-soliton systems allow for three types of dynamical regimes for large times, namely
AFR) asymptotically free regime when all 3 solitons move away with different velocities. This regime takes place if the initial amplitudes are given by eq. (31) with [12]:
$$\Delta \nu < \nu _ { \text{cr} } = 2 \sqrt { 2 \cos ( \theta _ { 1 } - \theta _ { 2 } ) } \nu _ { 0 } \exp \left ( - \nu _ { 0 } r _ { 0 } \right ) \\ \intertext { a n e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e r e } \Delta \Delta \Delta \nu < \nu _ { \text{cr} } = 2 \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \nolimits } = \partial \partial \partial \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \Delta \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \alpha \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \pi \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \Pi \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \beta \binom { 1 } { 2 } } \cdots \colon = 0 \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \eta \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \p \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \rp \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi\pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pi \pr \sigma } }$$
and the phases are as in (32aa). For our configuration with r 0 = 8 we have ν cr = 0 0246. . Such asymptotic regime is shown on the left panel of Figure 2;
MAR) mixed asymptotic regime, when two of the solitons form bound state and the third soliton goes away from them with different velocity; Such regime takes place if the amplitudes are chosen as in (29) and the phases are as in (32ab), see the left panel of Figure 3;
BSR) bound state regime when all solitons move asymptotically with the same velocity. Such regime takes place for amplitudes with ∆ ν > ν cr and the phases are as in (32aa). Such asymptotic regime is shown on the left panel of Figure 4.
It is natural to analyze separately all three regimes and to see what would be the effect of the external wells/humps on them. In particular, one can determine for which positions and intensities of the external potentials the solitons will undergo from one asymptotic regime to another.
Remark 1 The CTC and its perturbative version PCTC use the adiabatic approximation. If we assume that the distance between the solitons is r 0 = 8 , then the adiabatic parameter /epsilon1 /similarequal 0 01 . , so one can expect that the CTC model will hold true up to times of the order of 1 //epsilon1 /similarequal 100 . In figure 2 we see an excellent match between the MM and CTC up to times of the order of 300; after that the two models diverge.
Since the PCTC model is not integrable we will solve it numerically to find the predicted solitons trajectories ξ k ( ). t Besides we will solve numerically the MM with the initial condition (4) and extract the trajectories of max( | u 1 | 2 + | u 2 | 2 ), where /vector u ≡ ( u , u 1 2 ).
Figure 1: Graphs of P and R functions: for a single sech-potential centered at the origin in cyan and red colors; and for the superposed potential at the neighboring panel - in green and brown colors. (left); Single sech-potential in black color vs. superposed external potential V ( x ) = ∑ 32 s =0 c s sech ( 2 x -x s ), c s = -10 -1 , x s = -16 + sh , h = 1, s = 0 , ..., 32 - in blue color. The superposed potential forms a well. (right).
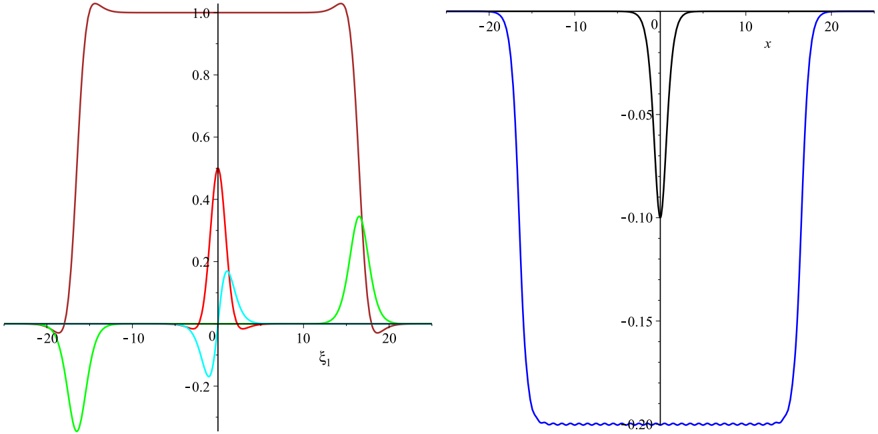
On the right panel of Figure 1 we plot samples of potential well with width 40 composed by 33 wells with depth c s = -0 1 . distributed uniformly between abscisas -16 and 16 and distance between them h = 1.
Evidently each Manakov soliton solution is parameterized by 6 parameters and four of them are the usual velocity, position, amplitude and phase. Two more parameters fix up the polarization vector. Having in mind the big parametric phenomenology of the solutions we fix the velocities, positions and polarization vectors and vary the initial amplitudes and phases in order to ensure one or another asymptotic regime [12]. Even with only three solitons configuration but with 13 to 33 potential wells/humps we have a large variety of combinations.
Potential wells, especially when broad enough attract the solitons and may be used to stabilize in a bound state. Potential humps repel the solitons; choosing their positions appropriately one can either split a soliton bound state into free solitons or force free solitons into bound state.
In what follows we compare the PCTC models with the numeric solutions of the corresponding (perturbed) MM. In doing this, to have better base for comparison we keep fixed some of the the initial parameters of the soliton trains. The other parameters may vary from run to run; their particular values will be specified in the captions of the figures. To avoid any confusion we mark the PCTC solutions by dashed lines, and the numeric solutions of the MM and the perturbed MM by solid lines. Also, we plot the centers of solitons and track their trajectories. Since the PCTC are derived in the framework of the adiabatic approximation, they are expected to be adequate only up to times of the order of /epsilon1 -1 . So, if the distance between neighboring solitons is 8 units, then /epsilon1 /similarequal 10 -2 and one might expect that the PCTC would be valid up to t /similarequal 100. Rather surprisingly, see we find that the models work well until t /similarequal 1000 or even longer. We also assume that ξ k < ξ k +1 , k = 1 2. ,
Below we provide several examples that illustrate our points. More specifically we set:
Time
500
400
300
200
100
0
-30
-20
-10
0
10
20
30
Position
Figure 2: AFR: Free potential behavior corresponding to real parts of eigenvalues of the Lax pair Re ζ 1 = -0 0116, . Re ζ 2 = 0, Re ζ 3 = 0 0116 (left . panel); External potential well V ( x ) = ∑ 32 s =0 c s sech ( 2 x -x s ), c s = -10 -1 , x s = -16 + s , s = 0 , ..., 32. The shaded area denotes the external potential at a half level (right panel).
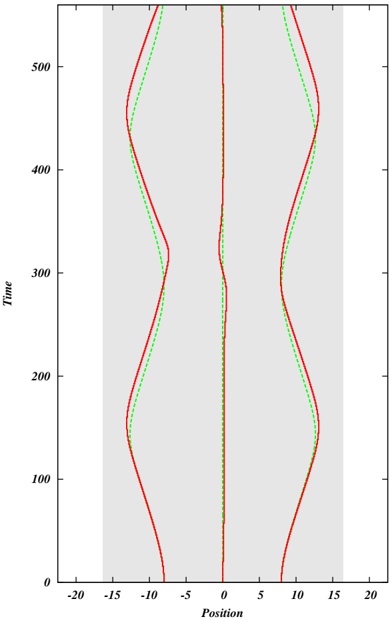
IC-2 The initial positions ξ 1 0 , = -8 , ξ 2 0 , = 0 , ξ 2 0 , = 8;
IC-3 Each of the initial polarization vectors /vector n k, 0 will be parameterized by its polarization angle θ k, 0 and a phase γ k, 0 as follows:
$$\stackrel { \sim } { \sim } \, ^ { \imath, \varphi } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \dots } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim } \, ^ { \delta } \, \stackrel { \sim } \, ^ { \delta } \, \stackrel { \sim } { \sim }$$
Generically the scalar products ( /vector n † k +1 , /vector n k ) are complex-valued. For simplicity here we assume that γ k, 0 = 0 for k = 1 2 3 so that ( , , /vector n † k +1 , /vector n k ) = cos( θ k +1 0 , -θ k, 0 ) and θ k, 0 = (4 -k π/ ) 10. Thus all scalar products just mentioned equal to cos( π/ 10) /similarequal 0 951; .
IC-4 The initial amplitudes
$$\nu _ { 1, 0 } = \nu _ { 0 } + \Delta \nu, \quad \nu _ { 2, 0 } = \nu _ { 0 } = 0. 5, \quad \nu _ { 3, 0 } = \nu _ { 0 } - \Delta \nu ;$$
IC-5 We use two types of initial phases configurations:
$$\mathbf a \mathbf ) \quad & \delta _ { 1, 0 } = 0, \quad \delta _ { 2, 0 } = \pi, \quad \delta _ { 3, 0 } = 0, \quad \Delta \nu = 0. 0 1. \\ & \quad \mathbf f \quad \Delta \nu < 0. 0 2 5 2 6 - \text{asymptotically free behavior} ;$$
$$b & \quad \delta _ { 1, 0 } = \delta _ { 2, 0 } = \delta _ { 3, 0 } = 0, \quad \Delta \nu = 0. 0 2. \\ & \quad \text{Bound state behavior for every } \quad \Delta \nu > 0.$$
Figure 3: BSR: Free potential behavior corresponding to real parts of eigenvalues of the Lax pair Re ζ 1 = Re ζ 2 = Re ζ 3 = 0(left); External potential hump V ( x ) = ∑ 12 s =0 c s sech ( 2 x -x s ), c s = 10 -2 , x s = -10 + sh , h = 5 3, / s = 0 , ..., 12. The shaded area denotes the external potential at a half level (right).
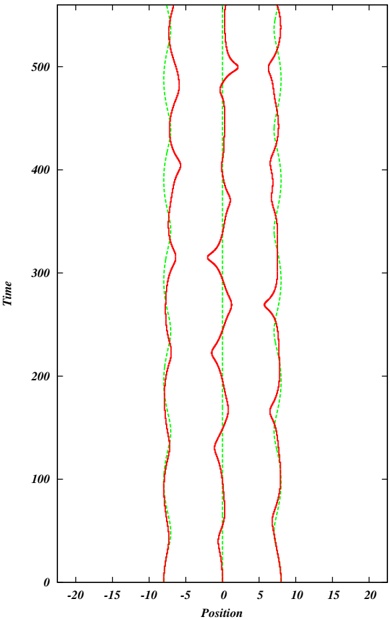
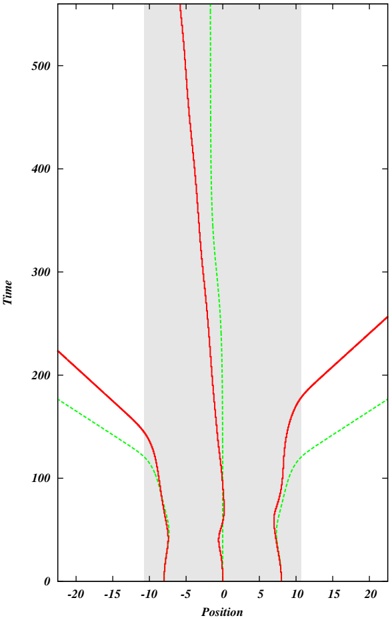
## 5 Results and Discussion
On the next figures we show some examples of 3-soliton systems. On the figures we plot the trajectories predicted by the PCTC (green dashed lines) with the MM (red solid lines). In order to ensure the adiabaticity condition we assume that initially the distance between the neighboring solitons r 0 = 8. The first example (Figure 2) clearly demonstrates the role of the external well on the stability of the asymptotically free 3-soliton configuration. The potential (shaded strip) does not allow the lateral solitons to leave the well and they start to oscillate. So, the new regime is bound state.
On the next Figure 3 the potential free regime is bound state. The influence of potential hump of width 24 and amplitude c s = 10 -2 leads to fast violation of this regime and transition to asymptotically free behavior of the lateral solitons.
On the Figure 4 is demonstrated the influence of external potential on the third possible regime - mixed asymptotic regime. In potential free configuration we have two bound stated solitons and one freely propagating. The adding of an external potential as superposed wells with amplitude (depth) c s = -10 -2 leads to a bound state behavior of all the three solitons.
On these figures the solutions obtained by VNSE are plotted by red solid lines while those obtained by CTC model by dashed green line. The comparison of the numerical predictions of the both models is fully satisfactory.
Time
500
400
300
200
100
0
-20
-15
-10
-5
0
5
10
15
20
Position
Figure 4: MAR: Free potential behavior corresponding to real parts of eigenvalues of the Lax pair Re ζ 1 = Re ζ 2 = -0 00321, . Re ζ 3 = 0 00642 (left); . External potential well V ( x ) = ∑ 32 s =0 c s sech ( 2 x -x s ), c s = -10 -2 , x s = -16 + sh , h = 1, s = 0 , ..., 32. The shaded area denotes the external potential at a half level (right).
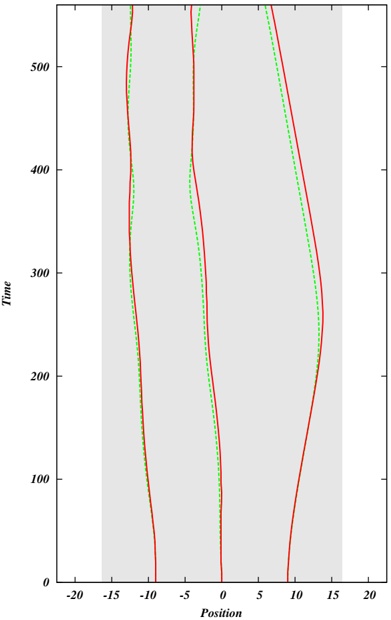
## 6 Conclusion
We have analyzed the effects of the external potential wells and humps on the VNLSE soliton interactions using the PCTC model. The comparison with the predictions of the more general VNLSE model [41]
$$\begin{smallmatrix} \nu _ { 1 } \\ & i \vec { u } _ { t } + \frac { 1 } { 2 } \vec { u } _ { x x } + ( \vec { u } \, ^ { \dagger }, \vec { u } ) \vec { u } + \alpha \vec { U } ( x, t ) = 0, \\ & & \quad \end{smallmatrix}$$
where /vector U = ( | u 2 | 2 u , 1 | u 1 | 2 u 2 ) T and the cross-modulation magnitude α is an excellent validation of the consistency and applicability of PCTC. The superposition of big number of wells/humps obviously complexify the motion of the soliton envelopes and can cause a transition from asymptotically free and mixed asymptotic regime to a bound state regime and vice versa. In particular, the latter means that the external potentials can be used to control the soliton motion in a given direction and therefore to achieve a predicted motion of the optical pulse. A general feature of the conducted experiments is that the predictions of both models match very well for a very long-time evolution. This means that PCTC is reliable model for predicting the evolution of the multisoliton solutions of Manakov model in adiabatic approximation.
## Acknowledgements
The investigation is supported partially by Bulgarian Science Foundation under grant DDVU02/71.
These results were presented and discussed at the 8-th IMACS Conference WAVES'13 at Athens, GA and the joint seminar of The Advanced Materials Research Institute and the Department of Physics by the University of New Orleans, LA.
## A List of integrals
We outline the method of calculating the integrals [17] needed to work out external well-type potentials as in Eq. (3). We start with the well known integral [37]:
$$K ( a, \Delta ) \equiv \int _ { - \infty } ^ { \infty } \frac { d z \, e ^ { i a z } } { 2 \cosh z \cosh ( z + \Delta ) } = \frac { \pi } { \sinh \Delta } \frac { \sin ( a \Delta / 2 ) } { \sinh ( \pi a / 2 ) } e ^ { - i a \Delta / 2 }.$$
Using the identity 2cosh( z -∆ 2)cosh( / z + ∆ 2) = cosh(2 ) + cosh(∆) and applying the / z substitution z → z -∆ 2 and we get /
$$\mathrm e ^ { i a \Delta / 2 } K ( a, \Delta ) = \underset { - \infty } { \overset { \infty } { \int } } \frac { d z e ^ { i a z } } { \cosh ( 2 z ) + \cosh ( \Delta ) } = \frac { \pi \sin ( a \Delta / 2 ) } { \sinh ( \Delta ) \sinh ( \pi a / 2 ) }.$$
Next we differentiate with respect to ∆ and divide by sinh ∆:
$$\underset { - \infty } { \int } \frac { d z e ^ { i a z } } { ( \cosh ( 2 z ) + \cosh ( \Delta ) ) ^ { 2 } } = - \frac { 1 } { \sinh ( \Delta ) } \frac { \partial } { \partial \Delta } \left ( \frac { \pi \sin ( a \Delta / 2 ) } { \sinh ( \Delta ) \sinh ( \pi a / 2 ) } \right ),$$
$$\int _ { - \infty } ^ { \infty } \frac { d z e ^ { i a z } } { ( \cosh ( 2 z ) + \cosh ( \Delta ) ) ^ { 3 } } = \frac { 1 } { \sinh ( \Delta ) } \frac { \partial } { \partial \Delta } \left ( \frac { 1 } { \sinh ( \Delta ) } \frac { \partial } { \partial \Delta } \left ( \frac { \pi \sin ( a \Delta / 2 ) } { \sinh ( \Delta ) \sinh ( \pi a / 2 ) } \right ) \right ).$$
Thus we have:
$$& \i \, \text{$two$ have} \colon \\ & N ( a, \Delta ) = - \frac { 2 } { \sinh ( \Delta ) } e ^ { - i a \Delta / 2 } \frac { \partial } { \partial \Delta } \left ( e ^ { i a \Delta / 2 } K ( a, \Delta ) \right ), \quad P ( \Delta ) = - \, \frac { 1 } { 2 } e ^ { i a \Delta } \frac { \partial N ( a, \Delta ) } { \partial \Delta } \Big | _ { a = 0 },$$
$$R ( \Delta ) = N ( 0, \Delta ) - \frac { 1 } { 2 i } \, \frac { \partial } { \partial a } \left ( e ^ { i a \Delta } \frac { \partial N ( a, \Delta ) } { \partial \Delta } \right ) \Big | _ { a = 0 }. \\ \text{If we have generic (complex-valued) potential } V ( x ) \, \text{we will}$$
$$\tilde { \ } - \frac { 1 } { 2 } \mathrm e ^ { i a \Delta } \frac { \partial N ( a, \Delta ) } { \partial \Delta } \Big | _ { a = 0 } \,,$$
If we have generic (complex-valued) potential V ( x ) we will have to calculate the integrals:
$$N ( \Delta ) = \underset { \infty } { \overset { \infty } { \int } } \frac { d z } { 2 \cosh ^ { 2 } ( z ) \cosh ^ { 2 } ( z - \Delta ) } = \frac { 2 \Delta \cosh ( \Delta ) - 2 \sinh ( \Delta ) } { \sinh ^ { 3 } ( \Delta ) },$$
$$Q ( \Delta ) = \int _ { - \infty } ^ { - \infty } \frac { d z z } { 2 \cosh ^ { 2 } ( z ) \cosh ^ { 2 } ( z - \Delta ) } = \frac { 2 \Delta \sinh ( \Delta ) - 2 \Delta ^ { 2 } \cosh ( \Delta ) } { \sinh ^ { 3 } ( \Delta ) },$$
while P (∆) and R (∆) are given in eq. (23).
## References
- [1] M. J. Ablowitz, B. Prinari, and A. D. Trubatch. Discrete and continuous nonlinear Schr¨dinger systems. o Lecture Notes Series vol. 302, London Mathematical Society, Cambridge University Press, London, 2004.
| [2] | D. Anderson, and M. Lisak. Nonlinear asymmetric self-phase modulation and self- steepening of pulses in long optical waveguides Phys. Rev. A , 27:1393-1398, 1983; D. Anderson, M. Lisak, and T. Reichel. Approximate analytical approaches to nonlinear pulse propagation in optical fibers: A comparison. Phys. Rev. A , 38: 1618-1620, 1988. |
|-------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [3] | S. M. Baker, J. N. Elgin, and J. Gibbons. Polarization dynamics of solitons in birefringent fibers. Phys. Rev. E , 62:4325-4332, 1999. |
| [4] | Th. Busch and J. R. Anglin. Dark-bright solitons in inhomogeneous Bose-Einstein con- densates. Phys. Rev. Lett. , 87:010401, 2001. |
| [5] | C. I. Christov, S. Dost, and G. A. Maugin. Inelasticity of soliton collisions in systems of coupled NLS equations. Physica Scripta , 50:449-454, 1994. |
| [6] | V. S. Gerdjikov. N -soliton interactions, the Complex Toda Chain and stability of NLS soliton trains. In: E. Kriezis (ed.), In Proc. of the Int. Symp. on Electromagnetic Theory , pages 307-309, Aristotle Univ. of Thessaloniki, vol. 1, 1998. |
| [7] | V. S. Gerdjikov, B. B. Baizakov, and M. Salerno. Modelling adiabatic N -soliton interac- tions and perturbations. Theor. Math. Phys. , 144(2):1138-1146, 2005. |
| [8] | V. S. Gerdjikov. Modeling soliton interactions of the perturbed vector nonlinear Schr¨dinger o equation. Bulgarian J. Phys. , 38:274-283, 2011. |
| [9] | V. S. Gerdjikov, B. B. Baizakov, M. Salerno, and N. A. Kostov. Adiabatic N -soliton interactions of Bose-Einstein condensates in external potentials. Phys. Rev. E. , 73:046606, 2006. |
| [10] | V. S. Gerdjikov, E. V. Doktorov, and N. P. Matsuka. N -soliton Train and Generalized Complex Toda Chain for Manakov System. Theor. Math. Phys. , 151(3):762-773, 2007. |
| [11] | V. S. Gerdjikov, E. G. Evstatiev, and R. I. Ivanov. The complex Toda chains and the simple Lie algebras - solutions and large time asymptotics. J. Phys. A: Math & Gen. , 31:8221-8232, 1998; V. S. Gerdjikov, E. G. Evstatiev, and R. I. Ivanov. The complex Toda chains and the simple Lie algebras - Solutions and large time asymptotics - II. J. Phys. A: Math & Gen. , 33:975-1006, 2000. |
| [12] | V. S. Gerdjikov, E. G. Evstatiev, D. J. Kaup, G. L. Diankov, and I. M. Uzunov. Stability and quasi-equidistant propagation of NLS soliton trains. Phys. Lett. A , 241:323-328, 1998. |
| [13] | V. S. Gerdjikov, D. J. Kaup, I. M. Uzunov, and E. G. Evstatiev. Asymptotic behavior of N -soliton trains of the nonlinear Schr¨dinger o equation. Phys. Rev. Lett. , 77:3943-3946, 1996. |
| [14] | V. S. Gerdjikov, N. A. Kostov, E. V. Doktorov, and N. P. Matsuka. Generalized Per- turbed Complex Toda Chain for Manakov System and exact solutions of the Bose-Einstein mixtures. Mathematics and Computers in Simulation , 80:112-119, 2009. |
| [15] | V. S. Gerdjikov, N. A. Kostov, and T. I. Valchev. Bose-Einstein condensates with F = 1 and F = 2. Reductions and soliton interactions of multi-component NLS models. In S. M. Saltiel et al . (eds.), International Conference on Ultrafast and Nonlinear Optics 2009, Proceedings of SPIE vol. 7501, 7501W, Burgas, 2009, arXiv: 1001.0168 [nlin.SI]. |
| [16] | V. S. Gerdjikov and M. D. Todorov. N -soliton interactions for the Manakov system. Effects of external potentials. In R. Carretero-Gonzalez et al. (eds.), Localized Excitations in Nonlinear Complex Systems, Nonlinear Systems and Complexity 7 , pages 147-169, Springer International Publishing Switzerland, 2014, doi 10.1007/978-3-319-02057-0 7. |
|--------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [17] | V. S. Gerdjikov and M. D. Todorov. 'On the effects of sech-like potentials on Manakov solitons. In M. D. Todorov (ed.) AMiTaNS'13, AIP CP1561 , pages 75-83, AIP, Melville, NY, 2013, doi 10.1063/1.4827216. |
| [18] | V. S. Gerdjikov, I. M. Uzunov, E. G. Evstatiev, and G. L. Diankov. Nonlinear Schr¨dinger o equation and N -soliton interactions: Generalized Karpman-Soloviev approach and the complex Toda chain. Phys. Rev. E , 55(5):6039-6060, 1997. |
| [19] | V. S. Gerdjikov and I. M. Uzunov. Adiabatic and non-adiabatic soliton interactions in nonlinear optics. Physica D , 152-153:355-362, 2001. |
| [20] | V. S. Gerdjikov, G. Vilasi, and A. B. Yanovski. Integrable Hamiltonian Hierarchies. Spectral and Geometric Methods. Lecture Notes in Physics vol. 748, Springer Verlag, Berlin-Heidelberg-New York, 2008, ISBN: 978-3-540-77054-1. |
| [21] | A. Griffin, T. Nikuni, and E. Zaremba. Bose-Condensed Gases at Finite Temperatures . Cambridge University press, Cambridge, UK, 2009. |
| [22] | T.-L. Ho. Spinor Bose condensates in optical traps. Phys. Rev. Lett. , 81:742, 1998. |
| [23] | J. Ieda, T. Miyakawa, and M. Wadati. Exact analysis of soliton dynamics in spinor Bose- Einstein condensates. Phys. Rev Lett. , 93:194102, 2004. |
| [24] | V. I. Karpman and V. V. Solov'ev. APerturbational approach to the two-solition systems. Physica D , 3:487-502, 1981. |
| [25] | P. G. Kevrekidis, D. J. Frantzeskakis, and R. Carretero-Gonzalez (eds.). Emergent Non- linear Phenomena in Bose-Einstein Condensates: Theory and Experiment. Springer, Vol. 45, 2008. |
| [26] | N. A. Kostov, V. Z. Enol'skii, V. S. Gerdjikov, V. V. Konotop, and M. Salerno. On two-component Bose-Einstein condensates in periodic potential. Phys. Rev. E , 70:056617, 2004. |
| [27] | N. A. Kostov and V. S. Gerdjikov. On the soliton interactions in NLS equation with external potentials. In P. A. Atanasov et al. (eds.), 14th International School on Quantum Electronics: Laser Physics and Applications. Proceedings of SPIE vol. 6604 , 66041S, 2007. |
| [28] | N. A. Kostov, V. S. Gerdjikov, and T. I. Valchev. Exact solutions for equations of Bose- Fermi mixtures in one-dimensional optical lattice. SIGMA , 3:paper 071, 14 pages, 2007, ArXiv: nlin.SI/0703057, http://www.emis.de/journals/SIGMA/ |
| [29] | T. I. Lakoba and D. J. Kaup. Perturbation theory for the Manakov soliton and its appli- cations to pulse propagation in randomly birefringent fibers. Phys. Rev. E , 56:6147-6165, 1997. |
| [30] | B. A. Malomed. Variational methods in nonlinear fiber optics and related fields. Progr. Opt. , 43:71-193, 2002. |
| [31] | S. V. Manakov. On the theory of two-dimensional stationary self-focusing of electromag- netic waves. Zh. Eksp. Teor. Fiz. , 65: 1392, 1973. English translation: Sov. Phys. JETP 38:248, 1974. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [32] | J. Moser. Dynamical Systems, Theory and Applications. Lecture Notes in Physics vol. 38, Springer Verlag, Berlin, 467 pages, 1975. |
| [33] | S. P. Novikov, S. V. Manakov, L. P. Pitaevski, and V. E. Zakharov. 'Theory of Solitons, the Inverse Scattering Method,' Consultant Bureau, New York, 1984. |
| [34] | L. P. Pitaevskii and S. Stringari. 'Bose-Einstein Condensation.' Oxford University Press, Oxford, UK, 2003. |
| [35] | T. Ohmi and K. Machida. Bose-Einstein condensation with internal degrees of freedom in alkali atom gases. J. Phys. Soc. Jpn. , 67:1822, 1998. |
| [36] | M. Modugno, F. Dalfovo, C. Fort, P. Maddaloni, and F. Minardi. Dynamics of two colliding Bose-Einstein condensates in an elongated magnetostatic trap. Phys. Rev. A , 62: 063607, 2000. |
| [37] | I. S. Gradsteyn and I. M. Ryzhik. Tables of Series, Products and Integrals Deutsch- Verlag, Frankfurt, 1981, Vol. 1. |
| [38] | V. S. Shchesnovich and E. V. Doktorov. Perturbation theory for solitons of the Manakov system. Phys. Rev. E , 55:7626, 1997. |
| [39] | M. Toda. 'Theory of Nonlinear Lattices.', Springer Verlag, Berlin, 1989. |
| [40] | M. D. Todorov and C. I. Christov. Conservative numerical scheme in complex arithmetic for coupled nonlinear Schrodinger equations. Discrete and Continuous Dynamical Systems , Supplement 2007, 982-992. |
| [41] | M. D. Todorov and C. I. Christov. Impact of the large cross-modulation parameter on the collision dynamics of quasi-particles governed by vector NLSE. Mathematics and Comput- ers in Simulation , 80:46-55, 2008. |
| [42] | M. D. Todorov and C. I. Christov. Collision dynamics of elliptically polarized solitons in coupled nonlinear Schr¨dinger o equations. Mathematics and Computers in Simulation , 82:1221-1232, 2012. |
| [43] | M. Uchiyama, J. Ieda, and M. Wadati. Multicomponent bright solitons in F = 2 spinor Bose-Einstein cndensates. J. Phys. Soc. Japan , 76(7):74005, 2007. |
| [44] | M. Ueda and M. Koashi. Theory of spin-2 Bose-Einstein condensates: Spin correlations, magnetic response, and excitation spectra. Phys. Rev. A , 65:063602, 2002. |
| [45] | J. Yang. Suppression of Manakov soliton interference in optical fibers. Phys. Rev. E , 65:036606, 2002. |
| [46] | V. E. Zakharov and A. B. Shabat. Exact theory of two-dimensional self-focusing and one-dimensional self-modulation of waves in nonlinear media. English translation: Soviet Physics-JETP , 34:62-69, 1972. | | null | [
"V. S. Gerdjikov",
"M. D. Todorov",
"A. V. Kyuldjiev"
] | 2014-08-01T16:48:27+00:00 | 2014-08-04T05:23:47+00:00 | [
"math-ph",
"math.MP",
"nlin.PS",
"35Q55, 35Q60, 37K10, 37K40"
] | Asymptotic Behavior of Manakov Solitons: Effects of Potential Wells and Humps | We consider the asymptotic behavior of the soliton solutions of Manakov's
system perturbed by external potentials. It has already been established that
its multisoliton interactions in the adiabatic approximation can be modeled by
the Complex Toda chain (CTC). The fact that the CTC is a completely integrable
system, enables us to determine the asymptotic behavior of the multisoliton
trains. In the present study we accent on the 3-soliton initial configurations
perturbed by sech-like external potentials and compare the numerical
predictions of the Manakov system and the perturbed CTC in different regimes.
The results of conducted analysis show that the perturbed CTC can reliably
predict the long-time evolution of the Manakov system. |
1408.0231v1 | ## One dimensional scattering from two-piece rising potentials: a new avenue of resonances
Zafar Ahmed , Shashin Pavaskar , Lakshmi Prakash 1 Nuclear Physics Division, Bhabha Atomic Research Centre, Mumbai, India 2 National Institute of Technology, Surathkal, Mangalore, 575025, India 3 University of Texas, Austin, TX, 78705, USA ∗
1 2 3
(Dated: August 4, 2014)
We study scattering from potentials that rise monotonically on one side; this is generally avoided. We report that resonant states are absent in such potentials when they are smooth and single-piece having less than three real turning points (like in the cases of Morse oscillator, exponential and linear potentials). But when these potentials are made two-piece, resonances can occur. We further show that rising potentials next to a well/step/barrier are rich models of multiple resonances (Gamow's decaying states) in one- dimension. We use linear, parabolic and exponential profiles as rising part and find complex-energy poles, E n = E n -i Γ n / 2 (Γ n > 0), in the reflection amplitude (s-matrix). The appearance of peaks in Wigner's (reflection) time-delay at E = glyph[epsilon1] n (close to E n ) and spatial catastrophe in the eigenfunction confirm the existence of resonances and meta-stable states in these systems.
PACS Nos.: 03.65.-w, 03.65.Nk
In one dimension, a potential having (at least) three real turning points at an energy (say, 0 < E < V b ) can entail metastable states which are characterized by discrete complex energy eigenvalues ( E n = E n -i Γ n / , 2 Γ n > 0). These potentials consist of a well next to a barrier of finite height ( V b ) and width. The potential V λ ( x ) = x / 2 4 -λx 3 [1] is the well known example. A rigid wall near a finite barrier is another class of potentials wherein the position of rigid wall itself acts as one real turning point. Ginocchio's versatile exactly solvable potential [2] in a parametric regime becomes a four real turning point system (a well surrounded by two finite side barriers) to bear both metastable ( E n < V b ) and resonance ( E n > V b ) states.
In one-dimension, consider a particle in a zero potential domain approaching a rigid wall at x = a from left. Its wave function will be given by ψ x ( ) = Ae ikx + Be -ikx . As it has to vanish at x = a , we have r E ( ) = B/A = -e 2 ika . Here k = √ 2 mE/h ¯ and r E ( ) is called reflection amplitude. Its modulus is 1 signifying total reflection from the rigid wall. The role of reflection amplitude r E ( ) in one-dimension is like that of S E ( ) in three-dimensions. Now let us ask as to what happens if the rigid wall is replaced by a rising repulsive potential, say V ( x ) = V e 0 2 x/a . Schr¨dinger o reflection and transmission through this exponential is well studied for V 0 < 0 [3]. For V 0 > 0, one would intuitively claim full reflection at this potential and leave it at that without further investigation.
Recently, inspired by complex energy eigenvalues in the cubic potential V ( x ) = -x 3 [4], the issue of scattering from a rising potential has been initiated [5] with the study of an odd parabolic potential. It turns out that for the rising potential (say for x > 0), one can actually demand ψ ( ∞ ∼ ) 0. For x ∼ -∞ , on the other hand, one can seek a linear
∗ Electronic address: 1: [email protected], 2: [email protected], 3:[email protected]
combination of reflected and transmitted wave solutions of the Schr¨dinger equation as per the potential for o x < 0. Unlike the usual reciprocal one-dimensional scattering, the scattering here is essentially one-sided, from left to right if V ( x ) is rising for x > 0 and vice-versa. One can then find the reflection amplitude r E ( ) justifying the intuitive result that | r E ( ) | 2 = 1. Subsequently, one can extract the complex energy ( E n -i Γ n / , 2 Γ n > 0) poles of r E ( ) = e iθ ( E ) (zeros of A E ( )); they cause maxima in the Wigner's time delay τ ( E ) = ¯ h dθ E ( ) dE [6]. These discrete complex energy states are called Gamow's decaying (time-wise) states. But spatially, they oscillate and grow asymptotically on either one or both sides depending on the potential profile. This behavior of Gamow's states is called catastrophe which should by now [6] be accepted and highlighted as the essence of Gamow's states (also known as Siegert states [7]). This provides a definite mathematical procedure for obtaining the much sought after resonances and metastable states (mostly, the former is used for both). Solving Schr¨dinger equation by complex scaling of co-ordinate [8] is yet another method of o finding resonances.
(〉〈 ∣
((
FIG. 1: Schematic depiction of smooth one-piece potentials having at most two real turning points - a: exponential (S0.1) , b: Morse (S0.2) , c: linear (S0.3) . These potentials, we show, do not entail resonances.
Here, we consider scattering from rising potentials. We show that resonances do not occur in smooth, one-piece potentials such as those in Fig 1(a,b,c) (See S0.1 , S0.2 , S0.3 below). However, they are found when the potential is made two-piece such as shown in Figs. 2-4 (See S1 , S2 , S3 below); these at times may be broad resonances. Regardless, they discretize energy in the positive continuum. In addition, we illustrate good, thin resonances for a rising potential (linear, parabolic, and exponential profiles) next to a well/step/barrier (See Figs. 5,6,8, see S4 through S7 below). In this new avenue, we attribute the occurrence of resonances to the rising potential and its two-piece nature (irrespective of the number of real turning points).
Earlier, in interesting analyses [9] of rectangular and Dirac delta potentials in a semi-harmonic background, discrete complex spectra have been found. However, this has been unduly attributed to the semi-harmonic (half-parabolic) potential in particular. It is much in the same way as the complex eigenvalues of V λ ( x ) = x / 2 4 -λx 3 [1] were attributed to the parabolic (harmonic) part, but now we know [4] that -bx 3 itself supports non-real discrete spectrum. Here we would like to remark that the the complex eigenvalues ( E n < V b ) in V λ ( x ) [1] are the metastable states due to three turning point nature of the potentials and those with E n > V b owe it to the rising nature of the potential on one side ( x ∼ -∞ ).
Historically, a particle subject to a one-dimensional potential governed by Schr¨dinger equation o
$$\frac { d ^ { 2 } \psi ( x ) } { d x ^ { 2 } } + [ k ^ { 2 } - \frac { 2 m } { \hbar { ^ { 2 } } } V ( x ) ] \psi ( x ) = 0, \ \ k = \sqrt { \frac { 2 m E } { \hbar { ^ { 2 } } } }.$$
has been at the heart of many phenomena of the micro-world and continues to be so even today. In this Letter, we solve (1) analytically for various one dimensional systems S0-S7 which essentially have a rising part in them. For each system, we calculate the reflection amplitude ( r E ( )), its complex energy poles ( E n ), and Wigner's (reflection)
time-delay ( τ ( E )). Let us define p, q, s , for use in sequel
$$p = \sqrt { \frac { 2 m [ E + V ^ { \prime } ] } { \hbar { ^ { 2 } } } }, \ q = \sqrt { \frac { 2 m [ E - V _ { 0 } ] } { \hbar { ^ { 2 } } } }, \ s = \sqrt { \frac { 2 m V _ { 0 } c ^ { 2 } } { \hbar { ^ { 2 } } } }.$$
## S0: One-piece rising potentials
Here, we consider an exponential potential ( V E ( x )) and the well-known Morse oscillator potential ( V M ( x )).
## S0.1: V E ( x ) = V e 0 2x c / : (see Fig. 1a)
The Eq. (1) for V E ( x ) can be transformed to Modified cylindrical Bessel equation [10]. We seek the modified Bessel function of second kind ψ x ( ) = K ikc ( se x/c ) as the physically acceptable solution. This vanishes for x ∼ ∞ since [10] K ν ( z ) ∼ √ π 2 z e -z → 0. Further, the identity K ν ( z ) = I -ν ( z ) -I ν ( z ) sin νπ [10], and I ν ( z ) ≈ ( z/ 2) ν Γ(1+ ) ν , z ∼ 0 [10], help us to write
$$\psi ( x ) \sim \begin{cases} \sqrt { \pi / 2 s } \ e ^ { - [ x / ( 2 c ) + s e ^ { x / c } ] }, \quad x \sim \infty \\ - ( i \pi k c ) ^ { - 1 } ( [ ( s / 2 ) ^ { i k c } \Gamma ( 1 - i k c ) ] e ^ { i k x } \\ + [ ( s / 2 ) ^ { - i k c } \Gamma ( 1 + i k c ) ] e ^ { - i k x } ). \quad x \sim - \infty \end{cases}$$
thereby giving reflection amplitude as
$$r ( E ) = - ( s / 2 ) ^ { - 2 i k c } \left ( \frac { \Gamma ( 1 + i k c ) } { \Gamma ( 1 - i k c ) } \right ).$$
It can be readily checked that the all the poles of r E ( ) are ikc = -( n +1). These are unphysical as they give rise to a false discrete spectrum ( E n = -(1 + n ) 2 ¯ h 2 2 mc 2 ). Hence, no complex energy resonances or peaks in τ ( E ) can be found (not shown here). We would like to remark that the wave function (see the dotted line in Fig. 7(c) below) converges to zero on the right and is a combination of incident and reflected waves on the left (as in Eq. (3)). This will be the typical behavior of scattering at a real positive energy (above the well, if any) for all systems ( S0 -S7 ) of potentials discussed here (see Figs. 1-6,8).
## S0.2: Morse Oscillator potential (Fig. 1(b))
## V M ( x ) = V 0 ( e 2x c / -2e x c / )
Morse oscillator is a well known exactly solvable potential having simple explicit expression for discrete energy eigenvalues [11,12]. Also the inverted form of this is called Morse barrier which possesses simple and exact expressions [13] for reflection and transmission coefficients. Studying of scattering (positive energy states) from V M ( x ) has been avoided as it rises monotonically at positive large distances. Here, we proceed to find the reflection amplitude, r E ( ), for Morse oscillator.
Inserting V M ( x ) in (1), introducing z = 2 se x/c , and using the well known transformation [11,12]: ψ z ( ) = z ikc e -z/ 2 W z ( ); we notice that W z ( ) satisfies the Confluent hyper-geometric equation (CHE): zW ′′ ( z )+( C -z W ) ′ ( z ) -AW z ( ) = 0 [9]. This in our case reads as
$$z W ^ { \prime \prime } ( z ) + ( 2 i k c + 1 - z ) W ^ { \prime } ( z ) - ( - s + i k c + \frac { 1 } { 2 } ) W ( z ) = 0.$$
The CHE, a second order linear differential equation, has got two pairs of linearly independent solutions: ( w , w 1 2 ) and ( w , w 3 4 ) [10]. Each one of these pairs is expressible as a linear combination of members from the other pair. w 1
is usually chosen as the appropriate solution for bound states. For scattering states w 3 = U A,C z ( ; ) ( U also denoted as ψ which we avoid here) is appropriate. We discard its other linearly independent partner w 4 as it would diverge for asymptotically large positive values. These considerations lead us to write
$$\psi ( x ) = z ^ { i k c } e ^ { - z / 2 } U ( - s + i k c + 1 / 2, 1 + 2 i k c ; 2 s e ^ { x / c } ).$$
Noting that U A,C z ( ; ) ∼ z -A for z ∼ ∞ , we find ψ x ( ) ∼ (2 s ) s -1 / 2 exp[ -{ se x/c -sx/c + x/ (2 ) c } ] → 0 as x →∞ . Next, we consider the identity[9]
$$w _ { 3 } = \frac { \Gamma ( 1 - C ) } { \Gamma ( 1 + A - C ) } w _ { 1 } + \frac { \Gamma ( C - 1 ) } { \Gamma ( A ) } w _ { 2 },$$
where w 1 = 1 F 1 ( A,C z ,w ; ) 2 = z 1 -C 1 F 1 (1 + A -C, 2 -C z ; ) are Confluent hyper-geometric series (CHS). Since CHS tends to 1 as z → 0 (equivalently x → -∞ ), the asymptotic behavior of ψ x ( ) is nothing but a combination of the incident and reflected waves. Using (6,7) we can now write
$$\psi ( x ) \sim ( 2 s ) ^ { i k c } \frac { \Gamma ( - 2 i k c ) e ^ { i k x } } { \Gamma ( 1 / 2 - s - i k c ) } + ( 2 s ) ^ { - i k c } \frac { \Gamma ( 2 i k c ) e ^ { - i k x } } { \Gamma ( 1 / 2 - s + i k c ) }$$
for x →-∞ . Finally, we extract
$$r ( E ) = ( 2 s ) ^ { - 2 i k c } \frac { \Gamma ( 2 i k c ) } { \Gamma ( - 2 i k c ) } \frac { \Gamma ( 1 / 2 - s - i k c ) } { \Gamma ( 1 / 2 - s + i k c ) }.$$
It readily follows that | r E ( ) | 2 = 1. The physical poles of r E ( ) are obtained by noting that Γ( -n ) = ∞ for n = 0 1 2 3 , , , and so on. We get 1 / 2 -s -ikc = -n (such that n +1 2 / < s ), which gives only the well known spectrum of Morse oscillator (Fig. 1(b)) as negative discrete eigenvalues: E n = ( n +1 2 / -s ) 2 ¯ h 2 2 mc 2 [10,11]. The negative energy poles due to Γ(2 ip ) are known to be unphysical. Thus, the Morse oscillator is devoid of resonances; it yields structureless τ ( E ).
## S1: Two-piece exponential potential
Now we make the exponential potential V E ( x ) of S0.1 two-piece as V ( x ) = V e 0 x/c , x ≤ 0; V e 0 x/d , x > 0. V ( x ) is continuous but non-differentiable at x = 0. Earlier, two-piece wells and semi-infinite (step) potentials have been found [14,15] to have a single deep minimum in reflectivity as a function of energy. This is opposed to the usual result of monotonically decreasing reflectivity. Again, we expect some striking difference in τ ( E ) due to the two-piece nature. As discussed above in S0.1 , the left hand solution of (1) can be expressed in terms of modified cylindrical
FIG. 2: Schematic depiction of potential, V ( x ), on the left and the corresponding time-delay, τ ( E ), on the right for system S1 . For E n , glyph[epsilon1] n , and other details, see Table 1.

Bessel functions. For x < 0, we seek ψ x ( ) = A s/ ( 2) -ikc Γ(1 + ikc I ) ikc ( se x/c ) + B s/ ( 2) ikc Γ(1 -ikc I ) -ikc ( se x/c ), and for x > 0 we take ψ x ( ) = CK ikd ( sζe x/d ). Using these solutions and introducing ζ = d/c , we obtain
$$r ( E ) = - ( s / 2 ) ^ { - 2 i k c } \frac { \Gamma ( 1 + i k c ) } { \Gamma ( 1 - i k c ) } \left [ \frac { I _ { i k c } ( s ) K ^ { \prime } _ { i k d } ( s \zeta ) - I ^ { \prime } _ { i k c } ( s ) K _ { i k d } ( s \zeta ) } { I _ { - i k c } ( s ) K ^ { \prime } _ { i k d } ( s \zeta ) - I ^ { \prime } _ { - i k c } ( s ) K _ { i k d } ( s \zeta ) } \right ].$$
glyph[negationslash]
When c = d , both the numerator and denominator in the square bracket are Wronskian functions: [ I ν ( z , K ) ν ( z )] = 1 /z [10] (real here). These cancel out, thereby giving us (4) back. But when c = d , K iν ( z ) is real for real ν and z ; the square bracket is uni-modular. Hence, it changes only the phase of r E ( ) as compared to the phase of r E ( ) in (4). r E ( ) in (10) gives rise to complex energy poles and corresponding peaks in time-delay, τ ( E ) (see Fig. 2 and Table 1). This can be seen as a direct consequence of making the potential two-piece.
## S2: Two-piece linear potential
FIG. 3: The same as in FIG. 2 for system S2 ; See Table 1.

Consider V ( x ) = hx , x < 0; V ( x ) = gx , x ≥ 0. This potential in Eq. (1) is exactly solvable [10,12] in terms of two linearly independent solutions Ai( u x ( )) , Bi( u x ( )) called Airy functions [9]. For the right, we seek ψ x ( ) = C Ai( u x ( )), where u x ( ) = 2 m ¯ h 2 ( gx -E g 2 / 3 ) . When x → ∞ , ψ x ( ) ∼ C u ′ -1 / 4 e -2 u 3 / 2 / 3 → 0. On the left, we use two interesting linear combinations: F ∓ ( x ) = √ 2 π [Bi( v x ( )) ∓ i Ai( v x ( ))] [10], where v x ( ) = 2 m ¯ h 2 ( hx -E h 2 / 3 ) . Next we notice that F ∓ ( x ) ∼ √ πφ v e ( ) ∓ iχ v ( ) , where χ v ( ) ∼ 2( -v ) 3 / 2 / 3. So when x →-∞ , F ∓ behave as incident and reflected waves respectively. Thus, we seek ψ x ( ) = AF -( v x ( )) + BF + ( v x ( )) for x < 0. We get
$$r ( E ) = - \frac { \eta \AA A i ^ { \prime } ( \bar { u } ) [ B i ( \bar { v } ) - i \AA A i ( \bar { v } ) ] - \AA A i ( \bar { u } ) [ B i ^ { \prime } ( \bar { v } ) - i \AA A i ^ { \prime } ( \bar { v } ) } { \eta \AA A i ^ { \prime } ( \bar { u } ) [ B i ( \bar { v } ) + i \AA A i ( \bar { v } ) ] - \AA A i ( \bar { u } ) [ B i ^ { \prime } ( \bar { v } ) + i \AA A i ^ { \prime } ( \bar { v } ) },$$
where ¯ = u -E/g 2 / 3 , v ¯ = -E/h 2 / 3 and η = ( g/h ) 1 / 3 . The primes denote differentiations with respect to the parameter in parenthesis. It can be readily checked that when g = h , numerator and denominator in (11) become Wronskian [Ai , Bi] = 1 /π [10] and r E ( ) becomes energy independent equaling a trivial form: -1. Hence, no resonances are found. This is the third instance (call it S0.3 ) of smooth single-piece rising potential devoid of any resonances. In Fig. 3, we present the cases of h = 0 , g = 1 ( S2.1 ) and h = 1 2 . , g = 1. See small wiggles in τ ( E ) representing broad resonances. See Table 1 for the acclaimed closeness of E n and the the peak-energies, glyph[epsilon1] n , in τ ( E ).
## S3: Parabolic well joined to a constant potential
FIG. 4: The same as in FIG. 2 for system S3 ; See Table 1.

We can write this potential as V ( x ) = V 0 = 1 2 mω a 2 2 , x < 0; V ( x ) = 1 2 mω 2 ( x -a ) 2 , x ≥ 0. Using the parabolic cylindrical solution [2,9] of (1) for parabolic well, we can write ψ x ( ) = CD ν ( β x ( -a )) for x > 0. When x → ∞ ,
ψ x ( ) ∼ C ′ ( x -a ) ν e -β 2 ( x -a ) 2 / 4 → 0. For x < 0, we seek Ae iqx + Be -iqx . Introducing ν = E ¯ hω -1 2 , we get
$$r ( E ) = \frac { - \beta D _ { \nu } ^ { \prime } ( - \beta a ) + i q D _ { \nu } ( - \beta a ) } { \beta D _ { \nu } ^ { \prime } ( - \beta a ) + i q D _ { \nu } ( - \beta a ) }, \ \beta = \sqrt { \frac { 2 m \omega } { \hbar } }.$$
## S4: Rising potential next to a step
We consider V ( x ) = -V ′ , x < 0; V ( x ) = gx , x > 0 (see Fig.5). Following the discussion of Airy function in S2 above, the solution of (1) for this potential can be written as ψ x ( ) = Ae ipx + Be -ipx , x ≤ 0; ψ x ( ) = C Ai( u x ( )), x ≥ 0. In this case, we find
$$r ( E ) = \frac { i p \text{Ai} ( \bar { u } ) - g ^ { 1 / 3 } \text{Ai} ^ { \prime } ( \bar { u } ) } { i p \text{Ai} ( \bar { u } ) + g ^ { 1 / 3 } \text{Ai} ^ { \prime } ( \bar { u } ) },$$
where u x , u ( ) ¯ are the same as in S2 above.
See Fig. 5 for good peaks in time-delay and Table 1 for closeness of E n and glyph[epsilon1] n .
FIG. 5: The same as in FIG. 2 for S4 and S5 ; see Table 1.
S5: Rising potential next to a Dirac-delta well This system is represented by V ( x ) = -V δ x ′ ( + a ), x < 0; V ( x ) = gx , x ≥ 0. Inserting this potential (see Fig. 5) in (1), the solution can be written as ψ x ( ) = Ae ikx + Be -ikx , x < -a ; ψ x ( ) = C sin kx + D cos kx , -a < x ≤ 0; F Ai( u x ( )), x > 0. We find
$$r ( E ) = e ^ { - 2 i k a } \left ( \frac { ( - V ^ { \prime } + i k ) ( - w \AA ^ { \prime } \sin k a + k \AA i \cos k a ) - k ( w \AA ^ { \prime } \cos k a + k \AA i \sin k a ) } { ( V ^ { \prime } + i k ) ( - w \AA ^ { \prime } \sin k a + k \AA i \cos k a ) + k ( w \AA ^ { \prime } \cos k a + k \AA i \sin k a ) } \right ),$$
where w = g 1 / 3 and ¯ is the argument of Ai and Ai . u ′
## S6: Rising potential next to a rectangular well
FIG. 6: The same as in FIG. 2 for S6.1, S6.2. The system S6.2 possesses metastable states for E < 5. See Table 1.

For this case, we have V ( x ) = 0, x ≤ -a ; -V ′ , -a < x < 0; gx , x ≥ 0. Fig 1(a) shows the schematic diagram of this system. For this potential, the solutions of (1) can be written as ψ x ( ) = Ae ikx + Be -ikx , x ≤ -a ; ψ x ( ) = C sin px + D cos px , -a < x < 0; ψ x ( ) = F Ai( u x ( )), x ≥ 0. We find
$$r ( E ) = e ^ { - 2 i k a } \left ( \frac { i k ( - w \mathbf A i ^ { \prime } \sin p a + p \mathbf A i \cos p a ) - p ( w \mathbf A i ^ { \prime } \sin p a + p \mathbf A i \cos p a ) } { i k ( - w \mathbf A i ^ { \prime } \sin p a + p \mathbf A i \cos p a ) + p ( w \mathbf A i ^ { \prime } \sin p a + p \mathbf A i \cos p a ) } \right )$$
See Fig. 6 for V ( x ) and τ ( E )
TABLE I: First five resonances in various systems. E n = E n -i Γ n / 2 (Γ n > 0) are the poles of r E ( ) and glyph[epsilon1] n are the peak positions in time-delay, τ ( E ). We take 2 m = 1 = ¯ h 2 . Notice the general closeness of E n and glyph[epsilon1] n , excepting the case of S3.1 .
| System | Fig. | Eq. | Parameters | E 0 ( glyph[epsilon1] 0 ) | E 1 ( glyph[epsilon1] 1 ) | E 2 ( glyph[epsilon1] 2 ) | E 3 ( glyph[epsilon1] 3 ) | E 4 ( glyph[epsilon1] 4 ) |
|----------|--------|-------|---------------------------|------------------------------------|------------------------------------|------------------------------|------------------------------|------------------------------|
| S1.1 | 2 | (10) | V 0 = 5 , c = 0 . 5 d = 5 | 8 . 88 - 1 . 50 i (8.89) | 13 . 14 - 1 . 87 i (13.21) | 17 . 30 - 2 . 17 i (17.34) | 21 . 51 - 2 . 45 i (21.65) | 25 . 80 - 2 . 70 i (26.05) |
| S1.2 | 2 | (10) | c = 0 , d = 5 V 0 = 5 | 9 . 42 - 1 . 23 i (9 . 36) | 13 . 77 - 1 . 49 i (13 . 46) | 18 . 01 - 1 . 69 i (18 . 04) | 22 . 28 - 1 . 89 i (22 . 14) | 26 . 62 - 2 . 07 i (26 . 43) |
| S2.1 | 3 | (11) | h = 0 , g = 1 | 2 . 79 - 1 . 09 i (2 . 89) | 4 . 45 - 1 . 03 i (4 . 62) | 5 . 85 - 0 . 98 i (5 . 85) | 7 . 08 - 0 . 94 i (7 . 12) | 8 . 22 - 0 . 91 i (8 . 26) |
| S2.2 | 3 | (11) | h = 1 . 2 , g = 1 | 1 . 88 - 1 . 69 i (1 . 92) | 3 . 73 - 1 . 47 i (3 . 98) | 5 . 21 - 1 . 35 i (5 . 24) | 6 . 50 - 1 . 27 i (6 . 53) | 7 . 68 - 1 . 22 i (7 . 76) |
| S3.1 | 4 | (12) | a = 0 , ¯ hω = 1 | 2 . 08 - 1 . 75 i (2 . 38) | 4 . 21 - 2 . 09 i (4 . 43) | 6 . 28 - 2 . 32 i (6 . 51) | 8 . 32 - 2 . 48 i (8 . 54) | 10 . 34 - 2 . 61 i (10 . 33) |
| S3.2 | 4 | (12) | a = 4 , ¯ hω = 1 | 4 . 32 - 0 . 22 i (4 . 31) | 5 . 56 - 0 . 48 i (5 . 56) | 6 . 86 - 0 . 65 i (6 . 86) | 8 . 20 - 0 . 78 i (8 . 21) | 9 . 58 - 0 . 89 i (9 . 63) |
| S4 | 5 | (13) | V ′ = 10 , g = 1 | 2 . 34 - 0 . 31 i (2 . 31) | 4 . 09 - 0 . 30 i (3 . 96) | 5 . 52 - 0 . 29 i (5 . 53) | 6 . 79 - 0 . 29 i (6 . 79) | 7 . 95 - 0 . 28 i (7 . 90) |
| S5 | 5 | (14) | V ′ = 2 , a = 1 g = 1 | 1 . 69 - 0 . 17 i (1 . 69) | 3 . 39 - 0 . 18 i (3 . 42) | 4 . 79 - 0 . 18 i (4 . 82) | 6 . 04 - 0 . 18 i (6 . 06) | 7 . 19 - 0 . 18 i (7 . 20) |
| S6.1 | 6 | (15) | V ′ = 5 , a = 2 g = 1 | 2 . 13 - 0 . 24 i (2 . 15) | 3 . 69 - 0 . 43 i (3 . 73) | 4 . 81 - 0 . 57 i (4 . 78) | 5 . 85 - 0 . 43 i (5 . 84) | 6 . 98 - 0 . 32 i (7 . 06) |
| S6.2 | 6 | (15) | V ′ = - 5 , a = 2 g = 1 | 1 . 86 - 0 . 5 × 10 - 3 i (1 . 85) | 3 . 56 - 0 . 3 × 10 - 3 i (3 . 56) | 4 . 93 - 0 . 01 i (4 . 95) | 6 . 08 - 0 . 07 i (6 . 10) | 7 . 04 - 0 . 25 i (7 . 03) |
FIG. 7: Depiction of spatial catastrophe in eigen function at the first resonant energy of S6.1 - (a) and (b) are for E = E 1 = 2 1263 . -0 2428 . . i The solid line in (c) is for E = E 1 and the dotted line for E = glyph[Rfractur] ( E 1 ) = 2 1263. . | ψ x ( ) | 2 for any energy, E > 0 (above the well, if any), come out to be similar for any of these rising potentials ( S0-S7 ).
## S7: Rising potential next to a Gaussian well
We write this potential as V ( x ) = -V e 0 -( x + ) a 2 /b 2 , x < 0; V ( x ) = gx , x ≥ 0. We find its reflection amplitude and
time- delay by numerically integrating Eq. (1). To testify this method, we have reproduced the results of S6 (see Eq. (15)). The numerically solved example of a Gaussian potential well juxtaposed to a linear rising potential (Fig.7 ) giving rise to multiple peaks in time-delay speaks of the good universality of resonances in two-piece rising potentials.
FIG. 8: The same as in FIG. 2 for system S7 . For S7 1 . : V ′ = 5, a = 1, b = √ 2, g = 1. Below E = 3, there are both positive and negative energy bound states (not in the graph). For S7.2 : V ′ = 10, a = 2, b = 31, . g = 1 . For S7.3 : V ′ = -5, a = 2, b = 31, . g = 1. For E < 5 ( E > 5) the peaks are for metastable (resonance) states.
Most remarkably, the other piece of the potential (for x < 0) could just be zero, a step or a well or a barrier. Moreover, the well itself may nor may not have bound states or resonances. All ( S1 to S7 ) show resonances which may be both broad (see S1-S3 ) and sharp (see S4-S7 ). Though not presented here, we find that a rising potential attached to more than two piece potentials also yield resonances. We have shown linear potential in systems ( S4-S7 ) as rising parts, this being easily achievable as a constant electric field for x > 0. Parabolic and exponential profiles also give the same effects(resonances as peaks in time-delay) qualitatively. The values of first five complex energy poles ( E n ) of r E ( ) and the peak positions ( glyph[epsilon1] n ) of time-delay, compiled in Table 1 for various systems, show a good agreement except in the curious case of S3.1 . For the typical catastrophic behavior of ψ x ( ) for these systems at E = E 0 , E 0 , and any other positive energy not within the well (if any), see Fig. 7.
The systems S6.2 and S7.3 have been presented here for both metastable states below the barrier height and resonances above it; see Table 1 for details. In these cases, if we increase the value of g , the rising part tends to become a hard (rigid) wall; Gamow's complex energy states become fewer and broader. Hence, we conclude that the strength of rising potential is crucial for controlling the number and quality of resonances in the new systems. Orthodox one-dimensional potentials with three real turning points may have paucity of resonances but they are found easily in rising potentials like V λ ( x ) [1] and the two-piece systems presented here.
We hope that the absence of resonances in rising one-piece potentials (Fig. 1) has been well noted; a proof for/against the same is welcome. We have attributed the occurrence of resonances to rising potentials and to their two-piece nature. In this regard, the odd parabolic potential, x x | | [4], is a curious example having only one peak in time delay and no catastrophe in the eigenfunction at E = E 0 . The cubic potential -x 3 is known [4] to have non-real discrete spectrum. However, it would be interesting to carry out the time delay analysis for this and other odd potentials like x 2 n +1 and x 2 n | x | ( n = 1 2 3 , , , .. ) to see if they compete with simple potentials presented here for peaks in time delay. It needs to be investigated if there exists a continuous two-piece rising potential (saturating towards x ∼ -∞ ) devoid of even wiggles in time-delay corresponding to E n (Γ n > 0) in all of its parametric regimes. Search for (the hitherto elusive) necessary condition for occurrence of resonances in a potential has now become more intriguing.
The intimate connection of quantum mechanics with (electromagnetic and matter) wave-propagation [15] ensures that the new avenue of resonances will be useful there as well, may be even more. The experimental verification and harnessing of the new avenue of resonances is the most pressing question arising here. In this regard, we hope that the system S2.1 presented above serves as a simple, feasible model which can be designed in laboratories easily; it is like a charged particle being injected in a region of constant electric field.
- [1] R. Yaris, J. Bendler, R. A. Lovett, C. M. Bender and P. A. Fedders 1978 Phys. Rev. A 18 1816 ; E. Caliceti, S. Graffi and M. Maioli 1980 Commun. Math. Phys. 75 51 ; G. Alvarez 1988 Phys. Rev. A 37 4079 .
- [2] J.N. Ginocchio 1984 Ann. of Phys. (N.Y) 152 203.
- [3] Z. Ahmed 2006 Int. J. Mod. Phys. A, 21 4439.
- [4] U. D. Jentschura, A. Surzhykov, M. Lubasch and J. Zinn-Justin 2008 J. Phys. A: Math. Theor. 41 095302.
- [5] E.M. Ferreria and J. Sesma 2012 J. Phys. A: Math. Theor. 45 615302.
- [6] A. Bohm, M. Gadella, G. B. Mainland 1989 Am. J. Phys. 57 1103; W. van Dijk and Y. Nogami 1999 Phys. Rev. Lett. 83 2867; R. de la Madrid amd M. Gadella 2002 Am. J. Phys. 70 626; Z. Ahmed and S.R. Jain 2004 J. Phys. A: Math. & Gen. 37 867,
- [7] K. Rapedius 2011 Eur. J. Phys. 32 1199.
- [8] N. Moiseyev 1998 Phys. Rep. 302 211.
- [9] N. Farnandez-Garcia and O. Rosas-Ortiz 2011 SIGMA 7 044.
- [10] M. Abramowitz, and I. A. Stegun 1970 Handbook of Mathematical Functions (Dover, N.Y.).
- [11] L. D. Landau, E. M. Lifshitz 1977 Quantum Mechanics (Pergamon Press, N.Y.) Ed. 3 rd .
- [12] S. Fl¨gge, 2009 u Practical Quantum Mechanics (Springer, New Delhi).
- [13] Z. Ahmed 1991 Phys. Lett. A 157 1 (1991).
- [14] H. Zhang and J. W. Lynn 1993 Phys. Rev. Lett. 70 77.
- [15] Z. Ahmed 2000 J. Phys. A: Math.Gen. 33 3161 (2000), and references therein.
- [16] J. Lekner 1987 Theory of reflection of electromagnetic and particle waves (Martinus Nijhoff, Dordrecht). | null | [
"Zafar Ahmed",
"Shashin Pavaskar",
"Lakshmi Prakash"
] | 2014-08-01T16:49:38+00:00 | 2014-08-01T16:49:38+00:00 | [
"quant-ph",
"math-ph",
"math.MP"
] | One dimensional scattering from two-piece rising potentials: a new avenue of resonances | We study scattering from potentials that rise monotonically on one side; this
is generally avoided. We report that resonant states are absent in such
potentials when they are smooth and single-piece having less than three real
turning points (like in the cases of Morse oscillator, exponential and linear
potentials). But when these potentials are made two-piece, resonances can
occur. We further show that rising potentials next to a well/step/barrier are
rich models of multiple resonances (Gamow's decaying states) in one- dimension.
We use linear, parabolic and exponential profiles as rising part and find
complex-energy poles, ${\cal E}_n=E_n-i\Gamma_n/2$ $(\Gamma_n > 0)$, in the
reflection amplitude (s-matrix). The appearance of peaks in Wigner's
(reflection) time-delay at $E=\epsilon_n$ (close to $E_n$) and spatial
catastrophe in the eigenfunction confirm the existence of resonances and
meta-stable states in these systems. PACS Nos.: 03.65.-w, 03.65.Nk |
1408.0232v1 | ## Jeans Instability in Superfluids
Itamar Hason and Yaron Oz Raymond and Beverly Sackler School of Physics and Astronomy, Tel-Aviv University, Tel-Aviv 69978, Israel (Dated: August 4, 2014)
## Abstract
We analyze the effect of a gravitational field on the sound modes of superfluids. We derive an instability condition that generalizes the well known Jeans instability of the sound mode in normal fluids. We discuss potential experimental implications.
PACS numbers: 47.37.+q, 26.60.-c
## I. INTRODUCTION
The Jeans instability of the sound mode in normal fluids that is caused by a gravitational field is a well known phenomenon [1]. It exhibits itself in astrophysical scenarios of aggregation of masses and galaxy formation. The Jeans dispersion relation of a normal fluid sound mode is obtained by linearizing the fluid equations in the presence of a gravitational field. It modifies the sound mode dispersion relation ω 2 = u /vector 2 1 k 2 to
$$\omega ^ { 2 } = u _ { 1 } ^ { 2 } \vec { k } ^ { 2 } - 4 \pi G \rho \.$$
ω is the frequency, /vector k is the momentum vector, u 1 is the speed of sound in a normal fluid u 2 1 = ∂p ∂ρ evaluated at fixed entropy, p is the pressure, ρ the local mass density and G is the gravitational coupling. Instability occurs when the RHS of (1) is negative
$$\vec { k } ^ { 2 } < \frac { 4 \pi G \rho } { u _ { 1 } ^ { 2 } } \.$$
It determines a Jeans length scale λ J , where all scales larger than that being unstable to a gravitational collapse.
In this letter we will analyze the effect of a gravitational field on the sound modes in superfluids. Superfluids are quantum fluids, i.e. fluids at temperatures close to zero where quantum effects are of primary importance [2]. They exhibit remarkable properties such as the ability to flow without viscosity in narrow capillaries. Superfluidity/superconductivity is also expected to be realized in Neutron stars matter (see e.g. [3]), as well as in high density phases of QCD [4].
The hydrodynamic description of superfluids consists of two separate motions, a normal flow and a super flow with densities ρ n and ρ s respectively, ρ n + ρ s = ρ [5, 6]. The super flow moves without viscosity, the normal flow is viscous, and the two flows do not exchange momentum between them. We denote by /vector v n and /vector v s the velocities of the normal and super flows, respectively. The superfluid velocity /vector v s corresponds to the gradient of the condensate phase that breaks spontaneously the global/local symmetry, which results in superfluidity/superconductivity, respectively. Thus, the superfluid motion is irrotational
$$\vec { \nabla } \times \vec { v } _ { s } = 0 \.$$
There are two sound modes in superfluids: the first sound u 1 which is a density wave as in normal fluids, and the second sound u 2 , which is a temperature wave and is unique to
superfluids. Its dispersion relation reads
$$\omega ^ { 2 } = u _ { 2 } ^ { 2 } \vec { k } ^ { 2 }, \quad u _ { 2 } ^ { 2 } = \frac { \rho _ { s } s ^ { 2 } } { \rho _ { n } \frac { \partial s } { \partial T } }$$
where T is the temperature, s is the entropy density per particle and the derivative is taken at fixed pressure. As expected, the second sound vanishes in the limit ρ s → 0. In general the waves can be a superposition of the two.
As we will show, in the absence of density fluctuations the pure second sound (4) remains stable, while density fluctuations imply a stability criterion for both sound modes and their superpositions. It reads
$$\vec { k } ^ { 2 } < \frac { 4 \pi G \rho } { u _ { 1 } ^ { 2 } + \frac { 1 } { ( 1 - J ) } u _ { 2 } ^ { 2 } }$$
where J = ∂s ∂ρ ∂p ∂T ∂s ∂ρ ∂T ∂p . This condition generalizes the ordinary Jeans instability (2) and reduces to it in the limit ρ s → 0. The RHS of (5) depends on the details of the system thermodynamic properties. An interesting limit to take is that of very low temperatures T → 0, where the super flow component is dominant. In this limit one has u 2 1 = 3 u 2 2 [6] and J → 0 [7]. Thus, at very low temperaure we have a larger Jeans length than that of a normal fluid by a factor of 2 √ 3 .
The letter is organized as follows. We will introduce a gravitational potential to the superfluid hydrodynamics equations and study fluctuations at the linear order. We will then analyze the instability conditions and derive (5), which is our main result. Finally, we will discuss potential experimental implications.
## II. GRAVITATIONAL INSTABILITY IN SUPERFLUID HYDRODYNAMICS
We will consider the evolution equations of a superfluid in the presence of a gravitational field. We denote the gravitational potential by φ . It satisfies Gauss's law
$$\nabla ^ { 2 } \phi = 4 \pi G \rho \.$$
## A. Self-gravitating superfluid hydrodynamics
We will consider an ideal superfluid. The superfluid density current reads
$$\vec { j } = \rho _ { n } \vec { v } _ { n } + \rho _ { s } \vec { v } _ { s }$$
and it satisfies a continuity equation, which is not affected by the gravitational field
$$\frac { \partial \rho } { \partial t } + \vec { \nabla } \cdot \vec { j } = 0 \.$$
Similarly, the entropy conservation is not affected by the gravitational field and reads
$$\frac { \partial } { \partial t } \left ( \rho s \right ) + \left ( \rho s \right ) \vec { \nabla } \cdot \vec { v } _ { n } = 0 \.$$
Note, that entropy is carried only by the normal flow and not by the super flow.
The energy and momentum conservation equations, however, are modified in the presence of the gravitational field and take the form
$$\frac { \partial j _ { i } } { \partial t } + \frac { \partial \Pi _ { i k } } { \partial x _ { k } } + \rho \frac { \partial \phi } { \partial x _ { i } } = 0$$
$$\frac { \partial E } { \partial t } + \vec { \nabla } \cdot \vec { Q } + \vec { j } \cdot \vec { \nabla } \phi = 0 \.$$
Π ik is the momentum flux tensor and /vector Q is the energy flux as calculated without a gravitational field in [6].
In order to derive the the modified equations in the presence of the gravitational field, one uses thermodynamics and the Galilean principle [6]. One denotes by K 0 the reference frame, where the super flow velocity is zero. The velocity of the normal flow in this frame is /vector v n -/vector v s . In this frame one has
$$E _ { 0 } = - p + T \rho s + \mu \rho + \phi \rho + ( \vec { v } _ { n } - \vec { v } _ { s } ) \cdot \vec { j } _ { 0 }$$
and
$$d \left ( \mu + \phi \right ) = - s d T + \frac { 1 } { \rho } d p - \frac { \rho _ { n } } { \rho } \left ( \vec { v } _ { n } - \vec { v } _ { s } \right ) d \left ( \vec { v } _ { n } - \vec { v } _ { s } \right ) \.$$
E 0 and j 0 are the energy and density current in the system K 0 , respectively. There are two effects of the gravitational field. First, to replace the chemical potential µ by µ + . Second, φ to introduce a new term in the fluid flow: in addition to the force term -∇ /vector p , we have - ∇ ρ /vector φ .
Finally, the super flow being a potential flow satisfies
$$\frac { \partial \vec { v } _ { s } } { \partial t } + \vec { \nabla } \left ( \frac { 1 } { 2 } \vec { v } _ { s } ^ { 2 } + \mu + \phi \right ) = 0 \. \quad \ \ \ ( 1 4 ) \\. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
It is straightforward to see that the hydrodynamics equations together with the thermodynamic relations constitute a complete set that determines all the charge densities and velocities.
## B. Self-gravitating superfluid sound
Linearizing the above ideal superfluid hydrodynamics equations in a presence of the gravitational field we get
$$\mathfrak { t } \quad & \frac { \partial \rho } { \partial t } + \vec { \nabla } \cdot \vec { j } = 0 \\ & \frac { \partial } { \partial t } \left ( \rho s \right ) + ( \rho s ) \, \vec { \nabla } \cdot \vec { v } _ { n } = 0 \\ & \frac { \partial \vec { j } } { \partial t } + \vec { \nabla } p + \rho \vec { \nabla } \phi = 0 \\ & \frac { \partial \vec { v } _ { s } } { \partial t } + \vec { \nabla } \mu + \vec { \nabla } \phi = 0 \, \\ \Delta ^ { 2 } \alpha$$
from which we derive
$$\frac { \partial ^ { 2 } \rho } { \partial t ^ { 2 } } & = \nabla ^ { 2 } p + \rho \nabla ^ { 2 } \phi, \\ \frac { \partial ^ { 2 } s } { \partial t ^ { 2 } } & = \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \nabla ^ { 2 } T + \frac { \rho _ { s } } { \rho _ { n } } s \nabla ^ { 2 } \phi \. \\ \intertext { a / 1 \in \bigvee \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \delta }$$
Perturbing 1 around (16), using Gauss's law for the gravitational potential, and expressing all quantities in terms of the pressure p and the temperature T we get
$$\begin{array} { c c c c c } \cdot & & \cdot & \cdot & \cdot & \cdot & \cdot & \searrow \\ & \frac { \partial \rho } { \partial p } \frac { \partial ^ { 2 } \delta p } { \partial t ^ { 2 } } + \frac { \partial \rho } { \partial T } \frac { \partial ^ { 2 } \delta T } { \partial t ^ { 2 } } = \nabla ^ { 2 } \delta p + 4 \pi G \rho \left ( \frac { \partial \rho } { \partial p } \delta p + \frac { \partial \rho } { \partial T } \delta T \right ) \\ & \frac { \partial s } { \partial p } \frac { \partial ^ { 2 } \delta p } { \partial t ^ { 2 } } + \frac { \partial s } { \partial T } \frac { \partial ^ { 2 } \delta T } { \partial t ^ { 2 } } = \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \nabla ^ { 2 } \delta T + 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \left ( \frac { \partial \rho } { \partial p } \delta p + \frac { \partial \rho } { \partial T } \delta T \right ) \. \\ \searrow \cdots & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot \end{array} \cdots \quad \begin{array} { c } \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot \end{array} \cdots \quad \begin{array} { c } \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot \\ \end{array}$$
This system of equations for a wave of the form exp ( i /vector k · /vector x -iωt ) reads
$$& \left ( \frac { \partial \rho } { \partial p } \left ( \omega ^ { 2 } + 4 \pi G \rho \right ) - \vec { k } ^ { 2 } \right ) \delta p + \frac { \partial \rho } { \partial T } \left ( \omega ^ { 2 } + 4 \pi G \rho \right ) \delta T = 0 \\ & \left ( \frac { \partial s } { \partial p } \omega ^ { 2 } + \frac { \partial \rho } { \partial p } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta p + \left ( \frac { \partial s } { \partial T } \omega ^ { 2 } - \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } + \frac { \partial \rho } { \partial T } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta T = 0 \. \\ \text{In the absence of a variational field } ( C \rightarrow \partial ) \text{ the equations reduce to the known analysis}$$
In the absence of a gravitational field ( G → 0) the equations reduce to the known analysis of superfluid sound modes [6].
In the general case, for a solution of these system of equations we require the determinant to vanish
$$H \omega ^ { 4 } + \left ( 4 \pi G H \rho - \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } + \frac { \partial s } { \partial T } \right ) \vec { k } ^ { 2 } \right ) \omega ^ { 2 } + \left ( \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } - 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \left ( \frac { \partial \rho } { \partial p } \rho s + \frac { \partial \rho } { \partial T } \right ) \right ) \vec { k } ^ { 2 } = 0$$
1 As in the ordinary Jeans instability analysis, we perturb around a stable state and therefore ignore the zeroth order contribution of the Laplacian of the gravitational potential ∇ 2 φ 0 .
where H = ∂ ρ,s ( ) ∂ p,T ( ) is the Jacobian for changing variables from ( ρ, s ) to ( p, T ), and we assume that H > 0. Solving for ω 2 we get
$$2 H \omega ^ { 2 } \, & = \, - \left ( 4 \pi G H \rho - \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } + \frac { \partial s } { \partial T } \right ) \vec { k } ^ { 2 } \right ) \\ & \, \pm \, \sqrt { \left ( 4 \pi G H \rho + \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } - \frac { \partial s } { \partial T } \right ) \vec { k } ^ { 2 } \right ) ^ { 2 } + 4 \frac { \partial \rho } { \partial T } \frac { \rho _ { s } } { \rho _ { n } } s \vec { k } ^ { 2 } \left ( 4 \pi G H + \frac { \partial s } { \partial p } s \vec { k } ^ { 2 } \right ) } \,. \, ( 2 0 ) \\ \text{In the absence of a gravitational field. we have the plus and minus sign solutions reducing}$$
In the absence of a gravitational field, we have the plus and minus sign solutions reducing to the first and second sounds, respectively.
Consider the leading effect of the super flow in the dimensionless parameter ρ s ρ n /lessmuch 1. At first order we get
$$2 H \omega ^ { 2 } & = \, - \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) \pm \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) \\ & \quad + \frac { \rho _ { s } } { \rho _ { n } } \left ( \frac { \partial \rho } { \partial p } s ^ { 2 } \pm \frac { \partial \rho } { \partial p } s ^ { 2 } \pm \frac { 2 \frac { \partial \rho } { \partial T } s \vec { k } ^ { 2 } \left ( 4 \pi G H + \frac { \partial s } { \partial p } s \vec { k } ^ { 2 } \right ) } { \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) } \right ) \,. \\ \intertext { o r e w e h e f i s t s o n d } \text{solution}$$
Therefore, we have the first sound solution
$$H \omega ^ { 2 } = & - \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) - \frac { \rho _ { s } } { \rho _ { n } } \left ( \frac { \frac { \partial \rho } { \partial T } s \vec { k } ^ { 2 } \left ( 4 \pi G H + \frac { \partial s } { \partial p } s \vec { k } ^ { 2 } \right ) } { \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) } \right ) \, \quad \ \ ( 2 2 ) \\ \text{and the second sound solution}$$
and the second sound solution
$$\cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \\ H \omega ^ { 2 } & = \frac { \rho _ { s } } { \rho _ { n } } \left ( \frac { \partial \rho } { \partial p } s ^ { 2 } + \frac { \frac { \partial \rho } { \partial T } s \vec { k } ^ { 2 } \left ( 4 \pi G H + \frac { \partial s } { \partial p } s \vec { k } ^ { 2 } \right ) } { \left ( 4 \pi G H \rho - \frac { \partial s } { \partial T } \vec { k } ^ { 2 } \right ) } \right ) \. \\ \\ \sim \quad \cdot \quad \cdot \quad \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots$$
## C. Comparison to the Non-Gravitational Case
It is instructive to compare special solutions to the superfluid sound equations in the presence of the gravitational interaction (18) to the non-gravitating case.
## 1. The Pure Second Sound Limit
In the limit ∂ρ ∂T = 0, the non-gravitational sound equations (setting G = 0 in (18)) read
$$\begin{array} { c } \psi \end{array} \left ( \frac { \partial \rho } { \partial p } \omega ^ { 2 } - \vec { k } ^ { 2 } \right ) \delta p = 0 \\ \left ( \frac { \partial s } { \partial p } \omega ^ { 2 } \right ) \delta p + \left ( \frac { \partial s } { \partial T } \omega ^ { 2 } - \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } \right ) \delta T = 0 \. \\ \hat { \ } \end{array} \right ) \hat { \ } \end{array}$$
One has a solution where δp = 0, δT arbitrary, and the dispersion relation (4) of the pure second sound describing the temperature wave. There is another solution, where the dispersion relation is that of a first sound mode, and the pressure and temperature variations are related by
$$\left ( \frac { \partial s } { \partial p } \right ) \delta p = \left ( \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \frac { \partial \rho } { \partial p } - \frac { \partial s } { \partial T } \right ) \delta T \. \\ \intertext { w h e o r a v i t v } \text{ still having } \underline { \partial \rho } - \partial \text{ } w o o t$$
When we introduce gravity, still having ∂ρ ∂T = 0, we get
$$\begin{array} { c } \Lambda _ { \nu } & \Lambda _ { \nu } & \Lambda _ { \nu } & \Lambda _ { \nu } \\ \left ( \frac { \partial \rho } { \partial p } \left ( \omega ^ { 2 } + 4 \pi G \rho \right ) - \vec { k } ^ { 2 } \right ) \delta p = 0 \\ \left ( \frac { \partial s } { \partial p } \omega ^ { 2 } + \frac { \partial \rho } { \partial p } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta p + \left ( \frac { \partial s } { \partial T } \omega ^ { 2 } - \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } \right ) \delta T = 0 \. \\ \text{see that the pure second sound solution (4) is not affected by gravity. This is expected} \end{array}$$
We see that the pure second sound solution (4) is not affected by gravity. This is expected since the pure second sound is characterized by no variation of the density, thus gravity does not affect it.
However, the first sound solution is changed. The dispersion relation is the same as the Jeans dispersion relation (1), but the pressure and temperature variations are related by a different formula
$$\left ( \frac { \partial s } { \partial p } \omega ^ { 2 } + \frac { \partial \rho } { \partial p } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta p & = \left ( \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } - \frac { \partial s } { \partial T } \right ) \omega ^ { 2 } + \frac { \partial \rho } { \partial p } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } \rho s ^ { 2 } \right ) \delta T \. \quad \left ( 2 7 \right ) \\ \text{$c$-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text$-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\tt{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\tt {-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text -\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text.-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text--\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{--\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text -\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\tt-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text
-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text}-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text -\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text1-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text'-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\textc-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{-\text{--$$
Comparing (25) and (27), we see a frequency dependence of the linear relation between pressure and temperature (27), which vanishes as ρ s → 0.
## 2. The Pure First Sound Limit
Consider next the classical pure first sound limit, ∂s ∂p = 0. The non-gravitational sound equations in this case are (setting G = 0 and ∂s ∂p = 0 in (18)) :
$$\lambda \lambda _ { \lambda } \varphi _ { \varphi } \lambda _ { \lambda } \bar { \ } \left ( \frac { \partial \rho } { \partial p } \omega ^ { 2 } - \vec { k } ^ { 2 } \right ) \delta p + \left ( \frac { \partial \rho } { \partial T } \omega ^ { 2 } \right ) \delta T = 0 \\ \left ( \frac { \partial s } { \partial T } \omega ^ { 2 } - \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } \right ) \delta T = 0 \. \\ \text{on where } \delta T = 0, \, \delta p \text{ arbitrary, and the dispersion relation of the pure first}$$
We have a solution where δT = 0, δp arbitrary, and the dispersion relation of the pure first sound. There is another solution, where the dispersion relation is (4), and the pressure and temperature variations are related by
$$\left ( \frac { \partial s } { \partial T } \frac { \rho _ { n } } { \rho _ { s } } \frac { 1 } { s ^ { 2 } } - \frac { \partial \rho } { \partial p } \right ) \delta p = \left ( \frac { \partial \rho } { \partial T } \right ) \delta T \.$$
When we introduce gravity, still with ∂s ∂p = 0, we get
$$\left ( \frac { \partial \rho } { \partial p } \left ( \omega ^ { 2 } + 4 \pi G \rho \right ) - \vec { k } ^ { 2 } \right ) \delta p + \frac { \partial \rho } { \partial T } \left ( \omega ^ { 2 } + 4 \pi G \rho \right ) \delta T = 0 \\ \left ( \frac { \partial \rho } { \partial p } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta p + \left ( \frac { \partial s } { \partial T } \omega ^ { 2 } - \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } \vec { k } ^ { 2 } + \frac { \partial \rho } { \partial T } \cdot 4 \pi G \frac { \rho _ { s } } { \rho _ { n } } s \right ) \delta T = 0 \. \\ \text{We see that the pure first sound solution is not pure anvmore. This is in contrast to the}$$
We see that the pure first sound solution is not pure anymore. This is in contrast to the pure second sound solution that was not modified by gravity.
## D. General Instability Conditions
In the following we will analyze the instability conditions arising from the roots (20).
## 1. Identical roots
Consider the case where the two solutions (20) are identical. In this case we have the same dispersion relation for the first and second sound and we obtain the instability condition
$$\vec { k } ^ { 2 } & < \frac { 4 \pi G H \rho } { \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } + \frac { \partial s } { \partial T } \right ) } \. \\ \text{react } ( 3 1 ) & \text{ as } ( 5 ). \text{ The constraint } ( 5 ) \text{ is a generalization of } ( 2 ) \text{ to }$$
Dividing by H , we can recast (31) as (5). The constraint (5) is a generalization of (2) to superflows, and is valid for both the first and second sounds. It reduces to (2) in the limit ρ s → 0. In limit T → 0, u 2 1 = 3 u 2 2 [6], and one can see from the data presented in [7] that J → 0. Thus we have that the Jeans length of superfluid is larger by a factor of 2 √ 3 than that of a normal fluid.
## 2. Different roots
The conditions for instability of the two sound modes are the upper bound on the momentum (5) as well as a lower bound
$$\vec { k } ^ { 2 } & > 4 \pi G \rho \left ( \frac { \partial \rho } { \partial p } + \frac { \partial \rho } { \partial T } \frac { 1 } { \rho s } \right ) \,, \\. & \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
which together imply a constraint on the system independent of the gravitational field
$$\left ( \frac { \partial \rho } { \partial p } + \frac { \partial \rho } { \partial T } \frac { 1 } { \rho s } \right ) \left ( \frac { \partial \rho } { \partial p } \frac { \rho _ { s } } { \rho _ { n } } s ^ { 2 } + \frac { \partial s } { \partial T } \right ) < H \.$$
## E. Discussion
As the ordinary Jeans instability has been observed experimentally, it is natural to inquire how can we observe the generalized instability conditions for superfluids. It is probably unlikely that current condensed matter experiments can detect the gravitational instability of superfluids. A potential experimental laboratory could be Neutron stars. Superfluidity is expected to occur both in the inner crust and the core of Neutron stars as a consequence of the formation of Cooper pairs of Neutrons that break spontaneously the U (1) Baryon symmetry [3]. Superfluidity has been invoked in order to explain, for instance, pulsar glitches [8]. Therefore the gravitational instability seems relevant to the dynamics of Neutron stars, such as its rotational and vibrational oscillations. It would be interesting to work out the details of the gravitational instability effects in this framework.
## Acknowledgements
This work is supported in part by the I-CORE program of Planning and Budgeting Committee (grant number 1937/12), and by the US-Israel Binational Science Foundation.
- [1] J. H. Jeans, 'The Stability of a Spherical Nebula'. Philosophical Transactions of the Royal Society A 199 , 1 (1902).
- [2] P. Kapitza, 'Viscosity of Liquid Helium Below the λ -Point', Nature 141 , 74 (1938).
- [3] U. Lombardo and H. J. Schulze, Lect. Notes Phys. 578 , 30 (2001) [astro-ph/0012209].
- [4] M. G. Alford, K. Rajagopal and F. Wilczek, 'QCD at finite baryon density: Nucleon droplets and color superconductivity,' Phys. Lett. B 422 , 247 (1998) [hep-ph/9711395].
- [5] L. D. Landau, 'The Theory of Superfluidity of Helium II', J. Phys. USSR, 5 , 71(1941).
- [6] E. M. Lifshitz and L. D. Landau, 'Course of Theoretical Physics, volume 6, Fluid Mechanics', Pergamon Press (1959).
- [7] J. Brooks and R. Donnelly, 'The Calculated Thermodynamic Properties of Superfluid Helium4', J. Phys. Chem. Data, 6 , 1 (1977).
- [8] P.W. Anderson and N. Itoh, 'Pulsar glitches and restlessness as a hard superfluidity phenomenon', Nature 256 , 25 (1975);. | 10.1140/epjc/s10052-014-3183-x | [
"Itamar Hason",
"Yaron Oz"
] | 2014-08-01T16:50:54+00:00 | 2014-08-01T16:50:54+00:00 | [
"hep-th"
] | Jeans Instability in Superfluids | We analyze the effect of a gravitational field on the sound modes of
superfluids. We derive an instability condition that generalizes the well known
Jeans instability of the sound mode in normal fluids. We discuss potential
experimental implications. |
1408.0233v2 | ## Nonabelian dark matter models for 3.5 keV X-rays
## James M. Cline a and Andrew R. Frey b
- a Department of Physics, McGill University, 3600 rue University, Montr´al, Qu´bec, Canada e e H3A 2T8
- b Department of Physics and Winnipeg Institute for Theoretical Physics, University of Winnipeg, Winnipeg, Manitoba, Canada R3B 2E9
E-mail: [email protected], [email protected]
Abstract. A recent analysis of XXM-Newton data reveals the possible presence of an X-ray line at approximately 3.55 keV, which is not readily explained by known atomic transitions. Numerous models of eV-scale decaying dark matter have been proposed to explain this signal. Here we explore models of multicomponent nonabelian dark matter with typical mass ∼ 1-10 GeV (higher values being allowed in some models) and eV-scale splittings that arise naturally from the breaking of the nonabelian gauge symmetry. Kinetic mixing between the photon and the hidden sector gauge bosons can occur through a dimension-5 or 6 operator. Radiative decays of the excited states proceed through transition magnetic moments that appear at one loop. The decaying excited states can either be primordial or else produced by upscattering of the lighter dark matter states. These models are significantly constrained by direct dark matter searches or cosmic microwave background distortions, and are potentially testable in fixed target experiments that search for hidden photons. We note that the upscattering mechanism could be distinguished from decays in future observations if sources with different dark matter velocity dispersions seem to require different values of the scattering cross section to match the observed line strengths.
Keywords: dark matter theory
## Contents
| 1 | Introduction | Introduction | 1 |
|-----|------------------------------------------|------------------------------------------|-----|
| 2 | XDM and the observed signal | XDM and the observed signal | 3 |
| 3 | General features of nonabelian DM models | General features of nonabelian DM models | 5 |
| 4 | Doublet DM model | Doublet DM model | 8 |
| | 4.1 | Long-lived decaying DM | 9 |
| | 4.2 | XDM doublet model | 11 |
| 5 | Triplet DM model | Triplet DM model | 12 |
| | 5.1 | Mass Splittings | 13 |
| | 5.2 | Decaying DM Model | 14 |
| | 5.3 | Triplet XDM | 15 |
| 6 | Discussion | Discussion | 17 |
| A | Magnetic moments | Magnetic moments | 18 |
| B | CMB bounds from DM annihilation | CMB bounds from DM annihilation | 20 |
## 1 Introduction
Aside from its total mass density, little is known about the particle nature of dark matter (DM). Only upper limits exist on its possible nongravitational interactions with the Standard Model (SM), or on its self-interactions that could come from dynamics of a hypothetical dark sector extending beyond the dark matter itself. Hints of positive detection from a variety of direct searches [1-6] are in apparent conflict with limits from other experiments [7-11], presenting an increasingly difficult challenge for theorists to find nonminimal models that could accommodate both kinds of results. Anomalies in astrophysical observations have also been interpreted as harbingers of the interaction of dark matter with the visible sector. These include observations of excess positrons in the 10 GeV-TeV range [12-15], a narrow feature in gamma rays at 130 GeV [16, 17], a gamma ray excess at energies below 10 GeV [18-21], and the long-studied galactic bulge positron population [22, 23], among others, as candidate signals of DM. Whether any of these observations ultimately prove to be related to DM, they have led to a greater understanding of the range of physics possible in the dark sector.
Recently, refs. [24, 25] identified an X-ray line with energy of approximately 3.55 keV in XMM-Newton observations of galaxy clusters and the M31 galaxy, that is not associated with any known atomic transition that could be consistent with the observed intensity. The line also appears in Chandra observations of the Perseus cluster [24]. In the absence of a clear astrophysical explanation, the possibility that this line is associated with DM is tantalizing; as proposed by the original two references, the decay of a sterile neutrino to a photon and SM neutrino is a well-motivated DM explanation (see also [26-35]). Alternative light DM candidates suggested as the source of the X-ray line include axions and axion-like
Figure 1 . (a,b) Diagrams for slow decay of relic excited state to lower state in the doublet and triplet DM models, respectively; (c,d) upscattering of lighter DM states to excited state, followed by fast decays back to lower state (XDM mechanism), in respective models.

particles [36-40], axinos [41-43], moduli [44-46], light superpartners [47-50], and others [5153]. It is also possible that more massive (GeV-scale or higher) multi-species DM with a transition dipole moment or other higher-dimension coupling can generate the 3.5-keV X-ray line [50, 54-60].
While recognizing that the slow decay of a relic excited DM state could account for the X-ray line, ref. [54] pointed out that collisional excitation of DM followed by a relatively rapid decay could also do so. This mechanism of exciting dark matter (XDM) leads to a distinct emission morphology (following the dark matter density profile squared rather than linearly) and was considered previously to address the galactic 511 keV emission (see [6174]). In this paper, we will explore these scenarios in detail in the context of spontaneously broken nonabelian DM models, that can naturally have the necessary ingredients of small mass splittings [75] and kinetic mixing with the photon through a dimension-5 or 6 operator.
We consider relatively simple hidden sectors, in which the DM is a Dirac or Majorana fermion χ a transforming as a doublet or triplet respectively of a hidden-sector SU(2) gauge symmetry. It is spontaneously broken by the vacuum expectation value (VEV) of a dark Higgs doublet in the doublet DM model, or by either two dark Higgs triplets or a doublet plus a triplet, in the triplet DM model. Significant kinetic mixing between the photon and one of the components of the dark gauge boson leads to a transition magnetic moment between DMstates [68], by which the excited state can decay to a lower state and a photon, producing the 3.5 keV X-ray. 1 The excited state might either be primordial in origin, with relatively long lifetime to explain the observed line, or it could be produced by upscattering of the lower states, followed by fast decays. The relevant processes are depicted in fig. 1.
We begin in sect. 2 with a review of the observed X-ray line and the general requirements for decaying or XDM mechanisms to match the observed line strength. Section 3 describes generic theoretical predictions of the models that are relevant to our study, including kinetic mixing, relic density, mass splittings, magnetic moments, and cross sections for inelastic self-scattering as well as scattering on protons. In section 4 we confront these predictions
1 Ref. [70] predicted, long before the 3.5 keV line, the existence of a several-keV X-ray line from exothermic models of XDM, but the expected value of flux was lower than required here, in the parameter space of interest for explaining excess low-energy galactic positrons.
to the experimental constraints on models of doublet dark matter, while section 5 does likewise for triplet DM. In section 6 we summarize our findings and discuss the relation of nonabelian DM models to other current anomalies that may be indirect signals of dark matter. Appendices give details of the computation of transition magnetic moments and cosmic microwave background (CMB) constraints.
## 2 XDM and the observed signal
We begin by summarizing the requirements on the lifetime or upscattering cross section from the observed line strength for the decaying or XDM mechanisms, respectively. For the decaying scenario, refs. [24, 25] found that the 3.5 keV line could be produced by sterile neutrino DM of mass m s ∼ 7 keV with a lifetime of τ s ∼ 6 2 . × 10 27 s (ref. [25] gives errors of about a factor of 3 in either direction). Here we consider instead a heavy DM candidate with several nearly degenerate states, including a metastable one χ x that decays to a lighter DM state plus a photon. Having in mind GeV-scale DM with a fractional abundance f x in the excited state, the required lifetime is
$$\tau = f _ { x } \left ( \frac { m _ { s } } { M _ { \chi } } \right ) \tau _ { s } = ( 4. 3 \times 1 0 ^ { 2 1 } \, s ) \, f _ { x } \left ( \frac { 1 0 \, \text{GeV} } { M _ { \chi } } \right ) \, \Longrightarrow \, \frac { \Gamma } { M _ { \chi } } = \frac { 1. 5 \times 1 0 ^ { - 4 7 } } { f _ { x } } \. \quad \ ( 2. 1 )$$
As in refs. [54-60], we are interested in a decay χ x → χ γ g to the ground state χ g (or possibly to another long-lived excited state) plus a photon. In our models this occurs via a transition dipole moment µ × ¯ χ x σ µν χ F g µν . For mass splitting δM χ , the decay rate corresponding to this operator is
$$\Phi _ { 0 } \, \infty \, \left ( \Gamma = \frac { 4 \mu _ { \times } ^ { 2 } } { \pi } \, \delta M _ { \chi } ^ { 3 } \,, \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right ) \, \right.$$
so the required dipole moment for the X-ray signal is
$$\mu _ { \times } = \frac { 1. 7 \times 1 0 ^ { - 1 5 } } { \text{GeV} } \sqrt { \frac { M _ { \chi } / f _ { x } } { 1 0 \text{ GeV} } } \.$$
On the other hand, if the transition dipole moment is larger than (2.3), the excited DM state will decay too rapidly, so there must be some mechanism to repopulate it. In XDM, this is accomplished through collisional excitation. In this case, the flux from a cluster or galaxy at distance d is
$$F = \frac { \eta _ { X } f _ { g } ^ { 2 } } { 4 \pi d ^ { 2 } g _ { X } } \int d ^ { 3 } x \, \frac { \rho _ { \chi } ^ { 2 } } { M _ { \chi } ^ { 2 } } \langle \sigma _ { \uparrow } v _ { \text{rel} } \rangle$$
where σ ↑ is the upscattering cross-section ρ χ is the DM mass density; f g ∼ 1 is the fractional abundance of the DM ground state (or possibly a cosmologically long-lived excited state), g χ = 2 or 4 depending on whether the DM is Majorana or Dirac, and η X is the number of X-rays produced per collision ( η X = 2 in our models). The cross section is dominated by contributions near the kinematic threshold, so we approximate
$$\langle \sigma _ { \uparrow } v _ { \text{rel} } \rangle & = \sigma _ { 0 } \, v _ { t } \, \gamma ; \\ \gamma & \equiv \left \langle \sqrt { v _ { \text{rel} } ^ { 2 } / v _ { t } ^ { 2 } - 1 } \, \Theta ( v _ { \text{rel} } - v _ { t } ) \right \rangle,$$
where v t = √ 8 δm /M χ χ is the threshold velocity for producing two excited states. For the phase space average, we assume a Maxwellian distribution f ( v ) = N exp( -( v/v 0 ) 2 ),
Figure 2 . Phase space average of ( v 2 rel /v 2 t -1) 1 / 2 , appearing in the upscattering cross section (2.5), for Maxwellian velocity distribution ∼ exp( -( v/v 0 ) 2 ), as a function of v /v 0 t , where v t = √ 8 δM /M χ χ is the threshold velocity.
where the velocity dispersion is σ v = 〈 v 2 〉 1 2 / = √ 3 2 / v 0 . Refs. [76, 77] find σ v = 150 km/s and 170 km/s respectively for M31; we take the median value 160 km/s = 5 3 . × 10 -4 c . The corresponding value for the Perseus cluster is 1300 km/s [78, 79]. Fig. 2 shows the dependence of γ on v /v 0 t . If v 0 glyph[greatermuch] v t for both M31 and the Perseus cluster, then the ratio of velocities 1300 / 160 = 8 1 translates into a similar ratio of fluxes for the two systems. . Below we will find a somewhat larger ratio glyph[greaterorsimilar] 20. While the quality of the determinations is not sufficiently high to trust this number, if correct, it could be accommodated by taking v 0 ∼ = 0 65 . v t for M31, fixing v t ∼ = 6 7 . × 10 -4 c . With v 0 ∼ = 0 3 . v t in M31, we can explain a factor of 100 difference between the cross sections for the two systems.
To estimate the required cross section in (2.5), we compare to the observations of the X-ray flux for M31 and the Perseus cluster. The DM halo of M31 can be modeled by an Einasto profile
$$\rho ( r ) = \rho _ { - 2 } \, \exp \left [ - \frac { 2 } { \alpha } \left ( \left ( \frac { r } { r _ { - 2 } } \right ) ^ { \alpha } - 1 \right ) \right ]$$
Ref. [80] finds two fits with α = 1 6, normalization / ρ -2 = (8 9 or 1 5) . . × 10 -2 GeV/cm , 3 and scale radius r -2 = (17 44 or 37 95) kpc respectively. . . The field of view for the on-center observations of M31 reported in [25] is approximately 480 square arcmin, corresponding to a radius of 2.8 kpc at the distance d = 785 kpc, and the flux is F ≈ 5 × 10 -6 s -1 cm -2 . Computing the volume integral in (2.4) using these two profiles, we estimate
$$\frac { \eta _ { X } f _ { g } ^ { 2 } \left < \sigma v _ { \text{rel} } \right > } { g _ { X } M _ { \chi } ^ { 2 } } \approx ( 5 \times 1 0 ^ { - 2 4 } \, \text{to} \, 3 \times 1 0 ^ { - 2 3 } ) \, \text{cm} ^ { 3 } s ^ { - 1 } \, \text{GeV} ^ { - 2 } \,.$$
(This is far below the limit 〈 σv rel 〉 glyph[lessorsimilar] 1 b/GeV on the self-interactions of dark matter from observations of systems like the Bullet Cluster; see ref. [81] for a recent review.)
The analogous computation for the Perseus cluster gives a volume integral of
$$\frac { 1 } { 4 \pi d ^ { 2 } } \int d ^ { 3 } x \, \rho ^ { 2 } \approx 1 0 ^ { 1 6. 2 5 } \text{ GeV} ^ { 2 } \text{cm} ^ { - 5 }$$
for the entire cluster [82]. Ref. [83] finds the similar value 10 16 15 . . The central value of flux from Perseus was measured to be 5 2 . × 10 -5 cm -2 s -1 (MOS, [24]), 7 0 . × 10 -6 cm -2 s -1 (MOS, [25]), or 9 2 . × 10 -6 cm -2 s -1 (PN, [25]). 2 These yield
$$\frac { \eta _ { X } f _ { g } ^ { 2 } \left \langle \sigma v _ { r e l } \right \rangle } { g _ { X } M _ { \chi } ^ { 2 } } \approx ( 5 \times 1 0 ^ { - 2 2 } \, \text{to} \, 4 \times 1 0 ^ { - 2 1 } ) \, \text{cm} ^ { 3 } s ^ { - 1 } \, \text{GeV} ^ { - 2 } \,.$$
The cluster values are systematically higher than those of M31 by a factor of ∼ 100. However the ranges in (2.7) and (2.9) are not necessarily correlated, so the actual ratio could smaller. In particular, if the true ratio is ∼ 8, this would be consistent with v t glyph[lessmuch] v 0 in fig. 2, both for v 0 of M31 and of the Perseus cluster. In summary, the required cross sections are of order f 2 g 〈 σ 0 v rel 〉 /M 2 χ ∼ 10 -22 cm s 3 -1 GeV -2 for M31, and ∼ 10 -100 times larger for Perseus, with the difference possibly being attributable to the higher DM velocities in the cluster.
## 3 General features of nonabelian DM models
Before investigating specific models with respect to the X-ray line, we summarize general features of the nonabelian DM models. We elaborate on results of ref. [68] concerning the kinetic mixing, mass splittings, magnetic moment, thermal relic density, self-scattering cross section, and interaction with nucleons here. The dark sector consists of a fermionic DM multiplet χ of mass M χ transforming under a nonabelian gauge symmetry with vector bosons B a µ and coupling g . We will consider only the simplest case of SU(2) for our specific examples, but in this section we give some results for general SU(N). The symmetry is spontaneously broken by some combination of doublet/fundamental ( h i ) or triplet/adjoint (∆ a ) dark Higgs fields, which leads to at least one component of B a kinetically mixing with SM hypercharge through a dimension-5 or 6 operator,
$$\frac { 1 } { \Lambda } \Delta ^ { a } B _ { a } ^ { \mu \nu } Y _ { \mu \nu } \ \text{ or } \ \frac { 1 } { \Lambda ^ { 2 } } ( h ^ { \dagger } \tau ^ { a } h ) \, B _ { a } ^ { \mu \nu } Y _ { \mu \nu }$$
where Λ is some heavy scale. Once the Higgs has gotten a VEV, this will lead to kinetic mixing of a particular component ˆ of the vector with the photon, We normalize it in the a conventional way as -( glyph[epsilon1]/ 2) B ˆ a µν F µν . Diagonalizing the photonB ˆ a kinetic terms gives B ˆ a a coupling of strength glyph[epsilon1]e to the electromagnetic current, which is the main portal between the dark and visible sectors.
Relic density. We will be generally be interested in scenarios where the dark matter has a bare mass M χ glyph[greaterorsimilar] 1 GeV, while the gauge bosons have masses m B a that are smaller. In the model where χ i is a doublet of SU(2), this bare mass term only exists if χ is Dirac, whereas a triplet fermion can be Majorana. Therefore the doublet DM model has a global charge and can be asymmetric, whereas the triplet would be expected to get its relic density through thermal freeze-out. In such a case, assuming that Yukawa couplings of χ to the Higgs bosons are negligible, freeze-out is determined by χχ → BB through the gauge interactions,
2 MOSand PN refer to the two different types of CCD cameras on XMM-Newton , metal oxide semiconductor and pn-junction respectively.
and one can constrain the coupling strength α g = g / 2 4 π via the relic density. Updating the results of ref. [70] in light of the more accurate relic density cross section of [84], we find
$$\alpha _ { g } \approx 1. 6 \times 1 0 ^ { - 4 } \left ( \frac { M _ { \chi } } { 1 0 \text{ GeV} } \right )$$
for the SU(2) triplet model, assuming M χ glyph[greaterorsimilar] 5 GeV. According to ref. [68], the doublet model requires α g to be 2 5 times larger, . 3 assuming only the symmetric component contributes to the relic density, A larger gauge group or DM representation requires a smaller α g . In the more general case where Yukawa couplings could be responsible for the relic density by annihilation into light Higgses, eq. (3.2) can be interpreted as an upper bound on α g to avoid suppressing the relic density.
Mass splittings. Of particular importance to our discussion, the states of the DM multiplet are generically split in mass due to symmetry breaking, both via Yukawa couplings and by differing gauge boson masses entering the DM self-energies [75]. For m B a glyph[lessmuch] M χ , the latter effect gives rise to a correction to the DM mass term,
$$M \delta _ { i j } - \frac { \alpha _ { g } } { 2 } \sum _ { B _ { a } } m _ { B _ { a } } \, ( T ^ { a } T ^ { a } ) _ { i j }$$
For DM in the doublet representation of SU(2), the square of any generator (since it is a Pauli matrix) is the unit matrix, so no splitting arises from this mechanism, and we are forced to rely upon splittings generated by VEVs of dark Higgs fields that couple to χ . For other representations, if all gauge boson masses are the same, the correction is proportional to the quadratic Casimir times δ ij , which leaves the states degenerate, but in general δM χ ∼ α δm g B / 2, where δm B is the typical splitting between the gauge boson masses. Assuming that δm B ∼ m B a and α g is given by (3.2) the desired δM χ of 3.5 keV requires gauge boson masses of order 40 MeV × (10 GeV /M χ ). However it should be kept in mind that Yukawa couplings can allow for larger m B a , both by directly contributing to the mass splittings, and by allowing for smaller α g as discussed above.
Magnetic moments. A unique feature of kinetic mixing in the form (3.1) is that it includes an interaction
$$\frac { 1 } { 2 } g \epsilon f ^ { \hat { a } b c } B _ { \mu } ^ { b } B _ { \nu } ^ { c } F ^ { \mu \nu }$$
by virtue of the nonabelian field strength tensor B ˆ a µν . This operator generates transition (and in some cases direct) magnetic moments among the DM states, as shown in figure 1(a,b) [68]. We calculate the transition moments in appendix A. For models in which χ is in the triplet representation of SU(2), we can take ˆ = 1 and find that the transition moment between a states 2 and 3 is given by 4
$$\nu _ { 3 } = \frac { \epsilon g ^ { 3 } } { 1 6 \pi ^ { 2 } \, M _ { \chi } } F _ { t } ( r _ { 2 }, r _ { 3 } )$$
where r i = ( m B i /M χ ) 2 . The function F t is given in (A.6), but can be approximated as
$$F _ { t } \sim \ln \left ( \frac { M _ { \chi } } { \bar { m } } \right ) - 1$$
3 Ref. [70] did a more careful computation of the triplet model relic density than [68], so we take the value of α g from the former reference, rescaled by the group theory factors found in the latter for the case of the doublet model.
4 We have corrected several factors of 2 relative to [68].
if ¯ m 2 ≡ ( m 2 B 2 + m 2 B 3 ) / 2 glyph[lessmuch] M 2 χ and if | m B 2 -m B 3 | is not too large compared to m B 1 . The behavior of F t is more generally illustrated in fig. 3, which shows that (3.6) is valid for ¯ m glyph[lessorsimilar] M / χ 10; above that value, µ × is of order O (0 1 . -1) glyph[epsilon1]g 3 / 16 π M 2 . For models in which χ is an adjoint of SU(N), eq. (3.5) is generalized by including the factor ( i/ 2) C 2 ( A T ) ˆ a 23 where C 2 ( A ) is the quadratic Casimir of the adjoint representation.
In models of doublet DM with kinetic mixing of B 3 , fig. 1(a), there is destructive interference between the two diagrams where χ 1 and χ 2 are in the loop, leading to a suppressed transition moment
$$\mu _ { 1 2 } = \frac { \epsilon g ^ { 3 } \, \delta M _ { \chi } } { 1 6 \pi ^ { 2 } \, M _ { \chi } ^ { 2 } } F _ { d } ( r )$$
where we ignore the gauge boson mass splittings (which anyway vanish if SU(2) is broken only by a Higgs doublet) and take r = ( m /M B χ ) 2 . The function F d is given in (A.11) and behaves as 1 / r 2 for small r , showing that the suppression is less severe than at first sight: µ 12 ∼ δM /m χ 2 B rather than δM /M χ 2 χ .
Inelastic self-scattering. The excitation of lower to higher DM states by inelastic scattering, as shown in fig. 1(d) for the triplet model, has the cross section
$$\langle \sigma _ { \uparrow } v _ { \text{rel} } \rangle = 2 \pi \alpha _ { g } ^ { 2 } v _ { t } \, \gamma \, \frac { M _ { \chi } ^ { 2 } } { m _ { B } ^ { 4 } } \mathcal { F } ( v _ { \text{rel} } / v _ { t } )$$
where γ is as defined in (2.5) and F is a slowly varying function that goes to unity near threshold [70]. (Recall that v t = (8 δM /M χ χ ) 1 2 / is the threshold velocity for the inelastic process.)
In the doublet model, two components of the gauge bosons are exchanged in the t, u -channels. There is a cancellation in the χ χ 1 1 → χ χ 2 2 amplitude that is exact in the case of degenerate gauge bosons, due to the group theory factors ∑ a =1 2 , ( τ a 12 ) 2 = 0. This changes the cross section by the replacement
$$m _ { B } ^ { - 4 } \rightarrow ( m _ { B _ { 1 } } ^ { - 2 } - m _ { B _ { 2 } } ^ { - 2 } ) ^ { 2 } \equiv \frac { ( \delta m _ { B } ^ { 2 } ) ^ { 2 } } { m _ { B } ^ { 8 } }$$
relative to (3.8). In the following, we will assume that the XDM doublet is asymmetric dark matter with such a gauge boson mass splitting, which requires the VEV of a triplet Higgs in the dark sector, in addition to the doublet Higgs, since δm B = 0 with only the latter.
Interaction with protons. Due to the kinetic mixing of B ˆ a with the photon, the component B ˆ a couples with strength glyph[epsilon1]e to protons, and thus mediates DM interactions with nuclei. (There is a similar but much smaller contribution from the Z boson that we ignore.) The spin-independent cross section on protons is
$$\sigma _ { p } = 1 6 \pi \epsilon ^ { 2 } \, \alpha \, \alpha _ { g } \, \frac { \mu _ { p } ^ { 2 } } { m _ { B } ^ { 4 } }$$
where µ p is the protonχ reduced mass. This will give rise to stringent constraints from direct detection searches for some of the scenarios we study in the remainder.
While the doublet DM model presented in section 4 scatters elastically from nuclei, the Majorana triplet DM models of section 5 scatter inelastically (either endothermically or exothermically). Since our focus is on astrophysical signals, we do not carry out a detailed analysis of the effects of this inelasticity on the nuclear recoil spectrum but rather consider
Figure 3 . The transition magnetic moment for triplet DM generated by kinetic mixing of a nonAbelian gauge group with the photon, F t ( r , r 2 3 ) of (3.5). ¯ m 2 = ( m 2 B 2 + m 2 B 3 ) / 2, and the relation of m 2 to m B 3 is labeled as in the legend for each curve. The (blue) dot-dashed curve is the ¯ m glyph[lessmuch] M χ approximation (3.6).
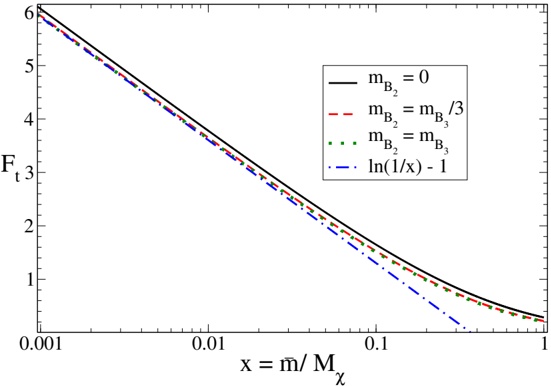
only the kinematic scaling of the overall event rate as in [70]. For endothermic or exothermic scattering, we rescale σ p by
$$\left \langle ( v ^ { 2 } \mp v _ { \delta } ^ { 2 } ) ^ { 1 / 2 } \, \Theta ( v \mp v _ { \delta } ) \right \rangle / \langle v \rangle, \quad v _ { \delta } = \left ( \frac { 2 | \delta M _ { \chi } | } { \mu _ { N \chi } } \right ) ^ { 1 / 2 }$$
respectively, where 〈· · · 〉 denotes the phase-space average in the standard halo model as described in [85], v is the DM speed in the earth frame, v δ is the threshold velocity for nuclear scattering, and µ N χ is the reduced mass for the χ -nucleus system. We will find that LUX is the most constraining experiment for the inelastic models, and will therefore take xenon as the relevant nucleus for determining µ N χ .
## 4 Doublet DM model
In the simplest version of doublet DM, χ is a Dirac field that has bare mass term M χ χ χ ¯ i i . However, as noted above, the radiative correction to the mass of the doublet states is proportional to the identity matrix and leads to no mass splitting. There are two ways to remedy this situation. (1) Introduce a heavy SU(2)-singlet fermion ψ with mass M 0 (that we take to be Dirac) and with couplings yχhψ ¯ + h c . . . If h gets the VEV ( v, 0) T in just the upper component (as we can choose with no loss of generality), then χ 1 and χ 2 get a mass splitting by the see-saw mechanism of δM χ = ( yv ) 2 /M 0 . (2) Enlarge the dark gauge group to SU(2) × U(1) and break it to U(1) by the Higgs doublet, just as in the standard model. This splits the gauge boson masses analogously to the W and Z . Moreover, simple kinetic mixing of the dark U(1) with the SM hypercharge would lead to the same structure of couplings as we outlined previously. In addition, the dark W bosons would be millicharged under electromagnetism. Although option (2) may be interesting, we will confine our attention to the first in this work, which is simpler in having no extra long-range forces to consider.
1
Figure 4 . Dark shaded regions are excluded by searches for light gauge bosons of mass m B coupling with strength glyph[epsilon1]e to electrons; cross hatched region is to be probed by HPS experiment. Diagonal lines are the values of glyph[epsilon1] needed for doublet DM model to explain the 3.5. keV X-ray line via decays of a long-lived excited state, assuming indicated values of gauge coupling α g and mass M χ . Dot-dashed lines assume value of α g needed for thermal relic density of χ . Background taken from ref. [86].
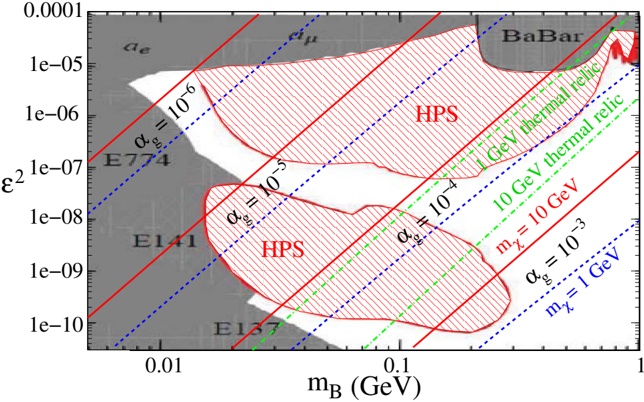
## 4.1 Long-lived decaying DM
We start with the scenario where χ 2 is cosmologically long-lived and decays into χ 1 + . By γ combining eq. (2.3) with (3.7), we find the constraint on the kinetic mixing parameter
$$\epsilon = \frac { 1. 5 \times 1 0 ^ { - 1 0 } } { \alpha _ { g } ^ { 3 / 2 } \hat { F } _ { d } ( r ) } \left ( \frac { 0. 5 } { f _ { x } } \right ) ^ { 1 / 2 } \left ( \frac { M _ { \chi } } { 1 0 \, \text{GeV} } \right ) ^ { 1 / 2 } \left ( \frac { m _ { B } } { 1 0 0 \, \text{MeV} } \right ) ^ { 2 }$$
where r = ( m /M B χ ) 2 and ˆ F d = 2 rF d such that ˆ F d goes from 1 to ∼ 1 5 for . r ∈ [0 , 1], and is approximated to better than 1% by ˆ F d ∼ = 1 + 0 716 . r 1 2 / -0 248 . r in that interval.
It is interesting to compare the prediction of (4.1) to the sensitivity of existing and proposed searches for dark photons. In fig. 4 we show the targeted region of the HPS (Heavy Photon Search) experiment [86] in the m B -glyph[epsilon1] plane, and the constraint (4.1), assuming different values for α g and M χ , and the relative abundance f x = 0 5 for the excited state. . Regions of constant α g are bounded by the solid and dashed lines, corresponding to M χ = 10 and 1 GeV, respectively. We note that there is intersection with the cross-hatched HPS regions of interest for a wide range of gauge couplings. Although the doublet model can be asymmetric and thus free from the constraints associated with a thermal origin, we also show as dot-dashed lines the contours of α g = 4 × 10 -4 ( M / χ 10 GeV) as needed for the thermal relic density, for M χ = 10 and 1 GeV. These also have significant overlap with the HPS regions, making this model more testable than many others that have been proposed to explain the 3.5 keV X-ray line. Gauge couplings lower than the relic density bound need not be excluded even for asymmetric DM, since there is another possible annihilation channel
Figure 5 . Cross section for doublet DM scattering on protons versus M χ , in the slowly decaying DM scenario, along with current experimental limits. Diagonal lines correspond to the model predictions for the indicated values of gauge coupling, α g = 10 -3 , . . . , 1, assuming glyph[epsilon1] is given by (4.1).
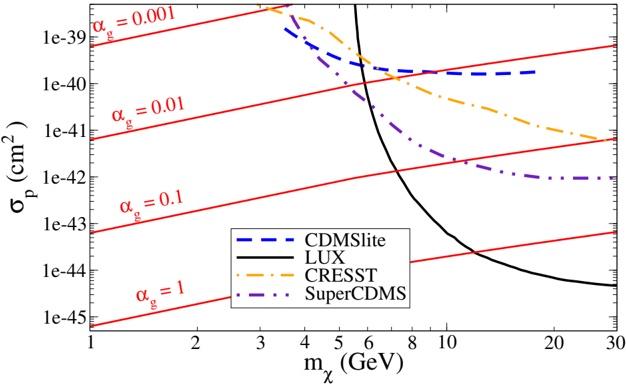
χχ → hh through the Yukawa interaction that splits the χ masses. This channel could be responsible for depleting the symmetric component of χ for small values of α g .
We can also compare (4.1) to constraints from direct detection searches, since the cross section for χ scattering on protons goes as glyph[epsilon1] 2 , eq. (3.10). Interestingly, for m B glyph[lessmuch] M χ , the m B -dependence cancels between (4.1) and (3.10) allowing for predictions of σ p ( M χ ) that depend upon only one unknown parameter, α g . Eliminating glyph[epsilon1] leads to the cross section on protons
$$\sigma _ { p } = \frac { 4 \times 1 0 ^ { - 4 5 } \text{ cm} ^ { 2 } } { \alpha _ { g } ^ { 2 } } \left ( \frac { 0. 5 } { f _ { x } } \right ) \left ( 1 + \frac { m _ { p } } { M _ { \chi } } \right ) ^ { - 2 } \left ( \frac { M _ { \chi } } { 1 0 \text{ GeV} } \right )$$
In fig. 5 we show the predicted value of σ p versus M χ for a range of fixed α g , along with the current upper limits from the LUX [10], CDMSlite [11], SuperCDMS [87], and CRESST [88] experiments. We have relaxed the published limits of the experiments by the factor ( Z/A ) 2 appropriate for each one, to account for our model coupling only to protons and not all nucleons. (For CRESST, it is assumed that the tungsten component gives the dominant constraint.) It is clear that mainly models with large values of α g glyph[greaterorsimilar] 10 -3 that would pertain to asymmetric DM are constrained by direct detection, and that M χ must be rather small, glyph[lessorsimilar] 10 GeV, to escape detection. Comparison with fig. 4 shows the complementarity of direct detection and electron beam dump experiments for constraining the model. Only in the case α g ∼ 10 -3 , M χ ∼ 3 GeV could there be some overlap in coverage, allowing for discovery by both kinds of experiments.
In terms of indirect limits, the strongest constraint on decaying DM comes from distortions of the cosmic microwave background due to injection of electromagnetic energy at the time of recombination [89-95]. Usually this is presented as a lower limit on the lifetime τ as a function of mass M χ , assuming that all the mass-energy goes into ionizing radiation. If only a fraction δM /M χ χ does so, the constraint on the lifetime is loosened by this factor. There can be a compensating factor of O (1) for the greater efficiency of absorption of keV
Figure 6 . Solid curve: CMB lower bound on lifetime of excited state versus mass for decays into 3.55 keV X-ray, adapted from ref. [95]. Dashed: required value from 3.55 keV line strength, eq. (2.1).
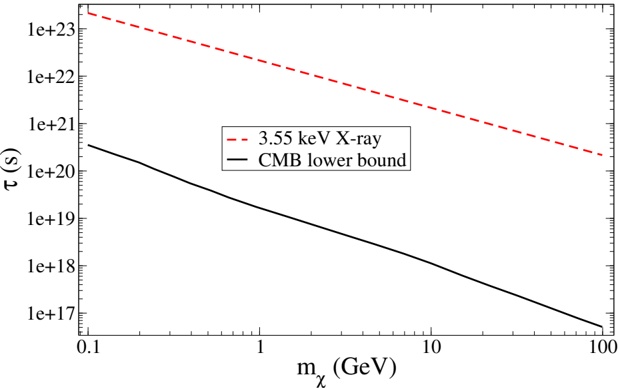
energies relative to multi-GeV's [93], but this does not affect our conclusions. We replot the strongest constraint from ref. [95] in fig. 6 taking account of this factor. We have also applied an additional correction factor of 3 55 (no relation to the energy of the X-ray line) for the . relative ionization efficiencies of photons and electrons [94] that further weakens their limit. The result is several orders of magnitude weaker than what is required to get the observed 3.55 keV line strength, eq. (2.1), also plotted in the figure.
## 4.2 XDM doublet model
As explained in section 3, it is necessary to introduce a mass splitting between the B 1 2 , gauge bosons in order to have nonvanishing inelastic scattering χ χ 1 1 → χ χ 2 2 for asymmetric doublet DM. 5 For example a triplet Higgs with VEV 〈 ∆ a 〉 = ∆ δ a, 1 splits the gauge boson masses by m 2 B 2 -m 2 B 1 = m 2 B 3 -m 2 B 1 = g 2 ∆ [68]. 2
In the scenario where χ χ 1 1 → χ χ 2 2 produces the excited state, we can constrain m B by equating the theoretical upscattering cross section (3.8, 3.9) to one of the observational estimates in (2.7) or (2.9). For definiteness, taking the lower value of (2.9) we find
$$m _ { B } \cong \left ( \frac { \delta m _ { B } } { m _ { B } } \right ) ^ { 1 / 2 } \left ( \frac { \alpha _ { g } ^ { 1 / 2 } } { 0. 1 } \right ) \ \frac { ( v _ { t } \gamma ) ^ { 1 / 4 } } { 0. 1 } \times 2 8 0 \text{ MeV}$$
where γ is the quantity plotted in fig. 2.
A further requirement in this scenario is that the excited state must decay faster than the current Hubble rate. But in that case, CMB constraints are important, and in fact require that the lifetime be less than approximately 10 12 s, so that primordial contributions have disappeared before the era of recombination (see for example ref. [93]). This puts a
5 One might also consider symmetric doublet DM, in which the inelastic scattering χ χ 1 ¯ 1 → χ χ 2 ¯ 2 can proceed through the s channel. But it turns out that this gives too small a cross section to explain the X-ray signal if α g is as small as required by the thermal relic density constraint (3.2).
1
Figure 7 . Like fig. 4, but for the XDM version of the doublet model. Here the diagonal lines are lower bounds from the requirement of sufficiently fast decay of the excited state. α g varies from 10 -4 to 1 as m B increases. Upper (red) curves correspond to M χ glyph[greaterorsimilar] 10 GeV, while lower (black) are for M χ = 1 GeV. Gauge boson mass splitting varies from δm B /m B = 0 005 to 0.1 as indicated. .
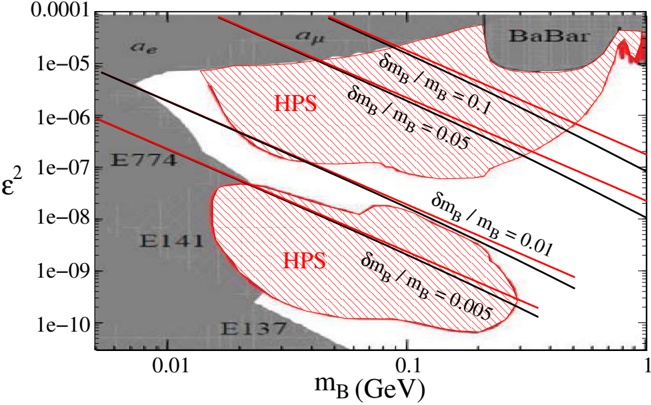
lower bound on the kinetic mixing:
$$\epsilon > \frac { 1. 1 \times 1 0 ^ { - 6 } } { \alpha _ { g } ^ { 3 / 2 } \hat { F } _ { d } ( r ) } \left ( \frac { m _ { B } } { 1 0 0 \, \text{MeV} } \right ) ^ { 2 } = \frac { 0. 0 9 } { \hat { F } _ { d } ( r ) } \left ( \frac { \delta m _ { B } } { m _ { B } } \right ) \left ( \frac { v _ { t } \gamma } { \alpha _ { g } } \right ) ^ { 1 / 2 }$$
where we used (4.3) to get the second expression. To compare with the sensitivity region of the HPS experiment, we vary α g between 10 -4 and 1 to generate parametric curves of glyph[epsilon1] versus m B from (4.3) and (4.4), assuming v γ t = 10 -3 for definiteness, and considering δm /m B B and M χ for several discrete values. The result is shown in fig. 7. Since these curves only indicate lower bounds on glyph[epsilon1] , there is considerable overlap between these predictions and the reach of HPS.
Moreover, (4.4) gives a lower bound for the cross section on protons from (3.10),
$$\sigma _ { p } > \frac { 1 0 ^ { - 3 6 } \, \text{cm} ^ { 2 } } { \alpha _ { g } ^ { 2 } \, \hat { F } _ { d } ^ { 2 } } \left ( 1 + \frac { m _ { p } } { M _ { \chi } } \right ) ^ { - 2 }$$
This constrains M < χ a few GeV in order to evade direct detection. (Such small masses could be dangerous from the point of view of CMB constraints on annihilations resulting in electrons, except that we have assumed the doublet is asymmetric dark matter in the XDM scenario.) The XDM version of the model thus predicts an enormous signal for future low-threshold direct detection experiments that would be sensitive to light dark matter.
## 5 Triplet DM model
Unlike doublet representation DM, in which both components couple equally to all gauge bosons, triplet DM components χ a each couple only to two of the three SU(2) gauge bosons
B a . As a result, radiative corrections lead to mass splittings of order δM χ ∼ α δm g B / 2 as in (3.3). Gauge boson mass differences of δm B ∼ 45 MeV × (10 GeV /M χ ) therefore lead to the appropriate splitting of δM χ = 3 55 keV. We will take . χ a to be Majorana for simplicity.
## 5.1 Mass Splittings
We consider two different dark Higgs sectors that turn out to have interestingly different predictions for direct detection, due to the spectra of gauge boson masses. In the first case, there are two triplet Higgs fields, denoted ∆ a and ∆ ′ a , with VEVs ∆ 1 = ∆ δ a 1 and ∆ ′ a = ∆ ′ δ a 2 . For simplicity we take only one of ∆ ∆ , ′ to appear in the kinetic mixing operator (3.1), so that only one gauge boson mixes with the photon. 6 In the second case, there is a single triplet Higgs ∆ a with VEV ∆ a = ∆ δ a 2 and a doublet Higgs h with VEV ( v/ √ 2)(1 1) , T . Again for simplicity we assume that only one of these fields appears in the kinetic mixing (3.1). 7
In either case, symmetries forbid any Yukawa couplings, so the DM mass splittings come exclusively from radiative corrections and for triplet DM take the form δM ab ≡ M χ b -M χ a = α g ( m B b -m B a ) / 2. With two triplet Higgs fields, the gauge boson masses are
$$m _ { B _ { 1 } } = g \Delta ^ { \prime }, \ \ m _ { B _ { 2 } } = g \Delta, \ \ m _ { B _ { 3 } } = g \sqrt { \Delta ^ { 2 } + \Delta ^ { \prime 2 } },$$
giving rise to radiative DM mass splittings [68]
$$\delta M _ { 1 2 } = \frac { 1 } { 2 } g \alpha _ { g } \left ( \Delta - \Delta ^ { \prime } \right ), \quad \delta M _ { 2 3 } = \frac { 1 } { 2 } g \alpha _ { g } \left ( \sqrt { \Delta ^ { 2 } + \Delta ^ { \prime 2 } } - \Delta \right )$$
where χ 3 is the heaviest DM state and has a transition magnetic moment with either χ 1 or χ 2 . With doublet and triplet Higgs (whose VEV is in the 2-direction), the gauge boson masses are
$$m _ { B _ { 1 } } = m _ { B _ { 3 } } = g \sqrt { v ^ { 2 } + \Delta ^ { 2 } }, \ \ m _ { B _ { 2 } } = g v$$
corresponding to DM mass splittings
$$\delta M _ { 2 1 } = \delta M _ { 2 3 } = \frac { 1 } { 2 } g \alpha _ { g } \left ( \sqrt { v ^ { 2 } + \Delta ^ { 2 } } - v \right ).$$
χ 2 is the lightest state, and χ , χ 1 3 are degenerate. We have chosen the h VEV = ( v, v ) T / √ 2 so that kinetic mixing of B 1 generates a transition magnetic moment between χ 3 and χ 2 .
If all the Higgs VEVs are of the same order of magnitude and the DM is produced thermally (so that α g is determined by (3.2)), then { ∆ ∆ , ′ , v } ∼ 1 GeV × (10 GeV /M χ ) 3 2 / and therefore gauge boson masses of order 45 MeV × (10 GeV /M χ ) yield the desired 3.55 keV mass splitting. On the other hand, we can obtain δM 23 =3.55 keV if ∆ glyph[greatermuch] ∆ or ′ v glyph[greatermuch] ∆ for the two Higgs sectors respectively, leading to mass splittings
$$\delta M _ { 2 3 } = \frac { 1 } { 4 } g \alpha _ { g } \left \{ \frac { ( \Delta ^ { \prime } ) ^ { 2 } } { \Delta }, \frac { \Delta ^ { 2 } } { v } \right \}$$
This gives (∆ ) ′ 2 = ∆ × (2 GeV)(10 GeV /M χ ) in the case of two triplets, and gauge boson masses m B 1 glyph[greaterorsimilar] 400 MeV and m B 2 3 , glyph[greaterorsimilar] 2 GeV, with approximate equality at ∆ ∼ 5∆ . ′ With one doublet and one triplet Higgs, all the gauge boson masses are m B a glyph[greaterorsimilar] 2 GeV. Nonthermal production of DM requires a larger gauge coupling and therefore allows for smaller Higgs VEVs and gauge boson masses.
6 More generally, if the VEVs are not quite orthogonal, the other gauge bosons pick up (smaller) kinetic mixings, as well, without changing the conclusions below in a substantial way.
7 Throughout, we take ∆ ∆ , ′ , v > 0 without loss of generality.
## 5.2 Decaying DM Model
For triplet DM, the transition dipole moment µ × is given by (3.5). If the X-ray line is produced through long-lived excited state DM decay, the kinetic mixing parameter is
$$\epsilon = \frac { 1. 1 \times 1 0 ^ { - 1 3 } } { \alpha _ { g } ^ { 3 / 2 } F _ { t } ( r _ { 2 }, r _ { 3 } ) } \left ( \frac { 0. 3 } { f _ { 3 } } \right ) ^ { 1 / 2 } \left ( \frac { M _ { \chi } } { 1 0 \, \text{GeV} } \right ) ^ { 3 / 2 } \,,$$
where r 2 3 , = ( m B 2 3 , /M χ ) 2 . Recall that the B 1 gauge boson is the one that mixes with the photon, and its mass depends on the dark Higgs sector of the model. In models with symmetry broken either by two triplet Higgs fields or by a triplet and a doublet, eqs. (5.1-5.4) imply that m B 3 -m B 2 = 45 MeV × (10 GeV /M χ ) ≡ f ( M χ ); however m B 1 = m B 3 for doublet plus triplet Higgses whereas m 2 B 1 = m 2 B 3 -m 2 B 2 for two triplets. This leads to the gauge boson mass relations
$$m _ { B _ { 2 } } & = m _ { B _ { 1 } } - f, \quad m _ { B _ { 3 } } = m _ { B _ { 1 } }, \quad \text{doublet + triplet Higgses} \\ m _ { B _ { 2 } } & = \frac { 1 } { 2 } ( m _ { B _ { 1 } } ^ { 2 } / f - f ), \quad m _ { B _ { 3 } } = \frac { 1 } { 2 } ( m _ { B _ { 1 } } ^ { 2 } / f + f ), \quad \text{two triplet Higgses}$$
which fixes m B 2 3 , in terms of m B 1 and M χ in what follows.
With any of the mass splittings and gauge boson masses discussed in section 5.1, the fractional relic abundance of χ 3 is 0 1 . glyph[lessorsimilar] f 3 glyph[lessorsimilar] 0 33 for thermal relic DM, as we have verified . using the methods described in [70]. Since F t runs between approximately 1/2 and 4 in the parameter space of interest, we find a required kinetic mixing glyph[epsilon1] glyph[lessorsimilar] 10 -8 , which avoids current laboratory constraints on light vector bosons (summarized in [96]). However constraints on supernova cooling require m B 1 glyph[greaterorsimilar] 100 MeV for 10 -10 glyph[lessorsimilar] glyph[epsilon1] glyph[lessorsimilar] 10 -7 [97]. Nonthermal DM production necessitates a stronger gauge coupling, which further suppresses the required kinetic mixing.
Using (5.6) and (3.2) (assuming thermal production of the DM), we can eliminate glyph[epsilon1] and α g from the predicted cross section (3.10) for scattering on protons,
$$\sigma _ { p } = \frac { 5. 9 \times 1 0 ^ { - 4 3 } \, \text{cm} ^ { 2 } } { F _ { t } ( r _ { 2 }, r _ { 3 } ) ^ { 2 } } \, \left ( \frac { 0. 3 } { f _ { 3 } } \right ) \left ( 1 + \frac { m _ { p } } { M _ { \chi } } \right ) ^ { - 2 } \left ( \frac { M _ { \chi } } { 1 0 \, \text{GeV} } \right ) \left ( \frac { 1 0 0 \, \text{MeV} } { m _ { B _ { 1 } } } \right ) ^ { 4 }, \quad \, ( 5. 8 )$$
recalling that the gauge boson masses are related as in (5.7), depending on the choice of Higgs sector. Scattering from nuclei in direct detection experiments can either be endothermic χ N 2 → χ N 3 or exothermic χ N 3 → χ N 2 events, since both states are populated at present day. The state χ 1 does not participate in nuclear scattering.
However, limits on σ p from direct detection experiments are expressed in terms of cross sections for elastic scattering. In the approximation that the inelasticity modifies the cross section through the phase space, but not the recoil spectrum, the event rate for the combination of endothermic and exothermic cross sections is equivalent to elastic scattering of the entire abundance of DM with a cross section on protons of
$$\tilde { \sigma } _ { p } = \frac { \sigma _ { p } } { \langle v \rangle } \left ( f _ { 2 } \left \langle \sqrt { v ^ { 2 } - v _ { \delta } ^ { 2 } } \, \Theta ( v - v _ { \delta } ) \right \rangle + f _ { 3 } \left \langle \sqrt { v ^ { 2 } + v _ { \delta } ^ { 2 } } \right \rangle \right )$$
as in eq. (3.11). The rescaled cross section ˜ σ p is shown in figure 8 for several values of the gauge boson masses for the two-Higgs-triplet model. Also shown are the experimental limits, rescaled by ( Z/A ) 2 because the DM couples only to charge in our models. Dark matter
Figure 8 . Cross section of triplet DM on protons, assuming glyph[epsilon1] chosen as in (5.6) to produce the X-ray line by long-lived excited DM decay, as well as the thermal relic value for α g , eq. (3.2). Each theoretically predicted curve is labeled by the B 1 gauge boson mass, assuming a dark Higgs sector with two triplets. As a function of m B 1 , the σ p curve reaches a minimum around m B 1 = 500 MeV, and increases slightly for larger m B 1 . Vertical dashed lines indicate CMB lower limit on M χ from annihilations, depending upon whether M χ 1 > M χ 2 (right line) or M χ 1 < M χ 2 (left line).
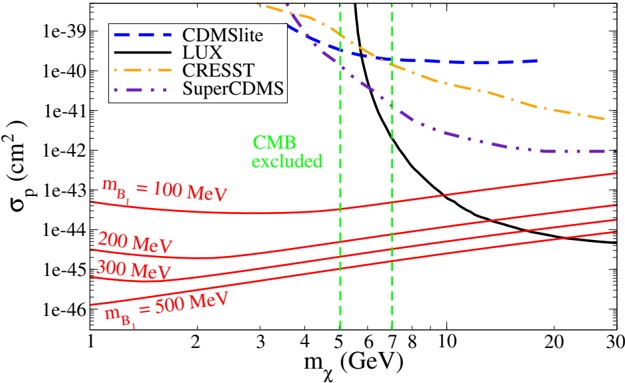
masses of M χ glyph[lessorsimilar] 10 GeV are allowed for m B 1 = 100 MeV, while larger M χ is allowed as m B 1 increases. However, this dependence on m B 1 is not monotonic, due to the factor F t ( r , r 2 3 ) -2 in (5.8) and the relations (5.7) between the gauge boson masses; in fact the growth in the allowed value of M χ saturates near the m B 1 = 500 MeV curve shown, so that higher values than M χ ∼ 20 GeV are not allowed by the LUX constraint. For the model with one triplet and one doublet Higgs field on the other hand, the dependence on m B 1 is monotonic, and for m B 1 > 300 MeV the predicted cross sections fall below the current LUX limit, as shown in figure 9.
Like their doublet DM model counterpart, these models of decaying triplet DM are potentially constrained by the CMB. Apart from the slightly different fractional abundance f x of excited DM in the two models, the decay rate is the same, so the CMB bounds from decays are robustly satisfied, as in figure 6. However, there are related CMB constraints on DM annihilations into SM particles that apply for the triplet model, since it is a symmetric DM candidate. Due to the nonabelian structure of the DM sector, the effective annihilation cross section does not take the canonical relic density value in the late universe. In appendix B we adapt the limits of ref. [98] to this model and find that it must satisfy M χ glyph[greaterorsimilar] 5 GeV (if M χ 1 < M χ 2 ) or M χ glyph[greaterorsimilar] 7 GeV ( M χ 2 < M χ 1 ), depending on the gauge boson masses, through both the mass splittings and primordial relative abundances. These constraints are compatible with limits on the DM mass from direct detection experiments for gauge boson masses m B 1 glyph[greaterorsimilar] 100 MeV and offer the possibility of detection as CMB limits improve.
## 5.3 Triplet XDM
We next consider the scenario where triplet DM undergoes collisional excitation followed by fast decays to give the 3.5 keV line. In this case the kinetic mixing is large enough so that
Figure 9 . Like figure 8 but for a dark Higgs sector of one triplet and one doublet.
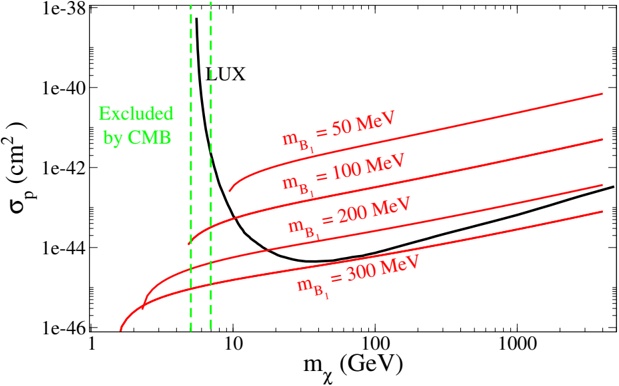
the primordial component of the excited DM state χ 3 has decayed, and is only repopulated by collisional excitation. As discussed in section 4.2, CMB constraints required the lifetime to be less than ∼ 10 12 s. This requires
$$\epsilon \gtrsim 3. 8 \times 1 0 ^ { - 9 } \, \frac { \left ( M _ { \chi } / 1 0 \, \text{GeV} \right ) } { F _ { t } ( r _ { 2 }, r _ { 3 } ) \, \alpha _ { g } ^ { 3 / 2 } } = ( 1. 9 \times 1 0 ^ { - 3 } ) \left ( \frac { 1 0 \, \text{GeV} } { M _ { \chi } } \right ) ^ { 1 / 2 } \frac { 1 } { F _ { t } ( r _ { 2 }, r _ { 3 } ) }, \quad \quad ( 5. 1 0 )$$
with the latter equality representing the bound for thermal relic DM.
We next consider the rate of upscattering needed to populate χ 3 for XDM-like production of the X-ray signal. Suppose first that the entire signal is produced by collisional excitation of a single DM state χ g , which could be either χ 1 or χ 2 , as both are stable in the models we consider. Taking the lower value from equation (2.9), we find that that the gauge boson mediating the upscattering χ χ g g → χ χ 3 3 has mass
$$m _ { B } \cong ( 3 \, \text{GeV} ) \left ( \frac { \alpha _ { g } f _ { g } } { 0. 3 3 } \right ) ^ { 1 / 2 } \left ( \frac { v _ { t } \gamma } { 1 3 0 0 \, \text{km/s} } \right ) ^ { 1 / 4 },$$
$$\cong ( 3 7 \, \text{MeV} ) \left ( \frac { f _ { g } } { 0. 3 3 } \right ) ^ { 1 / 2 } \left ( \frac { M _ { \chi } } { 1 0 \, \text{GeV} } \right ) ^ { 1 / 2 } \left ( \frac { v _ { t } \gamma } { 1 3 0 0 \, \text{km/s} } \right ) ^ { 1 / 4 } \, \quad \quad ( 5. 1 2 )$$
where the second line assumes the thermal relic value of the gauge coupling. If we consider excitation of χ 2 DM, then f g ∼ 2 3 because of the early universe decays / χ 3 → χ γ 2 . This gives a gauge boson mass m B 1 ∼ 50 MeV, very similar to the mass difference needed to account for the 3.55 keV DM mass splitting. It is also possible that χ χ 1 1 → χ χ 3 3 scattering produces the X-ray signal, either as the dominant contribution or along with χ χ 2 2 → χ χ 3 3 scattering. In this case, it is m B 2 that is glyph[greaterorsimilar] 37 MeV, and m B 1 can be somewhat higher. It is worth noting that the mass gap δM 13 may be either larger or smaller than 3.55 keV, so the relative contribution of each type of upscattering differs in M31 and the Perseus cluster. However, these corrections are all of order unity.
Direct detection imposes stringent constraints on these models for DM masses of order M χ = 10 GeV. Using (5.10) and (5.11), we find that the cross section for DM-proton inelastic
scattering is
$$\sigma _ { p } \gtrsim \frac { 2. 2 \times 1 0 ^ { - 4 7 } \, \text{cm} ^ { 2 } } { \alpha _ { g } ^ { 4 } \, F _ { t } ( r _ { 2 }, r _ { 3 } ) ^ { 2 } } \left ( 1 + \frac { m _ { p } } { M _ { \chi } } \right ) ^ { - 2 } \left ( \frac { M _ { \chi } } { 1 0 \, \text{GeV} } \right ) ^ { 2 } \left ( \frac { 0. 3 3 } { f _ { g } } \right ) ^ { 2 } \left ( \frac { 1 3 0 0 \, \text{km/s} } { v _ { t } \gamma } \right ),$$
where v γ t is the appropriate value for the Perseus cluster. For comparison to elastic scattering experiments, we rescale the cross section as in equation (5.9) with f 3 = 0. With nonthermal DM production, α g as small as 0 01 and somewhat lighter DM masses 3-5 GeV avoid current . direct detection constraints.
Using the thermal relic value for α g yields a much stronger constraint
$$\sigma _ { p } \gtrsim \frac { 4 \times 1 0 ^ { - 3 2 } \, \text{cm} ^ { 2 } } { F _ { t } ( r _ { 2 }, r _ { 3 } ) ^ { 2 } } \left ( 1 + \frac { m _ { p } } { M _ { \chi } } \right ) ^ { - 2 } \left ( \frac { 1 0 \, \text{GeV} } { M _ { \chi } } \right ) ^ { 2 } \left ( \frac { 0. 3 3 } { f _ { g } } \right ) ^ { 2 } \left ( \frac { 1 3 0 0 \, \text{km/s} } { v _ { t } \gamma } \right ),$$
which forces M χ ∼ 1 GeV, below the sensitivity of current direct detection experiments. At these low masses, kinematic suppression of the scattering rate due to the inelasticity becomes a strong effect and is worth studying in more detail as more sensitive direct detection experiments come online. This cross section can be reduced slightly if m B 1 is somewhat larger than (5.12) but only by about an order of magnitude, which does not by itself remove this constraint.
However, CMB constraints on DM annihilation will essentially rule out these models in combination with direct detection constraints. As described in appendix B, we find that CMB bounds require M > χ 6 GeV for triplet XDM. This would only be consistent with the direct detection constraints on the thermal WIMP model discussed above if some combination of parameter choices could drastically reduce the direct detection cross section. Nonthermal DM production with larger α g will reduce the DM-proton scattering cross section given in equation (5.13) at the cost of increasing the annihilation cross section and therefore tightening the CMB constraint. We would therefore have to consider replacing the Majorana DM with Dirac DM and taking an asymmetric DM model in order to make triplet XDM a viable option.
## 6 Discussion
Nonabelian dark matter models with a light kinetically mixed gauge boson can naturally incorporate the small mass splitting and coupling to photons that would be needed for decays of an excited DM state to explain the 3.5 keV X-ray line. We find that the DM mass should be in the approximate range 1 -10 GeV, with the possibility of larger masses for decaying triplet DM (depending on the dark Higgs content; see fig. 9), and the gauge bosons masses should be glyph[lessorsimilar] 1 GeV. There are good prospects for direct detection of the DM by its scattering on protons. Moreover the kinetic mixing parameter and gauge boson masses typically fall into regions that will be probed by the HPS experiment within the next year.
Generally, a given model can exist in either of two regimes, where the excited state is metastable and primordial, or else having a shorter lifetime and produced through inelastic scatterings (XDM mechanism). Models of the former kind easily satisfy CMB constraints from injection of electromagnetic energy during recombination, but the latter kind are more strongly constrained by the CMB, needing much larger values of the kinetic mixing in order to decay well before recombination. For the doublet XDM model, it requires taking M χ below a few GeV to evade direct detection, while for the triplet model, since it is a symmetric dark
matter candidate, this loophole is blocked by CMB constraints on annihilations, so that the XDM version of the triplet model is ruled out (though asymmetric Dirac triplet DM could be made acceptable).
In previous literature, nonabelian DM models were explored as a means of explaining the anomalous 511 keV gamma ray line from the galactic center [70]. One could be tempted to try to combine this and the 3.5 keV line in a triplet DM model where there are two mass splittings corresponding to these energies. We find (details not described here) that although it is possible to arrange for the desired splittings, the relative strengths of the two lines cannot be correctly reproduced in these models with small multiplets because the transition with the larger energy has too big a rate relative to the smaller one, due to the larger phase space for the decays.
Similarly, one may wonder whether our model could simultaneously explain the GeVscale galactic center excess [18, 19], since general models of DM interacting through kinetically mixed vector mediators have been shown to give a good fit to the data [99, 100]. However the best fit region is for m χ ∼ m B ∼ 30 GeV, which is generally incompatible with the parameters we have identified for the X-ray line. For example, eq. (4.1) for the slow-decaying doublet model implies glyph[epsilon1] ∼ 10 -5 /α 3 2 / g , giving a cross section on protons of σ p glyph[greaterorsimilar] 3 × 10 -44 cm 2 that is firmly excluded by LUX. More recently it has been pointed out that inclusion of inverse Compton scattering and brehmsstrahlung contributions can lead to lower best-fit values M χ ∼ 10 GeV consistent with leptonic final states [101, 102]. These authors do not consider the 4-lepton final states that would arise from pairs of gauge bosons, so we cannot draw any direct conclusions from their work, but if for example m B = 3 GeV rather than ∼ 30 GeV, this would reduce glyph[epsilon1] by a factor of 100 and σ p by a factor of 10 , safely below 4 current direct detection limits. We leave this interesting question for a separate study.
The 3.5 keV line awaits confirmation by higher-statistics observations. So far the only study to cast doubt on the observation is a negative search for the line in our own galactic center [103]; however the conclusions depend upon uncertain assumptions about the shape of the dark matter halo profile in this region. In our study we have pointed out a possible way of discriminating between and XDM and decaying models for the X-ray line: since the XDM mechanism depends upon the DM velocity dispersion through 〈 σv rel 〉 , one could expect that the line strength will be relatively stronger from galactic clusters with higher v rel than from individual galaxies like M31 (see also [54]). We quantified this for the predicted signal in fig. 2. There is already a hint of such an effect in the present determinations of the required value of 〈 σv rel 〉 . It will be interesting to see whether it persists as the observations improve.
Acknowledgment. We thank Wei Xue for helpful discussions concerning the galactic center gamma ray excess. Our work is supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada.
## A Magnetic moments
We derive the one-loop results for the transition magnetic moments of the dark matter multiplets, starting with the case of SU(2) triplet DM. In a constant external magnetic field, the triple-gauge interaction from the kinetic mixing operator takes the form glyph[epsilon1]g F µν B B µ 2 ν 3 . In the case of equal gauge boson masses, the effective operator involving F µν can be written as
$$\epsilon g ^ { 3 } \bar { u } _ { 2 } ( p ) \left [ \int \frac { d ^ { 4 } \ell } { ( 2 \pi ) ^ { 4 } } \frac { \gamma _ { \mu } ( \ell + M _ { \chi } ) \gamma _ { \nu } } { ( \ell ^ { 2 } + 2 \ell \cdot p ) ( \ell ^ { 2 } - m _ { B } ^ { 2 } + i \epsilon ) ^ { 2 } } \right ] u _ { 3 } ( p ) \, F ^ { \mu \nu }$$
setting the momentum of the constant field to zero and ignoring the small DM mass splittings. p is the external fermion momentum which is taken to be on shell, p 2 = M 2 χ . The term in brackets becomes
$$\frac { i } { 1 6 \pi ^ { 2 } } \int _ { 0 } ^ { 1 } d x \, ( 1 - x ) \frac { \gamma _ { \mu } ( \vec { p } ( 1 - x ) + M _ { \chi } ) \gamma _ { \nu } } { x ^ { 2 } \, M _ { \chi } ^ { 2 } + ( 1 - x ) \mu ^ { 2 } }$$
after doing the momentum integral. By anticommuting half of the / p term through each gamma matrix and using the Dirac equation, we find that / p → -m plus terms that are symmetric under µ ↔ ν , hence vanish under contraction with the field strength. The x integral can be done, resulting in the transition magnetic moment
$$\mu _ { \times } = \frac { \epsilon g ^ { 3 } } { 1 6 \pi ^ { 2 } \, M _ { \chi } } F _ { t } ( m _ { B } ^ { 2 } / M _ { \chi } ^ { 2 } )$$
where
$$F _ { t } ( r ) = \frac { 1 - r } { 2 } \ln \frac { 1 } { r } - 1 + \frac { 3 - r } { \sqrt { 4 / r - 1 } } \, \tan ^ { - 1 } \sqrt { 4 / r - 1 } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \cdot \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
\quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \,
\quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
\quad 0 \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,
\quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,$$
It has leading behavior 1 2 ln(1 /r ) at small r . For the case of two different gauge boson masses in the loop, we define r i = m 2 B i /M 2 χ and obtain in place of (A.2)
$$\frac { i } { 1 6 \pi ^ { 2 } } \int _ { 0 } ^ { 1 } d x \int _ { 0 } ^ { 1 - x } d y \, \frac { \gamma _ { \mu } ( \psi ( 1 - x ) + M _ { \chi } ) \gamma _ { \nu } } { x ^ { 2 } \, M _ { \chi } ^ { 2 } + y m _ { B _ { 1 } } ^ { 2 } + ( 1 - x - y ) m _ { B _ { 2 } } ^ { 2 } }$$
leading to
$$F _ { t } ( r _ { 1 }, r _ { 2 } ) & = \frac { \sqrt { ( 4 - r _ { 1 } ) } \, r _ { 1 } ^ { 3 / 2 } \tan ^ { - 1 } \sqrt { 4 / r _ { 1 } - 1 } - \sqrt { ( 4 - r _ { 2 } ) } \, r _ { 2 } ^ { 3 / 2 } \tan ^ { - 1 } \sqrt { 4 / r _ { 2 } - 1 } } { 2 ( r _ { 1 } - r _ { 2 } ) } \\ & + \frac { ( r _ { 1 } ^ { 2 } - 2 r _ { 1 } ) \ln r _ { 1 } - ( r _ { 2 } ^ { 2 } - 2 r _ { 2 } ) \ln r _ { 2 } } { 4 ( r _ { 1 } - r _ { 2 } ) } - \frac { 1 } { 2 }$$
One can show that (A.6) reduces to (A.4) in the limit r 1 → r 2 = . r
The above results can be generalized to other DM representations of SU(N) by including the group theory factor
$$G = f ^ { \hat { a } b c } T _ { 2 i } ^ { c } T _ { i 1 } ^ { b }$$
assuming that the DM mass eigenstates labeled 1 2 correspond to the generators , T b i 1 , T c 2 i respectively, and ˆ denotes the gauge boson that kinetically mixes with the photon. a One must sum over gauge bosons with masses m B b and m B c as well as the internal DM state with mass M χ i . If the mass differences can be neglected in the loop integral (as fig. 3 shows is often a good approximation) then the sums over i, b, c can be done directly in (A.7), giving
$$G = \frac { i } { 2 } C _ { 2 } ( A ) T _ { 2 1 } ^ { \hat { a } }$$
where C A ( ) is the quadratic Casimir invariant of the adjoint representation. The multiplicative correction factor (A.8) is unity for the triplet model in SU(2).
In the SU(2) doublet DM model, the transition magnetic moment gets nearly canceling contributions from both χ 1 and χ 2 in the loop, such that the result is suppressed by δM χ .
One must therefore be more careful in distinguishing the incoming and outgoing fermion momenta p 1 2 , , and keeping the dependence on the photon momentum q = p 1 -p 2 . The induced operator is
$$& \quad \epsilon g ^ { 3 } \bar { u } _ { 1 } ( p _ { 1 } ) \left [ \int \frac { d ^ { \, 4 } \ell } { ( 2 \pi ) ^ { 4 } } \frac { \gamma _ { \mu } ( \ell + p + m _ { 1 } ) \gamma _ { \nu } } { ( ( \ell + p ) ^ { 2 } - m _ { 1 } ^ { 2 } ) ( ( \ell - q / 2 ) ^ { 2 } + m _ { B } ^ { 2 } ) ( ( \ell + q / 2 ) ^ { 2 } + m _ { B } ^ { 2 } ) } \right ] u _ { 2 } ( p _ { 2 } ) \, F ^ { \mu \nu } ( q ) \\ - & \ \{ m _ { 1 } \to m _ { 2 } \}$$
where p = 1 2 ( p 1 + p 2 ). Introducing Feynman parameters x and y for the two gauge boson propagators (hence (1 -x -y ) for the fermion) we find the result
$$\mu _ { \times } = \frac { \epsilon g ^ { 3 } } { 1 6 \pi ^ { 2 } } \frac { \delta M _ { \chi } } { M _ { \chi } ^ { 2 } } \, F _ { d } ( r )$$
to leading order in δM χ for the transition magnetic moment, with r = m /M 2 B 2 χ and
$$F _ { d } ( r ) & = \int _ { 0 } ^ { 1 } d x \int _ { 0 } ^ { 1 - x } d y \frac { ( 1 - x - y ) + r ( x + y ) } { ( ( 1 - x - y ) ^ { 2 } + r ( x + y ) ) ^ { 2 } } \\ & = \frac { 2 - r } { r ( 4 - r ) } + 2 \frac { \tan ^ { - 1 } \sqrt { 4 / r - 1 } } { \sqrt { r } ( 4 - r ) ^ { 3 / 2 } }$$
which has leading behavior 1 / (2 r ) at small r . This implies that for m B glyph[lessmuch] M χ , the transition moment in the doublet model goes like δM /m χ 2 B instead of 1 /M χ .
## B CMB bounds from DM annihilation
In this appendix, we give details concerning the constraints on the mass M χ of triplet DM models described in section 5 coming from the cosmic microwave background. Combined limits from Planck, WMAP9, ACT, and SPT (plus low-redshift data) constrain DM with canonical annihilation cross section σv = 3 × 10 -26 cm 3 / s to have mass M > χ (26 GeV) f , where f is the effective energy deposition efficiency [98]. For 'XDM-like' annihilation processes χχ → BB followed by B 1 → e + e -, the efficiency is f = 0 67 for DM masses near . 10 GeV [98]. This efficiency is larger than for B 1 → 2 µ or B 1 → 2 π decay channels when they are allowed. Since we are mostly concerned with lighter gauge boson masses, we conservatively take f = 0 67. However, the constraints we find below are loosened somewhat for . m B 1 > 2 m µ .
We account for several additional effects in our models. First, as described in section 3, we use the adjusted value of the thermal relic cross section, which is approximately 0.7 of the canonical value at DM mass of 10 GeV but increases to the canonical value at 5 GeV DM mass.
There are other effects due to the nonabelian structure of the dark sector. The energy deposition efficiency is reduced by the fact that the relic abundance is determined by the total annihilation cross section for χχ → BB , but only B 1 gauge bosons decay into SM particles. Therefore, we count only annihilations with B 1 final particles toward the energy deposition efficiency (weighting final states with a single B 1 with 1/2). Finally, the relative abundances of the DM species differ in the present universe relative to those at chemical freeze out due to kinetic equilibration at lower temperatures during the Big Bang. As a result of these
two effects, the effective average annihilation cross section is modified in the late universe compared to the canonical value. As given in the appendix of [70], the colorand spinaveraged and summed square amplitude for the total annihilation cross section (assuming equal abundances for each 'color,' or DM state) is |M tot | 2 = 25 g / 4 6, not including any overcounting or symmetry factors for identical initial or final particles. This is composed of amplitudes for two types of processes, M 12 → 12 , which involves t -and s -channel diagrams, and M 22 → 11 , with t - and u -channel parts. As we approximate vanishing gauge boson masses, the amplitudes are equal when gauge indices are permuted. The effective squared amplitude at late times, including all permutations and weighting M 12 → 12 contributions by 1/2, is
$$| \mathcal { M } _ { e f f } | ^ { 2 } & = \frac { 4 } { 2 } f _ { 1 } f _ { 2 } | \mathcal { M } _ { 1 2 \to 1 2 } | ^ { 2 } + \frac { 4 } { 2 } f _ { 1 } f _ { 3 } | \mathcal { M } _ { 1 3 \to 1 3 } | ^ { 2 } + f _ { 2 } ^ { 2 } | \mathcal { M } _ { 2 2 \to 1 1 } | ^ { 2 } + f _ { 3 } ^ { 2 } | \mathcal { M } _ { 3 3 \to 1 1 } | ^ { 2 } \quad ( \text{B.1} ) \\ & = \left [ \frac { 9 } { 2 } f _ { 1 } ( 1 - f _ { 1 } ) + 4 ( f _ { 2 } ^ { 2 } + f _ { 3 } ^ { 2 } ) \right ] g ^ { 4 }.$$
We therefore rescale the energy deposition efficiency by |M eff | 2 / |M tot | 2 .
In the decaying triplet model, the fractional relic abundances f a are set by kinetic freezeout in the Big Bang. For fiducial values f 1 = f 2 = f 3 = 1 3, we find the bound / M χ glyph[greaterorsimilar] 6 GeV. For specific values of the mass splittings and gauge boson masses, the relative abundances change somewhat; representative abundances are f 1 = 0 66, . f 2 = 0 23, . f 3 = 0 11 . if M χ 1 < M χ 2 or f 1 = 0 23, . f 2 = 0 66, . f 3 = 0 11 if . M χ 2 < M χ 1 . These lead to CMB bounds of 5 GeV and 7 GeV respectively.
In the XDM model, the primordial χ 3 population decays early, adding to the χ 2 abundance. Therefore, the three cases described above have f 1 = 1 3, / f 2 = 2 3, / f 3 = 0 with M > χ 8 GeV, f 1 = 0 66, . f 2 = 0 34, . f 3 = 0 with M > χ 6 GeV, and f 1 = 0 23, . f 2 = 0 77, . f 3 = 0 with M > χ 9 GeV. These values are inconsistent with the direct detection bounds for the XDM model.
## References
- [1] DAMA Collaboration Collaboration, R. Bernabei et. al. , First results from DAMA/LIBRA and the combined results with DAMA/NaI , Eur.Phys.J. C56 (2008) 333-355, [ 0804.2741 ].
- [2] G. Angloher, M. Bauer, I. Bavykina, A. Bento, C. Bucci, et. al. , Results from 730 kg days of the CRESST-II Dark Matter Search , 1109.0702 .
- [3] C. Aalseth, P. Barbeau, J. Colaresi, J. Collar, J. Diaz Leon, et. al. , Search for an Annual Modulation in a P-type Point Contact Germanium Dark Matter Detector , Phys.Rev.Lett. 107 (2011) 141301, [ 1106.0650 ].
- [4] CoGeNT collaboration Collaboration, C. Aalseth et. al. , Results from a Search for Light-Mass Dark Matter with a P-type Point Contact Germanium Detector , Phys.Rev.Lett. 106 (2011) 131301, [ 1002.4703 ].
- [5] CoGeNT Collaboration Collaboration, C. Aalseth et. al. , Search for An Annual Modulation in Three Years of CoGeNT Dark Matter Detector Data , 1401.3295 .
- [6] CDMS Collaboration Collaboration, R. Agnese et. al. , Silicon Detector Dark Matter Results from the Final Exposure of CDMS II , Phys.Rev.Lett. 111 (2013) 251301, [ 1304.4279 ].
- [7] XENON10 Collaboration Collaboration, J. Angle et. al. , A search for light dark matter in XENON10 data , Phys.Rev.Lett. 107 (2011) 051301, [ 1104.3088 ].
- [8] XENON100 Collaboration Collaboration, E. Aprile et. al. , Analysis of the XENON100 Dark Matter Search Data , Astropart.Phys. 54 (2014) 11-24, [ 1207.3458 ].
- [9] XENON100 Collaboration Collaboration, E. Aprile et. al. , Dark Matter Results from 225 Live Days of XENON100 Data , Phys.Rev.Lett. 109 (2012) 181301, [ 1207.5988 ].
- [10] LUX Collaboration Collaboration, D. Akerib et. al. , First results from the LUX dark matter experiment at the Sanford Underground Research Facility , Phys.Rev.Lett. 112 (2014) 091303, [ 1310.8214 ].
- [11] SuperCDMSSoudan Collaboration Collaboration, R. Agnese et. al. , CDMSlite: A Search for Low-Mass WIMPs using Voltage-Assisted Calorimetric Ionization Detection in the SuperCDMS Experiment , Phys.Rev.Lett. 112 (2014) 041302, [ 1309.3259 ].
- [12] PAMELA Collaboration Collaboration, O. Adriani et. al. , An anomalous positron abundance in cosmic rays with energies 1.5-100 GeV , Nature 458 (2009) 607-609, [ 0810.4995 ].
- [13] HEAT Collaboration Collaboration, S. Barwick et. al. , Measurements of the cosmic ray positron fraction from 1-GeV to 50-GeV , Astrophys.J. 482 (1997) L191-L194, [ astro-ph/9703192 ].
- [14] J. Chang, J. Adams, H. Ahn, G. Bashindzhagyan, M. Christl, et. al. , An excess of cosmic ray electrons at energies of 300-800 GeV , Nature 456 (2008) 362-365.
- [15] PPB-BETS Collaboration Collaboration, S. Torii et. al. , High-energy electron observations by PPB-BETS flight in Antarctica , 0809.0760 .
- [16] T. Bringmann, X. Huang, A. Ibarra, S. Vogl, and C. Weniger, Fermi LAT Search for Internal Bremsstrahlung Signatures from Dark Matter Annihilation , JCAP 1207 (2012) 054, [ 1203.1312 ].
- [17] C. Weniger, A Tentative Gamma-Ray Line from Dark Matter Annihilation at the Fermi Large Area Telescope , JCAP 1208 (2012) 007, [ 1204.2797 ].
- [18] D. Hooper and T. Linden, On The Origin Of The Gamma Rays From The Galactic Center , Phys.Rev. D84 (2011) 123005, [ 1110.0006 ].
- [19] K. N. Abazajian and M. Kaplinghat, Detection of a Gamma-Ray Source in the Galactic Center Consistent with Extended Emission from Dark Matter Annihilation and Concentrated Astrophysical Emission , Phys.Rev. D86 (2012) 083511, [ 1207.6047 ].
- [20] D. Hooper and L. Goodenough, Dark Matter Annihilation in The Galactic Center As Seen by the Fermi Gamma Ray Space Telescope , Phys.Lett. B697 (2011) 412-428, [ 1010.2752 ].
- [21] L. Goodenough and D. Hooper, Possible Evidence For Dark Matter Annihilation In The Inner Milky Way From The Fermi Gamma Ray Space Telescope , 0910.2998 .
- [22] W. N. Johnson, III, F. R. Harnden, Jr., and R. C. Haymes, The Spectrum of Low-Energy Gamma Radiation from the Galactic-Center Region. , Astrophys.J.Lett. 172 (Feb., 1972) L1.
- [23] M. Leventhal, C. J. MacCallum, and P. D. Stang, Detection of 511 keV positron annihilation radiation from the galactic center direction , Astrophys.J.Lett. 225 (Oct., 1978) L11-L14.
- [24] E. Bulbul, M. Markevitch, A. Foster, R. K. Smith, M. Loewenstein, et. al. , Detection of An Unidentified Emission Line in the Stacked X-ray spectrum of Galaxy Clusters , 1402.2301 .
- [25] A. Boyarsky, O. Ruchayskiy, D. Iakubovskyi, and J. Franse, An unidentified line in X-ray spectra of the Andromeda galaxy and Perseus galaxy cluster , 1402.4119 .
- [26] H. Ishida, K. S. Jeong, and F. Takahashi, 7 keV sterile neutrino dark matter from split flavor mechanism , Phys.Lett. B732 (2014) 196-200, [ 1402.5837 ].
- [27] K. N. Abazajian, Resonantly-Produced 7 keV Sterile Neutrino Dark Matter Models and the Properties of Milky Way Satellites , Phys.Rev.Lett. 112 (2014) 161303, [ 1403.0954 ].
- [28] S. Baek and H. Okada, 7 keV Dark Matter as X-ray Line Signal in Radiative Neutrino Model , 1403.1710 .
- [29] B. Shuve and I. Yavin, A Dark Matter Progenitor: Light Vector Boson Decay into (Sterile) Neutrinos , Phys.Rev. D89 (2014) 113004, [ 1403.2727 ].
- [30] T. Tsuyuki, Neutrino masses, leptogenesis, and sterile neutrino dark matter , 1403.5053 .
- [31] F. Bezrukov and D. Gorbunov, Relic Gravity Waves and 7 keV Dark Matter from a GeV scale inflaton , 1403.4638 .
- [32] K. P. Modak, 3.5 keV X-ray Line Signal from Decay of Right-Handed Neutrino due to Transition Magnetic Moment , 1404.3676 .
- [33] D. J. Robinson and Y. Tsai, A Dynamical Framework for KeV Dirac Neutrino Warm Dark Matter , 1404.7118 .
- [34] S. Chakraborty, D. K. Ghosh, and S. Roy, 7 keV Sterile neutrino dark matter in U (1) R -lepton number model , 1405.6967 .
- [35] N. Haba, H. Ishida, and R. Takahashi, ν R dark matter-philic Higgs for 3.5 keV X-ray signal , 1407.6827 .
- [36] T. Higaki, K. S. Jeong, and F. Takahashi, The 7 keV axion dark matter and the X-ray line signal , Phys.Lett. B733 (2014) 25-31, [ 1402.6965 ].
- [37] J. Jaeckel, J. Redondo, and A. Ringwald, A 3.55 keV hint for decaying axion-like particle dark matter , Phys.Rev. D89 (2014) 103511, [ 1402.7335 ].
- [38] H. M. Lee, S. C. Park, and W.-I. Park, Cluster X-ray line at 3 5 keV . from axion-like dark matter , 1403.0865 .
- [39] M. Cicoli, J. P. Conlon, M. C. D. Marsh, and M. Rummel, A 3.55 keV Photon Line and its Morphology from a 3.55 keV ALP Line , 1403.2370 .
- [40] A. Dias, A. Machado, C. Nishi, A. Ringwald, and P. Vaudrevange, The Quest for an Intermediate-Scale Accidental Axion and Further ALPs , JHEP 1406 (2014) 037, [ 1403.5760 ].
- [41] J.-C. Park, S. C. Park, and K. Kong, X-ray line signal from 7 keV axino dark matter decay , Phys.Lett. B733 (2014) 217-220, [ 1403.1536 ].
[42]
K.-Y. Choi and O. Seto,
X-ray line signal from decaying axino warm dark matter
,
Phys.Lett.
B735
(2014) 92, [
1403.1782
].
- [43] S. P. Liew, Axino dark matter in light of an anomalous X-ray line , JCAP 1405 (2014) 044, [ 1403.6621 ].
- [44] R. Krall, M. Reece, and T. Roxlo, Effective field theory and keV lines from dark matter , 1403.1240 .
- [45] K. Nakayama, F. Takahashi, and T. T. Yanagida, The 3.5 keV X-ray line signal from decaying moduli with low cutoff scale , 1403.1733 .
- [46] K. Nakayama, F. Takahashi, and T. T. Yanagida, Anomaly-free flavor models for Nambu-Goldstone bosons and the 3.5 keV X-ray line signal , Phys.Lett. B734 (2014) 178-182, [ 1403.7390 ].
- [47] C. Kolda and J. Unwin, X-ray lines from R-parity violating decays of keV sparticles , 1403.5580 .
- [48] N. E. Bomark and L. Roszkowski, The 3.5 keV X-ray line from decaying gravitino dark matter , 1403.6503 .
- [49] S. Demidov and D. Gorbunov, SUSY in the sky or keV signature of sub-GeV gravitino dark matter , 1404.1339 .
- [50] B. Dutta, I. Gogoladze, R. Khalid, and Q. Shafi, 3.5 keV X-ray line and R-Parity Conserving Supersymmetry , 1407.0863 .
- [51] F. S. Queiroz and K. Sinha, The Poker Face of the Majoron Dark Matter Model: LUX to keV Line , Phys.Lett. B735 (2014) 69-74, [ 1404.1400 ].
- [52] E. Dudas, L. Heurtier, and Y. Mambrini, Generating X-ray lines from annihilating dark matter , 1404.1927 .
- [53] K. Babu and R. N. Mohapatra, 7 keV Scalar Dark Matter and the Anomalous Galactic X-ray Spectrum , Phys.Rev. D89 (2014) 115011, [ 1404.2220 ].
- [54] D. P. Finkbeiner and N. Weiner, An X-Ray Line from eXciting Dark Matter , 1402.6671 .
- [55] C. E. Aisati, T. Hambye, and T. Scarna, Can a millicharged dark matter particle emit an observable gamma-ray line? , 1403.1280 .
- [56] M. T. Frandsen, F. Sannino, I. M. Shoemaker, and O. Svendsen, X-ray Lines from Dark Matter: The Good, The Bad, and The Unlikely , JCAP 1405 (2014) 033, [ 1403.1570 ].
- [57] R. Allahverdi, B. Dutta, and Y. Gao, keV Photon Emission from Light Nonthermal Dark Matter , 1403.5717 .
- [58] J. M. Cline, Y. Farzan, Z. Liu, G. D. Moore, and W. Xue, 3.5 keV X-rays as the '21 cm line' of dark atoms, and a link to light sterile neutrinos , Phys.Rev. D89 (2014) 121302, [ 1404.3729 ].
- [59] H. Okada and T. Toma, The 3.55 keV X-ray Line Signal from Excited Dark Matter in Radiative Neutrino Model , 1404.4795 .
- [60] H. M. Lee, Magnetic dark matter for the X-ray line at 3.55 keV , 1404.5446 .
- [61] D. P. Finkbeiner and N. Weiner, Exciting Dark Matter and the INTEGRAL/SPI 511 keV signal , Phys.Rev. D76 (2007) 083519, [ astro-ph/0702587 ].
- [62] M. Pospelov and A. Ritz, The galactic 511 keV line from electroweak scale WIMPs , Phys.Lett. B651 (2007) 208-215, [ hep-ph/0703128 ].
- [63] D. P. Finkbeiner, N. Padmanabhan, and N. Weiner, CMB and 21-cm Signals for Dark Matter with a Long-Lived Excited State , Phys.Rev. D78 (2008) 063530, [ 0805.3531 ].
- [64] N. Arkani-Hamed, D. P. Finkbeiner, T. R. Slatyer, and N. Weiner, A Theory of Dark Matter , Phys.Rev. D79 (2009) 015014, [ 0810.0713 ].
- [65] F. Chen, J. M. Cline, and A. R. Frey, A New twist on excited dark matter: Implications for INTEGRAL, PAMELA/ATIC/PPB-BETS, DAMA Phys.Rev. , D79 (2009) 063530, [ 0901.4327 ].
- [66] D. P. Finkbeiner, T. R. Slatyer, N. Weiner, and I. Yavin, PAMELA, DAMA, INTEGRAL and Signatures of Metastable Excited WIMPs , JCAP 0909 (2009) 037, [ 0903.1037 ].
- [67] B. Batell, M. Pospelov, and A. Ritz, Direct Detection of Multi-component Secluded WIMPs , Phys.Rev. D79 (2009) 115019, [ 0903.3396 ].
- [68] F. Chen, J. M. Cline, and A. R. Frey, Nonabelian dark matter: Models and constraints , Phys.Rev. D80 (2009) 083516, [ 0907.4746 ].
- [69] F. Chen, J. M. Cline, A. Fradette, A. R. Frey, and C. Rabideau, Exciting dark matter in the galactic center , Phys.Rev. D81 (2010) 043523, [ 0911.2222 ].
- [70] J. M. Cline, A. R. Frey, and F. Chen, Metastable dark matter mechanisms for INTEGRAL 511 keV γ rays and DAMA/CoGeNT events , Phys.Rev. D83 (2011) 083511, [ 1008.1784 ].
- [71] A. C. Vincent, P. Martin, and J. M. Cline, Interacting dark matter contribution to the Galactic 511 keV gamma ray emission: constraining the morphology with INTEGRAL/SPI observations , JCAP 1204 (2012) 022, [ 1201.0997 ].
- [72] J. M. Cline and A. R. Frey, Abelian dark matter models for 511 keV gamma rays and direct detection , Annalen Phys. 524 (2012) 579-590, [ 1204.1965 ].
- [73] Y. Bai, M. Su, and Y. Zhao, Dichromatic Dark Matter , 1212.0864 .
- [74] A. R. Frey and N. B. Reid, Cosmic microwave background constraints on dark matter models of the Galactic center 511 keV signal , Phys.Rev. D87 (2013), no. 10 103508, [ 1301.0819 ].
- [75] S. D. Thomas and J. D. Wells, Phenomenology of Massive Vectorlike Doublet Leptons , Phys.Rev.Lett. 81 (1998) 34-37, [ hep-ph/9804359 ].
- [76] S. C. Chapman, R. Ibata, G. Lewis, A. Ferguson, M. Irwin, et. al. , A kinematically selected, metal-poor spheroid in the outskirts of m31 , Astrophys.J. 653 (2006) 255-266, [ astro-ph/0602604 ].
- [77] R. Saglia, M. Fabricius, R. Bender, M. Montalto, C.-H. Lee, et. al. , The old and heavy bulge of M31 I. Kinematics and stellar populations , 0910.5590 .
- [78] L. Danese, G. de Zotti, and G. di Tullio, On velocity dispersions of galaxies in rich clusters , Astronomy and Astrophysics 82 (Feb., 1980) 322-327.
- [79] S. M. Kent and W. L. W. Sargent, The dynamics of rich clusters of galaxies. II - The Perseus cluster , Astrophys.J. 88 (June, 1983) 697-708.
- [80] A. Tamm, E. Tempel, P. Tenjes, O. Tihhonova, and T. Tuvikene, Stellar mass map and dark matter distribution in M31 , 1208.5712 .
- [81] D. H. Weinberg, J. S. Bullock, F. Governato, R. K. de Naray, and A. H. G. Peter, Cold dark matter: controversies on small scales , 1306.0913 .
- [82] M. A. Sanchez-Conde, M. Cannoni, F. Zandanel, M. E. Gomez, and F. Prada, Dark matter searches with Cherenkov telescopes: nearby dwarf galaxies or local galaxy clusters? , JCAP 1112 (2011) 011, [ 1104.3530 ].
- [83] J. Aleksi´ c et al. (MAGIC Collaboration), MAGIC Gamma-ray Telescope Observation of the Perseus Cluster of Galaxies: Implications for Cosmic Rays, Dark Matter, and NGC 1275 , Astrophys.J. 710 (Feb., 2010) 634-647, [ 0909.3267 ].
- [84] G. Steigman, B. Dasgupta, and J. F. Beacom, Precise Relic WIMP Abundance and its Impact on Searches for Dark Matter Annihilation , Phys.Rev. D86 (2012) 023506, [ 1204.3622 ].
- [85] E. Del Nobile, G. B. Gelmini, P. Gondolo, and J.-H. Huh, Direct detection of Light Anapole and Magnetic Dipole DM , JCAP 1406 (2014) 002, [ 1401.4508 ].
- [86] HPS Collaboration, S. Stepanyan, Heavy photon search experiment at JLAB , AIP Conf.Proc. 1563 (2013) 155-158.
- [87] Collaboration for the SuperCDMS Collaboration, A. Anderson, Constraints on Light WIMPs from SuperCDMS , 1405.4210 .
- [88] CRESST Collaboration Collaboration, G. Angloher et. al. , Results on low mass WIMPs using an upgraded CRESST-II detector , 1407.3146 .
- [89] M. Mapelli, A. Ferrara, and E. Pierpaoli, Impact of dark matter decays and annihilations on reionzation , Mon.Not.Roy.Astron.Soc. 369 (2006) 1719-1724, [ astro-ph/0603237 ].
- [90] L. Zhang, X. Chen, M. Kamionkowski, Z.-g. Si, and Z. Zheng, Constraints on radiative dark-matter decay from the cosmic microwave background , Phys.Rev. D76 (2007) 061301, [ 0704.2444 ].
- [91] D. P. Finkbeiner, S. Galli, T. Lin, and T. R. Slatyer, Searching for Dark Matter in the CMB: A Compact Parameterization of Energy Injection from New Physics , Phys.Rev. D85 (2012) 043522, [ 1109.6322 ].
- [92] S. Yeung, M. Chan, and M.-C. Chu, Cosmic Microwave Background constraints of decaying dark matter particle properties , Astrophys.J. 755 (2012) 108, [ 1206.4114 ].
- [93] T. R. Slatyer, Energy Injection And Absorption In The Cosmic Dark Ages , 1211.0283 .
- [94] J. M. Cline and P. Scott, Dark Matter CMB Constraints and Likelihoods for Poor Particle Physicists , JCAP 1303 (2013) 044, [ 1301.5908 ].
- [95] R. Diamanti, L. Lopez-Honorez, O. Mena, S. Palomares-Ruiz, and A. C. Vincent, Constraining Dark Matter Late-Time Energy Injection: Decays and P-Wave Annihilations , JCAP 1402 (2014) 017, [ 1308.2578 ].
- [96] D. E. Morrissey and A. P. Spray, New Limits on Light Hidden Sectors from Fixed-Target Experiments , 1402.4817 .
- [97] J. B. Dent, F. Ferrer, and L. M. Krauss, Constraints on Light Hidden Sector Gauge Bosons from Supernova Cooling , 1201.2683 .
- [98] M. S. Madhavacheril, N. Sehgal, and T. R. Slatyer, Current Dark Matter Annihilation Constraints from CMB and Low-Redshift Data , Phys.Rev. D89 (2014) 103508, [ 1310.3815 ].
- [99] A. Berlin, P. Gratia, D. Hooper, and S. D. McDermott, Hidden Sector Dark Matter Models for the Galactic Center Gamma-Ray Excess , 1405.5204 .
- [100] J. M. Cline, G. Dupuis, Z. Liu, and W. Xue, The windows for kinetically mixed Z'-mediated dark matter and the galactic center gamma ray excess , 1405.7691 .
- [101] T. Lacroix, C. Boehm, and J. Silk, Fitting the Fermi-LAT GeV excess: on the importance of including the propagation of electrons from dark matter , 1403.1987 .
- [102] M. Cirelli, D. Gaggero, G. Giesen, M. Taoso, and A. Urbano, Antiproton constraints on the GeV gamma-ray excess: a comprehensive analysis , 1407.2173 .
- [103] S. Riemer-Sorensen, Questioning a 3.5 keV dark matter emission line , 1405.7943 . | 10.1088/1475-7516/2014/10/013 | [
"James M. Cline",
"Andrew R. Frey"
] | 2014-08-01T16:52:21+00:00 | 2014-08-06T20:43:23+00:00 | [
"hep-ph",
"astro-ph.CO"
] | Nonabelian dark matter models for 3.5 keV X-rays | A recent analysis of XXM-Newton data reveals the possible presence of an
X-ray line at approximately 3.55 keV, which is not readily explained by known
atomic transitions. Numerous models of eV-scale decaying dark matter have been
proposed to explain this signal. Here we explore models of multicomponent
nonabelian dark matter with typical mass ~ 1-10 GeV (higher values being
allowed in some models) and eV-scale splittings that arise naturally from the
breaking of the nonabelian gauge symmetry. Kinetic mixing between the photon
and the hidden sector gauge bosons can occur through a dimension-5 or 6
operator. Radiative decays of the excited states proceed through transition
magnetic moments that appear at one loop. The decaying excited states can
either be primordial or else produced by upscattering of the lighter dark
matter states. These models are significantly constrained by direct dark matter
searches or cosmic microwave background distortions, and are potentially
testable in fixed target experiments that search for hidden photons. We note
that the upscattering mechanism could be distinguished from decays in future
observations if sources with different dark matter velocity dispersions seem to
require different values of the scattering cross section to match the observed
line strengths. |
1408.0234v3 | ## Transfer of Spatial Reference Frame Using Singlet States and Classical Communication
Thomas B. Bahder
Aviation and Missile Research, Development, and Engineering Center,
US Army RDECOM, Redstone Arsenal, AL 35898, U.S.A.
(Dated: August 28, 2014)
A simple protocol is described for transferring spatial direction from Alice to Bob (two spatially separated observers) up to inversion. The two observers are assumed to share quantum singlet states and classical communication. The protocol assumes that Alice and Bob have complete free will (measurement independence) and is based on maximizing the Shannon mutual information between Alice and Bob's measurement outcomes. Repeated use of this protocol for each spatial axis of Alice allows transfer of a complete 3-dimensional reference frame, up to inversion of each of the axes. The technological complexity of this protocol is similar to that needed for BB84 quantum key distribution, and hence is much simpler to implement than recently proposed schemes for transmission of reference frames. A second protocol based on a Bayesian formalism is also presented.
## I. INTRODUCTION
Many technological applications require establishing a local reference frame that is spatially aligned with some predefined global reference frame. An example is a spacecraft that must reach a target position that is specified in a predefined global reference frame. The spacecraft must be able to align its internal reference frame with respect to an external global frame. Historically, mechanical gyroscopes were used, which maintained their spatial orientation with respect to the global frame. More recently, the classical optical Sagnac effect [1-4], which measures rotation rate along an axis, is being exploited in all modern rotation sensors [5] and their applications to inertial navigation systems [6]. Even more recently, much effort has been expended on experiments with quantum Sagnac interferometers, using single-photons [7], using cold atoms [8, 9] and using Bose-Einstein condensates(BEC) [10-12], in efforts to improve the sensitivity to rotation of the classical optical Sagnac effect, and schemes have also been proposed to improve the sensitivity of rotation sensing using multi-photon correlations [13] and using entangled particles, which are expected to have Heisenberg limited precision that scales as 1 /N , where N is the number of particles [14]. Limitations of classical gyroscopes have been discussed in Ref [5] and limits of classical Sagnac effects has been discussed in terms of Shannon mutual information in Ref [15].
In a different thread, transfer of spatial orientation and alignment of reference frames has been of recent interest from the point of view of quantum information [16-18]. Peres and Scudo have considered quantum particles carrying angular momentum to play the role of gyroscopes and exploited such particles to transfer direction, or orientation, in space [18]. Early it was realized that spatial direction, or reference frame orientation, is a special type of quantum information named 'unspeakable quantum information' [19], which is information that can- not be transmitted by sending classical bits of information. Instead, it requires transfer of physical particles, see Ref [20] for a review.
Subsequently, it was realized that a single quantum system, such as a hydrogen atom, can transmit all three axes of a Cartesian coordinate frame [21, 22]. In such schemes, the rotation matrix between the predefined reference frame and the local frame is determined by POVM measurements [23] on the exchanged quantum system. Such schemes are essentially multi-parameter estimation methods, where the parameters are the rotation angles that will align the frames. Such POVM measurements require implementing complicated quantum states and POVM measurements that would require multiple sensors to make simultaneous measurements, which essentially are measurements of multi-correlation functions. In practice, such schemes are very complex to carry out experimentally in a laboratory [19-21, 24-26].
In this Section II of this manuscript, I describe a simple protocol to transfer a spatial reference frame from one observer to another, from Alice to Bob. This protocol makes use of spin s = 1 2 singlet states and hence re-/ quires nothing more than a single Stern-Gerlach apparatus as a spin analyzer, and therefore, can be easily implemented in a laboratory with today's technology. Specifically, this protocol does not require complicated POVM, and hence does not require measurement of multi-particle ( N > 2) correlation functions.
This protocol assumes that Alice and Bob have complete free will (measurement independence) [31-37] to choose directions for their Stern-Gerlach spin analyzers. This protocol can be used to transfer a single spatial direction from Alice to Bob, up to an inversion. This protocol can be used repeatedly to transfer the orientation of three axes in order to define a local reference frame, up to inversion of each of the axes.
In Section III, I describe a Bayesian protocol to transfer a reference frame from Alice to Bob. Both, protocols
described below have the advantage that they are significantly easier to implement with today's technology than those in previous works. The technological complexity of these protocols is similar to that needed for the BB84 quantum key distribution [27, 28], and hence is much simpler to implement than recently proposed schemes for transmission of reference frames [24]. Also, the protocols presented have some similarity to, but are different than, secret communication of a reference frame [25]. In this work, I do not investigate security against eavesdroppers. Also, Heisenberg limited resolution is not the main concern here. Instead, technological simplicity of implementation is the main point.
## II. PROTOCOL BASED ON SHANNON MUTUAL INFORMATION
Consider two observers, Alice and Bob, where Alice has a predetermined spatial direction that she wants to communicate to Bob. Assume that Alice and Bob share pairs of spin s = 1 2 particles, where each pair is entan-/ gled in a spin singlet state
$$\left | \psi _ { o } \right \rangle = \frac { 1 } { \sqrt { 2 } } \left ( \left | -, \mathbf n \right \rangle _ { A } \left | +, \mathbf n \right \rangle _ { B } - \left | +, \mathbf n \right \rangle _ { A } \left | -, \mathbf n \right \rangle _ { B } \right ) \quad ( 1 )$$
where the basis states, |-, n 〉 A , | + , n 〉 A , are eigenstates of Alice's operator, σ A · n A , and |-, n 〉 B , | + , n 〉 B are eigenstates of Bob's operator, σ B · n B . Here, n A and n B are 3-dimensional unit vectors specifying the direction of measurement setting in a Stern-Gerlach type measurement, for Alice and Bob, respectively. For both Alice and Bob, the operators and states satisfy the eigenvalues equations:
$$\sigma \cdot \mathbf n | \pm, \mathbf n \rangle = \pm | \pm, \mathbf n \rangle \quad \quad ( 2 ) \quad \text{sur} \quad \text{tio}.$$
where σ = ( σ , σ x y , σ z ) is the vector of Pauli matrices,
$$\sigma _ { x } = \left ( \begin{smallmatrix} 0 & 1 \\ 1 & 0 \end{smallmatrix} \right ), \, \sigma _ { y } = \left ( \begin{smallmatrix} 0 & - i \\ i & 0 \end{smallmatrix} \right ), \, \sigma _ { z } = \left ( \begin{smallmatrix} 1 & 0 \\ 0 & 1 \end{smallmatrix} \right ) \quad ( 3 )$$
On any bipartite quantum state, | ψ 〉 , Alice and Bob can each make Stern-Gerlach projective measurements. The conditional probability, p a, b ( | x y , ), that Alice obtains measurement outcome a ∈ {-1 +1 , } and Bob obtains measurement outcome b ∈ {-1 +1 , given Alice , } and Bob's measurement settings were x and y , respectively, is computed using the Born rule from the expectation value of the POVM operator [29], ˆ M a | x ⊗ ˆ M b | y , as:
$$p ( a, b | \mathbf x, \mathbf y ) = \langle \psi | \hat { M } _ { a | \mathbf x } \otimes \hat { M } _ { b | \mathbf y } | \psi \rangle \quad \quad ( 4 )$$
where ˆ M a | x = | a, x 〉〈 a, x | and ˆ M b | x = | b, x 〉〈 b, x | are projective operators. The conditional probability, p a, b ( | x y , ), should properly be expressed as p a, b ( | x y , , ψ ), conditional on the state | ψ 〉 , however, I suppress the dependence in the notation.
For the singlet state | ψ o 〉 in Eq. (1), Alice and Bob's measurement outcomes, a and b , are statistically correlated. The correlations are expressed by the conditional probability
$$p ( a, b | { \mathbf x }, { \mathbf y } ) = \frac { 1 } { 4 } \left ( 1 - a b { \mathbf x } \cdot { \mathbf y } \right ) \text{ \quad \ \ } \text{(5)}$$
Alternatively, the correlations between Alice and Bob's measurement outcomes can be expressed in terms of the Shannon mutual information [30] between Alice and Bob's measurement outcomes:
$$I ( A ; B ) = \sum _ { a } \sum _ { b } \ p ( a, b ) \log _ { 2 } \left [ \frac { p ( a, b ) } { p ( a ) p ( b ) } \right ] \quad ( 6 )$$
where the marginal probability for measurement outcomes, p a, b ( ), is obtained from integrating the joint probability, p a, b, ( x y , ), given by
$$p ( a, b, \mathbf x, \mathbf y ) = p ( a, b | \mathbf x, \mathbf y ) \ p ( \mathbf x, \mathbf y ) \quad \quad ( 7 )$$
where p ( x y , ) is the prior probability that Alice and Bob have set their analyzer directions to x and y , respectively. The marginal probability for measurement outcomes is then given by
$$p ( a, b ) = \int d \Omega _ { x } \int d \Omega _ { y } \ p ( a, b | { \mathbf x }, { \mathbf y } ) p ( { \mathbf x }, { \mathbf y } ) \quad ( 8 )$$
where the prior probability is normalized
$$\int d \Omega _ { x } \int d \Omega _ { y } \, p ( { \mathbf x }, { \mathbf y } ) = 1$$
and the integrals are over solid angles associated with unit vectors x and y , respectively.
The marginal probabilities for Alice and Bob's measurement outcomes, p a ( ) and p b ( ), are given by summation over the marginal probability p a, b ( ),
$$p ( a ) & = \sum _ { b } p ( a, b ) \\ p ( b ) & = \sum _ { a } ^ { b } p ( a, b ) \\ \vdots & \text{-overload to one in } \mathbb { E } \alpha \cdots \mathbb { m } ( \mathbb { m } - \mathbb { m } ( \mathbb { m } - \mathbb { m } ( \mathbb { m } - 1 / 2 ) }$$
For the singlet correlations in Eq. (5), p a ( ) = p b ( ) = 1 / 2 for any arbitrary normalized distribution of measurement settings p x, y ( ).
I assume that Alice and Bob have complete free will or measurement independence [31-37] to choose their measurement directions. Specifically, I assume that Alice and Bob's choice of analyzer directions x and y is not correlated, therefore, I take the prior distribution p( x y , ) as a product distribution
$$p ( { \mathbf x }, { \mathbf y } ) = p ( { \mathbf x } ) \, p ( { \mathbf y } ) \, \text{ \quad \ \ } ( 1 1 )$$
Furthermore, I assume that Alice and Bob each have unrestricted measurement freedom to choose specific directions, x 0 and y 0 , respectively. Therefore, I take the prior distribution to be given by Dirac δ -functions:
$$p ( { \mathbf x }, { \mathbf y } ) = \delta ( { \mathbf x } - { \mathbf x } _ { o } ) \, \delta ( { \mathbf y } - { \mathbf y } _ { o } ) \, \quad \quad ( 1 2 )$$
FIG. 1. The Shannon mutual information between Alice and Bob's measurement outcomes, a and b , is plotted as a function of the angle θ between their chosen measurement directions.
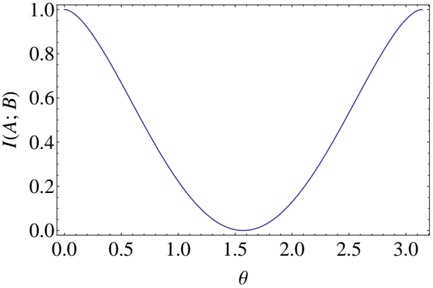
With these choices, the Shannon mutual information becomes
$$& I ( A ; B ) = \frac { 1 } { 2 } \log _ { 2 } \left [ 1 - ( { \mathbf x } _ { o } \cdot { \mathbf y } _ { o } ) ^ { 2 } \right ] - \frac { 1 } { 2 } { \mathbf x } _ { o } \cdot { \mathbf y } _ { o } \log _ { 2 } \left [ \frac { 1 - { \mathbf x } _ { o } \cdot { \mathbf y } _ { o } } { 1 + { \mathbf x } _ { o } \cdot { \mathbf y } _ { o } } \right ] ^ { \text{ información} } } _ { \substack { \text{ignorand} \\ \Imno one one is to control to the minimal information on why do} } ^ { \text{
} } \text{
\end{array} }$$
Since space is isotropic, the mutual information only depends on the relative angle θ between Alice and Bob's measurement settings,
$$\cos \theta = \mathbf x _ { o } \cdot \mathbf y _ { o } \quad \quad \ \ ( 1 4 ) \quad \ w l \\ \ \ \ 1,$$
The mutual information in Eq. (13) is a functional of the cosine of the angle between the vectors, and can be notated as I [ x o · y o ]. Using the polar coordinate representation for Alice and Bob's unit vectors, in Cartesian vector components
$$\mathbf x _ { o } & = ( \sin \theta _ { x } \cos \phi _ { x }, \sin \theta _ { x } \sin \phi _ { x }, \cos \theta _ { x } ) \quad \text{ \quad \sum \nolimits } \\ \mathbf y _ { o } & = ( \sin \theta _ { y } \cos \phi _ { y }, \sin \theta _ { y } \sin \phi _ { y }, \cos \theta _ { y } ) \quad ( 1 5 ) \quad \text{ \quad \text{recol} }$$
the cosine of the relative angle is written as
$$\cos \theta & = \sin \theta _ { x } \cos \phi _ { x } \sin \theta _ { y } \cos \phi _ { y } \\ & \quad + \sin \theta _ { x } \sin \phi _ { x } \sin \theta _ { y } \sin \phi _ { y } + \cos \theta _ { x } \cos \theta _ { y } ( 1 6 ) \quad \begin{array} { c } \text{By a} \\ \text{of me} \\ M \text{ m} \end{array} \end{array}$$
where θ x and φ x are the polar angles for Alice's unit vector, x o , and θ y and φ y are the polar angles for Bob's unit vector, y o . If Alice holds her unit vector x o constant, then Bob can determine Alice's vector y o , or its negative -x o , by searching for a maximum in the mutual information I [ x o · y o ] as a function of the two angles θ y and φ y that describe Bob's vector y o . The mutual information in Eq. (13) is plotted in Figure 1. The mutual information is a maximum when Alice and Bob's chosen vectors, x o and y o , are parallel or anti-parallel, i.e., when x o · y o = ± 1. This degeneracy in mutual information prevents it from being used to distinguish between these two cases. However, in practice we often know in which hemisphere the unknown unit vector points, so this may not be a concern. Alternatively, if we have complete
FIG. 2. The Shannon mutual information between Alice and Bob's measurement outcomes, I [ x o · y o ], is plotted as a function of the polar angles θ y and φ y that describe Bob's unit vector, for the case where Alice's unit vector is given by θ x = 1 5 . and φ x = 2 1. . The two peaks show the degeneracy in mutual information.
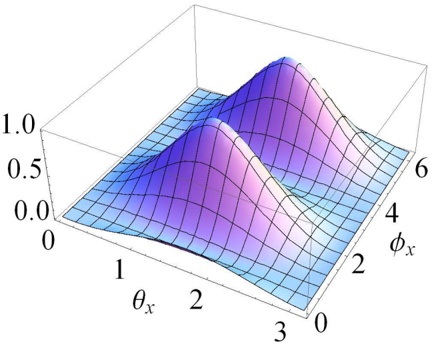
ignorance of the unknown unit vector, we may employ a quantum glove [38, 39], as mentioned below.
Assume that Alice wants to transmit to Bob the orientation of her unit vector x o . Assume that Alice and Bob share N distinguishable copies of spin singlet states, where each spin singlet state is labeled, say by integers, 1 2 , , · · · M . Assume that they agree to make M measurements on these spin singlet states, in order of increasing integer label. Alice chooses a fixed direction in 3-dimensional space, defined by her unit vector x o , that she wishes to transmit to Bob. Bob chooses a trial guess unit vector, y (1) o , to be the orientation of Alice's unit vector x o . Then, Alice and Bob make the M measurements on their shared singlet states. Alice and Bob each record their measurement outcomes, which are either -1 or +1. Alice has a string of M measurement outcomes, where M + A have value +1 and M -M + A have value -1. By a classical channel, Alice sends to Bob the sequence of measurement outcomes. Similarly, Bob has a string of M measurement outcomes, where M + B have value +1 and M -M + B have value -1. Bob can compute an estimate of p a ( ), defined as ˜( p a ), from the data that Alice sent to him by a classical channel:
$$\tilde { p } ( a = + 1 ) = \frac { M _ { A } ^ { + } } { M } \quad \text{ \quad \ \ } ( 1 7 )$$
Similarly Bob can estimate, p a ( = -1), defined as ˜( p a = -1),
$$\tilde { p } ( a = - 1 ) = \frac { M _ { A } ^ { - } } { M } \, \left ( \, \left ( 1 8 \right ) \, \right ) \, \right ) \,.$$
From his own measurement outcomes, Bob can make an estimate of p b ( = +1), defined as ˜( p b = +1),
$$\tilde { p } ( b = + 1 ) = \frac { M _ { B } ^ { + } } { M } \, \text{ \quad \ \ } ( 1 9 )$$
and similarly Bob can estimate, p b ( = -1), defined as ˜( p b = -1),
$$\tilde { p } ( b = - 1 ) = \frac { M _ { b } ^ { - } } { M } \, \quad \ \ \ ( 2 0 ) \, \quad \ \ \ \ \ B a \, \\ \ t i o \, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
For large values of measurements, M , the probabilities ˜( p a ) and ˜( ) are expected to have values close to 1 p b / 2. Furthermore, Bob can estimate the probabilities p a, b ( ) by comparing and counting correlations in his and Alice's measurement outcomes. From the data, Bob can compute the four numbers, M αβ AB , where α, β ∈ {-1 +1 , , } where M ++ ab is the number of times that both Alice and Bob had +1 in their measurements, M -+ AB is the number of times that Alice had -1 and Bob had +1 in their measurements, respectively, M + -AB is the number of times that Alice had +1 and Bob had -1 in their measurements, respectively, and M --AB is the number of times that both Alice and Bob had -1 in their measurements. Bob can then find an estimate, ˜( p a = α, b = β ), for the probabilities p a, b ( ),
$$\tilde { p } ( a = \alpha, b = \beta ) = \frac { M _ { A B } ^ { \alpha \beta } } { M } \quad \quad ( 2 1 ) \quad \text{Ass} _ { \text{tor} }.$$
where M = ∑ ∑ α β M αβ AB = 1.
Using the estimated distributions, ˜( p a ), ˜( p b ), and ˜( p a = α, b = β ), in Eq. (6) in place of the actual distributions, p a ( ), p b ( ), and p a, b ( ), Bob can compute an estimate of the Shannon mutual information, I est ( A B ; ), for the chosen pair of vectors, x o and y o . In this way, Bob can determine an estimate of the mutual information, I est [ x o · y o ], as a functional of his choice of vector y o . Alice and Bob can then repeat the process N times, each time Bob choosing a different direction vector y o . Bob then finds N estimates for the mutual information I est [ x o · y ( ) i o ] , for i = 1 2 , , · · · , N . The vector y ( ) i o giving the largest mutual information is then Bob's best estimate of Alice's vector x o . Of course, as mentioned above, the mutual information is a maximum when x o · y o = +1 and x o · y o = -1, so Bob's best estimate may by a vector that is anti-parallel to Alice's vector. This may not be an issue in practice if Bob has sufficient initial information (up to the hemisphere) about Alice's vector. Alternatively, if Bob is completely ignorant about Alice's vector, then he may employ a quantum glove [38, 39] approach to determine the correct orientation from the two possibilities. Obviously, the whole procedure above may be repeated two more times in order for Bob to determine a reference frame with three axes parallel to Alice's axes.
## III. BAYESIAN APPROACH
The above protocol can be compared to a Bayesian approach, where a probability distribution for the unknown quantity, x o · y o , is determined from the data. In the protocol of the previous section, I assumed that
Alice and Bob had the measurement freedom to choose directions x o and y o , so the prior distribution, p ( x y , ), was given by delta functions, see Eq (12). In the Bayesian approach, I assume that the prior distribution is flat, p ( x y , ) = 1 (4 / π ) 2 , so Alice and Bob have no prior knowledge of x o · y o . Assume that Alice and Bob make N total measurements on singlet states, leading to the data on measurement outcomes, { a , b i i } ≡ { ( a , b 1 1 ) , ( a , b 2 2 ) , · · · , ( a N , b N ) } . Each measurement outcome, ( a , b j j ), is independent in the sequence, so the data can be modeled by the product probability distribution
$$p ( \{ a _ { i }, b _ { i } \} | { \mathbf x }, { \mathbf y } ) = \prod _ { j = 1 } ^ { N } \frac { 1 } { 4 } \left ( 1 - a _ { j } b _ { j } { \mathbf x } \cdot { \mathbf y } \right ) \quad ( 2 2 )$$
Using Bayes' rule, I can write the conditional probability density for Alice and Bob's vectors, x and y , given the data { a , b i i } as:
$$\ t h \quad & p ( \mathbf x, \mathbf y | \{ a _ { i }, b _ { i } \} ) = \frac { p ( \{ a _ { i }, b _ { i } \} | \mathbf x, \mathbf y ) \, p ( \mathbf x, \mathbf y ) } { \int d \Omega _ { x } \int d \Omega _ { y } \, p ( \{ a _ { i }, b _ { i } \} | \mathbf x, \mathbf y ) \, p ( \mathbf x, \mathbf y ) } \\ \alpha _ { 1 } \vee \quad & \text{As minimum some complete information of the anole between vec}$$
Assuming complete ignorance of the angle between vectors x and y and therefore taking p ( x y , ) = 1 (4 / π ) 2 , I find
$$\text{and} \\ \text{dis-} \text{ on}$$
where the function in the denominator is
$$& d ( n _ { + }, n _ { - } ) = \overset { + 1 } { \underset { - 1 } { \int } } d \gamma ( 1 - \gamma ) ^ { n _ { + } } \left ( 1 + \gamma \right ) ^ { n _ { - } } \\ & = \frac { 2 F _ { 1 } ( 1, - n _ { - } ; 2 + n _ { + } ; - 1 ) } { 1 + n _ { + } } + \frac { 2 F _ { 1 } ( 1, - n _ { + } ; 2 + n _ { - } ; - 1 ) } { 1 + n _ { - } }$$
where 2 F 1 ( a, b ; c ; z ) is the hypergeometric function [40] and the two functions
$$\overset { \circ } { \text{esi} } \text{$\circ$}, \quad n _ { + } = n _ { + } ( ( a _ { 1 }, b _ { 1 } ), ( a _ { 2 }, b _ { 2 } ), \cdots, ( a _ { N }, b _ { N } ) ) = \sum _ { k = 1 } ^ { M } \delta _ { a _ { k } b _ { k }, 1 } \\ = + 1 \text{$\circ$} \text{$n_{-} = n_{-} ( ( a _ { 1 }, b _ { 1 } ), ( a _ { 2 }, b _ { 2 } ), \cdots, ( a _ { N }, b _ { N } ) ) = \sum _ { k = 1 } ^ { M } \delta _ { a _ { k } b _ { k }, - 1 } \\ \text{$\text{ation}$} \text{$\text{or}_{no_{-}$} } \text{$count how many times the product $a_{j} b_{i} = +1$ and $a_{j} b_{i}=}$$
count how many times the product a b j j = +1 and a b j j = -1, respectively, and
$$N = n _ { + } + n _ { - } \quad \quad \quad ( 2 7 )$$
The distribution in Eq. (24) can also be written in terms of the cosine of the angle between Alice and Bob's vectors
$$p ( { \mathbf x }, { \mathbf y } | \{ a _ { i }, b _ { i } \} ) = \frac { 2 ^ { N } } { 8 \pi ^ { 2 } } \frac { \left ( \sin \frac { \theta } { 2 } \right ) ^ { 2 n _ { + } } \left ( \cos \frac { \theta } { 2 } \right ) ^ { 2 n _ { - } } } { d ( n _ { + }, n _ { - } ) } \quad ( 2 8 )$$
where cos θ = x · y and 0 ≤ n + , n -≤ N . The distribution p ( x y , |{ a , b i i } ) satisfies the same normalization condition, given by Eq. (9), as the prior distribution p ( x y , ). Figure 3 shows a plot of this probability density. The
FIG. 3. The probability density p ( x y , |{ a , b i i } ), given in Eq.(28), is plotted versus the angle θ between unit vectors x and y , for total number of measurements N = 11 22 44 88. , , , For each N , there are two peaks symmetric about θ = 0. The width of each peak in the plots is successively smaller with increasing number of measurements N = n + + n -. The plots have a constant ratio of n + /n -= 5 6. / The plot have values ( n + , n -) = { (5 , 6) , (10 12) (20 24) , , , , (40 48) , } .
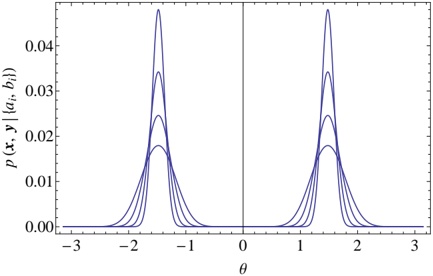
probability density is symmetric in angle θ , so there is an ambiguity in the angle between vectors x and y , similar to the ambiguity in the protocol based on mutual information. As the total number of measurements N increases, the peaks decrease in width. When the ratio of n + /n -changes, the peaks move farther or closer together, always remaining symmetrical about the origin. Note that the peaks are not Gaussian in shape. One must remember that the distribution in Eq. (28) is a normalized distribution when integrated over two solid angles, see Eq. (9), and not when integrated over the angle θ .
Differentiating Eq. (28) with respect to cos θ and solving for the root shows that the peak in the distribution occurs at
$$\cos \theta = \frac { n _ { - } - n _ { + } } { n _ { - } + n _ { + } } \quad \quad \ \ ( 2 9 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\quad \cos \theta = 1$$
Using Bayes' rule, I write the probability density for Bob's unit vector from Eq. (28):
$$p ( { \mathbf x } | \{ a _ { i }, b _ { i } \}, { \mathbf y } ) & = \frac { p ( { \mathbf x }, { \mathbf y } | \{ a _ { i }, b _ { i } \} ) } { p ( { \mathbf y } ) } \quad \begin{pmatrix} \text{can} \\ \text{and} \\ \text{three} \\ \text{of tl} \end{pmatrix}$$
- [1] G. Sagnac, Compt. Rend. 157 , 708 (1913).
- [2] G. Sagnac, Compt. Rend. 157 , 1410 (1913).
- [3] G. Sagnac, J. Phys. Radium 5th Series 4 , 177 (1914).
- [4] E. J. Post, Rev. Mod. Phys. 39 , 475 (1967).
- [5] H. Lefevre, The fiber-optic gyroscope (Artech House, Boston, USA, 1993).
- [6] D. H. Titterton and J. Weston, Strapdown Inertial Navigation Technology (The Insitution of Engineering and
where I have assumed that Alice's prior distribution is flat, p ( y ) = 1 (4 / π ). For a given data set, { a , b i i } , and given vector for Alice, y , the function p ( x |{ a , b i i } , y ) can be solved for two polar angles that define Bob's unit vector x . The distribution for Bob's vector is normalized by
$$\int d \Omega _ { x } \ p ( { \mathbf x } | \{ a _ { i }, b _ { i } \}, { \mathbf y } ) = 1 \quad \quad ( 3 1 )$$
and y , for total number of measurements N = n + + n -= 100, for values ( n + , n -) = (0 , 100) (10 90) (20 80) , , , , · · · , (100 0). , For ( n + , n -) = (0 , 100) there is one peak at θ = 0. For values of n + > 0, the one peak splits into two and moves symmetrically away from θ = 0 with increasing n + . For increasing values of n + , there are two peaks symmetric about θ = 0. The differing size of the peaks is due to the fact that probability density p ( x y , |{ a , b i i } ) is normalized in terms of the double integral over solid angles, given in Eq. (9), and not integration over angle θ .
## IV. SUMMARY
In previous work, it was shown that by exchanging a single quantum system between Alice and Bob, a reference frame can be transmitted from Alice to Bob [21, 22]. This requires implementing a complex POVM. In this paper, I show two simple protocols that can be used to transfer a reference frame (up to inversion of axes) from Alice to Bob. These protocols require that Alice and Bob share entangled singlet states and classical communication. The first protocol assumes that both Alice and Bob have complete free will or measurement independence [31-37] to choose directions for their Stern-Gerlach spin analyzers. This protocol is based on maximizing the Shannon mutual information between Alice and Bob's measurement results. The second protocol is based on a Bayesian approach. In both cases, Bob can determine the spatial direction of Alice's measurement apparatus, up to a spatial inversion. If there is enough prior knowledge on Alice's measurement settings, a unique direction can be transferred. Repeating the protocol for each x , y and z axis of Alice allows transfer to Bob of a complete three dimensional reference frame, up to inversion of each of the axes.
Technology and The American Institute of Aeronautics, London, U.K. and Reston, Virginia, USA, 2004), second edition ed.
- [7] G. Bertocchi, O. Alibart, D. B. Ostrowsky, S. Tanzilli, and P. Baldi, J. Phys. B 39 , 1011 (2006).
- [8] T. L. Gustavson, A. Landragin, and M. A. Kasevich, Class. Quantum Grav. 17 , 2385 (2000).
- [9] M. Gilowski, C. Schubert, T. Wendrich, P. Berg, G. Tackmann, W. Ertmer, and E. M. Rasel, Frequency Control Symposium, 2009 Joint with the 22nd European Frequency and Time forum. IEEE International pp. 1173 - 1175 (2009).
- [10] S. Gupta, K. W. Murch, K. L. Moore, T. P. Purdy, and D. M. Stamper-Kurn, Phys. Rev. Lett. 95 , 143201 (2005).
- [11] Y.-J. Wang, D. Z. Anderson, V. M. Bright, E. A. Cornell, Q. Diot, T. Kishimoto, M. Prentiss, R. A. Saravanan, S. R. Segal, and S. Wu, Phys. Rev. Lett. 94 , 090405 (2005).
- [12] O. I. Tolstikhin, T. Morishita, and S. Watanabe, Phys. Rev. A 72 , 051603(R) (2005).
- [13] A. Kolkiran and G. S. Agarwal, Optics Express 15 , 6798 (2007).
- [14] J. J. Cooper, D. W. Hallwood, and J. A. Dunningham, Phys. Rev. A 81 , 043624 (2010).
- [15] T. B. Bahder (2011), arXiv:1101.4634.
- [16] S. Massar, Phys. Rev. A 62 , 040101 (2000), URL http://link.aps.org/doi/10.1103/PhysRevA.62.040101 .
- [17] S. Massar and S. Popescu, Phys. Rev. Lett. 74 , 1259 (1995), URL http://link.aps.org/doi/10.1103/PhysRevLett.74.1259
.
- [18] A. Peres and P. F. Scudo, Phys. Rev. Lett. 86 , 4160 (2001), URL http://link.aps.org/doi/10.1103/PhysRevLett.86.4160
- [19] A. Peres and P. F. Scudo (2002), ph/0201017.
- . arXiv:quant-
- http://link.aps.org/doi/10.1103/PhysRevLett.98.120501 .
- [26] P. Kolenderski and R. Demkowicz-Dobrzanski, Phys. Rev. A 78 , 052333 (2008), URL http://link.aps.org/doi/10.1103/PhysRevA.78.052333 .
- [27] C. H. Bennett and G. Brassard, in Proceedings of IEEE International Conference on Computers, Systems and Signal Processing, Bangalore (Bangalore, India, 1984), pp. 175-189.
- [28] C. H. Bennett and G. Brassard, IBM Technical Disclosure Bulletin 28 , 3153 (1985).
- [29] S. M. Barnett, Quantum Information (Oxford University Press, Inc., New York, N.Y. USA, 2009).
- [30] T. M. Cover and J. A. Thomas, Elements of Information Theory (J. Wiley & Sons, Inc., Hoboken, New Jersey, 2006), second edition ed.
- [31] J. Kofler, T. Paterek, and i. c. v. Brukner, Phys. Rev. A 73 , 022104 (2006), URL http://link.aps.org/doi/10.1103/PhysRevA.73.022104 .
- [32] M. J. W. Hall, Phys. Rev. Lett. 105 , 250404 (2010), URL http://link.aps.org/doi/10.1103/PhysRevLett.105.250404 .
- [33] M. J. W. Hall, Phys. Rev. A 82 , 062117 (2010), URL http://link.aps.org/doi/10.1103/PhysRevA.82.062117 .
- [34] M. Banik, M. R. Gazi1, S. Das, A. Rai, and S. Kunkri, J. Phys. A: Math. Theor. 45 , 205301 (2012).
- [35] L. P. Thinh, L. Sheridan, and V. Scarani, Phys. Rev. A 87 , 062121 (2013), URL http://link.aps.org/doi/10.1103/PhysRevA.87.062121 .
- [36] J. E. Pope and A. Kay, Phys. Rev. A 88 , 032110 (2013), URL
- [20] S. D. Bartlett, T. Rudolph, and R. W. Spekkens, Rev. Mod. Phys. 79 , 555 (2007), URL http://link.aps.org/doi/10.1103/RevModPhys.79.555 .
http://link.aps.org/doi/10.1103/PhysRevA.88.032110
[37]
- [21] A. Peres and P. F. Scudo, Phys. Rev. Lett. 87 , 167901 (2001), URL http://link.aps.org/doi/10.1103/PhysRevLett.87.167901 .8] [3
- [22] N. H. Lindner, A. Peres, and D. R. Terno, Phys. Rev. A 68 , 042308 (2003), URL http://link.aps.org/doi/10.1103/PhysRevA.68.042308 . [39]
.
D.
E.
Koh,
M.
J.
W. Hall,
Setiawan,
J.
E.
Pope,
- C. Marletto, A. Kay, V. Scarani, and A. Ekert, Phys. Rev. Lett. 109 , 160404 (2012), URL http://link.aps.org/doi/10.1103/PhysRevLett.109.160404 . N. Gisin (2004), arXiv:quant-ph/0408095.
- D. Collins, L. Di´ osi, N. Gisin, S. Massar, and S. Popescu, Phys. Rev. A 72 , 022304 (2005), URL http://link.aps.org/doi/10.1103/PhysRevA.72.022304 .
- [23] C. W. Helstrom, Quantum Detection and Estimation Theory (Academic Press, New York, 1976).
- [24] G. Chiribella, G. M. D'Ariano, P. Perinotti, and M. F. Sacchi, Phys. Rev. Lett. 93 , 180503 (2004), URL http://link.aps.org/doi/10.1103/PhysRevLett.93.180503 .
- [40] M. Abromowitz and I. Stegun, Handbook of Mathematical Functions (Dover Publications, Inc., New York, N.Y. USA, 1972), tenth printing ed.
- [25] G. Chiribella, L. Maccone, and P. Perinotti, Phys. Rev. Lett. 98 , 120501 (2007), URL | null | [
"Thomas B. Bahder"
] | 2014-08-01T16:54:32+00:00 | 2014-08-27T16:21:48+00:00 | [
"quant-ph"
] | Transfer of Spatial Reference Frame Using Singlet States and Classical Communication | A simple protocol is described for transferring spatial direction from Alice
to Bob (two spatially separated observers) up to inversion. The two observers
are assumed to share quantum singlet states and classical communication. The
protocol assumes that Alice and Bob have complete free will (measurement
independence) and is based on maximizing the Shannon mutual information between
Alice and Bob's measurement outcomes. Repeated use of this protocol for each
spatial axis of Alice allows transfer of a complete 3-dimensional reference
frame, up to inversion of each of the axes. The technological complexity of
this protocol is similar to that needed for BB84 quantum key distribution, and
hence is much simpler to implement than recently proposed schemes for
transmission of reference frames. A second protocol based on a Bayesian
formalism is also presented. |
1408.0236v1 | ## A FLARE OBSERVED IN CORONAL, TRANSITION REGION AND HELIUM I 10830 ˚ EMISSIONS A
Zhicheng Zeng 1 2 , , Jiong Qiu , Wenda Cao 3 1 2 , , and Philip G. Judge 4
- 1.Center for Solar-Terrestrial Research, New Jersey Institute of Technology, 323 Martin Luther King Blvd., Newark, NJ 07102, USA
- 2. Big Bear Solar Observatory, 40386 North Shore Lane, Big Bear City, CA 92314, USA
- 3. Department of Physics, Montana State University, Bozeman, MT 59717-3840, USA
- 4. High Altitude Observatory, National Center for Atmospheric Research, Boulder CO 80307-3000, USA
## ABSTRACT
On June 17, 2012, we observed the evolution of a C-class flare associated with the eruption of a filament near a large sunspot in the active region NOAA 11504. We obtained high spatial resolution filtergrams using the 1.6 m New Solar Telescope at the Big Bear Solar Observatory in broad-band TiO at 706 nm (bandpass: 10 ˚ ) and He A I 10830 ˚ narrow-band (bandpass: A 0.5 A, centered 0.25 ˚ ˚ A to the blue). We analyze the spatio-temporal behavior of the He I 10830 A ˚ data, which were obtained over a 90 ′′ × 90 ′′ field of view with a cadence of 10 sec. We also analyze simultaneous data from the Atmospheric Imaging Assembly and Extreme Ultraviolet Variability Experiment instruments on board the Solar Dynamics Observatory spacecraft, and data from Reuven Ramaty High Energy Solar Spectroscopic Imager and GOES spacecrafts. Non-thermal effects are ignored in this analysis. Several quantitative aspects of the data, as well as models derived using the '0D' Enthalpy-Based Thermal Evolution of Loops model (EBTEL: Klimchuk et al. 2008) code, indicate that the triplet states of the 10830 ˚ multiplet are populated by photoionization of chromospheric plasma A followed by radiative recombination. Surprisingly, the He II 304 ˚ line is reaA sonably well matched by standard emission measure calculations, along with the C IV emission which dominates the AIA 1600 ˚ channel during flares. This work A lends support to some of our previous work combining X-ray, EUV and UV data of flares to build models of energy transport from corona to chromosphere.
Subject headings: Sun: chromosphere - Sun: transition region - Sun: corona - Sun: flares - Sun: infrared
## 1. INTRODUCTION
The spectra of helium atoms and ions in the Sun are not yet understood. The EUV resonance lines at He I 584 ˚ and He A II 304 ˚ respectively are anomalously bright, under A
quiescent conditions, by factors of several when compared with many other lines (Jordan 1975, 1980; Zirin 1975; Pietarila & Judge 2004; Judge & Pietarila 2004). Yet, these lines are some of the strongest EUV features in the solar spectrum, and as such they control to a significant degree the state of the earth's thermosphere and ionosphere. Until a clear understanding of the formation of these lines is available, attempts to model the EUV irradiance using models based upon the standard assumption of ionization equilibrium are doomed to fail. In the present study we analyze the evolution of flare emissions in EUV and UV radiation and emission from neutral and ionized helium, to probe the mechanisms leading to the strong helium emission. A broader goal of the present paper is to understand the evolution of the emitting plasmas during flares. We use the narrow-band tunable filtergraph for the New Solar Telescope at the Big Bear Solar Observatory (NST/BBSO; Goode & Cao 2012; Cao et al. 2010b) to capture flare emission in the 10830 ˚ line. A By combining these data with those of the adjacent chromosphere and corona seen at UV and EUV wavelengths with the Atmosphere Imaging Assembly (AIA; Lemen et al. 2012) and Extreme Ultraviolet Variability Experiment (EVE; Woods et al. 2012) instruments on the Solar Dynamic Observatory ( SDO ; Pesnell et al. 2012), we use the observed behavior to constrain the mechanisms by which helium emission can occur during flares.
Ground-based observations of helium lines that follow the evolution of flares are not common, the emission being confined to narrow kernels that are ill-suited to observation using slit spectrographs. Some important work by Tandberg-Hanssen (1967) found that in the weaker flares He I 10830 ˚ shows absorption and only class 2B and larger flares show A He I 10830 ˚ emission. A Later, He I 10830 ˚ emissions were observed in a C9.7 flare with A spectro-polarimetry (Penn & Kuhn 1995). Using an infrared (IR) spectrograph with a spatial resolution of 1 34 and a temporal cadence of 2.8 s, Li et al. (2007) found that only when the . ′′ GOES X-ray flux (which is integrated over the solar disk) reaches a threshold (about C6 class in their study) could they detect emission exceeding the continuum, which spatially corresponded to a bright H α kernel.
Kleint (2012) has analyzed data of photospheric Fe I 6302 ˚ and chromospheric Ca A II 8542 ˚ lines in a C3 class flare. A She finds that emission occurs only above the photosphere, within chromospheric plasma. It should be remembered that the chromosphere spans some 9 pressure scale heights between the quiescent (pre-flare) photosphere and overlying corona. These facts are suggestive that the He I 10830 ˚ emission should also arise from the chroA mospheric layers inside the flare footpoints.
Any process that can excite helium leading to line radiation requires a change in principle quantum number n from the n = 1 ground levels. Thus helium excitation is unusually sensitive to high energy tails in distribution functions of the radiation field and/or plasma electrons and ions . For example, the resonance lines (2 s -2 p ) of C IV have a 5x lower threshold than the resonance line of He II (1 s -2 p ) which form at similar temperatures, under ionization equilibrium conditions. One proposal uses 'high energy photons' (shortward of 228
and 504 ˚ ) to ionize ionized/neutral helium from which recombination populates the A n = 2 3 , levels of helium (Zirin 1975). By solving the standard non-LTE radiation transfer problem in 1D semi-empirical models of the solar atmosphere, it is found that the properties of the He I 10830 ˚ multiplet depend mainly on the density and the thickness of the chromosphere, A as well as on the incoming EUV coronal back-radiation. (Pozhalova 1988; Avrett et al. 1994; Centeno et al. 2008).
Another appeals to the diffusion of helium atoms and ions up steep temperature gradients where the locally higher temperature can excite the n = 2 levels faster than occurs for transitions such as the C IV resonance lines (Jordan 1975). Yet another uses unresolved plasma motion to achieve the same result (Andretta et al. 2000). Flare spectra of EUV helium emission lines, observed with the SO82A (spectroheliograph, or 'overlap-ogram') instrument, were analyzed in terms of a 'burst' model by Laming & Feldman (1992). Laming & Feldman (1992) assumed that, during flares, 'ionizing plasma' conditions exist in the Sun's transition region, permitting the excitation of n = 2 3 levels before ionization occurs. , Pietarila & Judge (2004) showed that all of these mechanisms can be unified into a common picture of excitation, by considering the conditions experienced by the motions of individual atoms and ions of helium (Lagrangian picture).
No matter the precise mechanism at play, helium may be expected to shed light on processes requiring much higher energies ( > 10 eV) than are present throughout the bulk of the chromosphere ( ∼ 0 6 eV). Near simultaneous observations of various photospheric and . chromospheric lines show that the chromosphere is the location of the footpoint emission from at least moderate (C-class) flares (Kleint 2012).
Furthermore, the importance of He I 10830 triplet is being realized from monitoring dynamical activity in the chromosphere and measuring the chromospheric magnetic fields. Trujillo Bueno & Asensio Ramos (2007) have modelled the scattering polarization by interpreting the observed polarization in terms of the Zeeman and Hanle effects.
We proceed by combining high angular resolution observations of the He I 10830 ˚ A multiplet with lower resolution measurements of He II 304 ˚ obtained with SDO. Other A observables from SDO, as well as X-ray emissions from the Reuven Ramaty High Energy Solar Spectroscopic Imager ( RHESSI ; Lin et al. 2002) and GOES will be used to understand the changing conditions in the emitting chromospheric and coronal plasma.
## 2. OBSERVATIONS
With the advent of the 1.6 meter NST at the BBSO, ground based IR observations with high resolution ( λ D ∼ 0 14 in 10830 ˚ are now regularly acquired. . ′′ A The off-axis design of NST reduces stray light since there is no central obscuration, and the site's good seeing conditions
combined with the high order adaptive optics (AO) have enabled us to obtain observations with a spatial resolution close to the diffraction limit of the telescope. On June 17, 2012, we observed a small filament eruption and the associated flaring activity. One footpoint of the filament was embedded in a small pore near a large sunspot in the active region NOAA 11504. High spatial resolution filtergrams were obtained in a broad band (bandpass: 10 ˚ ) A containing well-known TiO lines, and in a narrow band (bandpass: 0.5 ˚ ) in the blue wing A of the He I 10830 ˚ multiplet. A The latter images enabled us to establish the photospheric underpinning of the filament in the chromosphere and corona.
## 2.1. Infrared Data
Our TiO images have a cadence of 30 seconds, with a field-of-view (FOV) of 70 ′′ × 70 . ′′ The image scale is 0 0375/pixel. . ′′ TiO molecular bands are unusually sensitive to the photospheric temperature, they exhibit enhanced intensity contrast in the photosphere due to the stronger absorption of these bands in cool intergranular lanes. The 10830 ˚ Lyot A filter was made by the Nanjing Institute for Astronomical and Optical Technology. This narrow-band filter was tuned to -0.25 ˚ relative to the two blended strongest components A of the multiplet (at 10830.3 A), making the filtergram ˚ more sensitive to upward moving features. A high sensitivity HgCdTe CMOS IR focal plane array camera (Cao et al. 2010a) was employed to acquire the 10830 ˚ data with a cadence of 10 seconds. A The pixel size of the filtergrams is 0 0875, and the FOV is 90 . ′′ ′′ by 90 . ′′ With the aid of high order AO (Cao et al. 2010b) and speckle reconstruction post-processing (KISIP speckle reconstruction code, W¨ oger & von der L¨he 2007), u images with diffraction limited resolution at different bands were achieved. All NST data used in this paper are speckle reconstructed. More technical detail in data acquisition and reduction can be found in Cao et al. (2010c).
With the NST we observed the active region continuously for a few hours in good seeing conditions, providing a unique opportunity to follow the entire evolution of the flare with high spatial and temporal resolutions. A movie (NST flare 20120617.mpg) is available in on-line journal. Observations started before 17:00 UT, well before the flaring activity. Figure 1 is a snapshot of the 10830 ˚ filtergram during the maximum of the flare, with the bandpass A shown in the lower right panel. Since the bandpass is tuned to the blue wing of 10830 ˚ , A the filtergram captures some underlying continuum radiation, with photospheric features including sunspots, pores, and granules clearly visible in the image. The filament appears as a dark feature lying between two large sunspots. During the flare, impulsive brightenings in this bandpass are observed at a few locations, marked as patches 0 to 8 in the figure; these patches will be described as P0 - P8 in the following analysis.
## 2.2. Supporting Data from SDO and RHESSI
We also take advantage of the SDO's unique continuous coverage of the Sun. We analyze UV and EUV images observed by AIA, and full disk continuum images and line-of-sight (LOS) magnetograms from the Helioseismic and Magnetic Imager (HMI; Schou et al. 2012). AIA takes full-disk images in 7 EUV bands with a cadence of 12 s and spatial scale of 0 6. . ′′ These EUV telescopes observe emission from coronal plasmas at temperatures from 1 to 10 MK. Apart from these EUV channels, AIA also takes full-disk images at the UV 1600 ˚ A broadband at 24 s cadence. During flares, the C IV doublet is significantly enhanced to dominate emission in this band (Qiu et al. 2012), also confirmed in the present analysis. The C IV line emission is produced by plasmas near 100,000 K, typical of the mid transition region.
Spatial co-alignment among these data is done by first co-aligning the HMI continuum images with the NST TiO data. Using the granular patterns and sunspots, it is straightforward to precisely align the HMI/SDO continuum images with the NST TiO images. Then we co-align the TiO data with the 10830 ˚ filtergrams using the sunspots and bright granules. A AIA and HMI observations are co-aligned with each other using satellite pointing information, and the HMI continuum images serve as the intermediary for co-alignment between the AIA images and the NST images. The accuracy of the co-alignment is better than 0 5. . ′′
Finally, X-ray emission of the flare are also observed by GOES and RHESSI. Using the standard RHESSI software package, we obtain RHESSI X-ray light curves and images with pixel size of 2.26 ′′ by 2.26 ′′ (subcollimators 1, 3, 4, 5, 6, 8 are used). The RHESSI data are coaligned with the SDO data according to the coordinates provided in the FITS header. Light curves and images of the flare in the X-ray, EUV, UV, and IR wavelengths are illustrated in Figure 2 and Figure 3 respectively, derived as discussed below.
## 2.3. Overview of the Flare
In the top panel of Figure 2, X-ray light curves in several RHESSI channels and in GOES 1-8 ˚ channel are plotted . A 1 Colored curves in panel (b) of Figure 2 show normalized light curves in several wavelengths: the IR 10830 ˚ from NST, EUV bands at 94 ˚ and 171 ˚ from A A A AIA/SDO, and UV band at 1600 ˚ also from AIA/SDO. In panel (b), the 1600 ˚ light curve A A (green) is created from total counts of selected footpoint pixels that exhibit strong emission, or more specifically those pixels with a count rate greater than five times the median count rate ( I q = 71 DNs -1 ) of the quiescent region. Since the AIA data and NST data have been well co-aligned, the light curve of He I 10830 ˚ (black) is made from the counterpart of the A footpoint pixels in 1600 ˚ . The light curves in EUV 94 ˚ (blue) and 171 ˚ (red) are made A A A
1 Note that 10 keV corresponds to a photon wavelength of 1 ˚ . A
from pixels of the entire FOV shown in Figure 3. Each curve is subtracted by its minimum values and then divided by the residual maximum. As seen in Figure 2, flaring occurs in two phases, with the SXR emission in GOES 1-8 ˚ peaking at 17:28 UT and 17:39 UT, A respectively. Each phase is usually characterized by a rapid rise of the emission, followed by a more gradual decay. Remarkably, we find that emission in the IR and UV bands peaks first, along with a peak in the 171 ˚ channel, immediately followed by SXR emissions by A relatively high temperature plasmas, and then by lower temperature EUV emissions in 94 ˚ A (6 MK) and 171 ˚ (1 MK). For the EUV 171 ˚ light curve, the first two peaks coincide with A A the UV and IR peaks while the following ones correspond to the cooling of the post-flare coronal loops.
Figure 3 shows the evolving morphology of flaring plasma observed in several wavelengths. Before the flare onset, twisting of the dark filament can be seen in the 10830 ˚ A filtergrams (see panel a1 of Figure 3 and the on-line movie (NST flare 20120617.mpg)). Before the flare is seen in X-ray, the filament is dark in 10830 ˚ filtergram as shown in panel a1 A and there are no obvious signals in EUV images. However, in UV 1600 ˚ images (b1), there A are brightenings right in the middle of the filament, indicating the ongoing activity at upper chromosphere prior to the filament eruption and flare. These small events account for a minor emission peak at 17:22 UT before the flare as shown in Figure 2. Next, the filament brightening and eruption (second column in Figure 3) are coincident in time with the first major abrupt rise in the light curves. Ten minutes later, a second abrupt brightening phase (third column in Figure 3) was observed as the emission of the footpoint dramatically increases. The intensity of 10830 ˚ is significantly enhanced by more than 50% of pre-flare A state.
In the top panels of Figure 3, contours of the X-ray images by RHESSI are overlaid on the 10830 ˚ images. Strong soft X-ray (SXR) emission at photon energies from 6-15 keV (green A contours) is observed during both phases of the flare, from an extended coronal emission source lying above the foot-point patches significantly larger than the SXR RHESSI angular resolution ( ∼ 2 -3 ), also shown in Figure 3(a2-a3). ′′ There is also a small amount of X-ray emission above 25 keV, most likely the hard X-ray (HXR) emission (red contours), which is present for only a short time. So these weak signals above 25 keV suggest that the nonthermal effects are not significant in this event (Fletcher et al. 2011, section 2.4). The SXR emissions below 25 keV and in GOES 1-8 ˚ channel are usually produced by flare plasmas A heated to over 10 MK (Hannah et al. 2008).
During these two major phases of the flare, emissions in IR, UV, and EUV bands occur in the localized patches, P0-P8, which are connected by coronal loops brightened later on in 131 ˚ (e4) and 171 ˚ (d4). Therefore, these IR and UV bright kernels most likely correspond A A to footpoints of flare loops. The counterpart in the corona is shown in both 171 ˚ and 131 ˚ A A images (d1-e4), reflecting the loop structures with million degree plasma. EUV flux observed by AIA are saturated in 171 ˚ and 131 ˚ , especially during the first impulsive phase. A A In
the first impulsive phase, the saturations are in the middle of the filament which is shown in the column a2-e2 of Figure 3, and they coincide with both the RHESSI SXR contour and chromospheric brightenings in 1600 ˚ and 10830 ˚ . Then during the second peak, the A A footpoints become bright. These observations strongly suggest that the filament eruption starts from chromosphere (early activity in AIA 1600 ˚ inside filament) and when magnetic A reconnection happens, the released energy heats the plasma to the coronal temperature (SXR and EUV brightening in the first impulsive phase). Later, magnetic reconnection takes place in the disturbed corona, giving rise to more energy release and formation of new coronal loops as well as brightened foot-points; this generates the second phase of the flare. (The whole process is also seen in the on-line movie.).
Figure 4 shows the TiO images during the flare as well as one HMI photospheric magnetogram, showing only LOS components of the magnetic field. Blue contours superimposed in these images are IR foot-point patches brightened during the flare. The TiO images exhibit lots of small-scale bright points, but barely any enhanced flare emission at the locations of the bright IR patches. Therefore, we can assert that the foot-point brightening observed in the He 10830 ˚ band is not produced in the photosphere A . The panel (c) in Figure 4 shows one (typical) HMI LOS magnetogram. The blue and red contours are footpoint patches of the 10830 ˚ filtergram and coronal loop of the AIA 131 ˚ image, respectively. A A Further, the IR footpoint patches are located in penumbral magnetic fields with different polarity and most of them are seen to be connected by coronal loops. Patches P0, P1, P2, and P5 are located in magnetic fields of negative polarity, while P3, P4, P6, P7, and P8 are located in positive polarities. The loops in the AIA 131 ˚ seem to connect P0-P2 to P3-P4, and P5 appears to A be connected with P6. These loops are significantly inclined relative to the magnetic polarity inversion line.
## 2.4. Light Curves of Flare Foot-point Emission
In Figure 5, we plot light curves of P0, P4, and P6 in 10830 ˚ , AIA 1600 ˚ and 304 ˚ , A A A these being typical examples. The GOES 1-8 ˚ light curve is not plotted since it is not A spatially resolved. The patches are rectangular areas containing a combined 906 AIA pixels (each with scale of 0 6) . ′′ that are centered over the enhanced 10830 ˚ regions brightened A during the flare (see Fig. 1). In Figure 5 we have subtracted minimum values for each curve and then divided the curves by their residual maximum.
In this paper, the IR filtergram contains both line wing and part of the line center of the He I 10830 ˚ and the line profile before the flare is in absorption. A Approximations at the footpoint are made as follows:
- 1. Before the flare, the clear view of the penumbra indicates the absorption is optically thin and only a small fraction of continuum flux is absorbed. Hence the observed flux
before flare may be approximated as continuum.
- 2. The flare in this paper is not a white-light flare so the quiescent (pre-flare) continuum is the same as continuum during flare, which means that the emission enhancement is due to He I 10830 ˚ ; A
- 3. Therefore we assume that the flare enhancement with respect to pre-flare flux is approximately the same as enhancement over the quiescent continuum.
Figure 6 shows the histogram of the peak intensity, normalized to the pre-flare emission, of these 906 pixels in different wavelengths. The UV 1600 ˚ and EUV 304 ˚ flare emissions A A have increased by up to two orders of magnitude, and the IR intensity has grown by a factor of 1.2 to 2.5 over the pre-flare emission. It is noteworthy that, previous flare observations in the He I 10830 ˚ bandpass have shown IR darkening (Harvey & Recely 1984) and only when A the GOES X-ray flux reaches a threshold could they detect emission (Tandberg-Hanssen 1967; Li et al. 2007). However, in this flare, almost all flaring pixels exhibit IR emission even during the first phase when GOES 1-8 ˚ emission is only at C1 level. A
As shown in Figure 5, the emissions from P0, P4, P6 in 10830 ˚ , 1600 ˚ and 304 ˚ A A A all rise rapidly on the same timescale, and peak at the same time; they then decay more gradually but with quite different timescales: the 304 ˚ emission decays slightly slower than A the 1600 ˚ emission, and the 10830 ˚ IR intensity decays most slowly. A A Similar behavior is seen in individual pixels but with lower signal to noise ratios. The statistics of rise and decay timescales of all pixels are plotted in Figure 7. For each pixel, the maximum of light curve is recorded. Then the light curve from the onset of the flare to the time of maximum is fitted using a half Gaussian function. The rising timescale is calculated as half of the full width at half maximum of the fitted Gaussian function. Then the curve from maximum is fitted to an e-slope. The decay timescale is calculated from the time of its maximum to the time when it decays to 1 e of its maximum.
The flux of most pixels rise impulsively within one minute. The UV 1600 ˚ flux typically A decays within a few minutes while the decay timescale of the 304 ˚ flux is around 10 minutes. A The flux in 10830 ˚ decays on longer timescales of a few tens of minutes. A
## 3. ANALYSIS
## 3.1. Summary of Critical Observations
There are several critical aspects to IR 10830 ˚ narrow-band and other data (refer to A Figures 1-7) which we highlight and will draw upon below:
- 1. The 10830 ˚ emission is confined to patches that are mophologically a mixture of bright A
fibril-like structures (P1, P5, P7), and bright amorphous patches (P0, P2, P3, P6, P8) (Figure 1).
- 2. These patches lie mostly over penumbral regions, on large scales they are associated with bright UV/EUV emission (Figure 4).
- 3. The 10830 ˚ emission often has sharp edges (e.g. A P0), close to the resolution limit of the observations (0 14) (Figure 1). . ′′
- 4. The SXR emission observed below 15 keV by RHESSI is from a much extended source: in contrast to the sharp edges in 10830 ˚ (Figure 3). A
- 5. The simultaneous steep rise at 304, 1600 and 10830 ˚ footpoint emissions suggests that A the IR and UV/EUV emissions are related during this phase (Figure 5).
- 6. The 10830 ˚ emission decays an order of magnitude more slowly than other UV/EUV A emission, but has some similarity to the RHESSI and GOES decay curves (Figure 2).
## 3.2. Physical picture
In previous work Qiu et al. (2012) have found a simple physical picture which can account for the UV and EUV data of flares that are qualitatively similar to the new observations presented here. Some process to be identified transfers energy rapidly out of the corona. When this energy is directed towards the lower solar atmosphere then this atmosphere responds by trying to deal with the excess energy through ionization, radiation losses, fluid motions and perhaps other modes (MHD waves, particle acceleration).
Evolution of plasma at the feet of flare loops begins with a highly dynamic response to impulsive heating. In work by Qiu et al. (2012), the 'impulsive rise' 2 of the UV 1600 ˚ light A curves at the flare foot-points is used to estimate empirical heating rates through a '0D' model. The method, using only two free parameters, has been applied to analyze and model heating of thousands of flare loops in a few flares with agreeable comparison between synthetic and observed X-ray and EUV spectra and light curves (Qiu et al. 2012; Liu et al. 2013; Li et al. 2014). Using UV signatures to build heating rates, these studies not only resolve heating in individual loops but are not confined to flares that have significant thick-target HXRemissions. In the present paper, we make two further simplified assumptions based upon previous work (Qiu et al. 2012) and upon the weakness of HXR emissions: (1) the 1600 ˚ A emission during the flare is dominated by C IV emission and not the underlying continuum; (2) there are no significant non-thermal particles impacting the solar chromosphere from above.
2 Not to be confused with the 'impulsive' phase of many flares seen at radio and gamma ray wavelengths.
The thermal conduction from the site of energy deposition will generate a downward propagating shock front, which most likely produces the impulsive spike in the UV and EUV light curves (Fisher 1989). On the other hand, the cooling of the overlying corona governs the gradual decay. Such two phase evolution in the UV emissions has been reported by Hawley et al. (2003) in stellar flare observations, and they found that during the cooling phase, a few lines including C IV can be used as a transition region pressure gauge monitoring the coronal plasma evolution in overlying flare loops. The differential emission measure (DEM) throughout the transition region is proportional to the equilibrium coronal pressure since the entire loop is in approximate hydrostatic balance in the cooling phase (Fisher 1987; Griffiths et al. 1998; Hawley & Fisher 1992). In this 'pressure-gauge' approximation, the decay phase of UV/EUV emission in solar flares (Liu et al. 2013; Qiu et al. 2013) also compares favorably with the observations. Here, we adopt this model to compute decay-phase flare foot-point emission in EUV He II 304 ˚, and UV C A IV bands. The IR He I 10830 ˚ A emission is then studied in the context of this model. Below, we model plasma evolution in hundreds of flare loops observed in this flare to find the coronal/transition region structure overlying the IR patches. We then estimate He I 10830 ˚ enhancement due to different A physical processes in these patches to compare with observations.
## 3.3. Calculations with EBTEL
For loops during the decay phase in approximate hydrostatic balance, the DEM throughout the transition region is proportional to the equilibrium coronal pressure and the optically thin radiative losses are balanced by the downward conductive heat from the cooling coronal loops. With the plasma flow neglected, the DEM along the leg of the flux tube is computed analytically (Fisher 1987; Griffiths et al. 1998; Hawley & Fisher 1992) as
$$\xi _ { s e } ( T ) = \overline { P } \sqrt { \frac { \kappa _ { 0 } } { 8 k _ { B } ^ { 2 } } } T ^ { \frac { 1 } { 2 } } Q ^ { - \frac { 1 } { 2 } } ( T )$$
where
$$Q ( T ) = \underset { T _ { 0 } } { \overset { T } { \int } } T ^ { \prime \frac { 1 } { 2 } } \Lambda ( T ^ { \prime } ) d T ^ { \prime }$$
and Λ( T ) is the optically thin radiative loss function. κ 0 is the thermal conductivity coefficient and k B is Boltzmann constant. Expressing the temperature-dependent scaling constant as g se ( T ), the transition region DEM can be computed as ξ se ( T ) = g se ( T P ) , which is directly proportional to the mean pressure P calculated using the zero-dimensional loop heating model, the enthalpy-based thermal evolution of loops model (EBTEL; Klimchuk et al. 2008;
Cargill et al. 2012a,b). Qiu et al. (2013) and Liu et al. (2013) have already confirmed that this pressure-gauge approximation can re-produce observed gradual decay reasonably well.
We have used the spatially resolved AIA 1600 ˚ light curves to determine the empirical A heating rates of the observed flare loops. With these heating rates, a zero-dimensional EBTEL model is used to compute mean temperature and density of plasmas in these flare loops. EBTEL solves an energy equation and a mass equation, taking into account an ad-hoc heating term which we infer from foot-point UV light curve, coronal radiative loss, the loss through the transition region which in this study is scaled to the pressure of the coronal plasma, and thermal conduction and enthalpy flow between the corona and transition region. The synthetic coronal radiation in SXR and EUV bands are then computed and compared with observations by GOES and AIA to verify the very few parameters in the method.
Results of EBTEL calculations for the present datasets are shown in Figure 8. Using the 906 UV brightened pixels seen with SDO we have modeled 906 half loops anchored to these pixels. The lengths of these half loops are estimated from the EUV images, which range from 16 to 41 Mm. The heating rates of these loops are assumed to be proportional to the rise of the UV light curve at the foot-point pixel with a constant scaling factor which can be adjusted by best matching synthetic and observed EUV light curves. For this flare, the inferred heating rate in the 906 half loops ranges from 1 × 10 8 to 7.5 × 10 11 ergs s -1 cm -2 , and the total heating rate is plotted as dashed line in the top left panel of Figure 8 together with the UV total counts light curve. By assumption we ignore beam heating scenarios and assume that (non-radiative) magnetic heating primarily occurs in the corona. The other panels in the figure show synthetic SXR and EUV light curves in comparison with those observed by GOES 1-8 ˚ and 6 EUV bandpasses of AIA. Light curves in these passbands reflect evolution A of coronal plasmas that are heated to over 10 MK and then gradually cool down to 1-2 MK. As shown in Figure 8, the synthetic light curves reflect the cooling of the flare, with high temperature emissions (131 and 94 bands) peaking earlier than low-temperature emissions (211, 193, and 171 bands). The synthetic and observed light curves coincide with each other quite well: they exhibit very similar time profiles and the magnitude of the total counts are comparable by within a factor of 2. The good comparison indicates that the method is able to reproduce mean properties of the corona during the flare.
In these models, the plasma pressure at the coronal base increases from a pre-flare state between 0.1 and 1 dyne cm -2 up to pressures of several times 10 1 -2 dyne cm -2 during the flare. Accordingly, the emission from lines such as C IV increases by similar factors. The underlying UV continuum near 1600 ˚ , however, forms near pressures closer to 1 A -2 × 10 3 dyne cm -2 under quiescent conditions (Vernazza et al. 1981), over an order of magnitude higher. Thus, we would expect downward propagating flare energy to be attenuated before it can reach such high pressures, associated with the much deeper 'temperature minimum' region below the chromosphere.
Our observations show that the brightest IR 10830, UV 1600, and EUV 304 emission are generated in the lower-atmosphere at the footpoints of flare loops. Light curves in these wavelengths exhibit an impulsive rise, followed by a gradual decay. Using the transition region DEMs computed as above, we find, as a post-facto confirmation of our initial assumption, that the UV 1600 ˚ band is indeed dominated by the C A IV line. The emissivity /epsilon1 ( T ) (radiated power in erg cm -3 s -1 divided by N ) of the optically thin C 2 e IV multiplet is derived from CHIANTI 7.0 with ionization equilibrium (Dere et al. 1997; Landi et al. 2012). Using the DEM, the total C IV photon flux is computed in units of photons cm -1 s -1 sr -1 and by convolving with the AIA instrument response function, the flux is converted to observed count rate in units of DN s -1 . The right panel of Figure 9 shows the synthetic light curve of the C IV total counts summed up from foot-points of all flare loops, in comparison with the observed UV 1600 ˚ total counts. A It is seen that, during the decay phase, the synthetic light curve agrees very well with the observed light curve in both the evolution timescale and the magnitude. However, the impulsive phases are significantly underestimated by the model calculations, because the equilibrium approximation is not adequate during the rise (heating) phase of the flare.
The He II 304 ˚ line is usually formed in mid transition region temperature plasma (in A equilibrium conditions this would be close to 80,000 K). To understand the observed He II emission at the flare foot-points, we also calculate the contribution function of the He II line under conditions of statistical equilibrium, and convolved it with the transition region DEM and the AIA instrument's response function in this band. In Figure 9, the left panel shows the synthetic He II total counts light curve, which evolve along with the observed light curve with comparable amount of emission during the decay phase.
The successful comparison between the synthetic and observed C IV light curve during the decay phase confirms that the pressure-gauge approach reasonably describes the transition region during this phase. The similarity of the observed and computed light curves of He II 304 ˚ emission is remarkable, given the earlier work, A particularly that of Laming & Feldman (1992), cited in the introduction.
## 3.4. He I 10830 ˚ A
Our observations indicate that the He I 10830 ˚ line is formed somewhere in the stratA ified chromosphere. During the flare, this layer must be significantly heated to enhance the He I line against the continuum background. However, the chromosphere is an excellent thermostat, having enormous sinks of energy associated with latent heat of ionization of hydrogen and radiation losses. But if local heating exceeds a critical limit, then a thermal runaway to coronal temperatures is expected to occur, since once hydrogen is all ionized, a major sink of energy is lost (Judge 2010). Dumping of heat into the chromosphere bifurcates the temperature distribution such that either the temperature is below approx 8000 K or it
moves immediately, with a narrow transition region, to coronal temperatures. Since He I is rapidly ionized at coronal temperatures, we must look to the underlying chromosphere for the source of the 10830 photons during the flare.
Here we consider two pictures: the first is that EUV irradiation of the chromosphere from above ionized the neutral helium atoms. Then the recombination of the electrons and He II generates populations of the upper levels (1 s 2 p 3 P o 0 1 2 , , ) of the multiplet (Zirin 1975). The second is the 'burst model' advocated by Laming & Feldman (1992).
The observed enhancements of 10830 ˚ range from 1.2 to 2.5 times the pre-flare emission A (Figure 6): the median value is close to 1.3, which we now adopt. As mentioned above, most flare footpoints locate in the penumbra. Before the flare, the clear view of the sunspot penumbra indicates the shallow absorption in 10830 ˚ . Therefore, most flux comes from the A photosphere in these area. So we approximate emission during this stage by the continuum emission. The total emission is estimated in physical units from 10830 ˚ as follows. A The estimated continuum formation temperature at 10830 ˚ is around 6000 K at disk center A as shown by Maltby et al. (1986). 5600 K is adopted since the flare footpoints locate in penumbra. Assuming that the continuum is generated by black-body radiation, we can write the excess intensity as
$$I _ { e x } \approx ( 1. 3 - 1. 0 ) \times B _ { \lambda } ( 5 6 0 0 K ) \times \Delta \quad \text{erg cm} ^ { - 2 } \text{sr} ^ { - 1 } \text{s} ^ { - 1 },$$
Where ∆ is an (unknown) width of the excess emission line profile in wavelength units. Let ∆ = fw where f is the ratio of the radiation emitted by all 10830 A transitions divided ˚ by the fraction that we observe, which covers a width w = 0 5 ˚ . Values of 1 . A ≤ f < 10 seem reasonable values, we will use f = 2 since our bandpass cover almost half of the red component of 10830 ˚ spectrum. We have, using a photospheric radiation temperature near A 5600 K = 8 × 10 5 erg cm -2 sr -1 ˚ A -1 s -1 , and w = 0 5 ˚ . A
$$I _ { e x } \approx \left ( 0. 3 \right ) 2 \left ( 0. 5 \right ) 8 \times 1 0 ^ { 5 } \quad \text{erg cm} ^ { - 2 } \text{sr} ^ { - 1 } s ^ { - 1 },$$
or a total 10830 ˚ energy flux out of the optically thin slab of A
$$F _ { e x } = 2 \pi I _ { e x } \approx 1. 5 \times 1 0 ^ { 6 } \ \text{erg cm} ^ { - 2 } s ^ { - 1 }.$$
Since the energy of one 10830 photon is 1 83 . × 10 -12 erg, the photon flux is then
$$N _ { e x } \approx 0. 8 \times 1 0 ^ { 1 8 } \ \ \ p h \ c m ^ { - 2 } s ^ { - 1 }.$$
## 3.4.1. Photoionization-recombination picture
If the typical 10830 ˚ enhancements are produced via the photoionization-recombination A mechanism, the required energy flux of ionizing EUV photons is simply determined by computing the photoionization rate and the number of photons emitted in 10830 ˚ per ionization A
(e.g., Zirin 1975). Unlike Zirin's work, we need not consider photoexcitation by the photosphere since the photospheric radiation cannot generate emission above its own continuum. Using the HAOS-DIPER package (Judge 2007), we find that between 32 and 62% of all recombinations lead to 10830 emission, depending on whether the 504 ˚ continuum is assumed A optically thin or thick respectively. We adopt a value of 50% for optical depths close to unity where the bulk of the helium material will be photoionized. EUV photons at wavelengths below 504 ˚ are needed for photoionization of He A I . We can estimate the photon energy flux at 500 ˚ , which is the minimum required flux to generate the observed enhancement in the A photoionization-recombination picture, as
$$N _ { E U V } = N _ { e x } / 0. 5 = 1. 6 \times 1 0 ^ { 1 8 } \quad \text{ph cm} ^ { - 2 } s ^ { - 1 },$$
for an energy flux of
$$F _ { E U V } \approx 6 \times 1 0 ^ { 7 } \ \text{erg cm} ^ { - 2 } s ^ { - 1 }.$$
When distributed over an area of 906 AIA pixels, we find a total luminosity of the flare at wavelengths close to and below 504 ˚ of 1 1 A . × 10 26 erg s -1 . If distributed across the 9 patches, the average luminosity per patch is 1 2 . × 10 25 erg s -1 .
The solid lines in Figure 10 shows the estimated photon energy flux from the observed IR enhancement in each of the 8 patches. P5 is not plotted since its emission is blended with the absorption from the nearby filament. With the transition region DEM computed for every pixel, we estimate the total optically-thin radiation energy by transition region plasmas of up to 2 MK, as plotted in dotted lines in Figure 10. It is seen that, in most of these patches, the estimated radiation energy is comparable with the required photon energy to generate the enhanced IR emission during the decay phase for as long as observed. We conclude that photoionization by EUV photons in the overlying transition region is a viable mechanism for the prolonged He I emission at the flare foot-points.
An independent EUV photon energy flux produced in this flare can be estimated from observations by the Extreme Ultraviolet Variability Experiment (EVE; Woods et al. 2012) on SDO. Two EVE spectrographs measure the whole-Sun solar extreme ultraviolet (EUV) radiation spectrum from 10-1050 ˚ with a resolution of approximately 1 ˚ and a cadence A A of 10 seconds. During this flare the 'A' spectrograph on EVE acquired data in the range 60-380 ˚ , no data above 380 ˚ were obtained with the 'B' spectrograph. The net EUV flux A A from the flare, obtained by subtraction of pre-flare emission, is shown in Figure 11. The solid line is the total flux observed by EVE from 60-380 ˚ while the dotted line is the calculated A total optically-thin radiation by plasmas of up to 2 MK. The observed and measured fluxes are within ± a factor of three. Given the crude nature of the calculations and complex geometry of the flaring plasmas at various wavelengths, these measurements provide reassurance that the photon fluxes in the model are broadly compatible with the data.
Laming & Feldman (1992) estimate 2 -8 × 10 16 photons cm -2 s -1 sr -1 for the EUV ionizing intensity in the He I and He II continua. The number directed towards the chromo-
sphere is 2 π larger, or ∼ 3 × 10 17 photons cm -2 s -1 . This is a factor of 7 smaller than our estimate. This difference may be real, reflecting different flares, or it may reflect differences in the resolution of instruments used. Our data has a far higher angular resolution, necessarily leading to higher intensities as smaller flare kernels are better resolved.
## 3.4.2. Burst picture
The essence of this picture is that a burst of heating is assumed to occur in cool (chromospheric) plasma on time scales small compared with the time taken to ionize a given ion. During the burst the electron temperature is raised above the quiescent state, the hotter electrons lead to line emission before the ions involved become ionized. Heuristic arguments for this model have been given for EUV/UV helium lines by Laming & Feldman (1992). It has been placed on firmer theoretical grounds by Judge (2005). In the work of Laming and Feldman, burst temperatures near 1 8 . × 10 5 K were needed to reproduce spectra of He II which are consistent with spectra of He I .
This picture seems unlikely to be able to explain the 10830 ˚ line's behavior reported A here for the following reasons. The He I ionization times for pre-flare electron densities of around 5 × 10 10 cm -3 (the value in the pre-flare upper chromosphere from Vernazza et al. 1981) are about 100, 2 and 0.05 s for burst electron temperatures of 2 3 . × 10 , 4 6 4 . × 10 , and 4 9 3 . × 10 4 K ( ≡ 2, 4 and 8 eV), respectively. These values are simply scaled from Laming & Feldman's Figure 1. Excitation of the 1 s 2 p 3 P o levels by electron collisions naturally requires time scales with a similar temperature dependence because these levels lie at 21 eV, close to the continuum which is at 24.5 eV. Thus, populating these levels also leads to significant ionization. Further, a mere 1-2 eV is sufficient to ionize 50% of He I when photoionization from the n = 2 levels is considered (Laming & Feldman table 4). There are two difficulties: there is 'little room in temperature space' where electron collisions from below can provide significant populations of the 1 s 2 p 3 P o levelsif they are excited, the He I is also readily ionized; for electron temperatures equivalent to 4 eV or more, needed to provide significant populations of these levels, the ionization times are so short so that one must invoke very many bursts to maintain the observed light curves, even during the 'impulsive' rise phases (many tens of seconds for 10830 ˚ , see Figure 7). A
Thus, recombination appears the only way to significantly populate the 1 s 2 p 3 P o levels. If this occurs via EUV photons, helium is selectively enhanced by the process outlined above. If however electron collisions are responsible, then one would expect very bright UV and EUV emission from trace species such as C, N, O, Si. . . from the upper chromosphere. Simultaneous observations of UV emission lines of various ions, for example from the new IRIS spacecraft, would be needed to see if pictures involving electron impact excitation of He I from the 1 s 2 1 S level can be refuted or must be considered further.
## 4. DISCUSSIONS AND CONCLUSIONS
With the NST's high spatial resolution imaging observations as well as simultaneous space data from AIA on board SDO, we have given a detailed analysis of a C class flare observed continuously by all instruments at the cadence of 10-24 s (30 s for the TiO NST data). Specifically, we have tried to identify the dominant mechanism that produces the observed He I 10830 ˚ emissions. A
We adopt the picture that the flare energy released in the corona propagates downwards by heat conduction and radiation into the underlying chromosphere. Particle beams seem insignificant on the basis that HXR fluxes are very small for this flare. Furthermore, our analysis focus on the decay phase of the flare, when the thermal model is sufficient for fitting the RHESSI spectra (Liu 2014). We compute the conductive downflow by determining heating rates inferred from 906 UV brightened pixels and the zero-dimensional EBTEL model to compute mean plasma properties in the corona and transition region of flare loops anchored within these pixels. Remarkably, the method can reproduce not only the C IV emission generated in the transition region at the flare foot-points, but also He II 304 ˚ emission, A at least during the decay phases, to within a factor of two or so. This is remarkable agreement given the need to appeal to different mechanisms for bigger flares in previous work (Laming & Feldman 1992).
In terms of the He I 10830 ˚ multiplet, we argue that the downward propagation of A energy via EUV photons is an important mechanism for excitation during the flare. Thus photo-ionization followed by recombination (PR; Zirin 1975) appears to be a prominent component exciting the 10830 ˚ multiplet during this event. A Several pieces of evidence support this picture. Firstly, the morphology of the footpoint 10830 ˚ emission is qualitatively simA ilar to a mixture of EUV channels observed with AIA. Secondly, the light curve of 10830 ˚ A emission is, during the rise phase, similar to the (E)UV transition region light curves (304 ˚ A and C IV which dominates the 1600 ˚ channel); during the decaying phases, it is perhaps A more similar to the coronal SXR and EUV light curves. Thirdly, photon budgets are in reasonable agreement, as measured against both EVE data as well AIA data. Fourthly, the EUV radiation computed from the EBTEL models is also compatible with the photon budget for exciting 10830 ˚ via PR, during the decay phase. A
In Andretta et al. (2008), the calculated helium spectrum is strongly affected by the spectral distribution and overall level of EUV coronal back-illumination, which is consistent with our result. They also found that He I 10830 ˚ is not sensitive to chromospheric helium A abundance. In our calculation the helium abundance merely needs to be large enough so that it dominates most of the absorption of some EUV radiation, these photons being converted to longer wavelengths such as the 10830 ˚ line we computed down to the layer where EUV A no longer penetrate. Our calculations are therefore insensitive to modest changes in the abundance of helium.
But there is perhaps one problem with the PR mechanism: if this were the only source of photons in 10830 A, then there should be a close correspondence ˚ between the spatial distribution of the EUV photoionizing radiation and the underlying 10830 ˚ flare emission. A However, this is not always the case. Scatter plots of peak intensities of the light curves in AIA 1600 ˚ , AIA 304 ˚ and He A A I 10830 ˚ show little correlation. A One cause of the enormous scatter might be the fact that we observe only a 0.5 ˚ wide part of the 10830 ˚ line, shifted by A A 0.25 ˚ blueward of the line center. A Therefore the morphology and light curves might contain velocity-dependent information that is not present in the broad band (E)UV channels.
Nevertheless, we also examined a 'burst' picture which depends on non-equilibrium ionization to explain the large populations of the n = 2 triplet levels of helium. We concluded that this seems unlikely for the He I 10830 ˚ multiplet on several grounds, at least for the A decay phases. Occam's Razor would compel us to accept the PR mechanism as perhaps the 'simplest answer compatible with the data'.
The assumed steady-state and equilibrium conditions are not adequate for calculations during the impulsive phases with durations of 10-100 seconds or so. In this period, the 10830 ˚ have identical rapid enhancement with the (E)UV lines. Perhaps a 'burst' picture A would be successful during this phase. Further observations including more UV lines, such as can be observed with IRIS, would be desirable, since to leading order the lines would respond to bursts but not the PR mechanism.
We thank BBSO observing staff and instrument team for their support. We thank Dr. Haisheng Ji for providing the narrow-band 10830 ˚ Lyot Filter. We are grateful to Giuliana A de Toma for a careful reading of the paper. SDO is a project of NASA. Z. Z. and W. C. acknowledge the support of the US NSF (AGS-0847126, AGS-1146896 and AGS-1250818) and NASA (NNX13AG14G). J. Q. acknowledges the support by NSF (ATM-0748428) and NASA (NNX14AC06G). P. J. acknowledges the support by Montana State University Physics department, and the ASP and HAO programs at NCAR. NCAR is sponsored by the National Science Foundation. We thank the referee for carefully reading our paper and for providing valuable suggestions which substantially helped improving the quality of the paper.
## REFERENCES
Andretta, V., Jordan, S. D., Brosius, J. W., et al. 2000, ApJ, 535, 438
Andretta, V., Mauas, P. J. D., Falchi, A., & Teriaca, L. 2008, ApJ, 681, 650
Avrett, E. H., Fontenla, J. M., & Loeser, R. 1994, in IAU Symposium, Vol. 154, Infrared Solar Physics, ed. D. M. Rabin, J. T. Jefferies, & C. Lindsey, 35
Cao, W., Coulter, R., Gorceix, N., & Goode, P. R. 2010a, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 7742, Society of PhotoOptical Instrumentation Engineers (SPIE) Conference Series
Cao, W., Gorceix, N., Coulter, R., et al. 2010b, Astronomische Nachrichten, 331, 636
Cao, W., Gorceix, N., Coulter, R., et al. 2010c, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 7735, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series
Cargill, P. J., Bradshaw, S. J., & Klimchuk, J. A. 2012a, ApJ, 752, 161
-. 2012b, ApJ, 758, 5
Centeno, R., Trujillo Bueno, J., Uitenbroek, H., & Collados, M. 2008, ApJ, 677, 742
Dere, K. P., Landi, E., Mason, H. E., Monsignori Fossi, B. C., & Young, P. R. 1997, A&AS, 125, 149
Fisher, G. H. 1987, ApJ, 317, 502
-. 1989, ApJ, 346, 1019
Fletcher, L., Dennis, B. R., Hudson, H. S., et al. 2011, Space Sci. Rev., 159, 19
Goode, P. R., & Cao, W. 2012, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 8444, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series
Griffiths, N. W., Fisher, G. H., & Siegmund, O. H. W. 1998, in Astronomical Society of the Pacific Conference Series, Vol. 154, Cool Stars, Stellar Systems, and the Sun, ed. R. A. Donahue & J. A. Bookbinder, 621
Hannah, I. G., Christe, S., Krucker, S., et al. 2008, ApJ, 677, 704
Harvey, K. L., & Recely, F. 1984, Sol. Phys., 91, 127
Hawley, S. L., & Fisher, G. H. 1992, ApJS, 78, 565
Hawley, S. L., Allred, J. C., Johns-Krull, C. M., et al. 2003, ApJ, 597, 535
Jordan, C. 1975, MNRAS, 170, 429
-. 1980, A&A, 86, 355
Judge, P. G. 2005, J. Quant. Spec. Radiat. Transf., 92, 479
Judge, P. G. 2007, in The HAO Spectral Diagnostic Package for Emitted Radiation (HAOSDIPER) Reference Guide (Version 1.0), Technical Report NCAR/TN-473-STR, National Center for Atmospheric Research
-. 2010, Mem. Soc. Astron. Italiana, 81, 543 Judge, P. G., & Pietarila, A. 2004, ApJ, 606, 1258 Kleint, L. 2012, ApJ, 748, 138 Klimchuk, J. A., Patsourakos, S., & Cargill, P. J. 2008, ApJ, 682, 1351 Laming, J. M., & Feldman, U. 1992, ApJ, 386, 364 Landi, E., Del Zanna, G., Young, P. R., Dere, K. P., & Mason, H. E. 2012, ApJ, 744, 99 Lemen, J. R., Title, A. M., Akin, D. J., et al. 2012, Sol. Phys., 275, 17 Li, H., You, J., Yu, X., & Du, Q. 2007, Sol. Phys., 241, 301 Li, Y., Qiu, J., & Ding, M. D. 2014, ApJ, 781, 120 Lin, R. P., Dennis, B. R., Hurford, G. J., et al. 2002, Sol. Phys., 210, 3 Liu, W.-J. 2014, Determining Heating Rates in Reconnection Formed Flare Loops, PhD thesis, Department of Physics, Montana State University, Montana, USA Liu, W.-J., Qiu, J., Longcope, D. W., & Caspi, A. 2013, ApJ, 770, 111 Maltby, P., Avrett, E. H., Carlsson, M., et al. 1986, ApJ, 306, 284 Penn, M. J., & Kuhn, J. R. 1995, ApJ, 441, L51 Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, Sol. Phys., 275, 3 Pietarila, A., & Judge, P. G. 2004, ApJ, 606, 1239 Pozhalova, Z. A. 1988, Soviet Ast., 32, 542 Qiu, J., Liu, W.-J., & Longcope, D. W. 2012, ApJ, 752, 124 Qiu, J., Sturrock, Z., Longcope, D. W., Klimchuk, J. A., & Liu, W.-J. 2013, ApJ, 774, 14 Schou, J., Scherrer, P. H., Bush, R. I., et al. 2012, Sol. Phys., 275, 229 Tandberg-Hanssen, E. 1967, Solar activity Trujillo Bueno, J., & Asensio Ramos, A. 2007, ApJ, 655, 642 Vernazza, J. E., Avrett, E. H., & Loeser, R. 1981, ApJS, 45, 635
Woods, T. N., Eparvier, F. G., Hock, R., et al. 2012, Sol. Phys., 275, 115
W¨ oger, F., & von der L¨he, O. 2007, Appl. Opt., 46, 8015 u Zirin, H. 1975, ApJ, 199, L63
This preprint was prepared with the AAS LT E X macros v5.0. A
Fig. 1.- Snapshot of the He I 10830 ˚ observation. The bandpass of the narrow-band filter A is illustrated by a vertical strip in the solar spectrum on the lower right corner, and three vertical dashed lines depict the line centers of the He I 10830 ˚ triplets. A The field of view is 64 Mm × 64 Mm. The 9 small boxes with digits encompass the footpoints of the flare during its second peak.
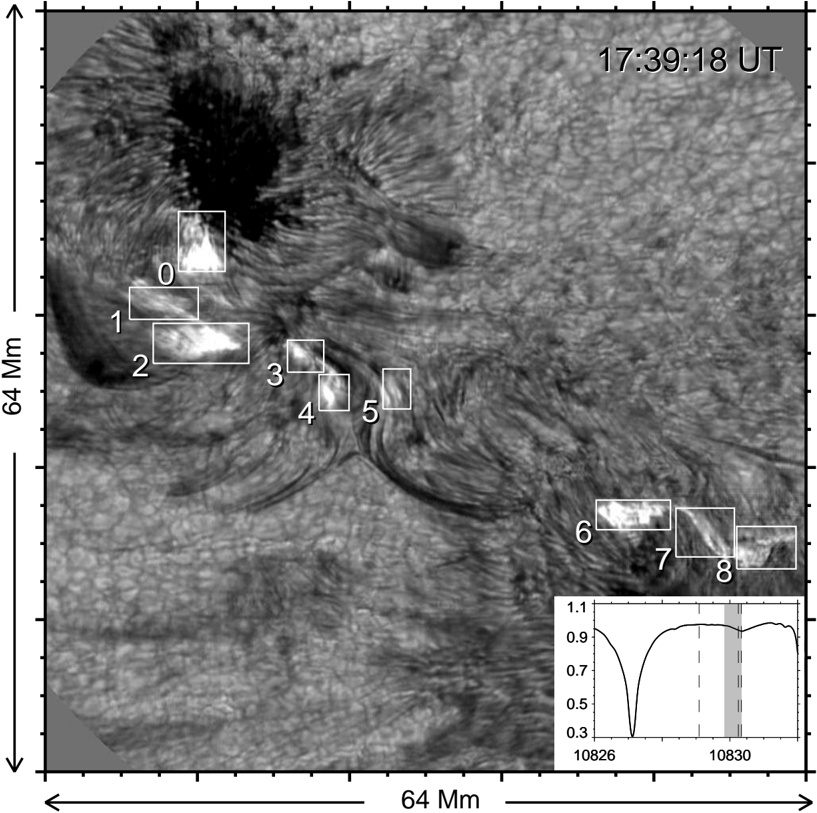
Fig. 2.- Light curves of the 2012 June 17 C3.9 flare. Both soft X-ray 1-8 ˚ from GOES A and some X-ray flux from RHESSI are shown in panel a. Time profiles in UV 1600 ˚ and A EUV 171 ˚ and 94 ˚ by AIA/SDO are plotted in panel b. Also plotted is the light curve of A A 10830 ˚ . A
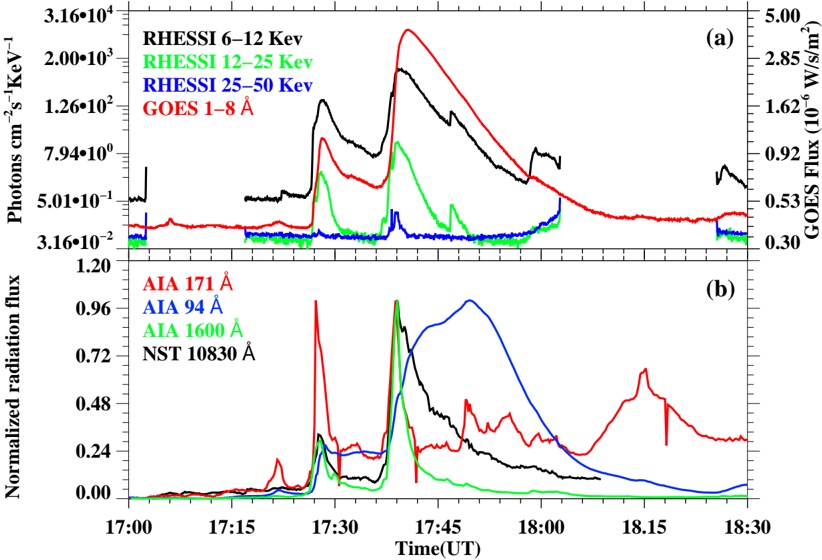
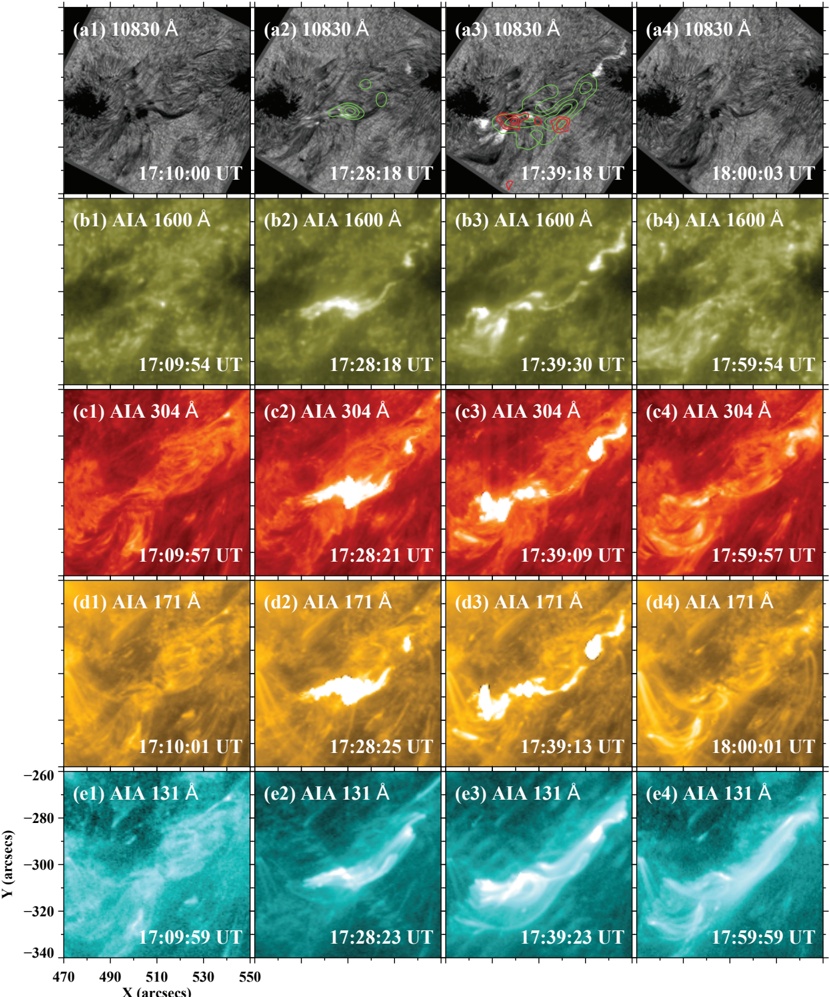
X (arcsecs)
Fig. 3.- Snapshots of the flare in a few bands at a few moments with the same field of view. Rows from top to bottom: He I 10830 ˚ , A UV 1600 ˚, EUV 304 ˚, 171 ˚ and A A A 131 ˚ . Left panels (a1-e1): A snapshots before the filament eruption. Middle panels (a2-e2): snapshots during the first peak of the flare. Panels (a3-e3): snapshots during the second peak of the flare. Right panels (a4-e4): snapshots after the flare. The contours on the 10830 ˚ filtergrams are from RHESSI images with channels of: A 6-15 keV (green) and 2550 keV (red). The RHESSI images are made from 17:28:10 UT with 10 seconds integration and from 17:38:30 UT with 1 minute integration, respectively. The contour levels are 90%, 75% and 60% of the peak intensity of each image.
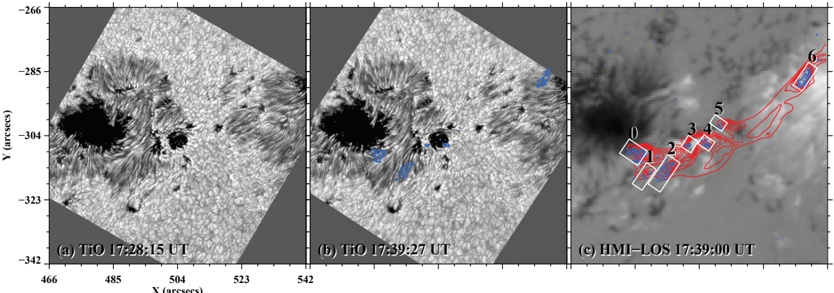
X (arcsecs)
Fig. 4.- Panel (a) and (b): TiO images from NST/BBSO during the two impulsive phase. Blue contours on panel (b) are regions of emission measured in He I 10830 ˚ . A Panel (c): HMI line-of-sight (LOS) magnetogram overlaid with foot-point contour in 10830 ˚ (Blue) A and loop contour in 131 ˚ (Red). A The boxes encompass the patches indicated in Figure 1. Three panels have the same field of view of 76 ′′ × 76 . ′′
Fig. 5.- Light curves in He I 10830 ˚ , AIA 1600 ˚ and 304 ˚ . Panel a to c represent for A A A patches 0, 4 and 6 noted in Figure 1, respectively. The minimum value is subtracted from each light curve, which then normalized to its maximum.
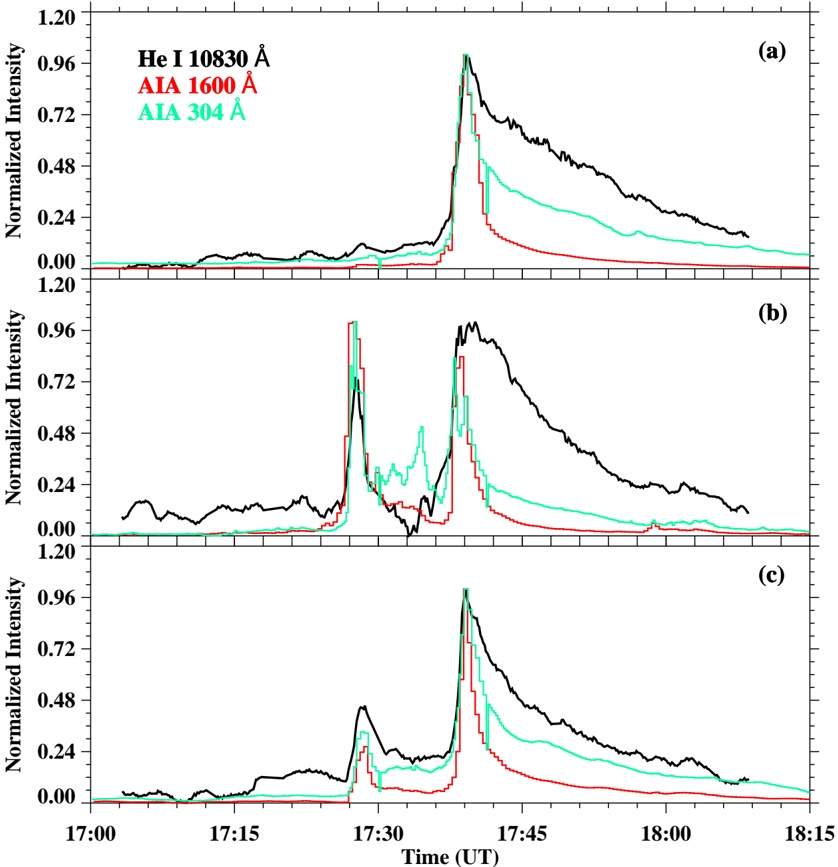
Fig. 6.- Histogram of peak intensities for all the footpoint pixels: x axis shows peak intensities as how many times the pre-flare intensity; y axis is in percentage. For the He I 10830 ˚ , the pre-flare intensity is approximated by the quiescent continuum. A
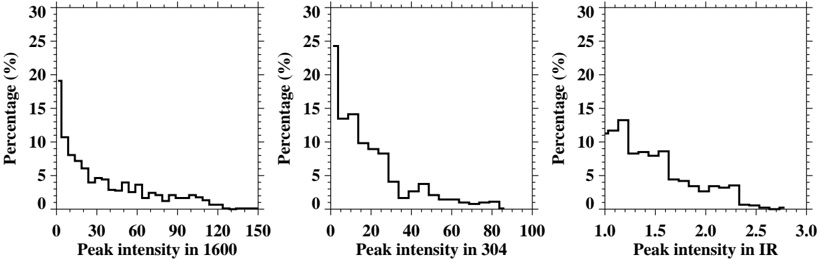
Fig. 7.- Histogram of 10830 ˚ , 1600 ˚ and 304 ˚ rise and decay timescales. A A A Upper panels: rise timescales. Bottom panels: decay timescales.
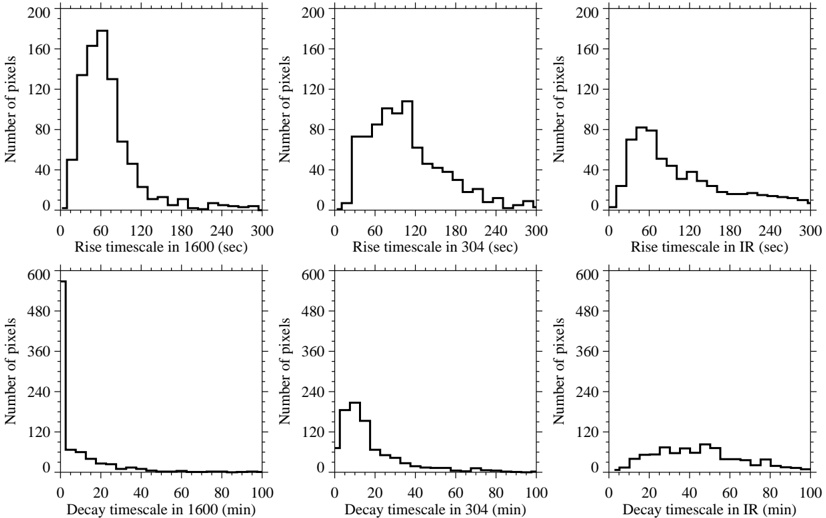
Fig. 8.- Comparison of observed and synthetic flux calculated through EBTEL model. The dotted and solid lines are the synthetic and observed light curves, respectively. The heating rate is given as the dashed light curve in the top left panel. The corresponding passbands are noted by the number on the right corner of each panel.
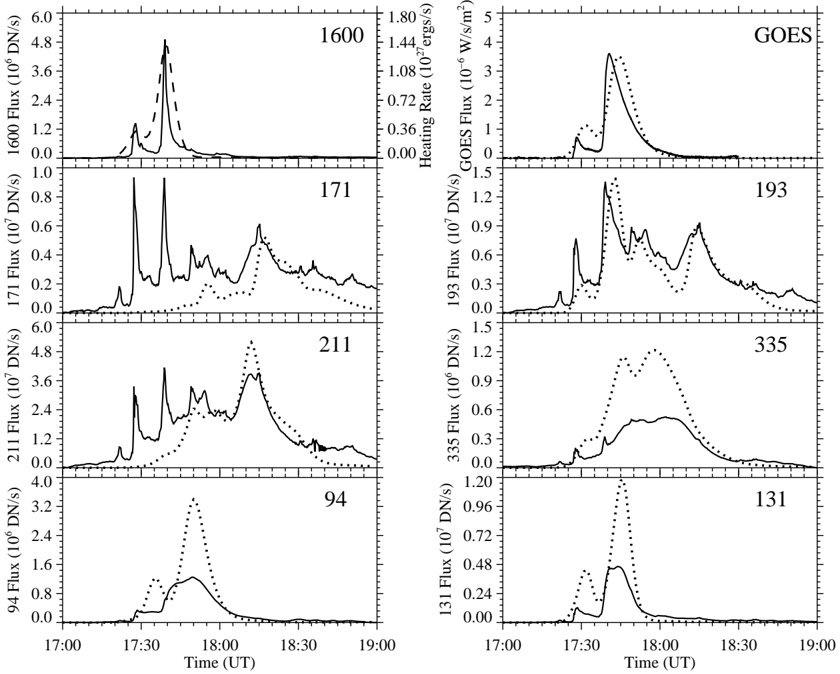
Fig. 9.- Dotted lines: computed light curves for 304 and 1600 A with pressure ˚ gauge assumption. Solid lines: observed data.
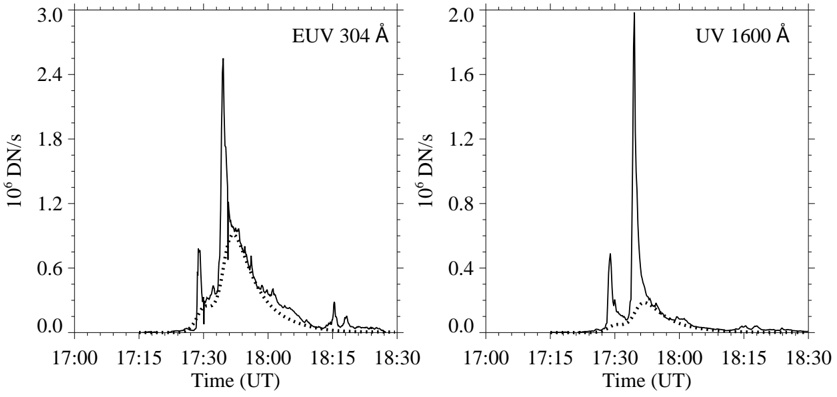
Fig. 10.- Total estimated optically-thin energy flux from the transition region (dotted line) compare with estimation from 10830 ˚ enhancement (solid line). The number on the upper A right conner of each panel denotes the patches showed in Figure 1. The patch P5 is not plotted here because the emissions are blended with the filament absorption.
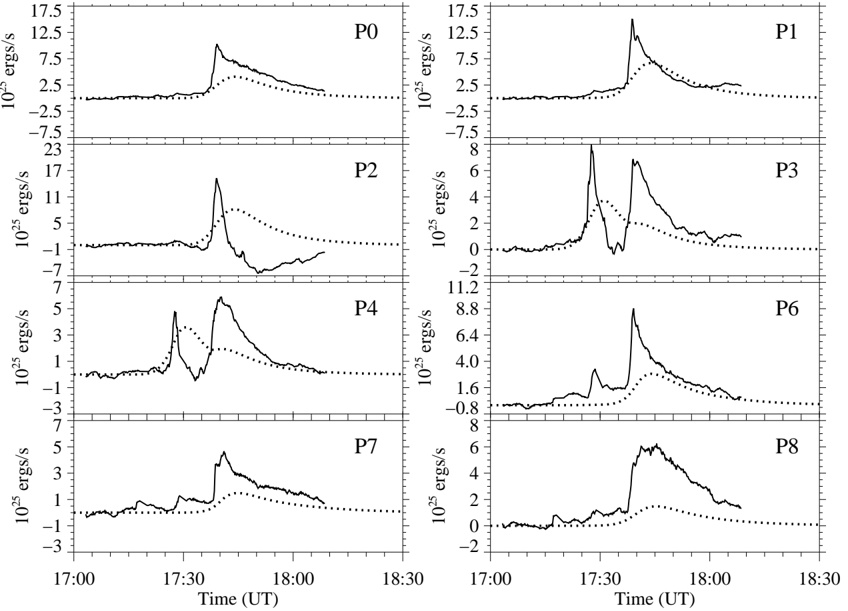
Fig. 11.- Solid line: EVE observed EUV flux summed up through the spectrum range from 60-380 ˚ with pre-flare emission subtracted. A Dotted line: model estimated total opticallythin radiation flux with pressure-gauge approximation.
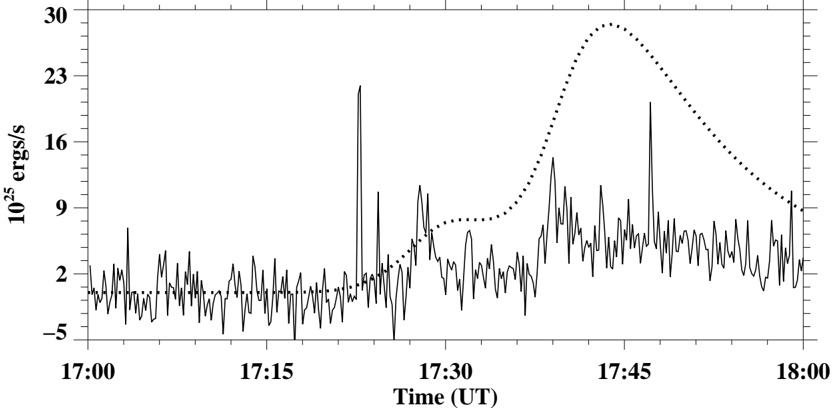 | 10.1088/0004-637X/793/2/87 | [
"Zhicheng Zeng",
"Jiong Qiu",
"Wenda Cao",
"Philip G. Judge"
] | 2014-08-01T17:02:55+00:00 | 2014-08-01T17:02:55+00:00 | [
"astro-ph.SR"
] | A Flare Observed in Coronal, Transition Region and Helium I 10830 Å\ Emissions | On June 17, 2012, we observed the evolution of a C-class flare associated
with the eruption of a filament near a large sunspot in the active region NOAA
11504. We obtained high spatial resolution filtergrams using the 1.6 m New
Solar Telescope at the Big Bear Solar Observatory in broad-band TiO at 706 nm
(bandpass:10 \AA) and He I 10830 \AA\ narrow-band (bandpass: 0.5 \AA, centered
0.25 \AA\ to the blue). We analyze the spatio-temporal behavior of the He I
10830 \AA\ data, which were obtained over a 90" X 90" field of view with a
cadence of 10 sec. We also analyze simultaneous data from the Atmospheric
Imaging Assembly and Extreme Ultraviolet Variability Experiment instruments on
board the Solar Dynamics Observatory spacecraft, and data from Reuven Ramaty
High Energy Solar Spectroscopic Imager and GOES spacecrafts. Non-thermal
effects are ignored in this analysis. Several quantitative aspects of the data,
as well as models derived using the "0D" Enthalpy-Based Thermal Evolution of
Loops model (EBTEL: Klimchuk et al. 2008) code, indicate that the triplet
states of the 10830 \AA\ multiplet are populated by photoionization of
chromospheric plasma followed by radiative recombination. Surprisingly, the He
II 304 \AA\ line is reasonably well matched by standard emission measure
calculations, along with the C IV emission which dominates the AIA 1600 \AA\
channel during flares. This work lends support to some of our previous work
combining X-ray, EUV and UV data of flares to build models of energy transport
from corona to chromosphere. |
1408.0237v1 | ## Topological nature of bound states in the radiation continuum
Bo Zhen, 1, ∗ Chia Wei Hsu, 1, 2, † Ling Lu, 1 A. Douglas Stone, 3 and Marin Soljaˇ ci´ c 1
1 Department of Physics, Massachusetts Institute of Technology, 77 Massachusetts Avenue, Cambridge, Massachusetts 02139, USA 2 Department of Physics, Harvard University, 17 Oxford Street, Cambridge, Massachusetts 02138, USA 3 Department of Applied Physics, Post Office Box 208284, Yale University, New Haven, CT 06520, USA (Dated: August 4, 2014)
∗ E-mail: [email protected]
† These authors contributed equally to this work.
Bound states in the continuum (BICs) are unusual solutions of wave equations describing light or matter: they are discrete and spatially bounded, but exist at the same energy as a continuum of states which propagate to infinity. Until recently, BICs were constructed through fine-tuning parameters in the wave equation 1-5 or exploiting the separability of the wave equation due to symmetry 6-8 . More recently, BICs that that are both robust and not symmetryprotected ('accidental') have been predicted 9-13 and experimentally realized 13 in periodic structures; the simplest such system is a periodic dielectric slab 13 , which also has symmetry-protected BICs. Here we show that both types of BICs in such systems are vortex centers in the polarization direction of far-field radiation. The robustness of these BICs is due to the existence of conserved and quantized topological charges, defined by the number of times the polarization vectors wind around the vortex centers. Such charges can only be generated or annihilated by making large changes in the system parameters, and then only according to strict rules, which we derive and test numerically. Our results imply that laser emission based on such states will generate vector beams 14 .
These BICs exist in photonics crystal slabs, which are dielectric slabs with a periodic modulation of refractive index at the wavelength scale 15 surrounded by air or a low-index medium. Photonic crystal slabs are used in many applications including surface-emitting lasers 16 , photovoltaics 17 , LEDs 18 , and biosensing 19,20 . The periodic modulation alters the dispersion relation of light in the slabs and gives rise to photonic bands, analogous to electronic band structures in solids. In general light can escape from the surface of the slab and propagate to the far-field, but a portion of the photonic band states (those 'below the light line') are perfectly confined to the slab by the generalized form of total internal reflection 15 . In contrast, modes above the light line appear generically as resonances with finite lifetimes due to their coupling to the continuum of extended modes 21 . It has been known for some time that bound states with infinite lifetimes also exist above the light line at isolated highsymmetry wavevectors. This type of BIC arises from the symmetry mismatch between their mode profiles inside the photonic crystal and those of the external propagating modes (radiation continuum) 8,21-23 . Recently, a new type of BIC, unprotected by symmetry, has been found (both theoretically and experimentally) to exist at arbitrary wavevectors in bands above the light line in photonic crystal slabs 13 . These BICs occur 'accidentally', when the
relevant couplings to the continuum (see below) all vanish simultaneously. However their existence does not require fine-tuning of system parameters; small changes in parameters simply shift the position of these special points along the band diagram. An intuitive understanding of why such BICs exist and are robust was previously lacking. Recently, an explanation based on accidental triangular symmetry of the radiating fields was proposed 24 but does not explain the robustness of these BICs and their occurrences in TE-like bands.
We now show that both types of BICs in photonic crystal slabs are vortex centers in the polarization direction of the far-field radiation of the slabs. Using the Bloch theorem for photonic crystals 15 , we write the electric field of a resonance as E k ( ρ , z ) = e i k · ρ u k ( ρ , z ), where k = k x x ˆ + k y y ˆ is the two-dimensional wave vector, ρ = xx ˆ + yy ˆ is the in-plane coordinate, u k is a periodic function in ρ , and z is the normal direction to the slab. While the fields inside the slab are periodically modulated, outside the slab each state consists of propagating plane waves and/or evanescent waves that decay exponentially away from the surface. For states above the light line (resonances), and wavelengths below the diffraction limit, the only non-zero propagating-wave amplitudes are the zero-order (constant in-plane) Fourier coefficients of u k , given by c k ( ) = c x ( k )ˆ + x c y ( k )ˆ (Fig. 1a). y Here, c x ( k ) = ˆ x · 〈 u k 〉 , c y ( k ) = ˆ y · 〈 u k 〉 , and the brackets denote spatial average over one unit cell on any horizontal plane outside the slab. Note that c k ( ) is the projection of 〈 u k 〉 onto the xy plane; it points in the polarization direction of the resonance in the far field, so we refer to c k ( ) as the 'polarization vector'.
A resonance turns into a BIC when the outgoing power is zero, which happens if and only if c x = c y = 0. In general, c x and c y are both complex functions of k , and varying the wave vector components ( k , k x y ) is not sufficient to guarantee a solution where c x = c y = 0. However, when the system is invariant under the operation C T z 2 , implying that glyph[epsilon1] ( x, y, z ) = glyph[epsilon1] ∗ ( -x, -y, z ), we show that c x and c y can be chosen to be real numbers simultaneously; in other words, the far field is linearly polarized (see Supplementary Information, here C z 2 is 180 ◦ rotation operator around z axis, and T is the time reversal operator). When the system also has up-down mirror symmetry ( σ z ), the outgoing waves on one side of the slab determine those on the other; for such systems, BICs are stable because they correspond to the intersections between the nodal line of c x and the nodal line of c y in the k x -k y plane. Such a nodal intersection naturally causes a vortex in the polarization vector field centered on the BIC, as illustrated in Fig. 1b, for the simplest case. Along the nodal line of c x (or
c y ), the direction of c k ( ) is along the y axis (or x axis), as illustrated in Fig. 1b. As one encircles the nodal intersection (BIC) in the k x -k y plane each component of the polarization vector flips sign as its nodal line is crossed so as to create a net circulation of ± 2 π in the polarization field. At the nodal intersection the polarization direction becomes undefined, since at the BIC there is zero emission into the far-field. Conversely one could say that BICs cannot radiate because there is no way to assign a far-field polarization that is consistent with neighbouring k points. Thus robust BICs are only possible when there is vorticity in the polarization field.
Vortices are characterized by their topological charges. Here, the topological charge ( q ) carried by a BIC is defined as:
$$q = \frac { 1 } { 2 \pi } \oint _ { C } d { \mathbf k } \cdot \nabla _ { \mathbf k } \phi ( { \mathbf k } ), \quad q \in \mathbb { Z }$$
which describes how many times the polarization vector winds around the BIC. Here, φ ( k ) = arg[ c x ( k ) + ic y ( k )] is the angle of the polarization vector, and C is a closed simple path in k space that goes around the BIC in the counterclockwise direction.The fields u k are chosen to be smooth functions of k , so φ ( k ) is differentiable in k along the path. The polarization vector has to come back to itself after the closed loop, so the overall angle change must be an integer multiple of 2 π , and q must be an integer. Fig. 1c shows examples of how the polarization vector winds around a BIC with charge q = +1 and also around a BIC with charge q = -1 along a loop C marked by 1 → → → → 2 3 4 1. Similar definitions of winding numbers as in Eq. 1 can be found in describing topological defects 25 of continuous two-dimensional spins, dislocations in crystals, and quantized vortices in helium II 26 . This formalism describing polarization vortices is also closely related to Berry phases in describing adiabatic changes of polarization of light 27 and Dirac cones in gaphenes 28 .
The far-field pattern at a definite k point by itself does not reflect the vorticity of polarization around a BIC, but laser emission centered on such a BIC will. Laser emission always has a finite width in k -space and this wave-packet will be centered on the BIC; hence it will consist of a superposition of plane waves from the neighborhood of the BIC, leading naturally to a spatial twist in the polarization for the outgoing beam. Such beams have been studied previously, and are known as vector beams 14 , although their connection with BICs does not appear to have been realized. The number of twists in the polarization direction is known as the order number of the vector beam, and we now see that it is given by
the topological charge carried by the BIC. Note that these vector beams are different from optical vortices, which usually have a fixed polarization direction.
In the example of Fig. 2, we show the topological charges of BICs for a structure that has been experimentally realized in ref. 13. In this example, there are five BICs on the lowestfrequency TM-like band (Fig. 2a). We obtain polarization vectors c k ( ) from finite-difference time-domain (FDTD) calculations, which reveal five vortices with topological charges of ± 1 at these five k points (Fig. 2b). As discussed above, the BICs and their topological charges can also be identified from the nodal-line crossings and the gray-scale colors of c x and c y (Fig. 2c).
The winding number of polarization vector along a closed path is given by the sum of the topological charges carried by all BICs enclosed within this path 25 . When system parameters vary continuously, the winding number defined on this path remains invariant, unless there are BICs crossing the boundary. Therefore, topological charge is a conserved quantity. This conservation rule leads to consequences/restrictions on behaviors of the BICs (Supplementary Information). For example, as long as the system retains C T z 2 and σ z symmetries, a BIC can only be destroyed through annihilation with another BIC of the exact opposite charge, or through bringing it outside of the continuum (below the light line).
The conservation of topological charges allows us to predict and understand the behaviors of BICs when the parameters of the system are varied over a wide range, as we now illustrate. First, consider the lowest-frequency TM-like mode (TM 1 band) of a 1D-periodic structure in air shown in Fig. 3a. This grating consists of a periodic array of dielectric bars with periodicity of a , width w = 0 45 . a , and refractive index n = 1 45. . Its calculated band structure is shown in Fig. 3b. When the thickness of the grating is h = 1 50 . a , there are two BICs on the k x axis, as indicated by the radiative quality factor of the resonances (Fig. 3c). The polarization vector c k ( ), also shown in Fig. 3c, characterizes both BICs as carrying charges q = +1. When the grating thickness is decreased to h/a = 1 43 (all other . parameters fixed), the two BICs move towards the center of the Brillouin zone, meet at the Γ point, and deflect onto the k y axis (Fig. 3d). This is inevitable due to the conservation of the topological charges: annihilation cannot happen between two BICs of the same charge.
Annihilation of BICs is only possible when charges of opposite signs are present. This can be seen in the lowest-frequency TE-like band of the same structure (Fig. 3e,f). When
h/a = 1 04, there are two off-. Γ BICs with charge -1 and a BIC with charge +1 at the Γ point (Fig. 3e). As h/a decreases, the two -1 charges move to the center and eventually annihilate with the +1 charge, leaving only one BIC with charge q = -1 (Fig. 3f).
Generation of BICs is also restricted by charge conservation, and can be understood as the reverse process of annihilation. We provide an example by considering the lowest-frequency TE-like mode in a photonic crystal slab of n = 3 6 with a square lattice of cylindrical air holes . of diameter d = 0 5 . a (Fig. 4a). As the slab thickness increases, BICs are generated at the Γ point. Each time, four pairs of BICs with exact opposite charges are generated, consistent with charge conservation and C 4 v symmetry of the structure. With further increase of the slab thickness, the eight BICs move outward along high-symmetry lines and eventually go outside of the continuum (fall below the light line).
Although the examples discussed so far only show topological charges of ± 1, other values of charges can be found in higher-frequency bands of the PC or in structures with higher rotational symmetry. For example, Fig. S2 in Supplementary Information shows a stable BIC of charge -2 at the Γ point arising from the double degeneracy of nodal lines caused by the C 6 v symmetry of the system.
The symmetries of the system also restrict the possible values of topological charges, since the nodal curves must respect the point symmetry. BICs at k points related by in-plane point-group symmetries of the system (mirror reflections and rotations) have the same topological charges (Supplementary Information). Using this fact, one can calculate all possible topological charges of BICs at high symmetry k points. For a system with C n symmetry, the possible topological charges at the Γ point on a singly-degenerate band are given in Table S1 (Supplementary information). This is consistent with all examples in this paper. This table can be used to predict the charges in other systems of interest and to design high order vector beams.
## Conclusions
We have demonstrated that BICs in photonic crystal slabs are associated with vortices in the polarization field and explained their robustness in terms of conserved topological charges. We derive the symmetries that constrain these charges and explain their generation, evolution and annihilation. We conjecture that all robust BICs 6-13 will correspond to vortices in an appropriate parameter space. Our finding connects electromagnetic BICs to a wide range of physical phenomena including Berry phases around Dirac points 28 , topo-
logical defects 25 , and general vortex physics 26 . Optical BICs in photonic crystals have a wealth of applications. Lasing action can naturally occur at BIC states where the quality factor diverges. The angular (wavevector) tunablity of the BICs makes them great candidates for on-chip beam-steering 29 . Furthermore, photonic crystal lasers through BICs are naturally vector beams 30,31 , which are important for particle accelerations, optical trapping and stimulated emission depletion microscopy.
## Acknowledgments
The authors thank Chong Wang, Scott Skirlo, David Liu, Fan Wang, Nicholas Rivera, Dr. Ido Kaminer, Dr. Homer Reid, Prof. Xiaogang Wen, Prof. Steven G. Johnson, and Prof. John D. Joannopoulos for helpful discussions. This work was partly supported by the Army Research Office through the Institute for Soldier Nanotechnologies under contract no. W911NF-07-D0004. B.Z., L.L., and M.S. were partly supported by S3TEC, an Energy Frontier Research Center funded by the US Department of Energy under grant no. desc0001299. L.L. was supported in part by the Materials Research Science and Engineering Center of the National Science Foundation (award no. DMR-0819762). A.D.S. was partly supported by NSF grant DMR-1307632.
## Author contributions
All authors discussed the results and made critical contributions to the work.
## Additional information
Supplementary information is available in the online version of the paper. Reprints and permissions information is available online at www.nature.com/reprints. Correspondence and requests for materials should be addressed to B.Z.
## Competing financial interests
The authors declare no competing financial interests.
## Supplementary information
## A. Symmetry requirements for stable BICs
Here, we give the proof that stable BICs at arbitrary k points can be found when the system is invariant under C T z 2 and σ z operators, and that stable BICs at C z 2 -invariant k points can be found when the system has C z 2 symmetry. Here, C z 2 means 180 ◦ rotation around z axis, and T means the time reversal operator. The schematics of the symmetry requirement is summarized in Fig. S1.
In region I , systems are invariant under the symmetry operator C T z 2 , namely glyph[epsilon1] glyph[star] ( x, y, z ) = glyph[epsilon1] ( -x, -y, z ). Let u k be an eigenfunction of the master operator 15 Θ = k 1 glyph[epsilon1] ( ∇ + i k ) × ∇ ( + i k ) × , and recall that k here only has x and y components since we are considering a slab structure that does not have translational symmetry in z . A short derivation shows that at any k point, u k ( r ) and C z 2 u ∗ k ( C z 2 r ) are both eigenfunctions of Θ k ( r ) with the same eigenvalue, so they must differ at most by a phase factor,
$$u _ { k } ( r ) & = e ^ { i \theta _ { k } } C _ { 2 } ^ { z } u _ { k } ^ { * } ( C _ { 2 } ^ { z } r ) \\ & = e ^ { i \theta _ { k } } ( - u _ { k } ^ { x * }, - u _ { k } ^ { y * }, u _ { k } ^ { z * } ) | _ { ( - x, - y, z ) }$$
Here θ k is an arbitrary phase factor. Meanwhile, we are free to multiply u k with any phase factor, and it remains a valid eigenfunction. For our purpose here, we explicitly choose the phase factor of u k such that e iθ k = -1 for all k . With this choice, we can average over x and y to get c k ( ) = c ∗ ( k ) for all k . That is, the polarization vector c k ( ) is purely real.
Using the fact that systems in region I also have the up-down mirror symmetry σ z , namely glyph[epsilon1] ( x, y, z ) = glyph[epsilon1] ( x, y, -z ), we can link the radiation loss above and below the photonic crystal slab denoted by c ↑ and c ↓ . At any k point, u k ( r ) and σ z u k ( σ z r ) are both eigenfunctions of Θ ( ) with the same eigenvalue, so k r
$$u _ { k } ( { \mathbf r } ) & = e ^ { i \theta _ { k } } \sigma _ { z } u _ { k } ( \sigma _ { z } { \mathbf r } ) \\ & = e ^ { i \theta _ { k } } ( u _ { k } ^ { x }, u _ { k } ^ { y }, - u _ { k } ^ { z } ) | _ { ( x, y, - z ) }$$
with θ k being an arbitrary phase factor (not to be confused with the one in Eq. (S.1)). Since σ 2 z = 1, we can apply Eq. (S.2) twice to show that e iθ k = ± 1. Averaging over x and y , we see that c ↑ = ± c ↓ .
After using these two symmetries, the number of independent real variables in all radiation coefficients c ↑ ↓ , x,y has been reduced from 8 to 2. Given that the number of independent tuning parameters is also 2: ( k , k x y ), we are able to get stable BICs. Note that the combination of C T z 2 and σ z is just one sufficient condition for stable BICs in photonic crystal slabs. There might be other different choices of symmetries. For example, PT and σ z is equivalent to C T z 2 and σ z , where P is the inversion operator. Also, the requirement of σ z is not necessary when there is leakage to one direction only (such as BICs on the surface of a photonic bandgap structure 12 ).
In region II , stable BICs at C z 2 -invariant k points can be found. Systems in this region have C z 2 symmetry, namely glyph[epsilon1] ( x, y, z ) = glyph[epsilon1] ( -x, -y, z ). k points are C z 2 -invariant when -k = k + G , with G being a reciprocal lattice vector. A short derivation shows that at any k point, u k ( r ) and C z 2 u -k ( C z 2 r ) are both eigenfunctions of Θ k ( r ) with the same eigenvalue, so
$$u _ { k } ( r ) = e ^ { i \theta _ { k } } C _ { 2 } ^ { z } u _ { - k } ( C _ { 2 } ^ { z } r ),$$
with θ k being an arbitrary phase factor (not to be confused with the two phase factors above). At these high-symmetry k points, using Bloch theorem we know: u -k = u k + G = u k , so we can apply Eq. (S.3) twice to get e iθ k = ± 1. When this factor is +1, we can average over x and y to see that c k ( ) = 0, corresponding to a BIC at this C z 2 -invariant k point.
In region III , both kinds of BICs can be found, where C z 2 , T and σ z are all present. All our numerical examples are within this region to make it easier to understand the relation and interaction between different types of BICs.
## B. Consequences of topological charge conservation
Since topological charge is a conserved quantity, there are a few consequences and restriction on the evolution of BICs. First, BICs are stable as long as the system retains required symmetries; however, perturbations that break these two required symmetries eliminate the existence of BICs. When C T z 2 symmetry is broken, the coefficients ( c x and c y ) require complex components, meaning the radiation becomes elliptically polarized instead of linearly polarized. When σ z symmetry is broken, the coefficients c ↑ ↓ , x,y are still real numbers, but radiation towards the top and towards the bottom become separate degrees of freedom and so they do not vanish simultaneously in general. Second, when BICs collide into each other
in the moment space, the sum of all topological charges they carry remains the same before and after the collision.
## C. Example of charge -2
We consider the lowest-frequency TE-like mode of a photonic crystal slab with a hexagonal lattice of cylindrical air holes (shown in Fig. S2a). The refractive index of the slab is n = 1 5; the air-hole diameter is 0 5 . . a ; and the thickness of the slab is 0.5a, where a is the lattice constant. This system has C z 6 symmetry. Normalized lifetime plot indicates a BIC at the center of the Brillouin zone shown in Fig. S2b. The polarization vector field characterizes the BIC carrying charge -2 shown in Fig. S2c. Charge -2 can also be understood from the double degeneracy of both nodal lines of c x (green) and c y (red), shown in the inset of Fig. S2c. All four nodal lines are pinned at Γ point stabilized by the C 6 symmetry.
## D. BICs related by point group symmetries have the same topological charges
Here, we prove that when the structure has a certain in-plane point group symmetry R (namely, glyph[epsilon1] ( r ) = glyph[epsilon1] ( R r ); R can be a combination of rotation and reflection on the x y -plane) and when the band has no degeneracy, a BIC at k indicates there is another BIC at R k with the same topological charge. The assumption here is that the eigenfunctions u k at different k points already have their phases chosen to ensure the reality of c k ( ), and the signs of u k at different k points have been chosen such that u k is continuous with respect to k (so that a small change in k leads to a small change in u k ).
We start by relating the eigenfunction at k and the eigenfunction at R k . Let u k be an eigenfunction of operator Θ k . Since the system is invariant under transformation R , we know ˆ O R u k is an eigenfunction of Θ R k , so in the absence of degeneracy, we can write ˆ O R u k = α k u R k , where α k is some number. The number α k must have unit magnitude (due to the normalization of u k and u R k ) and must be real-valued (because c k ( ) is real-valued), so it can only take on discrete values of ± 1. Also, α k must be a continuous function of k since u k is continuous with respect to k . Since α k is both discrete-valued and continuous, it must be a constant. Then, we may denote this constant with its value at the Γ point, as α k = α Γ . Note that R Γ = Γ , so we can determine coefficient α Γ using the mode profile:
ˆ O R u Γ = α Γ u Γ . In conclusion, we have u R k = α O Γ ˆ R u k .
Now we consider how the angle φ ( R k ) is related to φ ( k ). The vector field u k transforms under the rotation operator as ( ˆ O R u k )( r ) = R u k ( R -1 r ), so averaging over x and y we get 〈 ˆ O R u k 〉 = R〈 u k 〉 . Let P be the operator that projects a 3D vector onto the x y -plane, namely P r = r -( r · ˆ)ˆ; it commutes with z z R , since it does not alter the x or y component. Then c k ( ) = P 〈 u k 〉 , and
$$c ( \mathcal { R } k ) = P \langle \mathbf u _ { \mathcal { R } k } \rangle = P \langle \alpha _ { \Gamma } \hat { O } _ { \mathcal { R } } \mathbf u _ { k } \rangle = \alpha _ { \Gamma } \mathcal { R } P \langle \mathbf u _ { k } \rangle = \alpha _ { \Gamma } \mathcal { R } c ( k ).$$
So, the polarization vector at the the transformed k point is simply the original polarization vector transformed and times ± 1. So, the angle of the polarization vector only changes by a constant in the case of proper rotations (where det R = 1); in the case of improper rotations (where det R = -1), it also changes sign. So, in general, we can write
$$\phi ( \mathcal { R } { \mathbf k } ) = ( \det \mathcal { R } ) \phi ( { \mathbf k } ) + c$$
with c being a constant depending on R and α Γ . It follows that ∇ R k φ ( R k ) = (det R R∇ ) k φ ( k ), so the topological charge at R k is
$$\text{gical charge at } \mathcal { R } k & \text{is} \\ q _ { \mathcal { R } k } & = \frac { 1 } { 2 \pi } \oint _ { C _ { \mathcal { R } k } } \nabla _ { k ^ { \prime \prime } } \phi ( k ^ { \prime \prime } ) \cdot d k ^ { \prime \prime } \\ & = \frac { 1 } { 2 \pi } \oint _ { \mathcal { R } ^ { - 1 } C _ { \mathcal { R } k } } \nabla _ { \mathcal { R } k ^ { \prime } } \phi ( \mathcal { R } k ^ { \prime } ) \cdot \mathcal { R } d k ^ { \prime } \\ & = \frac { 1 } { 2 \pi } ( \det \mathcal { R } ) \oint _ { C _ { \mathcal { R } k } } \nabla _ { \mathcal { R } k ^ { \prime } } \phi ( \mathcal { R } k ^ { \prime } ) \cdot \mathcal { R } d k ^ { \prime } \\ & = \frac { 1 } { 2 \pi } ( \det \mathcal { R } ) ^ { 2 } \oint _ { C _ { \mathcal { R } } } \mathcal { R } \nabla _ { k ^ { \prime } } \phi ( k ^ { \prime } ) \cdot \mathcal { R } d k ^ { \prime } \\ & = q _ { k }, \\ \\ - \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
where C R k is a closed simple path that is centered on R k and loops in counterclockwise direction, R -1 C R k is this loop transformed by R -1 (which centers on k in counterclockwise direction if R is a proper rotation, or in clockwise direction if R is improper), and C k is this transformed loop traversed in counterclockwise direction.
In conclusion, we have proven that if a system has certain point group symmetry R , then the topological charges carried by the BIC at k and at R k on a singly degenerate band have to be the same. This conclusion agrees with all examples in Figs. 2-4.
## E. Allowed charges at Γ in systems with different symmetries
Allowed topological charges at high symmetry k points can be determined by the field eigenvalues of the rotational symmetry of a system. For systems with m -fold rotational symmetry, we can first determine the relationship between polarization direction at wavevector k and at rotated wavevector R k ( φ ( k ) and φ ( R k )) using Eq. (S.4). Since the wavevector gets back to its original point if applying this rotation m -times: R m k = k , we can then apply this relationship m times and get how many times the polarization vector rotates around the center of the Brillouin zone. From there, we categoraize all possible charges allowed at Γ as shown in Table S1. Allowed charges depend on two factors. The first one is which symmetry representation the band belongs to. The second one is the degeneracy of nodal lines at Γ, because more nodal lines intersecting at the same point usually leads to more oscillations in color and thus higher topological charges. This factor is reflected by the integer number n , depending on the number of equivalent Γ points at this frequency 30 . Note that only singly degenerate bands are considered in this Letter, having no crossing with other bands in the bandstructures, as can be seen in Table S1. Further research directions may include BICs on degenerate bands, as well as the search of BICs with higher-order and potentially fractional topological charges.
TABLE I. Allowed stable topological charges at Γ for singly degenerate bands. A B ( ) corresponds to modes of different representations of the symmetry operator 32 . Note that only singly degenerate representations of symmetry operators are included in here.
| Symmetries | Representation | Charges | Allowed n | Allowed charges |
|--------------|------------------|-----------|---------------|-------------------|
| C 2 | A | ± 1 +2 n | 0 | ± 1 |
| C 2 | B | 0 +2 n | 0 | 0 |
| C 3 | A | 1 +3 n | 0 , ± 1 , ... | +1,+4,-2,... |
| C 4 | A | 1 +4 n | 0 , ± 1 , ... | +1,+5,-3,... |
| C 4 | B | - 1 +4 n | 0 , ± 1 , ... | -1,-5,+3,... |
| C 6 | A | 1 +6 n | 0 , ± 1 , ... | +1,+7,-5,... |
| C 6 | B | - 2 +6 n | 0 , ± 1 , ... | -2,+4,-8,... |
## a Field decomposition
FIG. 1. Stable bound states in the continuum (BICs) as vortex centers of polarization vectors. a , Schematics of radiation field decomposition for resonances of a slab structure. The spatially-averaged Bloch part of the electric field 〈 uk 〉 is projected onto the x y -plane as the polarization vector c = ( c x , c y ). A resonance turns into a BIC if and only if c x = c y = 0. b , Schematic illustration for the nodal lines of c x (green) and of c y (red) in a region of k space near a BIC. The direction of vector c (shown in arrows) becomes undefined at the nodal line crossing, where a BIC is found. c , Two possible configurations of the polarization field near a BIC. Along a closed loop in k -space containing a BIC (loop goes in counterclockwise direction, 1 → → → 2 3 4), the polarization vector either rotates by angle 2 π (denoted by topological charge q = +1) or rotates by angle -2 π (denoted by topological charge q = -1). Different regions of the k space are colored in four gray-scale colors according to the signs of c x and c y . In this way, a BIC happens where all four gray-scale colors meet, and charge q = +1 corresponds to the color changing from white to black along the counterclockwise loop C , and charge q = -1 corresponds to the color changing from black to white.
FIG. 2. Characterization of BICs using topological charges. a , Calculated radiative quality factor Q of the TM 1 band on a square-lattice photonic crystal slab (as in ref. 13), plotted in the first Brillouin zone. Five BICs can be seen. b , Directions of the polarization vector field reveal vortices with topological charges of ± 1 at each of the five k points. The area shaded in blue indicates modes below the lightline and thus bounded by total internal reflection. c , Nodal lines and gray-scale colors of the polarization vector fields (same coloring scheme as in Fig. 1c).
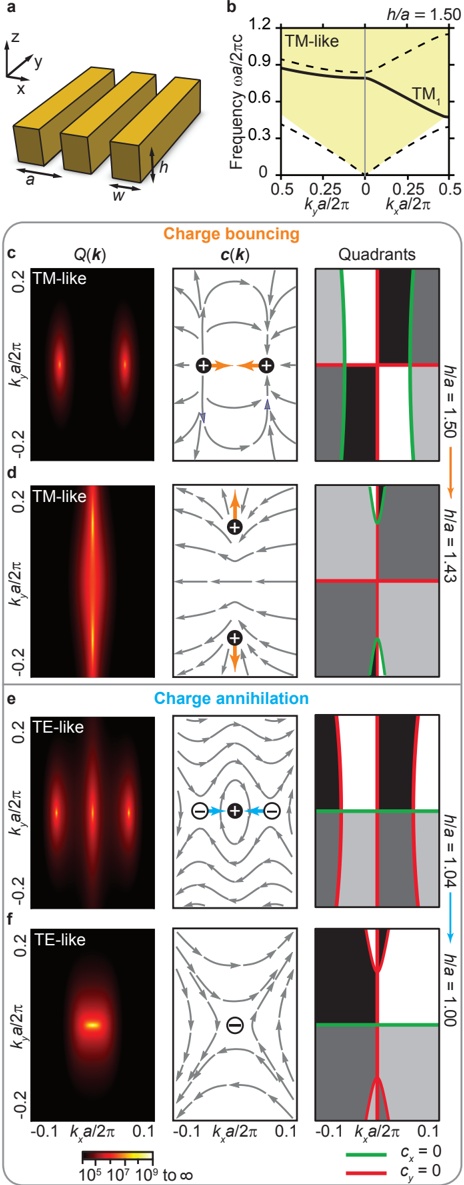
FIG. 3. Evolution of BICs and conservation of topological charges. a , Schematic drawing of a photonic crystal slab with one-dimensional periodicity in x and is infinitely long in y . b , Calculated TM-like band structure along k x axis and along k y axis. The area shaded in yellow indicates the light cone, where there is a continuum of radiation modes in the surrounding medium. c, d , An example showing topological charges with the same sign bouncing off each other. As the slab thickness h decreases, the two BICs with charge +1 move along the k x axis, meet at the origin, and then deflect onto the k y axis. This can be understood from the conservation of topological charges or from the evolution of nodal lines. e, f , An example of topological charge annihilation happening on the lowest-frequency TE-like band of the same structure with different slab thicknesses. As the slab thickness h decreases, two BICs with charge -1 meet with a BIC with charge +1 at the origin. These three BICs annihilate to yield one BIC with charge -1, as governed by charge conservation.
- [1] von Neumann, J. & Wigner, E. Uber merkw¨rdige diskrete eigenwerte. ¨ u Phys. Z. 30 , 465-467 (1929).
- [2] Friedrich, H. & Wintgen, D. Interfering resonances and bound states in the continuum. Phys. Rev. A 32 , 3231-3242 (1985).
- [3] Bulgakov, E. N. & Sadreev, A. F. Bound states in the continuum in photonic waveguides inspired by defects. Phys. Rev. B 78 , 075105 (2008).
- [4] Corrielli, G., Della Valle, G., Crespi, A., Osellame, R. & Longhi, S. Observation of surface states with algebraic localization. Phys. Rev. Lett. 111 , 220403 (2013).
- [5] Weimann, S. et al. Compact surface Fano states embedded in the continuum of waveguide arrays. Phys. Rev. Lett. 111 , 240403 (2013).
- [6] Evans, D. V., Levitin, M. & Vassiliev, D. Existence theorems for trapped modes. J. Fluid Mech. 261 , 21-31 (1994). URL http://journals.cambridge.org/article\_ S0022112094000236 .
- [7] Plotnik, Y. et al. Experimental observation of optical bound states in the continuum. Phys. Rev. Lett. 107 , 183901 (2011).
- [8] Lee, J. et al. Observation and differentiation of unique highQ optical resonances near zero wave vector in macroscopic photonic crystal slabs. Phys. Rev. Lett. 109 , 067401 (2012).
- [9] Porter, R. & Evans, D. Embedded rayleigh-bloch surface waves along periodic rectangular arrays. Wave Motion 43 , 29 - 50 (2005).
- [10] Marinica, D. C., Borisov, A. G. & Shabanov, S. V. Bound states in the continuum in photonics. Phys. Rev. Lett. 100 , 183902 (2008).
- [11] Liu, V., Povinelli, M. & Fan, S. Resonance-enhanced optical forces between coupled photonic crystal slabs. Opt. Express 17 , 21897-21909 (2009).
- [12] Hsu, C. W. et al. Bloch surface eigenstates within the radiation continuum. Light: Science & Applications 2 , e84 (2013).
- [13] Hsu, C. W. et al. Observation of trapped light within the radiation continuum. Nature 499 , 188-191 (2013).
- [14] Zhan, Q. Cylindrical vector beams: from mathematical concepts to applications. Adv. Opt. Photon. 1 , 1-57 (2009).
- [15] Joannopoulos, J. D., Johnson, S. G., Winn, J. N. & Meade, R. D. Photonic Crystals: Molding the Flow of Light (Princeton University Press, 2008), 2 edn.
- [16] Hirose, K. et al. Watt-class high-power, high-beam-quality photonic-crystal lasers. Nature Photon. 8 , 406-411 (2014).
- [17] Ko, D.-H. et al. Photonic crystal geometry for organic solar cells. Nano Letters 9 , 2742-2746 (2009).
- [18] Wierer, J. J., David, A. & Megens, M. M. III-nitride photonic-crystal light-emitting diodes with high extraction efficiency. Nature Photonics 3 , 163-169 (2009).
- [19] Ganesh, N. et al. Enhanced fluorescence emission from quantum dots on a photonic crystal surface. Nature Nanotech. 2 , 515-520 (2007).
- [20] Yanik, A. A. et al. Seeing protein monolayers with naked eye through plasmonic fano resonances. Proc. Natl. Acad. Sci. U.S.A. 108 , 11784-11789 (2011).
- [21] Fan, S. & Joannopoulos, J. D. Analysis of guided resonances in photonic crystal slabs. Phys. Rev. B 65 , 235112 (2002).
- [22] Pacradouni, V. et al. Photonic band structure of dielectric membranes periodically textured in two dimensions. Phys. Rev. B 62 , 4204-4207 (2000).
- [23] Ochiai, T. & Sakoda, K. Dispersion relation and optical transmittance of a hexagonal photonic crystal slab. Phys. Rev. B 63 , 125107 (2001).
- [24] Yang, Y., Peng, C., Liang, Y., Li, Z. & Noda, S. Analytical perspective for bound states in the continuum in photonic crystal slabs. Phys. Rev. Lett. 113 , 037401 (2014).
- [25] Mermin, N. D. The topological theory of defects in ordered media. Reviews of Modern Physics 51 , 591 (1979).
- [26] Donnelly, R. J. Quantized vortices in helium II , vol. 2 (Cambridge University Press, 1991).
- [27] Berry, M. The adiabatic phase and pancharatnam's phase for polarized light. Journal of Modern Optics 34 , 1401-1407 (1987).
- [28] Ma˜ nes, J. L., Guinea, F. & Vozmediano, M. A. Existence and topological stability of fermi points in multilayered graphene. Physical Review B 75 , 155424 (2007).
- [29] Kurosaka, Y. et al. On-chip beam-steering photonic-crystal lasers. Nature Photonics 4 , 447450 (2010).
- [30] Iwahashi, S. et al. Higher-order vector beams produced by photonic-crystal lasers. Opt. Express 19 , 11963-11968 (2011).
- [31] Kitamura, K., Sakai, K., Takayama, N., Nishimoto, M. & Noda, S. Focusing properties of vector vortex beams emitted by photonic-crystal lasers. Opt. Lett. 37 , 2421-2423 (2012).
- [32] Sakoda, K. Optical properties of photonic crystals , vol. 80 (Springer, 2005).
FIG. 4. Generation of BICs. a , Schematic drawing of a photonic crystal slab with twodimensional periodicity. b , Generation of BICs on the TE 1 band when the slab thickness h is increased. Each time, four pairs of BICs with charges ± 1 are generated simultaneously, consistent with the charge conservation and C 4 v symmetry. Insets show the locations of BICs in the k space and their corresponding topological charges for h/a = 1 0 1 2 1 35 1 8 . , . , . , . , and 2 4. As the slab thick-. ness increases, the BICs move outward and eventually fall below the light line into the area shaded in dark blue.
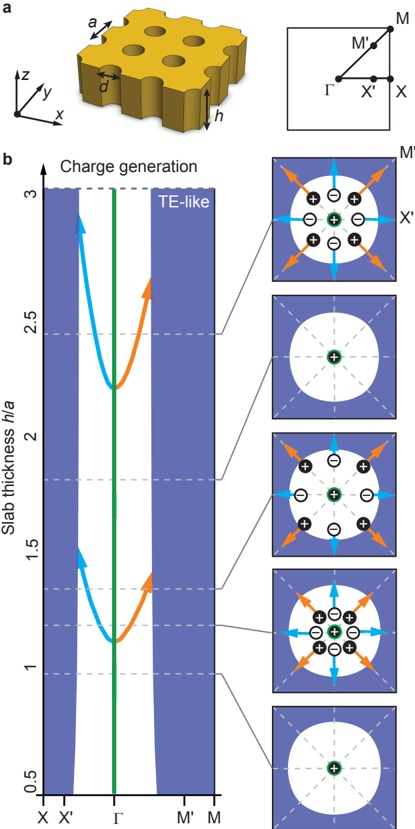
FIG. S1. Symmetry requirements for BICs. Systems in the blue circle are invariant under operators C T z 2 and σ z , where stable BICs at arbitrary wavevectors can be found. In the red circle, where C z 2 is a symmetry of the system, robust BICs can be found at high-symmetry wavevector points. Here, high-symmetry wavevectors mean C z 2 -invariant ones, while arbitrary wavectors are not necessarily C z 2 -invariant. In the overlapping area (region III ), both types BICs can be found. All numerical examples in this Letter are within region III .
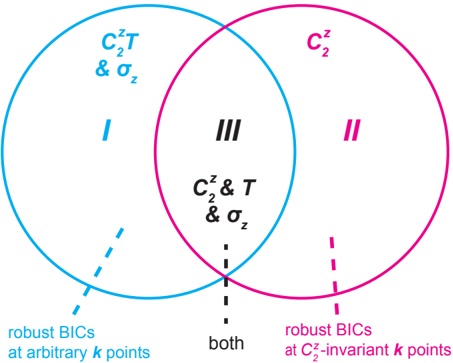
FIG. S2. Stable BIC with topological charge -2. a , Schematic drawing of the photonic crystal slab. b , Q plotted in the first Brillouin zone, showing a BIC at the Γ point. c , Polarization vector field characterizes the BIC with a stable topological charge of -2, as can be shown from double degeneracies of both nodal lines.
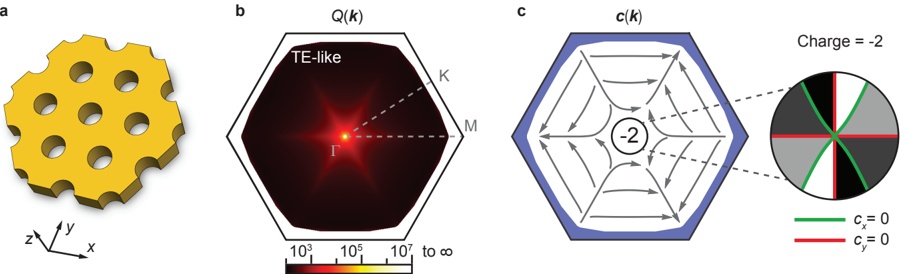 | 10.1103/PhysRevLett.113.257401 | [
"Bo Zhen",
"Chia Wei Hsu",
"Ling Lu",
"A. Doug Stone",
"Marin Soljacic"
] | 2014-08-01T17:04:56+00:00 | 2014-08-01T17:04:56+00:00 | [
"physics.optics"
] | Topological nature of bound states in the radiation continuum | Bound states in the continuum (BICs) are unusual solutions of wave equations
describing light or matter: they are discrete and spatially bounded, but exist
at the same energy as a continuum of states which propagate to infinity. Until
recently, BICs were constructed through fine-tuning parameters in the wave
equation or exploiting the separability of the wave equation due to symmetry.
More recently, BICs that that are both robust and not symmetry-protected
(accidental) have been predicted and experimentally realized in periodic
structures; the simplest such system is a periodic dielectric slab, which also
has symmetry-protected BICs. Here we show that both types of BICs in such
systems are vortex centers in the polarization direction of far-field
radiation. The robustness of these BICs is due to the existence of conserved
and quantized topological charges, defined by the number of times the
polarization vectors wind around the vortex centers. Such charges can only be
generated or annihilated by making large changes in the system parameters, and
then only according to strict rules, which we derive and test numerically. Our
results imply that laser emission based on such states will generate vector
beams. |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.